
第4章 Operator
4.1. Cluster Operator
Cluster Operator を使用して Kafka クラスターや他の Kafka コンポーネントをデプロイします。
Cluster Operator は YAML インストールファイルを使用してデプロイされます。Cluster Operator のデプロイメントに関する詳細は、Cluster Operator のデプロイ を参照してください。
Kafka で利用可能なデプロイメントオプションの詳細は、Kafka Cluster の設定 を参照してください。
OpenShift では、Kafka Connect デプロイメントに Source2Image 機能を組み込み、追加のコネクターを加えるための便利な方法として利用できます。
4.1.1. Cluster Operator
AMQ Streams では、Cluster Operator を使用して以下のクラスターをデプロイおよび管理します。
- Kafka (ZooKeeper、Entity Operator、Kafka Exporter、Cruise Control を含む)
- Kafka Connect
- Kafka MirrorMaker
- Kafka Bridge
クラスターのデプロイメントにはカスタムリソースが使用されます。
たとえば、以下のように Kafka クラスターをデプロイします。
-
クラスター設定のある
Kafkaリソースが OpenShift クラスター内で作成されます。 -
Kafkaリソースに宣言された内容を基にして、該当する Kafka クラスターが Cluster Operator によってデプロイされます。
Cluster Operator で以下もデプロイできます (Kafka リソースの設定より)。
-
KafkaTopicカスタムリソースより Operator スタイルのトピック管理を提供する Topic Operator -
KafkaUserカスタムリソースより Operator スタイルのユーザー管理を提供する User Operator
デプロイメントの Entity Operator 内の Topic Operator および User Operator 関数。
Cluster Operator のアーキテクチャー例
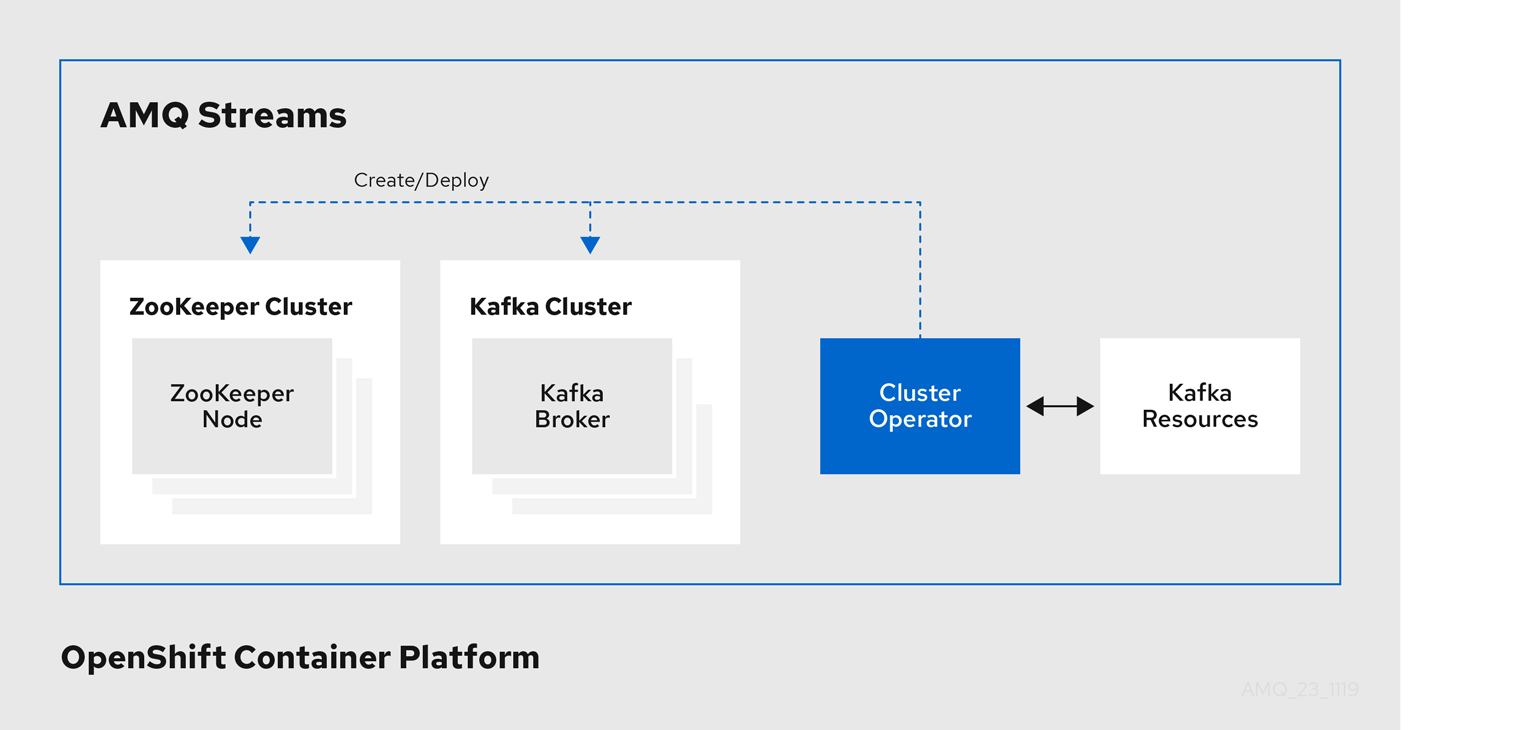
4.1.2. 調整
Operator は OpenShift クラスターから受信する必要なクラスターリソースに関するすべての通知に対応しますが、Operator が実行されていない場合や、何らかの理由で通知が受信されない場合、必要なリソースは実行中の OpenShift クラスターの状態と同期しなくなります。
フェイルオーバーを適切に処理するために、Cluster Operator によって定期的な調整プロセスが実行され、必要なリソースすべてで一貫した状態になるように、必要なリソースの状態を現在のクラスターデプロイメントと比較できます。[STRIMZI_FULL_RECONCILIATION_INTERVAL_MS] 変数を使用して、定期的な調整の時間間隔を設定できます。
4.1.3. Cluster Operator の設定
Cluster Operator は、以下のサポートされる環境変数を使用して設定できます。
STRIMZI_NAMESPACEOperator が操作する namespace のコンマ区切りのリスト。設定されていない場合や、空の文字列や
*に設定された場合は、Cluster Operator はすべての namespace で操作します。Cluster Operator デプロイメントでは OpenShift Downward API を使用して、これを Cluster Operator がデプロイされる namespace に自動設定することがあります。以下の例を参照してください。env: - name: STRIMZI_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace-
STRIMZI_FULL_RECONCILIATION_INTERVAL_MS - 任意設定、デフォルトは 120000 ミリ秒です。定期的な調整の間隔 (秒単位)。
STRIMZI_LOG_LEVEL-
任意設定、デフォルトは
INFOです。ロギングメッセージの出力レベル。値は、ERROR、WARNING、INFO、DEBUG、およびTRACEに設定できます。 STRIMZI_OPERATION_TIMEOUT_MS- 任意設定、デフォルトは 300000 ミリ秒です。内部操作のタイムアウト (ミリ秒単位)。この値は、標準の OpenShift 操作の時間が通常よりも長いクラスターで (Docker イメージのダウンロードが遅い場合など) AMQ Streams を使用する場合に増やす必要があります。
STRIMZI_KAFKA_IMAGES-
必須。Kafka バージョンから、そのバージョンの Kafka ブローカーが含まれる該当の Docker イメージへのマッピングが提供されます。必要な構文は、空白またはコンマ区切りの
<version>=<image>ペアです。例:2.4.1=registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.5.0, 2.5.0=registry.redhat.io/amq7/amq-streams-kafka-25-rhel7:1.5.0.これは、「コンテナーイメージ」 に説明されているように、Kafka.spec.kafka.versionプロパティーは指定されていてもKafka.spec.kafka.imageプロパティーは指定されていない場合に使用されます。 STRIMZI_DEFAULT_KAFKA_INIT_IMAGE-
任意設定、デフォルトは
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.5.0です。「コンテナーイメージ」 でkafka-init-imageとして指定されたイメージがない場合に、初期設定作業 (ラックサポート) のブローカーの前に開始される init コンテナーのデフォルトとして使用するイメージ名。 STRIMZI_DEFAULT_TLS_SIDECAR_KAFKA_IMAGE-
任意設定、デフォルトは
registry.redhat.io/amq7/amq-streams-kafka-25-rhel7:1.5.0です。「コンテナーイメージ」 でKafka.spec.kafka.tlsSidecar.imageとして指定されたイメージがない場合に、Kafka の TLS サポートを提供するサイドカーコンテナーをデプロイする際にデフォルトとして使用するイメージ名。 STRIMZI_KAFKA_CONNECT_IMAGES-
必須。Kafka バージョンから、そのバージョンの Kafka Connect が含まれる該当の Docker イメージへのマッピングが提供されます。必要な構文は、空白またはコンマ区切りの
<version>=<image>ペアです。例:2.4.1=registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.5.0, 2.5.0=registry.redhat.io/amq7/amq-streams-kafka-25-rhel7:1.5.0.これは、「コンテナーイメージ」 に説明されているように、KafkaConnect.spec.versionプロパティーが指定されていてもKafkaConnect.spec.imageプロパティーが指定されていない場合に使用されます。 STRIMZI_KAFKA_CONNECT_S2I_IMAGES-
必須。Kafka バージョンから、そのバージョンの Kafka Connect が含まれる該当の Docker イメージへのマッピングが提供されます。必要な構文は、空白またはコンマ区切りの
<version>=<image>ペアです。例:2.4.1=registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.5.0, 2.5.0=registry.redhat.io/amq7/amq-streams-kafka-25-rhel7:1.5.0.これは、「コンテナーイメージ」 に説明されているように、KafkaConnectS2I.spec.versionプロパティーが指定されていても、KafkaConnectS2I.spec.imageプロパティーが指定されていない場合に使用されます。 STRIMZI_KAFKA_MIRROR_MAKER_IMAGES-
必須。Kafka バージョンから、そのバージョンの Kafka Mirror Maker が含まれる該当の Docker イメージへのマッピングが提供されます。必要な構文は、空白またはコンマ区切りの
<version>=<image>ペアです。例:2.4.1=registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.5.0, 2.5.0=registry.redhat.io/amq7/amq-streams-kafka-25-rhel7:1.5.0.これは、「コンテナーイメージ」 に説明されているように、KafkaMirrorMaker.spec.versionプロパティーが指定されていても、KafkaMirrorMaker.spec.imageプロパティーが指定されていない場合に使用されます。 STRIMZI_DEFAULT_TOPIC_OPERATOR_IMAGE-
任意設定、デフォルトは
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.5.0です。Kafkaリソースの 「コンテナーイメージ」 にKafka.spec.entityOperator.topicOperator.imageとして指定されたイメージがない場合に、Topic Operator のデプロイ時にデフォルトとして使用するイメージ名。 STRIMZI_DEFAULT_USER_OPERATOR_IMAGE-
任意設定、デフォルトは
registry.redhat.io/amq7/amq-streams-rhel7-operator:1.5.0です。Kafkaリソースの「コンテナーイメージ」 にKafka.spec.entityOperator.userOperator.imageとして指定されたイメージがない場合に、User Operator のデプロイ時にデフォルトとして使用するイメージ名。 STRIMZI_DEFAULT_TLS_SIDECAR_ENTITY_OPERATOR_IMAGE-
任意設定、デフォルトは
registry.redhat.io/amq7/amq-streams-kafka-25-rhel7:1.5.0です。「コンテナーイメージ」 にKafka.spec.entityOperator.tlsSidecar.imageとして指定されたイメージがない場合に、Entity Operator の TLS サポートを提供するサイドカーコンテナーのデプロイ時にデフォルトとして使用するイメージ名。 STRIMZI_IMAGE_PULL_POLICY-
オプション。AMQ Streams の Cluster Operator によって管理されるすべての Pod のコンテナーに適用される
ImagePullPolicy。有効な値はAlways、IfNotPresent、およびNeverです。指定のない場合、OpenShift のデフォルトが使用されます。ポリシーを変更すると、すべての Kafka、Kafka Connect、および Kafka MirrorMaker クラスターのローリング更新が実行されます。 STRIMZI_IMAGE_PULL_SECRETS-
オプション:
Secret名のコンマ区切りのリスト。ここで参照されるシークレットには、コンテナーイメージがプルされるコンテナーレジストリーへのクレデンシャルが含まれます。シークレットは、Cluster Operator によって作成されるすべてのPodsのimagePullSecretsフィールドで使用されます。このリストを変更すると、Kafka、Kafka Connect、および Kafka MirrorMaker のすべてのクラスターのローリング更新が実行されます。 STRIMZI_KUBERNETES_VERSIONオプション:API サーバーから検出された OpenShift バージョン情報をオーバーライドします。以下の例を参照してください。
env: - name: STRIMZI_KUBERNETES_VERSION value: | major=1 minor=16 gitVersion=v1.16.2 gitCommit=c97fe5036ef3df2967d086711e6c0c405941e14b gitTreeState=clean buildDate=2019-10-15T19:09:08Z goVersion=go1.12.10 compiler=gc platform=linux/amd64KUBERNETES_SERVICE_DNS_DOMAINオプション:デフォルトの OpenShift DNS 接尾辞を上書きします。
デフォルトでは、OpenShfit クラスターで割り当てられるサービスに、デフォルトの接尾辞
cluster.localを使用する DNS ドメイン名があります。ブローカーが kafka-0 の場合の例は次のとおりです。
<cluster-name>-kafka-0.<cluster-name>-kafka-brokers.<namespace>.svc.cluster.local
DNS ドメイン名は、ホスト名の検証に使用される Kafka ブローカー証明書に追加されます。
クラスターで異なる DNS 接尾辞を使用している場合、Kafka ブローカーとの接続を確立するために、
KUBERNETES_SERVICE_DNS_DOMAIN環境変数をデフォルトから現在使用中の DNS 接尾辞に変更します。
4.1.4. ロールベースアクセス制御 (RBAC)
4.1.4.1. Cluster Operator のロールベースアクセス制御 (RBAC) のプロビジョニング
Cluster Operator が機能するには、Kafka、KafkaConnect などのリソースや ConfigMaps、Pods、Deployments、StatefulSets、Services などの管理リソースと対話するために OpenShift クラスター内でパーミッションが必要になり ます。このようなパーミッションは、OpenShift のロールベースアクセス制御 (RBAC) リソースに記述されます。
-
ServiceAccount -
RoleおよびClusterRole -
RoleBindingおよびClusterRoleBinding
Cluster Operator は、ClusterRoleBinding を使用して独自の ServiceAccount で実行される他に、OpenShift リソースへのアクセスを必要とするコンポーネントの RBAC リソースを管理します。
また OpenShift には、ServiceAccount で動作するコンポーネントが、その ServiceAccount にはない他の ServiceAccounts の権限を付与しないようにするための特権昇格の保護機能も含まれています。Cluster Operator は、ClusterRoleBindings と、それが管理するリソースで必要な RoleBindings を作成できる必要があるため、Cluster Operator にも同じ権限が必要です。
4.1.4.2. 委譲された権限
Cluster Operator が必要な Kafka リソースのリソースをデプロイする場合、以下のように ServiceAccounts、RoleBindings、および ClusterRoleBindings も作成します。
Kafka ブローカー Pod は、
cluster-name-kafkaというServiceAccountを使用します。-
ラック機能が使用されると、
strimzi-cluster-name-kafka-initClusterRoleBindingは、strimzi-kafka-brokerと呼ばれるClusterRole経由で、クラスター内のノードへのServiceAccountアクセスを付与するために使用されます。 - ラック機能が使用されていない場合は、バインディングは作成されません。
-
ラック機能が使用されると、
-
ZooKeeper Pod では
cluster-name-zookeeperというServiceAccountが使用されます。 Entity Operator Pod では
cluster-name-entity-operatorというServiceAccountが使用されます。-
Topic Operator はステータス情報のある OpenShift イベントを生成するため、
ServiceAccountはstrimzi-entity-operatorというClusterRoleにバインドされ、strimzi-entity-operatorRoleBinding経由でこのアクセス権限を付与します。
-
Topic Operator はステータス情報のある OpenShift イベントを生成するため、
-
KafkaConnectおよびKafkaConnectS2Iリソースの Pod は、cluster-name-cluster-connectというServiceAccountを使用します。 -
KafkaMirrorMakerの Pod は、cluster-name-mirror-makerというServiceAccountを使用します。 -
KafkaBridgeの Pod は、cluster-name-bridgeというServiceAccountを使用します。
4.1.4.3. ServiceAccount
Cluster Operator は ServiceAccount を使用して最適に実行されます。
Cluster Operator の ServiceAccount の例
apiVersion: v1
kind: ServiceAccount
metadata:
name: strimzi-cluster-operator
labels:
app: strimzi
その後、Cluster Operator の Deployment で、これを spec.template.spec.serviceAccountName に指定する必要があります。
Cluster Operator の Deployment の部分的な例
apiVersion: apps/v1
kind: Deployment
metadata:
name: strimzi-cluster-operator
labels:
app: strimzi
spec:
replicas: 1
selector:
matchLabels:
name: strimzi-cluster-operator
strimzi.io/kind: cluster-operator
template:
# ...
12 行目で、strimzi-cluster-operator ServiceAccount が serviceAccountName として指定されています。
4.1.4.4. ClusterRoles
Cluster Operator は、必要なリソースへのアクセス権限を付与する ClusterRole を使用して操作する必要があります。OpenShift クラスターの設定によっては、クラスター管理者が ClusterRoles を作成する必要があることがあります。
クラスター管理者の権限は ClusterRoles の作成にのみ必要です。Cluster Operator はクラスター管理者アカウントで実行されません。
ClusterRoles は、 最小権限の原則に従い、Kafka、Kafka Connect、および ZooKeeper クラスターを操作するために Cluster Operator が必要とする権限のみが含まれます。最初に割り当てられた一連の権限により、Cluster Operator で StatefulSets、Deployments、Pods、および ConfigMaps などの OpenShift リソースを管理できます。
Cluster Operator は ClusterRoles を使用して、namespace スコープリソースのレベルおよびクラスタースコープリソースのレベルで権限を付与します。
Cluster Operator の namespaced リソースのある ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: strimzi-cluster-operator-namespaced
labels:
app: strimzi
rules:
- apiGroups:
- ""
resources:
# The cluster operator needs to access and manage service accounts to grant Strimzi components cluster permissions
- serviceaccounts
verbs:
- get
- create
- delete
- patch
- update
- apiGroups:
- "rbac.authorization.k8s.io"
resources:
# The cluster operator needs to access and manage rolebindings to grant Strimzi components cluster permissions
- rolebindings
verbs:
- get
- create
- delete
- patch
- update
- apiGroups:
- ""
resources:
# The cluster operator needs to access and manage config maps for Strimzi components configuration
- configmaps
# The cluster operator needs to access and manage services to expose Strimzi components to network traffic
- services
# The cluster operator needs to access and manage secrets to handle credentials
- secrets
# The cluster operator needs to access and manage persistent volume claims to bind them to Strimzi components for persistent data
- persistentvolumeclaims
verbs:
- get
- list
- watch
- create
- delete
- patch
- update
- apiGroups:
- "kafka.strimzi.io"
resources:
# The cluster operator runs the KafkaAssemblyOperator, which needs to access and manage Kafka resources
- kafkas
- kafkas/status
# The cluster operator runs the KafkaConnectAssemblyOperator, which needs to access and manage KafkaConnect resources
- kafkaconnects
- kafkaconnects/status
# The cluster operator runs the KafkaConnectS2IAssemblyOperator, which needs to access and manage KafkaConnectS2I resources
- kafkaconnects2is
- kafkaconnects2is/status
# The cluster operator runs the KafkaConnectorAssemblyOperator, which needs to access and manage KafkaConnector resources
- kafkaconnectors
- kafkaconnectors/status
# The cluster operator runs the KafkaMirrorMakerAssemblyOperator, which needs to access and manage KafkaMirrorMaker resources
- kafkamirrormakers
- kafkamirrormakers/status
# The cluster operator runs the KafkaBridgeAssemblyOperator, which needs to access and manage BridgeMaker resources
- kafkabridges
- kafkabridges/status
# The cluster operator runs the KafkaMirrorMaker2AssemblyOperator, which needs to access and manage KafkaMirrorMaker2 resources
- kafkamirrormaker2s
- kafkamirrormaker2s/status
# The cluster operator runs the KafkaRebalanceAssemblyOperator, which needs to access and manage KafkaRebalance resources
- kafkarebalances
- kafkarebalances/status
verbs:
- get
- list
- watch
- create
- delete
- patch
- update
- apiGroups:
- ""
resources:
# The cluster operator needs to access and delete pods, this is to allow it to monitor pod health and coordinate rolling updates
- pods
verbs:
- get
- list
- watch
- delete
- apiGroups:
- ""
resources:
- endpoints
verbs:
- get
- list
- watch
- apiGroups:
# The cluster operator needs the extensions api as the operator supports Kubernetes version 1.11+
# apps/v1 was introduced in Kubernetes 1.14
- "extensions"
resources:
# The cluster operator needs to access and manage deployments to run deployment based Strimzi components
- deployments
- deployments/scale
# The cluster operator needs to access replica sets to manage Strimzi components and to determine error states
- replicasets
# The cluster operator needs to access and manage replication controllers to manage replicasets
- replicationcontrollers
# The cluster operator needs to access and manage network policies to lock down communication between Strimzi components
- networkpolicies
# The cluster operator needs to access and manage ingresses which allow external access to the services in a cluster
- ingresses
verbs:
- get
- list
- watch
- create
- delete
- patch
- update
- apiGroups:
- "apps"
resources:
# The cluster operator needs to access and manage deployments to run deployment based Strimzi components
- deployments
- deployments/scale
- deployments/status
# The cluster operator needs to access and manage stateful sets to run stateful sets based Strimzi components
- statefulsets
# The cluster operator needs to access replica-sets to manage Strimzi components and to determine error states
- replicasets
verbs:
- get
- list
- watch
- create
- delete
- patch
- update
- apiGroups:
- ""
resources:
# The cluster operator needs to be able to create events and delegate permissions to do so
- events
verbs:
- create
- apiGroups:
# OpenShift S2I requirements
- apps.openshift.io
resources:
- deploymentconfigs
- deploymentconfigs/scale
- deploymentconfigs/status
- deploymentconfigs/finalizers
verbs:
- get
- list
- watch
- create
- delete
- patch
- update
- apiGroups:
# OpenShift S2I requirements
- build.openshift.io
resources:
- buildconfigs
- builds
verbs:
- create
- delete
- get
- list
- patch
- watch
- update
- apiGroups:
# OpenShift S2I requirements
- image.openshift.io
resources:
- imagestreams
- imagestreams/status
verbs:
- create
- delete
- get
- list
- watch
- patch
- update
- apiGroups:
- networking.k8s.io
resources:
# The cluster operator needs to access and manage network policies to lock down communication between Strimzi components
- networkpolicies
verbs:
- get
- list
- watch
- create
- delete
- patch
- update
- apiGroups:
- route.openshift.io
resources:
# The cluster operator needs to access and manage routes to expose Strimzi components for external access
- routes
- routes/custom-host
verbs:
- get
- list
- create
- delete
- patch
- update
- apiGroups:
- policy
resources:
# The cluster operator needs to access and manage pod disruption budgets this limits the number of concurrent disruptions
# that a Strimzi component experiences, allowing for higher availability
- poddisruptionbudgets
verbs:
- get
- list
- watch
- create
- delete
- patch
- update
2 番目の一連の権限には、クラスタースコープリソースに必要な権限が含まれます。
Cluster Operator のクラスタースコープリソースのある ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: strimzi-cluster-operator-global
labels:
app: strimzi
rules:
- apiGroups:
- "rbac.authorization.k8s.io"
resources:
# The cluster operator needs to create and manage cluster role bindings in the case of an install where a user
# has specified they want their cluster role bindings generated
- clusterrolebindings
verbs:
- get
- create
- delete
- patch
- update
- watch
- apiGroups:
- storage.k8s.io
resources:
# The cluster operator requires "get" permissions to view storage class details
# This is because only a persistent volume of a supported storage class type can be resized
- storageclasses
verbs:
- get
- apiGroups:
- ""
resources:
# The cluster operator requires "list" permissions to view all nodes in a cluster
# The listing is used to determine the node addresses when NodePort access is configured
# These addresses are then exposed in the custom resource states
- nodes
verbs:
- list
strimzi-kafka-broker ClusterRole は、ラック機能に使用される Kafka Pod の init コンテナーが必要とするアクセス権限を表します。委譲された権限 で説明したように、このアクセスを委譲できるようにするには、このロールも Cluster Operator に必要です。
Cluster Operator の ClusterRole により、OpenShift ノードへのアクセスを Kafka ブローカー Pod に委譲できます。
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: strimzi-kafka-broker
labels:
app: strimzi
rules:
- apiGroups:
- ""
resources:
# The Kafka Brokers require "get" permissions to view the node they are on
# This information is used to generate a Rack ID that is used for High Availability configurations
- nodes
verbs:
- get
strimzi-topic-operator の ClusterRole は、Topic Operator が必要とするアクセスを表します。委譲された権限 で説明したように、このアクセスを委譲できるようにするには、このロールも Cluster Operator に必要です。
Cluster Operator の ClusterRole により、イベントへのアクセスを Topic Operator に委譲できます。
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: strimzi-entity-operator
labels:
app: strimzi
rules:
- apiGroups:
- "kafka.strimzi.io"
resources:
# The entity operator runs the KafkaTopic assembly operator, which needs to access and manage KafkaTopic resources
- kafkatopics
- kafkatopics/status
# The entity operator runs the KafkaUser assembly operator, which needs to access and manage KafkaUser resources
- kafkausers
- kafkausers/status
verbs:
- get
- list
- watch
- create
- patch
- update
- delete
- apiGroups:
- ""
resources:
- events
verbs:
# The entity operator needs to be able to create events
- create
- apiGroups:
- ""
resources:
# The entity operator user-operator needs to access and manage secrets to store generated credentials
- secrets
verbs:
- get
- list
- create
- patch
- update
- delete
4.1.4.5. ClusterRoleBindings
Operator には ClusterRoleBindings が必要であり、Operator の ClusterRole を ServiceAccount と関連付ける RoleBindings も必要です。ClusterRoleBindings はクラスタースコープリソースが含まれる ClusterRoles に必要です。
Cluster Operator の ClusterRoleBinding の例
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: strimzi-cluster-operator
labels:
app: strimzi
subjects:
- kind: ServiceAccount
name: strimzi-cluster-operator
namespace: myproject
roleRef:
kind: ClusterRole
name: strimzi-cluster-operator-global
apiGroup: rbac.authorization.k8s.io
ClusterRoleBindings は、委譲に必要な ClusterRole にも必要です。
Cluster Operator の RoleBinding の例
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: strimzi-cluster-operator-kafka-broker-delegation
labels:
app: strimzi
# The Kafka broker cluster role must be bound to the cluster operator service account so that it can delegate the cluster role to the Kafka brokers.
# This must be done to avoid escalating privileges which would be blocked by Kubernetes.
subjects:
- kind: ServiceAccount
name: strimzi-cluster-operator
namespace: myproject
roleRef:
kind: ClusterRole
name: strimzi-kafka-broker
apiGroup: rbac.authorization.k8s.io
namespaced リソースのみが含まれる ClusterRoles は、RoleBindings のみを使用してバインドされます。
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: strimzi-cluster-operator
labels:
app: strimzi
subjects:
- kind: ServiceAccount
name: strimzi-cluster-operator
namespace: myproject
roleRef:
kind: ClusterRole
name: strimzi-cluster-operator-namespaced
apiGroup: rbac.authorization.k8s.ioapiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: strimzi-cluster-operator-entity-operator-delegation
labels:
app: strimzi
# The Entity Operator cluster role must be bound to the cluster operator service account so that it can delegate the cluster role to the Entity Operator.
# This must be done to avoid escalating privileges which would be blocked by Kubernetes.
subjects:
- kind: ServiceAccount
name: strimzi-cluster-operator
namespace: myproject
roleRef:
kind: ClusterRole
name: strimzi-entity-operator
apiGroup: rbac.authorization.k8s.io