
第2章 AMQ Streams の使用
AMQ Streams は、パブリックおよびプライベートクラウドからデプロイメントを目的とするローカルデプロイメントまで、ディストリビューションに関係なくすべてのタイプの OpenShift クラスターで動作するよう設計されています。AMQ Streams は、OpenShift 固有の一部機能をサポートします。そのようなインテグレーションは OpenShift ユーザーに有用で、標準の OpenShift を使用して同様に実装することはできません。
本ガイドでは、OpenShift クラスターが使用できることを仮定し、さらに oc コマンドラインツールがインストールされ、稼働中のクラスターに接続するように設定されていることを仮定しています。
AMQ Streams は Strimzi 0.17.x をベースとしています。本章では、OpenShift 3.11 以降に AMQ Streams をデプロイする方法を説明します。
本ガイドのコマンドを実行するには、クラスターユーザーに RBAC (ロールベースアクセス制御) および CRD を管理する権限を付与する必要があります。
2.1. AMQ Streams のインストールおよびコンポーネントのデプロイ
AMQ Streams をインストールするには、AMQ Streams のダウンロードページ から amq-streams-x.y.z-ocp-install-examples.zip ファイルをダウンロードし、展開します。
フォルダーには、複数の YAML ファイルが含まれています。これらのファイルは、AMQ Streams のコンポーネントを OpenShift にデプロイするのに役立ち、共通の操作を実行し、Kafka クラスターを設定します。YAML ファイルは本書を通して参照されます。
本章の後半では、提供される YAML ファイルを使用してコンポーネントを OpenShift にデプロイするための各コンポーネントおよび手順の概要を取り上げます。
AMQ Streams のコンテナーイメージは Red Hat Container Catalog で使用できますが、この代わりに提供される YAML ファイルを使用することが推奨されます。
2.2. カスタムリソース
カスタムリソースを使用すると、デフォルトの AMQ Streams デプロイメントを設定し、変更を追加することができます。カスタムリソースを使用するには、最初にカスタムリソース定義を指定する必要があります。
カスタムリソース定義 (CRD) は Kubernetes API を拡張し、カスタムリソースを OpenShift クラスターに追加する定義を提供します。カスタムリソースは、CRD によって追加される API のインスタンスとして作成されます。
AMQ Streams では、Kafka、Kafka Connect、Kafka MirrorMaker 、ユーザーおよびトピックカスタムリソースなどの AMQ Streams に固有のカスタムリソースが CRD によって OpenShift クラスターに導入されます。CRD によって設定手順が提供され、AMQ Streams 固有のリソースをインスタンス化および管理するために使用されるスキーマが定義されます。また、CRD によって、CLI へのアクセスや設定検証などのネイティブ OpenShift 機能を AMQ Streams リソースで活用することもできます。
CRD はクラスターで 1 度インストールする必要があります。クラスターの設定によりますが、インストールには通常、クラスター管理者権限が必要です。
カスタムリソースの管理は、 AMQ Streams 管理者 のみが行えます。
CRD およびカスタムリソースは YAML ファイルとして定義されます。
kind:Kafka などの新しい kind リソースは、OpenShift クラスター内で CRD によって定義されます。
Kubernetes API サーバーを使用すると、kind を基にしたカスタムリソースの作成が可能になり、カスタムリソースが OpenShift クラスターに追加されたときにカスタムリソースの検証および格納方法を CRD から判断します。
CRD が削除されると、そのタイプのカスタムタイプも削除されます。さらに、Pod や Statefulset などのカスタムリソースによって作成されたリソースも削除されます。
2.2.1. AMQ Streams カスタムリソースの例
AMQ Streams 固有の各カスタムリソースは、リソースの kind の CRD によって定義されるスキーマに準拠します。
CRD とカスタムリソースの関係を理解するため、Kafka トピックの CRD の例を見てみましょう。
Kafka トピックの CRD
apiVersion: kafka.strimzi.io/v1beta1 kind: CustomResourceDefinition metadata: 1 name: kafkatopics.kafka.strimzi.io labels: app: strimzi spec: 2 group: kafka.strimzi.io versions: v1beta1 scope: Namespaced names: # ... singular: kafkatopic plural: kafkatopics shortNames: - kt 3 additionalPrinterColumns: 4 # ... subresources: status: {} 5 validation: 6 openAPIV3Schema: properties: spec: type: object properties: partitions: type: integer minimum: 1 replicas: type: integer minimum: 1 maximum: 32767 # ...
- 1
- CRD を識別するためのトピック CRD、その名前および名前のメタデータ。
- 2
- この CRD に指定された項目には、トピックの API にアクセスするため URL に使用されるグルShortNameープ (ドメイン) 名、複数名、およびサポートされるスキーマバージョンが含まれます。他の名前は、CLI のインスタンスリソースを識別するために使用されます。例:
oc get kafkatopic my-topicまたはoc get kafkatopics - 3
- ShortName は CLI コマンドで使用できます。たとえば、
oc get kafkatopicの代わりにoc get ktを略名として使用できます。 - 4
- カスタムリソースで
getコマンドを使用する場合に示される情報。 - 5
- リソースの スキーマ参照 に記載されている CRD の現在のステータス。
- 6
- openAPIV3Schema 検証によって、トピックカスタムリソースの作成が検証されます。たとえば、トピックには 1 つ以上のパーティションと 1 つのレプリカが必要です。
ファイル名に、インデックス番号とそれに続く「Crd」が含まれるため、AMQ Streams インストールファイルと提供される CRD YAML ファイルを識別できます。
KafkaTopic カスタムリソースに該当する例は次のとおりです。
Kafka トピックカスタムリソース
apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaTopic 1 metadata: name: my-topic labels: strimzi.io/cluster: my-cluster 2 spec: 3 partitions: 1 replicas: 1 config: retention.ms: 7200000 segment.bytes: 1073741824 status: conditions: 4 lastTransitionTime: "2019-08-20T11:37:00.706Z" status: "True" type: Ready observedGeneration: 1 / ...
- 1
kindおよびapiVersionによって、インスタンスであるカスタムリソースの CRD が特定されます。- 2
- トピックまたはユーザーが属する Kafka クラスターの名前 (
Kafkaリソースの名前と同じ) を定義する、KafkaTopicおよびKafkaUserリソースのみに適用可能なラベル。この名前は、トピックまたはユーザーの作成時に Kafka クラスターを識別するために Topic Operator および User Operator によって使用されます。
- 3
- 指定内容には、トピックのパーティション数およびレプリカ数や、トピック自体の設定パラメーターが示されています。この例では、メッセージがトピックに保持される期間や、ログのセグメントファイルサイズが指定されています。
- 4
KafkaTopicリソースのステータス条件。lastTransitionTimeでtype条件がReadyに変更されています。
プラットフォーム CLI からカスタムリソースをクラスターに適用できます。カスタムリソースが作成されると、Kubernetes API の組み込みリソースと同じ検証が使用されます。
KafkaTopic の作成後、Topic Operator は通知を受け取り、該当する Kafka トピックが AMQ Streams で作成されます。
2.2.2. AMQ Streams カスタムリソースのステータス
AMQ Streams カスタムリソースの status プロパティーは、リソースに関する情報を必要とするユーザーおよびツールにその情報をパブリッシュします。
下記の表のとおり、複数のリソースに status プロパティーがあります。
| AMQ Streams リソース | スキーマ参照 | ステータス情報がパブリッシュされる場所 |
|---|---|---|
|
| Kafka クラスター | |
|
| デプロイされている場合は Kafka Connect クラスター。 | |
|
| デプロイされている場合は Source-to-Image (S2I) サポートのある Kafka Connect クラスター。 | |
|
|
デプロイされている場合は | |
|
| デプロイされている場合は Kafka MirrorMakerツール。 | |
|
| Kafka クラスターの Kafka トピック | |
|
| Kafka クラスターの Kafka ユーザー。 | |
|
| デプロイされている場合は AMQ Streams の Kafka Bridge。 |
リソースの status プロパティーによって、リソースの下記項目の情報が提供されます。
-
status.conditionsプロパティーの Current state (現在の状態)。 -
status.observedGenerationプロパティーの Last observed generation (最後に確認された生成)。
status プロパティーによって、リソース固有の情報も提供されます。以下に例を示します。
-
KafkaConnectStatusによって、Kafka Connect コネクターの REST API エンドポイントが提供されます。 -
KafkaUserStatusによって、Kafka ユーザーの名前と、ユーザーのクレデンシャルが保存されるSecretが提供されます。 -
KafkaBridgeStatusによって、外部クライアントアプリケーションが Bridge サービスにアクセスできる HTTP アドレスが提供されます。
リソースの Current state (現在の状態) は、spec プロパティーによって定義される Desired state (望ましい状態) を実現するリソースに関する進捗を追跡するのに便利です。ステータス条件によって、リソースの状態が変更された時間および理由が提供され、Operator によるリソースの望ましい状態の実現を妨げたり遅らせたりしたイベントの詳細が提供されます。
Last observed generation (最後に確認された生成) は、Cluster Operator によって最後に照合されたリソースの生成です。observedGeneration の値が metadata.generation の値と異なる場合、リソースの最新の更新が Operator によって処理されていません。これらの値が同じである場合、リソースの最新の変更がステータス情報に反映されます。
AMQ Streams によってカスタムリソースのステータスが作成および維持されます。定期的にカスタムリソースの現在の状態が評価され、その結果に応じてステータスが更新されます。くださいーたとえば、oc edit を使用してカスタムリソースで更新を行う場合、その status は編集不可能です。さらに、status の変更は Kafka クラスターステータスの設定に影響しません。
以下では、Kafka カスタムリソースに status プロパティーが指定されています。
Kafka カスタムリソースとステータス
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: spec: # ... status: conditions: 1 - lastTransitionTime: 2019-07-23T23:46:57+0000 status: "True" type: Ready 2 observedGeneration: 4 3 listeners: 4 - addresses: - host: my-cluster-kafka-bootstrap.myproject.svc port: 9092 type: plain - addresses: - host: my-cluster-kafka-bootstrap.myproject.svc port: 9093 certificates: - | -----BEGIN CERTIFICATE----- ... -----END CERTIFICATE----- type: tls - addresses: - host: 172.29.49.180 port: 9094 certificates: - | -----BEGIN CERTIFICATE----- ... -----END CERTIFICATE----- type: external # ...
- 1
- status の
conditionsは、既存のリソース情報から推測できないステータスに関連する基準や、リソースのインスタンスに固有する基準を記述します。 - 2
Ready条件は、Cluster Operator が現在 Kafka クラスターでトラフィックの処理が可能であると判断するかどうかを示しています。- 3
observedGenerationは、最後に Cluster Operator によって照合されたKafkaカスタムリソースの生成を示しています。- 4
listenersは、現在の Kafka ブートストラップアドレスをタイプ別に示しています。重要タイプが
nodeportの外部リスナーのカスタムリソースステータスにおけるアドレスは、現在サポートされていません。
Kafka ブートストラップアドレスがステータスに一覧表示されても、それらのエンドポイントまたは Kafka クラスターが準備状態であるとは限りません。
ステータス情報のアクセス
リソースのステータス情報はコマンドラインから取得できます。詳細は 「カスタムリソースのステータスの確認」 を参照してください。
2.3. Cluster Operator
Cluster Operator は、OpenShift クラスター内で Apache Kafka クラスターのデプロイおよび管理を行います。
2.3.1. Cluster Operator
AMQ Streams では、Cluster Operator を使用して以下のクラスターをデプロイおよび管理します。
- Kafka (ZooKeeper、Entity Operator、および Kafka Exporter を含む)
- Kafka Connect
- Kafka MirrorMaker
- Kafka Bridge
クラスターのデプロイメントにはカスタムリソースが使用されます。
たとえば、以下のように Kafka クラスターをデプロイします。
-
クラスター設定のある
Kafkaリソースが OpenShift クラスター内で作成されます。 -
Kafkaリソースに宣言された内容を基にして、該当する Kafka クラスターが Cluster Operator によってデプロイされます。
Cluster Operator で以下もデプロイできます (Kafka リソースの設定より)。
-
KafkaTopicカスタムリソースより Operator スタイルのトピック管理を提供する Topic Operator -
KafkaUserカスタムリソースより Operator スタイルのユーザー管理を提供する User Operator
デプロイメントの Entity Operator 内の Topic Operator および User Operator 関数。
Cluster Operator のアーキテクチャー例

2.3.2. Cluster Operator デプロイメントの監視オプション
Cluster Operator の稼働中に、Kafka リソースの更新に対する監視が開始されます。
Cluster Operator はデプロイメントに応じて、以下から Kafka リソースを監視できます。
AMQ Streams では、デプロイメントの処理を簡単にするため、サンプル YAML ファイルが提供されます。
Cluster Operator では、以下のリソースの変更が監視されます。
-
Kafka クラスターの
Kafka。 -
KafkaConnectの Kafka Connect クラスター。 -
Source2Image がサポートされる Kafka Connect クラスターの
KafkaConnectS2I。 -
Kafka Connect クラスターでコネクターを作成および管理するための
KafkaConnector。 -
Kafka MirrorMaker インスタンスの
KafkaMirrorMaker。 -
Kafka Bridge インスタンスの
KafkaBridge。
OpenShift クラスターでこれらのリソースの 1 つが作成されると、Operator によってクラスターの詳細がリソースより取得されます。さらに、StatefulSet、Service、および ConfigMap などの必要な OpenShift リソースが作成され、リソースの新しいクラスターの作成が開始されます。
Kafka リソースが更新されるたびに、リソースのクラスターを構成する OpenShift リソースで該当する更新が Operator によって実行されます。
クラスターの望ましい状態がリソースのクラスターに反映されるようにするため、リソースへのパッチ適用後またはリソースの削除後にリソースが再作成されます。この操作は、サービスの中断を引き起こすローリングアップデートの原因となる可能性があります。
リソースが削除されると、Operator によってクラスターがアンデプロイされ、関連する OpenShift リソースがすべて削除されます。
2.3.3. 単一の namespace を監視対象とする Cluster Operator のデプロイメント
前提条件
-
この手順では、
CustomResourceDefinitions、ClusterRoles、およびClusterRoleBindingsを作成できる OpenShift ユーザーアカウントを使用する必要があります。通常、OpenShift クラスターでロールベースアクセス制御 (RBAC) を使用する場合、これらのリソースを作成、編集、および削除する権限を持つユーザーはsystem:adminなどの OpenShift クラスター管理者に限定されます。 Cluster Operator がインストールされる namespace に従い、インストールファイルを編集します。
Linux の場合は、以下を使用します。
sed -i 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yamlMacOS の場合は、以下を使用します。
sed -i '' 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yaml
手順
Cluster Operator をデプロイします。
oc apply -f install/cluster-operator -n my-namespace
2.3.4. 複数の namespace を監視対象とする Cluster Operator のデプロイメント
前提条件
-
この手順では、
CustomResourceDefinitions、ClusterRoles、およびClusterRoleBindingsを作成できる OpenShift ユーザーアカウントを使用する必要があります。通常、OpenShift クラスターでロールベースアクセス制御 (RBAC) を使用する場合、これらのリソースを作成、編集、および削除する権限を持つユーザーはsystem:adminなどの OpenShift クラスター管理者に限定されます。 Cluster Operator がインストールされる namespace にしたがって、インストールファイルを編集します。
Linux の場合は、以下を使用します。
sed -i 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yamlMacOS の場合は、以下を使用します。
sed -i '' 's/namespace: .*/namespace: my-namespace/' install/cluster-operator/*RoleBinding*.yaml
手順
install/cluster-operator/050-Deployment-strimzi-cluster-operator.yamlファイルを編集し、環境変数STRIMZI_NAMESPACEで、Cluster Operator がリソースを監視するすべての namespace を一覧表示します。以下に例を示します。apiVersion: apps/v1 kind: Deployment spec: # ... template: spec: serviceAccountName: strimzi-cluster-operator containers: - name: strimzi-cluster-operator image: registry.redhat.io/amq7/amq-streams-rhel7-operator:1.4.0 imagePullPolicy: IfNotPresent env: - name: STRIMZI_NAMESPACE value: watched-namespace-1,watched-namespace-2,watched-namespace-3Cluster Operator によって監視されるすべての namespace (上記の例では
watched-namespace-1、watched-namespace-2、およびwatched-namespace-3) に対して、RoleBindingsをインストールします。watched-namespaceは、直前のステップで使用した namespace に置き換えます。oc applyを使用してこれを行うことができます。oc apply -f install/cluster-operator/020-RoleBinding-strimzi-cluster-operator.yaml -n watched-namespace oc apply -f install/cluster-operator/031-RoleBinding-strimzi-cluster-operator-entity-operator-delegation.yaml -n watched-namespace oc apply -f install/cluster-operator/032-RoleBinding-strimzi-cluster-operator-topic-operator-delegation.yaml -n watched-namespace
Cluster Operator をデプロイします。
oc applyを使用してこれを行うことができます。oc apply -f install/cluster-operator -n my-namespace
2.3.5. すべての namespace を対象とする Cluster Operator のデプロイメント
OpenShift クラスターのすべての namespace で AMQ Streams リソースを監視するように Cluster Operator を設定できます。このモードで実行している場合、Cluster Operator によって、新規作成された namespace でクラスターが自動的に管理されます。
前提条件
-
この手順では、
CustomResourceDefinitions、ClusterRoles、およびClusterRoleBindingsを作成できる OpenShift ユーザーアカウントを使用する必要があります。通常、OpenShift クラスターでロールベースアクセス制御 (RBAC) を使用する場合、これらのリソースを作成、編集、および削除する権限を持つユーザーはsystem:adminなどの OpenShift クラスター管理者に限定されます。 - OpenShift クラスターが稼働している必要があります。
手順
すべての namespace を監視するように Cluster Operator を設定します。
-
050-Deployment-strimzi-cluster-operator.yamlファイルを編集します。 STRIMZI_NAMESPACE環境変数の値を*に設定します。apiVersion: apps/v1 kind: Deployment spec: # ... template: spec: # ... serviceAccountName: strimzi-cluster-operator containers: - name: strimzi-cluster-operator image: registry.redhat.io/amq7/amq-streams-rhel7-operator:1.4.0 imagePullPolicy: IfNotPresent env: - name: STRIMZI_NAMESPACE value: "*" # ...
-
クラスター全体ですべての namespace にアクセスできる権限を Cluster Operator に付与する
ClusterRoleBindingsを作成します。oc create clusterrolebindingコマンドを使用します。oc create clusterrolebinding strimzi-cluster-operator-namespaced --clusterrole=strimzi-cluster-operator-namespaced --serviceaccount my-namespace:strimzi-cluster-operator oc create clusterrolebinding strimzi-cluster-operator-entity-operator-delegation --clusterrole=strimzi-entity-operator --serviceaccount my-namespace:strimzi-cluster-operator oc create clusterrolebinding strimzi-cluster-operator-topic-operator-delegation --clusterrole=strimzi-topic-operator --serviceaccount my-namespace:strimzi-cluster-operator
my-namespaceは、Cluster Operator をインストールする namespace に置き換えます。Cluster Operator を OpenShift クラスターにデプロイします。
oc applyコマンドを使用します。oc apply -f install/cluster-operator -n my-namespace
2.3.6. OperatorHub からの Cluster Operator のデプロイ
OperatorHub から AMQ Streams Operator をインストールして、Cluster Operator を OpenShift クラスターにデプロイできます。OperatorHub は OpenShift 4 のみで使用できます
前提条件
-
Red Hat Operator の
OperatorSourceが OpenShift クラスターで有効になっている必要があります。適切なOperatorSourceが有効になっていれば OperatorHub に Red Hat Operator が表示されます。詳細は、『Operator』を参照してください。 - インストールには、Operator を OperatorHub からインストールするための権限を持つユーザーが必要です
手順
- OpenShift 4 Web コンソールで、Operators > OperatorHub をクリックします。
Streaming & Messaging カテゴリーの AMQ Streams Operator を検索または閲覧します。
- AMQ Streams タイルをクリックし、右側のサイドバーで Install をクリックします。
Create Operator Subscription 画面で、以下のインストールおよび更新オプションから選択します。
- Installation Mode: AMQ Streams Operator をクラスターのすべての (プロジェクト) namespace にインストール (デフォルト) するか、特定の (プロジェクト) namespace インストールするかを選択します。namespace を使用して関数を分離することが推奨されます。Kafka クラスターおよび他の AMQ Streams コンポーネントが含まれる namespace とは別に、独自の namespace に Operator をインストールすることが推奨されます。
- Approval Strategy: デフォルトでは、OLM (Operator Lifecycle Manager) によって、AMQ Streams Operator が自動的に最新の AMQ Streams バージョンにアップグレードされます。今後のアップグレードを手動で承認する場合は、Manual を選択します。詳細は、OpenShift ドキュメントの『Operator』を参照してください。
Subscribe をクリックすると、AMQ Streams Operator が OpenShift クラスターにインストールされます。
AMQ Streams Operator によって、Cluster Operator、CRD、およびロールベースアクセス制御 (RBAC) リソースは選択された namespace またはすべての namespace にデプロイされます。
Installed Operators 画面で、インストールの進捗を確認します。AMQ Streams Operator は、ステータスが InstallSucceeded に変更されると使用できます。

次に、YAML サンプルファイルを使用して、Kafka クラスターから順に AMQ Streams の他のコンポーネントをデプロイできます。
2.4. Kafka クラスター
AMQ Streams を使用して、一時または永続 Kafka クラスターを OpenShift にデプロイできます。Kafka をインストールする場合、AMQ Streams によって ZooKeeper クラスターもインストールされ、Kafka と ZooKeeper との接続に必要な設定が追加されます。
AMQ Streams を使用して、Kafka Exporter をデプロイすることもできます。
- 一時クラスター
-
通常、Kafka の一時クラスターは開発およびテスト環境での使用に適していますが、本番環境での使用には適していません。このデプロイメントでは、ブローカー情報 (ZooKeeper) と、トピックまたはパーティション (Kafka) を格納するための
emptyDirボリュームが使用されます。emptyDirボリュームを使用すると、その内容は厳密に Pod のライフサイクルと関連し、Pod がダウンすると削除されます。 - 永続クラスター
-
Kafka の永続クラスターでは、
PersistentVolumesを使用して ZooKeeper および Kafka データを格納します。PersistentVolumeClaimを使用してPersistentVolumeが取得され、PersistentVolumeの実際のタイプには依存しません。たとえば、YAML ファイルを変更しなくても Amazon AWS デプロイメントで Amazon EBS ボリュームを使用できます。PersistentVolumeClaimでStorageClassを使用し、自動ボリュームプロビジョニングをトリガーすることができます。
AMQ Streams には、Kafka クラスターをデプロイするサンプルが複数含まれています。
-
kafka-persistent.yamlは、3 つの Zookeeper ノードと 3 つの Kafka ノードを使用して永続クラスターをデプロイします。 -
kafka-jbod.yamlは、それぞれが複数の永続ボリューを使用する、3 つの ZooKeeper ノードと 3 つの Kafka ノードを使用して、永続クラスターをデプロイします。 -
kafka-persistent-single.yamlは、1 つの ZooKeeper ノードと 1 つの Kafka ノードを使用して、永続クラスターをデプロイします。 -
kafka-ephemeral.yamlは、3 つの ZooKeeper ノードと 3 つの Kafka ノードを使用して、一時クラスターをデプロイします。 -
kafka-ephemeral-single.yamlは、3 つの ZooKeeper ノードと 1 つの Kafka ノードを使用して、一時クラスターをデプロイします。
サンプルクラスターの名前はデフォルトで my-cluster になります。クラスター名はリソースの名前によって定義され、クラスターがデプロイされた後に変更できません。クラスターをデプロイする前にクラスター名を変更するには、関連する YAML ファイルのリソースの Kafka.metadata.name プロパティーを編集します。
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster # ...
2.4.1. Kafka クラスターのデプロイメント
コマンドラインで、Kafka の一時または永続クラスターを OpenShift にデプロイできます。
前提条件
- Cluster Operator がデプロイされている必要があります。
手順
クラスターを開発またはテストの目的で使用する予定である場合は、
oc applyを使用して一時クラスターを作成およびデプロイできます。oc apply -f examples/kafka/kafka-ephemeral.yaml
クラスターを実稼働で使用する予定である場合は、
oc applyを使用して永続クラスターを作成およびデプロイします。oc apply -f examples/kafka/kafka-persistent.yaml
その他のリソース
- Cluster Operator のデプロイメントに関する詳細は、「Cluster Operator」 を参照してください。
-
Kafkaリソースによってサポートされる異なる設定オプションの詳細は、「Kafka クラスターの設定」 を参照してください。
2.5. Kafka Connect
Kafka Connect は、Apache Kafka と外部システムとの間でデータをストリーミングするためのツールです。Kafka Connect では、スケーラビリティーと信頼性を維持しながら Kafka クラスターで大量のデータを出し入れするためのフレームワークが提供されます。Kafka Connect は通常、Kafka を外部データベース、ストレージシステム、およびメッセージングシステムと統合するために使用されます。
Kafka Connect では、ソースコネクター は外部システムからデータを取得し、それをメッセージとして Kafka に提供するランタイムエンティティーです。シンクコネクター は、Kafka トピックからメッセージを取得し、外部システムに提供するランタイムエンティティーです。コネクターのワークロードは タスク に分割されます。タスクは、Connect クラスター を構成するノード (ワーカー とも呼ばれる) の間で分散されます。これにより、メッセージのフローが非常にスケーラブルになり、信頼性が高くなります。
各コネクターは特定の コネクタークラス のインスタンスで、メッセージに関して関連する外部システムとの通信方法を認識しています。コネクターは多くの外部システムで使用でき、独自のコネクターを開発することもできます。
コネクター という用語は、Kafka Connect クラスター内で実行されているコネクターインスタンスや、コネクタークラスと同じ意味で使用されます。本ガイドでは、本文の内容で意味が明確である場合に コネクター という用語を使用します。
AMQ Stremas では以下を行うことが可能です。
- 必要なコネクターが含まれる Kafka Connect イメージの作成。
-
KafkaConnectリソースを使用した OpenShift 内での Kafka Connect クラスターのデプロイおよび管理。 -
任意で
KafkaConnectorリソースを使用して管理された Kafka Connect クラスター内でのコネクターの実行。
Kafka Connect には、ファイルベースのデータを Kafka クラスターで出し入れするために以下の組み込みコネクターが含まれています。
| ファイルコネクター | 説明 |
|---|---|
|
| ファイル (ソース) から Kafka クラスターにデータを転送します。 |
|
| Kafka クラスターからファイル (シンク) にデータを転送します。 |
その他のコネクタークラスを使用するには、以下の手順の 1 つにしたがってコネクターイメージを準備する必要があります。
Cluster Operator では、Kafka Connect クラスターを OpenShift クラスターにデプロイするために作成するイメージを使用できます。
Kafka Connect クラスターは、設定可能な数量のワーカーで Deployment として実装されます。
コネクターを作成および管理 するには、KafkaConnector リソースを使用するか、8083 番ポートで <connect-cluster-name>-connect-api サービスとして使用できる Kafka Connect REST API を手作業で使用します。REST API でサポートされる操作は、Apache Kafka のドキュメント を参照してください。
2.5.1. Kafka Connect のクラスターへのデプロイメント
Cluster Operator を使用して、Kafka Connect クラスターを OpenShift クラスターにデプロイできます。
前提条件
- Cluster Operator をデプロイ する必要があります。
手順
oc applyコマンドを使用して、kafka-connect.yamlファイルに基づいてKafkaConnectリソースを作成します。oc apply -f examples/kafka-connect/kafka-connect.yaml
2.5.2. コネクタープラグインでの Kafka Connect の拡張
Kafka Connect の AMQ Streams コンテナーイメージには、FileStreamSourceConnector と FileStreamSinkConnector の 2 つの組み込みファイルコネクターが含まれています。以下を行うと、独自のコネクターを追加できます。
- Kafka Connect ベースイメージからコンテナーイメージを作成します (たとえば、手作業による作成または CI (継続インテグレーション) を使用した作成)。
- OpenShift ビルドおよび S2I (Source-to-Image) を使用してコンテナーイメージを作成します (OpenShift の場合のみ)。
2.5.2.1. Kafka Connect ベースイメージからの Docker イメージの作成
Red Hat Container Catalog の Kafka コンテナーイメージを、追加のコネクタープラグインで独自のカスタムイメージを作成するためのベースイメージとして使用できます。
以下の手順では、カスタムイメージを作成し、/opt/kafka/plugins ディレクトリーに追加する方法を説明します。AMQ Stream バージョンの Kafka Connect は起動時に、/opt/kafka/plugins ディレクトリーに含まれるサードパーティーのコネクタープラグインをロードします。
前提条件
- Cluster Operator をデプロイ する必要があります。
手順
registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0をベースイメージとして使用して、新しいDockerfileを作成します。FROM registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0 USER root:root COPY ./my-plugins/ /opt/kafka/plugins/ USER 1001- コンテナーイメージをビルドします。
- カスタムイメージをコンテナーレジストリーにプッシュします。
新しいコンテナーイメージを示します。
以下のいずれかを行います。
KafkaConnectカスタムリソースのKafkaConnect.spec.imageプロパティーを編集します。設定された場合、このプロパティーによって Cluster Operator の
STRIMZI_KAFKA_CONNECT_IMAGES変数がオーバーライドされます。apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnect metadata: name: my-connect-cluster spec: #... image: my-new-container-image
または、以下を実行します。
-
install/cluster-operator/050-Deployment-strimzi-cluster-operator.yamlファイルのSTRIMZI_KAFKA_CONNECT_IMAGES変数を編集して新しいコンテナーイメージを示すようにした後、Cluster Operator を再インストールします。
その他のリソース
-
KafkaConnect.spec.image propertyの詳細は 「コンテナーイメージ」 を参照してください。 -
STRIMZI_KAFKA_CONNECT_IMAGES変数の詳細は 「Cluster Operator の設定」 を参照してください。
2.5.2.2. OpenShift ビルドおよび S2I (Source-to-Image) を使用したコンテナーイメージの作成
OpenShift ビルド と S2I (Source-to-Image) フレームワークを使用して、新しいコンテナーイメージを作成できます。OpenShift ビルドは、S2I がサポートされるビルダーイメージとともに、ユーザー提供のソースコードおよびバイナリーを取得し、これらを使用して新しいコンテナーイメージを構築します。構築後、コンテナーイメージは OpenShfit のローカルコンテナーイメージリポジトリーに格納され、デプロイメントで使用可能になります。
S2I がサポートされる Kafka Connect ビルダーイメージは、registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0 イメージの一部として、Red Hat Container Catalog で提供されます。このS2I イメージは、バイナリー (プラグインおよびコネクターとともに) を取得し、/tmp/kafka-plugins/s2i ディレクトリーに格納されます。このディレクトリーから、Kafka Connect デプロイメントとともに使用できる新しい Kafka Connect イメージを作成します。改良されたイメージの使用を開始すると、Kafka Connect は /tmp/kafka-plugins/s2i ディレクトリーからサードパーティープラグインをロードします。
手順
コマンドラインで
oc applyコマンドを使用し、Kafka Connect の S2I クラスターを作成およびデプロイします。oc apply -f examples/kafka-connect/kafka-connect-s2i.yaml
Kafka Connect プラグインでディレクトリーを作成します。
$ tree ./my-plugins/ ./my-plugins/ ├── debezium-connector-mongodb │ ├── bson-3.4.2.jar │ ├── CHANGELOG.md │ ├── CONTRIBUTE.md │ ├── COPYRIGHT.txt │ ├── debezium-connector-mongodb-0.7.1.jar │ ├── debezium-core-0.7.1.jar │ ├── LICENSE.txt │ ├── mongodb-driver-3.4.2.jar │ ├── mongodb-driver-core-3.4.2.jar │ └── README.md ├── debezium-connector-mysql │ ├── CHANGELOG.md │ ├── CONTRIBUTE.md │ ├── COPYRIGHT.txt │ ├── debezium-connector-mysql-0.7.1.jar │ ├── debezium-core-0.7.1.jar │ ├── LICENSE.txt │ ├── mysql-binlog-connector-java-0.13.0.jar │ ├── mysql-connector-java-5.1.40.jar │ ├── README.md │ └── wkb-1.0.2.jar └── debezium-connector-postgres ├── CHANGELOG.md ├── CONTRIBUTE.md ├── COPYRIGHT.txt ├── debezium-connector-postgres-0.7.1.jar ├── debezium-core-0.7.1.jar ├── LICENSE.txt ├── postgresql-42.0.0.jar ├── protobuf-java-2.6.1.jar └── README.md
oc start-buildコマンドで、準備したディレクトリーを使用してイメージの新しいビルドを開始します。oc start-build my-connect-cluster-connect --from-dir ./my-plugins/
注記ビルドの名前は、デプロイされた Kafka Connect クラスターと同じになります。
- ビルドが完了したら、Kafka Connect のデプロイメントによって新しいイメージが自動的に使用されます。
2.5.3. コネクターの作成および管理
コネクタープラグインのコンテナーイメージを作成したら、Kafka Connect クラスターにコネクターインスタンスを作成する必要があります。その後、稼働中のコネクターインスタンスを設定、監視、および管理できます。
AMQ Streams では、コネクターの作成および管理に 2 つの API が提供されます。
-
KafkaConnectorリソース (KafkaConnectorsと呼ばれます) - Kafka Connect REST API
API を使用すると、以下を行うことができます。
- コネクターインスタンスのステータスの確認。
- 稼働中のコネクターの再設定。
- コネクターインスタンスのタスク数の増減。
-
失敗したタスクの再起動 (
KafkaConnectorリソースによってサポートされません)。 - コネクターインスタンスの一時停止。
- 一時停止したコネクターインスタンスの再開。
- コネクターインスタンスの削除。
2.5.3.1. KafkaConnector リソース
KafkaConnectors を使用すると、Kafka Connect のコネクターインスタンスを OpenShift ネイティブに作成および管理できるため、cURL などの HTTP クライアントが必要ありません。その他の Kafka リソースと同様に、コネクターの望ましい状態を OpenShift クラスターにデプロイされた KafkaConnector YAML ファイルに宣言し、コネクターインスタンスを作成します。
該当する KafkaConnector を更新して稼働中のコネクターインスタンスを管理した後、更新を適用します。該当する KafkaConnector を削除して、コネクターを削除します。
これまでのバージョンの AMQ Streams との互換性を維持するため、KafkaConnectors はデフォルトで無効になっています。Kafka Connect クラスターのために有効にするには、KafkaConnect リソースでアノテーションを使用する必要があります。手順は、「KafkaConnector リソースの有効化」 を参照してください。
KafkaConnectors が有効になると、Cluster Operator によって監視が開始されます。KafkaConnectors に定義された設定と一致するよう、稼働中のコネクターインスタンスの設定を更新します。
AMQ Streams には、examples/connector/source-connector.yaml という名前のサンプル KafkaConnector が含まれています。このサンプルを使用して、FileStreamSourceConnector を作成および管理できます。
2.5.3.2. Kafka Connect REST API の可用性
Kafka Connect REST API は、<connect-cluster-name>-connect-api サービスとして 8083 番ポートで使用できます。
KafkaConnectors が有効になっている場合、Kafka Connect REST API に直接手作業で追加された変更は Cluster Operator によって元に戻されます。
2.5.4. KafkaConnector リソースの Kafka Connect へのデプロイ
サンプル KafkaConnector を Kafka Connect クラスターにデプロイします。YAML の例によって FileStreamSourceConnector が作成され、ライセンスファイルの各行が my-topic という名前のトピックでメッセージとして Kafka に送信されます。
前提条件
-
KafkaConnectorsが有効になっている Kafka Connect デプロイメントが必要です。 - 稼働中の Cluster Operator が必要です。
手順
examples/connector/source-connector.yamlファイルを編集します。apiVersion: kafka.strimzi.io/v1alpha1 kind: KafkaConnector metadata: name: my-source-connector 1 labels: strimzi.io/cluster: my-connect-cluster 2 spec: class: org.apache.kafka.connect.file.FileStreamSourceConnector 3 tasksMax: 2 4 config: 5 file: "/opt/kafka/LICENSE" topic: my-topic # ...
OpenShift クラスターに
KafkaConnectorを作成します。oc apply -f examples/connector/source-connector.yaml
リソースが作成されたことを確認します。
oc get kctr --selector strimzi.io/cluster=my-connect-cluster -o name
2.6. Kafka MirrorMaker
Cluster Operator によって、1 つ以上の Kafka MirrorMaker のレプリカがデプロイされ、Kafka クラスターの間でデータが複製されます。このプロセスはミラーリングと言われ、Kafka パーティションのレプリケーションの概念と混同しないようにします。MirrorMaker は、ソースクラスターからメッセージを消費し、これらのメッセージをターゲットクラスターにパブリッシュします。
リソースの例や Kafka MirrorMaker のデプロイ形式に関する詳細は、「Kafka MirrorMaker の設定」を参照してください。
2.6.1. Kafka MirrorMaker のデプロイ
前提条件
- Kafka MirrorMaker をデプロイする前に、Cluster Operator をデプロイする必要があります。
手順
コマンドラインから Kafka MirrorMaker クラスターを作成します。
oc apply -f examples/kafka-mirror-maker/kafka-mirror-maker.yaml
その他のリソース
- Cluster Operator のデプロイメントに関する詳細は、「Cluster Operator」 を参照してください。
2.7. Kafka Bridge
Cluster Operator によって、1 つ以上の Kafka Bridge のレプリカがデプロイされ、HTTP API 経由で Kafka クラスターとクライアントの間でデータが送信されます。
リソースの例や Kafka Bridge のデプロイ形式に関する詳細は、「Kafka Bridge の設定」を参照してください。
2.7.1. Kafka Bridge を OpenShift クラスターへデプロイ
Cluster Operator を使用して、Kafka Bridge クラスターを OpenShift クラスターにデプロイできます。
前提条件
- Cluster Operator を OpenShift にデプロイする必要があります。
手順
oc applyコマンドを使用して、kafka-bridge.yamlファイルに基づいてKafkaBridgeリソースを作成します。oc apply -f examples/kafka-bridge/kafka-bridge.yaml
その他のリソース
2.8. サンプルクライアントのデプロイ
前提条件
- クライアントが接続する既存の Kafka クラスターが必要です。
手順
プロデューサーをデプロイします。
oc runを使用します。oc run kafka-producer -ti --image=registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0 --rm=true --restart=Never -- bin/kafka-console-producer.sh --broker-list cluster-name-kafka-bootstrap:9092 --topic my-topic
- プロデューサーが実行しているコンソールにメッセージを入力します。
- Enter を押してメッセージを送信します。
コンシューマーをデプロイします。
oc runを使用します。oc run kafka-consumer -ti --image=registry.redhat.io/amq7/amq-streams-kafka-24-rhel7:1.4.0 --rm=true --restart=Never -- bin/kafka-console-consumer.sh --bootstrap-server cluster-name-kafka-bootstrap:9092 --topic my-topic --from-beginning
- コンシューマーコンソールに受信メッセージが表示されることを確認します。
2.9. Topic Operator
Topic Operator は、OpenShift クラスター内で稼働している Kafka クラスター内の Kafka トピックを管理します。
2.9.1. Topic Operator
Topic Operator は、OpenShift リソースより Kafka クラスターのトピックを管理する方法を提供します。
Topic Operator のアーキテクチャー例
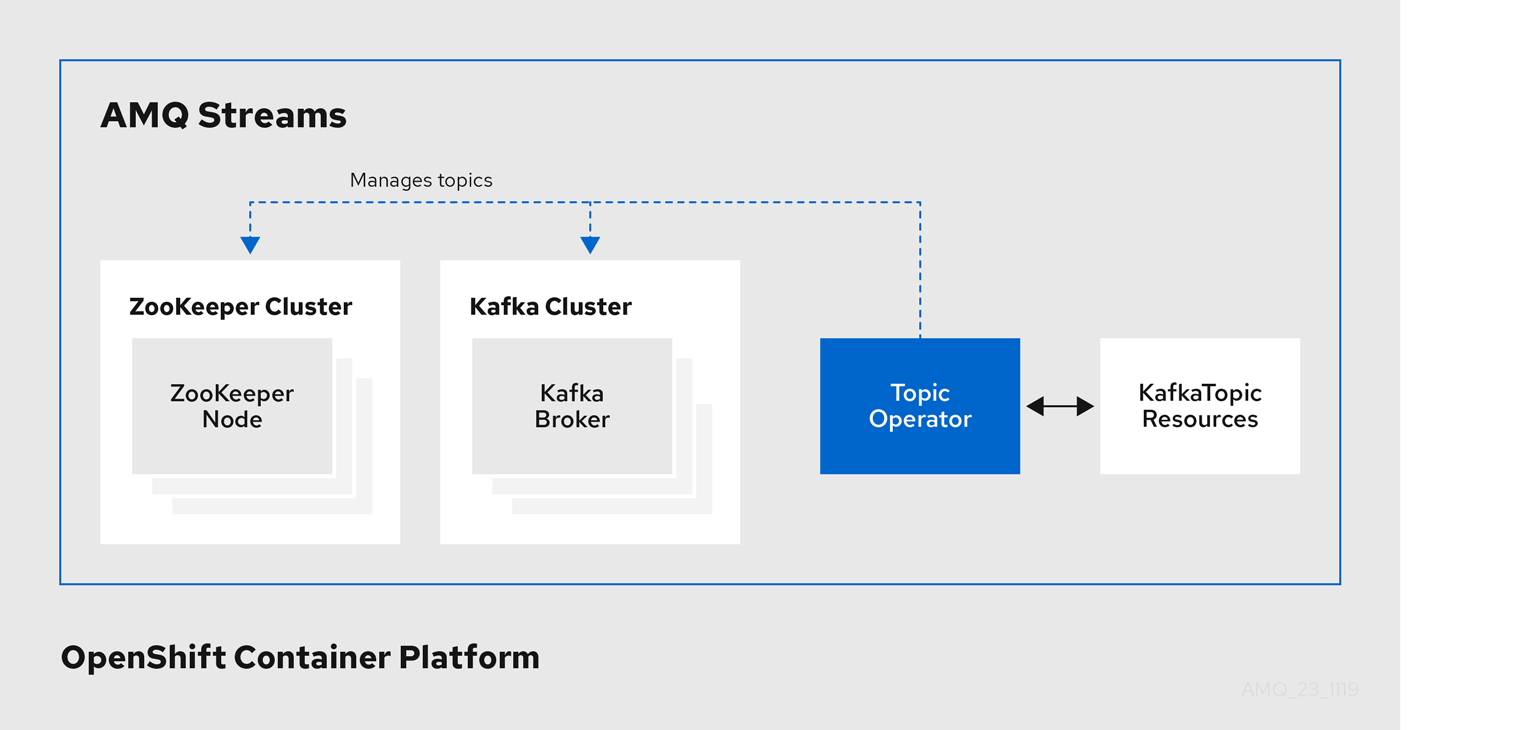
Topic Operator の役割は、対応する Kafka トピックと同期して Kafka トピックを記述する KafkaTopic OpenShift リソースのセットを保持することです。
KafkaTopic とトピックの関係は次のとおりです。
-
KafkaTopicが作成されると、Topic Operator によってトピックが作成されます。 -
KafkaTopicが削除されると、Topic Operator によってトピックが削除されます。 -
KafkaTopicが変更されると、Topick Operator によってトピックが更新されます。
上記と逆になるトピックと KafkaTopic の関係は次のとおりです。
-
トピックが Kafka クラスター内で作成されると、Operator によって
KafkaTopicが作成されます。 -
トピックが Kafka クラスターから削除されると、Operator によって
KafkaTopicが削除されます。 -
トピックが Kafka クラスターで変更されると、Operator によって
KafkaTopicが更新されます。
このため、KafkaTopic をアプリケーションのデプロイメントの一部として宣言でき、トピックの作成は Topic Operator によって行われます。アプリケーションは、必要なトピックからの作成または消費のみに対処する必要があります。
トピックが再設定された場合や、別の Kafka ノードに再割り当てされた場合、KafkaTopic は常に最新の状態になります。
2.9.2. Cluster Operator を使用した Topic Operator のデプロイ
この手順では、Cluster Operator を使用して Topic Operator をデプロイする方法を説明します。AMQ Streams によって管理されない Kafka クラスターを Topic Operator と使用する場合は、Topic Operator をスタンドアロンコンポーネントとしてデプロイする必要があります。詳細は「スタンドアロン Topic Operator のデプロイ」を参照してください。
前提条件
- 稼働中の Cluster Operator が必要です。
-
作成または更新する
Kafkaリソースが必要です。
手順
Kafka.spec.entityOperatorオブジェクトがKafkaリソースに存在することを確認します。このオブジェクトによって Entity Operator が設定されます。apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: #... entityOperator: topicOperator: {} userOperator: {}-
「
EntityTopicOperatorSpecスキーマ参照」 で説明されたプロパティーを使用して、Topic Operator を設定します。 OpenShift で Kafka リソースを作成または更新します。
oc applyを使用します。oc apply -f your-file
その他のリソース
- Cluster Operator のデプロイメントに関する詳細は、「Cluster Operator」 を参照してください。
- Entity Operator のデプロイメントに関する詳細は、「Entitiy Operator」 を参照してください。
-
Cluster Operator によってデプロイされた場合に Topic Operator の設定に使用される
Kafka.spec.entityOperatorオブジェクトに関する詳細は、「EntityOperatorSpecスキーマ参照」 を参照してください。
2.10. User Operator
User Operator は、OpenShift クラスター内で稼働している Kafka クラスター内の Kafka ユーザーを管理します。
2.10.1. User Operator
User Operator は、Kafka ユーザーが記述される KafkaUser リソースを監視して Kafka クラスターの Kafka ユーザーを管理し、Kafka ユーザーが Kafka クラスターで適切に設定されるようにします。
たとえば、KafkaUser とユーザーの関係は次のようになります。
-
KafkaUserが作成されると、User Operator によって記述されるユーザーが作成されます。 -
KafkaUserが削除されると、User Operator によって記述されるユーザーが削除されます。 -
KafkaUserが変更されると、User Operator によって記述されるユーザーが更新されます。
User Operator は Topic Operator とは異なり、Kafka クラスターからの変更は OpenShift リソースと同期されません。アプリケーションで直接 Kafka トピックを Kafka で作成することは可能ですが、ユーザーが User Operator と同時に直接 Kafka クラスターで管理されることは想定されません。
User Operator では、アプリケーションのデプロイメントの一部として KafkaUser リソースを宣言できます。ユーザーの認証および承認メカニズムを指定できます。たとえば、ユーザーがブローカーへのアクセスを独占しないようにするため、Kafka リソースの使用を制御する ユーザークォータ を設定することもできます。
ユーザーが作成されると、ユーザークレデンシャルが Secret に作成されます。アプリケーションはユーザーとそのクレデンシャルを使用して、認証やメッセージの生成または消費を行う必要があります。
User Operator は 認証のクレデンシャルを管理する他に、KafkaUser 宣言にユーザーのアクセス権限の記述を含めることで承認も管理します。
2.10.2. Cluster Operator を使用した User Operator のデプロイ
前提条件
- 稼働中の Cluster Operator が必要です。
-
作成または更新する
Kafkaリソースが必要です。
手順
-
Kafkaリソースを編集し、希望どおりに User Operator を設定するKafka.spec.entityOperator.userOperatorオブジェクトが含まれるようにします。 OpenShift で Kafka リソースを作成または更新します。
oc applyを使用してこれを行うことができます。oc apply -f your-file
その他のリソース
- Cluster Operator のデプロイメントに関する詳細は、「Cluster Operator」 を参照してください。
-
Cluster Operator によってデプロイされた場合に Topic Operator の設定に使用される
Kafka.spec.entityOperatorオブジェクトに関する詳細は「EntityOperatorSpecスキーマ参照」を参照してください。
2.11. Strimzi 管理者
AMQ Streams には複数のカスタムリソースが含まれています。デフォルトでは、これらのリソースを作成、編集、および削除する権限は OpenShift クラスター管理者に制限されます。クラスター管理者以外に AMQ Streams リソースを管理する権限を与える場合は、Strimzi 管理者ロールを割り当てる必要があります。
2.11.1. Strimzi 管理者の指名
前提条件
-
AMQ Streams の
CustomResourceDefinitionsがインストールされている必要があります。
手順
OpenShift で
strimzi-adminクラスターロールを作成します。oc applyを使用します。oc apply -f install/strimzi-admin
strimzi-adminClusterRoleを OpenShift クラスターの 1 人以上の既存ユーザーに割り当てます。oc createを使用します。oc create clusterrolebinding strimzi-admin --clusterrole=strimzi-admin --user=user1 --user=user2
2.12. コンテナーイメージ
AMQ Streams のコンテナーイメージは Red Hat Container Catalog にあります。AMQ Streams によって提供されるインストール YAML ファイルは、直接 Red Hat Container Catalog からイメージをプルします。
Red Hat Container Catalog にアクセスできない場合や独自のコンテナーリポジトリーを使用する場合は以下を行います。
- リストにある すべての コンテナーイメージをプルします。
- 独自のレジストリーにプッシュします。
- インストール YAML ファイルのイメージ名を更新します。
リリースに対してサポートされる各 Kafka バージョンには別のイメージがあります。
| コンテナーイメージ | namespace/リポジトリー | 説明 |
|---|---|---|
| Kafka |
| 次を含む、Kafka を実行するための AMQ Streams イメージ。
|
| Operator |
| Operator を実行するための AMQ Streams イメージ。
|
| Kafka Bridge |
| AMQ Streams Kafka Bridge を稼働するための AMQ Streams イメージ |