
OpenShift での AMQ Streams のデプロイおよびアップグレード
OpenShift Container Platform 上で AMQ Streams 1.6 を使用
概要
第1章 デプロイメントの概要
AMQ Streams は、OpenShift クラスターで Apache Kafka を実行するプロセスを簡素化します。
本ガイドでは、AMQ Streams をデプロイおよびアップグレードするすべての方法の手順を取り上げ、デプロイメントの対象や、OpenShift クラスターで Apache Kafka を実行するために必要なデプロイメントの順序について説明します。
デプロイメントの手順を説明する他に、デプロイメントを準備および検証するためのデプロイメントの前および後の手順についても説明します。追加のデプロイメントオプションには、メトリクスの導入手順が含まれます。アップグレードの手順は、「AMQ Streams および Kafka のアップグレード」を参照してください。
AMQ Streams は、パブリックおよびプライベートクラウドからデプロイメントを目的とするローカルデプロイメントまで、ディストリビューションに関係なくすべてのタイプの OpenShift クラスターで動作するよう設計されています。
1.1. AMQ Streams による Kafka のサポート
AMQ Streams は、Kafka を OpenShift で実行するためのコンテナーイメージおよび Operator を提供します。AMQ Streams Operator は、AMQ Streams の実行に必要です。AMQ Streams で提供される Operator は、Kafka を効果的に管理するために、専門的なオペレーション情報で目的に合うよう構築されています。
Operator は以下のプロセスを単純化します。
- Kafka クラスターのデプロイおよび実行。
- Kafka コンポーネントのデプロイおよび実行。
- Kafka へアクセスするための設定。
- Kafka へのアクセスをセキュア化。
- Kafka のアップグレード。
- ブローカーの管理。
- トピックの作成および管理。
- ユーザーの作成および管理。
1.2. AMQ Streams の Operator
AMQ Streams では Operator を使用して Kafka をサポートし、Kafka のコンポーネントおよび依存関係を OpenShift にデプロイして管理します。
Operator は、OpenShift アプリケーションのパッケージ化、デプロイメント、および管理を行う方法です。AMQ Streams Operator は OpenShift の機能を拡張し、Kafka デプロイメントに関連する共通タスクや複雑なタスクを自動化します。Kafka 操作の情報をコードに実装することで、Kafka の管理タスクは簡素化され、必要な手動の作業が少なくなります。
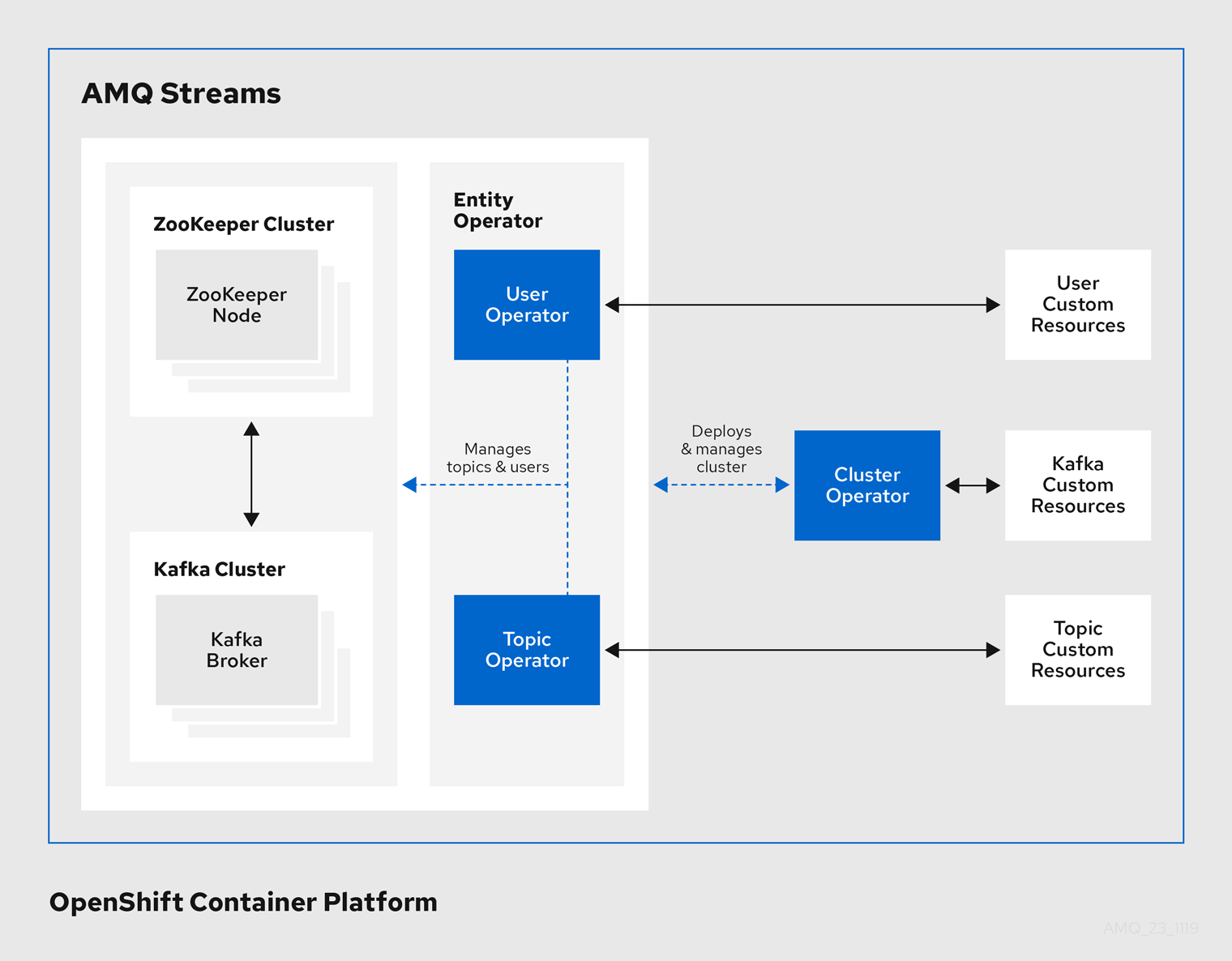
Operator
AMQ Streams は、OpenShift クラスター内で実行中の Kafka クラスターを管理するための Operator を提供します。
- Cluster Operator
- Apache Kafka クラスター、Kafka Connect、Kafka MirrorMaker、Kafka Bridge、Kafka Exporter、および Entity Operator をデプロイおよび管理します。
- Entitiy Operator
- Topic Operator および User Operator を構成します。
- Topic Operator
- Kafka トピックを管理します。
- User Operator
- Kafka ユーザーを管理します。
Cluster Operator は、Kafka クラスターと同時に、Topic Operator および User Operator を Entity Operator 設定の一部としてデプロイできます。
AMQ Streams アーキテクチャー内の Operator
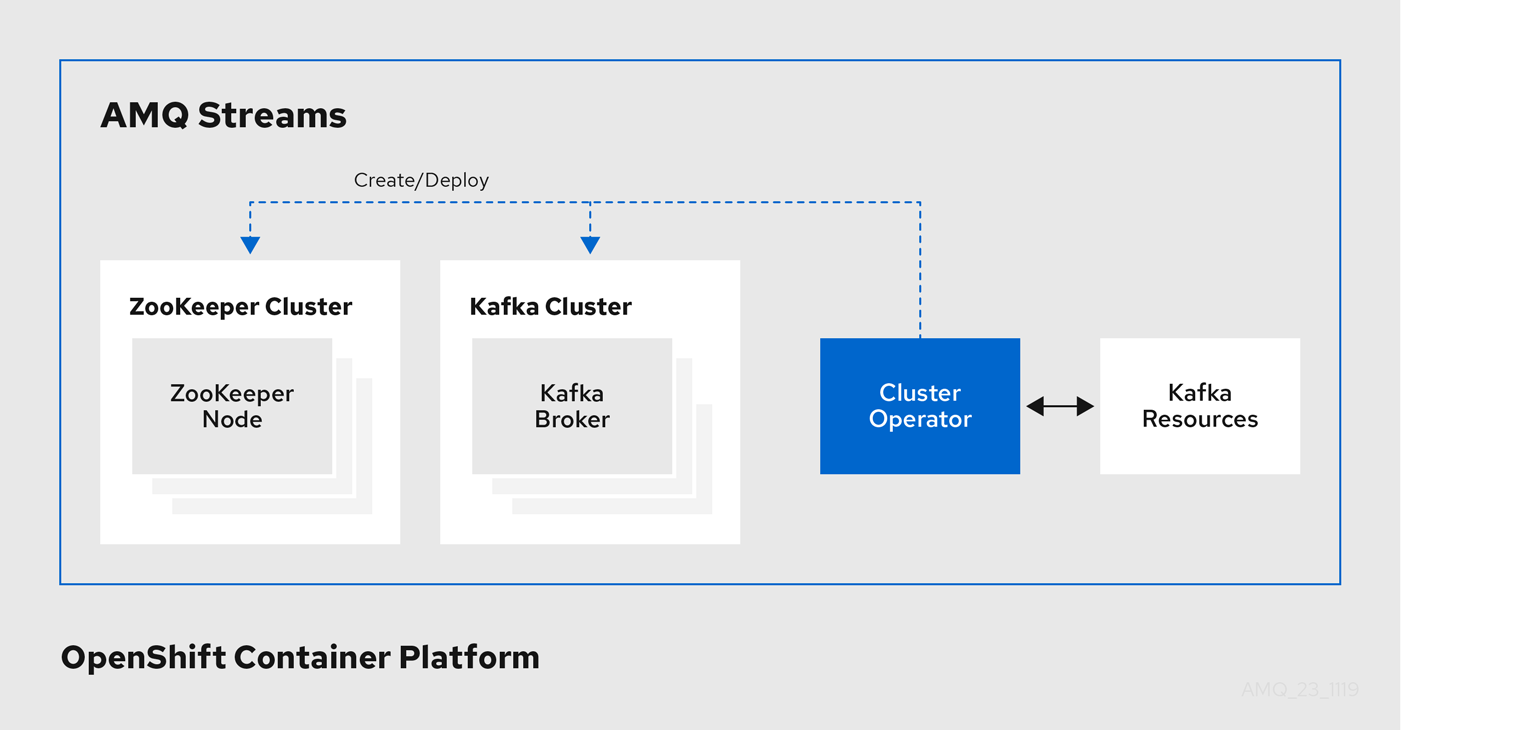
1.2.1. Cluster Operator
AMQ Streams では、Cluster Operator を使用して以下のクラスターをデプロイおよび管理します。
- Kafka (ZooKeeper、Entity Operator、Kafka Exporter、Cruise Control を含む)
- Kafka Connect
- Kafka MirrorMaker
- Kafka Bridge
クラスターのデプロイメントにはカスタムリソースが使用されます。
たとえば、以下のように Kafka クラスターをデプロイします。
-
クラスター設定のある
Kafkaリソースが OpenShift クラスター内で作成されます。 -
Kafkaリソースに宣言された内容を基にして、該当する Kafka クラスターが Cluster Operator によってデプロイされます。
Cluster Operator で以下もデプロイできます (Kafka リソースの設定より)。
-
KafkaTopicカスタムリソースより Operator スタイルのトピック管理を提供する Topic Operator -
KafkaUserカスタムリソースより Operator スタイルのユーザー管理を提供する User Operator
デプロイメントの Entity Operator 内の Topic Operator および User Operator 関数。
Cluster Operator のアーキテクチャー例
1.2.2. Topic Operator
Topic Operator は、OpenShift リソースより Kafka クラスターのトピックを管理する方法を提供します。
Topic Operator のアーキテクチャー例
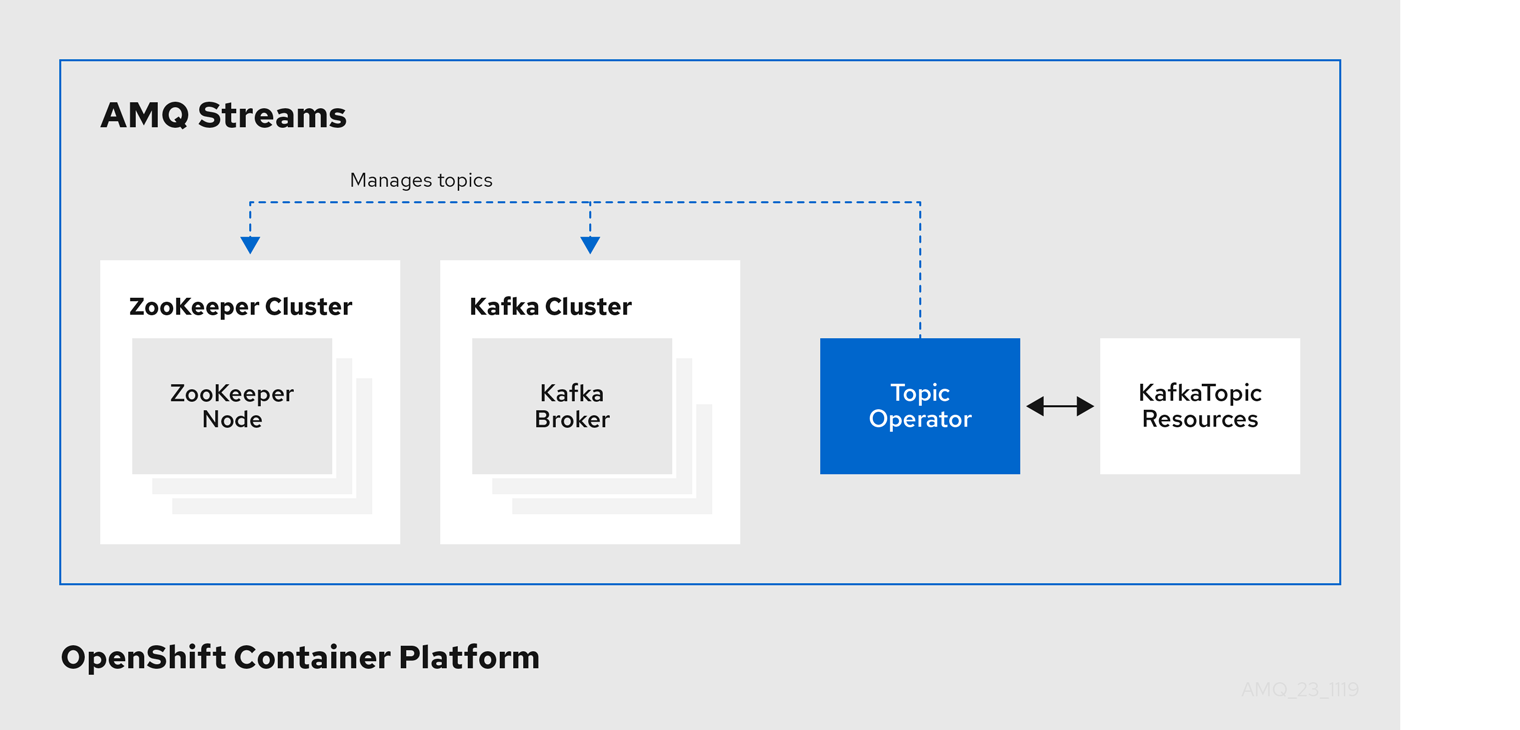
Topic Operator の役割は、対応する Kafka トピックと同期して Kafka トピックを記述する KafkaTopic OpenShift リソースのセットを保持することです。
KafkaTopic とトピックの関係は次のとおりです。
- KafkaTopic が作成されると、Topic Operator によってトピックが作成されます。
- が削除されると、Topic Operator によってトピックが削除されます。
- が変更されると、Topick Operator によってトピックが更新されます。
上記と逆になるトピックと KafkaTopic の関係は次のとおりです。
-
トピックが Kafka クラスター内で作成されると、Operator によって
KafkaTopicが作成されます。 -
トピックが Kafka クラスターから削除されると、Operator によって
KafkaTopicが削除されます。 -
トピックが Kafka クラスターで変更されると、Operator によって
KafkaTopicが更新されます。
このため、KafkaTopic をアプリケーションのデプロイメントの一部として宣言でき、トピックの作成は Topic Operator によって行われます。アプリケーションは、必要なトピックからの作成または消費のみに対処する必要があります。
トピックが再設定された場合や、別の Kafka ノードに再割り当てされた場合、KafkaTopic は常に最新の状態になります。
1.2.3. User Operator
User Operator は、Kafka ユーザーが記述される KafkaUser リソースを監視して Kafka クラスターの Kafka ユーザーを管理し、Kafka ユーザーが Kafka クラスターで適切に設定されるようにします。
たとえば、KafkaUser とユーザーの関係は次のようになります。
- KafkaUser が作成されると、User Operator によって記述されるユーザーが作成されます。
- が削除されると、User Operator によって記述されるユーザーが削除されます。
- が変更されると、User Operator によって記述されるユーザーが更新されます。
User Operator は Topic Operator とは異なり、Kafka クラスターからの変更は OpenShift リソースと同期されません。アプリケーションで直接 Kafka トピックを Kafka で作成することは可能ですが、ユーザーが User Operator と同時に直接 Kafka クラスターで管理されることは想定されません。
User Operator では、アプリケーションのデプロイメントの一部として KafkaUser リソースを宣言できます。ユーザーの認証および承認メカニズムを指定できます。たとえば、ユーザーがブローカーへのアクセスを独占しないようにするため、Kafka リソースの使用を制御する ユーザークォータ を設定することもできます。
ユーザーが作成されると、ユーザークレデンシャルが Secret に作成されます。アプリケーションはユーザーとそのクレデンシャルを使用して、認証やメッセージの生成または消費を行う必要があります。
User Operator は 認証のクレデンシャルを管理する他に、KafkaUser 宣言にユーザーのアクセス権限の記述を含めることで承認も管理します。
1.3. AMQ Streams のカスタムリソース
AMQ Streams を使用した Kafka コンポーネントの OpenShift クラスターへのデプロイメントは、カスタムリソースの適用により高度な設定が可能です。カスタムリソースは、OpenShift リソースを拡張するために CRD (カスタムリソース定義、Custom Resource Definition) によって追加される API のインスタンスとして作成されます。
CRD は、OpenShift クラスターでカスタムリソースを記述するための設定手順として機能し、デプロイメントで使用する Kafka コンポーネントごとに AMQ Streams で提供されます。CRD およびカスタムリソースは YAML ファイルとして定義されます。YAML ファイルのサンプルは AMQ Streams ディストリビューションに同梱されています。
また、CRD を使用すると、CLI へのアクセスや設定検証などのネイティブ OpenShift 機能を AMQ Streams リソースで活用することもできます。
1.3.1. AMQ Streams カスタムリソースの例
AMQ Streams 固有リソースのインスタンス化および管理に使用されるスキーマを定義するため、CRD をクラスターに 1 度インストールする必要があります。
CRD をインストールして新規カスタムリソースタイプをクラスターに追加した後に、その仕様に基づいてリソースのインスタンスを作成できます。
クラスターの設定によりますが、インストールには通常、クラスター管理者権限が必要です。
カスタムリソースの管理は、AMQ Streams 管理者のみが行えます。詳細は、『Deploying and Upgrading AMQ Streams on OpenShift』の「Designating AMQ Streams administrators」を参照してください。
kind:Kafka などの新しい kind リソースは、OpenShift クラスター内で CRD によって定義されます。
Kubernetes API サーバーを使用すると、kind を基にしたカスタムリソースの作成が可能になり、カスタムリソースが OpenShift クラスターに追加されたときにカスタムリソースの検証および格納方法を CRD から判断します。
CRD が削除されると、そのタイプのカスタムタイプも削除されます。さらに、Pod や Statefulset などのカスタムリソースによって作成されたリソースも削除されます。
AMQ Streams 固有の各カスタムリソースは、リソースの kind の CRD によって定義されるスキーマに準拠します。AMQ Streams コンポーネントのカスタムリソースには、specで定義される共通の設定プロパティーがあります。
CRD とカスタムリソースの関係を理解するため、Kafka トピックの CRD の例を見てみましょう。
Kafka トピックの CRD
apiVersion: kafka.strimzi.io/v1beta1 kind: CustomResourceDefinition metadata: 1 name: kafkatopics.kafka.strimzi.io labels: app: strimzi spec: 2 group: kafka.strimzi.io versions: v1beta1 scope: Namespaced names: # ... singular: kafkatopic plural: kafkatopics shortNames: - kt 3 additionalPrinterColumns: 4 # ... subresources: status: {} 5 validation: 6 openAPIV3Schema: properties: spec: type: object properties: partitions: type: integer minimum: 1 replicas: type: integer minimum: 1 maximum: 32767 # ...
- 1
- CRD を識別するためのトピック CRD、その名前および名前のメタデータ。
- 2
- この CRD に指定された項目には、トピックの API にアクセスするため URL に使用されるグルShortNameープ (ドメイン) 名、複数名、およびサポートされるスキーマバージョンが含まれます。他の名前は、CLI のインスタンスリソースを識別するために使用されます。たとえば、
oc get kafkaShortNametopic my-topicやoc get kafkatopicsなどです。 - 3
- ShortName は CLI コマンドで使用できます。たとえば、
oc get kafkatopicの代わりにoc get ktを略名として使用できます。 - 4
- カスタムリソースで
getコマンドを使用する場合に示される情報。 - 5
- リソースの スキーマ参照 に記載されている CRD の現在の状態。
- 6
- openAPIV3Schema 検証によって、トピックカスタムリソースの作成が検証されます。たとえば、トピックには 1 つ以上のパーティションと 1 つのレプリカが必要です。
ファイル名に、インデックス番号とそれに続く「Crd」が含まれるため、AMQ Streams インストールファイルと提供される CRD YAML ファイルを識別できます。
KafkaTopic カスタムリソースに該当する例は次のとおりです。
Kafka トピックカスタムリソース
apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaTopic 1 metadata: name: my-topic labels: strimzi.io/cluster: my-cluster 2 spec: 3 partitions: 1 replicas: 1 config: retention.ms: 7200000 segment.bytes: 1073741824 status: conditions: 4 lastTransitionTime: "2019-08-20T11:37:00.706Z" status: "True" type: Ready observedGeneration: 1 / ...
- 1
kindおよびapiVersionによって、インスタンスであるカスタムリソースの CRD が特定されます。- 2
- トピックまたはユーザーが属する Kafka クラスターの名前 (
Kafkaリソースの名前と同じ) を定義する、KafkaTopicおよびKafkaUserリソースのみに適用可能なラベル。 - 3
- 指定内容には、トピックのパーティション数およびレプリカ数や、トピック自体の設定パラメーターが示されています。この例では、メッセージがトピックに保持される期間や、ログのセグメントファイルサイズが指定されています。
- 4
KafkaTopicリソースのステータス条件。lastTransitionTimeでtype条件がReadyに変更されています。
プラットフォーム CLI からカスタムリソースをクラスターに適用できます。カスタムリソースが作成されると、Kubernetes API の組み込みリソースと同じ検証が使用されます。
KafkaTopic の作成後、Topic Operator は通知を受け取り、該当する Kafka トピックが AMQ Streams で作成されます。
1.4. AMQ Streams のインストール方法
AMQ Streams を OpenShift にインストールする方法は 2 つあります。
| インストール方法 | 説明 | サポート対象バージョン |
|---|---|---|
| インストールアーティファクト (YAML ファイル) |
AMQ Streams のダウンロードサイト から | OpenShift 3.11 以上 |
| OperatorHub | OperatorHub で AMQ Streams Operator を使用し、Cluster Operator を単一またはすべての namespace にデプロイします。 | OpenShift 4.x のみ |
柔軟性が重要な場合は、インストールアーティファクトによる方法を選択します。OpenShift 4 Web コンソールを使用して標準設定で AMQ Streams を OpenShift 4 にインストールする場合は、OperatorHub による方法を選択します。OperatorHub を使用すると、自動更新も利用できます。
どちらの方法でも、Cluster Operator は OpenShift クラスターにデプロイされ、提供される YAML サンプルファイルを使用して、Kafka クラスターから順に AMQ Streams の他のコンポーネントをデプロイする準備が整います。
AMQ Streams インストールアーティファクト
AMQ Streams インストールアーティファクトには、OpenShift にデプロイできるさまざまな YAML ファイルが含まれ、ocを使用して以下を含むカスタムリソースが作成されます。
- デプロイメント
- Custom Resource Definition (CRD)
- ロールおよびロールバインディング
- サービスアカウント
YAML インストールファイルは、Cluster Operator、Topic Operator、User Operator、および Strimzi Admin ロールに提供されます。
OperatorHub
OpenShift 4 では、Operator Lifecycle Manager (OLM) を使用することにより、クラスター管理者はクラスター全体で実行されるすべての Operator やそれらの関連サービスをインストール、更新、および管理できます。OLM は、Kubernetes のネイティブアプリケーション (Operator) を効率的に自動化された拡張可能な方法で管理するために設計されたオープンソースツールキットの Operator Framework の一部です。
OperatorHub は OpenShift 4 Web コンソールの一部です。クラスター管理者はこれを使用して Operator を検出、インストール、およびアップグレードできます。Operator は OperatorHub からプルでき、単一の (プロジェクト) namespace またはすべての (プロジェクト) namespace への OpenShift クラスターにインストールできます。Operator は OLM で管理できます。エンジニアリングチームは OLM を使用して、独自に開発、テスト、および本番環境でソフトウェアを管理できます。
OperatorHub は、バージョン 4 未満の OpenShift では使用できません。
AMQ Streams Operator
AMQ Streams Operator は OperatorHub からインストールできます。AMQ Streams Operator のインストール後、必要な CRD およびロールベースアクセス制御 (RBAC) リソースと共に Cluster Operator が OpenShift クラスターにデプロイされます。
その他のリソース
インストールアーティファクトを使用した AMQ Streams のインストール:
OperatorHub からの AMQ Streams のインストール:
- 「OperatorHub からの Cluster Operator のデプロイ」
- OpenShift ドキュメント『Operator』
第2章 AMQ Streams でデプロイされるもの
Apache Kafka コンポーネントは、AMQ Streams ディストリビューションを使用して OpenShift にデプロイするために提供されます。Kafka コンポーネントは通常、クラスターとして実行され、可用性を確保します。
Kafka コンポーネントが組み込まれた通常のデプロイメントには以下が含まれます。
- ブローカーノードの Kafka クラスター
- レプリケートされた ZooKeeper インスタンスの zookeeper クラスター
- 外部データ接続用の Kafka Connect クラスター
- セカンダリークラスターで Kafka クラスターをミラーリングする Kafka MirrorMaker クラスター
- 監視用に追加のKafka メトリクスデータを抽出する Kafka Exporter
- Kafka クラスターに対して HTTP ベースの要求を行う Kafka Bridge
少なくとも Kafka および ZooKeeper は必要ですが、上記のコンポーネントがすべて必須なわけではありません。MirrorMaker や Kafka Connect など、一部のコンポーネントでは Kafka なしでデプロイできます。
2.1. デプロイメントの順序
OpenShift クラスターへのデプロイメントで必要な順序は次のとおりです。
- Cluster Operator をデプロイし、Kafka クラスターを管理します。
- ZooKeeper クラスターとともに Kafka クラスターをデプロイし、Topic Operator および User Operator がデプロイメントに含まれるようにします。
任意で以下をデプロイします。
- Topic Operator および User Operator (Kafka クラスターとともにデプロイしなかった場合)
- Kafka Connect
- Kafka MirrorMaker
- Kafka Bridge
- メトリクスを監視するためのコンポーネント
2.2. その他のデプロイメント設定オプション
本書のデプロイメント手順では、AMQ Streams で提供されるインストール YAML ファイルのサンプルを使用するデプロイメントを説明します。手順では、検討する必要がある重要な設定事項について説明しますが、使用できる設定オプションをすべて取り上げるわけではありません。
カスタムリソースを使用するとデプロイメントを改良できます。
AMQ Streams をデプロイする前に、Kafka コンポーネントに使用できる設定オプションを確認できます。カスタムリソースによる設定の詳細は、『AMQ Streams on OpenShift の使用』の「デプロイメント設定」を参照してください。
2.2.1. Kafka のセキュリティー
デプロイメントでは、Cluster Operator はクラスター内でのデータの暗号化および認証に対して自動で TLS 証明書を設定します。
AMQ Streams では、『AMQ Streams on OpenShift の使用』で説明する 暗号化、認証、および 承認 の追加の設定オプションが提供されます。
- Kafka リソースを設定 して、Kafka クラスターとクライアント間のデータ交換をセキュアにします。
- 承認サーバーが OAuth 2.0 認証 および OAuth 2.0 承認 を使用するように、デプロイメントを設定します。
- 独自の証明書を使用して Kafka をセキュアにします。
2.2.2. デプロイメントの監視
AMQ Streams は、デプロイメントを監視する追加のデプロイメントオプションをサポートします。
- Prometheus および Grafana を Kafka クラスターでデプロイし、メトリクスを抽出して、Kafka コンポーネントを監視します。
- Kafka Exporter を Kafka クラスターでデプロイし、特にコンシューマーラグの監視に関する追加のメトリクスを抽出します。
- 『AMQ Streams on OpenShift の使用』で説明するように、分散トレーシングを設定して、エンドツーエンドのメッセージ追跡を行います。
第3章 AMQ Streams デプロイメントの準備
ここでは、AMQ Streams デプロイメントを準備する方法を説明します。
本ガイドのコマンドを実行するには、クラスターユーザーに RBAC (ロールベースアクセス制御) および CRD を管理する権限を付与する必要があります。
3.1. デプロイメントの前提条件
AMQ Streams のデプロイする場合、以下を確認してください。
OpenShift 3.11 以降のクラスターが利用できること。
AMQ Streams は Strimzi 0.20.x をベースとしています。
-
ocコマンドラインツールがインストールされ、稼働中のクラスターに接続するように設定されていること。
AMQ Streams は、OpenShift 固有の一部機能をサポートします。そのようなインテグレーションは OpenShift ユーザーに有用で、標準の Kubernetes を使用した同等の実装はありません。
3.2. AMQ Streams リリースアーティファクトのダウンロード
AMQ Streams をインストールするには、AMQ Streams のダウンロードページ から amq-streams-<version>-ocp-install-examples.zip ファイルをダウンロードし、リリースアーティファクトを展開します。
AMQ Streams のリリースアーティファクトには、YAML ファイルが含まれています。これらのファイルは、AMQ Streams コンポーネントの OpenShift へのデプロイ、共通の操作の実行、および Kafka クラスターの設定に便利です。
ocを使用して、ダウンロードした ZIP ファイルの install/cluster-operator フォルダーから Cluster Operator をデプロイします。Cluster Operator のデプロイメントおよび設定に関する詳細は、「Cluster Operator のデプロイ」 を参照してください。
また、AMQ Streams Cluster Operator によって管理されない Kafka クラスターをトピックおよび User Operator のスタンドアロンインストールと共に使用する場合は、install/topic-operator および install/user-operator フォルダーからデプロイできます。
AMQ Streams コンテナーイメージは、Red Hat Ecosystem Catalog から使用することもできます。しかし、提供される YAML ファイルを使用して AMQ Streams をデプロイすることが推奨されます。
3.3. コンテナーイメージを独自のレジストリーにプッシュ
AMQ Streams のコンテナーイメージは Red Hat Ecosystem Catalog にあります。AMQ Streams によって提供されるインストール YAML ファイルは、直接 Red Hat Ecosystem Catalog からイメージをプルします。
Red Hat Ecosystem Catalog にアクセスできない場合や独自のコンテナーリポジトリーを使用する場合は以下を行います。
- リストにある すべての コンテナーイメージをプルします。
- 独自のレジストリーにプッシュします。
- インストール YAML ファイルのイメージ名を更新します。
リリースに対してサポートされる各 Kafka バージョンには別のイメージがあります。
| コンテナーイメージ | namespace/リポジトリー | 説明 |
|---|---|---|
| Kafka |
| 次を含む、Kafka を実行するための AMQ Streams イメージ。
|
| 演算子 |
| Operator を実行するための AMQ Streams イメージ。
|
| Kafka Bridge |
| AMQ Streams Kafka Bridge を稼働するための AMQ Streams イメージ |
3.4. AMQ Streams の管理者の指名
AMQ Streams では、デプロイメントの設定にカスタムリソースが提供されます。デフォルトでは、これらのリソースを表示、作成、編集、および削除する権限は OpenShift クラスター管理者に制限されます。AMQ Streams には、このような権限を他のユーザーに割り当てするために使用する 2 つのクラスターロールがあります。
-
strimzi-viewロールを指定すると、ユーザーは AMQ Streams リソースを表示できます。 -
strimzi-adminロールを指定すると、ユーザーは AMQ Streams リソースを作成、編集、または削除することもできます。
これらのロールをインストールすると、これらの権限は自動でデフォルトの OpenShift クラスターロールに集約 (追加) されます。strimzi-view は view ロールに集約され、strimzi-admin は edit および admin ロールに集約されます。集約により、これらのロールを同様の権限を持つユーザーに割り当てする必要がない可能性があります。
以下の手順では、クラスター管理者でないユーザーが AMQ Streams リソースを管理できるようにする strimzi-admin ロールの割り当て方法を説明します。
システム管理者は、Cluster Operator のデプロイ後に AMQ Streams の管理者を指名できます。
前提条件
- Cluster Operator でデプロイとデプロイされた CRD (カスタムリソース定義) を管理する AMQ Streams の CRD リソースおよび RBAC (ロールベースアクセス制御) リソースが必要です。
手順
OpenShift で
strimzi-viewおよびstrimzi-adminクラスターロールを作成します。oc apply -f install/strimzi-admin
必要な場合は、ユーザーに必要なアクセス権限を付与するロールを割り当てます。
oc create clusterrolebinding strimzi-admin --clusterrole=strimzi-admin --user=user1 --user=user2
第4章 AMQ Streams のデプロイ
AMQ Streams のデプロイメント環境の準備 が整ったら、以下を実行できます。
- Kafka クラスターの作成方法
要件に応じてその他の Kafka コンポーネントをデプロイする任意の手順。
これらの手順は、OpenShift クラスターが利用可能で稼働していることを想定しています。
AMQ Streams は AMQ Streams Strimzi 0.20.x をベースとしています。ここでは、OpenShift 3.11 以降に AMQ Streams をデプロイする方法を説明します。
本ガイドのコマンドを実行するには、クラスターユーザーに RBAC (ロールベースアクセス制御) および CRD を管理する権限を付与する必要があります。
4.1. Kafka クラスターの作成
Kafka クラスターを作成するには、Cluster Operator をデプロイして Kafka クラスターを管理し、Kafka クラスターをデプロイします。
Kafka リソースを使用して Kafka クラスターをデプロイするときに、Topic Operator および User Operator を同時にデプロイできます。この代わりに、AMQ Streams ではない Kafka クラスターを使用している場合は、Topic Operator および User Operator をスタンドアロンコンポーネントとしてデプロイすることもできます。
Kafka クラスターを Topic Operator および User Operator とデプロイ
AMQ Streams によって管理される Kafka クラスターを Topic Operator および User Operator と使用する場合は、このデプロイメント手順を実行します。
- Cluster Operator をデプロイします。
Cluster Operator を使用して以下をデプロイします。
スタンドアロン Topic Operator および User Operator のデプロイ
AMQ Streams によって管理されない Kafka クラスターを Topic Operator および User Operator と使用する場合は、このデプロイメント手順を実行します。
4.1.1. Cluster Operator のデプロイ
Cluster Operator は、OpenShift クラスター内で Apache Kafka クラスターのデプロイおよび管理を行います。
本セクションの手順は以下を説明します。
以下を監視するよう Cluster Operator をデプロイする方法。
代替のデプロイメント
4.1.1.1. Cluster Operator デプロイメントの監視オプション
Cluster Operator の稼働中に、Kafka リソースの更新に対する監視が開始されます。
Cluster Operator をデプロイして、以下からの Kafka リソースの監視を選択できます。
- 単一の namespace (Cluster Operator が含まれる同じ namespace)
- 複数の namespace
- すべての namespace
AMQ Streams では、デプロイメントの処理を簡単にするため、YAML ファイルのサンプルが提供されます。
Cluster Operator では、以下のリソースの変更が監視されます。
-
Kafka クラスターの
Kafka。 -
Kafka Connect クラスターの
KafkaConnect。 -
Source2Image がサポートされる Kafka Connect クラスターの
KafkaConnectS2I。 -
Kafka Connect クラスターでコネクターを作成および管理するための
KafkaConnector。 -
Kafka MirrorMaker インスタンスの
KafkaMirrorMaker。 -
Kafka Bridge インスタンスの
KafkaBridge。
OpenShift クラスターでこれらのリソースの 1 つが作成されると、Operator によってクラスターの詳細がリソースより取得されます。さらに、StatefulSet、Service、および ConfigMap などの必要な OpenShift リソースが作成され、リソースの新しいクラスターの作成が開始されます。
Kafka リソースが更新されるたびに、リソースのクラスターを構成する OpenShift リソースで該当する更新が Operator によって実行されます。
クラスターの望ましい状態がリソースのクラスターに反映されるようにするため、リソースへのパッチ適用後またはリソースの削除後にリソースが再作成されます。この操作は、サービスの中断を引き起こすローリングアップデートの原因となる可能性があります。
リソースが削除されると、Operator によってクラスターがアンデプロイされ、関連する OpenShift リソースがすべて削除されます。
4.1.1.2. 単一の namespace を監視対象とする Cluster Operator のデプロイメント
この手順では、OpenShift クラスターの単一の namespace で AMQ Streams リソースを監視するように Cluster Operator をデプロイする方法を説明します。
前提条件
-
この手順では、
CustomResourceDefinitions、ClusterRoles、およびClusterRoleBindingsを作成できる OpenShift ユーザーアカウントを使用する必要があります。通常、OpenShift クラスターでロールベースアクセス制御 (RBAC) を使用する場合、これらのリソースを作成、編集、および削除する権限を持つユーザーはsystem:adminなどの OpenShift クラスター管理者に限定されます。
手順
Cluster Operator がインストールされる namespace を使用するように、AMQ Streams のインストールファイルを編集します。
たとえば、この手順では Cluster Operator は
my-cluster-operator-namespaceという namespace にインストールされます。Linux の場合は、以下を使用します。
sed -i 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yamlMacOS の場合は、以下を使用します。
sed -i '' 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yamlCluster Operator をデプロイします。
oc apply -f install/cluster-operator -n my-cluster-operator-namespaceCluster Operator が正常にデプロイされたことを確認します。
oc get deployments
4.1.1.3. 複数の namespace を監視対象とする Cluster Operator のデプロイメント
この手順では、OpenShift クラスターの複数の namespace 全体で AMQ Streams リソースを監視するように Cluster Operator をデプロイする方法を説明します。
前提条件
-
この手順では、
CustomResourceDefinitions、ClusterRoles、およびClusterRoleBindingsを作成できる OpenShift ユーザーアカウントを使用する必要があります。通常、OpenShift クラスターでロールベースアクセス制御 (RBAC) を使用する場合、これらのリソースを作成、編集、および削除する権限を持つユーザーはsystem:adminなどの OpenShift クラスター管理者に限定されます。
手順
Cluster Operator がインストールされる namespace を使用するように、AMQ Streams のインストールファイルを編集します。
たとえば、この手順では Cluster Operator は
my-cluster-operator-namespaceという namespace にインストールされます。Linux の場合は、以下を使用します。
sed -i 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yamlMacOS の場合は、以下を使用します。
sed -i '' 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yamlinstall/cluster-operator/060-Deployment-strimzi-cluster-operator.yamlファイルを編集し、Cluster Operator によって監視されるすべての namespace のリストをSTRIMZI_NAMESPACE環境変数に追加します。たとえば、この手順では Cluster Operator は
watched-namespace-1、watched-namespace-2、およびwatched-namespace-3という namespace を監視します。apiVersion: apps/v1 kind: Deployment spec: # ... template: spec: serviceAccountName: strimzi-cluster-operator containers: - name: strimzi-cluster-operator image: registry.redhat.io/amq7/amq-streams-rhel7-operator:1.6.7 imagePullPolicy: IfNotPresent env: - name: STRIMZI_NAMESPACE value: watched-namespace-1,watched-namespace-2,watched-namespace-3リストした各 namespace に
RoleBindingsをインストールします。この例では、コマンドの
watched-namespaceを前述のステップでリストした namespace に置き換えます。watched-namespace-1、watched-namespace-2、およびwatched-namespace-3に対してこれを行います。oc apply -f install/cluster-operator/020-RoleBinding-strimzi-cluster-operator.yaml -n watched-namespace oc apply -f install/cluster-operator/031-RoleBinding-strimzi-cluster-operator-entity-operator-delegation.yaml -n watched-namespace oc apply -f install/cluster-operator/032-RoleBinding-strimzi-cluster-operator-topic-operator-delegation.yaml -n watched-namespace
Cluster Operator をデプロイします。
oc apply -f install/cluster-operator -n my-cluster-operator-namespaceCluster Operator が正常にデプロイされたことを確認します。
oc get deployments
4.1.1.4. すべての namespace を対象とする Cluster Operator のデプロイメント
この手順では、OpenShift クラスターのすべての namespace 全体で AMQ Streams リソースを監視するように Cluster Operator をデプロイする方法を説明します。
このモードで実行している場合、Cluster Operator によって、新規作成された namespace でクラスターが自動的に管理されます。
前提条件
-
この手順では、
CustomResourceDefinitions、ClusterRoles、およびClusterRoleBindingsを作成できる OpenShift ユーザーアカウントを使用する必要があります。通常、OpenShift クラスターでロールベースアクセス制御 (RBAC) を使用する場合、これらのリソースを作成、編集、および削除する権限を持つユーザーはsystem:adminなどの OpenShift クラスター管理者に限定されます。
手順
Cluster Operator がインストールされる namespace を使用するように、AMQ Streams のインストールファイルを編集します。
たとえば、この手順では Cluster Operator は
my-cluster-operator-namespaceという namespace にインストールされます。Linux の場合は、以下を使用します。
sed -i 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yamlMacOS の場合は、以下を使用します。
sed -i '' 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yamlinstall/cluster-operator/060-Deployment-strimzi-cluster-operator.yamlファイルを編集し、STRIMZI_NAMESPACE環境変数の値を*に設定します。apiVersion: apps/v1 kind: Deployment spec: # ... template: spec: # ... serviceAccountName: strimzi-cluster-operator containers: - name: strimzi-cluster-operator image: registry.redhat.io/amq7/amq-streams-rhel7-operator:1.6.7 imagePullPolicy: IfNotPresent env: - name: STRIMZI_NAMESPACE value: "*" # ...クラスター全体ですべての namespace にアクセスできる権限を Cluster Operator に付与する
ClusterRoleBindingsを作成します。oc create clusterrolebinding strimzi-cluster-operator-namespaced --clusterrole=strimzi-cluster-operator-namespaced --serviceaccount my-cluster-operator-namespace:strimzi-cluster-operator oc create clusterrolebinding strimzi-cluster-operator-entity-operator-delegation --clusterrole=strimzi-entity-operator --serviceaccount my-cluster-operator-namespace:strimzi-cluster-operator oc create clusterrolebinding strimzi-cluster-operator-topic-operator-delegation --clusterrole=strimzi-topic-operator --serviceaccount my-cluster-operator-namespace:strimzi-cluster-operator
my-cluster-operator-namespaceは、Cluster Operator をインストールする namespace に置き換えます。Cluster Operator を OpenShift クラスターにデプロイします。
oc apply -f install/cluster-operator -n my-cluster-operator-namespaceCluster Operator が正常にデプロイされたことを確認します。
oc get deployments
4.1.1.5. OperatorHub からの Cluster Operator のデプロイ
OperatorHub から AMQ Streams Operator をインストールして、Cluster Operator を OpenShift クラスターにデプロイできます。OperatorHub は OpenShift 4 のみで使用できます
前提条件
-
Red Hat Operator の
OperatorSourceが OpenShift クラスターで有効になっている必要があります。適切なOperatorSourceが有効になっていれば OperatorHub に Red Hat Operator が表示されます。詳細は、『Operator』を参照してください。 - インストールには、Operator を OperatorHub からインストールするための権限を持つユーザーが必要です
手順
- OpenShift 4 Web コンソールで、Operators > OperatorHub をクリックします。
Streaming & Messaging カテゴリーの AMQ Streams Operator を検索または閲覧します。
- AMQ Streams タイルをクリックし、右側のサイドバーで Install をクリックします。
Create Operator Subscription 画面で、以下のインストールおよび更新オプションから選択します。
- インストールモード:AMQ Streams Operator をクラスター内のすべての(プロジェクト)namespace または特定の(プロジェクト)namespace にインストールすることを選択します。namespace を使用して関数を分離することが推奨されます。特定の namespace を Kafka クラスターおよびその他の AMQ Streams コンポーネントの専用とすることが推奨されます。
- Approval Strategy(承認ストラテジー ):デフォルトでは、AMQ Streams Operator は Operator Lifecycle Manager(OLM)によって最新の AMQ Streams バージョンにアップグレードされます。今後のアップグレードを手動で承認する場合は、Manual を選択します。詳細は、OpenShift ドキュメントの『Operator』を参照してください。
Subscribe をクリックすると、AMQ Streams Operator が OpenShift クラスターにインストールされます。
AMQ Streams Operator によって、Cluster Operator、CRD、およびロールベースアクセス制御 (RBAC) リソースは選択された namespace またはすべての namespace にデプロイされます。
Installed Operators 画面で、インストールの進捗を確認します。AMQ Streams Operator は、ステータスが InstallSucceeded に変更されると使用できます。

次に、YAML サンプルファイルを使用して、Kafka クラスターから順に AMQ Streams の他のコンポーネントをデプロイできます。
4.1.2. Kafka のデプロイ
Apache Kafka は、耐障害性のリアルタイムデータフィードを実現する、オープンソースの分散型 publish/subscribe メッセージングシステムです。
本セクションの手順は以下を説明します。
Cluster Operator を使用して以下をデプロイする方法
- 一時 または 永続 Kafka クラスター
Topic Operator および User Operator (
Kafkaカスタムリソースを設定してデプロイする)
Topic Operator および User Operator の代替のスタンドアロンデプロイメント手順
Kafka をインストールする場合、AMQ Streams によって ZooKeeper クラスターもインストールされ、Kafka と ZooKeeper との接続に必要な設定が追加されます。
4.1.2.1. Kafka クラスターのデプロイメント
この手順では、Cluster Operator を使用して Kafka クラスターを OpenShift にデプロイする方法を説明します。
デプロイメントでは、YAML ファイルの仕様を使って Kafka リソースが作成されます。
AMQ Streams では、デプロイメントの YAML ファイルのサンプルは examples/kafka/ にあります。
kafka-persistent.yaml- 3 つの Zookeeper ノードと 3 つの Kafka ノードを使用して永続クラスターをデプロイします。
kafka-jbod.yaml- それぞれが複数の永続ボリューを使用する、3 つの ZooKeeper ノードと 3 つの Kafka ノードを使用して、永続クラスターをデプロイします。
kafka-persistent-single.yaml- 1 つの ZooKeeper ノードと 1 つの Kafka ノードを使用して、永続クラスターをデプロイします。
kafka-ephemeral.yaml- 3 つの ZooKeeper ノードと 3 つの Kafka ノードを使用して、一時クラスターをデプロイします。
kafka-ephemeral-single.yaml- 3 つの ZooKeeper ノードと 1 つの Kafka ノードを使用して、一時クラスターをデプロイします。
この手順では、一時 および 永続 Kafka クラスターデプロイメントの例を使用します。
- 一時クラスター
-
通常、Kafka の一時クラスターは開発およびテスト環境での使用に適していますが、本番環境での使用には適していません。このデプロイメントでは、ブローカー情報 (ZooKeeper) と、トピックまたはパーティション (Kafka) を格納するための
emptyDirボリュームが使用されます。emptyDirボリュームを使用すると、その内容は厳密に Pod のライフサイクルと関連し、Pod がダウンすると削除されます。 - 永続クラスター
-
Kafka の永続クラスターでは、
PersistentVolumesを使用して ZooKeeper および Kafka データを格納します。PersistentVolumeClaimを使用してPersistentVolumeが取得され、PersistentVolumeの実際のタイプには依存しません。たとえば、YAML ファイルを変更しなくても Amazon AWS デプロイメントで Amazon EBS ボリュームを使用できます。PersistentVolumeClaimでStorageClassを使用し、自動ボリュームプロビジョニングをトリガーすることができます。
サンプルクラスターの名前はデフォルトで my-cluster になります。クラスター名はリソースの名前によって定義され、クラスターがデプロイされた後に変更できません。クラスターをデプロイする前にクラスター名を変更するには、関連する YAML ファイルにある Kafka リソースの Kafka.metadata.name プロパティーを編集します。
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster # ...
Kafka リソースの設定に関する詳細は、『Using AMQ Streams on OpenShift』の「Kafka cluster configuration」を参照してください。
手順
一時 または 永続 クラスターを作成およびデプロイします。
開発またはテストでは、一時クラスターの使用が適している可能性があります。永続クラスターはどのような状況でも使用することができます。
一時 クラスターを作成およびデプロイするには、以下を実行します。
oc apply -f examples/kafka/kafka-ephemeral.yaml
永続 クラスターを作成およびデプロイするには、以下を実行します。
oc apply -f examples/kafka/kafka-persistent.yaml
Kafka クラスターが正常にデプロイされたことを確認します。
oc get deployments
4.1.2.2. Cluster Operator を使用した Topic Operator のデプロイ
この手順では、Cluster Operator を使用して Topic Operator をデプロイする方法を説明します。
Kafka リソースの entityOperator プロパティーを設定し、topicOperator が含まれるようにします。
AMQ Streams によって管理されない Kafka クラスターを Topic Operator と使用する場合は、Topic Operator をスタンドアロンコンポーネントとしてデプロイする必要があります。
entityOperator および topicOperator プロパティーの設定に関する詳細は、『 AMQ Streams on OpenShift の使用 』の「 Entity Operator 」を参照してください。
手順
KafkaリソースのentityOperatorプロパティーを編集し、topicOperatorが含まれるようにします。apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: #... entityOperator: topicOperator: {} userOperator: {}「
EntityTopicOperatorSpecschema reference」に記載されているプロパティーを使用して、Topic Operator のspecを設定します。すべてのプロパティーにデフォルト値を使用する場合は、空のオブジェクト (
{}) を使用します。リソースを作成または更新します。
次のように
oc applyを使用します。oc apply -f <your-file>
4.1.2.3. Cluster Operator を使用した User Operator のデプロイ
この手順では、Cluster Operator を使用して User Operator をデプロイする方法を説明します。
Kafka リソースの entityOperator プロパティーを設定し、userOperator が含まれるようにします。
AMQ Streams によって管理されない Kafka クラスターを User Operator と使用する場合は、User Operator をスタンドアロンコンポーネントとしてデプロイする必要があります。
entityOperator および userOperator プロパティーの設定に関する詳細は、『 AMQ Streams on OpenShift の使用 』の「 Entity Operator 」を参照してください。
手順
KafkaリソースのentityOperatorプロパティーを編集し、userOperatorが含まれるようにします。apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: #... entityOperator: topicOperator: {} userOperator: {}『Using AMQ Streams on OpenShift』の「
EntityUserOperatorSpecschema reference」に記載されているプロパティーを使用して、User Operator のspecを設定します。すべてのプロパティーにデフォルト値を使用する場合は、空のオブジェクト (
{}) を使用します。リソースを作成または更新します。
oc apply -f <your-file>
4.1.3. AMQ Streams Operator の代替のスタンドアロンデプロイメントオプション
Cluster Operator を使用して Kafka クラスターをデプロイするときに、Topic Operator および User Operator をデプロイすることもできます。この代わりに、スタンドアロンデプロイメントを行うことができます。
スタンドアロンデプロイメントとは、Topic Operator および User Operator が AMQ Streams によって管理されない Kafka クラスターと操作できることを意味します。
4.1.3.1. スタンドアロン Topic Operator のデプロイ
この手順では、Topic Operator をスタンドアロンコンポーネントとしてデプロイする方法を説明します。
スタンドアロンデプロイメントには、環境変数の設定が必要で、Cluster Operator を使用した Topic Operator のデプロイよりも複雑です。しかし、Topic Operator は Cluster Operator によってデプロイされた Kafka クラスターに限らず、あらゆる Kafka クラスターと操作できるため、スタンドアロンデプロイメントの柔軟性は高くなります。
前提条件
- Topic Operator が接続する既存の Kafka クラスターが必要です。
手順
以下を設定し、
install/topic-operator/05-Deployment-strimzi-topic-operator.yamlファイルのDeployment.spec.template.spec.containers[0].envプロパティーを編集します。-
STRIMZI_KAFKA_BOOTSTRAP_SERVERS。hostname:portペアのコンマ区切りリストで Kafka クラスターのブートストラップブローカーを指定します。 -
STRIMZI_ZOOKEEPER_CONNECT。hostname:portペアのコンマ区切りリストで ZooKeeper ノードを指定します。これは、Kafka クラスターが使用する ZooKeeper クラスターと同じである必要があります。 -
STRIMZI_NAMESPACE。Operator がKafkaTopicリソースを監視する OpenShift namespace。 -
STRIMZI_RESOURCE_LABELS。Operator によって管理されるKafkaTopicリソースを識別するために使用されるラベルセレクター。 -
STRIMZI_FULL_RECONCILIATION_INTERVAL_MS。定期的な調整の間隔 (秒単位) を指定します。 -
STRIMZI_TOPIC_METADATA_MAX_ATTEMPTS。Kafka からトピックメタデータを取得するための試行回数を指定します。各試行の間隔は、指数バックオフとして定義されます。パーティションまたはレプリカの数によって、トピックの作成に時間がかかる可能性がある場合は、この値を増やすことを検討してください。デフォルトは6です。 -
STRIMZI_ZOOKEEPER_SESSION_TIMEOUT_MS。ZooKeeper セッションのタイムアウト (ミリ秒単位)。例:10000。デフォルトは20000(20 秒) です。 -
STRIMZI_TOPICS_PATH。Topic Operator がそのメタデータを保存する Zookeeper ノードパス。デフォルトは/strimzi/topicsです。 -
STRIMZI_TLS_ENABLED。Kafka ブローカーとの通信を暗号化するために、TLS サポートを有効にします。デフォルトはtrueです。 -
STRIMZI_TRUSTSTORE_LOCATION。TLS ベースの通信を有効にするための証明書が含まれるトラストストアへのパス。TLS がSTRIMZI_TLS_ENABLEDによって有効化された場合のみ必須です。 -
STRIMZI_TRUSTSTORE_PASSWORD。STRIMZI_TRUSTSTORE_LOCATIONで定義されるトラストストアにアクセスするためのパスワード。TLS がSTRIMZI_TLS_ENABLEDによって有効化された場合のみ必須です。 -
STRIMZI_KEYSTORE_LOCATION。TLS ベースの通信を有効にするための秘密鍵が含まれるキーストアへのパス。TLS がSTRIMZI_TLS_ENABLEDによって有効化された場合のみ必須です。 -
STRIMZI_KEYSTORE_PASSWORD。STRIMZI_KEYSTORE_LOCATIONで定義されるキーストアにアクセスするためのパスワード。TLS がSTRIMZI_TLS_ENABLEDによって有効化された場合のみ必須です。 -
STRIMZI_LOG_LEVEL。ロギングメッセージの出力レベル。値は以下に設定できます。ERROR、WARNING、INFO、DEBUG、およびTRACE。デフォルトはINFOです。 -
STRIMZI_JAVA_OPTS(任意)。Topic Operator を実行する JVM に使用される Java オプション。例:-Xmx=512M -Xms=256M -
STRIMZI_JAVA_SYSTEM_PROPERTIES(任意)。Topic Operator に設定される-Dオプションをリストします。例:-Djavax.net.debug=verbose -DpropertyName=value.
-
Topic Operator をデプロイします。
oc apply -f install/topic-operator
Topic Operator が正常にデプロイされていることを確認します。
oc describe deployment strimzi-topic-operator
Replicas:エントリーに1 availableが表示されれば、Topic Operator はデプロイされています。注記OpenShift への接続が低速な場合やイメージがこれまでダウンロードされたことがない場合は、デプロイメントに遅延が発生することがあります。
4.1.3.2. スタンドアロン User Operator のデプロイ
この手順では、User Operator をスタンドアロンコンポーネントとしてデプロイする方法を説明します。
スタンドアロンデプロイメントには、環境変数の設定が必要で、Cluster Operator を使用した User Operator のデプロイよりも複雑です。しかし、User Operator は Cluster Operator によってデプロイされた Kafka クラスターに限らず、あらゆる Kafka クラスターと操作できるため、スタンドアロンデプロイメントの柔軟性は高くなります。
前提条件
- User Operator が接続する既存の Kafka クラスターが必要です。
手順
以下を設定し、
install/user-operator/05-Deployment-strimzi-user-operator.yamlファイルのDeployment.spec.template.spec.containers[0].envプロパティーを編集します。-
STRIMZI_KAFKA_BOOTSTRAP_SERVERS。hostname:portペアのコンマ区切りリストで Kafka ブローカーを指定します。 -
STRIMZI_ZOOKEEPER_CONNECT。hostname:portペアのコンマ区切りリストで ZooKeeper ノードを指定します。これは、Kafka クラスターが使用する ZooKeeper クラスターと同じである必要があります。TLS 暗号化で ZooKeeper ノードに接続することはサポートされません。 -
STRIMZI_NAMESPACE。Operator がKafkaUserリソースを監視する OpenShift namespace。 -
STRIMZI_LABELS。Operator によって管理されるKafkaUserリソースを識別するために使用されるラベルセレクター。 -
STRIMZI_FULL_RECONCILIATION_INTERVAL_MS。定期的な調整の間隔 (秒単位) を指定します。 -
STRIMZI_ZOOKEEPER_SESSION_TIMEOUT_MS。ZooKeeper セッションのタイムアウト (ミリ秒単位)。例:10000。デフォルトは20000(20 秒) です。 -
STRIMZI_CA_CERT_NAME。TLS クライアント認証に対して新しいユーザー証明書を署名するための認証局の公開鍵が含まれる OpenShiftSecretを示します。Secretのca.crtキーに、認証局の公開鍵が含まれている必要があります。 -
STRIMZI_CA_KEY_NAME。TLS クライアント認証に対して新しいユーザー証明書を署名するための認証局の秘密鍵が含まれる OpenShiftSecretを示します。Secretのca.crtキーに、認証局の秘密鍵が含まれている必要があります。 -
STRIMZI_CLUSTER_CA_CERT_SECRET_NAME。TLS ベースの通信を有効にするために Kafka ブローカーの証明書の署名に使用される認証局の秘密鍵が含まれる OpenShiftSecretを示します。Secretのca.crtキーに、認証局の公開鍵が含まれている必要があります。この環境変数の設定は任意で、Kafka クラスターとの通信が TLS ベースである場合のみ設定する必要があります。 -
STRIMZI_EO_KEY_SECRET_NAME。Kafka クラスターに対する TLS クライアント認証の秘密鍵と関連する証明書が含まれる OpenShiftSecretを示します。Secretのentity-operator.p12キーに、秘密鍵と証明書が含まれるキーストアが含まれ、entity-operator.passwordキーに関連するパスワードが含まれる必要があります。この環境変数の設定は任意で、Kafka クラスターとの通信が TLS ベースで、TLS のクライアント認証が必要な場合のみ設定する必要があります。 -
STRIMZI_CA_VALIDITY。認証局の有効期限。デフォルトは365日です。 -
STRIMZI_CA_RENEWAL。認証局の更新期限。 -
STRIMZI_LOG_LEVEL。ロギングメッセージの出力レベル。値は以下に設定できます。ERROR、WARNING、INFO、DEBUG、およびTRACE。デフォルトはINFOです。 -
STRIMZI_GC_LOG_ENABLED。ガベージコレクション (GC) ロギングを有効にします。デフォルトはtrueです。デフォルトでは、古い証明書が期限切れになる前の証明書の更新期間は30日です。 -
STRIMZI_JAVA_OPTS(任意)。User Operator を実行する JVM に使用される Java オプション。例:-Xmx=512M -Xms=256M -
STRIMZI_JAVA_SYSTEM_PROPERTIES(任意)。User Operator に設定される-Dオプションをリストします。例:-Djavax.net.debug=verbose -DpropertyName=value.
-
User Operator をデプロイします。
oc apply -f install/user-operator
User Operator が正常にデプロイされていることを確認します。
oc describe deployment strimzi-user-operator
Replicas:エントリーに1 availableが表示されれば、User Operator はデプロイされています。注記OpenShift への接続が低速な場合やイメージがこれまでダウンロードされたことがない場合は、デプロイメントに遅延が発生することがあります。
4.2. Kafka Connect のデプロイ
Kafka Connect は、Apache Kafka と外部システムとの間でデータをストリーミングするためのツールです。
AMQ Streams では、Kafka Connect は分散 (distributed) モードでデプロイされます。Kafka Connect はスタンドアロンモードでも動作しますが、AMQ Streams ではサポートされません。
Kafka Connect では、コネクター の概念を使用し、スケーラビリティーと信頼性を維持しながら Kafka クラスターで大量のデータを出し入れするためのフレームワークが提供されます。
Kafka Connect は通常、Kafka を外部データベース、ストレージシステム、およびメッセージングシステムと統合するために使用されます。
本セクションの手順では以下の方法を説明します。
コネクター という用語は、Kafka Connect クラスター内で実行されているコネクターインスタンスや、コネクタークラスと同じ意味で使用されます。本ガイドでは、本文の内容で意味が明確である場合に コネクター という用語を使用します。
4.2.1. Kafka Connect の OpenShift クラスターへのデプロイ
この手順では、Cluster Operator を使用して Kafka Connect クラスターを OpenShift クラスターにデプロイする方法を説明します。
Kafka Connect クラスターは Deployment として実装されます。その Deployment には、コネクターのワークロードを タスク として分布するノード (ワーカー とも呼ばれる) の設定可能な数が含まれるため、メッセージフローのスケーラビリティーや信頼性が高くなります。
デプロイメントでは、YAML ファイルの仕様を使って KafkaConnect リソースが作成されます。
この手順では、AMQ Streams にある以下のサンプルファイルを使用します。
-
examples/connect/kafka-connect.yaml
KafkaConnect リソース(または Source-to-Image(S 2I)サポートのある KafkaConnectS 2I リソース)の設定に関する詳細は、『 AMQ Streams on OpenShift の使用 』の「 Kafka Connect クラスターの設定 」を参照してください。
手順
Kafka Connect を OpenShift クラスターにデプロイします。3 つ以上のブローカーを持つ Kafka クラスターの場合は、
examples/connect/kafka-connect.yamlファイルを使用します。3 つ未満のブローカーで構成される Kafka クラスターの場合は、examples/connect/kafka-connect-single-node-kafka.yamlファイルを使用します。oc apply -f examples/connect/kafka-connect.yaml
Kafka Connect が正常にデプロイされたことを確認します。
oc get deployments
4.2.2. コネクタープラグインでの Kafka Connect の拡張
Kafka Connect の AMQ Streams コンテナーイメージには、ファイルベースのデータを Kafka クラスターで出し入れするために 2 つの組み込みコネクターが含まれています。
表4.1 ファイルコネクター
| ファイルコネクター | 説明 |
|---|---|
|
| ファイル (ソース) から Kafka クラスターにデータを転送します。 |
|
| Kafka クラスターからファイル (シンク) にデータを転送します。 |
Cluster Operator では、Kafka Connect クラスターを OpenShift クラスターにデプロイするために作成したイメージを使用することもできます。
ここの手順では、以下を行って、独自のコネクタークラスをコネクターイメージに追加する方法を説明します。
Kafka Connect REST API または KafkaConnector カスタムリソースを使用 して直接コネクターの設定を作成します。
4.2.2.1. Kafka Connect ベースイメージからの Docker イメージの作成
この手順では、カスタムイメージを作成し、/opt/kafka/plugins ディレクトリーに追加する方法を説明します。
Red Hat Ecosystem Catalog の Kafka コンテナーイメージを、追加のコネクタープラグインで独自のカスタムイメージを作成するためのベースイメージとして使用できます。
AMQ Stream バージョンの Kafka Connect は起動時に、/opt/kafka/plugins ディレクトリーに含まれるサードパーティーのコネクタープラグインをロードします。
手順
registry.redhat.io/amq7/amq-streams-kafka-26-rhel7:1.6.7 をベースイメージとして使用して、新しいDockerfileを作成します。FROM registry.redhat.io/amq7/amq-streams-kafka-26-rhel7:1.6.7 USER root:root COPY ./my-plugins/ /opt/kafka/plugins/ USER 1001プラグインファイルの例
$ tree ./my-plugins/ ./my-plugins/ ├── debezium-connector-mongodb │ ├── bson-3.4.2.jar │ ├── CHANGELOG.md │ ├── CONTRIBUTE.md │ ├── COPYRIGHT.txt │ ├── debezium-connector-mongodb-0.7.1.jar │ ├── debezium-core-0.7.1.jar │ ├── LICENSE.txt │ ├── mongodb-driver-3.4.2.jar │ ├── mongodb-driver-core-3.4.2.jar │ └── README.md ├── debezium-connector-mysql │ ├── CHANGELOG.md │ ├── CONTRIBUTE.md │ ├── COPYRIGHT.txt │ ├── debezium-connector-mysql-0.7.1.jar │ ├── debezium-core-0.7.1.jar │ ├── LICENSE.txt │ ├── mysql-binlog-connector-java-0.13.0.jar │ ├── mysql-connector-java-5.1.40.jar │ ├── README.md │ └── wkb-1.0.2.jar └── debezium-connector-postgres ├── CHANGELOG.md ├── CONTRIBUTE.md ├── COPYRIGHT.txt ├── debezium-connector-postgres-0.7.1.jar ├── debezium-core-0.7.1.jar ├── LICENSE.txt ├── postgresql-42.0.0.jar ├── protobuf-java-2.6.1.jar └── README.md
- コンテナーイメージをビルドします。
- カスタムイメージをコンテナーレジストリーにプッシュします。
新しいコンテナーイメージを示します。
以下のいずれかを行います。
KafkaConnectカスタムリソースのKafkaConnect.spec.imageプロパティーを編集します。設定された場合、このプロパティーによって Cluster Operator の
STRIMZI_KAFKA_CONNECT_IMAGES変数がオーバーライドされます。apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaConnect metadata: name: my-connect-cluster spec: 1 #... image: my-new-container-image 2 config: 3 #...
または
-
install/cluster-operator/060-Deployment-strimzi-cluster-operator.yamlファイルのSTRIMZI_KAFKA_CONNECT_IMAGES変数を編集して新しいコンテナーイメージを示すようにした後、Cluster Operator を再インストールします。
関連情報
詳細は、『AMQ Streams on OpenShift の使用』を参照してください。
4.2.2.2. OpenShift ビルドおよび S2I (Source-to-Image) を使用したコンテナーイメージの作成
この手順では、OpenShift ビルド と S2I (Source-to-Image) フレームワークを使用して、新しいコンテナーイメージを作成する方法を説明します。
OpenShift ビルドは、S2I がサポートされるビルダーイメージとともに、ユーザー提供のソースコードおよびバイナリーを取得し、これらを使用して新しいコンテナーイメージを構築します。構築後、コンテナーイメージは OpenShfit のローカルコンテナーイメージリポジトリーに格納され、デプロイメントで使用可能になります。
S2I がサポートされる Kafka Connect ビルダーイメージは、registry. redhat.io/amq7/amq-streams-kafka-26-rhel7:1.6.7 イメージの一部として、Red Hat Ecosystem Catalog で提供されます。このS2I イメージは、バイナリー (プラグインおよびコネクターとともに) を取得し、/tmp/kafka-plugins/s2i ディレクトリーに格納されます。このディレクトリーから、Kafka Connect デプロイメントとともに使用できる新しい Kafka Connect イメージを作成します。改良されたイメージの使用を開始すると、Kafka Connect は /tmp/kafka-plugins/s2i ディレクトリーからサードパーティープラグインをロードします。
手順
コマンドラインで
oc applyコマンドを使用し、Kafka Connect の S2I クラスターを作成およびデプロイします。oc apply -f examples/connect/kafka-connect-s2i.yaml
Kafka Connect プラグインでディレクトリーを作成します。
$ tree ./my-plugins/ ./my-plugins/ ├── debezium-connector-mongodb │ ├── bson-3.4.2.jar │ ├── CHANGELOG.md │ ├── CONTRIBUTE.md │ ├── COPYRIGHT.txt │ ├── debezium-connector-mongodb-0.7.1.jar │ ├── debezium-core-0.7.1.jar │ ├── LICENSE.txt │ ├── mongodb-driver-3.4.2.jar │ ├── mongodb-driver-core-3.4.2.jar │ └── README.md ├── debezium-connector-mysql │ ├── CHANGELOG.md │ ├── CONTRIBUTE.md │ ├── COPYRIGHT.txt │ ├── debezium-connector-mysql-0.7.1.jar │ ├── debezium-core-0.7.1.jar │ ├── LICENSE.txt │ ├── mysql-binlog-connector-java-0.13.0.jar │ ├── mysql-connector-java-5.1.40.jar │ ├── README.md │ └── wkb-1.0.2.jar └── debezium-connector-postgres ├── CHANGELOG.md ├── CONTRIBUTE.md ├── COPYRIGHT.txt ├── debezium-connector-postgres-0.7.1.jar ├── debezium-core-0.7.1.jar ├── LICENSE.txt ├── postgresql-42.0.0.jar ├── protobuf-java-2.6.1.jar └── README.md
oc start-buildコマンドで、準備したディレクトリーを使用してイメージの新しいビルドを開始します。oc start-build my-connect-cluster-connect --from-dir ./my-plugins/
注記ビルドの名前は、デプロイされた Kafka Connect クラスターと同じになります。
- ビルドが完了したら、Kafka Connect のデプロイメントによって新しいイメージが自動的に使用されます。
4.2.3. コネクターの作成および管理
コネクタープラグインのコンテナーイメージを作成したら、Kafka Connect クラスターにコネクターインスタンスを作成する必要があります。その後、稼働中のコネクターインスタンスを設定、監視、および管理できます。
コネクターは特定の コネクタークラス のインスタンスで、メッセージに関して関連する外部システムとの通信方法を認識しています。コネクターは多くの外部システムで使用でき、独自のコネクターを作成することもできます。
ソース および シンク タイプのコネクターを作成できます。
- ソースコネクター
- ソースコネクターは、外部システムからデータを取得し、それをメッセージとして Kafka に提供するランタイムエンティティーです。
- シンクコネクター
- シンクコネクターは、Kafka トピックからメッセージを取得し、外部システムに提供するランタイムエンティティーです。
AMQ Streams では、コネクターの作成および管理に 2 つの API が提供されます。
-
KafkaConnectorリソース (KafkaConnectorsと呼ばれます) - Kafka Connect REST API
API を使用すると、以下を行うことができます。
- コネクターインスタンスのステータスの確認。
- 稼働中のコネクターの再設定。
- コネクターインスタンスのタスク数の増減。
-
失敗したタスクの再起動 (
KafkaConnectorリソースによってサポートされません)。 - コネクターインスタンスの一時停止。
- 一時停止したコネクターインスタンスの再開。
- コネクターインスタンスの削除。
4.2.3.1. KafkaConnector リソース
KafkaConnectors を使用すると、Kafka Connect のコネクターインスタンスを OpenShift ネイティブに作成および管理できるため、cURL などの HTTP クライアントが必要ありません。その他の Kafka リソースと同様に、コネクターの望ましい状態を OpenShift クラスターにデプロイされた KafkaConnector YAML ファイルに宣言し、コネクターインスタンスを作成します。
該当する KafkaConnector を更新して稼働中のコネクターインスタンスを管理した後、更新を適用します。該当する KafkaConnector を削除して、コネクターを削除します。
これまでのバージョンの AMQ Streams との互換性を維持するため、KafkaConnectors はデフォルトで無効になっています。Kafka Connect クラスターのために有効にするには、KafkaConnect リソースでアノテーションを使用する必要があります。手順は、『AMQ Streams on OpenShift の使用』の「Kafka Connect の設定」を参照してください。
KafkaConnectors が有効になると、Cluster Operator によって監視が開始されます。KafkaConnectors に定義された設定と一致するよう、稼働中のコネクターインスタンスの設定を更新します。
AMQ Streams には、examples/connect/source-connector.yaml という名前のサンプル KafkaConnector が含まれます。このサンプルを使用して、FileStreamSourceConnector を作成および管理できます。
4.2.3.2. Kafka Connect REST API の可用性
Kafka Connect REST API は、<connect-cluster-name>-connect-api サービスとして 8083 番ポートで使用できます。
KafkaConnectors が有効になっている場合、Kafka Connect REST API に直接手作業で追加された変更は Cluster Operator によって元に戻されます。
REST API でサポートされる操作は、Apache Kafka のドキュメント を参照してください。
4.2.4. KafkaConnector リソースの Kafka Connect へのデプロイ
この手順では、KafkaConnector の例を Kafka Connect クラスターにデプロイする方法を説明します。
YAML の例によって FileStreamSourceConnector が作成され、ライセンスファイルの各行が my-topic という名前のトピックでメッセージとして Kafka に送信されます。
前提条件
-
KafkaConnectorsが有効になっている Kafka Connect デプロイメントが必要です。 - 稼働中の Cluster Operator が必要です。
手順
examples/connect/source-connector.yamlファイルを編集します。apiVersion: kafka.strimzi.io/v1alpha1 kind: KafkaConnector metadata: name: my-source-connector 1 labels: strimzi.io/cluster: my-connect-cluster 2 spec: class: org.apache.kafka.connect.file.FileStreamSourceConnector 3 tasksMax: 2 4 config: 5 file: "/opt/kafka/LICENSE" topic: my-topic # ...
OpenShift クラスターで
KafkaConnectorを作成します。oc apply -f examples/connect/source-connector.yaml
リソースが作成されたことを確認します。
oc get kctr --selector strimzi.io/cluster=my-connect-cluster -o name
4.3. Kafka MirrorMaker のデプロイ
Cluster Operator によって、1 つ以上の Kafka MirrorMaker のレプリカがデプロイされ、Kafka クラスターの間でデータが複製されます。このプロセスはミラーリングと言われ、Kafka パーティションのレプリケーションの概念と混同しないようにします。MirrorMaker は、ソースクラスターからメッセージを消費し、これらのメッセージをターゲットクラスターにパブリッシュします。
4.3.1. Kafka MirrorMaker の OpenShift クラスターへのデプロイ
この手順では、Cluster Operator を使用して Kafka MirrorMaker クラスターを OpenShift クラスターにデプロイする方法を説明します。
デプロイメントでは、YAML ファイルの仕様を使って、デプロイされた MirrorMaker のバージョンに応じて KafkaMirrorMaker または KafkaMirrorMaker2 リソースが作成されます。
この手順では、AMQ Streams にある以下のサンプルファイルを使用します。
-
examples/mirror-maker/kafka-mirror-maker.yaml -
examples/mirror-maker/kafka-mirror-maker-2.yaml
KafkaMirrorMaker またはKafkaMirrorMaker 2 リソースの設定に関する詳細は、『 AMQ Streams on OpenShift の使用 』の「 Kafka MirrorMaker クラスターの設定 」を参照してください。
手順
Kafka MirrorMaker を OpenShift クラスターにデプロイします。
MirrorMaker の場合
oc apply -f examples/mirror-maker/kafka-mirror-maker.yaml
MirrorMaker 2.0 の場合
oc apply -f examples/mirror-maker/kafka-mirror-maker-2.yaml
MirrorMaker が正常にデプロイされたことを確認します。
oc get deployments
4.4. Kafka Bridge のデプロイ
Cluster Operator によって、1 つ以上の Kafka Bridge のレプリカがデプロイされ、HTTP API 経由で Kafka クラスターとクライアントの間でデータが送信されます。
4.4.1. Kafka Bridge を OpenShift クラスターへデプロイ
この手順では、Cluster Operator を使用して Kafka Bridge クラスターを OpenShift クラスターにデプロイする方法を説明します。
デプロイメントでは、YAML ファイルの仕様を使って KafkaBridge リソースが作成されます。
この手順では、AMQ Streams にある以下のサンプルファイルを使用します。
-
examples/bridge/kafka-bridge.yaml
KafkaBridge リソースの設定に関する詳細は、『 AMQ Streams on OpenShift の使用 』の「 Kafka Bridge クラスターの設定 」を参照してください。
手順
Kafka Bridge を OpenShift クラスターにデプロイします。
oc apply -f examples/bridge/kafka-bridge.yaml
Kafka Bridge が正常にデプロイされたことを確認します。
oc get deployments
第5章 Kafka クラスターへのクライアントアクセスの設定
AMQ Streams のデプロイ 後、本章では以下の操作を行う方法について説明します。
- サンプルプロデューサーおよびコンシューマークライアントをデプロイし、これを使用してデプロイメントを検証する
Kafka クラスターへの外部クライアントアクセスを設定する
OpenShift 外部のクライアントに Kafka クラスターへのアクセスを設定する手順はより複雑です。『AMQ Streams on OpenShift の使用』で説明する Kafka コンポーネントの設定手順 に精通している必要があります。
5.1. サンプルクライアントのデプロイ
この手順では、ユーザーが作成した Kafka クラスターを使用してメッセージを送受信するプロデューサーおよびコンシューマークライアントの例をデプロイする方法を説明します。
前提条件
- クライアントが Kafka クラスターを使用できる必要があります。
手順
Kafka プロデューサーをデプロイします。
oc run kafka-producer -ti --image=registry.redhat.io/amq7/amq-streams-kafka-26-rhel7:1.6.7 --rm=true --restart=Never -- bin/kafka-console-producer.sh --broker-list cluster-name-kafka-bootstrap:9092 --topic my-topic
- プロデューサーが稼働しているコンソールにメッセージを入力します。
- Enter を押してメッセージを送信します。
Kafka コンシューマーをデプロイします。
oc run kafka-consumer -ti --image=registry.redhat.io/amq7/amq-streams-kafka-26-rhel7:1.6.7 --rm=true --restart=Never -- bin/kafka-console-consumer.sh --bootstrap-server cluster-name-kafka-bootstrap:9092 --topic my-topic --from-beginning
- コンシューマーコンソールに受信メッセージが表示されることを確認します。
5.2. OpenShift 外クライアントのアクセスの設定
以下の手順では、OpenShift 外部からの Kafka クラスターへのクライアントアクセスを設定する方法を説明します。
Kafka クラスターのアドレスを使用して、異なる OpenShift namespace または完全に OpenShift 外のクライアントに外部アクセスを提供できます。
アクセスを提供するために、外部 Kafka リスナーを設定します。
以下のタイプの外部リスナーがサポートされます。
-
OpenShift
Routeおよびデフォルトの HAProxy ルーターを使用するroute -
ロードバランサーサービスを使用する
loadbalancer -
OpenShift ノードのポートを使用する
nodeport -
OpenShift Ingress と NGINX Ingress Controller for Kubernetes を使用する
ingress
要件ならびにお使いの環境およびインフラストラクチャーに応じて、選択するタイプは異なります。たとえば、ロードバランサーは、ベアメタル等の特定のインフラストラクチャーには適さない場合があります。ベアメタルでは、ノードポートがより適したオプションを提供します。
以下の手順では、
- TLS 暗号化および認証、ならびに Kafka 簡易承認 を有効にして、Kafka クラスターに外部リスナーが設定されます。
-
簡易承認 用に TLS 認証および アクセス制御リスト (ACL) を定義して、クライアントに
KafkaUserが作成されます。
TLS または SCRAM-SHA-512 認証を使用するようにリスナーを設定できます。これらはいずれも TLS 暗号化と共に使用できます。承認サーバーを使用している場合は、トークンベースの OAuth 2.0 認証 および OAuth 2.0 承認 を使用できます。Open Policy Agent (OPA) 承認も、Kafka 承認 オプションとしてサポートされます。
KafkaUser 認証および承認メカニズムを設定する場合、必ず同等の Kafka 設定と一致するようにしてください。
-
KafkaUser.spec.authenticationはKafka.spec.kafka.listeners[*].authenticationと一致します。 -
KafkaUser.spec.authorizationはKafka.spec.kafka.authorizationと一致します。
KafkaUser に使用する認証をサポートするリスナーが少なくとも 1 つ必要です。
Kafka ユーザーと Kafka ブローカー間の認証は、それぞれの認証設定によって異なります。たとえば、TLS が Kafka 設定で有効になっていない場合は、TLS でユーザーを認証できません。
AMQ Streams Operator により設定プロセスが自動されます。
- Cluster Operator はリスナーを作成し、クラスターおよびクライアント認証局 (CA) 証明書を設定して Kafka クラスター内で認証を有効にします。
- User Operator はクライアントに対応するユーザーを作成すると共に、選択した認証タイプに基づいて、クライアント認証に使用されるセキュリティークレデンシャルを作成します。
この手順では、Cluster Operator によって生成された証明書が使用されますが、独自の証明書をインストール してそれらを置き換えることができます。外部認証局によって管理される Kafka リスナー証明書を使用するようにリスナーを設定することもできます。
PKCS #12 形式 (.p12) および PEM 形式 (.crt) の証明書を利用できます。
前提条件
- クライアントが Kafka クラスターを使用できる必要があります。
- Cluster Operator および User Operator がクラスターで実行されている必要があります。
- OpenShift クラスター外のクライアントが Kafka クラスターに接続できる必要があります。
手順
externalKafka リスナーと共に Kafka クラスターを設定します。- リスナーを通じて Kafka ブローカーにアクセスするのに必要な認証を定義します。
Kafka ブローカーで承認を有効にします。
以下に例を示します。
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster namespace: myproject spec: kafka: # ... listeners: 1 - name: external 2 port: 9094 3 type: LISTENER-TYPE 4 tls: true 5 authentication: type: tls 6 configuration: preferredNodePortAddressType: InternalDNS 7 bootstrap and broker service overrides 8 #... authorization: 9 type: simple superUsers: - super-user-name 10 # ...- 1
- 外部リスナーを有効にする設定オプションは、汎用 Kafka リスナースキーマ参照 に記載されています。
- 2
- リスナーを識別するための名前。Kafka クラスター内で一意である必要があります。
- 3
- Kafka 内でリスナーによって使用されるポート番号。ポート番号は指定の Kafka クラスター内で一意である必要があります。許可されるポート番号は 9092 以上ですが、すでに Prometheus および JMX によって使用されているポート 9404 および 9999 以外になります。リスナーのタイプによっては、ポート番号は Kafka クライアントに接続するポート番号と同じではない場合があります。
- 4
route、loadbalancer、nodeport、またはingressとして指定される外部リスナータイプ。内部リスナーはinternalとして指定されます。- 5
- リスナーで TLS による暗号化を有効にします。デフォルトは
falseです。routeリスナーには TLS 暗号化は必要ありません。 - 6
- 認証は
tlsとして指定されます。 - 7
- (任意設定:
nodeportリスナーのみ) ノードアドレスとして AMQ Streams によって使用される最初のアドレスタイプの希望を指定します。 - 8
- (任意設定) AMQ Streams はクライアントに公開するアドレスを自動的に決定します。アドレスは OpenShift によって自動的に割り当てられます。AMQ Streams を実行しているインフラストラクチャーが正しい ブートストラップおよびブローカーサービスのアドレス を提供しない場合、そのアドレスを上書きできます。検証はオーバーライドに対しては実行されません。オーバーライド設定はリスナーのタイプによって異なります。たとえば、
routeの場合はホストを、loadbalancerの場合は DNS 名または IP アドレスを、またnodeportの場合はノードポートを、それぞれ上書きすることができます。 - 9
簡易(AclAuthorizerKafka プラグイン)を使用する認証。- 10
- (任意設定) スーパーユーザーは、ACL で定義されたアクセス制限に関係なく、すべてのブローカーにアクセスできます。
警告OpenShift Route アドレスは、Kafka クラスターの名前、リスナーの名前、および作成される namespace の名前で構成されます。たとえば、
my-cluster-kafka-listener1-bootstrap-myproject(CLUSTER-NAME-kafka-LISTENER-NAME-bootstrap-NAMESPACE) となります。routeリスナータイプを使用している場合、アドレス全体の長さが上限の 63 文字を超えないように注意してください。
Kafkaリソースを作成または更新します。oc apply -f KAFKA-CONFIG-FILEKafka クラスターは、TLS 認証を使用する Kafka ブローカーリスナーと共に設定されます。
Kafka ブローカー Pod ごとにサービスが作成されます。
サービスが作成され、Kafka クラスターに接続するための ブートストラップアドレス として機能します。
サービスは、
nodeportリスナーを使用した Kafka クラスターへの外部接続用 外部ブートストラップアドレス としても作成されます。kafka ブローカーの ID を検証するためのクラスター CA 証明書も、
Kafkaリソースと同じ名前で作成されます。Kafkaリソースのステータスからブートストラップアドレスおよびポートを見つけます。oc get kafka KAFKA-CLUSTER-NAME -o jsonpath='{.status.listeners[?(@.type=="external")].bootstrapServers}'Kafka クライアントのブートストラップアドレスを使用して、Kafka クラスターに接続します。
生成された
KAFKA-CLUSTER-NAME -cluster-ca-certSecret からパブリッククラスターの CA 証明書およびパスワードを抽出します。oc get secret KAFKA-CLUSTER-NAME-cluster-ca-cert -o jsonpath='{.data.ca\.p12}' | base64 -d > ca.p12oc get secret KAFKA-CLUSTER-NAME-cluster-ca-cert -o jsonpath='{.data.ca\.password}' | base64 -d > ca.passwordKafka クライアントの証明書およびパスワードを使用して、TLS 暗号化により Kafka クラスターに接続します。
注記デフォルトでは、クラスター CA 証明書は自動的に更新されます。専用の Kafka リスナー証明書を使用している場合は、証明書を手動で更新する 必要があります。
Kafka クラスターにアクセスする必要があるクライアントに対応するユーザーを作成または変更します。
-
Kafkaリスナーと同じ認証タイプを指定します。 簡易承認に承認 ACL を指定します。
以下に例を示します。
apiVersion: kafka.strimzi.io/v1beta1 kind: KafkaUser metadata: name: my-user labels: strimzi.io/cluster: my-cluster 1 spec: authentication: type: tls 2 authorization: type: simple acls: 3 - resource: type: topic name: my-topic patternType: literal operation: Read - resource: type: topic name: my-topic patternType: literal operation: Describe - resource: type: group name: my-group patternType: literal operation: Read
-
KafkaUserリソースを作成または変更します。oc apply -f USER-CONFIG-FILEKafkaUserリソースと同じ名前の Secret と共に、ユーザーが作成されます。Secret には、TLS クライアント認証の秘密鍵と公開鍵が含まれます。以下に例を示します。
apiVersion: v1 kind: Secret metadata: name: my-user labels: strimzi.io/kind: KafkaUser strimzi.io/cluster: my-cluster type: Opaque data: ca.crt: PUBLIC-KEY-OF-THE-CLIENT-CA user.crt: USER-CERTIFICATE-CONTAINING-PUBLIC-KEY-OF-USER user.key: PRIVATE-KEY-OF-USER user.p12: P12-ARCHIVE-FILE-STORING-CERTIFICATES-AND-KEYS user.password: PASSWORD-PROTECTING-P12-ARCHIVEKafka クラスターへのセキュアな接続を確立するのに必要なプロパティーを使用して Kafka クラスターに接続するように、クライアントを設定します。
パブリッククラスター証明書の認証詳細を追加します。
security.protocol: SSL 1 ssl.truststore.location: PATH-TO/ssl/keys/truststore 2 ssl.truststore.password: CLUSTER-CA-CERT-PASSWORD 3 ssl.truststore.type=PKCS12 4
注記security.protocol を使用します。SASL_SSL(TLS 経由で SCRAM-SHA 認証を使用する場合)。Kafka クラスターに接続するためのブートストラップアドレスおよびポートを追加します。
bootstrap.servers: BOOTSTRAP-ADDRESS:PORTパブリックユーザー証明書の認証情報を追加します。
ssl.keystore.location: PATH-TO/ssl/keys/user1.keystore 1 ssl.keystore.password: USER-CERT-PASSWORD 2
パブリックユーザー証明書は、作成時にクライアント CA により署名されます。
第6章 AMQ Streams のメトリクスおよびダッシュボードの設定
ダッシュボードでキーメトリクスを表示し、特定の条件下でトリガーされるアラートを設定すると、AMQ Streams デプロイメントを監視できます。メトリクスは、Kafka、ZooKeeper、および AMQ Streams の他のコンポーネントで利用できます。
AMQ Streams は、メトリクス情報を提供するために、Prometheus ルールと Grafana ダッシュボードを使用します。
Prometheus に AMQ Streams の各コンポーネントのルールセットが設定されている場合、Prometheus はクラスターで稼働している Pod からキーメトリクスを使用します。次に、Grafana はこれらのメトリクスをダッシュボードで可視化します。AMQ Streams には、デプロイメントに合わせてカスタマイズできる Grafana ダッシュボードのサンプルが含まれています。
OpenShift Container Platform 4.x では、AMQ Streams は ユーザー定義プロジェクトのモニタリング (OpenShift の機能) を使用し、Prometheus の設定プロセスを容易にします。
OpenShift Container Platform 3.11 では、Prometheus および Alertmanager コンポーネントを別々にクラスターにデプロイする必要があります。
OpenShift Container Platform のバージョンに関係なく、AMQ Streams に Prometheus メトリクス設定をデプロイ して開始する必要があります。
次に、OpenShift Container Platform のバージョンに適した手順に従います。
Prometheus および Grafana が設定されると、Grafana ダッシュボードおよびアラートルールのサンプルを使用して Kafka クラスターを監視できます。
追加の監視オプション
Kafka Exporter は、コンシューマーラグに関連する追加の監視を提供する任意のコンポーネントです。AMQ Streams で Kafka Exporter を使用する場合は、「Configure the Kafka resource to deploy Kafka Exporter with your Kafka cluster」を参照してください。
さらに、分散トレーシングを設定してメッセージをエンドツーエンドで追跡するように、デプロイメントを設定することもできます。詳細は、『AMQ Streams on OpenShift の使用』の「分散トレーシング」を参照してください。
その他のリソース
- Prometheus ドキュメント
- Grafana ドキュメント
- Kafka ドキュメントの Apache Kafka Monitoring では、Apache Kafka により公開される JMX メトリクスについて解説しています。
- ZooKeeper ドキュメントの ZooKeeper JMX では、Apache Zookeeper により公開される JMX メトリックについて解説しています。
6.1. メトリクスファイルの例
Grafana ダッシュボードおよびその他のメトリクス設定のサンプルファイルは、examples/metrics ディレクトリー にあります。以下のリストが示すように、一部のファイルは OpenShift Container Platform 3.11 のみで使用され、OpenShift Container Platform 4.x では使用されません。
AMQ Streams で提供されるサンプルメトリクスファイル
metrics ├── grafana-dashboards 1 │ ├── strimzi-cruise-control.json │ ├── strimzi-kafka-bridge.json │ ├── strimzi-kafka-connect.json │ ├── strimzi-kafka-exporter.json │ ├── strimzi-kafka-mirror-maker-2.json │ ├── strimzi-kafka.json │ ├── strimzi-operators.json │ └── strimzi-zookeeper.json ├── grafana-install │ └── grafana.yaml 2 ├── prometheus-additional-properties │ └── prometheus-additional.yaml - OPENSHIFT 3.11 ONLY 3 ├── prometheus-alertmanager-config │ └── alert-manager-config.yaml 4 ├── prometheus-install │ ├── alert-manager.yaml - OPENSHIFT 3.11 ONLY 5 │ ├── prometheus-rules.yaml 6 │ ├── prometheus.yaml - OPENSHIFT 3.11 ONLY 7 │ ├── strimzi-pod-monitor.yaml 8 ├── kafka-bridge-metrics.yaml 9 ├── kafka-connect-metrics.yaml 10 ├── kafka-cruise-control-metrics.yaml 11 ├── kafka-metrics.yaml 12 └── kafka-mirror-maker-2-metrics.yaml 13
- 1
- Grafana ダッシュボードのサンプル
- 2
- Grafana イメージのインストールファイル。
- 3
- OPENSHIFT 3.11 のみ:CPU、メモリー、およびディスクボリュームの使用状況についてのメトリクスをスクレープする追加の Prometheus 設定。これは、ノード上の OpenShift cAdvisor エージェントおよび kubelet から直接提供されます。
- 4
- Alertmanager による通知送信のためのフック定義。
- 5
- OPENSHIFT 3.11 のみ:Alertmanager をデプロイおよび設定するためのリソース。
- 6
- Prometheus Alertmanager と使用するアラートルールの例。
- 7
- OPENSHIFT 3.11 のみ:Prometheus イメージのインストールリソースファイル。
- 8
- Prometheus Operator によって Prometheus サーバーのジョブに変換される PodMonitor の定義。これにより、Pod から直接メトリクスデータをスクレープできます。
- 9
- メトリクスが有効になっている Kafka Bridge リソース。
- 10
- Kafka Connect に対する Prometheus JMX Exporter の再ラベル付けルールを定義するメトリクス設定。
- 11
- Cruise Control に対する Prometheus JMX Exporter の再ラベル付けルールを定義するメトリクス設定。
- 12
- Kafka および ZooKeeper に対する Prometheus JMX Exporter の再ラベル付けルールを定義するメトリクス設定。
- 13
- Kafka Mirror Maker 2.0 に対する Prometheus JMX Exporter の再ラベル付けルールを定義するメトリクス設定。
6.1.1. Grafana ダッシュボードのサンプル
Grafana ダッシュボードのサンプルは、以下のリソースを監視するために提供されます。
- AMQ Streams Kafka
以下のメトリクスを表示します。
- オンラインのブローカーの数
- クラスター内のアクティブなコントローラーの数
- 非同期レプリカがリーダーに選択される割合
- オンラインのレプリカ
- 複製の数が最低数未満であるパーティションの数
- 最小の In-Sync レプリカ数にあるパーティション
- 最小の In-Sync レプリカ数未満のパーティション
- アクティブなリーダーを持たないため、書き込みや読み取りができないパーティション
- Kafka ブローカー Pod のメモリー使用量
- 集約された Kafka ブローカー Pod の CPU 使用率
- Kafka ブローカー Pod のディスク使用量
- 使用されている JVM メモリー
- JVM ガベージコレクションの時間
- JVM ガベージコレクションの数
- 受信バイトレートの合計
- 送信バイトレートの合計
- 受信メッセージレート
- 生成要求レートの合計
- バイトレート
- 生成要求レート
- 取得要求レート
- ネットワークプロセッサーの平均時間アイドル率
- リクエストハンドラーの平均時間アイドル率
- ログサイズ
- AMQ Streams ZooKeeper
以下のメトリクスを表示します。
- ZooKeeper アンサンブルのクォーラムサイズ
- アクティブな 接続の数
- サーバーのキューに置かれたリクエストの数
- ウォッチャーの数
- ZooKeeper Pod のメモリー使用量
- 集約された ZooKeeper Pod の CPU 使用率
- ZooKeeper Pod のディスク使用量
- 使用されている JVM メモリー
- JVM ガベージコレクションの時間
- JVM ガベージコレクションの数
- サーバーがクライアントリクエストに応答するまでの時間 (最大、最小、および平均)
- AMQ Streams Kafka Connect
以下のメトリクスを表示します。
- 受信バイトレートの合計
- 送信バイトレートの合計
- ディスク使用量
- 使用されている JVM メモリー
- JVM ガベージコレクションの時間
- AMQ Streams Kafka MirrorMaker 2
以下のメトリクスを表示します。
- コネクターの数
- タスクの数
- 受信バイトレートの合計
- 送信バイトレートの合計
- ディスク使用量
- 使用されている JVM メモリー
- JVM ガベージコレクションの時間
- AMQ Streams の Operator
以下のメトリクスを表示します。
- カスタムリソース
- 1 時間あたりの成功したカスタムリソース調整の数
- 1 時間あたりの失敗したカスタムリソース調整の数
- 1 時間あたりのロックなしの調整の数
- 1 時間あたりの開始された調整の数
- 1 時間あたりの定期的な調整の数
- 最大の調整時間
- 平均の調整時間
- 使用されている JVM メモリー
- JVM ガベージコレクションの時間
- JVM ガベージコレクションの数
ダッシュボードは、AMQ Streams の Kafka Bridge および Cruise Control コンポーネントにも提供されます。
すべてのダッシュボードは、JVM メトリクスの他に、各コンポーネントに固有のメトリクスを提供します。たとえば、Operator ダッシュボードは、処理中の調整またはカスタムリソースの数に関する情報を提供します。
6.1.2. Prometheus メトリクス設定の例
AMQ Streams は、Prometheus JMX Exporter を使用して、Prometheus によってスクレープされる HTTP エンドポイントを使用して JMX メトリクスを公開します。
Grafana ダッシュボードが依存する Prometheus JMX Exporter の再ラベル付けルールは、カスタムリソース設定として AMQ Streams コンポーネントに対して定義されます。
ラベルは名前と値のペアです。再ラベル付けは、ラベルを動的に書き込むプロセスです。たとえば、ラベルの値は Kafka サーバーおよびクライアント ID の名前から派生されることがあります。
AMQ Streams では、再ラベル付けルールがすでに定義されたカスタムリソース設定 YAML ファイルのサンプルが提供されます。Prometheus メトリクス設定をデプロイする場合、カスタムリソースのサンプルをデプロイすることや、メトリクス設定を独自のカスタムリソース定義にコピーすることができます。
表6.1 メトリクス設定を含むカスタムリソースの例
| コンポーネント | カスタムリソース | サンプル YAML ファイル |
|---|---|---|
| Kafka および ZooKeeper |
|
|
| Kafka Connect |
|
|
| Kafka MirrorMaker 2.0 |
|
|
| Kafka Bridge |
|
|
| Cruise Control |
|
|
関連情報
- 「Prometheus メトリクス設定のデプロイ」
- 再ラベル付けの使用方法の詳細は、Prometheus ドキュメントの「Configuration」を参照してください。
6.2. Prometheus メトリクス設定のデプロイ
AMQ Streams では、再ラベル付けルールが含まれる カスタムリソース設定用の YAML ファイルのサンプル が提供されます。
再ラベル付けルールのメトリクス設定を適用するには、以下のいずれかを行います。
6.2.1. Prometheus メトリクス設定のカスタムリソースへのコピー
Grafana ダッシュボードを監視に使用するには、メトリクス設定サンプルをカスタムリソースにコピーします。
この手順では、Kafka リソースが更新されますが、監視をサポートするすべてのコンポーネントについて手順は同じです。
手順
デプロイメントの Kafka リソースごとに以下の手順を実行します。
エディターで
Kafkaリソースを更新します。oc edit kafka KAFKA-CONFIG-FILE-
kafka-metrics.yamlの設定例を、ユーザーのKafkaリソース定義にコピーします。 - ファイルを保存し、更新したリソースが調整されるのを待ちます。
6.2.2. Prometheus メトリクス設定での Kafka クラスターのデプロイメント
Grafana ダッシュボードを監視に使用するには、メトリクス設定でサンプル Kafka クラスターをデプロイできます。
この手順では、kafka-metrics.yaml ファイルが Kafka リソースに使用されます。
手順
メトリクス設定サンプルで Kafka クラスターをデプロイします。
oc apply -f kafka-metrics.yaml
6.3. OpenShift 4 での Kafka メトリクスおよびダッシュボードの表示
AMQ Streams が OpenShift Container Platform 4.x にデプロイされると、ユーザー定義プロジェクトのモニタリング によりメトリクスが提供されます。この OpenShift 機能により、開発者は独自のプロジェクト (例: Kafka プロジェクト) を監視するために別の Prometheus インスタンスにアクセスできます。
ユーザー定義プロジェクトのモニタリングが有効である場合、openshift-user-workload-monitoring プロジェクトには以下のコンポーネントが含まれます。
- Prometheus Operator
- Prometheus インスタンス (Prometheus Operator によって自動的にデプロイされます)
- Thanos Ruler インスタンス
AMQ Streams は、これらのコンポーネントを使用してメトリクスを消費します。
クラスター管理者は、ユーザー定義プロジェクトのモニタリングを有効にし、開発者およびその他のユーザーに独自のプロジェクト内のアプリケーションを監視するパーミッションを付与する必要があります。
Grafana のデプロイメント
Grafana インスタンスを、Kafka クラスターが含まれるプロジェクトにデプロイできます。その後、Grafana ダッシュボードのサンプルを使用して、AMQ Streams の Prometheus メトリクスを Grafana ユーザーインターフェースで可視化できます。
openshift-monitoring プロジェクトはコアプラットフォームコンポーネントのモニタリングを提供します。このプロジェクトの Prometheus および Grafana コンポーネントを使用して、OpenShift Container Platform 4.x 上の AMQ Streams の監視を設定しないでください。
Grafana バージョン 6.3 は、サポートされる最小バージョンです。
前提条件
- YAML ファイルのサンプルを使用して、Prometheus メトリクス設定がデプロイされている 必要があります。
ユーザー定義プロジェクトの監視が有効になっている必要があります。OpenShift Container Platform クラスターに、クラスター管理者が作成した
cluster-monitoring-configConfigMap が存在する必要があります。詳しい情報は、以下の資料を参照してください。- OpenShift Container Platform 4.6 の「ユーザー定義プロジェクトのモニタリングの有効化」。
- OpenShift Container Platform 4.5 の「独自のサービスのモニタリングの有効化」。
ユーザー定義のプロジェクトを監視するには、クラスター管理者がユーザーに
monitoring-rules-editまたはmonitoring-editロールを割り当て済みである必要があります。以下を参照してください。- OpenShift Container Platform 4.6 の「ユーザーに対するユーザー定義のプロジェクトをモニターするパーミッションの付与」。
- OpenShift Container Platform 4.5 の「WEB コンソールを使用したユーザーパーミッションの付与」
手順の概要
OpenShift Container Platform 4.x で AMQ Streams のモニタリングを設定するには、以下の手順を順番に行います。
6.3.1. Prometheus リソースのデプロイ
OpenShift Container Platform 4.x で AMQ Streams を実行している場合は、この手順を使用します。
Kafka メトリクスを使用するよう Prometheus を有効にするには、サンプルメトリクスファイルで PodMonitor リソースを設定およびデプロイします。PodMonitors は、Apache Kafka、ZooKeeper、Operator、Kafka Bridge、および Cruise Control から直接データをスクレープします。
次に、Alertmanager のアラートルールのサンプルをデプロイします。
前提条件
- 稼働中の Kafka クラスターが必要です。
- AMQ Streams で 提供されるアラートルールのサンプル を確認します。
手順
ユーザー定義プロジェクトのモニタリングが有効であることを確認します。
oc get pods -n openshift-user-workload-monitoring
有効であると、モニタリングコンポーネントの Pod が返されます。以下に例を示します。
NAME READY STATUS RESTARTS AGE prometheus-operator-5cc59f9bc6-kgcq8 1/1 Running 0 25s prometheus-user-workload-0 5/5 Running 1 14s prometheus-user-workload-1 5/5 Running 1 14s thanos-ruler-user-workload-0 3/3 Running 0 14s thanos-ruler-user-workload-1 3/3 Running 0 14s
Pod が返されなければ、ユーザー定義プロジェクトのモニタリングは無効になっています。「OpenShift 4 での Kafka メトリクスおよびダッシュボードの表示」 の前提条件を参照してください。
複数の
PodMonitorリソースは、examples/metrics/prometheus-install/strimzi-pod-monitor.yamlで定義されます。PodMonitorリソースごとにspec.namespaceSelector.matchNamesプロパティーを編集します。apiVersion: monitoring.coreos.com/v1 kind: PodMonitor metadata: name: cluster-operator-metrics labels: app: strimzi spec: selector: matchLabels: strimzi.io/kind: cluster-operator namespaceSelector: matchNames: - PROJECT-NAME 1 podMetricsEndpoints: - path: /metrics port: http # ...- 1
- メトリクスをスクレープする Pod が実行されているプロジェクト (例:
Kafka)。
strimzi-pod-monitor.yamlファイルを、Kafka クラスターが稼働しているプロジェクトにデプロイします。oc apply -f strimzi-pod-monitor.yaml -n MY-PROJECTPrometheus ルールのサンプルを同じプロジェクトにデプロイします。
oc apply -f prometheus-rules.yaml -n MY-PROJECT
その他のリソース
- OpenShift Container Platform 4.6 の『モニタリング』ガイド。
- 「アラートルールの例」
6.3.2. Grafana のサービスアカウントの作成
OpenShift Container Platform 4.x で AMQ Streams を実行している場合は、この手順を使用します。
AMQ Streams の Grafana インスタンスは、cluster-monitoring-view ロールが割り当てられたサービスアカウントで実行する必要があります。
前提条件
手順
Grafana の
ServiceAccountを作成します。ここでは、リソースの名前はgrafana-serviceaccountです。apiVersion: v1 kind: ServiceAccount metadata: name: grafana-serviceaccount labels: app: strimziServiceAccountを、Kafka クラスターが含まれるプロジェクトにデプロイします。oc apply -f GRAFANA-SERVICEACCOUNT -n MY-PROJECT
cluster-monitoring-viewロールを GrafanaServiceAccountに割り当てるClusterRoleBindingリソースを作成します。ここでは、リソースの名前はgrafana-cluster-monitoring-bindingです。apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: grafana-cluster-monitoring-binding labels: app: strimzi subjects: - kind: ServiceAccount name: grafana-serviceaccount namespace: MY-PROJECT 1 roleRef: kind: ClusterRole name: cluster-monitoring-view apiGroup: rbac.authorization.k8s.io- 1
- プロジェクトの名前。
ClusterRoleBindingを、Kafka クラスターが含まれるプロジェクトにデプロイします。oc apply -f GRAFANA-CLUSTER-MONITORING-BINDING -n MY-PROJECT
6.3.3. Prometheus データソースを使用した Grafana のデプロイ
OpenShift Container Platform 4.x で AMQ Streams を実行している場合は、この手順を使用します。
この手順では、OpenShift Container Platform 4.x モニタリングスタックに対して設定された Grafana アプリケーションをデプロイする方法を説明します。
OpenShift Container Platform 4.x では、openshift-monitoring プロジェクトに Thanos Querier インスタンスが含まれています。Thanos Querier は、プラットフォームメトリクスを集約するために使用されます。
必要なプラットフォームメトリクスを使用するには、Grafana インスタンスには Thanos Querier に接続できる Prometheus データソースが必要です。この接続を設定するには、トークンを使用し、Thanos Querier と並行して実行される oauth-proxy サイドカーに対して認証を行う Config Map を作成します。Datasource.yaml ファイルは Config Map のソースとして使用されます。
最後に、Kafka クラスターが含まれるプロジェクトにボリュームとしてマウントされた Config Map で Grafana アプリケーションをデプロイします。
手順
Grafana
ServiceAccountのアクセストークンを取得します。oc serviceaccounts get-token grafana-serviceaccount -n MY-PROJECT次のステップで使用するアクセストークンをコピーします。
Grafana の Thanos Querier 設定が含まれる
datasource.yamlファイルを作成します。以下に示すように、アクセストークンを
httpHeaderValue1プロパティーに貼り付けます。apiVersion: 1 datasources: - name: Prometheus type: prometheus url: https://thanos-querier.openshift-monitoring.svc.cluster.local:9091 access: proxy basicAuth: false withCredentials: false isDefault: true jsonData: timeInterval: 5s tlsSkipVerify: true httpHeaderName1: "Authorization" secureJsonData: httpHeaderValue1: "Bearer ${GRAFANA-ACCESS-TOKEN}" 1 editable: true- 1
GRAFANA-ACCESS-TOKEN:GrafanaServiceAccountのアクセストークンの値。
datasource.yamlファイルからgrafana-configという名前の Config Map を作成します。oc create configmap grafana-config --from-file=datasource.yaml -n MY-PROJECTDeploymentおよびServiceで構成される Grafana アプリケーションを作成します。grafana-configConfig Map はデータソース設定のボリュームとしてマウントされます。apiVersion: apps/v1 kind: Deployment metadata: name: grafana labels: app: strimzi spec: replicas: 1 selector: matchLabels: name: grafana template: metadata: labels: name: grafana spec: serviceAccountName: grafana-serviceaccount containers: - name: grafana image: grafana/grafana:6.3.0 ports: - name: grafana containerPort: 3000 protocol: TCP volumeMounts: - name: grafana-data mountPath: /var/lib/grafana - name: grafana-logs mountPath: /var/log/grafana - name: grafana-config mountPath: /etc/grafana/provisioning/datasources/datasource.yaml readOnly: true subPath: datasource.yaml readinessProbe: httpGet: path: /api/health port: 3000 initialDelaySeconds: 5 periodSeconds: 10 livenessProbe: httpGet: path: /api/health port: 3000 initialDelaySeconds: 15 periodSeconds: 20 volumes: - name: grafana-data emptyDir: {} - name: grafana-logs emptyDir: {} - name: grafana-config configMap: name: grafana-config --- apiVersion: v1 kind: Service metadata: name: grafana labels: app: strimzi spec: ports: - name: grafana port: 3000 targetPort: 3000 protocol: TCP selector: name: grafana type: ClusterIPGrafana アプリケーションを、Kafka クラスターが含まれるプロジェクトにデプロイします。
oc apply -f GRAFANA-APPLICATION -n MY-PROJECT
関連情報
- 「OpenShift 4 での Kafka メトリクスおよびダッシュボードの表示」
- OpenShift Container Platform 4.6 の『モニタリング』ガイド。
6.3.4. Grafana サービスへのルートの作成
OpenShift Container Platform 4.x で AMQ Streams を実行している場合は、この手順を使用します。
Grafana サービスを公開するルートを介して、Grafana ユーザーインターフェースにアクセスできます。
手順
grafanaサービスへのルートの作成:oc create route edge MY-GRAFANA-ROUTE --service=grafana --namespace=KAFKA-NAMESPACE
6.3.5. Grafana ダッシュボードサンプルのインポート
OpenShift Container Platform 4.x で AMQ Streams を実行している場合は、この手順を使用します。
Grafana ユーザーインターフェースを使用して Grafana ダッシュボードのサンプルをインポートします。
前提条件
手順
Grafana サービスへのルートの詳細を取得します。以下に例を示します。
oc get routes NAME HOST/PORT PATH SERVICES MY-GRAFANA-ROUTE MY-GRAFANA-ROUTE-amq-streams.net grafana
- Web ブラウザーで、Route ホストおよびポートの URL を使用して Grafana ログイン画面にアクセスします。
ユーザー名とパスワードを入力し、続いて Log In をクリックします。
デフォルトの Grafana ユーザー名およびパスワードは、どちらも
adminです。初回ログイン後に、パスワードを変更できます。- Configuration > Data Sources で、Prometheus データソースが作成済みであることを確認します。データソースは 「Prometheus データソースを使用した Grafana のデプロイ」 に作成されています。
- Dashboards > Manage をクリックしてから Import をクリックします。
-
examples/metrics/grafana-dashboardsで、インポートするダッシュボードの JSON をコピーします。 - JSON をテキストボックスに貼り付け、Load をクリックします。
- 他の Grafana ダッシュボードのサンプルに、ステップ 1 -7 を繰り返します。
インポートされた Grafana ダッシュボードは、Dashboards ホームページから表示できます。
6.4. OpenShift 3.11 での Kafka メトリクスおよびダッシュボードの表示
AMQ Streams が OpenShift Container Platform 3.11 にデプロイされた場合、Prometheus を使用して AMQ Streams で提供される Grafana ダッシュボードのサンプルのモニタリングデータを提供できます。Prometheus コンポーネントをクラスターに手動でデプロイする必要があります。
Grafana ダッシュボードのサンプルを実行するには、以下を行う必要があります。
このセクションで参照されるリソースは、まず監視を設定することを目的としており、これらはサンプルとしてのみ提供されます。実稼働環境で Prometheus または Grafana を設定、実行するためにサポートがさらに必要な場合は、それぞれのコミュニティーに連絡してください。
6.4.1. Prometheus のサポート
AMQ Streams が OpenShift Container Platform 3.11 にデプロイされた場合は、Prometheus サーバーはサポートされません。しかし、メトリクスを公開するために使用される Prometheus エンドポイントと Prometheus JMX Exporter はサポートされます。
Prometheus を使用して監視を行う場合に備え、詳細な手順とメトリクス設定ファイルのサンプルが提供されます。
6.4.2. Prometheus の設定
OpenShift Container Platform 3.11 で AMQ Streams を実行している場合は、以下の手順を使用します。
Prometheus では、システム監視とアラート通知のオープンソースのコンポーネントセットが提供されます。
ここでは、AMQ Streams が OpenShift Container Platform 3.11 にデプロイされている場合に、提供された Prometheus イメージと設定ファイルを使用して、Prometheus サーバーを実行および管理する方法を説明します。
前提条件
- 互換性のあるバージョンの Prometheus および Grafana を OpenShift Container Platform 3.11 クラスターにデプロイしている。
Prometheus サーバー Pod の実行に使用されるサービスアカウントが OpenShift API サーバーにアクセスできる。これにより、サービスアカウントはメトリクスの取得元となるクラスターにある Pod の一覧を取得できます。
詳細は、「Discovering services」を参照してください。
6.4.2.1. Prometheus の設定
AMQ Streams では、Prometheus サーバーの設定ファイルのサンプル が提供されます。
デプロイメント用に Prometheus イメージが提供されます。
-
prometheus.yaml
Prometheus 関連の追加設定も、以下のファイルに含まれています。
-
prometheus-additional.yaml -
prometheus-rules.yaml -
strimzi-pod-monitor.yaml
Prometheus が監視データを取得するには、互換性のあるバージョンの Prometheus を OpenShift Container Platform 3.11 クラスターにデプロイしている必要があります。
次に、設定ファイルを使用して Prometheus をデプロイ します。
6.4.2.2. Prometheus リソース
Prometheus 設定を適用すると、以下のリソースが OpenShift クラスターに作成され、Prometheus Operator によって管理されます。
-
ClusterRole。コンテナーメトリクスのために Kafka と ZooKeeper の Pod、cAdvisor および kubelet によって公開される health エンドポイントを読み取る権限を Prometheus に付与します。 -
ServiceAccount。これで Prometheus Pod が実行されます。 -
ClusterRoleBinding。ClusterRoleをServiceAccountにバインドします。 -
Deployment。Prometheus Operator Pod を管理します。 -
PodMonitor。Prometheus Pod の設定を管理します。 -
Prometheus。Prometheus Pod の設定を管理します。 -
PrometheusRule。Prometheus Pod のアラートルールを管理します。 -
Secret。Prometheus の追加設定を管理します。 -
Service。クラスターで稼働するアプリケーションが Prometheus に接続できるようにします (例: Prometheus をデータソースとして使用する Grafana)。
6.4.2.3. Prometheus のデプロイメント
Kafka クラスターの監視データを取得するには、独自の Prometheus デプロイメントを使用するか、Prometheus Docker イメージのインストールリソースサンプルファイルと Prometheus 関連リソースの YAML ファイル を適用して Prometheus をデプロイすることができます。
デプロイメントプロセスでは、ClusterRoleBinding が作成され、デプロイメントのために指定された namespace で Alertmanager インスタンスが検出されます。
前提条件
- 提供されるアラートルールのサンプルを確認します。
手順
Prometheus のインストール先となる namespace に従い、Prometheus インストールファイル (
prometheus.yaml) を変更します。Linux の場合は、以下を使用します。
sed -i 's/namespace: .*/namespace: my-namespace/' prometheus.yamlMacOS の場合は、以下を使用します。
sed -i '' 's/namespace: .*/namespace: my-namespace/' prometheus.yamlPodMonitorリソースをstrimzi-service-monitor.yamlで編集し、Pod からメトリクスデータをスクレープする Prometheus ジョブを定義します。namespaceSelector.matchNamesプロパティーを、メトリクスのスクレープ元の Pod が実行されている namespace で更新します。PodMonitorは、Apache Kafka、ZooKeeper、Operator、Kafka Bridge、および Cruise Control の Pod から直接データをスクレープするために使用されます。prometheus.yamlインストールファイルを編集し、ノードから直接メトリクスをスクレープするための追加設定を含めます。提供される Grafana ダッシュボードが表示する CPU、メモリー、およびディスクボリュームの使用状況についてのメトリクスは、ノード上の OpenShift cAdvisor エージェントおよび kubelet から直接提供されます。
設定ファイル (
prometheus-additional.yamlin theexamples/metrics/prometheus-additional-propertiesディレクトリー) からSecretリソースを作成します。oc apply -f prometheus-additional.yaml
-
prometheus.yamlファイルでadditionalScrapeConfigsプロパティーを編集して、Secretの名前とprometheus-additional.yamlファイルを含めます。
Prometheus リソースをデプロイします。
oc apply -f strimzi-pod-monitor.yaml oc apply -f prometheus-rules.yaml oc apply -f prometheus.yaml
6.4.3. Prometheus Alertmanager の設定
Prometheus Alertmanager は、アラートを処理して通知サービスにルーティングするためのプラグインです。Alertmanager は、アラートルールを基にして潜在的な問題と見られる状態を通知し、監視で必要な条件に対応します。
6.4.3.1. Alertmanager の設定
AMQ Streams には、Prometheus Alertmanager の設定ファイルのサンプルが含まれます。
設定ファイルは、Alertmanager をデプロイするためのリソースを定義します。
-
alert-manager.yaml
追加の設定ファイルには、Kafka クラスターから通知を送信するためのフック定義が含まれます。
-
alert-manager-config.yaml
Alertmanger で Prometheus アラートの処理を可能にするには、設定ファイルを使用して以下を行います。
6.4.3.2. アラートルール
アラートルールによって、メトリクスで監視される特定条件についての通知が提供されます。ルールは Prometheus サーバーで宣言されますが、アラート通知は Prometheus Alertmanager で対応します。
Prometheus アラートルールでは、継続的に評価される PromQL 表現を使用して条件が記述されます。
アラート表現が true になると、条件が満たされ、Prometheus サーバーからアラートデータが Alertmanager に送信されます。次に Alertmanager は、そのデプロイメントに設定された通信方法を使用して通知を送信します。
Alertmanager は、電子メール、チャットメッセージなどの通知方法を使用するように設定できます。
その他のリソース
アラートルールの設定についての詳細は、Prometheus ドキュメントの「Configuration」を参照してください。
6.4.3.3. アラートルールの例
Kafka および ZooKeeper メトリクスのアラートルールのサンプルは AMQ Streams に含まれており、Prometheus デプロイメントで使用できます。
アラートルールの定義に関する一般的な留意点:
-
forプロパティーはルールと併用され、アラートがトリガーされる前に条件が維持されなければならない期間を決定します。 -
ティック (tick) は ZooKeeper の基本的な時間単位です。ミリ秒単位で測定され、
Kafka.spec.zookeeper.configのtickTimeパラメーターを使用して設定されます。たとえば、ZooKeeper でtickTime=3000の場合、3 ティック (3 x 3000) は 9000 ミリ秒と等しくなります。 -
ZookeeperRunningOutOfSpaceメトリクスおよびアラートを利用できるかどうかは、使用される OpenShift 設定およびストレージ実装によります。特定のプラットフォームのストレージ実装では、メトリクスによるアラートの提供に必要な利用可能な領域について情報が提供されない場合があります。
Kafka アラートルール
UnderReplicatedPartitions-
現在のブローカーがリードレプリカでありながら、パーティションのトピックに設定された
min.insync.replicasよりも複製数が少ないパーティションの数が示されます。このメトリクスにより、フォロワーレプリカをホストするブローカーの詳細が提供されます。リーダーからこれらのフォロワーへの複製が追い付いていません。その理由として、現在または過去にオフライン状態になっていたり、過剰なスロットリングが適用されたブローカー間の複製であることが考えられます。この値がゼロより大きい場合にアラートが発生し、複製の数が最低数未満であるパーティションの情報がブローカー別に通知されます。 AbnormalControllerState- 現在のブローカーがクラスターのコントローラーであるかどうかを示します。メトリクスは 0 または 1 です。クラスターのライフサイクルでは、1 つのブローカーのみかコントローラーとなるはずで、クラスターには常にアクティブなコントローラーが存在する必要があります。複数のブローカーがコントローラーであることが示される場合は問題になります。そのような状態が続くと、すべてのブローカーのこのメトリクスの合計値が 1 でない場合にアラートが発生します。合計値が 0 であればアクティブなコントローラーがなく、合計値が 1 を超えればコントローラーが複数あることを意味します。
UnderMinIsrPartitionCount-
書き込み操作の完了を通知しなければならないリード Kafka ブローカーの ISR (In-Sync レプリカ) が最小数 (
min.insync.replicasを使用して指定) に達していないことを示します。このメトリクスでは、ブローカーがリードし、In-Sync レプリカの数が最小数に達していない、パーティションの数が定義されます。この値がゼロより大きい場合にアラートが発生し、完了通知 (ack) が最少数未満であった各ブローカーのパーティション数に関する情報が提供されます。 OfflineLogDirectoryCount- ハードウェア障害などの理由によりオフライン状態であるログディレクトリーの数を示します。そのため、ブローカーは受信メッセージを保存できません。この値がゼロより大きい場合にアラートが発生し、各ブローカーのオフライン状態であるログディレクトリーの数に関する情報が提供されます。
KafkaRunningOutOfSpace-
データの書き込みに使用できる残りのディスク容量を示します。この値が 5GiB 未満になるとアラートが発生し、永続ボリューム要求 (Persistent Volume Claim、PVC) ごとに容量不足のディスクに関する情報が提供されます。しきい値は
prometheus-rules.yamlで変更できます。
ZooKeeper アラートルール
AvgRequestLatency- サーバーがクライアントリクエストに応答するまでの時間を示します。この値が 10 (tick) を超えるとアラートが発生し、各サーバーの平均リクエストレイテンシーの実際の値が通知されます。
OutstandingRequests- サーバーでキューに置かれたリクエストの数を示します。この値は、サーバーが処理能力を超えるリクエストを受信すると上昇します。この値が 10 よりも大きい場合にアラートが発生し、各サーバーの未処理のリクエスト数が通知されます。
ZookeeperRunningOutOfSpace- このメトリクスは、ZooKeeper へのデータ書き込みに使用できる残りのディスク容量を示します。この値が 5GiB 未満になるとアラートが発生し、永続ボリューム要求 (Persistent Volume Claim、PVC) ごとに容量不足のディスクに関する情報が提供されます。
6.4.3.4. Alertmanager のデプロイメント
Alertmanager をデプロイするには、設定ファイルのサンプルを適用します。
AMQ Streams に含まれる設定サンプルでは、Slack チャネルに通知を送信するように Alertmanager を設定します。
デプロイメントで以下のリソースが定義されます。
-
Alertmanager。Alertmanager Pod を管理します。 -
Secret。Alertmanager の設定を管理します。 -
Service。参照しやすいホスト名を提供し、他のサービスが Alertmanager に接続できるようにします (Prometheus など)。
手順
Alertmanager 設定ファイル (
alert-manager-config.yaml) からSecretリソースを作成します。oc create secret generic alertmanager-alertmanager --from-file=alertmanager.yaml=alert-manager-config.yaml
以下を行って、
alert-manager-config.yamlファイルを更新します。-
slack_api_urlプロパティーを、Slack ワークスペースのアプリケーションに関連する Slack API URL の実際の値に置き換えます。 -
channelプロパティーを、通知が送信される実際の Slack チャネルに置き換えます。
-
Alertmanager をデプロイします。
oc apply -f alert-manager.yaml
6.4.4. Grafana の設定
Grafana では、Prometheus メトリクスを視覚化できます。
AMQ Streams で提供される Grafana ダッシュボードサンプルをデプロイして有効化できます。
6.4.4.1. Grafana のデプロイメント
Prometheus メトリクスを視覚化するには、独自の Grafana インストールを使用するか、examples/metrics ディレクトリーにある grafana.yaml ファイルを適用して Grafana をデプロイできます。
前提条件
手順
Grafana をデプロイします。
oc apply -f grafana.yaml
- Grafana ダッシュボードを有効にします。
6.4.4.2. Grafana ダッシュボードサンプルの有効化
AMQ Streams には、Grafana のダッシュボード設定ファイルのサンプル が含まれています。ダッシュボードのサンプルは、JSON ファイルとして提供され、examples/metrics ディレクトリーで提供されます。
-
strimzi-kafka.json -
strimzi-zookeeper.json -
strimzi-kafka-connect.json -
strimzi-kafka-mirror-maker-2.json -
strimzi-operators.json -
strimzi-kafka-bridge.json -
strimzi-cruise-control.json
ダッシュボードのサンプルは、主なメトリクスの監視を開始するための雛形として使用できますが、使用できるすべてのメトリックスを対象としていません。使用するインフラストラクチャーに応じて、ダッシュボードのサンプルの編集や、他のメトリクスの追加を行うことができます。
Prometheus および Grafana の設定後に、Grafana ダッシュボードで AMQ Streams データを可視化できます。
アラート通知ルールは定義されていません。
ダッシュボードにアクセスする場合、port-forward コマンドを使用して Grafana Pod からホストにトラフィックを転送できます。
Grafana Pod の名前はユーザーごとに異なります。
手順
Grafana サービスの詳細を取得します。
oc get service grafana
以下に例を示します。
NAME TYPE CLUSTER-IP PORT(S) grafana
ClusterIP
172.30.123.40
3000/TCP
ポート転送用のポート番号を書き留めておきます。
port-forwardを使用して、Grafana ユーザーインターフェースをlocalhost:3000にリダイレクトします。oc port-forward svc/grafana 3000:3000
Web ブラウザーで
http://localhost:3000を指定します。Grafana のログインページが表示されます。
ユーザー名とパスワードを入力し、続いて をクリックします。
デフォルトの Grafana ユーザー名およびパスワードは、どちらも
adminです。初回ログイン後に、パスワードを変更できます。Prometheus を データソース として追加します。
- 名前を指定します。
- Prometheus をタイプとして追加します。
Prometheus サーバーの URL (http://prometheus-operated:9090) を指定します。
詳細を追加したら、保存して接続をテストします。
- → から、ダッシュボードのサンプルをアップロードするか、JSON を直接貼り付けます。
上部のヘッダーでダッシュボードのドロップダウンメニューをクリックし、表示するダッシュボードを選択します。
Prometheus サーバーが AMQ Streams クラスターのメトリクスを収集すると、それがダッシュボードに反映されます。
図6.1 ダッシュボードの選択オプション
- AMQ Streams Kafka
以下のメトリクスを表示します。
- オンラインのブローカーの数
- クラスター内のアクティブなコントローラーの数
- 非同期レプリカがリーダーに選択される割合
- オンラインのレプリカ
- 複製の数が最低数未満であるパーティションの数
- 最小の In-Sync レプリカ数にあるパーティション
- 最小の In-Sync レプリカ数未満のパーティション
- アクティブなリーダーを持たないため、書き込みや読み取りができないパーティション
- Kafka ブローカー Pod のメモリー使用量
- 集約された Kafka ブローカー Pod の CPU 使用率
- Kafka ブローカー Pod のディスク使用量
- 使用されている JVM メモリー
- JVM ガベージコレクションの時間
- JVM ガベージコレクションの数
- 受信バイトレートの合計
- 送信バイトレートの合計
- 受信メッセージレート
- 生成要求レートの合計
- バイトレート
- 生成要求レート
- 取得要求レート
- ネットワークプロセッサーの平均時間アイドル率
- リクエストハンドラーの平均時間アイドル率
ログサイズ
図6.2 AMQ Streams Kafka ダッシュボード
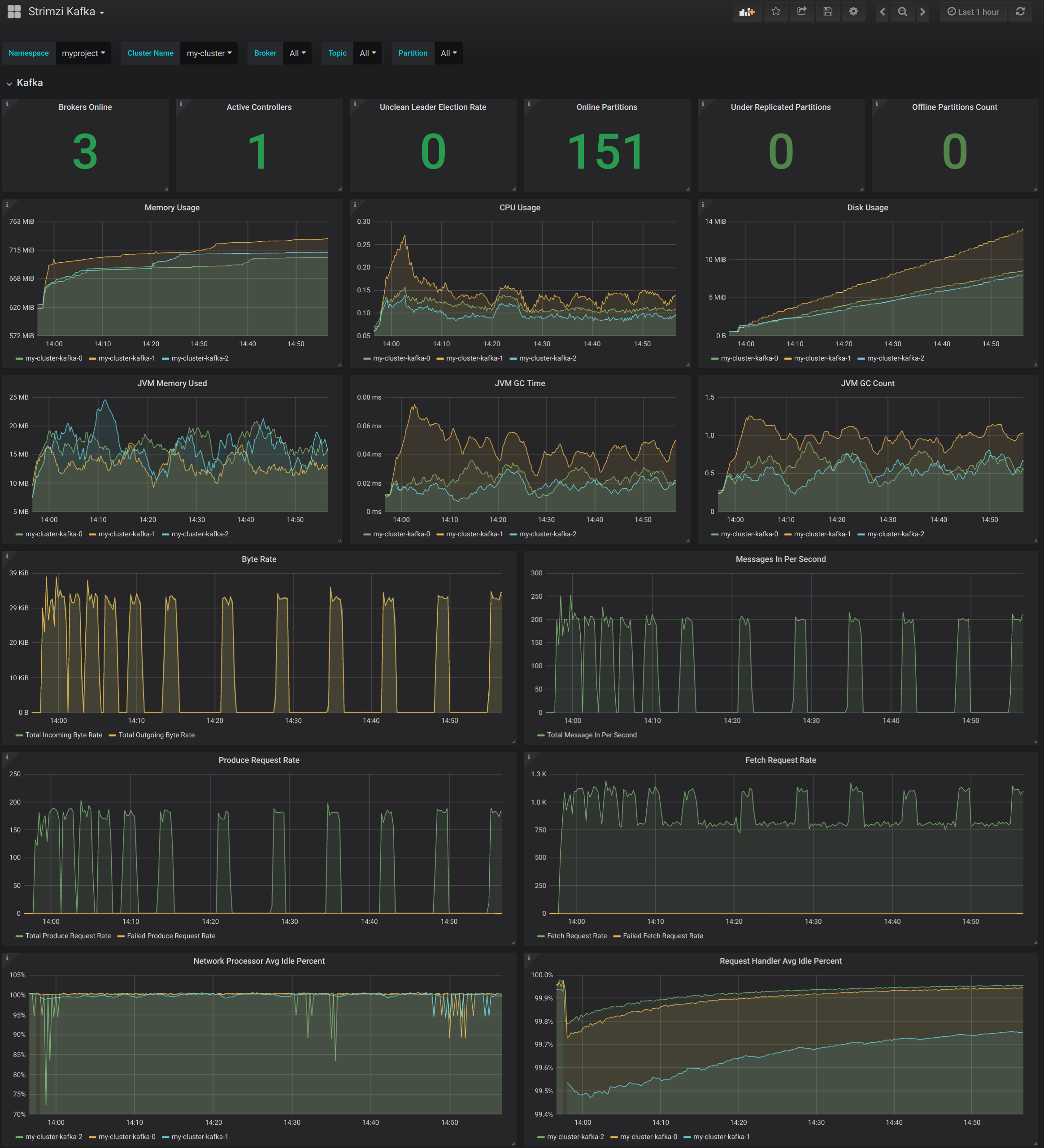
- AMQ Streams ZooKeeper
以下のメトリクスを表示します。
- ZooKeeper アンサンブルのクォーラムサイズ
- アクティブな 接続の数
- サーバーのキューに置かれたリクエストの数
- ウォッチャーの数
- ZooKeeper Pod のメモリー使用量
- 集約された ZooKeeper Pod の CPU 使用率
- ZooKeeper Pod のディスク使用量
- 使用されている JVM メモリー
- JVM ガベージコレクションの時間
- JVM ガベージコレクションの数
- サーバーがクライアントリクエストに応答するまでの時間 (最大、最小、および平均)
- AMQ Streams Kafka Connect
以下のメトリクスを表示します。
- 受信バイトレートの合計
- 送信バイトレートの合計
- ディスク使用量
- 使用されている JVM メモリー
- JVM ガベージコレクションの時間
- AMQ Streams Kafka MirrorMaker 2
以下のメトリクスを表示します。
- コネクターの数
- タスクの数
- 受信バイトレートの合計
- 送信バイトレートの合計
- ディスク使用量
- 使用されている JVM メモリー
- JVM ガベージコレクションの時間
- AMQ Streams の Operator
以下のメトリクスを表示します。
- カスタムリソース
- 1 時間あたりの成功したカスタムリソース調整の数
- 1 時間あたりの失敗したカスタムリソース調整の数
- 1 時間あたりのロックなしの調整の数
- 1 時間あたりの開始された調整の数
- 1 時間あたりの定期的な調整の数
- 最大の調整時間
- 平均の調整時間
- 使用されている JVM メモリー
- JVM ガベージコレクションの時間
- JVM ガベージコレクションの数
6.5. Kafka Exporter の追加
Kafka Exporter は、Apache Kafka ブローカーおよびクライアントの監視を強化するオープンソースプロジェクトです。Kafka Exporter は、Kafka クラスターとのデプロイメントを実現するために AMQ Streams で提供され、オフセット、コンシューマーグループ、コンシューマーラグ、およびトピックに関連する Kafka ブローカーから追加のメトリクスデータを抽出します。
一例として、メトリクスデータを使用すると、低速なコンシューマーの識別に役立ちます。
ラグデータは Prometheus メトリクスとして公開され、解析のために Grafana で使用できます。
ビルトイン Kafka メトリクスの監視のために Prometheus および Grafana をすでに使用している場合、Kafka Exporter Prometheus エンドポイントをスクレープするように Prometheus を設定することもできます。
6.5.1. コンシューマーラグの監視
コンシューマーラグは、メッセージの生成と消費の差を示しています。具体的には、指定のコンシューマーグループのコンシューマーラグは、パーティションの最後のメッセージと、そのコンシューマーが現在ピックアップしているメッセージとの時間差を示しています。
ラグには、パーティションログの最後を基準とする、コンシューマーオフセットの相対的な位置が反映されます。
プロデューサーおよびコンシューマーオフセット間のコンシューマーラグ
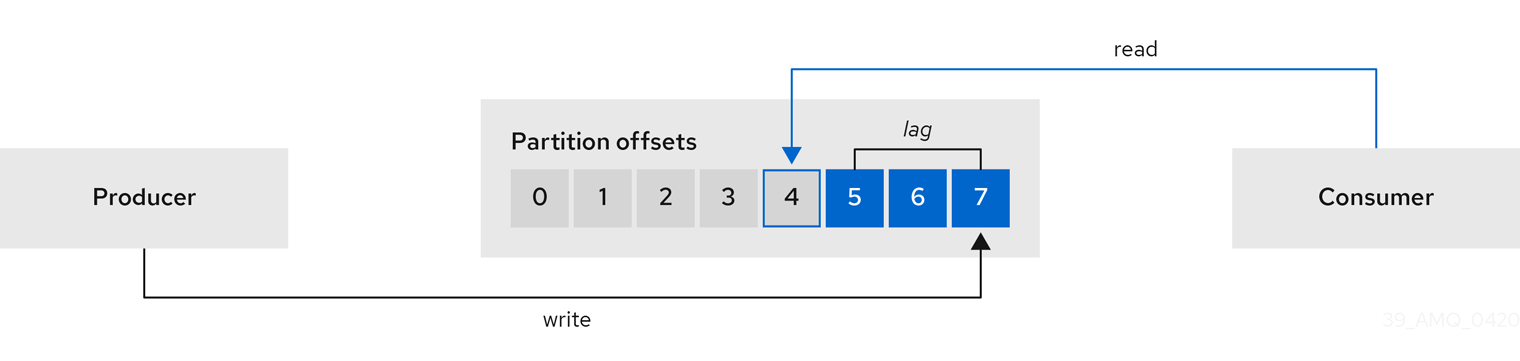
この差は、Kafka ブローカートピックパーティションの読み取りと書き込みの場所である、プロデューサーオフセットとコンシューマーオフセットの間の デルタ とも呼ばれます。
あるトピックで毎秒 100 個のメッセージがストリーミングされる場合を考えてみましょう。プロデューサーオフセット (トピックパーティションの先頭) と、コンシューマーが読み取った最後のオフセットとの間のラグが 1000 個のメッセージであれば、10 秒の遅延があることを意味します。
コンシューマーラグ監視の重要性
可能な限りリアルタイムのデータの処理に依存するアプリケーションでは、コンシューマーラグを監視して、ラグが過度に大きくならないようにチェックする必要があります。ラグが大きくなるほど、リアルタイム処理の達成から遠ざかります。
たとえば、パージされていない古いデータの大量消費や、予定外のシャットダウンが、コンシューマーラグの原因となることがあります。
コンシューマーラグの削減
通常、ラグを削減するには以下を行います。
- 新規コンシューマーを追加してコンシューマーグループをスケールアップします。
- メッセージがトピックに留まる保持時間を延長します。
- ディスク容量を追加してメッセージバッファーを増強します。
コンシューマーラグを減らす方法は、基礎となるインフラストラクチャーや、AMQ Streams によりサポートされるユースケースによって異なります。たとえば、ラグが生じているコンシューマーの場合、ディスクキャッシュからフェッチリクエストに対応できるブローカーを活用できる可能性は低いでしょう。場合によっては、コンシューマーの状態が改善されるまで、自動的にメッセージをドロップすることが許容されることがあります。
6.5.2. Kafka Exporter アラートルールの例
メトリクスをデプロイメントに導入するステップが実行済みである場合、Kafka Exporter をサポートするアラート通知ルールを使用するよう Kafka クラスターがすでに設定された状態になっています。
Kafka Exporter のルールは prometheus-rules.yaml に定義されており、Prometheus でデプロイされます。詳細は、「Prometheus」を参照してください。
Kafka Exporter に固有のサンプルのアラート通知ルールには以下があります。
UnderReplicatedPartition- トピックで複製の数が最低数未満であり、ブローカーがパーティションで十分な複製を作成していないことを警告するアラートです。デフォルトの設定では、トピックに複製の数が最低数未満のパーティションが 1 つ以上ある場合のアラートになります。このアラートは、Kafka インスタンスがダウンしているか Kafka クラスターがオーバーロードの状態であることを示す場合があります。レプリケーションプロセスを再起動するには、Kafka ブローカーの計画的な再起動が必要な場合があります。
TooLargeConsumerGroupLag- 特定のトピックパーティションでコンシューマーグループのラグが大きすぎることを警告するアラートです。デフォルト設定は 1000 レコードです。ラグが大きい場合、コンシューマーが遅すぎてプロデューサーの処理に追い付いてない可能性があります。
NoMessageForTooLong- トピックが一定期間にわたりメッセージを受信していないことを警告するアラートです。この期間のデフォルト設定は 10 分です。この遅れは、設定の問題により、プロデューサーがトピックにメッセージを公開できないことが原因である可能性があります。
これらのルールのデフォルト設定は、特定のニーズに合わせて調整してください。
6.5.3. Kafka Exporter メトリクスの公開
ラグ情報は、Grafana で示す Prometheus メトリクスとして Kafka Exporter によって公開されます。
Kafka Exporter は、ブローカー、トピック、およびコンシューマーグループのメトリクスデータを公開します。
抽出されるデータを以下に示します。
表6.2 ブローカーメトリクスの出力
| 名前 | 詳細 |
|---|---|
|
| Kafka クラスターに含まれるブローカーの数 |
表6.3 トピックメトリクスの出力
| 名前 | 詳細 |
|---|---|
|
| トピックのパーティション数 |
|
| ブローカーの現在のトピックパーティションオフセット |
|
| ブローカーの最も古いトピックパーティションオフセット |
|
| トピックパーティションの In-Sync レプリカ数 |
|
| トピックパーティションのリーダーブローカー ID |
|
|
トピックパーティションが優先ブローカーを使用している場合は、 |
|
| このトピックパーティションのレプリカ数 |
|
|
トピックパーティションの複製の数が最低数未満である場合に |
表6.4 コンシューマーグループメトリクスの出力
| 名前 | 詳細 |
|---|---|
|
| コンシューマーグループの現在のトピックパーティションオフセット |
|
| トピックパーティションのコンシューマーグループの現在のラグ (概算値) |
6.5.4. Kafka Exporter の設定
この手順では、KafkaExporter プロパティーから Kafka リソースの Kafka Exporter を設定する方法を説明します。
Kafka リソースの設定に関する詳細は、『 AMQ Streams on OpenShift の使用 』の「Kafka YAML の設定例 」を参照してください。
この手順では、Kafka Exporter 設定に関連するプロパティーを取り上げます。
これらのプロパティーは、Kafka クラスターのデプロイメントまたは再デプロイメントの一部として設定できます。
前提条件
- OpenShift クラスター。
- 稼働中の Cluster Operator。
手順
KafkaリソースのKafkaExporterプロパティーを編集します。設定可能なプロパティーは以下の例のとおりです。
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka metadata: name: my-cluster spec: # ... kafkaExporter: image: my-org/my-image:latest 1 groupRegex: ".*" 2 topicRegex: ".*" 3 resources: 4 requests: cpu: 200m memory: 64Mi limits: cpu: 500m memory: 128Mi logging: debug 5 enableSaramaLogging: true 6 template: 7 pod: metadata: labels: label1: value1 imagePullSecrets: - name: my-docker-credentials securityContext: runAsUser: 1000001 fsGroup: 0 terminationGracePeriodSeconds: 120 readinessProbe: 8 initialDelaySeconds: 15 timeoutSeconds: 5 livenessProbe: 9 initialDelaySeconds: 15 timeoutSeconds: 5 # ...リソースを作成または更新します。
oc apply -f kafka.yaml
次のステップ
Kafka Exporter の設定およびデプロイ後に、Grafana を有効にして Kafka Exporter ダッシュボードを表示できます。
6.5.5. Kafka Exporter Grafana ダッシュボードの有効化
AMQ Streams には、Grafana のダッシュボード設定ファイルのサンプル が含まれています。Kafka Exporter ダッシュボードは、JSON ファイルとして提供され、examples/metrics ディレクトリーに含まれています。
-
strimzi-kafka-exporter.json
Kafka Exporter を Kafka クラスターでデプロイした場合、公開されるメトリクスデータを Grafana ダッシュボードで可視化できます。
前提条件
この手順では、Grafana ユーザーインターフェースにアクセスでき、Prometheus がデータソースとして追加されていることを前提とします。ユーザーインターフェースに初めてアクセスする場合は、「Grafana」を参照してください。
手順
- Grafana ユーザーインターフェースにアクセスします。
Strimzi Kafka Exporter ダッシュボードを選択します。
メトリクスデータが収集されると、Kafka Exporter のチャートにデータが反映されます。
- AMQ Streams Kafka Exporter
以下のメトリクスを表示します。
- トピックの数
- パーティションの数
- レプリカの数
- In-Sync レプリカの数
- 複製の数が最低数未満であるパーティションの数
- 最小の In-Sync レプリカ数にあるパーティション
- 最小の In-Sync レプリカ数未満のパーティション
- 優先ノードにないパーティション
- 毎秒のトピックからのメッセージ
- 毎秒消費されるトピックからのメッセージ
- コンシューマーグループごとに毎分消費されるメッセージ
- コンシューマーグループごとのラグ
- パーティションの数
- 最新のオフセット
- 最も古いオフセット
Grafana のチャートを使用して、ラグを分析し、ラグ削減の方法が対象のコンシューマーグループに影響しているかどうかを確認します。たとえば、ラグを減らすように Kafka ブローカーを調整すると、ダッシュボードには コンシューマーグループごとのラグ のチャートが下降し 毎分のメッセージ消費 のチャートが上昇する状況が示されます。
6.6. Kafka Bridge の監視
ビルトイン Kafka メトリクスの監視のために Prometheus および Grafana をすでに使用している場合、Kafka Bridge Prometheus エンドポイントをスクレープするように Prometheus を設定することもできます。
Kafka Bridge の Grafana ダッシュボードのサンプルは以下を提供します。
- さまざまなエンドポイントへの HTTP 接続および関連リクエストに関する情報
- ブリッジによって使用される Kafka コンシューマーおよびプロデューサーに関する情報
- ブリッジ自体からの JVM メトリクス
6.6.1. Kafka Bridge の設定
KafkaBridge リソースの enableMetrics プロパティーを使用して、Kafka Bridge メトリクスを有効にできます。
このプロパティーは、Kafka Bridge のデプロイメントまたは再デプロイメントの一部として設定できます。
以下に例を示します。
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaBridge
metadata:
name: my-bridge
spec:
# ...
bootstrapServers: my-cluster-kafka:9092
http:
# ...
enableMetrics: true
# ...6.6.2. Kafka Bridge Grafana ダッシュボードの有効化
Kafka Bridge を Kafka クラスターでデプロイした場合、Grafana により公開されるメトリクスデータを表示するように Grafana を有効化できます。
Kafka Bridge ダッシュボードは、JSON ファイルとして提供され、examples/metrics ディレクトリーに含まれています。
-
strimzi-kafka-bridge.json
メトリクスデータが収集されると、Kafka Bridge のチャートにデータが反映されます。
- Kafka Bridge
以下のメトリクスを表示します。
- Kafka Bridge への HTTP 接続の数
- 処理中の HTTP リクエストの数
- HTTP メソッドごとに 1 秒あたり処理されるリクエスト
- レスポンスコード (2XX、4XX、5XX) ごとの要求レートの合計
- 1 秒あたりの受信および送信バイト数
- Kafka Bridge エンドポイントごとのリクエスト
- Kafka Bridge 自体によって使用される Kafka コンシューマー、プロデューサー、および関連するオープン接続の数
Kafka プロデューサー:
- 1 秒あたり送信される平均のレコード数 (トピックごとにグループ化)
- 1 秒あたりすべてのブローカーに送信される発信バイト数 (トピックごとにグループ化)
- エラーとなったレコードの 1 秒あたりの平均数 (トピックごとにグループ化)
Kafka コンシューマー:
- 1 秒あたり消費される平均のレコード数 (clientId-topic ごとにグループ化)
- 1 秒あたり消費される平均のバイト数 (clientId-topic ごとにグループ化)
- 割り当てられるパーティション (clientId ごとにグループ化)
- 使用されている JVM メモリー
- JVM ガベージコレクションの時間
- JVM ガベージコレクションの数
6.7. Cruise Control の監視
ビルトイン Kafka メトリクスの監視のために Prometheus および Grafana をすでに使用している場合、Cruise Control Prometheus エンドポイントをスクレープするように Prometheus を設定することもできます。
Cruise Control の Grafana ダッシュボードのサンプルは以下を提供します。
- 最適化プロポーザルの計算、ゴールの逸脱、クラスターのバランス状況などに関する情報
- リバランスプロポーザルおよび実際のリバランス操作の REST API コールに関する情報
- Cruise Control 自体からの JVM メトリクス
6.7.1. Cruise Control の設定
公開するメトリクスに関する JMX エクスポーター設定が含まれる cruiseControl.metrics プロパティーを使用すると、Kafka リソースの Cruise Control メトリクスを有効にできます。
以下は例になります。
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
metadata:
name: my-cluster
spec:
# ...
kafka:
# ...
zookeeper:
# ...
cruiseControl:
metrics:
lowercaseOutputName: true
rules:
- pattern: kafka.cruisecontrol<name=(.+)><>(\w+)
name: kafka_cruisecontrol_$1_$2
type: GAUGE6.7.2. Cruise Control Grafana ダッシュボードの有効化
メトリクスを有効にして Cruise Control を Kafka クラスターでデプロイした場合、Grafana により公開されるメトリクスデータを表示するように Grafana を有効化できます。
Cruise Control ダッシュボードは、JSON ファイルとして提供され、examples/metrics ディレクトリーに含まれています。
-
strimzi-cruise-control.json
メトリクスデータが収集されると、Cruise Control のチャートにデータが反映されます。
- Cruise Control
以下のメトリクスを表示します。
- Cruise Control によって監視されるスナップショットウィンドウの数
- 最適化プロポーザルを計算するのに十分なサンプルが含まれるため、有効とみなされる時間枠の数
- プロポーザルまたはリバランスのために実施中の実行の数
- Cruise Control の異常検出コンポーネントによって計算された (デフォルトでは 5 分ごと) Kafka クラスターの現在のバランス状態スコア
- 監視されるパーティションの割合
- 異常検出によって報告された (デフォルトでは 5 分ごと) ゴール逸脱の数
- ブローカーでディスクの読み取り障害が発生する頻度
- メトリクスサンプルの取得に失敗する割合
- 最適化プロポーザルの計算に必要な時間
- クラスターモデルの作成に必要な時間
- Cruise Control の REST API 経由でプロポーザルリクエストまたは実際のリバランスリクエストが実行される頻度
- Cruise Control の REST API 経由でクラスター全体の状態およびユーザータスクの状態が要求される頻度
- 使用されている JVM メモリー
- JVM ガベージコレクションの時間
- JVM ガベージコレクションの数
第7章 AMQ Streams のアップグレード
AMQ Streams は、クラスターのダウンタイムを発生せずにアップグレードできます。各バージョンの AMQ Streams は、単一または複数バージョンの Apache Kafka をサポートします。ご使用のバージョンの AMQ Streams によってサポートされれば、上位バージョンの Kafka にアップグレードできます。
より新しいバージョンの AMQ Streams はより新しいバージョンの Kafka をサポートしますが、AMQ Streams をアップグレードしてから、サポートされる上位バージョンの Kafka にアップグレードする必要があります。
AMQ Streams Operator をアップグレードするには、OpenShift Container Platform クラスターで Operator Lifecycle Manager (OLM) を使用できます。
該当する場合、AMQ Streams と Kafka をアップグレードしてから リソースのアップグレード を実行する 必要 があります。
7.1. AMQ Streams および Kafka のアップグレード
AMQ Streams のアップグレードは 2 段階のプロセスで行います。ダウンタイムなしでブローカーとクライアントをアップグレードするには、以下の順序でアップグレード手順を 必ず 完了してください。
Cluster Operator を最新の AMQ Streams バージョンに更新します。実施する手法は、Cluster Operator のデプロイ 方法によって異なります。
- インストール用 YAML ファイルを使用して Cluster Operator をデプロイした場合は、Operator のインストールファイルを変更して アップグレードを実行します。
OperatorHub から Cluster Operator をデプロイした場合は、Operator Lifecycle Manager (OLM) を使用して AMQ Streams Operator の更新チャネルを新しい AMQ Streams バージョンに変更します。
選択したアップグレードストラテジーに応じて、以下のチャネル更新のいずれかに従います。
- 自動 アップグレードが開始される。
- 手動 アップグレードでは、インストールを開始する前に承認が必要です。
OperatorHub を使用した Operator のアップグレードについての詳細は、「Upgrading installed Operators」を参照してください。
- すべての Kafka ブローカーとクライアントアプリケーションを、最新の Kafka バージョンにアップグレードします。
7.1.1. Kafka バージョン
Kafka のログメッセージ形式バージョンおよびブローカー間のプロトコルバージョンは、メッセージに追加されるログ形式バージョンとクラスターで使用されるプロトコルのバージョンを指定します。そのためアップグレードプロセスでは、既存の Kafka ブローカーの設定変更およびクライアントアプリケーション (コンシューマーおよびプロデューサー) のコード変更により、必ず正しいバージョンを使用されるようにする必要になります。
以下の表は、Kafka バージョンの違いを示しています。
| Kafka のバージョン | Interbroker プロトコルのバージョン | ログメッセージ形式のバージョン | ZooKeeper のバージョン |
|---|---|---|---|
| 2.5.0 | 2.5 | 2.5 | 3.5.8 |
| 2.6.0 | 2.6 | 2.6 | 3.5.8 |
メッセージ形式バージョン
プロデューサーが Kafka ブローカーにメッセージを送信すると、特定の形式を使用してメッセージがエンコードされます。この形式は Kafka のリリースによって変わるため、メッセージにはエンコードに使用された形式のバージョンが含まれます。ブローカーがメッセージをログに追加する前に、メッセージを新しい形式バージョンから特定の旧形式バージョンに変換するように、Kafka ブローカーを設定できます。
Kafka には、メッセージ形式のバージョンを設定する 2 通りの方法があります。
-
message.format.versionプロパティーをトピックに設定します。 -
log.message.format.versionプロパティーを Kafka ブローカーに設定します。
トピックの message.format.version のデフォルト値は、Kafka ブローカーに設定される log.message.format.version によって定義されます。トピックの message.format.version は、トピック設定を編集すると手動で設定できます。
本セクションのアップグレード作業では、メッセージ形式のバージョンが log.message.format.version によって定義されることを前提としています。
7.1.2. Cluster Operator のアップグレード
このセクションでは、AMQ Streams 1.6 を使用するように Cluster Operator デプロイメントをアップグレードする手順について説明します。
Cluster Operator によって管理される Kafka クラスターの可用性は、アップグレード操作による影響を受けません。
特定バージョンの AMQ Streams へのアップグレード方法については、そのバージョンをサポートするドキュメントを参照してください。
7.1.2.1. Cluster Operator の後続バージョンへのアップグレード
この手順では、Cluster Operator デプロイメントを後続バージョンにアップグレードする方法を説明します。
前提条件
- 既存の Cluster Operator デプロイメントを利用できる必要があります。
- すでに新規バージョンのインストールファイルをダウンロードしてある必要があります。
手順
-
既存の Cluster Operator リソース (
/install/cluster-operatorディレクトリー内) に追加した設定変更を覚えておきます。すべての変更は、新しいバージョンの Cluster Operator によって上書きされます。 Cluster Operator を更新します。
Cluster Operator を実行している namespace に従い、新しいバージョンのインストールファイルを編集します。
Linux の場合は、以下を使用します。
sed -i 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yamlMacOS の場合は、以下を使用します。
sed -i '' 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yaml-
既存の Cluster Operator
Deploymentで 1 つ以上の環境変数を編集した場合、install/cluster-operator/060-Deployment-cluster-operator.yamlファイルを編集し、これらの環境変数を使用します。
設定を更新したら、残りのインストールリソースとともにデプロイします。
oc apply -f install/cluster-operator
ローリングアップデートが完了するのを待ちます。
Kafka Pod のイメージを取得して、アップグレードが正常に完了したことを確認します。
oc get po my-cluster-kafka-0 -o jsonpath='{.spec.containers[0].image}'イメージタグには、新しい AMQ Streams バージョンと Kafka バージョンが順に示されます。例:
<New AMQ Streams version>-kafka-<Current Kafka version>既存のリソースを更新して、非推奨になったカスタムリソースプロパティーを処理します。
これで Cluster Operator が更新されましたが、その管理下にあるクラスターで実行している Kafka のバージョンは変わりません。
次のステップ
Cluster Operator のアップグレードの次に、Kafka アップグレードを実行できます。
7.1.3. Kafka のアップグレード。
Cluster Operator を 1.6 にアップグレードした後、次の手順では、すべての Kafka ブローカーをサポートされる最新バージョンの Kafka にアップグレードします。
Kafka のアップグレードは、Kafka ブローカーのローリングアップデートによって Cluster Operator によって実行されます。
Cluster Operator は、Kafka クラスターの設定に基づいてローリングアップデートを開始します。
Kafka.spec.kafka.config に以下が含まれている場合 | Cluster Operator によって開始されるもの |
|---|---|
|
|
単一のローリングアップデート更新後、 |
|
| 2 つのローリングアップデート |
|
| 2 つのローリングアップデート |
Cluster Operator は、Kafka のアップグレードの一環として、ZooKeeper のローリングアップデートを開始します。
- ZooKeeper バージョンが変更されなくても、単一のローリングアップデートが発生します。
- 新しいバージョンの Kafka に新しいバージョンの ZooKeeper が必要な場合、追加のローリングアップデートが発生します。
その他のリソース
7.1.3.1. Kafka バージョンおよびイメージマッピング
Kafka のアップグレード時に、STRIMZI_KAFKA_IMAGES および Kafka.spec.kafka.version プロパティーの設定について考慮してください。
-
それぞれの
KafkaリソースはKafka.spec.kafka.versionで設定できます。 Cluster Operator の
STRIMZI_KAFKA_IMAGES環境変数により、Kafka のバージョンと、指定のKafkaリソースでそのバージョンが要求されるときに使用されるイメージをマッピングできます。-
Kafka.spec.kafka.imageを設定しないと、そのバージョンのデフォルトのイメージが使用されます。 -
Kafka.spec.kafka.imageを設定すると、デフォルトのイメージがオーバーライドされます。
-
Cluster Operator は、Kafka ブローカーの想定されるバージョンが実際にイメージに含まれているかどうかを検証できません。所定のイメージが所定の Kafka バージョンに対応することを必ず確認してください。
7.1.3.2. クライアントをアップグレードするストラテジー
クライアントアプリケーション (Kafka Connect コネクターを含む) をアップグレードする最善の方法は、特定の状況によって異なります。
消費するアプリケーションは、そのアプリケーションが理解するメッセージ形式のメッセージを受信する必要があります。その状態であることを、以下のいずれかの方法で確認できます。
- プロデューサーをアップグレードする 前に、トピックのすべてのコンシューマーをアップグレードする。
- ブローカーでメッセージをダウンコンバートする。
ブローカーのダウンコンバートを使用すると、ブローカーに余分な負荷が加わるので、すべてのトピックで長期にわたりダウンコンバートに頼るのは最適な方法ではありません。ブローカーの実行を最適化するには、ブローカーがメッセージを一切ダウンコンバートしないようにしてください。
ブローカーのダウンコンバートは 2 通りの方法で設定できます。
-
トピックレベルの
message.format.versionでは単一のとピックが設定されます。 -
ブローカーレベルの
log.message.format.versionは、トピックレベルのmessage.format.versionが設定されてないトピックのデフォルトです。
新バージョンの形式でトピックにパブリッシュされるメッセージは、コンシューマーによって認識されます。これは、メッセージがコンシューマーに送信されるときでなく、ブローカーがプロデューサーからメッセージを受信するときに、ブローカーがダウンコンバートを実行するからです。
クライアントのアップグレードに使用できるストラテジーは複数あります。
- コンシューマーを最初にアップグレード
- コンシューマーとして機能するアプリケーションをすべてアップグレードします。
-
ブローカーレベル
log.message.format.versionを新バージョンに変更します。 プロデューサーとして機能するアプリケーションをアップグレードします。
このストラテジーは分かりやすく、ブローカーのダウンコンバートの発生をすべて防ぎます。ただし、所属組織内のすべてのコンシューマーを整然とアップグレードできることが前提になります。また、コンシューマーとプロデューサーの両方に該当するアプリケーションには通用しません。さらにリスクとして、アップグレード済みのクライアントに問題がある場合は、新しい形式のメッセージがメッセージログに追加され、以前のコンシューマーバージョンに戻せなくなる場合があります。
- トピック単位でコンシューマーを最初にアップグレード
トピックごとに以下を実行します。
- コンシューマーとして機能するアプリケーションをすべてアップグレードします。
-
トピックレベルの
message.format.versionを新バージョンに変更します。 プロデューサーとして機能するアプリケーションをアップグレードします。
このストラテジーではブローカーのダウンコンバートがすべて回避され、トピックごとにアップグレードできます。この方法は、同じトピックのコンシューマーとプロデューサーの両方に該当するアプリケーションには通用しません。ここでもリスクとして、アップグレード済みのクライアントに問題がある場合は、新しい形式のメッセージがメッセージログに追加される可能性があります。
- トピック単位でコンシューマーを最初にアップグレード、ダウンコンバートあり
トピックごとに以下を実行します。
-
トピックレベルの
message.format.versionを、旧バージョンに変更します (または、デフォルトがブローカーレベルのlog.message.format.versionのトピックを利用します)。 - コンシューマーおよびプロデューサーとして機能するアプリケーションをすべてアップグレードします。
- アップグレードしたアプリケーションが正しく機能することを確認します。
トピックレベルの
message.format.versionを新バージョンに変更します。このストラテジーにはブローカーのダウンコンバートが必要ですが、ダウンコンバートは一度に 1 つのトピック (またはトピックの小さなグループ) のみに必要になるので、ブローカーへの負荷は最小限に抑えられます。この方法は、同じトピックのコンシューマーとプロデューサーの両方に該当するアプリケーションにも通用します。この方法により、新しいメッセージ形式バージョンを使用する前に、アップグレードされたプロデューサーとコンシューマーが正しく機能することが保証されます。
この方法の主な欠点は、多くのトピックやアプリケーションが含まれるクラスターでの管理が複雑になる場合があることです。
-
トピックレベルの
クライアントアプリケーションをアップグレードするストラテジーは他にもあります。
複数のストラテジーを適用することもできます。たとえば、最初のいくつかのアプリケーションとトピックに、「トピック単位でコンシューマーを最初にアップグレード、ダウンコンバートあり」のストラテジーを適用します。これが問題なく適用されたら、より効率的な別のストラテジーの使用を検討できます。
7.1.3.3. Kafka ブローカーおよびクライアントアプリケーションのアップグレード
この手順では、AMQ Streams Kafka クラスターを最新のサポートされる Kafka バージョンにアップグレードする方法を説明します。
新しい Kafka バージョンを現在のバージョンと比較すると、新しいバージョンは ログメッセージ形式の上位バージョン、ブローカー間プロトコルの上位バージョン、またはその両方をサポートする可能性があります。必要に応じて、これらのバージョンをアップグレードする手順を実行します。詳細は、「Kafka バージョン」 を参照してください。
クライアントをアップグレードするストラテジーを選択する必要もあります。Kafka クライアントは、この手順の 6 でアップグレードされます。
前提条件
Kafka リソースをアップグレードするには、以下を確認します。
- 両バージョンの Kafka をサポートする Cluster Operator が稼働している。
-
Kafka.spec.kafka.configには、新しい Kafka バージョンでサポートされないオプションが含まれていない。
手順
Kafka クラスター設定を更新します。
oc edit kafka my-cluster設定されている場合、
Kafka.spec.kafka.configにlog.message.format.versionがあり、inter.broker.protocol.versionが現在の Kafka バージョンのデフォルトに設定されていることを確認します。たとえば、Kafka バージョン 2.5.0 から 2.6.0 へのアップグレードは以下のようになります。
kind: Kafka spec: # ... kafka: version: 2.5.0 config: log.message.format.version: "2.5" inter.broker.protocol.version: "2.5" # ...log.message.format.versionおよびinter.broker.protocol.versionが設定されていない場合、AMQ Streams では、次のステップの Kafka バージョンの更新後、これらのバージョンを現在のデフォルトに自動的に更新します。注記log.message.format.versionおよびinter.broker.protocol.versionの値は、浮動小数点数として解釈されないように文字列である必要があります。Kafka.spec.kafka.versionを変更して、新しい Kafka バージョンを指定します。現在の Kafka バージョンのデフォルトでlog.message.format.versionおよびinter.broker.protocol.versionのままにします。注記kafka.versionを変更すると、クラスターのすべてのブローカーがアップグレードされ、新しいブローカーバイナリの使用が開始されます。このプロセスでは、一部のブローカーは古いバイナリーを使用し、他のブローカーはすでに新しいバイナリーにアップグレードされています。Inter.broker.protocol.versionを変更しないと、ブローカーはアップグレード中も相互に通信を継続できます。たとえば、Kafka 2.5.0 から 2.6.0 へのアップグレードは以下のようになります。
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: # ... kafka: version: 2.6.0 1 config: log.message.format.version: "2.5" 2 inter.broker.protocol.version: "2.5" 3 # ...警告新しい Kafka バージョンの
inter.broker.protocol.versionが変更された場合は、Kafka をダウングレードできません。ブローカー間プロトコルのバージョンは、__consumer_offsetsに書き込まれたメッセージなど、ブローカーによって保存される永続メタデータに使用されるスキーマを判断します。ダウングレードされたクラスターはメッセージを理解しません。Kafka クラスターのイメージが
Kafka.spec.kafka.imageの Kafka カスタムリソースで定義されている場合、imageを更新して、新しい Kafka バージョンでコンテナーイメージを示すようにします。「Kafka バージョンおよびイメージマッピング」を参照してください。
エディターを保存して終了し、ローリングアップデートの完了を待ちます。
Pod の状態の遷移を監視して、ローリングアップデートの進捗を確認します。
oc get pods my-cluster-kafka-0 -o jsonpath='{.spec.containers[0].image}'ローリングアップデートにより、各 Pod が新バージョンの Kafka のブローカーバイナリーを使用するようになります。
クライアントのアップグレードに選択したストラテジーに応じて、新バージョンのクライアントバイナリーを使用するようにすべてのクライアントアプリケーションをアップグレードします。
必要に応じて、Kafka Connect および MirrorMaker の
versionプロパティーを新バージョンの Kafka として設定します。-
Kafka Connect では、
KafkaConnect.spec.versionを更新します。 -
MirrorMaker では、
KafkaMirrorMaker.spec.versionを更新します。 -
MirrorMaker 2.0 の場合は、
KafkaMirrorMaker2.spec.versionを更新します。
-
Kafka Connect では、
設定されている場合、新しい
inter.broker.protocol.versionバージョンを使用するように Kafka リソースを更新します。それ以外の場合は、ステップ 9 に進みます。たとえば、Kafka 2.6.0 へのアップグレードでは以下のようになります。
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: # ... kafka: version: 2.6.0 config: log.message.format.version: "2.5" inter.broker.protocol.version: "2.6" # ...- Cluster Operator によってクラスターが更新されるまで待ちます。
設定されている場合、新しい
log.message.format.versionバージョンを使用するように Kafka リソースを更新します。それ以外の場合は、ステップ 10 に移動します。たとえば、Kafka 2.6.0 へのアップグレードでは以下のようになります。
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: # ... kafka: version: 2.6.0 config: log.message.format.version: "2.6" inter.broker.protocol.version: "2.6" # ...Cluster Operator によってクラスターが更新されるまで待ちます。
- これで、Kafka クラスターおよびクライアントが新バージョンの Kafka を使用するようになります。
- ブローカーは、新バージョンの Kafka のブローカー間プロトコルバージョンとメッセージ形式バージョンを使用してメッセージを送信するように設定されます。
Kafka のアップグレードに従い、必要な場合は以下を行うことができます。
7.1.3.4. リスナー設定の更新
AMQ Streams では、Kafka リソースの KafkaListener スキーマが提供されます。
Kafka リスナーを設定するための Generic
GenericKafkaListener は、非推奨となった KafkaListeners スキーマに置き換わりました。
GenericKafkaListener スキーマ を使用すると、名前とポートが一意であれば、必要なリスナーをいくつでも設定できます。リスナー設定 は配列として定義されますが、非推奨の形式もサポートされます。
OpenShift クラスター内のクライアントの場合は、plain (暗号化なし)または tls internal リスナーを作成できます。
OpenShift クラスター外のクライアントの場合は、外部リスナー を作成し、nodeport、loadbalancer、ingress、または route などの接続メカニズムを指定します。
KafkaListeners スキーマは、plain、tls、および external リスナーのサブプロパティーを使用し、それぞれ固定ポートを使用します。Kafka のアップグレード後、KafkaListeners スキーマを使用して設定されたリスナーを
GenericKafkaListener スキーマの形式に変換できます。
たとえば、現在 Kafka 設定で以下の設定を使用しているとします。
これまでのリスナー設定
listeners:
plain:
# ...
tls:
# ...
external:
type: loadbalancer
# ...
以下を使用して、リスナーを新しい形式に変換します。
新しいリスナー設定
listeners:
#...
- name: plain
port: 9092
type: internal
tls: false 1
- name: tls
port: 9093
type: internal
tls: true
- name: external
port: 9094
type: EXTERNAL-LISTENER-TYPE 2
tls: true
必ず 正確な 名前とポート番号を使用してください。
古い形式で 使用される追加の プロパティーについては、新しい形式に更新する必要があります。
設定または オーバーライド
リスナー設定 に導入された変更:
-
overridesはconfigurationセクションとマージされます。 -
dnsAnnotationsの名前がアノテーションになりました。 -
preferredAddressTypeの名前がpreferredNodePortAddressType -
addressの名前がalternativeNames -
loadBalancerSourceRangesおよびexternalTrafficPolicyが、現在の非推奨のテンプレートからリスナー設定に移動します。
例として、以下の設定を見てみましょう。
従来の追加リスナー設定
listeners:
external:
type: loadbalancer
authentication:
type: tls
overrides:
bootstrap:
dnsAnnotations:
#...
これを以下に変更します。
新しい追加リスナー設定
listeners:
#...
- name: external
port: 9094
type:loadbalancer
tls: true
authentication:
type: tls
configuration:
bootstrap:
annotations:
#...
後方互換性を維持するため、新しいリスナー設定にある名前およびポート番号を使用する 必要 があります。他の値を使用すると、Kafka リスナーおよび OpenShift サービスの名前が変更されます。
各タイプのリスナーで利用可能な設定オプションの詳細は、「 GenericKafkaListener スキーマ参照」 を参照してください。
7.1.3.5. コンシューマーおよび Kafka Streams アプリケーションの Cooperative Rebalancing へのアップグレード
Kafka コンシューマーおよび Kafka Streams アプリケーションをアップグレードすることで、パーティションの再分散にデフォルトの Eager Rebalance プロトコルではなく Incremental Cooperative Rebalance プロトコルを使用できます。この新しいプロトコルが Kafka 2.4.0 に追加されました。
コンシューマーは、パーティションの割り当てを Cooperative Rebalance で保持し、クラスターの分散が必要な場合にプロセスの最後でのみ割り当てを取り消します。これにより、コンシューマーグループまたは Kafka Streams アプリケーションが使用不可能になる状態が削減されます。
Incremental Cooperative Rebalance プロトコルへのアップグレードは任意です。Eager Rebalance プロトコルは引き続きサポートされます。
前提条件
- Kafka 2.6.0 に Kafka ブローカーおよびクライアントアプリケーションをアップグレード済みであることが必要です。
手順
Incremental Cooperative Rebalance プロトコルを使用するように Kafka コンシューマーをアップグレードするには以下を行います。
-
Kafka クライアント
.jarファイルを新バージョンに置き換えます。 -
コンシューマー設定で、
partition.assignment.strategyにcooperative-stickyを追加します。たとえば、rangeストラテジーが設定されている場合は、設定をrange, cooperative-stickyに変更します。 - グループ内の各コンシューマーを順次再起動し、再起動後に各コンシューマーがグループに再度参加するまで待ちます。
-
コンシューマー設定から前述の
partition.assignment.strategyを削除して、グループの各コンシューマーを再設定し、cooperative-stickyストラテジーのみを残します。 - グループ内の各コンシューマーを順次再起動し、再起動後に各コンシューマーがグループに再度参加するまで待ちます。
Incremental Cooperative Rebalance プロトコルを使用するように Kafka Streams アプリケーションをアップグレードするには以下を行います。
-
Kafka Streams の
.jarファイルを新バージョンに置き換えます。 -
Kafka Streams の設定で、
upgrade.from設定パラメーターをアップグレード前の Kafka バージョンに設定します (例: 2.3)。 - 各ストリームプロセッサー (ノード) を順次再起動します。
-
upgrade.from設定パラメーターを Kafka Streams 設定から削除します。 - グループ内の各コンシューマーを順次再起動します。
関連情報
- Apache Kafka ドキュメントの「Notable changes in 2.4.0」。
7.2. AMQ Streams リソースのアップグレード
以下の AMQ Streams リソースでは、kafka .strimzi.io/v1alpha1 API バージョンは非推奨になりました。
-
Kafka -
KafkaConnect -
KafkaConnectS2I -
KafkaMirrorMaker -
KafkaTopic -
KafkaUser
これらのリソースを、kafka. strimzi.io/v1beta1 API バージョンを使用するように更新します。
ここでは、リソースのアップグレード手順を説明します。
リソースのアップグレードは、Cluster Operator をアップグレードしてから実施する 必要 があります。これにより、Cluster Operator がリソースを認識できるようになります。
リソースのアップグレードが実施されない場合
アップグレードが実施されない場合、apiVersion を更新するまでリソースを更新できないことを示す警告が、調整に関するログに記録されます。
更新をトリガーするには、カスタムリソースにアノテーション追加などの表面的な変更を加えます。
アノテーションの例:
metadata:
# ...
annotations:
upgrade: "Upgraded to kafka.strimzi.io/v1beta1"
以下の手順では、kafka. strimzi.io/v1beta1 API バージョンを使用するように特定のリソースを更新する手順を説明します。
7.2.1. Kafka リソースのアップグレード
前提条件
-
v1beta1API バージョンをサポートする Cluster Operator が稼働している必要があります。
手順
デプロイメントの Kafka リソースごとに以下の手順を実行します。
エディターで
Kafkaリソースを更新します。oc edit kafka my-cluster以下を置き換えます。
apiVersion: kafka.strimzi.io/v1alpha1
上のコマンドを、下のコマンドに置き換えます。
apiVersion: kafka.strimzi.io/v1beta1
Kafkaリソースに以下があるか確認します。Kafka.spec.topicOperator
ある場合は以下に変更します。
Kafka.spec.entityOperator.topicOperator
たとえば、以下がある場合を考えてみましょう。
spec: # ... topicOperator: {}この行を以下の行に変更します。
spec: # ... entityOperator: topicOperator: {}以下があるか確認します。
Kafka.spec.entityOperator.affinity
Kafka.spec.entityOperator.tolerations
これを以下に変更します。
Kafka.spec.entityOperator.template.pod.affinity
Kafka.spec.entityOperator.template.pod.tolerations
たとえば、以下の場合を考えてみましょう。
spec: # ... entityOperator: affinity {} tolerations {}これを以下に変更します。
spec: # ... entityOperator: template: pod: affinity {} tolerations {}以下があるか確認します。
Kafka.spec.kafka.affinity
Kafka.spec.kafka.tolerations
これを以下に変更します。
Kafka.spec.kafka.template.pod.affinity
Kafka.spec.kafka.template.pod.tolerations
たとえば、以下の場合を考えてみましょう。
spec: # ... kafka: affinity {} tolerations {}これを以下に変更します。
spec: # ... kafka: template: pod: affinity {} tolerations {}以下があるか確認します。
Kafka.spec.zookeeper.affinity
Kafka.spec.zookeeper.tolerations
これを以下に変更します。
Kafka.spec.zookeeper.template.pod.affinity
Kafka.spec.zookeeper.template.pod.tolerations
たとえば、以下の場合を考えてみましょう。
spec: # ... zookeeper: affinity {} tolerations {}これを以下に変更します。
spec: # ... zookeeper: template: pod: affinity {} tolerations {}- ファイルを保存し、エディターを終了して更新したリソースが調整されるのを待ちます。
7.2.2. Kafka Connect リソースのアップグレード
前提条件
-
v1beta1API バージョンをサポートする Cluster Operator が稼働している必要があります。
手順
デプロイメントの KafkaConnect リソースごとに以下の手順を実行します。
エディターで
KafkaConnectリソースを更新します。oc edit kafkaconnect my-connect以下を置き換えます。
apiVersion: kafka.strimzi.io/v1alpha1
この行を以下の行に変更します。
apiVersion: kafka.strimzi.io/v1beta1
以下があるか確認します。
KafkaConnect.spec.affinity
KafkaConnect.spec.tolerations
これを以下に変更します。
KafkaConnect.spec.template.pod.affinity
KafkaConnect.spec.template.pod.tolerations
たとえば、以下の場合を考えてみましょう。
spec: # ... affinity {} tolerations {}これを以下に変更します。
spec: # ... template: pod: affinity {} tolerations {}- ファイルを保存し、エディターを終了して更新したリソースが調整されるのを待ちます。
7.2.3. Kafka Connect S2I リソースのアップグレード
前提条件
-
v1beta1API バージョンをサポートする Cluster Operator が稼働している必要があります。
手順
デプロイメントの KafkaConnectS2I リソースごとに以下の手順を実行します。
エディターで
KafkaConnectS2Iリソースを更新します。oc edit kafkaconnects2i my-connect以下を置き換えます。
apiVersion: kafka.strimzi.io/v1alpha1
この行を以下の行に変更します。
apiVersion: kafka.strimzi.io/v1beta1
以下があるか確認します。
KafkaConnectS2I.spec.affinity
KafkaConnectS2I.spec.tolerations
これを以下に変更します。
KafkaConnectS2I.spec.template.pod.affinity
KafkaConnectS2I.spec.template.pod.tolerations
たとえば、以下の場合を考えてみましょう。
spec: # ... affinity {} tolerations {}これを以下に変更します。
spec: # ... template: pod: affinity {} tolerations {}- ファイルを保存し、エディターを終了して更新したリソースが調整されるのを待ちます。
7.2.4. Kafka MirrorMaker リソースのアップグレード
前提条件
-
v1beta1API バージョンをサポートする Cluster Operator が稼働している必要があります。
手順
デプロイメントの KafkaMirrorMaker リソースごとに以下の手順を実行します。
エディターで
KafkaMirrorMakerリソースを更新します。oc edit kafkamirrormaker my-connect以下を置き換えます。
apiVersion: kafka.strimzi.io/v1alpha1
この行を以下の行に変更します。
apiVersion: kafka.strimzi.io/v1beta1
以下があるか確認します。
KafkaConnectMirrorMaker.spec.affinity
KafkaConnectMirrorMaker.spec.tolerations
これを以下に変更します。
KafkaConnectMirrorMaker.spec.template.pod.affinity
KafkaConnectMirrorMaker.spec.template.pod.tolerations
たとえば、以下の場合を考えてみましょう。
spec: # ... affinity {} tolerations {}これを以下に変更します。
spec: # ... template: pod: affinity {} tolerations {}- ファイルを保存し、エディターを終了して更新したリソースが調整されるのを待ちます。
7.2.5. Kafka Topic リソースのアップグレード
前提条件
-
v1beta1API バージョンをサポートする Topic Operator が稼働している必要があります。
手順
デプロイメントの KafkaTopic リソースごとに以下の手順を実行します。
エディターで
KafkaTopicリソースを更新します。oc edit kafkatopic my-topic以下を置き換えます。
apiVersion: kafka.strimzi.io/v1alpha1
この行を以下の行に変更します。
apiVersion: kafka.strimzi.io/v1beta1
- ファイルを保存し、エディターを終了して更新したリソースが調整されるのを待ちます。
7.2.6. Kafka User リソースのアップグレード
前提条件
-
v1beta1API バージョンをサポートする User Operator が稼働している必要があります。
手順
デプロイメントの KafkaUser リソースごとに以下の手順を実行します。
エディターで
KafkaUserリソースを更新します。oc edit kafkauser my-user以下を置き換えます。
apiVersion: kafka.strimzi.io/v1alpha1
この行を以下の行に変更します。
apiVersion: kafka.strimzi.io/v1beta1
- ファイルを保存し、エディターを終了して更新したリソースが調整されるのを待ちます。
第8章 AMQ Streams のダウングレード
アップグレードしたバージョンの AMQ Streams で問題が発生した場合は、インストールを直前のバージョンに戻すことができます。
以下のダウングレードを実行できます。
Cluster Operator を以前の AMQ Streams バージョンに戻します。
すべての Kafka ブローカーとクライアントアプリケーションを、以前の Kafka バージョンにダウングレードします。
以前のバージョンの AMQ Streams では使用している Kafka バージョンがサポートされない場合、メッセージに追加されるログメッセージ形式のバージョンが一致すれば Kafka をダウングレードすることができます。
8.1. Cluster Operator の以前のバージョンへのダウングレード
AMQ Streams で問題が発生した場合は、インストールを元に戻すことができます。
この手順では、Cluster Operator デプロイメントを以前のバージョンにダウングレードする方法を説明します。
前提条件
- 既存の Cluster Operator デプロイメントを利用できる必要があります。
- 以前のバージョンのインストールファイルがダウンロード済みである必要があります。
手順
-
既存の Cluster Operator リソース (
/install/cluster-operatorディレクトリー内) に追加した設定変更を覚えておきます。すべての変更は、以前のバージョンの Cluster Operator によって上書きされます。 - カスタムリソースを元に戻して、ダウングレードする AMQ Streams バージョンで利用可能なサポート対象の設定オプションを反映します。
Cluster Operator を更新します。
Cluster Operator を実行している namespace に従い、以前のバージョンのインストールファイルを編集します。
Linux の場合は、以下を使用します。
sed -i 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yamlMacOS の場合は、以下を使用します。
sed -i '' 's/namespace: .*/namespace: my-cluster-operator-namespace/' install/cluster-operator/*RoleBinding*.yaml-
既存の Cluster Operator
Deploymentで 1 つ以上の環境変数を編集した場合、install/cluster-operator/060-Deployment-strimzi-cluster-operator.yamlファイルを編集し、これらの環境変数を使用します。
設定を更新したら、残りのインストールリソースとともにデプロイします。
oc apply -f install/cluster-operator
ローリングアップデートが完了するのを待ちます。
Kafka Pod のイメージを取得して、アップグレードが正常に完了したことを確認します。
oc get pod my-cluster-kafka-0 -o jsonpath='{.spec.containers[0].image}'イメージタグには、新しい AMQ Streams バージョンと Kafka バージョンが順に示されます。たとえば、NEW
-STREAMS-VERSION-kafka-CURRENT-KAFKA-VERSION です。
Cluster Operator は以前のバージョンにダウングレードされました。
8.2. Kafka のダウングレード
Kafka バージョンのダウングレードは、Cluster Operator によって実行されます。
8.2.1. ダウングレードでの Kafka バージョンの互換性
Kafka のダウングレードは、互換性のある現在およびターゲットの Kafka バージョン と、メッセージがログに記録された状態に依存します。
そのバージョンが、クラスターでこれまで使用された inter.broker.protocol.version 設定をサポートしない場合、または新しい log.message.format.version を使用するメッセージメッセージにメッセージが追加された場合は、下位バージョンの Kafka に戻すことはできません。
Inter.broker.protocol.version は、__consumer_offsets に書き込まれたメッセージのスキーマなど、ブローカーによって保存される永続メタデータに使用されるスキーマを判断します。クラスターで以前使用された Inter.broker.protocol.version が認識されない Kafka バージョンにダウングレードすると、ブローカーが認識できないデータが発生します。
ダウングレードする Kafka のバージョンの関係は次のとおりです。
-
ダウングレードする Kafka バージョンの
log.message.format.versionが現行バージョンと 同じ である場合、Cluster Operator は、ブローカーのローリング再起動を 1 回実行してダウングレードを行います。 別の
log.message.format.versionの場合、ダウングレード後の Kafka バージョンが使用するバージョンに設定されたlog.message.format.versionが常に 実行中のクラスターに存在する場合に限り、ダウングレードが可能です。通常は、アップグレードの手順がlog.message.format.versionの変更前に中止された場合にのみ該当します。その場合、ダウングレードには以下が必要です。- 2 つのバージョンで Interbroker プロトコルが異なる場合、ブローカーのローリング再起動が 2 回必要です。
- 両バージョンで同じ場合は、ローリング再起動が 1 回必要です。
以前のバージョンでサポートされない log.message.format.version が新バージョンで使われていた場合 (log.message.format.versionのデフォルト値が使われていた場合など)、ダウングレードは実行 できません。たとえば、このリソースは log.message.format.version が変更されていないため、Kafka バージョン 2.5.0 にダウングレードできます。
apiVersion: kafka.strimzi.io/v1beta1
kind: Kafka
spec:
# ...
kafka:
version: 2.6.0
config:
log.message.format.version: "2.5"
# ...
log.message.format.version が "2.6" に設定されているか、値がない(このためパラメーターに 2.6.0 ブローカーのデフォルト値 2.6 が採用される)場合は、ダウングレードは実施できません。
8.2.2. Kafka ブローカーおよびクライアントアプリケーションのダウングレード
この手順では、AMQ Streams Kafka クラスターを Kafka の下位 (以前の) バージョンにダウングレードする方法 (2.6.0 から 2.5.0 へのダウングレードなど) を説明します。
前提条件
Kafka リソースをダウングレードするには、以下を確認します。
- 重要:Kafka バージョンの互換性。
- 両バージョンの Kafka をサポートする Cluster Operator が稼働している。
-
Kafka.spec.kafka.configに、ダウングレードする Kafka バージョンでサポートされていないオプションが含まれていない。 -
Kafka.spec.kafka.configに、ダウングレード先の Kafka バージョンでサポートされるlog.message.format.versionとinter.broker.protocol.versionがある。
手順
必要に応じてエディターで Kafka クラスター設定を更新します。
oc edit kafka my-clusterKafka.spec.kafka.versionを変更して、以前のバージョンを指定します。たとえば、Kafka 2.6.0 から 2.5.0 へのダウングレードは以下のようになります。
apiVersion: kafka.strimzi.io/v1beta1 kind: Kafka spec: # ... kafka: version: 2.5.0 1 config: log.message.format.version: "2.5" 2 inter.broker.protocol.version: "2.5" 3 # ...注記log.message.format.versionの値とinter.broker.protocol.versionの値は、浮動小数点数として解釈されないように、文字列にする必要があります。Kafka バージョンのイメージが Cluster Operator の
STRIMZI_KAFKA_IMAGESに定義されているイメージとは異なる場合は、Kafka.spec.kafka.imageを更新します。「Kafka バージョンおよびイメージマッピング」 を参照してください。
エディターを保存して終了し、ローリングアップデートの完了を待ちます。
更新をログで確認するか、または Pod 状態の遷移を監視して確認します。
oc logs -f CLUSTER-OPERATOR-POD-NAME | grep -E "Kafka version downgrade from [0-9.]+ to [0-9.]+, phase ([0-9]+) of \1 completed"oc get pod -w
Cluster Operator ログで
INFOレベルのメッセージを確認します。Reconciliation #NUM(watch) Kafka(NAMESPACE/NAME): Kafka version downgrade from FROM-VERSION to TO-VERSION, phase 1 of 1 completed
すべてのクライアントアプリケーション (コンシューマー) をダウングレードして、以前のバージョンのクライアントバイナリーを使用します。
これで、Kafka クラスターおよびクライアントは以前の Kafka バージョンを使用するようになります。
付録A サブスクリプションの使用
AMQ Streams は、ソフトウェアサブスクリプションから提供されます。サブスクリプションを管理するには、Red Hat カスタマーポータルでアカウントにアクセスします。
アカウントへのアクセス
- access.redhat.com に移動します。
- アカウントがない場合は、作成します。
- アカウントにログインします。
サブスクリプションのアクティベート
- access.redhat.com に移動します。
- サブスクリプション に移動します。
- Activate a subscription に移動し、16 桁のアクティベーション番号を入力します。
Zip および Tar ファイルのダウンロード
zip または tar ファイルにアクセスするには、カスタマーポータルを使用して、ダウンロードする関連ファイルを検索します。RPM パッケージを使用している場合は、この手順は必要ありません。
- ブラウザーを開き、access.redhat.com/downloads で Red Hat カスタマーポータルの Product Downloads ページにログインします。
- JBOSS INTEGRATION AND AUTOMATION カテゴリーの Red Hat AMQ Streams エントリーを見つけます。
- 必要な AMQ Streams 製品を選択します。Software Downloads ページが開きます。
- コンポーネントの Download リンクをクリックします。
改訂日時: 2022-07-14 11:31:20 +1000