
第1章 環境の監視の紹介
可観測性サービスを有効にすると、Red Hat Advanced Cluster Management for Kubernetes を使用して、マネージドクラスターに関する理解を深め、最適化することができます。この情報は、コストを節約し、不要なイベントを防ぐことができます。
1.1. 環境の監視
Red Hat Advanced Cluster Management for Kubernetes を使用して、マネージドクラスターに関する理解を深め、最適化することができます。ハブクラスターで可観測性サービス Operator (multicluster-observability-operator) を有効にして、マネージドクラスターの状態を監視します。以下のセクションでは、マルチクラスター可観測性サービスのアーキテクチャーについて説明します。
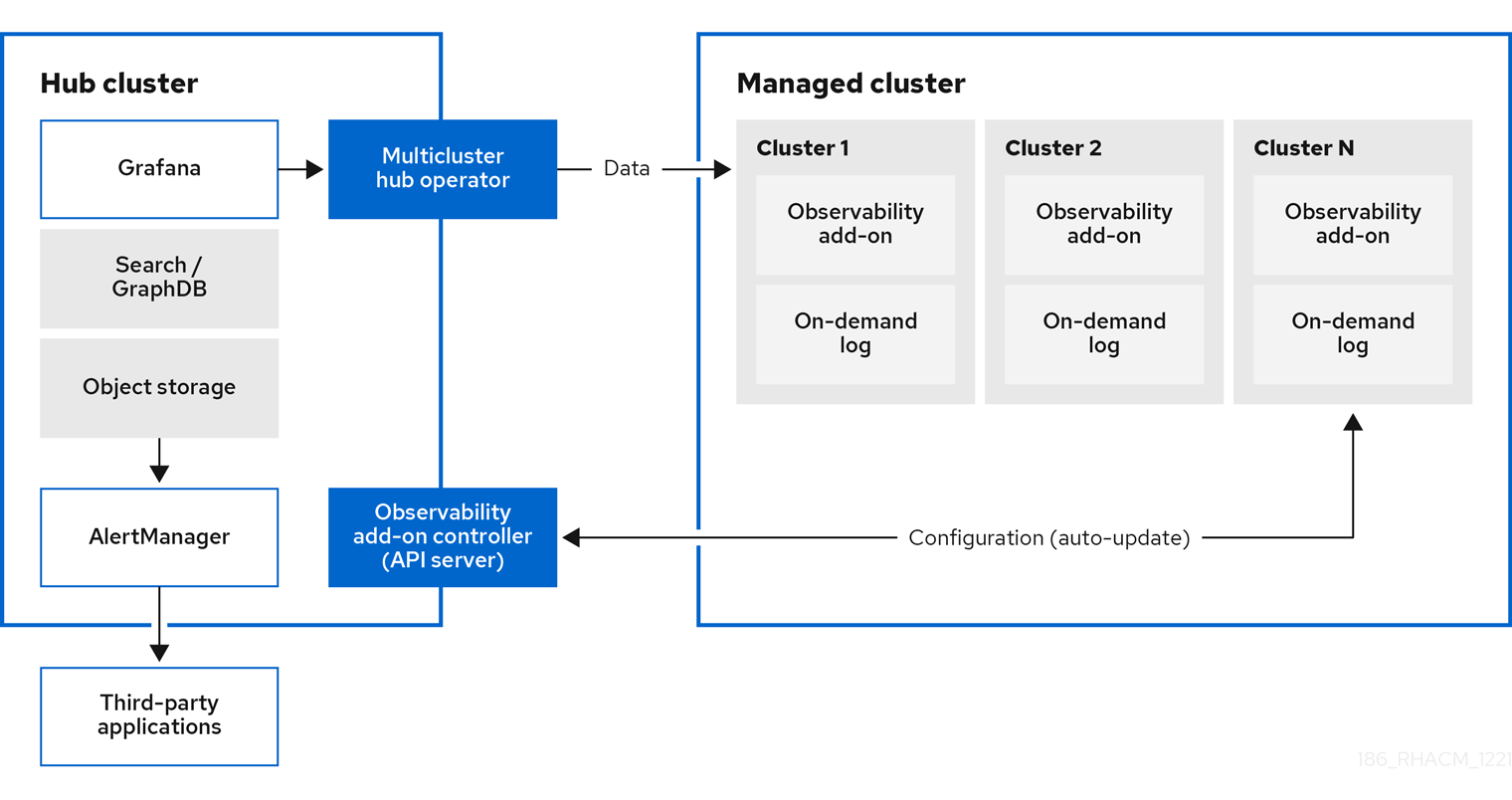
注記: オンデマンドログ は、特定 の Pod のログをリアルタイムで取得するエンジニア用のアクセスを提供します。ハブクラスターからのログは集約されません。これらのログは、検索サービスとコンソールの他の部分を使用してアクセスできます。
1.1.1. 可観測性サービス
デフォルトでは可観測性は、製品のインストール時に追加されますが、有効にはなっていません。永続ストレージの要件により、可観測性サービスはデフォルトで有効にはなりません。Red Hat Advanced Cluster Management は、以下の S3 互換のある、安定したオブジェクトストアをサポートします。
Amazon S3
注記: Thanos のオブジェクトストアインターフェイスは、AWS S3 RESTFUL API 互換の API、または Minio や Ceph などのその他の S3 と互換のあるオブジェクトストアをサポートします。
- Google Cloud Storage
- Azure ストレージ
Red Hat OpenShift Data Foundation
重要: オブジェクトストアを設定する場合は、機密データを永続化する時に必要な暗号化要件を満たすようにしてください。サポートされるオブジェクトストアの全一覧は、Thanos のドキュメント を参照してください。
サービスを有効にすると、observability-endpoint-operator はインポートまたは作成された各クラスターに自動的にデプロイされます。このコントローラーは、Red Hat OpenShift Container Platform Prometheus からデータを収集してから、Red Hat Advanced Cluster Management ハブクラスターに送信します。
ハブクラスターが local-cluster として自己インポートする場合は、可観測性もそのクラスターで有効になり、メトリクスがハブクラスターから収集されます。
可観測性サービスは、Prometheus AlertManager のインスタンスをデプロイすることで、サードパーティーのアプリケーションでのアラートの転送が可能になります。また、ダッシュボード (静的) またはデータ検索を使用してデータの可視化を有効にする Grafana のインスタンスも含まれます。Red Hat Advanced Cluster Management は、Grafana のバージョン 8.1.3 をサポートします。Grafana ダッシュボードを設計することもできます。詳細は、Grafana ダッシュボードの設計 を参照してください。
カスタムの レコーディングルール または アラートルール を作成して、可観測性サービスをカスタマイズできます。
可観測性有効化の詳細は、可観測性サービスの有効化 を参照してください。
1.1.2. メトリクスのタイプ
デフォルトで、OpenShift Container Platform は Telemetry サービスを使用してメトリクスを Red Hat に送信します。acm_managed_cluster_info は、Red Hat Advanced Cluster Management で利用でき、Telemetry に含まれていますが、Red Hat Advanced Cluster Management Observe 環境の概要 ダッシュボードには表示され ません。
OpenShift Container Platform ドキュメントで、Telemetry を使用して収集されて送信されるメトリクスのタイプについて確認します。詳細は、Telemetry で収集される 情報 を参照してください。
1.1.3. 可観測性 Pod の容量要求
可観測性サービスをインストールするには、可観測性コンポーネントで 2701mCPU および 11972Mi のメモリーが必要です。以下の表は、observability-addons が有効なマネージドクラスター 5 台の Pod 容量要求の一覧です。
表1.1 可観測性 Pod の容量要求
| デプロイメントまたは StatefulSet | コンテナー名 | CPU (mCPU) | メモリー (Mi) | レプリカ | Pod の合計 CPU | Pod の合計メモリー |
|---|---|---|---|---|---|---|
| observability-alertmanager | Alertmanager | 4 | 200 | 3 | 12 | 600 |
| config-reloader | 4 | 25 | 3 | 12 | 75 | |
| alertmanager-proxy | 1 | 20 | 3 | 3 | 60 | |
| observability-grafana | grafana | 4 | 100 | 2 | 8 | 200 |
| grafana-dashboard-loader | 4 | 50 | 2 | 8 | 100 | |
| observability-observatorium-api | observatorium-api | 20 | 128 | 2 | 40 | 256 |
| observability-observatorium-operator | observatorium-operator | 100 | 100 | 1 | 10 | 50 |
| observability-rbac-query-proxy | rbac-query-proxy | 20 | 100 | 2 | 40 | 200 |
| oauth-proxy | 1 | 20 | 2 | 2 | 40 | |
| observability-thanos-compact | thanos-compact | 100 | 512 | 1 | 100 | 512 |
| observability-thanos-query | thanos-query | 300 | 1024 | 2 | 600 | 2048 |
| observability-thanos-query-frontend | thanos-query-frontend | 100 | 256 | 2 | 200 | 512 |
| observability-thanos-query-frontend-memcached | Memcached CRD | 45 | 128 | 3 | 135 | 384 |
| exporter | 5 | 50 | 3 | 15 | 150 | |
| observability-thanos-receive-controller | thanos-receive-controller | 4 | 32 | 1 | 4 | 32 |
| observability-thanos-receive-default | thanos-receive | 300 | 512 | 3 | 900 | 1536 |
| observability-thanos-rule | thanos-rule | 50 | 512 | 3 | 150 | 1536 |
| configmap-reloader | 4 | 25 | 3 | 12 | 75 | |
| observability-thanos-store-memcached | Memcached CRD | 45 | 128 | 3 | 135 | 384 |
| exporter | 5 | 50 | 3 | 15 | 150 | |
| observability-thanos-store-shard | thanos-store | 100 | 1024 | 3 | 300 | 3072 |
1.1.4. 可観測性サービスで使用される永続ストア
Red Hat Advanced Cluster Management をインストールするときは、次の永続ボリューム (PV) を作成して、Persistent Volume Claims (PVC) を自動的にアタッチできるようにする必要があります。デフォルトのストレージクラスが指定されていない場合、またはデフォルト以外のストレージクラスを使用して PV をホストする場合は、MultiClusterObservability でストレージクラスを定義する必要があります。Prometheus が使用するものと同様に、ブロックストレージを使用することをお勧めします。また、alertmanager、thanos-compactor、thanos-ruler、thanos-receive-default、および thanos-store-shard の各レプリカには、独自の PV が必要です。次の表を参照します。
表1.2 永続ボリュームの表一覧
| 永続ボリューム名 | 目的 |
| Alertmanager |
Alertmanager は |
| thanos-compact | コンパクターは、処理の中間データとバケット状態キャッシュの保存にローカルのディスク領域が必要です。必要な領域は、下層にあるブロックサイズにより異なります。コンパクターには、すべてのソースブロックをダウンロードして、ディスクで圧縮ブロックを構築するのに十分な領域が必要です。ディスク上のデータは、次回の再起動までに安全に削除でき、最初の試行でクラッシュループコンパクターの停止が解決されるはずです。ただし、次の再起動までにバケットの状態キャッシュを効果的に使用するには、コンパクターの永続ディスクを用意することが推奨されます。 |
| thanos-rule |
thanos ruler は、固定の間隔でクエリーを発行して、選択したクエリー API に対して Prometheus 記録およびアラートルールを評価します。ルールの結果は、Prometheus 2.0 ストレージ形式でディスクに書き込まれます。このステートフルセットで保持されるデータの期間 (時間または日) は、API バージョンの |
| thanos-receive-default |
Thanos receiver は、受信データ (Prometheus リモート書き込みリクエスト) を受け入れて Prometheus TSDB のローカルインスタンスに書き込みます。TSDB ブロックは定期的 (2 時間) に、長期的に保存および圧縮するためにオブジェクトストレージにアップロードされます。ローカルキャッシュを実行するこのステートフルセットで保持される期間 (時間または日) は、API バージョン |
| thanos-store-shard | これは、主に API ゲートウェイとして機能するため、大量のローカルディスク容量は必要ありません。これは、起動時に Thanos クラスターに参加して、アクセスできるデータを広告します。ローカルディスク上のすべてのリモートブロックに関する情報のサイズを小さく保ち、バケットと同期させます。このデータは通常、起動時間が長くなると、再起動時に安全に削除できます。 |
注記: 時系列の履歴データはオブジェクトストアに保存されます。Thanos は、オブジェクトストレージをメトリクスおよび関連するメタデータのプライマリーストレージとして使用します。オブジェクトストレージおよび downsampling 機能の詳細は、可観測性サービスの有効化 を参照してください。
1.1.5. サポート
Red Hat Advanced Cluster Management は、Red Hat OpenShift Data Foundation (以前の Red Hat OpenShift Container Storage) によってテストされ、完全にサポートされています。
Red Hat Advanced Cluster Management は、S3 API と互換性のあるユーザー提供のオブジェクトストレージにおけるマルチクラスター可観測性 Operator の機能をサポートします。
Red Hat Advanced Cluster Management はビジネス的に妥当な範囲内で、根本原因の特定を支援します。
サポートチケットが発行され、根本的な原因がお客様が提供した S3 互換オブジェクトストレージの結果であると判断された場合は、カスタマーサポートチャネルを使用して問題を解決する必要があります。
Red Hat Advanced Cluster Management は、お客様が起票したサポートチケットの根本的な原因が S3 互換性のあるオブジェクトストレージプロバイダーである場合に、問題修正サポートの確約はありません。
可観測性サービスの設定、メトリクスおよびその他のデータの表示方法は、可観測性のカスタマイズ を参照してください。