
Web コンソール
コンソールコンポーネントの使用方法
概要
第1章 Web コンソール
Red Hat Advanced Cluster Management コンソールにアクセスする方法とコンソールのコンポーネントの使用方法を説明します。
1.1. コンソールへのアクセス
Red Hat OpenShift Container Platform の Web コンソールから Red Hat Advanced Cluster Management for Kubernetes のコンソールにアクセスできます。コンソールには、インストール後にターミナルからもアクセスできます。以下で、コンソールへのアクセス方法をすべて確認してください。
1.1.1. OpenShift Container Platform Web コンソールからのアクセス
- OpenShift Container Platform 4.8 以降では、ナビゲーションメニューの近くにあるパースペクティブスイッチャーから Red Hat Advanced Cluster Management を起動できます。
- OpenShift Container Platform の以前のバージョンでは、ヘッダーの アプリケーションランチャー をクリックして、Red Hat Advanced Cluster Managementfor Kubernetes オプションを選択できます。
左側のナビゲーションからコンソールにアクセスすることもできます。
- Networking > Routes をクリックします。
-
Project メニューから、Red Hat Advanced Cluster Management for Kubernetes がインストールされている namespace を選択します。デフォルトの名前空間は
open-cluster-managementです。 -
Location列からmulticloud-consoleURL をクリックします。
1.1.2. Red Hat OpenShift CLI からのアクセス
-
Red Hat OpenShift Container Platform にログインし、Red Hat Advanced Cluster Management for Kubernetes をインストールしたら、以下のコマンドを実行してルートを検索します。ここでは、
<namespace-from-install>を、当製品をインストールした namespace に置き換えます。
oc get routes -n <namespace-from-install>
-
open-cluster-management名とHost/Portコラムを確認し、URL を取得します。
Red Hat Advanced Cluster Management for Kubernetes コンソールの詳細は、Web コンソール を参照してください。
1.2. コンソールの概要
コンソールの表示、管理、またはカスタマイズに使用可能なコンソールのコンポーネントについて説明します。
以下で Red Hat Advanced Cluster Management for Kubernetes コンソールの ナビゲーション のイメージを参照してください。このコンソールについては、後続の各セクションで詳細を説明します。ナビゲーションに、主要な実稼働機能があることが分かります。
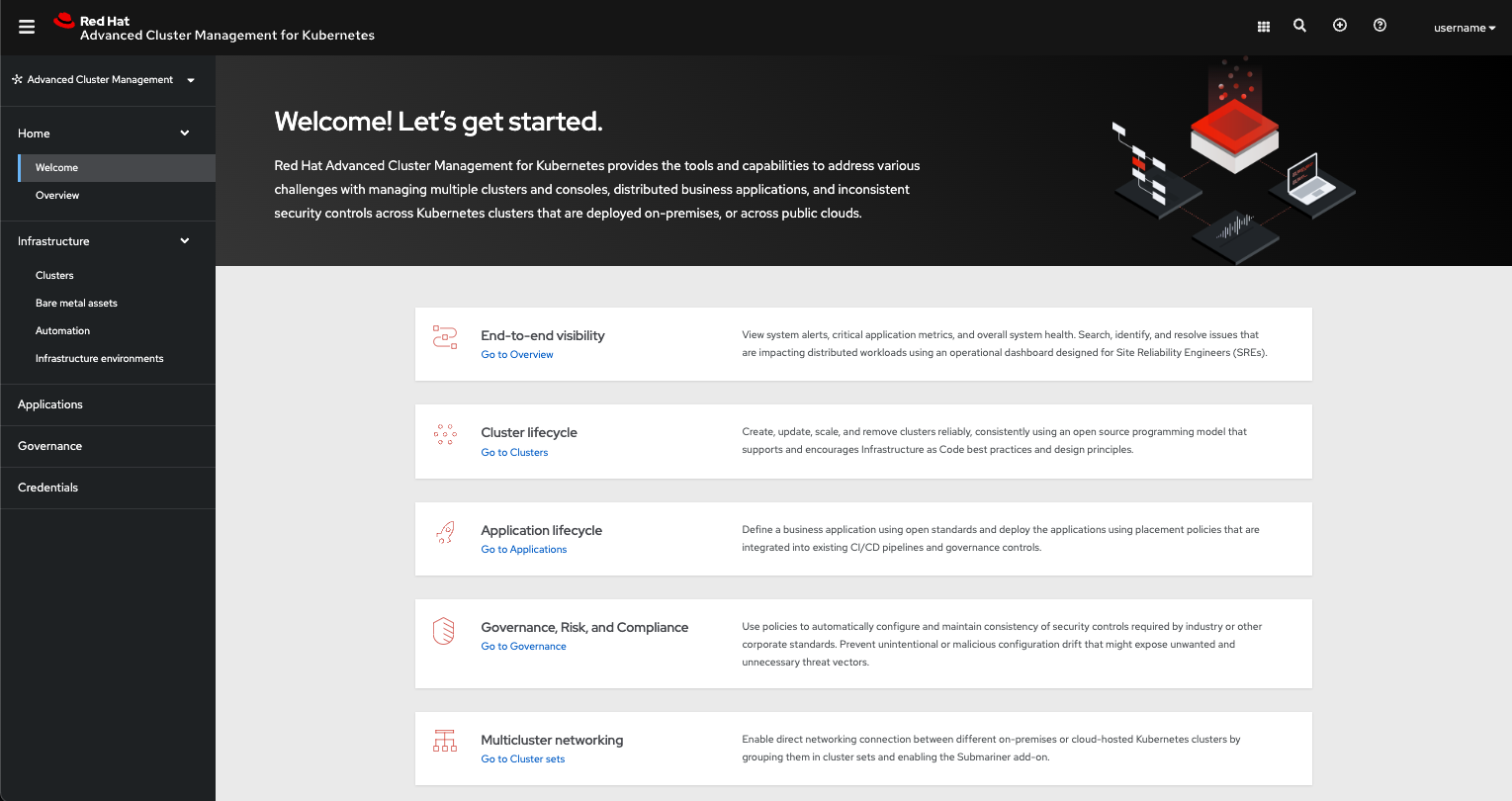
注記: Visual Web Terminal はこのリリースで削除され、Infrastructure environments は Infrastructure の追加タブです。
1.2.1. コンソールのコンポーネント
検索の詳細は、コンソールでの検索 を参照してください。
1.2.2. ホーム
Red Hat Advanced Cluster Management for Kubernetes の Home ページから、製品の詳細情報を取得して、ヘッダー機能や製品の主要なコンポーネントのページにアクセスできます。
Welcome ページおよび Overview にアクセスすると、クラスターを可視化できます。
以下のようなクラスター情報を 概要 ダッシュボードで表示できます。
- マネージドクラスターからのメトリクスデータ (Grafana リンクを選択)
- 全クラスターおよびプロバイダー別のクラスター、ノード、および Pod 数
- クラスターのステータス
- クラスターのコンプライアンス
- Pod のステータス
また、ダッシュボードにはクリック可能な要素が含まれており、この要素から関連のリソースの検索を表示できます。プロバイダーカードをクリックすると、単一プロバイダーからクラスターの情報が表示されます。
- Grafana を選択して Grafana ダッシュボードにアクセスします。
- Clusters ページで Add provider connections タブを選択します。
1.3. コンソールでの検索
Red Hat Advanced Cluster Management for Kubernetes では、検索機能でクラスター全体の Kubernetes リソースを視認できるようにします。検索すると、Kubernetes リソースや関係を他のリソースにインデックス化します。ストレージクラスおよびストレージサイズを変更する必要がある場合は、searchcustomization カスタムリソース (CR) を作成して、検索永続性のストレージ設定を定義できます。
1.3.1. 検索コンポーネント
検索アーキテクチャーは、以下のコンポーネントで設定されています。
-
collector: Kubernetes リソースを監視し、インデックスを作成します。
search-collectorは、マネージドクラスター内のリソースの関係を計算します。 -
aggregator: コレクターからデータを受け取り、データベースに書き込みます。
search-aggregatorは、ハブクラスターのリソースを監視し、マルチクラスターの関係を計算して、接続されたコレクターからのアクティビティーを追跡します。 - Search API: 検索インデックスでデータにアクセスできるようにして、ロールベースのアクセス制御を有効にします。
検索はデフォルトで有効となっています。また、マネージドクラスターのプロビジョニングまたは手動でのインポート時にも検索が有効です。マネージドクラスターの検索を無効にする場合は、クラスターの klusterlet アドオン設定の変更 を参照してください。
1.3.2. 検索カスタマイズ
Red Hat Advanced Cluster Management をインストールすると、インメモリーデータをファイルシステムに永続化するように製品が設定されます。StatefulSet search-redisgraph は Redisgraph Pod をデプロイし、これは persist という名前の永続ボリュームをマウントします。クラスターにデフォルトのストレージクラスが定義されている場合、検索コンポーネントはデフォルトのストレージクラスに 10Gi の Persistent Volume Claims (PVC) を作成します。デフォルトのストレージクラスがクラスターに存在しない場合は、検索によりインデックスが空のディレクトリー (emptyDir) に保存されます。
searchcustomization CR を作成して、検索用のストレージ設定をカスタマイズできます。検索カスタマイズは namespace にスコープ指定され、検索がハブクラスターにインストールされている場所にあります。検索カスタマイズ CR の以下の例を確認してください。
apiVersion: search.open-cluster-management.io/v1alpha1 kind: SearchCustomization metadata: name: searchcustomization namespace: open-cluster-management spec: persistence: true storageClass: gp2 storageSize: 12Gi
以下のコマンドを実行して、検索カスタマイズ CRD を表示します。
oc get crd searchcustomizations.search.open-cluster-management.io -o yaml
カスタマイズ CR の persistence フラグを false に更新し、永続性を無効にすると、検索インデックスのファイルシステムへの保存がオフになります。永続性のステータスは、検索 Operator (searchoperator) CR から取得されます。以下のコマンドを実行して検索 Operator CR を表示します (oc get searchoperator searchoperator -o yaml)。
1.3.2.1. 再ディスグラフメモリーを増やすためのオプション
再ディスグラフは、オブジェクトの数がキャッシュされるにつれてメモリーを直線的に増やす必要があるインメモリーデータベースです。多くのマネージドクラスターまたは多数の Kubernetes オブジェクトを含む Red Hat Advanced Cluster Management クラスターでは、redisgraph Pod のメモリー更新を制限する必要があります ( search-redisgraph-0)。
デフォルトでは redisgraph Pod (search-redisgraph-0) は、メモリーの上限が 4Gi としてデプロイされます。サイズの大きいクラスターを管理する場合には、ハブクラスターの namespace で searchoperator の redisgraph_resource.limit_memory を編集して、この上限を増やす必要があります。たとえば、次のコマンドを使用して上限を 8Gi に更新できます。
oc patch searchoperator searchoperator --type='merge' -p '{"spec":{"redisgraph_resource":{"limit_memory":"8Gi"}}}'
変更が行われると、search-redisgraph Pod は更新された設定で自動的に再起動します。
1.3.3. コンソールでのクエリー
検索ボックス にテキスト値を入力すると、名前や namespace などのプロパティーからのその値が含まれる結果が表示されます。空白のスペースを含む値の検索はできません。
検索結果をさらに絞り込むには、検索にプロパティーセレクターを追加します。プロパティーに関連する値を組み合わせて、検索範囲をより正確に指定できます。たとえば、cluster:dev red と検索すると、dev クラスター内で "red" の文字列と一致する結果が返されます。
以下の手順に従って、検索でクエリーを実行します。
- ナビゲーションメニューの 検索 をクリックします。
Search box に単語を入力すると、検索機能で、対象の値が含まれたリソースを見つけ出します。
- リソースを検索すると、元の検索結果に関連する他のリソースが表示されるので、リソースがシステム内にある他のリソースとどのように対話するのかを視覚的に確認できます。
- 検索すると、各クラスターと、検索したリソースが返され、一覧表示されます。ハブ クラスターのリソースの場合には、クラスター名は local-cluster として表示されます。
-
検索結果は、
kindでグループ化され、リソースのkindごとに表でグループ化されます。 検索オプションはクラスターオブジェクトにより異なります。特定のラベルで結果を絞り込むことができます。ラベルのクエリー時の検索は、大文字と小文字が区別されます。以下の名前、namespace、ステータス、その他のリソースフィールドの例を参照してください。自動補完では、補完候補を表示して検索を絞り込むことができます。以下の例を参照してください。
-
kind:podなど、フィールド 1 つを検索すると、すべての Pod リソースが返されます。 -
kind:pod namespace:defaultなど、複数のフィールドを検索すると、デフォルトの namespace にある Pod が返されます。
-
注記:
-
>, >=, <, <=, !=などの文字を使用して、条件を指定した検索も可能です。 複数の値を含む複数のプロパティーセレクターを検索すると、クエリーされた値のいずれかを返します。以下の例を参照してください。
-
kind:pod name:aと検索すると、aという名前の Pod が返されます。 -
kind:pod name:a,bと検索すると、aまたはbという名前の Pod が返されます。 -
kind:pod status:!Runningを検索すると、ステータスがRunningではないすべての Pod リソースが返されます。 -
kind:pod restarts:>1を検索すると、最低でも 2 回再起動した全 Pod が返されます。
-
- 検索を保存する場合は、Save search アイコンをクリックします。
1.3.3.1. ArgoCD アプリケーションのクエリー
ArgoCD アプリケーションを検索すると、Applications ページに移動します。Search ページから ArgoCD アプリケーションにアクセスするには、以下の手順を実行します。
- Red Hat Advanced Cluster Management ハブクラスターにログインします。
- コンソールヘッダーから Search アイコンを選択します。
-
kind:applicationおよびapigroup:argoproj.ioの値でクエリーをフィルターします。 - 表示するアプリケーションを選択します。アプリケーション ページでは、アプリケーションに関する情報の概要が表示されます。
Red Hat Advanced Cluster Management for Kubernetes コンソールの詳細は、Web コンソール を参照してください。