
OpenShift Dedicated の紹介
OpenShift Dedicated のアーキテクチャーの概要
概要
第1章 OpenShift Dedicated について
OpenShift Dedicated は Kubernetes を基盤とする完全な OpenShift Container Platform クラスターで、高可用性のために設定された、単一のお客様専用のクラウドサービスとして提供されます。
1.1. OpenShift Dedicated の概要
OpenShift Dedicated は Red Hat によって管理され、Amazon Web Services (AWS) または Google Cloud Platform (GCP) でホストされます。各 OpenShift Dedicated クラスターには、完全に管理される コントロールプレーン (Control および Infrastructure ノード)、アプリケーションノード、Red Hat Site Reliability Engineer (SRE) によるインストールおよび管理、プレミアム Red Hat サポート、およびクラスターサービス (ロギング、メトリック、監視、通知ポータル、クラスターポータル) が含まれます。
OpenShift Dedicated は、以下を含むエンタープライズ対応の拡張機能を Kubernetes に提供します。
- OpenShift Dedicated クラスターは AWS または GCP 環境にデプロイされ、アプリケーション管理のハイブリッドアプローチの一部として使用できます。
- Red Hat の統合されたテクノロジー。OpenShift Dedicated の主なコンポーネントは、Red Hat Enterprise Linux と関連する Red Hat の技術に由来します。OpenShift Dedicated は、Red Hat の高品質エンタープライズソフトウェアの集中的なテストや認定の取り組みによる数多くの利点を活用しています。
- オープンソースの開発モデル。開発はオープンソースで行われ、ソースコードはソフトウェアのパブリックリポジトリーから入手可能です。このオープンな共同作業が迅速な技術と開発を促進します。
OpenShift Container Platform でコンテナー化された Kubernetes アプリケーションをビルドおよびデプロイする際に作成できるアセットのオプションを確認するには、OpenShift Container Platform 開発について を参照してください。
1.1.1. カスタムオペレーティングシステム
OpenShift Dedicated はコンテナー指向の新しいオペレーティングシステムであり、CoreOS と Red Hat Atomic Host オペレーティングシステムの最良の機能の一部を組み合わせた Red Hat Enterprise Linux CoreOS (RHCOS) を採用しています。RHCOS は、OpenShift Dedicated のコンテナー化されたアプリケーションを実行する目的で設計されており、新規ツールと連携して迅速なインストール、Operator ベースの管理、および単純化されたアップグレードを実現します。
RHCOS には以下が含まれます。
- Ignition。OpenShift Dedicated が使用するマシンを最初に起動し、設定するための初回起動時のシステム設定です。
- CRI-O、Kubernetes ネイティブコンテナーランタイム実装。これはオペレーティングシステムに密接に統合し、Kubernetes の効率的で最適化されたエクスペリエンスを提供します。CRI-O は、コンテナーを実行、停止および再起動を実行するための機能を提供します。
- Kubelet、Kubernetes のプライマリーノードエージェント。 これは、コンテナーを起動し、これを監視します。
1.1.2. その他の主な機能
Operator は、OpenShift Dedicated コードベースの基本単位であるだけでなく、アプリケーションとアプリケーションで使用されるソフトウェアコンポーネントをデプロイするための便利な手段です。Operator をプラットフォームの基盤として使用することで、OpenShift Dedicated ではオペレーティングシステムおよびコントロールプレーンアプリケーションの手動によるアップグレードが不要になります。Cluster Version Operator や Machine Config Operator などの OpenShift Dedicated の Operator が、それらの重要なコンポーネントのクラスター全体での管理を単純化します。
Operator Lifecycle Manager (OLM) および OperatorHub は、Operator を保管し、アプリケーションの開発やデプロイを行う人々に Operator を提供する機能を提供します。
Red Hat Quay Container Registry は、ほとんどのコンテナーイメージと Operator を OpenShift Dedicated クラスターに提供する Quay.io コンテナーレジストリーです。Quay.io は、何百万ものイメージやタグを保存する Red Hat Quay の公開レジストリー版です。
OpenShift Dedicated での Kubernetes のその他の拡張には、SDN (Software Defined Networking)、認証、ログ集計、監視、およびルーティングの強化された機能が含まれます。OpenShift Dedicated は、包括的な Web コンソールとカスタム OpenShift CLI (oc) インタフェースも提供します。
1.1.3. OpenShift Dedicated のインターネットアクセスおよび Telemetry アクセス
OpenShift Dedicated では、クラスターのインストールおよびアップグレードにインターネットへのアクセスが必要です。
テレメトリーサービスを通じて、情報は OpenShift Dedicated クラスターから Red Hat に送信され、サブスクリプション管理の自動化を可能にし、クラスターの状態を監視し、サポートを支援し、カスタマーエクスペリエンスを向上させます。
テレメトリーサービスは自動的に実行し、クラスターは Red Hat OpenShift Cluster Manager に登録されます。OpenShift Dedicated では、リモートヘルスレポートは常に有効になっており、オプトアウトすることはできません。Red Hat Site Reliability Engineering (SRE) チームは、OpenShift Dedicated クラスターを効果的にサポートするための情報を必要としています。
関連情報
- OpenShift Dedicated クラスターのテレメトーリとリモートヘルスモニタリングの詳細については、リモートヘルスモニタリングについて を参照してください。
第2章 ポリシーおよびサービス定義
2.1. OpenShift Dedicated サービス定義
2.1.1. アカウント管理
2.1.1.1. 請求オプション
お客様は、OpenShift Dedicated (OSD) の年間サブスクリプションを購入するか、クラウドマーケットプレイスを通じてオンデマンドで利用するか選択できます。お客様は、Customer Cloud Subscription (CCS) と呼ばれる独自のクラウドインフラストラクチャーアカウントを使用するか、Red Hat が所有するクラウドプロバイダーアカウントにデプロイするか決定できます。以下の表は、請求に関する追加情報と、対応するサポート対象のデプロイメントオプションを示しています。
| OSD サブスクリプションタイプ | クラウドインフラストラクチャーアカウント | 請求の経由先 |
|---|---|---|
| Red Hat 経由、容量固定型の年間サブスクリプション | Red Hat クラウドアカウント | Red Hat 経由、OSD サブスクリプションとクラウドインフラストラクチャーの使用料 |
| お客様自身のクラウドアカウント | Red Hat 経由、OSD サブスクリプションの使用料 クラウドプロバイダー経由、クラウドインフラストラクチャーの使用料 | |
| Google Cloud Marketplace 経由、オンデマンドの使用量ベース | お客様自身の Google Cloud アカウント | Google Cloud 経由、クラウドインフラストラクチャーと Red Hat OSD サブスクリプションの使用料 |
| Red Hat Marketplace 経由、オンデマンドの使用量ベース | お客様自身のクラウドアカウント | Red Hat 経由、OSD サブスクリプションの使用料 クラウドプロバイダー経由、クラウドインフラストラクチャーの使用料 |
Customer Cloud Subscription (CSS) と呼ばれるお客様自身のクラウドインフラストラクチャーアカウントを使用する場合、お客様はクラウドインフラストラクチャーのコストを抑制するために、Reserved Instance (RI) コンピュートインスタンスを事前購入または提供する責任があります。
以下を含む追加のリソースを OpenShift Dedicated クラスター用に購入できます。
- 追加のノード (マシンプールの使用により異なるタイプおよびサイズになります)
- ミドルウェア (JBoss EAP、JBoss Fuse など): 特定のミドルウェアコンポーネントに基づく追加の価格
- 追加のストレージが 500 GB の増分 (標準のみ、100 GB を含む)
- 追加の 12 TiB ネットワーク I/O (標準のみ、12 TB が含まれる)
- サービスのロードバランサーは 4 のバンドルで利用できます。HTTP/SNI 以外のトラフィックまたは非標準ポートを有効にします (標準のみ)。
2.1.1.2. クラスターのセルフサービス
必要なサブスクリプションを購入している場合は、OpenShift Cluster Manager からクラスターを作成、スケーリング、および削除できます。
Red Hat OpenShift Cluster Manager で利用可能なアクションは、クラスター内から直接実行することはできません。これは、すべてのアクションが自動的に元に戻されるなど、悪影響を与える可能性があるためです。
2.1.1.3. クラウドプロバイダー
OpenShift Dedicated は、以下のクラウドプロバイダーで OpenShift Container Platform クラスターを管理サービスとして提供します。
- Amazon Web Services (AWS)
- Google Cloud Platform (GCP)
2.1.1.4. インスタンスタイプ
単一アベイラビリティーゾーンのクラスターでは、単一のアベイラビリティーゾーンにデプロイされた Customer Cloud Subscription (CCS) クラスター用に最低でも 2 つのワーカーノードが必要です。標準クラスターには、最低でも 4 つのワーカーノードが必要です。これらの 4 つのワーカーノードはベースサブスクリプションに含まれます。
複数のアベイラビリティーゾーンのクラスターでは、Customer Cloud Subscription (CCS) クラスター用に少なくとも 3 つのワーカーノードが必要です。3 つの各アベイラビリティーゾーンに 1 つずつデプロイされます。標準クラスターに 9 つ以上のワーカーノードが必要です。これらの 9 個以上のワーカーノードはベースサブスクリプションに含まれます。適切なノードの分散を維持するために、追加のノードを 3 の倍数に購入する必要があります。
単一の OpenShift Dedicated マシンプール内のワーカーノードはすべて、同じタイプとサイズである必要があります。ただし、OpenShift Dedicated クラスター内の複数のマシンプールにわたってワーカーノードが存在する場合は、異なるタイプやサイズに指定できます。
コントロールプレーンとインフラストラクチャーノードも Red Hat から提供されます。etcd および API 関連のワークロードを処理する 3 つ以上のコントロールプレーンノードが使用されます。メトリック、ルーティング、Web コンソール、および他のワークロードを処理するインフラストラクチャーノードが少なくとも 2 つあります。コントロールプレーンノードとインフラストラクチャーノードでワークロードを実行しないでください。実行する予定のワークロードはすべて、ワーカーノードにデプロイする必要があります。ワーカーノードにデプロイする必要がある Red Hat ワークロードの詳細は、以下の Red Hat Operator サポートセクションを参照してください。
約 1 vCPU コアおよび 1 GiB のメモリーが各ワーカーノードで予約され、割り当て可能なリソースから削除されます。これは、基礎となるプラットフォームに必要なプロセス を実行する必要があります。これには、udev、kubelet、コンテナーランタイムなどのシステムデーモンや、カーネル予約のアカウントが含まれます。監査ログの集計、メトリックコレクション、DNS、イメージレジストリー、SDN などの OpenShift Container Platform コアシステムは、追加の割り当て可能なリソースを使用し、クラスターの安定性および保守性を確保できる可能性があります。消費される追加リソースは、使用方法によって異なる場合があります。
OpenShift Dedicated 4.11 以降、デフォルトの Pod ごとの PID 制限は 4096 です。この PID 制限を有効にする場合は、OpenShift Dedicated クラスターを 4.11 以降にアップグレードする必要があります。以前のバージョンで実行されている OpenShift Dedicated クラスターは、デフォルトの PID 制限である 1024 を使用します。
OpenShift Dedicated クラスターでは、Pod ごとの PID 制限を設定することはできません。
2.1.1.5. Customer Cloud Subscription クラスターの AWS インスタンスタイプ
OpenShift Dedicated は以下のワーカーノードのインスタンスタイプおよび AWS のサイズを提供します。
例2.1 一般的用途
- m5.metal (96† vCPU、384 GiB)
- m5.xlarge (4 vCPU、16 GiB)
- m5.2xlarge (8 vCPU、32 GiB)
- m5.4xlarge (16 vCPU、64 GiB)
- m5.8xlarge (32 vCPU、128 GiB)
- m5.12xlarge (48 vCPU、192 GiB)
- m5.16xlarge (64 vCPU、256 GiB)
- m5.24xlarge (96 vCPU、384 GiB)
- m5a.xlarge (4 vCPU、16 GiB)
- m5a.2xlarge (8 vCPU、32 GiB)
- m5a.4xlarge (16 vCPU、64 GiB)
- m5a.8xlarge (32 vCPU、128 GiB)
- m5a.12xlarge (48 vCPU、192 GiB)
- m5a.16xlarge (64 vCPU、256 GiB)
- m5a.24xlarge (96 vCPU、384 GiB)
- m5ad.xlarge (4 vCPU、16 GiB)
- m5ad.2xlarge (8 vCPU、32 GiB)
- m5ad.4xlarge (16 vCPU、64 GiB)
- m5ad.8xlarge (32 vCPU、128 GiB)
- m5ad.12xlarge (48 vCPU、192 GiB)
- m5ad.16xlarge (64 vCPU、256 GiB)
- m5ad.24xlarge (96 vCPU、384 GiB)
- m5d.metal (96† vCPU、384 GiB)
- m5d.xlarge (4 vCPU、16 GiB)
- m5d.2xlarge (8 vCPU、32 GiB)
- m5d.4xlarge (16 vCPU、64 GiB)
- m5d.8xlarge (32 vCPU、128 GiB)
- m5d.12xlarge (48 vCPU、192 GiB)
- m5d.16xlarge (64 vCPU、256 GiB)
- m5d.24xlarge (96 vCPU、384 GiB)
- m5n.metal (96 vCPU、384 GiB)
- m5n.xlarge (4 vCPU、16 GiB)
- m5n.2xlarge (8 vCPU、32 GiB)
- m5n.4xlarge (16 vCPU、64 GiB)
- m5n.8xlarge (32 vCPU、128 GiB)
- m5n.12xlarge (48 vCPU、192 GiB)
- m5n.16xlarge (64 vCPU、256 GiB)
- m5n.24xlarge (96 vCPU、384 GiB)
- m5dn.metal (96 vCPU、384 GiB)
- m5dn.xlarge (4 vCPU、16 GiB)
- m5dn.2xlarge (8 vCPU、32 GiB)
- m5dn.4xlarge (16 vCPU、64 GiB)
- m5dn.8xlarge (32 vCPU、128 GiB)
- m5dn.12xlarge (48 vCPU、192 GiB)
- m5dn.16xlarge (64 vCPU、256 GiB)
- m5dn.24xlarge (96 vCPU、384 GiB)
- m5zn.metal (48 vCPU、192 GiB)
- m5zn.xlarge (4 vCPU、16 GiB)
- m5zn.2xlarge (8 vCPU、32 GiB)
- m5zn.3xlarge (12 vCPU、48 GiB)
- m5zn.6xlarge (24 vCPU、96 GiB)
- m5zn.12xlarge (48 vCPU、192 GiB)
- m6a.xlarge (4 vCPU、16 GiB)
- m6a.2xlarge (8 vCPU、32 GiB)
- m6a.4xlarge (16 vCPU、64 GiB)
- m6a.8xlarge (32 vCPU、128 GiB)
- m6a.12xlarge (48 vCPU、192 GiB)
- m6a.16xlarge (64 vCPU、256 GiB)
- m6a.24xlarge (96 vCPU、384 GiB)
- m6a.32xlarge (128 vCPU、512 GiB)
- m6a.48xlarge (192 vCPU、768 GiB)
- m6i.metal (128 vCPU、512 GiB)
- m6i.xlarge (4 vCPU、16 GiB)
- m6i.2xlarge (8 vCPU、32 GiB)
- m6i.4xlarge (16 vCPU、64 GiB)
- m6i.8xlarge (32 vCPU、128 GiB)
- m6i.12xlarge (48 vCPU、192 GiB)
- m6i.16xlarge (64 vCPU、256 GiB)
- m6i.24xlarge (96 vCPU、384 GiB)
- m6i.32xlarge (128 vCPU、512 GiB)
- m6id.xlarge (4 vCPU、16 GiB)
- m6id.2xlarge (8 vCPU、32 GiB)
- m6id.4xlarge (16 vCPU、64 GiB)
- m6id.8xlarge (32 vCPU、128 GiB)
- m6id.12xlarge (48 vCPU、192 GiB)
- m6id.16xlarge (64 vCPU、256 GiB)
- m6id.24xlarge (96 vCPU、384 GiB)
- m6id.32xlarge (128 vCPU、512 GiB)
- m7i.xlarge (4 vCPU、16 GiB)
- m7i.2xlarge (8 vCPU、32 GiB)
- m7i.4xlarge (16 vCPU、64 GiB)
- m7i.8xlarge (32 vCPU、128 GiB)
- m7i.12xlarge (48 vCPU、192 GiB)
- m7i.16xlarge (64 vCPU、256 GiB)
- m7i.24xlarge (96 vCPU、384 GiB)
- m7i.48xlarge (192 vCPU、768 GiB)
- m7i.metal-24xl (96 vCPU、384 GiB)
- m7i.metal-48xl (192 vCPU、768 GiB)
- m7i-flex.xlarge (4 vCPU、16 GiB)
- m7i-flex.2xlarge (8 vCPU、32 GiB)
- m7i-flex.4xlarge (16 vCPU、64 GiB)
- m7i-flex.8xlarge (32 vCPU、128 GiB)
- m7a.xlarge (4 vCPU、16 GiB)
- m7a.2xlarge (8 vCPU、32 GiB)
- m7a.4xlarge (16 vCPU、64 GiB)
- m7a.8xlarge (32 vCPU、128 GiB)
- m7a.12xlarge (48 vCPU、192 GiB)
- m7a.16xlarge (64 vCPU、256 GiB)
- m7a.24xlarge (96 vCPU、384 GiB)
- m7a.32xlarge (128 vCPU、512 GiB)
- m7a.48xlarge (192 vCPU、768 GiB)
- m7a.metal-48xl (192 vCPU、768 GiB)
† これらのインスタンスタイプは、48 個の物理コアで 96 個の論理プロセッサーを提供します。これらは、2 つの物理 Intel ソケットを備えた単一サーバー上で実行します。
例2.2 バースト可能な汎用目的
- t3.xlarge (4 vCPU、16 GiB)
- t3.2xlarge (8 vCPU、32 GiB)
- t3a.xlarge (4 vCPU、16 GiB)
- t3a.2xlarge (8 vCPU、32 GiB)
例2.3 メモリー集約型
- x1.16xlarge (64 vCPU、976 GiB)
- x1.32xlarge (128 vCPU、1952 GiB)
- x1e.xlarge (4 vCPU、122 GiB)
- x1e.2xlarge (8 vCPU、244 GiB)
- x1e.4xlarge (16 vCPU、488 GiB)
- x1e.8xlarge (32 vCPU、976 GiB)
- x1e.16xlarge (64 vCPU、1,952 GiB)
- x1e.32xlarge (128 vCPU、3,904 GiB)
- x2idn.16xlarge (64 vCPU、1024 GiB)
- x2idn.24xlarge (96 vCPU、1536 GiB)
- x2idn.32xlarge (128 vCPU、2048 GiB)
- x2iedn.xlarge (4 vCPU、128 GiB)
- x2iedn.2xlarge (8 vCPU、256 GiB)
- x2iedn.4xlarge (16 vCPU、512 GiB)
- x2iedn.8xlarge (32 vCPU、1024 GiB)
- x2iedn.16xlarge (64 vCPU、2048 GiB)
- x2iedn.24xlarge (96 vCPU、3072 GiB)
- x2iedn.32xlarge (128 vCPU、4096 GiB)
- x2iezn.2xlarge (8 vCPU、256 GiB)
- x2iezn.4xlarge (16vCPU、512 GiB)
- x2iezn.6xlarge (24vCPU、768 GiB)
- x2iezn.8xlarge (32vCPU、1,024 GiB)
- x2iezn.12xlarge (48vCPU、1,536 GiB)
- x2idn.metal (128vCPU、2,048 GiB)
- x2iedn.metal (128vCPU、4,096 GiB)
- x2iezn.metal (48 vCPU、1,536 GiB)
例2.4 最適化されたメモリー
- r4.xlarge (4 vCPU、30.5 GiB)
- r4.2xlarge (8 vCPU、61 GiB)
- r4.4xlarge (16 vCPU、122 GiB)
- r4.8xlarge (32 vCPU、244 GiB)
- r4.16xlarge (64 vCPU、488 GiB)
- r5.metal (96† vCPU、768 GiB)
- r5.xlarge (4 vCPU、32 GiB)
- r5.2xlarge (8 vCPU、64 GiB)
- r5.4xlarge (16 vCPU、128 GiB)
- r5.8xlarge (32 vCPU、256 GiB)
- r5.12xlarge (48 vCPU、384 GiB)
- r5.16xlarge (64 vCPU、512 GiB)
- r5.24xlarge (96 vCPU、768 GiB)
- r5a.xlarge (4 vCPU、32 GiB)
- r5a.2xlarge (8 vCPU、64 GiB)
- r5a.4xlarge (16 vCPU、128 GiB)
- r5a.8xlarge (32 vCPU、256 GiB)
- r5a.12xlarge (48 vCPU、384 GiB)
- r5a.16xlarge (64 vCPU、512 GiB)
- r5a.24xlarge (96 vCPU、768 GiB)
- r5ad.xlarge (4 vCPU、32 GiB)
- r5ad.2xlarge (8 vCPU、64 GiB)
- r5ad.4xlarge (16 vCPU、128 GiB)
- r5ad.8xlarge (32 vCPU、256 GiB)
- r5ad.12xlarge(48 vCPU、384 GiB)
- r5ad.16xlarge (64 vCPU、512 GiB)
- r5ad.24xlarge (96 vCPU、768 GiB)
- r5d.metal (96† vCPU、768 GiB)
- r5d.xlarge (4 vCPU、32 GiB)
- r5d.2xlarge (8 vCPU、64 GiB)
- r5d.4xlarge (16 vCPU、128 GiB)
- r5d.8xlarge (32 vCPU、256 GiB)
- r5d.12xlarge (48 vCPU、384 GiB)
- r5d.16xlarge (64 vCPU、512 GiB)
- r5d.24xlarge (96 vCPU、768 GiB)
- r5n.metal (96 vCPU、768 GiB)
- r5n.xlarge (4 vCPU、32 GiB)
- r5n.2xlarge (8 vCPU、64 GiB)
- r5n.4xlarge (16 vCPU、128 GiB)
- r5n.8xlarge (32 vCPU、256 GiB)
- r5n.12xlarge (48 vCPU、384 GiB)
- r5n.16xlarge (64 vCPU、512 GiB)
- r5n.24xlarge (96 vCPU、768 GiB)
- r5dn.metal (96 vCPU、768 GiB)
- r5dn.xlarge (4 vCPU、32 GiB)
- r5dn.2xlarge (8 vCPU、64 GiB)
- r5dn.4xlarge (16 vCPU、128 GiB)
- r5dn.8xlarge (32 vCPU、256 GiB)
- r5dn.12xlarge(48 vCPU、384 GiB)
- r5dn.16xlarge (64 vCPU、512 GiB)
- r5dn.24xlarge (96 vCPU、768 GiB)
- r6a.xlarge (4 vCPU、32 GiB)
- r6a.2xlarge (8 vCPU、64 GiB)
- r6a.4xlarge (16 vCPU、128 GiB)
- r6a.8xlarge (32 vCPU、256 GiB)
- r6a.12xlarge (48 vCPU、384 GiB)
- r6a.16xlarge (64 vCPU、512 GiB)
- r6a.24xlarge (96 vCPU、768 GiB)
- r6a.32xlarge (128 vCPU、1,024 GiB)
- r6a.48xlarge (192 vCPU、1,536 GiB)
- r6i.metal (128 vCPU、1,024 GiB)
- r6i.xlarge (4 vCPU、32 GiB)
- r6i.2xlarge (8 vCPU、64 GiB)
- r6i.4xlarge (16 vCPU、128 GiB)
- r6i.8xlarge (32 vCPU、256 GiB)
- r6i.12xlarge (48 vCPU、384 GiB)
- r6i.16xlarge (64 vCPU、512 GiB)
- r6i.24xlarge (96 vCPU、768 GiB)
- r6i.32xlarge (128 vCPU、1,024 GiB)
- r6id.xlarge (4 vCPU、32 GiB)
- r6id.2xlarge (8 vCPU、64 GiB)
- r6id.4xlarge (16 vCPU、128 GiB)
- r6id.8xlarge (32 vCPU、256 GiB)
- r6id.12xlarge (48 vCPU、384 GiB)
- r6id.16xlarge (64 vCPU、512 GiB)
- r6id.24xlarge (96 vCPU、768 GiB)
- r6id.32xlarge (128 vCPU、1,024 GiB)
- z1d.metal (48 vCPU、384 GiB)
- z1d.xlarge (4 vCPU、32 GiB)
- z1d.2xlarge (8 vCPU、64 GiB)
- z1d.3xlarge (12 vCPU、96 GiB)
- z1d.6xlarge (24 vCPU、192 GiB)
- z1d.12xlarge (48 vCPU、384 GiB)
- r7iz.xlarge (4 vCPU、32 GiB)
- r7iz.2xlarge (8 vCPU、64 GiB)
- r7iz.4xlarge (16 vCPU、128 GiB)
- r7iz.8xlarge (32 vCPU、256 GiB)
- r7iz.12xlarge (48 vCPU、384 GiB)
- r7iz.16xlarge (64 vCPU、512 GiB)
- r7iz.32xlarge (128 vCPU、1024 GiB)
- r7iz.metal-16xl (64 vCPU、512 GiB)
- r7iz.metal-32xl (128 vCPU、1024 GiB)
† これらのインスタンスタイプは、48 個の物理コアで 96 個の論理プロセッサーを提供します。これらは、2 つの物理 Intel ソケットを備えた単一サーバー上で実行します。
これらのインスタンスタイプは、24 個の物理コアで 48 個の論理プロセッサーを提供します。
例2.5 高速コンピューティング
- p3.2xlarge (8 vCPU、61 GiB)
- p3.8xlarge (32 vCPU、244 GiB)
- p3.16xlarge (64 vCPU、488 GiB)
- p3dn.24xlarge (96 vCPU、768 GiB)
- p4d.24xlarge (96 vCPU、1,152 GiB)
- p4de.24xlarge (96 vCPU、1,152 GiB)
- p5.48xlarge (192 vCPU、2,048 GiB)
- g4dn.xlarge (4 vCPU、16 GiB)
- g4dn.2xlarge (8 vCPU、32 GiB)
- g4dn.4xlarge (16 vCPU、64 GiB)
- g4dn.8xlarge (32 vCPU、128 GiB)
- g4dn.12xlarge (48 vCPU、192 GiB)
- g4dn.16xlarge (64 vCPU、256 GiB)
- g4dn.metal (96 vCPU、384 GiB)
- g5.xlarge (4 vCPU、16 GiB)
- g5.2xlarge (8 vCPU、32 GiB)
- g5.4xlarge (16 vCPU、64 GiB)
- g5.8xlarge (32 vCPU、128 GiB)
- g5.16xlarge (64 vCPU、256 GiB)
- g5.12xlarge (48 vCPU、192 GiB)
- g5.24xlarge (96 vCPU、384 GiB)
- g5.48xlarge (192 vCPU、768 GiB)
- dl1.24xlarge (96 vCPU、768 GiB)†
† Intel 固有で Nvidia で対応していません。
GPU インスタンスタイプソフトウェアスタックのサポートは AWS によって提供されます。AWS サービスクォータが必要な GPU インスタンスタイプに対応できることを確認します。
例2.6 最適化されたコンピュート
- c5.metal (96 vCPU、192 GiB)
- c5.xlarge (4 vCPU、8 GiB)
- c5.2xlarge (8 vCPU、16 GiB)
- c5.4xlarge (16 vCPU、32 GiB)
- c5.9xlarge (36 vCPU、72 GiB)
- c5.12xlarge (48 vCPU、96 GiB)
- c5.18xlarge (72 vCPU、144 GiB)
- c5.24xlarge (96 vCPU、192 GiB)
- c5d.metal (96 vCPU、192 GiB)
- c5d.xlarge (4 vCPU、8 GiB)
- c5d.2xlarge (8 vCPU、16 GiB)
- c5d.4xlarge (16 vCPU、32 GiB)
- c5d.9xlarge (36 vCPU、72 GiB)
- c5d.12xlarge (48 vCPU、96 GiB)
- c5d.18xlarge(72 vCPU、144 GiB)
- c5d.24xlarge (96 vCPU、192 GiB)
- c5a.xlarge (4 vCPU、8 GiB)
- c5a.2xlarge (8 vCPU、16 GiB)
- c5a.4xlarge (16 vCPU、32 GiB)
- c5a.8xlarge (32 vCPU、64 GiB)
- c5a.12xlarge (48 vCPU、96 GiB)
- c5a.16xlarge (64 vCPU、128 GiB)
- c5a.24xlarge (96 vCPU、192 GiB)
- c5ad.xlarge (4 vCPU、8 GiB)
- c5ad.2xlarge (8 vCPU、16 GiB)
- c5ad.4xlarge (16 vCPU、32 GiB)
- c5ad.8xlarge (32 vCPU、64 GiB)
- c5ad.12xlarge (48 vCPU、96 GiB)
- c5ad.16xlarge (64 vCPU、128 GiB)
- c5ad.24xlarge (96 vCPU、192 GiB)
- c5n.metal (72 vCPU、192 GiB)
- c5n.xlarge (4 vCPU、10.5 GiB)
- c5n.2xlarge (8 vCPU、21 GiB)
- c5n.4xlarge (16 vCPU、42 GiB)
- c5n.9xlarge (36 vCPU、96 GiB)
- c5n.18xlarge (72 vCPU、192 GiB)
- c6a.xlarge (4 vCPU、8 GiB)
- c6a.2xlarge (8 vCPU、16 GiB)
- c6a.4xlarge (16 vCPU、32 GiB)
- c6a.8xlarge (32 vCPU、64 GiB)
- c6a.12xlarge (48 vCPU、96 GiB)
- c6a.16xlarge (64 vCPU、128 GiB)
- c6a.24xlarge (96 vCPU、192 GiB)
- c6a.32xlarge (128 vCPU、256 GiB)
- c6a.48xlarge (192 vCPU、384 GiB)
- c6i.metal (128 vCPU、256 GiB)
- c6i.xlarge (4 vCPU、8 GiB)
- c6i.2xlarge (8 vCPU、16 GiB)
- c6i.4xlarge (16 vCPU、32 GiB)
- c6i.8xlarge (32 vCPU、64 GiB)
- c6i.12xlarge (48 vCPU、96 GiB)
- c6i.16xlarge (64 vCPU、128 GiB)
- c6i.24xlarge (96 vCPU、192 GiB)
- c6i.32xlarge (128 vCPU、256 GiB)
- c6id.xlarge (4 vCPU、8 GiB)
- c6id.2xlarge (8 vCPU、16 GiB)
- c6id.4xlarge (16 vCPU、32 GiB)
- c6id.8xlarge (32 vCPU、64 GiB)
- c6id.12xlarge (48 vCPU、96 GiB)
- c6id.16xlarge (64 vCPU、128 GiB)
- c6id.24xlarge (96 vCPU、192 GiB)
- c6id.32xlarge (128 vCPU、256 GiB)
例2.7 最適化されたストレージ
- i3.metal (72† vCPU、512 GiB)
- i3.xlarge (4 vCPU、30.5 GiB)
- i3.2xlarge (8 vCPU、61 GiB)
- i3.4xlarge (16 vCPU、122 GiB)
- i3.8xlarge (32 vCPU、244 GiB)
- i3.16xlarge (64 vCPU、488 GiB)
- i3en.metal (96 vCPU、768 GiB)
- i3en.xlarge (4 vCPU、32 GiB)
- i3en.2xlarge (8 vCPU、64 GiB)
- i3en.3xlarge (12 vCPU、96 GiB)
- i3en.6xlarge (24 vCPU、192 GiB)
- i3en.12xlarge (48 vCPU、384 GiB)
- i3en.24xlarge (96 vCPU、768 GiB)
- i4i.xlarge (4 vCPU、32 GiB)
- i4i.2xlarge (8 vCPU、64 GiB)
- i4i.4xlarge (16 vCPU、128 GiB)
- i4i.8xlarge (32 vCPU、256 GiB)
- i4i.12xlarge (48 vCPU、384 GiB)
- i4i.16xlarge (64 vCPU、512 GiB)
- i4i.24xlarge (96 vCPU、768 GiB)
- i4i.32xlarge (128 vCPU、1024 GiB)
- i4i.metal (128 vCPU、1024 GiB)
† このインスタンスタイプは、36 個の物理コアで 72 個の論理プロセッサーを提供します。
仮想インスタンスタイプは、.metal インスタンスタイプよりも速く初期化されます。
例2.8 高メモリー
- u-3tb1.56xlarge (224 vCPU、3,072 GiB)
- u-6tb1.56xlarge (224 vCPU、6,144 GiB)
- u-6tb1.112xlarge (448 vCPU、6,144 GiB)
- u-6tb1.metal (448 vCPU、6,144 GiB)
- u-9tb1.112xlarge (448 vCPU、9,216 GiB)
- u-9tb1.metal (448 vCPU、9,216 GiB)
- u-12tb1.112xlarge (448 vCPU、12,288 GiB)
- u-12tb1.metal (448 vCPU、12,288 GiB)
- u-18tb1.metal (448 vCPU、18,432 GiB)
- u-24tb1.metal (448 vCPU、24,576 GiB)
関連情報
2.1.1.6. 標準クラスターの AWS インスタンスタイプ
OpenShift Dedicated は以下のワーカーノードのタイプおよび AWS のサイズを提供します。
例2.9 一般的用途
- m5.xlarge (4 vCPU、16 GiB)
- m5.2xlarge (8 vCPU、32 GiB)
- m5.4xlarge (16 vCPU、64 GiB)
例2.10 メモリー最適化
- r5.xlarge (4 vCPU、32 GiB)
- r5.2xlarge (8 vCPU、64 GiB)
- r5.4xlarge (16 vCPU、128 GiB)
例2.11 コンピュート最適化
- c5.2xlarge (8 vCPU、16 GiB)
- c5.4xlarge (16 vCPU、32 GiB)
2.1.1.7. Google Cloud コンピュートタイプ
OpenShift Dedicated は、他のクラウドインスタンスタイプと同じ共通の CPU およびメモリーの容量を持つために選択される Google Cloud の以下のワーカーノードタイプおよびサイズを提供します。
例2.12 一般的用途
- custom-4-16384 (4 vCPU、16 GiB)
- custom-8-32768 (8 vCPU、32 GiB)
- custom-16-65536 (16 vCPU、64 GiB)
- custom-32-131072 (32 vCPU、128 GiB)
- custom-48-199608 (48 vCPU、192 GiB)
- custom-64-262144 (64 vCPU、256 GiB)
- custom-96-393216 (96 vCPU、384 GiB)
例2.13 メモリー最適化
- custom-4-32768-ext (4 vCPU、32 GiB)
- custom-8-65536-ext (8 vCPU、64 GiB)
- custom-16-131072-ext (16 vCPU、128 GiB)
例2.14 コンピュート最適化
- custom-8-16384 (8 vCPU、16 GiB)
- custom-16-32768 (16 vCPU、32 GiB)
- custom-36-73728 (36 vCPU、72 GiB)
- custom-48-98304 (48 vCPU、96 GiB)
- custom-72-147456 (72 vCPU、144 GiB)
- custom-96-196608 (96 vCPU、192 GiB)
2.1.1.8. リージョンおよびアベイラビリティーゾーン
以下の AWS リージョンは OpenShift Container Platform 4 でサポートされ、OpenShift Dedicated についてサポートされます。
- af-south-1 (Cape Town, AWS オプトインが必要)
- ap-east-1 (Hong Kong、AWS オプトインが必要)
- ap-northeast-1 (Tokyo)
- ap-northeast-2 (Seoul)
- ap-northeast-3 (Osaka)
- ap-south-1 (Mumbai)
- ap-south-2 (Hyderabad、AWS オプトインが必要)
- ap-southeast-1 (Singapore)
- ap-southeast-2 (Sydney)
- ap-southeast-3 (Jakarta、AWS オプトインが必要)
- ap-southeast-4 (Melbourne、AWS オプトインが必要)
- ca-central-1 (Central Canada)
- eu-central-1 (Frankfurt)
- eu-central-2 (Zurich、AWS オプトインが必要)
- eu-north-1 (Stockholm)
- eu-south-1 (Milan、AWS オプトインが必要)
- eu-south-2 (Spain、AWS オプトインが必要)
- eu-west-1 (Ireland)
- eu-west-2 (London)
- eu-west-3 (Paris)
- me-central-1 (UAE、AWS オプトインが必要)
- me-south-1 (Bahrain、AWS オプトインが必要)
- sa-east-1 (São Paulo)
- us-east-1 (N. Virginia)
- us-east-2 (Ohio)
- us-west-1 (N. California)
- us-west-2 (Oregon)
以下の Google Cloud リージョンが現在サポートされています。
- asia-east1, Changhua County, Taiwan
- asia-east2, Hong Kong
- asia-northeast1, Tokyo, Japan
- asia-northeast2, Osaka, Japan
- asia-south1, Mumbai, India
- asia-south2, Delhi, India
- asia-southeast1, Jurong West, Singapore
- australia-southeast1, Sydney, Australia
- europe-north1, Hamina, Finland
- europe-west1, St. Ghislain, Belgium
- europe-west2, London, England, UK
- europe-west3, Frankfurt, Germany
- europe-west4, Eemshaven, Netherlands
- europe-west6, Zürich, Switzerland
- northamerica-northeast1, Montréal, Québec, Canada
- southamerica-east1, Osasco (São Paulo), Brazil
- us-central1, Council Bluffs, Iowa, USA
- us-east1, Moncks Corner, South Carolina, USA
- us-east4, Ashburn, Northern Virginia, USA
- us-west1, The Dalles, Oregon, USA
- us-west2, Los Angeles, California, USA
Multi-AZ クラスターは、3 つ以上のアベイラビリティーゾーンを持つリージョンにのみデプロイできます (AWS および Google Cloud を参照してください)。
新規 OpenShift Dedicated クラスターは、単一のリージョンの専用 Virtual Private Cloud (VPC) 内にインストールされます。また、単一アベイラビリティーゾーン (Single-AZ) または複数のアベイラビリティーゾーン (Multi-AZ) にデプロイするオプションを選択できます。これにより、クラスターレベルのネットワークおよびリソースの分離が行われ、VPN 接続や VPC ピアリングなどのクラウドプロバイダーの VPC 設定が有効になります。永続ボリュームはクラウドブロックストレージによってサポートされ、それらがプロビジョニングされるアベイラビリティーゾーンに固有のものです。永続ボリュームは、Pod がスケジュール対象外にされないように、関連付けられた Pod リソースが特定のアベイラビリティーゾーンに割り当てられるまでボリュームにバインドされません。アベイラビリティーゾーン固有のリソースは、同じアベイラビリティーゾーン内のリソースでのみ利用できます。
リージョンおよび単一またはマルチアベイラビリティーゾーンの選択肢は、クラスターがデプロイされた後には変更できません。
2.1.1.9. サービスレベルアグリーメント (SLA)
サービスの SLA は、Red Hat Enterprise Agreement Appendix 4 (Online Subscription Services) の Appendix 4 で定義されています。
2.1.1.10. 限定サポートステータス
クラスターが 限定サポート ステータスに移行すると、Red Hat はクラスターをプロアクティブに監視しなくなり、SLA は適用されなくなり、SLA に対して要求されたクレジットは拒否されます。製品サポートがなくなったという意味ではありません。場合によっては、違反要因を修正すると、クラスターが完全にサポートされた状態に戻ることがあります。ただし、それ以外の場合は、クラスターを削除して再作成する必要があります。
クラスターは、次のシナリオなど、さまざまな理由で限定サポートステータスに移行する場合があります。
- サポート終了日までにクラスターをサポートされるバージョンにアップグレードしない場合
Red Hat は、サポート終了日以降のバージョンについて、ランタイムまたは SLA を保証しません。継続的なサポートを受けるには、サポートが終了する前に、クラスターを、サポートされているバージョンにアップグレードしてください。有効期限が切れる前にクラスターをアップグレードしない場合、クラスターは、サポートされているバージョンにアップグレードされるまで、限定サポートステータスに移行します。
Red Hat は、サポートされていないバージョンからサポートされているバージョンにアップグレードするための商業的に合理的なサポートを提供します。ただし、サポートされるアップグレードパスが利用できなくなった場合は、新規クラスターを作成し、ワークロードを移行することが必要になることがあります。
- ネイティブの OpenShift Dedicated コンポーネント、または Red Hat によってインストールおよび管理されているその他のコンポーネントを削除または交換した場合
- クラスター管理者パーミッションを使用した場合、Red Hat は、インフラストラクチャーサービス、サービスの可用性、またはデータ損失に影響を与えるアクションを含む、ユーザーまたは認可されたユーザーのアクションに対して責任を負いません。Red Hat がそのようなアクションを検出した場合、クラスターは限定サポートステータスに移行する可能性があります。Red Hat はステータスの変更を通知します。アクションを元に戻すか、サポートケースを作成して、クラスターの削除と再作成が必要になる可能性のある修復手順を検討する必要があります。
クラスターが限定サポートステータスに移行する可能性のある特定のアクションについて質問がある場合、またはさらに支援が必要な場合は、サポートチケットを作成します。
2.1.1.11. サポート
OpenShift Dedicated には Red Hat Premium サポートが含まれており、これは Red Hat カスタマーポータル を使用してアクセスできます。
OpenShift Dedicated のサポートに含まれるものについての 詳細は、製品サポートの対象範囲 を参照してください。
サポートの応答時間については、OpenShift Dedicated の SLA を参照してください。
2.1.2. ロギング
OpenShift Dedicated は、Amazon CloudWatch (AWS 上) または Google Cloud Logging (GCP 上) への任意の統合ログ転送を提供します。
詳細は、About log collection and forwarding を参照してください。
2.1.2.1. クラスター監査ロギング
クラスター監査ログは、インテグレーションが有効になっている場合、Amazon CloudWatch (AWS 上) または Google Cloud Logging (GCP 上) を通じて利用できます。インテグレーションが有効でない場合は、サポートケースを作成して監査ログをリクエストできます。監査ログのリクエストでは、日時の範囲が 21 日を超えないように指定する必要があります。監査ログをリクエストする際には、監査ログのサイズが 1 日あたり数 GB になることに注意してください。
2.1.2.2. アプリケーションロギング
STDOUT に送信されるアプリケーションログは、クラスターロギングスタックがインストールされている場合、それを介して Amazon CloudWatch (AWS 上) または Google Cloud Logging (GCP 上) に転送されます。
2.1.3. モニタリング
2.1.3.1. クラスターメトリック
OpenShift Dedicated クラスターには、CPU、メモリー、ネットワークベースのメトリクスを含むクラスターモニタリングの統合された Prometheus/Grafana スタックが同梱されます。これは Web コンソールからアクセスでき、Grafana ダッシュボードを使用してクラスターレベルのステータスおよび容量/使用状況を表示することもできます。また、これらのメトリックは OpenShift Dedicated ユーザーによって提供される CPU またはメモリーメトリックをベースとする Horizontal Pod Autoscaling を許可します。
2.1.3.2. クラスターステータスの通知
Red Hat は、Red Hat OpenShift Cluster Manager で利用可能なクラスターダッシュボードと、クラスターの初回デプロイで使用した連絡先のメールアドレスに送信されるメール通知を使用して、OpenShift Dedicated クラスターの正常性およびステータスについて通信します。
2.1.4. ネットワーク
2.1.4.1. アプリケーションのカスタムドメイン
OpenShift Dedicated 4.14 以降、Custom Domain Operator は非推奨になりました。OpenShift Dedicated 4.14 以降で Ingress を管理するには、Ingress Operator を使用します。OpenShift Dedicated 4.13 以前のバージョンでは機能に変更はありません。
ルートにカスタムホスト名を使用するには、正規名 (CNAME) レコードを作成して DNS プロバイダーを更新する必要があります。CNAME レコードは、OpenShift の正規ルーターのホスト名をカスタムドメインにマッピングする必要があります。OpenShift の正規ルーターのホスト名は、ルートの作成後に Route Details ページに表示されます。または、ワイルドカード CNAME レコードを 1 度作成して、指定のホスト名のすべてのサブドメインをクラスターのルーターにルーティングできます。
2.1.4.2. クラスターサービスのカスタムドメイン
カスタムドメインおよびサブドメインは、プラットフォームサービスルート (API、Web コンソールルート、またはデフォルトのアプリケーションルート) では使用できません。
2.1.4.3. ドメイン検証証明書
OpenShift Dedicated には、クラスターの内部サービスと外部サービスの両方に必要な TLS セキュリティー証明書が含まれます。外部ルートの場合、2 つの別個の TLS ワイルドカード証明書があり、各クラスターに提供され、これが各クラスターにインストールされます。1 つは Web コンソールとルートのデフォルトホスト名用、もう 1 つは API エンドポイント用です。Let's Encrypt は証明書に使用される認証局です。たとえば、内部 API エンドポイント などのクラスター内のルートでは、クラスターの組み込み認証局によって署名された TLS 証明書を使用し、TLS 証明書を信頼するためにすべての Pod で CA バンドルが利用可能である必要があります。
2.1.4.4. ビルド用のカスタム認証局
OpenShift Dedicated は、イメージレジストリーからイメージをプルする際にビルドによって信頼されるカスタム認証局の使用をサポートします。
2.1.4.5. ロードバランサー
OpenShift Dedicated は、最大 5 つの異なるロードバランサーを使用します。
- クラスターの内部にあり、内部クラスター通信のトラフィックのバランスを取るために使用される内部コントロールプレーンのロードバランサー。
- OpenShift Container Platform および Kubernetes API へのアクセスに使用される外部コントロールプレーンのロードバランサー。このロードバランサーは、Red Hat OpenShift Cluster Manager で無効にできます。このロードバランサーが無効になると、Red Hat は API DNS を内部コントロールロードバランサーを参照するように再設定します。
- Red Hat によるクラスター管理用に予約される Red Hat の外部コントロールプレーンのロードバランサー。アクセスは厳密に制御され、許可リストの bastion ホストからの通信のみが可能です。
-
デフォルトのアプリケーションロードバランサーであるデフォルトの router/ingress ロードバランサー (URL の
appsで表される)。デフォルトのロードバランサーを OpenShift Cluster Manager で設定して、インターネット上で一般にアクセス可能にしたり、既存のプライベート接続でプライベートにのみアクセス可能にしたりできます。ロギング UI、メトリック API、レジストリーなどのクラスターサービスを含む、クラスターのすべてのアプリケーションルートは、このデフォルトのルーターロードバランサーで公開されます。 -
オプション: セカンダリーアプリケーションロードバランサーであるセカンダリールーター/ingress ロードバランサー (URL の
apps2で表される)。セカンダリーロードバランサーを OpenShift Cluster Manager で設定して、インターネット上で一般にアクセス可能にしたり、既存のプライベート接続でプライベートにのみアクセス可能にしたりできます。Label match がこのルーターロードバランサーに設定されている場合は、このラベルに一致するアプリケーションルートのみがこのルーターロードバランサーで公開されます。そうでない場合は、すべてのアプリケーションルートもこのルーターのロードバランサーで公開されます。 - オプション: OpenShift Dedicated で実行しているサービスにマップできるサービスのロードバランサー。HTTP/SNI 以外のトラフィックや標準以外のポートの使用などの高度な ingress 機能を有効にします。これらは、標準クラスター用に 4 のグループで購入したり、Customer Cloud Subscription (CCS) クラスターで課金せずにプロビジョニングできます。ただし、各 AWS アカウントには、各クラスター内で使用できる Classic Load Balancer の数を制限する クォータがあります。
2.1.4.6. ネットワーク使用量
標準の OpenShift Dedicated クラスターの場合、ネットワーク使用量は、インバウンド、VPC ピアリング、VPN、および AZ トラフィック間のデータ転送に基づいて測定されます。標準の OpenShift Dedicated ベースクラスターで、ネットワーク I/O の 12 TB が提供されます。追加のネットワーク I/O は、12 TB の増分で購入できます。CCS OpenShift Dedicated クラスターの場合、ネットワークの使用量は監視されず、クラウドプロバイダーによって直接請求されます。
2.1.4.7. クラスター ingress
プロジェクト管理者は、IP 許可リストによる ingress コントロールなど、さまざまな目的でルートアノテーションを追加できます。
Ingress ポリシーは、ovs-networkpolicy プラグインを使用する NetworkPolicy オブジェクトを使用して変更することもできます。これにより、同じクラスターの Pod 間や同じ namespace にある Pod 間など、Ingress ネットワークポリシーを Pod レベルで完全に制御できます。
すべてのクラスター Ingress トラフィックは定義されたロードバランサーを通過します。すべてのノードへの直接のアクセスは、クラウド設定によりブロックされます。
2.1.4.8. クラスター egress
EgressNetworkPolicy オブジェクトでの Pod egress トラフィックの制御は、OpenShift Dedicated での送信トラフィックを防ぐか、これを制限するために使用できます。
コントロールプレーンおよびインフラストラクチャーノードからのパブリック送信トラフィックは、クラスターイメージのセキュリティーおよびクラスターのモニタリングを維持するために必要です。これには、0.0.0.0/0 ルートがインターネットゲートウェイにのみ属している必要があります。プライベート接続でこの範囲をルーティングすることはできません。
OpenShift Dedicated クラスターは NAT ゲートウェイを使用して、クラスターから出るパブリック送信トラフィックのパブリック静的 IP を表示します。クラスターがデプロイされる各サブネットは、個別の NAT ゲートウェイを受信します。複数のアベイラビリティーゾーンで AWS にデプロイされるクラスターの場合は、最大 3 つの固有の静的 IP アドレスがクラスターの egress トラフィック用に存在できます。アベイラビリティーゾーントポロジーに関係なく、Google Cloud にデプロイされたクラスターの場合は、ワーカーノードの egress トラフィックに 1 つの静的 IP アドレスがあります。クラスター内に留まるトラフィックや、パブリックインターネットに送信されないトラフィックは NAT ゲートウェイを通過せず、トラフィックの発信元のノードに属するソース IP アドレスを持ちます。ノードの IP アドレスは動的であるため、お客様はプライベートリソースへのアクセス時に個々の IP アドレスを許可しないようにする必要があります。
お客様は、クラスターで Pod を実行し、外部サービスをクエリーすることで、パブリックの静的 IP アドレスを判別できます。以下に例を示します。
$ oc run ip-lookup --image=busybox -i -t --restart=Never --rm -- /bin/sh -c "/bin/nslookup -type=a myip.opendns.com resolver1.opendns.com | grep -E 'Address: [0-9.]+'"
2.1.4.9. クラウドネットワーク設定
OpenShift Dedicated では、複数のクラウドプロバイダー管理テクノロジーを介したプライベートネットワーク接続の設定を可能にします。
- VPN 接続
- AWS VPC ピアリング
- AWS Transit Gateway
- AWS Direct Connect
- Google Cloud VPC Network ピアリング
- Google Cloud Classic VPN
- Google Cloud HA VPN
Red Hat SRE はプライベートネットワーク接続を監視しません。これらの接続の監視は、お客様の責任で行われます。
2.1.4.10. DNS 転送
プライベートクラウドネットワーク設定を持つ OpenShift Dedicated クラスターの場合、お客様は、明示的に提供されたドメインを照会する必要がある、そのプライベート接続で使用可能な内部 DNS サーバーを指定できます。
2.1.4.11. ネットワークの検証
OpenShift Dedicated クラスターを既存の Virtual Private Cloud (VPC) にデプロイするとき、またはクラスターに新しいサブネットを持つ追加のマシンプールを作成するときに、ネットワーク検証チェックが自動的に実行します。このチェックによりネットワーク設定が検証され、エラーが強調表示されるため、デプロイメント前に設定の問題を解決できます。
ネットワーク検証チェックを手動で実行して、既存のクラスターの設定を検証することもできます。
関連情報
- ネットワーク検証チェックの詳細は、ネットワーク検証 を参照してください。
2.1.5. ストレージ
2.1.5.1. 暗号化された保存時の OS /ノードストレージ
コントロールプレーンノードは、encrypted-at-rest-EBS ストレージを使用します。
2.1.5.2. 暗号化された保存時の PV
永続ボリューム (PV) に使用される EBS ボリュームは、デフォルトで保存時に暗号化されます。
2.1.5.3. ブロックストレージ (RWO)
永続ボリューム (PV) は、ReadWriteOnce (RWO) アクセスモードを使用する AWS EBS および Google Cloud の永続ディスクブロックストレージによってサポートされます。標準の OpenShift Dedicated ベースクラスターでは、100 GB のブロックストレージは、アプリケーション要求に基づいて動的にプロビジョニングされ、再利用されます。追加の永続ストレージは 500 GB の増分で購入できます。
PV は一度に 1 つのノードにのみ割り当てられ、それらがプロビジョニングされるアベイラビリティーゾーンに固有のものですが、アベイラビリティーゾーンの任意のノードに割り当てることができます。
各クラウドプロバイダーには、1 つのノードに割り当てることのできる PV の数について独自の制限があります。詳細は、AWS インスタンスタイプの制限 または Google Cloud Platform カスタムマシンタイプ を参照してください。
2.1.6. プラットフォーム
2.1.6.1. クラスターバックアップポリシー
お客様がアプリケーションとアプリケーションデータのバックアップ計画を立てることが重要です。
アプリケーションおよびアプリケーションデータのバックアップは、OpenShift Dedicated サービスの一部ではありません。各 OpenShift Dedicated クラスターのすべての Kubernetes オブジェクトは、クラスターが回復不能になる場合に備えて迅速なリカバリーを可能にするためにバックアップされます。
バックアップは、クラスターと同じアカウントのセキュアなオブジェクトストレージ (Multi-AZ) バケットに保存されます。Red Hat Enterprise Linux CoreOS は OpenShift Container Platform クラスターによって完全に管理され、ステートフルなデータはノードのルートボリュームに保存されないため、ノードのルートボリュームはバックアップされません。
以下の表は、バックアップの頻度を示しています。
| コンポーネント | スナップショットの頻度 | 保持期間 | 注記 |
|---|---|---|---|
| 完全なオブジェクトストアのバックアップ | 日次 (0100 UTC) | 7 日 | これは、すべての Kubernetes オブジェクトの完全バックアップです。このバックアップスケジュールでは、永続ボリューム (PV) がバックアップされていません。 |
| 完全なオブジェクトストアのバックアップ | 週次 (月曜日: 0200 UTC) | 30 日 | これは、すべての Kubernetes オブジェクトの完全バックアップです。このバックアップスケジュールでは、PV はバックアップされません。 |
| 完全なオブジェクトストアのバックアップ | 毎時 (1 時間ごとに 17 分を経過した時点) | 24 時間 | これは、すべての Kubernetes オブジェクトの完全バックアップです。このバックアップスケジュールでは、PV はバックアップされません。 |
2.1.6.2. 自動スケーリング
ノードの自動スケーリングは OpenShift Dedicated で利用できます。クラスター上のノードの自動スケーリングの詳細は、About autoscaling nodes on a cluster を参照してください。
2.1.6.3. デーモンセット
お客様は OpenShift Dedicated で DaemonSet を作成し、実行できます。DeamonSet をワーカーノードでのみの実行に制限するには、以下の nodeSelector を使用します。
...
spec:
nodeSelector:
role: worker
...2.1.6.4. 複数のアベイラビリティーゾーン
複数アベイラビリティーゾーンのクラスターでは、コントロールノードは複数のアベイラビリティーゾーンに分散され、各アベイラビリティーゾーンに 3 つ以上のワーカーノードが必要です。
2.1.6.5. ノードラベル
カスタムノードラベルはノードの作成時に Red Hat によって作成され、現時点では OpenShift Dedicated クラスターで変更することはできません。
2.1.6.6. OpenShift バージョン
OpenShift Dedicated はサービスとして実行し、最新の OpenShift Container Platform バージョンで最新の状態に維持されます。
2.1.6.7. アップグレード
アップグレードポリシーおよび手順についての詳細は、OpenShift Dedicated のライフサイクル を参照してください。
2.1.6.8. Windows コンテナー
Windows コンテナーは、現時点で OpenShift Dedicated では利用できません。
2.1.6.9. コンテナーエンジン
OpenShift Dedicated は OpenShift 4 で実行し、唯一の利用可能なコンテナーエンジンとして CRI-O を使用します。
2.1.6.10. オペレーティングシステム
OpenShift Dedicated は OpenShift 4 で実行し、すべてのコントロールプレーンおよびワーカーノードのオペレーティングシステムとして Red Hat Enterprise Linux CoreOS を使用します。
2.1.6.11. Red Hat Operator のサポート
通常、Red Hat ワークロードは、Operator Hub を通じて利用できる Red Hat 提供の Operator を指します。Red Hat ワークロードは Red Hat SRE チームによって管理されないため、ワーカーノードにデプロイする必要があります。これらの Operator は、追加の Red Hat サブスクリプションが必要になる場合があり、追加のクラウドインフラストラクチャーコストが発生する場合があります。これらの Red Hat 提供の Operator の例は次のとおりです。
- Red Hat Quay
- Red Hat Advanced Cluster Management
- Red Hat Advanced Cluster Security
- Red Hat OpenShift Service Mesh
- OpenShift Serverless
- Red Hat OpenShift Logging
- Red Hat OpenShift Pipelines
2.1.6.12. Kubernetes Operator のサポート
OperatorHub marketplace にリスト表示されるすべての Operator はインストールに利用できるはずです。Red Hat Operator を含む OperatorHub からインストールされる Operator は、OpenShift Dedicated サービスの一部として管理されている SRE ではありません。特定の Operator のサポート可能性についての詳細は、Red Hat カスタマーポータル を参照してください。
2.1.7. セキュリティー
このセクションでは、OpenShift Dedicated セキュリティーのサービス定義について説明します。
2.1.7.1. 認証プロバイダー
クラスターの認証は、 Red Hat OpenShift Cluster Manager クラスター作成プロセスの一部として設定されます。OpenShift はアイデンティティープロバイダーではないため、クラスターへのアクセスすべてが統合ソリューションの一部としてお客様によって管理される必要があります。同時にプロビジョニングされる複数のアイデンティティープロバイダーのプロビジョニングがサポートされています。以下のアイデンティティープロバイダーがサポートされます。
- GitHub または GitHub Enterprise OAuth
- GitLab OAuth
- Google OAuth
- LDAP
- OpenID Connect
2.1.7.2. 特権付きコンテナー
特権付きコンテナーは、デフォルトで OpenShift Dedicated では使用できません。anyuid および nonroot 以外の Security Context Constraints は dedicated-admins グループのメンバーに利用でき、多くのユースケースに対応する必要があります。特権付きコンテナーは cluster-admin ユーザーのみが利用できます。
2.1.7.3. お客様管理者ユーザー
OpenShift Dedicated は、通常のユーザーのほかに、dedicated-admin という OpenShift Dedicated 固有のグループへのアクセスを提供します。dedicated-admin グループのメンバーであるクラスターのすべてのユーザー:
- クラスターでお客様が作成したすべてのプロジェクトへの管理者アクセス権を持ちます。
- クラスターのリソースクォータと制限を管理できます。
-
NetworkPolicyオブジェクトを追加および管理できます。 - スケジューラー情報を含む、クラスター内の特定のノードおよび PV に関する情報を表示できます。
-
クラスター上の予約された
dedicated-adminプロジェクトにアクセスできます。これにより、昇格された権限を持つサービスアカウントの作成が可能になり、クラスター上のプロジェクトのデフォルトの制限とクォータを更新できるようになります。 -
OperatorHub から Operator をインストールできます (
*すべての*.operators.coreos.comAPI グループの動詞)。
2.1.7.4. クラスター管理ロール
Customer Cloud Subscriptions (CCS) のある OpenShift Dedicated の管理者として、cluster-admin ロールにアクセスできます。cluster-admin ロールを持つアカウントにログインしている場合、ユーザーはクラスターを制御し、設定するためのほとんど無制限のアクセスを持っています。クラスターの不安定化を防ぐため、または OpenShift Cluster Manager で管理されており、クラスター内の変更が上書きされるために、Webhook でブロックされる設定がいくつかあります。
2.1.7.5. プロジェクトのセルフサービス
デフォルトでは、すべてのユーザーにはプロジェクトの作成、更新、および削除を行うことができます。これは、dedicated-admin グループのメンバーが認証されたユーザーから self-provisioner ロールを削除すると制限されます。
$ oc adm policy remove-cluster-role-from-group self-provisioner system:authenticated:oauth
以下を適用すると、制限を元に戻すことができます。
$ oc adm policy add-cluster-role-to-group self-provisioner system:authenticated:oauth
2.1.7.6. 規制コンプライアンス
OpenShift Dedicated は、セキュリティーおよび管理に関する一般的な業界のベストプラクティスに従います。認定の概要を以下の表に示します。
表2.1 OpenShift Dedicated のセキュリティーおよびコントロール認定
| コンプライアンス | AWS 専用の OpenShift | GCP 専用の OpenShift |
|---|---|---|
| HIPAA Qualified | はい (Customer Cloud Subscriptions のみ) | はい (Customer Cloud Subscriptions のみ) |
| ISO 27001 | はい | はい |
| PCI DSS | はい | はい |
| SOC 2 タイプ 2 | はい | はい |
2.1.7.7. ネットワークセキュリティー
各 OpenShift Dedicated クラスターは、ファイアウォールルール (AWS Security Groups または Google Cloud Compute Engine ファイアウォールルール) を使用して、クラウドインフラストラクチャーレベルでセキュアなネットワーク設定で保護されます。AWS の OpenShift Dedicated のお客様は、AWS Shield Standard による DDoS 攻撃に対する保護されます。同様に、GCP 上の OpenShift Dedicated によって使用されるすべての GCP ロードバランサーとパブリック IP アドレスは、Google Cloud Armor Standard によって DDoS 攻撃から保護されます。
2.1.7.8. etcd 暗号化
OpenShift Dedicated では、コントロールプレーンストレージはデフォルトで保存時に暗号化されます。これには、etcd ボリュームの暗号化が含まれます。このストレージレベルの暗号化は、クラウドプロバイダーのストレージ層を介して提供されます。
etcd 暗号化を有効にして、キーではなく etcd のキーの値を暗号化することもできます。etcd 暗号化を有効にすると、以下の Kubernetes API サーバーおよび OpenShift API サーバーリソースが暗号化されます。
- シークレット
- 設定マップ
- ルート
- OAuth アクセストークン
- OAuth 認証トークン
etcd 暗号化機能はデフォルトで有効にされず、これはクラスターのインストール時にのみ有効にできます。etcd 暗号化が有効にされている場合でも、コントロールプレーンノードにアクセスできるユーザーまたは cluster-admin 権限を持つユーザーは、etcd キーの値にアクセスできます。
etcd のキー値の etcd 暗号化を有効にすると、約 20% のパフォーマンスのオーバーヘッドが発生します。このオーバーヘッドは、etcd ボリュームを暗号化するデフォルトのコントロールプレーンのストレージ暗号化に加えて、この 2 つ目の暗号化レイヤーの導入により生じます。Red Hat は、お客様のユースケースで特に etcd 暗号化が必要な場合にのみ有効にすることを推奨します。
2.2. 責任分担マトリクス
OpenShift Dedicated マネージドサービスにおける Red Hat、クラウドプロバイダー、およびお客様の責任についての理解。
2.2.1. OpenShift Dedicated における責任の概要
Red Hat は OpenShift Dedicated サービスを管理しますが、お客様は特定の側面に関して責任を負います。OpenShift Dedicated サービスは、リモートでアクセスされ、パブリッククラウドリソースでホストされ、Red Hat またはお客様が所有するクラウドサービスプロバイダーアカウントで作成され、Red Hat が所有する基礎となるプラットフォームおよびデータセキュリティーがあります。
cluster-admin ロールがクラスターで有効にされている場合は、Red Hat Enterprise Agreement Appendix 4 (Online Subscription Services) の責任および除外事項について参照してください。
| リソース | インシデントおよびオペレーション管理 | 変更管理 | アイデンティティーおよびアクセス管理 | セキュリティーおよび規制コンプライアンス | 障害復旧 |
|---|---|---|---|---|---|
| お客様データ | お客様 | お客様 | お客様 | お客様 | お客様 |
| お客様のアプリケーション | お客様 | お客様 | お客様 | お客様 | お客様 |
| 開発者サービス | お客様 | お客様 | お客様 | お客様 | お客様 |
| プラットフォームモニタリング | Red Hat | Red Hat | Red Hat | Red Hat | Red Hat |
| ロギング | Red Hat | 共有 | 共有 | 共有 | Red Hat |
| アプリケーションのネットワーク | 共有 | 共有 | 共有 | Red Hat | Red Hat |
| クラスターネットワーク | Red Hat | 共有 | 共有 | Red Hat | Red Hat |
| 仮想ネットワーク | 共有 | 共有 | 共有 | 共有 | 共有 |
| コントロールプレーンおよびインフラストラクチャーノード | Red Hat | Red Hat | Red Hat | Red Hat | Red Hat |
| ワーカーノード | Red Hat | Red Hat | Red Hat | Red Hat | Red Hat |
| クラスターのバージョン | Red Hat | 共有 | Red Hat | Red Hat | Red Hat |
| 容量の管理 | Red Hat | 共有 | Red Hat | Red Hat | Red Hat |
| 仮想ストレージ | Red Hat およびクラウドプロバイダー | Red Hat およびクラウドプロバイダー | Red Hat およびクラウドプロバイダー | Red Hat およびクラウドプロバイダー | Red Hat およびクラウドプロバイダー |
| 物理インフラストラクチャーおよびセキュリティー | クラウドプロバイダー | クラウドプロバイダー | クラウドプロバイダー | クラウドプロバイダー | クラウドプロバイダー |
2.2.3. データおよびアプリケーションに関するお客様の責任
お客様は、OpenShift Dedicated にデプロイするアプリケーション、ワークロード、およびデータに責任を負います。ただし、Red Hat は、お客様がプラットフォームでデータおよびアプリケーションを管理するのに役立つ各種ツールを提供します。
| リソース | Red Hat の責任 | お客様の責任 |
|---|---|---|
| お客様データ |
| プラットフォームに保存されるすべてのお客様データと、お客様のアプリケーションがこのデータを使用し、公開する方法について責任を持ちます。 |
| お客様のアプリケーション |
|
|
2.3. OpenShift Dedicated のプロセスおよびセキュリティーについて
2.3.1. インシデントおよびオペレーション管理
以下では、OpenShift Dedicated マネージドサービスにおける Red Hat の責任について詳しく説明します。
2.3.1.1. プラットフォームモニタリング
Red Hat Site Reliability Engineer (SRE) は、すべての OpenShift Dedicated クラスターコンポーネント、SRE サービス、および基礎となるクラウドプロバイダーアカウントに関する一元管理されたモニタリングおよびアラートシステムを維持します。プラットフォーム監査ログは、集中 SIEM (Security Information and Event Monitoring) システムに安全に転送されます。この場合は、SRE チームに対して設定されたアラートがトリガーされる可能性があり、手動によるレビューの対象となります。監査ログは SIEM に 1 年間保持されます。指定されたクラスターの監査ログは、クラスターの削除時に削除されません。
2.3.1.2. インシデント管理
インシデントは、1 つ以上の Red Hat サービスの低下や停止をもたらすイベントです。インシデントは、お客様または Customer Experience and Engagement (CEE) メンバーによって、一元化されたモニタリングおよびアラートシステムにより直接、または SRE チームのメンバーから直接作成されます。
サービスおよびお客様への影響に応じて、インシデントは 重大度 に基づいて分類されます。
新しいインシデントが Red Hat によってどのように管理されるかの一般的なワークフロー:
- SRE の最初の応答は新たなインシデントに警告され、最初の調査が開始されます。
- 初回の調査後、インシデントには復旧作業を調整するインシデントのリードが割り当てられます。
- インシデントのリードは、関連する通知やサポートケースの更新など、復旧に関するすべての通信および調整を管理します。
- インシデントの復旧が行われます。
- インシデントが文書化され、根本原因分析はインシデントの 5 営業日以内に行われます。
- 根本原因分析 (RCA) のドラフトドキュメントは、インシデント発生の 7 営業日以内にお客様に共有されます。
2.3.1.3. 通知
プラットフォーム通知は、メールを使用して設定されます。お客様通知も、対応する Red Hat アカウントチームに送信され、該当する場合は Red Hat Technical Account Manager に送信されます。
以下のアクティビティーは通知をトリガーできます。
- プラットフォームのインシデント
- パフォーマンスの低下
- クラスター容量に関する警告
- 重大な脆弱性および解決
- アップグレードのスケジュール
2.3.1.4. バックアップおよび復元
すべての OpenShift Dedicated クラスターは、クラウドプロバイダーのスナップショットを使用してバックアップされます。これには永続ボリューム (PV) に保存されるお客様データは含まれないことに留意してください。すべてのスナップショットは適切なクラウドプロバイダースナップショット API を使用して取得され、クラスターと同じアカウントでセキュアなオブジェクトストレージバケット (AWS の S3、および Google Cloud の GCS) にアップロードされます。
| コンポーネント | スナップショットの頻度 | 保持期間 | 注記 |
|---|---|---|---|
| 完全なオブジェクトストアのバックアップ | 毎日 | 7 日 | これは、etcd などのすべての Kubernetes オブジェクトの完全バックアップです。このバックアップスケジュールでは、PV はバックアップされません。 |
| 週次 | 30 日 | ||
| 完全なオブジェクトストアのバックアップ | 毎時 | 24 時間 | これは、etcd などのすべての Kubernetes オブジェクトの完全バックアップです。このバックアップスケジュールでは、PV はバックアップされません。 |
| ノードのルートボリューム | なし | 該当なし | ノードは短期的なものと見なされます。ノードのルートボリュームには、何も保存できません。 |
- Red Hat は、RTO (Recovery Point Objective) または RTO (Recovery Time Objective) にコミットしません。
- お客様はデータのバックアップを定期的に行う必要があります。
- お客様は、Kubernetes のベストプラクティスに従ったワークロードでマルチ AZ クラスターをデプロイして、リージョン内の高可用性を確保する必要があります。
- クラウドリージョン全体が利用できない場合、お客様は新しいクラスターを異なるリージョンにインストールし、バックアップデータを使用してアプリケーションを復元する必要があります。
2.3.1.5. クラスター容量
クラスター容量の評価および管理に関する責任は、Red Hat とお客様との間で共有されます。Red Hat SRE は、クラスター上のすべてのコントロールプレーンおよびインフラストラクチャーノードの容量に関する責任を負います。
Red Hat SRE はアップグレード時に、またクラスターのアラートへの対応としてクラスター容量の評価も行います。クラスターアップグレードの容量に与える影響は、アップグレードのテストプロセスの一部として評価され、容量がクラスターへの新たな追加内容の影響を受けないようにします。クラスターのアップグレード時にワーカーノードが追加され、クラスターの容量全体がアップグレードプロセス時に維持されるようにします。
SRE のスタッフによる容量評価は、クラスターからのアラートへの対応も行われます。また、使用状況のしきい値が一定期間を超えると、SRE スタッフによる容量の評価も行われます。このようなアラートにより、通知がお客様に出される可能性があります。
2.3.2. 変更管理
このセクションでは、クラスターおよび設定変更、パッチ、およびリリースの管理方法に関するポリシーを説明します。
2.3.2.1. お客様が開始する変更
クラスターデプロイメント、ワーカーノードのスケーリング、またはクラスターの削除などのセルフサービス機能を使用して変更を開始できます。
変更履歴は、OpenShift Cluster Manager の 概要タブ の クラスター履歴 セクションにキャプチャーされ、表示できます。変更履歴には、以下の変更のログが含まれますが、これに限定されません。
- アイデンティティープロバイダーの追加または削除
-
dedicated-adminsグループへの、またはそのグループからのユーザーの追加または削除 - クラスターコンピュートノードのスケーリング
- クラスターロードバランサーのスケーリング
- クラスター永続ストレージのスケーリング
- クラスターのアップグレード
以下のコンポーネントの OpenShift Cluster Manager での変更を回避することで、メンテナンスの除外を実装できます。
- クラスターの削除
- ID プロバイダーの追加、変更、または削除
- 昇格されたグループからのユーザーの追加、変更、または削除
- アドオンのインストールまたは削除
- クラスターネットワーク設定の変更
- マシンプールの追加、変更、または削除
- ユーザーワークロードの監視の有効化または無効化
- アップグレードの開始
メンテナンスの除外を適用するには、マシンプールの自動スケーリングまたは自動アップグレードポリシーが無効になっていることを確認してください。メンテナンスの除外が解除されたら、必要に応じてマシンプールの自動スケーリングまたは自動アップグレードポリシーを有効にします。
2.3.2.2. Red Hat が開始する変更
Red Hat サイトリライアビリティエンジニアリング (SRE) は、GitOps ワークフローと完全に自動化された CI/CD パイプラインを使用して、OpenShift Dedicated のインフラストラクチャー、コード、および設定を管理します。このプロセスにより、Red Hat は、お客様に悪影響を与えることなく、継続的にサービスの改善を安全に導入できます。
提案されるすべての変更により、チェック時にすぐに一連の自動検証が実行されます。変更は、自動統合テストが実行されるステージング環境にデプロイされます。最後に、変更は実稼働環境にデプロイされます。各ステップは完全に自動化されます。
認可された SRE レビュー担当者は、各ステップに進む前にこれを承認する必要があります。変更を提案した個人がレビュー担当者になることはできません。すべての変更および承認は、GitOps ワークフローの一部として完全に監査可能です。
一部の変更は、機能フラグを使用して指定されたクラスターまたはお客様に対する新機能の可用性を制御することで、段階的にリリースされます。
2.3.2.3. パッチ管理
OpenShift Container Platform ソフトウェアおよび基礎となるイミュータブルな Red Hat Enterprise Linux CoreOS (RHCOS) オペレーティングシステムイメージには、通常の z-stream アップグレードのバグおよび脆弱性のパッチが適用されます。OpenShift Container Platform ドキュメントの RHCOS アーキテクチャー を参照してください。
2.3.2.4. リリース管理
Red Hat はクラスターを自動的にアップグレードしません。OpenShift Cluster Manager Web コンソールを使用して、クラスターの更新を定期的に (定期的なアップグレード) または 1 回だけ (個別にアップグレード) 行うようにスケジュールできます。クラスターが重大な影響を与える CVE の影響を受ける場合にのみ、Red Hat はクラスターを新しい z-stream バージョンに強制的にアップグレードする可能性があります。お客様は OpenShift Cluster Manager Web コンソールで、すべてのクラスターアップグレードイベントの履歴を確認できます。リリースの詳細は、ライフサイクルポリシー を参照してください。
2.3.3. セキュリティーおよび規制コンプライアンス
セキュリティーおよび規制コンプライアンスには、セキュリティー管理の実装やコンプライアンス認定などのタスクが含まれます。
2.3.3.1. データの分類
Red Hat は、データの機密性を判断し、収集、使用、送信、保存、処理中にそのデータの機密性および整合性に対する固有のリスクを強調表示するために、データ分類標準を定義し、フォローします。お客様が所有するデータは、最高レベルの機密性と処理要件に分類されます。
2.3.3.2. データ管理
OpenShift Dedicated は、AWS Key Management Service (KMS) や Google Cloud KMS などのクラウドプロバイダーサービスを使用して、永続データの暗号化キーを安全に管理します。これらのキーは、すべてのコントロールプレーン、インフラストラクチャー、およびワーカーノードのルートボリュームを暗号化するのに使用されます。お客様は、インストール時にルートボリュームを暗号化するための独自の KMS キーを指定できます。永続ボリューム (PV) も、キー管理に KMS を使用します。お客様は、KMS キーの Amazon リソース名 (ARN) または ID を参照する新しい StorageClass を作成することにより、PV を暗号化するための独自の KMS キーを指定できます。
お客様が OpenShift Dedicated クラスターを削除すると、コントロールプレーンのデータボリュームや、永続ボリューム (PV) などのお客様のアプリケーションデータボリュームを含め、すべてのクラスターのデータが永久に削除されます。
2.3.3.3. 脆弱性管理
Red Hat は業界標準ツールを使用して OpenShift Dedicated の定期的な脆弱性スキャンを実行します。特定された脆弱性は、重大度に基づくタイムラインに応じて修復で追跡されます。コンプライアンス認定監査の過程で、脆弱性スキャンと修復のアクティビティーが文書化され、サードパーティーの評価者による検証が行われます。
2.3.3.4. ネットワークセキュリティー
2.3.3.4.1. ファイアウォールおよび DDoS 保護
各 OpenShift Dedicated クラスターは、ファイアウォールルール (AWS Security Groups または Google Cloud Compute Engine ファイアウォールルール) を使用して、クラウドインフラストラクチャーレベルでセキュアなネットワーク設定で保護されます。AWS の OpenShift Dedicated のお客様は、AWS Shield Standard による DDoS 攻撃に対する保護されます。同様に、GCP 上の OpenShift Dedicated によって使用されるすべての GCP ロードバランサーとパブリック IP アドレスは、Google Cloud Armor Standard によって DDoS 攻撃から保護されます。
2.3.3.4.2. プライベートクラスターおよびネットワーク接続
必要に応じて、OpenShift Dedicated クラスターエンドポイント (Web コンソール、API、およびアプリケーションルーター) をプライベートに設定し、クラスターのコントロールプレーンまたはアプリケーションがインターネットからアクセスできないようにできます。
AWS の場合、お客様は AWS VPC のピアリング、AWS VPN、または AWS Direct Connect を使用して OpenShift Dedicated クラスターへのプライベートネットワーク接続を設定できます。
現時点では、プライベートクラスターは Google Cloud の OpenShift Dedicated クラスターではサポートされません。
2.3.3.4.3. クラスターのネットワークアクセス制御
粒度の細かいネットワークアクセス制御ルールは、お客様が、NetworkPolicy オブジェクトおよび OpenShift SDN を使用してプロジェクトごとに設定できます。
2.3.3.5. ペネトレーションテスト
Red Hat は、OpenShift Dedicated に対して定期的なペネトレーションテストを実行します。テストは、業界標準ツールおよびベストプラクティスを使用して独立した内部チームによって実行されます。
検出される問題は、重大度に基づいて優先されます。オープンソースプロジェクトに属する問題については、解決のためにコミュニティーと共有されます。
2.3.3.6. コンプライアンス
OpenShift Dedicated は、セキュリティーおよび管理に関する一般的な業界のベストプラクティスに従います。認定の概要を以下の表に示します。
表2.2 OpenShift Dedicated のセキュリティーおよびコントロール認定
| コンプライアンス | AWS 専用の OpenShift | GCP 専用の OpenShift |
|---|---|---|
| HIPAA Qualified | はい (Customer Cloud Subscriptions のみ) | はい (Customer Cloud Subscriptions のみ) |
| ISO 27001 | はい | はい |
| PCI DSS | はい | はい |
| SOC 2 タイプ 2 | はい | はい |
関連情報
- SRE の常駐に関する詳細は、Red Hat Subprocessor List を参照してください。
2.3.4. 障害復旧
OpenShift Dedicated は、Pod、ワーカーノード、インフラストラクチャーノード、コントロールプレーンノード、およびアベイラビリティーゾーンレベルで発生する障害について障害復旧を行います。
すべての障害復旧では、必要な可用性レベルを確保するために、可用性の高いアプリケーション、ストレージ、およびクラスターアーキテクチャー (例: 単一ゾーンデプロイメント対マルチゾーンデプロイメント) をデプロイする上でベストプラクティスを使用する必要があります。
1 つの単一ゾーンクラスターは、アベイラビリティーゾーンやリージョンが停止した場合に、災害回避や復旧を行うことはできません。お客様によってメンテナンスされるフェイルオーバーが設定される複数の単一ゾーンクラスターは、ゾーンまたはリージョンレベルで停止に対応できます。
1 つのマルチゾーンクラスターは、リージョンが完全に停止した場合に障害を防止したり、リカバリーを行ったりしません。お客様によってメンテナンスされるフェイルオーバーが設定される複数のマルチゾーンクラスターは、リージョンレベルで停止に対応できます。
2.3.5. 関連情報
- Red Hat サイトリライアビリティーエンジニアリング (SRE) チームのアクセスの詳細は、アイデンティティーおよびアクセス管理 を参照してください。
2.4. SRE およびサービスアカウントのアクセス
2.4.1. アイデンティティーおよびアクセス管理
Red Hat Site Reliability Engineering (SRE) チームによるアクセスのほとんどは、自動化された設定管理によりクラスター Operator を使用して行われます。
2.4.1.1. サブプロセッサー
利用可能なサブプロセスのリストは、Red Hat カスタマーポータルの Red Hat Subprocessor List を参照してください。
2.4.1.2. SRE のすべての OpenShift Dedicated クラスターへのアクセス
SRE は、プロキシーを介して OpenShift Dedicated クラスターにアクセスします。プロキシーは、SRE がログインするときに、OpenShift Dedicated クラスター内のサービスアカウントをミントします。OpenShift Dedicated クラスター用に ID プロバイダーが設定されていないため、SRE はローカル Web コンソールコンテナーを実行してプロキシーにアクセスします。SRE は、クラスター Web コンソールに直接アクセスしません。SRE は、監査可能性を確保するために、個々のユーザーとして認証する必要があります。すべての認証試行は、セキュリティー情報およびイベント管理 (SIEM) システムに記録されます。
2.4.1.3. OpenShift Dedicated の特権アクセスの制御
Red Hat SRE は、OpenShift Dedicated およびパブリッククラウドプロバイダーのコンポーネントにアクセスする場合の最小限の権限の原則に従います。手動による SRE アクセスには、基本的に以下の 4 つのカテゴリーがあります。
- 通常の 2 要素認証を使用するが、権限の昇格のない Red Hat カスタマーポータル経由での SRE の管理者アクセス。
- 通常の 2 要素認証があり、権限の昇格のない Red Hat の企業 SSO を使用した SRE の管理者アクセス。
- OpenShift の昇格。これは Red Hat SSO を使用した手動による昇格です。これは完全に監査されており、SRE が行うすべての操作には管理者の承認が必要です。
- クラウドプロバイダーコンソールまたは CLI アクセスの手動昇格である、クラウドプロバイダーのアクセスまたは昇格。アクセスは 60 分間に制限され、完全に監査されます。
これらのアクセスタイプのそれぞれには、コンポーネントへの異なるレベルのアクセスがあります。
| コンポーネント | 通常の SRE 管理者アクセス (Red Hat カスタマーポータル) | 通常の SRE 管理者アクセス (Red Hat SSO) | OpenShift の昇格 | クラウドプロバイダーのアクセス |
|---|---|---|---|---|
| OpenShift Cluster Manager | R/W | アクセスなし | アクセスなし | アクセスなし |
| OpenShift Web コンソール | アクセスなし | R/W | R/W | アクセスなし |
| ノードのオペレーティングシステム | アクセスなし | 昇格した OS およびネットワークのパーミッションのリスト。 | 昇格した OS およびネットワークのパーミッションのリスト。 | アクセスなし |
| AWS コンソール | アクセスなし | アクセスはありませんが、これはクラウドプロバイダーのアクセスを要求するために使用されるアカウントです。 | アクセスなし | SRE アイデンティティーを使用したすべてのクラウドプロバイダーのパーミッション。 |
2.4.1.4. SRE のクラウドインフラストラクチャーアカウントへのアクセス
Red Hat の担当者は、通常の OpenShift Dedicated 操作ではクラウドインフラストラクチャーアカウントにアクセスしません。緊急のトラブルシューティングの目的で、Red Hat SRE にはクラウドインフラストラクチャーアカウントにアクセスするための明確に定義された監査可能な手順があります。
AWS では、SRE は AWS Security Token Service (STS) を使用して BYOCAdminAccess ユーザーの有効期限の短い AWS アクセストークンを生成します。STS トークンへのアクセスは監査ログに記録され、個別のユーザーまでトレースできます。BYOCAdminAccess には AdministratorAccess IAM ポリシーが割り当てられます。
Google Cloud では、SRE は Red Hat SAML アイデンティティープロバイダー (IDP) に対して認証された後にリソースにアクセスします。IDP は、生存期間のあるトークンを承認します。トークンの発行は、企業の Red Hat IT により監査可能で、個別のユーザーにリンクされます。
2.4.1.5. Red Hat サポートのアクセス
通常、Red Hat CEE チームメンバーは、クラスターの一部に対する読み取り専用アクセスを持ちます。特に、CEE にはコアおよび製品の namespace への制限されたアクセスがありますが、お客様の namespace にはアクセスできません。
| ロール | コア namespace | 階層化した製品 namespace | お客様の namespace | クラウドインフラストラクチャーアカウント* |
|---|---|---|---|---|
| OpenShift SRE | 読み取り: All 書き込み: Very 限定的 [1] | 読み取り: All 書き込み: None | 読み取り: None[2] 書き込み: None | 読み取り: All [3] 書き込み: All [3] |
| CEE | 読み取り: All 書き込み: None | 読み取り: All 書き込み: None | 読み取り: None[2] 書き込み: None | 読み取り: None 書き込み: None |
| お客様管理者 | 読み取り: None 書き込み: None | 読み取り: None 書き込み: None | 読み取り: All 書き込み: All | 読み取り: Limited[4] 書き込み: Limited[4] |
| お客様ユーザー | 読み取り: None 書き込み: None | 読み取り: None 書き込み: None | 読み取り: Limited[5] 書き込み: Limited[5] | 読み取り: None 書き込み: None |
| 上記以外 | 読み取り: None 書き込み: None | 読み取り: None 書き込み: None | 読み取り: None 書き込み: None | 読み取り: None 書き込み: None |
Cloud Infrastructure Account は基礎となる AWS または Google Cloud アカウントを参照します。
- デプロイメントの失敗、クラスターのアップグレード、および適切でないワーカーノードの置き換えなどの一般的なユースケースに対応することに限定されます。
- Red Hat は、デフォルトではお客様のデータにアクセスできません。
- SRE のクラウドインフラストラクチャーアカウントへのアクセスは、文書化されたインシデントの発生時の例外的なトラブルシューティングのための break-glass 手順です。
- 顧客管理者は、Cloud Infrastructure Access を通じてクラウドインフラストラクチャーアカウントコンソールへのアクセスが限定されます。
- 顧客管理者によって RBAC で許可される内容や、ユーザーが作成した namespace に限定されます。
2.4.1.6. お客様のアクセス
お客様のアクセスは、お客様によって作成される namespace および顧客管理者ロールによって RBAC を使用して付与されるパーミッションに限定されます。基礎となるインフラストラクチャーまたは製品 namespace へのアクセスは通常、cluster-admin アクセスなしでは許可されません。お客様のアクセスおよび認証の詳細は、本書の認証に関するセクションを参照してください。
2.4.1.7. アクセスの承認およびレビュー
新規の SRE ユーザーアクセスには、管理者の承認が必要です。分離された SRE アカウントまたは転送された SRE アカウントは、自動化されたプロセスで認可されたユーザーとして削除されます。さらに、SRE は、許可されたユーザーリストの管理のサインオフを含む定期的なアクセスレビューを実行します。
2.4.2. SRE クラスターアクセス
OpenShift Dedicated クラスターへの SRE アクセスは、複数の必要な認証階層を通じて制御され、すべて厳格な企業ポリシーによって管理されます。クラスターにアクセスするすべての認証試行とクラスター内で行われた変更は、それらのアクションを担当する SRE の特定のアカウント ID とともに監査ログに記録されます。これらの監査ログは、SRE によって顧客のクラスターに加えられたすべての変更が、Red Hat のマネージドサービスガイドラインを構成する厳格なポリシーと手順に準拠していることを確認するのに役立ちます。
以下に示す情報は、SRE が顧客のクラスターにアクセスするために実行する必要があるプロセスの概要です。
- SRE は、Red Hat SSO (クラウドサービス) に更新された ID トークンを要求します。このリクエストは認証されます。トークンは 15 分間有効です。トークンの有効期限が切れたら、トークンを再度更新して新しいトークンを受け取ることができます。新規トークンへの更新機能には期限はありません。ただし、新しいトークンに更新する機能は、非アクティブな状態が 30 日間続くと無効になります。
- SRE は Red Hat VPN に接続します。VPN への認証は、Red Hat Corporate Identity and Access Management システム (RH IAM) によって行います。RH IAM を使用すると、SRE は多要素になり、グループおよび既存のオンボーディングおよびオフボーディングプロセスによって組織ごとに内部管理できるようになります。SRE が認証されて接続されると、SRE はクラウドサービスフリート管理プレーンにアクセスできるようになります。クラウドサービスフリート管理プレーンの変更には何層にもわたる承認が必要であり、厳格な企業ポリシーによって維持されます。
- 承認が完了すると、SRE はフリート管理プレーンにログインし、フリート管理プレーンが作成したサービスアカウントトークンを受け取ります。トークンは 15 分間有効です。トークンは無効になると、削除されます。
フリート管理プレーンにアクセスが許可されると、SRE はネットワーク設定に応じてさまざまな方法を使用してクラスターにアクセスします。
- プライベートまたはパブリッククラスターへのアクセス: リクエストは、ポート 6443 で暗号化された HTTP 接続を使用して、特定のネットワークロードバランサー (NLB) 経由で送信されます。
- PrivateLink クラスターへのアクセス: リクエストは Red Hat Transit Gateway に送信され、リージョンごとに Red Hat VPC に接続されます。リクエストを受信する VPC は、ターゲットのプライベートクラスターのリージョンに依存します。VPC 内には、顧客の PrivateLink クラスターへの PrivateLink エンドポイントを含むプライベートサブネットがあります。
2.4.3. サービスアカウントが SRE 所有のプロジェクトで AWS IAM ロールを引き受ける方法
AWS Security Token Service (STS) を使用する OpenShift Dedicated クラスターをインストールすると、クラスター固有の Operator AWS Identity and Access Management (IAM) ロールが作成されます。これらの IAM ロールにより、OpenShift Dedicated クラスター Operator がコア OpenShift 機能を実行できるようになります。
クラスター Operator はサービスアカウントを使用して IAM ロールを引き受けます。サービスアカウントが IAM ロールを引き受けると、クラスター Operator の Pod で使用するサービスアカウントに一時的な STS 認証情報が提供されます。引き受けたロールに必要な AWS 権限がある場合、サービスアカウントは Pod で AWS SDK 操作を実行できます。
SRE 所有プロジェクトで AWS IAM ロールを引き受けるワークフロー
次の図は、SRE 所有プロジェクトで AWS IAM ロールを引き受けるためのワークフローを示しています。
図2.1 SRE 所有プロジェクトで AWS IAM ロールを引き受けるワークフロー
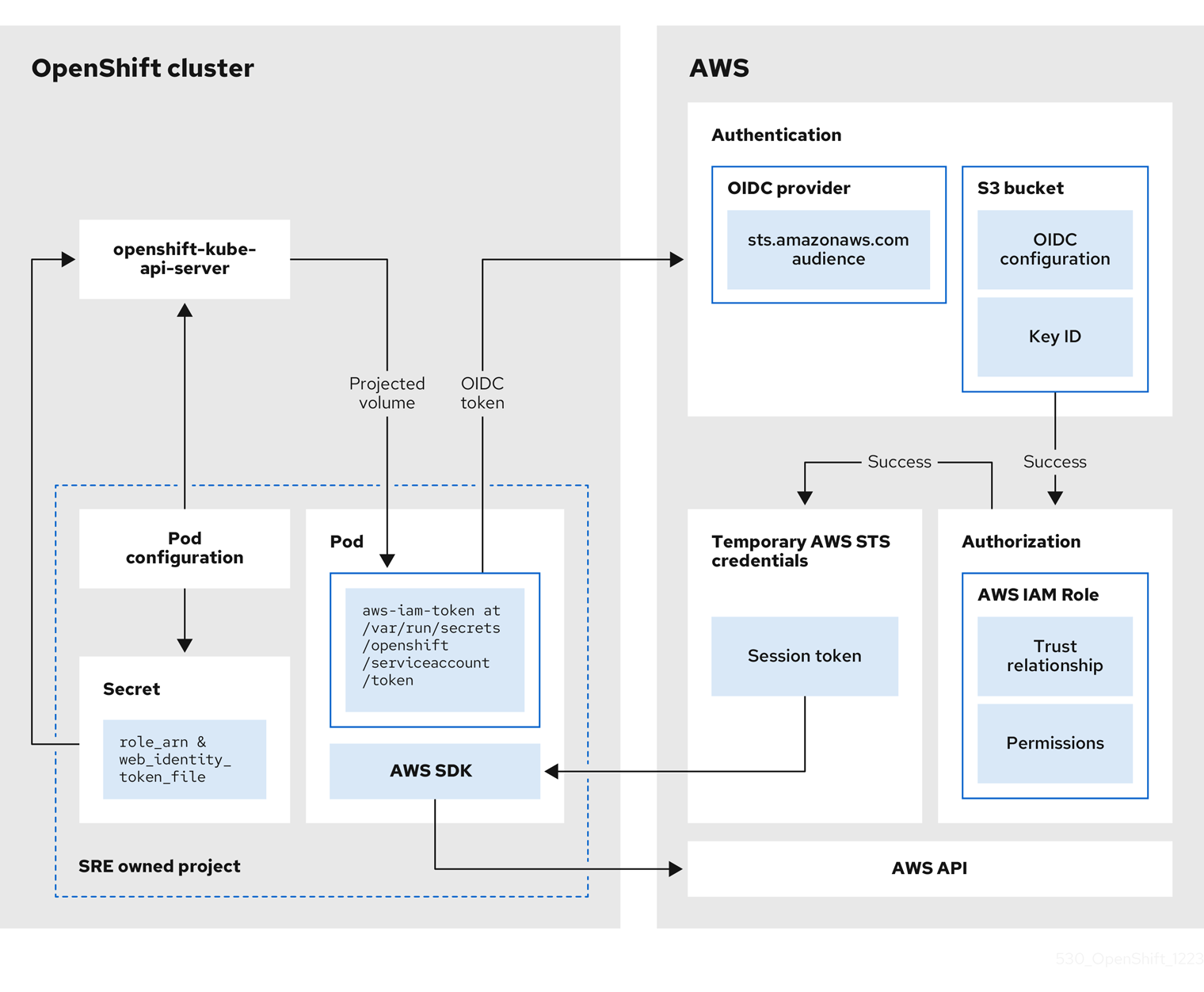
ワークフローには次の段階があります。
クラスター Operator が実行する各プロジェクト内で、Operator のデプロイメント仕様には、投影されたサービスアカウントトークンのボリュームマウントと、Pod の AWS 認証情報設定が含まれるシークレットがあります。トークンは、オーディエンスおよび時間の制限があります。OpenShift Dedicated は 1 時間ごとに新しいトークンを生成し、AWS SDK は AWS 認証情報の設定を含むマウントされたシークレットを読み取ります。この設定には、マウントされたトークンと AWS IAM ロール ARN へのパスが含まれています。シークレットの認証情報設定には次のものが含まれます。
-
AWS SDK オペレーションの実行に必要なパーミッションを持つ IAM ロールの ARN を含む
$AWS_ARN_ROLE変数。 -
サービスアカウントの OpenID Connect (OIDC) トークンへの Pod 内のフルパスを含む
$AWS_WEB_IDENTITY_TOKEN_FILE変数。完全パスは/var/run/secrets/openshift/serviceaccount/tokenです。
-
AWS SDK オペレーションの実行に必要なパーミッションを持つ IAM ロールの ARN を含む
-
クラスター Operator が AWS サービス(EC2 など)にアクセスするために AWS IAM ロールを引き受ける必要がある場合、Operator で実行される AWS SDK クライアントコードは
AssumeRoleWithWebIdentityAPI を呼び出します。 OIDC トークンは、Pod から OIDC プロバイダーに渡されます。次の要件が満たされている場合は、プロバイダーがサービスアカウント ID を認証します。
- ID 署名は有効であり、秘密鍵によって署名されています。
sts.amazonaws.comオーディエンスは OIDC トークンにリストされており、OIDC プロバイダーで設定されたオーディエンスと一致します。注記STS クラスターを使用する OpenShift Dedicated では、インストール中に OIDC プロバイダーが作成され、デフォルトでサービスアカウント発行者として設定されます。
sts.amazonaws.comオーディエンスは、デフォルトで OIDC プロバイダーに設定されています。- OIDC トークンの有効期限が切れていません。
- トークン内の発行者の値には、OIDC プロバイダーの URL が含まれています。
- プロジェクトとサービスアカウントが、引き受ける IAM ロールの信頼ポリシーのスコープ内にある場合は、認可が成功します。
- 認証と認可が成功すると、AWS アクセストークン、秘密鍵、セッショントークンの形式で一時的な AWS STS 認証情報が Pod に渡され、サービスアカウントで使用されます。認証情報を使用することで、IAM ロールで有効になっている AWS アクセス許可がサービスアカウントに一時的に付与されます。
- クラスター Operator が実行されると、Pod で AWS SDK を使用している Operator は、投影されたサービスアカウントへのパスが含まれるシークレットと AWS IAM ロール ARN を OIDC プロバイダーに対して認証するためのシークレットを消費します。OIDC プロバイダーは、AWS API に対する認証に使用できるように、一時的な STS 認証情報を返します。
2.5. OpenShift Dedicated の可用性について
可用性と障害回避は、どのアプリケーションプラットフォームでも非常に重要な要素です。OpenShift Dedicated は複数のレベルで障害に対する保護を提供しますが、お客様がデプロイするアプリケーションは高可用性を確保するために適切に設定される必要があります。さらに、複数のアベイラビリティーゾーンにクラスターをデプロイしたり、フェイルオーバーメカニズムで複数のクラスターを維持したりするなど、その他のオプションが生じる可能性のあるクラウドプロバイダーの停止に対応するため、いくつかのオプションを利用できます。
2.5.1. 潜在的な障害点
OpenShift Container Platform は、ダウンタイムに対してワークロードを保護するために多くの機能とオプションを提供しますが、アプリケーションはこれらの機能を利用できるように適切に設計される必要があります。
OpenShift Dedicated は、Red Hat Site Reliability Engineer (SRE) サポートと、マルチゾーンクラスターをデプロイするオプションを追加することで、Kubernetes の数多くの一般的な問題からさらに保護しますが、コンテナーまたはインフラストラクチャーが引き続き失敗できる数多くの方法を利用できます。潜在的な障害点を理解することで、リスクを理解し、アプリケーションとクラスターの両方が特定のレベルで必要に応じて回復性を持つように設計できます。
停止状態は、インフラストラクチャーおよびクラスターコンポーネントの複数の異なるレベルで生じる可能性があります。
2.5.1.1. コンテナーまたは Pod の障害
設計上、Pod は短期間存在することが意図されています。アプリケーション Pod の複数のインスタンスが個別の Pod またはコンテナーの問題から保護されるように、サービスを適切にスケーリングします。ノードスケジューラーは、回復性をさらに強化するために、これらのワークロードが異なるワーカーノードに分散されるようにすることもできます。
Pod の障害に対応する場合は、ストレージがアプリケーションに割り当てられる方法も理解することが重要になります。単一 Pod に割り当てられる単一の永続ボリュームは、Pod のスケーリングを完全に活用できませんが、複製されるデータベース、データベースサービス、または共有ストレージは使用できます。
アップグレードなど、計画メンテナンス中にアプリケーションが中断されるのを防ぐには、Pod の停止状態の予算を定義することが重要です。これらは Kubernetes API の一部で、他のオブジェクトタイプと同様に OpenShift CLI (oc) で管理できます。この設定により、メンテナンスのためのノードのドレイン (解放) などの操作時に Pod への安全面の各種の制約を指定できます。
2.5.1.2. ワーカーノードの障害
ワーカーノードは、アプリケーション Pod が含まれる仮想マシンです。デフォルトで、OpenShift Dedicated クラスターには単一アベイラビリティーゾーンクラスター用のワーカーノードが 4 つ以上含まれます。ワーカーノードに障害が発生した場合、Pod は、既存ノードに関する問題が解決するか、ノードが置き換えられるまで、十分な容量がある限り、機能しているワーカーノードに移行します。ワーカーノードを追加することは、単一ノードの停止に対する保護を強化し、ノードに障害が発生した場合に再スケジュールされた Pod の適切なクラスター容量を確保します。
ノードの障害に対応する場合、ストレージへの影響を把握することも重要になります。
2.5.1.3. クラスターの障害
OpenShift Dedicated クラスターには、選択したクラスタータイプに応じて、単一ゾーンまたはマルチゾーンのいずれかで、高可用性を確保するために事前設定された 3 つ以上のコントロールプレーンノードと 3 つのインフラストラクチャーノードがあります。つまり、コントロールプレーンノードとインフラストラクチャーノードはワーカーノードの回復性と同じ耐障害性を持ち、Red Hat によって完全に管理される利点を活用できます。
コントロールプレーンノードが完全に停止する場合、OpenShift API は機能せず、既存のワーカーノード Pod は影響を受けません。ただし、Pod またはノードが同時に停止している場合、コントロールプレーンノードは新規 Pod またはノードを追加またはスケジュールする前に復元する必要があります。
インフラストラクチャーノードで実行しているすべてのサービスは、高可用性を持ち、インフラストラクチャーノード間に分散されるように Red Hat によって設定されます。インフラストラクチャーが完全に停止すると、これらのノードが回復するまで、これらのサービスは利用できなくなります。
2.5.1.4. ゾーンの障害
パブリッククラウドプロバイダーからのゾーン障害は、ワーカーノード、ブロックまたは共有ストレージ、および単一のアベイラビリティーゾーンに固有のロードバランサーなどのすべての仮想コンポーネントに影響を与えます。ゾーンの障害から保護するために、OpenShift Dedicated は、マルチアベイラビリティーゾーンクラスターと呼ばれる 3 つのアベイラビリティーゾーンに分散されるクラスターのオプションを提供します。既存のステートレスワークロードは、十分な容量がある限り、停止時に影響を受けないゾーンに再分散されます。
2.5.1.5. ストレージの障害
ステートフルなアプリケーションをデプロイしている場合、ストレージは重要なコンポーネントであり、高可用性を検討する際に考慮に入れる必要があります。単一ブロックストレージ PV は、Pod レベルでも停止状態になった状態では実行できません。ストレージの可用性を維持する最適な方法として、複製されたストレージソリューション、停止による影響を受けない共有ストレージ、またはクラスターから独立したデータベースサービスを使用できます。
2.6. OpenShift Dedicated の更新ライフサイクル
2.6.1. 概要
Red Hat は、お客様およびパートナー各社がプラットフォームで実行するアプリケーションの計画、デプロイ、サポートを効果的に行えるように、OpenShift Dedicated の製品ライフサイクルを公開しています。Red Hat は、可能な限りの透明性を実現するためにこのライフサイクルを公開していますが、問題が発生した場合はこれらのポリシーに例外を設ける場合もあります。
OpenShift Dedicated は Red Hat OpenShift のマネージドインスタンスであり、独立したリリーススケジュールを維持します。マネージドオファリングの詳細は、OpenShift Dedicated のサービス定義を参照してください。特定バージョンのセキュリティーアドバイザリーおよびバグ修正アドバイザリーは、Red Hat OpenShift Container Platform のライフサイクルポリシーに基づいて利用可能となり、OpenShift Dedicated のメンテナンススケジュールに基づいて提供されます。
2.6.2. 定義
表2.3 バージョン参照
| バージョンの形式 | メジャー | マイナー | パッチ | major.minor.patch |
|---|---|---|---|---|
| x | y | z | x.y.z | |
| 例 | 4 | 5 | 21 | 4.5.21 |
- メジャーリリースまたは X リリース
メジャーリリース または X リリース (X.y.z) としてのみ言及されます。
例
- "メジャーリリース 5" → 5.y.z
- "メジャーリリース 4" → 4.y.z
- "メジャーリリース 3" → 3.y.z
- マイナーリリースまたは Y リリース
マイナーリリース または Y リリース (x.Y.z) としてのみ言及されます。
例
- "マイナーリリース 4" → 4.4.z
- "マイナーリリース 5" → 4.5.z
- "マイナーリリース 6" → 4.6.z
- パッチリリースまたは Z リリース
パッチリリース または Z リリース (x.y.Z) としてのみ言及されます。
例
- "マイナーリリース 5 のパッチリリース 14" → 4.5.14
- "マイナーリリース 5 のパッチリリース 25" → 4.5.25
- "マイナーリリース 6 のパッチリリース 26" → 4.6.26
2.6.3. メジャーバージョン (X.y.z)
OpenShift Dedicated のメジャーバージョン (例: バージョン 4 など) は、後続のメジャーバージョンのリリースまたは製品の終了後 1 年間サポートされます。
例
- OpenShift Dedicated バージョン 5 が 1 月 1 日に利用可能になる場合、バージョン 4 は 12 月 31 日までの 12 カ月間、マネージドクラスターで継続して稼働させることができます。その後、クラスターはバージョン 5 にアップグレードまたは移行する必要があります。
2.6.4. マイナーバージョン (x.Y.z)
4.8 OpenShift Container Platform マイナーバージョン以降、Red Hat は、特定のマイナーバージョンが一般公開されてから 16 か月間以上、すべてのマイナーバージョンをサポートします。パッチバージョンは、サポート期間の影響を受けません。
サポート期間が終了する 60 日前、30 日前、および 15 日前に、お客様に通知されます。サポート期間が終了する前に、サポート対象の最も古いマイナーバージョンの最新のパッチバージョンにクラスターをアップグレードする必要があります。アップグレードしないと、クラスターが "限定サポート" ステータスになります。
例
- 現時点で、お客様のクラスターは 4.13.8 で実行しているとします。4.13 マイナーバージョンは、2023 年 5 月 17 日に一般提供されました。
- 2024 年 7 月 19 日、8 月 16 日、および 9 月 2 日に、クラスターがサポート対象のマイナーバージョンにまだアップグレードされていない場合、2024 年 9 月 17 日にクラスターが "限定サポート" ステータスになることがお客様に通知されます。
- クラスターは、2024 年 9 月 17 日までに 4.14 以降にアップグレードする必要があります。
- アップグレードが実行されていない場合、クラスターに "限定サポート" ステータスのフラグが設定されます。
2.6.5. パッチバージョン (x.y.Z)
マイナーバージョンがサポートされる期間中、とくに指定がない限り、Red Hat はすべての OpenShift Container Platform パッチバージョンをサポートします。
プラットフォームのセキュリティーおよび安定性の理由から、あるパッチリリースが非推奨になる可能性があります。この場合は、そのリリースのインストールができなくなり、そのリリースからの強制的なアップグレードが必要となります。
例
- 4.7.6 に重要な CVE が含まれることが確認されるとします。
- CVE の影響を受けるすべてのリリースは、サポートされるパッチリリースのリストから削除されます。さらに、4.7.6 を実行するクラスターは、自動アップグレードのスケジュールが 48 時間以内に行われます。
2.6.6. 限定サポートステータス
クラスターが 限定サポート ステータスに移行すると、Red Hat はクラスターをプロアクティブに監視しなくなり、SLA は適用されなくなり、SLA に対して要求されたクレジットは拒否されます。製品サポートがなくなったという意味ではありません。場合によっては、違反要因を修正すると、クラスターが完全にサポートされた状態に戻ることがあります。ただし、それ以外の場合は、クラスターを削除して再作成する必要があります。
クラスターは、次のシナリオなど、さまざまな理由で限定サポートステータスに移行する場合があります。
- サポート終了日までにクラスターをサポートされるバージョンにアップグレードしない場合
Red Hat は、サポート終了日以降のバージョンについて、ランタイムまたは SLA を保証しません。継続的なサポートを受けるには、サポートが終了する前に、クラスターを、サポートされているバージョンにアップグレードしてください。有効期限が切れる前にクラスターをアップグレードしない場合、クラスターは、サポートされているバージョンにアップグレードされるまで、限定サポートステータスに移行します。
Red Hat は、サポートされていないバージョンからサポートされているバージョンにアップグレードするための商業的に合理的なサポートを提供します。ただし、サポートされるアップグレードパスが利用できなくなった場合は、新規クラスターを作成し、ワークロードを移行することが必要になることがあります。
- ネイティブの OpenShift Dedicated コンポーネント、または Red Hat によってインストールおよび管理されているその他のコンポーネントを削除または交換した場合
- クラスター管理者パーミッションを使用した場合、Red Hat は、インフラストラクチャーサービス、サービスの可用性、またはデータ損失に影響を与えるアクションを含む、ユーザーまたは認可されたユーザーのアクションに対して責任を負いません。Red Hat がそのようなアクションを検出した場合、クラスターは限定サポートステータスに移行する可能性があります。Red Hat はステータスの変更を通知します。アクションを元に戻すか、サポートケースを作成して、クラスターの削除と再作成が必要になる可能性のある修復手順を検討する必要があります。
クラスターが限定サポートステータスに移行する可能性のある特定のアクションについて質問がある場合、またはさらに支援が必要な場合は、サポートチケットを作成します。
2.6.7. サポート対象バージョンの例外ポリシー
Red Hat は、事前通知なしに新規または既存のバージョンを追加または削除したり、実稼働環境に影響を与える重要なバグまたはセキュリティーの問題があることが確認された今後のマイナーリリースバージョンを遅延させる権利を留保します。
2.6.8. インストールポリシー
Red Hat は、最新のサポートリリースのインストールを推奨していますが、OpenShift Dedicated は前述のポリシーに記載されているサポート対象のリリースのインストールをサポートします。
2.6.9. 必須アップグレード
Critical (重大) または Important (重要) の CVE、または Red Hat が特定するその他のバグが、クラスターのセキュリティーまたは安定性に大幅に影響を与える場合、お客様は 2 営業日 以内にサポート対象の次のパッチリリースにアップグレードする必要があります。
極端な状況下では、環境に対する CVE の重要性に関する Red Hat の評価に基づいて、Red Hat はお客様に対して、2 営業日 以内にクラスターを最新の安全なパッチリリースに更新するようスケジュールするか手動で更新するように通知します。2 営業日 が経過しても、更新が実行されない場合、Red Hat は潜在的なセキュリティー違反や不安定性を軽減するために、クラスターを最新の安全なパッチリリースに自動的に更新します。Red Hat は、サポートケース を通じてお客様からリクエストがあった場合、当社の判断で自動更新を一時的に延期することがあります。
2.6.10. ライフサイクルの日付
| バージョン | 一般公開 | ライフサイクルの終了日 |
|---|---|---|
| 4.15 | 2024 年 2 月 27 日 | 2025 年 6 月 30 日 |
| 4.14 | 2023 年 10 月 31 日: | 2025 年 2 月 28 日 |
| 4.13 | 2023 年 5 月 17 日 | 2024 年 9 月 17 日 |
| 4.12 | 2023 年 1 月 17 日 | 2024 年 5 月 17 日 |
| 4.11 | 2022 年 8 月 10 日 | 2023 年 12 月 10 日 |
| 4.10 | 2022 年 3 月 10 日 | 2023 年 9 月 10 日 |
| 4.9 | 2021 年 10 月 18 日 | 2022 年 12 月 18 日 |
| 4.8 | 2021 年 7 月 27 日 | 2022 年 9 月 27 日 |