
スケーラビリティーおよびパフォーマンス
実稼働環境における OpenShift Container Platform クラスターのスケーリングおよびパフォーマンスチューニング
概要
第1章 大規模なクラスターのインストールに推奨されるプラクティス
大規模なクラスターをインストールする場合や、クラスターを大きなノード数にスケーリングする際に、以下のプラクティスを適用します。
1.1. 大規模なクラスターのインストールに推奨されるプラクティス
大規模なクラスターをインストールする場合や、クラスターを大規模なノード数に拡張する場合、クラスターをインストールする前に、install-config.yaml ファイルに適宜クラスターネットワーク cidr を設定します。
networking:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
machineCIDR: 10.0.0.0/16
networkType: OpenShiftSDN
serviceNetwork:
- 172.30.0.0/16クラスターのサイズが 500 ノードを超える場合は、デフォルトの clusterNetwork cidr 10.128.0.0/14 を使用することはできません。500 ノードを超えるノード数にするには、10.128.0.0/12 または 10.128.0.0/10 に設定する必要があります。
第2章 ホストについての推奨されるプラクティス
このトピックでは、OpenShift Container Platform のホストについての推奨プラクティスについて説明します。
2.1. ノードホストについての推奨プラクティス
OpenShift Container Platform ノードの設定ファイルには、重要なオプションが含まれています。たとえば、podsPerCore および maxPods の 2 つのパラメーターはノードにスケジュールできる Pod の最大数を制御します。
両方のオプションが使用されている場合、2 つの値の低い方の値により、ノード上の Pod 数が制限されます。これらの値を超えると、以下の状態が生じる可能性があります。
- CPU 使用率の増大。
- Pod のスケジューリングの速度が遅くなる。
- (ノードのメモリー量によって) メモリー不足のシナリオが生じる可能性。
- IP アドレスのプールを消費する。
- リソースのオーバーコミット、およびこれによるアプリケーションのパフォーマンスの低下。
Kubernetes では、単一コンテナーを保持する Pod は実際には 2 つのコンテナーを使用します。2 つ目のコンテナーは実際のコンテナーの起動前にネットワークを設定するために使用されます。そのため、10 の Pod を使用するシステムでは、実際には 20 のコンテナーが実行されていることになります。
podsPerCore は、ノードのプロセッサーコア数に基づいてノードが実行できる Pod 数を設定します。たとえば、4 プロセッサーコアを搭載したノードで podsPerCore が 10 に設定される場合、このノードで許可される Pod の最大数は 40 になります。
kubeletConfig: podsPerCore: 10
podsPerCore を 0 に設定すると、この制限が無効になります。デフォルトは 0 です。podsPerCore は maxPods を超えることができません。
maxPods は、ノードのプロパティーにかかわらず、ノードが実行できる Pod 数を固定値に設定します。
kubeletConfig:
maxPods: 2502.2. kubelet パラメーターを編集するための KubeletConfig CRD の作成
kubelet 設定は、現時点で Ignition 設定としてシリアル化されているため、直接編集することができます。ただし、新規の kubelet-config-controller も Machine Config Controller (MCC) に追加されます。これにより、KubeletConfig カスタムリソース (CR) を作成して kubelet パラメーターを編集することができます。
手順
以下を実行します。
$ oc get machineconfig
これは、選択可能なマシン設定オブジェクトの一覧を提供します。デフォルトで、2 つの kubelet 関連の設定である
01-master-kubeletおよび01-worker-kubeletを選択できます。ノードあたりの最大 Pod の現在の値を確認するには、以下を実行します。
# oc describe node <node-ip> | grep Allocatable -A6
value: pods: <value>を検索します。以下は例になります。
# oc describe node ip-172-31-128-158.us-east-2.compute.internal | grep Allocatable -A6
出力例
Allocatable: attachable-volumes-aws-ebs: 25 cpu: 3500m hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 15341844Ki pods: 250
ワーカーノードでノードあたりの最大の Pod を設定するには、kubelet 設定を含むカスタムリソースファイルを作成します。たとえば、
change-maxPods-cr.yamlを使用します。apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: set-max-pods spec: machineConfigPoolSelector: matchLabels: custom-kubelet: large-pods kubeletConfig: maxPods: 500kubelet が API サーバーと通信する速度は、1 秒あたりのクエリー (QPS) およびバースト値により異なります。デフォルト値の
50(kubeAPIQPSの場合) および100(kubeAPIBurstの場合) は、各ノードで制限された Pod が実行されている場合には十分な値です。ノード上に CPU およびメモリーリソースが十分にある場合には、kubelet QPS およびバーストレートを更新することが推奨されます。apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: set-max-pods spec: machineConfigPoolSelector: matchLabels: custom-kubelet: large-pods kubeletConfig: maxPods: <pod_count> kubeAPIBurst: <burst_rate> kubeAPIQPS: <QPS>以下を実行します。
$ oc label machineconfigpool worker custom-kubelet=large-pods
以下を実行します。
$ oc create -f change-maxPods-cr.yaml
以下を実行します。
$ oc get kubeletconfig
これにより
set-max-podsが返されるはずです。クラスター内のワーカーノードの数によっては、ワーカーノードが 1 つずつ再起動されるのを待機します。3 つのワーカーノードを持つクラスターの場合は、10 分 から 15 分程度かかる可能性があります。
ワーカーノードを変更する
maxPodsの有無を確認します。$ oc describe node
以下を実行して変更を確認します。
$ oc get kubeletconfigs set-max-pods -o yaml
これは
Trueとtype:Successのステータスを表示します。
手順
デフォルトでは、kubelet 関連の設定を利用可能なワーカーノードに適用する場合に 1 つのマシンのみを利用不可の状態にすることが許可されます。大規模なクラスターの場合、設定の変更が反映されるまでに長い時間がかかる可能性があります。プロセスのスピードを上げるためにマシン数の調整をいつでも実行することができます。
以下を実行します。
$ oc edit machineconfigpool worker
maxUnavailableを必要な値に設定します。spec: maxUnavailable: <node_count>
重要値を設定する際に、クラスターで実行されているアプリケーションに影響を与えずに利用不可にできるワーカーノードの数を検討してください。
2.3. マスターノードのサイジング
マスターノードリソースの要件は、クラスター内のノード数によって異なります。マスターノードのサイズについての以下の推奨内容は、テストに重点を置いた場合のコントロールプレーンの密度の結果に基づいています。
| ワーカーノードの数 | CPU コア数 | メモリー (GB) |
|---|---|---|
| 25 | 4 | 16 |
| 100 | 8 | 32 |
| 250 | 16 | 96 |
実行中の OpenShift Container Platform 4.4 クラスターでマスターノードのサイズを変更することはできないため、ノードの合計数を見積もり、インストール時にマスターの推奨されるサイズを使用する必要があります。
OpenShift Container Platform 4.4 では、デフォルトで CPU コア (500 ミリコア) の半分がシステムによって予約されます (OpenShift Container Platform 3.11 以前のバージョンと比較)。サイズはこれを考慮に入れて決定されます。
2.4. etcd についての推奨されるプラクティス
大規模で高密度のクラスターの場合、キースペースが過剰に拡大し、領域のクォータを超えるために、etcd はパフォーマンスの低下による影響を受ける可能性があります。デフラグを含む etcd の定期的なメンテナーンスを行い、データストアの領域を解放する必要があります。Prometheus で etcd メトリクスを監視し、etcd がクラスター全体でのアラームを出す前にこのデフラグを実行することを強くお勧めします。監視する主要なメトリクスには、現在のクォータ制限である etcd_server_quota_backend_bytes、 履歴のコンパクト化後の実際のデータベース使用状況を示す etcd_mvcc_db_total_size_in_use_in_bytes、およびデフラグを待機する空き領域を含むデータベースのサイズを示す etcd_debugging_mvcc_db_total_size_in_bytes が含まれます。
etcd はすべてのメンバー間で要求を複製します。そのため、そのパフォーマンスはネットワーク入出力 (IO) のレイテンシーによって大きく変わります。ネットワークのレイテンシーが高くなると、etcd のハートビートの時間は選択のタイムアウトよりも長くなり、クラスターに中断をもたらすリーダーの選択が発生します。デプロイされた OpenShift Container Platform クラスターでのモニターの主要なメトリクスは、各 etcd クラスターメンバーの etcd ネットワークピアレイテンシーの 99 番目のパーセンタイルになります。Prometheus を使用してメトリクスを追跡します。histogram_quantile(0.99, rate(etcd_network_peer_round_trip_time_seconds_bucket[2m])) は、メンバー間のクライアント要求の複製を終了するまでの etcd のラウンドトリップタイムを報告します。これは 50 ミリ秒未満である必要があります。
2.5. 追加リソース
第3章 クラスタースケーリングに関する推奨プラクティス
本セクションのガイダンスは、クラウドプロバイダーの統合によるインストールにのみ関連します。
以下のベストプラクティスを適用して、OpenShift Container Platform クラスター内のワーカーマシンの数をスケーリングします。ワーカーのマシンセットで定義されるレプリカ数を増やしたり、減らしたりしてワーカーマシンをスケーリングします。
3.1. クラスターのスケーリングに関する推奨プラクティス
クラスターをノード数のより高い値にスケールアップする場合:
- 高可用性を確保するために、ノードを利用可能なすべてのゾーンに分散します。
- 1 度に 25 未満のマシンごとに 50 マシンまでスケールアップします。
- 定期的なプロバイダーの容量関連の制約を軽減するために、同様のサイズの別のインスタンスタイプを使用して、利用可能なゾーンごとに新規のマシンセットを作成することを検討してください。たとえば、AWS で、m5.large および m5d.large を使用します。
クラウドプロバイダーは API サービスのクォータを実装する可能性があります。そのため、クラスターは段階的にスケーリングします。
マシンセットのレプリカが 1 度に高い値に設定される場合に、コントローラーはマシンを作成できなくなる可能性があります。OpenShift Container Platform が上部にデプロイされているクラウドプラットフォームが処理できる要求の数はプロセスに影響を与えます。コントローラーは、該当するステータスのマシンの作成、確認、および更新を試行する間に、追加のクエリーを開始します。OpenShift Container Platform がデプロイされるクラウドプラットフォームには API 要求の制限があり、過剰なクエリーが生じると、クラウドプラットフォームの制限によりマシンの作成が失敗する場合があります。
大規模なノード数にスケーリングする際にマシンヘルスチェックを有効にします。障害が発生する場合、ヘルスチェックは状態を監視し、正常でないマシンを自動的に修復します。
大規模で高密度のクラスターをノード数を減らしてスケールダウンする場合には、長い時間がかかる可能性があります。このプロセスで、終了するノードで実行されているオブジェクトのドレイン (解放) またはエビクトが並行して実行されるためです。また、エビクトするオブジェクトが多過ぎる場合に、クライアントはリクエストのスロットリングを開始する可能性があります。デフォルトのクライアント QPS およびバーストレートは、現時点で 5 と 10 にそれぞれ設定されています。これらは OpenShift Container Platform で変更することはできません。
3.2. マシンセットの変更
マシンセットを変更するには、MachineSet YAML を編集します。次に、各マシンを削除するか、またはマシンセットを 0 レプリカにスケールダウンしてマシンセットに関連付けられたすべてのマシンを削除します。レプリカは必要な数にスケーリングします。マシンセットへの変更は既存のマシンに影響を与えません。
他の変更を加えずに、マシンセットをスケーリングする必要がある場合、マシンを削除する必要はありません。
デフォルトで、OpenShift Container Platform ルーター Pod はワーカーにデプロイされます。ルーターは Web コンソールなどの一部のクラスターリソースにアクセスすることが必要であるため、 ルーター Pod をまず再配置しない限り、ワーカーのマシンセットを 0 にスケーリングできません。
前提条件
-
OpenShift Container Platform クラスターおよび
ocコマンドラインをインストールすること。 -
cluster-adminパーミッションを持つユーザーとして、ocにログインする。
手順
マシンセットを編集します。
$ oc edit machineset <machineset> -n openshift-machine-api
マシンセットを
0にスケールダウンします。$ oc scale --replicas=0 machineset <machineset> -n openshift-machine-api
または、以下を実行します。
$ oc edit machineset <machineset> -n openshift-machine-api
マシンが削除されるまで待機します。
マシンセットを随時スケールアップします。
$ oc scale --replicas=2 machineset <machineset> -n openshift-machine-api
または、以下を実行します。
$ oc edit machineset <machineset> -n openshift-machine-api
マシンが起動するまで待ちます。新規マシンにはマシンセットに加えられた変更が含まれます。
3.3. マシンのヘルスチェック
MachineHealthCheck リソースを使用して、クラスター内のマシンが正常ではないとみなされる条件を定義できます。条件に一致するマシンは自動的に修復されます。
マシンの正常性を監視するには、監視する一連のマシンのラベルや、NotReady ステータスの期間を 15 分にしたり、 node-problem-detector に永続的な条件を表示したりするなど、チェックする条件を含む MachineHealthCheck カスタムリソース (CR) を作成します。
MachineHealthCheck CR を観察するコントローラーは定義した条件の有無をチェックします。マシンがヘルスチェックに失敗した場合、このマシンは自動的に検出され、新規マシンが代わりに作成されます。マシンが削除されると、machine deleted イベントが表示されます。
マスターロールを持つマシンの場合、マシンのヘルスチェックは正常でないノードの数を報告しますが、マシンは削除されません。以下は例になります。
出力例
$ oc get machinehealthcheck example -n openshift-machine-api
NAME MAXUNHEALTHY EXPECTEDMACHINES CURRENTHEALTHY example 40% 3 1
マシンの削除による破壊的な影響を制限するために、コントローラーは 1 度に 1 つのノードのみをドレイン (解放) し、これを削除します。マシンのターゲットプールで許可される maxUnhealthy しきい値を上回る数の正常でないマシンがある場合、コントローラーはマシンの削除を停止し、手動で介入する必要があります。
チェックを停止するには、カスタムリソースを削除します。
3.3.1. マシンヘルスチェックのデプロイ時の制限
マシンヘルスチェックをデプロイする前に考慮すべき制限事項があります。
- マシンセットが所有するマシンのみがマシンヘルスチェックによって修復されます。
- コントロールプレーンマシンは現在サポートされておらず、それらが正常でない場合にも修正されません。
- マシンのノードがクラスターから削除される場合、マシンヘルスチェックはマシンが正常ではないとみなし、すぐにこれを修復します。
-
nodeStartupTimeoutの後にマシンの対応するノードがクラスターに加わらない場合、マシンは修復されます。 -
MachineリソースフェーズがFailedの場合、マシンはすぐに修復されます。
3.4. サンプル MachineHealthCheck リソース
MachineHealthCheck リソースは以下の YAML ファイルのようになります。
MachineHealthCheck
apiVersion: machine.openshift.io/v1beta1 kind: MachineHealthCheck metadata: name: example 1 namespace: openshift-machine-api spec: selector: matchLabels: machine.openshift.io/cluster-api-machine-role: <role> 2 machine.openshift.io/cluster-api-machine-type: <role> 3 machine.openshift.io/cluster-api-machineset: <cluster_name>-<label>-<zone> 4 unhealthyConditions: - type: "Ready" timeout: "300s" 5 status: "False" - type: "Ready" timeout: "300s" 6 status: "Unknown" maxUnhealthy: "40%" 7 nodeStartupTimeout: "10m" 8
- 1
- デプロイするマシンヘルスチェックの名前を指定します。
- 2 3
- チェックする必要のあるマシンプールのラベルを指定します。
- 4
- 追跡するマシンセットを
<cluster_name>-<label>-<zone>形式で指定します。たとえば、prod-node-us-east-1aとします。 - 5 6
- ノードの状態のタイムアウト期間を指定します。タイムアウト期間の条件が満たされると、マシンは修正されます。タイムアウトの時間が長くなると、正常でないマシンのワークロードのダウンタイムが長くなる可能性があります。
- 7
- ターゲットプールで許可される正常でないマシンの量を指定します。これはパーセンテージまたは整数として設定できます。
- 8
- マシンが正常でないと判別される前に、ノードがクラスターに参加するまでマシンヘルスチェックが待機する必要のあるタイムアウト期間を指定します。
matchLabels はあくまでもサンプルであるため、特定のニーズに応じてマシングループをマッピングする必要があります。
3.4.1. マシンヘルスチェックによる修復の一時停止 (short-circuiting)
一時停止 (short-circuiting) が実行されることにより、マシンのヘルスチェックはクラスターが正常な場合にのみマシンを修復するようになります。一時停止 (short-circuiting) は、MachineHealthCheck リソースの maxUnhealthy フィールドで設定されます。
ユーザーがマシンの修復前に maxUnhealthy フィールドの値を定義する場合、MachineHealthCheck は maxUnhealthy の値を、正常でないと判別するターゲットプール内のマシン数と比較します。正常でないマシンの数が maxUnhealthy の制限を超える場合、修復は実行されません。
maxUnhealthy が設定されていない場合、値は 100% にデフォルト設定され、マシンはクラスターの状態に関係なく修復されます。
maxUnhealthy フィールドは整数またはパーセンテージのいずれかに設定できます。maxUnhealthy の値によって、修復の実装が異なります。
3.4.1.1. 絶対値を使用した maxUnhealthy の設定
maxUnhealthy が 2 に設定される場合:
- 2 つ以下のノードが正常でない場合に、修復が実行されます。
- 3 つ以上のノードが正常でない場合は、修復は実行されません。
これらの値は、マシンヘルスチェックによってチェックされるマシン数と別個の値です。
3.4.1.2. パーセンテージを使用した maxUnhealthy の設定
maxUnhealthy が 40% に設定され、25 のマシンがチェックされる場合:
- 10 以下のノードが正常でない場合に、修復が実行されます。
- 11 以上のノードが正常でない場合は、修復は実行されません。
maxUnhealthy が 40% に設定され、6 マシンがチェックされる場合:
- 2 つ以下のノードが正常でない場合に、修復が実行されます。
- 3 つ以上のノードが正常でない場合は、修復は実行されません。
チェックされる maxUnhealthy マシンの割合が整数ではない場合、マシンの許可される数は切り捨てられます。
3.5. MachineHealthCheck リソースの作成
クラスターに、すべての MachineSets の MachineHealthCheck リソースを作成できます。コントロールプレーンマシンをターゲットとする MachineHealthCheck リソースを作成することはできません。
前提条件
-
ocコマンドラインインターフェイスをインストールします。
手順
-
マシンヘルスチェックの定義を含む
healthcheck.ymlファイルを作成します。 healthcheck.ymlファイルをクラスターに適用します。$ oc apply -f healthcheck.yml
第4章 Node Tuning Operator の使用
Node Tuning Operator について説明し、この Operator を使用し、Tuned デーモンのオーケストレーションを実行してノードレベルのチューニングを管理する方法について説明します。
4.1. Node Tuning Operator について
Node Tuning Operator は、Tuned デーモンのオーケストレーションによるノードレベルのチューニングの管理に役立ちます。ほとんどの高パフォーマンスアプリケーションでは、一定レベルのカーネルのチューニングが必要です。Node Tuning Operator は、ノードレベルの sysctl の統一された管理インターフェイスをユーザーに提供し、ユーザーが指定するカスタムチューニングを追加できるよう柔軟性を提供します。Operator は、コンテナー化された OpenShift Container Platform の Tuned デーモンを Kubernetes デーモンセットとして管理します。これにより、カスタムチューニング仕様が、デーモンが認識する形式でクラスターで実行されるすべてのコンテナー化された Tuned デーモンに渡されます。デーモンは、ノードごとに 1 つずつ、クラスターのすべてのノードで実行されます。
コンテナー化された Tuned デーモンによって適用されるノードレベルの設定は、プロファイルの変更をトリガーするイベントで、または終了シグナルの受信および処理によってコンテナー化された Tuned デーモンが正常に終了する際にロールバックされます。
Node Tuning Operator は、バージョン 4.1 以降における標準的な OpenShift Container Platform インストールの一部となっています。
4.2. Node Tuning Operator 仕様サンプルへのアクセス
このプロセスを使用して Node Tuning Operator 仕様サンプルにアクセスします。
手順
以下を実行します。
$ oc get Tuned/default -o yaml -n openshift-cluster-node-tuning-operator
デフォルトの CR は、OpenShift Container Platform プラットフォームの標準的なノードレベルのチューニングを提供することを目的としており、Operator 管理の状態を設定するためにのみ変更できます。デフォルト CR へのその他のカスタム変更は、Operator によって上書きされます。カスタムチューニングの場合は、独自のチューニングされた CR を作成します。新規に作成された CR は、ノード/Pod ラベルおよびプロファイルの優先順位に基づいて OpenShift Container Platform ノードに適用されるデフォルトの CR およびカスタムチューニングと組み合わされます。
特定の状況で Pod ラベルのサポートは必要なチューニングを自動的に配信する便利な方法ですが、この方法は推奨されず、とくに大規模なクラスターにおいて注意が必要です。デフォルトの調整された CR は Pod ラベル一致のない状態で提供されます。カスタムプロファイルが Pod ラベル一致のある状態で作成される場合、この機能はその時点で有効になります。Pod ラベル機能は、Node Tuning Operator の今後のバージョンで非推奨になる場合があります。
4.3. クラスターに設定されるデフォルトのプロファイル
以下は、クラスターに設定されるデフォルトのプロファイルです。
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: default
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- name: "openshift"
data: |
[main]
summary=Optimize systems running OpenShift (parent profile)
include=${f:virt_check:virtual-guest:throughput-performance}
[selinux]
avc_cache_threshold=8192
[net]
nf_conntrack_hashsize=131072
[sysctl]
net.ipv4.ip_forward=1
kernel.pid_max=>4194304
net.netfilter.nf_conntrack_max=1048576
net.ipv4.conf.all.arp_announce=2
net.ipv4.neigh.default.gc_thresh1=8192
net.ipv4.neigh.default.gc_thresh2=32768
net.ipv4.neigh.default.gc_thresh3=65536
net.ipv6.neigh.default.gc_thresh1=8192
net.ipv6.neigh.default.gc_thresh2=32768
net.ipv6.neigh.default.gc_thresh3=65536
vm.max_map_count=262144
[sysfs]
/sys/module/nvme_core/parameters/io_timeout=4294967295
/sys/module/nvme_core/parameters/max_retries=10
- name: "openshift-control-plane"
data: |
[main]
summary=Optimize systems running OpenShift control plane
include=openshift
[sysctl]
# ktune sysctl settings, maximizing i/o throughput
#
# Minimal preemption granularity for CPU-bound tasks:
# (default: 1 msec# (1 + ilog(ncpus)), units: nanoseconds)
kernel.sched_min_granularity_ns=10000000
# The total time the scheduler will consider a migrated process
# "cache hot" and thus less likely to be re-migrated
# (system default is 500000, i.e. 0.5 ms)
kernel.sched_migration_cost_ns=5000000
# SCHED_OTHER wake-up granularity.
#
# Preemption granularity when tasks wake up. Lower the value to
# improve wake-up latency and throughput for latency critical tasks.
kernel.sched_wakeup_granularity_ns=4000000
- name: "openshift-node"
data: |
[main]
summary=Optimize systems running OpenShift nodes
include=openshift
[sysctl]
net.ipv4.tcp_fastopen=3
fs.inotify.max_user_watches=65536
fs.inotify.max_user_instances=8192
recommend:
- profile: "openshift-control-plane"
priority: 30
match:
- label: "node-role.kubernetes.io/master"
- label: "node-role.kubernetes.io/infra"
- profile: "openshift-node"
priority: 404.4. Tuned プロファイルが適用されていることの確認
この手順を使用して、すべてのノードに適用される Tuned プロファイルを確認します。
手順
各ノードで実行されている Tuned Pod を確認します。
$ oc get pods -n openshift-cluster-node-tuning-operator -o wide
出力例
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES cluster-node-tuning-operator-599489d4f7-k4hw4 1/1 Running 0 6d2h 10.129.0.76 ip-10-0-145-113.eu-west-3.compute.internal <none> <none> tuned-2jkzp 1/1 Running 1 6d3h 10.0.145.113 ip-10-0-145-113.eu-west-3.compute.internal <none> <none> tuned-g9mkx 1/1 Running 1 6d3h 10.0.147.108 ip-10-0-147-108.eu-west-3.compute.internal <none> <none> tuned-kbxsh 1/1 Running 1 6d3h 10.0.132.143 ip-10-0-132-143.eu-west-3.compute.internal <none> <none> tuned-kn9x6 1/1 Running 1 6d3h 10.0.163.177 ip-10-0-163-177.eu-west-3.compute.internal <none> <none> tuned-vvxwx 1/1 Running 1 6d3h 10.0.131.87 ip-10-0-131-87.eu-west-3.compute.internal <none> <none> tuned-zqrwq 1/1 Running 1 6d3h 10.0.161.51 ip-10-0-161-51.eu-west-3.compute.internal <none> <none>
各 Pod から適用されるプロファイルを抽出し、それらを直前の一覧に対して一致させます。
$ for p in `oc get pods -n openshift-cluster-node-tuning-operator -l openshift-app=tuned -o=jsonpath='{range .items[*]}{.metadata.name} {end}'`; do printf "\n*** $p ***\n" ; oc logs pod/$p -n openshift-cluster-node-tuning-operator | grep applied; done出力例
*** tuned-2jkzp *** 2020-07-10 13:53:35,368 INFO tuned.daemon.daemon: static tuning from profile 'openshift-control-plane' applied *** tuned-g9mkx *** 2020-07-10 14:07:17,089 INFO tuned.daemon.daemon: static tuning from profile 'openshift-node' applied 2020-07-10 15:56:29,005 INFO tuned.daemon.daemon: static tuning from profile 'openshift-node-es' applied 2020-07-10 16:00:19,006 INFO tuned.daemon.daemon: static tuning from profile 'openshift-node' applied 2020-07-10 16:00:48,989 INFO tuned.daemon.daemon: static tuning from profile 'openshift-node-es' applied *** tuned-kbxsh *** 2020-07-10 13:53:30,565 INFO tuned.daemon.daemon: static tuning from profile 'openshift-node' applied 2020-07-10 15:56:30,199 INFO tuned.daemon.daemon: static tuning from profile 'openshift-node-es' applied *** tuned-kn9x6 *** 2020-07-10 14:10:57,123 INFO tuned.daemon.daemon: static tuning from profile 'openshift-node' applied 2020-07-10 15:56:28,757 INFO tuned.daemon.daemon: static tuning from profile 'openshift-node-es' applied *** tuned-vvxwx *** 2020-07-10 14:11:44,932 INFO tuned.daemon.daemon: static tuning from profile 'openshift-control-plane' applied *** tuned-zqrwq *** 2020-07-10 14:07:40,246 INFO tuned.daemon.daemon: static tuning from profile 'openshift-control-plane' applied
4.5. カスタムチューニング仕様
Operator のカスタムリソース (CR) には 2 つの重要なセクションがあります。1 つ目のセクションの profile: は Tuned プロファイルおよびそれらの名前の一覧です。2 つ目の recommend: は、プロファイル選択ロジックを定義します。
複数のカスタムチューニング仕様は、Operator の namespace に複数の CR として共存できます。新規 CR の存在または古い CR の削除は Operator によって検出されます。既存のカスタムチューニング仕様はすべてマージされ、コンテナー化された Tuned デーモンの適切なオブジェクトは更新されます。
プロファイルデータ
profile: セクションは、Tuned プロファイルおよびそれらの名前を一覧表示します。
profile:
- name: tuned_profile_1
data: |
# Tuned profile specification
[main]
summary=Description of tuned_profile_1 profile
[sysctl]
net.ipv4.ip_forward=1
# ... other sysctl's or other Tuned daemon plug-ins supported by the containerized Tuned
# ...
- name: tuned_profile_n
data: |
# Tuned profile specification
[main]
summary=Description of tuned_profile_n profile
# tuned_profile_n profile settings推奨プロファイル
profile: 選択ロジックは、CR の recommend: セクションによって定義されます。recommend: セクションは、選択基準に基づくプロファイルの推奨項目の一覧です。
recommend: - match: # optional; if omitted, profile match is assumed unless a profile with a higher matches first <match> # an optional array priority: <priority> # profile ordering priority, lower numbers mean higher priority (0 is the highest priority) profile: <tuned_profile_name> # e.g. tuned_profile_1 # ... - match: <match> priority: <priority> profile: <tuned_profile_name> # e.g. tuned_profile_n
<match> が省略されている場合は、プロファイルの一致 (例: true) があることが想定されます。
<match> は、以下のように再帰的に定義されるオプションの配列です。
- label: <label_name> # node or Pod label name value: <label_value> # optional node or Pod label value; if omitted, the presence of <label_name> is enough to match type: <label_type> # optional node or Pod type (`node` or `pod`); if omitted, `node` is assumed <match> # an optional <match> array
<match> が省略されない場合、ネストされたすべての <match> セクションが true に評価される必要もあります。そうでない場合には false が想定され、それぞれの <match> セクションのあるプロファイルは適用されず、推奨されません。そのため、ネスト化 (子の <match> セクション) は論理 AND 演算子として機能します。これとは逆に、<match> 配列のいずれかの項目が一致する場合、<match> の全体の配列が true に評価されます。そのため、配列は論理 OR 演算子として機能します。
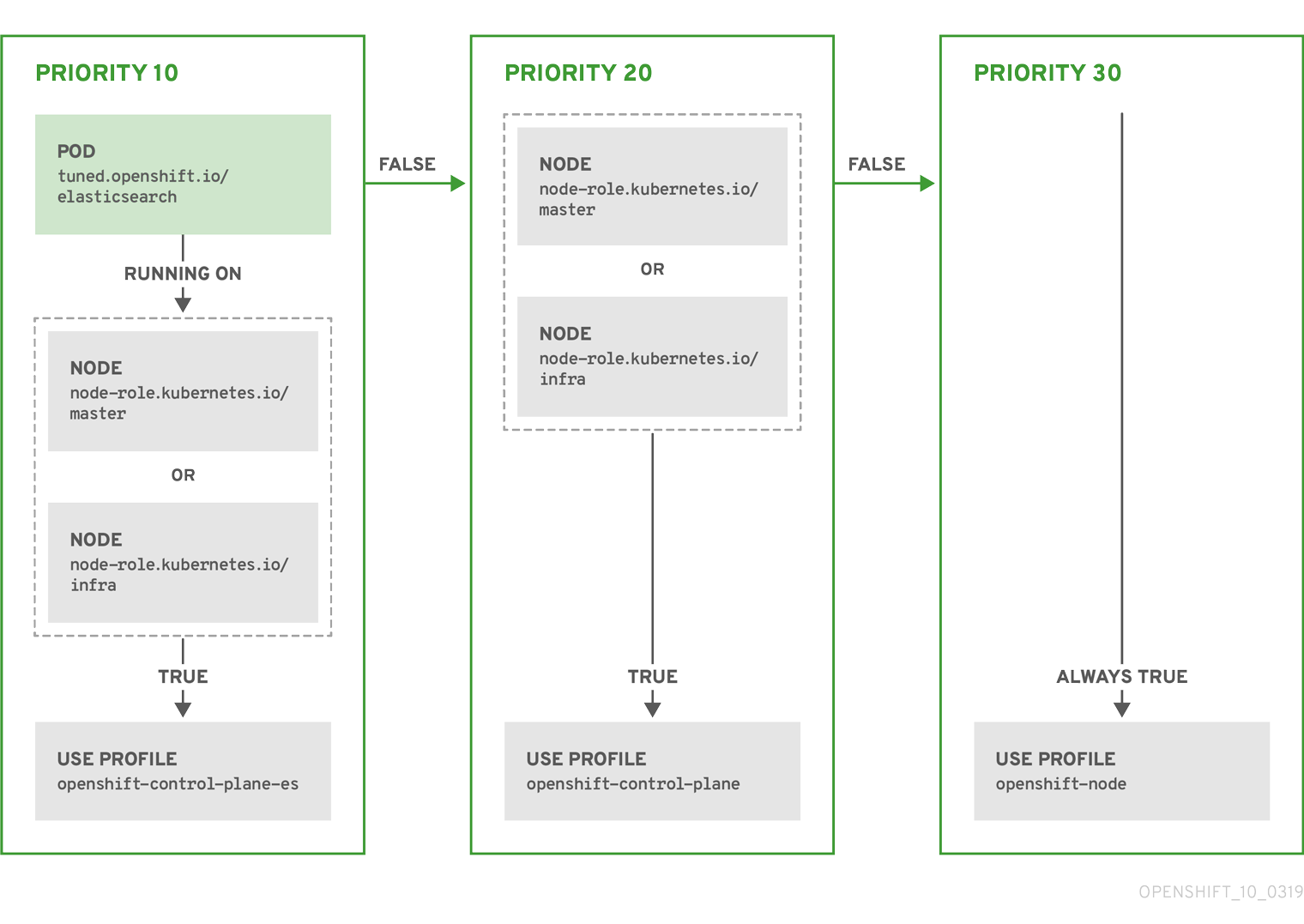
例
- match:
- label: tuned.openshift.io/elasticsearch
match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
type: pod
priority: 10
profile: openshift-control-plane-es
- match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
priority: 20
profile: openshift-control-plane
- priority: 30
profile: openshift-node
上記のコンテナー化された Tuned デーモンの CR は、プロファイルの優先順位に基づいてその recommend.conf ファイルに変換されます。最も高い優先順位 (10) を持つプロファイルは openshift-control-plane-es であるため、これが最初に考慮されます。指定されたノードで実行されるコンテナー化された Tuned デーモンは、同じノードに tuned.openshift.io/elasticsearch ラベルが設定された Pod が実行されているかどうかを確認します。これがない場合、 <match> セクション全体が false として評価されます。このラベルを持つこのような Pod がある場合、 <match> セクションが true に評価されるようにするには、ノードラベルは node-role.kubernetes.io/master または node-role.kubernetes.io/infra である必要もあります。
優先順位が 10 のプロファイルのラベルが一致した場合、openshift-control-plane-es プロファイルが適用され、その他のプロファイルは考慮されません。ノード/Pod ラベルの組み合わせが一致しない場合、2 番目に高い優先順位プロファイル (openshift-control-plane) が考慮されます。このプロファイルは、コンテナー化されたチューニング済み Pod が node-role.kubernetes.io/master または node-role.kubernetes.io/infra ラベルを持つノードで実行される場合に適用されます。
最後に、プロファイル openshift-node には最低の優先順位である 30 が設定されます。これには <match> セクションがないため、常に一致します。これは、より高い優先順位の他のプロファイルが指定されたノードで一致しない場合に openshift-node プロファイルを設定するために、最低の優先順位のノードが適用される汎用的な (catch-all) プロファイルとして機能します。
4.6. カスタムチューニングの例
以下の CR は、ラベル tuned.openshift.io/ingress-node-label を任意の値に設定した状態で OpenShift Container Platform ノードのカスタムノードレベルのチューニングを適用します。管理者として、以下のコマンドを使用してカスタムの Tune CR を作成します。
例
oc create -f- <<_EOF_
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: ingress
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=A custom OpenShift ingress profile
include=openshift-control-plane
[sysctl]
net.ipv4.ip_local_port_range="1024 65535"
net.ipv4.tcp_tw_reuse=1
name: openshift-ingress
recommend:
- match:
- label: tuned.openshift.io/ingress-node-label
priority: 10
profile: openshift-ingress
_EOF_
カスタムプロファイル作成者は、デフォルトの Tuned CR に含まれるデフォルトの調整されたデーモンプロファイルを組み込むことが強く推奨されます。上記の例では、デフォルトの openshift-control-plane プロファイルを使用してこれを実行します。
4.7. サポートされている Tuned デーモンプラグイン
[main] セクションを除き、以下の Tuned プラグインは、Tuned CR の profile: セクションで定義されたカスタムプロファイルを使用する場合にサポートされます。
- audio
- cpu
- disk
- eeepc_she
- modules
- mounts
- net
- scheduler
- scsi_host
- selinux
- sysctl
- sysfs
- usb
- video
- vm
これらのプラグインの一部によって提供される動的チューニング機能の中に、サポートされていない機能があります。以下の Tuned プラグインは現時点でサポートされていません。
- bootloader
- script
- systemd
詳細は、利用可能な Tuned プラグイン および Tuned の使用 を参照してください。
第5章 クラスターローダーの使用
クラスターローダーとは、クラスターに対してさまざまなオブジェクトを多数デプロイするツールであり、ユーザー定義のクラスターオブジェクトを作成します。クラスターローダーをビルド、設定、実行して、さまざまなクラスターの状態にある OpenShift Container Platform デプロイメントのパフォーマンスメトリクスを測定します。
5.1. クラスターローダーのインストール
手順
コンテナーイメージをプルするには、以下を実行します。
$ sudo podman pull quay.io/openshift/origin-tests:4.4
5.2. クラスターローダーの実行
前提条件
- リポジトリーは認証を要求するプロンプトを出します。レジストリーの認証情報を使用すると、一般的に利用できないイメージにアクセスできます。インストールからの既存の認証情報を使用します。
手順
組み込まれているテスト設定を使用してクラスターローダーを実行し、5 つのテンプレートビルドをデプロイして、デプロイメントが完了するまで待ちます。
$ sudo podman run -v ${LOCAL_KUBECONFIG}:/root/.kube/config:z -i \ quay.io/openshift/origin-tests:4.4 /bin/bash -c 'export KUBECONFIG=/root/.kube/config && \ openshift-tests run-test "[sig-scalability][Feature:Performance] Load cluster \ should populate the cluster [Slow][Serial] [Suite:openshift]"'または、
VIPERCONFIGの環境変数を設定して、ユーザー定義の設定でクラスターローダーを実行します。$ sudo podman run -v ${LOCAL_KUBECONFIG}:/root/.kube/config:z \ -v ${LOCAL_CONFIG_FILE_PATH}:/root/configs/:z \ -i quay.io/openshift/origin-tests:4.4 \ /bin/bash -c 'KUBECONFIG=/root/.kube/config VIPERCONFIG=/root/configs/test.yaml \ openshift-tests run-test "[sig-scalability][Feature:Performance] Load cluster \ should populate the cluster [Slow][Serial] [Suite:openshift]"'この例では、
${LOCAL_KUBECONFIG}はローカルファイルシステムのkubeconfigのパスを参照します。さらに、${LOCAL_CONFIG_FILE_PATH}というディレクトリーがあり、これはtest.yamlという設定ファイルが含まれるコンテナーにマウントされます。また、test.yamlが外部テンプレートファイルや podspec ファイルを参照する場合、これらもコンテナーにマウントされる必要があります。
5.3. クラスターローダーの設定
このツールは、複数のテンプレートや Pod を含む namespace (プロジェクト) を複数作成します。
5.3.1. クラスターローダー設定ファイルの例
クラスターローダーの設定ファイルは基本的な YAML ファイルです。
provider: local 1 ClusterLoader: cleanup: true projects: - num: 1 basename: clusterloader-cakephp-mysql tuning: default ifexists: reuse templates: - num: 1 file: cakephp-mysql.json - num: 1 basename: clusterloader-dancer-mysql tuning: default ifexists: reuse templates: - num: 1 file: dancer-mysql.json - num: 1 basename: clusterloader-django-postgresql tuning: default ifexists: reuse templates: - num: 1 file: django-postgresql.json - num: 1 basename: clusterloader-nodejs-mongodb tuning: default ifexists: reuse templates: - num: 1 file: quickstarts/nodejs-mongodb.json - num: 1 basename: clusterloader-rails-postgresql tuning: default templates: - num: 1 file: rails-postgresql.json tuningsets: 2 - name: default pods: stepping: 3 stepsize: 5 pause: 0 s rate_limit: 4 delay: 0 ms
この例では、外部テンプレートファイルや Pod 仕様ファイルへの参照もコンテナーにマウントされていることを前提とします。
Microsoft Azure でクラスターローダーを実行している場合、AZURE_AUTH_LOCATION 変数を、インストーラーディレクトリーにある terraform.azure.auto.tfvars.json の出力が含まれるファイルに設定する必要があります。
5.3.2. 設定フィールド
表5.1 クラスターローダーの最上位のフィールド
| フィールド | 説明 |
|---|---|
|
|
|
|
|
1 つまたは多数の定義が指定されたサブオブジェクト。 |
|
|
設定ごとに 1 つの定義が指定されたサブオブジェクト。 |
|
| 設定ごとに 1 つの定義が指定されたオプションのサブオブジェクト。オブジェクト作成時に同期できるかどうかについて追加します。 |
表5.2 projects の下にあるフィールド
| フィールド | 説明 |
|---|---|
|
| 整数。作成するプロジェクト数の 1 つの定義。 |
|
|
文字列。プロジェクトのベース名の定義。競合が発生しないように、同一の namespace の数が |
|
| 文字列。オブジェクトに適用するチューニングセットの 1 つの定義。 これは対象の namespace にデプロイします。 |
|
|
|
|
| キーと値のペア一覧。キーは設定マップの名前で、値はこの設定マップの作成元のファイルへのパスです。 |
|
| キーと値のペア一覧。キーはシークレットの名前で、値はこのシークレットの作成元のファイルへのパスです。 |
|
| デプロイする Pod の 1 つまたは多数の定義を持つサブオブジェクト |
|
| デプロイするテンプレートの 1 つまたは多数の定義を持つサブオブジェクト |
表5.3 pods および templates のフィールド
| フィールド | 説明 |
|---|---|
|
| 整数。デプロイする Pod またはテンプレート数。 |
|
| 文字列。プルが可能なリポジトリーに対する Docker イメージの URL |
|
| 文字列。作成するテンプレート (または Pod) のベース名の 1 つの定義。 |
|
| 文字列。ローカルファイルへのパス。 作成する Pod 仕様またはテンプレートのいずれかです。 |
|
|
キーと値のペア。 |
表5.4 tuningsets の下にあるフィールド
| フィールド | 説明 |
|---|---|
|
| 文字列。チューニングセットの名前。 プロジェクトのチューニングを定義する時に指定した名前と一致します。 |
|
|
Pod に適用される |
|
|
テンプレートに適用される |
表5.5 tuningsets pods または tuningsets templates の下にあるフィールド
| フィールド | 説明 |
|---|---|
|
| サブオブジェクト。ステップ作成パターンでオブジェクトを作成する場合に使用するステップ設定。 |
|
| サブオブジェクト。オブジェクト作成速度を制限するための速度制限チューニングセットの設定。 |
表5.6 tuningsets pods または tuningsets templates、stepping の下にあるフィールド
| フィールド | 説明 |
|---|---|
|
| 整数。オブジェクト作成を一時停止するまでに作成するオブジェクト数。 |
|
|
整数。 |
|
| 整数。オブジェクト作成に成功しなかった場合に失敗するまで待機する秒数。 |
|
| 整数。次の作成要求まで待機する時間 (ミリ秒)。 |
表5.7 sync の下にあるフィールド
| フィールド | 説明 |
|---|---|
|
|
|
|
|
ブール値。 |
|
|
ブール値。 |
|
|
|
|
|
文字列。 |
5.4. 既知の問題
- クラスターローダーは設定なしで呼び出される場合に失敗します。(BZ#1761925)
IDENTIFIERパラメーターがユーザーテンプレートで定義されていない場合には、テンプレートの作成はerror: unknown parameter name "IDENTIFIER"エラーを出して失敗します。テンプレートをデプロイする場合は、このエラーが発生しないように、以下のパラメーターをテンプレートに追加してください。{ "name": "IDENTIFIER", "description": "Number to append to the name of resources", "value": "1" }Pod をデプロイする場合は、このパラメーターを追加する必要はありません。
第6章 CPU マネージャーの使用
CPU マネージャーは、CPU グループを管理して、ワークロードを特定の CPU に制限します。
CPU マネージャーは、以下のような属性が含まれるワークロードに有用です。
- できるだけ長い CPU 時間が必要な場合
- プロセッサーのキャッシュミスの影響を受ける場合
- レイテンシーが低いネットワークアプリケーションの場合
- 他のプロセスと連携し、単一のプロセッサーキャッシュを共有することに利点がある場合
6.1. CPU マネージャーの設定
手順
オプション: ノードにラベルを指定します。
# oc label node perf-node.example.com cpumanager=true
CPU マネージャーを有効にする必要のあるノードの
MachineConfigPoolを編集します。この例では、すべてのワーカーで CPU マネージャーが有効にされています。# oc edit machineconfigpool worker
ラベルをワーカーのマシン設定プールに追加します。
metadata: creationTimestamp: 2020-xx-xxx generation: 3 labels: custom-kubelet: cpumanager-enabledKubeletConfig、cpumanager-kubeletconfig.yaml、カスタムリソース (CR) を作成します。直前の手順で作成したラベルを参照し、適切なノードを新規の kubelet 設定で更新します。machineConfigPoolSelectorセクションを参照してください。apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: cpumanager-enabled spec: machineConfigPoolSelector: matchLabels: custom-kubelet: cpumanager-enabled kubeletConfig: cpuManagerPolicy: static cpuManagerReconcilePeriod: 5s動的な kubelet 設定を作成します。
# oc create -f cpumanager-kubeletconfig.yaml
これにより、CPU マネージャー機能が kubelet 設定に追加され、必要な場合には Machine Config Operator (MCO) がノードを再起動します。CPU マネージャーを有効にするために再起動する必要はありません。
マージされた kubelet 設定を確認します。
# oc get machineconfig 99-worker-XXXXXX-XXXXX-XXXX-XXXXX-kubelet -o json | grep ownerReference -A7 "ownerReferences": [ { "apiVersion": "machineconfiguration.openshift.io/v1", "kind": "KubeletConfig", "name": "cpumanager-enabled", "uid": "7ed5616d-6b72-11e9-aae1-021e1ce18878" } ],ワーカーで更新された
kubelet.confを確認します。# oc debug node/perf-node.example.com sh-4.2# cat /host/etc/kubernetes/kubelet.conf | grep cpuManager cpuManagerPolicy: static 1 cpuManagerReconcilePeriod: 5s 2
コア 1 つまたは複数を要求する Pod を作成します。制限および要求の CPU の値は整数にする必要があります。これは、対象の Pod 専用のコア数です。
# cat cpumanager-pod.yaml apiVersion: v1 kind: Pod metadata: generateName: cpumanager- spec: containers: - name: cpumanager image: gcr.io/google_containers/pause-amd64:3.0 resources: requests: cpu: 1 memory: "1G" limits: cpu: 1 memory: "1G" nodeSelector: cpumanager: "true"Pod を作成します。
# oc create -f cpumanager-pod.yaml
Pod がラベル指定されたノードにスケジュールされていることを確認します。
# oc describe pod cpumanager Name: cpumanager-6cqz7 Namespace: default Priority: 0 PriorityClassName: <none> Node: perf-node.example.com/xxx.xx.xx.xxx ... Limits: cpu: 1 memory: 1G Requests: cpu: 1 memory: 1G ... QoS Class: Guaranteed Node-Selectors: cpumanager=truecgroupsが正しく設定されていることを確認します。pauseプロセスのプロセス ID (PID) を取得します。# ├─init.scope │ └─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 17 └─kubepods.slice ├─kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice │ ├─crio-b5437308f1a574c542bdf08563b865c0345c8f8c0b0a655612c.scope │ └─32706 /pause
QoS (quality of service) 階層
Guaranteedの Pod は、kubepods.sliceに配置されます。他の QoS の Pod は、kubepodsの子であるcgroupsに配置されます。# cd /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice/crio-b5437308f1ad1a7db0574c542bdf08563b865c0345c86e9585f8c0b0a655612c.scope # for i in `ls cpuset.cpus tasks` ; do echo -n "$i "; cat $i ; done cpuset.cpus 1 tasks 32706
対象のタスクで許可される CPU 一覧を確認します。
# grep ^Cpus_allowed_list /proc/32706/status Cpus_allowed_list: 1
システム上の別の Pod (この場合は
burstableQoS 階層にある Pod) が、GuaranteedPod に割り当てられたコアで実行できないことを確認します。# cat /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-podc494a073_6b77_11e9_98c0_06bba5c387ea.slice/crio-c56982f57b75a2420947f0afc6cafe7534c5734efc34157525fa9abbf99e3849.scope/cpuset.cpus 0
# oc describe node perf-node.example.com ... Capacity: attachable-volumes-aws-ebs: 39 cpu: 2 ephemeral-storage: 124768236Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 8162900Ki pods: 250 Allocatable: attachable-volumes-aws-ebs: 39 cpu: 1500m ephemeral-storage: 124768236Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 7548500Ki pods: 250 ------- ---- ------------ ---------- --------------- ------------- --- default cpumanager-6cqz7 1 (66%) 1 (66%) 1G (12%) 1G (12%) 29m Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 1440m (96%) 1 (66%)
この仮想マシンには、2 つの CPU コアがあります。
kube-reservedは 500 ミリコアに設定して、Node Allocatableの数になるようにノードの全容量からコアの半分を引きます。ここでAllocatable CPUは 1500 ミリコアであることを確認できます。これは、それぞれがコアを 1 つ受け入れるので、CPU マネージャー Pod の 1 つを実行できることを意味します。1 つのコア全体は 1000 ミリコアに相当します。2 つ目の Pod をスケジュールしようとする場合、システムは Pod を受け入れますが、これがスケジュールされることはありません。NAME READY STATUS RESTARTS AGE cpumanager-6cqz7 1/1 Running 0 33m cpumanager-7qc2t 0/1 Pending 0 11s
第7章 Topology Manager の使用
Topology Manager は、CPU マネージャーおよびデバイスマネージャーからヒントを収集し、Pod CPU およびデバイスリソースを同じ Non-Uniform Memory Access (NUMA) ノードに配置する Kubelet コンポーネントです。
Topology Manager は、収集したヒントのトポロジー情報を使用し、設定される Topology Manager ポリシーおよび要求される Pod リソースに基づいて、Pod がノードから許可されるか、または拒否されるかどうかを判別します。
Topology Manager は、ハードウェアアクセラレーターを使用して低遅延 (latency-critical) の実行と高スループットの並列計算をサポートするワークロードの場合に役立ちます。
Topology Manager は OpenShift Container Platform のアルファ機能です。
7.1. Topology Manager のセットアップ
前提条件
-
CPU マネージャーのポリシーを
staticに設定します。スケーラビリティーおよびパフォーマンスセクションの CPU マネージャーの使用を参照してください。
手順
LatencySensitive FeatureGate を有効にします。
# oc edit featuregate/cluster
Feature Set: LatencySensitive を仕様に追加します。
# oc describe featuregate/cluster Name: cluster Namespace: Labels: <none> Annotations: release.openshift.io/create-only: true API Version: config.openshift.io/v1 Kind: FeatureGate Metadata: Creation Timestamp: 2019-10-30T15:06:41Z Generation: 2 Resource Version: 7773803 Self Link: /apis/config.openshift.io/v1/featuregates/cluster UID: b00204ab-cc5e-4ca5-ad93-b9bdd738c1de Spec: Feature Set: LatencySensitive Events: <none>
KubeletConfig で Topology Manager ポリシーを設定します。
以下の YAML ファイルのサンプルには、
single-numa-nodeポリシーが指定されています。apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: cpumanager-enabled spec: machineConfigPoolSelector: matchLabels: custom-kubelet: cpumanager-enabled kubeletConfig: cpuManagerPolicy: static cpuManagerReconcilePeriod: 5s topologyManagerPolicy: single-numa-node 1- 1
- 選択した Topology Manager ポリシーを指定します。
# oc create -f topologymanager-kubeletconfig.yaml
7.2. Topology Manager ポリシー
Topology Manager は、以下の条件を満たすノードおよび Pod で機能します。
-
ノードの CPU マネージャーのポリシーは
staticとして設定されます。 -
Pod は
GuaranteedQoS クラスにあります。
上記の条件が満たされると、Topology Manager は Pod の CPU およびデバイス要求を配置します。
Topology Manager は 4 つの割り当てポリシーをサポートします。これらのポリシーは、Kubelet フラグ --topology-manager-policy を使用して設定されます。ポリシーは以下のとおりです。
-
none(デフォルト) -
best-effort -
restricted -
single-numa-node
7.2.1. ポリシーなし
これはデフォルトのポリシーで、トポロジーの配置は実行しません。
7.2.2. best-effort ポリシー
best-effort トポロジー管理ポリシーを持つ Pod のそれぞれのコンテナーの場合、kubelet は 各 Hint Provider を呼び出してそれらのリソースの可用性を検出します。この情報を使用して、Topology Manager は、そのコンテナーの推奨される NUMA ノードのアフィニティーを保存します。アフィニティーが優先されない場合、Topology Manager はこれを保管し、ノードに対して Pod を許可します。
7.2.3. 制限されたポリシー
restricted トポロジー管理ポリシーを持つ Pod のそれぞれのコンテナーの場合、kubelet は 各 Hint Provider を呼び出してそれらのリソースの可用性を検出します。この情報を使用して、Topology Manager は、そのコンテナーの推奨される NUMA ノードのアフィニティーを保存します。アフィニティーが優先されない場合、Topology Manager はこの Pod をノードから拒否します。これにより、Pod が Pod の受付の失敗により Terminated 状態になります。
7.2.4. single-numa-node
single-numa-node トポロジー管理ポリシーがある Pod のそれぞれのコンテナーの場合、kubelet は各 Hint Provider を呼び出してそれらのリソースの可用性を検出します。この情報を使用して、Topology Manager は単一の NUMA ノードのアフィニティーが可能かどうかを判別します。可能である場合、Pod はノードに許可されます。単一の NUMA ノードアフィニティーが使用できない場合には、Topology Manager は Pod をノードから拒否します。これにより、Pod は Pod の受付失敗と共に Terminated (終了) 状態になります。
7.3. Pod の Topology Manager ポリシーとの対話
以下のサンプル Pod 仕様は、Pod の Topology Manger との対話について説明しています。
以下の Pod は、リソース要求や制限が指定されていないために BestEffort QoS クラスで実行されます。
spec:
containers:
- name: nginx
image: nginx
以下の Pod は、要求が制限よりも小さいために Burstable QoS クラスで実行されます。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
選択したポリシーが none 以外の場合は、Topology Manager はこれらの Pod 仕様のいずれかも考慮しません。
以下の最後のサンプル Pod は、要求が制限と等しいために Guaranteed QoS クラスで実行されます。
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "2"
example.com/device: "1"Topology Manager はこの Pod を考慮します。Topology Manager は、利用可能な CPU のトポロジーを返す CPU マネージャーの静的ポリシーを確認します。また Topology Manager はデバイスマネージャーを確認し、example.com/device の利用可能なデバイスのトポロジーを検出します。
Topology Manager はこの情報を使用して、このコンテナーに最適なトポロジーを保管します。この Pod の場合、CPU マネージャーおよびデバイスマネージャーは、リソース割り当ての段階でこの保存された情報を使用します。
第8章 Cluster Monitoring Operator のスケーリング
OpenShift Container Platform は、Cluster Monitoring Operator が収集し、Prometheus ベースのモニターリングスタックに保存するメトリクスを公開します。管理者は、Grafana という 1 つのダッシュボードインターフェイスでシステムリソース、コンテナーおよびコンポーネントのメトリクスを表示できます。
8.1. Prometheus データベースのストレージ要件
Red Hat では、異なるスケールサイズに応じて各種のテストが実行されました。
表8.1 クラスター内のノード/Pod の数に基づく Prometheus データベースのストレージ要件
| ノード数 | Pod 数 | 1 日あたりの Prometheus ストレージの増加量 | 15 日ごとの Prometheus ストレージの増加量 | RAM 領域 (スケールサイズに基づく) | ネットワーク (tsdb チャンクに基づく) |
|---|---|---|---|---|---|
| 50 | 1800 | 6.3 GB | 94 GB | 6 GB | 16 MB |
| 100 | 3600 | 13 GB | 195 GB | 10 GB | 26 MB |
| 150 | 5400 | 19 GB | 283 GB | 12 GB | 36 MB |
| 200 | 7200 | 25 GB | 375 GB | 14 GB | 46 MB |
ストレージ要件が計算値を超過しないようにするために、オーバーヘッドとして予期されたサイズのおよそ 20% が追加されています。
上記の計算は、デフォルトの OpenShift Container Platform Cluster Monitoring Operator についての計算です。
CPU の使用率による影響は大きくありません。比率については、およそ 50 ノードおよび 1800 Pod ごとに 1 コア (/40) になります。
ラボ環境
以前のリリースでは、すべての実験は RHOSP 環境の OpenShift Container Platform で実行されました。
- インフラストラクチャーノード (VM) - 40 コア、157 GB RAM。
- CNS ノード (VM) - 16 コア、62 GB RAM、NVMe ドライブ。
OpenShift Container Platform についての推奨事項
- 3 つ以上のインフラストラクチャー (infra) ノードを使用します。
- NVMe (non-volatile memory express) ドライブを搭載した 3 つ以上の openshift-container-storage ノードを使用します。
8.2. クラスターモニターリングの設定
手順
Prometheus のストレージ容量を拡張するには、以下を実行します。
YAML 設定ファイル
cluster-monitoring-config.ymlを作成します。以下は例になります。apiVersion: v1 kind: ConfigMap data: config.yaml: | prometheusOperator: baseImage: quay.io/coreos/prometheus-operator prometheusConfigReloaderBaseImage: quay.io/coreos/prometheus-config-reloader configReloaderBaseImage: quay.io/coreos/configmap-reload nodeSelector: node-role.kubernetes.io/infra: "" prometheusK8s: retention: {{PROMETHEUS_RETENTION_PERIOD}} 1 baseImage: openshift/prometheus nodeSelector: node-role.kubernetes.io/infra: "" volumeClaimTemplate: spec: storageClassName: gp2 resources: requests: storage: {{PROMETHEUS_STORAGE_SIZE}} 2 alertmanagerMain: baseImage: openshift/prometheus-alertmanager nodeSelector: node-role.kubernetes.io/infra: "" volumeClaimTemplate: spec: storageClassName: gp2 resources: requests: storage: {{ALERTMANAGER_STORAGE_SIZE}} 3 nodeExporter: baseImage: openshift/prometheus-node-exporter kubeRbacProxy: baseImage: quay.io/coreos/kube-rbac-proxy kubeStateMetrics: baseImage: quay.io/coreos/kube-state-metrics nodeSelector: node-role.kubernetes.io/infra: "" grafana: baseImage: grafana/grafana nodeSelector: node-role.kubernetes.io/infra: "" auth: baseImage: openshift/oauth-proxy k8sPrometheusAdapter: nodeSelector: node-role.kubernetes.io/infra: "" metadata: name: cluster-monitoring-config namespace: openshift-monitoring- 1
- 標準の値は
PROMETHEUS_RETENTION_PERIOD=15dになります。時間は、接尾辞 s、m、h、d のいずれかを使用する単位で測定されます。 - 2
- 標準の値は
PROMETHEUS_STORAGE_SIZE=2000Giです。ストレージの値には、接尾辞 E、P、T、G、M、K のいずれかを使用した単純な整数または固定小数点整数を使用できます。 また、2 のべき乗の値 (Ei、Pi、Ti、Gi、Mi、Ki) を使用することもできます。 - 3
- 標準の値は
ALERTMANAGER_STORAGE_SIZE=20Giです。ストレージの値には、接尾辞 E、P、T、G、M、K のいずれかを使用した単純な整数または固定小数点整数を使用できます。 また、2 のべき乗の値 (Ei、Pi、Ti、Gi、Mi、Ki) を使用することもできます。
- 保持期間とストレージサイズなどの値を設定します。
以下を実行して変更を適用します。
$ oc create -f cluster-monitoring-config.yml
第9章 オブジェクトの最大値に合わせた環境計画
OpenShift Container Platform クラスターの計画時に以下のテスト済みのオブジェクトの最大値を考慮します。
これらのガイドラインは、最大規模のクラスターに基づいています。小規模なクラスターの場合、最大値はこれより低くなります。指定のしきい値に影響を与える要因には、etcd バージョンやストレージデータ形式などの多数の要因があります。
ほとんど場合、これらの制限値を超えると、パフォーマンスが全体的に低下します。ただし、これによって必ずしもクラスターに障害が発生する訳ではありません。
9.1. メジャーリリースについての OpenShift Container Platform のテスト済みクラスターの最大値
OpenShift Container Platform 3.x のテスト済みクラウドプラットフォーム: Red Hat OpenStack (RHOSP)、Amazon Web Services および Microsoft AzureOpenShift Container Platform 4.x のテスト済み Cloud Platform : Amazon Web Services、Microsoft Azure および Google Cloud Platform
| 最大値のタイプ | 3.x テスト済みの最大値 | 4.x テスト済みの最大値 |
|---|---|---|
| ノード数 | 2,000 | 2,000 |
| Pod 数 [1] | 150,000 | 150,000 |
| ノードあたりの Pod 数 | 250 | 500 [2] |
| コアあたりの Pod 数 | デフォルト値はありません。 | デフォルト値はありません。 |
| namespace 数 [3] | 10,000 | 10,000 |
| ビルド数 | 10,000(デフォルト Pod RAM 512 Mi)- Pipeline ストラテジー | 10,000(デフォルト Pod RAM 512 Mi)- Source-to-Image (S2I) ビルドストラテジー |
| namespace ごとの Pod 数 [4] | 25,000 | 25,000 |
| サービス数 [5] | 10,000 | 10,000 |
| namespace ごとのサービス数 | 5,000 | 5,000 |
| サービスごとのバックエンド数 | 5,000 | 5,000 |
| namespace ごとのデプロイメント数 [4] | 2,000 | 2,000 |
- ここで表示される Pod 数はテスト用の Pod 数です。実際の Pod 数は、アプリケーションのメモリー、CPU、ストレージ要件により異なります。
-
これは、ワーカーノードごとに 500 の Pod を持つ 100 ワーカーノードを含むクラスターでテストされています。デフォルトの
maxPodsは 250 です。500maxPodsに到達するには、クラスターはカスタム kubelet 設定を使用し、maxPodsが500に設定された状態で作成される必要があります。500 ユーザー Pod が必要な場合は、ノード上に 10-15 のシステム Pod がすでに実行されているため、hostPrefixが22である必要があります。永続ボリューム要求 (PVC) が割り当てられている Pod の最大数は、PVC の割り当て元のストレージバックエンドによって異なります。このテストでは、OpenShift Container Storage v4 (OCS v4) のみが本書で説明されているノードごとの Pod 数に対応することができました。 - 有効なプロジェクトが多数ある場合、キースペースが過剰に拡大し、スペースのクォータを超過すると、etcd はパフォーマンスの低下による影響を受ける可能性があります。etcd ストレージを解放するために、デフラグを含む etcd の定期的なメンテナーンスを行うことを強くお勧めします。
- システムには、状態の変更に対する対応として特定の namespace にある全オブジェクトに対して反復する多数のコントロールループがあります。単一の namespace に特定タイプのオブジェクトの数が多くなると、ループのコストが上昇し、特定の状態変更を処理する速度が低下します。この制限については、アプリケーションの各種要件を満たすのに十分な CPU、メモリー、およびディスクがシステムにあることが前提となっています。
- 各サービスポートと各サービスのバックエンドには、iptables の対応するエントリーがあります。特定のサービスのバックエンド数は、エンドポイントのオブジェクトサイズに影響があり、その結果、システム全体に送信されるデータサイズにも影響を与えます。
9.2. OpenShift Container Platform のテスト済みのクラスターの最大値
| 最大値のタイプ | 4.1 テスト済みの最大値 | 4.2 テスト済みの最大値 | 4.3 テスト済みの最大値 | 4.4 テスト済みの最大値 |
|---|---|---|---|---|
| ノード数 | 2,000 | 2,000 | 2,000 | 250 |
| Pod 数 [1] | 150,000 | 150,000 | 150,000 | 62,500 |
| ノードあたりの Pod 数 | 250 | 250 | 500 | 500 |
| コアあたりの Pod 数 | デフォルト値はありません。 | デフォルト値はありません。 | デフォルト値はありません。 | デフォルト値はありません。 |
| namespace 数 [2] | 10,000 | 10,000 | 10,000 | 10,000 |
| ビルド数 | 10,000(デフォルト Pod RAM 512 Mi)- Pipeline ストラテジー | 10,000(デフォルト Pod RAM 512 Mi)- Pipeline ストラテジー | 10,000(デフォルト Pod RAM 512 Mi)- Source-to-Image (S2I) ビルドストラテジー | 10,000(デフォルト Pod RAM 512 Mi)- Source-to-Image (S2I) ビルドストラテジー |
| namespace ごとの Pod 数 [3] | 25,000 | 25,000 | 25,000 | 25,000 |
| サービス数 [4] | 10,000 | 10,000 | 10,000 | 10,000 |
| namespace ごとのサービス数 | 5,000 | 5,000 | 5,000 | 5,000 |
| サービスごとのバックエンド数 | 5,000 | 5,000 | 5,000 | 5,000 |
| namespace ごとのデプロイメント数 [3] | 2,000 | 2,000 | 2,000 | 2,000 |
- ここで表示される Pod 数はテスト用の Pod 数です。実際の Pod 数は、アプリケーションのメモリー、CPU、ストレージ要件により異なります。
- 有効なプロジェクトが多数ある場合、キースペースが過剰に拡大し、スペースのクォータを超過すると、etcd はパフォーマンスの低下による影響を受ける可能性があります。etcd ストレージを解放するために、デフラグを含む etcd の定期的なメンテナーンスを行うことを強くお勧めします。
- システムには、状態の変更に対する対応として特定の namespace にある全オブジェクトに対して反復する多数のコントロールループがあります。単一の namespace に特定タイプのオブジェクトの数が多くなると、ループのコストが上昇し、特定の状態変更を処理する速度が低下します。この制限については、アプリケーションの各種要件を満たすのに十分な CPU、メモリー、およびディスクがシステムにあることが前提となっています。
- 各サービスポートと各サービスのバックエンドには、iptables の対応するエントリーがあります。特定のサービスのバックエンド数は、エンドポイントのオブジェクトサイズに影響があり、その結果、システム全体に送信されるデータサイズにも影響を与えます。
OpenShift Container Platform 4.4 では、CPU コア (500 ミリコア) の半分がシステムによって予約されます (OpenShift Container Platform 3.11 以前のバージョンと比較)。
9.3. テスト済みのクラスターの最大値に基づく環境計画
ノード上で物理リソースを過剰にサブスクライブすると、Kubernetes スケジューラーが Pod の配置時に行うリソースの保証に影響が及びます。メモリースワップを防ぐために実行できる処置について確認してください。
一部のテスト済みの最大値については、単一の namespace/ユーザーが作成するオブジェクトでのみ変更されます。これらの制限はクラスター上で数多くのオブジェクトが実行されている場合には異なります。
本書に記載されている数は、Red Hat のテスト方法、セットアップ、設定、およびチューニングに基づいています。これらの数は、独自のセットアップおよび環境に応じて異なります。
環境の計画時に、ノードに配置できる Pod 数を判別します。
required pods per cluster / pods per node = total number of nodes needed
ノードあたりの現在の Pod の最大数は 250 です。ただし、ノードに適合する Pod 数はアプリケーション自体によって異なります。アプリケーション要件に合わせて環境計画を立てる方法で説明されているように、アプリケーションのメモリー、CPU およびストレージの要件を検討してください。
シナリオ例
クラスターごとに 2200 の Pod のあるクラスターのスコープを設定する場合、ノードごとに最大 500 の Pod があることを前提として、最低でも 5 つのノードが必要になります。
2200 / 500 = 4.4
ノード数を 20 に増やす場合は、Pod 配分がノードごとに 110 の Pod に変わります。
2200 / 20 = 110
ここで、
required pods per cluster / total number of nodes = expected pods per node
9.4. アプリケーション要件に合わせて環境計画を立てる方法
アプリケーション環境の例を考えてみましょう。
| Pod タイプ | Pod 数 | 最大メモリー | CPU コア数 | 永続ストレージ |
|---|---|---|---|---|
| apache | 100 | 500 MB | 0.5 | 1 GB |
| node.js | 200 | 1 GB | 1 | 1 GB |
| postgresql | 100 | 1 GB | 2 | 10 GB |
| JBoss EAP | 100 | 1 GB | 1 | 1 GB |
推定要件: CPU コア 550 個、メモリー 450GB およびストレージ 1.4TB
ノードのインスタンスサイズは、希望に応じて増減を調整できます。ノードのリソースはオーバーコミットされることが多く、デプロイメントシナリオでは、小さいノードで数を増やしたり、大きいノードで数を減らしたりして、同じリソース量を提供することもできます。このデプロイメントシナリオでは、小さいノードで数を増やしたり、大きいノードで数を減らしたりして、同じリソース量を提供することもできます。運用上の敏捷性やインスタンスあたりのコストなどの要因を考慮する必要があります。
| ノードのタイプ | 数量 | CPU | RAM (GB) |
|---|---|---|---|
| ノード (オプション 1) | 100 | 4 | 16 |
| ノード (オプション 2) | 50 | 8 | 32 |
| ノード (オプション 3) | 25 | 16 | 64 |
アプリケーションによってはオーバーコミットの環境に適しているものもあれば、そうでないものもあります。たとえば、Java アプリケーションや Huge Page を使用するアプリケーションの多くは、オーバーコミットに対応できません。対象のメモリーは、他のアプリケーションに使用できません。上記の例では、環境は一般的な比率として約 30 % オーバーコミットされています。
第10章 ストレージの最適化
ストレージを最適化すると、すべてのリソースでストレージの使用を最小限に抑えることができます。管理者は、ストレージを最適化することで、既存のストレージリソースが効率的に機能できるようにすることができます。
10.1. 利用可能な永続ストレージオプション
永続ストレージオプションについて理解し、OpenShift Container Platform 環境を最適化できるようにします。
表10.1 利用可能なストレージオプション
| ストレージタイプ | 説明 | 例 |
|---|---|---|
| ブロック |
| AWS EBS および VMware vSphere は、OpenShift Container Platform で永続ボリューム (PV) の動的なプロビジョニングをサポートします。 |
| ファイル |
| RHEL NFS、NetApp NFS [1]、および Vendor NFS |
| オブジェクト |
| AWS S3 |
- NetApp NFS は Trident プラグインを使用する場合に動的 PV のプロビジョニングをサポートします。
現時点で、CNS は OpenShift Container Platform 4.4 ではサポートされていません。
10.2. 設定可能な推奨のストレージ技術
以下の表では、特定の OpenShift Container Platform クラスターアプリケーション向けに設定可能な推奨のストレージ技術についてまとめています。
表10.2 設定可能な推奨ストレージ技術
| ストレージタイプ | ROX1 | RWX2 | レジストリー | スケーリングされたレジストリー | メトリクス3 | ロギング | アプリ |
|---|---|---|---|---|---|---|---|
|
1
2 3 Prometheus はメトリクスに使用される基礎となるテクノロジーです。 4 これは、物理ディスク、VM 物理ディスク、VMDK、NFS 経由のループバック、AWS EBS、および Azure Disk には該当しません。
5 メトリクスの場合、 6 ロギングの場合、共有ストレージを使用することはアンチパターンとなります。elasticsearch ごとに 1 つのボリュームが必要です。 7 オブジェクトストレージは、OpenShift Container Platform の PV/PVC で消費されません。アプリは、オブジェクトストレージの REST API と統合する必要があります。 | |||||||
| ブロック | はい4 | いいえ | 設定可能 | 設定不可 | 推奨 | 推奨 | 推奨 |
| ファイル | はい4 | ○ | 設定可能 | 設定可能 | 設定可能5 | 設定可能6 | 推奨 |
| オブジェクト | ○ | ○ | 推奨 | 推奨 | 設定不可 | 設定不可 | 設定不可7 |
スケーリングされたレジストリーとは、2 つ以上の Pod レプリカが稼働する OpenShift Container Platform レジストリーのことです。
10.2.1. 特定アプリケーションのストレージの推奨事項
テストにより、NFS サーバーを Red Hat Enterprise Linux (RHEL) でコアサービスのストレージバックエンドとして使用することに関する問題が検出されています。これには、OpenShift Container レジストリーおよび Quay、メトリクスストレージの Prometheus、およびロギングストレージの Elasticsearch が含まれます。そのため、コアサービスで使用される PV をサポートするために RHEL NFS を使用することは推奨されていません。
他の NFS の実装ではこれらの問題が検出されない可能性があります。OpenShift Container Platform コアコンポーネントに対して実施された可能性のあるテストに関する詳細情報は、個別の NFS 実装ベンダーにお問い合わせください。
10.2.1.1. レジストリー
スケーリングなし/高可用性 (HA) ではない OpenShift Container Platform レジストリークラスターのデプロイメント:
- ストレージ技術は、RWX アクセスモードをサポートする必要はありません。
- ストレージ技術は、リードアフターライト (Read-After-Write) の一貫性を確保する必要があります。
- 推奨されるストレージ技術はオブジェクトストレージであり、次はブロックストレージです。
- ファイルストレージは、実稼働環境のワークロードを処理する OpenShift Container Platform レジストリークラスターのデプロイメントには推奨されません。
10.2.1.2. スケーリングされたレジストリー
スケーリングされた/高可用性 (HA) の OpenShift Container Platform レジストリーのクラスターデプロイメント:
- ストレージ技術は、RWX アクセスモードをサポートし、リードアフターライトの一貫性を確保する必要があります。
- 推奨されるストレージ技術はオブジェクトストレージです。
- Amazon Simple Storage Service (Amazon S3)、Google Cloud Storage (GCS)、Microsoft Azure Blob Storage、および OpenStack Swift はサポートされます。
- ストレージは S3 または Swift に準拠する必要があります。
- ファイルストレージは、実稼働環境のワークロードを処理するスケーリングされた/HA の OpenShift Container Platform レジストリークラスターのデプロイメントには推奨されません。
- vSphere やベアメタルインストールなどのクラウド以外のプラットフォームの場合、設定可能な技術はファイルストレージのみです。
- ブロックストレージは設定できません。
10.2.1.3. メトリクス
OpenShift Container Platform がホストするメトリクスのクラスターデプロイメント:
- 推奨されるストレージ技術はブロックストレージです。
- オブジェクトストレージは設定できません。
実稼働ワークロードがあるホスト型のメトリクスクラスターデプロイメントにファイルストレージを使用することは推奨されません。
10.2.1.4. ロギング
OpenShift Container Platform がホストするロギングのクラスターデプロイメント:
- 推奨されるストレージ技術はブロックストレージです。
- ファイルストレージは、実稼働環境のワークロードを処理するスケーリングされた/HA の OpenShift Container Platform レジストリークラスターのデプロイメントには推奨されません。
- オブジェクトストレージは設定できません。
テストにより、NFS サーバーを RHEL でコアサービスのストレージバックエンドとして使用することに関する問題が検出されています。これには、ロギングストレージの Elasticsearch が含まれます。そのため、コアサービスで使用される PV をサポートするために RHEL NFS を使用することは推奨されていません。
他の NFS の実装ではこれらの問題が検出されない可能性があります。OpenShift Container Platform コアコンポーネントに対して実施された可能性のあるテストに関する詳細情報は、個別の NFS 実装ベンダーにお問い合わせください。
10.2.1.5. アプリケーション
以下の例で説明されているように、アプリケーションのユースケースはアプリケーションごとに異なります。
- 動的な PV プロビジョニングをサポートするストレージ技術は、マウント時のレイテンシーが低く、ノードに関連付けられておらず、正常なクラスターをサポートします。
- アプリケーション開発者はアプリケーションのストレージ要件や、それがどのように提供されているストレージと共に機能するかを理解し、アプリケーションのスケーリング時やストレージレイヤーと対話する際に問題が発生しないようにしておく必要があります。
10.2.2. 特定のアプリケーションおよびストレージの他の推奨事項
-
OpenShift Container Platform Internal
etcd:etcdの信頼性を最も高く保つには、一貫してレイテンシーが最も低くなるストレージ技術が推奨されます。 -
NVMe や SSD などのシリアル書き込み (fsync) を迅速に処理するストレージで
etcdを使用することが強く推奨されます。Ceph、NFS、およびスピニングディスクは推奨されません。 - Red Hat OpenStack Platform (RHOSP) Cinder: RHOSP Cinder は ROX アクセスモードのユースケースで適切に機能する傾向があります。
- データベース: データベース (RDBMS、NoSQL DB など) は、専用のブロックストレージで最適に機能することが予想されます。
10.3. データストレージ管理
以下の表は、OpenShift Container Platform コンポーネントがデータを書き込むメインディレクトリーの概要を示しています。
表10.3 OpenShift Container Platform データを保存するメインディレクトリー
| ディレクトリー | 注記 | サイジング | 予想される拡張 |
|---|---|---|---|
| /var/log | すべてのコンポーネントのログファイルです。 | 10 から 30 GB。 | ログファイルはすぐに拡張する可能性があります。サイズは拡張するディスク別に管理するか、ログローテーションを使用して管理できます。 |
| /var/lib/etcd | データベースを保存する際に etcd ストレージに使用されます。 | 20 GB 未満。 データベースは、最大 8 GB まで拡張できます。 | 環境と共に徐々に拡張します。メタデータのみを格納します。 メモリーに 8 GB が追加されるたびに 20-25 GB を追加します。 |
| /var/lib/containers | これは CRI-O ランタイムのマウントポイントです。アクティブなコンテナーランタイム (Pod を含む) およびローカルイメージのストレージに使用されるストレージです。レジストリーストレージには使用されません。 | 16 GB メモリーの場合、1 ノードにつき 50 GB。このサイジングは、クラスターの最小要件の決定には使用しないでください。 メモリーに 8 GB が追加されるたびに 20-25 GB を追加します。 | 拡張は実行中のコンテナーの容量によって制限されます。 |
| /var/lib/kubelet | Pod の一時ボリュームストレージです。これには、ランタイムにコンテナーにマウントされる外部のすべての内容が含まれます。環境変数、kube シークレット、および永続ボリュームでサポートされていないデータボリュームが含まれます。 | 変動あり。 | ストレージを必要とする Pod が永続ボリュームを使用している場合は最小になります。一時ストレージを使用する場合はすぐに拡張する可能性があります。 |
第11章 ルーティングの最適化
OpenShift Container Platform HAProxy ルーターは、パフォーマンスを最適化するためにスケーリングします。
11.1. ベースラインのルーターパフォーマンス
OpenShift Container Platform ルーターは、宛先が OpenShift Container Platform サービスのすべての外部トラフィックに対する Ingress ポイントです。
1 秒に処理される HTTP 要求について、単一の HAProxy ルーターを評価する場合に、パフォーマンスは多くの要因により左右されます。特に以下が含まれます。
- HTTP keep-alive/close モード
- ルートタイプ
- TLS セッション再開のクライアントサポート
- ターゲットルートごとの同時接続数
- ターゲットルート数
- バックエンドサーバーのページサイズ
- 基礎となるインフラストラクチャー (ネットワーク/SDN ソリューション、CPU など)
個別の環境でのパフォーマンスは異なりますが、Red Hat ラボは、サイズが 4 vCPU/16GB RAM のパブリッククラウドインスタンスでテストします。 ルート 100 個を処理し、1kB 静的ページに対応するバックエンドで終端される 100 ルートを処理する単一の HAProxy ルーターは、1 秒ごとに以下の数のトランザクションを処理できます。
HTTP keep-alive モードのシナリオの場合:
| 暗号化 | LoadBalancerService | HostNetwork |
|---|---|---|
| なし | 21515 | 29622 |
| edge | 16743 | 22913 |
| passthrough | 36786 | 53295 |
| re-encrypt | 21583 | 25198 |
HTTP close (keep-alive なし) のシナリオの場合:
| 暗号化 | LoadBalancerService | HostNetwork |
|---|---|---|
| なし | 5719 | 8273 |
| edge | 2729 | 4069 |
| passthrough | 4121 | 5344 |
| re-encrypt | 2320 | 2941 |
ROUTER_THREADS=4 が設定されたデフォルトのルート設定が使用され、2 つの異なるエンドポイントの公開ストラテジー (LoadBalancerService/HostNetwork) がテストされています。TLS セッション再開は暗号化ルートについて使用されています。HTTP keep-alive の場合は、単一の HAProxy ルーターがページサイズが 8kB でも、1 Gbit の NIC を飽和させることができます。
最新のプロセッサーが搭載されたベアメタルで実行する場合は、上記のパブリッククラウドインスタンスのパフォーマンスの約 2 倍のパフォーマンスになることを予想できます。このオーバーヘッドは、パブリッククラウドにある仮想化層により発生し、プライベートクラウドベースの仮想化にも多くの場合、該当します。以下の表は、ルーターの背後で使用するアプリケーション数についてのガイドです。
| アプリケーション数 | アプリケーションタイプ |
|---|---|
| 5-10 | 静的なファイル/Web サーバーまたはキャッシュプロキシー |
| 100-1000 | 動的なコンテンツを生成するアプリケーション |
通常、HAProxy は、使用されるて技術に応じて 5 から 1000 のアプリケーションのルーターをサポートします。ルーターのパフォーマンスは、言語や静的コンテンツと動的コンテンツの違いを含め、その背後にあるアプリケーションの機能およびパフォーマンスによって制限される可能性があります。
ルーターのシャード化は、アプリケーションに対してより多くのルートを提供するために使用され、ルーティング層の水平スケーリングに役立ちます。
11.2. ルーターパフォーマンスの最適化
OpenShift Container Platform では、環境変数 (ROUTER_THREADS、 ROUTER_DEFAULT_TUNNEL_TIMEOUT、ROUTER_DEFAULT_CLIENT_TIMEOUT、ROUTER_DEFAULT_SERVER_TIMEOUT、および RELOAD_INTERVAL) を設定してルーターのデプロイメントを変更することをサポートしていません。
ルーターのデプロイメントは変更できますが、Ingress Operator が有効にされている場合、設定は上書きされます。
第12章 ネットワークの最適化
OpenShift SDN は OpenvSwitch、VXLAN (Virtual extensible LAN) トンネル、OpenFlow ルール、iptables を使用します。このネットワークは、ジャンボフレーム、ネットワークインターフェイスカード (NIC) のオフロード、マルチキュー、ethtool の設定を使用してチューニングが可能です。
OVN-Kubernetes は、トンネルプロトコルとして VXLAN ではなく Geneve (Generic Network Virtualization Encapsulation) を使用します。
VXLAN は、4096 から 1600 万以上にネットワーク数が増え、物理ネットワーク全体で階層 2 の接続が追加されるなど、VLAN での利点が提供されます。これにより、異なるシステム上で実行されている場合でも、サービスの背後にある Pod すべてが相互に通信できるようになります。
VXLAN は、User Datagram Protocol (UDP) パケットにトンネル化されたトラフィックをすべてカプセル化しますが、CPU 使用率が上昇してしまいます。これらの外部および内部パケットは、移動中にデータが破損しないようにするために通常のチェックサムルールの対象になります。これらの外部および内部パケットはどちらも、移動中にデータが破損しないように通常のチェックサムルールの対象になります。CPU のパフォーマンスによっては、この追加の処理オーバーヘッドによってスループットが減り、従来の非オーバーレイネットワークと比較してレイテンシーが高くなります。
クラウド、仮想マシン、ベアメタルの CPU パフォーマンスでは、1 Gbps をはるかに超えるネットワークスループットを処理できます。10 または 40 Gbps などの高い帯域幅のリンクを使用する場合には、パフォーマンスが低減する場合があります。これは、VXLAN ベースの環境では既知の問題で、コンテナーや OpenShift Container Platform 固有の問題ではありません。VXLAN トンネルに依存するネットワークも、VXLAN 実装により同様のパフォーマンスになります。
1 Gbps 以上にするには、以下を実行してください。
- Border Gateway Protocol (BGP) など、異なるルーティング技術を実装するネットワークプラグインを評価する。
- VXLAN オフロード対応のネットワークアダプターを使用します。VXLAN オフロードは、システムの CPU から、パケットのチェックサム計算と関連の CPU オーバーヘッドを、ネットワークアダプター上の専用のハードウェアに移動します。これにより、CPU サイクルを Pod やアプリケーションで使用できるように開放し、ネットワークインフラストラクチャーの帯域幅すべてをユーザーは活用できるようになります。
VXLAN オフロードはレイテンシーを短縮しません。ただし、CPU の使用率はレイテンシーテストでも削減されます。
12.1. ネットワークでの MTU の最適化
重要な Maximum Transmission Unit (MTU) が 2 つあります (ネットワークインターフェイスカード (NIC) MTU とクラスターネットワーク MTU です)。
NIC MTU は OpenShift Container Platform のインストール時にのみ設定されます。MTU は、お使いのネットワークの NIC でサポートされる最大の値以下でなければなりません。スループットを最適化する場合は、可能な限り大きい値を選択します。レイテンシーを最低限に抑えるために最適化するには、より小さい値を選択します。
SDN オーバーレイの MTU は、最低でも NIC MTU より 50 バイト少なくなければなりません。これは、SDN オーバーレイのヘッダーに相当します。そのため、通常のイーサネットネットワークでは、この値を 1450 に設定します。ジャンボフレームのイーサネットネットワークの場合は、これを 8950 に設定します。
OVN および Geneve については、MTU は最低でも NIC MTU より 100 バイト少なくなければなりません。
50 バイトのオーバーレイヘッダーは OpenShift SDN に関連します。他の SDN ソリューションの場合はこの値を若干変動させる必要があります。
12.2. 大規模なクラスターのインストールに推奨されるプラクティス
大規模なクラスターをインストールする場合や、クラスターを大規模なノード数に拡張する場合、クラスターをインストールする前に、install-config.yaml ファイルに適宜クラスターネットワーク cidr を設定します。
networking:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
machineCIDR: 10.0.0.0/16
networkType: OpenShiftSDN
serviceNetwork:
- 172.30.0.0/16クラスターのサイズが 500 ノードを超える場合は、デフォルトの clusterNetwork cidr 10.128.0.0/14 を使用することはできません。500 ノードを超えるノード数にするには、10.128.0.0/12 または 10.128.0.0/10 に設定する必要があります。
12.3. IPsec の影響
ノードホストの暗号化、復号化に CPU 機能が使用されるので、使用する IP セキュリティーシステムにかかわらず、ノードのスループットおよび CPU 使用率の両方でのパフォーマンスに影響があります。
IPSec は、NIC に到達する前に IP ペイロードレベルでトラフィックを暗号化して、NIC オフロードに使用されてしまう可能性のあるフィールドを保護します。つまり、IPSec が有効な場合には、NIC アクセラレーション機能を使用できない場合があり、スループットの減少、CPU 使用率の上昇につながります。
第13章 Huge Page の機能およびそれらがアプリケーションによって消費される仕組み
13.1. Huge Page の機能
メモリーは Page と呼ばれるブロックで管理されます。多くのシステムでは、1 ページは 4Ki です。メモリー 1Mi は 256 ページに、メモリー 1Gi は 256,000 ページに相当します。CPU には、内蔵のメモリー管理ユニットがあり、ハードウェアでこのようなページリストを管理します。トランスレーションルックアサイドバッファー (TLB: Translation Lookaside Buffer) は、仮想から物理へのページマッピングの小規模なハードウェアキャッシュのことです。ハードウェアの指示で渡された仮想アドレスが TLB にあれば、マッピングをすばやく決定できます。そうでない場合には、TLB ミスが発生し、システムは速度が遅く、ソフトウェアベースのアドレス変換にフォールバックされ、パフォーマンスの問題が発生します。TLB のサイズは固定されているので、TLB ミスの発生率を減らすには Page サイズを大きくする必要があります。
Huge Page とは、4Ki より大きいメモリーページのことです。x86_64 アーキテクチャーでは、2Mi と 1Gi の 2 つが一般的な Huge Page サイズです。別のアーキテクチャーではサイズは異なります。Huge Page を使用するには、アプリケーションが認識できるようにコードを書き込む必要があります。Transparent Huge Pages (THP) は、アプリケーションによる認識なしに、Huge Page の管理を自動化しようとしますが、制約があります。特に、ページサイズは 2Mi に制限されます。THP では、THP のデフラグが原因で、メモリー使用率が高くなり、断片化が起こり、パフォーマンスの低下につながり、メモリーページがロックされてしまう可能性があります。このような理由から、アプリケーションは THP ではなく、事前割り当て済みの Huge Page を使用するように設計 (また推奨) される場合があります。
OpenShift Container Platform では、Pod のアプリケーションが事前に割り当てられた Huge Page を割り当て、消費することができます。
13.2. Huge Page がアプリケーションによって消費される仕組み
ノードは、Huge Page の容量をレポートできるように Huge Page を事前に割り当てる必要があります。ノードは、単一サイズの Huge Page のみを事前に割り当てることができます。
Huge Page は、リソース名の hugepages-<size> を使用してコンテナーレベルのリソース要件で消費可能です。この場合、サイズは特定のノードでサポートされる整数値を使用した最もコンパクトなバイナリー表記です。たとえば、ノードが 2048KiB ページサイズをサポートする場合、これはスケジュール可能なリソース hugepages-2Mi を公開します。CPU やメモリーとは異なり、Huge Page はオーバーコミットをサポートしません。
apiVersion: v1
kind: Pod
metadata:
generateName: hugepages-volume-
spec:
containers:
- securityContext:
privileged: true
image: rhel7:latest
command:
- sleep
- inf
name: example
volumeMounts:
- mountPath: /dev/hugepages
name: hugepage
resources:
limits:
hugepages-2Mi: 100Mi 1
memory: "1Gi"
cpu: "1"
volumes:
- name: hugepage
emptyDir:
medium: HugePages- 1
hugepagesのメモリー量は、実際に割り当てる量に指定します。この値は、ページサイズで乗算したhugepagesのメモリー量に指定しないでください。たとえば、Huge Page サイズが 2MB と仮定し、アプリケーションに Huge Page でバックアップする RAM 100 MB を使用する場合には、Huge Page は 50 に指定します。OpenShift Container Platform により、計算処理が実行されます。上記の例にあるように、100MBを直接指定できます。
指定されたサイズの Huge Page の割り当て
プラットフォームによっては、複数の Huge Page サイズをサポートするものもあります。特定のサイズの Huge Page を割り当てるには、Huge Page の起動コマンドパラメーターの前に、Huge Page サイズの選択パラメーター hugepagesz=<size> を指定してください。<size> の値は、バイトで指定する必要があります。その際、オプションでスケール接尾辞 [kKmMgG] を指定できます。デフォルトの Huge Page サイズは、default_hugepagesz=<size> の起動パラメーターで定義できます。
Huge page の要件
- Huge Page 要求は制限と同じでなければなりません。制限が指定されているにもかかわらず、要求が指定されていない場合には、これがデフォルトになります。
- Huge Page は、Pod のスコープで分割されます。コンテナーの分割は、今後のバージョンで予定されています。
-
Huge Page がサポートする
EmptyDirボリュームは、Pod 要求よりも多くの Huge Page メモリーを消費することはできません。 -
shmget()でSHM_HUGETLBを使用して Huge Page を消費するアプリケーションは、proc/sys/vm/hugetlb_shm_group に一致する補助グループで実行する必要があります。
13.3. Huge Page の設定
ノードは、OpenShift Container Platform クラスターで使用される Huge Page を事前に割り当てる必要があります。Node Tuning Operator を使用し、特定のノードで Huge Page を割り当てます。
手順
ノードにタグを付け、割り当てる必要のある Huge Page を記述した Tuned プロファイルを適用するノードを Node Tuning Operator が識別できるようにします。
$ oc label node <node_using_hugepages> hugepages=true
以下の内容でファイルを作成し、これに
hugepages_tuning.yamlという名前を付けます。apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: hugepages 1 namespace: openshift-cluster-node-tuning-operator spec: profile: 2 - data: | [main] summary=Configuration for hugepages include=openshift-node [vm] transparent_hugepages=never [sysctl] vm.nr_hugepages=1024 name: node-hugepages recommend: - match: 3 - label: hugepages priority: 30 profile: node-hugepages
hugepages_tuning.yamlファイルを使用して、カスタムhugepagesTuned プロファイルを作成します。$ oc create -f hugepages_tuning.yaml
プロファイルの作成後、Operator は新規プロファイルを正確なノードに適用し、Huge Page を割り当てます。Huge Page を使用してノードでチューニングされた Pod のログをチェックして、以下を確認します。
$ oc logs <tuned_pod_on_node_using_hugepages> \ -n openshift-cluster-node-tuning-operator | grep 'applied$' | tail -n12019-08-08 07:20:41,286 INFO tuned.daemon.daemon: static tuning from profile 'node-hugepages' applied