
ネットワーク
クラスターネットワークの設定および管理
概要
第1章 ネットワークの概要
Red Hat OpenShift Networking は、1 つまたは複数のハイブリッドクラスターのネットワークトラフィックを管理するためにクラスターが必要とする高度なネットワーク関連機能で Kubernetes ネットワーキングを拡張する機能、プラグイン、高度なネットワーク機能のエコシステムです。このネットワーキング機能のエコシステムは、ingress、egress、ロードバランシング、高性能スループット、セキュリティー、クラスター間およびクラスター内のトラフィック管理を統合し、ロールベースの可観測性ツールを提供して複雑さを軽減します。
以下のリストは、クラスターで利用可能な最も一般的に使用される Red Hat OpenShift Networking 機能の一部を強調しています。
次の Container Network Interface (CNI) プラグインのいずれかによって提供されるプライマリークラスターネットワーク:
- OVN-Kubernetes ネットワークプラグイン (デフォルトのプラグイン)
- OpenShift SDN ネットワークプラグイン
- 認定されたサードパーティーの代替プライマリーネットワークプラグイン
- ネットワークプラグイン管理用の Cluster Network Operator
- TLS 暗号化 Web トラフィックの Ingress Operator
- 名前割り当てのための DNS Operator
- ベアメタルクラスターでのトラフィック負荷分散用の MetalLB Operator
- 高可用性のための IP フェイルオーバーのサポート
- macvlan、ipvlan、SR-IOV ハードウェアネットワークなど、複数の CNI プラグインによる追加のハードウェアネットワークサポート
- IPv4、IPv6、およびデュアルスタックアドレッシング
- Windows ベースのワークロード用のハイブリッド Linux-Windows ホストクラスター
- サービスのディスカバリー、ロードバランシング、サービス間認証、障害リカバリー、メトリクス、およびモニター用の Red Hat OpenShift Service Mesh
- シングルノード OpenShift
- ネットワークのデバッグと洞察のための Network Observability Operator
- クラスター間ネットワーキングのための Submariner および Red Hat Application Interconnect テクノロジー
第2章 ネットワークについて
クラスター管理者は、クラスターで実行されるアプリケーションを外部トラフィックに公開し、ネットワーク接続のセキュリティーを保護するための複数のオプションがあります。
- ノードポートやロードバランサーなどのサービスタイプ
-
IngressやRouteなどの API リソース
デフォルトで、Kubernetes は各 Pod に、Pod 内で実行しているアプリケーションの内部 IP アドレスを割り当てます。Pod とそのコンテナーはネットワーク接続が可能ですが、クラスター外のクライアントにはネットワークアクセスがありません。アプリケーションを外部トラフィックに公開する場合、各 Pod に IP アドレスを割り当てると、ポートの割り当て、ネットワーク、名前の指定、サービス検出、負荷分散、アプリケーション設定、移行などの点で、Pod を物理ホストや仮想マシンのように扱うことができます。
一部のクラウドプラットフォームでは、169.254.169.254 IP アドレスでリッスンするメタデータ API があります。これは、IPv4 169.254.0.0/16 CIDR ブロックのリンクローカル IP アドレスです。
この CIDR ブロックは Pod ネットワークから到達できません。これらの IP アドレスへのアクセスを必要とする Pod には、Pod 仕様の spec.hostNetwork フィールドを true に設定して、ホストのネットワークアクセスが付与される必要があります。
Pod ホストのネットワークアクセスを許可する場合、Pod に基礎となるネットワークインフラストラクチャーへの特権アクセスを付与します。
2.1. OpenShift Container Platform DNS
フロントエンドサービスやバックエンドサービスなど、複数のサービスを実行して複数の Pod で使用している場合、フロントエンド Pod がバックエンドサービスと通信できるように、ユーザー名、サービス IP などの環境変数を作成します。サービスが削除され、再作成される場合には、新規の IP アドレスがそのサービスに割り当てられるので、フロントエンド Pod がサービス IP の環境変数の更新された値を取得するには、これを再作成する必要があります。さらに、バックエンドサービスは、フロントエンド Pod を作成する前に作成し、サービス IP が正しく生成され、フロントエンド Pod に環境変数として提供できるようにする必要があります。
そのため、OpenShift Container Platform には DNS が組み込まれており、これにより、サービスは、サービス IP/ポートと共にサービス DNS によって到達可能になります。
2.2. OpenShift Container Platform Ingress Operator
OpenShift Container Platform クラスターを作成すると、クラスターで実行している Pod およびサービスにはそれぞれ独自の IP アドレスが割り当てられます。IP アドレスは、近くで実行されている他の Pod やサービスからアクセスできますが、外部クライアントの外部からはアクセスできません。Ingress Operator は IngressController API を実装し、OpenShift Container Platform クラスターサービスへの外部アクセスを可能にするコンポーネントです。
Ingress Operator を使用すると、ルーティングを処理する 1 つ以上の HAProxy ベースの Ingress Controller をデプロイおよび管理することにより、外部クライアントがサービスにアクセスできるようになります。OpenShift Container Platform Route および Kubernetes Ingress リソースを指定して、トラフィックをルーティングするために Ingress Operator を使用します。endpointPublishingStrategy タイプおよび内部負荷分散を定義する機能などの Ingress Controller 内の設定は、Ingress Controller エンドポイントを公開する方法を提供します。
2.2.1. ルートと Ingress の比較
OpenShift Container Platform の Kubernetes Ingress リソースは、クラスター内で Pod として実行される共有ルーターサービスと共に Ingress Controller を実装します。Ingress トラフィックを管理する最も一般的な方法は Ingress Controller を使用することです。他の通常の Pod と同様にこの Pod をスケーリングし、複製できます。このルーターサービスは、オープンソースのロードバランサーソリューションである HAProxy をベースとしています。
OpenShift Container Platform ルートは、クラスターのサービスに Ingress トラフィックを提供します。ルートは、Blue-Green デプロイメント向けに TLS 再暗号化、TLS パススルー、分割トラフィックなどの標準の Kubernetes Ingress Controller でサポートされない可能性のある高度な機能を提供します。
Ingress トラフィックは、ルートを介してクラスターのサービスにアクセスします。ルートおよび Ingress は、Ingress トラフィックを処理する主要なリソースです。Ingress は、外部要求を受け入れ、ルートに基づいてそれらを委譲するなどのルートと同様の機能を提供します。ただし、Ingress では、特定タイプの接続 (HTTP/2、HTTPS およびサーバー名 ID(SNI)、ならび証明書を使用した TLS のみを許可できます。OpenShift Container Platform では、ルートは、Ingress リソースで指定される各種の条件を満たすために生成されます。
2.3. OpenShift Container Platform ネットワーキングの一般用語集
この用語集では、ネットワーキングコンテンツで使用される一般的な用語を定義します。
- authentication
- OpenShift Container Platform クラスターへのアクセスを制御するために、クラスター管理者はユーザー認証を設定し、承認されたユーザーのみがクラスターにアクセスできます。OpenShift Container Platform クラスターと対話するには、OpenShift Container Platform API に対して認証する必要があります。Open Shift Container Platform API へのリクエストで、OAuth アクセストークンまたは X.509 クライアント証明書を提供することで認証できます。
- AWS Load Balancer Operator
-
AWS Load Balancer (ALB) Operator は、
aws-load-balancer-controllerのインスタンスをデプロイおよび管理します。 - Cluster Network Operator
- Cluster Network Operator (CNO) は、OpenShift Container Platform クラスター内のクラスターネットワークコンポーネントをデプロイおよび管理します。これには、インストール時にクラスター用に選択された Container Network Interface (CNI) ネットワークプラグインのデプロイが含まれます。
- ConfigMap
-
ConfigMap は、設定データを Pod に注入する方法を提供します。タイプ
ConfigMapのボリューム内の ConfigMap に格納されたデータを参照できます。Pod で実行しているアプリケーションは、このデータを使用できます。 - カスタムリソース (CR)
- CR は Kubernetes API の拡張です。カスタムリソースを作成できます。
- DNS
- クラスター DNS は、Kubernetes サービスの DNS レコードを提供する DNS サーバーです。Kubernetes により開始したコンテナーは、DNS 検索にこの DNS サーバーを自動的に含めます。
- DNS Operator
- DNS Operator は、CoreDNS をデプロイして管理し、Pod に名前解決サービスを提供します。これにより、OpenShift Container Platform で DNS ベースの Kubernetes サービス検出が可能になります。
- deployment
- アプリケーションのライフサイクルを維持する Kubernetes リソースオブジェクト。
- domain
- ドメインは、Ingress Controller によってサービスされる DNS 名です。
- egress
- Pod からのネットワークのアウトバウンドトラフィックを介して外部とデータを共有するプロセス。
- 外部 DNS Operator
- 外部 DNS Operator は、ExternalDNS をデプロイして管理し、外部 DNS プロバイダーから OpenShift Container Platform へのサービスおよびルートの名前解決を提供します。
- HTTP ベースのルート
- HTTP ベースのルートとは、セキュアではないルートで、基本的な HTTP ルーティングプロトコルを使用してセキュリティー保護されていないアプリケーションポートでサービスを公開します。
- Ingress
- OpenShift Container Platform の Kubernetes Ingress リソースは、クラスター内で Pod として実行される共有ルーターサービスと共に Ingress Controller を実装します。
- Ingress Controller
- Ingress Operator は Ingress Controller を管理します。Ingress Controller の使用は、最も一般的な、OpenShift Container Platform クラスターへの外部アクセスを許可する方法です。
- インストーラーでプロビジョニングされるインフラストラクチャー
- インストールプログラムは、クラスターが実行されるインフラストラクチャーをデプロイして設定します。
- kubelet
- コンテナーが Pod で実行されていることを確認するために、クラスター内の各ノードで実行されるプライマリーノードエージェント。
- Kubernetes NMState Operator
- Kubernetes NMState Operator は、NMState の OpenShift Container Platform クラスターのノード間でステートドリブンのネットワーク設定を実行するための Kubernetes API を提供します。
- kube-proxy
- Kube-proxy は、各ノードで実行するプロキシーサービスであり、外部ホストがサービスを利用できるようにするのに役立ちます。リクエストを正しいコンテナーに転送するのに役立ち、基本的な負荷分散を実行できます。
- ロードバランサー
- OpenShift Container Platform は、ロードバランサーを使用して、クラスターの外部からクラスターで実行されているサービスと通信します。
- MetalLB Operator
-
クラスター管理者は、MetalLB Operator をクラスターに追加し、タイプ
LoadBalancerのサービスがクラスターに追加されると、MetalLB はサービスの外部 IP アドレスを追加できます。 - multicast
- IP マルチキャストを使用すると、データが多数の IP アドレスに同時に配信されます。
- namespace
- namespace は、すべてのプロセスから見える特定のシステムリソースを分離します。namespace 内では、その namespace のメンバーであるプロセスのみがそれらのリソースを参照できます。
- networking
- OpenShift Container Platform クラスターのネットワーク情報。
- node
- OpenShift Container Platform クラスター内のワーカーマシン。ノードは、仮想マシン (VM) または物理マシンのいずれかです。
- OpenShift Container Platform Ingress Operator
-
Ingress Operator は
IngressControllerAPI を実装し、OpenShift Container Platform サービスへの外部アクセスを可能にするコンポーネントです。 - Pod
- OpenShift Container Platform クラスターで実行されている、ボリュームや IP アドレスなどの共有リソースを持つ 1 つ以上のコンテナー。Pod は、定義、デプロイ、および管理される最小のコンピュート単位です。
- PTP Operator
-
PTP Operator は、
linuxptpサービスを作成し、管理します。 - route
- OpenShift Container Platform ルートは、クラスターのサービスに Ingress トラフィックを提供します。ルートは、Blue-Green デプロイメント向けに TLS 再暗号化、TLS パススルー、分割トラフィックなどの標準の Kubernetes Ingress Controller でサポートされない可能性のある高度な機能を提供します。
- スケーリング
- リソース容量の増減。
- サービス
- 一連の Pod で実行中のアプリケーションを公開します。
- シングルルート I/O 仮想化 (SR-IOV) Network Operator
- Single Root I/O Virtualization (SR-IOV) ネットワーク Operator は、クラスターで SR-IOV ネットワークデバイスおよびネットワーク割り当てを管理します。
- ソフトウェア定義ネットワーク (SDN)
- OpenShift Container Platform は、Software Defined Networking (SDN) アプローチを使用して、クラスターのネットワークを統合し、OpenShift Container Platform クラスターの Pod 間の通信を可能にします。
- SCTP (Stream Control Transmission Protocol)
- SCTP は、IP ネットワークの上部で実行される信頼できるメッセージベースのプロトコルです。
- taint
- テイントと容認により、Pod が適切なノードに確実にスケジュールされます。ノードに 1 つ以上のテイントを適用できます。
- 容認
- Pod に容認を適用できます。Tolerations を使用すると、スケジューラーは、テイントが一致する Pod をスケジュールできます。
- Web コンソール
- OpenShift Container Platform を管理するためのユーザーインターフェイス (UI)。
第3章 ホストへのアクセス
OpenShift Container Platform インスタンスにアクセスして、セキュアシェル (SSH) アクセスでコントロールプレーンノードにアクセスするために bastion ホストを作成する方法を学びます。
3.1. インストーラーでプロビジョニングされるインフラストラクチャークラスターでの Amazon Web Services のホストへのアクセス
OpenShift Container Platform インストーラーは、OpenShift Container Platform クラスターにプロビジョニングされる Amazon Elastic Compute Cloud (Amazon EC2) インスタンスのパブリック IP アドレスを作成しません。OpenShift Container Platform ホストに対して SSH を実行できるようにするには、以下の手順を実行する必要があります。
手順
-
openshift-installコマンドで作成される仮想プライベートクラウド (VPC) に対する SSH アクセスを可能にするセキュリティーグループを作成します。 - インストーラーが作成したパブリックサブネットのいずれかに Amazon EC2 インスタンスを作成します。
パブリック IP アドレスを、作成した Amazon EC2 インスタンスに関連付けます。
OpenShift Container Platform のインストールとは異なり、作成した Amazon EC2 インスタンスを SSH キーペアに関連付ける必要があります。これにはインターネットを OpenShift Container Platform クラスターの VPC にブリッジ接続するための SSH bastion としてのみの単純な機能しかないため、このインスタンスにどのオペレーティングシステムを選択しても問題ありません。どの Amazon Machine Image (AMI) を使用するかについては、注意が必要です。たとえば、Red Hat Enterprise Linux CoreOS (RHCOS) では、インストーラーと同様に、Ignition でキーを指定することができます。
Amazon EC2 インスタンスをプロビジョニングし、これに対して SSH を実行した後に、OpenShift Container Platform インストールに関連付けた SSH キーを追加する必要があります。このキーは bastion インスタンスのキーとは異なる場合がありますが、異なるキーにしなければならない訳ではありません。
注記直接の SSH アクセスは、障害復旧を目的とする場合にのみ推奨されます。Kubernetes API が応答する場合、特権付き Pod を代わりに実行します。
-
oc get nodesを実行し、出力を検査し、マスターであるノードのいずれかを選択します。ホスト名はip-10-0-1-163.ec2.internalに類似したものになります。 Amazon EC2 に手動でデプロイした bastion SSH ホストから、そのコントロールプレーンホストに SSH を実行します。インストール時に指定したものと同じ SSH キーを使用するようにします。
$ ssh -i <ssh-key-path> core@<master-hostname>
第4章 ネットワーキング Operator の概要
OpenShift Container Platform は、複数のタイプのネットワーキング Operator をサポートします。これらのネットワーク Operator を使用して、クラスターネットワークを管理できます。
4.1. Cluster Network Operator
Cluster Network Operator (CNO) は、OpenShift Container Platform クラスター内のクラスターネットワークコンポーネントをデプロイおよび管理します。これには、インストール時にクラスター用に選択された Container Network Interface (CNI) ネットワークプラグインのデプロイが含まれます。詳細は、OpenShift Container Platform における Cluster Network Operator を参照してください。
4.2. DNS Operator
DNS Operator は、CoreDNS をデプロイして管理し、Pod に名前解決サービスを提供します。これにより、OpenShift Container Platform で DNS ベースの Kubernetes サービス検出が可能になります。詳細は、OpenShift Container Platform の DNS Operator を参照してください。
4.3. Ingress Operator
OpenShift Container Platform クラスターを作成すると、クラスターで実行している Pod およびサービスにはそれぞれの IP アドレスが割り当てられます。IP アドレスは、近くで実行されている他の Pod やサービスからアクセスできますが、外部クライアントの外部からはアクセスできません。Ingress Operator は IngressController API を実装し、OpenShift Container Platform クラスターサービスへの外部アクセスを可能にします。詳細は、OpenShift Container Platform の Ingress Operator を参照してください。
4.4. 外部 DNS Operator
外部 DNS Operator は、ExternalDNS をデプロイして管理し、外部 DNS プロバイダーから OpenShift Container Platform へのサービスおよびルートの名前解決を提供します。詳細は、Understanding the External DNS Operator を参照してください。
4.5. Ingress Node Firewall Operator
Ingress Node Firewall Operator は、拡張された Berkley Packet Filter (eBPF) と eXpress Data Path (XDP) プラグインを使用して、ノードファイアウォールルールを処理し、統計を更新し、ドロップされたトラフィックのイベントを生成します。Operator は、Ingress ノードファイアウォールリソースを管理し、ファイアウォール設定を検証し、クラスターアクセスを妨げる可能性がある誤設定されたルールを許可せず、ルールのオブジェクトで選択されたインターフェイスに Ingress ノードファイアウォール XDP プログラムをロードします。詳細は、Ingress Node Firewall Operator についてを参照してください。
4.6. Network Observability Operator
Network Observability Operator は、クラスター管理者が OpenShift Container Platform クラスターのネットワークトラフィックを観察するために使用できるオプションの Operator です。Network Observability Operator は、eBPF テクノロジーを使用してネットワークフローを作成します。その後、ネットワークフローは OpenShift Container Platform 情報で強化され、Loki に保存されます。保存されたネットワークフロー情報を OpenShift Container Platform コンソールで表示および分析して、さらなる洞察とトラブルシューティングを行うことができます。詳細は、Network Observability Operator について を参照してください。
第5章 OpenShift Container Platform における Cluster Network Operator
Cluster Network Operator (CNO) は、インストール時にクラスター用に選択される Container Network Interface (CNI) ネットワークプラグインを含む、OpenShift Container Platform クラスターの各種のクラスターネットワークコンポーネントをデプロイし、これらを管理します。
5.1. Cluster Network Operator
Cluster Network Operator は、operator.openshift.io API グループから network API を実装します。Operator は、デーモンセットを使用して、クラスターのインストール中に選択した OVN-Kubernetes ネットワークプラグインまたはネットワークプロバイダープラグインをデプロイします。
手順
Cluster Network Operator は、インストール時に Kubernetes Deployment としてデプロイされます。
以下のコマンドを実行して Deployment のステータスを表示します。
$ oc get -n openshift-network-operator deployment/network-operator
出力例
NAME READY UP-TO-DATE AVAILABLE AGE network-operator 1/1 1 1 56m
以下のコマンドを実行して、Cluster Network Operator の状態を表示します。
$ oc get clusteroperator/network
出力例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE network 4.5.4 True False False 50m
以下のフィールドは、Operator のステータス (
AVAILABLE、PROGRESSING、およびDEGRADED) についての情報を提供します。AVAILABLEフィールドは、Cluster Network Operator が Available ステータス条件を報告する場合にTrueになります。
5.2. クラスターネットワーク設定の表示
すべての新規 OpenShift Container Platform インストールには、cluster という名前の network.config オブジェクトがあります。
手順
oc describeコマンドを使用して、クラスターネットワーク設定を表示します。$ oc describe network.config/cluster
出力例
Name: cluster Namespace: Labels: <none> Annotations: <none> API Version: config.openshift.io/v1 Kind: Network Metadata: Self Link: /apis/config.openshift.io/v1/networks/cluster Spec: 1 Cluster Network: Cidr: 10.128.0.0/14 Host Prefix: 23 Network Type: OpenShiftSDN Service Network: 172.30.0.0/16 Status: 2 Cluster Network: Cidr: 10.128.0.0/14 Host Prefix: 23 Cluster Network MTU: 8951 Network Type: OpenShiftSDN Service Network: 172.30.0.0/16 Events: <none>
5.3. Cluster Network Operator のステータス表示
oc describe コマンドを使用して、Cluster Network Operator のステータスを検査し、その詳細を表示することができます。
手順
以下のコマンドを実行して、Cluster Network Operator のステータスを表示します。
$ oc describe clusteroperators/network
5.4. Cluster Network Operator ログの表示
oc logs コマンドを使用して、Cluster Network Operator ログを表示できます。
手順
以下のコマンドを実行して、Cluster Network Operator のログを表示します。
$ oc logs --namespace=openshift-network-operator deployment/network-operator
5.5. Cluster Network Operator (CNO) の設定
クラスターネットワークの設定は、Cluster Network Operator (CNO) 設定の一部として指定され、cluster という名前のカスタムリソース (CR) オブジェクトに保存されます。CR は operator.openshift.io API グループの Network API のフィールドを指定します。
CNO 設定は、Network.config.openshift.io API グループの Network API からクラスターのインストール時に以下のフィールドを継承し、これらのフィールドは変更できません。
clusterNetwork- Pod IP アドレスの割り当てに使用する IP アドレスプール。
serviceNetwork- サービスの IP アドレスプール。
defaultNetwork.type- OpenShift SDN や OVN-Kubernetes などのクラスターネットワークプラグイン。
クラスターのインストール後に、直前のセクションで一覧表示されているフィールドを変更することはできません。
defaultNetwork オブジェクトのフィールドを cluster という名前の CNO オブジェクトに設定することにより、クラスターのクラスターネットワークプラグイン設定を指定できます。
5.5.1. Cluster Network Operator 設定オブジェクト
Cluster Network Operator (CNO) のフィールドは以下の表で説明されています。
表5.1 Cluster Network Operator 設定オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
CNO オブジェクトの名前。この名前は常に |
|
|
| Pod ID アドレスの割り当て、サブネット接頭辞の長さのクラスター内の個別ノードへの割り当てに使用される IP アドレスのブロックを指定するリストです。以下に例を示します。 spec:
clusterNetwork:
- cidr: 10.128.0.0/19
hostPrefix: 23
- cidr: 10.128.32.0/19
hostPrefix: 23
この値は読み取り専用であり、クラスターのインストール時に |
|
|
| サービスの IP アドレスのブロック。OpenShift SDN および OVN-Kubernetes ネットワークプラグインは、サービスネットワークの単一 IP アドレスブロックのみをサポートします。以下に例を示します。 spec: serviceNetwork: - 172.30.0.0/14
この値は読み取り専用であり、クラスターのインストール時に |
|
|
| クラスターネットワークのネットワークプラグインを設定します。 |
|
|
| このオブジェクトのフィールドは、kube-proxy 設定を指定します。OVN-Kubernetes クラスターネットワークプラグインを使用している場合、kube-proxy 設定は機能しません。 |
defaultNetwork オブジェクト設定
defaultNetwork オブジェクトの値は、以下の表で定義されます。
表5.2 defaultNetwork オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
注記 OpenShift Container Platform は、デフォルトで OVN-Kubernetes ネットワークプラグインを使用します。 |
|
|
| このオブジェクトは、OpenShift SDN ネットワークプラグインに対してのみ有効です。 |
|
|
| このオブジェクトは、OVN-Kubernetes ネットワークプラグインに対してのみ有効です。 |
OpenShift SDN ネットワークプラグインの設定
以下の表では、OpenShift SDN ネットワークプラグインの設定フィールドについて説明します。
表5.3 openshiftSDNConfig オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
| OpenShiftSDN のネットワーク分離モード。 |
|
|
| VXLAN オーバーレイネットワークの最大転送単位 (MTU)。通常、この値は自動的に設定されます。 |
|
|
|
すべての VXLAN パケットに使用するポート。デフォルト値は |
クラスターのインストール時にのみクラスターネットワークプラグインの設定を変更することができます。
OpenShift SDN 設定の例
defaultNetwork:
type: OpenShiftSDN
openshiftSDNConfig:
mode: NetworkPolicy
mtu: 1450
vxlanPort: 4789
OVN-Kubernetes ネットワークプラグインの設定
次の表では、OVN-Kubernetes ネットワークプラグインの設定フィールドについて説明します。
表5.4 ovnKubernetesConfig オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
| Geneve (Generic Network Virtualization Encapsulation) オーバーレイネットワークの MTU (maximum transmission unit)。通常、この値は自動的に設定されます。 |
|
|
| Geneve オーバーレイネットワークの UDP ポート。 |
|
|
| フィールドがある場合、IPsec はクラスターに対して有効にされます。 |
|
|
| ネットワークポリシー監査ロギングをカスタマイズする設定オブジェクトを指定します。指定されていない場合は、デフォルトの監査ログ設定が使用されます。 |
|
|
| オプション: egress トラフィックのノードゲートウェイへの送信方法をカスタマイズするための設定オブジェクトを指定します。 注記 egress トラフィックの移行中は、Cluster Network Operator (CNO) が変更を正常にロールアウトするまで、ワークロードとサービストラフィックに多少の中断が発生することが予想されます。 |
|
|
既存のネットワークインフラストラクチャーが このフィールドは、インストール後に変更できません。 |
デフォルト値は |
|
|
既存のネットワークインフラストラクチャーが このフィールドは、インストール後に変更できません。 |
デフォルト値は |
表5.5 policyAuditConfig オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
| integer |
ノードごとに毎秒生成されるメッセージの最大数。デフォルト値は、1 秒あたり |
|
| integer |
監査ログの最大サイズ (バイト単位)。デフォルト値は |
|
| integer | 保持されるログファイルの最大数。 |
|
| string | 以下の追加の監査ログターゲットのいずれかになります。
|
|
| string |
RFC5424 で定義される |
表5.6 gatewayConfig オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
Pod からホストネットワークスタックへの egress トラフィックを送信するには、このフィールドを
このフィールドで、Open vSwitch ハードウェアオフロード機能との対話が可能になりました。このフィールドを |
クラスターのインストール中にのみクラスターネットワークプラグインの設定を変更できます。ただし、インストール後のアクティビティーとして実行時に変更できるgatewayConfigフィールドは除きます。
IPsec が有効な OVN-Kubernetes 設定の例
defaultNetwork:
type: OVNKubernetes
ovnKubernetesConfig:
mtu: 1400
genevePort: 6081
ipsecConfig: {}
kubeProxyConfig オブジェクト設定
kubeProxyConfig オブジェクトの値は以下の表で定義されます。
表5.7 kubeProxyConfig オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
注記
OpenShift Container Platform 4.3 以降で強化されたパフォーマンスの向上により、 |
|
|
|
kubeProxyConfig:
proxyArguments:
iptables-min-sync-period:
- 0s
|
5.5.2. Cluster Network Operator の設定例
以下の例では、詳細な CNO 設定が指定されています。
Cluster Network Operator オブジェクトのサンプル
apiVersion: operator.openshift.io/v1 kind: Network metadata: name: cluster spec: clusterNetwork: 1 - cidr: 10.128.0.0/14 hostPrefix: 23 serviceNetwork: 2 - 172.30.0.0/16 defaultNetwork: 3 type: OpenShiftSDN openshiftSDNConfig: mode: NetworkPolicy mtu: 1450 vxlanPort: 4789 kubeProxyConfig: iptablesSyncPeriod: 30s proxyArguments: iptables-min-sync-period: - 0s
5.6. 関連情報
第6章 OpenShift Container Platform の DNS Operator
DNS Operator は、Pod に対して名前解決サービスを提供するために CoreDNS をデプロイし、これを管理し、OpenShift Container Platform での DNS ベースの Kubernetes サービス検出を可能にします。
6.1. DNS Operator
DNS Operator は、operator.openshift.io API グループから dns API を実装します。この Operator は、デーモンセットを使用して CoreDNS をデプロイし、デーモンセットのサービスを作成し、 kubelet を Pod に対して名前解決に CoreDNS サービス IP を使用するように指示するように設定します。
手順
DNS Operator は、インストール時に Deployment オブジェクトを使用してデプロイされます。
oc getコマンドを使用してデプロイメントのステータスを表示します。$ oc get -n openshift-dns-operator deployment/dns-operator
出力例
NAME READY UP-TO-DATE AVAILABLE AGE dns-operator 1/1 1 1 23h
oc getコマンドを使用して DNS Operator の状態を表示します。$ oc get clusteroperator/dns
出力例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE dns 4.1.0-0.11 True False False 92m
AVAILABLE、PROGRESSINGおよびDEGRADEDは、Operator のステータスについての情報を提供します。AVAILABLEは、CoreDNS デーモンセットからの 1 つ以上の Pod がAvailableステータス条件を報告する場合はTrueになります。
6.2. DNS Operator managementState の変更
DNS は CoreDNS コンポーネントを管理し、クラスター内の Pod およびサービスの名前解決サービスを提供します。DNS Operator の managementState はデフォルトで Managed に設定されます。これは、DNS Operator がそのリソースをアクティブに管理できることを意味します。これを Unmanaged に変更できます。つまり、DNS Operator がそのリソースを管理していないことを意味します。
以下は、DNS Operator managementState を変更するためのユースケースです。
-
開発者であり、CoreDNS の問題が修正されているかどうかを確認するために設定変更をテストする必要があります。
managementStateをUnmanagedに設定すると、DNS Operator により修正が上書きされないようにできます。 -
クラスター管理者であり、CoreDNS の問題が報告されていますが、問題が修正されるまで回避策を適用する必要があります。DNS Operator の
managementStateフィールドをUnmanagedに設定して、回避策を適用できます。
手順
managementStateDNS Operator を変更します。oc patch dns.operator.openshift.io default --type merge --patch '{"spec":{"managementState":"Unmanaged"}}'
6.3. DNS Pod 配置の制御
DNS Operator には、CoreDNS 用と /etc/hosts ファイルを管理するための 2 つのデーモンセットがあります。/etc/hosts に設定されたデーモンは、イメージのプルをサポートするクラスターイメージレジストリーのエントリーを追加するために、すべてのノードホストで実行する必要があります。セキュリティーポリシーにより、ノードのペア間の通信が禁止され、CoreDNS のデーモンセットがすべてのノードで実行できなくなります。
クラスター管理者は、カスタムノードセレクターを使用して、CoreDNS のデーモンセットを特定のノードで実行するか、実行しないように設定できます。
前提条件
-
ocCLI がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインしている。
手順
特定のノード間の通信を防ぐには、
spec.nodePlacement.nodeSelectorAPI フィールドを設定します。defaultという名前の DNS Operator オブジェクトを変更します。$ oc edit dns.operator/default
spec.nodePlacement.nodeSelectorAPI フィールドにコントロールプレーンノードのみが含まれるノードセレクターを指定します。spec: nodePlacement: nodeSelector: node-role.kubernetes.io/worker: ""
CoreDNS のデーモンセットをノードで実行されるようにするには、テイントおよび容認を設定します。
defaultという名前の DNS Operator オブジェクトを変更します。$ oc edit dns.operator/default
テイントのテイントキーおよび容認を指定します。
spec: nodePlacement: tolerations: - effect: NoExecute key: "dns-only" operators: Equal value: abc tolerationSeconds: 3600 1- 1
- テイントが
dns-onlyである場合、それは無制限に許容できます。tolerationSecondsは省略できます。
6.4. デフォルト DNS の表示
すべての新規 OpenShift Container Platform インストールには、default という名前の dns.operator があります。
手順
oc describeコマンドを使用してデフォルトのdnsを表示します。$ oc describe dns.operator/default
出力例
Name: default Namespace: Labels: <none> Annotations: <none> API Version: operator.openshift.io/v1 Kind: DNS ... Status: Cluster Domain: cluster.local 1 Cluster IP: 172.30.0.10 2 ...
クラスターのサービス CIDR を見つけるには、
oc getコマンドを使用します。$ oc get networks.config/cluster -o jsonpath='{$.status.serviceNetwork}'
出力例
[172.30.0.0/16]
6.5. DNS 転送の使用
DNS 転送を使用して、次の方法で/etc/resolv.confファイルのデフォルトの転送設定を上書きできます。
- すべてのゾーンにネームサーバーを指定します。転送されるゾーンが OpenShift Container Platform によって管理される Ingress ドメインである場合、アップストリームネームサーバーがドメインについて認証される必要があります。
- アップストリーム DNS サーバーのリストを指定します。
- デフォルトの転送ポリシーを変更します。
デフォルトドメインの DNS 転送設定には、/etc/resolv.conf ファイルおよびアップストリーム DNS サーバーで指定されたデフォルトのサーバーの両方を設定できます。
手順
defaultという名前の DNS Operator オブジェクトを変更します。$ oc edit dns.operator/default
以前のコマンドを実行した後に、Operator は
Serverに基づく追加のサーバー設定ブロックを使用してdns-defaultという名前の config map を作成して更新します。クエリーに一致するゾーンがサーバーにない場合には、名前解決はアップストリーム DNS サーバーにフォールバックします。DNS 転送の設定
apiVersion: operator.openshift.io/v1 kind: DNS metadata: name: default spec: servers: - name: example-server 1 zones: 2 - example.com forwardPlugin: policy: Random 3 upstreams: 4 - 1.1.1.1 - 2.2.2.2:5353 upstreamResolvers: 5 policy: Random 6 upstreams: 7 - type: SystemResolvConf 8 - type: Network address: 1.2.3.4 9 port: 53 10
- 1
rfc6335サービス名の構文に準拠する必要があります。- 2
rfc1123サービス名構文のサブドメインの定義に準拠する必要があります。クラスタードメインのcluster.localは、zonesフィールドの無効なサブドメインです。- 3
- アップストリームリゾルバーを選択するためのポリシーを定義します。デフォルト値は
Randomです。RoundRobinおよびSequentialの値を使用することもできます。 - 4
forwardPluginごとに最大 15 のupstreamsが許可されます。- 5
- オプション: これを使用して、デフォルトポリシーを上書きし、デフォルトドメインで指定された DNS リゾルバー (アップストリームリゾルバー) に DNS 解決を転送できます。アップストリームリゾルバーを指定しない場合に、DNS 名のクエリーは
/etc/resolv.confのサーバーに送信されます。 - 6
- クエリー用にアップストリームサーバーが選択される順序を決定します。
Random、Round Robin、またはSequentialのいずれかの値を指定できます。デフォルト値はSequentialです。 - 7
- オプション: これを使用して、アップストリームリゾルバーを指定できます。
- 8
SystemResolvConfとNetworkの 2 種類のアップストリームを指定できます。SystemResolvConfで、アップストリームが/etc/resolv.confを使用するように設定して、NetworkでNetworkresolverを定義します。1 つまたは両方を指定できます。- 9
- 指定したタイプが
Networkの場合には、IP アドレスを指定する必要があります。addressフィールドは、有効な IPv4 または IPv6 アドレスである必要があります。 - 10
- 指定したタイプが
Networkの場合、必要に応じてポートを指定できます。portフィールドの値は1〜65535である必要があります。アップストリームのポートを指定しない場合、デフォルトでポート 853 が試行されます。
任意: 高度に規制された環境で作業する場合は、要求をアップストリームリゾルバーに転送する際に DNS トラフィックのセキュリティーを確保して、追加の DNS トラフィックおよびデータのプライバシーを確保できるようにする必要がある場合があります。クラスター管理者は、転送された DNS クエリーに Transport Layer Security (TLS) を設定できるようになりました。
TLS を使用した DNS 転送の設定
apiVersion: operator.openshift.io/v1 kind: DNS metadata: name: default spec: servers: - name: example-server 1 zones: 2 - example.com forwardPlugin: transportConfig: transport: TLS 3 tls: caBundle: name: mycacert serverName: dnstls.example.com 4 policy: Random 5 upstreams: 6 - 1.1.1.1 - 2.2.2.2:5353 upstreamResolvers: 7 transportConfig: transport: TLS tls: caBundle: name: mycacert serverName: dnstls.example.com upstreams: - type: Network 8 address: 1.2.3.4 9 port: 53 10
- 1
rfc6335サービス名の構文に準拠する必要があります。- 2
rfc1123サービス名構文のサブドメインの定義に準拠する必要があります。クラスタードメインのcluster.localは、zonesフィールドの無効なサブドメインです。クラスタードメインのcluster.localは、zonesの無効なsubdomainです。- 3
- 転送された DNS クエリーの TLS を設定する場合、
transportフィールドの値をTLSに設定します。デフォルトでは、CoreDNS は転送された接続を 10 秒間キャッシュします。要求が発行されない場合、CoreDNS はその 10 秒間、TCP 接続を開いたままにします。大規模なクラスターでは、ノードごとに接続を開始できるため、DNS サーバーが多くの新しい接続を開いたまま保持する可能性があることを認識しているか確認してください。パフォーマンスの問題を回避するために、それに応じて DNS 階層を設定します。 - 4
- 転送された DNS クエリー用に TLS を設定する場合、これは、アップストリーム TLS サーバー証明書を検証するための Server Name Indication (SNI) の一部として使用される必須のサーバー名です。
- 5
- アップストリームリゾルバーを選択するためのポリシーを定義します。デフォルト値は
Randomです。RoundRobinおよびSequentialの値を使用することもできます。 - 6
- 必須。これを使用して、アップストリームリゾルバーを指定できます。
forwardPluginエントリーごとに最大 15 のupstreamsエントリーが許可されます。 - 7
- オプション: これを使用して、デフォルトポリシーを上書きし、デフォルトドメインで指定された DNS リゾルバー (アップストリームリゾルバー) に DNS 解決を転送できます。アップストリームリゾルバーを指定しない場合に、DNS 名のクエリーは
/etc/resolv.confのサーバーに送信されます。 - 8
Networkタイプは、このアップストリームリゾルバーが/etc/resolv.confにリストされているアップストリームリゾルバーとは別に転送されたリクエストを処理する必要があることを示します。TLS を使用する場合、Networkタイプのみが許可され、IP アドレスを指定する必要があります。- 9
addressフィールドは、有効な IPv4 または IPv6 アドレスである必要があります。- 10
- オプションでポートを指定できます。
portの値は1〜65535である必要があります。アップストリームのポートを指定しない場合、デフォルトでポート 853 が試行されます。
注記serversが定義されていないか無効な場合、config map にはデフォルトサーバーのみが含まれます。
検証
config map を表示します。
$ oc get configmap/dns-default -n openshift-dns -o yaml
以前のサンプル DNS に基づく DNS ConfigMap の例
apiVersion: v1 data: Corefile: | example.com:5353 { forward . 1.1.1.1 2.2.2.2:5353 } bar.com:5353 example.com:5353 { forward . 3.3.3.3 4.4.4.4:5454 1 } .:5353 { errors health kubernetes cluster.local in-addr.arpa ip6.arpa { pods insecure upstream fallthrough in-addr.arpa ip6.arpa } prometheus :9153 forward . /etc/resolv.conf 1.2.3.4:53 { policy Random } cache 30 reload } kind: ConfigMap metadata: labels: dns.operator.openshift.io/owning-dns: default name: dns-default namespace: openshift-dns- 1
forwardPluginへの変更により、CoreDNS デーモンセットのローリング更新がトリガーされます。
関連情報
- DNS 転送の詳細は、CoreDNS forward のドキュメント を参照してください。
6.6. DNS Operator のステータス
oc describe コマンドを使用して、DNS Operator のステータスを検査し、その詳細を表示することができます。
手順
DNS Operator のステータスを表示します。
$ oc describe clusteroperators/dns
6.7. DNS Operator ログ
oc logs コマンドを使用して、DNS Operator ログを表示できます。
手順
DNS Operator のログを表示します。
$ oc logs -n openshift-dns-operator deployment/dns-operator -c dns-operator
6.8. CoreDNS ログレベルの設定
CoreDNS ログレベルを設定して、ログに記録されたエラーメッセージの情報量を決定できます。CoreDNS ログレベルの有効な値は、Normal、Debug、および Trace です。デフォルトのlog LevelはNormalです。
エラープラグインは常に有効になっています。次のlogLevel設定は、さまざまなエラー応答を報告します。
-
logLevel:Normalは "errors" class:log . { class error }を有効にします。 -
logLevel:Debugは "denial" class:log . { class denial error }を有効にします。 -
logLevel:Traceは "all" class:log . { class all }を有効にします。
手順
logLevelをDebugに設定するには、次のコマンドを入力します。$ oc patch dnses.operator.openshift.io/default -p '{"spec":{"logLevel":"Debug"}}' --type=mergelogLevelをTraceに設定するには、次のコマンドを入力します。$ oc patch dnses.operator.openshift.io/default -p '{"spec":{"logLevel":"Trace"}}' --type=merge
検証
目的のログレベルが設定されていることを確認するには、ConfigMap を確認します。
$ oc get configmap/dns-default -n openshift-dns -o yaml
6.9. CoreDNS Operator のログレベルの設定
クラスター管理者は、Operator ログレベルを設定して、OpenShift DNS の問題をより迅速に追跡できます。operatorLogLevelの有効な値は、 Normal、Debug、およびTraceです。Trace には最も詳細にわたる情報が含まれます。デフォルトのoperatorlogLevelはNormalです。問題のログレベルには、Trace、Debug、Info、Warning、Error、Fatal および Panic の 7 つがあります。ログレベルの設定後に、その重大度またはそれを超える重大度のログエントリーがログに記録されます。
-
operatorLogLevel: "Normal"はlogrus.SetLogLevel("Info")を設定します。 -
operatorLogLevel: "Debug"はlogrus.SetLogLevel("Debug")を設定します。 -
operatorLogLevel: "Trace"はlogrus.SetLogLevel("Trace")を設定します。
手順
operatorLogLevelをDebugに設定するには、次のコマンドを入力します。$ oc patch dnses.operator.openshift.io/default -p '{"spec":{"operatorLogLevel":"Debug"}}' --type=mergeoperatorLogLevelをTraceに設定するには、次のコマンドを入力します。$ oc patch dnses.operator.openshift.io/default -p '{"spec":{"operatorLogLevel":"Trace"}}' --type=merge
6.10. CoreDNS キャッシュのチューニング
CoreDNS によって実行される成功または失敗したキャッシュ (それぞれポジティブキャッシュまたはネガティブキャッシュとも呼ばれます) の最大期間を設定できます。DNS クエリー応答のキャッシュ期間を調整すると、上流の DNS リゾルバーの負荷を軽減できます。
手順
次のコマンドを実行して、
defaultという名前の DNS Operator オブジェクトを編集します。$ oc edit dns.operator.openshift.io/default
Time-to-Live (TTL) キャッシュ値を変更します。
DNS キャッシングの設定
apiVersion: operator.openshift.io/v1 kind: DNS metadata: name: default spec: cache: positiveTTL: 1h 1 negativeTTL: 0.5h10m 2警告TTL フィールドを低い値に設定すると、クラスター、上流のリゾルバー、またはその両方の負荷が増加する可能性があります。
第7章 OpenShift Container Platform の Ingress Operator
7.1. OpenShift Container Platform Ingress Operator
OpenShift Container Platform クラスターを作成すると、クラスターで実行している Pod およびサービスにはそれぞれ独自の IP アドレスが割り当てられます。IP アドレスは、近くで実行されている他の Pod やサービスからアクセスできますが、外部クライアントの外部からはアクセスできません。Ingress Operator は IngressController API を実装し、OpenShift Container Platform クラスターサービスへの外部アクセスを可能にするコンポーネントです。
Ingress Operator を使用すると、ルーティングを処理する 1 つ以上の HAProxy ベースの Ingress Controller をデプロイおよび管理することにより、外部クライアントがサービスにアクセスできるようになります。OpenShift Container Platform Route および Kubernetes Ingress リソースを指定して、トラフィックをルーティングするために Ingress Operator を使用します。endpointPublishingStrategy タイプおよび内部負荷分散を定義する機能などの Ingress Controller 内の設定は、Ingress Controller エンドポイントを公開する方法を提供します。
7.2. Ingress 設定アセット
インストールプログラムでは、config.openshift.io API グループの Ingress リソースでアセットを生成します (cluster-ingress-02-config.yml)。
Ingress リソースの YAML 定義
apiVersion: config.openshift.io/v1 kind: Ingress metadata: name: cluster spec: domain: apps.openshiftdemos.com
インストールプログラムは、このアセットを manifests/ ディレクトリーの cluster-ingress-02-config.yml ファイルに保存します。この Ingress リソースは、Ingress のクラスター全体の設定を定義します。この Ingress 設定は、以下のように使用されます。
- Ingress Operator は、クラスター Ingress 設定のドメインを、デフォルト Ingress Controller のドメインとして使用します。
-
OpenShift API Server Operator は、クラスター Ingress 設定からのドメインを使用します。このドメインは、明示的なホストを指定しない
Routeリソースのデフォルトホストを生成する際にも使用されます。
7.3. Ingress Controller 設定パラメーター
ingresscontrollers.operator.openshift.io リソースは以下の設定パラメーターを提供します。
| パラメーター | 説明 |
|---|---|
|
|
空の場合、デフォルト値は |
|
|
|
|
|
GCP、AWS、および Azure では、次の
設定されていない場合、デフォルト値は
ほとんどのプラットフォームでは、
|
|
|
シークレットには以下のキーおよびデータが含まれる必要があります: *
設定されていない場合、ワイルドカード証明書は自動的に生成され、使用されます。証明書は Ingress コントーラーの 使用中の証明書 (生成されるか、ユーザー指定の場合かを問わない) は OpenShift Container Platform のビルトイン OAuth サーバーに自動的に統合されます。 |
|
|
|
|
|
|
|
|
設定されていない場合は、デフォルト値が使用されます。 注記
nodePlacement:
nodeSelector:
matchLabels:
kubernetes.io/os: linux
tolerations:
- effect: NoSchedule
operator: Exists |
|
|
これが設定されていない場合、デフォルト値は
Ingress Controller の最小 TLS バージョンは 注記
設定されたセキュリティープロファイルの暗号および最小 TLS バージョンが 重要
Ingress Operator は TLS |
|
|
|
|
|
|
|
|
|
|
|
デフォルトでは、ポリシーは
これらの調整は、クリアテキスト、edge terminationd、および re-encrypt ルートにのみ適用され、HTTP/1 を使用する場合にのみ適用されます。
要求ヘッダーの場合、これらの調整は |
|
|
|
|
|
|
|
|
キャプチャーするすべての Cookie について、次のパラメーターが
以下に例を示します。 httpCaptureCookies:
- matchType: Exact
maxLength: 128
name: MYCOOKIE
|
|
|
httpCaptureHeaders:
request:
- maxLength: 256
name: Connection
- maxLength: 128
name: User-Agent
response:
- maxLength: 256
name: Content-Type
- maxLength: 256
name: Content-Length
|
|
|
|
|
|
|
|
|
これらの接続は、ロードバランサーのヘルスプローブまたは Web ブラウザーの投機的接続 (事前接続) から取得され、無視しても問題はありません。ただし、これらの要求はネットワークエラーによって引き起こされる可能性があります。そのため、このフィールドを |
すべてのパラメーターはオプションです。
7.3.1. Ingress Controller の TLS セキュリティープロファイル
TLS セキュリティープロファイルは、サーバーに接続する際に接続クライアントが使用できる暗号を規制する方法をサーバーに提供します。
7.3.1.1. TLS セキュリティープロファイルについて
TLS (Transport Layer Security) セキュリティープロファイルを使用して、さまざまな OpenShift Container Platform コンポーネントに必要な TLS 暗号を定義できます。OpenShift Container Platform の TLS セキュリティープロファイルは、Mozilla が推奨する設定 に基づいています。
コンポーネントごとに、以下の TLS セキュリティープロファイルのいずれかを指定できます。
表7.1 TLS セキュリティープロファイル
| プロファイル | 説明 |
|---|---|
|
| このプロファイルは、レガシークライアントまたはライブラリーでの使用を目的としています。このプロファイルは、Old 後方互換性 の推奨設定に基づいています。
注記 Ingress Controller の場合、TLS の最小バージョンは 1.0 から 1.1 に変換されます。 |
|
| このプロファイルは、大多数のクライアントに推奨される設定です。これは、Ingress Controller 、kubelet、およびコントロールプレーンのデフォルトの TLS セキュリティープロファイルです。このプロファイルは、Intermediate 互換性 の推奨設定に基づいています。
|
|
| このプロファイルは、後方互換性を必要としない Modern のクライアントでの使用を目的としています。このプロファイルは、Modern 互換性 の推奨設定に基づいています。
|
|
| このプロファイルを使用すると、使用する TLS バージョンと暗号を定義できます。 警告
無効な設定により問題が発生する可能性があるため、 |
事前定義されたプロファイルタイプのいずれかを使用する場合、有効なプロファイル設定はリリース間で変更される可能性があります。たとえば、リリース X.Y.Z にデプロイされた Intermediate プロファイルを使用する仕様がある場合、リリース X.Y.Z+1 へのアップグレードにより、新規のプロファイル設定が適用され、ロールアウトが生じる可能性があります。
7.3.1.2. Ingress Controller の TLS セキュリティープロファイルの設定
Ingress Controller の TLS セキュリティープロファイルを設定するには、IngressController カスタムリソース (CR) を編集して、事前定義済みまたはカスタムの TLS セキュリティープロファイルを指定します。TLS セキュリティープロファイルが設定されていない場合、デフォルト値は API サーバーに設定された TLS セキュリティープロファイルに基づいています。
Old TLS のセキュリティープロファイルを設定するサンプル IngressController CR
apiVersion: operator.openshift.io/v1
kind: IngressController
...
spec:
tlsSecurityProfile:
old: {}
type: Old
...
TLS セキュリティープロファイルは、Ingress Controller の TLS 接続の最小 TLS バージョンと TLS 暗号を定義します。
設定された TLS セキュリティープロファイルの暗号と最小 TLS バージョンは、Status.Tls Profile 配下の IngressController カスタムリソース (CR) と Spec.Tls Security Profile 配下の設定された TLS セキュリティープロファイルで確認できます。Custom TLS セキュリティープロファイルの場合、特定の暗号と最小 TLS バージョンは両方のパラメーターの下に一覧表示されます。
HAProxy Ingress Controller イメージは、TLS1.3 と Modern プロファイルをサポートしています。
また、Ingress Operator は TLS 1.0 の Old または Custom プロファイルを 1.1 に変換します。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
openshift-ingress-operatorプロジェクトのIngressControllerCR を編集して、TLS セキュリティープロファイルを設定します。$ oc edit IngressController default -n openshift-ingress-operator
spec.tlsSecurityProfileフィールドを追加します。CustomプロファイルのサンプルIngressControllerCRapiVersion: operator.openshift.io/v1 kind: IngressController ... spec: tlsSecurityProfile: type: Custom 1 custom: 2 ciphers: 3 - ECDHE-ECDSA-CHACHA20-POLY1305 - ECDHE-RSA-CHACHA20-POLY1305 - ECDHE-RSA-AES128-GCM-SHA256 - ECDHE-ECDSA-AES128-GCM-SHA256 minTLSVersion: VersionTLS11 ...- 変更を適用するためにファイルを保存します。
検証
IngressControllerCR にプロファイルが設定されていることを確認します。$ oc describe IngressController default -n openshift-ingress-operator
出力例
Name: default Namespace: openshift-ingress-operator Labels: <none> Annotations: <none> API Version: operator.openshift.io/v1 Kind: IngressController ... Spec: ... Tls Security Profile: Custom: Ciphers: ECDHE-ECDSA-CHACHA20-POLY1305 ECDHE-RSA-CHACHA20-POLY1305 ECDHE-RSA-AES128-GCM-SHA256 ECDHE-ECDSA-AES128-GCM-SHA256 Min TLS Version: VersionTLS11 Type: Custom ...
7.3.1.3. 相互 TLS 認証の設定
spec.clientTLS 値を設定して、相互 TLS (mTLS) 認証を有効にするように Ingress Controller を設定できます。clientTLS 値は、クライアント証明書を検証するように Ingress Controller を設定します。この設定には、ConfigMap の参照である clientCA 値の設定が含まれます。ConfigMap には、クライアントの証明書を検証するために使用される PEM でエンコードされた CA 証明書バンドルが含まれます。必要に応じて、証明書サブジェクトフィルターのリストも設定できます。
clientCA 値が X509v3 証明書失効リスト (CRL) ディストリビューションポイントを指定している場合、Ingress Operator は、提供された各証明書で指定されている HTTP URI X509v3 CRL Distribution Point に基づいて CRL config map をダウンロードおよび管理します。Ingress Controller は、mTLS/TLS ネゴシエーション中にこの config map を使用します。有効な証明書を提供しない要求は拒否されます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 - PEM でエンコードされた CA 証明書バンドルがある。
CA バンドルが CRL ディストリビューションポイントを参照する場合は、エンドエンティティーまたはリーフ証明書もクライアント CA バンドルに含める必要があります。この証明書には、RFC 5280 で説明されているとおり、この証明書の
CRL Distribution Pointsに HTTP URI が含まれている必要があります。以下に例を示します。Issuer: C=US, O=Example Inc, CN=Example Global G2 TLS RSA SHA256 2020 CA1 Subject: SOME SIGNED CERT X509v3 CRL Distribution Points: Full Name: URI:http://crl.example.com/example.crl
手順
openshift-confignamespace で、CA バンドルから config map を作成します。$ oc create configmap \ router-ca-certs-default \ --from-file=ca-bundle.pem=client-ca.crt \1 -n openshift-config- 1
- ConfigMap データキーは
ca-bundle.pemで、data の値は PEM 形式の CA 証明書である必要があります。
openshift-ingress-operatorプロジェクトでIngressControllerリソースを編集します。$ oc edit IngressController default -n openshift-ingress-operator
spec.clientTLSフィールドおよびサブフィールドを追加して相互 TLS を設定します。フィルタリングパターンを指定する
clientTLSプロファイルのサンプルIngressControllerCRapiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: clientTLS: clientCertificatePolicy: Required clientCA: name: router-ca-certs-default allowedSubjectPatterns: - "^/CN=example.com/ST=NC/C=US/O=Security/OU=OpenShift$"
7.4. デフォルト Ingress Controller の表示
Ingress Operator は、OpenShift Container Platform の中核となる機能であり、追加の設定なしに有効にできます。
すべての新規 OpenShift Container Platform インストールには、ingresscontroller の名前付きのデフォルトがあります。これは、追加の Ingress Controller で補足できます。デフォルトの ingresscontroller が削除される場合、Ingress Operator は 1 分以内にこれを自動的に再作成します。
手順
デフォルト Ingress Controller を表示します。
$ oc describe --namespace=openshift-ingress-operator ingresscontroller/default
7.5. Ingress Operator ステータスの表示
Ingress Operator のステータスを表示し、検査することができます。
手順
Ingress Operator ステータスを表示します。
$ oc describe clusteroperators/ingress
7.6. Ingress Controller ログの表示
Ingress Controller ログを表示できます。
手順
Ingress Controller ログを表示します。
$ oc logs --namespace=openshift-ingress-operator deployments/ingress-operator -c <container_name>
7.7. Ingress Controller ステータスの表示
特定の Ingress Controller のステータスを表示できます。
手順
Ingress Controller のステータスを表示します。
$ oc describe --namespace=openshift-ingress-operator ingresscontroller/<name>
7.8. Ingress Controller の設定
7.8.1. カスタムデフォルト証明書の設定
管理者として、 Secret リソースを作成し、IngressController カスタムリソース (CR) を編集して Ingress Controller がカスタム証明書を使用するように設定できます。
前提条件
- PEM エンコードされたファイルに証明書/キーのペアがなければなりません。ここで、証明書は信頼される認証局またはカスタム PKI で設定されたプライベートの信頼される認証局で署名されます。
証明書が以下の要件を満たしている必要があります。
- 証明書が Ingress ドメインに対して有効化されている必要があります。
-
証明書は拡張を使用して、
subjectAltName拡張を使用して、*.apps.ocp4.example.comなどのワイルドカードドメインを指定します。
IngressControllerCR がなければなりません。デフォルトの CR を使用できます。$ oc --namespace openshift-ingress-operator get ingresscontrollers
出力例
NAME AGE default 10m
Intermediate 証明書がある場合、それらはカスタムデフォルト証明書が含まれるシークレットの tls.crt ファイルに組み込まれる必要があります。証明書を指定する際の順序は重要になります。サーバー証明書の後に Intermediate 証明書をリスト表示します。
手順
以下では、カスタム証明書とキーのペアが、現在の作業ディレクトリーの tls.crt および tls.key ファイルにあることを前提とします。tls.crt および tls.key を実際のパス名に置き換えます。さらに、 Secret リソースを作成し、これを IngressController CR で参照する際に、custom-certs-default を別の名前に置き換えます。
このアクションにより、Ingress Controller はデプロイメントストラテジーを使用して再デプロイされます。
tls.crtおよびtls.keyファイルを使用して、カスタム証明書を含む Secret リソースをopenshift-ingressnamespace に作成します。$ oc --namespace openshift-ingress create secret tls custom-certs-default --cert=tls.crt --key=tls.key
IngressController CR を、新規証明書シークレットを参照するように更新します。
$ oc patch --type=merge --namespace openshift-ingress-operator ingresscontrollers/default \ --patch '{"spec":{"defaultCertificate":{"name":"custom-certs-default"}}}'更新が正常に行われていることを確認します。
$ echo Q |\ openssl s_client -connect console-openshift-console.apps.<domain>:443 -showcerts 2>/dev/null |\ openssl x509 -noout -subject -issuer -enddate
ここでは、以下のようになります。
<domain>- クラスターのベースドメイン名を指定します。
出力例
subject=C = US, ST = NC, L = Raleigh, O = RH, OU = OCP4, CN = *.apps.example.com issuer=C = US, ST = NC, L = Raleigh, O = RH, OU = OCP4, CN = example.com notAfter=May 10 08:32:45 2022 GM
ヒントまたは、以下の YAML を適用してカスタムのデフォルト証明書を設定できます。
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: defaultCertificate: name: custom-certs-default証明書シークレットの名前は、CR を更新するために使用された値に一致する必要があります。
IngressController CR が変更された後に、Ingress Operator はカスタム証明書を使用できるように Ingress Controller のデプロイメントを更新します。
7.8.2. カスタムデフォルト証明書の削除
管理者は、使用する Ingress Controller を設定したカスタム証明書を削除できます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。 - Ingress Controller のカスタムデフォルト証明書を設定している。
手順
カスタム証明書を削除し、OpenShift Container Platform に同梱されている証明書を復元するには、以下のコマンドを入力します。
$ oc patch -n openshift-ingress-operator ingresscontrollers/default \ --type json -p $'- op: remove\n path: /spec/defaultCertificate'
クラスターが新しい証明書設定を調整している間、遅延が発生する可能性があります。
検証
元のクラスター証明書が復元されたことを確認するには、次のコマンドを入力します。
$ echo Q | \ openssl s_client -connect console-openshift-console.apps.<domain>:443 -showcerts 2>/dev/null | \ openssl x509 -noout -subject -issuer -enddate
ここでは、以下のようになります。
<domain>- クラスターのベースドメイン名を指定します。
出力例
subject=CN = *.apps.<domain> issuer=CN = ingress-operator@1620633373 notAfter=May 10 10:44:36 2023 GMT
7.8.3. Ingress Controller の自動スケーリング
Ingress Controller は、スループットを増大させるための要件を含む、ルーティングのパフォーマンスや可用性に関する各種要件に動的に対応するために自動でスケーリングできます。以下の手順では、デフォルトの IngressController をスケールアップする例を示します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとして OpenShift Container Platform クラスターにアクセスできる。 - Custom Metrics Autoscaler Operator がインストールされている。
-
openshift-ingress-operatorプロジェクトの namespace に切り替えている。
手順
以下のコマンドを実行して、Thanos で認証するためのサービスアカウントを作成します。
$ oc create serviceaccount thanos && oc describe serviceaccount thanos
出力例
Name: thanos Namespace: openshift-ingress-operator Labels: <none> Annotations: <none> Image pull secrets: thanos-dockercfg-b4l9s Mountable secrets: thanos-dockercfg-b4l9s Tokens: thanos-token-c422q Events: <none>
サービスアカウントのトークンを使用して、
openshift-ingress-operatornamespace 内でTriggerAuthenticationオブジェクトを定義します。以下のコマンドを実行して、シークレットを含む変数
secretを定義します。$ secret=$(oc get secret | grep thanos-token | head -n 1 | awk '{ print $1 }')TriggerAuthenticationオブジェクトを作成し、secret変数の値をTOKENパラメーターに渡します。$ oc process TOKEN="$secret" -f - <<EOF | oc apply -f - apiVersion: template.openshift.io/v1 kind: Template parameters: - name: TOKEN objects: - apiVersion: keda.sh/v1alpha1 kind: TriggerAuthentication metadata: name: keda-trigger-auth-prometheus spec: secretTargetRef: - parameter: bearerToken name: \${TOKEN} key: token - parameter: ca name: \${TOKEN} key: ca.crt EOF
Thanos からメトリクスを読み取るためのロールを作成して適用します。
Pod およびノードからメトリクスを読み取る新規ロール
thanos-metrics-reader.yamlを作成します。thanos-metrics-reader.yaml
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: thanos-metrics-reader rules: - apiGroups: - "" resources: - pods - nodes verbs: - get - apiGroups: - metrics.k8s.io resources: - pods - nodes verbs: - get - list - watch - apiGroups: - "" resources: - namespaces verbs: - get
以下のコマンドを実行して新規ロールを適用します。
$ oc apply -f thanos-metrics-reader.yaml
以下のコマンドを入力して、新しいロールをサービスアカウントに追加します。
$ oc adm policy add-role-to-user thanos-metrics-reader -z thanos --role=namespace=openshift-ingress-operator
$ oc adm policy -n openshift-ingress-operator add-cluster-role-to-user cluster-monitoring-view -z thanos
注記引数
add-cluster-role-to-userは、namespace 間のクエリーを使用する場合にのみ必要になります。以下の手順では、この引数を必要とするkube-metricsnamespace からのクエリーを使用します。デフォルトの Ingress Controller デプロイメントをターゲットにする新しい
ScaledObjectYAML ファイルingress-autoscaler.yamlを作成します。ScaledObject定義の例apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: ingress-scaler spec: scaleTargetRef: 1 apiVersion: operator.openshift.io/v1 kind: IngressController name: default envSourceContainerName: ingress-operator minReplicaCount: 1 maxReplicaCount: 20 2 cooldownPeriod: 1 pollingInterval: 1 triggers: - type: prometheus metricType: AverageValue metadata: serverAddress: https://thanos-querier.openshift-monitoring.svc.cluster.local:9091 3 namespace: openshift-ingress-operator 4 metricName: 'kube-node-role' threshold: '1' query: 'sum(kube_node_role{role="worker",service="kube-state-metrics"})' 5 authModes: "bearer" authenticationRef: name: keda-trigger-auth-prometheus
重要namespace 間クエリーを使用している場合は、
serverAddressフィールドのポート 9092 ではなくポート 9091 をターゲットにする必要があります。また、このポートからメトリクスを読み取るには、昇格した権限が必要です。以下のコマンドを実行してカスタムリソース定義を適用します。
$ oc apply -f ingress-autoscaler.yaml
検証
以下のコマンドを実行して、デフォルトの Ingress Controller が
kube-state-metricsクエリーによって返される値に一致するようにスケールアウトされていることを確認します。grepコマンドを使用して、Ingress Controller の YAML ファイルでレプリカを検索します。$ oc get ingresscontroller/default -o yaml | grep replicas:
出力例
replicas: 3
openshift-ingressプロジェクトで Pod を取得します。$ oc get pods -n openshift-ingress
出力例
NAME READY STATUS RESTARTS AGE router-default-7b5df44ff-l9pmm 2/2 Running 0 17h router-default-7b5df44ff-s5sl5 2/2 Running 0 3d22h router-default-7b5df44ff-wwsth 2/2 Running 0 66s
7.8.4. Ingress Controller のスケーリング
Ingress Controller は、スループットを増大させるための要件を含む、ルーティングのパフォーマンスや可用性に関する各種要件に対応するために手動でスケーリングできます。oc コマンドは、IngressController リソースのスケーリングに使用されます。以下の手順では、デフォルトの IngressController をスケールアップする例を示します。
スケーリングは、必要な数のレプリカを作成するのに時間がかかるため、すぐに実行できるアクションではありません。
手順
デフォルト
IngressControllerの現在の利用可能なレプリカ数を表示します。$ oc get -n openshift-ingress-operator ingresscontrollers/default -o jsonpath='{$.status.availableReplicas}'出力例
2
oc patchコマンドを使用して、デフォルトのIngressControllerを必要なレプリカ数にスケーリングします。以下の例では、デフォルトのIngressControllerを 3 つのレプリカにスケーリングしています。$ oc patch -n openshift-ingress-operator ingresscontroller/default --patch '{"spec":{"replicas": 3}}' --type=merge出力例
ingresscontroller.operator.openshift.io/default patched
デフォルトの
IngressControllerが指定したレプリカ数にスケーリングされていることを確認します。$ oc get -n openshift-ingress-operator ingresscontrollers/default -o jsonpath='{$.status.availableReplicas}'出力例
3
ヒントまたは、以下の YAML を適用して Ingress Controller を 3 つのレプリカにスケーリングすることもできます。
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 3 1- 1
- 異なる数のレプリカが必要な場合は
replicas値を変更します。
7.8.5. Ingress アクセスロギングの設定
アクセスログを有効にするように Ingress Controller を設定できます。大量のトラフィックを受信しないクラスターがある場合、サイドカーにログインできます。クラスターのトラフィックが多い場合、ロギングスタックの容量を超えないようにしたり、OpenShift Container Platform 外のロギングインフラストラクチャーと統合したりするために、ログをカスタム syslog エンドポイントに転送することができます。アクセスログの形式を指定することもできます。
コンテナーロギングは、既存の Syslog ロギングインフラストラクチャーがない場合や、Ingress Controller で問題を診断する際に短期間使用する場合に、低トラフィックのクラスターのアクセスログを有効にするのに役立ちます。
アクセスログが OpenShift Logging スタックの容量を超える可能性があるトラフィックの多いクラスターや、ロギングソリューションが既存の Syslog ロギングインフラストラクチャーと統合する必要のある環境では、syslog が必要です。Syslog のユースケースは重複する可能性があります。
前提条件
-
cluster-admin権限を持つユーザーとしてログインしている。
手順
サイドカーへの Ingress アクセスロギングを設定します。
Ingress アクセスロギングを設定するには、
spec.logging.access.destinationを使用して宛先を指定する必要があります。サイドカーコンテナーへのロギングを指定するには、Containerspec.logging.access.destination.typeを指定する必要があります。以下の例は、コンテナーContainerの宛先に対してログ記録する Ingress Controller 定義です。apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: destination: type: ContainerIngress Controller をサイドカーに対してログを記録するように設定すると、Operator は Ingress Controller Pod 内に
logsという名前のコンテナーを作成します。$ oc -n openshift-ingress logs deployment.apps/router-default -c logs
出力例
2020-05-11T19:11:50.135710+00:00 router-default-57dfc6cd95-bpmk6 router-default-57dfc6cd95-bpmk6 haproxy[108]: 174.19.21.82:39654 [11/May/2020:19:11:50.133] public be_http:hello-openshift:hello-openshift/pod:hello-openshift:hello-openshift:10.128.2.12:8080 0/0/1/0/1 200 142 - - --NI 1/1/0/0/0 0/0 "GET / HTTP/1.1"
Syslog エンドポイントへの Ingress アクセスロギングを設定します。
Ingress アクセスロギングを設定するには、
spec.logging.access.destinationを使用して宛先を指定する必要があります。Syslog エンドポイント宛先へのロギングを指定するには、spec.logging.access.destination.typeにSyslogを指定する必要があります。宛先タイプがSyslogの場合、spec.logging.access.destination.syslog.endpointを使用して宛先エンドポイントも指定する必要があります。また、spec.logging.access.destination.syslog.facilityを使用してファシリティーを指定できます。以下の例は、Syslog宛先に対してログを記録する Ingress Controller の定義です。apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: destination: type: Syslog syslog: address: 1.2.3.4 port: 10514注記syslog宛先ポートは UDP である必要があります。
特定のログ形式で Ingress アクセスロギングを設定します。
spec.logging.access.httpLogFormatを指定して、ログ形式をカスタマイズできます。以下の例は、IP アドレスが 1.2.3.4 およびポート 10514 のsyslogエンドポイントに対してログを記録する Ingress Controller の定義です。apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: destination: type: Syslog syslog: address: 1.2.3.4 port: 10514 httpLogFormat: '%ci:%cp [%t] %ft %b/%s %B %bq %HM %HU %HV'
Ingress アクセスロギングを無効にします。
Ingress アクセスロギングを無効にするには、
spec.loggingまたはspec.logging.accessを空のままにします。apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: replicas: 2 logging: access: null
7.8.6. Ingress コントローラースレッド数の設定
クラスター管理者は、スレッド数を設定して、クラスターが処理できる受信接続の量を増やすことができます。既存の Ingress Controller にパッチを適用して、スレッドの数を増やすことができます。
前提条件
- 以下では、Ingress Controller がすでに作成されていることを前提とします。
手順
Ingress Controller を更新して、スレッド数を増やします。
$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"threadCount": 8}}}'注記大量のリソースを実行できるノードがある場合、
spec.nodePlacement.nodeSelectorを、意図されているノードの容量に一致するラベルで設定し、spec.tuningOptions.threadCountを随時高い値に設定します。
7.8.7. 内部ロードバランサーを使用するための Ingress Controller の設定
クラウドプラットフォームで Ingress Controller を作成する場合、Ingress Controller はデフォルトでパブリッククラウドロードバランサーによって公開されます。管理者は、内部クラウドロードバランサーを使用する Ingress Controller を作成できます。
クラウドプロバイダーが Microsoft Azure の場合、ノードを参照するパブリックロードバランサーが少なくとも 1 つ必要です。これがない場合、すべてのノードがインターネットへの egress 接続を失います。
IngressControllerのscopeを変更する場合は、カスタムリソース (CR) の作成後に.spec.endpoint Publishing Strategy.load Balancer.scopeパラメーターを変更できます。
図7.1 ロードバランサーの図
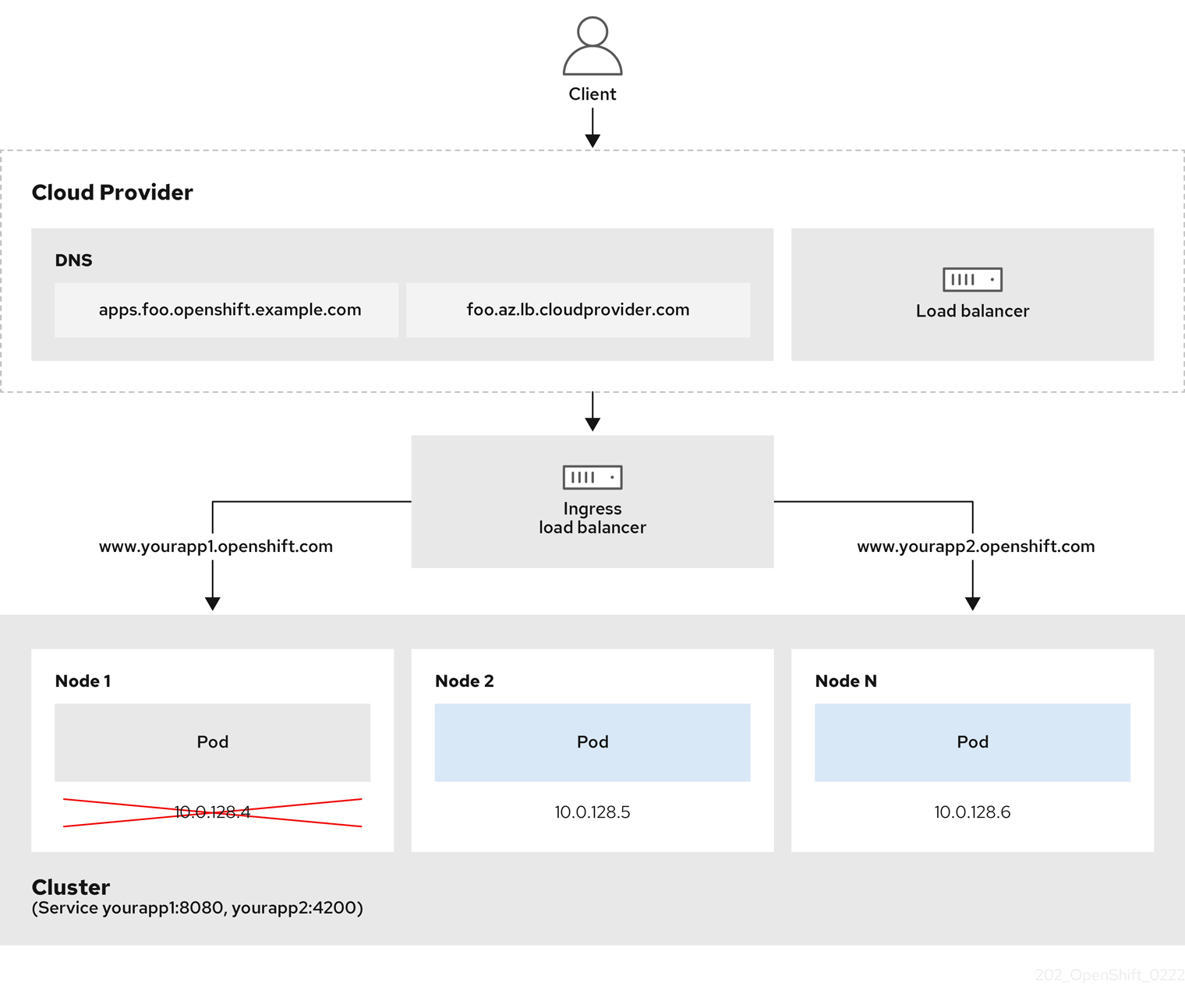
前述の図では、OpenShift Container Platform Ingress LoadBalancerService エンドポイントの公開戦略に関する以下のような概念を示しています。
- 負荷は、外部からクラウドプロバイダーのロードバランサーを使用するか、内部から OpenShift Ingress Controller Load Balancer を使用して、分散できます。
- ロードバランサーのシングル IP アドレスと、図にあるクラスターのように、8080 や 4200 といった馴染みのあるポートを使用することができます。
- 外部のロードバランサーからのトラフィックは、ダウンしたノードのインスタンスで記載されているように、Pod の方向に進められ、ロードバランサーが管理します。実装の詳細については、Kubernetes サービスドキュメント を参照してください。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
以下の例のように、
<name>-ingress-controller.yamlという名前のファイルにIngressControllerカスタムリソース (CR) を作成します。apiVersion: operator.openshift.io/v1 kind: IngressController metadata: namespace: openshift-ingress-operator name: <name> 1 spec: domain: <domain> 2 endpointPublishingStrategy: type: LoadBalancerService loadBalancer: scope: Internal 3
以下のコマンドを実行して、直前の手順で定義された Ingress Controller を作成します。
$ oc create -f <name>-ingress-controller.yaml 1- 1
<name>をIngressControllerオブジェクトの名前に置き換えます。
オプション: 以下のコマンドを実行して Ingress Controller が作成されていることを確認します。
$ oc --all-namespaces=true get ingresscontrollers
7.8.8. GCP での Ingress Controller のグローバルアクセスの設定
内部ロードバランサーで GCP で作成された Ingress Controller は、サービスの内部 IP アドレスを生成します。クラスター管理者は、グローバルアクセスオプションを指定できます。これにより、同じ VPC ネットワーク内の任意のリージョンでクラスターを有効にし、ロードバランサーとしてコンピュートリージョンを有効にして、クラスターで実行されるワークロードに到達できるようにできます。
詳細情報は、GCP ドキュメントの グローバルアクセス について参照してください。
前提条件
- OpenShift Container Platform クラスターを GCP インフラストラクチャーにデプロイしている。
- 内部ロードバランサーを使用するように Ingress Controller を設定している。
-
OpenShift CLI (
oc) がインストールされている。
手順
グローバルアクセスを許可するように Ingress Controller リソースを設定します。
注記Ingress Controller を作成し、グローバルアクセスのオプションを指定することもできます。
Ingress Controller リソースを設定します。
$ oc -n openshift-ingress-operator edit ingresscontroller/default
YAML ファイルを編集します。
サンプル
clientAccess設定をGlobalに設定します。spec: endpointPublishingStrategy: loadBalancer: providerParameters: gcp: clientAccess: Global 1 type: GCP scope: Internal type: LoadBalancerService- 1
gcp.clientAccessをGlobalに設定します。
- 変更を適用するためにファイルを保存します。
以下のコマンドを実行して、サービスがグローバルアクセスを許可することを確認します。
$ oc -n openshift-ingress edit svc/router-default -o yaml
この出力では、グローバルアクセスがアノテーション
networking.gke.io/internal-load-balancer-allow-global-accessで GCP について有効にされていることを示しています。
7.8.9. Ingress Controller のヘルスチェック間隔の設定
クラスター管理者は、ヘルスチェックの間隔を設定して、ルーターが連続する 2 回のヘルスチェックの間で待機する時間を定義できます。この値は、すべてのルートのデフォルトとしてグローバルに適用されます。デフォルト値は 5 秒です。
前提条件
- 以下では、Ingress Controller がすでに作成されていることを前提とします。
手順
Ingress Controller を更新して、バックエンドヘルスチェックの間隔を変更します。
$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"healthCheckInterval": "8s"}}}'注記単一ルートの
healthCheckIntervalをオーバーライドするには、ルートアノテーションrouter.openshift.io/haproxy.health.check.intervalを使用します
7.8.10. クラスターを内部に配置するためのデフォルト Ingress Controller の設定
削除や再作成を実行して、クラスターを内部に配置するように default Ingress Controller を設定できます。
クラウドプロバイダーが Microsoft Azure の場合、ノードを参照するパブリックロードバランサーが少なくとも 1 つ必要です。これがない場合、すべてのノードがインターネットへの egress 接続を失います。
IngressControllerのscopeを変更する場合は、カスタムリソース (CR) の作成後に.spec.endpoint Publishing Strategy.load Balancer.scopeパラメーターを変更できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
削除や再作成を実行して、クラスターを内部に配置するように
defaultIngress Controller を設定します。$ oc replace --force --wait --filename - <<EOF apiVersion: operator.openshift.io/v1 kind: IngressController metadata: namespace: openshift-ingress-operator name: default spec: endpointPublishingStrategy: type: LoadBalancerService loadBalancer: scope: Internal EOF
7.8.11. ルートの受付ポリシーの設定
管理者およびアプリケーション開発者は、同じドメイン名を持つ複数の namespace でアプリケーションを実行できます。これは、複数のチームが同じホスト名で公開されるマイクロサービスを開発する組織を対象としています。
複数の namespace での要求の許可は、namespace 間の信頼のあるクラスターに対してのみ有効にする必要があります。有効にしないと、悪意のあるユーザーがホスト名を乗っ取る可能性があります。このため、デフォルトの受付ポリシーは複数の namespace 間でのホスト名の要求を許可しません。
前提条件
- クラスター管理者の権限。
手順
以下のコマンドを使用して、
ingresscontrollerリソース変数の.spec.routeAdmissionフィールドを編集します。$ oc -n openshift-ingress-operator patch ingresscontroller/default --patch '{"spec":{"routeAdmission":{"namespaceOwnership":"InterNamespaceAllowed"}}}' --type=mergeイメージコントローラー設定例
spec: routeAdmission: namespaceOwnership: InterNamespaceAllowed ...ヒントまたは、以下の YAML を適用してルートの受付ポリシーを設定できます。
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: routeAdmission: namespaceOwnership: InterNamespaceAllowed
7.8.12. ワイルドカードルートの使用
HAProxy Ingress Controller にはワイルドカードルートのサポートがあります。Ingress Operator は wildcardPolicy を使用して、Ingress Controller の ROUTER_ALLOW_WILDCARD_ROUTES 環境変数を設定します。
Ingress Controller のデフォルトの動作では、ワイルドカードポリシーの None (既存の IngressController リソースとの後方互換性がある) を持つルートを許可します。
手順
ワイルドカードポリシーを設定します。
以下のコマンドを使用して
IngressControllerリソースを編集します。$ oc edit IngressController
specの下で、wildcardPolicyフィールドをWildcardsDisallowedまたはWildcardsAllowedに設定します。spec: routeAdmission: wildcardPolicy: WildcardsDisallowed # or WildcardsAllowed
7.8.13. X-Forwarded ヘッダーの使用
Forwarded および X-Forwarded-For を含む HTTP ヘッダーの処理方法についてのポリシーを指定するように HAProxy Ingress Controller を設定します。Ingress Operator は HTTPHeaders フィールドを使用して、Ingress Controller の ROUTER_SET_FORWARDED_HEADERS 環境変数を設定します。
手順
Ingress Controller 用に
HTTPHeadersフィールドを設定します。以下のコマンドを使用して
IngressControllerリソースを編集します。$ oc edit IngressController
specの下で、HTTPHeadersポリシーフィールドをAppend、Replace、IfNone、またはNeverに設定します。apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: httpHeaders: forwardedHeaderPolicy: Append
使用例
クラスター管理者として、以下を実行できます。
Ingress Controller に転送する前に、
X-Forwarded-Forヘッダーを各リクエストに挿入する外部プロキシーを設定します。ヘッダーを変更せずに渡すように Ingress Controller を設定するには、
neverポリシーを指定します。これにより、Ingress Controller はヘッダーを設定しなくなり、アプリケーションは外部プロキシーが提供するヘッダーのみを受信します。外部プロキシーが外部クラスター要求を設定する
X-Forwarded-Forヘッダーを変更せずに渡すように Ingress Controller を設定します。外部プロキシーを通過しない内部クラスター要求に
X-Forwarded-Forヘッダーを設定するように Ingress Controller を設定するには、if-noneポリシーを指定します。外部プロキシー経由で HTTP 要求にヘッダーがすでに設定されている場合、Ingress Controller はこれを保持します。要求がプロキシーを通過していないためにヘッダーがない場合、Ingress Controller はヘッダーを追加します。
アプリケーション開発者として、以下を実行できます。
X-Forwarded-Forヘッダーを挿入するアプリケーション固有の外部プロキシーを設定します。他の Route のポリシーに影響を与えずに、アプリケーションの Route 用にヘッダーを変更せずに渡すように Ingress Controller を設定するには、アプリケーションの Route に アノテーション
haproxy.router.openshift.io/set-forwarded-headers: if-noneまたはhaproxy.router.openshift.io/set-forwarded-headers: neverを追加します。注記Ingress Controller のグローバルに設定された値とは別に、
haproxy.router.openshift.io/set-forwarded-headersアノテーションをルートごとに設定できます。
7.8.14. HTTP/2 Ingress 接続の有効化
HAProxy で透過的なエンドツーエンド HTTP/2 接続を有効にすることができます。これにより、アプリケーションの所有者は、単一接続、ヘッダー圧縮、バイナリーストリームなど、HTTP/2 プロトコル機能を使用できます。
個別の Ingress Controller またはクラスター全体について、HTTP/2 接続を有効にすることができます。
クライアントから HAProxy への接続について HTTP/2 の使用を有効にするために、ルートはカスタム証明書を指定する必要があります。デフォルトの証明書を使用するルートは HTTP/2 を使用することができません。この制限は、クライアントが同じ証明書を使用する複数の異なるルートに接続を再使用するなどの、接続の結合 (coalescing) の問題を回避するために必要です。
HAProxy からアプリケーション Pod への接続は、re-encrypt ルートのみに HTTP/2 を使用でき、edge termination ルートまたは非セキュアなルートには使用しません。この制限は、HAProxy が TLS 拡張である Application-Level Protocol Negotiation (ALPN) を使用してバックエンドで HTTP/2 の使用をネゴシエートするためにあります。そのため、エンドツーエンドの HTTP/2 はパススルーおよび re-encrypt 使用できますが、非セキュアなルートまたは edge termination ルートでは使用できません。
再暗号化ルートで WebSocket を使用し、Ingress Controller で HTTP/2 を有効にするには、HTTP/2 を介した WebSocket のサポートが必要です。HTTP/2 上の WebSockets は HAProxy 2.4 の機能であり、現時点では OpenShift Container Platform ではサポートされていません。
パススルー以外のルートの場合、Ingress Controller はクライアントからの接続とは独立してアプリケーションへの接続をネゴシエートします。つまり、クライアントが Ingress Controller に接続して HTTP/1.1 をネゴシエートし、Ingress Controller は次にアプリケーションに接続して HTTP/2 をネゴシエートし、アプリケーションへの HTTP/2 接続を使用してクライアント HTTP/1.1 接続からの要求の転送を実行できます。Ingress Controller は WebSocket を HTTP/2 に転送できず、その HTTP/2 接続を WebSocket に対してアップグレードできないため、クライアントが後に HTTP/1.1 から WebSocket プロトコルに接続をアップグレードしようとすると問題が発生します。そのため、WebSocket 接続を受け入れることが意図されたアプリケーションがある場合、これは HTTP/2 プロトコルのネゴシエートを許可できないようにする必要があります。そうしないと、クライアントは WebSocket プロトコルへのアップグレードに失敗します。
手順
単一 Ingress Controller で HTTP/2 を有効にします。
Ingress Controller で HTTP/2 を有効にするには、
oc annotateコマンドを入力します。$ oc -n openshift-ingress-operator annotate ingresscontrollers/<ingresscontroller_name> ingress.operator.openshift.io/default-enable-http2=true
<ingresscontroller_name>をアノテーションを付ける Ingress Controller の名前に置き換えます。
クラスター全体で HTTP/2 を有効にします。
クラスター全体で HTTP/2 を有効にするには、
oc annotateコマンドを入力します。$ oc annotate ingresses.config/cluster ingress.operator.openshift.io/default-enable-http2=true
ヒントまたは、以下の YAML を適用してアノテーションを追加できます。
apiVersion: config.openshift.io/v1 kind: Ingress metadata: name: cluster annotations: ingress.operator.openshift.io/default-enable-http2: "true"
7.8.15. Ingress Controller の PROXY プロトコルの設定
クラスター管理者は、Ingress Controller が HostNetwork または NodePortService エンドポイントの公開ストラテジータイプのいずれかを使用する際に PROXY プロトコル を設定できます。PROXY プロトコルにより、ロードバランサーは Ingress Controller が受信する接続の元のクライアントアドレスを保持することができます。元のクライアントアドレスは、HTTP ヘッダーのロギング、フィルタリング、および挿入を実行する場合に便利です。デフォルト設定では、Ingress Controller が受信する接続には、ロードバランサーに関連付けられるソースアドレスのみが含まれます。
この機能は、クラウドデプロイメントではサポートされていません。この制限があるのは、OpenShift Container Platform がクラウドプラットフォームで実行され、IngressController がサービスロードバランサーを使用するように指定している場合に、Ingress Operator がロードバランサーサービスを設定し、ソースアドレスを保持するプラットフォーム要件に基づいて PROXY プロトコルを有効にするためです。
PROXY プロトコルまたは TCP を使用するには、OpenShift Container Platform と外部ロードバランサーの両方を設定する必要があります。
PROXY プロトコルは、Keepalived Ingress VIP を使用するクラウド以外のプラットフォーム上のインストーラーによってプロビジョニングされたクラスターを使用するデフォルトの Ingress Controller ではサポートされていません。
前提条件
- Ingress Controller を作成している。
手順
Ingress Controller リソースを編集します。
$ oc -n openshift-ingress-operator edit ingresscontroller/default
PROXY 設定を設定します。
Ingress Controller が hostNetwork エンドポイント公開ストラテジータイプを使用する場合は、
spec.endpointPublishingStrategy.nodePort.protocolサブフィールドをPROXYに設定します。PROXYへのhostNetworkの設定例spec: endpointPublishingStrategy: hostNetwork: protocol: PROXY type: HostNetworkIngress Controller が NodePortService エンドポイント公開ストラテジータイプを使用する場合は、
spec.endpointPublishingStrategy.nodePort.protocolサブフィールドをPROXYに設定します。PROXYへのサンプルnodePort設定spec: endpointPublishingStrategy: nodePort: protocol: PROXY type: NodePortService
7.8.16. appsDomain オプションを使用した代替クラスタードメインの指定
クラスター管理者は、appsDomain フィールドを設定して、ユーザーが作成したルートのデフォルトのクラスタードメインの代わりとなるものを指定できます。appsDomain フィールドは、domain フィールドで指定されているデフォルトの代わりに使用する OpenShift Container Platform のオプションのドメインです。代替ドメインを指定する場合、これは新規ルートのデフォルトホストを判別できるようにする目的でデフォルトのクラスタードメインを上書きします。
たとえば、所属企業の DNS ドメインを、クラスター上で実行されるアプリケーションのルートおよび ingress のデフォルトドメインとして使用できます。
前提条件
- OpenShift Container Platform クラスターをデプロイしていること。
-
ocコマンドラインインターフェイスをインストールしている。
手順
ユーザーが作成するルートに代替のデフォルトドメインを指定して
appsDomainフィールドを設定します。Ingress
clusterリソースを編集します。$ oc edit ingresses.config/cluster -o yaml
YAML ファイルを編集します。
test.example.comへのapps Domainの設定例apiVersion: config.openshift.io/v1 kind: Ingress metadata: name: cluster spec: domain: apps.example.com 1 appsDomain: <test.example.com> 2
ルートを公開し、ルートドメインの変更を確認して、既存のルートに、
appsDomainフィールドで指定したドメイン名が含まれていることを確認します。注記ルートを公開する前に
openshift-apiserverがローリング更新を終了するのを待機します。ルートを公開します。
$ oc expose service hello-openshift route.route.openshift.io/hello-openshift exposed
出力例:
$ oc get routes NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD hello-openshift hello_openshift-<my_project>.test.example.com hello-openshift 8080-tcp None
7.8.17. HTTP ヘッダーケースの変換
HAProxy 2.2 では、デフォルトで HTTP ヘッダー名を小文字化します。たとえば、Host: xyz.com を host: xyz.com に変更します。レガシーアプリケーションが HTTP ヘッダー名の大文字を認識する場合、Ingress Controller の spec.httpHeaders.headerNameCaseAdjustments API フィールドを、修正されるまでレガシーアプリケーションに対応するソリューションに使用します。
OpenShift Container Platform には HAProxy 2.2 が含まれるため、アップグレードする前に spec.httpHeaders.headerNameCaseAdjustments を使用して必要な設定を追加するようにしてください。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
クラスター管理者は、oc patch コマンドを入力するか、Ingress Controller YAML ファイルの HeaderNameCaseAdjustments フィールドを設定して HTTP ヘッダーのケースを変換できます。
oc patchコマンドを入力して、HTTP ヘッダーの大文字化を指定します。oc patchコマンドを入力して、HTTPhostヘッダーをHostに変更します。$ oc -n openshift-ingress-operator patch ingresscontrollers/default --type=merge --patch='{"spec":{"httpHeaders":{"headerNameCaseAdjustments":["Host"]}}}'アプリケーションのルートにアノテーションを付けます。
$ oc annotate routes/my-application haproxy.router.openshift.io/h1-adjust-case=true
次に、Ingress Controller は
host要求ヘッダーを指定どおりに調整します。
Ingress Controller の YAML ファイルを設定し、
HeaderNameCaseAdjustmentsフィールドを使用して調整を指定します。以下のサンプル Ingress Controller YAML は、適切にアノテーションが付けられたルートへの HTTP/1 要求について
hostヘッダーをHostに調整します。Ingress Controller YAML のサンプル
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: httpHeaders: headerNameCaseAdjustments: - Host以下のサンプルルートでは、
haproxy.router.openshift.io/h1-adjust-caseアノテーションを使用して HTTP 応答ヘッダー名のケース調整を有効にします。ルート YAML のサンプル
apiVersion: route.openshift.io/v1 kind: Route metadata: annotations: haproxy.router.openshift.io/h1-adjust-case: true 1 name: my-application namespace: my-application spec: to: kind: Service name: my-application- 1
haproxy.router.openshift.io/h1-adjust-caseを true に設定します。
7.8.18. ルーター圧縮の使用
特定の MIME タイプに対してルーター圧縮をグローバルに指定するように HAProxy Ingress Controller を設定します。mimeTypes変数を使用して、圧縮が適用される MIME タイプの形式を定義できます。タイプは、アプリケーション、イメージ、メッセージ、マルチパート、テキスト、ビデオ、または X-で始まるカスタムタイプです。MIME タイプとサブタイプの完全な表記を確認するには、RFC1341を参照してください。
圧縮用に割り当てられたメモリーは、最大接続数に影響を与える可能性があります。さらに、大きなバッファーを圧縮すると、正規表現による負荷が多い場合や正規表現のリストが長い場合など、レイテンシーが発生する可能性があります。
すべての MIME タイプが圧縮から利点を得るわけではありませんが、HAProxy は、指示された場合でもリソースを使用して圧縮を試みます。一般に、html、css、js などのテキスト形式は圧縮から利点を得ますが、イメージ、音声、ビデオなどのすでに圧縮済みの形式は、圧縮に時間とリソースが費やされるわりに利点はほぼありません。
手順
Ingress Controller の
httpCompressionフィールドを設定します。以下のコマンドを使用して
IngressControllerリソースを編集します。$ oc edit -n openshift-ingress-operator ingresscontrollers/default
specで、httpCompressionポリシーフィールドをmimeTypesに設定し、圧縮を適用する必要がある MIME タイプのリストを指定します。apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: httpCompression: mimeTypes: - "text/html" - "text/css; charset=utf-8" - "application/json" ...
7.8.19. ルーターメトリクスの公開
デフォルトで、HAProxy ルーターメトリクスをデフォルトの stats ポート (1936) に Prometheus 形式で公開できます。Prometheus などの外部メトリクス収集および集約システムは、HAProxy ルーターメメトリクスにアクセスできます。HAProxy ルーターメトリクスは、HTML およびコンマ区切り値 (CSV) 形式でブラウザーに表示できます。
前提条件
- ファイアウォールを、デフォルトの stats ポート (1936) にアクセスするように設定している。
手順
次のコマンドを実行して、ルーター Pod 名を取得します。
$ oc get pods -n openshift-ingress
出力例
NAME READY STATUS RESTARTS AGE router-default-76bfffb66c-46qwp 1/1 Running 0 11h
ルーター Pod が
/var/lib/haproxy/conf/metrics-auth/statsUsernameおよび/var/lib/haproxy/conf/metrics-auth/statsPasswordファイルに保存しているルーターのユーザー名およびパスワードを取得します。次のコマンドを実行して、ユーザー名を取得します。
$ oc rsh <router_pod_name> cat metrics-auth/statsUsername
次のコマンドを実行して、パスワードを取得します。
$ oc rsh <router_pod_name> cat metrics-auth/statsPassword
次のコマンドを実行して、ルーター IP およびメトリクス証明書を取得します。
$ oc describe pod <router_pod>
つぎのコマンドを実行して、Prometheus 形式で未加工の統計情報を取得します。
$ curl -u <user>:<password> http://<router_IP>:<stats_port>/metrics
次のコマンドを実行して、安全にメトリクスにアクセスします。
$ curl -u user:password https://<router_IP>:<stats_port>/metrics -k
次のコマンドを実行して、デフォルトの stats ポート (1936) にアクセスします。
$ curl -u <user>:<password> http://<router_IP>:<stats_port>/metrics
例7.1 出力例
... # HELP haproxy_backend_connections_total Total number of connections. # TYPE haproxy_backend_connections_total gauge haproxy_backend_connections_total{backend="http",namespace="default",route="hello-route"} 0 haproxy_backend_connections_total{backend="http",namespace="default",route="hello-route-alt"} 0 haproxy_backend_connections_total{backend="http",namespace="default",route="hello-route01"} 0 ... # HELP haproxy_exporter_server_threshold Number of servers tracked and the current threshold value. # TYPE haproxy_exporter_server_threshold gauge haproxy_exporter_server_threshold{type="current"} 11 haproxy_exporter_server_threshold{type="limit"} 500 ... # HELP haproxy_frontend_bytes_in_total Current total of incoming bytes. # TYPE haproxy_frontend_bytes_in_total gauge haproxy_frontend_bytes_in_total{frontend="fe_no_sni"} 0 haproxy_frontend_bytes_in_total{frontend="fe_sni"} 0 haproxy_frontend_bytes_in_total{frontend="public"} 119070 ... # HELP haproxy_server_bytes_in_total Current total of incoming bytes. # TYPE haproxy_server_bytes_in_total gauge haproxy_server_bytes_in_total{namespace="",pod="",route="",server="fe_no_sni",service=""} 0 haproxy_server_bytes_in_total{namespace="",pod="",route="",server="fe_sni",service=""} 0 haproxy_server_bytes_in_total{namespace="default",pod="docker-registry-5-nk5fz",route="docker-registry",server="10.130.0.89:5000",service="docker-registry"} 0 haproxy_server_bytes_in_total{namespace="default",pod="hello-rc-vkjqx",route="hello-route",server="10.130.0.90:8080",service="hello-svc-1"} 0 ...ブラウザーで以下の URL を入力して、stats ウィンドウを起動します。
http://<user>:<password>@<router_IP>:<stats_port>
オプション: ブラウザーに次の URL を入力して、CSV 形式で統計情報を取得します。
http://<user>:<password>@<router_ip>:1936/metrics;csv
7.8.20. HAProxy エラーコードの応答ページのカスタマイズ
クラスター管理者は、503、404、またはその両方のエラーページにカスタムのエラーコード応答ページを指定できます。HAProxy ルーターは、アプリケーション Pod が実行していない場合や、要求された URL が存在しない場合に 404 エラーページを提供する 503 エラーページを提供します。たとえば、503 エラーコードの応答ページをカスタマイズする場合は、アプリケーション Pod が実行していないときにページが提供されます。また、デフォルトの 404 エラーコード HTTP 応答ページは、誤ったルートまたは存在しないルートについて HAProxy ルーターによって提供されます。
カスタムエラーコードの応答ページは ConfigMap に指定し、Ingress Controller にパッチを適用されます。ConfigMap キーには、error-page-503.http と error-page-404.http の 2 つの利用可能なファイル名があります。
カスタムの HTTP エラーコードの応答ページは、HAProxy HTTP エラーページ設定のガイドライン に従う必要があります。以下は、デフォルトの OpenShift Container Platform HAProxy ルーターの http 503 エラーコード応答ページ の例です。デフォルトのコンテンツを、独自のカスタムページを作成するためのテンプレートとして使用できます。
デフォルトで、HAProxy ルーターは、アプリケーションが実行していない場合や、ルートが正しくないまたは存在しない場合に 503 エラーページのみを提供します。このデフォルトの動作は、OpenShift Container Platform 4.8 以前の動作と同じです。HTTP エラーコード応答をカスタマイズするための ConfigMap が提供されておらず、カスタム HTTP エラーコード応答ページを使用している場合、ルーターはデフォルトの 404 または 503 エラーコード応答ページを提供します。
OpenShift Container Platform のデフォルトの 503 エラーコードページをカスタマイズのテンプレートとして使用する場合、ファイル内のヘッダーで CRLF 改行コードを使用できるエディターが必要になります。
手順
openshift-configにmy-custom-error-code-pagesという名前の ConfigMap を作成します。$ oc -n openshift-config create configmap my-custom-error-code-pages \ --from-file=error-page-503.http \ --from-file=error-page-404.http
重要カスタムエラーコードの応答ページに適した形式を指定しない場合は、ルーター Pod が停止します。この停止を解決するには、ConfigMap を削除するか、修正し、影響を受けるルーター Pod を削除して、正しい情報で再作成できるようにします。
Ingress Controller にパッチを適用し、名前を指定して
my-custom-error-code-pagesConfigMap を参照します。$ oc patch -n openshift-ingress-operator ingresscontroller/default --patch '{"spec":{"httpErrorCodePages":{"name":"my-custom-error-code-pages"}}}' --type=mergeIngress Operator は、
openshift-confignamespace からopenshift-ingressnamespace にmy-custom-error-code-pagesConfigMap をコピーします。Operator は、openshift-ingressnamespace のパターン<your_ingresscontroller_name>-errorpagesに従って ConfigMap に名前を付けます。コピーを表示します。
$ oc get cm default-errorpages -n openshift-ingress
出力例
NAME DATA AGE default-errorpages 2 25s 1- 1
defaultの Ingress Controller カスタムリソース (CR) にパッチが適用されているため、ConfigMap 名の例はdefault-errorpagesです。
カスタムエラー応答ページを含む ConfigMap がルーターボリュームにマウントされることを確認します。ConfigMap キーは、カスタム HTTP エラーコード応答を持つファイル名です。
503 カスタム HTTP カスタムエラーコード応答の場合:
$ oc -n openshift-ingress rsh <router_pod> cat /var/lib/haproxy/conf/error_code_pages/error-page-503.http
404 カスタム HTTP カスタムエラーコード応答の場合:
$ oc -n openshift-ingress rsh <router_pod> cat /var/lib/haproxy/conf/error_code_pages/error-page-404.http
検証
カスタムエラーコード HTTP 応答を確認します。
テストプロジェクトおよびアプリケーションを作成します。
$ oc new-project test-ingress
$ oc new-app django-psql-example
503 カスタム http エラーコード応答の場合:
- アプリケーションのすべての Pod を停止します。
以下の curl コマンドを実行するか、ブラウザーでルートのホスト名にアクセスします。
$ curl -vk <route_hostname>
404 カスタム http エラーコード応答の場合:
- 存在しないルートまたは正しくないルートにアクセスします。
以下の curl コマンドを実行するか、ブラウザーでルートのホスト名にアクセスします。
$ curl -vk <route_hostname>
errorfile属性がhaproxy.configファイルで適切にあるかどうかを確認します。$ oc -n openshift-ingress rsh <router> cat /var/lib/haproxy/conf/haproxy.config | grep errorfile
7.8.21. Ingress Controller の最大接続数の設定
クラスター管理者は、OpenShift ルーターデプロイメントの同時接続の最大数を設定できます。既存の Ingress Controller にパッチを適用して、接続の最大数を増やすことができます。
前提条件
- 以下では、Ingress Controller が作成済みであることを前提とします。
手順
Ingress Controller を更新して、HAProxy の最大接続数を変更します。
$ oc -n openshift-ingress-operator patch ingresscontroller/default --type=merge -p '{"spec":{"tuningOptions": {"maxConnections": 7500}}}'警告spec.tuningOptions.maxConnectionsの値を現在のオペレーティングシステムの制限よりも大きく設定すると、HAProxy プロセスは開始しません。このパラメーターの詳細は、Ingress Controller 設定パラメーターセクションの表を参照してください。
7.9. 関連情報
第8章 OpenShift Container Platform での Ingress シャーディング
OpenShift Container Platform では、Ingress Controller はすべてのルートを提供することも、ルートのサブセットを提供することもできます。デフォルトでは、Ingress Controller は、クラスター内の任意の namespace で作成されたすべてのルートを提供します。別の Ingress Controller をクラスターに追加して、選択した特性に基づくルートのサブセットである シャード を作成することにより、ルーティングを最適化できます。ルートをシャードのメンバーとしてマークするには、ルートまたは namespace の メタデータ フィールドでラベルを使用します。Ingress Controller は、選択式 とも呼ばれる セレクター を使用して、ルートのプール全体からルートのサブセットを選択し、サービスを提供します。
Ingress シャーディングは、受信トラフィックを複数の Ingress Controller 間で負荷分散する場合に、トラフィックを分離して特定の Ingress Controller にルーティングする場合、または次のセクションで説明する他のさまざまな理由で役立ちます。
デフォルトでは、各ルートはクラスターのデフォルトドメインを使用します。ただし、代わりにルーターのドメインを使用するようにルートを設定できます。詳細は、Ingress Controller シャーディングのルートの作成 を参照してください。
8.1. Ingress Controller のシャード化
Ingress シャーディング (ルーターシャーディングとも呼ばれます) を使用して、ルート、namespace、またはその両方にラベルを追加することで、一連のルートを複数のルーターに分散できます。Ingress Controller は、対応する一連のセレクターを使用して、指定されたラベルが含まれるルートのみを許可します。各 Ingress シャードは、特定の選択式を使用してフィルタリングされたルートで設定されます。
トラフィックがクラスターに送信される主要なメカニズムとして、Ingress Controller への要求が大きくなる可能性があります。クラスター管理者は、以下を実行するためにルートをシャード化できます。
- Ingress Controller またはルーターを複数のルートに分散し、変更に対する応答を加速します。
- 特定のルートを他のルートとは異なる信頼性の保証を持つように割り当てます。
- 特定の Ingress Controller に異なるポリシーを定義することを許可します。
- 特定のルートのみが追加機能を使用することを許可します。
- たとえば、異なるアドレスで異なるルートを公開し、内部ユーザーおよび外部ユーザーが異なるルートを認識できるようにします。
- blue green デプロイ中に、アプリケーションの別のバージョンにトラフィックを転送します。
Ingress Controller がシャーディングされると、特定のルートがグループ内の 0 個以上の Ingress Controller に受け入れられます。ルートのステータスは、Ingress Controller がルートを受け入れたかどうかを示します。Ingress Controller は、ルートがそのシャードに固有である場合にのみルートを受け入れます。
Ingress Controller は、次の 3 つのシャーディング方法を使用できます。
- namespace セレクターとラベルが同じ namespace 内のすべてのルートが Ingress シャードに含まれるように、namespace セレクターのみを Ingress Controller に追加します。
- Ingress Controller にルートセレクターのみを追加して、ルートセレクターとラベルが同じ全ルートが Ingress シャードに含まれるようにします。
- namespace セレクターとラベルが同じ namespace 内のルートセレクターのラベルがルートと同じ場合に、Ingress シャード内に含まれるように、namespace セレクターとルートセレクターの両方を Ingress Controller に追加します。
シャーディングを使用すると、ルートのサブセットを複数の Ingress Controller に分散できます。これらのサブセットは、重複なし (従来 のシャーディングとも呼ばれる) にすることも、重複 (重複 シャーディングとも呼ばれる) にすることもできます。
8.1.1. 従来のシャーディングの例
Ingress Controller の finops-router は、ラベルセレクター spec.namespaceSelector.matchLabels.name を finance および ops に指定して設定されます。
finops-router の YAML 定義の例
apiVersion: operator.openshift.io/v1
kind: IngressController
metadata:
name: finops-router
namespace: openshift-ingress-operator
spec:
namespaceSelector:
matchLabels:
name:
- finance
- ops
2 番目の Ingress Controller dev-router は、ラベルセレクター spec.namespaceSelector.matchLabels.name を dev に指定して設定されます。
dev-router の YAML 定義の例
apiVersion: operator.openshift.io/v1
kind: IngressController
metadata:
name: dev-router
namespace: openshift-ingress-operator
spec:
namespaceSelector:
matchLabels:
name: dev
すべてのアプリケーションルートが個別の namespace にあり、それぞれに name:finance、name:ops、および name:dev というラベルが付けられている場合、この設定は 2 つの Ingress Controller 間でルートを効果的に分散します。コンソール、認証、およびその他の目的の OpenShift Container Platform ルートは処理しないでください。
上記のシナリオでは、シャード化は重複するセットを持たないパーティション設定の特別なケースとなります。ルートは複数のルーターシャード間で分割されます。
デフォルト の Ingress Controller は、namespaceSelector または routeSelector フィールドに除外対象のルートが含まれていない限り、引き続きすべてのルートを提供します。デフォルトの Ingress Controller からルートを除外する方法の詳細は、この Red Hat ナレッジベースのソリューション と「デフォルトの Ingress Controller のシャーディング」のセクションを参照してください。
8.1.2. 重複シャーディングの例
上記の例の finops-router と dev-router に加えて、ラベルセレクター spec.namespaceSelector.matchLabels.name を dev と ops に指定して設定された devops-router もあります。
Devops-router の YAML 定義の例
apiVersion: operator.openshift.io/v1
kind: IngressController
metadata:
name: devops-router
namespace: openshift-ingress-operator
spec:
namespaceSelector:
matchLabels:
name:
- dev
- ops
name:dev および name:ops という 名前の namespace のルートは、2 つの異なる Ingress Controller によって処理されるようになりました。この設定では、ルートのサブセットが重複しています。
重複するルートのサブセットを使用すると、より複雑なルーティングルールを作成できます。たとえば、優先度の低いトラフィックを devops-router に送信しながら、優先度の高いトラフィックを専用の finops-router に迂回させることができます。
8.1.3. デフォルトの Ingress Controller のシャーディング
新しい Ingress シャードを作成した後に、デフォルトの Ingress Controller と、新しい Ingress シャードの両方により許可されるルートが存在する場合があります。これは、デフォルトの Ingress Controller にセレクターがなく、デフォルトですべてのルートを許可するためです。
namespace セレクターまたはルートセレクターを使用して、Ingress Controller が特定のラベルが割り当てられたルートの処理を制限できます。次の手順では、namespace セレクターを使用して、デフォルトの Ingress Controller が新しく分割された finance、ops、および dev ルートにサービスを提供しないように制限します。これにより、Ingress シャードがさらに分離されます。
OpenShift Container Platform のすべての管理ルートを同じ Ingress Controller で保持する必要があります。したがって、これらの重要なルートを除外するセレクターをデフォルトのIngress Controller に追加することは避けてください。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - プロジェクト管理者としてログインしている。
手順
次のコマンドを実行して、デフォルトのIngress Controller を変更します。
$ oc edit ingresscontroller -n openshift-ingress-operator default
Ingress Controller を編集して、
finance、ops、およびdevラベルのいずれかを持つルートを除外するnamespaceSelectorを含めます。apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: namespaceSelector: matchExpressions: - key: type operator: NotIn values: - finance - ops - dev
デフォルトの Ingress Controller では、name:finance、name:ops、および name:dev という名前の namespace が提供されなくなります。
8.1.4. Ingress シャーディングと DNS
クラスター管理者は、プロジェクト内のルーターごとに個別の DNS エントリーを作成します。ルーターは不明なルートを別のルーターに転送することはありません。
以下の例を考慮してください。
-
Router A はホスト 192.168.0.5 にあり、
*.foo.comのルートを持つ。 -
Router B はホスト 192.168.1.9 にあり、
*.example.comのルートを持つ。
個別の DNS エントリーは、*.foo.com をルーター A をホストするノードに解決し、*.example.com をルーター B をホストするノードに解決する必要があります。
-
*.foo.com A IN 192.168.0.5 -
*.example.com A IN 192.168.1.9
8.1.5. ルートラベルを使用した Ingress Controller のシャード化の設定
ルートラベルを使用した Ingress Controller のシャード化とは、Ingress Controller がルートセレクターによって選択される任意 namespace の任意のルートを提供することを意味します。
図8.1 ルートラベルを使用した Ingress シャーディング
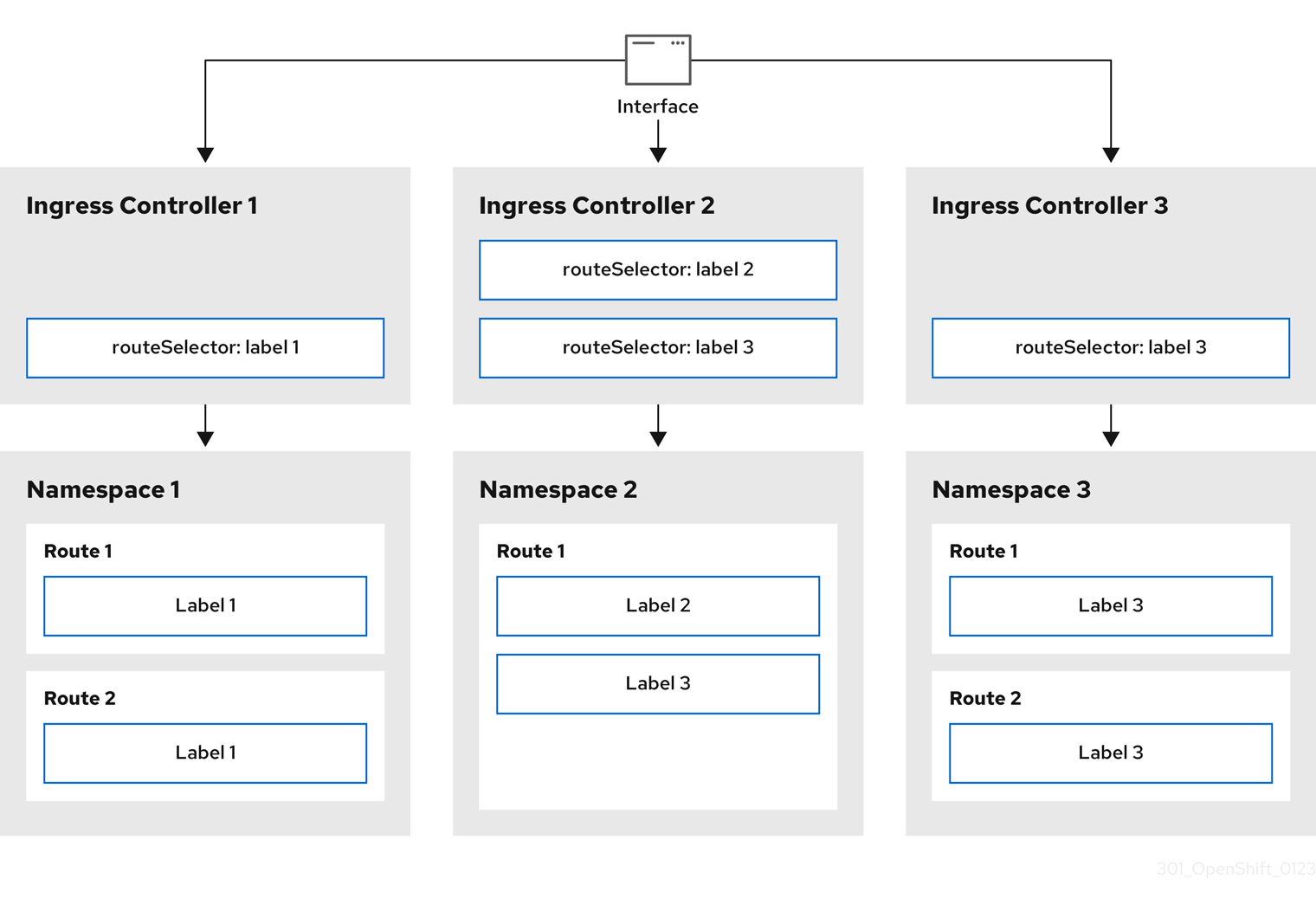
Ingress Controller のシャード化は、一連の Ingress Controller 間で着信トラフィックの負荷を分散し、トラフィックを特定の Ingress Controller に分離する際に役立ちます。たとえば、Company A のトラフィックをある Ingress Controller に指定し、Company B を別の Ingress Controller に指定できます。
手順
router-internal.yamlファイルを編集します。# cat router-internal.yaml apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: sharded namespace: openshift-ingress-operator spec: domain: <apps-sharded.basedomain.example.net> 1 nodePlacement: nodeSelector: matchLabels: node-role.kubernetes.io/worker: "" routeSelector: matchLabels: type: sharded- 1
- Ingress Controller が使用するドメインを指定します。このドメインは、デフォルトの Ingress Controller ドメインとは異なる必要があります。
Ingress Controller の
router-internal.yamlファイルを適用します。# oc apply -f router-internal.yaml
Ingress Controller は、
type: shardedというラベルのある namespace のルートを選択します。router-internal.yamlで設定されたドメインを使用して新しいルートを作成します。$ oc expose svc <service-name> --hostname <route-name>.apps-sharded.basedomain.example.net
8.1.6. namespace ラベルを使用した Ingress Controller のシャード化の設定
namespace ラベルを使用した Ingress Controller のシャード化とは、Ingress Controller が namespace セレクターによって選択される任意の namespace の任意のルートを提供することを意味します。
図8.2 namespace ラベルを使用した Ingress シャーディング
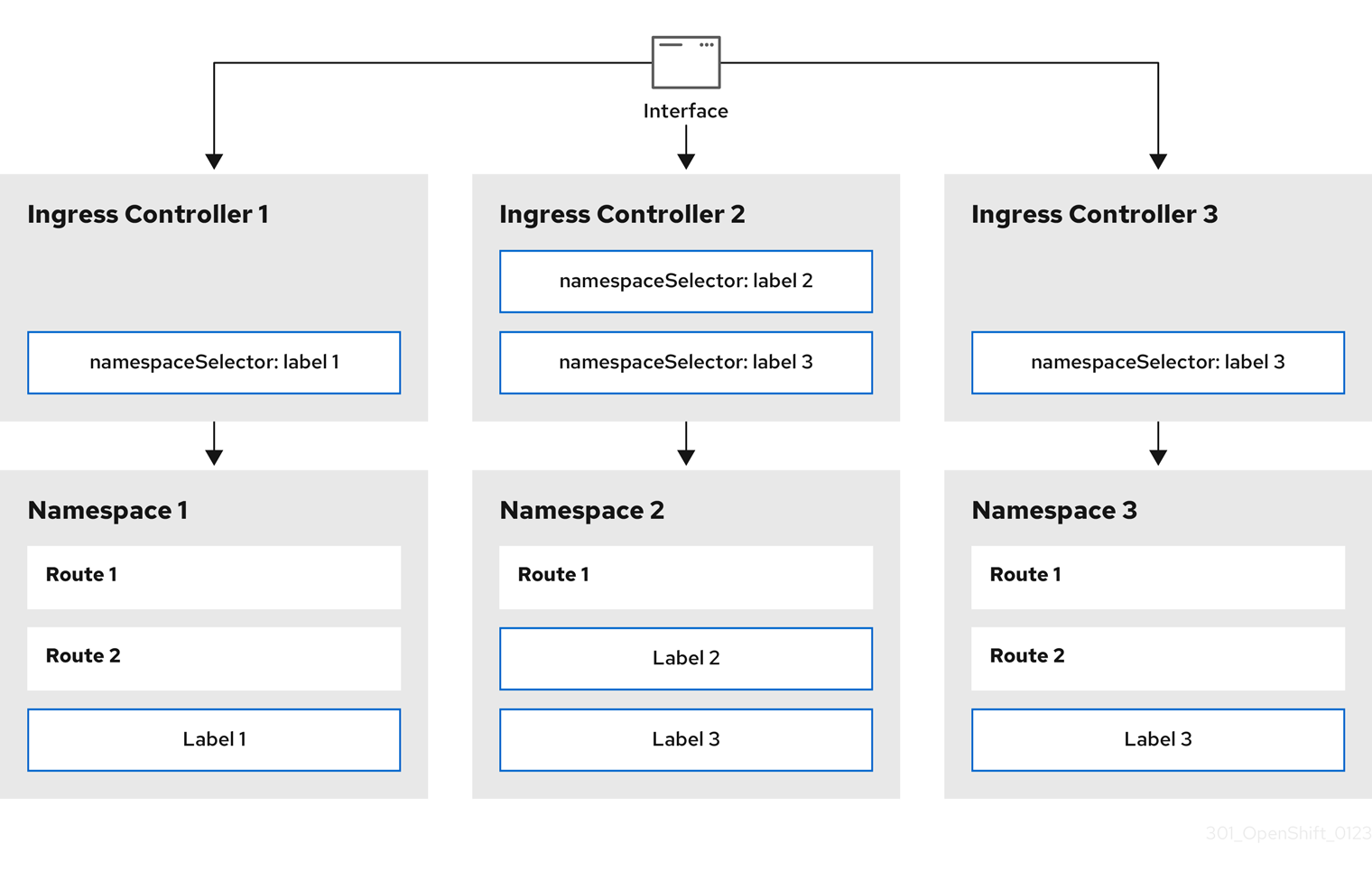
Ingress Controller のシャード化は、一連の Ingress Controller 間で着信トラフィックの負荷を分散し、トラフィックを特定の Ingress Controller に分離する際に役立ちます。たとえば、Company A のトラフィックをある Ingress Controller に指定し、Company B を別の Ingress Controller に指定できます。
手順
router-internal.yamlファイルを編集します。# cat router-internal.yaml
出力例
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: sharded namespace: openshift-ingress-operator spec: domain: <apps-sharded.basedomain.example.net> 1 nodePlacement: nodeSelector: matchLabels: node-role.kubernetes.io/worker: "" namespaceSelector: matchLabels: type: sharded- 1
- Ingress Controller が使用するドメインを指定します。このドメインは、デフォルトの Ingress Controller ドメインとは異なる必要があります。
Ingress Controller の
router-internal.yamlファイルを適用します。# oc apply -f router-internal.yaml
Ingress Controller は、
type: shardedというラベルのある namespace セレクターによって選択される namespace のルートを選択します。router-internal.yamlで設定されたドメインを使用して新しいルートを作成します。$ oc expose svc <service-name> --hostname <route-name>.apps-sharded.basedomain.example.net
8.2. Ingress Controller シャーディングのルート作成
ルートを使用すると、URL でアプリケーションをホストできます。この場合、ホスト名は設定されず、ルートは代わりにサブドメインを使用します。サブドメインを指定すると、ルートを公開する Ingress Controller のドメインが自動的に使用されます。ルートが複数の Ingress Controller によって公開されている状況では、ルートは複数の URL でホストされます。
以下の手順では、例として hello-openshift アプリケーションを使用して、Ingress Controller シャーディングのルートを作成する方法について説明します。
Ingress Controller のシャード化は、一連の Ingress Controller 間で着信トラフィックの負荷を分散し、トラフィックを特定の Ingress Controller に分離する際に役立ちます。たとえば、Company A のトラフィックをある Ingress Controller に指定し、Company B を別の Ingress Controller に指定できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - プロジェクト管理者としてログインしている。
- あるポートを公開する Web アプリケーションと、そのポートでトラフィックをリッスンする HTTP または TCP エンドポイントがある。
- シャーディング用に Ingress Controller を設定している。
手順
次のコマンドを実行して、
hello-openshiftというプロジェクトを作成します。$ oc new-project hello-openshift
以下のコマンドを実行してプロジェクトに Pod を作成します。
$ oc create -f https://raw.githubusercontent.com/openshift/origin/master/examples/hello-openshift/hello-pod.json
以下のコマンドを実行して、
hello-openshiftというサービスを作成します。$ oc expose pod/hello-openshift
hello-openshift-route.yamlというルート定義を作成します。シャーディング用に作成されたルートの YAML 定義:
apiVersion: route.openshift.io/v1 kind: Route metadata: labels: type: sharded 1 name: hello-openshift-edge namespace: hello-openshift spec: subdomain: hello-openshift 2 tls: termination: edge to: kind: Service name: hello-openshift次のコマンドを実行し、
hello-openshift-route.yamlを使用してhello-openshiftアプリケーションへのルートを作成します。$ oc -n hello-openshift create -f hello-openshift-route.yaml
検証
次のコマンドを使用して、ルートのステータスを取得します。
$ oc -n hello-openshift get routes/hello-openshift-edge -o yaml
結果の
Routeリソースは次のようになります。出力例
apiVersion: route.openshift.io/v1 kind: Route metadata: labels: type: sharded name: hello-openshift-edge namespace: hello-openshift spec: subdomain: hello-openshift tls: termination: edge to: kind: Service name: hello-openshift status: ingress: - host: hello-openshift.<apps-sharded.basedomain.example.net> 1 routerCanonicalHostname: router-sharded.<apps-sharded.basedomain.example.net> 2 routerName: sharded 3
関連情報
第9章 OpenShift Container Platform の Ingress Node Firewall Operator
Ingress Node Firewall Operator を使用すると、管理者はノードレベルでファイアウォール設定を管理できます。
9.1. Ingress Node Firewall Operator
Ingress Node Firewall Operator は、ファイアウォール設定で指定および管理するノードにデーモンセットをデプロイすることにより、ノードレベルで ingress ファイアウォールルールを提供します。デーモンセットをデプロイするには、IngressNodeFirewallConfig カスタムリソース (CR) を作成します。Operator は IngressNodeFirewallConfig CR を適用して、nodeSelector に一致するすべてのノードで実行されるingress ノードファイアウォールデーモンセット (daemon) を作成します。
IngressNodeFirewall CR の rule を設定し、nodeSelector を使用して値を true に設定してクラスターに適用します。
Ingress Node Firewall Operator は、ステートレスファイアウォールルールのみをサポートします。
最大転送単位 (MTU) パラメーターは、OpenShift Container Platform 4.13 では 4Kb (キロバイト) です。
ネイティブ XDP ドライバーをサポートしないネットワークインターフェイスコントローラー (NIC) は、より低いパフォーマンスで実行されます。
9.2. Ingress Node Firewall Operator のインストール
クラスター管理者は、OpenShift Container Platform CLI または Web コンソールを使用して Ingress Node Firewall Operator をインストールできます。
9.2.1. CLI を使用した Ingress Node Firewall Operator のインストール
クラスター管理者は、CLI を使用して Operator をインストールできます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - 管理者権限を持つアカウントを持っています。
手順
openshift-ingress-node-firewallnamespaceを作成するには、次のコマンドを入力します。$ cat << EOF| oc create -f - apiVersion: v1 kind: Namespace metadata: labels: pod-security.kubernetes.io/enforce: privileged pod-security.kubernetes.io/enforce-version: v1.24 name: openshift-ingress-node-firewall EOFOperatorGroupCR を作成するには、以下のコマンドを実行します。$ cat << EOF| oc create -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: ingress-node-firewall-operators namespace: openshift-ingress-node-firewall EOF
Ingress Node Firewall Operator にサブスクライブします。
Ingress Node Firewall Operator の
SubscriptionCR を作成するには、次のコマンドを入力します。$ cat << EOF| oc create -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: ingress-node-firewall-sub namespace: openshift-ingress-node-firewall spec: name: ingress-node-firewall channel: stable source: redhat-operators sourceNamespace: openshift-marketplace EOF
Operator がインストールされていることを確認するには、以下のコマンドを入力します。
$ oc get ip -n openshift-ingress-node-firewall
出力例
NAME CSV APPROVAL APPROVED install-5cvnz ingress-node-firewall.4.13.0-202211122336 Automatic true
Operator のバージョンを確認するには、次のコマンドを入力します。
$ oc get csv -n openshift-ingress-node-firewall
出力例
NAME DISPLAY VERSION REPLACES PHASE ingress-node-firewall.4.13.0-202211122336 Ingress Node Firewall Operator 4.13.0-202211122336 ingress-node-firewall.4.13.0-202211102047 Succeeded
9.2.2. Web コンソールを使用した Ingress Node Firewall Operator のインストール
クラスター管理者は、Web コンソールを使用して Operator をインストールできます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - 管理者権限を持つアカウントを持っています。
手順
Ingress Node Firewall Operator をインストールします。
- OpenShift Container Platform Web コンソールで、Operators → OperatorHub をクリックします。
- 利用可能な Operator のリストから Ingress Node Firewall Operator を選択し、Install をクリックします。
- Install Operator ページの Installed Namespace で、Operator recommend Namespace を選択します。
- Install をクリックします。
Ingress Node Firewall Operator が正常にインストールされていることを確認します。
- Operators → Installed Operators ページに移動します。
Ingress Node Firewall Operator が openshift-ingress-node-firewall プロジェクトにリストされ、Status が InstallSucceeded であることを確認します。
注記インストール時に、 Operator は Failed ステータスを表示する可能性があります。インストールが後に InstallSucceeded メッセージを出して正常に実行される場合は、Failed メッセージを無視できます。
Operator の Status が InstallSucceeded でない場合は、次の手順を使用してトラブルシューティングを行います。
- Operator Subscriptions および Install Plans タブで、Status の下の失敗またはエラーの有無を確認します。
-
Workloads → Pods ページに移動し、
openshift-ingress-node-firewallプロジェクトの Pod のログを確認します。 YAML ファイルの namespace を確認してください。アノテーションが抜けている場合は、次のコマンドを使用して、アノテーション
workload.openshift.io/allowed=managementを Operator namespace に追加できます。$ oc annotate ns/openshift-ingress-node-firewall workload.openshift.io/allowed=management
注記単一ノードの OpenShift クラスターの場合、
openshift-ingress-node-firewallnamespaceにはworkload.openshift.io/allowed=managementアノテーションが必要です。
9.3. Ingress Node Firewall Operator のデプロイ
前提条件
- Ingress Node Firewall Operator がインストールされます。
手順
Ingress Node Firewall Operator をデプロイするには、Operator のデーモンセットをデプロイする IngressNodeFirewallConfig カスタムリソースを作成します。ファイアウォールルールを適用することで、1 つまたは複数の IngressNodeFirewall CRD をノードにデプロイできます。
-
ingressnodefirewallconfigという名前のopenshift-ingress-node-firewallnamespace内にIngressNodeFirewallConfigを作成します。 次のコマンドを実行して、Ingress Node Firewall Operator ルールをデプロイします。
$ oc apply -f rule.yaml
9.3.1. ingress ノードファイアウォール設定オブジェクト
Ingress Node Firewall 設定オブジェクトのフィールドについて、次の表で説明します。
表9.1 ingress ノードファイアウォール設定オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
CR オブジェクトの名前。ファイアウォールルールオブジェクトの名前は |
|
|
|
Ingress Firewall Operator CR オブジェクトのnamespace。 |
|
|
| 指定されたノードラベルを介してノードをターゲットにするために使用されるノード選択制約。以下に例を示します。 spec:
nodeSelector:
node-role.kubernetes.io/worker: ""
注記
デーモンセットを開始するには、 |
Operator は CR を使用し、nodeSelector に一致するすべてのノード上に Ingress ノードファイアウォールデーモンセットを作成します。
Ingress Node Firewall Operator の設定例
次の例では、完全な Ingress ノードファイアウォール設定が指定されています。
ingress ノードファイアウォール設定オブジェクトの例
apiVersion: ingressnodefirewall.openshift.io/v1alpha1
kind: IngressNodeFirewallConfig
metadata:
name: ingressnodefirewallconfig
namespace: openshift-ingress-node-firewall
spec:
nodeSelector:
node-role.kubernetes.io/worker: ""
Operator は CR を使用し、nodeSelector に一致するすべてのノード上に Ingress ノードファイアウォールデーモンセットを作成します。
9.3.2. ingress ノードファイアウォールルールオブジェクト
ingress ノードファイアウォールルールオブジェクトのフィールドについて、次の表で説明します。
表9.2 ingress ノードファイアウォールルールオブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
| CR オブジェクトの名前。 |
|
|
|
このオブジェクトのフィールドは、ファイアウォールルールを適用するインターフェイスを指定します。たとえば、 |
|
|
|
|
|
|
|
|
Ingress オブジェクトの設定
Ingress オブジェクトの値は、次の表で定義されています。
表9.3 ingress オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
| CIDR ブロックを設定できます。異なるアドレスファミリーから複数の CIDR を設定できます。 注記
異なる CIDR を使用すると、同じ順序ルールを使用できます。CIDR が重複する同じノードおよびインターフェイスに対して複数の |
|
|
|
Ingress ファイアウォール
注記 ingress ファイアウォールルールは、無効な設定をブロックする検証 Webhook を使用して検証されます。検証 Webhook は、API サーバーや SSH などの重要なクラスターサービスをブロックすることを防ぎます。 |
ingress ノードファイアウォールルールオブジェクトの例
次の例では、完全な Ingress ノードファイアウォール設定が指定されています。
Ingress ノードファイアウォールの設定例
apiVersion: ingressnodefirewall.openshift.io/v1alpha1
kind: IngressNodeFirewall
metadata:
name: ingressnodefirewall
spec:
interfaces:
- eth0
nodeSelector:
matchLabels:
<ingress_firewall_label_name>: <label_value> 1
ingress:
- sourceCIDRs:
- 172.16.0.0/12
rules:
- order: 10
protocolConfig:
protocol: ICMP
icmp:
icmpType: 8 #ICMP Echo request
action: Deny
- order: 20
protocolConfig:
protocol: TCP
tcp:
ports: "8000-9000"
action: Deny
- sourceCIDRs:
- fc00:f853:ccd:e793::0/64
rules:
- order: 10
protocolConfig:
protocol: ICMPv6
icmpv6:
icmpType: 128 #ICMPV6 Echo request
action: Deny
- 1
- <label_name> と <label_value> はノード上に存在する必要があり、
ingressfirewallconfigCR を実行するノードに適用されるnodeselectorラベルと値に一致する必要があります。<label_value> は、trueまたはfalseです。nodeSelectorラベルを使用すると、ノードのグループを個別にターゲットにして、ingressfirewallconfigCR の使用に異なるルールを適用できます。
ゼロトラスト Ingress ノードファイアウォールルールオブジェクトの例
ゼロトラストの Ingress ノードファイアウォールルールは、マルチインターフェイスクラスターに追加のセキュリティーを提供できます。たとえば、ゼロトラストの Ingress ノードファイアウォールルールを使用して、SSH を除く特定のインターフェイス上のすべてのトラフィックをドロップできます。
次の例では、ゼロトラスト Ingress ノードファイアウォールルールセットの完全な設定が指定されています。
次の場合、ユーザーはアプリケーションが使用するすべてのポートを許可リストに追加して、適切な機能を確保する必要があります。
ゼロトラストの Ingress ノードファイアウォールルールの例
apiVersion: ingressnodefirewall.openshift.io/v1alpha1 kind: IngressNodeFirewall metadata: name: ingressnodefirewall-zero-trust spec: interfaces: - eth1 1 nodeSelector: matchLabels: <ingress_firewall_label_name>: <label_value> 2 ingress: - sourceCIDRs: - 0.0.0.0/0 3 rules: - order: 10 protocolConfig: protocol: TCP tcp: ports: 22 action: Allow - order: 20 action: Deny 4
9.4. Ingress Node Firewall Operator ルールの表示
手順
次のコマンドを実行して、現在のルールをすべて表示します。
$ oc get ingressnodefirewall
返された
<resource>名のいずれかを選択し、次のコマンドを実行してルールまたは設定を表示します。$ oc get <resource> <name> -o yaml
9.5. Ingress Node Firewall Operator のトラブルシューティング
次のコマンドを実行して、インストールされている Ingress ノードファイアウォールのカスタムリソース定義 (CRD) を一覧表示します。
$ oc get crds | grep ingressnodefirewall
出力例
NAME READY UP-TO-DATE AVAILABLE AGE ingressnodefirewallconfigs.ingressnodefirewall.openshift.io 2022-08-25T10:03:01Z ingressnodefirewallnodestates.ingressnodefirewall.openshift.io 2022-08-25T10:03:00Z ingressnodefirewalls.ingressnodefirewall.openshift.io 2022-08-25T10:03:00Z
次のコマンドを実行して、Ingress Node Firewall Operator の状態を表示します。
$ oc get pods -n openshift-ingress-node-firewall
出力例
NAME READY STATUS RESTARTS AGE ingress-node-firewall-controller-manager 2/2 Running 0 5d21h ingress-node-firewall-daemon-pqx56 3/3 Running 0 5d21h
次のフィールドは、Operator のステータスに関する情報を提供します:
READY、STATUS、AGE、およびRESTARTS。Ingress Node Firewall Operator が割り当てられたノードに設定されたデーモンをデプロイしている場合、STATUSフィールドはRunningになります。次のコマンドを実行して、すべての ingress ファイアウォールノード Pod のログを収集します。
$ oc adm must-gather – gather_ingress_node_firewall
ログは、
/sos_commands/ebpfにある eBPFbpftool出力を含む sos ノードのレポートで利用できます。これらのレポートには、Ingress ファイアウォール XDP がパケット処理を処理し、統計を更新し、イベントを発行するときに使用または更新されたルックアップテーブルが含まれます。
第10章 手動 DNS 管理のための Ingress Controller の設定
クラスター管理者として Ingress Controller を作成すると、Operator は DNS レコードを自動的に管理します。必要な DNS ゾーンがクラスター DNS ゾーンと異なる場合、または DNS ゾーンがクラウドプロバイダーの外部でホストされている場合、これにはいくつかの制限があります。
クラスター管理者は、Ingress Controller を設定して、自動 DNS 管理を停止し、手動 DNS 管理を開始することができます。dnsManagementPolicy を設定して、いつ自動または手動で管理するかを指定します。
Ingress Controller を Managed から Unmanaged DNS 管理ポリシーに変更すると、Operator はクラウドでプロビジョニングされた以前のワイルドカード DNS レコードをクリーンアップしません。Ingress Controller を Unmanaged から Managed DNS 管理ポリシーに変更すると、Operator は、クラウドプロバイダーに DNS レコードが存在しない場合は作成を試み、DNS レコードがすでに存在する場合は更新を試みます。
dnsManagementPolicy を unmanaged に設定すると、クラウドプロバイダーでワイルドカード DNS レコードのライフサイクルを手動で管理する必要があります。
10.1. Managed DNS 管理ポリシー
Ingress Controller の Managed DNS 管理ポリシーにより、クラウドプロバイダーのワイルドカード DNS レコードのライフサイクルが Operator によって自動的に管理されるようになります。
10.2. Unmanaged DNS 管理ポリシー
Ingress Controller の Unmanaged DNS 管理ポリシーにより、クラウドプロバイダーのワイルドカード DNS レコードのライフサイクルが自動的に管理されず、代わりにクラスター管理者の責任になります。
AWS クラウドプラットフォームでは、Ingress Controller のドメインが dnsConfig.Spec.BaseDomain と一致しない場合、DNS 管理ポリシーは自動的に Unmanaged に設定されます。
10.3. Unmanaged DNS 管理ポリシーを使用したカスタム Ingress Controller の作成
クラスター管理者は、Unmanaged DNS 管理ポリシーを使用して、新しいカスタム Ingress Controller を作成できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
以下を含む
sample-ingress.yamlという名前のカスタムリソース (CR) ファイルを作成します。apiVersion: operator.openshift.io/v1 kind: IngressController metadata: namespace: openshift-ingress-operator name: <name> 1 spec: domain: <domain> 2 endpointPublishingStrategy: type: LoadBalancerService loadBalancer: scope: External 3 dnsManagementPolicy: Unmanaged 4
変更を適用するためにファイルを保存します。
oc apply -f <name>.yaml 1
10.4. 既存の Ingress Controller の変更
クラスター管理者は、既存の Ingress Controller を変更して、DNS レコードのライフサイクルを手動で管理できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
選択した
IngressControllerを変更してdnsManagementPolicyを設定します。SCOPE=$(oc -n openshift-ingress-operator get ingresscontroller <name> -o=jsonpath="{.status.endpointPublishingStrategy.loadBalancer.scope}") oc -n openshift-ingress-operator patch ingresscontrollers/<name> --type=merge --patch='{"spec":{"endpointPublishingStrategy":{"type":"LoadBalancerService","loadBalancer":{"dnsManagementPolicy":"Unmanaged", "scope":"${SCOPE}"}}}}'- オプション: クラウドプロバイダーで関連付けられている DNS レコードを削除できます。
10.5. 関連情報
第11章 Ingress Controller エンドポイント公開戦略の設定
11.1. Ingress Controller エンドポイントの公開ストラテジー
NodePortService エンドポイントの公開ストラテジー
NodePortService エンドポイントの公開ストラテジーは、Kubernetes NodePort サービスを使用して Ingress Controller を公開します。
この設定では、Ingress Controller のデプロイメントはコンテナーのネットワークを使用します。NodePortService はデプロイメントを公開するために作成されます。特定のノードポートは OpenShift Container Platform によって動的に割り当てられますが、静的ポートの割り当てをサポートするために、管理される NodePortService のノードポートフィールドへの変更が保持されます。
図11.1 NodePortService の図
前述の図では、OpenShift Container Platform Ingress NodePort エンドポイントの公開戦略に関する以下のような概念を示しています。
- クラスターで利用可能なノードにはすべて、外部からアクセス可能な独自の IP アドレスが割り当てられています。クラスター内で動作するサービスは、全ノードに固有の NodePort にバインドされます。
-
たとえば、クライアントが図中の IP アドレス
10.0.128.4に接続してダウンしているノードに接続した場合に、ノードポートは、サービスを実行中で利用可能なノードにクライアントを直接接続します。このシナリオでは、ロードバランシングは必要ありません。イメージが示すように、10.0.128.4アドレスがダウンしており、代わりに別の IP アドレスを使用する必要があります。
Ingress Operator は、サービスの .spec.ports[].nodePort フィールドへの更新を無視します。
デフォルトで、ポートは自動的に割り当てられ、各種の統合用のポート割り当てにアクセスできます。ただし、既存のインフラストラクチャーと統合するために静的ポートの割り当てが必要になることがありますが、これは動的ポートに対応して簡単に再設定できない場合があります。静的ノードポートとの統合を実行するには、マネージドのサービスリソースを直接更新できます。
詳細は、NodePort についての Kubernetes サービスについてのドキュメント を参照してください。
HostNetwork エンドポイントの公開ストラテジー
HostNetwork エンドポイントの公開ストラテジーは、Ingress Controller がデプロイされるノードポートで Ingress Controller を公開します。
HostNetwork エンドポイント公開ストラテジーを持つ Ingress Controller には、ノードごとに単一の Pod レプリカのみを設定できます。n のレプリカを使用する場合、それらのレプリカをスケジュールできる n 以上のノードを使用する必要があります。各 Pod はスケジュールされるノードホストでポート 80 および 443 を要求するので、同じノードで別の Pod がそれらのポートを使用している場合、レプリカをノードにスケジュールすることはできません。
11.1.1. Ingress Controller エンドポイント公開スコープの内部への設定
クラスター管理者がクラスターをプライベートに指定せずに新しいクラスターをインストールすると、scopeがExternalに設定されたデフォルトの Ingress Controller が作成されます。クラスター管理者は、External スコープの Ingress Controller をInternalに変更できます。
前提条件
-
ocCLI をインストールした。
手順
Externalスコープの Ingress Controller をInternalに変更するには、次のコマンドを入力します。$ oc -n openshift-ingress-operator patch ingresscontrollers/default --type=merge --patch='{"spec":{"endpointPublishingStrategy":{"type":"LoadBalancerService","loadBalancer":{"scope":"Internal"}}}}'Ingress Controller のステータスを確認するには、次のコマンドを入力します。
$ oc -n openshift-ingress-operator get ingresscontrollers/default -o yaml
ステータス状態が
Progressingの場合は、さらにアクションを実行する必要があるかどうかを示します。たとえば、ステータスの状態によっては、次のコマンドを入力して、サービスを削除する必要があることを示している可能性があります。$ oc -n openshift-ingress delete services/router-default
サービスを削除すると、Ingress Operator はサービスを
Internalとして再作成します。
11.1.2. Ingress Controller エンドポイント公開スコープの外部への設定
クラスター管理者がクラスターをプライベートに指定せずに新しいクラスターをインストールすると、scopeがExternalに設定されたデフォルトの Ingress Controller が作成されます。
Ingress Controller のスコープは、インストール中またはインストール後にInternalになるように設定でき、クラスター管理者はInternal の Ingress Controller をExternalに変更できます。
一部のプラットフォームでは、サービスを削除して再作成する必要があります。
スコープを変更すると、場合によっては数分間、Ingress トラフィックが中断される可能性があります。これが該当するのは、サービスを削除して再作成する必要があるプラットフォームです。理由は、この手順により、OpenShift Container Platform が既存のサービスロードバランサーのプロビジョニングを解除して新しいサービスロードバランサーをプロビジョニングし、DNS を更新する可能性があるためです。
前提条件
-
ocCLI をインストールした。
手順
Internalスコープの入力コントローラーをExternalに変更するには、次のコマンドを入力します。$ oc -n openshift-ingress-operator patch ingresscontrollers/private --type=merge --patch='{"spec":{"endpointPublishingStrategy":{"type":"LoadBalancerService","loadBalancer":{"scope":"External"}}}}'Ingress Controller のステータスを確認するには、次のコマンドを入力します。
$ oc -n openshift-ingress-operator get ingresscontrollers/default -o yaml
ステータス状態が
Progressingの場合は、さらにアクションを実行する必要があるかどうかを示します。たとえば、ステータスの状態によっては、次のコマンドを入力して、サービスを削除する必要があることを示している可能性があります。$ oc -n openshift-ingress delete services/router-default
サービスを削除すると、Ingress Operator はサービスを
Externalとして再作成します。
11.2. 関連情報
- 詳細は、Ingress Controller configuration parameters を参照してください。
第12章 エンドポイントへの接続の確認
Cluster Network Operator (CNO) は、クラスター内のリソース間の接続ヘルスチェックを実行するコントローラーである接続性チェックコントローラーを実行します。ヘルスチェックの結果を確認して、調査している問題が原因で生じる接続の問題を診断したり、ネットワーク接続を削除したりできます。
12.1. 実行する接続ヘルスチェック
クラスターリソースにアクセスできることを確認するには、以下のクラスター API サービスのそれぞれに対して TCP 接続が行われます。
- Kubernetes API サーバーサービス
- Kubernetes API サーバーエンドポイント
- OpenShift API サーバーサービス
- OpenShift API サーバーエンドポイント
- ロードバランサー
サービスおよびサービスエンドポイントがクラスター内のすべてのノードで到達可能であることを確認するには、以下の各ターゲットに対して TCP 接続が行われます。
- ヘルスチェックターゲットサービス
- ヘルスチェックターゲットエンドポイント
12.2. 接続ヘルスチェックの実装
接続チェックコントローラーは、クラスター内の接続検証チェックをオーケストレーションします。接続テストの結果は、openshift-network-diagnostics namespace の PodNetworkConnectivity オブジェクトに保存されます。接続テストは、1 分ごとに並行して実行されます。
Cluster Network Operator (CNO) は、接続性ヘルスチェックを送受信するためにいくつかのリソースをクラスターにデプロイします。
- ヘルスチェックのソース
-
このプログラムは、
Deploymentオブジェクトで管理される単一の Pod レプリカセットにデプロイします。このプログラムはPodNetworkConnectivityオブジェクトを消費し、各オブジェクトで指定されるspec.targetEndpointに接続されます。 - ヘルスチェックのターゲット
- クラスターのすべてのノードにデーモンセットの一部としてデプロイされた Pod。Pod はインバウンドのヘルスチェックをリッスンします。すべてのノードにこの Pod が存在すると、各ノードへの接続をテストすることができます。
12.3. PodNetworkConnectivityCheck オブジェクトフィールド
PodNetworkConnectivityCheck オブジェクトフィールドについては、以下の表で説明されています。
表12.1 PodNetworkConnectivityCheck オブジェクトフィールド
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
以下の形式のオブジェクトの名前:
|
|
|
|
オブジェクトが関連付けられる namespace。この値は、常に |
|
|
|
接続チェックの起点となる Pod の名前 (例: |
|
|
|
|
|
|
| 使用する TLS 証明書の設定。 |
|
|
| 使用される TLS 証明書の名前 (ある場合)。デフォルト値は空の文字列です。 |
|
|
| 接続テストの状態を表す、および最近の接続の成功および失敗についてのログ。 |
|
|
| 接続チェックと最新のステータスと以前のステータス。 |
|
|
| 試行に失敗した接続テストのログ。 |
|
|
| 停止が生じた期間が含まれる接続テストのログ。 |
|
|
| 試行に成功した接続テストのログ。 |
以下の表は、status.conditions 配列内のオブジェクトのフィールドについて説明しています。
表12.2 status.conditions
| フィールド | 型 | 説明 |
|---|---|---|
|
|
| 接続の条件がある状態から別の状態に移行した時間。 |
|
|
| 人が判読できる形式の最後の移行についての詳細。 |
|
|
| マシンの読み取り可能な形式での移行の最後のステータス。 |
|
|
| 状態のテータス。 |
|
|
| 状態のタイプ。 |
以下の表は、status.conditions 配列内のオブジェクトのフィールドについて説明しています。
表12.3 status.outages
| フィールド | 型 | 説明 |
|---|---|---|
|
|
| 接続の障害が解決された時点からのタイムスタンプ。 |
|
|
| 接続ログエントリー (停止の正常な終了に関連するログエントリーを含む)。 |
|
|
| 人が判読できる形式の停止について詳細情報の要約。 |
|
|
| 接続の障害が最初に検知された時点からのタイムスタンプ。 |
|
|
| 元の障害を含む接続ログのエントリー。 |
接続ログフィールド
接続ログエントリーのフィールドの説明は以下の表で説明されています。オブジェクトは以下のフィールドで使用されます。
-
status.failures[] -
status.successes[] -
status.outages[].startLogs[] -
status.outages[].endLogs[]
表12.4 接続ログオブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
| アクションの期間を記録します。 |
|
|
| ステータスを人が判読できる形式で提供します。 |
|
|
|
ステータスの理由をマシンが判読できる形式で提供します。値は |
|
|
| ログエントリーが成功または失敗であるかを示します。 |
|
|
| 接続チェックの開始時間。 |
12.4. エンドポイントのネットワーク接続の確認
クラスター管理者は、API サーバー、ロードバランサー、サービス、または Pod などのエンドポイントの接続を確認できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
現在の
PodNetworkConnectivityCheckオブジェクトをリスト表示するには、以下のコマンドを入力します。$ oc get podnetworkconnectivitycheck -n openshift-network-diagnostics
出力例
NAME AGE network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-1 73m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-2 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-kubernetes-apiserver-service-cluster 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-kubernetes-default-service-cluster 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-load-balancer-api-external 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-load-balancer-api-internal 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-network-check-target-ci-ln-x5sv9rb-f76d1-4rzrp-master-0 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-network-check-target-ci-ln-x5sv9rb-f76d1-4rzrp-master-1 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-network-check-target-ci-ln-x5sv9rb-f76d1-4rzrp-master-2 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-network-check-target-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh 74m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-network-check-target-ci-ln-x5sv9rb-f76d1-4rzrp-worker-c-n8mbf 74m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-network-check-target-ci-ln-x5sv9rb-f76d1-4rzrp-worker-d-4hnrz 74m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-network-check-target-service-cluster 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-openshift-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-openshift-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-1 75m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-openshift-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-2 74m network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-openshift-apiserver-service-cluster 75m
接続テストログを表示します。
- 直前のコマンドの出力から、接続ログを確認するエンドポイントを特定します。
オブジェクトを表示するには、以下のコマンドを入力します。
$ oc get podnetworkconnectivitycheck <name> \ -n openshift-network-diagnostics -o yaml
ここで、
<name>はPodNetworkConnectivityCheckオブジェクトの名前を指定します。出力例
apiVersion: controlplane.operator.openshift.io/v1alpha1 kind: PodNetworkConnectivityCheck metadata: name: network-check-source-ci-ln-x5sv9rb-f76d1-4rzrp-worker-b-6xdmh-to-kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0 namespace: openshift-network-diagnostics ... spec: sourcePod: network-check-source-7c88f6d9f-hmg2f targetEndpoint: 10.0.0.4:6443 tlsClientCert: name: "" status: conditions: - lastTransitionTime: "2021-01-13T20:11:34Z" message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnectSuccess status: "True" type: Reachable failures: - latency: 2.241775ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: failed to establish a TCP connection to 10.0.0.4:6443: dial tcp 10.0.0.4:6443: connect: connection refused' reason: TCPConnectError success: false time: "2021-01-13T20:10:34Z" - latency: 2.582129ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: failed to establish a TCP connection to 10.0.0.4:6443: dial tcp 10.0.0.4:6443: connect: connection refused' reason: TCPConnectError success: false time: "2021-01-13T20:09:34Z" - latency: 3.483578ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: failed to establish a TCP connection to 10.0.0.4:6443: dial tcp 10.0.0.4:6443: connect: connection refused' reason: TCPConnectError success: false time: "2021-01-13T20:08:34Z" outages: - end: "2021-01-13T20:11:34Z" endLogs: - latency: 2.032018ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnect success: true time: "2021-01-13T20:11:34Z" - latency: 2.241775ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: failed to establish a TCP connection to 10.0.0.4:6443: dial tcp 10.0.0.4:6443: connect: connection refused' reason: TCPConnectError success: false time: "2021-01-13T20:10:34Z" - latency: 2.582129ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: failed to establish a TCP connection to 10.0.0.4:6443: dial tcp 10.0.0.4:6443: connect: connection refused' reason: TCPConnectError success: false time: "2021-01-13T20:09:34Z" - latency: 3.483578ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: failed to establish a TCP connection to 10.0.0.4:6443: dial tcp 10.0.0.4:6443: connect: connection refused' reason: TCPConnectError success: false time: "2021-01-13T20:08:34Z" message: Connectivity restored after 2m59.999789186s start: "2021-01-13T20:08:34Z" startLogs: - latency: 3.483578ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: failed to establish a TCP connection to 10.0.0.4:6443: dial tcp 10.0.0.4:6443: connect: connection refused' reason: TCPConnectError success: false time: "2021-01-13T20:08:34Z" successes: - latency: 2.845865ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnect success: true time: "2021-01-13T21:14:34Z" - latency: 2.926345ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnect success: true time: "2021-01-13T21:13:34Z" - latency: 2.895796ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnect success: true time: "2021-01-13T21:12:34Z" - latency: 2.696844ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnect success: true time: "2021-01-13T21:11:34Z" - latency: 1.502064ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnect success: true time: "2021-01-13T21:10:34Z" - latency: 1.388857ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnect success: true time: "2021-01-13T21:09:34Z" - latency: 1.906383ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnect success: true time: "2021-01-13T21:08:34Z" - latency: 2.089073ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnect success: true time: "2021-01-13T21:07:34Z" - latency: 2.156994ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnect success: true time: "2021-01-13T21:06:34Z" - latency: 1.777043ms message: 'kubernetes-apiserver-endpoint-ci-ln-x5sv9rb-f76d1-4rzrp-master-0: tcp connection to 10.0.0.4:6443 succeeded' reason: TCPConnect success: true time: "2021-01-13T21:05:34Z"
第13章 クラスターネットワークの MTU 変更
クラスター管理者は、クラスターのインストール後にクラスターネットワークの MTU を変更できます。MTU 変更の適用には、クラスターノードを再起動する必要があるため、変更により致命的な問題が発生する可能性があります。OVN-Kubernetes または OpenShift SDN ネットワークプラグインを使用して、クラスターの MTU のみを変更できます。
13.1. クラスター MTU について
インストール中に、クラスターネットワークの最大伝送ユニット (MTU) は、クラスター内のノードのプライマリーネットワークインターフェイスの MTU をもとに、自動的に検出されます。通常、検出された MTU を上書きする必要はありません。
以下のような理由でクラスターネットワークの MTU を変更する場合があります。
- クラスターのインストール中に検出された MTU が使用中のインフラストラクチャーに適していない
- クラスターインフラストラクチャーに異なる MTU が必要となった (例: パフォーマンスの最適化にさまざまな MTU を必要とするノードが追加された)。
OVN-Kubernetes および OpenShift SDN クラスターネットワークプラグインに対してのみ、クラスター MTU を変更できます。
13.1.1. サービス中断に関する考慮事項
クラスターで MTU の変更を開始すると、次の動作が原因でサービスの可用性に影響を与える可能性があります。
- 新しい MTU への移行を完了するには、少なくとも 2 回のローリングリブートが必要です。この間、一部のノードは再起動するため使用できません。
- 特定のアプリケーションに、絶対 TCP タイムアウト間隔よりもタイムアウトの間隔が短いクラスターにデプロイされた場合など、MTU の変更中に中断が発生する可能性があります。
13.1.2. MTU 値の選択
MTU の移行を計画するときは、関連しているが異なる MTU 値を 2 つ考慮する必要があります。
- ハードウェア MTU: この MTU 値は、ネットワークインフラストラクチャーの詳細に基づいて設定されます。
クラスターネットワーク MTU: この MTU 値は、クラスターネットワークオーバーレイのオーバーヘッドを考慮して、常にハードウェア MTU よりも小さくなります。特定のオーバーヘッドは、ネットワークプラグインによって決まります。
-
OVN-Kubernetes:
100バイト -
OpenShift SDN:
50バイト
-
OVN-Kubernetes:
クラスターがノードごとに異なる MTU 値を必要とする場合は、クラスター内の任意のノードで使用される最小の MTU 値から、ネットワークプラグインのオーバーヘッド値を差し引く必要があります。たとえば、クラスター内の一部のノードでは MTU が 9001 であり、MTU が 1500 のクラスターもある場合には、この値を 1400 に設定する必要があります。
ノードが受け入れられない MTU 値の選択を回避するには、ip -d link コマンドを使用して、ネットワークインターフェイスが受け入れる最大 MTU 値 (maxmtu) を確認します。
13.1.3. 移行プロセスの仕組み
以下の表は、プロセスのユーザーが開始する手順と、移行が応答として実行するアクション間を区分して移行プロセスを要約しています。
表13.1 クラスター MTU のライブマイグレーション
| ユーザーが開始する手順 | OpenShift Container Platform アクティビティー |
|---|---|
| Cluster Network Operator 設定で次の値を指定します。
| Cluster Network Operator (CNO): 各フィールドが有効な値に設定されていることを確認します。
指定の値が有効な場合に、CNO は、クラスターネットワークの MTU が Machine Config Operator (MCO): クラスター内の各ノードのローリングリブートを実行します。 |
| クラスター上のノードのプライマリーネットワークインターフェイスの MTU を再設定します。これを実現するには、次のようなさまざまな方法を使用できます。
| 該当なし |
|
ネットワークプラグインの CNO 設定で | Machine Config Operator (MCO): 新しい MTU 設定を使用して、クラスター内の各ノードのローリングリブートを実行します。 |
13.2. クラスター MTU の変更
クラスター管理者は、クラスターの最大転送単位 (MTU) を変更できます。移行には中断を伴い、MTU 更新が公開されると、クラスター内のノードが一時的に利用できなくなる可能性があります。
次の手順では、マシン設定、DHCP、または ISO のいずれかを使用してクラスター MTU を変更する方法について説明します。DHCP または ISO アプローチを使用する場合は、クラスターのインストール後に保持した設定アーティファクトを参照して、手順を完了する必要があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインしている。 クラスターのターゲット MTU を特定している。正しい MTU は、クラスターが使用するネットワークプラグインによって異なります。
-
OVN-Kubernetes: クラスター MTU は、クラスター内の最小のハードウェア MTU 値から
100を引いた数に設定する必要があります。 -
OpenShift SDN: クラスター MTU は、クラスター内の最小ハードウェア MTU 値から
50を引いた値に設定する必要があります。
-
OVN-Kubernetes: クラスター MTU は、クラスター内の最小のハードウェア MTU 値から
手順
クラスターネットワークの MTU を増減するには、次の手順を実行します。
クラスターネットワークの現在の MTU を取得するには、次のコマンドを入力します。
$ oc describe network.config cluster
出力例
... Status: Cluster Network: Cidr: 10.217.0.0/22 Host Prefix: 23 Cluster Network MTU: 1400 Network Type: OpenShiftSDN Service Network: 10.217.4.0/23 ...ハードウェア MTU の設定を準備します。
ハードウェア MTU が DHCP で指定されている場合は、次の dnsmasq 設定などで DHCP 設定を更新します。
dhcp-option-force=26,<mtu>
ここでは、以下のようになります。
<mtu>- DHCP サーバーがアドバタイズするハードウェア MTU を指定します。
- ハードウェア MTU が PXE を使用したカーネルコマンドラインで指定されている場合は、それに応じてその設定を更新します。
ハードウェア MTU が Network Manager 接続設定で指定されている場合は、以下のステップを実行します。OpenShift Container Platform では、これは、DHCP、カーネルコマンドラインなどの方法でネットワーク設定を明示的に指定していない場合のデフォルトのアプローチです。変更なしで次の手順を機能させるには、全クラスターノードで、同じ基盤となるネットワーク設定を使用する必要があります。
プライマリーネットワークインターフェイスを見つけます。
OpenShift SDN ネットワークプラグインを使用している場合は、次のコマンドを入力します。
$ oc debug node/<node_name> -- chroot /host ip route list match 0.0.0.0/0 | awk '{print $5 }'ここでは、以下のようになります。
<node_name>- クラスター内のノードの名前を指定します。
OVN-Kubernetes ネットワークプラグインを使用している場合は、次のコマンドを入力します。
$ oc debug node/<node_name> -- chroot /host nmcli -g connection.interface-name c show ovs-if-phys0
ここでは、以下のようになります。
<node_name>- クラスター内のノードの名前を指定します。
<interface>-mtu.confファイルに次の NetworkManager 設定を作成します。Network Manager 接続設定の例
[connection-<interface>-mtu] match-device=interface-name:<interface> ethernet.mtu=<mtu>
ここでは、以下のようになります。
<mtu>- 新しいハードウェア MTU 値を指定します。
<interface>- プライマリーネットワークインターフェイス名を指定します。
1 つはコントロールプレーンノード用、もう 1 つはクラスター内のワーカーノード用に、2 つの
MachineConfigオブジェクトを作成します。control-plane-interface.buファイルに次の Butane 設定を作成します。variant: openshift version: 4.13.0 metadata: name: 01-control-plane-interface labels: machineconfiguration.openshift.io/role: master storage: files: - path: /etc/NetworkManager/conf.d/99-<interface>-mtu.conf 1 contents: local: <interface>-mtu.conf 2 mode: 0600worker-interface.buファイルに次の Butane 設定を作成します。variant: openshift version: 4.13.0 metadata: name: 01-worker-interface labels: machineconfiguration.openshift.io/role: worker storage: files: - path: /etc/NetworkManager/conf.d/99-<interface>-mtu.conf 1 contents: local: <interface>-mtu.conf 2 mode: 0600次のコマンドを実行して、Butane 設定から
MachineConfigオブジェクトを作成します。$ for manifest in control-plane-interface worker-interface; do butane --files-dir . $manifest.bu > $manifest.yaml done
MTU 移行を開始するには、次のコマンドを入力して移行設定を指定します。Machine Config Operator は、MTU の変更に備えて、クラスター内のノードをローリングリブートします。
$ oc patch Network.operator.openshift.io cluster --type=merge --patch \ '{"spec": { "migration": { "mtu": { "network": { "from": <overlay_from>, "to": <overlay_to> } , "machine": { "to" : <machine_to> } } } } }'ここでは、以下のようになります。
<overlay_from>- 現在のクラスターネットワークの MTU 値を指定します。
<overlay_to>-
クラスターネットワークのターゲット MTU を指定します。この値は、
<machine_to>の値を基準にして設定され、それぞれ、OVN-Kubernetes の場合は100を、OpenShift SDN の場合は50を引いた値に指定します。 <machine_to>- 基盤となるホストネットワークのプライマリーネットワークインターフェイスの MTU を指定します。
クラスター MTU を増やす例
$ oc patch Network.operator.openshift.io cluster --type=merge --patch \ '{"spec": { "migration": { "mtu": { "network": { "from": 1400, "to": 9000 } , "machine": { "to" : 9100} } } } }'MCO がそれぞれのマシン設定プールのマシンを更新すると、各ノードが 1 つずつ再起動します。すべてのノードが更新されるまで待機する必要があります。以下のコマンドを実行してマシン設定プールのステータスを確認します。
$ oc get mcp
正常に更新されたノードには、
UPDATED=true、UPDATING=false、DEGRADED=falseのステータスがあります。注記デフォルトで、MCO はプールごとに一度に 1 つのマシンを更新するため、移行にかかる合計時間がクラスターのサイズと共に増加します。
ホスト上の新規マシン設定のステータスを確認します。
マシン設定の状態と適用されたマシン設定の名前をリスト表示するには、以下のコマンドを入力します。
$ oc describe node | egrep "hostname|machineconfig"
出力例
kubernetes.io/hostname=master-0 machineconfiguration.openshift.io/currentConfig: rendered-master-c53e221d9d24e1c8bb6ee89dd3d8ad7b machineconfiguration.openshift.io/desiredConfig: rendered-master-c53e221d9d24e1c8bb6ee89dd3d8ad7b machineconfiguration.openshift.io/reason: machineconfiguration.openshift.io/state: Done
以下のステートメントが true であることを確認します。
-
machineconfiguration.openshift.io/stateフィールドの値はDoneです。 -
machineconfiguration.openshift.io/currentConfigフィールドの値は、machineconfiguration.openshift.io/desiredConfigフィールドの値と等しくなります。
-
マシン設定が正しいことを確認するには、以下のコマンドを入力します。
$ oc get machineconfig <config_name> -o yaml | grep ExecStart
<config_name>はmachineconfiguration.openshift.io/currentConfigフィールドのマシン設定の名前です。マシン設定には、systemd 設定に以下の更新を含める必要があります。
ExecStart=/usr/local/bin/mtu-migration.sh
基盤となるネットワークインターフェイスの MTU 値を更新します。
Network Manager 接続設定で新しい MTU を指定する場合は、次のコマンドを入力します。Machine Config Operator は、クラスター内のノードのローリングリブートを自動的に実行します。
$ for manifest in control-plane-interface worker-interface; do oc create -f $manifest.yaml done- DHCP サーバーオプションまたはカーネルコマンドラインと PXE を使用して新しい MTU を指定する場合は、インフラストラクチャーに必要な変更を加えます。
MCO がそれぞれのマシン設定プールのマシンを更新すると、各ノードが 1 つずつ再起動します。すべてのノードが更新されるまで待機する必要があります。以下のコマンドを実行してマシン設定プールのステータスを確認します。
$ oc get mcp
正常に更新されたノードには、
UPDATED=true、UPDATING=false、DEGRADED=falseのステータスがあります。注記デフォルトで、MCO はプールごとに一度に 1 つのマシンを更新するため、移行にかかる合計時間がクラスターのサイズと共に増加します。
ホスト上の新規マシン設定のステータスを確認します。
マシン設定の状態と適用されたマシン設定の名前をリスト表示するには、以下のコマンドを入力します。
$ oc describe node | egrep "hostname|machineconfig"
出力例
kubernetes.io/hostname=master-0 machineconfiguration.openshift.io/currentConfig: rendered-master-c53e221d9d24e1c8bb6ee89dd3d8ad7b machineconfiguration.openshift.io/desiredConfig: rendered-master-c53e221d9d24e1c8bb6ee89dd3d8ad7b machineconfiguration.openshift.io/reason: machineconfiguration.openshift.io/state: Done
以下のステートメントが true であることを確認します。
-
machineconfiguration.openshift.io/stateフィールドの値はDoneです。 -
machineconfiguration.openshift.io/currentConfigフィールドの値は、machineconfiguration.openshift.io/desiredConfigフィールドの値と等しくなります。
-
マシン設定が正しいことを確認するには、以下のコマンドを入力します。
$ oc get machineconfig <config_name> -o yaml | grep path:
<config_name>はmachineconfiguration.openshift.io/currentConfigフィールドのマシン設定の名前です。マシン設定が正常にデプロイされた場合には、前の出力に
/etc/NetworkManager/system-connections/<connection_name>のファイルパスが含まれます。マシン設定には、
ExecStart=/usr/local/bin/mtu-migration.sh行を含めることはできません。
MTU 移行を完了するには、次のいずれかのコマンドを入力します。
OVN-Kubernetes ネットワークプラグインを使用している場合:
$ oc patch Network.operator.openshift.io cluster --type=merge --patch \ '{"spec": { "migration": null, "defaultNetwork":{ "ovnKubernetesConfig": { "mtu": <mtu> }}}}'ここでは、以下のようになります。
<mtu>-
<overlay_to>で指定した新しいクラスターネットワーク MTU を指定します。
OpenShift SDN ネットワークプラグインを使用している場合:
$ oc patch Network.operator.openshift.io cluster --type=merge --patch \ '{"spec": { "migration": null, "defaultNetwork":{ "openshiftSDNConfig": { "mtu": <mtu> }}}}'ここでは、以下のようになります。
<mtu>-
<overlay_to>で指定した新しいクラスターネットワーク MTU を指定します。
MTU の移行が完了すると、各 MCP ノードが 1 つずつ再起動します。すべてのノードが更新されるまで待機する必要があります。以下のコマンドを実行してマシン設定プールのステータスを確認します。
$ oc get mcp
正常に更新されたノードには、
UPDATED=true、UPDATING=false、DEGRADED=falseのステータスがあります。
検証
クラスター内のノードで、前の手順で指定した MTU が使用されていることを確認できます。
クラスターネットワークの現在の MTU を取得するには、次のコマンドを入力します。
$ oc describe network.config cluster
ノードのプライマリーネットワークインターフェイスの現在の MTU を取得します。
クラスター内のノードをリスト表示するには、次のコマンドを入力します。
$ oc get nodes
ノードのプライマリーネットワークインターフェイスの現在の MTU 設定を取得するには、次のコマンドを入力します。
$ oc debug node/<node> -- chroot /host ip address show <interface>
ここでは、以下のようになります。
<node>- 前のステップの出力をもとに、ノードを指定します。
<interface>- ノードのプライマリーネットワークインターフェイス名を指定します。
出力例
ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8051
13.3. 関連情報
第14章 ノードポートサービス範囲の設定
クラスター管理者は、利用可能なノードのポート範囲を拡張できます。クラスターで多数のノードポートが使用される場合、利用可能なポートの数を増やす必要がある場合があります。
デフォルトのポート範囲は 30000-32767 です。最初にデフォルト範囲を超えて拡張した場合でも、ポート範囲を縮小することはできません。
14.1. 前提条件
-
クラスターインフラストラクチャーは、拡張された範囲内で指定するポートへのアクセスを許可する必要があります。たとえば、ノードのポート範囲を
30000-32900に拡張する場合、ファイアウォールまたはパケットフィルタリングの設定によりこれに含まれるポート範囲32768-32900を許可する必要があります。
14.2. ノードのポート範囲の拡張
クラスターのノードポート範囲を拡張できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインする。
手順
ノードのポート範囲を拡張するには、以下のコマンドを入力します。
<port>を、新規の範囲内で最大のポート番号に置き換えます。$ oc patch network.config.openshift.io cluster --type=merge -p \ '{ "spec": { "serviceNodePortRange": "30000-<port>" } }'ヒントまたは、以下の YAML を適用してノードのポート範囲を更新することもできます。
apiVersion: config.openshift.io/v1 kind: Network metadata: name: cluster spec: serviceNodePortRange: "30000-<port>"
出力例
network.config.openshift.io/cluster patched
設定がアクティブであることを確認するには、以下のコマンドを入力します。更新が適用されるまでに数分の時間がかかることがあります。
$ oc get configmaps -n openshift-kube-apiserver config \ -o jsonpath="{.data['config\.yaml']}" | \ grep -Eo '"service-node-port-range":["[[:digit:]]+-[[:digit:]]+"]'出力例
"service-node-port-range":["30000-33000"]
14.3. 関連情報
第15章 クラスターネットワーク範囲の設定
クラスター管理者は、クラスターのインストール後にクラスターネットワークの範囲を拡張できます。追加ノード用にさらに多くの IP アドレスが必要な場合は、クラスターネットワーク範囲を拡張することを推奨します。
たとえば、クラスターをデプロイし、クラスターネットワーク範囲として 10.128.0.0/19 を指定し、ホスト接頭辞 23 を指定した場合、16 ノードに制限されます。クラスターの CIDR マスクを /14 に変更することで、これを 510 ノードに拡張できます。
クラスターのネットワークアドレス範囲を拡張する場合、クラスターは OVN-Kubernetes ネットワークプラグイン を使用する必要があります。他のネットワークプラグインはサポートされていません。
クラスターネットワークの IP アドレス範囲を変更する場合、次の制限が適用されます。
- 指定する CIDR マスクサイズは、現在設定されている CIDR マスクサイズより常に小さくする必要があります。これは、インストールされたクラスターにノードを追加することによってのみ IP スペースを増やすことができるためです。
- ホスト 接頭辞は変更できません
- オーバーライドされたデフォルトゲートウェイで設定された Pod は、クラスターネットワークの拡張後に再作成する必要があります。
15.1. クラスターネットワークの IP アドレス範囲の拡張
クラスターネットワークの IP アドレス範囲を拡張できます。この変更には新しい Operator 設定をクラスター全体にロールアウトする必要があるため、有効になるまでに最大 30 分かかる場合があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインする。 - クラスターが OVN-Kubernetes ネットワークプラグインを使用していることを確認します。
手順
クラスターのクラスターネットワーク範囲とホスト接頭辞を取得するには、次のコマンドを入力します。
$ oc get network.operator.openshift.io \ -o jsonpath="{.items[0].spec.clusterNetwork}"出力例
[{"cidr":"10.217.0.0/22","hostPrefix":23}]クラスターネットワークの IP アドレス範囲を拡張するには、次のコマンドを入力します。前のコマンドの出力から返された CIDR IP アドレス範囲とホスト接頭辞を使用します。
$ oc patch Network.config.openshift.io cluster --type='merge' --patch \ '{ "spec":{ "clusterNetwork": [ {"cidr":"<network>/<cidr>","hostPrefix":<prefix>} ], "networkType": "OVNKubernetes" } }'ここでは、以下のようになります。
<network>-
前の手順で取得した
cidrフィールドのネットワーク部分を指定します。この値は変更できません。 <cidr>-
ネットワーク接頭辞長を指定します。たとえば、
14です。この値を前の手順の出力の値よりも小さい数値に変更して、クラスターネットワークの範囲を拡大します。 <prefix>-
クラスターの現在のホスト接頭辞を指定します。この値は、前の手順で取得した
hostPrefixフィールドの値と同じである必要があります。
コマンドの例
$ oc patch Network.config.openshift.io cluster --type='merge' --patch \ '{ "spec":{ "clusterNetwork": [ {"cidr":"10.217.0.0/14","hostPrefix": 23} ], "networkType": "OVNKubernetes" } }'出力例
network.config.openshift.io/cluster patched
設定がアクティブであることを確認するには、以下のコマンドを入力します。この変更が有効になるまで、最大 30 分かかる場合があります。
$ oc get network.operator.openshift.io \ -o jsonpath="{.items[0].spec.clusterNetwork}"出力例
[{"cidr":"10.217.0.0/14","hostPrefix":23}]
15.2. 関連情報
第16章 IP フェイルオーバーの設定
このトピックでは、OpenShift Container Platform クラスターの Pod およびサービスの IP フェイルオーバーの設定について説明します。
IP フェイルオーバーは、ノードセットの仮想 IP (VIP) アドレスのプールを管理します。セットのすべての VIP はセットから選択されるノードによって提供されます。VIP は単一ノードが利用可能である限り提供されます。ノード上で VIP を明示的に配布する方法がないため、VIP のないノードがある可能性も、多数の VIP を持つノードがある可能性もあります。ノードが 1 つのみ存在する場合は、すべての VIP がそのノードに配置されます。
VIP はクラスター外からルーティングできる必要があります。
IP フェイルオーバーは各 VIP のポートをモニターし、ポートがノードで到達可能かどうかを判別します。ポートが到達不能な場合、VIP はノードに割り当てられません。ポートが 0 に設定されている場合、このチェックは抑制されます。check スクリプトは必要なテストを実行します。
IP フェイルオーバーは Keepalived を使用して、一連のホストでの外部からアクセスできる VIP アドレスのセットをホストします。各 VIP は 1 度に 1 つのホストによって提供されます。Keepalived は Virtual Router Redundancy Protocol (VRRP) を使用して、(一連のホストの) どのホストがどの VIP を提供するかを判別します。ホストが利用不可の場合や Keepalived が監視しているサービスが応答しない場合は、VIP は一連のホストの別のホストに切り換えられます。したがって、VIP はホストが利用可能である限り常に提供されます。
Keepalived を実行するノードが check スクリプトを渡す場合、ノードの VIP はプリエンプションストラテジーに応じて、その優先順位および現在のマスターの優先順位に基づいて master 状態になることができます。
クラスター管理者は OPENSHIFT_HA_NOTIFY_SCRIPT 変数を介してスクリプトを提供できます。このスクリプトは、ノードの VIP の状態が変更されるたびに呼び出されます。Keepalived は VIP を提供する場合は master 状態を、別のノードが VIP を提供する場合は backup 状態を、または check スクリプトが失敗する場合は fault 状態を使用します。notify スクリプトは、状態が変更されるたびに新規の状態で呼び出されます。
OpenShift Container Platform で IP フェイルオーバーのデプロイメント設定を作成できます。IP フェイルオーバーのデプロイメント設定は VIP アドレスのセットを指定し、それらの提供先となるノードのセットを指定します。クラスターには複数の IP フェイルオーバーのデプロイメント設定を持たせることができ、それぞれが固有な VIP アドレスの独自のセットを管理します。IP フェイルオーバー設定の各ノードは IP フェイルオーバー Pod として実行され、この Pod は Keepalived を実行します。
VIP を使用してホストネットワークを持つ Pod にアクセスする場合、アプリケーション Pod は IP フェイルオーバー Pod を実行しているすべてのノードで実行されます。これにより、いずれの IP フェイルオーバーノードもマスターになり、必要時に VIP を提供することができます。アプリケーション Pod が IP フェイルオーバーのすべてのノードで実行されていない場合、一部の IP フェイルオーバーノードが VIP を提供できないか、一部のアプリケーション Pod がトラフィックを受信できなくなります。この不一致を防ぐために、IP フェイルオーバーとアプリケーション Pod の両方に同じセレクターとレプリケーション数を使用します。
VIP を使用してサービスにアクセスしている間は、アプリケーション Pod が実行されている場所に関係なく、すべてのノードでサービスに到達できるため、任意のノードをノードの IP フェイルオーバーセットに含めることができます。いずれの IP フェイルオーバーノードも、いつでもマスターにすることができます。サービスは外部 IP およびサービスポートを使用するか、NodePort を使用することができます。
サービス定義で外部 IP を使用する場合、VIP は外部 IP に設定され、IP フェイルオーバーのモニタリングポートはサービスポートに設定されます。ノードポートを使用する場合、ポートはクラスター内のすべてのノードで開かれ、サービスは、現在 VIP にサービスを提供しているあらゆるノードからのトラフィックの負荷を分散します。この場合、IP フェイルオーバーのモニタリングポートはサービス定義で NodePort に設定されます。
NodePort のセットアップは特権付きの操作で実行されます。
サービス VIP の可用性が高い場合でも、パフォーマンスに影響が出る可能性があります。Keepalived は、各 VIP が設定内の一部のノードによってサービスされることを確認し、他のノードに VIP がない場合でも、複数の VIP が同じノードに配置される可能性があります。IP フェイルオーバーによって複数の VIP が同じノードに配置されると、VIP のセット全体で外部から負荷分散される戦略が妨げられる可能性があります。
ingressIP を使用する場合は、IP フェイルオーバーを ingressIP 範囲と同じ VIP 範囲を持つように設定できます。また、モニタリングポートを無効にすることもできます。この場合、すべての VIP がクラスター内の同じノードに表示されます。すべてのユーザーが ingressIP でサービスをセットアップし、これを高い可用性のあるサービスにすることができます。
クラスター内の VIP の最大数は 254 です。
16.1. IP フェイルオーバーの環境変数
以下の表は、IP フェイルオーバーの設定に使用される変数を示しています。
表16.1 IP フェイルオーバーの環境変数
| 変数名 | デフォルト | 説明 |
|---|---|---|
|
|
|
IP フェイルオーバー Pod は、各仮想 IP (VIP) のこのポートに対して TCP 接続を開こうとします。接続が設定されると、サービスは実行中であると見なされます。このポートが |
|
|
IP フェイルオーバーが Virtual Router Redundancy Protocol (VRRP) トラフィックの送信に使用するインターフェイス名。デフォルト値は | |
|
|
|
作成するレプリカの数です。これは、IP フェイルオーバーデプロイメント設定の |
|
|
レプリケートする IP アドレス範囲のリストです。これは指定する必要があります。例: | |
|
|
|
仮想ルーター ID の設定に使用されるオフセット値。異なるオフセット値を使用すると、複数の IP フェイルオーバー設定が同じクラスター内に存在できるようになります。デフォルトのオフセットは |
|
|
VRRP に作成するグループの数です。これが設定されていない場合、グループは | |
|
| INPUT |
iptables チェーンの名前であり、 |
|
| アプリケーションが動作していることを確認するために定期的に実行されるスクリプトの Pod ファイルシステム内の完全パス名です。 | |
|
|
| check スクリプトが実行される期間 (秒単位) です。 |
|
| 状態が変更されるたびに実行されるスクリプトの Pod ファイルシステム内の完全パス名です。 | |
|
|
|
新たな優先度の高いホストを処理するためのストラテジーです。 |
16.2. IP フェイルオーバーの設定
クラスター管理者は、クラスター全体に IP フェイルオーバーを設定することも、ラベルセレクターの定義に基づいてノードのサブセットに IP フェイルオーバーを設定することもできます。また、複数の IP フェイルオーバーのデプロイメント設定をクラスター内に設定することもでき、それぞれの設定をクラスター内で相互に切り離すことができます。
IP フェイルオーバーのデプロイメント設定により、フェイルオーバー Pod は、制約または使用されるラベルに一致する各ノードで確実に実行されます。
この Pod は Keepalived を実行します。これは、最初のノードがサービスまたはエンドポイントに到達できない場合に、エンドポイントを監視し、Virtual Router Redundancy Protocol (VRRP) を使用して仮想 IP (VIP) を別のノードにフェイルオーバーできます。
実稼働環境で使用する場合は、少なくとも 2 つのノードを選択し、選択したノードの数に相当する replicas を設定する selector を設定します。
前提条件
-
cluster-admin権限を持つユーザーとしてクラスターにログインしている。 - プルシークレットを作成している。
手順
IP フェイルオーバーのサービスアカウントを作成します。
$ oc create sa ipfailover
hostNetworkの SCC (Security Context Constraints) を更新します。$ oc adm policy add-scc-to-user privileged -z ipfailover $ oc adm policy add-scc-to-user hostnetwork -z ipfailover
デプロイメント YAML ファイルを作成して IP フェイルオーバーを設定します。
IP フェイルオーバー設定のデプロイメント YAML の例
apiVersion: apps/v1 kind: Deployment metadata: name: ipfailover-keepalived 1 labels: ipfailover: hello-openshift spec: strategy: type: Recreate replicas: 2 selector: matchLabels: ipfailover: hello-openshift template: metadata: labels: ipfailover: hello-openshift spec: serviceAccountName: ipfailover privileged: true hostNetwork: true nodeSelector: node-role.kubernetes.io/worker: "" containers: - name: openshift-ipfailover image: quay.io/openshift/origin-keepalived-ipfailover ports: - containerPort: 63000 hostPort: 63000 imagePullPolicy: IfNotPresent securityContext: privileged: true volumeMounts: - name: lib-modules mountPath: /lib/modules readOnly: true - name: host-slash mountPath: /host readOnly: true mountPropagation: HostToContainer - name: etc-sysconfig mountPath: /etc/sysconfig readOnly: true - name: config-volume mountPath: /etc/keepalive env: - name: OPENSHIFT_HA_CONFIG_NAME value: "ipfailover" - name: OPENSHIFT_HA_VIRTUAL_IPS 2 value: "1.1.1.1-2" - name: OPENSHIFT_HA_VIP_GROUPS 3 value: "10" - name: OPENSHIFT_HA_NETWORK_INTERFACE 4 value: "ens3" #The host interface to assign the VIPs - name: OPENSHIFT_HA_MONITOR_PORT 5 value: "30060" - name: OPENSHIFT_HA_VRRP_ID_OFFSET 6 value: "0" - name: OPENSHIFT_HA_REPLICA_COUNT 7 value: "2" #Must match the number of replicas in the deployment - name: OPENSHIFT_HA_USE_UNICAST value: "false" #- name: OPENSHIFT_HA_UNICAST_PEERS #value: "10.0.148.40,10.0.160.234,10.0.199.110" - name: OPENSHIFT_HA_IPTABLES_CHAIN 8 value: "INPUT" #- name: OPENSHIFT_HA_NOTIFY_SCRIPT 9 # value: /etc/keepalive/mynotifyscript.sh - name: OPENSHIFT_HA_CHECK_SCRIPT 10 value: "/etc/keepalive/mycheckscript.sh" - name: OPENSHIFT_HA_PREEMPTION 11 value: "preempt_delay 300" - name: OPENSHIFT_HA_CHECK_INTERVAL 12 value: "2" livenessProbe: initialDelaySeconds: 10 exec: command: - pgrep - keepalived volumes: - name: lib-modules hostPath: path: /lib/modules - name: host-slash hostPath: path: / - name: etc-sysconfig hostPath: path: /etc/sysconfig # config-volume contains the check script # created with `oc create configmap keepalived-checkscript --from-file=mycheckscript.sh` - configMap: defaultMode: 0755 name: keepalived-checkscript name: config-volume imagePullSecrets: - name: openshift-pull-secret 13
- 1
- IP フェイルオーバーデプロイメントの名前。
- 2
- レプリケートする IP アドレス範囲のリストです。これは指定する必要があります。例:
1.2.3.4-6,1.2.3.9 - 3
- VRRP に作成するグループの数です。これが設定されていない場合、グループは
OPENSHIFT_HA_VIP_GROUPS変数で指定されている仮想 IP 範囲ごとに作成されます。 - 4
- IP フェイルオーバーが VRRP トラフィックの送信に使用するインターフェイス名。デフォルトで
eth0が使用されます。 - 5
- IP フェイルオーバー Pod は、各 VIP のこのポートに対して TCP 接続を開こうとします。接続が設定されると、サービスは実行中であると見なされます。このポートが
0に設定される場合、テストは常にパスします。デフォルト値は80です。 - 6
- 仮想ルーター ID の設定に使用されるオフセット値。異なるオフセット値を使用すると、複数の IP フェイルオーバー設定が同じクラスター内に存在できるようになります。デフォルトのオフセットは
0で、許可される範囲は0から255までです。 - 7
- 作成するレプリカの数です。これは、IP フェイルオーバーデプロイメント設定の
spec.replicas値に一致する必要があります。デフォルト値は2です。 - 8
iptablesチェーンの名前であり、iptablesルールを自動的に追加し、VRRP トラフィックをオンにすることを許可するために使用されます。この値が設定されていない場合、iptablesルールは追加されません。チェーンが存在しない場合は作成されず、Keepalived はユニキャストモードで動作します。デフォルトはINPUTです。- 9
- 状態が変更されるたびに実行されるスクリプトの Pod ファイルシステム内の完全パス名です。
- 10
- アプリケーションが動作していることを確認するために定期的に実行されるスクリプトの Pod ファイルシステム内の完全パス名です。
- 11
- 新たな優先度の高いホストを処理するためのストラテジーです。デフォルト値は
preempt_delay 300で、優先順位の低いマスターが VIP を保持する場合に、Keepalived インスタンスが VIP を 5 分後に引き継ぎます。 - 12
- check スクリプトが実行される期間 (秒単位) です。デフォルト値は
2です。 - 13
- デプロイメントを作成する前にプルシークレットを作成します。作成しない場合には、デプロイメントの作成時にエラーが発生します。
16.3. 仮想 IP アドレスについて
Keepalived は一連の仮想 IP アドレス (VIP) を管理します。管理者はこれらすべてのアドレスについて以下の点を確認する必要があります。
- 仮想 IP アドレスは設定されたホストでクラスター外からアクセスできる。
- 仮想 IP アドレスはクラスター内でこれ以外の目的で使用されていない。
各ノードの Keepalived は、必要とされるサービスが実行中であるかどうかを判別します。実行中の場合、VIP がサポートされ、Keepalived はネゴシエーションに参加してどのノードが VIP を提供するかを決定します。これに参加するノードについては、このサービスが VIP の監視 ポートでリッスンしている、またはチェックが無効にされている必要があります。
セット内の各 VIP は最終的に別のノードによって提供される可能性があります。
16.4. check スクリプトおよび notify スクリプトの設定
Keepalived は、オプションのユーザー指定の check スクリプトを定期的に実行してアプリケーションの正常性をモニターします。たとえば、このスクリプトは要求を発行し、応答を検証することで web サーバーをテストします。
チェックスクリプトが指定されない場合、TCP 接続をテストする単純なデフォルトスクリプトが実行されます。このデフォルトテストは、モニターポートが 0 の場合は抑制されます。
各 IP フェイルオーバー Pod は、Pod が実行されているノードで 1 つ以上の仮想 IP (VIP) を管理する Keepalived デーモンを管理します。Keepalived デーモンは、ノードの各 VIP の状態を維持します。特定のノード上の特定の VIP は、master、backup、または fault 状態にある可能性があります。
master 状態にあるノードでその VIP の check スクリプトが失敗すると、そのノードの VIP は fault 状態になり、再ネゴシエーションがトリガーされます。再ネゴシエーションの中に fault 状態にないノード上のすべての VIP は、どのノードが VIP を引き継ぐかを決定することに参加します。最終的に VIP は一部のノードで master の状態に入り、VIP は他のノードで backup 状態のままになります。
backup 状態の VIP を持つノードに障害が発生すると、そのノードの VIP は fault 状態になります。fault 状態のノード上の VIP の check スクリプトが再度パスすると、そのノードの VIP は fault 状態を終了し、master 状態に入るためにネゴシエートします。次に、そのノードの VIP は、master 状態または backup 状態のいずれかになります。
クラスター管理者は、オプションの notify スクリプトを提供できます。このスクリプトは状態が変更されるたびに呼び出されます。Keepalived は以下の 3 つのパラメーターをこのスクリプトに渡します。
-
$1-groupまたはinstance -
$2:groupまたはinstanceの名前です。 -
$3: 新規の状態:master、backup、またはfault
check および notify スクリプトは、IP フェイルオーバー Pod で実行され、ホストファイルシステムではなく Pod ファイルシステムを使用します。ただし、IP フェイルオーバー Pod はホストファイルシステムが /hosts マウントパスで利用可能にします。check または notify スクリプトを設定する場合は、スクリプトへの完全パスを指定する必要があります。スクリプトを提供する方法として、ConfigMap の使用が推奨されます。
check および notify スクリプトの完全パス名は、Keepalived 設定ファイル (_/etc/keepalived/keepalived.conf) に追加されます。このファイルは、Keepalived が起動するたびにロードされます。スクリプトは、以下のように ConfigMap を使用して Pod に追加できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインしている。
手順
必要なスクリプトを作成し、これを保持する ConfigMap を作成します。スクリプトには入力引数は指定されず、
OKの場合は0を、failの場合は1を返す必要があります。check スクリプト
mycheckscript.sh:#!/bin/bash # Whatever tests are needed # E.g., send request and verify response exit 0ConfigMap を作成します。
$ oc create configmap mycustomcheck --from-file=mycheckscript.sh
スクリプトを Pod に追加します。マウントされた設定マップファイルの
defaultModeは、ocコマンドを使用して、またはデプロイメント設定を編集して実行できる必要があります。通常は、0755、493(10 進数) の値が使用されます。$ oc set env deploy/ipfailover-keepalived \ OPENSHIFT_HA_CHECK_SCRIPT=/etc/keepalive/mycheckscript.sh$ oc set volume deploy/ipfailover-keepalived --add --overwrite \ --name=config-volume \ --mount-path=/etc/keepalive \ --source='{"configMap": { "name": "mycustomcheck", "defaultMode": 493}}'注記oc set envコマンドは空白を区別します。=記号の両側に空白を入れることはできません。ヒントまたは、
ipfailover-keepalivedデプロイメント設定を編集することもできます。$ oc edit deploy ipfailover-keepalived
spec: containers: - env: - name: OPENSHIFT_HA_CHECK_SCRIPT 1 value: /etc/keepalive/mycheckscript.sh ... volumeMounts: 2 - mountPath: /etc/keepalive name: config-volume dnsPolicy: ClusterFirst ... volumes: 3 - configMap: defaultMode: 0755 4 name: customrouter name: config-volume ...変更を保存し、エディターを終了します。これにより
ipfailover-keepalivedが再起動されます。
16.5. VRRP プリエンプションの設定
ノードの仮想 IP (VIP) が check スクリプトを渡すことで fault 状態を終了すると、ノードの VIP は、現在 master 状態にあるノードの VIP よりも優先度が低い場合は backup 状態になります。ただし、fault 状態を終了するノードの VIP の優先度が高い場合は、プリエンプションストラテジーによってクラスター内でのそのロールが決定されます。
nopreempt ストラテジーは master をホスト上の優先度の低いホストからホスト上の優先度の高い VIP に移動しません。デフォルトの preempt_delay 300 の場合、Keepalived は指定された 300 秒の間待機し、master をホスト上の優先度の高い VIP に移動します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。
手順
プリエンプションを指定するには、
oc edit deploy ipfailover-keepalivedを入力し、ルーターのデプロイメント設定を編集します。$ oc edit deploy ipfailover-keepalived
... spec: containers: - env: - name: OPENSHIFT_HA_PREEMPTION 1 value: preempt_delay 300 ...- 1
OPENSHIFT_HA_PREEMPTIONの値を設定します。-
preempt_delay 300: Keepalived は、指定された 300 秒の間待機し、masterをホスト上の優先度の高い VIP に移動します。これはデフォルト値です。 -
nopreempt:masterをホスト上の優先度の低い VIP からホスト上の優先度の高い VIP に移動しません。
-
16.6. VRRP ID オフセットについて
IP フェイルオーバーのデプロイメント設定で管理される各 IP フェイルオーバー Pod (ノード/レプリカあたり 1 Pod) は Keepalived デーモンを実行します。設定される IP フェイルオーバーのデプロイメント設定が多くなると、作成される Pod も多くなり、共通の Virtual Router Redundancy Protocol (VRRP) ネゴシエーションに参加するデーモンも多くなります。このネゴシエーションはすべての Keepalived デーモンによって実行され、これはどのノードがどの仮想 IP (VIP) を提供するかを決定します。
Keepalived は内部で固有の vrrp-id を各 VIP に割り当てます。ネゴシエーションはこの vrrp-ids セットを使用し、決定後には優先される vrrp-id に対応する VIP が優先されるノードで提供されます。
したがって、IP フェイルオーバーのデプロイメント設定で定義されるすべての VIP について、IP フェイルオーバー Pod は対応する vrrp-id を割り当てる必要があります。これは、OPENSHIFT_HA_VRRP_ID_OFFSET から開始し、順序に従って vrrp-ids を VIP のリストに割り当てることによって実行されます。vrrp-ids には範囲 1..255 の値を設定できます。
複数の IP フェイルオーバーのデプロイメント設定がある場合は、OPENSHIFT_HA_VRRP_ID_OFFSET を指定して、デプロイメント設定内の VIP 数を増やす余地があり、vrrp-id 範囲が重複しないようにする必要があります。
16.7. 254 を超えるアドレスについての IP フェイルオーバーの設定
IP フェイルオーバー管理は、仮想 IP (VIP) アドレスの 254 グループに制限されています。デフォルトでは、OpenShift Container Platform は各グループに 1 つの IP アドレスを割り当てます。OPENSHIFT_HA_VIP_GROUPS 変数を使用してこれを変更し、複数の IP アドレスが各グループに含まれるようにして、IP フェイルオーバーを設定するときに各 Virtual Router Redundancy Protocol (VRRP) インスタンスで使用可能な VIP グループの数を定義できます。
VIP の作成により、VRRP フェイルオーバーの発生時の広範囲の VRRP の割り当てが作成され、これはクラスター内のすべてのホストがローカルにサービスにアクセスする場合に役立ちます。たとえば、サービスが ExternalIP で公開されている場合などがこれに含まれます。
フェイルオーバーのルールとして、ルーターなどのサービスは特定の 1 つのホストに制限しません。代わりに、サービスは、IP フェイルオーバーの発生時にサービスが新規ホストに再作成されないように各ホストに複製可能な状態にする必要があります。
OpenShift Container Platform のヘルスチェックを使用している場合、IP フェイルオーバーおよびグループの性質上、グループ内のすべてのインスタンスはチェックされません。そのため、Kubernetes ヘルスチェック を使用してサービスが有効であることを確認する必要があります。
前提条件
-
cluster-admin権限を持つユーザーとしてクラスターにログインしている。
手順
各グループに割り当てられた IP アドレスの数を変更するには、
OPENSHIFT_HA_VIP_GROUPS変数の値を変更します。次に例を示します。IP フェイルオーバー設定の
DeploymentYAML の例... spec: env: - name: OPENSHIFT_HA_VIP_GROUPS 1 value: "3" ...- 1
- たとえば、7 つの VIP のある環境で
OPENSHIFT_HA_VIP_GROUPSが3に設定されている場合、これは 3 つのグループを作成し、3 つの VIP を最初のグループに、2 つの VIP を 2 つの残りのグループにそれぞれ割り当てます。
OPENSHIFT_HA_VIP_GROUPS で設定されたグループの数が、フェイルオーバーに設定された IP アドレスの数より少ない場合、グループには複数の IP アドレスが含まれ、すべてのアドレスが 1 つのユニットとして移動します。
16.8. ingressIP の高可用性
クラウド以外のクラスターでは、IP フェイルオーバーおよびサービスへの ingressIP を組み合わせることができます。結果として、ingressIP を使用してサービスを作成するユーザーに高可用サービスが提供されます。
この方法では、まず ingressIPNetworkCIDR 範囲を指定し、次に ipfailover 設定を作成する際に同じ範囲を使用します。
IP フェイルオーバーはクラスター全体に対して最大 255 の VIP をサポートできるため、ingressIPNetworkCIDR は /24 以下に設定する必要があります。
16.9. IP フェイルオーバーの削除
IP フェイルオーバーが最初に設定されている場合、クラスターのワーカーノードは、Keepalived 用に 224.0.0.18 のマルチキャストパケットを明示的に許可する iptables ルールを使用して変更されます。ノードが変更されるため、IP フェイルオーバーを削除するには、ジョブを実行して iptables ルールを削除し、Keepalived が使用する仮想 IP アドレスを削除する必要があります。
手順
オプション: ConfigMap として保存されるチェックおよび通知スクリプトを特定し、削除します。
IP フェイルオーバーの Pod が ConfigMap をボリュームとして使用するかどうかを決定します。
$ oc get pod -l ipfailover \ -o jsonpath="\ {range .items[?(@.spec.volumes[*].configMap)]} {'Namespace: '}{.metadata.namespace} {'Pod: '}{.metadata.name} {'Volumes that use config maps:'} {range .spec.volumes[?(@.configMap)]} {'volume: '}{.name} {'configMap: '}{.configMap.name}{'\n'}{end} {end}"出力例
Namespace: default Pod: keepalived-worker-59df45db9c-2x9mn Volumes that use config maps: volume: config-volume configMap: mycustomcheck
前述の手順でボリュームとして使用される ConfigMap の名前が提供されている場合は、ConfigMap を削除します。
$ oc delete configmap <configmap_name>
IP フェイルオーバーの既存デプロイメントを特定します。
$ oc get deployment -l ipfailover
出力例
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE default ipfailover 2/2 2 2 105d
デプロイメントを削除します。
$ oc delete deployment <ipfailover_deployment_name>
ipfailoverサービスアカウントを削除します。$ oc delete sa ipfailover
IP フェイルオーバーの設定時に追加された IP テーブルルールを削除するジョブを実行します。
以下の例のような内容で
remove-ipfailover-job.yamlなどのファイルを作成します。apiVersion: batch/v1 kind: Job metadata: generateName: remove-ipfailover- labels: app: remove-ipfailover spec: template: metadata: name: remove-ipfailover spec: containers: - name: remove-ipfailover image: quay.io/openshift/origin-keepalived-ipfailover:4.13 command: ["/var/lib/ipfailover/keepalived/remove-failover.sh"] nodeSelector: kubernetes.io/hostname: <host_name> <.> restartPolicy: Never<.> IP フェイルオーバー用に設定されたクラスター内の各ノードのジョブを実行し、毎回ホスト名を置き換えます。
ジョブを実行します。
$ oc create -f remove-ipfailover-job.yaml
出力例
job.batch/remove-ipfailover-2h8dm created
検証
ジョブが IP フェイルオーバーの初期設定を削除していることを確認します。
$ oc logs job/remove-ipfailover-2h8dm
出力例
remove-failover.sh: OpenShift IP Failover service terminating. - Removing ip_vs module ... - Cleaning up ... - Releasing VIPs (interface eth0) ...
第17章 インターフェイスレベルのネットワーク sysctl の設定
Linux では、管理者は sysctl を使用してランタイム時にカーネルパラメーターを変更できます。チューニング Container Network Interface (CNI) メタプラグインを使用して、インターフェイスレベルのネットワーク sysctl を変更できます。チューニング CNI メタプラグインは、図に示すように、メインの CNI プラグインとチェーンで動作します。
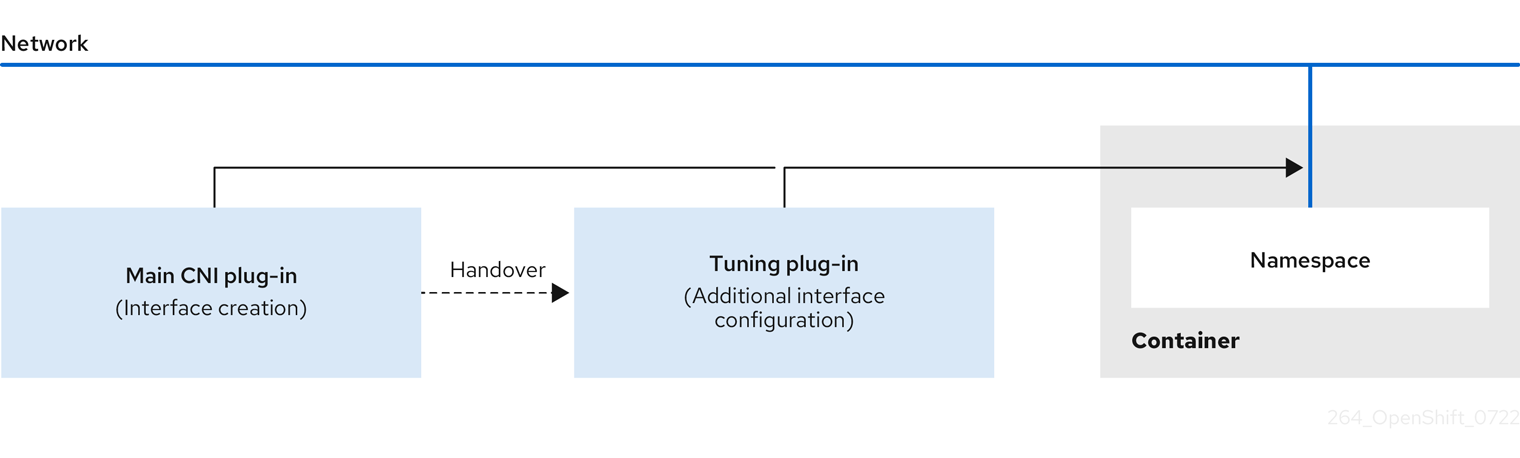
メインの CNI プラグインはインターフェイスを割り当て、これをランタイム時にチューニング CNI メタプラグインに渡します。チューニング CNI メタプラグインを使用して、ネットワーク namespace の一部の sysctl といくつかのインターフェイス属性 (プロミスキャスモード、オールマルチキャストモード、MTU、および MAC アドレス) を変更できます。チューニング CNI メタプラグイン設定では、インターフェイス名は IFNAME トークンで表され、ランタイム時にインターフェイスの実際の名前に置き換えられます。
OpenShift Container Platform では、チューニング CNI メタプラグインはインターフェイスレベルのネットワーク sysctl の変更のみをサポートします。
17.1. チューニング CNI の設定
次の手順では、チューニング CNI を設定し、インターフェイスレベルのネットワーク net.ipv4.conf.IFNAME.accept_redirects sysctl を変更します。この例では、ICMP リダイレクトパケットの受け入れと送信を有効にします。
手順
次の内容で、
tuning-example.yamlなどのネットワーク接続定義を作成します。apiVersion: "k8s.cni.cncf.io/v1" kind: NetworkAttachmentDefinition metadata: name: <name> 1 namespace: default 2 spec: config: '{ "cniVersion": "0.4.0", 3 "name": "<name>", 4 "plugins": [{ "type": "<main_CNI_plugin>" 5 }, { "type": "tuning", 6 "sysctl": { "net.ipv4.conf.IFNAME.accept_redirects": "1" 7 } } ] }
yaml ファイルの例を次に示します。
apiVersion: "k8s.cni.cncf.io/v1" kind: NetworkAttachmentDefinition metadata: name: tuningnad namespace: default spec: config: '{ "cniVersion": "0.4.0", "name": "tuningnad", "plugins": [{ "type": "bridge" }, { "type": "tuning", "sysctl": { "net.ipv4.conf.IFNAME.accept_redirects": "1" } } ] }'以下のコマンドを実行して yaml を適用します。
$ oc apply -f tuning-example.yaml
出力例
networkattachmentdefinition.k8.cni.cncf.io/tuningnad created
次のようなネットワーク接続定義を使用して、
examplepod.yamlなどの Pod を作成します。apiVersion: v1 kind: Pod metadata: name: tunepod namespace: default annotations: k8s.v1.cni.cncf.io/networks: tuningnad 1 spec: containers: - name: podexample image: centos command: ["/bin/bash", "-c", "sleep INF"] securityContext: runAsUser: 2000 2 runAsGroup: 3000 3 allowPrivilegeEscalation: false 4 capabilities: 5 drop: ["ALL"] securityContext: runAsNonRoot: true 6 seccompProfile: 7 type: RuntimeDefault- 1
- 設定済みの
NetworkAttachmentDefinitionの名前を指定します。 - 2
runAsUserは、コンテナーが実行されるユーザー ID を制御します。- 3
runAsGroupは、コンテナーが実行されるプライマリーグループ ID を制御します。- 4
allowPrivilegeEscalationは、Pod が特権の昇格を許可するように要求できるかどうかを決定します。指定しない場合、デフォルトで true に設定されます。このブール値は、no_new_privsフラグがコンテナープロセスに設定されるかどうかを直接制御します。- 5
capabilitiesは、完全なルートアクセスを許可せずに権限操作を許可します。このポリシーにより、すべての機能が Pod から削除されます。- 6
runAsNonRoot: trueは、コンテナーが 0 以外の任意の UID を持つユーザーで実行されることを要求します。- 7
RuntimeDefaultは、Pod またはコンテナーワークロードのデフォルトの seccomp プロファイルを有効にします。
以下のコマンドを実行して yaml を適用します。
$ oc apply -f examplepod.yaml
次のコマンドを実行して、Pod が作成されていることを確認します。
$ oc get pod
出力例
NAME READY STATUS RESTARTS AGE tunepod 1/1 Running 0 47s
次のコマンドを実行して、Pod にログインします。
$ oc rsh tunepod
設定された sysctl フラグの値を確認します。たとえば、次のコマンドを実行して、値
net.ipv4.conf.net1.accept_redirectsを見つけます。sh-4.4# sysctl net.ipv4.conf.net1.accept_redirects
予想される出力
net.ipv4.conf.net1.accept_redirects = 1
17.2. 関連情報
第18章 ベアメタルクラスターでの SCTP (Stream Control Transmission Protocol) の使用
クラスター管理者は、クラスターで SCTP (Stream Control Transmission Protocol) を使用できます。
18.1. OpenShift Container Platform での SCTP (Stream Control Transmission Protocol) のサポート
クラスター管理者は、クラスターのホストで SCTP を有効にできます。Red Hat Enterprise Linux CoreOS (RHCOS) で、SCTP モジュールはデフォルトで無効にされています。
SCTP は、IP ネットワークの上部で実行される信頼できるメッセージベースのプロトコルです。
これを有効にすると、SCTP を Pod、サービス、およびネットワークポリシーでプロトコルとして使用できます。Service オブジェクトは、type パラメーターを ClusterIP または NodePort のいずれかの値に設定して定義する必要があります。
18.1.1. SCTP プロトコルを使用した設定例
protocol パラメーターを Pod またはサービスリソース定義の SCTP 値に設定して、Pod またはサービスを SCTP を使用するように設定できます。
以下の例では、Pod は SCTP を使用するように設定されています。
apiVersion: v1
kind: Pod
metadata:
namespace: project1
name: example-pod
spec:
containers:
- name: example-pod
...
ports:
- containerPort: 30100
name: sctpserver
protocol: SCTP以下の例では、サービスは SCTP を使用するように設定されています。
apiVersion: v1
kind: Service
metadata:
namespace: project1
name: sctpserver
spec:
...
ports:
- name: sctpserver
protocol: SCTP
port: 30100
targetPort: 30100
type: ClusterIP
以下の例では、NetworkPolicy オブジェクトは、特定のラベルの付いた Pod からポート 80 の SCTP ネットワークトラフィックに適用するように設定されます。
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-sctp-on-http
spec:
podSelector:
matchLabels:
role: web
ingress:
- ports:
- protocol: SCTP
port: 8018.2. SCTP (Stream Control Transmission Protocol) の有効化
クラスター管理者は、クラスターのワーカーノードでブラックリストに指定した SCTP カーネルモジュールを読み込み、有効にできます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
以下の YAML 定義が含まれる
load-sctp-module.yamlという名前のファイルを作成します。apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: name: load-sctp-module labels: machineconfiguration.openshift.io/role: worker spec: config: ignition: version: 3.2.0 storage: files: - path: /etc/modprobe.d/sctp-blacklist.conf mode: 0644 overwrite: true contents: source: data:, - path: /etc/modules-load.d/sctp-load.conf mode: 0644 overwrite: true contents: source: data:,sctpMachineConfigオブジェクトを作成するには、以下のコマンドを入力します。$ oc create -f load-sctp-module.yaml
オプション: MachineConfig Operator が設定変更を適用している間にノードのステータスを確認するには、以下のコマンドを入力します。ノードのステータスが
Readyに移行すると、設定の更新が適用されます。$ oc get nodes
18.3. SCTP (Stream Control Transmission Protocol) が有効になっていることの確認
SCTP がクラスターで機能することを確認するには、SCTP トラフィックをリッスンするアプリケーションで Pod を作成し、これをサービスに関連付け、公開されたサービスに接続します。
前提条件
-
クラスターからインターネットにアクセスし、
ncパッケージをインストールすること。 -
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
SCTP リスナーを起動する Pod を作成します。
以下の YAML で Pod を定義する
sctp-server.yamlという名前のファイルを作成します。apiVersion: v1 kind: Pod metadata: name: sctpserver labels: app: sctpserver spec: containers: - name: sctpserver image: registry.access.redhat.com/ubi9/ubi command: ["/bin/sh", "-c"] args: ["dnf install -y nc && sleep inf"] ports: - containerPort: 30102 name: sctpserver protocol: SCTP以下のコマンドを入力して Pod を作成します。
$ oc create -f sctp-server.yaml
SCTP リスナー Pod のサービスを作成します。
以下の YAML でサービスを定義する
sctp-service.yamlという名前のファイルを作成します。apiVersion: v1 kind: Service metadata: name: sctpservice labels: app: sctpserver spec: type: NodePort selector: app: sctpserver ports: - name: sctpserver protocol: SCTP port: 30102 targetPort: 30102サービスを作成するには、以下のコマンドを入力します。
$ oc create -f sctp-service.yaml
SCTP クライアントの Pod を作成します。
以下の YAML で
sctp-client.yamlという名前のファイルを作成します。apiVersion: v1 kind: Pod metadata: name: sctpclient labels: app: sctpclient spec: containers: - name: sctpclient image: registry.access.redhat.com/ubi9/ubi command: ["/bin/sh", "-c"] args: ["dnf install -y nc && sleep inf"]Podオブジェクトを作成するには、以下のコマンドを入力します。$ oc apply -f sctp-client.yaml
サーバーで SCTP リスナーを実行します。
サーバー Pod に接続するには、以下のコマンドを入力します。
$ oc rsh sctpserver
SCTP リスナーを起動するには、以下のコマンドを入力します。
$ nc -l 30102 --sctp
サーバーの SCTP リスナーに接続します。
- ターミナルプログラムで新規のターミナルウィンドウまたはタブを開きます。
sctpserviceサービスの IP アドレスを取得します。以下のコマンドを入力します。$ oc get services sctpservice -o go-template='{{.spec.clusterIP}}{{"\n"}}'クライアント Pod に接続するには、以下のコマンドを入力します。
$ oc rsh sctpclient
SCTP クライアントを起動するには、以下のコマンドを入力します。
<cluster_IP>をsctpserviceサービスのクラスター IP アドレスに置き換えます。# nc <cluster_IP> 30102 --sctp
第19章 PTP ハードウェアの使用
OpenShift Container Platform クラスターノードでlinuxptp サービスを設定し、PTP 対応ハードウェアを使用できます。
19.1. PTP ハードウェアについて
PTP Operator をデプロイし、OpenShift Container Platform コンソールまたは OpenShift CLI (oc) を使用して PTP をインストールできます。PTP Operator は linuxptp サービスを作成し、管理し、以下の機能を提供します。
- クラスター内の PTP 対応デバイスの検出。
-
linuxptpサービスの設定の管理。 -
PTP Operator
cloud-event-proxyサイドカーによるアプリケーションのパフォーマンスおよび信頼性に悪影響を与える PTP クロックイベントの通知。
PTP Operator は、ベアメタルインフラストラクチャーでのみプロビジョニングされるクラスターの PTP 対応デバイスと連携します。
19.2. PTP について
Precision Time Protocol (PTP) は、ネットワーク内のクロックを同期するのに使用されます。ハードウェアサポートと併用する場合、PTP はマイクロ秒以下の正確性があり、Network Time Protocol (NTP) よりも正確になります。
19.2.1. PTP ドメインの要素
PTP は、ネットワークに接続された複数のノードを各ノードのクロックと同期するために使用されます。PTP で同期するクロックは、同期元と同期先の階層で整理されています。この階層は、best master clock (BMC) アルゴリズムで作成され、自動的に更新されます。宛先のクロックは、ソースとなるクロックに同期され、宛先クロック自体が他のダウンストリームクロックのソースになることができます。PTP クロックの 3 つの主要なタイプについて以下に説明します。
- グランドマスタークロック
- グランドマスタークロックは、ネットワーク全体の他のクロックに標準時間情報を提供し、正確で安定した同期を保証します。タイムスタンプを書き込み、他のクロックからの時間の要求に応答します。グランドマスタークロックは、Global Navigation Satellite System (GNSS) のタイムソースと同期します。Grandmaster クロックは、ネットワーク内の時刻の権威あるソースであり、他のすべてのデバイスに時刻同期を提供するロールを果たします。
- 通常のクロック
- 通常のクロックには、ネットワーク内の位置に応じて、送信元クロックまたは宛先クロックのロールを果たすことができる単一のポート接続があります。通常のクロックは、タイムスタンプの読み取りおよび書き込みが可能です。
- 境界クロック
- 境界クロックには、2 つ以上の通信パスにあるポートがあり、ソースと宛先の宛先を同時に他の宛先クロックに指定できます。境界クロックは、宛先クロックアップストリームとして機能します。宛先クロックはタイミングメッセージを受け取り、遅延に合わせて調整し、ネットワークを渡す新しいソースタイムシグナルを作成します。境界クロックは、ソースクロックと正しく同期され、ソースクロックに直接レポートする接続されたデバイスの数を減らすことができる新しいタイミングパケットを生成します。
19.2.2. NTP 上の PTP の利点
PTP が NTP を経由した主な利点の 1 つは、さまざまなネットワークインターフェイスコントローラー (NIC) およびネットワークスイッチにあるハードウェアサポートです。この特化されたハードウェアにより、PTP はメッセージ送信の遅れを説明でき、時間同期の精度を高められます。可能な限りの精度を実現するには、PTP クロック間の全ネットワークコンポーネントが PTP ハードウェアを有効にすることが推奨されます。
NIC は PTP パケットを送受信した瞬間にタイムスタンプを付けることができるため、ハードウェアベースの PTP は最適な精度を提供します。これをソフトウェアベースの PTP と比較します。これには、オペレーティングシステムによる PTP パケットの追加処理が必要になります。
PTP を有効にする前に、必要なノードについて NTP が無効になっていることを確認します。MachineConfig カスタムリソースを使用して chrony タイムサービス (chronyd) を無効にすることができます。詳細は chrony タイムサービスの無効化 を参照してください。
19.2.3. デュアル NIC ハードウェアでの PTP の使用
OpenShift Container Platform は、クラスター内の正確な PTP タイミングのためにシングルおよびデュアル NIC ハードウェアをサポートします。
ミッドバンドスペクトルカバレッジを提供する 5G 電話会社ネットワークの場合、各仮想分散ユニット (vDU) には 6 つの無線ユニット (RU) への接続が必要です。これらの接続を確立するには、各 vDU ホストに境界クロックとして設定された 2 つの NIC が必要です。
デュアル NIC ハードウェアを使用すると、各 NIC を同じアップストリームリーダークロックに接続し、NIC ごとに個別の ptp4l インスタンスをダウンストリームクロックに供給することができます。
19.3. OpenShift Container Platform ノードの linuxptp の概要
OpenShift Container Platform は、ベアメタルインフラストラクチャーでの高精度のシステムタイミングのために PTP および linuxptp を使用します。linuxptp パッケージには、システムクロック同期用の ts2phc、pmc、ptp4l、および phc2sys プログラムが含まれています。
- ts2phc
ts2phcは、PTP デバイス間で PTP ハードウェアクロック (PHC) を高精度で同期します。ts2phcはグランドマスタークロック設定で使用されます。Global Navigation Satellite System (GNSS) などの高精度クロックソースから正確なタイミング信号を受信します。GNSS は、大規模な分散ネットワークで使用するための、正確で信頼性の高い同期時刻ソースを提供します。GNSS クロックは通常、数ナノ秒の精度で時刻情報を提供します。ts2phcシステムデーモンは、グランドマスタークロックから時刻情報を読み取り、PHC 形式に変換することにより、グランドマスタークロックからのタイミング情報をネットワーク内の他の PTP デバイスに送信します。PHC 時間は、ネットワーク内の他のデバイスがクロックをグランドマスタークロックと同期させるために使用されます。- pmc
-
pmcは、IEEE 標準 1588.1588 に従って PTP 管理クライアント (pmc) を実装します。pmcは、ptp4lシステムデーモンの基本的な管理アクセスを提供します。pmcは、標準入力から読み取り、選択されたトランスポート経由で出力を送信し、受信した応答を出力します。 - ptp4l
ptp4lは、PTP 境界クロックと通常のクロックを実装し、システムデーモンとして実行されます。ptp4lは、以下を行います。- ハードウェアタイムスタンプを使用して PHC をソースクロックに同期します。
- ソフトウェアタイムスタンプを使用してシステムクロックをソースクロックに同期します。
- phc2sys
-
phc2sysは、システムクロックをネットワークインターフェイスコントローラー (NIC) 上の PHC に同期します。phc2sysシステムデーモンは、PHC のタイミング情報を継続的に監視します。PHC はタイミングエラーを検出すると、システムクロックを修正します。
19.4. CLI を使用した PTP Operator のインストール
クラスター管理者は、CLI を使用して Operator をインストールできます。
前提条件
- PTP に対応するハードウェアを持つノードでベアメタルハードウェアにインストールされたクラスター。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
PTP Operator の namespace を作成します。
次の YAML を
ptp-namespace.yamlファイルに保存します。apiVersion: v1 kind: Namespace metadata: name: openshift-ptp annotations: workload.openshift.io/allowed: management labels: name: openshift-ptp openshift.io/cluster-monitoring: "true"namespaceCR を作成します。$ oc create -f ptp-namespace.yaml
PTP Operator の Operator グループを作成します。
次の YAML を
ptp-operatorgroup.yamlファイルに保存します。apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: ptp-operators namespace: openshift-ptp spec: targetNamespaces: - openshift-ptp
OperatorGroupCR を作成します。$ oc create -f ptp-operatorgroup.yaml
PTP Operator にサブスクライブします。
次の YAML を
ptp-sub.yamlファイルに保存します。apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: ptp-operator-subscription namespace: openshift-ptp spec: channel: "stable" name: ptp-operator source: redhat-operators sourceNamespace: openshift-marketplace
SubscriptionCR を作成します。$ oc create -f ptp-sub.yaml
Operator がインストールされていることを確認するには、以下のコマンドを入力します。
$ oc get csv -n openshift-ptp -o custom-columns=Name:.metadata.name,Phase:.status.phase
出力例
Name Phase 4.13.0-202301261535 Succeeded
19.5. Web コンソールを使用した PTP Operator のインストール
クラスター管理者は、Web コンソールを使用して PTP Operator をインストールできます。
先のセクションで説明されているように namespace および Operator グループを作成する必要があります。
手順
OpenShift Container Platform Web コンソールを使用して PTP Operator をインストールします。
- OpenShift Container Platform Web コンソールで、Operators → OperatorHub をクリックします。
- 利用可能な Operator のリストから PTP Operator を選択してから Install をクリックします。
- Install Operator ページの A specific namespace on the cluster の下で openshift-ptp を選択します。次に、Install をクリックします。
オプション: PTP Operator が正常にインストールされていることを確認します。
- Operators → Installed Operators ページに切り替えます。
PTP Operator が Status が InstallSucceeded の状態で openshift-ptp プロジェクトにリスト表示されていることを確認します。
注記インストール時に、 Operator は Failed ステータスを表示する可能性があります。インストールが後に InstallSucceeded メッセージを出して正常に実行される場合は、Failed メッセージを無視できます。
Operator がインストール済みとして表示されない場合に、さらにトラブルシューティングを実行します。
- Operators → Installed Operators ページに移動し、Operator Subscriptions および Install Plans タブで Status にエラーがあるかどうかを検査します。
-
Workloads → Pods ページに移動し、
openshift-ptpプロジェクトで Pod のログを確認します。
19.6. PTP デバイスの設定
PTP Operator は NodePtpDevice.ptp.openshift.io カスタムリソース定義 (CRD) を OpenShift Container Platform に追加します。
インストールが完了すると、PTP Operator はクラスターを検索して各ノードで PTP 対応のネットワークデバイスを検索します。これは、互換性のある PTP 対応のネットワークデバイスを提供する各ノードの NodePtpDevice カスタムリソース (CR) オブジェクトを作成し、更新します。
19.6.1. クラスター内の PTP 対応ネットワークデバイスの検出
クラスター内の PTP 対応ネットワークデバイスの一覧を返すには、以下のコマンドを実行します。
$ oc get NodePtpDevice -n openshift-ptp -o yaml
出力例
apiVersion: v1 items: - apiVersion: ptp.openshift.io/v1 kind: NodePtpDevice metadata: creationTimestamp: "2022-01-27T15:16:28Z" generation: 1 name: dev-worker-0 1 namespace: openshift-ptp resourceVersion: "6538103" uid: d42fc9ad-bcbf-4590-b6d8-b676c642781a spec: {} status: devices: 2 - name: eno1 - name: eno2 - name: eno3 - name: eno4 - name: enp5s0f0 - name: enp5s0f1 ...
19.6.2. linuxptp サービスをグランドマスタークロックとして設定する
ホスト NIC を設定する PtpConfig カスタムリソース (CR) を作成することで、linuxptp サービス (ptp4l、phc2sys、ts2phc) をグランドマスタークロック (T-GM) として設定できます。
ts2phc ユーティリティーを使用すると、システムクロックを PTP グランドマスタークロックと同期できるため、ノードは高精度クロック信号をダウンストリームの PTP 通常クロックおよび境界クロックにストリーミングできます。
次の PtpConfig CR の例をベースとして使用して、linuxptp サービスを特定のハードウェアおよび環境のグランドマスタークロックとして設定します。この例の CR は PTP 高速イベントを設定しません。PTP 高速イベントを設定するには、ptp4lOpts、ptp4lConf、ptpClockThreshold に適切な値を設定します。ptpClockThreshold は、イベントが有効になっている場合にのみ使用されます。詳細は、「PTP 高速イベント通知パブリッシャーの設定」を参照してください。
前提条件
- 実稼働環境の T-GM クロックの場合は、ベアメタルクラスターホストに Intel E810 Westport Channel NIC がインストールされている。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。 - PTP Operator をインストールします。
手順
PtpConfigリソースを作成します。以下に例を示します。要件に応じて、デプロイメントに次の T-GM 設定のいずれかを使用します。YAML を
grandmaster-clock-ptp-config.yamlファイルに保存します。例19.1 PTP グランドマスタークロック設定の例
apiVersion: ptp.openshift.io/v1 kind: PtpConfig metadata: name: grandmaster-clock namespace: openshift-ptp annotations: {} spec: profile: - name: grandmaster-clock # The interface name is hardware-specific interface: $interface ptp4lOpts: "-2" phc2sysOpts: "-a -r -r -n 24" ptpSchedulingPolicy: SCHED_FIFO ptpSchedulingPriority: 10 ptpSettings: logReduce: "true" ptp4lConf: | [global] # # Default Data Set # twoStepFlag 1 slaveOnly 0 priority1 128 priority2 128 domainNumber 24 #utc_offset 37 clockClass 255 clockAccuracy 0xFE offsetScaledLogVariance 0xFFFF free_running 0 freq_est_interval 1 dscp_event 0 dscp_general 0 dataset_comparison G.8275.x G.8275.defaultDS.localPriority 128 # # Port Data Set # logAnnounceInterval -3 logSyncInterval -4 logMinDelayReqInterval -4 logMinPdelayReqInterval -4 announceReceiptTimeout 3 syncReceiptTimeout 0 delayAsymmetry 0 fault_reset_interval -4 neighborPropDelayThresh 20000000 masterOnly 0 G.8275.portDS.localPriority 128 # # Run time options # assume_two_step 0 logging_level 6 path_trace_enabled 0 follow_up_info 0 hybrid_e2e 0 inhibit_multicast_service 0 net_sync_monitor 0 tc_spanning_tree 0 tx_timestamp_timeout 50 unicast_listen 0 unicast_master_table 0 unicast_req_duration 3600 use_syslog 1 verbose 0 summary_interval 0 kernel_leap 1 check_fup_sync 0 clock_class_threshold 7 # # Servo Options # pi_proportional_const 0.0 pi_integral_const 0.0 pi_proportional_scale 0.0 pi_proportional_exponent -0.3 pi_proportional_norm_max 0.7 pi_integral_scale 0.0 pi_integral_exponent 0.4 pi_integral_norm_max 0.3 step_threshold 2.0 first_step_threshold 0.00002 max_frequency 900000000 clock_servo pi sanity_freq_limit 200000000 ntpshm_segment 0 # # Transport options # transportSpecific 0x0 ptp_dst_mac 01:1B:19:00:00:00 p2p_dst_mac 01:80:C2:00:00:0E udp_ttl 1 udp6_scope 0x0E uds_address /var/run/ptp4l # # Default interface options # clock_type OC network_transport L2 delay_mechanism E2E time_stamping hardware tsproc_mode filter delay_filter moving_median delay_filter_length 10 egressLatency 0 ingressLatency 0 boundary_clock_jbod 0 # # Clock description # productDescription ;; revisionData ;; manufacturerIdentity 00:00:00 userDescription ; timeSource 0xA0 recommend: - profile: grandmaster-clock priority: 4 match: - nodeLabel: "node-role.kubernetes.io/$mcp"注記PTP グランドマスタークロック設定の例は、テストのみを目的としており、実稼働環境向けのものではありません。
例19.2 E810 NIC の PTP グランドマスタークロック設定
apiVersion: ptp.openshift.io/v1 kind: PtpConfig metadata: name: grandmaster namespace: openshift-ptp annotations: ran.openshift.io/ztp-deploy-wave: "10" spec: profile: - name: "grandmaster" ptp4lOpts: "-2 --summary_interval -4" phc2sysOpts: -r -u 0 -m -O -37 -N 8 -R 16 -s $iface_master -n 24 ptpSchedulingPolicy: SCHED_FIFO ptpSchedulingPriority: 10 ptpSettings: logReduce: "true" plugins: e810: enableDefaultConfig: true ts2phcOpts: " " ts2phcConf: | [nmea] ts2phc.master 1 [global] use_syslog 0 verbose 1 logging_level 7 ts2phc.pulsewidth 100000000 ts2phc.nmea_serialport $gnss_serialport leapfile /usr/share/zoneinfo/leap-seconds.list [$iface_master] ts2phc.extts_polarity rising ts2phc.extts_correction 0 ptp4lConf: | [$iface_master] masterOnly 1 [$iface_master_1] masterOnly 1 [$iface_master_2] masterOnly 1 [$iface_master_3] masterOnly 1 [global] # # Default Data Set # twoStepFlag 1 priority1 128 priority2 128 domainNumber 24 #utc_offset 37 clockClass 6 clockAccuracy 0x27 offsetScaledLogVariance 0xFFFF free_running 0 freq_est_interval 1 dscp_event 0 dscp_general 0 dataset_comparison G.8275.x G.8275.defaultDS.localPriority 128 # # Port Data Set # logAnnounceInterval -3 logSyncInterval -4 logMinDelayReqInterval -4 logMinPdelayReqInterval 0 announceReceiptTimeout 3 syncReceiptTimeout 0 delayAsymmetry 0 fault_reset_interval -4 neighborPropDelayThresh 20000000 masterOnly 0 G.8275.portDS.localPriority 128 # # Run time options # assume_two_step 0 logging_level 6 path_trace_enabled 0 follow_up_info 0 hybrid_e2e 0 inhibit_multicast_service 0 net_sync_monitor 0 tc_spanning_tree 0 tx_timestamp_timeout 50 unicast_listen 0 unicast_master_table 0 unicast_req_duration 3600 use_syslog 1 verbose 0 summary_interval -4 kernel_leap 1 check_fup_sync 0 clock_class_threshold 7 # # Servo Options # pi_proportional_const 0.0 pi_integral_const 0.0 pi_proportional_scale 0.0 pi_proportional_exponent -0.3 pi_proportional_norm_max 0.7 pi_integral_scale 0.0 pi_integral_exponent 0.4 pi_integral_norm_max 0.3 step_threshold 2.0 first_step_threshold 0.00002 clock_servo pi sanity_freq_limit 200000000 ntpshm_segment 0 # # Transport options # transportSpecific 0x0 ptp_dst_mac 01:1B:19:00:00:00 p2p_dst_mac 01:80:C2:00:00:0E udp_ttl 1 udp6_scope 0x0E uds_address /var/run/ptp4l # # Default interface options # clock_type BC network_transport L2 delay_mechanism E2E time_stamping hardware tsproc_mode filter delay_filter moving_median delay_filter_length 10 egressLatency 0 ingressLatency 0 boundary_clock_jbod 0 # # Clock description # productDescription ;; revisionData ;; manufacturerIdentity 00:00:00 userDescription ; timeSource 0x20 recommend: - profile: "grandmaster" priority: 4 match: - nodeLabel: "node-role.kubernetes.io/$mcp"以下のコマンドを実行して CR を作成します。
$ oc create -f grandmaster-clock-ptp-config.yaml
検証
PtpConfigプロファイルがノードに適用されていることを確認します。以下のコマンドを実行して、
openshift-ptpnamespace の Pod の一覧を取得します。$ oc get pods -n openshift-ptp -o wide
出力例
NAME READY STATUS RESTARTS AGE IP NODE linuxptp-daemon-74m2g 3/3 Running 3 4d15h 10.16.230.7 compute-1.example.com ptp-operator-5f4f48d7c-x7zkf 1/1 Running 1 4d15h 10.128.1.145 compute-1.example.com
プロファイルが正しいことを確認します。
PtpConfigプロファイルで指定したノードに対応するlinuxptpデーモンのログを検査します。以下のコマンドを実行します。$ oc logs linuxptp-daemon-74m2g -n openshift-ptp -c linuxptp-daemon-container
出力例
ts2phc[94980.334]: [ts2phc.0.config] nmea delay: 98690975 ns ts2phc[94980.334]: [ts2phc.0.config] ens3f0 extts index 0 at 1676577329.999999999 corr 0 src 1676577330.901342528 diff -1 ts2phc[94980.334]: [ts2phc.0.config] ens3f0 master offset -1 s2 freq -1 ts2phc[94980.441]: [ts2phc.0.config] nmea sentence: GNRMC,195453.00,A,4233.24427,N,07126.64420,W,0.008,,160223,,,A,V phc2sys[94980.450]: [ptp4l.0.config] CLOCK_REALTIME phc offset 943 s2 freq -89604 delay 504 phc2sys[94980.512]: [ptp4l.0.config] CLOCK_REALTIME phc offset 1000 s2 freq -89264 delay 474
19.6.2.1. グランドマスタークロックの PtpConfig 設定リファレンス
このリファレンスでは、linuxptp サービス (ptp4l、phc2sys、ts2phc) をグランドマスタークロックとして設定する PtpConfig カスタムリソース (CR) の設定オプションについて説明します。
表19.1 PTP グランドマスタークロックの PtpConfig 設定オプション
| PtpConfig CR フィールド | 説明 |
|---|---|
|
|
grandmaster クロック動作用に NIC を設定する
プラグインメカニズムにより、PTP Operatro は自動ハードウェア設定を行うことができます。Intel Westport Channel NIC の場合、 |
|
|
|
|
|
|
|
| データを破棄する前に、送信者からの送信 (TX) タイムスタンプを待機する最大時間を指定します。 |
|
| JBOD 境界クロック時間遅延値を指定します。この値は、ネットワーク時間デバイス間で受け渡される時間値を修正するために使用されます。 |
|
|
注記
ここにリストされているネットワークインターフェイスがグランドマスターとして設定されており、 |
|
|
|
|
|
|
|
|
オプション: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
19.6.3. linuxptp サービスを通常のクロックとして設定
Ptp Configカスタムリソース (CR) オブジェクトを作成して、 linuxptpサービス (ptp4l、phc2sys) を通常のクロックとして設定できます。
次の例の PtpConfig CR を、特定のハードウェアおよび環境の通常クロックとして linuxptp サービスを設定する基礎として使用します。この例の CR は PTP 高速イベントを設定しません。PTP 高速イベントを設定するには、ptp4lOpts、ptp4lConf、ptpClockThreshold に適切な値を設定します。ptpClockThreshold は、イベントが有効な場合にのみ必要です。詳細は、「PTP 高速イベント通知パブリッシャーの設定」を参照してください。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。 - PTP Operator をインストールします。
手順
以下の
PtpConfigCR を作成してから、YAML をordinary-clock-ptp-config.yamlファイルに保存します。PTP 通常クロックの設定例
apiVersion: ptp.openshift.io/v1 kind: PtpConfig metadata: name: ordinary-clock namespace: openshift-ptp annotations: {} spec: profile: - name: ordinary-clock # The interface name is hardware-specific interface: $interface ptp4lOpts: "-2 -s" phc2sysOpts: "-a -r -n 24" ptpSchedulingPolicy: SCHED_FIFO ptpSchedulingPriority: 10 ptpSettings: logReduce: "true" ptp4lConf: | [global] # # Default Data Set # twoStepFlag 1 slaveOnly 1 priority1 128 priority2 128 domainNumber 24 #utc_offset 37 clockClass 255 clockAccuracy 0xFE offsetScaledLogVariance 0xFFFF free_running 0 freq_est_interval 1 dscp_event 0 dscp_general 0 dataset_comparison G.8275.x G.8275.defaultDS.localPriority 128 # # Port Data Set # logAnnounceInterval -3 logSyncInterval -4 logMinDelayReqInterval -4 logMinPdelayReqInterval -4 announceReceiptTimeout 3 syncReceiptTimeout 0 delayAsymmetry 0 fault_reset_interval -4 neighborPropDelayThresh 20000000 masterOnly 0 G.8275.portDS.localPriority 128 # # Run time options # assume_two_step 0 logging_level 6 path_trace_enabled 0 follow_up_info 0 hybrid_e2e 0 inhibit_multicast_service 0 net_sync_monitor 0 tc_spanning_tree 0 tx_timestamp_timeout 50 unicast_listen 0 unicast_master_table 0 unicast_req_duration 3600 use_syslog 1 verbose 0 summary_interval 0 kernel_leap 1 check_fup_sync 0 clock_class_threshold 7 # # Servo Options # pi_proportional_const 0.0 pi_integral_const 0.0 pi_proportional_scale 0.0 pi_proportional_exponent -0.3 pi_proportional_norm_max 0.7 pi_integral_scale 0.0 pi_integral_exponent 0.4 pi_integral_norm_max 0.3 step_threshold 2.0 first_step_threshold 0.00002 max_frequency 900000000 clock_servo pi sanity_freq_limit 200000000 ntpshm_segment 0 # # Transport options # transportSpecific 0x0 ptp_dst_mac 01:1B:19:00:00:00 p2p_dst_mac 01:80:C2:00:00:0E udp_ttl 1 udp6_scope 0x0E uds_address /var/run/ptp4l # # Default interface options # clock_type OC network_transport L2 delay_mechanism E2E time_stamping hardware tsproc_mode filter delay_filter moving_median delay_filter_length 10 egressLatency 0 ingressLatency 0 boundary_clock_jbod 0 # # Clock description # productDescription ;; revisionData ;; manufacturerIdentity 00:00:00 userDescription ; timeSource 0xA0 recommend: - profile: ordinary-clock priority: 4 match: - nodeLabel: "node-role.kubernetes.io/$mcp"表19.2 PTP 通常クロック CR 設定のオプション
カスタムリソースフィールド 説明 namePtpConfigCR の名前。profile1 つ以上の
profileオブジェクトの配列を指定します。各プロファイルの名前は一意である必要があります。interfaceptp4lサービスで使用するネットワークインターフェイスを指定します (例:ens787f1)。ptp4lOptsptp4lサービスのシステム設定オプションを指定します。たとえば、-2で IEEE 802.3 ネットワークトランスポートを選択します。ネットワークインターフェイス名とサービス設定ファイルが自動的に追加されるため、オプションには、ネットワークインターフェイス名-i <interface>およびサービス設定ファイル-f /etc/ptp4l.confを含めないでください。このインターフェイスで PTP 高速イベントを使用するには、--summary_interval -4を追加します。phc2sysOptsphc2sysサービスのシステム設定オプションを指定します。このフィールドが空の場合、PTP Operator はphc2sysサービスを開始しません。Intel Columbiaville 800 Series NIC の場合、phc2sysOptsオプションを-a -r -m -n 24 -N 8 -R 16に設定します。-mはメッセージをstdoutに出力します。linuxptp-daemonDaemonSetはログを解析し、Prometheus メトリックを生成します。ptp4lConfデフォルトの
/etc/ptp4l.confファイルを置き換える設定が含まれる文字列を指定します。デフォルト設定を使用するには、フィールドを空のままにします。tx_timestamp_timeoutIntel Columbiaville 800 Series NIC の場合、
tx_timestamp_timeoutを50に設定します。boundary_clock_jbodIntel Columbiaville 800 Series NIC の場合、
boundary_clock_jbodを0に設定します。ptpSchedulingPolicyptp4lとphc2sysプロセスのスケジューリングポリシー。デフォルト値はSCHED_OTHERです。FIFO スケジューリングをサポートするシステムでは、SCHED_FIFOを使用してください。ptpSchedulingPriorityptp SchedulingPolicyがSCHED_FIFOに設定されている場合に、ptp4lおよびphc2sysプロセスの FIFO の優先度を設定するために使用される 1-65 の整数値。ptpSchedulingPriorityフィールドは、ptpSchedulingPolicyがSCHED_OTHERに設定されている場合は使用されません。ptpClockThresholdオプション:
ptpClockThresholdが存在しない場合、ptpClockThresholdフィールドにはデフォルト値が使用されます。ptpClockThresholdは、PTP マスタークロックが切断されてから PTP イベントが発生するまでの時間を設定します。holdOverTimeoutは、PTP マスタークロックが切断されたときに、PTP クロックイベントの状態がFREERUNに変わるまでの時間値 (秒単位) です。maxOffsetThresholdおよびminOffsetThreshold設定は、CLOCK_REALTIME(phc2sys) またはマスターオフセット (ptp4l) の値と比較するナノ秒単位のオフセット値を設定します。ptp4lまたはphc2sysのオフセット値がこの範囲外の場合、PTP クロックの状態がFREERUNに設定されます。オフセット値がこの範囲内にある場合、PTP クロックの状態がLOCKEDに設定されます。recommendprofileがノードに適用される方法を定義する 1 つ以上のrecommendオブジェクトの配列を指定します。.recommend.profileprofileセクションで定義される.recommend.profileオブジェクト名を指定します。.recommend.priority通常クロックの
.recommend.priorityを0に設定します。.recommend.match.recommend.matchルールをnodeLabelまたはnodeNameの値に指定します。.recommend.match.nodeLabeloc get Nodes --show-labelsコマンドを使用して、ノードオブジェクトのnode.LabelsフィールドのkeyでnodeLabelを設定します。例:node-role.kubernetes.io/worker。.recommend.match.nodeNameoc get nodesコマンドを使用して、nodeNameをノードオブジェクトのnode.Nameフィールドの値に設定します。compute-1.example.comはその例です。次のコマンドを実行して、
PtpConfigCR を作成します。$ oc create -f ordinary-clock-ptp-config.yaml
検証
PtpConfigプロファイルがノードに適用されていることを確認します。以下のコマンドを実行して、
openshift-ptpnamespace の Pod の一覧を取得します。$ oc get pods -n openshift-ptp -o wide
出力例
NAME READY STATUS RESTARTS AGE IP NODE linuxptp-daemon-4xkbb 1/1 Running 0 43m 10.1.196.24 compute-0.example.com linuxptp-daemon-tdspf 1/1 Running 0 43m 10.1.196.25 compute-1.example.com ptp-operator-657bbb64c8-2f8sj 1/1 Running 0 43m 10.129.0.61 control-plane-1.example.com
プロファイルが正しいことを確認します。
PtpConfigプロファイルで指定したノードに対応するlinuxptpデーモンのログを検査します。以下のコマンドを実行します。$ oc logs linuxptp-daemon-4xkbb -n openshift-ptp -c linuxptp-daemon-container
出力例
I1115 09:41:17.117596 4143292 daemon.go:107] in applyNodePTPProfile I1115 09:41:17.117604 4143292 daemon.go:109] updating NodePTPProfile to: I1115 09:41:17.117607 4143292 daemon.go:110] ------------------------------------ I1115 09:41:17.117612 4143292 daemon.go:102] Profile Name: profile1 I1115 09:41:17.117616 4143292 daemon.go:102] Interface: ens787f1 I1115 09:41:17.117620 4143292 daemon.go:102] Ptp4lOpts: -2 -s I1115 09:41:17.117623 4143292 daemon.go:102] Phc2sysOpts: -a -r -n 24 I1115 09:41:17.117626 4143292 daemon.go:116] ------------------------------------
関連情報
- PTP ハードウェアでの FIFO 優先度スケジューリングの詳細については、PTP ハードウェアの FIFO 優先度スケジューリングの設定 を参照してください。
- PTP 高速イベントの設定の詳細は、PTP 高速イベント通知パブリッシャーの設定 を参照してください。
19.6.4. linuxptp サービスを境界クロックとして設定
PtpConfig カスタムリソース (CR) オブジェクトを作成して、linuxptp サービス (ptp4l、phc2sys を設定できます。
次の例の PtpConfig CR を、特定のハードウェアおよび環境の境界クロックとして linuxptp サービスを設定する基礎として使用します。この例の CR は PTP 高速イベントを設定しません。PTP 高速イベントを設定するには、ptp4lOpts、ptp4lConf、ptpClockThreshold に適切な値を設定します。ptpClockThreshold は、イベントが有効になっている場合にのみ使用されます。詳細は、「PTP 高速イベント通知パブリッシャーの設定」を参照してください。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。 - PTP Operator をインストールします。
手順
以下の
PtpConfigCR を作成してから、YAML をboundary-clock-ptp-config.yamlファイルに保存します。PTP 境界クロックの設定例
apiVersion: ptp.openshift.io/v1 kind: PtpConfig metadata: name: boundary-clock namespace: openshift-ptp annotations: {} spec: profile: - name: boundary-clock ptp4lOpts: "-2" phc2sysOpts: "-a -r -n 24" ptpSchedulingPolicy: SCHED_FIFO ptpSchedulingPriority: 10 ptpSettings: logReduce: "true" ptp4lConf: | # The interface name is hardware-specific [$iface_slave] masterOnly 0 [$iface_master_1] masterOnly 1 [$iface_master_2] masterOnly 1 [$iface_master_3] masterOnly 1 [global] # # Default Data Set # twoStepFlag 1 slaveOnly 0 priority1 128 priority2 128 domainNumber 24 #utc_offset 37 clockClass 248 clockAccuracy 0xFE offsetScaledLogVariance 0xFFFF free_running 0 freq_est_interval 1 dscp_event 0 dscp_general 0 dataset_comparison G.8275.x G.8275.defaultDS.localPriority 128 # # Port Data Set # logAnnounceInterval -3 logSyncInterval -4 logMinDelayReqInterval -4 logMinPdelayReqInterval -4 announceReceiptTimeout 3 syncReceiptTimeout 0 delayAsymmetry 0 fault_reset_interval -4 neighborPropDelayThresh 20000000 masterOnly 0 G.8275.portDS.localPriority 128 # # Run time options # assume_two_step 0 logging_level 6 path_trace_enabled 0 follow_up_info 0 hybrid_e2e 0 inhibit_multicast_service 0 net_sync_monitor 0 tc_spanning_tree 0 tx_timestamp_timeout 50 unicast_listen 0 unicast_master_table 0 unicast_req_duration 3600 use_syslog 1 verbose 0 summary_interval 0 kernel_leap 1 check_fup_sync 0 clock_class_threshold 135 # # Servo Options # pi_proportional_const 0.0 pi_integral_const 0.0 pi_proportional_scale 0.0 pi_proportional_exponent -0.3 pi_proportional_norm_max 0.7 pi_integral_scale 0.0 pi_integral_exponent 0.4 pi_integral_norm_max 0.3 step_threshold 2.0 first_step_threshold 0.00002 max_frequency 900000000 clock_servo pi sanity_freq_limit 200000000 ntpshm_segment 0 # # Transport options # transportSpecific 0x0 ptp_dst_mac 01:1B:19:00:00:00 p2p_dst_mac 01:80:C2:00:00:0E udp_ttl 1 udp6_scope 0x0E uds_address /var/run/ptp4l # # Default interface options # clock_type BC network_transport L2 delay_mechanism E2E time_stamping hardware tsproc_mode filter delay_filter moving_median delay_filter_length 10 egressLatency 0 ingressLatency 0 boundary_clock_jbod 0 # # Clock description # productDescription ;; revisionData ;; manufacturerIdentity 00:00:00 userDescription ; timeSource 0xA0 recommend: - profile: boundary-clock priority: 4 match: - nodeLabel: "node-role.kubernetes.io/$mcp"表19.3 PTP 境界クロックの CR 設定オプション
カスタムリソースフィールド 説明 namePtpConfigCR の名前。profile1 つ以上の
profileオブジェクトの配列を指定します。nameプロファイルオブジェクトを一意に識別するプロファイルオブジェクトの名前を指定します。
ptp4lOptsptp4lサービスのシステム設定オプションを指定します。ネットワークインターフェイス名とサービス設定ファイルが自動的に追加されるため、オプションには、ネットワークインターフェイス名-i <interface>およびサービス設定ファイル-f /etc/ptp4l.confを含めないでください。ptp4lConfptp4lを境界クロックとして起動するために必要な設定を指定します。たとえば、ens1f0はグランドマスタークロックから同期し、ens1f3は接続されたデバイスを同期します。<interface_1>同期クロックを受信するインターフェイス。
<interface_2>Synchronization クロックを送信するインターフェイス。
tx_timestamp_timeoutIntel Columbiaville 800 Series NIC の場合、
tx_timestamp_timeoutを50に設定します。boundary_clock_jbodIntel Columbiaville 800 Series NIC の場合、
boundary_clock_jbodが0に設定されていることを確認します。Intel Fortville X710 シリーズ NIC の場合、boundary_clock_jbodが1に設定されていることを確認します。phc2sysOptsphc2sysサービスのシステム設定オプションを指定します。このフィールドが空の場合、PTP Operator はphc2sysサービスを開始しません。ptpSchedulingPolicyptp4l と phc2sys プロセスのスケジューリングポリシー。デフォルト値は
SCHED_OTHERです。FIFO スケジューリングをサポートするシステムでは、SCHED_FIFOを使用してください。ptpSchedulingPriorityptp SchedulingPolicyがSCHED_FIFOに設定されている場合に、ptp4lおよびphc2sysプロセスの FIFO の優先度を設定するために使用される 1-65 の整数値。ptpSchedulingPriorityフィールドは、ptpSchedulingPolicyがSCHED_OTHERに設定されている場合は使用されません。ptpClockThresholdオプション:
ptpClockThresholdが存在しない場合、ptpClockThresholdフィールドにはデフォルト値が使用されます。ptpClockThresholdは、PTP マスタークロックが切断されてから PTP イベントが発生するまでの時間を設定します。holdOverTimeoutは、PTP マスタークロックが切断されたときに、PTP クロックイベントの状態がFREERUNに変わるまでの時間値 (秒単位) です。maxOffsetThresholdおよびminOffsetThreshold設定は、CLOCK_REALTIME(phc2sys) またはマスターオフセット (ptp4l) の値と比較するナノ秒単位のオフセット値を設定します。ptp4lまたはphc2sysのオフセット値がこの範囲外の場合、PTP クロックの状態がFREERUNに設定されます。オフセット値がこの範囲内にある場合、PTP クロックの状態がLOCKEDに設定されます。recommendprofileがノードに適用される方法を定義する 1 つ以上のrecommendオブジェクトの配列を指定します。.recommend.profileprofileセクションで定義される.recommend.profileオブジェクト名を指定します。.recommend.priority0から99までの整数値でpriorityを指定します。数値が大きいほど優先度が低くなるため、99の優先度は10よりも低くなります。ノードがmatchフィールドで定義されるルールに基づいて複数のプロファイルに一致する場合、優先順位の高いプロファイルがそのノードに適用されます。.recommend.match.recommend.matchルールをnodeLabelまたはnodeNameの値に指定します。.recommend.match.nodeLabeloc get Nodes --show-labelsコマンドを使用して、ノードオブジェクトのnode.LabelsフィールドのkeyでnodeLabelを設定します。例:node-role.kubernetes.io/worker。.recommend.match.nodeNameoc get nodesコマンドを使用して、nodeNameをノードオブジェクトのnode.Nameフィールドの値に設定します。compute-1.example.comはその例です。以下のコマンドを実行して CR を作成します。
$ oc create -f boundary-clock-ptp-config.yaml
検証
PtpConfigプロファイルがノードに適用されていることを確認します。以下のコマンドを実行して、
openshift-ptpnamespace の Pod の一覧を取得します。$ oc get pods -n openshift-ptp -o wide
出力例
NAME READY STATUS RESTARTS AGE IP NODE linuxptp-daemon-4xkbb 1/1 Running 0 43m 10.1.196.24 compute-0.example.com linuxptp-daemon-tdspf 1/1 Running 0 43m 10.1.196.25 compute-1.example.com ptp-operator-657bbb64c8-2f8sj 1/1 Running 0 43m 10.129.0.61 control-plane-1.example.com
プロファイルが正しいことを確認します。
PtpConfigプロファイルで指定したノードに対応するlinuxptpデーモンのログを検査します。以下のコマンドを実行します。$ oc logs linuxptp-daemon-4xkbb -n openshift-ptp -c linuxptp-daemon-container
出力例
I1115 09:41:17.117596 4143292 daemon.go:107] in applyNodePTPProfile I1115 09:41:17.117604 4143292 daemon.go:109] updating NodePTPProfile to: I1115 09:41:17.117607 4143292 daemon.go:110] ------------------------------------ I1115 09:41:17.117612 4143292 daemon.go:102] Profile Name: profile1 I1115 09:41:17.117616 4143292 daemon.go:102] Interface: I1115 09:41:17.117620 4143292 daemon.go:102] Ptp4lOpts: -2 I1115 09:41:17.117623 4143292 daemon.go:102] Phc2sysOpts: -a -r -n 24 I1115 09:41:17.117626 4143292 daemon.go:116] ------------------------------------
関連情報
- PTP ハードウェアでの FIFO 優先度スケジューリングの詳細については、PTP ハードウェアの FIFO 優先度スケジューリングの設定 を参照してください。
- PTP 高速イベントの設定の詳細は、PTP 高速イベント通知パブリッシャーの設定 を参照してください。
19.6.5. linuxptp サービスをデュアル NIC ハードウェアの境界クロックとして設定
デュアル NIC で境界クロックとして設定した PTP (Precision Time Protocol) ハードウェアは、テクノロジープレビュー機能としてのみ提供されています。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
NIC ごとに PtpConfig カスタムリソース (CR) オブジェクトを作成することにより、linuxptp サービス (ptp4l、phc2sys) をデュアル NIC ハードウェアの境界クロックとして設定できます。
デュアル NIC ハードウェアを使用すると、各 NIC を同じアップストリームリーダークロックに接続し、NIC ごとに個別の ptp4l インスタンスをダウンストリームクロックに供給することができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。 - PTP Operator をインストールします。
手順
linuxptp サービスを境界クロックとして設定の参照 CR を各 CR の基礎として使用して、NIC ごとに 1 つずつ、2 つの個別の
PtpConfigCRを作成します。以下に例を示します。phc2sysOptsの値を指定して、boundary-clock-ptp-config-nic1.yamlを作成します。apiVersion: ptp.openshift.io/v1 kind: PtpConfig metadata: name: boundary-clock-ptp-config-nic1 namespace: openshift-ptp spec: profile: - name: "profile1" ptp4lOpts: "-2 --summary_interval -4" ptp4lConf: | 1 [ens5f1] masterOnly 1 [ens5f0] masterOnly 0 ... phc2sysOpts: "-a -r -m -n 24 -N 8 -R 16" 2boundary-clock-ptp-config-nic2.yamlを作成し、phc2sysOptsフィールドを完全に削除して、2 番目の NIC のphc2sysサービスを無効にします。apiVersion: ptp.openshift.io/v1 kind: PtpConfig metadata: name: boundary-clock-ptp-config-nic2 namespace: openshift-ptp spec: profile: - name: "profile2" ptp4lOpts: "-2 --summary_interval -4" ptp4lConf: | 1 [ens7f1] masterOnly 1 [ens7f0] masterOnly 0 ...- 1
- 2 番目の NIC の境界クロックとして
ptp4lを開始するために必要なインターフェイスを指定します。
注記2 番目の NIC で
phc2sysサービスを無効にするには、2 番目のPtpConfigCR からphc2sysOptsフィールドを完全に削除する必要があります。
次のコマンドを実行して、デュアル NIC
PtpConfigCRを作成します。1 番目の NIC の PTP を設定する CR を作成します。
$ oc create -f boundary-clock-ptp-config-nic1.yaml
2 番目の NIC の PTP を設定する CR を作成します。
$ oc create -f boundary-clock-ptp-config-nic2.yaml
検証
PTP Operator が両方の NIC に
PtpConfigCRを適用していることを確認してください。デュアル NIC ハードウェアがインストールされているノードに対応するlinuxptpデーモンのログを調べます。たとえば、以下のコマンドを実行します。$ oc logs linuxptp-daemon-cvgr6 -n openshift-ptp -c linuxptp-daemon-container
出力例
ptp4l[80828.335]: [ptp4l.1.config] master offset 5 s2 freq -5727 path delay 519 ptp4l[80828.343]: [ptp4l.0.config] master offset -5 s2 freq -10607 path delay 533 phc2sys[80828.390]: [ptp4l.0.config] CLOCK_REALTIME phc offset 1 s2 freq -87239 delay 539
19.6.6. PTP 通常クロックの参照としての IntelColumbiavilleE800 シリーズ NIC
次の表に、Intel Columbiaville E800 シリーズ NIC を通常のクロックとして使用するために参照 PTP 設定に加える必要のある変更を示します。クラスターに適用する PtpConfig カスタムリソース (CR) に変更を加えます。
表19.4 Intel Columbiaville NIC の推奨 PTP 設定
| PTP 設定 | 推奨設定 |
|---|---|
|
|
|
|
|
|
|
|
|
phc2sysOpts の場合、-m はメッセージを stdout に出力します。linuxptp-daemon DaemonSet はログを解析し、Prometheus メトリックを生成します。
関連情報
-
linuxptpサービスを PTP 高速イベントを使用して通常クロックとして設定する CR の完全な例については、Configuring linuxptp services as ordinary clock を参照してください。
19.6.7. PTP ハードウェアの FIFO 優先スケジューリングの設定
低遅延のパフォーマンスを確保する必要のある通信業者や他のデプロイメント設定では、PTP デーモンスレッドは、制約された CPU フットプリントで、残りのインフラストラクチャーのコンポーネントと一緒に、実行されます。デフォルトでは、PTP スレッドは SCHED_OTHER ポリシーで実行されます。負荷が高いと、エラーなしで運用する必要のある、これらのスレッドのスケジューリングでレイテンシーが発生する可能性があります。
スケジューリングのレイテンシーでエラーが発生する可能性を軽減するために、SCHED_FIFO ポリシーでスレッドを実行できるように、PTP Operator の linuxptp サービスを設定できます。Ptp ConfigCR に SCHED_FIFO が設定されている場合には、ptp4l と phc2sys は、Ptp ConfigCR の ptp Scheduling Priority フィールドで設定された優先順位で、chrt の下の親コンテナーで実行されます。
ptp Scheduling Policy の設定はオプションで、レイテンシーエラーが発生している場合にのみ必要となります。
手順
Ptp ConfigCR プロファイルを編集します。$ oc edit PtpConfig -n openshift-ptp
ptp Scheduling Policyとptp Scheduling Priorityフィールドを変更します。apiVersion: ptp.openshift.io/v1 kind: PtpConfig metadata: name: <ptp_config_name> namespace: openshift-ptp ... spec: profile: - name: "profile1" ... ptpSchedulingPolicy: SCHED_FIFO 1 ptpSchedulingPriority: 10 2-
保存して終了すると、
Ptp ConfigCR に変更が適用されます。
検証
Ptp ConfigCR が適用されたlinuxptp-daemonPod と対応するノードの名前を取得します。$ oc get pods -n openshift-ptp -o wide
出力例
NAME READY STATUS RESTARTS AGE IP NODE linuxptp-daemon-gmv2n 3/3 Running 0 1d17h 10.1.196.24 compute-0.example.com linuxptp-daemon-lgm55 3/3 Running 0 1d17h 10.1.196.25 compute-1.example.com ptp-operator-3r4dcvf7f4-zndk7 1/1 Running 0 1d7h 10.129.0.61 control-plane-1.example.com
ptp4lプロセスが、更新されたchrtFIFO 優先度で実行されていることを確認します。$ oc -n openshift-ptp logs linuxptp-daemon-lgm55 -c linuxptp-daemon-container|grep chrt
出力例
I1216 19:24:57.091872 1600715 daemon.go:285] /bin/chrt -f 65 /usr/sbin/ptp4l -f /var/run/ptp4l.0.config -2 --summary_interval -4 -m
19.6.8. linuxptp サービスのログフィルタリングの設定
linuxptp デーモンは、デバッグに使用できるログを生成します。ストレージ容量が制限されている通信またはその他のデプロイメント設定では、これらのログはストレージ需要に追加できます。
ログメッセージの数を減らすために、PtpConfig カスタムリソース (CR) を設定して、master offset 値をレポートするログメッセージを除外できます。master offset ログメッセージは、現在のノードのクロックとマスタークロックの違いをナノ秒単位でレポートします。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。 - PTP Operator をインストールします。
手順
PtpConfigCR を編集します。$ oc edit PtpConfig -n openshift-ptp
spec.profileで、ptpSettings.logReduce仕様を追加し、値をtrueに設定します。apiVersion: ptp.openshift.io/v1 kind: PtpConfig metadata: name: <ptp_config_name> namespace: openshift-ptp ... spec: profile: - name: "profile1" ... ptpSettings: logReduce: "true"注記デバッグの目的で、この仕様を
Falseに戻すと、マスターオフセットメッセージを含めることができます。-
保存して終了すると、
Ptp ConfigCR に変更が適用されます。
検証
Ptp ConfigCR が適用されたlinuxptp-daemonPod と対応するノードの名前を取得します。$ oc get pods -n openshift-ptp -o wide
出力例
NAME READY STATUS RESTARTS AGE IP NODE linuxptp-daemon-gmv2n 3/3 Running 0 1d17h 10.1.196.24 compute-0.example.com linuxptp-daemon-lgm55 3/3 Running 0 1d17h 10.1.196.25 compute-1.example.com ptp-operator-3r4dcvf7f4-zndk7 1/1 Running 0 1d7h 10.129.0.61 control-plane-1.example.com
次のコマンドを実行して、マスターオフセットメッセージがログから除外されていることを確認します。
$ oc -n openshift-ptp logs <linux_daemon_container> -c linuxptp-daemon-container | grep "master offset" 1- 1
- <linux_daemon_container> は
linuxptp-daemonPod の名前です (例:linuxptp-daemon-gmv2n)。
logReduce仕様を設定する場合、このコマンドはlinuxptpデーモンのログにmaster offsetのインスタンスを報告しません。
19.7. 一般的な PTP Operator の問題のトラブルシューティング
以下の手順を実行して、PTP Operator で典型的な問題のトラブルシューティングを行います。
前提条件
-
OpenShift Container Platform CLI (
oc) をインストールします。 -
cluster-admin権限を持つユーザーとしてログインしている。 - PTP をサポートするホストを使用して、PTP Operator をベアメタルクラスターにインストールします。
手順
Operator およびオペランドが、設定されたノードについてクラスターに正常にデプロイされていることを確認します。
$ oc get pods -n openshift-ptp -o wide
出力例
NAME READY STATUS RESTARTS AGE IP NODE linuxptp-daemon-lmvgn 3/3 Running 0 4d17h 10.1.196.24 compute-0.example.com linuxptp-daemon-qhfg7 3/3 Running 0 4d17h 10.1.196.25 compute-1.example.com ptp-operator-6b8dcbf7f4-zndk7 1/1 Running 0 5d7h 10.129.0.61 control-plane-1.example.com
注記PTP 高速イベントバスが有効な場合には、準備できた
linuxptp-daemonPod の数は3/3になります。PTP 高速イベントバスが有効になっていない場合、2/2が表示されます。サポートされているハードウェアがクラスターにあることを確認します。
$ oc -n openshift-ptp get nodeptpdevices.ptp.openshift.io
出力例
NAME AGE control-plane-0.example.com 10d control-plane-1.example.com 10d compute-0.example.com 10d compute-1.example.com 10d compute-2.example.com 10d
ノードで利用可能な PTP ネットワークインターフェイスを確認します。
$ oc -n openshift-ptp get nodeptpdevices.ptp.openshift.io <node_name> -o yaml
ここでは、以下のようになります。
- <node_name>
問い合わせるノードを指定します (例:
compute-0.example.com)。出力例
apiVersion: ptp.openshift.io/v1 kind: NodePtpDevice metadata: creationTimestamp: "2021-09-14T16:52:33Z" generation: 1 name: compute-0.example.com namespace: openshift-ptp resourceVersion: "177400" uid: 30413db0-4d8d-46da-9bef-737bacd548fd spec: {} status: devices: - name: eno1 - name: eno2 - name: eno3 - name: eno4 - name: enp5s0f0 - name: enp5s0f1
対応するノードの
linuxptp-daemonPod にアクセスし、PTP インターフェイスがプライマリークロックに正常に同期されていることを確認します。以下のコマンドを実行して、
linuxptp-daemonPod の名前と、トラブルシューティングに使用するノードを取得します。$ oc get pods -n openshift-ptp -o wide
出力例
NAME READY STATUS RESTARTS AGE IP NODE linuxptp-daemon-lmvgn 3/3 Running 0 4d17h 10.1.196.24 compute-0.example.com linuxptp-daemon-qhfg7 3/3 Running 0 4d17h 10.1.196.25 compute-1.example.com ptp-operator-6b8dcbf7f4-zndk7 1/1 Running 0 5d7h 10.129.0.61 control-plane-1.example.com
リモートシェルが必要な
linuxptp-daemonコンテナーへのリモートシェルです。$ oc rsh -n openshift-ptp -c linuxptp-daemon-container <linux_daemon_container>
ここでは、以下のようになります。
- <linux_daemon_container>
-
診断するコンテナーです (例:
linuxptp-daemon-lmvgn)。
linuxptp-daemonコンテナーへのリモートシェル接続では、PTP 管理クライアント (pmc) ツールを使用して、ネットワークインターフェイスを診断します。以下のpmcコマンドを実行して、PTP デバイスの同期ステータスを確認します (例:ptp4l)。# pmc -u -f /var/run/ptp4l.0.config -b 0 'GET PORT_DATA_SET'
ノードがプライマリークロックに正常に同期されたときの出力例
sending: GET PORT_DATA_SET 40a6b7.fffe.166ef0-1 seq 0 RESPONSE MANAGEMENT PORT_DATA_SET portIdentity 40a6b7.fffe.166ef0-1 portState SLAVE logMinDelayReqInterval -4 peerMeanPathDelay 0 logAnnounceInterval -3 announceReceiptTimeout 3 logSyncInterval -4 delayMechanism 1 logMinPdelayReqInterval -4 versionNumber 2
19.7.1. Precision Time Protocol (PTP) Operator データの収集
oc adm must-gather CLI コマンドを使用して、クラスターに関する情報を収集できます。これには、Precision Time Protocol (PTP) Operator に関連する機能およびオブジェクトが含まれます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。 - PTP Operator がインストールされている。
手順
must-gatherを使用して PTP Operator データを収集するには、PTP Operatormust-gatherイメージを指定する必要があります。$ oc adm must-gather --image=registry.redhat.io/openshift4/ptp-must-gather-rhel8:v4.13
19.8. PTP ハードウェアの高速イベント通知フレームワーク
仮想 RAN (vRAN) などのクラウドネイティブアプリケーションでは、ネットワーク全体の機能に重要なハードウェアタイミングイベントに関する通知へのアクセスが必要です。PTP クロック同期エラーは、分散ユニット (DU) で実行している vRAN アプリケーションなど、低レイテンシーアプリケーションのパフォーマンスおよび信頼性に悪影響を及ぼす可能性があります。
19.8.1. PTP およびクロック同期エラーイベントについて
PTP 同期の損失は、RAN ネットワークでは重大なエラーです。ノードで同期が失われると、無線がシャットダウンされ、ネットワークの OTA(Over the Air) トラフィックがワイヤレスネットワーク内の別のノードにシフトされる可能性があります。高速のイベント通知は、クラスターノードが DU で実行している vRAN アプリケーションに対して PTP クロック同期ステータスと通信できるようにすることで、ワークロードのエラーを軽減します。
イベント通知は、同じ DU ノード上で実行されている vRAN アプリケーションで利用できます。パブリッシュ/サブスクライブ REST API は、イベント通知をメッセージングバスに渡します。パブリッシュ/サブスクライブメッセージング (パブリッシュ/サブスクライブメッセージング) は、トピックにパブリッシュされたメッセージがそのトピックのすべてのサブスクライバーによって即座に受信される、非同期のサービス間通信アーキテクチャーです。
PTP オペレーターは、すべての PTP 対応ネットワークインターフェイスに対して高速イベント通知を生成します。イベントには、HTTP またはアドバンストメッセージキュープロトコル (AMQP) メッセージバス経由で cloud-event-proxy サイドカーコンテナーを使用してアクセスできます。
PTP 高速イベント通知は、PTP 通常クロックまたは PTP 境界クロックを使用するように設定されたネットワークインターフェイスで使用できます。
HTTP トランスポートは、PTP およびベアメタルイベントのデフォルトのトランスポートです。可能な場合、PTP およびベアメタルイベントには AMQP ではなく HTTP トランスポートを使用してください。AMQ Interconnect は、2024 年 6 月 30 日で EOL になります。AMQ Interconnect の延長ライフサイクルサポート (ELS) は 2029 年 11 月 29 日に終了します。詳細は、Red Hat AMQ Interconnect のサポートステータス を参照してください。
19.8.2. PTP 高速イベント通知フレームワークについて
Precision Time Protocol (PTP) 高速イベント通知フレームワークを使用して、ベアメタルクラスターノードが生成する PTP イベントにクラスターアプリケーションをサブスクライブします。
高速イベント通知フレームワークは、通信に REST API を使用します。REST API は、O-RAN ALLIANCE 仕様 から入手できる O-RAN O-Cloud Notification API Specification for Event Consumers 3.0 に基づいています。
このフレームワークは、パブリッシャー、サブスクライバー、および AMQ または HTTP メッセージングプロトコルで構成され、パブリッシャーとサブスクライバーのアプリケーション間の通信を処理します。アプリケーションは、cloud-event-proxy コンテナーをサイドカーパターンで実行して、PTP イベントをサブスクライブします。cloud-event-proxy サイドカーコンテナーは、プライマリーアプリケーションのリソースをまったく使用せずに、大幅な待機時間なしで、プライマリーアプリケーションコンテナーと同じリソースにアクセスできます。
HTTP トランスポートは、PTP およびベアメタルイベントのデフォルトのトランスポートです。可能な場合、PTP およびベアメタルイベントには AMQP ではなく HTTP トランスポートを使用してください。AMQ Interconnect は、2024 年 6 月 30 日で EOL になります。AMQ Interconnect の延長ライフサイクルサポート (ELS) は 2029 年 11 月 29 日に終了します。詳細は、Red Hat AMQ Interconnect のサポートステータス を参照してください。
図19.1 PTP 高速イベントの概要
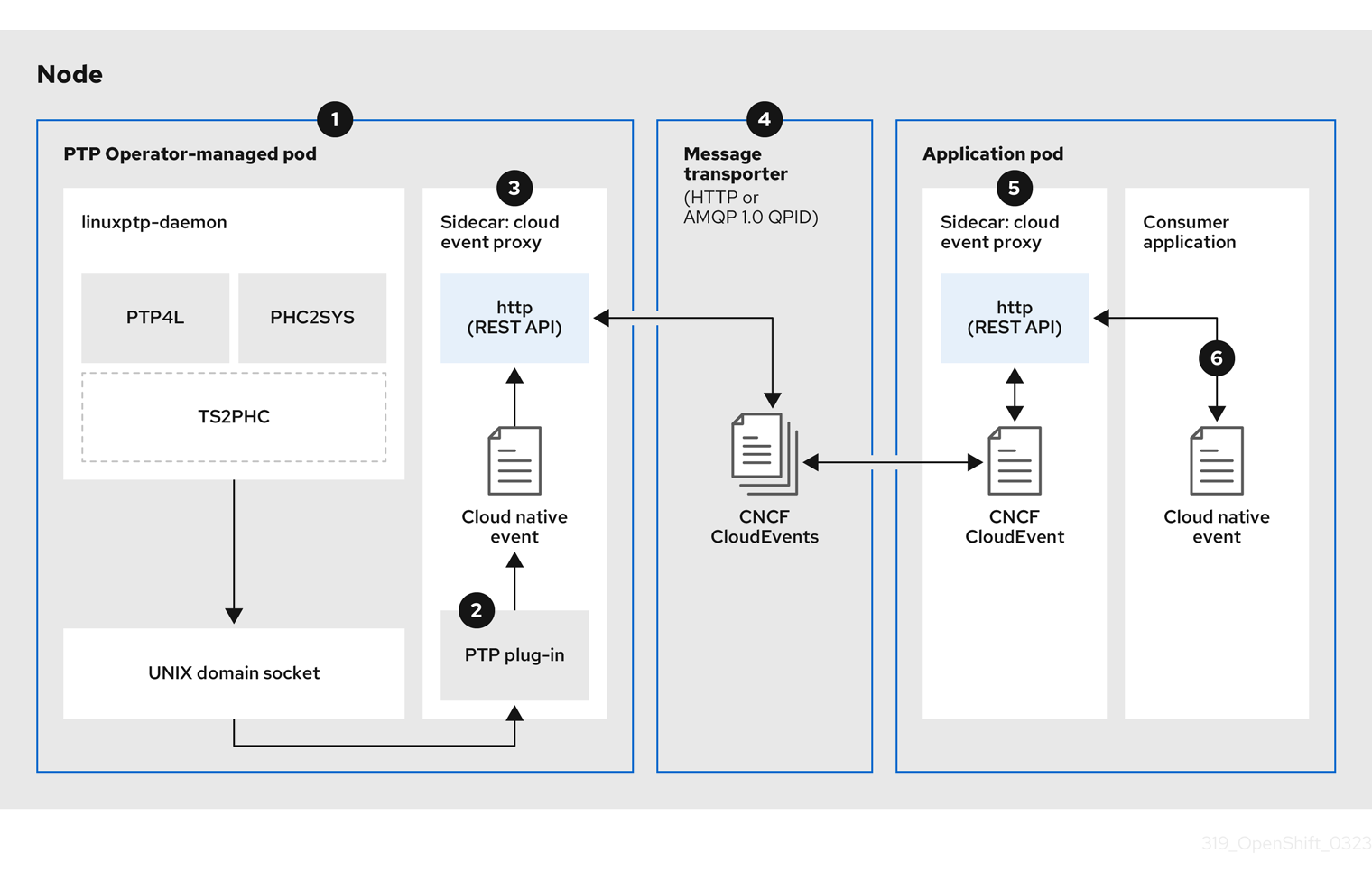
-
 イベントはクラスターホストで生成されます。
イベントはクラスターホストで生成されます。 -
PTP Operator が管理する Pod の
linuxptp-daemon は、KubernetesDaemonSetとして実行され、さまざまなlinuxptpプロセス (ptp4l、phc2sys、およびオプションでグランドマスタークロック用のts2phc) を管理します。linuxptp-daemonは、イベントを UNIX ドメインソケットに渡します。 -
 イベントが cloud-event-proxy サイドカーに渡されます。
イベントが cloud-event-proxy サイドカーに渡されます。 -
PTP プラグインは、UNIX ドメインソケットからイベントを読み取り、PTP Operator が管理する Pod 内の
cloud-event-proxyサイドカーに渡します。cloud-event-proxyは、イベントを Kubernetes インフラストラクチャーから Cloud-Native Network Functions (CNF) に低レイテンシーで配信します。 -
 イベントが永続化される
イベントが永続化される -
PTP Operator が管理する Pod 内の
cloud-event-proxyサイドカーは、REST API を使用してイベントを処理し、クラウドネイティブイベントを発行します。 -
 メッセージはトランスポートされます。
メッセージはトランスポートされます。 -
メッセージトランスポーターは、HTTP または AMQP 1.0 QPID を介して、アプリケーション Pod 内の
cloud-event-proxyサイドカーにイベントを転送します。 -
 イベントは REST API から入手できます。
イベントは REST API から入手できます。 -
アプリケーション Pod の
cloud-event-proxyサイドカーはイベントを処理し、REST API を使用して利用できるようにします。 -
 コンシューマーアプリケーションがサブスクリプションをリクエストし、サブスクライブされたイベントを受信します
コンシューマーアプリケーションがサブスクリプションをリクエストし、サブスクライブされたイベントを受信します -
コンシューマーアプリケーションは、API 要求をアプリケーション Pod の
cloud-event-proxyサイドカーに送信して、PTP イベントサブスクリプションを作成します。cloud-event-proxyサイドカーは、サブスクリプションで指定されたリソースの AMQ または HTTP メッセージングリスナープロトコルを作成します。
アプリケーション Pod の cloud-event-proxy サイドカーは、PTP Operator が管理する Pod からイベントを受信し、クラウドイベントオブジェクトをラッピング解除してデータを取得し、イベントをコンシューマーアプリケーションにポストします。コンシューマーアプリケーションは、リソース修飾子で指定されたアドレスをリッスンし、PTP イベントを受信して処理します。
19.8.3. PTP 高速イベント通知パブリッシャーの設定
クラスター内のネットワークインターフェイスの PTP 高速イベント通知の使用を開始するには、PTP Operator PtpOperatorConfig カスタムリソース (CR) で高速イベントパブリッシャーを有効にし、作成する PtpConfig CR に ptpClockThreshold 値を設定する必要があります。
前提条件
-
OpenShift Container Platform CLI (
oc) をインストールしている。 -
cluster-admin権限を持つユーザーとしてログインしている。 - PTP Operator がインストールされている。
手順
デフォルトの PTP Operator 設定を変更して、PTP 高速イベントを有効にします。
次の YAML を
ptp-operatorconfig.yamlファイルに保存します。apiVersion: ptp.openshift.io/v1 kind: PtpOperatorConfig metadata: name: default namespace: openshift-ptp spec: daemonNodeSelector: node-role.kubernetes.io/worker: "" ptpEventConfig: enableEventPublisher: true 1- 1
enableEventPublisherをtrueに設定して、PTP 高速イベント通知を有効にします。
注記OpenShift Container Platform 4.13 以降では、PTP イベントに HTTP トランスポートを使用するときに、
PtpOperatorConfigリソースのspec.ptpEventConfig.transportHostフィールドを設定する必要はありません。PTP イベントに AMQP トランスポートを使用する場合にのみ、transportHostを設定します。PtpOperatorConfigCR を更新します。$ oc apply -f ptp-operatorconfig.yaml
PTP 対応インターフェイスの
PtpConfigカスタムリソースを作成し、ptpClockThresholdおよびptp4lOptsに必要な値を設定します。次の YAML は、PtpConfigCR で設定する必要のある値 (必須) を示しています。spec: profile: - name: "profile1" interface: "enp5s0f0" ptp4lOpts: "-2 -s --summary_interval -4" 1 phc2sysOpts: "-a -r -m -n 24 -N 8 -R 16" 2 ptp4lConf: "" 3 ptpClockThreshold: 4 holdOverTimeout: 5 maxOffsetThreshold: 100 minOffsetThreshold: -100- 1
--summary_interval -4を追加して、PTP 高速イベントを使用します。- 2
phc2sysOptsの値が必要です。-mはメッセージをstdoutに出力します。linuxptp-daemonDaemonSetはログを解析し、Prometheus メトリックを生成します。- 3
- デフォルトの
/etc/ptp4l.confファイルを置き換える設定が含まれる文字列を指定します。デフォルト設定を使用するには、フィールドを空のままにします。 - 4
- オプション:
ptpClockThresholdスタンザが存在しない場合は、ptpClockThresholdフィールドにデフォルト値が使用されます。スタンザは、デフォルトのptpClockThreshold値を示します。ptpClockThreshold値は、PTP マスタークロックが PTP イベントが発生する前に切断されてからの期間を設定します。holdOverTimeoutは、PTP マスタークロックが切断されたときに、PTP クロックイベントの状態がFREERUNに変わるまでの時間値 (秒単位) です。maxOffsetThresholdおよびminOffsetThreshold設定は、CLOCK_REALTIME(phc2sys) またはマスターオフセット (ptp4l) の値と比較するナノ秒単位のオフセット値を設定します。ptp4lまたはphc2sysのオフセット値がこの範囲外の場合、PTP クロックの状態がFREERUNに設定されます。オフセット値がこの範囲内にある場合、PTP クロックの状態がLOCKEDに設定されます。
関連情報
-
linuxptpサービスを PTP 高速イベントを使用して通常クロックとして設定する CR の完全な例については、Configuring linuxptp services as ordinary clock を参照してください。
19.8.4. PTP またはベアメタルイベントに HTTP トランスポートを使用するためのコンシューマーアプリケーションの移行
以前に PTP またはベアメタルイベントのコンシューマーアプリケーションをデプロイしている場合は、HTTP メッセージトランスポートを使用するようにアプリケーションを更新する必要があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。 - PTP Operator または Bare Metal Event Relay を、デフォルトで HTTP トランスポートを使用するバージョン 4.13 以降に更新している。
手順
HTTP トランスポートを使用するようにイベントコンシューマーアプリケーションを更新します。クラウドイベントサイドカーデプロイメントの
http-event-publishers変数を設定します。たとえば、PTP イベントが設定されているクラスターでは、以下の YAML スニペットはクラウドイベントサイドカーデプロイメントを示しています。
containers: - name: cloud-event-sidecar image: cloud-event-sidecar args: - "--metrics-addr=127.0.0.1:9091" - "--store-path=/store" - "--transport-host=consumer-events-subscription-service.cloud-events.svc.cluster.local:9043" - "--http-event-publishers=ptp-event-publisher-service-NODE_NAME.openshift-ptp.svc.cluster.local:9043" 1 - "--api-port=8089"- 1
- PTP Operator は、PTP イベントを生成するホストに対して
NODE_NAMEを自動的に解決します。compute-1.example.comはその例です。
ベアメタルイベントが設定されているクラスターでは、クラウドイベントサイドカーデプロイメント CR で
http-event-publishersフィールドをhw-event-publisher-service.openshift-bare-metal-events.svc.cluster.local:9043に設定します。consumer-events-subscription-serviceサービスをイベントコンシューマーアプリケーションと併せてデプロイします。以下に例を示します。apiVersion: v1 kind: Service metadata: annotations: prometheus.io/scrape: "true" service.alpha.openshift.io/serving-cert-secret-name: sidecar-consumer-secret name: consumer-events-subscription-service namespace: cloud-events labels: app: consumer-service spec: ports: - name: sub-port port: 9043 selector: app: consumer clusterIP: None sessionAffinity: None type: ClusterIP
19.8.5. AMQ メッセージングバスのインストール
ノードのパブリッシャーとサブスクライバー間で PTP 高速イベント通知を渡すには、ノードでローカルに実行するように AMQ メッセージングバスをインストールおよび設定する必要があります。AMQ メッセージングを使用するには、AMQ Interconnect Operator をインストールする必要があります。
HTTP トランスポートは、PTP およびベアメタルイベントのデフォルトのトランスポートです。可能な場合、PTP およびベアメタルイベントには AMQP ではなく HTTP トランスポートを使用してください。AMQ Interconnect は、2024 年 6 月 30 日で EOL になります。AMQ Interconnect の延長ライフサイクルサポート (ELS) は 2029 年 11 月 29 日に終了します。詳細は、Red Hat AMQ Interconnect のサポートステータス を参照してください。
前提条件
-
OpenShift Container Platform CLI (
oc) をインストールします。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
-
AMQ Interconnect Operator を独自の
amq-interconnectnamespace にインストールします。Red Hat Integration - AMQ Interconnect Operator の追加 を参照してください。
検証
AMQ Interconnect Operator が利用可能で、必要な Pod が実行していることを確認します。
$ oc get pods -n amq-interconnect
出力例
NAME READY STATUS RESTARTS AGE amq-interconnect-645db76c76-k8ghs 1/1 Running 0 23h interconnect-operator-5cb5fc7cc-4v7qm 1/1 Running 0 23h
必要な
linuxptp-daemonPTP イベントプロデューサー Pod がopenshift-ptpnamespace で実行していることを確認します。$ oc get pods -n openshift-ptp
出力例
NAME READY STATUS RESTARTS AGE linuxptp-daemon-2t78p 3/3 Running 0 12h linuxptp-daemon-k8n88 3/3 Running 0 12h
19.8.6. DU アプリケーションを PTP イベントにサブスクライブする RESTAPI リファレンス
PTP イベント通知 REST API を使用して、分散ユニット (DU) アプリケーションを親ノードで生成される PTP イベントにサブスクライブします。
リソースアドレス/cluster/node/<node_name>/ptp を使用して、アプリケーションを PTP イベントにサブスクライブします。ここで、<node_name> は、DU アプリケーションを実行しているクラスターノードです。
cloud-event-consumerDUアプリケーションコンテナーとcloud-event-proxyサイドカーコンテナーを別々の DU アプリケーション Pod にデプロイします。cloud-event-consumer DU アプリケーションは、アプリケーション Pod のcloud-event-proxyコンテナーにサブスクライブします。
次の API エンドポイントを使用して、DU アプリケーション Pod の http://localhost:8089/api/ocloudNotifications/v1/ にある cloud-event-proxy コンテナーによってポストされた PTP イベントに cloud-event-consumer DU アプリケーションをサブスクライブします。
/api/ocloudNotifications/v1/subscriptions-
POST: 新しいサブスクリプションを作成します。 -
GET: サブスクリプションの一覧を取得します。
-
/api/ocloudNotifications/v1/subscriptions/<subscription_id>-
GET: 指定されたサブスクリプション ID の詳細を返します。
-
/api/ocloudNotifications/v1/health-
GET:ocloudNotificationsAPI の正常性ステータスを返します
-
api/ocloudNotifications/v1/publishers-
GET: クラスターノードのos-clock-sync-state、ptp-clock-class-change、およびlock-stateメッセージの配列を返します
-
/api/ocloudnotifications/v1/<resource_address>/CurrentState-
GET: 次のいずれかのイベントタイプの現在の状態を返します:os-clock-sync-state、ptp-clock-class-change、またはlock-stateイベント
-
9089 は、アプリケーション Pod にデプロイされた cloud-event-consumer コンテナーのデフォルトポートです。必要に応じて、DU アプリケーションに別のポートを設定できます。
19.8.6.1. api/ocloudNotifications/v1/subscriptions
HTTP メソッド
GET api/ocloudNotifications/v1/subscriptions
説明
サブスクリプションのリストを返します。サブスクリプションが存在する場合は、サブスクリプションの一覧とともに 200 OK のステータスコードが返されます。
API 応答の例
[
{
"id": "75b1ad8f-c807-4c23-acf5-56f4b7ee3826",
"endpointUri": "http://localhost:9089/event",
"uriLocation": "http://localhost:8089/api/ocloudNotifications/v1/subscriptions/75b1ad8f-c807-4c23-acf5-56f4b7ee3826",
"resource": "/cluster/node/compute-1.example.com/ptp"
}
]
HTTP メソッド
POST api/ocloudNotifications/v1/subscriptions
説明
新しいサブスクリプションを作成します。サブスクリプションが正常に作成されるか、すでに存在する場合は、201 Created ステータスコードが返されます。
表19.5 クエリーパラメーター
| パラメーター | 型 |
|---|---|
| subscription | data |
ペイロードの例
{
"uriLocation": "http://localhost:8089/api/ocloudNotifications/v1/subscriptions",
"resource": "/cluster/node/compute-1.example.com/ptp"
}
19.8.6.2. api/ocloudNotifications/v1/subscriptions/<subscription_id>
HTTP メソッド
GET api/ocloudNotifications/v1/subscriptions/<subscription_id>
説明
ID が <subscription_id>のサブスクリプションの詳細を返します。
表19.6 クエリーパラメーター
| パラメーター | 型 |
|---|---|
|
| string |
API 応答の例
{
"id":"48210fb3-45be-4ce0-aa9b-41a0e58730ab",
"endpointUri": "http://localhost:9089/event",
"uriLocation":"http://localhost:8089/api/ocloudNotifications/v1/subscriptions/48210fb3-45be-4ce0-aa9b-41a0e58730ab",
"resource":"/cluster/node/compute-1.example.com/ptp"
}
19.8.6.3. api/ocloudNotifications/v1/health/
HTTP メソッド
GET api/ocloudNotifications/v1/health/
説明
ocloudNotifications REST API の正常性ステータスを返します。
API 応答の例
OK
19.8.6.4. api/ocloudNotifications/v1/publishers
HTTP メソッド
GET api/ocloudNotifications/v1/publishers
説明
クラスターノードの os-clock-sync-state、ptp-clock-class-change、および lock-state の 詳細の配列を返します。関連する機器の状態が変化すると、システムは通知を生成します。
-
os-clock-sync-state通知は、ホストオペレーティングシステムのクロック同期状態を示します。LOCKEDまたはFREERUN状態になります。 -
ptp-clock-class-change通知は、PTP クロッククラスの現在の状態を示します。 -
lock-state通知は、PTP 機器のロック状態の現在のステータスを示します。LOCKED、HOLDOVER、またはFREERUN状態になります。
API 応答の例
[
{
"id": "0fa415ae-a3cf-4299-876a-589438bacf75",
"endpointUri": "http://localhost:9085/api/ocloudNotifications/v1/dummy",
"uriLocation": "http://localhost:9085/api/ocloudNotifications/v1/publishers/0fa415ae-a3cf-4299-876a-589438bacf75",
"resource": "/cluster/node/compute-1.example.com/sync/sync-status/os-clock-sync-state"
},
{
"id": "28cd82df-8436-4f50-bbd9-7a9742828a71",
"endpointUri": "http://localhost:9085/api/ocloudNotifications/v1/dummy",
"uriLocation": "http://localhost:9085/api/ocloudNotifications/v1/publishers/28cd82df-8436-4f50-bbd9-7a9742828a71",
"resource": "/cluster/node/compute-1.example.com/sync/ptp-status/ptp-clock-class-change"
},
{
"id": "44aa480d-7347-48b0-a5b0-e0af01fa9677",
"endpointUri": "http://localhost:9085/api/ocloudNotifications/v1/dummy",
"uriLocation": "http://localhost:9085/api/ocloudNotifications/v1/publishers/44aa480d-7347-48b0-a5b0-e0af01fa9677",
"resource": "/cluster/node/compute-1.example.com/sync/ptp-status/lock-state"
}
]
cloud-event-proxy コンテナーのログで、os-clock-sync-state、ptp-clock-class-change、および lock-state イベントを見つけることができます。以下に例を示します。
$ oc logs -f linuxptp-daemon-cvgr6 -n openshift-ptp -c cloud-event-proxy
os-clock-sync-state イベントの例
{
"id":"c8a784d1-5f4a-4c16-9a81-a3b4313affe5",
"type":"event.sync.sync-status.os-clock-sync-state-change",
"source":"/cluster/compute-1.example.com/ptp/CLOCK_REALTIME",
"dataContentType":"application/json",
"time":"2022-05-06T15:31:23.906277159Z",
"data":{
"version":"v1",
"values":[
{
"resource":"/sync/sync-status/os-clock-sync-state",
"dataType":"notification",
"valueType":"enumeration",
"value":"LOCKED"
},
{
"resource":"/sync/sync-status/os-clock-sync-state",
"dataType":"metric",
"valueType":"decimal64.3",
"value":"-53"
}
]
}
}
ptp-clock-class-change イベントの例
{
"id":"69eddb52-1650-4e56-b325-86d44688d02b",
"type":"event.sync.ptp-status.ptp-clock-class-change",
"source":"/cluster/compute-1.example.com/ptp/ens2fx/master",
"dataContentType":"application/json",
"time":"2022-05-06T15:31:23.147100033Z",
"data":{
"version":"v1",
"values":[
{
"resource":"/sync/ptp-status/ptp-clock-class-change",
"dataType":"metric",
"valueType":"decimal64.3",
"value":"135"
}
]
}
}
ロック状態イベントの例
{
"id":"305ec18b-1472-47b3-aadd-8f37933249a9",
"type":"event.sync.ptp-status.ptp-state-change",
"source":"/cluster/compute-1.example.com/ptp/ens2fx/master",
"dataContentType":"application/json",
"time":"2022-05-06T15:31:23.467684081Z",
"data":{
"version":"v1",
"values":[
{
"resource":"/sync/ptp-status/lock-state",
"dataType":"notification",
"valueType":"enumeration",
"value":"LOCKED"
},
{
"resource":"/sync/ptp-status/lock-state",
"dataType":"metric",
"valueType":"decimal64.3",
"value":"62"
}
]
}
}
19.8.6.5. /api/ocloudnotifications/v1/<resource_address>/CurrentState
HTTP メソッド
GET api/ocloudNotifications/v1/cluster/node/<node_name>/sync/ptp-status/lock-state/CurrentState
GET api/ocloudNotifications/v1/cluster/node/<node_name>/sync/sync-status/os-clock-sync-state/CurrentState
GET api/ocloudNotifications/v1/cluster/node/<node_name>/sync/ptp-status/ptp-clock-class-change/CurrentState
説明
クラスターノードの os-clock-sync-state、ptp-clock-class-change、または lock-state イベントの現在の状態を返すように CurrentState API エンドポイントを設定します。
-
os-clock-sync-state通知は、ホストオペレーティングシステムのクロック同期状態を示します。LOCKEDまたはFREERUN状態になります。 -
ptp-clock-class-change通知は、PTP クロッククラスの現在の状態を示します。 -
lock-state通知は、PTP 機器のロック状態の現在のステータスを示します。LOCKED、HOLDOVER、またはFREERUN状態になります。
表19.7 クエリーパラメーター
| パラメーター | 型 |
|---|---|
|
| string |
ロック状態 API レスポンスの例
{
"id": "c1ac3aa5-1195-4786-84f8-da0ea4462921",
"type": "event.sync.ptp-status.ptp-state-change",
"source": "/cluster/node/compute-1.example.com/sync/ptp-status/lock-state",
"dataContentType": "application/json",
"time": "2023-01-10T02:41:57.094981478Z",
"data": {
"version": "v1",
"values": [
{
"resource": "/cluster/node/compute-1.example.com/ens5fx/master",
"dataType": "notification",
"valueType": "enumeration",
"value": "LOCKED"
},
{
"resource": "/cluster/node/compute-1.example.com/ens5fx/master",
"dataType": "metric",
"valueType": "decimal64.3",
"value": "29"
}
]
}
}
os-clock-sync-state API レスポンスの例
{
"specversion": "0.3",
"id": "4f51fe99-feaa-4e66-9112-66c5c9b9afcb",
"source": "/cluster/node/compute-1.example.com/sync/sync-status/os-clock-sync-state",
"type": "event.sync.sync-status.os-clock-sync-state-change",
"subject": "/cluster/node/compute-1.example.com/sync/sync-status/os-clock-sync-state",
"datacontenttype": "application/json",
"time": "2022-11-29T17:44:22.202Z",
"data": {
"version": "v1",
"values": [
{
"resource": "/cluster/node/compute-1.example.com/CLOCK_REALTIME",
"dataType": "notification",
"valueType": "enumeration",
"value": "LOCKED"
},
{
"resource": "/cluster/node/compute-1.example.com/CLOCK_REALTIME",
"dataType": "metric",
"valueType": "decimal64.3",
"value": "27"
}
]
}
}
ptp-clock-class-change API レスポンスの例
{
"id": "064c9e67-5ad4-4afb-98ff-189c6aa9c205",
"type": "event.sync.ptp-status.ptp-clock-class-change",
"source": "/cluster/node/compute-1.example.com/sync/ptp-status/ptp-clock-class-change",
"dataContentType": "application/json",
"time": "2023-01-10T02:41:56.785673989Z",
"data": {
"version": "v1",
"values": [
{
"resource": "/cluster/node/compute-1.example.com/ens5fx/master",
"dataType": "metric",
"valueType": "decimal64.3",
"value": "165"
}
]
}
}
19.8.7. PTP 高速イベントメトリックのモニタリング
linuxptp-daemon が実行されているクラスターノードから PTP 高速イベントメトリクスを監視できます。事前に設定された自己更新型の Prometheus モニタリングスタックを使用して、OpenShift Container Platform Web コンソールで PTP 高速イベントメトリクスをモニタリングできます。
前提条件
-
OpenShift Container Platform CLI (
oc) をインストールしている。 -
cluster-admin権限を持つユーザーとしてログインしている。 - PTP 対応ハードウェアを搭載したノードに PTP Operator をインストールし、設定します。
手順
linuxptp-daemonが実行されている任意のノードで公開される PTP メトリクスを確認します。たとえば、以下のコマンドを実行します。$ curl http://<node_name>:9091/metrics
出力例
# HELP openshift_ptp_clock_state 0 = FREERUN, 1 = LOCKED, 2 = HOLDOVER # TYPE openshift_ptp_clock_state gauge openshift_ptp_clock_state{iface="ens1fx",node="compute-1.example.com",process="ptp4l"} 1 openshift_ptp_clock_state{iface="ens3fx",node="compute-1.example.com",process="ptp4l"} 1 openshift_ptp_clock_state{iface="ens5fx",node="compute-1.example.com",process="ptp4l"} 1 openshift_ptp_clock_state{iface="ens7fx",node="compute-1.example.com",process="ptp4l"} 1 # HELP openshift_ptp_delay_ns # TYPE openshift_ptp_delay_ns gauge openshift_ptp_delay_ns{from="master",iface="ens1fx",node="compute-1.example.com",process="ptp4l"} 842 openshift_ptp_delay_ns{from="master",iface="ens3fx",node="compute-1.example.com",process="ptp4l"} 480 openshift_ptp_delay_ns{from="master",iface="ens5fx",node="compute-1.example.com",process="ptp4l"} 584 openshift_ptp_delay_ns{from="master",iface="ens7fx",node="compute-1.example.com",process="ptp4l"} 482 openshift_ptp_delay_ns{from="phc",iface="CLOCK_REALTIME",node="compute-1.example.com",process="phc2sys"} 547 # HELP openshift_ptp_offset_ns # TYPE openshift_ptp_offset_ns gauge openshift_ptp_offset_ns{from="master",iface="ens1fx",node="compute-1.example.com",process="ptp4l"} -2 openshift_ptp_offset_ns{from="master",iface="ens3fx",node="compute-1.example.com",process="ptp4l"} -44 openshift_ptp_offset_ns{from="master",iface="ens5fx",node="compute-1.example.com",process="ptp4l"} -8 openshift_ptp_offset_ns{from="master",iface="ens7fx",node="compute-1.example.com",process="ptp4l"} 3 openshift_ptp_offset_ns{from="phc",iface="CLOCK_REALTIME",node="compute-1.example.com",process="phc2sys"} 12-
OpenShift Container Platform Web コンソールで PTP イベントを表示するには、クエリーする PTP メトリクスの名前 (例:
openshift_ptp_offset_ns) をコピーします。 - OpenShift Container Platform Web コンソールで、Observe → Metrics をクリックします。
- PTP メトリクスを Expression フィールドに貼り付け、Run queries をクリックします。
関連情報
第20章 PTP イベントコンシューマーアプリケーションの開発
ベアメタルクラスターノードで Precision Time Protocol (PTP)イベントを使用するコンシューマーアプリケーションを開発する場合は、コンシューマーアプリケーションと cloud-event-proxy コンテナーを別のアプリケーション Pod にデプロイする必要があります。cloud-event-proxy コンテナーは、PTP Operator Pod からイベントを受信し、これをコンシューマーアプリケーションに渡します。コンシューマーアプリケーションは、REST API を使用して cloud-event-proxy コンテナーで投稿されたイベントにサブスクライブします。
PTP イベントアプリケーションのデプロイに関する詳細は、About the PTP fast event notifications framework を参照してください。
以下の情報は、PTP イベントを使用するコンシューマーアプリケーションを開発するための一般的なガイダンスです。完全なイベントコンシューマーアプリケーションの例は、この情報の範囲外です。
20.1. PTP イベントコンシューマーアプリケーションのリファレンス
PTP イベントコンシューマーアプリケーションには次の機能が必要です。
-
POSTハンドラーで実行され、クラウドネイティブ PTP イベントの JSON ペイロードを受信する Web サービス -
PTP イベントプロデューサーをサブスクライブするための
createSubscription関数 -
PTP イベントプロデューサーの現在の状態をポーリングする
getCurrentState関数
次の Go スニペットの例は、これらの要件を示しています。
Go での PTP イベントコンシューマーサーバー関数の例
func server() {
http.HandleFunc("/event", getEvent)
http.ListenAndServe("localhost:8989", nil)
}
func getEvent(w http.ResponseWriter, req *http.Request) {
defer req.Body.Close()
bodyBytes, err := io.ReadAll(req.Body)
if err != nil {
log.Errorf("error reading event %v", err)
}
e := string(bodyBytes)
if e != "" {
processEvent(bodyBytes)
log.Infof("received event %s", string(bodyBytes))
} else {
w.WriteHeader(http.StatusNoContent)
}
}
PTP イベントの例 Go の createSubscription 関数
import (
"github.com/redhat-cne/sdk-go/pkg/pubsub"
"github.com/redhat-cne/sdk-go/pkg/types"
v1pubsub "github.com/redhat-cne/sdk-go/v1/pubsub"
)
// Subscribe to PTP events using REST API
s1,_:=createsubscription("/cluster/node/<node_name>/sync/sync-status/os-clock-sync-state") 1
s2,_:=createsubscription("/cluster/node/<node_name>/sync/ptp-status/ptp-clock-class-change")
s3,_:=createsubscription("/cluster/node/<node_name>/sync/ptp-status/lock-state")
// Create PTP event subscriptions POST
func createSubscription(resourceAddress string) (sub pubsub.PubSub, err error) {
var status int
apiPath:= "/api/ocloudNotifications/v1/"
localAPIAddr:=localhost:8989 // vDU service API address
apiAddr:= "localhost:8089" // event framework API address
subURL := &types.URI{URL: url.URL{Scheme: "http",
Host: apiAddr
Path: fmt.Sprintf("%s%s", apiPath, "subscriptions")}}
endpointURL := &types.URI{URL: url.URL{Scheme: "http",
Host: localAPIAddr,
Path: "event"}}
sub = v1pubsub.NewPubSub(endpointURL, resourceAddress)
var subB []byte
if subB, err = json.Marshal(&sub); err == nil {
rc := restclient.New()
if status, subB = rc.PostWithReturn(subURL, subB); status != http.StatusCreated {
err = fmt.Errorf("error in subscription creation api at %s, returned status %d", subURL, status)
} else {
err = json.Unmarshal(subB, &sub)
}
} else {
err = fmt.Errorf("failed to marshal subscription for %s", resourceAddress)
}
return
}
- 1
<node_name>を、PTP イベントを生成しているノードの FQDN に置き換えます。compute-1.example.comはその例です。
Go の PTP イベントコンシューマー getCurrentState 関数の例
//Get PTP event state for the resource
func getCurrentState(resource string) {
//Create publisher
url := &types.URI{URL: url.URL{Scheme: "http",
Host: localhost:8989,
Path: fmt.SPrintf("/api/ocloudNotifications/v1/%s/CurrentState",resource}}
rc := restclient.New()
status, event := rc.Get(url)
if status != http.StatusOK {
log.Errorf("CurrentState:error %d from url %s, %s", status, url.String(), event)
} else {
log.Debugf("Got CurrentState: %s ", event)
}
}
20.2. cloud-event-proxy のデプロイメントとサービス CR を参照する
PTP イベントコンシューマーアプリケーションをデプロイするときは、次の cloud-event-proxy デプロイメントとサブスクライバサービス CR の例を参考として使用してください。
HTTP トランスポートは、PTP およびベアメタルイベントのデフォルトのトランスポートです。可能な場合、PTP およびベアメタルイベントには AMQP ではなく HTTP トランスポートを使用してください。AMQ Interconnect は、2024 年 6 月 30 日で EOL になります。AMQ Interconnect の延長ライフサイクルサポート (ELS) は 2029 年 11 月 29 日に終了します。詳細は、Red Hat AMQ Interconnect のサポートステータス を参照してください。
HTTP トランスポートを使用した cloud-event-proxy デプロイメントの参照
apiVersion: apps/v1
kind: Deployment
metadata:
name: event-consumer-deployment
namespace: <namespace>
labels:
app: consumer
spec:
replicas: 1
selector:
matchLabels:
app: consumer
template:
metadata:
labels:
app: consumer
spec:
serviceAccountName: sidecar-consumer-sa
containers:
- name: event-subscriber
image: event-subscriber-app
- name: cloud-event-proxy-as-sidecar
image: openshift4/ose-cloud-event-proxy
args:
- "--metrics-addr=127.0.0.1:9091"
- "--store-path=/store"
- "--transport-host=consumer-events-subscription-service.cloud-events.svc.cluster.local:9043"
- "--http-event-publishers=ptp-event-publisher-service-NODE_NAME.openshift-ptp.svc.cluster.local:9043"
- "--api-port=8089"
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: NODE_IP
valueFrom:
fieldRef:
fieldPath: status.hostIP
volumeMounts:
- name: pubsubstore
mountPath: /store
ports:
- name: metrics-port
containerPort: 9091
- name: sub-port
containerPort: 9043
volumes:
- name: pubsubstore
emptyDir: {}
AMQ トランスポートを使用した cloud-event-proxy デプロイメントの参照
apiVersion: apps/v1
kind: Deployment
metadata:
name: cloud-event-proxy-sidecar
namespace: cloud-events
labels:
app: cloud-event-proxy
spec:
selector:
matchLabels:
app: cloud-event-proxy
template:
metadata:
labels:
app: cloud-event-proxy
spec:
nodeSelector:
node-role.kubernetes.io/worker: ""
containers:
- name: cloud-event-sidecar
image: openshift4/ose-cloud-event-proxy
args:
- "--metrics-addr=127.0.0.1:9091"
- "--store-path=/store"
- "--transport-host=amqp://router.router.svc.cluster.local"
- "--api-port=8089"
env:
- name: <node_name>
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: <node_ip>
valueFrom:
fieldRef:
fieldPath: status.hostIP
volumeMounts:
- name: pubsubstore
mountPath: /store
ports:
- name: metrics-port
containerPort: 9091
- name: sub-port
containerPort: 9043
volumes:
- name: pubsubstore
emptyDir: {}
cloud-event-proxy サブスクライバーサービスの参照
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: "true"
service.alpha.openshift.io/serving-cert-secret-name: sidecar-consumer-secret
name: consumer-events-subscription-service
namespace: cloud-events
labels:
app: consumer-service
spec:
ports:
- name: sub-port
port: 9043
selector:
app: consumer
clusterIP: None
sessionAffinity: None
type: ClusterIP
20.3. cloud-event-proxy サイドカー REST API から利用可能な PTP イベント
PTP イベントコンシューマーアプリケーションは、以下の PTP タイミングイベントの PTP イベントプロデューサーをポーリングできます。
表20.1 cloud-event-proxy サイドカーから利用可能な PTP イベント
| リソース URI | 説明 |
|---|---|
|
|
現在の PTP 機器のロック状態を説明します。 |
|
|
ホストオペレーティングシステムのクロック同期状態について説明します。 |
|
| PTP クロッククラスの現在の状態を説明します。 |
20.4. コンシューマーアプリケーションを PTP イベントにサブスクライブする
PTP イベントコンシューマーアプリケーションがイベントをポーリングできるようにするには、アプリケーションをイベントプロデューサーにサブスクライブする必要があります。
20.4.1. PTP lock-state イベントのサブスクライブ
PTP lock-state イベントのサブスクリプションを作成するには、次のペイロードを使用して、http://localhost:8081/api/ocloudNotifications/v1/subscriptions のクラウドイベント API に POST アクションを送信します。
{
"endpointUri": "http://localhost:8989/event",
"resource": "/cluster/node/<node_name>/sync/ptp-status/lock-state",
}応答の例
{
"id": "e23473d9-ba18-4f78-946e-401a0caeff90",
"endpointUri": "http://localhost:8989/event",
"uriLocation": "http://localhost:8089/api/ocloudNotifications/v1/subscriptions/e23473d9-ba18-4f78-946e-401a0caeff90",
"resource": "/cluster/node/<node_name>/sync/ptp-status/lock-state",
}
20.4.2. PTP os-lock-sync-state イベントのサブスクライブ
PTP os-clock-sync-state イベントのサブスクリプションを作成するには、次のペイロードを使用して、http://localhost:8081/api/ocloudNotifications/v1/subscriptions のクラウドイベント API に POST アクションを送信します。
{
"endpointUri": "http://localhost:8989/event",
"resource": "/cluster/node/<node_name>/sync/sync-status/os-clock-sync-state",
}応答の例
{
"id": "e23473d9-ba18-4f78-946e-401a0caeff90",
"endpointUri": "http://localhost:8989/event",
"uriLocation": "http://localhost:8089/api/ocloudNotifications/v1/subscriptions/e23473d9-ba18-4f78-946e-401a0caeff90",
"resource": "/cluster/node/<node_name>/sync/sync-status/os-clock-sync-state",
}
20.4.3. PTP ptp-lock-class-change イベントのサブスクライブ
PTP ptp-clock-class-change イベントのサブスクリプションを作成するには、次のペイロードを使用して、http://localhost:8081/api/ocloudNotifications/v1/subscriptions のクラウドイベント API に POST アクションを送信します。
{
"endpointUri": "http://localhost:8989/event",
"resource": "/cluster/node/<node_name>/sync/ptp-status/ptp-clock-class-change",
}応答の例
{
"id": "e23473d9-ba18-4f78-946e-401a0caeff90",
"endpointUri": "http://localhost:8989/event",
"uriLocation": "http://localhost:8089/api/ocloudNotifications/v1/subscriptions/e23473d9-ba18-4f78-946e-401a0caeff90",
"resource": "/cluster/node/<node_name>/sync/ptp-status/ptp-clock-class-change",
}
20.5. 現在の PTP クロックステータスの取得
ノードの現在の PTP ステータスを取得するには、GET アクションを以下のイベント REST API のいずれかに送信します。
-
http://localhost:8081/api/ocloudNotifications/v1/cluster/node/<node_name>/sync/ptp-status/lock-state/CurrentState -
http://localhost:8081/api/ocloudNotifications/v1/cluster/node/<node_name>/sync/sync-status/os-clock-sync-state/CurrentState -
http://localhost:8081/api/ocloudNotifications/v1/cluster/node/<node_name>/sync/ptp-status/ptp-clock-class-change/CurrentState
応答はクラウドネイティブイベント JSON オブジェクトです。以下に例を示します。
ロック状態 API レスポンスの例
{
"id": "c1ac3aa5-1195-4786-84f8-da0ea4462921",
"type": "event.sync.ptp-status.ptp-state-change",
"source": "/cluster/node/compute-1.example.com/sync/ptp-status/lock-state",
"dataContentType": "application/json",
"time": "2023-01-10T02:41:57.094981478Z",
"data": {
"version": "v1",
"values": [
{
"resource": "/cluster/node/compute-1.example.com/ens5fx/master",
"dataType": "notification",
"valueType": "enumeration",
"value": "LOCKED"
},
{
"resource": "/cluster/node/compute-1.example.com/ens5fx/master",
"dataType": "metric",
"valueType": "decimal64.3",
"value": "29"
}
]
}
}
20.6. PTP イベントコンシューマーアプリケーションがイベントを受信していることの確認
アプリケーション Pod の cloud-event-proxy コンテナーが PTP イベントを受信していることを確認します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。 - PTP Operator をインストールして設定している。
手順
アクティブな
linuxptp-daemonPod の一覧を取得します。以下のコマンドを実行します。$ oc get pods -n openshift-ptp
出力例
NAME READY STATUS RESTARTS AGE linuxptp-daemon-2t78p 3/3 Running 0 8h linuxptp-daemon-k8n88 3/3 Running 0 8h
次のコマンドを実行して、必要なコンシューマー側
cloud-event-proxyコンテナーのメトリックにアクセスします。$ oc exec -it <linuxptp-daemon> -n openshift-ptp -c cloud-event-proxy -- curl 127.0.0.1:9091/metrics
ここでは、以下のようになります。
- <linuxptp-daemon>
問い合わせる Pod を指定します (例:
linuxptp-daemon-2t78p)。出力例
# HELP cne_transport_connections_resets Metric to get number of connection resets # TYPE cne_transport_connections_resets gauge cne_transport_connection_reset 1 # HELP cne_transport_receiver Metric to get number of receiver created # TYPE cne_transport_receiver gauge cne_transport_receiver{address="/cluster/node/compute-1.example.com/ptp",status="active"} 2 cne_transport_receiver{address="/cluster/node/compute-1.example.com/redfish/event",status="active"} 2 # HELP cne_transport_sender Metric to get number of sender created # TYPE cne_transport_sender gauge cne_transport_sender{address="/cluster/node/compute-1.example.com/ptp",status="active"} 1 cne_transport_sender{address="/cluster/node/compute-1.example.com/redfish/event",status="active"} 1 # HELP cne_events_ack Metric to get number of events produced # TYPE cne_events_ack gauge cne_events_ack{status="success",type="/cluster/node/compute-1.example.com/ptp"} 18 cne_events_ack{status="success",type="/cluster/node/compute-1.example.com/redfish/event"} 18 # HELP cne_events_transport_published Metric to get number of events published by the transport # TYPE cne_events_transport_published gauge cne_events_transport_published{address="/cluster/node/compute-1.example.com/ptp",status="failed"} 1 cne_events_transport_published{address="/cluster/node/compute-1.example.com/ptp",status="success"} 18 cne_events_transport_published{address="/cluster/node/compute-1.example.com/redfish/event",status="failed"} 1 cne_events_transport_published{address="/cluster/node/compute-1.example.com/redfish/event",status="success"} 18 # HELP cne_events_transport_received Metric to get number of events received by the transport # TYPE cne_events_transport_received gauge cne_events_transport_received{address="/cluster/node/compute-1.example.com/ptp",status="success"} 18 cne_events_transport_received{address="/cluster/node/compute-1.example.com/redfish/event",status="success"} 18 # HELP cne_events_api_published Metric to get number of events published by the rest api # TYPE cne_events_api_published gauge cne_events_api_published{address="/cluster/node/compute-1.example.com/ptp",status="success"} 19 cne_events_api_published{address="/cluster/node/compute-1.example.com/redfish/event",status="success"} 19 # HELP cne_events_received Metric to get number of events received # TYPE cne_events_received gauge cne_events_received{status="success",type="/cluster/node/compute-1.example.com/ptp"} 18 cne_events_received{status="success",type="/cluster/node/compute-1.example.com/redfish/event"} 18 # HELP promhttp_metric_handler_requests_in_flight Current number of scrapes being served. # TYPE promhttp_metric_handler_requests_in_flight gauge promhttp_metric_handler_requests_in_flight 1 # HELP promhttp_metric_handler_requests_total Total number of scrapes by HTTP status code. # TYPE promhttp_metric_handler_requests_total counter promhttp_metric_handler_requests_total{code="200"} 4 promhttp_metric_handler_requests_total{code="500"} 0 promhttp_metric_handler_requests_total{code="503"} 0
第21章 外部 DNS Operator
21.1. OpenShift Container Platform の外部 DNS Operator
外部 DNS Operator は、ExternalDNS をデプロイして管理し、外部 DNS プロバイダーから OpenShift Container Platform へのサービスおよびルートの名前解決を提供します。
21.1.1. 外部 DNS Operator
外部 DNS Operator は、olm.openshift.io API グループから外部 DNS API を実装します。外部 DNS Operator は、サービス、ルート、外部 DNS プロバイダーを更新します。
前提条件
-
yqCLI ツールがインストールされている。
手順
OperatorHub からオンデマンドで外部 DNS Operator をデプロイできます。外部 DNS Operator をデプロイすると、Subscription オブジェクトが作成されます。
次のコマンドを実行して、インストールプランの名前を確認します。
$ oc -n external-dns-operator get sub external-dns-operator -o yaml | yq '.status.installplan.name'
出力例
install-zcvlr
次のコマンドを実行して、インストールプランのステータスが
Completeになっているか確認します。$ oc -n external-dns-operator get ip <install_plan_name> -o yaml | yq '.status.phase'
出力例
Complete
次のコマンドを実行して、
external-dns-operatorデプロイメントのステータスを表示します。$ oc get -n external-dns-operator deployment/external-dns-operator
出力例
NAME READY UP-TO-DATE AVAILABLE AGE external-dns-operator 1/1 1 1 23h
21.1.2. 外部 DNS Operator ログ
oc logs コマンドを使用して、外部 DNS Operator のログを表示できます。
手順
次のコマンドを実行して、外部 DNS Operator のログを表示します。
$ oc logs -n external-dns-operator deployment/external-dns-operator -c external-dns-operator
21.1.2.1. 外部 DNS Operator のドメイン名の制限
外部 DNS Operator は、TXT レコードの接頭辞を追加する TXT レジストリーを使用します。これにより、TXT レコードのドメイン名の最大長が短くなります。DNS レコードは対応する TXT レコードなしでは存在できないため、DNS レコードのドメイン名は TXT レコードと同じ制限に従う必要があります。たとえば、DNS レコードが <domain_name_from_source> の場合、TXT レコードは external-dns-<record_type>-<domain_name_from_source> になります。
外部 DNS Operator によって生成される DNS レコードのドメイン名には、次の制限があります。
| レコードの種類 | 文字数 |
|---|---|
| CNAME | 44 |
| AzureDNS のワイルドカード CNAME レコード | 42 |
| A | 48 |
| AzureDNS のワイルドカード A レコード | 46 |
生成されたドメイン名がドメイン名の制限を超える場合、外部 DNS Operator のログに次のエラーが表示されます。
time="2022-09-02T08:53:57Z" level=error msg="Failure in zone test.example.io. [Id: /hostedzone/Z06988883Q0H0RL6UMXXX]" time="2022-09-02T08:53:57Z" level=error msg="InvalidChangeBatch: [FATAL problem: DomainLabelTooLong (Domain label is too long) encountered with 'external-dns-a-hello-openshift-aaaaaaaaaa-bbbbbbbbbb-ccccccc']\n\tstatus code: 400, request id: e54dfd5a-06c6-47b0-bcb9-a4f7c3a4e0c6"
21.2. クラウドプロバイダーへの外部 DNS Operator のインストール
AWS、Azure、GCP などのクラウドプロバイダーに外部 DNS Operator をインストールできます。
21.2.1. External DNS Operator のインストール
OpenShift Container Platform OperatorHub を使用して、外部 DNS Operator をインストールできます。
手順
- OpenShift Container Platform Web コンソールで、Operators → OperatorHub をクリックします。
- 外部 DNS Operatorをクリックします。Filter by keyword のテキストボックスまたはフィルターリストを使用して、Operator のリストから外部 DNS Operator を検索できます。
-
external-dns-operatornamespace を選択します。 - External DNS Operator ページで Install をクリックします。
Install Operator ページで、次のオプションを選択していることを確認してください。
- チャネルを stable-v1.0 として更新している。
- インストールモードに A specific name on the cluster を選択している。
-
namespace を
external-dns-operatorとしてインストールしている。namespaceexternal-dns-operatorが存在しない場合は、Operator のインストール中に作成されます。 - 承認ストラテジー を Automatic または Manual として選択している。承認ストラテジーはデフォルトで Automatic に設定されます。
- Install をクリックします。
Automatic (自動) 更新を選択した場合、Operator Lifecycle Manager (OLM) は介入なしに、Operator の実行中のインスタンスを自動的にアップグレードします。
Manual 更新を選択した場合、OLM は更新要求を作成します。クラスター管理者は、Operator が新規バージョンに更新されるように更新要求を手動で承認する必要があります。
検証
外部 DNS Operator で、Installed Operators ダッシュボードの Status が Succeeded と表示されることを確認します。
21.3. 外部 DNS Operator 設定パラメーター
外部 DNS Operator には、次の設定パラメーターが含まれています。
21.3.1. 外部 DNS Operator 設定パラメーター
外部 DNS Operator には、次の設定パラメーターが含まれています。
| パラメーター | 説明 |
|---|---|
|
| クラウドプロバイダーのタイプを有効にします。 spec:
provider:
type: AWS 1
aws:
credentials:
name: aws-access-key 2
|
|
|
ドメインごとに DNS ゾーンを指定できます。ゾーンを指定しない場合、 zones:
- "myzoneid" 1
|
|
|
ドメインごとに AWS ゾーンを指定できます。ドメインを指定しない場合、 domains: - filterType: Include 1 matchType: Exact 2 name: "myzonedomain1.com" 3 - filterType: Include matchType: Pattern 4 pattern: ".*\\.otherzonedomain\\.com" 5 |
|
|
DNS レコードのソース ( source: 1 type: Service 2 service: serviceType:3 - LoadBalancer - ClusterIP labelFilter: 4 matchLabels: external-dns.mydomain.org/publish: "yes" hostnameAnnotation: "Allow" 5 fqdnTemplate: - "{{.Name}}.myzonedomain.com" 6
source: type: OpenShiftRoute 1 openshiftRouteOptions: routerName: default 2 labelFilter: matchLabels: external-dns.mydomain.org/publish: "yes" |
21.4. AWS での DNS レコードの作成
外部 DNS Operator を使用して、AWS および AWS GovCloud で DNS レコードを作成できます。
21.4.1. Red Hat 外部 DNS Operator を使用した AWS のパブリックホストゾーンへの DNS レコードの作成
Red Hat 外部 DNS Operator を使用して、AWS のパブリックホストゾーンに DNS レコードを作成できます。同じ手順を使用して、AWS GovCloud のホストゾーンに DNS レコードを作成できます。
手順
ユーザーを確認してください。ユーザーは、
kube-systemnamespace にアクセスできる必要があります。クレデンシャルがない場合は、kube-systemnamespace からクレデンシャルを取得すると、クラウドプロバイダークライアントを使用できます。$ oc whoami
出力例
system:admin
kube-systemnamespace に存在する aws-creds シークレットから値を取得します。$ export AWS_ACCESS_KEY_ID=$(oc get secrets aws-creds -n kube-system --template={{.data.aws_access_key_id}} | base64 -d) $ export AWS_SECRET_ACCESS_KEY=$(oc get secrets aws-creds -n kube-system --template={{.data.aws_secret_access_key}} | base64 -d)ルートを取得して、ドメインを確認します。
$ oc get routes --all-namespaces | grep console
出力例
openshift-console console console-openshift-console.apps.testextdnsoperator.apacshift.support console https reencrypt/Redirect None openshift-console downloads downloads-openshift-console.apps.testextdnsoperator.apacshift.support downloads http edge/Redirect None
DNS ゾーンのリストを取得して、以前に検出されたルートのドメインに対応するものを検索します。
$ aws route53 list-hosted-zones | grep testextdnsoperator.apacshift.support
出力例
HOSTEDZONES terraform /hostedzone/Z02355203TNN1XXXX1J6O testextdnsoperator.apacshift.support. 5
routeソースのExternalDNSリソースを作成します。$ cat <<EOF | oc create -f - apiVersion: externaldns.olm.openshift.io/v1beta1 kind: ExternalDNS metadata: name: sample-aws 1 spec: domains: - filterType: Include 2 matchType: Exact 3 name: testextdnsoperator.apacshift.support 4 provider: type: AWS 5 source: 6 type: OpenShiftRoute 7 openshiftRouteOptions: routerName: default 8 EOF
- 1
- 外部 DNS リソースの名前を定義します。
- 2
- デフォルトでは、すべてのホストゾーンがターゲット候補として選択されます。必要なホストゾーンを追加できます。
- 3
- ターゲットゾーンのドメインは、(正規表現の一致とは対照的に) 完全一致である必要があります。
- 4
- 更新するゾーンのドメインを正確に指定します。ルートのホスト名は、指定されたドメインのサブドメインである必要があります。
- 5
AWS Route53DNSプロバイダーを定義します。- 6
- DNS レコードのソースのオプションを定義します。
- 7
- 以前に指定された DNS プロバイダーで作成される DNS レコードのソースとして OpenShift
routeリソースを定義します。 - 8
- ソースが
OpenShiftRouteの場合に、OpenShift Ingress Controller 名を指定できます。外部 DNS Operator は、CNAME レコードの作成時に、そのルーターの正規のホスト名をターゲットとして選択します。
次のコマンドを使用して、OCP ルート用に作成されたレコードを確認します。
$ aws route53 list-resource-record-sets --hosted-zone-id Z02355203TNN1XXXX1J6O --query "ResourceRecordSets[?Type == 'CNAME']" | grep console
21.5. Azure での DNS レコードの作成
外部 DNS Operator を使用して、Azure 上に DNS レコードを作成できます。
21.5.1. Azure のパブリック DNS ゾーン上で DNS レコードを作成する
Red Hat 外部 DNS Operator を使用して、Azure のパブリック DNS ゾーンに DNS レコードを作成できます。
前提条件
- 管理者権限を持っている。
-
adminユーザーの場合、kube-systemnamespace にアクセスできる。
手順
クラウドプロバイダークライアントを使用するために、次のコマンドを実行して
kube-systemnamespace から認証情報を取得します。$ CLIENT_ID=$(oc get secrets azure-credentials -n kube-system --template={{.data.azure_client_id}} | base64 -d) $ CLIENT_SECRET=$(oc get secrets azure-credentials -n kube-system --template={{.data.azure_client_secret}} | base64 -d) $ RESOURCE_GROUP=$(oc get secrets azure-credentials -n kube-system --template={{.data.azure_resourcegroup}} | base64 -d) $ SUBSCRIPTION_ID=$(oc get secrets azure-credentials -n kube-system --template={{.data.azure_subscription_id}} | base64 -d) $ TENANT_ID=$(oc get secrets azure-credentials -n kube-system --template={{.data.azure_tenant_id}} | base64 -d)次のコマンドを実行して、Azure にログインします。
$ az login --service-principal -u "${CLIENT_ID}" -p "${CLIENT_SECRET}" --tenant "${TENANT_ID}"次のコマンドを実行して、ルートのリストを取得します。
$ oc get routes --all-namespaces | grep console
出力例
openshift-console console console-openshift-console.apps.test.azure.example.com console https reencrypt/Redirect None openshift-console downloads downloads-openshift-console.apps.test.azure.example.com downloads http edge/Redirect None
次のコマンドを実行して、DNS ゾーンのリストを取得します。
$ az network dns zone list --resource-group "${RESOURCE_GROUP}"ExternalDNSオブジェクトを定義する YAML ファイル (例:external-dns-sample-azure.yaml) を作成します。external-dns-sample-azure.yamlファイルの例apiVersion: externaldns.olm.openshift.io/v1beta1 kind: ExternalDNS metadata: name: sample-azure 1 spec: zones: - "/subscriptions/1234567890/resourceGroups/test-azure-xxxxx-rg/providers/Microsoft.Network/dnszones/test.azure.example.com" 2 provider: type: Azure 3 source: openshiftRouteOptions: 4 routerName: default 5 type: OpenShiftRoute 6
次のコマンドを実行して、OpenShift Container Platform ルートに対して作成された DNS レコードを確認します。
$ az network dns record-set list -g "${RESOURCE_GROUP}" -z test.azure.example.com | grep console注記プライベート Azure DNS のホストされたプライベートゾーンにレコードを作成するには、
zonesフィールドの下にプライベートゾーンを指定する必要があります。これにより、プロバイダータイプがExternalDNS引数のazure-private-dnsに入力されます。
21.6. GCP での DNS レコードの作成
外部 DNS Operator を使用して、GCP 上に DNS レコードを作成できます。
21.6.1. GCP のパブリックマネージドゾーン上で DNS レコードを作成する
外部 DNS Operator を使用して、GCP のパブリックマネージドゾーンに DNS レコードを作成できます。
前提条件
- 管理者権限を持っている。
手順
次のコマンドを実行して、
encoded-gcloud.jsonファイル内のgcp-credentialsシークレットをコピーします。$ oc get secret gcp-credentials -n kube-system --template='{{$v := index .data "service_account.json"}}{{$v}}' | base64 -d - > decoded-gcloud.json次のコマンドを実行して、Google の認証情報をエクスポートします。
$ export GOOGLE_CREDENTIALS=decoded-gcloud.json
次のコマンドを使用して、アカウントをアクティブ化します。
$ gcloud auth activate-service-account <client_email as per decoded-gcloud.json> --key-file=decoded-gcloud.json
次のコマンドを実行して、プロジェクトを設定します。
$ gcloud config set project <project_id as per decoded-gcloud.json>
次のコマンドを実行して、ルートのリストを取得します。
$ oc get routes --all-namespaces | grep console
出力例
openshift-console console console-openshift-console.apps.test.gcp.example.com console https reencrypt/Redirect None openshift-console downloads downloads-openshift-console.apps.test.gcp.example.com downloads http edge/Redirect None
次のコマンドを実行して、マネージドゾーンのリストを取得します。
$ gcloud dns managed-zones list | grep test.gcp.example.com
出力例
qe-cvs4g-private-zone test.gcp.example.com
ExternalDNSオブジェクトを定義する YAML ファイル (例:external-dns-sample-gcp.yaml) を作成します。external-dns-sample-gcp.yamlファイルの例apiVersion: externaldns.olm.openshift.io/v1beta1 kind: ExternalDNS metadata: name: sample-gcp 1 spec: domains: - filterType: Include 2 matchType: Exact 3 name: test.gcp.example.com 4 provider: type: GCP 5 source: openshiftRouteOptions: 6 routerName: default 7 type: OpenShiftRoute 8
- 1
- 外部 DNS 名を指定します。
- 2
- デフォルトでは、すべてのホストされたゾーンがターゲット候補として選択されます。ホストされたゾーンを含めることができます。
- 3
- ターゲットのドメインは、
nameキーで定義された文字列と一致する必要があります。 - 4
- 更新するゾーンのドメインを正確に指定します。ルートのホスト名は、指定されたドメインのサブドメインである必要があります。
- 5
- プロバイダータイプを定義します。
- 6
- DNS レコードのソースのオプションを定義できます。
- 7
- ソースタイプが
OpenShiftRouteの場合、OpenShift Ingress Controller 名を渡すことができます。外部 DNS は、CNAME レコードの作成時に、そのルーターの正規のホスト名をターゲットとして選択します。 - 8
routeリソースを GCP DNS レコードのソースとして定義します。
次のコマンドを実行して、OpenShift Container Platform ルートに対して作成された DNS レコードを確認します。
$ gcloud dns record-sets list --zone=qe-cvs4g-private-zone | grep console
21.7. Infoblox での DNS レコードの作成
外部 DNS Operator を使用して、Infoblox に DNS レコードを作成できます。
21.7.1. Infoblox のパブリック DNS ゾーンでの DNS レコードの作成
外部 DNS Operator を使用して、Infoblox のパブリック DNS ゾーンに DNS レコードを作成できます。
前提条件
-
OpenShift CLI (
oc) にアクセスできる。 - Infoblox UI にアクセスできる。
手順
次のコマンドを実行して、Infoblox クレデンシャルを使用して
secretオブジェクトを作成します。$ oc -n external-dns-operator create secret generic infoblox-credentials --from-literal=EXTERNAL_DNS_INFOBLOX_WAPI_USERNAME=<infoblox_username> --from-literal=EXTERNAL_DNS_INFOBLOX_WAPI_PASSWORD=<infoblox_password>
次のコマンドを実行して、ルートのリストを取得します。
$ oc get routes --all-namespaces | grep console
出力例
openshift-console console console-openshift-console.apps.test.example.com console https reencrypt/Redirect None openshift-console downloads downloads-openshift-console.apps.test.example.com downloads http edge/Redirect None
ExternalDNSオブジェクトを定義する YAML ファイル (例:external-dns-sample-infoblox.yaml) を作成します。external-dns-sample-infoblox.yamlファイルの例apiVersion: externaldns.olm.openshift.io/v1beta1 kind: ExternalDNS metadata: name: sample-infoblox 1 spec: provider: type: Infoblox 2 infoblox: credentials: name: infoblox-credentials gridHost: ${INFOBLOX_GRID_PUBLIC_IP} wapiPort: 443 wapiVersion: "2.3.1" domains: - filterType: Include matchType: Exact name: test.example.com source: type: OpenShiftRoute 3 openshiftRouteOptions: routerName: default 4
次のコマンドを実行して、Infoblox に
ExternalDNSリソースを作成します。$ oc create -f external-dns-sample-infoblox.yaml
Infoblox UI から、
consoleルート用に作成された DNS レコードを確認します。- Data Management → DNS → Zones をクリックします。
- ゾーン名を選択します。
21.8. 外部 DNS Operator でのクラスター全体のプロキシーの設定
クラスター全体のプロキシーを設定した後、Operator Lifecycle Manager (OLM) はデプロイされたすべての Operator に対して、HTTP_PROXY、HTTPS_PROXY、および NO_PROXY 環境変数の新しい内容の自動更新をトリガーします。
21.8.1. クラスター全体のプロキシーの認証局を信頼する
外部 DNS Operator を設定して、クラスター全体のプロキシーの認証局を信頼できます。
手順
次のコマンドを実行して、
external-dns-operatornamespace に CA バンドルを含める config map を作成します。$ oc -n external-dns-operator create configmap trusted-ca
信頼できる CA バンドルを config map に挿入するには、次のコマンドを実行して、
config.openshift.io/inject-trusted-cabundle=trueラベルを config map に追加します。$ oc -n external-dns-operator label cm trusted-ca config.openshift.io/inject-trusted-cabundle=true
次のコマンドを実行して、外部 DNS Operator のサブスクリプションを更新します。
$ oc -n external-dns-operator patch subscription external-dns-operator --type='json' -p='[{"op": "add", "path": "/spec/config", "value":{"env":[{"name":"TRUSTED_CA_CONFIGMAP_NAME","value":"trusted-ca"}]}}]'
検証
外部 DNS Operator のデプロイ後、次のコマンドを実行して、信頼できる CA 環境変数が
external-dns-operatorデプロイメントに追加されていることを確認します。$ oc -n external-dns-operator exec deploy/external-dns-operator -c external-dns-operator -- printenv TRUSTED_CA_CONFIGMAP_NAME
出力例
trusted-ca
第22章 ネットワークポリシー
22.1. ネットワークポリシーについて
クラスター管理者は、トラフィックをクラスター内の Pod に制限するネットワークポリシーを定義できます。
22.1.1. ネットワークポリシーについて
Kubernetes ネットワークポリシーをサポートするネットワークプラグインを使用するクラスターでは、ネットワーク分離は NetworkPolicy オブジェクトによって完全に制御されます。OpenShift Container Platform 4.13 では、OpenShift SDN はデフォルトのネットワーク分離モードでのネットワークポリシーの使用をサポートしています。
ネットワークポリシーは、ホストのネットワーク namespace には適用されません。ホストネットワークが有効にされている Pod はネットワークポリシールールによる影響を受けません。ただし、ホストネットワークの Pod に接続する Pod はネットワークポリシールールの影響を受ける可能性があります。
ネットワークポリシーは、ローカルホストまたは常駐ノードからのトラフィックをブロックすることはできません。
デフォルトで、プロジェクトのすべての Pod は他の Pod およびネットワークのエンドポイントからアクセスできます。プロジェクトで 1 つ以上の Pod を分離するには、そのプロジェクトで NetworkPolicy オブジェクトを作成し、許可する着信接続を指定します。プロジェクト管理者は独自のプロジェクト内で NetworkPolicy オブジェクトの作成および削除を実行できます。
Pod が 1 つ以上の NetworkPolicy オブジェクトのセレクターで一致する場合、Pod はそれらの 1 つ以上の NetworkPolicy オブジェクトで許可される接続のみを受け入れます。NetworkPolicy オブジェクトによって選択されていない Pod は完全にアクセス可能です。
ネットワークポリシーは、TCP、UDP、ICMP、および SCTP プロトコルにのみ適用されます。他のプロトコルは影響を受けません。
以下のサンプル NetworkPolicy オブジェクトは、複数の異なるシナリオをサポートすることを示しています。
すべてのトラフィックを拒否します。
プロジェクトに deny by default (デフォルトで拒否) を実行させるには、すべての Pod に一致するが、トラフィックを一切許可しない
NetworkPolicyオブジェクトを追加します。kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: deny-by-default spec: podSelector: {} ingress: []OpenShift Container Platform Ingress Controller からの接続のみを許可します。
プロジェクトで OpenShift Container Platform Ingress Controller からの接続のみを許可するには、以下の
NetworkPolicyオブジェクトを追加します。apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-openshift-ingress spec: ingress: - from: - namespaceSelector: matchLabels: network.openshift.io/policy-group: ingress podSelector: {} policyTypes: - Ingressプロジェクト内の Pod からの接続のみを受け入れます。
Pod が同じプロジェクト内の他の Pod からの接続を受け入れるが、他のプロジェクトの Pod からの接続を拒否するように設定するには、以下の
NetworkPolicyオブジェクトを追加します。kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-same-namespace spec: podSelector: {} ingress: - from: - podSelector: {}Pod ラベルに基づいて HTTP および HTTPS トラフィックのみを許可します。
特定のラベル (以下の例の
role=frontend) の付いた Pod への HTTP および HTTPS アクセスのみを有効にするには、以下と同様のNetworkPolicyオブジェクトを追加します。kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-http-and-https spec: podSelector: matchLabels: role: frontend ingress: - ports: - protocol: TCP port: 80 - protocol: TCP port: 443namespace および Pod セレクターの両方を使用して接続を受け入れます。
namespace と Pod セレクターを組み合わせてネットワークトラフィックのマッチングをするには、以下と同様の
NetworkPolicyオブジェクトを使用できます。kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-pod-and-namespace-both spec: podSelector: matchLabels: name: test-pods ingress: - from: - namespaceSelector: matchLabels: project: project_name podSelector: matchLabels: name: test-pods
NetworkPolicy オブジェクトは加算されるものです。 つまり、複数の NetworkPolicy オブジェクトを組み合わせて複雑なネットワーク要件を満すことができます。
たとえば、先の例で定義された NetworkPolicy オブジェクトの場合、同じプロジェト内に allow-same-namespace と allow-http-and-https ポリシーの両方を定義することができます。これにより、ラベル role=frontend の付いた Pod は各ポリシーで許可されるすべての接続を受け入れます。つまり、同じ namespace の Pod からのすべてのポート、およびすべての namespace の Pod からのポート 80 および 443 での接続を受け入れます。
22.1.1.1. allow-from-router ネットワークポリシーの使用
次の NetworkPolicy を使用して、ルーターの設定に関係なく外部トラフィックを許可します。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-from-router
spec:
ingress:
- from:
- namespaceSelector:
matchLabels:
policy-group.network.openshift.io/ingress: ""1
podSelector: {}
policyTypes:
- Ingress- 1
policy-group.network.openshift.io/ingress:""ラベルは、OpenShift-SDN と OVN-Kubernetes の両方をサポートします。
22.1.1.2. allow-from-hostnetwork ネットワークポリシーの使用
次の allow-from-hostnetwork NetworkPolicy オブジェクトを追加して、ホストネットワーク Pod からのトラフィックを転送します。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-from-hostnetwork
spec:
ingress:
- from:
- namespaceSelector:
matchLabels:
policy-group.network.openshift.io/host-network: ""
podSelector: {}
policyTypes:
- Ingress22.1.2. OpenShift SDN を使用したネットワークポリシー最適化
ネットワークポリシーを使用して、namespace 内でラベルで相互に区別される Pod を分離します。
NetworkPolicy オブジェクトを単一 namespace 内の多数の個別 Pod に適用することは効率的ではありません。Pod ラベルは IP レベルには存在しないため、ネットワークポリシーは、podSelector で選択されるすべての Pod 間のすべてのリンクについての別個の Open vSwitch (OVS) フロールールを生成します。
たとえば、仕様の podSelector および NetworkPolicy オブジェクト内の ingress podSelector のそれぞれが 200 Pod に一致する場合、40,000 (200*200) OVS フロールールが生成されます。これにより、ノードの速度が低下する可能性があります。
ネットワークポリシーを設計する場合は、以下のガイドラインを参照してください。
namespace を使用して分離する必要のある Pod のグループを組み込み、OVS フロールールの数を減らします。
namespace 全体を選択する
NetworkPolicyオブジェクトは、namespaceSelectorsまたは空のpodSelectorsを使用して、namespace の VXLAN 仮想ネットワーク ID に一致する単一の OVS フロールールのみを生成します。- 分離する必要のない Pod は元の namespace に維持し、分離する必要のある Pod は 1 つ以上の異なる namespace に移します。
- 追加のターゲット設定された namespace 間のネットワークポリシーを作成し、分離された Pod から許可する必要のある特定のトラフィックを可能にします。
22.1.3. OVN-Kubernetes ネットワークプラグインによるネットワークポリシーの最適化
ネットワークポリシーを設計する場合は、以下のガイドラインを参照してください。
-
同じ
spec.podSelector仕様を持つネットワークポリシーの場合、ingressルールまたはegressルールを持つ複数のネットワークポリシーを使用するよりも、複数のIngressルールまたはegressルールを持つ 1 つのネットワークポリシーを使用する方が効率的です。 podSelectorまたはnamespaceSelector仕様に基づくすべてのIngressまたはegressルールは、number of pods selected by network policy + number of pods selected by ingress or egress ruleに比例する数の OVS フローを生成します。そのため、Pod ごとに個別のルールを作成するのではなく、1 つのルールで必要な数の Pod を選択できるpodSelectorまたはnamespaceSelector仕様を使用することが推奨されます。たとえば、以下のポリシーには 2 つのルールが含まれています。
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: test-network-policy spec: podSelector: {} ingress: - from: - podSelector: matchLabels: role: frontend - from: - podSelector: matchLabels: role: backend以下のポリシーは、上記と同じ 2 つのルールを 1 つのルールとして表現しています。
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: test-network-policy spec: podSelector: {} ingress: - from: - podSelector: matchExpressions: - {key: role, operator: In, values: [frontend, backend]}同じガイドラインが
spec.podSelector仕様に適用されます。異なるネットワークポリシーに同じingressルールまたはegressルールがある場合、共通のspec.podSelector仕様で 1 つのネットワークポリシーを作成する方が効率的な場合があります。たとえば、以下の 2 つのポリシーには異なるルールがあります。apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: policy1 spec: podSelector: matchLabels: role: db ingress: - from: - podSelector: matchLabels: role: frontend --- apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: policy2 spec: podSelector: matchLabels: role: client ingress: - from: - podSelector: matchLabels: role: frontend以下のネットワークポリシーは、上記と同じ 2 つのルールを1 つのルールとして表現しています。
apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: policy3 spec: podSelector: matchExpressions: - {key: role, operator: In, values: [db, client]} ingress: - from: - podSelector: matchLabels: role: frontendこの最適化は、複数のセレクターを 1 つのセレクターとして表現する場合に限り適用できます。セレクターが異なるラベルに基づいている場合、この最適化は適用できない可能性があります。その場合は、ネットワークポリシーの最適化に特化して新規ラベルをいくつか適用することを検討してください。
22.1.4. 次のステップ
- ネットワークポリシーの作成
- オプション: デフォルトネットワークポリシーの定義
22.1.5. 関連情報
22.2. ネットワークポリシーの作成
admin ロールを持つユーザーは、namespace のネットワークポリシーを作成できます。
22.2.1. サンプル NetworkPolicy オブジェクト
以下は、サンプル NetworkPolicy オブジェクトにアノテーションを付けます。
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-27107 1 spec: podSelector: 2 matchLabels: app: mongodb ingress: - from: - podSelector: 3 matchLabels: app: app ports: 4 - protocol: TCP port: 27017
22.2.2. CLI を使用したネットワークポリシーの作成
クラスターの namespace に許可される Ingress または egress ネットワークトラフィックを記述する詳細なルールを定義するには、ネットワークポリシーを作成できます。
cluster-admin ロールを持つユーザーでログインしている場合、クラスター内の任意の namespace でネットワークポリシーを作成できます。
前提条件
-
クラスターは、
NetworkPolicyオブジェクトをサポートするネットワークプラグイン (mode: NetworkPolicyが設定された OVN-Kubernetes ネットワークプラグインや OpenShift SDN ネットワークプラグインなど) を使用します。このモードは OpenShiftSDN のデフォルトです。 -
OpenShift CLI (
oc) がインストールされている。 -
admin権限を持つユーザーとしてクラスターにログインしている。 - ネットワークポリシーが適用される namespace で作業している。
手順
ポリシールールを作成します。
<policy_name>.yamlファイルを作成します。$ touch <policy_name>.yaml
ここでは、以下のようになります。
<policy_name>- ネットワークポリシーファイル名を指定します。
作成したばかりのファイルで、以下の例のようなネットワークポリシーを定義します。
すべての namespace のすべての Pod から ingress を拒否します。
これは基本的なポリシーであり、他のネットワークポリシーの設定によって許可されたクロス Pod トラフィック以外のすべてのクロス Pod ネットワーキングをブロックします。
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: deny-by-default spec: podSelector: ingress: []
同じ namespace のすべての Pod から ingress を許可します。
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-same-namespace spec: podSelector: ingress: - from: - podSelector: {}特定のnamespaceから 1 つの Pod への上りトラフィックを許可する
このポリシーは、
namespace-yで実行されている Pod からpod-aというラベルの付いた Pod へのトラフィックを許可します。kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-traffic-pod spec: podSelector: matchLabels: pod: pod-a policyTypes: - Ingress ingress: - from: - namespaceSelector: matchLabels: kubernetes.io/metadata.name: namespace-y
ネットワークポリシーオブジェクトを作成するには、以下のコマンドを入力します。
$ oc apply -f <policy_name>.yaml -n <namespace>
ここでは、以下のようになります。
<policy_name>- ネットワークポリシーファイル名を指定します。
<namespace>- オプション: オブジェクトが現在の namespace 以外の namespace に定義されている場合は namespace を指定します。
出力例
networkpolicy.networking.k8s.io/deny-by-default created
cluster-admin 権限で Web コンソールにログインする場合、YAML で、または Web コンソールのフォームから、クラスターの任意の namespace でネットワークポリシーを直接作成できます。
22.2.3. デフォルトの全拒否ネットワークポリシーの作成
これは基本的なポリシーであり、他のデプロイメントされたネットワークポリシーの設定によって許可されたネットワークトラフィック以外のすべてのクロス Pod ネットワークをブロックします。この手順では、デフォルトの deny-by-default ポリシーを適用します。
cluster-admin ロールを持つユーザーでログインしている場合、クラスター内の任意の namespace でネットワークポリシーを作成できます。
前提条件
-
クラスターは、
NetworkPolicyオブジェクトをサポートするネットワークプラグイン (mode: NetworkPolicyが設定された OVN-Kubernetes ネットワークプラグインや OpenShift SDN ネットワークプラグインなど) を使用します。このモードは OpenShiftSDN のデフォルトです。 -
OpenShift CLI (
oc) がインストールされている。 -
admin権限を持つユーザーとしてクラスターにログインしている。 - ネットワークポリシーが適用される namespace で作業している。
手順
すべての namespace におけるすべての Pod からの ingress を拒否する
deny-by-defaultポリシーを定義する次の YAML を作成します。YAML をdeny-by-default.yamlファイルに保存します。kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: deny-by-default namespace: default 1 spec: podSelector: {} 2 ingress: [] 3
次のコマンドを入力して、ポリシーを適用します。
$ oc apply -f deny-by-default.yaml
出力例
networkpolicy.networking.k8s.io/deny-by-default created
22.2.4. 外部クライアントからのトラフィックを許可するネットワークポリシーの作成
deny-by-default ポリシーを設定すると、外部クライアントからラベル app=web を持つ Pod へのトラフィックを許可するポリシーの設定に進むことができます。
cluster-admin ロールを持つユーザーでログインしている場合、クラスター内の任意の namespace でネットワークポリシーを作成できます。
この手順に従って、パブリックインターネットから直接、またはロードバランサーを使用して Pod にアクセスすることにより、外部サービスを許可するポリシーを設定します。トラフィックは、ラベル app=web を持つ Pod にのみ許可されます。
前提条件
-
クラスターは、
NetworkPolicyオブジェクトをサポートするネットワークプラグイン (mode: NetworkPolicyが設定された OVN-Kubernetes ネットワークプラグインや OpenShift SDN ネットワークプラグインなど) を使用します。このモードは OpenShiftSDN のデフォルトです。 -
OpenShift CLI (
oc) がインストールされている。 -
admin権限を持つユーザーとしてクラスターにログインしている。 - ネットワークポリシーが適用される namespace で作業している。
手順
パブリックインターネットからのトラフィックが直接、またはロードバランサーを使用して Pod にアクセスできるようにするポリシーを作成します。YAML を
web-allow-external.yamlファイルに保存します。kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: web-allow-external namespace: default spec: policyTypes: - Ingress podSelector: matchLabels: app: web ingress: - {}次のコマンドを入力して、ポリシーを適用します。
$ oc apply -f web-allow-external.yaml
出力例
networkpolicy.networking.k8s.io/web-allow-external created
このポリシーは、次の図に示すように、外部トラフィックを含むすべてのリソースからのトラフィックを許可します。
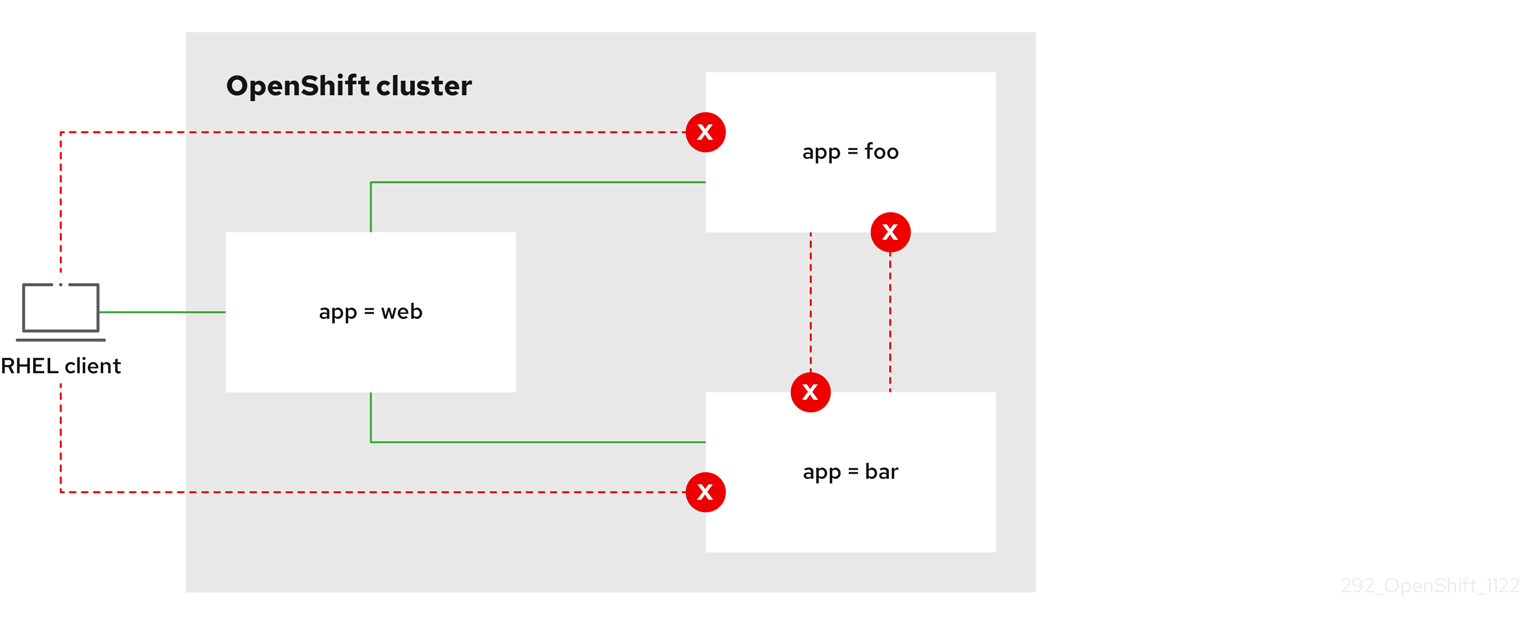
22.2.5. すべてのnamespaceからアプリケーションへのトラフィックを許可するネットワークポリシーを作成する
cluster-admin ロールを持つユーザーでログインしている場合、クラスター内の任意の namespace でネットワークポリシーを作成できます。
この手順に従って、すべてのnamespace内のすべての Pod から特定のアプリケーションへのトラフィックを許可するポリシーを設定します。
前提条件
-
クラスターは、
NetworkPolicyオブジェクトをサポートするネットワークプラグイン (mode: NetworkPolicyが設定された OVN-Kubernetes ネットワークプラグインや OpenShift SDN ネットワークプラグインなど) を使用します。このモードは OpenShiftSDN のデフォルトです。 -
OpenShift CLI (
oc) がインストールされている。 -
admin権限を持つユーザーとしてクラスターにログインしている。 - ネットワークポリシーが適用される namespace で作業している。
手順
すべてのnamespaceのすべての Pod から特定のアプリケーションへのトラフィックを許可するポリシーを作成します。YAML を
web-allow-all-namespaces.yamlファイルに保存します。kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: web-allow-all-namespaces namespace: default spec: podSelector: matchLabels: app: web 1 policyTypes: - Ingress ingress: - from: - namespaceSelector: {} 2注記デフォルトでは、
namespaceSelectorの指定を省略した場合、namespace は選択されません。つまり、ポリシーは、ネットワークポリシーがデプロイされている namespace からのトラフィックのみを許可します。次のコマンドを入力して、ポリシーを適用します。
$ oc apply -f web-allow-all-namespaces.yaml
出力例
networkpolicy.networking.k8s.io/web-allow-all-namespaces created
検証
次のコマンドを入力して、
defaultnamespace で Web サービスを開始します。$ oc run web --namespace=default --image=nginx --labels="app=web" --expose --port=80
次のコマンドを実行して、
alpineイメージをsecondarynamespace にデプロイし、シェルを開始します。$ oc run test-$RANDOM --namespace=secondary --rm -i -t --image=alpine -- sh
シェルで次のコマンドを実行し、リクエストが許可されていることを確認します。
# wget -qO- --timeout=2 http://web.default
予想される出力
<!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> html { color-scheme: light dark; } body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html>
22.2.6. namespaceからアプリケーションへのトラフィックを許可するネットワークポリシーの作成
cluster-admin ロールを持つユーザーでログインしている場合、クラスター内の任意の namespace でネットワークポリシーを作成できます。
特定の namespace からラベル app=web を持つ Pod へのトラフィックを許可するポリシーを設定するには、次の手順に従います。以下の場合にこれを行うことができます。
- 運用データベースへのトラフィックを、運用ワークロードがデプロイされているnamespaceのみに制限します。
- 特定のnamespaceにデプロイされた監視ツールを有効にして、現在のnamespaceからメトリックをスクレイピングします。
前提条件
-
クラスターは、
NetworkPolicyオブジェクトをサポートするネットワークプラグイン (mode: NetworkPolicyが設定された OVN-Kubernetes ネットワークプラグインや OpenShift SDN ネットワークプラグインなど) を使用します。このモードは OpenShiftSDN のデフォルトです。 -
OpenShift CLI (
oc) がインストールされている。 -
admin権限を持つユーザーとしてクラスターにログインしている。 - ネットワークポリシーが適用される namespace で作業している。
手順
ラベルが
purpose=productionの特定の namespace 内にあるすべての Pod からのトラフィックを許可するポリシーを作成します。YAML をweb-allow-prod.yamlファイルに保存します。kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: web-allow-prod namespace: default spec: podSelector: matchLabels: app: web 1 policyTypes: - Ingress ingress: - from: - namespaceSelector: matchLabels: purpose: production 2次のコマンドを入力して、ポリシーを適用します。
$ oc apply -f web-allow-prod.yaml
出力例
networkpolicy.networking.k8s.io/web-allow-prod created
検証
次のコマンドを入力して、
defaultnamespace で Web サービスを開始します。$ oc run web --namespace=default --image=nginx --labels="app=web" --expose --port=80
次のコマンドを実行して、
prodnamespace を作成します。$ oc create namespace prod
次のコマンドを実行して、
prodnamespace にラベルを付けます。$ oc label namespace/prod purpose=production
次のコマンドを実行して、
devnamespace を作成します。$ oc create namespace dev
次のコマンドを実行して、
devnamespace にラベルを付けます。$ oc label namespace/dev purpose=testing
次のコマンドを実行して、
alpineイメージをdevnamespace にデプロイし、シェルを開始します。$ oc run test-$RANDOM --namespace=dev --rm -i -t --image=alpine -- sh
シェルで次のコマンドを実行し、リクエストがブロックされていることを確認します。
# wget -qO- --timeout=2 http://web.default
予想される出力
wget: download timed out
次のコマンドを実行して、
alpineイメージをprodnamespace にデプロイし、シェルを開始します。$ oc run test-$RANDOM --namespace=prod --rm -i -t --image=alpine -- sh
シェルで次のコマンドを実行し、リクエストが許可されていることを確認します。
# wget -qO- --timeout=2 http://web.default
予想される出力
<!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> html { color-scheme: light dark; } body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html>
22.2.7. 関連情報
22.3. ネットワークポリシーの表示
admin ロールを持つユーザーは、namespace のネットワークポリシーを表示できます。
22.3.1. サンプル NetworkPolicy オブジェクト
以下は、サンプル NetworkPolicy オブジェクトにアノテーションを付けます。
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-27107 1 spec: podSelector: 2 matchLabels: app: mongodb ingress: - from: - podSelector: 3 matchLabels: app: app ports: 4 - protocol: TCP port: 27017
22.3.2. CLI を使用したネットワークポリシーの表示
namespace のネットワークポリシーを検査できます。
cluster-admin ロールを持つユーザーでログインしている場合、クラスター内の任意のネットワークポリシーを表示できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
admin権限を持つユーザーとしてクラスターにログインしている。 - ネットワークポリシーが存在する namespace で作業している。
手順
namespace のネットワークポリシーを一覧表示します。
namespace で定義されたネットワークポリシーオブジェクトを表示するには、以下のコマンドを実行します。
$ oc get networkpolicy
オプション: 特定のネットワークポリシーを検査するには、以下のコマンドを入力します。
$ oc describe networkpolicy <policy_name> -n <namespace>
ここでは、以下のようになります。
<policy_name>- 検査するネットワークポリシーの名前を指定します。
<namespace>- オプション: オブジェクトが現在の namespace 以外の namespace に定義されている場合は namespace を指定します。
以下に例を示します。
$ oc describe networkpolicy allow-same-namespace
oc describeコマンドの出力Name: allow-same-namespace Namespace: ns1 Created on: 2021-05-24 22:28:56 -0400 EDT Labels: <none> Annotations: <none> Spec: PodSelector: <none> (Allowing the specific traffic to all pods in this namespace) Allowing ingress traffic: To Port: <any> (traffic allowed to all ports) From: PodSelector: <none> Not affecting egress traffic Policy Types: Ingress
cluster-admin 権限で Web コンソールにログインする場合、YAML で、または Web コンソールのフォームから、クラスターの任意の namespace でネットワークポリシーを直接表示できます。
22.4. ネットワークポリシーの編集
admin ロールを持つユーザーは、namespace の既存のネットワークポリシーを編集できます。
22.4.1. ネットワークポリシーの編集
namespace のネットワークポリシーを編集できます。
cluster-admin ロールを持つユーザーでログインしている場合、クラスター内の任意の namespace でネットワークポリシーを編集できます。
前提条件
-
クラスターは、
NetworkPolicyオブジェクトをサポートするネットワークプラグイン (mode: NetworkPolicyが設定された OVN-Kubernetes ネットワークプラグインや OpenShift SDN ネットワークプラグインなど) を使用します。このモードは OpenShiftSDN のデフォルトです。 -
OpenShift CLI (
oc) がインストールされている。 -
admin権限を持つユーザーとしてクラスターにログインしている。 - ネットワークポリシーが存在する namespace で作業している。
手順
オプション: namespace のネットワークポリシーオブジェクトをリスト表示するには、以下のコマンドを入力します。
$ oc get networkpolicy
ここでは、以下のようになります。
<namespace>- オプション: オブジェクトが現在の namespace 以外の namespace に定義されている場合は namespace を指定します。
ネットワークポリシーオブジェクトを編集します。
ネットワークポリシーの定義をファイルに保存した場合は、ファイルを編集して必要な変更を加えてから、以下のコマンドを入力します。
$ oc apply -n <namespace> -f <policy_file>.yaml
ここでは、以下のようになります。
<namespace>- オプション: オブジェクトが現在の namespace 以外の namespace に定義されている場合は namespace を指定します。
<policy_file>- ネットワークポリシーを含むファイルの名前を指定します。
ネットワークポリシーオブジェクトを直接更新する必要がある場合、以下のコマンドを入力できます。
$ oc edit networkpolicy <policy_name> -n <namespace>
ここでは、以下のようになります。
<policy_name>- ネットワークポリシーの名前を指定します。
<namespace>- オプション: オブジェクトが現在の namespace 以外の namespace に定義されている場合は namespace を指定します。
ネットワークポリシーオブジェクトが更新されていることを確認します。
$ oc describe networkpolicy <policy_name> -n <namespace>
ここでは、以下のようになります。
<policy_name>- ネットワークポリシーの名前を指定します。
<namespace>- オプション: オブジェクトが現在の namespace 以外の namespace に定義されている場合は namespace を指定します。
cluster-admin 権限で Web コンソールにログインする場合、YAML で、または Web コンソールの Actions メニューのポリシーから、クラスターの任意の namespace でネットワークポリシーを直接編集できます。
22.4.2. サンプル NetworkPolicy オブジェクト
以下は、サンプル NetworkPolicy オブジェクトにアノテーションを付けます。
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-27107 1 spec: podSelector: 2 matchLabels: app: mongodb ingress: - from: - podSelector: 3 matchLabels: app: app ports: 4 - protocol: TCP port: 27017
22.4.3. 関連情報
22.5. ネットワークポリシーの削除
admin ロールを持つユーザーは、namespace からネットワークポリシーを削除できます。
22.5.1. CLI を使用したネットワークポリシーの削除
namespace のネットワークポリシーを削除できます。
cluster-admin ロールを持つユーザーでログインしている場合、クラスター内の任意のネットワークポリシーを削除できます。
前提条件
-
クラスターは、
NetworkPolicyオブジェクトをサポートするネットワークプラグイン (mode: NetworkPolicyが設定された OVN-Kubernetes ネットワークプラグインや OpenShift SDN ネットワークプラグインなど) を使用します。このモードは OpenShiftSDN のデフォルトです。 -
OpenShift CLI (
oc) がインストールされている。 -
admin権限を持つユーザーとしてクラスターにログインしている。 - ネットワークポリシーが存在する namespace で作業している。
手順
ネットワークポリシーオブジェクトを削除するには、以下のコマンドを入力します。
$ oc delete networkpolicy <policy_name> -n <namespace>
ここでは、以下のようになります。
<policy_name>- ネットワークポリシーの名前を指定します。
<namespace>- オプション: オブジェクトが現在の namespace 以外の namespace に定義されている場合は namespace を指定します。
出力例
networkpolicy.networking.k8s.io/default-deny deleted
cluster-admin 権限で Web コンソールにログインする場合、YAML で、または Web コンソールの Actions メニューのポリシーから、クラスターの任意の namespace でネットワークポリシーを直接削除できます。
22.6. プロジェクトのデフォルトネットワークポリシーの定義
クラスター管理者は、新規プロジェクトの作成時にネットワークポリシーを自動的に含めるように新規プロジェクトテンプレートを変更できます。新規プロジェクトのカスタマイズされたテンプレートがまだない場合には、まずテンプレートを作成する必要があります。
22.6.1. 新規プロジェクトのテンプレートの変更
クラスター管理者は、デフォルトのプロジェクトテンプレートを変更し、新規プロジェクトをカスタム要件に基づいて作成することができます。
独自のカスタムプロジェクトテンプレートを作成するには、以下を実行します。
手順
-
cluster-admin権限を持つユーザーとしてログインしている。 デフォルトのプロジェクトテンプレートを生成します。
$ oc adm create-bootstrap-project-template -o yaml > template.yaml
-
オブジェクトを追加するか、既存オブジェクトを変更することにより、テキストエディターで生成される
template.yamlファイルを変更します。 プロジェクトテンプレートは、
openshift-confignamespace に作成される必要があります。変更したテンプレートを読み込みます。$ oc create -f template.yaml -n openshift-config
Web コンソールまたは CLI を使用し、プロジェクト設定リソースを編集します。
Web コンソールの使用
- Administration → Cluster Settings ページに移動します。
- Configuration をクリックし、すべての設定リソースを表示します。
- Project のエントリーを見つけ、Edit YAML をクリックします。
CLI の使用
project.config.openshift.io/clusterリソースを編集します。$ oc edit project.config.openshift.io/cluster
specセクションを、projectRequestTemplateおよびnameパラメーターを組み込むように更新し、アップロードされたプロジェクトテンプレートの名前を設定します。デフォルト名はproject-requestです。カスタムプロジェクトテンプレートを含むプロジェクト設定リソース
apiVersion: config.openshift.io/v1 kind: Project metadata: # ... spec: projectRequestTemplate: name: <template_name> # ...- 変更を保存した後、変更が正常に適用されたことを確認するために、新しいプロジェクトを作成します。
22.6.2. 新規プロジェクトへのネットワークポリシーの追加
クラスター管理者は、ネットワークポリシーを新規プロジェクトのデフォルトテンプレートに追加できます。OpenShift Container Platform は、プロジェクトのテンプレートに指定されたすべての NetworkPolicy オブジェクトを自動的に作成します。
前提条件
-
クラスターは、
mode: NetworkPolicyが設定された OpenShift SDN ネットワークプラグインなど、NetworkPolicyオブジェクトをサポートするデフォルトの CNI ネットワークプラグインを使用します。このモードは OpenShiftSDN のデフォルトです。 -
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインする。 - 新規プロジェクトのカスタムデフォルトプロジェクトテンプレートを作成している。
手順
以下のコマンドを実行して、新規プロジェクトのデフォルトテンプレートを編集します。
$ oc edit template <project_template> -n openshift-config
<project_template>を、クラスターに設定したデフォルトテンプレートの名前に置き換えます。デフォルトのテンプレート名はproject-requestです。テンプレートでは、各
NetworkPolicyオブジェクトを要素としてobjectsパラメーターに追加します。objectsパラメーターは、1 つ以上のオブジェクトのコレクションを受け入れます。以下の例では、
objectsパラメーターのコレクションにいくつかのNetworkPolicyオブジェクトが含まれます。objects: - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-same-namespace spec: podSelector: {} ingress: - from: - podSelector: {} - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-openshift-ingress spec: ingress: - from: - namespaceSelector: matchLabels: network.openshift.io/policy-group: ingress podSelector: {} policyTypes: - Ingress - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-kube-apiserver-operator spec: ingress: - from: - namespaceSelector: matchLabels: kubernetes.io/metadata.name: openshift-kube-apiserver-operator podSelector: matchLabels: app: kube-apiserver-operator policyTypes: - Ingress ...オプション: 以下のコマンドを実行して、新規プロジェクトを作成し、ネットワークポリシーオブジェクトが正常に作成されることを確認します。
新規プロジェクトを作成します。
$ oc new-project <project> 1- 1
<project>を、作成しているプロジェクトの名前に置き換えます。
新規プロジェクトテンプレートのネットワークポリシーオブジェクトが新規プロジェクトに存在することを確認します。
$ oc get networkpolicy NAME POD-SELECTOR AGE allow-from-openshift-ingress <none> 7s allow-from-same-namespace <none> 7s
22.7. ネットワークポリシーを使用したマルチテナント分離の設定
クラスター管理者は、マルチテナントネットワークの分離を実行するようにネットワークポリシーを設定できます。
OpenShift SDN ネットワークプラグインを使用している場合、本セクションで説明されているようにネットワークポリシーを設定すると、マルチテナントモードと同様のネットワーク分離が行われますが、ネットワークポリシーモードが設定されます。
22.7.1. ネットワークポリシーを使用したマルチテナント分離の設定
他のプロジェクト namespace の Pod およびサービスから分離できるようにプロジェクトを設定できます。
前提条件
-
クラスターは、
NetworkPolicyオブジェクトをサポートするネットワークプラグイン (mode: NetworkPolicyが設定された OVN-Kubernetes ネットワークプラグインや OpenShift SDN ネットワークプラグインなど) を使用します。このモードは OpenShiftSDN のデフォルトです。このモードは OpenShiftSDN のデフォルトです。 -
OpenShift CLI (
oc) がインストールされている。 -
admin権限を持つユーザーとしてクラスターにログインしている。
手順
以下の
NetworkPolicyオブジェクトを作成します。allow-from-openshift-ingressという名前のポリシー:$ cat << EOF| oc create -f - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-openshift-ingress spec: ingress: - from: - namespaceSelector: matchLabels: policy-group.network.openshift.io/ingress: "" podSelector: {} policyTypes: - Ingress EOF注記policy-group.network.openshift.io/ingress: ""は、OpenShift SDN の推奨の namespace セレクターラベルです。network.openshift.io/policy-group: ingressnamespace セレクターラベルを使用できますが、これはレガシーラベルです。allow-from-openshift-monitoringという名前のポリシー。$ cat << EOF| oc create -f - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-openshift-monitoring spec: ingress: - from: - namespaceSelector: matchLabels: network.openshift.io/policy-group: monitoring podSelector: {} policyTypes: - Ingress EOFallow-same-namespaceという名前のポリシー:$ cat << EOF| oc create -f - kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-same-namespace spec: podSelector: ingress: - from: - podSelector: {} EOFallow-from-kube-apiserver-operatorという名前のポリシー:$ cat << EOF| oc create -f - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-kube-apiserver-operator spec: ingress: - from: - namespaceSelector: matchLabels: kubernetes.io/metadata.name: openshift-kube-apiserver-operator podSelector: matchLabels: app: kube-apiserver-operator policyTypes: - Ingress EOF詳細は、新規の New
kube-apiserver-operatorwebhook controller validating health of webhook を参照してください。
オプション: 以下のコマンドを実行し、ネットワークポリシーオブジェクトが現在のプロジェクトに存在することを確認します。
$ oc describe networkpolicy
出力例
Name: allow-from-openshift-ingress Namespace: example1 Created on: 2020-06-09 00:28:17 -0400 EDT Labels: <none> Annotations: <none> Spec: PodSelector: <none> (Allowing the specific traffic to all pods in this namespace) Allowing ingress traffic: To Port: <any> (traffic allowed to all ports) From: NamespaceSelector: network.openshift.io/policy-group: ingress Not affecting egress traffic Policy Types: Ingress Name: allow-from-openshift-monitoring Namespace: example1 Created on: 2020-06-09 00:29:57 -0400 EDT Labels: <none> Annotations: <none> Spec: PodSelector: <none> (Allowing the specific traffic to all pods in this namespace) Allowing ingress traffic: To Port: <any> (traffic allowed to all ports) From: NamespaceSelector: network.openshift.io/policy-group: monitoring Not affecting egress traffic Policy Types: Ingress
22.7.2. 次のステップ
22.7.3. 関連情報
第23章 CIDR 範囲の定義
次の CIDR 範囲には、重複しない範囲を指定する必要があります。
クラスターの作成後にマシンの CIDR 範囲を変更することはできません。
OpenShift Container Platform 4.11 以降のデフォルトのネットワークプロバイダーである OVN-Kubernetes は、IP アドレス範囲 100.64.0.0/16 を内部的に使用します。クラスターで OVN-Kubernetes を使用している場合は、クラスター内の他の CIDR 定義に IP アドレス範囲 100.64.0.0/16 を含めないでください。
23.1. Machine CIDR
Machine CIDR フィールドで、マシンまたはクラスターノードの IP アドレス範囲を指定する必要があります。
デフォルトは 10.0.0.0/16 です。この範囲は、接続されているネットワークと競合しないようにする必要があります。
23.2. Service CIDR
Service CIDR フィールドで、サービスの IP アドレス範囲を指定する必要があります。範囲は、ワークロードに対応するのに十分な大きさである必要があります。アドレスブロックは、クラスター内からアクセスする外部サービスと重複してはいけません。デフォルトは 172.30.0.0/16 です。
23.3. Pod CIDR
Pod CIDR フィールドで、Pod の IP アドレス範囲を指定する必要があります。
Pod CIDR は、clusterNetwork CIDR およびクラスター CIDR と同じです。範囲は、ワークロードに対応するのに十分な大きさである必要があります。アドレスブロックは、クラスター内からアクセスする外部サービスと重複してはいけません。デフォルトは 10.128.0.0/14 です。クラスターをインストールした後に、範囲を拡張できます。
23.4. ホスト接頭辞
Host Prefix フィールドで、個々のマシンにスケジュールされた Pod に割り当てられたサブネット接頭辞の長さを指定する必要があります。ホスト接頭辞は、各マシンの Pod IP アドレスプールを決定します。
例えば、ホスト接頭辞を /23 に設定した場合、各マシンには Pod CIDR アドレス範囲から /23 のサブネットが割り当てられます。デフォルトは /23 で、510 台のクラスターノードと、ノードごとに 510 個の Pod IP アドレスを許可します。
第24章 AWS Load Balancer Operator
24.1. AWS Load Balancer Operator リリースノート
AWS Load Balancer (ALB) Operator は、AWSLoadBalancerController リソースのインスタンスをデプロイおよび管理します。
これらのリリースノートは、OpenShift Container Platform での AWS Load Balancer Operator の開発を追跡します。
AWS Load Balancer Operator の概要は、OpenShift Container Platform の AWS Load Balancer Operator を参照してください。
AWS Load Balancer Operator は現在、AWS GovCloud をサポートしていません。
24.1.1. AWS Load Balancer Operator 1.0.0
このリリースで、AWS Load Balancer Operator の一般提供が開始されました。AWS Load Balancer Operator バージョン 1.0.0 は、AWS Load Balancer Controller バージョン 2.4.4 をサポートします。
AWS Load Balancer Operator バージョン 1.0.0 では、以下のアドバイザリーを利用できます。
24.1.1.1. 大きな変更
-
このリリースでは、新しい
v1API バージョンを使用しています。
24.1.1.2. バグ修正
- 以前のバージョンでは、AWS Load Balancer Operator によってプロビジョニングされたコントローラーは、クラスター全体のプロキシー設定を適切に使用しませんでした。これらの設定は、コントローラーに正しく適用されるようになりました。(OCPBUGS-4052、OCPBUGS-5295)
24.1.2. 以前のバージョン
AWS Load Balancer Operator の最初の 2 つのバージョンは、テクノロジープレビュー機能として利用できます。これらのバージョンは、実稼働クラスターで使用しないでください。Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
AWS Load Balancer Operator バージョン 0.2.0 では、以下のアドバイザリーを利用できます。
AWS Load Balancer Operator バージョン 0.0.1 では、以下のアドバイザリーを利用できます。
24.2. OpenShift Container Platform の AWS Load Balancer Operator
AWS Load Balancer Operator は、AWS Load Balancer Controller をデプロイおよび管理します。OpenShift Container Platform Web コンソールまたは CLI を使用して、OperatorHub から AWS Load Balancer Operator をインストールできます。
24.2.1. AWS Load Balancer Operator に関する考慮事項
AWS Load Balancer Operator をインストールして使用する前に、次の制限事項を確認してください。
- IP トラフィックモードは、AWS Elastic Kubernetes Service (EKS) でのみ機能します。AWS Load Balancer Operator は、AWS Load Balancer Controller の IP トラフィックモードを無効にします。IP トラフィックモードを無効にすると、AWS Load Balancer Controller は Pod readiness ゲートを使用できません。
-
AWS Load Balancer Operator は
--disable-ingress-class-annotationや--disable-ingress-group-name-annotationなどのコマンドラインフラグを AWS Load Balancer Controller に追加します。したがって、AWS Load Balancer Operator では、Ingressリソースでkubernetes.io/ingress.classおよびalb.ingress.kubernetes.io/group.nameアノテーションを使用できません。
24.2.2. AWS Load Balancer Operator
AWS Load Balancer Operator は kubernetes.io/role/elb タグがない場合に、パブリックサブネットにタグを付けることができます。また、AWS Load Balancer Operator は、基盤となる AWS クラウドから次の情報を検出します。
- Operator をホストするクラスターがデプロイされる仮想プライベートクラウド (VPC) の ID。
- 検出された VPC のパブリックおよびプライベートサブネット。
AWS Load Balancer Operator は、インスタンス ターゲットタイプのみで Network Load Balancer (NLB) を使用することにより、タイプ LoadBalancer の Kubernetes サービスリソースをサポートします。
前提条件
- AWS 認証情報シークレットが必要です。認証情報は、サブネットのタグ付けおよび VPC 検出機能を提供するために使用されます。
手順
次のコマンドを実行して
Subscriptionオブジェクトを作成することにより、OperatorHub からオンデマンドで AWS Load Balancer Operator をデプロイできます。$ oc -n aws-load-balancer-operator get sub aws-load-balancer-operator --template='{{.status.installplan.name}}{{"\n"}}'出力例
install-zlfbt
次のコマンドを実行して、インストールプランのステータスが
Completeになっているか確認します。$ oc -n aws-load-balancer-operator get ip <install_plan_name> --template='{{.status.phase}}{{"\n"}}'出力例
Complete
次のコマンドを実行して、
aws-load-balancer-operator-controller-managerデプロイメントのステータスを表示します。$ oc get -n aws-load-balancer-operator deployment/aws-load-balancer-operator-controller-manager
出力例
NAME READY UP-TO-DATE AVAILABLE AGE aws-load-balancer-operator-controller-manager 1/1 1 1 23h
24.2.3. AWS Load Balancer Operator ログ
oc logs コマンドを使用して、AWS Load Balancer Operator のログを表示できます。
手順
次のコマンドを実行して、AWS Load Balancer Operator のログを表示します。
$ oc logs -n aws-load-balancer-operator deployment/aws-load-balancer-operator-controller-manager -c manager
24.3. AWS Load Balancer Operator について
AWS Load Balancer Operator は、AWS Load Balancer Controller をデプロイおよび管理します。OpenShift Container Platform Web コンソールまたは CLI を使用して、OperatorHub から AWS Load Balancer Operator をインストールできます。
24.3.1. AWS Load Balancer Operator のインストール
OpenShift Container Platform Web コンソールを使用して、OperatorHub から AWS Load Balancer Operator をインストールできます。
前提条件
-
cluster-adminパーミッションのあるユーザーとして OpenShift Container Platform Web コンソールにログインしていること。 - クラスターは、AWS をプラットフォームタイプおよびクラウドプロバイダーとして設定されています。
手順
- OpenShift Container Platform Web コンソールで、Operators → OperatorHub に移動します。
- AWS Load Balancer Operator を選択します。Filter by keyword テキストボックスを使用するか、フィルターリストを使用して、Operator のリストから AWS Load Balancer Operator を検索できます。
-
aws-load-balancer-operatornamespace を選択します。 - 指示に従って、Operator をインストールする準備をします。
- AWS Load Balancer Operator ページで、Install をクリックします。
Install Operator ページで、次のオプションを選択します。
- stable-v1 に チャネルを更新 します。
- Installation mode を A specific namespace on the cluster にします。
-
Installed Namespace を
aws-load-balancer-operatorにします。aws-load-balancer-operatornamespace が存在しない場合は、Operator のインストール中に作成されます。 - Update approval で Automatic または Manual を選択します。デフォルトでは、Update approval は Automatic に設定されています。Automatic (自動) 更新を選択した場合、Operator Lifecycle Manager (OLM) は介入なしに、Operator の実行中のインスタンスを自動的にアップグレードします。手動更新を選択した場合、OLM は更新要求を作成します。クラスター管理者は、Operator を新規バージョンに更新できるように更新要求を手動で承認する必要があります。
- Install をクリックします。
検証
- AWS Load Balancer Operator で、インストール済み Operator ダッシュボードの Status が Succeeded と表示されることを確認します。
24.4. AWS Security Token Service (STS) を使用するクラスターに AWS Load Balancer Operator をインストールする
STS を使用するクラスターに AWS Load Balancer Operator をインストールできます。
AWS Load Balancer Operator は、CredentialsRequest オブジェクトに依存して Operator と AWS Load Balancer Controller をブートストラップします。AWS Load Balancer Operator は、必要なシークレットが作成されて利用可能になるまで待機します。Cloud Credential Operator は、STS クラスターでシークレットを自動的にプロビジョニングしません。ccoctl バイナリーを使用して、クレデンシャルシークレットを手動で設定する必要があります。
Cloud Credential Operator を使用して認証情報シークレットをプロビジョニングしたくない場合は、AWS ロードバランサーコントローラーのカスタムリソース (CR) で認証情報シークレットを指定することにより、STS クラスターで AWSLoadBalancerController インスタンスを設定できます。
24.4.1. Security Token Service クラスターでの AWS Load Balancer Operator のブートストラップ
前提条件
-
ccoctlバイナリーを抽出して準備する必要があります。
手順
次のコマンドを実行して、
aws-load-balancer-operatornamespace を作成します。$ oc create namespace aws-load-balancer-operator
AWS Load Balancer Operator の
CredentialsRequestカスタムリソース (CR) をダウンロードし、次のコマンドを実行して格納するディレクトリーを作成します。$ curl --create-dirs -o <path-to-credrequests-dir>/cr.yaml https://raw.githubusercontent.com/openshift/aws-load-balancer-operator/main/hack/operator-credentials-request.yaml
次のコマンドを実行して、
ccoctlツールを使用して AWS Load Balancer Operator のCredentialsRequestオブジェクトを処理します。$ ccoctl aws create-iam-roles \ --name <name> --region=<aws_region> \ --credentials-requests-dir=<path-to-credrequests-dir> \ --identity-provider-arn <oidc-arn>次のコマンドを実行して、クラスターのマニフェストディレクトリーに生成されたシークレットを適用します。
$ ls manifests/*-credentials.yaml | xargs -I{} oc apply -f {}次のコマンドを実行して、AWS Load Balancer Operator の認証情報シークレットが作成されていることを確認します。
$ oc -n aws-load-balancer-operator get secret aws-load-balancer-operator --template='{{index .data "credentials"}}' | base64 -d出力例
[default] sts_regional_endpoints = regional role_arn = arn:aws:iam::999999999999:role/aws-load-balancer-operator-aws-load-balancer-operator web_identity_token_file = /var/run/secrets/openshift/serviceaccount/token
24.4.2. 管理された CredentialsRequest オブジェクトを使用して、Security Token Service クラスターで AWS Load Balancer Operator を設定する
前提条件
-
ccoctlバイナリーを抽出して準備する必要があります。
手順
AWS Load Balancer Operator は、各
AWSLoadBalancerControllerカスタムリソース (CR) のopenshift-cloud-credential-operatornamespaceにCredentialsRequestオブジェクトを作成します。次のコマンドを実行すると、作成されたCredentialsRequestオブジェクトを抽出してディレクトリーに保存できます。$ oc get credentialsrequest -n openshift-cloud-credential-operator \ aws-load-balancer-controller-<cr-name> -o yaml > <path-to-credrequests-dir>/cr.yaml 1- 1
aws-load-balancer-controller-<cr-name>パラメーターは、AWS Load Balancer Operator によって作成された認証情報リクエスト名を指定します。cr-nameは、AWS Load Balancer Controller インスタンスの名前を指定します。
次のコマンドを実行し、
ccoctlツールを使用してcredrequestsディレクトリー内のすべてのCredentialsRequestオブジェクトを処理します。$ ccoctl aws create-iam-roles \ --name <name> --region=<aws_region> \ --credentials-requests-dir=<path-to-credrequests-dir> \ --identity-provider-arn <oidc-arn>次のコマンドを実行して、マニフェストディレクトリーで生成されたシークレットをクラスターに適用します。
$ ls manifests/*-credentials.yaml | xargs -I{} oc apply -f {}aws-load-balancer-controllerPod が作成されたことを確認します。$ oc -n aws-load-balancer-operator get pods NAME READY STATUS RESTARTS AGE aws-load-balancer-controller-cluster-9b766d6-gg82c 1/1 Running 0 137m aws-load-balancer-operator-controller-manager-b55ff68cc-85jzg 2/2 Running 0 3h26m
24.4.3. 特定の認証情報を使用して Security Token Service クラスターで AWS Load Balancer Operator を設定する
認証情報シークレットは、AWS Load Balancer Controller カスタムリソース (CR) の spec.credentials フィールドを使用して指定できます。コントローラーの定義済みの CredentialsRequest オブジェクトを使用して、必要なロールを知ることができます。
前提条件
-
ccoctlバイナリーを抽出して準備する必要があります。
手順
AWS Load Balancer Controller の CredentialsRequest カスタムリソース (CR) をダウンロードし、次のコマンドを実行して格納するディレクトリーを作成します。
$ curl --create-dirs -o <path-to-credrequests-dir>/cr.yaml https://raw.githubusercontent.com/openshift/aws-load-balancer-operator/main/hack/controller/controller-credentials-request.yaml
ccoctlツールを使用して、コントローラーのCredentialsRequestオブジェクトを処理します。$ ccoctl aws create-iam-roles \ --name <name> --region=<aws_region> \ --credentials-requests-dir=<path-to-credrequests-dir> \ --identity-provider-arn <oidc-arn>クラスターにシークレットを適用します。
$ ls manifests/*-credentials.yaml | xargs -I{} oc apply -f {}コントローラーで使用するためにクレデンシャルシークレットが作成されていることを確認します。
$ oc -n aws-load-balancer-operator get secret aws-load-balancer-controller-manual-cluster --template='{{index .data "credentials"}}' | base64 -d出力例
[default] sts_regional_endpoints = regional role_arn = arn:aws:iam::999999999999:role/aws-load-balancer-operator-aws-load-balancer-controller web_identity_token_file = /var/run/secrets/openshift/serviceaccount/tokenAWSLoadBalancerControllerリソース YAML ファイル (例:sample-aws-lb-manual-creds.yaml) を次のように作成します。apiVersion: networking.olm.openshift.io/v1 kind: AWSLoadBalancerController 1 metadata: name: cluster 2 spec: credentials: name: <secret-name> 3
24.4.4. 関連情報
24.5. AWS Load Balancer Controller のインスタンスを作成する
AWS Load Balancer Operator をインストールしたら、AWS Load Balancer Controller を作成できます。
24.5.1. AWS Load Balancer Controller の作成
クラスターにインストールできる AWSLoadBalancerController オブジェクトのインスタンスは 1 つだけです。CLI を使用して AWS Load Balancer Controller を作成できます。AWS Load Balancer Operator は、cluster という名前のリソースのみを調整します。
前提条件
-
echoservernamespace を作成している。 -
OpenShift CLI (
oc) にアクセスできる。
手順
AWSLoadBalancerControllerオブジェクトを定義する YAML ファイルを作成します。sample-aws-lb.yamlファイルの例apiVersion: networking.olm.openshift.io/v1 kind: AWSLoadBalancerController 1 metadata: name: cluster 2 spec: subnetTagging: Auto 3 additionalResourceTags: 4 - key: example.org/security-scope value: staging ingressClass: alb 5 config: replicas: 2 6 enabledAddons: 7 - AWSWAFv2 8
- 1
AWSLoadBalancerControllerオブジェクトを定義します。- 2
- AWS Load Balancer Controller 名を定義します。このインスタンス名は、関連するすべてのリソースの接尾辞として追加されます。
- 3
- AWS Load Balancer Controller のサブネットのタグ付け方法を設定します。次の値が有効です。
-
Auto: AWS Load Balancer Operator は、クラスターに属するサブネットを決定し、適切にタグ付けします。内部サブネットタグが内部サブネットに存在しない場合、Operator はロールを正しく判別できません。 -
Manual: クラスターに属するサブネットに適切なロールタグを手動でタグ付けします。ユーザー提供のインフラストラクチャーにクラスターをインストールした場合は、このオプションを使用します。
-
- 4
- AWS Load Balancer Controller が AWS リソースをプロビジョニングするときに使用するタグを定義します。
- 5
- Ingress クラス名を定義します。デフォルト値は
albです。 - 6
- AWS Load Balancer Controller のレプリカの数を指定します。
- 7
- AWS Load Balancer Controller のアドオンとしてアノテーションを指定します。
- 8
alb.ingress.kubernetes.io/wafv2-acl-arnアノテーションを有効にします。
次のコマンドを実行して、
AWSLoadBalancerControllerオブジェクトを作成します。$ oc create -f sample-aws-lb.yaml
Deploymentリソースを定義する YAML ファイルを作成します。sample-aws-lb.yamlファイルの例apiVersion: apps/v1 kind: Deployment 1 metadata: name: <echoserver> 2 namespace: echoserver spec: selector: matchLabels: app: echoserver replicas: 3 3 template: metadata: labels: app: echoserver spec: containers: - image: openshift/origin-node command: - "/bin/socat" args: - TCP4-LISTEN:8080,reuseaddr,fork - EXEC:'/bin/bash -c \"printf \\\"HTTP/1.0 200 OK\r\n\r\n\\\"; sed -e \\\"/^\r/q\\\"\"' imagePullPolicy: Always name: echoserver ports: - containerPort: 8080
Serviceリソースを定義する YAML ファイルを作成します。service-albo.yamlファイルの例:apiVersion: v1 kind: Service 1 metadata: name: <echoserver> 2 namespace: echoserver spec: ports: - port: 80 targetPort: 8080 protocol: TCP type: NodePort selector: app: echoserver
Ingressリソースを定義する YAML ファイルを作成します。Ingress-albo.yamlファイルの例:apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: <name> 1 namespace: echoserver annotations: alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/target-type: instance spec: ingressClassName: alb rules: - http: paths: - path: / pathType: Exact backend: service: name: <echoserver> 2 port: number: 80
検証
次のコマンドを実行して、
IngressリソースのステータスをHOST変数に保存します。$ HOST=$(oc get ingress -n echoserver echoserver --template='{{(index .status.loadBalancer.ingress 0).hostname}}')次のコマンドを実行して、
Ingressリソースのステータスを確認します。$ curl $HOST
24.6. 1 つの AWS ロードバランサーを介して複数の Ingress リソースを提供する
1 つの AWS Load Balancer を介して、1 つのドメインに含まれるさまざまなサービスにトラフィックをルーティングできます。各 Ingress リソースは、ドメインの異なるエンドポイントを提供します。
24.6.1. 1 つの AWS ロードバランサーを介して複数の Ingress リソースを作成する
CLI を使用すると、1 つの AWS ロードバランサーを介して複数の Ingress リソースにトラフィックをルーティングできます。
前提条件
-
OpenShift CLI (
oc) にアクセスできる。
手順
次のように、
IngressClassParamsリソースの YAML ファイル (例:sample-single-lb-params.yaml) を作成します。apiVersion: elbv2.k8s.aws/v1beta1 1 kind: IngressClassParams metadata: name: single-lb-params 2 spec: group: name: single-lb 3
次のコマンドを実行して、
IngressClassParamsリソースを作成します。$ oc create -f sample-single-lb-params.yaml
次のように、
IngressClassリソースの YAML ファイル (例:sample-single-lb-class.yaml) を作成します。apiVersion: networking.k8s.io/v1 1 kind: IngressClass metadata: name: single-lb 2 spec: controller: ingress.k8s.aws/alb 3 parameters: apiGroup: elbv2.k8s.aws 4 kind: IngressClassParams 5 name: single-lb-params 6
次のコマンドを実行して
IngressClassリソースを作成します。$ oc create -f sample-single-lb-class.yaml
次のように、
AWSLoadBalancerControllerリソース YAML ファイル (例:sample-single-lb.yaml) を作成します。apiVersion: networking.olm.openshift.io/v1 kind: AWSLoadBalancerController metadata: name: cluster spec: subnetTagging: Auto ingressClass: single-lb 1- 1
IngressClassリソースの名前を定義します。
次のコマンドを実行して、
AWSLoadBalancerControllerリソースを作成します。$ oc create -f sample-single-lb.yaml
次のように、
Ingressリソースの YAML ファイル (例:sample-multiple-ingress.yaml) を作成します。apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: example-1 1 annotations: alb.ingress.kubernetes.io/scheme: internet-facing 2 alb.ingress.kubernetes.io/group.order: "1" 3 alb.ingress.kubernetes.io/target-type: instance 4 spec: ingressClassName: single-lb 5 rules: - host: example.com 6 http: paths: - path: /blog 7 pathType: Prefix backend: service: name: example-1 8 port: number: 80 9 --- apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: example-2 annotations: alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/group.order: "2" alb.ingress.kubernetes.io/target-type: instance spec: ingressClassName: single-lb rules: - host: example.com http: paths: - path: /store pathType: Prefix backend: service: name: example-2 port: number: 80 --- apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: example-3 annotations: alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/group.order: "3" alb.ingress.kubernetes.io/target-type: instance spec: ingressClassName: single-lb rules: - host: example.com http: paths: - path: / pathType: Prefix backend: service: name: example-3 port: number: 80
- 1
- Ingress 名を指定します。
- 2
- インターネットにアクセスするためにパブリックサブネットにプロビジョニングするロードバランサーを示します。
- 3
- ロードバランサーで要求を受信したときに、複数の Ingress リソースからのルールをマッチする順序を指定します。
- 4
- ロードバランサーがサービスに到達するために OpenShift Container Platform ノードをターゲットにすることを示します。
- 5
- この Ingress に属する Ingress クラスを指定します。
- 6
- 要求のルーティングに使用するドメイン名を定義します。
- 7
- サービスにルーティングする必要があるパスを定義します。
- 8
Ingressリソースで設定されたエンドポイントを提供するサービス名を定義します。- 9
- エンドポイントにサービスを提供するサービスのポートを定義します。
次のコマンドを実行して
Ingressリソースを作成します。$ oc create -f sample-multiple-ingress.yaml
24.7. TLS Termination の追加
AWS Load Balancer に TLS Termination を追加できます。
24.7.1. AWS Load Balancer への TLS Termination の追加
ドメインのトラフィックをサービスの Pod にルーティングし、AWS Load Balancer に TLS Termination を追加できます。
前提条件
-
OpenShift CLI (
oc) にアクセスできる。
手順
AWSLoadBalancerControllerリソースを定義する YAML ファイルを作成します。add-tls-termination-albc.yamlファイルの例apiVersion: networking.olm.openshift.io/v1 kind: AWSLoadBalancerController metadata: name: cluster spec: subnetTagging: Auto ingressClass: tls-termination 1- 1
- Ingress クラス名を定義します。クラスター内に Ingress クラスが存在しない場合は、AWS Load Balancer Controller によって作成されます。
spec.controllerがingress.k8s.aws/albに設定されている場合、AWS Load Balancer Controller は追加の Ingress クラス値を調整します。
Ingressリソースを定義する YAML ファイルを作成します。add-tls-termination-ingress.yamlファイルの例apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: <example> 1 annotations: alb.ingress.kubernetes.io/scheme: internet-facing 2 alb.ingress.kubernetes.io/certificate-arn: arn:aws:acm:us-west-2:xxxxx 3 spec: ingressClassName: tls-termination 4 rules: - host: <example.com> 5 http: paths: - path: / pathType: Exact backend: service: name: <example-service> 6 port: number: 80
24.8. クラスター全体のプロキシーの設定
AWS Load Balancer Operator でクラスター全体のプロキシーを設定できます。クラスター全体のプロキシーを設定すると、Operator Lifecycle Manager (OLM) が、HTTP_PROXY、HTTPS_PROXY、NO_PROXY などの環境変数を使用して、Operator のすべてのデプロイメントを自動的に更新します。これらの変数は、AWS Load Balancer Operator によってマネージドコントローラーに入力されます。
24.8.1. クラスター全体のプロキシーの認証局を信頼する
次のコマンドを実行して、
aws-load-balancer-operatornamespace に認証局 (CA) バンドルを含める config map を作成します。$ oc -n aws-load-balancer-operator create configmap trusted-ca
信頼できる CA バンドルを config map に挿入するには、次のコマンドを実行して、
config.openshift.io/inject-trusted-cabundle=trueラベルを config map に追加します。$ oc -n aws-load-balancer-operator label cm trusted-ca config.openshift.io/inject-trusted-cabundle=true
次のコマンドを実行して、AWS Load Balancer Operator デプロイメントの config map にアクセスできるように AWS Load Balancer Operator サブスクリプションを更新します。
$ oc -n aws-load-balancer-operator patch subscription aws-load-balancer-operator --type='merge' -p '{"spec":{"config":{"env":[{"name":"TRUSTED_CA_CONFIGMAP_NAME","value":"trusted-ca"}],"volumes":[{"name":"trusted-ca","configMap":{"name":"trusted-ca"}}],"volumeMounts":[{"name":"trusted-ca","mountPath":"/etc/pki/tls/certs/albo-tls-ca-bundle.crt","subPath":"ca-bundle.crt"}]}}}'AWS Load Balancer Operator がデプロイされたら、次のコマンドを実行して、CA バンドルが
aws-load-balancer-operator-controller-managerデプロイメントに追加されていることを確認します。$ oc -n aws-load-balancer-operator exec deploy/aws-load-balancer-operator-controller-manager -c manager -- bash -c "ls -l /etc/pki/tls/certs/albo-tls-ca-bundle.crt; printenv TRUSTED_CA_CONFIGMAP_NAME"
出力例
-rw-r--r--. 1 root 1000690000 5875 Jan 11 12:25 /etc/pki/tls/certs/albo-tls-ca-bundle.crt trusted-ca
オプション: config-map が変更されるたびに、次のコマンドを実行して、AWS Load Balancer Operator のデプロイを再開します。
$ oc -n aws-load-balancer-operator rollout restart deployment/aws-load-balancer-operator-controller-manager
24.8.2. 関連情報
第25章 複数ネットワーク
25.1. 複数ネットワークについて
Kubernetes では、コンテナーネットワークは Container Network Interface (CNI) を実装するネットワークプラグインに委任されます。
OpenShift Container Platform は、Multus CNI プラグインを使用して CNI プラグインのチェーンを許可します。クラスターのインストール時に、デフォルト の Pod ネットワークを設定します。デフォルトのネットワークは、クラスターのすべての通常のネットワークトラフィックを処理します。利用可能な CNI プラグインに基づいて additional network を定義し、1 つまたは複数のネットワークを Pod に割り当てることができます。必要に応じて、クラスターの複数のネットワークを追加で定義することができます。これにより、スイッチングやルーティングなどのネットワーク機能を提供する Pod を設定する際に柔軟性が得られます。
25.1.1. 追加ネットワークの使用シナリオ
データプレーンとコントロールプレーンの分離など、ネットワークの分離が必要な状況で追加のネットワークを使用できます。トラフィックの分離は、以下のようなパフォーマンスおよびセキュリティー関連の理由で必要になります。
- パフォーマンス
- 各プレーンのトラフィック量を管理するために、2 つの異なるプレーンにトラフィックを送信できます。
- セキュリティー
- 機密トラフィックは、セキュリティー上の考慮に基づいて管理されているネットワークに送信でき、テナントまたはカスタマー間で共有できないプライベートを分離することができます。
クラスターのすべての Pod はクラスター全体のデフォルトネットワークを依然として使用し、クラスター全体での接続性を維持します。すべての Pod には、クラスター全体の Pod ネットワークに割り当てられる eth0 インターフェイスがあります。Pod のインターフェイスは、oc exec -it <pod_name> -- ip a コマンドを使用して表示できます。Multus CNI を使用するネットワークを追加する場合、それらの名前は net1、net2、…、 netN になります。
追加のネットワークを Pod に割り当てるには、インターフェイスの割り当て方法を定義する設定を作成する必要があります。それぞれのインターフェイスは、NetworkAttachmentDefinition カスタムリソース (CR) を使用して指定します。これらの CR のそれぞれにある CNI 設定は、インターフェイスの作成方法を定義します。
25.1.2. OpenShift Container Platform の追加ネットワーク
OpenShift Container Platform は、クラスターに追加のネットワークを作成するために使用する以下の CNI プラグインを提供します。
- bridge: ブリッジベースの追加ネットワークを設定する ことで、同じホストにある Pod が相互に、かつホストと通信できます。
- host-device: ホストデバイスの追加ネットワークを設定する ことで、Pod がホストシステム上の物理イーサネットネットワークデバイスにアクセスすることができます。
- ipvlan: ipvlan ベースの追加ネットワークを設定する ことで、macvlan ベースの追加ネットワークと同様に、ホスト上の Pod が他のホストやそれらのホストの Pod と通信できます。macvlan ベースの追加のネットワークとは異なり、各 Pod は親の物理ネットワークインターフェイスと同じ MAC アドレスを共有します。
- vlan: VLAN ベースの追加ネットワークを設定 して、VLAN ベースのネットワークの分離と Pod の接続を可能にします。
- macvlan: macvlan ベースの追加ネットワークを作成 することで、ホスト上の Pod が物理ネットワークインターフェイスを使用して他のホストやそれらのホストの Pod と通信できます。macvlan ベースの追加ネットワークに割り当てられる各 Pod には固有の MAC アドレスが割り当てられます。
- SR-IOV: SR-IOV ベースの追加ネットワークを設定する ことで、Pod を ホストシステム上の SR-IOV 対応ハードウェアの Virtual Function (VF) インターフェイスに割り当てることができます。
25.2. 追加のネットワークの設定
クラスター管理者は、クラスターの追加のネットワークを設定できます。以下のネットワークタイプに対応しています。
25.2.1. 追加のネットワークを管理するためのアプローチ
追加したネットワークのライフサイクルを管理するには、2 つのアプローチがあります。各アプローチは同時に使用できず、追加のネットワークを管理する場合に 1 つのアプローチしか使用できません。いずれの方法でも、追加のネットワークは、お客様が設定した Container Network Interface (CNI) プラグインで管理します。
追加ネットワークの場合には、IP アドレスは、追加ネットワークの一部として設定する IPAM(IP Address Management)CNI プラグインでプロビジョニングされます。IPAM プラグインは、DHCP や静的割り当てなど、さまざまな IP アドレス割り当ての方法をサポートしています。
-
Cluster Network Operator (CNO) の設定を変更する: CNO は自動的に
Network Attachment Definitionオブジェクトを作成し、管理します。CNO は、オブジェクトのライフサイクル管理に加えて、DHCP で割り当てられた IP アドレスを使用する追加のネットワークで確実に DHCP が利用できるようにします。 -
YAML マニフェストを適用する:
Network Attachment Definitionオブジェクトを作成することで、追加のネットワークを直接管理できます。この方法では、CNI プラグインを連鎖させることができます。
OVN SDN を使用して、Red Hat OpenStack Platform (RHOSP) に複数のネットワークインターフェイスを持つ OpenShift Container Platform ノードをデプロイすると、セカンダリーインターフェイスの DNS 設定がプライマリーインターフェイスの DNS 設定よりも優先される場合があります。この場合は、セカンダリーインターフェイスに接続されているサブネット ID の DNS ネームサーバーを削除します。
$ openstack subnet set --dns-nameserver 0.0.0.0 <subnet_id>
25.2.2. ネットワーク追加割り当ての設定
追加のネットワークは、k8s.cni.cncf.io API グループの NetworkAttachmentDefinition API を使用して設定されます。
Network Attachment Definition オブジェクトには、プロジェクト管理ユーザーがアクセスできるので、機密情報やシークレットを保存しないでください。
API の設定については、以下の表で説明されています。
表25.1 NetworkAttachmentDefinition API フィールド
| フィールド | 型 | 説明 |
|---|---|---|
|
|
| 追加のネットワークの名前です。 |
|
|
| オブジェクトが関連付けられる namespace。 |
|
|
| JSON 形式の CNI プラグイン設定。 |
25.2.2.1. Cluster Network Operator による追加ネットワークの設定
追加のネットワーク割り当ての設定は、Cluster Network Operator (CNO) の設定の一部として指定します。
以下の YAML は、CNO で追加のネットワークを管理するための設定パラメーターを記述しています。
Cluster Network Operator (CNO) の設定
apiVersion: operator.openshift.io/v1 kind: Network metadata: name: cluster spec: # ... additionalNetworks: 1 - name: <name> 2 namespace: <namespace> 3 rawCNIConfig: |- 4 { ... } type: Raw
25.2.2.2. YAML マニフェストからの追加ネットワークの設定
追加ネットワークの設定は、以下の例のように YAML 設定ファイルから指定します。
apiVersion: k8s.cni.cncf.io/v1 kind: NetworkAttachmentDefinition metadata: name: <name> 1 spec: config: |- 2 { ... }
25.2.3. 追加のネットワークタイプの設定
次のセクションでは、追加のネットワークの具体的な設定フィールドについて説明します。
25.2.3.1. ブリッジネットワークの追加設定
以下のオブジェクトは、ブリッジ CNI プラグインの設定パラメーターについて説明しています。
表25.2 Bridge CNI プラグイン JSON 設定オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
CNI 仕様のバージョン。値 |
|
|
|
CNO 設定に以前に指定した |
|
|
|
設定する CNI プラグインの名前: |
|
|
| IPAM CNI プラグインの設定オブジェクト。プラグインは、割り当て定義についての IP アドレスの割り当てを管理します。 |
|
|
|
オプション: 使用する仮想ブリッジの名前を指定します。ブリッジインターフェイスがホストに存在しない場合は、これが作成されます。デフォルト値は |
|
|
|
オプション: 仮想ネットワークから外すトラフィックの IP マスカレードを有効にするには、 |
|
|
|
オプション: IP アドレスをブリッジに割り当てるには |
|
|
|
オプション: ブリッジを仮想ネットワークのデフォルトゲートウェイとして設定するには、 |
|
|
|
オプション: 仮想ブリッジの事前に割り当てられた IP アドレスの割り当てを許可するには、 |
|
|
|
オプション: 仮想ブリッジが受信時に使用した仮想ポートでイーサネットフレームを送信できるようにするには、 |
|
|
|
オプション: ブリッジで無作為検出モード (Promiscuous Mode) を有効にするには、 |
|
|
| オプション: 仮想 LAN (VLAN) タグを整数値として指定します。デフォルトで、VLAN タグは割り当てません。 |
|
|
|
オプション: デフォルトの VLAN をブリッジに接続されている |
|
|
|
オプション: VLAN トランクタグを割り当てます。デフォルト値は |
|
|
| オプション: 最大転送単位 (MTU) を指定された値に設定します。デフォルト値はカーネルによって自動的に設定されます。 |
|
|
|
オプション: コンテナー側の |
|
|
|
オプション: MAC スプーフィングチェックを有効にして、コンテナーから発信されるトラフィックをインターフェイスの MAC アドレスに制限します。デフォルト値は |
VLAN パラメーターは、veth のホスト側に VLAN タグを設定し、ブリッジインターフェイスで vlan_filtering 機能を有効にします。
L2 ネットワークのアップリンクを設定するには、以下のコマンドを使用してアップリンクインターフェイスで vlan を許可する必要があります。
$ bridge vlan add vid VLAN_ID dev DEV
25.2.3.1.1. ブリッジ設定の例
以下の例では、bridge-net という名前の追加のネットワークを設定します。
{
"cniVersion": "0.3.1",
"name": "bridge-net",
"type": "bridge",
"isGateway": true,
"vlan": 2,
"ipam": {
"type": "dhcp"
}
}25.2.3.2. ホストデバイスの追加ネットワークの設定
device、hwaddr、kernelpath、または pciBusID のいずれかのパラメーターを設定してネットワークデバイスを指定します。
以下のオブジェクトは、ホストデバイス CNI プラグインの設定パラメーターについて説明しています。
表25.3 ホストデバイス CNI プラグイン JSON 設定オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
CNI 仕様のバージョン。値 |
|
|
|
CNO 設定に以前に指定した |
|
|
|
設定する CNI プラグインの名前: |
|
|
|
オプション: |
|
|
| オプション: デバイスハードウェアの MAC アドレス。 |
|
|
|
オプション: |
|
|
|
オプション: |
25.2.3.2.1. ホストデバイス設定例
以下の例では、hostdev-net という名前の追加のネットワークを設定します。
{
"cniVersion": "0.3.1",
"name": "hostdev-net",
"type": "host-device",
"device": "eth1"
}25.2.3.3. VLAN 追加ネットワークの設定
以下のオブジェクトは、VLAN CNI プラグインの設定パラメーターについて説明しています。
表25.4 VLAN CNI プラグイン JSON 設定オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
CNI 仕様のバージョン。値 |
|
|
|
CNO 設定に以前に指定した |
|
|
|
設定する CNI プラグインの名前: |
|
|
|
ネットワーク割り当てに関連付けるイーサネットインターフェイス。 |
|
|
| vlan の ID を設定します。 |
|
|
| IPAM CNI プラグインの設定オブジェクト。プラグインは、割り当て定義についての IP アドレスの割り当てを管理します。 |
|
|
| オプション: 最大転送単位 (MTU) を指定された値に設定します。デフォルト値はカーネルによって自動的に設定されます。 |
|
|
| オプション: 返す DNS 情報 (DNS ネームサーバーの優先順位リストなど)。 |
|
|
| オプション: マスターインターフェイスが、コンテナーネットワーク namespace とメインネットワーク namespace のどちらにあるかを指定します。 |
25.2.3.3.1. vlan 設定例
以下の例では、ipvlan-net という名前の追加ネットワークを設定します。
{
"name": "vlan-net",
"cniVersion": "0.3.1",
"type": "vlan",
"master": "eth0",
"mtu": 1500,
"vlanId": 5,
"linkInContainer": false,
"ipam": {
"type": "host-local",
"subnet": "10.1.1.0/24"
},
"dns": {
"nameservers": [ "10.1.1.1", "8.8.8.8" ]
}
}25.2.3.4. IPVLAN 追加ネットワークの設定
以下のオブジェクトは、IPVLAN CNI プラグインの設定パラメーターについて説明しています。
表25.5 IPVLAN CNI プラグイン JSON 設定オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
CNI 仕様のバージョン。値 |
|
|
|
CNO 設定に以前に指定した |
|
|
|
設定する CNI プラグインの名前: |
|
|
| IPAM CNI プラグインの設定オブジェクト。プラグインは、割り当て定義についての IP アドレスの割り当てを管理します。これは、プラグインが連鎖している場合を除き必要です。 |
|
|
|
オプション: 仮想ネットワークの操作モードを指定します。この値は、 |
|
|
|
オプション: ネットワーク割り当てに関連付けるイーサネットインターフェイスを指定します。 |
|
|
| オプション: 最大転送単位 (MTU) を指定された値に設定します。デフォルト値はカーネルによって自動的に設定されます。 |
-
ipvlanオブジェクトは、仮想インターフェイスがmasterインターフェイスと通信することを許可しません。したがって、コンテナーはipvlanインターフェイスを使用してホストに到達できなくなります。コンテナーが、Precision Time Protocol (PTP) をサポートするネットワークなど、ホストへの接続を提供するネットワークに参加していることを確認してください。 -
1 つのの
masterインターフェイスを、macvlanとipvlanの両方を使用するように同時に設定することはできません。 -
インターフェイスに依存できない IP 割り当てスキームの場合、
ipvlanプラグインは、このロジックを処理する以前のプラグインと連鎖させることができます。masterが省略された場合、前の結果にはスレーブにするipvlanプラグインのインターフェイス名が 1 つ含まれていなければなりません。ipamが省略された場合、ipvlanインターフェイスの設定には前の結果が使用されます。
25.2.3.4.1. IPVLAN 設定例
以下の例では、ipvlan-net という名前の追加のネットワークを設定します。
{
"cniVersion": "0.3.1",
"name": "ipvlan-net",
"type": "ipvlan",
"master": "eth1",
"mode": "l3",
"ipam": {
"type": "static",
"addresses": [
{
"address": "192.168.10.10/24"
}
]
}
}25.2.3.5. MACVLAN 追加ネットワークの設定
以下のオブジェクトは、macvlan CNI プラグインの設定パラメーターについて説明しています。
表25.6 MACVLAN CNI プラグイン JSON 設定オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
CNI 仕様のバージョン。値 |
|
|
|
CNO 設定に以前に指定した |
|
|
|
設定する CNI プラグインの名前: |
|
|
| IPAM CNI プラグインの設定オブジェクト。プラグインは、割り当て定義についての IP アドレスの割り当てを管理します。 |
|
|
|
オプション: 仮想ネットワークのトラフィックの可視性を設定します。 |
|
|
| オプション: 新しく作成された macvlan インターフェイスに関連付けるホストネットワークインターフェイス。値が指定されていない場合は、デフォルトのルートインターフェイスが使用されます。 |
|
|
| オプション: 指定された値への最大転送単位 (MTU)。デフォルト値はカーネルによって自動的に設定されます。 |
プラグイン設定の master キーを指定する場合は、競合の可能性を回避するために、プライマリーネットワークプラグインに関連付けられているものとは異なる物理ネットワークインターフェイスを使用してください。
25.2.3.5.1. macvlan 設定の例
以下の例では、macvlan-net という名前の追加のネットワークを設定します。
{
"cniVersion": "0.3.1",
"name": "macvlan-net",
"type": "macvlan",
"master": "eth1",
"mode": "bridge",
"ipam": {
"type": "dhcp"
}
}25.2.3.6. OVN-Kubernetes 追加ネットワークの設定
Red Hat OpenShift Networking OVN-Kubernetes ネットワークプラグインを使用すると、Pod のセカンダリーネットワークインターフェイスを設定できます。セカンダリーネットワークインターフェイスを設定するには、NetworkAttachmentDefinition カスタムリソース定義 (CRD) で設定を定義する必要があります。
OVN-Kubernetes 追加ネットワークの設定は、テクノロジープレビュー機能のみです。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
Pod およびマルチネットワークポリシーの作成は、ノード内の OVN-Kubernetes コントロールプレーンエージェントが関連する network-attachment-definition CR を処理するまで、保留状態のままになる場合があります。
次のセクションでは、OVN-Kubernetes で現在セカンダリーネットワークに許可されている各トポロジーの設定例を示します。
ネットワーク名は一意である必要があります。たとえば、同じネットワークを参照する異なる設定を持つ複数の NetworkAttachmentDefinition CRD の作成はサポートされていません。
25.2.3.6.1. OVN-Kubernetes ネットワークプラグインの JSON 設定テーブル
次の表では、OVN-Kubernetes CNI ネットワークプラグインの設定パラメーターについて説明します。
表25.7 OVN-Kubernetes ネットワークプラグインの JSON 設定テーブル
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
CNI 仕様のバージョン。必要な値は |
|
|
|
ネットワークの名前。これらのネットワークには namespace が使用されていません。たとえば、 |
|
|
|
設定する CNI プラグインの名前。必要な値は |
|
|
|
ネットワークのトポロジー設定。必要な値は |
|
|
|
クラスター全体のネットワークに使用するサブネット。
|
|
|
|
最大転送単位 (MTU) を指定された値。デフォルト値 |
|
|
|
この設定が含まれるネットワーク接続定義オブジェクトのメタデータ |
|
|
| CIDR と IP のコンマ区切りリスト。IP は割り当て可能な IP プールから削除され、Pod に渡されることはありません。省略した場合、ネットワークを実装する論理スイッチはレイヤー 2 通信のみを提供し、ユーザーは Pod の IP を設定する必要があります。ポートセキュリティーは、MAC スプーフィングのみを防止します。 |
25.2.3.6.2. スイッチドトポロジーの設定
スイッチド (レイヤー 2) トポロジーネットワークは、クラスター全体の論理スイッチを介してワークロードを相互接続します。この設定は、IPv6 およびデュアルスタックデプロイメントに使用できます。
レイヤー 2 スイッチドトポロジーネットワークでは、クラスター内の Pod 間のデータパケットの転送のみが許可されます。
次の NetworkAttachmentDefinition カスタムリソース定義 (CRD) YAML は、スイッチドセカンダリーネットワークを設定するために必要なフィールドを記述しています。
{
"cniVersion": "0.3.1",
"name": "l2-network",
"type": "ovn-k8s-cni-overlay",
"topology":"layer2",
"subnets": "10.100.200.0/24",
"mtu": 1300,
"netAttachDefName": "ns1/l2-network",
"excludeSubnets": "10.100.200.0/29"
}25.2.3.6.3. 追加ネットワーク用の Pod の設定
k8s.v1.cni.cncf.io/networks アノテーションを使用して、セカンダリーネットワーク割り当てを指定する必要があります。
次の例では、このガイドに示されている割り当て設定ごとに 1 つずつ、2 つのセカンダリー割り当てを持つ Pod をプロビジョニングします。
apiVersion: v1
kind: Pod
metadata:
annotations:
k8s.v1.cni.cncf.io/networks: l2-network
name: tinypod
namespace: ns1
spec:
containers:
- args:
- pause
image: k8s.gcr.io/e2e-test-images/agnhost:2.36
imagePullPolicy: IfNotPresent
name: agnhost-container25.2.3.6.4. 静的 IP アドレスを使用して Pod を設定する
次の例では、静的 IP アドレスを使用して Pod をプロビジョニングします。
- レイヤー 2 割り当てに対する Pod のセカンダリーネットワーク割り当ての IP アドレスのみを指定できます。
- Pod の静的 IP アドレスを指定できるのは、割り当て設定にサブネットが含まれていない場合のみです。
apiVersion: v1
kind: Pod
metadata:
annotations:
k8s.v1.cni.cncf.io/networks: '[
{
"name": "l2-network", 1
"mac": "02:03:04:05:06:07", 2
"interface": "myiface1", 3
"ips": [
"192.0.2.20/24"
] 4
}
]'
name: tinypod
namespace: ns1
spec:
containers:
- args:
- pause
image: k8s.gcr.io/e2e-test-images/agnhost:2.36
imagePullPolicy: IfNotPresent
name: agnhost-container25.2.4. 追加ネットワークの IP アドレス割り当ての設定
IPAM (IP アドレス管理) Container Network Interface (CNI) プラグインは、他の CNI プラグインの IP アドレスを提供します。
以下の IP アドレスの割り当てタイプを使用できます。
- 静的割り当て。
- DHCP サーバーを使用した動的割り当て。指定する DHCP サーバーは、追加のネットワークから到達可能である必要があります。
- Whereabouts IPAM CNI プラグインを使用した動的割り当て。
25.2.4.1. 静的 IP アドレス割り当ての設定
以下の表は、静的 IP アドレスの割り当ての設定について説明しています。
表25.8 ipam 静的設定オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
IPAM のアドレスタイプ。値 |
|
|
| 仮想インターフェイスに割り当てる IP アドレスを指定するオブジェクトの配列。IPv4 と IPv6 の IP アドレスの両方がサポートされます。 |
|
|
| Pod 内で設定するルートを指定するオブジェクトの配列です。 |
|
|
| オプション: DNS の設定を指定するオブジェクトの配列です。 |
addressesの配列には、以下のフィールドのあるオブジェクトが必要です。
表25.9 ipam.addresses[] 配列
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
指定する IP アドレスおよびネットワーク接頭辞。たとえば、 |
|
|
| egress ネットワークトラフィックをルーティングするデフォルトのゲートウェイ。 |
表25.10 ipam.routes[] 配列
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
CIDR 形式の IP アドレス範囲 ( |
|
|
| ネットワークトラフィックがルーティングされるゲートウェイ。 |
表25.11 ipam.dns オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
| DNS クエリーの送信先となる 1 つ以上の IP アドレスの配列。 |
|
|
|
ホスト名に追加するデフォルトのドメイン。たとえば、ドメインが |
|
|
|
DNS ルックアップのクエリー時に非修飾ホスト名に追加されるドメイン名の配列 (例: |
静的 IP アドレス割り当ての設定例
{
"ipam": {
"type": "static",
"addresses": [
{
"address": "191.168.1.7/24"
}
]
}
}
25.2.4.2. 動的 IP アドレス (DHCP) 割り当ての設定
以下の JSON は、DHCP を使用した動的 IP アドレスの割り当ての設定について説明しています。
Pod は、作成時に元の DHCP リースを取得します。リースは、クラスターで実行している最小限の DHCP サーバーデプロイメントで定期的に更新する必要があります。
DHCP サーバーのデプロイメントをトリガーするには、以下の例にあるように Cluster Network Operator 設定を編集して shim ネットワーク割り当てを作成する必要があります。
shim ネットワーク割り当ての定義例
apiVersion: operator.openshift.io/v1
kind: Network
metadata:
name: cluster
spec:
additionalNetworks:
- name: dhcp-shim
namespace: default
type: Raw
rawCNIConfig: |-
{
"name": "dhcp-shim",
"cniVersion": "0.3.1",
"type": "bridge",
"ipam": {
"type": "dhcp"
}
}
# ...
表25.12 ipam DHCP 設定オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
IPAM のアドレスタイプ。値 |
動的 IP アドレス (DHCP) 割り当ての設定例
{
"ipam": {
"type": "dhcp"
}
}
25.2.4.3. Whereabouts を使用した動的 IP アドレス割り当ての設定
Whereabouts CNI プラグインにより、DHCP サーバーを使用せずに IP アドレスを追加のネットワークに動的に割り当てることができます。
以下の表は、Whereabouts を使用した動的 IP アドレス割り当ての設定について説明しています。
表25.13 ipamwhereabouts 設定オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
IPAM のアドレスタイプ。値 |
|
|
| IP アドレスと範囲を CIDR 表記。IP アドレスは、この範囲内のアドレスから割り当てられます。 |
|
|
| オプション: CIDR 表記の IP アドレスと範囲 (0 個以上) のリスト。除外されたアドレス範囲内の IP アドレスは割り当てられません。 |
Whereabouts を使用する動的 IP アドレス割り当ての設定例
{
"ipam": {
"type": "whereabouts",
"range": "192.0.2.192/27",
"exclude": [
"192.0.2.192/30",
"192.0.2.196/32"
]
}
}
25.2.4.4. whereabouts-reconciler デーモンセットの作成
Whereabouts reconciler は、Whereabouts IP アドレス管理 (IPAM) ソリューションを使用して、クラスター内の Pod の動的 IP アドレス割り当てを管理します。これにより、各 Pod が指定の IP アドレス範囲から一意の IP アドレスを確実に取得します。また、Pod が削除またはスケールダウンされた場合の IP アドレスの解放も処理します。
NetworkAttachmentDefinition カスタムリソース (CR) を使用して動的 IP アドレスを割り当てることもできます。
whereabouts-reconciler デーモンセットは、Cluster Network Operator を通じて追加のネットワークを設定するときに自動的に作成されます。YAML マニフェストから追加のネットワークを設定する場合、これは自動的には作成されません。
whereabouts-reconciler デーモンセットのデプロイをトリガーするには、Cluster Network Operator のカスタムリソース (CR) ファイルを編集して、whereabouts-shim ネットワーク割り当てを手動で作成する必要があります。
whereabouts-reconciler デーモンセットをデプロイするには、次の手順を使用します。
手順
以下のコマンドを実行して、
Network.operator.openshift.ioカスタムリソース (CR) を編集します。$ oc edit network.operator.openshift.io cluster
この例で展開されている YAML の
additionalNetworksセクションを、カスタムリソース (CR) のspec定義内に含めます。apiVersion: operator.openshift.io/v1 kind: Network metadata: name: cluster # ... spec: additionalNetworks: - name: whereabouts-shim namespace: default rawCNIConfig: |- { "name": "whereabouts-shim", "cniVersion": "0.3.1", "type": "bridge", "ipam": { "type": "whereabouts" } } type: Raw # ...- ファイルを保存し、テキストエディターを編集します。
次のコマンドを実行して、
whereabouts-reconcilerデーモンセットが正常にデプロイされたことを確認します。$ oc get all -n openshift-multus | grep whereabouts-reconciler
出力例
pod/whereabouts-reconciler-jnp6g 1/1 Running 0 6s pod/whereabouts-reconciler-k76gg 1/1 Running 0 6s pod/whereabouts-reconciler-k86t9 1/1 Running 0 6s pod/whereabouts-reconciler-p4sxw 1/1 Running 0 6s pod/whereabouts-reconciler-rvfdv 1/1 Running 0 6s pod/whereabouts-reconciler-svzw9 1/1 Running 0 6s daemonset.apps/whereabouts-reconciler 6 6 6 6 6 kubernetes.io/os=linux 6s
25.2.4.5. Whereabouts IP リコンサイラーのスケジュールの設定
Whereabouts IPAM CNI プラグインは、IP リコンサイラーを毎日実行します。このプロセスは、IP が枯渇して新しい Pod に IP が割り当てられなくなる状態を避けるために、完了せずに残っている IP 割り当てをクリーンアップします。
IP リコンサイラーを実行する頻度を変更するには、次の手順を使用します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
whereabouts-reconcilerデーモンセットがデプロイされており、whereabouts-reconcilerPod が起動して実行されている。
手順
次のコマンドを実行して、IP リコンサイラー用の特定の cron 式を使用し、
openshift-multusnamespace にwhereabouts-configという名前のConfigMapオブジェクトを作成します。$ oc create configmap whereabouts-config -n openshift-multus --from-literal=reconciler_cron_expression="*/15 * * * *"
この cron 式は、IP リコンサイラーを 15 分ごとに実行するよう指定します。この式は固有の要件に基づいて調整してください。
注記whereabouts-reconcilerデーモンセットは、5 つのアスタリスクを含む cron 式パターンのみを使用できます。秒を表すために使用される 6 番目のアスタリスクは、現在サポートされていません。次のコマンドを実行して、
openshift-multusnamespace 内のwhereabouts-reconcilerデーモンセットおよび Pod に関連するリソースに関する情報を取得します。$ oc get all -n openshift-multus | grep whereabouts-reconciler
出力例
pod/whereabouts-reconciler-2p7hw 1/1 Running 0 4m14s pod/whereabouts-reconciler-76jk7 1/1 Running 0 4m14s pod/whereabouts-reconciler-94zw6 1/1 Running 0 4m14s pod/whereabouts-reconciler-mfh68 1/1 Running 0 4m14s pod/whereabouts-reconciler-pgshz 1/1 Running 0 4m14s pod/whereabouts-reconciler-xn5xz 1/1 Running 0 4m14s daemonset.apps/whereabouts-reconciler 6 6 6 6 6 kubernetes.io/os=linux 4m16s
次のコマンドを実行して、設定した間隔で
whereabouts-reconcilerPod が IP リコンサイラーを実行していることを確認します。$ oc -n openshift-multus logs whereabouts-reconciler-2p7hw
出力例
2024-02-02T16:33:54Z [debug] event not relevant: "/cron-schedule/..2024_02_02_16_33_54.1375928161": CREATE 2024-02-02T16:33:54Z [debug] event not relevant: "/cron-schedule/..2024_02_02_16_33_54.1375928161": CHMOD 2024-02-02T16:33:54Z [debug] event not relevant: "/cron-schedule/..data_tmp": RENAME 2024-02-02T16:33:54Z [verbose] using expression: */15 * * * * 2024-02-02T16:33:54Z [verbose] configuration updated to file "/cron-schedule/..data". New cron expression: */15 * * * * 2024-02-02T16:33:54Z [verbose] successfully updated CRON configuration id "00c2d1c9-631d-403f-bb86-73ad104a6817" - new cron expression: */15 * * * * 2024-02-02T16:33:54Z [debug] event not relevant: "/cron-schedule/config": CREATE 2024-02-02T16:33:54Z [debug] event not relevant: "/cron-schedule/..2024_02_02_16_26_17.3874177937": REMOVE 2024-02-02T16:45:00Z [verbose] starting reconciler run 2024-02-02T16:45:00Z [debug] NewReconcileLooper - inferred connection data 2024-02-02T16:45:00Z [debug] listing IP pools 2024-02-02T16:45:00Z [debug] no IP addresses to cleanup 2024-02-02T16:45:00Z [verbose] reconciler success
25.2.5. Cluster Network Operator による追加ネットワーク割り当ての作成
Cluster Network Operator (CNO) は追加ネットワークの定義を管理します。作成する追加ネットワークを指定する場合、CNO は NetworkAttachmentDefinition オブジェクトを自動的に作成します。
Cluster Network Operator が管理する NetworkAttachmentDefinition オブジェクトは編集しないでください。これを実行すると、追加ネットワークのネットワークトラフィックが中断する可能性があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
オプション: 追加のネットワークの namespace を作成します。
$ oc create namespace <namespace_name>
CNO 設定を編集するには、以下のコマンドを入力します。
$ oc edit networks.operator.openshift.io cluster
以下のサンプル CR のように、作成される追加ネットワークの設定を追加して、作成している CR を変更します。
apiVersion: operator.openshift.io/v1 kind: Network metadata: name: cluster spec: # ... additionalNetworks: - name: tertiary-net namespace: namespace2 type: Raw rawCNIConfig: |- { "cniVersion": "0.3.1", "name": "tertiary-net", "type": "ipvlan", "master": "eth1", "mode": "l2", "ipam": { "type": "static", "addresses": [ { "address": "192.168.1.23/24" } ] } }- 変更を保存し、テキストエディターを終了して、変更をコミットします。
検証
以下のコマンドを実行して、CNO が
NetworkAttachmentDefinitionオブジェクトを作成していることを確認します。CNO がオブジェクトを作成するまでに遅延が生じる可能性があります。$ oc get network-attachment-definitions -n <namespace>
ここでは、以下のようになります。
<namespace>- CNO の設定に追加したネットワーク割り当ての namespace を指定します。
出力例
NAME AGE test-network-1 14m
25.2.6. YAML マニフェストを適用した追加のネットワーク割り当ての作成
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
以下の例のように、追加のネットワーク設定を含む YAML ファイルを作成します。
apiVersion: k8s.cni.cncf.io/v1 kind: NetworkAttachmentDefinition metadata: name: next-net spec: config: |- { "cniVersion": "0.3.1", "name": "work-network", "type": "host-device", "device": "eth1", "ipam": { "type": "dhcp" } }追加のネットワークを作成するには、次のコマンドを入力します。
$ oc apply -f <file>.yaml
ここでは、以下のようになります。
<file>- YAML マニフェストを含むファイルの名前を指定します。
25.3. 仮想ルーティングおよび転送について
25.3.1. 仮想ルーティングおよび転送について
VRF (Virtual Routing and Forwarding) デバイスは IP ルールとの組み合わせにより、仮想ルーティングと転送ドメインを作成する機能を提供します。VRF は、CNF で必要なパーミッションの数を減らし、セカンダリーネットワークのネットワークトポロジーの可視性を強化します。VRF はマルチテナンシー機能を提供するために使用されます。たとえば、この場合、各テナントには固有のルーティングテーブルがあり、異なるデフォルトゲートウェイが必要です。
プロセスは、ソケットを VRF デバイスにバインドできます。バインドされたソケット経由のパケットは、VRF デバイスに関連付けられたルーティングテーブルを使用します。VRF の重要な機能として、これは OSI モデルレイヤー 3 以上にのみ影響を与えるため、LLDP などの L2 ツールは影響を受けません。これにより、ポリシーベースのルーティングなどの優先度の高い IP ルールが、特定のトラフィックを転送する VRF デバイスルールよりも優先されます。
25.3.1.1. Telecommunications Operator についての Pod のセカンダリーネットワークの利点
通信のユースケースでは、各 CNF が同じアドレス空間を共有する複数の異なるネットワークに接続される可能性があります。これらのセカンダリーネットワークは、クラスターのメインネットワーク CIDR と競合する可能性があります。CNI VRF プラグインを使用すると、ネットワーク機能は、同じ IP アドレスを使用して異なるユーザーのインフラストラクチャーに接続でき、複数の異なるお客様の分離された状態を維持します。IP アドレスは OpenShift Container Platform の IP スペースと重複します。CNI VRF プラグインは、CNF で必要なパーミッションの数も減らし、セカンダリーネットワークのネットワークトポロジーの可視性を高めます。
25.4. マルチネットワークポリシーの設定
クラスター管理者は、追加のネットワーク用にマルチネットワークを設定できます。SR-IOV および macvlan 追加ネットワークのマルチネットワークポリシーを指定できます。Macvlan 追加ネットワークは完全にサポートされています。ipvlan などの他の追加のネットワークタイプはサポートされていません。
SR-IOV 追加ネットワークのマルチネットワークポリシー設定のサポートはテクノロジープレビュー機能であり、カーネルネットワークインターフェイスカード (NIC) でのみサポートされます。SR-IOV は、データプレーン開発キット (DPDK) アプリケーションではサポートされていません。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
設定されたネットワークポリシーは、IPv6 ネットワークでは無視されます。
25.4.1. マルチネットワークポリシーとネットワークポリシーの違い
MultiNetworkPolicy API は、NetworkPolicy API を実装していますが、いくつかの重要な違いがあります。
以下の場合は、
MultiNetworkPolicyAPI を使用する必要があります。apiVersion: k8s.cni.cncf.io/v1beta1 kind: MultiNetworkPolicy
-
CLI を使用してマルチネットワークポリシーと対話する場合は、
multi-networkpolicyリソース名を使用する必要があります。たとえば、oc get multi-networkpolicy <name>コマンドを使用してマルチネットワークポリシーオブジェクトを表示できます。ここで、<name>はマルチネットワークポリシーの名前になります。 macvlan または SR-IOV 追加ネットワークを定義するネットワーク割り当て定義の名前でアノテーションを指定する必要があります。
apiVersion: k8s.cni.cncf.io/v1beta1 kind: MultiNetworkPolicy metadata: annotations: k8s.v1.cni.cncf.io/policy-for: <network_name>ここでは、以下のようになります。
<network_name>- ネットワーク割り当て定義の名前を指定します。
25.4.2. クラスターのマルチネットワークポリシーの有効化
クラスター管理者は、クラスターでマルチネットワークポリシーのサポートを有効にすることができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインする。
手順
以下の YAML で
multinetwork-enable-patch.yamlファイルを作成します。apiVersion: operator.openshift.io/v1 kind: Network metadata: name: cluster spec: useMultiNetworkPolicy: true
マルチネットワークポリシーを有効にするようにクラスターを設定します。
$ oc patch network.operator.openshift.io cluster --type=merge --patch-file=multinetwork-enable-patch.yaml
出力例
network.operator.openshift.io/cluster patched
25.4.3. マルチネットワークポリシーの使用
クラスター管理者は、マルチネットワークポリシーを作成、編集、表示、および削除することができます。
25.4.3.1. 前提条件
- クラスターのマルチネットワークポリシーサポートを有効にしている。
25.4.3.2. CLI を使用したマルチネットワークポリシーの作成
マルチネットワークポリシーを作成し、クラスターの namespace に許可される Ingress または egress ネットワークトラフィックを記述する詳細なルールを定義することができます。
前提条件
-
クラスターは、
NetworkPolicyオブジェクトをサポートするネットワークプラグイン (mode: NetworkPolicyが設定された OVN-Kubernetes ネットワークプラグインや OpenShift SDN ネットワークプラグインなど) を使用します。このモードは OpenShiftSDN のデフォルトです。 -
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインしている。 - マルチネットワークポリシーが適用される namespace で作業していること。
手順
ポリシールールを作成します。
<policy_name>.yamlファイルを作成します。$ touch <policy_name>.yaml
ここでは、以下のようになります。
<policy_name>- マルチネットワークポリシーのファイル名を指定します。
作成したばかりのファイルで、以下の例のようなマルチネットワークポリシーを定義します。
すべての namespace のすべての Pod から ingress を拒否します。
これは基本的なポリシーであり、他のネットワークポリシーの設定によって許可されたクロス Pod トラフィック以外のすべてのクロス Pod ネットワーキングをブロックします。
apiVersion: k8s.cni.cncf.io/v1beta1 kind: MultiNetworkPolicy metadata: name: deny-by-default annotations: k8s.v1.cni.cncf.io/policy-for: <network_name> spec: podSelector: ingress: []ここでは、以下のようになります。
<network_name>- ネットワーク割り当て定義の名前を指定します。
同じ namespace のすべての Pod から ingress を許可します。
apiVersion: k8s.cni.cncf.io/v1beta1 kind: MultiNetworkPolicy metadata: name: allow-same-namespace annotations: k8s.v1.cni.cncf.io/policy-for: <network_name> spec: podSelector: ingress: - from: - podSelector: {}ここでは、以下のようになります。
<network_name>- ネットワーク割り当て定義の名前を指定します。
特定のnamespaceから 1 つの Pod への上りトラフィックを許可する
このポリシーは、
namespace-yで実行されている Pod からpod-aというラベルの付いた Pod へのトラフィックを許可します。apiVersion: k8s.cni.cncf.io/v1beta1 kind: MultiNetworkPolicy metadata: name: allow-traffic-pod annotations: k8s.v1.cni.cncf.io/policy-for: <network_name> spec: podSelector: matchLabels: pod: pod-a policyTypes: - Ingress ingress: - from: - namespaceSelector: matchLabels: kubernetes.io/metadata.name: namespace-yここでは、以下のようになります。
<network_name>- ネットワーク割り当て定義の名前を指定します。
サービスへのトラフィックを制限する
このポリシーを適用すると、
app=bookstoreとrole=apiの両方のラベルを持つすべての Pod に、app=bookstoreというラベルを持つ Pod のみがアクセスできるようになります。この例では、アプリケーションは、ラベルapp=bookstoreおよびrole=apiでマークされた REST API サーバーである可能性があります。この例では、次のユースケースに対応します。
- サービスへのトラフィックを、それを使用する必要がある他のマイクロサービスのみに制限します。
データベースへの接続を制限して、それを使用するアプリケーションのみを許可します。
apiVersion: k8s.cni.cncf.io/v1beta1 kind: MultiNetworkPolicy metadata: name: api-allow annotations: k8s.v1.cni.cncf.io/policy-for: <network_name> spec: podSelector: matchLabels: app: bookstore role: api ingress: - from: - podSelector: matchLabels: app: bookstoreここでは、以下のようになります。
<network_name>- ネットワーク割り当て定義の名前を指定します。
マルチネットワークポリシーオブジェクトを作成するには、以下のコマンドを入力します。
$ oc apply -f <policy_name>.yaml -n <namespace>
ここでは、以下のようになります。
<policy_name>- マルチネットワークポリシーのファイル名を指定します。
<namespace>- オプション: オブジェクトが現在の namespace 以外の namespace に定義されている場合は namespace を指定します。
出力例
multinetworkpolicy.k8s.cni.cncf.io/deny-by-default created
cluster-admin 権限で Web コンソールにログインする場合、YAML で、または Web コンソールのフォームから、クラスターの任意の namespace でネットワークポリシーを直接作成できます。
25.4.3.3. マルチネットワークポリシーの編集
namespace のマルチネットワークポリシーを編集できます。
前提条件
-
クラスターは、
NetworkPolicyオブジェクトをサポートするネットワークプラグイン (mode: NetworkPolicyが設定された OVN-Kubernetes ネットワークプラグインや OpenShift SDN ネットワークプラグインなど) を使用します。このモードは OpenShiftSDN のデフォルトです。 -
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインしている。 - マルチネットワークポリシーが存在する namespace で作業している。
手順
オプション: namespace のマルチネットワークポリシーオブジェクトをリスト表示するには、以下のコマンドを入力します。
$ oc get multi-networkpolicy
ここでは、以下のようになります。
<namespace>- オプション: オブジェクトが現在の namespace 以外の namespace に定義されている場合は namespace を指定します。
マルチネットワークポリシーオブジェクトを編集します。
マルチネットワークポリシーの定義をファイルに保存した場合は、ファイルを編集して必要な変更を加えてから、以下のコマンドを入力します。
$ oc apply -n <namespace> -f <policy_file>.yaml
ここでは、以下のようになります。
<namespace>- オプション: オブジェクトが現在の namespace 以外の namespace に定義されている場合は namespace を指定します。
<policy_file>- ネットワークポリシーを含むファイルの名前を指定します。
マルチネットワークポリシーオブジェクトを直接更新する必要がある場合、以下のコマンドを入力できます。
$ oc edit multi-networkpolicy <policy_name> -n <namespace>
ここでは、以下のようになります。
<policy_name>- ネットワークポリシーの名前を指定します。
<namespace>- オプション: オブジェクトが現在の namespace 以外の namespace に定義されている場合は namespace を指定します。
マルチネットワークポリシーオブジェクトが更新されていることを確認します。
$ oc describe multi-networkpolicy <policy_name> -n <namespace>
ここでは、以下のようになります。
<policy_name>- マルチネットワークポリシーの名前を指定します。
<namespace>- オプション: オブジェクトが現在の namespace 以外の namespace に定義されている場合は namespace を指定します。
cluster-admin 権限で Web コンソールにログインする場合、YAML で、または Web コンソールの Actions メニューのポリシーから、クラスターの任意の namespace でネットワークポリシーを直接編集できます。
25.4.3.4. CLI を使用したマルチネットワークポリシーの表示
namespace のマルチネットワークポリシーを検査できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインしている。 - マルチネットワークポリシーが存在する namespace で作業している。
手順
namespace のマルチネットワークポリシーをリスト表示します。
namespace で定義されたマルチネットワークポリシーオブジェクトを表示するには、以下のコマンドを実行します。
$ oc get multi-networkpolicy
オプション: 特定のマルチネットワークポリシーを検査するには、以下のコマンドを入力します。
$ oc describe multi-networkpolicy <policy_name> -n <namespace>
ここでは、以下のようになります。
<policy_name>- 検査するマルチネットワークポリシーの名前を指定します。
<namespace>- オプション: オブジェクトが現在の namespace 以外の namespace に定義されている場合は namespace を指定します。
cluster-admin 権限で Web コンソールにログインする場合、YAML で、または Web コンソールのフォームから、クラスターの任意の namespace でネットワークポリシーを直接表示できます。
25.4.3.5. CLI を使用したマルチネットワークポリシーの削除
namespace のマルチネットワークポリシーを削除できます。
前提条件
-
クラスターは、
NetworkPolicyオブジェクトをサポートするネットワークプラグイン (mode: NetworkPolicyが設定された OVN-Kubernetes ネットワークプラグインや OpenShift SDN ネットワークプラグインなど) を使用します。このモードは OpenShiftSDN のデフォルトです。 -
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインしている。 - マルチネットワークポリシーが存在する namespace で作業している。
手順
マルチネットワークポリシーオブジェクトを削除するには、以下のコマンドを入力します。
$ oc delete multi-networkpolicy <policy_name> -n <namespace>
ここでは、以下のようになります。
<policy_name>- マルチネットワークポリシーの名前を指定します。
<namespace>- オプション: オブジェクトが現在の namespace 以外の namespace に定義されている場合は namespace を指定します。
出力例
multinetworkpolicy.k8s.cni.cncf.io/default-deny deleted
cluster-admin 権限で Web コンソールにログインする場合、YAML で、または Web コンソールの Actions メニューのポリシーから、クラスターの任意の namespace でネットワークポリシーを直接削除できます。
25.4.3.6. デフォルトのすべてのマルチネットワーク拒否ポリシーの作成
これは基本的なポリシーであり、他のデプロイメントされたネットワークポリシーの設定によって許可されたネットワークトラフィック以外のすべてのクロス Pod ネットワークをブロックします。この手順では、デフォルトの deny-by-default ポリシーを適用します。
cluster-admin ロールを持つユーザーでログインしている場合、クラスター内の任意の namespace でネットワークポリシーを作成できます。
前提条件
-
クラスターは、
NetworkPolicyオブジェクトをサポートするネットワークプラグイン (mode: NetworkPolicyが設定された OVN-Kubernetes ネットワークプラグインや OpenShift SDN ネットワークプラグインなど) を使用します。このモードは OpenShiftSDN のデフォルトです。 -
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインしている。 - マルチネットワークポリシーが適用される namespace で作業していること。
手順
すべての namespace におけるすべての Pod からの ingress を拒否する
deny-by-defaultポリシーを定義する次の YAML を作成します。YAML をdeny-by-default.yamlファイルに保存します。apiVersion: k8s.cni.cncf.io/v1beta1 kind: MultiNetworkPolicy metadata: name: deny-by-default namespace: default 1 annotations: k8s.v1.cni.cncf.io/policy-for: <network_name> 2 spec: podSelector: {} 3 ingress: [] 4
次のコマンドを入力して、ポリシーを適用します。
$ oc apply -f deny-by-default.yaml
出力例
multinetworkpolicy.k8s.cni.cncf.io/deny-by-default created
25.4.3.7. 外部クライアントからのトラフィックを許可するマルチネットワークポリシーの作成
deny-by-default ポリシーを設定すると、外部クライアントからラベル app=web を持つ Pod へのトラフィックを許可するポリシーの設定に進むことができます。
cluster-admin ロールを持つユーザーでログインしている場合、クラスター内の任意の namespace でネットワークポリシーを作成できます。
この手順に従って、パブリックインターネットから直接、またはロードバランサーを使用して Pod にアクセスすることにより、外部サービスを許可するポリシーを設定します。トラフィックは、ラベル app=web を持つ Pod にのみ許可されます。
前提条件
-
クラスターは、
NetworkPolicyオブジェクトをサポートするネットワークプラグイン (mode: NetworkPolicyが設定された OVN-Kubernetes ネットワークプラグインや OpenShift SDN ネットワークプラグインなど) を使用します。このモードは OpenShiftSDN のデフォルトです。 -
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインしている。 - マルチネットワークポリシーが適用される namespace で作業していること。
手順
パブリックインターネットからのトラフィックが直接、またはロードバランサーを使用して Pod にアクセスできるようにするポリシーを作成します。YAML を
web-allow-external.yamlファイルに保存します。apiVersion: k8s.cni.cncf.io/v1beta1 kind: MultiNetworkPolicy metadata: name: web-allow-external namespace: default annotations: k8s.v1.cni.cncf.io/policy-for: <network_name> spec: policyTypes: - Ingress podSelector: matchLabels: app: web ingress: - {}次のコマンドを入力して、ポリシーを適用します。
$ oc apply -f web-allow-external.yaml
出力例
multinetworkpolicy.k8s.cni.cncf.io/web-allow-external created
このポリシーは、次の図に示すように、外部トラフィックを含むすべてのリソースからのトラフィックを許可します。
25.4.3.8. すべてのnamespaceからアプリケーションへのトラフィックを許可するマルチネットワークポリシーの作成
cluster-admin ロールを持つユーザーでログインしている場合、クラスター内の任意の namespace でネットワークポリシーを作成できます。
この手順に従って、すべてのnamespace内のすべての Pod から特定のアプリケーションへのトラフィックを許可するポリシーを設定します。
前提条件
-
クラスターは、
NetworkPolicyオブジェクトをサポートするネットワークプラグイン (mode: NetworkPolicyが設定された OVN-Kubernetes ネットワークプラグインや OpenShift SDN ネットワークプラグインなど) を使用します。このモードは OpenShiftSDN のデフォルトです。 -
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインしている。 - マルチネットワークポリシーが適用される namespace で作業していること。
手順
すべてのnamespaceのすべての Pod から特定のアプリケーションへのトラフィックを許可するポリシーを作成します。YAML を
web-allow-all-namespaces.yamlファイルに保存します。apiVersion: k8s.cni.cncf.io/v1beta1 kind: MultiNetworkPolicy metadata: name: web-allow-all-namespaces namespace: default annotations: k8s.v1.cni.cncf.io/policy-for: <network_name> spec: podSelector: matchLabels: app: web 1 policyTypes: - Ingress ingress: - from: - namespaceSelector: {} 2注記デフォルトでは、
namespaceSelectorの指定を省略した場合、namespace は選択されません。つまり、ポリシーは、ネットワークポリシーがデプロイされている namespace からのトラフィックのみを許可します。次のコマンドを入力して、ポリシーを適用します。
$ oc apply -f web-allow-all-namespaces.yaml
出力例
multinetworkpolicy.k8s.cni.cncf.io/web-allow-all-namespaces created
検証
次のコマンドを入力して、
defaultnamespace で Web サービスを開始します。$ oc run web --namespace=default --image=nginx --labels="app=web" --expose --port=80
次のコマンドを実行して、
alpineイメージをsecondarynamespace にデプロイし、シェルを開始します。$ oc run test-$RANDOM --namespace=secondary --rm -i -t --image=alpine -- sh
シェルで次のコマンドを実行し、リクエストが許可されていることを確認します。
# wget -qO- --timeout=2 http://web.default
予想される出力
<!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> html { color-scheme: light dark; } body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html>
25.4.3.9. namespaceからアプリケーションへのトラフィックを許可するマルチネットワークポリシーの作成
cluster-admin ロールを持つユーザーでログインしている場合、クラスター内の任意の namespace でネットワークポリシーを作成できます。
特定の namespace からラベル app=web を持つ Pod へのトラフィックを許可するポリシーを設定するには、次の手順に従います。以下の場合にこれを行うことができます。
- 運用データベースへのトラフィックを、運用ワークロードがデプロイされているnamespaceのみに制限します。
- 特定のnamespaceにデプロイされた監視ツールを有効にして、現在のnamespaceからメトリックをスクレイピングします。
前提条件
-
クラスターは、
NetworkPolicyオブジェクトをサポートするネットワークプラグイン (mode: NetworkPolicyが設定された OVN-Kubernetes ネットワークプラグインや OpenShift SDN ネットワークプラグインなど) を使用します。このモードは OpenShiftSDN のデフォルトです。 -
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインしている。 - マルチネットワークポリシーが適用される namespace で作業していること。
手順
ラベルが
purpose=productionの特定の namespace 内にあるすべての Pod からのトラフィックを許可するポリシーを作成します。YAML をweb-allow-prod.yamlファイルに保存します。apiVersion: k8s.cni.cncf.io/v1beta1 kind: MultiNetworkPolicy metadata: name: web-allow-prod namespace: default annotations: k8s.v1.cni.cncf.io/policy-for: <network_name> spec: podSelector: matchLabels: app: web 1 policyTypes: - Ingress ingress: - from: - namespaceSelector: matchLabels: purpose: production 2次のコマンドを入力して、ポリシーを適用します。
$ oc apply -f web-allow-prod.yaml
出力例
multinetworkpolicy.k8s.cni.cncf.io/web-allow-prod created
検証
次のコマンドを入力して、
defaultnamespace で Web サービスを開始します。$ oc run web --namespace=default --image=nginx --labels="app=web" --expose --port=80
次のコマンドを実行して、
prodnamespace を作成します。$ oc create namespace prod
次のコマンドを実行して、
prodnamespace にラベルを付けます。$ oc label namespace/prod purpose=production
次のコマンドを実行して、
devnamespace を作成します。$ oc create namespace dev
次のコマンドを実行して、
devnamespace にラベルを付けます。$ oc label namespace/dev purpose=testing
次のコマンドを実行して、
alpineイメージをdevnamespace にデプロイし、シェルを開始します。$ oc run test-$RANDOM --namespace=dev --rm -i -t --image=alpine -- sh
シェルで次のコマンドを実行し、リクエストがブロックされていることを確認します。
# wget -qO- --timeout=2 http://web.default
予想される出力
wget: download timed out
次のコマンドを実行して、
alpineイメージをprodnamespace にデプロイし、シェルを開始します。$ oc run test-$RANDOM --namespace=prod --rm -i -t --image=alpine -- sh
シェルで次のコマンドを実行し、リクエストが許可されていることを確認します。
# wget -qO- --timeout=2 http://web.default
予想される出力
<!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> html { color-scheme: light dark; } body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html>
25.4.4. 関連情報
25.5. Pod の追加のネットワークへの割り当て
クラスターユーザーとして、Pod を追加のネットワークに割り当てることができます。
25.5.1. Pod の追加ネットワークへの追加
Pod を追加のネットワークに追加できます。Pod は、デフォルトネットワークで通常のクラスター関連のネットワークトラフィックを継続的に送信します。
Pod が作成されると、追加のネットワークが割り当てられます。ただし、Pod がすでに存在する場合は、追加のネットワークをこれに割り当てることはできません。
Pod が追加ネットワークと同じ namespace にあること。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - クラスターにログインする。
手順
アノテーションを
Podオブジェクトに追加します。以下のアノテーション形式のいずれかのみを使用できます。カスタマイズせずに追加ネットワークを割り当てるには、以下の形式でアノテーションを追加します。
<network>を、Pod に関連付ける追加ネットワークの名前に置き換えます。metadata: annotations: k8s.v1.cni.cncf.io/networks: <network>[,<network>,...] 1- 1
- 複数の追加ネットワークを指定するには、各ネットワークをコンマで区切ります。コンマの間にはスペースを入れないでください。同じ追加ネットワークを複数回指定した場合、Pod は複数のネットワークインターフェイスをそのネットワークに割り当てます。
カスタマイズして追加のネットワークを割り当てるには、以下の形式でアノテーションを追加します。
metadata: annotations: k8s.v1.cni.cncf.io/networks: |- [ { "name": "<network>", 1 "namespace": "<namespace>", 2 "default-route": ["<default-route>"] 3 } ]
Pod を作成するには、以下のコマンドを入力します。
<name>を Pod の名前に置き換えます。$ oc create -f <name>.yaml
オプション: アノテーションが
PodCR に存在することを確認するには、<name>を Pod の名前に置き換えて、以下のコマンドを入力します。$ oc get pod <name> -o yaml
以下の例では、
example-podPod が追加ネットワークのnet1に割り当てられています。$ oc get pod example-pod -o yaml apiVersion: v1 kind: Pod metadata: annotations: k8s.v1.cni.cncf.io/networks: macvlan-bridge k8s.v1.cni.cncf.io/network-status: |- 1 [{ "name": "openshift-sdn", "interface": "eth0", "ips": [ "10.128.2.14" ], "default": true, "dns": {} },{ "name": "macvlan-bridge", "interface": "net1", "ips": [ "20.2.2.100" ], "mac": "22:2f:60:a5:f8:00", "dns": {} }] name: example-pod namespace: default spec: ... status: ...- 1
k8s.v1.cni.cncf.io/network-statusパラメーターは、オブジェクトの JSON 配列です。各オブジェクトは、Pod に割り当てられる追加のネットワークのステータスについて説明します。アノテーションの値はプレーンテキストの値として保存されます。
25.5.1.1. Pod 固有のアドレスおよびルーティングオプションの指定
Pod を追加のネットワークに割り当てる場合、特定の Pod でそのネットワークに関するその他のプロパティーを指定する必要がある場合があります。これにより、ルーティングの一部を変更することができ、静的 IP アドレスおよび MAC アドレスを指定できます。これを実行するには、JSON 形式のアノテーションを使用できます。
前提条件
- Pod が追加ネットワークと同じ namespace にあること。
-
OpenShift CLI (
oc) がインストールされている。 - クラスターにログインすること。
手順
アドレスおよび/またはルーティングオプションを指定する間に Pod を追加のネットワークに追加するには、以下の手順を実行します。
Podリソース定義を編集します。既存のPodリソースを編集する場合は、以下のコマンドを実行してデフォルトエディターでその定義を編集します。<name>を、編集するPodリソースの名前に置き換えます。$ oc edit pod <name>
Podリソース定義で、k8s.v1.cni.cncf.io/networksパラメーターを Pod のmetadataマッピングに追加します。k8s.v1.cni.cncf.io/networksは、追加のプロパティーを指定するだけでなく、NetworkAttachmentDefinitionカスタムリソース (CR) 名を参照するオブジェクトリストの JSON 文字列を受け入れます。metadata: annotations: k8s.v1.cni.cncf.io/networks: '[<network>[,<network>,...]]' 1- 1
<network>を、以下の例にあるように JSON オブジェクトに置き換えます。一重引用符が必要です。
以下の例では、アノテーションで
default-routeパラメーターを使用して、デフォルトルートを持つネットワーク割り当てを指定します。apiVersion: v1 kind: Pod metadata: name: example-pod annotations: k8s.v1.cni.cncf.io/networks: '[ { "name": "net1" }, { "name": "net2", 1 "default-route": ["192.0.2.1"] 2 }]' spec: containers: - name: example-pod command: ["/bin/bash", "-c", "sleep 2000000000000"] image: centos/tools
デフォルトのルートにより、他のルートに指定されていないトラフィックがゲートウェイにルーティングされます。
OpenShift Container Platform のデフォルトのネットワークインターフェイス以外のインターフェイスへのデフォルトのルートを設定すると、Pod 間のトラフィックについて予想されるトラフィックが別のインターフェイスでルーティングされる可能性があります。
Pod のルーティングプロパティーを確認する場合、oc コマンドを Pod 内で ip コマンドを実行するために使用できます。
$ oc exec -it <pod_name> -- ip route
また、Pod の k8s.v1.cni.cncf.io/network-status を参照して、JSON 形式の一覧のオブジェクトで default-route キーの有無を確認し、デフォルトルートが割り当てられている追加ネットワークを確認することができます。
Pod に静的 IP アドレスまたは MAC アドレスを設定するには、JSON 形式のアノテーションを使用できます。これには、この機能をとくに許可するネットワークを作成する必要があります。これは、CNO の rawCNIConfig で指定できます。
以下のコマンドを実行して CNO CR を編集します。
$ oc edit networks.operator.openshift.io cluster
以下の YAML は、CNO の設定パラメーターについて説明しています。
Cluster Network Operator YAML の設定
name: <name> 1 namespace: <namespace> 2 rawCNIConfig: '{ 3 ... }' type: Raw
以下のオブジェクトは、macvlan CNI プラグインを使用して静的 MAC アドレスと IP アドレスを使用するための設定パラメーターについて説明しています。
静的 IP および MAC アドレスを使用した macvlan CNI プラグイン JSON 設定オブジェクト
{
"cniVersion": "0.3.1",
"name": "<name>", 1
"plugins": [{ 2
"type": "macvlan",
"capabilities": { "ips": true }, 3
"master": "eth0", 4
"mode": "bridge",
"ipam": {
"type": "static"
}
}, {
"capabilities": { "mac": true }, 5
"type": "tuning"
}]
}
上記のネットワーク割り当ては、特定の Pod に割り当てられる静的 IP アドレスと MAC アドレスを指定するキーと共に、JSON 形式のアノテーションで参照できます。
以下を使用して Pod を編集します。
$ oc edit pod <name>
静的 IP および MAC アドレスを使用した macvlan CNI プラグイン JSON 設定オブジェクト
apiVersion: v1
kind: Pod
metadata:
name: example-pod
annotations:
k8s.v1.cni.cncf.io/networks: '[
{
"name": "<name>", 1
"ips": [ "192.0.2.205/24" ], 2
"mac": "CA:FE:C0:FF:EE:00" 3
}
]'
静的 IP アドレスおよび MAC アドレスを同時に使用することはできません。これらは個別に使用することも、一緒に使用することもできます。
追加のネットワークを持つ Pod の IP アドレスと MAC プロパティーを検証するには、oc コマンドを使用して Pod 内で ip コマンドを実行します。
$ oc exec -it <pod_name> -- ip a
25.6. 追加ネットワークからの Pod の削除
クラスターユーザーとして、追加のネットワークから Pod を削除できます。
25.6.1. 追加ネットワークからの Pod の削除
Pod を削除するだけで、追加のネットワークから Pod を削除できます。
前提条件
- 追加のネットワークが Pod に割り当てられている。
-
OpenShift CLI (
oc) がインストールされている。 - クラスターにログインする。
手順
Pod を削除するには、以下のコマンドを入力します。
$ oc delete pod <name> -n <namespace>
-
<name>は Pod の名前です。 -
<namespace>は Pod が含まれる namespace です。
-
25.7. 追加ネットワークの編集
クラスター管理者は、既存の追加ネットワークの設定を変更することができます。
25.7.1. 追加ネットワーク割り当て定義の変更
クラスター管理者は、既存の追加ネットワークに変更を加えることができます。追加ネットワークに割り当てられる既存の Pod は更新されません。
前提条件
- クラスター用に追加のネットワークを設定している。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
クラスターの追加ネットワークを編集するには、以下の手順を実行します。
以下のコマンドを実行し、デフォルトのテキストエディターで Cluster Network Operator (CNO) CR を編集します。
$ oc edit networks.operator.openshift.io cluster
-
additionalNetworksコレクションで、追加ネットワークを変更内容で更新します。 - 変更を保存し、テキストエディターを終了して、変更をコミットします。
オプション: 以下のコマンドを実行して、CNO が
NetworkAttachmentDefinitionオブジェクトを更新していることを確認します。<network-name>を表示する追加ネットワークの名前に置き換えます。CNO がNetworkAttachmentDefinitionオブジェクトを更新して変更内容が反映されるまでに遅延が生じる可能性があります。$ oc get network-attachment-definitions <network-name> -o yaml
たとえば、以下のコンソールの出力は
net1という名前のNetworkAttachmentDefinitionオブジェクトを表示します。$ oc get network-attachment-definitions net1 -o go-template='{{printf "%s\n" .spec.config}}' { "cniVersion": "0.3.1", "type": "macvlan", "master": "ens5", "mode": "bridge", "ipam": {"type":"static","routes":[{"dst":"0.0.0.0/0","gw":"10.128.2.1"}],"addresses":[{"address":"10.128.2.100/23","gateway":"10.128.2.1"}],"dns":{"nameservers":["172.30.0.10"],"domain":"us-west-2.compute.internal","search":["us-west-2.compute.internal"]}} }
25.8. 追加ネットワークの削除
クラスター管理者は、追加のネットワーク割り当てを削除できます。
25.8.1. 追加ネットワーク割り当て定義の削除
クラスター管理者は、追加ネットワークを OpenShift Container Platform クラスターから削除できます。追加ネットワークは、割り当てられている Pod から削除されません。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
クラスターから追加ネットワークを削除するには、以下の手順を実行します。
以下のコマンドを実行して、デフォルトのテキストエディターで Cluster Network Operator (CNO) を編集します。
$ oc edit networks.operator.openshift.io cluster
削除しているネットワーク割り当て定義の
additionalNetworksコレクションから設定を削除し、CR を変更します。apiVersion: operator.openshift.io/v1 kind: Network metadata: name: cluster spec: additionalNetworks: [] 1- 1
additionalNetworksコレクションの追加ネットワーク割り当てのみの設定マッピングを削除する場合、空のコレクションを指定する必要があります。
- 変更を保存し、テキストエディターを終了して、変更をコミットします。
オプション: 以下のコマンドを実行して、追加ネットワーク CR が削除されていることを確認します。
$ oc get network-attachment-definition --all-namespaces
25.9. VRF へのセカンダリーネットワークの割り当て
クラスター管理者は、CNI VRF プラグインを使用して、仮想ルーティングおよび転送 (VRF) ドメインの追加ネットワークを設定できます。このプラグインが作成する仮想ネットワークは、指定した物理インターフェイスに関連付けられます。
VRF インスタンスでセカンダリーネットワークを使用すると、次の利点があります。
- ワークロードの分離
- 追加のネットワークの VRF インスタンスを設定して、ワークロードトラフィックを分離します。
- セキュリティーの向上
- VRF ドメイン内の分離されたネットワークパスを通じて、セキュリティーを向上させます。
- マルチテナンシーのサポート
- 各テナントの VRF ドメイン内で、一意のルーティングテーブルを使用したネットワークセグメンテーションを通じて、マルチテナントをサポートします。
VRF を使用するアプリケーションは、特定のデバイスに対してバインドする必要があります。一般的な使用方法として、ソケットに SO_BINDTODEVICE オプションを使用できます。SO_BINDTODEVICE オプションは、渡されたインターフェイス名 (例: eth1) で指定されたデバイスにソケットをバインドします。SO_BINDTODEVICE オプションを使用するには、アプリケーションに CAP_NET_RAW 機能が必要です。
ip vrf exec コマンドを使用した VRF の使用は、OpenShift Container Platform Pod ではサポートされません。VRF を使用するには、アプリケーションを VRF インターフェイスに直接バインドします。
関連情報
25.9.1. CNI VRF プラグインを使用した追加のネットワーク割り当ての作成
Cluster Network Operator (CNO) は追加ネットワークの定義を管理します。作成する追加ネットワークを指定する場合、CNO は NetworkAttachmentDefinition カスタムリソース (CR) を自動的に作成します。
Cluster Network Operator が管理する NetworkAttachmentDefinition CR は編集しないでください。これを実行すると、追加ネットワークのネットワークトラフィックが中断する可能性があります。
CNI VRF プラグインで追加のネットワーク割り当てを作成するには、以下の手順を実行します。
前提条件
- OpenShift Container Platform CLI (oc) をインストールします。
- cluster-admin 権限を持つユーザーとして OpenShift クラスターにログインします。
手順
以下のサンプル CR のように、追加のネットワーク割り当て用の
Networkカスタムリソース (CR) を作成し、追加ネットワークのrawCNIConfig設定を挿入します。YAML をadditional-network-attachment.yamlファイルとして保存します。apiVersion: operator.openshift.io/v1 kind: Network metadata: name: cluster spec: additionalNetworks: - name: test-network-1 namespace: additional-network-1 type: Raw rawCNIConfig: '{ "cniVersion": "0.3.1", "name": "macvlan-vrf", "plugins": [ 1 { "type": "macvlan", "master": "eth1", "ipam": { "type": "static", "addresses": [ { "address": "191.168.1.23/24" } ] } }, { "type": "vrf", 2 "vrfname": "vrf-1", 3 "table": 1001 4 }] }'- 1
pluginsは一覧である必要があります。リストの最初の項目は、VRF ネットワークのベースとなるセカンダリーネットワークである必要があります。一覧の 2 つ目の項目は、VRF プラグイン設定です。- 2
typeはvrfに設定する必要があります。- 3
vrfnameは、インターフェイスが割り当てられた VRF の名前です。これが Pod に存在しない場合は作成されます。- 4
- オプション:
tableはルーティングテーブル ID です。デフォルトで、tableidパラメーターが使用されます。これが指定されていない場合、CNI は空のルーティングテーブル ID を VRF に割り当てます。
注記VRF は、リソースが
netdeviceタイプの場合にのみ正常に機能します。Networkリソースを作成します。$ oc create -f additional-network-attachment.yaml
以下のコマンドを実行して、CNO が
NetworkAttachmentDefinitionCR を作成していることを確認します。<namespace>を、ネットワーク割り当ての設定時に指定した namespace に置き換えます (例:additional-network-1)。$ oc get network-attachment-definitions -n <namespace>
出力例
NAME AGE additional-network-1 14m
注記CNO が CR を作成するまでに遅延が生じる可能性があります。
検証
Pod を作成し、VRF インスタンスを使用して追加のネットワークに割り当てます。
Podリソースを定義する YAML ファイルを作成します。pod-additional-net.yamファイルの例apiVersion: v1 kind: Pod metadata: name: pod-additional-net annotations: k8s.v1.cni.cncf.io/networks: '[ { "name": "test-network-1" 1 } ]' spec: containers: - name: example-pod-1 command: ["/bin/bash", "-c", "sleep 9000000"] image: centos:8- 1
- VRF インスタンスを使用する追加ネットワークの名前を指定します。
次のコマンドを実行して、
Podリソースを作成します。$ oc create -f pod-additional-net.yaml
出力例
pod/test-pod created
Pod のネットワーク割り当てが VRF の追加ネットワークに接続されていることを確認します。Pod とのリモートセッションを開始し、次のコマンドを実行します。
$ ip vrf show
出力例
Name Table ----------------------- vrf-1 1001
VRF インターフェイスが追加インターフェイスのコントローラーであることを確認します。
$ ip link
出力例
5: net1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master red state UP mode
第26章 ハードウェアネットワーク
26.1. Single Root I/O Virtualization (SR-IOV) ハードウェアネットワークについて
Single Root I/O Virtualization (SR-IOV) 仕様は、単一デバイスを複数の Pod で共有できる PCI デバイス割り当てタイプの標準です。
SR-IOV を使用すると、準拠したネットワークデバイス (ホストノードで物理機能 (PF) として認識される) を複数の Virtual Function (VF) にセグメント化することができます。VF は他のネットワークデバイスと同様に使用されます。デバイスの SR-IOV ネットワークデバイスドライバーは、VF がコンテナーで公開される方法を判別します。
-
netdeviceドライバー: コンテナーのnetns内の通常のカーネルネットワークデバイス -
vfio-pciドライバー: コンテナーにマウントされるキャラクターデバイス
SR-IOV ネットワークデバイスは、ベアメタルまたは Red Hat Open Stack Platform (RHOSP) インフラ上にインストールされた OpenShift Container Platform クラスターにネットワークを追加して、高帯域または低遅延を確保する必要のあるアプリケーションに使用できます。
SR-IOV ネットワークのマルチネットワークポリシーを設定できます。これのサポートはテクノロジープレビューであり、SR-IOV 追加ネットワークはカーネル NIC でのみサポートされます。データプレーン開発キット (DPDK) アプリケーションではサポートされていません。
SR-IOV ネットワークでマルチネットワークポリシーを作成しても、マルチネットワークポリシーが設定されていない SR-IOV ネットワークと比較して、アプリケーションに同じパフォーマンスが提供されない場合があります。
SR-IOV ネットワークのマルチネットワークポリシーは、テクノロジープレビュー機能のみです。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
次のコマンドを使用して、ノードで SR-IOV を有効にできます。
$ oc label node <node_name> feature.node.kubernetes.io/network-sriov.capable="true"
26.1.1. SR-IOV ネットワークデバイスを管理するコンポーネント
SR-IOV Network Operator は SR-IOV スタックのコンポーネントを作成し、管理します。以下の機能を実行します。
- SR-IOV ネットワークデバイスの検出および管理のオーケストレーション
-
SR-IOV Container Network Interface (CNI) の
NetworkAttachmentDefinitionカスタムリソースの生成 - SR-IOV ネットワークデバイスプラグインの設定の作成および更新
-
ノード固有の
SriovNetworkNodeStateカスタムリソースの作成 -
各
SriovNetworkNodeStateカスタムリソースのspec.interfacesフィールドの更新
Operator は以下のコンポーネントをプロビジョニングします。
- SR-IOV ネットワーク設定デーモン
- SR-IOV Network Operator の起動時にワーカーノードにデプロイされるデーモンセット。デーモンは、クラスターで SR-IOV ネットワークデバイスを検出し、初期化します。
- SR-IOV Network Operator Webhook
- Operator カスタムリソースを検証し、未設定フィールドに適切なデフォルト値を設定する動的受付コントローラー Webhook。
- SR-IOV Network Resources Injector
-
SR-IOV VF などのカスタムネットワークリソースの要求および制限のある Kubernetes Pod 仕様のパッチを適用するための機能を提供する動的受付コントローラー Webhook。SR-IOV ネットワークリソースインジェクターは、 Pod 内の最初のコンテナーのみに
resourceフィールドを自動的に追加します。 - SR-IOV ネットワークデバイスプラグイン
- SR-IOV ネットワーク Virtual Function (VF) リソースの検出、公開、割り当てを実行するデバイスプラグイン。デバイスプラグインは、とりわけ物理デバイスでの制限されたリソースの使用を有効にするために Kubernetes で使用されます。デバイスプラグインは Kubernetes スケジューラーにリソースの可用性を認識させるため、スケジューラーはリソースが十分にあるノードで Pod をスケジュールできます。
- SR-IOV CNI プラグイン
- SR-IOV ネットワークデバイスプラグインから割り当てられる VF インターフェイスを直接 Pod に割り当てる CNI プラグイン。
- SR-IOV InfiniBand CNI プラグイン
- SR-IOV ネットワークデバイスプラグインから割り当てられる InfiniBand (IB) VF インターフェイスを直接 Pod に割り当てる CNI プラグイン。
SR-IOV Network Resources Injector および SR-IOV Network Operator Webhook は、デフォルトで有効にされ、default の SriovOperatorConfig CR を編集して無効にできます。SR-IOV Network Operator Admission Controller Webhook を無効にする場合は注意してください。トラブルシューティングなどの特定の状況下や、サポートされていないデバイスを使用する場合は、Webhook を無効にすることができます。
26.1.1.1. サポート対象のプラットフォーム
SR-IOV Network Operator は、以下のプラットフォームに対応しています。
- ベアメタル
- Red Hat OpenStack Platform (RHOSP)
26.1.1.2. サポートされるデバイス
以下のネットワークインターフェイスコントローラーは、OpenShift Container Platform でサポートされています。
表26.1 サポート対象のネットワークインターフェイスコントローラー
| 製造元 | モデル | ベンダー ID | デバイス ID |
|---|---|---|---|
| Broadcom | BCM57414 | 14e4 | 16d7 |
| Broadcom | BCM57508 | 14e4 | 1750 |
| Broadcom | BCM57504 | 14e4 | 1751 |
| Intel | X710 | 8086 | 1572 |
| Intel | XL710 | 8086 | 1583 |
| Intel | X710 Base T | 8086 | 15ff |
| Intel | XXV710 | 8086 | 158b |
| Intel | E810-CQDA2 | 8086 | 1592 |
| Intel | E810-2CQDA2 | 8086 | 1592 |
| Intel | E810-XXVDA2 | 8086 | 159b |
| Intel | E810-XXVDA4 | 8086 | 1593 |
| Intel | E810-XXVDA4T | 8086 | 1593 |
| Mellanox | MT27700 Family [ConnectX‑4] | 15b3 | 1013 |
| Mellanox | MT27710 Family [ConnectX‑4 Lx] | 15b3 | 1015 |
| Mellanox | MT27800 Family [ConnectX‑5] | 15b3 | 1017 |
| Mellanox | MT28880 Family [ConnectX‑5 Ex] | 15b3 | 1019 |
| Mellanox | MT28908 Family [ConnectX‑6] | 15b3 | 101b |
| Mellanox | MT2892 Family [ConnectX-6 Dx] | 15b3 | 101d |
| Mellanox | MT2894 Family [ConnectX‑6 Lx] | 15b3 | 101f |
| Mellanox | ConnectX-6 NIC モードの MT42822 BlueField-2 | 15b3 | a2d6 |
| Pensando [1] | Ionic ドライバー用 DSC-25 デュアルポート 25G 分散サービスカード | 0x1dd8 | 0x1002 |
| Pensando [1] | Ionic ドライバー用 DSC-100 デュアルポート 100G 分散サービスカード | 0x1dd8 | 0x1003 |
| Silicom | STS ファミリー | 8086 | 1591 |
- OpenShift SR-IOV はサポートされますが、SR-IOV を使用する際に SR-IOV CNI config ファイルを使用して静的な Virtual Function (VF) メディアアクセス制御 (MAC) アドレスを設定する必要があります。
サポートされているカードの最新リストおよび利用可能な互換性のある OpenShift Container Platform バージョンについては、Openshift Single Root I/O Virtualization (SR-IOV) and PTP hardware networks Support Matrix を参照してください。
26.1.1.3. SR-IOV ネットワークデバイスの自動検出
SR-IOV Network Operator は、クラスターでワーカーノード上の SR-IOV 対応ネットワークデバイスを検索します。Operator は、互換性のある SR-IOV ネットワークデバイスを提供する各ワーカーノードの SriovNetworkNodeState カスタムリソース (CR) を作成し、更新します。
CR にはワーカーノードと同じ名前が割り当てられます。status.interfaces リストは、ノード上のネットワークデバイスについての情報を提供します。
SriovNetworkNodeState オブジェクトは変更しないでください。Operator はこれらのリソースを自動的に作成し、管理します。
26.1.1.3.1. SriovNetworkNodeState オブジェクトの例
以下の YAML は、SR-IOV Network Operator によって作成される SriovNetworkNodeState オブジェクトの例です。
SriovNetworkNodeState オブジェクト
apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodeState metadata: name: node-25 1 namespace: openshift-sriov-network-operator ownerReferences: - apiVersion: sriovnetwork.openshift.io/v1 blockOwnerDeletion: true controller: true kind: SriovNetworkNodePolicy name: default spec: dpConfigVersion: "39824" status: interfaces: 2 - deviceID: "1017" driver: mlx5_core mtu: 1500 name: ens785f0 pciAddress: "0000:18:00.0" totalvfs: 8 vendor: 15b3 - deviceID: "1017" driver: mlx5_core mtu: 1500 name: ens785f1 pciAddress: "0000:18:00.1" totalvfs: 8 vendor: 15b3 - deviceID: 158b driver: i40e mtu: 1500 name: ens817f0 pciAddress: 0000:81:00.0 totalvfs: 64 vendor: "8086" - deviceID: 158b driver: i40e mtu: 1500 name: ens817f1 pciAddress: 0000:81:00.1 totalvfs: 64 vendor: "8086" - deviceID: 158b driver: i40e mtu: 1500 name: ens803f0 pciAddress: 0000:86:00.0 totalvfs: 64 vendor: "8086" syncStatus: Succeeded
26.1.1.4. Pod での Virtual Function (VF) の使用例
SR-IOV VF が割り当てられている Pod で、Remote Direct Memory Access (RDMA) または Data Plane Development Kit (DPDK) アプリケーションを実行できます。
以下の例では、RDMA モードで Virtual Function (VF) を使用する Pod を示しています。
RDMA モードを使用する Pod 仕様
apiVersion: v1
kind: Pod
metadata:
name: rdma-app
annotations:
k8s.v1.cni.cncf.io/networks: sriov-rdma-mlnx
spec:
containers:
- name: testpmd
image: <RDMA_image>
imagePullPolicy: IfNotPresent
securityContext:
runAsUser: 0
capabilities:
add: ["IPC_LOCK","SYS_RESOURCE","NET_RAW"]
command: ["sleep", "infinity"]
以下の例は、DPDK モードの VF のある Pod を示しています。
DPDK モードを使用する Pod 仕様
apiVersion: v1
kind: Pod
metadata:
name: dpdk-app
annotations:
k8s.v1.cni.cncf.io/networks: sriov-dpdk-net
spec:
containers:
- name: testpmd
image: <DPDK_image>
securityContext:
runAsUser: 0
capabilities:
add: ["IPC_LOCK","SYS_RESOURCE","NET_RAW"]
volumeMounts:
- mountPath: /dev/hugepages
name: hugepage
resources:
limits:
memory: "1Gi"
cpu: "2"
hugepages-1Gi: "4Gi"
requests:
memory: "1Gi"
cpu: "2"
hugepages-1Gi: "4Gi"
command: ["sleep", "infinity"]
volumes:
- name: hugepage
emptyDir:
medium: HugePages
26.1.1.5. コンテナーアプリケーションで使用する DPDK ライブラリー
オプションライブラリー の app-netutil は、その Pod 内で実行されるコンテナーから Pod についてのネットワーク情報を収集するための複数の API メソッドを提供します。
このライブラリーは、DPDK (Data Plane Development Kit) モードの SR-IOV Virtual Function (VF) のコンテナーへの統合を支援します。このライブラリーは Golang API と C API の両方を提供します。
現時点で 3 つの API メソッドが実装されています。
GetCPUInfo()- この機能は、コンテナーで利用可能な CPU を判別し、リストを返します。
GetHugepages()-
この機能は、各コンテナーの
Pod仕様で要求される huge page メモリーの量を判別し、値を返します。 GetInterfaces()- この機能は、コンテナーのインターフェイスセットを判別し、インターフェイスタイプとタイプ固有のデータと共にリストを返します。戻り値には、インターフェイスのタイプと、各インターフェイスのタイプ固有のデータが含まれます。
ライブラリーのリポジトリーには、コンテナーイメージ dpdk-app-centos をビルドするためのサンプル Dockerfile が含まれます。コンテナーイメージは、Pod 仕様の環境変数に応じて、l2fwd、l3wd または testpmd の DPDK サンプルアプリケーションのいずれかを実行できます。コンテナーイメージは、app-netutil ライブラリーをコンテナーイメージ自体に統合する例を提供します。ライブラリーを init コンテナーに統合することもできます。init コンテナーは必要なデータを収集し、データを既存の DPDK ワークロードに渡すことができます。
26.1.1.6. Downward API の Huge Page リソースの挿入
Pod 仕様に Huge Page のリソース要求または制限が含まれる場合、Network Resources Injector は Downward API フィールドを Pod 仕様に自動的に追加し、Huge Page 情報をコンテナーに提供します。
Network Resources Injector は、podnetinfo という名前のボリュームを追加し、Pod の各コンテナー用に /etc/podnetinfo にマウントされます。ボリュームは Downward API を使用し、Huge Page の要求および制限についてのファイルを追加します。ファイルの命名規則は以下のとおりです。
-
/etc/podnetinfo/hugepages_1G_request_<container-name> -
/etc/podnetinfo/hugepages_1G_limit_<container-name> -
/etc/podnetinfo/hugepages_2M_request_<container-name> -
/etc/podnetinfo/hugepages_2M_limit_<container-name>
直前のリストで指定されているパスは、app-netutil ライブラリーと互換性があります。デフォルトで、ライブラリーは、/etc/podnetinfo ディレクトリーのリソース情報を検索するように設定されます。Downward API パス項目を手動で指定する選択をする場合、app-netutil ライブラリーは前述のリストのパスに加えて以下のパスを検索します。
-
/etc/podnetinfo/hugepages_request -
/etc/podnetinfo/hugepages_limit -
/etc/podnetinfo/hugepages_1G_request -
/etc/podnetinfo/hugepages_1G_limit -
/etc/podnetinfo/hugepages_2M_request -
/etc/podnetinfo/hugepages_2M_limit
Network Resources Injector が作成できるパスと同様に、前述の一覧のパスの末尾にはオプションで _<container-name> 接尾辞を付けることができます。
26.1.2. 関連情報
26.1.3. 次のステップ
- SR-IOV Network Operator のインストール
- オプション: SR-IOV Network Operator の設定
- SR-IOV ネットワークデバイスの設定
- OpenShift Virtualization を使用する場合: 仮想マシンの SR-IOV ネットワークへの接続
- SR-IOV ネットワーク割り当ての設定
- Pod の SR-IOV の追加ネットワークへの追加
26.2. SR-IOV Network Operator のインストール
Single Root I/O Virtualization (SR-IOV) ネットワーク Operator をクラスターにインストールし、SR-IOV ネットワークデバイスとネットワークの割り当てを管理できます。
26.2.1. SR-IOV Network Operator のインストール
クラスター管理者は、OpenShift Container Platform CLI または Web コンソールを使用して SR-IOV Network Operator をインストールできます。
26.2.1.1. CLI: SR-IOV Network Operator のインストール
クラスター管理者は、CLI を使用して Operator をインストールできます。
前提条件
- SR-IOV に対応するハードウェアを持つノードでベアメタルハードウェアにインストールされたクラスター。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つアカウント。
手順
openshift-sriov-network-operatornamespace を作成するには、以下のコマンドを入力します。$ cat << EOF| oc create -f - apiVersion: v1 kind: Namespace metadata: name: openshift-sriov-network-operator annotations: workload.openshift.io/allowed: management EOFOperatorGroup CR を作成するには、以下のコマンドを実行します。
$ cat << EOF| oc create -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: sriov-network-operators namespace: openshift-sriov-network-operator spec: targetNamespaces: - openshift-sriov-network-operator EOF
SR-IOV Network Operator にサブスクライブします。
以下のコマンドを実行して OpenShift Container Platform のメジャーおよびマイナーバージョンを取得します。これは、次の手順の
channelの値に必要です。$ OC_VERSION=$(oc version -o yaml | grep openshiftVersion | \ grep -o '[0-9]*[.][0-9]*' | head -1)SR-IOV Network Operator の Subscription CR を作成するには、以下のコマンドを入力します。
$ cat << EOF| oc create -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: sriov-network-operator-subscription namespace: openshift-sriov-network-operator spec: channel: "${OC_VERSION}" name: sriov-network-operator source: redhat-operators sourceNamespace: openshift-marketplace EOF
Operator がインストールされていることを確認するには、以下のコマンドを入力します。
$ oc get csv -n openshift-sriov-network-operator \ -o custom-columns=Name:.metadata.name,Phase:.status.phase
出力例
Name Phase sriov-network-operator.4.13.0-202310121402 Succeeded
26.2.1.2. Web コンソール: SR-IOV Network Operator のインストール
クラスター管理者は、Web コンソールを使用して Operator をインストールできます。
前提条件
- SR-IOV に対応するハードウェアを持つノードでベアメタルハードウェアにインストールされたクラスター。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つアカウント。
手順
SR-IOV Network Operator をインストールします。
- OpenShift Container Platform Web コンソールで、Operators → OperatorHub をクリックします。
- 利用可能な Operator の一覧から SR-IOV Network Operator を選択してから Install をクリックします。
- Install Operator ページの Installed Namespace で、Operator recommend Namespace を選択します。
- Install をクリックします。
SR-IOV Network Operator が正常にインストールされていることを確認します。
- Operators → Installed Operators ページに移動します。
Status が InstallSucceeded の状態で、SR-IOV Network Operator が openshift-sriov-network-operator プロジェクトにリスト表示されていることを確認します。
注記インストール時に、 Operator は Failed ステータスを表示する可能性があります。インストールが後に InstallSucceeded メッセージを出して正常に実行される場合は、Failed メッセージを無視できます。
Operator がインストール済みとして表示されない場合に、さらにトラブルシューティングを実行します。
- Operator Subscriptions および Install Plans タブで、Status の下の失敗またはエラーの有無を確認します。
-
Workloads → Pods ページに移動し、
openshift-sriov-network-operatorプロジェクトで Pod のログを確認します。 YAML ファイルの namespace を確認してください。アノテーションが抜けている場合は、次のコマンドを使用して、アノテーション
workload.openshift.io/allowed=managementを Operator namespace に追加できます。$ oc annotate ns/openshift-sriov-network-operator workload.openshift.io/allowed=management
注記シングルノード OpenShift クラスターの場合は、namespace にアノテーション
workload.openshift.io/allowed=managementが必要です。
26.2.2. 次のステップ
- オプション: SR-IOV Network Operator の設定
26.3. SR-IOV Network Operator の設定
Single Root I/O Virtualization (SR-IOV) ネットワーク Operator は、クラスターで SR-IOV ネットワークデバイスおよびネットワーク割り当てを管理します。
26.3.1. SR-IOV Network Operator の設定
通常、SR-IOV Network Operator 設定を変更する必要はありません。デフォルト設定は、ほとんどのユースケースで推奨されます。Operator のデフォルト動作がユースケースと互換性がない場合にのみ、関連する設定を変更する手順を実行します。
SR-IOV Network Operator は SriovOperatorConfig.sriovnetwork.openshift.io CustomResourceDefinition リソースを追加します。Operator は、openshift-sriov-network-operator namespace に default という名前の SriovOperatorConfig カスタムリソース (CR) を自動的に作成します。
default CR には、クラスターの SR-IOV Network Operator 設定が含まれます。Operator 設定を変更するには、この CR を変更する必要があります。
26.3.1.1. SR-IOV Network Operator config カスタムリソース
sriovoperatorconfig カスタムリソースのフィールドは、以下の表で説明されています。
表26.2 SR-IOV Network Operator config カスタムリソース
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
SR-IOV Network Operator インスタンスの名前を指定します。デフォルト値は |
|
|
|
SR-IOV Network Operator インスタンスの namespace を指定します。デフォルト値は |
|
|
| 選択されたノードで SR-IOV Network Config Daemon のスケジューリングを制御するノードの選択オプションを指定します。デフォルトでは、このフィールドは設定されておらず、Operator はワーカーノードに SR-IOV Network Config デーモン セットを配置します。 |
|
|
|
新しいポリシーを適用してノードに NIC を設定する時に、ノードドレインプロセスを無効にするか、有効にするかを指定します。このフィールドを
シングルノードクラスターの場合は、Operator のインストール後にこのフィールドを |
|
|
|
Network Resources Injector デーモンセットを有効にするか無効にするかを指定します。デフォルトでは、このフィールドは |
|
|
|
Operator Admission Controller の Webhook デーモンセットを有効にするか無効にするかを指定します。デフォルトでは、このフィールドは |
|
|
|
Operator のログの冗長度を指定します。 |
26.3.1.2. Network Resources Injector について
Network Resources Injector は Kubernetes Dynamic Admission Controller アプリケーションです。これは、以下の機能を提供します。
- SR-IOV リソース名を SR-IOV ネットワーク割り当て定義アノテーションに従って追加するための、Pod 仕様でのリソース要求および制限の変更。
-
Pod のアノテーション、ラベル、および Huge Page の要求および制限を公開するための Downward API ボリュームでの Pod 仕様の変更。Pod で実行されるコンテナーは、公開される情報に
/etc/podnetinfoパスでファイルとしてアクセスできます。
デフォルトで、Network Resources Injector は SR-IOV Network Operator によって有効にされ、すべてのコントロールプレーンノードでデーモンセットとして実行されます。以下は、3 つのコントロールプレーンノードを持つクラスターで実行される Network Resources Injector Pod の例です。
$ oc get pods -n openshift-sriov-network-operator
出力例
NAME READY STATUS RESTARTS AGE network-resources-injector-5cz5p 1/1 Running 0 10m network-resources-injector-dwqpx 1/1 Running 0 10m network-resources-injector-lktz5 1/1 Running 0 10m
26.3.1.3. SR-IOV Network Operator Admission Controller Webhook について
SR-IOV Network Operator Admission Controller Webbook は Kubernetes Dynamic Admission Controller アプリケーションです。これは、以下の機能を提供します。
-
作成時または更新時の
SriovNetworkNodePolicyCR の検証 -
CR の作成または更新時の
priorityおよびdeviceTypeフィールドのデフォルト値の設定によるSriovNetworkNodePolicyCR の変更
デフォルトで、SR-IOV Network Operator Admission Controller Webhook は Operator によって有効にされ、すべてのコントロールプレーンノードでデーモンセットとして実行されます。
SR-IOV Network Operator Admission Controller Webhook を無効にする場合は注意してください。トラブルシューティングなどの特定の状況下や、サポートされていないデバイスを使用する場合は、Webhook を無効にすることができます。サポート対象外のデバイスの設定については、サポート対象外の NIC を使用するための SR-IOV Network Operator の設定 を参照してください。
以下は、3 つのコントロールプレーンノードを持つクラスターで実行される Operator Admission Controller Webhook Pod の例です。
$ oc get pods -n openshift-sriov-network-operator
出力例
NAME READY STATUS RESTARTS AGE operator-webhook-9jkw6 1/1 Running 0 16m operator-webhook-kbr5p 1/1 Running 0 16m operator-webhook-rpfrl 1/1 Running 0 16m
26.3.1.4. カスタムノードセレクターについて
SR-IOV Network Config デーモンは、クラスターノード上の SR-IOV ネットワークデバイスを検出し、設定します。デフォルトで、これはクラスター内のすべての worker ノードにデプロイされます。ノードラベルを使用して、SR-IOV Network Config デーモンが実行するノードを指定できます。
26.3.1.5. Network Resources Injector の無効化または有効化
デフォルトで有効にされている Network Resources Injector を無効にするか、有効にするには、以下の手順を実行します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。 - SR-IOV Network Operator がインストールされていること。
手順
enableInjectorフィールドを設定します。<value>をfalseに置き換えて機能を無効にするか、trueに置き換えて機能を有効にします。$ oc patch sriovoperatorconfig default \ --type=merge -n openshift-sriov-network-operator \ --patch '{ "spec": { "enableInjector": <value> } }'ヒントまたは、以下の YAML を適用して Operator を更新することもできます。
apiVersion: sriovnetwork.openshift.io/v1 kind: SriovOperatorConfig metadata: name: default namespace: openshift-sriov-network-operator spec: enableInjector: <value>
26.3.1.6. SR-IOV Network Operator Admission Controller Webhook の無効化または有効化
デフォルトで有効にされている なっている受付コントローラー Webhook を無効にするか、有効にするには、以下の手順を実行します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。 - SR-IOV Network Operator がインストールされていること。
手順
enableOperatorWebhookフィールドを設定します。<value>をfalseに置き換えて機能を無効するか、trueに置き換えて機能を有効にします。$ oc patch sriovoperatorconfig default --type=merge \ -n openshift-sriov-network-operator \ --patch '{ "spec": { "enableOperatorWebhook": <value> } }'ヒントまたは、以下の YAML を適用して Operator を更新することもできます。
apiVersion: sriovnetwork.openshift.io/v1 kind: SriovOperatorConfig metadata: name: default namespace: openshift-sriov-network-operator spec: enableOperatorWebhook: <value>
26.3.1.7. SRIOV Network Config Daemon のカスタム NodeSelector の設定
SR-IOV Network Config デーモンは、クラスターノード上の SR-IOV ネットワークデバイスを検出し、設定します。デフォルトで、これはクラスター内のすべての worker ノードにデプロイされます。ノードラベルを使用して、SR-IOV Network Config デーモンが実行するノードを指定できます。
SR-IOV Network Config デーモンがデプロイされるノードを指定するには、以下の手順を実行します。
configDaemonNodeSelector フィールドを更新する際に、SR-IOV Network Config デーモンがそれぞれの選択されたノードに再作成されます。デーモンが再作成されている間、クラスターのユーザーは新規の SR-IOV Network ノードポリシーを適用したり、新規の SR-IOV Pod を作成したりできません。
手順
Operator のノードセレクターを更新するには、以下のコマンドを入力します。
$ oc patch sriovoperatorconfig default --type=json \ -n openshift-sriov-network-operator \ --patch '[{ "op": "replace", "path": "/spec/configDaemonNodeSelector", "value": {<node_label>} }]'以下の例のように、
<node_label>を適用するラベルに置き換えます:"node-role.kubernetes.io/worker": ""ヒントまたは、以下の YAML を適用して Operator を更新することもできます。
apiVersion: sriovnetwork.openshift.io/v1 kind: SriovOperatorConfig metadata: name: default namespace: openshift-sriov-network-operator spec: configDaemonNodeSelector: <node_label>
26.3.1.8. 単一ノードのインストール用の SR-IOV Network Operator の設定
デフォルトでは、SR-IOV Network Operator は、ポリシーを変更するたびに、ノードからワークロードをドレイン (解放) します。Operator は、このアクションを実行して、再設定する前に Virtual Function を使用しているワークロードがないことを確認します。
1 つのノードにインストールする場合には、ワークロードを受信するノードは他にありません。そのため、Operator は、単一のノードからワークロードがドレインされないように設定する必要があります。
以下の手順を実行してワークロードのドレインを無効にした後に、SR-IOV ネットワークインターフェイスを使用しているワークロードを削除してから SR-IOV ネットワークノードのポリシーを変更する必要があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。 - SR-IOV Network Operator がインストールされていること。
手順
disable Drainフィールドをtrueに設定するには、次のコマンドを入力します。$ oc patch sriovoperatorconfig default --type=merge \ -n openshift-sriov-network-operator \ --patch '{ "spec": { "disableDrain": true } }'ヒントまたは、以下の YAML を適用して Operator を更新することもできます。
apiVersion: sriovnetwork.openshift.io/v1 kind: SriovOperatorConfig metadata: name: default namespace: openshift-sriov-network-operator spec: disableDrain: true
26.3.1.9. ホステッドコントロールプレーン用の SR-IOV Operator のデプロイ
ホストされたコントロールプレーンは、テクノロジープレビュー機能としてのみ利用できます。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
ホスティングサービスクラスターを設定してデプロイすると、ホストされたクラスターで SR-IOV Operator へのサブスクリプションを作成できます。SR-IOV Pod は、コントロールプレーンではなくワーカーマシンで実行されます。
前提条件
AWS 上でホストされたクラスターを設定およびデプロイしている。詳細は、AWS 上でのホストクラスターの設定 (テクノロジープレビュー) を参照してください。
手順
namespace と Operator グループを作成します。
apiVersion: v1 kind: Namespace metadata: name: openshift-sriov-network-operator --- apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: sriov-network-operators namespace: openshift-sriov-network-operator spec: targetNamespaces: - openshift-sriov-network-operator
SR-IOV Operator へのサブスクリプションを作成します。
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: sriov-network-operator-subsription namespace: openshift-sriov-network-operator spec: channel: "4.13" name: sriov-network-operator config: nodeSelector: node-role.kubernetes.io/worker: "" source: s/qe-app-registry/redhat-operators sourceNamespace: openshift-marketplace
検証
SR-IOV Operator の準備ができていることを確認するには、次のコマンドを実行し、結果の出力を表示します。
$ oc get csv -n openshift-sriov-network-operator
出力例
NAME DISPLAY VERSION REPLACES PHASE sriov-network-operator.4.13.0-202211021237 SR-IOV Network Operator 4.13.0-202211021237 sriov-network-operator.4.13.0-202210290517 Succeeded
SR-IOV Pod がデプロイされていることを確認するには、次のコマンドを実行します。
$ oc get pods -n openshift-sriov-network-operator
26.3.2. 次のステップ
26.4. SR-IOV ネットワークデバイスの設定
クラスターで Single Root I/O Virtualization (SR-IOV) デバイスを設定できます。
26.4.1. SR-IOV ネットワークノード設定オブジェクト
SR-IOV ネットワークノードポリシーを作成して、ノードの SR-IOV ネットワークデバイス設定を指定します。ポリシーの API オブジェクトは sriovnetwork.openshift.io API グループの一部です。
以下の YAML は SR-IOV ネットワークノードポリシーについて説明しています。
apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: <name> 1 namespace: openshift-sriov-network-operator 2 spec: resourceName: <sriov_resource_name> 3 nodeSelector: feature.node.kubernetes.io/network-sriov.capable: "true" 4 priority: <priority> 5 mtu: <mtu> 6 needVhostNet: false 7 numVfs: <num> 8 nicSelector: 9 vendor: "<vendor_code>" 10 deviceID: "<device_id>" 11 pfNames: ["<pf_name>", ...] 12 rootDevices: ["<pci_bus_id>", ...] 13 netFilter: "<filter_string>" 14 deviceType: <device_type> 15 isRdma: false 16 linkType: <link_type> 17 eSwitchMode: <mode> 18 excludeTopology: false 19
- 1
- カスタムリソースオブジェクトの名前。
- 2
- SR-IOV Network Operator がインストールされている namespace。
- 3
- SR-IOV ネットワークデバイスプラグインのリソース名。1 つのリソース名に複数の SR-IOV ネットワークポリシーを作成できます。
名前を指定するときは、
resourceNameで使用できる構文式^a-zA-Z0-9_+$を必ず使用してください。 - 4
- ノードセレクターは設定するノードを指定します。選択したノード上の SR-IOV ネットワークデバイスのみが設定されます。SR-IOV Container Network Interface (CNI) プラグインおよびデバイスプラグインは、選択したノードにのみデプロイされます。重要
SR-IOV Network Operator は、ノードネットワーク設定ポリシーを順番にノードに適用します。ノードネットワーク設定ポリシーを適用する前に、SR-IOV Network Operator は、ノードのマシン設定プール (MCP) が
DegradedまたはUpdatingなどの正常ではない状態にないか確認します。ノード正常ではない MCP にある場合、ノードネットワーク設定ポリシーをクラスター内のすべての対象ノードに適用するプロセスは、MCP が正常な状態に戻るまで一時停止します。正常でない MCP 内にあるノードが、他のノード (他の MCP 内のノードを含む) にノードネットワーク設定ポリシーを適用することを阻害しないようにするには、MCP ごとに別のノードネットワーク設定ポリシーを作成する必要があります。
- 5
- オプション: 優先度は
0から99までの整数値で指定されます。値が小さいほど優先度が高くなります。たとえば、10の優先度は99よりも高くなります。デフォルト値は99です。 - 6
- オプション: Virtual Function (VF) の最大転送単位 (MTU)。MTU の最大値は、複数の異なるネットワークインターフェイスコントローラー (NIC) に応じて異なります。重要
デフォルトのネットワークインターフェイス上に仮想機能を作成する場合は、MTU がクラスター MTU と一致する値に設定されていることを確認してください。
- 7
- オプション:
/dev/vhost-netデバイスを Pod にマウントするには、needVhostNetをtrueに設定します。Data Plane Development Kit(DPDK) と共にマウントされた/dev/vhost-netデバイスを使用して、トラフィックをカーネルネットワークスタックに転送します。 - 8
- SR-IOV 物理ネットワークデバイス用に作成する Virtual Function (VF) の数。Intel ネットワークインターフェイスコントローラー (NIC) の場合、VF の数はデバイスがサポートする VF の合計よりも大きくすることはできません。Mellanox NIC の場合、VF の数は
128よりも大きくすることはできません。 - 9
- NIC セレクターは、Operator が設定するデバイスを特定します。すべてのパラメーターの値を指定する必要はありません。意図せずにデバイスを選択しないように、ネットワークデバイスを極めて正確に特定することが推奨されます。
rootDevicesを指定する場合、vendor、deviceID、またはpfNameの値も指定する必要があります。pfNamesおよびrootDevicesの両方を同時に指定する場合、それらが同一のデバイスを参照していることを確認します。netFilterの値を指定する場合、ネットワーク ID は一意の ID であるためにその他のパラメーターを指定する必要はありません。 - 10
- オプション: SR-IOV ネットワークデバイスのベンダーの 16 進数コード。許可される値は
8086および15b3のみになります。 - 11
- オプション: SR-IOV ネットワークデバイスのデバイスの 16 進数コード。たとえば、
101bは Mellanox ConnectX-6 デバイスのデバイス ID です。 - 12
- オプション: 1 つ以上のデバイスの物理機能 (PF) 名の配列。
- 13
- オプション: デバイスの PF 用の 1 つ以上の PCI バスアドレスの配列。以下の形式でアドレスを指定します:
0000:02:00.1 - 14
- オプション: プラットフォーム固有のネットワークフィルター。サポートされるプラットフォームは Red Hat OpenStack Platform (RHOSP) のみです。許可される値は、
openstack/NetworkID:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxの形式を使用します。xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxを、/var/config/openstack/latest/network_data.jsonメタデータファイルの値に置き換えます。 - 15
- オプション: Virtual Function (VF) のドライバータイプ。許可される値は
netdeviceおよびvfio-pciのみです。デフォルト値はnetdeviceです。Mellanox NIC をベアメタルノードの DPDK モードで機能させるには、
netdeviceドライバータイプを使用し、isRdmaをtrueに設定します。 - 16
- オプション: Remote Direct Memory Access (RDMA) モードを有効にするかどうかを設定します。デフォルト値は
falseです。isRdmaパラメーターがtrueに設定される場合、引き続き RDMA 対応の VF を通常のネットワークデバイスとして使用できます。デバイスはどちらのモードでも使用できます。isRdmaをtrueに設定し、追加のneedVhostNetをtrueに設定して、Fast Datapath DPDK アプリケーションで使用する Mellanox NIC を設定します。 - 17
- オプション: VF のリンクタイプ。イーサネットのデフォルト値は
ethです。InfiniBand の場合、この値を ib に変更します。linkTypeがibに設定されている場合、SR-IOV Network Operator Webhook によってisRdmaはtrueに自動的に設定されます。linkTypeがibに設定されている場合、deviceTypeはvfio-pciに設定できません。SriovNetworkNodePolicy の linkType を eth に設定しないでください。デバイスプラグインによって報告される使用可能なデバイスの数が正しくなくなる可能性があります。
- 18
- オプション: NIC デバイスモード。許可される値は、
legacyまたはswitchdevのみです。eSwitchModeをlegacyに設定すると、デフォルトの SR-IOV 動作が有効になります。eSwitchModeをswitchdevに設定すると、ハードウェアオフロードが有効になります。 - 19
- オプション: SR-IOV ネットワークリソースの NUMA ノードを Topology Manager にアドバタイスする場合を除外するには、値を
trueに設定します。デフォルト値はfalseです。
26.4.1.1. SR-IOV ネットワークノードの設定例
以下の例では、InfiniBand デバイスの設定について説明します。
InfiniBand デバイスの設定例
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: policy-ib-net-1
namespace: openshift-sriov-network-operator
spec:
resourceName: ibnic1
nodeSelector:
feature.node.kubernetes.io/network-sriov.capable: "true"
numVfs: 4
nicSelector:
vendor: "15b3"
deviceID: "101b"
rootDevices:
- "0000:19:00.0"
linkType: ib
isRdma: true
以下の例では、RHOSP 仮想マシンの SR-IOV ネットワークデバイスの設定について説明します。
仮想マシンの SR-IOV デバイスの設定例
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: policy-sriov-net-openstack-1
namespace: openshift-sriov-network-operator
spec:
resourceName: sriovnic1
nodeSelector:
feature.node.kubernetes.io/network-sriov.capable: "true"
numVfs: 1 1
nicSelector:
vendor: "15b3"
deviceID: "101b"
netFilter: "openstack/NetworkID:ea24bd04-8674-4f69-b0ee-fa0b3bd20509" 2
26.4.1.2. SR-IOV デバイスの Virtual Function (VF) パーティション設定
Virtual Function (VF) を同じ物理機能 (PF) から複数のリソースプールに分割する必要がある場合があります。たとえば、VF の一部をデフォルトドライバーで読み込み、残りの VF を vfio-pci ドライバーで読み込む必要がある場合などです。このようなデプロイメントでは、SriovNetworkNodePolicy カスタムリソース (CR) の pfNames セレクターは、以下の形式を使用してプールの VF の範囲を指定するために使用できます: <pfname>#<first_vf>-<last_vf>
たとえば、以下の YAML は、VF が 2 から 7 まである netpf0 という名前のインターフェイスのセレクターを示します。
pfNames: ["netpf0#2-7"]
-
netpf0は PF インターフェイス名です。 -
2は、範囲に含まれる最初の VF インデックス (0 ベース) です。 -
7は、範囲に含まれる最後の VF インデックス (0 ベース) です。
以下の要件を満たす場合、異なるポリシー CR を使用して同じ PF から VF を選択できます。
-
numVfsの値は、同じ PF を選択するポリシーで同一である必要があります。 -
VF インデックスは、
0から<numVfs>-1の範囲にある必要があります。たとえば、numVfsが8に設定されているポリシーがある場合、<first_vf>の値は0よりも小さくすることはできず、<last_vf>は7よりも大きくすることはできません。 - 異なるポリシーの VF の範囲は重複しないようにしてください。
-
<first_vf>は<last_vf>よりも大きくすることはできません。
以下の例は、SR-IOV デバイスの NIC パーティション設定を示しています。
ポリシー policy-net-1 は、デフォルトの VF ドライバーと共に PF netpf0 の VF 0 が含まれるリソースプール net-1 を定義します。ポリシー policy-net-1-dpdk は、vfio VF ドライバーと共に PF netpf0 の VF 8 から 15 までが含まれるリソースプール net-1-dpdk を定義します。
ポリシー policy-net-1:
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: policy-net-1
namespace: openshift-sriov-network-operator
spec:
resourceName: net1
nodeSelector:
feature.node.kubernetes.io/network-sriov.capable: "true"
numVfs: 16
nicSelector:
pfNames: ["netpf0#0-0"]
deviceType: netdevice
ポリシー policy-net-1-dpdk:
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: policy-net-1-dpdk
namespace: openshift-sriov-network-operator
spec:
resourceName: net1dpdk
nodeSelector:
feature.node.kubernetes.io/network-sriov.capable: "true"
numVfs: 16
nicSelector:
pfNames: ["netpf0#8-15"]
deviceType: vfio-pciインターフェイスが正常にパーティショニングされていることを確認します
次のコマンドを実行して、インターフェイスが SR-IOV デバイスの Virtual Function (VF) にパーティショニングされていることを確認します。
$ ip link show <interface> 1- 1
<interface>を、SR-IOV デバイスの VF にパーティショニングするときに指定したインターフェイス (例:ens3f1) に置き換えます。
出力例
5: ens3f1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000 link/ether 3c:fd:fe:d1:bc:01 brd ff:ff:ff:ff:ff:ff vf 0 link/ether 5a:e7:88:25:ea:a0 brd ff:ff:ff:ff:ff:ff, spoof checking on, link-state auto, trust off vf 1 link/ether 3e:1d:36:d7:3d:49 brd ff:ff:ff:ff:ff:ff, spoof checking on, link-state auto, trust off vf 2 link/ether ce:09:56:97:df:f9 brd ff:ff:ff:ff:ff:ff, spoof checking on, link-state auto, trust off vf 3 link/ether 5e:91:cf:88:d1:38 brd ff:ff:ff:ff:ff:ff, spoof checking on, link-state auto, trust off vf 4 link/ether e6:06:a1:96:2f:de brd ff:ff:ff:ff:ff:ff, spoof checking on, link-state auto, trust off
26.4.2. SR-IOV ネットワークデバイスの設定
SR-IOV Network Operator は SriovNetworkNodePolicy.sriovnetwork.openshift.io CustomResourceDefinition を OpenShift Container Platform に追加します。SR-IOV ネットワークデバイスは、SriovNetworkNodePolicy カスタムリソース (CR) を作成して設定できます。
SriovNetworkNodePolicy オブジェクトで指定された設定を適用する際に、SR-IOV Operator はノードをドレイン (解放) する可能性があり、場合によってはノードの再起動を行う場合があります。
設定の変更が適用されるまでに数分かかる場合があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 - SR-IOV Network Operator がインストールされている。
- ドレイン (解放) されたノードからエビクトされたワークロードを処理するために、クラスター内に利用可能な十分なノードがあること。
- SR-IOV ネットワークデバイス設定についてコントロールプレーンノードを選択していないこと。
手順
-
SriovNetworkNodePolicyオブジェクトを作成してから、YAML を<name>-sriov-node-network.yamlファイルに保存します。<name>をこの設定の名前に置き換えます。 -
オプション: SR-IOV 対応のクラスターノードにまだラベルが付いていない場合は、
SriovNetworkNodePolicy.Spec.NodeSelectorでラベルを付けます。ノードのラベル付けについて、詳しくはノードのラベルを更新する方法についてを参照してください。 SriovNetworkNodePolicyオブジェクトを作成します。$ oc create -f <name>-sriov-node-network.yaml
ここで、
<name>はこの設定の名前を指定します。設定の更新が適用された後に、
sriov-network-operatornamespace のすべての Pod がRunningステータスに移行します。SR-IOV ネットワークデバイスが設定されていることを確認するには、以下のコマンドを実行します。
<node_name>を、設定したばかりの SR-IOV ネットワークデバイスを持つノードの名前に置き換えます。$ oc get sriovnetworknodestates -n openshift-sriov-network-operator <node_name> -o jsonpath='{.status.syncStatus}'
関連情報
26.4.3. SR-IOV 設定のトラブルシューティング
SR-IOV ネットワークデバイスの設定の手順を実行した後に、以下のセクションではエラー状態の一部に対応します。
ノードの状態を表示するには、以下のコマンドを実行します。
$ oc get sriovnetworknodestates -n openshift-sriov-network-operator <node_name>
ここで、<node_name> は SR-IOV ネットワークデバイスを持つノードの名前を指定します。
エラー出力: Cannot allocate memory
"lastSyncError": "write /sys/bus/pci/devices/0000:3b:00.1/sriov_numvfs: cannot allocate memory"
ノードがメモリーを割り当てることができないことを示す場合は、以下の項目を確認します。
- ノードの BIOS でグローバル SR-IOV 設定が有効になっていることを確認します。
- ノードの BIOS で VT-d が有効であることを確認します。
26.4.4. SR-IOV ネットワークの VRF への割り当て
クラスター管理者は、CNI VRF プラグインを使用して、SR-IOV ネットワークインターフェイスを VRF ドメインに割り当てることができます。
これを実行するには、VRF 設定を SriovNetwork リソースのオプションの metaPlugins パラメーターに追加します。
VRF を使用するアプリケーションを特定のデバイスにバインドする必要があります。一般的な使用方法として、ソケットに SO_BINDTODEVICE オプションを使用できます。SO_BINDTODEVICE は、渡されるインターフェイス名で指定されているデバイスにソケットをバインドします (例: eth1)。SO_BINDTODEVICE を使用するには、アプリケーションに CAP_NET_RAW 機能がある必要があります。
ip vrf exec コマンドを使用した VRF の使用は、OpenShift Container Platform Pod ではサポートされません。VRF を使用するには、アプリケーションを VRF インターフェイスに直接バインドします。
26.4.4.1. CNI VRF プラグインを使用した追加 SR-IOV ネットワーク割り当ての作成
SR-IOV Network Operator は追加ネットワークの定義を管理します。作成する追加ネットワークを指定する場合、SR-IOV Network Operator は NetworkAttachmentDefinition カスタムリソース (CR) を自動的に作成します。
SR-IOV Network Operator が管理する NetworkAttachmentDefinition カスタムリソースは編集しないでください。これを実行すると、追加ネットワークのネットワークトラフィックが中断する可能性があります。
CNI VRF プラグインで追加の SR-IOV ネットワーク割り当てを作成するには、以下の手順を実行します。
前提条件
- OpenShift Container Platform CLI (oc) をインストールします。
- cluster-admin 権限を持つユーザーとして OpenShift Container Platform クラスターにログインします。
手順
追加の SR-IOV ネットワーク割り当て用の
SriovNetworkカスタムリソース (CR) を作成し、以下のサンプル CR のようにmetaPlugins設定を挿入します。YAML をsriov-network-attachment.yamlファイルとして保存します。apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: example-network namespace: additional-sriov-network-1 spec: ipam: | { "type": "host-local", "subnet": "10.56.217.0/24", "rangeStart": "10.56.217.171", "rangeEnd": "10.56.217.181", "routes": [{ "dst": "0.0.0.0/0" }], "gateway": "10.56.217.1" } vlan: 0 resourceName: intelnics metaPlugins : | { "type": "vrf", 1 "vrfname": "example-vrf-name" 2 }SriovNetworkリソースを作成します。$ oc create -f sriov-network-attachment.yaml
NetworkAttachmentDefinition CR が正常に作成されることの確認
以下のコマンドを実行して、SR-IOV Network Operator が
NetworkAttachmentDefinitionCR を作成していることを確認します。$ oc get network-attachment-definitions -n <namespace> 1- 1
<namespace>を、ネットワーク割り当ての設定時に指定した namespace に置き換えます (例:additional-sriov-network-1)。
出力例
NAME AGE additional-sriov-network-1 14m
注記SR-IOV Network Operator が CR を作成するまでに遅延が生じる可能性があります。
追加の SR-IOV ネットワーク割り当てが正常であることの確認
VRF CNI が正しく設定され、追加の SR-IOV ネットワーク割り当てが接続されていることを確認するには、以下を実行します。
- VRF CNI を使用する SR-IOV ネットワークを作成します。
- ネットワークを Pod に割り当てます。
Pod のネットワーク割り当てが SR-IOV の追加ネットワークに接続されていることを確認します。Pod にリモートシェルを実行し、以下のコマンドを実行します。
$ ip vrf show
出力例
Name Table ----------------------- red 10
VRF インターフェイスがセカンダリーインターフェイスのマスターであることを確認します。
$ ip link
出力例
... 5: net1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master red state UP mode ...
26.4.5. NUMA 対応スケジューリング用の SR-IOV ネットワークトポロジーを除外する場合
NUMA 対応 Pod のスケジューリングでより柔軟な SR-IOV ネットワークデプロイメントを実現するために、SR-IOV ネットワークの Non-Uniform Memory Access (NUMA) ノードを Topology Manager にアドバタイズする場合を除外できます。
一部のシナリオでは、シングル NUMA ノード上の Pod の CPU およびメモリーリソースを最大化することが優先されます。Topology Manager に Pod の SR-IOV ネットワークリソースの NUMA ノードに関するヒントを提供しないことで、Topology Manager は SR-IOV ネットワークリソースと Pod の CPU およびメモリーリソースを異なる NUMA ノードにデプロイできます。その場合、NUMA ノード間のデータ転送により、ネットワーク遅延が増加する可能性があります。ただし、ワークロードが最適な CPU とメモリーのパフォーマンスを必要とするシナリオでは許容されます。
たとえば、2 つの NUMA ノード (uma0 と uma1) を備えたコンピュートノード compute-1 があるとします。SR-IOV が有効な NIC は numa0 にあります。Pod のスケジューリングに使用できる CPU は、numa1 にしかありません。excludeTopology 仕様を true に設定すると、Topology Manager は Pod の CPU およびメモリーリソースを numa1 に割り当て、同じ Pod の SR-IOV ネットワークリソースを numa0 に割り当てることができます。これは、excludeTopology 仕様を true に設定した場合にのみ可能です。そうではない場合、Topology Manager はすべてのリソースを同じ NUMA ノードに配置しようとします。
26.4.5.1. NUMA 対応スケジューリングのための SR-IOV ネットワークトポロジーの除外
SR-IOV ネットワークリソースの Non-Uniform Memory Access (NUMA) ノードを Topology Manager にアドバタイズする場合を除外するには、SriovNetworkNodePolicy カスタムリソースで excludeTopology 仕様を設定できます。NUMA 対応 Pod のスケジューリングでより柔軟な SR-IOV ネットワークデプロイメントを行うには、この設定を使用します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
CPU マネージャーのポリシーを
staticに設定している。CPU マネージャーの詳細は、関連情報 セクションを参照してください。 -
Topology Manager ポリシーを
single-numa-nodeに設定している。 - SR-IOV Network Operator がインストールされている。
手順
SriovNetworkNodePolicyCR を作成します。次の YAML を
sriov-network-node-policy.yamlファイルに保存し、環境に合わせて YAML 内の値を置き換えます。apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: <policy_name> namespace: openshift-sriov-network-operator spec: resourceName: sriovnuma0 1 nodeSelector: kubernetes.io/hostname: <node_name> numVfs: <number_of_Vfs> nicSelector: 2 vendor: "<vendor_ID>" deviceID: "<device_ID>" deviceType: netdevice excludeTopology: true 3
注記複数の
SriovNetworkNodePolicyリソースが同じ SR-IOV ネットワークリソースをターゲットとする場合、SriovNetworkNodePolicyリソースの値はexcludeTopology仕様と同じである必要があります。そうでない場合、矛盾するポリシーは拒否されます。次のコマンドを実行して、
SriovNetworkNodePolicyリソースを作成します。$ oc create -f sriov-network-node-policy.yaml
出力例
sriovnetworknodepolicy.sriovnetwork.openshift.io/policy-for-numa-0 created
SriovNetworkCR を作成します。次の YAML を
sriov-network.yamlファイルに保存します。その場合、YAML 内の値は環境に合わせて置き換えます。apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: sriov-numa-0-network 1 namespace: openshift-sriov-network-operator spec: resourceName: sriovnuma0 2 networkNamespace: <namespace> 3 ipam: |- 4 { "type": "<ipam_type>", }
次のコマンドを実行して、
SriovNetworkリソースを作成します。$ oc create -f sriov-network.yaml
出力例
sriovnetwork.sriovnetwork.openshift.io/sriov-numa-0-network created
Pod を作成し、前の手順で作成した SR-IOV ネットワークリソースを割り当てます。
次の YAML を
sriov-network-pod.yamlファイルに保存します。その場合、YAML 内の値は環境に合わせて置き換えます。apiVersion: v1 kind: Pod metadata: name: <pod_name> annotations: k8s.v1.cni.cncf.io/networks: |- [ { "name": "sriov-numa-0-network", 1 } ] spec: containers: - name: <container_name> image: <image> imagePullPolicy: IfNotPresent command: ["sleep", "infinity"]- 1
- これは、
SriovNetworkNodePolicyリソースを使用するSriovNetworkリソースの名前です。
次のコマンドを実行して、
Podリソースを作成します。$ oc create -f sriov-network-pod.yaml
出力例
pod/example-pod created
検証
次のコマンドを実行して、Pod のステータスを確認します。その場合、
<pod_name>は Pod の名前に置き換えます。$ oc get pod <pod_name>
出力例
NAME READY STATUS RESTARTS AGE test-deployment-sriov-76cbbf4756-k9v72 1/1 Running 0 45h
ターゲット Pod とのデバッグセッションを開き、SR-IOV ネットワークリソースがメモリーおよび CPU リソースとは異なるノードにデプロイされていることを確認します。
次のコマンドを実行して、Pod とのデバッグセッションを開きます。その場合、<pod_name> はターゲット Pod の名前に置き換えます。
$ oc debug pod/<pod_name>
/hostをデバッグシェル内の root ディレクトリーとして設定します。デバッグ Pod は、Pod 内の/hostにホストからのルートファイルシステムをマウントします。ルートディレクトリーを/hostに変更すると、ホストファイルシステムからのバイナリーを実行できます。$ chroot /host
次のコマンドを実行して、CPU 割り当てに関する情報を表示します。
$ lscpu | grep NUMA
出力例
NUMA node(s): 2 NUMA node0 CPU(s): 0,2,4,6,8,10,12,14,16,18,... NUMA node1 CPU(s): 1,3,5,7,9,11,13,15,17,19,...
$ cat /proc/self/status | grep Cpus
出力例
Cpus_allowed: aa Cpus_allowed_list: 1,3,5,7
$ cat /sys/class/net/net1/device/numa_node
出力例
0
この例では、CPU 1、3、5、7 が
NUMA node1に割り当てられていますが、SR-IOV ネットワークリソースはNUMA node0の NIC を使用できます。
excludeTopology 仕様が True に設定されている場合、必要なリソースが同じ NUMA ノードに存在する可能性があります。
関連情報
26.4.6. 次のステップ
26.5. SR-IOV イーサネットネットワーク割り当ての設定
クラスター内の Single Root I/O Virtualization (SR-IOV) デバイスのイーサネットネットワーク割り当てを設定できます。
26.5.1. イーサネットデバイス設定オブジェクト
イーサネットネットワークデバイスは、SriovNetwork オブジェクトを定義して設定できます。
以下の YAML は SriovNetwork オブジェクトについて説明しています。
apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: <name> 1 namespace: openshift-sriov-network-operator 2 spec: resourceName: <sriov_resource_name> 3 networkNamespace: <target_namespace> 4 vlan: <vlan> 5 spoofChk: "<spoof_check>" 6 ipam: |- 7 {} linkState: <link_state> 8 maxTxRate: <max_tx_rate> 9 minTxRate: <min_tx_rate> 10 vlanQoS: <vlan_qos> 11 trust: "<trust_vf>" 12 capabilities: <capabilities> 13
- 1
- オブジェクトの名前。SR-IOV Network Operator は、同じ名前を持つ
NetworkAttachmentDefinitionオブジェクトを作成します。 - 2
- SR-IOV Network Operator がインストールされている namespace。
- 3
- この追加ネットワークの SR-IOV ハードウェアを定義する
SriovNetworkNodePolicyオブジェクトのspec.resourceNameパラメーターの値。 - 4
SriovNetworkオブジェクトのターゲット namespace。ターゲット namespace の Pod のみを追加ネットワークに割り当てることができます。- 5
- オプション: 追加ネットワークの仮想 LAN (VLAN) ID。整数値は
0から4095である必要があります。デフォルト値は0です。 - 6
- オプション: VF の spoof チェックモード。許可される値は、文字列の
"on"および"off"です。重要指定する値は引用符で囲む必要があります。引用符で囲まないと、オブジェクトが SR-IOV Network Operator によって拒否されます。
- 7
- YAML ブロックスケーラーとしての IPAM CNI プラグインの設定オブジェクトプラグインは、割り当て定義についての IP アドレスの割り当てを管理します。
- 8
- オプション: Virtual Function (VF) のリンク状態。許可される値は、
enable、disable、およびautoです。 - 9
- オプション: VF の最大伝送レート (Mbps)。
- 10
- オプション: VF の最小伝送レート (Mbps)。この値は、最大伝送レート以下である必要があります。注記
Intel NIC は
minTxRateパラメーターをサポートしません。詳細は、BZ#1772847 を参照してください。 - 11
- オプション: VF の IEEE 802.1p 優先度レベル。デフォルト値は
0です。 - 12
- オプション: VF の信頼モード。許可される値は、文字列の
"on"および"off"です。重要指定する値を引用符で囲む必要があります。囲まないと、SR-IOV Network Operator はオブジェクトを拒否します。
- 13
- オプション: この追加ネットワークに設定する機能。IP アドレスのサポートを有効にするには、
"{ "ips": true }"を指定できます。または、MAC アドレスのサポートを有効にするには"{ "mac": true }"を指定します。
26.5.1.1. 追加ネットワークの IP アドレス割り当ての設定
IPAM (IP アドレス管理) Container Network Interface (CNI) プラグインは、他の CNI プラグインの IP アドレスを提供します。
以下の IP アドレスの割り当てタイプを使用できます。
- 静的割り当て。
- DHCP サーバーを使用した動的割り当て。指定する DHCP サーバーは、追加のネットワークから到達可能である必要があります。
- Whereabouts IPAM CNI プラグインを使用した動的割り当て。
26.5.1.1.1. 静的 IP アドレス割り当ての設定
以下の表は、静的 IP アドレスの割り当ての設定について説明しています。
表26.3 ipam 静的設定オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
IPAM のアドレスタイプ。値 |
|
|
| 仮想インターフェイスに割り当てる IP アドレスを指定するオブジェクトの配列。IPv4 と IPv6 の IP アドレスの両方がサポートされます。 |
|
|
| Pod 内で設定するルートを指定するオブジェクトの配列です。 |
|
|
| オプション: DNS の設定を指定するオブジェクトの配列です。 |
addressesの配列には、以下のフィールドのあるオブジェクトが必要です。
表26.4 ipam.addresses[] 配列
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
指定する IP アドレスおよびネットワーク接頭辞。たとえば、 |
|
|
| egress ネットワークトラフィックをルーティングするデフォルトのゲートウェイ。 |
表26.5 ipam.routes[] 配列
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
CIDR 形式の IP アドレス範囲 ( |
|
|
| ネットワークトラフィックがルーティングされるゲートウェイ。 |
表26.6 ipam.dns オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
| DNS クエリーの送信先となる 1 つ以上の IP アドレスの配列。 |
|
|
|
ホスト名に追加するデフォルトのドメイン。たとえば、ドメインが |
|
|
|
DNS ルックアップのクエリー時に非修飾ホスト名に追加されるドメイン名の配列 (例: |
静的 IP アドレス割り当ての設定例
{
"ipam": {
"type": "static",
"addresses": [
{
"address": "191.168.1.7/24"
}
]
}
}
26.5.1.1.2. 動的 IP アドレス (DHCP) 割り当ての設定
以下の JSON は、DHCP を使用した動的 IP アドレスの割り当ての設定について説明しています。
Pod は、作成時に元の DHCP リースを取得します。リースは、クラスターで実行している最小限の DHCP サーバーデプロイメントで定期的に更新する必要があります。
SR-IOV Network Operator は DHCP サーバーデプロイメントを作成しません。Cluster Network Operator は最小限の DHCP サーバーデプロイメントを作成します。
DHCP サーバーのデプロイメントをトリガーするには、以下の例にあるように Cluster Network Operator 設定を編集して shim ネットワーク割り当てを作成する必要があります。
shim ネットワーク割り当ての定義例
apiVersion: operator.openshift.io/v1
kind: Network
metadata:
name: cluster
spec:
additionalNetworks:
- name: dhcp-shim
namespace: default
type: Raw
rawCNIConfig: |-
{
"name": "dhcp-shim",
"cniVersion": "0.3.1",
"type": "bridge",
"ipam": {
"type": "dhcp"
}
}
# ...
表26.7 ipam DHCP 設定オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
IPAM のアドレスタイプ。値 |
動的 IP アドレス (DHCP) 割り当ての設定例
{
"ipam": {
"type": "dhcp"
}
}
26.5.1.1.3. Whereabouts を使用した動的 IP アドレス割り当ての設定
Whereabouts CNI プラグインにより、DHCP サーバーを使用せずに IP アドレスを追加のネットワークに動的に割り当てることができます。
以下の表は、Whereabouts を使用した動的 IP アドレス割り当ての設定について説明しています。
表26.8 ipamwhereabouts 設定オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
IPAM のアドレスタイプ。値 |
|
|
| IP アドレスと範囲を CIDR 表記。IP アドレスは、この範囲内のアドレスから割り当てられます。 |
|
|
| オプション: CIDR 表記の IP アドレスと範囲 (0 個以上) のリスト。除外されたアドレス範囲内の IP アドレスは割り当てられません。 |
Whereabouts を使用する動的 IP アドレス割り当ての設定例
{
"ipam": {
"type": "whereabouts",
"range": "192.0.2.192/27",
"exclude": [
"192.0.2.192/30",
"192.0.2.196/32"
]
}
}
26.5.2. SR-IOV の追加ネットワークの設定
SriovNetwork オブジェクト を作成して、SR-IOV ハードウェアを使用する追加のネットワークを設定できます。SriovNetwork オブジェクトの作成時に、SR-IOV Network Operator は NetworkAttachmentDefinition オブジェクトを自動的に作成します。
SriovNetwork オブジェクトが running 状態の Pod に割り当てられている場合、これを変更したり、削除したりしないでください。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
SriovNetworkオブジェクトを作成してから、YAML を<name>.yamlファイルに保存します。<name>はこの追加ネットワークの名前になります。オブジェクト仕様は以下の例のようになります。apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: attach1 namespace: openshift-sriov-network-operator spec: resourceName: net1 networkNamespace: project2 ipam: |- { "type": "host-local", "subnet": "10.56.217.0/24", "rangeStart": "10.56.217.171", "rangeEnd": "10.56.217.181", "gateway": "10.56.217.1" }オブジェクトを作成するには、以下のコマンドを入力します。
$ oc create -f <name>.yaml
ここで、
<name>は追加ネットワークの名前を指定します。オプション: 以下のコマンドを実行して、直前の手順で作成した
SriovNetworkオブジェクトに関連付けられたNetworkAttachmentDefinitionオブジェクトが存在することを確認するには、以下のコマンドを入力します。<namespace>をSriovNetworkオブジェクトで指定した networkNamespace に置き換えます。$ oc get net-attach-def -n <namespace>
26.5.3. 次のステップ
26.5.4. 関連情報
26.6. SR-IOV InfiniBand ネットワーク割り当ての設定
クラスター内の Single Root I/O Virtualization (SR-IOV) デバイスの InfiniBand (IB) ネットワーク割り当てを設定できます。
26.6.1. InfiniBand デバイス設定オブジェクト
SriovIBNetwork オブジェクトを定義することで、InfiniBand (IB) ネットワークデバイスを設定できます。
以下の YAML は、SriovIBNetwork オブジェクトについて説明しています。
apiVersion: sriovnetwork.openshift.io/v1 kind: SriovIBNetwork metadata: name: <name> 1 namespace: openshift-sriov-network-operator 2 spec: resourceName: <sriov_resource_name> 3 networkNamespace: <target_namespace> 4 ipam: |- 5 {} linkState: <link_state> 6 capabilities: <capabilities> 7
- 1
- オブジェクトの名前。SR-IOV Network Operator は、同じ名前を持つ
NetworkAttachmentDefinitionオブジェクトを作成します。 - 2
- SR-IOV Operator がインストールされている namespace。
- 3
- この追加ネットワークの SR-IOV ハードウェアを定義する
SriovNetworkNodePolicyオブジェクトのspec.resourceNameパラメーターの値。 - 4
SriovIBNetworkオブジェクトのターゲット namespace。ターゲット namespace の Pod のみをネットワークデバイスに割り当てることができます。- 5
- オプション: YAML ブロックスケーラーとしての IPAM CNI プラグインの設定オブジェクト。プラグインは、割り当て定義についての IP アドレスの割り当てを管理します。
- 6
- オプション: Virtual Function (VF) のリンク状態。許可される値は、
enable、disable、およびautoです。 - 7
- オプション: このネットワークに設定する機能。
"{ "ips": true }"を指定して IP アドレスのサポートを有効にするか、"{ "infinibandGUID": true }"を指定して IB Global Unique Identifier (GUID) サポートを有効にします。
26.6.1.1. 追加ネットワークの IP アドレス割り当ての設定
IPAM (IP アドレス管理) Container Network Interface (CNI) プラグインは、他の CNI プラグインの IP アドレスを提供します。
以下の IP アドレスの割り当てタイプを使用できます。
- 静的割り当て。
- DHCP サーバーを使用した動的割り当て。指定する DHCP サーバーは、追加のネットワークから到達可能である必要があります。
- Whereabouts IPAM CNI プラグインを使用した動的割り当て。
26.6.1.1.1. 静的 IP アドレス割り当ての設定
以下の表は、静的 IP アドレスの割り当ての設定について説明しています。
表26.9 ipam 静的設定オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
IPAM のアドレスタイプ。値 |
|
|
| 仮想インターフェイスに割り当てる IP アドレスを指定するオブジェクトの配列。IPv4 と IPv6 の IP アドレスの両方がサポートされます。 |
|
|
| Pod 内で設定するルートを指定するオブジェクトの配列です。 |
|
|
| オプション: DNS の設定を指定するオブジェクトの配列です。 |
addressesの配列には、以下のフィールドのあるオブジェクトが必要です。
表26.10 ipam.addresses[] 配列
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
指定する IP アドレスおよびネットワーク接頭辞。たとえば、 |
|
|
| egress ネットワークトラフィックをルーティングするデフォルトのゲートウェイ。 |
表26.11 ipam.routes[] 配列
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
CIDR 形式の IP アドレス範囲 ( |
|
|
| ネットワークトラフィックがルーティングされるゲートウェイ。 |
表26.12 ipam.dns オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
| DNS クエリーの送信先となる 1 つ以上の IP アドレスの配列。 |
|
|
|
ホスト名に追加するデフォルトのドメイン。たとえば、ドメインが |
|
|
|
DNS ルックアップのクエリー時に非修飾ホスト名に追加されるドメイン名の配列 (例: |
静的 IP アドレス割り当ての設定例
{
"ipam": {
"type": "static",
"addresses": [
{
"address": "191.168.1.7/24"
}
]
}
}
26.6.1.1.2. 動的 IP アドレス (DHCP) 割り当ての設定
以下の JSON は、DHCP を使用した動的 IP アドレスの割り当ての設定について説明しています。
Pod は、作成時に元の DHCP リースを取得します。リースは、クラスターで実行している最小限の DHCP サーバーデプロイメントで定期的に更新する必要があります。
DHCP サーバーのデプロイメントをトリガーするには、以下の例にあるように Cluster Network Operator 設定を編集して shim ネットワーク割り当てを作成する必要があります。
shim ネットワーク割り当ての定義例
apiVersion: operator.openshift.io/v1
kind: Network
metadata:
name: cluster
spec:
additionalNetworks:
- name: dhcp-shim
namespace: default
type: Raw
rawCNIConfig: |-
{
"name": "dhcp-shim",
"cniVersion": "0.3.1",
"type": "bridge",
"ipam": {
"type": "dhcp"
}
}
# ...
表26.13 ipam DHCP 設定オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
IPAM のアドレスタイプ。値 |
動的 IP アドレス (DHCP) 割り当ての設定例
{
"ipam": {
"type": "dhcp"
}
}
26.6.1.1.3. Whereabouts を使用した動的 IP アドレス割り当ての設定
Whereabouts CNI プラグインにより、DHCP サーバーを使用せずに IP アドレスを追加のネットワークに動的に割り当てることができます。
以下の表は、Whereabouts を使用した動的 IP アドレス割り当ての設定について説明しています。
表26.14 ipamwhereabouts 設定オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
IPAM のアドレスタイプ。値 |
|
|
| IP アドレスと範囲を CIDR 表記。IP アドレスは、この範囲内のアドレスから割り当てられます。 |
|
|
| オプション: CIDR 表記の IP アドレスと範囲 (0 個以上) のリスト。除外されたアドレス範囲内の IP アドレスは割り当てられません。 |
Whereabouts を使用する動的 IP アドレス割り当ての設定例
{
"ipam": {
"type": "whereabouts",
"range": "192.0.2.192/27",
"exclude": [
"192.0.2.192/30",
"192.0.2.196/32"
]
}
}
26.6.2. SR-IOV の追加ネットワークの設定
SriovIBNetwork オブジェクトを作成して、SR-IOV ハードウェアを使用する追加のネットワークを設定できます。SriovIBNetwork オブジェクトの作成時に、SR-IOV Operator は NetworkAttachmentDefinition オブジェクトを自動的に作成します。
SriovIBNetwork オブジェクトが、running 状態の Pod に割り当てられている場合、これを変更したり、削除したりしないでください。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
SriovIBNetworkCR を作成してから、YAML を<name>.yamlファイルに保存します。<name>は、この追加ネットワークの名前になります。オブジェクト仕様は以下の例のようになります。apiVersion: sriovnetwork.openshift.io/v1 kind: SriovIBNetwork metadata: name: attach1 namespace: openshift-sriov-network-operator spec: resourceName: net1 networkNamespace: project2 ipam: |- { "type": "host-local", "subnet": "10.56.217.0/24", "rangeStart": "10.56.217.171", "rangeEnd": "10.56.217.181", "gateway": "10.56.217.1" }オブジェクトを作成するには、以下のコマンドを入力します。
$ oc create -f <name>.yaml
ここで、
<name>は追加ネットワークの名前を指定します。オプション: 以下のコマンドを実行して、直前の手順で作成した
SriovIBNetworkオブジェクトに関連付けられたNetworkAttachmentDefinitionオブジェクトが存在することを確認します。<namespace>をSriovIBNetworkオブジェクトで指定した networkNamespace に置き換えます。$ oc get net-attach-def -n <namespace>
26.6.3. 次のステップ
26.6.4. 関連情報
26.7. Pod の SR-IOV の追加ネットワークへの追加
Pod を既存の Single Root I/O Virtualization (SR-IOV) ネットワークに追加できます。
26.7.1. ネットワーク割り当てのランタイム設定
Pod を追加のネットワークに割り当てる場合、ランタイム設定を指定して Pod の特定のカスタマイズを行うことができます。たとえば、特定の MAC ハードウェアアドレスを要求できます。
Pod 仕様にアノテーションを設定して、ランタイム設定を指定します。アノテーションキーは k8s.v1.cni.cncf.io/networks で、ランタイム設定を記述する JSON オブジェクトを受け入れます。
26.7.1.1. イーサネットベースの SR-IOV 割り当てのランタイム設定
以下の JSON は、イーサネットベースの SR-IOV ネットワーク割り当て用のランタイム設定オプションを説明しています。
[
{
"name": "<name>", 1
"mac": "<mac_address>", 2
"ips": ["<cidr_range>"] 3
}
]- 1
- SR-IOV ネットワーク割り当て定義 CR の名前。
- 2
- オプション: SR-IOV ネットワーク割り当て定義 CR で定義されるリソースタイプから割り当てられる SR-IOV デバイスの MAC アドレス。この機能を使用するには、
SriovNetworkオブジェクトで{ "mac": true }も指定する必要があります。 - 3
- オプション: SR-IOV ネットワーク割り当て定義 CR で定義されるリソースタイプから割り当てられる SR-IOV デバイスの IP アドレス。IPv4 と IPv6 アドレスの両方がサポートされます。この機能を使用するには、
SriovNetworkオブジェクトで{ "ips": true }も指定する必要があります。
ランタイム設定の例
apiVersion: v1
kind: Pod
metadata:
name: sample-pod
annotations:
k8s.v1.cni.cncf.io/networks: |-
[
{
"name": "net1",
"mac": "20:04:0f:f1:88:01",
"ips": ["192.168.10.1/24", "2001::1/64"]
}
]
spec:
containers:
- name: sample-container
image: <image>
imagePullPolicy: IfNotPresent
command: ["sleep", "infinity"]
26.7.1.2. InfiniBand ベースの SR-IOV 割り当てのランタイム設定
以下の JSON は、InfiniBand ベースの SR-IOV ネットワーク割り当て用のランタイム設定オプションを説明しています。
[
{
"name": "<network_attachment>", 1
"infiniband-guid": "<guid>", 2
"ips": ["<cidr_range>"] 3
}
]ランタイム設定の例
apiVersion: v1
kind: Pod
metadata:
name: sample-pod
annotations:
k8s.v1.cni.cncf.io/networks: |-
[
{
"name": "ib1",
"infiniband-guid": "c2:11:22:33:44:55:66:77",
"ips": ["192.168.10.1/24", "2001::1/64"]
}
]
spec:
containers:
- name: sample-container
image: <image>
imagePullPolicy: IfNotPresent
command: ["sleep", "infinity"]
26.7.2. Pod の追加ネットワークへの追加
Pod を追加のネットワークに追加できます。Pod は、デフォルトネットワークで通常のクラスター関連のネットワークトラフィックを継続的に送信します。
Pod が作成されると、追加のネットワークが割り当てられます。ただし、Pod がすでに存在する場合は、追加のネットワークをこれに割り当てることはできません。
Pod が追加ネットワークと同じ namespace にあること。
SR-IOV Network Resource Injector は、Pod の最初のコンテナーに resource フィールドを自動的に追加します。
データプレーン開発キット (DPDK) モードでインテル製のネットワークインターフェイスコントローラー (NIC) を使用している場合には、Pod 内の最初のコンテナーのみが NIC にアクセスできるように設定されています。SR-IOV 追加ネットワークは、Sriov Network Node Policy オブジェクトで device Type が vfio-pci に設定されてる場合は DPDK モードに設定されます。
この問題は、NIC にアクセスする必要のあるコンテナーが Pod オブジェクトで定義された最初のコンテナーであることを確認するか、Network Resource Injector を無効にすることで回避できます。詳細は、BZ#1990953 を参照してください。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - クラスターにログインする。
- SR-IOV Operator のインストール。
-
Pod を割り当てる
SriovNetworkオブジェクトまたはSriovIBNetworkオブジェクトのいずれかを作成する。
手順
アノテーションを
Podオブジェクトに追加します。以下のアノテーション形式のいずれかのみを使用できます。カスタマイズせずに追加ネットワークを割り当てるには、以下の形式でアノテーションを追加します。
<network>を、Pod に関連付ける追加ネットワークの名前に置き換えます。metadata: annotations: k8s.v1.cni.cncf.io/networks: <network>[,<network>,...] 1- 1
- 複数の追加ネットワークを指定するには、各ネットワークをコンマで区切ります。コンマの間にはスペースを入れないでください。同じ追加ネットワークを複数回指定した場合、Pod は複数のネットワークインターフェイスをそのネットワークに割り当てます。
カスタマイズして追加のネットワークを割り当てるには、以下の形式でアノテーションを追加します。
metadata: annotations: k8s.v1.cni.cncf.io/networks: |- [ { "name": "<network>", 1 "namespace": "<namespace>", 2 "default-route": ["<default-route>"] 3 } ]
Pod を作成するには、以下のコマンドを入力します。
<name>を Pod の名前に置き換えます。$ oc create -f <name>.yaml
オプション: アノテーションが
PodCR に存在することを確認するには、<name>を Pod の名前に置き換えて、以下のコマンドを入力します。$ oc get pod <name> -o yaml
以下の例では、
example-podPod が追加ネットワークのnet1に割り当てられています。$ oc get pod example-pod -o yaml apiVersion: v1 kind: Pod metadata: annotations: k8s.v1.cni.cncf.io/networks: macvlan-bridge k8s.v1.cni.cncf.io/network-status: |- 1 [{ "name": "openshift-sdn", "interface": "eth0", "ips": [ "10.128.2.14" ], "default": true, "dns": {} },{ "name": "macvlan-bridge", "interface": "net1", "ips": [ "20.2.2.100" ], "mac": "22:2f:60:a5:f8:00", "dns": {} }] name: example-pod namespace: default spec: ... status: ...- 1
k8s.v1.cni.cncf.io/network-statusパラメーターは、オブジェクトの JSON 配列です。各オブジェクトは、Pod に割り当てられる追加のネットワークのステータスについて説明します。アノテーションの値はプレーンテキストの値として保存されます。
26.7.3. Non-Uniform Memory Access (NUMA) で配置された SR-IOV Pod の作成
NUMA で配置された SR-IOV Pod は、restricted または single-numa-node Topology Manager ポリシーで同じ NUMA ノードから割り当てられる SR-IOV および CPU リソースを制限することによって作成できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
CPU マネージャーのポリシーを
staticに設定している。CPU マネージャーの詳細は、関連情報セクションを参照してください。 Topology Manager ポリシーを
single-numa-nodeに設定している。注記single-numa-nodeが要求を満たさない場合は、Topology Manager ポリシーをrestrictedにするように設定できます 。より柔軟な SR-IOV ネットワークリソーススケジューリングについては、関連情報 セクションの NUMA 対応スケジューリングにおける SR-IOV ネットワークトポロジーの除外 を参照してください。
手順
以下の SR-IOV Pod 仕様を作成してから、YAML を
<name>-sriov-pod.yamlファイルに保存します。<name>をこの Pod の名前に置き換えます。以下の例は、SR-IOV Pod 仕様を示しています。
apiVersion: v1 kind: Pod metadata: name: sample-pod annotations: k8s.v1.cni.cncf.io/networks: <name> 1 spec: containers: - name: sample-container image: <image> 2 command: ["sleep", "infinity"] resources: limits: memory: "1Gi" 3 cpu: "2" 4 requests: memory: "1Gi" cpu: "2"以下のコマンドを実行して SR-IOV Pod のサンプルを作成します。
$ oc create -f <filename> 1- 1
<filename>を、先の手順で作成したファイルの名前に置き換えます。
sample-podが Guaranteed QoS を指定して設定されていることを確認します。$ oc describe pod sample-pod
sample-podが排他的 CPU を指定して割り当てられていることを確認します。$ oc exec sample-pod -- cat /sys/fs/cgroup/cpuset/cpuset.cpus
sample-podに割り当てられる SR-IOV デバイスと CPU が同じ NUMA ノード上にあることを確認します。$ oc exec sample-pod -- cat /sys/fs/cgroup/cpuset/cpuset.cpus
26.7.4. OpenStack で SR-IOV を使用するクラスター用のテスト Pod テンプレート
次の testpmd Pod では、ヒュージページ、予約済み CPU、および SR-IOV ポートを使用したコンテナーの作成を紹介します。
testpmd Pod の例
apiVersion: v1
kind: Pod
metadata:
name: testpmd-sriov
namespace: mynamespace
annotations:
cpu-load-balancing.crio.io: "disable"
cpu-quota.crio.io: "disable"
# ...
spec:
containers:
- name: testpmd
command: ["sleep", "99999"]
image: registry.redhat.io/openshift4/dpdk-base-rhel8:v4.9
securityContext:
capabilities:
add: ["IPC_LOCK","SYS_ADMIN"]
privileged: true
runAsUser: 0
resources:
requests:
memory: 1000Mi
hugepages-1Gi: 1Gi
cpu: '2'
openshift.io/sriov1: 1
limits:
hugepages-1Gi: 1Gi
cpu: '2'
memory: 1000Mi
openshift.io/sriov1: 1
volumeMounts:
- mountPath: /dev/hugepages
name: hugepage
readOnly: False
runtimeClassName: performance-cnf-performanceprofile 1
volumes:
- name: hugepage
emptyDir:
medium: HugePages
- 1
- この例では、パフォーマンスプロファイルの名前が
cnf-performance profileであると想定しています。
26.7.5. 関連情報
26.8. SR-IOV ネットワークのインターフェイスレベルのネットワーク sysctl 設定の設定
クラスター管理者は、SR-IOV ネットワークデバイスに接続された Pod の Container Network Interface (CNI) メタプラグインの調整を使用して、インターフェイスレベルのネットワーク sysctl を変更できます。
26.8.1. SR-IOV 対応 NIC を使用したノードのラベル付け
SR-IOV 対応ノードのみで SR-IOV を有効にしたい場合は、いくつかの方法があります。
-
Node Feature Discovery (NFD) Operator をインストールします。NFD は SR-IOV 対応の NIC の存在を検出し、ノードに
node.alpha.kubernetes-incubator.io/nfd-network-sriov.capable = trueラベルを付けます。 各ノードの
SriovNetworkNodeStateCR を調べます。interfacesスタンザには、ワーカーノード上の SR-IOV Network Operator によって検出されるすべての SR-IOV デバイスの一覧が含まれます。次のコマンドを使用して、各ノードにfeature.node.kubernetes.io/network-sriov.capable: "true"というラベルを付けます。$ oc label node <node_name> feature.node.kubernetes.io/network-sriov.capable="true"
注記任意の名前でノードにラベルを付けることができます。
26.8.2. 1 つの sysctl フラグの設定
SR-IOV ネットワークデバイスに接続された Pod のインターフェイスレベルのネットワーク sysctl 設定を設定できます。
この例では、作成された仮想インターフェイスで net.ipv4.conf.IFNAME.accept_redirects が 1 に設定されます。
sysctl-tuning-test は、この例で使用される namespace です。
次のコマンドを使用して、
sysctl-tuning-testnamespace を作成します。$ oc create namespace sysctl-tuning-test
26.8.2.1. SR-IOV ネットワークデバイスを持つノードで 1 つの sysctl フラグを設定する
SR-IOV Network Operator は SriovNetworkNodePolicy.sriovnetwork.openshift.io カスタムリソース定義 (CRD) を OpenShift Container Platform に追加します。SR-IOV ネットワークデバイスは、SriovNetworkNodePolicy カスタムリソース (CR) を作成して設定できます。
SriovNetworkNodePolicy オブジェクトで指定された設定を適用すると、SR-IOV Operator がノードをドレインして再起動する場合があります。
設定の変更が適用されるまでに数分の時間がかかる場合があります。
この手順に従って、SriovNetworkNodePolicy カスタムリソース (CR) を作成します。
手順
SriovNetworkNodePolicyカスタムリソース (CR) を作成します。たとえば、次の YAML をファイルpolicyoneflag-sriov-node-network.yamlとして保存します。apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: policyoneflag 1 namespace: openshift-sriov-network-operator 2 spec: resourceName: policyoneflag 3 nodeSelector: 4 feature.node.kubernetes.io/network-sriov.capable="true" priority: 10 5 numVfs: 5 6 nicSelector: 7 pfNames: ["ens5"] 8 deviceType: "netdevice" 9 isRdma: false 10
- 1
- カスタムリソースオブジェクトの名前。
- 2
- SR-IOV Network Operator がインストールされている namespace。
- 3
- SR-IOV ネットワークデバイスプラグインのリソース名。1 つのリソース名に複数の SR-IOV ネットワークポリシーを作成できます。
- 4
- ノードセレクターは設定するノードを指定します。選択したノード上の SR-IOV ネットワークデバイスのみが設定されます。SR-IOV Container Network Interface (CNI) プラグインおよびデバイスプラグインは、選択したノードにのみデプロイされます。
- 5
- オプション: 優先度は
0から99までの整数値で指定されます。値が小さいほど優先度が高くなります。たとえば、10の優先度は99よりも高くなります。デフォルト値は99です。 - 6
- SR-IOV 物理ネットワークデバイス用に作成する Virtual Function (VF) の数。Intel ネットワークインターフェイスコントローラー (NIC) の場合、VF の数はデバイスがサポートする VF の合計よりも大きくすることはできません。Mellanox NIC の場合、VF の数は
128よりも大きくすることはできません。 - 7
- NIC セレクターは、Operator が設定するデバイスを特定します。すべてのパラメーターの値を指定する必要はありません。意図せずにデバイスを選択しないように、ネットワークデバイスを極めて正確に特定することが推奨されます。
rootDevicesを指定する場合、vendor、deviceID、またはpfNameの値も指定する必要があります。pfNamesおよびrootDevicesの両方を同時に指定する場合、それらが同一のデバイスを参照していることを確認します。netFilterの値を指定する場合、ネットワーク ID は一意の ID であるためにその他のパラメーターを指定する必要はありません。 - 8
- オプション: 1 つ以上のデバイスの物理機能 (PF) 名の配列。
- 9
- オプション: Virtual Function (VF) のドライバータイプ。許可される唯一の値は
netdeviceです。ベアメタルノードで Mellanox NIC を DPDK モードで動作させるには、isRdmaをtrueに設定します。 - 10
- オプション: Remote Direct Memory Access (RDMA) モードを有効にするかどうかを設定します。デフォルト値は
falseです。isRdmaパラメーターがtrueに設定される場合、引き続き RDMA 対応の VF を通常のネットワークデバイスとして使用できます。デバイスはどちらのモードでも使用できます。isRdmaをtrueに設定し、追加のneedVhostNetをtrueに設定して、Fast Datapath DPDK アプリケーションで使用する Mellanox NIC を設定します。
注記vfio-pciドライバータイプはサポートされていません。SriovNetworkNodePolicyオブジェクトを作成します。$ oc create -f policyoneflag-sriov-node-network.yaml
設定の更新が適用された後に、
sriov-network-operatornamespace 変更のすべての Pod がRunningステータスに移行します。SR-IOV ネットワークデバイスが設定されていることを確認するには、以下のコマンドを実行します。
<node_name>を、設定したばかりの SR-IOV ネットワークデバイスを持つノードの名前に置き換えます。$ oc get sriovnetworknodestates -n openshift-sriov-network-operator <node_name> -o jsonpath='{.status.syncStatus}'出力例
Succeeded
26.8.2.2. SR-IOV ネットワークでの sysctl の設定
SriovNetwork リソースのオプションの metaPlugins パラメーターにチューニング設定を追加することで、SR-IOV により作成された仮想インターフェイスにインターフェイス固有の sysctl 設定を設定できます。
SR-IOV Network Operator は追加ネットワークの定義を管理します。作成する追加ネットワークを指定する場合、SR-IOV Network Operator は NetworkAttachmentDefinition カスタムリソース (CR) を自動的に作成します。
SR-IOV Network Operator が管理する NetworkAttachmentDefinition カスタムリソースは編集しないでください。これを実行すると、追加ネットワークのネットワークトラフィックが中断する可能性があります。
インターフェイスレベルのネットワーク net.ipv4.conf.IFNAME.accept_redirects sysctl 設定を変更するには、Container Network Interface (CNI) チューニングプラグインを使用して追加の SR-IOV ネットワークを作成します。
前提条件
- OpenShift Container Platform CLI (oc) をインストールします。
- cluster-admin 権限を持つユーザーとして OpenShift Container Platform クラスターにログインします。
手順
追加の SR-IOV ネットワーク割り当て用の
SriovNetworkカスタムリソース (CR) を作成し、以下のサンプル CR のようにmetaPlugins設定を挿入します。YAML をsriov-network-interface-sysctl.yamlファイルとして保存します。apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: onevalidflag 1 namespace: openshift-sriov-network-operator 2 spec: resourceName: policyoneflag 3 networkNamespace: sysctl-tuning-test 4 ipam: '{ "type": "static" }' 5 capabilities: '{ "mac": true, "ips": true }' 6 metaPlugins : | 7 { "type": "tuning", "capabilities":{ "mac":true }, "sysctl":{ "net.ipv4.conf.IFNAME.accept_redirects": "1" } }
- 1
- オブジェクトの名前。SR-IOV Network Operator は、同じ名前を持つ NetworkAttachmentDefinition オブジェクトを作成します。
- 2
- SR-IOV Network Operator がインストールされている namespace。
- 3
- この追加ネットワークの SR-IOV ハードウェアを定義する
SriovNetworkNodePolicyオブジェクトのspec.resourceNameパラメーターの値。 - 4
SriovNetworkオブジェクトのターゲット namespace。ターゲット namespace の Pod のみを追加ネットワークに割り当てることができます。- 5
- YAML ブロックスケーラーとしての IPAM CNI プラグインの設定オブジェクトプラグインは、割り当て定義についての IP アドレスの割り当てを管理します。
- 6
- オプション: 追加のネットワークの機能を設定します。IP アドレスのサポートを有効にするには、
"{ "ips": true }"を指定できます。または、MAC アドレスのサポートを有効にするには"{ "mac": true }"を指定します。 - 7
- オプション: metaPlugins パラメーターは、デバイスに機能を追加するために使用されます。このユースケースでは、
typeフィールドをtuningに設定します。設定したいインターフェイスレベルのネットワークsysctlをsysctlフィールドに指定します。
SriovNetworkリソースを作成します。$ oc create -f sriov-network-interface-sysctl.yaml
NetworkAttachmentDefinition CR が正常に作成されることの確認
以下のコマンドを実行して、SR-IOV Network Operator が
NetworkAttachmentDefinitionCR を作成していることを確認します。$ oc get network-attachment-definitions -n <namespace> 1- 1
<namespace>を、SriovNetworkオブジェクトで指定したnetworkNamespaceの値に置き換えます。たとえば、sysctl-tuning-testです。
出力例
NAME AGE onevalidflag 14m
注記SR-IOV Network Operator が CR を作成するまでに遅延が生じる可能性があります。
追加の SR-IOV ネットワーク割り当てが正常であることの確認
チューニング CNI が正しく設定され、追加の SR-IOV ネットワーク割り当てが接続されていることを確認するには、以下を実行します。
PodCR を作成します。次の YAML をexamplepod.yamlファイルとして保存します。apiVersion: v1 kind: Pod metadata: name: tunepod namespace: sysctl-tuning-test annotations: k8s.v1.cni.cncf.io/networks: |- [ { "name": "onevalidflag", 1 "mac": "0a:56:0a:83:04:0c", 2 "ips": ["10.100.100.200/24"] 3 } ] spec: containers: - name: podexample image: centos command: ["/bin/bash", "-c", "sleep INF"] securityContext: runAsUser: 2000 runAsGroup: 3000 allowPrivilegeEscalation: false capabilities: drop: ["ALL"] securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault- 1
- SR-IOV ネットワーク割り当て定義 CR の名前。
- 2
- オプション: SR-IOV ネットワーク割り当て定義 CR で定義されるリソースタイプから割り当てられる SR-IOV デバイスの MAC アドレス。この機能を使用するには、SriovNetwork オブジェクトで
{ "mac": true }も指定する必要があります。 - 3
- オプション: SR-IOV ネットワーク割り当て定義 CR で定義されるリソースタイプから割り当てられる SR-IOV デバイスの IP アドレス。IPv4 と IPv6 アドレスの両方がサポートされます。この機能を使用するには、
SriovNetworkオブジェクトで{ "ips": true }も指定する必要があります。
PodCR を作成します。$ oc apply -f examplepod.yaml
次のコマンドを実行して、Pod が作成されていることを確認します。
$ oc get pod -n sysctl-tuning-test
出力例
NAME READY STATUS RESTARTS AGE tunepod 1/1 Running 0 47s
次のコマンドを実行して、Pod にログインします。
$ oc rsh -n sysctl-tuning-test tunepod
設定された sysctl フラグの値を確認します。次のコマンドを実行して、
net.ipv4.conf.IFNAME.accept_redirectsの値を見つけます。$ sysctl net.ipv4.conf.net1.accept_redirects
出力例
net.ipv4.conf.net1.accept_redirects = 1
26.8.3. ボンディングされた SR-IOV インターフェイスフラグに関連付けられた Pod の sysctl 設定の設定
ボンディングされた SR-IOV ネットワークデバイスに接続された Pod のインターフェイスレベルのネットワーク sysctl 設定を設定できます。
この例では、設定可能な特定のネットワークインターフェイスレベルの sysctl 設定がボンドインターフェイスに設定されています。
sysctl-tuning-test は、この例で使用される namespace です。
次のコマンドを使用して、
sysctl-tuning-testnamespace を作成します。$ oc create namespace sysctl-tuning-test
26.8.3.1. SR-IOV ネットワークデバイスがボンドされたノードですべての sysctl フラグを設定する
SR-IOV Network Operator は SriovNetworkNodePolicy.sriovnetwork.openshift.io カスタムリソース定義 (CRD) を OpenShift Container Platform に追加します。SR-IOV ネットワークデバイスは、SriovNetworkNodePolicy カスタムリソース (CR) を作成して設定できます。
SriovNetworkNodePolicy オブジェクトで指定された設定を適用する際に、SR-IOV Operator はノードをドレイン (解放) する可能性があり、場合によってはノードの再起動を行う場合があります。
設定の変更が適用されるまでに数分かかる場合があります。
この手順に従って、SriovNetworkNodePolicy カスタムリソース (CR) を作成します。
手順
SriovNetworkNodePolicyカスタムリソース (CR) を作成します。次の YAML をpolicyallflags-sriov-node-network.yamlファイルとして保存します。policyallflagsを設定の名前に置き換えます。apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: policyallflags 1 namespace: openshift-sriov-network-operator 2 spec: resourceName: policyallflags 3 nodeSelector: 4 node.alpha.kubernetes-incubator.io/nfd-network-sriov.capable = `true` priority: 10 5 numVfs: 5 6 nicSelector: 7 pfNames: ["ens1f0"] 8 deviceType: "netdevice" 9 isRdma: false 10
- 1
- カスタムリソースオブジェクトの名前。
- 2
- SR-IOV Network Operator がインストールされている namespace。
- 3
- SR-IOV ネットワークデバイスプラグインのリソース名。1 つのリソース名に複数の SR-IOV ネットワークポリシーを作成できます。
- 4
- ノードセレクターは設定するノードを指定します。選択したノード上の SR-IOV ネットワークデバイスのみが設定されます。SR-IOV Container Network Interface (CNI) プラグインおよびデバイスプラグインは、選択したノードにのみデプロイされます。
- 5
- オプション: 優先度は
0から99までの整数値で指定されます。値が小さいほど優先度が高くなります。たとえば、10の優先度は99よりも高くなります。デフォルト値は99です。 - 6
- SR-IOV 物理ネットワークデバイス用に作成する Virtual Function (VF) の数。Intel ネットワークインターフェイスコントローラー (NIC) の場合、VF の数はデバイスがサポートする VF の合計よりも大きくすることはできません。Mellanox NIC の場合、VF の数は
128よりも大きくすることはできません。 - 7
- NIC セレクターは、Operator が設定するデバイスを特定します。すべてのパラメーターの値を指定する必要はありません。意図せずにデバイスを選択しないように、ネットワークデバイスを極めて正確に特定することが推奨されます。
rootDevicesを指定する場合、vendor、deviceID、またはpfNameの値も指定する必要があります。pfNamesおよびrootDevicesの両方を同時に指定する場合、それらが同一のデバイスを参照していることを確認します。netFilterの値を指定する場合、ネットワーク ID は一意の ID であるためにその他のパラメーターを指定する必要はありません。 - 8
- オプション: 1 つ以上のデバイスの物理機能 (PF) 名の配列。
- 9
- オプション: Virtual Function (VF) のドライバータイプ。許可される唯一の値は
netdeviceです。ベアメタルノードで Mellanox NIC を DPDK モードで動作させるには、isRdmaをtrueに設定します。 - 10
- オプション: Remote Direct Memory Access (RDMA) モードを有効にするかどうかを設定します。デフォルト値は
falseです。isRdmaパラメーターがtrueに設定される場合、引き続き RDMA 対応の VF を通常のネットワークデバイスとして使用できます。デバイスはどちらのモードでも使用できます。isRdmaをtrueに設定し、追加のneedVhostNetをtrueに設定して、Fast Datapath DPDK アプリケーションで使用する Mellanox NIC を設定します。
注記vfio-pciドライバータイプはサポートされていません。SriovNetworkNodePolicy オブジェクトを作成します。
$ oc create -f policyallflags-sriov-node-network.yaml
設定の更新が適用された後に、sriov-network-operator namespace のすべての Pod が
Runningステータスに移行します。SR-IOV ネットワークデバイスが設定されていることを確認するには、以下のコマンドを実行します。
<node_name>を、設定したばかりの SR-IOV ネットワークデバイスを持つノードの名前に置き換えます。$ oc get sriovnetworknodestates -n openshift-sriov-network-operator <node_name> -o jsonpath='{.status.syncStatus}'出力例
Succeeded
26.8.3.2. ボンディングされた SR-IOV ネットワークでの sysctl の設定
2 つの SR-IOV インターフェイスから作成されたボンドインターフェイスで、インターフェイス固有の sysctl 設定を設定できます。これを行うには、bond ネットワーク接続定義のオプションの Plugins パラメーターにチューニング設定を追加します。
SR-IOV Network Operator が管理する NetworkAttachmentDefinition カスタムリソースは編集しないでください。これを実行すると、追加ネットワークのネットワークトラフィックが中断する可能性があります。
特定のインターフェイスレベルのネットワーク sysctl 設定を変更するには、次の手順を使用して、Container Network Interface (CNI) チューニングプラグインを使用して、SriovNetwork カスタムリソース (CR) を作成します。
前提条件
- OpenShift Container Platform CLI (oc) をインストールします。
- cluster-admin 権限を持つユーザーとして OpenShift Container Platform クラスターにログインします。
手順
次の例の CR のように、ボンドされたインターフェイスの
SriovNetworkカスタムリソース (CR) を作成します。YAML をsriov-network-attachment.yamlファイルとして保存します。apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: allvalidflags 1 namespace: openshift-sriov-network-operator 2 spec: resourceName: policyallflags 3 networkNamespace: sysctl-tuning-test 4 capabilities: '{ "mac": true, "ips": true }' 5
- 1
- オブジェクトの名前。SR-IOV Network Operator は、同じ名前を持つ NetworkAttachmentDefinition オブジェクトを作成します。
- 2
- SR-IOV Network Operator がインストールされている namespace。
- 3
- この追加ネットワークの SR-IOV ハードウェアを定義する
SriovNetworkNodePolicyオブジェクトのspec.resourceNameパラメーターの値。 - 4
SriovNetworkオブジェクトのターゲット namespace。ターゲット namespace の Pod のみを追加ネットワークに割り当てることができます。- 5
- オプション: この追加ネットワークに設定する機能。IP アドレスのサポートを有効にするには、
"{ "ips": true }"を指定できます。または、MAC アドレスのサポートを有効にするには"{ "mac": true }"を指定します。
SriovNetworkリソースを作成します。$ oc create -f sriov-network-attachment.yaml
次の例の CR のように、ボンドネットワーク接続定義を作成します。YAML を
sriov-bond-network-interface.yamlファイルとして保存します。apiVersion: "k8s.cni.cncf.io/v1" kind: NetworkAttachmentDefinition metadata: name: bond-sysctl-network namespace: sysctl-tuning-test spec: config: '{ "cniVersion":"0.4.0", "name":"bound-net", "plugins":[ { "type":"bond", 1 "mode": "active-backup", 2 "failOverMac": 1, 3 "linksInContainer": true, 4 "miimon": "100", "links": [ 5 {"name": "net1"}, {"name": "net2"} ], "ipam":{ 6 "type":"static" } }, { "type":"tuning", 7 "capabilities":{ "mac":true }, "sysctl":{ "net.ipv4.conf.IFNAME.accept_redirects": "0", "net.ipv4.conf.IFNAME.accept_source_route": "0", "net.ipv4.conf.IFNAME.disable_policy": "1", "net.ipv4.conf.IFNAME.secure_redirects": "0", "net.ipv4.conf.IFNAME.send_redirects": "0", "net.ipv6.conf.IFNAME.accept_redirects": "0", "net.ipv6.conf.IFNAME.accept_source_route": "1", "net.ipv6.neigh.IFNAME.base_reachable_time_ms": "20000", "net.ipv6.neigh.IFNAME.retrans_time_ms": "2000" } } ] }'- 1
- タイプは
bondです。 - 2
mode属性は、ボンドモードを指定します。サポートされているボンドモードは次のとおりです。-
balance-rr- 0 -
active-backup- 1 balance-xor- 2balance-rrまたはbalance-xorモードの場合には、SR-IOV Virtual Function のtrustモードをonに設定する必要があります。
-
- 3
failover属性は、active-backup モードでは必須です。- 4
linksInContainer=trueフラグは、必要なインターフェイスがコンテナー内にあることをボンディング CNI に通知します。デフォルトでは、ボンディング CNI は、SRIOV および Multus との統合で機能しないホストで、このようなインターフェイスを検索します。- 5
linksセクションは、結合の作成に使用するインターフェイスを定義します。デフォルトでは、Multus は接続されたインターフェイスに net と 1 から始まる連続した番号の名前を付けます。- 6
- YAML ブロックスケーラーとしての IPAM CNI プラグインの設定オブジェクトプラグインは、割り当て定義についての IP アドレスの割り当てを管理します。この Pod の例では、IP アドレスは手動で設定されているため、この場合、
ipamは static に設定されています。 - 7
- デバイスに追加の機能を追加します。たとえば、
typeフィールドをtuningに設定します。設定したいインターフェイスレベルのネットワークsysctlを sysctl フィールドに指定します。この例では、設定可能なすべてのインターフェイスレベルのネットワークsysctl設定を設定します。
ボンドネットワーク接続リソースを作成します。
$ oc create -f sriov-bond-network-interface.yaml
NetworkAttachmentDefinition CR が正常に作成されることの確認
以下のコマンドを実行して、SR-IOV Network Operator が
NetworkAttachmentDefinitionCR を作成していることを確認します。$ oc get network-attachment-definitions -n <namespace> 1- 1
<namespace>は、ネットワーク割り当ての設定時に指定した networkNamespace に置き換えます (例:sysctl-tuning-test)。
出力例
NAME AGE bond-sysctl-network 22m allvalidflags 47m
注記SR-IOV Network Operator が CR を作成するまでに遅延が生じる可能性があります。
SR-IOV ネットワークリソースの追加が成功したことの確認
チューニング CNI が正しく設定され、追加の SR-IOV ネットワーク割り当てが接続されていることを確認するには、以下を実行します。
PodCR を作成します。たとえば、次の YAML をexamplepod.yamlファイルとして保存します。apiVersion: v1 kind: Pod metadata: name: tunepod namespace: sysctl-tuning-test annotations: k8s.v1.cni.cncf.io/networks: |- [ {"name": "allvalidflags"}, 1 {"name": "allvalidflags"}, { "name": "bond-sysctl-network", "interface": "bond0", "mac": "0a:56:0a:83:04:0c", 2 "ips": ["10.100.100.200/24"] 3 } ] spec: containers: - name: podexample image: centos command: ["/bin/bash", "-c", "sleep INF"] securityContext: runAsUser: 2000 runAsGroup: 3000 allowPrivilegeEscalation: false capabilities: drop: ["ALL"] securityContext: runAsNonRoot: true seccompProfile: type: RuntimeDefault- 1
- SR-IOV ネットワーク割り当て定義 CR の名前。
- 2
- オプション: SR-IOV ネットワーク割り当て定義 CR で定義されるリソースタイプから割り当てられる SR-IOV デバイスの MAC アドレス。この機能を使用するには、SriovNetwork オブジェクトで
{ "mac": true }も指定する必要があります。 - 3
- オプション: SR-IOV ネットワーク割り当て定義 CR で定義されるリソースタイプから割り当てられる SR-IOV デバイスの IP アドレス。IPv4 と IPv6 アドレスの両方がサポートされます。この機能を使用するには、
SriovNetworkオブジェクトで{ "ips": true }も指定する必要があります。
YAML を適用します。
$ oc apply -f examplepod.yaml
次のコマンドを実行して、Pod が作成されていることを確認します。
$ oc get pod -n sysctl-tuning-test
出力例
NAME READY STATUS RESTARTS AGE tunepod 1/1 Running 0 47s
次のコマンドを実行して、Pod にログインします。
$ oc rsh -n sysctl-tuning-test tunepod
設定された
sysctlフラグの値を確認します。次のコマンドを実行して、net.ipv6.neigh.IFNAME.base_reachable_time_msの値を見つけます。$ sysctl net.ipv6.neigh.bond0.base_reachable_time_ms
出力例
net.ipv6.neigh.bond0.base_reachable_time_ms = 20000
26.9. 高パフォーマンスのマルチキャストの使用
Single Root I/O Virtualization (SR-IOV) ハードウェアネットワーク上でマルチキャストを使用できます。
26.9.1. 高パフォーマンスのマルチキャスト
OpenShift SDN ネットワークプラグインは、デフォルトネットワーク上の Pod 間のマルチキャストをサポートします。これは低帯域幅の調整またはサービスの検出での使用に最も適しており、高帯域幅のアプリケーションには適していません。インターネットプロトコルテレビ (IPTV) やマルチポイントビデオ会議など、ストリーミングメディアなどのアプリケーションでは、Single Root I/O Virtualization (SR-IOV) ハードウェアを使用してネイティブに近いパフォーマンスを提供できます。
マルチキャストに追加の SR-IOV インターフェイスを使用する場合:
- マルチキャストパッケージは、追加の SR-IOV インターフェイス経由で Pod によって送受信される必要があります。
- SR-IOV インターフェイスに接続する物理ネットワークは、OpenShift Container Platform で制御されないマルチキャストルーティングとトポロジーを判別します。
26.9.2. マルチキャストでの SR-IOV インターフェイスの設定
以下の手順では、サンプルのマルチキャスト用の SR-IOV インターフェイスを作成します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにログインする必要があります。
手順
SriovNetworkNodePolicyオブジェクトを作成します。apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: policy-example namespace: openshift-sriov-network-operator spec: resourceName: example nodeSelector: feature.node.kubernetes.io/network-sriov.capable: "true" numVfs: 4 nicSelector: vendor: "8086" pfNames: ['ens803f0'] rootDevices: ['0000:86:00.0']SriovNetworkオブジェクトを作成します。apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: net-example namespace: openshift-sriov-network-operator spec: networkNamespace: default ipam: | 1 { "type": "host-local", 2 "subnet": "10.56.217.0/24", "rangeStart": "10.56.217.171", "rangeEnd": "10.56.217.181", "routes": [ {"dst": "224.0.0.0/5"}, {"dst": "232.0.0.0/5"} ], "gateway": "10.56.217.1" } resourceName: example
マルチキャストアプリケーションで Pod を作成します。
apiVersion: v1 kind: Pod metadata: name: testpmd namespace: default annotations: k8s.v1.cni.cncf.io/networks: nic1 spec: containers: - name: example image: rhel7:latest securityContext: capabilities: add: ["NET_ADMIN"] 1 command: [ "sleep", "infinity"]- 1
NET_ADMIN機能は、アプリケーションがマルチキャスト IP アドレスを SR-IOV インターフェイスに割り当てる必要がある場合にのみ必要です。それ以外の場合は省略できます。
26.10. DPDK および RDMA の使用
コンテナー化された Data Plane Development Kit (DPDK) アプリケーションは OpenShift Container Platform でサポートされています。Single Root I/O Virtualization (SR-IOV) ネットワークハードウェアは、Data Plane Development Kit (DPDK) および Remote Direct Memory Access (RDMA) で利用できます。
対応しているデバイスの詳細は、Supported devices を参照してください。
26.10.1. NIC を使用した DPDK モードでの Virtual Function の使用
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - SR-IOV Network Operator をインストールします。
-
cluster-admin権限を持つユーザーとしてログインしている。
手順
以下の
SriovNetworkNodePolicyオブジェクトを作成してから、YAML をintel-dpdk-node-policy.yamlファイルに保存します。apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: intel-dpdk-node-policy namespace: openshift-sriov-network-operator spec: resourceName: intelnics nodeSelector: feature.node.kubernetes.io/network-sriov.capable: "true" priority: <priority> numVfs: <num> nicSelector: vendor: "8086" deviceID: "158b" pfNames: ["<pf_name>", ...] rootDevices: ["<pci_bus_id>", "..."] deviceType: vfio-pci 1- 1
- Virtual Function (VF) のドライバータイプを
vfio-pciに指定します。
注記SriovNetworkNodePolicyの各オプションに関する詳細は、Configuring SR-IOV network devicesセクションを参照してください。SriovNetworkNodePolicyオブジェクトで指定された設定を適用する際に、SR-IOV Operator はノードをドレイン (解放) する可能性があり、場合によってはノードの再起動を行う場合があります。設定の変更が適用されるまでに数分の時間がかかる場合があります。エビクトされたワークロードを処理するために、クラスター内に利用可能なノードが十分にあることを前もって確認します。設定の更新が適用された後に、
openshift-sriov-network-operatornamespace のすべての Pod がRunningステータスに変更されます。以下のコマンドを実行して
SriovNetworkNodePolicyオブジェクトを作成します。$ oc create -f intel-dpdk-node-policy.yaml
以下の
SriovNetworkオブジェクトを作成してから、YAML をintel-dpdk-network.yamlファイルに保存します。apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: intel-dpdk-network namespace: openshift-sriov-network-operator spec: networkNamespace: <target_namespace> ipam: |- # ... 1 vlan: <vlan> resourceName: intelnics- 1
- IPAM CNI プラグインの設定オブジェクトを YAML ブロックスケーラーとして指定します。プラグインは、割り当て定義についての IP アドレスの割り当てを管理します。
注記SriovNetworkの各オプションに関する詳細は、SR-IOV の追加ネットワークの設定セクションを参照してください。オプションのライブラリー app-netutil は、コンテナーの親 Pod に関するネットワーク情報を収集するための複数の API メソッドを提供します。
以下のコマンドを実行して、
SriovNetworkオブジェクトを作成します。$ oc create -f intel-dpdk-network.yaml
以下の
Pod仕様を作成してから、YAML をintel-dpdk-pod.yamlファイルに保存します。apiVersion: v1 kind: Pod metadata: name: dpdk-app namespace: <target_namespace> 1 annotations: k8s.v1.cni.cncf.io/networks: intel-dpdk-network spec: containers: - name: testpmd image: <DPDK_image> 2 securityContext: runAsUser: 0 capabilities: add: ["IPC_LOCK","SYS_RESOURCE","NET_RAW"] 3 volumeMounts: - mountPath: /mnt/huge 4 name: hugepage resources: limits: openshift.io/intelnics: "1" 5 memory: "1Gi" cpu: "4" 6 hugepages-1Gi: "4Gi" 7 requests: openshift.io/intelnics: "1" memory: "1Gi" cpu: "4" hugepages-1Gi: "4Gi" command: ["sleep", "infinity"] volumes: - name: hugepage emptyDir: medium: HugePages
- 1
SriovNetworkオブジェクトのintel-dpdk-networkが作成される同じtarget_namespaceを指定します。Pod を異なる namespace に作成する場合、target_namespaceをPod仕様およびSriovNetworkオブジェクトの両方で変更します。- 2
- アプリケーションとアプリケーションが使用する DPDK ライブラリーが含まれる DPDK イメージを指定します。
- 3
- hugepage の割り当て、システムリソースの割り当て、およびネットワークインターフェイスアクセス用のコンテナー内のアプリケーションに必要な追加機能を指定します。
- 4
- hugepage ボリュームを
/mnt/hugeの下の DPDK Pod にマウントします。hugepage ボリュームは、メディアがHugepagesに指定されている emptyDir ボリュームタイプでサポートされます。 - 5
- オプション: DPDK Pod に割り当てられる DPDK デバイスの数を指定します。このリソース要求および制限は、明示的に指定されていない場合、SR-IOV ネットワークリソースインジェクターによって自動的に追加されます。SR-IOV ネットワークリソースインジェクターは、SR-IOV Operator によって管理される受付コントローラーコンポーネントです。これはデフォルトで有効にされており、デフォルト
SriovOperatorConfigCR でenableInjectorオプションをfalseに設定して無効にすることができます。 - 6
- CPU の数を指定します。DPDK Pod には通常、kubelet から排他的 CPU を割り当てる必要があります。これは、CPU マネージャーポリシーを
staticに設定し、GuaranteedQoS を持つ Pod を作成して実行されます。 - 7
- hugepage サイズ
hugepages-1Giまたはhugepages-2Miを指定し、DPDK Pod に割り当てられる hugepage の量を指定します。2Miおよび1Gihugepage を別々に設定します。1Gihugepage を設定するには、カーネル引数をノードに追加する必要があります。たとえば、カーネル引数default_hugepagesz=1GB、hugepagesz=1Gおよびhugepages=16を追加すると、16*1Gihugepage がシステムの起動時に割り当てられます。
以下のコマンドを実行して DPDK Pod を作成します。
$ oc create -f intel-dpdk-pod.yaml
26.10.2. Mellanox NIC を使用した DPDK モードでの Virtual Function の使用
Mellanox NIC で DPDK モードの Virtual Function を使用して、ネットワークノードポリシーを作成し、Data Plane Development Kit (DPDK) Pod を作成できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - Single Root I/O Virtualization (SR-IOV) Network Operator をインストールしている。
-
cluster-admin権限を持つユーザーとしてログインしている。
手順
次の
SriovNetworkNodePolicyYAML 設定をmlx-dpdk-node-policy.yamlファイルに保存します。apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: mlx-dpdk-node-policy namespace: openshift-sriov-network-operator spec: resourceName: mlxnics nodeSelector: feature.node.kubernetes.io/network-sriov.capable: "true" priority: <priority> numVfs: <num> nicSelector: vendor: "15b3" deviceID: "1015" 1 pfNames: ["<pf_name>", ...] rootDevices: ["<pci_bus_id>", "..."] deviceType: netdevice 2 isRdma: true 3注記SriovNetworkNodePolicyオブジェクトの各オプションの詳細な説明については SR-IOV ネットワークデバイスの設定 を参照してください。SriovNetworkNodePolicyオブジェクトで指定された設定を適用する際に、SR-IOV Operator はノードをドレイン (解放) する可能性があり、場合によってはノードの再起動を行う場合があります。設定の変更が適用されるまでに数分かかる場合があります。エビクトされたワークロードを処理するために、クラスター内に利用可能なノードが十分にあることを前もって確認します。設定の更新が適用された後に、
openshift-sriov-network-operatornamespace のすべての Pod がRunningステータスに変更されます。以下のコマンドを実行して
SriovNetworkNodePolicyオブジェクトを作成します。$ oc create -f mlx-dpdk-node-policy.yaml
次の
SriovNetworkYAML 設定をmlx-dpdk-network.yamlファイルに保存します:apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: mlx-dpdk-network namespace: openshift-sriov-network-operator spec: networkNamespace: <target_namespace> ipam: |- 1 ... vlan: <vlan> resourceName: mlxnics- 1
- IP アドレス管理 (IPAM) コンテナーネットワークインターフェイス (CNI) プラグインの設定オブジェクトを YAML ブロックスカラーとして指定します。プラグインは、割り当て定義についての IP アドレスの割り当てを管理します。
注記SriovNetworkオブジェクトの各オプションの詳細な説明については SR-IOV ネットワークデバイスの設定 を参照してください。app-netutilオプションライブラリーには、コンテナーの親 Pod に関するネットワーク情報を収集するための API メソッドが複数あります。以下のコマンドを実行して、
SriovNetworkオブジェクトを作成します。$ oc create -f mlx-dpdk-network.yaml
次の
PodYAML 設定をmlx-dpdk-pod.yamlファイルに保存します。apiVersion: v1 kind: Pod metadata: name: dpdk-app namespace: <target_namespace> 1 annotations: k8s.v1.cni.cncf.io/networks: mlx-dpdk-network spec: containers: - name: testpmd image: <DPDK_image> 2 securityContext: runAsUser: 0 capabilities: add: ["IPC_LOCK","SYS_RESOURCE","NET_RAW"] 3 volumeMounts: - mountPath: /mnt/huge 4 name: hugepage resources: limits: openshift.io/mlxnics: "1" 5 memory: "1Gi" cpu: "4" 6 hugepages-1Gi: "4Gi" 7 requests: openshift.io/mlxnics: "1" memory: "1Gi" cpu: "4" hugepages-1Gi: "4Gi" command: ["sleep", "infinity"] volumes: - name: hugepage emptyDir: medium: HugePages
- 1
SriovNetworkオブジェクトのmlx-dpdk-networkが作成される同じtarget_namespaceを指定します。別の namespace で Pod を作成するには、Pod仕様とSriovNetworkオブジェクトの両方でtarget_namespaceを変更します。- 2
- アプリケーションとアプリケーションが使用する DPDK ライブラリーが含まれる DPDK イメージを指定します。
- 3
- hugepage の割り当て、システムリソースの割り当て、およびネットワークインターフェイスアクセス用のコンテナー内のアプリケーションに必要な追加機能を指定します。
- 4
- hugepage ボリュームを
/mnt/hugeの下の DPDK Pod にマウントします。hugepage ボリュームは、メディアがHugepagesに指定されているemptyDirボリュームタイプでサポートされます。 - 5
- オプション: DPDK Pod に割り当てられる DPDK デバイスの数を指定します。このリソース要求および制限は、明示的に指定されていない場合、SR-IOV ネットワークリソースインジェクターによって自動的に追加されます。SR-IOV ネットワークリソースインジェクターは、SR-IOV Operator によって管理される受付コントローラーコンポーネントです。これはデフォルトで有効にされており、デフォルト
SriovOperatorConfigCR でenableInjectorオプションをfalseに設定して無効にすることができます。 - 6
- CPU の数を指定します。DPDK Pod には通常、kubelet から排他的 CPU を割り当てる必要があります。これを行うには、CPU マネージャーポリシーを
staticに設定し、サービス品質 (QoS) がGuaranteedの Pod を作成します。 - 7
- hugepage サイズ
hugepages-1Giまたはhugepages-2Miを指定し、DPDK Pod に割り当てられる hugepage の量を指定します。2Miおよび1Gihugepage を別々に設定します。1Gihugepage を設定するには、カーネル引数をノードに追加する必要があります。
以下のコマンドを実行して DPDK Pod を作成します。
$ oc create -f mlx-dpdk-pod.yaml
26.10.3. 特定の DPDK ラインレート達成に関する概要
特定の Data Plane Development Kit (DPDK) ラインレートを実現するには、Node Tuning Operator をデプロイし、Single Root I/O Virtualization (SR-IOV) を設定します。次のリソースの DPDK 設定も調整する必要があります。
- 分離された CPU
- hugepage
- トポロジースケジューラー
OpenShift Container Platform の以前のバージョンでは、パフォーマンスアドオン Operator を使用して自動チューニングを実装し、OpenShift Container Platform アプリケーションの低レイテンシーパフォーマンスを実現していました。OpenShift Container Platform 4.11 以降では、この機能は Node Tuning Operator の一部です。
DPDK テスト環境
次の図は、トラフィックテスト環境のコンポーネントを示しています。
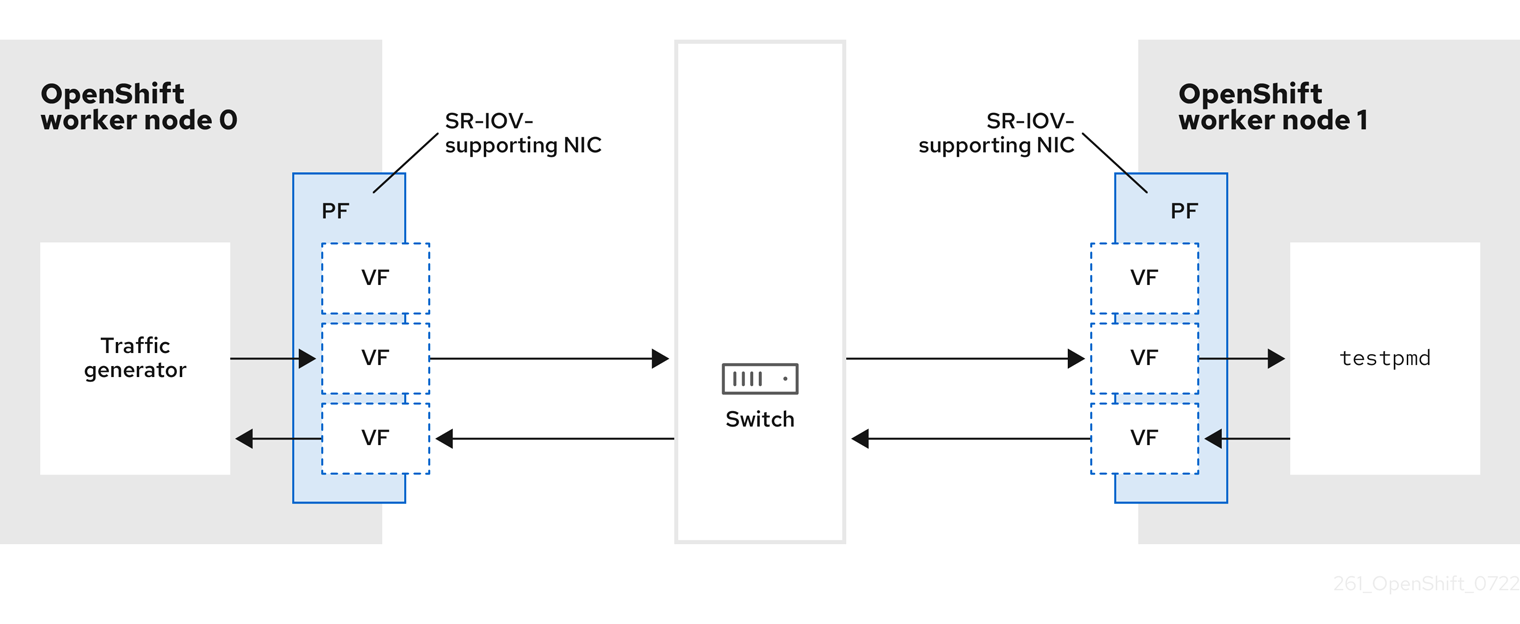
- トラフィックジェネレーター: 大量のパケットトラフィックを生成できるアプリケーション。
- SR-IOV 対応 NIC: SR-IOV に対応したネットワークインターフェイスカードです。カードは、物理インターフェイス上で多数の Virtual Function を実行します。
- Physical Function (PF): SR-IOV インターフェイスをサポートするネットワークアダプターの PCI Express (PCIe) 機能。
- Virtual Function (VF): SR-IOV をサポートするネットワークアダプター上の軽量の PCIe 機能。VF は、ネットワークアダプターの PCIe PF に関連付けられています。VF は、ネットワークアダプターの仮想化されたインスタンスを表します。
- スイッチ: ネットワークスイッチ。ノードは中断なしに接続することもできます。
-
testpmd: DPDK に含まれるサンプルアプリケーション。testpmdアプリケーションを使用して、パケット転送モードで DPDK をテストできます。testpmdアプリケーションは、DPDK ソフトウェア開発キット (SDK) を使用して本格的なアプリケーションを構築する方法の例でもあります。 - worker 0 および worker 1: OpenShift Container Platform ノード。
26.10.4. SR-IOV と Node Tuning Operator を使用した DPDK ラインレートの実現
Node Tuning Operator を使用して、分離された CPU、ヒュージページ、およびトポロジースケジューラーを設定できます。その後、Node Tuning Operator と Single Root I/O Virtualization (SR-IOV) を使用して、特定の Data Plane Development Kit (DPDK) ラインレートを実現できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - SR-IOV Network Operator がインストールされている。
-
cluster-admin権限を持つユーザーとしてログインしている。 スタンドアロン Node Tuning Operator をデプロイしている。
注記OpenShift Container Platform の以前のバージョンでは、パフォーマンスアドオン Operator を使用して自動チューニングを実装し、OpenShift アプリケーションの低レイテンシーパフォーマンスを実現していました。OpenShift Container Platform 4.11 以降では、この機能は Node Tuning Operator の一部です。
手順
次の例に基づいて
PerformanceProfileオブジェクトを作成します。apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: performance spec: globallyDisableIrqLoadBalancing: true cpu: isolated: 21-51,73-103 1 reserved: 0-20,52-72 2 hugepages: defaultHugepagesSize: 1G 3 pages: - count: 32 size: 1G net: userLevelNetworking: true numa: topologyPolicy: "single-numa-node" nodeSelector: node-role.kubernetes.io/worker-cnf: ""- 1
- システムでハイパースレッディングが有効になっている場合は、関連するシンボリックリンクを
isolatedおよびreservedの CPU グループに割り当てます。システムに複数の Non-Uniform Memory Access (NUMA) ノードが含まれている場合は、両方の NUMA から両方のグループに CPU を割り当てます。このタスクには Performance Profile Creator を使用することもできます。詳細は、コントロールプレーンプロファイルの作成 について参照してください。 - 2
- キューが予約済みの CPU 数に設定されているデバイスのリストを指定することもできます。詳細については Node Tuning Operator を使用した NIC キューの削減 を参照してください。
- 3
- 必要なヒュージページの数とサイズを割り当てます。ヒュージページの NUMA 設定を指定できます。デフォルトでは、システムは、そのシステムにあるすべての NUMA ノードに偶数分を割り当てます。必要に応じて、ノードのリアルタイムカーネルの使用をリクエストできます。詳しくは、 リアルタイム機能を備えたワーカーのプロビジョニング を参照してください。
-
yamlファイルをmlx-dpdk-perfprofile-policy.yamlとして保存します。 次のコマンドを使用して、パフォーマンスプロファイルを適用します。
$ oc create -f mlx-dpdk-perfprofile-policy.yaml
26.10.4.1. Virtual Function の SR-IOV Network Operator の例
Single Root I/O Virtualization (SR-IOV) ネットワーク Operator を使用して、ノード上の SR-IOV をサポートする Physical Function NIC から Virtual Function (VF) を割り当てて設定できます。
Operator のデプロイの詳細については、SR-IOV Network Operator のインストール を参照してください。SR-IOV ネットワークデバイスの設定の詳細については、SR-IOV ネットワークデバイスの設定 を参照してください。
Intel VF と Mellanox VF での Data Plane Development Kit (DPDK) ワークロードの実行にはいくつかの違いがあります。このセクションでは、両方の VF タイプのオブジェクト設定の例を示します。以下は、Intel NIC で DPDK アプリケーションを実行するために使用される sriovNetworkNodePolicy オブジェクトの例です。
apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: dpdk-nic-1 namespace: openshift-sriov-network-operator spec: deviceType: vfio-pci 1 needVhostNet: true 2 nicSelector: pfNames: ["ens3f0"] nodeSelector: node-role.kubernetes.io/worker-cnf: "" numVfs: 10 priority: 99 resourceName: dpdk_nic_1 --- apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: dpdk-nic-1 namespace: openshift-sriov-network-operator spec: deviceType: vfio-pci needVhostNet: true nicSelector: pfNames: ["ens3f1"] nodeSelector: node-role.kubernetes.io/worker-cnf: "" numVfs: 10 priority: 99 resourceName: dpdk_nic_2
以下は、Mellanox NIC の sriovNetworkNodePolicy オブジェクトの例です。
apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: dpdk-nic-1 namespace: openshift-sriov-network-operator spec: deviceType: netdevice 1 isRdma: true 2 nicSelector: rootDevices: - "0000:5e:00.1" nodeSelector: node-role.kubernetes.io/worker-cnf: "" numVfs: 5 priority: 99 resourceName: dpdk_nic_1 --- apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: dpdk-nic-2 namespace: openshift-sriov-network-operator spec: deviceType: netdevice isRdma: true nicSelector: rootDevices: - "0000:5e:00.0" nodeSelector: node-role.kubernetes.io/worker-cnf: "" numVfs: 5 priority: 99 resourceName: dpdk_nic_2
26.10.4.2. SR-IOV Network Operator の例
以下は、sriovNetwork オブジェクトの定義例です。この場合、Intel と Mellanox の設定は同じです。
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetwork
metadata:
name: dpdk-network-1
namespace: openshift-sriov-network-operator
spec:
ipam: '{"type": "host-local","ranges": [[{"subnet": "10.0.1.0/24"}]],"dataDir":
"/run/my-orchestrator/container-ipam-state-1"}' 1
networkNamespace: dpdk-test 2
spoofChk: "off"
trust: "on"
resourceName: dpdk_nic_1 3
---
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetwork
metadata:
name: dpdk-network-2
namespace: openshift-sriov-network-operator
spec:
ipam: '{"type": "host-local","ranges": [[{"subnet": "10.0.2.0/24"}]],"dataDir":
"/run/my-orchestrator/container-ipam-state-1"}'
networkNamespace: dpdk-test
spoofChk: "off"
trust: "on"
resourceName: dpdk_nic_2- 1
- Whereabouts など、別の IP Address Management (IPAM) 実装を使用できます。詳細については Whereabouts を使用した動的 IP アドレス割り当ての設定 を参照してください。
- 2
- ネットワーク接続定義が作成される
networkNamespaceを要求する必要があります。openshift-sriov-network-operatornamespace でsriovNetworkCR を作成する必要があります。 - 3
resourceNameの値は、sriovNetworkNodePolicyで作成されたresourceNameの値と一致する必要があります。
26.10.4.3. DPDK ベースワークロードの例
以下は、Data Plane Development Kit (DPDK) コンテナーの例です。
apiVersion: v1
kind: Namespace
metadata:
name: dpdk-test
---
apiVersion: v1
kind: Pod
metadata:
annotations:
k8s.v1.cni.cncf.io/networks: '[ 1
{
"name": "dpdk-network-1",
"namespace": "dpdk-test"
},
{
"name": "dpdk-network-2",
"namespace": "dpdk-test"
}
]'
irq-load-balancing.crio.io: "disable" 2
cpu-load-balancing.crio.io: "disable"
cpu-quota.crio.io: "disable"
labels:
app: dpdk
name: testpmd
namespace: dpdk-test
spec:
runtimeClassName: performance-performance 3
containers:
- command:
- /bin/bash
- -c
- sleep INF
image: registry.redhat.io/openshift4/dpdk-base-rhel8
imagePullPolicy: Always
name: dpdk
resources: 4
limits:
cpu: "16"
hugepages-1Gi: 8Gi
memory: 2Gi
requests:
cpu: "16"
hugepages-1Gi: 8Gi
memory: 2Gi
securityContext:
capabilities:
add:
- IPC_LOCK
- SYS_RESOURCE
- NET_RAW
- NET_ADMIN
runAsUser: 0
volumeMounts:
- mountPath: /mnt/huge
name: hugepages
terminationGracePeriodSeconds: 5
volumes:
- emptyDir:
medium: HugePages
name: hugepages
SLEEP 状態の Pod を起動し、その Pod で exec 操作を実行して testpmd または DPDK ワークロードを開始しないでください。これにより、exec プロセスがどの CPU にも固定されていないため、割り込みが追加される可能性があります。
26.10.4.4. testpmd スクリプトの例
以下は、testpmd を実行するスクリプトの例です。
#!/bin/bash
set -ex
export CPU=$(cat /sys/fs/cgroup/cpuset/cpuset.cpus)
echo ${CPU}
dpdk-testpmd -l ${CPU} -a ${PCIDEVICE_OPENSHIFT_IO_DPDK_NIC_1} -a ${PCIDEVICE_OPENSHIFT_IO_DPDK_NIC_2} -n 4 -- -i --nb-cores=15 --rxd=4096 --txd=4096 --rxq=7 --txq=7 --forward-mode=mac --eth-peer=0,50:00:00:00:00:01 --eth-peer=1,50:00:00:00:00:02
この例では、2 つの異なる sriovNetwork CR を使用しています。環境変数には、Pod に割り当てられた Virtual Function (VF) PCI アドレスが含まれています。Pod 定義で同じネットワークを使用する場合は、pciAddress を分割する必要があります。トラフィックジェネレータの正しい MAC アドレスを設定することが重要です。この例では、カスタム MAC アドレスを使用しています。
26.10.5. Mellanox NIC を使用した RDMA モードでの Virtual Function の使用
RoCE (RDMA over Converged Ethernet) はテクノロジープレビュー機能としてのみご利用いただけます。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
RoCE (RDMA over Converged Ethernet) は、OpenShift Container Platform で RDMA を使用する場合に唯一サポートされているモードです。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - SR-IOV Network Operator をインストールします。
-
cluster-admin権限を持つユーザーとしてログインしている。
手順
以下の
SriovNetworkNodePolicyオブジェクトを作成してから、YAML をmlx-rdma-node-policy.yamlファイルに保存します。apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: mlx-rdma-node-policy namespace: openshift-sriov-network-operator spec: resourceName: mlxnics nodeSelector: feature.node.kubernetes.io/network-sriov.capable: "true" priority: <priority> numVfs: <num> nicSelector: vendor: "15b3" deviceID: "1015" 1 pfNames: ["<pf_name>", ...] rootDevices: ["<pci_bus_id>", "..."] deviceType: netdevice 2 isRdma: true 3注記SriovNetworkNodePolicyの各オプションに関する詳細は、Configuring SR-IOV network devicesセクションを参照してください。SriovNetworkNodePolicyオブジェクトで指定された設定を適用する際に、SR-IOV Operator はノードをドレイン (解放) する可能性があり、場合によってはノードの再起動を行う場合があります。設定の変更が適用されるまでに数分の時間がかかる場合があります。エビクトされたワークロードを処理するために、クラスター内に利用可能なノードが十分にあることを前もって確認します。設定の更新が適用された後に、
openshift-sriov-network-operatornamespace のすべての Pod がRunningステータスに変更されます。以下のコマンドを実行して
SriovNetworkNodePolicyオブジェクトを作成します。$ oc create -f mlx-rdma-node-policy.yaml
以下の
SriovNetworkオブジェクトを作成してから、YAML をmlx-rdma-network.yamlファイルに保存します。apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetwork metadata: name: mlx-rdma-network namespace: openshift-sriov-network-operator spec: networkNamespace: <target_namespace> ipam: |- 1 # ... vlan: <vlan> resourceName: mlxnics- 1
- IPAM CNI プラグインの設定オブジェクトを YAML ブロックスケーラーとして指定します。プラグインは、割り当て定義についての IP アドレスの割り当てを管理します。
注記SriovNetworkの各オプションに関する詳細は、SR-IOV の追加ネットワークの設定セクションを参照してください。オプションのライブラリー app-netutil は、コンテナーの親 Pod に関するネットワーク情報を収集するための複数の API メソッドを提供します。
以下のコマンドを実行して
SriovNetworkNodePolicyオブジェクトを作成します。$ oc create -f mlx-rdma-network.yaml
以下の
Pod仕様を作成してから、YAML をmlx-rdma-pod.yamlファイルに保存します。apiVersion: v1 kind: Pod metadata: name: rdma-app namespace: <target_namespace> 1 annotations: k8s.v1.cni.cncf.io/networks: mlx-rdma-network spec: containers: - name: testpmd image: <RDMA_image> 2 securityContext: runAsUser: 0 capabilities: add: ["IPC_LOCK","SYS_RESOURCE","NET_RAW"] 3 volumeMounts: - mountPath: /mnt/huge 4 name: hugepage resources: limits: memory: "1Gi" cpu: "4" 5 hugepages-1Gi: "4Gi" 6 requests: memory: "1Gi" cpu: "4" hugepages-1Gi: "4Gi" command: ["sleep", "infinity"] volumes: - name: hugepage emptyDir: medium: HugePages
- 1
SriovNetworkオブジェクトのmlx-rdma-networkが作成される同じtarget_namespaceを指定します。Pod を異なる namespace に作成する場合は、target_namespaceをPod仕様およびSriovNetworkオブジェクトの両方で変更します。- 2
- アプリケーションとアプリケーションが使用する RDMA ライブラリーが含まれる RDMA イメージを指定します。
- 3
- hugepage の割り当て、システムリソースの割り当て、およびネットワークインターフェイスアクセス用のコンテナー内のアプリケーションに必要な追加機能を指定します。
- 4
- hugepage ボリュームを
/mnt/hugeの下の RDMA Pod にマウントします。hugepage ボリュームは、メディアがHugepagesに指定されている emptyDir ボリュームタイプでサポートされます。 - 5
- CPU の数を指定します。RDMA Pod には通常、kubelet から排他的 CPU を割り当てる必要があります。これは、CPU マネージャーポリシーを
staticに設定し、GuaranteedQoS を持つ Pod を作成して実行されます。 - 6
- hugepage サイズ
hugepages-1Giまたはhugepages-2Miを指定し、RDMA Pod に割り当てられる hugepage の量を指定します。2Miおよび1Gihugepage を別々に設定します。1Gihugepage を設定するには、カーネル引数をノードに追加する必要があります。
以下のコマンドを実行して RDMA Pod を作成します。
$ oc create -f mlx-rdma-pod.yaml
26.10.6. OpenStack で OVS-DPDK を使用するクラスター用のテスト Pod テンプレート
次の testpmd Pod では、ヒュージページ、予約済み CPU、および SR-IOV ポートを使用したコンテナーの作成を紹介します。
testpmd Pod の例
apiVersion: v1
kind: Pod
metadata:
name: testpmd-dpdk
namespace: mynamespace
annotations:
cpu-load-balancing.crio.io: "disable"
cpu-quota.crio.io: "disable"
# ...
spec:
containers:
- name: testpmd
command: ["sleep", "99999"]
image: registry.redhat.io/openshift4/dpdk-base-rhel8:v4.9
securityContext:
capabilities:
add: ["IPC_LOCK","SYS_ADMIN"]
privileged: true
runAsUser: 0
resources:
requests:
memory: 1000Mi
hugepages-1Gi: 1Gi
cpu: '2'
openshift.io/dpdk1: 1 1
limits:
hugepages-1Gi: 1Gi
cpu: '2'
memory: 1000Mi
openshift.io/dpdk1: 1
volumeMounts:
- mountPath: /mnt/huge
name: hugepage
readOnly: False
runtimeClassName: performance-cnf-performanceprofile 2
volumes:
- name: hugepage
emptyDir:
medium: HugePages
26.10.7. OpenStack で OVS ハードウェアオフロードを使用するクラスター用のテスト Pod テンプレート
次の testpmd Pod は、Red Hat OpenStack Platform (RHOSP) での Open vSwitch (OVS) ハードウェアオフロードを示しています。
testpmd Pod の例
apiVersion: v1
kind: Pod
metadata:
name: testpmd-sriov
namespace: mynamespace
annotations:
k8s.v1.cni.cncf.io/networks: hwoffload1
spec:
runtimeClassName: performance-cnf-performanceprofile 1
containers:
- name: testpmd
command: ["sleep", "99999"]
image: registry.redhat.io/openshift4/dpdk-base-rhel8:v4.9
securityContext:
capabilities:
add: ["IPC_LOCK","SYS_ADMIN"]
privileged: true
runAsUser: 0
resources:
requests:
memory: 1000Mi
hugepages-1Gi: 1Gi
cpu: '2'
limits:
hugepages-1Gi: 1Gi
cpu: '2'
memory: 1000Mi
volumeMounts:
- mountPath: /mnt/huge
name: hugepage
readOnly: False
volumes:
- name: hugepage
emptyDir:
medium: HugePages
- 1
- パフォーマンスプロファイルの名前が
cnf-performance profileでない場合は、その文字列を正しいパフォーマンスプロファイル名に置き換えます。
26.10.8. 関連情報
- パフォーマンスプロファイルの作成
- Node Tuning Operator を使用した NIC キューの削減
- リアルタイム機能のあるワーカーのプロビジョニング
- SR-IOV Network Operator のインストール
- SR-IOV ネットワークデバイスの設定
- Whereabouts を使用した動的 IP アドレス割り当ての設定
- 個別の Pod の割り込み処理の無効化
- SR-IOV イーサネットネットワーク割り当ての設定
- app-netutil library ライブラリーは、コンテナーの親 Pod に関するネットワーク情報を収集するための複数の API メソッドを提供します。
26.11. Pod レベルのボンディングの使用
Pod レベルでのボンディングは、高可用性とスループットを必要とする Pod 内のワークロードを有効にするために不可欠です。Pod レベルのボンディングでは、カーネルモードインターフェイスで複数の Single Root I/O Virtualization (SR-IOV) Virtual Function インターフェイスからボンドインターフェイスを作成できます。SR-IOV Virtual Function は Pod に渡され、カーネルドライバーに割り当てられます。
Pod レベルのボンディングが必要なシナリオには、異なる Physical Function 上の複数の SR-IOV Virtual Function からのボンディングインターフェイスの作成が含まれます。ホストの 2 つの異なる Physical Function からボンディングインターフェイスを作成して、Pod レベルで高可用性およびスループットを実現するために使用できます。
SR-IOV ネットワークの作成、ネットワークポリシー、ネットワーク接続定義、Pod などのタスクのガイダンスはSR-IOV ネットワークデバイスの設定を参照してください。
26.11.1. 2 つの SR-IOV インターフェイスからのボンドインターフェイスの設定
ボンディングを使用して、複数のネットワークインターフェイスを、1 つの論理的なボンディングされたインターフェイスに集約できます。Bond Container Network Interface (Bond-CNI) により、コンテナーでボンディング機能を使用できます。
Bond-CNI は、Single Root I/O Virtualization (SR-IOV) Virtual Function を使用して作成し、それらをコンテナーネットワーク namespace に配置できます。
OpenShift Container Platform は、SR-IOV Virtual Functions を使用する Bond-CNI のみをサポートします。SR-IOV Network Operator は、Virtual Function の管理に必要な SR-IOV CNI プラグインを提供します。他の CNI またはインターフェイスのタイプはサポートされていません。
前提条件
- SR-IOV Network Operator をインストールおよび設定して、コンテナー内の Virtual Functions を取得する必要があります。
- SR-IOV インターフェイスを設定するには、インターフェイスごとに SR-IOV ネットワークとポリシーを作成する必要があります。
- SR-IOV Network Operator は、定義された SR-IOV ネットワークとポリシーをもとに、各 SR-IOV インターフェイスのネットワーク接続定義を作成します。
-
linkStateは、SR-IOV Virtual Function のデフォルト値autoに設定されます。
26.11.1.1. ボンドネットワーク接続定義の作成
SR-IOV Virtual Function が使用可能になったので、ボンドネットワーク接続定義を作成できます。
apiVersion: "k8s.cni.cncf.io/v1"
kind: NetworkAttachmentDefinition
metadata:
name: bond-net1
namespace: demo
spec:
config: '{
"type": "bond", 1
"cniVersion": "0.3.1",
"name": "bond-net1",
"mode": "active-backup", 2
"failOverMac": 1, 3
"linksInContainer": true, 4
"miimon": "100",
"mtu": 1500,
"links": [ 5
{"name": "net1"},
{"name": "net2"}
],
"ipam": {
"type": "host-local",
"subnet": "10.56.217.0/24",
"routes": [{
"dst": "0.0.0.0/0"
}],
"gateway": "10.56.217.1"
}
}'- 1
- cni-type は常に
bondに設定されます。 - 2
mode属性は、ボンドモードを指定します。注記サポートされているボンドモードは次のとおりです。
-
balance-rr- 0 -
active-backup- 1 -
balance-xor- 2
balance-rrまたはbalance-xorモードの場合には、SR-IOV Virtual Function のtrustモードをonに設定する必要があります。-
- 3
- active-backup モードでは
フェイルオーバー属性が必須であり、1 に設定する必要があります。 - 4
linksInContainer=trueフラグは、必要なインターフェイスがコンテナー内にあることをボンディング CNI に通知します。デフォルトでは、ボンディング CNI は、SRIOV および Multus との統合で機能しないホストで、このようなインターフェイスを検索します。- 5
linksセクションは、結合の作成に使用するインターフェイスを定義します。デフォルトでは、Multus は接続されたインターフェイスに net と 1 から始まる連続した番号の名前を付けます。
26.11.1.2. ボンディングインターフェイスを使用した Pod の作成
podbonding.yamlなどの名前の YAMLファイル以下の内容を追加して Pod を作成し、この設定をテストします。apiVersion: v1 kind: Pod metadata: name: bondpod1 namespace: demo annotations: k8s.v1.cni.cncf.io/networks: demo/sriovnet1, demo/sriovnet2, demo/bond-net1 1 spec: containers: - name: podexample image: quay.io/openshift/origin-network-interface-bond-cni:4.11.0 command: ["/bin/bash", "-c", "sleep INF"]- 1
- ネットワークのアノテーションに注意してください。これには、SR-IOV ネットワーク割り当てが 2 つとボンドネットワーク割り当てが 1 つ含まれています。ボンド割り当ては、2 つの SR-IOV インターフェイスをボンドポートインターフェイスとして使用します。
以下のコマンドを実行して yaml を適用します。
$ oc apply -f podbonding.yaml
次のコマンドを使用して Pod インターフェイスを検査します。
$ oc rsh -n demo bondpod1 sh-4.4# sh-4.4# ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 3: eth0@if150: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue state UP link/ether 62:b1:b5:c8:fb:7a brd ff:ff:ff:ff:ff:ff inet 10.244.1.122/24 brd 10.244.1.255 scope global eth0 valid_lft forever preferred_lft forever 4: net3: <BROADCAST,MULTICAST,UP,LOWER_UP400> mtu 1500 qdisc noqueue state UP qlen 1000 link/ether 9e:23:69:42:fb:8a brd ff:ff:ff:ff:ff:ff 1 inet 10.56.217.66/24 scope global bond0 valid_lft forever preferred_lft forever 43: net1: <BROADCAST,MULTICAST,UP,LOWER_UP800> mtu 1500 qdisc mq master bond0 state UP qlen 1000 link/ether 9e:23:69:42:fb:8a brd ff:ff:ff:ff:ff:ff 2 44: net2: <BROADCAST,MULTICAST,UP,LOWER_UP800> mtu 1500 qdisc mq master bond0 state UP qlen 1000 link/ether 9e:23:69:42:fb:8a brd ff:ff:ff:ff:ff:ff 3
注記Pod アノテーションでインターフェイス名が設定されていない場合、インターフェイス名は
net<n>として自動的に割り当てられます (<n>は1から始まります)。オプション: たとえば
bond0などの特定のインターフェイス名を設定する場合は、次のようにk8s.v1.cni.cncf.io/networksアノテーションを編集し、bond0をインターフェイス名として設定します。annotations: k8s.v1.cni.cncf.io/networks: demo/sriovnet1, demo/sriovnet2, demo/bond-net1@bond0
26.12. ハードウェアオフロードの設定
クラスター管理者は、互換性のあるノードでハードウェアオフロードを設定して、データ処理パフォーマンスを向上させ、ホスト CPU の負荷を軽減できます。
26.12.1. ハードウェアのオフロードについて
Open vSwitch ハードウェアオフロードは、ネットワークタスクを CPU から迂回させ、ネットワークインターフェイスコントローラー上の専用プロセッサーにオフロードすることにより、ネットワークタスクを処理する方法です。その結果、クラスターは、データ転送速度の高速化、CPU ワークロードの削減、およびコンピューティングコストの削減の恩恵を受けることができます。
この機能の重要な要素は、SmartNIC と呼ばれる最新クラスのネットワークインターフェイスコントローラーです。SmartNIC は、計算量の多いネットワーク処理タスクを処理できるネットワークインターフェイスコントローラーです。専用のグラフィックカードがグラフィックパフォーマンスを向上させるのと同じように、SmartNIC はネットワークパフォーマンスを向上させることができます。いずれの場合も、専用プロセッサーにより、特定のタイプの処理タスクのパフォーマンスが向上します。
OpenShift Container Platform では、互換性のある SmartNIC を持つベアメタルノードのハードウェアオフロードを設定できます。ハードウェアオフロードは、SR-IOV Network Operator によって設定および有効化されます。
ハードウェアのオフロードは、すべてのワークロードまたはアプリケーションタイプと互換性があるわけではありません。次の 2 つの通信タイプのみがサポートされています。
- pod-to-pod
- pod-to-service。サービスは通常の Pod に基づく ClusterIP サービスです。
すべての場合において、ハードウェアのオフロードは、それらの Pod とサービスが互換性のある SmartNIC を持つノードに割り当てられている場合にのみ行われます。たとえば、ハードウェアをオフロードしているノードの Pod が、通常のノードのサービスと通信しようとしているとします。通常のノードでは、すべての処理がカーネルで行われるため、Pod からサービスへの通信の全体的なパフォーマンスは、その通常のノードの最大パフォーマンスに制限されます。ハードウェアオフロードは、DPDK アプリケーションと互換性がありません。
ノードでのハードウェアのオフロードを有効にし、使用する Pod を設定しないと、Pod トラフィックのスループットパフォーマンスが低下する可能性があります。OpenShift Container Platform で管理される Pod のハードウェアオフロードを設定することはできません。
26.12.2. サポートされるデバイス
ハードウェアオフロードは、次のネットワークインターフェイスコントローラーでサポートされています。
表26.15 サポート対象のネットワークインターフェイスコントローラー
| 製造元 | モデル | ベンダー ID | デバイス ID |
|---|---|---|---|
| Mellanox | MT27800 Family [ConnectX‑5] | 15b3 | 1017 |
| Mellanox | MT28880 Family [ConnectX‑5 Ex] | 15b3 | 1019 |
| Mellanox | MT2892 Family [ConnectX‑6 Dx] | 15b3 | 101d |
| Mellanox | MT2894 ファミリー ConnectX-6 Lx | 15b3 | 101f |
| Mellanox | ConnectX-6 NIC モードの MT42822 BlueField-2 | 15b3 | a2d6 |
26.12.3. 前提条件
- クラスターに、ハードウェアのオフロードがサポートされているネットワークインターフェイスコントローラーを備えたベアメタルマシンが少なくとも 1 台ある。
- SR-IOV Network Operator をインストール している。
- クラスターで OVN-Kubernetes ネットワークプラグインを使用 している。
-
OVN-Kubernetes ネットワークプラグイン設定 で、
gatewayConfig.routingViaHostフィールドがfalseに設定されています。
26.12.4. ハードウェアオフロード用のマシン設定プールの設定
ハードウェアオフロードを有効にするには、最初に専用のマシン設定プールを作成し、SR-IOV Network Operator と連携するように設定する必要があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
ハードウェアオフロードを使用するマシンのマシン設定プールを作成します。
次の例のようなコンテンツを含む
mcp-offloading.yamlなどのファイルを作成します。apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: mcp-offloading 1 spec: machineConfigSelector: matchExpressions: - {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,mcp-offloading]} 2 nodeSelector: matchLabels: node-role.kubernetes.io/mcp-offloading: "" 3
マシン設定プールの設定を適用します。
$ oc create -f mcp-offloading.yaml
マシン設定プールにノードを追加します。プールのノードロールラベルで各ノードにラベルを付けます。
$ oc label node worker-2 node-role.kubernetes.io/mcp-offloading=""
オプション: 新しいプールが作成されたことを確認するには、次のコマンドを実行します。
$ oc get nodes
出力例
NAME STATUS ROLES AGE VERSION master-0 Ready master 2d v1.26.0 master-1 Ready master 2d v1.26.0 master-2 Ready master 2d v1.26.0 worker-0 Ready worker 2d v1.26.0 worker-1 Ready worker 2d v1.26.0 worker-2 Ready mcp-offloading,worker 47h v1.26.0 worker-3 Ready mcp-offloading,worker 47h v1.26.0
このマシン設定プールを
SriovNetworkPoolConfigカスタムリソースに追加します。次の例のようなコンテンツを含むファイル (
sriov-pool-config.yamlなど) を作成します。apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkPoolConfig metadata: name: sriovnetworkpoolconfig-offload namespace: openshift-sriov-network-operator spec: ovsHardwareOffloadConfig: name: mcp-offloading 1- 1
- ハードウェアオフロード用のマシン設定プールの名前。
設定を適用します。
$ oc create -f <SriovNetworkPoolConfig_name>.yaml
注記SriovNetworkPoolConfigオブジェクトで指定された設定を適用すると、SR-IOV Operator は、マシン設定プール内のノードをドレインして再起動します。設定の変更が適用されるまでに数分かかる場合があります。
26.12.5. SR-IOV ネットワークノードポリシーの設定
SR-IOV ネットワークノードポリシーを作成することにより、ノードの SR-IOV ネットワークデバイス設定を作成できます。ハードウェアオフロードを有効にするには、値 "switchdev" を使用して .spec.eSwitchMode フィールドを定義する必要があります。
次の手順では、ハードウェアをオフロードするネットワークインターフェイスコントローラー用の SR-IOV インターフェイスを作成します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
次の例のようなコンテンツを含むファイル (
sriov-node-policy.yamlなど) を作成します。apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodePolicy metadata: name: sriov-node-policy <.> namespace: openshift-sriov-network-operator spec: deviceType: netdevice <.> eSwitchMode: "switchdev" <.> nicSelector: deviceID: "1019" rootDevices: - 0000:d8:00.0 vendor: "15b3" pfNames: - ens8f0 nodeSelector: feature.node.kubernetes.io/network-sriov.capable: "true" numVfs: 6 priority: 5 resourceName: mlxnics<.> カスタムリソースオブジェクトの名前。<.> 必須。ハードウェアのオフロードは
vfio-pciではサポートされていません。<.> 必須。ポリシーの設定を適用します。
$ oc create -f sriov-node-policy.yaml
注記SriovNetworkPoolConfigオブジェクトで指定された設定を適用すると、SR-IOV Operator は、マシン設定プール内のノードをドレインして再起動します。設定の変更が適用されるまでに数分かかる場合があります。
26.12.5.1. OpenStack の SR-IOV ネットワークノードポリシーの例
次の例では、Red Hat OpenStack Platform (RHOSP) でハードウェアオフロードを使用するネットワークインターフェイスコントローラー (NIC) の SR-IOV インターフェイスについて説明します。
RHOSP でのハードウェアオフロードを備えた NIC の SR-IOV インターフェイス
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: ${name}
namespace: openshift-sriov-network-operator
spec:
deviceType: switchdev
isRdma: true
nicSelector:
netFilter: openstack/NetworkID:${net_id}
nodeSelector:
feature.node.kubernetes.io/network-sriov.capable: 'true'
numVfs: 1
priority: 99
resourceName: ${name}
26.12.6. ネットワーク接続定義の作成
マシン設定プールと SR-IOV ネットワークノードポリシーを定義した後、指定したネットワークインターフェイスカードのネットワーク接続定義を作成できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
次の例のようなコンテンツを含むファイル (
net-attach-def.yamlなど) を作成します。apiVersion: "k8s.cni.cncf.io/v1" kind: NetworkAttachmentDefinition metadata: name: net-attach-def <.> namespace: net-attach-def <.> annotations: k8s.v1.cni.cncf.io/resourceName: openshift.io/mlxnics <.> spec: config: '{"cniVersion":"0.3.1","name":"ovn-kubernetes","type":"ovn-k8s-cni-overlay","ipam":{},"dns":{}}'<.> ネットワーク接続定義の名前。<.> ネットワーク接続定義の namespace。<.> これは、
SriovNetworkNodePolicyオブジェクトで指定したspec.resourceNameフィールドの値です。ネットワーク接続定義の設定を適用します。
$ oc create -f net-attach-def.yaml
検証
次のコマンドを実行して、新しい定義が存在するかどうかを確認します。
$ oc get net-attach-def -A
出力例
NAMESPACE NAME AGE net-attach-def net-attach-def 43h
26.12.7. ネットワーク接続定義を Pod へ追加
マシン設定プール、SriovNetworkPoolConfig および SriovNetworkNodePolicy カスタムリソース、およびネットワーク接続定義を作成した後、ネットワーク接続定義を Pod 仕様に追加することにより、これらの設定を Pod に適用できます。
手順
Pod 仕様で、
.metadata.annotations.k8s.v1.cni.cncf.io/networksフィールドを追加し、ハードウェアオフロード用に作成したネットワーク接続定義を指定します。.... metadata: annotations: v1.multus-cni.io/default-network: net-attach-def/net-attach-def <.><.> 値は、ハードウェアオフロード用に作成したネットワーク接続定義の名前と namespace である必要があります。
26.13. Bluefield-2 の DPU から NIC への切り替え
Bluefield-2 ネットワークデバイスをデータ処理ユニット (DPU) モードからネットワークインターフェイスコントローラー (NIC) モードに切り替えることができます。
26.13.1. Bluefield-2 を DPU モードから NIC モードに切り替える
以下の手順を使用して、Bluefield-2 をデータ処理ユニット (DPU) モードからネットワークインターフェイスコントローラー (NIC) モードに切り替えます。
現在、DPU から NIC モードへの Bluefield-2 の切り替えのみがサポートされています。NIC モードから DPU モードへの切り替えはサポートされていません。
前提条件
- SR-IOV Network Operator がインストールされている。詳細については、SR-IOV Network Operator のインストールを参照してください。
- Bluefield-2 を最新のファームウェアに更新している。詳細については 、NVIDIA BlueField-2 のファームウェア を参照してください。
手順
次のコマンドを入力して、各ワーカーノードに次のラベルを追加します。
$ oc label node <example_node_name_one> node-role.kubernetes.io/sriov=
$ oc label node <example_node_name_two> node-role.kubernetes.io/sriov=
SR-IOV Network Operator のマシン設定プールを作成します。次に例を示します。
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: sriov spec: machineConfigSelector: matchExpressions: - {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,sriov]} nodeSelector: matchLabels: node-role.kubernetes.io/sriov: ""次の
machineconfig.yamlファイルをワーカーノードに適用します。apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: sriov name: 99-bf2-dpu spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:text/plain;charset=utf-8;base64,ZmluZF9jb250YWluZXIoKSB7CiAgY3JpY3RsIHBzIC1vIGpzb24gfCBqcSAtciAnLmNvbnRhaW5lcnNbXSB8IHNlbGVjdCgubWV0YWRhdGEubmFtZT09InNyaW92LW5ldHdvcmstY29uZmlnLWRhZW1vbiIpIHwgLmlkJwp9CnVudGlsIG91dHB1dD0kKGZpbmRfY29udGFpbmVyKTsgW1sgLW4gIiRvdXRwdXQiIF1dOyBkbwogIGVjaG8gIndhaXRpbmcgZm9yIGNvbnRhaW5lciB0byBjb21lIHVwIgogIHNsZWVwIDE7CmRvbmUKISBzdWRvIGNyaWN0bCBleGVjICRvdXRwdXQgL2JpbmRhdGEvc2NyaXB0cy9iZjItc3dpdGNoLW1vZGUuc2ggIiRAIgo= mode: 0755 overwrite: true path: /etc/default/switch_in_sriov_config_daemon.sh systemd: units: - name: dpu-switch.service enabled: true contents: | [Unit] Description=Switch BlueField2 card to NIC/DPU mode RequiresMountsFor=%t/containers Wants=network.target After=network-online.target kubelet.service [Service] SuccessExitStatus=0 120 RemainAfterExit=True ExecStart=/bin/bash -c '/etc/default/switch_in_sriov_config_daemon.sh nic || shutdown -r now' 1 Type=oneshot [Install] WantedBy=multi-user.target- 1
- オプションです。オプションで、特定のカードの PCI アドレスを指定することができます。 例えば
ExecStart=/bin/bash -c '/etc/default/switch_in_sriov_config_daemon.sh nic 0000:5e:00.0 || echo done'。デフォルトでは、最初のデバイスが選択されています。複数のデバイスがある場合は、使用する PCI アドレスを指定する必要があります。Bluefield-2 を DPU モードから NIC モードに切り替えるすべてのノードで、PCI アドレスが同じである必要があります。
- ワーカーノードが再起動するまで待ちます。再起動後、ワーカーノードの Bluefield-2 ネットワークデバイスは NIC モードに切り替わります。
26.14. SR-IOV Network Operator のインストール
SR-IOV Network Operator をアンインストールするには、実行中の SR-IOV ワークロードをすべて削除し、Operator をアンインストールして、Operator が使用した Webhook を削除する必要があります。
26.14.1. SR-IOV Network Operator のインストール
クラスター管理者は、SR-IOV Network Operator をアンインストールできます。
前提条件
-
cluster-admin権限を持つアカウントを使用して OpenShift Container Platform クラスターにアクセスできる。 - SR-IOV Network Operator がインストールされている。
手順
すべての SR-IOV カスタムリソース (CR) を削除します。
$ oc delete sriovnetwork -n openshift-sriov-network-operator --all
$ oc delete sriovnetworknodepolicy -n openshift-sriov-network-operator --all
$ oc delete sriovibnetwork -n openshift-sriov-network-operator --all
- クラスターからの Operator の削除セクションに記載された手順に従い、クラスターから SR-IOV Network Operator を削除します。
SR-IOV Network Operator のアンインストール後にクラスターに残っている SR-IOV カスタムリソース定義を削除します。
$ oc delete crd sriovibnetworks.sriovnetwork.openshift.io
$ oc delete crd sriovnetworknodepolicies.sriovnetwork.openshift.io
$ oc delete crd sriovnetworknodestates.sriovnetwork.openshift.io
$ oc delete crd sriovnetworkpoolconfigs.sriovnetwork.openshift.io
$ oc delete crd sriovnetworks.sriovnetwork.openshift.io
$ oc delete crd sriovoperatorconfigs.sriovnetwork.openshift.io
SR-IOV Webhook を削除します。
$ oc delete mutatingwebhookconfigurations network-resources-injector-config
$ oc delete MutatingWebhookConfiguration sriov-operator-webhook-config
$ oc delete ValidatingWebhookConfiguration sriov-operator-webhook-config
SR-IOV Network Operator の namespace を削除します。
$ oc delete namespace openshift-sriov-network-operator
第27章 OVN-Kubernetes ネットワークプラグイン
27.1. OVN-Kubernetes ネットワークプラグインについて
OpenShift Container Platform クラスターは、Pod およびサービスネットワークに仮想化ネットワークを使用します。
Red Hat OpenShift Networking の一部である OVN-Kubernetes ネットワークプラグインは、OpenShift Container Platform のデフォルトのネットワークプロバイダーです。OVN-Kubernetes は Open Virtual Network (OVN) をベースとしており、オーバーレイベースのネットワーク実装を提供します。OVN-Kubernetes プラグインを使用するクラスターは、各ノードで Open vSwitch (OVS) も実行します。OVN は、宣言ネットワーク設定を実装するように各ノードで OVS を設定します。
OVN-Kubernetes は、OpenShift Container Platform および単一ノードの OpenShift デプロイメントのデフォルトのネットワークソリューションです。
OVS プロジェクトから生まれた OVN-Kubernetes は、オープンフロールールなど、同じコンストラクトの多くを使用して、パケットがネットワークを通過する方法を決定します。詳細は、Open Virtual Network の Web サイト を参照してください。
OVN-Kubernetes は、仮想ネットワーク設定を OpenFlow ルールに変換する OVS 用の一連のデーモンです。OpenFlow は、ネットワークスイッチおよびルーターと通信するためのプロトコルであり、ネットワークデバイス上のネットワークトラフィックのフローをリモートで制御する手段を提供し、ネットワーク管理者がネットワークトラフィックのフローを設定、管理、および監視できるようにします。
OVN-Kubernetes は、OpenFlow では利用できない高度な機能をさらに提供します。OVN は、分散仮想ルーター、分散論理スイッチ、アクセス制御、DHCP および DNS をサポートします。OVN は、オープンフローと同等のロジックフロー内に分散仮想ルーターを実装します。たとえば、ネットワーク上に DHCP リクエストを送信する Pod がある場合、Pod はそのブロードキャストを送信して DHCP アドレスを探します。また、そのパケットに一致するロジックフロールールが存在し、応答としてゲートウェイ、DNS サーバー、IP アドレスなどを提供します。
OVN-Kubernetes は、各ノードでデーモンを実行します。すべてのノードで実行されるデータベースおよび OVN コントローラー用のデーモンセットがあります。OVN コントローラーは、ネットワークプロバイダーの機能 (egress IP、ファイアウォール、ルーター、ハイブリッドネットワーク、IPSEC 暗号化、IPv6、ネットワークポリシー、ネットワークポリシーログ、ハードウェアオフロード、およびマルチキャスト) をサポートするために、ノード上で Open vSwitch デーモンをプログラムします。
27.1.1. OVN-Kubernetes の目的
OVN-Kubernetes ネットワークプラグインは、Open Virtual Network (OVN) を使用してネットワークトラフィックフローを管理する、オープンソースのフル機能の Kubernetes CNI プラグインです。OVN はコミュニティーで開発され、ベンダーに依存しないネットワーク仮想化ソリューションです。OVN-Kubernetes ネットワークプラグイン:
- Open Virtual Network (OVN) を使用してネットワークトラフィックフローを管理します。OVN はコミュニティーで開発され、ベンダーに依存しないネットワーク仮想化ソリューションです。
- ingress および egress ルールを含む Kubernetes ネットワークポリシーのサポートを実装します。
- ノード間にオーバーレイネットワークを作成するには、VXLAN ではなく GENEVE (Generic Network Virtualization Encapsulation) プロトコルを使用します。
OVN-Kubernetes ネットワークプラグインは、OpenShift SDN よりも次の利点があります。
- サポートされているプラットフォームでの IPv6 シングルスタックおよび IPv4/IPv6 デュアルスタックネットワークの完全サポート
- Linux と Microsoft Windows の両方のワークロードによるハイブリッドクラスターのサポート
- クラスター内通信のオプションの IPsec 暗号化
- ホスト CPU から互換性のあるネットワークカードおよびデータ処理ユニット (DPU) へのネットワークデータ処理のオフロード
27.1.2. サポートされているネットワークプラグイン機能のマトリックス
Red Hat OpenShift Networking は、ネットワークプラグイン用に OpenShift SDN と OVN-Kubernetes の 2 つのオプションを提供します。以下の表は、両方のネットワークプラグインの現在の機能サポートをまとめたものです。
表27.1 デフォルトの CNI ネットワークプラグイン機能の比較
| 機能 | OVN-Kubernetes | OpenShift SDN |
|---|---|---|
| Egress IP | サポート対象 | サポート対象 |
| Egress ファイアウォール [1] | サポート対象 | サポート対象 |
| Egress ルーター | サポート対象 [2] | サポート対象 |
| ハイブリッドネットワーク | サポート対象 | サポート対象外 |
| クラスター内通信の IPsec 暗号化 | サポート対象 | サポート対象外 |
| IPv6 | サポート対象 [3] [4] | サポート対象外 |
| Kubernetes ネットワークポリシー | サポート対象 | サポート対象 |
| Kubernetes ネットワークポリシーログ | サポート対象 | サポート対象外 |
| ハードウェアのオフロード | サポート対象 | サポート対象外 |
| マルチキャスト | サポート対象 | サポート対象 |
- egress ファイアウォールは、OpenShift SDN では egress ネットワークポリシーとしても知られています。これはネットワークポリシーの egress とは異なります。
- OVN-Kubernetes の egress ルーターはリダイレクトモードのみをサポートします。
- IPv6 は、ベアメタル、IBM Power、および IBM Z クラスターでのみサポートされます。
- IPv6 シングルスタックは、Kubernetes NMState をサポートしておらず、IBM Power および IBM Z クラスターでもサポートされていません。
27.1.3. OVN-Kubernetes IPv6 とデュアルスタックの制限
OVN-Kubernetes ネットワークプラグインには、次の制限があります。
デュアルスタックネットワークに設定されたクラスターでは、IPv4 と IPv6 の両方のトラフィックがデフォルトゲートウェイとして同じネットワークインターフェイスを使用する必要があります。この要件が満たされない場合には、
ovnkube-nodeデーモンセットのホストにある Pod は、CrashLoopBackOff状態になります。oc get pod -n openshift-ovn-kubernetes -l app=ovnkube-node -o yamlのようなコマンドで Pod を表示すると、以下の出力のように、statusフィールドにデフォルトゲートウェイに関する複数のメッセージが表示されます。I1006 16:09:50.985852 60651 helper_linux.go:73] Found default gateway interface br-ex 192.168.127.1 I1006 16:09:50.985923 60651 helper_linux.go:73] Found default gateway interface ens4 fe80::5054:ff:febe:bcd4 F1006 16:09:50.985939 60651 ovnkube.go:130] multiple gateway interfaces detected: br-ex ens4
唯一の解決策は、両方の IP ファミリーがデフォルトゲートウェイに同じネットワークインターフェイスを使用するように、ホストネットワークを再設定することです。
デュアルスタックネットワーク用に設定されたクラスターの場合、IPv4 と IPv6 の両方のルーティングテーブルにデフォルトゲートウェイが含まれている必要があります。この要件が満たされない場合には、
ovnkube-nodeデーモンセットのホストにある Pod は、CrashLoopBackOff状態になります。oc get pod -n openshift-ovn-kubernetes -l app=ovnkube-node -o yamlのようなコマンドで Pod を表示すると、以下の出力のように、statusフィールドにデフォルトゲートウェイに関する複数のメッセージが表示されます。I0512 19:07:17.589083 108432 helper_linux.go:74] Found default gateway interface br-ex 192.168.123.1 F0512 19:07:17.589141 108432 ovnkube.go:133] failed to get default gateway interface
唯一の解決策として、両方の IP ファミリーにデフォルトゲートウェイが含まれるようにホストネットワークを再設定できます。
27.1.4. セッションアフィニティー
セッションアフィニティーは、Kubernetes Service オブジェクトに適用される機能です。<service_VIP>:<Port> に接続するたびに、トラフィックが常に同じバックエンドに負荷分散されるようにする場合は、セッションアフィニティー を使用できます。クライアントの IP アドレスに基づいてセッションアフィニティーを設定する方法など、詳細は、セッションアフィニティー を参照してください。
セッションアフィニティーのスティッキタイムアウト
OpenShift Container Platform の OVN-Kubernetes ネットワークプラグインは、最後のパケットに基づいて、クライアントからのセッションのスティッキタイムアウトを計算します。たとえば、curl コマンドを 10 回実行すると、スティッキーセッションタイマーは最初のパケットではなく 10 番目のパケットから開始します。その結果、クライアントが継続的にサービスに接続している場合でも、セッションがタイムアウトすることはありません。タイムアウトは、timeoutSeconds パラメーターで設定された時間、サービスがパケットを受信しなかった場合に開始されます。
27.2. OVN-Kubernetes のアーキテクチャー
27.2.1. OVN-Kubernetes のアーキテクチャーの紹介
次の図は、OVN-Kubernetes のアーキテクチャーを示しています。
図27.1 OVN-Kubernetes のアーキテクチャー
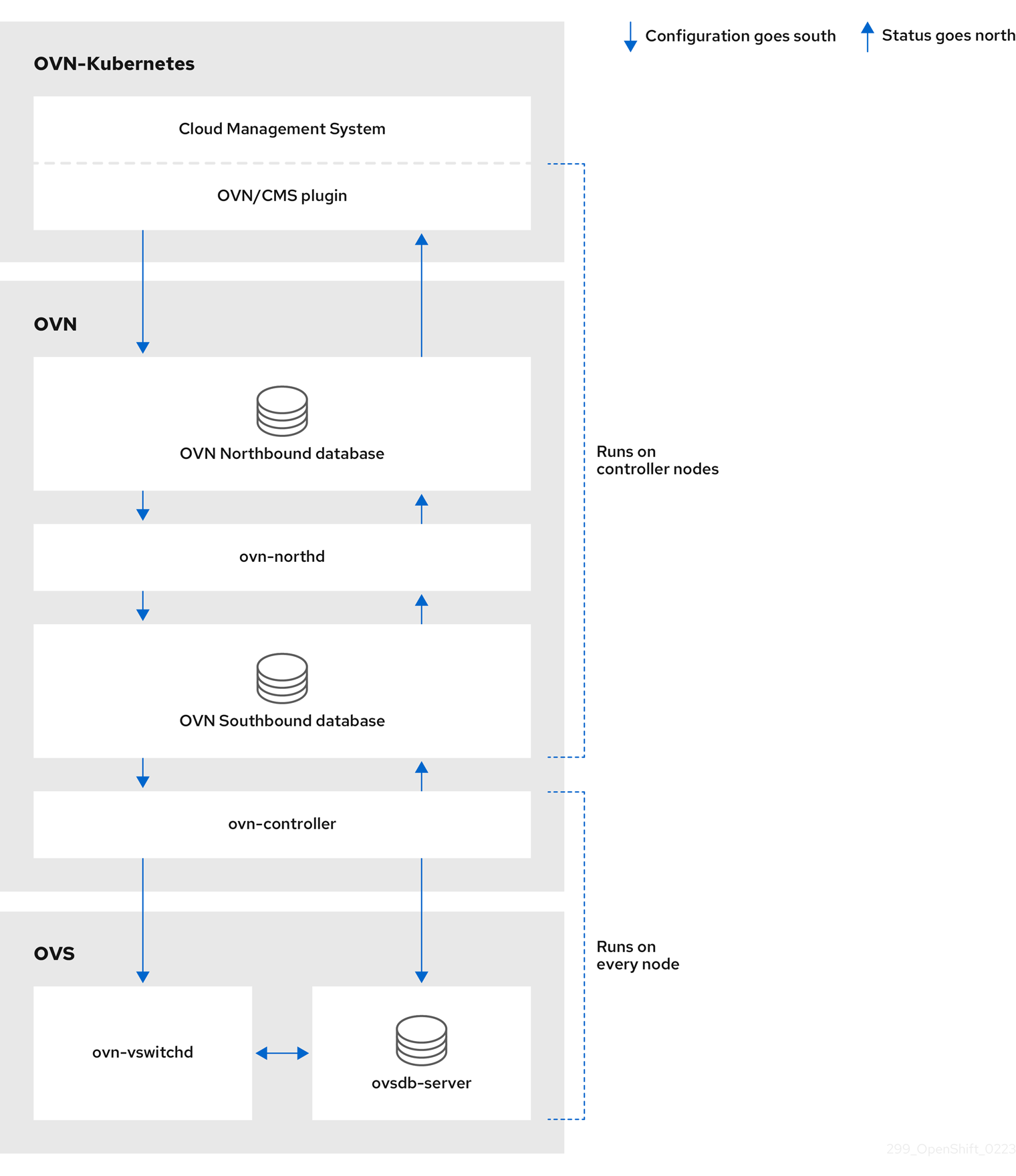
主なコンポーネントは次のとおりです。
- Cloud Management System (CMS) - OVN 統合用の CMS 固有のプラグインを提供する OVN 用のプラットフォーム固有のクライアント。このプラグインは、CMS 固有の形式で CMS 設定データベースに格納されているクラウド管理システムの論理ネットワーク設定の概念を、OVN が理解できる中間表現に変換します。
-
OVN ノースバウンドデータベース (
nbdb) - CMS プラグインによって渡された論理ネットワーク設定を格納します。 -
OVN サウスバウンドデータベース (
sbdb) - 各ノードの OpenVswitch (OVS) システムの物理および論理ネットワーク設定状態を、それらをバインドするテーブルを含めて格納します。 -
ovn-northd - これは
nbdbとsbdbの間の仲介クライアントです。これは、論理ネットワーク設定を、nbdbから取得した従来のネットワーク概念の観点から、その下のsbdbの論理データパスフローに変換します。コンテナー名はnorthdで、ovnkube-masterPod で実行されます。 -
ovn-controller -
sbdbに必要な情報または更新のために、OVS およびハイパーバイザーと対話する OVN エージェントです。ovn-controllerはsbdbから論理フローを読み取り、それらをOpenFlowフローに変換して、ノードの OVS デーモンに送信します。コンテナー名はovn-controllerで、ovnkube-nodePod で実行されます。
OVN ノースバウンドデータベースには、クラウド管理システム (CMS) によって渡された論理ネットワーク設定があります。OVN ノースバウンドデータベースには、ネットワークの現在の望ましい状態が含まれており、論理ポート、論理スイッチ、論理ルーターなどのコレクションとして提示されます。ovn-northd (northd コンテナー) は、OVN ノースバウンドデータベースと OVN サウスバウンドデータベースに接続します。これは、論理ネットワーク設定を、OVN ノースバウンドデータベースから取得した従来のネットワーク概念の観点から、OVN サウスバウンドデータベースの論理データパスフローに変換します。
OVN サウスバウンドデータベースには、ネットワークの物理的および論理的表現と、それらをリンクするバインディングテーブルがあります。クラスター内のすべてのノードはサウスバウンドデータベースで表され、管理者はノードに接続されているポートを確認できます。また、サウスバウンドデータベースには、すべてのロジックフローが含まれています。ロジックフローは各ノードで実行される ovn-controller プロセスと共有され、ovn-controller はそれらを Open vSwitch をプログラムする OpenFlow ルールに変換します。
Kubernetes コントロールプレーンノードにはそれぞれ、OVN のノースバウンドおよびサウスバウンドデータベースのコンテナーをホストする ovnkube-master Pod が含まれています。すべての OVN ノースバウンドデータベースは Raft クラスターを形成し、すべてのサウスバウンドデータベースは別個の Raft クラスターを形成します。常に 1 つの ovnkube-master Pod がリーダーとなり、他の ovnkube-master Pod がフォロワーとなります。
27.2.2. OVN-Kubernetes プロジェクト内のすべてのリソースの一覧表示
OVN-Kubernetes プロジェクトで実行されるリソースとコンテナーを見つけることは、OVN-Kubernetes ネットワークの実装を理解するのに役立ちます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、OVN-Kubernetes プロジェクト内のすべてのリソース、エンドポイント、および
ConfigMapを取得します。$ oc get all,ep,cm -n openshift-ovn-kubernetes
出力例
NAME READY STATUS RESTARTS AGE pod/ovnkube-master-9g7zt 6/6 Running 1 (48m ago) 57m pod/ovnkube-master-lqs4v 6/6 Running 0 57m pod/ovnkube-master-vxhtq 6/6 Running 0 57m pod/ovnkube-node-9k9kc 5/5 Running 0 57m pod/ovnkube-node-jg52r 5/5 Running 0 51m pod/ovnkube-node-k8wf7 5/5 Running 0 57m pod/ovnkube-node-tlwk6 5/5 Running 0 47m pod/ovnkube-node-xsvnk 5/5 Running 0 57m NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/ovn-kubernetes-master ClusterIP None <none> 9102/TCP 57m service/ovn-kubernetes-node ClusterIP None <none> 9103/TCP,9105/TCP 57m service/ovnkube-db ClusterIP None <none> 9641/TCP,9642/TCP 57m NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/ovnkube-master 3 3 3 3 3 beta.kubernetes.io/os=linux,node-role.kubernetes.io/master= 57m daemonset.apps/ovnkube-node 5 5 5 5 5 beta.kubernetes.io/os=linux 57m NAME ENDPOINTS AGE endpoints/ovn-kubernetes-master 10.0.132.11:9102,10.0.151.18:9102,10.0.192.45:9102 57m endpoints/ovn-kubernetes-node 10.0.132.11:9105,10.0.143.72:9105,10.0.151.18:9105 + 7 more... 57m endpoints/ovnkube-db 10.0.132.11:9642,10.0.151.18:9642,10.0.192.45:9642 + 3 more... 57m NAME DATA AGE configmap/control-plane-status 1 55m configmap/kube-root-ca.crt 1 57m configmap/openshift-service-ca.crt 1 57m configmap/ovn-ca 1 57m configmap/ovnkube-config 1 57m configmap/signer-ca 1 57m
コントロールプレーンノードで実行される 3 つの
ovnkube-mastersと、ovnkube-masterおよびovnkube-nodePod をデプロイするために使用される 2 つのデーモンセットがあります。クラスター内の各ノードには、1 つのovnkube-nodePod があります。ovnkube-configConfigMapには、オンラインマスターおよびovnkube-nodeによって起動された OpenShift Container Platform OVN-Kubernetes 設定があります。次のコマンドを実行して、
ovnkube-masterPod 内のすべてのコンテナーをリスト表示します。$ oc get pods ovnkube-master-9g7zt \ -o jsonpath='{.spec.containers[*].name}' -n openshift-ovn-kubernetes予想される出力
northd nbdb kube-rbac-proxy sbdb ovnkube-master ovn-dbchecker
ovnkube-masterPod は、複数のコンテナーで構成されています。ノースバウンドデータベース (nbdbコンテナー)、サウスバウンドデータベース (sbdbコンテナー) をホストし、Pod、egressIP、namespace、サービス、エンドポイント、egress ファイアウォール、およびネットワークポリシーのクラスターイベントを監視し、それらをノースバウンドデータベース (ovnkube-masterPod) に書き込みます。また、ノードへの Pod サブネット割り当てを管理します。次のコマンドを実行して、
ovnkube-nodePod 内のすべてのコンテナーをリスト表示します。$ oc get pods ovnkube-node-jg52r \ -o jsonpath='{.spec.containers[*].name}' -n openshift-ovn-kubernetes予想される出力
ovn-controller ovn-acl-logging kube-rbac-proxy kube-rbac-proxy-ovn-metrics ovnkube-node
ovnkube-nodePod には、各 OpenShift Container Platform ノードに常駐するコンテナー (ovn-controller) があります。各ノードのovn-controllerは、OVN ノースバウンドを OVN サウスバウンドデータベースに接続して、OVN 設定を把握します。ovn-controllerは、サウスバウンドを OpenFlow コントローラーとしてovs-vswitchdに接続し、ネットワークトラフィックを制御します。また、サウスバウンドをローカルのovsdb-serverに接続して、Open vSwitch 設定を監視および制御できるようにします。次のコマンドを実行して、現在選出されている OVN-Kubernetes マスターリーダーをリストします。
$ oc get lease -n openshift-ovn-kubernetes
予想される出力
NAME HOLDER AGE ovn-kubernetes-master ci-ln-gz990pb-72292-rthz2-master-2 50m
27.2.3. OVN-Kubernetes ノースバウンドデータベースの内容の一覧表示
ロジックフロールールを理解するには、ノースバウンドデータベースを調べて、そこにあるオブジェクトを理解して、それらがロジックフロールールにどのように変換されるかを確認する必要があります。最新の情報は OVN Raft リーダーに存在します。この手順では、Raft リーダーを検索し、続いてクエリーを実行して OVN ノースバウンドデータベースの内容を一覧表示する方法について説明します。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
ノースバウンドデータベースの OVN Raft リーダーを見つけます。
注記Raft リーダーは最新の情報を保存します。
次のコマンドを実行して、Pod を一覧表示します。
$ oc get po -n openshift-ovn-kubernetes
出力例
NAME READY STATUS RESTARTS AGE ovnkube-master-7j97q 6/6 Running 2 (148m ago) 149m ovnkube-master-gt4ms 6/6 Running 1 (140m ago) 147m ovnkube-master-mk6p6 6/6 Running 0 148m ovnkube-node-8qvtr 5/5 Running 0 149m ovnkube-node-fqdc9 5/5 Running 0 149m ovnkube-node-tlfwv 5/5 Running 0 149m ovnkube-node-wlwkn 5/5 Running 0 142m
マスター Pod の 1 つをランダムに選択し、次のコマンドを実行します。
$ oc exec -n openshift-ovn-kubernetes ovnkube-master-7j97q \ -- /usr/bin/ovn-appctl -t /var/run/ovn/ovnnb_db.ctl \ --timeout=3 cluster/status OVN_Northbound
出力例
Defaulted container "northd" out of: northd, nbdb, kube-rbac-proxy, sbdb, ovnkube-master, ovn-dbchecker 1c57 Name: OVN_Northbound Cluster ID: c48a (c48aa5c0-a704-4c77-a066-24fe99d9b338) Server ID: 1c57 (1c57b6fc-2849-49b7-8679-fbf18bafe339) Address: ssl:10.0.147.219:9643 Status: cluster member Role: follower 1 Term: 5 Leader: 2b4f 2 Vote: unknown Election timer: 10000 Log: [2, 3018] Entries not yet committed: 0 Entries not yet applied: 0 Connections: ->0000 ->0000 <-8844 <-2b4f Disconnections: 0 Servers: 1c57 (1c57 at ssl:10.0.147.219:9643) (self) 8844 (8844 at ssl:10.0.163.212:9643) last msg 8928047 ms ago 2b4f (2b4f at ssl:10.0.242.240:9643) last msg 620 ms ago 3
次のコマンドを使用して、IP アドレス
10.0.242.240で実行されているovnkube-masterPod を見つけます。$ oc get po -o wide -n openshift-ovn-kubernetes | grep 10.0.242.240 | grep -v ovnkube-node
出力例
ovnkube-master-gt4ms 6/6 Running 1 (143m ago) 150m 10.0.242.240 ip-10-0-242-240.ec2.internal <none> <none>
ovnkube-master-gt4msPod は、IP アドレス 10.0.242.240 で実行されています。
次のコマンドを実行して、ノースバウンドデータベース内のすべてのオブジェクトを表示します。
$ oc exec -n openshift-ovn-kubernetes -it ovnkube-master-gt4ms \ -c northd -- ovn-nbctl show
出力は長すぎてここにリストできません。リストには、NAT ルール、論理スイッチ、ロードバランサーなどが含まれます。
次のコマンドを実行して、コマンド
ovn-nbctlで使用可能なオプションを表示します。$ oc exec -n openshift-ovn-kubernetes -it ovnkube-master-mk6p6 \ -c northd ovn-nbctl --help
次のコマンドのいくつかを使用すると、特定のコンポーネントに絞り込むことができます。
次のコマンドを実行して、論理ルーターのリストを表示します。
$ oc exec -n openshift-ovn-kubernetes -it ovnkube-master-gt4ms \ -c northd -- ovn-nbctl lr-list
出力例
f971f1f3-5112-402f-9d1e-48f1d091ff04 (GR_ip-10-0-145-205.ec2.internal) 69c992d8-a4cf-429e-81a3-5361209ffe44 (GR_ip-10-0-147-219.ec2.internal) 7d164271-af9e-4283-b84a-48f2a44851cd (GR_ip-10-0-163-212.ec2.internal) 111052e3-c395-408b-97b2-8dd0a20a29a5 (GR_ip-10-0-165-9.ec2.internal) ed50ce33-df5d-48e8-8862-2df6a59169a0 (GR_ip-10-0-209-170.ec2.internal) f44e2a96-8d1e-4a4d-abae-ed8728ac6851 (GR_ip-10-0-242-240.ec2.internal) ef3d0057-e557-4b1a-b3c6-fcc3463790b0 (ovn_cluster_router)
注記この出力から、各ノードにルーターと
ovn_cluster_routerがあることがわかります。次のコマンドを実行して、論理スイッチのリストを表示します。
$ oc exec -n openshift-ovn-kubernetes -it ovnkube-master-gt4ms \ -c northd -- ovn-nbctl ls-list
出力例
82808c5c-b3bc-414a-bb59-8fec4b07eb14 (ext_ip-10-0-145-205.ec2.internal) 3d22444f-0272-4c51-afc6-de9e03db3291 (ext_ip-10-0-147-219.ec2.internal) bf73b9df-59ab-4c58-a456-ce8205b34ac5 (ext_ip-10-0-163-212.ec2.internal) bee1e8d0-ec87-45eb-b98b-63f9ec213e5e (ext_ip-10-0-165-9.ec2.internal) 812f08f2-6476-4abf-9a78-635f8516f95e (ext_ip-10-0-209-170.ec2.internal) f65e710b-32f9-482b-8eab-8d96a44799c1 (ext_ip-10-0-242-240.ec2.internal) 84dad700-afb8-4129-86f9-923a1ddeace9 (ip-10-0-145-205.ec2.internal) 1b7b448b-e36c-4ca3-9f38-4a2cf6814bfd (ip-10-0-147-219.ec2.internal) d92d1f56-2606-4f23-8b6a-4396a78951de (ip-10-0-163-212.ec2.internal) 6864a6b2-de15-4de3-92d8-f95014b6f28f (ip-10-0-165-9.ec2.internal) c26bf618-4d7e-4afd-804f-1a2cbc96ec6d (ip-10-0-209-170.ec2.internal) ab9a4526-44ed-4f82-ae1c-e20da04947d9 (ip-10-0-242-240.ec2.internal) a8588aba-21da-4276-ba0f-9d68e88911f0 (join)
注記この出力から、各ノードの ext スイッチに加えて、ノード名自体を持つスイッチと結合スイッチがあることがわかります。
次のコマンドを実行して、ロードバランサーのリストを表示します。
$ oc exec -n openshift-ovn-kubernetes -it ovnkube-master-gt4ms \ -c northd -- ovn-nbctl lb-list
出力例
UUID LB PROTO VIP IPs f0fb50f9-4968-4b55-908c-616bae4db0a2 Service_default/ tcp 172.30.0.1:443 10.0.147.219:6443,10.0.163.212:6443,169.254.169.2:6443 0dc42012-4f5b-432e-ae01-2cc4bfe81b00 Service_default/ tcp 172.30.0.1:443 10.0.147.219:6443,169.254.169.2:6443,10.0.242.240:6443 f7fff5d5-5eff-4a40-98b1-3a4ba8f7f69c Service_default/ tcp 172.30.0.1:443 169.254.169.2:6443,10.0.163.212:6443,10.0.242.240:6443 12fe57a0-50a4-4a1b-ac10-5f288badee07 Service_default/ tcp 172.30.0.1:443 10.0.147.219:6443,10.0.163.212:6443,10.0.242.240:6443 3f137fbf-0b78-4875-ba44-fbf89f254cf7 Service_openshif tcp 172.30.23.153:443 10.130.0.14:8443 174199fe-0562-4141-b410-12094db922a7 Service_openshif tcp 172.30.69.51:50051 10.130.0.84:50051 5ee2d4bd-c9e2-4d16-a6df-f54cd17c9ac3 Service_openshif tcp 172.30.143.87:9001 10.0.145.205:9001,10.0.147.219:9001,10.0.163.212:9001,10.0.165.9:9001,10.0.209.170:9001,10.0.242.240:9001 a056ae3d-83f8-45bc-9c80-ef89bce7b162 Service_openshif tcp 172.30.164.74:443 10.0.147.219:6443,10.0.163.212:6443,10.0.242.240:6443 bac51f3d-9a6f-4f5e-ac02-28fd343a332a Service_openshif tcp 172.30.0.10:53 10.131.0.6:5353 tcp 172.30.0.10:9154 10.131.0.6:9154 48105bbc-51d7-4178-b975-417433f9c20a Service_openshif tcp 172.30.26.159:2379 10.0.147.219:2379,169.254.169.2:2379,10.0.242.240:2379 tcp 172.30.26.159:9979 10.0.147.219:9979,169.254.169.2:9979,10.0.242.240:9979 7de2b8fc-342a-415f-ac13-1a493f4e39c0 Service_openshif tcp 172.30.53.219:443 10.128.0.7:8443 tcp 172.30.53.219:9192 10.128.0.7:9192 2cef36bc-d720-4afb-8d95-9350eff1d27a Service_openshif tcp 172.30.81.66:443 10.128.0.23:8443 365cb6fb-e15e-45a4-a55b-21868b3cf513 Service_openshif tcp 172.30.96.51:50051 10.130.0.19:50051 41691cbb-ec55-4cdb-8431-afce679c5e8d Service_openshif tcp 172.30.98.218:9099 169.254.169.2:9099 82df10ba-8143-400b-977a-8f5f416a4541 Service_openshif tcp 172.30.26.159:2379 10.0.147.219:2379,10.0.163.212:2379,169.254.169.2:2379 tcp 172.30.26.159:9979 10.0.147.219:9979,10.0.163.212:9979,169.254.169.2:9979 debe7f3a-39a8-490e-bc0a-ebbfafdffb16 Service_openshif tcp 172.30.23.244:443 10.128.0.48:8443,10.129.0.27:8443,10.130.0.45:8443 8a749239-02d9-4dc2-8737-716528e0da7b Service_openshif tcp 172.30.124.255:8443 10.128.0.14:8443 880c7c78-c790-403d-a3cb-9f06592717a3 Service_openshif tcp 172.30.0.10:53 10.130.0.20:5353 tcp 172.30.0.10:9154 10.130.0.20:9154 d2f39078-6751-4311-a161-815bbaf7f9c7 Service_openshif tcp 172.30.26.159:2379 169.254.169.2:2379,10.0.163.212:2379,10.0.242.240:2379 tcp 172.30.26.159:9979 169.254.169.2:9979,10.0.163.212:9979,10.0.242.240:9979 30948278-602b-455c-934a-28e64c46de12 Service_openshif tcp 172.30.157.35:9443 10.130.0.43:9443 2cc7e376-7c02-4a82-89e8-dfa1e23fb003 Service_openshif tcp 172.30.159.212:17698 10.128.0.48:17698,10.129.0.27:17698,10.130.0.45:17698 e7d22d35-61c2-40c2-bc30-265cff8ed18d Service_openshif tcp 172.30.143.87:9001 10.0.145.205:9001,10.0.147.219:9001,10.0.163.212:9001,10.0.165.9:9001,10.0.209.170:9001,169.254.169.2:9001 75164e75-e0c5-40fb-9636-bfdbf4223a02 Service_openshif tcp 172.30.150.68:1936 10.129.4.8:1936,10.131.0.10:1936 tcp 172.30.150.68:443 10.129.4.8:443,10.131.0.10:443 tcp 172.30.150.68:80 10.129.4.8:80,10.131.0.10:80 7bc4ee74-dccf-47e9-9149-b011f09aff39 Service_openshif tcp 172.30.164.74:443 10.0.147.219:6443,10.0.163.212:6443,169.254.169.2:6443 0db59e74-1cc6-470c-bf44-57c520e0aa8f Service_openshif tcp 10.0.163.212:31460 tcp 10.0.163.212:32361 c300e134-018c-49af-9f84-9deb1d0715f8 Service_openshif tcp 172.30.42.244:50051 10.130.0.47:50051 5e352773-429b-4881-afb3-a13b7ba8b081 Service_openshif tcp 172.30.244.66:443 10.129.0.8:8443,10.130.0.8:8443 54b82d32-1939-4465-a87d-f26321442a7a Service_openshif tcp 172.30.12.9:8443 10.128.0.35:8443注記この出力 (一部省略あり) から、多くの OVN-Kubernetes ロードバランサーがあることがわかります。OVN-Kubernetes のロードバランサーはサービスの表現です。
27.2.4. ノースバウンドデータベースの内容を調べるための ovn-nbctl のコマンドライン引数
次の表に、ノースバウンドデータベースの内容を調べるために ovn-nbctl で使用できるコマンドライン引数を示します。
表27.2 ノースバウンドデータベースの内容を調べるためのコマンドライン引数
| 引数 | 説明 |
|---|---|
|
| ノースバウンドデータベースの内容の概要。 |
|
| 指定されたスイッチまたはルーターに関連付けられた詳細を表示します。 |
|
| 論理ルーターを表示します。 |
|
|
|
|
| 指定されたルーターのネットワークアドレス変換の詳細を表示します。 |
|
| 論理スイッチを表示します。 |
|
|
|
|
| 論理ポートのタイプを取得します。 |
|
| ロードバランサーを表示します。 |
27.2.5. OVN-Kubernetes サウスバウンドデータベースの内容の一覧表示
ロジックフロールールは、インフラストラクチャーの表現であるサウスバウンドデータベースに格納されます。最新の情報は OVN Raft リーダーに存在します。この手順では、Raft リーダーを検索し、クエリーを実行して OVN サウスバウンドデータベースの内容を一覧表示する方法について説明します。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
サウスバウンドデータベースの OVN Raft リーダーを見つけます。
注記Raft リーダーは最新の情報を保存します。
次のコマンドを実行して、Pod を一覧表示します。
$ oc get po -n openshift-ovn-kubernetes
出力例
NAME READY STATUS RESTARTS AGE ovnkube-master-7j97q 6/6 Running 2 (134m ago) 135m ovnkube-master-gt4ms 6/6 Running 1 (126m ago) 133m ovnkube-master-mk6p6 6/6 Running 0 134m ovnkube-node-8qvtr 5/5 Running 0 135m ovnkube-node-bqztb 5/5 Running 0 117m ovnkube-node-fqdc9 5/5 Running 0 135m ovnkube-node-tlfwv 5/5 Running 0 135m ovnkube-node-wlwkn 5/5 Running 0 128m
マスター Pod の 1 つをランダムに選択し、次のコマンドを実行して OVN サウスバウンド Raft リーダーを見つけます。
$ oc exec -n openshift-ovn-kubernetes ovnkube-master-7j97q \ -- /usr/bin/ovn-appctl -t /var/run/ovn/ovnsb_db.ctl \ --timeout=3 cluster/status OVN_Southbound
出力例
Defaulted container "northd" out of: northd, nbdb, kube-rbac-proxy, sbdb, ovnkube-master, ovn-dbchecker 1930 Name: OVN_Southbound Cluster ID: f772 (f77273c0-7986-42dd-bd3c-a9f18e25701f) Server ID: 1930 (1930f4b7-314b-406f-9dcb-b81fe2729ae1) Address: ssl:10.0.147.219:9644 Status: cluster member Role: follower 1 Term: 3 Leader: 7081 2 Vote: unknown Election timer: 16000 Log: [2, 2423] Entries not yet committed: 0 Entries not yet applied: 0 Connections: ->0000 ->7145 <-7081 <-7145 Disconnections: 0 Servers: 7081 (7081 at ssl:10.0.163.212:9644) last msg 59 ms ago 3 1930 (1930 at ssl:10.0.147.219:9644) (self) 7145 (7145 at ssl:10.0.242.240:9644) last msg 7871735 ms ago
次のコマンドを使用して、IP アドレス
10.0.163.212で実行されているovnkube-masterPod を見つけます。$ oc get po -o wide -n openshift-ovn-kubernetes | grep 10.0.163.212 | grep -v ovnkube-node
出力例
ovnkube-master-mk6p6 6/6 Running 0 136m 10.0.163.212 ip-10-0-163-212.ec2.internal <none> <none>
ovnkube-master-mk6p6Pod は、IP アドレス 10.0.163.212 で実行されています。
次のコマンドを実行して、サウスバウンドデータベースに保存されているすべての情報を表示します。
$ oc exec -n openshift-ovn-kubernetes -it ovnkube-master-mk6p6 \ -c northd -- ovn-sbctl show
出力例
Chassis "8ca57b28-9834-45f0-99b0-96486c22e1be" hostname: ip-10-0-156-16.ec2.internal Encap geneve ip: "10.0.156.16" options: {csum="true"} Port_Binding k8s-ip-10-0-156-16.ec2.internal Port_Binding etor-GR_ip-10-0-156-16.ec2.internal Port_Binding jtor-GR_ip-10-0-156-16.ec2.internal Port_Binding openshift-ingress-canary_ingress-canary-hsblx Port_Binding rtoj-GR_ip-10-0-156-16.ec2.internal Port_Binding openshift-monitoring_prometheus-adapter-658fc5967-9l46x Port_Binding rtoe-GR_ip-10-0-156-16.ec2.internal Port_Binding openshift-multus_network-metrics-daemon-77nvz Port_Binding openshift-ingress_router-default-64fd8c67c7-df598 Port_Binding openshift-dns_dns-default-ttpcq Port_Binding openshift-monitoring_alertmanager-main-0 Port_Binding openshift-e2e-loki_loki-promtail-g2pbh Port_Binding openshift-network-diagnostics_network-check-target-m6tn4 Port_Binding openshift-monitoring_thanos-querier-75b5cf8dcb-qf8qj Port_Binding cr-rtos-ip-10-0-156-16.ec2.internal Port_Binding openshift-image-registry_image-registry-7b7bc44566-mp9b8この詳細な出力は、シャーシとシャーシに接続されているポート (この場合、すべてのルーターポートとホストネットワークのように動作するもの) を示しています。すべての Pod は、ソースネットワークアドレス変換 (SNAT) を使用して、より広いネットワークと通信します。Pod の IP アドレスは、Pod が実行されているノードの IP アドレスに変換され、ネットワークに送信されます。
シャーシ情報に加えて、サウスバウンドデータベースにはすべてのロジックフローがあります。これらのロジックフローは各ノードで実行されている
ovn-controllerに送信されます。ovn-controllerは、ロジックフローをオープンフロールールに変換し、最終的にOpenvSwitchをプログラムして、Pod がオープンフロールールに従ってネットワークの外に出られるようにします。次のコマンドを実行して、コマンド
ovn-sbctlで使用可能なオプションを表示します。$ oc exec -n openshift-ovn-kubernetes -it ovnkube-master-mk6p6 \ -c northd -- ovn-sbctl --help
27.2.6. サウスバウンドデータベースの内容を調べるための ovn-sbctl のコマンドライン引数
次の表に、サウスバウンドデータベースの内容を調べるために ovn-sbctl で使用できるコマンドライン引数を示します。
表27.3 サウスバウンドデータベースの内容を調べるためのコマンドライン引数
| 引数 | 説明 |
|---|---|
|
| サウスバウンドデータベースの内容の概要。 |
|
| 指定されたポートのサウスバウンドデータベースの内容を一覧表示します。 |
|
| 論理フローを一覧表示します。 |
27.2.7. OVN-Kubernetes の論理アーキテクチャー
OVN はネットワーク仮想化ソリューションです。OVN は論理スイッチとルーターを作成します。これらのスイッチとルーターは相互接続され、任意のネットワークトポロジーを作成します。ログレベルを 2 または 5 に設定して ovnkube-trace を実行すると、OVN-Kubernetes 論理コンポーネントが公開されます。以下の図は、ルーターとスイッチが OpenShift Container Platform でどのように接続されているかを示しています。
図27.2 OVN-Kubernetes のルーターおよびスイッチコンポーネント
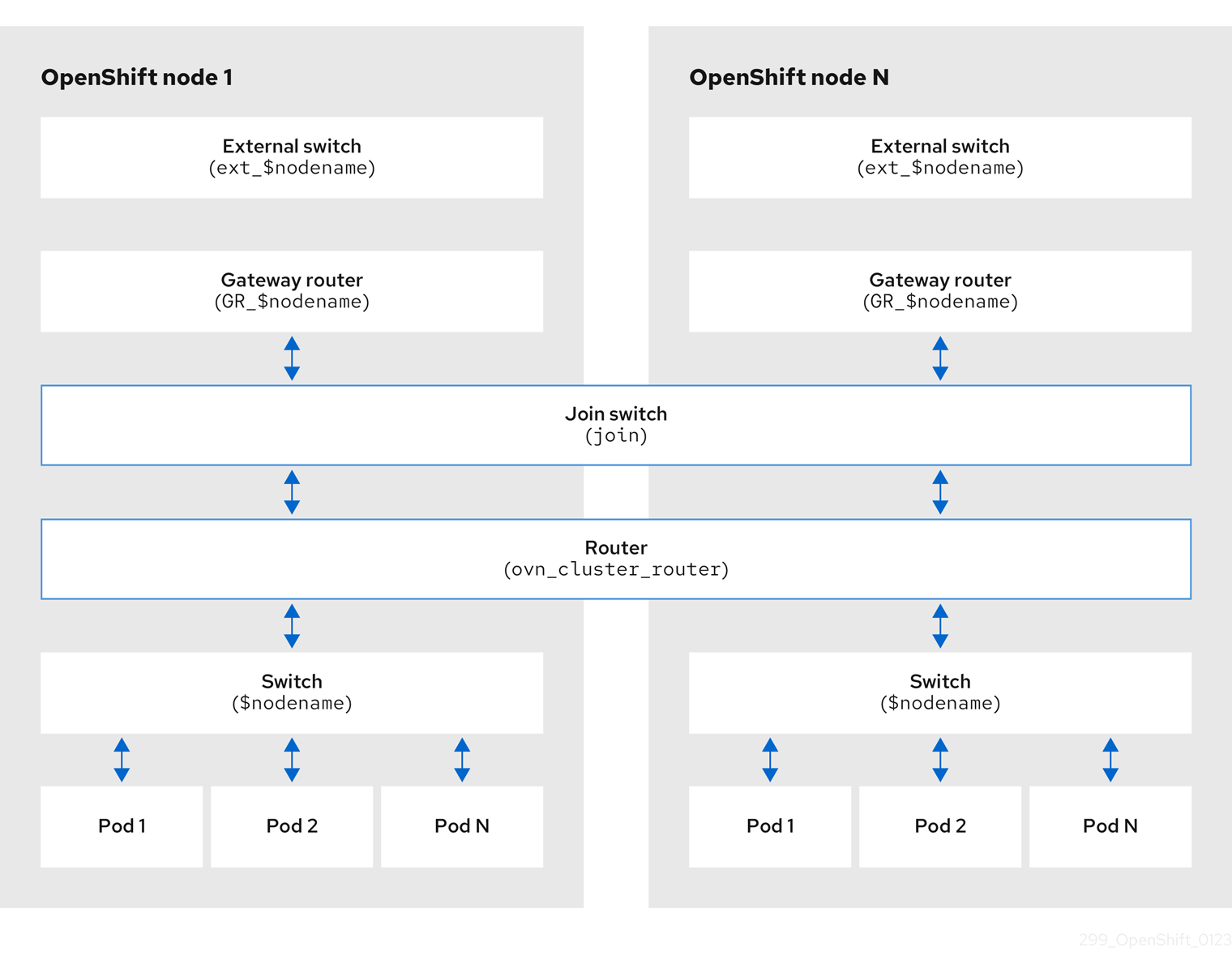
パケット処理に関係する主要なコンポーネントは次のとおりです。
- ゲートウェイルーター
-
L3 ゲートウェイルーターとも呼ばれるゲートウェイルーターは、通常、分散ルーターと物理ネットワークの間で使用されます。論理パッチポートを含むゲートウェイルーターは、(分散されていない) 物理的な場所またはシャーシにバインドされます。このルーターのパッチポートは、ovn-southbound データベース (
ovn-sbdb) では l3gateway ポートと呼ばれます。 - 分散論理ルーター
- 分散論理ルーターと、仮想マシンとコンテナーが接続されるその背後にある論理スイッチは、事実上、各ハイパーバイザーに常駐します。
- 結合ローカルスイッチ
- 結合ローカルスイッチは、分散ルーターとゲートウェイルーターを接続するために使用されます。これにより、分散ルーターで必要な IP アドレスの数が減ります。
- パッチポートを備えた論理スイッチ
- パッチポートを備えた論理スイッチは、ネットワークスタックを仮想化するために使用されます。これらは、トンネルを介してリモート論理ポートを接続します。
- localnet ポートを備えた論理スイッチ
- localnet ポートを備えた論理スイッチは、OVN を物理ネットワークに接続するために使用されます。これらは、localnet ポートを使用して直接接続された物理 L2 セグメントにパケットをブリッジすることにより、リモート論理ポートを接続します。
- パッチポート
- パッチポートは、論理スイッチと論理ルーターの間、およびピア論理ルーター間の接続を表します。1 つの接続には、このような接続ポイントごとに、両側に 1 つずつ、1 組のパッチポートがあります。
- l3gateway ポート
-
l3gateway ポートは、ゲートウェイルーターで使用される論理パッチポートの
ovn-sbdb内のポートバインディングエントリーです。これらのポートは、ゲートウェイルーター本体と同様にシャーシにバインドされているという事実を表すために、パッチポートではなく l3gateway ポートと呼ばれます。 - localnet ポート
-
localnet ポートは、各
ovn-controllerインスタンスからローカルにアクセス可能なネットワークへの接続を可能にするブリッジ論理スイッチに存在します。これは、論理スイッチから物理ネットワークへの直接接続をモデル化するのに役立ちます。論理スイッチに接続できる localnet ポートは 1 つだけです。
27.2.7.1. ローカルホストへの network-tools のインストール
ローカルホストに network-tools をインストールして、OpenShift Container Platform クラスターネットワークの問題をデバッグするための一連のツールを使用できるようにします。
手順
次のコマンドを使用して、
network-toolsリポジトリーのクローンをワークステーションに作成します。$ git clone git@github.com:openshift/network-tools.git
クローン作成したリポジトリーのディレクトリーに移動します。
$ cd network-tools
オプション: 使用可能なすべてのコマンドをリストします。
$ ./debug-scripts/network-tools -h
27.2.7.2. network-tools の実行
network-tools を実行して、論理スイッチとルーターに関する情報を取得します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインしている。 -
ローカルホストに
network-toolsがインストールされている。
手順
次のコマンドを実行して、ルーターを一覧表示します。
$ ./debug-scripts/network-tools ovn-db-run-command ovn-nbctl lr-list
出力例
Leader pod is ovnkube-master-vslqm 5351ddd1-f181-4e77-afc6-b48b0a9df953 (GR_helix13.lab.eng.tlv2.redhat.com) ccf9349e-1948-4df8-954e-39fb0c2d4d06 (GR_helix14.lab.eng.tlv2.redhat.com) e426b918-75a8-4220-9e76-20b7758f92b7 (GR_hlxcl7-master-0.hlxcl7.lab.eng.tlv2.redhat.com) dded77c8-0cc3-4b99-8420-56cd2ae6a840 (GR_hlxcl7-master-1.hlxcl7.lab.eng.tlv2.redhat.com) 4f6747e6-e7ba-4e0c-8dcd-94c8efa51798 (GR_hlxcl7-master-2.hlxcl7.lab.eng.tlv2.redhat.com) 52232654-336e-4952-98b9-0b8601e370b4 (ovn_cluster_router)
次のコマンドを実行して、localnet ポートを一覧表示します。
$ ./debug-scripts/network-tools ovn-db-run-command \ ovn-sbctl find Port_Binding type=localnet
出力例
Leader pod is ovnkube-master-vslqm _uuid : 3de79191-cca8-4c28-be5a-a228f0f9ebfc additional_chassis : [] additional_encap : [] chassis : [] datapath : 3f1a4928-7ff5-471f-9092-fe5f5c67d15c encap : [] external_ids : {} gateway_chassis : [] ha_chassis_group : [] logical_port : br-ex_helix13.lab.eng.tlv2.redhat.com mac : [unknown] nat_addresses : [] options : {network_name=physnet} parent_port : [] port_security : [] requested_additional_chassis: [] requested_chassis : [] tag : [] tunnel_key : 2 type : localnet up : false virtual_parent : [] _uuid : dbe21daf-9594-4849-b8f0-5efbfa09a455 additional_chassis : [] additional_encap : [] chassis : [] datapath : db2a6067-fe7c-4d11-95a7-ff2321329e11 encap : [] external_ids : {} gateway_chassis : [] ha_chassis_group : [] logical_port : br-ex_hlxcl7-master-2.hlxcl7.lab.eng.tlv2.redhat.com mac : [unknown] nat_addresses : [] options : {network_name=physnet} parent_port : [] port_security : [] requested_additional_chassis: [] requested_chassis : [] tag : [] tunnel_key : 2 type : localnet up : false virtual_parent : [] [...]次のコマンドを実行して、
l3gatewayポートを一覧表示します。$ ./debug-scripts/network-tools ovn-db-run-command \ ovn-sbctl find Port_Binding type=l3gateway
出力例
Leader pod is ovnkube-master-vslqm _uuid : 9314dc80-39e1-4af7-9cc0-ae8a9708ed59 additional_chassis : [] additional_encap : [] chassis : 336a923d-99e8-4e71-89a6-12564fde5760 datapath : db2a6067-fe7c-4d11-95a7-ff2321329e11 encap : [] external_ids : {} gateway_chassis : [] ha_chassis_group : [] logical_port : etor-GR_hlxcl7-master-2.hlxcl7.lab.eng.tlv2.redhat.com mac : ["52:54:00:3e:95:d3"] nat_addresses : ["52:54:00:3e:95:d3 10.46.56.77"] options : {l3gateway-chassis="7eb1f1c3-87c2-4f68-8e89-60f5ca810971", peer=rtoe-GR_hlxcl7-master-2.hlxcl7.lab.eng.tlv2.redhat.com} parent_port : [] port_security : [] requested_additional_chassis: [] requested_chassis : [] tag : [] tunnel_key : 1 type : l3gateway up : true virtual_parent : [] _uuid : ad7eb303-b411-4e9f-8d36-d07f1f268e27 additional_chassis : [] additional_encap : [] chassis : f41453b8-29c5-4f39-b86b-e82cf344bce4 datapath : 082e7a60-d9c7-464b-b6ec-117d3426645a encap : [] external_ids : {} gateway_chassis : [] ha_chassis_group : [] logical_port : etor-GR_helix14.lab.eng.tlv2.redhat.com mac : ["34:48:ed:f3:e2:2c"] nat_addresses : ["34:48:ed:f3:e2:2c 10.46.56.14"] options : {l3gateway-chassis="2e8abe3a-cb94-4593-9037-f5f9596325e2", peer=rtoe-GR_helix14.lab.eng.tlv2.redhat.com} parent_port : [] port_security : [] requested_additional_chassis: [] requested_chassis : [] tag : [] tunnel_key : 1 type : l3gateway up : true virtual_parent : [] [...]次のコマンドを実行して、パッチポートを一覧表示します。
$ ./debug-scripts/network-tools ovn-db-run-command \ ovn-sbctl find Port_Binding type=patch
出力例
Leader pod is ovnkube-master-vslqm _uuid : c48b1380-ff26-4965-a644-6bd5b5946c61 additional_chassis : [] additional_encap : [] chassis : [] datapath : 72734d65-fae1-4bd9-a1ee-1bf4e085a060 encap : [] external_ids : {} gateway_chassis : [] ha_chassis_group : [] logical_port : jtor-ovn_cluster_router mac : [router] nat_addresses : [] options : {peer=rtoj-ovn_cluster_router} parent_port : [] port_security : [] requested_additional_chassis: [] requested_chassis : [] tag : [] tunnel_key : 4 type : patch up : false virtual_parent : [] _uuid : 5df51302-f3cd-415b-a059-ac24389938f7 additional_chassis : [] additional_encap : [] chassis : [] datapath : 0551c90f-e891-4909-8e9e-acc7909e06d0 encap : [] external_ids : {} gateway_chassis : [] ha_chassis_group : [] logical_port : rtos-hlxcl7-master-1.hlxcl7.lab.eng.tlv2.redhat.com mac : ["0a:58:0a:82:00:01 10.130.0.1/23"] nat_addresses : [] options : {chassis-redirect-port=cr-rtos-hlxcl7-master-1.hlxcl7.lab.eng.tlv2.redhat.com, peer=stor-hlxcl7-master-1.hlxcl7.lab.eng.tlv2.redhat.com} parent_port : [] port_security : [] requested_additional_chassis: [] requested_chassis : [] tag : [] tunnel_key : 4 type : patch up : false virtual_parent : [] [...]
27.2.8. 関連情報
27.3. OVN-Kubernetes のトラブルシューティング
OVN-Kubernetes には、組み込みのヘルスチェックとログのソースが多数あります。
27.3.1. readiness プローブを使用した OVN-Kubernetes の正常性の監視
ovnkube-master および ovnkube-node Pod には、readiness プローブで設定されたコンテナーがあります。
前提条件
-
OpenShift CLI (
oc) へのアクセスがある。 -
cluster-admin権限でクラスターにアクセスできる。 -
jqがインストールされている。
手順
次のコマンドを実行して、
ovnkube-masterreadiness プローブの詳細を確認します。$ oc get pods -n openshift-ovn-kubernetes -l app=ovnkube-master \ -o json | jq '.items[0].spec.containers[] | .name,.readinessProbe'
ovnkube-masterPod 内のノースバウンドおよびサウスバウンドデータベースコンテナーの readiness プローブは、データベースをホストする Raft クラスターの健全性をチェックします。次のコマンドを実行して、
ovnkube-nodereadiness プローブの詳細を確認します。$ oc get pods -n openshift-ovn-kubernetes -l app=ovnkube-master \ -o json | jq '.items[0].spec.containers[] | .name,.readinessProbe'
ovnkube-nodePod 内のovnkube-nodeコンテナーには、ovn-kubernetes CNI 設定ファイルの存在を確認する readiness プローブがあります。この設定ファイルがない場合、Pod が実行されていないか、Pod を設定するリクエストを受け入れる準備ができていないません。次のコマンドを使用して、プローブの失敗を含む namespace のすべてのイベントを表示します。
$ oc get events -n openshift-ovn-kubernetes
この Pod だけのイベントを表示します。
$ oc describe pod ovnkube-master-tp2z8 -n openshift-ovn-kubernetes
クラスターネットワーク Operator からのメッセージとステータスを表示します。
$ oc get co/network -o json | jq '.status.conditions[]'
次のスクリプトを実行して、
ovnkube-masterPod 内の各コンテナーのreadyステータスを表示します。$ for p in $(oc get pods --selector app=ovnkube-master -n openshift-ovn-kubernetes \ -o jsonpath='{range.items[*]}{" "}{.metadata.name}'); do echo === $p ===; \ oc get pods -n openshift-ovn-kubernetes $p -o json | jq '.status.containerStatuses[] | .name, .ready'; \ done注記すべてのコンテナーのステータスが
trueとして報告されることが期待されます。readiness プローブが失敗すると、ステータスがfalseに設定されます。
27.3.2. コンソールでの OVN-Kubernetes アラートの表示
アラート UI は、アラートおよびそれらを規定するアラートルールおよびサイレンスについての詳細情報を提供します。
前提条件
- 開発者として、またはメトリクスで表示しているプロジェクトの表示パーミッションを持つユーザーとしてクラスターへのアクセスがある。
手順 (UI)
- Administrator パースペクティブで、Observe → Alerting を選択します。このパースペクティブのアラート UI の主なページには、Alerts、Silences、および Alerting Rules という 3 つのページがあります。
- Observe → Alerting → Alerting Rules を選択して、OVN-Kubernetes アラートのルールを表示します。
27.3.3. CLI での OVN-Kubernetes アラートの表示
コマンドラインから、アラートとその管理アラートルールおよびサイレンスに関する情報を取得できます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。 -
jqがインストールされている。
手順
次のコマンドを実行して、アクティブまたは発生中のアラートを表示します。
次のコマンドを実行して、アラートマネージャーのルート環境変数を設定します。
$ ALERT_MANAGER=$(oc get route alertmanager-main -n openshift-monitoring \ -o jsonpath='{@.spec.host}')次のコマンドを実行して、特定のフィールドを要求する正しい承認の詳細を指定して、アラートマネージャールート API に
curlリクエストを発行します。$ curl -s -k -H "Authorization: Bearer \ $(oc create token prometheus-k8s -n openshift-monitoring)" \ https://$ALERT_MANAGER/api/v1/alerts \ | jq '.data[] | "\(.labels.severity) \(.labels.alertname) \(.labels.pod) \(.labels.container) \(.labels.endpoint) \(.labels.instance)"'
次のコマンドを実行して、アラートルールを表示します。
$ oc -n openshift-monitoring exec -c prometheus prometheus-k8s-0 -- curl -s 'http://localhost:9090/api/v1/rules' | jq '.data.groups[].rules[] | select(((.name|contains("ovn")) or (.name|contains("OVN")) or (.name|contains("Ovn")) or (.name|contains("North")) or (.name|contains("South"))) and .type=="alerting")'
27.3.4. CLI を使用した OVN-Kubernetes ログの表示
OpenShift CLI (oc) を使用して、ovnkube-master および ovnkube-node Pod 内の各 Pod のログを表示できます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) へのアクセスがある。 -
jqがインストールされている。
手順
特定の Pod のログを表示します。
$ oc logs -f <pod_name> -c <container_name> -n <namespace>
ここでは、以下のようになります。
-f- オプション: ログに書き込まれている内容に沿って出力することを指定します。
<pod_name>- Pod の名前を指定します。
<container_name>- オプション: コンテナーの名前を指定します。Pod に複数のコンテナーがある場合、コンテナー名を指定する必要があります。
<namespace>- Pod が実行されている namespace を指定します。
以下に例を示します。
$ oc logs ovnkube-master-7h4q7 -n openshift-ovn-kubernetes
$ oc logs -f ovnkube-master-7h4q7 -n openshift-ovn-kubernetes -c ovn-dbchecker
ログファイルの内容が出力されます。
ovnkube-masterPod 内のすべてのコンテナーの最新のエントリーを調べます。$ for p in $(oc get pods --selector app=ovnkube-master -n openshift-ovn-kubernetes \ -o jsonpath='{range.items[*]}{" "}{.metadata.name}'); \ do echo === $p ===; for container in $(oc get pods -n openshift-ovn-kubernetes $p \ -o json | jq -r '.status.containerStatuses[] | .name');do echo ---$container---; \ oc logs -c $container $p -n openshift-ovn-kubernetes --tail=5; done; done次のコマンドを使用して、
ovnkube-masterPod 内のすべてのコンテナーのすべてのログの最後の 5 行を表示します。$ oc logs -l app=ovnkube-master -n openshift-ovn-kubernetes --all-containers --tail 5
27.3.5. Web コンソールを使用した OVN-Kubernetes ログの表示
Web コンソールで、ovnkube-master Pod と ovnkube-node Pod の各 Pod のログを表示できます。
前提条件
-
OpenShift CLI (
oc) へのアクセスがある。
手順
- OpenShift Container Platform コンソールで Workloads → Pods に移動するか、調査するリソースから Pod に移動します。
-
ドロップダウンメニューから
openshift-ovn-kubernetesプロジェクトを選択します。 - 調査する Pod の名前をクリックします。
-
Logs をクリックします。
ovnkube-masterのデフォルトでは、northdコンテナーに関連付けられたログが表示されます。 - ドロップダウンメニューを使用して、各コンテナーのログを順番に選択します。
27.3.5.1. OVN-Kubernetes のログレベルの変更
OVN-Kubernetes のデフォルトのログレベルは 2 です。OVN-Kubernetes をデバッグするには、ログレベルを 5 に設定します。次の手順に従って OVN-Kubernetes のログレベルを上げることで、問題のデバッグに役立てることができます。
前提条件
-
cluster-admin権限でクラスターにアクセスできる。 - OpenShift Container Platform Web コンソールにアクセスできる。
手順
次のコマンドを実行して、OVN-Kubernetes プロジェクト内のすべての Pod の詳細情報を取得します。
$ oc get po -o wide -n openshift-ovn-kubernetes
出力例
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES ovnkube-master-84nc9 6/6 Running 0 50m 10.0.134.156 ip-10-0-134-156.ec2.internal <none> <none> ovnkube-master-gmlqv 6/6 Running 0 50m 10.0.209.180 ip-10-0-209-180.ec2.internal <none> <none> ovnkube-master-nhts2 6/6 Running 1 (48m ago) 50m 10.0.147.31 ip-10-0-147-31.ec2.internal <none> <none> ovnkube-node-2cbh8 5/5 Running 0 43m 10.0.217.114 ip-10-0-217-114.ec2.internal <none> <none> ovnkube-node-6fvzl 5/5 Running 0 50m 10.0.147.31 ip-10-0-147-31.ec2.internal <none> <none> ovnkube-node-f4lzz 5/5 Running 0 24m 10.0.146.76 ip-10-0-146-76.ec2.internal <none> <none> ovnkube-node-jf67d 5/5 Running 0 50m 10.0.209.180 ip-10-0-209-180.ec2.internal <none> <none> ovnkube-node-np9mf 5/5 Running 0 40m 10.0.165.191 ip-10-0-165-191.ec2.internal <none> <none> ovnkube-node-qjldg 5/5 Running 0 50m 10.0.134.156 ip-10-0-134-156.ec2.internal <none> <none>
次の例のような
ConfigMapファイルを作成し、env-overrides.yamlなどのファイル名を使用します。ConfigMapファイルの例kind: ConfigMap apiVersion: v1 metadata: name: env-overrides namespace: openshift-ovn-kubernetes data: ip-10-0-217-114.ec2.internal: | 1 # This sets the log level for the ovn-kubernetes node process: OVN_KUBE_LOG_LEVEL=5 # You might also/instead want to enable debug logging for ovn-controller: OVN_LOG_LEVEL=dbg ip-10-0-209-180.ec2.internal: | # This sets the log level for the ovn-kubernetes node process: OVN_KUBE_LOG_LEVEL=5 # You might also/instead want to enable debug logging for ovn-controller: OVN_LOG_LEVEL=dbg _master: | 2 # This sets the log level for the ovn-kubernetes master process as well as the ovn-dbchecker: OVN_KUBE_LOG_LEVEL=5 # You might also/instead want to enable debug logging for northd, nbdb and sbdb on all masters: OVN_LOG_LEVEL=dbg
次のコマンドを使用して、
ConfigMapファイルを適用します。$ oc apply -n openshift-ovn-kubernetes -f env-overrides.yaml
出力例
configmap/env-overrides.yaml created
次のコマンドを使用して
ovnkubePod を再起動し、新しいログレベルを適用します。$ oc delete pod -n openshift-ovn-kubernetes \ --field-selector spec.nodeName=ip-10-0-217-114.ec2.internal -l app=ovnkube-node
$ oc delete pod -n openshift-ovn-kubernetes \ --field-selector spec.nodeName=ip-10-0-209-180.ec2.internal -l app=ovnkube-node
$ oc delete pod -n openshift-ovn-kubernetes -l app=ovnkube-master
27.3.6. OVN-Kubernetes Pod ネットワーク接続のチェック
OpenShift Container Platform 4.10 以降の接続チェックコントローラーは、クラスター内の接続検証チェックをオーケストレーションします。これには、Kubernetes API、OpenShift API、および個々のノードが含まれます。接続テストの結果は、openshift-network-diagnostics namespace の PodNetworkConnectivity オブジェクトに保存されます。接続テストは、1 分ごとに並行して実行されます。
前提条件
-
OpenShift CLI (
oc) へのアクセスがある。 -
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
jqがインストールされている。
手順
現在の
PodNetworkConnectivityCheckオブジェクトをリスト表示するには、以下のコマンドを入力します。$ oc get podnetworkconnectivitychecks -n openshift-network-diagnostics
次のコマンドを使用して、各接続オブジェクトの最新の成功を表示します。
$ oc get podnetworkconnectivitychecks -n openshift-network-diagnostics \ -o json | jq '.items[]| .spec.targetEndpoint,.status.successes[0]'
次のコマンドを使用して、各接続オブジェクトの最新のエラーを表示します。
$ oc get podnetworkconnectivitychecks -n openshift-network-diagnostics \ -o json | jq '.items[]| .spec.targetEndpoint,.status.failures[0]'
次のコマンドを使用して、各接続オブジェクトの最新の停止を表示します。
$ oc get podnetworkconnectivitychecks -n openshift-network-diagnostics \ -o json | jq '.items[]| .spec.targetEndpoint,.status.outages[0]'
接続チェックコントローラーは、これらのチェックからのメトリクスも Prometheus に記録します。
次のコマンドを実行して、すべてのメトリクスを表示します。
$ oc exec prometheus-k8s-0 -n openshift-monitoring -- \ promtool query instant http://localhost:9090 \ '{component="openshift-network-diagnostics"}'過去 5 分間のソース Pod と openshift api サービス間のレイテンシーを表示します。
$ oc exec prometheus-k8s-0 -n openshift-monitoring -- \ promtool query instant http://localhost:9090 \ '{component="openshift-network-diagnostics"}'
27.3.7. 関連情報
27.4. ovnkube-trace を使用した Openflow のトレース
OVN と OVS のトラフィックフローは、ovnkube-trace という単一のユーティリティーでシミュレートできます。ovnkube-trace ユーティリティーは、ovn-trace、ovs-appctl ofproto/trace、および ovn-detrace を実行し、その情報を 1 つの出力に関連付けます。
専用コンテナーから ovnkube-trace バイナリーを実行できます。OpenShift Container Platform 4.7 以降のリリースでは、バイナリーをローカルホストにコピーして、そのホストから実行することもできます。
現在、Quay イメージのバイナリーは、デュアル IP スタックまたは IPv6 のみの環境では機能しません。これらの環境では、ソースからビルドする必要があります。
27.4.1. ローカルホストへの ovnkube-trace のインストール
ovnkube-trace ツールは、OVN-Kubernetes で動作する OpenShift Container Platform クラスター内のポイント間における任意の UDP または TCP トラフィックのパケットシミュレーションをトレースします。ovnkube-trace バイナリーをローカルホストにコピーして、クラスターに対して実行できるようにします。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインしている。
手順
次のコマンドを使用して Pod 変数を作成します。
$ POD=$(oc get pods -n openshift-ovn-kubernetes -l app=ovnkube-master -o name | head -1 | awk -F '/' '{print $NF}')ローカルホストで次のコマンドを実行して、
ovnkube-masterPod からバイナリーをコピーします。$ oc cp -n openshift-ovn-kubernetes $POD:/usr/bin/ovnkube-trace ovnkube-trace
次のコマンドを実行して、
ovnkube-traceを実行可能にします。$ chmod +x ovnkube-trace
次のコマンドを実行して、
ovnkube-traceで使用可能なオプションを表示します。$ ./ovnkube-trace -help
予想される出力
I0111 15:05:27.973305 204872 ovs.go:90] Maximum command line arguments set to: 191102 Usage of ./ovnkube-trace: -dst string dest: destination pod name -dst-ip string destination IP address (meant for tests to external targets) -dst-namespace string k8s namespace of dest pod (default "default") -dst-port string dst-port: destination port (default "80") -kubeconfig string absolute path to the kubeconfig file -loglevel string loglevel: klog level (default "0") -ovn-config-namespace string namespace used by ovn-config itself -service string service: destination service name -skip-detrace skip ovn-detrace command -src string src: source pod name -src-namespace string k8s namespace of source pod (default "default") -tcp use tcp transport protocol -udp use udp transport protocolサポートされているコマンドライン引数は、namespace、Pod、サービスなど、よく知られた Kubernetes コンストラクトであるため、MAC アドレス、宛先ノードの IP アドレス、または ICMP タイプを見つける必要はありません。
ログレベルは次のとおりです。
- 0 (最小出力)
- 2 (トレースコマンドの結果を示すより詳細な出力)
- 5 (デバッグ出力)
27.4.2. ovnkube-trace の実行
ovn-trace を実行して、OVN 論理ネットワーク内のパケット転送をシミュレートします。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインしている。 -
ローカルホストに
ovnkube-traceがインストールされている。
例: デプロイされた Pod からの DNS 解決が機能することをテストする
この例は、デプロイされた Pod からクラスターで実行されるコア DNS Pod への DNS 解決をテストする方法を示しています。
手順
次のコマンドを入力して、default namespace で Web サービスを開始します。
$ oc run web --namespace=default --image=nginx --labels="app=web" --expose --port=80
openshift-dnsnamespace で実行されている Pod を一覧表示します。oc get pods -n openshift-dns
出力例
NAME READY STATUS RESTARTS AGE dns-default-467qw 2/2 Running 0 49m dns-default-6prvx 2/2 Running 0 53m dns-default-fkqr8 2/2 Running 0 53m dns-default-qv2rg 2/2 Running 0 49m dns-default-s29vr 2/2 Running 0 49m dns-default-vdsbn 2/2 Running 0 53m node-resolver-6thtt 1/1 Running 0 53m node-resolver-7ksdn 1/1 Running 0 49m node-resolver-8sthh 1/1 Running 0 53m node-resolver-c5ksw 1/1 Running 0 50m node-resolver-gbvdp 1/1 Running 0 53m node-resolver-sxhkd 1/1 Running 0 50m
次の
ovn-kube-traceコマンドを実行して、DNS 解決が機能していることを確認します。$ ./ovnkube-trace \ -src-namespace default \ 1 -src web \ 2 -dst-namespace openshift-dns \ 3 -dst dns-default-467qw \ 4 -udp -dst-port 53 \ 5 -loglevel 0 6
予想される出力
I0116 10:19:35.601303 17900 ovs.go:90] Maximum command line arguments set to: 191102 ovn-trace source pod to destination pod indicates success from web to dns-default-467qw ovn-trace destination pod to source pod indicates success from dns-default-467qw to web ovs-appctl ofproto/trace source pod to destination pod indicates success from web to dns-default-467qw ovs-appctl ofproto/trace destination pod to source pod indicates success from dns-default-467qw to web ovn-detrace source pod to destination pod indicates success from web to dns-default-467qw ovn-detrace destination pod to source pod indicates success from dns-default-467qw to web
この出力は、デプロイされた Pod から DNS ポートへの解決が成功し、その反対方向への解決も成功したことを示しています。つまり、Web Pod がコア DNS からの DNS 解決を行う場合に、UDP ポート 53 で双方向のトラフィックがサポートされていることがわかります。
たとえば、これが機能せず、ovn-trace、ovs-appctl ofproto/trace と ovn-detrace、およびその他のデバッグタイプ情報を取得する場合は、ログレベルを 2 に上げて、次のようにコマンドを再度実行します。
$ ./ovnkube-trace \ -src-namespace default \ -src web \ -dst-namespace openshift-dns \ -dst dns-default-467qw \ -udp -dst-port 53 \ -loglevel 2
このログレベルの出力は多すぎるため、ここにはリストできません。障害状況では、このコマンドの出力は、どのフローがそのトラフィックを破棄しているかを示します。たとえば、egress または ingress ネットワークポリシーが、そのトラフィックを許可しないクラスターで設定されている場合などがあります。
例: デバッグ出力を使用して設定済みのデフォルトの拒否を確認する
この例は、デバッグ出力を使用して、デフォルトのingress 拒否ポリシーがトラフィックをブロックしていることを特定する方法を示しています。
手順
すべての namespace におけるすべての Pod からの ingress を拒否する
deny-by-defaultポリシーを定義する次の YAML を作成します。YAML をdeny-by-default.yamlファイルに保存します。kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: deny-by-default namespace: default spec: podSelector: {} ingress: []次のコマンドを入力して、ポリシーを適用します。
$ oc apply -f deny-by-default.yaml
出力例
networkpolicy.networking.k8s.io/deny-by-default created
次のコマンドを入力して、
defaultnamespace で Web サービスを開始します。$ oc run web --namespace=default --image=nginx --labels="app=web" --expose --port=80
次のコマンドを実行して、
prodnamespace を作成します。$ oc create namespace prod
次のコマンドを実行して、
prodnamespace にラベルを付けます。$ oc label namespace/prod purpose=production
次のコマンドを実行して、
alpineイメージをprodnamespace にデプロイし、シェルを開始します。$ oc run test-6459 --namespace=prod --rm -i -t --image=alpine -- sh
- 別のターミナルセッションを開きます。
この新しいターミナルセッションで
ovn-traceを実行して、namespaceprodで実行されているソース Podtest-6459とdefaultnamespace で実行されている宛先 Pod 間の通信の失敗を確認します。$ ./ovnkube-trace \ -src-namespace prod \ -src test-6459 \ -dst-namespace default \ -dst web \ -tcp -dst-port 80 \ -loglevel 0
予想される出力
I0116 14:20:47.380775 50822 ovs.go:90] Maximum command line arguments set to: 191102 ovn-trace source pod to destination pod indicates failure from test-6459 to web
次のコマンドを実行して、ログレベルを 2 に上げて、失敗の理由を明らかにします。
$ ./ovnkube-trace \ -src-namespace prod \ -src test-6459 \ -dst-namespace default \ -dst web \ -tcp -dst-port 80 \ -loglevel 2
予想される出力
ct_lb_mark /* default (use --ct to customize) */ ------------------------------------------------ 3. ls_out_acl_hint (northd.c:6092): !ct.new && ct.est && !ct.rpl && ct_mark.blocked == 0, priority 4, uuid 32d45ad4 reg0[8] = 1; reg0[10] = 1; next; 4. ls_out_acl (northd.c:6435): reg0[10] == 1 && (outport == @a16982411286042166782_ingressDefaultDeny), priority 2000, uuid f730a887 1 ct_commit { ct_mark.blocked = 1; };- 1
- デフォルトの拒否ポリシーが設定されているため、ingress トラフィックがブロックされています。
ラベルが
purpose=productionの特定の namespace 内にあるすべての Pod からのトラフィックを許可するポリシーを作成します。YAML をweb-allow-prod.yamlファイルに保存します。kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: web-allow-prod namespace: default spec: podSelector: matchLabels: app: web policyTypes: - Ingress ingress: - from: - namespaceSelector: matchLabels: purpose: production次のコマンドを入力して、ポリシーを適用します。
$ oc apply -f web-allow-prod.yaml
次のコマンドを入力して、
ovnkube-traceを実行し、トラフィックが許可されていることを確認します。$ ./ovnkube-trace \ -src-namespace prod \ -src test-6459 \ -dst-namespace default \ -dst web \ -tcp -dst-port 80 \ -loglevel 0
予想される出力
I0116 14:25:44.055207 51695 ovs.go:90] Maximum command line arguments set to: 191102 ovn-trace source pod to destination pod indicates success from test-6459 to web ovn-trace destination pod to source pod indicates success from web to test-6459 ovs-appctl ofproto/trace source pod to destination pod indicates success from test-6459 to web ovs-appctl ofproto/trace destination pod to source pod indicates success from web to test-6459 ovn-detrace source pod to destination pod indicates success from test-6459 to web ovn-detrace destination pod to source pod indicates success from web to test-6459
開いているシェルで次のコマンドを実行します。
wget -qO- --timeout=2 http://web.default
予想される出力
<!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> html { color-scheme: light dark; } body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html>
27.4.3. 関連情報
27.5. OpenShift SDN ネットワークプラグインからの移行
クラスター管理者は、OpenShift SDN ネットワークプラグインから OVN-Kubernetes ネットワークプラグインに移行できます。
OVN-Kubernetes の詳細は、OVN-Kubernetes ネットワークプラグインについて を参照してください。
27.5.1. OVN-Kubernetes ネットワークプラグインへの移行
OVN-Kubernetes ネットワークプラグインへの移行は、クラスターに到達できないダウンタイムを含む手動プロセスです。ロールバック手順が提供されますが、移行は一方向プロセスとなることが意図されています。
OVN-Kubernetes ネットワークプラグインへの移行は、次のプラットフォームでサポートされています。
- ベアメタルハードウェア
- Amazon Web Services (AWS)
- Google Cloud Platform (GCP)
- IBM Cloud
- Microsoft Azure
- Red Hat OpenStack Platform (RHOSP)
- Red Hat Virtualization (RHV)
- VMware vSphere
OVN-Kubernetes ネットワークプラグインとの間の移行は、Red Hat OpenShift Dedicated、Azure Red Hat OpenShift (ARO)、Red Hat OpenShift Service on AWS (ROSA) などのマネージド OpenShift クラウドサービスではサポートされていません。
OpenShift SDN ネットワークプラグインから OVN-Kubernetes ネットワークプラグインへの移行は、Nutanix ではサポートされていません。
27.5.1.1. OVN-Kubernetes ネットワークプラグインへの移行についての考慮点
OpenShift Container Platform クラスターに 150 を超えるノードがある場合は、OVN-Kubernetes ネットワークプラグインへの移行について相談するサポートケースを開きます。
ノードに割り当てられたサブネット、および個々の Pod に割り当てられた IP アドレスは、移行時に保持されません。
OVN-Kubernetes ネットワークプラグインは、OpenShift SDN ネットワークプラグインに存在する多くの機能を実装していますが、設定は同じではありません。
クラスターが次の OpenShift SDN ネットワークプラグイン機能のいずれかを使用する場合、OVN-Kubernetes ネットワークプラグインで同じ機能を手動で設定する必要があります。
- namespace の分離
- Egress ルーター Pod
-
クラスターまたは周囲のネットワークが
100.64.0.0/16アドレス範囲の一部を使用している場合、spec.defaultNetwork.ovnKubernetesConfigオブジェクト定義でv4InternalSubnet仕様を指定して、別の未使用の IP 範囲を選択する必要があります。OVN-Kubernetes は、デフォルトで IP 範囲100.64.0.0/16を内部的に使用します。
以下のセクションでは、OVN-Kubernetes と OpenShift SDN ネットワークプラグインの前述の機能の設定の違いを強調しています。
namespace の分離
OVN-Kubernetes はネットワークポリシーの分離モードのみをサポートします。
クラスターがマルチテナントまたはサブネットの分離モードのいずれかで設定された OpenShift SDN を使用する場合、OVN-Kubernetes ネットワークプラグインに移行することはできません。
Egress IP アドレス
OpenShift SDN は、2 つの異なる Egress IP モードをサポートしています。
- 自動的に割り当てる 方法では、egress IP アドレス範囲はノードに割り当てられます。
- 手動で割り当てる 方法では、1 つ以上の Egress IP アドレスの一覧がノードに割り当てられます。
移行プロセスでは、自動割り当てモードを使用する Egress IP 設定の移行がサポートされています。
OVN-Kubernetes と OpenShift SDN との間に egress IP アドレスを設定する際の相違点は、以下の表で説明されています。
表27.4 egress IP アドレス設定の違い
| OVN-Kubernetes | OpenShift SDN |
|---|---|
|
|
OVN-Kubernetes で egress IP アドレスを使用する方法についての詳細は、egress IP アドレスの設定について参照してください。
Egress ネットワークポリシー
OVN-Kubernetes と OpenShift SDN との間に egress ファイアウォールとしても知られる egress ネットワークポリシーの設定についての相違点は、以下の表に記載されています。
表27.5 egress ネットワークポリシー設定の相違点
| OVN-Kubernetes | OpenShift SDN |
|---|---|
|
|
EgressFirewall オブジェクトの名前は default にしか設定できないため、移行後は、OpenShift SDN での名前に関係なく、移行されたすべての EgressNetworkPolicy オブジェクトに default という名前が付けられます。
その後、OpenShift SDN にロールバックすると、以前の名前が失われるため、すべての EgressNetworkPolicy オブジェクトに default という名前が付けられます。
OVN-Kubernetes で egress ファイアウォールを使用する方法についての詳細は、プロジェクトの egress ファイアウォールの設定について参照してください。
Egress ルーター Pod
OVN-Kubernetes は、リダイレクトモードで Egress ルーター Pod をサポートします。OVN-Kubernetes は、HTTP プロキシーモードまたは DNS プロキシーモードでは Egress ルーター Pod をサポートしません。
Cluster Network Operator で Egress ルーターをデプロイする場合、ノードセレクターを指定して、Egress ルーター Pod のホストに使用するノードを制御することはできません。
マルチキャスト
OVN-Kubernetes と OpenShift SDN でマルチキャストトラフィックを有効にする方法についての相違点は、以下の表で説明されています。
表27.6 マルチキャスト設定の相違点
| OVN-Kubernetes | OpenShift SDN |
|---|---|
|
|
OVN-Kubernetes でのマルチキャストの使用についての詳細は、プロジェクトのマルチキャストの有効化を参照してください。
ネットワークポリシー
OVN-Kubernetes は、networking.k8s.io/v1 API グループで Kubernetes NetworkPolicy API を完全にサポートします。OpenShift SDN から移行する際に、ネットワークポリシーで変更を加える必要はありません。
27.5.1.2. 移行プロセスの仕組み
以下の表は、プロセスのユーザーが開始する手順と、移行が応答として実行するアクション間を区分して移行プロセスを要約しています。
表27.7 OpenShift SDN から OVN-Kubernetes への移行
| ユーザーが開始する手順 | 移行アクティビティー |
|---|---|
|
|
|
|
|
|
| クラスターの各ノードを再起動します。 |
|
OpenShift SDN へのロールバックが必要な場合、以下の表がプロセスについて説明します。
表27.8 OpenShift SDN へのロールバックの実行
| ユーザーが開始する手順 | 移行アクティビティー |
|---|---|
| MCO を一時停止し、移行が中断されないようにします。 | MCO が停止します。 |
|
|
|
|
|
|
| クラスターの各ノードを再起動します。 |
|
| クラスターのすべてのノードが再起動した後に MCO を有効にします。 |
|
27.5.2. OVN-Kubernetes ネットワークプラグインへの移行
クラスター管理者は、クラスターのネットワークプラグインを OVN-Kubernetes に変更できます。移行時に、クラスター内のすべてのノードを再起動する必要があります。
移行の実行中はクラスターを利用できず、ワークロードが中断される可能性があります。サービスの中断が許容可能な場合にのみ移行を実行します。
前提条件
- ネットワークポリシー分離モードの OpenShift SDN CNI ネットワークプラグインで設定されたクラスター。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 - etcd データベースの最新のバックアップが利用可能である。
- 再起動は、ノードごとに手動でトリガーできます。
- クラスターは既知の正常な状態にあり、エラーがないこと。
-
ソフトウェア更新後のクラウドプラットフォームでは、すべてのノードに対してポート
6081で UDP パケットを許可するセキュリティーグループルールを設定する必要があります。
手順
クラスターネットワークの設定のバックアップを作成するには、以下のコマンドを入力します。
$ oc get Network.config.openshift.io cluster -o yaml > cluster-openshift-sdn.yaml
移行のすべてのノードを準備するには、以下のコマンドを入力して Cluster Network Operator 設定オブジェクトに
migrationフィールドを設定します。$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "migration": { "networkType": "OVNKubernetes" } } }'注記この手順では、OVN-Kubernetes はすぐにデプロイしません。その代わりに、
migrationフィールドを指定すると、新規マシン設定が OVN-Kubernetes デプロイメントの準備に向けてクラスター内のすべてのノードに適用されるように Machine Config Operator (MCO) がトリガーされます。オプション: いくつかの OpenShift SDN 機能の OVN-Kubernetes 同等機能への自動移行を無効にすることができます。
- Egress IP
- Egress ファイアウォール
- マルチキャスト
前述の OpenShift SDN 機能の設定の自動移行を無効にするには、次のキーを指定します。
$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "migration": { "networkType": "OVNKubernetes", "features": { "egressIP": <bool>, "egressFirewall": <bool>, "multicast": <bool> } } } }'ここでは、以下のようになります。
bool: 機能の移行を有効にするかどうかを指定します。デフォルトはtrueです。オプション: ネットワークインフラストラクチャーの要件を満たすように OVN-Kubernetes の以下の設定をカスタマイズできます。
最大伝送単位 (MTU)。このオプションの手順で MTU をカスタマイズする前に、以下を考慮してください。
- デフォルトの MTU を使用しており、移行中にデフォルトの MTU を維持したい場合は、この手順を無視できます。
- カスタム MTU を使用しており、移行中にカスタム MTU を維持する必要がある場合は、この手順でカスタム MTU 値を宣言する必要があります。
移行中に MTU 値を変更する場合、この手順は機能しません。代わりに、まず「クラスター MTU の変更」に記載された指示に従う必要があります。その後、この手順を実行してカスタム MTU 値を宣言すると、カスタム MTU 値を維持できます。
注記OpenShift-SDN と OVN-Kubernetes のオーバーレイオーバーヘッドは異なります。MTU 値は、「MTU 値の選択」ページにあるガイドラインに従って選択する必要があります。
- Geneve (Generic Network Virtualization Encapsulation) オーバーレイネットワークポート
- OVN-Kubernetes IPv4 内部サブネット
- OVN-Kubernetes IPv6 内部サブネット
以前の設定のいずれかをカスタマイズするには、以下のコマンドを入力してカスタマイズします。デフォルト値を変更する必要がない場合は、パッチのキーを省略します。
$ oc patch Network.operator.openshift.io cluster --type=merge \ --patch '{ "spec":{ "defaultNetwork":{ "ovnKubernetesConfig":{ "mtu":<mtu>, "genevePort":<port>, "v4InternalSubnet":"<ipv4_subnet>", "v6InternalSubnet":"<ipv6_subnet>" }}}}'ここでは、以下のようになります。
mtu-
Geneve オーバーレイネットワークの MTU。この値は通常は自動的に設定されますが、クラスターにあるノードすべてが同じ MTU を使用しない場合、これを最小のノード MTU 値よりも
100小さく設定する必要があります。 port-
Geneve オーバーレイネットワークの UDP ポート。値が指定されない場合、デフォルトは
6081になります。ポートは、OpenShift SDN で使用される VXLAN ポートと同じにすることはできません。VXLAN ポートのデフォルト値は4789です。 ipv4_subnet-
OVN-Kubernetes による内部使用のための IPv4 アドレス範囲。IP アドレス範囲が、OpenShift Container Platform インストールで使用される他のサブネットと重複しないようにする必要があります。IP アドレス範囲は、クラスターに追加できるノードの最大数より大きくする必要があります。デフォルト値は
100.64.0.0/16です。 ipv6_subnet-
OVN-Kubernetes による内部使用のための IPv6 アドレス範囲。IP アドレス範囲が、OpenShift Container Platform インストールで使用される他のサブネットと重複しないようにする必要があります。IP アドレス範囲は、クラスターに追加できるノードの最大数より大きくする必要があります。デフォルト値は
fd98::/48です。
mtuフィールドを更新するパッチコマンドの例$ oc patch Network.operator.openshift.io cluster --type=merge \ --patch '{ "spec":{ "defaultNetwork":{ "ovnKubernetesConfig":{ "mtu":1200 }}}}'MCO がそれぞれのマシン設定プールのマシンを更新すると、各ノードが 1 つずつ再起動します。すべてのノードが更新されるまで待機する必要があります。以下のコマンドを実行してマシン設定プールのステータスを確認します。
$ oc get mcp
正常に更新されたノードには、
UPDATED=true、UPDATING=false、DEGRADED=falseのステータスがあります。注記デフォルトで、MCO はプールごとに一度に 1 つのマシンを更新するため、移行にかかる合計時間がクラスターのサイズと共に増加します。
ホスト上の新規マシン設定のステータスを確認します。
マシン設定の状態と適用されたマシン設定の名前をリスト表示するには、以下のコマンドを入力します。
$ oc describe node | egrep "hostname|machineconfig"
出力例
kubernetes.io/hostname=master-0 machineconfiguration.openshift.io/currentConfig: rendered-master-c53e221d9d24e1c8bb6ee89dd3d8ad7b machineconfiguration.openshift.io/desiredConfig: rendered-master-c53e221d9d24e1c8bb6ee89dd3d8ad7b machineconfiguration.openshift.io/reason: machineconfiguration.openshift.io/state: Done
以下のステートメントが true であることを確認します。
-
machineconfiguration.openshift.io/stateフィールドの値はDoneです。 -
machineconfiguration.openshift.io/currentConfigフィールドの値は、machineconfiguration.openshift.io/desiredConfigフィールドの値と等しくなります。
-
マシン設定が正しいことを確認するには、以下のコマンドを入力します。
$ oc get machineconfig <config_name> -o yaml | grep ExecStart
<config_name>はmachineconfiguration.openshift.io/currentConfigフィールドのマシン設定の名前です。マシン設定には、systemd 設定に以下の更新を含める必要があります。
ExecStart=/usr/local/bin/configure-ovs.sh OVNKubernetes
ノードが
NotReady状態のままになっている場合、マシン設定デーモン Pod のログを調べ、エラーを解決します。Pod をリスト表示するには、以下のコマンドを入力します。
$ oc get pod -n openshift-machine-config-operator
出力例
NAME READY STATUS RESTARTS AGE machine-config-controller-75f756f89d-sjp8b 1/1 Running 0 37m machine-config-daemon-5cf4b 2/2 Running 0 43h machine-config-daemon-7wzcd 2/2 Running 0 43h machine-config-daemon-fc946 2/2 Running 0 43h machine-config-daemon-g2v28 2/2 Running 0 43h machine-config-daemon-gcl4f 2/2 Running 0 43h machine-config-daemon-l5tnv 2/2 Running 0 43h machine-config-operator-79d9c55d5-hth92 1/1 Running 0 37m machine-config-server-bsc8h 1/1 Running 0 43h machine-config-server-hklrm 1/1 Running 0 43h machine-config-server-k9rtx 1/1 Running 0 43h
設定デーモン Pod の名前は以下の形式になります。
machine-config-daemon-<seq><seq>値は、ランダムな 5 文字の英数字シーケンスになります。以下のコマンドを入力して、直前の出力に表示される最初のマシン設定デーモン Pod の Pod ログを表示します。
$ oc logs <pod> -n openshift-machine-config-operator
ここで、
podはマシン設定デーモン Pod の名前になります。- 直前のコマンドの出力で示されるログ内のエラーを解決します。
移行を開始するには、次のいずれかのコマンドを使用して OVN-Kubernetes ネットワークプラグインを設定します。
クラスターネットワークの IP アドレスブロックを変更せずにネットワークプロバイダーを指定するには、以下のコマンドを入力します。
$ oc patch Network.config.openshift.io cluster \ --type='merge' --patch '{ "spec": { "networkType": "OVNKubernetes" } }'別のクラスターネットワーク IP アドレスブロックを指定するには、以下のコマンドを入力します。
$ oc patch Network.config.openshift.io cluster \ --type='merge' --patch '{ "spec": { "clusterNetwork": [ { "cidr": "<cidr>", "hostPrefix": <prefix> } ], "networkType": "OVNKubernetes" } }'ここで、
cidrは CIDR ブロックであり、prefixはクラスター内の各ノードに割り当てられる CIDR ブロックのスライスです。OVN-Kubernetes ネットワークプロバイダーはこのブロックを内部で使用するため、100.64.0.0/16CIDR ブロックと重複する CIDR ブロックは使用できません。重要移行時に、サービスネットワークのアドレスブロックを変更することはできません。
Multus デーモンセットのロールアウトが完了したことを確認してから、後続の手順を続行します。
$ oc -n openshift-multus rollout status daemonset/multus
Multus Pod の名前の形式は
multus-<xxxxx>です。ここで、<xxxxx>は文字のランダムなシーケンスになります。Pod が再起動するまでにしばらく時間がかかる可能性があります。出力例
Waiting for daemon set "multus" rollout to finish: 1 out of 6 new pods have been updated... ... Waiting for daemon set "multus" rollout to finish: 5 of 6 updated pods are available... daemon set "multus" successfully rolled out
ネットワークプラグインの変更を完了するには、クラスター内の各ノードを再起動します。次のいずれかの方法で、クラスター内のノードを再起動できます。
oc rshコマンドでは、次のような bash スクリプトを使用できます。#!/bin/bash readarray -t POD_NODES <<< "$(oc get pod -n openshift-machine-config-operator -o wide| grep daemon|awk '{print $1" "$7}')" for i in "${POD_NODES[@]}" do read -r POD NODE <<< "$i" until oc rsh -n openshift-machine-config-operator "$POD" chroot /rootfs shutdown -r +1 do echo "cannot reboot node $NODE, retry" && sleep 3 done donesshコマンドでは、次のような bash スクリプトを使用できます。このスクリプトは、パスワードの入力を求めないように sudo が設定されていることを前提としています。#!/bin/bash for ip in $(oc get nodes -o jsonpath='{.items[*].status.addresses[?(@.type=="InternalIP")].address}') do echo "reboot node $ip" ssh -o StrictHostKeyChecking=no core@$ip sudo shutdown -r -t 3 done
移行が正常に完了したことを確認します。
ネットワークプラグインが OVN-Kubernetes であることを確認するには、次のコマンドを入力します。
status.networkTypeの値はOVNKubernetesである必要があります。$ oc get network.config/cluster -o jsonpath='{.status.networkType}{"\n"}'クラスターノードが
Ready状態にあることを確認するには、以下のコマンドを実行します。$ oc get nodes
Pod がエラー状態ではないことを確認するには、以下のコマンドを入力します。
$ oc get pods --all-namespaces -o wide --sort-by='{.spec.nodeName}'ノードの Pod がエラー状態にある場合は、そのノードを再起動します。
すべてのクラスター Operator が異常な状態にないことを確認するには、以下のコマンドを入力します。
$ oc get co
すべてのクラスター Operator のステータスは、
AVAILABLE="True"、PROGRESSING="False"、DEGRADED="False"になります。クラスター Operator が利用できないか、そのパフォーマンスが低下する場合には、クラスター Operator のログで詳細を確認します。
以下の手順は、移行に成功し、クラスターの状態が正常である場合にのみ実行します。
CNO 設定オブジェクトから移行設定を削除するには、以下のコマンドを入力します。
$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "migration": null } }'OpenShift SDN ネットワークプロバイダーのカスタム設定を削除するには、以下のコマンドを入力します。
$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "defaultNetwork": { "openshiftSDNConfig": null } } }'OpenShift SDN ネットワークプロバイダー namespace を削除するには、以下のコマンドを入力します。
$ oc delete namespace openshift-sdn
27.5.3. 関連情報
27.6. OpenShift SDN ネットワークプロバイダーへのロールバック
クラスター管理者は、OVN-Kubernetes への移行が失敗した場合に、OVN-Kubernetes ネットワークプラグインから OpenShift SDN ネットワークプラグインにロールバックできます。
27.6.1. OpenShift SDN ネットワークプラグインへの移行
クラスター管理者は、OpenShift SDN Container Network Interface (CNI) ネットワークプラグインに移行できます。移行中は、クラスター内のすべてのノードを再起動する必要があります。
OVN-Kubernetes への移行に失敗した場合に限り、OpenShift SDN にロールバックします。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 - インフラストラクチャーにインストールされたクラスターが OVN-Kubernetes ネットワークプラグインで設定されている。
- etcd データベースの最新のバックアップが利用可能である。
- 再起動は、ノードごとに手動でトリガーできます。
- クラスターは既知の正常な状態にあり、エラーがないこと。
手順
Machine Config Operator (MCO) によって管理されるすべてのマシン設定プールを停止します。
マスター設定プールを停止します。
$ oc patch MachineConfigPool master --type='merge' --patch \ '{ "spec": { "paused": true } }'ワーカーマシン設定プールを停止します。
$ oc patch MachineConfigPool worker --type='merge' --patch \ '{ "spec":{ "paused": true } }'
移行の準備をするには、次のコマンドを入力して移行フィールドを
nullに設定します。$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "migration": null } }'移行を開始するには、次のコマンドを入力して、ネットワークプラグインを OpenShift SDN に戻します。
$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "migration": { "networkType": "OpenShiftSDN" } } }' $ oc patch Network.config.openshift.io cluster --type='merge' \ --patch '{ "spec": { "networkType": "OpenShiftSDN" } }'オプション: いくつかの OVN-Kubernetes 機能の OpenShift SDN 同等機能への自動移行を無効にすることができます。
- Egress IP
- Egress ファイアウォール
- マルチキャスト
前述の OpenShift SDN 機能の設定の自動移行を無効にするには、次のキーを指定します。
$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "migration": { "networkType": "OpenShiftSDN", "features": { "egressIP": <bool>, "egressFirewall": <bool>, "multicast": <bool> } } } }'ここでは、以下のようになります。
bool: 機能の移行を有効にするかどうかを指定します。デフォルトはtrueです。オプション: ネットワークインフラストラクチャーの要件を満たすように OpenShift SDN の以下の設定をカスタマイズできます。
- Maximum transmission unit (MTU)
- VXLAN ポート
以前の設定のいずれかを両方をカスタマイズするには、カスタマイズし、以下のコマンドを入力します。デフォルト値を変更する必要がない場合は、パッチのキーを省略します。
$ oc patch Network.operator.openshift.io cluster --type=merge \ --patch '{ "spec":{ "defaultNetwork":{ "openshiftSDNConfig":{ "mtu":<mtu>, "vxlanPort":<port> }}}}'mtu-
VXLAN オーバーレイネットワークの MTU。この値は通常は自動的に設定されますが、クラスターにあるノードすべてが同じ MTU を使用しない場合、これを最小のノード MTU 値よりも
50小さく設定する必要があります。 port-
VXLAN オーバーレイネットワークの UDP ポート。値が指定されない場合は、デフォルトは
4789になります。ポートは OVN-Kubernetes で使用される Geneve ポートと同じにすることはできません。Geneve ポートのデフォルト値は6081です。
patch コマンドの例
$ oc patch Network.operator.openshift.io cluster --type=merge \ --patch '{ "spec":{ "defaultNetwork":{ "openshiftSDNConfig":{ "mtu":1200 }}}}'Multus デーモンセットのロールアウトが完了するまで待機します。
$ oc -n openshift-multus rollout status daemonset/multus
Multus Pod の名前の形式は
multus-<xxxxx>です。ここで、<xxxxx>は文字のランダムなシーケンスになります。Pod が再起動するまでにしばらく時間がかかる可能性があります。出力例
Waiting for daemon set "multus" rollout to finish: 1 out of 6 new pods have been updated... ... Waiting for daemon set "multus" rollout to finish: 5 of 6 updated pods are available... daemon set "multus" successfully rolled out
ネットワークプラグインの変更を完了するには、クラスター内の各ノードを再起動します。次のいずれかの方法で、クラスター内のノードを再起動できます。
oc rshコマンドでは、次のような bash スクリプトを使用できます。#!/bin/bash readarray -t POD_NODES <<< "$(oc get pod -n openshift-machine-config-operator -o wide| grep daemon|awk '{print $1" "$7}')" for i in "${POD_NODES[@]}" do read -r POD NODE <<< "$i" until oc rsh -n openshift-machine-config-operator "$POD" chroot /rootfs shutdown -r +1 do echo "cannot reboot node $NODE, retry" && sleep 3 done donesshコマンドでは、次のような bash スクリプトを使用できます。このスクリプトは、パスワードの入力を求めないように sudo が設定されていることを前提としています。#!/bin/bash for ip in $(oc get nodes -o jsonpath='{.items[*].status.addresses[?(@.type=="InternalIP")].address}') do echo "reboot node $ip" ssh -o StrictHostKeyChecking=no core@$ip sudo shutdown -r -t 3 done
クラスターのノードが再起動したら、すべてのマシン設定プールを起動します。
マスター設定プールを開始します。
$ oc patch MachineConfigPool master --type='merge' --patch \ '{ "spec": { "paused": false } }'ワーカー設定プールを開始します。
$ oc patch MachineConfigPool worker --type='merge' --patch \ '{ "spec": { "paused": false } }'
MCO が各設定プールのマシンを更新すると、各ノードを再起動します。
デフォルトで、MCO は一度にプールごとに単一のマシンを更新するため、移行が完了するまでに必要な時間がクラスターのサイズと共に増加します。
ホスト上の新規マシン設定のステータスを確認します。
マシン設定の状態と適用されたマシン設定の名前をリスト表示するには、以下のコマンドを入力します。
$ oc describe node | egrep "hostname|machineconfig"
出力例
kubernetes.io/hostname=master-0 machineconfiguration.openshift.io/currentConfig: rendered-master-c53e221d9d24e1c8bb6ee89dd3d8ad7b machineconfiguration.openshift.io/desiredConfig: rendered-master-c53e221d9d24e1c8bb6ee89dd3d8ad7b machineconfiguration.openshift.io/reason: machineconfiguration.openshift.io/state: Done
以下のステートメントが true であることを確認します。
-
machineconfiguration.openshift.io/stateフィールドの値はDoneです。 -
machineconfiguration.openshift.io/currentConfigフィールドの値は、machineconfiguration.openshift.io/desiredConfigフィールドの値と等しくなります。
-
マシン設定が正しいことを確認するには、以下のコマンドを入力します。
$ oc get machineconfig <config_name> -o yaml
<config_name>はmachineconfiguration.openshift.io/currentConfigフィールドのマシン設定の名前です。
移行が正常に完了したことを確認します。
ネットワークプラグインが OpenShift SDN であることを確認するには、次のコマンドを入力します。
status.networkTypeの値はOpenShiftSDNである必要があります。$ oc get network.config/cluster -o jsonpath='{.status.networkType}{"\n"}'クラスターノードが
Ready状態にあることを確認するには、以下のコマンドを実行します。$ oc get nodes
ノードが
NotReady状態のままになっている場合、マシン設定デーモン Pod のログを調べ、エラーを解決します。Pod をリスト表示するには、以下のコマンドを入力します。
$ oc get pod -n openshift-machine-config-operator
出力例
NAME READY STATUS RESTARTS AGE machine-config-controller-75f756f89d-sjp8b 1/1 Running 0 37m machine-config-daemon-5cf4b 2/2 Running 0 43h machine-config-daemon-7wzcd 2/2 Running 0 43h machine-config-daemon-fc946 2/2 Running 0 43h machine-config-daemon-g2v28 2/2 Running 0 43h machine-config-daemon-gcl4f 2/2 Running 0 43h machine-config-daemon-l5tnv 2/2 Running 0 43h machine-config-operator-79d9c55d5-hth92 1/1 Running 0 37m machine-config-server-bsc8h 1/1 Running 0 43h machine-config-server-hklrm 1/1 Running 0 43h machine-config-server-k9rtx 1/1 Running 0 43h
設定デーモン Pod の名前は以下の形式になります。
machine-config-daemon-<seq><seq>値は、ランダムな 5 文字の英数字シーケンスになります。直前の出力に表示されるそれぞれのマシン設定デーモン Pod の Pod ログを表示するには、以下のコマンドを入力します。
$ oc logs <pod> -n openshift-machine-config-operator
ここで、
podはマシン設定デーモン Pod の名前になります。- 直前のコマンドの出力で示されるログ内のエラーを解決します。
Pod がエラー状態ではないことを確認するには、以下のコマンドを入力します。
$ oc get pods --all-namespaces -o wide --sort-by='{.spec.nodeName}'ノードの Pod がエラー状態にある場合は、そのノードを再起動します。
以下の手順は、移行に成功し、クラスターの状態が正常である場合にのみ実行します。
Cluster Network Operator 設定オブジェクトから移行設定を削除するには、以下のコマンドを入力します。
$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "migration": null } }'OVN-Kubernetes 設定を削除するには、以下のコマンドを入力します。
$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "defaultNetwork": { "ovnKubernetesConfig":null } } }'OVN-Kubernetes ネットワークプロバイダー namespace を削除するには、以下のコマンドを入力します。
$ oc delete namespace openshift-ovn-kubernetes
27.7. Kuryr ネットワークプラグインから OVN-Kubernetes ネットワークプラグインへの移行
Kuryr から OVN-Kubernetes への移行は、テクノロジープレビュー機能のみです。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
Red Hat OpenStack Platform (RHOSP) 上で実行されるクラスターの管理者は、Kuryr SDN ネットワークプラグインから OVN-Kubernetes ネットワークプラグインに移行できます。
OVN-Kubernetes の詳細は、OVN-Kubernetes ネットワークプラグインについて を参照してください。
27.7.1. OVN-Kubernetes ネットワークプロバイダーへの移行
Red Hat OpenStack Platform (RHOSP) 上で実行されるクラスターを OVN-Kubernetes ネットワークプロバイダーに手動で移行できます。
OVN-Kubernetes への移行は一方向のプロセスです。移行中、クラスターは短時間アクセスできなくなります。
27.7.1.1. OVN-Kubernetes ネットワークプロバイダーへの移行についての考慮点
Kubernetes namespace は、Kuryr によって別の RHOSP ネットワーキングサービス (Neutron) サブネットに保持されます。個々の Pod に割り当てられているサブネットと IP アドレスは、移行中には保持されません。
27.7.1.2. 移行プロセスの仕組み
次の表は、ユーザーが実行する手順とクラスターおよび Operator が実行するアクションを関連付けて、移行プロセスをまとめたものです。
表27.9 Kuryr から OVN-Kubernetes への移行プロセス
| ユーザーが開始する手順 | 移行アクティビティー |
|---|---|
|
|
|
|
|
|
| クラスターの各ノードを再起動します。 |
|
| Kuryr が管理する残りのリソースをクリーンアップします。 |
|
27.7.2. OVN-Kubernetes ネットワークプラグインへの移行
クラスター管理者は、クラスターのネットワークプラグインを OVN-Kubernetes に変更できます。
移行時に、クラスター内のすべてのノードを再起動する必要があります。クラスターが利用できないため、ワークロードが中断される可能性があります。サービスの中断が許容される場合にのみ移行を実行してください。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 - etcd データベースの最新のバックアップが利用可能です。
- 各ノードを手動で再起動できます。
- 移行を計画しているクラスターは、エラーがなく、既知の良好な状態にあります。
- Python インタープリターがインストールされている。
-
openstacksdkPython パッケージがインストールされている。 -
openstackCLI ツールがインストールされています。 - 基盤となる RHOSP クラウドにアクセスできます。
手順
次のコマンドを実行して、クラスターネットワークの設定をバックアップします。
$ oc get Network.config.openshift.io cluster -o yaml > cluster-kuryr.yaml
CLUSTERID変数を設定するには、次のコマンドを実行します。$ CLUSTERID=$(oc get infrastructure.config.openshift.io cluster -o=jsonpath='{.status.infrastructureName}')すべてのノードの移行を準備するには、次のコマンドを実行して、Cluster Network Operator 設定オブジェクトの
migrationフィールドを設定します。$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "migration": { "networkType": "OVNKubernetes" } } }'注記この手順では、OVN-Kubernetes はすぐにデプロイしません。
migrationフィールドを指定すると、新規マシン設定がクラスター内のすべてのノードに適用されるように Machine Config Operator (MCO) がトリガーされます。これにより、OVN-Kubernetes デプロイメント用にクラスターが準備されます。オプション: ネットワークインフラストラクチャー要件に合わせて、OVN-Kubernetes の次の設定をカスタマイズします。
- Maximum transmission unit (MTU)
- Geneve (Generic Network Virtualization Encapsulation) オーバーレイネットワークポート
- OVN-Kubernetes IPv4 内部サブネット
- OVN-Kubernetes IPv6 内部サブネット
これらの設定をカスタマイズするには、次のコマンドを入力してカスタマイズします。
$ oc patch Network.operator.openshift.io cluster --type=merge \ --patch '{ "spec":{ "defaultNetwork":{ "ovnKubernetesConfig":{ "mtu":<mtu>, "genevePort":<port>, "v4InternalSubnet":"<ipv4_subnet>", "v6InternalSubnet":"<ipv6_subnet>" }}}}'ここでは、以下のようになります。
mtu-
Geneve オーバーレイネットワークの MTU を指定します。この値は通常は自動的に設定されますが、クラスターにあるノードすべてが同じ MTU を使用しない場合、これを最小のノード MTU 値よりも
100小さく設定する必要があります。 port-
Geneve オーバーレイネットワークの UDP ポートを指定します。値が指定されない場合、デフォルトは
6081になります。このポートは、Kuryr が使用する VXLAN ポートと同じにすることはできません。VXLAN ポートのデフォルト値は4789です。 ipv4_subnet-
OVN-Kubernetes による内部使用のための IPv4 アドレス範囲を指定します。IP アドレス範囲が、OpenShift Container Platform インストールで使用される他のサブネットと重複しないようにする必要があります。IP アドレス範囲は、クラスターに追加できるノードの最大数より大きくする必要があります。デフォルト値は
100.64.0.0/16です。 ipv6_subnet-
OVN-Kubernetes による内部使用のための IPv6 アドレス範囲を指定します。IP アドレス範囲が、OpenShift Container Platform インストールで使用される他のサブネットと重複しないようにする必要があります。IP アドレス範囲は、クラスターに追加できるノードの最大数より大きくする必要があります。デフォルト値は
fd98::/48です。
デフォルト値を変更する必要がない場合は、パッチのキーを省略します。
mtuフィールドを更新するパッチコマンドの例$ oc patch Network.operator.openshift.io cluster --type=merge \ --patch '{ "spec":{ "defaultNetwork":{ "ovnKubernetesConfig":{ "mtu":1200 }}}}'以下のコマンドを実行してマシン設定プールのステータスを確認します。
$ oc get mcp
MCO は各マシン設定プール内のマシンを更新する際に、各ノードを 1 つずつ再起動します。続行する前に、すべてのノードが更新されるまで待つ必要があります。
正常に更新されたノードには、
UPDATED=true、UPDATING=false、DEGRADED=falseのステータスがあります。注記デフォルトでは、MCO は一度にプールごとに 1 台のマシンを更新します。大規模なクラスターは、小規模なクラスターよりも移行に時間がかかります。
ホスト上の新規マシン設定のステータスを確認します。
マシン設定の状態と適用されたマシン設定の名前をリスト表示するには、以下のコマンドを入力します。
$ oc describe node | egrep "hostname|machineconfig"
出力例
kubernetes.io/hostname=master-0 machineconfiguration.openshift.io/currentConfig: rendered-master-c53e221d9d24e1c8bb6ee89dd3d8ad7b 1 machineconfiguration.openshift.io/desiredConfig: rendered-master-c53e221d9d24e1c8bb6ee89dd3d8ad7b 2 machineconfiguration.openshift.io/reason: machineconfiguration.openshift.io/state: Done
前のステップの出力を確認します。次のステートメントが真である必要があります。
-
machineconfiguration.openshift.io/stateフィールドの値はDoneです。 -
machineconfiguration.openshift.io/currentConfigフィールドの値は、machineconfiguration.openshift.io/desiredConfigフィールドの値と等しくなります。
-
マシン設定が正しいことを確認するには、以下のコマンドを入力します。
$ oc get machineconfig <config_name> -o yaml | grep ExecStart
ここでは、以下のようになります。
- <config_name>
machineconfiguration.openshift.io/currentConfigフィールドからマシン設定の名前を指定します。マシン設定には、systemd 設定に以下の更新を含める必要があります。
出力例
ExecStart=/usr/local/bin/configure-ovs.sh OVNKubernetes
ノードが
NotReady状態でスタックしている場合は、マシン設定デーモン Pod のログを調査し、エラーがあれば解決します。Pod をリスト表示するには、以下のコマンドを入力します。
$ oc get pod -n openshift-machine-config-operator
出力例
NAME READY STATUS RESTARTS AGE machine-config-controller-75f756f89d-sjp8b 1/1 Running 0 37m machine-config-daemon-5cf4b 2/2 Running 0 43h machine-config-daemon-7wzcd 2/2 Running 0 43h machine-config-daemon-fc946 2/2 Running 0 43h machine-config-daemon-g2v28 2/2 Running 0 43h machine-config-daemon-gcl4f 2/2 Running 0 43h machine-config-daemon-l5tnv 2/2 Running 0 43h machine-config-operator-79d9c55d5-hth92 1/1 Running 0 37m machine-config-server-bsc8h 1/1 Running 0 43h machine-config-server-hklrm 1/1 Running 0 43h machine-config-server-k9rtx 1/1 Running 0 43h
設定デーモン Pod の名前は以下の形式になります。
machine-config-daemon-<seq><seq>値は、ランダムな 5 文字の英数字シーケンスになります。以下のコマンドを入力して、直前の出力に表示される最初のマシン設定デーモン Pod の Pod ログを表示します。
$ oc logs <pod> -n openshift-machine-config-operator
ここでは、以下のようになります。
- <pod>
- マシン設定デーモン Pod の名前を指定します。
- 直前のコマンドの出力で示されるログ内のエラーを解決します。
移行を開始するには、次のいずれかのコマンドを使用して OVN-Kubernetes ネットワークプラグインを設定します。
クラスターネットワークの IP アドレスブロックを変更せずにネットワークプロバイダーを指定するには、以下のコマンドを入力します。
$ oc patch Network.config.openshift.io cluster \ --type='merge' --patch '{ "spec": { "networkType": "OVNKubernetes" } }'別のクラスターネットワーク IP アドレスブロックを指定するには、以下のコマンドを入力します。
$ oc patch Network.config.openshift.io cluster \ --type='merge' --patch '{ "spec": { "clusterNetwork": [ { "cidr": "<cidr>", "hostPrefix": "<prefix>" } ] "networkType": "OVNKubernetes" } }'ここでは、以下のようになります。
- <cidr>
- CIDR ブロックを指定します。
- <prefix>
クラスター内の各ノードに割り当てられる CIDR ブロックのスライスを指定します。
重要移行時に、サービスネットワークのアドレスブロックを変更することはできません。
OVN-Kubernetes ネットワークプロバイダーはこのブロックを内部で使用するため、
100.64.0.0/16CIDR ブロックと重複する CIDR ブロックは使用できません。
次のコマンドを入力して、Multus デーモンセットのロールアウトが完了していることを確認します。
$ oc -n openshift-multus rollout status daemonset/multus
Multus Pod の名前は
multus-<xxxxx>の形式で、<xxxxx>はランダムな文字のシーケンスです。Pod が再起動するまでにしばらく時間がかかる可能性があります。出力例
Waiting for daemon set "multus" rollout to finish: 1 out of 6 new pods have been updated... ... Waiting for daemon set "multus" rollout to finish: 5 of 6 updated pods are available... daemon set "multus" successfully rolled out
移行を完了するには、クラスター内の各ノードを再起動します。たとえば、以下のような bash スクリプトを使用できます。このスクリプトは、
sshを使用して各ホストに接続でき、sudoがパスワードを要求しないように設定されていることを前提としています。#!/bin/bash for ip in $(oc get nodes -o jsonpath='{.items[*].status.addresses[?(@.type=="InternalIP")].address}') do echo "reboot node $ip" ssh -o StrictHostKeyChecking=no core@$ip sudo shutdown -r -t 3 done注記SSH アクセスが利用できない場合は、
openstackコマンドを使用できます。$ for name in $(openstack server list --name ${CLUSTERID}\* -f value -c Name); do openstack server reboot $name; doneあるいは、インフラストラクチャープロバイダーの管理ポータルを通じて各ノードを再起動できる場合もあります。それ以外の場合は、適切な機関に問い合わせて、SSH または管理ポータルと OpenStack クライアントを介して仮想マシンにアクセスしてください。
検証
移行が成功したことを確認し、移行リソースを削除します。
ネットワークプラグインが OVN-Kubernetes であることを確認するには、次のコマンドを入力します。
$ oc get network.config/cluster -o jsonpath='{.status.networkType}{"\n"}'status.networkTypeの値はOVNKubernetesである必要があります。クラスターノードが
Ready状態にあることを確認するには、以下のコマンドを実行します。$ oc get nodes
Pod がエラー状態ではないことを確認するには、以下のコマンドを入力します。
$ oc get pods --all-namespaces -o wide --sort-by='{.spec.nodeName}'ノードの Pod がエラー状態にある場合は、そのノードを再起動します。
すべてのクラスター Operator が異常な状態にないことを確認するには、以下のコマンドを入力します。
$ oc get co
すべてのクラスター Operator のステータスは、
AVAILABLE="True"、PROGRESSING="False"、DEGRADED="False"になります。クラスター Operator が利用できないか、そのパフォーマンスが低下する場合には、クラスター Operator のログで詳細を確認します。重要これまでの検証手順のいずれかでエラーが示された場合は、続行しないでください。クリーンアップ中に削除されたファイナライザーが原因で、
Terminating状態の Pod が発生する場合があります。これらはエラーを示すものではありません。
移行が完了し、クラスターが良好な状態にある場合は、次のコマンドを入力して、CNO 設定オブジェクトから移行設定を削除します。
$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "migration": null } }'
27.7.3. 移行後のリソースのクリーンアップ
Kuryr ネットワークプラグインから OVN-Kubernetes ネットワークプラグインに移行した後、Kuryr が以前に作成したリソースをクリーンアップする必要があります。
クリーンアッププロセスは、Python 仮想環境に依存して、使用するパッケージバージョンが Octavia オブジェクトのタグをサポートしていることを確認します。環境で少なくとも次のものを使用していることが確実な場合は、仮想環境は必要ありません。* openstacksdk バージョン 0.54.0 * python-openstackclient バージョン 5.5.0 * python-octaviaclient バージョン 2.3.0
前提条件
-
OpenShift Container Platform CLI (
oc) をインストールしている。 - Python インタープリターをインストールしている。
-
openstacksdkPython パッケージがインストールされている。 -
openstackCLI がインストールされている。 - 基盤となる RHOSP クラウドにアクセスできます。
-
クラスター管理者ロールを持つユーザーとしてクラスターにアクセスできます。
手順
クリーンアップ Python 仮想環境を作成します。
環境用の一時ディレクトリーを作成します。以下に例を示します。
$ python3 -m venv /tmp/venv
/tmp/venvディレクトリーにある仮想環境は、すべてのクリーンアップ例で使用されます。仮想環境に入ります。以下に例を示します。
$ source /tmp/venv/bin/activate
次のコマンドを実行して、仮想環境で
pipコマンドをアップグレードします。(venv) $ pip install pip --upgrade
次のコマンドを実行して、必要な Python パッケージをインストールします。
(venv) $ pip install openstacksdk==0.54.0 python-openstackclient==5.5.0 python-octaviaclient==2.3.0
ターミナルで、次のコマンドを実行して、クラスター識別子と Kuryr 識別子に変数を設定します。
cluster ID を設定します。
(venv) $ CLUSTERID=$(oc get infrastructure.config.openshift.io cluster -o=jsonpath='{.status.infrastructureName}')cluster タグを設定します。
(venv) $ CLUSTERTAG="openshiftClusterID=${CLUSTERID}"router ID を設定します。
(venv) $ ROUTERID=$(oc get kuryrnetwork -A --no-headers -o custom-columns=":status.routerId"|head -n 1)
次のコマンドを実行して、指定されたリソースからファイナライザーを削除する Bash 関数を作成します。
(venv) $ function REMFIN { local resource=$1 local finalizer=$2 for res in $(oc get $resource -A --template='{{range $i,$p := .items}}{{ $p.metadata.name }}|{{ $p.metadata.namespace }}{{"\n"}}{{end}}'); do name=${res%%|*} ns=${res##*|} yaml=$(oc get -n $ns $resource $name -o yaml) if echo "${yaml}" | grep -q "${finalizer}"; then echo "${yaml}" | grep -v "${finalizer}" | oc replace -n $ns $resource $name -f - fi done }この関数は 2 つのパラメーターを受け取ります。最初のパラメーターはリソースの名前で、2 番目のパラメーターは削除するファイナライザーです。指定されたリソースがクラスターから削除され、その定義は、指定されたファイナライザーを除いて、コピーされたデータに置き換えられます。
Kuryr ファイナライザーをサービスから削除するには、次のコマンドを入力します。
(venv) $ REMFIN services kuryr.openstack.org/service-finalizer
Kuryr
service-subnet-gateway-ipサービスを削除するには、次のコマンドを入力します。(venv) $ if $(oc get -n openshift-kuryr service service-subnet-gateway-ip &>/dev/null); then oc -n openshift-kuryr delete service service-subnet-gateway-ip fiタグ付けされたすべての RHOSP ロードバランサーを Octavia から削除するには、次のコマンドを入力します。
(venv) $ for lb in $(openstack loadbalancer list --tags $CLUSTERTAG -f value -c id); do openstack loadbalancer delete --cascade $lb doneすべての
KuryrLoadBalancerCR から Kuryr ファイナライザーを削除するには、次のコマンドを入力します。(venv) $ REMFIN kuryrloadbalancers.openstack.org kuryr.openstack.org/kuryrloadbalancer-finalizers
openshift-kuryrnamespace を削除するには、次のコマンドを入力します。(venv) $ oc delete namespace openshift-kuryr
Kuryr サービスのサブネットをルーターから削除するには、次のコマンドを入力します。
(venv) $ openstack router remove subnet $ROUTERID ${CLUSTERID}-kuryr-service-subnetKuryr サービスネットワークを削除するには、次のコマンドを入力します。
(venv) $ openstack network delete ${CLUSTERID}-kuryr-service-networkすべての Pod から Kuryr ファイナライザーを削除するには、次のコマンドを入力します。
(venv) $ REMFIN pods kuryr.openstack.org/pod-finalizer
すべての
KuryrPortCR から Kuryr ファイナライザーを削除するには、次のコマンドを入力します。(venv) $ REMFIN kuryrports.openstack.org kuryr.openstack.org/kuryrport-finalizer
このコマンドは
KuryrPortCR を削除します。Kuryr ファイナライザーをネットワークポリシーから削除するには、次のコマンドを入力します。
(venv) $ REMFIN networkpolicy kuryr.openstack.org/networkpolicy-finalizer
残りのネットワークポリシーから Kuryr ファイナライザーを削除するには、次のコマンドを入力します。
(venv) $ REMFIN kuryrnetworkpolicies.openstack.org kuryr.openstack.org/networkpolicy-finalizer
Kuryr が作成したサブポートをトランクから削除するには、次のコマンドを入力します。
(venv) $ read -ra trunks <<< $(python -c "import openstack; n = openstack.connect().network; print(' '.join([x.id for x in n.trunks(any_tags='$CLUSTERTAG')]))") && \ i=0 && \ for trunk in "${trunks[@]}"; do i=$((i+1)) echo "Processing trunk $trunk, ${i}/${#trunks[@]}." subports=() for subport in $(python -c "import openstack; n = openstack.connect().network; print(' '.join([x['port_id'] for x in n.get_trunk('$trunk').sub_ports if '$CLUSTERTAG' in n.get_port(x['port_id']).tags]))"); do subports+=("$subport"); done args=() for sub in "${subports[@]}" ; do args+=("--subport $sub") done if [ ${#args[@]} -gt 0 ]; then openstack network trunk unset ${args[*]} $trunk fi doneKuryrNetworkCR からすべてのネットワークとサブネットを取得し、ポート、ルーターインターフェイス、およびネットワーク自体を削除するには、次のコマンドを入力します。(venv) $ mapfile -t kuryrnetworks < <(oc get kuryrnetwork -A --template='{{range $i,$p := .items}}{{ $p.status.netId }}|{{ $p.status.subnetId }}{{"\n"}}{{end}}') && \ i=0 && \ for kn in "${kuryrnetworks[@]}"; do i=$((i+1)) netID=${kn%%|*} subnetID=${kn##*|} echo "Processing network $netID, ${i}/${#kuryrnetworks[@]}" # Remove all ports from the network. for port in $(python -c "import openstack; n = openstack.connect().network; print(' '.join([x.id for x in n.ports(network_id='$netID') if x.device_owner != 'network:router_interface']))"); do ( openstack port delete $port ) & # Only allow 20 jobs in parallel. if [[ $(jobs -r -p | wc -l) -ge 20 ]]; then wait -n fi done wait # Remove the subnet from the router. openstack router remove subnet $ROUTERID $subnetID # Remove the network. openstack network delete $netID doneKuryr セキュリティーグループを削除するには、次のコマンドを入力します。
(venv) $ openstack security group delete ${CLUSTERID}-kuryr-pods-security-groupすべてのタグ付きサブネットプールを削除するには、次のコマンドを入力します。
(venv) $ for subnetpool in $(openstack subnet pool list --tags $CLUSTERTAG -f value -c ID); do openstack subnet pool delete $subnetpool doneKuryrNetworkCR に基づくすべてのネットワークが削除されたことを確認するには、次のコマンドを入力します。(venv) $ networks=$(oc get kuryrnetwork -A --no-headers -o custom-columns=":status.netId") && \ for existingNet in $(openstack network list --tags $CLUSTERTAG -f value -c ID); do if [[ $networks =~ $existingNet ]]; then echo "Network still exists: $existingNet" fi doneコマンドによって既存のネットワークが返された場合は、続行する前にそれらを調査して削除してください。
ネットワークポリシーに関連するセキュリティーグループを削除するには、次のコマンドを入力します。
(venv) $ for sgid in $(openstack security group list -f value -c ID -c Description | grep 'Kuryr-Kubernetes Network Policy' | cut -f 1 -d ' '); do openstack security group delete $sgid doneKuryrNetworkCR からファイナライザーを削除するには、次のコマンドを入力します。(venv) $ REMFIN kuryrnetworks.openstack.org kuryrnetwork.finalizers.kuryr.openstack.org
Kuryr ルーターを削除するには、次のコマンドを入力します。
(venv) $ if $(python3 -c "import sys; import openstack; n = openstack.connect().network; r = n.get_router('$ROUTERID'); sys.exit(0) if r.description != 'Created By OpenShift Installer' else sys.exit(1)"); then openstack router delete $ROUTERID fi
27.7.4. 関連情報
- OVN-Kubernetes ネットワークプラグインの設定パラメーター
- etcd のバックアップ
- ネットワークポリシーについて
OVN-Kubernetes 機能の詳細は、以下を参照してください。
27.8. IPv4/IPv6 デュアルスタックネットワークへの変換
クラスター管理者は、IPv4 および IPv6 アドレスファミリーをサポートするデュアルネットワーククラスターネットワークに、IPv4 の単一スタッククラスターを変換できます。デュアルスタックに変換した後、新規に作成された Pod はすべてデュアルスタック対応になります。
デュアルスタックネットワークは、ベアメタル、IBM Power インフラストラクチャー、および単一ノードの OpenShift クラスターでプロビジョニングされたクラスターでサポートされます。
デュアルスタックネットワークを使用している場合、IPv6 を必要とする、IPv4 にマッピングされ IPv6 アドレス (例: ::FFFF:198.51.100.1) は使用できません。
27.8.1. デュアルスタッククラスターネットワークへの変換
クラスター管理者は、単一スタッククラスターネットワークをデュアルスタッククラスターネットワークに変換できます。
デュアルスタックネットワークへの変換後に、新規に作成された Pod のみに IPv6 アドレスが割り当てられます。変換前に作成された Pod は、IPv6 アドレスを受信するように再作成される必要があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインしている。 - クラスターは OVN-Kubernetes ネットワークプラグインを使用します。
- クラスターノードに IPv6 アドレスがある。
- インフラストラクチャーに基づいて IPv6 対応ルーターを設定している。
手順
クラスターおよびサービスネットワークの IPv6 アドレスブロックを指定するには、以下の YAML を含むファイルを作成します。
- op: add path: /spec/clusterNetwork/- value: 1 cidr: fd01::/48 hostPrefix: 64 - op: add path: /spec/serviceNetwork/- value: fd02::/112 2
クラスターネットワーク設定にパッチを適用するには、以下のコマンドを入力します。
$ oc patch network.config.openshift.io cluster \ --type='json' --patch-file <file>.yaml
ここでは、以下のようになります。
file- 先の手順で作成したファイルの名前を指定します。
出力例
network.config.openshift.io/cluster patched
検証
以下の手順を実施して、クラスターネットワークが直前の手順で指定した IPv6 アドレスブロックを認識していることを確認します。
ネットワーク設定を表示します。
$ oc describe network
出力例
Status: Cluster Network: Cidr: 10.128.0.0/14 Host Prefix: 23 Cidr: fd01::/48 Host Prefix: 64 Cluster Network MTU: 1400 Network Type: OVNKubernetes Service Network: 172.30.0.0/16 fd02::/112
27.8.2. 単一スタッククラスターネットワークへの変換
クラスター管理者は、デュアルスタッククラスターネットワークを単一スタッククラスターネットワークに変換できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインしている。 - クラスターは OVN-Kubernetes ネットワークプラグインを使用します。
- クラスターノードに IPv6 アドレスがある。
- デュアルスタックネットワークを有効にしている。
手順
以下のコマンドを実行して、
networks.config.openshift.ioカスタムリソース (CR) を編集します。$ oc edit networks.config.openshift.io
-
前の手順で
cidrおよびhostPrefixフィールドに追加した IPv6 固有の設定を削除します。
27.9. Egress ファイアウォールとネットワークポリシールールのロギング
クラスター管理者は、クラスターの監査ロギングを設定し、1 つ以上の namespace のロギングを有効にできます。OpenShift Container Platform は、Egress ファイアウォールとネットワークポリシーの両方の監査ログを生成します。
監査ログは、OVN-Kubernetes ネットワークプラグイン でのみ使用できます。
27.9.1. 監査ロギング
OVN-Kubernetes ネットワークプラグインは、Open Virtual Network (OVN) ACL を使用して、egress ファイアウォールとネットワークポリシーを管理します。監査ロギングは ACL イベントの許可および拒否を公開します。
syslog サーバーや UNIX ドメインソケットなど、監査ログの宛先を設定できます。追加の設定に関係なく、監査ログは常にクラスター内の各 OVN-Kubernetes Pod の /var/log/ovn/acl-audit-log.log に保存されます。
以下の例のように、namespace に k8s.ovn.org/acl-logging キーでアノテーションを付けることにより、namespace ごとに監査ログを有効にします。
namespace アノテーションの例
kind: Namespace
apiVersion: v1
metadata:
name: example1
annotations:
k8s.ovn.org/acl-logging: |-
{
"deny": "info",
"allow": "info"
}
ロギング形式は RFC5424 によって定義される syslog と互換性があります。syslog ファシリティーは設定可能です。デフォルトは local0 です。ログエントリーの例は、以下のようになります。
ネットワークポリシーの ACL 拒否ログエントリーの例
Defaulting container name to ovn-controller. Use 'oc describe pod/ovnkube-node-hdb8v -n openshift-ovn-kubernetes' to see all of the containers in this pod. 2021-06-13T19:33:11.590Z|00005|acl_log(ovn_pinctrl0)|INFO|name="verify-audit-logging_ingressDefaultDeny", verdict=drop, severity=alert: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:39,dl_dst=0a:58:0a:80:02:37,nw_src=10.128.2.57,nw_dst=10.128.2.55,nw_tos=0,nw_ecn=0,nw_ttl=64,icmp_type=8,icmp_code=0 2021-06-13T19:33:12.614Z|00006|acl_log(ovn_pinctrl0)|INFO|name="verify-audit-logging_ingressDefaultDeny", verdict=drop, severity=alert: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:39,dl_dst=0a:58:0a:80:02:37,nw_src=10.128.2.57,nw_dst=10.128.2.55,nw_tos=0,nw_ecn=0,nw_ttl=64,icmp_type=8,icmp_code=0 2021-06-13T19:44:10.037Z|00007|acl_log(ovn_pinctrl0)|INFO|name="verify-audit-logging_allow-from-same-namespace_0", verdict=allow, severity=alert: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:3b,dl_dst=0a:58:0a:80:02:3a,nw_src=10.128.2.59,nw_dst=10.128.2.58,nw_tos=0,nw_ecn=0,nw_ttl=64,icmp_type=8,icmp_code=0 2021-06-13T19:44:11.037Z|00008|acl_log(ovn_pinctrl0)|INFO|name="verify-audit-logging_allow-from-same-namespace_0", verdict=allow, severity=alert: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:3b,dl_dst=0a:58:0a:80:02:3a,nw_src=10.128.2.59,nw_dst=10.128.2.58,nw_tos=0,nw_ecn=0,nw_ttl=64,icmp_type=8,icmp_code=0
以下の表は、namespace アノテーションの値について説明しています。
表27.10 監査ログの namespace の注釈
| Annotation | 値 |
|---|---|
|
|
namespace の監査ログを有効にするには、
|
27.9.2. 監査設定
監査ロギングの設定は、OVN-Kubernetes クラスターネットワークプロバイダー設定の一部として指定されます。次の YAML は、監査ログのデフォルト値を示しています。
監査ロギング設定
apiVersion: operator.openshift.io/v1
kind: Network
metadata:
name: cluster
spec:
defaultNetwork:
ovnKubernetesConfig:
policyAuditConfig:
destination: "null"
maxFileSize: 50
rateLimit: 20
syslogFacility: local0
次の表では、監査ログの設定フィールドについて説明します。
表27.11 policyAuditConfig オブジェクト
| フィールド | 型 | 説明 |
|---|---|---|
|
| integer |
ノードごとに毎秒生成されるメッセージの最大数。デフォルト値は、1 秒あたり |
|
| integer |
監査ログの最大サイズ (バイト単位)。デフォルト値は |
|
| integer | 保持されるログファイルの最大数。 |
|
| string | 以下の追加の監査ログターゲットのいずれかになります。
|
|
| string |
RFC5424 で定義される |
27.9.3. クラスターの Egress ファイアウォールとネットワークポリシー監査の設定
クラスター管理者は、クラスターの監査ログをカスタマイズできます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインする。
手順
監査ロギング設定をカスタマイズするには、次のコマンドを入力します。
$ oc edit network.operator.openshift.io/cluster
ヒントまたは、以下の YAML をカスタマイズして適用することで、監査ロギングを設定できます。
apiVersion: operator.openshift.io/v1 kind: Network metadata: name: cluster spec: defaultNetwork: ovnKubernetesConfig: policyAuditConfig: destination: "null" maxFileSize: 50 rateLimit: 20 syslogFacility: local0
検証
ネットワークポリシーを使用して namespace を作成するには、次の手順を実行します。
検証用の namespace を作成します。
$ cat <<EOF| oc create -f - kind: Namespace apiVersion: v1 metadata: name: verify-audit-logging annotations: k8s.ovn.org/acl-logging: '{ "deny": "alert", "allow": "alert" }' EOF出力例
namespace/verify-audit-logging created
namespace のネットワークポリシーを作成します。
$ cat <<EOF| oc create -n verify-audit-logging -f - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: deny-all spec: podSelector: matchLabels: policyTypes: - Ingress - Egress --- apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-same-namespace namespace: verify-audit-logging spec: podSelector: {} policyTypes: - Ingress - Egress ingress: - from: - podSelector: {} egress: - to: - namespaceSelector: matchLabels: kubernetes.io/metadata.name: verify-audit-logging EOF出力例
networkpolicy.networking.k8s.io/deny-all created networkpolicy.networking.k8s.io/allow-from-same-namespace created
ソーストラフィックの Pod を
defaultnamespace に作成します。$ cat <<EOF| oc create -n default -f - apiVersion: v1 kind: Pod metadata: name: client spec: containers: - name: client image: registry.access.redhat.com/rhel7/rhel-tools command: ["/bin/sh", "-c"] args: ["sleep inf"] EOFverify-audit-loggingnamespace に 2 つの Pod を作成します。$ for name in client server; do cat <<EOF| oc create -n verify-audit-logging -f - apiVersion: v1 kind: Pod metadata: name: ${name} spec: containers: - name: ${name} image: registry.access.redhat.com/rhel7/rhel-tools command: ["/bin/sh", "-c"] args: ["sleep inf"] EOF done出力例
pod/client created pod/server created
トラフィックを生成し、ネットワークポリシー監査ログエントリーを作成するには、以下の手順を実行します。
verify-audit-loggingnamespace でserverという名前の Pod の IP アドレスを取得します。$ POD_IP=$(oc get pods server -n verify-audit-logging -o jsonpath='{.status.podIP}')defaultの namespace のclientという名前の Pod の直前のコマンドから IP アドレスに ping し、すべてのパケットがドロップされていることを確認します。$ oc exec -it client -n default -- /bin/ping -c 2 $POD_IP
出力例
PING 10.128.2.55 (10.128.2.55) 56(84) bytes of data. --- 10.128.2.55 ping statistics --- 2 packets transmitted, 0 received, 100% packet loss, time 2041ms
verify-audit-loggingnamespace のclientという名前の Pod からPOD_IPシェル環境変数に保存されている IP アドレスに ping し、すべてのパケットが許可されていることを確認します。$ oc exec -it client -n verify-audit-logging -- /bin/ping -c 2 $POD_IP
出力例
PING 10.128.0.86 (10.128.0.86) 56(84) bytes of data. 64 bytes from 10.128.0.86: icmp_seq=1 ttl=64 time=2.21 ms 64 bytes from 10.128.0.86: icmp_seq=2 ttl=64 time=0.440 ms --- 10.128.0.86 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1001ms rtt min/avg/max/mdev = 0.440/1.329/2.219/0.890 ms
ネットワークポリシー監査ログの最新エントリーを表示します。
$ for pod in $(oc get pods -n openshift-ovn-kubernetes -l app=ovnkube-node --no-headers=true | awk '{ print $1 }') ; do oc exec -it $pod -n openshift-ovn-kubernetes -- tail -4 /var/log/ovn/acl-audit-log.log done出力例
Defaulting container name to ovn-controller. Use 'oc describe pod/ovnkube-node-hdb8v -n openshift-ovn-kubernetes' to see all of the containers in this pod. 2021-06-13T19:33:11.590Z|00005|acl_log(ovn_pinctrl0)|INFO|name="verify-audit-logging_ingressDefaultDeny", verdict=drop, severity=alert: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:39,dl_dst=0a:58:0a:80:02:37,nw_src=10.128.2.57,nw_dst=10.128.2.55,nw_tos=0,nw_ecn=0,nw_ttl=64,icmp_type=8,icmp_code=0 2021-06-13T19:33:12.614Z|00006|acl_log(ovn_pinctrl0)|INFO|name="verify-audit-logging_ingressDefaultDeny", verdict=drop, severity=alert: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:39,dl_dst=0a:58:0a:80:02:37,nw_src=10.128.2.57,nw_dst=10.128.2.55,nw_tos=0,nw_ecn=0,nw_ttl=64,icmp_type=8,icmp_code=0 2021-06-13T19:44:10.037Z|00007|acl_log(ovn_pinctrl0)|INFO|name="verify-audit-logging_allow-from-same-namespace_0", verdict=allow, severity=alert: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:3b,dl_dst=0a:58:0a:80:02:3a,nw_src=10.128.2.59,nw_dst=10.128.2.58,nw_tos=0,nw_ecn=0,nw_ttl=64,icmp_type=8,icmp_code=0 2021-06-13T19:44:11.037Z|00008|acl_log(ovn_pinctrl0)|INFO|name="verify-audit-logging_allow-from-same-namespace_0", verdict=allow, severity=alert: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:3b,dl_dst=0a:58:0a:80:02:3a,nw_src=10.128.2.59,nw_dst=10.128.2.58,nw_tos=0,nw_ecn=0,nw_ttl=64,icmp_type=8,icmp_code=0
27.9.4. namespace の Egress ファイアウォールとネットワークポリシーの監査ログを有効にする
クラスター管理者は、namespace の監査ログを有効にすることができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインする。
手順
namespace の監査ログを有効にするには、次のコマンドを入力します。
$ oc annotate namespace <namespace> \ k8s.ovn.org/acl-logging='{ "deny": "alert", "allow": "notice" }'ここでは、以下のようになります。
<namespace>- namespace の名前を指定します。
ヒントまたは、以下の YAML を適用して監査ロギングを有効化できます。
kind: Namespace apiVersion: v1 metadata: name: <namespace> annotations: k8s.ovn.org/acl-logging: |- { "deny": "alert", "allow": "notice" }出力例
namespace/verify-audit-logging annotated
検証
監査ログの最新のエントリーを表示します。
$ for pod in $(oc get pods -n openshift-ovn-kubernetes -l app=ovnkube-node --no-headers=true | awk '{ print $1 }') ; do oc exec -it $pod -n openshift-ovn-kubernetes -- tail -4 /var/log/ovn/acl-audit-log.log done出力例
Defaulting container name to ovn-controller. Use 'oc describe pod/ovnkube-node-hdb8v -n openshift-ovn-kubernetes' to see all of the containers in this pod. 2021-06-13T19:33:11.590Z|00005|acl_log(ovn_pinctrl0)|INFO|name="verify-audit-logging_ingressDefaultDeny", verdict=drop, severity=alert: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:39,dl_dst=0a:58:0a:80:02:37,nw_src=10.128.2.57,nw_dst=10.128.2.55,nw_tos=0,nw_ecn=0,nw_ttl=64,icmp_type=8,icmp_code=0 2021-06-13T19:33:12.614Z|00006|acl_log(ovn_pinctrl0)|INFO|name="verify-audit-logging_ingressDefaultDeny", verdict=drop, severity=alert: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:39,dl_dst=0a:58:0a:80:02:37,nw_src=10.128.2.57,nw_dst=10.128.2.55,nw_tos=0,nw_ecn=0,nw_ttl=64,icmp_type=8,icmp_code=0 2021-06-13T19:44:10.037Z|00007|acl_log(ovn_pinctrl0)|INFO|name="verify-audit-logging_allow-from-same-namespace_0", verdict=allow, severity=alert: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:3b,dl_dst=0a:58:0a:80:02:3a,nw_src=10.128.2.59,nw_dst=10.128.2.58,nw_tos=0,nw_ecn=0,nw_ttl=64,icmp_type=8,icmp_code=0 2021-06-13T19:44:11.037Z|00008|acl_log(ovn_pinctrl0)|INFO|name="verify-audit-logging_allow-from-same-namespace_0", verdict=allow, severity=alert: icmp,vlan_tci=0x0000,dl_src=0a:58:0a:80:02:3b,dl_dst=0a:58:0a:80:02:3a,nw_src=10.128.2.59,nw_dst=10.128.2.58,nw_tos=0,nw_ecn=0,nw_ttl=64,icmp_type=8,icmp_code=0
27.9.5. namespace の Egress ファイアウォールとネットワークポリシーの監査ログを無効にする
クラスター管理者は、namespace の監査ログを無効にすることができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインする。
手順
namespace の監査ログを無効にするには、次のコマンドを入力します。
$ oc annotate --overwrite namespace <namespace> k8s.ovn.org/acl-logging-
ここでは、以下のようになります。
<namespace>- namespace の名前を指定します。
ヒントまたは、以下の YAML を適用して監査ロギングを無効化できます。
kind: Namespace apiVersion: v1 metadata: name: <namespace> annotations: k8s.ovn.org/acl-logging: null出力例
namespace/verify-audit-logging annotated
27.9.6. 関連情報
27.10. IPsec 暗号化の設定
IPsec を有効にすると、OVN-Kubernetes クラスターネットワーク上のノード間の Pod 間ネットワークトラフィックはすべて IPsec トランスポートモード で暗号化されます。
IPsec はデフォルトで無効にされています。クラスターのインストール中またはインストール後に有効にできます。クラスターのインストールについて、詳しくは OpenShift Container Platform installation overview を参照してください。クラスターのインストール後に IPsec を有効にする必要がある場合は、IPsec ESP IP ヘッダーのオーバーヘッドを考慮して、まずクラスター MTU のサイズを変更する必要があります。
次のドキュメントでは、クラスターのインストール後に IPSec を有効または無効にする方法について説明します。
27.10.1. 前提条件
-
クラスター MTU のサイズを
46バイト減らして、IPsec ESP ヘッダーにオーバーヘッドを追加している。クラスターが使用する MTU のサイズ変更の詳細は クラスターネットワークの MTU 変更 を参照してください。
27.10.2. IPsec で暗号化したネットワークトラフィックフローのタイプ
IPsec を有効にすると、Pod 間の以下のネットワークトラフィックフローのみが暗号化されます。
- クラスターネットワーク上の複数の異なるノードの Pod 間のトラフィック
- ホストネットワークの Pod からクラスターネットワーク上の Pod へのトラフィック
以下のトラフィックフローは暗号化されません。
- クラスターネットワーク上の同じノードの Pod 間のトラフィック
- ホストネットワーク上の Pod 間のトラフィック
- クラスターネットワークの Pod からホストネットワークの Pod へのトラフィック
暗号化されていないフローと暗号化されていないフローを以下の図に示します。
27.10.2.1. IPsec が有効になっている場合のネットワーク接続要件
OpenShift Container Platform クラスターのコンポーネントが通信できるように、マシン間のネットワーク接続を設定する必要があります。すべてのマシンではクラスターの他のすべてのマシンのホスト名を解決できる必要があります。
表27.12 すべてのマシンからすべてのマシンへの通信に使用されるポート
| プロトコル | ポート | 説明 |
|---|---|---|
| UDP |
| IPsec IKE パケット |
|
| IPsec NAT-T パケット | |
| ESP | 該当なし | IPsec Encapsulating Security Payload (ESP) |
27.10.3. 暗号化プロトコルおよび IPsec モード
使用する暗号化は AES-GCM-16-256 です。整合性チェック値 (ICV) は 16 バイトです。鍵の長さは 256 ビットです。
使用される IPsec モードは トランスポートモード です。これは、元のパケットの IP ヘッダーに Encapsulated Security Payload (ESP) ヘッダーを追加してパケットデータを暗号化することで、エンドツーエンドの通信を暗号化するモードです。OpenShift Container Platform は現在、Pod 間通信に IPsec Tunnel モード を使用したり、サポートしたりしません。
27.10.4. セキュリティー証明書の生成およびローテーション
Cluster Network Operator (CNO) は、暗号化用に IPsec によって使用される自己署名の X.509 認証局 (CA) を生成します。各ノードの証明書署名要求 (CSR) は、CNO によって自動的に満たされます。
この CA は 10 年間有効です。個別のノード証明書は 5 年間有効で、4 年半が経過すると自動的にローテーションされます。
27.10.5. IPsec 暗号化の有効化
クラスター管理者は、クラスターのインストール後に IPsec 暗号化を有効にできます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインする。 -
クラスター MTU のサイズを
46バイト減らして、IPsec ESP ヘッダーにオーバーヘッドを設けている。
手順
IPsec 暗号化を有効にするには、次のコマンドを入力します。
$ oc patch networks.operator.openshift.io cluster --type=merge \ -p '{"spec":{"defaultNetwork":{"ovnKubernetesConfig":{"ipsecConfig":{ }}}}}'
検証
OVN-Kubernetes コントロールプレーン Pod の名前を見つけるには、次のコマンドを入力します。
$ oc get pods -l app=ovnkube-master -n openshift-ovn-kubernetes
出力例
NAME READY STATUS RESTARTS AGE ovnkube-master-fvtnh 6/6 Running 0 122m ovnkube-master-hsgmm 6/6 Running 0 122m ovnkube-master-qcmdc 6/6 Running 0 122m
次のコマンドを実行して、クラスターで IPsec が有効になっていることを確認します。
$ oc -n openshift-ovn-kubernetes rsh ovnkube-master-<XXXXX> \ ovn-nbctl --no-leader-only get nb_global . ipsec
ここでは、以下のようになります。
<XXXXX>- 前の手順の Pod の文字のランダムなシーケンスを指定します。
出力例
true
27.10.6. IPsec 暗号化の無効化
クラスター管理者は、クラスターのインストール後に IPsec を有効にした場合にのみ、IPsec 暗号化を無効にできます。
クラスターのインストール時に IPsec を有効にした場合、この手順では IPsec を無効化できません。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインする。
手順
IPsec 暗号化を無効にするには、次のコマンドを入力します。
$ oc patch networks.operator.openshift.io/cluster --type=json \ -p='[{"op":"remove", "path":"/spec/defaultNetwork/ovnKubernetesConfig/ipsecConfig"}]'-
オプション: IP パケットの IPsec ESP ヘッダーからのオーバーヘッドがなくなるため、クラスター MTU のサイズを
46バイト増やすことができます。 クラスターで IPsec が無効になっていることを確認します。
$ oc -n openshift-ovn-kubernetes -c nbdb rsh ovnkube-master-<XXXXX> \ ovn-nbctl --no-leader-only get nb_global . ipsec
ここでは、以下のようになります。
<XXXXX>- 前の手順の Pod の文字のランダムなシーケンスを指定します。
出力例
false
27.10.7. 関連情報
27.11. プロジェクトの egress ファイアウォールの設定
クラスター管理者は、OpenShift Container Platform クラスター外に出るプロジェクトのプロジェクについて、egress トラフィックを制限する egress ファイアウォールを作成できます。
27.11.1. egress ファイアウォールのプロジェクトでの機能
クラスター管理者は、 egress ファイアウォール を使用して、一部またはすべての Pod がクラスター内からアクセスできる外部ホストを制限できます。egress ファイアウォールポリシーは以下のシナリオをサポートします。
- Pod の接続を内部ホストに制限し、パブリックインターネットへの接続を開始できないようにする。
- Pod の接続をパブリックインターネットに制限し、OpenShift Container Platform クラスター外にある内部ホストへの接続を開始できないようにする。
- Pod は OpenShift Container Platform クラスター外の指定された内部サブネットまたはホストにアクセスできません。
- Pod は特定の外部ホストにのみ接続することができます。
たとえば、指定された IP 範囲へのあるプロジェクトへのアクセスを許可する一方で、別のプロジェクトへの同じアクセスを拒否することができます。または、アプリケーション開発者の (Python) pip mirror からの更新を制限したり、更新を承認されたソースからの更新のみに強制的に制限したりすることができます。
Egress ファイアウォールは、ホストネットワークの namespace には適用されません。ホストネットワークが有効になっている Pod は、Egress ファイアウォールルールの影響を受けません。
EgressFirewall カスタムリソース (CR) オブジェクトを作成して egress ファイアウォールポリシーを設定します。egress ファイアウォールは、以下のいずれかの基準を満たすネットワークトラフィックと一致します。
- CIDR 形式の IP アドレス範囲。
- IP アドレスに解決する DNS 名
- ポート番号
- プロトコル。TCP、UDP、および SCTP のいずれかになります。
egress ファイアウォールに 0.0.0.0/0 の拒否ルールが含まれる場合、OpenShift Container Platform API サーバーへのアクセスはブロックされます。API サーバーに接続するには、IP アドレスごとに許可ルールを追加するか、egress ポリシールールで nodeSelector タイプの許可ルールを使用する必要があります。
次の例は、API サーバーへのアクセスを確保するために必要な Egress ファイアウォールルールの順序を示しています。
apiVersion: k8s.ovn.org/v1 kind: EgressFirewall metadata: name: default namespace: <namespace> 1 spec: egress: - to: cidrSelector: <api_server_address_range> 2 type: Allow # ... - to: cidrSelector: 0.0.0.0/0 3 type: Deny
API サーバーの IP アドレスを見つけるには、oc get ep kubernetes -n default を実行します。
詳細は、BZ#1988324 を参照してください。
egress ファイアウォールルールは、ルーターを通過するトラフィックには適用されません。ルート CR オブジェクトを作成するパーミッションを持つユーザーは、禁止されている宛先を参照するルートを作成することにより、egress ファイアウォールポリシールールをバイパスできます。
27.11.1.1. egress ファイアウォールの制限
egress ファイアウォールには以下の制限があります。
- 複数の EgressFirewall オブジェクトを持つプロジェクトはありません。
- 最大 8,000 のルールを持つ最大 1 つの EgressFirewall オブジェクトはプロジェクトごとに定義できます。
- Red Hat OpenShift Networking の共有ゲートウェイモードで OVN-Kubernetes ネットワークプラグインを使用している場合に、リターン Ingress 応答は Egress ファイアウォールルールの影響を受けます。送信ファイアウォールルールが受信応答宛先 IP をドロップすると、トラフィックはドロップされます。
これらの制限のいずれかに違反すると、プロジェクトの Egress ファイアウォールが壊れます。その結果、すべての外部ネットワークトラフィックがドロップされ、組織にセキュリティーリスクが生じる可能性があります。
egress ファイアウォールリソースは、kube-node-lease、kube-public、kube-system、openshift、openshift- プロジェクトで作成できます。
27.11.1.2. egress ポリシールールのマッチング順序
egress ファイアウォールポリシールールは、最初から最後へと定義された順序で評価されます。Pod からの egress 接続に一致する最初のルールが適用されます。この接続では、後続のルールは無視されます。
27.11.1.3. DNS (Domain Name Server) 解決の仕組み
egress ファイアウォールポリシールールのいずれかで DNS 名を使用する場合、ドメイン名の適切な解決には、以下の制限が適用されます。
- ドメイン名の更新は、TTL (Time-to-live) 期間に基づいてポーリングされます。デフォルトで、期間は 30 分です。egress ファイアウォールコントローラーがローカルネームサーバーでドメイン名をクエリーする場合に、応答に 30 分未満の TTL が含まれる場合、コントローラーは DNS 名の期間を返される値に設定します。それぞれの DNS 名は、DNS レコードの TTL の期限が切れた後にクエリーされます。
- Pod は、必要に応じて同じローカルネームサーバーからドメインを解決する必要があります。そうしない場合、egress ファイアウォールコントローラーと Pod によって認識されるドメインの IP アドレスが異なる可能性があります。ホスト名の IP アドレスが異なる場合、egress ファイアウォールは一貫して実行されないことがあります。
- egress ファイアウォールコントローラーおよび Pod は同じローカルネームサーバーを非同期にポーリングするため、Pod は egress コントローラーが実行する前に更新された IP アドレスを取得する可能性があります。これにより、競合状態が生じます。この現時点の制限により、EgressFirewall オブジェクトのドメイン名の使用は、IP アドレスの変更が頻繁に生じないドメインの場合にのみ推奨されます。
egress ファイアウォールポリシーで DNS 名を使用しても、CoreDNS を介したローカル DNS 解決には影響しません。
ただし、egress ファイアウォールポリシーでドメイン名を使用し、外部 DNS サーバーで関連する Pod の DNS 解決を処理する場合は、DNS サーバーの IP アドレスへのアクセスを許可する egress ファイアウォールルールを含める必要があります。
27.11.2. EgressFirewall カスタムリソース (CR) オブジェクト
egress ファイアウォールのルールを 1 つ以上定義できます。ルールは、ルールが適用されるトラフィックを指定して Allow ルールまたは Deny ルールのいずれかになります。
以下の YAML は EgressFirewall CR オブジェクトについて説明しています。
EgressFirewall オブジェクト
apiVersion: k8s.ovn.org/v1 kind: EgressFirewall metadata: name: <name> 1 spec: egress: 2 ...
27.11.2.1. EgressFirewall ルール
以下の YAML は egress ファイアウォールルールオブジェクトについて説明しています。ユーザーは、CIDR 形式の IP アドレス範囲またはドメイン名を選択するか、nodeSelector を使用して、送信トラフィックを許可または拒否できます。egress スタンザは、単一または複数のオブジェクトの配列を予想します。
Egress ポリシールールのスタンザ
egress: - type: <type> 1 to: 2 cidrSelector: <cidr> 3 dnsName: <dns_name> 4 nodeSelector: <label_name>: <label_value> 5 ports: 6 ...
- 1
- ルールのタイプ。値には
AllowまたはDenyのいずれかを指定する必要があります。 - 2
cidrSelectorフィールドまたはdnsNameフィールドを指定する egress トラフィックのマッチングルールを記述するスタンザ。同じルールで両方のフィールドを使用することはできません。- 3
- CIDR 形式の IP アドレス範囲。
- 4
- DNS ドメイン名。
- 5
- ラベルは、ユーザーが定義するキーと値のペアです。ラベルは Pod などのオブジェクトに添付されます。
nodeSelectorを使用すると、1 つ以上のノードラベルを選択して、Pod に添付できます。 - 6
- オプション: ルールのネットワークポートおよびプロトコルのコレクションを記述するスタンザ。
ポートスタンザ
ports: - port: <port> 1 protocol: <protocol> 2
27.11.2.2. EgressFirewall CR オブジェクトの例
以下の例では、複数の egress ファイアウォールポリシールールを定義します。
apiVersion: k8s.ovn.org/v1
kind: EgressFirewall
metadata:
name: default
spec:
egress: 1
- type: Allow
to:
cidrSelector: 1.2.3.0/24
- type: Deny
to:
cidrSelector: 0.0.0.0/0- 1
- egress ファイアウォールポリシールールオブジェクトのコレクション。
以下の例では、トラフィックが TCP プロトコルおよび宛先ポート 80 または任意のプロトコルと宛先ポート 443 のいずれかを使用している場合に、IP アドレス 172.16.1.1 でホストへのトラフィックを拒否するポリシールールを定義します。
apiVersion: k8s.ovn.org/v1
kind: EgressFirewall
metadata:
name: default
spec:
egress:
- type: Deny
to:
cidrSelector: 172.16.1.1
ports:
- port: 80
protocol: TCP
- port: 44327.11.2.3. EgressFirewall の nodeSelector の例
クラスター管理者は、nodeSelector を使用して、ラベルを指定することにより、クラスター内のノードへのegress トラフィックを許可または拒否できます。ラベルは、1 つ以上のノードに適用できます。以下は、region=east ラベルを使用した例です。
apiVersion: k8s.ovn.org/v1
kind: EgressFirewall
metadata:
name: default
spec:
egress:
- to:
nodeSelector:
matchLabels:
region: east
type: Allowノード IP アドレスごとに手動でルールを追加する代わりに、ノードセレクターを使用して、egress ファイアウォールの背後にある Pod がホストネットワーク Pod にアクセスできるようにするラベルを作成します。
27.11.3. egress ファイアウォールポリシーオブジェクトの作成
クラスター管理者は、プロジェクトの egress ファイアウォールポリシーオブジェクトを作成できます。
プロジェクトに EgressFirewall オブジェクトがすでに定義されている場合、既存のポリシーを編集して egress ファイアウォールルールを変更する必要があります。
前提条件
- OVN-Kubernetes ネットワークプラグインを使用するクラスター。
-
OpenShift CLI (
oc) がインストールされている。 - クラスター管理者としてクラスターにログインする必要があります。
手順
ポリシールールを作成します。
-
<policy_name>.yamlファイルを作成します。この場合、<policy_name>は egress ポリシールールを記述します。 - 作成したファイルで、egress ポリシーオブジェクトを定義します。
-
以下のコマンドを入力してポリシーオブジェクトを作成します。
<policy_name>をポリシーの名前に、<project>をルールが適用されるプロジェクトに置き換えます。$ oc create -f <policy_name>.yaml -n <project>
以下の例では、新規の EgressFirewall オブジェクトが
project1という名前のプロジェクトに作成されます。$ oc create -f default.yaml -n project1
出力例
egressfirewall.k8s.ovn.org/v1 created
-
オプション: 後に変更できるように
<policy_name>.yamlファイルを保存します。
27.12. プロジェクトの egress ファイアウォールの表示
クラスター管理者は、既存の egress ファイアウォールの名前をリスト表示し、特定の egress ファイアウォールのトラフィックルールを表示できます。
27.12.1. EgressFirewall オブジェクトの表示
クラスターで EgressFirewall オブジェクトを表示できます。
前提条件
- OVN-Kubernetes ネットワークプラグインを使用するクラスター。
-
ocとして知られる OpenShift コマンドラインインターフェイス (CLI) のインストール。 - クラスターにログインすること。
手順
オプション: クラスターで定義された EgressFirewall オブジェクトの名前を表示するには、以下のコマンドを入力します。
$ oc get egressfirewall --all-namespaces
ポリシーを検査するには、以下のコマンドを入力します。
<policy_name>を検査するポリシーの名前に置き換えます。$ oc describe egressfirewall <policy_name>
出力例
Name: default Namespace: project1 Created: 20 minutes ago Labels: <none> Annotations: <none> Rule: Allow to 1.2.3.0/24 Rule: Allow to www.example.com Rule: Deny to 0.0.0.0/0
27.13. プロジェクトの egress ファイアウォールの編集
クラスター管理者は、既存の egress ファイアウォールのネットワークトラフィックルールを変更できます。
27.13.1. EgressFirewall オブジェクトの編集
クラスター管理者は、プロジェクトの egress ファイアウォールを更新できます。
前提条件
- OVN-Kubernetes ネットワークプラグインを使用するクラスター。
-
OpenShift CLI (
oc) がインストールされている。 - クラスター管理者としてクラスターにログインする必要があります。
手順
プロジェクトの EgressFirewall オブジェクトの名前を検索します。
<project>をプロジェクトの名前に置き換えます。$ oc get -n <project> egressfirewall
オプション: egress ネットワークファイアウォールの作成時に EgressFirewall オブジェクトのコピーを保存しなかった場合には、以下のコマンドを入力してコピーを作成します。
$ oc get -n <project> egressfirewall <name> -o yaml > <filename>.yaml
<project>をプロジェクトの名前に置き換えます。<name>をオブジェクトの名前に置き換えます。<filename>をファイルの名前に置き換え、YAML を保存します。ポリシールールに変更を加えたら、以下のコマンドを実行して EgressFirewall オブジェクトを置き換えます。
<filename>を、更新された EgressFirewall オブジェクトを含むファイルの名前に置き換えます。$ oc replace -f <filename>.yaml
27.14. プロジェクトからの egress ファイアウォールの削除
クラスター管理者は、プロジェクトから egress ファイアウォールを削除して、OpenShift Container Platform クラスター外に出るプロジェクトからネットワークトラフィックについてのすべての制限を削除できます。
27.14.1. EgressFirewall オブジェクトの削除
クラスター管理者は、プロジェクトから Egress ファイアウォールを削除できます。
前提条件
- OVN-Kubernetes ネットワークプラグインを使用するクラスター。
-
OpenShift CLI (
oc) がインストールされている。 - クラスター管理者としてクラスターにログインする必要があります。
手順
プロジェクトの EgressFirewall オブジェクトの名前を検索します。
<project>をプロジェクトの名前に置き換えます。$ oc get -n <project> egressfirewall
以下のコマンドを入力し、EgressFirewall オブジェクトを削除します。
<project>をプロジェクトの名前に、<name>をオブジェクトの名前に置き換えます。$ oc delete -n <project> egressfirewall <name>
27.15. egress IP アドレスの設定
クラスター管理者は、1 つ以上の egress IP アドレスを namespace に、または namespace 内の特定の pod に割り当てるように、OVN-Kubernetes の Container Network Interface (CNI) ネットワークプラグインを設定することができます。
27.15.1. Egress IP アドレスアーキテクチャーの設計および実装
OpenShift Container Platform の egress IP アドレス機能を使用すると、1 つ以上の namespace の 1 つ以上の Pod からのトラフィックに、クラスターネットワーク外のサービスに対する一貫したソース IP アドレスを持たせることができます。
たとえば、クラスター外のサーバーでホストされるデータベースを定期的にクエリーする Pod がある場合があります。サーバーにアクセス要件を適用するために、パケットフィルタリングデバイスは、特定の IP アドレスからのトラフィックのみを許可するよう設定されます。この特定の Pod のみからサーバーに確実にアクセスできるようにするには、サーバーに要求を行う Pod に特定の egress IP アドレスを設定できます。
namespace に割り当てられた egress IP アドレスは、特定の宛先にトラフィックを送信するために使用されるスロールーターとは異なります。
一部のクラスター設定では、アプリケーション Pod と Ingress ルーター Pod が同じノードで実行されます。このシナリオでアプリケーションプロジェクトの Egress IP アドレスを設定する場合、アプリケーションプロジェクトからルートに要求を送信するときに IP アドレスは使用されません。
egress IP アドレスは、ifcfg-eth0 などのように Linux ネットワーク設定ファイルで設定することはできません。
27.15.1.1. プラットフォームサポート
各種のプラットフォームでの egress IP アドレス機能のサポートについては、以下の表で説明されています。
| プラットフォーム | サポート対象 |
|---|---|
| ベアメタル | はい |
| VMware vSphere | はい |
| Red Hat OpenStack Platform (RHOSP) | はい |
| Amazon Web Services (AWS) | はい |
| Google Cloud Platform (GCP) | はい |
| Microsoft Azure | はい |
| IBM Z および IBM® LinuxONE | はい |
| IBM Z and IBM® LinuxONE for Red Hat Enterprise Linux (RHEL) KVM | はい |
| IBM Power | はい |
EgressIP 機能を持つコントロールプレーンノードへの egress IP アドレスの割り当ては、Amazon Web Services (AWS) でプロビジョニングされるクラスターではサポートされません。(BZ#2039656)
27.15.1.2. パブリッククラウドプラットフォームに関する考慮事項
パブリッククラウドインフラストラクチャーでプロビジョニングされたクラスターの場合は、ノードごとに割り当て可能な IP アドレスの絶対数に制約があります。ノードごとに割り当て可能な IP アドレスの最大数、つまりIP 容量は、次の式で表すことができます。
IP capacity = public cloud default capacity - sum(current IP assignments)
egress IP 機能はノードごとの IP アドレス容量を管理しますが、デプロイメントでこの制約を計画することが重要です。たとえば、8 ノードのベアメタルインフラストラクチャーにインストールされたクラスターの場合は、150 の egress IP アドレスを設定できます。ただし、パブリッククラウドプロバイダーが IP アドレスの容量をノードあたり 10 IP アドレスに制限している場合、割り当て可能な IP アドレスの総数はわずか 80 です。この例のクラウドプロバイダーで同じ IP アドレス容量を実現するには、7 つの追加ノードを割り当てる必要があります。
パブリッククラウド環境内の任意のノードの IP 容量とサブネットを確認するには、oc get node <node_name> -o yaml コマンドを入力します。cloud.network.openshift.io/egress-ipconfig アノテーションには、ノードの容量とサブネット情報が含まれています。
アノテーション値は、プライマリーネットワークインターフェイスに次の情報を提供するフィールドを持つ単一のオブジェクトを持つ配列です。
-
interface: AWS と Azure のインターフェイス ID と GCP のインターフェイス名を指定します。 -
ifaddr: 一方または両方の IP アドレスファミリーのサブネットマスクを指定します。 -
capacity: ノードの IP アドレス容量を指定します。AWS では、IP アドレス容量は IP アドレスファミリーごとに提供されます。Azure と GCP では、IP アドレスの容量には IPv4 アドレスと IPv6 アドレスの両方が含まれます。
ノード間のトラフィックの送信 IP アドレスの自動アタッチおよびデタッチが可能です。これにより、namespace 内の多くの Pod からのトラフィックが、クラスター外の場所への一貫した送信元 IP アドレスを持つことができます。これは、OpenShift Container Platform 4.13 の Red Hat OpenShift Networking のデフォルトのネットワーキングプラグインである OpenShift SDN および OVN-Kubernetes もサポートします。
RHOSP クラスター管理者が Floating IP を予約ポートに割り当てると、OpenShift Container Platform は予約ポートを削除できません。RHOSP クラスター管理者が予約ポートから Floating IP の割り当てを解除するまで、CloudPrivateIPConfig オブジェクトは削除および移動操作を実行できません。
次の例は、いくつかのパブリッククラウドプロバイダーのノードからのアノテーションを示しています。アノテーションは、読みやすくするためにインデントされています。
AWS での cloud.network.openshift.io/egress-ipconfig アノテーションの例
cloud.network.openshift.io/egress-ipconfig: [
{
"interface":"eni-078d267045138e436",
"ifaddr":{"ipv4":"10.0.128.0/18"},
"capacity":{"ipv4":14,"ipv6":15}
}
]
GCP での cloud.network.openshift.io/egress-ipconfig アノテーションの例
cloud.network.openshift.io/egress-ipconfig: [
{
"interface":"nic0",
"ifaddr":{"ipv4":"10.0.128.0/18"},
"capacity":{"ip":14}
}
]
次のセクションでは、容量計算で使用するためにサポートされているパブリッククラウド環境の IP アドレス容量を説明します。
27.15.1.2.1. Amazon Web Services (AWS) の IP アドレス容量の制限
AWS では、IP アドレスの割り当てに関する制約は、設定されているインスタンスタイプによって異なります。詳細は、IP addresses per network interface per instance type を参照してください。
27.15.1.2.2. Google Cloud Platform (GCP) の IP アドレス容量の制限
GCP では、ネットワークモデルは、IP アドレスの割り当てではなく、IP アドレスのエイリアス作成を介して追加のノード IP アドレスを実装します。ただし、IP アドレス容量は IP エイリアス容量に直接マッピングされます。
IP エイリアスの割り当てには、次の容量制限があります。
- ノードごとに、IPv4 と IPv6 の両方の IP エイリアスの最大数は 100 です。
- VPC ごとに、IP エイリアスの最大数は指定されていませんが、OpenShift Container Platform のスケーラビリティーテストでは、最大数が約 15,000 であることが明らかになっています。
詳細は、インスタンスごとのクォータとエイリアス IP 範囲の概要を参照してください。
27.15.1.2.3. Microsoft Azure IP アドレスの容量制限
Azure では、IP アドレスの割り当てに次の容量制限があります。
- NIC ごとに、IPv4 と IPv6 の両方で割り当て可能な IP アドレスの最大数は 256 です。
- 仮想ネットワークごとに、割り当てられる IP アドレスの最大数は 65,536 を超えることはできません。
詳細は、ネットワークの制限を参照してください。
27.15.1.3. egress IP の Pod への割り当て
1 つ以上の egress IP を namespace に、または namespace の特定の Pod に割り当てるには、以下の条件を満たす必要があります。
-
クラスター内の 1 つ以上のノードに
k8s.ovn.org/egress-assignable: ""ラベルがなければなりません。 -
EgressIPオブジェクトが存在し、これは namespace の Pod からクラスターを離脱するトラフィックのソース IP アドレスとして使用する 1 つ以上の egress IP アドレスを定義します。
egress IP の割り当て用にクラスター内のノードにラベルを付ける前に EgressIP オブジェクトを作成する場合、OpenShift Container Platform は k8s.ovn.org/egress-assignable: "" ラベルですべての egress IP アドレスを最初のノードに割り当てる可能性があります。
egress IP アドレスがクラスター内のノード全体に広く分散されるようにするには、EgressIP オブジェクトを作成する前に、egress IP アドレスをホストする予定のノードにラベルを常に適用します。
27.15.1.4. egress IP のノードへの割り当て
EgressIP オブジェクトを作成する場合、k8s.ovn.org/egress-assignable: "" ラベルのラベルが付いたノードに以下の条件が適用されます。
- egress IP アドレスは一度に複数のノードに割り当てられることはありません。
- egress IP アドレスは、egress IP アドレスをホストできる利用可能なノード間で均等に分散されます。
EgressIPオブジェクトのspec.EgressIPs配列が複数の IP アドレスを指定する場合は、以下の条件が適用されます。- 指定された IP アドレスを複数ホストするノードはありません。
- トラフィックは、指定された namespace の指定された IP アドレス間でほぼ均等に分散されます。
- ノードが利用不可の場合、そのノードに割り当てられる egress IP アドレスは自動的に再割り当てされます (前述の条件が適用されます)。
Pod が複数の EgressIP オブジェクトのセレクターに一致する場合、EgressIP オブジェクトに指定される egress IP アドレスのどれが Pod の egress IP アドレスとして割り当てられるのかという保証はありません。
さらに、EgressIP オブジェクトが複数の送信 IP アドレスを指定する場合、どの送信 IP アドレスが使用されるかは保証されません。たとえば、Pod が 10.10.20.1 と 10.10.20.2 の 2 つの egress IP アドレスを持つ EgressIP オブジェクトのセレクターと一致する場合、各 TCP 接続または UDP 会話にいずれかが使用される可能性があります。
27.15.1.5. egress IP アドレス設定のアーキテクチャー図
以下の図は、egress IP アドレス設定を示しています。この図では、クラスターの 3 つのノードで実行される 2 つの異なる namespace の 4 つの Pod について説明します。ノードには、ホストネットワークの 192.168.126.0/18 CIDR ブロックから IP アドレスが割り当てられます。
ノード 1 とノード 3 の両方に k8s.ovn.org/egress-assignable: "" というラベルが付けられるため、egress IP アドレスの割り当てに利用できます。
図の破線は、pod1、pod2、および pod3 からのトラフィックフローが Pod ネットワークを通過し、クラスターがノード 1 およびノード 3 から出る様子を示しています。外部サービスが、EgressIP オブジェクトの例で選択した Pod からトラフィックを受信する場合、ソース IP アドレスは 192.168.126.10 または 192.168.126.102 のいずれかになります。トラフィックはこれらの 2 つのノード間でほぼ均等に分散されます。
図にある次のリソースの詳細を以下に示します。
Namespaceオブジェクトnamespace は以下のマニフェストで定義されます。
namespace オブジェクト
apiVersion: v1 kind: Namespace metadata: name: namespace1 labels: env: prod --- apiVersion: v1 kind: Namespace metadata: name: namespace2 labels: env: prodEgressIPオブジェクト以下の
EgressIPオブジェクトは、envラベルがprodに設定される namespace のすべての Pod を選択する設定を説明しています。選択された Pod の egress IP アドレスは192.168.126.10および192.168.126.102です。EgressIPオブジェクトapiVersion: k8s.ovn.org/v1 kind: EgressIP metadata: name: egressips-prod spec: egressIPs: - 192.168.126.10 - 192.168.126.102 namespaceSelector: matchLabels: env: prod status: items: - node: node1 egressIP: 192.168.126.10 - node: node3 egressIP: 192.168.126.102直前の例の設定の場合、OpenShift Container Platform は両方の egress IP アドレスを利用可能なノードに割り当てます。
statusフィールドは、egress IP アドレスの割り当ての有無および割り当てられる場所を反映します。
27.15.2. EgressIP オブジェクト
以下の YAML は、EgressIP オブジェクトの API について説明しています。オブジェクトの範囲はクラスター全体です。これは namespace では作成されません。
apiVersion: k8s.ovn.org/v1 kind: EgressIP metadata: name: <name> 1 spec: egressIPs: 2 - <ip_address> namespaceSelector: 3 ... podSelector: 4 ...
以下の YAML は namespace セレクターのスタンザについて説明しています。
namespace セレクタースタンザ
namespaceSelector: 1
matchLabels:
<label_name>: <label_value>
- 1
- namespace の 1 つ以上のマッチングルール。複数のマッチングルールを指定すると、一致するすべての namespace が選択されます。
以下の YAML は Pod セレクターのオプションのスタンザについて説明しています。
Pod セレクタースタンザ
podSelector: 1
matchLabels:
<label_name>: <label_value>
- 1
- オプション: 指定された
namespaceSelectorルールに一致する、namespace の Pod の 1 つ以上のマッチングルール。これが指定されている場合、一致する Pod のみが選択されます。namespace の他の Pod は選択されていません。
以下の例では、EgressIP オブジェクトは 192.168.126.11 および 192.168.126.102 egress IP アドレスを、app ラベルが web に設定されており、env ラベルが prod に設定されている namespace にある Pod に関連付けます。
EgressIP オブジェクトの例
apiVersion: k8s.ovn.org/v1
kind: EgressIP
metadata:
name: egress-group1
spec:
egressIPs:
- 192.168.126.11
- 192.168.126.102
podSelector:
matchLabels:
app: web
namespaceSelector:
matchLabels:
env: prod
以下の例では、EgressIP オブジェクトは、192.168.127.30 および 192.168.127.40 egress IP アドレスを、environment ラベルが development に設定されていない Pod に関連付けます。
EgressIP オブジェクトの例
apiVersion: k8s.ovn.org/v1
kind: EgressIP
metadata:
name: egress-group2
spec:
egressIPs:
- 192.168.127.30
- 192.168.127.40
namespaceSelector:
matchExpressions:
- key: environment
operator: NotIn
values:
- development
27.15.3. EgressIPconfig オブジェクト
egress IP の機能として、reachabilityTotalTimeoutSeconds パラメーターは、プローブによって egress IP ノードに送信されるチェックの合計タイムアウトを設定します。egressIPConfig オブジェクトを使用すると、ユーザーは reachabilityTotalTimeoutSeconds spec を設定できます。このタイムアウト内に EgressIP ノードに到達できない場合、ノードはダウンしていると宣言されます。
ネットワークが現在のデフォルト値である 1 秒を処理できるほど安定していない場合は、この値を増やすことができます。
次の YAML は、reachabilityTotalTimeoutSeconds をデフォルトの 1 秒プローブから 5 秒プローブに変更する方法を記述しています。
apiVersion: operator.openshift.io/v1
kind: Network
metadata:
name: cluster
spec:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
defaultNetwork:
ovnKubernetesConfig:
egressIPConfig: 1
reachabilityTotalTimeoutSeconds: 5 2
gatewayConfig:
routingViaHost: false
genevePort: 608127.15.4. egress IP アドレスをホストするノードのラベル付け
OpenShift Container Platform が 1 つ以上の egress IP アドレスをノードに割り当てることができるように、k8s.ovn.org/egress-assignable="" ラベルをクラスター内のノードに適用することができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - クラスター管理者としてクラスターにログインします。
手順
1 つ以上の egress IP アドレスをホストできるようにノードにラベルを付けるには、以下のコマンドを入力します。
$ oc label nodes <node_name> k8s.ovn.org/egress-assignable="" 1- 1
- ラベルを付けるノードの名前。
ヒントまたは、以下の YAML を適用してラベルをノードに追加できます。
apiVersion: v1 kind: Node metadata: labels: k8s.ovn.org/egress-assignable: "" name: <node_name>
27.15.5. 次のステップ
27.15.6. 関連情報
27.16. egress IP アドレスの割り当て
クラスター管理者は、namespace または namespace の特定の Pod からクラスターを出るトラフィックに egress IP アドレスを割り当てることができます。
27.16.1. egress IP アドレスの namespace への割り当て
1 つ以上の egress IP アドレスを namespace または namespace の特定の Pod に割り当てることができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - クラスター管理者としてクラスターにログインします。
- egress IP アドレスをホストするように 1 つ以上のノードを設定します。
手順
EgressIPオブジェクトを作成します。-
<egressips_name>.yamlファイルを作成します。<egressips_name>はオブジェクトの名前になります。 作成したファイルで、以下の例のように
EgressIPsオブジェクトを定義します。apiVersion: k8s.ovn.org/v1 kind: EgressIP metadata: name: egress-project1 spec: egressIPs: - 192.168.127.10 - 192.168.127.11 namespaceSelector: matchLabels: env: qa
-
オブジェクトを作成するには、以下のコマンドを入力します。
$ oc apply -f <egressips_name>.yaml 1- 1
<egressips_name>をオブジェクトの名前に置き換えます。
出力例
egressips.k8s.ovn.org/<egressips_name> created
-
オプション: 後に変更できるように
<egressips_name>.yamlファイルを保存します。 egress IP アドレスを必要とする namespace にラベルを追加します。手順 1 で定義した
Egress IPオブジェクトの namespace にラベルを追加するには、以下のコマンドを実行します。$ oc label ns <namespace> env=qa 1- 1
<namespace>は、egress IP アドレスを必要とする namespace に置き換えてください。
27.16.2. 関連情報
27.17. egress ルーター Pod の使用についての考慮事項
27.17.1. egress ルーター Pod について
OpenShift Container Platform egress ルーター Pod は、他の用途で使用されていないプライベートソース IP アドレスから指定されたリモートサーバーにトラフィックをリダイレクトします。Egress ルーター Pod により、特定の IP アドレスからのアクセスのみを許可するように設定されたサーバーにネットワークトラフィックを送信できます。
egress ルーター Pod はすべての発信接続のために使用されることが意図されていません。多数の egress ルーター Pod を作成することで、ネットワークハードウェアの制限を引き上げられる可能性があります。たとえば、すべてのプロジェクトまたはアプリケーションに egress ルーター Pod を作成すると、ソフトウェアの MAC アドレスのフィルターに戻る前にネットワークインターフェイスが処理できるローカル MAC アドレス数の上限を超えてしまう可能性があります。
egress ルーターイメージには Amazon AWS, Azure Cloud またはレイヤー 2 操作をサポートしないその他のクラウドプラットフォームとの互換性がありません。 それらに macvlan トラフィックとの互換性がないためです。
27.17.1.1. Egress ルーターモード
リダイレクトモード では、egress ルーター Pod は、トラフィックを独自の IP アドレスから 1 つ以上の宛先 IP アドレスにリダイレクトするために iptables ルールをセットアップします。予約された送信元 IP アドレスを使用する必要があるクライアント Pod は、宛先 IP に直接接続するのではなく、スロールーターのサービスにアクセスするように設定する必要があります。curl コマンドを使用して、アプリケーション Pod から宛先サービスとポートにアクセスできます。以下に例を示します。
$ curl <router_service_IP> <port>
egress ルーター CNI プラグインはリダイレクトモードのみをサポートします。これは、OpenShift SDN でデプロイできる egress ルーター実装の相違点です。OpenShift SDN の Egress ルーターとは異なり、Egress ルーター CNI プラグインは HTTP プロキシーモードまたは DNS プロキシーモード をサポートしません。
27.17.1.2. egress ルーター Pod の実装
egress ルーターの実装では、egress ルーターの Container Network Interface (CNI) プラグインを使用します。プラグインはセカンダリーネットワークインターフェイスを Pod に追加します。
egress ルーターは、2 つのネットワークインターフェイスを持つ Pod です。たとえば、Pod には、eth0 および net1 ネットワークインターフェイスを使用できます。eth0 インターフェイスはクラスターネットワークにあり、Pod は通常のクラスター関連のネットワークトラフィックにこのインターフェイスを引き続き使用します。net1 インターフェイスはセカンダリーネットワークにあり、そのネットワークの IP アドレスとゲートウェイを持ちます。OpenShift Container Platform クラスターの他の Pod は egress ルーターサービスにアクセスでき、サービスにより Pod が外部サービスにアクセスできるようになります。egress ルーターは、Pod と外部システム間のブリッジとして機能します。
egress ルーターから出るトラフィックはノードで終了しますが、パケットには egress ルーター Pod からの net1 インターフェイスの MAC アドレスがあります。
Egress ルーターのカスタムリソースを追加すると、Cluster Network Operator は以下のオブジェクトを作成します。
-
Pod の
net1セカンダリーネットワークインターフェイス用のネットワーク接続定義。 - Egress ルーターのデプロイメント。
Egress ルーターカスタムリソースを削除する場合、Operator は Egress ルーターに関連付けられた直前のリストの 2 つのオブジェクトを削除します。
27.17.1.3. デプロイメントに関する考慮事項
egress ルーター Pod は追加の IP アドレスおよび MAC アドレスをノードのプライマリーネットワークインターフェイスに追加します。その結果、ハイパーバイザーまたはクラウドプロバイダーを、追加のアドレスを許可するように設定する必要がある場合があります。
- Red Hat OpenStack Platform (RHOSP)
OpenShift Container Platform を RHOSP にデプロイする場合、OpenStack 環境の egress ルーター Pod の IP および MAC アドレスからのトラフィックを許可する必要があります。トラフィックを許可しないと、通信は失敗 します。
$ openstack port set --allowed-address \ ip_address=<ip_address>,mac_address=<mac_address> <neutron_port_uuid>
- Red Hat Virtualization (RHV)
- RHV を使用している場合は、仮想インターフェイスカード (vNIC) に No Network Filter を選択する必要があります。
- VMware vSphere
- VMware vSphere を使用している場合は、vSphere 標準スイッチのセキュリティー保護についての VMware ドキュメント を参照してください。vSphere Web クライアントからホストの仮想スイッチを選択して、VMware vSphere デフォルト設定を表示し、変更します。
とくに、以下が有効にされていることを確認します。
27.17.1.4. フェイルオーバー設定
ダウンタイムを回避するにために、Cluster Network Operator は Egress ルーター Pod をデプロイメントリソースとしてデプロイします。デプロイメント名は egress-router-cni-deployment です。デプロイメントに対応する Pod には app=egress-router-cni のラベルがあります。
デプロイメントの新規サービスを作成するには、oc expose deployment/egress-router-cni-deployment --port <port_number> コマンドを使用するか、以下のようにファイルを作成します。
apiVersion: v1
kind: Service
metadata:
name: app-egress
spec:
ports:
- name: tcp-8080
protocol: TCP
port: 8080
- name: tcp-8443
protocol: TCP
port: 8443
- name: udp-80
protocol: UDP
port: 80
type: ClusterIP
selector:
app: egress-router-cni27.17.2. 関連情報
27.18. リダイレクトモードでの egress ルーター Pod のデプロイ
クラスター管理者は、トラフィックを予約されたソース IP アドレスから指定された宛先 IP アドレスにリダイレクトするように egress ルーター Pod をデプロイできます。
egress ルーターの実装では、egress ルーターの Container Network Interface (CNI) プラグインを使用します。
27.18.1. Egress ルーターのカスタムリソース
Egress ルーターのカスタムリソースで Egress ルーター Pod の設定を定義します。以下の YAML は、リダイレクトモードでの Egress ルーターの設定のフィールドについて説明しています。
apiVersion: network.operator.openshift.io/v1
kind: EgressRouter
metadata:
name: <egress_router_name>
namespace: <namespace> <.>
spec:
addresses: [ <.>
{
ip: "<egress_router>", <.>
gateway: "<egress_gateway>" <.>
}
]
mode: Redirect
redirect: {
redirectRules: [ <.>
{
destinationIP: "<egress_destination>",
port: <egress_router_port>,
targetPort: <target_port>, <.>
protocol: <network_protocol> <.>
},
...
],
fallbackIP: "<egress_destination>" <.>
}
<.> オプション: namespace フィールドは、Egress ルーターを作成するための namespace を指定します。ファイルまたはコマンドラインで値を指定しない場合には、default namespace が使用されます。
<.> addresses フィールドは、セカンダリーネットワークインターフェイスに設定する IP アドレスを指定します。
<.> ip フィールドは、ノードが Egress ルーター Pod と使用する物理ネットワークからの予約済みソース IP アドレスとネットマスクを指定します。CIDR 表記を使用して IP アドレスとネットマスクを指定します。
<.> gateway フィールドは、ネットワークゲートウェイの IP アドレスを指定します。
<.> オプション: redirectRules フィールドは、Egress 宛先 IP アドレス、Egress ルーターポート、およびプロトコルの組み合わせを指定します。指定されたポートとプロトコルでの Egress ルーターへの着信接続は、宛先 IP アドレスにルーティングされます。
<.> オプション: targetPort フィールドは、宛先 IP アドレスのネットワークポートを指定します。このフィールドが指定されていない場合、トラフィックは到達したネットワークポートと同じネットワークポートにルーティングされます。
<.> protocol フィールドは TCP、UDP、または SCTP をサポートします。
<.> オプション: fallbackIP フィールドは、宛先 IP アドレスを指定します。リダイレクトルールを指定しない場合、Egress ルーターはすべてのトラフィックをこのフォールバック IP アドレスに送信します。リダイレクトルールを指定する場合、ルールに定義されていないネットワークポートへの接続は、Egress ルーターによってこのフォールバック IP アドレスに送信されます。このフィールドを指定しない場合、Egress ルーターはルールで定義されていないネットワークポートへの接続を拒否します。
egress ルーター仕様の例
apiVersion: network.operator.openshift.io/v1
kind: EgressRouter
metadata:
name: egress-router-redirect
spec:
networkInterface: {
macvlan: {
mode: "Bridge"
}
}
addresses: [
{
ip: "192.168.12.99/24",
gateway: "192.168.12.1"
}
]
mode: Redirect
redirect: {
redirectRules: [
{
destinationIP: "10.0.0.99",
port: 80,
protocol: UDP
},
{
destinationIP: "203.0.113.26",
port: 8080,
targetPort: 80,
protocol: TCP
},
{
destinationIP: "203.0.113.27",
port: 8443,
targetPort: 443,
protocol: TCP
}
]
}
27.18.2. リダイレクトモードでの Egress ルーターのデプロイ
egress ルーターをデプロイして、独自の予約済みソース IP アドレスから 1 つ以上の宛先 IP アドレスにトラフィックをリダイレクトできます。
egress ルーターを追加した後に、予約済みソース IP アドレスを使用する必要のあるクライアント Pod は、宛先 IP に直接接続するのでなく、egress ルーターに接続するように変更される必要があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
- egress ルーター定義の作成
他の Pod が egress ルーター Pod の IP アドレスを見つられるようにするには、以下の例のように、egress ルーターを使用するサービスを作成します。
apiVersion: v1 kind: Service metadata: name: egress-1 spec: ports: - name: web-app protocol: TCP port: 8080 type: ClusterIP selector: app: egress-router-cni <.><.> egress ルーターのラベルを指定します。表示されている値は Cluster Network Operator によって追加され、設定不可能です。
サービスの作成後に、Pod はサービスに接続できます。egress ルーター Pod は、トラフィックを宛先 IP アドレスの対応するポートにリダイレクトします。接続は、予約されたソース IP アドレスを起点とします。
検証
Cluster Network Operator が egress ルーターを起動したことを確認するには、以下の手順を実行します。
Operator が egress ルーター用に作成したネットワーク接続定義を表示します。
$ oc get network-attachment-definition egress-router-cni-nad
ネットワーク接続定義の名前は設定できません。
出力例
NAME AGE egress-router-cni-nad 18m
egress ルーター Pod のデプロイメントを表示します。
$ oc get deployment egress-router-cni-deployment
デプロイメントの名前は設定できません。
出力例
NAME READY UP-TO-DATE AVAILABLE AGE egress-router-cni-deployment 1/1 1 1 18m
egress ルーター Pod のステータスを表示します。
$ oc get pods -l app=egress-router-cni
出力例
NAME READY STATUS RESTARTS AGE egress-router-cni-deployment-575465c75c-qkq6m 1/1 Running 0 18m
- egress ルーター Pod のログとルーティングテーブルを表示します。
egress ルーター Pod のノード名を取得します。
$ POD_NODENAME=$(oc get pod -l app=egress-router-cni -o jsonpath="{.items[0].spec.nodeName}")ターゲットノードのデバッグセッションに入ります。この手順は、
<node_name>-debugというデバッグ Pod をインスタンス化します。$ oc debug node/$POD_NODENAME
/hostをデバッグシェル内の root ディレクトリーとして設定します。デバッグ Pod は、Pod 内の/hostにホストのルートファイルシステムをマウントします。ルートディレクトリーを/hostに変更すると、ホストの実行可能パスに含まれるバイナリーを実行できます。# chroot /host
chroot環境コンソール内から、egress ルーターログを表示します。# cat /tmp/egress-router-log
出力例
2021-04-26T12:27:20Z [debug] Called CNI ADD 2021-04-26T12:27:20Z [debug] Gateway: 192.168.12.1 2021-04-26T12:27:20Z [debug] IP Source Addresses: [192.168.12.99/24] 2021-04-26T12:27:20Z [debug] IP Destinations: [80 UDP 10.0.0.99/30 8080 TCP 203.0.113.26/30 80 8443 TCP 203.0.113.27/30 443] 2021-04-26T12:27:20Z [debug] Created macvlan interface 2021-04-26T12:27:20Z [debug] Renamed macvlan to "net1" 2021-04-26T12:27:20Z [debug] Adding route to gateway 192.168.12.1 on macvlan interface 2021-04-26T12:27:20Z [debug] deleted default route {Ifindex: 3 Dst: <nil> Src: <nil> Gw: 10.128.10.1 Flags: [] Table: 254} 2021-04-26T12:27:20Z [debug] Added new default route with gateway 192.168.12.1 2021-04-26T12:27:20Z [debug] Added iptables rule: iptables -t nat PREROUTING -i eth0 -p UDP --dport 80 -j DNAT --to-destination 10.0.0.99 2021-04-26T12:27:20Z [debug] Added iptables rule: iptables -t nat PREROUTING -i eth0 -p TCP --dport 8080 -j DNAT --to-destination 203.0.113.26:80 2021-04-26T12:27:20Z [debug] Added iptables rule: iptables -t nat PREROUTING -i eth0 -p TCP --dport 8443 -j DNAT --to-destination 203.0.113.27:443 2021-04-26T12:27:20Z [debug] Added iptables rule: iptables -t nat -o net1 -j SNAT --to-source 192.168.12.99この手順で説明されているように、
EgressRouterオブジェクトを作成して egress ルーターを起動する場合、ロギングファイルの場所とロギングレベルは設定できません。chroot環境コンソール内で、コンテナー ID を取得します。# crictl ps --name egress-router-cni-pod | awk '{print $1}'出力例
CONTAINER bac9fae69ddb6
コンテナーのプロセス ID を判別します。この例では、コンテナー ID は
bac9fae69ddb6です。# crictl inspect -o yaml bac9fae69ddb6 | grep 'pid:' | awk '{print $2}'出力例
68857
コンテナーのネットワーク namespace を入力します。
# nsenter -n -t 68857
ルーティングテーブルを表示します。
# ip route
以下の出力例では、
net1ネットワークインターフェイスはデフォルトのルートです。クラスターネットワークのトラフィックはeth0ネットワークインターフェイスを使用します。192.168.12.0/24ネットワークのトラフィックは、net1ネットワークインターフェイスを使用し、予約されたソース IP アドレス192.168.12.99を起点とします。Pod は他のすべてのトラフィックを IP アドレス192.168.12.1のゲートウェイにルーティングします。サービスネットワークのルーティングは表示されません。出力例
default via 192.168.12.1 dev net1 10.128.10.0/23 dev eth0 proto kernel scope link src 10.128.10.18 192.168.12.0/24 dev net1 proto kernel scope link src 192.168.12.99 192.168.12.1 dev net1
27.19. プロジェクトのマルチキャストの有効化
27.19.1. マルチキャストについて
IP マルチキャストを使用すると、データが多数の IP アドレスに同時に配信されます。
- 現時点で、マルチキャストは低帯域幅の調整またはサービスの検出での使用に最も適しており、高帯域幅のソリューションとしては適していません。
-
デフォルトでは、ネットワークポリシーは namespace 内のすべての接続に影響します。ただし、マルチキャストはネットワークポリシーの影響を受けません。マルチキャストがネットワークポリシーと同じ namespace で有効にされている場合、
deny-allネットワークポリシーがある場合でも、マルチキャストは常に許可されます。クラスター管理者は、これを有効にする前に、ネットワークポリシーからマルチキャストが除外されることの影響を考慮する必要があります。
OpenShift Container Platform の Pod 間のマルチキャストトラフィックはデフォルトで無効にされます。OVN-Kubernetes ネットワークプラグインを使用している場合は、プロジェクトごとにマルチキャストを有効にできます。
27.19.2. Pod 間のマルチキャストの有効化
プロジェクトの Pod でマルチキャストを有効にすることができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにログインする必要があります。
手順
以下のコマンドを実行し、プロジェクトのマルチキャストを有効にします。
<namespace>を、マルチキャストを有効にする必要のある namespace に置き換えます。$ oc annotate namespace <namespace> \ k8s.ovn.org/multicast-enabled=trueヒントまたは、以下の YAML を適用してアノテーションを追加できます。
apiVersion: v1 kind: Namespace metadata: name: <namespace> annotations: k8s.ovn.org/multicast-enabled: "true"
検証
マルチキャストがプロジェクトについて有効にされていることを確認するには、以下の手順を実行します。
現在のプロジェクトを、マルチキャストを有効にしたプロジェクトに切り替えます。
<project>をプロジェクト名に置き換えます。$ oc project <project>
マルチキャストレシーバーとして機能する Pod を作成します。
$ cat <<EOF| oc create -f - apiVersion: v1 kind: Pod metadata: name: mlistener labels: app: multicast-verify spec: containers: - name: mlistener image: registry.access.redhat.com/ubi9 command: ["/bin/sh", "-c"] args: ["dnf -y install socat hostname && sleep inf"] ports: - containerPort: 30102 name: mlistener protocol: UDP EOFマルチキャストセンダーとして機能する Pod を作成します。
$ cat <<EOF| oc create -f - apiVersion: v1 kind: Pod metadata: name: msender labels: app: multicast-verify spec: containers: - name: msender image: registry.access.redhat.com/ubi9 command: ["/bin/sh", "-c"] args: ["dnf -y install socat && sleep inf"] EOF新しいターミナルウィンドウまたはタブで、マルチキャストリスナーを起動します。
Pod の IP アドレスを取得します。
$ POD_IP=$(oc get pods mlistener -o jsonpath='{.status.podIP}')次のコマンドを入力して、マルチキャストリスナーを起動します。
$ oc exec mlistener -i -t -- \ socat UDP4-RECVFROM:30102,ip-add-membership=224.1.0.1:$POD_IP,fork EXEC:hostname
マルチキャストトランスミッターを開始します。
Pod ネットワーク IP アドレス範囲を取得します。
$ CIDR=$(oc get Network.config.openshift.io cluster \ -o jsonpath='{.status.clusterNetwork[0].cidr}')マルチキャストメッセージを送信するには、以下のコマンドを入力します。
$ oc exec msender -i -t -- \ /bin/bash -c "echo | socat STDIO UDP4-DATAGRAM:224.1.0.1:30102,range=$CIDR,ip-multicast-ttl=64"マルチキャストが機能している場合、直前のコマンドは以下の出力を返します。
mlistener
27.20. プロジェクトのマルチキャストの無効化
27.20.1. Pod 間のマルチキャストの無効化
プロジェクトの Pod でマルチキャストを無効にすることができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにログインする必要があります。
手順
以下のコマンドを実行して、マルチキャストを無効にします。
$ oc annotate namespace <namespace> \ 1 k8s.ovn.org/multicast-enabled-- 1
- マルチキャストを無効にする必要のあるプロジェクトの
namespace。
ヒントまたは、以下の YAML を適用してアノテーションを削除できます。
apiVersion: v1 kind: Namespace metadata: name: <namespace> annotations: k8s.ovn.org/multicast-enabled: null
27.21. ネットワークフローの追跡
クラスター管理者は、以下の領域をサポートする、クラスターからの Pod ネットワークフローについての情報を収集できます。
- Pod ネットワークで ingress および egress トラフィックをモニターします。
- パフォーマンスに関する問題のトラブルシューティング
- 容量計画およびセキュリティー監査に関するデータを収集します。
ネットワークフローのコレクションを有効にすると、トラフィックに関するメタデータのみが収集されます。たとえば、パケットデータは収集されませんが、プロトコル、ソースアドレス、宛先アドレス、ポート番号、バイト数、その他のパケットレベルの情報を収集します。
データは、以下の 1 つ以上のレコード形式で収集されます。
- NetFlow
- sFlow
- IPFIX
1 つ以上のコレクター IP アドレスおよびポート番号を使用して Cluster Network Operator (CNO) を設定する場合、Operator は各ノードで Open vSwitch (OVS) を設定し、ネットワークフローレコードを各コレクターに送信します。
Operator を、複数のネットワークフローコレクターにレコードを送信するように設定できます。たとえば、レコードを NetFlow コレクターに送信し、レコードを sFlow コレクターに送信することもできます。
OVS がデータをコレクターに送信すると、それぞれのタイプのコレクターは同一レコードを受け取ります。たとえば、2 つの NetFlow コレクターを設定すると、ノード上の OVS は同じレコードを 2 つのコレクターに送信します。また、2 つの sFlow コレクターを設定した場合には、2 つの sFlow コレクターが同じレコードを受け取ります。ただし、各コレクタータイプには固有のレコード形式があります。
ネットワークフローデータを収集し、レコードをコレクターに送信すると、パフォーマンスに影響があります。ノードは低速でパケットを処理します。パフォーマンスへの影響が大きすぎる場合は、コレクターの宛先を削除し、ネットワークフローデータの収集を無効にしてパフォーマンスを回復できます。
ネットワークフローコレクターを有効にすると、クラスターネットワークの全体的なパフォーマンスに影響を与える可能性があります。
27.21.1. ネットワークフローを追跡するためのネットワークオブジェクト設定
Cluster Network Operator (CNO) でネットワークフローコレクターを設定するフィールドを以下の表に示します。
表27.13 ネットワークフローの設定
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
CNO オブジェクトの名前。この名前は常に |
|
|
|
1 つ以上の |
|
|
| 最大 10 コレクターの IP アドレスとネットワークポートのペアのリスト。 |
|
|
| 最大 10 コレクターの IP アドレスとネットワークポートのペアのリスト。 |
|
|
| 最大 10 コレクターの IP アドレスとネットワークポートのペアのリスト。 |
以下のマニフェストを CNO に適用した後に、Operator は、192.168.1.99:2056 でリッスンする NetFlow コレクターにネットワークフローレコードを送信するようにクラスター内の各ノードで Open vSwitch (OVS) を設定します。
ネットワークフローを追跡するための設定例
apiVersion: operator.openshift.io/v1
kind: Network
metadata:
name: cluster
spec:
exportNetworkFlows:
netFlow:
collectors:
- 192.168.1.99:2056
27.21.2. ネットワークフローコレクターの宛先の追加
クラスター管理者として、Cluster Network Operator (CNO) を設定して、Pod ネットワークについてのネットワークフローメタデータのネットワークフローコレクターへの送信を停止することができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインしている。 - ネットワークフローコレクターがあり、リッスンする IP アドレスとポートを把握している。
手順
ネットワークフローコレクターのタイプおよびコレクターの IP アドレスとポート情報を指定するパッチファイルを作成します。
spec: exportNetworkFlows: netFlow: collectors: - 192.168.1.99:2056ネットワークフローコレクターで CNO を設定します。
$ oc patch network.operator cluster --type merge -p "$(cat <file_name>.yaml)"
出力例
network.operator.openshift.io/cluster patched
検証
検証は通常必須ではありません。以下のコマンドを実行して、各ノードの Open vSwitch (OVS) がネットワークフローレコードを 1 つ以上のコレクターに送信するように設定されていることを確認できます。
Operator 設定を表示して、
exportNetworkFlowsフィールドが設定されていることを確認します。$ oc get network.operator cluster -o jsonpath="{.spec.exportNetworkFlows}"出力例
{"netFlow":{"collectors":["192.168.1.99:2056"]}}各ノードから OVS のネットワークフロー設定を表示します。
$ for pod in $(oc get pods -n openshift-ovn-kubernetes -l app=ovnkube-node -o jsonpath='{range@.items[*]}{.metadata.name}{"\n"}{end}'); do ; echo; echo $pod; oc -n openshift-ovn-kubernetes exec -c ovnkube-node $pod \ -- bash -c 'for type in ipfix sflow netflow ; do ovs-vsctl find $type ; done'; done出力例
ovnkube-node-xrn4p _uuid : a4d2aaca-5023-4f3d-9400-7275f92611f9 active_timeout : 60 add_id_to_interface : false engine_id : [] engine_type : [] external_ids : {} targets : ["192.168.1.99:2056"] ovnkube-node-z4vq9 _uuid : 61d02fdb-9228-4993-8ff5-b27f01a29bd6 active_timeout : 60 add_id_to_interface : false engine_id : [] engine_type : [] external_ids : {} targets : ["192.168.1.99:2056"]- ...
27.21.3. ネットワークフローコレクターのすべての宛先の削除
クラスター管理者として、Cluster Network Operator (CNO) を設定して、ネットワークフローメタデータのネットワークフローコレクターへの送信を停止することができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインしている。
手順
すべてのネットワークフローコレクターを削除します。
$ oc patch network.operator cluster --type='json' \ -p='[{"op":"remove", "path":"/spec/exportNetworkFlows"}]'出力例
network.operator.openshift.io/cluster patched
27.21.4. 関連情報
27.22. ハイブリッドネットワークの設定
クラスター管理者は、Red Hat OpenShift Networking OVN-Kubernetes ネットワークプラグインを設定して、Linux および Windows ノードがそれぞれ Linux および Windows ワークロードをホストできるようにすることができます。
27.22.1. OVN-Kubernetes を使用したハイブリッドネットワークの設定
OVN-Kubernetes ネットワークプラグインを使用してハイブリッドネットワークを使用するようにクラスターを設定できます。これにより、異なるノードのネットワーク設定をサポートするハイブリッドクラスターが可能になります。
この設定は、同じクラスター内で Linux ノードと Windows ノードの両方を実行するために必要です。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてクラスターにログインする。 - クラスターが OVN-Kubernetes ネットワークプラグインを使用していることを確認します。
手順
OVN-Kubernetes ハイブリッドネットワークオーバーレイを設定するには、次のコマンドを入力します。
$ oc patch networks.operator.openshift.io cluster --type=merge \ -p '{ "spec":{ "defaultNetwork":{ "ovnKubernetesConfig":{ "hybridOverlayConfig":{ "hybridClusterNetwork":[ { "cidr": "<cidr>", "hostPrefix": <prefix> } ], "hybridOverlayVXLANPort": <overlay_port> } } } } }'ここでは、以下のようになります。
cidr- 追加のオーバーレイネットワーク上のノードに使用される CIDR 設定を指定します。この CIDR はクラスターネットワーク CIDR と重複できません。
hostPrefix-
それぞれの個別ノードに割り当てるサブネット接頭辞の長さを指定します。たとえば、
hostPrefixが23に設定されている場合、各ノードに指定のcidrから/23サブネットが割り当てられます。これにより、510 (2^(32 - 23) - 2) Pod IP アドレスが許可されます。外部ネットワークからのノードへのアクセスを提供する必要がある場合には、ロードバランサーおよびルーターを、トラフィックを管理するように設定します。 hybridOverlayVXLANPort-
追加のオーバーレイネットワークのカスタム VXLAN ポートを指定します。これは、vSphere にインストールされたクラスターで Windows ノードを実行するために必要であり、その他のクラウドプロバイダー用に設定することはできません。カスタムポートには、デフォルトの
4789ポートを除くいずれかのオープンポートを使用できます。この要件についての詳細は、Microsoft ドキュメントの Pod-to-pod connectivity between hosts is broken を参照してください。
注記Windows Server Long-Term Servicing Channel (LTSC): Windows Server 2019 は、カスタムの VXLAN ポートの選択をサポートしないため、カスタムの
hybridOverlayVXLANPort値を持つクラスターではサポートされません。出力例
network.operator.openshift.io/cluster patched
設定がアクティブであることを確認するには、以下のコマンドを入力します。更新が適用されるまでに数分の時間がかかることがあります。
$ oc get network.operator.openshift.io -o jsonpath="{.items[0].spec.defaultNetwork.ovnKubernetesConfig}"
27.22.2. 関連情報
第28章 OpenShift SDN ネットワークプラグイン
28.1. OpenShift SDN ネットワークプラグインについて
Red Hat OpenShift Networking の一部である OpenShift SDN は、ソフトウェア定義ネットワーキング (SDN) アプローチを使用して、OpenShift Container Platform クラスター全体の Pod 間の通信を可能にする統合クラスターネットワークを提供するネットワークプラグインです。OpenShift SDN により、このような Pod ネットワークが確立され、メンテナンスされます。 OpenShift SDN は Open vSwitch (OVS) を使用してオーバーレイネットワークを設定します。
28.1.1. OpenShift SDN ネットワーク分離モード
OpenShift SDN では以下のように、Pod ネットワークを設定するための SDN モードを 3 つ提供します。
-
ネットワークポリシーモードは、プロジェクト管理者が
NetworkPolicyオブジェクトを使用して独自の分離ポリシーを設定することを可能にします。ネットワークポリシーは、OpenShift Container Platform 4.13 のデフォルトモードです。 - マルチテナント モードは、Pod およびサービスのプロジェクトレベルの分離を可能にします。異なるプロジェクトの Pod は、別のプロジェクトの Pod およびサービスとパケットの送受信をすることができなくなります。プロジェクトの分離を無効にし、クラスター全体のすべての Pod およびサービスにネットワークトラフィックを送信したり、それらの Pod およびサービスからネットワークトラフィックを受信したりすることができます。
- サブネット モードは、すべての Pod が他のすべての Pod およびサービスと通信できる Pod ネットワークを提供します。ネットワークポリシーモードは、サブネットモードと同じ機能を提供します。
28.1.2. サポートされているネットワークプラグイン機能のマトリックス
Red Hat OpenShift Networking は、ネットワークプラグイン用に OpenShift SDN と OVN-Kubernetes の 2 つのオプションを提供します。以下の表は、両方のネットワークプラグインの現在の機能サポートをまとめたものです。
表28.1 デフォルトの CNI ネットワークプラグイン機能の比較
| 機能 | OpenShift SDN | OVN-Kubernetes |
|---|---|---|
| Egress IP | サポート対象 | サポート対象 |
| Egress ファイアウォール [1] | サポート対象 | サポート対象 |
| Egress ルーター | サポート対象 | サポート対象 [2] |
| ハイブリッドネットワーク | サポート対象外 | サポート対象 |
| IPsec 暗号化 | サポート対象外 | サポート対象 |
| IPv6 | サポート対象外 | サポート対象 [3] [4] |
| Kubernetes ネットワークポリシー | サポート対象 | サポート対象 |
| Kubernetes ネットワークポリシーログ | サポート対象外 | サポート対象 |
| マルチキャスト | サポート対象 | サポート対象 |
| ハードウェアのオフロード | サポート対象外 | サポート対象 |
- egress ファイアウォールは、OpenShift SDN では egress ネットワークポリシーとしても知られています。これはネットワークポリシーの egress とは異なります。
- OVN-Kubernetes の egress ルーターはリダイレクトモードのみをサポートします。
- IPv6 は、ベアメタル、IBM Power、および IBM Z クラスターでのみサポートされます。
- IPv6 シングルスタックは、Kubernetes NMState をサポートしておらず、IBM Power および IBM Z クラスターでもサポートされていません。
28.2. OpenShift SDN ネットワークプラグインへの移行
クラスター管理者は、OVN-Kubernetes ネットワークプラグインから OpenShift SDN ネットワークプラグインに移行できます。
OpenShift SDN の詳細は、OpenShift SDN ネットワークプラグインについて を参照してください。
28.2.1. 移行プロセスの仕組み
以下の表は、プロセスのユーザーが開始する手順と、移行が応答として実行するアクション間を区分して移行プロセスを要約しています。
表28.2 OVN-Kubernetes から OpenShift SDN への移行
| ユーザーが開始する手順 | 移行アクティビティー |
|---|---|
|
|
|
|
|
|
| クラスターの各ノードを再起動します。 |
|
28.2.2. OpenShift SDN ネットワークプラグインへの移行
クラスター管理者は、OpenShift SDN Container Network Interface (CNI) ネットワークプラグインに移行できます。移行中は、クラスター内のすべてのノードを再起動する必要があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 - インフラストラクチャーにインストールされたクラスターが OVN-Kubernetes ネットワークプラグインで設定されている。
- etcd データベースの最新のバックアップが利用可能である。
- 再起動は、ノードごとに手動でトリガーできます。
- クラスターは既知の正常な状態にあり、エラーがないこと。
手順
Machine Config Operator (MCO) によって管理されるすべてのマシン設定プールを停止します。
マスター設定プールを停止します。
$ oc patch MachineConfigPool master --type='merge' --patch \ '{ "spec": { "paused": true } }'ワーカーマシン設定プールを停止します。
$ oc patch MachineConfigPool worker --type='merge' --patch \ '{ "spec":{ "paused": true } }'
移行の準備をするには、次のコマンドを入力して移行フィールドを
nullに設定します。$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "migration": null } }'移行を開始するには、次のコマンドを入力して、ネットワークプラグインを OpenShift SDN に戻します。
$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "migration": { "networkType": "OpenShiftSDN" } } }' $ oc patch Network.config.openshift.io cluster --type='merge' \ --patch '{ "spec": { "networkType": "OpenShiftSDN" } }'オプション: いくつかの OVN-Kubernetes 機能の OpenShift SDN 同等機能への自動移行を無効にすることができます。
- Egress IP
- Egress ファイアウォール
- マルチキャスト
前述の OpenShift SDN 機能の設定の自動移行を無効にするには、次のキーを指定します。
$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "migration": { "networkType": "OpenShiftSDN", "features": { "egressIP": <bool>, "egressFirewall": <bool>, "multicast": <bool> } } } }'ここでは、以下のようになります。
bool: 機能の移行を有効にするかどうかを指定します。デフォルトはtrueです。オプション: ネットワークインフラストラクチャーの要件を満たすように OpenShift SDN の以下の設定をカスタマイズできます。
- Maximum transmission unit (MTU)
- VXLAN ポート
以前の設定のいずれかを両方をカスタマイズするには、カスタマイズし、以下のコマンドを入力します。デフォルト値を変更する必要がない場合は、パッチのキーを省略します。
$ oc patch Network.operator.openshift.io cluster --type=merge \ --patch '{ "spec":{ "defaultNetwork":{ "openshiftSDNConfig":{ "mtu":<mtu>, "vxlanPort":<port> }}}}'mtu-
VXLAN オーバーレイネットワークの MTU。この値は通常は自動的に設定されますが、クラスターにあるノードすべてが同じ MTU を使用しない場合、これを最小のノード MTU 値よりも
50小さく設定する必要があります。 port-
VXLAN オーバーレイネットワークの UDP ポート。値が指定されない場合は、デフォルトは
4789になります。ポートは OVN-Kubernetes で使用される Geneve ポートと同じにすることはできません。Geneve ポートのデフォルト値は6081です。
patch コマンドの例
$ oc patch Network.operator.openshift.io cluster --type=merge \ --patch '{ "spec":{ "defaultNetwork":{ "openshiftSDNConfig":{ "mtu":1200 }}}}'Multus デーモンセットのロールアウトが完了するまで待機します。
$ oc -n openshift-multus rollout status daemonset/multus
Multus Pod の名前の形式は
multus-<xxxxx>です。ここで、<xxxxx>は文字のランダムなシーケンスになります。Pod が再起動するまでにしばらく時間がかかる可能性があります。出力例
Waiting for daemon set "multus" rollout to finish: 1 out of 6 new pods have been updated... ... Waiting for daemon set "multus" rollout to finish: 5 of 6 updated pods are available... daemon set "multus" successfully rolled out
ネットワークプラグインの変更を完了するには、クラスター内の各ノードを再起動します。次のいずれかの方法で、クラスター内のノードを再起動できます。
oc rshコマンドでは、次のような bash スクリプトを使用できます。#!/bin/bash readarray -t POD_NODES <<< "$(oc get pod -n openshift-machine-config-operator -o wide| grep daemon|awk '{print $1" "$7}')" for i in "${POD_NODES[@]}" do read -r POD NODE <<< "$i" until oc rsh -n openshift-machine-config-operator "$POD" chroot /rootfs shutdown -r +1 do echo "cannot reboot node $NODE, retry" && sleep 3 done donesshコマンドでは、次のような bash スクリプトを使用できます。このスクリプトは、パスワードの入力を求めないように sudo が設定されていることを前提としています。#!/bin/bash for ip in $(oc get nodes -o jsonpath='{.items[*].status.addresses[?(@.type=="InternalIP")].address}') do echo "reboot node $ip" ssh -o StrictHostKeyChecking=no core@$ip sudo shutdown -r -t 3 done
クラスターのノードが再起動したら、すべてのマシン設定プールを起動します。
マスター設定プールを開始します。
$ oc patch MachineConfigPool master --type='merge' --patch \ '{ "spec": { "paused": false } }'ワーカー設定プールを開始します。
$ oc patch MachineConfigPool worker --type='merge' --patch \ '{ "spec": { "paused": false } }'
MCO が各設定プールのマシンを更新すると、各ノードを再起動します。
デフォルトで、MCO は一度にプールごとに単一のマシンを更新するため、移行が完了するまでに必要な時間がクラスターのサイズと共に増加します。
ホスト上の新規マシン設定のステータスを確認します。
マシン設定の状態と適用されたマシン設定の名前をリスト表示するには、以下のコマンドを入力します。
$ oc describe node | egrep "hostname|machineconfig"
出力例
kubernetes.io/hostname=master-0 machineconfiguration.openshift.io/currentConfig: rendered-master-c53e221d9d24e1c8bb6ee89dd3d8ad7b machineconfiguration.openshift.io/desiredConfig: rendered-master-c53e221d9d24e1c8bb6ee89dd3d8ad7b machineconfiguration.openshift.io/reason: machineconfiguration.openshift.io/state: Done
以下のステートメントが true であることを確認します。
-
machineconfiguration.openshift.io/stateフィールドの値はDoneです。 -
machineconfiguration.openshift.io/currentConfigフィールドの値は、machineconfiguration.openshift.io/desiredConfigフィールドの値と等しくなります。
-
マシン設定が正しいことを確認するには、以下のコマンドを入力します。
$ oc get machineconfig <config_name> -o yaml
<config_name>はmachineconfiguration.openshift.io/currentConfigフィールドのマシン設定の名前です。
移行が正常に完了したことを確認します。
ネットワークプラグインが OpenShift SDN であることを確認するには、次のコマンドを入力します。
status.networkTypeの値はOpenShiftSDNである必要があります。$ oc get network.config/cluster -o jsonpath='{.status.networkType}{"\n"}'クラスターノードが
Ready状態にあることを確認するには、以下のコマンドを実行します。$ oc get nodes
ノードが
NotReady状態のままになっている場合、マシン設定デーモン Pod のログを調べ、エラーを解決します。Pod をリスト表示するには、以下のコマンドを入力します。
$ oc get pod -n openshift-machine-config-operator
出力例
NAME READY STATUS RESTARTS AGE machine-config-controller-75f756f89d-sjp8b 1/1 Running 0 37m machine-config-daemon-5cf4b 2/2 Running 0 43h machine-config-daemon-7wzcd 2/2 Running 0 43h machine-config-daemon-fc946 2/2 Running 0 43h machine-config-daemon-g2v28 2/2 Running 0 43h machine-config-daemon-gcl4f 2/2 Running 0 43h machine-config-daemon-l5tnv 2/2 Running 0 43h machine-config-operator-79d9c55d5-hth92 1/1 Running 0 37m machine-config-server-bsc8h 1/1 Running 0 43h machine-config-server-hklrm 1/1 Running 0 43h machine-config-server-k9rtx 1/1 Running 0 43h
設定デーモン Pod の名前は以下の形式になります。
machine-config-daemon-<seq><seq>値は、ランダムな 5 文字の英数字シーケンスになります。直前の出力に表示されるそれぞれのマシン設定デーモン Pod の Pod ログを表示するには、以下のコマンドを入力します。
$ oc logs <pod> -n openshift-machine-config-operator
ここで、
podはマシン設定デーモン Pod の名前になります。- 直前のコマンドの出力で示されるログ内のエラーを解決します。
Pod がエラー状態ではないことを確認するには、以下のコマンドを入力します。
$ oc get pods --all-namespaces -o wide --sort-by='{.spec.nodeName}'ノードの Pod がエラー状態にある場合は、そのノードを再起動します。
以下の手順は、移行に成功し、クラスターの状態が正常である場合にのみ実行します。
Cluster Network Operator 設定オブジェクトから移行設定を削除するには、以下のコマンドを入力します。
$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "migration": null } }'OVN-Kubernetes 設定を削除するには、以下のコマンドを入力します。
$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "defaultNetwork": { "ovnKubernetesConfig":null } } }'OVN-Kubernetes ネットワークプロバイダー namespace を削除するには、以下のコマンドを入力します。
$ oc delete namespace openshift-ovn-kubernetes
28.2.3. 関連情報
28.3. OVN-Kubernetes ネットワークプラグインへのロールバック
クラスター管理者は、OpenShift SDN への移行が失敗した場合に、OpenShift SDN ネットワークプラグインから OVN-Kubernetes ネットワークプラグインにロールバックできます。
OVN-Kubernetes の詳細は、OVN-Kubernetes ネットワークプラグインについて を参照してください。
28.3.1. OVN-Kubernetes ネットワークプラグインへの移行
クラスター管理者は、クラスターのネットワークプラグインを OVN-Kubernetes に変更できます。移行時に、クラスター内のすべてのノードを再起動する必要があります。
移行の実行中はクラスターを利用できず、ワークロードが中断される可能性があります。サービスの中断が許容可能な場合にのみ移行を実行します。
前提条件
- ネットワークポリシー分離モードの OpenShift SDN CNI ネットワークプラグインで設定されたクラスター。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 - etcd データベースの最新のバックアップが利用可能である。
- 再起動は、ノードごとに手動でトリガーできます。
- クラスターは既知の正常な状態にあり、エラーがないこと。
-
ソフトウェア更新後のクラウドプラットフォームでは、すべてのノードに対してポート
6081で UDP パケットを許可するセキュリティーグループルールを設定する必要があります。
手順
クラスターネットワークの設定のバックアップを作成するには、以下のコマンドを入力します。
$ oc get Network.config.openshift.io cluster -o yaml > cluster-openshift-sdn.yaml
移行のすべてのノードを準備するには、以下のコマンドを入力して Cluster Network Operator 設定オブジェクトに
migrationフィールドを設定します。$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "migration": { "networkType": "OVNKubernetes" } } }'注記この手順では、OVN-Kubernetes はすぐにデプロイしません。その代わりに、
migrationフィールドを指定すると、新規マシン設定が OVN-Kubernetes デプロイメントの準備に向けてクラスター内のすべてのノードに適用されるように Machine Config Operator (MCO) がトリガーされます。オプション: いくつかの OpenShift SDN 機能の OVN-Kubernetes 同等機能への自動移行を無効にすることができます。
- Egress IP
- Egress ファイアウォール
- マルチキャスト
前述の OpenShift SDN 機能の設定の自動移行を無効にするには、次のキーを指定します。
$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "migration": { "networkType": "OVNKubernetes", "features": { "egressIP": <bool>, "egressFirewall": <bool>, "multicast": <bool> } } } }'ここでは、以下のようになります。
bool: 機能の移行を有効にするかどうかを指定します。デフォルトはtrueです。オプション: ネットワークインフラストラクチャーの要件を満たすように OVN-Kubernetes の以下の設定をカスタマイズできます。
最大伝送単位 (MTU)。このオプションの手順で MTU をカスタマイズする前に、以下を考慮してください。
- デフォルトの MTU を使用しており、移行中にデフォルトの MTU を維持したい場合は、この手順を無視できます。
- カスタム MTU を使用しており、移行中にカスタム MTU を維持する必要がある場合は、この手順でカスタム MTU 値を宣言する必要があります。
移行中に MTU 値を変更する場合、この手順は機能しません。代わりに、まず「クラスター MTU の変更」に記載された指示に従う必要があります。その後、この手順を実行してカスタム MTU 値を宣言すると、カスタム MTU 値を維持できます。
注記OpenShift-SDN と OVN-Kubernetes のオーバーレイオーバーヘッドは異なります。MTU 値は、「MTU 値の選択」ページにあるガイドラインに従って選択する必要があります。
- Geneve (Generic Network Virtualization Encapsulation) オーバーレイネットワークポート
- OVN-Kubernetes IPv4 内部サブネット
- OVN-Kubernetes IPv6 内部サブネット
以前の設定のいずれかをカスタマイズするには、以下のコマンドを入力してカスタマイズします。デフォルト値を変更する必要がない場合は、パッチのキーを省略します。
$ oc patch Network.operator.openshift.io cluster --type=merge \ --patch '{ "spec":{ "defaultNetwork":{ "ovnKubernetesConfig":{ "mtu":<mtu>, "genevePort":<port>, "v4InternalSubnet":"<ipv4_subnet>", "v6InternalSubnet":"<ipv6_subnet>" }}}}'ここでは、以下のようになります。
mtu-
Geneve オーバーレイネットワークの MTU。この値は通常は自動的に設定されますが、クラスターにあるノードすべてが同じ MTU を使用しない場合、これを最小のノード MTU 値よりも
100小さく設定する必要があります。 port-
Geneve オーバーレイネットワークの UDP ポート。値が指定されない場合、デフォルトは
6081になります。ポートは、OpenShift SDN で使用される VXLAN ポートと同じにすることはできません。VXLAN ポートのデフォルト値は4789です。 ipv4_subnet-
OVN-Kubernetes による内部使用のための IPv4 アドレス範囲。IP アドレス範囲が、OpenShift Container Platform インストールで使用される他のサブネットと重複しないようにする必要があります。IP アドレス範囲は、クラスターに追加できるノードの最大数より大きくする必要があります。デフォルト値は
100.64.0.0/16です。 ipv6_subnet-
OVN-Kubernetes による内部使用のための IPv6 アドレス範囲。IP アドレス範囲が、OpenShift Container Platform インストールで使用される他のサブネットと重複しないようにする必要があります。IP アドレス範囲は、クラスターに追加できるノードの最大数より大きくする必要があります。デフォルト値は
fd98::/48です。
mtuフィールドを更新するパッチコマンドの例$ oc patch Network.operator.openshift.io cluster --type=merge \ --patch '{ "spec":{ "defaultNetwork":{ "ovnKubernetesConfig":{ "mtu":1200 }}}}'MCO がそれぞれのマシン設定プールのマシンを更新すると、各ノードが 1 つずつ再起動します。すべてのノードが更新されるまで待機する必要があります。以下のコマンドを実行してマシン設定プールのステータスを確認します。
$ oc get mcp
正常に更新されたノードには、
UPDATED=true、UPDATING=false、DEGRADED=falseのステータスがあります。注記デフォルトで、MCO はプールごとに一度に 1 つのマシンを更新するため、移行にかかる合計時間がクラスターのサイズと共に増加します。
ホスト上の新規マシン設定のステータスを確認します。
マシン設定の状態と適用されたマシン設定の名前をリスト表示するには、以下のコマンドを入力します。
$ oc describe node | egrep "hostname|machineconfig"
出力例
kubernetes.io/hostname=master-0 machineconfiguration.openshift.io/currentConfig: rendered-master-c53e221d9d24e1c8bb6ee89dd3d8ad7b machineconfiguration.openshift.io/desiredConfig: rendered-master-c53e221d9d24e1c8bb6ee89dd3d8ad7b machineconfiguration.openshift.io/reason: machineconfiguration.openshift.io/state: Done
以下のステートメントが true であることを確認します。
-
machineconfiguration.openshift.io/stateフィールドの値はDoneです。 -
machineconfiguration.openshift.io/currentConfigフィールドの値は、machineconfiguration.openshift.io/desiredConfigフィールドの値と等しくなります。
-
マシン設定が正しいことを確認するには、以下のコマンドを入力します。
$ oc get machineconfig <config_name> -o yaml | grep ExecStart
<config_name>はmachineconfiguration.openshift.io/currentConfigフィールドのマシン設定の名前です。マシン設定には、systemd 設定に以下の更新を含める必要があります。
ExecStart=/usr/local/bin/configure-ovs.sh OVNKubernetes
ノードが
NotReady状態のままになっている場合、マシン設定デーモン Pod のログを調べ、エラーを解決します。Pod をリスト表示するには、以下のコマンドを入力します。
$ oc get pod -n openshift-machine-config-operator
出力例
NAME READY STATUS RESTARTS AGE machine-config-controller-75f756f89d-sjp8b 1/1 Running 0 37m machine-config-daemon-5cf4b 2/2 Running 0 43h machine-config-daemon-7wzcd 2/2 Running 0 43h machine-config-daemon-fc946 2/2 Running 0 43h machine-config-daemon-g2v28 2/2 Running 0 43h machine-config-daemon-gcl4f 2/2 Running 0 43h machine-config-daemon-l5tnv 2/2 Running 0 43h machine-config-operator-79d9c55d5-hth92 1/1 Running 0 37m machine-config-server-bsc8h 1/1 Running 0 43h machine-config-server-hklrm 1/1 Running 0 43h machine-config-server-k9rtx 1/1 Running 0 43h
設定デーモン Pod の名前は以下の形式になります。
machine-config-daemon-<seq><seq>値は、ランダムな 5 文字の英数字シーケンスになります。以下のコマンドを入力して、直前の出力に表示される最初のマシン設定デーモン Pod の Pod ログを表示します。
$ oc logs <pod> -n openshift-machine-config-operator
ここで、
podはマシン設定デーモン Pod の名前になります。- 直前のコマンドの出力で示されるログ内のエラーを解決します。
移行を開始するには、次のいずれかのコマンドを使用して OVN-Kubernetes ネットワークプラグインを設定します。
クラスターネットワークの IP アドレスブロックを変更せずにネットワークプロバイダーを指定するには、以下のコマンドを入力します。
$ oc patch Network.config.openshift.io cluster \ --type='merge' --patch '{ "spec": { "networkType": "OVNKubernetes" } }'別のクラスターネットワーク IP アドレスブロックを指定するには、以下のコマンドを入力します。
$ oc patch Network.config.openshift.io cluster \ --type='merge' --patch '{ "spec": { "clusterNetwork": [ { "cidr": "<cidr>", "hostPrefix": <prefix> } ], "networkType": "OVNKubernetes" } }'ここで、
cidrは CIDR ブロックであり、prefixはクラスター内の各ノードに割り当てられる CIDR ブロックのスライスです。OVN-Kubernetes ネットワークプロバイダーはこのブロックを内部で使用するため、100.64.0.0/16CIDR ブロックと重複する CIDR ブロックは使用できません。重要移行時に、サービスネットワークのアドレスブロックを変更することはできません。
Multus デーモンセットのロールアウトが完了したことを確認してから、後続の手順を続行します。
$ oc -n openshift-multus rollout status daemonset/multus
Multus Pod の名前の形式は
multus-<xxxxx>です。ここで、<xxxxx>は文字のランダムなシーケンスになります。Pod が再起動するまでにしばらく時間がかかる可能性があります。出力例
Waiting for daemon set "multus" rollout to finish: 1 out of 6 new pods have been updated... ... Waiting for daemon set "multus" rollout to finish: 5 of 6 updated pods are available... daemon set "multus" successfully rolled out
ネットワークプラグインの変更を完了するには、クラスター内の各ノードを再起動します。次のいずれかの方法で、クラスター内のノードを再起動できます。
oc rshコマンドでは、次のような bash スクリプトを使用できます。#!/bin/bash readarray -t POD_NODES <<< "$(oc get pod -n openshift-machine-config-operator -o wide| grep daemon|awk '{print $1" "$7}')" for i in "${POD_NODES[@]}" do read -r POD NODE <<< "$i" until oc rsh -n openshift-machine-config-operator "$POD" chroot /rootfs shutdown -r +1 do echo "cannot reboot node $NODE, retry" && sleep 3 done donesshコマンドでは、次のような bash スクリプトを使用できます。このスクリプトは、パスワードの入力を求めないように sudo が設定されていることを前提としています。#!/bin/bash for ip in $(oc get nodes -o jsonpath='{.items[*].status.addresses[?(@.type=="InternalIP")].address}') do echo "reboot node $ip" ssh -o StrictHostKeyChecking=no core@$ip sudo shutdown -r -t 3 done
移行が正常に完了したことを確認します。
ネットワークプラグインが OVN-Kubernetes であることを確認するには、次のコマンドを入力します。
status.networkTypeの値はOVNKubernetesである必要があります。$ oc get network.config/cluster -o jsonpath='{.status.networkType}{"\n"}'クラスターノードが
Ready状態にあることを確認するには、以下のコマンドを実行します。$ oc get nodes
Pod がエラー状態ではないことを確認するには、以下のコマンドを入力します。
$ oc get pods --all-namespaces -o wide --sort-by='{.spec.nodeName}'ノードの Pod がエラー状態にある場合は、そのノードを再起動します。
すべてのクラスター Operator が異常な状態にないことを確認するには、以下のコマンドを入力します。
$ oc get co
すべてのクラスター Operator のステータスは、
AVAILABLE="True"、PROGRESSING="False"、DEGRADED="False"になります。クラスター Operator が利用できないか、そのパフォーマンスが低下する場合には、クラスター Operator のログで詳細を確認します。
以下の手順は、移行に成功し、クラスターの状態が正常である場合にのみ実行します。
CNO 設定オブジェクトから移行設定を削除するには、以下のコマンドを入力します。
$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "migration": null } }'OpenShift SDN ネットワークプロバイダーのカスタム設定を削除するには、以下のコマンドを入力します。
$ oc patch Network.operator.openshift.io cluster --type='merge' \ --patch '{ "spec": { "defaultNetwork": { "openshiftSDNConfig": null } } }'OpenShift SDN ネットワークプロバイダー namespace を削除するには、以下のコマンドを入力します。
$ oc delete namespace openshift-sdn
28.4. プロジェクトの egress IP の設定
クラスター管理者は、OpenShift SDN の Container Network Interface (CNI) ネットワークプラグインが 1 つ以上の egress IP アドレスをプロジェクトに割り当てるように設定できます。
28.4.1. Egress IP アドレスアーキテクチャーの設計および実装
OpenShift Container Platform の egress IP アドレス機能を使用すると、1 つ以上の namespace の 1 つ以上の Pod からのトラフィックに、クラスターネットワーク外のサービスに対する一貫したソース IP アドレスを持たせることができます。
たとえば、クラスター外のサーバーでホストされるデータベースを定期的にクエリーする Pod がある場合があります。サーバーにアクセス要件を適用するために、パケットフィルタリングデバイスは、特定の IP アドレスからのトラフィックのみを許可するよう設定されます。この特定の Pod のみからサーバーに確実にアクセスできるようにするには、サーバーに要求を行う Pod に特定の egress IP アドレスを設定できます。
namespace に割り当てられた egress IP アドレスは、特定の宛先にトラフィックを送信するために使用されるスロールーターとは異なります。
一部のクラスター設定では、アプリケーション Pod と Ingress ルーター Pod が同じノードで実行されます。このシナリオでアプリケーションプロジェクトの Egress IP アドレスを設定する場合、アプリケーションプロジェクトからルートに要求を送信するときに IP アドレスは使用されません。
egress IP アドレスは、ノードのプライマリーネットワークインターフェイスの追加 IP アドレスとして実装され、ノードのプライマリー IP アドレスと同じサブネットにある必要があります。追加の IP アドレスは、クラスター内の他のノードには割り当てないでください。
egress IP アドレスは、ifcfg-eth0 などのように Linux ネットワーク設定ファイルで設定することはできません。
28.4.1.1. プラットフォームサポート
各種のプラットフォームでの egress IP アドレス機能のサポートについては、以下の表で説明されています。
| プラットフォーム | サポート対象 |
|---|---|
| ベアメタル | はい |
| VMware vSphere | はい |
| Red Hat OpenStack Platform (RHOSP) | はい |
| Amazon Web Services (AWS) | はい |
| Google Cloud Platform (GCP) | はい |
| Microsoft Azure | はい |
| IBM Z および IBM® LinuxONE | はい |
| IBM Z and IBM® LinuxONE for Red Hat Enterprise Linux (RHEL) KVM | はい |
| IBM Power | はい |
EgressIP 機能を持つコントロールプレーンノードへの egress IP アドレスの割り当ては、Amazon Web Services (AWS) でプロビジョニングされるクラスターではサポートされません。(BZ#2039656)
28.4.1.2. パブリッククラウドプラットフォームに関する考慮事項
パブリッククラウドインフラストラクチャーでプロビジョニングされたクラスターの場合は、ノードごとに割り当て可能な IP アドレスの絶対数に制約があります。ノードごとに割り当て可能な IP アドレスの最大数、つまりIP 容量は、次の式で表すことができます。
IP capacity = public cloud default capacity - sum(current IP assignments)
egress IP 機能はノードごとの IP アドレス容量を管理しますが、デプロイメントでこの制約を計画することが重要です。たとえば、8 ノードのベアメタルインフラストラクチャーにインストールされたクラスターの場合は、150 の egress IP アドレスを設定できます。ただし、パブリッククラウドプロバイダーが IP アドレスの容量をノードあたり 10 IP アドレスに制限している場合、割り当て可能な IP アドレスの総数はわずか 80 です。この例のクラウドプロバイダーで同じ IP アドレス容量を実現するには、7 つの追加ノードを割り当てる必要があります。
パブリッククラウド環境内の任意のノードの IP 容量とサブネットを確認するには、oc get node <node_name> -o yaml コマンドを入力します。cloud.network.openshift.io/egress-ipconfig アノテーションには、ノードの容量とサブネット情報が含まれています。
アノテーション値は、プライマリーネットワークインターフェイスに次の情報を提供するフィールドを持つ単一のオブジェクトを持つ配列です。
-
interface: AWS と Azure のインターフェイス ID と GCP のインターフェイス名を指定します。 -
ifaddr: 一方または両方の IP アドレスファミリーのサブネットマスクを指定します。 -
capacity: ノードの IP アドレス容量を指定します。AWS では、IP アドレス容量は IP アドレスファミリーごとに提供されます。Azure と GCP では、IP アドレスの容量には IPv4 アドレスと IPv6 アドレスの両方が含まれます。
ノード間のトラフィックの送信 IP アドレスの自動アタッチおよびデタッチが可能です。これにより、namespace 内の多くの Pod からのトラフィックが、クラスター外の場所への一貫した送信元 IP アドレスを持つことができます。これは、OpenShift Container Platform 4.13 の Red Hat OpenShift Networking のデフォルトのネットワーキングプラグインである OpenShift SDN および OVN-Kubernetes もサポートします。
RHOSP egress IP アドレス機能は、egressip-<IP address> と呼ばれる Neutron 予約ポートを作成します。OpenShift Container Platform クラスターのインストールに使用したものと同じ RHOSP ユーザーを使用して、Floating IP アドレスをこの予約ポートに割り当て、egress トラフィック用の予測可能な SNAT アドレスを指定できます。RHOSP ネットワーク上の egress IP アドレスが、ノードのフェイルオーバーなどのためにあるノードから別のノードに移動されると、Neutron 予約ポートが削除され、再作成されます。これは、フローティング IP の関連付けが失われ、フローティング IP アドレスを新しい予約ポートに手動で再割り当てする必要があることを意味します。
RHOSP クラスター管理者が Floating IP を予約ポートに割り当てると、OpenShift Container Platform は予約ポートを削除できません。RHOSP クラスター管理者が予約ポートから Floating IP の割り当てを解除するまで、CloudPrivateIPConfig オブジェクトは削除および移動操作を実行できません。
次の例は、いくつかのパブリッククラウドプロバイダーのノードからのアノテーションを示しています。アノテーションは、読みやすくするためにインデントされています。
AWS での cloud.network.openshift.io/egress-ipconfig アノテーションの例
cloud.network.openshift.io/egress-ipconfig: [
{
"interface":"eni-078d267045138e436",
"ifaddr":{"ipv4":"10.0.128.0/18"},
"capacity":{"ipv4":14,"ipv6":15}
}
]
GCP での cloud.network.openshift.io/egress-ipconfig アノテーションの例
cloud.network.openshift.io/egress-ipconfig: [
{
"interface":"nic0",
"ifaddr":{"ipv4":"10.0.128.0/18"},
"capacity":{"ip":14}
}
]
次のセクションでは、容量計算で使用するためにサポートされているパブリッククラウド環境の IP アドレス容量を説明します。
28.4.1.2.1. Amazon Web Services (AWS) の IP アドレス容量の制限
AWS では、IP アドレスの割り当てに関する制約は、設定されているインスタンスタイプによって異なります。詳細は、IP addresses per network interface per instance type を参照してください。
28.4.1.2.2. Google Cloud Platform (GCP) の IP アドレス容量の制限
GCP では、ネットワークモデルは、IP アドレスの割り当てではなく、IP アドレスのエイリアス作成を介して追加のノード IP アドレスを実装します。ただし、IP アドレス容量は IP エイリアス容量に直接マッピングされます。
IP エイリアスの割り当てには、次の容量制限があります。
- ノードごとに、IPv4 と IPv6 の両方の IP エイリアスの最大数は 100 です。
- VPC ごとに、IP エイリアスの最大数は指定されていませんが、OpenShift Container Platform のスケーラビリティーテストでは、最大数が約 15,000 であることが明らかになっています。
詳細は、インスタンスごとのクォータとエイリアス IP 範囲の概要を参照してください。
28.4.1.2.3. Microsoft Azure IP アドレスの容量制限
Azure では、IP アドレスの割り当てに次の容量制限があります。
- NIC ごとに、IPv4 と IPv6 の両方で割り当て可能な IP アドレスの最大数は 256 です。
- 仮想ネットワークごとに、割り当てられる IP アドレスの最大数は 65,536 を超えることはできません。
詳細は、ネットワークの制限を参照してください。
28.4.1.3. 制限
OpenShift SDN ネットワークプラグインで egress IP アドレスを使用する場合、次の制限が適用されます。
- 手動で割り当てられた egress IP アドレスと、自動的に割り当てられた egress IP アドレスは同じノードで使用することができません。
- IP アドレス範囲から egress IP アドレスを手動で割り当てる場合、その範囲を自動の IP 割り当てで利用可能にすることはできません。
- OpenShift SDN egress IP アドレス実装を使用して、複数の namespace で egress IP アドレスを共有することはできません。
複数の namespace 間で IP アドレスを共有する必要がある場合は、OVN-Kubernetes ネットワークプラグインの egress IP アドレスの実装により、複数の namespace で IP アドレスを共有できます。
OpenShift SDN をマルチテナントモードで使用する場合、それらに関連付けられたプロジェクトによって別の namespace に参加している namespace と共に egress IP アドレスを使用することはできません。たとえば、project1 および project2 に oc adm pod-network join-projects --to=project1 project2 コマンドを実行して参加している場合、どちらもプロジェクトも egress IP アドレスを使用できません。詳細は、BZ#1645577 を参照してください。
28.4.1.4. IP アドレス割り当てアプローチ
egress IP アドレスは、NetNamespace オブジェクトの egressIPs パラメーターを設定して namespace に割り当てることができます。egress IP アドレスがプロジェクトに関連付けられた後に、OpenShift SDN は 2 つの方法で Egress IP アドレスをホストに割り当てることを可能にします。
- 自動的に割り当てる 方法では、egress IP アドレス範囲はノードに割り当てられます。
- 手動で割り当てる 方法では、1 つ以上の egress IP アドレスのリストがノードに割り当てられます。
egress IP アドレスを要求する namespace は、それらの egress IP アドレスをホストできるノードに一致し、egress IP アドレスはそれらのノードに割り当てられます。egressIPs パラメーターが NetNamespace オブジェクトに設定されるものの、ノードがその egress IP アドレスをホストしない場合、namespace からの egress トラフィックはドロップされます。
ノードの高可用性は自動的に実行されます。egress IP アドレスをホストするノードが到達不可能であり、egress IP アドレスをホストできるノードがある場合、egress IP アドレスは新規ノードに移行します。到達不可能なノードが再びオンラインに戻ると、ノード間で egress IP アドレスのバランスを図るために egress IP アドレスは自動的に移行します。
28.4.1.4.1. 自動的に割り当てられた egress IP アドレスを使用する場合の考慮事項
egress IP アドレスの自動割り当て方法を使用する場合、以下の考慮事項が適用されます。
-
各ノードの
HostSubnetリソースのegressCIDRsパラメーターを設定して、ノードでホストできる egress IP アドレスの範囲を指定します。OpenShift Container Platform は、指定する IP アドレス範囲に基づいてHostSubnetリソースのegressIPsパラメーターを設定します。
namespace の egress IP アドレスをホストするノードに到達できない場合、OpenShift Container Platform は互換性のある egress IP アドレス範囲を持つ別のノードに egress IP アドレスを再割り当てします。自動割り当て方法は、追加の IP アドレスをノードに関連付ける柔軟性のある環境にインストールされたクラスターに最も適しています。
28.4.1.4.2. 手動で割り当てられた egress IP アドレスを使用する場合の考慮事項
このアプローチにより、egress IP アドレスをホストできるノードを制御できます。
クラスターがパブリッククラウドインフラストラクチャーにインストールされている場合は、egress IP アドレスを割り当てる各ノードに、IP アドレスをホストするための十分な予備容量があることを確認する必要があります。詳細については、前のセクションのプラットフォームに関する考慮事項を参照してください。
egress IP アドレスに手動割り当て方法を使用する場合、以下の考慮事項が適用されます。
-
各ノードの
HostSubnetリソースのegressIPsパラメーターを設定して、ノードでホストできる IP アドレスを指定します。 - namespace ごとに複数の egress IP アドレスがサポートされます。
namespace に複数の egress IP アドレスがあり、それらのアドレスが複数のノードでホストされる場合、以下の追加の考慮事項が適用されます。
- Pod が egress IP アドレスをホストするノード上にある場合、その Pod はノード上の egress IP アドレスを常に使用します。
- Pod が egress IP アドレスをホストするノードにない場合、その Pod はランダムで egress IP アドレスを使用します。
28.4.2. namespace の自動的に割り当てられた egress IP アドレスの有効化
OpenShift Container Platform では、1 つ以上のノードで特定の namespace の egress IP アドレスの自動的な割り当てを有効にできます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
以下の JSON を使用して、
NetNamespaceオブジェクトを egress IP アドレスで更新します。$ oc patch netnamespace <project_name> --type=merge -p \ '{ "egressIPs": [ "<ip_address>" ] }'ここでは、以下のようになります。
<project_name>- プロジェクトの名前を指定します。
<ip_address>-
egressIPs配列の 1 つ以上の egress IP アドレスを指定します。
たとえば、
project1を IP アドレスの 192.168.1.100 に、project2を IP アドレスの 192.168.1.101 に割り当てるには、以下を実行します。$ oc patch netnamespace project1 --type=merge -p \ '{"egressIPs": ["192.168.1.100"]}' $ oc patch netnamespace project2 --type=merge -p \ '{"egressIPs": ["192.168.1.101"]}'注記OpenShift SDN は
NetNamespaceオブジェクトを管理するため、既存のNetNamespaceオブジェクトを変更することによってのみ変更を加えることができます。新規NetNamespaceオブジェクトは作成しません。以下の JSON を使用して、各ホストの
egressCIDRsパラメーターを設定して egress IP アドレスをホストできるノードを示します。$ oc patch hostsubnet <node_name> --type=merge -p \ '{ "egressCIDRs": [ "<ip_address_range>", "<ip_address_range>" ] }'ここでは、以下のようになります。
<node_name>- ノード名を指定します。
<ip_address_range>-
CIDR 形式の IP アドレス範囲を指定します。
egressCIDRs配列に複数のアドレス範囲を指定できます。
たとえば、
node1およびnode2を、192.168.1.0 から 192.168.1.255 の範囲で egress IP アドレスをホストするように設定するには、以下を実行します。$ oc patch hostsubnet node1 --type=merge -p \ '{"egressCIDRs": ["192.168.1.0/24"]}' $ oc patch hostsubnet node2 --type=merge -p \ '{"egressCIDRs": ["192.168.1.0/24"]}'OpenShift Container Platform はバランスを取りながら特定の egress IP アドレスを利用可能なノードに自動的に割り当てます。この場合、egress IP アドレス 192.168.1.100 を
node1に、egress IP アドレス 192.168.1.101 をnode2に割り当て、その逆も行います。
28.4.3. namespace の手動で割り当てられた egress IP アドレスの設定
OpenShift Container Platform で、1 つ以上の egress IP アドレスを namespace に関連付けることができます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
以下の JSON オブジェクトを必要な IP アドレスで指定して、
NetNamespaceオブジェクトを更新します。$ oc patch netnamespace <project_name> --type=merge -p \ '{ "egressIPs": [ "<ip_address>" ] }'ここでは、以下のようになります。
<project_name>- プロジェクトの名前を指定します。
<ip_address>-
egressIPs配列の 1 つ以上の egress IP アドレスを指定します。
たとえば、
project1プロジェクトを IP アドレス192.168.1.100および192.168.1.101に割り当てるには、以下を実行します。$ oc patch netnamespace project1 --type=merge \ -p '{"egressIPs": ["192.168.1.100","192.168.1.101"]}'高可用性を提供するには、
egressIPsの値を異なるノードの 2 つ以上の IP アドレスに設定します。複数の egress IP アドレスが設定されている場合、Pod はすべての egress IP アドレスをほぼ均等に使用します。注記OpenShift SDN は
NetNamespaceオブジェクトを管理するため、既存のNetNamespaceオブジェクトを変更することによってのみ変更を加えることができます。新規NetNamespaceオブジェクトは作成しません。egress IP アドレスをノードホストに手動で割り当てます。
クラスターがパブリッククラウドインフラストラクチャーにインストールされている場合は、ノードに使用可能な IP アドレス容量があることを確認する必要があります。
egressIPsパラメーターを、ノードホストのHostSubnetオブジェクトに設定します。以下の JSON を使用して、そのノードホストに割り当てる必要のある任意の数の IP アドレスを含めることができます。$ oc patch hostsubnet <node_name> --type=merge -p \ '{ "egressIPs": [ "<ip_address>", "<ip_address>" ] }'ここでは、以下のようになります。
<node_name>- ノード名を指定します。
<ip_address>-
IP アドレスを指定します。
egressIPs配列に複数の IP アドレスを指定できます。
たとえば、
node1に Egress IP192.168.1.100、192.168.1.101、および192.168.1.102が設定されるように指定するには、以下を実行します。$ oc patch hostsubnet node1 --type=merge -p \ '{"egressIPs": ["192.168.1.100", "192.168.1.101", "192.168.1.102"]}'直前の例では、
project1のすべての egress トラフィックは、指定された egress IP をホストするノードにルーティングされてから、その IP アドレスに Network Address Translation (NAT) を使用して接続されます。
28.4.4. 関連情報
- 手動の egress IP アドレス割り当てを設定している場合は、IP 容量計画の情報について、プラットフォームの考慮事項を参照してください。
28.5. プロジェクトの egress ファイアウォールの設定
クラスター管理者は、OpenShift Container Platform クラスター外に出るプロジェクトのプロジェクについて、egress トラフィックを制限する egress ファイアウォールを作成できます。
28.5.1. egress ファイアウォールのプロジェクトでの機能
クラスター管理者は、 egress ファイアウォール を使用して、一部またはすべての Pod がクラスター内からアクセスできる外部ホストを制限できます。egress ファイアウォールポリシーは以下のシナリオをサポートします。
- Pod の接続を内部ホストに制限し、パブリックインターネットへの接続を開始できないようにする。
- Pod の接続をパブリックインターネットに制限し、OpenShift Container Platform クラスター外にある内部ホストへの接続を開始できないようにする。
- Pod は OpenShift Container Platform クラスター外の指定された内部サブネットまたはホストにアクセスできません。
- Pod は特定の外部ホストにのみ接続することができます。
たとえば、指定された IP 範囲へのあるプロジェクトへのアクセスを許可する一方で、別のプロジェクトへの同じアクセスを拒否することができます。または、アプリケーション開発者の (Python) pip mirror からの更新を制限したり、更新を承認されたソースからの更新のみに強制的に制限したりすることができます。
Egress ファイアウォールは、ホストネットワークの namespace には適用されません。ホストネットワークが有効になっている Pod は、Egress ファイアウォールルールの影響を受けません。
EgressNetworkPolicy カスタムリソース (CR) オブジェクトを作成して egress ファイアウォールポリシーを設定します。egress ファイアウォールは、以下のいずれかの基準を満たすネットワークトラフィックと一致します。
- CIDR 形式の IP アドレス範囲。
- IP アドレスに解決する DNS 名
egress ファイアウォールに 0.0.0.0/0 の拒否ルールが含まれる場合、OpenShift Container Platform API サーバーへのアクセスはブロックされます。API サーバーに接続するには、IP アドレスごとに許可ルールを追加するか、egress ポリシールールで nodeSelector タイプの許可ルールを使用する必要があります。
次の例は、API サーバーへのアクセスを確保するために必要な Egress ファイアウォールルールの順序を示しています。
apiVersion: network.openshift.io/v1 kind: EgressNetworkPolicy metadata: name: default namespace: <namespace> 1 spec: egress: - to: cidrSelector: <api_server_address_range> 2 type: Allow # ... - to: cidrSelector: 0.0.0.0/0 3 type: Deny
API サーバーの IP アドレスを見つけるには、oc get ep kubernetes -n default を実行します。
詳細は、BZ#1988324 を参照してください。
egress ファイアウォールを設定するには、ネットワークポリシーまたはマルチテナントモードのいずれかを使用するように OpenShift SDN を設定する必要があります。
ネットワークポリシーモードを使用している場合、egress ファイアウォールは namespace ごとに 1 つのポリシーとのみ互換性を持ち、グローバルプロジェクトなどのネットワークを共有するプロジェクトでは機能しません。
egress ファイアウォールルールは、ルーターを通過するトラフィックには適用されません。ルート CR オブジェクトを作成するパーミッションを持つユーザーは、禁止されている宛先を参照するルートを作成することにより、egress ファイアウォールポリシールールをバイパスできます。
28.5.1.1. egress ファイアウォールの制限
egress ファイアウォールには以下の制限があります。
いずれのプロジェクトも複数の EgressNetworkPolicy オブジェクトを持つことができません。
重要複数の EgressNetworkPolicy オブジェクトの作成は可能ですが、作成するべきではありません。複数の EgressNetworkPolicy オブジェクトを作成すると、
dropping all rulesというメッセージが返されます。実際には、すべての外部トラフィックがドロップされるため、組織にセキュリティーリスクが生じる可能性があります。- 最大 1,000 のルールを持つ最大 1 つの EgressNetworkPolicy オブジェクトはプロジェクトごとに定義できます。
-
defaultプロジェクトは egress ファイアウォールを使用できません。 マルチテナントモードで OpenShift SDN ネットワークプラグインを使用する場合、以下の制限が適用されます。
-
グローバルプロジェクトは egress ファイアウォールを使用できません。
oc adm pod-network make-projects-globalコマンドを使用して、プロジェクトをグローバルにすることができます。 -
oc adm pod-network join-projectsコマンドを使用してマージされるプロジェクトでは、結合されたプロジェクトのいずれでも egress ファイアウォールを使用することはできません。
-
グローバルプロジェクトは egress ファイアウォールを使用できません。
これらの制限のいずれかに違反すると、プロジェクトの Egress ファイアウォールが壊れます。その結果、すべての外部ネットワークトラフィックがドロップされ、組織にセキュリティーリスクが生じる可能性があります。
egress ファイアウォールリソースは、kube-node-lease、kube-public、kube-system、openshift、openshift- プロジェクトで作成できます。
28.5.1.2. egress ポリシールールのマッチング順序
egress ファイアウォールポリシールールは、最初から最後へと定義された順序で評価されます。Pod からの egress 接続に一致する最初のルールが適用されます。この接続では、後続のルールは無視されます。
28.5.1.3. DNS (Domain Name Server) 解決の仕組み
egress ファイアウォールポリシールールのいずれかで DNS 名を使用する場合、ドメイン名の適切な解決には、以下の制限が適用されます。
- ドメイン名の更新は、TTL (Time-to-live) 期間に基づいてポーリングされます。デフォルトの期間は 30 秒です。egress ファイアウォールコントローラーがローカルネームサーバーでドメイン名をクエリーする場合に、応答に 30 秒未満の TTL が含まれる場合は、コントローラーはその期間を返される値に設定します。応答の TTL が 30 分を超える場合、コントローラーは期間を 30 分に設定します。TTL が 30 秒から 30 分の間に設定される場合、コントローラーは値を無視し、期間を 30 秒に設定します。
- Pod は、必要に応じて同じローカルネームサーバーからドメインを解決する必要があります。そうしない場合、egress ファイアウォールコントローラーと Pod によって認識されるドメインの IP アドレスが異なる可能性があります。ホスト名の IP アドレスが異なる場合、egress ファイアウォールは一貫して実行されないことがあります。
- egress ファイアウォールコントローラーおよび Pod は同じローカルネームサーバーを非同期にポーリングするため、Pod は egress コントローラーが実行する前に更新された IP アドレスを取得する可能性があります。これにより、競合状態が生じます。この現時点の制限により、EgressNetworkPolicy オブジェクトのドメイン名の使用は、IP アドレスの変更が頻繁に生じないドメインの場合にのみ推奨されます。
egress ファイアウォールポリシーで DNS 名を使用しても、CoreDNS を介したローカル DNS 解決には影響しません。
ただし、egress ファイアウォールポリシーでドメイン名を使用し、外部 DNS サーバーで関連する Pod の DNS 解決を処理する場合は、DNS サーバーの IP アドレスへのアクセスを許可する egress ファイアウォールルールを含める必要があります。
28.5.2. EgressNetworkPolicy カスタムリソース (CR) オブジェクト
egress ファイアウォールのルールを 1 つ以上定義できます。ルールは、ルールが適用されるトラフィックを指定して Allow ルールまたは Deny ルールのいずれかになります。
以下の YAML は EgressNetworkPolicy CR オブジェクトについて説明しています。
EgressNetworkPolicy オブジェクト
apiVersion: network.openshift.io/v1 kind: EgressNetworkPolicy metadata: name: <name> 1 spec: egress: 2 ...
28.5.2.1. EgressNetworkPolicy ルール
以下の YAML は egress ファイアウォールルールオブジェクトについて説明しています。ユーザーは、CIDR 形式の IP アドレス範囲またはドメイン名を選択するか、nodeSelector を使用して、送信トラフィックを許可または拒否できます。egress スタンザは、単一または複数のオブジェクトの配列を予想します。
Egress ポリシールールのスタンザ
egress: - type: <type> 1 to: 2 cidrSelector: <cidr> 3 dnsName: <dns_name> 4
28.5.2.2. EgressNetworkPolicy CR オブジェクトの例
以下の例では、複数の egress ファイアウォールポリシールールを定義します。
apiVersion: network.openshift.io/v1
kind: EgressNetworkPolicy
metadata:
name: default
spec:
egress: 1
- type: Allow
to:
cidrSelector: 1.2.3.0/24
- type: Allow
to:
dnsName: www.example.com
- type: Deny
to:
cidrSelector: 0.0.0.0/0- 1
- egress ファイアウォールポリシールールオブジェクトのコレクション。
28.5.3. egress ファイアウォールポリシーオブジェクトの作成
クラスター管理者は、プロジェクトの egress ファイアウォールポリシーオブジェクトを作成できます。
プロジェクトに EgressNetworkPolicy オブジェクトがすでに定義されている場合、既存のポリシーを編集して egress ファイアウォールルールを変更する必要があります。
前提条件
- OpenShift SDN ネットワークプラグインを使用するクラスター。
-
OpenShift CLI (
oc) がインストールされている。 - クラスター管理者としてクラスターにログインする必要があります。
手順
ポリシールールを作成します。
-
<policy_name>.yamlファイルを作成します。この場合、<policy_name>は egress ポリシールールを記述します。 - 作成したファイルで、egress ポリシーオブジェクトを定義します。
-
以下のコマンドを入力してポリシーオブジェクトを作成します。
<policy_name>をポリシーの名前に、<project>をルールが適用されるプロジェクトに置き換えます。$ oc create -f <policy_name>.yaml -n <project>
以下の例では、新規の EgressNetworkPolicy オブジェクトが
project1という名前のプロジェクトに作成されます。$ oc create -f default.yaml -n project1
出力例
egressnetworkpolicy.network.openshift.io/v1 created
-
オプション: 後に変更できるように
<policy_name>.yamlファイルを保存します。
28.6. プロジェクトの egress ファイアウォールの編集
クラスター管理者は、既存の egress ファイアウォールのネットワークトラフィックルールを変更できます。
28.6.1. EgressNetworkPolicy オブジェクトの表示
クラスターで EgressNetworkPolicy オブジェクトを表示できます。
前提条件
- OpenShiftSDN ネットワークプラグインを使用するクラスター。
-
ocとして知られる OpenShift コマンドラインインターフェイス (CLI) のインストール。 - クラスターにログインすること。
手順
オプション: クラスターで定義された EgressNetworkPolicy オブジェクトの名前を表示するには、以下のコマンドを入力します。
$ oc get egressnetworkpolicy --all-namespaces
ポリシーを検査するには、以下のコマンドを入力します。
<policy_name>を検査するポリシーの名前に置き換えます。$ oc describe egressnetworkpolicy <policy_name>
出力例
Name: default Namespace: project1 Created: 20 minutes ago Labels: <none> Annotations: <none> Rule: Allow to 1.2.3.0/24 Rule: Allow to www.example.com Rule: Deny to 0.0.0.0/0
28.7. プロジェクトの egress ファイアウォールの編集
クラスター管理者は、既存の egress ファイアウォールのネットワークトラフィックルールを変更できます。
28.7.1. EgressNetworkPolicy オブジェクトの編集
クラスター管理者は、プロジェクトの egress ファイアウォールを更新できます。
前提条件
- OpenShiftSDN ネットワークプラグインを使用するクラスター。
-
OpenShift CLI (
oc) がインストールされている。 - クラスター管理者としてクラスターにログインする必要があります。
手順
プロジェクトの EgressNetworkPolicy オブジェクトの名前を検索します。
<project>をプロジェクトの名前に置き換えます。$ oc get -n <project> egressnetworkpolicy
オプション: egress ネットワークファイアウォールの作成時に EgressNetworkPolicy オブジェクトのコピーを保存しなかった場合には、以下のコマンドを入力してコピーを作成します。
$ oc get -n <project> egressnetworkpolicy <name> -o yaml > <filename>.yaml
<project>をプロジェクトの名前に置き換えます。<name>をオブジェクトの名前に置き換えます。<filename>をファイルの名前に置き換え、YAML を保存します。ポリシールールに変更を加えたら、以下のコマンドを実行して EgressNetworkPolicy オブジェクトを置き換えます。
<filename>を、更新された EgressNetworkPolicy オブジェクトを含むファイルの名前に置き換えます。$ oc replace -f <filename>.yaml
28.8. プロジェクトからの egress ファイアウォールの削除
クラスター管理者は、プロジェクトから egress ファイアウォールを削除して、OpenShift Container Platform クラスター外に出るプロジェクトからネットワークトラフィックについてのすべての制限を削除できます。
28.8.1. EgressNetworkPolicy オブジェクトの削除
クラスター管理者は、プロジェクトから Egress ファイアウォールを削除できます。
前提条件
- OpenShiftSDN ネットワークプラグインを使用するクラスター。
-
OpenShift CLI (
oc) がインストールされている。 - クラスター管理者としてクラスターにログインする必要があります。
手順
プロジェクトの EgressNetworkPolicy オブジェクトの名前を検索します。
<project>をプロジェクトの名前に置き換えます。$ oc get -n <project> egressnetworkpolicy
以下のコマンドを入力し、EgressNetworkPolicy オブジェクトを削除します。
<project>をプロジェクトの名前に、<name>をオブジェクトの名前に置き換えます。$ oc delete -n <project> egressnetworkpolicy <name>
28.9. egress ルーター Pod の使用についての考慮事項
28.9.1. egress ルーター Pod について
OpenShift Container Platform egress ルーター Pod は、他の用途で使用されていないプライベートソース IP アドレスから指定されたリモートサーバーにトラフィックをリダイレクトします。Egress ルーター Pod により、特定の IP アドレスからのアクセスのみを許可するように設定されたサーバーにネットワークトラフィックを送信できます。
egress ルーター Pod はすべての発信接続のために使用されることが意図されていません。多数の egress ルーター Pod を作成することで、ネットワークハードウェアの制限を引き上げられる可能性があります。たとえば、すべてのプロジェクトまたはアプリケーションに egress ルーター Pod を作成すると、ソフトウェアの MAC アドレスのフィルターに戻る前にネットワークインターフェイスが処理できるローカル MAC アドレス数の上限を超えてしまう可能性があります。
egress ルーターイメージには Amazon AWS, Azure Cloud またはレイヤー 2 操作をサポートしないその他のクラウドプラットフォームとの互換性がありません。 それらに macvlan トラフィックとの互換性がないためです。
28.9.1.1. Egress ルーターモード
リダイレクトモード では、egress ルーター Pod は、トラフィックを独自の IP アドレスから 1 つ以上の宛先 IP アドレスにリダイレクトするために iptables ルールをセットアップします。予約された送信元 IP アドレスを使用する必要があるクライアント Pod は、宛先 IP に直接接続するのではなく、スロールーターのサービスにアクセスするように設定する必要があります。curl コマンドを使用して、アプリケーション Pod から宛先サービスとポートにアクセスできます。以下に例を示します。
$ curl <router_service_IP> <port>
HTTP プロキシーモードでは、egress ルーター Pod はポート 8080 で HTTP プロキシーとして実行されます。このモードは、HTTP または HTTPS ベースのサービスと通信するクライアントの場合にのみ機能しますが、通常それらを機能させるのにクライアント Pod への多くの変更は不要です。環境変数を設定することで、数多くのプログラムは HTTP プロキシーを使用するように指示されます。
DNS プロキシーモードでは、egress ルーター Pod は、トラフィックを独自の IP アドレスから 1 つ以上の宛先 IP アドレスに送信する TCP ベースのサービスの DNS プロキシーとして実行されます。予約されたソース IP アドレスを使用するには、クライアント Pod は、宛先 IP アドレスに直接接続するのでなく、egress ルーター Pod に接続するように変更される必要があります。この修正により、外部の宛先でトラフィックが既知のソースから送信されているかのように処理されます。
リダイレクトモードは、HTTP および HTTPS 以外のすべてのサービスで機能します。HTTP および HTTPS サービスの場合は、HTTP プロキシーモードを使用します。IP アドレスまたはドメイン名を持つ TCP ベースのサービスの場合は、DNS プロキシーモードを使用します。
28.9.1.2. egress ルーター Pod の実装
egress ルーター Pod の設定は、初期化コンテナーで実行されます。このコンテナーは特権付きコンテキストで実行され、macvlan インターフェイスを設定して iptables ルールを設定できます。初期化コンテナーが iptables ルールの設定を終了すると、終了します。次に、egress ルーター Pod はコンテナーを実行して egress ルーターのトラフィックを処理します。使用されるイメージは、egress ルーターモードによって異なります。
環境変数は、egress-router イメージが使用するアドレスを判別します。イメージは macvlan インターフェイスを、 EGRESS_SOURCE をその IP アドレスとして使用し、EGRESS_GATEWAY をゲートウェイの IP アドレスとして使用するように設定します。
ネットワークアドレス変換 (NAT) ルールは、TCP ポートまたは UDP ポート上の Pod のクラスター IP アドレスへの接続が EGRESS_DESTINATION 変数で指定される IP アドレスの同じポートにリダイレクトされるように設定されます。
クラスター内の一部のノードのみが指定されたソース IP アドレスを要求でき、指定されたゲートウェイを使用できる場合、受け入れ可能なノードを示す nodeName または nodeSelector を指定することができます。
28.9.1.3. デプロイメントに関する考慮事項
egress ルーター Pod は追加の IP アドレスおよび MAC アドレスをノードのプライマリーネットワークインターフェイスに追加します。その結果、ハイパーバイザーまたはクラウドプロバイダーを、追加のアドレスを許可するように設定する必要がある場合があります。
- Red Hat OpenStack Platform (RHOSP)
OpenShift Container Platform を RHOSP にデプロイする場合、OpenStack 環境の egress ルーター Pod の IP および MAC アドレスからのトラフィックを許可する必要があります。トラフィックを許可しないと、通信は失敗 します。
$ openstack port set --allowed-address \ ip_address=<ip_address>,mac_address=<mac_address> <neutron_port_uuid>
- Red Hat Virtualization (RHV)
- RHV を使用している場合は、仮想インターフェイスカード (vNIC) に No Network Filter を選択する必要があります。
- VMware vSphere
- VMware vSphere を使用している場合は、vSphere 標準スイッチのセキュリティー保護についての VMware ドキュメント を参照してください。vSphere Web クライアントからホストの仮想スイッチを選択して、VMware vSphere デフォルト設定を表示し、変更します。
とくに、以下が有効にされていることを確認します。
28.9.1.4. フェイルオーバー設定
ダウンタイムを回避するには、以下の例のように Deployment リソースで egress ルーター Pod をデプロイできます。サンプルのデプロイメント用に新規 Service オブジェクトを作成するには、oc expose deployment/egress-demo-controller コマンドを使用します。
apiVersion: apps/v1 kind: Deployment metadata: name: egress-demo-controller spec: replicas: 1 1 selector: matchLabels: name: egress-router template: metadata: name: egress-router labels: name: egress-router annotations: pod.network.openshift.io/assign-macvlan: "true" spec: 2 initContainers: ... containers: ...
28.9.2. 関連情報
28.10. リダイレクトモードでの egress ルーター Pod のデプロイ
クラスター管理者は、トラフィックを指定された宛先 IP アドレスにリダイレクトするように設定された egress ルーター Pod をデプロイできます。
28.10.1. リダイレクトモードの egress ルーター Pod 仕様
Pod オブジェクトで egress ルーター Pod の設定を定義します。以下の YAML は、リダイレクトモードでの egress ルーター Pod の設定のフィールドについて説明しています。
apiVersion: v1
kind: Pod
metadata:
name: egress-1
labels:
name: egress-1
annotations:
pod.network.openshift.io/assign-macvlan: "true" 1
spec:
initContainers:
- name: egress-router
image: registry.redhat.io/openshift4/ose-egress-router
securityContext:
privileged: true
env:
- name: EGRESS_SOURCE 2
value: <egress_router>
- name: EGRESS_GATEWAY 3
value: <egress_gateway>
- name: EGRESS_DESTINATION 4
value: <egress_destination>
- name: EGRESS_ROUTER_MODE
value: init
containers:
- name: egress-router-wait
image: registry.redhat.io/openshift4/ose-pod- 1
- このアノテーションは、OpenShift Container Platform に対して、プライマリーネットワークインターフェイスコントローラー (NIC) に macvlan ネットワークインターフェイスを作成し、その macvlan インターフェイスを Pod ネットワークの namespace に移動するよう指示します。引用符を
"true"値の周囲に含める必要があります。OpenShift Container Platform が別の NIC インターフェイスに macvlan インターフェイスを作成するには、アノテーションの値をそのインターフェイスの名前に設定します。たとえば、eth1を使用します。 - 2
- ノードが置かれている物理ネットワークの IP アドレスは egress ルーター Pod で使用するために予約されます。オプション: サブネットの長さ
/24接尾辞を組み込み、ローカルサブネットへの適切なルートがセットアップされるようにできます。サブネットの長さを指定しない場合、egress ルーターはEGRESS_GATEWAY変数で指定されたホストにのみアクセスでき、サブネットの他のホストにはアクセスできません。 - 3
- ノードで使用されるデフォルトゲートウェイと同じ値です。
- 4
- トラフィックの送信先となる外部サーバー。この例では、Pod の接続は
203.0.113.25にリダイレクトされます。 ソース IP アドレスは192.168.12.99です。
egress ルーター Pod 仕様の例
apiVersion: v1
kind: Pod
metadata:
name: egress-multi
labels:
name: egress-multi
annotations:
pod.network.openshift.io/assign-macvlan: "true"
spec:
initContainers:
- name: egress-router
image: registry.redhat.io/openshift4/ose-egress-router
securityContext:
privileged: true
env:
- name: EGRESS_SOURCE
value: 192.168.12.99/24
- name: EGRESS_GATEWAY
value: 192.168.12.1
- name: EGRESS_DESTINATION
value: |
80 tcp 203.0.113.25
8080 tcp 203.0.113.26 80
8443 tcp 203.0.113.26 443
203.0.113.27
- name: EGRESS_ROUTER_MODE
value: init
containers:
- name: egress-router-wait
image: registry.redhat.io/openshift4/ose-pod
28.10.2. egress 宛先設定形式
egress ルーター Pod がリダイレクトモードでデプロイされる場合、以下のいずれかの形式を使用してリダイレクトルールを指定できます。
-
<port> <protocol> <ip_address>: 指定される<port>への着信接続が指定される<ip_address>の同じポートにリダイレクトされます。<protocol>はtcpまたはudpのいずれかになります。 -
<port> <protocol> <ip_address> <remote_port>: 接続が<ip_address>の別の<remote_port>にリダイレクトされるのを除き、上記と同じになります。 -
<ip_address>: 最後の行が単一 IP アドレスである場合、それ以外のポートの接続はその IP アドレスの対応するポートにリダイレクトされます。フォールバック IP アドレスがない場合、他のポートでの接続は拒否されます。
以下の例では、複数のルールが定義されます。
-
最初の行はローカルポート
80から203.0.113.25のポート80にトラフィックをリダイレクトします。 -
2 番目と 3 番目の行では、ローカルポート
8080および8443を、203.0.113.26のリモートポート80および443にリダイレクトします。 - 最後の行は、先のルールで指定されていないポートのトラフィックに一致します。
設定例
80 tcp 203.0.113.25 8080 tcp 203.0.113.26 80 8443 tcp 203.0.113.26 443 203.0.113.27
28.10.3. リダイレクトモードでの egress ルーター Pod のデプロイ
リダイレクトモードでは、egress ルーター Pod は、トラフィックを独自の IP アドレスから 1 つ以上の宛先 IP アドレスにリダイレクトするために iptables ルールをセットアップします。予約された送信元 IP アドレスを使用する必要があるクライアント Pod は、宛先 IP に直接接続するのではなく、スロールーターのサービスにアクセスするように設定する必要があります。curl コマンドを使用して、アプリケーション Pod から宛先サービスとポートにアクセスできます。以下に例を示します。
$ curl <router_service_IP> <port>
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
- egress ルーター Pod の作成
他の Pod が egress ルーター Pod の IP アドレスを見つられるようにするには、以下の例のように、egress ルーター Pod を参照するサービスを作成します。
apiVersion: v1 kind: Service metadata: name: egress-1 spec: ports: - name: http port: 80 - name: https port: 443 type: ClusterIP selector: name: egress-1Pod がこのサービスに接続できるようになります。これらの接続は、予約された egress IP アドレスを使用して外部サーバーの対応するポートにリダイレクトされます。
28.10.4. 関連情報
28.11. HTTP プロキシーモードでの egress ルーター Pod のデプロイ
クラスター管理者は、トラフィックを指定された HTTP および HTTPS ベースのサービスにプロキシーするように設定された egress ルーター Pod をデプロイできます。
28.11.1. HTTP モードの egress ルーター Pod 仕様
Pod オブジェクトで egress ルーター Pod の設定を定義します。以下の YAML は、HTTP モードでの egress ルーター Pod の設定のフィールドについて説明しています。
apiVersion: v1
kind: Pod
metadata:
name: egress-1
labels:
name: egress-1
annotations:
pod.network.openshift.io/assign-macvlan: "true" 1
spec:
initContainers:
- name: egress-router
image: registry.redhat.io/openshift4/ose-egress-router
securityContext:
privileged: true
env:
- name: EGRESS_SOURCE 2
value: <egress-router>
- name: EGRESS_GATEWAY 3
value: <egress-gateway>
- name: EGRESS_ROUTER_MODE
value: http-proxy
containers:
- name: egress-router-pod
image: registry.redhat.io/openshift4/ose-egress-http-proxy
env:
- name: EGRESS_HTTP_PROXY_DESTINATION 4
value: |-
...
...- 1
- このアノテーションは、OpenShift Container Platform に対して、プライマリーネットワークインターフェイスコントローラー (NIC) に macvlan ネットワークインターフェイスを作成し、その macvlan インターフェイスを Pod ネットワークの namespace に移動するよう指示します。引用符を
"true"値の周囲に含める必要があります。OpenShift Container Platform が別の NIC インターフェイスに macvlan インターフェイスを作成するには、アノテーションの値をそのインターフェイスの名前に設定します。たとえば、eth1を使用します。 - 2
- ノードが置かれている物理ネットワークの IP アドレスは egress ルーター Pod で使用するために予約されます。オプション: サブネットの長さ
/24接尾辞を組み込み、ローカルサブネットへの適切なルートがセットアップされるようにできます。サブネットの長さを指定しない場合、egress ルーターはEGRESS_GATEWAY変数で指定されたホストにのみアクセスでき、サブネットの他のホストにはアクセスできません。 - 3
- ノードで使用されるデフォルトゲートウェイと同じ値です。
- 4
- プロキシーの設定方法を指定する文字列または YAML の複数行文字列です。これは、init コンテナーの他の環境変数ではなく、HTTP プロキシーコンテナーの環境変数として指定されることに注意してください。
28.11.2. egress 宛先設定形式
egress ルーター Pod が HTTP プロキシーモードでデプロイされる場合、以下の形式のいずれかを使用してリダイレクトルールを指定できます。これはすべてのリモート宛先への接続を許可することを意味します。 設定の各行には、許可または拒否する接続の 1 つのグループを指定します。
-
IP アドレス (例:
192.168.1.1) は該当する IP アドレスへの接続を許可します。 -
CIDR 範囲 (例:
192.168.1.0/24) は CIDR 範囲への接続を許可します。 -
ホスト名 (例:
www.example.com) は該当ホストへのプロキシーを許可します。 -
*.が前に付けられているドメイン名 (例:*.example.com) は該当ドメインおよびそのサブドメインのすべてへのプロキシーを許可します。 -
先の一致 (match) 式のいずれかの後に来る
!は接続を拒否します。 -
最後の行が
*の場合、明示的に拒否されていないすべてのものが許可されます。それ以外の場合、許可されないすべてのものが拒否されます。
* を使用してすべてのリモート宛先への接続を許可することもできます。
設定例
!*.example.com !192.168.1.0/24 192.168.2.1 *
28.11.3. HTTP プロキシーモードでの egress ルーター Pod のデプロイ
HTTP プロキシーモードでは、egress ルーター Pod はポート 8080 で HTTP プロキシーとして実行されます。このモードは、HTTP または HTTPS ベースのサービスと通信するクライアントの場合にのみ機能しますが、通常それらを機能させるのにクライアント Pod への多くの変更は不要です。環境変数を設定することで、数多くのプログラムは HTTP プロキシーを使用するように指示されます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
- egress ルーター Pod の作成
他の Pod が egress ルーター Pod の IP アドレスを見つられるようにするには、以下の例のように、egress ルーター Pod を参照するサービスを作成します。
apiVersion: v1 kind: Service metadata: name: egress-1 spec: ports: - name: http-proxy port: 8080 1 type: ClusterIP selector: name: egress-1- 1
httpポートが常に8080に設定されていることを確認します。
http_proxyまたはhttps_proxy変数を設定して、クライアント Pod (egress プロキシー Pod ではない) を HTTP プロキシーを使用するように設定します。apiVersion: v1 kind: Pod metadata: name: app-1 labels: name: app-1 spec: containers: env: - name: http_proxy value: http://egress-1:8080/ 1 - name: https_proxy value: http://egress-1:8080/ ...- 1
- 先の手順で作成したサービス。
注記すべてのセットアップに
http_proxyおよびhttps_proxy環境変数が必要になる訳ではありません。上記を実行しても作業用セットアップが作成されない場合は、Pod で実行しているツールまたはソフトウェアについてのドキュメントを参照してください。
28.11.4. 関連情報
28.12. DNS プロキシーモードでの egress ルーター Pod のデプロイ
クラスター管理者は、トラフィックを指定された DNS 名および IP アドレスにプロキシーするように設定された egress ルーター Pod をデプロイできます。
28.12.1. DNS モードの egress ルーター Pod 仕様
Pod オブジェクトで egress ルーター Pod の設定を定義します。以下の YAML は、DNS モードでの egress ルーター Pod の設定のフィールドについて説明しています。
apiVersion: v1
kind: Pod
metadata:
name: egress-1
labels:
name: egress-1
annotations:
pod.network.openshift.io/assign-macvlan: "true" 1
spec:
initContainers:
- name: egress-router
image: registry.redhat.io/openshift4/ose-egress-router
securityContext:
privileged: true
env:
- name: EGRESS_SOURCE 2
value: <egress-router>
- name: EGRESS_GATEWAY 3
value: <egress-gateway>
- name: EGRESS_ROUTER_MODE
value: dns-proxy
containers:
- name: egress-router-pod
image: registry.redhat.io/openshift4/ose-egress-dns-proxy
securityContext:
privileged: true
env:
- name: EGRESS_DNS_PROXY_DESTINATION 4
value: |-
...
- name: EGRESS_DNS_PROXY_DEBUG 5
value: "1"
...- 1
- このアノテーションは、OpenShift Container Platform に対して、プライマリーネットワークインターフェイスコントローラー (NIC) に macvlan ネットワークインターフェイスを作成し、その macvlan インターフェイスを Pod ネットワークの namespace に移動するよう指示します。引用符を
"true"値の周囲に含める必要があります。OpenShift Container Platform が別の NIC インターフェイスに macvlan インターフェイスを作成するには、アノテーションの値をそのインターフェイスの名前に設定します。たとえば、eth1を使用します。 - 2
- ノードが置かれている物理ネットワークの IP アドレスは egress ルーター Pod で使用するために予約されます。オプション: サブネットの長さ
/24接尾辞を組み込み、ローカルサブネットへの適切なルートがセットアップされるようにできます。サブネットの長さを指定しない場合、egress ルーターはEGRESS_GATEWAY変数で指定されたホストにのみアクセスでき、サブネットの他のホストにはアクセスできません。 - 3
- ノードで使用されるデフォルトゲートウェイと同じ値です。
- 4
- 1 つ以上のプロキシー宛先のリストを指定します。
- 5
- オプション: DNS プロキシーログ出力を
stdoutに出力するために指定します。
28.12.2. egress 宛先設定形式
ルーターが DNS プロキシーモードでデプロイされる場合、ポートおよび宛先マッピングのリストを指定します。宛先には、IP アドレスまたは DNS 名のいずれかを使用できます。
egress ルーター Pod は、ポートおよび宛先マッピングを指定するために以下の形式をサポートします。
- ポートおよびリモートアドレス
-
送信元ポートおよび宛先ホストは、2 つのフィールド形式 (
<port> <remote_address>) を使用して指定できます。
ホストには、IP アドレスまたは DNS 名を指定できます。DNS 名を指定すると、DNS 解決が起動時に行われます。特定のホストについては、プロキシーは、宛先ホスト IP アドレスへの接続時に、宛先ホストの指定された送信元ポートに接続されます。
ポートとリモートアドレスペアの例
80 172.16.12.11 100 example.com
- ポート、リモートアドレス、およびリモートポート
-
送信元ポート、宛先ホスト、および宛先ポートは、
<port> <remote_address> <remote_port>の 3 つのフィールドからなる形式を使用して指定できます。
3 つのフィールド形式は、2 つのフィールドバージョンと同じように動作しますが、宛先ポートが送信元ポートとは異なる場合があります。
ポート、リモートアドレス、およびリモートポートの例
8080 192.168.60.252 80 8443 web.example.com 443
28.12.3. DNS プロキシーモードでの egress ルーター Pod のデプロイ
DNS プロキシーモードでは、egress ルーター Pod は、トラフィックを独自の IP アドレスから 1 つ以上の宛先 IP アドレスに送信する TCP ベースのサービスの DNS プロキシーとして機能します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
- egress ルーター Pod の作成
egress ルーター Pod のサービスを作成します。
以下の YAML 定義が含まれる
egress-router-service.yamlという名前のファイルを作成します。spec.portsを、EGRESS_DNS_PROXY_DESTINATION環境変数に先に定義したポートのリストに設定します。apiVersion: v1 kind: Service metadata: name: egress-dns-svc spec: ports: ... type: ClusterIP selector: name: egress-dns-proxy以下に例を示します。
apiVersion: v1 kind: Service metadata: name: egress-dns-svc spec: ports: - name: con1 protocol: TCP port: 80 targetPort: 80 - name: con2 protocol: TCP port: 100 targetPort: 100 type: ClusterIP selector: name: egress-dns-proxyサービスを作成するには、以下のコマンドを入力します。
$ oc create -f egress-router-service.yaml
Pod がこのサービスに接続できるようになります。これらの接続は、予約された egress IP アドレスを使用して外部サーバーの対応するポートにプロキシー送信されます。
28.12.4. 関連情報
28.13. ConfigMap からの egress ルーター Pod 宛先一覧の設定
クラスター管理者は、egress ルーター Pod の宛先マッピングを指定する ConfigMap オブジェクトを定義できます。設定の特定の形式は、egress ルーター Pod のタイプによって異なります。形式についての詳細は、特定の egress ルーター Pod のドキュメントを参照してください。
28.13.1. ConfigMap を使用した egress ルーター宛先マッピングの設定
宛先マッピングのセットのサイズが大きいか、これが頻繁に変更される場合、ConfigMap を使用して一覧を外部で維持できます。この方法の利点は、設定マップを編集するパーミッションを cluster-admin 権限を持たないユーザーに委任できることです。egress ルーター Pod には特権付きコンテナーを必要とするため、cluster-admin 権限を持たないユーザーは Pod 定義を直接編集することはできません。
egress ルーター Pod は、ConfigMap が変更されても自動的に更新されません。更新を取得するには、egress ルーター Pod を再起動する必要があります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
以下の例のように、egress ルーター Pod のマッピングデータが含まれるファイルを作成します。
# Egress routes for Project "Test", version 3 80 tcp 203.0.113.25 8080 tcp 203.0.113.26 80 8443 tcp 203.0.113.26 443 # Fallback 203.0.113.27
空の行とコメントをこのファイルに追加できます。
このファイルから
ConfigMapオブジェクトを作成します。$ oc delete configmap egress-routes --ignore-not-found
$ oc create configmap egress-routes \ --from-file=destination=my-egress-destination.txt
直前のコマンドで、
egress-routes値は、作成するConfigMapオブジェクトの名前で、my-egress-destination.txtはデータの読み取り元のファイルの名前です。ヒントまたは、以下の YAML を適用して ConfigMap を作成できます。
apiVersion: v1 kind: ConfigMap metadata: name: egress-routes data: destination: | # Egress routes for Project "Test", version 3 80 tcp 203.0.113.25 8080 tcp 203.0.113.26 80 8443 tcp 203.0.113.26 443 # Fallback 203.0.113.27egress ルーター Pod 定義を作成し、environment スタンザの
EGRESS_DESTINATIONフィールドにconfigMapKeyRefスタンザを指定します。... env: - name: EGRESS_DESTINATION valueFrom: configMapKeyRef: name: egress-routes key: destination ...
28.13.2. 関連情報
28.14. プロジェクトのマルチキャストの有効化
28.14.1. マルチキャストについて
IP マルチキャストを使用すると、データが多数の IP アドレスに同時に配信されます。
- 現時点で、マルチキャストは低帯域幅の調整またはサービスの検出での使用に最も適しており、高帯域幅のソリューションとしては適していません。
-
デフォルトでは、ネットワークポリシーは namespace 内のすべての接続に影響します。ただし、マルチキャストはネットワークポリシーの影響を受けません。マルチキャストがネットワークポリシーと同じ namespace で有効にされている場合、
deny-allネットワークポリシーがある場合でも、マルチキャストは常に許可されます。クラスター管理者は、これを有効にする前に、ネットワークポリシーからマルチキャストが除外されることの影響を考慮する必要があります。
OpenShift Container Platform の Pod 間のマルチキャストトラフィックはデフォルトで無効にされます。OpenShift SDN ネットワークプラグインを使用している場合、プロジェクトごとにマルチキャストを有効にできます。
networkpolicy 分離モードで OpenShift SDN ネットワークプラグインを使用する場合は、以下を行います。
-
Pod によって送信されるマルチキャストパケットは、
NetworkPolicyオブジェクトに関係なく、プロジェクトの他のすべての Pod に送信されます。Pod はユニキャストで通信できない場合でもマルチキャストで通信できます。 -
1 つのプロジェクトの Pod によって送信されるマルチキャストパケットは、
NetworkPolicyオブジェクトがプロジェクト間の通信を許可する場合であっても、それ以外のプロジェクトの Pod に送信されることはありません。
multinenant 分離モードで OpenShift SDN ネットワークプラグインを使用する場合は、以下を行います。
- Pod で送信されるマルチキャストパケットはプロジェクトにあるその他の全 Pod に送信されます。
- あるプロジェクトの Pod によって送信されるマルチキャストパケットは、各プロジェクトが結合し、マルチキャストが結合した各プロジェクトで有効にされている場合にのみ、他のプロジェクトの Pod に送信されます。
28.14.2. Pod 間のマルチキャストの有効化
プロジェクトの Pod でマルチキャストを有効にすることができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにログインする必要があります。
手順
以下のコマンドを実行し、プロジェクトのマルチキャストを有効にします。
<namespace>を、マルチキャストを有効にする必要のある namespace に置き換えます。$ oc annotate netnamespace <namespace> \ netnamespace.network.openshift.io/multicast-enabled=true
検証
マルチキャストがプロジェクトについて有効にされていることを確認するには、以下の手順を実行します。
現在のプロジェクトを、マルチキャストを有効にしたプロジェクトに切り替えます。
<project>をプロジェクト名に置き換えます。$ oc project <project>
マルチキャストレシーバーとして機能する Pod を作成します。
$ cat <<EOF| oc create -f - apiVersion: v1 kind: Pod metadata: name: mlistener labels: app: multicast-verify spec: containers: - name: mlistener image: registry.access.redhat.com/ubi9 command: ["/bin/sh", "-c"] args: ["dnf -y install socat hostname && sleep inf"] ports: - containerPort: 30102 name: mlistener protocol: UDP EOFマルチキャストセンダーとして機能する Pod を作成します。
$ cat <<EOF| oc create -f - apiVersion: v1 kind: Pod metadata: name: msender labels: app: multicast-verify spec: containers: - name: msender image: registry.access.redhat.com/ubi9 command: ["/bin/sh", "-c"] args: ["dnf -y install socat && sleep inf"] EOF新しいターミナルウィンドウまたはタブで、マルチキャストリスナーを起動します。
Pod の IP アドレスを取得します。
$ POD_IP=$(oc get pods mlistener -o jsonpath='{.status.podIP}')次のコマンドを入力して、マルチキャストリスナーを起動します。
$ oc exec mlistener -i -t -- \ socat UDP4-RECVFROM:30102,ip-add-membership=224.1.0.1:$POD_IP,fork EXEC:hostname
マルチキャストトランスミッターを開始します。
Pod ネットワーク IP アドレス範囲を取得します。
$ CIDR=$(oc get Network.config.openshift.io cluster \ -o jsonpath='{.status.clusterNetwork[0].cidr}')マルチキャストメッセージを送信するには、以下のコマンドを入力します。
$ oc exec msender -i -t -- \ /bin/bash -c "echo | socat STDIO UDP4-DATAGRAM:224.1.0.1:30102,range=$CIDR,ip-multicast-ttl=64"マルチキャストが機能している場合、直前のコマンドは以下の出力を返します。
mlistener
28.15. プロジェクトのマルチキャストの無効化
28.15.1. Pod 間のマルチキャストの無効化
プロジェクトの Pod でマルチキャストを無効にすることができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにログインする必要があります。
手順
以下のコマンドを実行して、マルチキャストを無効にします。
$ oc annotate netnamespace <namespace> \ 1 netnamespace.network.openshift.io/multicast-enabled-- 1
- マルチキャストを無効にする必要のあるプロジェクトの
namespace。
28.16. OpenShift SDN を使用したネットワーク分離の設定
クラスターが OpenShift SDN ネットワークプラグインのマルチテナント分離モードを使用するように設定されている場合、各プロジェクトはデフォルトで分離されます。ネットワークトラフィックは、マルチテナント分離モードでは、異なるプロジェクトの Pod およびサービス間で許可されません。
プロジェクトのマルチテナント分離の動作を 2 つの方法で変更することができます。
- 1 つ以上のプロジェクトを結合し、複数の異なるプロジェクトの Pod とサービス間のネットワークトラフィックを可能にします。
- プロジェクトのネットワーク分離を無効にできます。これはグローバルにアクセスできるようになり、他のすべてのプロジェクトの Pod およびサービスからのネットワークトラフィックを受け入れます。グローバルにアクセス可能なプロジェクトは、他のすべてのプロジェクトの Pod およびサービスにアクセスできます。
28.16.1. 前提条件
- マルチテナント分離モードで OpenShift SDN ネットワークプラグインを使用するように設定されたクラスターが必要です。
28.16.2. プロジェクトの結合
2 つ以上のプロジェクトを結合し、複数の異なるプロジェクトの Pod とサービス間のネットワークトラフィックを可能にします。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにログインする必要があります。
手順
以下のコマンドを使用して、プロジェクトを既存のプロジェクトネットワークに参加させます。
$ oc adm pod-network join-projects --to=<project1> <project2> <project3>
または、特定のプロジェクト名を指定する代わりに
--selector=<project_selector>オプションを使用し、関連付けられたラベルに基づいてプロジェクトを指定できます。オプション: 以下のコマンドを実行し、結合した Pod ネットワークを表示します。
$ oc get netnamespaces
同じ Pod ネットワークのプロジェクトには、NETID 列に同じネットワーク ID があります。
28.16.3. プロジェクトの分離
他のプロジェクトの Pod およびサービスがその Pod およびサービスにアクセスできないようにするためにプロジェクトを分離することができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにログインする必要があります。
手順
クラスターのプロジェクトを分離するには、以下のコマンドを実行します。
$ oc adm pod-network isolate-projects <project1> <project2>
または、特定のプロジェクト名を指定する代わりに
--selector=<project_selector>オプションを使用し、関連付けられたラベルに基づいてプロジェクトを指定できます。
28.16.4. プロジェクトのネットワーク分離の無効化
プロジェクトのネットワーク分離を無効にできます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにログインする必要があります。
手順
プロジェクトの以下のコマンドを実行します。
$ oc adm pod-network make-projects-global <project1> <project2>
または、特定のプロジェクト名を指定する代わりに
--selector=<project_selector>オプションを使用し、関連付けられたラベルに基づいてプロジェクトを指定できます。
28.17. kube-proxy の設定
Kubernetes メットワークプロキシー (kube-proxy) は各ノードで実行され、Cluster Network Operator (CNO) で管理されます。kube-proxy は、サービスに関連付けられたエンドポイントの接続を転送するためのネットワークルールを維持します。
28.17.1. iptables ルールの同期について
同期の期間は、Kubernetes ネットワークプロキシー (kube-proxy) がノードで iptables ルールを同期する頻度を定めます。
同期は、以下のイベントのいずれかが生じる場合に開始します。
- サービスまたはエンドポイントのクラスターへの追加、またはクラスターからの削除などのイベントが発生する。
- 最後の同期以後の時間が kube-proxy に定義される同期期間を超過している。
28.17.2. kube-proxy 設定パラメーター
以下の kubeProxyConfig パラメーターを変更することができます。
OpenShift Container Platform 4.3 以降で強化されたパフォーマンスの向上により、iptablesSyncPeriod パラメーターを調整する必要はなくなりました。
表28.3 パラメーター
| パラメーター | 説明 | 値 | デフォルト |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
28.17.3. kube-proxy 設定の変化
クラスターの Kubernetes ネットワークプロキシー設定を変更することができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールで実行中のクラスターにログインします。
手順
以下のコマンドを実行して、
Network.operator.openshift.ioカスタムリソース (CR) を編集します。$ oc edit network.operator.openshift.io cluster
以下のサンプル CR のように、kube-proxy 設定への変更内容で、CR の
kubeProxyConfigパラメーターを変更します。apiVersion: operator.openshift.io/v1 kind: Network metadata: name: cluster spec: kubeProxyConfig: iptablesSyncPeriod: 30s proxyArguments: iptables-min-sync-period: ["30s"]ファイルを保存し、テキストエディターを編集します。
構文は、ファイルを保存し、エディターを終了する際に
ocコマンドによって検証されます。変更内容に構文エラーが含まれる場合、エディターはファイルを開き、エラーメッセージを表示します。以下のコマンドを実行して、設定の更新を確認します。
$ oc get networks.operator.openshift.io -o yaml
出力例
apiVersion: v1 items: - apiVersion: operator.openshift.io/v1 kind: Network metadata: name: cluster spec: clusterNetwork: - cidr: 10.128.0.0/14 hostPrefix: 23 defaultNetwork: type: OpenShiftSDN kubeProxyConfig: iptablesSyncPeriod: 30s proxyArguments: iptables-min-sync-period: - 30s serviceNetwork: - 172.30.0.0/16 status: {} kind: Listオプション: 以下のコマンドを実行し、Cluster Network Operator が設定変更を受け入れていることを確認します。
$ oc get clusteroperator network
出力例
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE network 4.1.0-0.9 True False False 1m
設定の更新が正常に適用されると、
AVAILABLEフィールドがTrueになります。
第29章 ルートの作成
29.1. ルート設定
29.1.1. HTTP ベースのルートの作成
ルートを使用すると、公開された URL でアプリケーションをホストできます。これは、アプリケーションのネットワークセキュリティー設定に応じて、セキュリティー保護または保護なしを指定できます。HTTP ベースのルートとは、セキュアではないルートで、基本的な HTTP ルーティングプロトコルを使用してセキュリティー保護されていないアプリケーションポートでサービスを公開します。
以下の手順では、hello-openshift アプリケーションを例に、Web アプリケーションへのシンプルな HTTP ベースのルートを作成する方法を説明します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - 管理者としてログインしている。
- あるポートを公開する Web アプリケーションと、そのポートでトラフィックをリッスンする TCP エンドポイントがあります。
手順
次のコマンドを実行して、
hello-openshiftというプロジェクトを作成します。$ oc new-project hello-openshift
以下のコマンドを実行してプロジェクトに Pod を作成します。
$ oc create -f https://raw.githubusercontent.com/openshift/origin/master/examples/hello-openshift/hello-pod.json
以下のコマンドを実行して、
hello-openshiftというサービスを作成します。$ oc expose pod/hello-openshift
次のコマンドを実行して、
hello-openshiftアプリケーションに対して、セキュアではないルートを作成します。$ oc expose svc hello-openshift
検証
作成した
routeリソースを確認するには、次のコマンドを実行します。$ oc get routes -o yaml <name of resource> 1- 1
- この例では、ルートの名前は
hello-openshiftです。
上記で作成されたセキュアでないルートの YAML 定義
apiVersion: route.openshift.io/v1 kind: Route metadata: name: hello-openshift spec: host: hello-openshift-hello-openshift.<Ingress_Domain> 1 port: targetPort: 8080 2 to: kind: Service name: hello-openshift
- 1
<Ingress_Domain>はデフォルトの Ingress ドメイン名です。ingresses.config/clusterオブジェクトはインストール中に作成され、変更できません。別のドメインを指定する場合は、appsDomainオプションを使用して別のクラスタードメインを指定できます。- 2
targetPortは、このルートが指すサービスによって選択される Pod のターゲットポートです。注記デフォルトの ingress ドメインを表示するには、以下のコマンドを実行します。
$ oc get ingresses.config/cluster -o jsonpath={.spec.domain}
29.1.2. Ingress Controller シャーディングのルート作成
ルートを使用すると、URL でアプリケーションをホストできます。この場合、ホスト名は設定されず、ルートは代わりにサブドメインを使用します。サブドメインを指定すると、ルートを公開する Ingress Controller のドメインが自動的に使用されます。ルートが複数の Ingress Controller によって公開されている状況では、ルートは複数の URL でホストされます。
以下の手順では、例として hello-openshift アプリケーションを使用して、Ingress Controller シャーディングのルートを作成する方法について説明します。
Ingress Controller のシャード化は、一連の Ingress Controller 間で着信トラフィックの負荷を分散し、トラフィックを特定の Ingress Controller に分離する際に役立ちます。たとえば、Company A のトラフィックをある Ingress Controller に指定し、Company B を別の Ingress Controller に指定できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - プロジェクト管理者としてログインしている。
- あるポートを公開する Web アプリケーションと、そのポートでトラフィックをリッスンする HTTP または TCP エンドポイントがある。
- シャーディング用に Ingress Controller を設定している。
手順
次のコマンドを実行して、
hello-openshiftというプロジェクトを作成します。$ oc new-project hello-openshift
以下のコマンドを実行してプロジェクトに Pod を作成します。
$ oc create -f https://raw.githubusercontent.com/openshift/origin/master/examples/hello-openshift/hello-pod.json
以下のコマンドを実行して、
hello-openshiftというサービスを作成します。$ oc expose pod/hello-openshift
hello-openshift-route.yamlというルート定義を作成します。シャーディング用に作成されたルートの YAML 定義:
apiVersion: route.openshift.io/v1 kind: Route metadata: labels: type: sharded 1 name: hello-openshift-edge namespace: hello-openshift spec: subdomain: hello-openshift 2 tls: termination: edge to: kind: Service name: hello-openshift次のコマンドを実行し、
hello-openshift-route.yamlを使用してhello-openshiftアプリケーションへのルートを作成します。$ oc -n hello-openshift create -f hello-openshift-route.yaml
検証
次のコマンドを使用して、ルートのステータスを取得します。
$ oc -n hello-openshift get routes/hello-openshift-edge -o yaml
結果の
Routeリソースは次のようになります。出力例
apiVersion: route.openshift.io/v1 kind: Route metadata: labels: type: sharded name: hello-openshift-edge namespace: hello-openshift spec: subdomain: hello-openshift tls: termination: edge to: kind: Service name: hello-openshift status: ingress: - host: hello-openshift.<apps-sharded.basedomain.example.net> 1 routerCanonicalHostname: router-sharded.<apps-sharded.basedomain.example.net> 2 routerName: sharded 3
29.1.3. ルートのタイムアウトの設定
Service Level Availability (SLA) で必要とされる、低タイムアウトが必要なサービスや、バックエンドでの処理速度が遅いケースで高タイムアウトが必要なサービスがある場合は、既存のルートに対してデフォルトのタイムアウトを設定することができます。
前提条件
- 実行中のクラスターでデプロイ済みの Ingress Controller が必要になります。
手順
oc annotateコマンドを使用して、ルートにタイムアウトを追加します。$ oc annotate route <route_name> \ --overwrite haproxy.router.openshift.io/timeout=<timeout><time_unit> 1- 1
- サポートされる時間単位は、マイクロ秒 (us)、ミリ秒 (ms)、秒 (s)、分 (m)、時間 (h)、または日 (d) です。
以下の例では、2 秒のタイムアウトを
myrouteという名前のルートに設定します。$ oc annotate route myroute --overwrite haproxy.router.openshift.io/timeout=2s
29.1.4. HTTP Strict Transport Security
HTTP Strict Transport Security (HSTS) ポリシーは、HTTPS トラフィックのみがルートホストで許可されるブラウザークライアントに通知するセキュリティーの拡張機能です。また、HSTS は、HTTP リダイレクトを使用せずに HTTPS トランスポートにシグナルを送ることで Web トラフィックを最適化します。HSTS は Web サイトとの対話を迅速化するのに便利です。
HSTS ポリシーが適用されると、HSTS はサイトから Strict Transport Security ヘッダーを HTTP および HTTPS 応答に追加します。HTTP を HTTPS にリダイレクトするルートで insecureEdgeTerminationPolicy 値を使用できます。HSTS を強制している場合は、要求の送信前にクライアントがすべての要求を HTTP URL から HTTPS に変更するため、リダイレクトの必要がなくなります。
クラスター管理者は、以下を実行するために HSTS を設定できます。
- ルートごとに HSTS を有効にします。
- ルートごとに HSTS を無効にします。
- ドメインごとに HSTS を適用するか、ドメインと組み合わせた namespace ラベルを使用します。
HSTS はセキュアなルート (edge-termination または re-encrypt) でのみ機能します。この設定は、HTTP またはパススルールートには適していません。
29.1.4.1. ルートごとの HTTP Strict Transport Security の有効化
HTTP 厳密なトランスポートセキュリティー (HSTS) は HAProxy テンプレートに実装され、haproxy.router.openshift.io/hsts_header アノテーションを持つ edge および re-encrypt ルートに適用されます。
前提条件
- プロジェクトの管理者権限があるユーザーで、クラスターにログインしている。
-
ocCLI がインストールされている。
手順
ルートで HSTS を有効にするには、
haproxy.router.openshift.io/hsts_header値を edge-termed または re-encrypt ルートに追加します。これを実行するには、oc annotateツールを使用してこれを実行できます。$ oc annotate route <route_name> -n <namespace> --overwrite=true "haproxy.router.openshift.io/hsts_header"="max-age=31536000;\ 1 includeSubDomains;preload"- 1
- この例では、最長期間は
31536000ミリ秒 (約 8 時間および半分) に設定されます。
注記この例では、等号 (
=) が引用符で囲まれています。これは、annotate コマンドを正しく実行するために必要です。アノテーションで設定されたルートの例
apiVersion: route.openshift.io/v1 kind: Route metadata: annotations: haproxy.router.openshift.io/hsts_header: max-age=31536000;includeSubDomains;preload 1 2 3 ... spec: host: def.abc.com tls: termination: "reencrypt" ... wildcardPolicy: "Subdomain"- 1
- 必須。
max-ageは、HSTS ポリシーが有効な期間 (秒単位) を測定します。0に設定すると、これはポリシーを無効にします。 - 2
- オプション:
includeSubDomainsは、クライアントに対し、ホストのすべてのサブドメインにホストと同じ HSTS ポリシーを持つ必要があることを指示します。 - 3
- オプション:
max-ageが 0 より大きい場合、preloadをhaproxy.router.openshift.io/hsts_headerに追加し、外部サービスがこのサイトをそれぞれの HSTS プリロードリストに含めることができます。たとえば、Google などのサイトはpreloadが設定されているサイトの一覧を作成します。ブラウザーはこれらのリストを使用し、サイトと対話する前でも HTTPS 経由で通信できるサイトを判別できます。preloadを設定していない場合、ブラウザーはヘッダーを取得するために、HTTPS を介してサイトと少なくとも 1 回対話している必要があります。
29.1.4.2. ルートごとの HTTP Strict Transport Security の無効化
ルートごとに HSTS (HTTP Strict Transport Security) を無効にするには、ルートアノテーションの max-age の値を 0 に設定します。
前提条件
- プロジェクトの管理者権限があるユーザーで、クラスターにログインしている。
-
ocCLI がインストールされている。
手順
HSTS を無効にするには、以下のコマンドを入力してルートアノテーションの
max-ageの値を0に設定します。$ oc annotate route <route_name> -n <namespace> --overwrite=true "haproxy.router.openshift.io/hsts_header"="max-age=0"
ヒントまたは、以下の YAML を適用して ConfigMap を作成できます。
ルートごとに HSTS を無効にする例
metadata: annotations: haproxy.router.openshift.io/hsts_header: max-age=0namespace のすべてのルートで HSTS を無効にするには、following コマンドを入力します。
$ oc annotate route --all -n <namespace> --overwrite=true "haproxy.router.openshift.io/hsts_header"="max-age=0"
検証
すべてのルートのアノテーションをクエリーするには、以下のコマンドを入力します。
$ oc get route --all-namespaces -o go-template='{{range .items}}{{if .metadata.annotations}}{{$a := index .metadata.annotations "haproxy.router.openshift.io/hsts_header"}}{{$n := .metadata.name}}{{with $a}}Name: {{$n}} HSTS: {{$a}}{{"\n"}}{{else}}{{""}}{{end}}{{end}}{{end}}'出力例
Name: routename HSTS: max-age=0
29.1.4.3. ドメインごとに HTTP Strict Transport Security の強制
安全なルートのドメインごとに HTTPStrict Transport Security(HSTS) を適用するには、requiredHSTSPolicies レコードを Ingress 仕様に追加して、HSTS ポリシーの設定を取得します。
requiredHSTSPolicy を設定して HSTS を適用する場合は、新規に作成されたルートは準拠された HSTS ポリシーアノテーションで設定する必要があります。
準拠しない HSTS ルートを持つアップグレードされたクラスターを処理するには、ソースでマニフェストを更新し、更新を適用できます。
oc expose route コマンドまたは oc create route コマンドを使用して、HSTS を強制するドメインにルートを追加することはできません。このコマンドの API はアノテーションを受け入れないためです。
HSTS がすべてのルートに対してグローバルに要求されている場合でも、セキュアではないルートや非 TLS ルートに適用することはできません。
前提条件
- プロジェクトの管理者権限があるユーザーで、クラスターにログインしている。
-
ocCLI がインストールされている。
手順
Ingress 設定ファイルを編集します。
$ oc edit ingresses.config.openshift.io/cluster
HSTS ポリシーの例
apiVersion: config.openshift.io/v1 kind: Ingress metadata: name: cluster spec: domain: 'hello-openshift-default.apps.username.devcluster.openshift.com' requiredHSTSPolicies: 1 - domainPatterns: 2 - '*hello-openshift-default.apps.username.devcluster.openshift.com' - '*hello-openshift-default2.apps.username.devcluster.openshift.com' namespaceSelector: 3 matchLabels: myPolicy: strict maxAge: 4 smallestMaxAge: 1 largestMaxAge: 31536000 preloadPolicy: RequirePreload 5 includeSubDomainsPolicy: RequireIncludeSubDomains 6 - domainPatterns: 7 - 'abc.example.com' - '*xyz.example.com' namespaceSelector: matchLabels: {} maxAge: {} preloadPolicy: NoOpinion includeSubDomainsPolicy: RequireNoIncludeSubDomains
- 1
- 必須。
requiredHSTSPoliciesは順番に検証され、最初に一致するdomainPatternsが適用されます。 - 2 7
- 必須。1 つ以上の
domainPatternsホスト名を指定する必要があります。任意の数のドメインをリスト表示できます。さまざまなdomainPatternsについて、Enforcing オプションの複数のセクションを含めることができます。 - 3
- オプション:
namespaceSelectorを含める場合、ルートを配置するプロジェクトのラベルと一致する必要があります。これにより、ルートに設定された HSTS ポリシーを適用する必要があります。domainPatternsではなくnamespaceSelectorのみに一致するルートは検証されません。 - 4
- 必須。
max-ageは、HSTS ポリシーが有効な期間 (秒単位) を測定します。このポリシー設定により、最小および最大のmax-ageを適用することができます。-
largestMaxAgeの値は0から2147483647の範囲内で指定する必要があります。これを指定しないと、上限が強制されないことを意味します。 -
smallestMaxAgeの値は0から2147483647の範囲内で指定する必要があります。トラブルシューティングのために HSTS を無効にするには、0を入力します。HSTS を無効にする必要がない場合は1を入力します。これを指定しないと、下限が強制されません。
-
- 5
- オプション:
haproxy.router.openshift.io/hsts_headerにpreloadを含めることで、外部サービスがこのサイトをそれぞれの HSTS プリロードリストに含めることができます。ブラウザーはこれらの一覧を使用し、サイトと対話する前でも HTTPS 経由で通信できるサイトを判別できます。preload設定がない場合、ブラウザーは少なくともサイトと通信してヘッダーを取得する必要があります。preloadは、以下のいずれかで設定できます。-
RequirePreload:preloadはRequiredHSTSPolicyで必要になります。 -
RequireNoPreload:preloadはRequiredHSTSPolicyによって禁止されます。 -
NoOpinion:preloadはRequiredHSTSPolicyに重要ではありません。
-
- 6
- オプション:
includeSubDomainsPolicyは、以下のいずれかで設定できます。-
RequireIncludeSubDomains:includeSubDomainsはRequiredHSTSPolicyで必要です。 -
RequireNoIncludeSubDomains:includeSubDomainsはRequiredHSTSPolicyによって禁止されています。 -
NoOpinion:includeSubDomainsはRequiredHSTSPolicyに重要ではありません。
-
oc annotate commandを入力して、HSTS をクラスターのすべてのルートまたは特定の namespace に適用することができます。HSTS をクラスターのすべてのルートに適用するには、
oc annotate commandを実行します。以下に例を示します。$ oc annotate route --all --all-namespaces --overwrite=true "haproxy.router.openshift.io/hsts_header"="max-age=31536000"
特定の namespace のすべてのルートに HSTS を適用するには、
oc annotate commandを実行します。以下に例を示します。$ oc annotate route --all -n my-namespace --overwrite=true "haproxy.router.openshift.io/hsts_header"="max-age=31536000"
検証
設定した HSTS ポリシーを確認できます。以下に例を示します。
必要な HSTS ポリシーの
maxAgeセットを確認するには、以下のコマンドを入力します。$ oc get clusteroperator/ingress -n openshift-ingress-operator -o jsonpath='{range .spec.requiredHSTSPolicies[*]}{.spec.requiredHSTSPolicies.maxAgePolicy.largestMaxAge}{"\n"}{end}'すべてのルートで HSTS アノテーションを確認するには、以下のコマンドを入力します。
$ oc get route --all-namespaces -o go-template='{{range .items}}{{if .metadata.annotations}}{{$a := index .metadata.annotations "haproxy.router.openshift.io/hsts_header"}}{{$n := .metadata.name}}{{with $a}}Name: {{$n}} HSTS: {{$a}}{{"\n"}}{{else}}{{""}}{{end}}{{end}}{{end}}'出力例
Name: <_routename_> HSTS: max-age=31536000;preload;includeSubDomains
29.1.5. スループットの問題のトラブルシューティング方法
OpenShift Container Platform でデプロイされるアプリケーションでは、特定のサービス間で非常に長い待ち時間が発生するなど、ネットワークのスループットの問題が生じることがあります。
Pod のログが問題の原因を指摘しない場合は、以下の方法を使用してパフォーマンスの問題を分析します。
pingまたはtcpdumpなどのパケットアナライザーを使用して Pod とそのノード間のトラフィックを分析します。たとえば、問題を生じさせる動作を再現している間に各ノードで
tcpdumpツールを実行 します。両サイトでキャプチャーしたデータを確認し、送信および受信タイムスタンプを比較して Pod への/からのトラフィックの待ち時間を分析します。待ち時間は、ノードのインターフェイスが他の Pod やストレージデバイス、またはデータプレーンからのトラフィックでオーバーロードする場合に OpenShift Container Platform で発生する可能性があります。$ tcpdump -s 0 -i any -w /tmp/dump.pcap host <podip 1> && host <podip 2> 1- 1
podipは Pod の IP アドレスです。oc get pod <pod_name> -o wideコマンドを実行して Pod の IP アドレスを取得します。
tcpdumpは、これらの 2 つの Pod 間のすべてのトラフィックが含まれる/tmp/dump.pcapのファイルを生成します。ファイルサイズを最小限に抑えるために問題を再現するすぐ前と問題を再現したすぐ後ににアナライザーを実行することが良いでしょう。以下のように ノード間でパケットアナライザーを実行すること もできます (式から SDN を排除する)。$ tcpdump -s 0 -i any -w /tmp/dump.pcap port 4789
ストリーミングのスループットおよび UDP スループットを測定するために
iperfなどの帯域幅測定ツールを使用します。最初に Pod からツールを実行し、次にノードから実行して、ボトルネックを特定します。-
iperfのインストールおよび使用についての詳細は、こちらの Red Hat ソリューション を参照してください。
-
- 場合によっては、レイテンシーの問題が原因で、クラスターがルーター Pod を含むノードを異常としてマークすることがあります。ワーカーレイテンシープロファイルを使用して、アクションを実行する前にクラスターがノードからステータスの最新情報を受け取る頻度を調節します。
-
クラスターでレイテンシーの低いノードとレイテンシーの高いノードが指定されている場合は、Ingress Controller の
spec.nodePlacementフィールドを設定して、ルーター Pod の配置を制御します。
29.1.6. Cookie の使用によるルートのステートフル性の維持
OpenShift Container Platform は、すべてのトラフィックを同じエンドポイントにヒットさせることによりステートフルなアプリケーションのトラフィックを可能にするスティッキーセッションを提供します。ただし、エンドポイント Pod が再起動、スケーリング、または設定の変更などによって終了する場合、このステートフル性はなくなります。
OpenShift Container Platform は Cookie を使用してセッションの永続化を設定できます。Ingress Controller はユーザー要求を処理するエンドポイントを選択し、そのセッションの Cookie を作成します。Cookie は要求の応答として戻され、ユーザーは Cookie をセッションの次の要求と共に送り返します。Cookie は Ingress Controller に対し、セッションを処理しているエンドポイントを示し、クライアント要求が Cookie を使用して同じ Pod にルーティングされるようにします。
cookie は、HTTP トラフィックを表示できないので、パススルールートで設定できません。代わりに、ソース IP アドレスをベースに数が計算され、バックエンドを判断します。
バックエンドが変わると、トラフィックが間違ったサーバーに転送されてしまい、スティッキーではなくなります。ソース IP を非表示にするロードバランサーを使用している場合は、すべての接続に同じ番号が設定され、トラフィックは同じ Pod に送られます。
29.1.6.1. Cookie を使用したルートのアノテーション
ルート用に自動生成されるデフォルト名を上書きするために Cookie 名を設定できます。これにより、ルートトラフィックを受信するアプリケーションが Cookie 名を認識できるようになります。Cookie を削除すると、次の要求でエンドポイントの再選択が強制的に実行される可能性があります。そのためサーバーがオーバーロードしている場合には、クライアントからの要求を取り除き、それらの再分配を試行します。
手順
指定される cookie 名でルートにアノテーションを付けます。
$ oc annotate route <route_name> router.openshift.io/cookie_name="<cookie_name>"
ここでは、以下のようになります。
<route_name>- Pod の名前を指定します。
<cookie_name>- cookie の名前を指定します。
たとえば、ルート
my_routeに cookie 名my_cookieでアノテーションを付けるには、以下を実行します。$ oc annotate route my_route router.openshift.io/cookie_name="my_cookie"
変数でルートのホスト名を取得します。
$ ROUTE_NAME=$(oc get route <route_name> -o jsonpath='{.spec.host}')ここでは、以下のようになります。
<route_name>- Pod の名前を指定します。
cookie を保存してからルートにアクセスします。
$ curl $ROUTE_NAME -k -c /tmp/cookie_jar
ルートに接続する際に、直前のコマンドによって保存される cookie を使用します。
$ curl $ROUTE_NAME -k -b /tmp/cookie_jar
29.1.7. パスベースのルート
パスベースのルートは、URL に対して比較できるパスコンポーネントを指定します。この場合、ルートのトラフィックは HTTP ベースである必要があります。そのため、それぞれが異なるパスを持つ同じホスト名を使用して複数のルートを提供できます。ルーターは、最も具体的なパスの順に基づいてルートと一致する必要があります。
以下の表は、ルートのサンプルおよびそれらのアクセシビリティーを示しています。
表29.1 ルートの可用性
| ルート | 比較対象 | アクセス可能 |
|---|---|---|
| www.example.com/test | www.example.com/test | はい |
| www.example.com | いいえ | |
| www.example.com/test および www.example.com | www.example.com/test | はい |
| www.example.com | はい | |
| www.example.com | www.example.com/text | Yes (ルートではなく、ホストで一致) |
| www.example.com | はい |
パスが 1 つでセキュリティー保護されていないルート
apiVersion: route.openshift.io/v1
kind: Route
metadata:
name: route-unsecured
spec:
host: www.example.com
path: "/test" 1
to:
kind: Service
name: service-name
- 1
- パスは、パスベースのルートに唯一追加される属性です。
ルーターは TLS を終了させず、要求のコンテンツを読み込みことができないので、パスベースのルーティングは、パススルー TLS を使用する場合には利用できません。
29.1.8. ルート固有のアノテーション
Ingress Controller は、公開するすべてのルートのデフォルトオプションを設定できます。個別のルートは、アノテーションに個別の設定を指定して、デフォルトの一部を上書きできます。Red Hat では、ルートアノテーションの Operator 管理ルートへの追加はサポートしません。
複数のソース IP またはサブネットのホワイトリストを作成するには、スペースで区切られたリストを使用します。他の区切りタイプを使用すると、リストが警告やエラーメッセージなしに無視されます。
表29.2 ルートアノテーション
| 変数 | 説明 | デフォルトで使用される環境変数 |
|---|---|---|
|
|
ロードバランシングアルゴリズムを設定します。使用できるオプションは、 |
パススルールートの |
|
|
関連の接続を追跡する cookie の使用を無効にします。 | |
|
| このルートに使用するオプションの cookie を指定します。名前は、大文字、小文字、数字、"_" または "-" を任意に組み合わせて指定する必要があります。デフォルトは、ルートのハッシュ化された内部キー名です。 | |
|
|
ルーターからバッキングされる Pod に対して許容される接続最大数を設定します。 | |
|
|
| |
|
|
同じソース IP アドレスで行われる同時 TCP 接続の数を制限します。数値を受け入れます。 | |
|
|
同じソース IP アドレスを持つクライアントが HTTP 要求を実行できるレートを制限します。数値を受け入れます。 | |
|
|
同じソース IP アドレスを持つクライアントが TCP 接続を確立するレートを制限します。数値を受け入れます。 | |
|
| ルートのサーバー側のタイムアウトを設定します。(TimeUnits) |
|
|
| このタイムアウトは、クリアテキスト、エッジ、再暗号化、またはパススルーのルートを介した Web Socket などトンネル接続に適用されます。cleartext、edge、または reencrypt のルートタイプでは、このアノテーションは、タイムアウト値がすでに存在するタイムアウトトンネルとして適用されます。パススルーのルートタイプでは、アノテーションは既存のタイムアウト値の設定よりも優先されます。 |
|
|
|
設定できるのは、Ingress Controller または ingress config です。このアノテーションでは、ルーターを再デプロイし、HA プロキシーが haproxy |
|
|
| バックエンドのヘルスチェックの間隔を設定します。(TimeUnits) |
|
|
| ルートの許可リストを設定します。許可リストは、承認したソースアドレスの IP アドレスおよび CIDR 範囲のリストをスペース区切りにしたリストです。許可リストに含まれていない IP アドレスからの要求は破棄されます。
| |
|
| edge terminated または re-encrypt ルートの Strick-Transport-Security ヘッダーを設定します。 | |
|
| バックエンドの要求の書き換えパスを設定します。 | |
|
| Cookie を制限するために値を設定します。値は以下のようになります。
この値は、re-encrypt および edge ルートにのみ適用されます。詳細は、SameSite cookie のドキュメント を参照してください。 | |
|
|
ルートごとに
|
|
許可リストの IP アドレスと CIDR 範囲の数が 61 を超えると、それらは別のファイルに書き込まれます。このファイルは
haproxy.configから参照されます。このファイルは、var/lib/haproxy/router/whitelistsフォルダーに保存されます。注記アドレスが許可リストに書き込まれることを確認するには、CIDR 範囲の完全なリストが Ingress Controller 設定ファイルに記載されていることを確認します。etcd オブジェクトサイズ制限は、ルートアノテーションのサイズを制限します。このため、許可リストに追加できる IP アドレスと CIDR 範囲の最大数のしきい値が作成されます。
環境変数を編集することはできません。
ルータータイムアウト変数
TimeUnits は数字、その後に単位を指定して表現します。 us *(マイクロ秒)、ms (ミリ秒、デフォルト)、s (秒)、m (分)、h *(時間)、d (日)
正規表現: [1-9][0-9]*(us\|ms\|s\|m\|h\|d)
| 変数 | デフォルト | 説明 |
|---|---|---|
|
|
| バックエンドでの後続の liveness チェックの時間の長さ。 |
|
|
| クライアントがルートに接続する場合の TCP FIN タイムアウトの期間を制御します。接続切断のために送信された FIN が指定の時間内に応答されない場合は、HAProxy が接続を切断します。小さい値を設定し、ルーターでリソースをあまり使用していない場合には、リスクはありません。 |
|
|
| クライアントがデータを確認するか、送信するための時間の長さ。 |
|
|
| 最大接続時間。 |
|
|
| ルーターからルートをバッキングする Pod の TCP FIN タイムアウトを制御します。 |
|
|
| サーバーがデータを確認するか、送信するための時間の長さ。 |
|
|
| TCP または WebSocket 接続が開放された状態で保つ時間数。このタイムアウト期間は、HAProxy が再読み込みされるたびにリセットされます。 |
|
|
|
新しい HTTP 要求が表示されるまで待機する最大時間を設定します。この値が低すぎる場合には、ブラウザーおよびアプリケーションの
有効なタイムアウト値には、想定した個別のタイムアウトではなく、特定の変数を合計した値に指定することができます。たとえば、 |
|
|
| HTTP 要求の伝送にかかる時間。 |
|
|
| ルーターがリロードし、新規の変更を受け入れる最小の頻度を許可します。 |
|
|
| HAProxy メトリクスの収集タイムアウト。 |
ルート設定のカスタムタイムアウト
apiVersion: route.openshift.io/v1
kind: Route
metadata:
annotations:
haproxy.router.openshift.io/timeout: 5500ms 1
...
- 1
- HAProxy 対応の単位 (
us、ms、s、m、h、d) で新規のタイムアウトを指定します。単位が指定されていない場合は、msがデフォルトになります。
パススルールートのサーバー側のタイムアウト値を低く設定し過ぎると、WebSocket 接続がそのルートで頻繁にタイムアウトする可能性があります。
特定の IP アドレスを 1 つだけ許可するルート
metadata:
annotations:
haproxy.router.openshift.io/ip_whitelist: 192.168.1.10
複数の IP アドレスを許可するルート
metadata:
annotations:
haproxy.router.openshift.io/ip_whitelist: 192.168.1.10 192.168.1.11 192.168.1.12
IP アドレスの CIDR ネットワークを許可するルート
metadata:
annotations:
haproxy.router.openshift.io/ip_whitelist: 192.168.1.0/24
IP アドレスと IP アドレスの CIDR ネットワークの両方を許可するルート
metadata:
annotations:
haproxy.router.openshift.io/ip_whitelist: 180.5.61.153 192.168.1.0/24 10.0.0.0/8
書き換えターゲットを指定するルート
apiVersion: route.openshift.io/v1
kind: Route
metadata:
annotations:
haproxy.router.openshift.io/rewrite-target: / 1
...
- 1
- バックエンドの要求の書き換えパスとして
/を設定します。
ルートに haproxy.router.openshift.io/rewrite-target アノテーションを設定すると、要求をバックエンドアプリケーションに転送する前に Ingress Controller がこのルートを使用して HTTP 要求のパスを書き換える必要があることを指定します。spec.path で指定されたパスに一致する要求パスの一部は、アノテーションで指定された書き換えターゲットに置き換えられます。
以下の表は、spec.path、要求パス、および書き換えターゲットの各種の組み合わせについてのパスの書き換え動作の例を示しています。
表29.3 rewrite-target の例:
| Route.spec.path | 要求パス | 書き換えターゲット | 転送された要求パス |
|---|---|---|---|
| /foo | /foo | / | / |
| /foo | /foo/ | / | / |
| /foo | /foo/bar | / | /bar |
| /foo | /foo/bar/ | / | /bar/ |
| /foo | /foo | /bar | /bar |
| /foo | /foo/ | /bar | /bar/ |
| /foo | /foo/bar | /baz | /baz/bar |
| /foo | /foo/bar/ | /baz | /baz/bar/ |
| /foo/ | /foo | / | 該当なし (要求パスがルートパスに一致しない) |
| /foo/ | /foo/ | / | / |
| /foo/ | /foo/bar | / | /bar |
29.1.9. ルートの受付ポリシーの設定
管理者およびアプリケーション開発者は、同じドメイン名を持つ複数の namespace でアプリケーションを実行できます。これは、複数のチームが同じホスト名で公開されるマイクロサービスを開発する組織を対象としています。
複数の namespace での要求の許可は、namespace 間の信頼のあるクラスターに対してのみ有効にする必要があります。有効にしないと、悪意のあるユーザーがホスト名を乗っ取る可能性があります。このため、デフォルトの受付ポリシーは複数の namespace 間でのホスト名の要求を許可しません。
前提条件
- クラスター管理者の権限。
手順
以下のコマンドを使用して、
ingresscontrollerリソース変数の.spec.routeAdmissionフィールドを編集します。$ oc -n openshift-ingress-operator patch ingresscontroller/default --patch '{"spec":{"routeAdmission":{"namespaceOwnership":"InterNamespaceAllowed"}}}' --type=mergeイメージコントローラー設定例
spec: routeAdmission: namespaceOwnership: InterNamespaceAllowed ...ヒントまたは、以下の YAML を適用してルートの受付ポリシーを設定できます。
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: default namespace: openshift-ingress-operator spec: routeAdmission: namespaceOwnership: InterNamespaceAllowed
29.1.10. Ingress オブジェクトを使用したルートの作成
一部のエコシステムコンポーネントには Ingress リソースとの統合機能がありますが、ルートリソースとは統合しません。これに対応するために、OpenShift Container Platform は Ingress オブジェクトの作成時に管理されるルートオブジェクトを自動的に作成します。これらのルートオブジェクトは、対応する Ingress オブジェクトが削除されると削除されます。
手順
OpenShift Container Platform コンソールで Ingress オブジェクトを定義するか、
oc createコマンドを実行します。Ingress の YAML 定義
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: frontend annotations: route.openshift.io/termination: "reencrypt" 1 route.openshift.io/destination-ca-certificate-secret: secret-ca-cert 2 spec: rules: - host: www.example.com 3 http: paths: - backend: service: name: frontend port: number: 443 path: / pathType: Prefix tls: - hosts: - www.example.com secretName: example-com-tls-certificate- 1
route.openshift.io/terminationアノテーションは、Routeのspec.tls.terminationフィールドを設定するために使用できます。Ingressにはこのフィールドがありません。許可される値はedge、passthrough、およびreencryptです。その他のすべての値は警告なしに無視されます。アノテーション値が設定されていない場合は、edgeがデフォルトルートになります。デフォルトのエッジルートを実装するには、TLS 証明書の詳細をテンプレートファイルで定義する必要があります。- 3
Ingressオブジェクトを操作する場合、ルートを操作する場合とは異なり、明示的なホスト名を指定する必要があります。<host_name>.<cluster_ingress_domain>構文 (apps.openshiftdemos.comなど) を使用して、*.<cluster_ingress_domain>ワイルドカード DNS レコードとクラスターのサービング証明書を利用できます。それ以外の場合は、選択したホスト名の DNS レコードがあることを確認する必要があります。route.openshift.io/terminationアノテーションでpassthroughの値を指定する場合は、仕様でpathを''に設定し、pathTypeをImplementationSpecificに設定します。spec: rules: - host: www.example.com http: paths: - path: '' pathType: ImplementationSpecific backend: service: name: frontend port: number: 443$ oc apply -f ingress.yaml
- 2
route.openshift.io/destination-ca-certificate-secretを Ingress オブジェクトで使用して、カスタム宛先証明書 (CA) でルートを定義できます。アノテーションは、生成されたルートに挿入される kubernetes シークレットsecret-ca-certを参照します。-
Ingress オブジェクトから宛先 CA を使用してルートオブジェクトを指定するには、シークレットの
data.tls.crt指定子に PEM エンコード形式の証明書を使用してkubernetes.io/tlsまたはOpaqueタイプのシークレットを作成する必要があります。
-
Ingress オブジェクトから宛先 CA を使用してルートオブジェクトを指定するには、シークレットの
ルートを一覧表示します。
$ oc get routes
結果には、
frontend-で始まる名前の自動生成ルートが含まれます。NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD frontend-gnztq www.example.com frontend 443 reencrypt/Redirect None
このルートを検査すると、以下のようになります。
自動生成されるルートの YAML 定義
apiVersion: route.openshift.io/v1 kind: Route metadata: name: frontend-gnztq ownerReferences: - apiVersion: networking.k8s.io/v1 controller: true kind: Ingress name: frontend uid: 4e6c59cc-704d-4f44-b390-617d879033b6 spec: host: www.example.com path: / port: targetPort: https tls: certificate: | -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE----- insecureEdgeTerminationPolicy: Redirect key: | -----BEGIN RSA PRIVATE KEY----- [...] -----END RSA PRIVATE KEY----- termination: reencrypt destinationCACertificate: | -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE----- to: kind: Service name: frontend
29.1.11. Ingress オブジェクトを介してデフォルトの証明書を使用してルートを作成する
TLS 設定を指定せずに Ingress オブジェクトを作成すると、OpenShift Container Platform は安全でないルートを生成します。デフォルトの Ingress 証明書を使用してセキュアなエッジ終端ルートを生成する Ingress オブジェクトを作成するには、次のように空の TLS 設定を指定できます。
前提条件
- 公開したいサービスがあります。
-
OpenShift CLI (
oc) にアクセスできる。
手順
Ingress オブジェクトの YAML ファイルを作成します。この例では、ファイルの名前は
example-ingress.yamlです。Ingress オブジェクトの YAML 定義
apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: frontend ... spec: rules: ... tls: - {} 1- 1
- この正確な構文を使用して、カスタム証明書を指定せずに TLS を指定します。
次のコマンドを実行して、Ingress オブジェクトを作成します。
$ oc create -f example-ingress.yaml
検証
以下のコマンドを実行して、OpenShift Container Platform が Ingress オブジェクトの予期されるルートを作成したことを確認します。
$ oc get routes -o yaml
出力例
apiVersion: v1 items: - apiVersion: route.openshift.io/v1 kind: Route metadata: name: frontend-j9sdd 1 ... spec: ... tls: 2 insecureEdgeTerminationPolicy: Redirect termination: edge 3 ...
29.1.12. Ingress アノテーションでの宛先 CA 証明書を使用したルート作成
route.openshift.io/destination-ca-certificate-secret アノテーションを Ingress オブジェクトで使用して、カスタム宛先 CA 証明書でルートを定義できます。
前提条件
- PEM エンコードされたファイルで証明書/キーのペアを持つことができます。ここで、証明書はルートホストに対して有効となっています。
- 証明書チェーンを完了する PEM エンコードされたファイルの別の CA 証明書が必要です。
- PEM エンコードされたファイルの別の宛先 CA 証明書が必要です。
- 公開する必要のあるサービスが必要です。
手順
route.openshift.io/destination-ca-certificate-secretを Ingress アノテーションに追加します。apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: frontend annotations: route.openshift.io/termination: "reencrypt" route.openshift.io/destination-ca-certificate-secret: secret-ca-cert 1 ...- 1
- アノテーションは kubernetes シークレットを参照します。
このアノテーションで参照されているシークレットは、生成されたルートに挿入されます。
出力例
apiVersion: route.openshift.io/v1 kind: Route metadata: name: frontend annotations: route.openshift.io/termination: reencrypt route.openshift.io/destination-ca-certificate-secret: secret-ca-cert spec: ... tls: insecureEdgeTerminationPolicy: Redirect termination: reencrypt destinationCACertificate: | -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE----- ...
29.1.13. デュアルスタックネットワーク用の OpenShift Container Platform Ingress Controller の設定
OpenShift Container Platform クラスターが IPv4 および IPv6 デュアルスタックネットワーク用に設定されている場合、クラスターは OpenShift Container Platform ルートによって外部からアクセス可能です。
Ingress Controller は、IPv4 エンドポイントと IPv6 エンドポイントの両方を持つサービスを自動的に提供しますが、シングルスタックまたはデュアルスタックサービス用に Ingress Controller を設定できます。
前提条件
- ベアメタルに OpenShift Container Platform クラスターをデプロイしていること。
-
OpenShift CLI (
oc) がインストールされている。
手順
Ingress Controller が、IPv4 / IPv6 を介してトラフィックをワークロードに提供するようにするには、
ipFamiliesフィールドおよびipFamilyPolicyフィールドを設定して、サービス YAML ファイルを作成するか、既存のサービス YAML ファイルを変更します。以下に例を示します。サービス YAML ファイルの例
apiVersion: v1 kind: Service metadata: creationTimestamp: yyyy-mm-ddT00:00:00Z labels: name: <service_name> manager: kubectl-create operation: Update time: yyyy-mm-ddT00:00:00Z name: <service_name> namespace: <namespace_name> resourceVersion: "<resource_version_number>" selfLink: "/api/v1/namespaces/<namespace_name>/services/<service_name>" uid: <uid_number> spec: clusterIP: 172.30.0.0/16 clusterIPs: 1 - 172.30.0.0/16 - <second_IP_address> ipFamilies: 2 - IPv4 - IPv6 ipFamilyPolicy: RequireDualStack 3 ports: - port: 8080 protocol: TCP targetport: 8080 selector: name: <namespace_name> sessionAffinity: None type: ClusterIP status: loadbalancer: {}これらのリソースは、対応する
endpointsを生成します。Ingress Controller は、endpointslicesを監視するようになりました。endpointsを表示するには、以下のコマンドを入力します。$ oc get endpoints
endpointslicesを表示するには、以下のコマンドを入力します。$ oc get endpointslices
29.2. セキュリティー保護されたルート
セキュアなルートは、複数の TLS 終端タイプを使用してクライアントに証明書を提供できます。以下のセクションでは、カスタム証明書を使用して re-encrypt、edge、および passthrough ルートを作成する方法を説明します。
パブリックエンドポイントを使用して Microsoft Azure にルートを作成する場合、リソース名は制限されます。特定の用語を使用するリソースを作成することはできません。Azure が制限する語のリストは、Azure ドキュメントの Resolve reserved resource name errors を参照してください。
29.2.1. カスタム証明書を使用した re-encrypt ルートの作成
oc create route コマンドを使用し、カスタム証明書と共に reencrypt TLS termination を使用してセキュアなルートを設定できます。
前提条件
- PEM エンコードされたファイルに証明書/キーのペアが必要です。ここで、証明書はルートホストに対して有効となっています。
- 証明書チェーンを完了する PEM エンコードされたファイルの別の CA 証明書が必要です。
- PEM エンコードされたファイルの別の宛先 CA 証明書が必要です。
- 公開する必要のあるサービスが必要です。
パスワードで保護されるキーファイルはサポートされません。キーファイルからパスフレーズを削除するには、以下のコマンドを使用します。
$ openssl rsa -in password_protected_tls.key -out tls.key
手順
この手順では、カスタム証明書および reencrypt TLS termination を使用して Route リソースを作成します。以下では、証明書/キーのペアが現在の作業ディレクトリーの tls.crt および tls.key ファイルにあることを前提としています。また、Ingress Controller がサービスの証明書を信頼できるように宛先 CA 証明書を指定する必要もあります。必要な場合には、証明書チェーンを完了するために CA 証明書を指定することもできます。tls.crt、 tls.key、cacert.crt、および (オプションで) ca.crt を実際のパス名に置き換えます。frontend を、公開する必要のある Service リソースに置き換えます。www.example.com を適切な名前に置き換えます。
reencrypt TLS 終端およびカスタム証明書を使用してセキュアな
Routeリソースを作成します。$ oc create route reencrypt --service=frontend --cert=tls.crt --key=tls.key --dest-ca-cert=destca.crt --ca-cert=ca.crt --hostname=www.example.com
結果として生成される
Routeリソースを検査すると、以下のようになります。セキュアなルートの YAML 定義
apiVersion: route.openshift.io/v1 kind: Route metadata: name: frontend spec: host: www.example.com to: kind: Service name: frontend tls: termination: reencrypt key: |- -----BEGIN PRIVATE KEY----- [...] -----END PRIVATE KEY----- certificate: |- -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE----- caCertificate: |- -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE----- destinationCACertificate: |- -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE-----他のオプションについては、
oc create route reencrypt --helpを参照してください。
29.2.2. カスタム証明書を使用した edge ルートの作成
oc create route コマンドを使用し、edge TLS termination とカスタム証明書を使用してセキュアなルートを設定できます。edge ルートの場合、Ingress Controller は、トラフィックを宛先 Pod に転送する前に TLS 暗号を終了します。ルートは、Ingress Controller がルートに使用する TLS 証明書およびキーを指定します。
前提条件
- PEM エンコードされたファイルに証明書/キーのペアが必要です。ここで、証明書はルートホストに対して有効となっています。
- 証明書チェーンを完了する PEM エンコードされたファイルの別の CA 証明書が必要です。
- 公開する必要のあるサービスが必要です。
パスワードで保護されるキーファイルはサポートされません。キーファイルからパスフレーズを削除するには、以下のコマンドを使用します。
$ openssl rsa -in password_protected_tls.key -out tls.key
手順
この手順では、カスタム証明書および edge TLS termination を使用して Route リソースを作成します。以下では、証明書/キーのペアが現在の作業ディレクトリーの tls.crt および tls.key ファイルにあることを前提としています。必要な場合には、証明書チェーンを完了するために CA 証明書を指定することもできます。tls.crt、 tls.key、および (オプションで) ca.crt を実際のパス名に置き換えます。frontend を、公開する必要のあるサービスの名前に置き換えます。www.example.com を適切な名前に置き換えます。
edge TLS termination およびカスタム証明書を使用して、セキュアな
Routeリソースを作成します。$ oc create route edge --service=frontend --cert=tls.crt --key=tls.key --ca-cert=ca.crt --hostname=www.example.com
結果として生成される
Routeリソースを検査すると、以下のようになります。セキュアなルートの YAML 定義
apiVersion: route.openshift.io/v1 kind: Route metadata: name: frontend spec: host: www.example.com to: kind: Service name: frontend tls: termination: edge key: |- -----BEGIN PRIVATE KEY----- [...] -----END PRIVATE KEY----- certificate: |- -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE----- caCertificate: |- -----BEGIN CERTIFICATE----- [...] -----END CERTIFICATE-----他のオプションについては、
oc create route edge --helpを参照してください。
29.2.3. passthrough ルートの作成
oc create route コマンドを使用し、passthrough termination を使用してセキュアなルートを設定できます。passthrough termination では、暗号化されたトラフィックが TLS 終端を提供するルーターなしに宛先に直接送信されます。そのため、ルートでキーや証明書は必要ありません。
前提条件
- 公開する必要のあるサービスが必要です。
手順
Routeリソースを作成します。$ oc create route passthrough route-passthrough-secured --service=frontend --port=8080
結果として生成される
Routeリソースを検査すると、以下のようになります。passthrough termination を使用したセキュリティー保護されたルート
apiVersion: route.openshift.io/v1 kind: Route metadata: name: route-passthrough-secured 1 spec: host: www.example.com port: targetPort: 8080 tls: termination: passthrough 2 insecureEdgeTerminationPolicy: None 3 to: kind: Service name: frontend
宛先 Pod は、エンドポイントでトラフィックに証明書を提供します。これは、必須となるクライアント証明書をサポートするための唯一の方法です (相互認証とも呼ばれる)。
第30章 ingress クラスタートラフィックの設定
30.1. ingress クラスタートラフィックの設定の概要
OpenShift Container Platform は、クラスター内で実行されるサービスを使用してクラスター外からの通信を可能にする以下の方法を提供します。
以下の方法が推奨されます。以下は、これらの方法の優先される順です。
- HTTP/HTTPS を使用する場合は Ingress Controller を使用する。
- HTTPS 以外の TLS で暗号化されたプロトコルを使用する場合、たとえば、SNI ヘッダーを使用する TLS の場合は、Ingress Controller を使用します。
-
それ以外の場合は、ロードバランサー、外部 IP、または
NodePortを使用します。
| 方法 | 目的 |
|---|---|
| HTTP/HTTPS トラフィックおよび HTTPS 以外の TLS で暗号化されたプロトコル (TLS と SNI ヘッダーの使用など) へのアクセスを許可します。 | |
| プールから割り当てられた IP アドレスを使用した非標準ポートへのトラフィックを許可します。ほとんどのクラウドプラットフォームは、ロードバランサーの IP アドレスでサービスを開始する方法を提供します。 | |
| マシンネットワーク上のプールから特定の IP アドレスまたはアドレスへのトラフィックを許可します。ベアメタルインストールまたはベアメタルのようなプラットフォームの場合、MetalLB は、ロードバランサーの IP アドレスを使用してサービスを開始する方法を提供します。 | |
| 特定の IP アドレスを使用した非標準ポートへのトラフィックを許可します。 | |
| クラスターのすべてのノードでサービスを公開します。 |
30.1.1. 比較: 外部 IP アドレスへのフォールトトレランスアクセス
外部 IP アドレスへのアクセスを提供する通信メソッドの場合、IP アドレスへのフォールトトレランスアクセスは別の考慮事項となります。以下の機能は、外部 IP アドレスへのフォールトトレランスアクセスを提供します。
- IP フェイルオーバー
- IP フェイルオーバーはノードセットの仮想 IP アドレスのプールを管理します。これは、Keepalived および Virtual Router Redundancy Protocol (VRRP) で実装されます。IP フェイルオーバーはレイヤー 2 のメカニズムのみで、マルチキャストに依存します。マルチキャストには、一部のネットワークに欠点がある場合があります。
- MetalLB
- MetalLB にはレイヤー 2 モードがありますが、マルチキャストは使用されません。レイヤー 2 モードには、1 つのノードで外部 IP アドレスのトラフィックをすべて転送する欠点があります。
- 外部 IP アドレスの手動割り当て
- クラスターを、外部 IP アドレスをサービスに割り当てるために使用される IP アドレスブロックで設定できます。デフォルトでは、この機能は無効にされています。この機能は柔軟性がありますが、クラスターまたはネットワーク管理者に最大の負担をかけます。クラスターは、外部 IP 宛てのトラフィックを受信する準備ができていますが、各顧客は、トラフィックをノードにルーティングする方法を決定する必要があります。
30.2. サービスの ExternalIP の設定
クラスター管理者は、トラフィックをクラスター内のサービスに送信できるクラスター外の IP アドレスブロックを指定できます。
この機能は通常、ベアメタルハードウェアにインストールされているクラスターに最も役立ちます。
30.2.1. 前提条件
- ネットワークインフラストラクチャーは、外部 IP アドレスのトラフィックをクラスターにルーティングする必要があります。
30.2.2. ExternalIP について
クラウド以外の環境では、OpenShift Container Platform は ExternalIP 機能を使用して外部 IP アドレスの Service オブジェクトの spec.externalIPs[] フィールドへの割り当てをサポートします。このフィールドを設定すると、OpenShift Container Platform は追加の仮想 IP アドレスをサービスに割り当てます。IP アドレスは、クラスターに定義されたサービスネットワーク外に指定できます。type=NodePort が設定されたサービスと同様に ExternalIP 機能で設定されたサービスにより、トラフィックを負荷分散のためにローカルノードに転送することができます。
ネットワークインフラストラクチャーを設定し、定義する外部 IP アドレスブロックがクラスターにルーティングされるようにする必要があります。そのため、IP アドレスがノードのネットワークインターフェイスに設定されません。トラフィックを処理するには、静的な Address Resolution Protocol (ARP) エントリーなどの方法を使用して、ルーティングと外部 IP へのアクセスを設定する必要があります。
OpenShift Container Platform は以下の機能を追加して Kubernetes の ExternalIP 機能を拡張します。
- 設定可能なポリシーでの、ユーザーによる外部 IP アドレスの使用の制限
- 要求時の外部 IP アドレスのサービスへの自動割り当て
ExternalIP 機能の使用はデフォルトで無効にされます。これは、外部 IP アドレスへのクラスター内のトラフィックがそのサービスにダイレクトされるため、セキュリティー上のリスクを生じさせる可能性があります。これにより、クラスターユーザーは外部リソースについての機密性の高いトラフィックをインターセプトできるようになります。
この機能は、クラウド以外のデプロイメントでのみサポートされます。クラウドデプロイメントの場合、クラウドの自動デプロイメントのためにロードバランサーサービスを使用し、サービスのエンドポイントをターゲットに設定します。
以下の方法で外部 IP アドレスを割り当てることができます。
- 外部 IP の自動割り当て
-
OpenShift Container Platform は、
spec.type=LoadBalancerを設定してServiceオブジェクトを作成する際に、IP アドレスをautoAssignCIDRsCIDR ブロックからspec.externalIPs[]配列に自動的に割り当てます。この場合、OpenShift Container Platform はロードバランサーサービスタイプのクラウド以外のバージョンを実装し、IP アドレスをサービスに割り当てます。自動割り当てはデフォルトで無効にされており、以下のセクションで説明されているように、これはクラスター管理者が設定する必要があります。 - 外部 IP の手動割り当て
-
OpenShift Container Platform は
Serviceオブジェクトの作成時にspec.externalIPs[]配列に割り当てられた IP アドレスを使用します。別のサービスによってすでに使用されている IP アドレスを指定することはできません。
30.2.2.1. ExternalIP の設定
OpenShift Container Platform での外部 IP アドレスの使用は、cluster という名前の Network.config.openshift.io CR の以下のフィールドで管理されます。
-
spec.externalIP.autoAssignCIDRsは、サービスの外部 IP アドレスを選択する際にロードバランサーによって使用される IP アドレスブロックを定義します。OpenShift Container Platform は、自動割り当て用の単一 IP アドレスブロックのみをサポートします。これは、ExternalIP をサービスに手動で割り当てる際に、制限された数の共有 IP アドレスのポート領域を管理しなくてはならない場合よりも単純になります。自動割り当てが有効な場合には、spec.type=LoadBalancerが設定されたServiceオブジェクトには外部 IP アドレスが割り当てられます。 -
spec.externalIP.policyは、IP アドレスを手動で指定する際に許容される IP アドレスブロックを定義します。OpenShift Container Platform は、spec.externalIP.autoAssignCIDRsで定義される IP アドレスブロックにポリシールールを適用しません。
ルーティングが正しく行われると、設定された外部 IP アドレスブロックからの外部トラフィックは、サービスが公開する TCP ポートまたは UDP ポートを介してサービスのエンドポイントに到達できます。
クラスター管理者は、OpenShiftSDN ネットワークタイプと OVN-Kubernetes ネットワークタイプの両方で externalIP へのルーティングを設定する必要があります。割り当てる IP アドレスブロックがクラスター内の 1 つ以上のノードで終了することを確認する必要もあります。詳細は、Kubernetes External IPs を参照してください。
OpenShift Container Platform は IP アドレスの自動および手動割り当ての両方をサポートしており、それぞれのアドレスは 1 つのサービスの最大数に割り当てられることが保証されます。これにより、各サービスは、ポートが他のサービスで公開されているかによらず、自らの選択したポートを公開できます。
OpenShift Container Platform の autoAssignCIDRs で定義された IP アドレスブロックを使用するには、ホストのネットワークに必要な IP アドレスの割り当ておよびルーティングを設定する必要があります。
以下の YAML は、外部 IP アドレスが設定されたサービスについて説明しています。
spec.externalIPs[] が設定された Service オブジェクトの例
apiVersion: v1
kind: Service
metadata:
name: http-service
spec:
clusterIP: 172.30.163.110
externalIPs:
- 192.168.132.253
externalTrafficPolicy: Cluster
ports:
- name: highport
nodePort: 31903
port: 30102
protocol: TCP
targetPort: 30102
selector:
app: web
sessionAffinity: None
type: LoadBalancer
status:
loadBalancer:
ingress:
- ip: 192.168.132.253
30.2.2.2. 外部 IP アドレスの割り当ての制限
クラスター管理者は、IP アドレスブロックを指定して許可および拒否できます。
制限は、cluster-admin 権限を持たないユーザーにのみ適用されます。クラスター管理者は、サービスの spec.externalIPs[] フィールドを任意の IP アドレスに常に設定できます。
spec.ExternalIP.policy フィールドを指定して、policy オブジェクトが定義された IP アドレスポリシーを設定します。ポリシーオブジェクトには以下の形があります。
{
"policy": {
"allowedCIDRs": [],
"rejectedCIDRs": []
}
}ポリシーの制限を設定する際に、以下のルールが適用されます。
-
policy={}が設定される場合、spec.ExternalIPs[]が設定されているServiceオブジェクトの作成は失敗します。これは OpenShift Container Platform のデフォルトです。policy=nullが設定される動作は同一です。 policyが設定され、policy.allowedCIDRs[]またはpolicy.rejectedCIDRs[]のいずれかが設定される場合、以下のルールが適用されます。-
allowedCIDRs[]とrejectedCIDRs[]の両方が設定される場合、rejectedCIDRs[]がallowedCIDRs[]よりも優先されます。 -
allowedCIDRs[]が設定される場合、spec.ExternalIPs[]が設定されているServiceオブジェクトの作成は、指定された IP アドレスが許可される場合にのみ正常に実行されます。 -
rejectedCIDRs[]が設定される場合、spec.ExternalIPs[]が設定されているServiceオブジェクトの作成は、指定された IP アドレスが拒否されていない場合にのみ正常に実行されます。
-
30.2.2.3. ポリシーオブジェクトの例
以下に続く例では、複数のポリシー設定の例を示します。
以下の例では、ポリシーは OpenShift Container Platform が外部 IP アドレスが指定されたサービスを作成するのを防ぎます。
Serviceオブジェクトのspec.externalIPs[]に指定された値を拒否するポリシーの例apiVersion: config.openshift.io/v1 kind: Network metadata: name: cluster spec: externalIP: policy: {} ...以下の例では、
allowedCIDRsおよびrejectedCIDRsフィールドの両方が設定されます。許可される、および拒否される CIDR ブロックの両方を含むポリシーの例
apiVersion: config.openshift.io/v1 kind: Network metadata: name: cluster spec: externalIP: policy: allowedCIDRs: - 172.16.66.10/23 rejectedCIDRs: - 172.16.66.10/24 ...以下の例では、
policyはnullに設定されます。nullに設定されている場合、oc get networks.config.openshift.io -o yamlを入力して設定オブジェクトを検査する際に、policyフィールドは出力に表示されません。Serviceオブジェクトのspec.externalIPs[]に指定された値を許可するポリシーの例apiVersion: config.openshift.io/v1 kind: Network metadata: name: cluster spec: externalIP: policy: null ...
30.2.3. ExternalIP アドレスブロックの設定
ExternalIP アドレスブロックの設定は、cluster という名前の Network カスタムリソース (CR) で定義されます。ネットワーク CR は config.openshift.io API グループに含まれます。
クラスターのインストール時に、Cluster Version Operator (CVO) は cluster という名前のネットワーク CR を自動的に作成します。このタイプのその他の CR オブジェクトの作成はサポートされていません。
以下の YAML は ExternalIP 設定について説明しています。
cluster という名前の network.config.openshift.io CR
apiVersion: config.openshift.io/v1
kind: Network
metadata:
name: cluster
spec:
externalIP:
autoAssignCIDRs: [] 1
policy: 2
...
以下の YAML は、policy スタンザのフィールドについて説明しています。
Network.config.openshift.io policy スタンザ
policy: allowedCIDRs: [] 1 rejectedCIDRs: [] 2
外部 IP 設定の例
外部 IP アドレスプールの予想される複数の設定が以下の例で表示されています。
以下の YAML は、自動的に割り当てられた外部 IP アドレスを有効にする設定について説明しています。
spec.externalIP.autoAssignCIDRsが設定された設定例apiVersion: config.openshift.io/v1 kind: Network metadata: name: cluster spec: ... externalIP: autoAssignCIDRs: - 192.168.132.254/29以下の YAML は、許可された、および拒否された CIDR 範囲のポリシールールを設定します。
spec.externalIP.policyが設定された設定例apiVersion: config.openshift.io/v1 kind: Network metadata: name: cluster spec: ... externalIP: policy: allowedCIDRs: - 192.168.132.0/29 - 192.168.132.8/29 rejectedCIDRs: - 192.168.132.7/32
30.2.4. クラスターの外部 IP アドレスブロックの設定
クラスター管理者は、以下の ExternalIP を設定できます。
-
Serviceオブジェクトのspec.clusterIPフィールドを自動的に設定するために OpenShift Container Platform によって使用される ExternalIP アドレスブロック。 -
IP アドレスを制限するポリシーオブジェクトは
Serviceオブジェクトのspec.clusterIP配列に手動で割り当てられます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。
手順
オプション: 現在の外部 IP 設定を表示するには、以下のコマンドを入力します。
$ oc describe networks.config cluster
設定を編集するには、以下のコマンドを入力します。
$ oc edit networks.config cluster
以下の例のように ExternalIP 設定を変更します。
apiVersion: config.openshift.io/v1 kind: Network metadata: name: cluster spec: ... externalIP: 1 ...- 1
externalIPスタンザの設定を指定します。
更新された ExternalIP 設定を確認するには、以下のコマンドを入力します。
$ oc get networks.config cluster -o go-template='{{.spec.externalIP}}{{"\n"}}'
30.2.5. 次のステップ
30.3. Ingress Controller を使用した Ingress クラスターの設定
OpenShift Container Platform は、クラスター内で実行されるサービスを使用してクラスター外からの通信を可能にする方法を提供します。この方法は Ingress Controller を使用します。
30.3.1. Ingress Controller およびルートの使用
Ingress Operator は Ingress Controller およびワイルドカード DNS を管理します。
Ingress Controller の使用は、最も一般的な、OpenShift Container Platform クラスターへの外部アクセスを許可する方法です。
Ingress Controller は外部要求を許可し、設定されたルートに基づいてそれらをプロキシー送信するよう設定されます。これは、HTTP、SNI を使用する HTTPS、SNI を使用する TLS に限定されており、SNI を使用する TLS で機能する Web アプリケーションやサービスには十分な設定です。
管理者と連携して Ingress Controller を設定します。外部要求を許可し、設定されたルートに基づいてそれらをプロキシー送信するように Ingress Controller を設定します。
管理者はワイルドカード DNS エントリーを作成してから Ingress Controller を設定できます。その後は管理者に問い合わせることなく edge Ingress Controller と連携できます。
デフォルトで、クラスター内のすべての Ingress Controller はクラスター内の任意のプロジェクトで作成されたすべてのルートを許可します。
Ingress Controller:
- デフォルトでは 2 つのレプリカがあるので、これは 2 つのワーカーノードで実行する必要があります。
- 追加のノードにレプリカを組み込むためにスケールアップすることができます。
このセクションの手順では、クラスターの管理者が事前に行っておく必要のある前提条件があります。
30.3.2. 前提条件
以下の手順を開始する前に、管理者は以下の条件を満たしていることを確認する必要があります。
- 要求がクラスターに到達できるように、クラスターネットワーク環境に対して外部ポートをセットアップします。
クラスター管理者ロールを持つユーザーが 1 名以上いることを確認します。このロールをユーザーに追加するには、以下のコマンドを実行します。
$ oc adm policy add-cluster-role-to-user cluster-admin username
- OpenShift Container Platform クラスターを、1 つ以上のマスターと 1 つ以上のノード、およびクラスターへのネットワークアクセスのあるクラスター外のシステムと共に用意します。この手順では、外部システムがクラスターと同じサブセットにあることを前提とします。別のサブセットの外部システムに必要な追加のネットワーク設定については、このトピックでは扱いません。
30.3.3. プロジェクトおよびサービスの作成
公開するプロジェクトおよびサービスが存在しない場合、最初にプロジェクトを作成し、次にサービスを作成します。
プロジェクトおよびサービスがすでに存在する場合は、サービスを公開してルートを作成する手順に進みます。
前提条件
-
クラスター管理者として
ocCLI をインストールし、ログインします。
手順
oc new-projectコマンドを実行して、サービス用の新しいプロジェクトを作成します。$ oc new-project myproject
oc new-appコマンドを使用してサービスを作成します。$ oc new-app nodejs:12~https://github.com/sclorg/nodejs-ex.git
サービスが作成されたことを確認するには、以下のコマンドを実行します。
$ oc get svc -n myproject
出力例
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nodejs-ex ClusterIP 172.30.197.157 <none> 8080/TCP 70s
デフォルトで、新規サービスには外部 IP アドレスがありません。
30.3.4. ルートの作成によるサービスの公開
oc expose コマンドを使用して、サービスをルートとして公開することができます。
手順
サービスを公開するには、以下を実行します。
- OpenShift Container Platform にログインします。
公開するサービスが置かれているプロジェクトにログインします。
$ oc project myproject
oc expose serviceコマンドを実行して、ルートを公開します。$ oc expose service nodejs-ex
出力例
route.route.openshift.io/nodejs-ex exposed
サービスが公開されていることを確認するには、cURL などのツールを使用して、クラスター外からサービスにアクセスできることを確認します。
ルートのホスト名を調べるには、
oc get routeコマンドを使用します。$ oc get route
出力例
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD nodejs-ex nodejs-ex-myproject.example.com nodejs-ex 8080-tcp None
cURL を使用して、ホストが GET 要求に応答することを確認します。
$ curl --head nodejs-ex-myproject.example.com
出力例
HTTP/1.1 200 OK ...
30.3.5. ルートラベルを使用した Ingress Controller のシャード化の設定
ルートラベルを使用した Ingress Controller のシャード化とは、Ingress Controller がルートセレクターによって選択される任意 namespace の任意のルートを提供することを意味します。
図30.1 ルートラベルを使用した Ingress シャーディング
Ingress Controller のシャード化は、一連の Ingress Controller 間で着信トラフィックの負荷を分散し、トラフィックを特定の Ingress Controller に分離する際に役立ちます。たとえば、Company A のトラフィックをある Ingress Controller に指定し、Company B を別の Ingress Controller に指定できます。
手順
router-internal.yamlファイルを編集します。# cat router-internal.yaml apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: sharded namespace: openshift-ingress-operator spec: domain: <apps-sharded.basedomain.example.net> 1 nodePlacement: nodeSelector: matchLabels: node-role.kubernetes.io/worker: "" routeSelector: matchLabels: type: sharded- 1
- Ingress Controller が使用するドメインを指定します。このドメインは、デフォルトの Ingress Controller ドメインとは異なる必要があります。
Ingress Controller の
router-internal.yamlファイルを適用します。# oc apply -f router-internal.yaml
Ingress Controller は、
type: shardedというラベルのある namespace のルートを選択します。router-internal.yamlで設定されたドメインを使用して新しいルートを作成します。$ oc expose svc <service-name> --hostname <route-name>.apps-sharded.basedomain.example.net
30.3.6. namespace ラベルを使用した Ingress Controller のシャード化の設定
namespace ラベルを使用した Ingress Controller のシャード化とは、Ingress Controller が namespace セレクターによって選択される任意の namespace の任意のルートを提供することを意味します。
図30.2 namespace ラベルを使用した Ingress シャーディング
Ingress Controller のシャード化は、一連の Ingress Controller 間で着信トラフィックの負荷を分散し、トラフィックを特定の Ingress Controller に分離する際に役立ちます。たとえば、Company A のトラフィックをある Ingress Controller に指定し、Company B を別の Ingress Controller に指定できます。
手順
router-internal.yamlファイルを編集します。# cat router-internal.yaml
出力例
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: sharded namespace: openshift-ingress-operator spec: domain: <apps-sharded.basedomain.example.net> 1 nodePlacement: nodeSelector: matchLabels: node-role.kubernetes.io/worker: "" namespaceSelector: matchLabels: type: sharded- 1
- Ingress Controller が使用するドメインを指定します。このドメインは、デフォルトの Ingress Controller ドメインとは異なる必要があります。
Ingress Controller の
router-internal.yamlファイルを適用します。# oc apply -f router-internal.yaml
Ingress Controller は、
type: shardedというラベルのある namespace セレクターによって選択される namespace のルートを選択します。router-internal.yamlで設定されたドメインを使用して新しいルートを作成します。$ oc expose svc <service-name> --hostname <route-name>.apps-sharded.basedomain.example.net
30.3.7. Ingress Controller シャーディングのルート作成
ルートを使用すると、URL でアプリケーションをホストできます。この場合、ホスト名は設定されず、ルートは代わりにサブドメインを使用します。サブドメインを指定すると、ルートを公開する Ingress Controller のドメインが自動的に使用されます。ルートが複数の Ingress Controller によって公開されている状況では、ルートは複数の URL でホストされます。
以下の手順では、例として hello-openshift アプリケーションを使用して、Ingress Controller シャーディングのルートを作成する方法について説明します。
Ingress Controller のシャード化は、一連の Ingress Controller 間で着信トラフィックの負荷を分散し、トラフィックを特定の Ingress Controller に分離する際に役立ちます。たとえば、Company A のトラフィックをある Ingress Controller に指定し、Company B を別の Ingress Controller に指定できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - プロジェクト管理者としてログインしている。
- あるポートを公開する Web アプリケーションと、そのポートでトラフィックをリッスンする HTTP または TCP エンドポイントがある。
- シャーディング用に Ingress Controller を設定している。
手順
次のコマンドを実行して、
hello-openshiftというプロジェクトを作成します。$ oc new-project hello-openshift
以下のコマンドを実行してプロジェクトに Pod を作成します。
$ oc create -f https://raw.githubusercontent.com/openshift/origin/master/examples/hello-openshift/hello-pod.json
以下のコマンドを実行して、
hello-openshiftというサービスを作成します。$ oc expose pod/hello-openshift
hello-openshift-route.yamlというルート定義を作成します。シャーディング用に作成されたルートの YAML 定義:
apiVersion: route.openshift.io/v1 kind: Route metadata: labels: type: sharded 1 name: hello-openshift-edge namespace: hello-openshift spec: subdomain: hello-openshift 2 tls: termination: edge to: kind: Service name: hello-openshift次のコマンドを実行し、
hello-openshift-route.yamlを使用してhello-openshiftアプリケーションへのルートを作成します。$ oc -n hello-openshift create -f hello-openshift-route.yaml
検証
次のコマンドを使用して、ルートのステータスを取得します。
$ oc -n hello-openshift get routes/hello-openshift-edge -o yaml
結果の
Routeリソースは次のようになります。出力例
apiVersion: route.openshift.io/v1 kind: Route metadata: labels: type: sharded name: hello-openshift-edge namespace: hello-openshift spec: subdomain: hello-openshift tls: termination: edge to: kind: Service name: hello-openshift status: ingress: - host: hello-openshift.<apps-sharded.basedomain.example.net> 1 routerCanonicalHostname: router-sharded.<apps-sharded.basedomain.example.net> 2 routerName: sharded 3
30.3.8. 関連情報
Ingress Operator はワイルドカード DNS を管理します。詳細は、以下を参照してください。
30.4. ロードバランサーを使用した ingress クラスターの設定
OpenShift Container Platform は、クラスター内で実行されるサービスを使用してクラスター外からの通信を可能にする方法を提供します。この方法では、ロードバランサーを使用します。
30.4.1. ロードバランサーを使用したトラフィックのクラスターへの送信
特定の外部 IP アドレスを必要としない場合、ロードバランサーサービスを OpenShift Container Platform クラスターへの外部アクセスを許可するよう設定することができます。
ロードバランサーサービスは固有の IP を割り当てます。ロードバランサーには単一の edge ルーター IP があります (これは仮想 IP (VIP) の場合もありますが、初期の負荷分散では単一マシンになります。
プールが設定される場合、これはクラスター管理者によってではなく、インフラストラクチャーレベルで実行されます。
このセクションの手順では、クラスターの管理者が事前に行っておく必要のある前提条件があります。
30.4.2. 前提条件
以下の手順を開始する前に、管理者は以下の条件を満たしていることを確認する必要があります。
- 要求がクラスターに到達できるように、クラスターネットワーク環境に対して外部ポートをセットアップします。
クラスター管理者ロールを持つユーザーが 1 名以上いることを確認します。このロールをユーザーに追加するには、以下のコマンドを実行します。
$ oc adm policy add-cluster-role-to-user cluster-admin username
- OpenShift Container Platform クラスターを、1 つ以上のマスターと 1 つ以上のノード、およびクラスターへのネットワークアクセスのあるクラスター外のシステムと共に用意します。この手順では、外部システムがクラスターと同じサブセットにあることを前提とします。別のサブセットの外部システムに必要な追加のネットワーク設定については、このトピックでは扱いません。
30.4.3. プロジェクトおよびサービスの作成
公開するプロジェクトおよびサービスが存在しない場合、最初にプロジェクトを作成し、次にサービスを作成します。
プロジェクトおよびサービスがすでに存在する場合は、サービスを公開してルートを作成する手順に進みます。
前提条件
-
クラスター管理者として
ocCLI をインストールし、ログインします。
手順
oc new-projectコマンドを実行して、サービス用の新しいプロジェクトを作成します。$ oc new-project myproject
oc new-appコマンドを使用してサービスを作成します。$ oc new-app nodejs:12~https://github.com/sclorg/nodejs-ex.git
サービスが作成されたことを確認するには、以下のコマンドを実行します。
$ oc get svc -n myproject
出力例
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nodejs-ex ClusterIP 172.30.197.157 <none> 8080/TCP 70s
デフォルトで、新規サービスには外部 IP アドレスがありません。
30.4.4. ルートの作成によるサービスの公開
oc expose コマンドを使用して、サービスをルートとして公開することができます。
手順
サービスを公開するには、以下を実行します。
- OpenShift Container Platform にログインします。
公開するサービスが置かれているプロジェクトにログインします。
$ oc project myproject
oc expose serviceコマンドを実行して、ルートを公開します。$ oc expose service nodejs-ex
出力例
route.route.openshift.io/nodejs-ex exposed
サービスが公開されていることを確認するには、cURL などのツールを使用して、クラスター外からサービスにアクセスできることを確認します。
ルートのホスト名を調べるには、
oc get routeコマンドを使用します。$ oc get route
出力例
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD nodejs-ex nodejs-ex-myproject.example.com nodejs-ex 8080-tcp None
cURL を使用して、ホストが GET 要求に応答することを確認します。
$ curl --head nodejs-ex-myproject.example.com
出力例
HTTP/1.1 200 OK ...
30.4.5. ロードバランサーサービスの作成
以下の手順を使用して、ロードバランサーサービスを作成します。
前提条件
- 公開するプロジェクトとサービスがあること。
- クラウドプロバイダーがロードバランサーをサポートしている。
手順
ロードバランサーサービスを作成するには、以下を実行します。
- OpenShift Container Platform にログインします。
公開するサービスが置かれているプロジェクトを読み込みます。
$ oc project project1
コントロールプレーンノードでテキストファイルを開き、以下のテキストを貼り付け、必要に応じてファイルを編集します。
ロードバランサー設定ファイルのサンプル
apiVersion: v1 kind: Service metadata: name: egress-2 1 spec: ports: - name: db port: 3306 2 loadBalancerIP: loadBalancerSourceRanges: 3 - 10.0.0.0/8 - 192.168.0.0/16 type: LoadBalancer 4 selector: name: mysql 5
注記ロードバランサーを通過するトラフィックを特定の IP アドレスに制限するには、Ingress Controller フィールド
spec.endpointPublishingStrategy.loadBalancer.allowedSourceRangesを使用することを推奨します。loadBalancerSourceRangesフィールドを設定しないでください。- ファイルを保存し、終了します。
以下のコマンドを実行してサービスを作成します。
$ oc create -f <file-name>
以下に例を示します。
$ oc create -f mysql-lb.yaml
以下のコマンドを実行して新規サービスを表示します。
$ oc get svc
出力例
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE egress-2 LoadBalancer 172.30.22.226 ad42f5d8b303045-487804948.example.com 3306:30357/TCP 15m
有効にされたクラウドプロバイダーがある場合、サービスには外部 IP アドレスが自動的に割り当てられます。
マスターで cURL などのツールを使用し、パブリック IP アドレスを使用してサービスに到達できることを確認します。
$ curl <public-ip>:<port>
以下に例を示します。
$ curl 172.29.121.74:3306
このセクションの例では、クライアントアプリケーションを必要とする MySQL サービスを使用しています。
Got packets out of orderのメッセージと共に文字ストリングを取得する場合は、このサービスに接続していることになります。MySQL クライアントがある場合は、標準 CLI コマンドでログインします。
$ mysql -h 172.30.131.89 -u admin -p
出力例
Enter password: Welcome to the MariaDB monitor. Commands end with ; or \g. MySQL [(none)]>
30.5. AWS での Ingress クラスタートラフィックの設定
OpenShift Container Platform は、クラスター内で実行されるサービスを使用してクラスター外からの通信を可能にする方法を提供します。この方法では、AWS のロードバランサー、具体的には Network Load Balancer (NLB) またはク Classic Load Balancer (CLB) を使用します。どちらのタイプのロードバランサーもクライアントの IP アドレスをノードに転送できますが、CLB にはプロキシープロトコルのサポートが必要です。これは OpenShift Container Platform によって自動的に有効になります。
NLB を使用するように Ingress Controller を設定するには、次の 2 つの方法があります。
-
現在 CLB を使用している Ingress Controller を強制的に置き換える。これにより、
IngressControllerオブジェクトが削除され、新しい DNS レコードが伝達され、NLB がプロビジョニングされている間、停止が発生します。 -
CLB を使用する既存の Ingress Controller を編集して、NLB を使用する。これにより、
IngressControllerオブジェクトを削除して再作成することなく、ロードバランサーが変更されます。
どちらの方法も、NLB から CLB への切り替えに使用できます。
これらのロードバランサーは、新規または既存の AWS クラスターで設定できます。
30.5.1. AWS での Classic Load Balancer タイムアウトの設定
OpenShift Container Platform は、特定のルートまたは Ingress Controller のカスタムタイムアウト期間を設定するためのメソッドを提供します。さらに、AWS Classic Load Balancer (CLB) には独自のタイムアウト期間があり、デフォルトは 60 秒です。
CLB のタイムアウト期間がルートタイムアウトまたは Ingress Controller タイムアウトよりも短い場合、ロードバランサーは接続を途中で終了する可能性があります。ルートと CLB の両方のタイムアウト期間を増やすことで、この問題を防ぐことができます。
30.5.1.1. ルートのタイムアウトの設定
Service Level Availability (SLA) で必要とされる、低タイムアウトが必要なサービスや、バックエンドでの処理速度が遅いケースで高タイムアウトが必要なサービスがある場合は、既存のルートに対してデフォルトのタイムアウトを設定することができます。
前提条件
- 実行中のクラスターでデプロイ済みの Ingress Controller が必要になります。
手順
oc annotateコマンドを使用して、ルートにタイムアウトを追加します。$ oc annotate route <route_name> \ --overwrite haproxy.router.openshift.io/timeout=<timeout><time_unit> 1- 1
- サポートされる時間単位は、マイクロ秒 (us)、ミリ秒 (ms)、秒 (s)、分 (m)、時間 (h)、または日 (d) です。
以下の例では、2 秒のタイムアウトを
myrouteという名前のルートに設定します。$ oc annotate route myroute --overwrite haproxy.router.openshift.io/timeout=2s
30.5.1.2. Classic Load Balancer タイムアウトの設定
Classic Load Balancer (CLB) のデフォルトのタイムアウトを設定して、アイドル接続を延長できます。
前提条件
- 実行中のクラスターにデプロイ済みの Ingress Controller がある。
手順
次のコマンドを実行して、デフォルト
ingresscontrollerの AWS 接続アイドルタイムアウトを 5 分に設定します。$ oc -n openshift-ingress-operator patch ingresscontroller/default \ --type=merge --patch='{"spec":{"endpointPublishingStrategy": \ {"type":"LoadBalancerService", "loadBalancer": \ {"scope":"External", "providerParameters":{"type":"AWS", "aws": \ {"type":"Classic", "classicLoadBalancer": \ {"connectionIdleTimeout":"5m"}}}}}}}'オプション: 次のコマンドを実行して、タイムアウトのデフォルト値を復元します。
$ oc -n openshift-ingress-operator patch ingresscontroller/default \ --type=merge --patch='{"spec":{"endpointPublishingStrategy": \ {"loadBalancer":{"providerParameters":{"aws":{"classicLoadBalancer": \ {"connectionIdleTimeout":null}}}}}}}'
現在のスコープがすでに設定されている場合を除き、接続タイムアウト値を変更するには scope フィールドを指定する必要があります。デフォルトのタイムアウト値に戻す場合は、scope フィールドを設定する際に再度設定する必要はありません。
30.5.2. ネットワークロードバランサーを使用した AWS での ingress クラスタートラフィックの設定
OpenShift Container Platform は、クラスター内で実行されるサービスを使用してクラスター外からの通信を可能にする方法を提供します。そのような方法の 1 つでは、Network Load Balancer (NLB) を使用します。NLB を新規または既存の AWS クラスターに設定することができます。
30.5.2.1. Ingress Controller を Classic Load Balancer から Network Load Balancer に切り替える
Classic Load Balancer (CLB) を使用している Ingress Controller を、AWS の Network Load Balancer (NLB) を使用する Ingress Controller に切り替えることができます。
これらのロードバランサーを切り替えても、IngressController オブジェクトは削除されません。
この手順により、次の問題が発生する可能性があります。
- 新しい DNS レコードの伝播、新しいロードバランサーのプロビジョニング、およびその他の要因により、数分間続く可能性のある停止。この手順を適用すると、Ingress Controller ロードバランサーの IP アドレスや正規名が変更になる場合があります。
- サービスのアノテーションの変更により、ロードバランサーリソースがリークする。
手順
NLB を使用して切り替える既存の Ingress Controller を変更します。この例では、デフォルトの Ingress Controller に
Externalスコープがあり、他のカスタマイズがないことを前提としています。ingresscontroller.yamlファイルの例apiVersion: operator.openshift.io/v1 kind: IngressController metadata: creationTimestamp: null name: default namespace: openshift-ingress-operator spec: endpointPublishingStrategy: loadBalancer: scope: External providerParameters: type: AWS aws: type: NLB type: LoadBalancerService注記spec.endpointPublishingStrategy.loadBalancer.providerParameters.aws.typeフィールドの値を指定しない場合、Ingress Controller は、インストール時に設定されたクラスターIngress設定のspec.loadBalancer.platform.aws.type値を使用します。ヒントIngress Controller に、ドメインの変更など、更新したい他のカスタマイズがある場合は、代わりに Ingress Controller 定義ファイルを強制的に置き換えることを検討してください。
次のコマンドを実行して、Ingress Controller YAML ファイルに変更を適用します。
$ oc apply -f ingresscontroller.yaml
Ingress Controller の更新中は、数分間の停止が予想されます。
30.5.2.2. Network Load Balancer の使用から Classic Load Balancer への Ingress Controller の切り替え
Network Load Balancer (NLB) を使用している Ingress Controller を、AWS の Classic Load Balancer (CLB) を使用する Ingress Controller に切り替えることができます。
これらのロードバランサーを切り替えても、IngressController オブジェクトは削除されません。
この手順により、新しい DNS レコードの伝播、新しいロードバランサーのプロビジョニング、およびその他の要因により、数分間続く停止が発生する可能性があります。この手順を適用すると、Ingress Controller ロードバランサーの IP アドレスや正規名が変更になる場合があります。
手順
CLB を使用して切り替える既存の Ingress Controller を変更します。この例では、デフォルトの Ingress Controller に
Externalスコープがあり、他のカスタマイズがないことを前提としています。ingresscontroller.yamlファイルの例apiVersion: operator.openshift.io/v1 kind: IngressController metadata: creationTimestamp: null name: default namespace: openshift-ingress-operator spec: endpointPublishingStrategy: loadBalancer: scope: External providerParameters: type: AWS aws: type: Classic type: LoadBalancerService注記spec.endpointPublishingStrategy.loadBalancer.providerParameters.aws.typeフィールドの値を指定しない場合、Ingress Controller は、インストール時に設定されたクラスターIngress設定のspec.loadBalancer.platform.aws.type値を使用します。ヒントIngress Controller に、ドメインの変更など、更新したい他のカスタマイズがある場合は、代わりに Ingress Controller 定義ファイルを強制的に置き換えることを検討してください。
次のコマンドを実行して、Ingress Controller YAML ファイルに変更を適用します。
$ oc apply -f ingresscontroller.yaml
Ingress Controller の更新中は、数分間の停止が予想されます。
30.5.2.3. Ingress Controller Classic Load Balancer の Network Load Balancer への置き換え
Classic Load Balancer (CLB) を使用している Ingress Controller は、AWS の Network Load Balancer (NLB) を使用している Ingress Controller に置き換えることができます。
この手順により、次の問題が発生する可能性があります。
- 新しい DNS レコードの伝播、新しいロードバランサーのプロビジョニング、およびその他の要因により、数分間続く可能性のある停止。この手順を適用すると、Ingress Controller ロードバランサーの IP アドレスや正規名が変更になる場合があります。
- サービスのアノテーションの変更により、ロードバランサーリソースがリークする。
手順
新しいデフォルトの Ingress Controller を含むファイルを作成します。以下の例では、デフォルトの Ingress Controller の範囲が
Externalで、その他のカスタマイズをしていないことを想定しています。ingresscontroller.ymlファイルの例apiVersion: operator.openshift.io/v1 kind: IngressController metadata: creationTimestamp: null name: default namespace: openshift-ingress-operator spec: endpointPublishingStrategy: loadBalancer: scope: External providerParameters: type: AWS aws: type: NLB type: LoadBalancerServiceデフォルトの Ingress Controller が他にカスタマイズされている場合には、それに応じてファイルを修正してください。
ヒントIngress Controller に他のカスタマイズがなく、ロードバランサータイプのみを更新する場合は、Switching the Ingress Controller from using a Classic Load Balancer to a Network Load Balancer に記載の手順に従ってください。
Ingress Controller の YAML ファイルを強制的に置き換えます。
$ oc replace --force --wait -f ingresscontroller.yml
Ingress Controller の置き換えが完了するまでお待ちください。数分間の停止が予想されます。
30.5.2.4. 既存 AWS クラスターでの Ingress Controller ネットワークロードバランサーの設定
AWS Network Load Balancer (NLB) がサポートする Ingress Controller を既存のクラスターに作成できます。
前提条件
- AWS クラスターがインストールされている。
インフラストラクチャーリソースの
PlatformStatusは AWS である必要があります。PlatformStatusが AWS であることを確認するには、以下を実行します。$ oc get infrastructure/cluster -o jsonpath='{.status.platformStatus.type}' AWS
手順
既存のクラスターの AWS NLB がサポートする Ingress Controller を作成します。
Ingress Controller のマニフェストを作成します。
$ cat ingresscontroller-aws-nlb.yaml
出力例
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: name: $my_ingress_controller1 namespace: openshift-ingress-operator spec: domain: $my_unique_ingress_domain2 endpointPublishingStrategy: type: LoadBalancerService loadBalancer: scope: External3 providerParameters: type: AWS aws: type: NLB
クラスターにリソースを作成します。
$ oc create -f ingresscontroller-aws-nlb.yaml
新規 AWS クラスターで Ingress コントローラー NLB を設定する前に、インストール設定ファイルの作成 手順を実行する必要があります。
30.5.2.5. 新規 AWS クラスターでの Ingress Controller ネットワークロードバランサーの設定
新規クラスターに AWS Network Load Balancer (NLB) がサポートする Ingress Controller を作成できます。
前提条件
-
install-config.yamlファイルを作成し、これに対する変更を完了します。
手順
新規クラスターの AWS NLB がサポートする Ingress Controller を作成します。
インストールプログラムが含まれるディレクトリーに切り替え、マニフェストを作成します。
$ ./openshift-install create manifests --dir <installation_directory> 1- 1
<installation_directory>については、クラスターのinstall-config.yamlファイルが含まれるディレクトリーの名前を指定します。
cluster-ingress-default-ingresscontroller.yamlという名前のファイルを<installation_directory>/manifests/ディレクトリーに作成します。$ touch <installation_directory>/manifests/cluster-ingress-default-ingresscontroller.yaml 1- 1
<installation_directory>については、クラスターのmanifests/ディレクトリーが含まれるディレクトリー名を指定します。
ファイルの作成後は、以下のようにいくつかのネットワーク設定ファイルが
manifests/ディレクトリーに置かれます。$ ls <installation_directory>/manifests/cluster-ingress-default-ingresscontroller.yaml
出力例
cluster-ingress-default-ingresscontroller.yaml
エディターで
cluster-ingress-default-ingresscontroller.yamlファイルを開き、必要な Operator 設定を記述するカスタムリソース (CR) を入力します。apiVersion: operator.openshift.io/v1 kind: IngressController metadata: creationTimestamp: null name: default namespace: openshift-ingress-operator spec: endpointPublishingStrategy: loadBalancer: scope: External providerParameters: type: AWS aws: type: NLB type: LoadBalancerService-
cluster-ingress-default-ingresscontroller.yamlファイルを保存し、テキストエディターを終了します。 -
オプション:
manifests/cluster-ingress-default-ingresscontroller.yamlファイルをバックアップします。インストールプログラムは、クラスターの作成時にmanifests/ディレクトリーを削除します。
30.5.3. 関連情報
- ネットワークのカスタマイズによる AWS へのクラスターのインストール
- NLB のサポートの詳細は、Network Load Balancer support on AWS を参照してください。
- CLB のプロキシープロトコルサポートの詳細は、Configure proxy protocol support for your Classic Load Balancer を参照してください。
30.6. サービスの外部 IP を使用した ingress クラスタートラフィックの設定
外部 IP アドレスをサービスに割り当てることで、これをクラスター外のトラフィックで使用できるようにします。通常、これはベアメタルハードウェアにインストールされているクラスターの場合にのみ役立ちます。外部ネットワークインフラストラクチャーは、トラフィックをサービスにルーティングするように正しく設定される必要があります。
30.6.1. 前提条件
クラスターは ExternalIP が有効にされた状態で設定されます。詳細は、サービスの ExternalIP の設定 を参照してください。
注記egress IP に同じ ExternalIP を使用しないでください。
30.6.2. ExternalIP のサービスへの割り当て
ExternalIP をサービスに割り当てることができます。クラスターが ExternalIP を自動的に割り当てするように設定されている場合、ExternalIP をサービスに手動で割り当てる必要がない場合があります。
手順
オプション: ExternalIP で使用するために設定される IP アドレス範囲を確認するには、以下のコマンドを入力します。
$ oc get networks.config cluster -o jsonpath='{.spec.externalIP}{"\n"}'autoAssignCIDRsが設定されている場合、spec.externalIPsフィールドが指定されていない場合、 OpenShift Container Platform は ExternalIP を新規Serviceオブジェクトに自動的に割り当てます。ExternalIP をサービスに割り当てます。
新規サービスを作成する場合は、
spec.externalIPsフィールドを指定し、1 つ以上の有効な IP アドレスの配列を指定します。以下に例を示します。apiVersion: v1 kind: Service metadata: name: svc-with-externalip spec: ... externalIPs: - 192.174.120.10
ExternalIP を既存のサービスに割り当てる場合は、以下のコマンドを入力します。
<name>をサービス名に置き換えます。<ip_address>を有効な ExternalIP アドレスに置き換えます。コンマで区切られた複数の IP アドレスを指定できます。$ oc patch svc <name> -p \ '{ "spec": { "externalIPs": [ "<ip_address>" ] } }'以下に例を示します。
$ oc patch svc mysql-55-rhel7 -p '{"spec":{"externalIPs":["192.174.120.10"]}}'出力例
"mysql-55-rhel7" patched
ExternalIP アドレスがサービスに割り当てられていることを確認するには、以下のコマンドを入力します。新規サービスに ExternalIP を指定した場合、まずサービスを作成する必要があります。
$ oc get svc
出力例
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE mysql-55-rhel7 172.30.131.89 192.174.120.10 3306/TCP 13m
30.6.3. 関連情報
30.7. NodePort を使用した ingress クラスタートラフィックの設定
OpenShift Container Platform は、クラスター内で実行されるサービスを使用してクラスター外からの通信を可能にする方法を提供します。この方法は NodePort を使用します。
30.7.1. NodePort を使用したトラフィックのクラスターへの送信
NodePort-type Service リソースを使用して、クラスター内のすべてのノードの特定のポートでサービスを公開します。ポートは Service リソースの .spec.ports[*].nodePort フィールドで指定されます。
ノードポートを使用するには、追加のポートリソースが必要です。
NodePort は、ノードの IP アドレスの静的ポートでサービスを公開します。NodePort はデフォルトで 30000 から 32767 の範囲に置かれます。つまり、 NodePort はサービスの意図されるポートに一致しないことが予想されます。たとえば、ポート 8080 はノードのポート 31020 として公開できます。
管理者は、外部 IP アドレスがノードにルーティングされることを確認する必要があります。
NodePort および外部 IP は独立しており、両方を同時に使用できます。
このセクションの手順では、クラスターの管理者が事前に行っておく必要のある前提条件があります。
30.7.2. 前提条件
以下の手順を開始する前に、管理者は以下の条件を満たしていることを確認する必要があります。
- 要求がクラスターに到達できるように、クラスターネットワーク環境に対して外部ポートをセットアップします。
クラスター管理者ロールを持つユーザーが 1 名以上いることを確認します。このロールをユーザーに追加するには、以下のコマンドを実行します。
$ oc adm policy add-cluster-role-to-user cluster-admin <user_name>
- OpenShift Container Platform クラスターを、1 つ以上のマスターと 1 つ以上のノード、およびクラスターへのネットワークアクセスのあるクラスター外のシステムと共に用意します。この手順では、外部システムがクラスターと同じサブセットにあることを前提とします。別のサブセットの外部システムに必要な追加のネットワーク設定については、このトピックでは扱いません。
30.7.3. プロジェクトおよびサービスの作成
公開するプロジェクトおよびサービスが存在しない場合、最初にプロジェクトを作成し、次にサービスを作成します。
プロジェクトおよびサービスがすでに存在する場合は、サービスを公開してルートを作成する手順に進みます。
前提条件
-
クラスター管理者として
ocCLI をインストールし、ログインします。
手順
oc new-projectコマンドを実行して、サービス用の新しいプロジェクトを作成します。$ oc new-project myproject
oc new-appコマンドを使用してサービスを作成します。$ oc new-app nodejs:12~https://github.com/sclorg/nodejs-ex.git
サービスが作成されたことを確認するには、以下のコマンドを実行します。
$ oc get svc -n myproject
出力例
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nodejs-ex ClusterIP 172.30.197.157 <none> 8080/TCP 70s
デフォルトで、新規サービスには外部 IP アドレスがありません。
30.7.4. ルートの作成によるサービスの公開
oc expose コマンドを使用して、サービスをルートとして公開することができます。
手順
サービスを公開するには、以下を実行します。
- OpenShift Container Platform にログインします。
公開するサービスが置かれているプロジェクトにログインします。
$ oc project myproject
アプリケーションのノードポートを公開するには、次のコマンドを入力して、サービスのカスタムリソース定義 (CRD) を変更します。
$ oc edit svc <service_name>
出力例
spec: ports: - name: 8443-tcp nodePort: 30327 1 port: 8443 protocol: TCP targetPort: 8443 sessionAffinity: None type: NodePort 2オプション: サービスが公開されるノードポートで利用可能なことを確認するには、以下のコマンドを入力します。
$ oc get svc -n myproject
出力例
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nodejs-ex ClusterIP 172.30.217.127 <none> 3306/TCP 9m44s nodejs-ex-ingress NodePort 172.30.107.72 <none> 3306:31345/TCP 39s
オプション:
oc new-appコマンドによって自動的に作成されたサービスを削除するには、以下のコマンドを入力します。$ oc delete svc nodejs-ex
検証
サービスノードポートが
30000 ~ 32767の範囲のポートで更新されていることを確認するには、次のコマンドを入力します。$ oc get svc
次の出力例では、更新されたポートは
30327です。出力例
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE httpd NodePort 172.xx.xx.xx <none> 8443:30327/TCP 109s
30.7.5. 関連情報
30.8. ロードバランサーの許可された送信元範囲を使用した ingress クラスタートラフィックの設定
IngressController の IP アドレス範囲の一覧を指定できます。endpointPublishingStrategy が LoadBalancerService の場合、これにより、ロードバランサーサービスへのアクセスが制限されます。
30.8.1. ロードバランサーの許可されるソース範囲の設定
spec.endpointPublishingStrategy.loadBalancer.allowedSourceRanges フィールドを有効にして設定できます。ロードバランサーの許可されるソース範囲を設定することで、Ingress Contoller のロードバランサーへのアクセスを、指定された IP アドレス範囲のリストに制限できます。Ingress Operator はロードバランサー Service を調整し、AllowedSourceRanges に基づいて spec.loadBalancerSourceRanges フィールドを設定します。
以前のバージョンの OpenShift Container Platform で spec.loadBalancerSourceRanges フィールドまたはロードバランサーサービスアノテーション service.beta.kubernetes.io/load-balancer-source-ranges をすでに設定している場合、Ingress Controller はアップグレード後に Progressing=True のレポートを開始します。.これを修正するには、spec.loadBalancerSourceRanges フィールドを上書きし、service.beta.kubernetes.io/load-balancer-source-ranges アノテーションをクリアする AllowedSourceRanges を設定します。Ingress Controller は、再び Progressing=False の報告を開始します。
前提条件
- 実行中のクラスターにデプロイされた Ingress Controller があります。
手順
次のコマンドを実行して、Ingress Controller の許可されるソース範囲 API を設定します。
$ oc -n openshift-ingress-operator patch ingresscontroller/default \ --type=merge --patch='{"spec":{"endpointPublishingStrategy": \ {"loadBalancer":{"allowedSourceRanges":["0.0.0.0/0"]}}}}' 1- 1
- 例の値
0.0.0.0/0は、許可されるソース範囲を指定します。
30.8.2. ロードバランサーの許可されたソース範囲への移行
注釈 service.beta.kubernetes.io/load-balancer-source-ranges をすでに設定している場合は、ロードバランサーの許可されたソース範囲に移行できます。AllowedSourceRanges を設定すると、Ingress Controller は AllowedSourceRanges 値に基づいて spec.loadBalancerSourceRanges フィールドを設定し、service.beta.kubernetes.io/load-balancer-source-ranges アノテーションを設定解除します。
以前のバージョンの OpenShift Container Platform で spec.loadBalancerSourceRanges フィールドまたはロードバランサーサービスアノテーション service.beta.kubernetes.io/load-balancer-source-ranges をすでに設定している場合、Ingress Controller はアップグレード後に Progressing=True のレポートを開始します。.これを修正するには、spec.loadBalancerSourceRanges フィールドを上書きし、service.beta.kubernetes.io/load-balancer-source-ranges アノテーションをクリアする AllowedSourceRanges を設定します。Ingress Controller は再び Progressing=False の報告を開始します。
前提条件
-
service.beta.kubernetes.io/load-balancer-source-rangesアノテーションを設定しました。
手順
service.beta.kubernetes.io/load-balancer-source-rangesが設定されていることを確認します。$ oc get svc router-default -n openshift-ingress -o yaml
出力例
apiVersion: v1 kind: Service metadata: annotations: service.beta.kubernetes.io/load-balancer-source-ranges: 192.168.0.1/32spec.loadBalancerSourceRangesフィールドが設定されていないことを確認します。$ oc get svc router-default -n openshift-ingress -o yaml
出力例
... spec: loadBalancerSourceRanges: - 0.0.0.0/0 ...
- クラスターを OpenShift Container Platform 4.13 に更新します。
次のコマンドを実行して、
ingresscontrollerの許可されるソース範囲 API を設定します。$ oc -n openshift-ingress-operator patch ingresscontroller/default \ --type=merge --patch='{"spec":{"endpointPublishingStrategy": \ {"loadBalancer":{"allowedSourceRanges":["0.0.0.0/0"]}}}}' 1- 1
- 例の値
0.0.0.0/0は、許可されるソース範囲を指定します。
30.8.3. 関連情報
第31章 Kubernetes NMState
31.1. Kubernetes NMState Operator について
Kubernetes NMState Operator は、NMState の OpenShift Container Platform クラスターのノード間でステートドリブンのネットワーク設定を実行するための Kubernetes API を提供します。Kubernetes NMState Operator は、ユーザーに対して、クラスターノードの各種のネットワークインターフェイスタイプ、DNS、およびルーティングを設定する機能を提供します。さらに、クラスターノードのデーモンは、各ノードの API サーバーへのネットワークインターフェイスの状態の定期的な報告を行います。
Red Hat は、ベアメタル、IBM Power、IBM Z、IBM® LinuxONE、VMware vSphere、および OpenStack インストール上の実稼働環境で Kubernetes NMState Operator をサポートします。
OpenShift Container Platform で NMState を使用する前に、Kubernetes NMState Operator をインストールする必要があります。
Kubernetes NMState Operator は、セカンダリー NIC のネットワーク設定を更新します。プライマリー NIC または br-ex ブリッジのネットワーク設定を更新できません。
OpenShift Container Platform は nmstate を使用して、ノードネットワークの状態を報告し、これを設定します。これにより、たとえばすべてのノードに Linux ブリッジを作成するなど、単一の設定マニフェストをクラスターに適用して、ネットワークポリシー設定を変更できるようになります。
ノードのネットワークは、以下のオブジェクトによって監視され更新されます。
NodeNetworkState- そのノード上のネットワークの状態を報告します。
NodeNetworkConfigurationPolicy-
ノードで要求されるネットワーク設定について説明します。
NodeNetworkConfigurationPolicyマニフェストをクラスターに適用して、インターフェイスの追加および削除など、ノードネットワーク設定を更新します。 NodeNetworkConfigurationEnactment- 各ノードに制定されたネットワークポリシーを報告します。
31.1.1. Kubernetes NMState Operator のインストール
ウェブコンソールまたは CLI を使用して、Kubernetes NMState Operator をインストールできます。
31.1.1.1. Web コンソールを使用した Kubernetes NMState Operator のインストール
Web コンソールを使用して Kubernetes NMState Operator をインストールできます。インストールが完了すると、Operator はすべてのクラスターノードに NMState State Controller をデーモンセットとしてデプロイできます。
前提条件
-
cluster-admin権限を持つユーザーとしてログインしている。
手順
- Operators → OperatorHub を選択します。
-
All Items の下の検索フィールドに、
nmstateと入力し、Enter をクリックして Kubernetes NMState Operator を検索します。 - Kubernetes NMState Operator の検索結果をクリックします。
- Install をクリックして、Install Operator ウィンドウを開きます。
- Install をクリックして Operator をインストールします。
- Operator のインストールが完了したら、View Operator をクリックします。
-
Provided APIs で Create Instance をクリックし、
kubernetes-nmstateのインスタンスを作成するダイアログボックスを開きます。 ダイアログボックスの Name フィールドで、インスタンスの名前が
nmstateであることを確認します。注記名前の制限は既知の問題です。インスタンスはクラスター全体のシングルトンです。
- デフォルト設定を受け入れ、Create をクリックしてインスタンスを作成します。
概要
完了後に、Operator はすべてのクラスターノードに NMState State Controller をデーモンセットとしてデプロイしています。
31.1.1.2. CLI を使用した Kubernetes NMState Operator のインストール
OpenShift CLI (oc) を使用して、Kubernetes NMState Operator をインストールできます。インストールが完了すると、Operator はすべてのクラスターノードに NMState State Controller をデーモンセットとしてデプロイできます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
nmstateOperatornamespace を作成します。$ cat << EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: labels: kubernetes.io/metadata.name: openshift-nmstate name: openshift-nmstate name: openshift-nmstate spec: finalizers: - kubernetes EOFOperatorGroupを作成します。$ cat << EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: annotations: olm.providedAPIs: NMState.v1.nmstate.io name: openshift-nmstate namespace: openshift-nmstate spec: targetNamespaces: - openshift-nmstate EOFnmstateOperator にサブスクライブします。$ cat << EOF| oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: labels: operators.coreos.com/kubernetes-nmstate-operator.openshift-nmstate: "" name: kubernetes-nmstate-operator namespace: openshift-nmstate spec: channel: stable installPlanApproval: Automatic name: kubernetes-nmstate-operator source: redhat-operators sourceNamespace: openshift-marketplace EOFnmstateOperator のインスタンスを作成します。$ cat << EOF | oc apply -f - apiVersion: nmstate.io/v1 kind: NMState metadata: name: nmstate EOF
検証
nmstateOperator のデプロイメントが実行されていることを確認します。oc get clusterserviceversion -n openshift-nmstate \ -o custom-columns=Name:.metadata.name,Phase:.status.phase
出力例
Name Phase kubernetes-nmstate-operator.4.13.0-202210210157 Succeeded
31.2. ノードのネットワーク状態と設定の監視と更新
31.2.1. ノードのネットワーク状態の表示
ノードのネットワーク状態は、クラスター内のすべてのノードのネットワーク設定です。NodeNetworkState オブジェクトはクラスター内のすべてのノードにあります。このオブジェクトは定期的に更新され、ノードのネットワークの状態を取得します。
手順
クラスターのすべての
NodeNetworkStateオブジェクトをリスト表示します。$ oc get nns
NodeNetworkStateオブジェクトを検査して、そのノードにネットワークを表示します。この例の出力は、明確にするために編集されています。$ oc get nns node01 -o yaml
出力例
apiVersion: nmstate.io/v1 kind: NodeNetworkState metadata: name: node01 1 status: currentState: 2 dns-resolver: # ... interfaces: # ... route-rules: # ... routes: # ... lastSuccessfulUpdateTime: "2020-01-31T12:14:00Z" 3
31.2.2. CLI を使用したポリシーの管理
31.2.2.1. ノード上でのインターフェイスの作成
NodeNetworkConfigurationPolicy マニフェストをクラスターに適用してクラスター内のノード上にインターフェイスを作成します。マニフェストには、インターフェイスの要求された設定の詳細が含まれます。
デフォルトでは、マニフェストはクラスター内のすべてのノードに適用されます。インターフェイスを特定ノードに追加するには、ノードセレクターの spec: nodeSelector パラメーターおよび適切な <key>:<value> を追加します。
複数の nmstate 対応ノードを同時に設定できます。この設定は、並列のノードの 50% に適用されます。このストラテジーでは、ネットワーク接続に障害が発生した場合にクラスター全体が使用できなくなるのを回避します。クラスターの特定の部分に、ポリシーの並行設定を適用するには、 maxUnavailableフィールドを使用します。
手順
NodeNetworkConfigurationPolicyマニフェストを作成します。以下の例は、すべてのワーカーノードで Linux ブリッジを設定し、DNS リゾルバーを設定します。apiVersion: nmstate.io/v1 kind: NodeNetworkConfigurationPolicy metadata: name: br1-eth1-policy 1 spec: nodeSelector: 2 node-role.kubernetes.io/worker: "" 3 maxUnavailable: 3 4 desiredState: interfaces: - name: br1 description: Linux bridge with eth1 as a port 5 type: linux-bridge state: up ipv4: dhcp: true enabled: true auto-dns: false bridge: options: stp: enabled: false port: - name: eth1 dns-resolver: 6 config: search: - example.com - example.org server: - 8.8.8.8
- 1
- ポリシーの名前。
- 2
- オプション:
nodeSelectorパラメーターを含めない場合、ポリシーはクラスター内のすべてのノードに適用されます。 - 3
- この例では
node-role.kubernetes.io/worker: ""ノードセレクターを使用し、クラスター内のすべてのワーカーノードを選択します。 - 4
- オプション: ポリシー設定を同時に適用できる nmstate 対応ノードの最大数を指定します。このパラメーターは、
10%などのパーセンテージ値 (文字列)、または3などの絶対値 (数値) のいずれかに設定できます。 - 5
- オプション: インターフェイスの人間が判読できる説明。
- 6
- オプション:DNS サーバーの検索およびサーバー設定を指定します。
ノードのネットワークポリシーを作成します。
$ oc apply -f br1-eth1-policy.yaml 1- 1
- ノードネットワーク設定ポリシーマニフェストのファイル名。
関連情報
31.2.3. ノード上でのノードネットワークポリシー更新の確認
NodeNetworkConfigurationPolicy マニフェストは、クラスターのノードについて要求されるネットワーク設定を記述します。ノードネットワークポリシーには、要求されたネットワーク設定と、クラスター全体でのポリシーの実行ステータスが含まれます。
ノードネットワークポリシーを適用する際に、NodeNetworkConfigurationEnactment オブジェクトがクラスター内のすべてのノードについて作成されます。ノードネットワーク設定の enactment (実行) は、そのノードでのポリシーの実行ステータスを表す読み取り専用オブジェクトです。ポリシーがノードに適用されない場合、そのノードの enactment (実行) にはトラブルシューティングのためのトレースバックが含まれます。
手順
ポリシーがクラスターに適用されていることを確認するには、ポリシーとそのステータスをリスト表示します。
$ oc get nncp
オプション: ポリシーの設定に想定されている以上の時間がかかる場合は、特定のポリシーの要求される状態とステータスの状態を検査できます。
$ oc get nncp <policy> -o yaml
オプション: ポリシーのすべてのノード上での設定に想定されている以上の時間がかかる場合は、クラスターの enactment (実行) のステータスをリスト表示できます。
$ oc get nnce
オプション: 特定の enactment (実行) の設定 (失敗した設定のエラーレポートを含む) を表示するには、以下を実行します。
$ oc get nnce <node>.<policy> -o yaml
31.2.4. ノードからインターフェイスの削除
NodeNetworkConfigurationPolicy オブジェクトを編集し、インターフェイスの state を absent に設定して、クラスターの 1 つ以上のノードからインターフェイスを削除できます。
ノードからインターフェイスを削除しても、ノードのネットワーク設定は以前の状態に自動的に復元されません。以前の状態に復元する場合、そのノードのネットワーク設定をポリシーで定義する必要があります。
ブリッジまたはボンディングインターフェイスを削除すると、そのブリッジまたはボンディングインターフェイスに以前に接続されたか、それらの下位にあるノード NIC は down の状態になり、到達できなくなります。接続が失われないようにするには、同じポリシーでノード NIC を設定し、ステータスを up にし、DHCP または静的 IP アドレスのいずれかになるようにします。
インターフェイスを追加したポリシーを削除しても、ノード上のポリシーの設定は変更されません。NodeNetworkConfigurationPolicy はクラスターのオブジェクトですが、これは要求される設定のみを表します。
同様に、インターフェイスを削除してもポリシーは削除されません。
手順
インターフェイスの作成に使用する
NodeNetworkConfigurationPolicyマニフェストを更新します。以下の例は Linux ブリッジを削除し、接続が失われないように DHCP でeth1NIC を設定します。apiVersion: nmstate.io/v1 kind: NodeNetworkConfigurationPolicy metadata: name: <br1-eth1-policy> 1 spec: nodeSelector: 2 node-role.kubernetes.io/worker: "" 3 desiredState: interfaces: - name: br1 type: linux-bridge state: absent 4 - name: eth1 5 type: ethernet 6 state: up 7 ipv4: dhcp: true 8 enabled: true 9
- 1
- ポリシーの名前。
- 2
- オプション:
nodeSelectorパラメーターを含めない場合、ポリシーはクラスター内のすべてのノードに適用されます。 - 3
- この例では
node-role.kubernetes.io/worker: ""ノードセレクターを使用し、クラスター内のすべてのワーカーノードを選択します。 - 4
- 状態を
absentに変更すると、インターフェイスが削除されます。 - 5
- ブリッジインターフェイスから接続が解除されるインターフェイスの名前。
- 6
- インターフェイスのタイプ。この例では、イーサネットネットワークインターフェイスを作成します。
- 7
- インターフェイスの要求された状態。
- 8
- オプション:
dhcpを使用しない場合は、静的 IP を設定するか、IP アドレスなしでインターフェイスを出ることができます。 - 9
- この例では
ipv4を有効にします。
ノード上でポリシーを更新し、インターフェイスを削除します。
$ oc apply -f <br1-eth1-policy.yaml> 1- 1
- ポリシーマニフェストのファイル名。
31.2.5. 異なるインターフェイスのポリシー設定の例
次の例は、さまざまな NodeNetworkConfigurationPolicy マニフェスト設定を示しています。
最高のパフォーマンスを得るには、ポリシーを適用するときに次の要素を考慮してください。
ポリシーを複数のノードに適用する必要がある場合は、ターゲットノードごとに
NodeNetworkConfigurationPolicyマニフェストを作成します。ポリシーの範囲を 1 つのノードに設定すると、Kubernetes NMState Operator によるポリシー適用にかかる総時間が短縮されます。対照的に、1 つのポリシーに複数のノードの設定が含まれている場合、Kubernetes NMState Operator はポリシーを各ノードに順番に適用するため、ポリシー適用にかかる総時間が長くなります。
関連するすべてのネットワーク設定を 1 つのポリシーで指定する必要があります。
ノードが再起動すると、Kubernetes NMState Operator はポリシーを適用する順序を制御できません。したがって、Kubernetes NMState Operator が相互依存するポリシーを順番に適用すると、ネットワークオブジェクトがデグレード状態になる可能性があります。
31.2.5.1. 例: Linux ブリッジインターフェイスノードネットワーク設定ポリシー
NodeNetworkConfigurationPolicy マニフェストをクラスターに適用してクラスター内のノード上に Linux ブリッジインターフェイスを作成します。
以下の YAML ファイルは、Linux ブリッジインターフェイスのマニフェストの例です。これには、独自の情報で置き換える必要のあるサンプルの値が含まれます。
apiVersion: nmstate.io/v1 kind: NodeNetworkConfigurationPolicy metadata: name: br1-eth1-policy 1 spec: nodeSelector: 2 kubernetes.io/hostname: <node01> 3 desiredState: interfaces: - name: br1 4 description: Linux bridge with eth1 as a port 5 type: linux-bridge 6 state: up 7 ipv4: dhcp: true 8 enabled: true 9 bridge: options: stp: enabled: false 10 port: - name: eth1 11
- 1
- ポリシーの名前。
- 2
- オプション:
nodeSelectorパラメーターを含めない場合、ポリシーはクラスター内のすべてのノードに適用されます。 - 3
- この例では、
hostnameノードセレクターを使用します。 - 4
- インターフェイスの名前。
- 5
- オプション: 人間が判読できるインターフェイスの説明。
- 6
- インターフェイスのタイプ。この例では、ブリッジを作成します。
- 7
- 作成後のインターフェイスの要求された状態。
- 8
- オプション:
dhcpを使用しない場合は、静的 IP を設定するか、IP アドレスなしでインターフェイスを出ることができます。 - 9
- この例では
ipv4を有効にします。 - 10
- この例では
stpを無効にします。 - 11
- ブリッジが接続されるノードの NIC。
31.2.5.2. 例: VLAN インターフェイスノードネットワークの設定ポリシー
NodeNetworkConfigurationPolicy マニフェストをクラスターに適用してクラスター内のノード上に VLAN インターフェイスを作成します。
1 つの NodeNetworkConfigurationPolicy マニフェストで、ノードの VLAN インターフェイスに関連するすべての設定を定義します。たとえば、同じ NodeNetworkConfigurationPolicy マニフェストで、ノードの VLAN インターフェイスと VLAN インターフェイスの関連ルートを定義します。
ノードが再起動すると、Kubernetes NMState Operator はポリシーを適用する順序を制御できません。したがって、関連するネットワーク設定に別々のポリシーを使用すると、Kubernetes NMState Operator がこれらのポリシーを順番に適用するため、ネットワークオブジェクトがデグレード状態になる可能性があります。
以下の YAML ファイルは、VLAN インターフェイスのマニフェストの例です。これには、独自の情報で置き換える必要のあるサンプルの値が含まれます。
apiVersion: nmstate.io/v1 kind: NodeNetworkConfigurationPolicy metadata: name: vlan-eth1-policy 1 spec: nodeSelector: 2 kubernetes.io/hostname: <node01> 3 desiredState: interfaces: - name: eth1.102 4 description: VLAN using eth1 5 type: vlan 6 state: up 7 vlan: base-iface: eth1 8 id: 102 9
- 1
- ポリシーの名前。
- 2
- オプション:
nodeSelectorパラメーターを含めない場合、ポリシーはクラスター内のすべてのノードに適用されます。 - 3
- この例では、
hostnameノードセレクターを使用します。 - 4
- インターフェイスの名前。ベアメタルにデプロイする場合、
<interface_name>.<vlan_number>VLAN 形式のみがサポートされます。 - 5
- オプション: 人間が判読できるインターフェイスの説明。
- 6
- インターフェイスのタイプ。以下の例では VLAN を作成します。
- 7
- 作成後のインターフェイスの要求された状態。
- 8
- VLAN が接続されているノードの NIC。
- 9
- VLAN タグ。
31.2.5.3. 例: ボンドインターフェイスノードネットワークの設定ポリシー
NodeNetworkConfigurationPolicy マニフェストをクラスターに適用してノード上にボンドインターフェイスを作成します。
OpenShift Container Platform は以下の bond モードのみをサポートします。
-
mode=1 active-backup
-
mode=2 balance-xor
-
mode=4 802.3ad
-
mode=5 balance-tlb
- mode=6 balance-alb
以下の YAML ファイルは、ボンドインターフェイスのマニフェストの例です。これには、独自の情報で置き換える必要のあるサンプルの値が含まれます。
apiVersion: nmstate.io/v1 kind: NodeNetworkConfigurationPolicy metadata: name: bond0-eth1-eth2-policy 1 spec: nodeSelector: 2 kubernetes.io/hostname: <node01> 3 desiredState: interfaces: - name: bond0 4 description: Bond with ports eth1 and eth2 5 type: bond 6 state: up 7 ipv4: dhcp: true 8 enabled: true 9 link-aggregation: mode: active-backup 10 options: miimon: '140' 11 port: 12 - eth1 - eth2 mtu: 1450 13
- 1
- ポリシーの名前。
- 2
- オプション:
nodeSelectorパラメーターを含めない場合、ポリシーはクラスター内のすべてのノードに適用されます。 - 3
- この例では、
hostnameノードセレクターを使用します。 - 4
- インターフェイスの名前。
- 5
- オプション: 人間が判読できるインターフェイスの説明。
- 6
- インターフェイスのタイプ。この例では、ボンドを作成します。
- 7
- 作成後のインターフェイスの要求された状態。
- 8
- オプション:
dhcpを使用しない場合は、静的 IP を設定するか、IP アドレスなしでインターフェイスを出ることができます。 - 9
- この例では
ipv4を有効にします。 - 10
- ボンドのドライバーモード。この例では、アクティブなバックアップモードを使用します。
- 11
- オプション: この例では、miimon を使用して 140ms ごとにボンドリンクを検査します。
- 12
- ボンド内の下位ノードの NIC。
- 13
- オプション: ボンドの Maximum transmission unit (MTU)指定がない場合、この値はデフォルトで
1500に設定されます。
31.2.5.4. 例: イーサネットインターフェイスノードネットワークの設定ポリシー
NodeNetworkConfigurationPolicy マニフェストをクラスターに適用してクラスター内のノードにイーサネットインターフェイスを作成します。
以下の YAML ファイルは、イーサネットインターフェイスのマニフェストの例です。これには、独自の情報で置き換える必要のあるサンプルの値が含まれます。
apiVersion: nmstate.io/v1 kind: NodeNetworkConfigurationPolicy metadata: name: eth1-policy 1 spec: nodeSelector: 2 kubernetes.io/hostname: <node01> 3 desiredState: interfaces: - name: eth1 4 description: Configuring eth1 on node01 5 type: ethernet 6 state: up 7 ipv4: dhcp: true 8 enabled: true 9
- 1
- ポリシーの名前。
- 2
- オプション:
nodeSelectorパラメーターを含めない場合、ポリシーはクラスター内のすべてのノードに適用されます。 - 3
- この例では、
hostnameノードセレクターを使用します。 - 4
- インターフェイスの名前。
- 5
- オプション: 人間が判読できるインターフェイスの説明。
- 6
- インターフェイスのタイプ。この例では、イーサネットネットワークインターフェイスを作成します。
- 7
- 作成後のインターフェイスの要求された状態。
- 8
- オプション:
dhcpを使用しない場合は、静的 IP を設定するか、IP アドレスなしでインターフェイスを出ることができます。 - 9
- この例では
ipv4を有効にします。
31.2.5.5. 例: 同じノードネットワーク設定ポリシーでの複数のインターフェイス
同じノードネットワーク設定ポリシーで複数のインターフェイスを作成できます。これらのインターフェイスは相互に参照でき、単一のポリシーマニフェストを使用してネットワーク設定をビルドし、デプロイできます。
以下の YAML ファイルの例では、2 つの NIC 間に bond10 という名前のボンドと、ボンドに接続する bond10.103 という名前の VLAN を作成します。
apiVersion: nmstate.io/v1 kind: NodeNetworkConfigurationPolicy metadata: name: bond-vlan 1 spec: nodeSelector: 2 kubernetes.io/hostname: <node01> 3 desiredState: interfaces: - name: bond10 4 description: Bonding eth2 and eth3 5 type: bond 6 state: up 7 link-aggregation: mode: balance-rr 8 options: miimon: '140' 9 port: 10 - eth2 - eth3 - name: bond10.103 11 description: vlan using bond10 12 type: vlan 13 state: up 14 vlan: base-iface: bond10 15 id: 103 16 ipv4: dhcp: true 17 enabled: true 18
- 1
- ポリシーの名前。
- 2
- オプション:
nodeSelectorパラメーターを含めない場合、ポリシーはクラスター内のすべてのノードに適用されます。 - 3
- この例では、
hostnameノードセレクターを使用します。 - 4 11
- インターフェイスの名前。
- 5 12
- オプション: 人間が判読できるインターフェイスの説明。
- 6 13
- インターフェイスのタイプ。
- 7 14
- 作成後のインターフェイスの要求された状態。
- 8
- ボンドのドライバーモード。
- 9
- オプション: この例では、miimon を使用して 140ms ごとにボンドリンクを検査します。
- 10
- ボンド内の下位ノードの NIC。
- 15
- VLAN が接続されているノードの NIC。
- 16
- VLAN タグ。
- 17
- オプション: dhcp を使用しない場合は、静的 IP を設定するか、IP アドレスなしでインターフェイスを出ることができます。
- 18
- この例では ipv4 を有効にします。
31.2.6. ブリッジに接続された NIC の静的 IP の取得
NIC の静的 IP のキャプチャーは、テクノロジープレビュー機能としてのみ提供されます。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。
Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
31.2.6.1. 例: ブリッジに接続された NIC から静的 IP アドレスを継承する Linux ブリッジインターフェイスノードネットワーク設定ポリシー
クラスター内のノードに Linux ブリッジインターフェイスを作成し、単一の NodeNetworkConfigurationPolicy マニフェストをクラスターに適用して NIC の静的 IP 設定をブリッジに転送します。
以下の YAML ファイルは、Linux ブリッジインターフェイスのマニフェストの例です。これには、独自の情報で置き換える必要のあるサンプルの値が含まれます。
apiVersion: nmstate.io/v1 kind: NodeNetworkConfigurationPolicy metadata: name: br1-eth1-copy-ipv4-policy 1 spec: nodeSelector: 2 node-role.kubernetes.io/worker: "" capture: eth1-nic: interfaces.name=="eth1" 3 eth1-routes: routes.running.next-hop-interface=="eth1" br1-routes: capture.eth1-routes | routes.running.next-hop-interface := "br1" desiredState: interfaces: - name: br1 description: Linux bridge with eth1 as a port type: linux-bridge 4 state: up ipv4: "{{ capture.eth1-nic.interfaces.0.ipv4 }}" 5 bridge: options: stp: enabled: false port: - name: eth1 6 routes: config: "{{ capture.br1-routes.routes.running }}"
- 1
- ポリシーの名前。
- 2
- オプション:
nodeSelectorパラメーターを含めない場合、ポリシーはクラスター内のすべてのノードに適用されます。この例ではnode-role.kubernetes.io/worker: ""ノードセレクターを使用し、クラスター内のすべてのワーカーノードを選択します。 - 3
- ブリッジを接続するノード NIC への参照。
- 4
- インターフェイスのタイプ。この例では、ブリッジを作成します。
- 5
- ブリッジインターフェイスの IP アドレス。この値は、
spec.capture.eth1-nicエントリーにより参照される NIC の IP アドレスと一致します。 - 6
- ブリッジが接続されるノードの NIC。
31.2.7. 例: IP 管理
以下の設定スニペットの例は、さまざまな IP 管理方法を示しています。
これらの例では、ethernet インターフェイスタイプを使用して、ポリシー設定に関連するコンテキストを表示しつつ、サンプルを単純化します。これらの IP 管理のサンプルは、他のインターフェイスタイプでも使用できます。
31.2.7.1. 静的
以下のスニペットは、イーサネットインターフェイスで IP アドレスを静的に設定します。
# ...
interfaces:
- name: eth1
description: static IP on eth1
type: ethernet
state: up
ipv4:
dhcp: false
address:
- ip: 192.168.122.250 1
prefix-length: 24
enabled: true
# ...- 1
- この値を、インターフェイスの静的 IP アドレスに置き換えます。
31.2.7.2. IP アドレスなし
以下のスニペットでは、インターフェイスに IP アドレスがないことを確認できます。
# ...
interfaces:
- name: eth1
description: No IP on eth1
type: ethernet
state: up
ipv4:
enabled: false
# ...31.2.7.3. 動的ホストの設定
以下のスニペットは、動的 IP アドレス、ゲートウェイアドレス、および DNS を使用するイーサネットインターフェイスを設定します。
# ...
interfaces:
- name: eth1
description: DHCP on eth1
type: ethernet
state: up
ipv4:
dhcp: true
enabled: true
# ...以下のスニペットは、動的 IP アドレスを使用しますが、動的ゲートウェイアドレスまたは DNS を使用しないイーサネットインターフェイスを設定します。
# ...
interfaces:
- name: eth1
description: DHCP without gateway or DNS on eth1
type: ethernet
state: up
ipv4:
dhcp: true
auto-gateway: false
auto-dns: false
enabled: true
# ...31.2.7.4. DNS
DNS 設定の定義は、/etc/resolv.conf ファイルの変更に類似しています。以下のスニペットは、ホストに DNS 設定を定義します。
# ...
interfaces: 1
...
ipv4:
...
auto-dns: false
...
dns-resolver:
config:
search:
- example.com
- example.org
server:
- 8.8.8.8
# ...- 1
- Kubernetes NMState がカスタム DNS 設定を保存するためには、インターフェイスを
auto-dns: falseで設定するか、インターフェイスで静的 IP 設定を使用する必要があります。
DNS リゾルバーの設定時に、インターフェイスとして OVNKubernetes が管理する Open vSwitch ブリッジである br-ex を使用することはできません。
31.2.7.5. 静的ルーティング
以下のスニペットは、インターフェイス eth1 に静的ルートおよび静的 IP を設定します。
# ...
interfaces:
- name: eth1
description: Static routing on eth1
type: ethernet
state: up
ipv4:
dhcp: false
address:
- ip: 192.0.2.251 1
prefix-length: 24
enabled: true
routes:
config:
- destination: 198.51.100.0/24
metric: 150
next-hop-address: 192.0.2.1 2
next-hop-interface: eth1
table-id: 254
# ...31.3. ノードのネットワーク設定のトラブルシューティング
ノードのネットワーク設定で問題が発生した場合には、ポリシーが自動的にロールバックされ、enactment (実行) レポートは失敗します。これには、以下のような問題が含まれます。
- ホストで設定を適用できません。
- ホストはデフォルトゲートウェイへの接続を失います。
- ホストは API サーバーへの接続を失います。
31.3.1. 正確でないノードネットワーク設定のポリシー設定のトラブルシューティング
ノードネットワーク設定ポリシーを適用し、クラスター全体でノードのネットワーク設定への変更を適用することができます。正確でない設定を適用する場合、以下の例を使用して、失敗したノードネットワークポリシーのトラブルシューティングと修正を行うことができます。
この例では、Linux ブリッジポリシーが、3 つのコントロールプレーンノードと 3 つのコンピュートノードを持つサンプルクラスターに適用されます。ポリシーは正しくないインターフェイスを参照するために、適用することができません。エラーを確認するには、利用可能な NMState リソースを調べます。その後に、正しい設定でポリシーを更新できます。
手順
ポリシーを作成し、これをクラスターに適用します。以下の例では、
ens01インターフェイスに単純なブリッジを作成します。apiVersion: nmstate.io/v1 kind: NodeNetworkConfigurationPolicy metadata: name: ens01-bridge-testfail spec: desiredState: interfaces: - name: br1 description: Linux bridge with the wrong port type: linux-bridge state: up ipv4: dhcp: true enabled: true bridge: options: stp: enabled: false port: - name: ens01$ oc apply -f ens01-bridge-testfail.yaml
出力例
nodenetworkconfigurationpolicy.nmstate.io/ens01-bridge-testfail created
以下のコマンドを実行してポリシーのステータスを確認します。
$ oc get nncp
この出力は、ポリシーが失敗したことを示しています。
出力例
NAME STATUS ens01-bridge-testfail FailedToConfigure
ただし、ポリシーのステータスのみでは、すべてのノードで失敗したか、ノードのサブセットで失敗したかを確認することはできません。
ノードのネットワーク設定の enactment (実行) をリスト表示し、ポリシーがいずれかのノードで成功したかどうかを確認します。このポリシーがノードのサブセットに対してのみ失敗した場合は、問題が特定のノード設定にあることが示唆されます。このポリシーがすべてのノードで失敗した場合には、問題はポリシーに関連するものであることが示唆されます。
$ oc get nnce
この出力は、ポリシーがすべてのノードで失敗したことを示しています。
出力例
NAME STATUS control-plane-1.ens01-bridge-testfail FailedToConfigure control-plane-2.ens01-bridge-testfail FailedToConfigure control-plane-3.ens01-bridge-testfail FailedToConfigure compute-1.ens01-bridge-testfail FailedToConfigure compute-2.ens01-bridge-testfail FailedToConfigure compute-3.ens01-bridge-testfail FailedToConfigure
失敗した enactment (実行) のいずれかを表示し、トレースバックを確認します。以下のコマンドは、出力ツール
jsonpathを使用して出力をフィルターします。$ oc get nnce compute-1.ens01-bridge-testfail -o jsonpath='{.status.conditions[?(@.type=="Failing")].message}'このコマンドは、簡潔にするために編集されている大きなトレースバックを返します。
出力例
error reconciling NodeNetworkConfigurationPolicy at desired state apply: , failed to execute nmstatectl set --no-commit --timeout 480: 'exit status 1' '' ... libnmstate.error.NmstateVerificationError: desired ======= --- name: br1 type: linux-bridge state: up bridge: options: group-forward-mask: 0 mac-ageing-time: 300 multicast-snooping: true stp: enabled: false forward-delay: 15 hello-time: 2 max-age: 20 priority: 32768 port: - name: ens01 description: Linux bridge with the wrong port ipv4: address: [] auto-dns: true auto-gateway: true auto-routes: true dhcp: true enabled: true ipv6: enabled: false mac-address: 01-23-45-67-89-AB mtu: 1500 current ======= --- name: br1 type: linux-bridge state: up bridge: options: group-forward-mask: 0 mac-ageing-time: 300 multicast-snooping: true stp: enabled: false forward-delay: 15 hello-time: 2 max-age: 20 priority: 32768 port: [] description: Linux bridge with the wrong port ipv4: address: [] auto-dns: true auto-gateway: true auto-routes: true dhcp: true enabled: true ipv6: enabled: false mac-address: 01-23-45-67-89-AB mtu: 1500 difference ========== --- desired +++ current @@ -13,8 +13,7 @@ hello-time: 2 max-age: 20 priority: 32768 - port: - - name: ens01 + port: [] description: Linux bridge with the wrong port ipv4: address: [] line 651, in _assert_interfaces_equal\n current_state.interfaces[ifname],\nlibnmstate.error.NmstateVerificationError:NmstateVerificationErrorは、desiredポリシー設定、ノード上のポリシーのcurrent設定、および一致しないパラメーターを強調表示するdifferenceをリスト表示します。この例では、portはdifferenceに組み込まれ、これは問題がポリシーのポート設定に関連するものであることを示唆します。ポリシーが適切に設定されていることを確認するには、
NodeNetworkStateオブジェクトを要求して、1 つまたはすべてのノードのネットワーク設定を表示します。以下のコマンドは、control-plane-1ノードのネットワーク設定を返します。$ oc get nns control-plane-1 -o yaml
出力は、ノード上のインターフェイス名は
ens1であるものの、失敗したポリシーがens01を誤って使用していることを示します。出力例
- ipv4: # ... name: ens1 state: up type: ethernet既存のポリシーを編集してエラーを修正します。
$ oc edit nncp ens01-bridge-testfail
# ... port: - name: ens1ポリシーを保存して修正を適用します。
ポリシーのステータスをチェックして、更新が正常に行われたことを確認します。
$ oc get nncp
出力例
NAME STATUS ens01-bridge-testfail SuccessfullyConfigured
更新されたポリシーは、クラスターのすべてのノードで正常に設定されました。
第32章 クラスター全体のプロキシーの設定
実稼働環境では、インターネットへの直接アクセスを拒否し、代わりに HTTP または HTTPS プロキシーを使用することができます。既存クラスターのプロキシーオブジェクトを変更 するか、または新規クラスターの install-config.yaml ファイルでプロキシー設定を行うことにより、OpenShift Container Platform をプロキシーを使用するように設定できます。
32.1. 前提条件
クラスターがアクセスする必要のあるサイト を確認し、プロキシーをバイパスする必要があるかどうかを判断します。デフォルトで、すべてのクラスターシステムの egress トラフィック (クラスターをホストするクラウドのクラウドプロバイダー API に対する呼び出しを含む) はプロキシーされます。システム全体のプロキシーは、ユーザーのワークロードではなく、システムコンポーネントにのみ影響を与えます。プロキシーオブジェクトの
spec.noProxyフィールドにサイトを追加し、必要に応じてプロキシーをバイパスします。注記プロキシーオブジェクトの
status.noProxyフィールドには、ほとんどのインストールタイプのインストール設定におけるnetworking.machineNetwork[].cidr、networking.clusterNetwork[].cidr、およびnetworking.serviceNetwork[]フィールドの値が設定されます。Amazon Web Services (AWS)、Google Cloud Platform (GCP)、Microsoft Azure、および Red Hat OpenStack Platform (RHOSP) へのインストールの場合、
Proxyオブジェクトのstatus.noProxyフィールドには、インスタンスメタデータのエンドポイント (169.254.169.254) も設定されます。重要使用しているインストールタイプに
networking.machineNetwork[].cidrフィールドの設定が含まれていない場合は、ノード間のトラフィックがプロキシーをバイパスできるようにするために、.status.noProxyフィールドにマシンの IP アドレスを手動で含める必要があります。
32.2. クラスター全体のプロキシーの有効化
Proxy オブジェクトは、クラスター全体の egress プロキシーを管理するために使用されます。プロキシーを設定せずにクラスターがインストールまたはアップグレードされると、Proxyオブジェクトは引き続き生成されますが、spec は設定されません。以下に例を示します。
apiVersion: config.openshift.io/v1
kind: Proxy
metadata:
name: cluster
spec:
trustedCA:
name: ""
status:
クラスター管理者は、この cluster Proxy オブジェクトを変更して OpenShift Container Platform のプロキシーを設定できます。
cluster という名前の Proxy オブジェクトのみがサポートされ、追加のプロキシーを作成することはできません。
前提条件
- クラスター管理者のパーミッション。
-
OpenShift Container Platform
ocCLI ツールがインストールされている。
手順
HTTPS 接続のプロキシーに必要な追加の CA 証明書が含まれる config map を作成します。
注記プロキシーのアイデンティティー証明書が RHCOS 信頼バンドルからの認証局によって署名される場合は、これを省略できます。
以下の内容で
user-ca-bundle.yamlというファイルを作成して、PEM でエンコードされた証明書の値を指定します。apiVersion: v1 data: ca-bundle.crt: | 1 <MY_PEM_ENCODED_CERTS> 2 kind: ConfigMap metadata: name: user-ca-bundle 3 namespace: openshift-config 4
このファイルから ConfigMap を作成します。
$ oc create -f user-ca-bundle.yaml
oc editコマンドを使用してProxyオブジェクトを変更します。$ oc edit proxy/cluster
プロキシーに必要なフィールドを設定します。
apiVersion: config.openshift.io/v1 kind: Proxy metadata: name: cluster spec: httpProxy: http://<username>:<pswd>@<ip>:<port> 1 httpsProxy: https://<username>:<pswd>@<ip>:<port> 2 noProxy: example.com 3 readinessEndpoints: - http://www.google.com 4 - https://www.google.com trustedCA: name: user-ca-bundle 5
- 1
- クラスター外の HTTP 接続を作成するために使用するプロキシー URL。URL スキームは
httpである必要があります。 - 2
- クラスター外で HTTPS 接続を作成するために使用するプロキシー URL。URL スキームは
httpまたはhttpsである必要があります。URL スキームをサポートするプロキシーの URL を指定します。たとえば、ほとんどのプロキシーは、httpsを使用するように設定されていても、httpしかサポートしていない場合、エラーを報告します。このエラーメッセージはログに反映されず、代わりにネットワーク接続エラーのように見える場合があります。クラスターからのhttps接続をリッスンするプロキシーを使用している場合は、プロキシーが使用する CA と証明書を受け入れるようにクラスターを設定する必要がある場合があります。 - 3
- プロキシーを除外するための宛先ドメイン名、ドメイン、IP アドレス、または他のネットワーク CIDR のコンマ区切りの一覧。
サブドメインのみと一致するように、ドメインの前に
.を付けます。たとえば、.y.comはx.y.comに一致しますが、y.comには一致しません。*を使用し、すべての宛先のプロキシーをバイパスします。インストール設定でnetworking.machineNetwork[].cidrフィールドで定義されるネットワークに含まれていないワーカーをスケールアップする場合、それらをこのリストに追加し、接続の問題を防ぐ必要があります。httpProxyまたはhttpsProxyフィールドのいずれも設定されていない場合に、このフィールドは無視されます。 - 4
httpProxyおよびhttpsProxyの値をステータスに書き込む前の readiness チェックに使用するクラスター外の 1 つ以上の URL。- 5
- HTTPS 接続のプロキシーに必要な追加の CA 証明書が含まれる、
openshift-confignamespace の config map の参照。ここで参照する前に config map が存在している必要があります。このフィールドは、プロキシーのアイデンティティー証明書が RHCOS 信頼バンドルからの認証局によって署名されない限り必要になります。
- 変更を適用するためにファイルを保存します。
32.3. クラスター全体のプロキシーの削除
cluster プロキシーオブジェクトは削除できません。クラスターからプロキシーを削除するには、プロキシーオブジェクトからすべての spec フィールドを削除します。
前提条件
- クラスター管理者のパーミッション。
-
OpenShift Container Platform
ocCLI ツールがインストールされている。
手順
oc editコマンドを使用してプロキシーを変更します。$ oc edit proxy/cluster
プロキシーオブジェクトからすべての
specフィールドを削除します。以下に例を示します。apiVersion: config.openshift.io/v1 kind: Proxy metadata: name: cluster spec: {}- 変更を適用するためにファイルを保存します。
関連情報
第33章 カスタム PKI の設定
Web コンソールなどの一部のプラットフォームコンポーネントは、通信にルートを使用し、それらと対話するために他のコンポーネントの証明書を信頼する必要があります。カスタムのパブリックキーインフラストラクチャー (PKI) を使用している場合は、プライベートに署名された CA 証明書がクラスター全体で認識されるようにこれを設定する必要があります。
プロキシー API を使用して、クラスター全体で信頼される CA 証明書を追加できます。インストール時またはランタイム時にこれを実行する必要があります。
インストール 時に、クラスター全体のプロキシーを設定します。プライベートに署名された CA 証明書は、
install-config.yamlファイルのadditionalTrustBundle設定で定義する必要があります。インストールプログラムは、定義した追加の CA 証明書が含まれる
user-ca-bundleという名前の ConfigMap を生成します。次に Cluster Network Operator は、これらの CA 証明書を Red Hat Enterprise Linux CoreOS (RHCOS) 信頼バンドルにマージするtrusted-ca-bundleConfigMap を作成し、この ConfigMap はプロキシーオブジェクトのtrustedCAフィールドで参照されます。-
ランタイム 時に、デフォルトのプロキシーオブジェクトを変更して、プライベートに署名された CA 証明書を追加 します (これは、クラスターのプロキシー有効化のワークフローの一部です)。これには、クラスターで信頼される必要があるプライベートに署名された CA 証明書が含まれる ConfigMap を作成し、次にプライベートに署名された証明書の ConfigMap を参照する
trustedCAでプロキシーリソースを変更することが関係します。
インストーラー設定の additionalTrustBundle フィールドおよびプロキシーリソースの trustedCA フィールドは、クラスター全体の信頼バンドルを管理するために使用されます。 additionalTrustBundle はインストール時に使用され、プロキシーの trustedCA がランタイム時に使用されます。
trustedCA フィールドは、クラスターコンポーネントによって使用されるカスタム証明書とキーのペアを含む ConfigMap の参照です。
33.1. インストール時のクラスター全体のプロキシーの設定
実稼働環境では、インターネットへの直接アクセスを拒否し、代わりに HTTP または HTTPS プロキシーを使用することができます。プロキシー設定を install-config.yaml ファイルで行うことにより、新規の OpenShift Container Platform クラスターをプロキシーを使用するように設定できます。
前提条件
-
既存の
install-config.yamlファイルがある。 クラスターがアクセスする必要のあるサイトを確認済みで、それらのいずれかがプロキシーをバイパスする必要があるかどうかを判別している。デフォルトで、すべてのクラスター egress トラフィック (クラスターをホストするクラウドについてのクラウドプロバイダー API に対する呼び出しを含む) はプロキシーされます。プロキシーを必要に応じてバイパスするために、サイトを
Proxyオブジェクトのspec.noProxyフィールドに追加している。注記Proxyオブジェクトのstatus.noProxyフィールドには、インストール設定のnetworking.machineNetwork[].cidr、networking.clusterNetwork[].cidr、およびnetworking.serviceNetwork[]フィールドの値が設定されます。Amazon Web Services (AWS)、Google Cloud Platform (GCP)、Microsoft Azure、および Red Hat OpenStack Platform (RHOSP) へのインストールの場合、
Proxyオブジェクトのstatus.noProxyフィールドには、インスタンスメタデータのエンドポイント (169.254.169.254) も設定されます。
手順
install-config.yamlファイルを編集し、プロキシー設定を追加します。以下に例を示します。apiVersion: v1 baseDomain: my.domain.com proxy: httpProxy: http://<username>:<pswd>@<ip>:<port> 1 httpsProxy: https://<username>:<pswd>@<ip>:<port> 2 noProxy: ec2.<aws_region>.amazonaws.com,elasticloadbalancing.<aws_region>.amazonaws.com,s3.<aws_region>.amazonaws.com 3 additionalTrustBundle: | 4 -----BEGIN CERTIFICATE----- <MY_TRUSTED_CA_CERT> -----END CERTIFICATE----- additionalTrustBundlePolicy: <policy_to_add_additionalTrustBundle> 5
- 1
- クラスター外の HTTP 接続を作成するために使用するプロキシー URL。URL スキームは
httpである必要があります。 - 2
- クラスター外で HTTPS 接続を作成するために使用するプロキシー URL。
- 3
- プロキシーから除外するための宛先ドメイン名、IP アドレス、または他のネットワーク CIDR のコンマ区切りのリスト。サブドメインのみと一致するように、ドメインの前に
.を付けます。たとえば、.y.comはx.y.comに一致しますが、y.comには一致しません。*を使用し、すべての宛先のプロキシーをバイパスします。AmazonEC2、Elastic Load Balancing、およびS3VPC エンドポイントを VPC に追加した場合は、これらのエンドポイントをnoProxyフィールドに追加する必要があります。 - 4
- 指定されている場合、インストールプログラムは HTTPS 接続のプロキシーに必要な 1 つ以上の追加の CA 証明書が含まれる
user-ca-bundleという名前の設定マップをopenshift-confignamespace に生成します。次に Cluster Network Operator は、これらのコンテンツを Red Hat Enterprise Linux CoreOS (RHCOS) 信頼バンドルにマージするtrusted-ca-bundle設定マップを作成し、この設定マップはProxyオブジェクトのtrustedCAフィールドで参照されます。additionalTrustBundleフィールドは、プロキシーのアイデンティティー証明書が RHCOS 信頼バンドルからの認証局によって署名されない限り必要になります。 - 5
- オプション:
trustedCAフィールドのuser-ca-bundle設定マップを参照するProxyオブジェクトの設定を決定するポリシー。許可される値はProxyonlyおよびAlwaysです。Proxyonlyを使用して、http/httpsプロキシーが設定されている場合にのみuser-ca-bundle設定マップを参照します。Alwaysを使用して、常にuser-ca-bundle設定マップを参照します。デフォルト値はProxyonlyです。
注記インストールプログラムは、プロキシーの
readinessEndpointsフィールドをサポートしません。注記インストーラーがタイムアウトした場合は、インストーラーの
wait-forコマンドを使用してデプロイメントを再起動してからデプロイメントを完了します。以下に例を示します。$ ./openshift-install wait-for install-complete --log-level debug
- ファイルを保存し、OpenShift Container Platform のインストール時にこれを参照します。
インストールプログラムは、指定の install-config.yaml ファイルのプロキシー設定を使用する cluster という名前のクラスター全体のプロキシーを作成します。プロキシー設定が指定されていない場合、cluster Proxy オブジェクトが依然として作成されますが、これには spec がありません。
cluster という名前の Proxy オブジェクトのみがサポートされ、追加のプロキシーを作成することはできません。
33.2. クラスター全体のプロキシーの有効化
Proxy オブジェクトは、クラスター全体の egress プロキシーを管理するために使用されます。プロキシーを設定せずにクラスターがインストールまたはアップグレードされると、Proxyオブジェクトは引き続き生成されますが、spec は設定されません。以下に例を示します。
apiVersion: config.openshift.io/v1
kind: Proxy
metadata:
name: cluster
spec:
trustedCA:
name: ""
status:
クラスター管理者は、この cluster Proxy オブジェクトを変更して OpenShift Container Platform のプロキシーを設定できます。
cluster という名前の Proxy オブジェクトのみがサポートされ、追加のプロキシーを作成することはできません。
前提条件
- クラスター管理者のパーミッション。
-
OpenShift Container Platform
ocCLI ツールがインストールされている。
手順
HTTPS 接続のプロキシーに必要な追加の CA 証明書が含まれる config map を作成します。
注記プロキシーのアイデンティティー証明書が RHCOS 信頼バンドルからの認証局によって署名される場合は、これを省略できます。
以下の内容で
user-ca-bundle.yamlというファイルを作成して、PEM でエンコードされた証明書の値を指定します。apiVersion: v1 data: ca-bundle.crt: | 1 <MY_PEM_ENCODED_CERTS> 2 kind: ConfigMap metadata: name: user-ca-bundle 3 namespace: openshift-config 4
このファイルから ConfigMap を作成します。
$ oc create -f user-ca-bundle.yaml
oc editコマンドを使用してProxyオブジェクトを変更します。$ oc edit proxy/cluster
プロキシーに必要なフィールドを設定します。
apiVersion: config.openshift.io/v1 kind: Proxy metadata: name: cluster spec: httpProxy: http://<username>:<pswd>@<ip>:<port> 1 httpsProxy: https://<username>:<pswd>@<ip>:<port> 2 noProxy: example.com 3 readinessEndpoints: - http://www.google.com 4 - https://www.google.com trustedCA: name: user-ca-bundle 5
- 1
- クラスター外の HTTP 接続を作成するために使用するプロキシー URL。URL スキームは
httpである必要があります。 - 2
- クラスター外で HTTPS 接続を作成するために使用するプロキシー URL。URL スキームは
httpまたはhttpsである必要があります。URL スキームをサポートするプロキシーの URL を指定します。たとえば、ほとんどのプロキシーは、httpsを使用するように設定されていても、httpしかサポートしていない場合、エラーを報告します。このエラーメッセージはログに反映されず、代わりにネットワーク接続エラーのように見える場合があります。クラスターからのhttps接続をリッスンするプロキシーを使用している場合は、プロキシーが使用する CA と証明書を受け入れるようにクラスターを設定する必要がある場合があります。 - 3
- プロキシーを除外するための宛先ドメイン名、ドメイン、IP アドレス、または他のネットワーク CIDR のコンマ区切りの一覧。
サブドメインのみと一致するように、ドメインの前に
.を付けます。たとえば、.y.comはx.y.comに一致しますが、y.comには一致しません。*を使用し、すべての宛先のプロキシーをバイパスします。インストール設定でnetworking.machineNetwork[].cidrフィールドで定義されるネットワークに含まれていないワーカーをスケールアップする場合、それらをこのリストに追加し、接続の問題を防ぐ必要があります。httpProxyまたはhttpsProxyフィールドのいずれも設定されていない場合に、このフィールドは無視されます。 - 4
httpProxyおよびhttpsProxyの値をステータスに書き込む前の readiness チェックに使用するクラスター外の 1 つ以上の URL。- 5
- HTTPS 接続のプロキシーに必要な追加の CA 証明書が含まれる、
openshift-confignamespace の config map の参照。ここで参照する前に config map が存在している必要があります。このフィールドは、プロキシーのアイデンティティー証明書が RHCOS 信頼バンドルからの認証局によって署名されない限り必要になります。
- 変更を適用するためにファイルを保存します。
33.3. Operator を使用した証明書の挿入
カスタム CA 証明書が ConfigMap 経由でクラスターに追加されると、Cluster Network Operator はユーザーによってプロビジョニングされる CA 証明書およびシステム CA 証明書を単一バンドルにマージし、信頼バンドルの挿入を要求する Operator にマージされたバンドルを挿入します。
config.openshift.io/inject-trusted-cabundle="true" ラベルを config map に追加すると、そこに格納されている既存データが削除されます。Cluster Network Operator は config map の所有権を取得し、ca-bundle をデータとしてのみ受け入れます。service.beta.openshift.io/inject-cabundle=true アノテーションまたは同様の設定を使用して service-ca.crt を保存するには、別の config map を使用する必要があります。同じ config map に config.openshift.io/inject-trusted-cabundle="true" ラベルと service.beta.openshift.io/inject-cabundle=true アノテーションを追加すると、問題が発生する可能性があります。
Operator は、以下のラベルの付いた空の ConfigMap を作成してこの挿入を要求します。
config.openshift.io/inject-trusted-cabundle="true"
空の ConfigMap の例:
apiVersion: v1
data: {}
kind: ConfigMap
metadata:
labels:
config.openshift.io/inject-trusted-cabundle: "true"
name: ca-inject 1
namespace: apache- 1
- 空の ConfigMap 名を指定します。
Operator は、この ConfigMap をコンテナーのローカル信頼ストアにマウントします。
信頼された CA 証明書の追加は、証明書が Red Hat Enterprise Linux CoreOS (RHCOS) 信頼バンドルに含まれない場合にのみ必要になります。
証明書の挿入は Operator に制限されません。Cluster Network Operator は、空の ConfigMap が config.openshift.io/inject-trusted-cabundle=true ラベルを使用して作成される場合に、すべての namespace で証明書を挿入できます。
ConfigMap はすべての namespace に置くことができますが、ConfigMap はカスタム CA を必要とする Pod 内の各コンテナーに対してボリュームとしてマウントされる必要があります。以下に例を示します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-example-custom-ca-deployment
namespace: my-example-custom-ca-ns
spec:
...
spec:
...
containers:
- name: my-container-that-needs-custom-ca
volumeMounts:
- name: trusted-ca
mountPath: /etc/pki/ca-trust/extracted/pem
readOnly: true
volumes:
- name: trusted-ca
configMap:
name: trusted-ca
items:
- key: ca-bundle.crt 1
path: tls-ca-bundle.pem 2第34章 RHOSP での負荷分散
34.1. ロードバランサーサービスの制限
Red Hat OpenStack Platform (RHOSP) 上の OpenShift Container Platform クラスターは、Octavia を使用してロードバランサーサービスを処理します。その結果、該当するクラスターには多くの機能的制限が生じます。
RHOSP Octavia では、Amphora と OVN の 2 つのプロバイダーがサポートされています。これらのプロバイダーでは、利用可能な機能と実装の詳細が異なります。そのような差異は、クラスター上に作成されるロードバランサーサービスに影響を及ぼします。
34.1.1. ローカルの外部トラフィックポリシー
ロードバランサーサービスで外部トラフィックポリシー (ETP) パラメーター .spec.externalTrafficPolicy を設定して、受信トラフィックがサービスエンドポイント Pod に到達する際に、そのソース IP アドレスを保存できます。ただし、クラスターが Amphora Octavia プロバイダーを使用している場合じゃ、トラフィックのソース IP は Amphora 仮想マシンの IP アドレスに置き換えられます。クラスターが OVN Octavia プロバイダーを使用している場合、この動作は発生しません。
ETP オプションを Local に設定する場合は、ロードバランサー用にヘルスモニターを作成する必要があります。ヘルスモニターがないと、トラフィックは機能エンドポイントを持たないノードにルーティングされる可能性があり、そうなると接続が切断されます。ヘルスモニターの作成を Cloud Provider OpenStack に強制するには、クラウドプロバイダー設定の create-monitor オプションの値を true に設定する必要があります。
RHOSP 16.2 では、OVN Octavia プロバイダーはヘルスモニターをサポートしません。そのため、EPP をローカルに設定することはサポートされていません。
RHOSP 16.2 では、Amphora Octavia プロバイダーは UDP プールでの HTTP モニターをサポートしません。その結果、UDP ロードバランサーサービスには UDP-CONNECT モニターが代わりに作成されます。実装の詳細に基づき、この設定は OVN-Kubernetes CNI プラグインでのみ適切に機能します。OpenShift SDN CNI プラグインを使用している場合、UDP サービスのアクティブなノードの検出が不確実になります。
34.1.2. ロードバランサーのソース範囲
.spec.loadBalancerSourceRanges プロパティーを使用して、ソース IP に従ってロードバランサーを通過できるトラフィックを制限します。このプロパティーは、Amphora Octavia プロバイダーで使用する場合に限りサポートされます。クラスターが OVN Octavia プロバイダーを使用している場合、オプションは無視され、トラフィックは制限されません。
34.2. Kuryr SDN を使用した Octavia OVN ロードバランサープロバイダードライバーの使用
Kuryr は非推奨の機能です。非推奨の機能は依然として OpenShift Container Platform に含まれており、引き続きサポートされますが、本製品の今後のリリースで削除されるため、新規デプロイメントでの使用は推奨されません。
OpenShift Container Platform で非推奨となったか、削除された主な機能の最新の一覧については、OpenShift Container Platform リリースノートの 非推奨および削除された機能セクションを参照してください。
OpenShift Container Platform クラスターが Kuryr を使用し、これが後に RHOSP 16 にアップグレードされた Red Hat OpenStack Platform (RHOSP) 13 クラウドにインストールされている場合、これを Octavia OVN プロバイダードライバーを使用するように設定できます。
Kuryr はプロバイダードライバーの変更後に既存のロードバランサーを置き換えます。このプロセスにより、ダウンタイムが生じます。
前提条件
-
RHOSP CLI の
openstackをインストールします。 -
OpenShift Container Platform CLI の
ocをインストールします。 RHOSP の Octavia OVN ドライバーが有効になっていることを確認している。
ヒント利用可能な Octavia ドライバーのリストを表示するには、コマンドラインで
openstack loadbalancer provider listを入力します。ovnドライバーはコマンドの出力に表示されます。
手順
Octavia Amphora プロバイダードライバーから Octavia OVN に変更するには、以下を実行します。
kuryr-configConfigMap を開きます。コマンドラインで、以下を実行します。$ oc -n openshift-kuryr edit cm kuryr-config
ConfigMap で、
kuryr-octavia-provider: defaultが含まれる行を削除します。以下に例を示します。... kind: ConfigMap metadata: annotations: networkoperator.openshift.io/kuryr-octavia-provider: default 1 ...- 1
- この行を削除します。クラスターは、
ovnを値としてこれを再生成します。
Cluster Network Operator が変更を検出し、
kuryr-controllerおよびkuryr-cniPod を再デプロイするのを待機します。このプロセスには数分の時間がかかる可能性があります。kuryr-configConfigMap アノテーションでovnをその値として表示されていることを確認します。コマンドラインで、以下を実行します。$ oc -n openshift-kuryr edit cm kuryr-config
ovnプロバイダーの値は出力に表示されます。... kind: ConfigMap metadata: annotations: networkoperator.openshift.io/kuryr-octavia-provider: ovn ...RHOSP がそのロードバランサーを再作成していることを確認します。
コマンドラインで、以下を実行します。
$ openstack loadbalancer list | grep amphora
単一の Amphora ロードバランサーが表示されます。以下に例を示します。
a4db683b-2b7b-4988-a582-c39daaad7981 | ostest-7mbj6-kuryr-api-loadbalancer | 84c99c906edd475ba19478a9a6690efd | 172.30.0.1 | ACTIVE | amphora
以下を入力して
ovnロードバランサーを検索します。$ openstack loadbalancer list | grep ovn
ovnタイプの残りのロードバランサーが表示されます。以下に例を示します。2dffe783-98ae-4048-98d0-32aa684664cc | openshift-apiserver-operator/metrics | 84c99c906edd475ba19478a9a6690efd | 172.30.167.119 | ACTIVE | ovn 0b1b2193-251f-4243-af39-2f99b29d18c5 | openshift-etcd/etcd | 84c99c906edd475ba19478a9a6690efd | 172.30.143.226 | ACTIVE | ovn f05b07fc-01b7-4673-bd4d-adaa4391458e | openshift-dns-operator/metrics | 84c99c906edd475ba19478a9a6690efd | 172.30.152.27 | ACTIVE | ovn
34.3. Octavia を使用したアプリケーショントラフィック用のクラスターのスケーリング
Red Hat OpenStack Platform (RHOSP) で実行される OpenShift Container Platform クラスターでは、Octavia 負荷分散サービスを使用して、複数の仮想マシン (VM) または Floating IP アドレスにトラフィックを分散することができます。この機能は、単一マシンまたはアドレスが生じさせるボトルネックを軽減します。
クラスターで Kuryr を使用する場合、Cluster Network Operator はデプロイメント時に内部 Octavia ロードバランサーを作成していました。アプリケーションネットワークのスケーリングには、このロードバランサーを使用できます。
クラスターで Kuryr を使用しない場合、アプリケーションのネットワークのスケーリングに使用する独自の Octavia ロードバランサーを作成する必要があります。
34.3.1. Octavia を使用したクラスターのスケーリング
複数の API ロードバランサーを使用する場合や、クラスターが Kuryr を使用しない場合、Octavia ロードバランサーを作成してから、クラスターをこれを使用するように設定します。
前提条件
- Octavia は Red Hat OpenStack Platform (RHOSP) デプロイメントで利用できます。
手順
コマンドラインから、Amphora ドライバーを使用する Octavia ロードバランサーを作成します。
$ openstack loadbalancer create --name API_OCP_CLUSTER --vip-subnet-id <id_of_worker_vms_subnet>
API_OCP_CLUSTERの代わりに、任意の名前を使用することができます。ロードバランサーがアクティブになったら、リスナーを作成します。
$ openstack loadbalancer listener create --name API_OCP_CLUSTER_6443 --protocol HTTPS--protocol-port 6443 API_OCP_CLUSTER
注記ロードバランサーのステータスを表示するには、
openstack loadbalancer listと入力します。ラウンドロビンアルゴリズムを使用し、セッションの永続性が有効にされているプールを作成します。
$ openstack loadbalancer pool create --name API_OCP_CLUSTER_pool_6443 --lb-algorithm ROUND_ROBIN --session-persistence type=<source_IP_address> --listener API_OCP_CLUSTER_6443 --protocol HTTPS
コントロールプレーンマシンが利用可能であることを確認するには、ヘルスモニターを作成します。
$ openstack loadbalancer healthmonitor create --delay 5 --max-retries 4 --timeout 10 --type TCP API_OCP_CLUSTER_pool_6443
コントロールプレーンマシンをロードバランサープールのメンバーとして追加します。
$ for SERVER in $(MASTER-0-IP MASTER-1-IP MASTER-2-IP) do openstack loadbalancer member create --address $SERVER --protocol-port 6443 API_OCP_CLUSTER_pool_6443 done
オプション: クラスター API の Floating IP アドレスを再利用するには、設定を解除します。
$ openstack floating ip unset $API_FIP
設定を解除された
API_FIP、または新規アドレスを、作成されたロードばランサー VIP に追加します。$ openstack floating ip set --port $(openstack loadbalancer show -c <vip_port_id> -f value API_OCP_CLUSTER) $API_FIP
クラスターは、負荷分散に Octavia を使用するようになりました。
Kuryr が Octavia Amphora ドライバーを使用する場合、すべてのトラフィックは単一の Amphora 仮想マシン (VM) 経由でルーティングされます。
この手順を繰り返して追加のロードバランサーを作成します。これにより、ボトルネックを軽減することができます。
34.3.2. Octavia の使用による Kuryr を使用するクラスターのスケーリング
Kuryr は非推奨の機能です。非推奨の機能は依然として OpenShift Container Platform に含まれており、引き続きサポートされますが、本製品の今後のリリースで削除されるため、新規デプロイメントでの使用は推奨されません。
OpenShift Container Platform で非推奨となったか、削除された主な機能の最新の一覧については、OpenShift Container Platform リリースノートの 非推奨および削除された機能セクションを参照してください。
クラスターで Kuryr を使用する場合は、クラスターの API Floating IP アドレスを既存の Octavia ロードバランサーに関連付けます。
前提条件
- OpenShift Container Platform クラスターは Kuryr を使用します。
- Octavia は Red Hat OpenStack Platform (RHOSP) デプロイメントで利用できます。
手順
オプション: コマンドラインからクラスター API の Floating IP アドレスを再利用するには、この設定を解除します。
$ openstack floating ip unset $API_FIP
設定を解除された
API_FIP、または新規アドレスを、作成されたロードばランサー VIP に追加します。$ openstack floating ip set --port $(openstack loadbalancer show -c <vip_port_id> -f value ${OCP_CLUSTER}-kuryr-api-loadbalancer) $API_FIP
クラスターは、負荷分散に Octavia を使用するようになりました。
Kuryr が Octavia Amphora ドライバーを使用する場合、すべてのトラフィックは単一の Amphora 仮想マシン (VM) 経由でルーティングされます。
この手順を繰り返して追加のロードバランサーを作成します。これにより、ボトルネックを軽減することができます。
34.4. RHOSP Octavia を使用した ingress トラフィックのスケーリング
Kuryr は非推奨の機能です。非推奨の機能は依然として OpenShift Container Platform に含まれており、引き続きサポートされますが、本製品の今後のリリースで削除されるため、新規デプロイメントでの使用は推奨されません。
OpenShift Container Platform で非推奨となったか、削除された主な機能の最新の一覧については、OpenShift Container Platform リリースノートの 非推奨および削除された機能セクションを参照してください。
Octavia ロードバランサーを使用して、Kuryr を使用するクラスターで Ingress Controller をスケーリングできます。
前提条件
- OpenShift Container Platform クラスターは Kuryr を使用します。
- Octavia は RHOSP デプロイメントで利用できます。
手順
現在の内部ルーターサービスをコピーするには、コマンドラインで以下を入力します。
$ oc -n openshift-ingress get svc router-internal-default -o yaml > external_router.yaml
external_router.yamlファイルで、metadata.nameおよびspec.typeの値をLoadBalancerに変更します。ルーターファイルの例
apiVersion: v1 kind: Service metadata: labels: ingresscontroller.operator.openshift.io/owning-ingresscontroller: default name: router-external-default 1 namespace: openshift-ingress spec: ports: - name: http port: 80 protocol: TCP targetPort: http - name: https port: 443 protocol: TCP targetPort: https - name: metrics port: 1936 protocol: TCP targetPort: 1936 selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller: default sessionAffinity: None type: LoadBalancer 2
ロードバランシングと関連性のないタイムスタンプやその他の情報を削除できます。
コマンドラインで、
external_router.yamlファイルからサービスを作成します。$ oc apply -f external_router.yaml
サービスの外部 IP アドレスがロードバランサーに関連付けられているものと同じであることを確認します。
コマンドラインで、サービスの外部 IP アドレスを取得します。
$ oc -n openshift-ingress get svc
出力例
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE router-external-default LoadBalancer 172.30.235.33 10.46.22.161 80:30112/TCP,443:32359/TCP,1936:30317/TCP 3m38s router-internal-default ClusterIP 172.30.115.123 <none> 80/TCP,443/TCP,1936/TCP 22h
ロードバランサーの IP アドレスを取得します。
$ openstack loadbalancer list | grep router-external
出力例
| 21bf6afe-b498-4a16-a958-3229e83c002c | openshift-ingress/router-external-default | 66f3816acf1b431691b8d132cc9d793c | 172.30.235.33 | ACTIVE | octavia |
直前のステップで取得したアドレスが、Floating IP のリストで相互に関連付けられていることを確認します。
$ openstack floating ip list | grep 172.30.235.33
出力例
| e2f80e97-8266-4b69-8636-e58bacf1879e | 10.46.22.161 | 172.30.235.33 | 655e7122-806a-4e0a-a104-220c6e17bda6 | a565e55a-99e7-4d15-b4df-f9d7ee8c9deb | 66f3816acf1b431691b8d132cc9d793c |
EXTERNAL-IP の値を新規 Ingress アドレスとして使用できるようになりました。
Kuryr が Octavia Amphora ドライバーを使用する場合、すべてのトラフィックは単一の Amphora 仮想マシン (VM) 経由でルーティングされます。
この手順を繰り返して追加のロードバランサーを作成します。これにより、ボトルネックを軽減することができます。
34.5. 外部ロードバランサー用のサービス
Red Hat OpenStack Platform (RHOSP) の OpenShift Container Platform クラスターを、デフォルトのロードバランサーの代わりに外部ロードバランサーを使用するように設定できます。
外部ロードバランサーの設定は、ベンダーのロードバランサーによって異なります。
このセクションの情報と例は、ガイドラインのみを目的としています。ベンダーのロードバランサーに関する詳細は、ベンダーのドキュメントを参照してください。
Red Hat は、外部ロードバランサーに対して次のサービスをサポートしています。
- Ingress Controller
- OpenShift API
- OpenShift MachineConfig API
外部ロードバランサーに対して、これらのサービスの 1 つまたはすべてを設定するように選択できます。一般的な設定オプションは、Ingress Controller サービスのみを設定することです。次の図は、各サービスの詳細を示しています。
図34.1 OpenShift Container Platform 環境で動作する Ingress Controller を示すネットワークワークフローの例
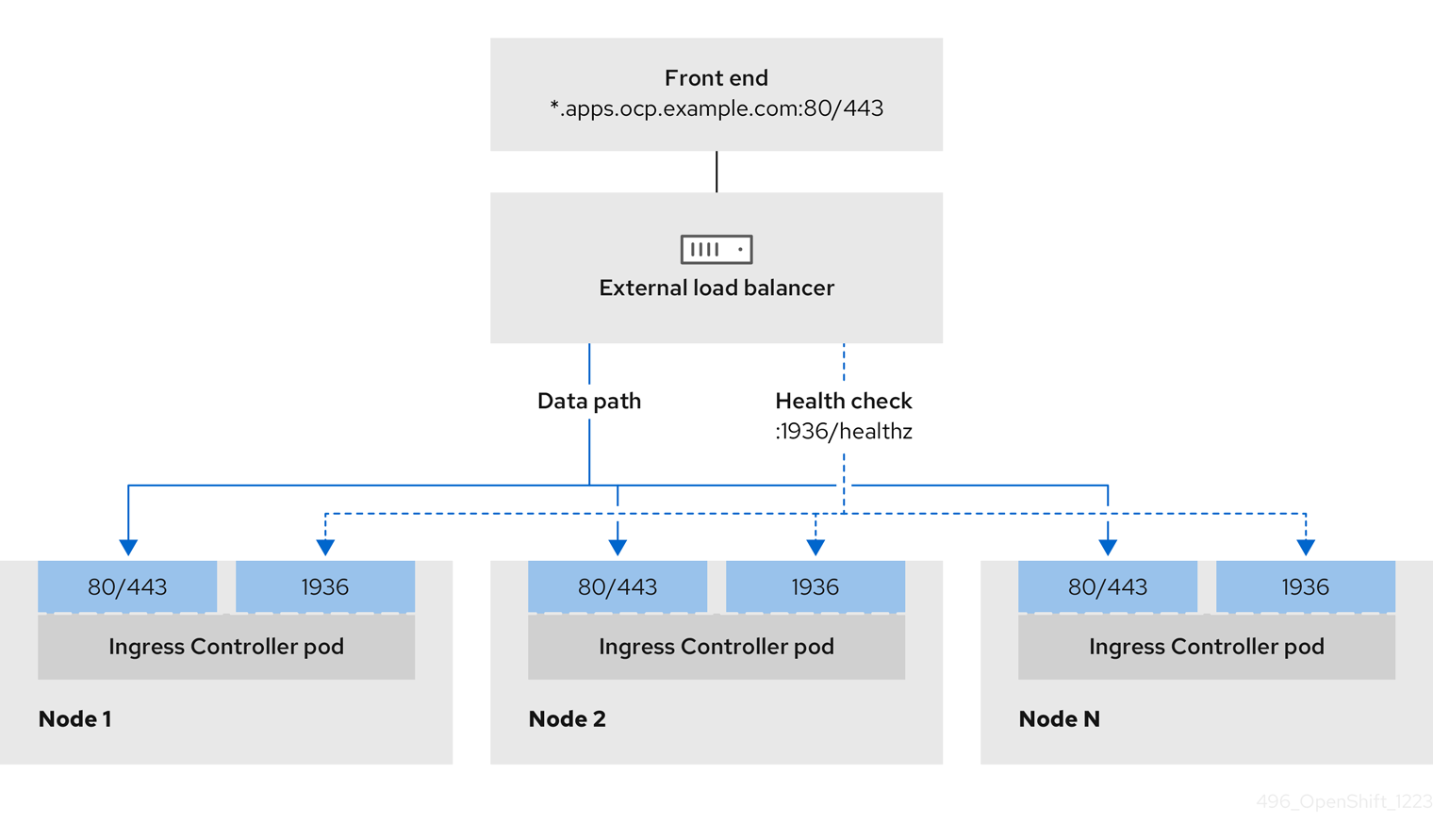
図34.2 OpenShift Container Platform 環境で動作する OpenShift API を示すネットワークワークフローの例
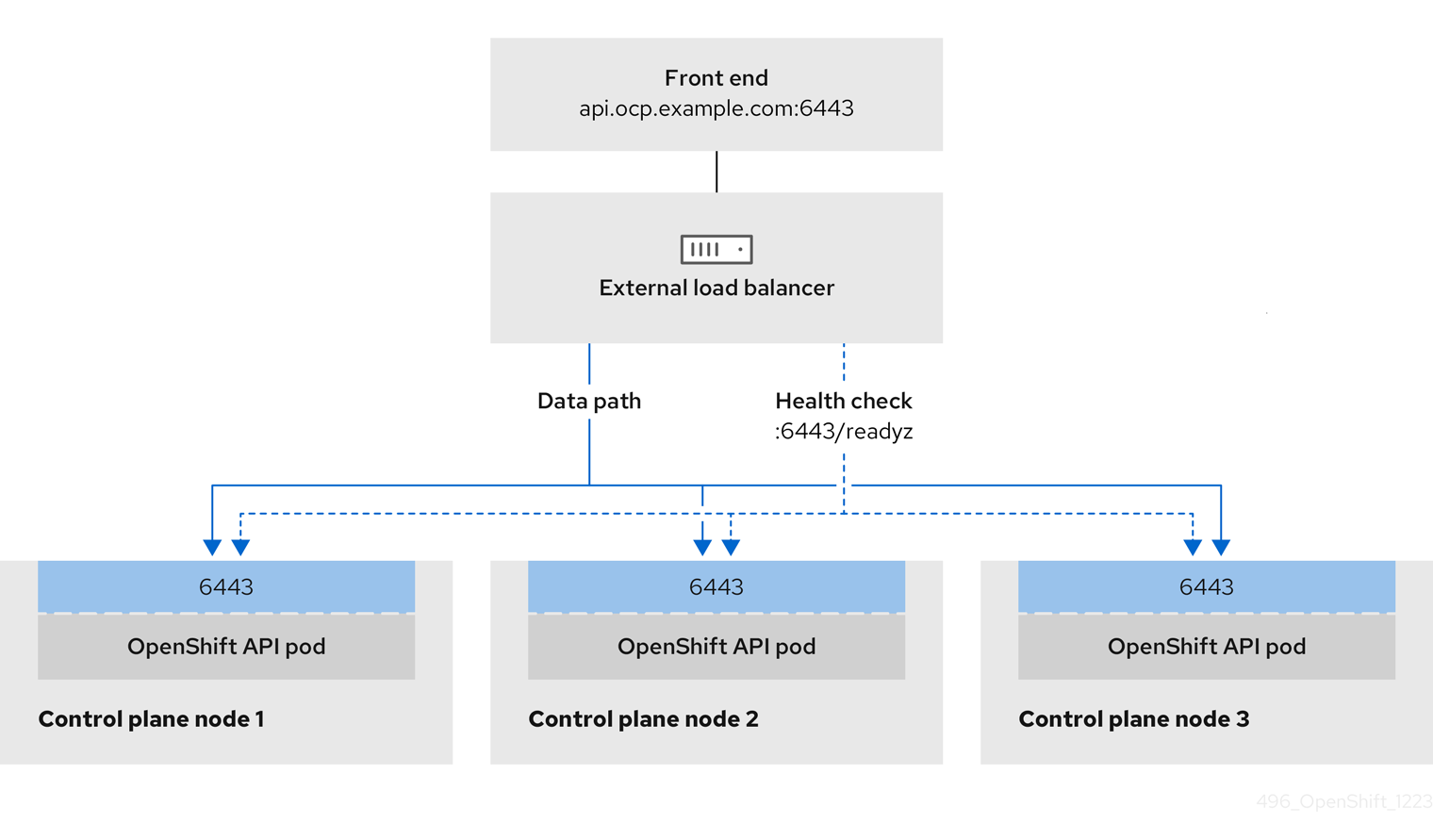
図34.3 OpenShift Container Platform 環境で動作する OpenShift MachineConfig API を示すネットワークワークフローの例
外部ロードバランサーでは、次の設定オプションがサポートされています。
- ノードセレクターを使用して、Ingress Controller を特定のノードのセットにマッピングします。このセットの各ノードに静的 IP アドレスを割り当てるか、 Dynamic Host Configuration Protocol (DHCP) から同じ IP アドレスを受け取るように各ノードを設定する必要があります。インフラストラクチャーノードは通常、このタイプの設定を受け取ります。
サブネット上のすべての IP アドレスをターゲットにします。この設定では、ロードバランサーターゲットを再設定せずにネットワーク内でノードを作成および破棄できるため、メンテナンスオーバーヘッドを削減できます。
/27や/28などの小規模なネットワーク上に設定されたマシンを使用して Ingress Pod をデプロイする場合、ロードバランサーのターゲットを簡素化できます。ヒントマシン config プールのリソースを確認することで、ネットワーク内に存在するすべての IP アドレスをリスト表示できます。
OpenShift Container Platform クラスターの外部ロードバランサーを設定する前に、以下の情報を考慮してください。
- フロントエンド IP アドレスの場合、フロントエンド IP アドレス、Ingress Controller のロードバランサー、および API ロードバランサーに同じ IP アドレスを使用できます。この機能については、ベンダーのドキュメントを確認してください。
バックエンド IP アドレスの場合、OpenShift Container Platform コントロールプレーンノードの IP アドレスが、外部ロードバランサーの存続期間中に変更されないようにください。次のいずれかのアクションを実行すると、これを実現できます。
- 各コントロールプレーンノードに静的 IP アドレスを割り当てます。
- ノードが DHCP リースを要求するたびに、DHCP から同じ IP アドレスを受信するように各ノードを設定します。ベンダーによっては、DHCP リースは IP 予約または静的 DHCP 割り当ての形式になる場合があります。
- Ingress Controller バックエンドサービスの外部ロードバランサーで、Ingress Controller を実行する各ノードを手動で定義します。たとえば、Ingress Controller が未定義のノードに移動すると、接続が停止する可能性があります。
34.5.1. 外部ロードバランサーの設定
Red Hat OpenStack Platform (RHOSP) の OpenShift Container Platform クラスターを、デフォルトのロードバランサーの代わりに外部ロードバランサーを使用するように設定できます。
外部ロードバランサーを設定する前に、「外部ロードバランサー用のサービス」セクションを必ず確認してください。
外部ロードバランサー用に設定するサービスに適用される次の前提条件を確認してください。
クラスター上で動作する MetalLB は、外部ロードバランサーとして機能します。
OpenShift API の前提条件
- フロントエンド IP アドレスを定義している。
TCP ポート 6443 および 22623 は、ロードバランサーのフロントエンド IP アドレスで公開されている。以下の項目を確認します。
- ポート 6443 が OpenShift API サービスにアクセスできる。
- ポート 22623 が Ignition 起動設定をノードに提供できる。
- フロントエンド IP アドレスとポート 6443 へは、OpenShift Container Platform クラスターの外部の場所にいるシステムのすべてのユーザーがアクセスできる。
- フロントエンド IP アドレスとポート 22623 は、OpenShift Container Platform ノードからのみ到達できる。
- ロードバランサーバックエンドは、ポート 6443 および 22623 の OpenShift Container Platform コントロールプレーンノードと通信できる。
Ingress Controller の前提条件
- フロントエンド IP アドレスを定義している。
- TCP ポート 443 および 80 はロードバランサーのフロントエンド IP アドレスで公開されている。
- フロントエンドの IP アドレス、ポート 80、ポート 443 へは、OpenShift Container Platform クラスターの外部の場所にあるシステムの全ユーザーがアクセスできる。
- フロントエンドの IP アドレス、ポート 80、ポート 443 は、OpenShift Container Platform クラスターで動作するすべてのノードから到達できる。
- ロードバランサーバックエンドは、ポート 80、443、および 1936 で Ingress Controller を実行する OpenShift Container Platform ノードと通信できる。
ヘルスチェック URL 仕様の前提条件
ほとんどのロードバランサーは、サービスが使用可能か使用不可かを判断するヘルスチェック URL を指定して設定できまうs.OpenShift Container Platform は、OpenShift API、Machine Configuration API、および Ingress Controller バックエンドサービスのこれらのヘルスチェックを提供します。
次の例は、前にリスト表示したバックエンドサービスのヘルスチェック仕様を示しています。
Kubernetes API ヘルスチェック仕様の例
Path: HTTPS:6443/readyz Healthy threshold: 2 Unhealthy threshold: 2 Timeout: 10 Interval: 10
Machine Config API ヘルスチェック仕様の例
Path: HTTPS:22623/healthz Healthy threshold: 2 Unhealthy threshold: 2 Timeout: 10 Interval: 10
Ingress Controller のヘルスチェック仕様の例
Path: HTTP:1936/healthz/ready Healthy threshold: 2 Unhealthy threshold: 2 Timeout: 5 Interval: 10
手順
HAProxy Ingress Controller を設定して、ポート 6443、443、および 80 でロードバランサーからクラスターへのアクセスを有効化できるようにします。
HAProxy 設定の例
#... listen my-cluster-api-6443 bind 192.168.1.100:6443 mode tcp balance roundrobin option httpchk http-check connect http-check send meth GET uri /readyz http-check expect status 200 server my-cluster-master-2 192.168.1.101:6443 check inter 10s rise 2 fall 2 server my-cluster-master-0 192.168.1.102:6443 check inter 10s rise 2 fall 2 server my-cluster-master-1 192.168.1.103:6443 check inter 10s rise 2 fall 2 listen my-cluster-machine-config-api-22623 bind 192.168.1.100:22623 mode tcp balance roundrobin option httpchk http-check connect http-check send meth GET uri /healthz http-check expect status 200 server my-cluster-master-2 192.168.1.101:22623 check inter 10s rise 2 fall 2 server my-cluster-master-0 192.168.1.102:22623 check inter 10s rise 2 fall 2 server my-cluster-master-1 192.168.1.103:22623 check inter 10s rise 2 fall 2 listen my-cluster-apps-443 bind 192.168.1.100:443 mode tcp balance roundrobin option httpchk http-check connect http-check send meth GET uri /healthz/ready http-check expect status 200 server my-cluster-worker-0 192.168.1.111:443 check port 1936 inter 10s rise 2 fall 2 server my-cluster-worker-1 192.168.1.112:443 check port 1936 inter 10s rise 2 fall 2 server my-cluster-worker-2 192.168.1.113:443 check port 1936 inter 10s rise 2 fall 2 listen my-cluster-apps-80 bind 192.168.1.100:80 mode tcp balance roundrobin option httpchk http-check connect http-check send meth GET uri /healthz/ready http-check expect status 200 server my-cluster-worker-0 192.168.1.111:80 check port 1936 inter 10s rise 2 fall 2 server my-cluster-worker-1 192.168.1.112:80 check port 1936 inter 10s rise 2 fall 2 server my-cluster-worker-2 192.168.1.113:80 check port 1936 inter 10s rise 2 fall 2 # ...curlCLI コマンドを使用して、外部ロードバランサーとそのリソースが動作していることを確認します。次のコマンドを実行して応答を観察し、クラスターマシン設定 API が Kubernetes API サーバーリソースにアクセスできることを確認します。
$ curl https://<loadbalancer_ip_address>:6443/version --insecure
設定が正しい場合は、応答として JSON オブジェクトを受信します。
{ "major": "1", "minor": "11+", "gitVersion": "v1.11.0+ad103ed", "gitCommit": "ad103ed", "gitTreeState": "clean", "buildDate": "2019-01-09T06:44:10Z", "goVersion": "go1.10.3", "compiler": "gc", "platform": "linux/amd64" }次のコマンドを実行して出力を確認し、クラスターマシン設定 API がマシン設定サーバーリソースからアクセスできることを確認します。
$ curl -v https://<loadbalancer_ip_address>:22623/healthz --insecure
設定が正しい場合、コマンドの出力には次の応答が表示されます。
HTTP/1.1 200 OK Content-Length: 0
次のコマンドを実行して出力を確認し、コントローラーがポート 80 の Ingress Controller リソースにアクセスできることを確認します。
$ curl -I -L -H "Host: console-openshift-console.apps.<cluster_name>.<base_domain>" http://<load_balancer_front_end_IP_address>
設定が正しい場合、コマンドの出力には次の応答が表示されます。
HTTP/1.1 302 Found content-length: 0 location: https://console-openshift-console.apps.ocp4.private.opequon.net/ cache-control: no-cache
次のコマンドを実行して出力を確認し、コントローラーがポート 443 の Ingress Controller リソースにアクセスできることを確認します。
$ curl -I -L --insecure --resolve console-openshift-console.apps.<cluster_name>.<base_domain>:443:<Load Balancer Front End IP Address> https://console-openshift-console.apps.<cluster_name>.<base_domain>
設定が正しい場合、コマンドの出力には次の応答が表示されます。
HTTP/1.1 200 OK referrer-policy: strict-origin-when-cross-origin set-cookie: csrf-token=UlYWOyQ62LWjw2h003xtYSKlh1a0Py2hhctw0WmV2YEdhJjFyQwWcGBsja261dGLgaYO0nxzVErhiXt6QepA7g==; Path=/; Secure; SameSite=Lax x-content-type-options: nosniff x-dns-prefetch-control: off x-frame-options: DENY x-xss-protection: 1; mode=block date: Wed, 04 Oct 2023 16:29:38 GMT content-type: text/html; charset=utf-8 set-cookie: 1e2670d92730b515ce3a1bb65da45062=1bf5e9573c9a2760c964ed1659cc1673; path=/; HttpOnly; Secure; SameSite=None cache-control: private
外部ロードバランサーのフロントエンド IP アドレスをターゲットにするように、クラスターの DNS レコードを設定します。ロードバランサー経由で、クラスター API およびアプリケーションの DNS サーバーのレコードを更新する必要があります。
変更された DNS レコードの例
<load_balancer_ip_address> A api.<cluster_name>.<base_domain> A record pointing to Load Balancer Front End
<load_balancer_ip_address> A apps.<cluster_name>.<base_domain> A record pointing to Load Balancer Front End
重要DNS の伝播では、各 DNS レコードが使用可能になるまでに時間がかかる場合があります。各レコードを検証する前に、各 DNS レコードが伝播されることを確認してください。
curlCLI コマンドを使用して、外部ロードバランサーと DNS レコード設定が動作していることを確認します。次のコマンドを実行して出力を確認し、クラスター API にアクセスできることを確認します。
$ curl https://api.<cluster_name>.<base_domain>:6443/version --insecure
設定が正しい場合は、応答として JSON オブジェクトを受信します。
{ "major": "1", "minor": "11+", "gitVersion": "v1.11.0+ad103ed", "gitCommit": "ad103ed", "gitTreeState": "clean", "buildDate": "2019-01-09T06:44:10Z", "goVersion": "go1.10.3", "compiler": "gc", "platform": "linux/amd64" }次のコマンドを実行して出力を確認し、クラスターマシン設定にアクセスできることを確認します。
$ curl -v https://api.<cluster_name>.<base_domain>:22623/healthz --insecure
設定が正しい場合、コマンドの出力には次の応答が表示されます。
HTTP/1.1 200 OK Content-Length: 0
以下のコマンドを実行して出力を確認し、ポートで各クラスターアプリケーションにアクセスできることを確認します。
$ curl http://console-openshift-console.apps.<cluster_name>.<base_domain> -I -L --insecure
設定が正しい場合、コマンドの出力には次の応答が表示されます。
HTTP/1.1 302 Found content-length: 0 location: https://console-openshift-console.apps.<cluster-name>.<base domain>/ cache-control: no-cacheHTTP/1.1 200 OK referrer-policy: strict-origin-when-cross-origin set-cookie: csrf-token=39HoZgztDnzjJkq/JuLJMeoKNXlfiVv2YgZc09c3TBOBU4NI6kDXaJH1LdicNhN1UsQWzon4Dor9GWGfopaTEQ==; Path=/; Secure x-content-type-options: nosniff x-dns-prefetch-control: off x-frame-options: DENY x-xss-protection: 1; mode=block date: Tue, 17 Nov 2020 08:42:10 GMT content-type: text/html; charset=utf-8 set-cookie: 1e2670d92730b515ce3a1bb65da45062=9b714eb87e93cf34853e87a92d6894be; path=/; HttpOnly; Secure; SameSite=None cache-control: private
次のコマンドを実行して出力を確認し、ポート 443 で各クラスターアプリケーションにアクセスできることを確認します。
$ curl https://console-openshift-console.apps.<cluster_name>.<base_domain> -I -L --insecure
設定が正しい場合、コマンドの出力には次の応答が表示されます。
HTTP/1.1 200 OK referrer-policy: strict-origin-when-cross-origin set-cookie: csrf-token=UlYWOyQ62LWjw2h003xtYSKlh1a0Py2hhctw0WmV2YEdhJjFyQwWcGBsja261dGLgaYO0nxzVErhiXt6QepA7g==; Path=/; Secure; SameSite=Lax x-content-type-options: nosniff x-dns-prefetch-control: off x-frame-options: DENY x-xss-protection: 1; mode=block date: Wed, 04 Oct 2023 16:29:38 GMT content-type: text/html; charset=utf-8 set-cookie: 1e2670d92730b515ce3a1bb65da45062=1bf5e9573c9a2760c964ed1659cc1673; path=/; HttpOnly; Secure; SameSite=None cache-control: private
第35章 MetalLB を使用した負荷分散
35.1. MetalLB および MetalLB Operator について
クラスター管理者は、MetalLB Operator をクラスターに追加し、タイプ LoadBalancer のサービスがクラスターに追加されると、MetalLB はサービスの外部 IP アドレスを追加できます。外部 IP アドレスがクラスターのホストネットワークに追加されます。
35.1.1. MetalLB を使用するタイミング
MetalLB の使用は、ベアメタルクラスター、またはベアメタルのようなインフラストラクチャーがある場合や、外部 IP アドレスを使用したアプリケーションへのフォールトトレラントがあるアクセスが必要な場合に役立ちます。
ネットワークインフラストラクチャーを設定し、外部 IP アドレスのネットワークトラフィックがクライアントからクラスターのホストネットワークにルーティングされるようにする必要があります。
MetalLB Operator を使用して MetalLB をデプロイした後、タイプ LoadBalancer のサービスを追加すると、MetalLB はプラットフォームネイティブなロードバランサーを提供します。
レイヤ 2 モードで動作する MetalLB は、IP フェイルオーバーと同様のメカニズムを利用してフェイルオーバーをサポートします。ただし、仮想ルーター冗長プロトコル (VRRP) とキープアライブに依存する代わりに、MetalLB はゴシップベースのプロトコルを利用してノード障害のインスタンスを識別します。フェイルオーバーが検出されると、別のノードがリーダーノードのロールを引き継ぎ、Gratuitous ARP メッセージがディスパッチされて、この変更がブロードキャストされます。
レイヤ 3 またはボーダーゲートウェイプロトコル (BGP) モードで動作する MetalLB は、障害検出をネットワークに委任します。OpenShift Container Platform ノードが接続を確立した BGP ルーターは、ノードの障害を識別し、そのノードへのルートを終了します。
Pod とサービスの高可用性を確保するには、IP フェイルオーバーの代わりに MetalLB を使用することを推奨します。
35.1.2. MetalLB Operator カスタムリソース
Metal LB Operator は、次のカスタムリソースについて独自の namespace を監視します。
MetalLB-
MetalLBカスタムリソースをクラスターに追加する際に、MetalLB Operator は MetalLB をクラスターにデプロイします。Operator はカスタムリソースの単一インスタンスのみをサポートします。インスタンスが削除されると、Operator はクラスターから MetalLB を削除します。 IPAddressPoolMetalLB には、タイプ
LoadBalancerのサービスを追加する際にサービスに割り当てることができる IP アドレスの 1 つ以上のプールが必要です。IPAddressPoolには、IP アドレスのリストが含まれています。リストは、1.1.1.1-1.1.1.1 などの範囲を使用して設定された単一の IP アドレス、CIDR 表記で指定された範囲、ハイフンで区切られた開始アドレスと終了アドレスとして指定された範囲、またはこの 3 つの組み合わせにすることができます。IPAddressPoolには名前が必要です。ドキュメントは、doc-example、doc-example-reserved、doc-example-ipv6などの名前を使用します。MetalLBcontrollerは、IPAddressPool内のアドレスのプールから IP アドレスを割り当てます。L2AdvertisementおよびBGPAdvertisementカスタムリソースは、指定されたプールからの指定された IP のアドバタイズメントを有効にします。IPAddressPoolカスタムリソースのIPAddressPool仕様を使用して、spec.serviceAllocationからサービスと namespace に IP アドレスを割り当てることができます。注記単一の
IPAddressPoolは、L2 アドバタイズメントと BGP アドバタイズメントによって参照できます。BGPPeer- BGP ピアカスタムリソースは、通信する MetalLB の BGP ルーター、ルーターの AS 番号、MetalLB の AS 番号、およびルートアドバタイズメントのカスタマイズを識別します。MetalLB は、サービスロードバランサーの IP アドレスのルートを 1 つ以上の BGP ピアにアドバタイズします。
BFDProfile- BFD プロファイルカスタムリソースは、BGP ピアの双方向フォワーディング検出 (BFD) を設定します。BFD は、BGP のみよりも、パスの障害検出が高速になります。
L2Advertisement-
L2Advertisement カスタムリソースは、L2 プロトコルを使用して
IPAddressPoolからの IP をアドバタイズします。 BGPAdvertisement-
BGPAdvertisement カスタムリソースは、BGP プロトコルを使用して
IPAddressPoolからの IP をアドバタイズします。
MetalLB カスタムリソースをクラスターに追加し、Operator が MetalLB をデプロイすると、controller および speaker MetalLB ソフトウェアコンポーネントは実行を開始します。
MetalLB は、関連するすべてのカスタムリソースを検証します。
35.1.3. MetalLB ソフトウェアコンポーネント
MetalLB Operator のインストール時に、metallb-operator-controller-manager デプロイメントは Pod を起動します。Pod は Operator の実装です。Pod は、関連するすべてのリソースへの変更を監視します。
Operator が MetalLB のインスタンスを起動すると、controller デプロイメントと speaker のデーモンセットが開始します。
MetalLB カスタムリソースでデプロイメント仕様を設定して、controller および speaker Pod がクラスターへのデプロイおよび実行方法を管理できます。これらの展開仕様の詳細については、その他のリソース セクションを参照してください。
controllerOperator はデプロイメントおよび単一の Pod を起動します。
LoadBalancerタイプのサービスを追加する場合、Kubernetes はcontrollerを使用してアドレスプールから IP アドレスを割り当てます。サービスに障害が発生した場合は、controllerPod のログに次のエントリーがあることを確認します。出力例
"event":"ipAllocated","ip":"172.22.0.201","msg":"IP address assigned by controller
speakerOperator は、
speakerPod 用に設定されたデーモンを起動します。デフォルトでは、Pod はクラスター内の各ノードで起動されます。Metal LB の起動時にMetalLBカスタムリソースでノードセレクターを指定して、Pod を特定のノードに制限できます。controllerがサービスに IP アドレスを割り当てても、サービスがまだ利用できない場合は、speakerPod のログを確認してください。スピーカーPod が使用できない場合は、oc describe pod -nコマンドを実行します。レイヤー 2 モードの場合には、
コントローラーがサービスに IP アドレスを割り当てた後に、speakerPod はアルゴリズムを使用して、どのノードの、どのspeakerPod がロードバランサーの IP アドレスをアナウンスするかを決定します。このアルゴリズムには、ノード名とロードバランサーの IP アドレスのハッシュが含まれます。詳細は、MetalLB と外部トラフィックポリシーを参照してください。speakerは、Address Resolution Protocol (ARP) を使用して IPv4 アドレスと Neighbor Discovery Protocol (NDP) を公開して、IPv6 アドレスにアナウンスします。
Border Gateway Protocol (BGP) モードの場合、コントローラーがサービスに IP アドレスを割り当てた後に、各speaker Pod はロードバランサーの IP アドレスを BGP ピアにアドバタイズします。どのノードが BGP ピアとの BGP セッションを開始するかを設定できます。
ロードバランサーの IP アドレスの要求は、IP アドレスを通知する speaker でノードにルーティングされます。ノードがパケットを受信した後に、サービスプロキシーはパケットをサービスのエンドポイントにルーティングします。エンドポイントは、最適なケースでは同じノードに配置することも、別のノードに配置することもできます。サービスプロキシーは、接続が確立されるたびにエンドポイントを選択します。
35.1.4. MetalLB と外部トラフィックポリシー
レイヤー 2 モードでは、クラスター内のノードはサービス IP アドレスのすべてのトラフィックを受信します。BGP モードでは、ホストネットワーク上のルーターが、新しいクライアントが接続を確立できるように、クラスター内のノードの 1 つに接続を開きます。クラスターがノードに入った後にトラフィックを処理する方法は、外部トラフィックポリシーの影響を受けます。
clusterこれは
spec.externalTrafficPolicyのデフォルト値です。clusterトラフィックポリシーでは、ノードがトラフィックを受信した後に、サービスプロキシーはトラフィックをサービスのすべての Pod に分散します。このポリシーは、Pod 全体に均一なトラフィック分散を提供しますが、クライアントの IP アドレスを覆い隠し、トラフィックがクライアントではなくノードから発信されているように Pod 内のアプリケーションに表示される可能性があります。locallocalトラフィックポリシーでは、ノードがトラフィックを受信した後に、サービスプロキシーはトラフィックを同じノードの Pod にのみ送信します。たとえば、ノード A のspeakerPod が外部サービス IP をアナウンスすると、すべてのトラフィックがノード A に送信されます。トラフィックがノード A に入った後、サービスプロキシーはノード A にあるサービスの Pod にのみトラフィックを送信します。追加のノードにあるサービスの Pod は、ノード A からトラフィックを受信しません。追加のノードにあるサービスの Pod は、フェイルオーバーが必要な場合にレプリカとして機能します。このポリシーは、クライアントの IP アドレスには影響しません。アプリケーション Pod は、受信接続からクライアント IP アドレスを判別できます。
次の情報は、BGP モードで外部トラフィックポリシーを設定する場合に重要です。
MetalLB は、適格なすべてのノードからロードバランサーの IP アドレスをアドバタイズしますが、サービスのロードバランシングを行うノードの数は、等コストマルチパス (ECMP) ルートを確立するルーターの容量によって制限される場合があります。IP をアドバタイズするノードの数がルーターの ECMP グループ制限よりも多い場合、ルーターは IP をアドバタイズするノードよりも少ないノードを使用します。
たとえば、外部トラフィックポリシーが local に設定され、ルーターの ECMP グループ制限が 16 に設定され、LoadBalancer サービスを実装する Pod が 30 ノードにデプロイされている場合、14 ノードにデプロイされた Pod はトラフィックを受信しません。この状況では、サービスの外部トラフィックポリシーを cluster に設定することを推奨します。
35.1.5. レイヤー 2 モードの MetalLB の概念
レイヤー 2 モードでは、1 つのノードの speaker Pod が、サービスの外部 IP アドレスをホストネットワークに公開します。ネットワークの観点からは、ノードで複数の IP アドレスがネットワークインターフェイスに割り当てられるように見えます。
レイヤ 2 モードでは、MetalLB は ARP と NDP に依存します。これらのプロトコルは、特定のサブネット内でローカルアドレス解決を実装します。このコンテキストでは、MetalLB が機能するために、クライアントは、サービスをアナウンスするノードと同じサブネット上に存在する MetalLB によって割り当てられた VIP に到達できなければなりません。
speaker Pod は、IPv4 サービスの ARP 要求と IPv6 の NDP 要求に応答します。
レイヤー 2 モードでは、サービス IP アドレスのすべてのトラフィックは 1 つのノードを介してルーティングされます。トラフィックがノードに入ると、CNI ネットワークプロバイダーのサービスプロキシーはトラフィックをサービスのすべての Pod に配信します。
サービスのすべてのトラフィックがレイヤー 2 モードで単一のノードを通過するので、より厳密な意味で、MetalLB はレイヤー 2 のロードバランサーを実装しません。むしろ、MetalLB はレイヤー 2 のフェイルオーバーメカニズムを実装しているため、speaker Pod が利用できなくなったときに、別のノードの speaker Pod がサービス IP アドレスをアナウンスできます。
ノードが使用できなくなると、フェイルオーバーが自動的に行われます。他のノードの speaker Pod は、ノードが使用できないことを検出し、障害が発生したノードから、新しい speaker Pod とノードがサービス IP アドレスの所有権を取得します。
前述のグラフは、MetalLB に関する以下の概念を示しています。
-
アプリケーションは、
172.130.0.0/16サブネットのクラスター IP を持つサービスで利用できます。その IP アドレスはクラスター内からアクセスできます。サービスには、MetalLB がサービス192.168.100.200に割り当てられている外部 IP アドレスもあります。 - ノード 1 および 3 には、アプリケーションの Pod があります。
-
speakerデーモンセットは、各ノードで Pod を実行します。MetalLB Operator はこれらの Pod を起動します。 -
各
speakerPod はホストネットワーク化された Pod です。Pod の IP アドレスは、ホストネットワーク上のノードの IP アドレスと同じです。 -
ノード 1 の
speakerPod は ARP を使用して、サービスの外部 IP アドレスに192.168.100.200を認識します。外部 IP アドレスをアナウンスするspeakerPod は、サービスのエンドポイントと同じノード上にあり、エンドポイントはReady状態である必要があります。 クライアントトラフィックはホストネットワークにルーティングされ、
192.168.100.200の IP アドレスに接続します。トラフィックがノードに入ると、サービスプロキシーは、サービスに設定した外部トラフィックポリシーに従って、同じノードまたは別のノードのアプリケーション Pod にトラフィックを送信します。-
サービスの外部トラフィックポリシーが
clusterに設定されている場合、speakerPod が実行されているノードから192.168.100.200ロードバランサーの IP アドレスをアドバタイズするノードが選択されます。そのノードのみがサービスのトラフィックを受信できます。 -
サービスの外部トラフィックポリシーが
localに設定されている場合、speakerPod が実行されているノードと少なくとも 1 つのサービスエンドポイントから192.168.100.200ロードバランサーの IP アドレスをアドバタイズするノードが選択されます。そのノードのみがサービスのトラフィックを受信できます。前の図では、ノード 1 または 3 のいずれかが192.168.100.200をアドバタイズします。
-
サービスの外部トラフィックポリシーが
-
ノード 1 が利用できない場合、外部 IP アドレスは別のノードにフェイルオーバーします。アプリケーション Pod およびサービスエンドポイントのインスタンスを持つ別のノードでは、
speakerPod は外部 IP アドレス192.168.100.200になり、新規ノードがクライアントトラフィックを受信します。図では、唯一の候補はノード 3 です。
35.1.6. BGP モードの MetalLB の概念
BGP モードでは、デフォルトで各 speaker Pod がサービスのロードバランサー IP アドレスを各 BGP ピアにアドバタイズします。オプションの BGP ピアのリストを追加すると、指定されたプールからの IP を指定されたピアセットにアドバタイズすることもできます。BGP ピアは通常、BGP プロトコルを使用するように設定されたネットワークルーターです。ルーターがロードバランサーの IP アドレスのトラフィックを受信すると、ルーターは IP アドレスをアドバタイズした speaker Pod が含まれるノードの 1 つを選択します。ルーターはトラフィックをそのノードに送信します。トラフィックがノードに入ると、CNI ネットワークプラグインのサービスプロキシーはトラフィックをサービスのすべての Pod に配信します。
クラスターノードと同じレイヤー 2 のネットワークセグメントに直接接続されたルーターは、BGP ピアとして設定できます。直接接続されたルーターが BGP ピアとして設定されていない場合は、ロードバランサーの IP アドレスのパケットが BGP ピアとspeakerPod を実行するクラスターノードの間でルーティングされるようにネットワークを設定する必要があります。
ルーターは、ロードバランサーの IP アドレスの新しいトラフィックを受信するたびに、ノードへの新しい接続を作成します。各ルーターのメーカーには、接続開始ノードを選択する実装固有のアルゴリズムがあります。ただし、アルゴリズムは通常、ネットワーク負荷のバランスをとるために、使用可能なノード間でトラフィックを分散するように設計されています。
ノードが使用できなくなった場合に、ルーターは、ロードバランサーの IP アドレスをアドバタイズするspeaker Pod が含まれる別のノードとの新しい接続を開始します。
図35.1 BGP モードの MetalLB トポロジーの図
前述のグラフは、MetalLB に関する以下の概念を示しています。
-
アプリケーションは、
172.130.0.0/16サブネットの IPv4 クラスター IP を持つサービスで利用できます。その IP アドレスはクラスター内からアクセスできます。サービスには、MetalLB がサービス203.0.113.200に割り当てられている外部 IP アドレスもあります。 - ノード 2 および 3 には、アプリケーションの Pod があります。
-
speakerデーモンセットは、各ノードで Pod を実行します。MetalLB Operator はこれらの Pod を起動します。MetalLB を設定して、speakerPod を実行するノードを指定できます。 -
各
speakerPod はホストネットワーク化された Pod です。Pod の IP アドレスは、ホストネットワーク上のノードの IP アドレスと同じです。 -
各
speakerPod は、すべての BGP ピアとの BGP セッションを開始し、ロードバランサーの IP アドレスまたは集約されたルートを BGP ピアにアドバタイズします。speakerPod は、Autonomous System 65010 の一部であることをアドバタイズします。この図ではルーター R1 を示しており、これは同じ Autonomous System 内の BGP ピアです。ただし、他の Autonomous System に属するピアとの BGP セッションを開始するように MetalLB を設定できます。 ノードに、ロードバランサーの IP アドレスをアドバタイズする
speakerPod がある場合にはすべて、サービスのトラフィックを受信できます。-
サービスの外部トラフィックポリシーが
clusterに設定されている場合、スピーカー Pod が実行されているすべてのノードが203.0.113.200ロードバランサーの IP アドレスをアドバタイズし、speakerPod を持つすべてのノードがサービスのトラフィックを受信できます。ホストの接頭辞は、外部トラフィックポリシーが cluster に設定されている場合にのみ、ルーターピアにアドバタイズされます。 -
サービスの外部トラフィックポリシーが
localに設定されている場合、speakerPod が実行されているノードとサービスが実行されている少なくとも 1 つのエンドポイントが、203.0.113.200ロードバランサーの IP アドレスをアドバタイズできます。これらのノードのみがサービスのトラフィックを受信できます。前の図では、ノード 2 と 3 は203.0.113.200をアドバタイズします。
-
サービスの外部トラフィックポリシーが
-
BGP ピアカスタムリソースの追加時にノードセレクターを指定して、特定の BGP ピアとの BGP セッションを開始する
speakerPod を制御するように MetalLB を設定できます。 - BGP を使用するように設定されている R1 などのルーターは、BGP ピアとして設定できます。
- クライアントトラフィックは、ホストネットワーク上のノードの 1 つにルーティングされます。トラフィックがノードに入ると、サービスプロキシーは、サービスに設定した外部トラフィックポリシーに従って、同じノードまたは別のノードのアプリケーション Pod にトラフィックを送信します。
- ノードが使用できなくなった場合に、ルーターは障害を検出し、別のノードとの新しい接続を開始します。BGP ピアに双方向フォワーディング検出 (BFD) プロファイルを使用するように MetalLB を設定できます。BFD は、リンク障害検出がより高速であるため、ルーターは BFD がない場合よりも早く新しい接続を開始できます。
35.1.7. 制限および制限
35.1.7.1. MetalLB のインフラストラクチャーについての考慮事項
MetalLB は、ネイティブのロードバランサー機能が含まれていないため、主にオンプレミスのベアメタルインストールに役立ちます。ベアメタルのインストールに加え、一部のインフラストラクチャーに OpenShift Container Platform をインストールする場合は、ネイティブのロードバランサー機能が含まれていない場合があります。たとえば、以下のインフラストラクチャーは MetalLB Operator を追加するのに役立ちます。
- ベアメタル
- VMware vSphere
- IBM Z および IBM® LinuxONE
- IBM Z and IBM® LinuxONE for Red Hat Enterprise Linux (RHEL) KVM
- IBM Power
MetalLB Operator および MetalLB は、OpenShift SDN および OVN-Kubernetes ネットワークプロバイダーでサポートされます。
35.1.7.2. レイヤー 2 モードの制限
35.1.7.2.1. 単一ノードのボトルネック
MetalLB は、1 つのノードを介してサービス内のすべてのトラフィックをルーティングします。この際、ノードはボトルネックとなり、パフォーマンスを制限する可能性があります。
レイヤー 2 モードは、サービスの Ingress 帯域幅を単一ノードの帯域幅に制限します。これは、ARP および NDP を使用してトラフィックを転送するための基本的な制限です。
35.1.7.2.2. フェイルオーバーのパフォーマンスの低下
ノード間のフェイルオーバーは、クライアントからの操作によって異なります。フェイルオーバーが発生すると、MetalLB は Gratuitous ARP パケットを送信して、サービス IP に関連付けられた MAC アドレスが変更されたことをクライアントに通知します。
ほとんどのクライアントオペレーティングシステムは、Gratuitous ARP パケットを正しく処理し、隣接キャッシュを迅速に更新します。クライアントがキャッシュを迅速に更新すると、フェイルオーバーは数秒以内に完了します。通常、クライアントは新しいノードに 10 秒以内にフェイルオーバーします。しかし、一部のクライアントオペレーティングシステムは Gratuitous ARP パケットをまったく処理しないか、キャッシュの更新を遅延させる古い実装があります。
Windows、macOS、Linux などの一般的なオペレーティングシステムの新しいバージョンは、レイヤー 2 フェイルオーバーを正しく実装します。フェイルオーバーが遅いという問題は、古くてあまり一般的ではないクライアントオペレーティングシステムを除いて、予期されていません。
古いクライアントで予定されているフェイルオーバーの影響を最小限にするには、リーダーシップをフラップした後に、古いノードを数分にわたって実行したままにします。古いノードは、キャッシュが更新されるまで、古いクライアントのトラフィックを転送することができます。
予定外のフェイルオーバー時に、古いクライアントがキャッシュエントリーを更新するまでサービス IP に到達できません。
35.1.7.2.3. 追加ネットワークと MetalLB は同じネットワークを使用できない
MetalLB とソース Pod 上に設定された追加のネットワークインターフェイスの両方に同じ VLAN を使用すると、接続エラーが発生する可能性があります。これは、MetalLB IP とソース Pod が同じノード上に存在する場合に発生します。
接続エラーを回避するには、ソース Pod が存在するサブネットとは異なるサブネットに MetalLB IP を配置します。この設定により、ソース Pod からのトラフィックがデフォルトゲートウェイを経由するようになります。その結果、トラフィックは OVN オーバーレイネットワークを使用して宛先に到達でき、接続が確実に意図したとおりに機能するようになります。
35.1.7.3. BGP モードの制限
35.1.7.3.1. ノードに障害が発生すると、アクティブなすべての接続が切断される可能性があります
MetalLB には、BGP ベースのロードバランシングに共通する制限があります。ノードに障害が発生した場合や speaker Pod が再起動した場合など、BGP セッションが中断されると、すべてのアクティブな接続がリセットされる可能性があります。エンドユーザーに、Connection reset by peer のメッセージが表示される可能性があります。
BGP セッションが中断された場合にどうなるかは、各ルーターの製造元の実装によります。ただし、speaker Pod の数を変更すると、BGP セッションの数に影響し、BGP ピアとのアクティブな接続が切断されることが予想されます。
サービスの中断の可能性を回避または低減するために、BGP ピアの追加時にノードセレクターを指定できます。BGP セッションを開始するノードの数を制限すると、BGP セッションのないノードでの障害が発生しても、サービスへの接続に影響はありません。
35.1.7.3.2. 単一の ASN とルーター ID のみのサポート
BGP ピアカスタムリソースを追加するときは、 spec.myASNフィールドを指定して、MetalLB が属する Autonomous System Number (ASN) を特定します。OpenShift Container Platform は、MetalLB を使用した BGP の実装を使用しますが、この実装は MetalLB が単一の ASN に所属する必要があります。BGP ピアを追加し、 spec.myASNに既存の BGP ピアカスタムリソースとは異なる値を指定しようとするとエラーが発生します。
同様に、BGP ピアカスタムリソースを追加する場合には、spec.router Dフィールドはオプションです。このフィールドに値を指定する場合は、追加する他の BGP ピアカスタムリソースすべてに、同じ値を指定する必要があります。
単一の ASN と単一のルーター ID のサポートに制限がある点が、コミュニティーがサポートする MetalLB の実装との違いです。
35.1.8. 関連情報
35.2. MetalLB Operator のインストール
クラスター管理者は、Operator がクラスター上の MetalLB インスタンスのライフサイクルを管理できるようにする MetallB Operator を追加できます。
MetalLB および IP フェイルオーバーは互換性がありません。クラスターの IP フェイルオーバーを設定している場合、Operator をインストールする前に IP フェイルオーバーを削除する 手順を実行します。
35.2.1. Web コンソールを使用した OperatorHub からの MetalLB Operator のインストール
クラスター管理者は、OpenShift Container Platform Web コンソールを使用して MetalLB Operator をインストールできます。
前提条件
-
cluster-admin権限を持つユーザーとしてログインしている。
手順
- OpenShift Container Platform Web コンソールで、Operators → OperatorHub ページに移動します。
キーワードを Filter by keyword ボックスに入力するか、目的の Operator までスクロールします。たとえば、
metallbと入力して MetalLB Operator を見つけます。また、インフラストラクチャー機能 でオプションをフィルターすることもできます。たとえば、非接続環境 (ネットワークが制限された環境ともしても知られる) で機能する Operator を表示するには、Disconnected を選択します。
- Install Operator ページで、デフォルトを受け入れて Install をクリックします。
検証
インストールが正常に行われたことを確認するには、以下を実行します。
- Operators → Installed Operators ページに移動します。
-
Operator が
openshift-operatorsの namespace 内に設置されていることと、その状態がSucceededとなっていることを確認してください。
Operator が正常にインストールされない場合は、Operator のステータスを確認し、ログを確認してください。
-
Operators → Installed Operators ページに移動し、
Status列でエラーまたは失敗の有無を確認します。 -
Workloads → Podsページにナビゲートし、問題を報告している
openshift-operatorsプロジェクトの Pod のログを確認します。
-
Operators → Installed Operators ページに移動し、
35.2.2. CLI を使用した OperatorHub からのインストール
OpenShift Container Platform Web コンソールを使用する代わりに、CLI を使用して OperatorHub から Operator をインストールできます。OpenShift CLI (oc) を使用して、MetalLB Operator をインストールできます。
CLI を使用する場合は、metallb-system namespace に Operator をインストールすることを推奨します。
前提条件
- ベアメタルハードウェアにインストールされたクラスター。
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
次のコマンドを入力して、MetalLB Operator の namespace を作成します。
$ cat << EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: metallb-system EOF
namespace に Operator グループのカスタムリソースを作成します。
$ cat << EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: metallb-operator namespace: metallb-system EOF
Operator グループが namespace にインストールされていることを確認します。
$ oc get operatorgroup -n metallb-system
出力例
NAME AGE metallb-operator 14m
SubscriptionCR を作成します。SubscriptionCR を定義し、YAML ファイルを保存します (例:metallb-sub.yaml)。apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: metallb-operator-sub namespace: metallb-system spec: channel: stable name: metallb-operator source: redhat-operators 1 sourceNamespace: openshift-marketplace- 1
redhat-operators値を指定する必要があります。
SubscriptionCR を作成するには、次のコマンドを実行します。$ oc create -f metallb-sub.yaml
オプション: BGP および BFD メトリックが Prometheus に表示されるようにするには、次のコマンドのように namespace にラベルを付けることができます。
$ oc label ns metallb-system "openshift.io/cluster-monitoring=true"
検証
検証手順は、MetallB Operator が metallb-system namespace にインストールされていることを前提としています。
インストール計画が namespace にあることを確認します。
$ oc get installplan -n metallb-system
出力例
NAME CSV APPROVAL APPROVED install-wzg94 metallb-operator.4.13.0-nnnnnnnnnnnn Automatic true
注記Operator のインストールには数秒かかる場合があります。
Operator がインストールされていることを確認するには、以下のコマンドを入力します。
$ oc get clusterserviceversion -n metallb-system \ -o custom-columns=Name:.metadata.name,Phase:.status.phase
出力例
Name Phase metallb-operator.4.13.0-nnnnnnnnnnnn Succeeded
35.2.3. クラスターでの MetalLB の起動
Operator のインストール後に、MetalLB カスタムリソースの単一のインスタンスを設定する必要があります。カスタムリソースの設定後、Operator はクラスターで MetalLB を起動します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。 - MetalLB Operator をインストールしている。
手順
この手順は、MetallB Operator が metallb-system namespace にインストールされていることを前提としています。Web コンソールを使用してインストールした場合は、namespace の代わりに openshift-operators を使用してください。
MetalLB カスタムリソースの単一のインスタンスを作成します。
$ cat << EOF | oc apply -f - apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-system EOF
検証
MetalLB コントローラーのデプロイメントと、BareLB スピーカーのデーモンセットが実行していることを確認します。
コントローラーのデプロイメントが稼働していることを検証します。
$ oc get deployment -n metallb-system controller
出力例
NAME READY UP-TO-DATE AVAILABLE AGE controller 1/1 1 1 11m
スピーカーに設定されているデーモンが実行されていることを検証します。
$ oc get daemonset -n metallb-system speaker
出力例
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE speaker 6 6 6 6 6 kubernetes.io/os=linux 18m
この出力例は、6 つの speaker Pod を示しています。クラスターの speaker Pod の数は出力例とは異なる場合があります。出力で各ノードの 1 つの Pod が表示されることを確認します。
35.2.4. MetalLB のデプロイメント仕様
MetalLB カスタムリソースを使用して MetalLB のインスタンスを起動すると、MetalLB カスタムリソースでデプロイメント仕様を設定して、controller または speaker Pod がクラスターにデプロイし、実行する方法を管理できます。これらのデプロイメント仕様を使用して、以下のタスクを管理します。
- MetalLB Pod デプロイメントのノードの選択
- Pod の優先順位および Pod のアフィニティーを使用してたケジューリングの管理
- MetalLB Pod の CPU 制限の割り当て
- MetalLB Pod のコンテナー RuntimeClass の割り当て
- MetalLB Pod のメタデータの割り当て
35.2.4.1. speaker Pod の特定のノードへの限定
デフォルトでは、MetalLB Operator を使用して MetalLB を開始すると、Operator はクラスター内の各ノードでspeakerPod のインスタンスを開始します。ロードバランサーの IP アドレスをアドバタイズできるのは、speaker Pod を備えたノードのみです。ノードセレクターを使用して MetalLBカスタムリソースを設定し、speakerPod を実行するノードを指定できます。
speaker Pod を特定のノードに制限する最も一般的な理由として、特定のネットワークにネットワークインターフェイスがあるノードのみがロードバランサーの IP アドレスをアドバタイズするようにすることが挙げられます。ロードバランサーの IP アドレスの宛先として、speaker Pod が実行されているノードのみがアドバタイズされます。
speaker Pod を特定のノードに制限し、サービスの外部トラフィックポリシーにローカル を指定する場合は、サービスのアプリケーション Pod が同じノードにデプロイされていることを確認する必要があります。
speaker Pod をワーカーノードに制限する設定例
apiVersion: metallb.io/v1beta1
kind: MetalLB
metadata:
name: metallb
namespace: metallb-system
spec:
nodeSelector: <.>
node-role.kubernetes.io/worker: ""
speakerTolerations: <.>
- key: "Example"
operator: "Exists"
effect: "NoExecute"
<.> 設定例では、スピーカー Pod をワーカーノードに割り当てるように指定していますが、ノードまたは任意の有効なノードセレクターに割り当てたラベルを指定できます。<.> この設定例では、この容認がアタッチされている Pod は、operator を使用して キー 値と effect 値に一致するテイントを容認します。
spec.nodeSelectorフィールドを使用してマニフェストを適用した後に、oc get daemonset -n metallb-systemspeaker コマンドを使用して Operator がデプロイした Pod の数を確認できます。同様に、oc get node -l node-role.kubernetes.io/worker =のようなコマンドを使用して、ラベルに一致するノードを表示できます。
オプションで、アフィニティールールを使用して、ノードがどの speaker Pod をスケジュールするか、スケジュールしないかを制御することができます。また、容認の一覧を適用してこれらの Pod を制限することもできます。アフィニティールール、テイント、および容認の詳細は、追加のリソースを参照してください。
35.2.4.2. MetalLB デプロイメントでのコンテナーランタイムクラスの設定
必要に応じて、MetalLB カスタムリソースを設定して、コンテナーランタイムクラスを controller Pod および speaker Pod に割り当てることができます。たとえば、Windows ワークロードでは、Windows ランタイムクラスを Pod に割り当てることができ、Pod のすべてのコンテナーに対してこのランタイムクラスが使用されるようになります。
前提条件
-
cluster-admin権限を持つユーザーとしてログインしている。 - MetalLB Operator がインストールされている。
手順
myRuntimeClass.yamlなどのRuntimeClassカスタムリソースを作成して、ランタイムクラスを定義します。apiVersion: node.k8s.io/v1 kind: RuntimeClass metadata: name: myclass handler: myconfiguration
RuntimeClassカスタムリソース設定を適用します。$ oc apply -f myRuntimeClass.yaml
MetalLBRuntime.yamlなどのMetalLBカスタムリソースを作成して、runtimeClassName値を指定します。apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-system spec: logLevel: debug controllerConfig: runtimeClassName: myclass annotations: 1 controller: demo speakerConfig: runtimeClassName: myclass annotations: 2 speaker: demoMetalLBカスタムリソース設定を適用します。$ oc apply -f MetalLBRuntime.yaml
検証
Pod のコンテナーランタイムを表示するには、以下のコマンドを実行します。
$ oc get pod -o custom-columns=NAME:metadata.name,STATUS:.status.phase,RUNTIME_CLASS:.spec.runtimeClassName
35.2.4.3. MetalLB デプロイメントでの Pod の優先順位および Pod アフィニティーの設定
オプションで、MetalLB カスタムリソースを設定して、Pod の優先順位と Pod のアフィニティールールを controller Pod および speaker Pod に割り当てることができます。Pod の優先順位は、ノード上の Pod の相対的な重要度を示し、この優先順位に基づいて Pod をスケジュールします。controller または speaker Pod に高い優先順位を設定して、ノード上の他の Pod よりも優先的にスケジューリングされるようにします。
Pod のアフィニティーは Pod 間の関係を管理します。Pod のアフィニティーを controller または speaker Pod に割り当て、スケジューラーが Pod 関係のコンテキストで Pod を配置するノードを制御します。たとえば、Pod アフィニティールールを使用して、複数の特定 Pod を同じノードまたは別のノードに配置するようにできます。これにより、ネットワーク通信が改善され、これらのコンポーネント間の遅延が縮小されます。
前提条件
-
cluster-admin権限を持つユーザーとしてログインしている。 - MetalLB Operator がインストールされている。
- クラスター上で MetalLB Operator を開始している。
手順
myPriorityClass.yamlなどのPriorityClassカスタムリソースを作成して、優先度レベルを設定します。この例では、high-priorityという名前のPriorityClassを、値1000000で定義します。この優先クラスが割り当てられた Pod は、スケジューリングにおいて、それより低い優先クラスの Pod より優先順位が高いとみなされます。apiVersion: scheduling.k8s.io/v1 kind: PriorityClass metadata: name: high-priority value: 1000000
PriorityClassカスタムリソース設定を適用します。$ oc apply -f myPriorityClass.yaml
MetalLBPodConfig.yamlなどのMetalLBカスタムリソースを作成して、priorityClassNameとpodAffinityの値を指定します。apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-system spec: logLevel: debug controllerConfig: priorityClassName: high-priority 1 affinity: podAffinity: 2 requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchLabels: app: metallb topologyKey: kubernetes.io/hostname speakerConfig: priorityClassName: high-priority affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchLabels: app: metallb topologyKey: kubernetes.io/hostname- 1
- MetalLB コントローラー Pod の優先クラスを指定します。この場合、
high-priorityに設定されます。 - 2
- Pod アフィニティールールを設定していることを指定します。これらのルールは、他の Pod またはノードに関連して Pod がどのようにスケジュールされるかを決定します。この設定は、
app: metallbラベルを持つ Pod を同じホスト名を共有するノードにスケジュールするようにスケジューラーに指示します。これは、MetalLB 関連の Pod を同じノード上に配置するのに役立ち、これらの Pod 間のネットワーク通信、遅延、リソース使用量を最適化できる可能性があります。
MetalLBカスタムリソース設定を適用します。$ oc apply -f MetalLBPodConfig.yaml
検証
metallb-systemnamespace の Pod に割り当てた優先クラスを表示するには、次のコマンドを実行します。$ oc get pods -n metallb-system -o custom-columns=NAME:.metadata.name,PRIORITY:.spec.priorityClassName
出力例
NAME PRIORITY controller-584f5c8cd8-5zbvg high-priority metallb-operator-controller-manager-9c8d9985-szkqg <none> metallb-operator-webhook-server-c895594d4-shjgx <none> speaker-dddf7 high-priority
スケジューラーが Pod アフィニティールールに従って Pod を配置したことを確認するには、次のコマンドを実行して Pod のノードのメタデータを表示します。
$ oc get pod -o=custom-columns=NODE:.spec.nodeName,NAME:.metadata.name -n metallb-system
35.2.4.4. MetalLB デプロイメントでの Pod CPU 制限の設定
オプションで、MetalLB カスタムリソースを設定することで、Pod の CPU 制限を controller Pod と speaker Pod に割り当てることができます。controller Pod または speaker Pod の CPU 制限を定義すると、ノード上のコンピュートリソースを管理するのに役立ちます。これにより、ノード上のすべての Pod に、ワークロードとクラスターのハウスキーピングを管理するために必要なコンピューティングリソースが確保されます。
前提条件
-
cluster-admin権限を持つユーザーとしてログインしている。 - MetalLB Operator がインストールされている。
手順
CPULimits.yamlなどのMetalLBカスタムリソースファイルを作成し、コントローラーおよびspeakerPod のcpu値を指定します。apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-system spec: logLevel: debug controllerConfig: resources: limits: cpu: "200m" speakerConfig: resources: limits: cpu: "300m"MetalLBカスタムリソース設定を適用します。$ oc apply -f CPULimits.yaml
検証
Pod のコンピューティングリソースを表示するには、次のコマンドを実行し、
<pod_name>をターゲット Pod に置き換えます。$ oc describe pod <pod_name>
35.2.5. 関連情報
35.2.6. 次のステップ
35.3. MetalLB のアップグレード
現在、MetalLB Operator のバージョン 4.10 以前のバージョンを実行している場合、4.10 以降のバージョンへの自動更新は機能しないことに注意してください。4.11 以降の任意のバージョンの MetalLB Operator から新しいバージョンへのアップグレードは成功します。たとえば、バージョン 4.12 からバージョン 4.13 へのアップグレードはスムーズに行われます。
4.10 以前からの MetalLB Operator のアップグレード手順の概要は次のとおりです。
-
インストールされている MetalLB Operator バージョン (4.10 など) を削除します。namespace と
metallbカスタムリソースが削除されていないことを確認してください。 - CLI を使用して、以前のバージョンの MetalLB Operator がインストールされていた namespace に MetalLB Operator 4.13 をインストールします。
この手順は、標準の簡単な方法に従う MetalLB Operator の自動 z ストリーム更新には適用されません。
MetalLB Operator を 4.10 以前からアップグレードする詳細な手順については、次のガイダンスを参照してください。クラスター管理者は、OpenShift CLI (oc) または Web コンソールを使用して MetalLB Operator を削除し、アップグレードプロセスを開始します。
35.3.1. Web コンソールを使用してクラスターから MetalLB Operator を削除
クラスター管理者は Web コンソールを使用して、選択した namespace からインストールされた Operator を削除できます。
前提条件
-
cluster-admin権限を持つアカウントを使用して OpenShift Container Platform クラスター Web コンソールにアクセスできる。
手順
- Operators → Installed Operators ページに移動します。
- MetalLB Operator を検索します。次に、それをクリックします。
Operator Details ページの右側で、Actions ドロップダウンメニューから Uninstall Operator を選択します。
Uninstall Operator? ダイアログボックスが表示されます。
Uninstall を選択し、Operator、Operator デプロイメント、および Pod を削除します。このアクションの後には、Operator は実行を停止し、更新を受信しなくなります。
注記このアクションは、カスタムリソース定義 (CRD) およびカスタムリソース (CR) など、Operator が管理するリソースは削除されません。Web コンソールおよび継続して実行されるクラスター外のリソースによって有効にされるダッシュボードおよびナビゲーションアイテムには、手動でのクリーンアップが必要になる場合があります。Operator のアンインストール後にこれらを削除するには、Operator CRD を手動で削除する必要があります。
35.3.2. CLI を使用してクラスターから MetalLB Operator を削除
クラスター管理者は CLI を使用して、選択した namespace からインストールされた Operator を削除できます。
前提条件
-
cluster-admin権限を持つアカウントを使用して OpenShift Container Platform クラスターにアクセスできる。 -
ocコマンドがワークステーションにインストールされていること。
手順
currentCSVフィールドでサブスクライブされた MetalLB Operator の現在のバージョンを確認します。$ oc get subscription metallb-operator -n metallb-system -o yaml | grep currentCSV
出力例
currentCSV: metallb-operator.4.10.0-202207051316
サブスクリプションを削除します。
$ oc delete subscription metallb-operator -n metallb-system
出力例
subscription.operators.coreos.com "metallb-operator" deleted
直前の手順で
currentCSV値を使用し、ターゲット namespace の Operator の CSV を削除します。$ oc delete clusterserviceversion metallb-operator.4.10.0-202207051316 -n metallb-system
出力例
clusterserviceversion.operators.coreos.com "metallb-operator.4.10.0-202207051316" deleted
35.3.3. MetalLB Operator Operator グループの編集
4.10 以前の MetalLB Operator バージョンから 4.11 以降にアップグレードする場合は、Operator グループのカスタムリソース (CR) から spec.targetNamespaces を削除します。MetalLB Operator の削除に Web コンソールや CLI を使用したかにかかわらず、仕様を削除する必要があります。
MetalLB Operator バージョン 4.11 以降は AllNamespaces インストールモードのみをサポートしますが、4.10 以前のバージョンは OwnNamespace モードまたは SingleNamespace モードをサポートします。
前提条件
-
cluster-admin権限を使用して OpenShift Container Platform クラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
次のコマンドを実行して、
metallb-systemnamespace 内の Operator グループをリスト表示します。$ oc get operatorgroup -n metallb-system
出力例
NAME AGE metallb-system-7jc66 85m
次のコマンドを実行して、
metallb-systemnamespace に関連付けられた Operator グループ CR にspec.targetNamespacesが存在することを確認します。$ oc get operatorgroup metallb-system-7jc66 -n metallb-system -o yaml
出力例
apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: annotations: olm.providedAPIs: "" creationTimestamp: "2023-10-25T09:42:49Z" generateName: metallb-system- generation: 1 name: metallb-system-7jc66 namespace: metallb-system resourceVersion: "25027" uid: f5f644a0-eef8-4e31-a306-e2bbcfaffab3 spec: targetNamespaces: - metallb-system upgradeStrategy: Default status: lastUpdated: "2023-10-25T09:42:49Z" namespaces: - metallb-system次のコマンドを実行して、Operator グループを編集し、
specセクション配下のtargetNamespacesとmetallb-systemを削除します。$ oc edit n metallb-system
出力例
operatorgroup.operators.coreos.com/metallb-system-7jc66 edited
次のコマンドを実行して、
metallb-systemnamespace に関連付けられた Operator グループのカスタムリソースからspec.targetNamespacesが削除されていることを確認します。$ oc get operatorgroup metallb-system-7jc66 -n metallb-system -o yaml
出力例
apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: annotations: olm.providedAPIs: "" creationTimestamp: "2023-10-25T09:42:49Z" generateName: metallb-system- generation: 2 name: metallb-system-7jc66 namespace: metallb-system resourceVersion: "61658" uid: f5f644a0-eef8-4e31-a306-e2bbcfaffab3 spec: upgradeStrategy: Default status: lastUpdated: "2023-10-25T14:31:30Z" namespaces: - ""
35.3.4. MetalLB Operator のアップグレード
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスします。
手順
metallb-systemnamespace がまだ存在することを確認します。$ oc get namespaces | grep metallb-system
出力例
metallb-system Active 31m
metallbカスタムリソースがまだ存在することを確認します。$ oc get metallb -n metallb-system
出力例
NAME AGE metallb 33m
CLI を使用した OperatorHub からのインストールに記載されたガイダンスに従い、MetalLB Operator の最新の 4.13 バージョンをインストールします。
注記MetalLB Operator の最新の 4.13 バージョンをインストールする場合、以前にインストールしたのと同じ namespace に Operator をインストールする必要があります。
Operator のアップグレードされたバージョンが 4.13 バージョンになったことを確認します。
$ oc get csv -n metallb-system
出力例
NAME DISPLAY VERSION REPLACES PHASE metallb-operator.4.13.0-202207051316 MetalLB Operator 4.13.0-202207051316 Succeeded
35.3.5. 関連情報
35.4. MetalLB アドレスプールの設定
クラスター管理者は、アドレスプールを追加、変更、および削除できます。MetalLB Operator は、アドレスプールカスタムリソースを使用して、MetalLB がサービスに割り当てることのできる IP アドレスを設定します。例で使用されている namespace は、namespace が metallb-system であることを前提としています。
35.4.1. IPAddressPool カスタムリソースについて
OpenShift Container Platform 4.10 の MetalLB を使用したロードバランシングに記載されているアドレスプールカスタムリソース定義 (CRD) および API は、4.13 でも引き続き使用できます。ただし、AddressPool CRD を使用する場合、レイヤ 2 プロトコルまたは BGP プロトコルを使用した IPAddressPool からの IP アドレスのアドバタイズに関連する拡張機能はサポートされません。
次の表では、IPAddressPool カスタムリソースのフィールドについて説明します。
表35.1 MetalLB IPAddressPool プールのカスタムリソース
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
アドレスプールの名前を指定します。サービスを追加する場合は、 |
|
|
| アドレスプールの namespace を指定します。MetalLB Operator が使用するものと同じ namespace を指定します。 |
|
|
|
オプション: |
|
|
| MetalLB Operator がサービスに割り当てる IP アドレスのリストを指定します。1 つのプールで複数の範囲を指定できます。それらはすべて同じ設定を共有します。CIDR 表記で各範囲を指定するか、開始および終了の IP アドレスをハイフンで区切って指定します。 |
|
|
|
オプション: MetalLB がこのプールから IP アドレスを自動的に割り当てるかどうかを指定します。 |
|
|
|
オプション: これを有効にすると、.0 および .255 で終わる IP アドレスがプールから割り当てられなくなります。デフォルト値は |
spec.serviceAllocation 仕様を設定することにより、IPAddressPool からサービスおよび namespace に IP アドレスを割り当てることができます。
表35.2 MetalLB IPAddressPool カスタムリソース spec.serviceAllocation サブフィールド
| フィールド | 型 | 説明 |
|---|---|---|
|
|
| オプション: 複数の IP アドレスプールがサービスまたは namespace に一致する場合の IP アドレスプール間の優先度を定義します。数字が小さいほど優先度が高いことを示します。 |
|
|
| オプション: IP アドレスプール内の IP アドレスに割り当てることができる namespace のリストを指定します。 |
|
|
| オプション: リスト形式のラベルセレクターを使用して、IP アドレスプールから IP アドレスに割り当てることができる namespace ラベルを指定します。 |
|
|
| オプション: リスト形式のラベルセレクターを使用して、アドレスプールから IP アドレスに割り当てることができるサービスラベルを指定します。 |
35.4.2. アドレスプールの設定
クラスター管理者は、クラスターにアドレスプールを追加して、MetaLLB がロードバランサーサービスに割り当てることのできる IP アドレスを制御できます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
以下の例のような内容で、
ipaddresspool.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb-system name: doc-example labels: 1 zone: east spec: addresses: - 203.0.113.1-203.0.113.10 - 203.0.113.65-203.0.113.75- 1
IPAddressPoolに割り当てられたこのラベルは、BGPAdvertisementCRD のipAddressPoolSelectorsによって参照され、IPAddressPoolをアドバタイズメントに関連付けることができます。
IP アドレスプールの設定を適用します。
$ oc apply -f ipaddresspool.yaml
検証
アドレスプールを表示します。
$ oc describe -n metallb-system IPAddressPool doc-example
出力例
Name: doc-example Namespace: metallb-system Labels: zone=east Annotations: <none> API Version: metallb.io/v1beta1 Kind: IPAddressPool Metadata: ... Spec: Addresses: 203.0.113.1-203.0.113.10 203.0.113.65-203.0.113.75 Auto Assign: true Events: <none>
doc-example などのアドレスプール名と IP アドレス範囲が出力に表示されることを確認します。
35.4.3. アドレスプールの設定例
35.4.3.1. 例: IPv4 および CIDR 範囲
CIDR 表記で IP アドレスの範囲を指定できます。CIDR 表記と、ハイフンを使用する表記を組み合わせて下層と上限を分けることができます。
apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: name: doc-example-cidr namespace: metallb-system spec: addresses: - 192.168.100.0/24 - 192.168.200.0/24 - 192.168.255.1-192.168.255.5
35.4.3.2. 例: IP アドレスの予約
MetalLB がプールから IP アドレスを自動的に割り当てないように autoAssign フィールドを false に設定できます。サービスを追加する場合は、プールから特定の IP アドレスを要求するか、そのプールから任意の IP アドレスを要求するためにアノテーションでプール名を指定できます。
apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: name: doc-example-reserved namespace: metallb-system spec: addresses: - 10.0.100.0/28 autoAssign: false
35.4.3.3. 例: IPv4 および IPv6 アドレス
IPv4 および IPv6 を使用するアドレスプールを追加できます。複数の IPv4 の例と同様に、addresses 一覧で複数の範囲を指定できます。
サービスに、単一の IPv4 アドレス、単一の IPv6 アドレス、またはその両方を割り当てるかどうかは、サービスの追加方法によって決まります。spec.ip Familiesフィールドとspec.ip Family Policyフィールドでは、IP アドレスをサービスに割り当てる方法を制御します。
apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: name: doc-example-combined namespace: metallb-system spec: addresses: - 10.0.100.0/28 - 2002:2:2::1-2002:2:2::100
35.4.3.4. 例: IP アドレスプールをサービスまたは namespace に割り当てる
IPAddressPool から指定したサービスと namespace に IP アドレスを割り当てることができます。
サービスまたは namespace を複数の IP アドレスプールに割り当てる場合、MetalLB は優先度の高い IP アドレスプールから使用可能な IP アドレスを使用します。割り当てられた優先度の高い IP アドレスプールから使用可能な IP アドレスがない場合、MetalLB は、優先度の低い、または優先度のない IP アドレスプールから使用可能な IP アドレスを使用します。
namespaceSelectors と serviceSelectors の仕様には、matchLabels ラベルセレクター、matchExpressions ラベルセレクター、またはその両方を使用できます。この例は、仕様ごとに 1 つのラベルセレクターを示しています。
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: doc-example-service-allocation
namespace: metallb-system
spec:
addresses:
- 192.168.20.0/24
serviceAllocation:
priority: 50 1
namespaces: 2
- namespace-a
- namespace-b
namespaceSelectors: 3
- matchLabels:
zone: east
serviceSelectors: 4
- matchExpressions:
- key: security
operator: In
values:
- S135.4.4. 関連情報
35.4.5. 次のステップ
- BGP モードについては、 MetalLBBGP ピアの設定を参照してください。
- MetalLB を使用するためのサービスの設定
35.5. IP アドレスプールのアドバタイズメントについて
IP アドレスがレイヤー 2 プロトコル、BGP プロトコル、またはその両方でアドバタイズされるように MetalLB を設定できます。レイヤー 2 では、MetalLB ではフォールトトレラントな外部 IP アドレスを使用できます。BGP を使用すると、MetalLB で外部 IP アドレスに対するフォールトトレランス機能および負荷分散が提供されます。
MetalLB は、同じ IP アドレスのセットに対して L2 と BGP を使用したアドバタイズをサポートします。
MetalLB は、ネットワーク上のノードのサブセットに対して、特定の BGP ピアにアドレスプールを効果的に割り当てる柔軟性を提供します。これにより、たとえばノードの分離やネットワークのセグメンテーションを容易にするなど、より複雑な設定が可能になります。
35.5.1. BGPAdvertisement カスタムリソースについて
bgp Advertisements オブジェクトのフィールドは、次の表に定義されています。
表35.3 BGPAdvertisements の設定
| フィールド | 型 | 説明 |
|---|---|---|
|
|
| BGP アドバタイズメントの名前を指定します。 |
|
|
| BGP アドバタイズメントの namespace を指定します。MetalLB Operator が使用するものと同じ namespace を指定します。 |
|
|
|
オプション: 32 ビット CIDR マスクに含めるビット数を指定します。マスクが複数のサービス IP アドレスのルートに適用され、speaker は集約されたルートをアドバタイズし、speaker が BGP ピアにアドバタイズするルートを集約します。たとえば、集約の長さが |
|
|
|
オプション: 128 ビット CIDR マスクに含めるビット数を指定します。たとえば、集約の長さが |
|
|
| オプション: 1 つ以上の BGP コミュニティーを指定します。各コミュニティーは、16 ビット値 2 つをコロン文字で区切って指定します。一般的なコミュニティーは、16 ビット値として指定する必要があります。
|
|
|
| オプション: このアドバタイズメントのローカル設定を指定します。この BGP 属性は、Autonomous System 内の BGP セッションに適用されます。 |
|
|
|
オプション: 名前で選択された、このアドバタイズメントでアドバタイズする |
|
|
|
オプション: このアドバタイズメントでアドバタイズされる |
|
|
|
オプション: |
|
|
| オプション: ピアは、選択したプールの IP をアドバタイズする BGP ピアを制限します。空の場合、ロードバランサー IP は設定されているすべての BGP ピアにアナウンスされます。 |
35.5.2. BGP アドバタイズメントと基本的なユースケースを使用する MetalLB の設定
MetalLB を次のとおり設定し、ピア BGP ルーターが、MetalLB がサービスに割り当てるロードバランサー IP アドレスごとに、203.0.113.200/32 ルート 1 つ、fc00:f853:ccd:e799::1/128 ルート 1 つを受信するようにします。local Prefおよびcommunitiesフィールドが指定されていないため、ルートはlocal Prefをゼロに設定して BGP コミュニティーなしでアドバタイズされます。
35.5.2.1. 例: BGP を使用する基本的なアドレスプール設定のアドバタイズメント
IPAddressPool が BGP プロトコルでアドバタイズされるように、MetalLB を次のように設定します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
IP アドレスプールを作成します。
以下の例のような内容で、
ipaddresspool.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb-system name: doc-example-bgp-basic spec: addresses: - 203.0.113.200/30 - fc00:f853:ccd:e799::/124IP アドレスプールの設定を適用します。
$ oc apply -f ipaddresspool.yaml
BGP アドバタイズメントを作成します。
以下の例のような内容で、
bgpadvertisement.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta1 kind: BGPAdvertisement metadata: name: bgpadvertisement-basic namespace: metallb-system spec: ipAddressPools: - doc-example-bgp-basic
設定を適用します。
$ oc apply -f bgpadvertisement.yaml
35.5.3. BGP アドバタイズメントと高度なユースケースを使用する MetalLB の設定
MetalLB を次のように設定し、MetalLB が 203.0.113.200 と 203.0.113.203、fc00:f853:ccd:e799::0 と fc00:f853:ccd:e799::f の範囲の IP アドレスを割り当てるようにします。
MetalLB が 203.0.113.200の IP アドレスをサービスに割り当てる例について見ていき、これら 2 つの BGP アドバタイズメントを説明します。この IP アドレスを例にとると、speaker は 2 つのルートを BGP ピアにアドバタイズします。
-
localPrefが100に、コミュニティーがNO_ADVERTISEコミュニティーの数値に設定されている203.0.113.200/32。この仕様は、ピアルーターにこのルートを使用できることを指定していますが、このルートに関する情報を BGP ピアに伝播しないようにします。 -
MetalLB で割り当てられたロードバランサーの IP アドレスを 1 つのルートに集約する
203.0.113.200/30。MetalLB は、コミュニティー属性が8000:800に設定された BGP ピアに集約ルートをアドバタイズします。BGP ピアは、203.0.113.200/30ルートを他の BGP ピアに伝播します。トラフィックが speaker のあるノードにルーティングされる場合には、203.0.113.200/32ルートを使用して、トラフィックがクラスターに転送され、サービスに関連付けられている Pod に転送されます。
さらにサービスを追加し、MetalLB でプールからより多くのロードバランサー IP アドレスを割り当てると、ピアルーターはサービスごとにローカルルート203.0.113.20x/32 を 1 つと、 203.0.113.200/30 集約ルートを受け取ります。追加する各サービスは/30ルートを生成しますが、MetalLB は、ピアルーターと通信する前に、ルートの重複を排除して 1 つの BGP アドバタイズにします。
35.5.3.1. 例: BGP を使用する高度なアドレスプール設定のアドバタイズメント
IPAddressPool が BGP プロトコルでアドバタイズされるように、MetalLB を次のように設定します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
IP アドレスプールを作成します。
以下の例のような内容で、
ipaddresspool.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb-system name: doc-example-bgp-adv labels: zone: east spec: addresses: - 203.0.113.200/30 - fc00:f853:ccd:e799::/124 autoAssign: falseIP アドレスプールの設定を適用します。
$ oc apply -f ipaddresspool.yaml
BGP アドバタイズメントを作成します。
以下の例のような内容で、
bgpadvertisement1.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta1 kind: BGPAdvertisement metadata: name: bgpadvertisement-adv-1 namespace: metallb-system spec: ipAddressPools: - doc-example-bgp-adv communities: - 65535:65282 aggregationLength: 32 localPref: 100設定を適用します。
$ oc apply -f bgpadvertisement1.yaml
以下の例のような内容で、
bgpadvertisement2.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta1 kind: BGPAdvertisement metadata: name: bgpadvertisement-adv-2 namespace: metallb-system spec: ipAddressPools: - doc-example-bgp-adv communities: - 8000:800 aggregationLength: 30 aggregationLengthV6: 124設定を適用します。
$ oc apply -f bgpadvertisement2.yaml
35.5.4. ノードのサブセットからの IP アドレスプールのアドバタイズ
特定のノードセットのみから IP アドレスプールから IP アドレスをアドバタイズするには、BGPAdvertisement カスタムリソースで .spec.nodeSelector 仕様を使用します。この仕様は、IP アドレスのプールをクラスター内の一連のノードに関連付けます。これは、クラスター内の異なるサブネット上にノードがあり、特定のサブネット (パブリックに面したサブネットのみなど) のアドレスプールから IP アドレスをアドバタイズしたい場合に役立ちます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
カスタムリソースを使用して IP アドレスプールを作成します。
apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb-system name: pool1 spec: addresses: - 4.4.4.100-4.4.4.200 - 2001:100:4::200-2001:100:4::400BGPAdvertisement カスタムリソースで
.spec.nodeSelector値を定義することにより、pool1からの IP アドレスがアドバタイズするクラスター内のノードを制御します。apiVersion: metallb.io/v1beta1 kind: BGPAdvertisement metadata: name: example spec: ipAddressPools: - pool1 nodeSelector: - matchLabels: kubernetes.io/hostname: NodeA - matchLabels: kubernetes.io/hostname: NodeB
この例では、pool1 の IP アドレスは NodeA と NodeB からの み アドバタイズします。
35.5.5. L2Advertisement カスタムリソースについて
l2Advertisements オブジェクトのフィールドは、次の表に定義されています。
表35.4 L2 アドバタイズメント設定
| フィールド | 型 | 説明 |
|---|---|---|
|
|
| L2 アドバタイズメントの名前を指定します。 |
|
|
| L2 アドバタイズメントの namespace を指定します。MetalLB Operator が使用するものと同じ namespace を指定します。 |
|
|
|
オプション: 名前で選択された、このアドバタイズメントでアドバタイズする |
|
|
|
オプション: このアドバタイズメントでアドバタイズされる |
|
|
|
オプション: 重要 ネクストホップとしてアナウンスするノードの制限は、テクノロジープレビュー機能としてのみ提供されます。テクノロジープレビュー機能は、Red Hat 製品サポートのサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではない場合があります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。テクノロジープレビュー機能は、最新の製品機能をいち早く提供して、開発段階で機能のテストを行いフィードバックを提供していただくことを目的としています。 Red Hat のテクノロジープレビュー機能のサポート範囲に関する詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。 |
|
|
|
オプション: ロードバランサー IP をアナウンスするために使用される |
35.5.6. L2 アドバタイズメントを使用した MetalLB の設定
IPAddressPool が L2 プロトコルでアドバタイズされるように、MetalLB を次のように設定します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
IP アドレスプールを作成します。
以下の例のような内容で、
ipaddresspool.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb-system name: doc-example-l2 spec: addresses: - 4.4.4.0/24 autoAssign: falseIP アドレスプールの設定を適用します。
$ oc apply -f ipaddresspool.yaml
L2 アドバタイズメントを作成します。
以下の例のような内容で、
l2advertisement.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: l2advertisement namespace: metallb-system spec: ipAddressPools: - doc-example-l2
設定を適用します。
$ oc apply -f l2advertisement.yaml
35.5.7. L2 アドバタイズメントとラベルを使用した MetalLB の設定
BGPAdvertisement および L2Advertisement カスタムリソース定義の ipAddressPoolSelectors フィールドは、名前自体ではなく、IPAddressPool に割り当てられたラベルに基づいて IPAddressPool をアドバタイズメントに関連付けるために使用されます。
この例は、ipAddressPoolSelectors フィールドを設定することにより、IPAddressPool が L2 プロトコルでアドバタイズされるように MetalLB を設定する方法を示しています。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
IP アドレスプールを作成します。
以下の例のような内容で、
ipaddresspool.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb-system name: doc-example-l2-label labels: zone: east spec: addresses: - 172.31.249.87/32IP アドレスプールの設定を適用します。
$ oc apply -f ipaddresspool.yaml
ipAddressPoolSelectorsを使用して IP をアドバタイズする L2 アドバタイズメントを作成します。以下の例のような内容で、
l2advertisement.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: l2advertisement-label namespace: metallb-system spec: ipAddressPoolSelectors: - matchExpressions: - key: zone operator: In values: - east設定を適用します。
$ oc apply -f l2advertisement.yaml
35.5.8. 選択したインターフェイスの L2 アドバタイズを使用した MetalLB の設定
デフォルトでは、サービスに割り当てられた IP アドレスプールの IP アドレスが、すべてのネットワークインターフェイスからアドバタイズされます。L2Advertisement カスタムリソース定義の interfaces フィールドは、IP アドレスプールをアドバタイズするネットワークインターフェイスを制限するために使用されます。
この例では、すべてのノードの interfaces フィールドにリストされているネットワークインターフェイスからのみ IP アドレスプールがアドバタイズされるように、MetalLB を設定する方法を示します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
IP アドレスプールを作成します。
ipaddresspool.yamlなどのファイルを作成し、次の例のように設定の詳細を入力します。apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb-system name: doc-example-l2 spec: addresses: - 4.4.4.0/24 autoAssign: false次の例のように、IP アドレスプールの設定を適用します。
$ oc apply -f ipaddresspool.yaml
interfacesセレクターを使用して IP をアドバタイズする L2 アドバタイズメントを作成します。l2advertisement.yamlなどの YAML ファイルを作成し、次の例のように設定の詳細を入力します。apiVersion: metallb.io/v1beta1 kind: L2Advertisement metadata: name: l2advertisement namespace: metallb-system spec: ipAddressPools: - doc-example-l2 interfaces: - interfaceA - interfaceB
次の例のように、広告の設定を適用します。
$ oc apply -f l2advertisement.yaml
インターフェイスセレクターは、MetalLB が L2 を使用して特定の IP をアナウンスするノードを選択する方法には影響しません。ノードが選択されたインターフェイスを持たない場合、選択されたノードはサービスをアナウンスしません。
35.5.9. 関連情報
35.6. MetalLB BGP ピアの設定
クラスター管理者は、ボーダーゲートウェイプロトコル (BGP) ピアを追加、変更、および削除できます。MetalLB Operator は、BGP ピアカスタムリソースを使用して、MetalLB speaker Pod が BGP セッションを開始するために接続するピアを識別します。ピアは、Metall B がサービスに割り当てるロードバランサー IP アドレスのルートアドバタイズメントを受信します。
35.6.1. BGP ピアカスタムリソースについて
次の表で、BGP ピアカスタムリソースのフィールドについて説明します。
表35.5 MetalLB BGP ピアカスタムリソース
| フィールド | 型 | 説明 |
|---|---|---|
|
|
| BGP ピアカスタムリソースの名前を指定します。 |
|
|
| BGP ピアカスタムリソースの namespace を指定します。 |
|
|
|
BGP セッションのローカルエンドの Autonomous System 番号を指定します。追加するすべての BGP ピアカスタムリソースに同じ値を指定します。範囲は |
|
|
|
BGP セッションのリモートエンドの Autonomous System 番号を指定します。範囲は |
|
|
| BGP セッションを確立するために接続するピアの IP アドレスを指定します。 |
|
|
| オプション: BGP セッションの確立時に使用する IP アドレスを指定します。値は IPv4 アドレスである必要があります。 |
|
|
|
オプション: BGP セッションを確立するために接続するピアのネットワークポートを指定します。範囲は |
|
|
|
オプション: BGP ピアに提案するホールドタイムの期間を指定します。最小値は 3 秒 ( |
|
|
|
オプション: キープアライブメッセージを BGP ピアに送信する間の最大間隔を指定します。このフィールドを指定する場合は、 |
|
|
| オプション: BGP ピアにアドバタイズするルーター ID を指定します。このフィールドを指定する場合は、追加するすべての BGP ピアカスタムリソースに同じ値を指定する必要があります。 |
|
|
| オプション: TCP MD5 認証が済んだ BGP セッションを実施するルーターのピアに送信する MD5 パスワードを指定します。 |
|
|
|
オプション: BGP ピアの認証シークレットの名前を指定します。シークレットは |
|
|
| オプション: BFD プロファイルの名前を指定します。 |
|
|
| オプション: 一致式と一致ラベルを使用してセレクターを指定し、BGP ピアに接続できるノードを制御します。 |
|
|
|
オプション: BGP ピアがネットワークホップ数回分を離れるように指定します。BGP ピアが同じネットワークに直接接続されていない場合には、このフィールドが |
passwordSecret フィールドは、password フィールドと相互に排他的であり、使用するパスワードを含むシークレットへの参照が含まれています。両方のフィールドを設定すると、解析が失敗します。
35.6.2. BGP ピアの設定
クラスター管理者は、BGP ピアカスタムリソースを追加して、ネットワークルーターとルーティング情報を交換し、サービスの IP アドレスをアドバタイズできます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。 - BGP アドバタイズメントを使用して MetalLB を設定します。
手順
以下の例のような内容で、
bgppeer.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta2 kind: BGPPeer metadata: namespace: metallb-system name: doc-example-peer spec: peerAddress: 10.0.0.1 peerASN: 64501 myASN: 64500 routerID: 10.10.10.10
BGP ピアの設定を適用します。
$ oc apply -f bgppeer.yaml
35.6.3. 指定されたアドレスプールに対して特定の BGP ピアセットを設定
これは、以下を実行するための手順です。
-
アドレスプールのセット (
pool1およびpool2) を設定します。 -
BGP ピアセット (
peer1およびpeer2) を設定します。 -
pool1をpeer1に、pool2をpeer2に割り当てるように BGP アドバタイズメントを設定します。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
アドレスプール
pool1を作成します。以下の例のような内容で、
ipaddresspool1.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb-system name: pool1 spec: addresses: - 4.4.4.100-4.4.4.200 - 2001:100:4::200-2001:100:4::400IP アドレスプール
pool1の設定を適用します。$ oc apply -f ipaddresspool1.yaml
アドレスプール
pool2を作成します。以下の例のような内容で、
ipaddresspool2.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb-system name: pool2 spec: addresses: - 5.5.5.100-5.5.5.200 - 2001:100:5::200-2001:100:5::400IP アドレスプール
pool2の設定を適用します。$ oc apply -f ipaddresspool2.yaml
BGP
peer1を作成します。以下の例のような内容で、
bgppeer1.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta2 kind: BGPPeer metadata: namespace: metallb-system name: peer1 spec: peerAddress: 10.0.0.1 peerASN: 64501 myASN: 64500 routerID: 10.10.10.10
BGP ピアの設定を適用します。
$ oc apply -f bgppeer1.yaml
BGP
peer2を作成します。以下の例のような内容で、
bgppeer2.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta2 kind: BGPPeer metadata: namespace: metallb-system name: peer2 spec: peerAddress: 10.0.0.2 peerASN: 64501 myASN: 64500 routerID: 10.10.10.10
BGP peer2 の設定を適用します。
$ oc apply -f bgppeer2.yaml
BGP advertisement 1 を作成します。
以下の例のような内容で、
bgpadvertisement1.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta1 kind: BGPAdvertisement metadata: name: bgpadvertisement-1 namespace: metallb-system spec: ipAddressPools: - pool1 peers: - peer1 communities: - 65535:65282 aggregationLength: 32 aggregationLengthV6: 128 localPref: 100設定を適用します。
$ oc apply -f bgpadvertisement1.yaml
BGP advertisement 2 を作成します。
以下の例のような内容で、
bgpadvertisement2.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta1 kind: BGPAdvertisement metadata: name: bgpadvertisement-2 namespace: metallb-system spec: ipAddressPools: - pool2 peers: - peer2 communities: - 65535:65282 aggregationLength: 32 aggregationLengthV6: 128 localPref: 100設定を適用します。
$ oc apply -f bgpadvertisement2.yaml
35.6.4. BGP ピア設定の例
35.6.4.1. 例: BGP ピアに接続するノードの制限
ノードセレクターフィールドを指定して、BGP ピアに接続できるノードを制御できます。
apiVersion: metallb.io/v1beta2
kind: BGPPeer
metadata:
name: doc-example-nodesel
namespace: metallb-system
spec:
peerAddress: 10.0.20.1
peerASN: 64501
myASN: 64500
nodeSelectors:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values: [compute-1.example.com, compute-2.example.com]35.6.4.2. 例: BGP ピアの BFD プロファイル指定
BGP ピアに関連付ける BFD プロファイルを指定できます。BFD は、BGP のみの場合よりも、ピア間の通信障害をより迅速に検出して、BGP を補完します。
apiVersion: metallb.io/v1beta2 kind: BGPPeer metadata: name: doc-example-peer-bfd namespace: metallb-system spec: peerAddress: 10.0.20.1 peerASN: 64501 myASN: 64500 holdTime: "10s" bfdProfile: doc-example-bfd-profile-full
双方向転送検出 (BFD) プロファイルを削除し、ボーダーゲートウェイプロトコル (BGP) ピアリソースに追加された bfdProfile を削除しても、BFD は無効になりません。代わりに、BGP ピアはデフォルトの BFD プロファイルの使用を開始します。BGP ピアリソースから BFD をディセーブルにするには、BGP ピア設定を削除し、BFD プロファイルなしで再作成します。詳細は、BZ#2050824 を参照してください。
35.6.4.3. 例: デュアルスタックネットワーク用の BGP ピア指定
デュアルスタックネットワーキングをサポートするには、IPv4 用に BGP ピアカスタムリソース 1 つと IPv6 用に BGP ピアカスタムリソースを 1 つ追加します。
apiVersion: metallb.io/v1beta2 kind: BGPPeer metadata: name: doc-example-dual-stack-ipv4 namespace: metallb-system spec: peerAddress: 10.0.20.1 peerASN: 64500 myASN: 64500 --- apiVersion: metallb.io/v1beta2 kind: BGPPeer metadata: name: doc-example-dual-stack-ipv6 namespace: metallb-system spec: peerAddress: 2620:52:0:88::104 peerASN: 64500 myASN: 64500
35.6.5. 次のステップ
35.7. コミュニティーエイリアスの設定
クラスター管理者は、コミュニティーエイリアスを設定して、さまざまなアドバタイズメントで使用できます。
35.7.1. コミュニティーカスタムリソースについて
community カスタムリソースは、コミュニティーのエイリアスのコレクションです。ユーザーは、BGPAdvertisement を使用して ipAddressPools をアドバタイズするときに使用される名前付きエイリアスを定義できます。次の表で、community カスタムリソースのフィールドについて説明します。
community CRD は BGPAdvertisement にのみ適用されます。
表35.6 MetalLB コミュニティーカスタムリソース
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
BGPAdvertisements で使用できる BGP コミュニティーエイリアスのリストを指定します。コミュニティーエイリアスは、名前 (エイリアス) と値 (番号:番号) のペアで構成されます。 |
表35.7 CommunityAlias
| フィールド | 型 | 説明 |
|---|---|---|
|
|
|
|
|
|
|
指定された名前に対応する BGP |
35.7.2. BGP アドバタイズメントとコミュニティーエイリアスを使用した MetalLB の設定
MetalLB を次のように設定し、IPAddressPool が BGP プロトコルでアドバタイズされ、コミュニティーエイリアスが NO_ADVERTISE コミュニティーの数値に設定されるようにします。
次の例では、ピア BGP ルーター doc-example-peer-community は、MetalLB がサービスに割り当てるロードバランサー IP アドレスごとに 1 つの 203.0.113.200/32 ルートと 1 つの fc00:f853:ccd:e799::1/128 ルートを受信します。コミュニティーエイリアスは、NO_ADVERTISE コミュニティーで設定されます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
IP アドレスプールを作成します。
以下の例のような内容で、
ipaddresspool.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta1 kind: IPAddressPool metadata: namespace: metallb-system name: doc-example-bgp-community spec: addresses: - 203.0.113.200/30 - fc00:f853:ccd:e799::/124IP アドレスプールの設定を適用します。
$ oc apply -f ipaddresspool.yaml
community1という名前のコミュニティーエイリアスを作成します。apiVersion: metallb.io/v1beta1 kind: Community metadata: name: community1 namespace: metallb-system spec: communities: - name: NO_ADVERTISE value: '65535:65282'doc-example-bgp-peerという名前の BGP ピアを作成します。以下の例のような内容で、
bgppeer.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta2 kind: BGPPeer metadata: namespace: metallb-system name: doc-example-bgp-peer spec: peerAddress: 10.0.0.1 peerASN: 64501 myASN: 64500 routerID: 10.10.10.10
BGP ピアの設定を適用します。
$ oc apply -f bgppeer.yaml
コミュニティーエイリアスを使用して BGP アドバタイズメントを作成します。
以下の例のような内容で、
bgpadvertisement.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta1 kind: BGPAdvertisement metadata: name: bgp-community-sample namespace: metallb-system spec: aggregationLength: 32 aggregationLengthV6: 128 communities: - NO_ADVERTISE 1 ipAddressPools: - doc-example-bgp-community peers: - doc-example-peer- 1
- ここでは、コミュニティーのカスタムリソース (CR) 名ではなく、
CommunityAlias.nameを指定します。
設定を適用します。
$ oc apply -f bgpadvertisement.yaml
35.8. MetalLB BFD プロファイルの設定
クラスター管理者は、双方向フォワーディング検出 (BFD) プロファイルを追加、変更、および削除できます。MetalLB Operator は、BFD プロファイルのカスタムリソースを使用して、BFD を使用する BGP セッションで、BGP だけの時よりも障害検出のパスを素早く見つけ出すセッションを特定します。
35.8.1. BFD プロファイルカスタムリソースについて
次の表で、BFD プロファイルのカスタムリソースのフィールドについて説明します。
表35.8 BFD プロファイルカスタムリソース
| フィールド | 型 | 説明 |
|---|---|---|
|
|
| BFD プロファイルカスタムリソースの名前を指定します。 |
|
|
| BFD プロファイルカスタムリソースの namespace を指定します。 |
|
|
| パケット損失を決定するための検出乗数を指定します。リモート送信間隔にこの値を乗算して、接続損失検出タイマーを決定します。
たとえば、ローカルシステムの検出乗数が
範囲は |
|
|
|
エコー送信モードを指定します。分散 BFD を使用していないと、エコー送信モードは、ピアが FRR でもある場合にのみ機能します。デフォルト値は
エコー送信モードが有効になっている場合は、制御パケットの送信間隔を増やして、帯域幅の使用量を減らすことを検討してください。たとえば、送信間隔を |
|
|
|
このシステムがエコーパケットの送受信に使用する最小送信間隔 (ジッターの軽減) を指定します。範囲は |
|
|
| 着信制御パケットに最小限必要な TTL を指定します。このフィールドは、マルチホップセッションにのみ適用されます。 最小 TTL を設定する目的は、パケット検証要件をより厳しくし、他のセッションからの制御パケットの受信を回避することです。
デフォルト値は |
|
|
| セッションをアクティブまたはパッシブとしてマークするかどうかを指定します。パッシブセッションは接続の開始を試行しません。代わりに、パッシブセッションは、応答の開始前にピアからの制御パケットを待機します。 セッションをパッシブとしてマークすることは、スターネットワークの中央ノードとして機能するルーターがあり、システムが送信する必要のない制御パケットの送信を避ける場合に役立ちます。
デフォルト値は |
|
|
|
このシステムが制御パケットを受信できる最小間隔を指定します。範囲は |
|
|
|
このシステムが制御パケットの送信に使用する最小送信間隔 (ジッターの軽減) を指定します。範囲は |
35.8.2. BFD プロファイルの設定
クラスター管理者は、BFD プロファイルを追加し、そのプロファイルを使用するように BGP ピアを設定できます。BFD は、BGP のみよりも、パスの障害検出が高速になります。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 -
cluster-admin権限を持つユーザーとしてログインしている。
手順
次の例のようなコンテンツを含む
bfdprofile.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta1 kind: BFDProfile metadata: name: doc-example-bfd-profile-full namespace: metallb-system spec: receiveInterval: 300 transmitInterval: 300 detectMultiplier: 3 echoMode: false passiveMode: true minimumTtl: 254
BFD プロファイルの設定を適用します。
$ oc apply -f bfdprofile.yaml
35.8.3. 次のステップ
- BFD プロファイルを使用するようにBGP ピアを設定します。
35.9. MetalLB を使用するためのサービスの設定
クラスター管理者は、タイプ LoadBalancer のサービスを追加するときに、MetalLB が IP アドレスを割り当てる方法を制御できます。
35.9.1. 特定の IP アドレスの要求
他のロードバランサーの実装と同様に、MetalLB はサービス仕様の spec.loadBalancerIP フィールドを受け入れます。
要求された IP アドレスが任意のアドレスプールの範囲内にある場合、MetalLB は要求された IP アドレスを割り当てます。要求された IP アドレスが範囲外の場合、MetalLB は警告を報告します。
特定の IP アドレスのサービス YAML の例
apiVersion: v1
kind: Service
metadata:
name: <service_name>
annotations:
metallb.universe.tf/address-pool: <address_pool_name>
spec:
selector:
<label_key>: <label_value>
ports:
- port: 8080
targetPort: 8080
protocol: TCP
type: LoadBalancer
loadBalancerIP: <ip_address>
MetalLB が要求された IP アドレスを割り当てることができない場合、サービスの EXTERNAL-IP が <pending> を報告し、oc describe service <service_name> の実行には、以下の例のようなイベントが含まれます。
MetalLB が要求された IP アドレスを割り当てることができない場合のイベントの例
... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning AllocationFailed 3m16s metallb-controller Failed to allocate IP for "default/invalid-request": "4.3.2.1" is not allowed in config
35.9.2. 特定のプールからの IP アドレスの要求
特定の範囲から IP アドレスを割り当てても、特定の IP アドレスを気にしない場合は、metallb.universe.tf/address-pool アノテーションを使用して、指定したアドレスプールから IP アドレスを要求できます。
特定プールからの IP アドレスのサービス YAML の例
apiVersion: v1
kind: Service
metadata:
name: <service_name>
annotations:
metallb.universe.tf/address-pool: <address_pool_name>
spec:
selector:
<label_key>: <label_value>
ports:
- port: 8080
targetPort: 8080
protocol: TCP
type: LoadBalancer
<address_pool_name> に指定するアドレスプールが存在しない場合、MetalLB は、自動割り当てを許可する任意のプールから IP アドレスを割り当てようとします。
35.9.3. 任意の IP アドレスを許可します。
デフォルトでは、アドレスプールは自動割り当てを許可するように設定されます。MetalLB は、これらのアドレスプールから IP アドレスを割り当てます。
自動割り当て用に設定されたプールから IP アドレスを受け入れるには、特別なアノテーションや設定は必要ありません。
任意の IP アドレスを受け入れるサービス YAML の例
apiVersion: v1
kind: Service
metadata:
name: <service_name>
spec:
selector:
<label_key>: <label_value>
ports:
- port: 8080
targetPort: 8080
protocol: TCP
type: LoadBalancer
35.9.5. MetalLB を使用したサービスの設定
アドレスプールから外部 IP アドレスを使用するように、負荷分散サービスを設定することができます。
前提条件
-
OpenShift CLI (
oc) がインストールされている。 - MetalLB Operator をインストールして、MetalLB を起動します。
- 1 つ以上のアドレスプールを設定します。
- トラフィックをクライアントからクラスターのホストネットワークにルーティングするようにネットワークを設定します。
手順
<service_name>.yamlファイルを作成します。このファイルで、spec.typeフィールドがLoadBalancerに設定されていることを確認します。MetalLB がサービスに割り当てる外部 IP アドレスを要求する方法については、例を参照してください。
サービスを作成します。
$ oc apply -f <service_name>.yaml
出力例
service/<service_name> created
検証
サービスを記述します。
$ oc describe service <service_name>
出力例
Name: <service_name> Namespace: default Labels: <none> Annotations: metallb.universe.tf/address-pool: doc-example <.> Selector: app=service_name Type: LoadBalancer <.> IP Family Policy: SingleStack IP Families: IPv4 IP: 10.105.237.254 IPs: 10.105.237.254 LoadBalancer Ingress: 192.168.100.5 <.> Port: <unset> 80/TCP TargetPort: 8080/TCP NodePort: <unset> 30550/TCP Endpoints: 10.244.0.50:8080 Session Affinity: None External Traffic Policy: Cluster Events: <.> Type Reason Age From Message ---- ------ ---- ---- ------- Normal nodeAssigned 32m (x2 over 32m) metallb-speaker announcing from node "<node_name>"
<.> 特定のプールから IP アドレスを要求すると、アノテーションが表示されます。<.> サービスタイプは
LoadBalancerを示す必要があります。<.> サービスが正しく割り当てられている場合、ロードバランサーの Ingress フィールドは外部 IP アドレスを示します。<.> events フィールドは、外部 IP アドレスを通知するために割り当てられたノード名を示します。エラーが発生した場合、events フィールドはエラーの理由を示します。
35.10. MetalLB のロギング、トラブルシューティング、サポート
MetalLB 設定のトラブルシューティングが必要な場合は、次のセクションで一般的に使用されるコマンドを参照してください。
35.10.1. MetalLB ログレベルの設定
MetalLB は、デフォルト設定の info を使用してコンテナーで FRRouting (FRR) を使用し、大量のログを生成します。この例に示すように logLevel を設定することにより、生成されるログの詳細度を制御できます。
次のように logLevel を debug に設定することで、MetalLB についてより深い洞察を得ることができます。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
以下の例のような内容で、
setdebugloglevel.yamlなどのファイルを作成します。apiVersion: metallb.io/v1beta1 kind: MetalLB metadata: name: metallb namespace: metallb-system spec: logLevel: debug nodeSelector: node-role.kubernetes.io/worker: ""設定を適用します。
$ oc replace -f setdebugloglevel.yaml
注記metallbCR はすでに作成されており、ここではログレベルを変更していることを理解たうえで、ocr eplaceを使用します。speakerPod の名前を表示します。$ oc get -n metallb-system pods -l component=speaker
出力例
NAME READY STATUS RESTARTS AGE speaker-2m9pm 4/4 Running 0 9m19s speaker-7m4qw 3/4 Running 0 19s speaker-szlmx 4/4 Running 0 9m19s
注記スピーカー Pod とコントローラー Pod が再作成され、更新されたログレベルが確実に適用されます。MetalLB のすべてのコンポーネントのログレベルが変更されます。
speakerログを表示します。$ oc logs -n metallb-system speaker-7m4qw -c speaker
出力例
{"branch":"main","caller":"main.go:92","commit":"3d052535","goversion":"gc / go1.17.1 / amd64","level":"info","msg":"MetalLB speaker starting (commit 3d052535, branch main)","ts":"2022-05-17T09:55:05Z","version":""} {"caller":"announcer.go:110","event":"createARPResponder","interface":"ens4","level":"info","msg":"created ARP responder for interface","ts":"2022-05-17T09:55:05Z"} {"caller":"announcer.go:119","event":"createNDPResponder","interface":"ens4","level":"info","msg":"created NDP responder for interface","ts":"2022-05-17T09:55:05Z"} {"caller":"announcer.go:110","event":"createARPResponder","interface":"tun0","level":"info","msg":"created ARP responder for interface","ts":"2022-05-17T09:55:05Z"} {"caller":"announcer.go:119","event":"createNDPResponder","interface":"tun0","level":"info","msg":"created NDP responder for interface","ts":"2022-05-17T09:55:05Z"} I0517 09:55:06.515686 95 request.go:665] Waited for 1.026500832s due to client-side throttling, not priority and fairness, request: GET:https://172.30.0.1:443/apis/operators.coreos.com/v1alpha1?timeout=32s {"Starting Manager":"(MISSING)","caller":"k8s.go:389","level":"info","ts":"2022-05-17T09:55:08Z"} {"caller":"speakerlist.go:310","level":"info","msg":"node event - forcing sync","node addr":"10.0.128.4","node event":"NodeJoin","node name":"ci-ln-qb8t3mb-72292-7s7rh-worker-a-vvznj","ts":"2022-05-17T09:55:08Z"} {"caller":"service_controller.go:113","controller":"ServiceReconciler","enqueueing":"openshift-kube-controller-manager-operator/metrics","epslice":"{\"metadata\":{\"name\":\"metrics-xtsxr\",\"generateName\":\"metrics-\",\"namespace\":\"openshift-kube-controller-manager-operator\",\"uid\":\"ac6766d7-8504-492c-9d1e-4ae8897990ad\",\"resourceVersion\":\"9041\",\"generation\":4,\"creationTimestamp\":\"2022-05-17T07:16:53Z\",\"labels\":{\"app\":\"kube-controller-manager-operator\",\"endpointslice.kubernetes.io/managed-by\":\"endpointslice-controller.k8s.io\",\"kubernetes.io/service-name\":\"metrics\"},\"annotations\":{\"endpoints.kubernetes.io/last-change-trigger-time\":\"2022-05-17T07:21:34Z\"},\"ownerReferences\":[{\"apiVersion\":\"v1\",\"kind\":\"Service\",\"name\":\"metrics\",\"uid\":\"0518eed3-6152-42be-b566-0bd00a60faf8\",\"controller\":true,\"blockOwnerDeletion\":true}],\"managedFields\":[{\"manager\":\"kube-controller-manager\",\"operation\":\"Update\",\"apiVersion\":\"discovery.k8s.io/v1\",\"time\":\"2022-05-17T07:20:02Z\",\"fieldsType\":\"FieldsV1\",\"fieldsV1\":{\"f:addressType\":{},\"f:endpoints\":{},\"f:metadata\":{\"f:annotations\":{\".\":{},\"f:endpoints.kubernetes.io/last-change-trigger-time\":{}},\"f:generateName\":{},\"f:labels\":{\".\":{},\"f:app\":{},\"f:endpointslice.kubernetes.io/managed-by\":{},\"f:kubernetes.io/service-name\":{}},\"f:ownerReferences\":{\".\":{},\"k:{\\\"uid\\\":\\\"0518eed3-6152-42be-b566-0bd00a60faf8\\\"}\":{}}},\"f:ports\":{}}}]},\"addressType\":\"IPv4\",\"endpoints\":[{\"addresses\":[\"10.129.0.7\"],\"conditions\":{\"ready\":true,\"serving\":true,\"terminating\":false},\"targetRef\":{\"kind\":\"Pod\",\"namespace\":\"openshift-kube-controller-manager-operator\",\"name\":\"kube-controller-manager-operator-6b98b89ddd-8d4nf\",\"uid\":\"dd5139b8-e41c-4946-a31b-1a629314e844\",\"resourceVersion\":\"9038\"},\"nodeName\":\"ci-ln-qb8t3mb-72292-7s7rh-master-0\",\"zone\":\"us-central1-a\"}],\"ports\":[{\"name\":\"https\",\"protocol\":\"TCP\",\"port\":8443}]}","level":"debug","ts":"2022-05-17T09:55:08Z"}FRR ログを表示します。
$ oc logs -n metallb-system speaker-7m4qw -c frr
出力例
Started watchfrr 2022/05/17 09:55:05 ZEBRA: client 16 says hello and bids fair to announce only bgp routes vrf=0 2022/05/17 09:55:05 ZEBRA: client 31 says hello and bids fair to announce only vnc routes vrf=0 2022/05/17 09:55:05 ZEBRA: client 38 says hello and bids fair to announce only static routes vrf=0 2022/05/17 09:55:05 ZEBRA: client 43 says hello and bids fair to announce only bfd routes vrf=0 2022/05/17 09:57:25.089 BGP: Creating Default VRF, AS 64500 2022/05/17 09:57:25.090 BGP: dup addr detect enable max_moves 5 time 180 freeze disable freeze_time 0 2022/05/17 09:57:25.090 BGP: bgp_get: Registering BGP instance (null) to zebra 2022/05/17 09:57:25.090 BGP: Registering VRF 0 2022/05/17 09:57:25.091 BGP: Rx Router Id update VRF 0 Id 10.131.0.1/32 2022/05/17 09:57:25.091 BGP: RID change : vrf VRF default(0), RTR ID 10.131.0.1 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF br0 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF ens4 2022/05/17 09:57:25.091 BGP: Rx Intf address add VRF 0 IF ens4 addr 10.0.128.4/32 2022/05/17 09:57:25.091 BGP: Rx Intf address add VRF 0 IF ens4 addr fe80::c9d:84da:4d86:5618/64 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF lo 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF ovs-system 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF tun0 2022/05/17 09:57:25.091 BGP: Rx Intf address add VRF 0 IF tun0 addr 10.131.0.1/23 2022/05/17 09:57:25.091 BGP: Rx Intf address add VRF 0 IF tun0 addr fe80::40f1:d1ff:feb6:5322/64 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF veth2da49fed 2022/05/17 09:57:25.091 BGP: Rx Intf address add VRF 0 IF veth2da49fed addr fe80::24bd:d1ff:fec1:d88/64 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF veth2fa08c8c 2022/05/17 09:57:25.091 BGP: Rx Intf address add VRF 0 IF veth2fa08c8c addr fe80::6870:ff:fe96:efc8/64 2022/05/17 09:57:25.091 BGP: Rx Intf add VRF 0 IF veth41e356b7 2022/05/17 09:57:25.091 BGP: Rx Intf address add VRF 0 IF veth41e356b7 addr fe80::48ff:37ff:fede:eb4b/64 2022/05/17 09:57:25.092 BGP: Rx Intf add VRF 0 IF veth1295c6e2 2022/05/17 09:57:25.092 BGP: Rx Intf address add VRF 0 IF veth1295c6e2 addr fe80::b827:a2ff:feed:637/64 2022/05/17 09:57:25.092 BGP: Rx Intf add VRF 0 IF veth9733c6dc 2022/05/17 09:57:25.092 BGP: Rx Intf address add VRF 0 IF veth9733c6dc addr fe80::3cf4:15ff:fe11:e541/64 2022/05/17 09:57:25.092 BGP: Rx Intf add VRF 0 IF veth336680ea 2022/05/17 09:57:25.092 BGP: Rx Intf address add VRF 0 IF veth336680ea addr fe80::94b1:8bff:fe7e:488c/64 2022/05/17 09:57:25.092 BGP: Rx Intf add VRF 0 IF vetha0a907b7 2022/05/17 09:57:25.092 BGP: Rx Intf address add VRF 0 IF vetha0a907b7 addr fe80::3855:a6ff:fe73:46c3/64 2022/05/17 09:57:25.092 BGP: Rx Intf add VRF 0 IF vethf35a4398 2022/05/17 09:57:25.092 BGP: Rx Intf address add VRF 0 IF vethf35a4398 addr fe80::40ef:2fff:fe57:4c4d/64 2022/05/17 09:57:25.092 BGP: Rx Intf add VRF 0 IF vethf831b7f4 2022/05/17 09:57:25.092 BGP: Rx Intf address add VRF 0 IF vethf831b7f4 addr fe80::f0d9:89ff:fe7c:1d32/64 2022/05/17 09:57:25.092 BGP: Rx Intf add VRF 0 IF vxlan_sys_4789 2022/05/17 09:57:25.092 BGP: Rx Intf address add VRF 0 IF vxlan_sys_4789 addr fe80::80c1:82ff:fe4b:f078/64 2022/05/17 09:57:26.094 BGP: 10.0.0.1 [FSM] Timer (start timer expire). 2022/05/17 09:57:26.094 BGP: 10.0.0.1 [FSM] BGP_Start (Idle->Connect), fd -1 2022/05/17 09:57:26.094 BGP: Allocated bnc 10.0.0.1/32(0)(VRF default) peer 0x7f807f7631a0 2022/05/17 09:57:26.094 BGP: sendmsg_zebra_rnh: sending cmd ZEBRA_NEXTHOP_REGISTER for 10.0.0.1/32 (vrf VRF default) 2022/05/17 09:57:26.094 BGP: 10.0.0.1 [FSM] Waiting for NHT 2022/05/17 09:57:26.094 BGP: bgp_fsm_change_status : vrf default(0), Status: Connect established_peers 0 2022/05/17 09:57:26.094 BGP: 10.0.0.1 went from Idle to Connect 2022/05/17 09:57:26.094 BGP: 10.0.0.1 [FSM] TCP_connection_open_failed (Connect->Active), fd -1 2022/05/17 09:57:26.094 BGP: bgp_fsm_change_status : vrf default(0), Status: Active established_peers 0 2022/05/17 09:57:26.094 BGP: 10.0.0.1 went from Connect to Active 2022/05/17 09:57:26.094 ZEBRA: rnh_register msg from client bgp: hdr->length=8, type=nexthop vrf=0 2022/05/17 09:57:26.094 ZEBRA: 0: Add RNH 10.0.0.1/32 type Nexthop 2022/05/17 09:57:26.094 ZEBRA: 0:10.0.0.1/32: Evaluate RNH, type Nexthop (force) 2022/05/17 09:57:26.094 ZEBRA: 0:10.0.0.1/32: NH has become unresolved 2022/05/17 09:57:26.094 ZEBRA: 0: Client bgp registers for RNH 10.0.0.1/32 type Nexthop 2022/05/17 09:57:26.094 BGP: VRF default(0): Rcvd NH update 10.0.0.1/32(0) - metric 0/0 #nhops 0/0 flags 0x6 2022/05/17 09:57:26.094 BGP: NH update for 10.0.0.1/32(0)(VRF default) - flags 0x6 chgflags 0x0 - evaluate paths 2022/05/17 09:57:26.094 BGP: evaluate_paths: Updating peer (10.0.0.1(VRF default)) status with NHT 2022/05/17 09:57:30.081 ZEBRA: Event driven route-map update triggered 2022/05/17 09:57:30.081 ZEBRA: Event handler for route-map: 10.0.0.1-out 2022/05/17 09:57:30.081 ZEBRA: Event handler for route-map: 10.0.0.1-in 2022/05/17 09:57:31.104 ZEBRA: netlink_parse_info: netlink-listen (NS 0) type RTM_NEWNEIGH(28), len=76, seq=0, pid=0 2022/05/17 09:57:31.104 ZEBRA: Neighbor Entry received is not on a VLAN or a BRIDGE, ignoring 2022/05/17 09:57:31.105 ZEBRA: netlink_parse_info: netlink-listen (NS 0) type RTM_NEWNEIGH(28), len=76, seq=0, pid=0 2022/05/17 09:57:31.105 ZEBRA: Neighbor Entry received is not on a VLAN or a BRIDGE, ignoring
35.10.1.1. FRRouting (FRR) ログレベル
次の表で、FRR ログレベルについて説明します。
表35.9 ログレベル
| ログレベル | 説明 |
|---|---|
|
| すべてのログレベルのすべてのログ情報を提供します。 |
|
|
診断に役立つ情報。詳細なトラブルシューティング情報を提供するには、 |
|
| 常にログに記録する必要がある情報を提供しますが、通常の状況ではユーザーの介入は必要ありません。これはデフォルトのログレベルです。 |
|
|
一貫性のない |
|
|
|
|
| すべてのロギングをオフにします。 |
35.10.2. BGP の問題のトラブルシューティング
Red Hat がサポートする BGP 実装は、speakerPod のコンテナーで FRRouting (FRR) を使用します。クラスター管理者は、BGP 設定の問題をトラブルシューティングする場合に、FRR コンテナーでコマンドを実行する必要があります。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
speakerPod の名前を表示します。$ oc get -n metallb-system pods -l component=speaker
出力例
NAME READY STATUS RESTARTS AGE speaker-66bth 4/4 Running 0 56m speaker-gvfnf 4/4 Running 0 56m ...
FRR の実行設定を表示します。
$ oc exec -n metallb-system speaker-66bth -c frr -- vtysh -c "show running-config"
出力例
Building configuration... Current configuration: ! frr version 7.5.1_git frr defaults traditional hostname some-hostname log file /etc/frr/frr.log informational log timestamp precision 3 service integrated-vtysh-config ! router bgp 64500 1 bgp router-id 10.0.1.2 no bgp ebgp-requires-policy no bgp default ipv4-unicast no bgp network import-check neighbor 10.0.2.3 remote-as 64500 2 neighbor 10.0.2.3 bfd profile doc-example-bfd-profile-full 3 neighbor 10.0.2.3 timers 5 15 neighbor 10.0.2.4 remote-as 64500 4 neighbor 10.0.2.4 bfd profile doc-example-bfd-profile-full 5 neighbor 10.0.2.4 timers 5 15 ! address-family ipv4 unicast network 203.0.113.200/30 6 neighbor 10.0.2.3 activate neighbor 10.0.2.3 route-map 10.0.2.3-in in neighbor 10.0.2.4 activate neighbor 10.0.2.4 route-map 10.0.2.4-in in exit-address-family ! address-family ipv6 unicast network fc00:f853:ccd:e799::/124 7 neighbor 10.0.2.3 activate neighbor 10.0.2.3 route-map 10.0.2.3-in in neighbor 10.0.2.4 activate neighbor 10.0.2.4 route-map 10.0.2.4-in in exit-address-family ! route-map 10.0.2.3-in deny 20 ! route-map 10.0.2.4-in deny 20 ! ip nht resolve-via-default ! ipv6 nht resolve-via-default ! line vty ! bfd profile doc-example-bfd-profile-full 8 transmit-interval 35 receive-interval 35 passive-mode echo-mode echo-interval 35 minimum-ttl 10 ! ! end
<.>
ルーターの bgpセクションは、MetalLB の ASN を示します。<.> 追加した各 BGP ピアカスタムリソースに対して、neighbor <ip-address> remote-as <peer-ASN>行が存在することを確認します。<.> BFD を設定した場合は、BFD プロファイルが正しい BGP ピアに関連付けられていること、および BFD プロファイルがコマンド出力に表示されることを確認します。<.>network <ip-address-range>行が、追加したアドレスプールカスタムリソースで指定した IP アドレス範囲と一致することを確認します。BGP サマリーを表示します。
$ oc exec -n metallb-system speaker-66bth -c frr -- vtysh -c "show bgp summary"
出力例
IPv4 Unicast Summary: BGP router identifier 10.0.1.2, local AS number 64500 vrf-id 0 BGP table version 1 RIB entries 1, using 192 bytes of memory Peers 2, using 29 KiB of memory Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd PfxSnt 10.0.2.3 4 64500 387 389 0 0 0 00:32:02 0 1 1 10.0.2.4 4 64500 0 0 0 0 0 never Active 0 2 Total number of neighbors 2 IPv6 Unicast Summary: BGP router identifier 10.0.1.2, local AS number 64500 vrf-id 0 BGP table version 1 RIB entries 1, using 192 bytes of memory Peers 2, using 29 KiB of memory Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd PfxSnt 10.0.2.3 4 64500 387 389 0 0 0 00:32:02 NoNeg 3 10.0.2.4 4 64500 0 0 0 0 0 never Active 0 4 Total number of neighbors 2
アドレスプールを受信した BGP ピアを表示します。
$ oc exec -n metallb-system speaker-66bth -c frr -- vtysh -c "show bgp ipv4 unicast 203.0.113.200/30"
ipv4をipv6に置き換えて、IPv6 アドレスプールを受信した BGP ピアを表示します。203.0.113.200/30は、アドレスプールの IPv4 または IPv6IP アドレス範囲に置き換えます。出力例
BGP routing table entry for 203.0.113.200/30 Paths: (1 available, best #1, table default) Advertised to non peer-group peers: 10.0.2.3 <.> Local 0.0.0.0 from 0.0.0.0 (10.0.1.2) Origin IGP, metric 0, weight 32768, valid, sourced, local, best (First path received) Last update: Mon Jan 10 19:49:07 2022<.> 出力に BGP ピアの IP アドレスが含まれていることを確認します。
35.10.3. BFD の問題のトラブルシューティング
Red Hat がサポートする双方向フォワーディング検出 (BFD) の実装では、speakerPod のコンテナーで FR Routing (FRR) を使用します。BFD の実装は、BFD ピアに依存しており、このピアは、BGP セッションが確立されている BGP ピアとして設定されています。クラスター管理者は、BFD 設定の問題をトラブルシューティングする場合に、FRR コンテナーでコマンドを実行する必要があります。
前提条件
-
cluster-adminロールを持つユーザーとしてクラスターにアクセスできる。 -
OpenShift CLI (
oc) がインストールされている。
手順
speakerPod の名前を表示します。$ oc get -n metallb-system pods -l component=speaker
出力例
NAME READY STATUS RESTARTS AGE speaker-66bth 4/4 Running 0 26m speaker-gvfnf 4/4 Running 0 26m ...
BFD ピアを表示します。
$ oc exec -n metallb-system speaker-66bth -c frr -- vtysh -c "show bfd peers brief"
出力例
Session count: 2 SessionId LocalAddress PeerAddress Status ========= ============ =========== ====== 3909139637 10.0.1.2 10.0.2.3 up <.>
<.>
PeerAddress列に各 BFD ピアが含まれていることを確認します。出力に含まれると予想される BFD ピア IP アドレスが出力にリストされていない場合は、ピアとの BGP 接続のトラブルシューティングを行います。ステータスフィールドがdownと表示されている場合は、ノードとピア間のリンクと機器の接続を確認します。speaker Pod のノード名は、oc get pods -n metallb-system speaker-66bth -o jsonpath='{.spec.nodeName}'などのコマンドで判断できます。
35.10.4. BGP および BFD の MetalLB メトリック
OpenShift Container Platform は、MetalLB および BGP ピアと BFD プロファイルに関連する以下のメトリックをキャプチャーします。
-
metallb_bfd_control_packet_inputは、各 BFD ピアから受信した BFD 制御パケットの数をカウントします。 -
metallb_bfd_control_packet_outputは、各 BFD ピアに送信された BFD 制御パケットの数をカウントします。 -
metallb_bfd_echo_packet_inputは、各 BFD ピアから受信した BFD エコーパケットの数をカウントします。 -
metallb_bfd_echo_packet_outputは、各 BFD ピアに送信された BFD エコーパケットの数をカウントします。 -
metallb_bfd_session_down_eventsは、ピアとの BFD セッションがdownの状態になった回数をカウントします。 -
metallb_bfd_session_upは、BFD ピアとの接続状態を示します。1はセッションがupであること、0はdownであることを示します。 -
metallb_bfd_session_up_eventsは、ピアとの BFD セッションがupの状態になった回数をカウントします。 -
metallb_bfd_zebra_notificationsは、各 BFD ピアの BFD Zebra 通知の数をカウントします。 -
metallb_bgp_announced_prefixes_totalは、BGP ピアにアドバタイズされるロードバランサーの IP アドレス接頭辞の数をカウントします。接頭辞と集約ルートという用語は同じ意味です。 -
metallb_bgp_session_upは、BGP ピアとの接続状態を示します。1はセッションがupであること、0はdownであることを示します。 -
metallb_bgp_updates_totalは、BGP ピアに送信された BGP更新メッセージの数をカウントします。
関連情報
- 監視ダッシュボードの使用については、メトリックのクエリーを参照してください。
35.10.5. Metal LB データの収集について
oc adm must-gather CLI コマンドを使用して、クラスター、MetalLB 設定、および MetalLB Operator に関する情報を収集できます。次の機能とオブジェクトは、MetalLB と MetalLB Operator に関連付けられています。
- MetalLB Operator がデプロイされている namespace と子オブジェクト
- すべての MetalLB Operator カスタムリソース定義 (CRD)
oc adm must-gatherCLI コマンドは、Red Hat が BGP および BFD 実装に使用する FR Routing (FRR) から次の情報を収集します。
-
/etc/frr/frr.conf -
/etc/frr/frr.log -
/etc/frr/daemons設定ファイル -
/etc/frr/vtysh.conf
上記のリストのログファイルと設定ファイルは、各speaker Pod の frr コンテナーから収集されます。
ログファイルと設定ファイル以外に、oc adm must-gather の CLI コマンドは、次のvtyshコマンドからの出力を収集します。
-
show running-config -
show bgp ipv4 -
show bgp ipv6 -
show bgp neighbor -
show bfd peer
oc adm must-gather CLI コマンドを実行する場合、追加の設定は必要ありません。
関連情報
第36章 セカンダリーインターフェイスメトリクスのネットワーク割り当てへの関連付け
36.1. モニタリングのためのセカンダリーネットワークメトリックの拡張
セカンダリーデバイス (インターフェイス) は、各種の用途に合わせて使用されます。セカンダリーデバイスのメトリックを同じ分類で集計するために、それらを分類する方法を確保する必要があります。
公開されるメトリクスにはインターフェイスが含まれますが、インターフェイスの出所は指定されません。これは、追加のインターフェイスがない場合に実行できます。ただし、セカンダリーインターフェイスが追加された場合、インターフェイス名だけを使用してインターフェイスを識別するのは難しいため、メトリックの使用が困難になる可能性があります。
セカンダリーインターフェイスを追加する場合、その名前は追加された順序によって異なります。また、異なるセカンダリーインターフェイスが異なるネットワークに属し、これらを異なる目的に使用できます。
pod_network_name_info を使用すると、現在のメトリクスをインターフェイスタイプを識別する追加情報を使用して拡張できます。このようにして、メトリクスを集約し、特定のインターフェイスタイプに特定のアラームを追加できます。
ネットワークタイプは、関連する NetworkAttachmentDefinition の名前を使用して生成されます。この名前は、セカンダリーネットワークの異なるクラスを区別するために使用されます。たとえば、異なるネットワークに属するインターフェイスや、異なる CNI を使用するインターフェイスは、異なるネットワーク割り当て定義名を使用します。
36.1.1. Network Metrics Daemon
Network Metrics Daemon は、ネットワーク関連のメトリックを収集し、公開するデーモンコンポーネントです。
kubelet はすでに確認できるネットワーク関連のメトリックを公開しています。以下は、これらのメトリックになります。
-
container_network_receive_bytes_total -
container_network_receive_errors_total -
container_network_receive_packets_total -
container_network_receive_packets_dropped_total -
container_network_transmit_bytes_total -
container_network_transmit_errors_total -
container_network_transmit_packets_total -
container_network_transmit_packets_dropped_total
これらのメトリックのラベルには、とくに以下が含まれます。
- Pod の名前
- Pod の namespace
-
インターフェイス名 (例:
eth0)
これらのメトリックは、たとえば Multus を使用して、新規インターフェイスが Pod に追加されるまで正常に機能します。
インターフェイスのラベルはインターフェイス名を参照しますが、そのインターフェイスの用途は明確ではありません。多くの異なるインターフェイスがある場合、監視しているメトリックが参照するネットワークを把握することはできません。
これには、以降のセクションで説明する新規の pod_network_name_info を導入して対応できます。
36.1.2. ネットワーク名を持つメトリック
この daemonset は、固定の値が 0 の pod_network_name_info 測定メトリックを公開します。
pod_network_name_info{interface="net0",namespace="namespacename",network_name="nadnamespace/firstNAD",pod="podname"} 0ネットワーク名ラベルは、Multus によって追加されるアノテーションを使用して生成されます。これは、ネットワークの割り当て定義が属する namespace の連結と、ネットワーク割り当て定義の名前です。
新しいメトリクスのみでは十分な値が提供されませんが、ネットワーク関連の container_network_* メトリクスと組み合わせて、セカンダリーネットワークの監視に対するサポートを強化します。
以下のような promql クエリーを使用すると、k8s.v1.cni.cncf.io/network-status アノテーションから取得した値とネットワーク名を含む新規のメトリクスを取得できます。
(container_network_receive_bytes_total) + on(namespace,pod,interface) group_left(network_name) ( pod_network_name_info ) (container_network_receive_errors_total) + on(namespace,pod,interface) group_left(network_name) ( pod_network_name_info ) (container_network_receive_packets_total) + on(namespace,pod,interface) group_left(network_name) ( pod_network_name_info ) (container_network_receive_packets_dropped_total) + on(namespace,pod,interface) group_left(network_name) ( pod_network_name_info ) (container_network_transmit_bytes_total) + on(namespace,pod,interface) group_left(network_name) ( pod_network_name_info ) (container_network_transmit_errors_total) + on(namespace,pod,interface) group_left(network_name) ( pod_network_name_info ) (container_network_transmit_packets_total) + on(namespace,pod,interface) group_left(network_name) ( pod_network_name_info ) (container_network_transmit_packets_dropped_total) + on(namespace,pod,interface) group_left(network_name)