
Red Hat Training
A Red Hat training course is available for Red Hat Enterprise Linux
Panoramica sul Cluster Suite
Red Hat Cluster Suite per Red Hat Enterprise Linux 5
Edizione 3
Sommario
Introduzione
- Red Hat Enterprise Linux Installation Guide — Fornisce tutte le informazioni necessarie per l'installazione di Red Hat Enterprise Linux 5.
- Red Hat Enterprise Linux Deployment Guide — Fornisce tutte le informazioni necessarie per l'impiego, la configurazione e l'amministrazione di Red Hat Enterprise Linux 5.
- Configurazione e gestione di un Red Hat Cluster — Contiene informazioni sull'installazione, configurazione e gestione dei componenti del Red Hat Cluster.
- LVM Administrator's Guide: Configuration and Administration — Provides a description of the Logical Volume Manager (LVM), including information on running LVM in a clustered environment.
- Global File System: Configurazione e Amministrazione — Contiene informazioni su come installare, configurare e gestire il Red Hat GFS (Red Hat Global File System).
- Global File System 2: Configurazione e Amministrazione — Contiene informazioni su come installare, configurare e gestire il Red Hat GFS (Red Hat Global File System 2).
- Utilizzo del Device-Mapper Multipath — Fornisce tutte le informazioni necessarie per l'impiego del Device-Mapper Multipath di Red Hat Enterprise Linux 5.
- Utilizzo di GNBD con il Global File System — Fornisce una panoramica su come usare il Global Network Block Device (GNBD) con Red Hat GFS.
- Amministrazione del server virtuale di Linux — Fornisce le informazioni su come configurare i servizi ed i sistemi ad alte prestazioni con il Linux Virtual Server (LVS).
- Note di rilascio di Red Hat Cluster Suite — Fornisce informazioni sulla release corrente del Red Hat Cluster Suite.
1. Commenti
Cluster_Suite_Overview(EN)-5 (2008-12-11T15:49)
Capitolo 1. Panoramica su Red Hat Cluster Suite
1.1. Concetti di base del cluster
- Storage
- High availability
- Bilanciamento del carico
- Elevate prestazioni
Nota
1.2. Red Hat Cluster Suite Introduction
- Infrastruttura del cluster — Fornisce le funzioni fondamentali per i nodi in modo che gli stessi possano operare insieme come un cluster: gestione della configurazione-file, gestione appartenenza, lock management, e fencing.
- High-availability Service Management — Fornisce il failover dei servizi da un nodo del cluster ad un altro, in caso in cui il nodo non è più operativo.
- Tool di amministrazione del cluster — Tool di gestione e configurazione per l'impostazione, la configurazione e la gestione di un cluster di Red Hat. È possibile utilizzare i suddetti tool con i componenti dell'infrastruttura del cluster, e con componenti per la Gestione del servizio, High availability e storage.
- Linux Virtual Server (LVS) — Software di instradamento che fornisce l'IP-Load-balancing. LVM viene eseguito su di una coppia di server ridondanti, che distribuisce le richieste del client in modo omogeneo ai real server dietro i server LVS.
- Red Hat GFS (Global File System) — Fornisce il file system del cluster per un utilizzo con Red Hat Cluster Suite. GFS permette ai nodi multipli di condividere lo storage ad un livello del blocco, come se lo storage fosse collegato localmente ad ogni nodo del cluster.
- Cluster Logical Volume Manager (CLVM) — Fornisce la gestione del volume del cluster storage.
Nota
When you create or modify a CLVM volume for a clustered environment, you must ensure that you are running theclvmddaemon. For further information, refer to Sezione 1.6, «Cluster Logical Volume Manager». - Global Network Block Device (GNBD) — Un componente ausiliario di GFS in grado di esportare uno storage del livello del blocco su Ethernet. Esso rappresenta un modo molto economico per rendere disponibile il suddetto storage a Red Hat GFS.

Figura 1.1. Red Hat Cluster Suite Introduction
Nota
1.3. Cluster Infrastructure
- Cluster management
- Lock management
- Fencing
- Gestione configurazione del cluster
1.3.1. Cluster Management
Nota

Figura 1.2. CMAN/DLM Overview
1.3.2. Lock Management
1.3.3. Fencing
fenced.
fenced, una volta notificata la presenza di un errore, isola il nodo in questione. Successivamente gli altri componenti dell'infrastruttura del cluster determinano le azioni da intraprendere — essi eseguiranno qualsiasi processo necessario per il ripristino. Per esempio, subito dopo la notificata di un errore a DLM e GFS, essi sospendono l'attività fino a quando non accerteranno il completamento del processo di fencing da parte di fenced. Previa conferma del completamento di tale operazione, DLM e GFS eseguono l'azione di ripristino. A questo punto DLM rilascia i blocchi del nodo fallito e GFS ripristina il jounal del suddetto nodo.
- Power fencing — Esso è il metodo utilizzato da un controllore di alimentazione per disalimentare il nodo non utilizzabile.
- Fibre Channel switch fencing — Rappresenta il metodo attraverso il quale viene disabilitata la porta del Fibre Channel la quale collega lo storage ad un nodo non utilizzabile.
- GNBD fencing — A fencing method that disables an inoperable node's access to a GNBD server.
- Altri tipi di fencing — Diversi metodi per il fencing che disabilitano l'I/O o l'alimentazione di un nodo non utilizzabile, incluso gli IBM Bladecenters, PAP, DRAC/MC, HP ILO, IPMI, IBM RSA II, ed altro ancora.

Figura 1.3. Power Fencing Example

Figura 1.4. Fibre Channel Switch Fencing Example

Figura 1.5. Fencing a Node with Dual Power Supplies

Figura 1.6. Fencing a Node with Dual Fibre Channel Connections
1.3.4. Il Cluster Configuration System

Figura 1.7. CCS Overview

Figura 1.8. Accessing Configuration Information
/etc/cluster/cluster.conf) è un file XML che descrive le seguenti caratteristiche:
- Nome del cluster — Mostra il nome del cluster, il livello della revisione del file di configurazione, e le proprietà di base sul tempo necessario per l'esecuzione del fencing, usate quando un nodo si unisce al cluster o viene isolato.
- Cluster — Mostra ogni nodo del cluster, specificandone il nome, l'ID ed il numero di voti del quorum del cluster insieme al metodo per il fencing corrispondente.
- Fence Device — Mostra i dispositivi per il fencing nel cluster. I parametri variano a seconda del tipo di dispositivo. Per esempio, per un controllore dell'alimentazione usato come un dispositivo per il fencing, la configurazione del cluster definisce il nome del controllore dell'alimentazione, l'indirizzo IP relativo, il login e la password.
- Risorse gestite — Mostrano le risorse necessarie per creare i servizi del cluster. Le risorse gestite includono la definizione dei domini di failover, delle risorse (per esempio un indirizzo IP), e dei servizi. Insieme, le risorse gestite definiscono i servizi del cluster ed il comportamento del failover dei servizi del cluster.
1.4. Gestione dei servizi High-availability
rgmanager, implementa un cold failover per applicazioni commerciali. In un cluster di Red Hat un'applicazione viene configurata con altre risorse del cluster in modo da formare un servizio high-availability. È possibile eseguire un failover nei confronti di tale servizio da un nodo del cluster ad un altro, senza interruzione apparente per i client. Il failover del servizio può verificarsi se un nodo fallisce o se un amministratore di sistema del cluster muove il servizio da un nodo ad un altro (per esempio, per una interruzione pianificata di un nodo).
Nota

Figura 1.9. Domini di failover
- Risorsa indirizzo IP — Indirizzo IP 10.10.10.201.
- An application resource named "httpd-content" — a web server application init script
/etc/init.d/httpd(specifyinghttpd). - A file system resource — Red Hat GFS named "gfs-content-webserver".

Figura 1.10. Web Server Cluster Service Example
1.5. Red Hat GFS
- Semplificazione della vostra infrastruttura dei dati
- Installazione e aggiornamenti eseguiti una sola volta per l'intero cluster.
- Elimina la necessità di copie ridondanti dei dati (duplicazione).
- Abilita un accesso lettura /scrittura simultaneo dei dati da parte di numerosi client.
- Semplifica il backup ed il disaster recovery (backup o ripristino di un solo file system)
- Massimizza l'utilizzo delle risorse dello storage, e minimizza i costi di amministrazione.
- Gestisce lo storage nella sua totalità invece di gestirlo tramite ogni singola partizione.
- Diminuisce le necessità di spazio, eliminando la necessita di replicare i dati.
- Varia la dimensione del cluster aggiungendo server o storage, durante il suo normale funzionamento.
- Non è più necessario il partizionamento dello storage con tecniche complicate.
- Aggiunge il server al cluster semplicemente montandoli al file system comune
Nota
1.5.1. Prestazione e scalabilità superiori

Figura 1.11. GFS with a SAN
1.5.2. Prestazione, scalabilità e prezzo moderato

Figura 1.12. GFS and GNBD with a SAN
1.5.3. Risparmio e prestazione

Figura 1.13. GFS e GNBD con uno storage collegato direttamente
1.6. Cluster Logical Volume Manager
clvmd. clvmd is a daemon that provides clustering extensions to the standard LVM2 tool set and allows LVM2 commands to manage shared storage. clvmd runs in each cluster node and distributes LVM metadata updates in a cluster, thereby presenting each cluster node with the same view of the logical volumes (refer to Figura 1.14, «CLVM Overview»). Logical volumes created with CLVM on shared storage are visible to all nodes that have access to the shared storage. CLVM allows a user to configure logical volumes on shared storage by locking access to physical storage while a logical volume is being configured. CLVM uses the lock-management service provided by the cluster infrastructure (refer to Sezione 1.3, «Cluster Infrastructure»).
Nota
clvmd) o degli High Availability Logical Volume Management agent (HA-LVM). Se non siete in grado di utilizzare il demone clvmd o HA-LVM per ragioni operative, o perchè non siete in possesso degli entitlement corretti, è consigliato non usare il single-instance LVM sul disco condiviso, poichè tale utilizzo potrebbe risultare in una corruzione dei dati. Per qualsiasi problema si prega di consultare un rappresentante per la gestione dei servizi di Red Hat.
Nota
/etc/lvm/lvm.conf per il cluster-wide locking.

Figura 1.14. CLVM Overview

Figura 1.15. LVM Graphical User Interface

Figura 1.16. Conga LVM Graphical User Interface

Figura 1.17. Creating Logical Volumes
1.7. Global Network Block Device

Figura 1.18. Panoramica di GNBD
1.8. Linux Virtual Server
- Bilanciare il carico attraverso i real server.
- Controllare l'integrità dei servizi su ogni real server.
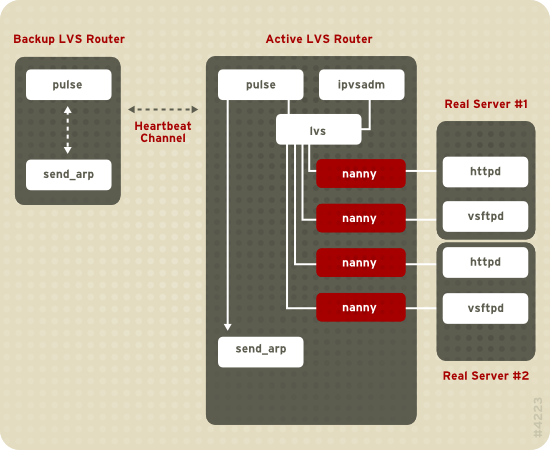
Figura 1.19. Components of a Running LVS Cluster
pulse viene eseguito sia sul router LVS attivo che su quello passivo. Sul router LVS di backup, pulse invia un heartbeat all'interfaccia pubblica del router attivo, in modo da assicurarsi che il router LVS attivo funzioni correttamente. Sul router LVS attivo, pulse avvia il demone lvs, e risponde alle interrogazioni heartbeat provenienti dal router LVS di backup.
lvs chiama l'utilità ipvsadm per configurare e gestire la tabella d'instradamento IPVS (IP Virtual Server) nel kernel, e successivamente avvia un processo nanny per ogni server virtuale configurato su ogni real server. Ogni processo nanny controlla lo stato di un servizio configurato su di un real server, ed indica al demone lvs se è presente un malfunzionamento del servizio su quel real server. Se tale malfunzionamento viene rilevato, il demone lvs indica a ipvsadm di rimuovere il real server in questione dalla tabella d'instradamento di IPVS.
send_arp, riassegnando tutti gli indirizzi IP virtuali agli indirizzi hardware NIC (indirizzo MAC) del router LVS di backup, ed inviando un comando al router LVS attivo tramite l'interfaccia di rete privata e quella pubblica in modo da interrompere il demone lvs sul router LVS attivo. A questo punto verrà avviato il demone lvs sul router LVS di backup ed accettate tutte le richieste per i server virtuali configurati.
- La sincronizzazione dei dati attraverso i real server.
- L'aggiunta di un terzo livello alla topologia per l'accesso dei dati condivisi.
rsync, per replicare i dati modificati attraverso tutti i nodi in un intervallo di tempo determinato. Tuttavia in ambienti dove gli utenti caricano spesso file o emettono transazioni del database, l'utilizzo di script o del comando rsync per la sincronizzazione dei dati, non funzionerà in maniera ottimale. Per questo motivo per real server con un numero di upload molto elevato, e per transazioni del database o di traffico simile, una topologia three-tiered risulta essere più appropriata se desiderate sincronizzare i dati.
1.8.1. Two-Tier LVS Topology
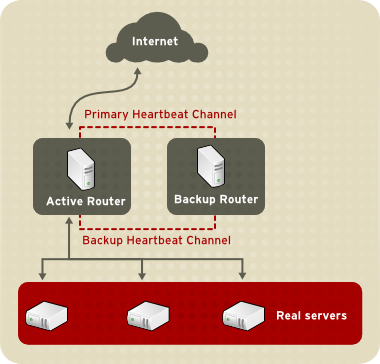
Figura 1.20. Two-Tier LVS Topology
eth0:1. Alternativamente ogni server virtuale può essere associato con un dispositivo separato per servizio. Per esempio, il traffico HTTP può essere gestito su eth0:1, ed il traffico FTP gestito su eth0:2.
- Round-Robin Scheduling — Distribuisce ogni richiesta in successione all'interno di un gruppo di real server. Utilizzando questo algoritmo, tutti i real server vengono trattati allo stesso modo, senza considerare la loro capacità o il loro carico.
- Weighted Round-Robin Scheduling — Distribuisce ogni richiesta in successione all'interno di un gruppo di real server, dando un carico di lavoro maggiore ai server con maggiore capacità. La capacità viene indicata da un fattore di peso assegnato dall'utente, e viene modificata in base alle informazioni sul carico dinamico. Essa rappresenta la scelta preferita se sono presenti differenze sostanziali di capacità dei real server all'interno di un gruppo di server. Tuttavia se la richiesta di carico varia sensibilmente, un server con un carico di lavoro molto elevato potrebbe operare oltre ai propri limiti.
- Least-Connection — Distribuisce un numero maggiore di richieste ai real server con un numero minore di collegamenti attivi. Questo è un tipo di algoritmo di programmazione dinamico, il quale rappresenta la scelta migliore se siete in presenza di una elevata variazione nelle richieste di carico. Offre il meglio di se per un gruppo di real server dove ogni nodo del server presenta una capacità simile. Se i real server in questione hanno una gamma varia di capacità, allora il weighted least-connection scheduling rappresenta la scelta migliore.
- Weighted Least-Connections (default) — Distribuisce un numero maggiore di richieste ai server con un numero minore di collegamenti attivi, in base alle proprie capacità. La capacità viene indicata da un peso assegnato dall'utente, e viene modificata in base alle informazioni relative al carico dinamico. L'aggiunta di peso rende questo algoritmo ideale quando il gruppo del real server contiene un hardware di varia capacità.
- Locality-Based Least-Connection Scheduling — Distribuisce un numero maggiore di richieste ai server con un numero minore di collegamenti attivi, in base ai propri IP di destinazione. Questo algoritmo viene utilizzato in un cluster di server proxy-cache. Esso indirizza i pacchetti per un indirizzo IP al server per quel indirizzo, a meno che il server in questione non abbia superato la sua capacità e sia presente al tempo stesso un server che utilizzi metà della propria capacità. In questo caso l'indirizzo IP verrà assegnato al real server con un carico minore.
- Locality-Based Least-Connection Scheduling con Replication Scheduling — Distribuisce un numero maggiore di richieste ai server con un numero minore di collegamenti attivi, in base ai propri IP di destinazione. Questo algoritmo viene usato anche in un cluster di server proxy-cache. Esso differisce da Locality-Based Least-Connection Scheduling a causa della mappatura dell'indirizzo IP target su di un sottoinsieme di nodi del real server. Le richieste vengono indirizzate ad un server presente in questo sottoinsieme con il numero più basso di collegamenti. Se tutti i nodi per l'IP di destinazione sono al di sopra della propria capacità, esso sarà in grado di replicare un nuovo server per quel indirizzo IP di destinazione, aggiungendo il real server con un numero minore di collegamenti del gruppo di real server, al sottoinsieme di real server per quel IP di destinazione. Il nodo maggiormente carico verrà rilasciato dal sottoinsieme di real server in modo da evitare un processo di riproduzione non corretto.
- Source Hash Scheduling — Distribuisce le richieste al gruppo di real server, cercando l'IP sorgente in una tabella hash statica. Questo algoritmo viene usato per i router LVS con firewall multipli.
1.8.2. Three-Tier LVS Topology
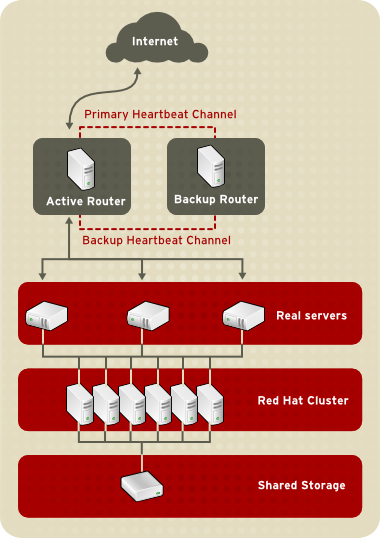
Figura 1.21. Three-Tier LVS Topology
1.8.3. Metodi di instradamento
1.8.3.1. NAT Routing
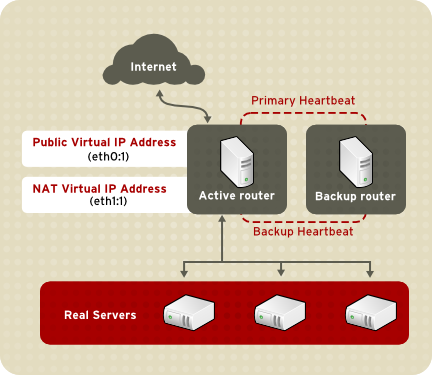
Figura 1.22. LVS Implemented with NAT Routing
1.8.3.2. Instradamento diretto
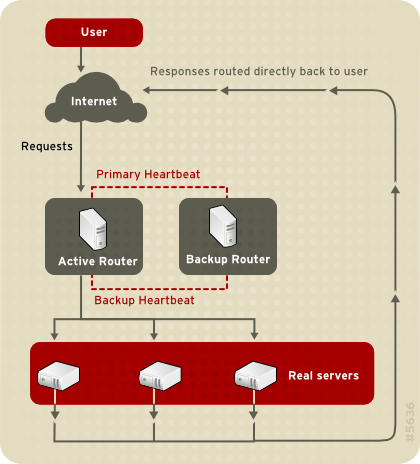
Figura 1.23. LVS Implemented with Direct Routing
arptables di filtraggio del pacchetto.
1.8.4. Persistenza e Firewall Mark
1.8.4.1. Persistence
1.8.4.2. Firewall Mark
1.9. Tool di amministrazione del cluster
1.9.1. Conga
- Una interfaccia web per la gestione dello storage e del cluster
- Implementazione automatizzata dei dati del cluster e pacchetti di supporto
- Integrazione semplice con i cluster esistenti
- Nessuna necessità di eseguire la riautenticazione
- Integrazione dello stato del cluster e dei log
- Controllo più meticoloso sui permessi dell'utente
- — Fornisce i tool usati per aggiungere e cancellare i computer, gli utenti e per la configurazione dei privilegi dell'utente. Solo un amministratore di sistema è in grado di accedere a questa scheda.
- — Fornisce i tool usati per la creazione e la configurazione dei cluster. Ogni istanza di luci elenca i cluster impostati con quel luci. Un amministratore del sistema può gestire tutti i cluster presenti su questa scheda. Altri utenti potranno amministrare solo i cluster verso i quali l'utente avrà i permessi per la gestione (conferiti da un amministratore).
- — Fornisce i tool per l'amministrazione remota dello storage. Con i tool presenti su questa scheda, sarete in grado di gestire lo storage sui computer, senza considerare se essi appartengono o meno ad un cluster.

Figura 1.24. Scheda di luci

Figura 1.25. Scheda di luci

Figura 1.26. Scheda di luci
1.9.2. GUI di amministrazione del cluster
system-config-cluster cluster administration graphical user interface (GUI) available with Red Hat Cluster Suite. The GUI is for use with the cluster infrastructure and the high-availability service management components (refer to Sezione 1.3, «Cluster Infrastructure» and Sezione 1.4, «Gestione dei servizi High-availability»). The GUI consists of two major functions: the Cluster Configuration Tool and the Cluster Status Tool. The Cluster Configuration Tool provides the capability to create, edit, and propagate the cluster configuration file (/etc/cluster/cluster.conf). The Cluster Status Tool provides the capability to manage high-availability services. The following sections summarize those functions.
1.9.2.1. Cluster Configuration Tool

Figura 1.27. Cluster Configuration Tool
/etc/cluster/cluster.conf), con un display grafico gerarchico nel pannello di sinistra. Una icona triangolare a sinistra del nome del componente, indica che il componente stesso possiede uno o due componenti subordinati assegnati. Facendo clic sull'icona triangolare sarete in grado di espandere o comprimere la porzione d'albero situata sotto un componente. I componenti visualizzati nella GUI vengono riassunti nel seguente modo:
- Nodi del Cluster — Visualizza i nodi del cluster. I nodi vengono rappresentati per nome come elementi subordinati sotto Nodi del Cluster. Utilizzando i pulsanti per la configurazione della struttura (sotto Proprietà), sarà possibile aggiungere, cancellare i nodi e modificare le loro proprietà, configurando anche i metodi di fencing per ogni nodo.
- Dispositivi Fence — Mostra i dispositivi Fence. I suddetti dispositivi vengono rappresentati come elementi subordinati sotto Dispositivi Fence. Utilizzando i pulsanti di configurazione nella parte inferiore della struttura (sotto Proprietà), sarà possibile aggiungere e cancellare i dispositivi Fence, e modificarne le loro proprietà. È necessario definire questi dispositivi prima di configurare il processo di fencing (tramite il pulsante ) per ogni nodo.
- Risorse gestite — Visualizza i domini di failover, le risorse ed i servizi.
- Domini di Failover — Per la configurazione di uno o più sottoinsiemi dei nodi del cluster usati per eseguire un servizio high-availability nell'evento del fallimento di un nodo. I domini di failover sono rappresentati come elementi subordinati sotto i Domini di Failover. Utilizzando i pulsanti per la configurazione nella parte bassa della struttura (sotto Proprietà), è possibile creare i domini di failover (quando viene selezionato Domini di Failover, oppure modificare le proprietà del dominio di failover (quando è stato selezionato un dominio di failover).
- Risorse — Per la configurazione delle risorse condivise utilizzate dai servizi high-availability. Le risorse condivise consistono in file system, indirizzi IP, esportazioni e montaggi NFS e script creati dall'utente disponibili per qualsiasi servizio high-availability nel cluster. Le risorse vengono rappresentate come elementi subordinati sotto Risorse. Utilizzando i pulsanti di configurazione nella parte bassa della struttura (sotto Proprietà), è possibile creare le risorse (se Risorse è stato selezionato), oppure modificare la proprietà di una risorsa (se avete selezionato una risorsa).
Nota
Il Cluster Configuration Tool fornisce la capacità di configurare le risorse private. Una risorsa privata è una risorsa configurata per l'utilizzo con un solo servizio. È possibile configurare una risorsa privata all'interno di un componente di Service tramite la GUI. - Servizi — Per la creazione e la configurazione di servizi high-availability. Un servizio viene configurato attraverso l'assegnazione delle risorse (condivise o private), assegnando un dominio di failover, e definendo una policy di ripristino per il servizio. I servizi vengono rappresentati come elementi subordinati sotto Servizi. Utilizzando i pulsanti di configurazione nella parte bassa della struttura (sotto Proprietà), è possibile creare i servizi (se Servizi è stato selezionato), oppure modificare le proprietà di un servizio (se avete selezionato un servizio).
1.9.2.2. Cluster Status Tool

Figura 1.28. Cluster Status Tool
/etc/cluster/cluster.conf). È possibile utilizzare il Cluster Status Tool per abilitare, disabilitare, riavviare o riposizionare un servizio high-availability.
1.9.3. Tool di amministrazione della linea di comando
system-config-cluster Cluster Administration GUI, command line tools are available for administering the cluster infrastructure and the high-availability service management components. The command line tools are used by the Cluster Administration GUI and init scripts supplied by Red Hat. Tabella 1.1, «Tool della linea di comando» summarizes the command line tools.
Tabella 1.1. Tool della linea di comando
| Tool della linea di comando | Usato con | Scopo |
|---|---|---|
ccs_tool — Tool del sistema di configurazione del cluster | Cluster Infrastructure | ccs_tool è un programma usato per creare aggiornamenti online per il file di configurazione del cluster. Esso conferisce la capacità di creare e modificare i componenti dell'infrastruttura del cluster (per esempio creare un cluster, o aggiungere e rimuovere un nodo). Per maggiori informazioni su questo tool, consultate la pagina man di ccs_tool(8). |
cman_tool — Tool di gestione del cluster | Cluster Infrastructure | cman_tool è un programma che gestisce il CMAN cluster manager. Esso fornisce la possibilità di unirsi o abbandonare un cluster, di terminare un nodo, o di modificare i voti del quorum previsti di un nodo in un cluster. Per maggiori informazioni su questo tool, consultate la pagina man di cman_tool(8). |
fence_tool — Tool di Fence | Cluster Infrastructure | fence_tool è un programma usato per unirsi o abbandonare il dominio predefinito di fence. In modo specifico, avviare il demone di fence (fenced), unirsi al dominio, terminare fenced, e per abbandonare il dominio in questione. Per maggiori informazioni su questo tool consultate la pagina man di fence_tool(8). |
clustat — Utilità dello stato del cluster | Componenti di gestione del servizio High-availability | Il comando clustat visualizza lo status del cluster. Esso mostra le informazioni sull'appartenenza, la vista sul quorum e lo stato di tutti i servizi utente configurati. Per maggiori informazioni su questo tool, consultate la pagina man di clustat(8). |
clusvcadm — Utilità di amministrazione del servizio utente del cluster | Componenti di gestione del servizio High-availability | Il comando clusvcadm vi permette di abilitare, disabilitare, riposizionare e riavviare i servizi high-availability in un cluster. Per maggiori informazioni su questo tool, consultate la pagina man di clusvcadm(8). |
1.10. GUI di amministrazione del server virtuale di Linux
/etc/sysconfig/ha/lvs.cf.
piranha-gui sul router LVS attivo. È possibile accedere al Piranha Configuration Tool in modo locale o remoto tramite un web browser. Per l'accesso locale è possibile utilizzare il seguente URL: http://localhost:3636. Per un accesso remoto è possibile utilizzare un hostname o l'indirizzo IP reale seguito da :3636. Se state per accedere al Piranha Configuration Tool in modo remoto, allora avrete bisogno di un collegamento ssh per il router LVS attivo come utente root.
Figura 1.29. The Welcome Panel
1.10.1. CONTROL/MONITORING
pulse, la tabella d'instradamento LVS, ed i processi nanny generati da LVS.
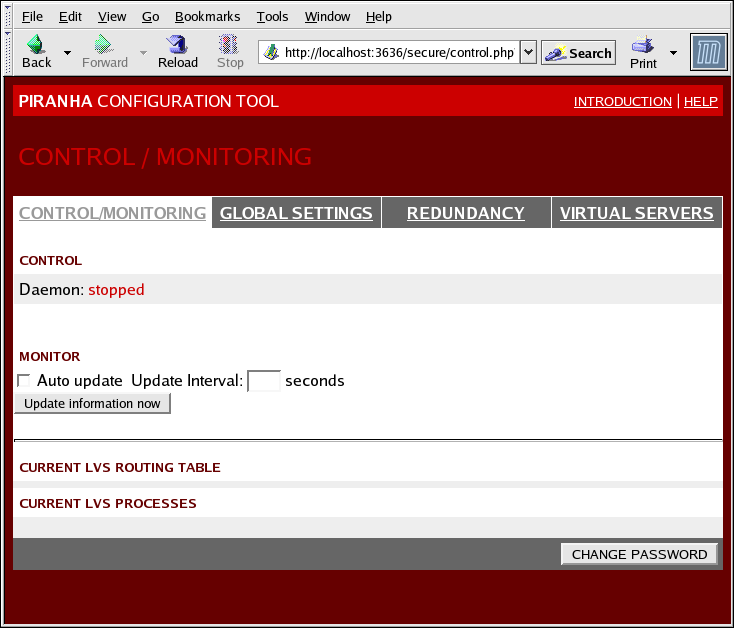
Figura 1.30. The CONTROL/MONITORING Panel
- Auto update
- Permette l'aggiornamento automatico del display dello stato, ad un intervallo configurato dall'utente all'interno della casella Frequenza di aggiornamento in secondi (il valore predefinito è 10 secondi).Non è consigliato impostare l'aggiornamento automatico ad un intervallo di tempo inferiore a 10 secondi, poichè così facendo sarà difficile riconfigurare l'intervallo di Aggiornamento automatico poichè la pagina verrà aggiornata troppo frequentemente. Se incontrate questo problema fate clic su di un altro pannello e successivamente su CONTROLLO/MONITORAGGIO.
- Fornisce l'aggiornamento manuale delle informazioni sullo stato.
- Facendo clic su questo pulsante verrete direzionati su di una schermata d'aiuto, contenente le informazioni su come modificare la password amministrativa per il Piranha Configuration Tool.
1.10.2. GLOBAL SETTINGS
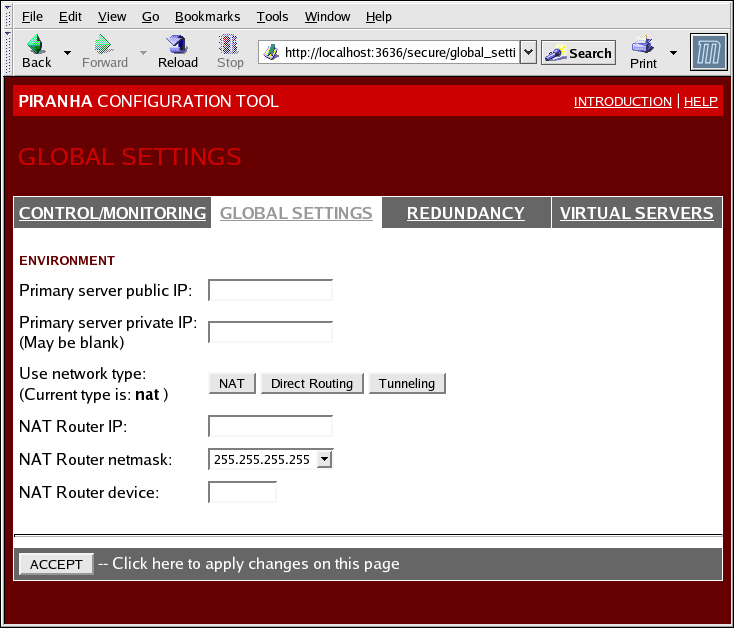
Figura 1.31. The GLOBAL SETTINGS Panel
- Primary server public IP
- Indirizzo IP reale pubblicamente instradabile per il nodo LVS primario.
- Primary server private IP
- L'indirizzo IP reale per una interfaccia di rete alternativa sul nodo LVS primario. Questo indirizzo viene utilizzato solo come canale heartbeat alternativo per il router di backup.
- Use network type
- Seleziona scegli NAT routing.
- NAT Router IP
- L'IP floating privato in questo campo di testo. Il suddetto IP floating deve essere usato come gateway per i real server.
- NAT Router netmask
- If the NAT router's floating IP needs a particular netmask, select it from drop-down list.
- NAT Router device
- Definisce il nome del dispositivo dell'interfaccia di rete per l'indirizzo IP floating, come ad esempio
eth1:1.
1.10.3. REDUNDANCY
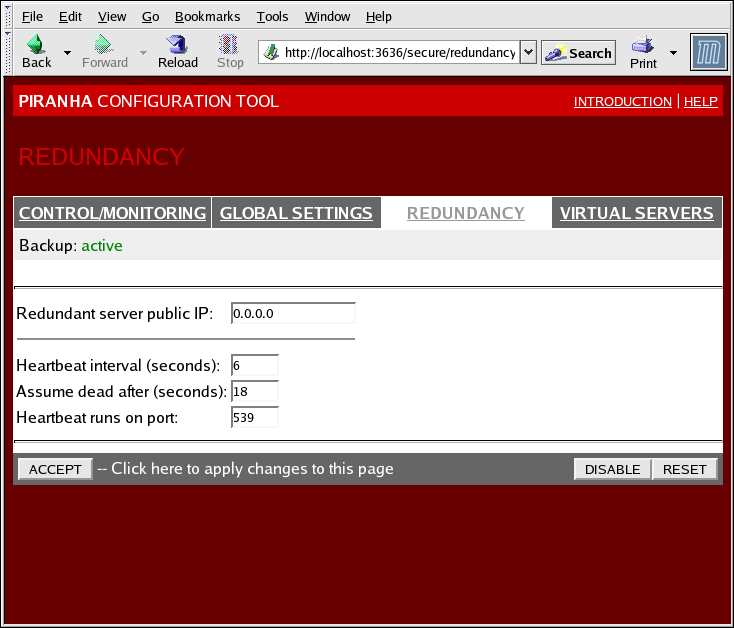
Figura 1.32. The REDUNDANCY Panel
- Redundant server public IP
- Indirizzo IP reale pubblico per il router LVS di backup.
- Redundant server private IP
- The backup router's private real IP address.
- Heartbeat Interval (seconds)
- Imposta il numero di secondi tra gli heartbeat — l'intervallo entro il quale il nodo di backup controllerà la funzionalità dello stato del nodo LVS primario.
- Assume dead after (seconds)
- Se il nodo LVS primario non risponde dopo il suddetto numero di secondi, allora il nodo del router LVS di backup inizierà un processo di failover.
- Heartbeat runs on port
- Imposta la porta sulla quale l'heartbeat comunica con il nodo LVS primario. Il default viene impostato su 539 se questo campo viene lasciato vuoto.
1.10.4. VIRTUAL SERVERS

Figura 1.33. The VIRTUAL SERVERS Panel
1.10.4.1. Sottosezione SERVER VIRTUALE
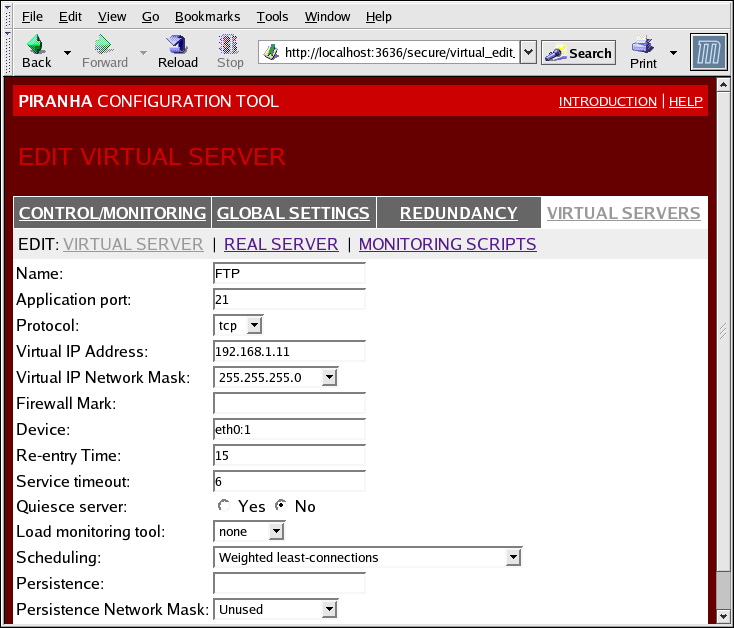
Figura 1.34. The VIRTUAL SERVERS Subsection
- Name
- Un nome descrittivo per identificare il server virtuale. Questo nome non è l'hostname per la macchina, quindi rendetelo descrittivo e facilmente identificabile. Potrete altresì riferirvi al protocollo usato dal server virtuale, come ad esempio HTTP.
- Application port
- Il numero della porta attraverso la quale il service application sarà in ascolto.
- Fornisce una scelta di UDP o TCP, in un menu a tendina.
- Virtual IP Address
- The virtual server's floating IP address.
- La maschera di rete per questo server virtuale nel menu a tendina.
- Firewall Mark
- Usato per inserire un valore intero di un firewall mark durante l'unione di protocolli multi-port, o per la creazione di un server virtuale multi-port per protocolli relativi ma separati.
- Device
- Il nome del dispositivo di rete al quale desiderate unire l'indirizzo IP floating definito nel campo Indirizzo IP virtuale.È consigliato l'alias dell'indirizzo IP floating pubblico sull'interfaccia Ethernet collegata alla rete pubblica.
- Re-entry Time
- Un valore intero che definisce il numero di secondi prima che il router LVS attivo possa cercare di utilizzare un real server dopo il suo fallimento.
- Service Timeout
- Un valore intero che definisce il numero di secondi prima che un real server venga considerato morto e quindi non disponibile.
- Quiesce server
- Quando un nodo del real server è online, dopo aver selezionato il pulsante radio server Quiesce la tabella delle least-connection viene azzerata. Così facendo il router LVS attivo indirizza le richieste come se i real server fossero stati appena aggiunti al cluster. Questa opzione impedisce ad un nuovo server di saturarsi a causa di un numero elevato di collegamenti al momento dell'ingresso nel cluster.
- Load monitoring tool
- Il router LVS è in grado di monitorare il carico sui vari real server tramite l'utilizzo sia di
rupche diruptime. Se selezionaterupdal menu a tendina, ogni real server deve eseguire il serviziorstatd. Se invece selezionateruptime, ogni real server deve eseguire il serviziorwhod. - Scheduling
- L'algoritmo preferito per la programmazione dal menu a tendina. Il default è
Weighted least-connection. - Persistenza
- Utilizzato se avete bisogno di collegamenti persistenti per il server virtuale durante le transazioni del client. Specifica in questo campo il numero di secondi di inattività prima che un collegamento possa scadere.
- Per poter limitare la persistenza di una particolare sottorete, selezionate la maschera di rete appropriata dal menu a tendina.
1.10.4.2. Sottosezione REAL SERVER
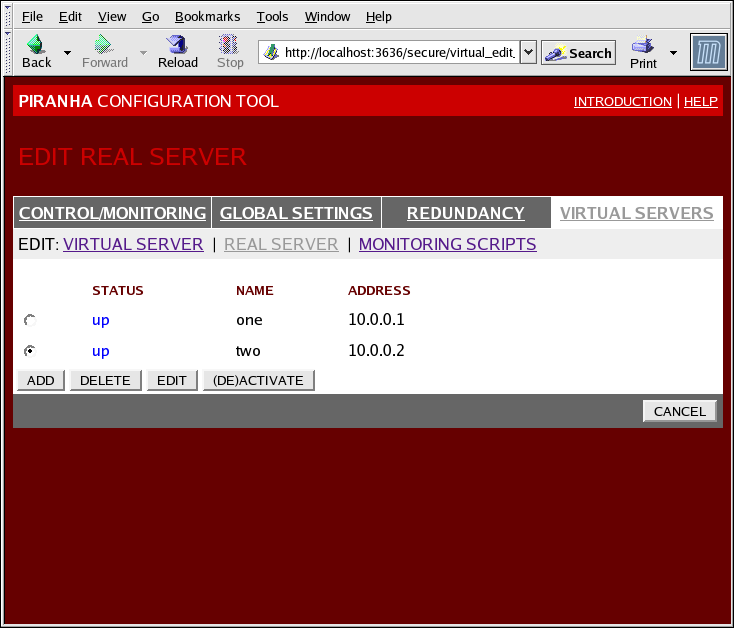
Figura 1.35. The REAL SERVER Subsection
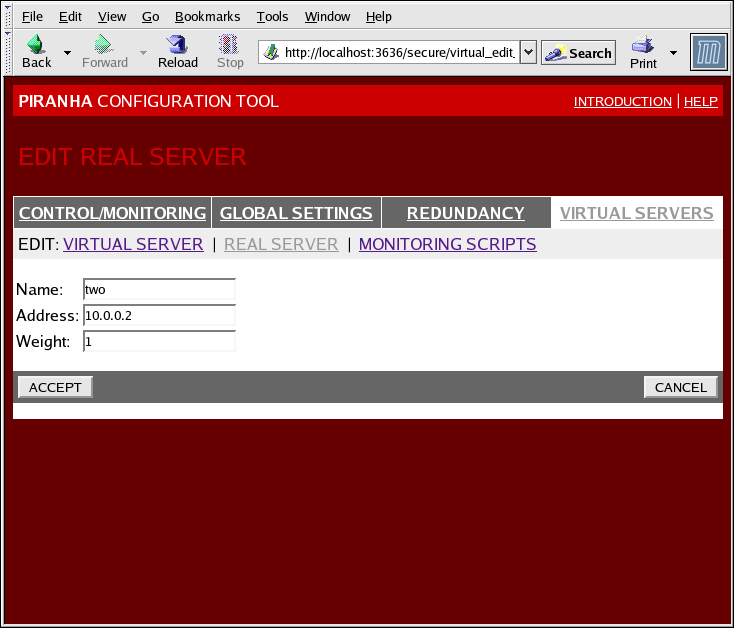
Figura 1.36. The REAL SERVER Configuration Panel
- Name
- Un nome descrittivo per il real server.
Nota
Questo nome non è l'hostname per la macchina, quindi rendetelo descrittivo e facilmente identificabile. - Address
- The real server's IP address. Since the listening port is already specified for the associated virtual server, do not add a port number.
- Weight
- An integer value indicating this host's capacity relative to that of other hosts in the pool. The value can be arbitrary, but treat it as a ratio in relation to other real servers.
1.10.4.3. EDIT MONITORING SCRIPTS Subsection
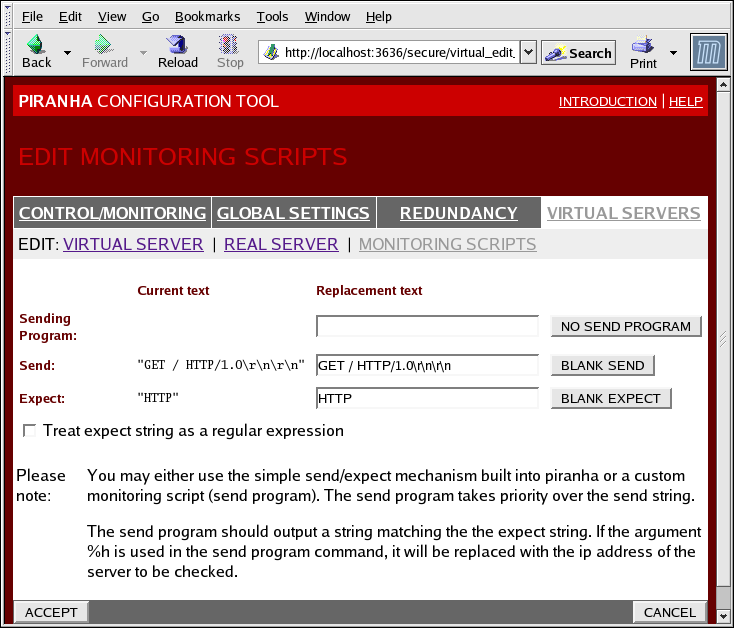
Figura 1.37. The EDIT MONITORING SCRIPTS Subsection
- Sending Program
- Per una verifica dei servizi molto più avanzata è possibile utilizzare questo campo per specificare il percorso per uno script di controllo del servizio. Questa funzione è particolarmente utile per servizi che richiedono una modifica dinamica dei dati, come ad esempio HTTPS o SSL.Per utilizzare questa funzione è necessario scrivere uno script il quale ritorna una risposta testuale, impostatela in modo da essere eseguibile e digitate il percorso relativo nel campo Programma mittente.
Nota
Se viene inserito nel campo Programma mittente un programma esterno, allora il campo Invio viene ignorato. - Send
- Una stringa per il demone
nannyda inviare ad ogni real server in questo campo. Per default il campo relativo a HTTP è stato completato. È possibile alterare questo valore a seconda delle vostre esigenze. Se lasciate questo campo vuoto, il demonenannycerca di aprire la porta, e se ha successo assume che il servizio è in esecuzione.In questo campo è permesso solo una sola sequenza d'invio, e può contenere solo caratteri ASCII stampabili insieme ai seguenti caratteri:- \n per una nuova riga.
- \r per il ritorno a capo del cursore.
- \t per tab.
- \ escape del carattere successivo che lo segue.
- Expect
- La risposta testuale che il server dovrebbe ritornare se funziona correttamente. Se avete scritto il vostro programma mittente, inserite la risposta da inviare in caso di successo.
Capitolo 2. Sommario dei componenti di Red Hat Cluster Suite
2.1. Componenti del cluster
Tabella 2.1. Componenti del sottosistema software di Red Hat Cluster Suite
| Funzione | Componenti | Descrizione |
|---|---|---|
| Conga | luci | Sistema di gestione remoto - Stazione di gestione. |
ricci | Sistema di gestione remoto - Stazione gestita. | |
| Cluster Configuration Tool | system-config-cluster | Comando usato per gestire la configurazione del cluster in una impostazione grafica. |
| Cluster Logical Volume Manager (CLVM) | clvmd | Il demone che distribuisce gli aggiornamenti dei metadata LVM in un cluster. Esso deve essere in esecuzione su tutti i nodi nel cluster, ed emetterà un errore se è presente un nodo in un cluster il quale non possiederà un demone in esecuzione. |
lvm | Tool LVM2. Fornisce i tool della linea di comando per LVM2. | |
system-config-lvm | Fornisce l'interfaccia utente grafica per LVM2. | |
lvm.conf | Il file di configurazione LVM. Il percorso completo è /etc/lvm/lvm.conf. | |
| Cluster Configuration System (CCS) | ccs_tool | ccs_tool fà parte di un Cluster Configuration System (CCS). Viene utilizzato per creare aggiornamenti online dei file di configurazione CCS. È possibile usarlo anche per aggiornare i file di configurazione del cluster dagli archivi CCS creati con GFS 6.0 (e versioni precedenti) al formato della configurazione del formato XML usato con questa release di Red Hat Cluster Suite. |
ccs_test | Comando diagnostico e di prova usato per ripristinare le informazioni dai file di configurazione attraverso ccsd. | |
ccsd | Demone CCS eseguito su tutti i nodi del cluster, che fornisce i dati del file di configurazione al software del cluster. | |
cluster.conf | Questo è il file di configurazione del cluster. Il percorso completo è /etc/cluster/cluster.conf. | |
| Cluster Manager (CMAN) | cman.ko | Il modulo del kernel per CMAN. |
cman_tool | Rappresenta il front end amministrativo per CMAN. Esso è in grado di avviare ed arrestare CMAN e modificare alcuni parametri interni come ad esempio i voti. | |
dlm_controld | Demone avviato dallo script init cman per gestire dlm nel kernel; non usato dall'utente. | |
gfs_controld | Demone avviato dallo script init cman per gestire gfs nel kernel; non usato dall'utente. | |
group_tool | Usato per ottenere un elenco di gruppi relativi al fencing, DLM, GFS, e per ottenere le informazioni di debug; include ciò che viene fornito da cman_tool services in RHEL 4. | |
groupd | Demone avviato dallo script init cman per interfacciare openais/cman e dlm_controld/gfs_controld/fenced; non usato dall'utente. | |
libcman.so.<version number> | Librerie per programmi che devono interagire con cman.ko. | |
| Resource Group Manager (rgmanager) | clusvcadm | Comando usato per abilitare, disabilitare, riposizionare e riavviare manualmente i servizi dell'utente in un cluster. |
clustat | Comando usato per visualizzare lo stato del cluster, inclusa l'appartenenza del nodo ed i servizi in esecuzione. | |
clurgmgrd | Demone usato per gestire le richieste del servizio dell'utente incluso service start, service disable, service relocate, e service restart. | |
clurmtabd | Demone usato per gestire le tabelle NFS mount clusterizzate. | |
| Fence | fence_apc | Fence agent per l'interrutore di alimentazione APC. |
fence_bladecenter | Fence agent per IBM Bladecenters con interfacia Telnet. | |
fence_bullpap | Fence agent per l'interfaccia Bull Novascale Platform Administration Processor (PAP). | |
fence_drac | Fencing agent per la scheda d'accesso remoto Dell. | |
fence_ipmilan | Fence agent per macchine controllate da IPMI (Intelligent Platform Management Interface) attraverso la LAN. | |
fence_wti | Fence agent per l'interruttore di alimentazione WTI. | |
fence_brocade | Fence agent per l'interruttore del Brocade Fibre Channel. | |
fence_mcdata | Fence agent per l'interruttore del McData Fibre Channel. | |
fence_vixel | Fence agent per l'interruttore del Vixel Fibre Channel. | |
fence_sanbox2 | Fence agent per l'interruttore del SANBox2 Fibre Channel. | |
fence_ilo | Fence agent per le interfacce ILO di HP (chiamate precedentemente fence_rib). | |
fence_rsa | I/O Fencing agent per IBM RSA II. | |
fence_gnbd | Fence agent usato con lo storage GNBD. | |
fence_scsi | I/O fencing agent per le prenotazioni persistenti di SCSI. | |
fence_egenera | Fence agent usato con il sistema Egenera BladeFrame. | |
fence_manual | Fence agent per una interazione manuale. NOTA BENE Questo componente non è supportato per ambienti di produzione. | |
fence_ack_manual | Interfaccia utente per fence_manual agent. | |
fence_node | Un programma che esegue I/O fencing su di un nodo singolo. | |
fence_xvm | I/O Fencing agent per macchine virtuali Xen. | |
fence_xvmd | I/O Fencing agent host per macchine virtuali Xen. | |
fence_tool | Un programma utilizzato per entrare ed uscire dal dominio fence. | |
fenced | Il demone Fencing I/O. | |
| DLM | libdlm.so.<version number> | Libreria per il supporto del Distributed Lock Manager (DLM). |
| GFS | gfs.ko | Modulo del kernel che implementa il file system GFS caricato sui nodi del cluster GFS. |
gfs_fsck | Comando che ripara un file system GFS non montato. | |
gfs_grow | Comando usato per espandere un file system GFS montato. | |
gfs_jadd | Comando che aggiunge i journal ad un file system GFS montato. | |
gfs_mkfs | Comando che crea un file system GFS su di un dispositivo di storage. | |
gfs_quota | Comando che gestisce i quota su di un file system GFS montato. | |
gfs_tool | Comando che configura o regola un file system GFS. Questo comando è in grado di raccogliere una varietà di informazioni sul file system. | |
mount.gfs | Icona d'aiuto di mount chiamata da mount(8); non usato dall'utente. | |
| GNBD | gnbd.ko | Modulo del kernel che implementa il driver del dispositivo GNBD sui client. |
gnbd_export | Comando usato per creare, esportare e gestire GNBD, su di un server GNBD. | |
gnbd_import | Comando usato per importare e gestire GNBD su di un client GNBD. | |
gnbd_serv | Un demone del server che permette ad un nodo di esportare lo storage locale attraverso la rete. | |
| LVS | pulse | This is the controlling process which starts all other daemons related to LVS routers. At boot time, the daemon is started by the /etc/rc.d/init.d/pulse script. It then reads the configuration file /etc/sysconfig/ha/lvs.cf. On the active LVS router, pulse starts the LVS daemon. On the backup router, pulse determines the health of the active router by executing a simple heartbeat at a user-configurable interval. If the active LVS router fails to respond after a user-configurable interval, it initiates failover. During failover, pulse on the backup LVS router instructs the pulse daemon on the active LVS router to shut down all LVS services, starts the send_arp program to reassign the floating IP addresses to the backup LVS router's MAC address, and starts the lvs daemon. |
lvsd | Il demone lvs viene eseguito sul router LVS attivo una volta chiamato da pulse. Esso legge il file di configurazione /etc/sysconfig/ha/lvs.cf, chiama l'utilità ipvsadm per compilare e gestire la tabella di routing IPVS, e assegna un processo nanny per ogni servizio LVS configurato. Se nanny riporta la presenza di un real server inattivo, lvs indica alla utilità ipvsadm di rimuovere il real server in questione dalla tabella di routing IPVS. | |
ipvsadm | Questo servizio aggiorna la tabella del routing IPVS nel kernel. Il demone lvs imposta e gestisce LVS, chiamando ipvsadm in modo da aggiungere, modificare o cancellare le voci presenti nella tabella del routing IPVS. | |
nanny | Il demone di controllo nanny viene eseguito sul router LVS attivo. Attraverso questo demone, il router LVS attivo determina lo stato di ogni real server, e facoltativamente, controlla il carico di lavoro relativo. Viene eseguito un processo separato per ogni servizio definito su ogni real server. | |
lvs.cf | Questo è il file di configurazione di LVS. Il percorso completo per il file è /etc/sysconfig/ha/lvs.cf. Direttamente o indirettamente tutti i demoni ottengono le proprie informazioni sulla configurazione da questo file. | |
| Piranha Configuration Tool | Questo è il tool basato sul web per il monitoraggio, configurazione e gestione di LVS. Esso rappresenta il tool predefinito per gestire il file di configurazione di LVS /etc/sysconfig/ha/lvs.cf. | |
send_arp | Questo programma invia i broadcast ARP quando l'indirizzo IP floating cambia da un nodo ad un altro durante un failover. | |
| Quorum Disk | qdisk | Un demone del quorum basato sul disco per CMAN / Linux-Cluster. |
mkqdisk | Utilità disco quorum del cluster. | |
qdiskd | Demone disco quorum del cluster. |
2.2. Pagine man
- Infrastruttura del cluster
- ccs_tool (8) - Il tool usato per creare aggiornamenti online dei file di configurazione CCS
- ccs_test (8) - Il tool diagnostico per un Cluster Configuration System
- ccsd (8) - Il demone usato per accedere al file di configurazione del cluster di CCS
- ccs (7) - Cluster Configuration System
- cman_tool (8) - Cluster Management Tool
- cluster.conf [cluster] (5) - Il file di configurazione per i prodotti del cluster
- qdisk (5) - un demone del quorum basato sul disco per CMAN / Linux-Cluster
- mkqdisk (8) - Cluster Quorum Disk Utility
- qdiskd (8) - Cluster Quorum Disk Daemon
- fence_ack_manual (8) - programma eseguito da un operatore come parte di un I/O Fencing manuale
- fence_apc (8) - I/O Fencing agent per APC MasterSwitch
- fence_bladecenter (8) - I/O Fencing agent per IBM Bladecenter
- fence_brocade (8) - I/O Fencing agent per interruttori Brocade FC
- fence_bullpap (8) - I/O Fencing agent per l'architettura Bull FAME controllata da una console di gestione PAP
- fence_drac (8) - fencing agent per il Dell Remote Access Card
- fence_egenera (8) - I/O Fencing agent per Egenera BladeFrame
- fence_gnbd (8) - I/O Fencing agent per cluster GFS basati su GNBD
- fence_ilo (8) - I/O Fencing agent per HP Integrated Lights Out card
- fence_ipmilan (8) - I/O Fencing agent per macchine controllate da IPMI tramite LAN
- fence_manual (8) - programma eseguita da fenced come parte del manuale I/O Fencing
- fence_mcdata (8) - I/O Fencing agent per interruttori McData FC
- fence_node (8) - Un programma che esegue I/O fencing su di un nodo singolo
- fence_rib (8) - I/O Fencing agent per Compaq Remote Insight Lights Out card
- fence_rsa (8) - I/O Fencing agent per IBM RSA II
- fence_sanbox2 (8) - I/O Fencing agent per interruttori QLogic SANBox2 FC
- fence_scsi (8) - I/O fencing agent per SCSI persistent reservations
- fence_tool (8) - Un programma utilizzato per entrare ed uscire dal dominio fence
- fence_vixel (8) - I/O Fencing agent per interruttori Vixel FC
- fence_wti (8) - I/O Fencing agent per WTI Network Power Switch
- fence_xvm (8) - I/O Fencing agent per macchine virtuali Xen
- fence_xvmd (8) - I/O Fencing agent host per macchine virtuali Xen
- fenced (8) - Il demone I/O Fencing
- High-availability Service Management
- clusvcadm (8) - Utilità Cluster User Service Administration
- clustat (8) - Utilità Cluster Status
- Clurgmgrd [clurgmgrd] (8) - Resource Group (Cluster Service) Manager Daemon
- clurmtabd (8) - Cluster NFS Remote Mount Table Daemon
- GFS
- gfs_fsck (8) - Controllore file system GFS Offline
- gfs_grow (8) - Espande un file system GFS
- gfs_jadd (8) - Aggiunge i journal ad un file system GFS
- gfs_mount (8) - opzioni di montaggio GFS
- gfs_quota (8) - Manipola i disk quotas del GFS
- gfs_tool (8) - interfaccia per le chiamate gfs ioctl
- Cluster Logical Volume Manager
- clvmd (8) - Demone LVM del cluster
- lvm (8) - Tool LVM2
- lvm.conf [lvm] (5) - File di configurazione per LVM2
- lvmchange (8) - modifica gli attributi del logical volume manager
- pvcreate (8) - inizializza un disco o una partizione per un utilizzo da parte di LVM
- lvs (8) - riporta informazioni sui volumi logici
- Global Network Block Device
- gnbd_export (8) - l'interfaccia per esportare GNBD
- gnbd_import (8) - manipola i dispositivi a blocchi GNBD su di un client
- gnbd_serv (8) - demone del server gnbd
- LVS
- pulse (8) - demone heartbeating per il monitoraggio della salute dei nodi del cluster
- lvs.cf [lvs] (5) - file di configurazione per lvs
- lvscan (8) - esegue la scansione (su tutti i dischi) per la presenza di volumi logici
- lvsd (8) - demone per controllare i Red Hat clustering service
- ipvsadm (8) - Amministrazione del server virtuale di Linux
- ipvsadm-restore (8) - ripristina la tabella IPVS da stdin
- ipvsadm-save (8) - salva la tabella IPVS su stdout
- nanny (8) - tool per il monitoraggio dello stato dei servizi in un cluster
- send_arp (8) - tool usato per notificare ad una rete la presenza di una nuova mappatura dell'indirizzo IP / MAC
2.3. Hardware compatibile
Appendice A. Cronologia della revisione
| Diario delle Revisioni | |||
|---|---|---|---|
| Revisione 3-7.400 | 2013-10-31 | ||
| |||
| Revisione 3-7 | 2012-07-18 | ||
| |||
| Revisione 1.0-0 | Tue Jan 20 2008 | ||
| |||
Indice analitico
C
- cluster
- displaying status, Cluster Status Tool
- cluster administration
- displaying cluster and service status, Cluster Status Tool
- cluster component compatible hardware, Hardware compatibile
- cluster component man pages, Pagine man
- cluster components table, Componenti del cluster
- Cluster Configuration Tool
- accessing, Cluster Configuration Tool
- cluster service
- displaying status, Cluster Status Tool
- command line tools table, Tool di amministrazione della linea di comando
- compatible hardware
- cluster components, Hardware compatibile
- Conga
- overview, Conga
- Conga overview, Conga
F
- feedback, Commenti
I
- introduction, Introduzione
- other Red Hat Enterprise Linux documents, Introduzione
L
- LVS
- direct routing
- requirements, hardware, Instradamento diretto
- requirements, network, Instradamento diretto
- requirements, software, Instradamento diretto
- routing methods
- three tiered
- high-availability cluster, Three-Tier LVS Topology
M
- man pages
- cluster components, Pagine man
N
- NAT
- routing methods, LVS, Metodi di instradamento
- network address translation (vedi NAT)
O
- overview
- economy, Red Hat GFS
- performance, Red Hat GFS
- scalability, Red Hat GFS
P
- Piranha Configuration Tool
- CONTROL/MONITORING, CONTROL/MONITORING
- EDIT MONITORING SCRIPTS Subsection, EDIT MONITORING SCRIPTS Subsection
- GLOBAL SETTINGS, GLOBAL SETTINGS
- login panel, GUI di amministrazione del server virtuale di Linux
- necessary software, GUI di amministrazione del server virtuale di Linux
- REAL SERVER subsection, Sottosezione REAL SERVER
- REDUNDANCY, REDUNDANCY
- VIRTUAL SERVER subsection, VIRTUAL SERVERS
- Firewall Mark , Sottosezione SERVER VIRTUALE
- Persistence , Sottosezione SERVER VIRTUALE
- Scheduling , Sottosezione SERVER VIRTUALE
- Virtual IP Address , Sottosezione SERVER VIRTUALE
- VIRTUAL SERVERS, VIRTUAL SERVERS
R
- Red Hat Cluster Suite
- components, Componenti del cluster
T
- table
- cluster components, Componenti del cluster
- command line tools, Tool di amministrazione della linea di comando