
Red Hat Training
A Red Hat training course is available for Red Hat Enterprise Linux
Guide d'administration du stockage
Déployer et configurer un stockage à nœud unique dans Red Hat Enterprise Linux 6
Édition 2
Résumé
Chapitre 1. Aperçu
1.1. Les nouveautés de Red Hat Enterprise Linux 6
Chiffrement de système de fichiers (aperçu technologique)
Mise en cache de systèmes de fichiers (aperçu technologique)
Btrfs (Aperçu technologique)
Traitement des limites d'E/S
Prise en charge ext4
Stockage de bloc réseau
Partie I. Systèmes de fichiers
Chapitre 2. Structure et maintenance des systèmes de fichiers
- Fichiers partageables vs fichiers non-partageables
- Fichiers variables vs fichiers statiques
2.1. Vue d'ensemble du standard de hiérarchie des systèmes de fichiers (FHS, ou « Filesystem Hierarchy Standard »)
- La compatibilité avec d'autres systèmes conformes à FHS
- La possibilité de monter une partition
/usr/en lecture seule. Ceci est particulièrement important car/usr/contient des fichiers exécutables communs et ne devrait pas être modifié par les utilisateurs. En outre, comme la partition/usr/est montée en lecture seule, elle devrait pouvoir être montée à partir du lecteur CD-ROM ou depuis une autre machine via un montage NFS en lecture seule.
2.1.1. Organisation FHS
2.1.1.1. Collecte des informations sur les systèmes de fichiers
df rapporte l'utilisation de l'espace disque du système. Sa sortie est similaire à la suivante :
Exemple 2.1. Sortie de la commande df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup00-LogVol00
11675568 6272120 4810348 57% / /dev/sda1
100691 9281 86211 10% /boot
none 322856 0 322856 0% /dev/shmdf affiche la taille de la partition en blocs de 1 kilo-octets, ainsi que la quantité d'espace disque utilisée et disponible en kilo-octets. Pour afficher ces informations en méga-octets et giga-octets, veuillez utiliser la commande df -h. L'argument -h se traduit par l'utilisation d'un format lisible (« human-readable »). La sortie de df -h est similaire à la suivante :
Exemple 2.2. Sortie de la commande df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup00-LogVol00
12G 6.0G 4.6G 57% / /dev/sda1
99M 9.1M 85M 10% /boot
none 316M 0 316M 0% /dev/shmNote
/dev/shm représente le système de fichiers de la mémoire virtuelle du système.
du affiche la quantité estimée d'espace utilisé par des fichiers dans un répertoire, et l'utilisation d'espace disque de chaque sous-répertoire. La dernière ligne dans la sortie de du affiche la totalité de l'utilisation d'espace disque du répertoire. Pour afficher la totalité de l'utilisation d'espace disque sous un format lisible, veuillez utiliser du -hs. Pour plus d'options, veuillez consulter man du.
gnome-system-monitor. Sélectionnez l'onglet Systèmes de fichiers pour afficher les partitions du système. La figure ci-dessous illustre l'onglet Systèmes de fichiers.
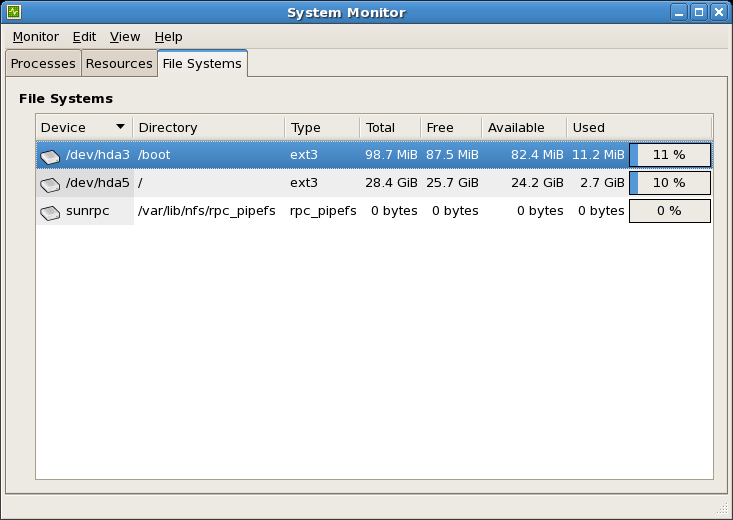
Figure 2.1. Onglet Surveillance système GNOME des systèmes de fichiers
2.1.1.2. Répertoire /boot/
/boot/ contient des fichiers statiques requis pour démarrer le système, par exemple le noyau Linux. Ces fichiers sont essentiels pour que le système puisse démarrer correctement.
Avertissement
/boot/. Le système ne pourra plus être démarré si ce répertoire est supprimé.
2.1.1.3. Répertoire /dev/
/dev/ contient des nœuds de périphériques qui représente les types de périphériques suivants :
- les périphériques attachés au système ;
- les périphériques fournis par le noyau.
udevd crée et supprime les nœuds de périphérique dans /dev/ selon les besoins.
/dev/ et ses sous-répertoires sont définis en tant que caractère (fournissant uniquement un flux en série d'entrées et sortie, par exemple une souris ou un clavier) ou bloc (accessible de manière aléatoire, par exemple un disque dur ou un lecteur de disquettes). Si GNOME ou KDE est installé, certains périphériques de stockage seront automatiquement détectés lorsqu'ils sont connectés (comme les lecteurs USB), ou insérés (comme avec un lecteur CD ou DVD), puis une fenêtre contextuelle affichant le contenu apparaîtra.
Tableau 2.1. Exemples de fichiers communs dans le répertoire /dev
| Fichier | Description |
|---|---|
| /dev/hda | Périphérique maître sur le canal IDE principal. |
| /dev/hdb | Périphérique esclave sur le canal IDE principal. |
| /dev/tty0 | Première console virtuelle. |
| /dev/tty1 | Seconde console virtuelle. |
| /dev/sda | Premier périphérique sur le canal principal SCSI ou SATA. |
| /dev/lp0 | Premier port parallèle. |
| /dev/ttyS0 | Port série. |
2.1.1.4. Répertoire /etc/
/etc/ est réservé aux fichiers de configuration qui sont locaux à l'ordinateur. Il ne doit contenir aucun fichier binaire ; tout fichier binaire devrait être déplacé dans /bin/ ou /sbin/.
/etc/skel/ stocke les fichiers utilisateur « squelette », qui sont utilisés pour remplir un répertoire de base lorsqu'un utilisateur est créé pour la première fois. Les applications stockent aussi leurs fichiers de configuration dans ce répertoire et peuvent les référencer lors de leur exécution. Le fichier /etc/exports contrôle quels systèmes de fichiers sont exportés vers des hôtes distants.
2.1.1.5. Répertoire /lib/
/lib/ doit uniquement contenir les bibliothèques nécessaires à l'exécution des binaires dans /bin/ et /sbin/. Ces images de bibliothèques partagées sont utilisées pour démarrer le système ou exécuter des commandes à l'intérieur du système de fichiers.
2.1.1.6. Répertoire /media/
/media/ contient des sous-répertoires utilisés comme points de montage pour des supports amovibles, tels que les supports de stockage USB, les DVD et les CD-ROM.
2.1.1.7. Répertoire /mnt/
/mnt/ est réservé aux systèmes de fichiers montés de manière temporaire, comme les montages de systèmes de fichiers NFS. Pour tous les supports de stockage amovibles, veuillez utiliser le répertoire /media/. Les supports de stockage amovibles détectés automatiquement seront montés dans le répertoire /media.
Important
/mnt ne doit pas être utilisé par des programmes d'installation.
2.1.1.8. Répertoire /opt/
/opt/ est habituellement réservé aux paquets logiciels et aux paquets de modules complémentaires ne faisant pas partie de l'installation par défaut. Un paquet effectuant une installation sur /opt/ crée un répertoire portant son nom, par exemple /opt/packagename/. Dans la plupart des cas, ce genre de paquets observe une structure prédictible de sous-répertoires. La plupart stockent leurs binaires dans /opt/packagename/bin/ et leurs pages man dans /opt/packagename/man/.
2.1.1.9. Répertoire /proc/
/proc/ contient des fichiers spéciaux qui extraient des informations du noyau ou y envoie des informations. Des exemples de ce genre d'informations incluent la mémoire système, des informations sur le CPU et la configuration du matériel. Pour obtenir des informations supplémentaires sur /proc/, veuillez consulter le Section 2.3, « Système de fichiers virtuel /proc ».
2.1.1.10. Répertoire /sbin/
/sbin/ stocke les binaires essentiels au démarrage, à la restauration, la récupération, ou la réparation du système. Les binaires dans /sbin/ requièrent des privilèges root pour être utilisés. En outre, /sbin/ contient des binaires utilisés par le système avant que le répertoire /usr/ ne soit monté. Tout utilitaire système utilisé après le montage de /usr/ sera habituellement placé dans /usr/sbin/.
/sbin/ :
arpclockhaltinitfsck.*grubifconfigmingettymkfs.*mkswaprebootrouteshutdownswapoffswapon
2.1.1.11. Répertoire /srv/
/srv/ contient des données spécifiques au site servies par un système Red Hat Enterprise Linux. Ce répertoire donne aux utilisateurs l'emplacement des fichiers de données pour un service particulier, tel que FTP, WWW, ou CVS. Les données pertinentes à un utilisateur en particulier doivent être placées dans le répertoire /home/.
Note
/var/www/html pour le contenu servi.
2.1.1.12. Répertoire /sys/
/sys/ utilise le nouveau système de fichiers virtuel spécifique au noyau 2.6, sysfs. Grâce à la meilleure prise en de l'enfichage à chaud de périphériques matériels dans le noyau 2.6, le répertoire /sys/ contient des informations similaires à celles offertes par /proc/, mais affiche une vue hiérarchique des informations des périphériques qui est spécifique aux périphériques enfichables à chaud.
2.1.1.13. Répertoire /usr/
/usr/ est utilisé pour les fichiers pouvant être partagés à travers de multiples machines. Le répertoire /usr/ se trouve souvent sur sa propre partition et est monté en lecture seule. Le répertoire /usr/ contient habituellement les sous-répertoires suivants :
/usr/bin- Ce répertoire est utilisé pour les binaires.
/usr/etc- Ce répertoire est utilisé pour les fichiers de configuration globaux.
/usr/games- Ce répertoire est utilisé pour stocker les jeux.
/usr/include- Ce répertoire est utilisé pour les fichiers en-têtes C.
/usr/kerberos- Ce répertoire est utilisé pour les fichiers et binaires liés à Kerberos.
/usr/lib- Ce répertoire est utilisé pour les fichiers objets et les bibliothèques qui ne sont pas conçus pour être directement utilisés par des scripts shell ou des utilisateurs. Ce répertoire est destiné aux systèmes 32-bit.
/usr/lib64- Ce répertoire est utilisé pour les fichiers objets et les bibliothèques qui ne sont pas conçus pour être directement utilisés par des scripts shell ou des utilisateurs. Ce répertoire est destiné aux systèmes 64-bit.
/usr/libexec- Ce répertoire contient les programmes d'assistance de petite taille appelés par d'autres programmes.
/usr/sbin- Ce répertoire stocke les binaires d'administration système qui n'appartiennent pas à
/sbin/. /usr/share- Ce répertoire stocke les fichiers qui ne sont pas particuliers à l'architecture.
/usr/src- Ce répertoire stocke le code source.
/usr/tmplié à/var/tmp- Ce répertoire stocke les fichiers temporaires.
/usr/ devrait aussi contenir un sous-répertoire /local/. Comme recommandé par la norme FHS, ce sous-répertoire est utilisé par l'administrateur système lors de l'installation locale de logiciels et ne doit pas être écrasé pendant les mises à jour du système. Le répertoire /usr/local possède une structure similaire à /usr/ et contient les sous-répertoires suivants :
/usr/local/bin/usr/local/etc/usr/local/games/usr/local/include/usr/local/lib/usr/local/libexec/usr/local/sbin/usr/local/share/usr/local/src
/usr/local/ diffère légèrement de la norme FHS. La norme FHS déclare que /usr/local/ devrait être utilisé pour stocker des logiciels qui ne doivent pas être affectés par les mises à niveau de logiciels système. Comme le gestionnaire de paquet RPM, « RPM Package Manager », peut effectuer des mises à niveau de logiciels en toute sécurité, il n'est pas nécessaire de protéger les fichiers en les stockant dans /usr/local/.
/usr/local/ pour les logiciels locaux. Par exemple, si le répertoire /usr/ est monté en tant que partage NFS en lecture seule à partir d'un hôte distant, il est toujours possible d'installer un paquet ou programme sous le répertoire /usr/local/.
2.1.1.14. Répertoire /var/
/usr/ en lecture seule, tout programme qui écrit des fichiers journaux ou nécessite les répertoires spool/ ou lock/ devrait les écrire sur le répertoire /var/. La norme FHS déclare que /var/ est utilisé pour les données variables, ce qui inclut les répertoires et fichier spool, les données de journalisation, et les fichiers transitoires et temporaires.
/var/, selon ce qui installé sur le système :
/var/account//var/arpwatch//var/cache//var/crash//var/db//var/empty//var/ftp//var/gdm//var/kerberos//var/lib//var/local//var/lock//var/log//var/maillié à/var/spool/mail//var/mailman//var/named//var/nis//var/opt//var/preserve//var/run//var/spool//var/tmp//var/tux//var/www//var/yp/
messages et lastlog, sont placés dans le répertoire /var/log/. Le répertoire /var/lib/rpm/ contient des bases de données RPM du système. Les fichiers de verrouillage sont placés dans le répertoire /var/lock/, habituellement dans les répertoires du programme utilisant le fichier. Le répertoire /var/spool/ contient des sous-répertoires qui stockent les fichiers de données de certains programmes. Ces sous-répertoires peuvent inclure :
/var/spool/at//var/spool/clientmqueue//var/spool/cron//var/spool/cups//var/spool/exim//var/spool/lpd//var/spool/mail//var/spool/mailman//var/spool/mqueue//var/spool/news//var/spool/postfix//var/spool/repackage//var/spool/rwho//var/spool/samba//var/spool/squid//var/spool/squirrelmail//var/spool/up2date//var/spool/uucp//var/spool/uucppublic//var/spool/vbox/
2.2. Emplacement des fichiers Red Hat Enterprise Linux spéciaux
/var/lib/rpm/. Pour obtenir des informations supplémentaires sur les RPM, veuillez consulter man rpm.
/var/cache/yum/ contient des fichiers utilisés par Package Updater, y compris les informations d'en-tête RPM de ce système. L'emplacement peut aussi être utilisé pour stocker temporairement les RPM téléchargés pendant la mise à jour du système. Pour obtenir davantage d'informations sur Red Hat Network, veuillez consulter la documentation en ligne sur https://rhn.redhat.com/.
/etc/sysconfig/ est un autre emplacement spécifique à Red Hat Enterprise Linux. Ce répertoire stocke toute un ensemble d'informations de configuration. De nombreux scripts exécutés lors du démarrage utilisent des fichiers situés dans ce répertoire.
2.3. Système de fichiers virtuel /proc
/proc ne contient ni texte, ni fichiers binaires. Au lieu de cela, il héberge des fichiers virtuels ; ainsi, /proc fait habituellement référence à un système de fichiers virtuel. La taille typique de ces fichiers virtuels est de zéro octets, même s'ils contiennent de grandes quantités d'informations.
/proc n'est pas utilisé pour le stockage. Son but principal est de fournir une interface basée sur fichiers pour le matériel, la mémoire, les processus en cours d'exécution, ainsi que pour les autres composants du système. Des informations en temps réel peuvent être récupérées sur de nombreux composants de système en affichant son fichier /proc correspondant. Certains des fichiers dans /proc peuvent également être manipulés (par les utilisateurs et les applications) pour configurer le noyau.
/proc suivants sont utiles pour le contrôle et la gestion du stockage du système :
- /proc/devices
- Affiche divers périphériques bloc et caractères actuellement configurés.
- /proc/filesystems
- Répertorie les types de systèmes de fichiers actuellemet pris en charge par le noyau.
- /proc/mdstat
- Contient des informations sur les configurations à disques multiples ou les configurations RAID sur le système, s'il y en a.
- /proc/mounts
- Répertorie tous les montages en cours d'utilisation par le système.
- /proc/partitions
- Contient les informations sur l'allocation de blocs de partitions.
/proc, veuillez consulter le Guide de déploiement Red Hat Enterprise Linux 6.
2.4. Abandonner les blocs inutilisés
fstrim. Cette commande abandonne tous les blocs inutilisés dans un système de fichiers correspondant aux critères de l'utilisateur. Ces deux types d'opération sont pris en charge pour une utilisation avec les systèmes de fichier ext4 dans Red Hat Enterprise Linux 6.2 et ses versions supérieures, tant que le périphérique bloc sous-jacent au système de fichiers prend en charge les opérations d'abandon physique. Ceci est aussi le cas avec les systèmes de fichiers XFS dans Red Hat Enterprise Linux 6.4 et ses versions supérieures. Les opérations d'abandon physique sont prises en charge si la valeur de /sys/block/device/queue/discard_max_bytes n'est pas zéro.
-o discard (soit dans /etc/fstab ou en faisant partie de la commande mount) et exécutées en temps réel sans intervention de la part de l'utilisateur. Les opérations d'abandon en ligne abandonnent uniquement les blocs passant de « Utilisé » à « Libre ». Les opérations d'abandon en ligne sont prises en charge sur les systèmes de fichiers ext4 dans Red Hat Enterprise Linux 6.2 et ses versions supérieures, ainsi que sur les systèmes de fichiers XFS dans Red Hat Enterprise Linux 6.4 et ses versions supérieures.
Chapitre 3. Système de fichiers chiffré
mkfs. Au contraire, eCryptfs est initié par l'exécution d'une commande de montage particulière. Pour gérer des systèmes de fichiers protégés par eCryptfs, le paquet ecryptfs-utils doit tout d'abord être installé.
3.1. Monter un système de fichiers comme chiffré
# mount -t ecryptfs /source /destination/source dans l'exemple ci-dessus) avec eCryptfs signifie le monter sur un point de montage chiffré par eCryptfs (/destination dans l'exemple ci-dessus). Toutes les opérations sur /destination seront passées chiffrées au système de fichiers sous-jacent /source. Cependant, dans certains cas, il peut être possible pour une opération de fichier de modifier /source directement, sans passer par la couche eCryptfs, ce qui pourrait mener à des incohérences.
/source et /destination soient identiques. Par exemple :
# mount -t ecryptfs /home /home/home passent effectivement via la couche eCryptfs.
mount permettra aux paramètres suivants d'être configurés :
- Type de clé de chiffrement
openssl,tspi, oupassphrase(« phrase de passe »). Lorsque vous choisissezpassphrase,mountvous demandera une phrase de passe.- Cipher
aes,blowfish,des3_ede,cast6, oucast5.- Taille d'octets de la clé
16,32, ou24.passthrough texte clair- Activé ou désactivé.
chiffrement du nom de fichier- Activé ou désactivé.
mount affichera toutes les sélections effectuées et procédera au montage. Cette sortie contient les équivalences des options de ligne de commande de chaque paramètre choisi. Par exemple, pour monter /home avec un type de clé phrase de passe, un chiffrement aes, une taille d'octet de 16 avec le relais en texte clair et le chiffrement de nom de fichier désactivés, la sortie sera :
Attempting to mount with the following options: ecryptfs_unlink_sigs ecryptfs_key_bytes=16 ecryptfs_cipher=aes ecryptfs_sig=c7fed37c0a341e19 Mounted eCryptfs
-o de la commande mount. Par exemple :
# mount -t ecryptfs /home /home -o ecryptfs_unlink_sigs\ecryptfs_key_bytes=16 ecryptfs_cipher=aes ecryptfs_sig=c7fed37c0a341e19[2]
3.2. Informations Supplémentaires
man ecryptfs (fourni par le paquet ecryptfs-utils). Le document sur le noyau suivant (fourni par le paquet kernel-doc) offre également des informations supplémentaires sur eCryptfs :
/usr/share/doc/kernel-doc-version/Documentation/filesystems/ecryptfs.txt
Chapitre 4. Btrfs
Note
4.1. Fonctionnalités de Btrfs
- Restauration de système intégrée
- Des instantanés du système de fichiers permettent la restauration du système sur un état précédent, connu et fonctionnant bien, au cas où un incident ne se produise.
- Compression intégrée
- Ceci permet d'économiser de l'espace plus facilement.
- Fonctionnalité Checksum
- Ceci permet d'améliorer la détection d'erreurs.
- l'ajout ou la suppression en ligne, dynamique de nouveaux périphériques de stockage ;
- la prise en charge interne de RAID à travers les périphériques composants ;
- la possibilité d'utiliser différents niveaux RAID pour les métadonnées ou pour les données utilisateurs ;
- la fonctionnalité checksum complète pour toutes les métadonnées et pour toutes les données utilisateur.
Chapitre 5. Système de fichiers Ext3
- Disponibilité
- Après une panne d'alimentation ou une panne du système inattendue (aussi appelé un arrêt du système incorrect), la cohérence de chaque système de fichiers ext2 monté sur la machine doit être vérifiée par le programme
e2fsck. Ce long processus peut retarder le démarrage du système de manière importante, particulièrement pour les volumes de grande taille contenant de nombreux fichiers. Pendant ce délai, on ne peut pas accéder aux données sur les volumes.Il est possible d'exécuterfsck -nsur un système de fichiers en direct. Cependant, aucun changement ne sera effectué et des résultats trompeurs pourraient être retournés s'il y a des métadonnées partiellement écrites.Si LVM est utilisé dans la pile, une autre option consiste à prendre un instantané LVM du système de fichiers et d'exécuterfsckdessus à la place.Finalement, il existe une option pour remonter le système de fichiers en lecture seule. Toutes les mises à jour (et écritures) de métadonnées en attente sont ensuite forcées sur le disque avant qu'il soit remonté. Ceci permet d'assurer que le système de fichiers se trouve dans un état cohérent, à condition qu'il n'y ait pas de corruption précédente. Il est désormais possible d'exécuterfsck -n.La journalisation offerte par le système de fichiers ext3 signifie que ce type de vérification de système de fichiers n'est plus nécessaire après un arrêt du système incorrect. La seule fois qu'une vérification de cohérence se produit en utilisant ext3 est dans certains rares cas de panne de matériel, comme lors de pannes de disque dur. Le temps pris pour récupérer un système de fichiers ext3 après un arrêt de système incorrect ne dépend pas de la taille du système de fichiers ou du nombre de fichiers, il dépend de la taille du journal utilisé pour maintenir une certaine cohérence. La taille de journal par défaut prend environ une seconde pour reprendre, en fonction de la vitesse du matériel.Note
Le seul mode de journalisation d'ext3 pris en charge par Red Hat estdata=ordered(par défaut). - Intégrité des données
- Le système de fichiers ext3 empêche la perte d'intégrité des données dans le cas où un arrêt du système incorrect se produirait. Le système de fichiers ext3 vous permet de choisir le type et le niveau de protection pour vos données. Quant à l'état du système de fichiers, les volumes ext3 sont configurés de manière à fournir un haut niveau de cohérence des données par défaut.
- Vitesse
- Malgré l'écriture de certaines données plus d'une fois, ext3 possède un plus haut débit que ext2 dans la plupart des cas car la journalisation d'ext3 optimise les mouvements de disque dur. Vous pouvez choisir parmi trois modes de journalisation pour optimiser la vitesse, mais ce faire entrainera des compromis au niveau de l'intégrité des données si jamais le système devait tomber en panne.
- Transition facile
- Il est facile de migrer d'ext2 à ext3 et de tirer profit des bénéfices d'un système de fichiers offrant une journalisation robuste sans reformatage. Veuillez consulter la Section 5.2, « Conversion vers un système de fichiers ext3 » pour obtenir des informations supplémentaire sur la manière d'accomplir cette tâche.
La taille par défaut de l'inode sur disque a augmenté afin de permettre un stockage plus efficace des attributs étendus, par exemple les attributs des listes ACL ou de SELinux. Avec ce changement, le nombre d'inodes créés par défaut sur un système de fichiers d'une taille donnée a été réduit. La taille d'inode peut être sélectionnée avec l'option mke2fs -I ou spécifiée dans /etc/mke2fs.conf pour définir les valeurs globales par défaut de mke2fs.
Note
data_err
Une nouvelle option de montage a été ajoutée : data_err=abort. Cette option ordonne à ext3 d'abandonner le journal si une erreur se produit dans un espace de données de fichier (et non dans un espace de métadonnées de fichier) sous le mode data=ordered. Cette option est désactivée par défaut (définie comme data_err=ignore).
Lors de la création d'un système de fichiers (avec mkfs), mke2fs tentera « d'abandonner » ou « d'éditer » les blocs qui ne sont pas utilisés par les métadonnées du système de fichiers. Ceci permet de faciliter l'optimisation des SSD ou de l'allocation dynamique. Pour supprimer ce comportement, veuillez utiliser l'option mke2fs -K.
5.1. Créer un système de fichiers ext3
Procédure 5.1. Créer un système de fichiers ext3
- Formatez la partition avec le système de fichiers ext3 en utilisant
mkfs. - Étiquetez le système de fichiers en utilisant
e2label.
5.2. Conversion vers un système de fichiers ext3
tune2fs convertit un système de fichiers ext2 en ext3.
Note
e2fsck afin de vérifier votre système de fichiers avant et après avoir utilisé tune2fs. Avant d'essayer de convertir ext2 en ext3, veuillez effectuer des copies de sauvegarde de tous les systèmes de fichiers au cas ou une erreur se produirait.
ext2 en système de fichiers ext3, connectez-vous en tant que root et saisissez la commande suivante dans une fenêtre de terminal :
# tune2fs -j block_device- Un périphérique mappé
- Un volume logique dans un groupe de volumes. Par exemple,
/dev/mapper/VolGroup00-LogVol02. - Un périphérique statique
- Un volume de stockage traditionnel. Par exemple,
/dev/sdbX, où sdb est un nom de périphérique de stockage et où X est le numéro de la partition.
df pour afficher les systèmes de fichiers montés.
5.3. Rétablir un système de fichiers Ext2
/dev/mapper/VolGroup00-LogVol02
Procédure 5.2. Rétablir depuis ext3 vers ext2
- Démontez la partition en vous connectant en tant que root et en saisissant :
# umount /dev/mapper/VolGroup00-LogVol02 - Modifiez le type du système de fichiers en ext2 en saisissant la commande suivante :
# tune2fs -O ^has_journal /dev/mapper/VolGroup00-LogVol02 - Vérifiez si la partition contient des erreurs en saisissant la commande suivante :
# e2fsck -y /dev/mapper/VolGroup00-LogVol02 - Puis montez la partition à nouveau en tant que système de fichiers ext2 en saisissant :
# mount -t ext2 /dev/mapper/VolGroup00-LogVol02 /mount/pointDans la commande ci-dessus, remplacez /mount/point par le point de montage de la partition.Note
Si un fichier.journalexiste au niveau root de la partition, supprimez-le.
/etc/fstab, sinon l'autre type de système de fichiers sera rétabli après un démarrage.
Chapitre 6. Le système de fichiers Ext4
Note
fsck. Pour obtenir des informations supplémentaires, veuillez consulter le Chapitre 5, Système de fichiers Ext3.
- Fonctionnalités principales
- Ext4 utilise des extensions (contrairement au schéma de mappage de blocs traditionnellement utilisé par ext2 et ext3), ce qui améliore les performances lors de l'utilisation de fichiers de grande taille, et réduit les en-têtes des métadonnées des fichiers de grande taille. En outre, ext4 étiquette également les groupes de blocs et les sections de tables d'inodes en conséquence, ce qui leur permet d'être ignorés pendant les vérifications de systèmes de fichiers. Ceci permet d'effectuer des vérifications de systèmes de fichiers plus rapides, qui deviendront de plus en plus avantageuses au fur et à mesure que la taille du système de fichiers augmente.
- Fonctionnalités d'allocation
- Le système de fichiers ext4 offre les schémas d'allocation suivants :
- La pré-allocation persistante
- L'allocation différée
- L'allocation multi-blocs
- L'allocation par entrelacement
À cause de l'allocation différée, et dû à d'autres optimisations des performances, le comportement d'ext4 lors de l'écriture sur disque est différent d'ext3. Avec ext4, lorsqu'un programme est écrit sur le système de fichiers, il n'est pas garanti que ce soit effectivement sur disque à moins que le programme n'exécute un appelfsync()après.Par défaut, ext3 force automatiquement les fichiers récemment créés sur le disque de manière quasi immédiate, même sansfsync(). Ce comportement cache les bogues des programmes qui n'ont pas utiliséfsync()afin de s'assurer que les données écrites l'étaient sur disque. Contrairement à cela, le système de fichiers ext4 attend souvent plusieurs secondes pour écrire les changements sur le disque, lui permettant de combiner et de réarranger les écritures pour offrir de meilleures performances qu'ext3.Avertissement
Contrairement à ext3, le système de fichiers ext4 ne force pas les données sur disque lors des enregistrements de transactions. Ainsi, des écritures mises en mémoire tampon mettent plus longtemps pour être vidées sur le disque. Quant aux systèmes de fichiers, veuillez utiliser des appels d'intégrité de données, tels quefsync(), afin de vous assurer que les données soient effectivement écrites sur un stockage permanent. - Autres fonctionnalités Ext4
- Le système de fichiers ext4 prend également en charge :
- Les attributs étendus (
xattr) — Ceux-ci permettent au système d'associer plusieurs noms et paires de valeurs supplémentaires par fichier. - Journalisation de quotas — Ceci permet d'éviter le besoin de longues vérifications de la cohérence des quotas après une panne.
Note
Le seul mode de journalisation pris en charge sur ext4 estdata=ordered(par défaut). - Horodatage subsecond — Ceci donne la deuxième décimale des secondes à l'horodatage.
6.1. Créer un système de fichiers Ext4
mkfs.ext4. En général, les options par défaut sont optimales pour la plupart des scénarios d’utilisation :
# mkfs.ext4 /dev/deviceExemple 6.1. Sortie de la commande mkfs.ext4
~]# mkfs.ext4 /dev/sdb1 mke2fs 1.41.12 (17-May-2010) Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) Stride=0 blocks, Stripe width=0 blocks 245280 inodes, 979456 blocks 48972 blocks (5.00%) reserved for the super user First data block=0 Maximum filesystem blocks=1006632960 30 block groups 32768 blocks per group, 32768 fragments per group 8176 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736 Writing inode tables: done Creating journal (16384 blocks): done Writing superblocks and filesystem accounting information: done This filesystem will be automatically checked every 20 mounts or 180 days, whichever comes first. Use tune2fs -c or -i to override.
mkfs.ext4 choisit une géométrie optimale. Ceci peut également s'appliquer à certains types de matériel RAID qui exportent des informations sur la géométrie au système d'exploitation.
-E de mkfs.ext4 (c'est-à-dire les options de système de fichiers étendues) avec les sous-options suivantes :
- stride=value
- Spécifie la taille du bloc RAID.
- stripe-width=value
- Spécifie le nombre de disques de données dans un périphérique RAID, ou le nombre d'unités d'entrelacement dans l'entrelacement.
value » doit être spécifiée en unités de bloc de système de fichiers. Par exemple, pour créer un système de fichiers avec un stride de 64k (c'est-à-dire 16 x 4096) sur un système de fichiers de blocs de 4k, veuillez utiliser la commande suivante :
# mkfs.ext4 -E stride=16,stripe-width=64 /dev/deviceman mkfs.ext4.
Important
tune2fs pour activer certaines fonctionnalités ext4 sur des systèmes de fichiers ext3, et d'utiliser le pilote ext4 pour monter un système de fichiers ext3. Cependant, ces actions ne sont pas prises en charge sur Red Hat Enterprise Linux 6 car elles n'ont pas été totalement testées. À cause de cela, Red Hat ne peut pas garantir de performance cohérente ou de comportement prévisible pour les systèmes de fichiers ext3 convertis ou montés de cette manière.
6.2. Monter un système de fichiers Ext4
# mount /dev/device /mount/pointacl active les listes de contrôle d'accès (« ACL »), tandis que le paramètre user_xattr active les attributs étendus d'utilisateur. Pour activer les deux options, veuillez utiliser leurs paramètres respectifs avec -o, comme suit :
# mount -o acl,user_xattr /dev/device /mount/pointtune2fs permet également aux administrateurs définir les options de montage par défaut dans le superbloc du système de fichiers. Pour obtenir des informations supplémentaires, veuillez consulter man tune2fs.
Barrières d'écriture
nobarrier, comme suit :
# mount -o nobarrier /dev/device /mount/point6.3. Redimensionner un système de fichiers Ext4
resize2fs :
# resize2fs /mount/device noderesize2fs peut également réduire la taille d'un système de fichiers ext4 non monté :
# resize2fs /dev/device sizeresize2fs lit la taille de bloc du système de fichiers en unités, à moins qu'un suffixe indiquant une unité particulière ne soit utilisé. Les suffixes suivants indiquent des unités particulières :
s— secteurs de 512 octets sectorsK— kilooctetsM— mégaoctetsG— gigaoctets
Note
resize2fs s'étend automatiquement pour remplir tout l'espace disponible du conteneur, habituellement un volume ou une partition logique.
man resize2fs.
6.4. Sauvegarde des systèmes de fichiers ext2/3/4
Procédure 6.1. Exemple de sauvegarde des systèmes de fichiers ext2/3/4
- Toutes les données doivent être sauvegardées avant de tenter les opérations de restauration. Les sauvegardes de données doivent être effectuées régulièrement. En plus des données, il y a des informations de configuration qui doivent être sauvegardées, y compris
/etc/fstabet la sortie defdisk -l. Exécuter un sosreport/sysreport capturera cette information et est fortement conseillé.# cat /etc/fstab LABEL=/ / ext3 defaults 1 1 LABEL=/boot1 /boot ext3 defaults 1 2 LABEL=/data /data ext3 defaults 0 0 tmpfs /dev/shm tmpfs defaults 0 0 devpts /dev/pts devpts gid=5,mode=620 0 0 sysfs /sys sysfs defaults 0 0 proc /proc proc defaults 0 0 LABEL=SWAP-sda5 swap swap defaults 0 0 /dev/sda6 /backup-files ext3 defaults 0 0 # fdisk -l Device Boot Start End Blocks Id System /dev/sda1 * 1 13 104391 83 Linux /dev/sda2 14 1925 15358140 83 Linux /dev/sda3 1926 3200 10241437+ 83 Linux /dev/sda4 3201 4864 13366080 5 Extended /dev/sda5 3201 3391 1534176 82 Linux swap / Solaris /dev/sda6 3392 4864 11831841 83 Linux
Dans cet exemple, nous allons utiliser la partition/dev/sda6pour sauvegarder des fichiers de sauvegarde, et nous assumons que/dev/sda6est monté sur le fichier/backup-files. - Si la partition sauvegardée est dans une partition de système d'exploitation, démarrez votre système en mode Single User. Cette étape n'est pas utile dans les cas de partitions de données normales.
- Utiliser la commande
dumppour sauvegarder le contenu des partitions :Note
- Si le système est en cours d'exécution depuis un bon moment, il est conseillé d'exécuter
e2fscksur les partitions avant la sauvegarde. dumpne doit pas être utilisé sur un système de fichiers monté et à forte charge car des versions corrompues de fichiers pourraient être sauvegardées. Ce problème a été soulevé dans dump.sourceforge.net.Important
Quand on sauvegarde des partitions de système d'exploitation, la partition doit être dé-montée.Bien qu'il soit possible de sauvegarder une partition de données ordinaire montée, il vaut mieux la dé-monter si possible. Si la partition de données est montée, les résultats de la sauvegarde sont imprévisibles.
# dump -0uf /backup-files/sda1.dump /dev/sda1 # dump -0uf /backup-files/sda2.dump /dev/sda2 # dump -0uf /backup-files/sda3.dump /dev/sda3
Si vous souhaitez effectuer une sauvegarde à distance, vous pourrez utiliser ssh ou bien vous pourrez configurer une connexion sans mot de passe.Note
Si vous utilisez une redirection standard, l'option « -f » devra être passée séparemment.# dump -0u -f - /dev/sda1 | ssh root@remoteserver.example.com dd of=/tmp/sda1.dump
6.5. Restaurer un système de fichiers ext2/3/4
Procédure 6.2. Exemple de restauration d'un système de fichiers ext2/3/4
- Si vous restaurez une partition de système d'exploitation, démarrez votre système en mode Rescue. Cette étape n'est pas requise pour les partitions de données ordinaires.
- Reconstruire sda1/sda2/sda3/sda4/sda5 à l'aise de la commande
fdisk.Note
Si nécessaire, créer des partitions qui puissent contenir les systèmes de fichiers restaurés. Les nouvelles partitions doivent être suffisamment grandes pour pouvoir contenir les données restaurées. Il est important d'avoir les bons numéros de début et de fin ; ce sont les numéros de secteurs de début et de fin des partitions. - Formater les partitions de destination en utilisant la commande
mkfs, comme montré ci-dessous.Important
NE PAS formater/dev/sda6dans l'exemple ci-dessus car il sauvegarde les fichiers de sauvegarde.# mkfs.ext3 /dev/sda1 # mkfs.ext3 /dev/sda2 # mkfs.ext3 /dev/sda3
- Si vous créez des nouvelles partitions, rénommez toutes les partitions pour qu'elles puissent correspondre au fichier
fstab. Cette étape n'est pas utile si les partitions ne sont pas créées à nouveau.# e2label /dev/sda1 /boot1 # e2label /dev/sda2 / # e2label /dev/sda3 /data # mkswap -L SWAP-sda5 /dev/sda5
- Préparer les répertoires de travail.
# mkdir /mnt/sda1 # mount -t ext3 /dev/sda1 /mnt/sda1 # mkdir /mnt/sda2 # mount -t ext3 /dev/sda2 /mnt/sda2 # mkdir /mnt/sda3 # mount -t ext3 /dev/sda3 /mnt/sda3 # mkdir /backup-files # mount -t ext3 /dev/sda6 /backup-files
- Restaurer les données.
# cd /mnt/sda1 # restore -rf /backup-files/sda1.dump # cd /mnt/sda2 # restore -rf /backup-files/sda2.dump # cd /mnt/sda3 # restore -rf /backup-files/sda3.dump
Si vous souhaitez restaurer à partir d'un hôte éloigné ou d'un fichier de sauvegarde d'un hôte éloigné, utiliser ssh ou rsh. Vous devrez configurer une connexion sans mot de passe pour les exemples suivants :Connectez-vous à 10.0.0.87, et restaurez sda1 à partir du fichier local sda1.dump :# ssh 10.0.0.87 "cd /mnt/sda1 && cat /backup-files/sda1.dump | restore -rf -"
Connectez-vous à 10.0.0.87, et restaurez sda1 à partir du fichier distant 10.66.0.124 sda1.dump :# ssh 10.0.0.87 "cd /mnt/sda1 && RSH=/usr/bin/ssh restore -r -f 10.66.0.124:/tmp/sda1.dump"
- Démarrez à nouveau.
6.6. Autres utilitaires du système de fichiers Ext4
- e2fsck
- Utilisé pour réparer un système de fichiers ext4. Cet outil vérifie et répare un système de fichiers ext4 plus efficacement qu'ext3, grâce aux mises à jour apportées à la structure de disque ext4.
- e2label
- Change l'étiquette sur un système de fichiers ext4. Cet outil fonctionne également sur les systèmes de fichiers ext2 et ext3.
- quota
- Contrôle et effectue des rapports sur l'utilisation de l'espace disque (les blocs) et des fichiers (inodes) par les utilisateurs et les groupes sur un système de fichiers ext4. Pour obtenir des informations sur l'utilisation de
quota, veuillez consulterman quotaet la Section 16.1, « Configurer les quotas de disques ».
tune2fs peut également ajuster des paramètres de systèmes de fichiers configurables pour les systèmes de fichiers ext2, ext3, et ext4. En outre, les outils suivants sont aussi utiles pour le débogage et l'analyse des système de fichiers ext4 :
- debugfs
- Débogue les systèmes de fichiers ext2, ext3, ou ext4.
- e2image
- Enregistre les métadonnées critiques des systèmes de fichiers ext2, ext3, ou ext4 sur un fichier.
man respectives.
Chapitre 7. Global File System 2
fsck sur un système de fichiers de très grande taille peut prendre longtemps et consommer beaucoup de mémoire. De plus, en cas de défaillance d'un disque ou d'un sous-système de disque, le temps de récupération sera limité par la vitesse de votre support de sauvegarde.
clvmd, qui est exécuté dans un cluster de Red Hat Cluster Suite. Le démon facilite l'utilisation de LVM2 pour gérer les volumes logiques à travers un cluster, permettant ainsi à tous les nœuds du cluster de partager les volumes logiques. Pour obtenir des informations sur le gestionnaire de volumes logiques LVM, veuillez consulter le guide de Red Hat Administration du gestionnaire de volumes logiques.
gfs2.ko implémente le système de fichiers GFS2 et est chargé dans les nœuds de cluster GFS2.
Chapitre 8. Le système de fichiers XFS
- Fonctionnalités principales
- XFS prend en charge la journalisation de métadonnées, ce qui facilite une récupération après incident plus rapide. Le système de fichiers XFS peut aussi être défragmenté et élargi alors qu'il est monté et actif. En outre, Red Hat Enterprise Linux 6 prend en charge les utilitaires de sauvegarde et de restauration spécifiques à XFS.
- Fonctionnalités d'allocation
- XFS offre les schémas d'allocation suivants :
- Allocation basée sur extensions
- Politiques d'allocation par entrelacement
- L'allocation différée
- Pré-allocation de l'espace
L'allocation différée et les autres optimisations des performances affectent XFS de la même manière qu'ext4. Autrement dit, les écritures d'un programme sur un système de fichiers XFS ne garantissent pas d'être sur disque à moins que le programme n'effectue un appelfsync()après.Pour obtenir des informations supplémentaires sur les implications de l'allocation différée sur un système de fichiers, veuillez consulter les Fonctionnalités de l'allocation dans le Chapitre 6, Le système de fichiers Ext4. La solution de contournement pour s'assurer des écritures sur disque s'applique également à XFS. - Autres fonctionnalités XFS
- Le système de fichiers XFS prend également en charge ce qui suit :
- Attributs étendus (
xattr) - Ceci permet au système d'associer plusieurs paires nom/valeur supplémentaires par fichiers.
- Journalisation de quotas
- Ceci permet d'éviter le besoin de longues vérifications de cohérence des quotas après une panne.
- Quotas de projets/répertoires
- Ceci permet les restrictions de quotas sur une arborescence de répertoires.
- Horodatage subsecond
- Ceci permet à l'horodatage de donner la deuxième décimale des secondes.
- Attributs étendus (
8.1. Créer un système de fichiers XFS
mkfs.xfs /dev/device. En général, les options par défaut sont optimales pour un usage commun.
mkfs.xfs sur un périphérique bloc contenant un système de fichiers, veuillez utiliser l'option -f pour forcer le remplacement de ce système de fichiers.
Exemple 8.1. Sortie de la commande mkfs.xfs
mkfs.xfs :
meta-data=/dev/device isize=256 agcount=4, agsize=3277258 blks
= sectsz=512 attr=2
data = bsize=4096 blocks=13109032, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0
log =internal log bsize=4096 blocks=6400, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0Note
xfs_growfs (veuillez consulter Section 8.4, « Augmenter la taille d'un système de fichiers XFS »).
mkfs.xfs choisit une géométrie optimale. Ceci peut également s'appliquer à certains types de matériel RAID qui exportent des informations sur la géométrie au système d'exploitation.
mkfs.xfs suivantes :
- su=value
- Spécifie une unité d'entrelacement ou une taille de morceau RAID. La valeur
valuedoit être indiquée en octets, avec un suffixe optionnelk,m, oug. - sw=value
- Spécifie le nombre de disques de données dans un périphérique RAID, ou le nombre d'unités d'entrelacement dans l'entrelacement.
# mkfs.xfs -d su=64k,sw=4 /dev/deviceman mkfs.xfs.
8.2. Monter un système de fichiers XFS
# mount /dev/device /mount/pointinode64. Cette option configure XFS pour allouer des inodes et données à travers le système de fichiers tout entier, ce qui peut améliorer les performances :
# mount -o inode64 /dev/device /mount/pointBarrières d'écriture
nobarrier :
# mount -o nobarrier /dev/device /mount/point8.3. Gestion des quotas XFS
noenforce ; ceci permettra d'effectuer des rapport d'utilisation sans appliquer de limite. Les options de montage de quotas valides incluent :
uquota/uqnoenforce- Quotas d'utilisateursgquota/gqnoenforce- Quotas de groupespquota/pqnoenforce- Quotas de projets
xfs_quota peut être utilisé pour définir les limites et effectuer un rapport sur l'utilisation du disque. Par défaut, xfs_quota est exécuté de manière interactive et dans le mode de base. Les sous-commandes du mode de base rapportent simplement l'usage et sont disponibles à tous les utilisateurs. Les sous-commandes xfs_quota de base incluent :
- quota username/userID
- Afficher l'utilisation et les limites pour le nom d'utilisateur
usernamedonné ou l'ID numériqueuserIDdonné - df
- Afficher le compte des blocs et inodes disponibles et utilisés
xfs_quota possède également un mode expert. Les sous-commandes de ce mode permettent la configuration des limites, et sont uniquement disponibles aux utilisateurs possédant des privilièges élevés. Pour utiliser les sous-commandes du mode expert de manière interactive, veuillez exécuter xfs_quota -x. Les sous-commandes du mode expert incluent :
- report /path
- Rapport des informations sur les quotas d'un système de fichiers particulier
- limit
- Modifier les limites de quota.
help.
-c, avec -x pour les sous-commandes du mode expert.
Exemple 8.2. Afficher un exemple de rapport de quotas
/home (sur /dev/blockdevice), veuillez utiliser la commande xfs_quota -cx 'report -h' /home. Ceci affichera une sortie similaire à la suivante :
User quota on /home (/dev/blockdevice)
Blocks
User ID Used Soft Hard Warn/Grace
---------- ---------------------------------
root 0 0 0 00 [------]
testuser 103.4G 0 0 00 [------]
...john (dont le répertoire d'acceuil est /home/john), veuillez utiliser la commande suivante :
# xfs_quota -x -c 'limit isoft=500 ihard=700 /home/john'limit reconnaît les cibles en tant qu'utilisateurs. Lors de la configuration des limites d'un groupe, veuillez utiliser l'option -g (comme dans l'exemple précédent). De la même manière, veuillez utiliser -p pour les projets.
bsoft ou bhard au lieu de isoft ou ihard.
Exemple 8.3. Définir une limite douce (« soft ») et une limite dure (« hard »)
accounting sur le système de fichiers /target/path, veuillez utiliser la commande suivante :
# xfs_quota -x -c 'limit -g bsoft=1000m bhard=1200m accounting' /target/pathImportant
rtbhard/rtbsoft) sont décrits dans man xfs_quota comme étant des unités valides lors du paramétrage de quotas, le sous-volume en temps réel n'est pas activé dans cette version. Ainsi, les options rtbhard et rtbsoft ne sont pas applicables.
Paramétrer des limites de projets
/etc/projects. Les noms de projets peuvent être ajoutés à /etc/projectid pour lier les ID de projets aux noms de projets. Une fois qu'un projet est ajouté à /etc/projects, veuillez initialiser son répertoire de projet en utilisant la commande suivante :
# xfs_quota -c 'project -s projectname'
# xfs_quota -x -c 'limit -p bsoft=1000m bhard=1200m projectname'quota, repquota, et edquota) peuvent également être utilisés pour manipuler les quotas XF. Cependant, ces outils ne peuvent pas être utilisés avec les quotas des projets XFS.
man xfs_quota.
8.4. Augmenter la taille d'un système de fichiers XFS
xfs_growfs :
# xfs_growfs /mount/point -D size-D size permet d'augmenter la taille du système de fichiers à la taille size spécifiée (exprimée en nombre de blocs de système de fichier). Sans l'option -D size, xfs_growfs augmentera la taille du système de fichiers à la taille maximum prise en charge par le périphérique.
-D size, assurez-vous que la taille du périphérique bloc sous-jacent sera appropriée pour contenir le système de fichiers. Veuillez utiliser les méthodes correctes de redimensionnement pour les périphériques bloc affectés.
Note
man xfs_growfs.
8.5. Réparer un système de fichiers XFS
xfs_repair:
# xfs_repair /dev/devicexfs_repair est hautement évolutif et a également été conçu pour réparer des systèmes de fichiers de très grande taille avec de nombreux inodes de manière efficace. Contrairement aux autres systèmes de fichiers Linux, xfs_repair n'est pas exécuté lors du démarrage, même lorsqu'un système de fichiers XFS n'a pas été monté correctement. En cas de démontage incorrect, xfs_repair rediffuse simplement le journal pendant le montage, s'assurant ainsi d'un système de fichiers cohérent.
Avertissement
xfs_repair ne peut pas réparer un système de fichiers XFS avec un journal endommagé. Pour supprimer le journal, montez et démontez le système de fichiers. Si le journal est corrompu et qu'il ne peut pas être réutilisé, veuillez utiliser l'option -L (« forcer la mise à zéro du journal ») pour supprimer le journal, c'est-à-dire xfs_repair -L /dev/device. Prenez note que cette opération peut provoquer une corruption ou des pertes de données supplémentaires.
man xfs_repair.
8.6. Suspendre un système de fichier XFS
xfs_freeze. La suspension d'activités d'écriture permet l'utilisation des instantanés de périphériques basés matériel pour capturer le système de fichiers dans un état cohérent.
Note
xfs_freeze est fournit par le paquet xfsprogs, qui est uniquement disponbible sur x86_64.
# xfs_freeze -f /mount/point
# xfs_freeze -u /mount/pointxfs_freeze pour suspendre le système de fichiers avant tout. Au contraire, les outils de gestion LVM suspendront automatiquement le système de fichiers XFS avant de prendre l'instantané.
Note
xfs_freeze peut également être utilisé pour geler ou dégeler un système de fichier ext3, ext4, GFS2, XFS, et BTRFS. La syntaxe pour ce faire est la même.
man xfs_freeze.
8.7. Sauvegarde et restauration des systèmes de fichiers XFS
xfsdump et xfsrestore.
xfsdump. Red Hat Enterprise Linux 6 prend en charge les sauvegardes sur lecteurs de bande ou images fichiers normales, et permet également d'écrire plusieurs vidages sur le même lecteur. L'utilitaire xfsdump permet aussi à un vidage de s'étendre sur plusieurs lecteurs, même si un vidage peut être écrit sur un fichier normal. En outre, xfsdump prend en charge les sauvegardes incrémentales, et peut exclure des fichiers d'une sauvegarde en utilisant la taille, une sous-arborescence, ou des indicateurs d'inodes pour les filtrer.
xfsdump utilise des niveaux de vidage pour déterminer un vidage de base auquel un vidage particulier est relatif. L'option -l spécifie un niveau de vidage (0-9). Pour effectuer une copie de sauvegarde complète, veuillez effectuer un vidage de niveau 0 sur le système de fichiers (c'est-à-dire /path/to/filesystem), comme suit :
# xfsdump -l 0 -f /dev/device /path/to/filesystemNote
-f spécifie une destination pour la sauvegarde. Par exemple, la destination /dev/st0 est normalement utilisée pour les lecteurs de bande. Une destination xfsdump peut être un lecteur de bande, un fichier normal, ou un périphérique de bande distant.
# xfsdump -l 1 -f /dev/st0 /path/to/filesystemxfsrestore restaure les systèmes de fichiers depuis les vidages produits par xfsdump. L'utilitaire xfsrestore possède deux modes : un mode par défaut simple, et un mode cumulatif. Les vidages spécifiques sont identifiés par ID de session ou par étiquette de session. Ainsi, restaurer un vidage requiert son ID ou étiquette de session correspondant. Pour afficher les ID et étiquettes de session de tous les vidages (complets et incrémentaux), veuillez utiliser l'option -I :
# xfsrestore -IExemple 8.4. ID et étiquettes de session de tous les vidages
file system 0: fs id: 45e9af35-efd2-4244-87bc-4762e476cbab session 0: mount point: bear-05:/mnt/test device: bear-05:/dev/sdb2 time: Fri Feb 26 16:55:21 2010 session label: "my_dump_session_label" session id: b74a3586-e52e-4a4a-8775-c3334fa8ea2c level: 0 resumed: NO subtree: NO streams: 1 stream 0: pathname: /mnt/test2/backup start: ino 0 offset 0 end: ino 1 offset 0 interrupted: NO media files: 1 media file 0: mfile index: 0 mfile type: data mfile size: 21016 mfile start: ino 0 offset 0 mfile end: ino 1 offset 0 media label: "my_dump_media_label" media id: 4a518062-2a8f-4f17-81fd-bb1eb2e3cb4f xfsrestore: Restore Status: SUCCESS
Mode simple de xfsrestore
session-ID), veuillez le restaurer complètement sur /path/to/destination en utilisant :
# xfsrestore -f /dev/st0 -S session-ID /path/to/destinationNote
-f spécifie l'emplacement du vidage, tandis que l'option -S ou -L indique le vidage particulier à restaurer. L'option -S est utilisée pour spécifier un ID de session, tandis que l'option -L est utilisée pour les étiquettes de session. L'option -I affiche les étiquettes et ID de session de chaque vidage.
Mode cumulatif de xfsrestore
xfsrestore permet la restauration de systèmes de fichier à partir d'une sauvegarde incrémentale particulière, par exemple, du niveau 1 au niveau 9. Pour restaurer un système de fichiers à partir d'une sauvegarde incrémentale, veuillez simplement ajouter l'option -r :
# xfsrestore -f /dev/st0 -S session-ID -r /path/to/destinationOpération interactive
xfsrestore permet également à des fichiers particuliers d'un vidage d'être extraits, ajoutés ou supprimés. Pour utiliser xfsrestore de manière interactive, veuillez utiliser l'option -i, comme suit :
xfsrestore -f /dev/st0 -i
xfsrestore termine de lire le périphérique spécifié. Les commandes de cette boîte de dialogue incluent cd, ls, add, delete, et extract ; pour obtenir une liste complète des commandes, veuillez utiliser help.
man xfsdump et man xfsrestore.
8.8. Autres utilitaires des systèmes de fichiers XFS
- xfs_fsr
- Utilisé pour défragmenter les systèmes de fichiers XFS montés. Lorsqu'invoqué sans arguments,
xfs_fsrdéfragmente tous les fichiers normaux dans tous les systèmes de fichiers XFS montés. Cet utilitaire permet également aux utilisateurs de suspendre une défragmentation à une heure spécifiée et de la reprendre au même endroit ultérieurement.En outre,xfs_fsrpermet également la défragmentation d'un seul fichier, comme dansxfs_fsr /path/to/file. Red Hat recommande d'éviter de défragmenter un système de fichiers entier de manière périodique car ceci n'est normalement pas justifié. - xfs_bmap
- Imprime la carte des blocs de disque utilisés par les fichiers dans un système de fichiers XFS. Cette carte répertorie chaque extension utilisés par un fichier spécifié, ainsi que les régions du fichiers n'offrant pas de bloc correspondant (c'est-à-dire, des trous).
- xfs_info
- Imprime les informations du système de fichiers XFS.
- xfs_admin
- Modifie les paramètres d'un système de fichiers XFS. L'utilitaire
xfs_adminpeut uniquement modifier les paramètres de périphériques ou systèmes de fichiers non montés. - xfs_copy
- Copie la totalité du contenu d'un système de fichiers XFS entier sur une ou plusieurs cibles en parallèle.
- xfs_metadump
- Copie les métadonnées du système de fichiers XFS sur un fichier. L'utilitaire
xfs_metadumpdoit uniquement être utilisé pour copier les systèmes de fichiers non montés, en lecture seule, ou gelés ou suspendus ; sinon les vidages générés pourraient être corrompus ou incohérents. - xfs_mdrestore
- Restaure une image metadump XFS (générée avec
xfs_metadump) sur une image de système de fichiers. - xfs_db
- Débogue un système de fichiers XFS.
man respectives.
Chapitre 9. Network File System (NFS)
9.1. Fonctionnement NFS
rpcbind, prend en charge les ACL, et utilise des opérations « Stateful » (avec état). Red Hat Enterprise Linux 6 prend en charge les clients NFSv2, NFSv3, et NFSv4. Lors du montage d'un système de fichiers via NFS, Red Hat Enterprise Linux utilise NFSv4 par défaut si le serveur le prend en charge.
rpcbind [3], lockd, et rpc.statd. Le démon rpc.mountd est requis sur le serveur NFS pour créer les exports.
Note
'-p' pouvant définir le port, ce qui rend la configuration du pare-feu plus facile.
/etc/exports pour déterminer si le client a le droit d'accéder à un système de fichiers exporté. Une fois cette vérification effectuée, toutes les opérations des fichiers et répertoires seront disponibles pour l'utilisateur.
Important
rpc.nfsd permettent désormais la liaison vers tout port spécifié pendant le démarrage système. Cependant, ceci est prône aux erreurs si le port est indisponible, ou s'il est en conflit avec un autre démon.
9.1.1. Services requis
rpcbind. Pour partager ou monter les systèmes de fichiers NFS, les services suivants travaillent ensemble selon la version NFS implémentée :
Note
portmap a été utilisé pour mapper les numéros de programmes RPC à des combinaisons de numéros de port d'adresses IP dans des versions plus récentes de Red Hat Enterprise Linux. Ce service est désormais remplacé par rpcbind dans Red Hat Enterprise Linux 6 afin de permettre la prise en charge d'IPv6. Pour obtenir des informations supplémentaires sur ce changement, veuillez consulter les liens suivants :
- TI-RPC / prise en charge rpcbind : http://nfsv4.bullopensource.org/doc/tirpc_rpcbind.php
- Prise en charge IPv6 sur NFS : http://nfsv4.bullopensource.org/doc/nfs_ipv6.php
- nfs
service nfs startlance le serveur NFS et les processus RPC appropriés pour servir les requêtes des systèmes de fichiers NFS partagés.- nfslock
service nfslock startactive un service obligatoire qui lance les processus RPC appropriés, ce qui permet aux clients NFS de verrouiller des fichiers sur le serveur.- rpcbind
rpcbindaccepte les réservations de ports des services RPC locaux. Ces ports sont ensuite mis à disponibilité (ou publicisés) afin que les services RPC à distance correspondants puissent y accéder.rpcbindrépond à des requêtes de service RPC et paramètre des connexions vers le service RPC requis. Ceci n'est pas utilisé avec NFSv4.- rpc.nfsd
rpc.nfsdpermet de définir les versions et protocoles NFS explicites publicisés par le serveur. Celui-ci fonctionne avec le noyau Linux afin de répondre aux demandes des clients NFS, comme pour fournir des threads chaque fois qu'un client NFS se connecte. Ce processus correspond au servicenfs.Note
À partir de Red Hat Enterprise Linux 6.3, seul le serveur NFSv4 utiliserpc.idmapd. Le client NFSv4 utilisenfsidmapde l'imapper basé-keyring .nfsidmapest un programme autonome appelé par le noyau à la demande pour effectuer les mappages d'ID ; ce n'est pas un démon. S'il y a un problème avecnfsidmap, le client utilise alorsrpc.idmapd. Vous trouverez plus d'informations surnfsidmapdans la page man de nfsidmap.
- rpc.mountd
- Ce processus est utilisé par un serveur NFS pour traiter les requêtes
MOUNTdes clients NFSv2 et NFSv3. Il vérifie que le partage NFS requis est actuellement exporté par le serveur NFS, et que le client est autorisé à y accéder. Si la requête de montage est autorisée, le serveur rpc.mountd répond avec le statutSuccess(« Opération réussie ») et retourne l'identificateur de fichier «File-Handle» de ce partage NFS au client NFS. - lockd
lockdest un thread du noyau qui peut être exécuté sur les clients et les serveurs. Il implémente le protocole NLM (« Network Lock Manager »), qui permet aux clients NFSv2 et NFSv3 de verrouiller des fichiers sur le serveur. Il est lancé automatiquement à chaque fois que le serveur NFS est exécuté et à chaque fois qu'un système de fichiers NFS est monté.- rpc.statd
- Ce processus implémente le protocole RPC NSM (« Network Status Monitor »), qui notifie les clients NFS lorsqu'un serveur NFS est redémarré sans avoir tout d'abord été éteint correctement.
rpc.statdest automatiquement démarré par le servicenfslock, et ne requiert pas de configuration utilisateur. Ce protocole n'est pas utilisé avec NFSv4. - rpc.rquotad
- Ce processus fournit des informations sur le quota d'utilisateur des utilisateurs distants.
rpc.rquotadest automatiquement démarré par le servicenfset ne requiert pas de configuration utilisateur. - rpc.idmapd
rpc.idmapdfournit des appels ascendants client et serveur NFSv4, qui mappent simultanément les noms NFSv4 (chaînes sous le formatutilisateur@domaine) et les UID et GID locaux. Pour queidmapdpuisse fonctionner avec NFSv4, le fichier/etc/idmapd.confdoit être configuré. Au minimum, le paramètre « Domaine », qui définit le domaine de mappage NFSv4, doit être spécifié. Si le domaine de mappage NFSv4 est le même que le nom de domaine DNS, oubliez ce paramètre. Le client et le serveur doivent se mettre d'accord sur le domaine de mappage NFSv4 pour que le mappage d'ID fonctionne correctement. Veuillez consulter l'article de la base de connaissances https://access.redhat.com/site/solutions/130783 lorsque vous utilisez un domaine local.
9.2. pNFS
-o minorversion=1-o v4.1nfs_layout_nfsv41_files est automatiquement chargé sur le premier montage. Veuillez utiliser la commande suivante pour vérifier que le module a bien été chargé :
$ lsmod | grep nfs_layout_nfsv41_filesmount permet également de vérifier qu'un montage NFSv4.1 a été effectué avec succès. L'entrée de montage dans la sortie devrait contenir minorversion=1.
Important
9.3. Configuration du client NFS
mount monte les partages NFS côté client. Son format est comme suit :
# mount -t nfs -o options server:/remote/export /local/directory- options
- Liste d'options de montage séparées par des virgules. Veuillez consulter la Section 9.5, « Options de montage NFS courantes » pour obtenir des détails sur les options de montage NFS valides.
- server
- Nom d'hôte, adresse IP, ou nom de domaine complet du serveur exportant le système de fichiers que vous souhaitez monter
- /remote/export
- Système de fichiers ou répertoire en cours d'exportation du serveur, c'est-à-dire le répertoire que vous souhaitez monter
- /local/directory
- Emplacement du client où /remote/export est monté
mount nfsvers ou vers. Par défaut, mount utilisera NFSv4 avec mount -t nfs. Si le serveur ne prend pas en charge NFSv4, le client passera automatiquement à une version prise en charge par le serveur. Si l'option nfsvers/vers est utilisée pour passer une version particulière qui n'est pas prise en charge par le serveur, le montage échouera. Le type de système de fichiers nfs4 est également disponible pour des raisons d'héritage ; ceci est équivalent à exécuter mount -t nfs -o nfsvers=4 host:/remote/export /local/directory.
man mount pour davantage de détails.
/etc/fstab et le service autofs. Veuillez consulter la Section 9.3.1, « Monter des systèmes de fichiers NFS à l'aide de /etc/fstab » et Section 9.4, « autofs » pour obtenir davantage d'informations.
9.3.1. Monter des systèmes de fichiers NFS à l'aide de /etc/fstab
/etc/fstab. La ligne doit faire état du nom d'hôte du serveur NFS, du répertoire en cours d'exportation sur le serveur, et du répertoire sur l'ordinateur local où le partage NFS sera monté. Vous devez vous connecter en tant qu'utilisateur root afin de modifier le fichier /etc/fstab.
Exemple 9.1. Exemple de syntaxe
/etc/fstab est comme suit :
server:/usr/local/pub /pub nfs defaults 0 0
/pub doit exister sur l'ordinateur client avant que cette commande puisse être exécutée. Après avoir ajouté cette ligne à /etc/fstab sur le système client, veuillez utiliser la commande mount /pub, et le point de montage /pub est monté à partir du serveur.
/etc/fstab est référencé par le service netfs au moment du démarrage, ainsi les lignes faisant référence aux partages NFS ont le même effet que la saisie manuelle de la commande mount pendant le processus de démarrage.
/etc/fstab valide pour monter un export NFS doit contenir les informations suivantes :
server:/remote/export /local/directory nfs options 0 0
Note
/etc/fstab. Sinon le montage échouera.
/etc/fstab, veuillez consulter man fstab.
9.4. autofs
/etc/fstab fait que peu importe la fréquence à laquelle un utilisateur accède au système de fichiers NFS monté, le système doit dédier des ressources afin de garder le système de fichiers en place. Il ne s'agit pas d'un problème avec un ou deux montages, mais lorsque le système maintient les montages de nombreux systèmes à la fois, les performances générales du système peuvent être affectées. Une alternative à /etc/fstab consiste à utiliser l'utilitaire basé noyau automount. Automounter consiste en deux composants :
- Un module de noyau qui implémente un système de fichiers, et
- un démon de l'espace utilisateur qui effectue toutes les autres fonctions.
automount peut monter et démonter des systèmes de fichiers NFS automatiquement (montage à la demande), et permet donc d'économiser des ressources système. Il peut être utilisé pour monter d'autres systèmes de fichiers, y compris AFS, SMBFS, CIFS, et des systèmes de fichiers locaux.
Important
autofs utilise /etc/auto.master (mappage principal) comme fichier de configuration principal. Ceci peut être changé afin d'utiliser une autre source réseau et un autre nom pris en charge en utilisant la configuration autofs (dans /etc/sysconfig/autofs) en conjonction avec le mécanisme NSS (« Name Service Switch »). Une instance du démon autofs version 4 était exécutée pour chaque point de montage configuré dans le mappage principal, lui permettant d'être exécutée manuellement à partir de la ligne de commande pour tout point de montage donné. Ceci n'est pas possible avec autofs version 5, car un seul démon est utilisé pour gérer tous les points de montage configurés dans le mappage principal. Ceci est effectué conformément aux conditions préalables des autres automounters (monteurs automatiques) standards du secteur. Les points de montage, noms d'hôte, répertoires exportés, et les options peuvent tous être spécifiés dans un ensemble de fichiers (ou autres sources réseau prises en charge) plutôt que de devoir les configurer manuellement pour chaque hôte.
9.4.1. Améliorations de autofs Version 5 par rapport à la Version 4
autofs version 5 offre les améliorations suivantes par rapport à la version 4 :
- Prise en charge du mappage direct
- Les mappages directs dans
autofsoffrent un mécanisme pour monter les systèmes de fichiers automatiquement sur des points arbitraires dans la hiérarchie du système de fichiers. Un mappage direct est indiqué par un point de montage/-dans le mappage principal. Les entrées dans un mappage direct contiennent un nom de chemin absolu comme clé (au lieu des noms de chemin relatifs utilisés pour les mappages indirects). - Prise en charge des montages et démontages « lazy »
- Les entrées de mappage à multiples montages décrivent une hiérarchie de points de montage sous une clé unique. Un bon exemple de ceci est le mappage
-hosts, couramment utilisé pour effectuer le montage automatique de tous les exports à partir d'un hôte sous/net/hosten tant qu'entrée de mappage à multiples montages. Lors de l'utilisation du mappage-hosts, la commandelsde/net/hostmontera les montages de déclencheurs autofs de chaque export de l'hôte. Ceux-ci seront ensuite montés et expireront au fur et à mesure qu'on y accédera. Ceci peut grandement réduire le nombre de montages actifs nécessaires lors de l'accession à un serveur avec un grand nombre d'exports. - Prise en charge LDAP améliorée
- Le fichier de configuration
autofs(/etc/sysconfig/autofs) offre un mécanisme pour spécifier le schémaautofsimplémenté par un site, éliminant ainsi le besoin de déterminer ceci intuitivement dans l'application. En outre, les liaisons authentifiées sur le serveur LDAP sont désormais prises en charge, en utilisant la plupart des mécanismes pris en charge par les implémentations de serveurs LDAP courantes. Un nouveau fichier de configuration a été ajouté pour cette prise en charge :/etc/autofs_ldap_auth.conf. La configuration par défaut explique bien les choses et utilise un format XML. - Utilisation correcte de la configuration « Name Service Switch » (
nsswitch). - Le fichier de configuration du « Name Service Switch » existe pour fournir un moyen de déterminer d'où proviennent des données de configuration spécifiques. Le but de cette configuration est d'offrir aux administrateurs la flexibilité d'utiliser la base de données d'arrière-plan de leur choix, tout en conservant une interface logiciel uniforme pour accéder aux données. Malgré le fait qu'automounter version 4 gère de mieux en mieux la configuration NSS, celui-ci ne la gère pas totalement. En revanche, Autofs version 5 offre une implémentation totale.Veuillez consulter
man nsswitch.confpour obtenir des informations supplémentaires sur la syntaxe prise en charge de ce fichier. Toutes les bases de données NSS ne sont pas des sources de mappage valides et l'analyseur rejettera celles qui ne sont pas valides. Les sources valides incluent les fichiers,yp,nis,nisplus,ldap, ethesiod. - Entrées multiples de mappage principal par point de montage autofs
- Une chose fréquemment utilisée mais qui n'a pas encore été mentionnée est la gestion de multiples entrées de mappage principal pour le point de montage direct
/-. Les clés de mappage de chaque entrée sont fusionnées et se comportent comme une seule carte.Exemple 9.2. Entrées multiples de mappage principal par point de montage autofs
Ci-dessous figure un exemple des mappages de test connectathon pour les montages directs :/- /tmp/auto_dcthon /- /tmp/auto_test3_direct /- /tmp/auto_test4_direct
9.4.2. Configuration autofs
/etc/auto.master est le fichier de configuration principal pour automounter, également appelé mappage principal, ce qui peut être modifié comme décrit dans la Section 9.4.1, « Améliorations de autofs Version 5 par rapport à la Version 4 ». Le mappage principal répertorie les points de montage du système contrôlé par autofs, ainsi que leurs fichiers de configuration ou sources réseau correspondants, également appelés cartes automount. Le format du mappage principal est comme suit :
mount-point map-name options
- mount-point
- Point de montage
autofs, par exemple/home. - map-name
- Nom d'une source de mappage qui contient une liste de points de montage, et l'emplacement du système de fichiers à partir duquel ces points de montage doivent être montés. La syntaxe d'une entrée de mappage est décrite ci-dessous.
- options
- Si fournies, celles-ci seront applicables à toutes les entrées du mappage donné, à condition qu'elles ne possèdent pas elles-même d'options spécifiées. Ce comportement est différent de celui d'
autofsversion 4, où les options étaient cumulatives. Cela a été modifié afin d'implémenter une compatibilité d'environnements mélangés.
Exemple 9.3. Fichier /etc/auto.master
/etc/auto.master (affiché en saisissant cat /etc/auto.master) :
/home /etc/auto.misc
mount-point [options] emplacement
- mount-point
- Référence au point de montage
autofs. Il peut s'agir d'un nom de répertoire unique pour un montage indirect ou du chemin complet du point de montage pour les montages directs. Chaque clé d'entrée de mappage direct et indirect (mount-pointabove) peut être suivie d'une liste de répertoires décalés (les noms de sous-répertoires commencent tous par le caractère « / ») séparés par des virgules, en faisant ainsi une entrée à montages multiples. - options
- Lorsqu'elles sont fournies, celles-ci servent d'options de montage pour les entrées de mappage ne spécifiant pas leurs propres options.
- emplacement
- Ceci fait référence à un emplacement de système de fichiers, tel qu'un chemin de système de fichiers local (précédé par le caractère d'échappement du format de mappage Sun « : » pour les noms de mappage commençant par une barre oblique « / »), un système de fichiers NFS, ou tout autre emplacement de système de fichiers valide.
/etc/auto.misc) :
payroll -fstype=nfs personnel:/exports/payroll sales -fstype=ext3 :/dev/hda4
autofs (sales et payroll provenant du serveur nommé personnel). La seconde colonne indique les options du montage autofs tandis que la troisième colonne indique la source du montage. Selon la configuration ci-dessus, les points de montage autofs seront nommés /home/payroll et /home/sales. L'option -fstype= est souvent omise et n'est généralement pas utile au bon fonctionnement de ce fichier.
service autofs start(si le démon automount est à l'arrêt)service autofs restart
autofs non monté, tel que /home/payroll/2006/July.sxc, le démon automount monte automatiquement le répertoire. Si un délai d'expiration a été spécifié et qu'aucun accès au répertoire n'est effectué pendant cette période, alors le répertoire sera automatiquement démonté.
# service autofs status9.4.3. Remplacer ou augmenter les fichiers de configuration du site
- Les mappages Automounter sont stockés dans le système d'informations réseau (ou NIS) et le fichier
/etc/nsswitch.confcontient la directive suivante :automount: files nis
- Ci-dessous figure le contenu du fichier
auto.master:+auto.master
- Ci-dessous figure le contenu du fichier de mappage
auto.masterdu NIS :/home auto.home
- Ci-dessous figure le contenu du mappage
auto.homedu NIS :beth fileserver.example.com:/export/home/beth joe fileserver.example.com:/export/home/joe * fileserver.example.com:/export/home/&
- Le fichier de mappage
/etc/auto.homen'existe pas.
auto.home et monter les répertoires d'accueil du montage à partir d'un serveur différent. Dans ce cas, le client devra utiliser le mappage /etc/auto.master suivant :
/home /etc/auto.home +auto.master
/etc/auto.home contient l'entrée :
* labserver.example.com:/export/home/&
/home contiendra le contenu de /etc/auto.home au lieu de celui du mappage NIS auto.home.
auto.home du site avec quelques entrées uniquement, veuillez créer un mappage du fichier /etc/auto.home et y inclure les nouvelles entrées. À la fin, veuillez inclure le mappage NIS auto.home. Ainsi, le mappage du fichier /etc/auto.home sera similaire à :
mydir someserver:/export/mydir +auto.home
auto.home répertorié ci-dessus, ls /home retournera :
beth joe mydir
autofs n'inclut pas le contenu d'un mappage de fichier du même nom que celui qu'il lit. Ainsi, autofs se déplace vers la prochaine source de mappage de la configuration nsswitch.
9.4.4. Utiliser LDAP pour stocker des mappages Automounter
openldap devrait être installé automatiquement en tant que dépendance d'automounter. Pour configurer l'accès LDAP, veuillez modifier /etc/openldap/ldap.conf. Assurez-vous que les valeurs BASE, URI, et schema soient définies correctement pour votre site.
rfc2307bis. Pour utiliser ce schéma, il est nécessaire de le définir dans la configuration autofs /etc/autofs.conf en supprimant les caractères de commentaires de la définition du schéma.
Exemple 9.4. Paramétrer la configuration autofs
map_object_class = automountMap entry_object_class = automount map_attribute = automountMapName entry_attribute = automountKey value_attribute = automountInformation
Note
/etc/autofs.conf au lieu du fichier /etc/systemconfig/autofs comme c'était le cas dans les versions précédentes.
automountKey remplace l'attribut cn dans le schéma rfc2307bis. Un LDIF d'un exemple de configuration est décrit ci-dessous :
Exemple 9.5. Configuration LDIF
# extended LDIF # # LDAPv3 # base <> with scope subtree # filter: (&(objectclass=automountMap)(automountMapName=auto.master)) # requesting: ALL # # auto.master, example.com dn: automountMapName=auto.master,dc=example,dc=com objectClass: top objectClass: automountMap automountMapName: auto.master # extended LDIF # # LDAPv3 # base <automountMapName=auto.master,dc=example,dc=com> with scope subtree # filter: (objectclass=automount) # requesting: ALL # # /home, auto.master, example.com dn: automountMapName=auto.master,dc=example,dc=com objectClass: automount cn: /home automountKey: /home automountInformation: auto.home # extended LDIF # # LDAPv3 # base <> with scope subtree # filter: (&(objectclass=automountMap)(automountMapName=auto.home)) # requesting: ALL # # auto.home, example.com dn: automountMapName=auto.home,dc=example,dc=com objectClass: automountMap automountMapName: auto.home # extended LDIF # # LDAPv3 # base <automountMapName=auto.home,dc=example,dc=com> with scope subtree # filter: (objectclass=automount) # requesting: ALL # # foo, auto.home, example.com dn: automountKey=foo,automountMapName=auto.home,dc=example,dc=com objectClass: automount automountKey: foo automountInformation: filer.example.com:/export/foo # /, auto.home, example.com dn: automountKey=/,automountMapName=auto.home,dc=example,dc=com objectClass: automount automountKey: / automountInformation: filer.example.com:/export/&
9.5. Options de montage NFS courantes
mount, des paramètres /etc/fstab, et avec autofs.
- intr
- Permet aux requêtes NFS d'être interrompues si le serveur tombe en panne ou ne peut pas être contacté.
- lookupcache=mode
- Spécifie la manière par laquelle le noyau va gérer le cache de ses entrées de répertoire pour un point de montage donné. Les arguments valides de mode sont
all(« tout »),none(« rien »), oupos/positive. - nfsvers=version
- Spécifie la version du protocole NFS à utiliser, où version est égal à 2, 3, ou 4. Ceci est utile pour les hôtes qui exécutent de multiples serveurs NFS. Si aucune version n'est spécifiée, NFS utilise le numéro de version le plus haut pris en charge par le noyau et la commande
mount.L'optionversest identique ànfsverset est incluse dans cette version pour des raisons de compatibilité. - noacl
- Annule tout traitement d'ACL. Ce paramètre peut être nécessaire lors d'interactions avec des versions plus anciennes de Red Hat Enterprise Linux, Red Hat Linux, ou Solaris, car les technologies ACL les plus récentes ne sont pas compatibles avec des systèmes plus anciens.
- nolock
- Désactive le verrouillage de fichiers. Ce paramètre est occasionnellement requis lors des connexions aux serveurs NFS plus anciens.
- noexec
- Empêche l'exécution de binaires sur des systèmes de fichiers montés. Ceci est utile si le système monte un système de fichiers Linux contenant des binaires incompatibles.
- nosuid
- Désactive les bits
set-user-identifierouset-group-identifier. Ceci empêche les utilisateurs distants de gagner des privilèges plus élevés en exécutant un programmesetuid. - port=num
port=num— Spécifie la valeur numérique du port du serveur NFS. Sinumest égal à0(valeur par défaut), alorsmountinterrogera le servicerpcbindde l'hôte distant sur le numéro de port à utiliser. Si le démon NFS de l'hôte distant n'est pas enregistré avec son servicerpcbind, le numéro de port NFS standard TCP 2049 sera alors utilisé.- rsize=num et wsize=num
- Ces paramètres accélèrent les communications NFS pour les lectures (
rsize) et les écritures (wsize) en définissant une taille de bloc de données plus importante (num, en octets) à transférer. Soyez prudent lorsque vous modifiez ces valeurs car certains noyaux Linux et cartes réseau ne fonctionnent pas bien avec des tailles de bloc plus importantes.Note
Si une valeur rsize n'est pas spécifiée, ou si la valeur spécifiée est plus élevée que la valeur maximum prise en charge par le client ou le serveur, alors le client et le serveur négocieront la valeur de redimensionnement la plus élevée qu'ils peuvent tous deux prendre en charge. - sec=mode
- Spécifie le type de sécurité à utiliser lors de l'authentification d'une connexion NFS. Le paramètre par défaut est
sec=sys, qui fait usage d'UID et GID UNIX locaux en utilisantAUTH_SYSpour authentifier les opérations NFS.sec=krb5utilise Kerberos V5 à la place d'UID et GID UNIX locaux pour authentifier les utilisateurs.sec=krb5iutilise Kerberos V5 pour authentifier les utilisateurs et vérifie l'intégrité des opérations NFS en utilisant des checksums sécurisés pour empêcher toute altération de données.sec=krb5putilise Kerberos V5 pour l'authentification d'utilisateurs, les vérifications d'integrité, et chiffre le trafic NFS pour empêcher le reniflage du trafic. Ce paramètre est le plus sécurisé, mais il implique également une surcharge des performances plus importante. - tcp
- Ordonne au montage NFS d'utiliser le protocole TCP.
- udp
- Ordonne au montage NFS d'utiliser le protocole UDP.
man mount et man nfs.
9.6. Démarrage et arrêt NFS
rpcbind[3] doit être en cours d'exécution. Pour vérifier que rpcbind soit effectivement actif, veuillez utiliser la commande suivante :
# service rpcbind statusrpcbind est en cours d'exécution, alors le service nfs peut être lancé. Pour démarrer un serveur NFS, veuillez utiliser la commande suivante :
# service nfs startnfslock doit aussi être démarré pour que le client et le serveur NFS puissent fonctionner correctement. Pour lancer le verrouillage NFS, veuillez utiliser la commande suivante :
# service nfslock startnfslock démarre également en exécutant chkconfig --list nfslock. Si nfslock n'est pas paramétré sur « Marche » (on), cela signifie que vous devrez manuellement exécuter service nfslock start chaque fois que l'ordinateur démarre. Pour paramétrer nfslock pour qu'il soit lancé automatiquement au démarrage, veuillez utiliser chkconfig nfslock on.
nfslock est uniquement nécessaire pour NFSv2 et NFSv3.
# service nfs stoprestart est une façon rapide d'arrêter, puis de redémarrer NFS. Cette manière est la plus efficace pour que les changements de configuration puissent prendre effet après avoir modifié le fichier de configuration pour NFS. Pour redémarrer le serveur, veuillez saisir :
# service nfs restartcondrestart (redémarrage conditionnel) démarrera uniquement nfs s'il est en cours d'exécution. Cette option est utile pour les scripts, car elle ne démarre pas le démon si celui-ci n'est pas en cours d'exécution. Pour redémarrer le serveur de manière conditionelle, veuillez saisir :
# service nfs condrestart
# service nfs reload9.7. Configuration du serveur NFS
- La configuration manuelle du fichier de configuration NFS
/etc/exports, et - à l'aide de la ligne de commande, en utilisant la commande
exportfs
9.7.1. Fichier de configuration /etc/exports
/etc/exports contrôle quels systèmes de fichiers sont exportés vers des hôtes distants et spécifie les options. Les règles de syntaxes suivantes sont observées :
- Les lignes vides sont ignorées.
- Pour ajouter un commentaire, commencez la ligne par le caractère dièse (
#). - Pour les longues lignes, il est possible d'effectuer des retours à la ligne avec une barre oblique inversée (
\). - Chaque système de fichiers exporté devrait se trouver sur une ligne individuelle.
- Toute liste d'hôtes non autorisés placée après un système de fichiers exporté doit être séparée par des caractères d'espace.
- Les options de chaque hôte doivent être placées directement après l'identifiant de l'hôte, sans espace séparant l'hôte et la première parenthèse.
export host(options)
- export
- Répertoire en cours d'exportation
- host
- Hôte ou réseau sur lequel l'exportation est partagée
- options
- Options à utiliser pour l'hôte
export host1(options1) host2(options2) host3(options3)
/etc/exports spécifie uniquement le répertoire exporté et les hôtes autorisés à y accéder, comme dans l'exemple suivant :
Exemple 9.6. Fichier /etc/exports
/exported/directory bob.example.com
bob.example.com peut monter /exported/directory/ à partir du serveur NFS. Comme aucune autre fonction n'est spécifiée dans cet exemple, NFS utilisera les paramètres par défaut.
- ro
- Le système de fichiers exporté est accessible en lecture seule. Les hôtes distants ne peuvent pas modifier les données partagées sur le système de fichiers. Pour autoriser des hôtes à effectuer des modifications sur le système de fichiers (par exemple, lecture/écriture), veuillez spécifier l'option
rw. - sync
- Le serveur NFS ne répondra pas aux requêtes effectuées avant que les changements demandés par les requêtes précédentes soient écrits sur disque. Sinon, pour activer les écritures asynchrones, veuillez spécifier l'option
async. - wdelay
- Le serveur NFS retardera l'écriture sur disque s'il suspecte qu'une autre requête d'écriture est imminente. Ceci peut améliorer les performances car il y a une réduction du nombre d'accès au disque par le biais de commandes d'écriture séparées, réduisant ainsi également l'alourdissement des écritures. Pour désactiver ce comportement, veuillez spécifier
no_wdelay.no_wdelayest uniquement disponible si l'option par défautsyncest également spécifiée. - root_squash
- Ceci empêche les utilisateurs root connectés à distance (et non locaux) d'avoir des privilèges root. Au lieu de cela, le serveur NFS leurs assignera l'ID d'utilisateur
nfsnobody. Ceci « écrasera » (ou réduira) les capacités de l'utilisateur root à celles d'un utilisateur local du plus bas niveau possible, empêchant ainsi toute écriture non autorisée sur le serveur distant. Pour désactiver l'écrasement root, veuillez spécifierno_root_squash.
all_squash. Pour spécifier les ID des groupes et des utilisateurs que le serveur NFS devrait assigner à des utilisateurs distants à partir d'un hôte en particulier, veuillez utiliser les options anonuid et anongid respectives, comme suit :
export host(anonuid=uid,anongid=gid)
anonuid et anongid vous permettent de créer un compte utilisateur et groupe spécifique que les utilisateurs NFS distants peuvent partager.
no_acl lorsque vous exportez le système de fichiers.
rw n'est pas spécifiée, alors le système de fichiers exporté est partagé en lecture seule. Ci-dessous figure un exemple de ligne de /etc/exports qui remplace deux options par défaut :
/another/exported/directory 192.168.0.3(rw,async)
192.168.0.3 peut monter /another/exported/directory/ en lecture/écriture et toutes les écritures sur disque seront asynchrones. Pour obtenir davantage d'informations sur les options d'export, veuillez consulter man exportfs.
man exports pour obtenir davantage de détails sur ces options moins souvent utilisées.
Important
/etc/exports est très précis, particulièrement au regard de l'utilisation du caractère espace. Rappelez-vous de toujours séparer les systèmes de fichiers exportés des hôtes et les hôtes les uns des autres avec un caractère espace. Toutefois, il ne devrait pas y avoir d'autres caractères espace dans le fichier, sauf sur les lignes de commentaire.
/home bob.example.com(rw) /home bob.example.com (rw)
bob.example.com d'accéder en lecture/écriture au répertoire /home. La seconde ligne autorise les utilisateurs de bob.example.com de monter le répertoire en tant que lecture seule (par défaut), tandis que le reste du monde peut le monter en lecture/écriture.
9.7.2. Commande exportfs
/etc/exports. Lorsque le service nfs démarre, la commande /usr/sbin/exportfs lance et lit ce fichier, passe le contrôle à rpc.mountd (si NFSv2 ou NFSv3 est utilisé) pour le processus de montage, puis à rpc.nfsd où les systèmes de fichiers seront ensuite disponibles aux utilisateurs distants.
/usr/sbin/exportfs permet à l'utilisateur root d'exporter ou d'annuler l'export des répertoires de manière sélective, sans redémarrer le service NFS. Lorsque les bonnes options sont passées, la commande /usr/sbin/exportfs écrit les systèmes de fichiers exportés sur /var/lib/nfs/etab. Comme rpc.mountd fait référence au fichier etab lors de la décision d'octroiement des privilèges d'accès à un système de fichiers, tout changement apporté à la liste des systèmes de fichiers exportés prendra effet immédiatement.
/usr/sbin/exportfs :
- -r
- Cause à tous les répertoires répertoriés dans
/etc/exportsd'être exportés en construisant une nouvelle liste d'exports dans/etc/lib/nfs/etab. Cette option réactualise la liste des exports avec les changements apportés à/etc/exports. - -a
- Cause à tous les répertoires d'être exportés ou annule leur export, en fonction des autres options passées à
/usr/sbin/exportfs. Si aucune autre option n'est spécifée,/usr/sbin/exportfsexportera tous les systèmes de fichiers spécifiés dans/etc/exports. - -o file-systems
- Spécifie les répertoires à exporter qui ne sont pas répertoriés dans
/etc/exports. Remplacez file-systems par les systèmes de fichiers supplémentaires à exporter. Ces systèmes de fichiers doivent être formatés de la même manière qu'ils sont spécifiés dans/etc/exports. Cette option est souvent utilisée pour tester un système de fichiers exporté avant de l'ajouter de manière permanente à la liste des systèmes de fichiers devant être exportés. Veuillez consulter Section 9.7.1, « Fichier de configuration/etc/exports» pour obtenir des informations supplémentaires sur la syntaxe/etc/exports. - -i
- Ignore
/etc/exports; seules les options passées avec la ligne de commande sont utilisées pour définir les systèmes de fichiers exportés. - -u
- Annule l'export de tous les répertoires partagés. La commande
/usr/sbin/exportfs -uasuspend le partage NFS tout en laissant les démons NFS fonctionner. Pour réactiver le partage NFS, veuillez utiliserexportfs -r. - -v
- Opération détaillée, les systèmes de fichiers dont l'export ou l'annulation de l'export est en cours sont affichés avec plus de détails lorsque la commande
exportfsest exécutée.
exportfs, celle-ci affichera une liste des systèmes de fichiers actuellement exportés. Pour obtenir des informations supplémentaires sur la commande exportfs, veuillez consulter man exportfs.
9.7.2.1. Utiliser exportfs avec NFSv4
RPCNFSDARGS= -N 4 dans /etc/sysconfig/nfs.
9.7.3. Exécuter NFS derrière un pare-feu
rpcbind, qui assigne dynamiquement des ports pour les services RPC et peut provoquer des problèmes avec la configuration des règles de pare-feu. Pour autoriser les clients à accéder aux partages NFS derrière un pare-feu, veuillez modifier le fichier de configuration /etc/sysconfig/nfs pour contrôler les ports sur lesquels les services RPC requis seront exécutés.
/etc/sysconfig/nfs pourrait ne pas exister par défaut sur tous les systèmes. Si cela s'avère être le cas, veuillez le créer puis ajoutez les variables suivantes, en remplaçant port par un numéro de port non utilisé (alternativement, si le fichier existe, dé-commentez et modifiez les entrées comme nécessaire) :
MOUNTD_PORT=port- Contrôle quel port TCP et UDP
mountd(rpc.mountd) utilise. STATD_PORT=port- Contrôle quel statut de port TCP et UDP (
rpc.statd) utilise. LOCKD_TCPPORT=port- Contrôle quel port TCP
nlockmgr(lockd) utilise. LOCKD_UDPPORT=port- Contrôle quel port UDP
nlockmgr(lockd) utilise.
/var/log/messages. Normalement, le démarrage de NFS échouera si vous spécifiez un numéro de port qui est déjà en cours d'utilisation. Après avoir modifié /etc/sysconfig/nfs, veuillez redémarrer le service NFS en utilisant service nfs restart. Exécutez la commande rpcinfo -p pour confirmer les modifications.
Procédure 9.1. Configurer un pare-feu afin d'autoriser NFS
- Autoriser le port TCP et UDP 2049 pour NFS.
- Autoriser le port TCP et UDP 111 (
rpcbind/sunrpc). - Autoriser le port TCP et UDP spécifié avec
MOUNTD_PORT="port" - Autoriser le port TCP et UDP spécifié avec
STATD_PORT="port" - Autoriser le port TCP spécifié avec
LOCKD_TCPPORT="port" - Autoriser le port UDP spécifié avec
LOCKD_UDPPORT="port"
Note
/proc/sys/fs/nfs/nfs_callback_tcpport et autorisez le serveur à se connecter à ce port sur le client.
mountd, statd, et lockd ne sont pas requis dans un environnement NFSv4 pu.
9.7.3.1. Découverte des exports NFS
showmount :
$ showmount -e myserver Export list for mysever /exports/foo /exports/bar
/ et observez son contenu.
# mount myserver:/ /mnt/
#cd /mnt/
exports
# ls exports
foo
barNote
9.7.4. Formats des noms d'hôtes
- Machine unique
- Un nom de domaine complet (pouvant être résolu par le serveur), un nom d'hôte (pouvant être résolu par le serveur), ou une adresse IP.
- Série d'ordinateurs spécifiés avec des caractères génériques
- Utilisez le caractère
*ou?pour spécifier une chaîne correspondante. Les caractères génériques ne doivent pas être utilisés avec les adresses IP. Cependant, cela peut fonctionner accidentellement si des recherches DNS inversées échouent. Lors de la spécification de caractères génériques dans des noms de domaine complets, les points (.) ne sont pas inclus dans la recherche. Par exemple,*.example.cominclutone.example.commais n'inclut pasone.two.example.com. - Réseaux IP
- Utilisez a.b.c.d/z, où a.b.c.d est le réseau et z est le nombre d'octets dans le masque réseau (par exemple, 192.168.0.0/24). Un autre format acceptable est a.b.c.d/netmask, où a.b.c.d est le réseau et netmask est le masque réseau (par exemple, 192.168.100.8/255.255.255.0).
- Netgroups
- Veuillez utiliser le format @group-name, où group-name est le nom du netgroup NIS.
9.7.5. NFS sur RDMA
Procédure 9.2. Activez RDMA à partir du serveur
- Assurez-vous que le RPM RDMA est installé et que le service RDMA est activé en exécutant la commande suivante :
# yum install rdma; chkconfig --level 2345 rdma on - Assurez-vous que le paquet qui fournit le service nfs-rdma est installé et que le service est activé à l'aide de la commande suivante :
# yum install rdma; chkconfig --level 345 nfs-rdma on - Assurez-vous que le port RDMA est paramétré comme étant le port par défaut (le port par défaut sur Red Hat Enterprise Linux 6 est le port 2050). Pour ce faire, veuillez modifier le fichier
/etc/rdma/rdma.confde manière à paramétrer NFSoRDMA_LOAD=yes et NFSoRDMA_PORT sur le port souhaité. - Paramétrez le système de fichiers exporté comme à la normale pour les montages NFS.
Procédure 9.3. Activez RDMA à partir du client
- Assurez-vous que le RPM RDMA est installé et que le service RDMA est activé en exécutant la commande suivante :
# yum install rdma; chkconfig --level 2345 rdma on - Montez la partition NFS exportée à l'aide de l'option RDMA lors de l'appel au montage. L'option du port peut être optionnellement ajoutée à l'appel.
# mount -t nfs -o rdma,port=port_number
9.8. Sécurisation de NFS
9.8.1. Sécurité NFS avec AUTH_SYS et les contrôles d'export
AUTH_SYS (aussi appelé AUTH_UNIX), qui se fie au client pour indiquer l'UID et le GID de l'utilisateur. Soyez conscient que cela signifie qu'un client mal configuré ou malicieux pourrait facilement mal comprendre ceci et autoriser un utilisateur à accéder à des fichiers auxquels il ne devrait pas avoir accès.
rpcbind[3] avec des enveloppes TCP. La création de règles avec iptables peut également limiter l'accès aux ports utilisés par rpcbind, rpc.mountd, et rpc.nfsd.
rpcbind, veuillez consulter man iptables.
9.8.2. Sécurité NFS avec AUTH_GSS
Note
Procédure 9.4. Paramétrer RPCSEC_GSS
- Créez les principaux
nfs/client.mydomain@MYREALMetnfs/server.mydomain@MYREALM. - Ajoutez les clés correspondant aux onglets principaux pour le client et le serveur.
- Du côté serveur, veuillez ajouter
sec=krb5,krb5i,krb5pà l'export. Pour continuer à autoriser AUTH_SYS, veuillez ajoutersec=sys,krb5,krb5i,krb5pà la place. - Du côté client, veuillez ajouter
sec=krb5(ousec=krb5i, ousec=krb5p, en fonction de l'installation) aux options de montage.
krb5, krb5i, et krb5p, veuillez consulter les pages man exports et nfs ou la Section 9.5, « Options de montage NFS courantes ».
RPCSEC_GSS, y compris sur la manière par laquelle rpc.svcgssd et rpc.gssd interagissent, veuillez consulter http://www.citi.umich.edu/projects/nfsv4/gssd/.
9.8.2.1. Sécurité NFS avec NFSv4
MOUNT pour monter les systèmes de fichiers. Ce protocole présentait des failles de sécurité possibles à cause de la manière par laquelle il traitait les identificateurs de fichiers.
9.8.3. Permissions de fichier
su - pour accéder à tous les fichiers du partage NFS.
nobody (personne). Le root squashing est contrôlé par l'option par défaut root_squash. Pour obtenir des informations supplémentaires sur cette option, veuillez consulter Section 9.7.1, « Fichier de configuration /etc/exports ». Dans la mesure du possible, ne désactivez jamais le root squashing.
all_squash. Cette option fait que tout utilisateur accédant au système de fichiers exporté prendra l'ID utilisateur de l'utilisateur nfsnobody.
9.9. NFS et rpcbind
Note
rpcbind pour une compatibilité ascendante.
rpcbind[3] mappe les services RPC aux ports qu'ils écoutent. Les processus RPC notifient rpcbind lorsqu'ils démarrent, en enregistrant les ports qu'ils écoutent et les numéros de programme RPC qu'ils prévoient de servir. Le système client contacte ensuite rpcbind sur le serveur avec un numéro de programme RPC particulier. Le service rpcbind redirige le client vers le numéro de port correct afin de pouvoir communiquer avec le service requis.
rpcbind pour effectuer toutes les connexions avec les requêtes client entrantes, rpcbind doit être disponible avant que ces services ne démarrent.
rpcbind utilise des enveloppes TCP pour le contrôle d'accès, les règles de contrôle d'accès de rpcbind affectent tous les services basés RPC. De manière alternative, il est possible de spécifier les règles de contrôle d'accès de chacun des démons RPC NFS. Les pages man de rpc.mountd et rpc.statd contiennent des informations concernant la syntaxe précise de ces règles.
9.9.1. Résolution des problèmes NFS et rpcbind
rpcbind[3] fournit la coordination entre les services RPC et les numéros de port utilisés pour communiquer avec ceux-ci, il est utile d'afficher le statut des services RPC en cours à l'aide de rpcbind lors des résolutions de problèmes. La commande rpcinfo affiche chaque service basé RPC avec les numéros de port, un numéro de programme RPC, un numéro de version, et un type de protocole IP (TCP ou UDP).
rpcbind, veuillez saisir la commande suivante :
# rpcinfo -pExemple 9.7. Sortie de la comande rpcinfo -p
program vers proto port service
100021 1 udp 32774 nlockmgr
100021 3 udp 32774 nlockmgr
100021 4 udp 32774 nlockmgr
100021 1 tcp 34437 nlockmgr
100021 3 tcp 34437 nlockmgr
100021 4 tcp 34437 nlockmgr
100011 1 udp 819 rquotad
100011 2 udp 819 rquotad
100011 1 tcp 822 rquotad
100011 2 tcp 822 rquotad
100003 2 udp 2049 nfs
100003 3 udp 2049 nfs
100003 2 tcp 2049 nfs
100003 3 tcp 2049 nfs
100005 1 udp 836 mountd
100005 1 tcp 839 mountd
100005 2 udp 836 mountd
100005 2 tcp 839 mountd
100005 3 udp 836 mountd
100005 3 tcp 839 mountdrpcbind sera incapable de mapper les requêtes RPC des clients de ce service sur le bon port. Dans de nombreux cas, si NFS n'est pas présent dans la sortie rpcinfo, redémarrer NFS entraînera le bon enregistrement du service avec rpcbind et le début de son fonctionnement.
man rpcinfo pour obtenir des informations supplémentaires ainsi qu'une liste de ses options.
9.10. Références
Documentation installée
man mount— offre une vue d'ensemble complète sur les options de montage pour les configurations du serveur NFS et du client NFS.man fstab— fournit des détails sur le format du fichier/etc/fstabutilisé pour monter les systèmes de fichiers lors du démarrage.man nfs— fournit des détails sur les options de montage et d'exportation des systèmes de fichiers spécifiques à NFS.man exports— affiche les options courantes utilisées dans le fichier/etc/exportslors de l'exportation de systèmes de fichiers NFS.man 8 nfsidmap— explique la commandenfsidmapet liste les options communes.
Sites Web utiles
- http://linux-nfs.org — Site pour développeurs sur lequel les mises à jour du statut des projets peuvent être observées.
- http://nfs.sourceforge.net/ — Ancien site pour développeurs, celui-ci contient toujours de nombreuses informations utiles.
- http://www.citi.umich.edu/projects/nfsv4/linux/ — Ressource NFSv4 pour noyau Linux 2.6.
- http://www.vanemery.com/Linux/NFSv4/NFSv4-no-rpcsec.html — Décrit les détails de NFSv4 avec Fedora Core 2, qui inclut le noyau 2.6.
- http://citeseer.ist.psu.edu/viewdoc/summary?doi=10.1.1.111.4086 — Excellent livre blanc sur les fonctionnalités et améliorations du protocole NFS Version 4.
rpcbind remplace portmap, qui était utilisé dans des versions précédentes de Red Hat Enterprise Linux pour mapper les numéros de programme RPC sur les combinaisons de numéros de port d'adresses IP. Pour obtenir des informations supplémentaires, veuillez consulter la Section 9.1.1, « Services requis ».
Chapitre 10. FS-Cache
Figure 10.1. Aperçu de FS-Cache
cachefs sur Solaris, FS-Cache permet à un système de fichiers d'interagir directement avec le cache local d'un client sans créer de système de fichiers surmonté. Avec NFS, une option de montage ordonne au client de monter le partage NFS avec FS-cache activé.
cachefiles). Dans ce cas, FS-Cache requiert un système de fichiers monté basé sur blocs, qui prendrait en charge bmap et des attributs étendus (par exemple ext3) en tant que backend de cache.
Note
cachefilesd n'est pas installé par défaut et doit donc l'être manuellement.
10.1. Garantie des performances
10.2. Paramétrer un cache
cachefiles. Le démon cachefilesd initialise et gère cachefiles. Le fichier /etc/cachefilesd.conf contrôle la manière par laquelle cachefiles fournit ses services de mise en cache. Pour configurer un backend de cache de ce type, le paquet cachefilesd doit être installé.
$ dir /path/to/cache/etc/cachefilesd.conf en tant que /var/cache/fscache, comme suit :
$ dir /var/cache/fscache
/path/to/cache. Sur un ordinateur portable, il est conseillé d'utiliser le système de fichiers root (/) en tant que système de fichier hôte, mais pour un ordinateur de bureau, il serait plus prudent de monter une partition de disque spécifiquement pour le cache.
- ext3 (avec des attributs étendus activés)
- ext4
- BTRFS
- XFS
device), veuillez utiliser :
# tune2fs -o user_xattr /dev/device
# mount /dev/device /path/to/cache -o user_xattrcachefilesd :
# service cachefilesd startcachefilesd pour être lancé lors du démarrage, veuillez exécuter la commande suivante en tant que root :
# chkconfig cachefilesd on10.3. Utiliser le cache avec NFS
-o fsc à la commande mount :
# mount nfs-share:/ /mount/point -o fsc/mount/point passeront par le cache, sauf si le fichier est ouvert pour des E/S ou écritures directes (veuillez consulter Section 10.3.2, « Limitations des caches avec NFS » pour obtenir des informations supplémentaires). NFS indexe le contenu du cache à l'aide d'un gestionnaire de fichiers NFS, et non avec le nom du fichier ; cela signifie que les fichiers avec des liens physiques partagent le cache correctement.
10.3.1. Partage de cache
- Niveau 1 : Détails du serveur
- Niveau 2 : Certaines options de montage, type de sécurité, FSID, uniquifier
- Niveau 3 : Identificateur de fichier
- Niveau 4 : Numéro de la page dans le fichier
Exemple 10.1. Partager un cache
mount suivantes :
mount home0:/disk0/fred /home/fred -o fsc
mount home0:/disk0/jim /home/jim -o fsc
/home/fred et /home/jim partageront probablement le superrbloc car ils possèdent les mêmes options, particulièrement s'ils proviennent du même volume ou de la même partition sur le serveur NFS (home0). Prenez en considération les deux commandes de montage suivantes :
mount home0:/disk0/fred /home/fred -o fsc,rsize=230
mount home0:/disk0/jim /home/jim -o fsc,rsize=231
/home/fred et /home/jim ne partageront pas le super bloc car leurs paramètres d'accès réseau sont différents, et ceux-ci font partie de la clé du Niveau 2. La même chose est valable pour la séquence de montage suivante :
mount home0:/disk0/fred /home/fred1 -o fsc,rsize=230
mount home0:/disk0/fred /home/fred2 -o fsc,rsize=231
/home/fred1 et /home/fred2) seront mis en cache deux fois.
nosharecache. Voici un exemple :
mount home0:/disk0/fred /home/fred -o nosharecache,fsc
mount home0:/disk0/jim /home/jim -o nosharecache,fsc
home0:/disk0/fred et home0:/disk0/jim. Pour répondre à ce problème, veuillez ajouter un identifiant unique sur un des montages au moins, c-a-d fsc=unique-identifier. Par exemple :
mount home0:/disk0/fred /home/fred -o nosharecache,fsc
mount home0:/disk0/jim /home/jim -o nosharecache,fsc=jim
jim sera ajouté à la clé de Niveau 2 utilisée dans le cache pour /home/jim.
10.3.2. Limitations des caches avec NFS
10.4. Définir les limites d'élimination du cache
cachefilesd fonctionne en mettant en cache des données à distance provenant des systèmes de fichiers pour libérer de l'espace sur le disque. Cela pourrait potentiellement consommer tout l'espace libre, ce qui serait problématique si le disque héberge aussi la partition root. Pour contrôler ceci, cachefilesd tente de maintenir une certaine quantité d'espace libre en abandonnant certains anciens objets (c'est-à-dire qui n'ont pas été accédés depuis un certain temps) du cache. Ce comportement est aussi connu sous le nom de cache culling ou d'élimination du cache.
/etc/cachefilesd.conf :
- brun N% (pourcentage de blocs), frun N% (pourcentage de fichiers)
- Si la quantité d'espace libre et le nombre de fichiers disponibles dans le cache dépassent ces deux limites, alors l'élimination est désactivée.
- bcull N% (pourcentage de blocs), fcull N% (pourcentage de fichiers)
- Si la quantité d'espace disponible ou le nombre de fichiers dans le cache se trouve sous l'une de ces limites, alors l'élimination est lancée.
- bstop N% (pourcentage de blocs), fstop N% (pourcentage de fichiers)
- Si la quantité d'espace disponible ou le nombre de fichiers disponibles dans le cache se trouve sous l'une de ces limites, alors l'allocation d'espace disque ou de fichiers ne sera plus permise tant que l'élimination du cache n'aura pas fait que ces limites soient à nouveau dépassées.
N pour chaque paramètre est comme suit :
brun/frun- 10%bcull/fcull- 7%bstop/fstop- 3%
bstop < bcull < brun < 100
fstop < fcull < frun < 100
df.
Important
10.5. Informations statistiques
cat /proc/fs/fscache/stats
/usr/share/doc/kernel-doc-version/Documentation/filesystems/caching/fscache.txt
10.6. Références
cachefilesd et sur la manière de le configurer, veuillez consulter man cachefilesd et man cachefilesd.conf. Les documents sur le noyau suivants offrent également des informations supplémentaires :
/usr/share/doc/cachefilesd-version-number/README/usr/share/man/man5/cachefilesd.conf.5.gz/usr/share/man/man8/cachefilesd.8.gz
/usr/share/doc/kernel-doc-version/Documentation/filesystems/caching/fscache.txt
Partie II. Administration du stockage
Chapitre 11. Besoins de stockage à prendre en compte pendant l'installation
11.1. Mises à jour de la configuration du stockage pendant l'installation
Anaconda peut désormais configurer les périphériques de stockage FCoE pendant l'installation.
Anaconda possède désormais un contrôle amélioré sur les périphériques de stockage utilisés pendant l'installation. Vous pouvez maintenant contrôler quels périphériques sont disponibles ou visibles à l'installateur en plus de pouvoir voir quels périphériques sont utilisés pour le stockage du système. Il y a deux chemins pour le filtrage du périphérique :
- Chemin de base
- Pour les systèmes qui utilisent uniquement des disques attachés localement et des matrices RAID micrologiciel en tant que périphériques de stockage.
- Chemin avancé
- Pour les systèmes utilisant des périphériques SAN (par ex. : multipath, iSCSI, FCoE)
Le partitionnement automatique crée désormais un volume logique séparé pour le système de fichiers /home lorsque 50 Go ou plus sont disponibles pour l'allocation de volumes physiques LVM. Le système de fichiers root (/) sera limité à un maximum de 50 Go lors de la création d'un volume logique /home séparé, mais le volume logique /home augmentera afin d'occuper tout l'espace disponible restant dans le groupe de volumes.
11.2. Aperçu des systèmes de fichiers pris en charge
Tableau 11.1. Spécifications techniques des systèmes de fichiers pris en charge
| Système de fichiers | Taille maximale prise en charge | Décalage de fichiers maximal | Nombre maximal de sous-répertoires (par répertoire) | Profondeur maximale des liens symboliques | Prise en charge des ACL | Détails |
|---|---|---|---|---|---|---|
| Ext2 | 8 To | 2 To | 32,000 | 8 | Oui | N/A |
| Ext3 | 16 To | 2 To | 32,000 | 8 | Oui | Chapitre 5, Système de fichiers Ext3 |
| Ext4 | 16 To | 16 To[a] | Illimité[b] | 8 | Oui | Chapitre 6, Le système de fichiers Ext4 |
| XFS | 100 To | 100 To[c] | Illimité | 8 | Oui | Chapitre 8, Le système de fichiers XFS |
[a]
Cette taille de fichier maximale est basée sur des ordinateurs 64 bits. Sur un ordinateur 32 bits, la taille maximale des fichiers est de 8 To.
[b]
Lorsque le compte des liens dépasse 65 000, celui-ci est réinitialisé sur 1 et n'augmentera plus.
[c]
Cette taille de fichier maximale se trouve uniquement sur les ordinateurs 64 bits. Red Hat Enterprise Linux ne prend pas en charge XFS sur les ordinateurs 32 bits.
| ||||||
Note
11.3. Considérations particulières
Partitions séparées pour /home, /opt, /usr/local
/home, /opt, et /usr/local sur un périphérique séparé. Ceci vous permettra de reformater les périphériques ou systèmes de fichiers contenant le système d'exploitation tout en préservant vos données utilisateur et applications.
Périphériques DASD et zFCP sur IBM System Z
DASD= dans la ligne de commande de démarrage ou dans un fichier de configuration CMS.
FCP_x= dans la ligne de commande de démarrage (ou dans un fichier de configuration CMS) vous permettent de spécifier ces informations pour l'installateur.
Chiffrer des périphériques blocs avec LUKS
dm-crypt détruira tout formatage existant sur ce périphérique. Ainsi, vous devriez décider quels périphériques chiffrer avant que la configuration du stockage du nouveau système ne soit activée dans le cadre du processus d'installation.
Métadonnées RAID BIOS périmées
Avertissement
dmraid -r -E /device/
man dmraid et le Chapitre 17, Réseau redondant de disques indépendants (RAID, de l'anglais « Redundant Array of Independent Disks »).
Détection et configuration iSCSI
Détection et configuration FCoE
DASD
Périphériques bloc avec DIF/DIX activé
mmap(2) ne fonctionneront pas de manière stable, car il n'y a pas de verrouillage dans le chemin d'écriture en mémoire tampon pour empêcher les données en tampon d'être remplacées une fois que le checksum DIF/DIX est calculé.
mmap(2). Ainsi, il n'est pas possible de contourner les erreurs causées par ces remplacements.
O_DIRECT. De telles applications doivent utiliser le périphérique bloc brut. De manière alternative, il est également sûr d'utiliser le système de fichiers XFS sur un périphérique bloc activé DIF/DIX, tant que seules les E/S O_DIRECT soient passées à travers le système de fichiers. XFS est le seul système de fichiers qui ne se replie pas sur les E/S mises en mémoire tampon lorsqu'il effectue certaines opérations d'allocation.
O_DIRECT et le matériel DIF/DIX doivent utiliser DIF/DIX.
Chapitre 12. Vérification du système de fichiers (fsck)
fsck, fsck est une version raccourcie de file system check (vérification du système de fichiers).
Note
/etc/fstab au moment du démarrage. Pour les systèmes de fichiers journalisant, ceci consiste souvent en une très courte opération, car la journalisation des métadonnées du système de fichiers assure la cohérence des données même après une panne.
Important
/etc/fstab sur 0.
12.1. Meilleures pratiques avec fsck
- Test à vide
- La plupart des vérificateurs de systèmes de fichiers possèdent un mode opératoire qui vérifie mais ne répare pas le système de fichiers. Dans ce mode, le vérificateur imprimera toutes les erreurs qu'il trouvera et toutes les actions qu'il aurait effectuées sans pour autant modifier le système de fichiers.
Note
Les phase ultérieures de la vérification de cohérence peuvent imprimer des erreurs supplémentaires en découvrant les incohérences qui auraient pu être corrigées dans des phases antérieures si celles-ci avaient fonctionné en mode de réparation. - Opérer avant tout sur une image de système de fichiers
- La plupart des systèmes de fichiers prennent en charge la création d'une image des métadonnées, une copie fragmentée du système de fichiers qui ne contient que les métadonnées. Comme les vérificateurs de système de fichiers opèrent uniquement sur les métadonnées, de telles images peuvent être utilisées pour effectuer le test à vide d'une réparation de système de fichiers, et pour évaluer les modifications qui seront ainsi effectuées. Si les modifications sont acceptables, alors la réparation pourra être effectuée sur le système de fichiers.
Note
Des systèmes de fichiers sévèrement endommagés peuvent causer des problèmes avec la création d'images de métadonnées. - Enregistrer une image de système de fichiers pour les vérifications du support technique
- Une image des métadonnées du système de fichiers avant les réparations peut souvent se révéler utile pour les vérifications du support technique si cette corruption résulte d'un bogue de logiciel. Des schémas de corruption présents dans l'image pré-réparation peut aider lors de l'analyse de la cause principale.
- Opérer sur les systèmes de fichiers non-montés uniquement
- Une réparation de système de fichiers doit uniquement être exécutée sur un système de fichiers qui n'est pas monté. L'outil doit être le seul à avoir accès au système de fichiers ou des dommages supplémentaires pourraient être provoqués. La plupart des outils de systèmes de fichiers appliquent cette condition en mode de réparation, même si certains prennent uniquement en charge le mode de vérification seule sur un système de fichiers monté. Si le mode vérification-seule est exécuté sur un système de fichiers monté, il pourrait trouver de fausses erreurs qui n'auraient pas été trouvées avec une exécution sur un système de fichiers non-monté.
- Erreurs de disque
- Les outils de vérification de système de fichiers ne peuvent pas réparer les problèmes de matériel. Un système de fichiers doit être totalement lisible et inscriptible pour que la réparation puisse s'effectuer correctement. Si un système de fichiers est corrompu à cause d'un problème matériel, le système de fichiers doit d'abord être déplacé sur un disque en bon état, par exemple à l'aide de l'utilitaire
dd(8).
12.2. Informations spécifiques aux systèmes de fichiers pour fsck
12.2.1. ext2, ext3, et ext4
e2fsck pour effectuer leurs vérifications et réparations de système de fichiers. Les noms de fichiers fsck.ext2, fsck.ext3, et fsck.ext4 sont des liens vers ce même binaire. Ces binaires sont exécutés automatiquement lors du démarrage et leur comportement diffère basé sur le fait que le système de fichiers est en cours de vérification, et selon l'état du système de fichiers.
e2fsck découvre qu'un système de fichiers est marqué d'une telle erreur, e2fsck effectuera une vérification complète après avoir répété le journal (s'il est présent).
e2fsck peut demander une entrée à l'utilisateur pendant l'exécution si l'option -p n'est pas spécifiée. L'option -p indique à e2fsck d'effectuer automatiquement toutes les réparations pouvant être faites sans risque. Si une intervention de l'utilisateur est requise, e2fsck indiquera le problème non corrigé dans sa sortie et reflétera ce statut dans le code de sortie.
e2fsck habituellement utilisées incluent :
-n- Mode sans modifications. Opération de vérification seule.
- superbloc
-b - Spécifie le numéro de bloc d'un superbloc alternatif si le bloc principal est endommagé.
-f- Force une vérification complète même si le superbloc n'a aucune erreur enregistrée.
-jjournal-dev- Spécifie le périphérique journal externe, s'il y en a un.
-p- Répare automatiquement ou « nettoie » le système de fichiers sans saisie de la part de l'utilisateur.
-y- Répondre « oui » à toutes les questions.
e2fsck sont spécifiées dans la page man de e2fsck(8).
e2fsck pendant l'exécution des :
- vérifications des inodes, des blocs et des tailles.
- vérifications des structures des répertoires.
- vérifications de la connectivité des répertoires.
- vérifications des comptes des références.
- vérifications des informations des résumés de groupes.
e2image(8) peut être utilisé pour créer une image de métadonnées avant d'effectuer les réparations dans le but de fournir un diagnostique ou pour faire des tests. L'option -r doit être utilisée pour effectuer des tests afin de créer une fichier partiellement alloué de la même taille que le système de fichiers. e2fsck peut ensuite opérer directement sur le fichier résultant. L'option -Q doit être spécifiée si l'image va ensuite être archivée ou utilisée pour fournir un diagnostique. Ceci crée un format de fichier plus compact, qui convient mieux aux transferts.
12.2.2. XFS
xfs_repair est utilisé.
Note
fsck.xfs se trouve dans le paquet xfsprogs, il n'est présent que pour satisfaire les initscripts qui recherchent un binaire fsck.filesystem au moment du démarrage. fsck.xfs se ferme immédiatement avec un code de sortie 0.
xfs_check. Cet outil est très lent et s'adapte mal aux systèmes de fichiers de grande taille. Ainsi, il a été déconseillé en faveur de xfs_repair -n.
xfs_repair d'opérer. Si le système de fichiers n'a pas été démonté correctement, il doit être monté, puis démonté avant d'utiliser xfs_repair. Si le journal est corrompu et ne peut être relu, l'option -L peut être utilisée pour remettre le journal à zéro.
Important
-L doit uniquement être utilisée si le journal ne peut pas être relu. L'option ignore toutes les mises à jour de métadonnées dans le journal et provoquera des incohérences supplémentaires.
xfs_repair lors de tests à vide, en mode de vérification seule, en utilisant l'option -n. Aucune modification ne se produira sur le système de fichiers lorsque cette option est indiquée.
xfs_repair ne peut prendre qu'un petit nombre d'options. Les options communément utilisées incluent :
-n- Mode sans modifications. Opération de vérification seule.
-L- Journal sans métadonnées. Utiliser uniquement si le journal ne peut pas être relu en étant monté.
-mmaxmem- Limite la mémoire utilisée pendant l'exécution à maxmem MB. 0 peut être spécifié pour obtenir une estimation approximative de la quantité minimum de mémoire requise.
-llogdev- Spécifie le périphérique de journalisation externe, si présent.
xfs_repair sont indiquées dans la page man xfs_repair(8).
xfs_repair pendant l'exécution des :
- vérifications des inodes et des mappages (addressage) de blocs d'inodes.
- vérifications des cartes d'allocation d'inodes.
- vérifications de la taille des inodes.
- vérifications des répertoires.
- vérifications des noms de chemins d'accès.
- vérification du nombre de liens.
- Vérifications Freemap.
- vérifications des superblocs.
xfs_repair(8).
xfs_repair n'est pas interactif. Toutes les opérations sont effectuées automatiquement sans saisie de la part de l'utilisateur.
xfs_metadump(8) et xfs_mdrestore(8) peuvent être utilisés.
12.2.3. Btrfs
btrfsck est utilisé pour vérifier et réparer les systèmes de fichiers btrfs. Cet outil est toujours en cours de développement et pourrait ne pas détecter ou réparer tous les types de corruption de système de fichiers.
btrfsck n'effectue pas de modification sur le système de fichiers ; autrement dit, il exécute le mode vérification-seule par défaut. Si des réparations sont souhaitées, l'option --repair doit être spécifiée.
btrfsck pendant l'exécution des :
- vérifications des extensions.
- vérifications de la racine du système de fichiers.
- vérifications des comptes des références root.
btrfs-image(8) peut être utilisé pour créer une image des métadonnées avant les réparations afin d'effectuer des diagnostiques ou de faire des tests.
Chapitre 13. Partitions
parted permet aux utilisateurs de :
- Afficher la table de partitions existante
- Modifier la taille des partitions existantes
- Ajouter des partitions à partir d'espace libre ou de disques durs supplémentaires
parted est inclus dans l'installation de Red Hat Enterprise Linux. Pour lancer parted, connectez-vous en tant que root et saisissez la commande parted /dev/sda à l'invite shell (où /dev/sda est le nom de périphérique du lecteur que vous souhaitez configurer).
umount et désactiver tout l'espace swap sur le disque dur avec la commande swapoff.
parted » contient une liste de commandes parted couramment utilisées. Les sections suivantes expliquent certains de ces arguments et commandes de manière plus détaillée.
Tableau 13.1. Commandes parted
| Commande | Description |
|---|---|
check minor-num | Effectuer une simple vérification du système de fichiers |
cp depuis vers | Copier le système de fichiers d'une partition à une autre ; depuis et vers sont les numéros mineurs des partitions |
help | Afficher la liste des commandes disponibles |
mklabel étiquette | Créer une étiquette de disque pour la table de partitions |
mkfs minor-num file-system-type | Créer un système de fichiers de type file-system-type |
mkpart part-type fs-type start-mb end-mb | Créer une partition sans créer de nouveau système de fichiers |
mkpartfs part-type fs-type start-mb end-mb | Créer une partition et créer le système de fichiers spécifié |
move minor-num start-mb end-mb | Déplacer la partition |
name minor-num nom | Nommer la partition uniquement pour disklabels Mac et PC98 |
print | Afficher la table de partitions |
quit | Quitter parted |
rescue start-mb end-mb | Secourir une partition perdue de start-mb à end-mb |
resize minor-num start-mb end-mb | Redimensionner la partition de start-mb à end-mb |
rm minor-num | Supprimer la partition |
select périphérique | Sélectionner un autre périphérique à configurer |
set minor-num flag state | Paramétrer l'indicateur sur une partition ; l'état est soit « on », soit « off » |
toggle [NUMBER [FLAG] | Basculer l'état de l'indicateur FLAG sur le numéro de partition NUMBER |
unit UNIT | Paramétrer l'unité par défaut sur UNIT |
13.1. Afficher la table de partitions
parted, veuillez utiliser la commande print pour afficher la table de partitions. Une table similaire à la suivante s'affiche :
Exemple 13.1. Table de partitions
Model: ATA ST3160812AS (scsi) Disk /dev/sda: 160GB Sector size (logical/physical): 512B/512B Partition Table: msdos Number Start End Size Type File system Flags 1 32.3kB 107MB 107MB primary ext3 boot 2 107MB 105GB 105GB primary ext3 3 105GB 107GB 2147MB primary linux-swap 4 107GB 160GB 52.9GB extended root 5 107GB 133GB 26.2GB logical ext3 6 133GB 133GB 107MB logical ext3 7 133GB 160GB 26.6GB logical lvm
numéro de la partition. Par exemple, la partition avec le numéro mineur 1 correspond à /dev/sda1. Les valeurs Start et End sont en méga-octets. Les types Type valides sont les métadonnées (« metadata ») « free », « primary », « extended », ou « logical ». Filesystem est le type de système de fichiers, qui peut être n'importe lequel des types suivants :
- ext2
- ext3
- fat16
- fat32
- hfs
- jfs
- linux-swap
- ntfs
- reiserfs
- hp-ufs
- sun-ufs
- xfs
Filesystem d'un périphérique n'affiche aucune valeur, cela signifie que son type de système de fichiers est inconnu.
13.2. Création d'une partition
Avertissement
Procédure 13.1. Création d'une partition
- Avant de créer une partition, veuillez démarrer en mode de secours (ou démontez toute partition sur le périphérique et éteignez tout espace swap sur le périphérique).
- Démarrez
parted, où/dev/sdaest le périphérique sur lequel créer la partition :# parted /dev/sda - Afficher la table de partitions pour déterminer s'il y a suffisament d'espace libre :
# print
13.2.1. Créer la partition
# mkpart primary ext3 1024 2048Note
mkpartfs, le système de fichiers sera créé après la création de la partition. Cependant, parted ne prend pas en charge la création d'un système de fichiers ext3. Ainsi, si vous souhaitez créer un système de fichiers ext3, veuillez utiliser mkpart et créer le système de fichiers avec la commande mkfs comme décrit ultérieurement.
print pour confirmer que celle-ci se trouve effectivement dans la table de partitions avec le bon type de partition, le bon type de système de fichiers, et la bonne taille. Veuillez également vous rappeler du numéro mineur de la nouvelle partition afin d'être en mesure d'étiqueter un système de fichiers dessus. Vous devriez aussi afficher la sortie de cat /proc/partitions une fois que « parted » est fermé afin de vous assurer que le noyau reconnaisse la nouvelle partition.
13.2.2. Formatage et étiquetage de la partition
Procédure 13.2. Formater et étiqueter la partition
- La partition ne possède toujours pas de système de fichiers. Pour en créer un, veuillez utiliser la commande suivante :
# /sbin/mkfs -t ext3 /dev/sda6Avertissement
Formater la partition détruira de manière permanente toutes les données s'y trouvant. - Ensuite, veuillez donner une étiquette au système de fichiers sur la partition. Par exemple, si le système de fichiers sur la nouvelle partition est nommé
/dev/sda6et que vous souhaitez l'étiqueter/work, veuillez utiliser :# e2label /dev/sda6 /work
/work) en tant que root.
13.2.3. Ajoutez-le à /etc/fstab
/etc/fstab afin d'inclure la nouvelle partition à l'aide de son UUID. Veuillez utiliser la commande blkid -o list pour obtenir une liste complète de l'UUID de la partition, ou blkid device pour obtenir les détails individuels du périphérique.
UUID= suivi de l'UUID du système de fichiers. La seconde colonne doit contenir le point de montage de la nouvelle partition, et la colonne suivante doit être le type de système de fichiers (par exemple, ext3 ou swap). Si vous souhaitez obtenir des informations supplémentaires sur le format, veuillez lire la page man avec la commande man fstab.
defaults, alors la partition sera montée au moment du démarrage. Pour monter la partition sans effectuer de redémarrage, veuillez saisir la commande suivante en tant que root :
mount /work
13.3. Suppression de partition
Avertissement
Procédure 13.3. Supprimer une partition
- Avant de supprimer une partition, veuillez démarrer en mode de secours (ou démontez toute partition sur le périphérique, puis éteignez tout espace swap présent sur le périphérique).
- Lancez
parted, où/dev/sdaest le périphérique sur lequel supprimer la partition :# parted /dev/sda - Affichez la table de la partition actuelle pour déterminer le numéro mineur de la partition à supprimer :
# print - Supprimez la partition à l'aide de la commande
rm. Par exemple, pour supprimer la partition portant le numéro mineur 3, saisissez la commande suivante :# rm 3Les modifications prendront effet dès que vous appuierez sur Entrée. Ainsi, veuillez vérifier la commande avant de l'exécuter. - Après avoir supprimé la partition, utilisez la commande
printpour confirmer sa suppression de la table de partitions. Vous devriez également afficher la sortie de/proc/partitionsafin de vous assurer que le noyau sache effectivement que la partition a été supprimée.# cat /proc/partitions - La dernière étape consiste à la supprimer du fichier
/etc/fstab. Trouvez la ligne qui déclare la partition supprimée, puis supprimez-la du fichier.
13.4. Redimensionnement d'une partition
Avertissement
Procédure 13.4. Redimensionner une partition
- Avant de redimensionner une partition, veuillez démarrer en mode de secours (ou démontez toute partition sur le périphérique, puis éteignez tout espace swap présent sur le périphérique).
- Lancez
parted, où/dev/sdaest le périphérique sur lequel redimensionner la partition :# parted /dev/sda - Affichez la table de la partition actuelle pour déterminer le numéro mineur de la partition à redimensionner, ainsi que les points de début et de fin de la partition :
# print - Pour redimensionner la partition, veuillez utiliser la commande
resizesuivie du numéro mineur de la partition, du point de départ en méga-octets, et du point d'arrivée en méga-octets.Exemple 13.2. Redimensionner une partition
Par exemple:resize 3 1024 2048Avertissement
Une partition ne peut pas être plus grande que l'espace disponible sur le disque - Après voir redimensionné la partition, veuillez utiliser la commande
printpour confirmer que la partition a effectivement été redimensionnée correctement, et que son type de partition et son type de système de fichiers soient corrects. - Après avoir redémarré le système en mode normal, veuillez utiliser la commande
dfafin de vous assurer que la partition a bien été montée correctement et qu'elle soit reconnue avec la nouvelle taille.
Chapitre 14. Gestionnaire de volumes logiques LVM (« Logical Volume Manager »)
/boot/. La partition /boot/ ne peut pas se trouver dans un groupe de volumes logiques car le chargeur de démarrage ne peut pas la lire. Si la partition root (/) se trouve sur un volume logique, veuillez créer une partition /boot/ séparée qui ne fera pas partie d'un groupe de volumes.
Figure 14.1. Volumes logiques
/home et / et des types de systèmes de fichiers, comme ext2 ou ext3. Lorsque les « partitions » atteignent leur capacité totale, l'espace libre du groupe de volumes peut être ajouté au volume logique pour augmenter la taille de la partition. Lorsqu'un nouveau disque dur est ajouté au système, il peut être ajouté au groupe de volumes et la taille des partitions, qui sont des volumes logiques, peut être augmentée.
Figure 14.2. Volumes logiques
Important
system-config-lvm. Pour des informations complètes sur la création et la configuration de partitions LVM dans des stockages en cluster et sans clusters, veuillez consulter le guide Administration du gestionnaire de volumes logique LVM, qui est aussi fourni pas Red Hat.
14.1. Qu'est-ce que LVM2 ?
14.2. Utilisation de system-config-lvm
# yum install system-config-lvm
system-config-lvm à partir d'un terminal.
Exemple 14.1. Créer un groupe de volumes pendant l'installation
/boot - (Ext3) système de fichiers. Affiché sous « Entités non-initialisées ». (NE PAS initialiser cette partition). LogVol00 - (LVM) contient le répertoire (/) (312 espaces). LogVol02 - (LVM) contient le répertoire (/home) (128 espaces). LogVol03 - (LVM) swap (28 espaces).
/dev/hda2 tandis que /boot a été créé dans /dev/hda1. Le système consiste également en « entités non-initialisées », qui sont illustrées dans Exemple 14.2, « Entrées non-initialisées ». La figure ci-dessous illustre la fenêtre principale dans l'utilitaire LVM. Les affichages logiques et physiques de la configuration ci-dessus sont illustrés ci-dessous. Les trois volumes logiques existent sur le même volume physique (hda2).
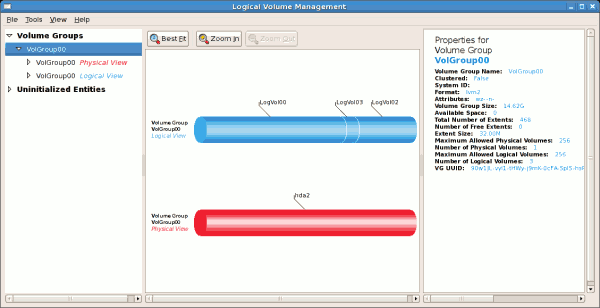
Figure 14.3. Fenêtre principale de LVM

Figure 14.4. Fenêtre d'affichage physique
Figure 14.5. Fenêtre d'affichage logique

Figure 14.6. Modifier le volume logique
14.2.1. Utiliser des entités non-initialisées
/boot. Des entités non-initialisées sont illustrées ci-dessous.
Exemple 14.2. Entrées non-initialisées

14.2.2. Ajouter des volumes non alloués à un groupe de volumes
- créer un nouveau groupe de volumes,
- ajouter le volume non-alloué à un groupe de volumes,
- supprimer le volume de LVM.
Figure 14.7. Volumes non-alloués
Exemple 14.3. Ajouter un volume physique au groupe de volumes

- créer un nouveau volume logique (cliquez sur le bouton ),
- sélectionner un des volumes logiques et augmenter le nombre d'extensions (voir Section 14.2.6, « Étendre un groupe de volumes »),
- sélectionner un volume logique et le supprimer du groupe de volumes en cliquant sur le bouton . Il n'est pas possible de sélectionner de l'espace inutilisé pour effectuer cette opération.
Figure 14.8. Affichage logique du groupe de volumes
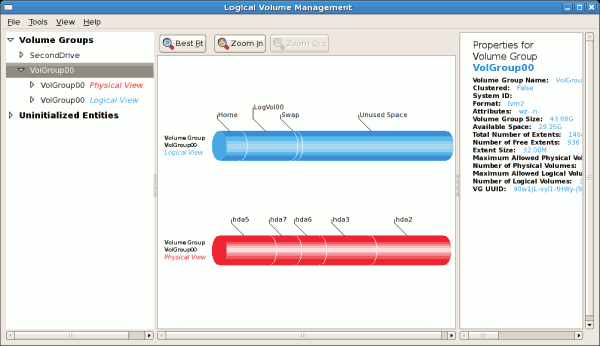
Figure 14.9. Affichage logique du groupe de volumes
14.2.3. Migrer des extensions
Figure 14.10. Migrer des extensions
Figure 14.11. Migration d'extensions en cours
Figure 14.12. Affichage logique et physique d'un groupe de volumes
14.2.4. Ajouter un nouveau disque dur avec LVM

Figure 14.13. Disque dur non-initialisé
14.2.5. Ajouter un nouveau groupe de volumes
Exemple 14.4. Créer un nouveau groupe de volumes

Exemple 14.5. Sélectionner les extensions
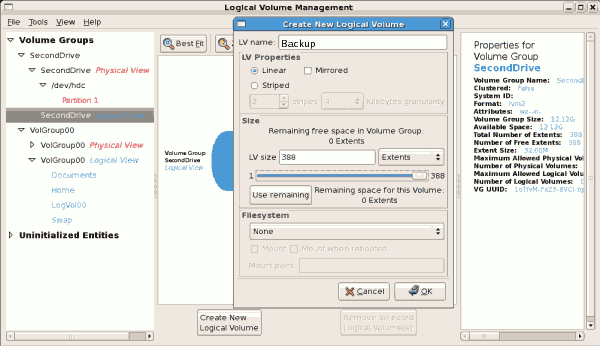
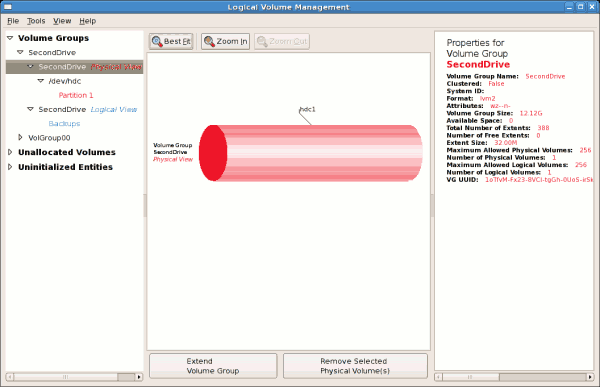
Figure 14.14. Affichage physique du nouveau groupe de volumes
14.2.6. Étendre un groupe de volumes
/dev/hda6 a été sélectionnée.
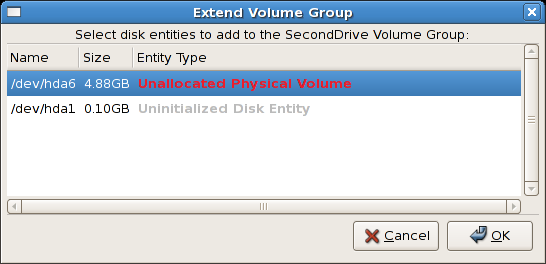
Figure 14.15. Sélectionner les entités de disque
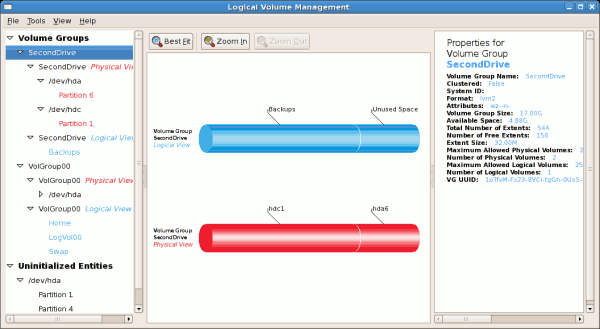
Figure 14.16. Affichage logique et physique d'un groupe de volumes étendu
14.2.7. Modifier un volume logique
Figure 14.17. Modifier le volume logique
/mnt/backups. Ceci est illustré ci-dessous.

Figure 14.18. Modifier le volume logique - spécifier des options de montage

Figure 14.19. Modifier le volume logique
14.3. Références LVM
Documentation installée
rpm -qd lvm2— Cette commande affiche toute la documentation disponible à partir du paquetlvm, y compris les pages man.lvm help— Cette commande affiche toutes les commandes LVM disponibles.
Sites Web utiles
- http://sources.redhat.com/lvm2 — page web LVM2, qui contient une vue d'ensemble, des liens vers les listes de diffusion, et plus encore.
- http://tldp.org/HOWTO/LVM-HOWTO/ — Document LVM HOWTO provenant du projet de documentation Linux (« Linux Documentation Project »).
Chapitre 15. Espace swap
Important
Tableau 15.1. Espace swap recommandé
| Quantité de RAM du système | Espace swap recommandé | Espace swap recommandé si l'hibernation est autorisée |
|---|---|---|
| ⩽ 2 Go | 2 fois la quantité de RAM | 3 fois la quantité de RAM |
| > 2 Go – 8 Go | Égal à la quantité de RAM | 2 fois la quantité de RAM |
| > 8 Go – 64 Go | Au moins 4 Go | 1,5 fois la quantité de RAM |
| > 64 Go | Au moins 4 Go | L'hibernation n'est pas recommandée |
Important
free et cat /proc/swaps pour vérifier combien d'espace swap est en cours d'utilisation et où il se trouve.
rescue ; voir Booting Your Computer with the Rescue Mode du Red Hat Enterprise Linux 6 Installation Guide. Lorsqu'il vous sera demandé de monter le système de fichiers, sélectionnez .
15.1. Ajouter de l'espace swap
15.1.1. Étendre Swap dans un Volume logique LVM2
/dev/VolGroup00/LogVol01 est le volume que vous souhaitez augmenter de 2 Go) :
Procédure 15.1. Étendre Swap dans un Volume logique LVM2
- Désactiver le swapping pour le volume logique associé :
# swapoff -v /dev/VolGroup00/LogVol01
- Modifiez la taille du volume logique LVM2 de 2 Go supplémentaires :
# lvresize /dev/VolGroup00/LogVol01 -L +2G
- Formatter le nouvel espace swap :
# mkswap /dev/VolGroup00/LogVol01
- Activer le volume logique étendu :
# swapon -v /dev/VolGroup00/LogVol01
cat /proc/swaps ou free pour inspecter l'espace swap.
15.1.2. Création d'un volume logique LVM2 avec Swap
/dev/VolGroup00/LogVol02 est le volume swap que vous souhaitez ajouter) :
- Créer le volume logique LVM2 avec une taille de 2 Go :
#
lvcreate VolGroup00 -n LogVol02 -L 2G - Formatter le nouvel espace swap :
#
mkswap /dev/VolGroup00/LogVol02 - Ajouter l'entrée suivante au fichier
/etc/fstab:#
/dev/VolGroup00/LogVol02 swap swap defaults 0 0 - Activer le volume logique étendu :
#
swapon -v /dev/VolGroup00/LogVol02
cat /proc/swaps ou free pour inspecter l'espace swap.
15.1.3. Création d'un fichier Swap
Procédure 15.2. Ajouter un fichier swap
- Déterminer la taille du nouveau fichier swap en mégaoctets et multipliez-la par 1024 pour déterminer le nombre de blocs. Ainsi, la taille de bloc d'un fichier swap de 64 Mo est 65536.
- Saisir la commande suivante avec
countcorrespondant à la taille de bloc souhaitée :#
dd if=/dev/zero of=/swapfile bs=1024 count=65536 - Définir le fichier swap par la commande :
#
mkswap /swapfile - Il est conseillé de changer les permissions pour éviter que le fichier swap soit lisible par tout le monde.
#
chmod 0600 /swapfile - Pour activer le fichier swap immédiatement, mais pas automatiquement au démarrage :
#
swapon /swapfile - Pour l'activer au démarrage, modifier le fichier
/etc/fstabpour y inclure l'entrée suivante :/swapfile swap swap defaults 0 0Le nouveau fichier swap sera activé lors du prochain démarrage du système.
cat /proc/swaps ou free pour inspecter l'espace swap.
15.2. Supprimer de l'espace swap
15.2.1. Réduire un Swap dans un Volume logique LVM2
/dev/VolGroup00/LogVol01 soit le volume swap que vous souhaitez réduire) :
Procédure 15.3. Réduire un volume logique LVM2 swap
- Désactiver le swapping pour le volume logique associé :
#
swapoff -v /dev/VolGroup00/LogVol01 - Réduire la taille du volume logique LVM2 de 512 Mo :
#
lvreduce /dev/VolGroup00/LogVol01 -L -512M - Formater le nouvel espace swap :
#
mkswap /dev/VolGroup00/LogVol01 - Activer le volume logique étendu :
#
swapon -v /dev/VolGroup00/LogVol01
cat /proc/swaps ou free pour inspecter l'espace swap.
15.2.2. Supprimer un volume logique LVM2 avec Swap
/dev/VolGroup00/LogVol02 est le volume swap que vous souhaitez supprimer) :
Procédure 15.4. Comment supprimer un volume swap :
- Désactiver le swapping pour le volume logique associé :
#
swapoff -v /dev/VolGroup00/LogVol02 - Supprimer le volume logique LVM2 d'une taille de 512 Mo :
#
lvremove /dev/VolGroup00/LogVol02 - Supprimer l'entrée suivante du fichier
/etc/fstab:/dev/VolGroup00/LogVol02 swap swap defaults 0 0
cat /proc/swaps ou free pour inspecter l'espace swap.
15.2.3. Supprimer un fichier swap
Procédure 15.5. Supprimer un fichier swap
- À l'invite de commande, exécutez la commande suivante pour désactiver le fichier suivant (si
/swapfileest le fichier swap) :#
swapoff -v /swapfile - Supprimer son entrée du fichier
/etc/fstab: - Supprimer le fichier :
#
rm /swapfile
Chapitre 16. Quotas de disques
quota doit être installé pour implémenter les quotas de disques.
16.1. Configurer les quotas de disques
- Activez les quotas par système de fichiers en modifiant le fichier
/etc/fstab. - Remontez le(s) système(s) de fichiers.
- Créez les fichiers de la base de données des quotas et générez le tableau d'utilisation du disque.
- Assignez les politiques des quotas.
16.1.1. Activer les quotas
/etc/fstab.
Exemple 16.1. Modifiez /etc/fstab
vim, veuillez saisir :
# vim /etc/fstab
usrquota ou grpquota aux systèmes de fichiers qui requièrent des quotas :
Exemple 16.2. Ajoutez les quotas
/dev/VolGroup00/LogVol00 / ext3 defaults 1 1 LABEL=/boot /boot ext3 defaults 1 2 none /dev/pts devpts gid=5,mode=620 0 0 none /dev/shm tmpfs defaults 0 0 none /proc proc defaults 0 0 none /sys sysfs defaults 0 0 /dev/VolGroup00/LogVol02 /home ext3 defaults,usrquota,grpquota 1 2 /dev/VolGroup00/LogVol01 swap swap defaults 0 0 . . .
/home possède des quotas utilisateurs et groupes activés.
Note
/home a été créée pendant l'installation de Red Hat Enterprise Linux. La partition root (/) peut être utilisée pour définir les politiques de quotas dans le fichier /etc/fstab.
16.1.2. Remonter les systèmes de fichiers
usrquota ou grpquota, veuillez remonter chaque système de fichier dont l'entrée fstab a été modifiée. Si le système de fichiers n'est pas en cours d'utilisation, veuillez utiliser les commandes suivantes :
umount /mount-point
umount /work.
mount /file-system /mount-point
mount /dev/vdb1 /work.
16.1.3. Créer les fichiers de base de données de quotas
quotacheck.
quotacheck examine les systèmes de fichier dont les quotas sont activés et crée un tableau de l'utilisation actuelle du disque par système de fichiers. Le tableau est ensuite utilisé pour mettre à jour la copie de l'utilisation du disque du système d'exploitation. En outre, les fichiers de quotas du système de fichiers sont aussi mis à jour.
aquota.user et aquota.group) sur le système de fichiers, veuillez utiliser l'option -c de la commande quotacheck.
Exemple 16.3. Créer des fichiers de quotas
/home, veuillez créer les fichiers dans le répertoire /home :
# quotacheck -cug /home-c indique que des fichiers de quotas doivent être créés pour chaque système de fichiers sur lequel les quotas sont activés, l'option -u indique que les quotas d'utilisateurs seront vérifiés, et l'option -g indique que les quotas de groupes seront vérifiés.
-u ou -g ne sont pas spécifiées, seul le fichier du quota d'utilisateurs sera créé. Si seule l'option -g est spécifiée, seul le fichier du quota de groupes sera créé.
# quotacheck -avug- a
- Vérifie tous les systèmes de fichiers montés localement avec quotas activés
- v
- Affiche les informations détaillées pendant la progression de la vérification du quota
- u
- Vérifie les informations du quota de disques de l'utilisateur
- g
- Vérifie les informations du quota de disques de groupe
quotacheck a terminé son exécution, les fichiers de quotas correspondants aux quotas activés (d'utilisateurs ou de groupes) sont remplis avec des données pour chaque système de fichiers monté localement avec quotas activés, tel que /home.
16.1.4. Allouer les quotas par utilisateur
edquota.
# edquota username/etc/fstab pour la partition /home (/dev/VolGroup00/LogVol02 dans l'exemple ci-dessous) et que la commande edquota testuser est exécutée, vous verrez ce qui suit dans l'éditeur configuré par défaut dans le système :
Disk quotas for user testuser (uid 501): Filesystem blocks soft hard inodes soft hard /dev/VolGroup00/LogVol02 440436 0 0 37418 0 0
Note
EDITOR est utilisé par edquota. Pour changer l'éditeur, définir la variable d'environnement EDITOR dans votre fichier ~/.bash_profile vers le chemin d'accès de l'éditeur de votre choix.
inodes affiche le nombre d'inodes actuellement en cours d'utilisation par l'utilisateur. Les deux dernières colonnes sont utilisées pour définir les limites d'inode « soft » et « hard » pour l'utilisateur sur le système de fichiers.
Exemple 16.4. Modifier les limites souhaitées
Disk quotas for user testuser (uid 501): Filesystem blocks soft hard inodes soft hard /dev/VolGroup00/LogVol02 440436 500000 550000 37418 0 0
# quota username
Disk quotas for user username (uid 501):
Filesystem blocks quota limit grace files quota limit grace
/dev/sdb 1000* 1000 1000 0 0 016.1.5. Assigner les quotas par groupe
devel (le groupe doit exister avant de définir le quota du groupe), veuillez utiliser la commande :
# edquota -g develDisk quotas for group devel (gid 505): Filesystem blocks soft hard inodes soft hard /dev/VolGroup00/LogVol02 440400 0 0 37418 0 0
# quota -g devel16.1.6. Définir la période de grâce pour les limites soft
# edquota -tImportant
edquota opèrent sur les quotas d'un utilisateur ou d'un groupe particulier, l'option -t opère sur tous les systèmes de fichiers dont les quotas sont activés.
16.2. Gérer les quotas de disque
16.2.1. Activation et désactivation
# quotaoff -vaug-u ou -g ne sont pas spécifiées, seuls les quotas d'utilisateur seront désactivés. Si seule l'option -g est spécifiée, seuls les quotas de groupe seront désactivés. L'interrupteur -v provoque l'affichage des informations verbeuses du statut lorsque la commande est exécutée.
quotaon avec les mêmes options.
# quotaon -vaug/home, veuillez utiliser la commande suivante :
# quotaon -vug /home-u ou -g ne sont pas spécifiées, seuls les quotas d'utilisateur seront activés. Si seule l'option -g est spécifiée, seuls les quotas de groupe seront activés.
16.2.2. Rapports sur les quotas de disques
repquota.
Exemple 16.5. Sortie de la commande repquota
repquota /home produit la sortie suivante :
*** Report for user quotas on device /dev/mapper/VolGroup00-LogVol02 Block grace time: 7days; Inode grace time: 7days Block limits File limits User used soft hard grace used soft hard grace ---------------------------------------------------------------------- root -- 36 0 0 4 0 0 kristin -- 540 0 0 125 0 0 testuser -- 440400 500000 550000 37418 0 0
-a), utiliser la commande suivante :
# repquota -a-- qui sont affichés après chaque utilisateur servent à déterminer si les limites du bloc ou de l'inode ont été dépassées. Si la limite soft est dépassée, le caractère + apparaîtra à la place du caractère - correspondant ; le premier caractère - représente la limite du bloc, et le second représente la limite de l'inode.
grace sont normalement vides. Si une limite soft a été dépassée, la colonne affichera le temps correspondant au délai restant de la période de grâce. Si la période de grâce a été dépassée, la chaîne none (aucun) s'affichera à sa place.
16.2.3. Contrôler l'exactitude des quotas
quotacheck. Cependant, quotacheck peut être exécuté de manière régulière, même si le système n'est pas tombé en panne. Les méthodes sûres pour exécuter quotacheck périodiquement incluent :
- L'assurance que quotacheck sera exécuté lors du prochain redémarrage
Note
Cette méthode fonctionne mieux pour les systèmes multi-utilisateur (occupés) qui sont redémarrés périodiquement.En tant qu'utilisateur root, veuillez placer un script shell dans le répertoire/etc/cron.daily/ou/etc/cron.weekly/qui contient la commandetouch /forcequotacheck— ou planifiez-en un à l'aide de la commandecrontab -e. Ceci crée un fichierforcequotacheckvide dans le répertoire root, que le script init du sytème cherchera lors du démarrage. Si celui-ci est trouvé, le script init exécuteraquotacheck. Puis le script init supprimera le fichier/forcequotacheck; ainsi, la planification de la création périodique de ce fichier aveccronassure quequotachecksoit effectivement exécuté lors du prochain redémarrage.Pour obtenir davantage d'informations surcron, veuillez consulterman cron.- Exécuter quotacheck en mode mono-utilisateur
- Une manière alternative d'exécuter
quotachecksûrement consiste à démarrer le système en mode mono-utilisateur, ce qui empêche toute possibilité de corruption de données dans les fichiers de quota, puis d'exécuter les commandes suivantes :#
quotaoff -vaug /file_system#
quotacheck -vaug /file_system#
quotaon -vaug /file_system - Exécuter quotacheck sur un système en cours d'exécution
- Si nécessaire, il est possible d'exécuter
quotachecksur un ordinateur à un moment où aucun utilisateur n'est connecté, ainsi il n'y aura aucun fichier ouvert sur le système en cours de vérification. Exécutez la commandequotacheck -vaug file_system; cette commande échouera siquotacheckne peut pas monter à nouveau le système de fichiers donné file_system en lecture seule. Remarquez qu'après la vérification, le système de fichiers sera remonté en lecture-écriture.Avertissement
Exécuterquotachecksur un système de fichiers en cours d'exécution monté en lecture-écriture n'est pas recommandé à cause de la possibilité de corruption de fichier(s) de quota.
man cron pour obtenir davantage d'informations sur la configuration de cron.
Chapitre 17. Réseau redondant de disques indépendants (RAID, de l'anglais « Redundant Array of Independent Disks »)
- Amélioration de la vitesse
- Augmentation des capacités de stockage à l'aide d'un seul disque virtuel
- Perte de données due aux échecs de disque minimisée
17.1. Types RAID
RAID microprogramme
Matériel RAID
RAID logiciel
- Conception multi-threads
- Portabilité des matrices entre ordinateurs Linux sans reconstruction
- Reconstruction de matrices en arrière-plan à l'aide des ressources système inactives
- Prise en charge des disques enfichables à chaud
- Détection de CPU automatique pour tirer profit de certaines fonctionnalités, comme la prise en charge du streaming SIMD
- Correction automatique des mauvais secteurs sur les disques d'une matrice
- Vérifications régulières de la consistance des données RAID afin de s'assurer de la bonne santé de la matrice
- Surveillance pro-active des matrices avec des alertes par courrier électronique envoyées sur une adresse désignée lors d'événements importants
- Les « write-intent bitmap », qui augmentent dramatiquement la vitesse des événements de resynchronisation en permettant au noyau de savoir précisément quelles portions d'un disque doivent être resynchronisées au lieu de devoir resynchroniser la matrice toute entière
- Resynchronisez les points de contrôle. Ainsi, si vous redémarrez votre ordinateur pendant une resynchronisation, pendant le démarrage, la resynchronisation reprendra à l'emplacement où elle s'était arrêtée et ne devra pas recommencer depuis le début.
- La capacité à changer les paramètres de la matrice après l'installation. Par exemple, vous pouvez agrandir une matrice RAID5 à 4 disques en matrice RAID5 à 5 disques lorsque vous avez un nouveau disque à ajouter. Cette opération d'agrandissement se fait à chaud et ne requiert pas de réinstallation sur la nouvelle matrice.
17.2. Niveaux RAID et prise en charge linéaire
- Niveau 0
- RAID niveau 0, souvent appelé « entrelacement », est une technique de mappage de données entrelacées orientée performances. Cela signifie que les données écrites sur la matrice sont divisées en bandes et écrites sur les disques membres de la matrice, permettant ainsi de hautes performances d'E/S pour un moindre coût, mais cela ne fournit pas de redondance.De nombreuses implémentations RAID niveau 0 entrelaceront uniquement les données à travers les périphériques membres d'une taille égale à ou inférieure à la taille du plus petit périphérique de la matrice. Cela signifie que si vous possédez plusieurs périphériques de tailles légèrement différentes, chaque périphérique sera traité comme s'il était égal au plus petit disque. Ainsi, la capacité de stockage courante d'une matrice de niveau 0 est égale au plus petit disque dans la matrice RAID matériel, ou à la capacité de la plus petite partition membre dans une matrice RAID logiciel multipliée par le nombre de disques ou partitions dans la matrice.
- Niveau 1
- RAID niveau 1, ou la « mise en miroir », a été utilisé depuis plus longtemps que toute autre forme de RAID. Le niveau 1 fournit de la redondance en écrivant des données identiques sur chaque disque membre de la matrice, laissant un copie « miroir » sur chaque disque. La mise en miroir est populaire du fait de sa simplicité et du haut niveau de disponibilité de données offert. Le niveau 1 fonctionne avec deux disques ou plus et offre une très bonne fiabilité de donnés et améliore les performances des applications à lecture intensive, mais à coût relativement élevé. [5]La capacité de stockage d'une matrice de niveau 1 est égale à la capacité du disque dur miroir le plus petit dans une matrice RAID matériel ou à la partition miroir la plus petite dans une matrice RAID logiciel. La redondance du niveau 1 est la plus élevée possible parmi les différents types RAID, la matrice étant capable de fonctionner avec un seul disque présent.
- Niveau 4
- Le niveau 4 utilise une parité [6] concentrée sur un seul disque pour protéger les données. Comme le disque de parité dédié représente un goulot d'étranglement inhérent à toutes les transactions d'écriture sur la matrice RAID, le niveau 4 est rarement utilisé sans technologie d'accompagnement telle que le cache en écriture différée, ou dans des circonstances particulières, où l'administrateur système conçoit le périphérique RAID logiciel avec ce goulot d'étranglement en tête (par exemple, avec une matrice qui aurait peu ou pas de transactions d'écriture une fois remplie de données). RAID niveau 4 est si rarement utilisé qu'il n'est pas disponible en tant qu'option dans Anaconda. Cependant, il peut être créé manuellement par l'utilisateur si réellement nécessaire.La capacité de stockage RAID matériel niveau 4 est égale à la capacité de la partition membre la plus petite, multiplié par le nombre de partitions moins un. Les performances d'une matrice RAID niveau 4 seront toujours asymétriques, ce qui signifie que les lectures seront plus performantes que les écritures. Ceci est dû au fait que les écritures consomment davantage de ressources du CPU et de bande passante de la mémoire lors de la génération de parité, qui consomme également davantage de bande passante du bus lors de l'écriture des données sur disque car vous n'écrivez pas seulement les données, mais aussi la parité. Les lectures ne font que lire les données et non la parité, à moins que la matrice ne se trouve dans un état dégradé. Par conséquent, les lectures génèrent moins de trafic sur les disques et à travers les bus de l'ordinateur pour une même quantité de données transférée que sous des conditions normales.
- Niveau 5
- Type RAID le plus commun. En distribuant la parité à travers tous les disques membres d'une matrice, RAID niveau 5 élimine le goulot d'étranglement des écritures, qui est inhérent au niveau 4. Le seul goulot d'étranglement des performances est le processus de calcul de parité en soi-même. Avec les CPU modernes et RAID logiciel, il n'y a habituellement pas de goulot d'étranglement, car tous les CPU modernes peuvent générer une parité très rapidement. Cependant, si vous possédez suffisamment de périphériques membres dans une matrice RAID5 logiciel, permettant ainsi une grande vitesse de transfert de données agrégées à travers tous les périphériques, alors ce goulot d'étranglement peut se révéler problématique.Comme avec le niveau 4, le niveau 5 offre des performances asymétriques, avec des lectures considérablement plus performantes que les écritures. La capacité de stockage RAID niveau 5 est calculée de la même manière qu'avec le niveau 4.
- Niveau 6
- Ce niveau RAID commun, sur lequel la redondance et la préservation des données, et non les performances forment le but principal, considère l'inefficacité en termes d'espace du niveau 1 inacceptable. Le niveau 6 utilise un schéma de parité complexe afin d'être en mesure de récupérer après la perte de deux disques de la matrice. Ce schéma de parité complexe crée un fardeau pour le CPU bien plus important sur les périphériques RAID logiciel, mais aussi pendant les transactions d'écriture. Ainsi, le niveau 6 est considérablement plus asymétrique quant aux performances que les niveaux 4 et 5.La capacité totale d'une matrice RAID niveau 6 est calculée de manière similaire à celles des matrices RAID niveaux 4 et 5, à l'exception que vous devrez soustraire 2 périphériques (au lieu d'un seul) du compte des périphériques pour l'espace de stockage supplémentaire de la parité.
- Niveau 10
- Ce niveau RAID tente de combiner les avantages de performance du niveau 0 avec la redondance du niveau 1. Il aide également à alléger une certaine quantité de l'espace gaspillé dans les matrices niveau 1 contenant plus de deux périphériques. Avec le niveau 10, il est possible de créer une matrice à 3 disques configurée pour stocker uniquement 2 copies de chaque « morceau » de données, ce qui permettra ensuite à la taille de la matrice de faire 1,5 fois la taille du périphérique le plus petit, au lieu d'être égal à la taille de celui-ci (comme cela aurait été le cas avec une matrice niveau 1 à trois périphériques).Le nombre d'options disponible lors de la création de matrices de niveau 10 (ainsi que la complexité de la sélection des bonnes options pour un cas d'utilisation particulier) rend la création pendant une installation très peu pratique. Il est possible d'en créer une manuellement à l'aide de l'outil en ligne de commande
mdadm. Pour obtenir davantage de détails sur les options et les compromis en termes de performance, veuillez consulterman md. - RAID linéaire
- RAID linéaire est un simple regroupement de disques servant à créer un disque virtuel de plus grande taille. Avec une matrice RAID linéaire, les morceaux sont alloués de manière séquentielle, d'un disque au suivant, en allant au second disque qu'une fois que le premier disque aura été entièrement rempli. Ce regroupement ne fournit pas de bénéfices de performance, car il est très improbable que des opérations d'E/S soient divisées entre disques membres. RAID linéaire n'offre pas non plus de redondance, et réduit la fiabilité. — si un disque membre échoue, la matrice toute entière ne pourra pas être utilisée. La capacité est égale au total des disques membres.
17.3. Sous-systèmes RAID Linux
Pilotes de contrôleurs RAID matériel Linux
mdraid
mdraid a été conçu comme solution RAID logiciel pour Linux ; celui-ci est également la solution préférée pour RAID logiciel sous Linux. Ce sous-système utilise son propre format de métadonnées, habituellement appelé « métadonnées mdraid natives ».
mdraid prend également en charge d'autre formats de métadonnées, appelées métadonnées externes. Red Hat Enterprise Linux 6 utilise mdraid avec des métadonnées externes pour accéder aux ensembles ISW / IMSM (RAID microprogramme d'Intel). Les ensembles mdraid sont configurés et contrôlés via l'utilitaire mdadm.
dmraid
dmraid fait référence au code du noyau mappeur de périphériques qui offre un mécanisme permettant d'assembler des disques pour former un ensemble RAID. Ce même code du noyau ne fournit aucun mécanisme de configuration RAID.
dmraid est entièrement configuré dans l'espace utilisateur, ce qui rend la prise en charge des différents formats de métadonnées plus facile. Ainsi, dmraid est utilisé sur un large éventail d'implémentations RAID microprogramme. dmraid prend aussi en charge le RAID microprogramme d'Intel, malgré le fait que Red Hat Enterprise Linux 6 utilise mdraid pour accéder aux ensembles RAID microprogramme d'Intel.
17.4. Prise en charge RAID dans l'installateur
mdraid, et peut reconnaître les ensembles mdraid existants.
initrd quel(s) ensemble(s) RAID doivent être activés avant de chercher le système de fichiers root.
17.5. Configuration d'ensembles RAID
mdadm
mdadm est utilisé pour gérer RAID logiciel sur Linux, c'est-à-dire mdraid. Pour obtenir des informations sur les différents modes et options mdadm, veuillez consulter man mdadm. La page man contient également des exemples utiles pour des opérations communes, comme la création, le contrôle, et l'assemblage de matrices RAID logiciel.
dmraid
dmraid est utilisé pour gérer les ensembles RAID du mappeur de périphériques device-mapper. L'outil dmraid trouve les périphériques ATARAID en utilisant plusieurs gestionnaires de format de métadonnées, chacun prenant en charge divers formats. Pour afficher une liste complète des formats pris en charge, veuillez exécuter dmraid -l.
dmraid ne peut pas configurer les ensembles RAID après leur création. Pour obtenir des informations supplémentaires sur l'utilisation de dmraid, veuillez consulter man dmraid.
17.6. Création de périphériques RAID avancée
/boot ou de matrices du système de fichiers root sur un périphérique RAID complexe ; dans de tels cas, vous pourriez devoir utiliser des options de matrices qui ne sont pas prises en charge par Anaconda. Pour contourner ce problème, veuillez observer la procédure suivante :
Procédure 17.1. Création avancée de périphériques RAID
- Insérez le disque d'installation comme d'habitude.
- Pendant le démarrage initial, veuillez sélectionner le mode de secours (« ») au lieu de l'installation (« ») ou de la mise à niveau (« »). Lorsque le système est entièrement démarré en mode de secours (« Rescue mode »), un terminal de ligne de commande sera présenté à l'utilisateur.
- À partir de ce terminal, veuillez utiliser
partedpour créer des partitions RAID sur les disques durs cibles. Puis, utilisezmdadmpour créer des matrices RAID manuellement à partir de ces partitions en utilisant tous les paramètres et options disponibles. Pour obtenir des informations supplémentaires sur la manière d'accomplir cela, veuillez consulter Chapitre 13, Partitions,man parted, etman mdadm. - Une fois les matrices créées, il est optionnellement possible de créer des systèmes de fichiers sur les matrices. Veuillez consulter Section 11.2, « Aperçu des systèmes de fichiers pris en charge » pour obtenir des informations techniques de base sur les systèmes de fichiers pris en charge par Red Hat Enterprise Linux 6.
- Redémarrez l'ordinateur et sélectionnez Installation (« ») ou Mise à niveau (« ») pour effectuer l'installation normalement. Comme Anaconda recherche les disques dans le système, il trouvera les périphériques RAID pré-existants.
- Lorsqu'il vous sera demandé comment utiliser les disques du système, veuillez sélectionner Structure personnalisée (« »), puis cliquez sur Suivant (« »). Les périphériques RAID MD pré-existants y seront répertoriés.
- Sélectionnez un périphérique RAID, cliquez sur Modifier (« »), puis configurez sont point de montage et (optionnellement) le type de fichier que le système de fichiers devrait utiliser (si vous n'en avez pas déjà créé un auparavant). Veuillez ensuite cliquer sur Terminé (« »). Anaconda effectuera l'installation sur ce périphérique RAID pré-existant, tout en conservant les options personnalisées que vous avez sélectionnées lors de sa création dans le mode de secours (« Rescue Mode »).
Note
man. man mdadm et man md contiennent des informations utiles à la création de matrices RAID personnalisées, et peuvent être nécessaires tout au long de la solution de contournement. Ainsi, il peut être utile d'avoir accès à une machine avec ces pages man présentes, ou de les imprimer avant de démarrer en Mode de secours et de créer vos propres matrices personnalisées.
Chapitre 18. Utilisation de la commande mount
mount ou umount. Ce chapitre décrit l'utilisation de base de ces commandes, ainsi que certains sujets avancés, tels que le déplacement de points de montage ou la création de sous-structures partagées.
18.1. Répertorier les systèmes de fichiers actuellement montés
mount sans arguments supplémentaires :
mountpériphérique sur le type de répertoire type (options)
findmnt, qui permet aux utilisateurs de répertorier les systèmes de fichiers montés sous la forme d'une arborescence, est également disponible à partir de Red Hat Enterprise Linux 6.1. Pour afficher tous les systèmes de fichiers actuellement attachés, veuillez exécuter la commande findmnt sans arguments supplémentaires :
findmnt18.1.1. Spécifier le type de système de fichiers
mount inclut divers systèmes de fichiers virtuels, tels que sysfs et tmpfs. Pour afficher uniquement les périphériques avec un certain type de système de fichiers, veuillez ajouter l'option -t sur la ligne de commande :
mount-ttype
findmnt, veuillez saisir :
findmnt-ttype
ext4 actuellement montés ».
Exemple 18.1. Répertorier les systèmes de fichiers ext4 actuellement montés
/ et /boot sont formatées pour utiliser ext4. Pour afficher uniquement les points de montage qui utilisent ce système de fichiers, veuillez saisir ce qui suit dans l'invite shell :
~]$ mount -t ext4
/dev/sda2 on / type ext4 (rw)
/dev/sda1 on /boot type ext4 (rw)findmnt, veuillez saisir :
~]$ findmnt -t ext4
TARGET SOURCE FSTYPE OPTIONS
/ /dev/sda2 ext4 rw,realtime,seclabel,barrier=1,data=ordered
/boot /dev/sda1 ext4 rw,realtime,seclabel,barrier=1,data=ordered18.2. Monter un système de fichiers
mount sous la forme suivante :
mount [option…] device directoryImportant
findmnt avec le répertoire en tant qu'argument et vérifiez le code de sortie :
findmntdirectory;echo$?
1.
mount est exécutée sans toutes les informations requises (c'est-à-dire sans le nom de périphérique, le répertoire cible, ou le type de système de fichiers), le contenu du fichiers de configuration /etc/fstab est lu pour voir si le système de fichiers donné est répertorié. Ce fichier contient une liste de noms de périphériques et les répertoires dans lesquels les systèmes de fichiers sélectionnés doivent être montés, ainsi que le type de système de fichiers et les options de montage. De ce fait, lors du montage d'un système de fichiers qui est spécifié dans ce fichier, vous pouvez utiliser l'une des variantes suivantes de la commande :
mount[option…] directorymount[option…] device
root (voir la Section 18.2.2, « Spécifier les options de montage »).
Note
blkid sous le format suivant :
blkid device/dev/sda3, veuillez saisir :
~]# blkid /dev/sda3
/dev/sda3: LABEL="home" UUID="34795a28-ca6d-4fd8-a347-73671d0c19cb" TYPE="ext3"18.2.1. Spécifier le type de système de fichiers
mount détecte le système de fichiers automatiquement. Cependant, certains systèmes de fichiers, tels que NFS (« Network File System ») ou CIFS (« Common Internet File System ») ne sont pas reconnus, et doivent être spécifiés manuellement. Pour spécifier le type de système de fichiers, veuillez utiliser la commande mount sous le format suivant :
mount-ttype périphérique répertoire
mount. Pour une liste complète de tous les types de système de fichiers disponibles, veuillez consulter la page du manuel correspondante comme indiqué dans la Section 18.4.1, « Documentation installée ».
Tableau 18.1. Types de systèmes de fichiers communs
| Type | Description |
|---|---|
ext2 | Système de fichiers ext2. |
ext3 | Système de fichier ext3. |
ext4 | Système de fichiers ext4. |
iso9660 | Système de fichiers ISO 9660. Communément utilisé par les supports optiques, comme les CD. |
jfs | Système de fichier JFS, créé par IBM. |
nfs | Système de fichiers NFS. Celui-ci est communément utilisé pour accéder à des fichiers sur un réseau. |
nfs4 | Système de fichiers NFSv4. Celui-ci est communément utilisé pour accéder à des fichiers sur un réseau. |
ntfs | Système de fichiers NTFS. Celui-ci est communément utilisé sur des ordinateurs exécutant un système d'exploitation Windows. |
udf | Système de fichiers UDF. Communément utilisé par les supports optiques, comme les DVD. |
vfat | Système de fichiers FAT. Celui-ci est communément utilisé sur les ordinateurs exécutant un système d'exploitation Windows ainsi que sur certains supports numériques, tels que les lecteurs flash USB ou les disquettes. |
Exemple 18.2. Monter un disque flash USB
/dev/sdc1 et que le répertoire /media/flashdisk/ existe, veuillez le monter sur ce répertoire en saisissant ce qui suit à l'invite shell en tant qu'utilisateur root :
~]# mount -t vfat /dev/sdc1 /media/flashdisk18.2.2. Spécifier les options de montage
mount-ooptions périphérique répertoire
mount interprétera incorrectement les valeurs qui suivent les espaces en tant que paramètres supplémentaires.
Tableau 18.2. Options de montage communes
| Option | Description |
|---|---|
async | Permet les opérations d'entrées/sorties asynchrones sur le système de fichiers. |
auto | Permet au système de fichiers d'être monté automatiquement en utilisant la commande mount -a. |
defaults | Fournit un alias pour async,auto,dev,exec,nouser,rw,suid. |
exec | Permet l'exécution de fichiers binaires sur un système de fichiers particulier. |
loop | Monte une image en tant que périphérique boucle. |
noauto | Le comportement par défaut interdit le montage automatique du système de fichiers à l'aide de la commande mount -a. |
noexec | Interdit l'exécution de fichiers binaires sur le système de fichiers en particulier. |
nouser | Interdit à un utilisateur normal (c'est-à-dire autre que root) de monter et démonter le système de fichiers. |
remount | Remonte le système de fichiers au cas où il serait déjà monté. |
ro | Monte le système de fichiers en lecture seule. |
rw | Monte le système de fichier en lecture et écriture. |
user | Permet à un utilisateur normal (c'est-à-dire autre que root) de monter et démonter le système de fichiers. |
Exemple 18.3. Monter une image ISO
/media/cdrom/ existe, veuillez monter l'image sur ce répertoire en exécutant la commande suivante en tant qu'utilisateur root :
~]# mount -o ro,loop Fedora-14-x86_64-Live-Desktop.iso /media/cdrom18.2.3. Partager des montages
mount implémente l'option --bind qui fournit un moyen pour dupliquer certains montages. Son utilisation fonctionne comme suit :
mount--bindold_directory new_directory
mount--rbindold_directory new_directory
- Montage partagé
- Un montage partagé permet la création d'une réplique exacte d'un point de montage donné. Lorsqu'un point de montage est marqué en tant que montage partagé, tout montage à l'intérieur du point de montage d'origine est reflété dedans, et vice-versa. Pour modifier le type d'un point de montage en montage partagé, veuillez saisir la commande suivante à l'invite shell :
mount--make-sharedmount_pointDe manière alternative, pour modifier le type de montage du point de montage sélectionné et de tous les points de montage se trouvant sous celui-ci, veuillez saisir :mount--make-rsharedmount_pointVeuillez consulter Exemple 18.4, « Créer un point de montage partagé » pour un exemple d'utilisation. - Montage esclave
- Un montage esclave permet la création d'un double limité d'un point de montage donné. Lorsqu'un point de montage est marqué en tant que montage esclave, tout montage dans le point de montage d'origine y sera reflété, mais aucun montage à l'intérieur d'un montage esclave n'est reflété dans son point d'origine. Pour modifier le type d'un point de montage en montage esclave, veuillez saisir ce qui suit à l'invite shell :
mount--make-slavemount_pointAlternativement, il est possible de modifier le type de montage du point de montage sélectionné et de tous les points de montage se trouvant sous celui-ci en saisissant :mount--make-rslavemount_pointVeuillez consulter l'Exemple 18.5, « Créer un point de montage esclave » pour voir un exemple d'utilisation.Exemple 18.5. Créer un point de montage esclave
Cet exemple montre comment faire pour que le contenu du répertoire/mediasoit également affiché dans/mnt, mais sans qu'aucun montage du répertoire/mntne soit reflété dans/media. En tant qu'utilisateurroot, veuillez marquer le répertoire/mediaen tant que répertoire « partagé » :~]#
mount --bind /media /media~]#mount --make-shared /mediaPuis créez son dupliqué dans/mnt, mais marquez-le en tant qu'« esclave » :~]#
mount --bind /media /mnt~]#mount --make-slave /mntVeuillez vérifier qu'un montage à l'intérieur de/mediaapparaîsse aussi dans/mnt. Par exemple, si le lecteur CD-ROM contient un support qui n'est pas vide et que le répertoire/media/cdrom/existe, veuillez exécuter les commandes suivantes :~]#
mount /dev/cdrom /media/cdrom~]#ls /media/cdromEFI GPL isolinux LiveOS ~]#ls /mnt/cdromEFI GPL isolinux LiveOSVeuillez également vérifier qu'aucun des systèmes de fichiers montés dans le répertoire/mntne soit reflété dans/media. Par exemple, si un lecteur flash USB qui utilise le périphérique/dev/sdc1est attaché et que le répertoire/mnt/flashdisk/est présent, veuillez saisir :~]#
mount /dev/sdc1 /mnt/flashdisk~]#ls /media/flashdisk~]#ls /mnt/flashdisken-US publican.cfg - Montage privé
- Un montage privé est le type de montage par défaut, contrairement à un montage privé ou partagé, il ne reçoit et ne transfère pas d'événements de propagation. Pour marquer explicitement un point de montage en tant que montage privé, veuillez saisir ce qui suit à l'invite shell :
mount--make-privatemount_pointAlternativement, il est possible de modifier le type de montage du point de montage sélectionné et de tous les points de montage se trouvant sous celui-ci :mount--make-rprivatemount_pointVeuillez consulter l'Exemple 18.6, « Créer un point de montage privé » pour voir un exemple d'utilisation.Exemple 18.6. Créer un point de montage privé
En prenant en compte le scénario dans l'Exemple 18.4, « Créer un point de montage partagé », supposez que le point de montage partagé a été créé auparavant en utilisant les commandes suivantes en tant qu'utilisateurroot:~]#
mount --bind /media /media~]#mount --make-shared /media~]#mount --bind /media /mntPour marquer le répertoire/mnten tant que « privé », veuillez saisir :~]#
mount --make-private /mntIl est désormais possible de vérifier qu'aucun des montages présents à l'intérieur de/median'apparaisse dans/mnt. Par exemple, si le lecteur CD-ROM contient un support qui n'est pas vide et que le répertoire/media/cdrom/existe, veuillez exécuter les commandes suivantes :~]#
mount /dev/cdrom /media/cdrom~]#ls /media/cdromEFI GPL isolinux LiveOS ~]#ls /mnt/cdrom~]#Il est également possible de vérifier qu'aucun des systèmes de fichiers montés dans le répertoire/mntne soit reflété dans/media. Par exemple, si un lecteur flash USB qui utilise le périphérique/dev/sdc1est attaché et que le répertoire/mnt/flashdisk/est présent, veuillez saisir :~]#
mount /dev/sdc1 /mnt/flashdisk~]#ls /media/flashdisk~]#ls /mnt/flashdisken-US publican.cfg - Montage ne pouvant pas être lié
- Pour empêcher qu'un point de montage donné ne soit dupliqué, un montage ne pouvant pas être lié peut être utilisé. Pour modifier le type d'un point de montage en montage ne pouvant pas être lié, veuillez saisir ce qui suit à l'invite shell :
mount--make-unbindablemount_pointAlternativement, il est possible de modifier le type de montage du point de montage sélectionné et de tous les points de montage se trouvant sous celui-ci :mount--make-runbindablemount_pointVeuillez consulter l'Exemple 18.7, « Créer un point de montage ne pouvant pas être lié » pour voir un exemple d'utilisation.Exemple 18.7. Créer un point de montage ne pouvant pas être lié
Pour empêcher que le répertoire/mediasoit partagé, veuillez saisir ce qui suit à l'invite shell en tant qu'utilisateurroot:~]#
mount --bind /media /media~]#mount --make-unbindable /mediaAinsi, toute tentative conséquente de créer un dupliqué de ce montage échouera avec une erreur :~]#
mount --bind /media /mntmount: wrong fs type, bad option, bad superblock on /media, missing codepage or helper program, or other error In some cases useful info is found in syslog - try dmesg | tail or so
18.2.4. Déplacer un point de montage
mount--moveold_directory new_directory
Exemple 18.8. Déplacer un point de montage NFS existant
/mnt/userdirs/. En tant qu'utilisateur root, veuillez déplacer ce point de montage sur /home en utilisant la commande suivante :
~]# mount --move /mnt/userdirs /home~]#ls /mnt/userdirs~]#ls /homejill joe
18.3. Démonter un système de fichiers
umount :
umountdirectoryumountdevice
root, les bonnes permissions doivent être disponibles pour démonter le système de fichiers (veuillez consulter la Section 18.2.2, « Spécifier les options de montage »). Voir Exemple 18.9, « Démonter un CD » pour un exemple d'utilisation.
Important
umount échouera avec un erreur. Pour déterminer quels processus accèdent au système de fichiers, veuillez utiliser la commande fuser sous le format suivant :
fuser-mdirectory
/media/cdrom/, veuillez saisir :
~]$ fuser -m /media/cdrom
/media/cdrom: 1793 2013 2022 2435 10532c 10672cExemple 18.9. Démonter un CD
/media/cdrom/, veuillez saisir ce qui suit à l'invite shell :
~]$ umount /media/cdrom18.4. Références de la commande mount
18.4.1. Documentation installée
man 8 mount— Page du manuel pour la commandemount, celle-ci fournit une documentation complète sur sont utilisation.man 8 umount— Page du manuel pour la commandeumount, celle-ci fournit une documentation complète sur sont utilisation.man 8 findmnt— Page du manuel pour la commandefindmnt, celle-ci fournit une documentation complète sur sont utilisation.man 5 fstab— Page du manuel fournissant une description détaillée du format de fichier/etc/fstab.
18.4.2. Sites Web utiles
- Sous-arborescences partagées — Un article LWN couvrant le concept de sous-arborescence partagée.
Chapitre 19. Fonction volume_key
volume_key. libvolume_key est une bibliothèque pour manipuler des clés de chiffrment du volume de stockage et pour les stocker hors des volumes. volume_key est un outil de ligne de commande associé utilisé pour extraire les clés et phrases de passe afin de restaurer l'accès à un disque dur chiffré.
volume_key pour effectuer des copies de sauvegarde des clés de chiffrement avant de rendre l'ordinateur à l'utilisateur final.
volume_key prend uniquement en charge le format de chiffrement de volumes LUKS.
Note
volume_key n'est pas inclus dans une installation standard du serveur Red Hat Enterprise Linux 6. Pour obtenir des informations sur son installation, veuillez consulter http://fedoraproject.org/wiki/Disk_encryption_key_escrow_use_cases.
19.1. Commandes
volume_key est :
volume_key [OPTION]... OPERANDvolume_key sont déterminés par une des options suivantes :
--save- Cette commande attend l’opérande volume [paquet]. Si un paquet est fourni, alors
volume_keyen extraira les clés et les phrases secrètes. Si le paquet n’est pas fourni, alorsvolume_keyva extraire les clés et phrases secrètes du volume, en invitant l’utilisateur si nécessaire. Ces clés et les phrases secrètes seront alors stockées dans un ou plusieurs paquets de sortie. --restore- Cette commande attend les opérandes de paquets de volume. Puis, il ouvre le volume et utilise les clés et phrases secrètes du paquet pour rendre le volume accessible à nouveau, invitant l’utilisateur à saisir un nouveau mot de passe, par exemple.
--setup-volume- Cette commande s'attend aux opérandes nom de paquet de volume, puis, ouvre le volume et utilise les clés et phrases secrètes du paquet pour configurer le volume à utiliser des données déchiffrées comme un nom.Nom est le nom d’un volume de dm-crypt. Cette opération rend le volume décrypté disponible comme
/dev/mapper/nom.Cette opération ne modifie pas en permanence le volume en ajoutant une nouvelle phrase secrète, par exemple. L’utilisateur peut accéder et modifier le volume décrypté, en modifiant le volume dans le processus. --reencrypt,--secrets, et--dump- Ces trois commandes exécutent des fonctions semblables avec diverses méthodes de sortie. Chacune d’entre elle requiert l'opérande paquet et ouvre le paquet, décryptant si nécessaire.
--reencryptstocke ensuite les informations dans un ou plusieurs nouveaux paquets de sortie. Les sorties de--secretssont des clés et des phrases secrètes contenues dans le paquet.--dumpaffiche le contenu du paquet, bien que les clés et les phrases secrètes ne soient pas des sorties par défaut. Ceci peut être changé en ajoutant--with-secretsà la commande. Il est également possible de vider uniquement les pièces non cryptées du paquet, le cas échéant, à l’aide de la commande--unencrypted. Cela ne nécessite pas de phrase secrète ou d'accès de clé privée.
-o,--output packet- Cette commande écrit la phrase secrète ou le mot de passe par défaut dans le paquet. La phrase secrète ou le mot de passe par défaut dépendent du format de volume. S’assurer qu'ils ne risquent pas d’expirer, et qu'ils permettront à
--restorede restaurer l’accès au volume. --output-format format- Cette commande utilise le format spécifié pour tous les paquets de sortie. Actuellement, le format peut correspondre à l'une des conditions suivantes :
asymmetric: utilise CMS pour encrypter le paquet, et exige un certificatasymmetric_wrap_secret_only: englobe seulement le secret, ou les clés et les phrases secrètes et exige un certificatpassphrase: utilise GPG pour déchiffrer tout le paquet, et exige une phrase secrète
--create-random-passphrase packet- Cette commande génère une phrase secrète alphanumérique au hasard, l'ajoute au volume (sans affecter les autres phrases secrètes) et stocke ensuite ce mot de passe aléatoire dans le paquet.
19.2. Exécutez volume_key en tant qu'utilisateur individuel
volume_key peut être utilisé pour sauvegarder les clés d'encodage par la procédure suivante.
Note
/path/to/volume est un périphérique LUKS, et non pas un périphérique en texte brut intégré. La commande blkid -s type /path/to/volume doit rapporter type="crypto_LUKS".
Procédure 19.1. Exécutez volume_key en autonome
- Exécutez:
Vous apercevrez alors une invite vous demandant une phrase secrète de paquet escrow pour protéger la clé.volume_key --save/path/to/volume-o escrow-packet - Sauvegarder le fichier
escrow-packet, en veillant à ne pas oublier la phrase secrète.
Procédure 19.2. Restaurer l'accès aux données par le paquet escrow
- Déamarrer le système dans un environnement où
volume_keypeut être exécuté et où un paquet escrow est disponible (en mode de secours, par exemple). - Exécutez:
Vous apercevrez alors une invite vous demandant la phrase secrète de paquet escrow qui a été utilisée lors de la création du paquet, et pour la nouvelle phrase secrète du volume.volume_key --restore/path/to/volumeescrow-packet - Mounter le volume en utilisant la phrase secrète choisie.
cryptsetup luksKillSlot.
19.3. Exécutez volume_key dans une grande organisation
volume_key peut utiliser la cryptographie asymétrique pour réduire le nombre de personnes qui connaissent le mot de passe requis pour accéder aux données cryptées sur un ordinateur.
19.3.1. Se préparer à enregistrer vos clés de chiffrement.
Procédure 19.3. Préparation
- Créer une paire privée/certificat X509.
- Indique les utilisateurs auxquels on fait confiance pour ne pas compromettre la clé privée. Ces utilisateurs seront en mesure de décrypter les paquets escrow.
- Choisir les systèmes qui seront utilisés pour décrypter les paquets escrow. Sur ces systèmes, définir une base de données NSS qui contienne la clé privée.Si la clé privée n'a pas été créée dans une base de données NSS, suivre les étapes suivantes :
- Stocker le certificat et la clé privée dans un fichier
PKCS#12. - Exécutez:
certutil -d/the/nss/directory-NÀ ce stade, il est possible de choisir un mot de passe de base de données NSS. Chaque base de données NSS peut avoir un mot de passe différent, donc les utilisateurs désignés n'ont pas besoin de partager un mot de passe unique, si une base de données NSS séparée est utilisé par chaque utilisateur. - Exécutez:
pk12util -d/the/nss/directory-ithe-pkcs12-file
- Distribuer le certificat à quiconque installant des systèmes ou sauvegardant des clé sur les systèmes existants.
- Pour les clés privées sauvegardées, préparez un stockage qui leur permette d'être consultées par une machine et un volume. Il peut s'agir, par exemple, d'un simple répertoire avec un sous-répertoire par machine, ou d'une base de données utilisée pour d'autres tâches de gestion de système également.
19.3.2. Sauvegarde des clés de chiffrement
Note
/path/to/volume est un périphérique LUKS, et non pas un périphérique en texte brut intégré. La commandeblkid -s type /path/to/volume doit rapporter type="crypto_LUKS".
Procédure 19.4. Sauvegarde des clés de chiffrement
- Exécutez:
volume_key --save/path/to/volume-c/path/to/certescrow-packet - Sauvegarder le fichier
escrow-packetcréé dans le stockage préparé, en l'associant avec le système et le volume.
19.3.3. Restaurer l'accès à un volume
Procédure 19.5. Restaurer l'accès à un volume
- Extraire le paquet escrow pour le volume, du stockage de paquets, et envoyez le vers l'un des utilisateurs désignées afin qu'il soit décrypté.
- L'utilisateur désigné exécute :
volume_key --reencrypt -d/the/nss/directoryescrow-packet-in -o escrow-packet-outAprès avoir fourni le mot de passe de base de données NSS, l’utilisateur désigné choisira une phrase secrète pour le chiffrementescrow-paquet-out. Cette phrase secrète peut varier à chaque fois et ne protège que les clés de cryptage que lorsqu'elles sont transférées de l’utilisateur désigné au le système cible. - Obtenir le fichier
escrow-packet-outet la phrase secrète de l'utilisateur désigné. - Démarrer le système cible dans un environnement où
volume_keypeut être exécuté et où un paquetescrow-packet-outest disponible (en mode de secours, par exemple). - Exécutez:
volume_key --restore/path/to/volumeescrow-packet-outVous apercevrez alors une invite vous demandant la phrase secrète de paquet qui a été choisie par l'utilisateur désigné, et la nouvelle phrase secrète du volume. - Monter le volume en utilisant la phrase secrète de volume choisie.
cryptsetup luksKillSlot, par exemple, afin de libérer l'emplacement pour la phrase secrète dans l’en-tête de LUKS du volume chiffré. Cela se fait par la commande cryptsetup luksKillSlot device key-slot. Pour plus d’informations et d’exemples, voir cryptsetup--aider.
19.3.4. Configurer les phrases secrètes pour les urgences
volume_key peut fonctionner avec des phrases secrètes, ainsi qu'avec des clés de chiffrement.
volume_key --save /path/to/volume -c /path/to/ert --create-random-passphrase passphrase-packetpassphrase-packet. Il est également possible de combiner les options --create-random-passphrase et -o pour générer les deux paquets en même temps.
volume_key --secrets -d /your/nss/directory passphrase-packet19.4. Références volume_key
volume_key à l'adresse suivante :
- dans le fichier readme qui se situe
/usr/share/doc/volume_key-*/README - dans la page man de
volume_keyen exécutantman volume_key - en ligne à l'adresse suivante http://fedoraproject.org/wiki/Disk_encryption_key_escrow_use_cases
Chapitre 20. Listes des contrôle d'accès (ACL)
acl et la prise en charge dans le noyau sont requis pour implémenter les ACL. Ce paquet contient les utilitaires nécessaires pour l'ajout, la modification, la suppression et la récupération d'informations sur les ACL.
cp et mv copient ou déplacent toutes les ACL associées à des fichiers et répertoires.
20.1. Monter des systèmes de fichiers
mount -t ext3 -o acl device-name partition
mount -t ext3 -o acl /dev/VolGroup00/LogVol02 /work
/etc/fstab, l'entrée de la partition peut inclure l'option acl :
LABEL=/work /work ext3 acl 1 2
--with-acl-support. Aucun indicateur particulier n'est requis lors de l'accession ou du montage d'un partage Samba.
20.1.1. NFS
noacl sur la ligne de commande.
20.2. Définir les ACL d'accès
- Par utilisateur
- Par groupe
- Via le masque des droits en vigueur
- Pour les utilisateur ne se trouvant pas dans le groupe d'utilisateurs du fichier
setfacl définit les ACL pour les fichiers et répertoires. Veuillez utiliser l'option -m pour ajouter ou modifier l'ACL d'un fichier ou répertoire :
# setfacl -m rules files
u:uid:perms- Définit l'ACL d'accès d'un utilisateur. Le nom d'utilisateur, ou UID, peut être spécifié. L'utilisateur peut être tout utilisateur valide sur le système.
g:gid:perms- Définit l'ACL d'accès d'un groupe. Le nom du groupe, ou GID, peut être spécifié. Le groupe peut être tout groupe valide sur le système.
m:perms- Définit le masque des permissions. Le masque est l'union de toutes les permissions du groupe propriétaire et des toutes les entrées d'utilisateur et de groupe.
o:perms- Définit l'ACL d'accès du fichier pour les utilisateurs ne faisant pas partie du groupe.
r, w et x pour lecture, écriture, et exécution.
setfacl est utilisée, les règles supplémentaires sont ajoutées à l'ACL existante ou la règle existante sera modifiée.
Exemple 20.1. Donner des permissions de lecture et écriture
# setfacl -m u:andrius:rw /project/somefile
-x et ne spécifier aucune permission :
# setfacl -x rules files
Exemple 20.2. Supprimer toutes les permissions
# setfacl -x u:500 /project/somefile
20.3. Définit les ACL par défaut
d: avant la règle et spécifiez un répertoire à la place d'un nom de fichier.
Exemple 20.3. Définir les ACL par défaut
/share/ afin de pouvoir effectuer des lectures et exécutions pour les utilisateurs ne se trouvant pas dans le groupe d'utilisateurs (une ACL d'accès pour un fichier individuel peut la remplacer) :
# setfacl -m d:o:rx /share
20.4. Récupérer des ACL
getfacl. Dans l'exemple ci-dessous, getfacl est utilisé pour déterminer les ACL existantes pour un fichier.
Exemple 20.4. Récupérer des ACL
# getfacl home/john/picture.png
# file: home/john/picture.png # owner: john # group: john user::rw- group::r-- other::r--
getfacl home/sales/ affichera une sortie similaire à la suivante :
# file: home/sales/ # owner: john # group: john user::rw- user:barryg:r-- group::r-- mask::r-- other::r-- default:user::rwx default:user:john:rwx default:group::r-x default:mask::rwx default:other::r-x
20.5. Archiver des systèmes de fichiers avec des ACL
dump préserve désormais les ACL pendant les opérations de sauvegarde. Lors de l'archivage d'un fichier ou d'un système de fichiers avec tar, utilisez l'option --acls pour préserver les ACL. De manière similaire, lors de l'utilisation de cp pour copier des fichiers avec des ACL, veuillez inclure l'option --preserve=mode afin de vous assurer que les ACL soient également copiées. En outre, l'option -a (équivalente à -dR --preserve=all) de cp préserve également les ACL lors des opérations de sauvegarde ainsi que d'autres informations, commes les horodatages, les contextes SELinux, etc. Pour obtenir davantage d'informations sur dump, tar, ou cp, veuillez consulter les pages man respectives.
star est similaire à l'utilitaire tar car il peut être utilisé pour générer des archives de fichiers ; cependant, certaines de ses options sont différentes. Veuillez consulter le Tableau 20.1, « Options de ligne de commande pour star » pour obtenir une liste des options communément utilisées. Pour toutes les options disponibles, veuillez consulter man star. Le paquet star est requis pour faire usage de cet utilitaire.
Tableau 20.1. Options de ligne de commande pour star
| Option | Description |
|---|---|
-c | Crée un fichier archive. |
-n | Ne pas extraire les fichiers. À utiliser en conjonction avec -x pour afficher le résultat provoqué par l'extraction de fichiers. |
-r | Remplace les fichiers dans l'archive. Les fichiers sont écrits à la fin du fichier archive, remplaçant tout fichier ayant le même chemin et le même nom de fichier. |
-t | Affiche le contenu du fichier archive. |
-u | Met à jour le fichier archive. Les fichiers sont écrits à la fin de l'archive si les conditions suivantes s'appliquent :
|
-x | Extrait les fichiers de l'archive. Si utilisé avec -U et qu'un fichier dans l'archive est plus ancien que le fichier correspondant sur le système de fichers, le fichier ne sera pas extrait. |
-help | Affiche les options les plus importantes. |
-xhelp | Affiche les options les moins importantes. |
-/ | Ne pas supprimer les barres obliques des noms de fichiers lors de l'extraction de fichiers d'une archive. Par défaut, celles-ci sont supprimées lorsque les fichiers sont extraits. |
-acl | Pendant la création ou l'extraction, archive ou restaure toute ACL associée aux fichiers et répertoires. |
20.6. Compatibilité avec d'anciens systèmes
ext_attr. Cet attribut peut être affiché à l'aide de la commande suivante :
# tune2fs -l filesystem-device
ext_attr peut être monté avec d'anciens noyaux, mais ces noyaux n'appliqueront aucune ACL définie.
e2fsck incluses dans la version 1.22 et dans les versions supérieures du paquet e2fsprogs (y compris les versions dans Red Hat Enterprise Linux 2.1 et 4) peuvent vérifier un système de fichiers avec l'attribut ext_attr. Les versions plus anciennes refuseront de le vérifier.
20.7. Références des ACL
man acl— Description des ACLman getfacl— Traite de la manière d'obtenir des listes de contrôle d'accèsman setfacl— Explique comment définir des listes de contrôle d'accès aux fichiersman star— Explique l'utilitairestaret ses nombreuses options
Chapitre 21. Directives de déploiement des disques SSD
TRIM pour ATA, et WRITE SAME si UNMAP est défini, ou la commande UNMAP pour SCSI).
discard est surtout utile lorsqu'il y a de l'espace libre sur le système de fichiers, mais le système de fichiers a déjà écrit sur la plupart des blocs logiques du périphérique de stockage sous-jacent. Pour obtenir des informations supplémentaires sur TRIM, veuillez consulter le document Data Set Management T13 Specifications, disponible sur le lien suivant :
UNMAP, veuillez consulter la section 4.7.3.4 du document SCSI Block Commands 3 T10 Specification, disponible sur le lien suivant :
Note
discard. Pour déterminer si votre disque dur offre la prise en charge de discard, veuillez vérifier la présence de /sys/block/sda/queue/discard_granularity.
21.1. Considérations pour le déploiement
mdadm) écrivent sur tous les blocs du périphérique de stockage pour s'assurer que les checksums fonctionnent correctement. Ceci entraine une dégradation rapide des performances du disque SSD.
Note
--nosync sur RAID1, RAID10, et les RAID de parité, car la parité sera calculée pour cette bande dans la minute de la première écriture, conservant ainsi toute homogénéité. Cependant, lors des opérations de nettoyage des données, les parties non écrites seront considérées comme étant mismatched/inconsistent (non correspondantes/inconsistantes).
discard. Dans les versions précédentes de Red Hat Enterprise Linux 6, seul ext4 prenait totalement en charge discard. Pour activer les commandes discard sur un périphérique, veuillez utiliser l'option mount de discard. Par exemple, pour monter /dev/sda2 sur /mnt lorsque discard est activé, veuillez exécuter :
# mount -t ext4 -o discard /dev/sda2 /mnt
discard. Cela est le cas afin d'éviter tout problème sur des périphériquers qui pourraient ne pas implémenter la commande discard correctement. Le code swap Linux délivrera les commandes discard aux périphériques sur lesquels discard est activé, il n'existe aucune option pour contrôler ce comportement.
21.2. Considérations pour le paramétrage
Planificateur d'E/S
/usr/share/doc/kernel-version/Documentation/block/switching-sched.txt
Mémoire virtuelle
vm_dirty_background_ratio et vm_dirty_ratio, car une augmentation des activités d'écriture ne devrait pas avoir d'impact négatif sur la latence des autres opérations sur le disque. Cependant, ceci peut également générer davantage d'E/S générales est n'est donc pas recommandé sans effectuer de tests spécifiques aux charges au préalable.
Chapitre 22. Barrières d'écriture
fsync() persistent lors de pannes de courant.
fsync(), ou qui créent et suppriment de nombreux fichiers de petite taille fonctionneront probablement bien plus lentement.
22.1. Importance des barrières d'écriture
- Premièrement, le système de fichiers envoie le corps de la transaction au périphérique de stockage.
- Puis le système de fichiers envoie un bloc de validation.
- Si la transaction et son bloc de validation correspondant sont écrits sur le disque, le système de fichiers supposera que la transaction pourra survivre à une panne de courant.
Comment les barrières d'écriture fonctionnent
- Le disque contient bien toutes les données.
- Aucun changement d'ordre ne s'est produit.
fsync() provoquera également le vidage du cache du stockage. Ceci garantit la persistance sur disque des données de fichiers même si une panne de courant se produit peu après le retour de fsync().
22.2. Activer/désactiver les barrières d'écriture
-o nobarrier de mount. Cependant, certains périphériques ne prennent pas en charge les barrières d'écriture ; ce type de périphérique journalisera un message d'erreur sur /var/log/messages (veuillez consulter Tableau 22.1, « Messages d'erreur des barrières d'écriture par système de fichiers »).
Tableau 22.1. Messages d'erreur des barrières d'écriture par système de fichiers
| Système de fichiers | Message d'erreur |
|---|---|
| ext3/ext4 | JBD: barrier-based sync failed on device - disabling barriers |
| XFS | Filesystem device - Disabling barriers, trial barrier write failed |
| btrfs | btrfs: disabling barriers on dev device |
Note
nobarrier n'est plus recommandée sur Red Hat Enterprise Linux 6 car l'impact de performance négatif des barrières d'écriture est négligeable (environ 3%). Habituellement, les bénéfices des barrières d'écriture sont plus importants que les bénéfices de performance dus à leur désactivation. En outre, l'option nobarrier ne devrait jamais être utilisée sur un stockage configuré sur des machines virtuelles.
22.3. Considérations pour barrières d'écriture
Désactiver les caches d'écriture
hdparm, comme suit :
# hdparm -W0 /device/
Caches d'écriture avec batteries de secours
MegaCli64 pour gérer les disques cibles. Pour afficher l'état de tous les disques d'arrière-plan pour SAS Megaraid LSI, veuillez utiliser :
# MegaCli64 -LDGetProp -DskCache -LAll -aALL
# MegaCli64 -LDSetProp -DisDskCache -Lall -aALL
Note
Matrices haut de gamme
NFS
Chapitre 23. Alignement et taille des E/S de stockage
parted, lvm, mkfs.*, etc. ) d'optimiser le placement et l'accès aux données. Si un périphérique hérité n'exporte pas les données d'alignement et de taille des E/S, alors les outils de gestion de stockage Red Hat Enterprise Linux 6 aligneront de manière conservative les E/S sur une limite de 4 Ko (ou sur une puissance de 2). Ceci assurera que les périphériques à secteurs de 4 Ko opérerent correctement même s'ils n'indiquent pas d'alignement et de taille d'E/S requis ou préféré.
23.1. Paramètres d'accès au stockage
- physical_block_size
- Unité interne la plus petite sur laquelle le périphérique peut opérer
- logical_block_size
- Utilisé de manière externe pour adresser un emplacement sur le périphérique
- alignment_offset
- Nombre d'octets de décalage du début du périphérique bloc Linux (périphérique partition/MD/LVM) par rapport à l'alignement physique sous-jacent
- minimum_io_size
- Unité minimale préférée du périphérique pour les E/S aléatoires
- optimal_io_size
- Unité préférée du périphérique pour la transmission d'E/S
physical_block_size de 4K de manière interne mais présenter une taille logical_block_size de 512 octets plus granuleuse dans Linux. Cet écart présente un certain potentiel pour des E/S non-alignées. Pour répondre à ce problème, la pile d'E/S Red Hat Enterprise Linux 6 tentera de démarrer toutes les zones de données sur une limite naturellement alignée (physical_block_size) en s'assurant de prendre en compte tout décalage d'alignement « alignment_offset » si le début du périphérique bloc est décalé par rapport à l'alignement physique sous-jacent.
minimum_io_size) ainsi que pour les E/S de transmission (optimal_io_size) d'un périphérique. Par exemple, minimum_io_size et optimal_io_size pourraient correspondre, respectivement, aux tailles de bloc et d'entrelacement d'un périphérique RAID.
23.2. Accès à l'espace utilisateur
logical_block_size, et sur des multiples de logical_block_size.
logical_block_size font 4K) il est désormais critique que les applications effectuent des E/S directes multiples de logical_block_size. Ceci signifie que les applications échoueront avec les périphériques 4k qui effectuent des E/S alignées sur 512 octets plutôt que sur des E/S alignées 4k.
sysfs et ioctl de périphérique bloc.
man libblkid. Cette page man est fournie par le paquet libblkid-devel.
Interface sysfs
- /sys/block/
disk/alignment_offset - /sys/block/
disk/partition/alignment_offset - /sys/block/
disk/queue/physical_block_size - /sys/block/
disk/queue/logical_block_size - /sys/block/
disk/queue/minimum_io_size - /sys/block/
disk/queue/optimal_io_size
sysfs pour les périphériques « hérités » qui ne fournissent pas d'informations sur les paramètres d'E/S, par exemple :
Exemple 23.1. Interface sysfs
alignment_offset: 0 physical_block_size: 512 logical_block_size: 512 minimum_io_size: 512 optimal_io_size: 0
23.3. Standards
ATA
IDENTIFY DEVICE. Les périphériques ATA rapportent uniquement les paramètres d'E/S pour physical_block_size, logical_block_size, et alignment_offset. Les indicateurs d'E/S supplémentaires se trouvent hors du champ de l'ensemble des commandes ATA.
SCSI
BLOCK LIMITS VPD) et une commande READ CAPACITY(16) sur les périphériques se réclamant être conformes à SPC-3.
READ CAPACITY(16) fournit le décalage des tailles et alignements des blocs :
LOGICAL BLOCK LENGTH IN BYTES(« Longueur de bloc logique en octets ») est utilisé pour dériver/sys/block/disque/queue/physical_block_sizeLOGICAL BLOCKS PER PHYSICAL BLOCK EXPONENT(« Blocs logiques par exposant de bloc physique ») est utilisé pour dériver/sys/block/disque/queue/logical_block_sizeLOWEST ALIGNED LOGICAL BLOCK ADDRESS(« Adresse du bloc logique aligné au plus bas ») est utilisée pour dériver :/sys/block/disk/alignment_offset/sys/block/disk/partition/alignment_offset
BLOCK LIMITS VPD (0xb0) fournit les indicateurs d'E/S. OPTIMAL TRANSFER LENGTH GRANULARITY et OPTIMAL TRANSFER LENGTH sont également utilisés pour dériver :
/sys/block/disk/queue/minimum_io_size/sys/block/disk/queue/optimal_io_size
sg3_utils fournit l'utilitaire sg_inq, qui peut être utilisé pour accéder à la page BLOCK LIMITS VPD. Pour ce faire, veuillez exécuter :
# sg_inq -p 0xb0 disk
23.4. Empiler les paramètres d'E/S
- Seulement une couche dans la pile d'E/S doit s'ajuster pour un décalage
alignment_offsetqui n'est pas égal à zéro ; une fois que la couche s'ajuste de manière correspondante, un périphérique avec un décalagealignment_offsetde zéro sera exporté. - Un périphérique DM (« Device Mapper ») entrelacé créé avec LVM doit exporter des valeurs
minimum_io_sizeetoptimal_io_sizerelatives au compte des entrelacements (nombre de disques) et à la taille de bloc fournie par l'utilisateur.
logical_block_size de 4K. Les systèmes de fichiers en couche sur de tels périphériques hybrides supposent que l'écriture sur 4K sera atomique, mais en réalité, cela s'étendra sur 8 adresses de blocs logiques lors de l'exécution sur le périphérique de 512 octets. L'utilisation de la valeur logical_block_size 4K pour un périphérique de 512 octets de haut niveau augmente le potentiel d'écriture partielle sur le périphérique de 512 octets en cas de panne du système.
23.5. Gestionnaire de volumes logiques LVM
alignment_offset qui n'est pas égal à zéro et associé à tout périphérique géré par LVM. Cela signifie que les volumes logiques seront correctement alignés (alignment_offset=0).
alignment_offset, mais ce comportement peut être désactivé en paramétrant data_alignment_offset_detection sur 0 dans /etc/lvm/lvm.conf. Cette désactivation n'est pas recommandée.
minimum_io_size ou optimal_io_size exposées dans sysfs. LVM utilisera minimum_io_size si la valeur optimal_io_size n'est pas définie (c'est-à-dire égale à 0).
data_alignment_detection sur 0 dans /etc/lvm/lvm.conf. Cette désactivation n'est pas recommandée.
23.6. Outils des partitions et systèmes de fichiers
libblkid de util-linux-ng et fdisk
libblkid fournie avec le paquet util-linux-ng inclut une interface de programmation pour accéder aux paramètres d'E/S d'un périphérique. libblkid permet aux applications, particulièrement celles qui utilisent des E/S directes, de redimensionner correctement leurs requêtes d'E/S. L'utilitaire fdisk de util-linux-ng utilise libblkid pour déterminer les paramètres d'E/S d'un périphérique pour un placement optimal de toutes les partitions. L'utilitaire fdisk alignera toutes les partitions sur une limite de 1 Mo.
parted et libparted
libparted de parted utilis également l'interface de programmation des paramètres d'E/S de libblkid. L'installateur Red Hat Enterprise Linux 6 (Anaconda) utilise libparted, ce qui signifie que toutes les partitions créées par l'installateur ou parted seront correctement alignés. Pour les partitions créées sur un périphérique qui ne semble pas fournir de paramètres d'E/S, l'alignement par défaut sera de 1 Mo.
parted sont comme suit :
- Veuillez toujours utiliser la valeur
alignment_offsetrapportée comme décalage pour le lancement de la première partition principale. - Si
optimal_io_sizeest défini (c'est-à-dire différent de0), veuillez aligner toutes les partitions sur une limiteoptimal_io_size. - Si
optimal_io_sizen'est pas défini (c'est-à-dire égal à0), alorsalignment_offsetest égal à0, etminimum_io_sizeest une puissance de 2, utilisez un alignement par défaut de 1 Mo.Ceci sert à récupérer tous les périphériques « hérités » qui ne semblent pas fournir d'indicateur d'E/S. Ainsi, toutes les partitions par défaut seront alignées sur une limite de 1 Mo.Note
Red Hat Enterprise Linux 6 ne fait pas de distinction entre les périphériques qui ne fournissent pas d'indicateurs d'E/S et ceux qui en fournissent par le biais dealignment_offset=0etoptimal_io_size=0. Un tel périphérique peut être un périphérique 4K SAS unique. De cette manière, au pire seul 1 Mo est perdu lors du démarrage du disque.
Outils de systèmes de fichiers
mkfs.filesystem ont aussi été amélioré afin de consommer les paramètres d'E/S d'un périphérique. Ces utilitaires ne permettront pas à un système de fichiers d'être formaté pour utiliser une taille de bloc plus petite que la taille logical_block_size du périphérique de stockage sous-jacent.
mkfs.gfs2, tous les autres utilitaires mkfs.filesystem utilisent également les indicateurs d'E/S pour agencer la structure des données sur disque et les zones de données relatives aux valeurs minimum_io_size et optimal_io_size des périphériques de stockage sous-jacent. Ceci permet aux systèmes de fichiers d'être formatés de manière optimale pour divers agencements (entrelacés) RAID.
Chapitre 24. Paramétrer un système sans disque distant
system-config-netboot) n'est plus disponible dans Red Hat Enterprise Linux 6. Le déploiement de systèmes sans disque est désormais possible dans cette version sans avoir à utiliser system-config-netboot.
tftp-serverxinetddhcpsyslinuxdracut-network
tftp (fourni par tftp-server) et un service DHCP (fourni par dhcp). Le service tftp est utilisé pour récupérer l'image du noyau et initrd sur le réseau via le chargeur PXE.
24.1. Configuration d'un service tftp pour des clients sans disque
tftp est désactivé par défaut. Pour l'activer et autoriser le démarrage PXE via le réseau, définissez l'option Disabled (désactivé) dans /etc/xinetd.d/tftp sur no. Pour configurer tftp, veuillez effectuer les étapes suivantes :
Procédure 24.1. Pour configurer tftp
- Le répertoire racine
tftp(chroot) est situé dans/var/lib/tftpboot. Copiez/usr/share/syslinux/pxelinux.0sur/var/lib/tftpboot/:cp /usr/share/syslinux/pxelinux.0 /var/lib/tftpboot/ - Créez un répertoire
pxelinux.cfgdans le répertoire roottftp:mkdir -p /var/lib/tftpboot/pxelinux.cfg/
tftp. Comme tftp prend en charge les emballages TCP, vous pouvez configurer l'accès des hôtes à tftp via /etc/hosts.allow. Pour obtenir des informations supplémentaires sur la configuration des emballages TCP et sur le fichier de configuration /etc/hosts.allow, veuillez consulter le Guide de sécurité de Red Hat Enterprise Linux 6. man hosts_access fournit également des informations sur /etc/hosts.allow.
tftp pour des clients sans disque, veuillez configurer DHCP, NFS, et le système de fichiers exporté. Veuillez consulter Section 24.2, « Configuration DHCP pour les clients sans disque » et Section 24.3, « Configuration d'un système de fichiers exporté pour les clients sans disque » pour obtenir des instructions sur la manière de procéder.
24.2. Configuration DHCP pour les clients sans disque
tftp, vous devrez paramétrer un service DHCP sur la même machine hôte. Veuillez consulter le Guide de déploiement Red Hat Enterprise Linux 6 pour obtenir des instructions sur la manière de paramétrer un serveur DHCP. En outre, vous devrez activer le démarrage P sur le serveur DHCP ; pour ce faire, veuillez ajouter la configuration suivante au fichier /etc/dhcp/dhcp.conf :
allow booting;
allow bootp;
class "pxeclients" {
match if substring(option vendor-class-identifier, 0, 9) = "PXEClient";
next-server server-ip;
filename "pxelinux.0";
}server-ip par l'adresse IP de la machine hôte sur laquelle les services tftp et DHCP résident. Maintenant que tftp et DHCP sont configurés, il ne reste plus qu'à configurer NFS et le système de fichiers exporté. Veuillez consulter Section 24.3, « Configuration d'un système de fichiers exporté pour les clients sans disque » afin d'obtenir des instructions.
24.3. Configuration d'un système de fichiers exporté pour les clients sans disque
/etc/exports. Pour obtenir des instructions sur la manière d'effectuer cela, veuillez consulter Section 9.7.1, « Fichier de configuration /etc/exports ».
rsync :
# rsync -a -e ssh --exclude='/proc/*' --exclude='/sys/*' hostname.com:/ /exported/root/directory
hostname.com par le nom d'hôte du système d'exploitation du système en cours d'exécution avec lequel se synchroniser via rsync. /exported/root/directory est le chemin vers le système de fichiers exporté.
yum avec l'option --installroot pour installer Red Hat Enterprise Linux sur un emplacement spécifique. Par exemple :
yum groupinstall Base --installroot=/exported/root/directory
Procédure 24.2. Configurer le système de fichiers
- Configurez le fichier
/etc/fstabdu système de fichiers afin qu'il contienne (au minimum) la configuration suivante :none /tmp tmpfs defaults 0 0 tmpfs /dev/shm tmpfs defaults 0 0 sysfs /sys sysfs defaults 0 0 proc /proc proc defaults 0 0
- Sélectionnez le noyau que les clients sans disque devront utiliser (
vmlinuz-kernel-version) et copiez-le sur le répertoire roottftp:# cp /boot/vmlinuz-kernel-version /var/lib/tftpboot/
- Créez le fichier
initrd(c'est-à-direinitramfs-kernel-version.img) avec le support réseau :# dracut initramfs-kernel-version.img kernel-version
Copiez également le fichierinitramfs-kernel-version.imgrésultant dans le répertoire de démarragetftp. - Modifiez la configuration de démarrage par défaut afin d'utiliser
initrdet le noyau situé à l'intérieur de/var/lib/tftpboot. Cette configuration devrait instruire au répertoire root du client sans disque de monter le système de fichiers exporté (/exported/root/directory) en lecture-écriture. Pour ce faire, veuillez configurer/var/lib/tftpboot/pxelinux.cfg/defaultavec :default rhel6 label rhel6 kernel vmlinuz-kernel-version append initrd=initramfs-kernel-version.img root=nfs:server-ip:/exported/root/directory rw
Remplacezserver-ipavec l'adresse IP de la machine hôte sur laquelle les servicestftpet DHCP résident.
Chapitre 25. Device Mapper Multipathing (Mappeur de périphériques à multiples chemins d'accès) et le Stockage virtuel
25.1. Stockage virtuel
- Fibre Channel
- iSCSI
- NFS
- GFS2
libvirt pour gérer les instances virtuelles. L'utilitaire libvirt utilise le concept de pools de stockage pour gérer le stockage d'invités virtualisés. Un pool de stockage est un stockage pouvant être divisé en volumes de plus petite taille ou directement alloué(s) à un invité. Les volumes d'un pool de stockage peuvent être alloués à des invités virtualisés. Deux catégories de pools de stockage sont disponibles :
- Pools de stockage locaux
- Le stockage local couvre les périphériques de stockage, fichiers ou répertoires directement attachés à un hôte. Le stockage local inclut les répertoires locaux, les disques directement attachés, et les groupes de volumes LVM.
- Pools de stockage en réseau (partagés)
- Le stockage en réseau couvre les périphériques de stockage partagés sur un réseau à l'aide de protocoles standards. Ce type de stockage inclut les périphériques de stockage partagé utilisant les protocoles Fibre Channel, iSCSI, NFS, GFS2 et SCSI RDMA, et est une condition nécessaire pour effectuer des migrations d'invités virtualisés entre hôtes.
Important
25.2. DM-Multipath
- Redondance
- DM-Multipath peut amener à un échec dans une configuration active/passive. Dans une configuration active/passive, on utilise seulement la moitié des chemins à tout moment pour E/S. Si un élément (le câble, le commutateur, ou le contrôleur) d'un chemin E/S échoue, DM-Multipath passe à un chemin alternatif.
- Performance améliorée
- DM-Multipath peut être configurée dans un mode actif/actif, où E/S est étendu à travers les chemins en circuit cyclique. Dans certaines configurations, DM-Multipath peut détecter un chargement sur le chemin E/S et re-équilibrer le chargement de façon dynamique.
Important
Partie III. Stockage en ligne
Chapitre 26. Fibre Channel
26.1. Interface de programmation Fibre Channel
/sys/class/ qui contiennent des fichiers utilisés pour fournir l'API de l'espace utilisateur. Dans chaque élément, les numéros des hôtes sont désignés par H, les numéros des bus par B, les cibles par T, les numéros d'unité logique (LUN) par L, et les numéros de ports distants par R.
Important
- Transport :
/sys/class/fc_transport/targetH:B:T/ port_id— ID/adresse du port 24 bitsnode_name— nom du nœud 64 bitsport_name— nom du port 64 bits
- Port distant :
/sys/class/fc_remote_ports/rport-H:B-R/ port_idnode_nameport_namedev_loss_tmo— nombre de secondes à attendre avant de marquer un lien comme étant « erroné ». Une fois qu'un lien est marqué comme étant erroné, les E/S exécutées sur le chemin correspondant (ainsi que toute nouvelle E/S sur ce chemin) échoueront.La valeur par défautdev_loss_tmovarie, en fonction du pilote ou périphérique utilisé. Si un adaptateur Qlogic est utilisé, la valeur par défaut est de 35 secondes, tandis que si un adaptateur Emulex est utilisé, elle sera de 30 secondes. La valeurdev_loss_tmopeut être modifiée via le paramètredev_loss_tmodu modulescsi_transport_fc, même si le pilote peut remplacer cette valeur de délai d'expiration.La valeur maximum dedev_loss_tmoest de 600 secondes. Sidev_loss_tmoest paramétré sur zéro ou toute valeur plus importante que 600, alors les délais d'expiration internes du pilote seront utilisés à la place.fast_io_fail_tmo— temps à attendre avant de faire échouer les E/S exécutées lorsqu'un problème de lien est détecté. Les E/S qui atteignent le pilote échoueront. Si des E/S se trouvent dans une file d'attente bloquée, elles n'échoueront pas avant quedev_loss_tmon'expire et que la file ne soit débloquée.
- Hôte :
/sys/class/fc_host/hostH/
26.2. Pilotes et capacités natifs Fibre Channel
lpfcqla2xxxzfcpmptfcbfa
Tableau 26.1. Capacités de l'API Fibre-Channel
lpfc | qla2xxx | zfcp | mptfc | bfa | |
|---|---|---|---|---|---|
Transport port_id | X | X | X | X | X |
Transport node_name | X | X | X | X | X |
Transport port_name | X | X | X | X | X |
Port distant dev_loss_tmo | X | X | X | X | X |
Port distant fast_io_fail_tmo | X | X [a] | X [b] | X | |
Hôte port_id | X | X | X | X | X |
Hôte issue_lip | X | X | X | ||
[a]
Pris en charge à partir de Red Hat Enterprise Linux 5.4
[b]
Pris en charge à partir de Red Hat Enterprise Linux 6.0
| |||||
Chapitre 27. Installer une Cible iSCSI et un Initiateur
Note
--child-timeout doit être utilisée afin d'éviter des échecs de démarrage. L'option --child-timeout définit le nombre de secondes d'attente pour que toutes les sondes de disques soient exécutées. Par exemple, pour forcer le démon hal à attendre 10 minutes et 30 secondes, l'option doit afficher --child-timeout=630. La valeur par défaut est de 250 secondes. Bien que cela signifie que le démon hal prendre plus de temps à démarrer, il devrait y avoir suffisamment de temps pour que tous les périphériques de disques soient reconnus et évitent les échecs de démarrage.
27.1. Création de Cible iSCSI
Procédure 27.1. Créer une Cible iSCSI
- Installer
scsi-target-utils.~]# yum install scsi-target-utils
- Ouvrir le port 3260 dans le pare feu.
~]# iptables -I INPUT -p tcp -m tcp --dport 3260 -j ACCEPT ~]# service iptables save
- Active et lance le service cible.
~]# service tgtd start ~]# chkconfig tgtd on
- Alloue le stockage des LUN. Dans cet exemple, on crée une nouvelle partition de stockage en bloc.
~]# fdisk /dev/vdb Welcome to fdisk (util-linux 2.23.2). Changes will remain in memory only, until you decide to write them. Be careful before using the write command. Device does not contain a recognized partition table Building a new DOS disklabel with disk identifier 0x43eb8efd. Command (m for help): n Partition type: p primary (0 primary, 0 extended, 4 free) e extended Select (default p): *Enter* Using default response p Partition number (1-4, default 1): *Enter* First sector (2048-2097151, default 2048): *Enter* Using default value 2048 Last sector, +sectors or +size{K,M,G} (2048-2097151, default 2097151): +250M Partition 1 of type Linux and of size 250 MiB is set Command (m for help): w The partition table has been altered! Calling ioctl() to re-read partition table. Syncing disks. - Modifiez le fichier
/etc/tgt/targets.confpour créer la cible.~]# cat /etc/tgt/targets.conf ... default-driver iscsi <target iqn.2015-06.com.example.test:target1> backing-store /dev/vdb1 initiator-address 10.10.1.1 </target>
Dans l'exemple ci-dessus, on a créé une simple cible qui contient un store de sauvegarde et un initiateur autorisé. Il doit comprendre un nom iqn sous le formatiqn.YYYY-MM.reverse.domain.name:OptionalIdentifier. Le store de sauvegarde correspond au périphérique sur lequel le stockage se trouve. L'initiator-address correspond à l'adresse IP de l'initiateur qui doit accéder au stockage. - Redémarrer le service cible.
~]# service tgtd restart Stopping SCSI target daemon: [ OK ] Starting SCSI target daemon: [ OK ]
- Vérifier la configuration.
~]# tgt-admin --show Target 1: iqn.2015.06.com.example.test: server System information: Driver: iscsi State: ready I_T nexus information: LUN information: Lun: 0 Type: controller SCSI ID: IET 00010000 SCSI SN: beaf10 Size: 0 MB, Block size: 1 Online: Yes Removable media: No Prevent removal: No Readonly: No Backing store type: null Backing store path: None Backing store flags: LUN: 1 Type: disk SCSI ID: IET 00010001 SCSI SN: beaf11 Size: 2147 MB, Block size: 512 Online: Yes Removable media: No Prevent removal: No Readonly: No Backing store type: rdwr Backing store path: /dev/vdb1 Backing store flags: Account information: ACL information: 10.10.1.1
27.2. Création de l'initiateur iSCSI
Procédure 27.2. Créer un initiateur iSCSI
- Installer
iscsi-initiator-utils.~]# yum install iscsi-initiator-utils
- Découvrez la cible. Utiliser l'adresse IP de la cible, celle qui est utilisée ci-dessous n'est utilisée qu'à titre d'exemple.
~]# iscsiadm -m discovery -t sendtargets -p 192.168.1.1 Starting iscsid: [ OK ] 192.168.1.1:3260,1 iqn.2015-06.com.example.test:target1
L'exemple ci-dessus montre d'adresse IP de la cible et l'adresse IQN. C'est l'adresse IQN dont on a besoin pour les prochaines étapes. - Connectez-vous à la cible.
~]# iscsiadm -m node -T iqn.2015-06.com.example:target1 --login Logging in to [iface: default, target: iqn.2015-06.com.example:target1, portal: 192.168.1.1,3260] (multiple) Login in to [iface: default, target: iqn.2015-06.com.example:target1, portal: 192.168.1.1,3260] successful.
- Cherchez le nom du disque iSCSI.
~]# grep "Attached SCSI" /var/log/messages Jun 19 01:30:26 test kernel: sd 7:0:0:1 [sdb] Attached SCSI disk
- Créez un système de fichiers sur ce disque.
~]# mkfs.ext4 /dev/sdb
- Montez le système de fichiers.
~]# mkdir /mnt/iscsiTest ~]# mount /dev/sdb /mnt/iscsiTest
- Rendez-le persistant à travers les démarrages en modifiant le fichier
/etc/fstab.~]# blkid /dev/sdb /dev/sdb: UUID="766a3bf4-beeb-4157-8a9a-9007be1b9e78" TYPE="ext4" ~]# vim /etc/fstab UUID=766a3bf4-beeb-4157-8a9a-9007be1b9e78 /mnt/iscsiTest ext4 _netdev 0 0
Chapitre 28. Dénomination persistante
- Identifiant PCI de l'adaptateur de bus hôte (HBA)
- numéro de canal sur ce HBA
- adresse de la cible SCSI à distance
- LUN (numéro d'unité logique, « Logical Unit Number »)
/dev/sd ; l'autre est le numéro major:minor. Un troisième est un lien symbolique maintenu dans le répertoire /dev/disk/by-path/. Ce lien symbolique mappe l'identifiant de chemin vers le nom /dev/sd actuel. Par exemple, pour un périphérique Fibre Channel, les informations PCI Host:BusTarget:LUN peuvent apparaître comme suit :
pci-0000:02:0e.0-scsi-0:0:0:0 -> ../../sda
by-path/ effectuent le mappage depuis le nom de la cible et les informations du portail au nom sd.
28.1. WWID
0x83) ou le numéro de série de l'unité (page 0x80). Les mappages de ces WWID aux noms /dev/sd actuels peuvent être observés sur les liens symboliques maintenus dans le répertoire /dev/disk/by-id/.
Exemple 28.1. WWID
0x83 aurait :
scsi-3600508b400105e210000900000490000 -> ../../sda
0x80 aurait :
scsi-SSEAGATE_ST373453LW_3HW1RHM6 -> ../../sda
/dev/sd sur ce système. Les applications peuvent utiliser le nom /dev/disk/by-id/ pour référencer les données sur le disque, même si le chemin vers le périphérique change, et même pendant l'accession à ce périphérique par différents systèmes.
/dev/mapper/wwid, tel que /dev/mapper/3600508b400105df70000e00000ac0000.
multipath -l affiche le mappage vers les identificateurs non-persistants : Hôte:Canal:Cible:LUN, le nom /dev/sd, et le numéro major:minor.
3600508b400105df70000e00000ac0000 dm-2 vendor,product [size=20G][features=1 queue_if_no_path][hwhandler=0][rw] \_ round-robin 0 [prio=0][active] \_ 5:0:1:1 sdc 8:32 [active][undef] \_ 6:0:1:1 sdg 8:96 [active][undef] \_ round-robin 0 [prio=0][enabled] \_ 5:0:0:1 sdb 8:16 [active][undef] \_ 6:0:0:1 sdf 8:80 [active][undef]
/dev/sd correspondant sur le système. Ces noms sont persistants à travers les changements de chemin, et sont cohérents lors de l'accession au périphérique à partir de différents systèmes.
user_friendly_names (de device-mapper-multipath) est utilisée, le WWID est mappé à un nom sous le format /dev/mapper/mpathn. Par défaut, ce mappage est maintenu dans le fichier /etc/multipath/bindings. Ces noms mpathn sont persistants tant que le fichier est maintenu.
Important
user_friendly_names, alors des étapes supplémentaires sont requises pour obtenir des noms cohérents dans un cluster. Veuillez consulter les « Noms cohérents de périphériques multivoies » dans la section « Cluster » de l'ouvrage Utilisation de l'administration et de la configuration DM Multipath.
udev pour implémenter des noms persistants de votre choix, mappés au WWID du stockage. Pour obtenir davantage d'informations à ce sujet, veuillez consulter http://kbase.redhat.com/faq/docs/DOC-7319.
28.2. UUID et autres identificateurs persistants
- UUID (Universally Unique Identifier)
- Étiquette du système de fichiers
/dev/disk/by-label/ (par exemple, boot -> ../../sda1) et /dev/disk/by-uuid/ (par exemple, f8bf09e3-4c16-4d91-bd5e-6f62da165c08 -> ../../sda1).
md et LVM écrivent des métadonnées sur le périphérique de stockage, et lisent ces donnéées lorsqu'ils scannent les périphériques. Dans chaque cas, les métadonnées contiennent un UUID afin que le périphérique puisse être identifié, peu importe le chemin (ou système) utilisé pour y accéder. Par conséquent, les noms des périphériques présentés par cet équipement sont persistants tant que les métadonnées ne sont pas modifiées.
Chapitre 29. Supprimer un périphérique de stockage
vmstat 1 100 ; la suppression du périphérique n'est pas recommandée si :
- La mémoire disponible fait moins de 5% de la totalité de la mémoire dans plus de 10 échantillons pour 100 (la commande
freepeut également être utilisée pour afficher la mémoire totale). - La fonction swap est active (colonnes
sietsonon égales à zéro dans la sortievmstat).
Procédure 29.1. S'assurer d'une suppression de périphérique normale
- Fermez tous les utilisateurs du périphérique et effectuez une copie de sauvegarde des données du périphérique selon les besoins.
- Veuillez utiliser
umountpour démonter tout système de fichiers qui aurait monté le périphérique. - Supprimez le périphérique de tout volume
mdet LVM qui l'utilise. Si le périphérique est un membre d'un groupe de volumes LVM, alors il faudra sans doute déplacer les données hors du périphérique en utilisant la commandepvmove, puis utiliser la commandevgreducepour supprimer le volume physique, et (optionnellement)pvremovepour supprimer les métadonnées LVM du disque. - Si le périphérique utilise la fonction multivoies, veuillez exécuter
multipath -let prendre note de tous les chemins menant au périphérique. Ensuite, veuillez supprimer le périphérique multivoies en utilisantmultipath -f device. - Veuillez exécuter
blockdev --flushbufs devicepour vider toute E/S restante sur tous les chemins vers le périphérique. Ceci est particulièrement important pour les périphériques bruts, lorsqu'il n'y a pas d'opérationumountouvgreducepour causer un vidage d'E/S. - Veuillez supprimer toute référence au nom basée sur le chemin du périphérique, comme
/dev/sd,/dev/disk/by-pathou sur le numéromajor:minor, dans les applications, scripts, ou utilitaires du système. Ceci est important pour s'assurer que les différents périphériques ajoutés dans le futur ne soient pas confondus avec le périphérique actuel. - Finalement, veuillez supprimer chaque chemin vers le périphérique à partir du sous-système SCSI. Pour ce faire, veuillez utiliser la commande
echo 1 > /sys/block/device-name/device/delete, oùdevice-namepourrait, par exemple, êtresde.Une autre variation de cette opération estecho 1 > /sys/class/scsi_device/h:c:t:l/device/delete, oùhest le numéro HBA,cest le canal sur le HBA,test l'ID de la cible SCSI, etlest le LUN.Note
L'ancienne forme de ces commandes,echo "scsi remove-single-device 0 0 0 0" > /proc/scsi/scsi, est déconseillée.
nom-du-périphérique, le numéro du HBA, canal du HBA, l'ID et le LUN de la cible SCSI d'un périphérique à l'aide de diverses commandes, telles que lsscsi, scsi_id, multipath -l, et ls -l /dev/disk/by-*.
Chapitre 30. Supprimer un chemin vers un périphérique de stockage
Procédure 30.1. Supprimer un chemin vers un périphérique de stockage
- Veuillez supprimer toute référence au nom basée sur le chemin du périphérique, comme
/dev/sd,/dev/disk/by-pathou sur le numéromajor:minor, dans les applications, scripts, ou utilitaires du système. Ceci est important pour s'assurer que les différents périphériques ajoutés dans le futur ne soient pas confondus avec le périphérique actuel. - Mettez le chemin hors-ligne en utilisant
echo offline > /sys/block/sda/device/state.Ceci provoquera l'échec immédiat de toute E/S ultérieure envoyée sur ce chemin. Device-mapper-multipath continuera d'utiliser les chemins restants vers le périphérique. - Veuillez supprimer le chemin du sous-système SCSI. Pour ce faire, veuillez utiliser la commande
echo 1 > /sys/block/device-name/device/delete, oùdevice-namepourrait, par exemple, êtresde(comme décrit dans Procédure 29.1, « S'assurer d'une suppression de périphérique normale »).
Chapitre 31. Ajouter un périphérique ou un chemin de stockage
/dev/sd, le numéro de major:minor et le nom de /dev/disk/by-path) assigné par le système au nouveau périphérique peut déjà avoir été utilisé par un périphérique qui a depuis été supprimé. Ainsi, veuillez vous assurer que toutes les anciennes références au nom du périphérique basé chemin ont bien été supprimées. Autrement, le nouveau périphérique pourrait malencontreusement passer pour l'ancien périphérique.
Procédure 31.1. Ajouter un périphérique ou un chemin de stockage
- La première étape de l'ajout d'un périphérique ou d'un chemin de stockage consiste à physiquement activer l'accès au nouveau périphérique de stockage ou à physiquement activer un nouveau chemin vers un périphérique existant. Ceci peut être effectué à l'aide de commandes appartenant aux vendeurs sur le serveur de stockage iSCSI ou Fibre Channel. Une fois effectué, prenez note de la valeur LUN du nouveau stockage qui sera présenté à votre hôte. Si le serveur de stockage est Fibre Channel, veuillez aussi prendre note du WWNN (World Wide Node Name) du serveur de stockage et déterminez s'il y a un WWNN unique pour tous les ports sur le serveur de stockage. Si ce n'est pas le cas, veuillez noter le WWPN (World Wide Port Name) de chaque port qui sera utilisé pour accéder au nouveau LUN.
- Veuillez ensuite indiquer le nouveau périphérique de stockage au système d'exploitation, ou le nouveau chemin à un périphérique existant. La commande recommandée est la suivante :
$ echo "c t l" > /sys/class/scsi_host/hosth/scan
Dans la commande précédente,hest le numéro HBA,cest le canal sur le HBA,test l'ID de la cible SCSI etlest le LUN.Note
La plus ancienne forme de cette commande,echo "scsi add-single-device 0 0 0 0" > /proc/scsi/scsi, est dépréciée.- Sur certains matériaux Fibre Channel, un nouveau LUN créé sur la matrice RAID pourrait ne pas être visible au système d'exploitation tant qu'une opération LIP (Loop Initialization Protocol) n'est pas effectuée. Reportez-vous à Chapitre 34, Scanner les interconnexions du stockage pour obtenir des instructions sur la manière d'effectuer cela.
Important
Il sera nécessaire d'arrêter les E/S tant que cette opération est exécutée, si un LIP est requis. - Si un nouveau LUN a été ajouté à la matrice RAID mais qu'il n'est toujours pas configuré par le système d'exploitation, veuillez confirmer la liste des LUN qui sont exportés par la matrice à l'aide de la commande
sg_luns, faisant partie du paquet sg3_utils. Ceci délivrera la commandeSCSI REPORT LUNSà la matrice RAID et retournera une liste des LUN présents.
Pour les serveurs de stockage Fibre Channel qui implémentent un WWNN unique pour tous les ports, vous pouvez déterminer les valeursh,cettcorrectes (c'est-à-dire le numéro HBA, le canal HBA et l'ID de la cible SCSI) en recherchant le WWNN danssysfs.Exemple 31.1. Déterminer les valeurs
h,cettcorrectesPar exemple, si le WWNN du serveur de stockage est0x5006016090203181veuillez utiliser :$ grep 5006016090203181 /sys/class/fc_transport/*/node_name
La sortie résultante devrait être similaire à ceci :/sys/class/fc_transport/target5:0:2/node_name:0x5006016090203181 /sys/class/fc_transport/target5:0:3/node_name:0x5006016090203181 /sys/class/fc_transport/target6:0:2/node_name:0x5006016090203181 /sys/class/fc_transport/target6:0:3/node_name:0x5006016090203181
Ceci indique qu'il y a quatre routes Fibre Channel vers cette cible (deux HBA à canal unique, menant chacune à deux ports de stockage). En supposant qu'une valeur LUN est56, alors la commande suivante configurera le premier chemin :$ echo "0 2 56" > /sys/class/scsi_host/host5/scan
Ceci doit être effectué pour chaque chemin vers le nouveau périphérique.Pour les serveurs de stockage Fibre Channel qui n'implémentent pas un WWNN unique pour tous les ports, vous pouvez déterminer le numéro HBA, le canal HBA et l'ID de la cible SCSI qui conviennent en recherchant chaque WWNN danssysfs.Il est aussi possible de déterminer la numéro HBA, le canal HBA et l'ID de la cible SCSI en vous référant à un autre périphérique déjà configuré sur le même chemin que le nouveau périphérique. Ceci peut être accompli à l'aide de diverses commandes, commelsscsi,scsi_id,multipath -letls -l /dev/disk/by-*. Ces informations, en plus du numéro LUN du nouveau périphérique, peuvent être utilisés, comme expliqué ci-dessus, afin d'analyser et de configurer ce chemin vers le nouveau périphérique. - Après avoir ajouté tous les chemins SCSI au périphérique, veuillez exécuter la commande
multipathet vérifier que le périphérique a été configuré correctement. À ce moment, le périphérique peut, par exemple, être ajouté àmd, LVM,mkfs, ou àmount.
Chapitre 32. Configurer une interface FCoE (« Fibre-Channel Over Ethernet »)
fcoe-utilslldpad
Procédure 32.1. Configurer une interface Ethernet pour utiliser FCoE
- Configurez un nouveau réseau VLAN en copiant un script réseau existante (par exemple,
/etc/fcoe/cfg-eth0) sur le nom du périphérique Ethernet qui prend en charge FCoE. Ceci vous fournira un fichier par défaut à configurer. Étant donné que le périphérique FCoE est nomméethX, veuillez exécuter :# cp /etc/fcoe/cfg-eth0 /etc/fcoe/cfg-ethX
Modifiez le contenu decfg-ethXcomme nécessaire.DCB_REQUIREDdevrait être défini surnopour les interfaces réseau qui implémentent un client DCBX matériel. - Si vous souhaitez que le périphérique soit automatiquement chargé pendant le démarrage, définissez
ONBOOT=yesdans le fichier/etc/sysconfig/network-scripts/ifcfg-ethXcorrespondant. Par exemple, si le périphérique FCoE est nommé eth2, alors veuillez modifier/etc/sysconfig/network-scripts/ifcfg-eth2en conséquence. - Lancez le démon de pontage du centre de données (
dcbd) à l'aide de la commande suivante :# /etc/init.d/lldpad start
- Pour les interfaces réseau qui implémentent un client DCBX matériel, ignorez cette étape et passez directement à la suivante.Pour les interfaces qui requièrent un client DCBX logiciel, veuillez activer le pontage de centre de données sur l'interface Ethernet à l'aide des commandes suivante :
# dcbtool sc ethX dcb on
Puis, activez FCoE sur l'interface Ethernet en exécutant :# dcbtool sc ethX app:fcoe e:1
Note
Ces commandes fonctionneront uniquement si les paramètresdcbdde l'interface Ethernet n'ont pas été modifiés. - Chargez le périphérique FCoE en utilisant :
# ifconfig ethX up
- Lancez FCoE en utilisant :
# service fcoe start
Le périphérique FCoE apparaîtra sous peu, en supposant que tous les autres paramètres de la structure soient corrects. Pour afficher les périphériques FCoE configurés, veuillez exécuter :# fcoeadm -i
lldpad pour s'exécuter lors du démarrage. Pour ce faire, veuillez utiliser chkconfig, comme dans :
# chkconfig lldpad on
# chkconfig fcoe on
Avertissement
32.1. Paramétrage de cible FCoE (« Fibre-Channel over Ethernet »)
Important
fcoeadm -i affiche les interfaces FCoE configurées.
Procédure 32.2. Configurer un cible FCoE
- Paramétrer une cible FCoE requiert l'installation du paquet
fcoe-target-utilsainsi que de ses dépendances.# yum install fcoe-target-utils - La prise en charge de cibles FCoE est basée sur la cible du noyau LIO et ne requiert pas de démon de l'espace utilisateur. Cependant, il est toujours utile d'activer le service fcoe-target pour charger les modules de noyau nécessaires et conserver la configuration aux redémarrages.
# service fcoe-target start# chkconfig fcoe-target on - La configuration d'une cible FCoE est effectuée à l'aide de l'utilitaire
targetcli, plutôt qu'en modifiant un fichier.confcomme cela pourrait être attendu. Ces paramètres sont ensuite enregistrés afin de pouvoir les restaurer si le système redémarre.# targetclitargetcliest un shell de configuration hiérarchique. Effectuez des déplacements entre nœuds dans le shell en utilisantcd, et utilisezlspour afficher le contenu du nœud de configuration. Pour connaître des options supplémentaires, utiliser la commandehelp. - Définissez le fichier, périphérique bloc, ou périphérique SCSI de transfert pour exporter en tant que « backstore ».
Exemple 32.1. Exemple 1 de définition d'un périphérique
/> backstores/block create example1 /dev/sda4Ceci crée un « backstore » nomméexample1, qui mène au périphérique bloc/dev/sda4.Exemple 32.2. Exemple 2 de définition d'un périphérique
/> backstores/fileio create example2 /srv/example2.img 100MCeci crée un « backstore » nomméexample2, qui mène au fichier donné. Si le fichier n'existe pas, il sera créé. La taille de fichier peut utiliser les abréviations K, M, ou G et n'est utile que lorsque le fichier de sauvegarde n'existe pas.Note
Si l'option globaleauto_cd_after_createest activée (ce qui est le cas par défaut), exécuter une commande de création modifiera le nœud de configuration actuel et le changera en l'objet nouvellement créé. Ceci peut être désactivé avecset global auto_cd_after_create=false. Retourner au nœud root est possible aveccd /. - Créer une instance de cible FCoE sur une interface FCoE.
/> tcm_fc/ create 00:11:22:33:44:55:66:77Si des interfaces FCoE sont présentes sur le système, la complétion par la touche de tabulation après la saisie decreaterépertoriera les interfaces disponibles. Si ce n'est pas le cas, assurez-vous quefcoeadm -iaffiche bien des interfaces actives. - Mettre en correspondance un « backstore » avec une instance cible.
Exemple 32.3. Exemple de mise en correspondance d'un « backstore » avec l'instance cible.
/> cd tcm_fc/00:11:22:33:44:55:66:77/> luns/ create /backstores/fileio/example2 - Autoriser l'accès au LUN à partir d'un initiateur FCoE.
/> acls/ create 00:99:88:77:66:55:44:33Le LUN devrait désormais être accessible à cet initiateur. - Quittez
targetclien saisissantexitou ctrl+D.
targetcli enregistrera la configuration par défaut. Celle-ci peut toutefois être explicitement enregistrée par la commande saveconfig.
targetcli pour obtenir davantage d'informations.
Chapitre 33. Configurer une interface FCoE pour qu'elle soit automatiquement montée lors du démarrage
Note
/usr/share/doc/fcoe-utils-version/README à partir de Red Hat Enterprise Linux 6.1. Veuillez consulter ce document en cas de changement lors des sorties de versions mineures.
udev, autofs, et autres méthodes similaires. Cependant, de temps à autres un service particulier peut nécessiter que le disque FCoE soit monté pendant le démarrage. Dans de tels cas, le disque FCoE devrait être monté dès que le service fcoe est exécuté et avant l'initialisation de tout service qui requiert le disque FCoE.
fcoe. Le script de démarrage fcoe se trouve ici : /etc/init.d/fcoe.
Exemple 33.1. Code de montage FCoE
/etc/fstab :
mount_fcoe_disks_from_fstab()
{
local timeout=20
local done=1
local fcoe_disks=($(egrep 'by-path\/fc-.*_netdev' /etc/fstab | cut -d ' ' -f1))
test -z $fcoe_disks && return 0
echo -n "Waiting for fcoe disks . "
while [ $timeout -gt 0 ]; do
for disk in ${fcoe_disks[*]}; do
if ! test -b $disk; then
done=0
break
fi
done
test $done -eq 1 && break;
sleep 1
echo -n ". "
done=1
let timeout--
done
if test $timeout -eq 0; then
echo "timeout!"
else
echo "done!"
fi
# mount any newly discovered disk
mount -a 2>/dev/null
}mount_fcoe_disks_from_fstab doit être invoquée après que le script du service fcoe ait lancé le démon fcoemon. Ceci montera les disques FCoE spécifiés par les chemins suivants dans /etc/fstab :
/dev/disk/by-path/fc-0xXX:0xXX /mnt/fcoe-disk1 ext3 defaults,_netdev 0 0 /dev/disk/by-path/fc-0xYY:0xYY /mnt/fcoe-disk2 ext3 defaults,_netdev 0 0
fc- et _netdev activent la fonction mount_fcoe_disks_from_fstab pour identifier les entrées de montage de disques FCoE. Pour obtenir davantage d'informations sur les entrées /etc/fstab, veuillez consulter man 5 fstab.
Note
fcoe n'implémente pas de délai d'expiration pour la récupération de disque FCoE. Ainsi, le code de montage FCoE doit implémenter son propre délai d'expiration.
Chapitre 34. Scanner les interconnexions du stockage
- Toutes les E/S sur interconnexions affectées doivent être mises sur pause et vidées avant d'exécuter la procédure, et les résultats du scan doivent être vérifiés avant de reprendre les E/S.
- Comme pour la suppression de périphériques, scanner des interconnexions n'est pas recommandé lorsque le système se trouve sous pression mémoire. Pour déterminer le niveau de pression mémoire, exécutez la commande
vmstat 1 100. Scanner les interconnexions n'est pas recommandé si la quantité de mémoire disponible fait moins de 5% de la mémoire totale dans plus de 10 échantillons pour 100. Aussi, le scan d'interconexions n'est pas recommandé si la fonction swap est active (avec des colonnessietsoqui ne sont pas égales à zéro dans la sortievmstat). La commandefreepeut également afficher la mémoire totale.
echo "1" > /sys/class/fc_host/host/issue_lip- Cette opération effectue un Loop Initialization Protocol (LIP), analyse l’interconnexion et met à jour la couche SCSI pour refléter les périphériques actuellement présents sur le bus. Essentiellement, un LIP est une réinitialisation du bus et entraîne l'ajout ou la suppression de périphériques. Cette procédure est nécessaire pour configurer une nouvelle cible SCSI sur un réseau d’interconnexion Fibre Channel.Notez que
issue_lipest une opération asynchrone. La commande peut finaliser son but avant la fin du scan. Vous pourrez vérifier dans le fichier/var/log/messagessi la commandeissue_lipest terminée.Les piloteslpfc,qla2xxx, etbnx2fcsupportentissue_lip. Pour plus d'informations sur les fonctions des API supportées par chaque pilote dans Red Hat Enterprise Linux, consulter Tableau 26.1, « Capacités de l'API Fibre-Channel ». /usr/bin/rescan-scsi-bus.sh- Le script
/usr/bin/rescan-scsi-bus.sha été introduit dans Red Hat Enterprise Linux 5.4. Par défaut, ce script scanne tous les bus SCSI du système, et met à jour la couche SCSI pour refléter la présence de nouveaux périphériques sur le bus. Le script fournit des options supplémentaires pour permettre la suppresion de périphériques, et le lancement des LIP. Pour obtenir plus d'informations sur ce script, y compris les problèmes connus, consulter Chapitre 38, Ajouter ou supprimer une unité logique avec rescan-scsi-bus.sh. echo "- - -" > /sys/class/scsi_host/hosth/scan- C’est la même commande, comme décrit dans Chapitre 31, Ajouter un périphérique ou un chemin de stockage, qui sert à ajouter un périphérique de stockage ou le chemin d’accès. Dans ce cas, toutefois, le numéro du canal, l'ID cible SCSI, et des valeurs LUN sont remplacés par des caractères génériques. Toute combinaison de caractères génériques et d'identificateurs est autorisée, donc vous pouvez rendre la commande aussi précise qu'englobante selon les besoins. Cette procédure ajoute des LUN, mais ne les supprime pas.
modprobe --remove driver-name,modprobe driver-name- En exécutant la commande
modprobe--remove driver-namesuivie de la commandemodprobe driver-name, vous ré-initialisez totalement l’état de toutes les interconnexions controlées par le pilote. Bien qu’il s'agisse d'une mesure relativement extrême, utiliser les commandes décrites peut être appropriée dans certaines situations. Les commandes peuvent être utilisées, par exemple, pour redémarrer le pilote avec une valeur de paramètre de module différente.
Chapitre 35. Configurer le déchargement et la liaison d'interfaces iSCSI
$ ping -I ethX target_IP
ping échoue, alors vous ne pourrez pas lier une session à un NIC. Si cela est le cas, veuillez vérifier les paramètres réseau en premier.
35.1. Afficher les configurations iface disponibles
- La pile Software iSCSI — comme les modules
scsi_tcpetib_iseralloue une instance d'hôte iSCSI (apr ex.scsi_host) par session, avec une seule connexion par session. De ce fait,/sys/class_scsi_hostet/proc/scsireporteront unscsi_hostpour chaque connexion/session à laquelle vous vous connectez. - Le pile Offload iSCSI — comme le modules Chelsio
cxgb3i, Broadcombnx2iet ServerEnginesbe2iscsimodules, alloue une instancescsi_hostà chaque périphérique PCI. Ainsi, chaque port s'affichera en tant que périphérique PCI séparé sur un adaptateur de bus d'hôte, avec un différentscsi_hostpar port HBA.
iscsiadm utilise la structure iface. Avec cette structure, une configuration iface doit être saisie dans /var/lib/iscsi/ifaces pour chaque port HBA, chaque logiciel iSCSI, ou chaque périphérique de réseau (ethX) utilisé pour lier les sessions.
iface disponibles, exécutez iscsiadm -m iface. Cela permettre d'afficher les informations iface dans le format suivant :
iface_name transport_name,hardware_address,ip_address,net_ifacename,initiator_name
Tableau 35.1. Configurations iface
| Paramètre | Description |
|---|---|
iface_name | nom de configuration iface. |
transport_name | Nom du pilote |
hardware_address | adresse MAC |
ip_address | Adresse IP pour ce port |
net_iface_name | Nom utilisé pour le vlan ou pour l'alias de liaison d'une sessions iSCSI. Pour les déchargements iSCSI, net_iface_name sera <vide> car cette valeur n'est pas persistante au redémarrage. |
initiator_name | Configuration utilisée pour substituer un nouveau nom au nom par défaut de l'initiateur, défini dans /etc/iscsi/initiatorname.iscsi |
Exemple 35.1. Échantillon de sortie de la commande iscsiadm -m iface
iscsiadm -m iface :
iface0 qla4xxx,00:c0:dd:08:63:e8,20.15.0.7,default,iqn.2005-06.com.redhat:madmax iface1 qla4xxx,00:c0:dd:08:63:ea,20.15.0.9,default,iqn.2005-06.com.redhat:madmax
iface doit avoir un nom unique (de moins de 65 caractères). Le nom iface_name des périphériques réseau qui supportent le déchargement apparaît sous le format transport_name.hardware_name.
Exemple 35.2. Sortie de la commande iscsiadm -m iface avec une carte réseau Chelsio
iscsiadm -m iface sur un système utilisant une carte réseau Chelsio :
default tcp,<empty>,<empty>,<empty>,<empty> iser iser,<empty>,<empty>,<empty>,<empty> cxgb3i.00:07:43:05:97:07 cxgb3i,00:07:43:05:97:07,<empty>,<empty>,<empty>
iface particulière d'une façon plus agréable pour l'utilisateur. Pour cela, utiliser l'option -I iface_name. Cela affichera les paramètres dans le format suivant :
iface.paramètre = valeur
Exemple 35.3. Utiliser les paramètres de configuration iface avec un adaptateur de réseau Chelsio convergé
iface du même adaptateur de réseau Chelsio convergé (par ex. iscsiadm -m iface -I cxgb3i.00:07:43:05:97:07) s'afficheront ainsi :
# BEGIN RECORD 2.0-871 iface.iscsi_ifacename = cxgb3i.00:07:43:05:97:07 iface.net_ifacename = <empty> iface.ipaddress = <empty> iface.hwaddress = 00:07:43:05:97:07 iface.transport_name = cxgb3i iface.initiatorname = <empty> # END RECORD
35.2. Configurer un iface pour iSCSI logiciel
iface est requise pour chaque objet réseau qui sera utilisé pour lier une session.
iface pour iSCSI logiciel, veuillez exécuter la commande suivante :
# iscsiadm -m iface -I iface_name --op=new
iface vide avec une valeur iface_name spécifiée. Si une configuration iface existante possède déjà la même valeur iface_name, alors celle-ci sera écrasée par une autre, nouvelle et vide.
iface, veuillez utiliser la commande suivante :
# iscsiadm -m iface -I iface_name --op=update -n iface.setting -v hw_address
Exemple 35.4. Définir l'adresse MAC de iface0
hardware_address) de iface0 sur 00:0F:1F:92:6B:BF, veuillez exécuter :
# iscsiadm -m iface -I iface0 --op=update -n iface.hwaddress -v 00:0F:1F:92:6B:BF
Avertissement
default ou iser comme noms iface. Ces deux chaînes sont des valeurs spéciales utilisées par iscsiadm pour une compatibilité ascendante. Toute configuration iface créée manuellement nommée default ou iser désactivera la compatibilité ascendante.
35.3. Configurer un iface pour le déchargement iSCSI
iscsiadm créera une configuration iface pour chaque port Chelsio, Broadcom, et ServerEngines. Pour afficher les configurations iface disponibles, veuillez utiliser la même commande que pour le logiciel iSCSI, c'est-à-dire iscsiadm -m iface.
iface d'une carte réseau pour le déchargement iSCSI, veuillez commencer par définir l'adresse IP (target_IP) que le périphérique devrait utiliser. Pour les périphériques ServerEngines qui utilisent le pilote be2iscsi (c'est-à-dire des HBA iSCSI ServerEngines), l'adresse IP est configurée dans l'écran de paramétrage BIOS de ServerEngines.
iface. Ainsi, pour configurer l'adresse IP de l'iface, veuillez utiliser :
# iscsiadm -m iface -I iface_name -o update -n iface.ipaddress -v target_IP
Exemple 35.5. Paramétrez l'adresse IP de l'iface d'une carte Chelsio
iface d'une carte Chelsio (avec le nom iface cxgb3i.00:07:43:05:97:07) sur 20.15.0.66, veuillez utiliser :
# iscsiadm -m iface -I cxgb3i.00:07:43:05:97:07 -o update -n iface.ipaddress -v 20.15.0.66
35.4. Lier ou délier un iface sur un portail
iscsiadm est utilisé pour rechercher des interconnexions, la vérification commencera par les paramètres iface.transport de chaque configuration iface dans /var/lib/iscsi/ifaces. L'utilitaire iscsiadm liera ensuite les portails découverts avec tout iface dont iface.transport est tcp.
-I iface_name pour spécifier quel portail lier à un iface, comme suit :
# iscsiadm -m discovery -t st -p target_IP:port -I iface_name -P 1
iscsiadm ne liera pas automatiquement tous les portails aux configurations iface utilisant le déchargement. Ceci est dû au fait que de telles configurations iface n'ont pas paramétré iface.transport sur tcp. Ainsi, les configurations iface des ports Chelsio, Broadcom, et ServerEngines doivent être liées manuellement aux portails découverts.
iface existant. Pour ce faire, veuillez utiliser default comme iface_name de la manière suivante :
# iscsiadm -m discovery -t st -p IP:port -I default -P 1
iface, veuillez utiliser :
# iscsiadm -m node -targetname proper_target_name -I iface0 --op=delete[7]
iface particulier, veuillez utiliser :
# iscsiadm -m node -I iface_name --op=delete
# iscsiadm -m node -p IP:port -I iface_name --op=delete
Note
iface définie dans /var/lib/iscsi/iface et que l'option -I n'est pas utilisée, iscsiadm autorisera le sous-système du réseau à décider quel périphérique un portail particulier devrait utiliser.
proper_target_name.
Chapitre 36. Scanner les Cibles iSCSI par des Portails ou LUN multiples
sendtargets sur l'hôte pour trouver de nouveaux portails sur la cible. Puis, scannez à nouveau les sessions existantes en utilisant :
# iscsiadm -m session --rescan
SID comme suit :
# iscsiadm -m session -r SID --rescan[8]
sendtargets sur les hôtes pour trouver les nouveaux portails de chaque cible. Puis scannez à nouveau les sessions existantes pour découvrir de nouvelles unités logiques (par exemple, en utilisant l'option --rescan).
Important
sendtargets utilisée pour récupérer les valeurs --targetname et --portal remplace le contenu de la base de données /var/lib/iscsi/nodes. Cette base de données sera alors remplie à nouveau en utilisant les paramètres du fichier /etc/iscsi/iscsid.conf. Cependant, ceci ne se produira pas si une session est actuellement connectée et en cours d'utilisation.
-o new ou -o delete, respectivement. Par exemple, pour ajouter de nouveaux portails ou cibles sans écraser /var/lib/iscsi/nodes, veuillez utiliser la commande suivante :
iscsiadm -m discovery -t st -p target_IP -o new
/var/lib/iscsi/nodes que la cible n'a pas affichées pendant la découverte, veuillez utiliser :
iscsiadm -m discovery -t st -p target_IP -o delete
iscsiadm -m discovery -t st -p target_IP -o delete -o new
sendtargets générera la sortie suivante :
ip:port,target_portal_group_tag proper_target_name
Exemple 36.1. Sortie de la commande sendtargets
equallogic-iscsi1 en tant que target_name, la sortie devrait être similaire à la suivante :
10.16.41.155:3260,0 iqn.2001-05.com.equallogic:6-8a0900-ac3fe0101-63aff113e344a4a2-dl585-03-1
proper_target_name et ip:port,target_portal_group_tag sont identiques aux valeurs du même nom dans Section 27.2, « Création de l'initiateur iSCSI ».
--targetname et --portal nécessaires pour scanner manuellement les périphériques iSCSI. Pour ce faire, veuillez exécuter la commande suivante :
# iscsiadm --mode node --targetname proper_target_name --portal ip:port,target_portal_group_tag \ --login [9]
Exemple 36.2. Commande iscsiadm complète
proper_target_name est equallogic-iscsi1), la commande complète aura la forme suivante :
# iscsiadm --mode node --targetname \ iqn.2001-05.com.equallogic:6-8a0900-ac3fe0101-63aff113e344a4a2-dl585-03-1 \ --portal 10.16.41.155:3260,0 --login[9]
Chapitre 37. Redimensionner une Unité logique En ligne
Note
37.1. Redimensionner des unités logiques Fibre Channel
$ echo 1 > /sys/block/sdX/device/rescan
Important
sd1, sd2, et ainsi de suite...) qui représente un chemin pour l'unité logique multivoies. Pour déterminer quels périphériques sont des chemins pour une unité logique mulitvoies, veuillez utiliser multipath -ll ; puis trouvez l'entrée correspondant à l'unité logique en cours de redimensionnement. Il est recommandé de faire référence à l'ID global (WWID) de chaque entrée afin de faciliter la recherche de celui qui correspond à l'unité logique en cours de redimensionnement.
37.2. Redimensionner une unité logique iSCSI
# iscsiadm -m node --targetname target_name -R
target_name par le nom de la cible sur laquelle le périphérique se trouve.
Note
# iscsiadm -m node -R -I interface
interface par le nom d'interface correspondant de l'unité logique redimensionnée (par exemple, iface0). Cette commande effectue deux opérations :
- Un scan est effectué pour trouver de nouveaux périphériques de la même manière que le fait la commande
echo "- - -" > /sys/class/scsi_host/host/scan(veuillez consulter Chapitre 36, Scanner les Cibles iSCSI par des Portails ou LUN multiples). - Un second scan est effectué pour trouver les nouvelles unités logiques ou les unités logiques modifiées de la même manière que le fait la commande
echo 1 > /sys/block/sdX/device/rescan. Remarquez que cette commande est également la même que celle utilisée pour scanner à nouveau des unités logiques Fibre Channel.
37.3. Mettre à jour la taille du périphérique multivoies (« Multipath »)
multipathd. Tout d'abord, veuillez vous assurer que multipathd soit bien en cours d'exécution en utilisant service multipathd status. Une fois le bon fonctionnement de multipathd vérifié, veuillez exécuter la commande suivante :
# multipathd -k"resize map multipath_device"
multipath_device est l'entrée multivoies correspondante du périphérique dans /dev/mapper. Selon la manière par laquelle la fonction multivoies est configurée sur le système, multipath_device peut se trouver sous deux différents formats :
mpathX, oùXest l'entrée correspondante du périphérique (par exemple,mpath0)- un WWID ; par exemple,
3600508b400105e210000900000490000
multipath -ll. Ceci affiche une liste de toutes les entrées multivoies dans le système, ainsi que les chiffres majeurs et mineurs des périphériques correspondants.
Important
multipathd -k"resize map multipath_device" si des commandes sont en file d'attente sur multipath_device. Autrement dit, veuillez ne pas utiliser cette commande lorsque le paramètre no_path_retry (dans /etc/multipath.conf) est défini sur "queue", et qu'il n'existe aucun chemin actif vers le périphérique.
multipathd de reconnaître les modifications apportées à l'unité logique redimensionnée (et de s'y ajuster) :
Procédure 37.1. Redimensionner le périphérique multivoies correspondant (requis pour Red Hat Enterprise Linux 5.0 - 5.2)
- Videz la table du mappeur de périphérique du périphérique multivoies en utilisant :
dmsetup table multipath_device - Enregistrez la table du mappeur de périphériques vidé sous le nom
table_name. Cette table sera chargée à nouveau et modifiée ultérieurement. - Examinez la table du mappeur de périphériques. Remarquez que les deux premiers chiffres de chaque ligne correspondent respectivement aux secteurs du début et de la fin du disque.
- Veuillez suspendre la cible du mappeur de périphériques :
dmsetup suspend multipath_device - Ouvrez la table du mappeur de périphériques enregistrée au préalable (
table_name). Modifiez le second chiffre (le secteur de fin du disque) afin qu'il reflète le nouveau chiffre de 512 secteurs d'octets sur le disque. Par exemple, si la nouvelle taille de disque fait 2 Go, le second chiffre devra être 4194304. - Veuillez charger à nouveau la table modifiée du mappeur de périphériques :
dmsetup reload multipath_device table_name - Réactivez la cible du mappeur de périphériques :
dmsetup resume multipath_device
37.4. Modifier l'état de lecture/écriture d'une unité logique en ligne
# blockdev --getro /dev/sdXYZ
# cat /sys/block/sdXYZ/ro 1 = read-only 0 = read-writemultipath -ll. Exemple :
36001438005deb4710000500000640000 dm-8 GZ,GZ500 [size=20G][features=0][hwhandler=0][ro] \_ round-robin 0 [prio=200][active] \_ 6:0:4:1 sdax 67:16 [active][ready] \_ 6:0:5:1 sday 67:32 [active][ready] \_ round-robin 0 [prio=40][enabled] \_ 6:0:6:1 sdaz 67:48 [active][ready] \_ 6:0:7:1 sdba 67:64 [active][ready]
Procédure 37.2. Modifier l'état R/W
- Pour déplacer l'état du périphérique de RO à R/W, veuillez consulter l'étape 2.Pour déplacer l'état du périphérique de R/W à RO, assurez-vous qu'aucune écriture supplémentaire ne sera passée. Ceci peut être fait en arrêtant l'application, ou en utilisant une action correspondante spécifique à l'application.Assurez-vous que toutes les E/S d'écriture restantes soient bien terminées par la commande suivante :
# blockdev --flushbufs /dev/deviceRemplacez device par l'appellation souhaitée. Pour un périphérique multivoies mappeur de périphériques, il s'agit de l'entrée du périphérique dansdev/mapper. Par exemple,/dev/mapper/mpath3. - Veuillez utiliser l'interface de gestion du périphérique de stockage pour changer l'état de l'unité logique de RW (lecture/écriture) à RO (lecture seule), ou au contraire de RO à R/W. Cette procédure est différente pour chaque matrice. Pour obtenir davantage d'informations, veuillez consulter la documentation du fournisseur de matrice de stockage applicable.
- Scannez à nouveau le périphérique pour mettre à jour l'affichage de l'état R/W du système d'exploitation du périphérique. Si vous utilisez un périphérique mappeur multivoies, veuillez ré-effectuer ce scan pour chaque chemin vers le périphérique avant de passer la commande ordonnant au périphérique multivoies de recharger ses cartes de périphérique.Ce processus est expliqué en détails dans Section 37.4.1, « Scanner à nouveau des unités logiques ».
37.4.1. Scanner à nouveau des unités logiques
# echo 1 > /sys/block/sdX/device/rescanmultipath -11, puis trouvez l'entrée qui correspond à l'unité logique devant être modifiée.
Exemple 37.1. Utilisation de la commande multipath -11
multipath -11 affiche le chemin pour le LUN avec l'ID WWID 36001438005deb4710000500000640000. Dans ce cas, veuillez saisir :
# echo 1 > /sys/block/sdax/device/rescan# echo 1 > /sys/block/sday/device/rescan# echo 1 > /sys/block/sdaz/device/rescan# echo 1 > /sys/block/sdba/device/rescan
37.4.2. Mettre à jour l'état R/W d'un périphérique multivoies
# multipath -rmultipath -11 peut être utilisée pour confirmer le changement.
37.4.3. Documentation
Chapitre 38. Ajouter ou supprimer une unité logique avec rescan-scsi-bus.sh
sg3_utils fournit le script rescan-scsi-bus.sh, qui peut automatiquement mettre à jour la configuration de l'unité logique de l'hôte selon les besoins (après l'ajout du périphérique au système). Le script rescan-scsi-bus.sh peut également effectuer une opération issue_lip sur les périphériques pris en charge. Pour obtenir davantage d'informations sur l'utilisation de ce script, veuillez consulter rescan-scsi-bus.sh --help.
sg3_utils, veuillez exécuter yum install sg3_utils.
Problèmes connus avec rescan-scsi-bus.sh
rescan-scsi-bus.sh, veuillez prendre note des problèmes connus suivants :
- Afin que
rescan-scsi-bus.shfonctionne correctement,LUN0devrait être la première unité logique mise en correspondance.rescan-scsi-bus.shpeut uniquement détecter la première unité logique mise en correspondance s'il s'agit deLUN0.rescan-scsi-bus.shne pourra pas scanner d'autre unité logique sans avoir détecté la première unité logique au préalable, même si vous utilisez l'option--nooptscan. - Une condition race requiert que
rescan-scsi-bus.shsoit exécuté deux fois si les unités logiques sont mises en correspondance pour la première fois. Pendant cette première recherche,rescan-scsi-bus.shajoute uniquementLUN0; toutes les autres unités logiques seront ajoutées pendant la seconde recherche. - Un bogue dans le script
rescan-scsi-bus.shexécute incorrectement la fonctionnalité de reconnaissance du changement de taille de l'unité logique lorsque l'option--removeest utilisée. - Le script
rescan-scsi-bus.shne reconnaît pas les suppressions d'unités logiques ISCSI.
Chapitre 39. Modifier le comportement de la perte de lien
39.1. Fibre Channel
dev_loss_tmo de transport, les tentatives d'accès à un périphérique via un lien seront bloquées lorsqu'un problème de transport est détecté. Pour vérifier si un périphérique est bloqué, exécutez la commande suivante :
$ cat /sys/block/device/device/state
blocked (« bloqué ») si le périphérique est bloqué. Si le périphérique fonctionne normalement, alors cette commande retournera running (« en cours d'exécution »).
Procédure 39.1. Déterminer l'état d'un port distant
- Pour déterminer l'état d'un port distant, exécutez la commande suivante :
$ cat /sys/class/fc_remote_port/rport-H:B:R/port_state
- Cette commande retournera
Blocked(« bloqué ») lorsque le port distant ainsi que les périphériques pouvant être atteints par ce biais sont bloqués. Si le port distant fonctionne normalement, la commande retourneraOnline(« en ligne »). - Si le problème n'est pas résolu en
dev_loss_tmosecondes, le port et les périphériques seront débloqués et toutes les E/S exécutées sur ce périphérique (ainsi que toute nouvelle E/S envoyée sur celui-ci) échoueront.
Procédure 39.2. Modifier dev_loss_tmo
- Pour modifier la valeur de
dev_loss_tmo, saisissez avecechola valeur souhaitée dans le fichier. Par exemple, pour définirdev_loss_tmosur 30 secondes, veuillez exécuter :$ echo 30 > /sys/class/fc_remote_port/rport-H:B:R/dev_loss_tmo
dev_loss_tmo, veuillez consulter Section 26.1, « Interface de programmation Fibre Channel ».
dev_loss_tmo, les périphériques scsi_device et sdN sont supprimés. La liaison d'ID SCSI du port cible est enregistrée. Lorsque la cible est retournée, l'adresse SCSI et les assignations sdN peuvent être modifiées. L'adresse SCSI changera si tout changement de la configuration LUN se produit derrière le port cible. Les noms sdN peuvent être modifiés selon les variations du timing pendant le processus de découverte LUN ou en raison d'une modification de la configuration LUN dans le stockage. Ces assignations ne sont pas persistantes comme décrit dans Chapitre 28, Dénomination persistante. Veuillez consulter la section Chapitre 28, Dénomination persistante pour connaître des méthodes alternatives de dénomination de périphérique qui soient persistantes.
39.2. Paramètres iSCSI avec dm-multipath
dm-multipath est implémenté, il est recommandé de paramétrer les minuteurs iSCSI immédiatement pour déférer les commandes sur la couche multipath. Pour configurer ceci, ajoutez la ligne suivante à device { dans /etc/multipath.conf :
features "1 queue_if_no_path"
dm-multipath.
replacement_timeout sont des minuteurs iSCSI disponibles et configurables, dont il est question dans les sections suivantes.
39.2.1. Intervalle/délai d'expiration NOP-Out
dm-multipath est utilisé, la couche SCSI fera échouer les commandes en cours d'exécution et les déferrera sur la couche multipath. Puis, la couche multipath tentera à nouveau ces commandes sur un autre chemin. Si dm-multipath n'est pas en cours d'utilisation, ces commandes seront tentées à nouveau cinq fois avant d'être en échec.
/etc/iscsi/iscsid.conf et modifiez la ligne suivante :
node.conn[0].timeo.noop_out_interval = [valeur de l'intervalle]
/etc/iscsi/iscsid.conf et modifiez la ligne suivante :
node.conn[0].timeo.noop_out_timeout = [timeout value]
SCSI Error Handler
replacement_timeout secondes. Pour obtenir davantage d'informations sur replacement_timeout, veuillez consulter Section 39.2.2, « replacement_timeout ».
# iscsiadm -m session -P 3
39.2.2. replacement_timeout
replacement_timeout contrôle le temps que la couche iSCSI doit attendre pour qu'un chemin ou une session dont le délai a expiré puisse se rétablir avant de faire échouer ses commandes. La valeur par défaut de replacement_timeout s'élève à 120 secondes.
replacement_timeout, ouvrez /etc/iscsi/iscsid.conf et modifiez la ligne suivante :
node.session.timeo.replacement_timeout = [replacement_timeout]
1 queue_if_no_path dans /etc/multipath.conf paramètres les horodateurs iSCSI pour déférer immédiatement les commandes sur la couche multipath (veuillez consulter Section 39.2, « Paramètres iSCSI avec dm-multipath »). Ce paramètre empêche les erreurs d'E/S de se propager à l'application. Par conséquent, vous pouvez définir replacement_timeout sur 15 à 20 secondes.
replacement_timeout plus basse, les E/S sont rapidement envoyées vers un nouveau chemin et exécutées (en cas de dépassement du délai NOP-Out) tandis que la couche iSCSI tente de rétablir le chemin ou la session en échec. Si le délai expire pour tous les chemins, alors la couche du mappeur de périphérique et du multipath mettront les E/S en file d'attente interne, en se basant sur les paramètres du fichier /etc/multipath.conf au lieu de ceux de /etc/iscsi/iscsid.conf.
Important
replacement_timeout dépendra également d'autres facteurs. Ces autres facteurs incluent le réseau, la cible, et la charge de travail du système. Ainsi, il est recommandé de minutieusement tester replacements_timeout avec toute nouvelle configuration avant de l'appliquer sur un système à mission critique.
39.3. Root iSCSI
dm-multipath est implémenté.
/etc/iscsi/iscsid.conf et modifiez-le comme suit :
node.conn[0].timeo.noop_out_interval = 0 node.conn[0].timeo.noop_out_timeout = 0
replacement_timeout doit être élevé. Cela instruira au système d'attendre plus longtemps qu'un chemin ou une session se rétablisse. Pour ajuster replacement_timeout, ouvrez /etc/iscsi/iscsid.conf et modifiez la ligne suivante :
node.session.timeo.replacement_timeout = replacement_timeout
/etc/iscsi/iscsid.conf, vous devriez effectuer une redécouverte du stockage affecté. Cela permettra au système de charger et d'utiliser les valeurs nouvelles dans /etc/iscsi/iscsid.conf. Pour obtenir davantage d'informations sur la manière de découvrir les périphériques iSCSI, veuillez consulter Chapitre 36, Scanner les Cibles iSCSI par des Portails ou LUN multiples.
Configurer des délais d'expiration pour une session particulière
/etc/iscsi/iscsid.conf). Pour effectuer ceci, exécutez la commande suivante (en remplaçant les variables au besoin) :
# iscsiadm -m node -T target_name -p target_IP:port -o update -n node.session.timeo.replacement_timeout -v $timeout_value
Important
dm-multipath), veuillez consulter Section 39.2, « Paramètres iSCSI avec dm-multipath ».
Chapitre 40. Contrôle du Minuteur de Commande SCSI et du Statut de Périphérique
- Annuler la commande.
- Réinitialiser le périphérique.
- Réinitialiser le bus.
- Réninialiser l'hôte.
offline. Dans un tel cas, toutes les E/S de ce périphérique échoueront, jusqu'à ce que le problème soit corrigé et que l'utilisateur définisse le périphérique à running.
rport est bloqué, les pilotes attendent quelques secondes pour que le rport revienne en ligne à nouveau avant d’activer le gestionnaire d’erreurs. Cela empêche les périphériques d'être hors ligne en raison de problèmes de transport temporaires.
Chapitre 41. Résolution de problème de configuration de stockage en ligne
- Le statut de la suppression d'unité logique n'est pas reflétée sur l'hôte.
- Lorsqu'une unité logique est supprimée sur un fichier configuré, le changement ne se reflète pas sur l'hôte. Dans de tels cas, les commandes
lvmseront en suspend indéfiniement quanddm-multipathsera utilisé, car l'unité logique est maintenant caduque.Pour contourner ce problème, effectuez la procédure suivante :Procédure 41.1. Contourner le problème d'unités logiques caduques
- Déterminer les entrées du lien
mpathde/etc/lvm/cache/.cachequi sont spécifiques à l'unité logique caduque. Pour cela, exécutez la commande suivante :$ ls -l /dev/mpath | grep stale-logical-unit
Exemple 41.1. Déterminer les entrées de lien
mpathspécifiquesPar exemple, sistale-logical-unitcorrespond à 3600d0230003414f30000203a7bc41a00, les résultats suivants apparaîtront :lrwxrwxrwx 1 root root 7 Aug 2 10:33 /3600d0230003414f30000203a7bc41a00 -> ../dm-4 lrwxrwxrwx 1 root root 7 Aug 2 10:33 /3600d0230003414f30000203a7bc41a00p1 -> ../dm-5
Cela signifie que 3600d0230003414f30000203a7bc41a00 est mappé à deux liensmpath:dm-4etdm-5. - Puis, ouvrez
/etc/lvm/cache/.cache. Supprimer toutes les lignes contenantstale-logical-unitet les liensmpathauxquelsstale-logical-unitse mappe.Exemple 41.2. Supprimer les lignes qui conviennent
En utilisant l'exemple de l'étape précédente, voici les lignes qu'il vous faudra supprimer :/dev/dm-4 /dev/dm-5 /dev/mapper/3600d0230003414f30000203a7bc41a00 /dev/mapper/3600d0230003414f30000203a7bc41a00p1 /dev/mpath/3600d0230003414f30000203a7bc41a00 /dev/mpath/3600d0230003414f30000203a7bc41a00p1
Annexe A. Historique des versions
| Historique des versions | ||||
|---|---|---|---|---|
| Version 2-64.3 | Thu Oct 13 2016 | |||
| ||||
| Version 2-64.2 | Thu Oct 13 2016 | |||
| ||||
| Version 2-64.1 | Fri Sep 23 2016 | |||
| ||||
| Version 2-64 | Thu May 10 2016 | |||
| ||||
| Version 2-63 | Thu Mar 31 2016 | |||
| ||||
| Version 2-52 | Wed Mar 25 2015 | |||
| ||||
| Version 2-51 | Thu Oct 9 2014 | |||
| ||||
| Version 2-38 | Mon Nov 18 2013 | |||
| ||||
| Version 2-35 | Thu Sep 05 2013 | |||
| ||||
| Version 2-11 | Mon Feb 18 2013 | |||
| ||||
| Version 2-1 | Fri Oct 19 2012 | |||
| ||||
| Version 1-45 | Mon Jun 18 2012 | |||
| ||||