
Red Hat Training
A Red Hat training course is available for Red Hat Enterprise Linux
Guide de gestion de l'alimentation
(Bêta) Gestion de la consommation d'énergie sur Red Hat Enterprise Linux 6
Édition 0.2
Résumé
Chapitre 1. Vue d'ensemble
1.1. Importance de la gestion de l'alimentation
- la réduction de la consommation d'énergie en général dans le but de réduire les coûts
- une réduction de chaleur pour les serveurs et les centres de calcul
- des coûts secondaires réduits, y compris le refroidissement, l'espace, les cables, les générateurs, et les systèmes d'alimentation sans coupure (UPS)
- une augmentation de l'autonomie de la batterie pour les ordinateurs portables
- une baisse de la production de dioxyde de carbone
- conformité avec la réglementation du gouvernement ou avec les exigences légales concernant l'IT verte, par exemple Energy Star
- conformité avec la ligne de conduite de la compagnie sur les nouveaux systèmes
- Q : Est-ce que je dois vraiment optimiser ?
- Q : À quel point devrais-je optimiser ?
- Q : Est-ce que l'optimisation va réduire la performance du système à un niveau inacceptable ?
- Q : Le temps pris et les ressources utilisées pour optimiser le système sont-ils plus importants que les gains à obtenir ?
1.2. Bases de la gestion de l'alimentation
Le noyau de Red Hat Enterprise Linux 5 utilisait un minuteur périodique pour chaque CPU. Ce minuteur empêchait le CPU de réellement devenir inactif en l'obligeant à calculer chaque événement de minuteur (ce qui arrive toutes les quelques millisecondes, en fonction du paramétrage), sans tenir compte de quels processus étaient (ou n'étaient pas) en cours d'exécution. Une grande partie de la gestion de l'alimentation implique la réduction de la fréquence des réveils du CPU.
Ceci est particulièrement vrai pour les périphériques qui possèdent des pièces mobiles (par exemple, des disques durs). De plus, certaines applications peuvent laisser un périphérique qui est activé mais non-utilisé sur un état « ouvert » (de l'anglais, « open ») ; lorsque ceci se produit, le noyau assume que le périphérique est en cours d'utilisation, ce qui peut empêcher le périphérique de se mettre dans un état d'économie d'énergie.
Dans de nombreux cas, ceci dépend d'un matériel moderne et d'une configuration BIOS correcte. Les composants de système plus anciens ne prennent pas en charge certaines des nouvelles fonctionnalités prises en charge dans Red Hat Enterprise Linux 6. Assurez-vous de bien utiliser le microprogramme le plus récent dans vos systèmes et que les fonctionnalités de gestion de l'alimentation dans les sections de gestion de l'alimentation ou de configuration de périphériques sont activées. Ci-dessous figurent quelques unes des fonctionnalités à rechercher :
- SpeedStep
- PowerNow!
- Cool'n'Quiet
- ACPI (C state)
- Smart
Les CPUs modernes ainsi que l'ACPI (de l'anglais, Advanced Configuration and Power Interface) offrent différents états d'alimentation. Les trois différents états sont :
- Veille (C-states)
- Fréquence (P-states)
- Sortie de chaleur (T-states ou "états thermaux")
Aussi évident que cela puisse paraître, la meilleure manière d'économiser de l'énergie est d'éteindre les systèmes. Par exemple, votre compagnie peut développer une culture d'entreprise autour de « l'IT verte » avec une ligne de conduite dans laquelle il vous faudrait éteindre les machines pendant les coupures déjeuner, ou lorsque vous rentrez chez vous. Vous pourriez aussi consolider plusieurs serveurs physique en un grand serveur et les virtualiser à l'aide de la technologie de virtualisation que nous vous fournissons avec Red Hat Enterprise Linux 6.
Chapitre 2. Audit et analyse de la gestion de l'alimentation
2.1. Aperçu des audits et des analyses
2.2. PowerTOP
yum install powertoppowertopincrease the VM dirty writeback time », et la touche (W) sur laquelle appuyer pour accepter la suggestion.
C4 étant plus haut que C3), mieux c'est ; de plus, cela indique aussi que le système est paramétré dans le but d'utiliser le CPU de manière plus efficace. L'idéal étant que le CPU soit à 90% ou plus dans l'état C ou P le plus haut lorsque le système est inactif.
<>), alors les réveils sont souvent associés au pilote spécifique qui les provoque. Paramétrer les pilotes requiert habituellement des modifications du noyau allant au-delà de la portée de ce document. Cependant, les processus de l'espace utilisateur qui envoient des réveils sont plus faciles à gérer. Commencez par identifier si ce service ou cette application doit réellement s'exécuter sur le système ou non. Si non, désactivez-le (ou désactivez-la). Pour désactiver un service de manière permanente, exécutez :
chkconfig nomduservice offps -awux | grep nomducomposantstrace -p idprocessus
increase the VM dirty writeback time, ainsi que la touche (W) sur laquelle appuyer pour accepter la suggestion. Ces changements ne seront actifs que lors du prochain redémarrage. Pour vous aider à rendre ces changements permanents, PowerTOP affiche la commande exacte qu'il utilise pour effectuer cette optimisation. Ajoutez la commande à votre fichier /etc/rc.local à l'aide de votre éditeur de texte préféré afin que ce changement soit effectué à chaque fois que l'ordinateur est démarré.
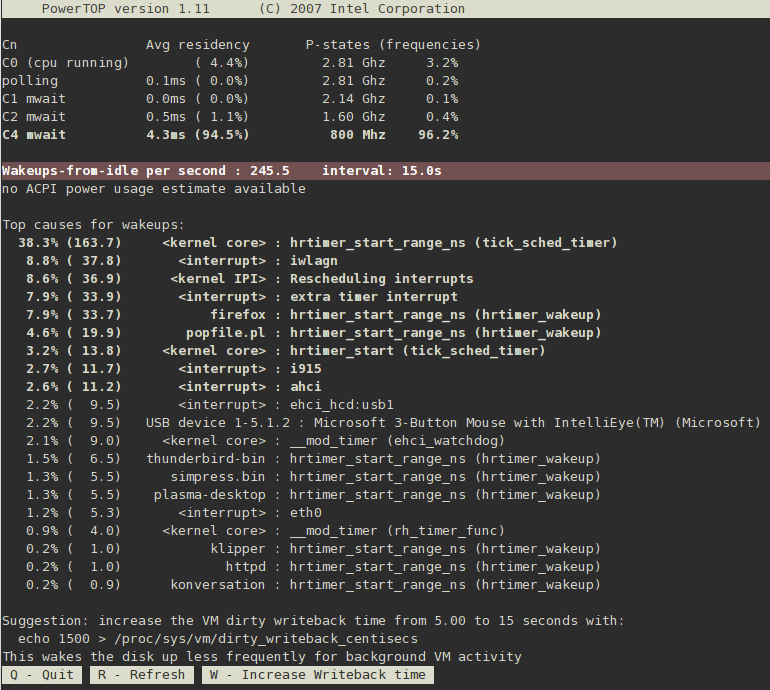
Figure 2.1. Opération de PowerTOP
2.3. Diskdevstat et netdevstat
yum install systemtap tuned-utils kernel-debuginfodiskdevstatnetdevstatdiskdevstat update_interval total_duration display_histogram
netdevstat update_interval total_duration display_histogram
- update_interval
- Le temps en secondes entre les mises à jour de l'affichage. Par défaut :
5 - total_duration
- Le temps en secondes pour la totalité de l'exécution. Par défaut :
86400(1 jour) - display_histogram
- Indiquez s'il faut inclure toutes les données collectées dans l'histogramme à la fin de l'exécution.
PID UID DEV WRITE_CNT WRITE_MIN WRITE_MAX WRITE_AVG READ_CNT READ_MIN READ_MAX READ_AVG COMMAND 2789 2903 sda1 854 0.000 120.000 39.836 0 0.000 0.000 0.000 plasma 15494 0 sda1 0 0.000 0.000 0.000 758 0.000 0.012 0.000 0logwatch 15520 0 sda1 0 0.000 0.000 0.000 140 0.000 0.009 0.000 perl 15549 0 sda1 0 0.000 0.000 0.000 140 0.000 0.009 0.000 perl 15585 0 sda1 0 0.000 0.000 0.000 108 0.001 0.002 0.000 perl 2573 0 sda1 63 0.033 3600.015 515.226 0 0.000 0.000 0.000 auditd 15429 0 sda1 0 0.000 0.000 0.000 62 0.009 0.009 0.000 crond 15379 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 15473 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 15415 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 15433 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 15425 0 sda1 0 0.000 0.000 0.000 62 0.007 0.007 0.000 crond 15375 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 15477 0 sda1 0 0.000 0.000 0.000 62 0.007 0.007 0.000 crond 15469 0 sda1 0 0.000 0.000 0.000 62 0.007 0.007 0.000 crond 15419 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 15481 0 sda1 0 0.000 0.000 0.000 61 0.000 0.001 0.000 crond 15355 0 sda1 0 0.000 0.000 0.000 37 0.000 0.014 0.001 laptop_mode 2153 0 sda1 26 0.003 3600.029 1290.730 0 0.000 0.000 0.000 rsyslogd 15575 0 sda1 0 0.000 0.000 0.000 16 0.000 0.000 0.000 cat 15581 0 sda1 0 0.000 0.000 0.000 12 0.001 0.002 0.000 perl 15582 0 sda1 0 0.000 0.000 0.000 12 0.001 0.002 0.000 perl 15579 0 sda1 0 0.000 0.000 0.000 12 0.000 0.001 0.000 perl 15580 0 sda1 0 0.000 0.000 0.000 12 0.001 0.001 0.000 perl 15354 0 sda1 0 0.000 0.000 0.000 12 0.000 0.170 0.014 sh 15584 0 sda1 0 0.000 0.000 0.000 12 0.001 0.002 0.000 perl 15548 0 sda1 0 0.000 0.000 0.000 12 0.001 0.014 0.001 perl 15577 0 sda1 0 0.000 0.000 0.000 12 0.001 0.003 0.000 perl 15519 0 sda1 0 0.000 0.000 0.000 12 0.001 0.005 0.000 perl 15578 0 sda1 0 0.000 0.000 0.000 12 0.001 0.001 0.000 perl 15583 0 sda1 0 0.000 0.000 0.000 12 0.001 0.001 0.000 perl 15547 0 sda1 0 0.000 0.000 0.000 11 0.000 0.002 0.000 perl 15576 0 sda1 0 0.000 0.000 0.000 11 0.001 0.001 0.000 perl 15518 0 sda1 0 0.000 0.000 0.000 11 0.000 0.001 0.000 perl 15354 0 sda1 0 0.000 0.000 0.000 10 0.053 0.053 0.005 lm_lid.sh
- PID
- l'ID du processus de l'application
- UID
- l'ID utilisateur sous lequel l'application est exécutée
- DEV
- le périphérique sur lequel les E/S ont eu lieu
- WRITE_CNT
- le nombre total des opérations d'écriture
- WRITE_MIN
- le temps le moins long pris pour deux écritures consécutives (en secondes)
- WRITE_MAX
- le temps le plus long pris pour deux écritures consécutives (en secondes)
- WRITE_AVG
- le temps moyen pris pour deux écritures consécutives (en secondes)
- READ_CNT
- le nombre total des opérations de lecture
- READ_MIN
- le temps le moins long pris pour deux lectures consécutives (en secondes)
- READ_MAX
- le temps le plus long pris pour deux lectures consécutives (en secondes)
- READ_AVG
- le temps moyen pris pour deux lectures consécutives (en secondes)
- COMMAND
- le nom du processus
PID UID DEV WRITE_CNT WRITE_MIN WRITE_MAX WRITE_AVG READ_CNT READ_MIN READ_MAX READ_AVG COMMAND 2789 2903 sda1 854 0.000 120.000 39.836 0 0.000 0.000 0.000 plasma 2573 0 sda1 63 0.033 3600.015 515.226 0 0.000 0.000 0.000 auditd 2153 0 sda1 26 0.003 3600.029 1290.730 0 0.000 0.000 0.000 rsyslogd
WRITE_CNT plus important que 0, ce qui veut dire qu'elles ont effectuées quelque sorte d'écriture pendant la mesure. De celles-ci, plasma fut la pire et de loin : cette application a effectuée la plupart des opérations d'écriture, et bien sûr le temps moyen entre les écritures était le plus bas. Plasma serait donc l'application idéale à étudier si vous vous sentiez concerné par les applications inefficaces au niveau de la consommation d'énergie.
strace -p 2789strace contient un schéma se répétant toutes les 45 secondes qui ouvre le fichier cache de l'icône KDE de l'utilisateur pour une écriture, suivi par la fermeture immédiate du fichier. Ceci a nécessairement conduit à une écriture physique sur le disque dur puisque les métadonnées du fichier (plus spécifiquement l'heure de la modification) avaient changées. Le correctif final servait à prévenir ces appels inutiles lorsqu'il n'y avait pas eu de mises à jour des icônes.
2.4. Battery Life Tool Kit
-a.
office écrit un texte, le corrige, et refera la même chose sur une feuille de calcul. L'exécution de BLTK, combinée avec PowerTOP, ou tout autre outil d'audit ou d'analyse, vous permettra de vérifier si l'optimisation que vous avez effectuée aurait un effet lorsque la machine est utilisée au lieu de lorsqu'elle n'est que simplement inactive. Comme vous pouvez exécuter la même charge de travail de multiples fois avec différents paramètres, vous pourrez comparer les résultats de ceux-ci.
yum install bltkbltk workload optionsinactive pendant 120 secondes :
bltk -I -T 120-I,--idle- système est inactif, pour utiliser comme ligne de base pour comparer avec d'autres charges de travail
-R,--reader- simule la lecture de documents (par défaut avec Firefox)
-P,--player- simule la lecture de fichiers multimédia depuis un lecteur CD ou DVD (par défaut avec mplayer)
-O,--office- simule la modification de documents avec la suite bureautique OpenOffice.org
-a,--ac-ignore- ignore si l'alimentation secteur est disponible (nécessaire pour l'utilisation d'ordinateurs de bureau)
-T nombre_de_secondes,--time nombre_de_secondes- le temps (en secondes) pris pour l'exécution du test ; utilisez cette option avec la charge de travail
inactive -F nom_de_fichier,--file nom_de_fichier- spécifie un fichier devant être utilisé par une charge de travail en particulier, par exemple un fichier pour la charge de travail
playerpour lire au lieu d'accéder au lecteur CD ou DVD. -W application,--prog application- spécifie une application devant être utilisée par une charge de travail, par exemple un navigateur autre que Firefox pour la charge de travail
reader
bltk.
/etc/bltk.conf — par défaut, ~/.bltk/workload.results.number/. Par exemple, le répertoire ~/.bltk/reader.results.002/ contient les résultats du troisième test avec la charge de travail reader (le premier test n'est pas numéroté). Les résultats sont éparpillés sur plusieurs fichiers texte. Pour convertir ces résultats dans un format facile à lire, exécutez :
bltk_report chemin_vers_le_répertoire_des_résultatsReport dans le répertoire des résultats. Pour voir les résultats dans un émulateur de terminal, utilisez l'option -o :
bltk_report -o chemin_vers_le_répertoire_des_résultats2.5. Tuned et Ktune
yum install tuned/etc/tuned.conf et active le profil par défaut.
service tuned startchkconfig tuned on-d,--daemon- démarre Tuned comme un démon plutôt que sur l'avant-plan.
-c,--conffile- utilise un fichier de configuration avec le nom et chemin spécifié, par exemple,
--conffile=/etc/tuned2.conf. Le défaut est/etc/tuned.conf. -D,--debug- utilise le plus haut niveau de journalisation.
2.5.1. Le fichier tuned.conf
tuned.conf contient des paramètres de configuration pour tuned. Par défaut, il se trouve sur /etc/tuned.conf, mais vous pouvez spécifier un nom et un emplacement différent en démarrant tuned avec l'option --conffile.
[main] qui définit les paramètres généraux pour tuned. Le fichier contient ensuite une section pour chaque plugin.
[main] contient les options suivantes :
interval- l'intervalle, en secondes, auquel tuned devrait suivre et paramétrer le système. La valeur par défaut est
10. verbose- spécifie si la sortie doit être verbeuse ou non. La valeur par défaut est
False. logging- spécifie la priorité minimum des messages à journaliser. Dans un ordre descendant, les valeurs acceptables sont :
critical,error,warning,info, etdebug. La valeur par défaut estinfo. logging_disable- spécifie la priorité maximum des messages à journaliser, tout message avec cette priorité ou avec une priorité plus basse ne sera pas journalisé. Dans un ordre descendant, les valeurs acceptables sont :
critical,error,warning,info, etdebug. La valeurnotsetdésactive cette option.
[CPUTuning]. Chaque plugin peut posséder ses propres options, mais les options suivantes s'appliquent à tous les plugins :
enabled- spécifie si le plugin est activé ou non. La valeur par défaut est
True. verbose- spécifie si la sortie doit être verbeuse ou non. Si ce n'est pas défini pour ce plugin, la valeur est héritée de
[main]. logging- spécifie la priorité minimum des messages à journaliser. Si ce n'est pas défini pour ce plugin, la valeur est héritée de
[main].
[main] interval=10 pidfile=/var/run/tuned.pid logging=info logging_disable=notset # Disk monitoring section [DiskMonitor] enabled=True logging=debug # Disk tuning section [DiskTuning] enabled=True hdparm=False alpm=False logging=debug # Net monitoring section [NetMonitor] enabled=True logging=debug # Net tuning section [NetTuning] enabled=True logging=debug # CPU monitoring section [CPUMonitor] # Enabled or disable the plugin. Default is True. Any other value # disables it. enabled=True # CPU tuning section [CPUTuning] # Enabled or disable the plugin. Default is True. Any other value # disables it. enabled=True
2.5.2. Tuned-adm
tuned-adm, mais vous pouvez aussi créer, modifier, ou supprimer des profils vous-même.
tuned-adm listtuned-adm activetuned-adm profile nom_du_profiltuned-adm profile server-powersavetuned-adm offdéfaut sera actif. Red Hat Enterprise Linux 6 inclut aussi les profils prédéfinis suivants :
- défaut
- le profil d'économie d'énergie par défaut. Il a l'impact le plus léger sur les économies d'énergie de tous les profils disponibles et n'active que les CPU et plugins disque de tuned.
- desktop-powersave
- un profil d'économie d'énergie pour systèmes de bureau. Active l'économie d'énergie ALPM pour les adaptateurs d'hôtes SATA (reportez-vous à la Section 3.6, « Aggressive Link Power Management ») ainsi que les plugins CPU, Ethernet, et disque de tuned.
- server-powersave
- un profil d'économie d'énergie pour systèmes de serveurs. Active l'économie d'énergie ALPM pour les adaptateurs d'hôtes SATA, désactive les interrogations de CD-ROM avec HAL (reportez-vous à la page man hal-disable-polling, et active les plugins CPU et disque de tuned.
- laptop-ac-powersave
- un profil d'économie d'énergie d'impact moyen pour ordinateurs portables fonctionnant sur batterie. Active l'économie d'énergie ALPM pour les adaptateurs hôte SATA, WiFi, ainsi que pour les plugins CPU, Ethernet, et disque de tuned.
- laptop-battery-powersave
- un profil d'économie d'énergie d'impact fort pour les ordinateurs portables fonctionnant sur batterie. Il active tous les mécanismes d'économie d'énergie des profils précédents, il active aussi le planificateur d'économie d'énergie multicoeurs pour des systèmes avec peu de réveils, vérifie que le gouverneur ondemand est bien en marche, et que l'économie d'énergie audio AC97 est bien activée. Vous pouvez utiliser ce profil pour économiser un maximum d'énergie sur n'importe quel type de système, pas seulement sur des ordinateurs portables en mode batterie. Ce profil est activé au compromis d'un impact remarquable sur la performance, plus particulièrement sur la latence de disque et les E/S réseau.
- throughput-performance
- un profil serveur pour un paramétrage de performance de débit typique. Il désactive les mécanismes d'économie d'énergie tuned et ktune, active les paramètres sysctl qui améliorent la performance de débit de votre disque et des E/S de réseau, et passe au deadline scheduler.
- latency-performance
- un profil serveur pour un paramétrage de performance de la latence typique. Il désactive les mécanismes d'économie d'énergie tuned et ktune, et active les paramètres sysctl qui améliorent la performance de la latence de vos E/S de réseau.
/etc/tune-profiles. Ainsi, /etc/tune-profiles/desktop-powersave contient tous les fichiers et paramètres nécessaires à ce profil. Chacun de ces répertoires peut contenir jusqu'à quatre fichiers :
tuned.conf- la configuration pour que le service tuned soit activé pour ce profil.
sysctl.ktune- les paramètres sysctl utilisés par ktune. Le format est identique au fichier
/etc/sysconfig/sysctl(reportez-vous au pages man sysctl et sysctl.conf). ktune.sysconfig- le fichier de configuration de ktune, habituellement
/etc/sysconfig/ktune. ktune.sh- un script shell de type init utilisé par le service ktune qui peut exécuter des commandes spécifiques lors du démarrage du système pour paramétrer celui-ci.
laptop-battery-powersave contient un riche ensemble de paramètres prêt à utiliser et constitue ainsi un bon point de départ. Copiez simplement la totalité du répertoire sous un nouveau nom de profil comme suit :
cp -a /etc/tune-profiles/laptop-battery-powersave/ /etc/tune-profiles/myprofile# Disable HAL polling of CDROMS # for i in /dev/scd*; do hal-disable-polling --device $i; done > /dev/null 2>&1
2.6. DeviceKit-power et devkit-power
devkit-power et les options suivantes :
--enumerate,-e- affiche un chemin d'objet pour chaque périphérique d'alimentation sur le système, par exemple :
/org/freedesktop/DeviceKit/power/devices/line_power_AC/org/freedesktop/UPower/DeviceKit/power/battery_BAT0 --dump,-d- affiche les paramètres pour tous les périphériques d'alimentation sur le système.
--wakeups,-w- affiche les réveils CPU sur le système.
--monitor,-m- surveille les modifications apportées aux périphériques d'alimentation sur sur le sys. Par exemple, la connexion ou déconnexion de la source d'alimentation secteur, ou l'épuisement d'une batterie. Pressez sur Ctrl+C pour arrêter la surveillance du système.ème
--monitor-detail- surveille les modifications apportées aux périphériques d'alimentation sur le système. Par exemple, la connexion ou déconnexion de la source d'alimentation secteur, ou l'épuisement d'une batterie. L'option
--monitor-detailprésente davantage de détails que l'option--monitor. Pressez sur Ctrl+C pour arrêter la surveillance du système. --show-info chemin_de_l'objet,-i chemin_de_l'objet- affiche toutes les informations disponibles sur un chemin d'objet particulier. Par exemple, pour obtenir des informations sur une batterie de votre système représentée par le chemin d'objet
/org/freedesktop/UPower/DeviceKit/power/battery_BAT0, exécutez :devkit-power -i /org/freedesktop/UPower/DeviceKit/power/battery_BAT0
2.7. Gestionnaire d'alimentation GNOME
- Alimentation secteur
- Alimentation batterie
- Général
2.8. Autres manières d'auditer
- vmstat
- vmstat vous donne des détaillées sur les processus, la mémoire, la pagination, les E/S de bloc, les déroutements, et l'activité du CPU. Utilisez cette commande pour voir de plus près ce que le système fait et où il est occupé.
- iostat
- iostat est similaire à vmstat, mais seulement pour les E/S des périphériques de bloc. Cette commande fournit aussi une sortie et des statistiques plus verbeuses.
- blktrace
- blktrace est un programme de suivi détaillé des E/S de bloc. Il décompose les informations en blocs uniques associés à des applications. Il se révèle très utile en conjonction avec diskdevstat.
Chapitre 3. Infrastructure et mécanique principale
3.1. États inactifs du CPU
- C0
- l'état d'opération, ou d'exécution. Dans cet état, le CPU fonctionne et n'est pas inactif.
- C1, Halt
- un état dans lequel le processeur n'exécute pas d'instructions mais n'est habituellement pas dans un état de basse alimentation. Le CPU peut continuer ses calculs avec pratiquement aucun délai. Tous les processeurs offrant des états C-States doivent pouvoir prendre cet état en charge. Les processeurs Pentium 4 prennent en charge un état C1 amélioré nommé C1E qui est en fait un état de consommation d'électricité moindre.
- C2, Stop-Clock
- un état où l'horloge est gelée pour le processeur, mais qui reste dans son état complet pour ses registres et caches, de manière à ce que les processeurs recommencent leurs calculs dès le démarrage de l'horloge. Il s'agit d'un état optionnel.
- C3, Sleep
- un état où le processeur entre réellement dans un état de sommeil et n'a pas besoin de garder son cache à jour. À cause de ceci, le réveiller de cet état prendra considérablement plus de temps que le réveiller de C2. Une fois de plus, il s'agit ici d'un état optionnel.
3.2. Utilisation des gouverneurs CPUfreq
- Réduction de chaleur pour les serveurs
- Augmentation de l'autonomie de la batterie pour les ordinateurs portables
3.2.1. Types de gouverneurs CPUfreq
Le gouverneur Performance force le CPU à utiliser la plus haute fréquence d'horloge possible. Cette fréquence est statiquement réglée, et ne changera pas. Ainsi, ce gouverneur en particulier n'offre aucune économie d'énergie. Il n'est utile que pour de longues heures de charges de travail intensives, et lorsque le CPU est rarement (ou n'est pas) inactif.
Parcontre, le gouverneur Powersave force le CPU à utiliser la plus basse fréquence d'horloge possible. Cette fréquence est réglée statiquement, et ne changera pas. Ainsi, ce gouverneur en particulier offre une économie d'énergie maximale, mais ceci au prix d'une performance de CPU plus basse.
Le gouverneur Ondemand est un gouverneur dynamique qui permet au CPU d'atteindre une fréquence d'horloge maximalelorsque la charge du système est importante, et d'atteindre une fréquence minimale lorsque le système est inactif. Tandis que ceci permet d'ajuster la consommation d'énergie en fonction de la charge du système, cette opération se produit au détriment de la latence entre les changements de fréquences. Ainsi, la latence peut contrebalancer les bénéfices de performance/d'énergie du gouverneur Ondemand si le système change trop souvent entre inactivité et charges de travail intenses.
Le gouverneur Userspace permet aux programmes de l'espace utilisateur (ou à tout autre processus exécuté en tant que root) de définir la fréquence. Ce gouverneur est normalement utilisé avec le démon cpuspeed. De tous les gouverneurs, Userspace est le plus personnalisable ; et selon sa configuration, il peut fournir le meilleur équilibre entre performance et consommation pour votre système.
Tout comme le gouverneur Ondemand, le gouverneur Conservative ajuste aussi la fréquence de l'horloge en fonction de l'utilisation (comme le gouverneur Ondemand). Cependant, tandis que gouverneur le fait d'une manière plus aggressive (du maximum au minimum, et vice-versa), le gouverneur Conservative change de fréquence de manière plus graduelle.
Note
cron. Ceci vous permettra de définir automatiquement des gouverneurs particuliers à des moments spécifique de la journée. Ainsi, vous pouvez spécifier un gouverneur de basse latence pendant les périodes d'inactivité (par exemple hors des heures de travail traditionnelles), puis retourner à un gouverneur de fréquence plus importante durant les heures de charges de travail plus importantes.
3.2.2. Installation de CPUfreq
Procédure 3.1. Comment ajouter un pilote CPUfreq
- Utilisez la commande suivante pour voir quels pilotes CPUfreq sont disponibles pour votre système :
ls /lib/modules/[version du noyau]/kernel/arch/[architecture]/kernel/cpu/cpufreq/ - Utilisez
modprobeafin d'ajouter le pilote CPUfreq approprié.modprobe [pilote CPUfreq]Lors de l'utilisation de la commande ci-dessus, assurez-vous de bien supprimer le suffixe de nom de fichier.ko.Important
Lors de la sélection d'un pilote CPUfreq approprié, choisissez toujoursacpi-cpufreqplutôt quep4-clockmod. Alors que l'utilisation du pilotep4-clockmodréduit la fréquence d'horloge d'un CPU, il ne réduit pas son voltage. D'un autre côté,acpi-cpufreq, réduit le voltage ainsi que la fréquence d'horloge du CPU, permettant une moindre consommation d'énergie et sortie de chaleur pour chaque réduction d'unité en performance. - Une fois que le pilote CPUfreq est installé, vous pourrez voir quel gouverneur le système utilise avec :
cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor
cat /sys/devices/system/cpu/[ID du cpu]/cpufreq/scaling_available_governorsmodprobe pour ajouter les modules de noyau nécessaires pour activer le gouverneur CPUfreq que vous souhaitez utiliser en particulier. Ces modules de noyau sont disponibles dans /lib/modules/[version du noyau]/kernel/drivers/cpufreq/.
Procédure 3.2. Activer un gouverneur CPUfreq
- Si un gouverneur spécifique n'est pas disponible pour votre CPU, utilisez
modprobepour activer le gouverneur que vous souhaitez utiliser. Par exemple, si le gouverneurondemandn'est pas disponible pour votre CPU, utilisez la commande suivante :modprobe cpufreq_ondemand - Une fois qu'un gouverneur est listé comme disponible pour votre CPU, vous pourrez l'activer à l'aide de :
echo [governor] > /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor
3.2.3. Paramétrer la politique CPUfreq et la vitesse
/sys/devices/system/cpu/[ID du cpu]/cpufreq/. Ces paramètres sont :
cpuinfo_min_freq— Affiche la fréquence minimale de fonctionnement disponible du CPU (en KHz).cpuinfo_max_freq— Affiche la fréquence maximale de fonctionnement disponible du CPU (en KHz).scaling_driver— Affiche quel pilote de CPUfreq est utilisé pour paramétrer la fréquence sur ce CPU.scaling_available_governors— Affiche les gouverneurs CPUfreq disponibles dans ce noyau. Si vous souhaitez utiliser un gouverneur CPUfreq qui n'est pas listé dans ce fichier, reportez-vous à la Procédure 3.2, « Activer un gouverneur CPUfreq » in Section 3.2.2, « Installation de CPUfreq » pour obtenir des instructions.scaling_governor— Affiche quel gouverneur CPUfreq est actuellement en cours d'utilisation. Pour utiliser un différent gouverneur, utilisez simplementecho [gouverneur] > /sys/devices/system/cpu/[ID du cpu]/cpufreq/scaling_governor(reportez-vous à la Procédure 3.2, « Activer un gouverneur CPUfreq » dans la Section 3.2.2, « Installation de CPUfreq » pour obtenir plus d'informations).cpuinfo_cur_freq— Affiche la vitesse actuelle du CPU (en KHz).scaling_available_frequencies— Liste les fréquences disponible pour le CPU, en KHz.scaling_min_freqetscaling_max_freq— Définissent les limites de la politique du CPU, en KHz.affected_cpus— Liste les CPUs qui requièrent un logiciel de coordination de fréquence.scaling_setspeed— Utilisé pour modifier la vitesse d'horloge du processeur, en KHz. Vous pouvez uniquement définir une vitesse dans les limites imposées par la politique du processeur (c'est-à-dire parscaling_min_freqetscaling_max_freq).
cat [paramètre]. Par exemple, pour voir la vitesse actuelle de cpu0 (en KHz), utilisez :
cat /sys/devices/system/cpu/cpu0/cpufreq/cpuinfo_cur_freq.
echo [valeur] > /sys/devices/system/cpu/[ID du cpu]/cpufreq/[paramètre]. Par exemple, pour régler la vitesse d'horloge de processeur minimum de cpu0 sur 360 KHz, utilisez :
echo 360000 > /sys/devices/system/cpu/cpu0/cpufreq/scaling_min_freq
3.3. Suspension et reprise
3.4. Noyau Tickless
3.5. Gestion de l'alimentation en état actif
- default
- établit les états d'alimentation du lien PCIe en fnctions des valeurs par défaut spécifiées par le microprogramme du système (par exemple, BIOS). Ceci est l'état par défaut d'ASPM.
- powersave
- règle ASPM de manière à économiser de l'énergie à chaque occasion, sans tenir compte de la performance en résultant.
- performance
- désactive ASPM afin de permettre aux liens PCIe d'opérer avec une performance maximale.
/sys/module/pcie_aspm/parameters/policy, mais elles peuvent aussi être spécifiées lors du démarrage avec le paramètre de noyau pcie_aspm, où pcie_aspm=off désactive ASPM et pcie_aspm=force active ASPM, même sur les périphériques ne prenant pas ASPM en charge.
Avertissement
pcie_aspm=force est défini, le matériel qui ne prend pas en charge ASPM peut provoquer une cessation de réponse du système. Avant de définir pcie_aspm=force, assurez-vous que tout le matériel PCIe sur le système prend ASPM en charge.
3.6. Aggressive Link Power Management
Ce mode définit le lien sur son état le plus bas (SLUMBER) lorsqu'il n'y a pas d'E/S sur le disque. Ce mode est utile lorsque de longues périodes d'inactivité sont à prévoir.
Ce mode définit le lien sur le second état le plus bas (PARTIAL) lorsqu'il n'y a pas d'E/S sur le disque. Ce mode est conçu afin de permettre des transitions entre états d'alimentation (par exemple lorsqu'il y a des alternances entre une utilisation intense d'E/S et une période d'inactivité d'E/S) tout en limitant au maximum l'impact sur la performance.
medium_power permet au lien de faire la transition entre les états PARTIAL et alimentation complète (c'est-à-dire "ACTIVE"), et ce en fonction de la charge. Remarquez qu'il n'est pas possible d'établir une transition de lien directement de PARTIAL à SLUMBER (et vice-versa) ; dans ce cas, les états d'alimentation ne peuvent pas passer de l'un à l'autre sans transiter par l'état ACTIVE au préalable.
ALPM est désactivé, le lien ne peut pas entrer dans un état de faible alimentation lorsqu'il n'y a pas d'E/S sur le disque.
/sys/class/scsi_host/host*/link_power_management_policy existe. Pour changer les paramètres, écrivez simplement les valeurs décrites dans cette section sur ces fichiers, ou affichez les fichiers pour vérifier le paramètre actuel.
3.7. Optimisation d'accès au disque Relatime
atime, et la maintenir requiert une constante série d'opérations d'écriture sur le stockage. Ces écritures gardent les périphériques de stockage et leurs liens occupés et allumés. Comme peu d'applications utilisent les données atime, l'activité de ce périphérique de stockage gaspille de l'énergie. De plus, l'écriture sur le stockage se produirait même si le fichier n'était pas lu à partir du stockage, mais à partir du cache. Depuis quelques temps, le noyau Linux prend en charge une option noatime pour mount et n'écrirait pas de données atime sur les systèmes de fichiers montés avec cette option. Cependant, l'arrêt de cette fonctionnalité est problématique car certaines applications reposent sur les données atime, et elles échoueront si ces données ne sont pas disponibles.
relatime. Relatime effectue la maintenance de atime, mais pas à chaque fois qu'on accède à un fichier. Avec l'activation de cette option, les données atime sont écrites sur le disque seulement si le fichier a été modifié depuis que la dernière fois que les données atime ont été mises à jour (mtime), ou si le dernier accès au fichier a eu lieu depuis plus d'un certain temps (par défaut, un jour).
relatime activé. Pour supprimer cette fonctionnalité sur un système entier, utilisez le paramètre de démarrage default_relatime=0. Si relatime est activé sur un système par défaut, vous pouvez le supprimer sur n'importe quel système de fichiers en particulier en montant ce système de fichiers avec l'option norelatime. Finalement, pour changer le délai à partir duquel le système devra mettre à jour les données atime d'un fichier, utilisez le paramètre relatime_interval=, en spécifiant la période en secondes. La valeur par défaut est 86400.
3.8. Limitation de la consommation
Le Dynamic Power Capping est une fonctionnalité disponible sur les serveurs sélectionnés ProLiant et BladeSystem, elle permet aux administrateurs systèmes de limiter la consommation de l'alimentation d'un serveur ou d'un groupe de serveurs. Cette limitation est un limite définitive que le serveur ne pourra pas dépasser, peu importe sa charge de travail. Celle-ci n'aura aucun effet jusqu'à ce que le serveur n'atteigne la limite de consommation. À ce moment, un processeur de gestion ajustera les états P (ou P-states) du CPU, et la limitation d'horloge afin de limiter l'énergie consommée.
/dev/hpilo/dXccbN. Le noyau inclut aussi une extension de l'interface hwmon sysfs pour prendre en charge les fonctionnalités de limitation de la consommation, ainsi qu'un pilote hwmon pour mesureurs d'alimentation ACPI 4.0 qui utilisent l'interface sysfs. Ensemble, ces fonctionnalités permettent au système d'exploitation et aux outils de l'espace utilisateur de lire la valeur configurée pour la limitation de consommation, ainsi que la consommation actuelle du système.
Le gestionnaire de noeuds Intel impose une limitation de la consommation aux systèmes, à l'aide du processeur des états P et T (T-states et P-states) pour limiter la performance du CPU et par conséquent la consommation de l'alimentation. En définissant une politique de gestion de l'alimentation, les administrateurs peuvent configurer les systèmes afin qu'ils utilisent moins d'énergie lorsque les charges du système sont basses, par exemple pendant la nuit ou les week-ends.
3.9. Gestion améliorée de l'alimentation des graphismes
La signalisation différentielle à basse tension (de l'anglais, low-voltage differential signalling, ou LVDS) est un système transportant des signaux électroniques sur des fils de cuivre. Une application importante de ce système est la transmission d'informations de pixels sur les écrans LCD (de l'anglais, liquid crystal display) d'ordinateurs portables. Tous les affichages possèdent des fréquences de rafraîchissement — la fréquence à laquelle ils reçoivent des nouvelles données depuis un contrôleur graphique et redessinent l'image à l'écran. Habituellement, l'écran reçoit de nouvelles données soixante fois par seconde (une fréquence de 60 Hz). Lorsqu'un écran et un contrôleur graphique sont liés par LVDS, le système LVDS utilise de l'énergie à chaque cycle de rafraîchissement. En période d'inactivité, la fréquence de rafraîchissement de nombreux écrans LCD peut descendre jusqu'à 30 Hz sans que cela ne puisse particulièrement se remarquer (contrairement aux moniteurs à tube cathodique (ou CRT), pour lesquels la baisse de la fréquence de rafraîchissement produit un scintillement distinct). Le pilote des adaptateurs graphiques Intel, qui est intégré dans le noyau utilisé dans Red Hat Enterprise Linux 6 effectue cette baisse d'horloge automatiquement, et permet d'économiser environ 0.5 W lorsque l'écran est inactif.
La mémoire vive dynamique synchrone (ou SDRAM) — comme celle utilisée pour la mémoire vidéo dans les adaptateurs graphiques — est rechargée des milliers de fois par seconde de manière à ce que les cellules de mémoire individuelles puissent retenir les données stockées en elles. À part sa fonction principale de gestion de données circulant vers et hors de la mémoire, le contrôleur de mémoire est habituellement responsable de l'initiation de ces cycles de rafraîchissement. Toutefois, SDRAM possède aussi un mode de rafraîchissement de basse consommation. Dans ce mode, la mémoire utilise un compteur interne pour générer ses propres cycles de rafraîchissement, permettant ainsi au système de fermer le contrôleur de mémoire sans pour mettre en danger les données présentes en mémoire. Le noyau utilisé dans Red Hat Enterprise Linux 6 peut ainsi déclencher le rafraîchissement automatique de la mémoire avec les adaptateurs graphiques d'Intel lorsqu'ils sont inactifs, ce qui permet déconomiser autour de 0,8 W.
Les GPUs (de l'anglais, graphical processing units) typiques contiennent des horloges internes gouvernant différentes parties de leur circuiterie interne. Le noyau utilisé dans Red Hat Enterprise Linux 6 peut réduire la fréquence de certaines horloges internes des GPUs d'Intel et d'ATI. La réduction du nombre de cycles effectués par les composants GPU sur un temps donné permet d'économiser de l'énergie qu'ils auraient consommé lors de cycles qu'ils n'avaient pas à effectuer. Le noyau réduit automatiquement la vitesse de ces horloges lorsque le GPU est inactif, et l'augmente lorsque l'activité de celui-ci augmente. La réduction des cycles d'horloge des GPUs peut vous économiser jusqu'à 5 W.
Les pilotes graphiques Intel et ATI dans Red Hat Enterprise Linux 6 peuvent détecter lorsqu'aucun moniteur n'est attaché à un adaptateur et éteint ainsi complètement le GPU. Cette fonctionnalité est particulièrement significative pour les serveurs ne possédant pas de moniteur de manière régulière.
3.10. RFKill
/dev/rfkill, qui contient l'état actuel de tous les transmetteurs radio sur le système. Chaque périphérique possède son propre état RFKill enregistré dans sysfs. De plus, RFKill fournit des uevents pour chaque changement d'état dans un périphérique pour lequel RFKill est activé.
rfkill list pour obtenir une liste des périphériques, chacun d'entre eux aura un numéro d'index qui lui est associé, commençant par 0. Vous pourrez utiliser ce numéro d'index pour dire à rfkill de bloquer ou débloquer un service, par exemple :
rfkill block 0rfkill block wifirfkill block allrfkill unblock au lieu de rfkill block. Pour obtenir la liste complète des catégories de périphériques que rfkill peut bloquer, exécutez rfkill help
3.11. Optimisations dans l'espace utilisateur
Red Hat Enterprise Linux 6 utilise un noyau tickless (ou sans « tic », reportez-vous à la Section 3.4, « Noyau Tickless »), qui permet aux CPUs de rester plus longtemps dans des états inactifs plus profonds. Cependant, le timer tick (ou compteur de « tics ») n'est pas la seule source de réveils CPU excessifs, et les appels de fonctions des applications peuvent aussi empêcher les CPUs d'entrer ou de rester en état inactif. Les appels de fonctions non-nécessaires ont été réduits dans plus de 50 applications.
Les entrées ou sorties (E/S) de périphériques de stockage et d'interfaces réseau forcent les périphériques à consommer de l'électricité. Pour les périphériques de stockages et réseau qui proposent des états d'alimentation réduits lorsqu'ils sont inactifs (par exemple, ALPM ou ASPM), ce trafic peut empêcher le périphérique d'entrer ou de rester dans un état inactif, et peut ainsi empêcher les disques durs de réduire leur vitesse de rotation lorsqu'ils ne sont pas utilisés. Les demandes excessives et non-nécessaires sur le stockage ont été minimisées dans certaines applications. En particulier, les demandes qui empêchaient les disques durs de réduire leur vitesse de rotation.
Les services qui démarrent automatiquement qu'ils soient requis de le faire ou non, présentent une perte des ressources du système potentielle. Ces services devraient plutôt être par défaut « off » (éteints) ou « on demand » (à la demande) dans la mesure du possible. Par exemple, le service BlueZ, qui active la prise en charge Bluetooth, se mettait auparavant automatiquement en route, dès lors que le système était allumé ; et ce, que du matériel Bluetooth soit présent ou non. L'initscript BlueZ vérifie maintenant que du matériel Bluetooth est présent sur le système avant de lancer ce service.
Chapitre 4. Cas d'utilisation
4.1. Exemple — Serveur
Un serveur web nécessite un réseau et une E/S de disque. Selon la vitesse de connexion extérieure, 100 Mo/s peut suffire. Si la machin sert principalement à des pages statiques, la performance du CPU peut ne pas être très importante. Ainsi, les choix de gestion de l'alimentation qui s'offrent à vous incluent :
- aucun plugin de réseau ou de disque pour tuned.
- ALPM en marche.
- Gouverneur
ondemanden marche. - carte réseau limitée à 100 Mo/s.
Un serveur de calcul nécessite principalement des CPU. Les choix de gestion de l'alimentation s'offrant à vous incluent :
- des plugins de réseau ou de disque pour tuned selon les tâches et l'endroit où sont stockées les données ; ou pour des systèmes en mode batch, tuned est totalement actif.
- selon l'utilisation, le gouverneur
performance.
Un serveur mail nécessite principalement des E/S de disque et des CPU. Les choix de gestion de l'alimentation s'offrant à vous incluent :
- Le gouverneur
ondemandactivé, car les derniers pourcentages de la performance du CPU ne sont pas importants. - aucun plugin de réseau ou de disque pour tuned.
- la vitesse du réseau ne devrait pas être limitée, car les mails sont souvent internes et peuvent ainsi bénéficier d'un lien de 1 Go/s ou de 10 Go/s.
Les prérequis d'un serveur de fichiers sont similaires à ceux d'un serveur mail, mais selon le protocole utilisé, celui-ci peut nécessiter une meilleure performance CPU. Typiquement, les serveurs basés sur Samba requièrent davantage de CPU que NFS, et NFS en requiert plus que iSCSI. Même ainsi, vous devriez être en mesure d'utiliser le gouverneur ondemand.
Typiquement, un serveur d'annuaire requiert moins d'E/S de disque, particulièrement si il est équipé de suffisamment de RAM. La latence du réseau est importante, les E/S de réseau le sont moins. Prenez en considération le paramétrage de la latence du réseau à une vitesse de lien moindre, mais testez soigneusement ceci pour le réseau en question.
4.2. Exemple — Ordinateur portable
- La configuration du BIOS du système afin de désactiver tout le matériel que vous n'utilisez pas. Par exemple, les ports parallèles ou sériels, lecteurs de cartes, webcams, WiFi, Bluetooth, etc.
- Atténuez l'affichage dans des environnements plus sombres, lorsque vous n'avez pas besoin d'un éclairage maximum pour lire l'écran de manière confortable. Utilisez + → sur le bureau GNOME, +++ → sur le bureau KDE ; ou gnome-power-manager ou xbacklight dans la ligne de commande ; ou utilisez les touches de fonction sur votre ordinateur portable.
- Utilisez le profil
laptop-battery-powersavede tuned-adm pour activer un ensemble de mécanismes d'économie d'énergie. Remarquez qu'il y aura un impact sur la performance et la latence du disque dur et de l'interface réseau.
- utilisez le gouverneur
ondemand(par défaut activé dans Red Hat Enterprise Linux 6) - activez le mode ordinateur portable (faisant partie du profil
laptop-battery-powersave) :echo 5 > /proc/sys/vm/laptop_mode - augmente le délai de vidage sur disque (fait partie du profil
laptop-battery-powersave) :echo 1500 > /proc/sys/vm/dirty_writeback_centisecs - désactive le watchdog nmi (fait partie du profil
laptop-battery-powersave) :echo 0 > /proc/sys/kernel/nmi_watchdog - active l'économie d'énergie AC97 (activé par défaut dans Red Hat Enterprise Linux 6) :
echo Y > /sys/module/snd_ac97_codec/parameters/power_save - active l'économie d'énergie multicoeur (fait partie du profil
laptop-battery-powersave) :echo Y > /sys/module/snd_ac97_codec/parameters/power_save - active l'auto-suspension USB :
for i in /sys/bus/usb/devices/*/power/autosuspend; do echo 1 > $i; doneRemarquez que l'auto-suspension USB ne fonctionne pas correctement avec tous les périphériques USB. - active le paramètre d'alimentation minimum pour ALPM (fait partie du profil
laptop-battery-powersave) :echo min_power > /sys/class/scsi_host/host*/link_power_management_policy - monte un système de fichiers à l'aide de relatime (par défaut dans Red Hat Enterprise Linux 6) :
mount -o remount,relatime point_de_montage - active le meilleur mode d'économie d'énergie pour les disques durs (fait partie du profil
laptop-battery-powersave) :hdparm -B 1 -S 200 /dev/sd* - désactive les interrogations de CD-ROM (fait partie du profil
laptop-battery-powersave) :hal-disable-polling --device /dev/scd* - réduit la luminosité de l'écran à
50ou moins, par exemple :xbacklight -set 50 - active DPMS pour écran inactif :
xset +dpms; xset dpms 0 0 300 - réduit les niveaux de puissance Wi-Fi (fait partie du profil
laptop-battery-powersave) :for i in /sys/bus/pci/devices/*/power_level ; do echo 5 > $i ; done - désactive le Wi-Fi :
echo 1 > /sys/bus/pci/devices/*/rf_kill - limite le réseau cablé à 100 Mo/s (fait partie du profil
laptop-battery-powersave) :ethtool -s eth0 advertise 0x0F
Annexe A. Astuces pour les développeurs
- l'utilisation de threads.
- les réveils CPU inutiles et l'utilisation incorrecte des réveils. Si vous devez effectuer un réveil, faites-le en une seule fois et aussi vite que possible (en anglais, « race to idle »).
- l'utilisation de
[f]sync()sans que cela ne soit nécessaire. - les interrogations actives inutiles, ou l'utilisation de délais d'attente réguliers et de courtes durées. (Au lieu de cela, il vaut mieux réagir aux événements)
- une utilisation des réveils inefficace.
- un accès disque inefficace. Utilisez des mémoires-tampons de grande taille pour éviter un accès au disque trop fréquent. N'écrivez qu'un grand bloc à la fois.
- une utilisation inefficace des minuteurs. Groupez les minuteurs sur plusieurs applications (ou même sur plusieurs systèmes) si possible.
- des E/S, ou une consommation d'énergie ou utilisation de mémoire excessive (y compris les fuites mémoires)
- l'exécution de calculs inutiles.
A.1. Utilisation de threads
Python utilise le verrou global, Global Lock Interpreter[1], ainsi le threading n'est utile que pour de grandes opérations d'E/S. Unladen-swallow [2] est une implémentation plus rapide de Python avec laquelle vous serez probablement en mesure d'optimiser votre code.
À l'origine, les threads Perl furent créés pour des applications exécutées sur des systèmes sans bifurcation (de l'anglais, forking) (comme sur les systèmes avec système d'exploitation 32-bit 32-bit). Dans les threads Perl, les données sont copiées pour chaque thread (copie sur écriture). Par défaut, les données ne sont pas partagées, car les utilisateurs devraient pouvoir être en mesure de définir le niveau de partage des données. Pour le partage de données, le module threads::shared doit être inclut.Cependant, les données ne sont pas seulement copiées (copie sur écriture), mais le module crée aussi des variables attachées pour ces données, ce qui prendra encore plus de temps et sera encore plus lent. [3]Windows
Les threads C partagent la même mémoire, chaque thread possède sa propre pile, et le noyau n'a pas à créer de nouveaux descripteurs de fichiers ou à allouer de nouvel espace mémoire. C peut réellement utiliser la prise en charge de plus de CPUs pour plus de threads, Ainsi, vous pouvez utiliser un langage de bas niveau tel que C ou C++ afin de maximiser la performance de vos threads. Si vous utilisez un langage de script, prenez en considération un binding avec C. Utilisez des profileurs afin d'identifier les parties de votre code performant mal. [4]
A.2. Réveils
int fd;
fd = inotify_init();
int wd;
/* checking modification of a file - writing into */
wd = inotify_add_watch(fd, "./myConfig", IN_MODIFY);
if (wd < 0) {
inotify_cant_be_used();
switching_back_to_previous_checking();
}
...
fd_set rdfs;
struct timeval tv;
int retval;
FD_ZERO(&rdfs);
FD_SET(0, &rdfs);
tv.tv_sec = 5;
value = select(1, &rdfs, NULL, NULL, &tv);
if (value == -1)
perror(select);
else {
do_some_stuff();
}
.../proc/sys/fs/inotify/max_user_watches et même s'il peut être changé, ceci n'est pas recommandé. De plus, au cas où inotify échouerait, le code devra utiliser une différente méthode de vérification, ce qui devrait signifier qu'il y aura de nombreuses occurrences de #if #define dans le code source.
A.3. Fsync
Fsync est connu pour être une opération d'E/S coûteuse, mais ce n'est pas totalement vrai. Par exemple, reportez-vous à l'article de Theodore Ts'o Don't fear the fsync! [5] et à la discussion l'accompagnant.
fsync et à cause des paramètres du système de fichiers (principalement ext3 avec le mode data-ordered), il y avait une longue latence lorsque rien ne se passait. Ceci pouvait ainsi prendre longtemps (jusqu'à 30 secondes) si un autre processus copiait un fichier de grande taille au même moment.
fsync n'était pas du tout utilisé, des problèmes sont survenus lors du basculement vers les systèmes de fichiers ext4. Ext3 était réglé sur le mode data-ordered, qui vide la mémoire toutes les quelques secondes et l'enregistre sur le disque. Avec ext4 et laptop_mode, l'intervalle entre les enregistrements était plus long et les données pouvaient être perdues lorsque le système était éteint de manière inattendue. Il existe maintenant un patch pour ext4, mais il faut tout de même prendre en considération le design de nos applications avec prudence, et utiliser fsync de manière appropriée.
/* open and read configuration file e.g. ~/.kde/myconfig */
fd = open("./kde/myconfig", O_WRONLY|O_TRUNC|O_CREAT);
read(myconfig);
...
write(fd, bufferOfNewData, sizeof(bufferOfNewData));
close(fd);open("/.kde/myconfig", O_WRONLY|O_TRUNC|O_CREAT);
read(myconfig);
...
fd = open("/.kde/myconfig.suffix", O_WRONLY|O_TRUNC|O_CREAT);
write(fd, bufferOfNewData, sizeof(bufferOfNewData));
fsync; /* paranoia - optional */
...
close(fd);
rename("/.kde/myconfig", "/.kde/myconfig~"); /* paranoia - optional */
rename("/.kde/myconfig.suffix", "/.kde/myconfig");Annexe B. Historique des révisions
| Historique des versions | ||||||
|---|---|---|---|---|---|---|
| Version 0.2-12.400 | 2013-10-31 | |||||
| ||||||
| Version 0.2-12 | 2012-07-18 | |||||
| ||||||
| Version 0.2-19 | Tue Jul 20 2010 | |||||
| ||||||
| Version 0.2-18 | Fri Jul 16 2010 | |||||
| ||||||
| Version 0.2-17 | Thu Jul 8 2010 | |||||
| ||||||
| Version 0.2-16 | Thu Jul 8 2010 | |||||
| ||||||
| Version 0.2-15 | Wed Jun 30 2010 | |||||
| ||||||
| Version 0.2-14 | Tue Mar 15 2010 | |||||
| ||||||
| Version 0.2-13 | Mon Mar 15 2010 | |||||
| ||||||
| Version 0.2-12 | Mon Mar 15 2010 | |||||
| ||||||
| Version 0.2-11 | Mon Mar 15 2010 | |||||
| ||||||
| Version 0.2-10 | Mon Mar 15 2010 | |||||
| ||||||
| Version 0.2-9 | Mon Mar 15 2010 | |||||
| ||||||
| Version 0.2-8 | Mon Mar 15 2010 | |||||
| ||||||
| Version 0.2-7 | Sun Mar 14 2010 | |||||
| ||||||
| Version 0.2-6 | Sun Mar 14 2010 | |||||
| ||||||
| Version 0.2-5 | Sun Mar 14 2010 | |||||
| ||||||
| Version 0.2-4 | Sat Mar 13 2010 | |||||
| ||||||
| Version 0.2-3 | Sat Mar 13 2010 | |||||
| ||||||
| Version 0.2-2 | Tue Mar 9 2010 | |||||
| ||||||
| Version 0.2-1 | Mon Mar 8 2010 | |||||
| ||||||
| Version 0.2-0 | Thu Dec 17 2009 | |||||
| ||||||
| Version 0.1-0 | Tue Sep 23 2008 | |||||
| ||||||