
Sécurité et conformité
Apprendre et gérer la sécurité pour OpenShift Container Platform
Résumé
Chapitre 1. Sécurité et conformité de la plateforme OpenShift Container
1.1. Aperçu de la sécurité
Il est important de comprendre comment sécuriser correctement les différents aspects de votre cluster OpenShift Container Platform.
Sécurité des conteneurs
Un bon point de départ pour comprendre la sécurité d'OpenShift Container Platform est de revoir les concepts de la section Comprendre la sécurité des conteneurs. Cette section et les suivantes fournissent un aperçu de haut niveau des mesures de sécurité des conteneurs disponibles dans OpenShift Container Platform, y compris les solutions pour la couche hôte, la couche de conteneur et d'orchestration, et la couche de construction et d'application. Ces sections comprennent également des informations sur les sujets suivants :
- Pourquoi la sécurité des conteneurs est importante et comment elle se compare aux normes de sécurité existantes.
- Quelles mesures de sécurité des conteneurs sont fournies par la couche hôte (RHCOS et RHEL) et lesquelles sont fournies par OpenShift Container Platform.
- Comment évaluer le contenu de vos conteneurs et les sources de vulnérabilité.
- Comment concevoir votre processus de construction et de déploiement pour vérifier de manière proactive le contenu des conteneurs.
- Comment contrôler l'accès aux conteneurs par l'authentification et l'autorisation.
- Comment le réseau et le stockage attaché sont sécurisés dans OpenShift Container Platform.
- Solutions conteneurisées pour la gestion des API et le SSO.
Audit
L'audit d'OpenShift Container Platform fournit un ensemble chronologique d'enregistrements pertinents pour la sécurité, documentant la séquence des activités qui ont affecté le système par des utilisateurs individuels, des administrateurs ou d'autres composants du système. Les administrateurs peuvent configurer la politique des journaux d'audit et visualiser les journaux d'audit.
Certificats
Les certificats sont utilisés par divers composants pour valider l'accès au cluster. Les administrateurs peuvent remplacer le certificat d'entrée par défaut, ajouter des certificats de serveur API ou ajouter un certificat de service.
Vous pouvez également consulter plus de détails sur les types de certificats utilisés par le cluster :
- Certificats fournis par l'utilisateur pour le serveur API
- Certificats de procuration
- Certificats d'AC de service
- Certificats de nœuds
- Certificats Bootstrap
- certificats etcd
- Certificats OLM
- Certificats agrégés pour les clients de l'API
- Certificats d'opérateur de configuration de machine
- Certificats fournis par l'utilisateur pour l'entrée par défaut
- Certificats d'ingérence
- Surveillance et journalisation des clusters Certificats des composants de l'opérateur
- Certificats du plan de contrôle
Cryptage des données
Vous pouvez activer le chiffrement etcd pour votre cluster afin de fournir une couche supplémentaire de sécurité des données. Par exemple, cela peut aider à protéger la perte de données sensibles si une sauvegarde etcd est exposée à des parties incorrectes.
Analyse de la vulnérabilité
Les administrateurs peuvent utiliser Red Hat Quay Container Security Operator pour exécuter des analyses de vulnérabilité et examiner les informations sur les vulnérabilités détectées.
1.2. Aperçu de la conformité
Pour de nombreux clients d'OpenShift Container Platform, la préparation réglementaire, ou la conformité, est requise à un certain niveau avant que tout système puisse être mis en production. Cette préparation réglementaire peut être imposée par des normes nationales, des normes industrielles ou le cadre de gouvernance d'entreprise de l'organisation.
Contrôle de conformité
Les administrateurs peuvent utiliser l'opérateur de conformité pour effectuer des analyses de conformité et recommander des remédiations pour tout problème détecté. Le pluginoc-compliance est un plugin OpenShift CLI (oc) qui fournit un ensemble d'utilitaires pour interagir facilement avec l'Opérateur de Conformité.
Contrôle de l'intégrité des fichiers
Les administrateurs peuvent utiliser l'opérateur d'intégrité des fichiers pour exécuter en permanence des contrôles d'intégrité des fichiers sur les nœuds de la grappe et fournir un journal des fichiers qui ont été modifiés.
1.3. Ressources supplémentaires
Chapitre 2. Sécurité des conteneurs
2.1. Comprendre la sécurité des conteneurs
La sécurisation d'une application conteneurisée repose sur plusieurs niveaux de sécurité :
La sécurité des conteneurs commence par une image de conteneur de base fiable et se poursuit tout au long du processus de construction du conteneur, à mesure qu'il se déplace dans votre pipeline CI/CD.
ImportantPar défaut, les flux d'images ne sont pas mis à jour automatiquement. Ce comportement par défaut peut créer un problème de sécurité car les mises à jour de sécurité des images référencées par un flux d'images ne se produisent pas automatiquement. Pour plus d'informations sur la manière de remplacer ce comportement par défaut, voir Configuration de l'importation périodique des imagestreamtags.
- Lorsqu'un conteneur est déployé, sa sécurité dépend de son fonctionnement sur des systèmes d'exploitation et des réseaux sécurisés, et de l'établissement de frontières solides entre le conteneur lui-même et les utilisateurs et hôtes qui interagissent avec lui.
- Le maintien de la sécurité dépend de la capacité à analyser les images des conteneurs pour détecter les vulnérabilités et à disposer d'un moyen efficace de corriger et de remplacer les images vulnérables.
Au-delà de ce qu'une plateforme telle qu'OpenShift Container Platform offre, votre organisation aura probablement ses propres exigences en matière de sécurité. Un certain niveau de vérification de la conformité pourrait être nécessaire avant même d'introduire OpenShift Container Platform dans votre centre de données.
De même, vous devrez peut-être ajouter vos propres agents, des pilotes matériels spécialisés ou des fonctions de chiffrement à OpenShift Container Platform, avant qu'elle ne puisse répondre aux normes de sécurité de votre organisation.
Ce guide fournit un aperçu de haut niveau des mesures de sécurité des conteneurs disponibles dans OpenShift Container Platform, y compris des solutions pour la couche hôte, la couche conteneur et orchestration, et la couche de construction et d'application. Il vous oriente ensuite vers la documentation spécifique d'OpenShift Container Platform pour vous aider à mettre en œuvre ces mesures de sécurité.
Ce guide contient les informations suivantes :
- Pourquoi la sécurité des conteneurs est importante et comment elle se compare aux normes de sécurité existantes.
- Quelles mesures de sécurité des conteneurs sont fournies par la couche hôte (RHCOS et RHEL) et lesquelles sont fournies par OpenShift Container Platform.
- Comment évaluer le contenu de vos conteneurs et les sources de vulnérabilité.
- Comment concevoir votre processus de construction et de déploiement pour vérifier de manière proactive le contenu des conteneurs.
- Comment contrôler l'accès aux conteneurs par l'authentification et l'autorisation.
- Comment le réseau et le stockage attaché sont sécurisés dans OpenShift Container Platform.
- Solutions conteneurisées pour la gestion des API et le SSO.
L'objectif de ce guide est de comprendre les avantages incroyables en matière de sécurité de l'utilisation d'OpenShift Container Platform pour vos charges de travail conteneurisées et comment l'ensemble de l'écosystème Red Hat joue un rôle dans la sécurisation et le maintien des conteneurs. Il vous aidera également à comprendre comment vous pouvez vous engager avec OpenShift Container Platform pour atteindre les objectifs de sécurité de votre organisation.
2.1.1. Qu'est-ce qu'un conteneur ?
Les conteneurs regroupent une application et toutes ses dépendances dans une image unique qui peut passer du développement au test, puis à la production, sans changement. Un conteneur peut faire partie d'une application plus vaste qui travaille en étroite collaboration avec d'autres conteneurs.
Les conteneurs assurent la cohérence entre les environnements et les cibles de déploiement multiples : serveurs physiques, machines virtuelles (VM) et nuages privés ou publics.
Voici quelques-uns des avantages de l'utilisation de conteneurs :
| Infrastructure | Applications |
|---|---|
| Processus d'application en bac à sable sur un noyau partagé du système d'exploitation Linux | Paqueter mon application et toutes ses dépendances |
| Plus simple, plus léger et plus dense que les machines virtuelles | Déployer dans n'importe quel environnement en quelques secondes et activer CI/CD |
| Portable dans différents environnements | Accéder facilement aux composants conteneurisés et les partager |
Pour en savoir plus sur les conteneurs Linux, consultez la section Comprendre les conteneurs Linux du portail client Red Hat. Pour en savoir plus sur les outils de conteneur RHEL, voir Construire, exécuter et gérer des conteneurs dans la documentation produit RHEL.
2.1.2. Qu'est-ce que OpenShift Container Platform ?
L'automatisation du déploiement, de l'exécution et de la gestion des applications conteneurisées est le travail d'une plateforme telle qu'OpenShift Container Platform. À la base, OpenShift Container Platform s'appuie sur le projet Kubernetes pour fournir le moteur d'orchestration des conteneurs sur de nombreux nœuds dans des centres de données évolutifs.
Kubernetes est un projet qui peut fonctionner avec différents systèmes d'exploitation et des composants complémentaires qui n'offrent aucune garantie de prise en charge par le projet. Par conséquent, la sécurité des différentes plateformes Kubernetes peut varier.
OpenShift Container Platform est conçu pour verrouiller la sécurité de Kubernetes et intégrer la plateforme avec une variété de composants étendus. Pour ce faire, OpenShift Container Platform s'appuie sur le vaste écosystème Red Hat de technologies open source qui comprend les systèmes d'exploitation, l'authentification, le stockage, la mise en réseau, les outils de développement, les images de conteneurs de base et de nombreux autres composants.
OpenShift Container Platform peut tirer parti de l'expérience de Red Hat dans la découverte et le déploiement rapide de correctifs pour les vulnérabilités dans la plateforme elle-même ainsi que dans les applications conteneurisées fonctionnant sur la plateforme. L'expérience de Red Hat s'étend également à l'intégration efficace de nouveaux composants à OpenShift Container Platform au fur et à mesure de leur disponibilité et à l'adaptation des technologies aux besoins individuels des clients.
Ressources supplémentaires
2.2. Comprendre la sécurité des hôtes et des machines virtuelles
Les conteneurs et les machines virtuelles permettent de séparer les applications exécutées sur un hôte du système d'exploitation lui-même. Comprendre RHCOS, qui est le système d'exploitation utilisé par OpenShift Container Platform, vous aidera à voir comment les systèmes hôtes protègent les conteneurs et les hôtes les uns des autres.
2.2.1. Sécuriser les conteneurs sur Red Hat Enterprise Linux CoreOS (RHCOS)
Les conteneurs simplifient le déploiement de nombreuses applications sur le même hôte, en utilisant le même noyau et le même moteur d'exécution pour chaque conteneur. Les applications peuvent appartenir à de nombreux utilisateurs et, parce qu'elles sont séparées, elles peuvent fonctionner simultanément avec des versions différentes, voire incompatibles, de ces applications sans aucun problème.
Dans Linux, les conteneurs ne sont qu'un type spécial de processus, de sorte que la sécurisation des conteneurs est similaire à bien des égards à la sécurisation de n'importe quel autre processus en cours d'exécution. Un environnement pour l'exécution de conteneurs commence par un système d'exploitation capable de sécuriser le noyau de l'hôte vis-à-vis des conteneurs et des autres processus s'exécutant sur l'hôte, ainsi que de sécuriser les conteneurs les uns vis-à-vis des autres.
Étant donné qu'OpenShift Container Platform 4.12 fonctionne sur des hôtes RHCOS, avec la possibilité d'utiliser Red Hat Enterprise Linux (RHEL) comme nœuds de travail, les concepts suivants s'appliquent par défaut à tout cluster OpenShift Container Platform déployé. Ces fonctionnalités de sécurité RHEL sont au cœur de ce qui rend l'exécution de conteneurs dans OpenShift Container Platform plus sûre :
- Linux namespaces les conteneurs permettent de créer une abstraction d'une ressource système globale particulière afin qu'elle apparaisse comme une instance distincte pour les processus au sein d'un espace de noms. Par conséquent, plusieurs conteneurs peuvent utiliser simultanément la même ressource informatique sans créer de conflit. Les espaces de noms des conteneurs qui sont séparés de l'hôte par défaut comprennent la table de montage, la table de processus, l'interface réseau, l'utilisateur, le groupe de contrôle, l'UTS et les espaces de noms IPC. Les conteneurs qui ont besoin d'un accès direct aux espaces de noms de l'hôte doivent disposer d'autorisations élevées pour demander cet accès. Voir Overview of Containers in Red Hat Systems dans la documentation sur les conteneurs de RHEL 8 pour plus de détails sur les types d'espaces de noms.
- SELinux fournit une couche de sécurité supplémentaire pour isoler les conteneurs les uns des autres et de l'hôte. SELinux permet aux administrateurs d'appliquer des contrôles d'accès obligatoires (MAC) pour chaque utilisateur, application, processus et fichier.
Disabling SELinux on RHCOS is not supported.
- CGroups (groupes de contrôle) limitent, comptabilisent et isolent l'utilisation des ressources (CPU, mémoire, E/S disque, réseau, etc.) d'un ensemble de processus. Les groupes de contrôle sont utilisés pour s'assurer que les conteneurs situés sur le même hôte ne sont pas affectés les uns par les autres.
- Secure computing mode (seccomp) peuvent être associés à un conteneur pour restreindre les appels système disponibles. Voir la page 94 du OpenShift Security Guide pour plus de détails sur seccomp.
- Le déploiement de conteneurs à l'aide de RHCOS réduit la surface d'attaque en minimisant l'environnement hôte et en l'adaptant aux conteneurs. Le moteur de conteneurs CRI-O réduit encore cette surface d'attaque en implémentant uniquement les fonctionnalités requises par Kubernetes et OpenShift Container Platform pour exécuter et gérer les conteneurs, contrairement à d'autres moteurs de conteneurs qui implémentent des fonctionnalités autonomes orientées vers le poste de travail.
RHCOS est une version de Red Hat Enterprise Linux (RHEL) spécialement configurée pour fonctionner en tant que plan de contrôle (maître) et nœuds de travail sur les clusters OpenShift Container Platform. RHCOS est donc réglé pour exécuter efficacement les charges de travail de conteneurs, ainsi que les services Kubernetes et OpenShift Container Platform.
Pour mieux protéger les systèmes RHCOS dans les clusters OpenShift Container Platform, la plupart des conteneurs, à l'exception de ceux qui gèrent ou surveillent le système hôte lui-même, doivent s'exécuter en tant qu'utilisateur non root. L'abaissement du niveau de privilège ou la création de conteneurs avec le moins de privilèges possible est la meilleure pratique recommandée pour protéger vos propres clusters OpenShift Container Platform.
Ressources supplémentaires
- Comment les nœuds appliquent les contraintes de ressources
- Gestion des contraintes liées au contexte de sécurité
- Plateformes prises en charge pour les clusters OpenShift
- Requirements for a cluster with user-provisioned infrastructure
- Choix de la configuration de RHCOS
- Allumage
- Arguments du noyau
- Modules du noyau
- Cryptographie FIPS
- Cryptage des disques
- Service de l'heure chronologique
- À propos du service de mise à jour OpenShift
2.2.2. Comparaison entre la virtualisation et les conteneurs
La virtualisation traditionnelle offre un autre moyen de séparer les environnements d'application sur le même hôte physique. Cependant, les machines virtuelles fonctionnent différemment des conteneurs. La virtualisation repose sur un hyperviseur qui fait tourner des machines virtuelles invitées (VM), chacune d'entre elles ayant son propre système d'exploitation (OS), représenté par un noyau en cours d'exécution, ainsi que l'application en cours d'exécution et ses dépendances.
Avec les VM, l'hyperviseur isole les invités les uns des autres et du noyau hôte. Moins de personnes et de processus ont accès à l'hyperviseur, ce qui réduit la surface d'attaque sur le serveur physique. Cela dit, la sécurité doit toujours être surveillée : une VM invitée pourrait être en mesure d'utiliser les bogues de l'hyperviseur pour accéder à une autre VM ou au noyau hôte. Et lorsque le système d'exploitation doit être corrigé, il doit l'être sur toutes les machines virtuelles invitées qui l'utilisent.
Les conteneurs peuvent être exécutés à l'intérieur de machines virtuelles invitées, et il peut y avoir des cas d'utilisation où cela est souhaitable. Par exemple, vous pouvez déployer une application traditionnelle dans un conteneur, peut-être pour transférer une application dans le nuage.
La séparation des conteneurs sur un seul hôte offre toutefois une solution de déploiement plus légère, plus flexible et plus facile à mettre à l'échelle. Ce modèle de déploiement est particulièrement adapté aux applications "cloud-native". Les conteneurs sont généralement beaucoup plus petits que les VM et consomment moins de mémoire et de CPU.
Voir Linux Containers Compared to KVM Virtualization dans la documentation sur les conteneurs de RHEL 7 pour en savoir plus sur les différences entre les conteneurs et les machines virtuelles.
2.2.3. Sécuriser OpenShift Container Platform
Lorsque vous déployez OpenShift Container Platform, vous avez le choix entre une infrastructure fournie par l'installateur (il existe plusieurs plateformes disponibles) et votre propre infrastructure fournie par l'utilisateur. Certaines configurations de bas niveau liées à la sécurité, telles que l'activation de la conformité FIPS ou l'ajout de modules de noyau requis au premier démarrage, peuvent bénéficier d'une infrastructure fournie par l'utilisateur. De même, l'infrastructure fournie par l'utilisateur est appropriée pour les déploiements déconnectés d'OpenShift Container Platform.
Gardez à l'esprit que, lorsqu'il s'agit d'apporter des améliorations de sécurité et d'autres changements de configuration à OpenShift Container Platform, les objectifs doivent inclure :
- Garder les nœuds sous-jacents aussi génériques que possible. Vous voulez pouvoir facilement jeter et faire tourner des nœuds similaires rapidement et de manière prescriptive.
- Gérer autant que possible les modifications apportées aux nœuds par l'intermédiaire d'OpenShift Container Platform, plutôt que d'apporter des modifications directes et ponctuelles aux nœuds.
Pour atteindre ces objectifs, la plupart des modifications de nœuds doivent être effectuées lors de l'installation par Ignition ou ultérieurement à l'aide de MachineConfigs qui sont appliquées à des ensembles de nœuds par l'opérateur de configuration de la machine. Voici quelques exemples de modifications de configuration liées à la sécurité que vous pouvez effectuer de cette manière :
- Ajouter des arguments au noyau
- Ajouter des modules au noyau
- Prise en charge de la cryptographie FIPS
- Configuration du cryptage des disques
- Configuration du service chronologique
En plus de l'opérateur de configuration des machines, il existe plusieurs autres opérateurs disponibles pour configurer l'infrastructure d'OpenShift Container Platform qui sont gérés par l'opérateur de version de cluster (CVO). Le CVO est capable d'automatiser de nombreux aspects des mises à jour des clusters d'OpenShift Container Platform.
2.3. Durcissement du RHCOS
RHCOS a été créé et optimisé pour être déployé dans OpenShift Container Platform avec peu ou pas de changements nécessaires sur les nœuds RHCOS. Chaque organisation qui adopte OpenShift Container Platform a ses propres exigences en matière de renforcement du système. En tant que système RHEL auquel ont été ajoutées des modifications et des fonctionnalités spécifiques à OpenShift (telles que Ignition, ostree et un site /usr en lecture seule pour assurer une immutabilité limitée), RHCOS peut être renforcé comme n'importe quel système RHEL. La différence réside dans la manière dont vous gérez le durcissement.
L'une des principales caractéristiques d'OpenShift Container Platform et de son moteur Kubernetes est de pouvoir faire évoluer rapidement les applications et l'infrastructure à la hausse et à la baisse, selon les besoins. À moins que cela ne soit inévitable, vous ne voulez pas apporter de modifications directes à RHCOS en vous connectant à un hôte et en ajoutant des logiciels ou en modifiant des paramètres. Vous souhaitez que l'installateur et le plan de contrôle d'OpenShift Container Platform gèrent les modifications apportées au RHCOS afin que de nouveaux nœuds puissent être mis en service sans intervention manuelle.
Ainsi, si vous souhaitez renforcer les nœuds RHCOS dans OpenShift Container Platform pour répondre à vos besoins en matière de sécurité, vous devez prendre en compte à la fois les éléments à renforcer et la manière de procéder à ce renforcement.
2.3.1. Choisir ce qu'il faut durcir dans le RHCOS
Le guide de renforcement de la sécurité de RHEL 8 décrit la manière dont vous devez aborder la sécurité pour tout système RHEL.
Ce guide vous explique comment aborder la cryptographie, évaluer les vulnérabilités et les menaces qui pèsent sur différents services. De même, vous apprendrez à analyser les normes de conformité, à vérifier l'intégrité des fichiers, à effectuer des audits et à chiffrer les périphériques de stockage.
Si vous savez quelles caractéristiques vous souhaitez renforcer, vous pouvez alors décider de la manière de les renforcer dans le RHCOS.
2.3.2. Choix du durcissement du RHCOS
La modification directe des systèmes RHCOS dans OpenShift Container Platform est déconseillée. Il faut plutôt penser à modifier les systèmes dans des pools de nœuds, tels que les nœuds de travail et les nœuds de plan de contrôle. Lorsqu'un nouveau nœud est nécessaire, dans les installations non bare metal, vous pouvez demander un nouveau nœud du type que vous souhaitez et il sera créé à partir d'une image RHCOS plus les modifications que vous avez créées précédemment.
Il est possible de modifier RHCOS avant l'installation, pendant l'installation et une fois que le cluster est opérationnel.
2.3.2.1. Durcissement avant installation
Pour les installations bare metal, vous pouvez ajouter des fonctionnalités de renforcement à RHCOS avant de commencer l'installation d'OpenShift Container Platform. Par exemple, vous pouvez ajouter des options de noyau lorsque vous démarrez le programme d'installation de RHCOS pour activer ou désactiver des fonctions de sécurité, telles que divers booléens SELinux ou des paramètres de bas niveau, tels que le multithreading symétrique.
La désactivation de SELinux sur les nœuds RHCOS n'est pas prise en charge.
Bien que les installations RHCOS bare metal soient plus difficiles, elles offrent la possibilité de mettre en place des modifications du système d'exploitation avant de commencer l'installation d'OpenShift Container Platform. Cela peut s'avérer important lorsque vous devez vous assurer que certaines fonctionnalités, telles que le chiffrement des disques ou des paramètres réseau spéciaux, sont configurées le plus tôt possible.
2.3.2.2. Durcissement pendant l'installation
Vous pouvez interrompre le processus d'installation d'OpenShift Container Platform et modifier les configs Ignition. Grâce aux configs Ignition, vous pouvez ajouter vos propres fichiers et services systemd aux nœuds RHCOS. Vous pouvez également apporter des modifications de base liées à la sécurité au fichier install-config.yaml utilisé pour l'installation. Le contenu ajouté de cette manière est disponible au premier démarrage de chaque nœud.
2.3.2.3. Durcissement après le démarrage du cluster
Une fois que le cluster OpenShift Container Platform est opérationnel, il y a plusieurs façons d'appliquer des fonctionnalités de durcissement au RHCOS :
-
Daemon set : Si vous avez besoin qu'un service s'exécute sur chaque nœud, vous pouvez l'ajouter à l'aide d'un objet Kubernetes
DaemonSet. -
Machine config :
MachineConfigobjets contiennent un sous-ensemble de configurations Ignition dans le même format. En appliquant les configurations de machine à tous les nœuds de travailleur ou de plan de contrôle, vous pouvez vous assurer que le prochain nœud du même type qui est ajouté au cluster bénéficie des mêmes modifications.
Toutes les fonctionnalités mentionnées ici sont décrites dans la documentation du produit OpenShift Container Platform.
Ressources supplémentaires
- Guide de sécurité OpenShift
- Choix de la configuration de RHCOS
- Modification des nœuds
- Création manuelle du fichier de configuration de l'installation
- Création du manifeste Kubernetes et des fichiers de configuration Ignition
- Installation de RHCOS à l'aide d'une image ISO
- Personnalisation des nœuds
- Ajouter des arguments de noyau aux nœuds
-
Paramètres de configuration de l'installation - voir
fips - Support for FIPS cryptography
- Composants cryptographiques du noyau RHEL
2.4. Signatures d'images de conteneurs
Red Hat fournit des signatures pour les images dans les registres de conteneurs Red Hat. Ces signatures peuvent être automatiquement vérifiées lors de leur transfert vers les clusters d'OpenShift Container Platform 4 à l'aide de l'opérateur de configuration de machine (MCO).
Quay.io sert la plupart des images qui composent OpenShift Container Platform, et seule l'image release est signée. Les images release font référence aux images approuvées d'OpenShift Container Platform, ce qui offre un certain degré de protection contre les attaques de la chaîne d'approvisionnement. Cependant, certaines extensions d'OpenShift Container Platform, telles que la journalisation, la surveillance et le maillage de services, sont livrées en tant qu'opérateurs à partir de l'Operator Lifecycle Manager (OLM). Ces images sont livrées à partir du registre d'images de conteneurs Red Hat Ecosystem Catalog.
Pour vérifier l'intégrité de ces images entre les registres Red Hat et votre infrastructure, activez la vérification des signatures.
2.4.1. Activation de la vérification des signatures pour les registres de conteneurs Red Hat
L'activation de la validation des signatures de conteneurs pour les registres de conteneurs Red Hat nécessite l'écriture d'un fichier de politique de vérification des signatures spécifiant les clés pour vérifier les images à partir de ces registres. Pour les nœuds RHEL8, les registres sont déjà définis par défaut dans /etc/containers/registries.d.
Procédure
Créer un fichier de configuration Butane,
51-worker-rh-registry-trust.bu, contenant la configuration nécessaire pour les nœuds de travail.NoteSee "Creating machine configs with Butane" for information about Butane.
variant: openshift version: 4.12.0 metadata: name: 51-worker-rh-registry-trust labels: machineconfiguration.openshift.io/role: worker storage: files: - path: /etc/containers/policy.json mode: 0644 overwrite: true contents: inline: | { "default": [ { "type": "insecureAcceptAnything" } ], "transports": { "docker": { "registry.access.redhat.com": [ { "type": "signedBy", "keyType": "GPGKeys", "keyPath": "/etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release" } ], "registry.redhat.io": [ { "type": "signedBy", "keyType": "GPGKeys", "keyPath": "/etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release" } ] }, "docker-daemon": { "": [ { "type": "insecureAcceptAnything" } ] } } }Utiliser Butane pour générer un fichier YAML de configuration de la machine,
51-worker-rh-registry-trust.yaml, contenant le fichier à écrire sur le disque des nœuds de travail :$ butane 51-worker-rh-registry-trust.bu -o 51-worker-rh-registry-trust.yaml
Appliquer la configuration de la machine créée :
$ oc apply -f 51-worker-rh-registry-trust.yaml
Vérifier que le pool de configuration de la machine de travail a été déployé avec la nouvelle configuration de la machine :
Vérifiez que la nouvelle configuration de la machine a été créée :
$ oc get mc
Exemple de sortie
NAME GENERATEDBYCONTROLLER IGNITIONVERSION AGE 00-master a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 25m 00-worker a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 25m 01-master-container-runtime a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 25m 01-master-kubelet a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 25m 01-worker-container-runtime a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 25m 01-worker-kubelet a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 25m 51-master-rh-registry-trust 3.2.0 13s 51-worker-rh-registry-trust 3.2.0 53s 1 99-master-generated-crio-seccomp-use-default 3.2.0 25m 99-master-generated-registries a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 25m 99-master-ssh 3.2.0 28m 99-worker-generated-crio-seccomp-use-default 3.2.0 25m 99-worker-generated-registries a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 25m 99-worker-ssh 3.2.0 28m rendered-master-af1e7ff78da0a9c851bab4be2777773b a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 8s rendered-master-cd51fd0c47e91812bfef2765c52ec7e6 a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 24m rendered-worker-2b52f75684fbc711bd1652dd86fd0b82 a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 24m rendered-worker-be3b3bce4f4aa52a62902304bac9da3c a2178ad522c49ee330b0033bb5cb5ea132060b0a 3.2.0 48s 2
Vérifier que le pool de configuration de la machine travailleuse est mis à jour avec la nouvelle configuration de la machine :
$ oc get mcp
Exemple de sortie
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-af1e7ff78da0a9c851bab4be2777773b True False False 3 3 3 0 30m worker rendered-worker-be3b3bce4f4aa52a62902304bac9da3c False True False 3 0 0 0 30m 1- 1
- Lorsque le champ
UPDATINGestTrue, le pool de configuration de la machine est mis à jour avec la nouvelle configuration de la machine. Lorsque le champ devientFalse, le pool de configuration de la machine du travailleur est passé à la nouvelle configuration de la machine.
Si votre cluster utilise des nœuds de travail RHEL7, lorsque le pool de configuration de la machine de travail est mis à jour, créez des fichiers YAML sur ces nœuds dans le répertoire
/etc/containers/registries.d, qui spécifient l'emplacement des signatures détachées pour un serveur de registre donné. L'exemple suivant ne fonctionne que pour les images hébergées dansregistry.access.redhat.cometregistry.redhat.io.Démarrez une session de débogage sur chaque nœud de travail RHEL7 :
oc debug node/<node_name>
Changez votre répertoire racine en
/host:sh-4.2# chroot /host
Créez un fichier
/etc/containers/registries.d/registry.redhat.io.yamlcontenant les éléments suivants :docker: registry.redhat.io: sigstore: https://registry.redhat.io/containers/sigstoreCréez un fichier
/etc/containers/registries.d/registry.access.redhat.com.yamlcontenant les éléments suivants :docker: registry.access.redhat.com: sigstore: https://access.redhat.com/webassets/docker/content/sigstore- Quitter la session de débogage.
2.4.2. Vérification de la configuration de la vérification de la signature
Après avoir appliqué les configurations de machine au cluster, le Machine Config Controller détecte le nouvel objet MachineConfig et génère une nouvelle version de rendered-worker-<hash>.
Conditions préalables
- Vous avez activé la vérification des signatures en utilisant un fichier de configuration de la machine.
Procédure
Sur la ligne de commande, exécutez la commande suivante pour afficher des informations sur un travailleur donné :
$ oc describe machineconfigpool/worker
Exemple de résultat de la surveillance initiale des travailleurs
Name: worker Namespace: Labels: machineconfiguration.openshift.io/mco-built-in= Annotations: <none> API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfigPool Metadata: Creation Timestamp: 2019-12-19T02:02:12Z Generation: 3 Resource Version: 16229 Self Link: /apis/machineconfiguration.openshift.io/v1/machineconfigpools/worker UID: 92697796-2203-11ea-b48c-fa163e3940e5 Spec: Configuration: Name: rendered-worker-f6819366eb455a401c42f8d96ab25c02 Source: API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 00-worker API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 01-worker-container-runtime API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 01-worker-kubelet API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 51-worker-rh-registry-trust API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 99-worker-92697796-2203-11ea-b48c-fa163e3940e5-registries API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 99-worker-ssh Machine Config Selector: Match Labels: machineconfiguration.openshift.io/role: worker Node Selector: Match Labels: node-role.kubernetes.io/worker: Paused: false Status: Conditions: Last Transition Time: 2019-12-19T02:03:27Z Message: Reason: Status: False Type: RenderDegraded Last Transition Time: 2019-12-19T02:03:43Z Message: Reason: Status: False Type: NodeDegraded Last Transition Time: 2019-12-19T02:03:43Z Message: Reason: Status: False Type: Degraded Last Transition Time: 2019-12-19T02:28:23Z Message: Reason: Status: False Type: Updated Last Transition Time: 2019-12-19T02:28:23Z Message: All nodes are updating to rendered-worker-f6819366eb455a401c42f8d96ab25c02 Reason: Status: True Type: Updating Configuration: Name: rendered-worker-d9b3f4ffcfd65c30dcf591a0e8cf9b2e Source: API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 00-worker API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 01-worker-container-runtime API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 01-worker-kubelet API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 99-worker-92697796-2203-11ea-b48c-fa163e3940e5-registries API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 99-worker-ssh Degraded Machine Count: 0 Machine Count: 1 Observed Generation: 3 Ready Machine Count: 0 Unavailable Machine Count: 1 Updated Machine Count: 0 Events: <none>Exécutez à nouveau la commande
oc describe:$ oc describe machineconfigpool/worker
Exemple de sortie après la mise à jour du travailleur
... Last Transition Time: 2019-12-19T04:53:09Z Message: All nodes are updated with rendered-worker-f6819366eb455a401c42f8d96ab25c02 Reason: Status: True Type: Updated Last Transition Time: 2019-12-19T04:53:09Z Message: Reason: Status: False Type: Updating Configuration: Name: rendered-worker-f6819366eb455a401c42f8d96ab25c02 Source: API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 00-worker API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 01-worker-container-runtime API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 01-worker-kubelet API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 51-worker-rh-registry-trust API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 99-worker-92697796-2203-11ea-b48c-fa163e3940e5-registries API Version: machineconfiguration.openshift.io/v1 Kind: MachineConfig Name: 99-worker-ssh Degraded Machine Count: 0 Machine Count: 3 Observed Generation: 4 Ready Machine Count: 3 Unavailable Machine Count: 0 Updated Machine Count: 3 ...NoteLe paramètre
Observed Generationindique un nombre accru basé sur la génération de la configuration produite par le contrôleur. Ce contrôleur met à jour cette valeur même s'il ne parvient pas à traiter la spécification et à générer une révision. La valeurConfiguration Sourcerenvoie à la configuration51-worker-rh-registry-trust.Confirmez l'existence du fichier
policy.jsonà l'aide de la commande suivante :$ oc debug node/<node> -- chroot /host cat /etc/containers/policy.json
Exemple de sortie
Starting pod/<node>-debug ... To use host binaries, run `chroot /host` { "default": [ { "type": "insecureAcceptAnything" } ], "transports": { "docker": { "registry.access.redhat.com": [ { "type": "signedBy", "keyType": "GPGKeys", "keyPath": "/etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release" } ], "registry.redhat.io": [ { "type": "signedBy", "keyType": "GPGKeys", "keyPath": "/etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release" } ] }, "docker-daemon": { "": [ { "type": "insecureAcceptAnything" } ] } } }Confirmez l'existence du fichier
registry.redhat.io.yamlà l'aide de la commande suivante :$ oc debug node/<node> -- chroot /host cat /etc/containers/registries.d/registry.redhat.io.yaml
Exemple de sortie
Starting pod/<node>-debug ... To use host binaries, run `chroot /host` docker: registry.redhat.io: sigstore: https://registry.redhat.io/containers/sigstoreConfirmez l'existence du fichier
registry.access.redhat.com.yamlà l'aide de la commande suivante :$ oc debug node/<node> -- chroot /host cat /etc/containers/registries.d/registry.access.redhat.com.yaml
Exemple de sortie
Starting pod/<node>-debug ... To use host binaries, run `chroot /host` docker: registry.access.redhat.com: sigstore: https://access.redhat.com/webassets/docker/content/sigstore
2.4.3. Ressources supplémentaires
2.5. Comprendre la conformité
Pour de nombreux clients d'OpenShift Container Platform, la préparation réglementaire, ou la conformité, est requise à un certain niveau avant que tout système puisse être mis en production. Cette préparation réglementaire peut être imposée par des normes nationales, des normes industrielles ou le cadre de gouvernance d'entreprise de l'organisation.
2.5.1. Comprendre la conformité et la gestion des risques
La conformité FIPS est l'un des éléments les plus critiques requis dans les environnements hautement sécurisés, afin de garantir que seules les technologies cryptographiques prises en charge sont autorisées sur les nœuds.
The use of FIPS Validated / Modules in Process cryptographic libraries is only supported on OpenShift Container Platform deployments on the x86_64 architecture.
Pour comprendre le point de vue de Red Hat sur les cadres de conformité d'OpenShift Container Platform, reportez-vous au chapitre Gestion des risques et préparation aux réglementations du livre-guide sur la sécurité d'OpenShift.
Ressources supplémentaires
2.6. Sécuriser le contenu des conteneurs
Pour garantir la sécurité du contenu de vos conteneurs, vous devez commencer par des images de base fiables, telles que les Red Hat Universal Base Images, et ajouter des logiciels fiables. Pour vérifier la sécurité continue de vos images de conteneurs, il existe des outils Red Hat et des outils tiers pour analyser les images.
2.6.1. Sécurisation à l'intérieur du conteneur
Les applications et les infrastructures sont composées d'éléments facilement disponibles, dont beaucoup sont des logiciels libres tels que le système d'exploitation Linux, JBoss Web Server, PostgreSQL et Node.js.
Des versions conteneurisées de ces paquets sont également disponibles. Cependant, vous devez savoir d'où proviennent les paquets, quelles sont les versions utilisées, qui les a construits et s'ils contiennent du code malveillant.
Voici quelques questions auxquelles il faut répondre :
- Ce qui se trouve à l'intérieur des conteneurs risque-t-il de compromettre votre infrastructure ?
- Existe-t-il des vulnérabilités connues dans la couche applicative ?
- Les couches du système d'exécution et du système d'exploitation sont-elles à jour ?
En construisant vos conteneurs à partir des images de base universelles de Red Hat (UBI), vous êtes assuré d'avoir une base pour vos images de conteneurs qui consiste en les mêmes logiciels emballés par RPM que ceux inclus dans Red Hat Enterprise Linux. Aucun abonnement n'est nécessaire pour utiliser ou redistribuer les images UBI.
Pour assurer la sécurité continue des conteneurs eux-mêmes, les fonctions d'analyse de sécurité, utilisées directement à partir de RHEL ou ajoutées à OpenShift Container Platform, peuvent vous alerter lorsqu'une image que vous utilisez présente des vulnérabilités. L'analyse d'image OpenSCAP est disponible dans RHEL et Red Hat Quay Container Security Operator peut être ajouté pour vérifier les images de conteneurs utilisées dans OpenShift Container Platform.
2.6.2. Créer des images redistribuables avec UBI
Pour créer des applications conteneurisées, vous commencez généralement par une image de base fiable qui offre les composants habituellement fournis par le système d'exploitation. Il s'agit notamment des bibliothèques, des utilitaires et des autres fonctionnalités que l'application s'attend à trouver dans le système de fichiers du système d'exploitation.
Les images de base universelles de Red Hat (UBI) ont été créées pour encourager toute personne construisant ses propres conteneurs à commencer par une image entièrement constituée de paquets rpm Red Hat Enterprise Linux et d'autres contenus. Ces images UBI sont régulièrement mises à jour pour tenir compte des correctifs de sécurité et sont libres d'utilisation et de redistribution avec des images de conteneurs construites pour inclure vos propres logiciels.
Effectuez une recherche dans le catalogue de l'écosystème Red Hat pour trouver et vérifier l'état de différentes images UBI. En tant que créateur d'images de conteneurs sécurisés, vous pourriez être intéressé par ces deux types généraux d'images UBI :
-
UBI: Il existe des images UBI standard pour RHEL 7 et 8 (
ubi7/ubietubi8/ubi), ainsi que des images minimales basées sur ces systèmes (ubi7/ubi-minimaletubi8/ubi-mimimal). Toutes ces images sont préconfigurées pour pointer vers des dépôts libres de logiciels RHEL que vous pouvez ajouter aux images de conteneurs que vous construisez, en utilisant les commandes standardyumetdnf. Red Hat encourage l'utilisation de ces images sur d'autres distributions, telles que Fedora et Ubuntu. -
Red Hat Software Collections: Faites une recherche dans le catalogue de l'écosystème Red Hat pour
rhscl/afin de trouver des images créées pour être utilisées en tant qu'images de base pour des types d'applications spécifiques. Par exemple, il existe des images rhscl Apache httpd (rhscl/httpd-*), Python (rhscl/python-*), Ruby (rhscl/ruby-*), Node.js (rhscl/nodejs-*) et Perl (rhscl/perl-*).
Gardez à l'esprit que si les images UBI sont librement disponibles et redistribuables, la prise en charge de ces images par Red Hat n'est disponible que par le biais d'abonnements aux produits Red Hat.
Voir Utilisation des images de base universelles de Red Hat dans la documentation de Red Hat Enterprise Linux pour obtenir des informations sur la manière d'utiliser et de construire sur des images UBI standard, minimales et init.
2.6.3. Analyse de sécurité dans RHEL
Pour les systèmes Red Hat Enterprise Linux (RHEL), l'analyse OpenSCAP est disponible à partir du paquetage openscap-utils. Dans RHEL, vous pouvez utiliser la commande openscap-podman pour rechercher les vulnérabilités dans les images. Voir Recherche de vulnérabilités dans les conteneurs et les images de conteneurs dans la documentation de Red Hat Enterprise Linux.
OpenShift Container Platform vous permet d'exploiter les scanners RHEL dans le cadre de votre processus CI/CD. Par exemple, vous pouvez intégrer des outils d'analyse statique du code qui testent les failles de sécurité dans votre code source et des outils d'analyse de la composition des logiciels qui identifient les bibliothèques open source afin de fournir des métadonnées sur ces bibliothèques, telles que les vulnérabilités connues.
2.6.3.1. Analyse des images OpenShift
Pour les images de conteneurs qui sont exécutées dans OpenShift Container Platform et qui sont tirées des registres Red Hat Quay, vous pouvez utiliser un opérateur pour lister les vulnérabilités de ces images. L'opérateur Red Hat Quay Container Security peut être ajouté à OpenShift Container Platform pour fournir des rapports de vulnérabilité pour les images ajoutées aux espaces de noms sélectionnés.
L'analyse des images de conteneurs pour Red Hat Quay est effectuée par l'analyseur de sécurité Clair. Dans Red Hat Quay, Clair peut rechercher et signaler les vulnérabilités dans les images construites à partir des logiciels des systèmes d'exploitation RHEL, CentOS, Oracle, Alpine, Debian et Ubuntu.
2.6.4. Intégration de l'analyse externe
OpenShift Container Platform utilise les annotations d'objets pour étendre les fonctionnalités. Les outils externes, tels que les scanners de vulnérabilité, peuvent annoter les objets image avec des métadonnées pour résumer les résultats et contrôler l'exécution du pod. Cette section décrit le format reconnu de cette annotation afin qu'elle puisse être utilisée de manière fiable dans les consoles pour afficher des données utiles aux utilisateurs.
2.6.4.1. Métadonnées de l'image
Il existe différents types de données relatives à la qualité de l'image, notamment les vulnérabilités des paquets et le respect des licences des logiciels libres. En outre, il peut y avoir plus d'un fournisseur de ces métadonnées. C'est pourquoi le format d'annotation suivant a été réservé :
quality.images.openshift.io/<qualityType>.<providerId> : {}Tableau 2.1. Format des clés d'annotation
| Composant | Description | Valeurs acceptables |
|---|---|---|
|
| Type de métadonnées |
|
|
| Chaîne d'identification du prestataire |
|
2.6.4.1.1. Exemples de clés d'annotation
quality.images.openshift.io/vulnerability.blackduck: {}
quality.images.openshift.io/vulnerability.jfrog: {}
quality.images.openshift.io/license.blackduck: {}
quality.images.openshift.io/vulnerability.openscap: {}La valeur de l'annotation de la qualité de l'image est une donnée structurée qui doit respecter le format suivant :
Tableau 2.2. Format des valeurs d'annotation
| Field | Nécessaire ? | Description | Type |
|---|---|---|---|
|
| Oui | Nom d'affichage du prestataire | String |
|
| Oui | Horodatage de l'analyse | String |
|
| Non | Brève description | String |
|
| Oui | URL de la source d'information ou de plus amples détails. Requis pour que l'utilisateur puisse valider les données. | String |
|
| Non | Version du scanner | String |
|
| Non | Conformité réussie ou échouée | Booléen |
|
| Non | Résumé des problèmes constatés | Liste (voir tableau ci-dessous) |
Le champ summary doit respecter le format suivant :
Tableau 2.3. Format de la valeur du champ résumé
| Field | Description | Type |
|---|---|---|
|
| Afficher le libellé du composant (par exemple, "critique", "important", "modéré", "faible" ou "santé") | String |
|
| Données relatives à ce composant (par exemple, nombre de vulnérabilités trouvées ou score) | String |
|
|
Indice de composant permettant d'ordonner et d'attribuer une représentation graphique. La valeur est comprise entre | Integer |
|
| URL de la source d'information pour plus de détails. En option. | String |
2.6.4.1.2. Exemples de valeurs d'annotation
Cet exemple montre une annotation OpenSCAP pour une image avec des données de résumé de vulnérabilité et un booléen de conformité :
Annotation OpenSCAP
{
"name": "OpenSCAP",
"description": "OpenSCAP vulnerability score",
"timestamp": "2016-09-08T05:04:46Z",
"reference": "https://www.open-scap.org/930492",
"compliant": true,
"scannerVersion": "1.2",
"summary": [
{ "label": "critical", "data": "4", "severityIndex": 3, "reference": null },
{ "label": "important", "data": "12", "severityIndex": 2, "reference": null },
{ "label": "moderate", "data": "8", "severityIndex": 1, "reference": null },
{ "label": "low", "data": "26", "severityIndex": 0, "reference": null }
]
}
Cet exemple montre la section Images de conteneurs du catalogue de l'écosystème Red Hat pour une image avec des données d'index de santé avec une URL externe pour des détails supplémentaires :
Annotation du catalogue de l'écosystème Red Hat
{
"name": "Red Hat Ecosystem Catalog",
"description": "Container health index",
"timestamp": "2016-09-08T05:04:46Z",
"reference": "https://access.redhat.com/errata/RHBA-2016:1566",
"compliant": null,
"scannerVersion": "1.2",
"summary": [
{ "label": "Health index", "data": "B", "severityIndex": 1, "reference": null }
]
}
2.6.4.2. Annoter les objets de l'image
Alors que les objets de flux d'images sont ce que l'utilisateur final d'OpenShift Container Platform utilise, les objets d'images sont annotés avec des métadonnées de sécurité. Les objets image sont de type "cluster-scoped", c'est-à-dire qu'ils pointent vers une seule image qui peut être référencée par de nombreux flux d'images et tags.
2.6.4.2.1. Exemple de commande CLI annotate
Remplacez <image> par un condensé d'image, par exemple sha256:401e359e0f45bfdcf004e258b72e253fd07fba8cc5c6f2ed4f4608fb119ecc2:
$ oc annotate image <image> \
quality.images.openshift.io/vulnerability.redhatcatalog='{ \
"name": "Red Hat Ecosystem Catalog", \
"description": "Container health index", \
"timestamp": "2020-06-01T05:04:46Z", \
"compliant": null, \
"scannerVersion": "1.2", \
"reference": "https://access.redhat.com/errata/RHBA-2020:2347", \
"summary": "[ \
{ "label": "Health index", "data": "B", "severityIndex": 1, "reference": null } ]" }'2.6.4.3. Contrôler l'exécution des pods
Utilisez la politique d'image images.openshift.io/deny-execution pour contrôler par programme si une image peut être exécutée.
2.6.4.3.1. Exemple d'annotation
annotations: images.openshift.io/deny-execution: true
2.6.4.4. Référence d'intégration
Dans la plupart des cas, les outils externes tels que les scanners de vulnérabilité développent un script ou un plugin qui surveille les mises à jour de l'image, effectue l'analyse et annote l'objet image associé avec les résultats. Généralement, cette automatisation fait appel aux API REST d'OpenShift Container Platform 4.12 pour écrire l'annotation. Voir OpenShift Container Platform REST APIs pour des informations générales sur les API REST.
2.6.4.4.1. Exemple d'appel à l'API REST
L'exemple d'appel suivant, qui utilise curl, remplace la valeur de l'annotation. Veillez à remplacer les valeurs de <token>, <openshift_server>, <image_id>, et <image_annotation>.
Appel de l'API du correctif
$ curl -X PATCH \
-H "Authorization: Bearer <token>" \
-H "Content-Type: application/merge-patch+json" \
https://<openshift_server>:6443/apis/image.openshift.io/v1/images/<image_id> \
--data '{ <image_annotation> }'
Voici un exemple de données de charge utile sur le site PATCH:
Données d'appel de correctifs
{
"metadata": {
"annotations": {
"quality.images.openshift.io/vulnerability.redhatcatalog":
"{ 'name': 'Red Hat Ecosystem Catalog', 'description': 'Container health index', 'timestamp': '2020-06-01T05:04:46Z', 'compliant': null, 'reference': 'https://access.redhat.com/errata/RHBA-2020:2347', 'summary': [{'label': 'Health index', 'data': '4', 'severityIndex': 1, 'reference': null}] }"
}
}
}
Ressources supplémentaires
2.7. Utiliser les registres de conteneurs en toute sécurité
Les registres de conteneurs stockent les images des conteneurs :
- Rendre les images accessibles aux autres
- Organiser les images dans des référentiels qui peuvent inclure plusieurs versions d'une image
- Il est possible de limiter l'accès aux images en fonction de différentes méthodes d'authentification ou de les rendre accessibles au public
Il existe des registres de conteneurs publics, tels que Quay.io et Docker Hub, où de nombreuses personnes et organisations partagent leurs images. Le Red Hat Registry propose des images Red Hat et partenaires prises en charge, tandis que le Red Hat Ecosystem Catalog propose des descriptions détaillées et des contrôles de santé pour ces images. Pour gérer votre propre registre, vous pouvez acheter un registre de conteneurs tel que Red Hat Quay.
Du point de vue de la sécurité, certains registres proposent des fonctions spéciales pour vérifier et améliorer la santé de vos conteneurs. Par exemple, Red Hat Quay propose une analyse des vulnérabilités des conteneurs avec Clair Security Scanner, des déclencheurs de construction pour reconstruire automatiquement les images lorsque le code source est modifié dans GitHub et d'autres emplacements, et la possibilité d'utiliser le contrôle d'accès basé sur les rôles (RBAC) pour sécuriser l'accès aux images.
2.7.1. Savoir d'où viennent les conteneurs ?
Il existe des outils que vous pouvez utiliser pour analyser et suivre le contenu de vos images de conteneurs téléchargées et déployées. Cependant, il existe de nombreuses sources publiques d'images de conteneurs. Lorsque vous utilisez des registres de conteneurs publics, vous pouvez ajouter une couche de protection en utilisant des sources fiables.
2.7.2. Conteneurs immuables et certifiés
La consommation des mises à jour de sécurité est particulièrement importante lors de la gestion de immutable containers. Les conteneurs immuables sont des conteneurs qui ne seront jamais modifiés en cours d'exécution. Lorsque vous déployez des conteneurs immuables, vous n'intervenez pas dans le conteneur en cours d'exécution pour remplacer un ou plusieurs binaires. D'un point de vue opérationnel, vous reconstruisez et redéployez une image de conteneur mise à jour pour remplacer un conteneur au lieu de le modifier.
Les images certifiées par Red Hat sont les suivantes :
- Absence de vulnérabilités connues dans les composants ou les couches de la plate-forme
- Compatible avec toutes les plateformes RHEL, du bare metal au cloud
- Supporté par Red Hat
La liste des vulnérabilités connues est en constante évolution, vous devez donc suivre le contenu de vos images de conteneurs déployées, ainsi que les images nouvellement téléchargées, au fil du temps. Vous pouvez utiliser les Red Hat Security Advisories (RHSA ) pour vous avertir de tout problème récemment découvert dans les images de conteneurs certifiées par Red Hat, et vous diriger vers l'image mise à jour. Vous pouvez également consulter le catalogue de l'écosystème Red Hat pour rechercher ces problèmes et d'autres problèmes liés à la sécurité pour chaque image Red Hat.
2.7.3. Obtenir des conteneurs à partir du Red Hat Registry et de l'Ecosystem Catalog
Red Hat répertorie les images de conteneurs certifiées pour les produits Red Hat et les offres des partenaires dans la section Images de conteneurs du catalogue de l'écosystème Red Hat. À partir de ce catalogue, vous pouvez voir les détails de chaque image, y compris le CVE, les listes de paquets logiciels et les scores de santé.
Les images Red Hat sont en fait stockées dans ce que l'on appelle le Red Hat Registry, qui est représenté par un registre de conteneurs public (registry.access.redhat.com) et un registre authentifié (registry.redhat.io). Les deux comprennent fondamentalement le même ensemble d'images de conteneurs, registry.redhat.io comprenant quelques images supplémentaires qui nécessitent une authentification avec les informations d'identification de l'abonnement Red Hat.
Le contenu des conteneurs est surveillé par Red Hat pour détecter les vulnérabilités et est mis à jour régulièrement. Lorsque Red Hat publie des mises à jour de sécurité, telles que des correctifs pour glibc, DROWN, ou Dirty Cow, toutes les images de conteneurs affectées sont également reconstruites et poussées vers le Red Hat Registry.
Red Hat utilise une adresse health index pour refléter le risque de sécurité de chaque conteneur fourni par le catalogue de l'écosystème Red Hat. Étant donné que les conteneurs consomment des logiciels fournis par Red Hat et le processus d'errata, les conteneurs anciens et périmés ne sont pas sûrs, tandis que les nouveaux conteneurs sont plus sûrs.
Pour illustrer l'âge des conteneurs, le Red Hat Ecosystem Catalog utilise un système de classement. Une note de fraîcheur est une mesure des errata de sécurité les plus anciens et les plus graves disponibles pour une image. \L'image "A" est plus à jour que l'image "F". Voir les notes de l'Indice de santé des conteneurs utilisées dans le Catalogue de l'écosystème Red Hat pour plus de détails sur ce système de notation.
Consultez le Centre de sécurité des produits Red Hat pour obtenir des détails sur les mises à jour de sécurité et les vulnérabilités liées aux logiciels Red Hat. Consultez les avis de sécurité de Red Hat pour rechercher des avis spécifiques et des CVE.
2.7.4. Registre des conteneurs OpenShift
OpenShift Container Platform inclut OpenShift Container Registry, un registre privé fonctionnant comme un composant intégré de la plateforme que vous pouvez utiliser pour gérer vos images de conteneurs. L'OpenShift Container Registry fournit des contrôles d'accès basés sur les rôles qui vous permettent de gérer qui peut tirer et pousser quelles images de conteneurs.
OpenShift Container Platform prend également en charge l'intégration avec d'autres registres privés que vous utilisez peut-être déjà, tels que Red Hat Quay.
Ressources supplémentaires
2.7.5. Stockage de conteneurs à l'aide de Red Hat Quay
Red Hat Quay est un produit de registre de conteneurs de qualité professionnelle de Red Hat. Le développement de Red Hat Quay se fait par le biais du projet Quay en amont. Red Hat Quay peut être déployé sur site ou via la version hébergée de Red Hat Quay sur Quay.io.
Les fonctionnalités de Red Hat Quay relatives à la sécurité sont les suivantes :
- Time machine: Permet aux images comportant des balises anciennes d'expirer après une période définie ou en fonction d'un délai d'expiration choisi par l'utilisateur.
- Repository mirroring: Vous permet de mettre en miroir d'autres registres pour des raisons de sécurité, comme l'hébergement d'un référentiel public sur Red Hat Quay derrière le pare-feu d'une entreprise, ou pour des raisons de performance, afin de garder les registres plus près de l'endroit où ils sont utilisés.
- Action log storage: Sauvegarder la sortie des journaux de Red Hat Quay dans le stockage Elasticsearch pour permettre une recherche et une analyse ultérieures.
- Clair security scanning: Analyser les images par rapport à diverses bases de données de vulnérabilités Linux, en fonction de l'origine de chaque image de conteneur.
- Internal authentication: Utilisez la base de données locale par défaut pour gérer l'authentification RBAC à Red Hat Quay ou choisissez entre LDAP, Keystone (OpenStack), l'authentification personnalisée JWT ou l'authentification par jeton d'application externe.
- External authorization (OAuth): Autoriser l'accès à Red Hat Quay à partir de GitHub, GitHub Enterprise ou Google Authentication.
- Access settings: Générer des jetons pour permettre l'accès à Red Hat Quay à partir de docker, rkt, l'accès anonyme, les comptes créés par l'utilisateur, les mots de passe client cryptés, ou l'autocomplétion du préfixe du nom d'utilisateur.
L'intégration de Red Hat Quay avec OpenShift Container Platform se poursuit, avec plusieurs opérateurs OpenShift Container Platform particulièrement intéressants. L'opérateur Quay Bridge vous permet de remplacer le registre d'images interne d'OpenShift par Red Hat Quay. L'opérateur Red Hat Quay Container Security Operator vous permet de vérifier les vulnérabilités des images exécutées dans OpenShift Container Platform qui ont été extraites des registres Red Hat Quay.
2.8. Sécuriser le processus de construction
Dans un environnement de conteneurs, le processus de construction du logiciel est l'étape du cycle de vie où le code de l'application est intégré aux bibliothèques d'exécution requises. La gestion de ce processus est essentielle pour sécuriser la pile logicielle.
2.8.1. Construire une fois, déployer partout
L'utilisation d'OpenShift Container Platform comme plateforme standard pour les constructions de conteneurs vous permet de garantir la sécurité de l'environnement de construction. L'adhésion à la philosophie "construire une fois, déployer partout" permet de s'assurer que le produit du processus de construction est exactement ce qui est déployé en production.
Il est également important de maintenir l'immuabilité de vos conteneurs. Vous ne devez pas patcher les conteneurs en cours d'exécution, mais les reconstruire et les redéployer.
Au fur et à mesure que votre logiciel passe par les étapes de construction, de test et de production, il est important que les outils qui composent votre chaîne d'approvisionnement en logiciels soient fiables. La figure suivante illustre le processus et les outils qui pourraient être incorporés dans une chaîne d'approvisionnement de logiciels de confiance pour les logiciels conteneurisés :

OpenShift Container Platform peut être intégrée à des référentiels de code fiables (tels que GitHub) et à des plateformes de développement (telles que Che) pour créer et gérer du code sécurisé. Les tests unitaires peuvent s'appuyer sur Cucumber et JUnit. Vous pouvez inspecter vos conteneurs pour détecter les vulnérabilités et les problèmes de conformité avec Anchore ou Twistlock, et utiliser des outils d'analyse d'images tels qu'AtomicScan ou Clair. Des outils tels que Sysdig peuvent assurer une surveillance continue de vos applications conteneurisées.
2.8.2. Gestion des constructions
Vous pouvez utiliser Source-to-Image (S2I) pour combiner le code source et les images de base. Builder images utilise S2I pour permettre à vos équipes de développement et d'exploitation de collaborer sur un environnement de construction reproductible. Avec les images S2I de Red Hat disponibles en tant qu'images de base universelles (UBI), vous pouvez désormais redistribuer librement vos logiciels avec des images de base construites à partir de véritables paquets RHEL RPM. Red Hat a supprimé les restrictions d'abonnement pour permettre cela.
Lorsque les développeurs livrent du code avec Git pour une application utilisant des images de construction, OpenShift Container Platform peut exécuter les fonctions suivantes :
- Déclencher, à l'aide de webhooks sur le dépôt de code ou d'un autre processus d'intégration continue automatisé, l'assemblage automatique d'une nouvelle image à partir des artefacts disponibles, de l'image du constructeur S2I et du code nouvellement livré.
- Déployer automatiquement l'image nouvellement créée pour la tester.
- Promouvoir l'image testée vers la production où elle peut être déployée automatiquement à l'aide d'un processus CI.
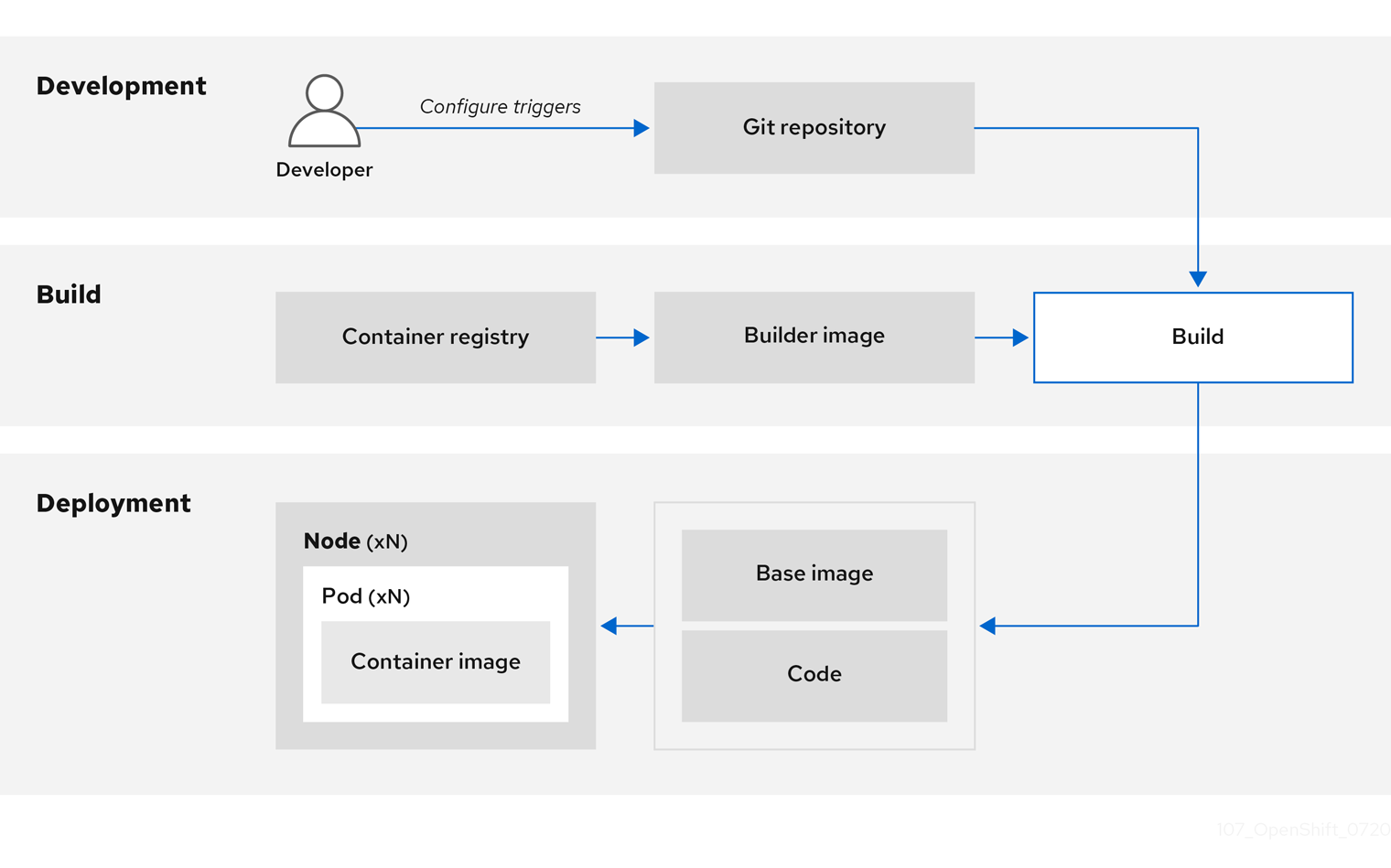
Vous pouvez utiliser le registre intégré OpenShift Container Registry pour gérer l'accès aux images finales. Les images S2I et les images natives sont automatiquement poussées vers votre OpenShift Container Registry.
En plus de Jenkins for CI, vous pouvez également intégrer votre propre environnement de construction et de CI à OpenShift Container Platform à l'aide d'API RESTful, ainsi qu'utiliser n'importe quel registre d'images compatible avec l'API.
2.8.3. Sécuriser les entrées lors de la construction
Dans certains cas, les opérations de compilation nécessitent des informations d'identification pour accéder à des ressources dépendantes, mais il n'est pas souhaitable que ces informations d'identification soient disponibles dans l'image finale de l'application produite par la compilation. Vous pouvez définir des secrets d'entrée à cette fin.
Par exemple, lorsque vous créez une application Node.js, vous pouvez configurer votre miroir privé pour les modules Node.js. Pour télécharger des modules à partir de ce miroir privé, vous devez fournir un fichier .npmrc personnalisé pour la construction qui contient une URL, un nom d'utilisateur et un mot de passe. Pour des raisons de sécurité, vous ne devez pas exposer vos informations d'identification dans l'image de l'application.
Dans cet exemple, vous pouvez ajouter un secret de saisie à un nouvel objet BuildConfig:
Créer le secret, s'il n'existe pas :
$ oc create secret generic secret-npmrc --from-file=.npmrc=~/.npmrc
Cela crée un nouveau secret nommé
secret-npmrc, qui contient le contenu encodé en base64 du fichier~/.npmrc.Ajoutez le secret à la section
sourcedans l'objet existantBuildConfig:source: git: uri: https://github.com/sclorg/nodejs-ex.git secrets: - destinationDir: . secret: name: secret-npmrcPour inclure le secret dans un nouvel objet
BuildConfig, exécutez la commande suivante :$ oc new-build \ openshift/nodejs-010-centos7~https://github.com/sclorg/nodejs-ex.git \ --build-secret secret-npmrc
2.8.4. Concevoir votre processus de construction
Vous pouvez concevoir votre gestion d'image de conteneur et votre processus de construction pour utiliser des couches de conteneur afin de pouvoir séparer le contrôle.
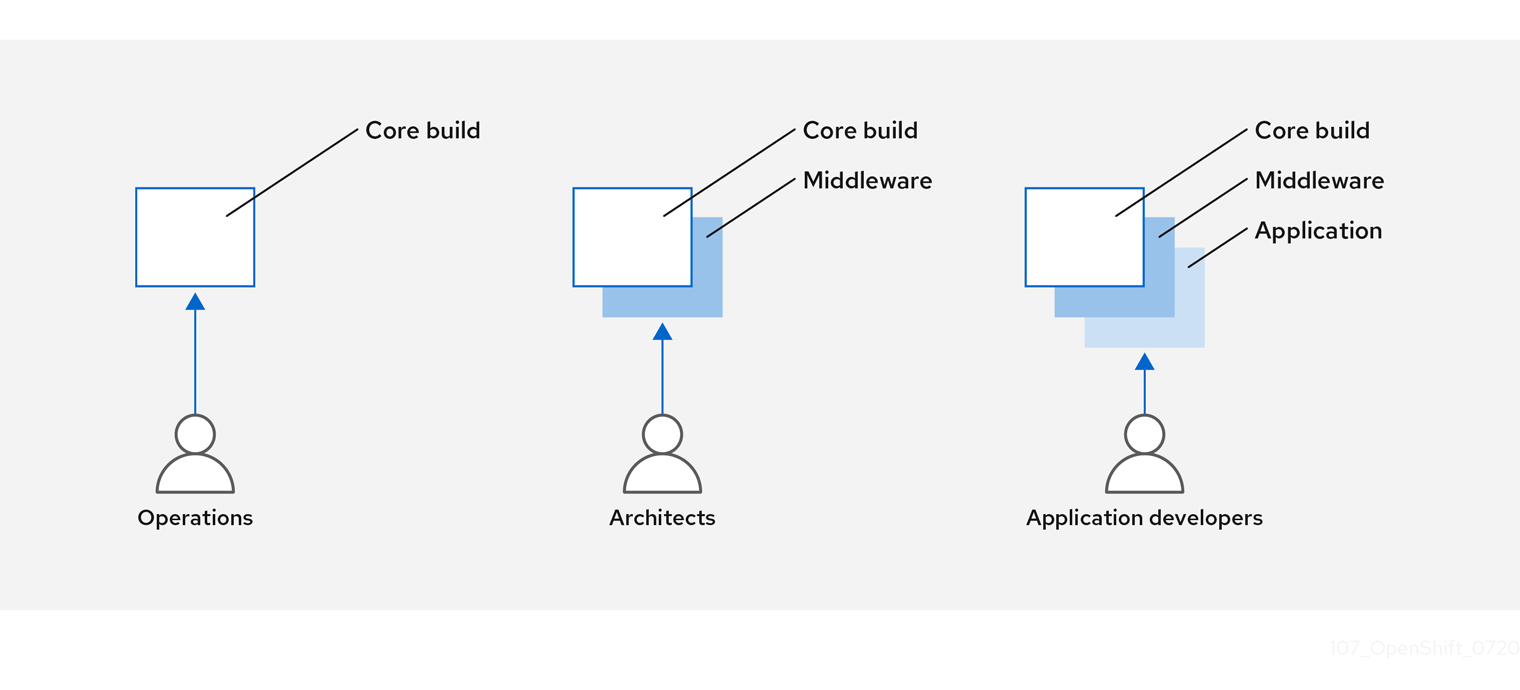
Par exemple, une équipe d'exploitation gère les images de base, tandis que les architectes gèrent les logiciels intermédiaires, les moteurs d'exécution, les bases de données et d'autres solutions. Les développeurs peuvent alors se concentrer sur les couches applicatives et sur l'écriture du code.
Comme de nouvelles vulnérabilités sont identifiées chaque jour, vous devez vérifier de manière proactive le contenu des conteneurs au fil du temps. Pour ce faire, vous devez intégrer des tests de sécurité automatisés dans votre processus de construction ou d'intégration. Par exemple :
- SAST / DAST - Outils de test de sécurité statique et dynamique.
- Des scanners permettant de vérifier en temps réel les vulnérabilités connues. Les outils de ce type cataloguent les paquets open source dans votre conteneur, vous informent des vulnérabilités connues et vous mettent à jour lorsque de nouvelles vulnérabilités sont découvertes dans des paquets précédemment analysés.
Votre processus d'intégration des données doit inclure des politiques qui signalent les constructions présentant des problèmes découverts par les analyses de sécurité, afin que votre équipe puisse prendre les mesures appropriées pour résoudre ces problèmes. Vous devez signer vos conteneurs personnalisés pour vous assurer que rien n'est altéré entre la construction et le déploiement.
En utilisant la méthodologie GitOps, vous pouvez utiliser les mêmes mécanismes CI/CD pour gérer non seulement les configurations de vos applications, mais aussi votre infrastructure OpenShift Container Platform.
2.8.5. Construire des applications Knative sans serveur
En s'appuyant sur Kubernetes et Kourier, vous pouvez construire, déployer et gérer des applications sans serveur en utilisant OpenShift Serverless dans OpenShift Container Platform.
Comme pour les autres builds, vous pouvez utiliser les images S2I pour construire vos conteneurs, puis les servir à l'aide des services Knative. Visualisez les builds d'applications Knative via la vue Topology de la console web OpenShift Container Platform.
2.8.6. Ressources supplémentaires
2.9. Déployer des conteneurs
Vous pouvez utiliser diverses techniques pour vous assurer que les conteneurs que vous déployez contiennent le dernier contenu de qualité de production et qu'ils n'ont pas été altérés. Ces techniques comprennent la mise en place de déclencheurs de construction pour intégrer le code le plus récent et l'utilisation de signatures pour s'assurer que le conteneur provient d'une source fiable et n'a pas été modifié.
2.9.1. Contrôler les déploiements de conteneurs avec des déclencheurs
Si quelque chose se produit au cours du processus de construction, ou si une vulnérabilité est découverte après le déploiement d'une image, vous pouvez utiliser des outils pour un déploiement automatisé, basé sur des règles, afin de remédier à la situation. Vous pouvez utiliser des déclencheurs pour reconstruire et remplacer les images, en garantissant le processus de conteneurs immuables, au lieu de patcher les conteneurs en cours d'exécution, ce qui n'est pas recommandé.
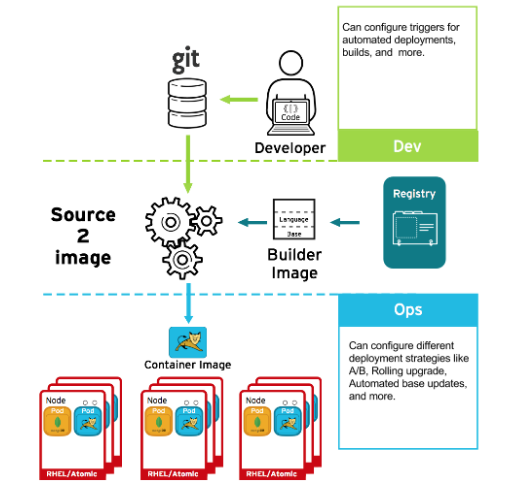
Par exemple, vous construisez une application en utilisant trois couches d'images de conteneurs : le noyau, l'intergiciel et les applications. Un problème est découvert dans l'image core et cette image est reconstruite. Une fois la construction terminée, l'image est poussée vers votre OpenShift Container Registry. OpenShift Container Platform détecte que l'image a changé et reconstruit et déploie automatiquement l'image de l'application, en fonction des déclencheurs définis. Ce changement incorpore les bibliothèques corrigées et garantit que le code de production est identique à l'image la plus récente.
Vous pouvez utiliser la commande oc set triggers pour définir un déclencheur de déploiement. Par exemple, pour définir un déclencheur de déploiement appelé déploiement-exemple :
$ oc set triggers deploy/deployment-example \
--from-image=example:latest \
--containers=web2.9.2. Contrôle des sources d'images pouvant être déployées
Il est important que les images prévues soient effectivement déployées, que les images et leur contenu proviennent de sources fiables et qu'elles n'aient pas été modifiées. La signature cryptographique fournit cette assurance. OpenShift Container Platform permet aux administrateurs de clusters d'appliquer une politique de sécurité plus ou moins large, en fonction de l'environnement de déploiement et des exigences de sécurité. Deux paramètres définissent cette politique :
- un ou plusieurs registres, avec un espace de noms de projet optionnel
- le type de confiance, tel qu'accepter, rejeter ou exiger une ou plusieurs clés publiques
Vous pouvez utiliser ces paramètres de stratégie pour autoriser, refuser ou exiger une relation de confiance pour des registres entiers, des parties de registres ou des images individuelles. En utilisant des clés publiques de confiance, vous pouvez vous assurer que la source est vérifiée cryptographiquement. Les règles de stratégie s'appliquent aux nœuds. La stratégie peut être appliquée uniformément à tous les nœuds ou ciblée en fonction des charges de travail des différents nœuds (par exemple, construction, zone ou environnement).
Exemple de fichier de politique de signature d'image
{
"default": [{"type": "reject"}],
"transports": {
"docker": {
"access.redhat.com": [
{
"type": "signedBy",
"keyType": "GPGKeys",
"keyPath": "/etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release"
}
]
},
"atomic": {
"172.30.1.1:5000/openshift": [
{
"type": "signedBy",
"keyType": "GPGKeys",
"keyPath": "/etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release"
}
],
"172.30.1.1:5000/production": [
{
"type": "signedBy",
"keyType": "GPGKeys",
"keyPath": "/etc/pki/example.com/pubkey"
}
],
"172.30.1.1:5000": [{"type": "reject"}]
}
}
}
La politique peut être enregistrée sur un nœud sous le nom de /etc/containers/policy.json. La meilleure façon d'enregistrer ce fichier sur un nœud est d'utiliser un nouvel objet MachineConfig. Cet exemple applique les règles suivantes :
-
Exiger que les images du Red Hat Registry (
registry.access.redhat.com) soient signées par la clé publique de Red Hat. -
Exiger que les images de votre OpenShift Container Registry dans l'espace de noms
openshiftsoient signées par la clé publique Red Hat. -
Exigez que les images de votre OpenShift Container Registry dans l'espace de noms
productionsoient signées par la clé publique deexample.com. -
Rejeter tous les autres registres non spécifiés dans la définition globale de
default.
2.9.3. Utilisation des transports de signature
Un transport de signature est un moyen de stocker et de récupérer le blob de signature binaire. Il existe deux types de transport de signature.
-
atomic: Géré par l'API de la plateforme OpenShift Container. -
docker: Servi en tant que fichier local ou par un serveur web.
L'API OpenShift Container Platform gère les signatures qui utilisent le type de transport atomic. Vous devez stocker les images qui utilisent ce type de signature dans votre OpenShift Container Registry. Comme l'API docker/distribution extensions découvre automatiquement le point de terminaison de la signature de l'image, aucune configuration supplémentaire n'est nécessaire.
Les signatures qui utilisent le type de transport docker sont servies par un serveur de fichiers ou un serveur web local. Ces signatures sont plus souples ; vous pouvez servir des images à partir de n'importe quel registre d'images de conteneurs et utiliser un serveur indépendant pour fournir des signatures binaires.
Cependant, le type de transport docker nécessite une configuration supplémentaire. Vous devez configurer les nœuds avec l'URI du serveur de signatures en plaçant des fichiers YAML aux noms arbitraires dans un répertoire du système hôte, /etc/containers/registries.d par défaut. Les fichiers de configuration YAML contiennent un URI de registre et un URI de serveur de signatures, ou sigstore:
Exemple de fichier registries.d
docker:
access.redhat.com:
sigstore: https://access.redhat.com/webassets/docker/content/sigstore
Dans cet exemple, le Red Hat Registry, access.redhat.com, est le serveur de signatures qui fournit des signatures pour le type de transport docker. Son URI est défini dans le paramètre sigstore. Vous pouvez nommer ce fichier /etc/containers/registries.d/redhat.com.yaml et utiliser l'opérateur Machine Config pour placer automatiquement le fichier sur chaque nœud de votre cluster. Aucun redémarrage de service n'est nécessaire puisque les fichiers Policy et registries.d sont chargés dynamiquement par le runtime du conteneur.
2.9.4. Création de secrets et de cartes de configuration
Le type d'objet Secret fournit un mécanisme pour contenir des informations sensibles telles que les mots de passe, les fichiers de configuration du client OpenShift Container Platform, les fichiers dockercfg et les informations d'identification du référentiel source privé. Les secrets découplent le contenu sensible des pods. Vous pouvez monter des secrets dans des conteneurs à l'aide d'un plugin de volume ou le système peut utiliser des secrets pour effectuer des actions au nom d'un pod.
Par exemple, pour ajouter un secret à votre configuration de déploiement afin qu'il puisse accéder à un référentiel d'images privé, procédez comme suit :
Procédure
- Connectez-vous à la console web de OpenShift Container Platform.
- Créer un nouveau projet.
-
Naviguez jusqu'à Resources → Secrets et créez un nouveau secret. Définissez
Secret TypesurImage SecretetAuthentication TypesurImage Registry Credentialspour saisir les informations d'identification permettant d'accéder à un référentiel d'images privé. -
Lors de la création d'une configuration de déploiement (par exemple, à partir de la page Add to Project → Deploy Image ), donnez à
Pull Secretla valeur de votre nouveau secret.
Les cartes de configuration sont similaires aux secrets, mais elles sont conçues pour permettre de travailler avec des chaînes qui ne contiennent pas d'informations sensibles. L'objet ConfigMap contient des paires clé-valeur de données de configuration qui peuvent être consommées dans des pods ou utilisées pour stocker des données de configuration pour des composants du système tels que les contrôleurs.
2.9.5. Automatiser le déploiement continu
Vous pouvez intégrer votre propre outil de déploiement continu (CD) à OpenShift Container Platform.
En tirant parti de CI/CD et d'OpenShift Container Platform, vous pouvez automatiser le processus de reconstruction de l'application afin d'intégrer les dernières corrections, de tester et de veiller à ce qu'elle soit déployée partout dans l'environnement.
Ressources supplémentaires
2.10. Sécuriser la plate-forme de conteneurs
Les API d'OpenShift Container Platform et de Kubernetes sont essentielles pour automatiser la gestion des conteneurs à grande échelle. Les API sont utilisées pour :
- Valider et configurer les données pour les pods, les services et les contrôleurs de réplication.
- Effectuer la validation du projet sur les demandes entrantes et invoquer les déclencheurs sur d'autres composants majeurs du système.
Les fonctionnalités liées à la sécurité dans OpenShift Container Platform qui sont basées sur Kubernetes comprennent :
- Multitenancy, qui combine les contrôles d'accès basés sur les rôles et les politiques de réseau pour isoler les conteneurs à plusieurs niveaux.
- Les plugins d'admission, qui forment des frontières entre une API et ceux qui font des demandes à l'API.
OpenShift Container Platform utilise des opérateurs pour automatiser et simplifier la gestion des fonctions de sécurité au niveau de Kubernetes.
2.10.1. Isolement des conteneurs avec multitenancy
La multitenance permet aux applications d'un cluster OpenShift Container Platform appartenant à plusieurs utilisateurs et s'exécutant sur plusieurs hôtes et espaces de noms de rester isolées les unes des autres et des attaques extérieures. Vous obtenez la multitenance en appliquant le contrôle d'accès basé sur les rôles (RBAC) aux espaces de noms Kubernetes.
Dans Kubernetes, namespaces sont des zones où les applications peuvent s'exécuter de manière distincte des autres applications. OpenShift Container Platform utilise et étend les espaces de noms en ajoutant des annotations supplémentaires, y compris l'étiquetage MCS dans SELinux, et en identifiant ces espaces de noms étendus comme projects. Dans le cadre d'un projet, les utilisateurs peuvent gérer leurs propres ressources de cluster, y compris les comptes de service, les politiques, les contraintes et divers autres objets.
Les objets RBAC sont assignés aux projets afin d'autoriser les utilisateurs sélectionnés à accéder à ces projets. Cette autorisation prend la forme de règles, de rôles et de liaisons :
- Les règles définissent ce qu'un utilisateur peut créer ou accéder dans un projet.
- Les rôles sont des ensembles de règles que vous pouvez lier à des utilisateurs ou à des groupes sélectionnés.
- Les liaisons définissent l'association entre les utilisateurs ou les groupes et les rôles.
Les rôles et fixations RBAC locaux rattachent un utilisateur ou un groupe à un projet particulier. Le système RBAC de grappe permet d'attribuer des rôles et des liaisons à l'échelle de la grappe à tous les projets de la grappe. Il existe des rôles de cluster par défaut qui peuvent être attribués pour fournir un accès à admin, basic-user, cluster-admin et cluster-status.
2.10.2. Protéger le plan de contrôle avec des plugins d'admission
Alors que RBAC contrôle les règles d'accès entre les utilisateurs, les groupes et les projets disponibles, admission plugins définit l'accès à l'API principale d'OpenShift Container Platform. Les plugins d'admission forment une chaîne de règles qui se compose de :
- Plugins d'admission par défaut : Ils mettent en œuvre un ensemble de politiques et de limites de ressources par défaut qui sont appliquées aux composants du plan de contrôle d'OpenShift Container Platform.
- Les plugins d'admission mutants : Ces plugins étendent dynamiquement la chaîne d'admission. Ils font appel à un serveur webhook et peuvent à la fois authentifier une demande et modifier la ressource sélectionnée.
- Les plugins de validation d'admission : Ils valident les demandes pour une ressource sélectionnée et peuvent à la fois valider la demande et s'assurer que la ressource n'est pas modifiée à nouveau.
Les demandes d'API passent par les modules d'admission en chaîne, tout échec en cours de route entraînant le rejet de la demande. Chaque plugin d'admission est associé à des ressources particulières et ne répond qu'aux demandes concernant ces ressources.
2.10.2.1. Contraintes du contexte de sécurité (SCC)
Vous pouvez utiliser security context constraints (SCC) pour définir un ensemble de conditions qu'un pod doit remplir pour être accepté dans le système.
Certains aspects peuvent être gérés par les CSC :
- Exécution de conteneurs privilégiés
- Capacités dont un conteneur peut demander l'ajout
- Utilisation des répertoires de l'hôte comme volumes
- Contexte SELinux du conteneur
- ID de l'utilisateur du conteneur
Si vous disposez des autorisations nécessaires, vous pouvez modifier les règles par défaut de la CSC pour les rendre plus permissives, le cas échéant.
2.10.2.2. Attribution de rôles aux comptes de service
Vous pouvez attribuer des rôles aux comptes de service, de la même manière que les utilisateurs se voient attribuer un accès basé sur des rôles. Trois comptes de service sont créés par défaut pour chaque projet. Un compte de service :
- est limité à un projet particulier
- tire son nom de son projet
- se voit automatiquement attribuer un jeton API et des informations d'identification pour accéder à l'OpenShift Container Registry
Les comptes de service associés aux composants de la plate-forme font automatiquement l'objet d'une rotation de leurs clés.
2.10.3. Authentification et autorisation
2.10.3.1. Contrôler l'accès à l'aide d'OAuth
Vous pouvez utiliser le contrôle d'accès à l'API via l'authentification et l'autorisation pour sécuriser votre plateforme de conteneurs. Le master OpenShift Container Platform comprend un serveur OAuth intégré. Les utilisateurs peuvent obtenir des jetons d'accès OAuth pour s'authentifier auprès de l'API.
En tant qu'administrateur, vous pouvez configurer OAuth pour vous authentifier à l'aide d'un identity provider, tel que LDAP, GitHub ou Google. Le fournisseur d'identité est utilisé par défaut pour les nouveaux déploiements d'OpenShift Container Platform, mais vous pouvez le configurer au moment de l'installation initiale ou de la post-installation.
2.10.3.2. Contrôle et gestion de l'accès à l'API
Les applications peuvent avoir plusieurs services API indépendants qui ont des points d'extrémité différents nécessitant une gestion. OpenShift Container Platform inclut une version conteneurisée de la passerelle API 3scale afin que vous puissiez gérer vos API et en contrôler l'accès.
3scale vous offre une variété d'options standard pour l'authentification et la sécurité de l'API, qui peuvent être utilisées seules ou en combinaison pour émettre des informations d'identification et contrôler l'accès : clés API standard, ID d'application et paire de clés, et OAuth 2.0.
Vous pouvez restreindre l'accès à des points finaux, méthodes et services spécifiques et appliquer une politique d'accès à des groupes d'utilisateurs. Les plans d'application vous permettent de définir des limites de taux pour l'utilisation de l'API et de contrôler le flux de trafic pour des groupes de développeurs.
Pour un tutoriel sur l'utilisation d'APIcast v2, la passerelle API 3scale conteneurisée, voir Running APIcast on Red Hat OpenShift dans la documentation 3scale.
2.10.3.3. Red Hat Single Sign-On
Le serveur Red Hat Single Sign-On vous permet de sécuriser vos applications en fournissant des capacités d'authentification unique sur le Web basées sur des normes, y compris SAML 2.0, OpenID Connect et OAuth 2.0. Le serveur peut agir en tant que fournisseur d'identité (IdP) basé sur SAML ou OpenID Connect, en servant de médiateur avec l'annuaire des utilisateurs de votre entreprise ou un fournisseur d'identité tiers pour les informations d'identité et vos applications à l'aide de jetons basés sur les normes. Vous pouvez intégrer Red Hat Single Sign-On avec des services d'annuaire basés sur LDAP, y compris Microsoft Active Directory et Red Hat Enterprise Linux Identity Management.
2.10.3.4. Console web sécurisée en libre-service
OpenShift Container Platform fournit une console web en libre-service pour s'assurer que les équipes n'accèdent pas à d'autres environnements sans autorisation. OpenShift Container Platform garantit un maître multitenant sécurisé en fournissant les éléments suivants :
- L'accès au maître utilise la sécurité de la couche de transport (TLS)
- L'accès au serveur API utilise des certificats X.509 ou des jetons d'accès OAuth
- Le quota du projet limite les dégâts qu'un jeton malhonnête pourrait causer
- Le service etcd n'est pas exposé directement au cluster
2.10.4. Gestion des certificats pour la plate-forme
OpenShift Container Platform a plusieurs composants dans son cadre qui utilisent la communication HTTPS basée sur REST en tirant parti du cryptage via des certificats TLS. Le programme d'installation d'OpenShift Container Platform configure ces certificats lors de l'installation. Certains composants principaux génèrent ce trafic :
- maîtres (serveur API et contrôleurs)
- etcd
- nœuds
- registre
- routeur
2.10.4.1. Configuration des certificats personnalisés
Vous pouvez configurer des certificats de service personnalisés pour les noms d'hôte publics du serveur API et de la console web lors de l'installation initiale ou lors du redéploiement des certificats. Vous pouvez également utiliser une autorité de certification personnalisée.
Ressources supplémentaires
- Introduction à OpenShift Container Platform
- Utilisation de RBAC pour définir et appliquer des autorisations
- A propos des plugins d'admission
- Gestion des contraintes liées au contexte de sécurité
- Commandes de référence du CCN
- Exemples d'attribution de rôles aux comptes de service
- Configuration du serveur OAuth interne
- Comprendre la configuration du fournisseur d'identité
- Types de certificats et descriptions
- Certificats de procuration
2.11. Sécurisation des réseaux
La sécurité du réseau peut être gérée à plusieurs niveaux. Au niveau du pod, les espaces de noms du réseau peuvent empêcher les conteneurs de voir d'autres pods ou le système hôte en limitant l'accès au réseau. Les stratégies réseau vous permettent de contrôler l'autorisation et le rejet des connexions. Vous pouvez gérer le trafic entrant et sortant de vos applications conteneurisées.
2.11.1. Utilisation des espaces de noms du réseau
OpenShift Container Platform utilise un réseau défini par logiciel (SDN) pour fournir un réseau de cluster unifié qui permet la communication entre les conteneurs à travers le cluster.
Le mode stratégie réseau, par défaut, rend tous les pods d'un projet accessibles aux autres pods et aux points d'extrémité du réseau. Pour isoler un ou plusieurs pods dans un projet, vous pouvez créer des objets NetworkPolicy dans ce projet pour indiquer les connexions entrantes autorisées. En utilisant le mode multitenant, vous pouvez fournir une isolation au niveau du projet pour les pods et les services.
2.11.2. Isolement des pods avec des politiques de réseau
En utilisant network policies, vous pouvez isoler les pods les uns des autres dans le même projet. Les stratégies de réseau peuvent refuser tout accès réseau à un module, n'autoriser que les connexions pour le contrôleur d'entrée, rejeter les connexions des modules dans d'autres projets, ou définir des règles similaires pour le comportement des réseaux.
Ressources supplémentaires
2.11.3. Utilisation de plusieurs réseaux de pods
Chaque conteneur en cours d'exécution n'a qu'une seule interface réseau par défaut. Le plugin CNI de Multus vous permet de créer plusieurs réseaux CNI, puis d'attacher n'importe lequel de ces réseaux à vos pods. De cette façon, vous pouvez faire des choses comme séparer les données privées sur un réseau plus restreint et avoir plusieurs interfaces réseau sur chaque nœud.
Ressources supplémentaires
2.11.4. Isolation des applications
OpenShift Container Platform vous permet de segmenter le trafic réseau sur un seul cluster pour créer des clusters multitenant qui isolent les utilisateurs, les équipes, les applications et les environnements des ressources non globales.
Ressources supplémentaires
2.11.5. Sécurisation du trafic entrant
La configuration de l'accès à vos services Kubernetes depuis l'extérieur de votre cluster OpenShift Container Platform a de nombreuses implications en termes de sécurité. Outre l'exposition des routes HTTP et HTTPS, le routage d'entrée vous permet de configurer les types d'entrée NodePort ou LoadBalancer. NodePort expose l'objet API de service d'une application à partir de chaque travailleur du cluster. LoadBalancer vous permet d'affecter un équilibreur de charge externe à un objet API de service associé dans votre cluster OpenShift Container Platform.
Ressources supplémentaires
2.11.6. Sécurisation du trafic de sortie
OpenShift Container Platform permet de contrôler le trafic de sortie à l'aide d'un routeur ou d'un pare-feu. Par exemple, vous pouvez utiliser la liste blanche d'IP pour contrôler l'accès à la base de données. Un administrateur de cluster peut attribuer une ou plusieurs adresses IP de sortie à un projet dans un fournisseur de réseau SDN OpenShift Container Platform. De même, un administrateur de cluster peut empêcher le trafic egress de sortir d'un cluster OpenShift Container Platform à l'aide d'un pare-feu egress.
En attribuant une adresse IP de sortie fixe, vous pouvez affecter tout le trafic sortant à cette adresse IP pour un projet particulier. Avec le pare-feu de sortie, vous pouvez empêcher un pod de se connecter à un réseau externe, empêcher un pod de se connecter à un réseau interne ou limiter l'accès d'un pod à des sous-réseaux internes spécifiques.
2.12. Sécuriser le stockage attaché
OpenShift Container Platform prend en charge plusieurs types de stockage, à la fois pour les fournisseurs sur site et dans le nuage. En particulier, OpenShift Container Platform peut utiliser des types de stockage qui prennent en charge l'interface de stockage des conteneurs.
2.12.1. Plugins de volume persistant
Les conteneurs sont utiles pour les applications avec ou sans état. La protection du stockage attaché est un élément clé de la sécurisation des services avec état. En utilisant l'interface de stockage des conteneurs (CSI), OpenShift Container Platform peut incorporer le stockage à partir de n'importe quel back-end de stockage qui prend en charge l'interface CSI.
OpenShift Container Platform propose des plugins pour plusieurs types de stockage, notamment :
- Red Hat OpenShift Data Foundation *
- AWS Elastic Block Stores (EBS) *
- Système de fichiers élastiques AWS (EFS) *
- Disque Azure *
- Azure File *
- OpenStack Cinder *
- Disques persistants de la CME *
- VMware vSphere *
- Système de fichiers en réseau (NFS)
- FlexVolume
- Fibre Channel
- iSCSI
Les plugins pour les types de stockage avec provisionnement dynamique sont marqués d'un astérisque (*). Les données en transit sont chiffrées via HTTPS pour tous les composants d'OpenShift Container Platform qui communiquent entre eux.
Vous pouvez monter un volume persistant (PV) sur un hôte de n'importe quelle manière prise en charge par votre type de stockage. Les différents types de stockage ont des capacités différentes et les modes d'accès de chaque PV sont définis en fonction des modes spécifiques pris en charge par ce volume particulier.
Par exemple, NFS peut prendre en charge plusieurs clients en lecture/écriture, mais un PV NFS spécifique peut être exporté sur le serveur en lecture seule. Chaque PV possède son propre ensemble de modes d'accès décrivant ses capacités spécifiques, tels que ReadWriteOnce, ReadOnlyMany, et ReadWriteMany.
2.12.3. Stockage en bloc
Pour les fournisseurs de stockage par blocs comme AWS Elastic Block Store (EBS), GCE Persistent Disks et iSCSI, OpenShift Container Platform utilise les fonctionnalités SELinux pour sécuriser la racine du volume monté pour les pods non privilégiés, ce qui fait que le volume monté appartient au conteneur auquel il est associé et n'est visible que par ce dernier.
2.13. Surveillance des événements et des journaux des clusters
La possibilité de surveiller et d'auditer un cluster OpenShift Container Platform est un élément important de la protection du cluster et de ses utilisateurs contre une utilisation inappropriée.
Il existe deux sources principales d'informations au niveau du cluster qui sont utiles à cette fin : les événements et la journalisation.
2.13.1. Observer les événements de la grappe
Les administrateurs de clusters sont invités à se familiariser avec le type de ressource Event et à consulter la liste des événements système pour déterminer ceux qui les intéressent. Les événements sont associés à un espace de noms, soit l'espace de noms de la ressource à laquelle ils sont liés, soit, pour les événements de grappe, l'espace de noms default. L'espace de noms par défaut contient les événements pertinents pour le contrôle ou l'audit d'une grappe, tels que les événements de nœuds et les événements de ressources liés aux composants de l'infrastructure.
L'API principale et la commande oc ne fournissent pas de paramètres permettant de limiter la liste des événements aux seuls événements liés aux nœuds. Une approche simple consisterait à utiliser la commande grep:
$ oc get event -n default | grep Node
Exemple de sortie
1h 20h 3 origin-node-1.example.local Node Normal NodeHasDiskPressure ...
Une approche plus souple consiste à produire les événements sous une forme que d'autres outils peuvent traiter. Par exemple, l'exemple suivant utilise l'outil jq contre une sortie JSON pour extraire uniquement les événements NodeHasDiskPressure:
$ oc get events -n default -o json \ | jq '.items[] | select(.involvedObject.kind == "Node" and .reason == "NodeHasDiskPressure")'
Exemple de sortie
{
"apiVersion": "v1",
"count": 3,
"involvedObject": {
"kind": "Node",
"name": "origin-node-1.example.local",
"uid": "origin-node-1.example.local"
},
"kind": "Event",
"reason": "NodeHasDiskPressure",
...
}
Les événements liés à la création, à la modification ou à la suppression de ressources peuvent également être de bons candidats pour détecter une mauvaise utilisation du cluster. La requête suivante, par exemple, peut être utilisée pour rechercher des tirages excessifs d'images :
$ oc get events --all-namespaces -o json \ | jq '[.items[] | select(.involvedObject.kind == "Pod" and .reason == "Pulling")] | length'
Exemple de sortie
4
Lorsqu'un espace de noms est supprimé, ses événements le sont également. Les événements peuvent également expirer et sont supprimés pour éviter d'encombrer le stockage etcd. Les événements ne sont pas stockés de manière permanente et des interrogations fréquentes sont nécessaires pour obtenir des statistiques au fil du temps.
2.13.2. Enregistrement
À l'aide de la commande oc log, vous pouvez consulter les journaux des conteneurs, les configurations de construction et les déploiements en temps réel. Différents utilisateurs peuvent avoir un accès différent aux journaux :
- Les utilisateurs qui ont accès à un projet peuvent voir les journaux de ce projet par défaut.
- Les utilisateurs ayant un rôle d'administrateur peuvent accéder à tous les journaux de conteneurs.
Pour sauvegarder vos logs en vue d'un audit et d'une analyse ultérieurs, vous pouvez activer la fonctionnalité complémentaire cluster-logging pour collecter, gérer et afficher les logs du système, du conteneur et de l'audit. Vous pouvez déployer, gérer et mettre à jour OpenShift Logging via OpenShift Elasticsearch Operator et Red Hat OpenShift Logging Operator.
2.13.3. Journaux d'audit
Avec audit logs, vous pouvez suivre une séquence d'activités associées au comportement d'un utilisateur, d'un administrateur ou d'un autre composant d'OpenShift Container Platform. La journalisation de l'audit de l'API est effectuée sur chaque serveur.
Ressources supplémentaires
Chapitre 3. Configuration des certificats
3.1. Remplacement du certificat d'entrée par défaut
3.1.1. Comprendre le certificat d'entrée par défaut
Par défaut, OpenShift Container Platform utilise l'opérateur d'ingestion pour créer une autorité de certification interne et émettre un certificat générique valable pour les applications du sous-domaine .apps. La console web et le CLI utilisent également ce certificat.
Les certificats de l'autorité de certification de l'infrastructure interne sont auto-signés. Bien que ce processus puisse être perçu comme une mauvaise pratique par certaines équipes de sécurité ou d'ICP, le risque est minime. Les seuls clients qui font implicitement confiance à ces certificats sont les autres composants du cluster. Le remplacement du certificat joker par défaut par un certificat délivré par une autorité de certification publique déjà incluse dans le paquet d'autorités de certification fourni par l'espace utilisateur du conteneur permet aux clients externes de se connecter en toute sécurité aux applications fonctionnant sous le sous-domaine .apps.
3.1.2. Remplacement du certificat d'entrée par défaut
Vous pouvez remplacer le certificat d'entrée par défaut pour toutes les applications sous le sous-domaine .apps. Après avoir remplacé le certificat, toutes les applications, y compris la console web et le CLI, bénéficieront du cryptage fourni par le certificat spécifié.
Conditions préalables
-
Vous devez disposer d'un certificat Wildcard pour le sous-domaine
.appsentièrement qualifié et de la clé privée correspondante. Chaque certificat doit se trouver dans un fichier séparé au format PEM. - La clé privée doit être non chiffrée. Si votre clé est cryptée, décryptez-la avant de l'importer dans OpenShift Container Platform.
-
Le certificat doit inclure l'extension
subjectAltNameindiquant*.apps.<clustername>.<domain>. - Le fichier de certificats peut contenir un ou plusieurs certificats dans une chaîne. Le certificat générique doit être le premier certificat du fichier. Il peut être suivi de tous les certificats intermédiaires, et le fichier doit se terminer par le certificat de l'autorité de certification racine.
- Copiez le certificat de l'autorité de certification racine dans un fichier supplémentaire au format PEM.
Procédure
Créez une carte de configuration qui inclut uniquement le certificat de l'autorité de certification racine utilisé pour signer le certificat générique :
$ oc create configmap custom-ca \ --from-file=ca-bundle.crt=</path/to/example-ca.crt> \1 -n openshift-config- 1
</path/to/example-ca.crt>est le chemin d'accès au fichier du certificat de l'autorité de certification racine sur votre système de fichiers local.
Mettre à jour la configuration du proxy à l'échelle du cluster avec la carte de configuration nouvellement créée :
$ oc patch proxy/cluster \ --type=merge \ --patch='{"spec":{"trustedCA":{"name":"custom-ca"}}}'Créez un secret qui contient la chaîne et la clé du certificat générique :
$ oc create secret tls <secret> \1 --cert=</path/to/cert.crt> \2 --key=</path/to/cert.key> \3 -n openshift-ingress
Mettre à jour la configuration du contrôleur d'entrée avec le nouveau secret créé :
$ oc patch ingresscontroller.operator default \ --type=merge -p \ '{"spec":{"defaultCertificate": {"name": "<secret>"}}}' \1 -n openshift-ingress-operator- 1
- Remplacez
<secret>par le nom utilisé pour le secret à l'étape précédente.
Ressources supplémentaires
3.2. Ajout de certificats de serveur API
Le certificat du serveur API par défaut est émis par une autorité de certification interne du cluster OpenShift Container Platform. Les clients extérieurs au cluster ne pourront pas vérifier le certificat du serveur API par défaut. Ce certificat peut être remplacé par un certificat émis par une autorité de certification à laquelle les clients font confiance.
3.2.1. Ajouter un serveur API nommé certificat
Le certificat du serveur API par défaut est émis par une autorité de certification interne du cluster OpenShift Container Platform. Vous pouvez ajouter un ou plusieurs certificats alternatifs que le serveur API renverra en fonction du nom de domaine entièrement qualifié (FQDN) demandé par le client, par exemple lorsqu'un proxy inverse ou un équilibreur de charge est utilisé.
Conditions préalables
- Vous devez disposer d'un certificat pour le FQDN et de la clé privée correspondante. Chacun d'eux doit se trouver dans un fichier séparé au format PEM.
- La clé privée doit être non chiffrée. Si votre clé est cryptée, décryptez-la avant de l'importer dans OpenShift Container Platform.
-
Le certificat doit inclure l'extension
subjectAltNameindiquant le FQDN. - Le fichier de certificats peut contenir un ou plusieurs certificats dans une chaîne. Le certificat pour le FQDN du serveur API doit être le premier certificat du fichier. Il peut être suivi de tous les certificats intermédiaires et le fichier doit se terminer par le certificat de l'autorité de certification racine.
Ne fournissez pas de certificat nommé pour l'équilibreur de charge interne (nom d'hôte api-int.<cluster_name>.<base_domain>). Si vous le faites, votre cluster se retrouvera dans un état dégradé.
Procédure
Connectez-vous à la nouvelle API en tant qu'utilisateur
kubeadmin.$ oc login -u kubeadmin -p <password> https://FQDN:6443
Obtenir le fichier
kubeconfig.oc config view --flatten > kubeconfig-newapi
Créez un secret contenant la chaîne de certificats et la clé privée dans l'espace de noms
openshift-config.$ oc create secret tls <secret> \1 --cert=</path/to/cert.crt> \2 --key=</path/to/cert.key> \3 -n openshift-config
Mettre à jour le serveur API pour qu'il fasse référence au secret créé.
$ oc patch apiserver cluster \ --type=merge -p \ '{"spec":{"servingCerts": {"namedCertificates": [{"names": ["<FQDN>"], 1 "servingCertificate": {"name": "<secret>"}}]}}}' 2Examinez l'objet
apiserver/clusteret confirmez que le secret est maintenant référencé.$ oc get apiserver cluster -o yaml
Exemple de sortie
... spec: servingCerts: namedCertificates: - names: - <FQDN> servingCertificate: name: <secret> ...Consultez l'opérateur
kube-apiserveret vérifiez qu'une nouvelle révision du serveur API Kubernetes est déployée. L'opérateur peut mettre une minute à détecter le changement de configuration et à déclencher un nouveau déploiement. Pendant le déploiement de la nouvelle révision,PROGRESSINGsignaleraTrue.$ oc get clusteroperators kube-apiserver
Ne passez pas à l'étape suivante tant que
PROGRESSINGn'est pas répertorié commeFalse, comme le montre le résultat suivant :Exemple de sortie
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE kube-apiserver 4.12.0 True False False 145m
Si
PROGRESSINGafficheTrue, attendez quelques minutes et réessayez.
3.3. Sécurisation du trafic des services à l'aide de secrets de certificats de service
3.3.1. Comprendre les certificats de service après-vente
Les certificats de service sont destinés à prendre en charge des applications intermédiaires complexes nécessitant un chiffrement. Ces certificats sont émis en tant que certificats de serveur web TLS.
Le contrôleur service-ca utilise l'algorithme de signature x509.SHA256WithRSA pour générer des certificats de service.
Le certificat et la clé générés sont au format PEM, stockés respectivement dans tls.crt et tls.key, au sein d'un secret créé. Le certificat et la clé sont automatiquement remplacés lorsqu'ils sont proches de l'expiration.
Le certificat de l'autorité de certification de service, qui émet les certificats de service, est valable 26 mois et fait l'objet d'une rotation automatique lorsqu'il reste moins de 13 mois de validité. Après la rotation, la configuration précédente de l'AC de service reste fiable jusqu'à son expiration. Cela permet à tous les services concernés de bénéficier d'une période de grâce pour actualiser leur matériel de clés avant l'expiration. Si vous ne mettez pas à niveau votre cluster pendant cette période de grâce, qui redémarre les services et actualise leurs clés, vous devrez peut-être redémarrer manuellement les services pour éviter les défaillances après l'expiration de l'ancienne autorité de certification.
Vous pouvez utiliser la commande suivante pour redémarrer manuellement tous les modules du cluster. Sachez que l'exécution de cette commande entraîne une interruption de service, car elle supprime tous les modules en cours d'exécution dans chaque espace de noms. Ces modules redémarreront automatiquement après avoir été supprimés.
$ for I in $(oc get ns -o jsonpath='{range .items[*]} {.metadata.name}{"\n"} {end}'); \
do oc delete pods --all -n $I; \
sleep 1; \
done3.3.2. Ajouter un certificat de service
Pour sécuriser la communication avec votre service, générez un certificat de service signé et une paire de clés dans un secret dans le même espace de noms que le service.
Le certificat généré n'est valable que pour le nom DNS du service interne <service.name>.<service.namespace>.svc, et n'est valable que pour les communications internes. Si votre service est un service headless (pas de valeur clusterIP définie), le certificat généré contient également un sujet joker au format *.<service.name>.<service.namespace>.svc.
Étant donné que les certificats générés contiennent des caractères génériques pour les services sans tête, vous ne devez pas utiliser l'autorité de certification de service si votre client doit faire la distinction entre les différents modules. Dans ce cas :
- Générer des certificats TLS individuels en utilisant une autre autorité de certification.
- N'acceptez pas l'autorité de certification de service comme autorité de certification de confiance pour les connexions qui sont dirigées vers des modules individuels et qui ne doivent pas être personnalisées par d'autres modules. Ces connexions doivent être configurées pour faire confiance à l'autorité de certification utilisée pour générer les certificats TLS individuels.
Prérequis :
- Un service doit être défini.
Procédure
Annoter le service avec
service.beta.openshift.io/serving-cert-secret-name:$ oc annotate service <service_name> \1 service.beta.openshift.io/serving-cert-secret-name=<secret_name> 2
Par exemple, utilisez la commande suivante pour annoter le service
test1:$ oc annotate service test1 service.beta.openshift.io/serving-cert-secret-name=test1
Examinez le service pour confirmer que les annotations sont présentes :
oc describe service <service_name> $ oc describe service <service_name>
Exemple de sortie
... Annotations: service.beta.openshift.io/serving-cert-secret-name: <service_name> service.beta.openshift.io/serving-cert-signed-by: openshift-service-serving-signer@1556850837 ...-
Une fois que le cluster a généré un secret pour votre service, votre spec
Podpeut le monter, et le pod s'exécutera dès qu'il sera disponible.
Ressources supplémentaires
- Vous pouvez utiliser un certificat de service pour configurer un itinéraire sécurisé à l'aide de la terminaison TLS reencrypt. Pour plus d'informations, voir Création d'un itinéraire reencrypt avec un certificat personnalisé.
3.3.3. Ajouter le service CA bundle à une carte de configuration
Un pod peut accéder au certificat de l'autorité de certification de service en montant un objet ConfigMap qui est annoté avec service.beta.openshift.io/inject-cabundle=true. Une fois annoté, le cluster injecte automatiquement le certificat de l'autorité de certification de service dans la clé service-ca.crt de la carte de configuration. L'accès à ce certificat CA permet aux clients TLS de vérifier les connexions aux services utilisant des certificats de service.
Après avoir ajouté cette annotation à une carte de configuration, toutes les données existantes sont supprimées. Il est recommandé d'utiliser une carte de configuration séparée pour contenir le site service-ca.crt, plutôt que d'utiliser la même carte de configuration que celle qui stocke la configuration de votre pod.
Procédure
Annoter la carte de configuration avec
service.beta.openshift.io/inject-cabundle=true:$ oc annotate configmap <config_map_name> \1 service.beta.openshift.io/inject-cabundle=true- 1
- Remplacez
<config_map_name>par le nom de la carte de configuration à annoter.
NoteLe fait de référencer explicitement la clé
service-ca.crtdans un montage de volume empêchera un pod de démarrer jusqu'à ce que la carte de configuration ait été injectée avec le bundle de l'autorité de certification. Ce comportement peut être modifié en définissant le champoptionalsurtruepour la configuration du certificat de service du volume.Par exemple, la commande suivante permet d'annoter la carte config
test1:$ oc annotate configmap test1 service.beta.openshift.io/inject-cabundle=true
Affichez la carte de configuration pour vous assurer que le service CA bundle a été injecté :
oc get configmap <config_map_name> -o yaml
La liasse d'AC est affichée en tant que valeur de la clé
service-ca.crtdans la sortie YAML :apiVersion: v1 data: service-ca.crt: | -----BEGIN CERTIFICATE----- ...
3.3.4. Ajouter le service CA bundle à un service API
Vous pouvez annoter un objet APIService avec service.beta.openshift.io/inject-cabundle=true pour que son champ spec.caBundle soit rempli avec le service CA bundle. Cela permet au serveur API Kubernetes de valider le certificat de l'autorité de certification du service utilisé pour sécuriser le point de terminaison ciblé.
Procédure
Annoter le service API avec
service.beta.openshift.io/inject-cabundle=true:$ oc annotate apiservice <api_service_name> \1 service.beta.openshift.io/inject-cabundle=true- 1
- Remplacez
<api_service_name>par le nom du service API à annoter.
Par exemple, utilisez la commande suivante pour annoter le service API
test1:$ oc annotate apiservice test1 service.beta.openshift.io/inject-cabundle=true
Affichez le service API pour vous assurer que le service CA bundle a été injecté :
oc get apiservice <api_service_name> -o yaml
L'ensemble de CA est affiché dans le champ
spec.caBundlede la sortie YAML :apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: annotations: service.beta.openshift.io/inject-cabundle: "true" ... spec: caBundle: <CA_BUNDLE> ...
3.3.5. Ajouter le service CA bundle à une définition de ressource personnalisée
Vous pouvez annoter un objet CustomResourceDefinition (CRD) avec service.beta.openshift.io/inject-cabundle=true pour que son champ spec.conversion.webhook.clientConfig.caBundle soit rempli avec le bundle de l'autorité de certification de service. Cela permet au serveur API Kubernetes de valider le certificat de l'autorité de certification du service utilisé pour sécuriser le point de terminaison ciblé.
Le service CA bundle ne sera injecté dans le CRD que si le CRD est configuré pour utiliser un webhook pour la conversion. Il n'est utile d'injecter le service CA bundle que si le webhook d'un CRD est sécurisé par un certificat de l'AC de service.
Procédure
Annoter le CRD avec
service.beta.openshift.io/inject-cabundle=true:$ oc annotate crd <crd_name> \1 service.beta.openshift.io/inject-cabundle=true- 1
- Remplacer
<crd_name>par le nom du CRD à annoter.
Par exemple, utilisez la commande suivante pour annoter le CRD
test1:$ oc annotate crd test1 service.beta.openshift.io/inject-cabundle=true
Consultez le CRD pour vous assurer que le paquet d'AC de service a bien été injecté :
oc get crd <crd_name> -o yaml
L'ensemble de CA est affiché dans le champ
spec.conversion.webhook.clientConfig.caBundlede la sortie YAML :apiVersion: apiextensions.k8s.io/v1 kind: CustomResourceDefinition metadata: annotations: service.beta.openshift.io/inject-cabundle: "true" ... spec: conversion: strategy: Webhook webhook: clientConfig: caBundle: <CA_BUNDLE> ...
3.3.6. Ajouter le service CA bundle à une configuration webhook mutante
Vous pouvez annoter un objet MutatingWebhookConfiguration avec service.beta.openshift.io/inject-cabundle=true pour que le champ clientConfig.caBundle de chaque webhook soit rempli avec le service CA bundle. Cela permet au serveur API Kubernetes de valider le certificat de l'autorité de certification du service utilisé pour sécuriser le point de terminaison ciblé.
Ne définissez pas cette annotation pour les configurations de webhooks d'admission qui doivent spécifier différents groupes d'autorités de certification pour différents webhooks. Si vous le faites, l'ensemble d'AC de service sera injecté pour tous les webhooks.
Procédure
Annoter la configuration du webhook en mutation avec
service.beta.openshift.io/inject-cabundle=true:$ oc annotate mutatingwebhookconfigurations <mutating_webhook_name> \1 service.beta.openshift.io/inject-cabundle=true- 1
- Remplacez
<mutating_webhook_name>par le nom de la configuration du webhook de mutation à annoter.
Par exemple, utilisez la commande suivante pour annoter la configuration du webhook de mutation
test1:$ oc annotate mutatingwebhookconfigurations test1 service.beta.openshift.io/inject-cabundle=true
Affichez la configuration du webhook de mutation pour vous assurer que le service CA bundle a été injecté :
oc get mutatingwebhookconfigurations <mutating_webhook_name> -o yaml
Le bundle CA est affiché dans le champ
clientConfig.caBundlede tous les webhooks dans la sortie YAML :apiVersion: admissionregistration.k8s.io/v1 kind: MutatingWebhookConfiguration metadata: annotations: service.beta.openshift.io/inject-cabundle: "true" ... webhooks: - myWebhook: - v1beta1 clientConfig: caBundle: <CA_BUNDLE> ...
3.3.7. Ajouter le service CA bundle à une configuration de webhook de validation
Vous pouvez annoter un objet ValidatingWebhookConfiguration avec service.beta.openshift.io/inject-cabundle=true pour que le champ clientConfig.caBundle de chaque webhook soit rempli avec le service CA bundle. Cela permet au serveur API Kubernetes de valider le certificat de l'autorité de certification du service utilisé pour sécuriser le point de terminaison ciblé.
Ne définissez pas cette annotation pour les configurations de webhooks d'admission qui doivent spécifier différents groupes d'autorités de certification pour différents webhooks. Si vous le faites, l'ensemble d'AC de service sera injecté pour tous les webhooks.
Procédure
Annoter la configuration du webhook de validation avec
service.beta.openshift.io/inject-cabundle=true:$ oc annotate validatingwebhookconfigurations <validating_webhook_name> \1 service.beta.openshift.io/inject-cabundle=true- 1
- Remplacez
<validating_webhook_name>par le nom de la configuration du webhook de validation à annoter.
Par exemple, utilisez la commande suivante pour annoter la configuration du webhook de validation
test1:$ oc annotate validatingwebhookconfigurations test1 service.beta.openshift.io/inject-cabundle=true
Affichez la configuration du webhook de validation pour vous assurer que le service CA bundle a été injecté :
oc get validatingwebhookconfigurations <validating_webhook_name> -o yaml
Le bundle CA est affiché dans le champ
clientConfig.caBundlede tous les webhooks dans la sortie YAML :apiVersion: admissionregistration.k8s.io/v1 kind: ValidatingWebhookConfiguration metadata: annotations: service.beta.openshift.io/inject-cabundle: "true" ... webhooks: - myWebhook: - v1beta1 clientConfig: caBundle: <CA_BUNDLE> ...
3.3.8. Rotation manuelle du certificat de service généré
Vous pouvez faire pivoter le certificat de service en supprimant le secret associé. La suppression du secret entraîne la création automatique d'un nouveau secret, ce qui donne lieu à un nouveau certificat.
Conditions préalables
- Un secret contenant le certificat et la paire de clés doit avoir été généré pour le service.
Procédure
Examinez le service pour déterminer le secret contenant le certificat. Celui-ci se trouve dans l'annotation
serving-cert-secret-name, comme indiqué ci-dessous.oc describe service <service_name> $ oc describe service <service_name>
Exemple de sortie
... service.beta.openshift.io/serving-cert-secret-name: <secret> ...
Supprimer le secret généré pour le service. Ce processus recréera automatiquement le secret.
oc delete secret <secret> $ oc delete secret <secret> 1- 1
- Remplacez
<secret>par le nom du secret de l'étape précédente.
Confirmez que le certificat a été recréé en obtenant le nouveau secret et en examinant le site
AGE.oc get secret <service_name>
Exemple de sortie
NAME TYPE DATA AGE <service.name> kubernetes.io/tls 2 1s
3.3.9. Rotation manuelle du certificat de l'autorité de certification de service
L'AC de service est valable 26 mois et est automatiquement actualisé lorsqu'il reste moins de 13 mois de validité.
Si nécessaire, vous pouvez actualiser manuellement l'AC de service à l'aide de la procédure suivante.
Une AC de service à rotation manuelle ne maintient pas la confiance avec l'AC de service précédente. Vous risquez de subir une interruption de service temporaire jusqu'à ce que les pods du cluster soient redémarrés, ce qui garantit que les pods utilisent les certificats de service délivrés par la nouvelle autorité de certification de service.
Conditions préalables
- Vous devez être connecté en tant qu'administrateur de cluster.
Procédure
Affichez la date d'expiration du certificat de l'autorité de certification de service actuel à l'aide de la commande suivante.
$ oc get secrets/signing-key -n openshift-service-ca \ -o template='{{index .data "tls.crt"}}' \ | base64 --decode \ | openssl x509 -noout -enddateRotation manuelle de l'autorité de certification de service. Ce processus génère une nouvelle autorité de certification de service qui sera utilisée pour signer les nouveaux certificats de service.
$ oc delete secret/signing-key -n openshift-service-ca
Pour appliquer les nouveaux certificats à tous les services, redémarrez tous les pods de votre cluster. Cette commande garantit que tous les services utilisent les certificats mis à jour.
$ for I in $(oc get ns -o jsonpath='{range .items[*]} {.metadata.name}{"\n"} {end}'); \ do oc delete pods --all -n $I; \ sleep 1; \ doneAvertissementCette commande provoque une interruption de service, car elle passe en revue et supprime tous les pods en cours d'exécution dans chaque espace de noms. Ces modules redémarreront automatiquement après avoir été supprimés.
3.4. Mise à jour du paquet d'AC
3.4.1. Comprendre le certificat de la liasse de l'autorité de certification
Les certificats proxy permettent aux utilisateurs de spécifier une ou plusieurs autorités de certification (CA) personnalisées utilisées par les composants de la plate-forme lors de l'établissement de connexions de sortie.
Le champ trustedCA de l'objet Proxy est une référence à une carte de configuration qui contient un ensemble d'autorités de certification (CA) de confiance fourni par l'utilisateur. Cet ensemble est fusionné avec l'ensemble de confiance de Red Hat Enterprise Linux CoreOS (RHCOS) et injecté dans le magasin de confiance des composants de la plate-forme qui effectuent des appels HTTPS de sortie. Par exemple, image-registry-operator appelle un registre d'images externe pour télécharger des images. Si trustedCA n'est pas spécifié, seul l'ensemble de confiance RHCOS est utilisé pour les connexions HTTPS proxy. Fournissez des certificats CA personnalisés à l'ensemble de confiance RHCOS si vous souhaitez utiliser votre propre infrastructure de certificats.
Le champ trustedCA ne doit être consommé que par un validateur de proxy. Le validateur est chargé de lire le paquet de certificats de la clé requise ca-bundle.crt et de le copier dans une carte de configuration nommée trusted-ca-bundle dans l'espace de noms openshift-config-managed. L'espace de noms de la carte de configuration référencée par trustedCA est openshift-config:
apiVersion: v1
kind: ConfigMap
metadata:
name: user-ca-bundle
namespace: openshift-config
data:
ca-bundle.crt: |
-----BEGIN CERTIFICATE-----
Custom CA certificate bundle.
-----END CERTIFICATE-----3.4.2. Remplacement du certificat de l'ensemble CA
Procédure
Créez une carte de configuration qui inclut le certificat de l'autorité de certification racine utilisé pour signer le certificat générique :
$ oc create configmap custom-ca \ --from-file=ca-bundle.crt=</path/to/example-ca.crt> \1 -n openshift-config- 1
</path/to/example-ca.crt>est le chemin d'accès au paquet de certificats de l'autorité de certification sur votre système de fichiers local.
Mettre à jour la configuration du proxy à l'échelle du cluster avec la carte de configuration nouvellement créée :
$ oc patch proxy/cluster \ --type=merge \ --patch='{"spec":{"trustedCA":{"name":"custom-ca"}}}'
Ressources supplémentaires
Chapitre 4. Types de certificats et descriptions
4.1. Certificats fournis par l'utilisateur pour le serveur API
4.1.1. Objectif
Les clients externes au cluster peuvent accéder au serveur API à l'adresse api.<cluster_name>.<base_domain>. Il se peut que vous souhaitiez que les clients accèdent au serveur API sous un autre nom d'hôte ou sans avoir à distribuer aux clients les certificats de l'autorité de certification (CA) gérés par le cluster. L'administrateur doit définir un certificat par défaut personnalisé qui sera utilisé par le serveur API lors de la diffusion de contenu.
4.1.2. Location
Les certificats fournis par l'utilisateur doivent être fournis dans un type kubernetes.io/tls Secret dans l'espace de noms openshift-config. Mettez à jour la configuration du cluster du serveur API, la ressource apiserver/cluster, pour permettre l'utilisation du certificat fourni par l'utilisateur.
4.1.3. Management
Les certificats fournis par l'utilisateur sont gérés par ce dernier.
4.1.4. Expiration
L'expiration du certificat du client du serveur API est inférieure à cinq minutes.
Les certificats fournis par l'utilisateur sont gérés par ce dernier.
4.1.5. Personnalisation
Mettez à jour le secret contenant le certificat géré par l'utilisateur si nécessaire.
Ressources supplémentaires
4.2. Certificats de procuration
4.2.1. Objectif
Les certificats proxy permettent aux utilisateurs de spécifier un ou plusieurs certificats d'autorité de certification (CA) personnalisés utilisés par les composants de la plate-forme lors de l'établissement de connexions de sortie.
Le champ trustedCA de l'objet Proxy est une référence à une carte de configuration qui contient un ensemble d'autorités de certification (CA) de confiance fourni par l'utilisateur. Cet ensemble est fusionné avec l'ensemble de confiance de Red Hat Enterprise Linux CoreOS (RHCOS) et injecté dans le magasin de confiance des composants de la plate-forme qui effectuent des appels HTTPS de sortie. Par exemple, image-registry-operator appelle un registre d'images externe pour télécharger des images. Si trustedCA n'est pas spécifié, seul l'ensemble de confiance RHCOS est utilisé pour les connexions HTTPS proxy. Fournissez des certificats CA personnalisés à l'ensemble de confiance RHCOS si vous souhaitez utiliser votre propre infrastructure de certificats.
Le champ trustedCA ne doit être consommé que par un validateur de proxy. Le validateur est chargé de lire le paquet de certificats de la clé requise ca-bundle.crt et de le copier dans une carte de configuration nommée trusted-ca-bundle dans l'espace de noms openshift-config-managed. L'espace de noms de la carte de configuration référencée par trustedCA est openshift-config:
apiVersion: v1
kind: ConfigMap
metadata:
name: user-ca-bundle
namespace: openshift-config
data:
ca-bundle.crt: |
-----BEGIN CERTIFICATE-----
Custom CA certificate bundle.
-----END CERTIFICATE-----Ressources supplémentaires
4.2.2. Gestion des certificats proxy lors de l'installation
La valeur additionalTrustBundle de la configuration de l'installateur est utilisée pour spécifier tout certificat d'autorité de certification approuvé par le proxy lors de l'installation. Par exemple :
$ cat install-config.yaml
Exemple de sortie
...
proxy:
httpProxy: http://<https://username:password@proxy.example.com:123/>
httpsProxy: https://<https://username:password@proxy.example.com:123/>
noProxy: <123.example.com,10.88.0.0/16>
additionalTrustBundle: |
-----BEGIN CERTIFICATE-----
<MY_HTTPS_PROXY_TRUSTED_CA_CERT>
-----END CERTIFICATE-----
...
4.2.3. Location
L'ensemble de confiance fourni par l'utilisateur est représenté sous la forme d'une carte de configuration. La carte de configuration est montée dans le système de fichiers des composants de la plate-forme qui effectuent des appels HTTPS de sortie. En règle générale, les opérateurs montent la carte de configuration sur /etc/pki/ca-trust/extracted/pem/tls-ca-bundle.pem, mais cela n'est pas exigé par le proxy. Un proxy peut modifier ou inspecter la connexion HTTPS. Dans les deux cas, il doit générer et signer un nouveau certificat pour la connexion.
La prise en charge complète du proxy signifie que l'on se connecte au proxy spécifié et que l'on fait confiance à toutes les signatures qu'il a générées. Il est donc nécessaire de permettre à l'utilisateur de spécifier une racine de confiance, de sorte que toute chaîne de certificats connectée à cette racine de confiance soit également fiable.
Si vous utilisez l'ensemble de confiance RHCOS, placez les certificats d'autorité de certification à l'adresse /etc/pki/ca-trust/source/anchors.
Pour plus d'informations, reportez-vous à la section Utilisation de certificats de système partagés dans la documentation de Red Hat Enterprise Linux.
4.2.4. Expiration
L'utilisateur définit la durée d'expiration de l'ensemble de confiance fourni par l'utilisateur.
Le délai d'expiration par défaut est défini par le certificat de l'autorité de certification lui-même. Il appartient à l'administrateur de l'autorité de certification de la configurer pour le certificat avant qu'il ne puisse être utilisé par OpenShift Container Platform ou RHCOS.
Red Hat ne surveille pas l'expiration des AC. Cependant, en raison de la longue durée de vie des AC, ce n'est généralement pas un problème. Cependant, il se peut que vous deviez périodiquement mettre à jour l'ensemble de confiance.
4.2.5. Services
Par défaut, tous les composants de la plate-forme qui effectuent des appels HTTPS sortants utiliseront l'ensemble de confiance RHCOS. Si trustedCA est défini, il sera également utilisé.
Tout service fonctionnant sur le nœud RHCOS peut utiliser l'ensemble de confiance du nœud.
4.2.6. Management
Ces certificats sont gérés par le système et non par l'utilisateur.
4.2.7. Personnalisation
La mise à jour de l'ensemble de confiance fourni par l'utilisateur consiste soit à
-
mise à jour des certificats codés en PEM dans la carte de configuration référencée par
trustedCA,ou -
création d'une carte de configuration dans l'espace de noms
openshift-configqui contient le nouveau paquet de confiance et mise à jour detrustedCApour faire référence au nom de la nouvelle carte de configuration.
Le mécanisme d'écriture des certificats CA dans le trust bundle du RHCOS est exactement le même que l'écriture de n'importe quel autre fichier dans le RHCOS, qui se fait par l'utilisation de configs de machine. Lorsque l'opérateur de configuration de machine (MCO) applique la nouvelle configuration de machine qui contient les nouveaux certificats d'autorité de certification, le nœud est redémarré. Lors du prochain redémarrage, le service coreos-update-ca-trust.service s'exécute sur les nœuds du RHCOS, qui mettent automatiquement à jour le trust bundle avec les nouveaux certificats d'autorité de certification. Par exemple :
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: worker
name: 50-examplecorp-ca-cert
spec:
config:
ignition:
version: 3.1.0
storage:
files:
- contents:
source: data:text/plain;charset=utf-8;base64,LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUVORENDQXh5Z0F3SUJBZ0lKQU51bkkwRDY2MmNuTUEwR0NTcUdTSWIzRFFFQkN3VUFNSUdsTVFzd0NRWUQKV1FRR0V3SlZVekVYTUJVR0ExVUVDQXdPVG05eWRHZ2dRMkZ5YjJ4cGJtRXhFREFPQmdOVkJBY01CMUpoYkdWcApBMmd4RmpBVUJnTlZCQW9NRFZKbFpDQklZWFFzSUVsdVl5NHhFekFSQmdOVkJBc01DbEpsWkNCSVlYUWdTVlF4Ckh6QVpCZ05WQkFNTUVsSmxaQ0JJWVhRZ1NWUWdVbTl2ZENCRFFURWhNQjhHQ1NxR1NJYjNEUUVKQVJZU2FXNW0KWGpDQnBURUxNQWtHQTFVRUJoTUNWVk14RnpBVkJnTlZCQWdNRGs1dmNuUm9JRU5oY205c2FXNWhNUkF3RGdZRApXUVFIREFkU1lXeGxhV2RvTVJZd0ZBWURWUVFLREExU1pXUWdTR0YwTENCSmJtTXVNUk13RVFZRFZRUUxEQXBTCkFXUWdTR0YwSUVsVU1Sc3dHUVlEVlFRRERCSlNaV1FnU0dGMElFbFVJRkp2YjNRZ1EwRXhJVEFmQmdrcWhraUcKMHcwQkNRRVdFbWx1Wm05elpXTkFjbVZrYUdGMExtTnZiVENDQVNJd0RRWUpLb1pJaHZjTkFRRUJCUUFEZ2dFUApCRENDQVFvQ2dnRUJBTFF0OU9KUWg2R0M1TFQxZzgwcU5oMHU1MEJRNHNaL3laOGFFVHh0KzVsblBWWDZNSEt6CmQvaTdsRHFUZlRjZkxMMm55VUJkMmZRRGsxQjBmeHJza2hHSUlaM2lmUDFQczRsdFRrdjhoUlNvYjNWdE5xU28KSHhrS2Z2RDJQS2pUUHhEUFdZeXJ1eTlpckxaaW9NZmZpM2kvZ0N1dDBaV3RBeU8zTVZINXFXRi9lbkt3Z1BFUwpZOXBvK1RkQ3ZSQi9SVU9iQmFNNzYxRWNyTFNNMUdxSE51ZVNmcW5obzNBakxRNmRCblBXbG82MzhabTFWZWJLCkNFTHloa0xXTVNGa0t3RG1uZTBqUTAyWTRnMDc1dkNLdkNzQ0F3RUFBYU5qTUdFd0hRWURWUjBPQkJZRUZIN1IKNXlDK1VlaElJUGV1TDhacXczUHpiZ2NaTUI4R0ExVWRJd1FZTUJhQUZIN1I0eUMrVWVoSUlQZXVMOFpxdzNQegpjZ2NaTUE4R0ExVWRFd0VCL3dRRk1BTUJBZjh3RGdZRFZSMFBBUUgvQkFRREFnR0dNQTBHQ1NxR1NJYjNEUUVCCkR3VUFBNElCQVFCRE52RDJWbTlzQTVBOUFsT0pSOCtlbjVYejloWGN4SkI1cGh4Y1pROGpGb0cwNFZzaHZkMGUKTUVuVXJNY2ZGZ0laNG5qTUtUUUNNNFpGVVBBaWV5THg0ZjUySHVEb3BwM2U1SnlJTWZXK0tGY05JcEt3Q3NhawpwU29LdElVT3NVSks3cUJWWnhjckl5ZVFWMnFjWU9lWmh0UzV3QnFJd09BaEZ3bENFVDdaZTU4UUhtUzQ4c2xqCjVlVGtSaml2QWxFeHJGektjbGpDNGF4S1Fsbk92VkF6eitHbTMyVTB4UEJGNEJ5ZVBWeENKVUh3MVRzeVRtZWwKU3hORXA3eUhvWGN3bitmWG5hK3Q1SldoMWd4VVp0eTMKLS0tLS1FTkQgQ0VSVElGSUNBVEUtLS0tLQo=
mode: 0644
overwrite: true
path: /etc/pki/ca-trust/source/anchors/examplecorp-ca.crtLe registre de confiance des machines doit également permettre de mettre à jour le registre de confiance des nœuds.
4.2.8. Renouvellement
Aucun opérateur ne peut renouveler automatiquement les certificats sur les nœuds RHCOS.
Red Hat ne surveille pas l'expiration des AC. Cependant, en raison de la longue durée de vie des AC, ce n'est généralement pas un problème. Cependant, il se peut que vous deviez périodiquement mettre à jour l'ensemble de confiance.
4.3. Certificats d'AC de service
4.3.1. Objectif
service-ca est un opérateur qui crée une autorité de certification auto-signée lors du déploiement d'un cluster OpenShift Container Platform.
4.3.2. Expiration
Un délai d'expiration personnalisé n'est pas pris en charge. L'autorité de certification auto-signée est stockée dans un secret portant le nom qualifié service-ca/signing-key dans les champs tls.crt (certificat(s)), tls.key (clé privée) et ca-bundle.crt (regroupement d'autorités de certification).
D'autres services peuvent demander un certificat de service en annotant une ressource de service avec service.beta.openshift.io/serving-cert-secret-name: <secret name>. En réponse, l'opérateur génère un nouveau certificat ( tls.crt) et une clé privée ( tls.key ) pour le secret indiqué. Le certificat est valable deux ans.
D'autres services peuvent demander que l'ensemble d'AC pour l'AC de service soit injecté dans les ressources du service API ou de la carte de configuration en annotant avec service.beta.openshift.io/inject-cabundle: true pour prendre en charge la validation des certificats générés par l'AC de service. En réponse, l'opérateur écrit son ensemble d'AC actuel dans le champ CABundle d'un service API ou en tant que service-ca.crt dans une carte de configuration.
Depuis OpenShift Container Platform 4.3.5, la rotation automatisée est supportée et est rétroportée dans certaines versions 4.2.z et 4.3.z. Pour toute version prenant en charge la rotation automatisée, l'AC de service est valide pendant 26 mois et est automatiquement actualisée lorsqu'il reste moins de 13 mois de validité. Si nécessaire, vous pouvez actualiser manuellement l'autorité de certification de service.
L'expiration de l'autorité de certification de service de 26 mois est plus longue que l'intervalle de mise à niveau prévu pour un cluster OpenShift Container Platform pris en charge, de sorte que les consommateurs de certificats d'autorité de certification de service hors plan de contrôle seront actualisés après la rotation de l'autorité de certification et avant l'expiration de l'autorité de certification de pré-rotation.
Une AC de service à rotation manuelle ne maintient pas la confiance avec l'AC de service précédente. Vous risquez de subir une interruption de service temporaire jusqu'à ce que les pods du cluster soient redémarrés, ce qui garantit que les pods utilisent les certificats de service délivrés par la nouvelle autorité de certification de service.
4.3.3. Management
Ces certificats sont gérés par le système et non par l'utilisateur.
4.3.4. Services
Les services qui utilisent des certificats d'AC de service sont les suivants
- cluster-autoscaler-operator
- opérateur de surveillance des clusters
- cluster-authentication-operator
- opérateur de registre d'images en grappe
- opérateur d'avertissement en grappe (cluster-ingress-operator)
- cluster-kube-apiserver-operator
- cluster-kube-controller-manager-operator
- cluster-kube-scheduler-operator
- opérateur de mise en réseau de clusters
- cluster-openshift-apiserver-operator
- cluster-openshift-controller-manager-operator
- opérateur de regroupement d'échantillons
- machine-config-operator
- opérateur de console
- opérateur de connaissances
- machine-api-opérateur
- gestionnaire du cycle de vie de l'opérateur
Cette liste n'est pas exhaustive.
Ressources supplémentaires
4.4. Certificats de nœuds
4.4.1. Objectif
Les certificats de nœuds sont signés par la grappe ; ils proviennent d'une autorité de certification (CA) générée par le processus d'amorçage. Après l'installation de la grappe, les certificats de nœuds font l'objet d'une rotation automatique.
4.4.2. Management
Ces certificats sont gérés par le système et non par l'utilisateur.
Ressources supplémentaires
4.5. Certificats Bootstrap
4.5.1. Objectif
Le kubelet, dans OpenShift Container Platform 4 et les versions ultérieures, utilise le certificat bootstrap situé dans /etc/kubernetes/kubeconfig pour démarrer initialement. Cette étape est suivie du processus d'initialisation du bootstrap et de l'autorisation du kubelet à créer une CSR.
Dans ce processus, le kubelet génère une CSR tout en communiquant sur le canal d'amorçage. Le gestionnaire du contrôleur signe la CSR, ce qui donne un certificat que le kubelet gère.
4.5.2. Management
Ces certificats sont gérés par le système et non par l'utilisateur.
4.5.3. Expiration
Cette AC d'amorçage est valable pendant 10 ans.
Le certificat géré par les kubelets est valable un an et fait l'objet d'une rotation automatique à environ 80 % de sa durée.
OpenShift Lifecycle Manager (OLM) ne met pas à jour les certificats des Opérateurs qu'il gère dans les environnements proxy. Ces certificats doivent être gérés par l'utilisateur à l'aide de la configuration de l'abonnement.
4.5.4. Personnalisation
Vous ne pouvez pas personnaliser les certificats d'amorçage.
4.6. certificats etcd
4.6.1. Objectif
les certificats etcd sont signés par le signataire etcd ; ils proviennent d'une autorité de certification (CA) générée par le processus d'amorçage.
4.6.2. Expiration
Les certificats de l'autorité de certification sont valables 10 ans. Les certificats de l'homologue, du client et du serveur ont une durée de validité de trois ans.
4.6.3. Management
Ces certificats ne sont gérés que par le système et font l'objet d'une rotation automatique.
4.6.4. Services
les certificats etcd sont utilisés pour la communication cryptée entre les membres etcd, ainsi que pour le trafic client crypté. Les certificats suivants sont générés et utilisés par etcd et d'autres processus qui communiquent avec etcd :
- Certificats de pairs : Utilisés pour la communication entre les membres d'etcd.
-
Certificats clients : Utilisés pour la communication cryptée entre le serveur et le client. Les certificats clients ne sont actuellement utilisés que par le serveur API, et aucun autre service ne doit se connecter directement à etcd, à l'exception du proxy. Les secrets clients (
etcd-client,etcd-metric-client,etcd-metric-signer, etetcd-signer) sont ajoutés aux espaces de nomsopenshift-config,openshift-monitoring, etopenshift-kube-apiserver. - Certificats de serveur : Utilisés par le serveur etcd pour authentifier les demandes des clients.
- Certificats de métriques : Tous les consommateurs de métriques se connectent au proxy avec des certificats de clients de métriques.
Ressources supplémentaires
4.7. Certificats OLM
4.7.1. Management
Tous les certificats des composants OpenShift Lifecycle Manager (OLM) (olm-operator, catalog-operator, packageserver, et marketplace-operator) sont gérés par le système.
Lors de l'installation d'opérateurs qui incluent des webhooks ou des services API dans leur objet ClusterServiceVersion (CSV), OLM crée et fait tourner les certificats pour ces ressources. Les certificats pour les ressources dans l'espace de noms openshift-operator-lifecycle-manager sont gérés par OLM.
OLM ne met pas à jour les certificats des opérateurs qu'il gère dans des environnements proxy. Ces certificats doivent être gérés par l'utilisateur à l'aide de la configuration de l'abonnement.
4.8. Certificats agrégés pour les clients de l'API
4.8.1. Objectif
Les certificats des clients de l'API agrégée sont utilisés pour authentifier le KubeAPIServer lors de la connexion aux serveurs de l'API agrégée.
4.8.2. Management
Ces certificats sont gérés par le système et non par l'utilisateur.
4.8.3. Expiration
Cette AC est valable pour une durée de 30 jours.
Les certificats clients gérés sont valables pendant 30 jours.
Les certificats de l'autorité de certification et des clients font l'objet d'une rotation automatique grâce à l'utilisation de contrôleurs.
4.8.4. Personnalisation
Vous ne pouvez pas personnaliser les certificats de serveur API agrégés.
4.9. Certificats d'opérateur de configuration de machine
4.9.1. Objectif
Les certificats de l'opérateur Machine Config sont utilisés pour sécuriser les connexions entre les nœuds Red Hat Enterprise Linux CoreOS (RHCOS) et le serveur Machine Config.
Currently, there is no supported way to block or restrict the machine config server endpoint. The machine config server must be exposed to the network so that newly-provisioned machines, which have no existing configuration or state, are able to fetch their configuration. In this model, the root of trust is the certificate signing requests (CSR) endpoint, which is where the kubelet sends its certificate signing request for approval to join the cluster. Because of this, machine configs should not be used to distribute sensitive information, such as secrets and certificates.
To ensure that the machine config server endpoints, ports 22623 and 22624, are secured in bare metal scenarios, customers must configure proper network policies.
Ressources supplémentaires
4.9.2. Management
Ces certificats sont gérés par le système et non par l'utilisateur.
4.9.3. Expiration
Cet AC est valable pour une durée de 10 ans.
Les certificats de service délivrés sont valables 10 ans.
4.9.4. Personnalisation
Vous ne pouvez pas personnaliser les certificats de l'opérateur de configuration de la machine.
4.10. Certificats fournis par l'utilisateur pour l'entrée par défaut
4.10.1. Objectif
Les applications sont généralement exposées à l'adresse <route_name>.apps.<cluster_name>.<base_domain>. Les adresses <cluster_name> et <base_domain> proviennent du fichier de configuration de l'installation. <route_name> est le champ hôte de la route, s'il est spécifié, ou le nom de la route. Par exemple, hello-openshift-default.apps.username.devcluster.openshift.com. hello-openshift est le nom de l'itinéraire et l'itinéraire se trouve dans l'espace de noms par défaut. Il se peut que vous souhaitiez que les clients accèdent aux applications sans qu'il soit nécessaire de leur distribuer les certificats d'autorité de certification gérés par le cluster. L'administrateur doit définir un certificat par défaut personnalisé lorsqu'il sert le contenu de l'application.
L'opérateur d'ingestion génère un certificat par défaut pour un contrôleur d'ingestion qui servira de substitut jusqu'à ce que vous configuriez un certificat par défaut personnalisé. N'utilisez pas les certificats par défaut générés par l'opérateur dans les clusters de production.
4.10.2. Location
Les certificats fournis par l'utilisateur doivent l'être dans une ressource de type tls Secret dans l'espace de noms openshift-ingress. Mettez à jour le CR IngressController dans l'espace de noms openshift-ingress-operator pour permettre l'utilisation du certificat fourni par l'utilisateur. Pour plus d'informations sur ce processus, voir Définition d'un certificat par défaut personnalisé.
4.10.3. Management
Les certificats fournis par l'utilisateur sont gérés par ce dernier.
4.10.4. Expiration
Les certificats fournis par l'utilisateur sont gérés par ce dernier.
4.10.5. Services
Les applications déployées sur le cluster utilisent des certificats fournis par l'utilisateur pour l'entrée par défaut.
4.10.6. Personnalisation
Mettez à jour le secret contenant le certificat géré par l'utilisateur si nécessaire.
Ressources supplémentaires
4.11. Certificats d'ingérence
4.11.1. Objectif
L'opérateur d'entrée utilise des certificats pour
- Sécuriser l'accès aux métriques pour Prometheus.
- Sécuriser l'accès aux itinéraires.
4.11.2. Location
Pour sécuriser l'accès aux mesures de l'opérateur d'entrée et du contrôleur d'entrée, l'opérateur d'entrée utilise des certificats de service. L'opérateur demande un certificat au contrôleur service-ca pour ses propres mesures, et le contrôleur service-ca place le certificat dans un secret nommé metrics-tls dans l'espace de noms openshift-ingress-operator. En outre, l'opérateur d'entrée demande un certificat pour chaque contrôleur d'entrée et le contrôleur service-ca place le certificat dans un secret nommé router-metrics-certs-<name>, où <name> est le nom du contrôleur d'entrée, dans l'espace de noms openshift-ingress.
Chaque contrôleur d'entrée dispose d'un certificat par défaut qu'il utilise pour les itinéraires sécurisés qui ne spécifient pas leurs propres certificats. À moins que vous n'indiquiez un certificat personnalisé, l'opérateur utilise par défaut un certificat auto-signé. L'opérateur utilise son propre certificat de signature auto-signé pour signer tout certificat par défaut qu'il génère. L'opérateur génère ce certificat de signature et le place dans un secret nommé router-ca dans l'espace de noms openshift-ingress-operator. Lorsque l'opérateur génère un certificat par défaut, il le place dans un secret nommé router-certs-<name> (où <name> est le nom du contrôleur d'entrée) dans l'espace de noms openshift-ingress.
L'opérateur d'ingestion génère un certificat par défaut pour un contrôleur d'ingestion qui servira de substitut jusqu'à ce que vous configuriez un certificat par défaut personnalisé. N'utilisez pas les certificats par défaut générés par l'opérateur dans les clusters de production.
4.11.3. Flux de travail
Figure 4.1. Flux de travail des certificats personnalisés
Figure 4.2. Flux de travail du certificat par défaut
![]() Si le champ
Si le champ defaultCertificate est vide, l'opérateur d'entrée utilise son autorité de certification auto-signée pour générer un certificat de service pour le domaine spécifié.
![]() Certificat et clé de l'autorité de certification par défaut générés par l'opérateur d'entrée. Utilisé pour signer les certificats de service par défaut générés par l'opérateur.
Certificat et clé de l'autorité de certification par défaut générés par l'opérateur d'entrée. Utilisé pour signer les certificats de service par défaut générés par l'opérateur.
![]() Dans le flux de travail par défaut, il s'agit du certificat de service par défaut avec caractère générique, créé par l'opérateur d'entrée et signé à l'aide du certificat de l'autorité de certification par défaut généré. Dans le flux de travail personnalisé, il s'agit du certificat fourni par l'utilisateur.
Dans le flux de travail par défaut, il s'agit du certificat de service par défaut avec caractère générique, créé par l'opérateur d'entrée et signé à l'aide du certificat de l'autorité de certification par défaut généré. Dans le flux de travail personnalisé, il s'agit du certificat fourni par l'utilisateur.
![]() Le déploiement du routeur. Utilise le certificat dans
Le déploiement du routeur. Utilise le certificat dans secrets/router-certs-default comme certificat de serveur frontal par défaut.
![]() Dans le flux de travail par défaut, le contenu du certificat de service par défaut (parties publique et privée) est copié ici pour permettre l'intégration OAuth. Dans le flux de travail personnalisé, il s'agit du certificat fourni par l'utilisateur.
Dans le flux de travail par défaut, le contenu du certificat de service par défaut (parties publique et privée) est copié ici pour permettre l'intégration OAuth. Dans le flux de travail personnalisé, il s'agit du certificat fourni par l'utilisateur.
![]() La partie publique (certificat) du certificat de service par défaut. Remplace la ressource
La partie publique (certificat) du certificat de service par défaut. Remplace la ressource configmaps/router-ca.
![]() L'utilisateur met à jour la configuration du proxy de cluster avec le certificat CA qui a signé le certificat de service
L'utilisateur met à jour la configuration du proxy de cluster avec le certificat CA qui a signé le certificat de service ingresscontroller. Cela permet à des composants tels que auth, console et le registre de faire confiance au certificat de service.
![]() Le groupe d'AC de confiance à l'échelle du cluster contenant les groupes d'AC combinés de Red Hat Enterprise Linux CoreOS (RHCOS) et fournis par l'utilisateur ou un groupe RHCOS uniquement si un groupe d'utilisateurs n'est pas fourni.
Le groupe d'AC de confiance à l'échelle du cluster contenant les groupes d'AC combinés de Red Hat Enterprise Linux CoreOS (RHCOS) et fournis par l'utilisateur ou un groupe RHCOS uniquement si un groupe d'utilisateurs n'est pas fourni.
![]() Le paquet de certificats CA personnalisés, qui indique à d'autres composants (par exemple,
Le paquet de certificats CA personnalisés, qui indique à d'autres composants (par exemple, auth et console) de faire confiance à un ingresscontroller configuré avec un certificat personnalisé.
![]() Le champ
Le champ trustedCA est utilisé pour référencer l'ensemble de CA fourni par l'utilisateur.
![]() L'opérateur du réseau de clusters injecte le paquet d'AC de confiance dans la carte de configuration
L'opérateur du réseau de clusters injecte le paquet d'AC de confiance dans la carte de configuration proxy-ca.
![]() OpenShift Container Platform 4.12 et les versions plus récentes utilisent
OpenShift Container Platform 4.12 et les versions plus récentes utilisent default-ingress-cert.
4.11.4. Expiration
Les délais d'expiration des certificats de l'opérateur d'entrée sont les suivants :
-
La date d'expiration des certificats de métriques créés par le contrôleur
service-caest de deux ans après la date de création. - La date d'expiration du certificat de signature de l'opérateur est de deux ans après la date de création.
- La date d'expiration des certificats de défaut générés par l'Opérateur est de deux ans après la date de création.
Vous ne pouvez pas spécifier de conditions d'expiration personnalisées pour les certificats créés par l'opérateur d'entrée ou le contrôleur service-ca.
Lors de l'installation d'OpenShift Container Platform, vous ne pouvez pas spécifier de délai d'expiration pour les certificats créés par l'opérateur d'ingestion ou le contrôleur service-ca.
4.11.5. Services
Prometheus utilise les certificats qui sécurisent les métriques.
L'opérateur d'entrée utilise son certificat de signature pour signer les certificats par défaut qu'il génère pour les contrôleurs d'entrée pour lesquels vous ne définissez pas de certificats par défaut personnalisés.
Les composants du cluster qui utilisent des routes sécurisées peuvent utiliser le certificat par défaut du contrôleur d'entrée.
L'entrée dans le cluster via une route sécurisée utilise le certificat par défaut du contrôleur d'entrée par lequel la route est accessible, à moins que la route ne spécifie son propre certificat.
4.11.6. Management
Les certificats d'entrée sont gérés par l'utilisateur. Pour plus d'informations, voir Remplacement du certificat d'entrée par défaut.
4.11.7. Renouvellement
Le contrôleur service-ca effectue une rotation automatique des certificats qu'il émet. Cependant, il est possible d'utiliser oc delete secret <secret> pour effectuer une rotation manuelle des certificats de service.
L'opérateur d'ingestion n'effectue pas de rotation de son propre certificat de signature ou des certificats par défaut qu'il génère. Les certificats par défaut générés par l'opérateur sont destinés à remplacer les certificats par défaut personnalisés que vous configurez.
4.12. Certificats des composants Monitoring et OpenShift Logging Operator
4.12.1. Expiration
Les composants de surveillance sécurisent leur trafic à l'aide de certificats d'AC de service. Ces certificats sont valables pendant deux ans et sont remplacés automatiquement lors de la rotation de l'autorité de certification de service, c'est-à-dire tous les 13 mois.
Si le certificat se trouve dans l'espace de noms openshift-monitoring ou openshift-logging, il est géré par le système et fait l'objet d'une rotation automatique.
4.12.2. Management
Ces certificats sont gérés par le système et non par l'utilisateur.
4.13. Certificats du plan de contrôle
4.13.1. Location
Les certificats du plan de contrôle sont inclus dans ces espaces de noms :
- openshift-config-managed
- openshift-kube-apiserver
- openshift-kube-apiserver-operator
- openshift-kube-controller-manager
- openshift-kube-controller-manager-operator
- openshift-kube-scheduler
4.13.2. Management
Les certificats du plan de contrôle sont gérés par le système et font l'objet d'une rotation automatique.
Dans le cas rare où vos certificats de plan de contrôle ont expiré, voir Récupération des certificats de plan de contrôle expirés.
Chapitre 5. Opérateur de conformité
5.1. Notes de mise à jour de l'opérateur de conformité
L'opérateur de conformité permet aux administrateurs d'OpenShift Container Platform de décrire l'état de conformité requis d'un cluster et leur fournit un aperçu des lacunes et des moyens d'y remédier.
Ces notes de version suivent le développement de l'opérateur de conformité dans la plateforme OpenShift Container.
Pour une vue d'ensemble de l'Opérateur de Conformité, voir Comprendre l'Opérateur de Conformité.
Pour accéder à la dernière version, voir Mise à jour de l'opérateur de conformité.
5.1.1. OpenShift Compliance Operator 1.0.0
L'avis suivant est disponible pour OpenShift Compliance Operator 1.0.0 :
5.1.1.1. Nouvelles fonctionnalités et améliorations
-
L'Opérateur de Conformité est maintenant stable et le canal de diffusion est mis à jour à
stable. Les prochaines versions suivront le principe de versionnement sémantique. Pour accéder à la dernière version, voir Mise à jour de l'Opérateur de Conformité.
5.1.1.2. Bug fixes
- Avant cette mise à jour, la métrique compliance_operator_compliance_scan_error_total avait une étiquette ERROR avec une valeur différente pour chaque message d'erreur. Avec cette mise à jour, la métrique compliance_operator_compliance_scan_error_total n'augmente pas en valeur. (OCPBUGS-1803)
-
Avant cette mise à jour, la règle
ocp4-api-server-audit-log-maxsizeentraînait l'étatFAIL. Avec cette mise à jour, le message d'erreur a été supprimé de la métrique, ce qui réduit la cardinalité de la métrique conformément aux meilleures pratiques. (OCPBUGS-7520) -
Avant cette mise à jour, la description de la règle
rhcos4-enable-fips-modeinduisait en erreur en indiquant que le système FIPS pouvait être activé après l'installation. Avec cette mise à jour, la description de la règlerhcos4-enable-fips-modeprécise que le FIPS doit être activé au moment de l'installation. (OCPBUGS-8358)
5.1.2. OpenShift Compliance Operator 0.1.61
L'avis suivant est disponible pour l'OpenShift Compliance Operator 0.1.61 :
5.1.2.1. Nouvelles fonctionnalités et améliorations
-
L'opérateur de conformité prend désormais en charge la configuration du délai d'attente pour les Scanner Pods. Le délai est spécifié dans l'objet
ScanSetting. Si l'analyse n'est pas terminée dans le délai imparti, elle recommence jusqu'à ce que le nombre maximum de tentatives soit atteint. Pour plus d'informations, consultez la section Configuration du délai d'attente de ScanSetting.
5.1.2.2. Bug fixes
-
Avant cette mise à jour, les remédiations de l'opérateur de conformité nécessitaient des variables en entrée. Les remédiations sans variables définies étaient appliquées à l'ensemble du cluster et entraînaient des nœuds bloqués, même s'il semblait que la remédiation s'appliquait correctement. Avec cette mise à jour, l'Opérateur de Conformité valide si une variable doit être fournie en utilisant
TailoredProfilepour une remédiation. (OCPBUGS-3864) -
Avant cette mise à jour, les instructions pour
ocp4-kubelet-configure-tls-cipher-suitesétaient incomplètes, obligeant les utilisateurs à affiner la requête manuellement. Avec cette mise à jour, la requête fournie dansocp4-kubelet-configure-tls-cipher-suitesrenvoie les résultats réels pour effectuer les étapes de l'audit. (OCPBUGS-3017) -
Avant cette mise à jour, les objets
ScanSettingBindingcréés sans variablesettingRefn'utilisaient pas de valeur par défaut appropriée. Avec cette mise à jour, les objetsScanSettingBindingsans variablesettingRefutilisent la valeurdefault. (OCPBUGS-3420) - Avant cette mise à jour, les paramètres réservés au système n'étaient pas générés dans les fichiers de configuration kubelet, ce qui faisait que l'opérateur de conformité ne parvenait pas à débloquer le pool de configuration de la machine. Avec cette mise à jour, l'opérateur de conformité omet les paramètres réservés au système lors de l'évaluation du pool de configuration de la machine. (OCPBUGS-4445)
-
Avant cette mise à jour, les objets
ComplianceCheckResultn'avaient pas de descriptions correctes. Avec cette mise à jour, l'opérateur de conformité extrait les informations deComplianceCheckResultde la description de la règle. (OCPBUGS-4615) - Avant cette mise à jour, l'Opérateur de Conformité ne vérifiait pas la présence de fichiers de configuration kubelet vides lors de l'analyse des configurations des machines. En conséquence, l'Opérateur de Conformité paniquait et se plantait. Avec cette mise à jour, l'Opérateur de Conformité met en œuvre une vérification améliorée de la structure de données de la configuration kubelet et ne continue que si elle est entièrement rendue. (OCPBUGS-4621)
- Avant cette mise à jour, l'opérateur de conformité générait des remédiations pour les évictions de kubelets en fonction du nom du pool de configuration de la machine et d'une période de grâce, ce qui entraînait plusieurs remédiations pour une seule règle d'éviction. Avec cette mise à jour, l'opérateur de conformité applique toutes les mesures correctives pour une seule règle. (OCPBUGS-4338)
-
Avant cette mise à jour, la ré-exécution d'analyses sur des remédiations qui se trouvaient auparavant à l'adresse
Appliedpouvait être marquée commeOutdatedaprès la ré-exécution des analyses, bien que le contenu de la remédiation n'ait pas été modifié. La comparaison des analyses ne prenait pas correctement en compte les métadonnées de la remédiation. Avec cette mise à jour, les remédiations conservent le statutAppliedgénéré précédemment. (OCPBUGS-6710) -
Avant cette mise à jour, une régression se produisait lors de la création d'un site
ScanSettingBindingutilisant un siteTailoredProfileavec un siteMachineConfigPoolqui n'était pas par défaut et qui marquait le siteScanSettingBindingen tant que siteFailed. Avec cette mise à jour, la fonctionnalité est rétablie et lesScanSettingBindingpersonnalisés utilisant unTailoredProfilefonctionnent correctement. (OCPBUGS-6827) Avant cette mise à jour, certains paramètres de configuration des kubelets n'avaient pas de valeurs par défaut. Avec cette mise à jour, les paramètres suivants contiennent des valeurs par défaut (OCPBUGS-6708) :
-
ocp4-cis-kubelet-enable-streaming-connections -
ocp4-cis-kubelet-eviction-thresholds-set-hard-imagefs-available -
ocp4-cis-kubelet-eviction-thresholds-set-hard-imagefs-inodesfree -
ocp4-cis-kubelet-eviction-thresholds-set-hard-memory-available -
ocp4-cis-kubelet-eviction-thresholds-set-hard-nodefs-available
-
-
Avant cette mise à jour, la règle
selinux_confinement_of_daemonsne fonctionnait pas sur le kubelet en raison des permissions nécessaires à son exécution. Avec cette mise à jour, la règleselinux_confinement_of_daemonsest désactivée. (OCPBUGS-6968)
5.1.3. OpenShift Compliance Operator 0.1.59
L'avis suivant est disponible pour l'OpenShift Compliance Operator 0.1.59 :
5.1.3.1. Nouvelles fonctionnalités et améliorations
-
L'opérateur de conformité prend désormais en charge les profils PCI-DSS (Payment Card Industry Data Security Standard)
ocp4-pci-dssetocp4-pci-dss-nodesur l'architectureppc64le.
5.1.3.2. Bug fixes
-
Auparavant, l'Opérateur de Conformité ne prenait pas en charge les profils Payment Card Industry Data Security Standard (PCI DSS)
ocp4-pci-dssetocp4-pci-dss-nodesur différentes architectures telles queppc64le. Désormais, l'opérateur de conformité prend en charge les profilsocp4-pci-dssetocp4-pci-dss-nodesur l'architectureppc64le. (OCPBUGS-3252) -
Auparavant, après la récente mise à jour vers la version 0.1.57, le compte de service
rerunner(SA) n'était plus détenu par la version de service du cluster (CSV), ce qui entraînait la suppression du SA lors de la mise à niveau de l'opérateur. Désormais, le CSV possède le SArerunnerdans la version 0.1.59, et les mises à niveau à partir d'une version antérieure n'entraîneront pas de SA manquant. (OCPBUGS-3452) -
Dans la version 0.1.57, l'opérateur a démarré le point de terminaison des métriques du contrôleur en écoutant sur le port
8080. Cela a donné lieu à des alertesTargetDowncar le port attendu par la surveillance des clusters est8383. Avec la version 0.1.59, l'opérateur lance l'écoute sur le port8383comme prévu. (OCPBUGS-3097)
5.1.4. OpenShift Compliance Operator 0.1.57
L'avis suivant est disponible pour l'OpenShift Compliance Operator 0.1.57 :
5.1.4.1. Nouvelles fonctionnalités et améliorations
-
KubeletConfigvérifie le passage du typeNodeau typePlatform.KubeletConfigvérifie la configuration par défaut du typeKubeletConfig. Les fichiers de configuration sont regroupés à partir de tous les nœuds dans un emplacement unique par pool de nœuds. Voir Évaluation des règlesKubeletConfigpar rapport aux valeurs de configuration par défaut. -
La ressource personnalisée
ScanSettingpermet désormais aux utilisateurs de remplacer les limites de CPU et de mémoire par défaut des modules de numérisation par le biais de l'attributscanLimits. Pour plus d'informations, voir Augmenter les limites de ressources de l'opérateur de conformité. -
Un objet
PriorityClasspeut désormais être défini par le biais deScanSetting. Cela permet de s'assurer que l'opérateur de conformité est prioritaire et de minimiser les risques de non-conformité de la grappe. Pour plus d'informations, voir DéfinirPriorityClasspour les analysesScanSetting.
5.1.4.2. Bug fixes
-
Auparavant, l'opérateur de conformité codait en dur les notifications dans l'espace de noms par défaut
openshift-compliance. Si l'opérateur était installé dans un espace de noms autre que celui par défaut, les notifications ne fonctionnaient pas comme prévu. Désormais, les notifications fonctionnent dans les espaces de noms autres queopenshift-compliance. (BZ#2060726) - Auparavant, l'opérateur de conformité n'était pas en mesure d'évaluer les configurations par défaut utilisées par les objets kubelet, ce qui entraînait des résultats inexacts et des faux positifs. Cette nouvelle fonctionnalité évalue la configuration des kubelets et produit désormais un rapport précis. (BZ#2075041)
-
Auparavant, l'opérateur de conformité signalait la règle
ocp4-kubelet-configure-event-creationdans un étatFAILaprès avoir appliqué une remédiation automatique parce que la valeureventRecordQPSétait supérieure à la valeur par défaut. Désormais, la remédiation de la règleocp4-kubelet-configure-event-creationdéfinit la valeur par défaut et la règle s'applique correctement. (BZ#2082416) -
La règle
ocp4-configure-network-policiesnécessite une intervention manuelle pour être efficace. De nouvelles instructions descriptives et des mises à jour de la règle augmentent l'applicabilité de la règleocp4-configure-network-policiespour les clusters utilisant des CNI Calico. (BZ#2091794) -
Auparavant, l'opérateur de conformité ne nettoyait pas les pods utilisés pour analyser l'infrastructure lors de l'utilisation de l'option
debug=truedans les paramètres d'analyse. Les pods restaient donc sur le cluster même après la suppression deScanSettingBinding. Désormais, les pods sont toujours supprimés lorsqu'unScanSettingBindingest supprimé.(BZ#2092913) -
Auparavant, l'opérateur de conformité utilisait une ancienne version de la commande
operator-sdkqui provoquait des alertes concernant des fonctionnalités obsolètes. Maintenant, une version mise à jour de la commandeoperator-sdkest incluse et il n'y a plus d'alertes concernant des fonctionnalités obsolètes. (BZ#2098581) - Auparavant, l'opérateur de conformité ne parvenait pas à appliquer les remédiations s'il ne pouvait pas déterminer la relation entre les configurations des kubelets et des machines. Désormais, l'opérateur de conformité a amélioré la gestion des configurations de machines et est capable de déterminer si une configuration de kubelet est un sous-ensemble d'une configuration de machine. (BZ#2102511)
-
Auparavant, la règle pour
ocp4-cis-node-master-kubelet-enable-cert-rotationne décrivait pas correctement les critères de réussite. Par conséquent, les exigences pourRotateKubeletClientCertificaten'étaient pas claires. Désormais, la règle pourocp4-cis-node-master-kubelet-enable-cert-rotationproduit un rapport précis quelle que soit la configuration présente dans le fichier de configuration du kubelet. (BZ#2105153) - Auparavant, la règle de vérification des délais d'inactivité des flux ne prenait pas en compte les valeurs par défaut, ce qui entraînait des rapports de règles inexacts. Désormais, des contrôles plus robustes garantissent une plus grande précision des résultats basés sur les valeurs de configuration par défaut. (BZ#2105878)
-
Auparavant, l'Opérateur de Conformité ne parvenait pas à récupérer les ressources de l'API lors de l'analyse des configurations de machines sans spécifications Ignition, ce qui provoquait le plantage en boucle des processus
api-check-pods. Désormais, l'Opérateur de Conformité gère correctement les pools de configurations de machines qui n'ont pas de spécifications d'allumage. (BZ#2117268) -
Auparavant, les règles évaluant la configuration
modprobeéchouaient même après l'application des remédiations en raison d'une incohérence dans les valeurs de la configurationmodprobe. Désormais, les mêmes valeurs sont utilisées pour la configurationmodprobedans les vérifications et les remédiations, ce qui garantit des résultats cohérents. (BZ#2117747)
5.1.4.3. Dépréciations
-
Le fait de spécifier Install into all namespaces in the cluster ou de définir la variable d'environnement
WATCH_NAMESPACESsur""n'affecte plus tous les espaces de noms. Toutes les ressources API installées dans des espaces de noms non spécifiés au moment de l'installation de l'Opérateur de conformité ne sont plus opérationnelles. Les ressources API peuvent nécessiter une création dans l'espace de noms sélectionné ou dans l'espace de nomsopenshift-compliancepar défaut. Ce changement améliore l'utilisation de la mémoire de l'Opérateur de Conformité.
5.1.5. OpenShift Compliance Operator 0.1.53
L'avis suivant est disponible pour l'OpenShift Compliance Operator 0.1.53 :
5.1.5.1. Bug fixes
-
Auparavant, la règle
ocp4-kubelet-enable-streaming-connectionscontenait une comparaison de variables incorrecte, ce qui entraînait des résultats d'analyse faussement positifs. Désormais, l'opérateur de conformité fournit des résultats d'analyse précis lorsqu'il définitstreamingConnectionIdleTimeout. (BZ#2069891) -
Auparavant, la propriété du groupe pour
/etc/openvswitch/conf.dbétait incorrecte sur les architectures IBM Z, ce qui entraînait des échecs du contrôle deocp4-cis-node-worker-file-groupowner-ovs-conf-db. Désormais, le contrôle est marquéNOT-APPLICABLEsur les systèmes d'architecture IBM Z. (BZ#2072597) -
Auparavant, la règle
ocp4-cis-scc-limit-container-allowed-capabilitiesétait signalée dans l'étatFAILen raison de données incomplètes concernant les règles de contraintes de contexte de sécurité (SCC) dans le déploiement. Désormais, le résultat estMANUAL, ce qui est cohérent avec d'autres contrôles nécessitant une intervention humaine. (BZ#2077916) Auparavant, les règles suivantes ne tenaient pas compte des chemins de configuration supplémentaires pour les serveurs API et les certificats et clés TLS, ce qui entraînait des échecs même si les certificats et les clés étaient correctement définis :
-
ocp4-cis-api-server-kubelet-client-cert -
ocp4-cis-api-server-kubelet-client-key -
ocp4-cis-kubelet-configure-tls-cert -
ocp4-cis-kubelet-configure-tls-key
Désormais, les règles produisent des rapports précis et respectent les chemins d'accès aux fichiers hérités spécifiés dans le fichier de configuration de la kubelet. (BZ#2079813)
-
-
Auparavant, la règle
content_rule_oauth_or_oauthclient_inactivity_timeoutne tenait pas compte d'un délai configurable défini par le déploiement lors de l'évaluation de la conformité des délais. La règle échouait donc même si le délai était valide. Désormais, l'opérateur de conformité utilise la variablevar_oauth_inactivity_timeoutpour définir la durée du délai d'attente. (BZ#2081952) - Auparavant, l'opérateur de conformité utilisait des autorisations administratives sur des espaces de noms qui n'étaient pas étiquetés de manière appropriée pour une utilisation privilégiée, ce qui entraînait des messages d'avertissement concernant des violations du niveau de sécurité des pods. Désormais, l'opérateur de conformité dispose des étiquettes d'espace de noms appropriées et des ajustements de permissions pour accéder aux résultats sans enfreindre les permissions. (BZ#2088202)
-
Auparavant, l'application de remédiations automatiques pour
rhcos4-high-master-sysctl-kernel-yama-ptrace-scopeetrhcos4-sysctl-kernel-core-patternentraînait l'échec de ces règles dans les résultats de l'analyse, même si elles avaient été remédiées. Désormais, les règles signalentPASSavec précision, même après l'application de mesures correctives.(BZ#2094382) -
Auparavant, l'opérateur de conformité échouait dans un état
CrashLoopBackoffen raison d'exceptions hors mémoire. Désormais, l'Opérateur de Conformité est amélioré pour gérer de grands ensembles de données de configuration de machine en mémoire et fonctionner correctement. (BZ#2094854)
5.1.5.2. Problème connu
Lorsque
"debug":trueest défini dans l'objetScanSettingBinding, les pods générés par l'objetScanSettingBindingne sont pas supprimés lorsque cette liaison est supprimée. Pour contourner ce problème, exécutez la commande suivante pour supprimer les pods restants :$ oc delete pods -l compliance.openshift.io/scan-name=ocp4-cis
5.1.6. OpenShift Compliance Operator 0.1.52
L'avis suivant est disponible pour l'OpenShift Compliance Operator 0.1.52 :
5.1.6.1. Nouvelles fonctionnalités et améliorations
- Le profil FedRAMP high SCAP est désormais disponible pour une utilisation dans les environnements OpenShift Container Platform. Pour plus d'informations, voir Profils de conformité pris en charge.
5.1.6.2. Bug fixes
-
Auparavant, le conteneur
OpenScapse bloquait en raison d'un problème de permission de montage dans un environnement de sécurité où la capacitéDAC_OVERRIDEest abandonnée. Désormais, les autorisations de montage des exécutables sont appliquées à tous les utilisateurs. (BZ#2082151) -
Auparavant, la règle de conformité
ocp4-configure-network-policiespouvait être configurée commeMANUAL. Désormais, la règle de conformitéocp4-configure-network-policiesest configurée sous la formeAUTOMATIC. (BZ#2072431) - Auparavant, le Cluster Autoscaler ne parvenait pas à se mettre à l'échelle parce que les pods d'analyse de l'opérateur de conformité n'étaient jamais supprimés après une analyse. Désormais, les modules sont supprimés de chaque nœud par défaut, sauf s'ils sont explicitement sauvegardés à des fins de débogage. (BZ#2075029)
-
Auparavant, l'application de l'opérateur de conformité à l'adresse
KubeletConfigentraînait l'entrée du nœud dans l'étatNotReadyen raison de la désactivation prématurée des pools de configuration de machines. Désormais, les pools de configuration de machines sont désactivés de manière appropriée et le nœud fonctionne correctement. (BZ#2071854) -
Auparavant, l'opérateur de configuration des machines utilisait le code
base64au lieu deurl-encodeddans la dernière version, ce qui entraînait l'échec de la remédiation de l'opérateur de conformité. Désormais, l'opérateur de conformité vérifie l'encodage pour gérer les codes de configuration machinebase64eturl-encodedet la remédiation s'applique correctement. (BZ#2082431)
5.1.6.3. Problème connu
Lorsque
"debug":trueest défini dans l'objetScanSettingBinding, les pods générés par l'objetScanSettingBindingne sont pas supprimés lorsque cette liaison est supprimée. Pour contourner ce problème, exécutez la commande suivante pour supprimer les pods restants :$ oc delete pods -l compliance.openshift.io/scan-name=ocp4-cis
5.1.7. OpenShift Compliance Operator 0.1.49
L'avis suivant est disponible pour l'OpenShift Compliance Operator 0.1.49 :
5.1.7.1. Nouvelles fonctionnalités et améliorations
L'opérateur de conformité est désormais pris en charge sur les architectures suivantes :
- IBM Power
- IBM Z
- IBM LinuxONE
5.1.7.2. Bug fixes
-
Auparavant, le contenu de
openshift-compliancen'incluait pas les contrôles spécifiques à la plateforme pour les types de réseau. Par conséquent, les contrôles spécifiques à OVN et SDN s'affichaient commefailedau lieu denot-applicableen fonction de la configuration du réseau. Désormais, les nouvelles règles contiennent des contrôles de plateforme pour les règles de mise en réseau, ce qui permet une évaluation plus précise des contrôles spécifiques au réseau. (BZ#1994609) -
Auparavant, la règle
ocp4-moderate-routes-protected-by-tlsvérifiait incorrectement les paramètres TLS, ce qui entraînait l'échec de la règle, même si la connexion était sécurisée par le protocole SSL/TLS. Désormais, la vérification évalue correctement les paramètres TLS qui sont cohérents avec les conseils de mise en réseau et les recommandations de profil. (BZ#2002695) -
Auparavant,
ocp-cis-configure-network-policies-namespaceutilisait la pagination lors de la demande d'espaces de noms. Cela entraînait l'échec de la règle car les déploiements tronquaient les listes de plus de 500 espaces de noms. Désormais, la liste complète des espaces de noms est demandée et la règle de vérification des stratégies réseau configurées fonctionne pour les déploiements comportant plus de 500 espaces de noms. (BZ#2038909) -
Auparavant, les remédiations utilisant les macros
sshd jinjaétaient codées en dur sur des configurations sshd spécifiques. En conséquence, les configurations n'étaient pas cohérentes avec le contenu que les règles vérifiaient et la vérification échouait. Désormais, la configuration sshd est paramétrée et les règles s'appliquent avec succès. (BZ#2049141) -
Auparavant, le site
ocp4-cluster-version-operator-verify-integrityvérifiait toujours la première entrée dans l'historique du Cluter Version Operator (CVO). Par conséquent, la mise à niveau échouait dans les situations où les versions suivantes de {nom-du-produit} étaient vérifiées. Désormais, le résultat du contrôle de conformité pourocp4-cluster-version-operator-verify-integrityest capable de détecter les versions vérifiées et est précis avec l'historique CVO. (BZ#2053602) -
Auparavant, la règle
ocp4-api-server-no-adm-ctrl-plugins-disabledne vérifiait pas la présence d'une liste de plugins de contrôleurs d'admission vides. Par conséquent, la règle échouait toujours, même si tous les plugins d'admission étaient activés. Désormais, la règleocp4-api-server-no-adm-ctrl-plugins-disabledfait l'objet d'une vérification plus rigoureuse et passe avec succès lorsque tous les plugins de contrôleurs d'admission sont activés. (BZ#2058631) - Auparavant, les analyses ne contenaient pas de vérifications de plate-forme pour l'exécution contre des nœuds de travail Linux. Par conséquent, l'exécution d'analyses sur des nœuds de travail qui n'étaient pas basés sur Linux entraînait une boucle d'analyse sans fin. Désormais, l'analyse est planifiée de manière appropriée en fonction du type de plate-forme et les étiquettes se terminent avec succès. (BZ#2056911)
5.1.8. OpenShift Compliance Operator 0.1.48
L'avis suivant est disponible pour l'OpenShift Compliance Operator 0.1.48 :
5.1.8.1. Bug fixes
-
Auparavant, certaines règles associées à des définitions OVAL (Open Vulnerability and Assessment Language) étendues avaient un
checkTypedeNone. Cela était dû au fait que l'opérateur de conformité ne traitait pas les définitions OVAL étendues lors de l'analyse des règles. Avec cette mise à jour, le contenu des définitions OVAL étendues est analysé de sorte que ces règles ont maintenant uncheckTypedeNodeouPlatform. (BZ#2040282) -
Auparavant, un objet
MachineConfigcréé manuellement pourKubeletConfigempêchait la génération d'un objetKubeletConfigpour la remédiation, laissant la remédiation dans l'étatPending. Avec cette version, un objetKubeletConfigest créé par la remédiation, même s'il existe un objetMachineConfigcréé manuellement pourKubeletConfig. Par conséquent, les remédiationsKubeletConfigfonctionnent désormais comme prévu. (BZ#2040401)
5.1.9. OpenShift Compliance Operator 0.1.47
L'avis suivant est disponible pour l'OpenShift Compliance Operator 0.1.47 :
5.1.9.1. Nouvelles fonctionnalités et améliorations
L'opérateur de conformité prend désormais en charge les critères de conformité suivants pour la norme de sécurité des données de l'industrie des cartes de paiement (PCI DSS) :
- ocp4-pci-dss
- ocp4-pci-dss-node
- Des règles et des remédiations supplémentaires pour le niveau d'impact modéré de FedRAMP sont ajoutées aux profils OCP4-moderate, OCP4-moderate-node et rhcos4-moderate.
- Les remédiations pour KubeletConfig sont maintenant disponibles dans les profils au niveau des nœuds.
5.1.9.2. Bug fixes
Auparavant, si votre cluster exécutait OpenShift Container Platform 4.6 ou une version antérieure, les remédiations pour les règles liées à USBGuard échouaient pour le profil modéré. En effet, les remédiations créées par l'opérateur de conformité étaient basées sur une ancienne version d'USBGuard qui ne prenait pas en charge les répertoires de dépôt. Désormais, les remédiations invalides pour les règles liées à USBGuard ne sont pas créées pour les clusters utilisant OpenShift Container Platform 4.6. Si votre cluster utilise OpenShift Container Platform 4.6, vous devez créer manuellement des remédiations pour les règles liées à USBGuard.
En outre, les mesures correctives ne sont créées que pour les règles qui satisfont aux exigences minimales en matière de version. (BZ#1965511)
-
Auparavant, lors du rendu des remédiations, l'opérateur de conformité vérifiait que la remédiation était bien formée en utilisant une expression régulière trop stricte. Par conséquent, certaines mesures correctives, telles que celles qui rendent
sshd_config, ne passaient pas le contrôle de l'expression régulière et n'étaient donc pas créées. L'expression régulière s'est avérée inutile et a été supprimée. Les remédiations sont maintenant rendues correctement. (BZ#2033009)
5.1.10. OpenShift Compliance Operator 0.1.44
L'avis suivant est disponible pour l'OpenShift Compliance Operator 0.1.44 :
5.1.10.1. Nouvelles fonctionnalités et améliorations
-
Dans cette version, l'option
strictNodeScanest désormais ajoutée aux CRComplianceScan,ComplianceSuiteetScanSetting. Cette option est définie par défaut surtrue, ce qui correspond au comportement précédent, où une erreur se produisait si une analyse ne pouvait pas être programmée sur un nœud. En définissant l'option surfalse, l'opérateur de conformité peut être plus permissif en ce qui concerne la programmation des analyses. Les environnements avec des nœuds éphémères peuvent définir la valeurstrictNodeScansur false, ce qui permet à une analyse de conformité de se dérouler, même si certains nœuds du cluster ne sont pas disponibles pour la planification. -
Vous pouvez maintenant personnaliser le nœud utilisé pour planifier la charge de travail du serveur de résultats en configurant les attributs
nodeSelectorettolerationsde l'objetScanSetting. Ces attributs sont utilisés pour placer le podResultServer, le pod utilisé pour monter un volume de stockage PV et stocker les résultats bruts ARF (Asset Reporting Format). Auparavant, les paramètresnodeSelectorettolerationssélectionnaient par défaut l'un des nœuds du plan de contrôle et toléraientnode-role.kubernetes.io/master taint, ce qui ne fonctionnait pas dans les environnements où les nœuds du plan de contrôle ne sont pas autorisés à monter des PV. Cette fonctionnalité vous permet de sélectionner le nœud et de tolérer une altération différente dans ces environnements. -
L'opérateur de conformité peut maintenant remédier aux objets
KubeletConfig. - Un commentaire contenant un message d'erreur est désormais ajouté pour aider les développeurs de contenu à faire la différence entre les objets qui n'existent pas dans le cluster et les objets qui ne peuvent pas être récupérés.
-
Les objets de règle contiennent désormais deux nouveaux attributs,
checkTypeetdescription. Ces attributs vous permettent de déterminer si la règle concerne un contrôle de nœud ou un contrôle de plate-forme, et vous permettent également d'examiner ce que fait la règle. -
Cette amélioration supprime l'obligation d'étendre un profil existant pour créer un profil sur mesure. Cela signifie que le champ
extendsdans le CRDTailoredProfilen'est plus obligatoire. Vous pouvez désormais sélectionner une liste d'objets de règles pour créer un profil personnalisé. Notez que vous devez choisir si votre profil s'applique aux nœuds ou à la plate-forme en définissant l'annotationcompliance.openshift.io/product-type:ou en définissant le suffixe-nodepour le CRTailoredProfile. -
Dans cette version, l'opérateur de conformité est désormais en mesure de programmer des analyses sur tous les nœuds, indépendamment de leurs taches. Auparavant, les pods d'analyse ne toléraient que
node-role.kubernetes.io/master taint, ce qui signifie qu'ils s'exécutaient soit sur des nœuds sans taint, soit uniquement sur des nœuds avec le taintnode-role.kubernetes.io/master. Dans les déploiements qui utilisent des taints personnalisés pour leurs nœuds, les analyses n'étaient pas planifiées sur ces nœuds. Désormais, les pods d'analyse tolèrent tous les taints de nœuds. Dans cette version, l'opérateur de conformité prend en charge les profils de sécurité suivants de la North American Electric Reliability Corporation (NERC) :
- ocp4-nerc-cip
- ocp4-nerc-cip-node
- rhcos4-nerc-cip
- Dans cette version, l'opérateur de conformité prend en charge la ligne de base NIST 800-53 Moderate-Impact pour le profil de sécurité Red Hat OpenShift - Node level, ocp4-moderate-node.
5.1.10.2. Modélisation et utilisation de variables
- Dans cette version, le modèle de remédiation autorise désormais les variables à valeurs multiples.
-
Avec cette mise à jour, l'opérateur de conformité peut modifier les mesures correctives en fonction des variables définies dans le profil de conformité. Ceci est utile pour les remédiations qui incluent des valeurs spécifiques au déploiement telles que les délais, les noms d'hôtes des serveurs NTP, ou similaires. En outre, les objets
ComplianceCheckResultutilisent désormais l'étiquettecompliance.openshift.io/check-has-valuequi répertorie les variables utilisées par un contrôle.
5.1.10.3. Bug fixes
- Auparavant, lors de l'exécution d'un balayage, une fin inattendue se produisait dans l'un des conteneurs de balayage des pods. Dans cette version, l'opérateur de conformité utilise la dernière version d'OpenSCAP 1.3.5 pour éviter un crash.
-
Auparavant, l'utilisation de
autoReplyRemediationspour appliquer des mesures correctives déclenchait une mise à jour des nœuds du cluster. Cette opération était gênante si certaines mesures correctives n'incluaient pas toutes les variables d'entrée requises. Désormais, s'il manque à une remédiation une ou plusieurs variables d'entrée requises, elle se voit attribuer l'étatNeedsReview. Si une ou plusieurs remédiations sont dans l'étatNeedsReview, le pool de configuration de la machine reste en pause et les remédiations ne sont pas appliquées tant que toutes les variables requises n'ont pas été définies. Cela permet de minimiser les perturbations sur les nœuds. - Le rôle RBAC et le Role Binding utilisés pour les métriques Prometheus sont remplacés par 'ClusterRole' et 'ClusterRoleBinding' afin de garantir que la surveillance fonctionne sans personnalisation.
-
Auparavant, si une erreur survenait lors de l'analyse d'un profil, les objets règles ou variables étaient retirés et supprimés du profil. Désormais, si une erreur se produit pendant l'analyse, le site
profileparserannote l'objet avec une annotation temporaire qui empêche la suppression de l'objet jusqu'à la fin de l'analyse. (BZ#1988259) -
Auparavant, une erreur se produisait si les titres ou les descriptions étaient absents d'un profil personnalisé. La norme XCCDF exigeant des titres et des descriptions pour les profils personnalisés, les titres et les descriptions doivent désormais être définis dans les CR de
TailoredProfile. -
Auparavant, lors de l'utilisation de profils personnalisés, les valeurs des variables
TailoredProfilene pouvaient être définies qu'à l'aide d'un ensemble de sélection spécifique. Cette restriction est désormais supprimée et les variablesTailoredProfilepeuvent être réglées sur n'importe quelle valeur.
5.1.11. Notes de publication pour Compliance Operator 0.1.39
L'avis suivant est disponible pour l'OpenShift Compliance Operator 0.1.39 :
5.1.11.1. Nouvelles fonctionnalités et améliorations
- Auparavant, l'opérateur de conformité n'était pas en mesure d'analyser les références à la norme de sécurité des données de l'industrie des cartes de paiement (PCI DSS). Désormais, l'opérateur peut analyser le contenu de conformité fourni avec les profils PCI DSS.
- Auparavant, l'Opérateur de Conformité n'était pas en mesure d'exécuter les règles pour le contrôle de l'AU-5 dans le profil modéré. Désormais, l'opérateur dispose d'une autorisation lui permettant de lire les objets Prometheusrules.monitoring.coreos.com et d'exécuter les règles qui couvrent le contrôle de l'AU-5 dans le profil modéré.
5.1.12. Ressources supplémentaires
5.2. Profils de conformité pris en charge
Plusieurs profils sont disponibles dans le cadre de l'installation de l'opérateur de conformité (CO).
L'opérateur de conformité pourrait rapporter des résultats incorrects sur les plateformes gérées, telles que OpenShift Dedicated, Red Hat OpenShift Service on AWS, et Azure Red Hat OpenShift. Pour plus d'informations, consultez la solution #6983418 de la base de connaissances de Red Hat.
5.2.1. Profils de conformité
L'opérateur de conformité fournit les profils de conformité suivants :
Tableau 5.1. Profils de conformité pris en charge
| Profile | Titre du profil | Application | Conformité Version de l'opérateur | Critères de conformité de l'industrie | Architectures prises en charge |
|---|---|---|---|---|---|
| ocp4-cis | CIS Red Hat OpenShift Container Platform 4 Benchmark | Plate-forme | 0.1.39 | CIS Benchmarks ™ [1] |
|
| ocp4-cis-node | CIS Red Hat OpenShift Container Platform 4 Benchmark | Nœud [2] | 0.1.39 | CIS Benchmarks ™ [1] |
|
| ocp4-e8 | Centre australien de cybersécurité (ACSC) Huit éléments essentiels | Plate-forme | 0.1.39 |
| |
| ocp4-modéré | NIST 800-53 Baseline à impact modéré pour Red Hat OpenShift - Niveau de la plateforme | Plate-forme | 0.1.39 |
| |
| rhcos4-e8 | Centre australien de cybersécurité (ACSC) Huit éléments essentiels | Nœud | 0.1.39 |
| |
| rhcos4-modéré | Base de référence NIST 800-53 à impact modéré pour Red Hat Enterprise Linux CoreOS | Nœud | 0.1.39 |
| |
| ocp4-moderate-node | NIST 800-53 Baseline à impact modéré pour Red Hat OpenShift - Niveau Node | Nœud [2] | 0.1.44 |
| |
| ocp4-nerc-cip | Profil de normes de cybersécurité de la North American Electric Reliability Corporation (NERC) sur la protection des infrastructures critiques (CIP) pour la plateforme Red Hat OpenShift Container Platform - niveau plateforme | Plate-forme | 0.1.44 |
| |
| ocp4-nerc-cip-node | Profil de normes de cybersécurité de la North American Electric Reliability Corporation (NERC) sur la protection des infrastructures critiques (CIP) pour la plateforme de conteneurs Red Hat OpenShift - niveau Node | Nœud [2] | 0.1.44 |
| |
| rhcos4-nerc-cip | Profil de normes de cybersécurité de la North American Electric Reliability Corporation (NERC) Critical Infrastructure Protection (CIP) pour Red Hat Enterprise Linux CoreOS | Nœud | 0.1.44 |
| |
| ocp4-pci-dss | Base de contrôle PCI-DSS v3.2.1 pour Red Hat OpenShift Container Platform 4 | Plate-forme | 0.1.47 | Bibliothèque de documents du Conseil des normes de sécurité PCI |
|
| ocp4-pci-dss-node | Base de contrôle PCI-DSS v3.2.1 pour Red Hat OpenShift Container Platform 4 | Nœud [2] | 0.1.47 | Bibliothèque de documents du Conseil des normes de sécurité PCI |
|
| ocp4-haut | NIST 800-53 High-Impact Baseline for Red Hat OpenShift - Niveau de la plateforme | Plate-forme | 0.1.52 |
| |
| ocp4-high-node | NIST 800-53 High-Impact Baseline for Red Hat OpenShift - Node level (ligne de base à fort impact pour Red Hat OpenShift - niveau nœud) | Nœud [2] | 0.1.52 |
| |
| rhcos4-haut | NIST 800-53 High-Impact Baseline pour Red Hat Enterprise Linux CoreOS | Nœud | 0.1.52 |
|
-
Pour trouver le CIS OpenShift Container Platform v4 Benchmark, allez sur CIS Benchmarks et tapez
Kubernetesdans le champ de recherche. Cliquez sur Kubernetes puis sur Download Latest CIS Benchmark, où vous pourrez vous enregistrer pour télécharger le benchmark. - Les profils de nœuds doivent être utilisés avec le profil de plate-forme correspondant. Pour plus d'informations, voir les types de profil de l'opérateur de conformité.
5.2.2. Ressources supplémentaires
5.3. Installation de l'opérateur de conformité
Avant de pouvoir utiliser l'opérateur de conformité, vous devez vous assurer qu'il est déployé dans le cluster.
L'opérateur de conformité pourrait rapporter des résultats incorrects sur les plateformes gérées, telles que OpenShift Dedicated, Red Hat OpenShift Service on AWS, et Microsoft Azure Red Hat OpenShift. Pour plus d'informations, consultez la solution #6983418 de la base de connaissances de Red Hat.
5.3.1. Installation de l'Opérateur de Conformité via la console web
Conditions préalables
-
Vous devez avoir les privilèges de
admin.
Procédure
- Dans la console web d'OpenShift Container Platform, naviguez vers Operators → OperatorHub.
- Recherchez l'opérateur de conformité, puis cliquez sur Install.
-
Conservez la sélection par défaut de Installation mode et namespace pour vous assurer que l'opérateur sera installé dans l'espace de noms
openshift-compliance. - Cliquez sur Install.
Vérification
Pour confirmer que l'installation a réussi :
- Naviguez jusqu'à la page Operators → Installed Operators.
-
Vérifiez que l'opérateur de conformité est installé dans l'espace de noms
openshift-complianceet que son statut estSucceeded.
Si l'opérateur n'est pas installé correctement :
-
Naviguez jusqu'à la page Operators → Installed Operators et vérifiez que la colonne
Statusne contient pas d'erreurs ou de défaillances. -
Naviguez jusqu'à la page Workloads → Pods et vérifiez les journaux de tous les pods du projet
openshift-compliancequi signalent des problèmes.
Si les contraintes du contexte de sécurité (SCC) de restricted ont été modifiées pour contenir le groupe system:authenticated ou ont ajouté requiredDropCapabilities, l'opérateur de conformité peut ne pas fonctionner correctement en raison de problèmes de permissions.
Vous pouvez créer un SCC personnalisé pour le compte de service du scanner de l'opérateur de conformité. Pour plus d'informations, voir Création d'un SCC personnalisé pour l'Opérateur de conformité.
5.3.2. Installation de l'opérateur de conformité à l'aide de l'interface de programmation
Conditions préalables
-
Vous devez avoir les privilèges de
admin.
Procédure
Définir un objet
Namespace:Exemple
namespace-object.yamlapiVersion: v1 kind: Namespace metadata: labels: openshift.io/cluster-monitoring: "true" pod-security.kubernetes.io/enforce: privileged 1 name: openshift-compliance- 1
- Dans OpenShift Container Platform 4.12, l'étiquette de sécurité du pod doit être définie sur
privilegedau niveau de l'espace de noms.
Créer l'objet
Namespace:$ oc create -f namespace-object.yaml
Définir un objet
OperatorGroup:Exemple
operator-group-object.yamlapiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: compliance-operator namespace: openshift-compliance spec: targetNamespaces: - openshift-compliance
Créer l'objet
OperatorGroup:$ oc create -f operator-group-object.yaml
Définir un objet
Subscription:Exemple
subscription-object.yamlapiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: compliance-operator-sub namespace: openshift-compliance spec: channel: "release-0.1" installPlanApproval: Automatic name: compliance-operator source: redhat-operators sourceNamespace: openshift-marketplace
Créer l'objet
Subscription:$ oc create -f subscription-object.yaml
Si vous définissez la fonctionnalité de planification globale et activez defaultNodeSelector, vous devez créer l'espace de noms manuellement et mettre à jour les annotations de l'espace de noms openshift-compliance, ou de l'espace de noms où l'Opérateur de Conformité a été installé, avec openshift.io/node-selector: “”. Cela supprime le sélecteur de nœuds par défaut et évite les échecs de déploiement.
Vérification
Vérifiez que l'installation a réussi en inspectant le fichier CSV :
$ oc get csv -n openshift-compliance
Vérifiez que l'opérateur de conformité est opérationnel :
$ oc get deploy -n openshift-compliance
Si les contraintes du contexte de sécurité (SCC) de restricted ont été modifiées pour contenir le groupe system:authenticated ou ont ajouté requiredDropCapabilities, l'opérateur de conformité peut ne pas fonctionner correctement en raison de problèmes de permissions.
Vous pouvez créer un SCC personnalisé pour le compte de service du scanner de l'opérateur de conformité. Pour plus d'informations, voir Création d'un SCC personnalisé pour l'Opérateur de conformité.
5.3.3. Ressources supplémentaires
- L'opérateur de conformité est pris en charge dans un environnement réseau restreint. Pour plus d'informations, voir Utiliser Operator Lifecycle Manager sur des réseaux restreints.
5.4. Mise à jour de l'opérateur de conformité
En tant qu'administrateur de cluster, vous pouvez mettre à jour l'opérateur de conformité sur votre cluster OpenShift Container Platform.
5.4.1. Préparation de la mise à jour de l'opérateur
L'abonnement d'un opérateur installé spécifie un canal de mise à jour qui suit et reçoit les mises à jour de l'opérateur. Vous pouvez modifier le canal de mise à jour pour commencer à suivre et à recevoir des mises à jour à partir d'un canal plus récent.
Les noms des canaux de mise à jour dans un abonnement peuvent varier d'un opérateur à l'autre, mais le système de dénomination suit généralement une convention commune au sein d'un opérateur donné. Par exemple, les noms des canaux peuvent correspondre à un flux de mises à jour de versions mineures pour l'application fournie par l'opérateur (1.2, 1.3) ou à une fréquence de publication (stable, fast).
Vous ne pouvez pas changer les opérateurs installés pour un canal plus ancien que le canal actuel.
Red Hat Customer Portal Labs comprend l'application suivante qui aide les administrateurs à préparer la mise à jour de leurs opérateurs :
Vous pouvez utiliser l'application pour rechercher des opérateurs basés sur Operator Lifecycle Manager et vérifier la version disponible de l'opérateur par canal de mise à jour à travers différentes versions d'OpenShift Container Platform. Les opérateurs basés sur la version du cluster ne sont pas inclus.
5.4.2. Changer le canal de mise à jour d'un opérateur
Vous pouvez changer le canal de mise à jour d'un opérateur en utilisant la console web d'OpenShift Container Platform.
Si la stratégie d'approbation de l'abonnement est définie sur Automatic, le processus de mise à jour est lancé dès qu'une nouvelle version de l'opérateur est disponible dans le canal sélectionné. Si la stratégie d'approbation est définie sur Manual, vous devez approuver manuellement les mises à jour en attente.
Conditions préalables
- Un opérateur précédemment installé à l'aide de l'outil Operator Lifecycle Manager (OLM).
Procédure
- Dans la perspective Administrator de la console web, naviguez vers Operators → Installed Operators.
- Cliquez sur le nom de l'opérateur dont vous souhaitez modifier le canal de mise à jour.
- Cliquez sur l'onglet Subscription.
- Cliquez sur le nom du canal de mise à jour sous Channel.
- Cliquez sur le canal de mise à jour le plus récent vers lequel vous souhaitez passer, puis cliquez sur Save.
Pour les abonnements avec une stratégie d'approbation Automatic, la mise à jour commence automatiquement. Retournez à la page Operators → Installed Operators pour suivre la progression de la mise à jour. Une fois la mise à jour terminée, le statut passe à Succeeded et Up to date.
Pour les abonnements avec une stratégie d'approbation Manual, vous pouvez approuver manuellement la mise à jour à partir de l'onglet Subscription.
5.4.3. Approbation manuelle d'une mise à jour de l'opérateur en attente
Si la stratégie d'approbation de l'abonnement d'un opérateur installé est définie sur Manual, lorsque de nouvelles mises à jour sont publiées dans son canal de mise à jour actuel, la mise à jour doit être approuvée manuellement avant que l'installation ne puisse commencer.
Conditions préalables
- Un opérateur précédemment installé à l'aide de l'outil Operator Lifecycle Manager (OLM).
Procédure
- Dans la perspective Administrator de la console web OpenShift Container Platform, naviguez vers Operators → Installed Operators.
- Les opérateurs dont la mise à jour est en cours affichent un statut avec Upgrade available. Cliquez sur le nom de l'opérateur que vous souhaitez mettre à jour.
- Cliquez sur l'onglet Subscription. Toute mise à jour nécessitant une approbation est affichée à côté de Upgrade Status. Par exemple, il peut s'agir de 1 requires approval.
- Cliquez sur 1 requires approval, puis sur Preview Install Plan.
- Examinez les ressources répertoriées comme étant disponibles pour une mise à jour. Lorsque vous êtes satisfait, cliquez sur Approve.
- Retournez à la page Operators → Installed Operators pour suivre la progression de la mise à jour. Une fois la mise à jour terminée, le statut passe à Succeeded et Up to date.
5.5. Opérateur de conformité scans
Les API ScanSetting et ScanSettingBinding sont recommandées pour exécuter des analyses de conformité avec l'opérateur de conformité. Pour plus d'informations sur ces objets API, exécutez :
$ oc explain scansettings
ou
$ oc explain scansettingbindings
5.5.1. Exécution d'analyses de conformité
Vous pouvez lancer une analyse à l'aide des profils du Center for Internet Security (CIS). Pour des raisons pratiques, l'Opérateur de Conformité crée un objet ScanSetting avec des valeurs par défaut raisonnables au démarrage. Cet objet ScanSetting est nommé default.
Pour les nœuds de plan de contrôle et de travailleur tout-en-un, l'analyse de conformité s'exécute deux fois sur les nœuds de plan de contrôle et de travailleur. L'analyse de conformité peut générer des résultats incohérents. Vous pouvez éviter les résultats incohérents en ne définissant qu'un seul rôle dans l'objet ScanSetting.
Procédure
Inspecter l'objet
ScanSettingen courant :$ oc describe scansettings default -n openshift-compliance
Exemple de sortie
Name: default Namespace: openshift-compliance Labels: <none> Annotations: <none> API Version: compliance.openshift.io/v1alpha1 Kind: ScanSetting Metadata: Creation Timestamp: 2022-10-10T14:07:29Z Generation: 1 Managed Fields: API Version: compliance.openshift.io/v1alpha1 Fields Type: FieldsV1 fieldsV1: f:rawResultStorage: .: f:nodeSelector: .: f:node-role.kubernetes.io/master: f:pvAccessModes: f:rotation: f:size: f:tolerations: f:roles: f:scanTolerations: f:schedule: f:showNotApplicable: f:strictNodeScan: Manager: compliance-operator Operation: Update Time: 2022-10-10T14:07:29Z Resource Version: 56111 UID: c21d1d14-3472-47d7-a450-b924287aec90 Raw Result Storage: Node Selector: node-role.kubernetes.io/master: Pv Access Modes: ReadWriteOnce 1 Rotation: 3 2 Size: 1Gi 3 Tolerations: Effect: NoSchedule Key: node-role.kubernetes.io/master Operator: Exists Effect: NoExecute Key: node.kubernetes.io/not-ready Operator: Exists Toleration Seconds: 300 Effect: NoExecute Key: node.kubernetes.io/unreachable Operator: Exists Toleration Seconds: 300 Effect: NoSchedule Key: node.kubernetes.io/memory-pressure Operator: Exists Roles: master 4 worker 5 Scan Tolerations: 6 Operator: Exists Schedule: 0 1 * * * 7 Show Not Applicable: false Strict Node Scan: true Events: <none>- 1
- L'opérateur de conformité crée un volume persistant (PV) qui contient les résultats des analyses. Par défaut, le PV utilisera le mode d'accès
ReadWriteOncecar l'opérateur de conformité ne peut pas faire d'hypothèses sur les classes de stockage configurées sur le cluster. De plus, le mode d'accèsReadWriteOnceest disponible sur la plupart des clusters. Si vous avez besoin de récupérer les résultats de l'analyse, vous pouvez le faire en utilisant un pod d'aide, qui lie également le volume. Les volumes qui utilisent le mode d'accèsReadWriteOncene peuvent être montés que par un seul pod à la fois, il est donc important de ne pas oublier de supprimer les pods d'assistance. Sinon, l'opérateur de conformité ne pourra pas réutiliser le volume pour les analyses suivantes. - 2
- L'opérateur de conformité conserve les résultats de trois balayages ultérieurs dans le volume ; les balayages plus anciens font l'objet d'une rotation.
- 3
- L'opérateur de conformité alloue un Go d'espace de stockage pour les résultats de l'analyse.
- 4 5
- Si le paramètre d'analyse utilise des profils qui analysent les nœuds de cluster, analysez ces rôles de nœuds.
- 6
- L'objet du paramètre d'analyse par défaut analyse tous les nœuds.
- 7
- L'objet du paramètre de balayage par défaut exécute des balayages à 01:00 chaque jour.
Pour remplacer le paramètre de numérisation par défaut, vous pouvez utiliser
default-auto-apply, dont les paramètres sont les suivants :Name: default-auto-apply Namespace: openshift-compliance Labels: <none> Annotations: <none> API Version: compliance.openshift.io/v1alpha1 Auto Apply Remediations: true Auto Update Remediations: true Kind: ScanSetting Metadata: Creation Timestamp: 2022-10-18T20:21:00Z Generation: 1 Managed Fields: API Version: compliance.openshift.io/v1alpha1 Fields Type: FieldsV1 fieldsV1: f:autoApplyRemediations: 1 f:autoUpdateRemediations: 2 f:rawResultStorage: .: f:nodeSelector: .: f:node-role.kubernetes.io/master: f:pvAccessModes: f:rotation: f:size: f:tolerations: f:roles: f:scanTolerations: f:schedule: f:showNotApplicable: f:strictNodeScan: Manager: compliance-operator Operation: Update Time: 2022-10-18T20:21:00Z Resource Version: 38840 UID: 8cb0967d-05e0-4d7a-ac1c-08a7f7e89e84 Raw Result Storage: Node Selector: node-role.kubernetes.io/master: Pv Access Modes: ReadWriteOnce Rotation: 3 Size: 1Gi Tolerations: Effect: NoSchedule Key: node-role.kubernetes.io/master Operator: Exists Effect: NoExecute Key: node.kubernetes.io/not-ready Operator: Exists Toleration Seconds: 300 Effect: NoExecute Key: node.kubernetes.io/unreachable Operator: Exists Toleration Seconds: 300 Effect: NoSchedule Key: node.kubernetes.io/memory-pressure Operator: Exists Roles: master worker Scan Tolerations: Operator: Exists Schedule: 0 1 * * * Show Not Applicable: false Strict Node Scan: true Events: <none>Créez un objet
ScanSettingBindingqui se lie à l'objet par défautScanSettinget analyse le cluster à l'aide des profilscisetcis-node. Par exemple :apiVersion: compliance.openshift.io/v1alpha1 kind: ScanSettingBinding metadata: name: cis-compliance namespace: openshift-compliance profiles: - name: ocp4-cis-node kind: Profile apiGroup: compliance.openshift.io/v1alpha1 - name: ocp4-cis kind: Profile apiGroup: compliance.openshift.io/v1alpha1 settingsRef: name: default kind: ScanSetting apiGroup: compliance.openshift.io/v1alpha1Créez l'objet
ScanSettingBindingen exécutant la commande$ oc create -f <file-name>.yaml -n openshift-compliance
A ce stade du processus, l'objet
ScanSettingBindingest rapproché et basé sur les paramètresBindingetBound. L'opérateur de conformité crée un objetComplianceSuiteet les objetsComplianceScanassociés.Suivez la progression de l'analyse de conformité en exécutant le programme :
$ oc get compliancescan -w -n openshift-compliance
Les analyses passent par les phases d'analyse et atteignent finalement la phase
DONElorsqu'elles sont terminées. Dans la plupart des cas, le résultat de l'analyse estNON-COMPLIANT. Vous pouvez examiner les résultats de l'analyse et commencer à appliquer des mesures correctives pour rendre le cluster conforme. Pour plus d'informations, reportez-vous à la section Gestion de la remédiation de l'opérateur de conformité.
5.5.2. Programmation du pod du serveur de résultats sur un nœud de travailleur
Le pod du serveur de résultats monte le volume persistant (PV) qui stocke les résultats bruts de l'analyse au format ARF (Asset Reporting Format). Les attributs nodeSelector et tolerations vous permettent de configurer l'emplacement du module de serveur de résultats.
Cette fonction est utile dans les environnements où les nœuds du plan de contrôle ne sont pas autorisés à monter des volumes persistants.
Procédure
Créer une ressource personnalisée (CR)
ScanSettingpour l'opérateur de conformité :Définissez le CR
ScanSettinget enregistrez le fichier YAML, par exemplers-workers.yaml:apiVersion: compliance.openshift.io/v1alpha1 kind: ScanSetting metadata: name: rs-on-workers namespace: openshift-compliance rawResultStorage: nodeSelector: node-role.kubernetes.io/worker: "" 1 pvAccessModes: - ReadWriteOnce rotation: 3 size: 1Gi tolerations: - operator: Exists 2 roles: - worker - master scanTolerations: - operator: Exists schedule: 0 1 * * *Pour créer le CR
ScanSetting, exécutez la commande suivante :$ oc create -f rs-workers.yaml
Vérification
Pour vérifier que l'objet
ScanSettingest créé, exécutez la commande suivante :$ oc get scansettings rs-on-workers -n openshift-compliance -o yaml
Exemple de sortie
apiVersion: compliance.openshift.io/v1alpha1 kind: ScanSetting metadata: creationTimestamp: "2021-11-19T19:36:36Z" generation: 1 name: rs-on-workers namespace: openshift-compliance resourceVersion: "48305" uid: 43fdfc5f-15a7-445a-8bbc-0e4a160cd46e rawResultStorage: nodeSelector: node-role.kubernetes.io/worker: "" pvAccessModes: - ReadWriteOnce rotation: 3 size: 1Gi tolerations: - operator: Exists roles: - worker - master scanTolerations: - operator: Exists schedule: 0 1 * * * strictNodeScan: true
5.5.3. ScanSetting Ressource personnalisée
La ressource personnalisée ScanSetting vous permet désormais d'outrepasser les limites de mémoire et de CPU par défaut des modules de numérisation grâce à l'attribut scan limits. L'Opérateur de Conformité utilisera les valeurs par défaut de 500Mi de mémoire, 100m CPU pour le conteneur scanner, et 200Mi de mémoire avec 100m CPU pour le conteneur api-resource-collector. Pour définir les limites de mémoire de l'opérateur, modifiez l'objet Subscription s'il est installé via OLM ou le déploiement de l'opérateur lui-même.
Pour augmenter les limites par défaut du CPU et de la mémoire de l'Opérateur de Conformité, voir Increasing Compliance Operator resource limits.
Il est nécessaire d'augmenter la limite de mémoire de l'opérateur de conformité ou des modules de numérisation si les limites par défaut ne sont pas suffisantes et que l'opérateur ou les modules de numérisation se terminent par le processus Out Of Memory (OOM).
5.5.4. Application des demandes et des limites de ressources
Lorsque le kubelet démarre un conteneur dans le cadre d'un pod, il transmet les demandes et les limites de ce conteneur en matière de mémoire et d'unité centrale à l'exécution du conteneur. Sous Linux, l'exécution du conteneur configure les cgroups du noyau qui appliquent et font respecter les limites que vous avez définies.
La limite de CPU définit le temps de CPU que le conteneur peut utiliser. Au cours de chaque intervalle de planification, le noyau Linux vérifie si cette limite est dépassée. Si c'est le cas, le noyau attend avant d'autoriser le cgroup à reprendre son exécution.
Si plusieurs conteneurs différents (cgroups) veulent s'exécuter sur un système contended, les charges de travail ayant des demandes d'UC plus importantes se voient attribuer plus de temps d'UC que les charges de travail ayant des demandes moins importantes. La demande de mémoire est utilisée lors de la planification des pods. Sur un nœud qui utilise cgroups v2, le moteur d'exécution du conteneur peut utiliser la demande de mémoire comme indice pour définir les valeurs memory.min et memory.low.
Si un conteneur tente d'allouer plus de mémoire que cette limite, le sous-système de sortie de mémoire du noyau Linux s'active et intervient en arrêtant l'un des processus du conteneur qui a tenté d'allouer de la mémoire. La limite de mémoire pour le Pod ou le conteneur peut également s'appliquer à des pages dans des volumes adossés à la mémoire, tels qu'un emptyDir.
Le kubelet suit les volumes tmpfs emptyDir au fur et à mesure que la mémoire du conteneur est utilisée, plutôt que comme un stockage éphémère local. Si un conteneur dépasse sa demande de mémoire et que le nœud sur lequel il s'exécute manque de mémoire, le conteneur du pod peut être expulsé.
Un conteneur ne peut pas dépasser sa limite de CPU pendant de longues périodes. Les temps d'exécution des conteneurs n'arrêtent pas les pods ou les conteneurs en cas d'utilisation excessive du processeur. Pour déterminer si un conteneur ne peut pas être planifié ou s'il est tué en raison de limites de ressources, voir Troubleshooting the Compliance Operator.
5.5.5. Ordonnancement des pods avec les demandes de ressources des conteneurs
Lorsqu'un module est créé, le planificateur sélectionne un nœud sur lequel le module doit s'exécuter. Chaque nœud a une capacité maximale pour chaque type de ressource en ce qui concerne la quantité de CPU et de mémoire qu'il peut fournir aux Pods. L'ordonnanceur veille à ce que la somme des demandes de ressources des conteneurs programmés soit inférieure à la capacité des nœuds pour chaque type de ressource.
Même si l'utilisation de la mémoire ou de l'unité centrale sur les nœuds est très faible, le planificateur peut toujours refuser de placer un pod sur un nœud si la vérification de la capacité ne permet pas de se prémunir contre une pénurie de ressources sur un nœud.
Pour chaque conteneur, vous pouvez spécifier les limites de ressources et les demandes suivantes :
spec.containers[].resources.limits.cpu spec.containers[].resources.limits.memory spec.containers[].resources.limits.hugepages-<size> spec.containers[].resources.requests.cpu spec.containers[].resources.requests.memory spec.containers[].resources.requests.hugepages-<size>
Bien que vous puissiez spécifier des demandes et des limites pour des conteneurs individuels, il est également utile de prendre en compte les demandes et les limites de ressources globales pour un module. Pour une ressource particulière, une demande ou une limite de ressource de conteneur est la somme des demandes ou des limites de ressources de ce type pour chaque conteneur dans le module.
Exemple de demandes et de limites de ressources pour les conteneurs
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests: 1
memory: "64Mi"
cpu: "250m"
limits: 2
memory: "128Mi"
cpu: "500m"
- name: log-aggregator
image: images.my-company.example/log-aggregator:v6
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
5.6. Comprendre l'opérateur de conformité
L'opérateur de conformité permet aux administrateurs d'OpenShift Container Platform de décrire l'état de conformité requis d'un cluster et leur fournit une vue d'ensemble des lacunes et des moyens d'y remédier. L'opérateur de conformité évalue la conformité des ressources API Kubernetes d'OpenShift Container Platform, ainsi que des nœuds exécutant le cluster. L'opérateur de conformité utilise OpenSCAP, un outil certifié par le NIST, pour analyser et appliquer les politiques de sécurité fournies par le contenu.
L'opérateur de conformité est disponible uniquement pour les déploiements de Red Hat Enterprise Linux CoreOS (RHCOS).
5.6.1. Profils des opérateurs de conformité
Plusieurs profils sont disponibles dans le cadre de l'installation de l'Opérateur de Conformité. Vous pouvez utiliser la commande oc get pour afficher les profils disponibles, les détails des profils et les règles spécifiques.
Voir les profils disponibles :
$ oc get -n openshift-compliance profiles.compliance
Exemple de sortie
NAME AGE ocp4-cis 94m ocp4-cis-node 94m ocp4-e8 94m ocp4-high 94m ocp4-high-node 94m ocp4-moderate 94m ocp4-moderate-node 94m ocp4-nerc-cip 94m ocp4-nerc-cip-node 94m ocp4-pci-dss 94m ocp4-pci-dss-node 94m rhcos4-e8 94m rhcos4-high 94m rhcos4-moderate 94m rhcos4-nerc-cip 94m
Ces profils représentent différents critères de conformité. Le nom du produit auquel il s'applique est ajouté en préfixe au nom de chaque profil.
ocp4-e8applique le référentiel Essential 8 au produit OpenShift Container Platform, tandis querhcos4-e8applique le référentiel Essential 8 au produit Red Hat Enterprise Linux CoreOS (RHCOS).Exécutez la commande suivante pour afficher les détails du profil
rhcos4-e8:$ oc get -n openshift-compliance -oyaml profiles.compliance rhcos4-e8
Exemple 5.1. Exemple de sortie
apiVersion: compliance.openshift.io/v1alpha1 description: 'This profile contains configuration checks for Red Hat Enterprise Linux CoreOS that align to the Australian Cyber Security Centre (ACSC) Essential Eight. A copy of the Essential Eight in Linux Environments guide can be found at the ACSC website: https://www.cyber.gov.au/acsc/view-all-content/publications/hardening-linux-workstations-and-servers' id: xccdf_org.ssgproject.content_profile_e8 kind: Profile metadata: annotations: compliance.openshift.io/image-digest: pb-rhcos4hrdkm compliance.openshift.io/product: redhat_enterprise_linux_coreos_4 compliance.openshift.io/product-type: Node creationTimestamp: "2022-10-19T12:06:49Z" generation: 1 labels: compliance.openshift.io/profile-bundle: rhcos4 name: rhcos4-e8 namespace: openshift-compliance ownerReferences: - apiVersion: compliance.openshift.io/v1alpha1 blockOwnerDeletion: true controller: true kind: ProfileBundle name: rhcos4 uid: 22350850-af4a-4f5c-9a42-5e7b68b82d7d resourceVersion: "43699" uid: 86353f70-28f7-40b4-bf0e-6289ec33675b rules: - rhcos4-accounts-no-uid-except-zero - rhcos4-audit-rules-dac-modification-chmod - rhcos4-audit-rules-dac-modification-chown - rhcos4-audit-rules-execution-chcon - rhcos4-audit-rules-execution-restorecon - rhcos4-audit-rules-execution-semanage - rhcos4-audit-rules-execution-setfiles - rhcos4-audit-rules-execution-setsebool - rhcos4-audit-rules-execution-seunshare - rhcos4-audit-rules-kernel-module-loading-delete - rhcos4-audit-rules-kernel-module-loading-finit - rhcos4-audit-rules-kernel-module-loading-init - rhcos4-audit-rules-login-events - rhcos4-audit-rules-login-events-faillock - rhcos4-audit-rules-login-events-lastlog - rhcos4-audit-rules-login-events-tallylog - rhcos4-audit-rules-networkconfig-modification - rhcos4-audit-rules-sysadmin-actions - rhcos4-audit-rules-time-adjtimex - rhcos4-audit-rules-time-clock-settime - rhcos4-audit-rules-time-settimeofday - rhcos4-audit-rules-time-stime - rhcos4-audit-rules-time-watch-localtime - rhcos4-audit-rules-usergroup-modification - rhcos4-auditd-data-retention-flush - rhcos4-auditd-freq - rhcos4-auditd-local-events - rhcos4-auditd-log-format - rhcos4-auditd-name-format - rhcos4-auditd-write-logs - rhcos4-configure-crypto-policy - rhcos4-configure-ssh-crypto-policy - rhcos4-no-empty-passwords - rhcos4-selinux-policytype - rhcos4-selinux-state - rhcos4-service-auditd-enabled - rhcos4-sshd-disable-empty-passwords - rhcos4-sshd-disable-gssapi-auth - rhcos4-sshd-disable-rhosts - rhcos4-sshd-disable-root-login - rhcos4-sshd-disable-user-known-hosts - rhcos4-sshd-do-not-permit-user-env - rhcos4-sshd-enable-strictmodes - rhcos4-sshd-print-last-log - rhcos4-sshd-set-loglevel-info - rhcos4-sysctl-kernel-dmesg-restrict - rhcos4-sysctl-kernel-kptr-restrict - rhcos4-sysctl-kernel-randomize-va-space - rhcos4-sysctl-kernel-unprivileged-bpf-disabled - rhcos4-sysctl-kernel-yama-ptrace-scope - rhcos4-sysctl-net-core-bpf-jit-harden title: Australian Cyber Security Centre (ACSC) Essential EightExécutez la commande suivante pour afficher les détails de la règle
rhcos4-audit-rules-login-events:$ oc get -n openshift-compliance -oyaml rules rhcos4-audit-rules-login-events
Exemple 5.2. Exemple de sortie
apiVersion: compliance.openshift.io/v1alpha1 checkType: Node description: |- The audit system already collects login information for all users and root. If the auditd daemon is configured to use the augenrules program to read audit rules during daemon startup (the default), add the following lines to a file with suffix.rules in the directory /etc/audit/rules.d in order to watch for attempted manual edits of files involved in storing logon events: -w /var/log/tallylog -p wa -k logins -w /var/run/faillock -p wa -k logins -w /var/log/lastlog -p wa -k logins If the auditd daemon is configured to use the auditctl utility to read audit rules during daemon startup, add the following lines to /etc/audit/audit.rules file in order to watch for unattempted manual edits of files involved in storing logon events: -w /var/log/tallylog -p wa -k logins -w /var/run/faillock -p wa -k logins -w /var/log/lastlog -p wa -k logins id: xccdf_org.ssgproject.content_rule_audit_rules_login_events kind: Rule metadata: annotations: compliance.openshift.io/image-digest: pb-rhcos4hrdkm compliance.openshift.io/rule: audit-rules-login-events control.compliance.openshift.io/NIST-800-53: AU-2(d);AU-12(c);AC-6(9);CM-6(a) control.compliance.openshift.io/PCI-DSS: Req-10.2.3 policies.open-cluster-management.io/controls: AU-2(d),AU-12(c),AC-6(9),CM-6(a),Req-10.2.3 policies.open-cluster-management.io/standards: NIST-800-53,PCI-DSS creationTimestamp: "2022-10-19T12:07:08Z" generation: 1 labels: compliance.openshift.io/profile-bundle: rhcos4 name: rhcos4-audit-rules-login-events namespace: openshift-compliance ownerReferences: - apiVersion: compliance.openshift.io/v1alpha1 blockOwnerDeletion: true controller: true kind: ProfileBundle name: rhcos4 uid: 22350850-af4a-4f5c-9a42-5e7b68b82d7d resourceVersion: "44819" uid: 75872f1f-3c93-40ca-a69d-44e5438824a4 rationale: Manual editing of these files may indicate nefarious activity, such as an attacker attempting to remove evidence of an intrusion. severity: medium title: Record Attempts to Alter Logon and Logout Events warning: Manual editing of these files may indicate nefarious activity, such as an attacker attempting to remove evidence of an intrusion.
5.6.1.1. Conformité Types de profils d'opérateurs
Il existe deux types de profils de conformité : Plateforme et Nœud.
- Plate-forme
- Platform ciblent votre cluster OpenShift Container Platform.
- Nœud
- Les balayages de nœuds ciblent les nœuds de la grappe.
Pour les profils de conformité qui ont des applications Node et Platform, tels que les profils de conformité pci-dss, vous devez exécuter les deux dans votre environnement OpenShift Container Platform.
5.6.2. Ressources supplémentaires
5.7. Gestion de l'opérateur de conformité
Cette section décrit le cycle de vie du contenu de sécurité, y compris la manière d'utiliser une version mise à jour du contenu de conformité et de créer un objet personnalisé ProfileBundle.
5.7.1. Exemple de ProfileBundle CR
L'objet ProfileBundle nécessite deux informations : l'URL d'une image de conteneur qui contient contentImage et le fichier qui contient le contenu de conformité. Le paramètre contentFile est relatif à la racine du système de fichiers. Vous pouvez définir l'objet intégré rhcos4 ProfileBundle comme indiqué dans l'exemple suivant :
apiVersion: compliance.openshift.io/v1alpha1 kind: ProfileBundle metadata: creationTimestamp: "2022-10-19T12:06:30Z" finalizers: - profilebundle.finalizers.compliance.openshift.io generation: 1 name: rhcos4 namespace: openshift-compliance resourceVersion: "46741" uid: 22350850-af4a-4f5c-9a42-5e7b68b82d7d spec: contentFile: ssg-rhcos4-ds.xml 1 contentImage: registry.redhat.io/compliance/openshift-compliance-content-rhel8@sha256:900e... 2 status: conditions: - lastTransitionTime: "2022-10-19T12:07:51Z" message: Profile bundle successfully parsed reason: Valid status: "True" type: Ready dataStreamStatus: VALID
5.7.2. Mise à jour du contenu de sécurité
Le contenu de sécurité est inclus en tant qu'images de conteneur auxquelles les objets ProfileBundle font référence. Pour suivre avec précision les mises à jour de ProfileBundles et les ressources personnalisées analysées à partir des paquets, telles que les règles ou les profils, identifiez l'image du conteneur avec le contenu de conformité en utilisant un condensé au lieu d'une balise :
$ oc -n openshift-compliance get profilebundles rhcos4 -oyaml
Exemple de sortie
apiVersion: compliance.openshift.io/v1alpha1
kind: ProfileBundle
metadata:
creationTimestamp: "2022-10-19T12:06:30Z"
finalizers:
- profilebundle.finalizers.compliance.openshift.io
generation: 1
name: rhcos4
namespace: openshift-compliance
resourceVersion: "46741"
uid: 22350850-af4a-4f5c-9a42-5e7b68b82d7d
spec:
contentFile: ssg-rhcos4-ds.xml
contentImage: registry.redhat.io/compliance/openshift-compliance-content-rhel8@sha256:900e... 1
status:
conditions:
- lastTransitionTime: "2022-10-19T12:07:51Z"
message: Profile bundle successfully parsed
reason: Valid
status: "True"
type: Ready
dataStreamStatus: VALID
- 1
- Image du conteneur de sécurité.
Chaque site ProfileBundle est soutenu par un déploiement. Lorsque l'opérateur de conformité détecte que le résumé de l'image du conteneur a changé, le déploiement est mis à jour pour refléter le changement et analyser à nouveau le contenu. L'utilisation d'un condensé au lieu d'une balise garantit l'utilisation d'un ensemble de profils stables et prévisibles.
5.7.3. Ressources supplémentaires
- L'opérateur de conformité est pris en charge dans un environnement réseau restreint. Pour plus d'informations, voir Utiliser Operator Lifecycle Manager sur des réseaux restreints.
5.8. Adapter l'opérateur de conformité
Bien que l'Opérateur de Conformité soit livré avec des profils prêts à l'emploi, ceux-ci doivent être modifiés pour répondre aux besoins et aux exigences de l'organisation. Le processus de modification d'un profil est appelé tailoring.
L'opérateur de conformité fournit l'objet TailoredProfile pour aider à adapter les profils.
5.8.1. Création d'un nouveau profil personnalisé
Vous pouvez créer un profil personnalisé à partir de zéro en utilisant l'objet TailoredProfile. Définissez un title et un description appropriés et laissez le champ extends vide. Indiquez à l'opérateur de conformité le type d'analyse que ce profil personnalisé va générer :
- Analyse des nœuds : Analyse du système d'exploitation.
- Platform scan : Analyse la configuration d'OpenShift.
Procédure
Définissez l'annotation suivante sur l'objet TailoredProfile:
exemple new-profile.yaml
apiVersion: compliance.openshift.io/v1alpha1
kind: TailoredProfile
metadata:
name: new-profile
annotations:
compliance.openshift.io/product-type: Node 1
spec:
extends:
description: My custom profile 2
title: Custom profile 3- 1
- Définissez
NodeouPlatformen conséquence. - 2
- Utilisez le champ
descriptionpour décrire la fonction du nouvel objetTailoredProfile. - 3
- Donnez un titre à votre objet
TailoredProfileà l'aide du champtitle.NoteL'ajout du suffixe
-nodeau champnamede l'objetTailoredProfileest similaire à l'ajout de l'annotation de type de produitNodeet génère une analyse du système d'exploitation.
5.8.2. Utiliser des profils personnalisés pour étendre les ProfileBundles existants
Alors que la norme TailoredProfile CR permet les opérations d'adaptation les plus courantes, la norme XCCDF offre encore plus de flexibilité dans l'adaptation des profils OpenSCAP. En outre, si votre organisation a déjà utilisé OpenScap, il se peut que vous disposiez d'un fichier d'adaptation XCCDF et que vous puissiez le réutiliser.
L'objet ComplianceSuite contient un attribut facultatif TailoringConfigMap qui permet de pointer vers un fichier d'adaptation personnalisé. La valeur de l'attribut TailoringConfigMap est le nom d'une carte de configuration, qui doit contenir une clé appelée tailoring.xml et la valeur de cette clé est le contenu de l'adaptation.
Procédure
Parcourez les règles disponibles pour Red Hat Enterprise Linux CoreOS (RHCOS)
ProfileBundle:$ oc get rules.compliance -n openshift-compliance -l compliance.openshift.io/profile-bundle=rhcos4
Parcourez les variables disponibles sur le même site
ProfileBundle:$ oc get variables.compliance -n openshift-compliance -l compliance.openshift.io/profile-bundle=rhcos4
Créez un profil personnalisé nommé
nist-moderate-modified:Choisissez les règles que vous souhaitez ajouter au profil personnalisé
nist-moderate-modified. Cet exemple étend le profilrhcos4-moderateen désactivant deux règles et en modifiant une valeur. Utilisez la valeurrationalepour décrire la raison de ces changements :Exemple
new-profile-node.yamlapiVersion: compliance.openshift.io/v1alpha1 kind: TailoredProfile metadata: name: nist-moderate-modified spec: extends: rhcos4-moderate description: NIST moderate profile title: My modified NIST moderate profile disableRules: - name: rhcos4-file-permissions-var-log-messages rationale: The file contains logs of error messages in the system - name: rhcos4-account-disable-post-pw-expiration rationale: No need to check this as it comes from the IdP setValues: - name: rhcos4-var-selinux-state rationale: Organizational requirements value: permissiveTableau 5.2. Attributs des variables de spécification
Attribut Description extendsNom de l'objet
Profilesur lequelTailoredProfileest construit.titleTitre lisible par l'homme de l'adresse
TailoredProfile.disableRulesUne liste de paires de noms et de raisons. Chaque nom renvoie au nom d'un objet de règle à désactiver. La valeur de justification est un texte lisible par l'homme décrivant la raison pour laquelle la règle est désactivée.
manualRulesUne liste de paires de noms et de justifications. Lorsqu'une règle manuelle est ajoutée, le statut du résultat de la vérification sera toujours
manualet la remédiation ne sera pas générée. Cet attribut est automatique et n'a pas de valeur par défaut lorsqu'il est défini en tant que règle manuelle.enableRulesUne liste de paires de noms et de justifications. Chaque nom fait référence au nom d'un objet de règle qui doit être activé. La valeur rationale est un texte lisible par l'homme décrivant la raison pour laquelle la règle est activée.
descriptionTexte lisible par l'homme décrivant le site
TailoredProfile.setValuesUne liste de groupes de noms, de raisons d'être et de valeurs. Chaque nom fait référence à un nom de l'ensemble de valeurs. La justification est un texte lisible par l'homme décrivant l'ensemble. La valeur est le paramètre réel.
Ajouter l'attribut
tailoredProfile.spec.manualRules:Exemple
tailoredProfile.spec.manualRules.yamlapiVersion: compliance.openshift.io/v1alpha1 kind: TailoredProfile metadata: name: ocp4-manual-scc-check spec: extends: ocp4-cis description: This profile extends ocp4-cis by forcing the SCC check to always return MANUAL title: OCP4 CIS profile with manual SCC check manualRules: - name: ocp4-scc-limit-container-allowed-capabilities rationale: We use third party software that installs its own SCC with extra privilegesCréer l'objet
TailoredProfile:oc create -n openshift-compliance -f new-profile-node.yaml 1- 1
- L'objet
TailoredProfileest créé dans l'espace de noms par défautopenshift-compliance.
Exemple de sortie
tailoredprofile.compliance.openshift.io/nist-moderate-modified created
Définir l'objet
ScanSettingBindingpour lier le nouveau profil personnalisénist-moderate-modifiedà l'objet par défautScanSetting.Exemple
new-scansettingbinding.yamlapiVersion: compliance.openshift.io/v1alpha1 kind: ScanSettingBinding metadata: name: nist-moderate-modified profiles: - apiGroup: compliance.openshift.io/v1alpha1 kind: Profile name: ocp4-moderate - apiGroup: compliance.openshift.io/v1alpha1 kind: TailoredProfile name: nist-moderate-modified settingsRef: apiGroup: compliance.openshift.io/v1alpha1 kind: ScanSetting name: defaultCréer l'objet
ScanSettingBinding:$ oc create -n openshift-compliance -f new-scansettingbinding.yaml
Exemple de sortie
scansettingbinding.compliance.openshift.io/nist-moderate-modified created
5.9. Récupération des résultats bruts de l'opérateur de conformité
Lorsque vous prouvez la conformité de votre cluster OpenShift Container Platform, vous pouvez avoir besoin de fournir les résultats de l'analyse à des fins d'audit.
5.9.1. Obtention des résultats bruts de l'opérateur de conformité à partir d'un volume persistant
Procédure
L'opérateur de conformité génère et stocke les résultats bruts dans un volume persistant. Ces résultats sont au format ARF (Asset Reporting Format).
Explorez l'objet
ComplianceSuite:$ oc get compliancesuites nist-moderate-modified \ -o json -n openshift-compliance | jq '.status.scanStatuses[].resultsStorage'
Exemple de sortie
{ "name": "ocp4-moderate", "namespace": "openshift-compliance" } { "name": "nist-moderate-modified-master", "namespace": "openshift-compliance" } { "name": "nist-moderate-modified-worker", "namespace": "openshift-compliance" }Cela montre les réclamations en volume persistantes où les résultats bruts sont accessibles.
Vérifiez l'emplacement des données brutes en utilisant le nom et l'espace de noms de l'un des résultats :
$ oc get pvc -n openshift-compliance rhcos4-moderate-worker
Exemple de sortie
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE rhcos4-moderate-worker Bound pvc-548f6cfe-164b-42fe-ba13-a07cfbc77f3a 1Gi RWO gp2 92m
Récupérer les résultats bruts en créant un pod qui monte le volume et copie les résultats :
$ oc create -n openshift-compliance -f pod.yaml
Exemple pod.yaml
apiVersion: "v1" kind: Pod metadata: name: pv-extract spec: containers: - name: pv-extract-pod image: registry.access.redhat.com/ubi8/ubi command: ["sleep", "3000"] volumeMounts: - mountPath: "/workers-scan-results" name: workers-scan-vol volumes: - name: workers-scan-vol persistentVolumeClaim: claimName: rhcos4-moderate-workerUne fois le pod en cours d'exécution, téléchargez les résultats :
$ oc cp pv-extract:/workers-scan-results -n openshift-compliance .
ImportantLa création d'un pod qui monte le volume persistant conservera la revendication en tant que
Bound. Si la classe de stockage en cours d'utilisation du volume a des autorisations définies surReadWriteOnce, le volume ne peut être monté que par un seul module à la fois. Vous devez supprimer le module une fois terminé, sinon l'opérateur ne pourra pas planifier un module et continuer à stocker les résultats à cet emplacement.Une fois l'extraction terminée, le pod peut être supprimé :
$ oc delete pod pv-extract -n openshift-compliance
5.10. Gestion des résultats de l'opérateur de conformité et remédiation
Chaque ComplianceCheckResult représente le résultat d'un contrôle de la règle de conformité. Si la règle peut être corrigée automatiquement, un objet ComplianceRemediation portant le même nom et appartenant à ComplianceCheckResult est créé. Sauf demande, les remédiations ne sont pas appliquées automatiquement, ce qui donne à l'administrateur d'OpenShift Container Platform la possibilité d'examiner ce que fait la remédiation et de n'appliquer une remédiation qu'une fois qu'elle a été vérifiée.
5.10.1. Filtres pour les résultats des contrôles de conformité
Par défaut, les objets ComplianceCheckResult sont étiquetés avec plusieurs étiquettes utiles qui vous permettent d'interroger les contrôles et de décider des étapes suivantes une fois les résultats générés.
Liste des chèques appartenant à une suite spécifique :
$ oc get -n openshift-compliance compliancecheckresults \ -l compliance.openshift.io/suite=workers-compliancesuite
Liste des chèques appartenant à une analyse spécifique :
$ oc get -n openshift-compliance compliancecheckresults \ -l compliance.openshift.io/scan=workers-scan
Tous les objets ComplianceCheckResult ne créent pas d'objets ComplianceRemediation. Seuls les objets ComplianceCheckResult qui peuvent être remédiés automatiquement le font. Un objet ComplianceCheckResult a une remédiation associée s'il est étiqueté avec le label compliance.openshift.io/automated-remediation. Le nom de la remédiation est le même que celui du contrôle.
Dressez la liste de tous les contrôles défaillants qui peuvent être corrigés automatiquement :
$ oc get -n openshift-compliance compliancecheckresults \ -l 'compliance.openshift.io/check-status=FAIL,compliance.openshift.io/automated-remediation'
Liste de tous les contrôles défaillants, classés par gravité :
$ oc get compliancecheckresults -n openshift-compliance \ -l 'compliance.openshift.io/check-status=FAIL,compliance.openshift.io/check-severity=high'
Exemple de sortie
NAME STATUS SEVERITY nist-moderate-modified-master-configure-crypto-policy FAIL high nist-moderate-modified-master-coreos-pti-kernel-argument FAIL high nist-moderate-modified-master-disable-ctrlaltdel-burstaction FAIL high nist-moderate-modified-master-disable-ctrlaltdel-reboot FAIL high nist-moderate-modified-master-enable-fips-mode FAIL high nist-moderate-modified-master-no-empty-passwords FAIL high nist-moderate-modified-master-selinux-state FAIL high nist-moderate-modified-worker-configure-crypto-policy FAIL high nist-moderate-modified-worker-coreos-pti-kernel-argument FAIL high nist-moderate-modified-worker-disable-ctrlaltdel-burstaction FAIL high nist-moderate-modified-worker-disable-ctrlaltdel-reboot FAIL high nist-moderate-modified-worker-enable-fips-mode FAIL high nist-moderate-modified-worker-no-empty-passwords FAIL high nist-moderate-modified-worker-selinux-state FAIL high ocp4-moderate-configure-network-policies-namespaces FAIL high ocp4-moderate-fips-mode-enabled-on-all-nodes FAIL high
Dressez la liste de tous les contrôles défaillants qui doivent être corrigés manuellement :
$ oc get -n openshift-compliance compliancecheckresults \ -l 'compliance.openshift.io/check-status=FAIL,!compliance.openshift.io/automated-remediation'
Les étapes de remédiation manuelle sont généralement stockées dans l'attribut description de l'objet ComplianceCheckResult.
Tableau 5.3. Statut du résultat du contrôle de conformité
| Statut du résultat du contrôle de conformité | Description |
|---|---|
| PASSER | Le contrôle de conformité s'est déroulé jusqu'à son terme et s'est avéré concluant. |
| ÉCHEC | Le contrôle de conformité s'est déroulé jusqu'à son terme et a échoué. |
| INFO | Le contrôle de conformité s'est déroulé jusqu'à son terme et a révélé un problème qui n'est pas suffisamment grave pour être considéré comme une erreur. |
| MANUEL | Le contrôle de conformité n'a pas de moyen d'évaluer automatiquement le succès ou l'échec et doit être vérifié manuellement. |
| INCONSISTANT | Le contrôle de conformité signale différents résultats provenant de différentes sources, généralement des nœuds de cluster. |
| ERREUR | Le contrôle de conformité a été exécuté, mais n'a pas pu se terminer correctement. |
| NON-APPLICABLE | Le contrôle de conformité n'a pas été exécuté parce qu'il n'est pas applicable ou n'est pas sélectionné. |
5.10.2. Révision d'une mesure corrective
Examinez l'objet ComplianceRemediation et l'objet ComplianceCheckResult qui possède la remédiation. L'objet ComplianceCheckResult contient des descriptions lisibles par l'homme de ce que fait le contrôle et du durcissement qu'il tente d'empêcher, ainsi que d'autres informations metadata telles que la gravité et les contrôles de sécurité associés. L'objet ComplianceRemediation représente un moyen de résoudre le problème décrit dans l'objet ComplianceCheckResult. Après la première analyse, vérifiez les mesures correctives avec l'état MissingDependencies.
Vous trouverez ci-dessous un exemple de contrôle et de remédiation appelé sysctl-net-ipv4-conf-all-accept-redirects. Cet exemple est expurgé pour ne montrer que spec et status et omet metadata:
spec:
apply: false
current:
object:
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
spec:
config:
ignition:
version: 3.2.0
storage:
files:
- path: /etc/sysctl.d/75-sysctl_net_ipv4_conf_all_accept_redirects.conf
mode: 0644
contents:
source: data:,net.ipv4.conf.all.accept_redirects%3D0
outdated: {}
status:
applicationState: NotApplied
Le payload de la remédiation est stocké dans l'attribut spec.current. Le payload peut être n'importe quel objet Kubernetes, mais comme cette remédiation a été produite par un scan de nœud, le payload de remédiation dans l'exemple ci-dessus est un objet MachineConfig. Pour les analyses de plateforme, la charge utile de la remédiation est souvent un autre type d'objet (par exemple, un objet ConfigMap ou Secret ), mais l'application de cette remédiation est généralement du ressort de l'administrateur, car sinon l'opérateur de conformité aurait eu besoin d'un ensemble très large de permissions pour manipuler n'importe quel objet Kubernetes générique. Un exemple de remédiation d'un contrôle de plateforme est fourni plus loin dans le texte.
Pour voir exactement ce que fait la remédiation lorsqu'elle est appliquée, le contenu de l'objet MachineConfig utilise les objets Ignition pour la configuration. Voir la spécification Ignition pour plus d'informations sur le format. Dans notre exemple, l'attribut the spec.config.storage.files[0].path spécifie le fichier créé par cette remédiation (/etc/sysctl.d/75-sysctl_net_ipv4_conf_all_accept_redirects.conf) et l'attribut spec.config.storage.files[0].contents.source spécifie le contenu de ce fichier.
Le contenu des fichiers est codé en URL.
Utilisez le script Python suivant pour afficher le contenu :
$ echo "net.ipv4.conf.all.accept_redirects%3D0" | python3 -c "import sys, urllib.parse; print(urllib.parse.unquote(''.join(sys.stdin.readlines())))"Exemple de sortie
net.ipv4.conf.all.accept_redirects=0
5.10.3. Application de la remédiation lors de l'utilisation de pools de configuration de machines personnalisés
Lorsque vous créez une MachineConfigPool personnalisée, ajoutez une étiquette à la MachineConfigPool afin que la machineConfigPoolSelector présente dans la KubeletConfig puisse faire correspondre l'étiquette à la MachineConfigPool.
Ne définissez pas protectKernelDefaults: false dans le fichier KubeletConfig, car l'objet MachineConfigPool pourrait ne pas se débloquer de manière inattendue une fois que l'opérateur de conformité a fini d'appliquer la remédiation.
Procédure
Dresser la liste des nœuds.
$ oc get nodes -n openshift-compliance
Exemple de sortie
NAME STATUS ROLES AGE VERSION ip-10-0-128-92.us-east-2.compute.internal Ready master 5h21m v1.25.0 ip-10-0-158-32.us-east-2.compute.internal Ready worker 5h17m v1.25.0 ip-10-0-166-81.us-east-2.compute.internal Ready worker 5h17m v1.25.0 ip-10-0-171-170.us-east-2.compute.internal Ready master 5h21m v1.25.0 ip-10-0-197-35.us-east-2.compute.internal Ready master 5h22m v1.25.0
Ajouter une étiquette aux nœuds.
$ oc -n openshift-compliance \ label node ip-10-0-166-81.us-east-2.compute.internal \ node-role.kubernetes.io/<machine_config_pool_name>=
Exemple de sortie
node/ip-10-0-166-81.us-east-2.compute.internal labeled
Créer des
MachineConfigPoolCR personnalisés.apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: <machine_config_pool_name> labels: pools.operator.machineconfiguration.openshift.io/<machine_config_pool_name>: '' 1 spec: machineConfigSelector: matchExpressions: - {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,<machine_config_pool_name>]} nodeSelector: matchLabels: node-role.kubernetes.io/<machine_config_pool_name>: ""- 1
- Le champ
labelsdéfinit le nom de l'étiquette à ajouter pour le pool de configuration de la machine (MCP).
Vérifier que le MCP a été créé avec succès.
$ oc get mcp -w
5.10.4. Évaluation des règles KubeletConfig par rapport aux valeurs de configuration par défaut
L'infrastructure d'OpenShift Container Platform peut contenir des fichiers de configuration incomplets au moment de l'exécution, et les nœuds supposent des valeurs de configuration par défaut pour les options de configuration manquantes. Certaines options de configuration peuvent être transmises en tant qu'arguments de ligne de commande. Par conséquent, l'opérateur de conformité ne peut pas vérifier si le fichier de configuration sur le nœud est complet car il peut manquer des options utilisées dans les vérifications de règles.
Pour éviter les résultats faussement négatifs lorsque la valeur de configuration par défaut passe le contrôle, l'opérateur de conformité utilise l'API Node/Proxy pour récupérer la configuration de chaque nœud d'un groupe de nœuds, puis toutes les options de configuration qui sont cohérentes entre les nœuds du groupe de nœuds sont stockées dans un fichier qui représente la configuration de tous les nœuds de ce groupe de nœuds. Cela permet d'améliorer la précision des résultats de l'analyse.
Aucune modification supplémentaire de la configuration n'est nécessaire pour utiliser cette fonction avec les configurations par défaut des pools de nœuds master et worker.
5.10.5. Analyse des pools de nœuds personnalisés
L'opérateur de conformité ne conserve pas de copie de la configuration de chaque groupe de nœuds. Il regroupe les options de configuration cohérentes pour tous les nœuds d'un pool de nœuds unique dans une copie du fichier de configuration. L'opérateur de conformité utilise ensuite le fichier de configuration pour un groupe de nœuds particulier afin d'évaluer les règles applicables aux nœuds de ce groupe.
Si votre cluster utilise des pools de nœuds personnalisés en dehors des pools de nœuds par défaut worker et master, vous devez fournir des variables supplémentaires pour que l'Opérateur de Conformité agrège un fichier de configuration pour ce pool de nœuds.
Procédure
Pour vérifier la configuration par rapport à tous les pools d'un exemple de cluster contenant les pools de nœuds
master,workeretexamplepersonnalisé, définissez la valeur des champsocp-var-role-masteretopc-var-role-workersurexampledans l'objetTailoredProfile:apiVersion: compliance.openshift.io/v1alpha1 kind: TailoredProfile metadata: name: cis-example-tp spec: extends: ocp4-cis title: My modified NIST profile to scan example nodes setValues: - name: ocp4-var-role-master value: example rationale: test for example nodes - name: ocp4-var-role-worker value: example rationale: test for example nodes description: cis-example-scanAjoutez le rôle
exampleà l'objetScanSettingqui sera stocké dans le CRScanSettingBinding:apiVersion: compliance.openshift.io/v1alpha1 kind: ScanSetting metadata: name: default namespace: openshift-compliance rawResultStorage: rotation: 3 size: 1Gi roles: - worker - master - example scanTolerations: - effect: NoSchedule key: node-role.kubernetes.io/master operator: Exists schedule: '0 1 * * *'
Créez un scan qui utilise le
ScanSettingBindingCR :apiVersion: compliance.openshift.io/v1alpha1 kind: ScanSettingBinding metadata: name: cis namespace: openshift-compliance profiles: - apiGroup: compliance.openshift.io/v1alpha1 kind: Profile name: ocp4-cis - apiGroup: compliance.openshift.io/v1alpha1 kind: Profile name: ocp4-cis-node - apiGroup: compliance.openshift.io/v1alpha1 kind: TailoredProfile name: cis-example-tp settingsRef: apiGroup: compliance.openshift.io/v1alpha1 kind: ScanSetting name: default
L'opérateur de conformité vérifie la version d'exécution KubeletConfig à l'aide de l'objet API Node/Proxy et utilise ensuite des variables telles que ocp-var-role-master et ocp-var-role-worker pour déterminer les nœuds sur lesquels il effectue le contrôle. Sur le site ComplianceCheckResult, les règles KubeletConfig sont affichées sous la forme ocp4-cis-kubelet-*. L'analyse n'est réussie que si tous les nœuds sélectionnés passent cette vérification.
Vérification
Les règles de Platform KubeletConfig sont vérifiées par le biais de l'objet
Node/Proxy. Vous pouvez trouver ces règles en exécutant la commande suivante :$ oc get rules -o json | jq '.items[] | select(.checkType == "Platform") | select(.metadata.name | contains("ocp4-kubelet-")) | .metadata.name'
5.10.6. Assainissement des sous-piscines KubeletConfig
KubeletConfig des étiquettes de remédiation peuvent être appliquées aux sous-pools de MachineConfigPool.
Procédure
Ajouter une étiquette au sous-pool
MachineConfigPoolCR :$ oc label mcp <sub-pool-name> pools.operator.machineconfiguration.openshift.io/<sub-pool-name>=
5.10.7. Application d'une remédiation
L'attribut booléen spec.apply contrôle si la remédiation doit être appliquée par l'opérateur de conformité. Vous pouvez appliquer la remédiation en définissant l'attribut sur true:
$ oc -n openshift-compliance \
patch complianceremediations/<scan-name>-sysctl-net-ipv4-conf-all-accept-redirects \
--patch '{"spec":{"apply":true}}' --type=merge
Une fois que l'opérateur de conformité a traité la correction appliquée, l'attribut status.ApplicationState devient Applied ou Error s'il est incorrect. Lorsqu'une remédiation de la configuration de la machine est appliquée, cette remédiation ainsi que toutes les autres remédiations appliquées sont rendues dans un objet MachineConfig nommé 75-$scan-name-$suite-name. Cet objet MachineConfig est ensuite rendu par l'opérateur de configuration de machine et finalement appliqué à tous les nœuds d'un pool de configuration de machine par une instance du démon de contrôle de machine s'exécutant sur chaque nœud.
Notez que lorsque l'opérateur de configuration des machines applique un nouvel objet MachineConfig aux nœuds d'un pool, tous les nœuds appartenant au pool sont redémarrés. Cela peut s'avérer gênant lors de l'application de plusieurs remédiations, chacune d'entre elles restituant l'objet composite 75-$scan-name-$suite-name MachineConfig . Pour éviter d'appliquer la remédiation immédiatement, vous pouvez mettre en pause le pool de configuration de machines en définissant l'attribut .spec.paused d'un objet MachineConfigPool sur true.
Assurez-vous que les pools ne sont pas interrompus lorsque la rotation des certificats d'AC a lieu. Si les MCP sont en pause, le MCO ne peut pas envoyer les nouveaux certificats à ces nœuds. Cela entraîne la dégradation du cluster et l'échec de plusieurs commandes oc, notamment oc debug, oc logs, oc exec et oc attach. Vous recevez des alertes dans l'interface utilisateur d'alerte de la console Web d'OpenShift Container Platform si un MCP est mis en pause lors de la rotation des certificats.
L'opérateur de conformité peut appliquer des remédiations automatiquement. Définissez autoApplyRemediations: true dans l'objet de premier niveau ScanSetting.
L'application automatique de mesures correctives ne doit se faire qu'après mûre réflexion.
5.10.8. Remédier manuellement à un contrôle de plate-forme
Les contrôles des analyses de la plate-forme doivent généralement être effectués manuellement par l'administrateur, et ce pour deux raisons :
- Il n'est pas toujours possible de déterminer automatiquement la valeur qui doit être définie. L'un des contrôles exige qu'une liste des registres autorisés soit fournie, mais l'analyseur n'a aucun moyen de savoir quels registres l'organisation souhaite autoriser.
-
Différentes vérifications modifient différents objets API, ce qui nécessite une remédiation automatisée pour posséder
rootou un accès superutilisateur pour modifier les objets dans le cluster, ce qui n'est pas conseillé.
Procédure
L'exemple ci-dessous utilise la règle
ocp4-ocp-allowed-registries-for-import, qui échouerait sur une installation par défaut d'OpenShift Container Platform. Inspectez la règleoc get rule.compliance/ocp4-ocp-allowed-registries-for-import -oyaml, qui limite les registres à partir desquels les utilisateurs sont autorisés à importer des images en définissant l'attributallowedRegistriesForImport. L'attribut warning de la règle indique également l'objet API vérifié, de sorte qu'il peut être modifié et remédier au problème :$ oc edit image.config.openshift.io/cluster
Exemple de sortie
apiVersion: config.openshift.io/v1 kind: Image metadata: annotations: release.openshift.io/create-only: "true" creationTimestamp: "2020-09-10T10:12:54Z" generation: 2 name: cluster resourceVersion: "363096" selfLink: /apis/config.openshift.io/v1/images/cluster uid: 2dcb614e-2f8a-4a23-ba9a-8e33cd0ff77e spec: allowedRegistriesForImport: - domainName: registry.redhat.io status: externalRegistryHostnames: - default-route-openshift-image-registry.apps.user-cluster-09-10-12-07.devcluster.openshift.com internalRegistryHostname: image-registry.openshift-image-registry.svc:5000Exécutez à nouveau l'analyse :
$ oc -n openshift-compliance \ annotate compliancescans/rhcos4-e8-worker compliance.openshift.io/rescan=
5.10.9. Mise à jour des mesures correctives
Lorsqu'une nouvelle version du contenu de conformité est utilisée, elle peut fournir une version nouvelle et différente d'une remédiation par rapport à la version précédente. L'opérateur de conformité conservera l'ancienne version de la remédiation appliquée. L'administrateur d'OpenShift Container Platform est également notifié de la nouvelle version à réviser et à appliquer. Un objet ComplianceRemediation qui avait été appliqué précédemment, mais qui a été mis à jour, change de statut et devient Outdated. Les objets obsolètes sont étiquetés de manière à pouvoir être recherchés facilement.
Le contenu de la remédiation précédemment appliquée serait alors stocké dans l'attribut spec.outdated d'un objet ComplianceRemediation et le nouveau contenu mis à jour serait stocké dans l'attribut spec.current. Après avoir mis à jour le contenu vers une version plus récente, l'administrateur doit alors revoir la remédiation. Tant que l'attribut spec.outdated existe, il est utilisé pour rendre l'objet MachineConfig résultant. Une fois l'attribut spec.outdated supprimé, l'opérateur de conformité rend à nouveau l'objet MachineConfig qui en résulte, ce qui l'amène à pousser la configuration vers les nœuds.
Procédure
Recherchez les mesures correctives périmées :
$ oc -n openshift-compliance get complianceremediations \ -l complianceoperator.openshift.io/outdated-remediation=
Exemple de sortie
NAME STATE workers-scan-no-empty-passwords Outdated
La remédiation actuellement appliquée est stockée dans l'attribut
Outdatedet la nouvelle remédiation non appliquée est stockée dans l'attributCurrent. Si vous êtes satisfait de la nouvelle version, supprimez le champOutdated. Si vous souhaitez conserver le contenu mis à jour, supprimez les attributsCurrentetOutdated.Appliquer la version la plus récente de la remédiation :
$ oc -n openshift-compliance patch complianceremediations workers-scan-no-empty-passwords \ --type json -p '[{"op":"remove", "path":/spec/outdated}]'L'état de remédiation passera de
OutdatedàApplied:$ oc get -n openshift-compliance complianceremediations workers-scan-no-empty-passwords
Exemple de sortie
NAME STATE workers-scan-no-empty-passwords Applied
- Les nœuds appliqueront la version de remédiation la plus récente et redémarreront.
5.10.10. Non-application d'une mesure corrective
Il peut être nécessaire d'annuler une mesure corrective déjà appliquée.
Procédure
Fixer le drapeau
applyàfalse:$ oc -n openshift-compliance \ patch complianceremediations/rhcos4-moderate-worker-sysctl-net-ipv4-conf-all-accept-redirects \ --patch '{"spec":{"apply":false}}' --type=mergeLe statut de l'assainissement passera à
NotAppliedet l'objet compositeMachineConfigsera redessiné pour ne pas inclure l'assainissement.ImportantTous les nœuds concernés par la remédiation seront redémarrés.
5.10.11. Suppression d'une remédiation KubeletConfig
KubeletConfig sont incluses dans les profils au niveau des nœuds. Pour supprimer une remédiation KubeletConfig, vous devez la supprimer manuellement des objets KubeletConfig. Cet exemple montre comment supprimer le contrôle de conformité pour la remédiation one-rule-tp-node-master-kubelet-eviction-thresholds-set-hard-imagefs-available.
Procédure
Localisez le site
scan-nameet vérifiez la conformité de l'assainissement du siteone-rule-tp-node-master-kubelet-eviction-thresholds-set-hard-imagefs-available:$ oc -n openshift-compliance get remediation \ one-rule-tp-node-master-kubelet-eviction-thresholds-set-hard-imagefs-available -o yaml
Exemple de sortie
apiVersion: compliance.openshift.io/v1alpha1 kind: ComplianceRemediation metadata: annotations: compliance.openshift.io/xccdf-value-used: var-kubelet-evictionhard-imagefs-available creationTimestamp: "2022-01-05T19:52:27Z" generation: 1 labels: compliance.openshift.io/scan-name: one-rule-tp-node-master 1 compliance.openshift.io/suite: one-rule-ssb-node name: one-rule-tp-node-master-kubelet-eviction-thresholds-set-hard-imagefs-available namespace: openshift-compliance ownerReferences: - apiVersion: compliance.openshift.io/v1alpha1 blockOwnerDeletion: true controller: true kind: ComplianceCheckResult name: one-rule-tp-node-master-kubelet-eviction-thresholds-set-hard-imagefs-available uid: fe8e1577-9060-4c59-95b2-3e2c51709adc resourceVersion: "84820" uid: 5339d21a-24d7-40cb-84d2-7a2ebb015355 spec: apply: true current: object: apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig spec: kubeletConfig: evictionHard: imagefs.available: 10% 2 outdated: {} type: Configuration status: applicationState: AppliedNoteSi la remédiation invoque une configuration kubelet
evictionHard, vous devez spécifier tous les paramètresevictionHard:memory.availablenodefs.available,nodefs.inodesFree,imagefs.availableetimagefs.inodesFree. Si vous ne spécifiez pas tous les paramètres, seuls les paramètres spécifiés sont appliqués et la remédiation ne fonctionnera pas correctement.Retirer l'assainissement :
Définir
applyà false pour l'objet de remédiation :$ oc -n openshift-compliance patch \ complianceremediations/one-rule-tp-node-master-kubelet-eviction-thresholds-set-hard-imagefs-available \ -p '{"spec":{"apply":false}}' --type=mergeA l'aide de
scan-name, trouvez l'objetKubeletConfigauquel la remédiation a été appliquée :$ oc -n openshift-compliance get kubeletconfig \ --selector compliance.openshift.io/scan-name=one-rule-tp-node-master
Exemple de sortie
NAME AGE compliance-operator-kubelet-master 2m34s
Supprimez manuellement la remédiation,
imagefs.available: 10%, de l'objetKubeletConfig:$ oc edit -n openshift-compliance KubeletConfig compliance-operator-kubelet-master
ImportantTous les nœuds concernés par la remédiation seront redémarrés.
Vous devez également exclure la règle de toutes les analyses planifiées dans vos profils personnalisés qui appliquent automatiquement la correction, sinon la correction sera réappliquée lors de la prochaine analyse planifiée.
5.10.12. ComplianceScan incohérent
L'objet ScanSetting répertorie les rôles de nœuds que les analyses de conformité générées à partir des objets ScanSetting ou ScanSettingBinding doivent analyser. Chaque rôle de nœud correspond généralement à un pool de configuration de machine.
Il est prévu que toutes les machines d'un pool de configuration soient identiques et que tous les résultats d'analyse des nœuds d'un pool soient identiques.
Si certains résultats sont différents des autres, l'opérateur de conformité signale un objet ComplianceCheckResult dont certains nœuds seront signalés comme étant INCONSISTENT. Tous les objets ComplianceCheckResult sont également étiquetés avec compliance.openshift.io/inconsistent-check.
Comme le nombre de machines dans un pool peut être très important, l'opérateur de conformité tente de trouver l'état le plus courant et de dresser la liste des nœuds qui diffèrent de l'état courant. L'état le plus courant est stocké dans l'annotation compliance.openshift.io/most-common-status et l'annotation compliance.openshift.io/inconsistent-source contient des paires de hostname:status d'états de contrôle qui diffèrent de l'état le plus courant. Si aucun état commun ne peut être trouvé, toutes les paires hostname:status sont répertoriées dans l'annotation compliance.openshift.io/inconsistent-source annotation.
Si possible, une remédiation est encore créée afin que le cluster puisse converger vers un statut conforme. Cependant, cela n'est pas toujours possible et la correction de la différence entre les nœuds doit être effectuée manuellement. L'analyse de conformité doit être réexécutée pour obtenir un résultat cohérent en annotant l'analyse avec l'option compliance.openshift.io/rescan=:
$ oc -n openshift-compliance \ annotate compliancescans/rhcos4-e8-worker compliance.openshift.io/rescan=
5.10.13. Ressources supplémentaires
5.11. Exécution de tâches avancées de l'opérateur de conformité
L'opérateur de conformité comprend des options pour les utilisateurs avancés à des fins de débogage ou d'intégration avec l'outillage existant.
5.11.1. Utiliser directement les objets ComplianceSuite et ComplianceScan
Bien qu'il soit recommandé aux utilisateurs de tirer parti des objets ScanSetting et ScanSettingBinding pour définir les suites et les balayages, il existe des cas d'utilisation valables pour définir directement les objets ComplianceSuite:
-
Spécification d'une seule règle à analyser. Cela peut être utile pour le débogage avec l'attribut
debug: truequi augmente la verbosité de l'analyseur OpenSCAP, car le mode de débogage a tendance à devenir assez verbeux autrement. Limiter le test à une seule règle permet de réduire la quantité d'informations de débogage. - Fournir un nodeSelector personnalisé. Pour qu'une remédiation soit applicable, le nodeSelector doit correspondre à un pool.
- Orienter le scanner vers une carte de configuration sur mesure avec un fichier d'adaptation.
- Pour les tests ou le développement, lorsqu'il n'est pas nécessaire d'analyser les profils à partir des paquets.
L'exemple suivant montre un site ComplianceSuite qui analyse les machines de travail avec une seule règle :
apiVersion: compliance.openshift.io/v1alpha1
kind: ComplianceSuite
metadata:
name: workers-compliancesuite
spec:
scans:
- name: workers-scan
profile: xccdf_org.ssgproject.content_profile_moderate
content: ssg-rhcos4-ds.xml
contentImage: quay.io/complianceascode/ocp4:latest
debug: true
rule: xccdf_org.ssgproject.content_rule_no_direct_root_logins
nodeSelector:
node-role.kubernetes.io/worker: ""
L'objet ComplianceSuite et les objets ComplianceScan mentionnés ci-dessus spécifient plusieurs attributs dans un format attendu par OpenSCAP.
Pour connaître les valeurs du profil, du contenu ou de la règle, vous pouvez commencer par créer une suite similaire à partir de ScanSetting et ScanSettingBinding ou inspecter les objets analysés à partir des objets ProfileBundle tels que les règles ou les profils. Ces objets contiennent les identifiants xccdf_org que vous pouvez utiliser pour y faire référence à partir de ComplianceSuite.
5.11.2. Réglage de PriorityClass pour les scans de ScanSetting
Dans les environnements à grande échelle, l'objet par défaut PriorityClass peut être trop bas pour garantir que les pods exécutent les analyses à temps. Pour les clusters qui doivent maintenir la conformité ou garantir l'analyse automatisée, il est recommandé de définir la variable PriorityClass afin de garantir que l'opérateur de conformité est toujours prioritaire dans les situations où les ressources sont limitées.
Procédure
Définir la variable
PriorityClass:apiVersion: compliance.openshift.io/v1alpha1 strictNodeScan: true metadata: name: default namespace: openshift-compliance priorityClass: compliance-high-priority 1 kind: ScanSetting showNotApplicable: false rawResultStorage: nodeSelector: node-role.kubernetes.io/master: '' pvAccessModes: - ReadWriteOnce rotation: 3 size: 1Gi tolerations: - effect: NoSchedule key: node-role.kubernetes.io/master operator: Exists - effect: NoExecute key: node.kubernetes.io/not-ready operator: Exists tolerationSeconds: 300 - effect: NoExecute key: node.kubernetes.io/unreachable operator: Exists tolerationSeconds: 300 - effect: NoSchedule key: node.kubernetes.io/memory-pressure operator: Exists schedule: 0 1 * * * roles: - master - worker scanTolerations: - operator: Exists- 1
- Si le site
PriorityClassmentionné dans le siteScanSettingest introuvable, l'opérateur laissera le sitePriorityClassvide, émettra un avertissement et continuera à programmer des balayages sansPriorityClass.
5.11.3. Utilisation de profils bruts personnalisés
Alors que la norme TailoredProfile CR permet les opérations d'adaptation les plus courantes, la norme XCCDF offre encore plus de flexibilité dans l'adaptation des profils OpenSCAP. En outre, si votre organisation a déjà utilisé OpenScap, il se peut que vous disposiez d'un fichier d'adaptation XCCDF et que vous puissiez le réutiliser.
L'objet ComplianceSuite contient un attribut facultatif TailoringConfigMap qui permet de pointer vers un fichier d'adaptation personnalisé. La valeur de l'attribut TailoringConfigMap est le nom d'une carte de configuration qui doit contenir une clé appelée tailoring.xml et la valeur de cette clé est le contenu de l'adaptation.
Procédure
Créer l'objet
ConfigMapà partir d'un fichier :$ oc -n openshift-compliance \ create configmap nist-moderate-modified \ --from-file=tailoring.xml=/path/to/the/tailoringFile.xml
Référencer le fichier d'adaptation dans un scan qui appartient à une suite :
apiVersion: compliance.openshift.io/v1alpha1 kind: ComplianceSuite metadata: name: workers-compliancesuite spec: debug: true scans: - name: workers-scan profile: xccdf_org.ssgproject.content_profile_moderate content: ssg-rhcos4-ds.xml contentImage: quay.io/complianceascode/ocp4:latest debug: true tailoringConfigMap: name: nist-moderate-modified nodeSelector: node-role.kubernetes.io/worker: ""
5.11.4. Exécution d'un rescan
En règle générale, vous souhaitez réexécuter une analyse selon un calendrier défini, par exemple tous les lundis ou tous les jours. Il peut également être utile de réexécuter une analyse après avoir résolu un problème sur un nœud. Pour effectuer une analyse unique, annotez l'analyse avec l'option compliance.openshift.io/rescan=:
$ oc -n openshift-compliance \ annotate compliancescans/rhcos4-e8-worker compliance.openshift.io/rescan=
Un rescan génère quatre mc supplémentaires pour le profil rhcos-moderate:
$ oc get mc
Exemple de sortie
75-worker-scan-chronyd-or-ntpd-specify-remote-server 75-worker-scan-configure-usbguard-auditbackend 75-worker-scan-service-usbguard-enabled 75-worker-scan-usbguard-allow-hid-and-hub
Lorsque le paramètre d'analyse default-auto-apply label est appliqué, les mesures correctives sont appliquées automatiquement et les mesures correctives obsolètes sont automatiquement mises à jour. S'il existe des mesures correctives qui n'ont pas été appliquées en raison de dépendances, ou des mesures correctives qui étaient obsolètes, une nouvelle analyse applique les mesures correctives et peut déclencher un redémarrage. Seules les mesures correctives qui utilisent des objets MachineConfig déclenchent des redémarrages. S'il n'y a pas de mises à jour ou de dépendances à appliquer, aucun redémarrage ne se produit.
5.11.5. Définition d'une taille de stockage personnalisée pour les résultats
Bien que les ressources personnalisées telles que ComplianceCheckResult représentent un résultat agrégé d'une vérification sur tous les nœuds analysés, il peut être utile d'examiner les résultats bruts tels qu'ils sont produits par l'analyseur. Les résultats bruts sont produits au format ARF et peuvent être volumineux (des dizaines de mégaoctets par nœud), il n'est pas pratique de les stocker dans une ressource Kubernetes soutenue par le magasin de valeurs clés etcd. Au lieu de cela, chaque analyse crée un volume persistant (PV) dont la taille par défaut est de 1 Go. En fonction de votre environnement, vous pouvez augmenter la taille du PV en conséquence. Cela se fait à l'aide de l'attribut rawResultStorage.size qui est exposé dans les ressources ScanSetting et ComplianceScan.
Un paramètre connexe est rawResultStorage.rotation, qui détermine le nombre de balayages conservés dans le PV avant que les balayages les plus anciens ne fassent l'objet d'une rotation. La valeur par défaut est de 3. En fixant la politique de rotation à 0, vous désactivez la rotation. Compte tenu de la politique de rotation par défaut et d'une estimation de 100 Mo pour un rapport d'analyse ARF brut, vous pouvez calculer la taille du PV adaptée à votre environnement.
5.11.5.1. Utilisation de valeurs de stockage de résultats personnalisées
Comme OpenShift Container Platform peut être déployé dans une variété de nuages publics ou de métal nu, l'opérateur de conformité ne peut pas déterminer les configurations de stockage disponibles. Par défaut, l'Opérateur de Conformité essaiera de créer le PV pour stocker les résultats en utilisant la classe de stockage par défaut du cluster, mais une classe de stockage personnalisée peut être configurée en utilisant l'attribut rawResultStorage.StorageClassName.
Si votre cluster ne spécifie pas de classe de stockage par défaut, cet attribut doit être défini.
Configurez la ressource personnalisée ScanSetting pour qu'elle utilise une classe de stockage standard et crée des volumes persistants d'une taille de 10 Go qui conservent les 10 derniers résultats :
Exemple ScanSetting CR
apiVersion: compliance.openshift.io/v1alpha1 kind: ScanSetting metadata: name: default namespace: openshift-compliance rawResultStorage: storageClassName: standard rotation: 10 size: 10Gi roles: - worker - master scanTolerations: - effect: NoSchedule key: node-role.kubernetes.io/master operator: Exists schedule: '0 1 * * *'
5.11.6. Application des remédiations générées par les analyses de la suite
Bien que vous puissiez utiliser le paramètre booléen autoApplyRemediations dans un objet ComplianceSuite, vous pouvez également annoter l'objet avec compliance.openshift.io/apply-remediations. Cela permet à l'opérateur d'appliquer toutes les mesures correctives créées.
Procédure
-
Appliquez l'annotation
compliance.openshift.io/apply-remediationsen exécutant :
$ oc -n openshift-compliance \ annotate compliancesuites/workers-compliancesuite compliance.openshift.io/apply-remediations=
5.11.7. Mise à jour automatique des mesures correctives
Dans certains cas, une analyse avec un contenu plus récent peut marquer les remédiations comme OUTDATED. En tant qu'administrateur, vous pouvez appliquer l'annotation compliance.openshift.io/remove-outdated pour appliquer de nouvelles mesures correctives et supprimer celles qui sont obsolètes.
Procédure
-
Appliquez l'annotation
compliance.openshift.io/remove-outdated:
$ oc -n openshift-compliance \ annotate compliancesuites/workers-compliancesuite compliance.openshift.io/remove-outdated=
Vous pouvez également activer l'indicateur autoUpdateRemediations dans un objet ScanSetting ou ComplianceSuite pour mettre à jour les mesures correctives automatiquement.
5.11.8. Création d'un SCC personnalisé pour l'opérateur de conformité
Dans certains environnements, vous devez créer un fichier de contraintes de contexte de sécurité (SCC) personnalisé pour vous assurer que les autorisations correctes sont disponibles pour l'opérateur de conformité api-resource-collector.
Conditions préalables
-
Vous devez avoir les privilèges de
admin.
Procédure
Définir le SCC dans un fichier YAML nommé
restricted-adjusted-compliance.yaml:SecurityContextConstraintsdéfinition de l'objetallowHostDirVolumePlugin: false allowHostIPC: false allowHostNetwork: false allowHostPID: false allowHostPorts: false allowPrivilegeEscalation: true allowPrivilegedContainer: false allowedCapabilities: null apiVersion: security.openshift.io/v1 defaultAddCapabilities: null fsGroup: type: MustRunAs kind: SecurityContextConstraints metadata: name: restricted-adjusted-compliance priority: 30 1 readOnlyRootFilesystem: false requiredDropCapabilities: - KILL - SETUID - SETGID - MKNOD runAsUser: type: MustRunAsRange seLinuxContext: type: MustRunAs supplementalGroups: type: RunAsAny users: - system:serviceaccount:openshift-compliance:api-resource-collector 2 volumes: - configMap - downwardAPI - emptyDir - persistentVolumeClaim - projected - secretCréer le CCN :
$ oc create -n openshift-compliance -f restricted-adjusted-compliance.yaml
Exemple de sortie
securitycontextconstraints.security.openshift.io/restricted-adjusted-compliance created
Vérification
Vérifier que le SCC a été créé :
$ oc get -n openshift-compliance scc restricted-adjusted-compliance
Exemple de sortie
NAME PRIV CAPS SELINUX RUNASUSER FSGROUP SUPGROUP PRIORITY READONLYROOTFS VOLUMES restricted-adjusted-compliance false <no value> MustRunAs MustRunAsRange MustRunAs RunAsAny 30 false ["configMap","downwardAPI","emptyDir","persistentVolumeClaim","projected","secret"]
5.11.9. Ressources supplémentaires
5.12. Dépannage de l'opérateur de conformité
Cette section décrit comment dépanner l'Opérateur de Conformité. Les informations peuvent être utiles pour diagnostiquer un problème ou pour fournir des informations dans un rapport de bogue. Quelques conseils généraux :
L'opérateur de conformité émet des événements Kubernetes lorsque quelque chose d'important se produit. Vous pouvez afficher tous les événements dans le cluster à l'aide de la commande :
$ oc get events -n openshift-compliance
Vous pouvez également afficher les événements d'un objet tel qu'un balayage à l'aide de la commande :
$ oc describe -n openshift-compliance compliancescan/cis-compliance
L'opérateur de conformité se compose de plusieurs contrôleurs, environ un par objet API. Il pourrait être utile de filtrer uniquement les contrôleurs qui correspondent à l'objet API qui pose problème. Si un
ComplianceRemediationne peut pas être appliqué, affichez les messages du contrôleurremediationctrl. Vous pouvez filtrer les messages d'un seul contrôleur en les analysant avecjq:$ oc -n openshift-compliance logs compliance-operator-775d7bddbd-gj58f \ | jq -c 'select(.logger == "profilebundlectrl")'Les horodatages sont enregistrés en secondes depuis l'époque UNIX en UTC. Pour les convertir en une date lisible par l'homme, utilisez
date -d @timestamp --utc, par exemple :$ date -d @1596184628.955853 --utc
-
De nombreuses ressources personnalisées, notamment
ComplianceSuiteetScanSetting, permettent de définir l'optiondebug. L'activation de cette option augmente la verbosité des pods d'analyse OpenSCAP, ainsi que d'autres pods d'aide. -
Si une seule règle réussit ou échoue de manière inattendue, il peut être utile d'exécuter un seul balayage ou une suite avec uniquement cette règle pour trouver l'ID de la règle à partir de l'objet
ComplianceCheckResultcorrespondant et l'utiliser comme valeur d'attributruledans un CRScan. Ensuite, avec l'optiondebugactivée, les journaux du conteneurscannerdans le pod scanner montreraient les journaux bruts d'OpenSCAP.
5.12.1. Anatomie d'un scan
Les sections suivantes décrivent les composantes et les étapes de l'analyse de l'opérateur de conformité.
5.12.1.1. Sources de conformité
Le contenu de la conformité est stocké dans des objets Profile générés à partir d'un objet ProfileBundle. L'opérateur de conformité crée un objet ProfileBundle pour le cluster et un autre pour les nœuds du cluster.
$ oc get -n openshift-compliance profilebundle.compliance
$ oc get -n openshift-compliance profile.compliance
Les objets ProfileBundle sont traités par les déploiements portant le nom Bundle. Pour résoudre un problème avec Bundle, vous pouvez trouver le déploiement et consulter les journaux des pods dans un déploiement :
$ oc logs -n openshift-compliance -lprofile-bundle=ocp4 -c profileparser
$ oc get -n openshift-compliance deployments,pods -lprofile-bundle=ocp4
$ oc logs -n openshift-compliance pods/<pod-name>
oc describe -n openshift-compliance pod/<pod-name> -c profileparser
5.12.1.2. Cycle de vie des objets ScanSetting et ScanSettingBinding et débogage
Avec des sources de contenu de conformité valides, les objets de haut niveau ScanSetting et ScanSettingBinding peuvent être utilisés pour générer des objets ComplianceSuite et ComplianceScan:
apiVersion: compliance.openshift.io/v1alpha1
kind: ScanSetting
metadata:
name: my-companys-constraints
debug: true
# For each role, a separate scan will be created pointing
# to a node-role specified in roles
roles:
- worker
---
apiVersion: compliance.openshift.io/v1alpha1
kind: ScanSettingBinding
metadata:
name: my-companys-compliance-requirements
profiles:
# Node checks
- name: rhcos4-e8
kind: Profile
apiGroup: compliance.openshift.io/v1alpha1
# Cluster checks
- name: ocp4-e8
kind: Profile
apiGroup: compliance.openshift.io/v1alpha1
settingsRef:
name: my-companys-constraints
kind: ScanSetting
apiGroup: compliance.openshift.io/v1alpha1
Les objets ScanSetting et ScanSettingBinding sont gérés par le même contrôleur étiqueté avec logger=scansettingbindingctrl. Ces objets n'ont pas de statut. Tout problème est communiqué sous la forme d'événements :
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuiteCreated 9m52s scansettingbindingctrl ComplianceSuite openshift-compliance/my-companys-compliance-requirements created
Un objet ComplianceSuite est alors créé. Le flux continue à réconcilier l'objet nouvellement créé ComplianceSuite.
5.12.1.3. Cycle de vie et débogage des ressources personnalisées ComplianceSuite
Le CR ComplianceSuite est une enveloppe autour des CR ComplianceScan. Le CR ComplianceSuite est géré par le contrôleur étiqueté logger=suitectrl. Ce contrôleur s'occupe de créer des analyses à partir d'une suite, de réconcilier et d'agréger les états d'analyse individuels en un seul état de suite. Si une suite est définie pour être exécutée périodiquement, le contrôleur suitectrl gère également la création d'un CR CronJob qui ré-exécute les scans de la suite une fois l'exécution initiale terminée :
$ oc get cronjobs
Exemple de sortie
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE <cron_name> 0 1 * * * False 0 <none> 151m
Pour les questions les plus importantes, des événements sont émis. Vous pouvez les visualiser à l'aide de oc describe compliancesuites/<name>. Les objets Suite ont également une sous-ressource Status qui est mise à jour lorsque l'un des objets Scan appartenant à cette suite met à jour sa sous-ressource Status. Une fois que tous les scans prévus ont été créés, le contrôle est transmis au contrôleur de scan.
5.12.1.4. Cycle de vie et débogage des ressources personnalisées ComplianceScan
Les CR ComplianceScan sont gérés par le contrôleur scanctrl. C'est également là que se déroulent les balayages proprement dits et que sont créés les résultats de ces balayages. Chaque analyse passe par plusieurs phases :
5.12.1.4.1. Phase d'attente
L'exactitude de l'analyse est validée au cours de cette phase. Si certains paramètres, tels que la taille de stockage, ne sont pas valides, l'analyse passe à la phase DONE avec un résultat ERROR, sinon elle passe à la phase Launching.
5.12.1.4.2. Phase de lancement
Dans cette phase, plusieurs cartes de configuration contiennent soit l'environnement pour les modules d'analyse, soit directement le script que les modules d'analyse évalueront. Dressez la liste des cartes de configuration :
$ oc -n openshift-compliance get cm \ -l compliance.openshift.io/scan-name=rhcos4-e8-worker,complianceoperator.openshift.io/scan-script=
Ces cartes de configuration seront utilisées par les pods de l'analyseur. Si vous avez besoin de modifier le comportement du scanner, de changer le niveau de débogage du scanner ou d'imprimer les résultats bruts, vous pouvez modifier les cartes de configuration. Ensuite, un volume persistant est créé pour chaque analyse afin de stocker les résultats bruts de l'ARF :
$ oc get pvc -n openshift-compliance -lcompliance.openshift.io/scan-name=rhcos4-e8-worker
Les PVC sont montés par un déploiement par scanner ResultServer. Le site ResultServer est un simple serveur HTTP sur lequel les différents pods scanners téléchargent les résultats complets de l'ARF. Chaque serveur peut fonctionner sur un nœud différent. Les résultats complets de l'ARF peuvent être très volumineux et vous ne pouvez pas supposer qu'il serait possible de créer un volume qui pourrait être monté à partir de plusieurs nœuds en même temps. Une fois l'analyse terminée, le déploiement de ResultServer est réduit. Le PVC contenant les résultats bruts peut être monté à partir d'un autre pod personnalisé et les résultats peuvent être récupérés ou inspectés. Le trafic entre les modules d'analyse et le site ResultServer est protégé par des protocoles TLS mutuels.
Enfin, les modules d'analyse sont lancés au cours de cette phase : un module d'analyse pour une instance d'analyse Platform et un module d'analyse par nœud correspondant pour une instance d'analyse node. Les modules par nœud sont étiquetés avec le nom du nœud. Chaque module est toujours étiqueté avec le nom ComplianceScan:
$ oc get pods -lcompliance.openshift.io/scan-name=rhcos4-e8-worker,workload=scanner --show-labels
Exemple de sortie
NAME READY STATUS RESTARTS AGE LABELS rhcos4-e8-worker-ip-10-0-169-90.eu-north-1.compute.internal-pod 0/2 Completed 0 39m compliance.openshift.io/scan-name=rhcos4-e8-worker,targetNode=ip-10-0-169-90.eu-north-1.compute.internal,workload=scanner
L'analyse passe ensuite à la phase d'exécution.
5.12.1.4.3. Phase d'exécution
La phase d'exécution attend que les modules d'analyse se terminent. Les termes et processus suivants sont utilisés dans la phase d'exécution :
-
init container: Il existe un conteneur init appelé
content-container. Il lance le conteneur contentImage et exécute une commande unique qui copie le conteneur contentFile dans le répertoire/contentpartagé avec les autres conteneurs de ce pod. -
scanner: Ce conteneur exécute l'analyse. Pour les analyses de nœuds, le conteneur monte le système de fichiers du nœud en tant que
/hostet monte le contenu fourni par le conteneur init. Le conteneur monte également leentrypointConfigMapcréé dans la phase de lancement et l'exécute. Le script par défaut dans le point d'entréeConfigMapexécute OpenSCAP et stocke les fichiers de résultats dans le répertoire/resultspartagé entre les conteneurs du pod. Les journaux de ce module peuvent être consultés pour déterminer ce que l'analyseur OpenSCAP a vérifié. Une sortie plus verbeuse peut être visualisée avec l'optiondebug. logcollector: Le conteneur logcollector attend que le conteneur scanner se termine. Ensuite, il télécharge les résultats ARF complets sur le site
ResultServeret télécharge séparément les résultats XCCDF avec le résultat de l'analyse et le code de résultat OpenSCAP en tant queConfigMap.. Ces cartes de configuration des résultats sont étiquetées avec le nom de l'analyse (compliance.openshift.io/scan-name=rhcos4-e8-worker) :$ oc describe cm/rhcos4-e8-worker-ip-10-0-169-90.eu-north-1.compute.internal-pod
Exemple de sortie
Name: rhcos4-e8-worker-ip-10-0-169-90.eu-north-1.compute.internal-pod Namespace: openshift-compliance Labels: compliance.openshift.io/scan-name-scan=rhcos4-e8-worker complianceoperator.openshift.io/scan-result= Annotations: compliance-remediations/processed: compliance.openshift.io/scan-error-msg: compliance.openshift.io/scan-result: NON-COMPLIANT OpenSCAP-scan-result/node: ip-10-0-169-90.eu-north-1.compute.internal Data ==== exit-code: ---- 2 results: ---- <?xml version="1.0" encoding="UTF-8"?> ...
Les nacelles des scanners Platform sont similaires, à l'exception de ce qui suit :
-
Il existe un conteneur init supplémentaire appelé
api-resource-collectorqui lit le contenu OpenSCAP fourni par le conteneur init content-container, détermine les ressources API que le contenu doit examiner et stocke ces ressources API dans un répertoire partagé où le conteneurscannerles lira. -
Le conteneur
scannern'a pas besoin de monter le système de fichiers de l'hôte.
Lorsque les modules d'analyse sont terminés, les analyses passent à la phase d'agrégation.
5.12.1.4.4. Phase d'agrégation
Dans la phase d'agrégation, le contrôleur d'analyse crée un autre pod appelé pod agrégateur. Son objectif est de prendre les objets ConfigMap, de lire les résultats et de créer l'objet Kubernetes correspondant pour chaque résultat de contrôle. Si l'échec du contrôle peut être corrigé automatiquement, un objet ComplianceRemediation est créé. Pour fournir des métadonnées lisibles par l'homme pour les contrôles et les remédiations, le pod agrégateur monte également le contenu OpenSCAP à l'aide d'un conteneur init.
Lorsqu'une carte de configuration est traitée par un pod agrégateur, elle reçoit l'étiquette compliance-remediations/processed. Le résultat de cette phase est constitué d'objets ComplianceCheckResult:
$ oc get compliancecheckresults -lcompliance.openshift.io/scan-name=rhcos4-e8-worker
Exemple de sortie
NAME STATUS SEVERITY rhcos4-e8-worker-accounts-no-uid-except-zero PASS high rhcos4-e8-worker-audit-rules-dac-modification-chmod FAIL medium
et ComplianceRemediation:
$ oc get complianceremediations -lcompliance.openshift.io/scan-name=rhcos4-e8-worker
Exemple de sortie
NAME STATE rhcos4-e8-worker-audit-rules-dac-modification-chmod NotApplied rhcos4-e8-worker-audit-rules-dac-modification-chown NotApplied rhcos4-e8-worker-audit-rules-execution-chcon NotApplied rhcos4-e8-worker-audit-rules-execution-restorecon NotApplied rhcos4-e8-worker-audit-rules-execution-semanage NotApplied rhcos4-e8-worker-audit-rules-execution-setfiles NotApplied
Une fois ces CR créés, le pod agrégateur se retire et l'analyse passe à la phase Terminé.
5.12.1.4.5. Phase terminée
Lors de la phase finale de l'analyse, les ressources de l'analyse sont nettoyées si nécessaire et le déploiement de ResultServer est soit réduit (si l'analyse est ponctuelle), soit supprimé si l'analyse est continue ; l'instance d'analyse suivante recréera alors le déploiement.
Il est également possible de déclencher une nouvelle exécution d'une analyse dans la phase Terminé en l'annotant :
$ oc -n openshift-compliance \ annotate compliancescans/rhcos4-e8-worker compliance.openshift.io/rescan=
Une fois que l'analyse a atteint la phase Done, rien d'autre ne se produit, sauf si les remédiations sont définies pour être appliquées automatiquement à l'aide de autoApplyRemediations: true. L'administrateur d'OpenShift Container Platform doit alors examiner les remédiations et les appliquer si nécessaire. Si les remédiations sont définies pour être appliquées automatiquement, le contrôleur ComplianceSuite prend le relais dans la phase Done, met en pause le pool de configuration de machines auquel l'analyse est liée et applique toutes les remédiations en une seule fois. Si une correction est appliquée, le contrôleur ComplianceRemediation prend le relais.
5.12.1.5. ConformitéRemédiation Cycle de vie du contrôleur et débogage
L'analyse de l'exemple a fait état de certaines découvertes. L'une des mesures correctives peut être activée en faisant passer son attribut apply à true:
$ oc patch complianceremediations/rhcos4-e8-worker-audit-rules-dac-modification-chmod --patch '{"spec":{"apply":true}}' --type=merge
Le contrôleur ComplianceRemediation (logger=remediationctrl) réconcilie l'objet modifié. Le résultat du rapprochement est un changement de statut de l'objet de remédiation qui est rapproché, mais aussi un changement de l'objet rendu par suite MachineConfig qui contient toutes les remédiations appliquées.
L'objet MachineConfig commence toujours par 75- et porte le nom de l'analyse et de la suite :
$ oc get mc | grep 75-
Exemple de sortie
75-rhcos4-e8-worker-my-companys-compliance-requirements 3.2.0 2m46s
Les remédiations dont se compose actuellement le site mc sont répertoriées dans les annotations de la configuration de la machine :
$ oc describe mc/75-rhcos4-e8-worker-my-companys-compliance-requirements
Exemple de sortie
Name: 75-rhcos4-e8-worker-my-companys-compliance-requirements Labels: machineconfiguration.openshift.io/role=worker Annotations: remediation/rhcos4-e8-worker-audit-rules-dac-modification-chmod:
L'algorithme du contrôleur ComplianceRemediation fonctionne comme suit :
- Toutes les remédiations actuellement appliquées sont lues dans un ensemble de remédiations initial.
- Si la mesure corrective réconciliée est censée être appliquée, elle est ajoutée à l'ensemble.
-
Un objet
MachineConfigest rendu à partir de l'ensemble et annoté avec les noms des remédiations de l'ensemble. Si l'ensemble est vide (la dernière mesure corrective n'a pas été appliquée), l'objetMachineConfigrendu est supprimé. - Si et seulement si la configuration de la machine rendue est différente de celle déjà appliquée dans le cluster, la MC appliquée est mise à jour (ou créée, ou supprimée).
-
La création ou la modification d'un objet
MachineConfigdéclenche un redémarrage des nœuds correspondant à l'étiquettemachineconfiguration.openshift.io/role- voir la documentation Machine Config Operator pour plus de détails.
La boucle de remédiation se termine une fois que la configuration de la machine rendue est mise à jour, si nécessaire, et que le statut de l'objet de remédiation réconcilié est mis à jour. Dans notre cas, l'application de la remédiation déclencherait un redémarrage. Après le redémarrage, annotez l'analyse pour la réexécuter :
$ oc -n openshift-compliance \ annotate compliancescans/rhcos4-e8-worker compliance.openshift.io/rescan=
L'analyse s'exécute et se termine. Vérifiez que la remédiation est réussie :
$ oc -n openshift-compliance \ get compliancecheckresults/rhcos4-e8-worker-audit-rules-dac-modification-chmod
Exemple de sortie
NAME STATUS SEVERITY rhcos4-e8-worker-audit-rules-dac-modification-chmod PASS medium
5.12.1.6. Étiquettes utiles
Chaque module créé par l'opérateur de conformité porte une étiquette spécifique indiquant l'analyse à laquelle il appartient et le travail qu'il effectue. L'identifiant de l'analyse porte l'étiquette compliance.openshift.io/scan-name. L'identifiant de la charge de travail porte l'étiquette workload.
L'opérateur de conformité planifie les charges de travail suivantes :
- scanner: Effectue l'analyse de conformité.
- resultserver: Enregistre les résultats bruts de l'analyse de conformité.
- aggregator: Agrége les résultats, détecte les incohérences et produit des objets de résultat (résultats de contrôle et remédiations).
- suitererunner: Marque une suite pour qu'elle soit exécutée à nouveau (lorsqu'un calendrier est défini).
- profileparser: Analyse un flux de données et crée les profils, règles et variables appropriés.
Lorsque le débogage et les journaux sont nécessaires pour une certaine charge de travail, exécutez :
oc logs -l workload=<workload_name> -c <container_name>
5.12.2. Augmentation des limites de ressources de l'opérateur de conformité
Dans certains cas, l'opérateur de conformité peut avoir besoin de plus de mémoire que les limites par défaut ne le permettent. La meilleure façon de résoudre ce problème est de définir des limites de ressources personnalisées.
Pour augmenter les limites par défaut de la mémoire et de l'unité centrale des modules de numérisation, voir `ScanSetting` Custom resource.
Procédure
Pour augmenter les limites de mémoire de l'opérateur à 500 Mi, créez le fichier patch suivant, nommé
co-memlimit-patch.yaml:spec: config: resources: limits: memory: 500MiAppliquer le fichier patch :
$ oc patch sub compliance-operator -nopenshift-compliance --patch-file co-memlimit-patch.yaml --type=merge
5.12.3. Configuration des contraintes de ressources de l'opérateur
Le champ resources définit les contraintes de ressources pour tous les conteneurs du pod créé par l'Operator Lifecycle Manager (OLM).
Les contraintes de ressources appliquées au cours de ce processus remplacent les contraintes de ressources existantes.
Procédure
Injecter une demande de 0,25 cpu et 64 Mi de mémoire, et une limite de 0,5 cpu et 128 Mi de mémoire dans chaque conteneur en éditant l'objet
Subscription:kind: Subscription metadata: name: custom-operator spec: package: etcd channel: alpha config: resources: requests: memory: "64Mi" cpu: "250m" limits: memory: "128Mi" cpu: "500m"
5.12.4. Configuration du délai d'attente de ScanSetting
L'objet ScanSetting dispose d'une option de délai qui peut être spécifiée dans l'objet ComplianceScanSetting sous la forme d'une chaîne de durée, telle que 1h30m. Si l'analyse n'est pas terminée dans le délai spécifié, elle recommence jusqu'à ce que la limite de maxRetryOnTimeout soit atteinte.
Procédure
Pour définir un
timeoutet unmaxRetryOnTimeoutdans ScanSetting, modifiez un objetScanSettingexistant :apiVersion: compliance.openshift.io/v1alpha1 kind: ScanSetting metadata: name: default namespace: openshift-compliance rawResultStorage: rotation: 3 size: 1Gi roles: - worker - master scanTolerations: - effect: NoSchedule key: node-role.kubernetes.io/master operator: Exists schedule: '0 1 * * *' timeout: '10m0s' 1 maxRetryOnTimeout: 3 2
5.12.5. Obtenir de l'aide
Si vous rencontrez des difficultés avec une procédure décrite dans cette documentation, ou avec OpenShift Container Platform en général, visitez le portail client de Red Hat. À partir du portail client, vous pouvez :
- Recherchez ou parcourez la base de connaissances de Red Hat qui contient des articles et des solutions relatifs aux produits Red Hat.
- Soumettre un cas d'assistance à Red Hat Support.
- Accéder à d'autres documents sur les produits.
Pour identifier les problèmes liés à votre cluster, vous pouvez utiliser Insights dans OpenShift Cluster Manager Hybrid Cloud Console. Insights fournit des détails sur les problèmes et, le cas échéant, des informations sur la manière de les résoudre.
Si vous avez une suggestion pour améliorer cette documentation ou si vous avez trouvé une erreur, soumettez un problème Jira pour le composant de documentation le plus pertinent. Veuillez fournir des détails spécifiques, tels que le nom de la section et la version d'OpenShift Container Platform.
5.13. Désinstallation de l'opérateur de conformité
Vous pouvez supprimer l'OpenShift Compliance Operator de votre cluster en utilisant la console web OpenShift Container Platform ou le CLI.
5.13.1. Désinstallation de l'OpenShift Compliance Operator d'OpenShift Container Platform à l'aide de la console web
Pour supprimer l'Opérateur de conformité, vous devez d'abord supprimer les objets de l'espace de noms. Une fois les objets supprimés, vous pouvez supprimer l'opérateur et son espace de noms en supprimant le projet openshift-compliance.
Conditions préalables
-
Accès à un cluster OpenShift Container Platform à l'aide d'un compte disposant des autorisations
cluster-admin. - L'opérateur de conformité OpenShift doit être installé.
Procédure
Pour supprimer l'opérateur de conformité en utilisant la console web d'OpenShift Container Platform :
Allez à la page Operators → Installed Operators → Compliance Operator.
- Cliquez sur All instances.
-
Dans All namespaces, cliquez sur le menu Options
 et supprimez tous les objets ScanSettingBinding, ComplainceSuite, ComplianceScan et ProfileBundle.
et supprimez tous les objets ScanSettingBinding, ComplainceSuite, ComplianceScan et ProfileBundle.
- Passez à la page Administration → Operators → Installed Operators.
-
Cliquez sur le menu Options
sur l'entrée Compliance Operator et sélectionnez Uninstall Operator.
- Passez à la page Home → Projects.
- Recherche de "compliance".
Cliquez sur le menu Options
à côté du projet openshift-compliance et sélectionnez Delete Project.
-
Confirmez la suppression en tapant
openshift-compliancedans la boîte de dialogue, puis cliquez sur Delete.
-
Confirmez la suppression en tapant
5.13.2. Désinstallation de l'OpenShift Compliance Operator de OpenShift Container Platform à l'aide de la CLI
Pour supprimer l'Opérateur de conformité, vous devez d'abord supprimer les objets de l'espace de noms. Une fois les objets supprimés, vous pouvez supprimer l'opérateur et son espace de noms en supprimant le projet openshift-compliance.
Conditions préalables
-
Accès à un cluster OpenShift Container Platform à l'aide d'un compte disposant des autorisations
cluster-admin. - L'opérateur de conformité OpenShift doit être installé.
Procédure
Supprime tous les objets de l'espace de noms.
Supprimer les objets
ScanSettingBinding:oc delete ssb <ScanSettingBinding-name> -n openshift-compliance
Supprimer les objets
ScanSetting:$ oc delete ss <ScanSetting-name> -n openshift-compliance
Supprimer les objets
ComplianceSuite:oc delete suite <compliancesuite-name> -n openshift-compliance
Supprimer les objets
ComplianceScan:oc delete scan <compliancescan-name> -n openshift-compliance
Obtenir les objets
ProfileBundle:$ oc get profilebundle.compliance -n openshift-compliance
Exemple de sortie
NAME CONTENTIMAGE CONTENTFILE STATUS ocp4 registry.redhat.io/compliance/openshift-compliance-content-rhel8@sha256:<hash> ssg-ocp4-ds.xml VALID rhcos4 registry.redhat.io/compliance/openshift-compliance-content-rhel8@sha256:<hash> ssg-rhcos4-ds.xml VALID
Supprimer les objets
ProfileBundle:$ oc delete profilebundle.compliance ocp4 rhcos4 -n openshift-compliance
Exemple de sortie
profilebundle.compliance.openshift.io "ocp4" deleted profilebundle.compliance.openshift.io "rhcos4" deleted
Supprimer l'objet Abonnement :
oc delete sub <Subscription-Name> -n openshift-compliance
Supprimer l'objet CSV :
$ oc delete CSV -n openshift-compliance
Supprimer le projet :
$ oc delete project -n openshift-compliance
Exemple de sortie
project.project.openshift.io "openshift-compliance" deleted
Vérification
Confirmez la suppression de l'espace de noms :
$ oc get project/openshift-compliance
Exemple de sortie
Error from server (NotFound): namespaces "openshift-compliance" not found
5.14. Utilisation du plugin oc-compliance
Bien que l'Opérateur de Conformité automatise de nombreux contrôles et remédiations pour le cluster, le processus complet de mise en conformité d'un cluster nécessite souvent une interaction de l'administrateur avec l'API de l'Opérateur de Conformité et d'autres composants. Le plugin oc-compliance facilite ce processus.
5.14.1. Installation du plugin oc-compliance
Procédure
Extraire l'image
oc-compliancepour obtenir le binaireoc-compliance:$ podman run --rm -v ~/.local/bin:/mnt/out:Z registry.redhat.io/compliance/oc-compliance-rhel8:stable /bin/cp /usr/bin/oc-compliance /mnt/out/
Exemple de sortie
W0611 20:35:46.486903 11354 manifest.go:440] Chose linux/amd64 manifest from the manifest list.
Vous pouvez maintenant lancer
oc-compliance.
5.14.2. Récupération des résultats bruts
Lorsqu'un contrôle de conformité est terminé, les résultats des contrôles individuels sont répertoriés dans la ressource personnalisée (CR) ComplianceCheckResult qui en résulte. Cependant, un administrateur ou un auditeur peut avoir besoin des détails complets de l'analyse. L'outil OpenSCAP crée un fichier au format ARF (Advanced Recording Format) contenant les résultats détaillés. Ce fichier ARF est trop volumineux pour être stocké dans une carte de configuration ou une autre ressource Kubernetes standard, un volume persistant (PV) est donc créé pour le contenir.
Procédure
L'obtention des résultats du PV avec l'Opérateur de Conformité est un processus en quatre étapes. Cependant, avec le plugin
oc-compliance, vous pouvez utiliser une seule commande :$ oc compliance fetch-raw <object-type> <object-name> -o <output-path>
-
<object-type>peut êtrescansettingbinding,compliancescanoucompliancesuite, en fonction de l'objet avec lequel les balayages ont été lancés. <object-name>est le nom de la reliure, de la suite ou de l'objet de numérisation pour lequel le fichier ARF doit être rassemblé, et<output-path>est le répertoire local dans lequel les résultats doivent être placés.Par exemple :
$ oc compliance fetch-raw scansettingbindings my-binding -o /tmp/
Exemple de sortie
Fetching results for my-binding scans: ocp4-cis, ocp4-cis-node-worker, ocp4-cis-node-master Fetching raw compliance results for scan 'ocp4-cis'....... The raw compliance results are available in the following directory: /tmp/ocp4-cis Fetching raw compliance results for scan 'ocp4-cis-node-worker'........... The raw compliance results are available in the following directory: /tmp/ocp4-cis-node-worker Fetching raw compliance results for scan 'ocp4-cis-node-master'...... The raw compliance results are available in the following directory: /tmp/ocp4-cis-node-master
Affiche la liste des fichiers du répertoire :
$ ls /tmp/ocp4-cis-node-master/
Exemple de sortie
ocp4-cis-node-master-ip-10-0-128-89.ec2.internal-pod.xml.bzip2 ocp4-cis-node-master-ip-10-0-150-5.ec2.internal-pod.xml.bzip2 ocp4-cis-node-master-ip-10-0-163-32.ec2.internal-pod.xml.bzip2
Extraire les résultats :
$ bunzip2 -c resultsdir/worker-scan/worker-scan-stage-459-tqkg7-compute-0-pod.xml.bzip2 > resultsdir/worker-scan/worker-scan-ip-10-0-170-231.us-east-2.compute.internal-pod.xml
Voir les résultats :
$ ls resultsdir/worker-scan/
Exemple de sortie
worker-scan-ip-10-0-170-231.us-east-2.compute.internal-pod.xml worker-scan-stage-459-tqkg7-compute-0-pod.xml.bzip2 worker-scan-stage-459-tqkg7-compute-1-pod.xml.bzip2
5.14.3. Réexécution des analyses
Bien qu'il soit possible d'exécuter des analyses en tant que tâches planifiées, vous devez souvent réexécuter une analyse à la demande, en particulier après l'application de remédiations ou lorsque d'autres changements sont apportés au cluster.
Procédure
La relance d'une analyse à l'aide de l'opérateur de conformité nécessite l'utilisation d'une annotation sur l'objet de l'analyse. Cependant, avec le plugin
oc-compliance, vous pouvez réexécuter une analyse à l'aide d'une seule commande. Entrez la commande suivante pour réexécuter les analyses de l'objetScanSettingBindingnommémy-binding:$ oc compliance rerun-now scansettingbindings my-binding
Exemple de sortie
Rerunning scans from 'my-binding': ocp4-cis Re-running scan 'openshift-compliance/ocp4-cis'
5.14.4. Utilisation des ressources personnalisées ScanSettingBinding
En utilisant les ressources personnalisées (CR) ScanSetting et ScanSettingBinding fournies par l'Opérateur de Conformité, il est possible d'exécuter des analyses pour plusieurs profils tout en utilisant un ensemble commun d'options d'analyse, telles que schedule, machine roles, tolerations, et ainsi de suite. Bien que cela soit plus facile que de travailler avec plusieurs objets ComplianceSuite ou ComplianceScan, cela peut perturber les nouveaux utilisateurs.
La sous-commande oc compliance bind vous aide à créer un CR ScanSettingBinding.
Procédure
Exécutez :
$ oc compliance bind [--dry-run] -N <binding nom> [-S <scansetting nom>] <objtype/objname> [..<objtype/objname>]
-
Si vous omettez l'indicateur
-S, le paramètre de balayagedefaultfourni par l'opérateur de conformité est utilisé. -
Le type d'objet est le type d'objet Kubernetes, qui peut être
profileoutailoredprofile. Plusieurs objets peuvent être fournis. -
Le nom de l'objet est le nom de la ressource Kubernetes, par exemple
.metadata.name. Ajouter l'option
--dry-runpour afficher le fichier YAML des objets créés.Par exemple, compte tenu des profils et des paramètres de numérisation suivants :
$ oc get profile.compliance -n openshift-compliance
Exemple de sortie
NAME AGE ocp4-cis 9m54s ocp4-cis-node 9m54s ocp4-e8 9m54s ocp4-moderate 9m54s ocp4-ncp 9m54s rhcos4-e8 9m54s rhcos4-moderate 9m54s rhcos4-ncp 9m54s rhcos4-ospp 9m54s rhcos4-stig 9m54s
$ oc get scansettings -n openshift-compliance
Exemple de sortie
NAME AGE default 10m default-auto-apply 10m
-
Si vous omettez l'indicateur
Pour appliquer les paramètres de
defaultaux profilsocp4-cisetocp4-cis-node, exécutez :$ oc compliance bind -N my-binding profile/ocp4-cis profile/ocp4-cis-node
Exemple de sortie
Creating ScanSettingBinding my-binding
Une fois que le CR
ScanSettingBindingest créé, le profil lié commence à numériser pour les deux profils avec les paramètres correspondants. Dans l'ensemble, il s'agit de la méthode la plus rapide pour commencer la numérisation avec l'opérateur de conformité.
5.14.5. Contrôles d'impression
Les normes de conformité sont généralement organisées selon la hiérarchie suivante :
- Un référentiel est la définition de haut niveau d'un ensemble de contrôles pour une norme particulière. Par exemple, FedRAMP Moderate ou Center for Internet Security (CIS) v.1.6.0.
- Un contrôle décrit une famille d'exigences qui doivent être respectées pour être en conformité avec le référentiel. Par exemple, FedRAMP AC-01 (politique et procédures de contrôle d'accès).
- Une règle est un contrôle unique spécifique au système mis en conformité, et une ou plusieurs de ces règles correspondent à un contrôle.
- L'Opérateur de Conformité gère le regroupement des règles dans un profil pour un seul benchmark. Il peut être difficile de déterminer les contrôles que l'ensemble des règles d'un profil satisfait.
Procédure
La sous-commande
oc compliancecontrolsfournit un rapport sur les normes et les contrôles auxquels un profil donné satisfait :$ oc compliance controls profile ocp4-cis-node
Exemple de sortie
+-----------+----------+ | FRAMEWORK | CONTROLS | +-----------+----------+ | CIS-OCP | 1.1.1 | + +----------+ | | 1.1.10 | + +----------+ | | 1.1.11 | + +----------+ ...
5.14.6. Récupérer les détails de la mise en conformité
L'opérateur de conformité fournit des objets de remédiation qui sont utilisés pour automatiser les changements nécessaires pour rendre le cluster conforme. La sous-commande fetch-fixes peut vous aider à comprendre exactement quelles remédiations de configuration sont utilisées. Utilisez la sous-commande fetch-fixes pour extraire les objets de remédiation d'un profil, d'une règle ou d'un objet ComplianceRemediation dans un répertoire à inspecter.
Procédure
Voir les remédiations pour un profil :
$ oc compliance fetch-fixes profile ocp4-cis -o /tmp
Exemple de sortie
No fixes to persist for rule 'ocp4-api-server-api-priority-flowschema-catch-all' 1 No fixes to persist for rule 'ocp4-api-server-api-priority-gate-enabled' No fixes to persist for rule 'ocp4-api-server-audit-log-maxbackup' Persisted rule fix to /tmp/ocp4-api-server-audit-log-maxsize.yaml No fixes to persist for rule 'ocp4-api-server-audit-log-path' No fixes to persist for rule 'ocp4-api-server-auth-mode-no-aa' No fixes to persist for rule 'ocp4-api-server-auth-mode-node' No fixes to persist for rule 'ocp4-api-server-auth-mode-rbac' No fixes to persist for rule 'ocp4-api-server-basic-auth' No fixes to persist for rule 'ocp4-api-server-bind-address' No fixes to persist for rule 'ocp4-api-server-client-ca' Persisted rule fix to /tmp/ocp4-api-server-encryption-provider-cipher.yaml Persisted rule fix to /tmp/ocp4-api-server-encryption-provider-config.yaml- 1
- L'avertissement
No fixes to persistest attendu chaque fois que des règles d'un profil n'ont pas de remédiation correspondante, soit parce que la règle ne peut pas être remédiée automatiquement, soit parce qu'une remédiation n'a pas été fournie.
Vous pouvez visualiser un exemple de fichier YAML. La commande
headvous montrera les 10 premières lignes :$ head /tmp/ocp4-api-server-audit-log-maxsize.yaml
Exemple de sortie
apiVersion: config.openshift.io/v1 kind: APIServer metadata: name: cluster spec: maximumFileSizeMegabytes: 100
Visualiser la remédiation à partir d'un objet
ComplianceRemediationcréé après une analyse :$ oc get complianceremediations -n openshift-compliance
Exemple de sortie
NAME STATE ocp4-cis-api-server-encryption-provider-cipher NotApplied ocp4-cis-api-server-encryption-provider-config NotApplied
$ oc compliance fetch-fixes complianceremediations ocp4-cis-api-server-encryption-provider-cipher -o /tmp
Exemple de sortie
Persisted compliance remediation fix to /tmp/ocp4-cis-api-server-encryption-provider-cipher.yaml
Vous pouvez visualiser un exemple de fichier YAML. La commande
headvous montrera les 10 premières lignes :$ head /tmp/ocp4-cis-api-server-encryption-provider-cipher.yaml
Exemple de sortie
apiVersion: config.openshift.io/v1 kind: APIServer metadata: name: cluster spec: encryption: type: aescbc
Soyez prudent avant d'appliquer les mesures correctives directement. Certaines remédiations peuvent ne pas être applicables en bloc, comme les règles usbguard dans le profil modéré. Dans ce cas, autorisez l'opérateur de conformité à appliquer les règles, car cela permet de traiter les dépendances et de s'assurer que le cluster reste dans un bon état.
5.14.7. Visualisation des détails de l'objet ComplianceCheckResult
Lorsque les analyses sont terminées, les objets ComplianceCheckResult sont créés pour les règles d'analyse individuelles. La sous-commande view-result fournit une sortie lisible par l'homme des détails de l'objet ComplianceCheckResult.
Procédure
Exécutez :
$ oc compliance view-result ocp4-cis-scheduler-no-bind-address
5.15. Comprendre les définitions de ressources personnalisées
L'opérateur de conformité dans OpenShift Container Platform vous fournit plusieurs définitions de ressources personnalisées (CRD) pour réaliser les analyses de conformité. Pour exécuter un contrôle de conformité, il s'appuie sur les politiques de sécurité prédéfinies, qui sont dérivées du projet communautaire ComplianceAsCode. L'opérateur de conformité convertit ces politiques de sécurité en CRD, que vous pouvez utiliser pour exécuter des analyses de conformité et obtenir des mesures correctives pour les problèmes détectés.
5.15.1. Flux de travail des CRD
Le document de référence vous fournit le flux de travail suivant pour effectuer les contrôles de conformité :
- Définir les exigences de l'analyse de conformité
- Configurer les paramètres de l'analyse de conformité
- Traiter les exigences de conformité avec les paramètres des analyses de conformité
- Contrôler les analyses de conformité
- Vérifier les résultats de l'analyse de conformité
5.15.2. Définir les exigences de l'analyse de conformité
Par défaut, les CRD de l'opérateur de conformité comprennent les objets ProfileBundle et Profile, dans lesquels vous pouvez définir et fixer les règles pour vos exigences d'analyse de conformité. Vous pouvez également personnaliser les profils par défaut en utilisant un objet TailoredProfile.
5.15.2.1. Objet ProfileBundle
Lorsque vous installez l'Opérateur de Conformité, il inclut des objets ProfileBundle prêts à être exécutés. L'Opérateur de Conformité analyse l'objet ProfileBundle et crée un objet Profile pour chaque profil de l'ensemble. Il analyse également les objets Rule et Variable, qui sont utilisés par l'objet Profile.
Exemple d'objet ProfileBundle
apiVersion: compliance.openshift.io/v1alpha1
kind: ProfileBundle
name: <profile bundle name>
namespace: openshift-compliance
status:
dataStreamStatus: VALID 1
- 1
- Indique si l'opérateur de conformité a pu analyser les fichiers de contenu.
Lorsque le site contentFile échoue, un attribut errorMessage apparaît, qui fournit des détails sur l'erreur qui s'est produite.
Résolution de problèmes
Lorsque vous revenez à une image de contenu connue à partir d'une image non valide, l'objet ProfileBundle ne répond plus et affiche l'état PENDING. En guise de solution de contournement, vous pouvez passer à une image différente de la précédente. Vous pouvez également supprimer et recréer l'objet ProfileBundle pour revenir à l'état de fonctionnement.
5.15.2.2. Objet du profil
L'objet Profile définit les règles et les variables qui peuvent être évaluées pour une certaine norme de conformité. Il contient des détails analysés sur un profil OpenSCAP, tels que son identifiant XCCDF et les contrôles de profil pour un type Node ou Platform. Vous pouvez utiliser directement l'objet Profile ou le personnaliser davantage en utilisant un objet TailorProfile.
Vous ne pouvez pas créer ou modifier l'objet Profile manuellement car il est dérivé d'un seul objet ProfileBundle. En règle générale, un seul objet ProfileBundle peut inclure plusieurs objets Profile.
Exemple d'objet Profile
apiVersion: compliance.openshift.io/v1alpha1 description: <description of the profile> id: xccdf_org.ssgproject.content_profile_moderate 1 kind: Profile metadata: annotations: compliance.openshift.io/product: <product name> compliance.openshift.io/product-type: Node 2 creationTimestamp: "YYYY-MM-DDTMM:HH:SSZ" generation: 1 labels: compliance.openshift.io/profile-bundle: <profile bundle name> name: rhcos4-moderate namespace: openshift-compliance ownerReferences: - apiVersion: compliance.openshift.io/v1alpha1 blockOwnerDeletion: true controller: true kind: ProfileBundle name: <profile bundle name> uid: <uid string> resourceVersion: "<version number>" selfLink: /apis/compliance.openshift.io/v1alpha1/namespaces/openshift-compliance/profiles/rhcos4-moderate uid: <uid string> rules: 3 - rhcos4-account-disable-post-pw-expiration - rhcos4-accounts-no-uid-except-zero - rhcos4-audit-rules-dac-modification-chmod - rhcos4-audit-rules-dac-modification-chown title: <title of the profile>
- 1
- Indiquez le nom XCCDF du profil. Utilisez cet identifiant lorsque vous définissez un objet
ComplianceScancomme valeur de l'attribut de profil de l'analyse. - 2
- Spécifiez une adresse
NodeouPlatform. Les profils de nœuds analysent les nœuds du cluster et les profils de plateforme analysent la plateforme Kubernetes. - 3
- Spécifiez la liste des règles pour le profil. Chaque règle correspond à un seul contrôle.
5.15.2.3. Objet de la règle
L'objet Rule, qui forme les profils, est également exposé en tant qu'objet. Utilisez l'objet Rule pour définir vos exigences en matière de contrôle de conformité et spécifier comment il pourrait être corrigé.
Exemple d'objet Rule
apiVersion: compliance.openshift.io/v1alpha1
checkType: Platform 1
description: <description of the rule>
id: xccdf_org.ssgproject.content_rule_configure_network_policies_namespaces 2
instructions: <manual instructions for the scan>
kind: Rule
metadata:
annotations:
compliance.openshift.io/rule: configure-network-policies-namespaces
control.compliance.openshift.io/CIS-OCP: 5.3.2
control.compliance.openshift.io/NERC-CIP: CIP-003-3 R4;CIP-003-3 R4.2;CIP-003-3
R5;CIP-003-3 R6;CIP-004-3 R2.2.4;CIP-004-3 R3;CIP-007-3 R2;CIP-007-3 R2.1;CIP-007-3
R2.2;CIP-007-3 R2.3;CIP-007-3 R5.1;CIP-007-3 R6.1
control.compliance.openshift.io/NIST-800-53: AC-4;AC-4(21);CA-3(5);CM-6;CM-6(1);CM-7;CM-7(1);SC-7;SC-7(3);SC-7(5);SC-7(8);SC-7(12);SC-7(13);SC-7(18)
labels:
compliance.openshift.io/profile-bundle: ocp4
name: ocp4-configure-network-policies-namespaces
namespace: openshift-compliance
rationale: <description of why this rule is checked>
severity: high 3
title: <summary of the rule>
- 1
- Spécifiez le type de contrôle que cette règle exécute. Les profils
Nodeanalysent les nœuds de cluster et les profilsPlatformanalysent la plateforme Kubernetes. Une valeur vide indique qu'il n'y a pas de contrôle automatisé. - 2
- Indiquez le nom XCCDF de la règle, qui est analysé directement à partir du flux de données.
- 3
- Spécifiez la gravité de la règle en cas d'échec.
L'objet Rule reçoit une étiquette appropriée pour faciliter l'identification de l'objet ProfileBundle associé. L'adresse ProfileBundle est également spécifiée dans l'adresse OwnerReferences de cet objet.
5.15.2.4. Objet TailoredProfile
Utilisez l'objet TailoredProfile pour modifier l'objet par défaut Profile en fonction des besoins de votre organisation. Vous pouvez activer ou désactiver des règles, définir des valeurs variables et justifier la personnalisation. Après validation, l'objet TailoredProfile crée un objet ConfigMap, qui peut être référencé par un objet ComplianceScan.
Vous pouvez utiliser l'objet TailoredProfile en le référençant dans un objet ScanSettingBinding. Pour plus d'informations sur ScanSettingBinding, voir l'objet ScanSettingBinding.
Exemple d'objet TailoredProfile
apiVersion: compliance.openshift.io/v1alpha1 kind: TailoredProfile metadata: name: rhcos4-with-usb spec: extends: rhcos4-moderate 1 title: <title of the tailored profile> disableRules: - name: <name of a rule object to be disabled> rationale: <description of why this rule is checked> status: id: xccdf_compliance.openshift.io_profile_rhcos4-with-usb 2 outputRef: name: rhcos4-with-usb-tp 3 namespace: openshift-compliance state: READY 4
- 1
- Ce nom est facultatif. Nom de l'objet
Profilesur lequelTailoredProfileest construit. Si aucune valeur n'est définie, un nouveau profil est créé à partir de la listeenableRules. - 2
- Spécifie le nom XCCDF du profil personnalisé.
- 3
- Spécifie le nom
ConfigMap, qui peut être utilisé comme valeur de l'attributtailoringConfigMap.named'unComplianceScan. - 4
- Indique l'état de l'objet tel que
READY,PENDING, etFAILURE. Si l'état de l'objet estERROR, alors l'attributstatus.errorMessagefournit la raison de l'échec.
Avec l'objet TailoredProfile, il est possible de créer un nouvel objet Profile en utilisant la construction TailoredProfile. Pour créer un nouvel objet Profile, définissez les paramètres de configuration suivants :
- un titre approprié
-
extendsla valeur doit être vide l'annotation du type de balayage sur l'objet
TailoredProfile:compliance.openshift.io/product-type: Platform/Node
NoteSi vous n'avez pas défini l'annotation
product-type, l'Opérateur de Conformité utilise par défaut le type de scanPlatform. L'ajout du suffixe-nodeau nom de l'objetTailoredProfilepermet d'obtenir le type de balayagenode.
5.15.3. Configuration des paramètres de l'analyse de conformité
Après avoir défini les exigences du contrôle de conformité, vous pouvez le configurer en spécifiant le type de contrôle, l'occurrence du contrôle et l'emplacement du contrôle. Pour ce faire, l'Opérateur de Conformité vous fournit un objet ScanSetting.
5.15.3.1. Objet ScanSetting
Utilisez l'objet ScanSetting pour définir et réutiliser les politiques opérationnelles pour exécuter vos analyses. Par défaut, l'opérateur de conformité crée les objets ScanSetting suivants :
- default - il effectue un balayage tous les jours à 1 heure du matin sur les nœuds maître et travailleur à l'aide d'un volume persistant (PV) de 1Gi et conserve les trois derniers résultats. La remédiation n'est ni appliquée ni mise à jour automatiquement.
-
default-auto-apply - il effectue un scan tous les jours à 1 heure du matin sur le plan de contrôle et les nœuds de travail à l'aide d'un volume persistant (PV) de 1Gi et conserve les trois derniers résultats. Les valeurs
autoApplyRemediationsetautoUpdateRemediationssont toutes deux définies comme étant vraies.
Exemple d'objet ScanSetting
Name: default-auto-apply
Namespace: openshift-compliance
Labels: <none>
Annotations: <none>
API Version: compliance.openshift.io/v1alpha1
Auto Apply Remediations: true
Auto Update Remediations: true
Kind: ScanSetting
Metadata:
Creation Timestamp: 2022-10-18T20:21:00Z
Generation: 1
Managed Fields:
API Version: compliance.openshift.io/v1alpha1
Fields Type: FieldsV1
fieldsV1:
f:autoApplyRemediations: 1
f:autoUpdateRemediations: 2
f:rawResultStorage:
.:
f:nodeSelector:
.:
f:node-role.kubernetes.io/master:
f:pvAccessModes:
f:rotation:
f:size:
f:tolerations:
f:roles:
f:scanTolerations:
f:schedule:
f:showNotApplicable:
f:strictNodeScan:
Manager: compliance-operator
Operation: Update
Time: 2022-10-18T20:21:00Z
Resource Version: 38840
UID: 8cb0967d-05e0-4d7a-ac1c-08a7f7e89e84
Raw Result Storage:
Node Selector:
node-role.kubernetes.io/master:
Pv Access Modes:
ReadWriteOnce
Rotation: 3 3
Size: 1Gi 4
Tolerations:
Effect: NoSchedule
Key: node-role.kubernetes.io/master
Operator: Exists
Effect: NoExecute
Key: node.kubernetes.io/not-ready
Operator: Exists
Toleration Seconds: 300
Effect: NoExecute
Key: node.kubernetes.io/unreachable
Operator: Exists
Toleration Seconds: 300
Effect: NoSchedule
Key: node.kubernetes.io/memory-pressure
Operator: Exists
Roles: 5
master
worker
Scan Tolerations:
Operator: Exists
Schedule: "0 1 * * *" 6
Show Not Applicable: false
Strict Node Scan: true
Events: <none>
- 1
- La valeur
truepermet d'activer les remédiations automatiques. La valeurfalsepermet de désactiver les remédiations automatiques. - 2
- La valeur
truepermet d'activer les remédiations automatiques pour les mises à jour de contenu. La valeurfalsedésactive les remédiations automatiques pour les mises à jour de contenu. - 3
- Indiquez le nombre de balayages stockés dans le format de résultat brut. La valeur par défaut est
3. Comme les résultats les plus anciens font l'objet d'une rotation, l'administrateur doit stocker les résultats ailleurs avant que la rotation n'ait lieu. - 4
- Indiquez la taille de la mémoire qui doit être créée pour l'analyse afin de stocker les résultats bruts. La valeur par défaut est
1Gi - 6
- Spécifiez la fréquence d'exécution de l'analyse au format cron.Note
Pour désactiver la politique de rotation, réglez la valeur sur
0. - 5
- Spécifiez la valeur de l'étiquette
node-role.kubernetes.iopour programmer l'analyse pour le typeNode. Cette valeur doit correspondre au nom d'un siteMachineConfigPool.
5.15.4. Traitement des exigences de contrôle de conformité avec les paramètres des contrôles de conformité
Lorsque vous avez défini les exigences de l'analyse de conformité et configuré les paramètres pour exécuter les analyses, l'opérateur de conformité les traite à l'aide de l'objet ScanSettingBinding.
5.15.4.1. Objet ScanSettingBinding
Utilisez l'objet ScanSettingBinding pour spécifier vos exigences de conformité en référence à l'objet Profile ou TailoredProfile. Il est ensuite lié à un objet ScanSetting, qui fournit les contraintes opérationnelles pour l'analyse. L'opérateur de conformité génère ensuite l'objet ComplianceSuite sur la base des objets ScanSetting et ScanSettingBinding.
Exemple d'objet ScanSettingBinding
apiVersion: compliance.openshift.io/v1alpha1 kind: ScanSettingBinding metadata: name: <name of the scan> profiles: 1 # Node checks - name: rhcos4-with-usb kind: TailoredProfile apiGroup: compliance.openshift.io/v1alpha1 # Cluster checks - name: ocp4-moderate kind: Profile apiGroup: compliance.openshift.io/v1alpha1 settingsRef: 2 name: my-companys-constraints kind: ScanSetting apiGroup: compliance.openshift.io/v1alpha1
La création des objets ScanSetting et ScanSettingBinding donne lieu à la suite de conformité. Pour obtenir la liste des suites de conformité, exécutez la commande suivante :
$ oc get compliancesuites
Si vous supprimez ScanSettingBinding, la suite de mesures de conformité est également supprimée.
5.15.5. Suivi des analyses de conformité
Après la création de la suite de conformité, vous pouvez contrôler l'état des analyses déployées à l'aide de l'objet ComplianceSuite.
5.15.5.1. Objet ComplianceSuite
L'objet ComplianceSuite vous aide à suivre l'état des scans. Il contient les paramètres bruts utilisés pour créer les balayages et le résultat global.
Pour les analyses de type Node, vous devez mapper l'analyse sur le site MachineConfigPool, car il contient les mesures correctives pour tous les problèmes. Si vous spécifiez une étiquette, assurez-vous qu'elle s'applique directement à un pool.
Exemple d'objet ComplianceSuite
apiVersion: compliance.openshift.io/v1alpha1 kind: ComplianceSuite metadata: name: <name of the scan> spec: autoApplyRemediations: false 1 schedule: "0 1 * * *" 2 scans: 3 - name: workers-scan scanType: Node profile: xccdf_org.ssgproject.content_profile_moderate content: ssg-rhcos4-ds.xml contentImage: quay.io/complianceascode/ocp4:latest rule: "xccdf_org.ssgproject.content_rule_no_netrc_files" nodeSelector: node-role.kubernetes.io/worker: "" status: Phase: DONE 4 Result: NON-COMPLIANT 5 scanStatuses: - name: workers-scan phase: DONE result: NON-COMPLIANT
- 1
- La valeur
truepermet d'activer les remédiations automatiques. La valeurfalsepermet de désactiver les remédiations automatiques. - 2
- Spécifiez la fréquence d'exécution de l'analyse au format cron.
- 3
- Spécifiez une liste de spécifications d'analyse à exécuter dans le cluster.
- 4
- Indique l'état d'avancement des analyses.
- 5
- Indique le verdict global de la suite.
La suite crée en arrière-plan l'objet ComplianceScan sur la base du paramètre scans. Vous pouvez récupérer par programme les événements de ComplianceSuites. Pour obtenir les événements de la suite, exécutez la commande suivante :
oc get events --field-selector involvedObject.kind=ComplianceSuite,involvedObject.name=<nom de la suite>
Vous risquez de créer des erreurs lorsque vous définissez manuellement le site ComplianceSuite, car il contient les attributs XCCDF.
5.15.5.2. Objet ComplianceScan avancé
L'Opérateur de Conformité comprend des options pour les utilisateurs avancés pour le débogage ou l'intégration avec l'outillage existant. Bien qu'il soit recommandé de ne pas créer directement un objet ComplianceScan, vous pouvez le gérer à l'aide d'un objet ComplianceSuite.
Exemple Objet avancé ComplianceScan
apiVersion: compliance.openshift.io/v1alpha1 kind: ComplianceScan metadata: name: <name of the scan> spec: scanType: Node 1 profile: xccdf_org.ssgproject.content_profile_moderate 2 content: ssg-ocp4-ds.xml contentImage: quay.io/complianceascode/ocp4:latest 3 rule: "xccdf_org.ssgproject.content_rule_no_netrc_files" 4 nodeSelector: 5 node-role.kubernetes.io/worker: "" status: phase: DONE 6 result: NON-COMPLIANT 7
- 1
- Spécifiez
NodeouPlatform. Les profils de nœuds analysent les nœuds du cluster et les profils de plateforme analysent la plateforme Kubernetes. - 2
- Indiquez l'identifiant XCCDF du profil que vous souhaitez exécuter.
- 3
- Spécifiez l'image du conteneur qui encapsule les fichiers de profil.
- 4
- Elle est facultative. Spécifiez l'analyse pour exécuter une seule règle. Cette règle doit être identifiée par l'ID XCCDF et doit appartenir au profil spécifié.Note
Si vous ignorez le paramètre
rule, l'analyse s'exécute pour toutes les règles disponibles du profil spécifié. - 5
- Si vous êtes sur OpenShift Container Platform et que vous souhaitez générer une remédiation, le label nodeSelector doit correspondre au label
MachineConfigPool.NoteSi vous ne spécifiez pas le paramètre
nodeSelectorou si vous ne correspondez pas à l'étiquetteMachineConfig, l'analyse s'exécutera quand même, mais elle ne créera pas de remédiation. - 6
- Indique la phase actuelle du balayage.
- 7
- Indique le verdict de l'analyse.
Si vous supprimez un objet ComplianceSuite, tous les balayages associés sont supprimés.
Lorsque l'analyse est terminée, elle génère le résultat sous forme de ressources personnalisées de l'objet ComplianceCheckResult. Toutefois, les résultats bruts sont disponibles au format ARF. Ces résultats sont stockés dans un volume persistant (PV), auquel une revendication de volume persistant (PVC) est associée au nom de l'analyse. Vous pouvez récupérer par programme les événements ComplianceScans. Pour générer des événements pour la suite, exécutez la commande suivante :
oc get events --field-selector involvedObject.kind=ComplianceScan,involvedObject.name=<nom de la suite>
5.15.6. Visualisation des résultats de conformité
Lorsque la suite de conformité atteint la phase DONE, vous pouvez consulter les résultats de l'analyse et les mesures correctives possibles.
5.15.6.1. Objet ComplianceCheckResult
Lorsque vous exécutez une analyse avec un profil spécifique, plusieurs règles des profils sont vérifiées. Pour chacune de ces règles, un objet ComplianceCheckResult est créé, qui fournit l'état du cluster pour une règle spécifique.
Exemple d'objet ComplianceCheckResult
apiVersion: compliance.openshift.io/v1alpha1
kind: ComplianceCheckResult
metadata:
labels:
compliance.openshift.io/check-severity: medium
compliance.openshift.io/check-status: FAIL
compliance.openshift.io/suite: example-compliancesuite
compliance.openshift.io/scan-name: workers-scan
name: workers-scan-no-direct-root-logins
namespace: openshift-compliance
ownerReferences:
- apiVersion: compliance.openshift.io/v1alpha1
blockOwnerDeletion: true
controller: true
kind: ComplianceScan
name: workers-scan
description: <description of scan check>
instructions: <manual instructions for the scan>
id: xccdf_org.ssgproject.content_rule_no_direct_root_logins
severity: medium 1
status: FAIL 2
- 1
- Décrit la gravité de la vérification de l'analyse.
- 2
- Décrit le résultat du contrôle. Les valeurs possibles sont les suivantes :
- PASS : la vérification a été effectuée avec succès.
- FAIL : la vérification n'a pas abouti.
- INFO : la vérification a été effectuée avec succès et a permis de détecter un problème qui n'est pas suffisamment grave pour être considéré comme une erreur.
- MANUEL : le contrôle ne peut pas évaluer automatiquement l'état et un contrôle manuel est nécessaire.
- INCONSISTANT : différents nœuds rapportent des résultats différents.
- ERREUR : le contrôle a été exécuté avec succès, mais n'a pas pu se terminer.
- NOTAPPLICABLE : le contrôle n'a pas été effectué car il n'est pas applicable.
Pour obtenir tous les résultats de contrôle d'une suite, exécutez la commande suivante :
oc get compliancecheckresults \ -l compliance.openshift.io/suite=workers-compliancesuite
5.15.6.2. Objet ComplianceRemediation
Pour un contrôle spécifique, vous pouvez avoir un correctif spécifié par datastream. Cependant, si un correctif Kubernetes est disponible, l'opérateur de conformité crée un objet ComplianceRemediation.
Exemple d'objet ComplianceRemediation
apiVersion: compliance.openshift.io/v1alpha1
kind: ComplianceRemediation
metadata:
labels:
compliance.openshift.io/suite: example-compliancesuite
compliance.openshift.io/scan-name: workers-scan
machineconfiguration.openshift.io/role: worker
name: workers-scan-disable-users-coredumps
namespace: openshift-compliance
ownerReferences:
- apiVersion: compliance.openshift.io/v1alpha1
blockOwnerDeletion: true
controller: true
kind: ComplianceCheckResult
name: workers-scan-disable-users-coredumps
uid: <UID>
spec:
apply: false 1
object:
current: 2
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
spec:
config:
ignition:
version: 2.2.0
storage:
files:
- contents:
source: data:,%2A%20%20%20%20%20hard%20%20%20core%20%20%20%200
filesystem: root
mode: 420
path: /etc/security/limits.d/75-disable_users_coredumps.conf
outdated: {} 3
- 1
trueindique que la mesure corrective a été appliquée.falseindique que la mesure corrective n'a pas été appliquée.- 2
- Inclut la définition de la remédiation.
- 3
- Indique une remédiation qui a été précédemment analysée à partir d'une version antérieure du contenu. L'opérateur de conformité conserve les objets périmés afin de permettre à l'administrateur de revoir les nouvelles mesures correctives avant de les appliquer.
Pour obtenir toutes les mesures correctives d'une suite, exécutez la commande suivante :
oc get complianceremediations \ -l compliance.openshift.io/suite=workers-compliancesuite
Pour dresser la liste de tous les contrôles défaillants qui peuvent être corrigés automatiquement, exécutez la commande suivante :
oc get compliancecheckresults \ -l 'compliance.openshift.io/check-status in (FAIL),compliance.openshift.io/automated-remediation'
Pour dresser la liste de tous les contrôles défaillants qui peuvent être corrigés manuellement, exécutez la commande suivante :
oc get compliancecheckresults \ -l 'compliance.openshift.io/check-status in (FAIL),!compliance.openshift.io/automated-remediation'
Chapitre 6. Opérateur d'intégrité des fichiers
6.1. Notes de mise à jour de l'opérateur d'intégrité des fichiers
L'opérateur d'intégrité des fichiers pour OpenShift Container Platform exécute continuellement des contrôles d'intégrité des fichiers sur les nœuds RHCOS.
Ces notes de version suivent le développement de l'opérateur d'intégrité des fichiers dans la plateforme OpenShift Container.
Pour une vue d'ensemble de l'opérateur d'intégrité des fichiers, voir Comprendre l'opérateur d'intégrité des fichiers.
Pour accéder à la dernière version, voir Mise à jour de l'opérateur d'intégrité des fichiers.
6.1.1. Opérateur d'intégrité des fichiers OpenShift 1.2.1
L'avis suivant est disponible pour OpenShift File Integrity Operator 1.2.1 :
- RHBA-2023:1684 Mise à jour de la correction de bogues de l'opérateur d'intégrité de fichiers d'OpenShift
- Cette version inclut la mise à jour des dépendances des conteneurs.
6.1.2. Opérateur d'intégrité des fichiers OpenShift 1.2.0
L'avis suivant est disponible pour OpenShift File Integrity Operator 1.2.0 :
6.1.2.1. Nouvelles fonctionnalités et améliorations
-
La ressource personnalisée (CR) File Integrity Operator contient désormais une fonction
initialDelayqui spécifie le nombre de secondes à attendre avant de lancer le premier contrôle d'intégrité AIDE. Pour plus d'informations, voir Création de la ressource personnalisée FileIntegrity. -
L'opérateur d'intégrité des fichiers est désormais stable et le canal de diffusion est mis à jour à
stable. Les prochaines versions suivront le principe de versionnement sémantique. Pour accéder à la dernière version, voir Mise à jour de l'opérateur d'intégrité des fichiers.
6.1.3. Opérateur d'intégrité des fichiers OpenShift 1.0.0
L'avis suivant est disponible pour OpenShift File Integrity Operator 1.0.0 :
6.1.4. OpenShift File Integrity Operator 0.1.32
L'avis suivant est disponible pour OpenShift File Integrity Operator 0.1.32 :
6.1.4.1. Bug fixes
- Auparavant, les alertes émises par l'opérateur d'intégrité des fichiers ne définissaient pas d'espace de noms, ce qui rendait difficile la compréhension de l'espace de noms d'où provenait l'alerte. Désormais, l'opérateur définit l'espace de noms approprié, ce qui permet d'obtenir davantage d'informations sur l'alerte. (BZ#2112394)
- Auparavant, l'opérateur d'intégrité des fichiers ne mettait pas à jour le service de métrologie au démarrage de l'opérateur, ce qui rendait les cibles de métrologie inaccessibles. Avec cette version, l'opérateur d'intégrité des fichiers s'assure désormais que le service de métrologie est mis à jour au démarrage de l'opérateur. (BZ#2115821)
6.1.5. OpenShift File Integrity Operator 0.1.30
L'avis suivant est disponible pour OpenShift File Integrity Operator 0.1.30 :
6.1.5.1. Nouvelles fonctionnalités et améliorations
L'opérateur d'intégrité des fichiers est désormais pris en charge sur les architectures suivantes :
- IBM Power
- IBM Z et LinuxONE
6.1.5.2. Bug fixes
- Auparavant, les alertes émises par l'opérateur d'intégrité des fichiers ne définissaient pas d'espace de noms, ce qui rendait difficile la compréhension de l'origine de l'alerte. Désormais, l'opérateur définit l'espace de noms approprié, ce qui améliore la compréhension de l'alerte. (BZ#2101393)
6.1.6. OpenShift File Integrity Operator 0.1.24
L'avis suivant est disponible pour OpenShift File Integrity Operator 0.1.24 :
6.1.6.1. Nouvelles fonctionnalités et améliorations
-
Vous pouvez désormais configurer le nombre maximum de sauvegardes stockées dans la ressource personnalisée (CR)
FileIntegrityà l'aide de l'attributconfig.maxBackups. Cet attribut spécifie le nombre de sauvegardes de la base de données et des journaux AIDE laissées par le processusre-inità conserver sur le nœud. Les sauvegardes plus anciennes dépassant le nombre configuré sont automatiquement élaguées. La valeur par défaut est de cinq sauvegardes.
6.1.6.2. Bug fixes
-
Auparavant, la mise à jour de l'Opérateur à partir de versions antérieures à 0.1.21 vers 0.1.22 pouvait entraîner l'échec de la fonctionnalité
re-init. Cela était dû au fait que l'opérateur ne parvenait pas à mettre à jour les étiquettes de ressources deconfigMap. Désormais, la mise à niveau vers la dernière version corrige les étiquettes de ressources. (BZ#2049206) -
Auparavant, lors de l'application du contenu par défaut du script
configMap, les mauvaises clés de données étaient comparées. De ce fait, le scriptaide-reinitn'était pas correctement mis à jour après une mise à niveau de l'opérateur et le processusre-initéchouait. Désormais,daemonSetss'exécute jusqu'au bout et le processusre-initde la base de données AIDE s'exécute avec succès. (BZ#2072058)
6.1.7. OpenShift File Integrity Operator 0.1.22
L'avis suivant est disponible pour OpenShift File Integrity Operator 0.1.22 :
6.1.7.1. Bug fixes
-
Auparavant, un système avec un opérateur d'intégrité de fichier installé pouvait interrompre la mise à jour d'OpenShift Container Platform, à cause du fichier
/etc/kubernetes/aide.reinit. Cela se produisait si le fichier/etc/kubernetes/aide.reinitétait présent, mais supprimé par la suite avant la validation deostree. Avec cette mise à jour,/etc/kubernetes/aide.reinitest déplacé dans le répertoire/runafin de ne pas entrer en conflit avec la mise à jour d'OpenShift Container Platform. (BZ#2033311)
6.1.8. OpenShift File Integrity Operator 0.1.21
L'avis suivant est disponible pour OpenShift File Integrity Operator 0.1.21 :
6.1.8.1. Nouvelles fonctionnalités et améliorations
-
Les mesures relatives aux résultats de l'analyse de
FileIntegrityet aux mesures de traitement sont affichées sur le tableau de bord de surveillance de la console web. Les résultats sont étiquetés avec le préfixefile_integrity_operator_. -
Si un nœud présente un défaut d'intégrité pendant plus d'une seconde, l'adresse par défaut
PrometheusRulefournie dans l'espace de noms de l'opérateur émet un avertissement. Les chemins d'accès aux fichiers dynamiques suivants, liés à l'opérateur de configuration de la machine et à l'opérateur de version du cluster, sont exclus de la stratégie AIDE par défaut afin d'éviter les faux positifs lors des mises à jour des nœuds :
- /etc/machine-config-daemon/currentconfig
- /etc/pki/ca-trust/extracted/java/cacerts
- /etc/cvo/updatepayloads
- /root/.kube
- Le processus du démon AIDE a amélioré sa stabilité par rapport à la version 0.1.16, et résiste mieux aux erreurs qui peuvent survenir lors de l'initialisation de la base de données AIDE.
6.1.8.2. Bug fixes
- Auparavant, lorsque l'opérateur effectuait une mise à niveau automatique, les jeux de démons obsolètes n'étaient pas supprimés. Avec cette version, les jeux de démons obsolètes sont supprimés lors de la mise à niveau automatique.
6.1.9. Ressources supplémentaires
6.2. Installation de l'opérateur d'intégrité des fichiers
6.2.1. Installation de l'opérateur d'intégrité des fichiers à l'aide de la console web
Conditions préalables
-
Vous devez avoir les privilèges de
admin.
Procédure
- Dans la console web d'OpenShift Container Platform, naviguez vers Operators → OperatorHub.
- Recherchez l'opérateur d'intégrité des fichiers, puis cliquez sur Install.
-
Conservez la sélection par défaut de Installation mode et namespace pour vous assurer que l'opérateur sera installé dans l'espace de noms
openshift-file-integrity. - Cliquez sur Install.
Vérification
Pour confirmer que l'installation a réussi :
- Naviguez jusqu'à la page Operators → Installed Operators.
-
Vérifiez que l'Opérateur est installé dans l'espace de noms
openshift-file-integrityet que son statut estSucceeded.
Si l'opérateur n'est pas installé correctement :
-
Naviguez jusqu'à la page Operators → Installed Operators et vérifiez que la colonne
Statusne contient pas d'erreurs ou de défaillances. -
Naviguez jusqu'à la page Workloads → Pods et vérifiez les journaux de tous les pods du projet
openshift-file-integrityqui signalent des problèmes.
6.2.2. Installation de l'opérateur d'intégrité des fichiers à l'aide de l'interface de programmation (CLI)
Conditions préalables
-
Vous devez avoir les privilèges de
admin.
Procédure
Créez un fichier YAML de l'objet
Namespaceen exécutant :oc create -f <nom-de-fichier>.yaml
Exemple de sortie
apiVersion: v1 kind: Namespace metadata: labels: openshift.io/cluster-monitoring: "true" pod-security.kubernetes.io/enforce: privileged 1 name: openshift-file-integrity- 1
- Dans OpenShift Container Platform 4.12, l'étiquette de sécurité du pod doit être définie sur
privilegedau niveau de l'espace de noms.
Créer le fichier YAML de l'objet
OperatorGroup:oc create -f <nom-de-fichier>.yaml
Exemple de sortie
apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: file-integrity-operator namespace: openshift-file-integrity spec: targetNamespaces: - openshift-file-integrity
Créer le fichier YAML de l'objet
Subscription:oc create -f <nom-de-fichier>.yaml
Exemple de sortie
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: file-integrity-operator namespace: openshift-file-integrity spec: channel: "stable" installPlanApproval: Automatic name: file-integrity-operator source: redhat-operators sourceNamespace: openshift-marketplace
Vérification
Vérifiez que l'installation a réussi en inspectant le fichier CSV :
$ oc get csv -n openshift-file-integrity
Vérifiez que l'opérateur d'intégrité des fichiers est opérationnel :
$ oc get deploy -n openshift-file-integrity
6.2.3. Ressources supplémentaires
- L'opérateur d'intégrité des fichiers est pris en charge dans un environnement réseau restreint. Pour plus d'informations, voir Utilisation d'Operator Lifecycle Manager sur des réseaux restreints.
6.3. Mise à jour de l'opérateur d'intégrité des fichiers
En tant qu'administrateur de cluster, vous pouvez mettre à jour l'opérateur d'intégrité des fichiers sur votre cluster OpenShift Container Platform.
6.3.1. Préparation de la mise à jour de l'opérateur
L'abonnement d'un opérateur installé spécifie un canal de mise à jour qui suit et reçoit les mises à jour de l'opérateur. Vous pouvez modifier le canal de mise à jour pour commencer à suivre et à recevoir des mises à jour à partir d'un canal plus récent.
Les noms des canaux de mise à jour dans un abonnement peuvent varier d'un opérateur à l'autre, mais le système de dénomination suit généralement une convention commune au sein d'un opérateur donné. Par exemple, les noms des canaux peuvent correspondre à un flux de mises à jour de versions mineures pour l'application fournie par l'opérateur (1.2, 1.3) ou à une fréquence de publication (stable, fast).
Vous ne pouvez pas changer les opérateurs installés pour un canal plus ancien que le canal actuel.
Red Hat Customer Portal Labs comprend l'application suivante qui aide les administrateurs à préparer la mise à jour de leurs opérateurs :
Vous pouvez utiliser l'application pour rechercher des opérateurs basés sur Operator Lifecycle Manager et vérifier la version disponible de l'opérateur par canal de mise à jour à travers différentes versions d'OpenShift Container Platform. Les opérateurs basés sur la version du cluster ne sont pas inclus.
6.3.2. Changer le canal de mise à jour d'un opérateur
Vous pouvez changer le canal de mise à jour d'un opérateur en utilisant la console web d'OpenShift Container Platform.
Si la stratégie d'approbation de l'abonnement est définie sur Automatic, le processus de mise à jour est lancé dès qu'une nouvelle version de l'opérateur est disponible dans le canal sélectionné. Si la stratégie d'approbation est définie sur Manual, vous devez approuver manuellement les mises à jour en attente.
Conditions préalables
- Un opérateur précédemment installé à l'aide de l'outil Operator Lifecycle Manager (OLM).
Procédure
- Dans la perspective Administrator de la console web, naviguez vers Operators → Installed Operators.
- Cliquez sur le nom de l'opérateur dont vous souhaitez modifier le canal de mise à jour.
- Cliquez sur l'onglet Subscription.
- Cliquez sur le nom du canal de mise à jour sous Channel.
- Cliquez sur le canal de mise à jour le plus récent vers lequel vous souhaitez passer, puis cliquez sur Save.
Pour les abonnements avec une stratégie d'approbation Automatic, la mise à jour commence automatiquement. Retournez à la page Operators → Installed Operators pour suivre la progression de la mise à jour. Une fois la mise à jour terminée, le statut passe à Succeeded et Up to date.
Pour les abonnements avec une stratégie d'approbation Manual, vous pouvez approuver manuellement la mise à jour à partir de l'onglet Subscription.
6.3.3. Approbation manuelle d'une mise à jour de l'opérateur en attente
Si la stratégie d'approbation de l'abonnement d'un opérateur installé est définie sur Manual, lorsque de nouvelles mises à jour sont publiées dans son canal de mise à jour actuel, la mise à jour doit être approuvée manuellement avant que l'installation ne puisse commencer.
Conditions préalables
- Un opérateur précédemment installé à l'aide de l'outil Operator Lifecycle Manager (OLM).
Procédure
- Dans la perspective Administrator de la console web OpenShift Container Platform, naviguez vers Operators → Installed Operators.
- Les opérateurs dont la mise à jour est en cours affichent un statut avec Upgrade available. Cliquez sur le nom de l'opérateur que vous souhaitez mettre à jour.
- Cliquez sur l'onglet Subscription. Toute mise à jour nécessitant une approbation est affichée à côté de Upgrade Status. Par exemple, il peut s'agir de 1 requires approval.
- Cliquez sur 1 requires approval, puis sur Preview Install Plan.
- Examinez les ressources répertoriées comme étant disponibles pour une mise à jour. Lorsque vous êtes satisfait, cliquez sur Approve.
- Retournez à la page Operators → Installed Operators pour suivre la progression de la mise à jour. Une fois la mise à jour terminée, le statut passe à Succeeded et Up to date.
6.4. Comprendre l'opérateur d'intégrité des fichiers
L'opérateur d'intégrité des fichiers est un opérateur de la plateforme de conteneurs OpenShift qui exécute continuellement des contrôles d'intégrité des fichiers sur les nœuds du cluster. Il déploie un ensemble de démons qui initialise et exécute des conteneurs AIDE (advanced intrusion detection environment) privilégiés sur chaque nœud, en fournissant un objet d'état avec un journal des fichiers modifiés lors de l'exécution initiale des pods de l'ensemble de démons.
Actuellement, seuls les nœuds Red Hat Enterprise Linux CoreOS (RHCOS) sont pris en charge.
6.4.1. Création de la ressource personnalisée FileIntegrity
Une instance d'une ressource personnalisée (CR) FileIntegrity représente un ensemble d'analyses continues de l'intégrité des fichiers pour un ou plusieurs nœuds.
Chaque CR FileIntegrity est soutenu par un ensemble de démons exécutant AIDE sur les nœuds correspondant à la spécification du CR FileIntegrity.
Procédure
Créez l'exemple suivant
FileIntegrityCR nomméworker-fileintegrity.yamlpour activer les analyses sur les nœuds de travail :Exemple de FileIntegrity CR
apiVersion: fileintegrity.openshift.io/v1alpha1 kind: FileIntegrity metadata: name: worker-fileintegrity namespace: openshift-file-integrity spec: nodeSelector: 1 node-role.kubernetes.io/worker: "" tolerations: 2 - key: "myNode" operator: "Exists" effect: "NoSchedule" config: 3 name: "myconfig" namespace: "openshift-file-integrity" key: "config" gracePeriod: 20 4 maxBackups: 5 5 initialDelay: 60 6 debug: false status: phase: Active 7
- 1
- Définit le sélecteur pour la planification des analyses de nœuds.
- 2
- Spécifier
tolerationspour planifier les nœuds avec des taches personnalisées. Si elle n'est pas spécifiée, une tolérance par défaut permettant l'exécution sur les nœuds principaux et infra est appliquée. - 3
- Définir un site
ConfigMapcontenant une configuration AIDE à utiliser. - 4
- Nombre de secondes de pause entre les contrôles d'intégrité AIDE. Les contrôles AIDE fréquents sur un nœud peuvent être gourmands en ressources, il peut donc être utile de spécifier un intervalle plus long. La valeur par défaut est de 900 secondes (15 minutes).
- 5
- Le nombre maximum de sauvegardes de la base de données et des journaux AIDE (restes du processus de réinitialisation) à conserver sur un nœud. Les anciennes sauvegardes au-delà de ce nombre sont automatiquement élaguées par le démon. La valeur par défaut est de 5.
- 6
- Nombre de secondes à attendre avant de lancer le premier contrôle d'intégrité AIDE. La valeur par défaut est 0.
- 7
- L'état d'exécution de l'instance
FileIntegrity. Les statuts sontInitializing,Pending, ouActive.
InitializingL'objet
FileIntegrityest en train d'initialiser ou de réinitialiser la base de données AIDE.PendingLe déploiement de
FileIntegrityest toujours en cours de création.ActiveLes analyses sont actives et en cours.
Appliquer le fichier YAML à l'espace de noms
openshift-file-integrity:$ oc apply -f worker-fileintegrity.yaml -n openshift-file-integrity
Vérification
Confirmez que l'objet
FileIntegritya été créé avec succès en exécutant la commande suivante :$ oc get fileintegrities -n openshift-file-integrity
Exemple de sortie
NAME AGE worker-fileintegrity 14s
6.4.2. Vérification de l'état de la ressource personnalisée FileIntegrity
La ressource personnalisée (CR) FileIntegrity signale son état par l'intermédiaire de la sous-ressource .status.phase.
Procédure
Pour demander l'état de
FileIntegrityCR, exécutez la commande suivante :$ oc get fileintegrities/worker-fileintegrity -o jsonpath="{ .status.phase }"Exemple de sortie
Active
6.4.3. Phases de ressources personnalisées FileIntegrity
-
Pending- Phase qui suit la création de la ressource personnalisée (CR). -
Active- Phase au cours de laquelle le démon de sauvegarde est opérationnel. -
Initializing- Phase de réinitialisation de la base de données AIDE.
6.4.4. Comprendre l'objet FileIntegrityNodeStatuses
Les résultats de l'analyse du CR FileIntegrity sont consignés dans un autre objet appelé FileIntegrityNodeStatuses.
$ oc get fileintegritynodestatuses
Exemple de sortie
NAME AGE worker-fileintegrity-ip-10-0-130-192.ec2.internal 101s worker-fileintegrity-ip-10-0-147-133.ec2.internal 109s worker-fileintegrity-ip-10-0-165-160.ec2.internal 102s
Les résultats de l'objet FileIntegrityNodeStatus peuvent prendre un certain temps avant d'être disponibles.
Il y a un objet de résultat par nœud. L'attribut nodeName de chaque objet FileIntegrityNodeStatus correspond au nœud analysé. L'état de l'analyse de l'intégrité du fichier est représenté dans le tableau results, qui contient les conditions d'analyse.
$ oc get fileintegritynodestatuses.fileintegrity.openshift.io -ojsonpath='{.items[*].results}' | jq
L'objet fileintegritynodestatus signale le dernier état d'une exécution AIDE et indique l'état sous la forme Failed, Succeeded ou Errored dans un champ status.
$ oc get fileintegritynodestatuses -w
Exemple de sortie
NAME NODE STATUS example-fileintegrity-ip-10-0-134-186.us-east-2.compute.internal ip-10-0-134-186.us-east-2.compute.internal Succeeded example-fileintegrity-ip-10-0-150-230.us-east-2.compute.internal ip-10-0-150-230.us-east-2.compute.internal Succeeded example-fileintegrity-ip-10-0-169-137.us-east-2.compute.internal ip-10-0-169-137.us-east-2.compute.internal Succeeded example-fileintegrity-ip-10-0-180-200.us-east-2.compute.internal ip-10-0-180-200.us-east-2.compute.internal Succeeded example-fileintegrity-ip-10-0-194-66.us-east-2.compute.internal ip-10-0-194-66.us-east-2.compute.internal Failed example-fileintegrity-ip-10-0-222-188.us-east-2.compute.internal ip-10-0-222-188.us-east-2.compute.internal Succeeded example-fileintegrity-ip-10-0-134-186.us-east-2.compute.internal ip-10-0-134-186.us-east-2.compute.internal Succeeded example-fileintegrity-ip-10-0-222-188.us-east-2.compute.internal ip-10-0-222-188.us-east-2.compute.internal Succeeded example-fileintegrity-ip-10-0-194-66.us-east-2.compute.internal ip-10-0-194-66.us-east-2.compute.internal Failed example-fileintegrity-ip-10-0-150-230.us-east-2.compute.internal ip-10-0-150-230.us-east-2.compute.internal Succeeded example-fileintegrity-ip-10-0-180-200.us-east-2.compute.internal ip-10-0-180-200.us-east-2.compute.internal Succeeded
6.4.5. Types de statut FileIntegrityNodeStatus CR
Ces conditions sont signalées dans le tableau de résultats de l'état FileIntegrityNodeStatus CR correspondant :
-
Succeeded- Le contrôle d'intégrité a réussi ; les fichiers et répertoires couverts par le contrôle AIDE n'ont pas été modifiés depuis la dernière initialisation de la base de données. -
Failed- Le contrôle d'intégrité a échoué ; certains fichiers ou répertoires couverts par le contrôle AIDE ont été modifiés depuis la dernière initialisation de la base de données. -
Errored- Le scanner AIDE a rencontré une erreur interne.
6.4.5.1. FileIntegrityNodeStatus CR exemple de réussite
Exemple de sortie d'une condition avec un statut de réussite
[
{
"condition": "Succeeded",
"lastProbeTime": "2020-09-15T12:45:57Z"
}
]
[
{
"condition": "Succeeded",
"lastProbeTime": "2020-09-15T12:46:03Z"
}
]
[
{
"condition": "Succeeded",
"lastProbeTime": "2020-09-15T12:45:48Z"
}
]
Dans ce cas, les trois scanners ont réussi et il n'y a jusqu'à présent aucune autre condition.
6.4.5.2. FileIntegrityNodeStatus Exemple de statut d'échec CR
Pour simuler une condition d'échec, modifiez l'un des fichiers suivis par AIDE. Par exemple, modifiez /etc/resolv.conf sur l'un des nœuds de travail :
$ oc debug node/ip-10-0-130-192.ec2.internal
Exemple de sortie
Creating debug namespace/openshift-debug-node-ldfbj ... Starting pod/ip-10-0-130-192ec2internal-debug ... To use host binaries, run `chroot /host` Pod IP: 10.0.130.192 If you don't see a command prompt, try pressing enter. sh-4.2# echo "# integrity test" >> /host/etc/resolv.conf sh-4.2# exit Removing debug pod ... Removing debug namespace/openshift-debug-node-ldfbj ...
Au bout d'un certain temps, la condition Failed est signalée dans le tableau des résultats de l'objet FileIntegrityNodeStatus correspondant. La condition Succeeded précédente est conservée, ce qui vous permet de déterminer le moment où la vérification a échoué.
$ oc get fileintegritynodestatuses.fileintegrity.openshift.io/worker-fileintegrity-ip-10-0-130-192.ec2.internal -ojsonpath='{.results}' | jq -rAlternativement, si vous ne mentionnez pas le nom de l'objet, exécutez :
$ oc get fileintegritynodestatuses.fileintegrity.openshift.io -ojsonpath='{.items[*].results}' | jqExemple de sortie
[
{
"condition": "Succeeded",
"lastProbeTime": "2020-09-15T12:54:14Z"
},
{
"condition": "Failed",
"filesChanged": 1,
"lastProbeTime": "2020-09-15T12:57:20Z",
"resultConfigMapName": "aide-ds-worker-fileintegrity-ip-10-0-130-192.ec2.internal-failed",
"resultConfigMapNamespace": "openshift-file-integrity"
}
]
La condition Failed pointe vers une carte de configuration qui donne plus de détails sur ce qui a échoué et pourquoi :
$ oc describe cm aide-ds-worker-fileintegrity-ip-10-0-130-192.ec2.internal-failed
Exemple de sortie
Name: aide-ds-worker-fileintegrity-ip-10-0-130-192.ec2.internal-failed
Namespace: openshift-file-integrity
Labels: file-integrity.openshift.io/node=ip-10-0-130-192.ec2.internal
file-integrity.openshift.io/owner=worker-fileintegrity
file-integrity.openshift.io/result-log=
Annotations: file-integrity.openshift.io/files-added: 0
file-integrity.openshift.io/files-changed: 1
file-integrity.openshift.io/files-removed: 0
Data
integritylog:
------
AIDE 0.15.1 found differences between database and filesystem!!
Start timestamp: 2020-09-15 12:58:15
Summary:
Total number of files: 31553
Added files: 0
Removed files: 0
Changed files: 1
---------------------------------------------------
Changed files:
---------------------------------------------------
changed: /hostroot/etc/resolv.conf
---------------------------------------------------
Detailed information about changes:
---------------------------------------------------
File: /hostroot/etc/resolv.conf
SHA512 : sTQYpB/AL7FeoGtu/1g7opv6C+KT1CBJ , qAeM+a8yTgHPnIHMaRlS+so61EN8VOpg
Events: <none>
En raison de la limite de taille des données de la carte de configuration, les journaux AIDE de plus de 1 Mo sont ajoutés à la carte de configuration des défaillances sous la forme d'une archive gzip codée en base64. Dans ce cas, vous souhaitez diriger la sortie de la commande ci-dessus vers base64 --decode | gunzip. Les journaux compressés sont indiqués par la présence d'une clé d'annotation file-integrity.openshift.io/compressed dans la carte de configuration.
6.4.6. Comprendre les événements
Les transitions dans l'état des objets FileIntegrity et FileIntegrityNodeStatus sont enregistrées par events. L'heure de création de l'événement reflète la dernière transition, par exemple de Initializing à Active, et pas nécessairement le dernier résultat de l'analyse. Cependant, l'événement le plus récent reflète toujours l'état le plus récent.
$ oc get events --field-selector reason=FileIntegrityStatus
Exemple de sortie
LAST SEEN TYPE REASON OBJECT MESSAGE 97s Normal FileIntegrityStatus fileintegrity/example-fileintegrity Pending 67s Normal FileIntegrityStatus fileintegrity/example-fileintegrity Initializing 37s Normal FileIntegrityStatus fileintegrity/example-fileintegrity Active
Lorsqu'une analyse de nœud échoue, un événement est créé avec les informations add/changed/removed et config map.
$ oc get events --field-selector reason=NodeIntegrityStatus
Exemple de sortie
LAST SEEN TYPE REASON OBJECT MESSAGE 114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-134-173.ec2.internal 114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-168-238.ec2.internal 114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-169-175.ec2.internal 114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-152-92.ec2.internal 114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-158-144.ec2.internal 114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-131-30.ec2.internal 87m Warning NodeIntegrityStatus fileintegrity/example-fileintegrity node ip-10-0-152-92.ec2.internal has changed! a:1,c:1,r:0 \ log:openshift-file-integrity/aide-ds-example-fileintegrity-ip-10-0-152-92.ec2.internal-failed
Toute modification du nombre de fichiers ajoutés, modifiés ou supprimés entraîne un nouvel événement, même si l'état du nœud n'a pas changé.
$ oc get events --field-selector reason=NodeIntegrityStatus
Exemple de sortie
LAST SEEN TYPE REASON OBJECT MESSAGE 114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-134-173.ec2.internal 114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-168-238.ec2.internal 114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-169-175.ec2.internal 114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-152-92.ec2.internal 114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-158-144.ec2.internal 114m Normal NodeIntegrityStatus fileintegrity/example-fileintegrity no changes to node ip-10-0-131-30.ec2.internal 87m Warning NodeIntegrityStatus fileintegrity/example-fileintegrity node ip-10-0-152-92.ec2.internal has changed! a:1,c:1,r:0 \ log:openshift-file-integrity/aide-ds-example-fileintegrity-ip-10-0-152-92.ec2.internal-failed 40m Warning NodeIntegrityStatus fileintegrity/example-fileintegrity node ip-10-0-152-92.ec2.internal has changed! a:3,c:1,r:0 \ log:openshift-file-integrity/aide-ds-example-fileintegrity-ip-10-0-152-92.ec2.internal-failed
6.5. Configuration de l'opérateur d'intégrité de fichier personnalisé
6.5.1. Visualisation des attributs de l'objet FileIntegrity
Comme pour toutes les ressources personnalisées (CR) de Kubernetes, vous pouvez exécuter oc explain fileintegrity, puis examiner les attributs individuels à l'aide de :
$ oc explain fileintegrity.spec
$ oc explain fileintegrity.spec.config
6.5.2. Attributs importants
Tableau 6.1. Attributs importants des sites spec et spec.config
| Attribut | Description |
|---|---|
|
|
Une carte de paires clé-valeur qui doivent correspondre aux étiquettes du nœud pour que les pods AIDE puissent être planifiés sur ce nœud. L'utilisation typique est de définir une seule paire clé-valeur où |
|
|
Attribut booléen. S'il vaut |
|
| Spécifier les tolérances à planifier sur les nœuds avec des taches personnalisées. Si elle n'est pas spécifiée, une tolérance par défaut est appliquée, ce qui permet aux tolérances de s'exécuter sur les nœuds du plan de contrôle. |
|
|
Nombre de secondes de pause entre les contrôles d'intégrité AIDE. Les contrôles AIDE fréquents sur un nœud peuvent être gourmands en ressources, il peut donc être utile de spécifier un intervalle plus long. La valeur par défaut est |
|
|
Le nombre maximum de sauvegardes de la base de données et des journaux AIDE laissées par le processus |
|
| Nom d'un configMap contenant la configuration personnalisée de l'AIDE. En cas d'omission, une configuration par défaut est créée. |
|
| Espace de noms d'un configMap contenant la configuration personnalisée de l'AIDE. S'il n'est pas défini, l'interface génère une configuration par défaut adaptée aux systèmes RHCOS. |
|
|
Clé qui contient la configuration actuelle d'AIDE dans une carte de configuration spécifiée par |
|
| Le nombre de secondes à attendre avant de lancer le premier contrôle d'intégrité AIDE. La valeur par défaut est 0. Cet attribut est facultatif. |
6.5.3. Examiner la configuration par défaut
La configuration par défaut de l'opérateur d'intégrité des fichiers est stockée dans une carte de configuration portant le même nom que le CR FileIntegrity.
Procédure
Pour examiner la configuration par défaut, exécutez :
$ oc describe cm/worker-fileintegrity
6.5.4. Comprendre la configuration par défaut de l'opérateur d'intégrité des fichiers
Voici un extrait de la clé aide.conf de la carte de configuration :
@@define DBDIR /hostroot/etc/kubernetes
@@define LOGDIR /hostroot/etc/kubernetes
database=file:@@{DBDIR}/aide.db.gz
database_out=file:@@{DBDIR}/aide.db.gz
gzip_dbout=yes
verbose=5
report_url=file:@@{LOGDIR}/aide.log
report_url=stdout
PERMS = p+u+g+acl+selinux+xattrs
CONTENT_EX = sha512+ftype+p+u+g+n+acl+selinux+xattrs
/hostroot/boot/ CONTENT_EX
/hostroot/root/\..* PERMS
/hostroot/root/ CONTENT_EX
La configuration par défaut d'une instance FileIntegrity permet de couvrir les fichiers situés dans les répertoires suivants :
-
/root -
/boot -
/usr -
/etc
Les répertoires suivants ne sont pas couverts :
-
/var -
/opt -
Quelques exclusions spécifiques à OpenShift Container Platform sous la rubrique
/etc/
6.5.5. Fournir une configuration AIDE personnalisée
Toutes les entrées qui configurent le comportement interne d'AIDE, telles que DBDIR, LOGDIR, database et database_out, sont écrasées par l'opérateur. L'opérateur ajouterait un préfixe à /hostroot/ avant tous les chemins à surveiller pour les changements d'intégrité. Cela facilite la réutilisation des configurations AIDE existantes qui peuvent souvent ne pas être adaptées à un environnement conteneurisé et commencer à partir du répertoire racine.
/hostroot est le répertoire dans lequel les pods exécutant AIDE montent le système de fichiers de l'hôte. La modification de la configuration entraîne une réinitialisation de la base de données.
6.5.6. Définition d'une configuration personnalisée de l'opérateur d'intégrité des fichiers
Cet exemple se concentre sur la définition d'une configuration personnalisée pour un scanner qui s'exécute sur les nœuds du plan de contrôle, sur la base de la configuration par défaut fournie pour le CR worker-fileintegrity. Ce flux de travail peut être utile si vous envisagez de déployer un logiciel personnalisé fonctionnant comme un ensemble de démons et stockant ses données sous /opt/mydaemon sur les nœuds du plan de contrôle.
Procédure
- Faites une copie de la configuration par défaut.
- Modifiez la configuration par défaut en indiquant les fichiers qui doivent être surveillés ou exclus.
- Stocker le contenu modifié dans une nouvelle carte de configuration.
-
Pointer l'objet
FileIntegrityvers la nouvelle carte de configuration par le biais des attributs despec.config. Extraire la configuration par défaut :
$ oc extract cm/worker-fileintegrity --keys=aide.conf
Cela crée un fichier nommé
aide.confque vous pouvez modifier. Pour illustrer la façon dont l'opérateur traite les chemins d'accès, cet exemple ajoute un répertoire d'exclusion sans le préfixe :$ vim aide.conf
Exemple de sortie
/hostroot/etc/kubernetes/static-pod-resources !/hostroot/etc/kubernetes/aide.* !/hostroot/etc/kubernetes/manifests !/hostroot/etc/docker/certs.d !/hostroot/etc/selinux/targeted !/hostroot/etc/openvswitch/conf.db
Exclure un chemin spécifique aux nœuds du plan de contrôle :
!/opt/mydaemon/
Conservez les autres contenus sur
/etc:/hostroot/etc/ CONTENT_EX
Créer une carte de configuration basée sur ce fichier :
$ oc create cm master-aide-conf --from-file=aide.conf
Définir un manifeste
FileIntegrityCR qui fait référence à la carte de configuration :apiVersion: fileintegrity.openshift.io/v1alpha1 kind: FileIntegrity metadata: name: master-fileintegrity namespace: openshift-file-integrity spec: nodeSelector: node-role.kubernetes.io/master: "" config: name: master-aide-conf namespace: openshift-file-integrityL'opérateur traite le fichier de carte de configuration fourni et stocke le résultat dans une carte de configuration portant le même nom que l'objet
FileIntegrity:$ oc describe cm/master-fileintegrity | grep /opt/mydaemon
Exemple de sortie
!/hostroot/opt/mydaemon
6.5.7. Modification de la configuration personnalisée de l'intégrité des fichiers
Pour modifier la configuration de l'intégrité des fichiers, ne modifiez jamais la carte de configuration générée. Modifiez plutôt la carte de configuration liée à l'objet FileIntegrity par l'intermédiaire des attributs spec.name, namespace et key.
6.6. Exécution de tâches avancées de l'opérateur d'intégrité des fichiers personnalisés
6.6.1. Réinitialisation de la base de données
Si l'opérateur d'intégrité des fichiers détecte une modification planifiée, il peut être amené à réinitialiser la base de données.
Procédure
Annoter la ressource personnalisée (CR)
FileIntegrityavecfile-integrity.openshift.io/re-init:$ oc annotate fileintegrities/worker-fileintegrity file-integrity.openshift.io/re-init=
L'ancienne base de données et les fichiers journaux sont sauvegardés et une nouvelle base de données est initialisée. L'ancienne base de données et les journaux sont conservés sur les nœuds sous
/etc/kubernetes, comme le montre la sortie suivante d'un pod créé à l'aide deoc debug:Exemple de sortie
ls -lR /host/etc/kubernetes/aide.* -rw-------. 1 root root 1839782 Sep 17 15:08 /host/etc/kubernetes/aide.db.gz -rw-------. 1 root root 1839783 Sep 17 14:30 /host/etc/kubernetes/aide.db.gz.backup-20200917T15_07_38 -rw-------. 1 root root 73728 Sep 17 15:07 /host/etc/kubernetes/aide.db.gz.backup-20200917T15_07_55 -rw-r--r--. 1 root root 0 Sep 17 15:08 /host/etc/kubernetes/aide.log -rw-------. 1 root root 613 Sep 17 15:07 /host/etc/kubernetes/aide.log.backup-20200917T15_07_38 -rw-r--r--. 1 root root 0 Sep 17 15:07 /host/etc/kubernetes/aide.log.backup-20200917T15_07_55
Pour assurer une certaine permanence des enregistrements, les cartes de configuration résultantes n'appartiennent pas à l'objet
FileIntegrity, de sorte qu'un nettoyage manuel est nécessaire. Par conséquent, tout défaut d'intégrité antérieur serait toujours visible dans l'objetFileIntegrityNodeStatus.
6.6.2. Intégration de la configuration de la machine
Dans OpenShift Container Platform 4, la configuration des nœuds de cluster est fournie par le biais d'objets MachineConfig. Vous pouvez supposer que les modifications apportées aux fichiers par un objet MachineConfig sont attendues et ne devraient pas entraîner l'échec de l'analyse de l'intégrité des fichiers. Pour supprimer les modifications apportées aux fichiers par les mises à jour de l'objet MachineConfig, l'opérateur d'intégrité des fichiers surveille les objets de nœuds ; lorsqu'un nœud est en cours de mise à jour, les analyses AIDE sont suspendues pendant la durée de la mise à jour. Lorsque la mise à jour est terminée, la base de données est réinitialisée et les analyses reprennent.
Cette logique de pause et de reprise ne s'applique qu'aux mises à jour effectuées par l'intermédiaire de l'API MachineConfig, car elles sont reflétées dans les annotations de l'objet nœud.
6.6.3. Exploration des ensembles de démons
Chaque objet FileIntegrity représente une analyse sur un certain nombre de nœuds. L'analyse elle-même est effectuée par des pods gérés par un ensemble de démons.
Pour trouver l'ensemble de démons qui représente un objet FileIntegrity, exécutez la commande suivante :
$ oc -n openshift-file-integrity get ds/aide-worker-fileintegrity
Pour lister les pods de cet ensemble de démons, exécutez :
$ oc -n openshift-file-integrity get pods -lapp=aide-worker-fileintegrity
Pour consulter les journaux d'un seul pod AIDE, appelez oc logs sur l'un des pods.
$ oc -n openshift-file-integrity logs pod/aide-worker-fileintegrity-mr8x6
Exemple de sortie
Starting the AIDE runner daemon initializing AIDE db initialization finished running aide check ...
Les cartes de configuration créées par le démon AIDE ne sont pas conservées et sont supprimées après leur traitement par l'opérateur d'intégrité des fichiers. Toutefois, en cas d'échec ou d'erreur, le contenu de ces cartes de configuration est copié dans la carte de configuration vers laquelle pointe l'objet FileIntegrityNodeStatus.
6.7. Dépannage de l'opérateur d'intégrité des fichiers
6.7.1. Dépannage général
- Enjeu
- Vous souhaitez résoudre des problèmes d'ordre général avec l'opérateur d'intégrité des fichiers.
- Résolution
-
Activez l'indicateur de débogage dans l'objet
FileIntegrity. L'indicateurdebugaugmente la verbosité des démons qui s'exécutent dans les podsDaemonSetet qui effectuent les contrôles AIDE.
6.7.2. Vérification de la configuration de l'AIDE
- Enjeu
- Vous voulez vérifier la configuration d'AIDE.
- Résolution
-
La configuration AIDE est stockée dans une carte de configuration portant le même nom que l'objet
FileIntegrity. Toutes les cartes de configuration de la configuration AIDE sont étiquetées avecfile-integrity.openshift.io/aide-conf.
6.7.3. Détermination de la phase de l'objet FileIntegrity
- Enjeu
-
Vous souhaitez déterminer si l'objet
FileIntegrityexiste et connaître son statut actuel. - Résolution
Pour connaître l'état actuel de l'objet
FileIntegrity, exécutez la commande suivante :$ oc get fileintegrities/worker-fileintegrity -o jsonpath="{ .status }"Une fois l'objet
FileIntegrityet le jeu de démons de soutien créés, l'état devrait passer àActive. Si ce n'est pas le cas, vérifiez les journaux du pod de l'opérateur.
6.7.4. Déterminer que les pods de l'ensemble de démons fonctionnent sur les nœuds prévus
- Enjeu
- Vous souhaitez confirmer que l'ensemble de démons existe et que ses pods s'exécutent sur les nœuds sur lesquels vous souhaitez qu'ils s'exécutent.
- Résolution
Exécutez :
$ oc -n openshift-file-integrity get pods -lapp=aide-worker-fileintegrity
NoteL'ajout de
-owidecomprend l'adresse IP du nœud sur lequel le pod est exécuté.Pour vérifier les journaux des pods démon, exécutez
oc logs.Vérifier la valeur de retour de la commande AIDE pour voir si la vérification a réussi ou échoué.
Chapitre 7. Opérateur de profils de sécurité
7.1. Profils de sécurité Aperçu de l'opérateur
OpenShift Container Platform Security Profiles Operator (SPO) permet de définir des profils informatiques sécurisés(seccomp) et des profils SELinux en tant que ressources personnalisées, en synchronisant les profils sur chaque nœud d'un espace de noms donné. Pour les dernières mises à jour, voir les notes de version.
L'opérateur de profils de sécurité peut distribuer des ressources personnalisées à chaque nœud, tandis qu'une boucle de réconciliation garantit la mise à jour des profils. Voir Comprendre l'opérateur de profils de sécurité.
Le SPO gère les stratégies SELinux et les profils seccomp pour les charges de travail en espace nominatif. Pour plus d'informations, voir Activation de l'opérateur de profils de sécurité.
Vous pouvez créer des profils seccomp et SELinux, lier des politiques à des pods, enregistrer des charges de travail et synchroniser tous les nœuds de travail dans un espace de noms.
Utilisez les tâches de l'opérateur de profil de sécurité avancé pour activer l'enrichisseur de journaux, configurer les webhooks et les métriques, ou restreindre les profils à un seul espace de noms.
Dépannez l'Opérateur de profils de sécurité si nécessaire, ou faites appel à l'assistance de Red Hat.
Vous pouvez désinstaller l'opérateur des profils de sécurité en supprimant les profils avant de supprimer l'opérateur.
7.2. Notes de mise à jour de l'opérateur de profils de sécurité
L'opérateur de profils de sécurité permet de définir des profils SELinux et d'informatique sécurisée(seccomp) en tant que ressources personnalisées, en synchronisant les profils avec chaque nœud d'un espace de noms donné.
Ces notes de version suivent le développement de l'opérateur de profils de sécurité dans OpenShift Container Platform.
Pour une présentation de l'opérateur de profils de sécurité, voir Présentation de l'opérateur de profils de sécurité.
7.2.1. Opérateur de profils de sécurité 0.5.2
L'avis suivant est disponible pour le Security Profiles Operator 0.5.2 :
Cette mise à jour corrige une CVE dans une dépendance sous-jacente.
Problème connu
-
Lors de la désinstallation de l'Opérateur de profils de sécurité, l'objet
MutatingWebhookConfigurationn'est pas supprimé et doit être supprimé manuellement. Pour contourner le problème, supprimez l'objetMutatingWebhookConfigurationaprès avoir désinstallé l'Opérateur de profils de sécurité. Ces étapes sont définies dans Désinstallation de l'Opérateur de profils de sécurité. (OCPBUGS-4687)
7.2.2. Opérateur de profils de sécurité 0.5.0
L'avis suivant est disponible pour l'opérateur de profils de sécurité 0.5.0 :
Problème connu
-
Lors de la désinstallation de l'Opérateur de profils de sécurité, l'objet
MutatingWebhookConfigurationn'est pas supprimé et doit être supprimé manuellement. Pour contourner le problème, supprimez l'objetMutatingWebhookConfigurationaprès avoir désinstallé l'Opérateur de profils de sécurité. Ces étapes sont définies dans Désinstallation de l'Opérateur de profils de sécurité. (OCPBUGS-4687)
7.3. Comprendre l'opérateur des profils de sécurité
Les administrateurs d'OpenShift Container Platform peuvent utiliser l'opérateur de profils de sécurité pour définir des mesures de sécurité accrues dans les clusters.
7.3.1. À propos des profils de sécurité
Les profils de sécurité permettent de renforcer la sécurité au niveau des conteneurs dans votre cluster.
Les profils de sécurité Seccomp dressent la liste des appels système qu'un processus peut effectuer. Les autorisations sont plus larges que SELinux, permettant aux utilisateurs de restreindre les opérations à l'échelle du système, telles que write.
Les profils de sécurité SELinux fournissent un système basé sur des étiquettes qui restreint l'accès et l'utilisation des processus, des applications ou des fichiers dans un système. Tous les fichiers d'un environnement ont des étiquettes qui définissent les autorisations. Les profils SELinux peuvent définir l'accès au sein d'une structure donnée, comme les répertoires.
7.4. Activation de l'opérateur de profils de sécurité
Avant de pouvoir utiliser l'Opérateur de profils de sécurité, vous devez vous assurer que l'Opérateur est déployé dans le cluster.
7.4.1. Installation de l'opérateur de profils de sécurité
Conditions préalables
-
Vous devez avoir les privilèges de
admin.
Procédure
- Dans la console web d'OpenShift Container Platform, naviguez vers Operators → OperatorHub.
- Recherchez l'opérateur de profils de sécurité, puis cliquez sur Install.
-
Conservez la sélection par défaut de Installation mode et namespace pour vous assurer que l'opérateur sera installé dans l'espace de noms
openshift-security-profiles. - Cliquez sur Install.
Vérification
Pour confirmer que l'installation a réussi :
- Naviguez jusqu'à la page Operators → Installed Operators.
-
Vérifiez que l'Opérateur de profils de sécurité est installé dans l'espace de noms
openshift-security-profileset que son statut estSucceeded.
Si l'opérateur n'est pas installé correctement :
-
Naviguez jusqu'à la page Operators → Installed Operators et vérifiez que la colonne
Statusne contient pas d'erreurs ou de défaillances. -
Naviguez jusqu'à la page Workloads → Pods et vérifiez les journaux de tous les pods du projet
openshift-security-profilesqui signalent des problèmes.
7.4.2. Installation de l'opérateur de profils de sécurité à l'aide de l'interface de programmation (CLI)
Conditions préalables
-
Vous devez avoir les privilèges de
admin.
Procédure
Définir un objet
Namespace:Exemple
namespace-object.yamlapiVersion: v1 kind: Namespace metadata: name: openshift-security-profiles labels: openshift.io/cluster-monitoring: "true"Créer l'objet
Namespace:$ oc create -f namespace-object.yaml
Définir un objet
OperatorGroup:Exemple
operator-group-object.yamlapiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: security-profiles-operator namespace: openshift-security-profiles
Créer l'objet
OperatorGroup:$ oc create -f operator-group-object.yaml
Définir un objet
Subscription:Exemple
subscription-object.yamlapiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: security-profiles-operator-sub namespace: openshift-security-profiles spec: channel: release-alpha-rhel-8 installPlanApproval: Automatic name: security-profiles-operator source: redhat-operators sourceNamespace: openshift-marketplace
Créer l'objet
Subscription:$ oc create -f subscription-object.yaml
Si vous définissez la fonctionnalité de planification globale et activez defaultNodeSelector, vous devez créer l'espace de noms manuellement et mettre à jour les annotations de l'espace de noms openshift-security-profiles, ou de l'espace de noms où l'opérateur de profils de sécurité a été installé, à l'aide de openshift.io/node-selector: “”. Cette opération supprime le sélecteur de nœuds par défaut et évite les échecs de déploiement.
Vérification
Vérifiez que l'installation a réussi en examinant le fichier CSV suivant :
$ oc get csv -n openshift-security-profiles
Vérifiez que l'opérateur de profils de sécurité est opérationnel en exécutant la commande suivante :
$ oc get deploy -n openshift-security-profiles
7.4.3. Configuration de la verbosité de la journalisation
L'opérateur de profils de sécurité prend en charge la verbosité de journalisation par défaut ( 0 ) et la verbosité améliorée ( 1).
Procédure
Pour activer la verbosité de la journalisation améliorée, corrigez la configuration de
spodet ajustez la valeur en exécutant la commande suivante :$ oc -n openshift-security-profiles patch spod \ spod --type=merge -p '{"spec":{"verbosity":1}}'Exemple de sortie
securityprofilesoperatordaemon.security-profiles-operator.x-k8s.io/spod patched
7.5. Gestion des profils seccomp
Créer et gérer des profils seccomp et les lier à des charges de travail.
7.5.1. Création de profils seccomp
Utilisez l'objet SeccompProfile pour créer des profils.
SeccompProfile peuvent restreindre les appels de service dans un conteneur, limitant ainsi l'accès de votre application.
Procédure
Créer l'objet
SeccompProfile:apiVersion: security-profiles-operator.x-k8s.io/v1beta1 kind: SeccompProfile metadata: namespace: my-namespace name: profile1 spec: defaultAction: SCMP_ACT_LOG
Le profil seccomp est sauvegardé sur /var/lib/kubelet/seccomp/operator/<namespace>/<name>.json.
Un conteneur init crée le répertoire racine de l'Opérateur de profils de sécurité pour exécuter l'Opérateur sans les privilèges du groupe root ou de l'ID utilisateur. Un lien symbolique est créé à partir du stockage de profil sans racine /var/lib/openshift-security-profiles vers le chemin racine par défaut seccomp à l'intérieur de la racine du kubelet /var/lib/kubelet/seccomp/operator.
7.5.2. Application des profils seccomp à un pod
Créer un pod pour appliquer l'un des profils créés.
Procédure
Créer un objet pod qui définit un
securityContext:apiVersion: v1 kind: Pod metadata: name: test-pod spec: securityContext: seccompProfile: type: Localhost localhostProfile: operator/my-namespace/profile1.json containers: - name: test-container image: quay.io/security-profiles-operator/test-nginx-unprivileged:1.21Affichez le chemin d'accès au profil de l'attribut
seccompProfile.localhostProfileen exécutant la commande suivante :$ oc -n my-namespace get seccompprofile profile1 --output wide
Exemple de sortie
NAME STATUS AGE SECCOMPPROFILE.LOCALHOSTPROFILE profile1 Active 14s operator/my-namespace/profile1.json
Affichez le chemin d'accès au profil localhost en exécutant la commande suivante :
$ oc get sp profile1 --output=jsonpath='{.status.localhostProfile}'Exemple de sortie
operator/my-namespace/profile1.json
Appliquer la sortie de
localhostProfileau fichier patch :spec: template: spec: securityContext: seccompProfile: type: Localhost localhostProfile: operator/my-namespace/profile1.jsonAppliquez le profil à un objet
Deploymenten exécutant la commande suivante :$ oc -n my-namespace patch deployment myapp --patch-file patch.yaml --type=merge
Exemple de sortie
deployment.apps/myapp patched
Vérification
Confirmez que le profil a été appliqué correctement en exécutant la commande suivante :
$ oc -n my-namespace get deployment myapp --output=jsonpath='{.spec.template.spec.securityContext}' | jq .Exemple de sortie
{ "seccompProfile": { "localhostProfile": "operator/my-namespace/profile1.json", "type": "localhost" } }
7.5.2.1. Lier les charges de travail aux profils avec ProfileBindings
Vous pouvez utiliser la ressource ProfileBinding pour lier un profil de sécurité à la ressource SecurityContext d'un conteneur.
Procédure
Pour lier un pod qui utilise une image
quay.io/security-profiles-operator/test-nginx-unprivileged:1.21au profil de l'exempleSeccompProfile, créez un objetProfileBindingdans le même espace de noms que le pod et les objetsSeccompProfile:apiVersion: security-profiles-operator.x-k8s.io/v1alpha1 kind: ProfileBinding metadata: namespace: my-namespace name: nginx-binding spec: profileRef: kind: SeccompProfile 1 name: profile 2 image: quay.io/security-profiles-operator/test-nginx-unprivileged:1.21Etiqueter l'espace de noms avec
enable-binding=trueen exécutant la commande suivante :$ oc label ns my-namespace spo.x-k8s.io/enable-binding=true
Supprimer et recréer le pod pour utiliser l'objet
ProfileBinding:$ oc delete pods test-pod && oc create -f pod01.yaml
Vérification
Confirmez que le pod hérite de
ProfileBindingen exécutant la commande suivante :$ oc get pod test-pod -o jsonpath='{.spec.containers[*].securityContext.seccompProfile}'Exemple de sortie
{"localhostProfile":"operator/my-namespace/profile.json","type":"Localhost"}
7.5.3. Enregistrement de profils à partir de charges de travail
L'opérateur de profils de sécurité peut enregistrer les appels système avec les objets ProfileRecording, ce qui facilite la création de profils de référence pour les applications.
Lors de l'utilisation de l'enrichisseur de journaux pour l'enregistrement des profils seccomp, vérifiez que la fonction d'enrichissement de journaux est activée. Voir Additional resources pour plus d'informations.
Un conteneur avec des restrictions de contexte de sécurité privileged: true empêche l'enregistrement basé sur le journal. Les conteneurs privilégiés ne sont pas soumis aux politiques seccomp, et l'enregistrement basé sur les journaux fait appel à un profil seccomp spécial pour enregistrer les événements.
Procédure
Etiqueter l'espace de noms avec
enable-recording=trueen exécutant la commande suivante :$ oc label ns my-namespace spo.x-k8s.io/enable-recording=true
Créer un objet
ProfileRecordingcontenant une variablerecorder: logs:apiVersion: security-profiles-operator.x-k8s.io/v1alpha1 kind: ProfileRecording metadata: name: test-recording spec: kind: SeccompProfile recorder: logs podSelector: matchLabels: app: my-appCréer une charge de travail à enregistrer :
apiVersion: v1 kind: Pod metadata: name: my-pod labels: app: my-app spec: containers: - name: nginx image: quay.io/security-profiles-operator/test-nginx-unprivileged:1.21 ports: - containerPort: 8080 - name: redis image: quay.io/security-profiles-operator/redis:6.2.1Confirmez que le pod est dans un état
Runningen entrant la commande suivante :$ oc -n openshift-security-profiles get pods
Exemple de sortie
NAME READY STATUS RESTARTS AGE my-pod 2/2 Running 0 18s
Confirmez que l'enrichisseur indique qu'il reçoit les journaux d'audit pour ces conteneurs :
$ oc -n openshift-security-profiles logs --since=1m --selector name=spod -c log-enricher
Exemple de sortie
… I0705 12:08:18.729660 1843190 enricher.go:136] log-enricher "msg"="audit" "container"="redis" "executable"="/usr/local/bin/redis-server" "namespace"="default" "node"="127.0.0.1" "pid"=1847839 "pod"="my-pod" "syscallID"=232 "syscallName"="epoll_wait" "timestamp"="1625486870.273:187492" "type"="{type}"
Vérification
Retirer la gousse :
$ oc -n openshift-security-profiles delete pod my-pod
Confirmez que l'opérateur de profils de sécurité rapproche les deux profils seccomp :
$ oc -n openshift-security-profiles get sp
Exemple de sortie
NAME STATUS AGE test-recording-nginx Installed 15s test-recording-redis Installed 15s
7.5.3.1. Fusionner des instances de profil par conteneur
Par défaut, chaque instance de conteneur est enregistrée dans un profil distinct. L'opérateur de profils de sécurité peut fusionner les profils par conteneur en un seul profil. La fusion des profils est utile lors du déploiement d'applications utilisant les objets ReplicaSet ou Deployment.
Procédure
Modifier un objet
ProfileRecordingpour y inclure une variablemergeStrategy: containers:apiVersion: security-profiles-operator.x-k8s.io/v1alpha1 kind: ProfileRecording metadata: # The name of the Recording is the same as the resulting SeccompProfile CRD # after reconciliation. name: test-recording spec: kind: SeccompProfile recorder: logs mergeStrategy: containers podSelector: matchLabels: app: sp-recordCréer la charge de travail :
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deploy spec: replicas: 3 selector: matchLabels: app: sp-record template: metadata: labels: app: sp-record spec: serviceAccountName: spo-record-sa containers: - name: nginx-record image: quay.io/security-profiles-operator/test-nginx-unprivileged:1.21 ports: - containerPort: 8080Pour enregistrer les profils individuels, supprimez le déploiement en exécutant la commande suivante :
$ oc delete deployment nginx-deploy
Pour fusionner les profils, supprimez l'enregistrement du profil en exécutant la commande suivante :
$ oc delete profilerecording test-recording
Pour lancer l'opération de fusion et générer le profil de résultats, exécutez la commande suivante :
$ oc get sp -lspo.x-k8s.io/recording-id=test-recording
Exemple de sortie
NAME STATUS AGE test-recording-nginx-record Installed 17m
Pour afficher les appels de service utilisés par l'un des conteneurs, exécutez la commande suivante :
$ oc get sp test-recording-nginx-record -o yaml
Ressources supplémentaires
7.6. Gestion des profils SELinux
Créer et gérer des profils SELinux et les associer à des charges de travail.
7.6.1. Création de profils SELinux
Utilisez l'objet SelinuxProfile pour créer des profils.
L'objet SelinuxProfile présente plusieurs caractéristiques qui permettent de renforcer la sécurité et d'améliorer la lisibilité :
-
Limite les profils dont il faut hériter à l'espace de noms actuel ou à un profil général. Étant donné que de nombreux profils sont généralement installés sur le système, mais que seul un sous-ensemble doit être utilisé par les charges de travail en cluster, les profils système héritables sont répertoriés dans l'instance
spodà l'adressespec.selinuxOptions.allowedSystemProfiles. - Effectue une validation de base des autorisations, des classes et des étiquettes.
-
Ajoute un nouveau mot-clé
@selfqui décrit le processus utilisant la politique. Cela permet de réutiliser facilement une politique entre les charges de travail et les espaces de noms, car l'utilisation de la politique est basée sur le nom et l'espace de noms. - Ajoute des fonctionnalités pour améliorer le renforcement de la sécurité et la lisibilité par rapport à l'écriture d'un profil directement dans le langage SELinux CIL.
Procédure
Créez une politique qui peut être utilisée avec une charge de travail non privilégiée en créant l'objet
SelinuxProfilesuivant :apiVersion: security-profiles-operator.x-k8s.io/v1alpha2 kind: SelinuxProfile metadata: name: nginx-secure namespace: nginx-deploy spec: allow: '@self': tcp_socket: - listen http_cache_port_t: tcp_socket: - name_bind node_t: tcp_socket: - node_bind inherit: - kind: System name: containerAttendez que
selinuxdinstalle la politique en exécutant la commande suivante :$ oc wait --for=condition=ready -n nginx-deploy selinuxprofile nginx-secure
Exemple de sortie
selinuxprofile.security-profiles-operator.x-k8s.io/nginx-secure condition met
Les politiques sont placées sur un site
emptyDirdans le conteneur appartenant à l'opérateur de profils de sécurité. Les politiques sont sauvegardées au format Common Intermediate Language (CIL) dans/etc/selinux.d/<name>_<namespace>.cil.Accédez au pod en exécutant la commande suivante :
$ oc -n openshift-security-profiles rsh -c selinuxd ds/spod
Vérification
Affichez le contenu du fichier à l'aide de
caten exécutant la commande suivante :$ cat /etc/selinux.d/nginx-secure_nginx-deploy.cil
Exemple de sortie
(block nginx-secure_nginx-deploy (blockinherit container) (allow process nginx-secure_nginx-deploy.process ( tcp_socket ( listen ))) (allow process http_cache_port_t ( tcp_socket ( name_bind ))) (allow process node_t ( tcp_socket ( node_bind ))) )
Vérifiez qu'une politique a été installée en exécutant la commande suivante :
$ semodule -l | grep nginx-secure
Exemple de sortie
nginx-secure_nginx-deploy
7.6.2. Appliquer des profils SELinux à un pod
Créer un pod pour appliquer l'un des profils créés.
Pour les profils SELinux, l'espace de noms doit être étiqueté pour autoriser les charges de travail privilégiées.
Procédure
Appliquez l'étiquette
scc.podSecurityLabelSync=falseà l'espace de nomsnginx-deployen exécutant la commande suivante :$ oc label ns nginx-deploy security.openshift.io/scc.podSecurityLabelSync=false
Appliquez l'étiquette
privilegedà l'espace de nomsnginx-deployen exécutant la commande suivante :$ oc label ns nginx-deploy --overwrite=true pod-security.kubernetes.io/enforce=privileged
Obtenez la chaîne d'utilisation du profil SELinux en exécutant la commande suivante :
$ oc get selinuxprofile.security-profiles-operator.x-k8s.io/nginx-secure -n nginx-deploy -ojsonpath='{.status.usage}'Exemple de sortie
nginx-secure_nginx-deploy.process%
Appliquer la chaîne de sortie dans le manifeste de charge de travail dans l'attribut
.spec.containers[].securityContext.seLinuxOptions:apiVersion: v1 kind: Pod metadata: name: nginx-secure namespace: nginx-deploy spec: containers: - image: nginxinc/nginx-unprivileged:1.21 name: nginx securityContext: seLinuxOptions: # NOTE: This uses an appropriate SELinux type type: nginx-secure_nginx-deploy.processImportantLe site SELinux
typedoit exister avant la création de la charge de travail.
7.6.2.1. Application des politiques de journalisation SELinux
Pour consigner les violations de la politique ou les refus d'AVC, définissez le profil SElinuxProfile sur permissive.
Cette procédure définit les politiques de journalisation. Elle ne définit pas de politiques de mise en œuvre.
Procédure
Ajouter
permissive: trueàSElinuxProfile:apiVersion: security-profiles-operator.x-k8s.io/v1alpha2 kind: SelinuxProfile metadata: name: nginx-secure namespace: nginx-deploy spec: permissive: true
7.6.2.2. Lier les charges de travail aux profils avec ProfileBindings
Vous pouvez utiliser la ressource ProfileBinding pour lier un profil de sécurité à la ressource SecurityContext d'un conteneur.
Procédure
Pour lier un module qui utilise une image
quay.io/security-profiles-operator/test-nginx-unprivileged:1.21au profil de l'exempleSelinuxProfile, créez un objetProfileBindingdans le même espace de noms que le module et les objetsSelinuxProfile:apiVersion: security-profiles-operator.x-k8s.io/v1alpha1 kind: ProfileBinding metadata: namespace: my-namespace name: nginx-binding spec: profileRef: kind: SelinuxProfile 1 name: profile 2 image: quay.io/security-profiles-operator/test-nginx-unprivileged:1.21Etiqueter l'espace de noms avec
enable-binding=trueen exécutant la commande suivante :$ oc label ns my-namespace spo.x-k8s.io/enable-binding=true
Supprimer et recréer le pod pour utiliser l'objet
ProfileBinding:$ oc delete pods test-pod && oc create -f pod01.yaml
Vérification
Confirmez que le pod hérite de
ProfileBindingen exécutant la commande suivante :$ oc get pod test-pod -o jsonpath='{.spec.containers[*].securityContext.seLinuxOptions.type}'Exemple de sortie
profile_nginx-binding.process
7.6.2.3. Réplication des contrôleurs et des SecurityContextConstraints
Lors du déploiement de politiques SELinux pour les contrôleurs de réplication, tels que les déploiements ou les ensembles de démons, notez que les objets Pod créés par les contrôleurs ne sont pas exécutés avec l'identité de l'utilisateur qui crée la charge de travail. À moins qu'une adresse ServiceAccount ne soit sélectionnée, les pods risquent de revenir à l'utilisation d'une adresse SecurityContextConstraints restreinte (SCC) qui ne permet pas l'utilisation de politiques de sécurité personnalisées.
Procédure
Créez l'objet
RoleBindingsuivant pour permettre l'utilisation des politiques SELinux dans l'espace de nomsnginx-secure:kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: spo-use-seccomp-scc namespace: nginx-secure subjects: - kind: ServiceAccount name: spo-deploy-test roleRef: kind: Role name: spo-use-seccomp-scc apiGroup: rbac.authorization.k8s.io
Créer l'objet
Role:apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: creationTimestamp: null name: spo-use-seccomp-scc namespace: nginx-secure rules: - apiGroups: - security.openshift.io resources: - securitycontextconstraints resourceNames: - privileged verbs: - use
Créer l'objet
ServiceAccount:apiVersion: v1 kind: ServiceAccount metadata: creationTimestamp: null name: spo-deploy-test namespace: nginx-secure
Créer l'objet
Deployment:apiVersion: apps/v1 kind: Deployment metadata: name: selinux-test namespace: nginx-secure metadata: labels: app: selinux-test spec: replicas: 3 selector: matchLabels: app: selinux-test template: metadata: labels: app: selinux-test spec: serviceAccountName: spo-deploy-test securityContext: seLinuxOptions: type: nginx-secure_nginx-secure.process 1 containers: - name: nginx-unpriv image: quay.io/security-profiles-operator/test-nginx-unprivileged:1.21 ports: - containerPort: 8080- 1
- Le site
.seLinuxOptions.typedoit exister avant la création du déploiement.
NoteLe type SELinux n'est pas spécifié dans la charge de travail et est géré par le SCC. Lorsque les pods sont créés par le déploiement et le site
ReplicaSet, ils s'exécutent avec le profil approprié.
Assurez-vous que votre CCN n'est utilisable que par le bon compte de service. Pour plus d'informations, consultez le site Additional resources.
7.6.3. Enregistrement de profils à partir de charges de travail
L'opérateur de profils de sécurité peut enregistrer les appels système avec les objets ProfileRecording, ce qui facilite la création de profils de référence pour les applications.
Lors de l'utilisation de l'enrichisseur de journaux pour l'enregistrement des profils SELinux, vérifiez que la fonction d'enrichissement de journaux est activée. Voir Additional resources pour plus d'informations.
Un conteneur avec privileged: true security context restraints empêche l'enregistrement basé sur le journal. Les conteneurs privilégiés ne sont pas soumis aux politiques SELinux, et l'enregistrement basé sur les journaux utilise un profil SELinux spécial pour enregistrer les événements.
Procédure
Etiqueter l'espace de noms avec
enable-recording=trueen exécutant la commande suivante :$ oc label ns my-namespace spo.x-k8s.io/enable-recording=true
Créer un objet
ProfileRecordingcontenant une variablerecorder: logs:apiVersion: security-profiles-operator.x-k8s.io/v1alpha1 kind: ProfileRecording metadata: name: test-recording spec: kind: SelinuxProfile recorder: logs podSelector: matchLabels: app: my-appCréer une charge de travail à enregistrer :
apiVersion: v1 kind: Pod metadata: name: my-pod labels: app: my-app spec: containers: - name: nginx image: quay.io/security-profiles-operator/test-nginx-unprivileged:1.21 ports: - containerPort: 8080 - name: redis image: quay.io/security-profiles-operator/redis:6.2.1Confirmez que le pod est dans un état
Runningen entrant la commande suivante :$ oc -n openshift-security-profiles get pods
Exemple de sortie
NAME READY STATUS RESTARTS AGE my-pod 2/2 Running 0 18s
Confirmez que l'enrichisseur indique qu'il reçoit les journaux d'audit pour ces conteneurs :
$ oc -n openshift-security-profiles logs --since=1m --selector name=spod -c log-enricher
Exemple de sortie
… I0705 12:08:18.729660 1843190 enricher.go:136] log-enricher "msg"="audit" "container"="redis" "executable"="/usr/local/bin/redis-server" "namespace"="default" "node"="127.0.0.1" "pid"=1847839 "pod"="my-pod" "syscallID"=232 "syscallName"="epoll_wait" "timestamp"="1625486870.273:187492" "type"="{type}"
Vérification
Retirer la gousse :
$ oc -n openshift-security-profiles delete pod my-pod
Confirmez que l'opérateur de profils de sécurité réconcilie les deux profils SELinux :
$ oc -n openshift-security-profiles get sp
Exemple de sortie
NAME STATUS AGE test-recording-nginx Installed 15s test-recording-redis Installed 15s
7.6.3.1. Fusionner des instances de profil par conteneur
Par défaut, chaque instance de conteneur est enregistrée dans un profil distinct. L'opérateur de profils de sécurité peut fusionner les profils par conteneur en un seul profil. La fusion des profils est utile lors du déploiement d'applications utilisant les objets ReplicaSet ou Deployment.
Procédure
Modifier un objet
ProfileRecordingpour y inclure une variablemergeStrategy: containers:apiVersion: security-profiles-operator.x-k8s.io/v1alpha1 kind: ProfileRecording metadata: # The name of the Recording is the same as the resulting SelinuxProfile CRD # after reconciliation. name: test-recording spec: kind: SelinuxProfile recorder: logs mergeStrategy: containers podSelector: matchLabels: app: sp-recordCréer la charge de travail :
apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deploy spec: replicas: 3 selector: matchLabels: app: sp-record template: metadata: labels: app: sp-record spec: serviceAccountName: spo-record-sa containers: - name: nginx-record image: quay.io/security-profiles-operator/test-nginx-unprivileged:1.21 ports: - containerPort: 8080Pour enregistrer les profils individuels, supprimez le déploiement en exécutant la commande suivante :
$ oc delete deployment nginx-deploy
Pour fusionner les profils, supprimez l'enregistrement du profil en exécutant la commande suivante :
$ oc delete profilerecording test-recording
Pour lancer l'opération de fusion et générer le profil de résultats, exécutez la commande suivante :
$ oc get sp -lspo.x-k8s.io/recording-id=test-recording
Exemple de sortie
NAME STATUS AGE test-recording-nginx-record Installed 17m
Pour afficher les appels de service utilisés par l'un des conteneurs, exécutez la commande suivante :
$ oc get sp test-recording-nginx-record -o yaml
7.6.3.2. À propos de seLinuxContext : RunAsAny
L'enregistrement des politiques SELinux est mis en œuvre avec un webhook qui injecte un type SELinux spécial dans les pods enregistrés. Le type SELinux fait tourner le pod en mode permissive, en enregistrant tous les refus d'AVC dans audit.log. Par défaut, une charge de travail n'est pas autorisée à s'exécuter avec une politique SELinux personnalisée, mais utilise un type généré automatiquement.
Pour enregistrer une charge de travail, celle-ci doit utiliser un compte de service disposant des autorisations nécessaires pour utiliser un SCC permettant au webhook d'injecter le type SELinux permissif. Le SCC privileged contient seLinuxContext: RunAsAny.
En outre, l'espace de noms doit être étiqueté avec pod-security.kubernetes.io/enforce: privileged si votre cluster active l'admission de sécurité des pods, car seul le standard de sécurité des pods privileged autorise l'utilisation d'une politique SELinux personnalisée.
Ressources supplémentaires
7.7. Profils de sécurité avancés Tâches de l'opérateur
Utilisez les tâches avancées pour activer les mesures, configurer les webhooks ou restreindre les appels de service.
7.7.1. Restreindre les appels de service autorisés dans les profils seccomp
Par défaut, l'Opérateur de profils de sécurité ne restreint pas syscalls dans les profils seccomp. Vous pouvez définir la liste des syscalls autorisés dans la configuration de spod.
Procédure
Pour définir la liste des
allowedSyscalls, ajustez le paramètrespecen exécutant la commande suivante :$ oc -n openshift-security-profiles patch spod spod --type merge \ -p '{"spec":{"allowedSyscalls": ["exit", "exit_group", "futex", "nanosleep"]}}'
L'opérateur n'installera que les profils seccomp, qui ont un sous-ensemble de syscalls défini dans la liste autorisée. Tous les profils ne respectant pas cet ensemble de règles sont rejetés.
Lorsque la liste des syscalls autorisés est modifiée dans la configuration de spod, l'Opérateur identifiera les profils déjà installés qui ne sont pas conformes et les supprimera automatiquement.
7.7.2. Appels système de base pour un runtime de conteneur
Vous pouvez utiliser l'attribut baseProfileName pour établir le minimum requis syscalls pour une durée d'exécution donnée afin de démarrer un conteneur.
Procédure
Modifiez l'objet de type
SeccompProfileet ajoutezbaseProfileName: runc-v1.0.0au champspec:apiVersion: security-profiles-operator.x-k8s.io/v1beta1 kind: SeccompProfile metadata: namespace: my-namespace name: example-name spec: defaultAction: SCMP_ACT_ERRNO baseProfileName: runc-v1.0.0 syscalls: - action: SCMP_ACT_ALLOW names: - exit_group
7.7.3. Utiliser des indicateurs
L'espace de noms openshift-security-profiles fournit des points d'extrémité pour les mesures, qui sont sécurisés par le conteneur kube-rbac-proxy. Toutes les mesures sont exposées par le service metrics dans l'espace de noms openshift-security-profiles.
L'opérateur de profils de sécurité comprend un rôle de cluster et un lien correspondant spo-metrics-client pour récupérer les métriques au sein du cluster. Il existe deux chemins d'accès aux métriques :
-
metrics.openshift-security-profiles/metricspour les mesures de la durée d'exécution des contrôleurs -
metrics.openshift-security-profiles/metrics-spodpour les métriques du démon Operator
Procédure
Pour afficher l'état du service de métrologie, exécutez la commande suivante :
$ oc get svc/metrics -n openshift-security-profiles
Exemple de sortie
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE metrics ClusterIP 10.0.0.228 <none> 443/TCP 43s
Pour récupérer les métriques, interrogez le point de terminaison du service à l'aide du jeton par défaut
ServiceAccountdans l'espace de nomsopenshift-security-profilesen exécutant la commande suivante :$ oc run --rm -i --restart=Never --image=registry.fedoraproject.org/fedora-minimal:latest \ -n openshift-security-profiles metrics-test -- bash -c \ 'curl -ks -H "Authorization: Bearer $(cat /var/run/secrets/kubernetes.io/serviceaccount/token)" https://metrics.openshift-security-profiles/metrics-spod'Exemple de sortie
# HELP security_profiles_operator_seccomp_profile_total Counter about seccomp profile operations. # TYPE security_profiles_operator_seccomp_profile_total counter security_profiles_operator_seccomp_profile_total{operation="delete"} 1 security_profiles_operator_seccomp_profile_total{operation="update"} 2Pour récupérer les métriques d'un autre espace de noms, reliez le site
ServiceAccountau sitespo-metrics-clientClusterRoleBindingen exécutant la commande suivante :$ oc get clusterrolebinding spo-metrics-client -o wide
Exemple de sortie
NAME ROLE AGE USERS GROUPS SERVICEACCOUNTS spo-metrics-client ClusterRole/spo-metrics-client 35m openshift-security-profiles/default
7.7.3.1. controller-runtime metrics
Le controller-runtime metrics et le DaemonSet endpoint metrics-spod fournissent un ensemble de mesures par défaut. Des mesures supplémentaires sont fournies par le démon, qui sont toujours préfixées par security_profiles_operator_.
Tableau 7.1. Mesures disponibles pour le temps d'exécution du contrôleur
| Clé métrique | Étiquettes possibles | Type | Objectif |
|---|---|---|---|
|
|
| Compteur | Nombre d'opérations de profil seccomp. |
|
|
| Compteur | Nombre d'opérations d'audit du profil seccomp. Nécessite l'activation de l'enrichisseur de journaux. |
|
|
| Compteur | Nombre d'opérations bpf du profil seccomp. L'enregistreur bpf doit être activé. |
|
|
| Compteur | Nombre d'erreurs de profil seccomp. |
|
|
| Compteur | Nombre d'opérations de profil SELinux. |
|
|
| Compteur | Nombre d'opérations d'audit du profil SELinux. Nécessite l'activation de l'enrichisseur de journaux. |
|
|
| Compteur | Nombre d'erreurs de profil SELinux. |
7.7.4. Utilisation de l'enrichisseur de billes
L'Opérateur de profils de sécurité contient une fonction d'enrichissement des journaux, qui est désactivée par défaut. Le conteneur d'enrichissement des journaux s'exécute avec les autorisations privileged pour lire les journaux d'audit du nœud local. L'enrichisseur de journaux s'exécute dans l'espace de noms PID de l'hôte, hostPID.
L'enrichisseur de journaux doit avoir le droit de lire les processus de l'hôte.
Procédure
Modifiez la configuration de
spodpour activer l'enrichisseur de journaux en exécutant la commande suivante :$ oc -n openshift-security-profiles patch spod spod \ --type=merge -p '{"spec":{"enableLogEnricher":true}}'Exemple de sortie
securityprofilesoperatordaemon.security-profiles-operator.x-k8s.io/spod patched
NoteL'opérateur de profils de sécurité redéploiera automatiquement le jeu de démons
spod.Affichez les journaux d'audit en exécutant la commande suivante :
$ oc -n openshift-security-profiles logs -f ds/spod log-enricher
Exemple de sortie
I0623 12:51:04.257814 1854764 deleg.go:130] setup "msg"="starting component: log-enricher" "buildDate"="1980-01-01T00:00:00Z" "compiler"="gc" "gitCommit"="unknown" "gitTreeState"="clean" "goVersion"="go1.16.2" "platform"="linux/amd64" "version"="0.4.0-dev" I0623 12:51:04.257890 1854764 enricher.go:44] log-enricher "msg"="Starting log-enricher on node: 127.0.0.1" I0623 12:51:04.257898 1854764 enricher.go:46] log-enricher "msg"="Connecting to local GRPC server" I0623 12:51:04.258061 1854764 enricher.go:69] log-enricher "msg"="Reading from file /var/log/audit/audit.log" 2021/06/23 12:51:04 Seeked /var/log/audit/audit.log - &{Offset:0 Whence:2}
7.7.4.1. Utiliser l'enrichisseur de logs pour tracer une application
Vous pouvez utiliser l'enrichisseur de journaux de l'opérateur des profils de sécurité pour tracer une application.
Procédure
Pour tracer une application, créez un profil de journalisation
SeccompProfile:apiVersion: security-profiles-operator.x-k8s.io/v1beta1 kind: SeccompProfile metadata: name: log namespace: default spec: defaultAction: SCMP_ACT_LOG
Créer un objet pod pour utiliser le profil :
apiVersion: v1 kind: Pod metadata: name: log-pod spec: securityContext: seccompProfile: type: Localhost localhostProfile: operator/default/log.json containers: - name: log-container image: quay.io/security-profiles-operator/test-nginx-unprivileged:1.21Examinez la sortie de l'enrichisseur de journaux en exécutant la commande suivante :
$ oc -n openshift-security-profiles logs -f ds/spod log-enricher
Exemple 7.1. Exemple de sortie
… I0623 12:59:11.479869 1854764 enricher.go:111] log-enricher "msg"="audit" "container"="log-container" "executable"="/" "namespace"="default" "node"="127.0.0.1" "pid"=1905792 "pod"="log-pod" "syscallID"=3 "syscallName"="close" "timestamp"="1624453150.205:1061" "type"="seccomp" I0623 12:59:11.487323 1854764 enricher.go:111] log-enricher "msg"="audit" "container"="log-container" "executable"="/" "namespace"="default" "node"="127.0.0.1" "pid"=1905792 "pod"="log-pod" "syscallID"=157 "syscallName"="prctl" "timestamp"="1624453150.205:1062" "type"="seccomp" I0623 12:59:11.492157 1854764 enricher.go:111] log-enricher "msg"="audit" "container"="log-container" "executable"="/" "namespace"="default" "node"="127.0.0.1" "pid"=1905792 "pod"="log-pod" "syscallID"=157 "syscallName"="prctl" "timestamp"="1624453150.205:1063" "type"="seccomp" … I0623 12:59:20.258523 1854764 enricher.go:111] log-enricher "msg"="audit" "container"="log-container" "executable"="/usr/sbin/nginx" "namespace"="default" "node"="127.0.0.1" "pid"=1905792 "pod"="log-pod" "syscallID"=12 "syscallName"="brk" "timestamp"="1624453150.235:2873" "type"="seccomp" I0623 12:59:20.263349 1854764 enricher.go:111] log-enricher "msg"="audit" "container"="log-container" "executable"="/usr/sbin/nginx" "namespace"="default" "node"="127.0.0.1" "pid"=1905792 "pod"="log-pod" "syscallID"=21 "syscallName"="access" "timestamp"="1624453150.235:2874" "type"="seccomp" I0623 12:59:20.354091 1854764 enricher.go:111] log-enricher "msg"="audit" "container"="log-container" "executable"="/usr/sbin/nginx" "namespace"="default" "node"="127.0.0.1" "pid"=1905792 "pod"="log-pod" "syscallID"=257 "syscallName"="openat" "timestamp"="1624453150.235:2875" "type"="seccomp" I0623 12:59:20.358844 1854764 enricher.go:111] log-enricher "msg"="audit" "container"="log-container" "executable"="/usr/sbin/nginx" "namespace"="default" "node"="127.0.0.1" "pid"=1905792 "pod"="log-pod" "syscallID"=5 "syscallName"="fstat" "timestamp"="1624453150.235:2876" "type"="seccomp" I0623 12:59:20.363510 1854764 enricher.go:111] log-enricher "msg"="audit" "container"="log-container" "executable"="/usr/sbin/nginx" "namespace"="default" "node"="127.0.0.1" "pid"=1905792 "pod"="log-pod" "syscallID"=9 "syscallName"="mmap" "timestamp"="1624453150.235:2877" "type"="seccomp" I0623 12:59:20.454127 1854764 enricher.go:111] log-enricher "msg"="audit" "container"="log-container" "executable"="/usr/sbin/nginx" "namespace"="default" "node"="127.0.0.1" "pid"=1905792 "pod"="log-pod" "syscallID"=3 "syscallName"="close" "timestamp"="1624453150.235:2878" "type"="seccomp" I0623 12:59:20.458654 1854764 enricher.go:111] log-enricher "msg"="audit" "container"="log-container" "executable"="/usr/sbin/nginx" "namespace"="default" "node"="127.0.0.1" "pid"=1905792 "pod"="log-pod" "syscallID"=257 "syscallName"="openat" "timestamp"="1624453150.235:2879" "type"="seccomp" …
7.7.5. Configuration des webhooks
Les objets de liaison et d'enregistrement de profil peuvent utiliser des webhooks. Les configurations de la liaison de profil et des objets d'enregistrement sont MutatingWebhookConfiguration CR, gérées par l'opérateur de profils de sécurité.
Pour modifier la configuration du webhook, le CR spod expose un champ webhookOptions qui permet de modifier les variables failurePolicy, namespaceSelector et objectSelector. Cela vous permet de configurer les webhooks en mode "soft-fail" ou de les restreindre à un sous-ensemble d'espaces de noms de sorte que même si les webhooks échouent, les autres espaces de noms ou ressources ne sont pas affectés.
Procédure
Définissez la configuration du webhook
recording.spo.iopour enregistrer uniquement les pods étiquetés avecspo-record=trueen créant le fichier patch suivant :spec: webhookOptions: - name: recording.spo.io objectSelector: matchExpressions: - key: spo-record operator: In values: - "true"Apportez un correctif à l'instance
spod/spoden exécutant la commande suivante :$ oc -n openshift-security-profiles patch spod \ spod -p $(cat /tmp/spod-wh.patch) --type=mergePour visualiser l'objet
MutatingWebhookConfigurationrésultant, exécutez la commande suivante :$ oc get MutatingWebhookConfiguration \ spo-mutating-webhook-configuration -oyaml
7.8. Dépannage de l'opérateur de profils de sécurité
Dépanner l'Opérateur de profils de sécurité pour diagnostiquer un problème ou fournir des informations dans un rapport de bogue.
7.8.1. Inspection des profils seccomp
Des profils seccomp corrompus peuvent perturber vos charges de travail. Veillez à ce que l'utilisateur ne puisse pas abuser du système en n'autorisant pas d'autres charges de travail à mapper n'importe quelle partie du chemin d'accès /var/lib/kubelet/seccomp/operator.
Procédure
Confirmez que le profil est réconcilié en exécutant la commande suivante :
oc -n openshift-security-profiles logs openshift-security-profiles-<id>
Exemple 7.2. Exemple de sortie
I1019 19:34:14.942464 1 main.go:90] setup "msg"="starting openshift-security-profiles" "buildDate"="2020-10-19T19:31:24Z" "compiler"="gc" "gitCommit"="a3ef0e1ea6405092268c18f240b62015c247dd9d" "gitTreeState"="dirty" "goVersion"="go1.15.1" "platform"="linux/amd64" "version"="0.2.0-dev" I1019 19:34:15.348389 1 listener.go:44] controller-runtime/metrics "msg"="metrics server is starting to listen" "addr"=":8080" I1019 19:34:15.349076 1 main.go:126] setup "msg"="starting manager" I1019 19:34:15.349449 1 internal.go:391] controller-runtime/manager "msg"="starting metrics server" "path"="/metrics" I1019 19:34:15.350201 1 controller.go:142] controller "msg"="Starting EventSource" "controller"="profile" "reconcilerGroup"="security-profiles-operator.x-k8s.io" "reconcilerKind"="SeccompProfile" "source"={"Type":{"metadata":{"creationTimestamp":null},"spec":{"defaultAction":""}}} I1019 19:34:15.450674 1 controller.go:149] controller "msg"="Starting Controller" "controller"="profile" "reconcilerGroup"="security-profiles-operator.x-k8s.io" "reconcilerKind"="SeccompProfile" I1019 19:34:15.450757 1 controller.go:176] controller "msg"="Starting workers" "controller"="profile" "reconcilerGroup"="security-profiles-operator.x-k8s.io" "reconcilerKind"="SeccompProfile" "worker count"=1 I1019 19:34:15.453102 1 profile.go:148] profile "msg"="Reconciled profile from SeccompProfile" "namespace"="openshift-security-profiles" "profile"="nginx-1.19.1" "name"="nginx-1.19.1" "resource version"="728" I1019 19:34:15.453618 1 profile.go:148] profile "msg"="Reconciled profile from SeccompProfile" "namespace"="openshift-security-profiles" "profile"="openshift-security-profiles" "name"="openshift-security-profiles" "resource version"="729"Confirmez que les profils
seccompsont enregistrés dans le bon chemin en exécutant la commande suivante :$ oc exec -t -n openshift-security-profiles openshift-security-profiles-<id> \ -- ls /var/lib/kubelet/seccomp/operator/my-namespace/my-workloadExemple de sortie
profile-block.json profile-complain.json
7.9. Désinstallation de l'opérateur de profils de sécurité
Vous pouvez supprimer l'opérateur de profils de sécurité de votre cluster en utilisant la console web d'OpenShift Container Platform.
7.9.1. Désinstaller l'opérateur de profils de sécurité à l'aide de la console web
Pour supprimer l'opérateur des profils de sécurité, vous devez d'abord supprimer les profils seccomp et SELinux. Une fois les profils supprimés, vous pouvez supprimer l'opérateur et son espace de noms en supprimant le projet openshift-security-profiles.
Conditions préalables
-
Accès à un cluster OpenShift Container Platform qui utilise un compte avec des permissions
cluster-admin. - L'Opérateur de profils de sécurité est installé.
Procédure
Pour supprimer l'opérateur de profils de sécurité en utilisant la console web de OpenShift Container Platform :
- Naviguez jusqu'à la page Operators → Installed Operators.
-
Supprimer tous les profils
seccomp, les profils SELinux et les configurations webhook. - Passez à la page Administration → Operators → Installed Operators.
-
Cliquez sur le menu Options
sur l'entrée Security Profiles Operator et sélectionnez Uninstall Operator.
- Passez à la page Home → Projects.
-
Recherche de
security profiles. Cliquez sur le menu Options
à côté du projet openshift-security-profiles et sélectionnez Delete Project.
-
Confirmez la suppression en tapant
openshift-security-profilesdans la boîte de dialogue, puis cliquez sur Delete.
-
Confirmez la suppression en tapant
Supprimez l'objet
MutatingWebhookConfigurationen exécutant la commande suivante :$ oc delete MutatingWebhookConfiguration spo-mutating-webhook-configuration
Chapitre 8. cert-manager Opérateur pour Red Hat OpenShift
8.1. aperçu de cert-manager Operator pour Red Hat OpenShift
L'opérateur cert-manager pour Red Hat OpenShift est un service à l'échelle du cluster qui fournit une gestion du cycle de vie des certificats d'application. L'opérateur cert-manager pour Red Hat OpenShift vous permet d'intégrer des autorités de certification externes et assure l'approvisionnement, le renouvellement et le retrait des certificats.
8.1.1. À propos de l'opérateur cert-manager pour Red Hat OpenShift
Le projet cert-manager introduit les autorités de certification et les certificats en tant que types de ressources dans l'API Kubernetes, ce qui permet de fournir des certificats à la demande aux développeurs travaillant dans votre cluster. L'opérateur cert-manager pour Red Hat OpenShift fournit un moyen supporté d'intégrer cert-manager dans votre cluster OpenShift Container Platform.
L'opérateur cert-manager pour Red Hat OpenShift offre les fonctionnalités suivantes :
- Prise en charge de l'intégration avec des autorités de certification externes
- Outils de gestion des certificats
- Possibilité pour les développeurs de fournir eux-mêmes des certificats
- Renouvellement automatique des certificats
N'essayez pas d'utiliser plus d'un opérateur cert-manager dans votre cluster. Si un Opérateur cert-manager communautaire est installé dans votre cluster, vous devez le désinstaller avant d'installer l'Opérateur cert-manager pour Red Hat OpenShift.
8.1.2. Types d'émetteurs pris en charge
L'opérateur cert-manager pour Red Hat OpenShift prend en charge les types d'émetteurs suivants :
- Environnement de gestion automatisée des certificats (ACME)
- Autorité de certification (AC)
- Auto-signé
8.1.3. Méthodes de demande de certificat
Il y a deux façons de demander un certificat en utilisant l'opérateur cert-manager pour Red Hat OpenShift :
- Utilisation de l'objet
cert-manager.io/CertificateRequest -
Avec cette méthode, un développeur de services crée un objet
CertificateRequestavec unissuerRefvalide pointant vers un émetteur configuré (configuré par un administrateur d'infrastructure de services). L'administrateur de l'infrastructure de services accepte ou refuse alors la demande de certificat. Seules les demandes de certificat acceptées créent un certificat correspondant. - Utilisation de l'objet
cert-manager.io/Certificate -
Avec cette méthode, un développeur de services crée un objet
Certificateavec unissuerRefvalide et obtient un certificat à partir d'un secret qu'il a attribué à l'objetCertificate.
8.1.4. Ressources supplémentaires
8.2. cert-manager Operator for Red Hat OpenShift - notes de version
L'opérateur cert-manager pour Red Hat OpenShift est un service à l'échelle du cluster qui fournit une gestion du cycle de vie des certificats d'application.
Ces notes de version suivent le développement de cert-manager Operator pour Red Hat OpenShift.
Pour plus d'informations, voir À propos de l'opérateur cert-manager pour Red Hat OpenShift.
8.2.1. Notes de version pour cert-manager Operator pour Red Hat OpenShift 1.10.2
Publié : 2023-03-23
L'avis suivant est disponible pour l'opérateur cert-manager pour Red Hat OpenShift 1.10.2 :
Pour plus d'informations, voir les notes de publication du projet cert-manager pour la version 1.10.
Si vous avez utilisé la version Technology Preview de l'Opérateur cert-manager pour Red Hat OpenShift, vous devez la désinstaller et supprimer toutes les ressources liées à la version Technology Preview avant d'installer cette version de l'Opérateur cert-manager pour Red Hat OpenShift.
Pour plus d'informations, voir Désinstallation de l'opérateur cert-manager pour Red Hat OpenShift.
8.2.1.1. Nouvelles fonctionnalités et améliorations
Il s'agit de la version de disponibilité générale (GA) de l'opérateur cert-manager pour Red Hat OpenShift.
Les types d'émetteurs suivants sont pris en charge :
- Environnement de gestion automatisée des certificats (ACME)
- Autorité de certification (AC)
- Auto-signé
Les types de défis ACME suivants sont pris en charge :
- DNS-01
- HTTP-01
Les fournisseurs DNS-01 suivants sont pris en charge pour les émetteurs ACME :
- Amazon Route 53
- Azure DNS
- Google Cloud DNS
- L'opérateur cert-manager pour Red Hat OpenShift prend désormais en charge l'injection de certificats CA personnalisés et la propagation de variables d'environnement de proxy egress à l'échelle du cluster.
8.2.1.2. Bug fixes
Auparavant, le champ
unsupportedConfigOverridesremplaçait les arguments fournis par l'utilisateur au lieu de les ajouter. Désormais, le champunsupportedConfigOverridesajoute correctement les arguments fournis par l'utilisateur. (CM-23)AvertissementL'utilisation de la section
unsupportedConfigOverridespour modifier la configuration d'un opérateur n'est pas supportée et peut bloquer les mises à jour du cluster.- Auparavant, l'opérateur cert-manager pour Red Hat OpenShift était installé en tant qu'opérateur de cluster. Avec cette version, l'opérateur cert-manager pour Red Hat OpenShift est maintenant correctement installé en tant qu'opérateur OLM. (CM-35)
8.2.1.3. Problèmes connus
-
L'utilisation des objets
Routen'est pas entièrement prise en charge. Actuellement, pour utiliser cert-manager Operator pour Red Hat OpenShift avecRoutes, les utilisateurs doivent créer des objetsIngress, qui sont traduits en objetsRoutepar le contrôleur Ingress-to-Route. (CM-16) - L'opérateur cert-manager pour Red Hat OpenShift ne prend pas en charge l'utilisation des identités de pods Azure Active Directory (Azure AD) pour attribuer une identité gérée à un pod. En guise de solution de contournement, vous pouvez utiliser un principal de service pour attribuer une identité gérée. (OCPBUGS-8665)
- L'opérateur cert-manager pour Red Hat OpenShift ne prend pas en charge l'utilisation de la fédération d'identité de la charge de travail de Google. (OCPBUGS-9998)
- Lors de la désinstallation du cert-manager Operator pour Red Hat OpenShift, si vous sélectionnez la case à cocher Delete all operand instances for this operator dans la console web OpenShift Container Platform, l'Operator n'est pas désinstallé correctement. Comme solution de contournement, ne sélectionnez pas cette case à cocher lors de la désinstallation du cert-manager Operator pour Red Hat OpenShift. (OCPBUGS-9960)
8.2.2. Notes de publication pour cert-manager Operator pour Red Hat OpenShift 1.7.1-1 (Technology Preview)
Publié : 2022-04-11
L'avis suivant est disponible pour l'opérateur cert-manager pour Red Hat OpenShift 1.7.1-1 :
Pour plus d'informations, voir les notes de version du projet cert-manager pour la version 1.7.1.
8.2.2.1. Nouvelles fonctionnalités et améliorations
- Il s'agit de la version initiale, Technology Preview, de l'opérateur cert-manager pour Red Hat OpenShift.
8.2.2.2. Problèmes connus
-
L'utilisation des objets
Routen'est pas entièrement prise en charge. Actuellement, cert-manager Operator pour Red Hat OpenShift s'intègre aux objetsRouteen créant des objetsIngressvia le contrôleur Ingress. (CM-16)
8.3. Installation de l'opérateur cert-manager pour Red Hat OpenShift
Le cert-manager Operator pour Red Hat OpenShift n'est pas installé par défaut dans OpenShift Container Platform. Vous pouvez installer l'Opérateur cert-manager pour Red Hat OpenShift en utilisant la console web.
8.3.1. Installation de l'opérateur cert-manager pour Red Hat OpenShift à l'aide de la console web
Vous pouvez utiliser la console web pour installer l'opérateur cert-manager pour Red Hat OpenShift.
Conditions préalables
-
Vous avez accès au cluster avec les privilèges
cluster-admin. - Vous avez accès à la console web de OpenShift Container Platform.
Procédure
- Connectez-vous à la console web de OpenShift Container Platform.
- Naviguez jusqu'à Operators → OperatorHub.
- Saisissez cert-manager Operator for Red Hat OpenShift dans le champ de filtre.
- Sélectionnez le site cert-manager Operator for Red Hat OpenShift et cliquez sur Install.
Sur la page Install Operator:
- Mettez à jour le site Update channel, si nécessaire. Le canal est par défaut stable-v1, qui installe la dernière version stable de l'opérateur cert-manager pour Red Hat OpenShift.
Choisissez le site Installed Namespace pour l'Opérateur. L'espace de noms par défaut de l'opérateur est
cert-manager-operator.Si l'espace de noms
cert-manager-operatorn'existe pas, il est créé pour vous.Sélectionnez une stratégie Update approval.
- La stratégie Automatic permet à Operator Lifecycle Manager (OLM) de mettre automatiquement à jour l'opérateur lorsqu'une nouvelle version est disponible.
- La stratégie Manual exige qu'un utilisateur disposant des informations d'identification appropriées approuve la mise à jour de l'opérateur.
- Cliquez sur Install.
Vérification
- Naviguez jusqu'à Operators → Installed Operators.
-
Vérifiez que cert-manager Operator for Red Hat OpenShift est répertorié avec un Status de Succeeded dans l'espace de noms
cert-manager-operator.
8.3.2. Ressources supplémentaires
8.4. Gestion des certificats avec un émetteur ACME
L'opérateur cert-manager pour Red Hat OpenShift prend en charge l'utilisation de serveurs ACME CA, tels que Let's Encrypt, pour émettre des certificats.
8.4.1. À propos des émetteurs de l'ACME
Le type d'émetteur ACME pour l'opérateur cert-manager de Red Hat OpenShift représente un serveur d'autorité de certification (CA) ACME (Automated Certificate Management Environment). Les serveurs ACME CA s'appuient sur challenge pour vérifier qu'un client possède les noms de domaine pour lesquels le certificat est demandé. Si le défi est réussi, le cert-manager Operator pour Red Hat OpenShift peut émettre le certificat. Si le défi échoue, l'opérateur de cert-manager pour Red Hat OpenShift n'émet pas le certificat.
8.4.1.1. Types de défis ACME pris en charge
L'opérateur cert-manager pour Red Hat OpenShift prend en charge les types de défis suivants pour les émetteurs ACME :
- HTTP-01
Avec le type de défi HTTP-01, vous fournissez une clé calculée à un point d'extrémité HTTP URL dans votre domaine. Si le serveur ACME CA peut obtenir la clé à partir de l'URL, il peut vous valider en tant que propriétaire du domaine.
Pour plus d'informations, voir HTTP01 dans la documentation de cert-manager en amont.
- DNS-01
Avec le type de défi DNS-01, vous fournissez une clé calculée dans un enregistrement DNS TXT. Si le serveur de l'ACME CA peut obtenir la clé par consultation DNS, il peut vous valider en tant que propriétaire du domaine.
Pour plus d'informations, voir DNS01 dans la documentation de cert-manager en amont.
8.4.1.2. Fournisseurs DNS-01 pris en charge
L'opérateur cert-manager pour Red Hat OpenShift prend en charge les fournisseurs DNS-01 suivants pour les émetteurs ACME :
- Amazon Route 53
Azure DNS
NoteL'opérateur cert-manager pour Red Hat OpenShift ne prend pas en charge l'utilisation des identités de pods Azure Active Directory (Azure AD) pour attribuer une identité gérée à un pod.
Google Cloud DNS
NoteL'opérateur cert-manager pour Red Hat OpenShift ne prend pas en charge l'utilisation de la fédération d'identité de la charge de travail de Google.
8.4.2. Configuration d'un émetteur ACME pour résoudre les problèmes HTTP-01
Vous pouvez utiliser cert-manager Operator pour Red Hat OpenShift pour configurer un émetteur ACME afin de résoudre les défis HTTP-01. Cette procédure utilise Let's Encrypt comme serveur ACME.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez un service que vous voulez exposer. Dans cette procédure, le service est nommé
sample-workload.
Procédure
Créer un émetteur de cluster ACME.
Créer un fichier YAML qui définit l'objet
ClusterIssuer:Exemple de fichier
acme-cluster-issuer.yamlapiVersion: cert-manager.io/v1 kind: ClusterIssuer metadata: name: letsencrypt-staging 1 spec: acme: preferredChain: "" privateKeySecretRef: name: <secret_for_private_key> 2 server: https://acme-staging-v02.api.letsencrypt.org/directory 3 solvers: - http01: ingress: class: openshift-default 4
- 1
- Indiquez le nom de l'émetteur du cluster.
- 2
- Remplacez
<secret_private_key>par le nom du secret dans lequel vous souhaitez stocker la clé privée du compte ACME. - 3
- Indiquez l'URL permettant d'accéder au point de terminaison
directorydu serveur ACME. Cet exemple utilise l'environnement de préparation de Let's Encrypt. - 4
- Spécifiez la classe d'entrée.
Créez l'objet
ClusterIssueren exécutant la commande suivante :$ oc create -f acme-cluster-issuer.yaml
Créer une entrée pour exposer le service de la charge de travail de l'utilisateur.
Créer un fichier YAML qui définit un objet
Namespace:Exemple de fichier
namespace.yamlapiVersion: v1 kind: Namespace metadata: name: my-ingress-namespace 1- 1
- Spécifiez l'espace de noms pour l'entrée.
Créez l'objet
Namespaceen exécutant la commande suivante :$ oc create -f namespace.yaml
Créer un fichier YAML qui définit l'objet
Ingress:Exemple de fichier
ingress.yamlapiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: sample-ingress 1 namespace: my-ingress-namespace 2 annotations: cert-manager.io/cluster-issuer: letsencrypt-staging 3 acme.cert-manager.io/http01-ingress-class: openshift-default 4 spec: ingressClassName: openshift-default 5 tls: - hosts: - <hostname> 6 secretName: sample-tls 7 rules: - host: <hostname> 8 http: paths: - path: / pathType: Prefix backend: service: name: sample-workload 9 port: number: 80
- 1
- Spécifiez le nom de l'entrée.
- 2
- Spécifiez l'espace de noms que vous avez créé pour l'Ingress.
- 3
- Indiquez l'émetteur de cluster que vous avez créé.
- 4
- Spécifiez la classe d'entrée.
- 5
- Spécifiez la classe d'entrée.
- 6
- Remplacez
<hostname>par le Subject Alternative Name à associer au certificat. Ce nom est utilisé pour ajouter des noms DNS au certificat. - 7
- Indiquez le secret dans lequel le certificat créé doit être stocké.
- 8
- Remplacez
<hostname>par le nom d'hôte. Vous pouvez utiliser la syntaxe<host_name>.<cluster_ingress_domain>pour tirer parti de l'enregistrement DNS générique*.<cluster_ingress_domain>et du certificat de service pour le cluster. Par exemple, vous pouvez utiliserapps.<cluster_base_domain>. Sinon, vous devez vous assurer qu'un enregistrement DNS existe pour le nom d'hôte choisi. - 9
- Spécifiez le nom du service à exposer. Cet exemple utilise un service nommé
sample-workload.
Créez l'objet
Ingressen exécutant la commande suivante :$ oc create -f ingress.yaml
8.4.3. Configuration d'un émetteur ACME pour résoudre les problèmes liés au DNS-01
Vous pouvez utiliser cert-manager Operator pour Red Hat OpenShift pour configurer un émetteur ACME afin de résoudre les défis DNS-01. Cette procédure utilise Let’s Encrypt comme serveur ACME CA et montre comment résoudre les défis DNS-01 avec Amazon Route 53.
Les zones DNS privées ne sont pas prises en charge.
Conditions préalables
-
Vous avez accès au cluster OpenShift Container Platform en tant qu'utilisateur ayant le rôle
cluster-admin. Vous avez configuré un rôle IAM pour Amazon Route 53. Pour plus d'informations, voir Route53 dans la documentation de cert-manager en amont.
NoteSi votre cluster est configuré à l'adresse not pour utiliser le service de jetons de sécurité AWS (STS), vous devez fournir des informations d'identification explicites pour
accessKeyIDetsecretAccessKey. Si votre cluster utilise AWS STS, vous pouvez utiliser des informations d'identification ambiantes implicites.
Procédure
Facultatif : Remplacer les paramètres du serveur de noms pour l'autocontrôle DNS-01 :
Cette étape n'est nécessaire que si la zone cible hébergée publiquement chevauche la zone hébergée privée par défaut du cluster.
Modifiez la ressource
CertManageren exécutant la commande suivante :$ oc edit certmanager cluster
Ajoutez une section
spec.controllerConfigavec les arguments de substitution suivants :apiVersion: operator.openshift.io/v1alpha1 kind: CertManager metadata: name: cluster ... spec: ... controllerConfig: 1 overrideArgs: - '--dns01-recursive-nameservers=1.1.1.1:53' 2 - '--dns01-recursive-nameservers-only' 3
- 1
- Ajouter la section
spec.controllerConfig. - 2
- Fournir une liste de serveurs de noms
<host>:<port>séparés par des virgules à interroger pour l'auto-vérification DNS-01. - 3
- Indiquer d'utiliser uniquement les serveurs de noms récursifs au lieu de vérifier les serveurs de noms faisant autorité associés à ce domaine.
- Enregistrez le fichier pour appliquer les modifications.
Facultatif : Créez un espace de noms pour l'émetteur.
Créer un fichier YAML qui définit un objet
Namespace:Exemple de fichier
namespace.yamlapiVersion: v1 kind: Namespace metadata: name: my-issuer-namespace 1- 1
- Indiquer l'espace de noms de l'émetteur.
Créez l'objet
Namespaceen exécutant la commande suivante :$ oc create -f namespace.yaml
Créez un secret dans lequel vous stockerez vos informations d'identification AWS en exécutant la commande suivante :
$ oc create secret generic aws-secret --from-literal=awsSecretAccessKey=<aws_secret_access_key> \ 1 -n my-issuer-namespace- 1
- Remplacez
<aws_secret_access_key>par votre clé d'accès secrète AWS.
Créer un émetteur.
Créer un fichier YAML qui définit l'objet
Issuer:Exemple de fichier
issuer.yamlapiVersion: cert-manager.io/v1 kind: Issuer metadata: name: letsencrypt-staging 1 namespace: my-issuer-namespace 2 spec: acme: server: https://acme-staging-v02.api.letsencrypt.org/directory 3 email: "<email_address>" 4 privateKeySecretRef: name: <secret_private_key> 5 solvers: - dns01: route53: accessKeyID: <aws_key_id> 6 hostedZoneID: <hosted_zone_id> 7 region: us-east-1 secretAccessKeySecretRef: name: "aws-secret" 8 key: "awsSecretAccessKey" 9
- 1
- Indiquez le nom de l'émetteur.
- 2
- Indiquez l'espace de noms que vous avez créé pour l'émetteur.
- 3
- Indiquez l'URL permettant d'accéder au point de terminaison
directorydu serveur ACME. Cet exemple utilise l'environnement de préparation Let’s Encrypt. - 4
- Remplacez
<email_address>par votre adresse électronique. - 5
- Remplacez
<secret_private_key>par le nom du secret dans lequel stocker la clé privée du compte ACME. - 6
- Remplacez
<aws_key_id>par votre ID de clé AWS. - 7
- Remplacez
<hosted_zone_id>par l'ID de votre zone hébergée. - 8
- Indiquez le nom du secret que vous avez créé.
- 9
- Indiquez la clé dans le secret que vous avez créé et qui stocke votre clé d'accès au secret AWS.
Créez l'objet
Issueren exécutant la commande suivante :$ oc create -f issuer.yaml
Créer un certificat.
Créer un fichier YAML qui définit l'objet
Certificate:Exemple de fichier
certificate.yamlapiVersion: cert-manager.io/v1 kind: Certificate metadata: name: my-tls-cert 1 namespace: my-issuer-namespace 2 spec: isCA: false commonName: '<common_name>' 3 secretName: my-tls-cert 4 dnsNames: - '<domain_name>' 5 issuerRef: name: letsencrypt-staging 6 kind: Issuer
- 1
- Indiquez un nom pour le certificat.
- 2
- Indiquez l'espace de noms que vous avez créé pour l'émetteur.
- 3
- Remplacez
<common_name>par votre nom commun (CN). - 4
- Indiquez le nom du secret à créer qui contiendra le certificat.
- 5
- Remplacez
<domain_name>par votre nom de domaine. - 6
- Indiquez le nom de l'émetteur que vous avez créé.
Créez l'objet
Certificateen exécutant la commande suivante :$ oc create -f certificate.yaml
8.5. Configurer le proxy egress pour l'opérateur cert-manager pour Red Hat OpenShift
Si un proxy egress à l'échelle du cluster est configuré dans OpenShift Container Platform, Operator Lifecycle Manager (OLM) configure automatiquement les opérateurs qu'il gère avec le proxy à l'échelle du cluster. OLM met automatiquement à jour tous les déploiements de l'opérateur avec les variables d'environnement HTTP_PROXY, HTTPS_PROXY, NO_PROXY.
Vous pouvez injecter tous les certificats CA requis pour les connexions HTTPS par proxy dans l'opérateur cert-manager pour Red Hat OpenShift.
8.5.1. Injecter un certificat CA personnalisé pour l'opérateur cert-manager de Red Hat OpenShift
Si votre cluster OpenShift Container Platform a activé le proxy à l'échelle du cluster, vous pouvez injecter tous les certificats CA qui sont requis pour les connexions HTTPS par proxy dans l'opérateur cert-manager pour Red Hat OpenShift.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. - Vous avez activé le proxy pour OpenShift Container Platform.
Procédure
Créez une carte de configuration dans l'espace de noms
cert-manageren exécutant la commande suivante :$ oc create configmap trusted-ca -n cert-manager
Injectez le bundle CA qui est approuvé par OpenShift Container Platform dans la carte de configuration en exécutant la commande suivante :
$ oc label cm trusted-ca config.openshift.io/inject-trusted-cabundle=true -n cert-manager
Mettez à jour le déploiement de l'opérateur cert-manager pour Red Hat OpenShift afin d'utiliser la carte de configuration en exécutant la commande suivante :
$ oc -n cert-manager-operator patch subscription cert-manager-operator --type='merge' -p '{"spec":{"config":{"env":[{"name":"TRUSTED_CA_CONFIGMAP_NAME","value":"trusted-ca"}]}}}'
Vérification
Vérifiez que les déploiements sont terminés en exécutant la commande suivante :
$ oc rollout status deployment/cert-manager-operator-controller-manager -n cert-manager-operator && \ oc rollout status deployment/cert-manager -n cert-manager && \ oc rollout status deployment/cert-manager-webhook -n cert-manager && \ oc rollout status deployment/cert-manager-cainjector -n cert-manager
Exemple de sortie
deployment "cert-manager-operator-controller-manager" successfully rolled out deployment "cert-manager" successfully rolled out deployment "cert-manager-webhook" successfully rolled out deployment "cert-manager-cainjector" successfully rolled out
Vérifiez que le paquet CA a été monté en tant que volume en exécutant la commande suivante :
$ oc get deployment cert-manager -n cert-manager -o=jsonpath={.spec.template.spec.'containers[0].volumeMounts'}Exemple de sortie
[{"mountPath":"/etc/pki/tls/certs/cert-manager-tls-ca-bundle.crt","name":"trusted-ca","subPath":"ca-bundle.crt"}]Vérifiez que la source du bundle CA est la carte de configuration
trusted-caen exécutant la commande suivante :$ oc get deployment cert-manager -n cert-manager -o=jsonpath={.spec.template.spec.volumes}Exemple de sortie
[{"configMap":{"defaultMode":420,"name":"trusted-ca"},"name":"trusted-ca"}]
8.5.2. Ressources supplémentaires
8.6. Désinstallation de l'opérateur cert-manager pour Red Hat OpenShift
Vous pouvez supprimer l'opérateur cert-manager pour Red Hat OpenShift de OpenShift Container Platform en désinstallant l'opérateur et en supprimant ses ressources associées.
8.6.1. Désinstallation de l'opérateur cert-manager pour Red Hat OpenShift
Vous pouvez désinstaller l'opérateur cert-manager pour Red Hat OpenShift en utilisant la console web.
Conditions préalables
-
Vous avez accès au cluster avec les privilèges
cluster-admin. - Vous avez accès à la console web de OpenShift Container Platform.
- L'opérateur cert-manager pour Red Hat OpenShift est installé.
Procédure
- Connectez-vous à la console web de OpenShift Container Platform.
Désinstallez le cert-manager Operator pour Red Hat OpenShift Operator.
- Naviguez jusqu'à Operators → Installed Operators.
-
Cliquez sur le menu Options
à côté de l'entrée cert-manager Operator for Red Hat OpenShift et cliquez sur Uninstall Operator.
- Dans la boîte de dialogue de confirmation, cliquez sur Uninstall.
8.6.2. Suppression de cert-manager Operator pour les ressources Red Hat OpenShift
En option, après avoir désinstallé l'opérateur cert-manager pour Red Hat OpenShift, vous pouvez supprimer ses ressources connexes de votre cluster.
Conditions préalables
-
Vous avez accès au cluster avec les privilèges
cluster-admin. - Vous avez accès à la console web de OpenShift Container Platform.
Procédure
- Connectez-vous à la console web de OpenShift Container Platform.
Supprimez les CRDs qui ont été installés par l'Opérateur de cert-manager pour Red Hat OpenShift :
- Naviguez jusqu'à Administration → CustomResourceDefinitions.
-
Saisissez
certmanagerdans le champ Name pour filtrer les CRD. Cliquez sur le menu Options
en regard de chacun des CRD suivants et sélectionnez Delete Custom Resource Definition:
-
Certificate -
CertificateRequest -
CertManager(operator.openshift.io) -
Challenge -
ClusterIssuer -
Issuer -
Order
-
Supprimer l'espace de noms
cert-manager-operator.- Naviguez jusqu'à Administration → Namespaces.
-
Cliquez sur le menu Options
à côté de cert-manager-operator et sélectionnez Delete Namespace.
-
Dans la boîte de dialogue de confirmation, saisissez
cert-manager-operatordans le champ et cliquez sur Delete.
Chapitre 9. Visualisation des journaux d'audit
L'audit d'OpenShift Container Platform fournit un ensemble d'enregistrements chronologiques pertinents pour la sécurité, documentant la séquence des activités qui ont affecté le système par des utilisateurs individuels, des administrateurs ou d'autres composants du système.
9.1. À propos du journal d'audit de l'API
L'audit fonctionne au niveau du serveur API, en enregistrant toutes les demandes arrivant sur le serveur. Chaque journal d'audit contient les informations suivantes :
Tableau 9.1. Champs du journal d'audit
| Field | Description |
|---|---|
|
| Le niveau d'audit auquel l'événement a été généré. |
|
| Un identifiant d'audit unique, généré pour chaque demande. |
|
| L'étape du traitement de la demande au cours de laquelle cette instance d'événement a été générée. |
|
| L'URI de la demande tel qu'il est envoyé par le client à un serveur. |
|
| Le verbe Kubernetes associé à la demande. Pour les requêtes ne portant pas sur des ressources, il s'agit de la méthode HTTP en minuscules. |
|
| Les informations sur l'utilisateur authentifié. |
|
| Facultatif. Les informations relatives à l'utilisateur usurpé, si la demande vise à usurper l'identité d'un autre utilisateur. |
|
| Facultatif. Les adresses IP source, d'où provient la demande et les éventuels serveurs mandataires intermédiaires. |
|
| Facultatif. Chaîne de l'agent utilisateur signalée par le client. Notez que l'agent utilisateur est fourni par le client et qu'il ne doit pas être fiable. |
|
|
Facultatif. La référence de l'objet visé par cette demande. Ceci ne s'applique pas aux demandes de type |
|
|
Facultatif. L'état de la réponse, renseigné même si l'adresse |
|
|
Facultatif. L'objet API de la demande, au format JSON. Le site |
|
|
Facultatif. L'objet API renvoyé dans la réponse, au format JSON. Le site |
|
| Heure à laquelle la demande a atteint le serveur API. |
|
| Heure à laquelle la demande a atteint le stade actuel de l'audit. |
|
|
Facultatif. Une carte de valeurs clés non structurée stockée avec un événement d'audit qui peut être définie par les plugins invoqués dans la chaîne de service de la demande, y compris les plugins d'authentification, d'autorisation et d'admission. Notez que ces annotations concernent l'événement d'audit et ne correspondent pas à l'adresse |
Exemple de sortie pour le serveur API Kubernetes :
{"kind":"Event","apiVersion":"audit.k8s.io/v1","level":"Metadata","auditID":"ad209ce1-fec7-4130-8192-c4cc63f1d8cd","stage":"ResponseComplete","requestURI":"/api/v1/namespaces/openshift-kube-controller-manager/configmaps/cert-recovery-controller-lock?timeout=35s","verb":"update","user":{"username":"system:serviceaccount:openshift-kube-controller-manager:localhost-recovery-client","uid":"dd4997e3-d565-4e37-80f8-7fc122ccd785","groups":["system:serviceaccounts","system:serviceaccounts:openshift-kube-controller-manager","system:authenticated"]},"sourceIPs":["::1"],"userAgent":"cluster-kube-controller-manager-operator/v0.0.0 (linux/amd64) kubernetes/$Format","objectRef":{"resource":"configmaps","namespace":"openshift-kube-controller-manager","name":"cert-recovery-controller-lock","uid":"5c57190b-6993-425d-8101-8337e48c7548","apiVersion":"v1","resourceVersion":"574307"},"responseStatus":{"metadata":{},"code":200},"requestReceivedTimestamp":"2020-04-02T08:27:20.200962Z","stageTimestamp":"2020-04-02T08:27:20.206710Z","annotations":{"authorization.k8s.io/decision":"allow","authorization.k8s.io/reason":"RBAC: allowed by ClusterRoleBinding \"system:openshift:operator:kube-controller-manager-recovery\" of ClusterRole \"cluster-admin\" to ServiceAccount \"localhost-recovery-client/openshift-kube-controller-manager\""}}9.2. Visualisation des journaux d'audit
Vous pouvez consulter les journaux du serveur API OpenShift, du serveur API Kubernetes, du serveur API OpenShift OAuth et du serveur OpenShift OAuth pour chaque nœud du plan de contrôle.
Procédure
Pour consulter les journaux d'audit :
Consulter les journaux d'audit du serveur OpenShift API :
Répertorie les journaux d'audit du serveur OpenShift API disponibles pour chaque nœud du plan de contrôle :
$ oc adm node-logs --role=master --path=openshift-apiserver/
Exemple de sortie
ci-ln-m0wpfjb-f76d1-vnb5x-master-0 audit-2021-03-09T00-12-19.834.log ci-ln-m0wpfjb-f76d1-vnb5x-master-0 audit.log ci-ln-m0wpfjb-f76d1-vnb5x-master-1 audit-2021-03-09T00-11-49.835.log ci-ln-m0wpfjb-f76d1-vnb5x-master-1 audit.log ci-ln-m0wpfjb-f76d1-vnb5x-master-2 audit-2021-03-09T00-13-00.128.log ci-ln-m0wpfjb-f76d1-vnb5x-master-2 audit.log
Visualiser un journal d'audit spécifique du serveur OpenShift API en fournissant le nom du nœud et le nom du journal :
$ oc adm node-logs <node_name> --path=openshift-apiserver/<log_name>
Par exemple :
$ oc adm node-logs ci-ln-m0wpfjb-f76d1-vnb5x-master-0 --path=openshift-apiserver/audit-2021-03-09T00-12-19.834.log
Exemple de sortie
{"kind":"Event","apiVersion":"audit.k8s.io/v1","level":"Metadata","auditID":"381acf6d-5f30-4c7d-8175-c9c317ae5893","stage":"ResponseComplete","requestURI":"/metrics","verb":"get","user":{"username":"system:serviceaccount:openshift-monitoring:prometheus-k8s","uid":"825b60a0-3976-4861-a342-3b2b561e8f82","groups":["system:serviceaccounts","system:serviceaccounts:openshift-monitoring","system:authenticated"]},"sourceIPs":["10.129.2.6"],"userAgent":"Prometheus/2.23.0","responseStatus":{"metadata":{},"code":200},"requestReceivedTimestamp":"2021-03-08T18:02:04.086545Z","stageTimestamp":"2021-03-08T18:02:04.107102Z","annotations":{"authorization.k8s.io/decision":"allow","authorization.k8s.io/reason":"RBAC: allowed by ClusterRoleBinding \"prometheus-k8s\" of ClusterRole \"prometheus-k8s\" to ServiceAccount \"prometheus-k8s/openshift-monitoring\""}}
Consulter les journaux d'audit du serveur API Kubernetes :
Répertorie les journaux d'audit du serveur API Kubernetes disponibles pour chaque nœud de plan de contrôle :
$ oc adm node-logs --role=master --path=kube-apiserver/
Exemple de sortie
ci-ln-m0wpfjb-f76d1-vnb5x-master-0 audit-2021-03-09T14-07-27.129.log ci-ln-m0wpfjb-f76d1-vnb5x-master-0 audit.log ci-ln-m0wpfjb-f76d1-vnb5x-master-1 audit-2021-03-09T19-24-22.620.log ci-ln-m0wpfjb-f76d1-vnb5x-master-1 audit.log ci-ln-m0wpfjb-f76d1-vnb5x-master-2 audit-2021-03-09T18-37-07.511.log ci-ln-m0wpfjb-f76d1-vnb5x-master-2 audit.log
Affichez le journal d'audit d'un serveur API Kubernetes spécifique en indiquant le nom du nœud et le nom du journal :
$ oc adm node-logs <node_name> --path=kube-apiserver/<log_name>
Par exemple :
$ oc adm node-logs ci-ln-m0wpfjb-f76d1-vnb5x-master-0 --path=kube-apiserver/audit-2021-03-09T14-07-27.129.log
Exemple de sortie
{"kind":"Event","apiVersion":"audit.k8s.io/v1","level":"Metadata","auditID":"cfce8a0b-b5f5-4365-8c9f-79c1227d10f9","stage":"ResponseComplete","requestURI":"/api/v1/namespaces/openshift-kube-scheduler/serviceaccounts/openshift-kube-scheduler-sa","verb":"get","user":{"username":"system:serviceaccount:openshift-kube-scheduler-operator:openshift-kube-scheduler-operator","uid":"2574b041-f3c8-44e6-a057-baef7aa81516","groups":["system:serviceaccounts","system:serviceaccounts:openshift-kube-scheduler-operator","system:authenticated"]},"sourceIPs":["10.128.0.8"],"userAgent":"cluster-kube-scheduler-operator/v0.0.0 (linux/amd64) kubernetes/$Format","objectRef":{"resource":"serviceaccounts","namespace":"openshift-kube-scheduler","name":"openshift-kube-scheduler-sa","apiVersion":"v1"},"responseStatus":{"metadata":{},"code":200},"requestReceivedTimestamp":"2021-03-08T18:06:42.512619Z","stageTimestamp":"2021-03-08T18:06:42.516145Z","annotations":{"authentication.k8s.io/legacy-token":"system:serviceaccount:openshift-kube-scheduler-operator:openshift-kube-scheduler-operator","authorization.k8s.io/decision":"allow","authorization.k8s.io/reason":"RBAC: allowed by ClusterRoleBinding \"system:openshift:operator:cluster-kube-scheduler-operator\" of ClusterRole \"cluster-admin\" to ServiceAccount \"openshift-kube-scheduler-operator/openshift-kube-scheduler-operator\""}}
Consulter les journaux d'audit du serveur OpenShift OAuth API :
Liste des journaux d'audit du serveur OpenShift OAuth API disponibles pour chaque nœud du plan de contrôle :
$ oc adm node-logs --role=master --path=oauth-apiserver/
Exemple de sortie
ci-ln-m0wpfjb-f76d1-vnb5x-master-0 audit-2021-03-09T13-06-26.128.log ci-ln-m0wpfjb-f76d1-vnb5x-master-0 audit.log ci-ln-m0wpfjb-f76d1-vnb5x-master-1 audit-2021-03-09T18-23-21.619.log ci-ln-m0wpfjb-f76d1-vnb5x-master-1 audit.log ci-ln-m0wpfjb-f76d1-vnb5x-master-2 audit-2021-03-09T17-36-06.510.log ci-ln-m0wpfjb-f76d1-vnb5x-master-2 audit.log
Visualiser un journal d'audit spécifique du serveur OpenShift OAuth API en fournissant le nom du nœud et le nom du journal :
$ oc adm node-logs <node_name> --path=oauth-apiserver/<log_name>
Par exemple :
$ oc adm node-logs ci-ln-m0wpfjb-f76d1-vnb5x-master-0 --path=oauth-apiserver/audit-2021-03-09T13-06-26.128.log
Exemple de sortie
{"kind":"Event","apiVersion":"audit.k8s.io/v1","level":"Metadata","auditID":"dd4c44e2-3ea1-4830-9ab7-c91a5f1388d6","stage":"ResponseComplete","requestURI":"/apis/user.openshift.io/v1/users/~","verb":"get","user":{"username":"system:serviceaccount:openshift-monitoring:prometheus-k8s","groups":["system:serviceaccounts","system:serviceaccounts:openshift-monitoring","system:authenticated"]},"sourceIPs":["10.0.32.4","10.128.0.1"],"userAgent":"dockerregistry/v0.0.0 (linux/amd64) kubernetes/$Format","objectRef":{"resource":"users","name":"~","apiGroup":"user.openshift.io","apiVersion":"v1"},"responseStatus":{"metadata":{},"code":200},"requestReceivedTimestamp":"2021-03-08T17:47:43.653187Z","stageTimestamp":"2021-03-08T17:47:43.660187Z","annotations":{"authorization.k8s.io/decision":"allow","authorization.k8s.io/reason":"RBAC: allowed by ClusterRoleBinding \"basic-users\" of ClusterRole \"basic-user\" to Group \"system:authenticated\""}}
Consulter les journaux d'audit du serveur OpenShift OAuth :
Liste des journaux d'audit du serveur OpenShift OAuth disponibles pour chaque nœud du plan de contrôle :
$ oc adm node-logs --role=master --path=oauth-server/
Exemple de sortie
ci-ln-m0wpfjb-f76d1-vnb5x-master-0 audit-2022-05-11T18-57-32.395.log ci-ln-m0wpfjb-f76d1-vnb5x-master-0 audit.log ci-ln-m0wpfjb-f76d1-vnb5x-master-1 audit-2022-05-11T19-07-07.021.log ci-ln-m0wpfjb-f76d1-vnb5x-master-1 audit.log ci-ln-m0wpfjb-f76d1-vnb5x-master-2 audit-2022-05-11T19-06-51.844.log ci-ln-m0wpfjb-f76d1-vnb5x-master-2 audit.log
Afficher un journal d'audit spécifique du serveur OpenShift OAuth en fournissant le nom du nœud et le nom du journal :
$ oc adm node-logs <node_name> --path=oauth-server/<log_name>
Par exemple :
$ oc adm node-logs ci-ln-m0wpfjb-f76d1-vnb5x-master-0 --path=oauth-server/audit-2022-05-11T18-57-32.395.log
Exemple de sortie
{"kind":"Event","apiVersion":"audit.k8s.io/v1","level":"Metadata","auditID":"13c20345-f33b-4b7d-b3b6-e7793f805621","stage":"ResponseComplete","requestURI":"/login","verb":"post","user":{"username":"system:anonymous","groups":["system:unauthenticated"]},"sourceIPs":["10.128.2.6"],"userAgent":"Mozilla/5.0 (X11; Linux x86_64; rv:91.0) Gecko/20100101 Firefox/91.0","responseStatus":{"metadata":{},"code":302},"requestReceivedTimestamp":"2022-05-11T17:31:16.280155Z","stageTimestamp":"2022-05-11T17:31:16.297083Z","annotations":{"authentication.openshift.io/decision":"error","authentication.openshift.io/username":"kubeadmin","authorization.k8s.io/decision":"allow","authorization.k8s.io/reason":""}}Les valeurs possibles pour l'annotation
authentication.openshift.io/decisionsontallow,deny, ouerror.
9.3. Filtrage des journaux d'audit
Vous pouvez utiliser jq ou un autre outil d'analyse JSON pour filtrer les journaux d'audit du serveur API.
La quantité d'informations consignées dans les journaux d'audit du serveur API est contrôlée par la stratégie de journal d'audit définie.
La procédure suivante fournit des exemples d'utilisation de jq pour filtrer les journaux d'audit sur le nœud du plan de contrôle node-1.example.com. Voir le manuel jq pour des informations détaillées sur l'utilisation de jq.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Vous avez installé
jq.
Procédure
Filtrer les journaux d'audit du serveur API OpenShift par utilisateur :
$ oc adm node-logs node-1.example.com \ --path=openshift-apiserver/audit.log \ | jq 'select(.user.username == "myusername")'
Filtrer les journaux d'audit du serveur OpenShift API par agent utilisateur :
$ oc adm node-logs node-1.example.com \ --path=openshift-apiserver/audit.log \ | jq 'select(.userAgent == "cluster-version-operator/v0.0.0 (linux/amd64) kubernetes/$Format")'
Filtrer les journaux d'audit du serveur API Kubernetes en fonction d'une certaine version de l'API et n'afficher que l'agent utilisateur :
$ oc adm node-logs node-1.example.com \ --path=kube-apiserver/audit.log \ | jq 'select(.requestURI | startswith("/apis/apiextensions.k8s.io/v1beta1")) | .userAgent'Filtrer les journaux d'audit du serveur OpenShift OAuth API en excluant un verbe :
$ oc adm node-logs node-1.example.com \ --path=oauth-apiserver/audit.log \ | jq 'select(.verb != "get")'
Filtrer les journaux d'audit du serveur OpenShift OAuth en fonction des événements qui ont identifié un nom d'utilisateur et qui ont échoué avec une erreur :
$ oc adm node-logs node-1.example.com \ --path=oauth-server/audit.log \ | jq 'select(.annotations["authentication.openshift.io/username"] != null and .annotations["authentication.openshift.io/decision"] == "error")'
9.4. Collecte des journaux d'audit
Vous pouvez utiliser l'outil must-gather pour collecter les journaux d'audit afin de déboguer votre cluster, que vous pouvez examiner ou envoyer à l'assistance Red Hat.
Procédure
Exécutez la commande
oc adm must-gatheravec-- /usr/bin/gather_audit_logs:$ oc adm must-gather -- /usr/bin/gather_audit_logs
Créez un fichier compressé à partir du répertoire
must-gatherqui vient d'être créé dans votre répertoire de travail. Par exemple, sur un ordinateur utilisant un système d'exploitation Linux, exécutez la commande suivante :$ tar cvaf must-gather.tar.gz must-gather.local.472290403699006248 1- 1
- Remplacez
must-gather-local.472290403699006248par le nom du répertoire.
- Joignez le fichier compressé à votre demande d'assistance sur le portail client de Red Hat.
9.5. Ressources supplémentaires
Chapitre 10. Configuration de la politique du journal d'audit
Vous pouvez contrôler la quantité d'informations consignées dans les journaux d'audit du serveur API en choisissant le profil de stratégie de journal d'audit à utiliser.
10.1. À propos des profils de stratégie de journal d'audit
Les profils de journaux d'audit définissent comment enregistrer les demandes qui arrivent sur le serveur API OpenShift, le serveur API Kubernetes, le serveur API OpenShift OAuth et le serveur OpenShift OAuth.
OpenShift Container Platform fournit les profils de politique d'audit prédéfinis suivants :
| Profile | Description |
|---|---|
|
| Enregistre uniquement les métadonnées des demandes de lecture et d'écriture ; n'enregistre pas le corps des demandes, sauf pour les demandes de jetons d'accès OAuth. Il s'agit de la politique par défaut. |
|
|
Outre l'enregistrement des métadonnées pour toutes les demandes, il enregistre les corps de demande pour chaque demande d'écriture aux serveurs API ( |
|
|
En plus d'enregistrer les métadonnées de toutes les demandes, il enregistre les corps de demande pour chaque demande de lecture et d'écriture aux serveurs API ( |
|
| Aucune demande n'est enregistrée ; même les demandes de jetons d'accès OAuth et les demandes de jetons d'autorisation OAuth ne sont pas enregistrées. Avertissement
Il n'est pas recommandé de désactiver la journalisation des audits à l'aide du profil |
-
Les ressources sensibles, telles que les objets
Secret,Route, etOAuthClient, ne sont jamais enregistrées qu'au niveau des métadonnées. Les événements du serveur OpenShift OAuth ne sont jamais enregistrés qu'au niveau des métadonnées.
Par défaut, OpenShift Container Platform utilise le profil d'audit Default. Vous pouvez utiliser un autre profil de politique d'audit qui enregistre également les corps des requêtes, mais soyez conscient de l'augmentation de l'utilisation des ressources (CPU, mémoire et E/S).
10.2. Configuration de la politique du journal d'audit
Vous pouvez configurer la stratégie de journal d'audit à utiliser pour consigner les demandes adressées aux serveurs API.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Modifier la ressource
APIServer:$ oc edit apiserver cluster
Mettre à jour le champ
spec.audit.profile:apiVersion: config.openshift.io/v1 kind: APIServer metadata: ... spec: audit: profile: WriteRequestBodies 1- 1
- Le profil est défini sur
Default,WriteRequestBodies,AllRequestBodiesouNone. Le profil par défaut estDefault.
AvertissementIl n'est pas recommandé de désactiver la journalisation des audits à l'aide du profil
None, sauf si vous êtes pleinement conscient des risques liés à l'absence de journalisation de données qui peuvent s'avérer utiles lors de la résolution de problèmes. Si vous désactivez la journalisation des audits et qu'une situation d'assistance se présente, vous devrez peut-être activer la journalisation des audits et reproduire le problème afin de le résoudre correctement.- Enregistrez le fichier pour appliquer les modifications.
Vérification
Vérifiez qu'une nouvelle révision des pods du serveur Kubernetes API est déployée. La mise à jour de tous les nœuds vers la nouvelle révision peut prendre plusieurs minutes.
$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'Examinez la condition d'état
NodeInstallerProgressingpour le serveur API Kubernetes afin de vérifier que tous les nœuds sont à la dernière révision. La sortie indiqueAllNodesAtLatestRevisionlorsque la mise à jour est réussie :AllNodesAtLatestRevision 3 nodes are at revision 12 1- 1
- Dans cet exemple, le dernier numéro de révision est
12.
Si la sortie affiche un message similaire à l'un des messages suivants, la mise à jour est toujours en cours. Attendez quelques minutes et réessayez.
-
3 nodes are at revision 11; 0 nodes have achieved new revision 12 -
2 nodes are at revision 11; 1 nodes are at revision 12
10.3. Configuration de la politique du journal d'audit avec des règles personnalisées
Vous pouvez configurer une politique de journal d'audit qui définit des règles personnalisées. Vous pouvez spécifier plusieurs groupes et définir le profil à utiliser pour chaque groupe.
Ces règles personnalisées ont la priorité sur le champ de profil de niveau supérieur. Les règles personnalisées sont évaluées de haut en bas, et la première qui correspond est appliquée.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Modifier la ressource
APIServer:$ oc edit apiserver cluster
Ajouter le champ
spec.audit.customRules:apiVersion: config.openshift.io/v1 kind: APIServer metadata: ... spec: audit: customRules: 1 - group: system:authenticated:oauth profile: WriteRequestBodies - group: system:authenticated profile: AllRequestBodies profile: Default 2- 1
- Ajoutez un ou plusieurs groupes et spécifiez le profil à utiliser pour ce groupe. Ces règles personnalisées ont la priorité sur le champ de profil de niveau supérieur. Les règles personnalisées sont évaluées de haut en bas, et la première qui correspond est appliquée.
- 2
- Définissez
Default,WriteRequestBodies,AllRequestBodiesouNone. Si vous ne définissez pas ce champ de niveau supérieuraudit.profile, le profilDefaultest utilisé par défaut.
AvertissementIl n'est pas recommandé de désactiver la journalisation des audits à l'aide du profil
None, sauf si vous êtes pleinement conscient des risques liés à l'absence de journalisation de données qui peuvent s'avérer utiles lors de la résolution de problèmes. Si vous désactivez la journalisation des audits et qu'une situation d'assistance se présente, vous devrez peut-être activer la journalisation des audits et reproduire le problème afin de le résoudre correctement.- Enregistrez le fichier pour appliquer les modifications.
Vérification
Vérifiez qu'une nouvelle révision des pods du serveur Kubernetes API est déployée. La mise à jour de tous les nœuds vers la nouvelle révision peut prendre plusieurs minutes.
$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'Examinez la condition d'état
NodeInstallerProgressingpour le serveur API Kubernetes afin de vérifier que tous les nœuds sont à la dernière révision. La sortie indiqueAllNodesAtLatestRevisionlorsque la mise à jour est réussie :AllNodesAtLatestRevision 3 nodes are at revision 12 1- 1
- Dans cet exemple, le dernier numéro de révision est
12.
Si la sortie affiche un message similaire à l'un des messages suivants, la mise à jour est toujours en cours. Attendez quelques minutes et réessayez.
-
3 nodes are at revision 11; 0 nodes have achieved new revision 12 -
2 nodes are at revision 11; 1 nodes are at revision 12
10.4. Désactivation de la journalisation des audits
Vous pouvez désactiver la journalisation des audits pour OpenShift Container Platform. Lorsque vous désactivez la journalisation des audits, même les demandes de jetons d'accès OAuth et les demandes de jetons d'autorisation OAuth ne sont pas journalisées.
Il n'est pas recommandé de désactiver la journalisation des audits à l'aide du profil None, sauf si vous êtes pleinement conscient des risques liés à l'absence de journalisation de données qui peuvent s'avérer utiles lors de la résolution de problèmes. Si vous désactivez la journalisation des audits et qu'une situation d'assistance se présente, vous devrez peut-être activer la journalisation des audits et reproduire le problème afin de le résoudre correctement.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Modifier la ressource
APIServer:$ oc edit apiserver cluster
Définissez le champ
spec.audit.profilesurNone:apiVersion: config.openshift.io/v1 kind: APIServer metadata: ... spec: audit: profile: NoneNoteVous pouvez également désactiver la journalisation des audits pour des groupes spécifiques en spécifiant des règles personnalisées dans le champ
spec.audit.customRules.- Enregistrez le fichier pour appliquer les modifications.
Vérification
Vérifiez qu'une nouvelle révision des pods du serveur Kubernetes API est déployée. La mise à jour de tous les nœuds vers la nouvelle révision peut prendre plusieurs minutes.
$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'Examinez la condition d'état
NodeInstallerProgressingpour le serveur API Kubernetes afin de vérifier que tous les nœuds sont à la dernière révision. La sortie indiqueAllNodesAtLatestRevisionlorsque la mise à jour est réussie :AllNodesAtLatestRevision 3 nodes are at revision 12 1- 1
- Dans cet exemple, le dernier numéro de révision est
12.
Si la sortie affiche un message similaire à l'un des messages suivants, la mise à jour est toujours en cours. Attendez quelques minutes et réessayez.
-
3 nodes are at revision 11; 0 nodes have achieved new revision 12 -
2 nodes are at revision 11; 1 nodes are at revision 12
Chapitre 11. Configuration des profils de sécurité TLS
Les profils de sécurité TLS permettent aux serveurs de réglementer les algorithmes qu'un client peut utiliser lorsqu'il se connecte au serveur. Cela permet de s'assurer que les composants d'OpenShift Container Platform utilisent des bibliothèques cryptographiques qui n'autorisent pas les protocoles, les algorithmes de chiffrement ou les algorithmes non sécurisés connus.
Les administrateurs de clusters peuvent choisir le profil de sécurité TLS à utiliser pour chacun des composants suivants :
- le contrôleur d'entrée
le plan de contrôle
Il s'agit du serveur API Kubernetes, du gestionnaire de contrôleur Kubernetes, du planificateur Kubernetes, du serveur API OpenShift, du serveur API OpenShift OAuth, du serveur OpenShift OAuth et de etcd.
- le kubelet, lorsqu'il agit en tant que serveur HTTP pour le serveur API de Kubernetes
11.1. Comprendre les profils de sécurité TLS
Vous pouvez utiliser un profil de sécurité TLS (Transport Layer Security) pour définir les algorithmes TLS requis par les différents composants d'OpenShift Container Platform. Les profils de sécurité TLS d'OpenShift Container Platform sont basés sur les configurations recommandées par Mozilla.
Vous pouvez spécifier l'un des profils de sécurité TLS suivants pour chaque composant :
Tableau 11.1. Profils de sécurité TLS
| Profile | Description |
|---|---|
|
| Ce profil est destiné à être utilisé avec des clients ou des bibliothèques anciens. Il est basé sur l'ancienne configuration recommandée pour la rétrocompatibilité.
Le profil Note Pour le contrôleur d'entrée, la version minimale de TLS passe de 1.0 à 1.1. |
|
| Ce profil est la configuration recommandée pour la majorité des clients. Il s'agit du profil de sécurité TLS par défaut pour le contrôleur d'entrée, le kubelet et le plan de contrôle. Le profil est basé sur la configuration recommandée pour la compatibilité intermédiaire.
Le profil |
|
| Ce profil est destiné à être utilisé avec des clients modernes qui n'ont pas besoin de rétrocompatibilité. Ce profil est basé sur la configuration recommandée pour la compatibilité moderne.
Le profil |
|
| Ce profil permet de définir la version de TLS et les algorithmes de chiffrement à utiliser. Avertissement
Soyez prudent lorsque vous utilisez un profil |
Lorsque l'on utilise l'un des types de profil prédéfinis, la configuration effective du profil est susceptible d'être modifiée entre les versions. Par exemple, si l'on spécifie l'utilisation du profil intermédiaire déployé dans la version X.Y.Z, une mise à niveau vers la version X.Y.Z 1 peut entraîner l'application d'une nouvelle configuration de profil, ce qui se traduit par un déploiement.
11.2. Affichage des détails du profil de sécurité TLS
Vous pouvez afficher la version TLS minimale et les algorithmes de chiffrement pour les profils de sécurité TLS prédéfinis pour chacun des composants suivants : Contrôleur d'entrée, plan de contrôle et kubelet.
La configuration effective de la version minimale de TLS et de la liste des algorithmes de chiffrement pour un profil peut varier d'un composant à l'autre.
Procédure
Afficher les détails d'un profil de sécurité TLS spécifique :
oc explain <component>.spec.tlsSecurityProfile.<profile> 1- 1
- Pour
<component>, indiquezingresscontroller,apiserver, oukubeletconfig. Pour<profile>, indiquezold,intermediate, oucustom.
Par exemple, pour vérifier les algorithmes de chiffrement inclus dans le profil
intermediatepour le plan de contrôle :$ oc explain apiserver.spec.tlsSecurityProfile.intermediate
Exemple de sortie
KIND: APIServer VERSION: config.openshift.io/v1 DESCRIPTION: intermediate is a TLS security profile based on: https://wiki.mozilla.org/Security/Server_Side_TLS#Intermediate_compatibility_.28recommended.29 and looks like this (yaml): ciphers: - TLS_AES_128_GCM_SHA256 - TLS_AES_256_GCM_SHA384 - TLS_CHACHA20_POLY1305_SHA256 - ECDHE-ECDSA-AES128-GCM-SHA256 - ECDHE-RSA-AES128-GCM-SHA256 - ECDHE-ECDSA-AES256-GCM-SHA384 - ECDHE-RSA-AES256-GCM-SHA384 - ECDHE-ECDSA-CHACHA20-POLY1305 - ECDHE-RSA-CHACHA20-POLY1305 - DHE-RSA-AES128-GCM-SHA256 - DHE-RSA-AES256-GCM-SHA384 minTLSVersion: TLSv1.2Afficher tous les détails du champ
tlsSecurityProfiled'un composant :oc explain <component>.spec.tlsSecurityProfile 1- 1
- Pour
<component>, spécifiezingresscontroller,apiserver, oukubeletconfig.
Par exemple, pour vérifier tous les détails du champ
tlsSecurityProfilepour le contrôleur d'entrée :$ oc explain ingresscontroller.spec.tlsSecurityProfile
Exemple de sortie
KIND: IngressController VERSION: operator.openshift.io/v1 RESOURCE: tlsSecurityProfile <Object> DESCRIPTION: ... FIELDS: custom <> custom is a user-defined TLS security profile. Be extremely careful using a custom profile as invalid configurations can be catastrophic. An example custom profile looks like this: ciphers: - ECDHE-ECDSA-CHACHA20-POLY1305 - ECDHE-RSA-CHACHA20-POLY1305 - ECDHE-RSA-AES128-GCM-SHA256 - ECDHE-ECDSA-AES128-GCM-SHA256 minTLSVersion: TLSv1.1 intermediate <> intermediate is a TLS security profile based on: https://wiki.mozilla.org/Security/Server_Side_TLS#Intermediate_compatibility_.28recommended.29 and looks like this (yaml): ... 1 modern <> modern is a TLS security profile based on: https://wiki.mozilla.org/Security/Server_Side_TLS#Modern_compatibility and looks like this (yaml): ... 2 NOTE: Currently unsupported. old <> old is a TLS security profile based on: https://wiki.mozilla.org/Security/Server_Side_TLS#Old_backward_compatibility and looks like this (yaml): ... 3 type <string> ...
11.3. Configuration du profil de sécurité TLS pour le contrôleur d'entrée
Pour configurer un profil de sécurité TLS pour un contrôleur d'entrée, modifiez la ressource personnalisée (CR) IngressController afin de spécifier un profil de sécurité TLS prédéfini ou personnalisé. Si aucun profil de sécurité TLS n'est configuré, la valeur par défaut est basée sur le profil de sécurité TLS défini pour le serveur API.
Exemple de CR IngressController qui configure le profil de sécurité TLS Old
apiVersion: operator.openshift.io/v1
kind: IngressController
...
spec:
tlsSecurityProfile:
old: {}
type: Old
...
Le profil de sécurité TLS définit la version minimale de TLS et les algorithmes de chiffrement TLS pour les connexions TLS des contrôleurs d'entrée.
Les chiffres et la version TLS minimale du profil de sécurité TLS configuré sont indiqués dans la ressource personnalisée (CR) IngressController sous Status.Tls Profile et dans le profil de sécurité TLS configuré sous Spec.Tls Security Profile. Pour le profil de sécurité TLS Custom, les algorithmes de chiffrement spécifiques et la version TLS minimale sont répertoriés sous les deux paramètres.
L'image du contrôleur d'entrée HAProxy prend en charge TLS 1.3 et le profil Modern.
L'opérateur d'entrée convertit également le TLS 1.0 d'un profil Old ou Custom en 1.1.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Modifiez le CR
IngressControllerdans le projetopenshift-ingress-operatorpour configurer le profil de sécurité TLS :$ oc edit IngressController default -n openshift-ingress-operator
Ajouter le champ
spec.tlsSecurityProfile:Exemple de CR
IngressControllerpour un profilCustomapiVersion: operator.openshift.io/v1 kind: IngressController ... spec: tlsSecurityProfile: type: Custom 1 custom: 2 ciphers: 3 - ECDHE-ECDSA-CHACHA20-POLY1305 - ECDHE-RSA-CHACHA20-POLY1305 - ECDHE-RSA-AES128-GCM-SHA256 - ECDHE-ECDSA-AES128-GCM-SHA256 minTLSVersion: VersionTLS11 ...- 1
- Spécifiez le type de profil de sécurité TLS (
Old,Intermediate, ouCustom). La valeur par défaut estIntermediate. - 2
- Spécifiez le champ approprié pour le type sélectionné :
-
old: {} -
intermediate: {} -
custom:
-
- 3
- Pour le type
custom, spécifiez une liste de chiffrements TLS et la version TLS minimale acceptée.
- Enregistrez le fichier pour appliquer les modifications.
Vérification
Vérifiez que le profil est défini dans le CR
IngressController:$ oc describe IngressController default -n openshift-ingress-operator
Exemple de sortie
Name: default Namespace: openshift-ingress-operator Labels: <none> Annotations: <none> API Version: operator.openshift.io/v1 Kind: IngressController ... Spec: ... Tls Security Profile: Custom: Ciphers: ECDHE-ECDSA-CHACHA20-POLY1305 ECDHE-RSA-CHACHA20-POLY1305 ECDHE-RSA-AES128-GCM-SHA256 ECDHE-ECDSA-AES128-GCM-SHA256 Min TLS Version: VersionTLS11 Type: Custom ...
11.4. Configuration du profil de sécurité TLS pour le plan de contrôle
Pour configurer un profil de sécurité TLS pour le plan de contrôle, modifiez la ressource personnalisée (CR) APIServer afin de spécifier un profil de sécurité TLS prédéfini ou personnalisé. La définition du profil de sécurité TLS dans la CR APIServer propage le paramètre aux composants suivants du plan de contrôle :
- Serveur API Kubernetes
- Gestionnaire de contrôleur Kubernetes
- Ordonnanceur Kubernetes
- Serveur API OpenShift
- Serveur OpenShift OAuth API
- Serveur OpenShift OAuth
- etcd
Si aucun profil de sécurité TLS n'est configuré, le profil de sécurité TLS par défaut est Intermediate.
Le profil de sécurité TLS par défaut du contrôleur d'entrée est basé sur le profil de sécurité TLS défini pour le serveur API.
Exemple de CR APIServer qui configure le profil de sécurité TLS Old
apiVersion: config.openshift.io/v1
kind: APIServer
...
spec:
tlsSecurityProfile:
old: {}
type: Old
...
Le profil de sécurité TLS définit la version minimale de TLS et les algorithmes de chiffrement TLS requis pour communiquer avec les composants du plan de contrôle.
Vous pouvez voir le profil de sécurité TLS configuré dans la ressource personnalisée (CR) APIServer sous Spec.Tls Security Profile. Pour le profil de sécurité TLS Custom, les algorithmes de chiffrement spécifiques et la version TLS minimale sont répertoriés.
Le plan de contrôle ne prend pas en charge TLS 1.3 en tant que version minimale de TLS ; le profil Modern n'est pas pris en charge car il nécessite TLS 1.3.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Modifiez l'adresse
APIServerCR par défaut pour configurer le profil de sécurité TLS :$ oc edit APIServer cluster
Ajouter le champ
spec.tlsSecurityProfile:Exemple de CR
APIServerpour un profilCustomapiVersion: config.openshift.io/v1 kind: APIServer metadata: name: cluster spec: tlsSecurityProfile: type: Custom 1 custom: 2 ciphers: 3 - ECDHE-ECDSA-CHACHA20-POLY1305 - ECDHE-RSA-CHACHA20-POLY1305 - ECDHE-RSA-AES128-GCM-SHA256 - ECDHE-ECDSA-AES128-GCM-SHA256 minTLSVersion: VersionTLS11- 1
- Spécifiez le type de profil de sécurité TLS (
Old,Intermediate, ouCustom). La valeur par défaut estIntermediate. - 2
- Spécifiez le champ approprié pour le type sélectionné :
-
old: {} -
intermediate: {} -
custom:
-
- 3
- Pour le type
custom, spécifiez une liste de chiffrements TLS et la version TLS minimale acceptée.
- Enregistrez le fichier pour appliquer les modifications.
Vérification
Vérifiez que le profil de sécurité TLS est défini dans le CR
APIServer:$ oc describe apiserver cluster
Exemple de sortie
Name: cluster Namespace: ... API Version: config.openshift.io/v1 Kind: APIServer ... Spec: Audit: Profile: Default Tls Security Profile: Custom: Ciphers: ECDHE-ECDSA-CHACHA20-POLY1305 ECDHE-RSA-CHACHA20-POLY1305 ECDHE-RSA-AES128-GCM-SHA256 ECDHE-ECDSA-AES128-GCM-SHA256 Min TLS Version: VersionTLS11 Type: Custom ...Vérifiez que le profil de sécurité TLS est défini dans le CR
etcd:$ oc describe etcd cluster
Exemple de sortie
Name: cluster Namespace: ... API Version: operator.openshift.io/v1 Kind: Etcd ... Spec: Log Level: Normal Management State: Managed Observed Config: Serving Info: Cipher Suites: TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256 TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384 TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305_SHA256 TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256 Min TLS Version: VersionTLS12 ...
11.5. Configuration du profil de sécurité TLS pour le kubelet
Pour configurer un profil de sécurité TLS pour le kubelet lorsqu'il agit en tant que serveur HTTP, créez une ressource personnalisée (CR) KubeletConfig pour spécifier un profil de sécurité TLS prédéfini ou personnalisé pour des nœuds spécifiques. Si aucun profil de sécurité TLS n'est configuré, le profil de sécurité TLS par défaut est Intermediate.
Le kubelet utilise son serveur HTTP/GRPC pour communiquer avec le serveur API de Kubernetes, qui envoie des commandes aux pods, recueille des journaux et exécute des commandes sur les pods par l'intermédiaire du kubelet.
Exemple de CR KubeletConfig qui configure le profil de sécurité TLS Old sur les nœuds de travail
apiVersion: config.openshift.io/v1
kind: KubeletConfig
...
spec:
tlsSecurityProfile:
old: {}
type: Old
machineConfigPoolSelector:
matchLabels:
pools.operator.machineconfiguration.openshift.io/worker: ""
Vous pouvez voir les codes et la version TLS minimale du profil de sécurité TLS configuré dans le fichier kubelet.conf sur un nœud configuré.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Créez un CR
KubeletConfigpour configurer le profil de sécurité TLS :Exemple de CR
KubeletConfigpour un profilCustomapiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: set-kubelet-tls-security-profile spec: tlsSecurityProfile: type: Custom 1 custom: 2 ciphers: 3 - ECDHE-ECDSA-CHACHA20-POLY1305 - ECDHE-RSA-CHACHA20-POLY1305 - ECDHE-RSA-AES128-GCM-SHA256 - ECDHE-ECDSA-AES128-GCM-SHA256 minTLSVersion: VersionTLS11 machineConfigPoolSelector: matchLabels: pools.operator.machineconfiguration.openshift.io/worker: "" 4- 1
- Spécifiez le type de profil de sécurité TLS (
Old,Intermediate, ouCustom). La valeur par défaut estIntermediate. - 2
- Spécifiez le champ approprié pour le type sélectionné :
-
old: {} -
intermediate: {} -
custom:
-
- 3
- Pour le type
custom, spécifiez une liste de chiffrements TLS et la version TLS minimale acceptée. - 4
- Facultatif : Indiquez l'étiquette du pool de configuration de la machine pour les nœuds auxquels vous souhaitez appliquer le profil de sécurité TLS.
Créer l'objet
KubeletConfig:$ oc create -f <filename>
En fonction du nombre de nœuds de travail dans la grappe, attendez que les nœuds configurés soient redémarrés un par un.
Vérification
Pour vérifier que le profil est défini, effectuez les étapes suivantes une fois que les nœuds sont dans l'état Ready:
Démarrer une session de débogage pour un nœud configuré :
oc debug node/<node_name>
Définir
/hostcomme répertoire racine dans l'interpréteur de commandes de débogage :sh-4.4# chroot /host
Consulter le fichier
kubelet.conf:sh-4.4# cat /etc/kubernetes/kubelet.conf
Exemple de sortie
kind: KubeletConfiguration apiVersion: kubelet.config.k8s.io/v1beta1 ... "tlsCipherSuites": [ "TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256", "TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256", "TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384", "TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384", "TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305_SHA256", "TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256" ], "tlsMinVersion": "VersionTLS12",
Chapitre 12. Configuration des profils seccomp
Un conteneur OpenShift Container Platform ou un pod exécute une application unique qui effectue une ou plusieurs tâches bien définies. L'application ne nécessite généralement qu'un petit sous-ensemble des API du noyau du système d'exploitation sous-jacent. Le mode de calcul sécurisé, seccomp, est une fonctionnalité du noyau Linux qui peut être utilisée pour limiter le processus s'exécutant dans un conteneur à l'utilisation d'un sous-ensemble d'appels système disponibles.
Le SCC restricted-v2 s'applique à tous les pods nouvellement créés dans la version 4.12. Le profil seccomp par défaut runtime/default est appliqué à ces modules.
Les profils Seccomp sont stockés sous forme de fichiers JSON sur le disque.
Les profils Seccomp ne peuvent pas être appliqués aux conteneurs privilégiés.
12.1. Vérification du profil seccomp par défaut appliqué à un pod
OpenShift Container Platform est livré avec un profil seccomp par défaut qui est référencé comme runtime/default. Dans la version 4.12, les pods nouvellement créés ont la contrainte de contexte de sécurité (SCC) définie sur restricted-v2 et le profil seccomp par défaut s'applique au pod.
Procédure
Vous pouvez vérifier la contrainte de contexte de sécurité (SCC) et le profil seccomp par défaut défini sur un pod en exécutant les commandes suivantes :
Vérifier quels pods sont en cours d'exécution dans l'espace de noms :
$ oc get pods -n <namespace>
Par exemple, pour vérifier quels pods sont en cours d'exécution dans l'espace de noms
workshop, exécutez ce qui suit :$ oc get pods -n workshop
Exemple de sortie
NAME READY STATUS RESTARTS AGE parksmap-1-4xkwf 1/1 Running 0 2m17s parksmap-1-deploy 0/1 Completed 0 2m22s
Inspecter les gousses :
$ oc get pod parksmap-1-4xkwf -n workshop -o yaml
Exemple de sortie
apiVersion: v1 kind: Pod metadata: annotations: k8s.v1.cni.cncf.io/network-status: |- [{ "name": "openshift-sdn", "interface": "eth0", "ips": [ "10.131.0.18" ], "default": true, "dns": {} }] k8s.v1.cni.cncf.io/networks-status: |- [{ "name": "openshift-sdn", "interface": "eth0", "ips": [ "10.131.0.18" ], "default": true, "dns": {} }] openshift.io/deployment-config.latest-version: "1" openshift.io/deployment-config.name: parksmap openshift.io/deployment.name: parksmap-1 openshift.io/generated-by: OpenShiftWebConsole openshift.io/scc: restricted-v2 1 seccomp.security.alpha.kubernetes.io/pod: runtime/default 2
12.1.1. Cluster amélioré
Dans les clusters mis à jour vers la version 4.12, tous les utilisateurs authentifiés ont accès à restricted et restricted-v2 SCC.
Une charge de travail admise par le SCC restricted par exemple, sur un cluster OpenShift Container Platform v4.10 lors d'une mise à niveau peut être admise par restricted-v2. En effet, restricted-v2 est le SCC le plus restrictif entre restricted et restricted-v2.
La charge de travail doit pouvoir être exécutée à l'adresse retricted-v2.
À l'inverse, dans le cas d'une charge de travail nécessitant privilegeEscalation: true, cette charge de travail continuera à disposer du CSC restricted pour tout utilisateur authentifié. En effet, restricted-v2 n'autorise pas privilegeEscalation.
12.1.2. Cluster nouvellement installé
Pour les clusters OpenShift Container Platform 4.11 ou ultérieurs nouvellement installés, le restricted-v2 remplace le restricted SCC en tant que SCC disponible pour être utilisé par n'importe quel utilisateur authentifié. Une charge de travail avec privilegeEscalation: true, n'est pas admise dans le cluster car restricted-v2 est le seul SCC disponible par défaut pour les utilisateurs authentifiés.
L'élément privilegeEscalation est autorisé par restricted mais pas par restricted-v2. Le nombre de fonctionnalités refusées par restricted-v2 est supérieur au nombre de fonctionnalités autorisées par restricted SCC.
Une charge de travail avec privilegeEscalation: true peut être admise dans un cluster OpenShift Container Platform 4.11 ou plus récent. Pour donner accès au SCC restricted au ServiceAccount qui exécute la charge de travail (ou tout autre SCC qui peut admettre cette charge de travail) à l'aide d'un RoleBinding, exécutez la commande suivante :
oc -n <workload-namespace> adm policy add-scc-to-user <scc-name> -z <serviceaccount_name>
Dans OpenShift Container Platform 4.12, la possibilité d'ajouter les annotations pod seccomp.security.alpha.kubernetes.io/pod: runtime/default et container.seccomp.security.alpha.kubernetes.io/<container_name>: runtime/default est obsolète.
12.2. Configuration d'un profil seccomp personnalisé
Vous pouvez configurer un profil seccomp personnalisé, qui vous permet de mettre à jour les filtres en fonction des exigences de l'application. Cela permet aux administrateurs de clusters d'avoir un meilleur contrôle sur la sécurité des charges de travail s'exécutant dans OpenShift Container Platform.
Les profils de sécurité Seccomp répertorient les appels système (syscalls) qu'un processus peut effectuer. Les autorisations sont plus larges que SELinux, qui limite les opérations, telles que write, à l'ensemble du système.
12.2.1. Création de profils seccomp
Vous pouvez utiliser l'objet MachineConfig pour créer des profils.
Seccomp peut restreindre les appels système (syscalls) dans un conteneur, limitant ainsi l'accès de votre application.
Conditions préalables
- Vous avez des droits d'administrateur de cluster.
- Vous avez créé des contraintes de contexte de sécurité (SCC) personnalisées. Pour plus d'informations, voir Additional resources.
Procédure
Créer l'objet
MachineConfig:apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: custom-seccomp spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:text/plain;charset=utf-8;base64,<hash> filesystem: root mode: 0644 path: /var/lib/kubelet/seccomp/seccomp-nostat.json
12.2.2. Configuration du profil seccomp personnalisé
Prérequis
- Vous avez des droits d'administrateur de cluster.
- Vous avez créé des contraintes de contexte de sécurité (SCC) personnalisées. Pour plus d'informations, voir "Ressources supplémentaires".
- Vous avez créé un profil seccomp personnalisé.
Procédure
-
Téléchargez votre profil seccomp personnalisé sur
/var/lib/kubelet/seccomp/<custom-name>.jsonà l'aide de Machine Config. Voir "Ressources supplémentaires" pour les étapes détaillées. Mettre à jour le SCC personnalisé en fournissant une référence au profil seccomp personnalisé créé :
seccompProfiles: - localhost/<custom-name>.json 1- 1
- Indiquez le nom de votre profil seccomp personnalisé.
12.2.3. Application du profil seccomp personnalisé à la charge de travail
Prérequis
- L'administrateur du cluster a configuré le profil seccomp personnalisé. Pour plus de détails, voir "Setting up the custom seccomp profile".
Procédure
Appliquez le profil seccomp à la charge de travail en définissant le champ
securityContext.seccompProfile.typecomme suit :Exemple :
spec: securityContext: seccompProfile: type: Localhost localhostProfile: <custom-name>.json 1- 1
- Indiquez le nom de votre profil seccomp personnalisé.
Vous pouvez également utiliser les annotations de pods
seccomp.security.alpha.kubernetes.io/pod: localhost/<custom-name>.json. Cependant, cette méthode est obsolète dans OpenShift Container Platform 4.12.
Lors du déploiement, le contrôleur d'admission valide les éléments suivants :
- Les annotations par rapport aux CCN actuels autorisées par le rôle de l'utilisateur.
- Le SCC, qui comprend le profil seccomp, est autorisé pour le pod.
Si le SCC est autorisé pour le pod, le kubelet exécute le pod avec le profil seccomp spécifié.
Assurez-vous que le profil seccomp est déployé sur tous les nœuds de travail.
Le SCC personnalisé doit avoir la priorité appropriée pour être automatiquement attribué au pod ou remplir d'autres conditions requises par le pod, telles que l'autorisation de CAP_NET_ADMIN.
12.3. Ressources supplémentaires
Chapitre 13. Permettre un accès au serveur API basé sur JavaScript à partir d'autres hôtes
13.1. Permettre un accès au serveur API basé sur JavaScript à partir d'autres hôtes
La configuration par défaut d'OpenShift Container Platform permet uniquement à la console web d'envoyer des requêtes au serveur API.
Si vous devez accéder au serveur API ou au serveur OAuth à partir d'une application JavaScript utilisant un nom d'hôte différent, vous pouvez configurer des noms d'hôtes supplémentaires à autoriser.
Conditions préalables
-
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Modifier la ressource
APIServer:$ oc edit apiserver.config.openshift.io cluster
Ajoutez le champ
additionalCORSAllowedOriginssous la sectionspecet indiquez un ou plusieurs noms d'hôtes supplémentaires :apiVersion: config.openshift.io/v1 kind: APIServer metadata: annotations: release.openshift.io/create-only: "true" creationTimestamp: "2019-07-11T17:35:37Z" generation: 1 name: cluster resourceVersion: "907" selfLink: /apis/config.openshift.io/v1/apiservers/cluster uid: 4b45a8dd-a402-11e9-91ec-0219944e0696 spec: additionalCORSAllowedOrigins: - (?i)//my\.subdomain\.domain\.com(:|\z) 1- 1
- Le nom d'hôte est spécifié sous la forme d'une expression régulière Golang qui correspond aux en-têtes CORS des requêtes HTTP adressées au serveur API et au serveur OAuth.
NoteCet exemple utilise la syntaxe suivante :
-
Le site
(?i)ne tient pas compte des majuscules et des minuscules. -
Le
//se réfère au début du domaine et correspond à la double barre oblique qui suithttp:ouhttps:. -
Le site
\.échappe aux points dans le nom de domaine. -
Le
(:|\z)correspond à la fin du nom de domaine(\z)ou à un séparateur de port(:).
- Enregistrez le fichier pour appliquer les modifications.
Chapitre 14. Chiffrement des données etcd
14.1. À propos du chiffrement d'etcd
Par défaut, les données etcd ne sont pas cryptées dans OpenShift Container Platform. Vous pouvez activer le chiffrement etcd pour votre cluster afin de fournir une couche supplémentaire de sécurité des données. Par exemple, cela peut aider à protéger la perte de données sensibles si une sauvegarde etcd est exposée à des parties incorrectes.
Lorsque vous activez le chiffrement etcd, les ressources suivantes du serveur API OpenShift et du serveur API Kubernetes sont chiffrées :
- Secrets
- Cartes de configuration
- Routes
- Jetons d'accès OAuth
- Jetons d'autorisation OAuth
Lorsque vous activez le chiffrement etcd, des clés de chiffrement sont créées. Ces clés font l'objet d'une rotation hebdomadaire. Vous devez disposer de ces clés pour restaurer une sauvegarde etcd.
Le cryptage Etcd ne crypte que les valeurs, pas les clés. Les types de ressources, les espaces de noms et les noms d'objets ne sont pas chiffrés.
Si le chiffrement etcd est activé pendant une sauvegarde, le fichier static_kuberesources_<datetimestamp>.tar.gz contient les clés de chiffrement de l'instantané etcd. Pour des raisons de sécurité, ce fichier doit être stocké séparément de l'instantané etcd. Cependant, ce fichier est nécessaire pour restaurer un état antérieur de etcd à partir de l'instantané etcd correspondant.
14.2. Activation du chiffrement d'etcd
Vous pouvez activer le chiffrement etcd pour chiffrer les ressources sensibles de votre cluster.
Ne sauvegardez pas les ressources etcd tant que le processus de cryptage initial n'est pas terminé. Si le processus de chiffrement n'est pas terminé, la sauvegarde risque de n'être que partiellement chiffrée.
Après avoir activé le chiffrement d'etcd, plusieurs changements peuvent survenir :
- Le chiffrement d'etcd peut affecter la consommation de mémoire de quelques ressources.
- Il se peut que vous remarquiez un effet transitoire sur les performances de la sauvegarde, car le leader doit servir la sauvegarde.
- Une entrée/sortie de disque peut affecter le nœud qui reçoit l'état de sauvegarde.
Conditions préalables
-
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Modifier l'objet
APIServer:$ oc edit apiserver
Définissez le type de champ
encryptionsuraescbc:spec: encryption: type: aescbc 1- 1
- Le type
aescbcsignifie que le chiffrement est effectué par AES-CBC avec un remplissage PKCS#7 et une clé de 32 octets.
Enregistrez le fichier pour appliquer les modifications.
Le processus de cryptage démarre. Ce processus peut durer 20 minutes ou plus, en fonction de la taille de votre cluster.
Vérifiez que le chiffrement d'etcd a réussi.
Examinez la condition d'état
Encryptedpour le serveur OpenShift API afin de vérifier que ses ressources ont été chiffrées avec succès :$ oc get openshiftapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'La sortie indique
EncryptionCompletedlorsque le cryptage a réussi :EncryptionCompleted All resources encrypted: routes.route.openshift.io
Si la sortie indique
EncryptionInProgress, le cryptage est toujours en cours. Attendez quelques minutes et réessayez.Consultez la condition d'état
Encryptedpour le serveur API Kubernetes afin de vérifier que ses ressources ont été chiffrées avec succès :$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'La sortie indique
EncryptionCompletedlorsque le cryptage a réussi :EncryptionCompleted All resources encrypted: secrets, configmaps
Si la sortie indique
EncryptionInProgress, le cryptage est toujours en cours. Attendez quelques minutes et réessayez.Examinez l'état
Encryptedpour le serveur OpenShift OAuth API afin de vérifier que ses ressources ont été chiffrées avec succès :$ oc get authentication.operator.openshift.io -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'La sortie indique
EncryptionCompletedlorsque le cryptage a réussi :EncryptionCompleted All resources encrypted: oauthaccesstokens.oauth.openshift.io, oauthauthorizetokens.oauth.openshift.io
Si la sortie indique
EncryptionInProgress, le cryptage est toujours en cours. Attendez quelques minutes et réessayez.
14.3. Désactiver le chiffrement d'etcd
Vous pouvez désactiver le chiffrement des données etcd dans votre cluster.
Conditions préalables
-
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Modifier l'objet
APIServer:$ oc edit apiserver
Définissez le type de champ
encryptionsuridentity:spec: encryption: type: identity 1- 1
- Le type
identityest la valeur par défaut et signifie qu'aucun cryptage n'est effectué.
Enregistrez le fichier pour appliquer les modifications.
Le processus de décryptage démarre. Ce processus peut durer 20 minutes ou plus, en fonction de la taille de votre cluster.
Vérifier que le décryptage d'etcd a été effectué avec succès.
Examinez la condition d'état
Encryptedpour le serveur OpenShift API afin de vérifier que ses ressources ont été déchiffrées avec succès :$ oc get openshiftapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'La sortie montre
DecryptionCompletedlorsque le décryptage est réussi :DecryptionCompleted Encryption mode set to identity and everything is decrypted
Si la sortie indique
DecryptionInProgress, le décryptage est toujours en cours. Attendez quelques minutes et réessayez.Consultez la condition d'état
Encryptedpour le serveur API Kubernetes afin de vérifier que ses ressources ont été déchiffrées avec succès :$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'La sortie montre
DecryptionCompletedlorsque le décryptage est réussi :DecryptionCompleted Encryption mode set to identity and everything is decrypted
Si la sortie indique
DecryptionInProgress, le décryptage est toujours en cours. Attendez quelques minutes et réessayez.Examinez l'état
Encryptedpour le serveur OpenShift OAuth API afin de vérifier que ses ressources ont été déchiffrées avec succès :$ oc get authentication.operator.openshift.io -o=jsonpath='{range .items[0].status.conditions[?(@.type=="Encrypted")]}{.reason}{"\n"}{.message}{"\n"}'La sortie montre
DecryptionCompletedlorsque le décryptage est réussi :DecryptionCompleted Encryption mode set to identity and everything is decrypted
Si la sortie indique
DecryptionInProgress, le décryptage est toujours en cours. Attendez quelques minutes et réessayez.
Chapitre 15. Recherche de vulnérabilités dans les pods
En utilisant Red Hat Quay Container Security Operator, vous pouvez accéder aux résultats de l'analyse de vulnérabilité à partir de la console web d'OpenShift Container Platform pour les images de conteneurs utilisées dans les pods actifs sur le cluster. L'Opérateur de sécurité des conteneurs Red Hat Quay :
- Surveille les conteneurs associés aux pods sur tous les espaces de noms ou sur les espaces de noms spécifiés
- Interroge le registre de conteneurs d'où proviennent les conteneurs pour obtenir des informations sur les vulnérabilités, à condition que le registre d'une image exécute une analyse d'image (comme Quay.io ou un registre Quay de Red Hat avec une analyse Clair)
-
Expose des vulnérabilités via l'objet
ImageManifestVulndans l'API Kubernetes
En utilisant les instructions ici, Red Hat Quay Container Security Operator est installé dans l'espace de noms openshift-operators, il est donc disponible pour tous les espaces de noms sur votre cluster OpenShift Container Platform.
15.1. Exécuter l'opérateur de sécurité des conteneurs Red Hat Quay
Vous pouvez démarrer l'opérateur Red Hat Quay Container Security depuis la console web OpenShift Container Platform en sélectionnant et en installant cet opérateur depuis le Hub de l'opérateur, comme décrit ici.
Conditions préalables
- Disposer de privilèges d'administrateur sur le cluster OpenShift Container Platform
- Faites tourner sur votre cluster des conteneurs provenant d'un registre Red Hat Quay ou Quay.io
Procédure
- Naviguez vers Operators → OperatorHub et sélectionnez Security.
- Sélectionnez l'opérateur Container Security, puis Install pour accéder à la page Créer un abonnement opérateur.
- Vérifiez les paramètres. Tous les espaces de noms et la stratégie d'approbation automatique sont sélectionnés par défaut.
- Sélectionnez Install. L'opérateur Container Security apparaît après quelques instants sur l'écran Installed Operators.
Facultatif : Vous pouvez ajouter des certificats personnalisés à l'Opérateur de sécurité Red Hat Quay Container. Dans cet exemple, créez un certificat nommé
quay.crtdans le répertoire actuel. Exécutez ensuite la commande suivante pour ajouter le certificat à l'Opérateur de sécurité pour conteneurs Red Hat Quay :$ oc create secret generic container-security-operator-extra-certs --from-file=quay.crt -n openshift-operators
- Si vous avez ajouté un certificat personnalisé, redémarrez l'Operator Pod pour que les nouveaux certificats prennent effet.
Ouvrez le tableau de bord OpenShift (
Home→Overview). Un lien vers Quay Image Security apparaît sous la section status, avec une liste du nombre de vulnérabilités trouvées jusqu'à présent. Sélectionnez le lien pour voir une page Quay Image Security breakdown, comme le montre la figure suivante :
À ce stade, vous pouvez faire l'une des deux choses suivantes pour donner suite aux vulnérabilités détectées :
Sélectionnez le lien vers la vulnérabilité. Vous êtes redirigé vers le registre de conteneurs d'où provient le conteneur, où vous pouvez voir des informations sur la vulnérabilité. La figure suivante montre un exemple de vulnérabilités détectées dans un registre Quay.io :
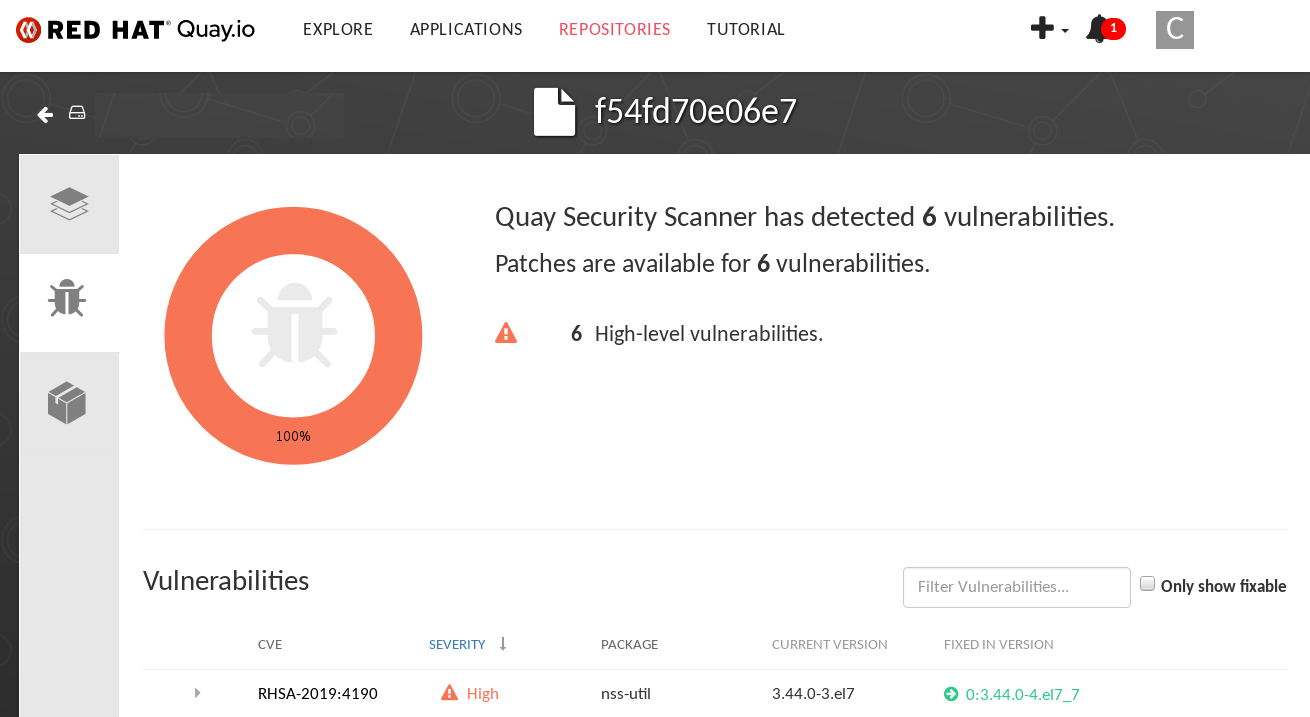
Sélectionnez le lien namespaces pour accéder à l'écran ImageManifestVuln, où vous pouvez voir le nom de l'image sélectionnée et tous les espaces de noms dans lesquels cette image est exécutée. La figure suivante indique qu'une image vulnérable particulière est exécutée dans l'espace de noms
quay-enterprise:
À ce stade, vous savez quelles images sont vulnérables, ce que vous devez faire pour corriger ces vulnérabilités, et tous les espaces de noms dans lesquels l'image a été exécutée. Vous pouvez donc
- Alerter toute personne exécutant l'image qu'elle doit corriger la vulnérabilité
- Arrêtez l'exécution des images en supprimant le déploiement ou tout autre objet qui a démarré le module dans lequel se trouve l'image
Notez que si vous supprimez le module, la réinitialisation de la vulnérabilité sur le tableau de bord peut prendre plusieurs minutes.
15.2. Interroger les vulnérabilités des images à partir de l'interface de gestion
À l'aide de la commande oc, vous pouvez afficher des informations sur les vulnérabilités détectées par Red Hat Quay Container Security Operator.
Conditions préalables
- Exécutez l'opérateur Red Hat Quay Container Security sur votre instance OpenShift Container Platform
Procédure
Pour rechercher les vulnérabilités détectées dans les images de conteneurs, tapez
$ oc get vuln --all-namespaces
Exemple de sortie
NAMESPACE NAME AGE default sha256.ca90... 6m56s skynet sha256.ca90... 9m37s
Pour afficher les détails d'une vulnérabilité particulière, indiquez le nom de la vulnérabilité et son espace de noms à la commande
oc describe. Cet exemple montre un conteneur actif dont l'image inclut un paquetage RPM présentant une vulnérabilité :$ oc describe vuln --namespace mynamespace sha256.ac50e3752...
Exemple de sortie
Name: sha256.ac50e3752... Namespace: quay-enterprise ... Spec: Features: Name: nss-util Namespace Name: centos:7 Version: 3.44.0-3.el7 Versionformat: rpm Vulnerabilities: Description: Network Security Services (NSS) is a set of libraries...
Chapitre 16. Chiffrement des disques en réseau (NBDE)
16.1. À propos de la technologie de cryptage des disques
Network-Bound Disk Encryption (NBDE) permet de chiffrer les volumes racines des disques durs des machines physiques et virtuelles sans avoir à saisir manuellement un mot de passe lors du redémarrage des machines.
16.1.1. Comparaison des technologies de cryptage des disques
Pour comprendre les avantages du chiffrement de disque lié au réseau (NBDE) pour la sécurisation des données au repos sur les serveurs périphériques, comparez le chiffrement de disque avec dépôt de clé et TPM sans Clevis au NBDE sur des systèmes fonctionnant sous Red Hat Enterprise Linux (RHEL).
Le tableau suivant présente quelques compromis à prendre en compte concernant le modèle de menace et la complexité de chaque solution de chiffrement.
| Scénario | Séquestre de clés | Chiffrement du disque par TPM (sans Clevis) | NBDE |
|---|---|---|---|
| Protection contre le vol d'un seul disque | X | X | X |
| Protection contre le vol d'un serveur entier | X | X | |
| Les systèmes peuvent redémarrer indépendamment du réseau | X | ||
| Pas de recomposition périodique de la clé | X | ||
| La clé n'est jamais transmise sur un réseau | X | X | |
| Supporté par OpenShift | X | X |
16.1.1.1. Séquestre de clés
Le dépôt de clés est le système traditionnel de stockage des clés cryptographiques. Le serveur de clés du réseau stocke la clé de chiffrement d'un nœud doté d'un disque de démarrage chiffré et la renvoie lorsqu'il est interrogé. Les complexités liées à la gestion des clés, au cryptage du transport et à l'authentification n'en font pas un choix raisonnable pour le cryptage du disque de démarrage.
Bien que disponible dans Red Hat Enterprise Linux (RHEL), la configuration et la gestion du chiffrement de disque basé sur un dépôt de clés est un processus manuel et non adapté aux opérations d'automatisation d'OpenShift Container Platform, y compris l'ajout automatisé de nœuds, et actuellement non pris en charge par OpenShift Container Platform.
16.1.1.2. Cryptage TPM
Le chiffrement des disques par le Trusted Platform Module (TPM) convient mieux aux centres de données ou aux installations dans des lieux protégés éloignés. Les utilitaires de chiffrement intégral des disques, tels que dm-crypt et BitLocker, chiffrent les disques à l'aide d'une clé de liaison TPM, puis stockent la clé de liaison TPM dans le TPM, qui est attaché à la carte mère du nœud. Le principal avantage de cette méthode est qu'il n'y a pas de dépendance externe et que le nœud est capable de décrypter ses propres disques au démarrage sans aucune interaction externe.
Le chiffrement du disque TPM protège contre le déchiffrement des données si le disque est volé au nœud et analysé à l'extérieur. Toutefois, pour les sites non sécurisés, cette protection peut s'avérer insuffisante. Par exemple, si un attaquant vole le nœud entier, il peut intercepter les données lors de la mise sous tension du nœud, car le nœud déchiffre ses propres disques. Cela s'applique aux nœuds dotés de puces TPM2 physiques ainsi qu'aux machines virtuelles dotées d'un accès Virtual Trusted Platform Module (VTPM).
16.1.1.3. Chiffrement des disques en réseau (NBDE)
Le chiffrement de disque lié au réseau (NBDE) lie effectivement la clé de chiffrement à un serveur externe ou à un ensemble de serveurs de manière sécurisée et anonyme à travers le réseau. Il ne s'agit pas d'un dépôt de clé, dans la mesure où les nœuds ne stockent pas la clé de chiffrement et ne la transfèrent pas sur le réseau, mais le comportement est similaire.
Clevis et Tang sont des composants client et serveur génériques qui fournissent un chiffrement lié au réseau. Red Hat Enterprise Linux CoreOS (RHCOS) utilise ces composants en conjonction avec Linux Unified Key Setup-on-disk-format (LUKS) pour chiffrer et déchiffrer les volumes de stockage racine et non racine afin de réaliser un chiffrement de disque lié au réseau.
Lorsqu'un nœud démarre, il tente de contacter un ensemble prédéfini de serveurs Tang en effectuant une poignée de main cryptographique. S'il parvient à atteindre le nombre requis de serveurs Tang, le nœud peut construire sa clé de déchiffrement de disque et déverrouiller les disques pour poursuivre le démarrage. Si le nœud ne peut pas accéder à un serveur Tang en raison d'une panne de réseau ou de l'indisponibilité du serveur, le nœud ne peut pas démarrer et continue à réessayer indéfiniment jusqu'à ce que les serveurs Tang redeviennent disponibles. La clé étant effectivement liée à la présence du nœud dans un réseau, un pirate tentant d'accéder aux données au repos devrait obtenir à la fois les disques du nœud et l'accès réseau au serveur Tang.
La figure suivante illustre le modèle de déploiement de l'EDNB.
La figure suivante illustre le comportement de l'EDNB lors d'un redémarrage.
16.1.1.4. Cryptage avec partage du secret
Le partage du secret de Shamir (sss) est un algorithme cryptographique qui permet de diviser, de distribuer et de réassembler les clés en toute sécurité. Grâce à cet algorithme, OpenShift Container Platform peut prendre en charge des combinaisons plus complexes de protection des clés.
Lorsque vous configurez un nœud de cluster pour utiliser plusieurs serveurs Tang, OpenShift Container Platform utilise sss pour configurer une politique de déchiffrement qui réussira si au moins un des serveurs spécifiés est disponible. Vous pouvez créer des couches de sécurité supplémentaires. Par exemple, vous pouvez définir une politique dans laquelle OpenShift Container Platform exige à la fois le TPM et l'un des serveurs Tang de la liste donnée pour déchiffrer le disque.
16.1.2. Cryptage des disques du serveur Tang
Les composants et technologies suivants mettent en œuvre le chiffrement des disques liés au réseau (NBDE).
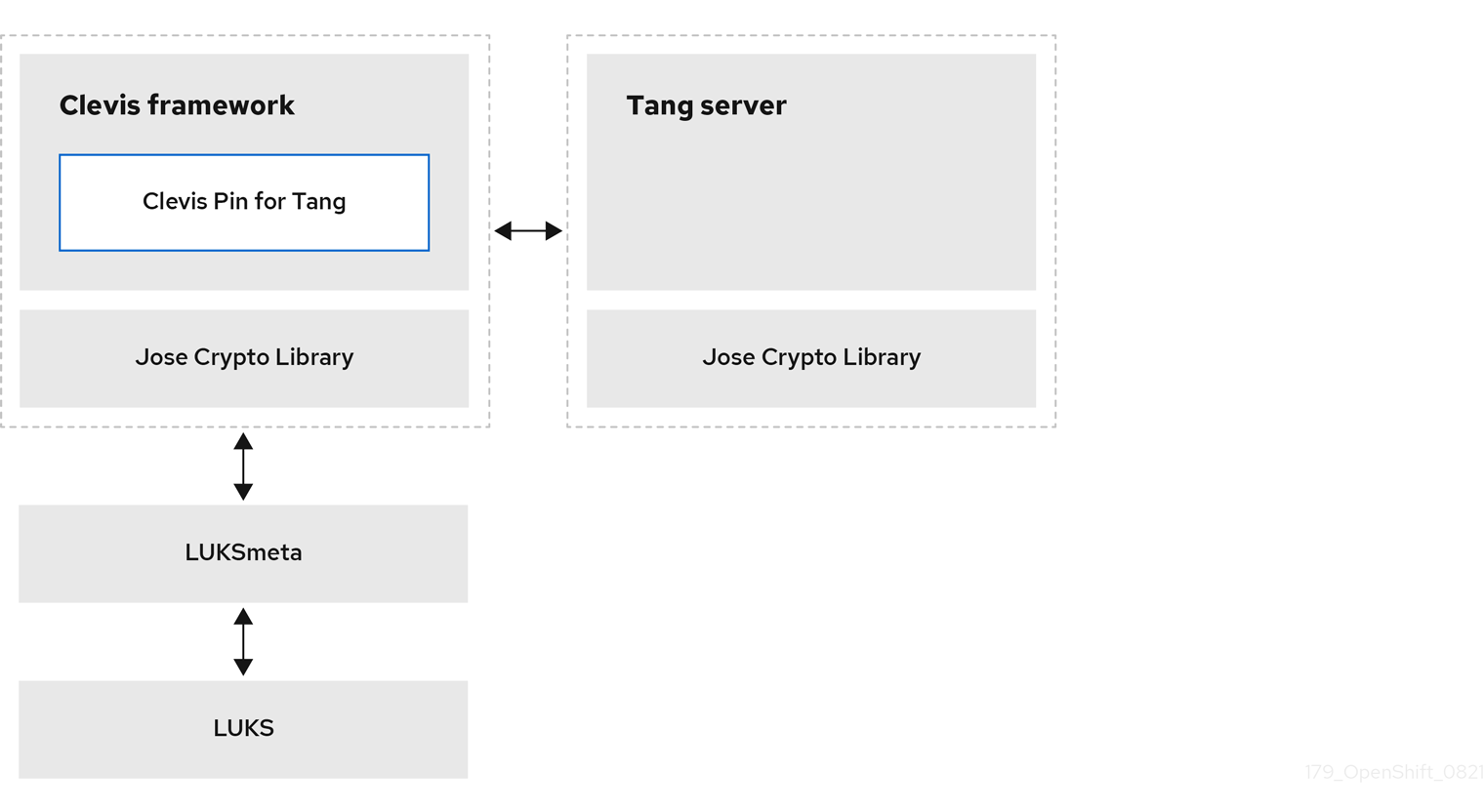
Tang est un serveur permettant de lier les données à la présence du réseau. Il rend un nœud contenant des données disponible lorsque le nœud est lié à un certain réseau sécurisé. Tang est sans état et ne nécessite pas de Transport Layer Security (TLS) ni d'authentification. Contrairement aux solutions basées sur le dépôt fiduciaire, où le serveur de clés stocke toutes les clés de chiffrement et a connaissance de chaque clé de chiffrement, Tang n'interagit jamais avec les clés des nœuds et n'obtient donc jamais d'informations d'identification de la part du nœud.
Clevis est un cadre enfichable pour le déchiffrement automatisé qui permet de déverrouiller automatiquement les volumes LUKS (Linux Unified Key Setup-on-disk-format). Le paquet Clevis s'exécute sur le nœud et fournit le côté client de la fonctionnalité.
Le site Clevis pin est un module d'extension de la structure Clevis. Il existe trois types de broches :
- TPM2
- Lie le chiffrement du disque au TPM2.
- Tang
- Lier le chiffrement du disque à un serveur Tang pour activer l'EDNB.
- Partage du secret de Shamir (sss)
Il permet des combinaisons plus complexes d'autres épingles. Il permet des politiques plus nuancées telles que les suivantes :
- Il doit être possible d'accéder à l'un de ces trois serveurs Tang
- Doit pouvoir atteindre trois de ces cinq serveurs Tang
- Il doit être possible d'atteindre le TPM2 ET au moins l'un de ces trois serveurs Tang
16.1.3. Planification de l'emplacement du serveur Tang
Lorsque vous planifiez votre environnement de serveurs Tang, tenez compte de l'emplacement physique et de l'emplacement du réseau des serveurs Tang.
- Emplacement physique
L'emplacement géographique des serveurs Tang est relativement peu important, pour autant qu'ils soient convenablement protégés contre l'accès non autorisé ou le vol et qu'ils offrent la disponibilité et l'accessibilité nécessaires à l'exécution d'un service critique.
Les nœuds dotés de clients Clevis n'ont pas besoin de serveurs Tang locaux tant que ces derniers sont disponibles à tout moment. La reprise après sinistre nécessite une alimentation redondante et une connectivité réseau redondante pour les serveurs Tang, quel que soit leur emplacement.
- Localisation du réseau
Tout nœud ayant un accès réseau aux serveurs Tang peut décrypter ses propres partitions de disque ou tout autre disque crypté par les mêmes serveurs Tang.
Choisissez des emplacements réseau pour les serveurs Tang qui garantissent que la présence ou l'absence de connectivité réseau à partir d'un hôte donné permet l'autorisation de décryptage. Par exemple, des protections par pare-feu peuvent être mises en place pour interdire l'accès à partir de tout type de réseau invité ou public, ou de toute prise réseau située dans une zone non sécurisée du bâtiment.
En outre, il convient de maintenir une séparation entre les réseaux de production et de développement. Cela permet de définir les emplacements appropriés du réseau et d'ajouter une couche supplémentaire de sécurité.
Ne déployez pas les serveurs Tang sur la même ressource, par exemple le même cluster
rolebindings.rbac.authorization.k8s.io, qu'ils sont chargés de déverrouiller. Toutefois, une grappe de serveurs Tang et d'autres ressources de sécurité peut constituer une configuration utile pour permettre la prise en charge de plusieurs grappes et ressources de grappes supplémentaires.
16.1.4. Exigences en matière de dimensionnement du serveur Tang
Les exigences relatives à la disponibilité, au réseau et à l'emplacement physique déterminent le nombre de serveurs Tang à utiliser, plutôt que la capacité des serveurs.
Les serveurs Tang ne conservent pas l'état des données chiffrées à l'aide des ressources Tang. Les serveurs Tang sont soit totalement indépendants, soit ne partagent que leurs clés, ce qui leur permet de s'adapter facilement.
Les serveurs Tang traitent les documents clés de deux manières différentes :
Plusieurs serveurs Tang partagent les clés :
- Vous devez équilibrer la charge des serveurs Tang partageant des clés derrière la même URL. La configuration peut être aussi simple qu'un DNS round-robin, ou vous pouvez utiliser des équilibreurs de charge physiques.
- Vous pouvez passer d'un serveur Tang unique à plusieurs serveurs Tang. La mise à l'échelle des serveurs Tang ne nécessite pas de nouvelle clé ou de reconfiguration du client sur le nœud lorsque les serveurs Tang partagent le même matériel de clé et la même URL.
- La configuration des nœuds clients et la rotation des clés ne nécessitent qu'un seul serveur Tang.
Plusieurs serveurs Tang génèrent leurs propres clés :
- Vous pouvez configurer plusieurs serveurs Tang au moment de l'installation.
- Vous pouvez faire évoluer un serveur Tang individuel derrière un équilibreur de charge.
- Tous les serveurs Tang doivent être disponibles lors de l'installation des nœuds clients ou de la rotation des clés.
- Lorsqu'un nœud client démarre avec la configuration par défaut, le client Clevis contacte tous les serveurs Tang. Seuls les serveurs Tang n doivent être en ligne pour procéder au décryptage. La valeur par défaut de n est 1.
- Red Hat ne prend pas en charge la configuration post-installation qui modifie le comportement des serveurs Tang.
16.1.5. Considérations relatives à la journalisation
L'enregistrement centralisé du trafic Tang est avantageux car il peut vous permettre de détecter des éléments tels que des demandes de décryptage inattendues. Par exemple :
- Un nœud demandant le déchiffrement d'une phrase d'authentification qui ne correspond pas à sa séquence d'amorçage
- Un nœud demandant le déchiffrement en dehors d'une activité de maintenance connue, telle que le renouvellement des clés
16.2. Considérations relatives à l'installation du serveur Tang
16.2.1. Scénarios d'installation
Tenez compte des recommandations suivantes lorsque vous planifiez l'installation d'un serveur Tang :
Les petits environnements peuvent utiliser un seul jeu de clés, même s'ils utilisent plusieurs serveurs Tang :
- Les rotations de clés sont plus faciles.
- Les serveurs Tang peuvent évoluer facilement pour permettre une haute disponibilité.
Les grands environnements peuvent bénéficier de plusieurs séries de documents clés :
- Les installations physiquement différentes ne nécessitent pas la copie et la synchronisation des documents clés entre les régions géographiques.
- La rotation des clés est plus complexe dans les grands environnements.
- L'installation des nœuds et le changement de clé nécessitent une connectivité réseau à tous les serveurs Tang.
- Une légère augmentation du trafic réseau peut se produire en raison de l'interrogation de tous les serveurs Tang par un nœud d'amorçage pendant le décryptage. Notez que si une seule requête du client Clevis doit aboutir, Clevis interroge tous les serveurs Tang.
Plus de complexité :
-
Une reconfiguration manuelle supplémentaire peut permettre le partage du secret de Shamir (sss) de
any N of M servers onlineafin de décrypter la partition du disque. Le décryptage des disques dans ce scénario nécessite plusieurs jeux de clés et une gestion manuelle des serveurs Tang et des nœuds avec des clients Clevis après l'installation initiale.
-
Une reconfiguration manuelle supplémentaire peut permettre le partage du secret de Shamir (sss) de
Recommandations de haut niveau :
- Pour un déploiement RAN unique, un ensemble limité de serveurs Tang peut fonctionner dans le contrôleur de domaine (DC) correspondant.
- Pour les déploiements RAN multiples, vous devez décider si vous voulez exécuter des serveurs Tang dans chaque DC correspondant ou si un environnement Tang global répond mieux aux autres besoins et exigences du système.
16.2.2. Installation d'un serveur Tang
Procédure
Vous pouvez installer un serveur Tang sur une machine Red Hat Enterprise Linux (RHEL) à l'aide de l'une des commandes suivantes :
Installez le serveur Tang à l'aide de la commande
yum:$ sudo yum install tang
Installez le serveur Tang à l'aide de la commande
dnf:$ sudo dnf install tang
L'installation peut également être conteneurisée et est très légère.
16.2.2.1. Exigences en matière de calcul
Les exigences en matière de calcul pour le serveur Tang sont très faibles. Toute configuration typique de serveur que vous utiliseriez pour déployer un serveur en production peut fournir une capacité de calcul suffisante.
Les considérations relatives à la haute disponibilité concernent uniquement la disponibilité et non une puissance de calcul supplémentaire pour satisfaire les demandes des clients.
16.2.2.2. Démarrage automatique au démarrage
En raison de la nature sensible des clés utilisées par le serveur Tang, vous devez garder à l'esprit que l'intervention manuelle pendant la séquence de démarrage du serveur Tang peut être bénéfique.
Par défaut, si un serveur Tang démarre et ne dispose pas de matériel de clé dans le volume local prévu, il créera du matériel neuf et le servira. Vous pouvez éviter ce comportement par défaut en démarrant avec des clés préexistantes ou en interrompant le démarrage et en attendant une intervention manuelle.
16.2.2.3. HTTP contre HTTPS
Le trafic vers le serveur Tang peut être crypté (HTTPS) ou en clair (HTTP). Le chiffrement de ce trafic ne présente pas d'avantages significatifs en termes de sécurité, et le fait de le laisser déchiffré supprime toute complexité ou condition d'échec liée à la vérification des certificats TLS (Transport Layer Security) dans le nœud exécutant un client Clevis.
Bien qu'il soit possible d'effectuer une surveillance passive du trafic non crypté entre le client Clevis du nœud et le serveur Tang, la capacité d'utiliser ce trafic pour déterminer le matériel de la clé est au mieux une préoccupation théorique future. Une telle analyse du trafic nécessiterait de grandes quantités de données capturées. La rotation des clés l'invaliderait immédiatement. Enfin, tout acteur de la menace capable d'effectuer une surveillance passive a déjà obtenu l'accès au réseau nécessaire pour effectuer des connexions manuelles au serveur Tang et peut effectuer le décryptage manuel plus simple des en-têtes Clevis capturés.
Cependant, étant donné que d'autres politiques de réseau en place sur le site d'installation peuvent exiger le chiffrement du trafic indépendamment de l'application, il est préférable de laisser cette décision à l'administrateur de la grappe.
16.2.3. Considérations relatives à l'installation du chiffrement des disques liés au réseau
Le chiffrement des disques liés au réseau (NBDE) doit être activé lors de l'installation d'un nœud de cluster. Cependant, vous pouvez modifier la politique de chiffrement des disques à tout moment après son initialisation lors de l'installation.
16.3. Gestion des clés de chiffrement du serveur Tang
Le mécanisme cryptographique permettant de recréer la clé de chiffrement est basé sur le site blinded key stocké sur le nœud et sur la clé privée des serveurs Tang concernés. Pour se protéger contre la possibilité qu'un attaquant obtienne à la fois la clé privée du serveur Tang et le disque crypté du nœud, il est conseillé de recréer périodiquement une clé.
Vous devez effectuer l'opération de renouvellement de clé pour chaque nœud avant de pouvoir supprimer l'ancienne clé du serveur Tang. Les sections suivantes décrivent les procédures de recodage et de suppression des anciennes clés.
16.3.1. Sauvegarde des clés d'un serveur Tang
Le serveur Tang utilise /usr/libexec/tangd-keygen pour générer de nouvelles clés et les stocke par défaut dans le répertoire /var/db/tang. Pour récupérer le serveur Tang en cas de panne, sauvegardez ce répertoire. Les clés sont sensibles et, comme elles sont capables d'effectuer le décryptage du disque de démarrage de tous les hôtes qui les ont utilisées, elles doivent être protégées en conséquence.
Procédure
-
Copiez la clé de sauvegarde du répertoire
/var/db/tangdans le répertoire temp à partir duquel vous pouvez restaurer la clé.
16.3.2. Récupération des clés d'un serveur Tang
Vous pouvez récupérer les clés d'un serveur Tang en accédant aux clés d'une sauvegarde.
Procédure
Restaurer la clé de votre dossier de sauvegarde dans le répertoire
/var/db/tang/.Lorsque le serveur Tang démarre, il annonce et utilise ces clés restaurées.
16.3.3. Remise en service des serveurs Tang
Cette procédure utilise comme exemple un ensemble de trois serveurs Tang, chacun avec des clés uniques.
L'utilisation de serveurs Tang redondants réduit les risques d'échec du démarrage automatique des nœuds.
Le recodage d'un serveur Tang et de tous les nœuds chiffrés NBDE associés est une procédure en trois étapes.
Conditions préalables
- Une installation fonctionnelle de Network-Bound Disk Encryption (NBDE) sur un ou plusieurs nœuds.
Procédure
- Générer une nouvelle clé de serveur Tang.
- Recomposer la clé de tous les nœuds chiffrés par l'EDNB de manière à ce qu'ils utilisent la nouvelle clé.
Supprimer l'ancienne clé du serveur Tang.
NoteLa suppression de l'ancienne clé avant que tous les nœuds chiffrés par l'EDNB n'aient terminé leur remise en clé entraîne une dépendance excessive de ces nœuds à l'égard de tout autre serveur Tang configuré.
Figure 16.1. Exemple de flux de travail pour le changement de clé d'un serveur Tang
16.3.3.1. Générer une nouvelle clé de serveur Tang
Conditions préalables
- Un shell root sur la machine Linux qui exécute le serveur Tang.
Pour faciliter la vérification de la rotation des clés du serveur Tang, cryptez un petit fichier test avec l'ancienne clé :
# echo plaintext | clevis encrypt tang '{"url":"http://localhost:7500"}' -y >/tmp/encrypted.oldkeyVérifiez que le cryptage a réussi et que le fichier peut être décrypté pour produire la même chaîne
plaintext:# clevis decrypt </tmp/encrypted.oldkey
Procédure
Localisez et accédez au répertoire qui stocke la clé du serveur Tang. Il s'agit généralement du répertoire
/var/db/tang. Vérifiez l'empreinte de la clé actuellement annoncée :# tang-show-keys 7500
Exemple de sortie
36AHjNH3NZDSnlONLz1-V4ie6t8
Entrez le répertoire des clés du serveur Tang :
# cd /var/db/tang/
Liste des clés actuelles du serveur Tang :
# ls -A1
Exemple de sortie
36AHjNH3NZDSnlONLz1-V4ie6t8.jwk gJZiNPMLRBnyo_ZKfK4_5SrnHYo.jwk
Lors du fonctionnement normal du serveur Tang, ce répertoire contient deux fichiers
.jwk: l'un pour la signature et la vérification, l'autre pour la dérivation des clés.Désactiver la publicité des anciennes clés :
# for key in *.jwk; do \ mv -- "$key" ".$key"; \ done
Les nouveaux clients qui configurent le cryptage des disques liés au réseau (NBDE) ou qui demandent des clés ne verront plus les anciennes clés. Les clients existants peuvent toujours accéder aux anciennes clés et les utiliser jusqu'à ce qu'elles soient supprimées. Le serveur Tang lit les clés stockées dans les fichiers cachés UNIX, qui commencent par le caractère
., mais n'en fait pas la publicité.Générer une nouvelle clé :
# /usr/libexec/tangd-keygen /var/db/tang
Lister les clés actuelles du serveur Tang pour vérifier que les anciennes clés ne sont plus annoncées, car elles sont désormais des fichiers cachés, et que de nouvelles clés sont présentes :
# ls -A1
Exemple de sortie
.36AHjNH3NZDSnlONLz1-V4ie6t8.jwk .gJZiNPMLRBnyo_ZKfK4_5SrnHYo.jwk Bp8XjITceWSN_7XFfW7WfJDTomE.jwk WOjQYkyK7DxY_T5pMncMO5w0f6E.jwk
Tang annonce automatiquement les nouvelles clés.
NoteLes installations plus récentes du serveur Tang comprennent un répertoire d'aide
/usr/libexec/tangd-rotate-keysqui se charge de désactiver la publicité et de générer les nouvelles clés simultanément.- Si vous utilisez plusieurs serveurs Tang derrière un équilibreur de charge qui partagent le même matériel clé, assurez-vous que les modifications apportées ici sont correctement synchronisées sur l'ensemble des serveurs avant de continuer.
Vérification
Vérifiez que le serveur Tang annonce la nouvelle clé et non l'ancienne :
# tang-show-keys 7500
Exemple de sortie
WOjQYkyK7DxY_T5pMncMO5w0f6E
Vérifiez que l'ancienne clé, bien qu'elle ne soit pas annoncée, est toujours disponible pour les demandes de déchiffrement :
# clevis decrypt </tmp/encrypted.oldkey
16.3.3.2. Recomposition de tous les nœuds de l'EDNB
Vous pouvez recléer tous les nœuds d'un cluster distant à l'aide d'un objet DaemonSet sans que le cluster distant ne subisse de temps d'arrêt.
Si un nœud perd de l'énergie pendant le rekeying, il est possible qu'il devienne non amorçable et qu'il doive être redéployé via Red Hat Advanced Cluster Management (RHACM) ou un pipeline GitOps.
Conditions préalables
-
cluster-adminà tous les clusters dotés de nœuds NBDE (Network-Bound Disk Encryption). - Tous les serveurs Tang doivent être accessibles à chaque nœud de l'EDNB lors du renouvellement des clés, même si les clés d'un serveur Tang n'ont pas changé.
- Obtenir l'URL du serveur Tang et l'empreinte de la clé pour chaque serveur Tang.
Procédure
Créez un objet
DaemonSetbasé sur le modèle suivant. Ce modèle met en place trois serveurs Tang redondants, mais peut être facilement adapté à d'autres situations. Modifiez les URL et les empreintes des serveurs Tang dans l'environnementNEW_TANG_PINpour les adapter à votre environnement :apiVersion: apps/v1 kind: DaemonSet metadata: name: tang-rekey namespace: openshift-machine-config-operator spec: selector: matchLabels: name: tang-rekey template: metadata: labels: name: tang-rekey spec: containers: - name: tang-rekey image: registry.access.redhat.com/ubi8/ubi-minimal:8.4 imagePullPolicy: IfNotPresent command: - "/sbin/chroot" - "/host" - "/bin/bash" - "-ec" args: - | rm -f /tmp/rekey-complete || true echo "Current tang pin:" clevis-luks-list -d $ROOT_DEV -s 1 echo "Applying new tang pin: $NEW_TANG_PIN" clevis-luks-edit -f -d $ROOT_DEV -s 1 -c "$NEW_TANG_PIN" echo "Pin applied successfully" touch /tmp/rekey-complete sleep infinity readinessProbe: exec: command: - cat - /host/tmp/rekey-complete initialDelaySeconds: 30 periodSeconds: 10 env: - name: ROOT_DEV value: /dev/disk/by-partlabel/root - name: NEW_TANG_PIN value: >- {"t":1,"pins":{"tang":[ {"url":"http://tangserver01:7500","thp":"WOjQYkyK7DxY_T5pMncMO5w0f6E"}, {"url":"http://tangserver02:7500","thp":"I5Ynh2JefoAO3tNH9TgI4obIaXI"}, {"url":"http://tangserver03:7500","thp":"38qWZVeDKzCPG9pHLqKzs6k1ons"} ]}} volumeMounts: - name: hostroot mountPath: /host securityContext: privileged: true volumes: - name: hostroot hostPath: path: / nodeSelector: kubernetes.io/os: linux priorityClassName: system-node-critical restartPolicy: Always serviceAccount: machine-config-daemon serviceAccountName: machine-config-daemonDans ce cas, même s'il s'agit d'une nouvelle clé pour
tangserver01, vous devez spécifier non seulement la nouvelle empreinte detangserver01, mais aussi les empreintes actuelles de tous les autres serveurs Tang. Le fait de ne pas spécifier toutes les empreintes pour une opération de recomposition de clé ouvre la voie à une attaque de type "man-in-the-middle".Pour distribuer le jeu de démons à tous les clusters qui doivent être recodés, exécutez la commande suivante :
$ oc apply -f tang-rekey.yaml
Cependant, pour fonctionner à l'échelle, il faut envelopper l'ensemble de démons dans une politique ACM. Cette configuration ACM doit contenir une politique pour déployer l'ensemble de démons, une deuxième politique pour vérifier que tous les pods de l'ensemble de démons sont PRÊTS, et une règle de placement pour l'appliquer à l'ensemble approprié de clusters.
Après avoir vérifié que l'ensemble de démons a réussi à recoder tous les serveurs, supprimez l'ensemble de démons. Si vous ne supprimez pas le jeu de démons, il doit l'être avant la prochaine opération de recomposition de clés.
Vérification
Après avoir distribué le jeu de démons, surveillez les jeux de démons pour vous assurer que la reconnexion s'est bien déroulée. Le script de l'exemple de jeu de démons se termine par une erreur si le rechargement a échoué, et reste dans l'état CURRENT s'il a réussi. Il existe également une sonde de préparation qui marque le pod comme READY lorsque le rekeying a été effectué avec succès.
Voici un exemple de liste de sortie pour l'ensemble de démons avant que la recomposition des clés ne soit terminée :
$ oc get -n openshift-machine-config-operator ds tang-rekey
Exemple de sortie
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE tang-rekey 1 1 0 1 0 kubernetes.io/os=linux 11s
Voici un exemple de liste de sortie pour l'ensemble de démons après que la recomposition des clés a été effectuée avec succès :
$ oc get -n openshift-machine-config-operator ds tang-rekey
Exemple de sortie
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE tang-rekey 1 1 1 1 1 kubernetes.io/os=linux 13h
La recomposition de la clé ne prend généralement que quelques minutes.
Si vous utilisez des stratégies ACM pour distribuer les ensembles de démons à plusieurs clusters, vous devez inclure une stratégie de conformité qui vérifie que le compte READY de chaque ensemble de démons est égal au compte DESIRED. De cette façon, la conformité à une telle politique démontre que tous les pods de l'ensemble démon sont READY et que le rekeying s'est déroulé avec succès. Vous pouvez également utiliser une recherche ACM pour interroger tous les états des ensembles de démons.
16.3.3.3. Dépannage des erreurs de recomposition temporaire des clés pour les serveurs Tang
Pour déterminer si la condition d'erreur liée à la recomposition des clés des serveurs Tang est temporaire, procédez comme suit. Les conditions d'erreur temporaires peuvent être les suivantes
- Interruptions temporaires du réseau
- Maintenance du serveur Tang
En général, lorsque ce type d'erreur temporaire se produit, vous pouvez attendre que l'ensemble de démons parvienne à résoudre l'erreur ou vous pouvez supprimer l'ensemble de démons et ne pas réessayer tant que l'erreur temporaire n'a pas été résolue.
Procédure
- Redémarrez le pod qui effectue l'opération de remise en clé à l'aide de la politique normale de redémarrage des pods de Kubernetes.
- Si l'un des serveurs Tang associés n'est pas disponible, essayez d'établir une nouvelle clé jusqu'à ce que tous les serveurs soient de nouveau en ligne.
16.3.3.4. Dépannage des erreurs de recomposition permanente des clés pour les serveurs Tang
Si, après la remise en service des serveurs Tang, le nombre de READY n'est pas égal au nombre de DESIRED après une période prolongée, cela peut indiquer une condition de défaillance permanente. Dans ce cas, les conditions suivantes peuvent s'appliquer :
-
Une erreur typographique dans l'URL du serveur Tang ou dans l'empreinte de la définition de
NEW_TANG_PIN. - Le serveur Tang est mis hors service ou les clés sont définitivement perdues.
Conditions préalables
- Les commandes présentées dans cette procédure peuvent être exécutées sur le serveur Tang ou sur tout système Linux ayant un accès réseau au serveur Tang.
Procédure
Validez la configuration du serveur Tang en effectuant une simple opération de cryptage et de décryptage sur la configuration de chaque serveur Tang, telle qu'elle est définie dans le jeu de démons.
Voici un exemple de tentative de cryptage et de décryptage avec une mauvaise empreinte :
$ echo "okay" | clevis encrypt tang \ '{"url":"http://tangserver02:7500","thp":"badthumbprint"}' | \ clevis decryptExemple de sortie
Unable to fetch advertisement: 'http://tangserver02:7500/adv/badthumbprint'!
Voici un exemple de tentative de cryptage et de décryptage avec une bonne empreinte :
$ echo "okay" | clevis encrypt tang \ '{"url":"http://tangserver03:7500","thp":"goodthumbprint"}' | \ clevis decryptExemple de sortie
okay
Après avoir identifié la cause première, il faut remédier à la situation sous-jacente :
- Supprimer le jeu de démons qui ne fonctionne pas.
Modifiez la définition du jeu de démons pour résoudre le problème sous-jacent. Il peut s'agir de l'une des actions suivantes :
- Modifier l'entrée d'un serveur Tang pour corriger l'URL et l'empreinte.
- Supprimer un serveur Tang qui n'est plus en service.
- Ajouter un nouveau serveur Tang en remplacement d'un serveur déclassé.
- Distribuer à nouveau le jeu de démons mis à jour.
Lors du remplacement, de la suppression ou de l'ajout d'un serveur Tang dans une configuration, l'opération de reconnexion réussit si au moins un serveur d'origine est encore fonctionnel, y compris le serveur en cours de reconnexion. Si aucun des serveurs Tang d'origine n'est fonctionnel ou ne peut être récupéré, la récupération du système est impossible et vous devez redéployer les nœuds concernés.
Vérification
Vérifiez les journaux de chaque module de l'ensemble de démons pour déterminer si la recomposition s'est déroulée correctement. En cas d'échec, les journaux peuvent indiquer une condition d'échec.
Localisez le nom du conteneur qui a été créé par l'ensemble de démons :
$ oc get pods -A | grep tang-rekey
Exemple de sortie
openshift-machine-config-operator tang-rekey-7ks6h 1/1 Running 20 (8m39s ago) 89m
Imprimez les journaux du conteneur. Le journal suivant est celui d'une opération de recomposition de clé réussie :
$ oc logs tang-rekey-7ks6h
Exemple de sortie
Current tang pin: 1: sss '{"t":1,"pins":{"tang":[{"url":"http://10.46.55.192:7500"},{"url":"http://10.46.55.192:7501"},{"url":"http://10.46.55.192:7502"}]}}' Applying new tang pin: {"t":1,"pins":{"tang":[ {"url":"http://tangserver01:7500","thp":"WOjQYkyK7DxY_T5pMncMO5w0f6E"}, {"url":"http://tangserver02:7500","thp":"I5Ynh2JefoAO3tNH9TgI4obIaXI"}, {"url":"http://tangserver03:7500","thp":"38qWZVeDKzCPG9pHLqKzs6k1ons"} ]}} Updating binding... Binding edited successfully Pin applied successfully
16.3.4. Suppression des anciennes clés du serveur Tang
Conditions préalables
- Un shell root sur la machine Linux qui exécute le serveur Tang.
Procédure
Localisez et accédez au répertoire où la clé du serveur Tang est stockée. Il s'agit généralement du répertoire
/var/db/tang:# cd /var/db/tang/
Liste des clés actuelles du serveur Tang, indiquant les clés annoncées et non annoncées :
# ls -A1
Exemple de sortie
.36AHjNH3NZDSnlONLz1-V4ie6t8.jwk .gJZiNPMLRBnyo_ZKfK4_5SrnHYo.jwk Bp8XjITceWSN_7XFfW7WfJDTomE.jwk WOjQYkyK7DxY_T5pMncMO5w0f6E.jwk
Supprimer les anciennes clés :
# rm .*.jwk
Dresser la liste des clés actuelles du serveur Tang pour vérifier que les clés non annoncées ne sont plus présentes :
# ls -A1
Exemple de sortie
Bp8XjITceWSN_7XFfW7WfJDTomE.jwk WOjQYkyK7DxY_T5pMncMO5w0f6E.jwk
Vérification
À ce stade, le serveur annonce toujours les nouvelles clés, mais toute tentative de décryptage sur la base de l'ancienne clé échoue.
Demande au serveur Tang les empreintes de clés actuellement annoncées :
# tang-show-keys 7500
Exemple de sortie
WOjQYkyK7DxY_T5pMncMO5w0f6E
Décrypter le fichier test créé précédemment pour vérifier que le décryptage avec les anciennes clés échoue :
# clevis decrypt </tmp/encryptValidation
Exemple de sortie
Error communicating with the server!
Si vous utilisez plusieurs serveurs Tang derrière un équilibreur de charge qui partagent le même matériel clé, assurez-vous que les modifications apportées sont correctement synchronisées sur l'ensemble des serveurs avant de poursuivre.
16.4. Considérations relatives à la reprise après sinistre
Cette section décrit plusieurs situations de catastrophes potentielles et les procédures à suivre pour chacune d'entre elles. D'autres situations seront ajoutées au fur et à mesure qu'elles seront découvertes ou présumées possibles.
16.4.1. Perte d'une machine cliente
La perte d'un nœud de cluster qui utilise le serveur Tang pour déchiffrer sa partition de disque est not un désastre. Que la machine ait été volée, qu'elle ait subi une panne matérielle ou qu'elle ait connu un autre scénario de perte n'a pas d'importance : les disques sont cryptés et considérés comme irrécupérables.
Toutefois, en cas de vol, il serait prudent de procéder à une rotation préventive des clés du serveur Tang et de recomposer les clés de tous les nœuds restants afin de s'assurer que les disques restent irrécupérables, même dans le cas où les voleurs parviendraient à accéder aux serveurs Tang.
Pour sortir de cette situation, il faut réinstaller ou remplacer le nœud.
16.4.2. Planification en cas de perte de connectivité du réseau client
La perte de connectivité réseau d'un nœud individuel l'empêchera de démarrer sans surveillance.
Si vous prévoyez des travaux susceptibles d'entraîner une perte de connectivité réseau, vous pouvez révéler la phrase d'authentification pour qu'un technicien sur place l'utilise manuellement, puis faire pivoter les clés par la suite pour l'invalider :
Procédure
Avant que le réseau ne devienne indisponible, affichez le mot de passe utilisé dans le premier slot
-s 1de l'appareil/dev/vda2à l'aide de cette commande :$ sudo clevis luks pass -d /dev/vda2 -s 1
Invalidez cette valeur et régénérez une nouvelle phrase d'authentification aléatoire au démarrage à l'aide de cette commande :
$ sudo clevis luks regen -d /dev/vda2 -s 1
16.4.3. Perte inattendue de la connectivité du réseau
Si l'interruption du réseau est inattendue et qu'un nœud redémarre, envisagez les scénarios suivants :
- Si des nœuds sont encore en ligne, veillez à ce qu'ils ne redémarrent pas tant que la connectivité réseau n'est pas rétablie. Cela ne s'applique pas aux clusters à un seul nœud.
- Le nœud restera hors ligne jusqu'à ce que la connectivité réseau soit rétablie ou qu'une phrase de passe préétablie soit saisie manuellement dans la console. Dans des circonstances exceptionnelles, les administrateurs de réseau peuvent être en mesure de reconfigurer des segments de réseau pour rétablir l'accès, mais cela va à l'encontre de l'intention de l'EDNB, qui veut que l'absence d'accès au réseau signifie l'absence de capacité à démarrer.
- On peut raisonnablement s'attendre à ce que l'absence d'accès au réseau au niveau du nœud ait une incidence sur la capacité de ce nœud à fonctionner ainsi que sur sa capacité à démarrer. Même si le nœud pouvait démarrer par une intervention manuelle, l'absence d'accès au réseau le rendrait inutilisable.
16.4.4. Rétablissement manuel de la connectivité réseau
Le technicien sur site dispose également d'un processus quelque peu complexe et manuel pour la récupération du réseau.
Procédure
- Le technicien sur place extrait l'en-tête Clevis des disques durs. En fonction du verrouillage du BIOS, cela peut impliquer de retirer les disques et de les installer dans une machine de laboratoire.
- Le technicien sur place transmet les en-têtes Clevis à un collègue disposant d'un accès légitime au réseau Tang, qui procède alors au décryptage.
- En raison de la nécessité d'un accès limité au réseau Tang, le technicien ne devrait pas pouvoir accéder à ce réseau par le biais d'un VPN ou d'une autre connectivité à distance. De même, le technicien ne peut pas connecter le serveur distant à ce réseau afin de décrypter automatiquement les disques.
- Le technicien réinstalle le disque et saisit manuellement la phrase de passe en texte clair fournie par son collègue.
- La machine démarre avec succès même sans accès direct aux serveurs Tang. Notez que la transmission du matériel de clé du site d'installation vers un autre site avec accès au réseau doit être effectuée avec précaution.
- Lorsque la connectivité du réseau est rétablie, le technicien fait tourner les clés de chiffrement.
16.4.5. Rétablissement d'urgence de la connectivité du réseau
Si vous ne parvenez pas à rétablir manuellement la connectivité réseau, envisagez les étapes suivantes. Sachez que ces étapes sont déconseillées si d'autres méthodes de rétablissement de la connectivité réseau sont disponibles.
- Cette méthode ne doit être effectuée que par un technicien de confiance.
- Le fait d'emmener les clés du serveur Tang sur le site distant est considéré comme une violation des clés et tous les serveurs doivent être recodés et recryptés.
- Cette méthode ne doit être utilisée que dans des cas extrêmes, ou comme méthode de récupération pour démontrer sa viabilité.
- Une solution tout aussi extrême, mais théoriquement possible, consiste à alimenter le serveur en question à l'aide d'un système d'alimentation sans coupure (UPS), à le transporter vers un lieu disposant d'une connectivité réseau pour démarrer et décrypter les disques, puis à le restaurer à son emplacement d'origine sur batterie pour qu'il puisse continuer à fonctionner.
- Si vous souhaitez utiliser une phrase de passe manuelle de sauvegarde, vous devez la créer avant que la situation d'échec ne se produise.
- Tout comme les scénarios d'attaque deviennent plus complexes avec TPM et Tang par rapport à une installation Tang autonome, les processus de reprise après sinistre sont également plus complexes si l'on utilise la même méthode.
16.4.6. Perte d'un segment de réseau
La perte d'un segment de réseau, rendant un serveur Tang temporairement indisponible, a les conséquences suivantes :
- Les nœuds OpenShift Container Platform continuent de démarrer normalement, à condition que d'autres serveurs soient disponibles.
- Les nouveaux nœuds ne peuvent pas établir leurs clés de chiffrement tant que le segment de réseau n'est pas restauré. Dans ce cas, assurez la connectivité avec les sites géographiques distants à des fins de haute disponibilité et de redondance. En effet, lorsque vous installez un nouveau nœud ou que vous remettez une clé dans un nœud existant, tous les serveurs Tang auxquels vous faites référence dans cette opération doivent être disponibles.
Un modèle hybride pour un réseau très diversifié, tel que cinq régions géographiques dans lesquelles chaque client est connecté aux trois clients les plus proches, mérite d'être étudié.
Dans ce scénario, les nouveaux clients peuvent établir leurs clés de chiffrement avec le sous-ensemble de serveurs qui sont joignables. Par exemple, dans l'ensemble de serveurs tang1, tang2 et tang3, si tang2 devient inaccessible, les clients peuvent encore établir leurs clés de chiffrement avec tang1 et tang3, et ultérieurement les rétablir avec l'ensemble complet. Cela peut nécessiter une intervention manuelle ou une automatisation plus complexe.
16.4.7. Perte d'un serveur Tang
La perte d'un serveur Tang individuel au sein d'un ensemble équilibré de serveurs disposant de clés identiques est totalement transparente pour les clients.
La défaillance temporaire de tous les serveurs Tang associés à la même URL, c'est-à-dire l'ensemble des serveurs à charge équilibrée, peut être considérée comme la perte d'un segment de réseau. Les clients existants ont la possibilité de décrypter leurs partitions de disque tant qu'un autre serveur Tang préconfiguré est disponible. Les nouveaux clients ne peuvent pas s'inscrire tant qu'au moins un de ces serveurs n'est pas remis en ligne.
Vous pouvez atténuer la perte physique d'un serveur Tang en réinstallant le serveur ou en le restaurant à partir de sauvegardes. Veillez à ce que les processus de sauvegarde et de restauration du matériel clé soient protégés de manière adéquate contre tout accès non autorisé.
16.4.8. Recomposition des clés compromises
Si les clés sont potentiellement exposées à des tiers non autorisés, par exemple en cas de vol physique d'un serveur Tang ou des données associées, procédez immédiatement à une rotation des clés.
Procédure
- Recomposer les clés de tout serveur Tang contenant le matériel concerné.
- Recomposer la clé de tous les clients utilisant le serveur Tang.
- Détruire le support original de la clé.
- Examinez minutieusement tout incident entraînant une exposition involontaire de la clé de chiffrement principale. Si possible, mettez les nœuds compromis hors ligne et recryptez leurs disques.
Le reformatage et la réinstallation sur le même matériel physique, bien que lents, sont faciles à automatiser et à tester.