
Évolutivité et performance
Mise à l'échelle de votre cluster OpenShift Container Platform et optimisation des performances dans les environnements de production
Résumé
Chapitre 1. Pratiques recommandées en matière de performance et d'évolutivité
Cette rubrique fournit des pratiques recommandées en matière de performances et d'évolutivité pour OpenShift Container Platform.
1.1. Pratiques recommandées pour la mise à l'échelle du cluster
Les conseils de cette section ne s'appliquent qu'aux installations intégrant un fournisseur de services en nuage.
Appliquez les meilleures pratiques suivantes pour faire évoluer le nombre de machines de travail dans votre cluster OpenShift Container Platform. Vous faites évoluer les machines de travail en augmentant ou en diminuant le nombre de répliques définies dans l'ensemble de machines de travail.
Lors de l'extension de la grappe à un plus grand nombre de nœuds :
- Répartir les nœuds dans toutes les zones disponibles pour une plus grande disponibilité.
- Ne pas dépasser 25 à 50 machines à la fois.
- Envisagez de créer de nouveaux ensembles de machines de calcul dans chaque zone disponible avec des types d'instance alternatifs de taille similaire afin d'atténuer les contraintes de capacité périodiques des fournisseurs. Par exemple, sur AWS, utilisez m5.large et m5d.large.
Les fournisseurs de cloud peuvent mettre en place un quota pour les services API. Il convient donc de faire évoluer progressivement le cluster.
Le contrôleur peut ne pas être en mesure de créer les machines si les répliques dans les ensembles de machines de calcul sont réglées sur des nombres plus élevés en une seule fois. Le nombre de requêtes que la plateforme cloud, sur laquelle OpenShift Container Platform est déployée, est capable de traiter a un impact sur le processus. Le contrôleur commencera à faire plus de requêtes en essayant de créer, de vérifier et de mettre à jour l'état des machines. La plateforme cloud sur laquelle OpenShift Container Platform est déployée a des limites de requêtes API ; des requêtes excessives peuvent conduire à des échecs de création de machines en raison des limitations de la plateforme cloud.
Activez les contrôles de santé des machines lorsque vous passez à un grand nombre de nœuds. En cas de défaillance, les contrôles de santé surveillent l'état des machines et les réparent automatiquement.
Lors de la mise à l'échelle de grappes importantes et denses vers un nombre inférieur de nœuds, cela peut prendre beaucoup de temps car le processus implique la vidange ou l'expulsion des objets s'exécutant sur les nœuds qui sont terminés en parallèle. En outre, le client peut commencer à limiter les requêtes s'il y a trop d'objets à expulser. Les taux de requêtes par seconde (QPS) et de rafales par défaut du client sont actuellement fixés à 5 et 10 respectivement. Ces valeurs ne peuvent pas être modifiées dans OpenShift Container Platform.
1.2. Dimensionnement des nœuds du plan de contrôle
Les besoins en ressources des nœuds du plan de contrôle dépendent du nombre et du type de nœuds et d'objets dans le cluster. Les recommandations suivantes concernant la taille des nœuds du plan de contrôle sont basées sur les résultats d'un test focalisé sur la densité du plan de contrôle, ou Cluster-density. Ce test crée les objets suivants dans un nombre donné d'espaces de noms :
- 1 flux d'images
- 1 construire
-
5 déploiements, avec 2 répliques de pods à l'état
sleep, montant chacun 4 secrets, 4 cartes de configuration et 1 volume d'API descendant - 5 services, chacun pointant vers les ports TCP/8080 et TCP/8443 d'un des déploiements précédents
- 1 itinéraire menant au premier des services précédents
- 10 secrets contenant 2048 caractères aléatoires
- 10 cartes de configuration contenant 2048 caractères aléatoires
| Number of worker nodes | Densité de la grappe (espaces nominatifs) | Cœurs de l'unité centrale | Mémoire (GB) |
|---|---|---|---|
| 24 | 500 | 4 | 16 |
| 120 | 1000 | 8 | 32 |
| 252 | 4000 | 16, mais 24 si l'on utilise le plug-in réseau OVN-Kubernetes | 64, mais 128 si l'on utilise le plug-in réseau OVN-Kubernetes |
| 501, mais non testé avec le plug-in réseau OVN-Kubernetes | 4000 | 16 | 96 |
Les données du tableau ci-dessus sont basées sur une plateforme de conteneurs OpenShift fonctionnant au-dessus d'AWS, utilisant des instances r5.4xlarge comme nœuds de plan de contrôle et des instances m5.2xlarge comme nœuds de travail.
Dans un grand cluster dense comprenant trois nœuds de plan de contrôle, l'utilisation du processeur et de la mémoire augmente lorsque l'un des nœuds est arrêté, redémarré ou tombe en panne. Les pannes peuvent être dues à des problèmes inattendus d'alimentation, de réseau, d'infrastructure sous-jacente, ou à des cas intentionnels où le cluster est redémarré après avoir été arrêté pour réduire les coûts. Les deux nœuds restants du plan de contrôle doivent gérer la charge afin d'être hautement disponibles, ce qui entraîne une augmentation de l'utilisation des ressources. Ce phénomène se produit également lors des mises à niveau, car les nœuds du plan de contrôle sont isolés, vidés et redémarrés en série pour appliquer les mises à jour du système d'exploitation, ainsi que la mise à jour des opérateurs du plan de contrôle. Pour éviter les défaillances en cascade, maintenez l'utilisation globale des ressources CPU et mémoire sur les nœuds du plan de contrôle à un maximum de 60 % de la capacité disponible afin de gérer les pics d'utilisation des ressources. Augmentez l'UC et la mémoire des nœuds du plan de contrôle en conséquence pour éviter les temps d'arrêt potentiels dus au manque de ressources.
Le dimensionnement des nœuds varie en fonction du nombre de nœuds et d'objets dans la grappe. Il dépend également de la création active d'objets sur la grappe. Pendant la création des objets, le plan de contrôle est plus actif en termes d'utilisation des ressources que lorsque les objets sont dans la phase running.
Operator Lifecycle Manager (OLM) s'exécute sur les nœuds du plan de contrôle et son empreinte mémoire dépend du nombre d'espaces de noms et d'opérateurs installés par l'utilisateur qu'OLM doit gérer sur la grappe. Les nœuds du plan de contrôle doivent être dimensionnés en conséquence afin d'éviter les pertes de mémoire (OOM kills). Les points de données suivants sont basés sur les résultats des tests de maximisation des grappes.
| Nombre d'espaces de noms | Mémoire OLM au repos (GB) | Mémoire OLM avec 5 opérateurs utilisateurs installés (GB) |
|---|---|---|
| 500 | 0.823 | 1.7 |
| 1000 | 1.2 | 2.5 |
| 1500 | 1.7 | 3.2 |
| 2000 | 2 | 4.4 |
| 3000 | 2.7 | 5.6 |
| 4000 | 3.8 | 7.6 |
| 5000 | 4.2 | 9.02 |
| 6000 | 5.8 | 11.3 |
| 7000 | 6.6 | 12.9 |
| 8000 | 6.9 | 14.8 |
| 9000 | 8 | 17.7 |
| 10,000 | 9.9 | 21.6 |
Vous pouvez modifier la taille des nœuds du plan de contrôle dans un cluster OpenShift Container Platform 4.12 en cours d'exécution pour les configurations suivantes uniquement :
- Clusters installés avec une méthode d'installation fournie par l'utilisateur.
- Clusters AWS installés avec une méthode d'installation d'infrastructure fournie par l'installateur.
- Les clusters qui utilisent un jeu de machines du plan de contrôle pour gérer les machines du plan de contrôle.
Pour toutes les autres configurations, vous devez estimer le nombre total de nœuds et utiliser la taille de nœud suggérée pour le plan de contrôle lors de l'installation.
Les recommandations sont basées sur les points de données capturés sur les clusters OpenShift Container Platform avec OpenShift SDN comme plugin réseau.
Dans OpenShift Container Platform 4.12, la moitié d'un cœur de CPU (500 millicores) est désormais réservée par le système par défaut par rapport à OpenShift Container Platform 3.11 et aux versions précédentes. Les tailles sont déterminées en tenant compte de cela.
1.2.1. Sélection d'un type d'instance Amazon Web Services plus important pour les machines du plan de contrôle
Si les machines du plan de contrôle d'un cluster Amazon Web Services (AWS) ont besoin de plus de ressources, vous pouvez sélectionner un type d'instance AWS plus important pour les machines du plan de contrôle.
La procédure pour les clusters qui utilisent un jeu de machines du plan de contrôle est différente de la procédure pour les clusters qui n'utilisent pas de jeu de machines du plan de contrôle.
Si vous n'êtes pas sûr de l'état de la CR ControlPlaneMachineSet dans votre cluster, vous pouvez vérifier l'état de la CR.
1.2.1.1. Modifier le type d'instance Amazon Web Services à l'aide d'un jeu de machines du plan de contrôle
Vous pouvez modifier le type d'instance Amazon Web Services (AWS) que vos machines du plan de contrôle utilisent en mettant à jour la spécification dans la ressource personnalisée (CR) de l'ensemble de machines du plan de contrôle.
Conditions préalables
- Votre cluster AWS utilise un jeu de machines de plan de contrôle.
Procédure
Modifiez le jeu de machines CR de votre plan de contrôle en exécutant la commande suivante :
$ oc --namespace openshift-machine-api edit controlplanemachineset.machine.openshift.io cluster
Modifiez la ligne suivante sous le champ
providerSpec:providerSpec: value: ... instanceType: <compatible_aws_instance_type> 1- 1
- Spécifiez un type d'instance AWS plus important avec la même base que la sélection précédente. Par exemple, vous pouvez remplacer
m6i.xlargeparm6i.2xlargeoum6i.4xlarge.
Enregistrez vos modifications.
-
Pour les clusters qui utilisent la stratégie de mise à jour par défaut
RollingUpdate, l'opérateur propage automatiquement les modifications à votre configuration du plan de contrôle. -
Pour les clusters configurés pour utiliser la stratégie de mise à jour
OnDelete, vous devez remplacer manuellement les machines du plan de contrôle.
-
Pour les clusters qui utilisent la stratégie de mise à jour par défaut
Ressources supplémentaires
1.2.1.2. Modifier le type d'instance Amazon Web Services à l'aide de la console AWS
Vous pouvez modifier le type d'instance Amazon Web Services (AWS) utilisé par les machines du plan de contrôle en mettant à jour le type d'instance dans la console AWS.
Conditions préalables
- Vous avez accès à la console AWS avec les permissions nécessaires pour modifier l'Instance EC2 de votre cluster.
-
Vous avez accès au cluster OpenShift Container Platform en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
- Ouvrez la console AWS et récupérez les instances des machines du plan de contrôle.
Choisissez une instance de machine de plan de contrôle.
- Pour la machine de plan de contrôle sélectionnée, sauvegardez les données etcd en créant un instantané etcd. Pour plus d'informations, voir "Sauvegarde de etcd".
- Dans la console AWS, arrêtez l'instance de machine du plan de contrôle.
- Sélectionnez l'instance arrêtée et cliquez sur Actions → Instance Settings → Change instance type.
-
Remplacez l'instance par un type plus grand, en veillant à ce que le type soit de la même base que la sélection précédente, et appliquez les modifications. Par exemple, vous pouvez remplacer
m6i.xlargeparm6i.2xlargeoum6i.4xlarge. - Démarrer l'instance.
-
Si votre cluster OpenShift Container Platform possède un objet
Machinecorrespondant à l'instance, mettez à jour le type d'instance de l'objet pour qu'il corresponde au type d'instance défini dans la console AWS.
- Répétez ce processus pour chaque machine du plan de contrôle.
Ressources supplémentaires
1.3. Pratiques recommandées pour etcd
Comme etcd écrit des données sur le disque et y conserve des propositions, ses performances dépendent de celles du disque. Bien que etcd ne soit pas particulièrement gourmand en E/S, il a besoin d'un périphérique de bloc à faible latence pour des performances et une stabilité optimales. Comme le protocole de consensus d'etcd dépend du stockage persistant des métadonnées dans un journal (WAL), etcd est sensible à la latence de l'écriture sur disque. Les disques lents et l'activité du disque par d'autres processus peuvent causer de longues latences de synchronisation.
Ces latences peuvent amener etcd à manquer des battements de cœur, à ne pas livrer de nouvelles propositions sur le disque à temps et, en fin de compte, à subir des dépassements de délai de requête et des pertes de leader temporaires. Des latences d'écriture élevées entraînent également une lenteur de l'API OpenShift, ce qui affecte les performances du cluster. Pour ces raisons, évitez de colocaliser d'autres charges de travail sur les nœuds du plan de contrôle.
En termes de latence, exécutez etcd au-dessus d'un périphérique bloc qui peut écrire au moins 50 IOPS de 8000 octets de long séquentiellement. C'est-à-dire avec une latence de 10 ms, en gardant à l'esprit que etcd utilise fdatasync pour synchroniser chaque écriture dans le WAL. Pour les clusters très chargés, 500 IOPS séquentiels de 8000 octets (2 ms) sont recommandés. Pour mesurer ces chiffres, vous pouvez utiliser un outil d'analyse comparative, tel que fio.
Pour obtenir de telles performances, exécutez etcd sur des machines soutenues par des disques SSD ou NVMe avec une faible latence et un débit élevé. Considérons les disques d'état solide (SSD) à cellule à niveau unique (SLC), qui fournissent 1 bit par cellule de mémoire, sont durables et fiables, et sont idéaux pour les charges de travail à forte intensité d'écriture.
Les caractéristiques suivantes du disque dur permettent d'optimiser les performances du système etcd :
- Faible latence pour permettre une lecture rapide.
- Écritures à large bande passante pour des compactions et des défragmentations plus rapides.
- Lecture à large bande passante pour une reprise plus rapide en cas de défaillance.
- Les disques d'état solide sont une sélection minimale, mais les disques NVMe sont préférables.
- Matériel de qualité serveur provenant de différents fabricants pour une plus grande fiabilité.
- Technologie RAID 0 pour des performances accrues.
- Disques etcd dédiés. Ne placez pas de fichiers journaux ou d'autres charges de travail lourdes sur les disques etcd.
Évitez les configurations NAS ou SAN et les disques en rotation. Effectuez toujours des analyses comparatives à l'aide d'utilitaires tels que fio. Surveillez en permanence les performances de la grappe au fur et à mesure qu'elles augmentent.
Évitez d'utiliser le protocole NFS (Network File System) ou d'autres systèmes de fichiers basés sur le réseau.
Certaines mesures clés à surveiller sur un cluster OpenShift Container Platform déployé sont p99 of etcd disk write ahead log duration et le nombre de changements de leader etcd. Utilisez Prometheus pour suivre ces métriques.
La taille des bases de données des membres etcd peut varier dans un cluster au cours des opérations normales. Cette différence n'affecte pas les mises à niveau du cluster, même si la taille du leader est différente de celle des autres membres.
Pour valider le matériel pour etcd avant ou après la création du cluster OpenShift Container Platform, vous pouvez utiliser fio.
Conditions préalables
- Les moteurs d'exécution de conteneurs tels que Podman ou Docker sont installés sur la machine que vous testez.
-
Les données sont écrites sur le chemin
/var/lib/etcd.
Procédure
Exécutez fio et analysez les résultats :
Si vous utilisez Podman, exécutez cette commande :
$ sudo podman run --volume /var/lib/etcd:/var/lib/etcd:Z quay.io/openshift-scale/etcd-perf
Si vous utilisez Docker, exécutez cette commande :
$ sudo docker run --volume /var/lib/etcd:/var/lib/etcd:Z quay.io/openshift-scale/etcd-perf
La sortie indique si le disque est assez rapide pour héberger etcd en comparant le 99ème percentile de la métrique fsync capturée lors de l'exécution pour voir si elle est inférieure à 10 ms. Voici quelques-unes des métriques etcd les plus importantes qui peuvent être affectées par les performances d'E/S :
-
etcd_disk_wal_fsync_duration_seconds_bucketla métrique indique la durée de la synchronisation WAL de etcd -
etcd_disk_backend_commit_duration_seconds_bucketla métrique indique la durée de latence du commit du backend etcd -
etcd_server_leader_changes_seen_totalrapports métriques le leader change
Comme etcd réplique les requêtes entre tous les membres, ses performances dépendent fortement de la latence des entrées/sorties du réseau. Des latences réseau élevées entraînent des battements de cœur etcd plus longs que le délai d'élection, ce qui se traduit par des élections de leaders qui perturbent le cluster. Une mesure clé à surveiller sur un cluster OpenShift Container Platform déployé est le 99e percentile de la latence des pairs du réseau etcd sur chaque membre du cluster etcd. Utilisez Prometheus pour suivre cette métrique.
La métrique histogram_quantile(0.99, rate(etcd_network_peer_round_trip_time_seconds_bucket[2m])) indique le temps d'aller-retour pour que etcd finisse de répliquer les requêtes des clients entre les membres. Assurez-vous qu'il est inférieur à 50 ms.
1.4. Déplacer etcd sur un autre disque
Vous pouvez déplacer etcd d'un disque partagé vers un disque séparé afin d'éviter ou de résoudre les problèmes de performances.
Conditions préalables
-
L'adresse
MachineConfigPooldoit correspondre à l'adressemetadata.labels[machineconfiguration.openshift.io/role]. Cela s'applique à un contrôleur, à un travailleur ou à un pool personnalisé. -
Le périphérique de stockage auxiliaire du nœud, tel que
/dev/sdb, doit correspondre à sdb. Modifiez cette référence à tous les endroits du fichier.
Cette procédure ne permet pas de déplacer des parties du système de fichiers racine, telles que /var/, vers un autre disque ou une autre partition sur un nœud installé.
L'opérateur de configuration de machine (MCO) est chargé de monter un disque secondaire pour un stockage de conteneur OpenShift Container Platform 4.12.
Procédez comme suit pour déplacer etcd vers un autre périphérique :
Procédure
Créez un fichier YAML
machineconfignomméetcd-mc.ymlet ajoutez les informations suivantes :apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: master name: 98-var-lib-etcd spec: config: ignition: version: 3.2.0 systemd: units: - contents: | [Unit] Description=Make File System on /dev/sdb DefaultDependencies=no BindsTo=dev-sdb.device After=dev-sdb.device var.mount Before=systemd-fsck@dev-sdb.service [Service] Type=oneshot RemainAfterExit=yes ExecStart=/usr/lib/systemd/systemd-makefs xfs /dev/sdb TimeoutSec=0 [Install] WantedBy=var-lib-containers.mount enabled: true name: systemd-mkfs@dev-sdb.service - contents: | [Unit] Description=Mount /dev/sdb to /var/lib/etcd Before=local-fs.target Requires=systemd-mkfs@dev-sdb.service After=systemd-mkfs@dev-sdb.service var.mount [Mount] What=/dev/sdb Where=/var/lib/etcd Type=xfs Options=defaults,prjquota [Install] WantedBy=local-fs.target enabled: true name: var-lib-etcd.mount - contents: | [Unit] Description=Sync etcd data if new mount is empty DefaultDependencies=no After=var-lib-etcd.mount var.mount Before=crio.service [Service] Type=oneshot RemainAfterExit=yes ExecCondition=/usr/bin/test ! -d /var/lib/etcd/member ExecStart=/usr/sbin/setenforce 0 ExecStart=/bin/rsync -ar /sysroot/ostree/deploy/rhcos/var/lib/etcd/ /var/lib/etcd/ ExecStart=/usr/sbin/setenforce 1 TimeoutSec=0 [Install] WantedBy=multi-user.target graphical.target enabled: true name: sync-var-lib-etcd-to-etcd.service - contents: | [Unit] Description=Restore recursive SELinux security contexts DefaultDependencies=no After=var-lib-etcd.mount Before=crio.service [Service] Type=oneshot RemainAfterExit=yes ExecStart=/sbin/restorecon -R /var/lib/etcd/ TimeoutSec=0 [Install] WantedBy=multi-user.target graphical.target enabled: true name: restorecon-var-lib-etcd.serviceCréez la configuration de la machine en entrant les commandes suivantes :
$ oc login -u ${ADMIN} -p ${ADMINPASSWORD} ${API} ... output omitted ...$ oc create -f etcd-mc.yml machineconfig.machineconfiguration.openshift.io/98-var-lib-etcd created
$ oc login -u ${ADMIN} -p ${ADMINPASSWORD} ${API} [... output omitted ...]$ oc create -f etcd-mc.yml machineconfig.machineconfiguration.openshift.io/98-var-lib-etcd created
Les nœuds sont mis à jour et redémarrés. Une fois le redémarrage terminé, les événements suivants se produisent :
- Un système de fichiers XFS est créé sur le disque spécifié.
-
Le disque est monté sur
/var/lib/etc. -
Le contenu de
/sysroot/ostree/deploy/rhcos/var/lib/etcdest synchronisé avec/var/lib/etcd. -
Une restauration des étiquettes de
SELinuxest forcée pour/var/lib/etcd. - L'ancien contenu n'est pas supprimé.
Une fois que les nœuds sont sur un disque séparé, mettez à jour le fichier de configuration de la machine,
etcd-mc.ymlavec les informations suivantes :apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: master name: 98-var-lib-etcd spec: config: ignition: version: 3.2.0 systemd: units: - contents: | [Unit] Description=Mount /dev/sdb to /var/lib/etcd Before=local-fs.target Requires=systemd-mkfs@dev-sdb.service After=systemd-mkfs@dev-sdb.service var.mount [Mount] What=/dev/sdb Where=/var/lib/etcd Type=xfs Options=defaults,prjquota [Install] WantedBy=local-fs.target enabled: true name: var-lib-etcd.mountAppliquez la version modifiée qui supprime la logique de création et de synchronisation du périphérique en entrant la commande suivante :
$ oc replace -f etcd-mc.yml
L'étape précédente empêche les nœuds de redémarrer.
Ressources supplémentaires
1.5. Défragmentation des données etcd
Pour les clusters importants et denses, etcd peut souffrir de mauvaises performances si l'espace-clé devient trop grand et dépasse le quota d'espace. Maintenez et défragmentez périodiquement etcd pour libérer de l'espace dans le magasin de données. Surveillez les métriques etcd dans Prometheus et défragmentez-le si nécessaire ; sinon, etcd peut déclencher une alarme à l'échelle de la grappe qui la met en mode de maintenance n'acceptant que les lectures et les suppressions de clés.
Surveillez ces paramètres clés :
-
etcd_server_quota_backend_bytesce qui correspond à la limite actuelle du quota -
etcd_mvcc_db_total_size_in_use_in_bytesqui indique l'utilisation réelle de la base de données après un compactage de l'historique -
etcd_mvcc_db_total_size_in_bytesqui indique la taille de la base de données, y compris l'espace libre en attente de défragmentation
Défragmenter les données etcd pour récupérer de l'espace disque après des événements qui provoquent la fragmentation du disque, comme le compactage de l'historique etcd.
Le compactage de l'historique est effectué automatiquement toutes les cinq minutes et laisse des trous dans la base de données back-end. Cet espace fragmenté peut être utilisé par etcd, mais n'est pas disponible pour le système de fichiers hôte. Vous devez défragmenter etcd pour rendre cet espace disponible au système de fichiers hôte.
La défragmentation se produit automatiquement, mais vous pouvez également la déclencher manuellement.
La défragmentation automatique est une bonne chose dans la plupart des cas, car l'opérateur etcd utilise les informations sur les clusters pour déterminer l'opération la plus efficace pour l'utilisateur.
1.5.1. Défragmentation automatique
L'opérateur etcd défragmente automatiquement les disques. Aucune intervention manuelle n'est nécessaire.
Vérifiez que le processus de défragmentation s'est déroulé correctement en consultant l'un de ces journaux :
- journaux etcd
- cluster-etcd-operator pod
- statut de l'opérateur journal des erreurs
La défragmentation automatique peut provoquer une défaillance de l'élection du leader dans divers composants de base d'OpenShift, tels que le gestionnaire de contrôleur Kubernetes, ce qui déclenche un redémarrage du composant défaillant. Le redémarrage est inoffensif et déclenche le basculement vers la prochaine instance en cours d'exécution ou le composant reprend le travail après le redémarrage.
Exemple de sortie de journal pour une défragmentation réussie
le membre etcd a été défragmenté : <member_name>, memberID : <member_id>
Exemple de sortie de journal pour une défragmentation infructueuse
échec de la défragmentation sur le membre : <member_name>, memberID : <member_id>: <error_message>
1.5.2. Défragmentation manuelle
Une alerte Prometheus vous indique si vous devez utiliser la défragmentation manuelle. L'alerte s'affiche dans deux cas :
- Lorsque etcd utilise plus de 50 % de son espace disponible pendant plus de 10 minutes
- Lorsque etcd utilise activement moins de 50 % de la taille totale de sa base de données pendant plus de 10 minutes
Vous pouvez également déterminer si une défragmentation est nécessaire en vérifiant la taille de la base de données etcd en Mo qui sera libérée par la défragmentation avec l'expression PromQL : (etcd_mvcc_db_total_size_in_bytes - etcd_mvcc_db_total_size_in_use_in_bytes)/1024/1024
La défragmentation de etcd est une action bloquante. Le membre etcd ne répondra pas tant que la défragmentation ne sera pas terminée. Pour cette raison, attendez au moins une minute entre les actions de défragmentation sur chacun des pods pour permettre au cluster de récupérer.
Suivez cette procédure pour défragmenter les données etcd sur chaque membre etcd.
Conditions préalables
-
Vous avez accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin.
Procédure
Déterminer quel membre etcd est le leader, car le leader doit être défragmenté en dernier.
Obtenir la liste des pods etcd :
$ oc -n openshift-etcd get pods -l k8s-app=etcd -o wide
Exemple de sortie
etcd-ip-10-0-159-225.example.redhat.com 3/3 Running 0 175m 10.0.159.225 ip-10-0-159-225.example.redhat.com <none> <none> etcd-ip-10-0-191-37.example.redhat.com 3/3 Running 0 173m 10.0.191.37 ip-10-0-191-37.example.redhat.com <none> <none> etcd-ip-10-0-199-170.example.redhat.com 3/3 Running 0 176m 10.0.199.170 ip-10-0-199-170.example.redhat.com <none> <none>
Choisissez un pod et exécutez la commande suivante pour déterminer quel membre etcd est le leader :
$ oc rsh -n openshift-etcd etcd-ip-10-0-159-225.example.redhat.com etcdctl endpoint status --cluster -w table
Exemple de sortie
Defaulting container name to etcdctl. Use 'oc describe pod/etcd-ip-10-0-159-225.example.redhat.com -n openshift-etcd' to see all of the containers in this pod. +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://10.0.191.37:2379 | 251cd44483d811c3 | 3.4.9 | 104 MB | false | false | 7 | 91624 | 91624 | | | https://10.0.159.225:2379 | 264c7c58ecbdabee | 3.4.9 | 104 MB | false | false | 7 | 91624 | 91624 | | | https://10.0.199.170:2379 | 9ac311f93915cc79 | 3.4.9 | 104 MB | true | false | 7 | 91624 | 91624 | | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
D'après la colonne
IS LEADERde cette sortie, le point d'extrémitéhttps://10.0.199.170:2379est le leader. En faisant correspondre ce point d'extrémité avec la sortie de l'étape précédente, le nom de pod du leader estetcd-ip-10-0-199-170.example.redhat.com.
Défragmenter un membre etcd.
Se connecter au conteneur etcd en cours d'exécution, en indiquant le nom d'un pod qui est not le leader :
$ oc rsh -n openshift-etcd etcd-ip-10-0-159-225.example.redhat.com
Désactivez la variable d'environnement
ETCDCTL_ENDPOINTS:sh-4.4# unset ETCDCTL_ENDPOINTS
Défragmenter le membre etcd :
sh-4.4# etcdctl --command-timeout=30s --endpoints=https://localhost:2379 defrag
Exemple de sortie
Finished defragmenting etcd member[https://localhost:2379]
En cas d'erreur de temporisation, augmentez la valeur de
--command-timeoutjusqu'à ce que la commande réussisse.Vérifiez que la taille de la base de données a été réduite :
sh-4.4# etcdctl endpoint status -w table --cluster
Exemple de sortie
+---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://10.0.191.37:2379 | 251cd44483d811c3 | 3.4.9 | 104 MB | false | false | 7 | 91624 | 91624 | | | https://10.0.159.225:2379 | 264c7c58ecbdabee | 3.4.9 | 41 MB | false | false | 7 | 91624 | 91624 | | 1 | https://10.0.199.170:2379 | 9ac311f93915cc79 | 3.4.9 | 104 MB | true | false | 7 | 91624 | 91624 | | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+Cet exemple montre que la taille de la base de données pour ce membre etcd est maintenant de 41 Mo, alors qu'elle était de 104 Mo au départ.
Répétez ces étapes pour vous connecter à chacun des autres membres etcd et les défragmenter. Défragmentez toujours le leader en dernier.
Attendez au moins une minute entre les actions de défragmentation pour permettre au pod etcd de se rétablir. Tant que le pod etcd n'est pas rétabli, le membre etcd ne répond pas.
Si des alarmes
NOSPACEont été déclenchées en raison du dépassement du quota d'espace, effacez-les.Vérifiez s'il y a des alarmes sur
NOSPACE:sh-4.4# etcdctl alarm list
Exemple de sortie
memberID:12345678912345678912 alarm:NOSPACE
Effacer les alarmes :
sh-4.4# etcdctl alarm disarm
Prochaines étapes
Après la défragmentation, si etcd utilise toujours plus de 50 % de son espace disponible, envisagez d'augmenter le quota de disque pour etcd.
1.6. Dimensionnement des nœuds d'infrastructure
Infrastructure nodes sont des nœuds étiquetés pour exécuter des éléments de l'environnement OpenShift Container Platform. Les besoins en ressources des nœuds d'infrastructure dépendent de l'âge du cluster, des nœuds et des objets du cluster, car ces facteurs peuvent entraîner une augmentation du nombre de métriques ou de séries temporelles dans Prometheus. Les recommandations suivantes concernant la taille des nœuds d'infrastructure sont basées sur les résultats observés lors des tests de densité des clusters détaillés dans la section Control plane node sizing, où la pile de surveillance et le contrôleur d'entrée par défaut ont été déplacés vers ces nœuds.
| Number of worker nodes | Densité des clusters, ou nombre d'espaces de noms | Cœurs de l'unité centrale | Mémoire (GB) |
|---|---|---|---|
| 27 | 500 | 4 | 24 |
| 120 | 1000 | 8 | 48 |
| 252 | 4000 | 16 | 128 |
| 501 | 4000 | 32 | 128 |
En général, trois nœuds d'infrastructure sont recommandés par grappe.
Ces recommandations de dimensionnement doivent être utilisées à titre indicatif. Prometheus est une application très gourmande en mémoire ; l'utilisation des ressources dépend de divers facteurs, notamment du nombre de nœuds, d'objets, de l'intervalle de récupération des métriques Prometheus, des métriques ou des séries temporelles, et de l'âge du cluster. En outre, l'utilisation des ressources du routeur peut également être affectée par le nombre d'itinéraires et la quantité/le type de requêtes entrantes.
Ces recommandations ne s'appliquent qu'aux nœuds d'infrastructure hébergeant les composants d'infrastructure Monitoring, Ingress et Registry installés lors de la création du cluster.
Dans OpenShift Container Platform 4.12, la moitié d'un cœur de CPU (500 millicores) est désormais réservée par le système par défaut par rapport à OpenShift Container Platform 3.11 et aux versions précédentes. Cela influe sur les recommandations de dimensionnement énoncées.
1.7. Ressources supplémentaires
Chapitre 2. Pratiques d'hébergement recommandées pour les environnements IBM zSystems & IBM(R) LinuxONE
Cette rubrique fournit des pratiques d'hébergement recommandées pour OpenShift Container Platform sur IBM zSystems et IBM® LinuxONE.
L'architecture s390x est unique à bien des égards. Par conséquent, certaines recommandations formulées ici peuvent ne pas s'appliquer à d'autres plates-formes.
Sauf indication contraire, ces pratiques s'appliquent aux installations z/VM et Red Hat Enterprise Linux (RHEL) KVM sur IBM zSystems et IBM® LinuxONE.
2.1. Gestion du surengagement de l'unité centrale
Dans un environnement IBM zSystems hautement virtualisé, vous devez planifier avec soin la configuration et le dimensionnement de l'infrastructure. L'une des caractéristiques les plus importantes de la virtualisation est la possibilité de surcharger les ressources, c'est-à-dire d'allouer aux machines virtuelles plus de ressources qu'il n'y en a réellement au niveau de l'hyperviseur. Cela dépend beaucoup de la charge de travail et il n'existe pas de règle d'or applicable à toutes les configurations.
En fonction de votre configuration, tenez compte des meilleures pratiques suivantes concernant le surengagement du processeur :
- Au niveau du LPAR (hyperviseur PR/SM), évitez d'attribuer tous les cœurs physiques (IFL) disponibles à chaque LPAR. Par exemple, avec quatre IFL physiques disponibles, vous ne devriez pas définir trois LPAR avec quatre IFL logiques chacun.
- Vérifier et comprendre les parts et les poids des LPAR.
- Un nombre excessif de processeurs virtuels peut nuire aux performances. Ne définissez pas plus de processeurs virtuels pour un invité que de processeurs logiques définis pour le LPAR.
- Configurez le nombre de processeurs virtuels par invité en fonction de la charge de travail maximale, pas plus.
- Commencez par une petite quantité et surveillez la charge de travail. Augmentez progressivement le nombre de vCPU si nécessaire.
- Toutes les charges de travail ne se prêtent pas à des taux de surengagement élevés. Si la charge de travail est intensive en termes de CPU, vous ne pourrez probablement pas atteindre des ratios élevés sans problèmes de performance. Les charges de travail plus intensives en E/S peuvent conserver des performances constantes même avec des ratios de surengagement élevés.
2.2. Désactiver les grandes pages transparentes
Les pages volumineuses transparentes (THP) tentent d'automatiser la plupart des aspects de la création, de la gestion et de l'utilisation des pages volumineuses. Comme THP gère automatiquement les pages volumineuses, cela n'est pas toujours optimal pour tous les types de charges de travail. THP peut entraîner une régression des performances, car de nombreuses applications gèrent elles-mêmes les pages volumineuses. Par conséquent, envisagez de désactiver THP.
2.3. Améliorer les performances du réseau avec Receive Flow Steering
Receive Flow Steering (RFS) étend Receive Packet Steering (RPS) en réduisant davantage la latence du réseau. Le RFS est techniquement basé sur le RPS et améliore l'efficacité du traitement des paquets en augmentant le taux de réussite du cache de l'unité centrale. Pour ce faire, et en plus de tenir compte de la longueur de la file d'attente, RFS détermine l'unité centrale la plus pratique pour le calcul, de sorte que les occurrences dans la mémoire cache ont plus de chances de se produire au sein de l'unité centrale. Ainsi, le cache de l'unité centrale est moins invalidé et nécessite moins de cycles pour le reconstruire. Cela peut contribuer à réduire le temps d'exécution du traitement des paquets.
2.3.1. Utiliser l'opérateur de configuration de la machine (MCO) pour activer le RFS
Procédure
Copiez l'exemple de profil MCO suivant dans un fichier YAML. Par exemple,
enable-rfs.yaml:apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 50-enable-rfs spec: config: ignition: version: 2.2.0 storage: files: - contents: source: data:text/plain;charset=US-ASCII,%23%20turn%20on%20Receive%20Flow%20Steering%20%28RFS%29%20for%20all%20network%20interfaces%0ASUBSYSTEM%3D%3D%22net%22%2C%20ACTION%3D%3D%22add%22%2C%20RUN%7Bprogram%7D%2B%3D%22/bin/bash%20-c%20%27for%20x%20in%20/sys/%24DEVPATH/queues/rx-%2A%3B%20do%20echo%208192%20%3E%20%24x/rps_flow_cnt%3B%20%20done%27%22%0A filesystem: root mode: 0644 path: /etc/udev/rules.d/70-persistent-net.rules - contents: source: data:text/plain;charset=US-ASCII,%23%20define%20sock%20flow%20enbtried%20for%20%20Receive%20Flow%20Steering%20%28RFS%29%0Anet.core.rps_sock_flow_entries%3D8192%0A filesystem: root mode: 0644 path: /etc/sysctl.d/95-enable-rps.confCréer le profil MCO :
$ oc create -f enable-rfs.yaml
Vérifiez qu'une entrée nommée
50-enable-rfsest répertoriée :$ oc get mc
Pour désactiver, entrez :
$ oc delete mc 50-enable-rfs
2.4. Choisissez votre configuration de réseau
La pile réseau est l'un des composants les plus importants pour un produit basé sur Kubernetes comme OpenShift Container Platform. Pour les installations IBM zSystems, la configuration du réseau dépend de l'hyperviseur de votre choix. En fonction de la charge de travail et de l'application, la meilleure adaptation change généralement avec le cas d'utilisation et le modèle de trafic.
En fonction de votre configuration, tenez compte des meilleures pratiques suivantes :
- Envisagez toutes les options concernant les dispositifs de mise en réseau afin d'optimiser votre schéma de trafic. Explorez les avantages d'OSA-Express, RoCE Express, HiperSockets, z/VM VSwitch, Linux Bridge (KVM), et d'autres encore, afin de déterminer l'option la plus avantageuse pour votre installation.
- Utilisez toujours la dernière version disponible de la carte d'interface réseau. Par exemple, OSA Express 7S 10 GbE montre une grande amélioration par rapport à OSA Express 6S 10 GbE avec les types de charges de travail transactionnelles, bien que les deux soient des adaptateurs 10 GbE.
- Chaque commutateur virtuel ajoute une couche de latence supplémentaire.
- L'équilibreur de charge joue un rôle important dans la communication réseau en dehors du cluster. Envisagez d'utiliser un équilibreur de charge matériel de niveau production si cette fonction est essentielle pour votre application.
- OpenShift Container Platform SDN introduit des flux et des règles qui ont un impact sur les performances du réseau. Veillez à prendre en compte les affinités et les placements de pods, afin de bénéficier de la localité des services où la communication est critique.
- Équilibrer le compromis entre performance et fonctionnalité.
2.5. Garantir des performances de disque élevées avec HyperPAV sur z/VM
Les périphériques DASD et ECKD sont des types de disques couramment utilisés dans les environnements IBM zSystems. Dans une configuration typique d'OpenShift Container Platform dans des environnements z/VM, les disques DASD sont généralement utilisés pour prendre en charge le stockage local des nœuds. Vous pouvez configurer des périphériques alias HyperPAV pour fournir plus de débit et de meilleures performances d'E/S pour les disques DASD qui prennent en charge les invités z/VM.
L'utilisation d'HyperPAV pour les périphériques de stockage locaux permet d'améliorer considérablement les performances. Cependant, vous devez être conscient qu'il existe un compromis entre le débit et les coûts de l'unité centrale.
2.5.1. Utiliser le Machine Config Operator (MCO) pour activer les alias HyperPAV dans les nœuds utilisant des minidisques z/VM full-pack
Pour les configurations OpenShift Container Platform basées sur z/VM qui utilisent des minidisques full-pack, vous pouvez tirer parti de l'avantage des profils MCO en activant les alias HyperPAV dans tous les nœuds. Vous devez ajouter des configurations YAML pour le plan de contrôle et les nœuds de calcul.
Procédure
Copiez l'exemple de profil MCO suivant dans un fichier YAML pour le nœud du plan de contrôle. Par exemple,
05-master-kernelarg-hpav.yaml:$ cat 05-master-kernelarg-hpav.yaml apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: master name: 05-master-kernelarg-hpav spec: config: ignition: version: 3.1.0 kernelArguments: - rd.dasd=800-805Copiez l'exemple de profil MCO suivant dans un fichier YAML pour le nœud de calcul. Par exemple,
05-worker-kernelarg-hpav.yaml:$ cat 05-worker-kernelarg-hpav.yaml apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 05-worker-kernelarg-hpav spec: config: ignition: version: 3.1.0 kernelArguments: - rd.dasd=800-805NoteVous devez modifier les arguments de
rd.dasdpour qu'ils correspondent aux identifiants des appareils.Créer les profils MCO :
$ oc create -f 05-master-kernelarg-hpav.yaml
$ oc create -f 05-worker-kernelarg-hpav.yaml
Pour désactiver, entrez :
$ oc delete -f 05-master-kernelarg-hpav.yaml
$ oc delete -f 05-worker-kernelarg-hpav.yaml
2.6. Recommandations pour RHEL KVM sur les hôtes IBM zSystems
L'optimisation d'un environnement de serveurs virtuels KVM dépend fortement des charges de travail des serveurs virtuels et des ressources disponibles. La même action qui améliore les performances dans un environnement peut avoir des effets négatifs dans un autre. Trouver le meilleur équilibre pour un environnement particulier peut s'avérer difficile et implique souvent des expérimentations.
La section suivante présente quelques bonnes pratiques lors de l'utilisation d'OpenShift Container Platform avec RHEL KVM sur les environnements IBM zSystems et IBM® LinuxONE.
2.6.1. Utiliser plusieurs files d'attente pour les interfaces réseau VirtIO
Avec plusieurs unités centrales virtuelles, vous pouvez transférer des paquets en parallèle si vous prévoyez plusieurs files d'attente pour les paquets entrants et sortants. Utilisez l'attribut queues de l'élément driver pour configurer plusieurs files d'attente. Spécifiez un nombre entier d'au moins 2 qui ne dépasse pas le nombre de CPU virtuels du serveur virtuel.
L'exemple de spécification suivant configure deux files d'attente d'entrée et de sortie pour une interface réseau :
<interface type="direct">
<source network="net01"/>
<model type="virtio"/>
<driver ... queues="2"/>
</interface>Les files d'attente multiples sont conçues pour améliorer les performances d'une interface réseau, mais elles utilisent également des ressources de mémoire et d'unité centrale. Commencez par définir deux files d'attente pour les interfaces très fréquentées. Essayez ensuite de définir deux files d'attente pour les interfaces à faible trafic ou plus de deux files d'attente pour les interfaces très fréquentées.
2.6.2. Utiliser des threads d'E/S pour vos blocs virtuels
Pour que les périphériques de blocs virtuels utilisent des threads d'E/S, vous devez configurer un ou plusieurs threads d'E/S pour le serveur virtuel et chaque périphérique de bloc virtuel doit utiliser l'un de ces threads d'E/S.
L'exemple suivant indique que <iothreads>3</iothreads> doit configurer trois threads d'E/S, avec les ID de threads décimaux consécutifs 1, 2 et 3. Le paramètre iothread="2" spécifie l'élément du pilote de l'unité de disque qui doit utiliser le fil d'exécution d'E/S avec l'ID 2.
Exemple de spécification d'un fil d'E/S
... <domain> <iothreads>3</iothreads>1 ... <devices> ... <disk type="block" device="disk">2 <driver ... iothread="2"/> </disk> ... </devices> ... </domain>
Les threads peuvent augmenter les performances des opérations d'E/S pour les périphériques de disque, mais ils utilisent également de la mémoire et des ressources de l'unité centrale. Vous pouvez configurer plusieurs périphériques pour qu'ils utilisent le même thread. Le meilleur mappage des threads aux périphériques dépend des ressources disponibles et de la charge de travail.
Commencez par un petit nombre de fils d'entrée/sortie. Souvent, un seul thread d'E/S pour tous les périphériques de disque est suffisant. Ne configurez pas plus de threads que le nombre de CPU virtuels et ne configurez pas de threads inactifs.
Vous pouvez utiliser la commande virsh iothreadadd pour ajouter des threads d'E/S avec des ID de threads spécifiques à un serveur virtuel en cours d'exécution.
2.6.3. Éviter les périphériques SCSI virtuels
Ne configurez les périphériques SCSI virtuels que si vous avez besoin d'adresser le périphérique par le biais d'interfaces spécifiques SCSI. Configurez l'espace disque en tant que périphériques de bloc virtuels plutôt qu'en tant que périphériques SCSI virtuels, indépendamment de la sauvegarde sur l'hôte.
Cependant, vous pouvez avoir besoin d'interfaces spécifiques SCSI pour :
- LUN d'un lecteur de bandes SCSI sur l'hôte.
- Un fichier ISO de DVD sur le système de fichiers de l'hôte qui est monté sur un lecteur de DVD virtuel.
2.6.4. Configurer la mise en cache du disque par l'invité
Configurez vos périphériques de disque pour que la mise en cache soit effectuée par l'invité et non par l'hôte.
Assurez-vous que l'élément pilote de l'unité de disque inclut les paramètres cache="none" et io="native".
<disk type="block" device="disk">
<driver name="qemu" type="raw" cache="none" io="native" iothread="1"/>
...
</disk>2.6.5. Exclure le dispositif de ballon de mémoire
À moins que vous n'ayez besoin d'une taille de mémoire dynamique, ne définissez pas de périphérique de ballon de mémoire et assurez-vous que libvirt n'en crée pas un pour vous. Incluez le paramètre memballoon en tant qu'enfant de l'élément devices dans votre fichier XML de configuration de domaine.
Vérifier la liste des profils actifs :
<memballoon model="none"/>
2.6.6. Ajuster l'algorithme de migration de l'unité centrale de l'ordonnanceur de l'hôte
Ne modifiez pas les paramètres de l'ordonnanceur si vous n'êtes pas un expert qui en comprend les implications. N'appliquez pas de modifications aux systèmes de production sans les avoir testées et avoir confirmé qu'elles ont l'effet escompté.
Le paramètre kernel.sched_migration_cost_ns spécifie un intervalle de temps en nanosecondes. Après la dernière exécution d'une tâche, le cache de l'unité centrale est considéré comme ayant un contenu utile jusqu'à l'expiration de cet intervalle. L'augmentation de cet intervalle permet de réduire le nombre de migrations de tâches. La valeur par défaut est 500000 ns.
Si le temps d'inactivité du CPU est plus élevé que prévu lorsqu'il y a des processus exécutables, essayez de réduire cet intervalle. Si les tâches passent trop souvent d'un CPU ou d'un nœud à l'autre, essayez de l'augmenter.
Pour définir dynamiquement l'intervalle à 60000 ns, entrez la commande suivante :
# sysctl kernel.sched_migration_cost_ns=60000
Pour modifier de façon permanente la valeur de 60000 ns, ajoutez l'entrée suivante à /etc/sysctl.conf:
kernel.sched_migration_cost_ns=60000
2.6.7. Désactiver le contrôleur cpuset cgroup
Ce paramètre ne s'applique qu'aux hôtes KVM dotés de cgroups version 1. Pour activer le hotplug du processeur sur l'hôte, désactivez le contrôleur cgroup.
Procédure
-
Ouvrez
/etc/libvirt/qemu.confavec l'éditeur de votre choix. -
Allez à la ligne
cgroup_controllers. - Dupliquez la ligne entière et supprimez le premier signe numérique (#) de la copie.
Retirez l'entrée
cpuseten procédant comme suit :cgroup_controllers = [ "cpu", "devices", "memory", "blkio", "cpuacct" ]
Pour que le nouveau paramètre prenne effet, vous devez redémarrer le démon libvirtd :
- Arrêter toutes les machines virtuelles.
Exécutez la commande suivante :
# systemctl restart libvirtd
- Redémarrer les machines virtuelles.
Ce paramètre persiste lors des redémarrages de l'hôte.
2.6.8. Régler la période d'interrogation des CPU virtuels inactifs
Lorsqu'un processeur virtuel est inactif, KVM recherche les conditions de réveil du processeur virtuel avant d'allouer la ressource hôte. Vous pouvez spécifier l'intervalle de temps pendant lequel l'interrogation a lieu dans sysfs à l'adresse /sys/module/kvm/parameters/halt_poll_ns. Pendant la durée spécifiée, l'interrogation réduit la latence de réveil de l'unité centrale virtuelle au détriment de l'utilisation des ressources. En fonction de la charge de travail, une durée d'interrogation plus longue ou plus courte peut être bénéfique. L'intervalle de temps est spécifié en nanosecondes. La valeur par défaut est de 50000 ns.
Pour optimiser la consommation de l'unité centrale, entrez une petite valeur ou écrivez 0 pour désactiver l'interrogation :
# echo 0 > /sys/module/kvm/paramètres/halt_poll_ns
Pour optimiser la latence, par exemple pour les charges de travail transactionnelles, saisissez une valeur élevée :
# echo 80000 > /sys/module/kvm/paramètres/halt_poll_ns
Ressources supplémentaires
Chapitre 3. Utilisation de l'opérateur Node Tuning
Découvrez l'opérateur d'optimisation des nœuds et la manière dont vous pouvez l'utiliser pour gérer l'optimisation au niveau des nœuds en orchestrant le démon d'optimisation.
3.1. À propos de l'opérateur Node Tuning
L'opérateur d'optimisation des nœuds vous aide à gérer l'optimisation au niveau des nœuds en orchestrant le démon TuneD et à obtenir des performances à faible latence en utilisant le contrôleur de profil de performance. La majorité des applications à hautes performances nécessitent un certain niveau de réglage du noyau. Le Node Tuning Operator offre une interface de gestion unifiée aux utilisateurs de sysctls au niveau des nœuds et plus de flexibilité pour ajouter des réglages personnalisés en fonction des besoins de l'utilisateur.
L'opérateur gère le démon TuneD conteneurisé pour OpenShift Container Platform en tant qu'ensemble de démons Kubernetes. Il s'assure que la spécification de réglage personnalisé est transmise à tous les démons TuneD conteneurisés s'exécutant dans le cluster dans le format que les démons comprennent. Les démons s'exécutent sur tous les nœuds du cluster, un par nœud.
Les paramètres de niveau nœud appliqués par le démon TuneD conteneurisé sont annulés lors d'un événement qui déclenche un changement de profil ou lorsque le démon TuneD conteneurisé se termine de manière élégante en recevant et en gérant un signal de fin.
L'opérateur de réglage des nœuds utilise le contrôleur de profil de performance pour mettre en œuvre un réglage automatique afin d'obtenir des performances de faible latence pour les applications OpenShift Container Platform. L'administrateur du cluster configure un profil de performance pour définir des paramètres au niveau du nœud, tels que les suivants :
- Mise à jour du noyau vers kernel-rt.
- Choix des unités centrales de traitement pour l'entretien ménager.
- Choix des unités centrales pour l'exécution des charges de travail.
Actuellement, la désactivation de l'équilibrage de la charge du CPU n'est pas prise en charge par cgroup v2. Par conséquent, il se peut que vous n'obteniez pas le comportement souhaité des profils de performance si vous avez activé cgroup v2. L'activation de cgroup v2 n'est pas recommandée si vous utilisez des profils de performance.
L'opérateur Node Tuning fait partie de l'installation standard d'OpenShift Container Platform à partir de la version 4.1.
Dans les versions antérieures d'OpenShift Container Platform, l'opérateur Performance Addon était utilisé pour mettre en œuvre un réglage automatique afin d'obtenir des performances de faible latence pour les applications OpenShift. Dans OpenShift Container Platform 4.11 et les versions ultérieures, cette fonctionnalité fait partie de l'opérateur Node Tuning.
3.2. Accéder à un exemple de spécification de l'opérateur Node Tuning
Cette procédure permet d'accéder à un exemple de spécification de l'opérateur de réglage des nœuds.
Procédure
Exécutez la commande suivante pour accéder à un exemple de spécification de l'opérateur Node Tuning :
$ oc get Tuned/default -o yaml -n openshift-cluster-node-tuning-operator
Le CR par défaut est destiné à fournir un réglage standard au niveau du nœud pour la plateforme OpenShift Container Platform et il ne peut être modifié que pour définir l'état de gestion de l'opérateur. Toute autre modification personnalisée de la CR par défaut sera écrasée par l'opérateur. Pour un réglage personnalisé, créez vos propres CR réglés. Les CR nouvellement créés seront combinés avec le CR par défaut et les réglages personnalisés appliqués aux nœuds d'OpenShift Container Platform en fonction des étiquettes de nœuds ou de pods et des priorités de profil.
Bien que dans certaines situations, la prise en charge des étiquettes de pods puisse être un moyen pratique de fournir automatiquement les réglages nécessaires, cette pratique est déconseillée et fortement déconseillée, en particulier dans les clusters à grande échelle. Le CR Tuned par défaut est livré sans correspondance d'étiquettes de pods. Si un profil personnalisé est créé avec la correspondance des étiquettes de pods, alors la fonctionnalité sera activée à ce moment-là. La fonctionnalité d'étiquetage de pods sera obsolète dans les versions futures de l'opérateur de tuning de nœuds.
3.3. Profils par défaut définis sur un cluster
Les profils par défaut définis sur un cluster sont les suivants.
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: default
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Optimize systems running OpenShift (provider specific parent profile)
include=-provider-${f:exec:cat:/var/lib/tuned/provider},openshift
name: openshift
recommend:
- profile: openshift-control-plane
priority: 30
match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
- profile: openshift-node
priority: 40
Depuis OpenShift Container Platform 4.9, tous les profils OpenShift TuneD sont livrés avec le package TuneD. Vous pouvez utiliser la commande oc exec pour voir le contenu de ces profils :
$ oc exec $tuned_pod -n openshift-cluster-node-tuning-operator -- find /usr/lib/tuned/openshift{,-control-plane,-node} -name tuned.conf -exec grep -H ^ {} \;3.4. Vérification de l'application des profils TuneD
Vérifiez les profils TuneD appliqués à votre nœud de cluster.
$ oc get profile -n openshift-cluster-node-tuning-operator
Exemple de sortie
NAME TUNED APPLIED DEGRADED AGE master-0 openshift-control-plane True False 6h33m master-1 openshift-control-plane True False 6h33m master-2 openshift-control-plane True False 6h33m worker-a openshift-node True False 6h28m worker-b openshift-node True False 6h28m
-
NAME: Nom de l'objet Profil. Il y a un objet Profil par nœud et leurs noms correspondent. -
TUNED: Nom du profil TuneD à appliquer. -
APPLIED(True) si le démon TuneD a appliqué le profil souhaité. (True/False/Unknown). -
DEGRADEDle profil TuneD peut être modifié par l'intermédiaire de l'adresse suivante :Truesi des erreurs ont été signalées lors de l'application du profil TuneD (True/False/Unknown). -
AGE: Temps écoulé depuis la création de l'objet Profil.
3.5. Spécification de réglage personnalisé
La ressource personnalisée (CR) de l'opérateur comporte deux sections principales. La première section, profile:, est une liste de profils TuneD et de leurs noms. La seconde, recommend:, définit la logique de sélection des profils.
Plusieurs spécifications de réglage personnalisées peuvent coexister en tant que CR multiples dans l'espace de noms de l'opérateur. L'existence de nouveaux CR ou la suppression d'anciens CR est détectée par l'Opérateur. Toutes les spécifications de réglage personnalisées existantes sont fusionnées et les objets appropriés pour les démons TuneD conteneurisés sont mis à jour.
Management state
L'état de gestion de l'opérateur est défini en ajustant le CR accordé par défaut. Par défaut, l'opérateur est en état de gestion et le champ spec.managementState n'est pas présent dans le CR accordé par défaut. Les valeurs valides pour l'état de gestion de l'opérateur sont les suivantes :
- Géré : l'opérateur met à jour ses opérandes au fur et à mesure que les ressources de configuration sont mises à jour
- Non géré : l'opérateur ignore les changements apportés aux ressources de configuration
- Retiré : l'opérateur retire ses opérandes et les ressources qu'il a fournies
Profile data
La section profile: dresse la liste des profils TuneD et de leurs noms.
profile:
- name: tuned_profile_1
data: |
# TuneD profile specification
[main]
summary=Description of tuned_profile_1 profile
[sysctl]
net.ipv4.ip_forward=1
# ... other sysctl's or other TuneD daemon plugins supported by the containerized TuneD
# ...
- name: tuned_profile_n
data: |
# TuneD profile specification
[main]
summary=Description of tuned_profile_n profile
# tuned_profile_n profile settingsRecommended profiles
La logique de sélection de profile: est définie par la section recommend: du CR. La section recommend: est une liste d'éléments permettant de recommander les profils sur la base d'un critère de sélection.
recommend: <recommend-item-1> # ... <recommend-item-n>
Les différents éléments de la liste :
- machineConfigLabels: 1 <mcLabels> 2 match: 3 <match> 4 priority: <priority> 5 profile: <tuned_profile_name> 6 operand: 7 debug: <bool> 8 tunedConfig: reapply_sysctl: <bool> 9
- 1
- En option.
- 2
- Un dictionnaire d'étiquettes clé/valeur
MachineConfig. Les clés doivent être uniques. - 3
- En cas d'omission, la correspondance des profils est présumée, sauf si un profil ayant une priorité plus élevée correspond en premier ou si
machineConfigLabelsest défini. - 4
- Une liste facultative.
- 5
- Ordre de priorité des profils. Les chiffres les plus bas signifient une priorité plus élevée (
0est la priorité la plus élevée). - 6
- Un profil TuneD à appliquer sur un match. Par exemple
tuned_profile_1. - 7
- Configuration facultative de l'opérande.
- 8
- Active ou désactive le débogage du démon TuneD. Les options sont
truepour on oufalsepour off. La valeur par défaut estfalse. - 9
- Active ou désactive la fonctionnalité
reapply_sysctlpour le démon TuneD. Les options sonttruepour on etfalsepour off.
<match> est une liste optionnelle définie récursivement comme suit :
- label: <label_name> 1 value: <label_value> 2 type: <label_type> 3 <match> 4
- 1
- Nom de l'étiquette du nœud ou du pod.
- 2
- Valeur facultative de l'étiquette du nœud ou du pod. Si elle est omise, la présence de
<label_name>suffit à établir une correspondance. - 3
- Type d'objet facultatif (
nodeoupod). En cas d'omission,nodeest considéré comme tel. - 4
- Une liste facultative
<match>.
Si <match> n'est pas omis, toutes les sections imbriquées <match> doivent également être évaluées à true. Sinon, false est supposé et le profil avec la section <match> correspondante ne sera pas appliqué ou recommandé. Par conséquent, l'imbrication (sections <match> enfant) fonctionne comme un opérateur logique ET. Inversement, si un élément de la liste <match> correspond, toute la liste <match> est évaluée à true. La liste agit donc comme un opérateur logique OU.
Si machineConfigLabels est défini, la correspondance basée sur le pool de configuration de la machine est activée pour l'élément de liste recommend: donné. <mcLabels> spécifie les étiquettes d'une configuration de la machine. La configuration de la machine est créée automatiquement pour appliquer les paramètres de l'hôte, tels que les paramètres de démarrage du noyau, pour le profil <tuned_profile_name>. Il s'agit de trouver tous les pools de configuration de machine dont le sélecteur de configuration de machine correspond à <mcLabels> et de définir le profil <tuned_profile_name> sur tous les nœuds auxquels sont attribués les pools de configuration de machine trouvés. Pour cibler les nœuds qui ont à la fois un rôle de maître et de travailleur, vous devez utiliser le rôle de maître.
Les éléments de la liste match et machineConfigLabels sont reliés par l'opérateur logique OR. L'élément match est évalué en premier, en court-circuit. Par conséquent, s'il est évalué à true, l'élément machineConfigLabels n'est pas pris en compte.
Lors de l'utilisation de la correspondance basée sur le pool de configuration machine, il est conseillé de regrouper les nœuds ayant la même configuration matérielle dans le même pool de configuration machine. Si cette pratique n'est pas respectée, les opérandes TuneD peuvent calculer des paramètres de noyau contradictoires pour deux nœuds ou plus partageant le même pool de configuration de machine.
Exemple : correspondance basée sur l'étiquette d'un nœud ou d'un pod
- match:
- label: tuned.openshift.io/elasticsearch
match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
type: pod
priority: 10
profile: openshift-control-plane-es
- match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
priority: 20
profile: openshift-control-plane
- priority: 30
profile: openshift-node
Le CR ci-dessus est traduit pour le démon TuneD conteneurisé dans son fichier recommend.conf en fonction des priorités du profil. Le profil ayant la priorité la plus élevée (10) est openshift-control-plane-es et, par conséquent, il est considéré en premier. Le démon TuneD conteneurisé fonctionnant sur un nœud donné vérifie s'il existe un pod fonctionnant sur le même nœud avec l'étiquette tuned.openshift.io/elasticsearch définie. Si ce n'est pas le cas, toute la section <match> est évaluée comme false. S'il existe un pod avec le label, pour que la section <match> soit évaluée comme true, le label du nœud doit également être node-role.kubernetes.io/master ou node-role.kubernetes.io/infra.
Si les étiquettes du profil ayant la priorité 10 correspondent, le profil openshift-control-plane-es est appliqué et aucun autre profil n'est pris en considération. Si la combinaison d'étiquettes nœud/pod ne correspond pas, le deuxième profil le plus prioritaire (openshift-control-plane) est pris en compte. Ce profil est appliqué si le pod TuneD conteneurisé fonctionne sur un nœud avec les étiquettes node-role.kubernetes.io/master ou node-role.kubernetes.io/infra.
Enfin, le profil openshift-node a la priorité la plus basse de 30. Il ne contient pas la section <match> et, par conséquent, correspondra toujours. Il sert de profil fourre-tout pour définir le profil openshift-node si aucun autre profil ayant une priorité plus élevée ne correspond à un nœud donné.
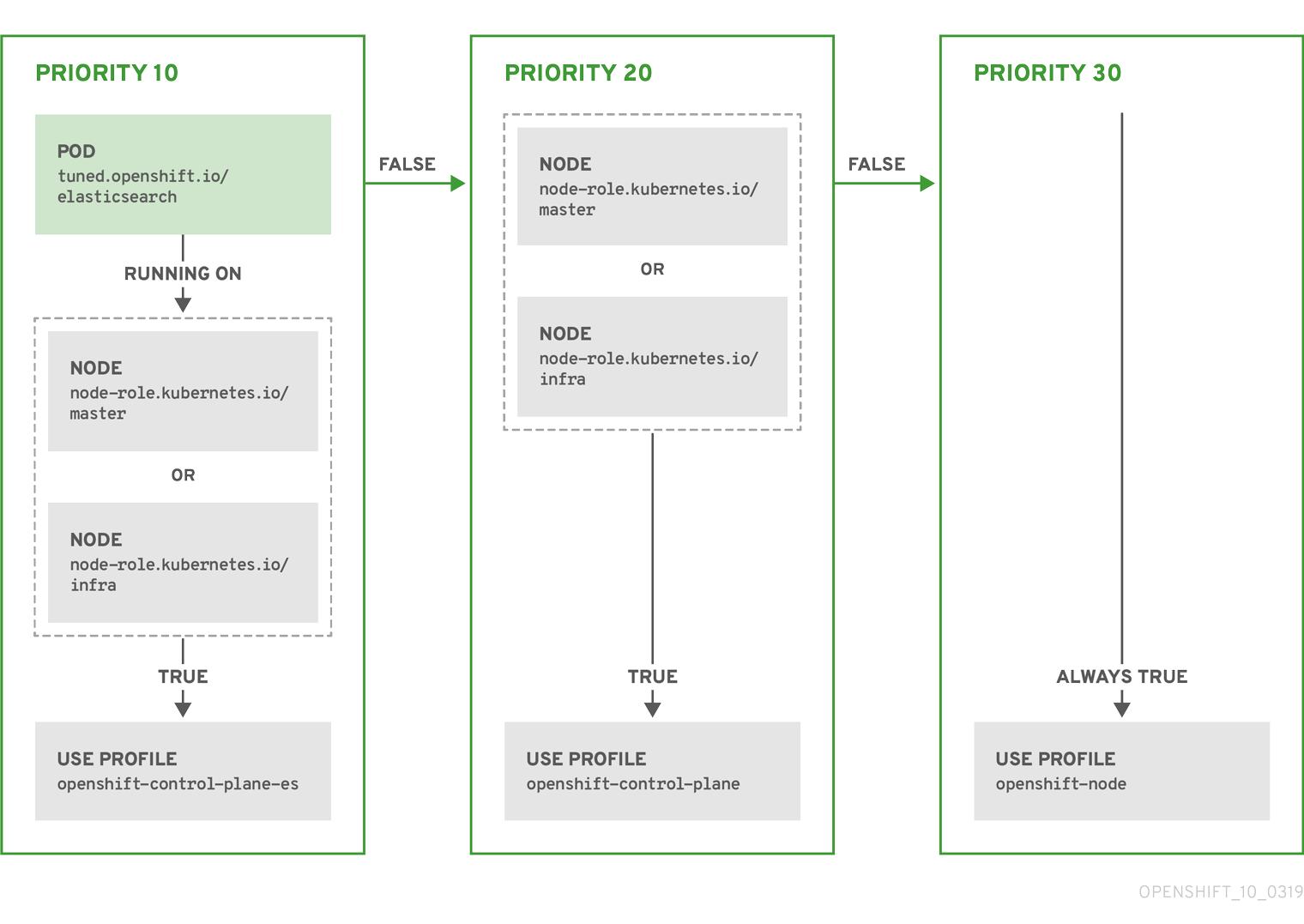
Exemple : correspondance basée sur le pool de configuration de la machine
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: openshift-node-custom
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Custom OpenShift node profile with an additional kernel parameter
include=openshift-node
[bootloader]
cmdline_openshift_node_custom=+skew_tick=1
name: openshift-node-custom
recommend:
- machineConfigLabels:
machineconfiguration.openshift.io/role: "worker-custom"
priority: 20
profile: openshift-node-custom
Pour minimiser les redémarrages de nœuds, il faut étiqueter les nœuds cibles avec une étiquette que le sélecteur de nœuds du pool de configuration de la machine fera correspondre, puis créer le Tuned CR ci-dessus et enfin créer le pool de configuration de la machine personnalisé lui-même.
Cloud provider-specific TuneD profiles
Avec cette fonctionnalité, tous les nœuds spécifiques à un fournisseur de Cloud peuvent commodément se voir attribuer un profil TuneD spécifiquement adapté à un fournisseur de Cloud donné sur un cluster OpenShift Container Platform. Cela peut être accompli sans ajouter d'étiquettes de nœuds supplémentaires ou regrouper les nœuds dans des pools de configuration de machines.
Cette fonctionnalité tire parti des valeurs de l'objet de nœud spec.providerID sous la forme de <cloud-provider>://<cloud-provider-specific-id> et écrit le fichier /var/lib/tuned/provider avec la valeur <cloud-provider> dans les conteneurs d'opérandes NTO. Le contenu de ce fichier est ensuite utilisé par TuneD pour charger le profil provider-<cloud-provider> s'il existe.
Le profil openshift dont les profils openshift-control-plane et openshift-node héritent des paramètres est maintenant mis à jour pour utiliser cette fonctionnalité grâce à l'utilisation du chargement conditionnel de profil. Ni NTO ni TuneD ne fournissent actuellement de profils spécifiques aux fournisseurs de Cloud. Cependant, il est possible de créer un profil personnalisé provider-<cloud-provider> qui sera appliqué à tous les nœuds de cluster spécifiques au fournisseur de cloud.
Exemple de profil de fournisseur GCE Cloud
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: provider-gce
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=GCE Cloud provider-specific profile
# Your tuning for GCE Cloud provider goes here.
name: provider-gce
En raison de l'héritage des profils, tout paramètre spécifié dans le profil provider-<cloud-provider> sera remplacé par le profil openshift et ses profils enfants.
3.6. Exemples de réglages personnalisés
Using TuneD profiles from the default CR
La CR suivante applique un réglage personnalisé au niveau du nœud pour les nœuds OpenShift Container Platform dont l'étiquette tuned.openshift.io/ingress-node-label est définie sur n'importe quelle valeur.
Exemple : réglage personnalisé à l'aide du profil openshift-control-plane TuneD
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: ingress
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=A custom OpenShift ingress profile
include=openshift-control-plane
[sysctl]
net.ipv4.ip_local_port_range="1024 65535"
net.ipv4.tcp_tw_reuse=1
name: openshift-ingress
recommend:
- match:
- label: tuned.openshift.io/ingress-node-label
priority: 10
profile: openshift-ingress
Les auteurs de profils personnalisés sont fortement encouragés à inclure les profils de démon TuneD par défaut fournis avec le CR Tuned par défaut. L'exemple ci-dessus utilise le profil par défaut openshift-control-plane.
Using built-in TuneD profiles
Étant donné le succès du déploiement de l'ensemble des démons gérés par NTO, les opérandes TuneD gèrent tous la même version du démon TuneD. Pour obtenir la liste des profils TuneD intégrés pris en charge par le démon, interrogez n'importe quel module TuneD de la manière suivante :
$ oc exec $tuned_pod -n openshift-cluster-node-tuning-operator -- find /usr/lib/tuned/ -name tuned.conf -printf '%h\n' | sed 's|^.*/||'
Vous pouvez utiliser les noms de profil ainsi récupérés dans votre spécification de réglage personnalisé.
Exemple : utilisation du profil TuneD intégré de hpc-compute
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: openshift-node-hpc-compute
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Custom OpenShift node profile for HPC compute workloads
include=openshift-node,hpc-compute
name: openshift-node-hpc-compute
recommend:
- match:
- label: tuned.openshift.io/openshift-node-hpc-compute
priority: 20
profile: openshift-node-hpc-compute
En plus du profil intégré hpc-compute, l'exemple ci-dessus inclut le profil du démon openshift-node TuneD fourni avec le CR Tuned par défaut afin d'utiliser un réglage spécifique à OpenShift pour les nœuds de calcul.
3.7. Plugins de démon TuneD pris en charge
À l'exception de la section [main], les plugins TuneD suivants sont pris en charge lors de l'utilisation des profils personnalisés définis dans la section profile: du CR Tuned :
- audio
- cpu
- disque
- eeepc_she
- modules
- montures
- net
- planificateur
- scsi_host
- selinux
- sysctl
- sysfs
- uSB
- vidéo
- vm
- chargeur de démarrage
Certains de ces plugins offrent une fonctionnalité d'accord dynamique qui n'est pas prise en charge. Les plugins TuneD suivants ne sont actuellement pas pris en charge :
- scénario
- systemd
Le plugin TuneD bootloader est actuellement pris en charge sur les nœuds de travail Red Hat Enterprise Linux CoreOS (RHCOS) 8.x. Pour les nœuds de travail Red Hat Enterprise Linux (RHEL) 7.x, le plugin de chargeur de démarrage TuneD n'est actuellement pas pris en charge.
Voir Plugins TuneD disponibles et Démarrer avec TuneD pour plus d'informations.
3.8. Configuration de l'optimisation des nœuds dans un cluster hébergé
Les plans de contrôle hébergés sont une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Pour définir le réglage au niveau du nœud sur les nœuds de votre cluster hébergé, vous pouvez utiliser l'opérateur de réglage des nœuds. Dans les plans de contrôle hébergés, vous pouvez configurer l'optimisation des nœuds en créant des cartes de configuration contenant des objets Tuned et en référençant ces cartes de configuration dans vos pools de nœuds.
Procédure
Créez une carte de configuration contenant un manifeste accordé valide et faites référence à ce manifeste dans un pool de nœuds. Dans l'exemple suivant, un manifeste
Tuneddéfinit un profil qui attribue la valeur 55 àvm.dirty_ratiosur les nœuds contenant l'étiquette de nœudtuned-1-node-labelavec n'importe quelle valeur. Enregistrez le manifesteConfigMapsuivant dans un fichier nommétuned-1.yaml:apiVersion: v1 kind: ConfigMap metadata: name: tuned-1 namespace: clusters data: tuning: | apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: tuned-1 namespace: openshift-cluster-node-tuning-operator spec: profile: - data: | [main] summary=Custom OpenShift profile include=openshift-node [sysctl] vm.dirty_ratio="55" name: tuned-1-profile recommend: - priority: 20 profile: tuned-1-profileNoteSi vous n'ajoutez pas d'étiquettes à une entrée de la section
spec.recommendde la spécification accordée, la correspondance basée sur le pool de nœuds est supposée, de sorte que le profil de priorité le plus élevé de la sectionspec.recommendest appliqué aux nœuds du pool. Bien que vous puissiez obtenir une correspondance plus fine basée sur les étiquettes de nœuds en définissant une valeur d'étiquette dans la section Tuned.spec.recommend.match, les étiquettes de nœuds ne seront pas conservées lors d'une mise à niveau, à moins que vous ne définissiez la valeur.spec.management.upgradeTypedu pool de nœuds surInPlace.Créez l'objet
ConfigMapdans le cluster de gestion :$ oc --kubeconfig="$MGMT_KUBECONFIG" create -f tuned-1.yaml
Faites référence à l'objet
ConfigMapdans le champspec.tuningConfigde la réserve de nœuds, soit en modifiant une réserve de nœuds, soit en en créant une. Dans cet exemple, nous supposons que vous n'avez qu'un seulNodePool, nomménodepool-1, qui contient 2 nœuds.apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: ... name: nodepool-1 namespace: clusters ... spec: ... tuningConfig: - name: tuned-1 status: ...NoteVous pouvez référencer la même carte de configuration dans plusieurs pools de nœuds. Dans les plans de contrôle hébergés, l'opérateur d'accord de nœud ajoute un hachage du nom du pool de nœuds et de l'espace de noms au nom des CR accordés pour les distinguer. En dehors de ce cas, ne créez pas plusieurs profils TuneD du même nom dans différents CR accordés pour le même cluster hébergé.
Vérification
Maintenant que vous avez créé l'objet ConfigMap qui contient un manifeste Tuned et que vous l'avez référencé dans un manifeste NodePool, l'opérateur Node Tuning synchronise les objets Tuned dans le cluster hébergé. Vous pouvez vérifier quels objets Tuned sont définis et quels profils TuneD sont appliqués à chaque nœud.
Liste des objets
Tuneddans le cluster hébergé :$ oc --kubeconfig="$HC_KUBECONFIG" get Tuneds -n openshift-cluster-node-tuning-operator
Exemple de sortie
NAME AGE default 7m36s rendered 7m36s tuned-1 65s
Liste des objets
Profiledans le cluster hébergé :$ oc --kubeconfig="$HC_KUBECONFIG" get Profiles -n openshift-cluster-node-tuning-operator
Exemple de sortie
NAME TUNED APPLIED DEGRADED AGE nodepool-1-worker-1 tuned-1-profile True False 7m43s nodepool-1-worker-2 tuned-1-profile True False 7m14s
NoteSi aucun profil personnalisé n'est créé, le profil
openshift-nodeest appliqué par défaut.Pour confirmer que le réglage a été appliqué correctement, lancez un shell de débogage sur un nœud et vérifiez les valeurs sysctl :
$ oc --kubeconfig="$HC_KUBECONFIG" debug node/nodepool-1-worker-1 -- chroot /host sysctl vm.dirty_ratio
Exemple de sortie
vm.dirty_ratio = 55
3.9. Réglage avancé des nœuds pour les clusters hébergés en définissant les paramètres de démarrage du noyau
Les plans de contrôle hébergés sont une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Pour des réglages plus avancés dans les plans de contrôle hébergés, qui nécessitent la définition de paramètres d'amorçage du noyau, vous pouvez également utiliser l'opérateur de réglage des nœuds. L'exemple suivant montre comment créer un pool de nœuds avec d'énormes pages réservées.
Procédure
Créez un objet
ConfigMapqui contient un manifeste d'objetTunedpour la création de 10 pages énormes d'une taille de 2 Mo. Enregistrez ce manifesteConfigMapdans un fichier nommétuned-hugepages.yaml:apiVersion: v1 kind: ConfigMap metadata: name: tuned-hugepages namespace: clusters data: tuning: | apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: hugepages namespace: openshift-cluster-node-tuning-operator spec: profile: - data: | [main] summary=Boot time configuration for hugepages include=openshift-node [bootloader] cmdline_openshift_node_hugepages=hugepagesz=2M hugepages=50 name: openshift-node-hugepages recommend: - priority: 20 profile: openshift-node-hugepagesNoteLe champ
.spec.recommend.matchest intentionnellement laissé vide. Dans ce cas, l'objetTunedest appliqué à tous les nœuds du pool de nœuds dans lequel l'objetConfigMapest référencé. Regroupez les nœuds ayant la même configuration matérielle dans le même pool de nœuds. Sinon, les opérandes TuneD peuvent calculer des paramètres de noyau contradictoires pour deux nœuds ou plus qui partagent le même pool de nœuds.Créez l'objet
ConfigMapdans le cluster de gestion :$ oc --kubeconfig="$MGMT_KUBECONFIG" create -f tuned-hugepages.yaml
Créez un fichier YAML de manifeste
NodePool, personnalisez le type de mise à niveau deNodePoolet faites référence à l'objetConfigMapque vous avez créé dans la sectionspec.tuningConfig. Créez le manifesteNodePoolet enregistrez-le dans un fichier nomméhugepages-nodepool.yamlà l'aide du CLIhypershift:NODEPOOL_NAME=hugepages-example INSTANCE_TYPE=m5.2xlarge NODEPOOL_REPLICAS=2 hypershift create nodepool aws \ --cluster-name $CLUSTER_NAME \ --name $NODEPOOL_NAME \ --node-count $NODEPOOL_REPLICAS \ --instance-type $INSTANCE_TYPE \ --render > hugepages-nodepool.yamlDans le fichier
hugepages-nodepool.yaml, définissez.spec.management.upgradeTypecommeInPlace, et définissez.spec.tuningConfigcomme faisant référence à l'objettuned-hugepagesConfigMapque vous avez créé.apiVersion: hypershift.openshift.io/v1alpha1 kind: NodePool metadata: name: hugepages-nodepool namespace: clusters ... spec: management: ... upgradeType: InPlace ... tuningConfig: - name: tuned-hugepagesNotePour éviter de recréer inutilement des nœuds lorsque vous appliquez les nouveaux objets
MachineConfig, définissez.spec.management.upgradeTypesurInPlace. Si vous utilisez le type de mise à niveauReplace, les nœuds sont entièrement supprimés et de nouveaux nœuds peuvent les remplacer lorsque vous appliquez les nouveaux paramètres d'amorçage du noyau calculés par l'opérande TuneD.Créez le site
NodePooldans le cluster de gestion :$ oc --kubeconfig="$MGMT_KUBECONFIG" create -f hugepages-nodepool.yaml
Vérification
Une fois les nœuds disponibles, le démon TuneD conteneurisé calcule les paramètres d'amorçage du noyau requis en fonction du profil TuneD appliqué. Une fois que les nœuds sont prêts et redémarrent une fois pour appliquer l'objet MachineConfig généré, vous pouvez vérifier que le profil TuneD est appliqué et que les paramètres d'amorçage du noyau sont définis.
Liste des objets
Tuneddans le cluster hébergé :$ oc --kubeconfig="$HC_KUBECONFIG" get Tuneds -n openshift-cluster-node-tuning-operator
Exemple de sortie
NAME AGE default 123m hugepages-8dfb1fed 1m23s rendered 123m
Liste des objets
Profiledans le cluster hébergé :$ oc --kubeconfig="$HC_KUBECONFIG" get Profiles -n openshift-cluster-node-tuning-operator
Exemple de sortie
NAME TUNED APPLIED DEGRADED AGE nodepool-1-worker-1 openshift-node True False 132m nodepool-1-worker-2 openshift-node True False 131m hugepages-nodepool-worker-1 openshift-node-hugepages True False 4m8s hugepages-nodepool-worker-2 openshift-node-hugepages True False 3m57s
Les deux nœuds de travail du nouveau site
NodePoolsont dotés du profilopenshift-node-hugepages.Pour confirmer que le réglage a été appliqué correctement, démarrez un shell de débogage sur un nœud et vérifiez
/proc/cmdline.$ oc --kubeconfig="$HC_KUBECONFIG" debug node/nodepool-1-worker-1 -- chroot /host cat /proc/cmdline
Exemple de sortie
BOOT_IMAGE=(hd0,gpt3)/ostree/rhcos-... hugepagesz=2M hugepages=50
Ressources supplémentaires
Pour plus d'informations sur les plans de contrôle hébergés, voir Plans de contrôle hébergés pour Red Hat OpenShift Container Platform (Technology Preview).
Chapitre 4. Utilisation du gestionnaire de CPU et du gestionnaire de topologie
Le gestionnaire de CPU gère des groupes de CPU et limite les charges de travail à des CPU spécifiques.
CPU Manager est utile pour les charges de travail qui présentent certaines de ces caractéristiques :
- Exiger le plus de temps possible de l'unité centrale.
- Sont sensibles aux défaillances de la mémoire cache du processeur.
- Sont des applications réseau à faible latence.
- Coordonnez-vous avec d'autres processus et profitez du partage de la mémoire cache d'un seul processeur.
Le gestionnaire de topologie recueille des indices auprès du gestionnaire de CPU, du gestionnaire de périphériques et d'autres fournisseurs d'indices afin d'aligner les ressources de pods, telles que les CPU, les VF SR-IOV et d'autres ressources de périphériques, pour toutes les classes de qualité de service (QoS) sur le même nœud d'accès à la mémoire non uniforme (NUMA).
Le gestionnaire de topologie utilise les informations topologiques provenant des indices collectés pour décider si un module peut être accepté ou rejeté sur un nœud, en fonction de la politique configurée du gestionnaire de topologie et des ressources de module demandées.
Topology Manager est utile pour les charges de travail qui utilisent des accélérateurs matériels pour prendre en charge l'exécution critique en termes de latence et le calcul parallèle à haut débit.
Pour utiliser le gestionnaire de topologie, vous devez configurer le gestionnaire de CPU avec la politique static.
4.1. Configuration du gestionnaire de CPU
Procédure
Facultatif : Étiqueter un nœud :
# oc label node perf-node.example.com cpumanager=true
Modifiez le site
MachineConfigPooldes nœuds pour lesquels le gestionnaire de CPU doit être activé. Dans cet exemple, tous les travailleurs ont activé le gestionnaire de CPU :# oc edit machineconfigpool worker
Ajouter une étiquette au pool de configuration de la machine de travail :
metadata: creationTimestamp: 2020-xx-xxx generation: 3 labels: custom-kubelet: cpumanager-enabledCréez une ressource personnalisée (CR)
KubeletConfig,cpumanager-kubeletconfig.yaml. Référez-vous à l'étiquette créée à l'étape précédente pour que les nœuds corrects soient mis à jour avec la nouvelle configuration du kubelet. Voir la sectionmachineConfigPoolSelector:apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: cpumanager-enabled spec: machineConfigPoolSelector: matchLabels: custom-kubelet: cpumanager-enabled kubeletConfig: cpuManagerPolicy: static 1 cpuManagerReconcilePeriod: 5s 2- 1
- Spécifier une politique :
-
none. Cette politique active explicitement le schéma d'affinité CPU par défaut existant, ne fournissant aucune affinité au-delà de ce que le planificateur fait automatiquement. Il s'agit de la stratégie par défaut. -
static. Cette politique autorise les conteneurs dans les pods garantis avec des demandes de CPU entières. Elle limite également l'accès aux CPU exclusifs sur le nœud. Sistatic, vous devez utiliser une minuscules.
-
- 2
- Facultatif. Indiquez la fréquence de rapprochement du gestionnaire de CPU. La valeur par défaut est
5s.
Créer la configuration dynamique du kubelet :
# oc create -f cpumanager-kubeletconfig.yaml
Cela ajoute la fonction CPU Manager à la configuration du kubelet et, si nécessaire, le Machine Config Operator (MCO) redémarre le nœud. Pour activer le gestionnaire de CPU, un redémarrage n'est pas nécessaire.
Vérifier la configuration du kubelet fusionné :
# oc get machineconfig 99-worker-XXXXXX-XXXXX-XXXX-XXXXX-kubelet -o json | grep ownerReference -A7
Exemple de sortie
"ownerReferences": [ { "apiVersion": "machineconfiguration.openshift.io/v1", "kind": "KubeletConfig", "name": "cpumanager-enabled", "uid": "7ed5616d-6b72-11e9-aae1-021e1ce18878" } ]Consultez le travailleur pour obtenir la mise à jour de
kubelet.conf:# oc debug node/perf-node.example.com sh-4.2# cat /host/etc/kubernetes/kubelet.conf | grep cpuManager
Exemple de sortie
cpuManagerPolicy: static 1 cpuManagerReconcilePeriod: 5s 2
Créer un pod qui demande un ou plusieurs cœurs. Les limites et les demandes doivent avoir une valeur CPU égale à un entier. Il s'agit du nombre de cœurs qui seront dédiés à ce module :
# cat cpumanager-pod.yaml
Exemple de sortie
apiVersion: v1 kind: Pod metadata: generateName: cpumanager- spec: containers: - name: cpumanager image: gcr.io/google_containers/pause-amd64:3.0 resources: requests: cpu: 1 memory: "1G" limits: cpu: 1 memory: "1G" nodeSelector: cpumanager: "true"Créer la capsule :
# oc create -f cpumanager-pod.yaml
Vérifiez que le pod est planifié sur le nœud que vous avez étiqueté :
# oc describe pod cpumanager
Exemple de sortie
Name: cpumanager-6cqz7 Namespace: default Priority: 0 PriorityClassName: <none> Node: perf-node.example.com/xxx.xx.xx.xxx ... Limits: cpu: 1 memory: 1G Requests: cpu: 1 memory: 1G ... QoS Class: Guaranteed Node-Selectors: cpumanager=trueVérifiez que l'adresse
cgroupsest correctement configurée. Obtenir l'ID du processus (PID) du processuspause:# ├─init.scope │ └─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 17 └─kubepods.slice ├─kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice │ ├─crio-b5437308f1a574c542bdf08563b865c0345c8f8c0b0a655612c.scope │ └─32706 /pause
Les pods du niveau de qualité de service (QoS)
Guaranteedsont placés à l'intérieur du sitekubepods.slice. Les pods des autres niveaux de QoS se retrouvent dans les enfantscgroupsdekubepods:# cd /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice/crio-b5437308f1ad1a7db0574c542bdf08563b865c0345c86e9585f8c0b0a655612c.scope # for i in `ls cpuset.cpus tasks` ; do echo -n "$i "; cat $i ; done
Exemple de sortie
cpuset.cpus 1 tasks 32706
Vérifiez la liste des unités centrales autorisées pour la tâche :
# grep ^Cpus_allowed_list /proc/32706/status
Exemple de sortie
Cpus_allowed_list: 1
Vérifiez qu'un autre pod (dans ce cas, le pod du niveau de qualité de service
burstable) sur le système ne peut pas fonctionner sur le cœur alloué au podGuaranteed:# cat /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-podc494a073_6b77_11e9_98c0_06bba5c387ea.slice/crio-c56982f57b75a2420947f0afc6cafe7534c5734efc34157525fa9abbf99e3849.scope/cpuset.cpus 0 # oc describe node perf-node.example.com
Exemple de sortie
... Capacity: attachable-volumes-aws-ebs: 39 cpu: 2 ephemeral-storage: 124768236Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 8162900Ki pods: 250 Allocatable: attachable-volumes-aws-ebs: 39 cpu: 1500m ephemeral-storage: 124768236Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 7548500Ki pods: 250 ------- ---- ------------ ---------- --------------- ------------- --- default cpumanager-6cqz7 1 (66%) 1 (66%) 1G (12%) 1G (12%) 29m Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 1440m (96%) 1 (66%)
Cette VM dispose de deux cœurs de processeur. Le paramètre
system-reservedréserve 500 millicores, ce qui signifie que la moitié d'un cœur est soustraite de la capacité totale du nœud pour obtenir la quantitéNode Allocatable. Vous pouvez voir queAllocatable CPUest de 1500 millicores. Cela signifie que vous pouvez exécuter l'un des pods du gestionnaire de CPU, puisque chacun d'entre eux prendra un cœur entier. Un cœur entier est équivalent à 1000 millicores. Si vous essayez de planifier un deuxième module, le système acceptera le module, mais il ne sera jamais planifié :NAME READY STATUS RESTARTS AGE cpumanager-6cqz7 1/1 Running 0 33m cpumanager-7qc2t 0/1 Pending 0 11s
4.2. Politiques du gestionnaire de topologie
Topology Manager aligne les ressources Pod de toutes les classes de qualité de service (QoS) en recueillant des indices topologiques auprès des fournisseurs d'indices, tels que CPU Manager et Device Manager, et en utilisant les indices recueillis pour aligner les ressources Pod.
Topology Manager prend en charge quatre politiques d'allocation, que vous attribuez dans la ressource personnalisée (CR) cpumanager-enabled:
nonepolitique- Il s'agit de la stratégie par défaut, qui n'effectue aucun alignement topologique.
best-effortpolitique-
Pour chaque conteneur d'un module avec la politique de gestion de la topologie
best-effort, kubelet appelle chaque fournisseur d'indices pour connaître la disponibilité de ses ressources. À l'aide de ces informations, le gestionnaire de topologie enregistre l'affinité préférée du nœud NUMA pour ce conteneur. Si l'affinité n'est pas préférée, le gestionnaire de topologie le stocke et admet le pod au nœud. restrictedpolitique-
Pour chaque conteneur d'un module avec la politique de gestion de la topologie
restricted, kubelet appelle chaque fournisseur d'indices pour connaître la disponibilité de ses ressources. À l'aide de ces informations, le gestionnaire de topologie enregistre l'affinité préférée du nœud NUMA pour ce conteneur. Si l'affinité n'est pas préférée, le gestionnaire de topologie rejette ce pod du nœud, ce qui se traduit par un pod dans l'étatTerminatedavec un échec d'admission de pod. single-numa-nodepolitique-
Pour chaque conteneur d'un pod avec la politique de gestion de la topologie
single-numa-node, kubelet appelle chaque fournisseur d'indices pour connaître la disponibilité de ses ressources. À l'aide de ces informations, le gestionnaire de topologie détermine si une affinité avec un seul nœud NUMA est possible. Si c'est le cas, le pod est admis dans le nœud. Si une affinité de nœud NUMA unique n'est pas possible, le gestionnaire de topologie rejette le module du nœud. Le résultat est un pod en état Terminé avec un échec d'admission de pod.
4.3. Configuration du gestionnaire de topologie
Pour utiliser le gestionnaire de topologie, vous devez configurer une politique d'allocation dans la ressource personnalisée (CR) cpumanager-enabled. Ce fichier peut exister si vous avez configuré le Gestionnaire de CPU. Si le fichier n'existe pas, vous pouvez le créer.
Prequisites
-
Configurez la politique du gestionnaire de CPU pour qu'elle soit
static.
Procédure
Pour activer Topololgy Manager :
Configurer la politique d'allocation du gestionnaire de topologie dans la ressource personnalisée (CR)
cpumanager-enabled.$ oc edit KubeletConfig cpumanager-enabled
apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: cpumanager-enabled spec: machineConfigPoolSelector: matchLabels: custom-kubelet: cpumanager-enabled kubeletConfig: cpuManagerPolicy: static 1 cpuManagerReconcilePeriod: 5s topologyManagerPolicy: single-numa-node 2
4.4. Interactions des pods avec les politiques de Topology Manager
Les exemples de spécifications Pod ci-dessous permettent d'illustrer les interactions entre les pods et Topology Manager.
Le pod suivant s'exécute dans la classe de qualité de service BestEffort car aucune demande ou limite de ressources n'est spécifiée.
spec:
containers:
- name: nginx
image: nginx
Le pod suivant fonctionne dans la classe de qualité de service Burstable car les demandes sont inférieures aux limites.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
Si la politique sélectionnée est autre que none, Topology Manager ne tiendra compte d'aucune de ces spécifications Pod.
Le dernier exemple de pod ci-dessous s'exécute dans la classe de qualité de service garantie parce que les demandes sont égales aux limites.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "2"
example.com/device: "1"Le gestionnaire de topologie prend en compte ce module. Le gestionnaire de topologie consulte les fournisseurs d'indices, à savoir le gestionnaire de CPU et le gestionnaire de périphériques, afin d'obtenir des indices topologiques pour le module.
Le gestionnaire de topologie utilisera ces informations pour stocker la meilleure topologie pour ce conteneur. Dans le cas de ce module, le gestionnaire de CPU et le gestionnaire de périphériques utiliseront ces informations stockées lors de la phase d'allocation des ressources.
Chapitre 5. Ordonnancement des charges de travail compatibles avec les NUMA
Découvrez l'ordonnancement NUMA-aware et comment vous pouvez l'utiliser pour déployer des charges de travail hautes performances dans un cluster OpenShift Container Platform.
L'ordonnancement NUMA-aware est une fonctionnalité de l'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
L'opérateur de ressources NUMA vous permet de planifier des charges de travail hautes performances dans la même zone NUMA. Il déploie un agent d'exportation des ressources de nœuds qui signale les ressources NUMA de nœuds de cluster disponibles, et un planificateur secondaire qui gère les charges de travail.
5.1. À propos de l'ordonnancement NUMA
L'accès non uniforme à la mémoire (NUMA) est une architecture de plate-forme informatique qui permet à différents processeurs d'accéder à différentes régions de la mémoire à des vitesses différentes. La topologie des ressources NUMA fait référence à l'emplacement des unités centrales, de la mémoire et des périphériques PCI les uns par rapport aux autres dans le nœud de calcul. Les ressources co-localisées sont dites être dans le même NUMA zone. Pour les applications à haute performance, le cluster doit traiter les charges de travail des pods dans une seule zone NUMA.
L'architecture NUMA permet à une unité centrale dotée de plusieurs contrôleurs de mémoire d'utiliser toute la mémoire disponible dans les complexes d'unités centrales, quel que soit l'emplacement de la mémoire. Cela permet d'accroître la flexibilité au détriment des performances. Une unité centrale traitant une charge de travail utilisant une mémoire située en dehors de sa zone NUMA est plus lente qu'une charge de travail traitée dans une seule zone NUMA. En outre, pour les charges de travail soumises à des contraintes d'E/S, l'interface réseau située dans une zone NUMA éloignée ralentit la vitesse à laquelle les informations peuvent atteindre l'application. Les charges de travail à haute performance, telles que les charges de travail de télécommunications, ne peuvent pas fonctionner selon les spécifications dans ces conditions. L'ordonnancement NUMA-aware permet d'aligner les ressources de calcul du cluster (CPU, mémoire, périphériques) demandées dans la même zone NUMA afin de traiter efficacement les charges de travail sensibles à la latence ou très performantes. L'ordonnancement NUMA-aware améliore également la densité de pods par nœud de calcul pour une meilleure efficacité des ressources.
La logique de planification par défaut du planificateur de pods d'OpenShift Container Platform prend en compte les ressources disponibles de l'ensemble du nœud de calcul, et non des zones NUMA individuelles. Si l'alignement des ressources le plus restrictif est demandé dans le gestionnaire de topologie des kubelets, des conditions d'erreur peuvent survenir lors de l'admission du pod sur un nœud. Inversement, si l'alignement des ressources le plus restrictif n'est pas demandé, le module peut être admis dans le nœud sans que l'alignement des ressources soit correct, ce qui entraîne des performances moins bonnes ou imprévisibles. Par exemple, la création de pods avec des statuts Topology Affinity Error peut se produire lorsque le planificateur de pods prend des décisions de planification sous-optimales pour des charges de travail de pods garanties, car il ne sait pas si les ressources demandées par le pod sont disponibles. Les décisions d'inadéquation de l'ordonnancement peuvent entraîner des retards indéfinis dans le démarrage des modules. En outre, en fonction de l'état du cluster et de l'allocation des ressources, de mauvaises décisions d'ordonnancement de pods peuvent entraîner une charge supplémentaire sur le cluster en raison de l'échec des tentatives de démarrage.
L'opérateur de ressources NUMA déploie un planificateur secondaire de ressources NUMA personnalisé et d'autres ressources pour atténuer les lacunes du planificateur de pods par défaut d'OpenShift Container Platform. Le diagramme suivant fournit un aperçu de haut niveau de la planification de pods tenant compte de la NUMA.
Figure 5.1. Vue d'ensemble de l'ordonnancement NUMA
- API NodeResourceTopology
-
L'API
NodeResourceTopologydécrit les ressources de la zone NUMA disponibles dans chaque nœud de calcul. - Ordonnanceur compatible avec les NUMA
-
L'ordonnanceur secondaire NUMA-aware reçoit des informations sur les zones NUMA disponibles de l'API
NodeResourceTopologyet planifie les charges de travail à haute performance sur un nœud où elles peuvent être traitées de manière optimale. - Exportateur de topologie de nœuds
-
L'exportateur de topologie de nœuds expose les ressources de la zone NUMA disponibles pour chaque nœud de calcul à l'API
NodeResourceTopology. Le démon de l'exportateur de topologie de nœuds suit l'allocation des ressources de la kubelet à l'aide de l'APIPodResources. - API PodResources
-
L'API
PodResourcesest locale à chaque nœud et expose la topologie des ressources et les ressources disponibles au kubelet.
Ressources supplémentaires
- Pour plus d'informations sur l'exécution de planificateurs de pods secondaires dans votre cluster et sur le déploiement de pods avec un planificateur de pods secondaire, voir Planification de pods à l'aide d'un planificateur secondaire.
5.2. Installation de l'opérateur de ressources NUMA
NUMA Resources Operator déploie des ressources qui vous permettent de planifier des charges de travail et des déploiements compatibles avec NUMA. Vous pouvez installer l'opérateur de ressources NUMA à l'aide de la CLI d'OpenShift Container Platform ou de la console Web.
5.2.1. Installation de l'opérateur de ressources NUMA à l'aide du CLI
En tant qu'administrateur de cluster, vous pouvez installer l'Opérateur à l'aide de la CLI.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créer un espace de noms pour l'opérateur de ressources NUMA :
Enregistrez le YAML suivant dans le fichier
nro-namespace.yaml:apiVersion: v1 kind: Namespace metadata: name: openshift-numaresources
Créez le CR
Namespaceen exécutant la commande suivante :$ oc create -f nro-namespace.yaml
Créez le groupe d'opérateurs pour l'opérateur de ressources NUMA :
Enregistrez le YAML suivant dans le fichier
nro-operatorgroup.yaml:apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: numaresources-operator namespace: openshift-numaresources spec: targetNamespaces: - openshift-numaresources
Créez le CR
OperatorGroupen exécutant la commande suivante :$ oc create -f nro-operatorgroup.yaml
Créer l'abonnement pour l'opérateur de ressources NUMA :
Enregistrez le YAML suivant dans le fichier
nro-sub.yaml:apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: numaresources-operator namespace: openshift-numaresources spec: channel: "4.12" name: numaresources-operator source: redhat-operators sourceNamespace: openshift-marketplace
Créez le CR
Subscriptionen exécutant la commande suivante :$ oc create -f nro-sub.yaml
Vérification
Vérifiez que l'installation a réussi en inspectant la ressource CSV dans l'espace de noms
openshift-numaresources. Exécutez la commande suivante :$ oc get csv -n openshift-numaresources
Exemple de sortie
NAME DISPLAY VERSION REPLACES PHASE numaresources-operator.v4.12.2 numaresources-operator 4.12.2 Succeeded
5.2.2. Installation de l'opérateur de ressources NUMA à l'aide de la console Web
En tant qu'administrateur de cluster, vous pouvez installer l'opérateur de ressources NUMA à l'aide de la console Web.
Procédure
Installez l'opérateur de ressources NUMA à l'aide de la console web d'OpenShift Container Platform :
- Dans la console Web OpenShift Container Platform, cliquez sur Operators → OperatorHub.
- Choisissez NUMA Resources Operator dans la liste des opérateurs disponibles, puis cliquez sur Install.
Facultatif : Vérifiez que l'opérateur de ressources NUMA a été installé avec succès :
- Passez à la page Operators → Installed Operators.
Assurez-vous que NUMA Resources Operator est listé dans le projet default avec un Status de InstallSucceeded.
NotePendant l'installation, un opérateur peut afficher un état Failed. Si l'installation réussit par la suite avec un message InstallSucceeded, vous pouvez ignorer le message Failed.
Si l'opérateur n'apparaît pas tel qu'il a été installé, il convient de poursuivre le dépannage :
- Allez à la page Operators → Installed Operators et inspectez les onglets Operator Subscriptions et Install Plans pour voir s'il y a des défaillances ou des erreurs sous Status.
-
Allez sur la page Workloads → Pods et vérifiez les journaux pour les pods dans le projet
default.
5.3. Création de la ressource personnalisée NUMAResourcesOperator
Une fois l'opérateur de ressources NUMA installé, créez la ressource personnalisée (CR) NUMAResourcesOperator qui demande à l'opérateur de ressources NUMA d'installer toute l'infrastructure de cluster nécessaire à la prise en charge du planificateur NUMA, y compris les jeux de démons et les API.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Installer l'opérateur de ressources NUMA.
Procédure
Créez la ressource personnalisée
MachineConfigPoolqui permet de personnaliser les configurations des kubelets pour les nœuds de travail :Enregistrez le YAML suivant dans le fichier
nro-machineconfig.yaml:apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: labels: cnf-worker-tuning: enabled machineconfiguration.openshift.io/mco-built-in: "" pools.operator.machineconfiguration.openshift.io/worker: "" name: worker spec: machineConfigSelector: matchLabels: machineconfiguration.openshift.io/role: worker nodeSelector: matchLabels: node-role.kubernetes.io/worker: ""Créez le CR
MachineConfigPoolen exécutant la commande suivante :$ oc create -f nro-machineconfig.yaml
Créer la ressource personnalisée
NUMAResourcesOperator:Enregistrez le YAML suivant dans le fichier
nrop.yaml:apiVersion: nodetopology.openshift.io/v1alpha1 kind: NUMAResourcesOperator metadata: name: numaresourcesoperator spec: nodeGroups: - machineConfigPoolSelector: matchLabels: pools.operator.machineconfiguration.openshift.io/worker: "" 1- 1
- Doit correspondre à l'étiquette appliquée aux nœuds de travail dans le CR
MachineConfigPoolcorrespondant.
Créez le CR
NUMAResourcesOperatoren exécutant la commande suivante :$ oc create -f nrop.yaml
Vérification
Vérifiez que l'opérateur de ressources NUMA a été déployé avec succès en exécutant la commande suivante :
$ oc get numaresourcesoperators.nodetopology.openshift.io
Exemple de sortie
NAME AGE numaresourcesoperator 10m
5.4. Déploiement de l'ordonnanceur de pods secondaire NUMA-aware
Après avoir installé l'opérateur de ressources NUMA, procédez comme suit pour déployer le planificateur de pods secondaire compatible NUMA :
- Configurer la politique d'admission des pods pour le profil de machine requis
- Créer le pool de configuration machine requis
- Déployer l'ordonnanceur secondaire compatible NUMA
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Installer l'opérateur de ressources NUMA.
Procédure
Créez la ressource personnalisée
KubeletConfigqui configure la politique d'admission des pods pour le profil de la machine :Enregistrez le YAML suivant dans le fichier
nro-kubeletconfig.yaml:apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: cnf-worker-tuning spec: machineConfigPoolSelector: matchLabels: cnf-worker-tuning: enabled kubeletConfig: cpuManagerPolicy: "static" 1 cpuManagerReconcilePeriod: "5s" reservedSystemCPUs: "0,1" memoryManagerPolicy: "Static" 2 evictionHard: memory.available: "100Mi" kubeReserved: memory: "512Mi" reservedMemory: - numaNode: 0 limits: memory: "1124Mi" systemReserved: memory: "512Mi" topologyManagerPolicy: "single-numa-node" 3 topologyManagerScope: "pod"Créez la ressource personnalisée (CR)
KubeletConfigen exécutant la commande suivante :$ oc create -f nro-kubeletconfig.yaml
Créer la ressource personnalisée
NUMAResourcesSchedulerqui déploie le planificateur de pods personnalisé NUMA-aware :Enregistrez le YAML suivant dans le fichier
nro-scheduler.yaml:apiVersion: nodetopology.openshift.io/v1alpha1 kind: NUMAResourcesScheduler metadata: name: numaresourcesscheduler spec: imageSpec: "registry.redhat.io/openshift4/noderesourcetopology-scheduler-container-rhel8:v4.12"
Créez le CR
NUMAResourcesScheduleren exécutant la commande suivante :$ oc create -f nro-scheduler.yaml
Vérification
Vérifiez que les ressources requises ont été déployées avec succès en exécutant la commande suivante :
$ oc get all -n openshift-numaresources
Exemple de sortie
NAME READY STATUS RESTARTS AGE pod/numaresources-controller-manager-7575848485-bns4s 1/1 Running 0 13m pod/numaresourcesoperator-worker-dvj4n 2/2 Running 0 16m pod/numaresourcesoperator-worker-lcg4t 2/2 Running 0 16m pod/secondary-scheduler-56994cf6cf-7qf4q 1/1 Running 0 16m NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/numaresourcesoperator-worker 2 2 2 2 2 node-role.kubernetes.io/worker= 16m NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/numaresources-controller-manager 1/1 1 1 13m deployment.apps/secondary-scheduler 1/1 1 1 16m NAME DESIRED CURRENT READY AGE replicaset.apps/numaresources-controller-manager-7575848485 1 1 1 13m replicaset.apps/secondary-scheduler-56994cf6cf 1 1 1 16m
5.5. Ordonnancement des charges de travail avec l'ordonnanceur NUMA-aware
Vous pouvez planifier des charges de travail avec le planificateur NUMA-aware à l'aide de Deployment CR qui spécifient les ressources minimales requises pour traiter la charge de travail.
L'exemple de déploiement suivant utilise l'ordonnancement NUMA-aware pour un exemple de charge de travail.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Installez l'opérateur de ressources NUMA et déployez l'ordonnanceur secondaire compatible NUMA.
Procédure
Obtenez le nom de l'ordonnanceur NUMA-aware déployé dans le cluster en exécutant la commande suivante :
$ oc get numaresourcesschedulers.nodetopology.openshift.io numaresourcesscheduler -o json | jq '.status.schedulerName'
Exemple de sortie
topo-aware-scheduler
Créez un CR
Deploymentqui utilise l'ordonnanceur nommétopo-aware-scheduler, par exemple :Enregistrez le YAML suivant dans le fichier
nro-deployment.yaml:apiVersion: apps/v1 kind: Deployment metadata: name: numa-deployment-1 namespace: openshift-numaresources spec: replicas: 1 selector: matchLabels: app: test template: metadata: labels: app: test spec: schedulerName: topo-aware-scheduler 1 containers: - name: ctnr image: quay.io/openshifttest/hello-openshift:openshift imagePullPolicy: IfNotPresent resources: limits: memory: "100Mi" cpu: "10" requests: memory: "100Mi" cpu: "10" - name: ctnr2 image: gcr.io/google_containers/pause-amd64:3.0 imagePullPolicy: IfNotPresent command: ["/bin/sh", "-c"] args: [ "while true; do sleep 1h; done;" ] resources: limits: memory: "100Mi" cpu: "8" requests: memory: "100Mi" cpu: "8"- 1
schedulerNamedoit correspondre au nom de l'ordonnanceur NUMA-aware déployé dans votre cluster, par exempletopo-aware-scheduler.
Créez le CR
Deploymenten exécutant la commande suivante :$ oc create -f nro-deployment.yaml
Vérification
Vérifiez que le déploiement s'est déroulé correctement :
$ oc get pods -n openshift-numaresources
Exemple de sortie
NAME READY STATUS RESTARTS AGE numa-deployment-1-56954b7b46-pfgw8 2/2 Running 0 129m numaresources-controller-manager-7575848485-bns4s 1/1 Running 0 15h numaresourcesoperator-worker-dvj4n 2/2 Running 0 18h numaresourcesoperator-worker-lcg4t 2/2 Running 0 16h secondary-scheduler-56994cf6cf-7qf4q 1/1 Running 0 18h
Vérifiez que le site
topo-aware-schedulerplanifie le pod déployé en exécutant la commande suivante :$ oc describe pod numa-deployment-1-56954b7b46-pfgw8 -n openshift-numaresources
Exemple de sortie
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 130m topo-aware-scheduler Successfully assigned openshift-numaresources/numa-deployment-1-56954b7b46-pfgw8 to compute-0.example.com
NoteLes déploiements qui demandent plus de ressources qu'il n'y en a de disponibles pour la planification échoueront avec une erreur
MinimumReplicasUnavailable. Le déploiement réussit lorsque les ressources requises sont disponibles. Les pods restent dans l'étatPendingjusqu'à ce que les ressources nécessaires soient disponibles.Vérifiez que les ressources allouées prévues sont répertoriées pour le nœud. Exécutez la commande suivante :
$ oc describe noderesourcetopologies.topology.node.k8s.io
Exemple de sortie
... Zones: Costs: Name: node-0 Value: 10 Name: node-1 Value: 21 Name: node-0 Resources: Allocatable: 39 Available: 21 1 Capacity: 40 Name: cpu Allocatable: 6442450944 Available: 6442450944 Capacity: 6442450944 Name: hugepages-1Gi Allocatable: 134217728 Available: 134217728 Capacity: 134217728 Name: hugepages-2Mi Allocatable: 262415904768 Available: 262206189568 Capacity: 270146007040 Name: memory Type: Node- 1
- La capacité de
Availableest réduite en raison des ressources qui ont été allouées au pod garanti.
Les ressources consommées par les pods garantis sont soustraites des ressources de nœuds disponibles répertoriées sous
noderesourcetopologies.topology.node.k8s.io.Les allocations de ressources pour les modules ayant une qualité de service
Best-effortouBurstable(qosClass) ne sont pas reflétées dans les ressources des nœuds NUMA sousnoderesourcetopologies.topology.node.k8s.io. Si les ressources consommées par un pod ne sont pas prises en compte dans le calcul des ressources du nœud, vérifiez que le pod aqosClassdeGuaranteeden exécutant la commande suivante :$ oc get pod <pod_name> -n <pod_namespace> -o jsonpath="{ .status.qosClass }"Exemple de sortie
Guaranteed
5.6. Résolution des problèmes liés à l'ordonnancement NUMA
Pour résoudre les problèmes courants liés à l'ordonnancement de pods NUMA-aware, procédez comme suit.
Conditions préalables
-
Installez le CLI OpenShift Container Platform (
oc). - Connectez-vous en tant qu'utilisateur disposant des privilèges d'administrateur de cluster.
- Installez l'opérateur de ressources NUMA et déployez l'ordonnanceur secondaire compatible NUMA.
Procédure
Vérifiez que le CRD
noderesourcetopologiesest déployé dans le cluster en exécutant la commande suivante :$ oc get crd | grep noderesourcetopologies
Exemple de sortie
NAME CREATED AT noderesourcetopologies.topology.node.k8s.io 2022-01-18T08:28:06Z
Vérifiez que le nom de l'ordonnanceur NUMA-aware correspond au nom spécifié dans vos charges de travail NUMA-aware en exécutant la commande suivante :
$ oc get numaresourcesschedulers.nodetopology.openshift.io numaresourcesscheduler -o json | jq '.status.schedulerName'
Exemple de sortie
topo-aware-scheduler
Vérifiez que les nœuds programmables compatibles NUMA ont reçu l'application
noderesourcetopologiesCR. Exécutez la commande suivante :$ oc get noderesourcetopologies.topology.node.k8s.io
Exemple de sortie
NAME AGE compute-0.example.com 17h compute-1.example.com 17h
NoteLe nombre de nœuds doit être égal au nombre de nœuds de travailleur configurés par la définition de travailleur du pool de configuration de la machine (
mcp).Vérifiez la granularité de la zone NUMA pour tous les nœuds programmables en exécutant la commande suivante :
$ oc get noderesourcetopologies.topology.node.k8s.io -o yaml
Exemple de sortie
apiVersion: v1 items: - apiVersion: topology.node.k8s.io/v1alpha1 kind: NodeResourceTopology metadata: annotations: k8stopoawareschedwg/rte-update: periodic creationTimestamp: "2022-06-16T08:55:38Z" generation: 63760 name: worker-0 resourceVersion: "8450223" uid: 8b77be46-08c0-4074-927b-d49361471590 topologyPolicies: - SingleNUMANodeContainerLevel zones: - costs: - name: node-0 value: 10 - name: node-1 value: 21 name: node-0 resources: - allocatable: "38" available: "38" capacity: "40" name: cpu - allocatable: "134217728" available: "134217728" capacity: "134217728" name: hugepages-2Mi - allocatable: "262352048128" available: "262352048128" capacity: "270107316224" name: memory - allocatable: "6442450944" available: "6442450944" capacity: "6442450944" name: hugepages-1Gi type: Node - costs: - name: node-0 value: 21 - name: node-1 value: 10 name: node-1 resources: - allocatable: "268435456" available: "268435456" capacity: "268435456" name: hugepages-2Mi - allocatable: "269231067136" available: "269231067136" capacity: "270573244416" name: memory - allocatable: "40" available: "40" capacity: "40" name: cpu - allocatable: "1073741824" available: "1073741824" capacity: "1073741824" name: hugepages-1Gi type: Node - apiVersion: topology.node.k8s.io/v1alpha1 kind: NodeResourceTopology metadata: annotations: k8stopoawareschedwg/rte-update: periodic creationTimestamp: "2022-06-16T08:55:37Z" generation: 62061 name: worker-1 resourceVersion: "8450129" uid: e8659390-6f8d-4e67-9a51-1ea34bba1cc3 topologyPolicies: - SingleNUMANodeContainerLevel zones: 1 - costs: - name: node-0 value: 10 - name: node-1 value: 21 name: node-0 resources: 2 - allocatable: "38" available: "38" capacity: "40" name: cpu - allocatable: "6442450944" available: "6442450944" capacity: "6442450944" name: hugepages-1Gi - allocatable: "134217728" available: "134217728" capacity: "134217728" name: hugepages-2Mi - allocatable: "262391033856" available: "262391033856" capacity: "270146301952" name: memory type: Node - costs: - name: node-0 value: 21 - name: node-1 value: 10 name: node-1 resources: - allocatable: "40" available: "40" capacity: "40" name: cpu - allocatable: "1073741824" available: "1073741824" capacity: "1073741824" name: hugepages-1Gi - allocatable: "268435456" available: "268435456" capacity: "268435456" name: hugepages-2Mi - allocatable: "269192085504" available: "269192085504" capacity: "270534262784" name: memory type: Node kind: List metadata: resourceVersion: "" selfLink: ""- 1
- Chaque strophe sous
zonesdécrit les ressources d'une seule zone NUMA. - 2
resourcesdécrit l'état actuel des ressources de la zone NUMA. Vérifiez que les ressources répertoriées sousitems.zones.resources.availablecorrespondent aux ressources exclusives de la zone NUMA allouées à chaque pod garanti.
5.6.1. Vérification des journaux de l'ordonnanceur NUMA-aware
Dépannez les problèmes liés à l'ordonnanceur NUMA-aware en examinant les journaux. Si nécessaire, vous pouvez augmenter le niveau de journalisation de l'ordonnanceur en modifiant le champ spec.logLevel de la ressource NUMAResourcesScheduler. Les valeurs acceptables sont Normal, Debug, et Trace, Trace étant l'option la plus verbeuse.
Pour modifier le niveau de journalisation de l'ordonnanceur secondaire, supprimez la ressource de l'ordonnanceur en cours d'exécution et redéployez-la avec le niveau de journalisation modifié. L'ordonnanceur n'est pas disponible pour l'ordonnancement de nouvelles charges de travail pendant ce temps d'arrêt.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Supprimer la ressource
NUMAResourcesScheduleren cours d'exécution :Obtenez le site actif
NUMAResourcesScheduleren exécutant la commande suivante :$ oc get NUMAResourcesScheduler
Exemple de sortie
NAME AGE numaresourcesscheduler 90m
Supprimez la ressource du planificateur secondaire en exécutant la commande suivante :
$ oc delete NUMAResourcesScheduler numaresourcesscheduler
Exemple de sortie
numaresourcesscheduler.nodetopology.openshift.io "numaresourcesscheduler" deleted
Enregistrez le YAML suivant dans le fichier
nro-scheduler-debug.yaml. Cet exemple modifie le niveau de journalisation àDebug:apiVersion: nodetopology.openshift.io/v1alpha1 kind: NUMAResourcesScheduler metadata: name: numaresourcesscheduler spec: imageSpec: "registry.redhat.io/openshift4/noderesourcetopology-scheduler-container-rhel8:v4.12" logLevel: Debug
Créez la ressource
DebugloggingNUMAResourcesSchedulermise à jour en exécutant la commande suivante :$ oc create -f nro-scheduler-debug.yaml
Exemple de sortie
numaresourcesscheduler.nodetopology.openshift.io/numaresourcesscheduler created
Verification steps
Vérifiez que l'ordonnanceur NUMA-aware a été déployé avec succès :
Exécutez la commande suivante pour vérifier que le CRD a été créé avec succès :
$ oc get crd | grep numaresourcesschedulers
Exemple de sortie
NAME CREATED AT numaresourcesschedulers.nodetopology.openshift.io 2022-02-25T11:57:03Z
Vérifiez que le nouvel ordonnanceur personnalisé est disponible en exécutant la commande suivante :
$ oc get numaresourcesschedulers.nodetopology.openshift.io
Exemple de sortie
NAME AGE numaresourcesscheduler 3h26m
Vérifiez que les journaux de l'ordonnanceur affichent le niveau de journal augmenté :
Obtenez la liste des pods fonctionnant dans l'espace de noms
openshift-numaresourcesen exécutant la commande suivante :$ oc get pods -n openshift-numaresources
Exemple de sortie
NAME READY STATUS RESTARTS AGE numaresources-controller-manager-d87d79587-76mrm 1/1 Running 0 46h numaresourcesoperator-worker-5wm2k 2/2 Running 0 45h numaresourcesoperator-worker-pb75c 2/2 Running 0 45h secondary-scheduler-7976c4d466-qm4sc 1/1 Running 0 21m
Obtenez les journaux du module de planification secondaire en exécutant la commande suivante :
$ oc logs secondary-scheduler-7976c4d466-qm4sc -n openshift-numaresources
Exemple de sortie
... I0223 11:04:55.614788 1 reflector.go:535] k8s.io/client-go/informers/factory.go:134: Watch close - *v1.Namespace total 11 items received I0223 11:04:56.609114 1 reflector.go:535] k8s.io/client-go/informers/factory.go:134: Watch close - *v1.ReplicationController total 10 items received I0223 11:05:22.626818 1 reflector.go:535] k8s.io/client-go/informers/factory.go:134: Watch close - *v1.StorageClass total 7 items received I0223 11:05:31.610356 1 reflector.go:535] k8s.io/client-go/informers/factory.go:134: Watch close - *v1.PodDisruptionBudget total 7 items received I0223 11:05:31.713032 1 eventhandlers.go:186] "Add event for scheduled pod" pod="openshift-marketplace/certified-operators-thtvq" I0223 11:05:53.461016 1 eventhandlers.go:244] "Delete event for scheduled pod" pod="openshift-marketplace/certified-operators-thtvq"
5.6.2. Dépannage de l'exportateur de topologie de ressources
Dépanner les objets noderesourcetopologies pour lesquels des résultats inattendus se produisent en inspectant les journaux resource-topology-exporter correspondants.
Il est recommandé de nommer les instances de l'exportateur de topologie de ressources NUMA dans le cluster en fonction des nœuds auxquels elles se réfèrent. Par exemple, un nœud de travail portant le nom worker doit avoir un objet noderesourcetopologies correspondant appelé worker.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Obtenir les daemonsets gérés par l'opérateur de ressources NUMA. Chaque daemonset a un
nodeGroupcorrespondant dans le CRNUMAResourcesOperator. Exécutez la commande suivante :$ oc get numaresourcesoperators.nodetopology.openshift.io numaresourcesoperator -o jsonpath="{.status.daemonsets[0]}"Exemple de sortie
{"name":"numaresourcesoperator-worker","namespace":"openshift-numaresources"}Obtenir l'étiquette du daemonset concerné en utilisant la valeur de
nameobtenue à l'étape précédente :$ oc get ds -n openshift-numaresources numaresourcesoperator-worker -o jsonpath="{.spec.selector.matchLabels}"Exemple de sortie
{"name":"resource-topology"}Obtenez les pods en utilisant l'étiquette
resource-topologyen exécutant la commande suivante :$ oc get pods -n openshift-numaresources -l name=resource-topology -o wide
Exemple de sortie
NAME READY STATUS RESTARTS AGE IP NODE numaresourcesoperator-worker-5wm2k 2/2 Running 0 2d1h 10.135.0.64 compute-0.example.com numaresourcesoperator-worker-pb75c 2/2 Running 0 2d1h 10.132.2.33 compute-1.example.com
Examinez les journaux du conteneur
resource-topology-exporters'exécutant sur le module de travail correspondant au nœud que vous dépannez. Exécutez la commande suivante :$ oc logs -n openshift-numaresources -c resource-topology-exporter numaresourcesoperator-worker-pb75c
Exemple de sortie
I0221 13:38:18.334140 1 main.go:206] using sysinfo: reservedCpus: 0,1 reservedMemory: "0": 1178599424 I0221 13:38:18.334370 1 main.go:67] === System information === I0221 13:38:18.334381 1 sysinfo.go:231] cpus: reserved "0-1" I0221 13:38:18.334493 1 sysinfo.go:237] cpus: online "0-103" I0221 13:38:18.546750 1 main.go:72] cpus: allocatable "2-103" hugepages-1Gi: numa cell 0 -> 6 numa cell 1 -> 1 hugepages-2Mi: numa cell 0 -> 64 numa cell 1 -> 128 memory: numa cell 0 -> 45758Mi numa cell 1 -> 48372Mi
5.6.3. Correction d'une carte de configuration de l'exportateur de topologie de ressources manquante
Si vous installez l'opérateur de ressources NUMA dans un cluster dont les paramètres sont mal configurés, dans certaines circonstances, l'opérateur est indiqué comme étant actif, mais les journaux des pods du démon RTE (resource topology exporter) montrent que la configuration du RTE est manquante, par exemple :
Info: couldn't find configuration in "/etc/resource-topology-exporter/config.yaml"
Ce message indique que la configuration requise de kubeletconfig n'a pas été correctement appliquée dans le cluster, ce qui entraîne l'absence d'une RTE configmap. Par exemple, il manque une ressource personnalisée (CR) numaresourcesoperator-worker configmap dans le cluster suivant :
$ oc get configmap
Exemple de sortie
NAME DATA AGE 0e2a6bd3.openshift-kni.io 0 6d21h kube-root-ca.crt 1 6d21h openshift-service-ca.crt 1 6d21h topo-aware-scheduler-config 1 6d18h
Dans un groupe correctement configuré, oc get configmap renvoie également un CR numaresourcesoperator-worker configmap .
Conditions préalables
-
Installez le CLI OpenShift Container Platform (
oc). - Connectez-vous en tant qu'utilisateur disposant des privilèges d'administrateur de cluster.
- Installez l'opérateur de ressources NUMA et déployez l'ordonnanceur secondaire compatible NUMA.
Procédure
Comparez les valeurs de
spec.machineConfigPoolSelector.matchLabelsdanskubeletconfiget demetadata.labelsdansMachineConfigPool(mcp) worker CR à l'aide des commandes suivantes :Vérifiez les étiquettes
kubeletconfigen exécutant la commande suivante :$ oc get kubeletconfig -o yaml
Exemple de sortie
machineConfigPoolSelector: matchLabels: cnf-worker-tuning: enabledVérifiez les étiquettes
mcpen exécutant la commande suivante :$ oc get mcp worker -o yaml
Exemple de sortie
labels: machineconfiguration.openshift.io/mco-built-in: "" pools.operator.machineconfiguration.openshift.io/worker: ""
L'étiquette
cnf-worker-tuning: enabledn'est pas présente dans l'objetMachineConfigPool.
Modifiez le CR
MachineConfigPoolpour inclure l'étiquette manquante, par exemple :$ oc edit mcp worker -o yaml
Exemple de sortie
labels: machineconfiguration.openshift.io/mco-built-in: "" pools.operator.machineconfiguration.openshift.io/worker: "" cnf-worker-tuning: enabled
- Appliquez les changements d'étiquettes et attendez que le cluster applique la configuration mise à jour. Exécutez la commande suivante :
Vérification
Vérifier que le
numaresourcesoperator-workerconfigmapCR manquant est appliqué :$ oc get configmap
Exemple de sortie
NAME DATA AGE 0e2a6bd3.openshift-kni.io 0 6d21h kube-root-ca.crt 1 6d21h numaresourcesoperator-worker 1 5m openshift-service-ca.crt 1 6d21h topo-aware-scheduler-config 1 6d18h
Chapitre 6. Mise à l'échelle de l'opérateur de surveillance des clusters
OpenShift Container Platform expose les métriques que l'opérateur de surveillance des clusters collecte et stocke dans la pile de surveillance basée sur Prometheus. En tant qu'administrateur, vous pouvez afficher des tableaux de bord pour les ressources système, les conteneurs et les métriques des composants dans la console Web d'OpenShift Container Platform en naviguant vers Observe → Dashboards.
6.1. Exigences en matière de stockage de la base de données Prometheus
Red Hat a effectué plusieurs tests pour différentes tailles d'échelle.
Les exigences de stockage de Prometheus ci-dessous ne sont pas normatives. Une consommation de ressources plus importante peut être observée dans votre cluster en fonction de l'activité de la charge de travail et de l'utilisation des ressources.
Tableau 6.1. Besoins de stockage de la base de données Prometheus en fonction du nombre de nœuds/podes dans le cluster
| Nombre de nœuds | Nombre de gousses | Croissance du stockage de Prométhée par jour | Croissance du stockage de Prometheus par 15 jours | Espace RAM (par taille d'échelle) | Réseau (par élément de la base de données) |
|---|---|---|---|---|---|
| 50 | 1800 | 6.3 GB | 94 GB | 6 GB | 16 MB |
| 100 | 3600 | 13 GB | 195 GB | 10 GB | 26 MB |
| 150 | 5400 | 19 GB | 283 GB | 12 GB | 36 MB |
| 200 | 7200 | 25 GB | 375 GO | 14 GB | 46 MB |
Environ 20 % de la taille prévue a été ajoutée comme frais généraux pour garantir que les besoins de stockage ne dépassent pas la valeur calculée.
Le calcul ci-dessus concerne l'opérateur de surveillance de cluster par défaut d'OpenShift Container Platform.
L'utilisation du processeur a un impact mineur. Le ratio est d'environ 1 cœur sur 40 pour 50 nœuds et 1800 pods.
Recommendations for OpenShift Container Platform
- Utiliser au moins trois nœuds d'infrastructure (infra).
- Utilisez au moins trois nœuds openshift-container-storage avec des disques NVMe (non-volatile memory express).
6.2. Configuration de la surveillance des clusters
Vous pouvez augmenter la capacité de stockage du composant Prometheus dans la pile de surveillance des clusters.
Procédure
Augmenter la capacité de stockage de Prometheus :
Créez un fichier de configuration YAML,
cluster-monitoring-config.yaml. Par exemple :apiVersion: v1 kind: ConfigMap data: config.yaml: | prometheusK8s: retention: {{PROMETHEUS_RETENTION_PERIOD}} 1 nodeSelector: node-role.kubernetes.io/infra: "" volumeClaimTemplate: spec: storageClassName: {{STORAGE_CLASS}} 2 resources: requests: storage: {{PROMETHEUS_STORAGE_SIZE}} 3 alertmanagerMain: nodeSelector: node-role.kubernetes.io/infra: "" volumeClaimTemplate: spec: storageClassName: {{STORAGE_CLASS}} 4 resources: requests: storage: {{ALERTMANAGER_STORAGE_SIZE}} 5 metadata: name: cluster-monitoring-config namespace: openshift-monitoring- 1
- Une valeur typique est
PROMETHEUS_RETENTION_PERIOD=15d. Les unités sont mesurées en temps en utilisant l'un des suffixes suivants : s, m, h, d. - 2 4
- La classe de stockage pour votre cluster.
- 3
- Une valeur typique est
PROMETHEUS_STORAGE_SIZE=2000Gi. Les valeurs de stockage peuvent être des entiers simples ou des entiers à virgule fixe en utilisant l'un des suffixes suivants : E, P, T, G, M, K. Vous pouvez également utiliser les équivalents en puissance de deux : Ei, Pi, Ti, Gi, Mi, Ki. - 5
- Une valeur typique est
ALERTMANAGER_STORAGE_SIZE=20Gi. Les valeurs de stockage peuvent être des entiers simples ou des entiers à virgule fixe en utilisant l'un des suffixes suivants : E, P, T, G, M, K. Vous pouvez également utiliser les équivalents en puissance de deux : Ei, Pi, Ti, Gi, Mi, Ki.
- Ajoutez des valeurs pour la période de rétention, la classe de stockage et les tailles de stockage.
- Enregistrer le fichier.
Appliquez les modifications en exécutant le programme :
$ oc create -f cluster-monitoring-config.yaml
Chapitre 7. Planifier votre environnement en fonction des maxima d'objets
Prenez en compte les maximums d'objets testés suivants lorsque vous planifiez votre cluster OpenShift Container Platform.
Ces lignes directrices sont basées sur la plus grande grappe possible. Pour les clusters plus petits, les maxima sont inférieurs. De nombreux facteurs influencent les seuils indiqués, notamment la version d'etcd ou le format des données de stockage.
Dans la plupart des cas, le dépassement de ces nombres entraîne une baisse des performances globales. Cela ne signifie pas nécessairement que la grappe échouera.
Les clusters qui subissent des changements rapides, tels que ceux qui ont de nombreux pods qui démarrent et s'arrêtent, peuvent avoir une taille maximale pratique inférieure à celle qui est documentée.
7.1. OpenShift Container Platform a testé les maximums de clusters pour les versions majeures
Red Hat ne fournit pas de conseils directs sur le dimensionnement de votre cluster OpenShift Container Platform. En effet, pour déterminer si votre cluster est dans les limites supportées par OpenShift Container Platform, il faut prendre en compte tous les facteurs multidimensionnels qui limitent l'échelle du cluster.
OpenShift Container Platform prend en charge des maximums de clusters testés plutôt que des maximums absolus de clusters. Toutes les combinaisons de version d'OpenShift Container Platform, de charge de travail du plan de contrôle et de plugin réseau ne sont pas testées, de sorte que le tableau suivant ne représente pas une attente absolue d'échelle pour tous les déploiements. Il se peut qu'il ne soit pas possible d'atteindre une échelle maximale sur toutes les dimensions simultanément. Le tableau contient des maxima testés pour des charges de travail et des configurations de déploiement spécifiques, et sert de guide d'échelle pour ce à quoi on peut s'attendre avec des déploiements similaires.
| Type maximum | 4.x maximum testé |
|---|---|
| Nombre de nœuds | 2,000 [1] |
| Nombre de nacelles [2] | 150,000 |
| Nombre de pods par nœud | 500 [3] |
| Nombre de pods par cœur | Il n'y a pas de valeur par défaut. |
| Nombre d'espaces de noms [4] | 10,000 |
| Nombre de constructions | 10 000 (pod par défaut RAM 512 Mi) - Stratégie de construction Source-to-Image (S2I) |
| Nombre de pods par espace de noms [5] | 25,000 |
| Nombre de routes et de back ends par contrôleur d'entrée | 2 000 euros par routeur |
| Nombre de secrets | 80,000 |
| Nombre de cartes de configuration | 90,000 |
| Nombre de services [6] | 10,000 |
| Nombre de services par espace de noms | 5,000 |
| Nombre de backends par service | 5,000 |
| Nombre de déploiements par espace de noms [5] | 2,000 |
| Nombre de configurations de construction | 12,000 |
| Nombre de définitions de ressources personnalisées (CRD) | 512 [7] |
- Les pods de pause ont été déployés pour mettre à l'épreuve les composants du plan de contrôle d'OpenShift Container Platform à l'échelle de 2000 nœuds. La capacité à évoluer vers des nombres similaires variera en fonction des paramètres spécifiques de déploiement et de charge de travail.
- Le nombre de modules affiché ici correspond au nombre de modules de test. Le nombre réel de modules dépend des besoins de l'application en matière de mémoire, d'unité centrale et de stockage.
-
Ceci a été testé sur un cluster de 100 nœuds de travail avec 500 pods par nœud de travail. La valeur par défaut de
maxPodsest toujours de 250. Pour atteindre 500maxPods, le cluster doit être créé avec unmaxPodsdéfini sur500en utilisant une configuration kubelet personnalisée. Si vous avez besoin de 500 user pods, vous avez besoin d'unhostPrefixde22parce qu'il y a 10-15 system pods déjà en cours d'exécution sur le nœud. Le nombre maximum de pods avec des réclamations de volumes persistants (PVC) dépend du backend de stockage à partir duquel les PVC sont alloués. Dans nos tests, seul OpenShift Data Foundation v4 (OCS v4) a été en mesure de satisfaire le nombre de pods par nœud discuté dans ce document. - Lorsqu'il y a un grand nombre de projets actifs, etcd peut souffrir de mauvaises performances si l'espace-clé devient excessivement grand et dépasse le quota d'espace. Une maintenance périodique de etcd, y compris une défragmentation, est fortement recommandée pour libérer l'espace de stockage de etcd.
- Le système comporte un certain nombre de boucles de contrôle qui doivent passer en revue tous les objets d'un espace de noms donné en réaction à certains changements d'état. Le fait d'avoir un grand nombre d'objets d'un type donné dans un seul espace de noms peut rendre ces boucles coûteuses et ralentir le traitement des changements d'état. La limite suppose que le système dispose de suffisamment d'unité centrale, de mémoire et de disque pour répondre aux exigences de l'application.
- Chaque port de service et chaque back-end de service a une entrée correspondante dans iptables. Le nombre de back-ends d'un service donné a un impact sur la taille des objets des endpoints, ce qui a un impact sur la taille des données qui sont envoyées dans tout le système.
-
OpenShift Container Platform a une limite de 512 définitions de ressources personnalisées (CRD), y compris celles installées par OpenShift Container Platform, les produits intégrant OpenShift Container Platform et les CRD créés par l'utilisateur. S'il y a plus de 512 CRD créés, il est possible que les demandes de commandes
ocsoient limitées.
7.1.1. Exemple de scénario
À titre d'exemple, 500 nœuds de travail (m5.2xl) ont été testés et sont pris en charge avec OpenShift Container Platform 4.12, le plugin réseau OVN-Kubernetes et les objets de charge de travail suivants :
- 200 espaces de noms, en plus des valeurs par défaut
- 60 pods par nœud ; 30 pods serveur et 30 pods client (30k au total)
- 57 flux d'images/ns (11,4k au total)
- 15 services/ns soutenus par les pods serveurs (3k au total)
- 15 routes/ns soutenues par les services précédents (3k au total)
- 20 secrets/ns (4k au total)
- 10 cartes de configuration/ns (2k au total)
- 6 politiques réseau/ns, y compris les règles de refus d'accès, d'autorisation d'accès à l'entrée et à l'intérieur de l'espace de nommage
- 57 constructions/ns
Les facteurs suivants sont connus pour affecter la mise à l'échelle des charges de travail des clusters, positivement ou négativement, et doivent être pris en compte dans les chiffres d'échelle lors de la planification d'un déploiement. Pour plus d'informations et de conseils, contactez votre représentant commercial ou l'assistance Red Hat.
- Nombre de pods par nœud
- Nombre de conteneurs par gousse
- Type de sondes utilisées (par exemple, vivacité/préparation, exec/http)
- Nombre de politiques de réseau
- Nombre de projets ou d'espaces de noms
- Nombre de flux d'images par projet
- Nombre de constructions par projet
- Nombre de services/points de terminaison et type
- Nombre d'itinéraires
- Nombre de tessons
- Nombre de secrets
- Nombre de cartes de configuration
Taux d'appels à l'API, ou "churn" du cluster, qui est une estimation de la vitesse à laquelle les choses changent dans la configuration du cluster.
-
Requête Prometheus pour les demandes de création de pods par seconde sur des fenêtres de 5 minutes :
sum(irate(apiserver_request_count{resource="pods",verb="POST"}[5m])) -
Requête Prometheus pour toutes les demandes d'API par seconde sur des fenêtres de 5 minutes :
sum(irate(apiserver_request_count{}[5m]))
-
Requête Prometheus pour les demandes de création de pods par seconde sur des fenêtres de 5 minutes :
- Consommation de ressources du nœud de la grappe par l'unité centrale
- Consommation de ressources de la mémoire par le nœud de la grappe
7.2. Environnement et configuration d'OpenShift Container Platform sur lesquels les maxima des clusters sont testés
7.2.1. Plate-forme en nuage AWS
| Nœud | Saveur | vCPU | RAM(GiB) | Type de disque | Taille du disque (GiB)/IOS | Compter | Region |
|---|---|---|---|---|---|---|---|
| Plan de contrôle/etcd [1] | r5.4xlarge | 16 | 128 | gp3 | 220 | 3 | us-west-2 |
| Infra [2] | m5.12xlarge | 48 | 192 | gp3 | 100 | 3 | us-west-2 |
| Charge de travail [3] | m5.4xlarge | 16 | 64 | gp3 | 500 [4] | 1 | us-west-2 |
| Compute | m5.2xlarge | 8 | 32 | gp3 | 100 | 3/25/250/500 [5] | us-west-2 |
- les disques gp3 avec une performance de base de 3000 IOPS et 125 MiB par seconde sont utilisés pour les nœuds du plan de contrôle/etcd parce que etcd est sensible à la latence. Les volumes gp3 n'utilisent pas la performance en rafale.
- Les nœuds Infra sont utilisés pour héberger les composants de surveillance, d'entrée et de registre afin de s'assurer qu'ils disposent de suffisamment de ressources pour fonctionner à grande échelle.
- Le nœud de charge de travail est dédié à l'exécution des générateurs de charge de travail de performance et d'évolutivité.
- Une taille de disque plus importante est utilisée afin de disposer de suffisamment d'espace pour stocker les grandes quantités de données collectées lors des tests de performance et d'évolutivité.
- La grappe est mise à l'échelle par itérations et les tests de performance et d'évolutivité sont exécutés aux nombres de nœuds spécifiés.
7.2.2. Plate-forme IBM Power
| Nœud | vCPU | RAM(GiB) | Type de disque | Taille du disque (GiB)/IOS | Compter |
|---|---|---|---|---|---|
| Plan de contrôle/etcd [1] | 16 | 32 | io1 | 120 / 10 IOPS par GiB | 3 |
| Infra [2] | 16 | 64 | gp2 | 120 | 2 |
| Charge de travail [3] | 16 | 256 | gp2 | 120 [4] | 1 |
| Compute | 16 | 64 | gp2 | 120 | 2 à 100 [5] |
- les disques io1 avec 120 / 10 IOPS par GiB sont utilisés pour les nœuds de plan de contrôle/etcd car etcd est intensif en E/S et sensible à la latence.
- Les nœuds Infra sont utilisés pour héberger les composants de surveillance, d'entrée et de registre afin de s'assurer qu'ils disposent de suffisamment de ressources pour fonctionner à grande échelle.
- Le nœud de charge de travail est dédié à l'exécution des générateurs de charge de travail de performance et d'évolutivité.
- Une taille de disque plus importante est utilisée afin de disposer de suffisamment d'espace pour stocker les grandes quantités de données collectées lors des tests de performance et d'évolutivité.
- La grappe est échelonnée en itérations.
7.2.3. Plate-forme IBM zSystems
| Nœud | vCPU [4] | RAM(GiB)[5] | Type de disque | Taille du disque (GiB)/IOS | Compter |
|---|---|---|---|---|---|
| Plan de contrôle/etcd [1,2] | 8 | 32 | ds8k | 300 / LCU 1 | 3 |
| Calculer [1,3] | 8 | 32 | ds8k | 150 / LCU 2 | 4 nœuds (échelonnés à 100/250/500 pods par nœud) |
- Les nœuds sont répartis entre deux unités de contrôle logique (LCU) afin d'optimiser la charge d'E/S sur disque des nœuds du plan de contrôle/etcd, car etcd est gourmand en E/S et sensible à la latence. La demande d'E/S d'Etcd ne doit pas interférer avec d'autres charges de travail.
- Quatre nœuds de calcul sont utilisés pour les tests en effectuant plusieurs itérations avec 100/250/500 pods en même temps. Tout d'abord, des pods au ralenti ont été utilisés pour évaluer si les pods peuvent être instanciés. Ensuite, une charge de travail client/serveur exigeante en termes de réseau et de CPU a été utilisée pour évaluer la stabilité du système sous contrainte. Les modules clients et serveurs ont été déployés par paire et chaque paire a été répartie sur deux nœuds de calcul.
- Aucun nœud de charge de travail séparé n'a été utilisé. La charge de travail simule une charge de travail de microservice entre deux nœuds de calcul.
- Le nombre physique de processeurs utilisés est de six installations intégrées pour Linux (IFL).
- La mémoire physique totale utilisée est de 512 GiB.
7.3. Comment planifier votre environnement en fonction des maximums de grappes testés ?
La sursouscription des ressources physiques sur un nœud affecte les garanties de ressources que le planificateur Kubernetes effectue lors du placement des pods. Découvrez les mesures à prendre pour éviter les échanges de mémoire.
Certains des maximums testés ne sont étendus qu'à une seule dimension. Ils varient lorsque de nombreux objets sont en cours d'exécution sur le cluster.
Les chiffres indiqués dans cette documentation sont basés sur la méthodologie de test, l'installation, la configuration et les réglages de Red Hat. Ces chiffres peuvent varier en fonction de votre propre configuration et de vos environnements.
Lors de la planification de votre environnement, déterminez le nombre de pods par nœud :
required pods per cluster / pods per node = total number of nodes needed
Par défaut, le nombre maximal de pods par nœud est de 250. Cependant, le nombre de pods pouvant être installés sur un nœud dépend de l'application elle-même. Prenez en compte les besoins de l'application en termes de mémoire, de CPU et de stockage, comme décrit dans "Comment planifier votre environnement en fonction des besoins de l'application".
Exemple de scénario
Si vous souhaitez étendre votre cluster à 2200 pods par cluster, vous aurez besoin d'au moins cinq nœuds, en supposant qu'il y ait au maximum 500 pods par nœud :
2200 / 500 = 4.4
Si vous augmentez le nombre de nœuds à 20, la distribution des pods passe à 110 pods par nœud :
2200 / 20 = 110
Où ?
required pods per cluster / total number of nodes = expected pods per node
OpenShift Container Platform est livré avec plusieurs pods système, tels que SDN, DNS, Operators, et d'autres, qui s'exécutent sur chaque nœud de travail par défaut. Par conséquent, le résultat de la formule ci-dessus peut varier.
7.4. Comment planifier votre environnement en fonction des exigences de l'application
Prenons un exemple d'environnement d'application :
| Type de cosse | Quantité de gousses | Mémoire maximale | Cœurs de l'unité centrale | Stockage permanent |
|---|---|---|---|---|
| apache | 100 | 500 MO | 0.5 | 1 GB |
| node.js | 200 | 1 GB | 1 | 1 GB |
| postgresql | 100 | 1 GB | 2 | 10 GB |
| JBoss EAP | 100 | 1 GB | 1 | 1 GB |
Exigences extrapolées : 550 cœurs de CPU, 450 Go de RAM et 1,4 To de stockage.
La taille de l'instance pour les nœuds peut être modulée à la hausse ou à la baisse, selon vos préférences. Les nœuds sont souvent surchargés en ressources. Dans ce scénario de déploiement, vous pouvez choisir d'exécuter des nœuds supplémentaires plus petits ou moins de nœuds plus grands pour fournir la même quantité de ressources. Des facteurs tels que l'agilité opérationnelle et le coût par instance doivent être pris en compte.
| Type de nœud | Quantité | CPUs | RAM (GB) |
|---|---|---|---|
| Nœuds (option 1) | 100 | 4 | 16 |
| Nœuds (option 2) | 50 | 8 | 32 |
| Nœuds (option 3) | 25 | 16 | 64 |
Certaines applications se prêtent bien aux environnements de surengagement, d'autres non. La plupart des applications Java et des applications qui utilisent d'énormes pages sont des exemples d'applications qui ne permettraient pas un surengagement. Cette mémoire ne peut pas être utilisée pour d'autres applications. Dans l'exemple ci-dessus, l'environnement serait sur-engagé à environ 30 %, un ratio courant.
Les modules d'application peuvent accéder à un service en utilisant des variables d'environnement ou le DNS. Si l'on utilise des variables d'environnement, pour chaque service actif, les variables sont injectées par le kubelet lorsqu'un pod est exécuté sur un nœud. Un serveur DNS conscient du cluster surveille l'API Kubernetes pour les nouveaux services et crée un ensemble d'enregistrements DNS pour chacun d'entre eux. Si le DNS est activé dans l'ensemble de votre cluster, tous les pods devraient automatiquement être en mesure de résoudre les services par leur nom DNS. La découverte de services à l'aide du DNS peut être utilisée si vous devez aller au-delà de 5000 services. Lorsque vous utilisez des variables d'environnement pour la découverte de services, la liste d'arguments dépasse la longueur autorisée après 5000 services dans un espace de noms, les pods et les déploiements commenceront alors à échouer. Désactivez les liens de service dans le fichier de spécification de service du déploiement pour résoudre ce problème :
---
apiVersion: template.openshift.io/v1
kind: Template
metadata:
name: deployment-config-template
creationTimestamp:
annotations:
description: This template will create a deploymentConfig with 1 replica, 4 env vars and a service.
tags: ''
objects:
- apiVersion: apps.openshift.io/v1
kind: DeploymentConfig
metadata:
name: deploymentconfig${IDENTIFIER}
spec:
template:
metadata:
labels:
name: replicationcontroller${IDENTIFIER}
spec:
enableServiceLinks: false
containers:
- name: pause${IDENTIFIER}
image: "${IMAGE}"
ports:
- containerPort: 8080
protocol: TCP
env:
- name: ENVVAR1_${IDENTIFIER}
value: "${ENV_VALUE}"
- name: ENVVAR2_${IDENTIFIER}
value: "${ENV_VALUE}"
- name: ENVVAR3_${IDENTIFIER}
value: "${ENV_VALUE}"
- name: ENVVAR4_${IDENTIFIER}
value: "${ENV_VALUE}"
resources: {}
imagePullPolicy: IfNotPresent
capabilities: {}
securityContext:
capabilities: {}
privileged: false
restartPolicy: Always
serviceAccount: ''
replicas: 1
selector:
name: replicationcontroller${IDENTIFIER}
triggers:
- type: ConfigChange
strategy:
type: Rolling
- apiVersion: v1
kind: Service
metadata:
name: service${IDENTIFIER}
spec:
selector:
name: replicationcontroller${IDENTIFIER}
ports:
- name: serviceport${IDENTIFIER}
protocol: TCP
port: 80
targetPort: 8080
clusterIP: ''
type: ClusterIP
sessionAffinity: None
status:
loadBalancer: {}
parameters:
- name: IDENTIFIER
description: Number to append to the name of resources
value: '1'
required: true
- name: IMAGE
description: Image to use for deploymentConfig
value: gcr.io/google-containers/pause-amd64:3.0
required: false
- name: ENV_VALUE
description: Value to use for environment variables
generate: expression
from: "[A-Za-z0-9]{255}"
required: false
labels:
template: deployment-config-template
Le nombre de modules d'application pouvant être exécutés dans un espace de noms dépend du nombre de services et de la longueur du nom du service lorsque les variables d'environnement sont utilisées pour la découverte des services. ARG_MAX sur le système définit la longueur maximale des arguments pour un nouveau processus et elle est fixée à 2097152 octets (2 MiB) par défaut. Le Kubelet injecte des variables d'environnement dans chaque pod programmé pour s'exécuter dans l'espace de noms, y compris :
-
<SERVICE_NAME>_SERVICE_HOST=<IP> -
<SERVICE_NAME>_SERVICE_PORT=<PORT> -
<SERVICE_NAME>_PORT=tcp://<IP>:<PORT> -
<SERVICE_NAME>_PORT_<PORT>_TCP=tcp://<IP>:<PORT> -
<SERVICE_NAME>_PORT_<PORT>_TCP_PROTO=tcp -
<SERVICE_NAME>_PORT_<PORT>_TCP_PORT=<PORT> -
<SERVICE_NAME>_PORT_<PORT>_TCP_ADDR=<ADDR>
Les pods de l'espace de noms commenceront à échouer si la longueur de l'argument dépasse la valeur autorisée et si le nombre de caractères dans le nom d'un service a un impact. Par exemple, dans un espace de noms comprenant 5000 services, la limite du nom de service est de 33 caractères, ce qui vous permet d'exécuter 5000 pods dans l'espace de noms.
Chapitre 8. Optimiser le stockage
L'optimisation du stockage permet de minimiser l'utilisation du stockage sur l'ensemble des ressources. En optimisant le stockage, les administrateurs s'assurent que les ressources de stockage existantes fonctionnent de manière efficace.
8.1. Options de stockage permanent disponibles
Comprenez vos options de stockage persistant afin d'optimiser votre environnement OpenShift Container Platform.
Tableau 8.1. Options de stockage disponibles
| Type de stockage | Description | Examples |
|---|---|---|
| Bloc |
| AWS EBS et VMware vSphere prennent en charge le provisionnement dynamique de volumes persistants (PV) de manière native dans OpenShift Container Platform. |
| Fichier |
| RHEL NFS, NetApp NFS [1] et Vendor NFS |
| Objet |
| AWS S3 |
- NetApp NFS prend en charge le provisionnement dynamique des PV lors de l'utilisation du plugin Trident.
Actuellement, CNS n'est pas pris en charge dans OpenShift Container Platform 4.12.
8.2. Technologie de stockage configurable recommandée
Le tableau suivant résume les technologies de stockage recommandées et configurables pour l'application de cluster OpenShift Container Platform donnée.
Tableau 8.2. Technologie de stockage recommandée et configurable
| Type de stockage | ROX1 | RWX2 | Registre | Registre échelonné | Métriques3 | Enregistrement | Applications |
|---|---|---|---|---|---|---|---|
|
1
2 3 Prometheus est la technologie sous-jacente utilisée pour les mesures. 4 Cela ne s'applique pas au disque physique, au disque physique de la VM, au VMDK, au loopback sur NFS, à AWS EBS et à Azure Disk.
5 Pour les mesures, l'utilisation du stockage de fichiers avec le mode d'accès 6 Pour la journalisation, consultez la solution de stockage recommandée dans la section Configuration d'un stockage persistant pour le magasin de journaux. L'utilisation du stockage NFS en tant que volume persistant ou via NAS, tel que Gluster, peut corrompre les données. Par conséquent, NFS n'est pas pris en charge pour le stockage Elasticsearch et le magasin de journaux LokiStack dans OpenShift Container Platform Logging. Vous devez utiliser un seul type de volume persistant par magasin de journaux. 7 Le stockage d'objets n'est pas consommé par les PV ou PVC d'OpenShift Container Platform. Les applications doivent s'intégrer à l'API REST de stockage d'objets. | |||||||
| Bloc | Oui4 | Non | Configurable | Non configurable | Recommandé | Recommandé | Recommandé |
| Fichier | Oui4 | Oui | Configurable | Configurable | Configurable5 | Configurable6 | Recommandé |
| Objet | Oui | Oui | Recommandé | Recommandé | Non configurable | Non configurable | Non configurable7 |
Un registre mis à l'échelle est un registre d'images OpenShift dans lequel deux répliques de pods ou plus sont en cours d'exécution.
8.2.1. Recommandations spécifiques pour le stockage des applications
Les tests montrent des problèmes avec l'utilisation du serveur NFS sur Red Hat Enterprise Linux (RHEL) comme backend de stockage pour les services principaux. Cela inclut OpenShift Container Registry et Quay, Prometheus pour la surveillance du stockage, et Elasticsearch pour la journalisation du stockage. Par conséquent, l'utilisation de RHEL NFS pour sauvegarder les PV utilisés par les services principaux n'est pas recommandée.
D'autres implémentations NFS sur le marché peuvent ne pas avoir ces problèmes. Contactez le vendeur de l'implémentation NFS pour plus d'informations sur les tests qui ont pu être réalisés avec ces composants de base d'OpenShift Container Platform.
8.2.1.1. Registre
Dans un déploiement de cluster de registre d'images OpenShift non échelonné/haute disponibilité (HA) :
- La technologie de stockage ne doit pas nécessairement prendre en charge le mode d'accès RWX.
- La technologie de stockage doit garantir la cohérence lecture-écriture.
- La technologie de stockage privilégiée est le stockage d'objets, suivi du stockage de blocs.
- Le stockage de fichiers n'est pas recommandé pour le déploiement d'un cluster de registres d'images OpenShift avec des charges de travail de production.
8.2.1.2. Registre échelonné
Dans un déploiement de cluster de registre d'images OpenShift scaled/HA :
- La technologie de stockage doit prendre en charge le mode d'accès RWX.
- La technologie de stockage doit garantir la cohérence lecture-écriture.
- La technologie de stockage privilégiée est le stockage d'objets.
- Red Hat OpenShift Data Foundation (ODF), Amazon Simple Storage Service (Amazon S3), Google Cloud Storage (GCS), Microsoft Azure Blob Storage et OpenStack Swift sont pris en charge.
- Le stockage d'objets doit être conforme aux normes S3 ou Swift.
- Pour les plateformes non cloud, telles que vSphere et les installations bare metal, la seule technologie configurable est le stockage de fichiers.
- Le stockage en bloc n'est pas configurable.
8.2.1.3. Metrics
Dans un déploiement de cluster de métriques hébergé par OpenShift Container Platform :
- La technologie de stockage privilégiée est le stockage par blocs.
- Le stockage d'objets n'est pas configurable.
Il n'est pas recommandé d'utiliser le stockage de fichiers pour le déploiement d'un cluster de métriques hébergé avec des charges de travail de production.
8.2.1.4. Enregistrement
Dans un déploiement de cluster de journalisation hébergé par OpenShift Container Platform :
- La technologie de stockage privilégiée est le stockage par blocs.
- Le stockage d'objets n'est pas configurable.
8.2.1.5. Applications
Les cas d'utilisation varient d'une application à l'autre, comme le montrent les exemples suivants :
- Les technologies de stockage qui prennent en charge l'approvisionnement dynamique en PV ont des temps de latence de montage faibles et ne sont pas liées aux nœuds, ce qui permet de maintenir une grappe saine.
- Il incombe aux développeurs d'applications de connaître et de comprendre les exigences de leur application en matière de stockage, ainsi que la manière dont elle fonctionne avec le stockage fourni, afin de s'assurer que des problèmes ne surviennent pas lorsqu'une application évolue ou interagit avec la couche de stockage.
8.2.2. Autres recommandations spécifiques en matière de stockage des applications
Il n'est pas recommandé d'utiliser des configurations RAID pour les charges de travail intensives Write, telles que etcd. Si vous utilisez etcd avec une configuration RAID, vous risquez de rencontrer des problèmes de performance avec vos charges de travail.
- Red Hat OpenStack Platform (RHOSP) Cinder : RHOSP Cinder tend à être compétent dans les cas d'utilisation du mode d'accès ROX.
- Bases de données : Les bases de données (SGBDR, bases de données NoSQL, etc.) ont tendance à mieux fonctionner avec un stockage en bloc dédié.
- La base de données etcd doit disposer d'une capacité de stockage et de performances suffisante pour permettre la mise en place d'un grand cluster. Des informations sur les outils de surveillance et d'analyse comparative permettant d'établir une capacité de stockage suffisante et un environnement performant sont décrites à l'adresse suivante : Recommended etcd practices.
8.3. Gestion du stockage des données
Le tableau suivant résume les principaux répertoires dans lesquels les composants d'OpenShift Container Platform écrivent des données.
Tableau 8.3. Principaux répertoires pour le stockage des données de OpenShift Container Platform
| Annuaire | Notes | Taille | Croissance attendue |
|---|---|---|---|
| /var/log | Fichiers journaux pour tous les composants. | 10 à 30 Go. | Les fichiers journaux peuvent croître rapidement ; leur taille peut être gérée en augmentant la taille des disques ou en utilisant la rotation des journaux. |
| /var/lib/etcd | Utilisé pour le stockage etcd lors du stockage de la base de données. | Moins de 20 Go. La base de données peut atteindre 8 Go. | S'adaptera lentement à l'environnement. Stockage des métadonnées uniquement. 20-25 Go supplémentaires pour chaque 8 Go de mémoire supplémentaire. |
| /var/lib/containers | Il s'agit du point de montage du runtime CRI-O. Stockage utilisé pour les runtimes de conteneurs actifs, y compris les pods, et le stockage des images locales. Il n'est pas utilisé pour le stockage du registre. | 50 Go pour un nœud avec 16 Go de mémoire. Notez que ce dimensionnement ne doit pas être utilisé pour déterminer les exigences minimales d'un cluster. 20-25 Go supplémentaires pour chaque 8 Go de mémoire supplémentaire. | La croissance est limitée par la capacité de fonctionnement des conteneurs. |
| /var/lib/kubelet | Stockage de volume éphémère pour les pods. Il s'agit de tout ce qui est monté dans un conteneur au moment de l'exécution. Cela inclut les variables d'environnement, les secrets kube et les volumes de données qui ne sont pas soutenus par des volumes persistants. | Varies | Minime si les pods nécessitant du stockage utilisent des volumes persistants. En cas d'utilisation d'un stockage éphémère, ce nombre peut augmenter rapidement. |
8.4. Ressources supplémentaires
Chapitre 9. Optimisation de l'acheminement
Le routeur HAProxy d'OpenShift Container Platform peut être dimensionné ou configuré pour optimiser les performances.
9.1. Performances de base du contrôleur d'entrée (routeur)
Le contrôleur d'entrée de la plateforme OpenShift Container, ou routeur, est le point d'entrée du trafic d'entrée pour les applications et les services qui sont configurés à l'aide de routes et d'entrées.
Lorsque l'on évalue les performances d'un routeur HAProxy unique en termes de requêtes HTTP traitées par seconde, les performances varient en fonction de nombreux facteurs. En particulier :
- Mode de maintien/fermeture HTTP
- Type d'itinéraire
- Prise en charge du client de reprise de session TLS
- Nombre de connexions simultanées par route cible
- Nombre de routes cibles
- Taille des pages du serveur dorsal
- Infrastructure sous-jacente (solution réseau/SDN, CPU, etc.)
Bien que les performances dans votre environnement spécifique varient, les tests du laboratoire Red Hat sur une instance de cloud public de taille 4 vCPU/16GB RAM. Un routeur HAProxy unique gérant 100 routes terminées par des backends servant des pages statiques de 1kB est capable de gérer le nombre suivant de transactions par seconde.
Dans les scénarios du mode "keep-alive" de HTTP :
| Encryption | LoadBalancerService | HostNetwork |
|---|---|---|
| aucun | 21515 | 29622 |
| bord | 16743 | 22913 |
| traversée | 36786 | 53295 |
| ré-encrypter | 21583 | 25198 |
Dans les scénarios de fermeture HTTP (pas de keep-alive) :
| Encryption | LoadBalancerService | HostNetwork |
|---|---|---|
| aucun | 5719 | 8273 |
| bord | 2729 | 4069 |
| traversée | 4121 | 5344 |
| ré-encrypter | 2320 | 2941 |
La configuration par défaut du contrôleur d'entrée a été utilisée avec le champ spec.tuningOptions.threadCount défini sur 4. Deux stratégies différentes de publication des points finaux ont été testées : Load Balancer Service et Host Network. La reprise de session TLS a été utilisée pour les itinéraires cryptés. Avec HTTP keep-alive, un seul routeur HAProxy est capable de saturer un NIC de 1 Gbit avec des pages d'une taille aussi petite que 8 kB.
Lorsque le système est exécuté sur du métal nu avec des processeurs modernes, vous pouvez vous attendre à des performances environ deux fois supérieures à celles de l'instance de nuage public ci-dessus. Cette surcharge est introduite par la couche de virtualisation en place sur les nuages publics et s'applique également à la virtualisation basée sur les nuages privés. Le tableau suivant indique le nombre d'applications à utiliser derrière le routeur :
| Number of applications | Application type |
|---|---|
| 5-10 | fichier statique/serveur web ou proxy de mise en cache |
| 100-1000 | les applications générant un contenu dynamique |
En général, HAProxy peut prendre en charge des routes pour un maximum de 1 000 applications, en fonction de la technologie utilisée. Les performances du contrôleur d'entrée peuvent être limitées par les capacités et les performances des applications qui se trouvent derrière lui, comme la langue ou le contenu statique par rapport au contenu dynamique.
La mise en commun des entrées, ou routeurs, devrait être utilisée pour servir davantage de routes vers les applications et contribuer à la mise à l'échelle horizontale du niveau de routage.
Pour plus d'informations sur la répartition des entrées, voir Configuration de la répartition du contrôleur d'entrée à l'aide d'étiquettes d'itinéraire et Configuration de la répartition du contrôleur d'entrée à l'aide d'étiquettes d'espace de noms.
Vous pouvez modifier le déploiement du contrôleur d'ingestion à l'aide des informations fournies dans la section Définition du nombre de threads du contrôleur d'ing estion et des paramètres de configuration du contrôleur d'ing estion pour les délais d'attente, ainsi que d'autres configurations de réglage dans la spécification du contrôleur d'ingestion.
9.2. Configuration des sondes de disponibilité, de préparation et de démarrage du contrôleur d'entrée
Les administrateurs de cluster peuvent configurer les valeurs de délai d'attente pour les sondes de disponibilité, de préparation et de démarrage du kubelet pour les déploiements de routeurs qui sont gérés par le contrôleur d'entrée de la plateforme OpenShift Container (routeur). Les sondes de disponibilité et de préparation du routeur utilisent la valeur de temporisation par défaut de 1 seconde, qui est trop courte lorsque les performances du réseau ou de l'exécution sont gravement dégradées. Les délais d'attente des sondes peuvent entraîner des redémarrages intempestifs du routeur qui interrompent les connexions des applications. La possibilité de définir des valeurs de délai plus importantes peut réduire le risque de redémarrages inutiles et non désirés.
Vous pouvez mettre à jour la valeur timeoutSeconds dans les paramètres livenessProbe, readinessProbe et startupProbe du conteneur de routeur.
| Paramètres | Description |
|---|---|
|
|
Le site |
|
|
Le site |
|
|
Le site |
L'option de configuration du délai d'attente est une technique de réglage avancée qui peut être utilisée pour contourner les problèmes. Cependant, ces problèmes doivent être diagnostiqués et éventuellement faire l'objet d'un dossier d'assistance ou d'une question Jira pour tout problème entraînant un dépassement du délai d'attente des sondes.
L'exemple suivant montre comment vous pouvez corriger directement le déploiement du routeur par défaut pour définir un délai d'attente de 5 secondes pour les sondes de disponibilité et d'état de préparation :
$ oc -n openshift-ingress patch deploy/router-default --type=strategic --patch='{"spec":{"template":{"spec":{"containers":[{"name":"router","livenessProbe":{"timeoutSeconds":5},"readinessProbe":{"timeoutSeconds":5}}]}}}}'Vérification
$ oc -n openshift-ingress describe deploy/router-default | grep -e Liveness: -e Readiness:
Liveness: http-get http://:1936/healthz delay=0s timeout=5s period=10s #success=1 #failure=3
Readiness: http-get http://:1936/healthz/ready delay=0s timeout=5s period=10s #success=1 #failure=3
9.3. Configuration de l'intervalle de recharge de HAProxy
Lorsque vous mettez à jour une route ou un point d'extrémité associé à une route, le routeur OpenShift Container Platform met à jour la configuration de HAProxy. Ensuite, HAProxy recharge la configuration mise à jour pour que ces modifications prennent effet. Lorsque HAProxy se recharge, il génère un nouveau processus qui gère les nouvelles connexions à l'aide de la configuration mise à jour.
HAProxy maintient l'ancien processus en cours d'exécution pour gérer les connexions existantes jusqu'à ce qu'elles soient toutes fermées. Lorsque d'anciens processus ont des connexions de longue durée, ils peuvent accumuler et consommer des ressources.
L'intervalle minimum de rechargement de HAProxy par défaut est de cinq secondes. Vous pouvez configurer un contrôleur d'entrée à l'aide de son champ spec.tuningOptions.reloadInterval pour définir un intervalle de recharge minimum plus long.
La définition d'une valeur élevée pour l'intervalle minimum de rechargement de HAProxy peut entraîner une latence dans l'observation des mises à jour des itinéraires et de leurs points d'extrémité. Pour réduire ce risque, évitez de définir une valeur supérieure à la latence tolérable pour les mises à jour.
Procédure
Modifiez l'intervalle minimum de rechargement de HAProxy du contrôleur d'entrée par défaut pour le porter à 15 secondes en exécutant la commande suivante :
$ oc -n openshift-ingress-operator patch ingresscontrollers/default --type=merge --patch='{"spec":{"tuningOptions":{"reloadInterval":"15s"}}}'
Chapitre 10. Optimiser la mise en réseau
Le SDN OpenShift utilise OpenvSwitch, des tunnels LAN virtuels extensibles (VXLAN), des règles OpenFlow et iptables. Ce réseau peut être réglé en utilisant des trames jumbo, des contrôleurs d'interface réseau (NIC) offloads, des files d'attente multiples et des paramètres ethtool.
OVN-Kubernetes utilise Geneve (Generic Network Virtualization Encapsulation) au lieu de VXLAN comme protocole de tunnel.
VXLAN offre des avantages par rapport aux VLAN, tels qu'une augmentation des réseaux de 4096 à plus de 16 millions, et une connectivité de couche 2 à travers les réseaux physiques. Cela permet à tous les pods derrière un service de communiquer entre eux, même s'ils fonctionnent sur des systèmes différents.
VXLAN encapsule tout le trafic tunnelé dans des paquets UDP (User Datagram Protocol). Toutefois, cela entraîne une augmentation de l'utilisation de l'unité centrale. Ces paquets externes et internes sont soumis aux règles normales de somme de contrôle pour garantir que les données ne sont pas corrompues pendant le transit. En fonction des performances de l'unité centrale, ce surcroît de traitement peut entraîner une réduction du débit et une augmentation de la latence par rapport aux réseaux traditionnels non superposés.
Les performances des CPU Cloud, VM et bare metal peuvent être capables de gérer un débit réseau bien supérieur à 1 Gbps. Lors de l'utilisation de liens à bande passante plus élevée, tels que 10 ou 40 Gbps, des performances réduites peuvent se produire. Il s'agit d'un problème connu dans les environnements basés sur VXLAN et qui n'est pas spécifique aux conteneurs ou à OpenShift Container Platform. Tout réseau reposant sur des tunnels VXLAN aura des performances similaires en raison de l'implémentation de VXLAN.
Si vous souhaitez aller au-delà d'un Gbps, c'est possible :
- Évaluer les plugins réseau qui mettent en œuvre différentes techniques de routage, telles que le protocole de passerelle frontalière (BGP).
- Utiliser des adaptateurs réseau compatibles avec la charge VXLAN. VXLAN-offload déplace le calcul de la somme de contrôle des paquets et le surcoût associé de l'unité centrale du système vers un matériel dédié sur l'adaptateur réseau. Cela libère des cycles de CPU pour les pods et les applications, et permet aux utilisateurs d'utiliser toute la bande passante de leur infrastructure réseau.
Le VXLAN-offload ne réduit pas la latence. Cependant, l'utilisation du CPU est réduite même dans les tests de latence.
10.1. Optimiser le MTU pour votre réseau
Il existe deux unités de transmission maximale (MTU) importantes : la MTU du contrôleur d'interface réseau (NIC) et la MTU du réseau en grappe.
Le MTU de la carte réseau n'est configuré qu'au moment de l'installation d'OpenShift Container Platform. Le MTU doit être inférieur ou égal à la valeur maximale supportée par le NIC de votre réseau. Si vous optimisez le débit, choisissez la valeur la plus élevée possible. Si vous optimisez la latence, choisissez une valeur plus faible.
Le MTU du plugin réseau OpenShift SDN doit être inférieur au MTU du NIC d'au moins 50 octets. Cela tient compte de l'en-tête de la couche SDN. Ainsi, sur un réseau Ethernet normal, cette valeur doit être fixée à 1450. Sur un réseau Ethernet à trame jumbo, elle doit être réglée sur 8950. Ces valeurs doivent être réglées automatiquement par l'opérateur de réseau de cluster en fonction du MTU configuré de la carte d'interface réseau. Par conséquent, les administrateurs de clusters ne mettent généralement pas à jour ces valeurs. Les environnements Amazon Web Services (AWS) et bare-metal prennent en charge les réseaux Ethernet à trame jumbo. Ce paramètre améliore le débit, en particulier avec le protocole de contrôle de transmission (TCP).
Pour OVN et Geneve, le MTU doit être inférieur au MTU du NIC de 100 octets au minimum.
Cet en-tête de recouvrement de 50 octets est pertinent pour le plugin réseau SDN d'OpenShift. D'autres solutions SDN peuvent nécessiter une valeur supérieure ou inférieure.
10.2. Pratiques recommandées pour l'installation de clusters à grande échelle
Lors de l'installation de clusters de grande taille ou de l'extension du cluster à un plus grand nombre de nœuds, définissez le réseau du cluster cidr en conséquence dans votre fichier install-config.yaml avant d'installer le cluster :
networking:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
machineNetwork:
- cidr: 10.0.0.0/16
networkType: OVNKubernetes
serviceNetwork:
- 172.30.0.0/16
Le réseau de cluster par défaut cidr 10.128.0.0/14 ne peut pas être utilisé si la taille du cluster est supérieure à 500 nœuds. Il doit être défini sur 10.128.0.0/12 ou 10.128.0.0/10 pour obtenir un nombre de nœuds supérieur à 500.
10.3. Impact d'IPsec
Étant donné que le chiffrement et le déchiffrement des hôtes des nœuds utilisent l'énergie du processeur, les performances sont affectées à la fois en termes de débit et d'utilisation du processeur sur les nœuds lorsque le chiffrement est activé, quel que soit le système de sécurité IP utilisé.
IPSec crypte le trafic au niveau de la charge utile IP, avant qu'il n'atteigne la carte réseau, protégeant ainsi les champs qui seraient autrement utilisés pour le délestage de la carte réseau. Cela signifie que certaines fonctions d'accélération de la carte réseau peuvent ne pas être utilisables lorsque l'IPSec est activé, ce qui entraînera une diminution du débit et une augmentation de l'utilisation de l'unité centrale.
10.4. Ressources supplémentaires
- Modification des paramètres avancés de configuration du réseau
- Paramètres de configuration du plugin réseau OVN-Kubernetes
- Paramètres de configuration du plugin réseau OpenShift SDN
- Amélioration de la stabilité des grappes dans les environnements à forte latence à l'aide de profils de latence des travailleurs
Chapitre 11. Optimisation de l'utilisation de l'unité centrale avec l'encapsulation de l'espace de noms de montage
Vous pouvez optimiser l'utilisation du CPU dans les clusters OpenShift Container Platform en utilisant l'encapsulation mount namespace pour fournir un espace de noms privé pour les processus kubelet et CRI-O. Cela réduit les ressources CPU du cluster utilisées par systemd sans différence de fonctionnalité.
L'encapsulation de l'espace de noms de montage est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes d'un point de vue fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
11.1. Encapsulation des espaces de noms des montages
Les espaces de noms de montage sont utilisés pour isoler les points de montage afin que les processus dans différents espaces de noms ne puissent pas voir les fichiers des autres. L'encapsulation est le processus qui consiste à déplacer les espaces de noms de montage Kubernetes vers un autre emplacement où ils ne seront pas constamment analysés par le système d'exploitation hôte.
Le système d'exploitation hôte utilise systemd pour analyser en permanence tous les espaces de noms de montage : à la fois les montages Linux standard et les nombreux montages que Kubernetes utilise pour fonctionner. L'implémentation actuelle de kubelet et de CRI-O utilise l'espace de noms de premier niveau pour tous les points de montage de l'exécution du conteneur et de kubelet. Cependant, l'encapsulation de ces points de montage spécifiques aux conteneurs dans un espace de noms privé réduit la charge de travail de systemd sans différence de fonctionnalité. L'utilisation d'un espace de noms de montage distinct pour CRI-O et kubelet permet d'encapsuler les montages spécifiques aux conteneurs à partir de toute interaction avec systemd ou d'autres systèmes d'exploitation hôtes.
Cette capacité à réaliser potentiellement une optimisation majeure du CPU est désormais disponible pour tous les administrateurs d'OpenShift Container Platform. L'encapsulation peut également améliorer la sécurité en stockant les points de montage spécifiques à Kubernetes dans un emplacement à l'abri de l'inspection par des utilisateurs non privilégiés.
Les diagrammes suivants illustrent une installation Kubernetes avant et après l'encapsulation. Les deux scénarios montrent des exemples de conteneurs dont les paramètres de propagation des montages sont bidirectionnels, host-to-container et none.
Ici, nous voyons systemd, les processus du système d'exploitation hôte, kubelet et le runtime du conteneur partager un seul espace de noms de montage.
- systemd, les processus du système d'exploitation hôte, kubelet et le runtime du conteneur ont tous accès à tous les points de montage et en ont la visibilité.
-
Le conteneur 1, configuré avec la propagation bidirectionnelle des montages, peut accéder aux montages de systemd et de l'hôte, aux montages de kubelet et de CRI-O. Un montage provenant du conteneur 1, tel que
/run/a, est visible par systemd, les processus du système d'exploitation hôte, kubelet, le runtime du conteneur et d'autres conteneurs configurés avec une propagation de montage hôte à conteneur ou bidirectionnelle (comme dans le conteneur 2). -
Le conteneur 2, configuré avec la propagation des montages d'hôte à conteneur, peut accéder aux montages de systemd et d'hôte, ainsi qu'aux montages de kubelet et de CRI-O. Un montage provenant du conteneur 2, tel que
/run/b, n'est visible pour aucun autre contexte. -
Le conteneur 3, configuré sans propagation des montages, n'a aucune visibilité sur les points de montage externes. Un montage provenant du conteneur 3, tel que
/run/c, n'est visible pour aucun autre contexte.
Le diagramme suivant illustre l'état du système après l'encapsulation.
- Le processus principal de systemd n'est plus consacré à l'analyse inutile des points de montage spécifiques à Kubernetes. Il ne surveille que les points de montage spécifiques au système et les points de montage de l'hôte.
- Les processus du système d'exploitation hôte ne peuvent accéder qu'aux points de montage de systemd et de l'hôte.
- L'utilisation d'un espace de noms de montage distinct pour CRI-O et kubelet sépare complètement tous les montages spécifiques aux conteneurs de toute interaction avec systemd ou tout autre système d'exploitation hôte.
-
Le comportement du conteneur 1 est inchangé, sauf qu'un montage qu'il crée, tel que
/run/a, n'est plus visible par systemd ou les processus du système d'exploitation de l'hôte. Il est toujours visible pour kubelet, CRI-O et d'autres conteneurs avec une propagation de montage hôte à conteneur ou bidirectionnelle configurée (comme le conteneur 2). - Le comportement des conteneurs 2 et 3 reste inchangé.
11.2. Configuration de l'encapsulation de l'espace de noms de montage
Vous pouvez configurer l'encapsulation de l'espace de noms de montage de manière à ce qu'un cluster fonctionne avec moins de ressources.
L'encapsulation de l'espace de noms de montage est une fonctionnalité de l'aperçu technologique et elle est désactivée par défaut. Pour l'utiliser, vous devez l'activer manuellement.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté en tant qu'utilisateur avec les privilèges
cluster-admin.
Procédure
Créer un fichier appelé
mount_namespace_config.yamlavec le YAML suivant :apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: master name: 99-kubens-master spec: config: ignition: version: 3.2.0 systemd: units: - enabled: true name: kubens.service --- apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 99-kubens-worker spec: config: ignition: version: 3.2.0 systemd: units: - enabled: true name: kubens.serviceAppliquez l'espace de noms mount
MachineConfigCR en exécutant la commande suivante :$ oc apply -f mount_namespace_config.yaml
Exemple de sortie
machineconfig.machineconfiguration.openshift.io/99-kubens-master created machineconfig.machineconfiguration.openshift.io/99-kubens-worker created
La CR
MachineConfigpeut prendre jusqu'à 30 minutes pour finir d'être appliquée dans le cluster. Vous pouvez vérifier l'état de la CRMachineConfigen exécutant la commande suivante :$ oc get mcp
Exemple de sortie
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-03d4bc4befb0f4ed3566a2c8f7636751 False True False 3 0 0 0 45m worker rendered-worker-10577f6ab0117ed1825f8af2ac687ddf False True False 3 1 1
Attendez que la CR
MachineConfigsoit appliquée avec succès sur tous les nœuds de plan de contrôle et de travail après l'exécution de la commande suivante :$ oc wait --for=condition=Updated mcp --all --timeout=30m
Exemple de sortie
machineconfigpool.machineconfiguration.openshift.io/master condition met machineconfigpool.machineconfiguration.openshift.io/worker condition met
Vérification
Pour vérifier l'encapsulation d'un hôte de cluster, exécutez les commandes suivantes :
Ouvrez un shell de débogage sur l'hôte du cluster :
oc debug node/<node_name>
Ouvrez une session
chroot:sh-4.4# chroot /host
Vérifiez l'espace de noms de montage de systemd :
sh-4.4# readlink /proc/1/ns/mnt
Exemple de sortie
mnt:[4026531953]
Vérifier l'espace de noms du montage kubelet :
sh-4.4# readlink /proc/$(pgrep kubelet)/ns/mnt
Exemple de sortie
mnt:[4026531840]
Vérifiez l'espace de noms de la monture CRI-O :
sh-4.4# readlink /proc/$(pgrep crio)/ns/mnt
Exemple de sortie
mnt:[4026531840]
Ces commandes renvoient les espaces de noms de montage associés à systemd, kubelet et à l'exécution du conteneur. Dans OpenShift Container Platform, l'exécution du conteneur est CRI-O.
L'encapsulation est effective si systemd se trouve dans un espace de noms de montage différent de kubelet et CRI-O, comme dans l'exemple ci-dessus. L'encapsulation n'est pas effective si les trois processus se trouvent dans le même espace de noms de montage.
11.3. Inspection des espaces de noms encapsulés
Vous pouvez inspecter les points de montage spécifiques à Kubernetes dans le système d'exploitation hôte du cluster à des fins de débogage ou d'audit en utilisant le script kubensenter disponible dans Red Hat Enterprise Linux CoreOS (RHCOS).
Les sessions shell SSH vers l'hôte du cluster sont dans l'espace de noms par défaut. Pour inspecter les points de montage spécifiques à Kubernetes dans une invite du shell SSH, vous devez exécuter le script kubensenter en tant que root. Le script kubensenter est conscient de l'état de l'encapsulation du montage, et peut être exécuté en toute sécurité même si l'encapsulation n'est pas activée.
oc debug les sessions shell distantes démarrent par défaut dans l'espace de noms Kubernetes. Vous n'avez pas besoin d'exécuter kubensenter pour inspecter les points de montage lorsque vous utilisez oc debug.
Si la fonction d'encapsulation n'est pas activée, les commandes kubensenter findmnt et findmnt produisent le même résultat, qu'elles soient exécutées dans une session oc debug ou dans une invite du shell SSH.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté en tant qu'utilisateur avec les privilèges
cluster-admin. - Vous avez configuré l'accès SSH à l'hôte du cluster.
Procédure
Ouvrez un shell SSH distant vers l'hôte du cluster. Par exemple :
ssh core@<node_name>
Exécutez les commandes à l'aide du script
kubensenterfourni en tant qu'utilisateur root. Pour exécuter une commande unique dans l'espace de noms Kubernetes, fournissez la commande et les arguments éventuels au scriptkubensenter. Par exemple, pour exécuter la commandefindmntdans l'espace de noms Kubernetes, exécutez la commande suivante :[core@control-plane-1 ~]$ sudo kubensenter findmnt
Exemple de sortie
kubensenter: Autodetect: kubens.service namespace found at /run/kubens/mnt TARGET SOURCE FSTYPE OPTIONS / /dev/sda4[/ostree/deploy/rhcos/deploy/32074f0e8e5ec453e56f5a8a7bc9347eaa4172349ceab9c22b709d9d71a3f4b0.0] | xfs rw,relatime,seclabel,attr2,inode64,logbufs=8,logbsize=32k,prjquota shm tmpfs ...Pour démarrer un nouveau shell interactif dans l'espace de noms Kubernetes, exécutez le script
kubensentersans aucun argument :[core@control-plane-1 ~]$ sudo kubensenter
Exemple de sortie
kubensenter: Autodetect: kubens.service namespace found at /run/kubens/mnt
11.4. Exécution de services supplémentaires dans l'espace de noms encapsulé
Tout outil de surveillance qui s'appuie sur la capacité à s'exécuter dans le système d'exploitation hôte et à avoir une visibilité sur les points de montage créés par kubelet, CRI-O ou les conteneurs eux-mêmes, doit entrer dans l'espace de noms de montage de conteneur pour voir ces points de montage. Le script kubensenter fourni avec OpenShift Container Platform exécute une autre commande à l'intérieur du point de montage Kubernetes et peut être utilisé pour adapter les outils existants.
Le script kubensenter est conscient de l'état de la fonctionnalité d'encapsulation du montage et peut être exécuté en toute sécurité même si l'encapsulation n'est pas activée. Dans ce cas, le script exécute la commande fournie dans l'espace de noms mount par défaut.
Par exemple, si un service systemd doit s'exécuter dans le nouvel espace de noms Kubernetes mount, modifiez le fichier de service et utilisez la ligne de commande ExecStart= avec kubensenter.
[Unit] Description=Example service [Service] ExecStart=/usr/bin/kubensenter /path/to/original/command arg1 arg2
11.5. Ressources supplémentaires
Chapitre 12. Gestion d'hôtes "bare metal" (métal nu)
Lorsque vous installez OpenShift Container Platform sur un cluster bare metal, vous pouvez provisionner et gérer les nœuds bare metal en utilisant machine et machineset custom resources (CRs) pour les hôtes bare metal qui existent dans le cluster.
12.1. À propos des hôtes et nœuds bare metal
Pour provisionner un hôte bare metal de Red Hat Enterprise Linux CoreOS (RHCOS) en tant que nœud dans votre cluster, créez d'abord un objet custom resource (CR) MachineSet qui correspond au matériel de l'hôte bare metal. Les ensembles de machines de calcul de l'hôte bare metal décrivent les composants d'infrastructure spécifiques à votre configuration. Vous appliquez des étiquettes Kubernetes spécifiques à ces ensembles de machines de calcul, puis vous mettez à jour les composants d'infrastructure pour qu'ils s'exécutent uniquement sur ces machines.
Machine Les CR sont créés automatiquement lorsque vous mettez à l'échelle le site MachineSet contenant une annotation metal3.io/autoscale-to-hosts. OpenShift Container Platform utilise les CR Machine pour provisionner le nœud bare metal correspondant à l'hôte spécifié dans le CR MachineSet.
12.2. Maintenance des hôtes bare metal
Vous pouvez maintenir les détails des hôtes bare metal de votre cluster à partir de la console web d'OpenShift Container Platform. Naviguez vers Compute → Bare Metal Hosts, et sélectionnez une tâche dans le menu déroulant Actions. Ici, vous pouvez gérer des éléments tels que les détails BMC, l'adresse MAC de démarrage pour l'hôte, activer la gestion de l'alimentation, etc. Vous pouvez également consulter les détails des interfaces réseau et des lecteurs de l'hôte.
Vous pouvez déplacer un hôte bare metal en mode maintenance. Lorsque vous mettez un hôte en mode maintenance, le planificateur déplace toutes les charges de travail gérées hors du nœud bare metal correspondant. Aucune nouvelle charge de travail n'est planifiée en mode maintenance.
Vous pouvez déprovisionner un hôte bare metal dans la console web. Le déprovisionnement d'un hôte permet d'effectuer les actions suivantes :
-
Annote le CR de l'hôte bare metal avec
cluster.k8s.io/delete-machine: true - Réduire l'ensemble des machines de calcul associées
La mise hors tension de l'hôte sans déplacement préalable de l'ensemble démon et des pods statiques non gérés vers un autre nœud peut entraîner une interruption de service et une perte de données.
Ressources supplémentaires
12.2.1. Ajouter un hôte bare metal à la grappe à l'aide de la console web
Vous pouvez ajouter des hôtes en métal nu au cluster dans la console web.
Conditions préalables
- Installer un cluster RHCOS sur du métal nu.
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
- Dans la console web, naviguez vers Compute → Bare Metal Hosts.
- Sélectionnez Add Host → New with Dialog.
- Spécifiez un nom unique pour le nouvel hôte bare metal.
- Régler l'adresse Boot MAC address.
- Régler l'adresse Baseboard Management Console (BMC) Address.
- Saisissez les informations d'identification de l'utilisateur pour le contrôleur de gestion de carte de base (BMC) de l'hôte.
- Sélectionnez pour mettre l'hôte sous tension après la création, puis sélectionnez Create.
- Augmentez le nombre de répliques pour qu'il corresponde au nombre de machines nues disponibles. Naviguez jusqu'à Compute → MachineSets, et augmentez le nombre de répliques de machines dans le cluster en sélectionnant Edit Machine count dans le menu déroulant Actions.
Vous pouvez également gérer le nombre de nœuds en métal nu à l'aide de la commande oc scale et de l'ensemble de machines de calcul en métal nu approprié.
12.2.2. Ajouter un hôte bare metal au cluster en utilisant YAML dans la console web
Vous pouvez ajouter des hôtes bare metal au cluster dans la console web en utilisant un fichier YAML qui décrit l'hôte bare metal.
Conditions préalables
- Installer une machine de calcul RHCOS sur une infrastructure bare metal pour l'utiliser dans le cluster.
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. -
Créez un CR
Secretpour l'hôte bare metal.
Procédure
- Dans la console web, naviguez vers Compute → Bare Metal Hosts.
- Sélectionnez Add Host → New from YAML.
Copiez et collez le YAML ci-dessous, en modifiant les champs pertinents avec les détails de votre hôte :
apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: <bare_metal_host_name> spec: online: true bmc: address: <bmc_address> credentialsName: <secret_credentials_name> 1 disableCertificateVerification: True 2 bootMACAddress: <host_boot_mac_address>- 1
credentialsNamedoit faire référence à unSecretCR valide. Le sitebaremetal-operatorne peut pas gérer l'hôte bare metal sans un siteSecretvalide référencé dans le sitecredentialsName. Pour plus d'informations sur les secrets et la manière de les créer, voir Comprendre les secrets.- 2
- Le réglage de
disableCertificateVerificationsurtruedésactive la validation d'hôte TLS entre le cluster et le contrôleur de gestion de carte de base (BMC).
- Sélectionnez Create pour enregistrer le YAML et créer le nouvel hôte bare metal.
Augmentez le nombre de répliques pour qu'il corresponde au nombre d'hôtes bare metal disponibles. Naviguez jusqu'à Compute → MachineSets, et augmentez le nombre de machines dans le cluster en sélectionnant Edit Machine count dans le menu déroulant Actions.
NoteVous pouvez également gérer le nombre de nœuds en métal nu à l'aide de la commande
oc scaleet de l'ensemble de machines de calcul en métal nu approprié.
12.2.3. Mise à l'échelle automatique des machines en fonction du nombre d'hôtes bare metal disponibles
Pour créer automatiquement le nombre d'objets Machine correspondant au nombre d'objets BareMetalHost disponibles, ajoutez une annotation metal3.io/autoscale-to-hosts à l'objet MachineSet.
Conditions préalables
-
Installez les machines de calcul RHCOS en métal nu pour les utiliser dans le cluster et créez les objets
BareMetalHostcorrespondants. -
Installez le CLI OpenShift Container Platform (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Annotez l'ensemble de machines de calcul que vous souhaitez configurer pour la mise à l'échelle automatique en ajoutant l'annotation
metal3.io/autoscale-to-hosts. Remplacez<machineset>par le nom de l'ensemble de machines de calcul.$ oc annotate machineset <machineset> -n openshift-machine-api 'metal3.io/autoscale-to-hosts=<any_value>'
Attendez que les nouvelles machines à échelle commencent à fonctionner.
Lorsque vous utilisez un objet BareMetalHost pour créer une machine dans le cluster et que les étiquettes ou les sélecteurs sont ensuite modifiés sur le site BareMetalHost, l'objet BareMetalHost continue d'être compté dans le site MachineSet à partir duquel l'objet Machine a été créé.
12.2.4. Suppression des hôtes bare metal du nœud de provisionnement
Dans certaines circonstances, vous pouvez vouloir retirer temporairement les hôtes bare metal du nœud de provisionnement. Par exemple, pendant le provisionnement, lorsqu'un redémarrage de l'hôte bare metal est déclenché à l'aide de la console d'administration d'OpenShift Container Platform ou à la suite d'une mise à jour du pool de configuration des machines, OpenShift Container Platform se connecte au contrôleur d'accès à distance Dell intégré (iDrac) et émet une suppression de la file d'attente des tâches.
Pour éviter que la gestion du nombre d'objets Machine ne corresponde au nombre d'objets BareMetalHost disponibles, ajoutez une annotation baremetalhost.metal3.io/detached à l'objet MachineSet.
Cette annotation n'a d'effet que pour les objets BareMetalHost qui sont dans l'état Provisioned, ExternallyProvisioned ou Ready/Available.
Conditions préalables
-
Installez les machines de calcul RHCOS en métal nu pour les utiliser dans le cluster et créez les objets
BareMetalHostcorrespondants. -
Installez le CLI OpenShift Container Platform (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Annotez l'ensemble de machines de calcul que vous souhaitez supprimer du nœud du provisionneur en ajoutant l'annotation
baremetalhost.metal3.io/detached.$ oc annotate machineset <machineset> -n openshift-machine-api 'baremetalhost.metal3.io/detached'
Attendez que les nouvelles machines démarrent.
NoteLorsque vous utilisez un objet
BareMetalHostpour créer une machine dans le cluster et que les étiquettes ou les sélecteurs sont ensuite modifiés sur le siteBareMetalHost, l'objetBareMetalHostcontinue d'être compté dans le siteMachineSetà partir duquel l'objetMachinea été créé.Dans le cas d'utilisation du provisionnement, supprimez l'annotation une fois le redémarrage terminé à l'aide de la commande suivante :
$ oc annotate machineset <machineset> -n openshift-machine-api 'baremetalhost.metal3.io/detached-'
Ressources supplémentaires
Chapitre 13. Ce que font les grandes pages et comment elles sont consommées par les applications
13.1. Ce que font les grandes pages
La mémoire est gérée par blocs appelés pages. Sur la plupart des systèmes, une page correspond à 4Ki. 1Mi de mémoire équivaut à 256 pages ; 1Gi de mémoire équivaut à 256 000 pages, et ainsi de suite. Les unités centrales de traitement disposent d'une unité de gestion de la mémoire intégrée qui gère une liste de ces pages au niveau matériel. Le Translation Lookaside Buffer (TLB) est une petite mémoire cache matérielle des correspondances entre les pages virtuelles et les pages physiques. Si l'adresse virtuelle transmise dans une instruction matérielle peut être trouvée dans le TLB, la correspondance peut être déterminée rapidement. Si ce n'est pas le cas, la TLB est manquée et le système revient à une traduction d'adresse plus lente, basée sur le logiciel, ce qui entraîne des problèmes de performance. La taille de la TLB étant fixe, le seul moyen de réduire le risque d'erreur de la TLB est d'augmenter la taille de la page.
Une page énorme est une page de mémoire dont la taille est supérieure à 4Ki. Sur les architectures x86_64, il existe deux tailles courantes de pages énormes : 2Mi et 1Gi. Les tailles varient sur les autres architectures. Pour utiliser les pages énormes, le code doit être écrit de manière à ce que les applications en soient conscientes. Les pages énormes transparentes (THP) tentent d'automatiser la gestion des pages énormes sans que l'application en ait connaissance, mais elles ont des limites. En particulier, elles sont limitées à des tailles de page de 2Mi. Les THP peuvent entraîner une dégradation des performances sur les nœuds à forte utilisation ou fragmentation de la mémoire en raison des efforts de défragmentation des THP, qui peuvent bloquer les pages de mémoire. Pour cette raison, certaines applications peuvent être conçues pour (ou recommander) l'utilisation d'énormes pages pré-allouées au lieu de THP.
Dans OpenShift Container Platform, les applications d'un pod peuvent allouer et consommer des pages énormes pré-allouées.
13.2. Comment les pages volumineuses sont consommées par les applications
Les nœuds doivent pré-allouer des pages volumineuses pour que le nœud puisse indiquer sa capacité de pages volumineuses. Un nœud ne peut pré-allouer des pages volumineuses que pour une seule taille.
Les pages volumineuses peuvent être consommées par le biais des exigences de ressources au niveau du conteneur en utilisant le nom de la ressource hugepages-<size>, où la taille est la notation binaire la plus compacte utilisant des valeurs entières prises en charge par un nœud particulier. Par exemple, si un nœud prend en charge des tailles de page de 2048 Ko, il expose une ressource planifiable hugepages-2Mi. Contrairement à l'unité centrale ou à la mémoire, les pages volumineuses ne permettent pas le surengagement.
apiVersion: v1
kind: Pod
metadata:
generateName: hugepages-volume-
spec:
containers:
- securityContext:
privileged: true
image: rhel7:latest
command:
- sleep
- inf
name: example
volumeMounts:
- mountPath: /dev/hugepages
name: hugepage
resources:
limits:
hugepages-2Mi: 100Mi 1
memory: "1Gi"
cpu: "1"
volumes:
- name: hugepage
emptyDir:
medium: HugePages- 1
- Spécifiez la quantité de mémoire pour
hugepagescomme étant la quantité exacte à allouer. Ne spécifiez pas cette valeur comme étant la quantité de mémoire pourhugepagesmultipliée par la taille de la page. Par exemple, compte tenu d'une taille de page énorme de 2 Mo, si vous souhaitez utiliser 100 Mo de RAM soutenue par des pages énormes pour votre application, vous devez allouer 50 pages énormes. OpenShift Container Platform fait le calcul pour vous. Comme dans l'exemple ci-dessus, vous pouvez spécifier100MBdirectement.
Allocating huge pages of a specific size
Certaines plates-formes prennent en charge plusieurs tailles de pages volumineuses. Pour allouer des pages volumineuses d'une taille spécifique, faites précéder les paramètres de la commande d'amorçage des pages volumineuses d'un paramètre de sélection de la taille des pages volumineuses hugepagesz=<size>. La valeur de <size> doit être spécifiée en octets avec un suffixe d'échelle facultatif [kKmMgG]. La taille par défaut des pages énormes peut être définie à l'aide du paramètre d'amorçage default_hugepagesz=<size>.
Huge page requirements
- Les demandes de pages volumineuses doivent être égales aux limites. Il s'agit de la valeur par défaut si des limites sont spécifiées, mais que les demandes ne le sont pas.
- Les pages volumineuses sont isolées au niveau du pod. L'isolation des conteneurs est prévue dans une prochaine itération.
-
EmptyDirles volumes soutenus par des pages volumineuses ne doivent pas consommer plus de mémoire de page volumineuse que la demande de pod. -
Les applications qui consomment des pages volumineuses via
shmget()avecSHM_HUGETLBdoivent fonctionner avec un groupe supplémentaire qui correspond à proc/sys/vm/hugetlb_shm_group.
13.3. Consommation d'énormes pages de ressources à l'aide de l'API Downward
Vous pouvez utiliser l'API Downward pour injecter des informations sur les ressources de pages volumineuses consommées par un conteneur.
Vous pouvez injecter l'allocation des ressources sous la forme de variables d'environnement, d'un plugin de volume ou des deux. Les applications que vous développez et exécutez dans le conteneur peuvent déterminer les ressources disponibles en lisant les variables d'environnement ou les fichiers dans les volumes spécifiés.
Procédure
Créez un fichier
hugepages-volume-pod.yamlsimilaire à l'exemple suivant :apiVersion: v1 kind: Pod metadata: generateName: hugepages-volume- labels: app: hugepages-example spec: containers: - securityContext: capabilities: add: [ "IPC_LOCK" ] image: rhel7:latest command: - sleep - inf name: example volumeMounts: - mountPath: /dev/hugepages name: hugepage - mountPath: /etc/podinfo name: podinfo resources: limits: hugepages-1Gi: 2Gi memory: "1Gi" cpu: "1" requests: hugepages-1Gi: 2Gi env: - name: REQUESTS_HUGEPAGES_1GI <.> valueFrom: resourceFieldRef: containerName: example resource: requests.hugepages-1Gi volumes: - name: hugepage emptyDir: medium: HugePages - name: podinfo downwardAPI: items: - path: "hugepages_1G_request" <.> resourceFieldRef: containerName: example resource: requests.hugepages-1Gi divisor: 1Gi<.> Spécifie de lire l'utilisation des ressources à partir de
requests.hugepages-1Giet d'exposer la valeur en tant que variable d'environnementREQUESTS_HUGEPAGES_1GI. <.> Spécifie de lire l'utilisation des ressources à partir derequests.hugepages-1Giet d'exposer la valeur en tant que fichier/etc/podinfo/hugepages_1G_request.Créer le pod à partir du fichier
hugepages-volume-pod.yaml:$ oc create -f hugepages-volume-pod.yaml
Vérification
Vérifiez la valeur de la variable d'environnement
REQUESTS_HUGEPAGES_1GI:$ oc exec -it $(oc get pods -l app=hugepages-example -o jsonpath='{.items[0].metadata.name}') \ -- env | grep REQUESTS_HUGEPAGES_1GIExemple de sortie
REQUESTS_HUGEPAGES_1GI=2147483648
Vérifier la valeur du fichier
/etc/podinfo/hugepages_1G_request:$ oc exec -it $(oc get pods -l app=hugepages-example -o jsonpath='{.items[0].metadata.name}') \ -- cat /etc/podinfo/hugepages_1G_requestExemple de sortie
2
Ressources supplémentaires
13.4. Configuration de pages volumineuses
Les nœuds doivent pré-allouer les pages volumineuses utilisées dans un cluster OpenShift Container Platform. Il existe deux façons de réserver des pages volumineuses : au démarrage et à l'exécution. La réservation au démarrage augmente les chances de succès car la mémoire n'a pas encore été fragmentée de manière significative. Le Node Tuning Operator prend actuellement en charge l'allocation de pages volumineuses au moment du démarrage sur des nœuds spécifiques.
13.4.1. Au moment du démarrage
Procédure
Pour minimiser les redémarrages de nœuds, l'ordre des étapes ci-dessous doit être respecté :
Étiqueter tous les nœuds qui ont besoin du même réglage de pages énormes par une étiquette.
oc label node <node_using_hugepages> node-role.kubernetes.io/worker-hp= $ oc label node <node_using_hugepages> node-role.kubernetes.io/worker-hp=
Créez un fichier avec le contenu suivant et nommez-le
hugepages-tuned-boottime.yaml:apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: hugepages 1 namespace: openshift-cluster-node-tuning-operator spec: profile: 2 - data: | [main] summary=Boot time configuration for hugepages include=openshift-node [bootloader] cmdline_openshift_node_hugepages=hugepagesz=2M hugepages=50 3 name: openshift-node-hugepages recommend: - machineConfigLabels: 4 machineconfiguration.openshift.io/role: "worker-hp" priority: 30 profile: openshift-node-hugepages
- 1
- Réglez le site
namede la ressource accordée surhugepages. - 2
- Définir la section
profilepour allouer des pages volumineuses. - 3
- L'ordre des paramètres est important, car certaines plates-formes prennent en charge des pages volumineuses de différentes tailles.
- 4
- Activer la correspondance basée sur le pool de configuration de la machine.
Créer l'objet Tuned
hugepages$ oc create -f hugepages-tuned-boottime.yaml
Créez un fichier avec le contenu suivant et nommez-le
hugepages-mcp.yaml:apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: worker-hp labels: worker-hp: "" spec: machineConfigSelector: matchExpressions: - {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,worker-hp]} nodeSelector: matchLabels: node-role.kubernetes.io/worker-hp: ""Créer le pool de configuration de la machine :
$ oc create -f hugepages-mcp.yaml
Avec suffisamment de mémoire non fragmentée, tous les nœuds du pool de configuration de la machine worker-hp devraient maintenant avoir 50 pages énormes de 2Mi allouées.
$ oc get node <node_using_hugepages> -o jsonpath="{.status.allocatable.hugepages-2Mi}"
100MiLe plugin TuneD bootloader est actuellement pris en charge sur les nœuds de travail Red Hat Enterprise Linux CoreOS (RHCOS) 8.x. Pour les nœuds de travail Red Hat Enterprise Linux (RHEL) 7.x, le plugin de chargeur de démarrage TuneD n'est actuellement pas pris en charge.
13.5. Désactivation des pages énormes transparentes
Les pages volumineuses transparentes (THP) tentent d'automatiser la plupart des aspects de la création, de la gestion et de l'utilisation des pages volumineuses. Comme THP gère automatiquement les pages volumineuses, cela n'est pas toujours optimal pour tous les types de charges de travail. THP peut entraîner une régression des performances, car de nombreuses applications gèrent elles-mêmes les pages volumineuses. Il convient donc d'envisager la désactivation de THP. Les étapes suivantes décrivent comment désactiver THP à l'aide de Node Tuning Operator (NTO).
Procédure
Créez un fichier avec le contenu suivant et nommez-le
thp-disable-tuned.yaml:apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: thp-workers-profile namespace: openshift-cluster-node-tuning-operator spec: profile: - data: | [main] summary=Custom tuned profile for OpenShift to turn off THP on worker nodes include=openshift-node [vm] transparent_hugepages=never name: openshift-thp-never-worker recommend: - match: - label: node-role.kubernetes.io/worker priority: 25 profile: openshift-thp-never-workerCréer l'objet Tuned :
$ oc create -f thp-disable-tuned.yaml
Vérifier la liste des profils actifs :
$ oc get profile -n openshift-cluster-node-tuning-operator
Vérification
Connectez-vous à l'un des nœuds et effectuez un contrôle THP régulier pour vérifier si les nœuds ont appliqué le profil avec succès :
$ cat /sys/kernel/mm/transparent_hugepage/enabled
Exemple de sortie
always madvise [never]
Chapitre 14. Accord à faible latence
14.1. Comprendre la faible latence
L'émergence de l'Edge computing dans le domaine Telco / 5G joue un rôle clé dans la réduction des problèmes de latence et de congestion et dans l'amélioration des performances des applications.
En termes simples, la latence détermine la vitesse à laquelle les données (paquets) se déplacent de l'expéditeur au destinataire et reviennent à l'expéditeur après avoir été traitées par le destinataire. Le maintien d'une architecture de réseau avec un délai de latence le plus faible possible est essentiel pour répondre aux exigences de performance du réseau de la 5G. Par rapport à la technologie 4G, dont le temps de latence moyen est de 50 ms, la 5G vise à atteindre des temps de latence de 1 ms ou moins. Cette réduction du temps de latence multiplie par 10 le débit des réseaux sans fil.
De nombreuses applications déployées dans l'espace Telco nécessitent une faible latence qui ne peut tolérer qu'une perte de paquets nulle. Le réglage pour une perte de paquets nulle permet d'atténuer les problèmes inhérents qui dégradent les performances du réseau. Pour plus d'informations, voir Tuning for Zero Packet Loss dans Red Hat OpenStack Platform (RHOSP).
L'initiative Edge computing entre également en jeu pour réduire les taux de latence. Il s'agit d'être à la périphérie du nuage et plus proche de l'utilisateur. Cela réduit considérablement la distance entre l'utilisateur et les centres de données éloignés, ce qui permet de réduire les temps de réponse des applications et la latence des performances.
Les administrateurs doivent pouvoir gérer leurs nombreux sites Edge et services locaux de manière centralisée afin que tous les déploiements puissent fonctionner au coût de gestion le plus bas possible. Ils ont également besoin d'un moyen simple de déployer et de configurer certains nœuds de leur cluster pour des applications en temps réel à faible latence et à haute performance. Les nœuds à faible latence sont utiles pour des applications telles que Cloud-native Network Functions (CNF) et Data Plane Development Kit (DPDK).
OpenShift Container Platform fournit actuellement des mécanismes pour régler les logiciels sur un cluster OpenShift Container Platform pour un fonctionnement en temps réel et une faible latence (environ <20 microsecondes de temps de réaction). Cela inclut le réglage du noyau et des valeurs d'ensemble d'OpenShift Container Platform, l'installation d'un noyau et la reconfiguration de la machine. Mais cette méthode nécessite de configurer quatre opérateurs différents et d'effectuer de nombreuses configurations qui, lorsqu'elles sont effectuées manuellement, sont complexes et peuvent être sujettes à des erreurs.
OpenShift Container Platform utilise le Node Tuning Operator pour mettre en œuvre un réglage automatique afin d'obtenir des performances de faible latence pour les applications OpenShift Container Platform. L'administrateur du cluster utilise cette configuration de profil de performance qui facilite la réalisation de ces changements de manière plus fiable. L'administrateur peut spécifier s'il faut mettre à jour le noyau vers kernel-rt, réserver les CPU pour les tâches d'entretien du cluster et du système d'exploitation, y compris les conteneurs pod infra, et isoler les CPU pour les conteneurs d'application afin d'exécuter les charges de travail.
Actuellement, la désactivation de l'équilibrage de la charge du CPU n'est pas prise en charge par cgroup v2. Par conséquent, il se peut que vous n'obteniez pas le comportement souhaité des profils de performance si vous avez activé cgroup v2. L'activation de cgroup v2 n'est pas recommandée si vous utilisez des profils de performance.
OpenShift Container Platform prend également en charge les indices de charge de travail pour le Node Tuning Operator qui peut régler le site PerformanceProfile pour répondre aux exigences des différents environnements industriels. Des indices de charge de travail sont disponibles pour highPowerConsumption (très faible latence au prix d'une consommation d'énergie accrue) et realTime (priorité donnée à une latence optimale). Une combinaison de paramètres true/false pour ces conseils peut être utilisée pour traiter les profils et les exigences de charge de travail spécifiques à l'application.
Les indices de charge de travail simplifient l'ajustement des performances aux paramètres sectoriels. Au lieu d'une approche "unique", les indices de charge de travail peuvent s'adapter aux schémas d'utilisation, par exemple en donnant la priorité à.. :
- Faible latence
- Capacité en temps réel
- Utilisation efficace de l'énergie
Dans un monde idéal, tous ces éléments seraient prioritaires : dans la réalité, certains le sont au détriment d'autres. L'opérateur d'optimisation des nœuds est maintenant conscient des attentes de la charge de travail et est mieux à même de répondre aux exigences de la charge de travail. L'administrateur du cluster peut maintenant spécifier dans quel cas d'utilisation cette charge de travail s'inscrit. L'opérateur de réglage des nœuds utilise le site PerformanceProfile pour affiner les paramètres de performance de la charge de travail.
L'environnement dans lequel une application fonctionne influence son comportement. Pour un centre de données typique sans exigences strictes en matière de temps de latence, seul un réglage par défaut minimal est nécessaire pour permettre le partitionnement de l'unité centrale pour certains modules de charge de travail à haute performance. Pour les centres de données et les charges de travail où la latence est une priorité plus importante, des mesures sont toujours prises pour optimiser la consommation d'énergie. Les cas les plus complexes sont les clusters situés à proximité d'équipements sensibles à la latence, tels que les machines de production et les radios logicielles. Cette dernière catégorie de déploiement est souvent appelée "Far edge". Pour les déploiements en périphérie lointaine, une latence ultra-faible est la priorité absolue et est obtenue au détriment de la gestion de l'énergie.
Dans OpenShift Container Platform version 4.10 et les versions précédentes, l'opérateur Performance Addon était utilisé pour mettre en œuvre un réglage automatique afin d'obtenir des performances de faible latence. Désormais, cette fonctionnalité fait partie de l'opérateur Node Tuning.
14.1.1. À propos de l'hyperthreading pour les applications à faible latence et en temps réel
L'hyperthreading est une technologie de processeur Intel qui permet à un cœur de processeur physique de fonctionner comme deux cœurs logiques, exécutant simultanément deux threads indépendants. L'hyperthreading permet d'améliorer le débit du système pour certains types de charges de travail où le traitement parallèle est bénéfique. La configuration par défaut d'OpenShift Container Platform prévoit que l'hyperthreading est activé par défaut.
Pour les applications de télécommunications, il est important de concevoir l'infrastructure de l'application de manière à minimiser la latence autant que possible. L'hyperthreading peut ralentir les temps de performance et affecter négativement le débit pour les charges de travail à forte intensité de calcul qui nécessitent une faible latence. La désactivation de l'hyperthreading garantit des performances prévisibles et peut réduire les temps de traitement pour ces charges de travail.
L'implémentation et la configuration de l'hyperthreading diffèrent selon le matériel sur lequel vous exécutez OpenShift Container Platform. Consultez les informations de réglage du matériel hôte concerné pour plus de détails sur l'implémentation de l'hyperthreading spécifique à ce matériel. La désactivation de l'hyperthreading peut augmenter le coût par cœur du cluster.
Ressources supplémentaires
14.2. Approvisionnement des charges de travail en temps réel et à faible latence
De nombreuses industries et organisations ont besoin d'un calcul extrêmement performant et pourraient avoir besoin d'une latence faible et prévisible, en particulier dans les secteurs de la finance et des télécommunications. Pour ces industries, avec leurs exigences uniques, OpenShift Container Platform fournit le Node Tuning Operator pour mettre en œuvre un réglage automatique afin d'obtenir des performances de faible latence et un temps de réponse cohérent pour les applications OpenShift Container Platform.
L'administrateur du cluster peut utiliser cette configuration du profil de performance pour effectuer ces changements de manière plus fiable. L'administrateur peut spécifier s'il faut mettre à jour le noyau vers kernel-rt (temps réel), réserver les CPU pour les tâches de maintenance du cluster et du système d'exploitation, y compris les conteneurs pod infra, isoler les CPU pour les conteneurs d'application afin d'exécuter les charges de travail, et désactiver les CPU inutilisés afin de réduire la consommation d'énergie.
L'utilisation de sondes d'exécution en conjonction avec des applications qui nécessitent des CPU garantis peut provoquer des pics de latence. Il est recommandé d'utiliser d'autres sondes, telles qu'un ensemble de sondes réseau correctement configurées, comme alternative.
Dans les versions antérieures d'OpenShift Container Platform, l'opérateur Performance Addon était utilisé pour mettre en œuvre un réglage automatique afin d'obtenir des performances de faible latence pour les applications OpenShift. Dans OpenShift Container Platform 4.11 et les versions ultérieures, ces fonctions font partie de l'opérateur Node Tuning.
14.2.1. Limitations connues pour le temps réel
Dans la plupart des déploiements, kernel-rt est pris en charge uniquement sur les nœuds de travail lorsque vous utilisez un cluster standard avec trois nœuds de plan de contrôle et trois nœuds de travail. Il existe des exceptions pour les nœuds compacts et uniques dans les déploiements de OpenShift Container Platform. Pour les installations sur un seul nœud, kernel-rt est pris en charge sur le seul nœud de plan de contrôle.
Pour utiliser pleinement le mode temps réel, les conteneurs doivent être exécutés avec des privilèges élevés. Voir Définir les capacités d'un conteneur pour plus d'informations sur l'octroi de privilèges.
OpenShift Container Platform limite les capacités autorisées, il se peut donc que vous deviez également créer un site SecurityContext.
Cette procédure est entièrement prise en charge par les installations "bare metal" utilisant les systèmes Red Hat Enterprise Linux CoreOS (RHCOS).
L'établissement d'attentes correctes en matière de performances renvoie au fait que le noyau en temps réel n'est pas une panacée. Son objectif est un déterminisme cohérent, à faible latence, offrant des temps de réponse prévisibles. Le noyau en temps réel entraîne des frais généraux supplémentaires. Cela est dû principalement à la gestion des interruptions matérielles dans des threads programmés séparément. L'augmentation des frais généraux dans certaines charges de travail entraîne une dégradation du débit global. L'ampleur exacte de la dégradation dépend fortement de la charge de travail, allant de 0 % à 30 %. Cependant, c'est le coût du déterminisme.
14.2.2. Fournir à un travailleur des capacités en temps réel
- Facultatif : Ajoutez un nœud au cluster OpenShift Container Platform. Voir Définition des paramètres du BIOS pour le réglage du système.
-
Ajoutez le label
worker-rtaux nœuds de travail qui ont besoin de la capacité en temps réel en utilisant la commandeoc. Créer un nouveau pool de configuration de machines pour les nœuds en temps réel :
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: worker-rt labels: machineconfiguration.openshift.io/role: worker-rt spec: machineConfigSelector: matchExpressions: - { key: machineconfiguration.openshift.io/role, operator: In, values: [worker, worker-rt], } paused: false nodeSelector: matchLabels: node-role.kubernetes.io/worker-rt: ""Notez qu'un pool de configuration de machines worker-rt est créé pour le groupe de nœuds ayant l'étiquette
worker-rt.Ajoutez le nœud au pool de configuration de la machine appropriée en utilisant les étiquettes de rôle de nœud.
NoteVous devez décider quels nœuds sont configurés avec des charges de travail en temps réel. Vous pouvez configurer tous les nœuds de la grappe ou un sous-ensemble de nœuds. Le Node Tuning Operator qui s'attend à ce que tous les nœuds fassent partie d'un pool de configuration de machines dédiées. Si vous utilisez tous les nœuds, vous devez indiquer à l'opérateur de réglage des nœuds l'étiquette de rôle du nœud travailleur. Si vous utilisez un sous-ensemble, vous devez regrouper les nœuds dans un nouveau pool de configuration de machine.
-
Créez le site
PerformanceProfileavec l'ensemble approprié de noyaux d'entretien etrealTimeKernel: enabled: true. Vous devez définir
machineConfigPoolSelectordansPerformanceProfile:apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: example-performanceprofile spec: ... realTimeKernel: enabled: true nodeSelector: node-role.kubernetes.io/worker-rt: "" machineConfigPoolSelector: machineconfiguration.openshift.io/role: worker-rtVérifier qu'il existe un pool de configuration machine correspondant avec un label :
$ oc describe mcp/worker-rt
Exemple de sortie
Name: worker-rt Namespace: Labels: machineconfiguration.openshift.io/role=worker-rt
- OpenShift Container Platform va commencer à configurer les nœuds, ce qui peut impliquer plusieurs redémarrages. Attendez que les nœuds s'installent. Cela peut prendre beaucoup de temps en fonction du matériel spécifique que vous utilisez, mais il faut compter 20 minutes par nœud.
- Vérifier que tout fonctionne comme prévu.
14.2.3. Vérification de l'installation du noyau en temps réel
Cette commande permet de vérifier que le noyau temps réel est installé :
$ oc get node -o wide
Notez le travailleur avec le rôle worker-rt qui contient la chaîne 4.18.0-305.30.1.rt7.102.el8_4.x86_64 cri-o://1.25.0-99.rhaos4.10.gitc3131de.el8:
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME rt-worker-0.example.com Ready worker,worker-rt 5d17h v1.25.0 128.66.135.107 <none> Red Hat Enterprise Linux CoreOS 46.82.202008252340-0 (Ootpa) 4.18.0-305.30.1.rt7.102.el8_4.x86_64 cri-o://1.25.0-99.rhaos4.10.gitc3131de.el8 [...]
14.2.4. Créer une charge de travail en temps réel
Utilisez les procédures suivantes pour préparer une charge de travail qui utilisera les capacités en temps réel.
Procédure
-
Créer un pod avec une classe QoS de
Guaranteed. - En option : Désactiver l'équilibrage de la charge du CPU pour DPDK.
- Attribuer un sélecteur de nœud approprié.
Lorsque vous écrivez vos applications, suivez les recommandations générales décrites dans la section Réglage et déploiement des applications.
14.2.5. Création d'un pod avec une classe de QoS de Guaranteed
Gardez les points suivants à l'esprit lorsque vous créez un pod auquel est attribuée une classe de qualité de service (QoS) de Guaranteed:
- Chaque conteneur du pod doit avoir une limite de mémoire et une demande de mémoire, et elles doivent être identiques.
- Chaque conteneur du pod doit avoir une limite et une demande de CPU, et elles doivent être identiques.
L'exemple suivant montre le fichier de configuration d'un module qui a un conteneur. Le conteneur a une limite de mémoire et une demande de mémoire, toutes deux égales à 200 MiB. Le conteneur a une limite de CPU et une demande de CPU, toutes deux égales à 1 CPU.
apiVersion: v1
kind: Pod
metadata:
name: qos-demo
namespace: qos-example
spec:
containers:
- name: qos-demo-ctr
image: <image-pull-spec>
resources:
limits:
memory: "200Mi"
cpu: "1"
requests:
memory: "200Mi"
cpu: "1"Créer la capsule :
$ oc apply -f qos-pod.yaml --namespace=qos-example
Afficher des informations détaillées sur le pod :
$ oc get pod qos-demo --namespace=qos-example --output=yaml
Exemple de sortie
spec: containers: ... status: qosClass: GuaranteedNoteSi un conteneur spécifie sa propre limite de mémoire, mais ne spécifie pas de demande de mémoire, OpenShift Container Platform attribue automatiquement une demande de mémoire qui correspond à la limite. De même, si un conteneur spécifie sa propre limite de CPU, mais ne spécifie pas de demande de CPU, OpenShift Container Platform attribue automatiquement une demande de CPU qui correspond à la limite.
14.2.6. Optionnel : Désactivation de l'équilibrage de la charge du CPU pour DPDK
La fonctionnalité permettant de désactiver ou d'activer l'équilibrage de la charge du CPU est mise en œuvre au niveau du CRI-O. Le code sous le CRI-O ne désactive ou n'active l'équilibrage de la charge du CPU que lorsque les conditions suivantes sont remplies.
Le pod doit utiliser la classe d'exécution
performance-<profile-name>. Vous pouvez obtenir le nom approprié en regardant le statut du profil de performance, comme indiqué ici :apiVersion: performance.openshift.io/v2 kind: PerformanceProfile ... status: ... runtimeClass: performance-manual
Actuellement, la désactivation de l'équilibrage de la charge du CPU n'est pas prise en charge par cgroup v2.
L'opérateur de réglage des nœuds est responsable de la création de l'extrait de configuration du gestionnaire d'exécution haute performance sous les nœuds concernés et de la création de la classe d'exécution haute performance sous le cluster. Son contenu sera le même que celui du gestionnaire d'exécution par défaut, sauf qu'il activera la fonctionnalité de configuration de l'équilibrage de la charge du processeur.
Pour désactiver l'équilibrage de la charge du CPU pour le pod, la spécification Pod doit inclure les champs suivants :
apiVersion: v1
kind: Pod
metadata:
...
annotations:
...
cpu-load-balancing.crio.io: "disable"
...
...
spec:
...
runtimeClassName: performance-<profile_name>
...Ne désactivez l'équilibrage de la charge du CPU que lorsque la politique statique du gestionnaire de CPU est activée et pour les pods avec QoS garantie qui utilisent des CPU entiers. Dans le cas contraire, la désactivation de l'équilibrage de la charge du CPU peut affecter les performances d'autres conteneurs dans le cluster.
14.2.7. Attribution d'un sélecteur de nœud approprié
La meilleure façon d'assigner un pod à des nœuds est d'utiliser le même sélecteur de nœuds que celui utilisé par le profil de performance, comme indiqué ici :
apiVersion: v1
kind: Pod
metadata:
name: example
spec:
# ...
nodeSelector:
node-role.kubernetes.io/worker-rt: ""Pour plus d'informations, voir Placer des pods sur des nœuds spécifiques à l'aide de sélecteurs de nœuds.
14.2.8. Programmation d'une charge de travail sur un travailleur doté de capacités en temps réel
Utilisez des sélecteurs d'étiquettes qui correspondent aux nœuds attachés au pool de configuration de machines qui a été configuré pour une faible latence par l'opérateur de réglage des nœuds. Pour plus d'informations, voir Affectation de pods à des nœuds.
14.2.9. Réduire la consommation d'énergie en mettant les unités centrales hors ligne
Vous pouvez généralement anticiper les charges de travail des télécommunications. Lorsque toutes les ressources de l'unité centrale ne sont pas nécessaires, l'opérateur Node Tuning vous permet de mettre hors ligne les unités centrales inutilisées afin de réduire la consommation d'énergie en mettant à jour manuellement le profil de performance.
Pour mettre hors ligne les unités centrales inutilisées, vous devez effectuer les tâches suivantes :
Définissez les CPU hors ligne dans le profil de performance et enregistrez le contenu du fichier YAML :
Exemple de profil de performance avec des unités centrales hors ligne
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: performance spec: additionalKernelArgs: - nmi_watchdog=0 - audit=0 - mce=off - processor.max_cstate=1 - intel_idle.max_cstate=0 - idle=poll cpu: isolated: "2-23,26-47" reserved: "0,1,24,25" offlined: “48-59” 1 nodeSelector: node-role.kubernetes.io/worker-cnf: "" numa: topologyPolicy: single-numa-node realTimeKernel: enabled: true- 1
- Facultatif. Vous pouvez répertorier les unités centrales dans le champ
offlinedpour mettre hors ligne les unités centrales spécifiées.
Appliquez le profil mis à jour en exécutant la commande suivante :
$ oc apply -f my-performance-profile.yaml
14.2.10. En option : Configurations d'économie d'énergie
Vous pouvez activer l'économie d'énergie pour un nœud dont les charges de travail à faible priorité sont colocalisées avec des charges de travail à haute priorité sans avoir d'impact sur la latence ou le débit des charges de travail à haute priorité. L'économie d'énergie est possible sans modifier les charges de travail elles-mêmes.
Cette fonctionnalité est prise en charge par les processeurs Intel Ice Lake et les générations suivantes. Les capacités du processeur peuvent avoir un impact sur la latence et le débit des charges de travail hautement prioritaires.
Lorsque vous configurez un nœud avec une configuration d'économie d'énergie, vous devez configurer les charges de travail hautement prioritaires avec une configuration de performance au niveau du pod, ce qui signifie que la configuration s'applique à tous les cœurs utilisés par le pod.
En désactivant les états P et les états C au niveau du pod, vous pouvez configurer les charges de travail hautement prioritaires pour obtenir les meilleures performances et la latence la plus faible.
Tableau 14.1. Configuration pour les charges de travail hautement prioritaires
| Annotation | Description |
|---|---|
annotations: cpu-c-states.crio.io: "disable" cpu-freq-governor.crio.io: "<governor>" |
Permet d'obtenir les meilleures performances pour un pod en désactivant les états C et en spécifiant le type de gouverneur pour la mise à l'échelle du CPU. Le gouverneur |
Conditions préalables
- Vous avez activé les états C et les états P contrôlés par le système d'exploitation dans le BIOS
Procédure
Générer un
PerformanceProfileavecper-pod-power-managementfixé àtrue:$ podman run --entrypoint performance-profile-creator -v \ /must-gather:/must-gather:z registry.redhat.io/openshift4/performance-addon-rhel8-operator:v4.12 \ --mcp-name=worker-cnf --reserved-cpu-count=20 --rt-kernel=true \ --split-reserved-cpus-across-numa=false --topology-manager-policy=single-numa-node \ --must-gather-dir-path /must-gather -power-consumption-mode=low-latency \ 1 --per-pod-power-management=true > my-performance-profile.yaml- 1
- L'adresse
power-consumption-modedoit êtredefaultoulow-latencylorsque l'adresseper-pod-power-managementesttrue.
Exemple
PerformanceProfileavecperPodPowerManagementapiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: performance spec: [.....] workloadHints: realTime: true highPowerConsumption: false perPodPowerManagement: trueDéfinir le gouverneur par défaut de
cpufreqcomme argument supplémentaire du noyau dans la ressource personnalisée (CR) dePerformanceProfile:apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: performance spec: ... additionalKernelArgs: - cpufreq.default_governor=schedutil 1- 1
- Il est recommandé d'utiliser le régulateur
schedutil, mais il est possible d'utiliser d'autres régulateurs tels que les régulateursondemandoupowersave.
Définissez la fréquence maximale de l'unité centrale sur le site
TunedPerformancePatchCR :spec: profile: - data: | [sysfs] /sys/devices/system/cpu/intel_pstate/max_perf_pct = <x> 1- 1
- La valeur
max_perf_pctcontrôle la fréquence maximale que le pilotecpufreqest autorisé à définir en tant que pourcentage de la fréquence maximale supportée par le processeur. Cette valeur s'applique à tous les processeurs. Vous pouvez vérifier la fréquence maximale supportée sur/sys/devices/system/cpu/cpu0/cpufreq/cpuinfo_max_freq. Comme point de départ, vous pouvez utiliser un pourcentage qui plafonne tous les CPU à la fréquenceAll Cores Turbo. La fréquenceAll Cores Turboest la fréquence à laquelle tous les cœurs fonctionneront lorsqu'ils seront tous occupés.
Ajoutez les annotations souhaitées à vos pods de charge de travail hautement prioritaires. Les annotations remplacent les paramètres de
default.Exemple d'annotation de charge de travail hautement prioritaire
apiVersion: v1 kind: Pod metadata: ... annotations: ... cpu-c-states.crio.io: "disable" cpu-freq-governor.crio.io: "<governor>" ... ... spec: ... runtimeClassName: performance-<profile_name> ...- Redémarrer les pods.
Ressources supplémentaires
- Pour plus d'informations sur la configuration recommandée du micrologiciel, voir Configuration recommandée du micrologiciel pour les hôtes de cluster vDU.
14.2.11. Gestion du traitement des interruptions de périphériques pour les unités centrales isolées à pods garantis
Le Node Tuning Operator peut gérer les CPU de l'hôte en les divisant en CPU réservés pour les tâches d'entretien du cluster et du système d'exploitation, y compris les conteneurs pod infra, et en CPU isolés pour les conteneurs d'application afin d'exécuter les charges de travail. Cela vous permet de définir les CPU pour les charges de travail à faible latence comme étant isolées.
Les interruptions de périphériques sont réparties entre toutes les unités centrales isolées et réservées afin d'éviter que les unités centrales ne soient surchargées, à l'exception des unités centrales pour lesquelles un module garanti est en cours d'exécution. Les CPU des pods garantis sont empêchés de traiter les interruptions de périphériques lorsque les annotations correspondantes sont définies pour le pod.
Dans le profil de performance, globallyDisableIrqLoadBalancing est utilisé pour gérer le traitement ou non des interruptions de périphériques. Pour certaines charges de travail, les CPU réservées ne sont pas toujours suffisantes pour traiter les interruptions de périphériques, et pour cette raison, les interruptions de périphériques ne sont pas globalement désactivées sur les CPU isolées. Par défaut, Node Tuning Operator ne désactive pas les interruptions de périphériques sur les unités centrales isolées.
Pour obtenir une faible latence pour les charges de travail, certains pods (mais pas tous) exigent que les CPU sur lesquels ils s'exécutent ne traitent pas les interruptions de périphériques. Une annotation de pod, irq-load-balancing.crio.io, est utilisée pour définir si les interruptions de périphériques sont traitées ou non. Lorsqu'il est configuré, CRI-O désactive les interruptions de périphérique tant que le module est en cours d'exécution.
14.2.11.1. Désactivation du quota CFS de l'unité centrale
Pour réduire l'étranglement du CPU pour les pods individuels garantis, créez une spécification de pod avec l'annotation cpu-quota.crio.io: "disable". Cette annotation désactive le quota CFS (completely fair scheduler) de l'unité centrale au moment de l'exécution du pod. La spécification de pod suivante contient cette annotation :
apiVersion: performance.openshift.io/v2
kind: Pod
metadata:
annotations:
cpu-quota.crio.io: "disable"
spec:
runtimeClassName: performance-<profile_name>
...Ne désactivez le quota CFS CPU que lorsque la politique statique du gestionnaire de CPU est activée et pour les pods avec QoS garantie qui utilisent des CPU entiers. Dans le cas contraire, la désactivation du quota de CPU CFS peut affecter les performances d'autres conteneurs dans le cluster.
14.2.11.2. Désactivation de la gestion des interruptions globales de périphériques dans Node Tuning Operator
Pour configurer Node Tuning Operator afin qu'il désactive les interruptions de périphérique globales pour l'ensemble de CPU isolées, définissez le champ globallyDisableIrqLoadBalancing dans le profil de performance à true. Lorsque true, les annotations de pods conflictuelles sont ignorées. Avec false, les charges d'IRQ sont équilibrées entre tous les processeurs.
Un extrait de profil de performance illustre ce paramètre :
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: globallyDisableIrqLoadBalancing: true ...
14.2.11.3. Désactivation du traitement des interruptions pour les pods individuels
Pour désactiver le traitement des interruptions pour les pods individuels, assurez-vous que globallyDisableIrqLoadBalancing est défini sur false dans le profil de performance. Ensuite, dans la spécification du pod, définissez l'annotation du pod irq-load-balancing.crio.io sur disable. La spécification du pod suivante contient cette annotation :
apiVersion: performance.openshift.io/v2
kind: Pod
metadata:
annotations:
irq-load-balancing.crio.io: "disable"
spec:
runtimeClassName: performance-<profile_name>
...14.2.12. Mise à jour du profil de performance pour utiliser le traitement des interruptions de périphériques
Lorsque vous mettez à niveau la définition de ressource personnalisée (CRD) du profil de performance de l'opérateur Node Tuning de v1 ou v1alpha1 vers v2, globallyDisableIrqLoadBalancing est défini sur true pour les profils existants.
globallyDisableIrqLoadBalancing permet de désactiver ou non l'équilibrage de la charge d'IRQ pour l'ensemble de CPU isolés. Lorsque l'option est définie sur true, elle désactive l'équilibrage de la charge d'IRQ pour l'ensemble de CPU isolés. Le réglage de l'option sur false permet d'équilibrer les IRQ sur tous les CPU.
14.2.12.1. Versions de l'API prises en charge
L'opérateur de réglage des nœuds prend en charge v2, v1, et v1alpha1 pour le champ apiVersion du profil de performance. Les API v1 et v1alpha1 sont identiques. L'API v2 comprend un champ booléen facultatif globallyDisableIrqLoadBalancing dont la valeur par défaut est false.
14.2.12.1.1. Mise à jour de l'API Node Tuning Operator de v1alpha1 à v1
Lors de la mise à niveau de la version API de l'opérateur de réglage des nœuds de v1alpha1 à v1, les profils de performance de v1alpha1 sont convertis à la volée à l'aide d'une stratégie de conversion "None" et servis à l'opérateur de réglage des nœuds avec la version API v1.
14.2.12.1.2. Mise à jour de l'API de l'opérateur Node Tuning de v1alpha1 ou v1 à v2
Lors d'une mise à niveau à partir d'une ancienne version de l'API Node Tuning Operator, les profils de performance v1 et v1alpha1 existants sont convertis à l'aide d'un webhook de conversion qui injecte le champ globallyDisableIrqLoadBalancing avec une valeur de true.
14.3. Réglage des nœuds pour une faible latence à l'aide du profil de performance
Le profil de performance vous permet de contrôler les aspects de réglage de la latence des nœuds qui appartiennent à un certain pool de configuration de machines. Après avoir spécifié vos paramètres, l'objet PerformanceProfile est compilé en plusieurs objets qui effectuent le réglage au niveau du nœud :
-
Un fichier
MachineConfigqui manipule les nœuds. -
Un fichier
KubeletConfigqui configure le gestionnaire de topologie, le gestionnaire de CPU et les nœuds d'OpenShift Container Platform. - Le profil d'accord qui configure l'opérateur d'accord du nœud.
Vous pouvez utiliser un profil de performance pour spécifier s'il faut mettre à jour le noyau vers kernel-rt, allouer d'énormes pages et partitionner les CPU pour qu'ils effectuent des tâches ménagères ou exécutent des charges de travail.
Vous pouvez créer manuellement l'objet PerformanceProfile ou utiliser le Performance Profile Creator (PPC) pour générer un profil de performance. Voir les ressources supplémentaires ci-dessous pour plus d'informations sur le PPC.
Exemple de profil de performance
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: performance spec: cpu: isolated: "5-15" 1 reserved: "0-4" 2 hugepages: defaultHugepagesSize: "1G" pages: - size: "1G" count: 16 node: 0 realTimeKernel: enabled: true 3 numa: 4 topologyPolicy: "best-effort" nodeSelector: node-role.kubernetes.io/worker-cnf: "" 5
- 1
- Ce champ permet d'isoler des unités centrales spécifiques à utiliser avec des conteneurs d'application pour les charges de travail.
- 2
- Utilisez ce champ pour réserver des unités centrales spécifiques à utiliser avec des conteneurs infra pour l'entretien.
- 3
- Utilisez ce champ pour installer le noyau en temps réel sur le nœud. Les valeurs valides sont
trueoufalse. La valeurtrueinstalle le noyau en temps réel. - 4
- Ce champ permet de configurer la politique du gestionnaire de topologie. Les valeurs valides sont
none(par défaut),best-effort,restrictedetsingle-numa-node. Pour plus d'informations, voir Politiques du gestionnaire de topologie. - 5
- Utilisez ce champ pour spécifier un sélecteur de nœuds afin d'appliquer le profil de performance à des nœuds spécifiques.
Ressources supplémentaires
- Pour plus d'informations sur l'utilisation du Performance Profile Creator (PPC) pour générer un profil de performance, voir Création d'un profil de performance.
14.3.1. Configuration de pages volumineuses
Les nœuds doivent pré-allouer les pages volumineuses utilisées dans un cluster OpenShift Container Platform. Utilisez l'opérateur Node Tuning pour allouer des pages volumineuses sur un nœud spécifique.
OpenShift Container Platform fournit une méthode pour créer et allouer d'énormes pages. Node Tuning Operator fournit une méthode plus simple pour le faire en utilisant le profil de performance.
Par exemple, dans la section hugepages pages du profil de performance, vous pouvez spécifier plusieurs blocs de size, count et, éventuellement, node:
hugepages:
defaultHugepagesSize: "1G"
pages:
- size: "1G"
count: 4
node: 0 1- 1
nodeest le nœud NUMA dans lequel les pages volumineuses sont allouées. Si vous ometteznode, les pages sont réparties uniformément entre tous les nœuds NUMA.
Attendez que le statut du pool de configuration de la machine concerné indique que la mise à jour est terminée.
Ce sont les seules étapes de configuration que vous devez effectuer pour allouer des pages volumineuses.
Vérification
Pour vérifier la configuration, consultez le fichier
/proc/meminfosur le nœud :$ oc debug node/ip-10-0-141-105.ec2.internal
# grep -i huge /proc/meminfo
Exemple de sortie
AnonHugePages: ###### ## ShmemHugePages: 0 kB HugePages_Total: 2 HugePages_Free: 2 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: #### ## Hugetlb: #### ##
Utilisez
oc describepour indiquer la nouvelle taille :$ oc describe node worker-0.ocp4poc.example.com | grep -i huge
Exemple de sortie
hugepages-1g=true hugepages-###: ### hugepages-###: ###
14.3.2. Allocation de plusieurs pages de grande taille
Vous pouvez demander des pages volumineuses de différentes tailles dans le même conteneur. Cela vous permet de définir des pods plus complexes composés de conteneurs ayant des besoins différents en matière de taille des pages.
Par exemple, vous pouvez définir les tailles 1G et 2M et l'opérateur Node Tuning configurera les deux tailles sur le nœud, comme illustré ci-dessous :
spec:
hugepages:
defaultHugepagesSize: 1G
pages:
- count: 1024
node: 0
size: 2M
- count: 4
node: 1
size: 1G14.3.3. Configuration d'un nœud pour l'équilibrage dynamique de la charge par IRQ
Configurez un nœud de cluster pour l'équilibrage de charge dynamique IRQ afin de contrôler quels cœurs peuvent recevoir des demandes d'interruption de périphérique (IRQ).
Conditions préalables
- Pour l'isolation du noyau, tous les composants matériels du serveur doivent prendre en charge l'affinité IRQ. Pour plus d'informations, voir la section Additional resources.
Procédure
- Connectez-vous au cluster OpenShift Container Platform en tant qu'utilisateur disposant des privilèges cluster-admin.
-
Définissez le profil de performance
apiVersionpour utiliserperformance.openshift.io/v2. -
Supprimez le champ
globallyDisableIrqLoadBalancingou attribuez-lui la valeurfalse. Définissez les CPU isolés et réservés appropriés. L'extrait suivant illustre un profil qui réserve 2 CPU. L'équilibrage de la charge des IRQ est activé pour les pods fonctionnant sur l'ensemble de CPU
isolated:apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: dynamic-irq-profile spec: cpu: isolated: 2-5 reserved: 0-1 ...NoteLorsque vous configurez des CPU réservés et isolés, les conteneurs d'infrastructure dans les pods utilisent les CPU réservés et les conteneurs d'application utilisent les CPU isolés.
Créez le pod qui utilise des CPU exclusifs et attribuez les annotations
irq-load-balancing.crio.ioetcpu-quota.crio.ioàdisable. Par exemple :apiVersion: v1 kind: Pod metadata: name: dynamic-irq-pod annotations: irq-load-balancing.crio.io: "disable" cpu-quota.crio.io: "disable" spec: containers: - name: dynamic-irq-pod image: "registry.redhat.io/openshift4/cnf-tests-rhel8:v4.4.12" command: ["sleep", "10h"] resources: requests: cpu: 2 memory: "200M" limits: cpu: 2 memory: "200M" nodeSelector: node-role.kubernetes.io/worker-cnf: "" runtimeClassName: performance-dynamic-irq-profile ...-
Saisissez le pod
runtimeClassNamesous la forme performance-<profile_name>, où <profile_name> est lenamedu YAMLPerformanceProfile, dans cet exemple,performance-dynamic-irq-profile. - Définir le sélecteur de nœud pour cibler un travailleur cnf.
Assurez-vous que le pod fonctionne correctement. Le statut doit être
running, et le nœud cnf-worker correct doit être défini :$ oc get pod -o wide
Résultats attendus
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES dynamic-irq-pod 1/1 Running 0 5h33m <ip-address> <node-name> <none> <none>
Obtenir les unités centrales sur lesquelles le pod configuré pour l'équilibrage de charge dynamique IRQ fonctionne :
$ oc exec -it dynamic-irq-pod -- /bin/bash -c "grep Cpus_allowed_list /proc/self/status | awk '{print $2}'"Résultats attendus
Cpus_allowed_list: 2-3
Assurez-vous que la configuration du nœud est appliquée correctement. Accédez au nœud par SSH pour vérifier la configuration.
$ oc debug node/<node-name>
Résultats attendus
Starting pod/<node-name>-debug ... To use host binaries, run `chroot /host` Pod IP: <ip-address> If you don't see a command prompt, try pressing enter. sh-4.4#
Vérifiez que vous pouvez utiliser le système de fichiers du nœud :
sh-4.4# chroot /host
Résultats attendus
sh-4.4#
Assurez-vous que le masque d'affinité CPU du système par défaut n'inclut pas les CPU
dynamic-irq-pod, par exemple, les CPU 2 et 3.$ cat /proc/irq/default_smp_affinity
Exemple de sortie
33
Assurez-vous que les IRQ du système ne sont pas configurées pour fonctionner sur les unités centrales
dynamic-irq-pod:find /proc/irq/ -name smp_affinity_list -exec sh -c 'i="$1"; mask=$(cat $i); file=$(echo $i); echo $file: $mask' _ {} \;Exemple de sortie
/proc/irq/0/smp_affinity_list: 0-5 /proc/irq/1/smp_affinity_list: 5 /proc/irq/2/smp_affinity_list: 0-5 /proc/irq/3/smp_affinity_list: 0-5 /proc/irq/4/smp_affinity_list: 0 /proc/irq/5/smp_affinity_list: 0-5 /proc/irq/6/smp_affinity_list: 0-5 /proc/irq/7/smp_affinity_list: 0-5 /proc/irq/8/smp_affinity_list: 4 /proc/irq/9/smp_affinity_list: 4 /proc/irq/10/smp_affinity_list: 0-5 /proc/irq/11/smp_affinity_list: 0 /proc/irq/12/smp_affinity_list: 1 /proc/irq/13/smp_affinity_list: 0-5 /proc/irq/14/smp_affinity_list: 1 /proc/irq/15/smp_affinity_list: 0 /proc/irq/24/smp_affinity_list: 1 /proc/irq/25/smp_affinity_list: 1 /proc/irq/26/smp_affinity_list: 1 /proc/irq/27/smp_affinity_list: 5 /proc/irq/28/smp_affinity_list: 1 /proc/irq/29/smp_affinity_list: 0 /proc/irq/30/smp_affinity_list: 0-5
Certains contrôleurs d'IRQ ne prennent pas en charge le rééquilibrage des IRQ et exposent toujours tous les CPU en ligne comme masque d'IRQ. Ces contrôleurs d'IRQ fonctionnent effectivement sur l'unité centrale 0. Pour plus d'informations sur la configuration de l'hôte, connectez-vous en SSH à l'hôte et exécutez la commande suivante, en remplaçant <irq-num> par le numéro de l'unité centrale que vous souhaitez interroger :
$ cat /proc/irq/<irq-num>/effective_affinity
Ressources supplémentaires
14.3.3.1. Compatibilité matérielle avec l'affinité IRQ
Pour l'isolation du noyau, tous les composants matériels du serveur doivent prendre en charge l'affinité IRQ. Pour vérifier si les composants matériels de votre serveur prennent en charge l'affinité IRQ, consultez les spécifications matérielles du serveur ou contactez votre fournisseur de matériel.
OpenShift Container Platform prend en charge les périphériques matériels suivants pour l'équilibrage dynamique de la charge :
Tableau 14.2. Contrôleurs d'interface réseau pris en charge
| Fabricant | Model | ID du vendeur | ID de l'appareil |
|---|---|---|---|
| Broadcom | BCM57414 | 14e4 | 16d7 |
| Broadcom | BCM57508 | 14e4 | 1750 |
| Intel | X710 | 8086 | 1572 |
| Intel | XL710 | 8086 | 1583 |
| Intel | XXV710 | 8086 | 158b |
| Intel | E810-CQDA2 | 8086 | 1592 |
| Intel | E810-2CQDA2 | 8086 | 1592 |
| Intel | E810-XXVDA2 | 8086 | 159b |
| Intel | E810-XXVDA4 | 8086 | 1593 |
| Mellanox | Famille MT27700 [ConnectX-4] | 15b3 | 1013 |
| Mellanox | Famille MT27710 [ConnectX-4 Lx] | 15b3 | 1015 |
| Mellanox | Famille MT27800 [ConnectX-5] | 15b3 | 1017 |
| Mellanox | Famille MT28880 [ConnectX-5 Ex] | 15b3 | 1019 |
| Mellanox | Famille MT28908 [ConnectX-6] | 15b3 | 101b |
| Mellanox | Famille MT2892 [ConnectX-6 Dx] | 15b3 | 101d |
| Mellanox | Famille MT2894 [ConnectX-6 Lx] | 15b3 | 101f |
| Mellanox | MT42822 BlueField-2 en mode NIC ConnectX-6 | 15b3 | a2d6 |
| Pensando | DSC-25 carte de services distribués 25G à double port pour pilote ionique | 0x1dd8 | 0x1002 |
| Pensando | DSC-100 carte de services distribués 100G à double port pour pilote ionique | 0x1dd8 | 0x1003 |
| Silicom | Famille STS | 8086 | 1591 |
14.3.4. Configuration de l'hyperthreading pour un cluster
Pour configurer l'hyperthreading pour un cluster OpenShift Container Platform, définissez les threads CPU dans le profil de performance sur les mêmes cœurs que ceux configurés pour les pools de CPU réservés ou isolés.
Si vous configurez un profil de performance et que vous modifiez par la suite la configuration de l'hyperthreading pour l'hôte, assurez-vous de mettre à jour les champs CPU isolated et reserved dans le PerformanceProfile YAML pour qu'ils correspondent à la nouvelle configuration.
La désactivation d'une configuration d'hyperthreading de l'hôte précédemment activée peut entraîner l'inexactitude des ID des cœurs de CPU répertoriés dans le fichier PerformanceProfile YAML. Cette configuration incorrecte peut entraîner l'indisponibilité du nœud car les CPU répertoriés ne peuvent plus être trouvés.
Conditions préalables
-
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. - Installer le CLI OpenShift (oc).
Procédure
Vérifiez quels threads s'exécutent sur quels processeurs pour l'hôte que vous souhaitez configurer.
Vous pouvez voir quels threads sont en cours d'exécution sur les CPU hôtes en vous connectant au cluster et en exécutant la commande suivante :
$ lscpu --all --extended
Exemple de sortie
CPU NODE SOCKET CORE L1d:L1i:L2:L3 ONLINE MAXMHZ MINMHZ 0 0 0 0 0:0:0:0 yes 4800.0000 400.0000 1 0 0 1 1:1:1:0 yes 4800.0000 400.0000 2 0 0 2 2:2:2:0 yes 4800.0000 400.0000 3 0 0 3 3:3:3:0 yes 4800.0000 400.0000 4 0 0 0 0:0:0:0 yes 4800.0000 400.0000 5 0 0 1 1:1:1:0 yes 4800.0000 400.0000 6 0 0 2 2:2:2:0 yes 4800.0000 400.0000 7 0 0 3 3:3:3:0 yes 4800.0000 400.0000
Dans cet exemple, il y a huit cœurs logiques de CPU fonctionnant sur quatre cœurs physiques de CPU. CPU0 et CPU4 fonctionnent sur le Core0 physique, CPU1 et CPU5 fonctionnent sur le Core 1 physique, et ainsi de suite.
Pour afficher les threads définis pour un cœur de processeur physique particulier (
cpu0dans l'exemple ci-dessous), ouvrez une invite de commande et exécutez la commande suivante :$ cat /sys/devices/system/cpu/cpu0/topology/thread_siblings_list
Exemple de sortie
0-4
Appliquez les CPU isolés et réservés dans le YAML
PerformanceProfile. Par exemple, vous pouvez définir les cœurs logiques CPU0 et CPU4 commeisolated, et les cœurs logiques CPU1 à CPU3 et CPU5 à CPU7 commereserved. Lorsque vous configurez des CPU réservés et isolés, les conteneurs d'infrastructure dans les pods utilisent les CPU réservés et les conteneurs d'application utilisent les CPU isolés.... cpu: isolated: 0,4 reserved: 1-3,5-7 ...NoteLes pools de CPU réservés et isolés ne doivent pas se chevaucher et doivent couvrir tous les cœurs disponibles dans le nœud de travail.
L'hyperthreading est activé par défaut sur la plupart des processeurs Intel. Si vous activez l'hyperthreading, tous les threads traités par un cœur particulier doivent être isolés ou traités sur le même cœur.
14.3.4.1. Désactivation de l'hyperthreading pour les applications à faible latence
Lorsque vous configurez des clusters pour un traitement à faible latence, vous devez vous demander si vous souhaitez désactiver l'hyperthreading avant de déployer le cluster. Pour désactiver l'hyperthreading, procédez comme suit :
- Créez un profil de performance adapté à votre matériel et à votre topologie.
Définir
nosmtcomme un argument supplémentaire du noyau. L'exemple de profil de performance suivant illustre ce paramètre :apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: example-performanceprofile spec: additionalKernelArgs: - nmi_watchdog=0 - audit=0 - mce=off - processor.max_cstate=1 - idle=poll - intel_idle.max_cstate=0 - nosmt cpu: isolated: 2-3 reserved: 0-1 hugepages: defaultHugepagesSize: 1G pages: - count: 2 node: 0 size: 1G nodeSelector: node-role.kubernetes.io/performance: '' realTimeKernel: enabled: trueNoteLorsque vous configurez des CPU réservés et isolés, les conteneurs d'infrastructure dans les pods utilisent les CPU réservés et les conteneurs d'application utilisent les CPU isolés.
14.3.5. Comprendre les indices de charge de travail
Le tableau suivant décrit l'impact des combinaisons de consommation d'énergie et de paramètres en temps réel sur la latence.
Les indices de charge de travail suivants peuvent être configurés manuellement. Vous pouvez également utiliser les indices de charge de travail à l'aide du Créateur de profil de performance. Pour plus d'informations sur le profil de performance, voir la section "Création d'un profil de performance".
| Paramètres du créateur du profil de performance | Indice | Environnement | Description |
|---|---|---|---|
| Défaut |
workloadHints: highPowerConsumption: false realTime: false | Cluster à haut débit sans exigences de latence | Performances obtenues grâce au partitionnement de l'unité centrale uniquement. |
| Faible latence |
workloadHints: highPowerConsumption: false realTime: true | Centres de données régionaux | Des économies d'énergie et une faible latence sont souhaitables : il faut trouver un compromis entre la gestion de l'énergie, la latence et le débit. |
| Très faible latence |
workloadHints: highPowerConsumption: true realTime: true | Clusters de pointe, charges de travail critiques en termes de latence | Optimisé pour une latence minimale absolue et un déterminisme maximal au prix d'une consommation d'énergie accrue. |
| Gestion de l'alimentation par pod |
workloadHints: realTime: true highPowerConsumption: false perPodPowerManagement: true | Charges de travail critiques et non critiques | Permet la gestion de l'énergie par module. |
Ressources supplémentaires
- Pour plus d'informations sur l'utilisation du Performance Profile Creator (PPC) pour générer un profil de performance, voir Création d'un profil de performance.
14.3.6. Configuration manuelle des indices de charge de travail
Procédure
-
Créez un site
PerformanceProfileadapté au matériel et à la topologie de l'environnement, comme décrit dans le tableau de la section "Comprendre les indices de charge de travail". Ajustez le profil pour qu'il corresponde à la charge de travail prévue. Dans cet exemple, nous réglons la latence pour qu'elle soit la plus faible possible. Ajoutez les indices de charge de travail
highPowerConsumptionetrealTime. Les deux sont réglés surtrueici.apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: workload-hints spec: ... workloadHints: highPowerConsumption: true 1 realTime: true 2
14.3.7. Limiter les CPU pour les conteneurs d'infrastructures et d'applications
Les tâches génériques de maintenance et de charge de travail utilisent les CPU d'une manière qui peut avoir un impact sur les processus sensibles à la latence. Par défaut, le moteur d'exécution des conteneurs utilise tous les processeurs en ligne pour exécuter tous les conteneurs ensemble, ce qui peut entraîner des changements de contexte et des pics de latence. Le partitionnement des CPU empêche les processus bruyants d'interférer avec les processus sensibles à la latence en les séparant les uns des autres. Le tableau suivant décrit comment les processus s'exécutent sur une unité centrale après avoir réglé le nœud à l'aide de l'opérateur de réglage du nœud :
Tableau 14.3. Affectation de l'unité centrale du processus
| Type de processus | Détails |
|---|---|
|
| Fonctionne sur n'importe quelle unité centrale, sauf en cas de charge de travail à faible latence |
| Pods d'infrastructure | Fonctionne sur n'importe quelle unité centrale, sauf en cas de charge de travail à faible latence |
| Interruptions | Redirections vers des CPU réservés (optionnel dans OpenShift Container Platform 4.7 et plus) |
| Processus du noyau | Broches vers les unités centrales réservées |
| Pods de charge de travail sensibles aux temps de latence | Pins vers un ensemble spécifique d'unités centrales exclusives du pool isolé |
| Processus du système d'exploitation/services Systemd | Broches vers les unités centrales réservées |
La capacité allouable des cœurs sur un nœud pour les pods de tous les types de processus QoS, Burstable, BestEffort, ou Guaranteed, est égale à la capacité du pool isolé. La capacité du pool réservé est retirée de la capacité totale des cœurs du nœud pour être utilisée par le cluster et les tâches ménagères du système d'exploitation.
Exemple 1
Un nœud a une capacité de 100 cœurs. À l'aide d'un profil de performance, l'administrateur de la grappe alloue 50 cœurs au pool isolé et 50 cœurs au pool réservé. L'administrateur de cluster attribue 25 cœurs aux pods QoS Guaranteed et 25 cœurs aux pods BestEffort ou Burstable. Cela correspond à la capacité du pool isolé.
Exemple 2
Un nœud a une capacité de 100 cœurs. À l'aide d'un profil de performance, l'administrateur de la grappe alloue 50 cœurs au pool isolé et 50 cœurs au pool réservé. L'administrateur de cluster attribue 50 cœurs aux pods QoS Guaranteed et un cœur pour les pods BestEffort ou Burstable. La capacité du pool isolé est ainsi dépassée d'un cœur. La planification des pods échoue en raison d'une capacité insuffisante de l'unité centrale.
Le modèle de partitionnement exact à utiliser dépend de nombreux facteurs tels que le matériel, les caractéristiques de la charge de travail et la charge prévue du système. Voici quelques exemples de cas d'utilisation :
- Si la charge de travail sensible à la latence utilise un matériel spécifique, tel qu'un contrôleur d'interface réseau (NIC), assurez-vous que les CPU du pool isolé sont aussi proches que possible de ce matériel. Au minimum, vous devez placer la charge de travail dans le même nœud NUMA (Non-Uniform Memory Access).
- Le pool réservé est utilisé pour gérer toutes les interruptions. Lorsque vous dépendez du réseau du système, allouez un pool de réserve suffisamment grand pour gérer toutes les interruptions de paquets entrants. Dans la version 4.12 et les versions ultérieures, les charges de travail peuvent éventuellement être qualifiées de sensibles.
La décision concernant les unités centrales spécifiques à utiliser pour les partitions réservées et isolées nécessite une analyse et des mesures détaillées. Des facteurs tels que l'affinité NUMA des périphériques et de la mémoire jouent un rôle. La sélection dépend également de l'architecture de la charge de travail et du cas d'utilisation spécifique.
Les pools de CPU réservés et isolés ne doivent pas se chevaucher et doivent couvrir tous les cœurs disponibles dans le nœud de travail.
Pour garantir que les tâches ménagères et les charges de travail n'interfèrent pas les unes avec les autres, spécifiez deux groupes de CPU dans la section spec du profil de performance.
-
isolated- Spécifie les unités centrales pour les charges de travail des conteneurs d'application. Ces unités centrales ont la latence la plus faible. Les processus de ce groupe n'ont pas d'interruptions et peuvent, par exemple, atteindre une bande passante DPDK sans perte de paquets beaucoup plus élevée. -
reserved- Spécifie les unités centrales pour les tâches d'entretien du cluster et du système d'exploitation. Les threads du groupereservedsont souvent occupés. N'exécutez pas d'applications sensibles aux temps de latence dans le groupereserved. Les applications sensibles aux temps de latence sont exécutées dans le groupeisolated.
Procédure
- Créer un profil de performance adapté au matériel et à la topologie de l'environnement.
Ajoutez les paramètres
reservedetisolatedavec les CPU que vous souhaitez réserver et isoler pour les conteneurs d'infrastructure et d'application :apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: infra-cpus spec: cpu: reserved: "0-4,9" 1 isolated: "5-8" 2 nodeSelector: 3 node-role.kubernetes.io/worker: ""- 1
- Spécifiez les unités centrales destinées aux conteneurs infra pour effectuer les tâches de maintenance du cluster et du système d'exploitation.
- 2
- Spécifiez les unités centrales destinées aux conteneurs d'application pour l'exécution des charges de travail.
- 3
- Facultatif : Spécifiez un sélecteur de nœuds pour appliquer le profil de performance à des nœuds spécifiques.
14.4. Réduction des files d'attente NIC à l'aide de l'opérateur Node Tuning
L'opérateur de réglage des nœuds vous permet d'ajuster le nombre de files d'attente du contrôleur d'interface réseau (NIC) pour chaque périphérique réseau en configurant le profil de performance. Les files d'attente des périphériques réseau permettent de répartir les paquets entre différentes files d'attente physiques et chaque file d'attente dispose d'un fil d'exécution distinct pour le traitement des paquets.
Dans les systèmes en temps réel ou à faible latence, toutes les lignes de demande d'interruption (IRQ) inutiles reliées aux unités centrales isolées doivent être déplacées vers des unités centrales réservées ou de maintien.
Dans les déploiements avec des applications qui nécessitent un système, une mise en réseau OpenShift Container Platform ou dans les déploiements mixtes avec des charges de travail Data Plane Development Kit (DPDK), plusieurs files d'attente sont nécessaires pour obtenir un bon débit et le nombre de files d'attente NIC devrait être ajusté ou rester inchangé. Par exemple, pour obtenir une faible latence, le nombre de files d'attente NIC pour les charges de travail basées sur le DPDK doit être réduit au nombre de CPU réservés ou de maintenance.
Trop de files d'attente sont créées par défaut pour chaque unité centrale et elles ne s'intègrent pas dans les tables d'interruption des unités centrales de gestion lorsque l'on cherche à réduire la latence. La réduction du nombre de files d'attente permet un réglage correct. Un plus petit nombre de files d'attente signifie un plus petit nombre d'interruptions qui s'intègrent alors dans la table IRQ.
Dans les versions antérieures d'OpenShift Container Platform, l'opérateur Performance Addon permettait de régler automatiquement les performances des applications à faible latence. Dans OpenShift Container Platform 4.11 et les versions ultérieures, cette fonctionnalité fait partie de l'opérateur Node Tuning.
14.4.1. Ajuster les files d'attente NIC avec le profil de performance
Le profil de performance vous permet d'ajuster le nombre de files d'attente pour chaque périphérique réseau.
Périphériques réseau pris en charge :
- Dispositifs de réseau non virtuels
- Dispositifs de réseau prenant en charge plusieurs files d'attente (canaux)
Périphériques réseau non pris en charge :
- Interfaces réseau purement logicielles
- Dispositifs de blocage
- Fonctions virtuelles Intel DPDK
Conditions préalables
-
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Installez le CLI OpenShift (
oc).
Procédure
-
Connectez-vous au cluster OpenShift Container Platform exécutant Node Tuning Operator en tant qu'utilisateur disposant des privilèges
cluster-admin. - Créez et appliquez un profil de performance adapté à votre matériel et à votre topologie. Pour obtenir des conseils sur la création d'un profil, reportez-vous à la section "Création d'un profil de performances".
Modifier le profil de performance créé :
oc edit -f <votre_nom_de_profil>.yaml
Remplir le champ
specavec l'objetnet. La liste d'objets peut contenir deux champs :-
userLevelNetworkingest un champ obligatoire spécifié sous la forme d'un indicateur booléen. SiuserLevelNetworkingesttrue, le nombre de files d'attente correspond au nombre d'unités centrales réservées pour tous les périphériques pris en charge. La valeur par défaut estfalse. devicesest un champ facultatif spécifiant une liste de périphériques dont les files d'attente seront réglées sur le nombre de CPU réservé. Si la liste des périphériques est vide, la configuration s'applique à tous les périphériques du réseau. La configuration est la suivante :interfaceName: Ce champ indique le nom de l'interface et prend en charge les caractères génériques de type shell, qui peuvent être positifs ou négatifs.-
Les exemples de syntaxe des caractères génériques sont les suivants :
<string> .* -
Les règles négatives sont précédées d'un point d'exclamation. Pour appliquer les modifications apportées à la file d'attente du réseau à tous les périphériques autres que ceux de la liste d'exclusion, utilisez
!<device>, par exemple,!eno1.
-
Les exemples de syntaxe des caractères génériques sont les suivants :
-
vendorID: L'ID du fournisseur de l'appareil réseau représenté par un nombre hexadécimal de 16 bits avec un préfixe0x. deviceID: L'ID de l'appareil réseau (modèle) représenté par un nombre hexadécimal de 16 bits avec un préfixe0x.NoteLorsqu'un
deviceIDest spécifié, levendorIDdoit également être défini. Un dispositif qui correspond à tous les identificateurs de dispositif spécifiés dans une entrée de dispositifinterfaceName,vendorID, ou une paire devendorIDplusdeviceIDest qualifié de dispositif de réseau. Le nombre de files d'attente nettes de ce périphérique réseau est alors fixé au nombre d'unités centrales réservées.Lorsque deux dispositifs ou plus sont spécifiés, le nombre de files d'attente nettes est fixé à tout dispositif net correspondant à l'un d'entre eux.
-
Définissez le nombre de files d'attente sur le nombre de CPU réservées pour tous les périphériques en utilisant cet exemple de profil de performance :
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,54-103 reserved: 0-2,52-54 net: userLevelNetworking: true nodeSelector: node-role.kubernetes.io/worker-cnf: ""Définissez le nombre de files d'attente sur le nombre d'unités centrales réservées pour tous les périphériques correspondant à l'un des identifiants de périphérique définis en utilisant cet exemple de profil de performance :
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,54-103 reserved: 0-2,52-54 net: userLevelNetworking: true devices: - interfaceName: “eth0” - interfaceName: “eth1” - vendorID: “0x1af4” - deviceID: “0x1000” nodeSelector: node-role.kubernetes.io/worker-cnf: ""Définissez le nombre de files d'attente sur le nombre de CPU réservées pour tous les périphériques commençant par le nom d'interface
ethen utilisant cet exemple de profil de performance :apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,54-103 reserved: 0-2,52-54 net: userLevelNetworking: true devices: - interfaceName: “eth*” nodeSelector: node-role.kubernetes.io/worker-cnf: ""Définissez le nombre de files d'attente sur le nombre d'unités centrales réservées pour tous les périphériques dont l'interface porte un nom autre que
eno1à l'aide de cet exemple de profil de performances :apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,54-103 reserved: 0-2,52-54 net: userLevelNetworking: true devices: - interfaceName: “!eno1” nodeSelector: node-role.kubernetes.io/worker-cnf: ""Définissez le nombre de files d'attente sur le nombre de CPU réservées pour tous les périphériques ayant un nom d'interface
eth0,vendorIDde0x1af4, etdeviceIDde0x1000en utilisant cet exemple de profil de performance :apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,54-103 reserved: 0-2,52-54 net: userLevelNetworking: true devices: - interfaceName: “eth0” - vendorID: “0x1af4” - deviceID: “0x1000” nodeSelector: node-role.kubernetes.io/worker-cnf: ""Appliquer le profil de performance mis à jour :
oc apply -f <votre_nom_de_profil>.yaml
Ressources supplémentaires
14.4.2. Vérification de l'état de la file d'attente
Dans cette section, un certain nombre d'exemples illustrent différents profils de performance et la manière de vérifier que les changements sont appliqués.
Exemple 1
Dans cet exemple, le nombre de files d'attente nettes est défini sur le nombre de CPU réservé (2) pour les périphériques pris en charge par all.
La section correspondante du profil de performance est la suivante :
apiVersion: performance.openshift.io/v2
metadata:
name: performance
spec:
kind: PerformanceProfile
spec:
cpu:
reserved: 0-1 #total = 2
isolated: 2-8
net:
userLevelNetworking: true
# ...Affichez l'état des files d'attente associées à un périphérique à l'aide de la commande suivante :
NoteExécutez cette commande sur le nœud où le profil de performance a été appliqué.
$ ethtool -l <device>
Vérifier l'état de la file d'attente avant l'application du profil :
$ ethtool -l ens4
Exemple de sortie
Channel parameters for ens4: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 4 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 4
Vérifiez l'état de la file d'attente après l'application du profil :
$ ethtool -l ens4
Exemple de sortie
Channel parameters for ens4: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 4 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 2 1
- 1
- Le canal combiné montre que le nombre total de CPU réservés pour les périphériques pris en charge par all est de 2. Cela correspond à ce qui est configuré dans le profil de performance.
Exemple 2
Dans cet exemple, le nombre de files d'attente nettes est défini sur le nombre de CPU réservé (2) pour les périphériques réseau pris en charge par all avec une adresse spécifique vendorID.
La section correspondante du profil de performance est la suivante :
apiVersion: performance.openshift.io/v2
metadata:
name: performance
spec:
kind: PerformanceProfile
spec:
cpu:
reserved: 0-1 #total = 2
isolated: 2-8
net:
userLevelNetworking: true
devices:
- vendorID = 0x1af4
# ...Affichez l'état des files d'attente associées à un périphérique à l'aide de la commande suivante :
NoteExécutez cette commande sur le nœud où le profil de performance a été appliqué.
$ ethtool -l <device>
Vérifiez l'état de la file d'attente après l'application du profil :
$ ethtool -l ens4
Exemple de sortie
Channel parameters for ens4: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 4 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 2 1
- 1
- Le nombre total d'unités centrales réservées pour tous les périphériques pris en charge avec
vendorID=0x1af4est de 2. Par exemple, s'il y a un autre périphérique réseauens2avecvendorID=0x1af4, il aura également un total de files d'attente nettes de 2. Cela correspond à ce qui est configuré dans le profil de performance.
Exemple 3
Dans cet exemple, le nombre de files d'attente nettes est défini sur le nombre d'unités centrales réservées (2) pour les périphériques réseau pris en charge par all qui correspondent à l'un des identifiants de périphérique définis.
La commande udevadm info permet d'obtenir un rapport détaillé sur un appareil. Dans cet exemple, les appareils sont les suivants
# udevadm info -p /sys/class/net/ens4 ... E: ID_MODEL_ID=0x1000 E: ID_VENDOR_ID=0x1af4 E: INTERFACE=ens4 ...
# udevadm info -p /sys/class/net/eth0 ... E: ID_MODEL_ID=0x1002 E: ID_VENDOR_ID=0x1001 E: INTERFACE=eth0 ...
Définissez les files d'attente nettes à 2 pour un appareil dont la valeur
interfaceNameest égale àeth0et pour tous les appareils dont la valeurvendorID=0x1af4présente le profil de performance suivant :apiVersion: performance.openshift.io/v2 metadata: name: performance spec: kind: PerformanceProfile spec: cpu: reserved: 0-1 #total = 2 isolated: 2-8 net: userLevelNetworking: true devices: - interfaceName = eth0 - vendorID = 0x1af4 ...Vérifiez l'état de la file d'attente après l'application du profil :
$ ethtool -l ens4
Exemple de sortie
Channel parameters for ens4: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 4 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 2 1- 1
- Le nombre total d'unités centrales réservées pour tous les périphériques pris en charge avec
vendorID=0x1af4est fixé à 2. Par exemple, s'il existe un autre périphérique réseauens2avecvendorID=0x1af4, le nombre total de files d'attente nettes sera également fixé à 2. De même, un périphérique avecinterfaceNameégal àeth0aura le nombre total de files d'attente nettes fixé à 2.
14.4.3. Journalisation associée à l'ajustement des files d'attente NIC
Les messages de logs détaillant les appareils assignés sont enregistrés dans les logs respectifs du démon Tuned. Les messages suivants peuvent être enregistrés dans le fichier /var/log/tuned/tuned.log:
Un message
INFOest enregistré, détaillant les dispositifs attribués avec succès :INFO tuned.plugins.base: instance net_test (net): assigning devices ens1, ens2, ens3
Un message
WARNINGest enregistré si aucun des dispositifs ne peut être attribué :WARNING tuned.plugins.base: instance net_test: no matching devices available
14.5. Débogage de l'état des réglages du CNF à faible latence
La ressource personnalisée (CR) PerformanceProfile contient des champs d'état permettant de signaler l'état des réglages et de déboguer les problèmes de dégradation de la latence. Ces champs indiquent les conditions qui décrivent l'état de la fonctionnalité de rapprochement de l'opérateur.
Un problème typique peut survenir lorsque l'état des pools de configuration de machines attachés au profil de performance est dégradé, ce qui entraîne une dégradation de l'état de PerformanceProfile. Dans ce cas, le pool de configuration de machines émet un message d'échec.
L'opérateur Node Tuning contient le champ d'état performanceProfile.spec.status.Conditions:
Status:
Conditions:
Last Heartbeat Time: 2020-06-02T10:01:24Z
Last Transition Time: 2020-06-02T10:01:24Z
Status: True
Type: Available
Last Heartbeat Time: 2020-06-02T10:01:24Z
Last Transition Time: 2020-06-02T10:01:24Z
Status: True
Type: Upgradeable
Last Heartbeat Time: 2020-06-02T10:01:24Z
Last Transition Time: 2020-06-02T10:01:24Z
Status: False
Type: Progressing
Last Heartbeat Time: 2020-06-02T10:01:24Z
Last Transition Time: 2020-06-02T10:01:24Z
Status: False
Type: Degraded
Le champ Status contient Conditions qui spécifie les valeurs Type indiquant le statut du profil de performance :
Available- Toutes les configurations de machines et tous les profils accordés ont été créés avec succès et sont disponibles pour les composants du cluster chargés de les traiter (NTO, MCO, Kubelet).
Upgradeable- Indique si les ressources gérées par l'opérateur sont dans un état qui permet de les mettre à niveau en toute sécurité.
Progressing- Indique que le processus de déploiement du profil de performance a commencé.
DegradedIndique une erreur si :
- La validation du profil de performance a échoué.
- La création de tous les composants pertinents n'a pas abouti.
Chacun de ces types contient les champs suivants :
Status-
L'état pour le type spécifique (
trueoufalse). Timestamp- L'horodatage de la transaction.
Reason string- Le motif lisible par machine.
Message string- Raison lisible par l'homme décrivant l'état et les détails de l'erreur, le cas échéant.
14.5.1. Pools de configuration de machines
Un profil de performance et ses produits créés sont appliqués à un nœud en fonction d'un pool de configuration machine (MCP) associé. Le MCP contient des informations précieuses sur l'avancement de l'application des configurations de machine créées par les profils de performance qui englobent les args du noyau, la configuration de kube, l'allocation de pages énormes et le déploiement de rt-kernel. Le contrôleur de profil de performance surveille les changements dans le MCP et met à jour le statut du profil de performance en conséquence.
Les seules conditions renvoyées par le GPE à l'état de profil de performance sont celles où le GPE est Degraded, ce qui conduit à performaceProfile.status.condition.Degraded = true.
Exemple :
L'exemple suivant concerne un profil de performance auquel est associé un pool de configuration de machine (worker-cnf) qui a été créé pour lui :
Le pool de configuration de la machine associée est dans un état dégradé :
# oc get mcp
Exemple de sortie
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-2ee57a93fa6c9181b546ca46e1571d2d True False False 3 3 3 0 2d21h worker rendered-worker-d6b2bdc07d9f5a59a6b68950acf25e5f True False False 2 2 2 0 2d21h worker-cnf rendered-worker-cnf-6c838641b8a08fff08dbd8b02fb63f7c False True True 2 1 1 1 2d20h
La section
describedu PCM en donne la raison :# oc describe mcp worker-cnf
Exemple de sortie
Message: Node node-worker-cnf is reporting: "prepping update: machineconfig.machineconfiguration.openshift.io \"rendered-worker-cnf-40b9996919c08e335f3ff230ce1d170\" not found" Reason: 1 nodes are reporting degraded status on syncL'état dégradé devrait également apparaître dans le champ du profil de performance
statusmarqué commedegraded = true:# oc describe performanceprofiles performance
Exemple de sortie
Message: Machine config pool worker-cnf Degraded Reason: 1 nodes are reporting degraded status on sync. Machine config pool worker-cnf Degraded Message: Node yquinn-q8s5v-w-b-z5lqn.c.openshift-gce-devel.internal is reporting: "prepping update: machineconfig.machineconfiguration.openshift.io \"rendered-worker-cnf-40b9996919c08e335f3ff230ce1d170\" not found". Reason: MCPDegraded Status: True Type: Degraded
14.6. Collecte de données de débogage de réglage à faible latence pour Red Hat Support
Lorsque vous ouvrez un dossier d'assistance, il est utile de fournir des informations de débogage sur votre cluster à l'équipe d'assistance de Red Hat.
L'outil must-gather vous permet de collecter des informations de diagnostic sur votre cluster OpenShift Container Platform, y compris le réglage des nœuds, la topologie NUMA et d'autres informations nécessaires pour déboguer les problèmes de configuration à faible latence.
Pour une assistance rapide, fournissez des informations de diagnostic pour OpenShift Container Platform et pour le réglage de la faible latence.
14.6.1. À propos de l'outil de collecte obligatoire
La commande CLI oc adm must-gather recueille les informations de votre cluster les plus susceptibles d'être nécessaires pour le débogage, telles que
- Définitions des ressources
- Journaux d'audit
- Journaux de service
Vous pouvez spécifier une ou plusieurs images lorsque vous exécutez la commande en incluant l'argument --image. Lorsque vous spécifiez une image, l'outil collecte les données relatives à cette fonctionnalité ou à ce produit. Lorsque vous exécutez la commande oc adm must-gather, un nouveau module est créé sur le cluster. Les données sont collectées sur ce module et enregistrées dans un nouveau répertoire commençant par must-gather.local. Ce répertoire est créé dans votre répertoire de travail actuel.
14.6.2. A propos de la collecte de données de réglage à faible latence
Utilisez la commande CLI oc adm must-gather pour collecter des informations sur votre cluster, y compris les fonctionnalités et les objets associés au réglage de la faible latence, notamment :
- Les espaces de noms et les objets enfants de l'opérateur d'optimisation des nœuds.
-
MachineConfigPoolet les objetsMachineConfigassociés. - L'opérateur d'accord de nœud et les objets accordés associés.
- Options de ligne de commande du noyau Linux.
- Topologie CPU et NUMA
- Informations de base sur les périphériques PCI et la localité NUMA.
Pour collecter des informations de débogage avec must-gather, vous devez spécifier l'image de l'opérateur Performance Addon must-gather:
--image=registry.redhat.io/openshift4/performance-addon-operator-must-gather-rhel8:v4.12.
Dans les versions antérieures d'OpenShift Container Platform, l'opérateur Performance Addon permettait de régler automatiquement les performances des applications à faible latence. Dans OpenShift Container Platform 4.11 et les versions ultérieures, cette fonctionnalité fait partie de l'opérateur Node Tuning. Cependant, vous devez toujours utiliser l'image performance-addon-operator-must-gather lors de l'exécution de la commande must-gather.
14.6.3. Collecte de données sur des caractéristiques spécifiques
Vous pouvez obtenir des informations de débogage sur des fonctionnalités spécifiques en utilisant la commande CLI oc adm must-gather avec l'argument --image ou --image-stream. L'outil must-gather prend en charge plusieurs images, ce qui vous permet de recueillir des données sur plus d'une fonctionnalité en exécutant une seule commande.
Pour collecter les données par défaut must-gather en plus des données relatives à des caractéristiques spécifiques, ajoutez l'argument --image-stream=openshift/must-gather.
Dans les versions antérieures d'OpenShift Container Platform, l'opérateur Performance Addon permettait de régler automatiquement les performances des applications à faible latence. Dans OpenShift Container Platform 4.11, ces fonctions font partie de l'opérateur Node Tuning. Cependant, vous devez toujours utiliser l'image performance-addon-operator-must-gather lors de l'exécution de la commande must-gather.
Conditions préalables
-
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. - Le CLI (oc) de la plateforme de conteneurs OpenShift est installé.
Procédure
-
Accédez au répertoire dans lequel vous souhaitez stocker les données
must-gather. Exécutez la commande
oc adm must-gatheravec un ou plusieurs arguments--imageou--image-stream. Par exemple, la commande suivante rassemble à la fois les données par défaut de la grappe et les informations spécifiques à l'opérateur Node Tuning :$ oc adm must-gather \ --image-stream=openshift/must-gather \ 1 --image=registry.redhat.io/openshift4/performance-addon-operator-must-gather-rhel8:v4.12 2
Créez un fichier compressé à partir du répertoire
must-gatherqui a été créé dans votre répertoire de travail. Par exemple, sur un ordinateur utilisant un système d'exploitation Linux, exécutez la commande suivante :$ tar cvaf must-gather.tar.gz must-gather.local.5421342344627712289/ 1- 1
- Remplacez
must-gather-local.5421342344627712289/par le nom du répertoire.
- Joignez le fichier compressé à votre demande d'assistance sur le portail client de Red Hat.
Ressources supplémentaires
- Pour plus d'informations sur MachineConfig et KubeletConfig, voir Gestion des nœuds.
- Pour plus d'informations sur l'opérateur de réglage des nœuds, voir Utilisation de l'opérateur de réglage des nœuds.
- Pour plus d'informations sur le PerformanceProfile, voir Configuration des pages énormes.
- Pour plus d'informations sur la consommation de pages volumineuses à partir de vos conteneurs, voir Comment les pages volumineuses sont consommées par les applications.
Chapitre 15. Réalisation de tests de latence pour la vérification de la plate-forme
Vous pouvez utiliser l'image de tests Cloud-native Network Functions (CNF) pour effectuer des tests de latence sur un cluster OpenShift Container Platform compatible CNF, où tous les composants nécessaires à l'exécution des charges de travail CNF sont installés. Exécutez les tests de latence pour valider le réglage des nœuds pour votre charge de travail.
L'image du conteneur cnf-tests est disponible à l'adresse registry.redhat.io/openshift4/cnf-tests-rhel8:v4.12.
L'image cnf-tests comprend également plusieurs tests qui ne sont pas pris en charge par Red Hat à l'heure actuelle. Seuls les tests de latence sont pris en charge par Red Hat.
15.1. Conditions préalables à l'exécution de tests de latence
Votre cluster doit remplir les conditions suivantes pour que vous puissiez effectuer les tests de latence :
- Vous avez configuré un profil de performance avec l'opérateur Node Tuning.
- Vous avez appliqué toutes les configurations CNF requises dans le cluster.
-
Vous avez un
MachineConfigPoolCR préexistant appliqué dans le cluster. Le pool de travailleurs par défaut estworker-cnf.
Ressources supplémentaires
- Pour plus d'informations sur la création du profil de performance de la grappe, voir Provisionnement d'un travailleur avec des capacités en temps réel.
15.2. A propos du mode de découverte pour les tests de latence
Le mode découverte permet de valider le fonctionnement d'un cluster sans en modifier la configuration. Les configurations existantes de l'environnement sont utilisées pour les tests. Les tests peuvent trouver les éléments de configuration nécessaires et les utiliser pour exécuter les tests. Si les ressources nécessaires à l'exécution d'un test spécifique ne sont pas trouvées, le test est ignoré et un message approprié est envoyé à l'utilisateur. Une fois les tests terminés, aucun nettoyage des éléments de configuration préconfigurés n'est effectué et l'environnement de test peut être immédiatement utilisé pour un autre test.
Lors de l'exécution des tests de latence, always exécute les tests avec -e DISCOVERY_MODE=true et -ginkgo.focus réglés sur le test de latence approprié. Si vous n'exécutez pas les tests de latence en mode découverte, la configuration du profil de performance de votre cluster live sera modifiée par l'exécution du test.
Limiter les nœuds utilisés lors des tests
Les nœuds sur lesquels les tests sont exécutés peuvent être limités en spécifiant une variable d'environnement NODES_SELECTOR, par exemple -e NODES_SELECTOR=node-role.kubernetes.io/worker-cnf. Toutes les ressources créées par le test sont limitées aux nœuds dont les étiquettes correspondent.
Si vous souhaitez remplacer le groupe de travailleurs par défaut, passez la variable -e ROLE_WORKER_CNF=<custom_worker_pool> à la commande en spécifiant une étiquette appropriée.
15.3. Mesure de la latence
L'image cnf-tests utilise trois outils pour mesurer la latence du système :
-
hwlatdetect -
cyclictest -
oslat
Chaque outil a un usage spécifique. Utilisez les outils dans l'ordre pour obtenir des résultats de test fiables.
- hwlatdetect
-
Mesure la ligne de base que le matériel bare-metal peut atteindre. Avant de procéder au test de latence suivant, assurez-vous que la latence signalée par
hwlatdetectrespecte le seuil requis, car vous ne pouvez pas corriger les pics de latence du matériel en réglant le système d'exploitation. - cyclocontrôle
-
Vérifie la latence de l'ordonnanceur du noyau en temps réel après que
hwlatdetecta passé la validation. L'outilcyclictestprogramme un timer répété et mesure la différence entre le temps de déclenchement souhaité et le temps de déclenchement réel. Cette différence peut mettre en évidence des problèmes de base dans le réglage, causés par des interruptions ou des priorités de processus. L'outil doit fonctionner sur un noyau en temps réel. - oslat
- Se comporte comme une application DPDK à forte intensité de CPU et mesure toutes les interruptions et perturbations de la boucle occupée qui simule un traitement de données à forte intensité de CPU.
Les tests introduisent les variables d'environnement suivantes :
Tableau 15.1. Variables d'environnement pour le test de latence
| Variables d’environnement | Description |
|---|---|
|
| Spécifie le temps en secondes après lequel le test commence à s'exécuter. Vous pouvez utiliser cette variable pour permettre à la boucle de réconciliation du gestionnaire de CPU de mettre à jour le pool de CPU par défaut. La valeur par défaut est 0. |
|
| Spécifie le nombre de CPU que le pod exécutant les tests de latence utilise. Si vous ne définissez pas cette variable, la configuration par défaut inclut toutes les unités centrales isolées. |
|
| Spécifie le temps en secondes pendant lequel le test de latence doit être exécuté. La valeur par défaut est de 300 secondes. |
|
|
Spécifie la latence matérielle maximale acceptable en microsecondes pour la charge de travail et le système d'exploitation. Si vous ne définissez pas la valeur de |
|
|
Spécifie la latence maximale en microsecondes que tous les threads attendent avant de se réveiller pendant l'exécution de |
|
|
Spécifie la latence maximale acceptable en microsecondes pour les résultats du test |
|
| Variable unifiée qui spécifie la latence maximale acceptable en microsecondes. Applicable à tous les outils de latence disponibles. |
|
|
Paramètre booléen qui indique si les tests doivent être exécutés. |
Les variables spécifiques à un outil de latence ont la priorité sur les variables unifiées. Par exemple, si OSLAT_MAXIMUM_LATENCY est réglé sur 30 microsecondes et MAXIMUM_LATENCY sur 10 microsecondes, le test oslat sera exécuté avec une latence maximale acceptable de 30 microsecondes.
15.4. Exécution des tests de latence
Exécutez les tests de latence du cluster pour valider le réglage des nœuds pour votre charge de travail Cloud-native Network Functions (CNF).
Always exécuter les tests de latence avec DISCOVERY_MODE=true. Si vous ne le faites pas, la suite de tests apportera des modifications à la configuration du cluster en cours d'exécution.
Lorsque vous exécutez les commandes podman en tant qu'utilisateur non root ou non privilégié, les chemins de montage peuvent échouer avec des erreurs permission denied. Pour que la commande podman fonctionne, ajoutez :Z à la création des volumes ; par exemple, -v $(pwd)/:/kubeconfig:Z. Cela permet à podman d'effectuer le réétiquetage SELinux approprié.
Procédure
Ouvrez une invite dans le répertoire contenant le fichier
kubeconfig.Vous fournissez à l'image de test un fichier
kubeconfigdans le répertoire courant et la variable d'environnement$KUBECONFIGcorrespondante, montée par l'intermédiaire d'un volume. Cela permet au conteneur en cours d'exécution d'utiliser le fichierkubeconfigdepuis l'intérieur du conteneur.Exécutez les tests de latence en entrant la commande suivante :
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUN=true -e DISCOVERY_MODE=true -e FEATURES=performance registry.redhat.io/openshift4/cnf-tests-rhel8:v4.12 \ /usr/bin/test-run.sh -ginkgo.focus="\[performance\]\ Latency\ Test"
-
En option : Ajoutez
-ginkgo.dryRunpour exécuter les tests de latence en mode "dry-run". Ceci est utile pour vérifier ce que les tests exécutent. -
Facultatif : Ajoutez
-ginkgo.vpour exécuter les tests avec une verbosité accrue. Facultatif : Pour effectuer les tests de latence en fonction d'un profil de performance spécifique, exécutez la commande suivante, en remplaçant les valeurs appropriées :
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUN=true -e FEATURES=performance -e LATENCY_TEST_RUNTIME=600 -e MAXIMUM_LATENCY=20 \ -e PERF_TEST_PROFILE=<performance_profile> registry.redhat.io/openshift4/cnf-tests-rhel8:v4.12 \ /usr/bin/test-run.sh -ginkgo.focus="[performance]\ Latency\ Test"
où :
- <performance_profile>
- Est le nom du profil de performance sur lequel vous souhaitez effectuer les tests de latence.
ImportantPour que les résultats des tests de latence soient valables, les tests doivent être effectués pendant au moins 12 heures.
15.4.1. Exécution de hwlatdetect
L'outil hwlatdetect est disponible dans le paquetage rt-kernel avec un abonnement normal à Red Hat Enterprise Linux (RHEL) 8.x.
Always exécuter les tests de latence avec DISCOVERY_MODE=true. Si vous ne le faites pas, la suite de tests apportera des modifications à la configuration du cluster en cours d'exécution.
Lorsque vous exécutez les commandes podman en tant qu'utilisateur non root ou non privilégié, les chemins de montage peuvent échouer avec des erreurs permission denied. Pour que la commande podman fonctionne, ajoutez :Z à la création des volumes ; par exemple, -v $(pwd)/:/kubeconfig:Z. Cela permet à podman d'effectuer le réétiquetage SELinux approprié.
Conditions préalables
- Vous avez installé le noyau temps réel dans le cluster.
-
Vous vous êtes connecté à
registry.redhat.ioavec vos identifiants du portail client.
Procédure
Pour exécuter les tests
hwlatdetect, lancez la commande suivante, en remplaçant les valeurs des variables par celles qui conviennent :$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUN=true -e DISCOVERY_MODE=true -e FEATURES=performance -e ROLE_WORKER_CNF=worker-cnf \ -e LATENCY_TEST_RUNTIME=600 -e MAXIMUM_LATENCY=20 \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.12 \ /usr/bin/test-run.sh -ginkgo.v -ginkgo.focus="hwlatdetect"
Le test
hwlatdetectdure 10 minutes (600 secondes). Le test se déroule avec succès lorsque la latence maximale observée est inférieure àMAXIMUM_LATENCY(20 μs).Si les résultats dépassent le seuil de latence, le test échoue.
ImportantPour obtenir des résultats valables, le test doit durer au moins 12 heures.
Exemple de sortie de panne
running /usr/bin/cnftests -ginkgo.v -ginkgo.focus=hwlatdetect I0908 15:25:20.023712 27 request.go:601] Waited for 1.046586367s due to client-side throttling, not priority and fairness, request: GET:https://api.hlxcl6.lab.eng.tlv2.redhat.com:6443/apis/imageregistry.operator.openshift.io/v1?timeout=32s Running Suite: CNF Features e2e integration tests ================================================= Random Seed: 1662650718 Will run 1 of 194 specs [...] • Failure [283.574 seconds] [performance] Latency Test /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:62 with the hwlatdetect image /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:228 should succeed [It] /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:236 Log file created at: 2022/09/08 15:25:27 Running on machine: hwlatdetect-b6n4n Binary: Built with gc go1.17.12 for linux/amd64 Log line format: [IWEF]mmdd hh:mm:ss.uuuuuu threadid file:line] msg I0908 15:25:27.160620 1 node.go:39] Environment information: /proc/cmdline: BOOT_IMAGE=(hd1,gpt3)/ostree/rhcos-c6491e1eedf6c1f12ef7b95e14ee720bf48359750ac900b7863c625769ef5fb9/vmlinuz-4.18.0-372.19.1.el8_6.x86_64 random.trust_cpu=on console=tty0 console=ttyS0,115200n8 ignition.platform.id=metal ostree=/ostree/boot.1/rhcos/c6491e1eedf6c1f12ef7b95e14ee720bf48359750ac900b7863c625769ef5fb9/0 ip=dhcp root=UUID=5f80c283-f6e6-4a27-9b47-a287157483b2 rw rootflags=prjquota boot=UUID=773bf59a-bafd-48fc-9a87-f62252d739d3 skew_tick=1 nohz=on rcu_nocbs=0-3 tuned.non_isolcpus=0000ffff,ffffffff,fffffff0 systemd.cpu_affinity=4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79 intel_iommu=on iommu=pt isolcpus=managed_irq,0-3 nohz_full=0-3 tsc=nowatchdog nosoftlockup nmi_watchdog=0 mce=off skew_tick=1 rcutree.kthread_prio=11 + + I0908 15:25:27.160830 1 node.go:46] Environment information: kernel version 4.18.0-372.19.1.el8_6.x86_64 I0908 15:25:27.160857 1 main.go:50] running the hwlatdetect command with arguments [/usr/bin/hwlatdetect --threshold 1 --hardlimit 1 --duration 100 --window 10000000us --width 950000us] F0908 15:27:10.603523 1 main.go:53] failed to run hwlatdetect command; out: hwlatdetect: test duration 100 seconds detector: tracer parameters: Latency threshold: 1us 1 Sample window: 10000000us Sample width: 950000us Non-sampling period: 9050000us Output File: None Starting test test finished Max Latency: 326us 2 Samples recorded: 5 Samples exceeding threshold: 5 ts: 1662650739.017274507, inner:6, outer:6 ts: 1662650749.257272414, inner:14, outer:326 ts: 1662650779.977272835, inner:314, outer:12 ts: 1662650800.457272384, inner:3, outer:9 ts: 1662650810.697273520, inner:3, outer:2 [...] JUnit report was created: /junit.xml/cnftests-junit.xml Summarizing 1 Failure: [Fail] [performance] Latency Test with the hwlatdetect image [It] should succeed /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:476 Ran 1 of 194 Specs in 365.797 seconds FAIL! -- 0 Passed | 1 Failed | 0 Pending | 193 Skipped --- FAIL: TestTest (366.08s) FAIL
Exemple de résultats du test hwlatdetect
Vous pouvez capturer les types de résultats suivants :
- Les résultats bruts qui sont recueillis après chaque exécution pour créer un historique de l'impact de toute modification apportée tout au long de l'essai.
- L'ensemble combiné des tests bruts avec les meilleurs résultats et paramètres de configuration.
Exemple de bons résultats
hwlatdetect: test duration 3600 seconds detector: tracer parameters: Latency threshold: 10us Sample window: 1000000us Sample width: 950000us Non-sampling period: 50000us Output File: None Starting test test finished Max Latency: Below threshold Samples recorded: 0
L'outil hwlatdetect ne fournit un résultat que si l'échantillon dépasse le seuil spécifié.
Exemple de mauvais résultats
hwlatdetect: test duration 3600 seconds detector: tracer parameters:Latency threshold: 10usSample window: 1000000us Sample width: 950000usNon-sampling period: 50000usOutput File: None Starting tests:1610542421.275784439, inner:78, outer:81 ts: 1610542444.330561619, inner:27, outer:28 ts: 1610542445.332549975, inner:39, outer:38 ts: 1610542541.568546097, inner:47, outer:32 ts: 1610542590.681548531, inner:13, outer:17 ts: 1610543033.818801482, inner:29, outer:30 ts: 1610543080.938801990, inner:90, outer:76 ts: 1610543129.065549639, inner:28, outer:39 ts: 1610543474.859552115, inner:28, outer:35 ts: 1610543523.973856571, inner:52, outer:49 ts: 1610543572.089799738, inner:27, outer:30 ts: 1610543573.091550771, inner:34, outer:28 ts: 1610543574.093555202, inner:116, outer:63
La sortie de hwlatdetect montre que plusieurs échantillons dépassent le seuil. Cependant, la même sortie peut indiquer des résultats différents en fonction des facteurs suivants :
- La durée du test
- Le nombre de cœurs de l'unité centrale
- Paramètres du micrologiciel de l'hôte
Avant de procéder au test de latence suivant, assurez-vous que la latence signalée par hwlatdetect respecte le seuil requis. Pour résoudre les problèmes de latence liés au matériel, vous devrez peut-être contacter le service d'assistance du fournisseur du système.
Les pics de latence ne sont pas tous liés au matériel. Veillez à régler le microprogramme de l'hôte pour répondre aux exigences de votre charge de travail. Pour plus d'informations, voir Définition des paramètres du microprogramme pour l'optimisation du système.
15.4.2. Test cyclique en cours d'exécution
L'outil cyclictest mesure la latence de l'ordonnanceur du noyau en temps réel sur les unités centrales spécifiées.
Always exécuter les tests de latence avec DISCOVERY_MODE=true. Si vous ne le faites pas, la suite de tests apportera des modifications à la configuration du cluster en cours d'exécution.
Lorsque vous exécutez les commandes podman en tant qu'utilisateur non root ou non privilégié, les chemins de montage peuvent échouer avec des erreurs permission denied. Pour que la commande podman fonctionne, ajoutez :Z à la création des volumes ; par exemple, -v $(pwd)/:/kubeconfig:Z. Cela permet à podman d'effectuer le réétiquetage SELinux approprié.
Conditions préalables
-
Vous vous êtes connecté à
registry.redhat.ioavec vos identifiants du portail client. - Vous avez installé le noyau temps réel dans le cluster.
- Vous avez appliqué un profil de performance de cluster en utilisant Node Tuning Operator.
Procédure
Pour effectuer l'opération
cyclictest, exécutez la commande suivante, en remplaçant les valeurs des variables par d'autres, le cas échéant :$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUN=true -e DISCOVERY_MODE=true -e FEATURES=performance -e ROLE_WORKER_CNF=worker-cnf \ -e LATENCY_TEST_CPUS=10 -e LATENCY_TEST_RUNTIME=600 -e MAXIMUM_LATENCY=20 \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.12 \ /usr/bin/test-run.sh -ginkgo.v -ginkgo.focus="cyclictest"
La commande exécute l'outil
cyclictestpendant 10 minutes (600 secondes). Le test s'exécute avec succès lorsque la latence maximale observée est inférieure àMAXIMUM_LATENCY(dans cet exemple, 20 μs). Les pics de latence de 20 μs et plus ne sont généralement pas acceptables pour les charges de travail telco RAN.Si les résultats dépassent le seuil de latence, le test échoue.
ImportantPour obtenir des résultats valables, le test doit durer au moins 12 heures.
Exemple de sortie de panne
running /usr/bin/cnftests -ginkgo.v -ginkgo.focus=cyclictest I0908 13:01:59.193776 27 request.go:601] Waited for 1.046228824s due to client-side throttling, not priority and fairness, request: GET:https://api.compute-1.example.com:6443/apis/packages.operators.coreos.com/v1?timeout=32s Running Suite: CNF Features e2e integration tests ================================================= Random Seed: 1662642118 Will run 1 of 194 specs [...] Summarizing 1 Failure: [Fail] [performance] Latency Test with the cyclictest image [It] should succeed /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:220 Ran 1 of 194 Specs in 161.151 seconds FAIL! -- 0 Passed | 1 Failed | 0 Pending | 193 Skipped --- FAIL: TestTest (161.48s) FAIL
Exemple de résultats d'un test cyclique
La même sortie peut indiquer des résultats différents pour des charges de travail différentes. Par exemple, des pics allant jusqu'à 18μs sont acceptables pour les charges de travail de l'UD 4G, mais pas pour les charges de travail de l'UD 5G.
Exemple de bons résultats
running cmd: cyclictest -q -D 10m -p 1 -t 16 -a 2,4,6,8,10,12,14,16,54,56,58,60,62,64,66,68 -h 30 -i 1000 -m # Histogram 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000001 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000002 579506 535967 418614 573648 532870 529897 489306 558076 582350 585188 583793 223781 532480 569130 472250 576043 More histogram entries ... # Total: 000600000 000600000 000600000 000599999 000599999 000599999 000599998 000599998 000599998 000599997 000599997 000599996 000599996 000599995 000599995 000599995 # Min Latencies: 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 # Avg Latencies: 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 # Max Latencies: 00005 00005 00004 00005 00004 00004 00005 00005 00006 00005 00004 00005 00004 00004 00005 00004 # Histogram Overflows: 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 00000 # Histogram Overflow at cycle number: # Thread 0: # Thread 1: # Thread 2: # Thread 3: # Thread 4: # Thread 5: # Thread 6: # Thread 7: # Thread 8: # Thread 9: # Thread 10: # Thread 11: # Thread 12: # Thread 13: # Thread 14: # Thread 15:
Exemple de mauvais résultats
running cmd: cyclictest -q -D 10m -p 1 -t 16 -a 2,4,6,8,10,12,14,16,54,56,58,60,62,64,66,68 -h 30 -i 1000 -m # Histogram 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000001 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000000 000002 564632 579686 354911 563036 492543 521983 515884 378266 592621 463547 482764 591976 590409 588145 589556 353518 More histogram entries ... # Total: 000599999 000599999 000599999 000599997 000599997 000599998 000599998 000599997 000599997 000599996 000599995 000599996 000599995 000599995 000599995 000599993 # Min Latencies: 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 # Avg Latencies: 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 00002 # Max Latencies: 00493 00387 00271 00619 00541 00513 00009 00389 00252 00215 00539 00498 00363 00204 00068 00520 # Histogram Overflows: 00001 00001 00001 00002 00002 00001 00000 00001 00001 00001 00002 00001 00001 00001 00001 00002 # Histogram Overflow at cycle number: # Thread 0: 155922 # Thread 1: 110064 # Thread 2: 110064 # Thread 3: 110063 155921 # Thread 4: 110063 155921 # Thread 5: 155920 # Thread 6: # Thread 7: 110062 # Thread 8: 110062 # Thread 9: 155919 # Thread 10: 110061 155919 # Thread 11: 155918 # Thread 12: 155918 # Thread 13: 110060 # Thread 14: 110060 # Thread 15: 110059 155917
15.4.3. Course à pied de l'oslat
Le test oslat simule une application DPDK à forte intensité de CPU et mesure toutes les interruptions et perturbations afin de tester la manière dont le cluster gère le traitement des données à forte intensité de CPU.
Always exécuter les tests de latence avec DISCOVERY_MODE=true. Si vous ne le faites pas, la suite de tests apportera des modifications à la configuration du cluster en cours d'exécution.
Lorsque vous exécutez les commandes podman en tant qu'utilisateur non root ou non privilégié, les chemins de montage peuvent échouer avec des erreurs permission denied. Pour que la commande podman fonctionne, ajoutez :Z à la création des volumes ; par exemple, -v $(pwd)/:/kubeconfig:Z. Cela permet à podman d'effectuer le réétiquetage SELinux approprié.
Conditions préalables
-
Vous vous êtes connecté à
registry.redhat.ioavec vos identifiants du portail client. - Vous avez appliqué un profil de performance de cluster en utilisant l'opérateur Node Tuning.
Procédure
Pour effectuer le test
oslat, exécutez la commande suivante, en remplaçant les valeurs des variables par celles qui conviennent :$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUN=true -e DISCOVERY_MODE=true -e FEATURES=performance -e ROLE_WORKER_CNF=worker-cnf \ -e LATENCY_TEST_CPUS=10 -e LATENCY_TEST_RUNTIME=600 -e MAXIMUM_LATENCY=20 \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.12 \ /usr/bin/test-run.sh -ginkgo.v -ginkgo.focus="oslat"
LATENCY_TEST_CPUSspécifie la liste des unités centrales à tester avec la commandeoslat.La commande exécute l'outil
oslatpendant 10 minutes (600 secondes). Le test s'exécute avec succès lorsque la latence maximale observée est inférieure àMAXIMUM_LATENCY(20 μs).Si les résultats dépassent le seuil de latence, le test échoue.
ImportantPour obtenir des résultats valables, le test doit durer au moins 12 heures.
Exemple de sortie de panne
running /usr/bin/cnftests -ginkgo.v -ginkgo.focus=oslat I0908 12:51:55.999393 27 request.go:601] Waited for 1.044848101s due to client-side throttling, not priority and fairness, request: GET:https://compute-1.example.com:6443/apis/machineconfiguration.openshift.io/v1?timeout=32s Running Suite: CNF Features e2e integration tests ================================================= Random Seed: 1662641514 Will run 1 of 194 specs [...] • Failure [77.833 seconds] [performance] Latency Test /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:62 with the oslat image /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:128 should succeed [It] /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:153 The current latency 304 is bigger than the expected one 1 : 1 [...] Summarizing 1 Failure: [Fail] [performance] Latency Test with the oslat image [It] should succeed /remote-source/app/vendor/github.com/openshift/cluster-node-tuning-operator/test/e2e/performanceprofile/functests/4_latency/latency.go:177 Ran 1 of 194 Specs in 161.091 seconds FAIL! -- 0 Passed | 1 Failed | 0 Pending | 193 Skipped --- FAIL: TestTest (161.42s) FAIL- 1
- Dans cet exemple, la latence mesurée est en dehors de la valeur maximale autorisée.
15.5. Génération d'un rapport d'échec du test de latence
Utilisez les procédures suivantes pour générer un résultat de test de latence JUnit et un rapport d'échec de test.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté en tant qu'utilisateur avec les privilèges
cluster-admin.
Procédure
Créez un rapport d'échec de test avec des informations sur l'état du cluster et les ressources pour le dépannage en passant le paramètre
--reportavec le chemin d'accès à l'endroit où le rapport est extrait :$ podman run -v $(pwd)/:/kubeconfig:Z -v $(pwd)/reportdest:<report_folder_path> \ -e KUBECONFIG=/kubeconfig/kubeconfig -e DISCOVERY_MODE=true -e FEATURES=performance \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.12 \ /usr/bin/test-run.sh --report <report_folder_path> \ -ginkgo.focus="\[performance\]\ Latency\ Test"
où :
- <report_folder_path>
- Chemin d'accès au dossier dans lequel le rapport est généré.
15.6. Générer un rapport de test de latence JUnit
Utilisez les procédures suivantes pour générer un résultat de test de latence JUnit et un rapport d'échec de test.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté en tant qu'utilisateur avec les privilèges
cluster-admin.
Procédure
Créez un rapport XML conforme à JUnit en passant le paramètre
--junitainsi que le chemin d'accès à l'endroit où le rapport est déposé :$ podman run -v $(pwd)/:/kubeconfig:Z -v $(pwd)/junitdest:<junit_folder_path> \ -e KUBECONFIG=/kubeconfig/kubeconfig -e DISCOVERY_MODE=true -e FEATURES=performance \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.12 \ /usr/bin/test-run.sh --junit <junit_folder_path> \ -ginkgo.focus="\[performance\]\ Latency\ Test"
où :
- <junit_folder_path>
- Le chemin d'accès au dossier dans lequel le rapport junit est généré
15.7. Exécution de tests de latence sur un cluster OpenShift à un nœud
Vous pouvez effectuer des tests de latence sur des clusters OpenShift à nœud unique.
Always exécuter les tests de latence avec DISCOVERY_MODE=true. Si vous ne le faites pas, la suite de tests apportera des modifications à la configuration du cluster en cours d'exécution.
Lorsque vous exécutez les commandes podman en tant qu'utilisateur non root ou non privilégié, les chemins de montage peuvent échouer avec des erreurs permission denied. Pour que la commande podman fonctionne, ajoutez :Z à la création des volumes ; par exemple, -v $(pwd)/:/kubeconfig:Z. Cela permet à podman d'effectuer le réétiquetage SELinux approprié.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté en tant qu'utilisateur avec les privilèges
cluster-admin.
Procédure
Pour exécuter les tests de latence sur un cluster OpenShift à nœud unique, exécutez la commande suivante :
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e DISCOVERY_MODE=true -e FEATURES=performance -e ROLE_WORKER_CNF=master \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.12 \ /usr/bin/test-run.sh -ginkgo.focus="\[performance\]\ Latency\ Test"
NoteROLE_WORKER_CNF=masterest nécessaire car le maître est le seul pool de machines auquel le nœud appartient. Pour plus d'informations sur la configuration deMachineConfigPoolpour les tests de latence, voir "Conditions préalables à l'exécution des tests de latence".Après l'exécution de la suite de tests, toutes les ressources en suspens sont nettoyées.
15.8. Exécution de tests de latence dans un cluster déconnecté
L'image de tests CNF peut exécuter des tests dans un cluster déconnecté qui n'est pas en mesure d'accéder à des registres externes. Cela nécessite deux étapes :
-
Mise en miroir de l'image
cnf-testsavec le registre personnalisé déconnecté. - Demander aux tests de consommer les images du registre personnalisé déconnecté.
Mise en miroir des images dans un registre personnalisé accessible depuis le cluster
Un exécutable mirror est livré avec l'image afin de fournir les données requises par oc pour reproduire l'image de test dans un registre local.
Exécutez cette commande à partir d'une machine intermédiaire qui a accès au cluster et au registre.redhat.io:
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.12 \ /usr/bin/mirror -registry <disconnected_registry> | oc image mirror -f -
où :
- <registre_déconnecté>
-
Le registre du miroir déconnecté est-il celui que vous avez configuré, par exemple,
my.local.registry:5000/.
Lorsque vous avez mis en miroir l'image
cnf-testsdans le registre déconnecté, vous devez remplacer le registre d'origine utilisé pour récupérer les images lors de l'exécution des tests, par exemple :$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e DISCOVERY_MODE=true -e FEATURES=performance -e IMAGE_REGISTRY="<disconnected_registry>" \ -e CNF_TESTS_IMAGE="cnf-tests-rhel8:v4.12" \ /usr/bin/test-run.sh -ginkgo.focus="\[performance\]\ Latency\ Test"
Configurer les tests pour qu'ils consomment des images provenant d'un registre personnalisé
Vous pouvez exécuter les tests de latence à l'aide d'une image de test personnalisée et d'un registre d'images en utilisant les variables CNF_TESTS_IMAGE et IMAGE_REGISTRY.
Pour configurer les tests de latence afin d'utiliser une image de test personnalisée et un registre d'images, exécutez la commande suivante :
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e IMAGE_REGISTRY="<custom_image_registry>" \ -e CNF_TESTS_IMAGE="<custom_cnf-tests_image>" \ -e FEATURES=performance \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.12 /usr/bin/test-run.sh
où :
- <registre_d'images_personnalisé>
-
est le registre de l'image personnalisée, par exemple,
custom.registry:5000/. - <custom_cnf-tests_image>
-
est l'image personnalisée de cnf-tests, par exemple,
custom-cnf-tests-image:latest.
Mise en miroir des images vers le registre d'images OpenShift du cluster
OpenShift Container Platform fournit un registre d'images de conteneurs intégré, qui s'exécute comme une charge de travail standard sur le cluster.
Procédure
Obtenir un accès externe au registre en l'exposant à l'aide d'une route :
$ oc patch configs.imageregistry.operator.openshift.io/cluster --patch '{"spec":{"defaultRoute":true}}' --type=mergeRécupérez le point de terminaison du registre en exécutant la commande suivante :
$ REGISTRY=$(oc get route default-route -n openshift-image-registry --template='{{ .spec.host }}')Créer un espace de noms pour exposer les images :
$ oc create ns cnftests
Mettre le flux d'images à la disposition de tous les espaces de noms utilisés pour les tests. Cela est nécessaire pour permettre aux espaces de noms de tests de récupérer les images du flux d'images
cnf-tests. Exécutez les commandes suivantes :$ oc policy add-role-to-user system:image-puller system:serviceaccount:cnf-features-testing:default --namespace=cnftests
$ oc policy add-role-to-user system:image-puller system:serviceaccount:performance-addon-operators-testing:default --namespace=cnftests
Récupérez le nom secret de docker et le jeton d'authentification en exécutant les commandes suivantes :
$ SECRET=$(oc -n cnftests get secret | grep builder-docker | awk {'print $1'}$ TOKEN=$(oc -n cnftests get secret $SECRET -o jsonpath="{.data['\.dockercfg']}" | base64 --decode | jq '.["image-registry.openshift-image-registry.svc:5000"].auth')Créez un fichier
dockerauth.json, par exemple :$ echo "{\"auths\": { \"$REGISTRY\": { \"auth\": $TOKEN } }}" > dockerauth.jsonEffectuer la mise en miroir de l'image :
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:4.12 \ /usr/bin/mirror -registry $REGISTRY/cnftests | oc image mirror --insecure=true \ -a=$(pwd)/dockerauth.json -f -
Exécutez les tests :
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e DISCOVERY_MODE=true -e FEATURES=performance -e IMAGE_REGISTRY=image-registry.openshift-image-registry.svc:5000/cnftests \ cnf-tests-local:latest /usr/bin/test-run.sh -ginkgo.focus="\[performance\]\ Latency\ Test"
Miroir d'un ensemble différent d'images de test
Vous pouvez éventuellement modifier les images en amont par défaut qui sont mises en miroir pour les tests de latence.
Procédure
La commande
mirrortente par défaut de refléter les images en amont. Ceci peut être surchargé en passant un fichier au format suivant à l'image :[ { "registry": "public.registry.io:5000", "image": "imageforcnftests:4.12" } ]Transmettez le fichier à la commande
mirror, par exemple en l'enregistrant localement sousimages.json. Avec la commande suivante, le chemin local est monté dans/kubeconfigà l'intérieur du conteneur et peut être transmis à la commande mirror.$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.12 /usr/bin/mirror \ --registry "my.local.registry:5000/" --images "/kubeconfig/images.json" \ | oc image mirror -f -
15.9. Résolution des erreurs avec le conteneur cnf-tests
Pour effectuer des tests de latence, le cluster doit être accessible depuis le conteneur cnf-tests.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté en tant qu'utilisateur avec les privilèges
cluster-admin.
Procédure
Vérifiez que le cluster est accessible depuis l'intérieur du conteneur
cnf-testsen exécutant la commande suivante :$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.12 \ oc get nodes
Si cette commande ne fonctionne pas, il se peut qu'il y ait une erreur liée au DNS spanning across, à la taille du MTU ou à l'accès au pare-feu.
Chapitre 16. Amélioration de la stabilité des grappes dans les environnements à forte latence à l'aide de profils de latence des travailleurs
Tous les nœuds envoient des battements de cœur à l'opérateur du contrôleur Kubernetes (kube controller) dans le cluster OpenShift Container Platform toutes les 10 secondes, par défaut. Si le cluster ne reçoit pas de battements de cœur d'un nœud, OpenShift Container Platform répond à l'aide de plusieurs mécanismes par défaut.
Par exemple, si l'opérateur du gestionnaire de contrôleur Kubernetes perd le contact avec un nœud après une période configurée :
-
Le contrôleur de nœuds sur le plan de contrôle met à jour l'état du nœud à
Unhealthyet marque l'état du nœudReadycommeUnknown. - En réponse, l'ordonnanceur arrête de programmer des pods sur ce nœud.
-
Le contrôleur de nœuds sur site ajoute au nœud une tare
node.kubernetes.io/unreachableavec un effetNoExecuteet planifie l'éviction de tous les pods du nœud après cinq minutes, par défaut.
Ce comportement peut poser des problèmes si votre réseau est sujet à des problèmes de latence, en particulier si vous avez des nœuds à la périphérie du réseau. Dans certains cas, l'opérateur du gestionnaire de contrôleur Kubernetes peut ne pas recevoir de mise à jour d'un nœud sain en raison de la latence du réseau. L'opérateur du gestionnaire de contrôleur Kubernetes expulserait alors les pods du nœud, même si celui-ci est sain. Pour éviter ce problème, vous pouvez utiliser worker latency profiles pour ajuster la fréquence à laquelle le kubelet et le Kubernetes Controller Manager Operator attendent les mises à jour d'état avant d'agir. Ces ajustements permettent de s'assurer que votre cluster fonctionne correctement dans le cas où la latence du réseau entre le plan de contrôle et les nœuds de travail n'est pas optimale.
Ces profils de latence des travailleurs sont trois ensembles de paramètres prédéfinis avec des valeurs soigneusement ajustées qui vous permettent de contrôler la réaction du cluster aux problèmes de latence sans avoir à déterminer les meilleures valeurs manuellement.
Vous pouvez configurer les profils de latence des travailleurs lors de l'installation d'un cluster ou à tout moment lorsque vous constatez une augmentation de la latence dans votre réseau de clusters.
16.1. Comprendre les profils de latence des travailleurs
Les profils de latence des travailleurs sont des ensembles multiples de valeurs soigneusement ajustées pour les paramètres node-status-update-frequency, node-monitor-grace-period, default-not-ready-toleration-seconds et default-unreachable-toleration-seconds. Ces paramètres vous permettent de contrôler la réaction du cluster aux problèmes de latence sans avoir à déterminer manuellement les meilleures valeurs.
Tous les profils de latence des travailleurs configurent les paramètres suivants :
-
node-status-update-frequency. Spécifie le temps en secondes pendant lequel un kubelet met à jour son statut auprès de l'opérateur du gestionnaire de contrôleur Kubernetes. -
node-monitor-grace-period. Spécifie la durée en secondes pendant laquelle l'opérateur Kubernetes Controller Manager attend une mise à jour d'un kubelet avant de marquer le nœud comme étant malsain et d'ajouter l'erreurnode.kubernetes.io/not-readyounode.kubernetes.io/unreachableau nœud. -
default-not-ready-toleration-seconds. Spécifie la durée en secondes après le marquage d'un nœud insalubre que l'opérateur Kubernetes Controller Manager attend avant d'expulser les pods de ce nœud. -
default-unreachable-toleration-seconds. Spécifie la durée en secondes pendant laquelle l'opérateur du gestionnaire de contrôle Kubernetes attend qu'un nœud soit marqué comme inaccessible avant d'expulser les pods de ce nœud.
La modification manuelle du paramètre node-monitor-grace-period n'est pas possible.
Les opérateurs suivants surveillent les modifications apportées aux profils de latence des travailleurs et réagissent en conséquence :
-
L'opérateur de configuration de la machine (MCO) met à jour le paramètre
node-status-update-frequencysur les nœuds de travail. -
L'opérateur du gestionnaire de contrôleur Kubernetes met à jour le paramètre
node-monitor-grace-periodsur les nœuds du plan de contrôle. -
L'opérateur du serveur API Kubernetes met à jour les paramètres
default-not-ready-toleration-secondsetdefault-unreachable-toleration-secondssur les nœuds de la plance de contrôle.
Bien que la configuration par défaut fonctionne dans la plupart des cas, OpenShift Container Platform propose deux autres profils de latence du travailleur pour les situations où le réseau connaît une latence plus élevée que d'habitude. Les trois profils de latence des travailleurs sont décrits dans les sections suivantes :
- Profil de latence du travailleur par défaut
Avec le profil
Default, chaque kubelet signale l'état de son nœud au Kubelet Controller Manager Operator (kube controller) toutes les 10 secondes. L'opérateur du gestionnaire du contrôleur de kubelet vérifie l'état du kubelet toutes les 5 secondes.L'opérateur du gestionnaire de contrôle Kubernetes attend 40 secondes pour une mise à jour de l'état avant de considérer ce nœud comme malsain. Il marque le nœud avec la taint
node.kubernetes.io/not-readyounode.kubernetes.io/unreachableet expulse les pods sur ce nœud. Si un pod sur ce nœud a la toléranceNoExecute, le pod est expulsé en 300 secondes. Si le pod a le paramètretolerationSeconds, l'expulsion attend la période spécifiée par ce paramètre.Profile Composant Paramètres Valeur Défaut
kubelet
node-status-update-frequency10s
Gestionnaire de contrôleur Kubelet
node-monitor-grace-period40s
Serveur API Kubernetes
default-not-ready-toleration-seconds300s
Serveur API Kubernetes
default-unreachable-toleration-seconds300s
- Profil de latence du travailleur moyen
Utilisez le profil
MediumUpdateAverageReactionsi la latence du réseau est légèrement plus élevée que d'habitude.Le profil
MediumUpdateAverageReactionréduit la fréquence des mises à jour des kubelets à 20 secondes et modifie la période d'attente de ces mises à jour par l'opérateur du contrôleur Kubernetes à 2 minutes. La période d'éviction d'un pod sur ce nœud est réduite à 60 secondes. Si le pod a le paramètretolerationSeconds, l'éviction attend la période spécifiée par ce paramètre.L'opérateur Kubernetes Controller Manager attend 2 minutes pour considérer qu'un nœud n'est pas sain. Une minute plus tard, le processus d'expulsion commence.
Profile Composant Paramètres Valeur Moyenne des mises à jour
kubelet
node-status-update-frequency20s
Gestionnaire de contrôleur Kubelet
node-monitor-grace-period2m
Serveur API Kubernetes
default-not-ready-toleration-seconds60s
Serveur API Kubernetes
default-unreachable-toleration-seconds60s
- Profil de latence faible pour les travailleurs
Utilisez le profil
LowUpdateSlowReactionsi la latence du réseau est extrêmement élevée.Le profil
LowUpdateSlowReactionréduit la fréquence des mises à jour des kubelets à 1 minute et modifie la période d'attente de ces mises à jour par l'opérateur du contrôleur Kubernetes à 5 minutes. La période d'éviction d'un pod sur ce nœud est réduite à 60 secondes. Si le pod a le paramètretolerationSeconds, l'éviction attend la période spécifiée par ce paramètre.L'opérateur Kubernetes Controller Manager attend 5 minutes pour considérer qu'un nœud n'est pas sain. Dans une minute, le processus d'expulsion commence.
Profile Composant Paramètres Valeur Faible mise à jourRéaction lente
kubelet
node-status-update-frequency1m
Gestionnaire de contrôleur Kubelet
node-monitor-grace-period5m
Serveur API Kubernetes
default-not-ready-toleration-seconds60s
Serveur API Kubernetes
default-unreachable-toleration-seconds60s
16.2. Utilisation des profils de latence des travailleurs
Pour mettre en œuvre un profil de latence du travailleur afin de gérer la latence du réseau, modifiez l'objet node.config pour ajouter le nom du profil. Vous pouvez modifier le profil à tout moment lorsque la latence augmente ou diminue.
Vous devez déplacer un profil de latence de travailleur à la fois. Par exemple, vous ne pouvez pas passer directement du profil Default au profil LowUpdateSlowReaction. Vous devez d'abord passer du profil default au profil MediumUpdateAverageReaction, puis à LowUpdateSlowReaction. De même, lorsque vous revenez au profil par défaut, vous devez d'abord passer du profil bas au profil moyen, puis au profil par défaut.
Vous pouvez également configurer les profils de latence des travailleurs lors de l'installation d'un cluster OpenShift Container Platform.
Procédure
Pour quitter le profil de latence par défaut du travailleur :
Passer au profil de latence du travailleur moyen :
Modifiez l'objet
node.config:$ oc edit nodes.config/cluster
Ajouter
spec.workerLatencyProfile: MediumUpdateAverageReaction:Exemple d'objet
node.configapiVersion: config.openshift.io/v1 kind: Node metadata: annotations: include.release.openshift.io/ibm-cloud-managed: "true" include.release.openshift.io/self-managed-high-availability: "true" include.release.openshift.io/single-node-developer: "true" release.openshift.io/create-only: "true" creationTimestamp: "2022-07-08T16:02:51Z" generation: 1 name: cluster ownerReferences: - apiVersion: config.openshift.io/v1 kind: ClusterVersion name: version uid: 36282574-bf9f-409e-a6cd-3032939293eb resourceVersion: "1865" uid: 0c0f7a4c-4307-4187-b591-6155695ac85b spec: workerLatencyProfile: MediumUpdateAverageReaction 1 ...- 1
- Spécifie la politique de latence du travailleur moyen.
La programmation sur chaque nœud de travailleur est désactivée au fur et à mesure de l'application de la modification.
Lorsque tous les nœuds reviennent à l'état
Ready, vous pouvez utiliser la commande suivante pour vérifier dans le Kubernetes Controller Manager qu'elle a bien été appliquée :$ oc get KubeControllerManager -o yaml | grep -i workerlatency -A 5 -B 5
Exemple de sortie
... - lastTransitionTime: "2022-07-11T19:47:10Z" reason: ProfileUpdated status: "False" type: WorkerLatencyProfileProgressing - lastTransitionTime: "2022-07-11T19:47:10Z" 1 message: all static pod revision(s) have updated latency profile reason: ProfileUpdated status: "True" type: WorkerLatencyProfileComplete - lastTransitionTime: "2022-07-11T19:20:11Z" reason: AsExpected status: "False" type: WorkerLatencyProfileDegraded - lastTransitionTime: "2022-07-11T19:20:36Z" status: "False" ...- 1
- Spécifie que le profil est appliqué et actif.
Optionnel : Passez au profil de faible latence du travailleur :
Modifiez l'objet
node.config:$ oc edit nodes.config/cluster
Modifiez la valeur de
spec.workerLatencyProfileenLowUpdateSlowReaction:Exemple d'objet
node.configapiVersion: config.openshift.io/v1 kind: Node metadata: annotations: include.release.openshift.io/ibm-cloud-managed: "true" include.release.openshift.io/self-managed-high-availability: "true" include.release.openshift.io/single-node-developer: "true" release.openshift.io/create-only: "true" creationTimestamp: "2022-07-08T16:02:51Z" generation: 1 name: cluster ownerReferences: - apiVersion: config.openshift.io/v1 kind: ClusterVersion name: version uid: 36282574-bf9f-409e-a6cd-3032939293eb resourceVersion: "1865" uid: 0c0f7a4c-4307-4187-b591-6155695ac85b spec: workerLatencyProfile: LowUpdateSlowReaction 1 ...- 1
- Spécifie l'utilisation de la politique de faible latence du travailleur.
La programmation sur chaque nœud de travailleur est désactivée au fur et à mesure de l'application de la modification.
Pour transformer le profil bas en profil moyen ou le profil moyen en profil bas, modifiez l'objet node.config et réglez le paramètre spec.workerLatencyProfile sur la valeur appropriée.
Chapitre 17. Topology Aware Lifecycle Manager pour les mises à jour des clusters
Vous pouvez utiliser le Topology Aware Lifecycle Manager (TALM) pour gérer le cycle de vie des logiciels de plusieurs clusters. TALM utilise les stratégies de Red Hat Advanced Cluster Management (RHACM) pour effectuer des changements sur les clusters cibles.
17.1. À propos de la configuration du gestionnaire du cycle de vie Topology Aware
Le Topology Aware Lifecycle Manager (TALM) gère le déploiement des politiques de Red Hat Advanced Cluster Management (RHACM) pour un ou plusieurs clusters d'OpenShift Container Platform. L'utilisation de TALM dans un grand réseau de clusters permet le déploiement progressif des politiques vers les clusters en lots limités. Cela permet de minimiser les éventuelles interruptions de service lors de la mise à jour. Avec TALM, vous pouvez contrôler les actions suivantes :
- Le calendrier de la mise à jour
- Le nombre de clusters gérés par RHACM
- Le sous-ensemble de clusters gérés auquel les politiques doivent être appliquées
- L'ordre de mise à jour des grappes
- L'ensemble des politiques remédiées au cluster
- L'ordre des politiques remédiées dans le cluster
- L'affectation d'une grappe de canaris
Pour OpenShift à nœud unique, le Topology Aware Lifecycle Manager (TALM) offre les fonctionnalités suivantes :
- Créer une sauvegarde d'un déploiement avant une mise à niveau
- Mise en cache préalable des images pour les grappes à bande passante limitée
TALM prend en charge l'orchestration des mises à jour des y-streams et z-streams d'OpenShift Container Platform, ainsi que les opérations du deuxième jour sur les y-streams et z-streams.
17.2. A propos des politiques gérées utilisées avec Topology Aware Lifecycle Manager
Le Topology Aware Lifecycle Manager (TALM) utilise les stratégies RHACM pour les mises à jour des clusters.
TALM peut être utilisé pour gérer le déploiement de toute politique CR dont le champ remediationAction est défini sur inform. Les cas d'utilisation pris en charge sont les suivants :
- Création manuelle par l'utilisateur de CR de politique
-
Politiques générées automatiquement à partir de la définition des ressources personnalisées (CRD) de
PolicyGenTemplate
Pour les politiques qui mettent à jour un abonnement d'opérateur avec une approbation manuelle, TALM fournit une fonctionnalité supplémentaire qui approuve l'installation de l'opérateur mis à jour.
Pour plus d'informations sur les politiques gérées, voir Policy Overview dans la documentation RHACM.
Pour plus d'informations sur le CRD PolicyGenTemplate, voir la section "À propos du CRD PolicyGenTemplate" dans "Configuration des clusters gérés avec des stratégies et des ressources PolicyGenTemplate".
17.3. Installation du Topology Aware Lifecycle Manager à l'aide de la console web
Vous pouvez utiliser la console web d'OpenShift Container Platform pour installer le Topology Aware Lifecycle Manager.
Conditions préalables
- Installer la dernière version de l'opérateur RHACM.
- Mettre en place un hub cluster avec des registres déconnectés.
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
- Dans la console web d'OpenShift Container Platform, naviguez vers Operators → OperatorHub.
- Recherchez le site Topology Aware Lifecycle Manager dans la liste des opérateurs disponibles, puis cliquez sur Install.
- Conservez la sélection par défaut de Installation mode [\N- Tous les espaces de noms sur le cluster (par défaut)\N] et Installed Namespace (\N- openshift-operators\N) pour vous assurer que l'Opérateur est installé correctement.
- Cliquez sur Install.
Vérification
Pour confirmer que l'installation a réussi :
- Naviguez jusqu'à la page Operators → Installed Operators.
-
Vérifiez que l'Opérateur est installé dans l'espace de noms
All Namespaceset que son statut estSucceeded.
Si l'opérateur n'est pas installé correctement :
-
Naviguez jusqu'à la page Operators → Installed Operators et vérifiez que la colonne
Statusne contient pas d'erreurs ou de défaillances. -
Naviguez jusqu'à la page Workloads → Pods et vérifiez les journaux de tous les conteneurs du pod
cluster-group-upgrades-controller-managerqui signalent des problèmes.
17.4. Installation du gestionnaire de cycle de vie Topology Aware à l'aide de la CLI
Vous pouvez utiliser le CLI OpenShift (oc) pour installer le Topology Aware Lifecycle Manager (TALM).
Conditions préalables
-
Installez le CLI OpenShift (
oc). - Installer la dernière version de l'opérateur RHACM.
- Mise en place d'un hub cluster avec un registre déconnecté.
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Créer un CR
Subscription:Définissez le CR
Subscriptionet enregistrez le fichier YAML, par exempletalm-subscription.yaml:apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: openshift-topology-aware-lifecycle-manager-subscription namespace: openshift-operators spec: channel: "stable" name: topology-aware-lifecycle-manager source: redhat-operators sourceNamespace: openshift-marketplace
Créez le CR
Subscriptionen exécutant la commande suivante :$ oc create -f talm-subscription.yaml
Vérification
Vérifiez que l'installation a réussi en inspectant la ressource CSV :
$ oc get csv -n openshift-operators
Exemple de sortie
NAME DISPLAY VERSION REPLACES PHASE topology-aware-lifecycle-manager.4.12.x Topology Aware Lifecycle Manager 4.12.x Succeeded
Vérifier que le TALM est opérationnel :
$ oc get deploy -n openshift-operators
Exemple de sortie
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE openshift-operators cluster-group-upgrades-controller-manager 1/1 1 1 14s
17.5. À propos du CR ClusterGroupUpgrade
Le Topology Aware Lifecycle Manager (TALM) construit le plan de remédiation à partir de la CR ClusterGroupUpgrade pour un groupe de clusters. Vous pouvez définir les spécifications suivantes dans un CR ClusterGroupUpgrade:
- Clusters dans le groupe
-
Blocage des CR
ClusterGroupUpgrade - Liste des politiques gérées applicables
- Nombre de mises à jour simultanées
- Mises à jour des canaris applicables
- Actions à effectuer avant et après la mise à jour
- Calendrier de mise à jour
Vous pouvez contrôler l'heure de début d'une mise à jour en utilisant le champ enable dans le CR ClusterGroupUpgrade. Par exemple, si vous avez une fenêtre de maintenance programmée de quatre heures, vous pouvez préparer un CR ClusterGroupUpgrade avec le champ enable défini sur false.
Vous pouvez définir le délai d'attente en configurant le paramètre spec.remediationStrategy.timeout comme suit :
spec
remediationStrategy:
maxConcurrency: 1
timeout: 240
Vous pouvez utiliser l'adresse batchTimeoutAction pour déterminer ce qui se passe si une mise à jour échoue pour un cluster. Vous pouvez spécifier continue pour ignorer le cluster défaillant et continuer à mettre à jour les autres clusters, ou abort pour arrêter la remédiation des politiques pour tous les clusters. Une fois le délai écoulé, TALM supprime toutes les politiques enforce pour s'assurer qu'aucune autre mise à jour n'est effectuée sur les clusters.
Pour appliquer les modifications, vous définissez le champ enabled sur true.
Pour plus d'informations, voir la section "Application des stratégies de mise à jour aux clusters gérés".
Au fur et à mesure que TALM remédie aux politiques vers les clusters spécifiés, le CR ClusterGroupUpgrade peut signaler des statuts vrais ou faux pour un certain nombre de conditions.
Une fois que TALM a terminé la mise à jour d'un cluster, le cluster n'est plus mis à jour sous le contrôle du même CR ClusterGroupUpgrade. Vous devez créer un nouveau CR ClusterGroupUpgrade dans les cas suivants :
- Lorsque vous devez à nouveau mettre à jour le cluster
-
Lorsque le cluster devient non conforme à la politique
informaprès avoir été mis à jour
17.5.1. Sélection des grappes
TALM construit un plan de remédiation et sélectionne les clusters en fonction des champs suivants :
-
Le champ
clusterLabelSelectorspécifie les étiquettes des grappes que vous souhaitez mettre à jour. Il s'agit d'une liste de sélecteurs d'étiquettes standard provenant dek8s.io/apimachinery/pkg/apis/meta/v1. Chaque sélecteur de la liste utilise soit des paires de valeurs d'étiquettes, soit des expressions d'étiquettes. Les correspondances de chaque sélecteur sont ajoutées à la liste finale des grappes avec les correspondances des champsclusterSelectoretcluster. -
Le champ
clustersspécifie une liste de grappes à mettre à jour. -
Le champ
canariesspécifie les clusters pour les mises à jour canari. -
Le champ
maxConcurrencyindique le nombre de grappes à mettre à jour dans un lot.
Vous pouvez utiliser les champs clusters, clusterLabelSelector, et clusterSelector ensemble pour créer une liste combinée de clusters.
Le plan de remédiation commence par les clusters listés dans le champ canaries. Chaque grappe canarienne forme un lot à grappe unique.
Exemple de ClusterGroupUpgrade CR avec l'activation de field réglée sur false
apiVersion: ran.openshift.io/v1alpha1
kind: ClusterGroupUpgrade
metadata:
creationTimestamp: '2022-11-18T16:27:15Z'
finalizers:
- ran.openshift.io/cleanup-finalizer
generation: 1
name: talm-cgu
namespace: talm-namespace
resourceVersion: '40451823'
uid: cca245a5-4bca-45fa-89c0-aa6af81a596c
Spec:
actions:
afterCompletion:
deleteObjects: true
beforeEnable: {}
backup: false
clusters: 1
- spoke1
enable: false 2
managedPolicies: 3
- talm-policy
preCaching: false
remediationStrategy: 4
canaries: 5
- spoke1
maxConcurrency: 2 6
timeout: 240
clusterLabelSelectors: 7
- matchExpressions:
- key: label1
operator: In
values:
- value1a
- value1b
batchTimeoutAction: 8
status: 9
computedMaxConcurrency: 2
conditions:
- lastTransitionTime: '2022-11-18T16:27:15Z'
message: All selected clusters are valid
reason: ClusterSelectionCompleted
status: 'True'
type: ClustersSelected 10
- lastTransitionTime: '2022-11-18T16:27:15Z'
message: Completed validation
reason: ValidationCompleted
status: 'True'
type: Validated 11
- lastTransitionTime: '2022-11-18T16:37:16Z'
message: Not enabled
reason: NotEnabled
status: 'False'
type: Progressing
managedPoliciesForUpgrade:
- name: talm-policy
namespace: talm-namespace
managedPoliciesNs:
talm-policy: talm-namespace
remediationPlan:
- - spoke1
- - spoke2
- spoke3
status:
- 1
- Définit la liste des grappes à mettre à jour.
- 2
- Le champ
enableest défini surfalse. - 3
- Répertorie l'ensemble des politiques définies par l'utilisateur pour remédier à la situation.
- 4
- Définit les spécificités des mises à jour de la grappe.
- 5
- Définit les clusters pour les mises à jour canari.
- 6
- Définit le nombre maximal de mises à jour simultanées dans un lot. Le nombre de lots de remédiation est le nombre de clusters canaris, plus le nombre de clusters, à l'exception des clusters canaris, divisé par la valeur maxConcurrency. Les clusters qui sont déjà conformes à toutes les politiques gérées sont exclus du plan de remédiation.
- 7
- Affiche les paramètres de sélection des grappes.
- 8
- Contrôle ce qui se passe en cas de dépassement du délai d'exécution d'un lot. Les valeurs possibles sont
abortoucontinue. Si aucune valeur n'est spécifiée, la valeur par défaut estcontinue. - 9
- Affiche des informations sur l'état des mises à jour.
- 10
- La condition
ClustersSelectedmontre que toutes les grappes sélectionnées sont valides. - 11
- La condition
Validatedmontre que toutes les grappes sélectionnées ont été validées.
Toute défaillance au cours de la mise à jour d'une grappe canarienne interrompt le processus de mise à jour.
Lorsque le plan de remédiation est créé avec succès, vous pouvez définir le champ enable sur true et TALM commence à mettre à jour les clusters non conformes avec les politiques gérées spécifiées.
Vous ne pouvez modifier les champs spec que si le champ enable du CR ClusterGroupUpgrade est défini sur false.
17.5.2. Valider
TALM vérifie que toutes les politiques gérées spécifiées sont disponibles et correctes, et utilise la condition Validated pour signaler l'état et les raisons comme suit :
trueLa validation est terminée.
falseLes politiques sont manquantes ou invalides, ou une image de plate-forme invalide a été spécifiée.
17.5.3. Mise en cache préalable
Les clusters peuvent avoir une bande passante limitée pour accéder au registre des images de conteneurs, ce qui peut entraîner un dépassement de délai avant que les mises à jour ne soient terminées. Sur les clusters OpenShift à nœud unique, vous pouvez utiliser la mise en cache préalable pour éviter ce problème. La mise en cache préalable de l'image de conteneur commence lorsque vous créez un CR ClusterGroupUpgrade avec le champ preCaching défini sur true.
TALM utilise la condition PrecacheSpecValid pour signaler les informations d'état comme suit :
trueLa spécification relative à la mise en cache préalable est valide et cohérente.
falseLa spécification relative à la mise en cache préalable est incomplète.
TALM utilise la condition PrecachingSucceeded pour signaler les informations d'état comme suit :
trueTALM a terminé le processus de pré-mise en cache. Si le pré-caching échoue pour un cluster, la mise à jour échoue pour ce cluster mais se poursuit pour tous les autres clusters. Un message vous informe de l'échec de la mise en cache pour l'un des clusters.
falseLa mise en cache est toujours en cours pour un ou plusieurs clusters ou a échoué pour tous les clusters.
Pour plus d'informations, voir la section "Using the container image pre-cache feature".
17.5.4. Création d'une sauvegarde
Pour OpenShift à nœud unique, TALM peut créer une sauvegarde d'un déploiement avant une mise à jour. Si la mise à jour échoue, vous pouvez récupérer la version précédente et restaurer un cluster à un état fonctionnel sans nécessiter un reprovisionnement des applications. Pour utiliser la fonctionnalité de sauvegarde, vous devez d'abord créer un CR ClusterGroupUpgrade avec le champ backup défini sur true. Pour garantir que le contenu de la sauvegarde est à jour, la sauvegarde n'est pas effectuée tant que vous n'avez pas défini le champ enable dans le CR ClusterGroupUpgrade sur true.
TALM utilise la condition BackupSucceeded pour signaler l'état et les raisons comme suit :
trueLa sauvegarde est terminée pour tous les clusters ou l'exécution de la sauvegarde s'est terminée mais a échoué pour un ou plusieurs clusters. Si la sauvegarde échoue pour un cluster, la mise à jour échoue pour ce cluster mais se poursuit pour tous les autres clusters.
falseLa sauvegarde est toujours en cours pour un ou plusieurs clusters ou a échoué pour tous les clusters.
Pour plus d'informations, voir la section "Création d'une sauvegarde des ressources du cluster avant la mise à niveau".
17.5.5. Mise à jour des grappes
TALM applique les politiques en suivant le plan de remédiation. L'application des politiques pour les lots suivants commence immédiatement après que tous les clusters du lot en cours sont conformes à toutes les politiques gérées. Si le lot s'arrête, TALM passe au lot suivant. La valeur du délai d'attente d'un lot est le champ spec.timeout divisé par le nombre de lots dans le plan de remédiation.
TALM utilise la condition Progressing pour signaler l'état et les raisons comme suit :
trueTALM remédie aux politiques non conformes.
falseLa mise à jour n'est pas en cours. Les raisons possibles sont les suivantes :
- Tous les clusters sont conformes à toutes les politiques gérées.
- La mise à jour a été interrompue car la remédiation de la politique a pris trop de temps.
- Les CR bloquants sont absents du système ou n'ont pas encore été achevés.
-
Le CR
ClusterGroupUpgraden'est pas activé. - La sauvegarde est toujours en cours.
Les politiques gérées s'appliquent dans l'ordre dans lequel elles sont listées dans le champ managedPolicies du CR ClusterGroupUpgrade. Une politique gérée est appliquée aux grappes spécifiées à la fois. Lorsqu'un cluster est conforme à la politique actuelle, la politique gérée suivante lui est appliquée.
Exemple ClusterGroupUpgrade CR dans l'état Progressing
apiVersion: ran.openshift.io/v1alpha1
kind: ClusterGroupUpgrade
metadata:
creationTimestamp: '2022-11-18T16:27:15Z'
finalizers:
- ran.openshift.io/cleanup-finalizer
generation: 1
name: talm-cgu
namespace: talm-namespace
resourceVersion: '40451823'
uid: cca245a5-4bca-45fa-89c0-aa6af81a596c
Spec:
actions:
afterCompletion:
deleteObjects: true
beforeEnable: {}
backup: false
clusters:
- spoke1
enable: true
managedPolicies:
- talm-policy
preCaching: true
remediationStrategy:
canaries:
- spoke1
maxConcurrency: 2
timeout: 240
clusterLabelSelectors:
- matchExpressions:
- key: label1
operator: In
values:
- value1a
- value1b
batchTimeoutAction:
status:
clusters:
- name: spoke1
state: complete
computedMaxConcurrency: 2
conditions:
- lastTransitionTime: '2022-11-18T16:27:15Z'
message: All selected clusters are valid
reason: ClusterSelectionCompleted
status: 'True'
type: ClustersSelected
- lastTransitionTime: '2022-11-18T16:27:15Z'
message: Completed validation
reason: ValidationCompleted
status: 'True'
type: Validated
- lastTransitionTime: '2022-11-18T16:37:16Z'
message: Remediating non-compliant policies
reason: InProgress
status: 'True'
type: Progressing 1
managedPoliciesForUpgrade:
- name: talm-policy
namespace: talm-namespace
managedPoliciesNs:
talm-policy: talm-namespace
remediationPlan:
- - spoke1
- - spoke2
- spoke3
status:
currentBatch: 2
currentBatchRemediationProgress:
spoke2:
state: Completed
spoke3:
policyIndex: 0
state: InProgress
currentBatchStartedAt: '2022-11-18T16:27:16Z'
startedAt: '2022-11-18T16:27:15Z'
- 1
- Les champs
Progressingmontrent que TALM est en train de remédier aux politiques.
17.5.6. Mise à jour du statut
TALM utilise la condition Succeeded pour signaler l'état et les raisons comme suit :
trueTous les clusters sont conformes aux politiques de gestion spécifiées.
falseLa remédiation de la politique a échoué parce qu'il n'y avait pas de clusters disponibles pour la remédiation, ou parce que la remédiation de la politique a pris trop de temps pour l'une des raisons suivantes :
- Le lot actuel contient des mises à jour canaris et le cluster dans le lot ne respecte pas toutes les politiques gérées dans le délai d'expiration du lot.
-
Les clusters n'ont pas respecté les politiques gérées dans la limite de la valeur
timeoutspécifiée dans le champremediationStrategy.
Exemple ClusterGroupUpgrade CR dans l'état Succeeded
apiVersion: ran.openshift.io/v1alpha1
kind: ClusterGroupUpgrade
metadata:
name: cgu-upgrade-complete
namespace: default
spec:
clusters:
- spoke1
- spoke4
enable: true
managedPolicies:
- policy1-common-cluster-version-policy
- policy2-common-pao-sub-policy
remediationStrategy:
maxConcurrency: 1
timeout: 240
status: 1
clusters:
- name: spoke1
state: complete
- name: spoke4
state: complete
conditions:
- message: All selected clusters are valid
reason: ClusterSelectionCompleted
status: "True"
type: ClustersSelected
- message: Completed validation
reason: ValidationCompleted
status: "True"
type: Validated
- message: All clusters are compliant with all the managed policies
reason: Completed
status: "False"
type: Progressing 2
- message: All clusters are compliant with all the managed policies
reason: Completed
status: "True"
type: Succeeded 3
managedPoliciesForUpgrade:
- name: policy1-common-cluster-version-policy
namespace: default
- name: policy2-common-pao-sub-policy
namespace: default
remediationPlan:
- - spoke1
- - spoke4
status:
completedAt: '2022-11-18T16:27:16Z'
startedAt: '2022-11-18T16:27:15Z'
- 2
- Dans les champs
Progressing, l'état estfalsecar la mise à jour est terminée ; les clusters sont conformes à toutes les politiques gérées. - 3
- Les champs
Succeededindiquent que les validations se sont déroulées avec succès. - 1
- Le champ
statuscomprend une liste de clusters et leurs statuts respectifs. Le statut d'un groupe peut êtrecompleteoutimedout.
Exemple ClusterGroupUpgrade CR dans l'état timedout
apiVersion: ran.openshift.io/v1alpha1
kind: ClusterGroupUpgrade
metadata:
creationTimestamp: '2022-11-18T16:27:15Z'
finalizers:
- ran.openshift.io/cleanup-finalizer
generation: 1
name: talm-cgu
namespace: talm-namespace
resourceVersion: '40451823'
uid: cca245a5-4bca-45fa-89c0-aa6af81a596c
spec:
actions:
afterCompletion:
deleteObjects: true
beforeEnable: {}
backup: false
clusters:
- spoke1
- spoke2
enable: true
managedPolicies:
- talm-policy
preCaching: false
remediationStrategy:
maxConcurrency: 2
timeout: 240
status:
clusters:
- name: spoke1
state: complete
- currentPolicy: 1
name: talm-policy
status: NonCompliant
name: spoke2
state: timedout
computedMaxConcurrency: 2
conditions:
- lastTransitionTime: '2022-11-18T16:27:15Z'
message: All selected clusters are valid
reason: ClusterSelectionCompleted
status: 'True'
type: ClustersSelected
- lastTransitionTime: '2022-11-18T16:27:15Z'
message: Completed validation
reason: ValidationCompleted
status: 'True'
type: Validated
- lastTransitionTime: '2022-11-18T16:37:16Z'
message: Policy remediation took too long
reason: TimedOut
status: 'False'
type: Progressing
- lastTransitionTime: '2022-11-18T16:37:16Z'
message: Policy remediation took too long
reason: TimedOut
status: 'False'
type: Succeeded 2
managedPoliciesForUpgrade:
- name: talm-policy
namespace: talm-namespace
managedPoliciesNs:
talm-policy: talm-namespace
remediationPlan:
- - spoke1
- spoke2
status:
startedAt: '2022-11-18T16:27:15Z'
completedAt: '2022-11-18T20:27:15Z'
17.5.7. Blocage des CR de ClusterGroupUpgrade
Vous pouvez créer plusieurs CR ClusterGroupUpgrade et contrôler leur ordre d'application.
Par exemple, si vous créez ClusterGroupUpgrade CR C qui bloque le démarrage de ClusterGroupUpgrade CR A, ClusterGroupUpgrade CR A ne peut pas démarrer tant que le statut de ClusterGroupUpgrade CR C ne devient pas UpgradeComplete.
Un CR ClusterGroupUpgrade peut avoir plusieurs CR bloquants. Dans ce cas, tous les CR bloquants doivent être terminés avant que la mise à niveau du CR actuel puisse commencer.
Conditions préalables
- Installez le gestionnaire de cycle de vie Topology Aware (TALM).
- Provisionner un ou plusieurs clusters gérés.
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Créer des stratégies RHACM dans le cluster hub.
Procédure
Enregistrez le contenu des CR
ClusterGroupUpgradedans les fichierscgu-a.yaml,cgu-b.yamletcgu-c.yaml.apiVersion: ran.openshift.io/v1alpha1 kind: ClusterGroupUpgrade metadata: name: cgu-a namespace: default spec: blockingCRs: 1 - name: cgu-c namespace: default clusters: - spoke1 - spoke2 - spoke3 enable: false managedPolicies: - policy1-common-cluster-version-policy - policy2-common-pao-sub-policy - policy3-common-ptp-sub-policy remediationStrategy: canaries: - spoke1 maxConcurrency: 2 timeout: 240 status: conditions: - message: The ClusterGroupUpgrade CR is not enabled reason: UpgradeNotStarted status: "False" type: Ready copiedPolicies: - cgu-a-policy1-common-cluster-version-policy - cgu-a-policy2-common-pao-sub-policy - cgu-a-policy3-common-ptp-sub-policy managedPoliciesForUpgrade: - name: policy1-common-cluster-version-policy namespace: default - name: policy2-common-pao-sub-policy namespace: default - name: policy3-common-ptp-sub-policy namespace: default placementBindings: - cgu-a-policy1-common-cluster-version-policy - cgu-a-policy2-common-pao-sub-policy - cgu-a-policy3-common-ptp-sub-policy placementRules: - cgu-a-policy1-common-cluster-version-policy - cgu-a-policy2-common-pao-sub-policy - cgu-a-policy3-common-ptp-sub-policy remediationPlan: - - spoke1 - - spoke2- 1
- Définit les CR de blocage. La mise à jour de
cgu-ane peut pas commencer tant quecgu-cn'est pas terminé.
apiVersion: ran.openshift.io/v1alpha1 kind: ClusterGroupUpgrade metadata: name: cgu-b namespace: default spec: blockingCRs: 1 - name: cgu-a namespace: default clusters: - spoke4 - spoke5 enable: false managedPolicies: - policy1-common-cluster-version-policy - policy2-common-pao-sub-policy - policy3-common-ptp-sub-policy - policy4-common-sriov-sub-policy remediationStrategy: maxConcurrency: 1 timeout: 240 status: conditions: - message: The ClusterGroupUpgrade CR is not enabled reason: UpgradeNotStarted status: "False" type: Ready copiedPolicies: - cgu-b-policy1-common-cluster-version-policy - cgu-b-policy2-common-pao-sub-policy - cgu-b-policy3-common-ptp-sub-policy - cgu-b-policy4-common-sriov-sub-policy managedPoliciesForUpgrade: - name: policy1-common-cluster-version-policy namespace: default - name: policy2-common-pao-sub-policy namespace: default - name: policy3-common-ptp-sub-policy namespace: default - name: policy4-common-sriov-sub-policy namespace: default placementBindings: - cgu-b-policy1-common-cluster-version-policy - cgu-b-policy2-common-pao-sub-policy - cgu-b-policy3-common-ptp-sub-policy - cgu-b-policy4-common-sriov-sub-policy placementRules: - cgu-b-policy1-common-cluster-version-policy - cgu-b-policy2-common-pao-sub-policy - cgu-b-policy3-common-ptp-sub-policy - cgu-b-policy4-common-sriov-sub-policy remediationPlan: - - spoke4 - - spoke5 status: {}- 1
- La mise à jour de
cgu-bne peut pas commencer tant quecgu-an'est pas terminée.
apiVersion: ran.openshift.io/v1alpha1 kind: ClusterGroupUpgrade metadata: name: cgu-c namespace: default spec: 1 clusters: - spoke6 enable: false managedPolicies: - policy1-common-cluster-version-policy - policy2-common-pao-sub-policy - policy3-common-ptp-sub-policy - policy4-common-sriov-sub-policy remediationStrategy: maxConcurrency: 1 timeout: 240 status: conditions: - message: The ClusterGroupUpgrade CR is not enabled reason: UpgradeNotStarted status: "False" type: Ready copiedPolicies: - cgu-c-policy1-common-cluster-version-policy - cgu-c-policy4-common-sriov-sub-policy managedPoliciesCompliantBeforeUpgrade: - policy2-common-pao-sub-policy - policy3-common-ptp-sub-policy managedPoliciesForUpgrade: - name: policy1-common-cluster-version-policy namespace: default - name: policy4-common-sriov-sub-policy namespace: default placementBindings: - cgu-c-policy1-common-cluster-version-policy - cgu-c-policy4-common-sriov-sub-policy placementRules: - cgu-c-policy1-common-cluster-version-policy - cgu-c-policy4-common-sriov-sub-policy remediationPlan: - - spoke6 status: {}- 1
- La mise à jour
cgu-cne comporte pas de CR bloquante. Le TALM lance la mise à jourcgu-clorsque le champenableest défini surtrue.
Créez les CR
ClusterGroupUpgradeen exécutant la commande suivante pour chaque CR concerné :$ oc apply -f <name>.yaml
Lancez le processus de mise à jour en exécutant la commande suivante pour chaque CR concerné :
$ oc --namespace=default patch clustergroupupgrade.ran.openshift.io/<name> \ --type merge -p '{"spec":{"enable":true}}'Les exemples suivants montrent des CR
ClusterGroupUpgradeoù le champenableest remplacé partrue:Exemple pour
cgu-aavec des CR bloquantsapiVersion: ran.openshift.io/v1alpha1 kind: ClusterGroupUpgrade metadata: name: cgu-a namespace: default spec: blockingCRs: - name: cgu-c namespace: default clusters: - spoke1 - spoke2 - spoke3 enable: true managedPolicies: - policy1-common-cluster-version-policy - policy2-common-pao-sub-policy - policy3-common-ptp-sub-policy remediationStrategy: canaries: - spoke1 maxConcurrency: 2 timeout: 240 status: conditions: - message: 'The ClusterGroupUpgrade CR is blocked by other CRs that have not yet completed: [cgu-c]' 1 reason: UpgradeCannotStart status: "False" type: Ready copiedPolicies: - cgu-a-policy1-common-cluster-version-policy - cgu-a-policy2-common-pao-sub-policy - cgu-a-policy3-common-ptp-sub-policy managedPoliciesForUpgrade: - name: policy1-common-cluster-version-policy namespace: default - name: policy2-common-pao-sub-policy namespace: default - name: policy3-common-ptp-sub-policy namespace: default placementBindings: - cgu-a-policy1-common-cluster-version-policy - cgu-a-policy2-common-pao-sub-policy - cgu-a-policy3-common-ptp-sub-policy placementRules: - cgu-a-policy1-common-cluster-version-policy - cgu-a-policy2-common-pao-sub-policy - cgu-a-policy3-common-ptp-sub-policy remediationPlan: - - spoke1 - - spoke2 status: {}- 1
- Affiche la liste des CR bloquants.
Exemple pour
cgu-bavec des CR bloquantsapiVersion: ran.openshift.io/v1alpha1 kind: ClusterGroupUpgrade metadata: name: cgu-b namespace: default spec: blockingCRs: - name: cgu-a namespace: default clusters: - spoke4 - spoke5 enable: true managedPolicies: - policy1-common-cluster-version-policy - policy2-common-pao-sub-policy - policy3-common-ptp-sub-policy - policy4-common-sriov-sub-policy remediationStrategy: maxConcurrency: 1 timeout: 240 status: conditions: - message: 'The ClusterGroupUpgrade CR is blocked by other CRs that have not yet completed: [cgu-a]' 1 reason: UpgradeCannotStart status: "False" type: Ready copiedPolicies: - cgu-b-policy1-common-cluster-version-policy - cgu-b-policy2-common-pao-sub-policy - cgu-b-policy3-common-ptp-sub-policy - cgu-b-policy4-common-sriov-sub-policy managedPoliciesForUpgrade: - name: policy1-common-cluster-version-policy namespace: default - name: policy2-common-pao-sub-policy namespace: default - name: policy3-common-ptp-sub-policy namespace: default - name: policy4-common-sriov-sub-policy namespace: default placementBindings: - cgu-b-policy1-common-cluster-version-policy - cgu-b-policy2-common-pao-sub-policy - cgu-b-policy3-common-ptp-sub-policy - cgu-b-policy4-common-sriov-sub-policy placementRules: - cgu-b-policy1-common-cluster-version-policy - cgu-b-policy2-common-pao-sub-policy - cgu-b-policy3-common-ptp-sub-policy - cgu-b-policy4-common-sriov-sub-policy remediationPlan: - - spoke4 - - spoke5 status: {}- 1
- Affiche la liste des CR bloquants.
Exemple pour
cgu-cavec des CR bloquantsapiVersion: ran.openshift.io/v1alpha1 kind: ClusterGroupUpgrade metadata: name: cgu-c namespace: default spec: clusters: - spoke6 enable: true managedPolicies: - policy1-common-cluster-version-policy - policy2-common-pao-sub-policy - policy3-common-ptp-sub-policy - policy4-common-sriov-sub-policy remediationStrategy: maxConcurrency: 1 timeout: 240 status: conditions: - message: The ClusterGroupUpgrade CR has upgrade policies that are still non compliant 1 reason: UpgradeNotCompleted status: "False" type: Ready copiedPolicies: - cgu-c-policy1-common-cluster-version-policy - cgu-c-policy4-common-sriov-sub-policy managedPoliciesCompliantBeforeUpgrade: - policy2-common-pao-sub-policy - policy3-common-ptp-sub-policy managedPoliciesForUpgrade: - name: policy1-common-cluster-version-policy namespace: default - name: policy4-common-sriov-sub-policy namespace: default placementBindings: - cgu-c-policy1-common-cluster-version-policy - cgu-c-policy4-common-sriov-sub-policy placementRules: - cgu-c-policy1-common-cluster-version-policy - cgu-c-policy4-common-sriov-sub-policy remediationPlan: - - spoke6 status: currentBatch: 1 remediationPlanForBatch: spoke6: 0- 1
- La mise à jour du site
cgu-cne comporte pas de CR bloquants.
17.6. Mise à jour des politiques sur les clusters gérés
Le Topology Aware Lifecycle Manager (TALM) remédie à un ensemble de politiques inform pour les clusters spécifiés dans le CR ClusterGroupUpgrade. Le TALM remédie aux politiques inform en faisant des copies enforce des politiques RHACM gérées. Chaque politique copiée possède sa propre règle de placement RHACM et son propre lien de placement RHACM.
Un par un, TALM ajoute chaque cluster du lot actuel à la règle de placement qui correspond à la politique gérée applicable. Si un cluster est déjà conforme à une politique, le TALM passe à l'application de cette politique sur le cluster conforme. TALM passe ensuite à l'application de la politique suivante au cluster non conforme. Une fois que TALM a terminé les mises à jour d'un lot, tous les clusters sont supprimés des règles de placement associées aux politiques copiées. La mise à jour du lot suivant commence alors.
Si un cluster spoke ne signale aucun état de conformité à RHACM, les politiques gérées sur le cluster hub peuvent manquer d'informations d'état dont le TALM a besoin. TALM gère ces cas de la manière suivante :
-
Si le champ
status.compliantd'une politique est manquant, TALM ignore la politique et ajoute une entrée de journal. Ensuite, TALM continue à regarder le champstatus.statusde la politique. -
Si le site
status.statusd'une police est manquant, TALM produit une erreur. -
Si le statut de conformité d'un cluster n'est pas indiqué dans le champ
status.statusde la politique, TALM considère que ce cluster n'est pas conforme à cette politique.
La valeur batchTimeoutAction de la CR ClusterGroupUpgrade détermine ce qui se passe en cas d'échec de la mise à niveau d'un cluster. Vous pouvez spécifier continue pour ignorer le cluster défaillant et continuer à mettre à niveau les autres clusters, ou spécifier abort pour arrêter la remédiation de la politique pour tous les clusters. Une fois le délai écoulé, TALM supprime toutes les politiques d'application pour s'assurer qu'aucune autre mise à jour n'est effectuée sur les clusters.
Pour plus d'informations sur les politiques du RHACM, voir Aperçu des politiques.
Ressources supplémentaires
Pour plus d'informations sur le CRD PolicyGenTemplate, voir À propos du CRD PolicyGenTemplate.
17.6.1. Appliquer des stratégies de mise à jour aux clusters gérés
Vous pouvez mettre à jour vos clusters gérés en appliquant vos politiques.
Conditions préalables
- Installez le gestionnaire de cycle de vie Topology Aware (TALM).
- Provisionner un ou plusieurs clusters gérés.
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Créer des stratégies RHACM dans le cluster hub.
Procédure
Enregistrez le contenu du CR
ClusterGroupUpgradedans le fichiercgu-1.yaml.apiVersion: ran.openshift.io/v1alpha1 kind: ClusterGroupUpgrade metadata: name: cgu-1 namespace: default spec: managedPolicies: 1 - policy1-common-cluster-version-policy - policy2-common-nto-sub-policy - policy3-common-ptp-sub-policy - policy4-common-sriov-sub-policy enable: false clusters: 2 - spoke1 - spoke2 - spoke5 - spoke6 remediationStrategy: maxConcurrency: 2 3 timeout: 240 4 batchTimeoutAction: 5
- 1
- Le nom des politiques à appliquer.
- 2
- La liste des clusters à mettre à jour.
- 3
- Le champ
maxConcurrencyindique le nombre de grappes mises à jour en même temps. - 4
- Le délai de mise à jour en minutes.
- 5
- Contrôle ce qui se passe en cas de dépassement du délai d'exécution d'un lot. Les valeurs possibles sont
abortoucontinue. Si aucune valeur n'est spécifiée, la valeur par défaut estcontinue.
Créez le CR
ClusterGroupUpgradeen exécutant la commande suivante :$ oc create -f cgu-1.yaml
Vérifiez que le CR
ClusterGroupUpgradea été créé dans le cluster hub en exécutant la commande suivante :$ oc get cgu --all-namespaces
Exemple de sortie
NAMESPACE NAME AGE STATE DETAILS default cgu-1 8m55 NotEnabled Not Enabled
Vérifiez l'état de la mise à jour en exécutant la commande suivante :
$ oc get cgu -n default cgu-1 -ojsonpath='{.status}' | jqExemple de sortie
{ "computedMaxConcurrency": 2, "conditions": [ { "lastTransitionTime": "2022-02-25T15:34:07Z", "message": "Not enabled", 1 "reason": "NotEnabled", "status": "False", "type": "Progressing" } ], "copiedPolicies": [ "cgu-policy1-common-cluster-version-policy", "cgu-policy2-common-nto-sub-policy", "cgu-policy3-common-ptp-sub-policy", "cgu-policy4-common-sriov-sub-policy" ], "managedPoliciesContent": { "policy1-common-cluster-version-policy": "null", "policy2-common-nto-sub-policy": "[{\"kind\":\"Subscription\",\"name\":\"node-tuning-operator\",\"namespace\":\"openshift-cluster-node-tuning-operator\"}]", "policy3-common-ptp-sub-policy": "[{\"kind\":\"Subscription\",\"name\":\"ptp-operator-subscription\",\"namespace\":\"openshift-ptp\"}]", "policy4-common-sriov-sub-policy": "[{\"kind\":\"Subscription\",\"name\":\"sriov-network-operator-subscription\",\"namespace\":\"openshift-sriov-network-operator\"}]" }, "managedPoliciesForUpgrade": [ { "name": "policy1-common-cluster-version-policy", "namespace": "default" }, { "name": "policy2-common-nto-sub-policy", "namespace": "default" }, { "name": "policy3-common-ptp-sub-policy", "namespace": "default" }, { "name": "policy4-common-sriov-sub-policy", "namespace": "default" } ], "managedPoliciesNs": { "policy1-common-cluster-version-policy": "default", "policy2-common-nto-sub-policy": "default", "policy3-common-ptp-sub-policy": "default", "policy4-common-sriov-sub-policy": "default" }, "placementBindings": [ "cgu-policy1-common-cluster-version-policy", "cgu-policy2-common-nto-sub-policy", "cgu-policy3-common-ptp-sub-policy", "cgu-policy4-common-sriov-sub-policy" ], "placementRules": [ "cgu-policy1-common-cluster-version-policy", "cgu-policy2-common-nto-sub-policy", "cgu-policy3-common-ptp-sub-policy", "cgu-policy4-common-sriov-sub-policy" ], "precaching": { "spec": {} }, "remediationPlan": [ [ "spoke1", "spoke2" ], [ "spoke5", "spoke6" ] ], "status": {} }- 1
- Le champ
spec.enabledans le CRClusterGroupUpgradeest mis àfalse.
Vérifiez l'état des politiques en exécutant la commande suivante :
$ oc get policies -A
Exemple de sortie
NAMESPACE NAME REMEDIATION ACTION COMPLIANCE STATE AGE default cgu-policy1-common-cluster-version-policy enforce 17m 1 default cgu-policy2-common-nto-sub-policy enforce 17m default cgu-policy3-common-ptp-sub-policy enforce 17m default cgu-policy4-common-sriov-sub-policy enforce 17m default policy1-common-cluster-version-policy inform NonCompliant 15h default policy2-common-nto-sub-policy inform NonCompliant 15h default policy3-common-ptp-sub-policy inform NonCompliant 18m default policy4-common-sriov-sub-policy inform NonCompliant 18m- 1
- Le champ
spec.remediationActiondes politiques actuellement appliquées aux clusters est défini surenforce. Les politiques gérées en modeinformà partir de la CRClusterGroupUpgraderestent en modeinformpendant la mise à jour.
Remplacez la valeur du champ
spec.enablepartrueen exécutant la commande suivante :$ oc --namespace=default patch clustergroupupgrade.ran.openshift.io/cgu-1 \ --patch '{"spec":{"enable":true}}' --type=merge
Vérification
Vérifiez à nouveau l'état de la mise à jour en exécutant la commande suivante :
$ oc get cgu -n default cgu-1 -ojsonpath='{.status}' | jqExemple de sortie
{ "computedMaxConcurrency": 2, "conditions": [ 1 { "lastTransitionTime": "2022-02-25T15:33:07Z", "message": "All selected clusters are valid", "reason": "ClusterSelectionCompleted", "status": "True", "type": "ClustersSelected", "lastTransitionTime": "2022-02-25T15:33:07Z", "message": "Completed validation", "reason": "ValidationCompleted", "status": "True", "type": "Validated", "lastTransitionTime": "2022-02-25T15:34:07Z", "message": "Remediating non-compliant policies", "reason": "InProgress", "status": "True", "type": "Progressing" } ], "copiedPolicies": [ "cgu-policy1-common-cluster-version-policy", "cgu-policy2-common-nto-sub-policy", "cgu-policy3-common-ptp-sub-policy", "cgu-policy4-common-sriov-sub-policy" ], "managedPoliciesContent": { "policy1-common-cluster-version-policy": "null", "policy2-common-nto-sub-policy": "[{\"kind\":\"Subscription\",\"name\":\"node-tuning-operator\",\"namespace\":\"openshift-cluster-node-tuning-operator\"}]", "policy3-common-ptp-sub-policy": "[{\"kind\":\"Subscription\",\"name\":\"ptp-operator-subscription\",\"namespace\":\"openshift-ptp\"}]", "policy4-common-sriov-sub-policy": "[{\"kind\":\"Subscription\",\"name\":\"sriov-network-operator-subscription\",\"namespace\":\"openshift-sriov-network-operator\"}]" }, "managedPoliciesForUpgrade": [ { "name": "policy1-common-cluster-version-policy", "namespace": "default" }, { "name": "policy2-common-nto-sub-policy", "namespace": "default" }, { "name": "policy3-common-ptp-sub-policy", "namespace": "default" }, { "name": "policy4-common-sriov-sub-policy", "namespace": "default" } ], "managedPoliciesNs": { "policy1-common-cluster-version-policy": "default", "policy2-common-nto-sub-policy": "default", "policy3-common-ptp-sub-policy": "default", "policy4-common-sriov-sub-policy": "default" }, "placementBindings": [ "cgu-policy1-common-cluster-version-policy", "cgu-policy2-common-nto-sub-policy", "cgu-policy3-common-ptp-sub-policy", "cgu-policy4-common-sriov-sub-policy" ], "placementRules": [ "cgu-policy1-common-cluster-version-policy", "cgu-policy2-common-nto-sub-policy", "cgu-policy3-common-ptp-sub-policy", "cgu-policy4-common-sriov-sub-policy" ], "precaching": { "spec": {} }, "remediationPlan": [ [ "spoke1", "spoke2" ], [ "spoke5", "spoke6" ] ], "status": { "currentBatch": 1, "currentBatchStartedAt": "2022-02-25T15:54:16Z", "remediationPlanForBatch": { "spoke1": 0, "spoke2": 1 }, "startedAt": "2022-02-25T15:54:16Z" } }- 1
- Reflète l'état d'avancement de la mise à jour du lot en cours. Exécutez à nouveau cette commande pour recevoir des informations actualisées sur l'état d'avancement.
Si les politiques incluent des abonnements d'opérateurs, vous pouvez vérifier la progression de l'installation directement sur le cluster à nœud unique.
Exportez le fichier
KUBECONFIGdu cluster à nœud unique dont vous souhaitez vérifier la progression de l'installation en exécutant la commande suivante :export KUBECONFIG=<cluster_kubeconfig_absolute_path>
Vérifiez tous les abonnements présents sur le cluster à nœud unique et recherchez celui de la politique que vous essayez d'installer via le CR
ClusterGroupUpgradeen exécutant la commande suivante :oc get subs -A | grep -i <nom_de_l'abonnement>
Exemple de résultat pour la politique
cluster-loggingNAMESPACE NAME PACKAGE SOURCE CHANNEL openshift-logging cluster-logging cluster-logging redhat-operators stable
Si l'une des stratégies gérées inclut une CR
ClusterVersion, vérifiez l'état des mises à jour de la plate-forme dans le lot actuel en exécutant la commande suivante sur le cluster de rayons :$ oc get clusterversion
Exemple de sortie
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.9.5 True True 43s Working towards 4.9.7: 71 of 735 done (9% complete)
Vérifiez l'abonnement de l'opérateur en exécutant la commande suivante :
$ oc get subs -n <operator-namespace> <operator-subscription> -ojsonpath="{.status}"Vérifiez les plans d'installation présents sur le cluster à nœud unique associé à l'abonnement souhaité en exécutant la commande suivante :
oc get installplan -n <subscription_namespace>
Exemple de sortie pour
cluster-loggingOperatorNAMESPACE NAME CSV APPROVAL APPROVED openshift-logging install-6khtw cluster-logging.5.3.3-4 Manual true 1- 1
- Le champ
Approvaldes plans d'installation est défini surManualet le champApprovedpasse defalseàtrueaprès l'approbation du plan d'installation par TALM.
NoteLorsque TALM remédie à une politique contenant un abonnement, il approuve automatiquement tous les plans d'installation liés à cet abonnement. Lorsque plusieurs plans d'installation sont nécessaires pour amener l'opérateur à la dernière version connue, le TALM peut approuver plusieurs plans d'installation, en passant par une ou plusieurs versions intermédiaires pour arriver à la version finale.
Vérifiez si la version du service de cluster pour l'opérateur de la politique que
ClusterGroupUpgradeinstalle a atteint la phaseSucceededen exécutant la commande suivante :oc get csv -n <operator_namespace>
Exemple de sortie pour OpenShift Logging Operator
NAME DISPLAY VERSION REPLACES PHASE cluster-logging.5.4.2 Red Hat OpenShift Logging 5.4.2 Succeeded
17.7. Création d'une sauvegarde des ressources du cluster avant la mise à niveau
Pour OpenShift à nœud unique, le Topology Aware Lifecycle Manager (TALM) peut créer une sauvegarde d'un déploiement avant une mise à niveau. Si la mise à niveau échoue, vous pouvez récupérer la version précédente et restaurer un cluster à un état fonctionnel sans nécessiter un reprovisionnement des applications.
Pour utiliser la fonction de sauvegarde, vous devez d'abord créer un CR ClusterGroupUpgrade avec le champ backup défini sur true. Pour garantir que le contenu de la sauvegarde est à jour, la sauvegarde n'est pas effectuée tant que vous n'avez pas défini le champ enable dans le CR ClusterGroupUpgrade sur true.
TALM utilise la condition BackupSucceeded pour signaler l'état et les raisons comme suit :
trueLa sauvegarde est terminée pour tous les clusters ou l'exécution de la sauvegarde s'est terminée mais a échoué pour un ou plusieurs clusters. Si la sauvegarde échoue pour un cluster, la mise à jour ne se fait pas pour ce cluster.
falseLa sauvegarde est toujours en cours pour un ou plusieurs clusters ou a échoué pour tous les clusters. Le processus de sauvegarde s'exécutant dans les clusters de rayons peut avoir les statuts suivants :
PreparingToStartLa première passe de réconciliation est en cours. Le TALM supprime toutes les ressources d'espace de noms de sauvegarde de rayon et de vue de hub qui ont été créées lors d'une tentative de mise à niveau qui a échoué.
StartingLes conditions préalables à la sauvegarde et la tâche de sauvegarde sont en cours de création.
ActiveLa sauvegarde est en cours.
SucceededLa sauvegarde a réussi.
BackupTimeoutLa sauvegarde des artefacts est partiellement effectuée.
UnrecoverableErrorLa sauvegarde s'est terminée avec un code de sortie non nul.
Si la sauvegarde d'un cluster échoue et entre dans l'état BackupTimeout ou UnrecoverableError, la mise à jour du cluster ne se fait pas pour ce cluster. Les mises à jour des autres clusters ne sont pas affectées et se poursuivent.
17.7.1. Création d'un ClusterGroupUpgrade CR avec sauvegarde
Vous pouvez créer une sauvegarde d'un déploiement avant une mise à niveau sur des clusters OpenShift à nœud unique. Si la mise à niveau échoue, vous pouvez utiliser le script upgrade-recovery.sh généré par Topology Aware Lifecycle Manager (TALM) pour ramener le système à son état avant la mise à niveau. La sauvegarde se compose des éléments suivants :
- Sauvegarde de la grappe
-
Un instantané de
etcdet des manifestes de pods statiques. - Sauvegarde du contenu
-
Sauvegardes de dossiers, par exemple,
/etc,/usr/local,/var/lib/kubelet. - Sauvegarde des fichiers modifiés
-
Tous les fichiers gérés par
machine-configqui ont été modifiés. - Déploiement
-
Déploiement d'une épingle
ostree. - Images (optionnel)
- Toutes les images de conteneurs utilisées.
Conditions préalables
- Installez le gestionnaire de cycle de vie Topology Aware (TALM).
- Provisionner un ou plusieurs clusters gérés.
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Installez Red Hat Advanced Cluster Management (RHACM).
Il est fortement recommandé de créer une partition de récupération. Voici un exemple de ressource personnalisée (CR) SiteConfig pour une partition de récupération de 50 Go :
nodes:
- hostName: "snonode.sno-worker-0.e2e.bos.redhat.com"
role: "master"
rootDeviceHints:
hctl: "0:2:0:0"
deviceName: /dev/sda
........
........
#Disk /dev/sda: 893.3 GiB, 959119884288 bytes, 1873281024 sectors
diskPartition:
- device: /dev/sda
partitions:
- mount_point: /var/recovery
size: 51200
start: 800000Procédure
Enregistrez le contenu du CR
ClusterGroupUpgradeavec les champsbackupetenabledéfinis surtruedans le fichierclustergroupupgrades-group-du.yaml:apiVersion: ran.openshift.io/v1alpha1 kind: ClusterGroupUpgrade metadata: name: du-upgrade-4918 namespace: ztp-group-du-sno spec: preCaching: true backup: true clusters: - cnfdb1 - cnfdb2 enable: true managedPolicies: - du-upgrade-platform-upgrade remediationStrategy: maxConcurrency: 2 timeout: 240Pour lancer la mise à jour, appliquez le CR
ClusterGroupUpgradeen exécutant la commande suivante :$ oc apply -f clustergroupupgrades-group-du.yaml
Vérification
Vérifiez l'état de la mise à niveau dans le cluster du concentrateur en exécutant la commande suivante :
$ oc get cgu -n ztp-group-du-sno du-upgrade-4918 -o jsonpath='{.status}'Exemple de sortie
{ "backup": { "clusters": [ "cnfdb2", "cnfdb1" ], "status": { "cnfdb1": "Succeeded", "cnfdb2": "Failed" 1 } }, "computedMaxConcurrency": 1, "conditions": [ { "lastTransitionTime": "2022-04-05T10:37:19Z", "message": "Backup failed for 1 cluster", 2 "reason": "PartiallyDone", 3 "status": "True", 4 "type": "Succeeded" } ], "precaching": { "spec": {} }, "status": {}
17.7.2. Récupération d'un cluster après l'échec d'une mise à niveau
Si la mise à niveau d'un cluster échoue, vous pouvez vous connecter manuellement au cluster et utiliser la sauvegarde pour remettre le cluster dans l'état où il se trouvait avant la mise à niveau. Il y a deux étapes :
- Retour en arrière
- Si la tentative de mise à niveau comprenait une modification du déploiement du système d'exploitation de la plate-forme, vous devez revenir à la version précédente avant d'exécuter le script de récupération.
- Récupération
- La récupération arrête les conteneurs et utilise les fichiers de la partition de sauvegarde pour relancer les conteneurs et restaurer les clusters.
Conditions préalables
- Installez le gestionnaire de cycle de vie Topology Aware (TALM).
- Provisionner un ou plusieurs clusters gérés.
- Installez Red Hat Advanced Cluster Management (RHACM).
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Exécuter une mise à niveau configurée pour la sauvegarde.
Procédure
Supprimez la ressource personnalisée (CR)
ClusterGroupUpgradecréée précédemment en exécutant la commande suivante :$ oc delete cgu/du-upgrade-4918 -n ztp-group-du-sno
- Connectez-vous au cluster que vous souhaitez récupérer.
Vérifiez l'état du déploiement du système d'exploitation de la plate-forme en exécutant la commande suivante :
$ ostree admin status
Exemples de résultats
[root@lab-test-spoke2-node-0 core]# ostree admin status * rhcos c038a8f08458bbed83a77ece033ad3c55597e3f64edad66ea12fda18cbdceaf9.0 Version: 49.84.202202230006-0 Pinned: yes 1 origin refspec: c038a8f08458bbed83a77ece033ad3c55597e3f64edad66ea12fda18cbdceaf9- 1
- Le déploiement actuel est verrouillé. Il n'est pas nécessaire de revenir sur le déploiement du système d'exploitation de la plate-forme.
[root@lab-test-spoke2-node-0 core]# ostree admin status * rhcos f750ff26f2d5550930ccbe17af61af47daafc8018cd9944f2a3a6269af26b0fa.0 Version: 410.84.202204050541-0 origin refspec: f750ff26f2d5550930ccbe17af61af47daafc8018cd9944f2a3a6269af26b0fa rhcos ad8f159f9dc4ea7e773fd9604c9a16be0fe9b266ae800ac8470f63abc39b52ca.0 (rollback) 1 Version: 410.84.202203290245-0 Pinned: yes 2 origin refspec: ad8f159f9dc4ea7e773fd9604c9a16be0fe9b266ae800ac8470f63abc39b52caPour déclencher un rollback du déploiement du système d'exploitation de la plate-forme, exécutez la commande suivante :
$ rpm-ostree rollback -r
La première phase de la récupération arrête les conteneurs et restaure les fichiers de la partition de sauvegarde dans les répertoires ciblés. Pour commencer la récupération, exécutez la commande suivante :
$ /var/recovery/upgrade-recovery.sh
Lorsque vous y êtes invité, redémarrez le cluster en exécutant la commande suivante :
$ systemctl reboot
Après le redémarrage, relancez la récupération en exécutant la commande suivante :
$ /var/recovery/upgrade-recovery.sh --resume
Si l'utilitaire de récupération échoue, vous pouvez réessayer avec l'option --restart:
$ /var/recovery/upgrade-recovery.sh --restart
Vérification
Pour vérifier l'état de la récupération, exécutez la commande suivante :
$ oc get clusterversion,nodes,clusteroperator
Exemple de sortie
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS clusterversion.config.openshift.io/version 4.9.23 True False 86d Cluster version is 4.9.23 1 NAME STATUS ROLES AGE VERSION node/lab-test-spoke1-node-0 Ready master,worker 86d v1.22.3+b93fd35 2 NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE clusteroperator.config.openshift.io/authentication 4.9.23 True False False 2d7h 3 clusteroperator.config.openshift.io/baremetal 4.9.23 True False False 86d ..............
17.8. Utilisation de la fonction de pré-cache de l'image du conteneur
Les clusters OpenShift à un seul nœud peuvent avoir une bande passante limitée pour accéder au registre des images de conteneurs, ce qui peut entraîner un dépassement de délai avant que les mises à jour ne soient terminées.
L'heure de la mise à jour n'est pas fixée par TALM. Vous pouvez appliquer le CR ClusterGroupUpgrade au début de la mise à jour par application manuelle ou par automatisation externe.
La mise en cache préalable de l'image du conteneur commence lorsque le champ preCaching est défini sur true dans le CR ClusterGroupUpgrade.
TALM utilise la condition PrecacheSpecValid pour signaler les informations d'état comme suit :
trueLa spécification relative à la mise en cache préalable est valide et cohérente.
falseLa spécification relative à la mise en cache préalable est incomplète.
TALM utilise la condition PrecachingSucceeded pour signaler les informations d'état comme suit :
trueTALM a terminé le processus de pré-mise en cache. Si le pré-caching échoue pour un cluster, la mise à jour échoue pour ce cluster mais se poursuit pour tous les autres clusters. Un message vous informe de l'échec de la mise en cache pour l'un des clusters.
falseLa mise en cache est toujours en cours pour un ou plusieurs clusters ou a échoué pour tous les clusters.
Une fois que le processus de mise en cache préalable a réussi, vous pouvez commencer à remédier aux politiques. Les actions de remédiation commencent lorsque le champ enable est défini sur true. En cas d'échec de la mise en cache préalable sur un cluster, la mise à niveau échoue pour ce cluster. Le processus de mise à niveau se poursuit pour tous les autres clusters dont le pré-cache a réussi.
Le processus de pré-cache peut se trouver dans les états suivants :
NotStartedIl s'agit de l'état initial auquel tous les clusters sont automatiquement assignés lors du premier passage de réconciliation du CR
ClusterGroupUpgrade. Dans cet état, le TALM supprime tout espace de noms de pré-mise en cache et les ressources de vue du hub des clusters de rayons qui restent des mises à jour incomplètes précédentes. Le TALM crée ensuite une nouvelle ressourceManagedClusterViewpour l'espace de noms de mise en cache préalable des rayons afin de vérifier sa suppression dans l'étatPrecachePreparing.PreparingToStartLe nettoyage des ressources restantes des précédentes mises à jour incomplètes est en cours.
StartingLes conditions préalables de la tâche de mise en cache et la tâche sont créées.
ActiveL'emploi est en état "actif".
SucceededLe travail de pré-cache a réussi.
PrecacheTimeoutLa mise en cache de l'artefact est partiellement réalisée.
UnrecoverableErrorLe travail se termine avec un code de sortie non nul.
17.8.1. Création d'un ClusterGroupUpgrade CR avec mise en cache préalable
Pour OpenShift à nœud unique, la fonction de pré-cache permet aux images de conteneurs requises d'être présentes sur le cluster de rayons avant que la mise à jour ne commence.
Conditions préalables
- Installez le gestionnaire de cycle de vie Topology Aware (TALM).
- Provisionner un ou plusieurs clusters gérés.
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Enregistrez le contenu du CR
ClusterGroupUpgradeavec le champpreCachingdéfini surtruedans le fichierclustergroupupgrades-group-du.yaml:apiVersion: ran.openshift.io/v1alpha1 kind: ClusterGroupUpgrade metadata: name: du-upgrade-4918 namespace: ztp-group-du-sno spec: preCaching: true 1 clusters: - cnfdb1 - cnfdb2 enable: false managedPolicies: - du-upgrade-platform-upgrade remediationStrategy: maxConcurrency: 2 timeout: 240- 1
- Le champ
preCachingest défini surtrue, ce qui permet à TALM d'extraire les images des conteneurs avant de lancer la mise à jour.
Lorsque vous voulez commencer la mise en cache, appliquez le CR
ClusterGroupUpgradeen exécutant la commande suivante :$ oc apply -f clustergroupupgrades-group-du.yaml
Vérification
Vérifiez si le CR
ClusterGroupUpgradeexiste dans le cluster du concentrateur en exécutant la commande suivante :$ oc get cgu -A
Exemple de sortie
NAMESPACE NAME AGE STATE DETAILS ztp-group-du-sno du-upgrade-4918 10s InProgress Precaching is required and not done 1- 1
- Le CR est créé.
Vérifiez l'état de la tâche de mise en cache en exécutant la commande suivante :
$ oc get cgu -n ztp-group-du-sno du-upgrade-4918 -o jsonpath='{.status}'Exemple de sortie
{ "conditions": [ { "lastTransitionTime": "2022-01-27T19:07:24Z", "message": "Precaching is required and not done", "reason": "InProgress", "status": "False", "type": "PrecachingSucceeded" }, { "lastTransitionTime": "2022-01-27T19:07:34Z", "message": "Pre-caching spec is valid and consistent", "reason": "PrecacheSpecIsWellFormed", "status": "True", "type": "PrecacheSpecValid" } ], "precaching": { "clusters": [ "cnfdb1" 1 "cnfdb2" ], "spec": { "platformImage": "image.example.io"}, "status": { "cnfdb1": "Active" "cnfdb2": "Succeeded"} } }- 1
- Affiche la liste des clusters identifiés.
Vérifiez l'état de la tâche de mise en cache préalable en exécutant la commande suivante sur le cluster de rayons :
$ oc get jobs,pods -n openshift-talo-pre-cache
Exemple de sortie
NAME COMPLETIONS DURATION AGE job.batch/pre-cache 0/1 3m10s 3m10s NAME READY STATUS RESTARTS AGE pod/pre-cache--1-9bmlr 1/1 Running 0 3m10s
Vérifiez l'état de
ClusterGroupUpgradeCR en exécutant la commande suivante :$ oc get cgu -n ztp-group-du-sno du-upgrade-4918 -o jsonpath='{.status}'Exemple de sortie
"conditions": [ { "lastTransitionTime": "2022-01-27T19:30:41Z", "message": "The ClusterGroupUpgrade CR has all clusters compliant with all the managed policies", "reason": "UpgradeCompleted", "status": "True", "type": "Ready" }, { "lastTransitionTime": "2022-01-27T19:28:57Z", "message": "Precaching is completed", "reason": "PrecachingCompleted", "status": "True", "type": "PrecachingSucceeded" 1 }- 1
- Les tâches de pré-cache sont terminées.
17.9. Dépannage du gestionnaire de cycle de vie Topology Aware
Le Topology Aware Lifecycle Manager (TALM) est un opérateur de OpenShift Container Platform qui remédie aux politiques RHACM. Lorsque des problèmes surviennent, utilisez la commande oc adm must-gather pour recueillir des détails et des journaux et pour prendre des mesures de débogage.
Pour plus d'informations sur les sujets connexes, voir la documentation suivante :
- Matrice de prise en charge de Red Hat Advanced Cluster Management for Kubernetes 2.4
- Dépannage de Red Hat Advanced Cluster Management
- La section "Troubleshooting Operator issues" (dépannage des problèmes de l'opérateur)
17.9.1. Dépannage général
Vous pouvez déterminer la cause du problème en répondant aux questions suivantes :
La configuration que vous appliquez est-elle prise en charge ?
- Les versions du RHACM et de l'OpenShift Container Platform sont-elles compatibles ?
- Les versions du TALM et du RHACM sont-elles compatibles ?
Parmi les composants suivants, lequel est à l'origine du problème ?
Pour vous assurer que la configuration de ClusterGroupUpgrade est fonctionnelle, vous pouvez procéder comme suit :
-
Créez le CR
ClusterGroupUpgradeavec le champspec.enabledéfini surfalse. - Attendez que le statut soit mis à jour et répondez aux questions de dépannage.
-
Si tout se passe comme prévu, réglez le champ
spec.enablesurtruedans le CRClusterGroupUpgrade.
Après avoir attribué la valeur true au champ spec.enable dans la CR ClusterUpgradeGroup, la procédure de mise à jour commence et vous ne pouvez plus modifier les champs spec de la CR.
17.9.2. Impossible de modifier le CR ClusterUpgradeGroup
- Enjeu
-
Vous ne pouvez pas modifier le CR
ClusterUpgradeGroupaprès avoir activé la mise à jour. - Résolution
Relancez la procédure en procédant comme suit :
Supprimez l'ancien
ClusterGroupUpgradeCR en exécutant la commande suivante :$ oc delete cgu -n <ClusterGroupUpgradeCR_namespace> <ClusterGroupUpgradeCR_name>
Vérifier et résoudre les problèmes existants avec les clusters et les politiques gérés.
- Assurez-vous que tous les clusters sont gérés et disponibles.
-
Assurez-vous que toutes les politiques existent et que le champ
spec.remediationActionest défini surinform.
Créez un nouveau CR
ClusterGroupUpgradeavec les configurations correctes.oc apply -f <ClusterGroupUpgradeCR_YAML>
17.9.3. Politiques gérées
Vérification des politiques gérées sur le système
- Enjeu
- Vous voulez vérifier si vous avez les bonnes stratégies gérées sur le système.
- Résolution
Exécutez la commande suivante :
$ oc get cgu lab-upgrade -ojsonpath='{.spec.managedPolicies}'Exemple de sortie
["group-du-sno-validator-du-validator-policy", "policy2-common-nto-sub-policy", "policy3-common-ptp-sub-policy"]
Vérification du mode de remédiationAction
- Enjeu
-
Vous voulez vérifier si le champ
remediationActionest défini surinformdans lespecdes politiques gérées. - Résolution
Exécutez la commande suivante :
$ oc get policies --all-namespaces
Exemple de sortie
NAMESPACE NAME REMEDIATION ACTION COMPLIANCE STATE AGE default policy1-common-cluster-version-policy inform NonCompliant 5d21h default policy2-common-nto-sub-policy inform Compliant 5d21h default policy3-common-ptp-sub-policy inform NonCompliant 5d21h default policy4-common-sriov-sub-policy inform NonCompliant 5d21h
Vérification de l'état de conformité de la politique
- Enjeu
- Vous souhaitez vérifier l'état de conformité des politiques.
- Résolution
Exécutez la commande suivante :
$ oc get policies --all-namespaces
Exemple de sortie
NAMESPACE NAME REMEDIATION ACTION COMPLIANCE STATE AGE default policy1-common-cluster-version-policy inform NonCompliant 5d21h default policy2-common-nto-sub-policy inform Compliant 5d21h default policy3-common-ptp-sub-policy inform NonCompliant 5d21h default policy4-common-sriov-sub-policy inform NonCompliant 5d21h
17.9.4. Clusters
Vérification de la présence de clusters gérés
- Enjeu
-
Vous voulez vérifier si les clusters dans le CR
ClusterGroupUpgradesont des clusters gérés. - Résolution
Exécutez la commande suivante :
$ oc get managedclusters
Exemple de sortie
NAME HUB ACCEPTED MANAGED CLUSTER URLS JOINED AVAILABLE AGE local-cluster true https://api.hub.example.com:6443 True Unknown 13d spoke1 true https://api.spoke1.example.com:6443 True True 13d spoke3 true https://api.spoke3.example.com:6443 True True 27h
Vous pouvez également consulter les journaux du gestionnaire TALM :
Obtenez le nom du gestionnaire TALM en exécutant la commande suivante :
$ oc get pod -n openshift-operators
Exemple de sortie
NAME READY STATUS RESTARTS AGE cluster-group-upgrades-controller-manager-75bcc7484d-8k8xp 2/2 Running 0 45m
Vérifiez les journaux du gestionnaire TALM en exécutant la commande suivante :
$ oc logs -n openshift-operators \ cluster-group-upgrades-controller-manager-75bcc7484d-8k8xp -c manager
Exemple de sortie
ERROR controller-runtime.manager.controller.clustergroupupgrade Reconciler error {"reconciler group": "ran.openshift.io", "reconciler kind": "ClusterGroupUpgrade", "name": "lab-upgrade", "namespace": "default", "error": "Cluster spoke5555 is not a ManagedCluster"} 1 sigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).processNextWorkItem- 1
- Le message d'erreur indique que le cluster n'est pas un cluster géré.
Vérification de la disponibilité des clusters gérés
- Enjeu
-
Vous voulez vérifier si les clusters gérés spécifiés dans le CR
ClusterGroupUpgradesont disponibles. - Résolution
Exécutez la commande suivante :
$ oc get managedclusters
Exemple de sortie
NAME HUB ACCEPTED MANAGED CLUSTER URLS JOINED AVAILABLE AGE local-cluster true https://api.hub.testlab.com:6443 True Unknown 13d spoke1 true https://api.spoke1.testlab.com:6443 True True 13d 1 spoke3 true https://api.spoke3.testlab.com:6443 True True 27h 2
Vérification du clusterLabelSelector
- Enjeu
-
Vous voulez vérifier si le champ
clusterLabelSelectorspécifié dans le CRClusterGroupUpgradecorrespond à au moins un des clusters gérés. - Résolution
Exécutez la commande suivante :
oc get managedcluster --selector=upgrade=true 1- 1
- L'étiquette des clusters que vous souhaitez mettre à jour est
upgrade:true.
Exemple de sortie
NAME HUB ACCEPTED MANAGED CLUSTER URLS JOINED AVAILABLE AGE spoke1 true https://api.spoke1.testlab.com:6443 True True 13d spoke3 true https://api.spoke3.testlab.com:6443 True True 27h
Vérification de la présence de grappes de canaris
- Enjeu
Vous voulez vérifier si les clusters canaris sont présents dans la liste des clusters.
Exemple
ClusterGroupUpgradeCRspec: remediationStrategy: canaries: - spoke3 maxConcurrency: 2 timeout: 240 clusterLabelSelectors: - matchLabels: upgrade: true- Résolution
Exécutez les commandes suivantes :
$ oc get cgu lab-upgrade -ojsonpath='{.spec.clusters}'Exemple de sortie
["spoke1", "spoke3"]
Vérifiez si les clusters canaris sont présents dans la liste des clusters qui correspondent aux étiquettes
clusterLabelSelectoren exécutant la commande suivante :$ oc get managedcluster --selector=upgrade=true
Exemple de sortie
NAME HUB ACCEPTED MANAGED CLUSTER URLS JOINED AVAILABLE AGE spoke1 true https://api.spoke1.testlab.com:6443 True True 13d spoke3 true https://api.spoke3.testlab.com:6443 True True 27h
Un groupe peut être présent sur le site spec.clusters et correspondre à l'étiquette spec.clusterLabelSelector.
Vérification de l'état de la mise en cache sur les clusters de rayons
Vérifiez l'état de la mise en cache préalable en exécutant la commande suivante sur le cluster de rayons :
$ oc get jobs,pods -n openshift-talo-pre-cache
17.9.5. Stratégie d'assainissement
Vérification de la présence de remediationStrategy dans le CR ClusterGroupUpgrade
- Enjeu
-
Vous voulez vérifier si le
remediationStrategyest présent dans leClusterGroupUpgradeCR. - Résolution
Exécutez la commande suivante :
$ oc get cgu lab-upgrade -ojsonpath='{.spec.remediationStrategy}'Exemple de sortie
{"maxConcurrency":2, "timeout":240}
Vérification de la spécification de maxConcurrency dans le CR ClusterGroupUpgrade
- Enjeu
-
Vous voulez vérifier si le
maxConcurrencyest spécifié dans leClusterGroupUpgradeCR. - Résolution
Exécutez la commande suivante :
$ oc get cgu lab-upgrade -ojsonpath='{.spec.remediationStrategy.maxConcurrency}'Exemple de sortie
2
17.9.6. Gestionnaire du cycle de vie tenant compte de la topologie
Vérification du message de condition et du statut dans le CR ClusterGroupUpgrade
- Enjeu
-
Vous voulez vérifier la valeur du champ
status.conditionsdans le CRClusterGroupUpgrade. - Résolution
Exécutez la commande suivante :
$ oc get cgu lab-upgrade -ojsonpath='{.status.conditions}'Exemple de sortie
{"lastTransitionTime":"2022-02-17T22:25:28Z", "message":"Missing managed policies:[policyList]", "reason":"NotAllManagedPoliciesExist", "status":"False", "type":"Validated"}
Vérification des politiques copiées correspondantes
- Enjeu
-
Vous voulez vérifier si chaque politique de
status.managedPoliciesForUpgradea une politique correspondante dansstatus.copiedPolicies. - Résolution
Exécutez la commande suivante :
$ oc get cgu lab-upgrade -oyaml
Exemple de sortie
status: … copiedPolicies: - lab-upgrade-policy3-common-ptp-sub-policy managedPoliciesForUpgrade: - name: policy3-common-ptp-sub-policy namespace: default
Vérifier si status.remediationPlan a été calculé
- Enjeu
-
Vous voulez vérifier si
status.remediationPlanest calculé. - Résolution
Exécutez la commande suivante :
$ oc get cgu lab-upgrade -ojsonpath='{.status.remediationPlan}'Exemple de sortie
[["spoke2", "spoke3"]]
Erreurs dans le conteneur du gestionnaire TALM
- Enjeu
- Vous voulez vérifier les journaux du conteneur gestionnaire de TALM.
- Résolution
Exécutez la commande suivante :
$ oc logs -n openshift-operators \ cluster-group-upgrades-controller-manager-75bcc7484d-8k8xp -c manager
Exemple de sortie
ERROR controller-runtime.manager.controller.clustergroupupgrade Reconciler error {"reconciler group": "ran.openshift.io", "reconciler kind": "ClusterGroupUpgrade", "name": "lab-upgrade", "namespace": "default", "error": "Cluster spoke5555 is not a ManagedCluster"} 1 sigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).processNextWorkItem- 1
- Affiche l'erreur.
Les clusters ne sont pas conformes à certaines politiques après l'achèvement d'une CR ClusterGroupUpgrade
- Enjeu
L'état de conformité de la politique que TALM utilise pour décider si une remédiation est nécessaire n'a pas encore été complètement mis à jour pour tous les clusters. Cela peut s'expliquer par les raisons suivantes
- L'UGT a été lancée trop tôt après la création ou la mise à jour d'une politique.
-
La remédiation d'une politique affecte la conformité des politiques suivantes dans le CR
ClusterGroupUpgrade.
- Résolution
-
Créez une nouvelle application
ClusterGroupUpdateCR avec les mêmes spécifications.
Ressources supplémentaires
- Pour plus d'informations sur le dépannage, voir OpenShift Container Platform Troubleshooting Operator Issues.
- Pour plus d'informations sur l'utilisation de Topology Aware Lifecycle Manager dans le flux de travail ZTP, voir Mise à jour des politiques gérées avec Topology Aware Lifecycle Manager.
-
Pour plus d'informations sur le CRD
PolicyGenTemplate, voir À propos du CRD PolicyGenTemplate
Chapitre 18. Création d'un profil de performance
Découvrez le Performance Profile Creator (PPC) et la manière dont vous pouvez l'utiliser pour créer un profil de performance.
Actuellement, la désactivation de l'équilibrage de la charge du CPU n'est pas prise en charge par cgroup v2. Par conséquent, il se peut que vous n'obteniez pas le comportement souhaité des profils de performance si vous avez activé cgroup v2. L'activation de cgroup v2 n'est pas recommandée si vous utilisez des profils de performance.
18.1. À propos du créateur de profil de performance
Le Performance Profile Creator (PPC) est un outil en ligne de commande, fourni avec le Node Tuning Operator, utilisé pour créer le profil de performance. L'outil utilise les données must-gather de la grappe et plusieurs arguments de profil fournis par l'utilisateur. Le PPC génère un profil de performance adapté à votre matériel et à votre topologie.
L'outil est exécuté selon l'une des méthodes suivantes :
-
Invoquer
podman - Appel d'un script wrapper
18.1.1. Collecte de données sur votre cluster à l'aide de la commande must-gather
L'outil Performance Profile Creator (PPC) nécessite des données must-gather. En tant qu'administrateur d'une grappe, exécutez la commande must-gather pour obtenir des informations sur votre grappe.
Dans les versions antérieures d'OpenShift Container Platform, l'opérateur Performance Addon permettait de régler automatiquement les performances des applications à faible latence. Dans OpenShift Container Platform 4.11 et les versions ultérieures, cette fonctionnalité fait partie de l'opérateur Node Tuning. Cependant, vous devez toujours utiliser l'image performance-addon-operator-must-gather lors de l'exécution de la commande must-gather.
Conditions préalables
-
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. -
Accès à l'image de l'opérateur Performance Addon
must gather. -
L'OpenShift CLI (
oc) est installé.
Procédure
Facultatif : Vérifiez qu'il existe un pool de configuration machine correspondant avec une étiquette :
$ oc describe mcp/worker-rt
Exemple de sortie
Name: worker-rt Namespace: Labels: machineconfiguration.openshift.io/role=worker-rt
S'il n'existe pas d'étiquette correspondante, ajoutez une étiquette pour un pool de configuration de machine (MCP) qui correspond au nom du MCP :
$ oc label mcp <mcp_name> <mcp_name>=""
-
Accédez au répertoire dans lequel vous souhaitez stocker les données
must-gather. Exécutez
must-gathersur votre cluster :oc adm must-gather --image=<PAO_must_gather_image> --dest-dir=<dir> $ oc adm must-gather --image=<PAO_must_gather_image>
NoteLa commande
must-gatherdoit être exécutée avec l'imageperformance-addon-operator-must-gather. La sortie peut éventuellement être compressée. La sortie compressée est nécessaire si vous exécutez le script wrapper Performance Profile Creator.Exemple :
oc adm must-gather --image=registry.redhat.io/openshift4/performance-addon-operator-must-gather-rhel8:v4.12 --dest-dir=<path_to_must-gather>/must-gather
Créer un fichier compressé à partir du répertoire
must-gather:$ tar cvaf must-gather.tar.gz must-gather/
18.1.2. Exécuter le créateur de profil de performance à l'aide de podman
En tant qu'administrateur de cluster, vous pouvez exécuter podman et le Créateur de profil de performance pour créer un profil de performance.
Conditions préalables
-
Accès au cluster en tant qu'utilisateur ayant le rôle
cluster-admin. - Un cluster installé sur du matériel bare-metal.
-
Un nœud avec
podmanet OpenShift CLI (oc) installés. - Accès à l'image de l'opérateur de réglage des nœuds.
Procédure
Vérifiez le pool de configuration de la machine :
$ oc get mcp
Exemple de sortie
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-acd1358917e9f98cbdb599aea622d78b True False False 3 3 3 0 22h worker-cnf rendered-worker-cnf-1d871ac76e1951d32b2fe92369879826 False True False 2 1 1 0 22h
Utilisez Podman pour vous authentifier sur
registry.redhat.io:$ podman login registry.redhat.io
Username: myrhusername Password: ************
Facultatif : Affiche l'aide pour l'outil PPC :
$ podman run --rm --entrypoint performance-profile-creator registry.redhat.io/openshift4/ose-cluster-node-tuning-operator:v4.12 -h
Exemple de sortie
A tool that automates creation of Performance Profiles Usage: performance-profile-creator [flags] Flags: --disable-ht Disable Hyperthreading -h, --help help for performance-profile-creator --info string Show cluster information; requires --must-gather-dir-path, ignore the other arguments. [Valid values: log, json] (default "log") --mcp-name string MCP name corresponding to the target machines (required) --must-gather-dir-path string Must gather directory path (default "must-gather") --offlined-cpu-count int Number of offlined CPUs --power-consumption-mode string The power consumption mode. [Valid values: default, low-latency, ultra-low-latency] (default "default") --profile-name string Name of the performance profile to be created (default "performance") --reserved-cpu-count int Number of reserved CPUs (required) --rt-kernel Enable Real Time Kernel (required) --split-reserved-cpus-across-numa Split the Reserved CPUs across NUMA nodes --topology-manager-policy string Kubelet Topology Manager Policy of the performance profile to be created. [Valid values: single-numa-node, best-effort, restricted] (default "restricted") --user-level-networking Run with User level Networking(DPDK) enabledExécutez l'outil Performance Profile Creator en mode découverte :
NoteLe mode découverte inspecte votre cluster à l'aide de la sortie de
must-gather. La sortie produite comprend des informations sur :- Le partitionnement de la cellule NUMA avec les identifiants de l'unité centrale alloués
- Si l'hyperthreading est activé
En utilisant ces informations, vous pouvez définir des valeurs appropriées pour certains des arguments fournis à l'outil Performance Profile Creator.
$ podman run --entrypoint performance-profile-creator -v <path_to_must-gather>/must-gather:/must-gather:z registry.redhat.io/openshift4/ose-cluster-node-tuning-operator:v4.12 --info log --must-gather-dir-path /must-gather
NoteCette commande utilise le créateur de profil de performance comme nouveau point d'entrée vers
podman. Elle mappe les donnéesmust-gatherpour l'hôte dans l'image du conteneur et invoque les arguments de profil fournis par l'utilisateur pour produire le fichiermy-performance-profile.yaml.L'option
-vpeut être le chemin d'accès à l'un ou l'autre :-
Le répertoire de sortie de
must-gather -
Un répertoire existant contenant l'archive décompressée
must-gather
L'option
inforequiert une valeur qui spécifie le format de sortie. Les valeurs possibles sont log et JSON. Le format JSON est réservé au débogage.Exécuter
podman:$ podman run --entrypoint performance-profile-creator -v /must-gather:/must-gather:z registry.redhat.io/openshift4/ose-cluster-node-tuning-operator:v4.12 --mcp-name=worker-cnf --reserved-cpu-count=4 --rt-kernel=true --split-reserved-cpus-across-numa=false --must-gather-dir-path /must-gather --power-consumption-mode=ultra-low-latency --offlined-cpu-count=6 > my-performance-profile.yaml
NoteLes arguments du Créateur de profil de performance sont présentés dans le tableau des arguments du Créateur de profil de performance. Les arguments suivants sont nécessaires :
-
reserved-cpu-count -
mcp-name -
rt-kernel
Dans cet exemple, l'argument
mcp-nameest défini surworker-cnfen fonction de la sortie de la commandeoc get mcp. Pour OpenShift à nœud unique, utilisez--mcp-name=master.-
Examinez le fichier YAML créé :
$ cat my-performance-profile.yaml
Exemple de sortie
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: performance spec: cpu: isolated: 2-39,48-79 offlined: 42-47 reserved: 0-1,40-41 machineConfigPoolSelector: machineconfiguration.openshift.io/role: worker-cnf nodeSelector: node-role.kubernetes.io/worker-cnf: "" numa: topologyPolicy: restricted realTimeKernel: enabled: true workloadHints: highPowerConsumption: true realTime: trueAppliquer le profil généré :
$ oc apply -f my-performance-profile.yaml
18.1.2.1. Comment lancer le site podman pour créer un profil de performance ?
L'exemple suivant montre comment exécuter podman pour créer un profil de performance avec 20 CPU réservés qui doivent être répartis sur les nœuds NUMA.
Configuration du matériel du nœud :
- 80 CPU
- Hyperthreading activé
- Deux nœuds NUMA
- Les unités centrales paires sont exécutées sur le nœud NUMA 0 et les unités centrales impaires sur le nœud NUMA 1
Lancez podman pour créer le profil de performance :
$ podman run --entrypoint performance-profile-creator -v /must-gather:/must-gather:z registry.redhat.io/openshift4/ose-cluster-node-tuning-operator:v4.12 --mcp-name=worker-cnf --reserved-cpu-count=20 --rt-kernel=true --split-reserved-cpus-across-numa=true --must-gather-dir-path /must-gather > my-performance-profile.yaml
Le profil créé est décrit dans le fichier YAML suivant :
apiVersion: performance.openshift.io/v2
kind: PerformanceProfile
metadata:
name: performance
spec:
cpu:
isolated: 10-39,50-79
reserved: 0-9,40-49
nodeSelector:
node-role.kubernetes.io/worker-cnf: ""
numa:
topologyPolicy: restricted
realTimeKernel:
enabled: trueDans ce cas, 10 CPU sont réservés sur le nœud NUMA 0 et 10 sur le nœud NUMA 1.
18.1.3. Exécution du script wrapper Performance Profile Creator
Le script d'habillage du profil de performance simplifie l'exécution de l'outil Performance Profile Creator (PPC). Il masque les complexités associées à l'exécution de podman et à la spécification des répertoires de mappage et permet la création du profil de performance.
Conditions préalables
- Accès à l'image de l'opérateur de réglage des nœuds.
-
Accès à l'archive
must-gather.
Procédure
Créez un fichier sur votre machine locale nommé, par exemple,
run-perf-profile-creator.sh:$ vi run-perf-profile-creator.sh
Collez le code suivant dans le fichier :
#!/bin/bash readonly CONTAINER_RUNTIME=${CONTAINER_RUNTIME:-podman} readonly CURRENT_SCRIPT=$(basename "$0") readonly CMD="${CONTAINER_RUNTIME} run --entrypoint performance-profile-creator" readonly IMG_EXISTS_CMD="${CONTAINER_RUNTIME} image exists" readonly IMG_PULL_CMD="${CONTAINER_RUNTIME} image pull" readonly MUST_GATHER_VOL="/must-gather" NTO_IMG="registry.redhat.io/openshift4/ose-cluster-node-tuning-operator:v4.12" MG_TARBALL="" DATA_DIR="" usage() { print "Wrapper usage:" print " ${CURRENT_SCRIPT} [-h] [-p image][-t path] -- [performance-profile-creator flags]" print "" print "Options:" print " -h help for ${CURRENT_SCRIPT}" print " -p Node Tuning Operator image" print " -t path to a must-gather tarball" ${IMG_EXISTS_CMD} "${NTO_IMG}" && ${CMD} "${NTO_IMG}" -h } function cleanup { [ -d "${DATA_DIR}" ] && rm -rf "${DATA_DIR}" } trap cleanup EXIT exit_error() { print "error: $*" usage exit 1 } print() { echo "$*" >&2 } check_requirements() { ${IMG_EXISTS_CMD} "${NTO_IMG}" || ${IMG_PULL_CMD} "${NTO_IMG}" || \ exit_error "Node Tuning Operator image not found" [ -n "${MG_TARBALL}" ] || exit_error "Must-gather tarball file path is mandatory" [ -f "${MG_TARBALL}" ] || exit_error "Must-gather tarball file not found" DATA_DIR=$(mktemp -d -t "${CURRENT_SCRIPT}XXXX") || exit_error "Cannot create the data directory" tar -zxf "${MG_TARBALL}" --directory "${DATA_DIR}" || exit_error "Cannot decompress the must-gather tarball" chmod a+rx "${DATA_DIR}" return 0 } main() { while getopts ':hp:t:' OPT; do case "${OPT}" in h) usage exit 0 ;; p) NTO_IMG="${OPTARG}" ;; t) MG_TARBALL="${OPTARG}" ;; ?) exit_error "invalid argument: ${OPTARG}" ;; esac done shift $((OPTIND - 1)) check_requirements || exit 1 ${CMD} -v "${DATA_DIR}:${MUST_GATHER_VOL}:z" "${NTO_IMG}" "$@" --must-gather-dir-path "${MUST_GATHER_VOL}" echo "" 1>&2 } main "$@"Ajoutez des permissions d'exécution pour tout le monde sur ce script :
$ chmod a+x run-perf-profile-creator.sh
Facultatif : Affichez l'utilisation de la commande
run-perf-profile-creator.sh:$ ./run-perf-profile-creator.sh -h
Résultats attendus
Wrapper usage: run-perf-profile-creator.sh [-h] [-p image][-t path] -- [performance-profile-creator flags] Options: -h help for run-perf-profile-creator.sh -p Node Tuning Operator image 1 -t path to a must-gather tarball 2 A tool that automates creation of Performance Profiles Usage: performance-profile-creator [flags] Flags: --disable-ht Disable Hyperthreading -h, --help help for performance-profile-creator --info string Show cluster information; requires --must-gather-dir-path, ignore the other arguments. [Valid values: log, json] (default "log") --mcp-name string MCP name corresponding to the target machines (required) --must-gather-dir-path string Must gather directory path (default "must-gather") --offlined-cpu-count int Number of offlined CPUs --power-consumption-mode string The power consumption mode. [Valid values: default, low-latency, ultra-low-latency] (default "default") --profile-name string Name of the performance profile to be created (default "performance") --reserved-cpu-count int Number of reserved CPUs (required) --rt-kernel Enable Real Time Kernel (required) --split-reserved-cpus-across-numa Split the Reserved CPUs across NUMA nodes --topology-manager-policy string Kubelet Topology Manager Policy of the performance profile to be created. [Valid values: single-numa-node, best-effort, restricted] (default "restricted") --user-level-networking Run with User level Networking(DPDK) enabled
NoteIl existe deux types d'arguments :
-
Les arguments enveloppants, à savoir
-h,-pet-t - Arguments du CPP
- 1
- En option : Spécifiez l'image de l'opérateur Node Tuning. Si elle n'est pas définie, l'image en amont par défaut est utilisée :
registry.redhat.io/openshift4/ose-cluster-node-tuning-operator:v4.12. - 2
-test un argument obligatoire du script wrapper et spécifie le chemin d'accès à l'archivemust-gather.
-
Les arguments enveloppants, à savoir
Exécutez l'outil de création de profils de performance en mode découverte :
NoteLe mode découverte inspecte votre cluster à l'aide de la sortie de
must-gather. La sortie produite comprend des informations sur :- Le partitionnement de la cellule NUMA avec les ID d'unité centrale attribués
- Si l'hyperthreading est activé
En utilisant ces informations, vous pouvez définir des valeurs appropriées pour certains des arguments fournis à l'outil Performance Profile Creator.
$ ./run-perf-profile-creator.sh -t /must-gather/must-gather.tar.gz -- --info=log
NoteL'option
inforequiert une valeur qui spécifie le format de sortie. Les valeurs possibles sont log et JSON. Le format JSON est réservé au débogage.Vérifiez le pool de configuration de la machine :
$ oc get mcp
Exemple de sortie
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-acd1358917e9f98cbdb599aea622d78b True False False 3 3 3 0 22h worker-cnf rendered-worker-cnf-1d871ac76e1951d32b2fe92369879826 False True False 2 1 1 0 22h
Créer un profil de performance :
./run-perf-profile-creator.sh -t /must-gather/must-gather.tar.gz -- --mcp-name=worker-cnf --reserved-cpu-count=2 --rt-kernel=true > my-performance-profile.yaml
NoteLes arguments du Créateur de profil de performance sont présentés dans le tableau des arguments du Créateur de profil de performance. Les arguments suivants sont nécessaires :
-
reserved-cpu-count -
mcp-name -
rt-kernel
Dans cet exemple, l'argument
mcp-nameest défini surworker-cnfen fonction de la sortie de la commandeoc get mcp. Pour OpenShift à nœud unique, utilisez--mcp-name=master.-
Examinez le fichier YAML créé :
$ cat my-performance-profile.yaml
Exemple de sortie
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: performance spec: cpu: isolated: 1-39,41-79 reserved: 0,40 nodeSelector: node-role.kubernetes.io/worker-cnf: "" numa: topologyPolicy: restricted realTimeKernel: enabled: falseAppliquer le profil généré :
NoteInstallez l'opérateur de réglage des nœuds avant d'appliquer le profil.
$ oc apply -f my-performance-profile.yaml
18.1.4. Arguments du créateur de profil de performance
Tableau 18.1. Arguments du créateur de profil de performance
| Argument | Description |
|---|---|
|
| Désactiver l'hyperthreading.
Valeurs possibles :
Valeur par défaut : Avertissement
Si cet argument est défini à |
|
|
Il capture des informations sur les clusters et n'est utilisé qu'en mode découverte. Le mode découverte nécessite également l'argument Valeurs possibles :
Valeur par défaut : |
|
|
Nom du MCP par exemple |
|
| Doit rassembler le chemin d'accès au répertoire. Ce paramètre est obligatoire.
Lorsque l'utilisateur exécute l'outil avec le script wrapper |
|
| Nombre d'unités centrales hors ligne. Note Il doit s'agir d'un nombre naturel supérieur à 0. Si le nombre de processeurs logiques déconnectés est insuffisant, des messages d'erreur sont enregistrés. Ces messages sont les suivants : Error: failed to compute the reserved and isolated CPUs: please ensure that reserved-cpu-count plus offlined-cpu-count should be in the range [0,1] Error: failed to compute the reserved and isolated CPUs: please specify the offlined CPU count in the range [0,1] |
|
| Le mode de consommation d'énergie. Valeurs possibles :
Valeur par défaut : |
|
|
Nom du profil de performance à créer. Valeur par défaut : |
|
| Nombre d'unités centrales réservées. Ce paramètre est obligatoire. Note Il doit s'agir d'un nombre naturel. La valeur 0 n'est pas autorisée. |
|
| Activer le noyau en temps réel. Ce paramètre est obligatoire.
Valeurs possibles : |
|
| Répartir les unités centrales réservées sur les nœuds NUMA.
Valeurs possibles :
Valeur par défaut : |
|
| Politique du Kubelet Topology Manager du profil de performance à créer. Valeurs possibles :
Valeur par défaut : |
|
| Exécution avec la mise en réseau au niveau de l'utilisateur (DPDK) activée.
Valeurs possibles :
Valeur par défaut : |
18.2. Profils de performance de référence
18.2.1. Un modèle de profil de performance pour les clusters qui utilisent OVS-DPDK sur OpenStack
Pour maximiser les performances des machines dans un cluster qui utilise Open vSwitch avec le kit de développement du plan de données (OVS-DPDK) sur Red Hat OpenStack Platform (RHOSP), vous pouvez utiliser un profil de performance.
Vous pouvez utiliser le modèle de profil de performance suivant pour créer un profil pour votre déploiement.
Un modèle de profil de performance pour les clusters qui utilisent OVS-DPDK
apiVersion: performance.openshift.io/v2
kind: PerformanceProfile
metadata:
name: cnf-performanceprofile
spec:
additionalKernelArgs:
- nmi_watchdog=0
- audit=0
- mce=off
- processor.max_cstate=1
- idle=poll
- intel_idle.max_cstate=0
- default_hugepagesz=1GB
- hugepagesz=1G
- intel_iommu=on
cpu:
isolated: <CPU_ISOLATED>
reserved: <CPU_RESERVED>
hugepages:
defaultHugepagesSize: 1G
pages:
- count: <HUGEPAGES_COUNT>
node: 0
size: 1G
nodeSelector:
node-role.kubernetes.io/worker: ''
realTimeKernel:
enabled: false
globallyDisableIrqLoadBalancing: true
Insérez les valeurs appropriées à votre configuration pour les clés CPU_ISOLATED, CPU_RESERVED, et HUGEPAGES_COUNT.
Pour savoir comment créer et utiliser les profils de performance, voir la page "Créer un profil de performance" dans la section "Scalabilité et performance" de la documentation OpenShift Container Platform.
18.3. Ressources supplémentaires
-
Pour plus d'informations sur l'outil
must-gather, voir Collecte de données sur votre cluster.
Chapitre 19. Partitionnement de la charge de travail dans OpenShift à nœud unique
Dans les environnements à ressources limitées, tels que les déploiements OpenShift à nœud unique, utilisez le partitionnement de la charge de travail pour isoler les services OpenShift Container Platform, les charges de travail de gestion de cluster et les pods d'infrastructure afin qu'ils s'exécutent sur un ensemble réservé d'unités centrales.
Le nombre minimum de CPU réservés requis pour la gestion de cluster dans OpenShift à nœud unique est de quatre Hyper-Threads (HT) de CPU. Avec le partitionnement de la charge de travail, vous annotez l'ensemble des pods de gestion de cluster et un ensemble d'opérateurs complémentaires typiques à inclure dans la partition de la charge de travail de gestion de cluster. Ces modules fonctionnent normalement dans le cadre de la configuration minimale de l'unité centrale. Les opérateurs supplémentaires ou les charges de travail en dehors de l'ensemble de pods de gestion de grappes minimales nécessitent l'ajout de CPU supplémentaires à la partition de la charge de travail.
Le partitionnement de la charge de travail isole les charges de travail des utilisateurs de celles de la plateforme à l'aide des capacités d'ordonnancement standard de Kubernetes.
Voici un aperçu des configurations requises pour le partitionnement de la charge de travail :
-
Le partitionnement de la charge de travail qui utilise
/etc/crio/crio.conf.d/01-workload-partitioningrelie les pods de l'infrastructure OpenShift Container Platform à une configurationcpusetdéfinie. Le profil de performance épingle les services de cluster tels que systemd et kubelet aux unités centrales définies dans le champ
spec.cpu.reserved.NoteÀ l'aide de l'opérateur de réglage du nœud, vous pouvez configurer le profil de performance pour épingler également les applications au niveau du système pour une configuration complète de partitionnement de la charge de travail sur le nœud.
-
Les CPU que vous spécifiez dans le champ du profil de performance
spec.cpu.reservedet dans le champ du partitionnement de la charge de travailcpusetdoivent correspondre.
Le partitionnement de la charge de travail introduit une ressource <workload-type>.workload.openshift.io/cores étendue pour chaque pool de CPU défini, ou workload type. Kubelet annonce les ressources et les demandes de CPU par les pods alloués au pool dans la ressource correspondante. Lorsque le partitionnement de la charge de travail est activé, la ressource <workload-type>.workload.openshift.io/cores permet d'accéder à la capacité de CPU de l'hôte, et pas seulement au pool de CPU par défaut.
Ressources supplémentaires
- Pour connaître la configuration de partitionnement de la charge de travail recommandée pour les clusters OpenShift à nœud unique, voir Partitionnement de la charge de travail.
Chapitre 20. Demander des données de profilage CRI-O et Kubelet en utilisant l'opérateur d'observabilité du nœud
L'opérateur d'observabilité des nœuds collecte et stocke les données de profilage CRI-O et Kubelet des nœuds de travail. Vous pouvez interroger les données de profilage pour analyser les tendances des performances de CRI-O et de Kubelet et déboguer les problèmes liés aux performances.
L'opérateur d'observabilité de nœud est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas leur utilisation en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information au cours du processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
20.1. Fonctionnement de l'opérateur d'observabilité des nœuds
Le flux de travail suivant explique comment interroger les données de profilage à l'aide de l'opérateur d'observabilité des nœuds :
- Installez l'opérateur d'observabilité Node dans le cluster OpenShift Container Platform.
- Créez une ressource personnalisée NodeObservability pour activer le profilage CRI-O sur les nœuds de travail de votre choix.
- Exécutez la requête de profilage pour générer les données de profilage.
20.2. Installation de l'opérateur d'observabilité du nœud
Le Node Observability Operator n'est pas installé par défaut dans OpenShift Container Platform. Vous pouvez installer le Node Observability Operator en utilisant le CLI d'OpenShift Container Platform ou la console web.
20.2.1. Installation de l'opérateur d'observabilité du nœud à l'aide du CLI
Vous pouvez installer l'opérateur d'observabilité Node en utilisant la CLI d'OpenShift (oc).
Conditions préalables
- Vous avez installé le CLI OpenShift (oc).
-
Vous avez accès au cluster avec les privilèges
cluster-admin.
Procédure
Confirmez que l'opérateur d'observabilité du nœud est disponible en exécutant la commande suivante :
$ oc get packagemanifests -n openshift-marketplace node-observability-operator
Exemple de sortie
NAME CATALOG AGE node-observability-operator Red Hat Operators 9h
Créez l'espace de noms
node-observability-operatoren exécutant la commande suivante :$ oc new-project node-observability-operator
Créer un fichier YAML de l'objet
OperatorGroup:cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: node-observability-operator namespace: node-observability-operator spec: targetNamespaces: [] EOF
Créer un fichier YAML de l'objet
Subscriptionpour abonner un espace de noms à un opérateur :cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: node-observability-operator namespace: node-observability-operator spec: channel: alpha name: node-observability-operator source: redhat-operators sourceNamespace: openshift-marketplace EOF
Vérification
Affichez le nom du plan d'installation en exécutant la commande suivante :
$ oc -n node-observability-operator get sub node-observability-operator -o yaml | yq '.status.installplan.name'
Exemple de sortie
install-dt54w
Vérifiez l'état du plan d'installation en exécutant la commande suivante :
oc -n node-observability-operator get ip <install_plan_name> -o yaml | yq '.status.phase' $ oc -n node-observability-operator get ip <install_plan_name> -o yaml
<install_plan_name>est le nom du plan d'installation que vous avez obtenu à partir de la sortie de la commande précédente.Exemple de sortie
COMPLETE
Vérifiez que l'opérateur d'observabilité du nœud est opérationnel :
$ oc get deploy -n node-observability-operator
Exemple de sortie
NAME READY UP-TO-DATE AVAILABLE AGE node-observability-operator-controller-manager 1/1 1 1 40h
20.2.2. Installation du Node Observability Operator à l'aide de la console web
Vous pouvez installer l'opérateur d'observabilité Node à partir de la console web d'OpenShift Container Platform.
Conditions préalables
-
Vous avez accès au cluster avec les privilèges
cluster-admin. - Vous avez accès à la console web de OpenShift Container Platform.
Procédure
- Connectez-vous à la console web de OpenShift Container Platform.
- Dans le panneau de navigation de l'administrateur, développez Operators → OperatorHub.
- Dans le champ All items, entrez Node Observability Operator et sélectionnez la tuile Node Observability Operator.
- Cliquez sur Install.
Sur la page Install Operator, configurez les paramètres suivants :
- Dans la zone Update channel, cliquez sur alpha.
- Dans la zone Installation mode, cliquez sur A specific namespace on the cluster.
- Dans la liste Installed Namespace, sélectionnez node-observability-operator.
- Dans la zone Update approval, sélectionnez Automatic.
- Cliquez sur Install.
Vérification
- Dans le panneau de navigation de l'administrateur, développez Operators → Installed Operators.
- Vérifiez que l'opérateur d'observabilité du nœud figure dans la liste des opérateurs.
20.3. Création de la ressource personnalisée Node Observability
Vous devez créer et exécuter la ressource personnalisée (CR) NodeObservability avant d'exécuter la requête de profilage. Lorsque vous exécutez la CR NodeObservability, elle crée les CR machine config et machine config pool nécessaires pour activer le profilage CRI-O sur les nœuds de travail correspondant à la ressource nodeSelector.
Si le profilage CRI-O n'est pas activé sur les nœuds de travail, la ressource NodeObservabilityMachineConfig est créée. Les nœuds de travail correspondant à la ressource nodeSelector spécifiée dans NodeObservability CR redémarrent. Cette opération peut durer 10 minutes ou plus.
Le profilage des Kubelets est activé par défaut.
Le socket unix CRI-O du nœud est monté sur le pod de l'agent, ce qui permet à l'agent de communiquer avec le CRI-O pour exécuter la requête pprof. De même, la chaîne de certificats kubelet-serving-ca est montée sur le pod de l'agent, ce qui permet une communication sécurisée entre l'agent et le point de terminaison kubelet du nœud.
Conditions préalables
- Vous avez installé l'opérateur d'observabilité du nœud.
- Vous avez installé le CLI OpenShift (oc).
-
Vous avez accès au cluster avec les privilèges
cluster-admin.
Procédure
Connectez-vous au CLI de OpenShift Container Platform en exécutant la commande suivante :
$ oc login -u kubeadmin https://<HOSTNAME>:6443
Revenez à l'espace de noms
node-observability-operatoren exécutant la commande suivante :$ oc project node-observability-operator
Créez un fichier CR nommé
nodeobservability.yamlqui contient le texte suivant :apiVersion: nodeobservability.olm.openshift.io/v1alpha2 kind: NodeObservability metadata: name: cluster 1 spec: nodeSelector: kubernetes.io/hostname: <node_hostname> 2 type: crio-kubeletExécutez le CR
NodeObservability:oc apply -f nodeobservability.yaml
Exemple de sortie
nodeobservability.olm.openshift.io/cluster created
Vérifiez l'état de
NodeObservabilityCR en exécutant la commande suivante :$ oc get nob/cluster -o yaml | yq '.status.conditions'
Exemple de sortie
conditions: conditions: - lastTransitionTime: "2022-07-05T07:33:54Z" message: 'DaemonSet node-observability-ds ready: true NodeObservabilityMachineConfig ready: true' reason: Ready status: "True" type: ReadyNodeObservabilityL'exécution du CR est terminée lorsque le motif estReadyet le statutTrue.
20.4. Exécution de la requête de profilage
Pour exécuter la requête de profilage, vous devez créer une ressource NodeObservabilityRun. La requête de profilage est une opération bloquante qui récupère les données de profilage CRI-O et Kubelet pour une durée de 30 secondes. Une fois la requête de profilage terminée, vous devez récupérer les données de profilage dans le répertoire /run/node-observability du système de fichiers du conteneur. La durée de vie des données est liée au module d'agent par l'intermédiaire du volume emptyDir, de sorte que vous pouvez accéder aux données de profilage lorsque le module d'agent est dans l'état running.
Vous ne pouvez demander qu'une seule requête de profilage à la fois.
Conditions préalables
- Vous avez installé l'opérateur d'observabilité du nœud.
-
Vous avez créé la ressource personnalisée (CR)
NodeObservability. -
Vous avez accès au cluster avec les privilèges
cluster-admin.
Procédure
Créez un fichier de ressources
NodeObservabilityRunnomménodeobservabilityrun.yamlqui contient le texte suivant :apiVersion: nodeobservability.olm.openshift.io/v1alpha2 kind: NodeObservabilityRun metadata: name: nodeobservabilityrun spec: nodeObservabilityRef: name: clusterDéclenchez la requête de profilage en exécutant la ressource
NodeObservabilityRun:$ oc apply -f nodeobservabilityrun.yaml
Vérifiez l'état du site
NodeObservabilityRunen exécutant la commande suivante :$ oc get nodeobservabilityrun nodeobservabilityrun -o yaml | yq '.status.conditions'
Exemple de sortie
conditions: - lastTransitionTime: "2022-07-07T14:57:34Z" message: Ready to start profiling reason: Ready status: "True" type: Ready - lastTransitionTime: "2022-07-07T14:58:10Z" message: Profiling query done reason: Finished status: "True" type: Finished
La requête de profilage est terminée lorsque le statut est
Trueet le typeFinished.Récupérez les données de profilage à partir du chemin d'accès au conteneur
/run/node-observabilityen exécutant le script bash suivant :for a in $(oc get nodeobservabilityrun nodeobservabilityrun -o yaml | yq .status.agents[].name); do echo "agent ${a}" mkdir -p "/tmp/${a}" for p in $(oc exec "${a}" -c node-observability-agent -- bash -c "ls /run/node-observability/*.pprof"); do f="$(basename ${p})" echo "copying ${f} to /tmp/${a}/${f}" oc exec "${a}" -c node-observability-agent -- cat "${p}" > "/tmp/${a}/${f}" done done
Chapitre 21. Clusters à la périphérie du réseau
21.1. Les défis de la périphérie du réseau
L'informatique en périphérie présente des défis complexes lorsqu'il s'agit de gérer de nombreux sites géographiquement éloignés. Utilisez le zero touch provisioning (ZTP) et GitOps pour approvisionner et gérer les sites à la périphérie du réseau.
21.1.1. Relever les défis de la périphérie du réseau
Aujourd'hui, les fournisseurs de services souhaitent déployer leur infrastructure à la périphérie du réseau. Cela pose des défis importants :
- Comment gérer les déploiements de plusieurs sites périphériques en parallèle ?
- Que se passe-t-il lorsque vous devez déployer des sites dans des environnements déconnectés ?
- Comment gérer le cycle de vie de grandes flottes de clusters ?
Zero touch provisioning (ZTP) et GitOps relèvent ces défis en vous permettant de provisionner des sites périphériques distants à l'échelle avec des définitions de site déclaratives et des configurations pour l'équipement bare-metal. Les configurations de modèle ou de superposition installent les fonctionnalités d'OpenShift Container Platform qui sont requises pour les charges de travail CNF. Le cycle de vie complet de l'installation et des mises à jour est géré par le pipeline ZTP.
ZTP utilise GitOps pour les déploiements d'infrastructure. Avec GitOps, vous utilisez des fichiers YAML déclaratifs et d'autres modèles définis stockés dans des dépôts Git. Red Hat Advanced Cluster Management (RHACM) utilise vos référentiels Git pour piloter le déploiement de votre infrastructure.
GitOps assure la traçabilité, le contrôle d'accès basé sur les rôles (RBAC) et une source unique de vérité pour l'état souhaité de chaque site. Les problèmes d'évolutivité sont traités par les méthodologies Git et les opérations basées sur les événements par le biais de webhooks.
Vous démarrez le flux de travail ZTP en créant des ressources personnalisées (CR) déclaratives de définition et de configuration de site que le pipeline ZTP transmet aux nœuds périphériques.
Le diagramme suivant montre comment ZTP fonctionne dans le cadre de la périphérie éloignée.
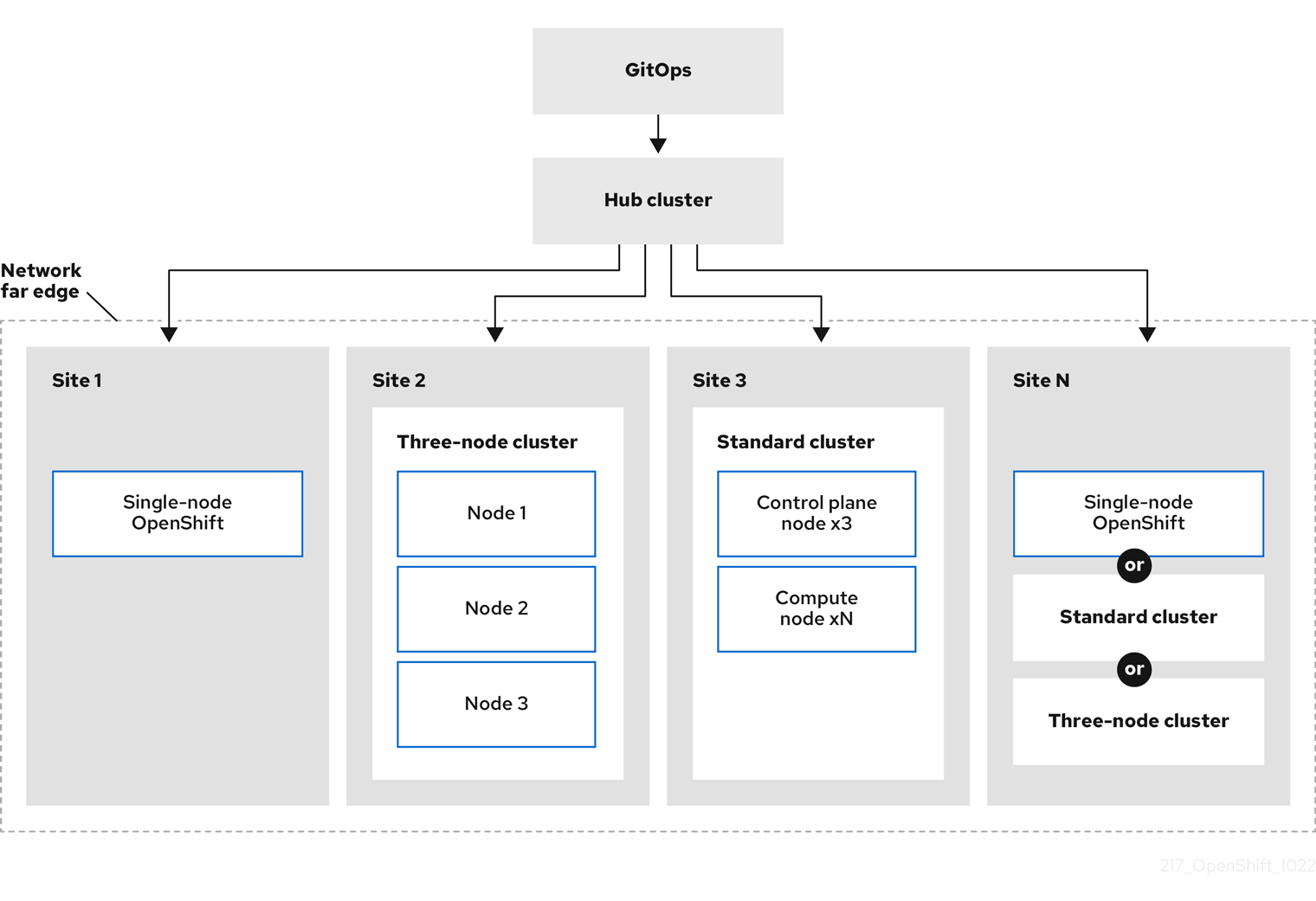
21.1.2. Utilisation de ZTP pour provisionner des clusters à la périphérie du réseau
Red Hat Advanced Cluster Management (RHACM) gère les clusters dans une architecture hub-and-spoke, où un seul cluster hub gère de nombreux clusters spoke. Les clusters concentrateurs exécutant RHACM provisionnent et déploient les clusters gérés en utilisant le zero touch provisioning (ZTP) et le service assisté qui est déployé lors de l'installation de RHACM.
Le service assisté gère le provisionnement d'OpenShift Container Platform sur des clusters à un seul nœud, des clusters à trois nœuds ou des clusters standard fonctionnant sur du bare metal.
Voici un aperçu de haut niveau de l'utilisation de ZTP pour provisionner et maintenir des hôtes bare-metal avec OpenShift Container Platform :
- Un hub cluster exécutant RHACM gère un registre d'images OpenShift qui reflète les images des versions d'OpenShift Container Platform. RHACM utilise le registre d'images OpenShift pour provisionner les clusters gérés.
- Vous gérez les hôtes nus dans un fichier d'inventaire au format YAML, versionné dans un dépôt Git.
- Vous préparez les hôtes pour le provisionnement en tant que clusters gérés, et utilisez RHACM et le service assisté pour installer les hôtes bare-metal sur site.
L'installation et le déploiement des clusters est un processus en deux étapes, comprenant une phase d'installation initiale et une phase de configuration ultérieure. Le diagramme suivant illustre ce processus :
21.1.3. Installation de clusters gérés avec des ressources SiteConfig et RHACM
GitOps ZTP utilise les ressources personnalisées (CR) SiteConfig dans un référentiel Git pour gérer les processus d'installation des clusters OpenShift Container Platform. La CR SiteConfig contient les paramètres spécifiques aux clusters requis pour l'installation. Elle comporte des options permettant d'appliquer certaines CR de configuration pendant l'installation, y compris des manifestes supplémentaires définis par l'utilisateur.
Le plugin ZTP GitOps traite les CR SiteConfig pour générer une collection de CR sur le cluster hub. Cela déclenche le service assisté dans Red Hat Advanced Cluster Management (RHACM) pour installer OpenShift Container Platform sur l'hôte bare-metal. Vous pouvez trouver l'état de l'installation et les messages d'erreur dans ces CR sur le cluster du concentrateur.
Vous pouvez approvisionner des grappes individuelles manuellement ou par lots à l'aide de ZTP :
- Approvisionnement d'un seul cluster
-
Créez un CR
SiteConfigunique et les CR d'installation et de configuration associés pour le cluster, et appliquez-les dans le cluster hub pour commencer le provisionnement du cluster. C'est un bon moyen de tester vos CR avant de les déployer à plus grande échelle. - Approvisionnement de nombreux clusters
-
Installez des clusters gérés par lots de 400 au maximum en définissant
SiteConfiget les CR associés dans un référentiel Git. ArgoCD utilise les CRSiteConfigpour déployer les sites. Le générateur de politiques RHACM crée les manifestes et les applique au cluster hub. Ceci démarre le processus de provisionnement du cluster.
21.1.4. Configuration de clusters gérés avec des politiques et des ressources PolicyGenTemplate
Le Zero Touch Provisioning (ZTP) utilise Red Hat Advanced Cluster Management (RHACM) pour configurer les clusters en utilisant une approche de gouvernance basée sur des règles pour appliquer la configuration.
Le générateur de politiques ou PolicyGen est un plugin pour l'opérateur GitOps qui permet de créer des politiques RHACM à partir d'un modèle concis. L'outil peut combiner plusieurs CR en une seule politique, et vous pouvez générer plusieurs politiques qui s'appliquent à divers sous-ensembles de clusters dans votre flotte.
Pour des raisons d'évolutivité et pour réduire la complexité de la gestion des configurations dans le parc de grappes, utilisez des CR de configuration présentant autant de points communs que possible.
- Dans la mesure du possible, appliquer les RC de configuration à l'aide d'une politique commune à l'ensemble de la flotte.
- La préférence suivante consiste à créer des groupements logiques de clusters pour gérer autant que possible les configurations restantes dans le cadre d'une politique de groupe.
- Lorsqu'une configuration est propre à un site individuel, utilisez RHACM templating sur le cluster hub pour injecter les données spécifiques au site dans une stratégie commune ou de groupe. Il est également possible d'appliquer une politique de site individuelle pour le site.
Le diagramme suivant montre comment le générateur de politiques interagit avec GitOps et RHACM dans la phase de configuration du déploiement du cluster.
Pour les grandes flottes de clusters, il est courant que la configuration de ces clusters soit très cohérente.
La structure des politiques recommandée ci-après combine les CR de configuration pour atteindre plusieurs objectifs :
- Décrire les configurations courantes et les appliquer à la flotte.
- Réduire le nombre de politiques maintenues et gérées.
- Favoriser la flexibilité dans les configurations communes pour les variantes de grappes.
Tableau 21.1. Catégories de politiques recommandées dans PolicyGenTemplate
| Catégorie de politique | Description |
|---|---|
| Communs |
Une politique qui existe dans la catégorie commune est appliquée à tous les clusters du parc. Utilisez les CR communs |
| Groupes |
Une stratégie qui existe dans la catégorie des groupes est appliquée à un groupe de clusters dans le parc. Utilisez les CR de groupe |
| Sites | Une politique qui existe dans la catégorie des sites est appliquée à un site spécifique de la grappe. Chaque cluster peut avoir ses propres politiques spécifiques gérées. |
Ressources supplémentaires
-
Pour plus d'informations sur l'extraction des CR de référence
SiteConfigetPolicyGenTemplatede l'image du conteneurztp-site-generate, voir Préparation du dépôt ZTP Git.
21.2. Préparation de la grappe du concentrateur pour ZTP
Pour utiliser RHACM dans un environnement déconnecté, créez un registre miroir qui reflète les images de version d'OpenShift Container Platform et le catalogue Operator Lifecycle Manager (OLM) qui contient les images d'opérateurs requises. OLM gère, installe et met à niveau les opérateurs et leurs dépendances dans le cluster. Vous pouvez également utiliser un hôte miroir déconnecté pour servir les images de disque RHCOS ISO et RootFS qui sont utilisées pour provisionner les hôtes bare-metal.
21.2.1. Versions logicielles de la solution Telco RAN 4.12 validées
La solution Red Hat Telco Radio Access Network (RAN) version 4.12 a été validée à l'aide des produits logiciels Red Hat suivants.
Tableau 21.2. Logiciel de solution validé Telco RAN 4.12
| Produit | Version du logiciel |
|---|---|
| Cluster OpenShift Container Platform version | 4.12 |
| Plugin GitOps ZTP | 4.10, 4.11 ou 4.12 |
| Red Hat Advanced Cluster Management (RHACM) | 2.6, 2.7 |
| Red Hat OpenShift GitOps | 1.6 |
| Gestionnaire du cycle de vie tenant compte de la topologie (TALM) | 4.10, 4.11 ou 4.12 |
21.2.2. Installation de GitOps ZTP dans un environnement déconnecté
Utilisez Red Hat Advanced Cluster Management (RHACM), Red Hat OpenShift GitOps et Topology Aware Lifecycle Manager (TALM) sur le cluster hub dans l'environnement déconnecté pour gérer le déploiement de plusieurs clusters gérés.
Conditions préalables
-
Vous avez installé le CLI OpenShift Container Platform (
oc). -
Vous vous êtes connecté en tant qu'utilisateur avec les privilèges
cluster-admin. Vous avez configuré un registre miroir déconnecté à utiliser dans le cluster.
NoteLe registre miroir déconnecté que vous créez doit contenir une version des images de sauvegarde et de pré-cache de TALM qui correspond à la version de TALM en cours d'exécution dans le cluster hub. Le cluster de rayons doit pouvoir résoudre ces images dans le registre miroir déconnecté.
Procédure
- Installez RHACM dans le cluster hub. Voir Installation de RHACM dans un environnement déconnecté.
- Installer GitOps et TALM dans le hub cluster.
Ressources supplémentaires
21.2.3. Ajout d'images RHCOS ISO et RootFS à l'hôte miroir déconnecté
Avant de commencer à installer des clusters dans l'environnement déconnecté avec Red Hat Advanced Cluster Management (RHACM), vous devez d'abord héberger les images Red Hat Enterprise Linux CoreOS (RHCOS) pour qu'elles soient utilisées. Utilisez un miroir déconnecté pour héberger les images RHCOS.
Conditions préalables
- Déployer et configurer un serveur HTTP pour héberger les ressources de l'image RHCOS sur le réseau. Vous devez pouvoir accéder au serveur HTTP depuis votre ordinateur et depuis les machines que vous créez.
Les images RHCOS peuvent ne pas changer avec chaque version d'OpenShift Container Platform. Vous devez télécharger les images avec la version la plus élevée qui est inférieure ou égale à la version que vous installez. Utilisez les versions d'image qui correspondent à votre version d'OpenShift Container Platform si elles sont disponibles. Vous avez besoin d'images ISO et RootFS pour installer RHCOS sur les hôtes. Les images RHCOS QCOW2 ne sont pas prises en charge pour ce type d'installation.
Procédure
- Connectez-vous à l'hôte miroir.
Obtenez les images RHCOS ISO et RootFS à partir de mirror.openshift.com, par exemple :
Exporter les noms des images requises et la version d'OpenShift Container Platform en tant que variables d'environnement :
$ export ISO_IMAGE_NAME=<iso_image_name> 1$ export ROOTFS_IMAGE_NAME=<rootfs_image_name> 1$ export OCP_VERSION=<ocp_version> 1Téléchargez les images nécessaires :
$ sudo wget https://mirror.openshift.com/pub/openshift-v4/dependencies/rhcos/4.12/${OCP_VERSION}/${ISO_IMAGE_NAME} -O /var/www/html/${ISO_IMAGE_NAME}$ sudo wget https://mirror.openshift.com/pub/openshift-v4/dependencies/rhcos/4.12/${OCP_VERSION}/${ROOTFS_IMAGE_NAME} -O /var/www/html/${ROOTFS_IMAGE_NAME}
Verification steps
Vérifiez que les images ont été téléchargées avec succès et qu'elles sont servies sur l'hôte miroir déconnecté, par exemple :
$ wget http://$(hostname)/${ISO_IMAGE_NAME}Exemple de sortie
Saving to: rhcos-4.12.1-x86_64-live.x86_64.iso rhcos-4.12.1-x86_64-live.x86_64.iso- 11%[====> ] 10.01M 4.71MB/s
Ressources supplémentaires
21.2.4. Activation du service assisté et mise à jour de AgentServiceConfig sur le cluster hub
Red Hat Advanced Cluster Management (RHACM) utilise le service assisté pour déployer les clusters OpenShift Container Platform. Le service assisté est déployé automatiquement lorsque vous activez l'opérateur MultiClusterHub avec Central Infrastructure Management (CIM). Lorsque vous avez activé CIM sur le cluster hub, vous devez alors mettre à jour la ressource personnalisée (CR) AgentServiceConfig avec des références aux images ISO et RootFS qui sont hébergées sur le serveur HTTP du registre miroir.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté au cluster hub en tant qu'utilisateur avec les privilèges
cluster-admin. - Vous avez activé le service assisté sur le cluster du concentrateur. Pour plus d'informations, voir Activation du service de gestion de l'infrastructure centrale.
Procédure
Mettez à jour le CR
AgentServiceConfigen exécutant la commande suivante :$ oc edit AgentServiceConfig
Ajouter l'entrée suivante au champ
items.spec.osImagesdu CR :- cpuArchitecture: x86_64 openshiftVersion: "4.12" rootFSUrl: https://<host>/<path>/rhcos-live-rootfs.x86_64.img url: https://<mirror-registry>/<path>/rhcos-live.x86_64.isooù :
- <host>
- Nom de domaine complet (FQDN) du serveur HTTP du registre miroir cible.
- <sentier>
- Chemin d'accès à l'image sur le registre du miroir cible.
Enregistrez et quittez l'éditeur pour appliquer les modifications.
21.2.5. Configuration du cluster hub pour utiliser un registre miroir déconnecté
Vous pouvez configurer le hub cluster pour utiliser un registre miroir déconnecté pour un environnement déconnecté.
Conditions préalables
- Vous avez une installation de cluster hub déconnecté avec Red Hat Advanced Cluster Management (RHACM) 2.5 installé.
-
Vous avez hébergé les images
rootfsetisosur un serveur HTTP.
Si vous activez TLS pour le serveur HTTP, vous devez confirmer que le certificat racine est signé par une autorité approuvée par le client et vérifier la chaîne de certificats approuvés entre votre hub OpenShift Container Platform et les clusters gérés et le serveur HTTP. L'utilisation d'un serveur configuré avec un certificat non approuvé empêche le téléchargement des images vers le service de création d'images. L'utilisation de serveurs HTTPS non approuvés n'est pas prise en charge.
Procédure
Créer un
ConfigMapcontenant la configuration du registre miroir :apiVersion: v1 kind: ConfigMap metadata: name: assisted-installer-mirror-config namespace: assisted-installer labels: app: assisted-service data: ca-bundle.crt: <certificate> 1 registries.conf: | 2 unqualified-search-registries = ["registry.access.redhat.com", "docker.io"] [[registry]] location = <mirror_registry_url> 3 insecure = false mirror-by-digest-only = true- 1
- Certificat du registre miroir utilisé lors de la création du registre miroir.
- 2
- Le fichier de configuration du registre des miroirs. La configuration du registre miroir ajoute des informations de miroir à
/etc/containers/registries.confdans l'image de découverte. Ces informations sont stockées dans la sectionimageContentSourcesdu fichierinstall-config.yamllorsqu'elles sont transmises au programme d'installation. Le pod de service assisté fonctionnant sur le cluster HUB récupère les images des conteneurs à partir du registre miroir configuré. - 3
- L'URL du registre miroir.
Cette opération met à jour
mirrorRegistryRefdans la ressource personnaliséeAgentServiceConfig, comme indiqué ci-dessous :Exemple de sortie
apiVersion: agent-install.openshift.io/v1beta1 kind: AgentServiceConfig metadata: name: agent namespace: assisted-installer spec: databaseStorage: volumeName: <db_pv_name> accessModes: - ReadWriteOnce resources: requests: storage: <db_storage_size> filesystemStorage: volumeName: <fs_pv_name> accessModes: - ReadWriteOnce resources: requests: storage: <fs_storage_size> mirrorRegistryRef: name: 'assisted-installer-mirror-config' osImages: - openshiftVersion: <ocp_version> rootfs: <rootfs_url> 1 url: <iso_url> 2
Un serveur NTP valide est requis lors de l'installation des clusters. Assurez-vous qu'un serveur NTP approprié est disponible et qu'il est accessible depuis les grappes installées via le réseau déconnecté.
21.2.6. Configurer le hub cluster pour utiliser des registres non authentifiés
Vous pouvez configurer le cluster hub pour utiliser des registres non authentifiés. Les registres non authentifiés ne nécessitent pas d'authentification pour accéder aux images et les télécharger.
Conditions préalables
- Vous avez installé et configuré un cluster de type hub et installé Red Hat Advanced Cluster Management (RHACM) sur le cluster de type hub.
- Vous avez installé le CLI (oc) de OpenShift Container Platform.
-
Vous vous êtes connecté en tant qu'utilisateur avec les privilèges
cluster-admin. - Vous avez configuré un registre non authentifié à utiliser avec le cluster hub.
Procédure
Mettez à jour la ressource personnalisée (CR)
AgentServiceConfigen exécutant la commande suivante :$ oc edit AgentServiceConfig agent
Ajouter le champ
unauthenticatedRegistriesdans le CR :apiVersion: agent-install.openshift.io/v1beta1 kind: AgentServiceConfig metadata: name: agent spec: unauthenticatedRegistries: - example.registry.com - example.registry2.com ...
Les registres non authentifiés sont répertoriés sous
spec.unauthenticatedRegistriesdans la ressourceAgentServiceConfig. Tout registre figurant sur cette liste n'est pas tenu d'avoir une entrée dans le secret d'extraction utilisé pour l'installation du cluster de rayons.assisted-servicevalide le secret d'extraction en s'assurant qu'il contient les informations d'authentification pour chaque registre d'image utilisé pour l'installation.
Les registres miroirs sont automatiquement ajoutés à la liste des ignorés et n'ont pas besoin d'être ajoutés sous spec.unauthenticatedRegistries. La spécification de la variable d'environnement PUBLIC_CONTAINER_REGISTRIES dans ConfigMap remplace les valeurs par défaut par la valeur spécifiée. Les valeurs par défaut de PUBLIC_CONTAINER_REGISTRIES sont quay.io et registry.svc.ci.openshift.org.
Vérification
Vérifiez que vous pouvez accéder au registre nouvellement ajouté à partir du cluster hub en exécutant les commandes suivantes :
Ouvrez un shell de débogage vers le cluster du concentrateur :
oc debug node/<node_name>
Testez l'accès au registre non authentifié en exécutant la commande suivante :
sh-4.4# podman login -u kubeadmin -p $(oc whoami -t) <unauthenticated_registry>
où :
- <registre_non-authentifié>
-
Le nouveau registre est-il, par exemple,
unauthenticated-image-registry.openshift-image-registry.svc:5000.
Exemple de sortie
Login Succeeded!
21.2.7. Configuration du cluster hub avec ArgoCD
Vous pouvez configurer le cluster hub avec un ensemble d'applications ArgoCD qui génèrent les ressources personnalisées (CR) d'installation et de stratégie requises pour chaque site avec GitOps zero touch provisioning (ZTP).
Red Hat Advanced Cluster Management (RHACM) utilise les CR SiteConfig pour générer les CR d'installation de cluster géré du jour 1 pour ArgoCD. Chaque application ArgoCD peut gérer un maximum de 300 CR SiteConfig.
Conditions préalables
- Vous avez un hub cluster OpenShift Container Platform avec Red Hat Advanced Cluster Management (RHACM) et Red Hat OpenShift GitOps installés.
-
Vous avez extrait le déploiement de référence du conteneur du plugin ZTP GitOps comme décrit dans la section "Préparation du référentiel de configuration du site GitOps ZTP". L'extraction du déploiement de référence crée le répertoire
out/argocd/deploymentauquel il est fait référence dans la procédure suivante.
Procédure
Préparer la configuration du pipeline ArgoCD :
- Créez un dépôt Git avec une structure de répertoire similaire au répertoire d'exemple. Pour plus d'informations, voir "Preparing the GitOps ZTP site configuration repository".
Configurez l'accès au référentiel en utilisant l'interface utilisateur d'ArgoCD. Sous Settings, configurez les éléments suivants :
-
Repositories - Ajoutez les informations de connexion. L'URL doit se terminer par
.git, par exemple,https://repo.example.com/repo.gitet les informations d'identification. - Certificates - Ajoutez le certificat public pour le référentiel, si nécessaire.
-
Repositories - Ajoutez les informations de connexion. L'URL doit se terminer par
Modifiez les deux applications ArgoCD,
out/argocd/deployment/clusters-app.yamletout/argocd/deployment/policies-app.yaml, en fonction de votre dépôt Git :-
Mettez à jour l'URL pour qu'elle pointe vers le dépôt Git. L'URL se termine par
.git, par exemple,https://repo.example.com/repo.git. -
Le site
targetRevisionindique la branche du dépôt Git à surveiller. -
pathspécifie le chemin vers les CRSiteConfigetPolicyGenTemplate, respectivement.
-
Mettez à jour l'URL pour qu'elle pointe vers le dépôt Git. L'URL se termine par
Pour installer le plugin ZTP GitOps, vous devez patcher l'instance ArgoCD dans le cluster hub en utilisant le fichier patch précédemment extrait dans le répertoire
out/argocd/deployment/. Exécutez la commande suivante :$ oc patch argocd openshift-gitops \ -n openshift-gitops --type=merge \ --patch-file out/argocd/deployment/argocd-openshift-gitops-patch.json
Appliquez la configuration du pipeline à votre cluster hub en utilisant la commande suivante :
$ oc apply -k out/argocd/deployment
21.2.8. Préparation du dépôt de configuration du site ZTP de GitOps
Avant d'utiliser le pipeline ZTP GitOps, vous devez préparer le dépôt Git qui hébergera les données de configuration du site.
Conditions préalables
- Vous avez configuré les applications GitOps du hub cluster pour générer les ressources personnalisées (CR) d'installation et de stratégie requises.
- Vous avez déployé les clusters gérés à l'aide du Zero Touch Provisioning (ZTP).
Procédure
-
Créez une structure de répertoire avec des chemins distincts pour les CR
SiteConfigetPolicyGenTemplate. Exportez le répertoire
argocdà partir de l'image du conteneurztp-site-generateà l'aide des commandes suivantes :$ podman pull registry.redhat.io/openshift4/ztp-site-generate-rhel8:v4.12
$ mkdir -p ./out
$ podman run --log-driver=none --rm registry.redhat.io/openshift4/ztp-site-generate-rhel8:v4.12 extract /home/ztp --tar | tar x -C ./out
Vérifiez que le répertoire
outcontient les sous-répertoires suivants :-
out/extra-manifestcontient les fichiers CR source queSiteConfigutilise pour générer le manifeste supplémentaireconfigMap. -
out/source-crscontient les fichiers CR source quePolicyGenTemplateutilise pour générer les stratégies de Red Hat Advanced Cluster Management (RHACM). -
out/argocd/deploymentcontient des correctifs et des fichiers YAML à appliquer sur le cluster hub pour l'étape suivante de cette procédure. -
out/argocd/examplecontient les exemples de fichiersSiteConfigetPolicyGenTemplatequi représentent la configuration recommandée.
-
La structure des répertoires sous out/argocd/example sert de référence pour la structure et le contenu de votre dépôt Git. L'exemple inclut SiteConfig et PolicyGenTemplate, des CR de référence pour les clusters à un nœud, à trois nœuds et standard. Supprimez les références aux types de clusters que vous n'utilisez pas. L'exemple suivant décrit un ensemble de CR pour un réseau de clusters à nœud unique :
example
├── policygentemplates
│ ├── common-ranGen.yaml
│ ├── example-sno-site.yaml
│ ├── group-du-sno-ranGen.yaml
│ ├── group-du-sno-validator-ranGen.yaml
│ ├── kustomization.yaml
│ └── ns.yaml
└── siteconfig
├── example-sno.yaml
├── KlusterletAddonConfigOverride.yaml
└── kustomization.yaml
Conservez les CR SiteConfig et PolicyGenTemplate dans des répertoires distincts. Les répertoires SiteConfig et PolicyGenTemplate doivent contenir un fichier kustomization.yaml qui inclut explicitement les fichiers de ce répertoire.
Cette structure de répertoire et les fichiers kustomization.yaml doivent être validés et transférés dans votre dépôt Git. Le premier transfert vers Git doit inclure les fichiers kustomization.yaml. Les fichiers SiteConfig (example-sno.yaml) et PolicyGenTemplate (common-ranGen.yaml, group-du-sno*.yaml, et example-sno-site.yaml) peuvent être omis et transférés ultérieurement si nécessaire lors du déploiement d'un site.
Le fichier KlusterletAddonConfigOverride.yaml n'est requis que si un ou plusieurs CR SiteConfig qui y font référence sont validés et poussés sur Git. Voir example-sno.yaml pour un exemple d'utilisation.
21.3. Installation de clusters gérés avec RHACM et les ressources SiteConfig
Vous pouvez provisionner des clusters OpenShift Container Platform à l'échelle avec Red Hat Advanced Cluster Management (RHACM) en utilisant le service assisté et le générateur de politiques du plugin GitOps avec la technologie de réduction du noyau activée. Le pipeline ZTP (zero touch priovisioning) effectue les installations de clusters. ZTP peut être utilisé dans un environnement déconnecté.
21.3.1. GitOps ZTP et Topology Aware Lifecycle Manager (Gestionnaire de cycle de vie avec prise en compte de la topologie)
GitOps zero touch provisioning (ZTP) génère des CR d'installation et de configuration à partir de manifestes stockés dans Git. Ces artefacts sont appliqués à un cluster hub centralisé où Red Hat Advanced Cluster Management (RHACM), le service assisté et le Topology Aware Lifecycle Manager (TALM) utilisent les CR pour installer et configurer le cluster géré. La phase de configuration du pipeline ZTP utilise le TALM pour orchestrer l'application des CR de configuration au cluster. Il existe plusieurs points d'intégration clés entre GitOps ZTP et le TALM.
- Informer les politiques
-
Par défaut, le ZTP GitOps crée toutes les politiques avec une action de remédiation de
inform. Ces politiques provoquent un rapport du RHACM sur l'état de conformité des clusters concernés par les politiques, mais n'appliquent pas la configuration souhaitée. Au cours du processus ZTP, après l'installation d'OpenShift, le TALM passe en revue les politiquesinformcréées et les applique au(x) cluster(s) géré(s) cible(s). Cela permet d'appliquer la configuration au cluster géré. En dehors de la phase ZTP du cycle de vie du cluster, cela vous permet de modifier les politiques sans risquer de déployer immédiatement ces changements sur les clusters gérés affectés. Vous pouvez contrôler le calendrier et l'ensemble des clusters remédiés en utilisant TALM. - Création automatique des CR de ClusterGroupUpgrade
Pour automatiser la configuration initiale des clusters nouvellement déployés, le TALM surveille l'état de tous les CR
ManagedClustersur le cluster hub. Tout CRManagedClusterqui n'a pas d'étiquetteztp-doneappliquée, y compris les CRManagedClusternouvellement créés, entraîne la création automatique par le TALM d'un CRClusterGroupUpgradeavec les caractéristiques suivantes :-
Le CR
ClusterGroupUpgradeest créé et activé dans l'espace de nomsztp-install. -
ClusterGroupUpgradeCR porte le même nom que leManagedClusterCR. -
Le sélecteur de grappes n'inclut que la grappe associée à la CR
ManagedCluster. -
L'ensemble des politiques gérées comprend toutes les politiques que RHACM a liées au cluster au moment de la création de
ClusterGroupUpgrade. - La mise en cache préalable est désactivée.
- Le délai d'attente est fixé à 4 heures (240 minutes).
La création automatique d'une adresse
ClusterGroupUpgradeactivée garantit que le déploiement initial des grappes se fait sans intervention de l'utilisateur. En outre, la création automatique d'un CRClusterGroupUpgradepour toutManagedClustersans le labelztp-donepermet de redémarrer une installation ZTP défaillante en supprimant simplement le CRClusterGroupUpgradepour le cluster.-
Le CR
- Vagues
Chaque politique générée à partir d'une CR
PolicyGenTemplatecomprend une annotationztp-deploy-wave. Cette annotation est basée sur la même annotation de chaque RC qui est incluse dans cette politique. L'annotation "vague" est utilisée pour ordonner les politiques dans la CRClusterGroupUpgradegénérée automatiquement. L'annotation de la vague n'est pas utilisée ailleurs que dans le CR auto-généréClusterGroupUpgrade.NoteTous les CR d'une même politique doivent avoir le même paramètre pour l'annotation
ztp-deploy-wave. La valeur par défaut de cette annotation pour chaque CR peut être remplacée dans . La valeur par défaut de cette annotation pour chaque RC peut être remplacée par l'annotationPolicyGenTemplate. L'annotation wave dans le RC source est utilisée pour déterminer et fixer l'annotation wave de la politique. Cette annotation est supprimée de chaque RC construit qui est inclus dans la politique générée au moment de l'exécution.Le TALM applique les politiques de configuration dans l'ordre spécifié par les annotations de vagues. Le TALM attend que chaque politique soit conforme avant de passer à la politique suivante. Il est important de s'assurer que l'annotation d'onde pour chaque RC prend en compte les conditions préalables à l'application de ces RC au cluster. Par exemple, un opérateur doit être installé avant ou en même temps que la configuration de l'opérateur. De même, le site
CatalogSourcepour un opérateur doit être installé dans une vague avant ou en même temps que l'abonnement de l'opérateur. La valeur par défaut de la vague pour chaque CR tient compte de ces conditions préalables.Plusieurs CR et politiques peuvent partager le même numéro d'onde. Le fait d'avoir moins de politiques peut accélérer les déploiements et réduire l'utilisation de l'unité centrale. La meilleure pratique consiste à regrouper de nombreux CR en un nombre relativement restreint de vagues.
Pour vérifier la valeur par défaut de la vague dans chaque CR source, exécutez la commande suivante dans le répertoire out/source-crs extrait de l'image du conteneur ztp-site-generate:
$ grep -r "ztp-deploy-wave" out/source-crs
- Étiquettes de phase
Le CR
ClusterGroupUpgradeest automatiquement créé et comprend des directives pour annoter le CRManagedClusteravec des étiquettes au début et à la fin du processus ZTP.Lorsque la configuration ZTP post-installation commence, l'étiquette
ztp-runningest appliquée à l'adresseManagedCluster. Lorsque toutes les politiques sont remédiées dans le cluster et sont entièrement conformes, ces directives amènent le TALM à supprimer le labelztp-runninget à appliquer le labelztp-done.Pour les déploiements qui utilisent la politique
informDuValidator, le labelztp-doneest appliqué lorsque le cluster est entièrement prêt pour le déploiement des applications. Cela inclut tous les rapprochements et les effets résultants des CR de configuration appliqués par ZTP. Le labelztp-doneaffecte la création automatique de CRClusterGroupUpgradepar TALM. Ne manipulez pas ce label après l'installation initiale de la grappe par ZTP.- CR liés
-
La CR
ClusterGroupUpgradecréée automatiquement a la même référence propriétaire que la CRManagedClusterdont elle est dérivée. Cette référence garantit que la suppression de la CRManagedClusterentraîne la suppression de l'instance de la CRClusterGroupUpgradeet de toutes les ressources qui la soutiennent.
21.3.2. Vue d'ensemble du déploiement de grappes gérées avec ZTP
Red Hat Advanced Cluster Management (RHACM) utilise le zero touch provisioning (ZTP) pour déployer des clusters OpenShift Container Platform à un nœud, des clusters à trois nœuds et des clusters standard. Vous gérez les données de configuration du site en tant que ressources personnalisées (CR) OpenShift Container Platform dans un référentiel Git. ZTP utilise une approche GitOps déclarative pour un modèle de développement unique et de déploiement en tout lieu afin de déployer les clusters gérés.
Le déploiement des grappes comprend
- Installation du système d'exploitation hôte (RHCOS) sur un serveur vierge
- Déployer OpenShift Container Platform
- Création de politiques de cluster et d'abonnements à des sites
- Effectuer les configurations réseau nécessaires au système d'exploitation du serveur
- Déployer les opérateurs de profil et effectuer toute configuration logicielle nécessaire, telle que le profil de performance, le PTP et le SR-IOV
Vue d'ensemble du processus d'installation d'un site géré
Une fois que vous avez appliqué les ressources personnalisées (CR) du site géré sur le cluster du concentrateur, les actions suivantes se produisent automatiquement :
- Un fichier ISO d'image de découverte est généré et démarré sur l'hôte cible.
- Lorsque le fichier ISO démarre avec succès sur l'hôte cible, il communique au RHACM les informations relatives au matériel de l'hôte.
- Une fois tous les hôtes découverts, OpenShift Container Platform est installé.
-
Lorsque l'installation d'OpenShift Container Platform est terminée, le hub installe le service
klusterletsur le cluster cible. - Les services complémentaires demandés sont installés sur le cluster cible.
Le processus ISO de l'image de découverte est terminé lorsque le CR Agent pour le cluster géré est créé sur le cluster concentrateur.
L'hôte bare-metal cible doit répondre aux exigences en matière de réseau, de firmware et de matériel énumérées dans Configuration recommandée d'un cluster OpenShift à nœud unique pour les charges de travail des applications vDU.
21.3.3. Création des secrets de l'hôte bare-metal géré
Ajoutez les ressources personnalisées (CR) Secret requises pour l'hôte bare-metal géré au cluster du concentrateur. Vous avez besoin d'un secret pour le pipeline ZTP afin d'accéder au Baseboard Management Controller (BMC) et d'un secret pour le service d'installation assistée afin d'extraire les images d'installation de cluster du registre.
Les secrets sont référencés à partir du CR SiteConfig par leur nom. L'espace de noms doit correspondre à l'espace de noms de SiteConfig.
Procédure
Créer un fichier secret YAML contenant les informations d'identification pour le contrôleur de gestion de carte de base (BMC) de l'hôte et un secret d'extraction requis pour l'installation d'OpenShift et de tous les opérateurs de cluster supplémentaires :
Enregistrer le YAML suivant dans le fichier
example-sno-secret.yaml:apiVersion: v1 kind: Secret metadata: name: example-sno-bmc-secret namespace: example-sno 1 data: 2 password: <base64_password> username: <base64_username> type: Opaque --- apiVersion: v1 kind: Secret metadata: name: pull-secret namespace: example-sno 3 data: .dockerconfigjson: <pull_secret> 4 type: kubernetes.io/dockerconfigjson
-
Ajoutez le chemin relatif vers
example-sno-secret.yamlau fichierkustomization.yamlque vous utilisez pour installer le cluster.
21.3.4. Configuration des arguments du noyau Discovery ISO pour les installations utilisant GitOps ZTP
Le flux de travail GitOps ZTP utilise l'ISO Discovery dans le cadre du processus d'installation d'OpenShift Container Platform sur les hôtes bare-metal gérés. Vous pouvez éditer la ressource InfraEnv pour spécifier les arguments du noyau pour l'ISO de découverte. Ceci est utile pour les installations de clusters avec des exigences environnementales spécifiques. Par exemple, configurez l'argument de noyau rd.net.timeout.carrier pour l'ISO de découverte afin de faciliter la mise en réseau statique du cluster ou de recevoir une adresse DHCP avant de télécharger le système de fichiers racine pendant l'installation.
Dans OpenShift Container Platform 4.12, vous ne pouvez qu'ajouter des arguments de noyau. Vous ne pouvez pas remplacer ou supprimer des arguments du noyau.
Conditions préalables
- Vous avez installé le CLI OpenShift (oc).
- Vous vous êtes connecté au cluster hub en tant qu'utilisateur disposant des privilèges cluster-admin.
Procédure
Créez le CR
InfraEnvet modifiez la spécificationspec.kernelArgumentspour configurer les arguments du noyau.Enregistrez le YAML suivant dans un fichier
InfraEnv-example.yaml:NoteDans cet exemple, la CR
InfraEnvutilise une syntaxe de modèle telle que{{ .Cluster.ClusterName }}qui est remplie en fonction des valeurs de la CRSiteConfig. La CRSiteConfigremplit automatiquement les valeurs de ces modèles pendant le déploiement. Ne modifiez pas les modèles manuellement.apiVersion: agent-install.openshift.io/v1beta1 kind: InfraEnv metadata: annotations: argocd.argoproj.io/sync-wave: "1" name: "{{ .Cluster.ClusterName }}" namespace: "{{ .Cluster.ClusterName }}" spec: clusterRef: name: "{{ .Cluster.ClusterName }}" namespace: "{{ .Cluster.ClusterName }}" kernelArguments: - operation: append 1 value: audit=0 2 - operation: append value: trace=1 sshAuthorizedKey: "{{ .Site.SshPublicKey }}" proxy: "{{ .Cluster.ProxySettings }}" pullSecretRef: name: "{{ .Site.PullSecretRef.Name }}" ignitionConfigOverride: "{{ .Cluster.IgnitionConfigOverride }}" nmStateConfigLabelSelector: matchLabels: nmstate-label: "{{ .Cluster.ClusterName }}" additionalNTPSources: "{{ .Cluster.AdditionalNTPSources }}"
Livrez le CR
InfraEnv-example.yamlau même endroit dans votre dépôt Git que le CRSiteConfiget repoussez vos modifications. L'exemple suivant montre un exemple de structure de dépôt Git :~/example-ztp/install └── site-install ├── siteconfig-example.yaml ├── InfraEnv-example.yaml ...Modifiez la spécification
spec.clusters.crTemplatesdans le CRSiteConfigpour faire référence au CRInfraEnv-example.yamldans votre référentiel Git :clusters: crTemplates: InfraEnv: "InfraEnv-example.yaml"Lorsque vous êtes prêt à déployer votre cluster en validant et en poussant le CR
SiteConfig, le pipeline de construction utilise le CR personnaliséInfraEnv-exampledans votre dépôt Git pour configurer l'environnement d'infrastructure, y compris les arguments personnalisés du noyau.
Vérification
Pour vérifier que les arguments du noyau sont appliqués, après que l'image Discovery a vérifié qu'OpenShift Container Platform est prêt pour l'installation, vous pouvez vous connecter en SSH à l'hôte cible avant que le processus d'installation ne commence. À ce moment-là, vous pouvez voir les arguments du noyau pour l'ISO Discovery dans le fichier /proc/cmdline.
Ouvrez une session SSH avec l'hôte cible :
$ ssh -i /path/to/privatekey core@<nom_de_l'hôte>
Affichez les arguments du noyau du système à l'aide de la commande suivante :
$ cat /proc/cmdline
21.3.5. Déploiement d'un cluster géré avec SiteConfig et ZTP
Suivez la procédure suivante pour créer une ressource personnalisée (CR) SiteConfig et les fichiers associés, et pour lancer le déploiement du cluster ZTP (Zero Touch Provisioning).
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté au cluster hub en tant qu'utilisateur avec les privilèges
cluster-admin. - Vous avez configuré le cluster du concentrateur pour générer les CR d'installation et de stratégie nécessaires.
Vous avez créé un dépôt Git dans lequel vous gérez les données de configuration de votre site personnalisé. Le référentiel doit être accessible depuis le cluster du concentrateur et vous devez le configurer comme référentiel source pour l'application ArgoCD. Voir "Préparation du dépôt de configuration de site GitOps ZTP" pour plus d'informations.
NoteLorsque vous créez le référentiel source, assurez-vous de patcher l'application ArgoCD avec le fichier de patches
argocd/deployment/argocd-openshift-gitops-patch.jsonque vous extrayez du conteneurztp-site-generate. Voir "Configuration du cluster hub avec ArgoCD".Pour être prêt à provisionner des clusters gérés, vous devez disposer des éléments suivants pour chaque hôte bare-metal :
- Connectivité du réseau
- Votre réseau a besoin de DNS. Les hôtes des clusters gérés doivent être joignables depuis le hub cluster. Assurez-vous que la connectivité de couche 3 existe entre le cluster hub et l'hôte du cluster géré.
- Détails du contrôleur de gestion de la carte de base (BMC)
-
ZTP utilise le nom d'utilisateur et le mot de passe de la BMC pour se connecter à la BMC lors de l'installation du cluster. Le plugin ZTP de GitOps gère les CR
ManagedClustersur le cluster hub en se basant sur le CRSiteConfigdans le repo Git de votre site. Vous devez créer manuellement les CRBMCSecretpour chaque hôte.
Procédure
Créez les secrets de cluster gérés requis sur le cluster concentrateur. Ces ressources doivent se trouver dans un espace de noms dont le nom correspond à celui du cluster. Par exemple, dans
out/argocd/example/siteconfig/example-sno.yaml, le nom du cluster et l'espace de noms sontexample-sno.Exportez l'espace de noms du cluster en exécutant la commande suivante :
$ export CLUSTERNS=example-sno
Créer l'espace de noms :
$ oc create namespace $CLUSTERNS
Créez un secret d'extraction et des CR BMC
Secretpour le cluster géré. Le secret d'extraction doit contenir toutes les informations d'identification nécessaires à l'installation d'OpenShift Container Platform et de tous les opérateurs requis. Voir "Creating the managed bare-metal host secrets" pour plus d'informations.NoteLes secrets sont référencés à partir de la ressource personnalisée (CR)
SiteConfigpar leur nom. L'espace de noms doit correspondre à l'espace de nomsSiteConfig.Créez un
SiteConfigCR pour votre cluster dans votre clone local du dépôt Git :Choisissez l'exemple approprié pour votre CR dans le dossier
out/argocd/example/siteconfig/. Ce dossier contient des fichiers d'exemple pour les grappes à un nœud, à trois nœuds et standard :-
example-sno.yaml -
example-3node.yaml -
example-standard.yaml
-
Modifiez les détails de la grappe et de l'hôte dans le fichier d'exemple pour qu'ils correspondent au type de grappe que vous souhaitez. Par exemple :
Exemple de cluster OpenShift à nœud unique SiteConfig CR
apiVersion: ran.openshift.io/v1 kind: SiteConfig metadata: name: "<site_name>" namespace: "<site_name>" spec: baseDomain: "example.com" pullSecretRef: name: "assisted-deployment-pull-secret" 1 clusterImageSetNameRef: "openshift-4.12" 2 sshPublicKey: "ssh-rsa AAAA..." 3 clusters: - clusterName: "<site_name>" networkType: "OVNKubernetes" clusterLabels: 4 common: true group-du-sno: "" sites : "<site_name>" clusterNetwork: - cidr: 1001:1::/48 hostPrefix: 64 machineNetwork: - cidr: 1111:2222:3333:4444::/64 serviceNetwork: - 1001:2::/112 additionalNTPSources: - 1111:2222:3333:4444::2 #crTemplates: # KlusterletAddonConfig: "KlusterletAddonConfigOverride.yaml" 5 nodes: - hostName: "example-node.example.com" 6 role: "master" bmcAddress: idrac-virtualmedia://<out_of_band_ip>/<system_id>/ 7 bmcCredentialsName: name: "bmh-secret" 8 bootMACAddress: "AA:BB:CC:DD:EE:11" bootMode: "UEFI" 9 rootDeviceHints: wwn: "0x11111000000asd123" cpuset: "0-1,52-53" 10 nodeNetwork: 11 interfaces: - name: eno1 macAddress: "AA:BB:CC:DD:EE:11" config: interfaces: - name: eno1 type: ethernet state: up ipv4: enabled: false ipv6: 12 enabled: true address: - ip: 1111:2222:3333:4444::aaaa:1 prefix-length: 64 dns-resolver: config: search: - example.com server: - 1111:2222:3333:4444::2 routes: config: - destination: ::/0 next-hop-interface: eno1 next-hop-address: 1111:2222:3333:4444::1 table-id: 254- 1
- Créez le CR
assisted-deployment-pull-secretavec le même espace de noms que le CRSiteConfig. - 2
clusterImageSetNameRefdéfinit un jeu d'images disponible sur le hub cluster. Pour voir la liste des versions supportées sur votre hub cluster, exécutezoc get clusterimagesets.- 3
- Configurer la clé publique SSH utilisée pour accéder au cluster.
- 4
- Les libellés des grappes doivent correspondre au champ
bindingRulesdans les CRPolicyGenTemplateque vous définissez. Par exemple,policygentemplates/common-ranGen.yamls'applique à tous les clusters dont le champcommon: trueest défini,policygentemplates/group-du-sno-ranGen.yamls'applique à tous les clusters dont le champgroup-du-sno: ""est défini. - 5
- Facultatif. Le CR spécifié sous
KlusterletAddonConfigest utilisé pour remplacer le CR par défautKlusterletAddonConfigqui est créé pour le cluster. - 6
- Pour les déploiements à un seul nœud, définissez un seul hôte. Pour les déploiements à trois nœuds, définissez trois hôtes. Pour les déploiements standard, définissez trois hôtes avec
role: masteret deux hôtes ou plus avecrole: worker. - 7
- Adresse BMC que vous utilisez pour accéder à l'hôte. S'applique à tous les types de clusters.
- 8
- Nom du CR
bmh-secretque vous créez séparément avec les informations d'identification BMC de l'hôte. Lorsque vous créez le CRbmh-secret, utilisez le même espace de noms que le CRSiteConfigqui approvisionne l'hôte. - 9
- Configure le mode de démarrage de l'hôte. La valeur par défaut est
UEFI. UtilisezUEFISecureBootpour activer le démarrage sécurisé sur l'hôte. - 10
cpusetdoit correspondre à la valeur définie dans le champ clusterPerformanceProfileCRspec.cpu.reservedpour le partitionnement de la charge de travail.- 11
- Spécifie les paramètres du réseau pour le nœud.
- 12
- Configure l'adresse IPv6 pour l'hôte. Pour les clusters OpenShift à un seul nœud avec des adresses IP statiques, l'API spécifique au nœud et les IP d'entrée doivent être les mêmes.
NotePour plus d'informations sur l'adressage BMC, voir la section "Ressources supplémentaires".
-
Vous pouvez consulter l'ensemble par défaut des CR extra-manifest
MachineConfigà l'adresseout/argocd/extra-manifest. Il est automatiquement appliqué au cluster lors de son installation. -
Facultatif : Pour provisionner des manifestes d'installation supplémentaires sur le cluster provisionné, créez un répertoire dans votre référentiel Git, par exemple,
sno-extra-manifest/, et ajoutez vos CRs de manifestes personnalisés à ce répertoire. Si votreSiteConfig.yamlfait référence à ce répertoire dans le champextraManifestPath, tous les CRs de ce répertoire référencé sont ajoutés à l'ensemble par défaut des manifestes supplémentaires.
-
Ajoutez le CR
SiteConfigau fichierkustomization.yamldans la sectiongenerators, comme dans l'exemple présenté dansout/argocd/example/siteconfig/kustomization.yaml. Commencez le CR
SiteConfiget les changementskustomization.yamlassociés dans votre dépôt Git et repoussez les changements.Le pipeline ArgoCD détecte les changements et commence le déploiement du cluster géré.
21.3.6. Suivi de la progression de l'installation des clusters gérés
Le pipeline ArgoCD utilise le CR SiteConfig pour générer les CR de configuration du cluster et le synchronise avec le cluster hub. Vous pouvez suivre la progression de la synchronisation dans le tableau de bord ArgoCD.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté au cluster hub en tant qu'utilisateur avec les privilèges
cluster-admin.
Procédure
Lorsque la synchronisation est terminée, l'installation se déroule généralement comme suit :
L'opérateur de service assisté installe OpenShift Container Platform sur le cluster. Vous pouvez surveiller la progression de l'installation du cluster à partir du tableau de bord RHACM ou de la ligne de commande en exécutant les commandes suivantes :
Exporter le nom du cluster :
$ export CLUSTER=<clusterName>
Interrogez le CR
AgentClusterInstallpour le cluster géré :$ oc get agentclusterinstall -n $CLUSTER $CLUSTER -o jsonpath='{.status.conditions[?(@.type=="Completed")]}' | jqObtenir les événements d'installation pour le cluster :
$ curl -sk $(oc get agentclusterinstall -n $CLUSTER $CLUSTER -o jsonpath='{.status.debugInfo.eventsURL}') | jq '.[-2,-1]'
21.3.7. Dépannage de GitOps ZTP en validant les CR d'installation
Le pipeline ArgoCD utilise les ressources personnalisées (CR) SiteConfig et PolicyGenTemplate pour générer les CR de configuration du cluster et les stratégies de Red Hat Advanced Cluster Management (RHACM). Utilisez les étapes suivantes pour résoudre les problèmes qui peuvent survenir au cours de ce processus.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté au cluster hub en tant qu'utilisateur avec les privilèges
cluster-admin.
Procédure
Vérifiez que les CR d'installation ont été créés en utilisant la commande suivante :
oc get AgentClusterInstall -n <cluster_name>
Si aucun objet n'est renvoyé, utilisez les étapes suivantes pour résoudre le problème du flux du pipeline ArgoCD depuis les fichiers
SiteConfigjusqu'aux CR d'installation.Vérifiez que la CR
ManagedClustera été générée à l'aide de la CRSiteConfigsur le cluster hub :$ oc get managedcluster
Si le site
ManagedClusterest manquant, vérifiez si l'applicationclustersn'a pas échoué à synchroniser les fichiers du référentiel Git vers le hub cluster :$ oc describe -n openshift-gitops application clusters
Vérifiez le champ
Status.Conditionspour afficher les journaux d'erreurs du cluster géré. Par exemple, la définition d'une valeur non valide pourextraManifestPath:dans le CRSiteConfigentraîne l'erreur suivante :Status: Conditions: Last Transition Time: 2021-11-26T17:21:39Z Message: rpc error: code = Unknown desc = `kustomize build /tmp/https___git.com/ran-sites/siteconfigs/ --enable-alpha-plugins` failed exit status 1: 2021/11/26 17:21:40 Error could not create extra-manifest ranSite1.extra-manifest3 stat extra-manifest3: no such file or directory 2021/11/26 17:21:40 Error: could not build the entire SiteConfig defined by /tmp/kust-plugin-config-913473579: stat extra-manifest3: no such file or directory Error: failure in plugin configured via /tmp/kust-plugin-config-913473579; exit status 1: exit status 1 Type: ComparisonErrorVérifiez le champ
Status.Sync. S'il y a des erreurs dans le journal, le champStatus.Syncpourrait indiquer une erreurUnknown:Status: Sync: Compared To: Destination: Namespace: clusters-sub Server: https://kubernetes.default.svc Source: Path: sites-config Repo URL: https://git.com/ran-sites/siteconfigs/.git Target Revision: master Status: Unknown
21.3.8. Suppression d'un site de cluster géré du pipeline ZTP
Vous pouvez supprimer un site géré et les CR de politique d'installation et de configuration associés du pipeline ZTP.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté au cluster hub en tant qu'utilisateur avec les privilèges
cluster-admin.
Précédent
Supprimez un site et les CR associés en supprimant les fichiers
SiteConfigetPolicyGenTemplatedu fichierkustomization.yaml.Lorsque vous exécutez à nouveau le pipeline ZTP, les CR générés sont supprimés.
-
Facultatif : Si vous souhaitez supprimer définitivement un site, vous devez également supprimer du dépôt Git les fichiers
SiteConfigetPolicyGenTemplatespécifiques au site. -
Facultatif : Si vous souhaitez supprimer temporairement un site, par exemple lors du redéploiement d'un site, vous pouvez laisser les CR
SiteConfigetPolicyGenTemplatespécifiques au site dans le référentiel Git.
Après avoir supprimé le fichier SiteConfig du référentiel Git, si les clusters correspondants sont bloqués dans le processus de détachement, vérifiez Red Hat Advanced Cluster Management (RHACM) sur le cluster hub pour obtenir des informations sur le nettoyage du cluster détaché.
Ressources supplémentaires
- Pour plus d'informations sur la suppression d'une grappe, voir Supprimer une grappe de la gestion.
21.3.9. Suppression du contenu obsolète du pipeline ZTP
Si une modification de la configuration de PolicyGenTemplate entraîne des politiques obsolètes, par exemple si vous renommez des politiques, utilisez la procédure suivante pour supprimer les politiques obsolètes.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté au cluster hub en tant qu'utilisateur avec les privilèges
cluster-admin.
Procédure
-
Supprimer les fichiers
PolicyGenTemplateconcernés du dépôt Git, valider et pousser vers le dépôt distant. - Attendez que les modifications soient synchronisées par l'application et que les stratégies concernées soient supprimées du cluster du concentrateur.
Ajouter les fichiers
PolicyGenTemplatemis à jour au dépôt Git, puis valider et pousser vers le dépôt distant.NoteLa suppression des politiques de zero touch provisioning (ZTP) du référentiel Git, et par conséquent leur suppression du hub cluster, n'affecte pas la configuration du cluster géré. La politique et les CR gérés par cette politique restent en place sur le cluster géré.
Facultatif : Après avoir apporté des modifications aux CR
PolicyGenTemplatequi entraînent des stratégies obsolètes, vous pouvez supprimer manuellement ces stratégies du cluster du concentrateur. Vous pouvez supprimer les politiques à partir de la console RHACM en utilisant l'onglet Governance ou en exécutant la commande suivante :oc delete policy -n <namespace> <policy_name>
21.3.10. Démantèlement du pipeline ZTP
Vous pouvez supprimer le pipeline ArgoCD et tous les artefacts ZTP générés.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté au cluster hub en tant qu'utilisateur avec les privilèges
cluster-admin.
Procédure
- Détachez tous les clusters de Red Hat Advanced Cluster Management (RHACM) sur le cluster concentrateur.
Supprimez le fichier
kustomization.yamldans le répertoiredeploymentà l'aide de la commande suivante :$ oc delete -k out/argocd/deployment
- Validez et transférez vos modifications dans le référentiel du site.
21.4. Configuration de clusters gérés avec des politiques et des ressources PolicyGenTemplate
Les ressources personnalisées (CR) de stratégie appliquée configurent les clusters gérés que vous provisionnez. Vous pouvez personnaliser la façon dont Red Hat Advanced Cluster Management (RHACM) utilise les CR PolicyGenTemplate pour générer les CR de stratégie appliquée.
21.4.1. À propos du CRD PolicyGenTemplate
La définition des ressources personnalisées (CRD) de PolicyGenTemplate indique au générateur de politiques PolicyGen les ressources personnalisées (CR) à inclure dans la configuration du cluster, la manière de combiner les CR dans les politiques générées et les éléments de ces CR qui doivent être mis à jour avec le contenu superposé.
L'exemple suivant montre un CR PolicyGenTemplate (common-du-ranGen.yaml) extrait du conteneur de référence ztp-site-generate. Le fichier common-du-ranGen.yaml définit deux politiques de Red Hat Advanced Cluster Management (RHACM). Les politiques gèrent une collection de CR de configuration, une pour chaque valeur unique de policyName dans le CR. common-du-ranGen.yaml crée une liaison de placement unique et une règle de placement pour lier les politiques aux clusters en fonction des étiquettes répertoriées dans la section bindingRules.
Exemple de PolicyGenTemplate CR - common-du-ranGen.yaml
---
apiVersion: ran.openshift.io/v1
kind: PolicyGenTemplate
metadata:
name: "common"
namespace: "ztp-common"
spec:
bindingRules:
common: "true" 1
sourceFiles: 2
- fileName: SriovSubscription.yaml
policyName: "subscriptions-policy"
- fileName: SriovSubscriptionNS.yaml
policyName: "subscriptions-policy"
- fileName: SriovSubscriptionOperGroup.yaml
policyName: "subscriptions-policy"
- fileName: SriovOperatorStatus.yaml
policyName: "subscriptions-policy"
- fileName: PtpSubscription.yaml
policyName: "subscriptions-policy"
- fileName: PtpSubscriptionNS.yaml
policyName: "subscriptions-policy"
- fileName: PtpSubscriptionOperGroup.yaml
policyName: "subscriptions-policy"
- fileName: PtpOperatorStatus.yaml
policyName: "subscriptions-policy"
- fileName: ClusterLogNS.yaml
policyName: "subscriptions-policy"
- fileName: ClusterLogOperGroup.yaml
policyName: "subscriptions-policy"
- fileName: ClusterLogSubscription.yaml
policyName: "subscriptions-policy"
- fileName: ClusterLogOperatorStatus.yaml
policyName: "subscriptions-policy"
- fileName: StorageNS.yaml
policyName: "subscriptions-policy"
- fileName: StorageOperGroup.yaml
policyName: "subscriptions-policy"
- fileName: StorageSubscription.yaml
policyName: "subscriptions-policy"
- fileName: StorageOperatorStatus.yaml
policyName: "subscriptions-policy"
- fileName: ReduceMonitoringFootprint.yaml
policyName: "config-policy"
- fileName: OperatorHub.yaml 3
policyName: "config-policy"
- fileName: DefaultCatsrc.yaml 4
policyName: "config-policy" 5
metadata:
name: redhat-operators
spec:
displayName: disconnected-redhat-operators
image: registry.example.com:5000/disconnected-redhat-operators/disconnected-redhat-operator-index:v4.9
- fileName: DisconnectedICSP.yaml
policyName: "config-policy"
spec:
repositoryDigestMirrors:
- mirrors:
- registry.example.com:5000
source: registry.redhat.io
- 1
common: "true"applique les politiques à tous les clusters portant cette étiquette.- 2
- Les fichiers répertoriés sous
sourceFilescréent les stratégies d'opérateur pour les clusters installés. - 3
OperatorHub.yamlconfigure l'OperatorHub pour le registre déconnecté.- 4
DefaultCatsrc.yamlconfigure la source du catalogue pour le registre déconnecté.- 5
policyName: "config-policy"configure les abonnements des opérateurs. La CROperatorHubdésactive la valeur par défaut et cette CR remplaceredhat-operatorspar une CRCatalogSourcequi pointe vers le registre déconnecté.
Une CR PolicyGenTemplate peut être construite avec n'importe quel nombre de CR incluses. Appliquez l'exemple de CR suivant dans le cluster du hub pour générer une politique contenant un seul CR :
apiVersion: ran.openshift.io/v1
kind: PolicyGenTemplate
metadata:
name: "group-du-sno"
namespace: "ztp-group"
spec:
bindingRules:
group-du-sno: ""
mcp: "master"
sourceFiles:
- fileName: PtpConfigSlave.yaml
policyName: "config-policy"
metadata:
name: "du-ptp-slave"
spec:
profile:
- name: "slave"
interface: "ens5f0"
ptp4lOpts: "-2 -s --summary_interval -4"
phc2sysOpts: "-a -r -n 24"
En utilisant le fichier source PtpConfigSlave.yaml comme exemple, le fichier définit un CR PtpConfig. La politique générée pour l'exemple PtpConfigSlave est nommée group-du-sno-config-policy. La RC PtpConfig définie dans la politique générée group-du-sno-config-policy est nommée du-ptp-slave. Le spec défini dans PtpConfigSlave.yaml est placé sous du-ptp-slave avec les autres éléments spec définis dans le fichier source.
L'exemple suivant montre le CR group-du-sno-config-policy:
apiVersion: policy.open-cluster-management.io/v1
kind: Policy
metadata:
name: group-du-ptp-config-policy
namespace: groups-sub
annotations:
policy.open-cluster-management.io/categories: CM Configuration Management
policy.open-cluster-management.io/controls: CM-2 Baseline Configuration
policy.open-cluster-management.io/standards: NIST SP 800-53
spec:
remediationAction: inform
disabled: false
policy-templates:
- objectDefinition:
apiVersion: policy.open-cluster-management.io/v1
kind: ConfigurationPolicy
metadata:
name: group-du-ptp-config-policy-config
spec:
remediationAction: inform
severity: low
namespaceselector:
exclude:
- kube-*
include:
- '*'
object-templates:
- complianceType: musthave
objectDefinition:
apiVersion: ptp.openshift.io/v1
kind: PtpConfig
metadata:
name: du-ptp-slave
namespace: openshift-ptp
spec:
recommend:
- match:
- nodeLabel: node-role.kubernetes.io/worker-du
priority: 4
profile: slave
profile:
- interface: ens5f0
name: slave
phc2sysOpts: -a -r -n 24
ptp4lConf: |
[global]
#
# Default Data Set
#
twoStepFlag 1
slaveOnly 0
priority1 128
priority2 128
domainNumber 24
.....21.4.2. Recommandations pour la personnalisation des CR PolicyGenTemplate
Tenez compte des meilleures pratiques suivantes lorsque vous personnalisez la configuration du site PolicyGenTemplate ressources personnalisées (CR) :
-
Utiliser aussi peu de politiques que nécessaire. L'utilisation de moins de politiques nécessite moins de ressources. Chaque politique supplémentaire crée des frais généraux pour le cluster hub et le cluster géré déployé. Les CR sont combinés en politiques sur la base du champ
policyNamedans le CRPolicyGenTemplate. Les CR du mêmePolicyGenTemplatequi ont la même valeur pourpolicyNamesont gérés dans le cadre d'une seule politique. -
Dans les environnements déconnectés, utilisez une source de catalogue unique pour tous les opérateurs en configurant le registre comme un index unique contenant tous les opérateurs. Chaque
CatalogSourceCR supplémentaire sur les clusters gérés augmente l'utilisation du CPU. -
MachineConfigLes CR doivent être incluses en tant queextraManifestsdans la CRSiteConfigafin qu'elles soient appliquées lors de l'installation. Cela peut réduire le temps global nécessaire pour que le cluster soit prêt à déployer des applications. -
PolicyGenTemplatesdoit remplacer le champ "channel" pour identifier explicitement la version souhaitée. Cela permet de s'assurer que les modifications apportées au CR source lors des mises à niveau ne mettent pas à jour l'abonnement généré.
Ressources supplémentaires
- Pour des recommandations sur la mise à l'échelle des clusters avec RHACM, voir Performances et évolutivité.
Lorsque vous gérez un grand nombre de grappes de rayons sur la grappe pivot, minimisez le nombre de stratégies afin de réduire la consommation de ressources.
Le regroupement de plusieurs CR de configuration en une seule politique ou en un nombre limité de politiques est un moyen de réduire le nombre total de politiques sur le cluster du concentrateur. Lorsque l'on utilise la hiérarchie des politiques communes, de groupe et de site pour gérer la configuration du site, il est particulièrement important de combiner la configuration spécifique au site dans une seule politique.
21.4.3. PolicyGenTemplate CRs pour les déploiements RAN
Utilisez les ressources personnalisées (CR) PolicyGenTemplate (PGT) pour personnaliser la configuration appliquée au cluster en utilisant le pipeline GitOps zero touch provisioning (ZTP). La PGT CR vous permet de générer une ou plusieurs politiques pour gérer l'ensemble des CR de configuration sur votre flotte de clusters. Le PGT identifie l'ensemble des CR gérés, les regroupe dans des politiques, construit l'enveloppe de la politique autour de ces CR et associe les politiques aux clusters en utilisant des règles de liaison d'étiquettes.
La configuration de référence, obtenue à partir du conteneur ZTP GitOps, est conçue pour fournir un ensemble de fonctionnalités critiques et de paramètres de réglage des nœuds qui garantissent que le cluster peut prendre en charge les contraintes strictes de performance et d'utilisation des ressources typiques des applications RAN (Radio Access Network) Distributed Unit (DU). Les modifications ou omissions de la configuration de base peuvent affecter la disponibilité des fonctionnalités, les performances et l'utilisation des ressources. Utilisez les CR de référence PolicyGenTemplate comme base pour créer une hiérarchie de fichiers de configuration adaptés aux exigences spécifiques de votre site.
Les CR de référence PolicyGenTemplate définies pour la configuration du cluster DU RAN peuvent être extraites du conteneur GitOps ZTP ztp-site-generate. Voir "Preparing the GitOps ZTP site configuration repository" pour plus de détails.
Les CR de PolicyGenTemplate se trouvent dans le dossier ./out/argocd/example/policygentemplates. L'architecture de référence comporte des CR de configuration communs, de groupe et spécifiques au site. Chaque CR PolicyGenTemplate fait référence à d'autres CR qui se trouvent dans le dossier ./out/source-crs.
Les CR PolicyGenTemplate relatifs à la configuration des grappes RAN sont décrits ci-dessous. Des variantes sont fournies pour le groupe PolicyGenTemplate CR afin de tenir compte des différences entre les configurations de grappes à un nœud, à trois nœuds compactes et standard. De même, des variantes de configuration spécifiques au site sont fournies pour les grappes à un nœud et les grappes à plusieurs nœuds (compactes ou standard). Utilisez les variantes de configuration spécifiques au groupe et au site qui sont pertinentes pour votre déploiement.
Tableau 21.3. PolicyGenTemplate CRs pour les déploiements RAN
| PolicyGenTemplate CR | Description |
|---|---|
|
| Contient un ensemble de CR qui s'appliquent aux clusters multi-nœuds. Ces CR configurent les caractéristiques SR-IOV typiques des installations RAN. |
|
| Contient un ensemble de CRs qui s'appliquent aux clusters OpenShift à nœud unique. Ces CRs configurent les fonctionnalités SR-IOV typiques des installations RAN. |
|
| Contient un ensemble de CR RAN communs qui sont appliqués à tous les clusters. Ces CR souscrivent à un ensemble d'opérateurs fournissant des fonctionnalités de cluster typiques pour la RAN ainsi que des réglages de cluster de base. |
|
| Contient les politiques RAN pour les clusters à trois nœuds uniquement. |
|
| Contient les politiques RAN pour les clusters à nœud unique uniquement. |
|
| Contient les politiques RAN pour les trois clusters de plan de contrôle standard. |
|
|
|
|
|
|
|
|
|
Ressources supplémentaires
21.4.4. Personnalisation d'un cluster géré avec des CR PolicyGenTemplate
Utilisez la procédure suivante pour personnaliser les stratégies appliquées au cluster géré que vous provisionnez à l'aide du pipeline ZTP (Zero Touch Provisioning).
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté au cluster hub en tant qu'utilisateur avec les privilèges
cluster-admin. - Vous avez configuré le cluster du concentrateur pour générer les CR d'installation et de stratégie nécessaires.
- Vous avez créé un dépôt Git dans lequel vous gérez les données de configuration de votre site personnalisé. Le référentiel doit être accessible depuis le cluster hub et être défini comme référentiel source pour l'application Argo CD.
Procédure
Créer un CR
PolicyGenTemplatepour les CR de configuration spécifiques au site.-
Choisissez l'exemple approprié pour votre CR dans le dossier
out/argocd/example/policygentemplates, par exemple,example-sno-site.yamlouexample-multinode-site.yaml. Modifiez le champ
bindingRulesdans le fichier d'exemple pour qu'il corresponde à l'étiquette spécifique au site incluse dans le CRSiteConfig. Dans l'exemple de fichierSiteConfig, l'étiquette spécifique au site estsites: example-sno.NoteVeillez à ce que les étiquettes définies dans votre champ
PolicyGenTemplatebindingRulescorrespondent aux étiquettes définies dans les clusters gérés connexesSiteConfigCR.- Modifiez le contenu du fichier d'exemple pour qu'il corresponde à la configuration souhaitée.
-
Choisissez l'exemple approprié pour votre CR dans le dossier
Facultatif : Créez une CR
PolicyGenTemplatepour toutes les CR de configuration commune qui s'appliquent à l'ensemble de la flotte de clusters.-
Sélectionnez l'exemple approprié pour votre CR dans le dossier
out/argocd/example/policygentemplates, par exemplecommon-ranGen.yaml. - Modifiez le contenu du fichier d'exemple pour qu'il corresponde à la configuration souhaitée.
-
Sélectionnez l'exemple approprié pour votre CR dans le dossier
Facultatif : Créez un CR
PolicyGenTemplatepour tous les CR de configuration de groupe qui s'appliquent à certains groupes de clusters dans la flotte.Assurez-vous que le contenu des fichiers spec superposés correspond à l'état final souhaité. À titre de référence, le répertoire out/source-crs contient la liste complète des sources-crs disponibles pour être incluses et superposées par vos modèles PolicyGenTemplate.
NoteEn fonction des exigences spécifiques de vos clusters, il se peut que vous ayez besoin de plus d'une stratégie de groupe par type de cluster, surtout si l'on considère que les stratégies de groupe de l'exemple ont chacune un seul fichier PerformancePolicy.yaml qui ne peut être partagé sur un ensemble de clusters que si ces clusters sont constitués de configurations matérielles identiques.
-
Sélectionnez l'exemple approprié pour votre CR dans le dossier
out/argocd/example/policygentemplates, par exemplegroup-du-sno-ranGen.yaml. - Modifiez le contenu du fichier d'exemple pour qu'il corresponde à la configuration souhaitée.
-
Sélectionnez l'exemple approprié pour votre CR dans le dossier
-
Facultatif. Créez un validator inform policy
PolicyGenTemplateCR pour signaler que l'installation et la configuration ZTP de la grappe déployée sont terminées. Pour plus d'informations, voir "Creating a validator inform policy". Définir tous les espaces de noms de la politique dans un fichier YAML similaire à l'exemple de fichier
out/argocd/example/policygentemplates/ns.yaml.ImportantNe pas inclure le CR
Namespacedans le même fichier que le CRPolicyGenTemplate.-
Ajoutez les CR
PolicyGenTemplateetNamespaceau fichierkustomization.yamldans la section des générateurs, comme dans l'exemple présenté dansout/argocd/example/policygentemplates/kustomization.yaml. Commencez les CR
PolicyGenTemplate, CRNamespaceet le fichierkustomization.yamlassocié dans votre dépôt Git et repoussez les changements.Le pipeline ArgoCD détecte les modifications et commence le déploiement du cluster géré. Vous pouvez pousser les modifications vers le CR
SiteConfiget le CRPolicyGenTemplatesimultanément.
21.4.5. Suivi de l'avancement du déploiement de la politique de cluster géré
Le pipeline ArgoCD utilise les CR PolicyGenTemplate dans Git pour générer les politiques RHACM et les synchroniser avec le cluster central. Vous pouvez surveiller la progression de la synchronisation des politiques du cluster géré après que le service d'assistance a installé OpenShift Container Platform sur le cluster géré.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté au cluster hub en tant qu'utilisateur avec les privilèges
cluster-admin.
Procédure
Le Topology Aware Lifecycle Manager (TALM) applique les politiques de configuration liées à la grappe.
Une fois l'installation du cluster terminée et le cluster devenu
Ready, un CRClusterGroupUpgradecorrespondant à ce cluster, avec une liste de politiques ordonnées définies parran.openshift.io/ztp-deploy-wave annotations, est automatiquement créé par le TALM. Les politiques de la grappe sont appliquées dans l'ordre indiqué dansClusterGroupUpgradeCR.Vous pouvez contrôler l'avancement de la réconciliation des politiques de configuration à l'aide des commandes suivantes :
$ export CLUSTER=<clusterName>
$ oc get clustergroupupgrades -n ztp-install $CLUSTER -o jsonpath='{.status.conditions[-1:]}' | jqExemple de sortie
{ "lastTransitionTime": "2022-11-09T07:28:09Z", "message": "Remediating non-compliant policies", "reason": "InProgress", "status": "True", "type": "Progressing" }Vous pouvez contrôler l'état détaillé de la conformité de la politique de cluster en utilisant le tableau de bord RHACM ou la ligne de commande.
Pour vérifier la conformité de la politique à l'aide de
oc, exécutez la commande suivante :$ oc get policies -n $CLUSTER
Exemple de sortie
NAME REMEDIATION ACTION COMPLIANCE STATE AGE ztp-common.common-config-policy inform Compliant 3h42m ztp-common.common-subscriptions-policy inform NonCompliant 3h42m ztp-group.group-du-sno-config-policy inform NonCompliant 3h42m ztp-group.group-du-sno-validator-du-policy inform NonCompliant 3h42m ztp-install.example1-common-config-policy-pjz9s enforce Compliant 167m ztp-install.example1-common-subscriptions-policy-zzd9k enforce NonCompliant 164m ztp-site.example1-config-policy inform NonCompliant 3h42m ztp-site.example1-perf-policy inform NonCompliant 3h42m
Pour vérifier l'état des politiques à partir de la console Web RHACM, effectuez les actions suivantes :
- Cliquez sur Governance → Find policies.
- Cliquez sur une politique de cluster pour vérifier son statut.
Lorsque toutes les politiques de la grappe sont conformes, l'installation et la configuration de ZTP pour la grappe sont terminées. Le label ztp-done est ajouté à la grappe.
Dans la configuration de référence, la politique finale qui devient conforme est celle définie dans la politique *-du-validator-policy. Cette politique, lorsqu'elle est conforme sur un cluster, garantit que toute la configuration du cluster, l'installation de l'Opérateur et la configuration de l'Opérateur sont terminées.
21.4.6. Validation de la génération des CR de la politique de configuration
Les ressources personnalisées (CR) de stratégie sont générées dans le même espace de noms que le site PolicyGenTemplate à partir duquel elles sont créées. Le même flux de dépannage s'applique à toutes les CR de stratégie générées à partir de PolicyGenTemplate, qu'elles soient basées sur ztp-common, ztp-group ou ztp-site, comme le montrent les commandes suivantes :
$ export NS=<espace de noms>
$ oc get policy -n $NS
L'ensemble attendu de CR enveloppés dans une politique doit être affiché.
Si la synchronisation des politiques a échoué, suivez les étapes de dépannage suivantes.
Procédure
Pour afficher des informations détaillées sur les politiques, exécutez la commande suivante :
$ oc describe -n openshift-gitops application policies
Vérifiez que
Status: Conditions:est affiché dans les journaux d'erreurs. Par exemple, la définition d'une adressesourceFile→fileName:invalide génère l'erreur suivante :Status: Conditions: Last Transition Time: 2021-11-26T17:21:39Z Message: rpc error: code = Unknown desc = `kustomize build /tmp/https___git.com/ran-sites/policies/ --enable-alpha-plugins` failed exit status 1: 2021/11/26 17:21:40 Error could not find test.yaml under source-crs/: no such file or directory Error: failure in plugin configured via /tmp/kust-plugin-config-52463179; exit status 1: exit status 1 Type: ComparisonErrorVérifiez
Status: Sync:. S'il y a des erreurs d'enregistrement àStatus: Conditions:, le siteStatus: Sync:afficheUnknownouError:Status: Sync: Compared To: Destination: Namespace: policies-sub Server: https://kubernetes.default.svc Source: Path: policies Repo URL: https://git.com/ran-sites/policies/.git Target Revision: master Status: ErrorLorsque Red Hat Advanced Cluster Management (RHACM) reconnaît que des stratégies s'appliquent à un objet
ManagedCluster, les objets CR de stratégie sont appliqués à l'espace de noms du cluster. Vérifiez si les stratégies ont été copiées dans l'espace de noms du cluster :$ oc get policy -n $CLUSTER
Exemple de sortie :
NAME REMEDIATION ACTION COMPLIANCE STATE AGE ztp-common.common-config-policy inform Compliant 13d ztp-common.common-subscriptions-policy inform Compliant 13d ztp-group.group-du-sno-config-policy inform Compliant 13d Ztp-group.group-du-sno-validator-du-policy inform Compliant 13d ztp-site.example-sno-config-policy inform Compliant 13d
RHACM copie toutes les politiques applicables dans l'espace de noms du cluster. Les noms des stratégies copiées ont le format suivant :
<policyGenTemplate.Namespace>.<policyGenTemplate.Name>-<policyName>.Vérifiez la règle de placement pour toutes les politiques qui n'ont pas été copiées dans l'espace de noms du cluster. Les
matchSelectordans lePlacementRulepour ces politiques doivent correspondre aux étiquettes de l'objetManagedCluster:$ oc get placementrule -n $NS
Notez le nom
PlacementRuleapproprié pour la politique, le commun, le groupe ou le site manquant, à l'aide de la commande suivante :oc get placementrule -n $NS <placementRuleName> -o yaml
- Les décisions d'état doivent inclure le nom de votre cluster.
-
La paire clé-valeur de
matchSelectordans la spécification doit correspondre aux étiquettes de votre cluster géré.
Vérifiez les étiquettes de l'objet
ManagedClusterà l'aide de la commande suivante :$ oc get ManagedCluster $CLUSTER -o jsonpath='{.metadata.labels}' | jqVérifiez quelles politiques sont conformes à l'aide de la commande suivante :
$ oc get policy -n $CLUSTER
Si les stratégies
Namespace,OperatorGroupetSubscriptionsont conformes mais que les stratégies de configuration de l'opérateur ne le sont pas, il est probable que les opérateurs ne se sont pas installés sur le cluster géré. Dans ce cas, les politiques de configuration de l'opérateur ne s'appliquent pas car le CRD n'est pas encore appliqué au rayon.
21.4.7. Redémarrage du rapprochement des politiques
Vous pouvez relancer le rapprochement des politiques en cas de problèmes de conformité inattendus, par exemple lorsque la ressource personnalisée (CR) ClusterGroupUpgrade a expiré.
Procédure
Un CR
ClusterGroupUpgradeest généré dans l'espace de nomsztp-installpar le Topology Aware Lifecycle Manager une fois que le cluster géré devientReady:$ export CLUSTER=<clusterName>
$ oc get clustergroupupgrades -n ztp-install $CLUSTER
Si des problèmes inattendus surviennent et que les politiques ne sont pas réclamées dans le délai configuré (4 heures par défaut), l'état de la CR
ClusterGroupUpgradeest indiqué parUpgradeTimedOut:$ oc get clustergroupupgrades -n ztp-install $CLUSTER -o jsonpath='{.status.conditions[?(@.type=="Ready")]}'Un CR
ClusterGroupUpgradedans l'étatUpgradeTimedOutredémarre automatiquement son rapprochement des politiques toutes les heures. Si vous avez modifié vos politiques, vous pouvez lancer une nouvelle tentative immédiatement en supprimant le CRClusterGroupUpgradeexistant. Cela déclenche la création automatique d'un nouveau CRClusterGroupUpgradequi commence immédiatement à réconcilier les politiques :$ oc delete clustergroupupgrades -n ztp-install $CLUSTER
Notez que lorsque le CR ClusterGroupUpgrade se termine avec le statut UpgradeCompleted et que le cluster géré a l'étiquette ztp-done appliquée, vous pouvez effectuer des changements de configuration supplémentaires en utilisant PolicyGenTemplate. La suppression du CR ClusterGroupUpgrade existant ne permet pas au TALM de générer un nouveau CR.
À ce stade, ZTP a terminé son interaction avec le cluster et toute interaction ultérieure doit être traitée comme une mise à jour et un nouveau CR ClusterGroupUpgrade créé pour la remédiation des politiques.
Ressources supplémentaires
-
Pour plus d'informations sur l'utilisation de Topology Aware Lifecycle Manager (TALM) pour construire votre propre CR
ClusterGroupUpgrade, voir À propos du CR ClusterGroupUpgrade.
21.4.8. Indication de la réalisation pour les installations ZTP
Le Zero Touch Provisioning (ZTP) simplifie le processus de vérification de l'état de l'installation ZTP d'une grappe. L'état ZTP passe par trois phases : installation du cluster, configuration du cluster et ZTP terminé.
- Phase d'installation du cluster
-
La phase d'installation du cluster est indiquée par les conditions
ManagedClusterJoinedetManagedClusterAvailabledans le CRManagedCluster. Si le CRManagedClusterne contient pas ces conditions, ou si la condition est fixée àFalse, la grappe est toujours en phase d'installation. Des détails supplémentaires sur l'installation sont disponibles dans les CRAgentClusterInstalletClusterDeployment. Pour plus d'informations, voir "Troubleshooting GitOps ZTP". - Phase de configuration du cluster
-
La phase de configuration de la grappe est indiquée par une étiquette
ztp-runningappliquée à la CRManagedClusterde la grappe. - ZTP fait
L'installation et la configuration du cluster sont terminées dans la phase ZTP done. Cela se traduit par la suppression de l'étiquette
ztp-runninget l'ajout de l'étiquetteztp-doneà la CRManagedCluster. L'étiquetteztp-doneindique que la configuration a été appliquée et que la configuration de base de l'UA a terminé la mise au point du cluster.La transition vers l'état ZTP done est conditionnée par l'état de conformité d'une politique d'information du validateur de Red Hat Advanced Cluster Management (RHACM). Cette politique capture les critères existants pour une installation terminée et valide qu'elle passe à un état conforme uniquement lorsque le provisionnement ZTP du cluster géré est terminé.
La politique d'information des validateurs permet de s'assurer que la configuration du cluster est entièrement appliquée et que les opérateurs ont terminé leur initialisation. La politique valide les éléments suivants :
-
Le site cible
MachineConfigPoolcontient les entrées attendues et a fini d'être mis à jour. Tous les nœuds sont disponibles et ne sont pas dégradés. -
L'opérateur SR-IOV a terminé l'initialisation, comme l'indique au moins un site
SriovNetworkNodeStateavecsyncStatus: Succeeded. - Le jeu de démons PTP Operator existe.
-
Le site cible
21.5. Installation manuelle d'un cluster OpenShift à un nœud avec ZTP
Vous pouvez déployer un cluster OpenShift géré à nœud unique en utilisant Red Hat Advanced Cluster Management (RHACM) et le service assisté.
Si vous créez plusieurs clusters gérés, utilisez la méthode SiteConfig décrite dans Déploiement de sites distants avec ZTP.
L'hôte bare-metal cible doit répondre aux exigences en matière de réseau, de firmware et de matériel énumérées dans Configuration de cluster recommandée pour les charges de travail de l'application vDU.
21.5.1. Générer manuellement les CR d'installation et de configuration de ZTP
Utilisez le point d'entrée generator pour le conteneur ztp-site-generate afin de générer les ressources personnalisées (CR) d'installation et de configuration du site pour un cluster basé sur les CR SiteConfig et PolicyGenTemplate.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté au cluster hub en tant qu'utilisateur avec les privilèges
cluster-admin.
Procédure
Créez un dossier de sortie en exécutant la commande suivante :
$ mkdir -p ./out
Exporter le répertoire
argocdà partir de l'image du conteneurztp-site-generate:$ podman run --log-driver=none --rm registry.redhat.io/openshift4/ztp-site-generate-rhel8:v4.12 extract /home/ztp --tar | tar x -C ./out
Le répertoire
./outcontient les CR de référencePolicyGenTemplateetSiteConfigdans le dossierout/argocd/example/.Exemple de sortie
out └── argocd └── example ├── policygentemplates │ ├── common-ranGen.yaml │ ├── example-sno-site.yaml │ ├── group-du-sno-ranGen.yaml │ ├── group-du-sno-validator-ranGen.yaml │ ├── kustomization.yaml │ └── ns.yaml └── siteconfig ├── example-sno.yaml ├── KlusterletAddonConfigOverride.yaml └── kustomization.yamlCréez un dossier de sortie pour les CR d'installation du site :
$ mkdir -p ./site-install
Modifiez l'exemple de CR
SiteConfigpour le type de cluster que vous voulez installer. Copiezexample-sno.yamlverssite-1-sno.yamlet modifiez le CR pour qu'il corresponde aux détails du site et de l'hôte bare-metal que vous souhaitez installer, par exemple :Exemple de cluster OpenShift à nœud unique SiteConfig CR
apiVersion: ran.openshift.io/v1 kind: SiteConfig metadata: name: "<site_name>" namespace: "<site_name>" spec: baseDomain: "example.com" pullSecretRef: name: "assisted-deployment-pull-secret" 1 clusterImageSetNameRef: "openshift-4.12" 2 sshPublicKey: "ssh-rsa AAAA..." 3 clusters: - clusterName: "<site_name>" networkType: "OVNKubernetes" clusterLabels: 4 common: true group-du-sno: "" sites : "<site_name>" clusterNetwork: - cidr: 1001:1::/48 hostPrefix: 64 machineNetwork: - cidr: 1111:2222:3333:4444::/64 serviceNetwork: - 1001:2::/112 additionalNTPSources: - 1111:2222:3333:4444::2 #crTemplates: # KlusterletAddonConfig: "KlusterletAddonConfigOverride.yaml" 5 nodes: - hostName: "example-node.example.com" 6 role: "master" bmcAddress: idrac-virtualmedia://<out_of_band_ip>/<system_id>/ 7 bmcCredentialsName: name: "bmh-secret" 8 bootMACAddress: "AA:BB:CC:DD:EE:11" bootMode: "UEFI" 9 rootDeviceHints: wwn: "0x11111000000asd123" cpuset: "0-1,52-53" 10 nodeNetwork: 11 interfaces: - name: eno1 macAddress: "AA:BB:CC:DD:EE:11" config: interfaces: - name: eno1 type: ethernet state: up ipv4: enabled: false ipv6: 12 enabled: true address: - ip: 1111:2222:3333:4444::aaaa:1 prefix-length: 64 dns-resolver: config: search: - example.com server: - 1111:2222:3333:4444::2 routes: config: - destination: ::/0 next-hop-interface: eno1 next-hop-address: 1111:2222:3333:4444::1 table-id: 254- 1
- Créez le CR
assisted-deployment-pull-secretavec le même espace de noms que le CRSiteConfig. - 2
clusterImageSetNameRefdéfinit un jeu d'images disponible sur le hub cluster. Pour voir la liste des versions supportées sur votre hub cluster, exécutezoc get clusterimagesets.- 3
- Configurer la clé publique SSH utilisée pour accéder au cluster.
- 4
- Les libellés des grappes doivent correspondre au champ
bindingRulesdans les CRPolicyGenTemplateque vous définissez. Par exemple,policygentemplates/common-ranGen.yamls'applique à tous les clusters dont le champcommon: trueest défini,policygentemplates/group-du-sno-ranGen.yamls'applique à tous les clusters dont le champgroup-du-sno: ""est défini. - 5
- Facultatif. Le CR spécifié sous
KlusterletAddonConfigest utilisé pour remplacer le CR par défautKlusterletAddonConfigqui est créé pour le cluster. - 6
- Pour les déploiements à un seul nœud, définissez un seul hôte. Pour les déploiements à trois nœuds, définissez trois hôtes. Pour les déploiements standard, définissez trois hôtes avec
role: masteret deux hôtes ou plus avecrole: worker. - 7
- Adresse BMC que vous utilisez pour accéder à l'hôte. S'applique à tous les types de clusters.
- 8
- Nom du CR
bmh-secretque vous créez séparément avec les informations d'identification BMC de l'hôte. Lorsque vous créez le CRbmh-secret, utilisez le même espace de noms que le CRSiteConfigqui approvisionne l'hôte. - 9
- Configure le mode de démarrage de l'hôte. La valeur par défaut est
UEFI. UtilisezUEFISecureBootpour activer le démarrage sécurisé sur l'hôte. - 10
cpusetdoit correspondre à la valeur définie dans le champ clusterPerformanceProfileCRspec.cpu.reservedpour le partitionnement de la charge de travail.- 11
- Spécifie les paramètres du réseau pour le nœud.
- 12
- Configure l'adresse IPv6 pour l'hôte. Pour les clusters OpenShift à un seul nœud avec des adresses IP statiques, l'API spécifique au nœud et les IP d'entrée doivent être les mêmes.
Générer les CR d'installation du jour 0 en traitant le CR
SiteConfigmodifiésite-1-sno.yamlen exécutant la commande suivante :$ podman run -it --rm -v `pwd`/out/argocd/example/siteconfig:/resources:Z -v `pwd`/site-install:/output:Z,U registry.redhat.io/openshift4/ztp-site-generate-rhel8:v4.12.1 generator install site-1-sno.yaml /output
Exemple de sortie
site-install └── site-1-sno ├── site-1_agentclusterinstall_example-sno.yaml ├── site-1-sno_baremetalhost_example-node1.example.com.yaml ├── site-1-sno_clusterdeployment_example-sno.yaml ├── site-1-sno_configmap_example-sno.yaml ├── site-1-sno_infraenv_example-sno.yaml ├── site-1-sno_klusterletaddonconfig_example-sno.yaml ├── site-1-sno_machineconfig_02-master-workload-partitioning.yaml ├── site-1-sno_machineconfig_predefined-extra-manifests-master.yaml ├── site-1-sno_machineconfig_predefined-extra-manifests-worker.yaml ├── site-1-sno_managedcluster_example-sno.yaml ├── site-1-sno_namespace_example-sno.yaml └── site-1-sno_nmstateconfig_example-node1.example.com.yamlFacultatif : Générer uniquement les CR d'installation du jour 0
MachineConfigpour un type de cluster particulier en traitant le CR de référenceSiteConfigavec l'option-E. Par exemple, exécutez les commandes suivantes :Créer un dossier de sortie pour les CR
MachineConfig:$ mkdir -p ./site-machineconfig
Générer les CR d'installation de
MachineConfig:$ podman run -it --rm -v `pwd`/out/argocd/example/siteconfig:/resources:Z -v `pwd`/site-machineconfig:/output:Z,U registry.redhat.io/openshift4/ztp-site-generate-rhel8:v4.12.1 generator install -E site-1-sno.yaml /output
Exemple de sortie
site-machineconfig └── site-1-sno ├── site-1-sno_machineconfig_02-master-workload-partitioning.yaml ├── site-1-sno_machineconfig_predefined-extra-manifests-master.yaml └── site-1-sno_machineconfig_predefined-extra-manifests-worker.yaml
Générez et exportez les CR de configuration du jour 2 en utilisant les CR de référence
PolicyGenTemplatede l'étape précédente. Exécutez les commandes suivantes :Créer un dossier de sortie pour les CR du jour 2 :
$ mkdir -p ./ref
Générer et exporter les CR de configuration du jour 2 :
$ podman run -it --rm -v `pwd`/out/argocd/example/policygentemplates:/resources:Z -v `pwd`/ref:/output:Z,U registry.redhat.io/openshift4/ztp-site-generate-rhel8:v4.12.1 generator config -N . /output
La commande génère des exemples de CR de groupe et de site
PolicyGenTemplatepour OpenShift à un nœud, des clusters à trois nœuds et des clusters standard dans le dossier./ref.Exemple de sortie
ref └── customResource ├── common ├── example-multinode-site ├── example-sno ├── group-du-3node ├── group-du-3node-validator │ └── Multiple-validatorCRs ├── group-du-sno ├── group-du-sno-validator ├── group-du-standard └── group-du-standard-validator └── Multiple-validatorCRs
- Utilisez les CR générés comme base pour les CR que vous utilisez pour installer le cluster. Vous appliquez les CR d'installation au cluster concentrateur comme décrit dans la section "Installation d'un cluster géré unique". Les CR de configuration peuvent être appliqués à la grappe une fois l'installation de la grappe terminée.
Ressources supplémentaires
21.5.2. Création des secrets de l'hôte bare-metal géré
Ajoutez les ressources personnalisées (CR) Secret requises pour l'hôte bare-metal géré au cluster du concentrateur. Vous avez besoin d'un secret pour le pipeline ZTP afin d'accéder au Baseboard Management Controller (BMC) et d'un secret pour le service d'installation assistée afin d'extraire les images d'installation de cluster du registre.
Les secrets sont référencés à partir du CR SiteConfig par leur nom. L'espace de noms doit correspondre à l'espace de noms de SiteConfig.
Procédure
Créer un fichier secret YAML contenant les informations d'identification pour le contrôleur de gestion de carte de base (BMC) de l'hôte et un secret d'extraction requis pour l'installation d'OpenShift et de tous les opérateurs de cluster supplémentaires :
Enregistrer le YAML suivant dans le fichier
example-sno-secret.yaml:apiVersion: v1 kind: Secret metadata: name: example-sno-bmc-secret namespace: example-sno 1 data: 2 password: <base64_password> username: <base64_username> type: Opaque --- apiVersion: v1 kind: Secret metadata: name: pull-secret namespace: example-sno 3 data: .dockerconfigjson: <pull_secret> 4 type: kubernetes.io/dockerconfigjson
-
Ajoutez le chemin relatif vers
example-sno-secret.yamlau fichierkustomization.yamlque vous utilisez pour installer le cluster.
21.5.3. Configuration des arguments du noyau Discovery ISO pour les installations manuelles à l'aide de GitOps ZTP
Le flux de travail GitOps ZTP utilise l'ISO Discovery dans le cadre du processus d'installation d'OpenShift Container Platform sur les hôtes bare-metal gérés. Vous pouvez éditer la ressource InfraEnv pour spécifier les arguments du noyau pour l'ISO de découverte. Ceci est utile pour les installations de clusters avec des exigences environnementales spécifiques. Par exemple, configurez l'argument de noyau rd.net.timeout.carrier pour l'ISO de découverte afin de faciliter la mise en réseau statique du cluster ou de recevoir une adresse DHCP avant de télécharger le système de fichiers racine pendant l'installation.
Dans OpenShift Container Platform 4.12, vous ne pouvez qu'ajouter des arguments de noyau. Vous ne pouvez pas remplacer ou supprimer des arguments du noyau.
Conditions préalables
- Vous avez installé le CLI OpenShift (oc).
- Vous vous êtes connecté au cluster hub en tant qu'utilisateur disposant des privilèges cluster-admin.
- Vous avez généré manuellement les ressources personnalisées (RC) d'installation et de configuration.
Procédure
-
Modifiez la spécification
spec.kernelArgumentsdans le CRInfraEnvpour configurer les arguments du noyau :
apiVersion: agent-install.openshift.io/v1beta1
kind: InfraEnv
metadata:
name: <cluster_name>
namespace: <cluster_name>
spec:
kernelArguments:
- operation: append 1
value: audit=0 2
- operation: append
value: trace=1
clusterRef:
name: <cluster_name>
namespace: <cluster_name>
pullSecretRef:
name: pull-secret
La CR SiteConfig génère la ressource InfraEnv dans le cadre des CR d'installation du jour 0.
Vérification
Pour vérifier que les arguments du noyau sont appliqués, après que l'image Discovery a vérifié qu'OpenShift Container Platform est prêt pour l'installation, vous pouvez vous connecter en SSH à l'hôte cible avant que le processus d'installation ne commence. À ce moment-là, vous pouvez voir les arguments du noyau pour l'ISO Discovery dans le fichier /proc/cmdline.
Ouvrez une session SSH avec l'hôte cible :
$ ssh -i /path/to/privatekey core@<nom_de_l'hôte>
Affichez les arguments du noyau du système à l'aide de la commande suivante :
$ cat /proc/cmdline
21.5.4. Installation d'un seul cluster géré
Vous pouvez déployer manuellement un seul cluster géré à l'aide du service assisté et de Red Hat Advanced Cluster Management (RHACM).
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté au cluster hub en tant qu'utilisateur avec les privilèges
cluster-admin. -
Vous avez créé le contrôleur de gestion de carte de base (BMC)
Secretet le secret d'extraction d'imageSecretressources personnalisées (CR). Voir "Création des secrets de l'hôte bare-metal géré" pour plus de détails. - L'hôte bare-metal cible répond aux exigences matérielles et de mise en réseau pour les clusters gérés.
Procédure
Créez un
ClusterImageSetpour chaque version spécifique du cluster à déployer, par exempleclusterImageSet-4.12.yaml. UnClusterImageSeta le format suivant :apiVersion: hive.openshift.io/v1 kind: ClusterImageSet metadata: name: openshift-4.12.0 1 spec: releaseImage: quay.io/openshift-release-dev/ocp-release:4.12.0-x86_64 2
- 1
- La version descriptive que vous souhaitez déployer.
- 2
- Spécifie le site
releaseImageà déployer et détermine la version de l'image du système d'exploitation. L'ISO de découverte est basée sur la version de l'image définie parreleaseImage, ou sur la dernière version si la version exacte n'est pas disponible.
Appliquer la CR
clusterImageSet:$ oc apply -f clusterImageSet-4.12.yaml
Créer le CR
Namespacedans le fichiercluster-namespace.yaml:apiVersion: v1 kind: Namespace metadata: name: <cluster_name> 1 labels: name: <cluster_name> 2Appliquez la CR
Namespaceen exécutant la commande suivante :$ oc apply -f cluster-namespace.yaml
Appliquez les CR du jour 0 que vous avez extraites du conteneur
ztp-site-generateet que vous avez personnalisées pour répondre à vos besoins :$ oc apply -R ./site-install/site-sno-1
Ressources supplémentaires
21.5.5. Surveillance de l'état de l'installation du cluster géré
Assurez-vous que le provisionnement de la grappe a réussi en vérifiant l'état de la grappe.
Conditions préalables
-
Toutes les ressources personnalisées ont été configurées et provisionnées, et la ressource personnalisée
Agentest créée sur le hub pour le cluster géré.
Procédure
Vérifiez l'état du cluster géré :
$ oc get managedcluster
Trueindique que le cluster géré est prêt.Vérifier le statut de l'agent :
oc get agent -n <cluster_name>
Utilisez la commande
describepour obtenir une description détaillée de l'état de l'agent. Les statuts à connaître sontBackendError,InputError,ValidationsFailing,InstallationFailedetAgentIsConnected. Ces statuts concernent les ressources personnaliséesAgentetAgentClusterInstall.oc describe agent -n <cluster_name>
Vérifier l'état de l'approvisionnement du cluster :
oc get agentclusterinstall -n <cluster_name>
Utilisez la commande
describepour obtenir une description détaillée de l'état de l'approvisionnement de la grappe :oc describe agentclusterinstall -n <cluster_name>
Vérifiez l'état des services complémentaires du cluster géré :
oc get managedclusteraddon -n <cluster_name>
Récupérer les informations d'authentification du fichier
kubeconfigpour le cluster géré :$ oc get secret -n <cluster_name> <cluster_name>-admin-kubeconfig -o jsonpath={.data.kubeconfig} | base64 -d > <directory>/<cluster_name>-kubeconfig
21.5.6. Dépannage du cluster géré
Cette procédure permet de diagnostiquer les problèmes d'installation qui pourraient survenir avec le cluster géré.
Procédure
Vérifiez l'état du cluster géré :
$ oc get managedcluster
Exemple de sortie
NAME HUB ACCEPTED MANAGED CLUSTER URLS JOINED AVAILABLE AGE SNO-cluster true True True 2d19h
Si le statut dans la colonne
AVAILABLEestTrue, le cluster géré est géré par le hub.Si le statut dans la colonne
AVAILABLEestUnknown, le cluster géré n'est pas géré par le concentrateur. Suivez les étapes suivantes pour continuer la vérification et obtenir plus d'informations.Vérifiez l'état de l'installation de
AgentClusterInstall:oc get clusterdeployment -n <cluster_name>
Exemple de sortie
NAME PLATFORM REGION CLUSTERTYPE INSTALLED INFRAID VERSION POWERSTATE AGE Sno0026 agent-baremetal false Initialized 2d14h
Si l'état de la colonne
INSTALLEDestfalse, l'installation a échoué.Si l'installation a échoué, entrez la commande suivante pour vérifier l'état de la ressource
AgentClusterInstall:oc describe agentclusterinstall -n <cluster_name> <cluster_name> $ oc describe agentclusterinstall -n <cluster_name>
Résolvez les erreurs et réinitialisez le cluster :
Supprimer la ressource cluster gérée du cluster :
oc delete managedcluster <cluster_name> $ oc delete managedcluster <cluster_name>
Supprimer l'espace de noms du cluster :
oc delete namespace <cluster_name> $ oc delete namespace <cluster_name>
Cette opération supprime toutes les ressources personnalisées de l'espace de nommage créées pour ce cluster. Vous devez attendre que la suppression de
ManagedClusterCR soit terminée avant de poursuivre.- Recréer les ressources personnalisées pour le cluster géré.
21.5.7. Référence des CR d'installation de clusters générés par RHACM
Red Hat Advanced Cluster Management (RHACM) prend en charge le déploiement d'OpenShift Container Platform sur des clusters à un nœud, des clusters à trois nœuds et des clusters standard avec un ensemble spécifique de ressources personnalisées (CR) d'installation que vous générez à l'aide de SiteConfig CR pour chaque site.
Chaque cluster géré possède son propre espace de noms, et tous les CR d'installation, à l'exception de ManagedCluster et ClusterImageSet, se trouvent dans cet espace de noms. ManagedCluster et ClusterImageSet sont à l'échelle du cluster, et non à l'échelle de l'espace de noms. L'espace de noms et les noms des CR correspondent au nom du cluster.
Le tableau suivant répertorie les CR d'installation qui sont automatiquement appliqués par le service RHACM assisté lorsqu'il installe des clusters à l'aide des CR SiteConfig que vous configurez.
Tableau 21.4. CR d'installation de clusters générés par le RHACM
| CR | Description | Utilisation |
|---|---|---|
|
| Contient les informations de connexion pour le contrôleur de gestion de la carte de base (BMC) de l'hôte nu-métal cible. | Permet d'accéder à la BMC pour charger et démarrer l'image de découverte sur le serveur cible à l'aide du protocole Redfish. |
|
| Contient des informations pour l'installation d'OpenShift Container Platform sur l'hôte bare-metal cible. |
Utilisé avec |
|
|
Spécifie les détails de la configuration du cluster géré, tels que la mise en réseau et le nombre de nœuds du plan de contrôle. Affiche le cluster | Spécifie les informations de configuration du cluster géré et fournit un statut pendant l'installation du cluster. |
|
|
Fait référence au CR |
Utilisé avec |
|
|
Fournit des informations sur la configuration du réseau, telles que l'adresse | Définit une adresse IP statique pour le serveur API Kube du cluster géré. |
|
| Contient des informations matérielles sur l'hôte bare-metal cible. | Créé automatiquement sur le concentrateur lorsque l'image de découverte de la machine cible démarre. |
|
| Lorsqu'un cluster est géré par le hub, il doit être importé et connu. Cet objet Kubernetes fournit cette interface. | Le hub utilise cette ressource pour gérer et afficher l'état des clusters gérés. |
|
|
Contient la liste des services fournis par le hub à déployer sur la ressource |
Indique au concentrateur les services complémentaires à déployer sur la ressource |
|
|
Espace logique pour les ressources |
Propage les ressources sur le site |
|
|
Deux CR sont créés : |
|
|
| Contient des informations sur l'image OpenShift Container Platform, telles que le dépôt et le nom de l'image. | Passé dans les ressources pour fournir des images OpenShift Container Platform. |
21.6. Configuration recommandée d'un cluster OpenShift à nœud unique pour les charges de travail des applications vDU
Utilisez les informations de référence suivantes pour comprendre les configurations OpenShift à nœud unique requises pour déployer des applications d'unités distribuées virtuelles (vDU) dans le cluster. Les configurations comprennent les optimisations de cluster pour les charges de travail à haute performance, l'activation du partitionnement de la charge de travail et la minimisation du nombre de redémarrages requis après l'installation.
Ressources supplémentaires
- Pour déployer un seul cluster à la main, voir Installation manuelle d'un cluster OpenShift à nœud unique avec ZTP.
- Pour déployer une flotte de clusters à l'aide de GitOps zero touch provisioning (ZTP), voir Déploiement de sites distants avec ZTP.
21.6.1. Exécuter des applications à faible latence sur OpenShift Container Platform
OpenShift Container Platform permet un traitement à faible latence pour les applications exécutées sur du matériel commercial (COTS) en utilisant plusieurs technologies et dispositifs matériels spécialisés :
- Noyau temps réel pour RHCOS
- Veille à ce que les charges de travail soient traitées avec un degré élevé de déterminisme des processus.
- Isolation de l'unité centrale
- Évite les retards dans la programmation de l'unité centrale et garantit la disponibilité constante de la capacité de l'unité centrale.
- Gestion de la topologie en fonction des NUMA
- Alignement de la mémoire et des pages volumineuses sur les périphériques CPU et PCI afin d'épingler la mémoire garantie du conteneur et les pages volumineuses sur le nœud d'accès non uniforme à la mémoire (NUMA). Les ressources pod pour toutes les classes de qualité de service (QoS) restent sur le même nœud NUMA. Cela permet de réduire la latence et d'améliorer les performances du nœud.
- Gestion de la mémoire des pages volumineuses
- L'utilisation de pages de grande taille améliore les performances du système en réduisant la quantité de ressources système nécessaires pour accéder aux tables de pages.
- Synchronisation de précision à l'aide du protocole PTP
- Permet la synchronisation entre les nœuds du réseau avec une précision inférieure à la microseconde.
21.6.2. Configuration recommandée pour les charges de travail des applications vDU
L'exécution des charges de travail des applications vDU nécessite un hôte bare-metal disposant de ressources suffisantes pour exécuter les services OpenShift Container Platform et les charges de travail de production.
Tableau 21.5. Minimum resource requirements
| Profile | vCPU | Mémoire | Stockage |
|---|---|---|---|
| Minimum | 4 à 8 cœurs vCPU | 32 Go de RAM | 120GB |
Une vCPU équivaut à un cœur physique lorsque le multithreading simultané (SMT), ou Hyper-Threading, n'est pas activé. Lorsqu'il est activé, utilisez la formule suivante pour calculer le ratio correspondant :
- (threads per core × cores) × sockets = vCPUs
The server must have a Baseboard Management Controller (BMC) when booting with virtual media.
21.6.3. Configuration du micrologiciel hôte pour une faible latence et des performances élevées
Les hôtes bare-metal nécessitent la configuration du firmware avant que l'hôte puisse être provisionné. La configuration du micrologiciel dépend du matériel spécifique et des exigences particulières de votre installation.
Procédure
-
Réglez le site UEFI/BIOS Boot Mode sur
UEFI. - Dans l'ordre de démarrage de l'hôte, définir Hard drive first.
Appliquez la configuration de micrologiciel spécifique à votre matériel. Le tableau suivant décrit une configuration représentative du micrologiciel pour un serveur Intel Xeon Skylake ou Intel Cascade Lake, basée sur la conception de référence Intel FlexRAN 4G et 5G baseband PHY.
ImportantLa configuration exacte du micrologiciel dépend de vos exigences spécifiques en matière de matériel et de réseau. L'exemple de configuration suivant n'est donné qu'à titre d'illustration.
Tableau 21.6. Exemple de configuration du micrologiciel pour un serveur Intel Xeon Skylake ou Cascade Lake
Réglage du micrologiciel Configuration Politique de puissance et de performance de l'unité centrale
Performances
Mise à l'échelle de la fréquence Uncore
Handicapés
Performance Limite P
Handicapés
Technologie Intel SpeedStep ® améliorée
Activé
TDP configurable par Intel
Activé
Niveau TDP configurable
Niveau 2
Technologie Intel® Turbo Boost
Activé
Turbo à haut rendement énergétique
Handicapés
Matériel P-States
Handicapés
Paquet C-State
État C0/C1
C1E
Handicapés
Processeur C6
Handicapés
Activer les paramètres SR-IOV et VT-d globaux dans le micrologiciel de l'hôte. Ces paramètres sont pertinents pour les environnements bare-metal.
21.6.4. Conditions préalables de connectivité pour les réseaux de clusters gérés
Avant d'installer et de provisionner un cluster géré avec le pipeline GitOps Zero Touch Provisioning (ZTP), l'hôte du cluster géré doit remplir les conditions préalables suivantes en matière de réseau :
- Il doit y avoir une connectivité bidirectionnelle entre le conteneur ZTP GitOps dans le cluster hub et le contrôleur de gestion de carte de base (BMC) de l'hôte bare-metal cible.
Le cluster géré doit pouvoir résoudre et atteindre le nom d'hôte API du hub et le nom d'hôte
*.apps. Voici un exemple du nom d'hôte API du concentrateur et du nom d'hôte*.apps:-
api.hub-cluster.internal.domain.com -
console-openshift-console.apps.hub-cluster.internal.domain.com
-
Le cluster hub doit pouvoir résoudre et atteindre l'API et le nom d'hôte
*.appsdu cluster géré. Voici un exemple du nom d'hôte API du cluster géré et du nom d'hôte*.apps:-
api.sno-managed-cluster-1.internal.domain.com -
console-openshift-console.apps.sno-managed-cluster-1.internal.domain.com
-
21.6.5. Partitionnement de la charge de travail dans OpenShift à nœud unique avec GitOps ZTP
Le partitionnement des charges de travail configure les services OpenShift Container Platform, les charges de travail de gestion de cluster et les pods d'infrastructure pour qu'ils s'exécutent sur un nombre réservé de CPU hôtes.
Pour configurer le partitionnement de la charge de travail avec GitOps ZTP, vous spécifiez les ressources CPU de gestion de cluster avec le champ cpuset de la ressource personnalisée (CR) SiteConfig et le champ reserved de la CR de groupe PolicyGenTemplate. Le pipeline GitOps ZTP utilise ces valeurs pour remplir les champs requis dans le partitionnement de la charge de travail MachineConfig CR (cpuset) et PerformanceProfile CR (reserved) qui configurent le cluster OpenShift à nœud unique.
Pour des performances optimales, assurez-vous que les ensembles de CPU reserved et isolated ne partagent pas les cœurs de CPU dans les zones NUMA.
-
Le partitionnement de la charge de travail
MachineConfigCR relie les pods de l'infrastructure OpenShift Container Platform à une configurationcpusetdéfinie. -
L'adresse
PerformanceProfileCR relie les services systemd aux unités centrales réservées.
La valeur du champ reserved spécifiée dans le CR PerformanceProfile doit correspondre au champ cpuset dans le CR MachineConfig de partitionnement de la charge de travail.
Ressources supplémentaires
- Pour connaître la configuration de partitionnement de la charge de travail OpenShift recommandée pour un seul nœud, voir Partitionnement de la charge de travail.
21.6.6. Configurations de clusters recommandées lors de l'installation
Le pipeline ZTP applique les ressources personnalisées (CR) suivantes lors de l'installation du cluster. Ces CR de configuration garantissent que le cluster répond aux exigences de fonctionnalité et de performance nécessaires à l'exécution d'une application vDU.
Lors de l'utilisation du plugin ZTP GitOps et des CRs SiteConfig pour le déploiement en cluster, les CRs MachineConfig suivants sont inclus par défaut.
Utilisez le filtre SiteConfig extraManifests pour modifier les CR inclus par défaut. Pour plus d'informations, voir Configuration avancée des clusters gérés avec les CR SiteConfig.
21.6.6.1. Répartition de la charge de travail
Les clusters OpenShift à nœud unique qui exécutent des charges de travail DU nécessitent un partitionnement de la charge de travail. Cela limite les cœurs autorisés à exécuter les services de la plateforme, maximisant ainsi le cœur du CPU pour les charges utiles de l'application.
Le partitionnement de la charge de travail ne peut être activé que lors de l'installation du cluster. Vous ne pouvez pas désactiver le partitionnement de la charge de travail après l'installation. Cependant, vous pouvez reconfigurer le partitionnement de la charge de travail en mettant à jour la valeur cpu que vous définissez dans le profil de performance et dans la ressource personnalisée (CR) MachineConfig correspondante.
Le CR codé en base64 qui permet le partitionnement de la charge de travail contient l'ensemble de CPU auquel les charges de travail de gestion sont limitées. Encodez les valeurs spécifiques à l'hôte pour
crio.confetkubelet.confen base64. Ajustez le contenu pour qu'il corresponde à l'ensemble de CPU spécifié dans le profil de performance de la grappe. Il doit correspondre au nombre de cœurs de l'hôte de la grappe.Configuration recommandée pour le partitionnement de la charge de travail
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: master name: 02-master-workload-partitioning spec: config: ignition: version: 3.2.0 storage: files: - contents: source: data:text/plain;charset=utf-8;base64,W2NyaW8ucnVudGltZS53b3JrbG9hZHMubWFuYWdlbWVudF0KYWN0aXZhdGlvbl9hbm5vdGF0aW9uID0gInRhcmdldC53b3JrbG9hZC5vcGVuc2hpZnQuaW8vbWFuYWdlbWVudCIKYW5ub3RhdGlvbl9wcmVmaXggPSAicmVzb3VyY2VzLndvcmtsb2FkLm9wZW5zaGlmdC5pbyIKcmVzb3VyY2VzID0geyAiY3B1c2hhcmVzIiA9IDAsICJjcHVzZXQiID0gIjAtMSw1Mi01MyIgfQo= mode: 420 overwrite: true path: /etc/crio/crio.conf.d/01-workload-partitioning user: name: root - contents: source: data:text/plain;charset=utf-8;base64,ewogICJtYW5hZ2VtZW50IjogewogICAgImNwdXNldCI6ICIwLTEsNTItNTMiCiAgfQp9Cg== mode: 420 overwrite: true path: /etc/kubernetes/openshift-workload-pinning user: name: root
Une fois configuré dans l'hôte du cluster, le contenu de
/etc/crio/crio.conf.d/01-workload-partitioningdoit ressembler à ceci :[crio.runtime.workloads.management] activation_annotation = "target.workload.openshift.io/management" annotation_prefix = "resources.workload.openshift.io" resources = { "cpushares" = 0, "cpuset" = "0-1,52-53" } 1- 1
- La valeur de
cpusetvarie en fonction de l'installation. Si l'Hyper-Threading est activé, indiquez les deux threads pour chaque cœur. La valeurcpusetdoit correspondre aux CPU réservés que vous avez définis dans le champspec.cpu.reserveddu profil de performance.
Une fois configuré dans le cluster, le contenu de
/etc/kubernetes/openshift-workload-pinningdevrait ressembler à ceci :{ "management": { "cpuset": "0-1,52-53" 1 } }- 1
- La valeur de
cpusetdoit correspondre à celle decpusetdans/etc/crio/crio.conf.d/01-workload-partitioning.
Vérification
Vérifiez que l'affectation des CPU des applications et du système de cluster est correcte. Exécutez les commandes suivantes :
Ouvrez une connexion shell à distance au cluster géré :
$ oc debug node/example-sno-1
Vérifiez que l'épinglage du processeur des applications utilisateur est correct :
sh-4.4# pgrep ovn | while read i; do taskset -cp $i; done
Exemple de sortie
pid 8481's current affinity list: 0-3 pid 8726's current affinity list: 0-3 pid 9088's current affinity list: 0-3 pid 9945's current affinity list: 0-3 pid 10387's current affinity list: 0-3 pid 12123's current affinity list: 0-3 pid 13313's current affinity list: 0-3
Vérifier que l'affectation du CPU aux applications du système est correcte :
sh-4.4# pgrep systemd | while read i; do taskset -cp $i; done
Exemple de sortie
pid 1's current affinity list: 0-3 pid 938's current affinity list: 0-3 pid 962's current affinity list: 0-3 pid 1197's current affinity list: 0-3
21.6.6.2. Réduction de l'empreinte de la gestion de la plate-forme
Pour réduire l'empreinte de gestion globale de la plateforme, une ressource personnalisée (CR) MachineConfig est nécessaire pour placer tous les points de montage spécifiques à Kubernetes dans un nouvel espace de noms distinct du système d'exploitation hôte. L'exemple suivant de CR codée en base64 MachineConfig illustre cette configuration.
Configuration recommandée de l'espace de noms pour le montage du conteneur
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: master
name: container-mount-namespace-and-kubelet-conf-master
spec:
config:
ignition:
version: 3.2.0
storage:
files:
- contents:
source: data:text/plain;charset=utf-8;base64,IyEvYmluL2Jhc2gKCmRlYnVnKCkgewogIGVjaG8gJEAgPiYyCn0KCnVzYWdlKCkgewogIGVjaG8gVXNhZ2U6ICQoYmFzZW5hbWUgJDApIFVOSVQgW2VudmZpbGUgW3Zhcm5hbWVdXQogIGVjaG8KICBlY2hvIEV4dHJhY3QgdGhlIGNvbnRlbnRzIG9mIHRoZSBmaXJzdCBFeGVjU3RhcnQgc3RhbnphIGZyb20gdGhlIGdpdmVuIHN5c3RlbWQgdW5pdCBhbmQgcmV0dXJuIGl0IHRvIHN0ZG91dAogIGVjaG8KICBlY2hvICJJZiAnZW52ZmlsZScgaXMgcHJvdmlkZWQsIHB1dCBpdCBpbiB0aGVyZSBpbnN0ZWFkLCBhcyBhbiBlbnZpcm9ubWVudCB2YXJpYWJsZSBuYW1lZCAndmFybmFtZSciCiAgZWNobyAiRGVmYXVsdCAndmFybmFtZScgaXMgRVhFQ1NUQVJUIGlmIG5vdCBzcGVjaWZpZWQiCiAgZXhpdCAxCn0KClVOSVQ9JDEKRU5WRklMRT0kMgpWQVJOQU1FPSQzCmlmIFtbIC16ICRVTklUIHx8ICRVTklUID09ICItLWhlbHAiIHx8ICRVTklUID09ICItaCIgXV07IHRoZW4KICB1c2FnZQpmaQpkZWJ1ZyAiRXh0cmFjdGluZyBFeGVjU3RhcnQgZnJvbSAkVU5JVCIKRklMRT0kKHN5c3RlbWN0bCBjYXQgJFVOSVQgfCBoZWFkIC1uIDEpCkZJTEU9JHtGSUxFI1wjIH0KaWYgW1sgISAtZiAkRklMRSBdXTsgdGhlbgogIGRlYnVnICJGYWlsZWQgdG8gZmluZCByb290IGZpbGUgZm9yIHVuaXQgJFVOSVQgKCRGSUxFKSIKICBleGl0CmZpCmRlYnVnICJTZXJ2aWNlIGRlZmluaXRpb24gaXMgaW4gJEZJTEUiCkVYRUNTVEFSVD0kKHNlZCAtbiAtZSAnL15FeGVjU3RhcnQ9LipcXCQvLC9bXlxcXSQvIHsgcy9eRXhlY1N0YXJ0PS8vOyBwIH0nIC1lICcvXkV4ZWNTdGFydD0uKlteXFxdJC8geyBzL15FeGVjU3RhcnQ9Ly87IHAgfScgJEZJTEUpCgppZiBbWyAkRU5WRklMRSBdXTsgdGhlbgogIFZBUk5BTUU9JHtWQVJOQU1FOi1FWEVDU1RBUlR9CiAgZWNobyAiJHtWQVJOQU1FfT0ke0VYRUNTVEFSVH0iID4gJEVOVkZJTEUKZWxzZQogIGVjaG8gJEVYRUNTVEFSVApmaQo=
mode: 493
path: /usr/local/bin/extractExecStart
- contents:
source: data:text/plain;charset=utf-8;base64,IyEvYmluL2Jhc2gKbnNlbnRlciAtLW1vdW50PS9ydW4vY29udGFpbmVyLW1vdW50LW5hbWVzcGFjZS9tbnQgIiRAIgo=
mode: 493
path: /usr/local/bin/nsenterCmns
systemd:
units:
- contents: |
[Unit]
Description=Manages a mount namespace that both kubelet and crio can use to share their container-specific mounts
[Service]
Type=oneshot
RemainAfterExit=yes
RuntimeDirectory=container-mount-namespace
Environment=RUNTIME_DIRECTORY=%t/container-mount-namespace
Environment=BIND_POINT=%t/container-mount-namespace/mnt
ExecStartPre=bash -c "findmnt ${RUNTIME_DIRECTORY} || mount --make-unbindable --bind ${RUNTIME_DIRECTORY} ${RUNTIME_DIRECTORY}"
ExecStartPre=touch ${BIND_POINT}
ExecStart=unshare --mount=${BIND_POINT} --propagation slave mount --make-rshared /
ExecStop=umount -R ${RUNTIME_DIRECTORY}
enabled: true
name: container-mount-namespace.service
- dropins:
- contents: |
[Unit]
Wants=container-mount-namespace.service
After=container-mount-namespace.service
[Service]
ExecStartPre=/usr/local/bin/extractExecStart %n /%t/%N-execstart.env ORIG_EXECSTART
EnvironmentFile=-/%t/%N-execstart.env
ExecStart=
ExecStart=bash -c "nsenter --mount=%t/container-mount-namespace/mnt \
${ORIG_EXECSTART}"
name: 90-container-mount-namespace.conf
name: crio.service
- dropins:
- contents: |
[Unit]
Wants=container-mount-namespace.service
After=container-mount-namespace.service
[Service]
ExecStartPre=/usr/local/bin/extractExecStart %n /%t/%N-execstart.env ORIG_EXECSTART
EnvironmentFile=-/%t/%N-execstart.env
ExecStart=
ExecStart=bash -c "nsenter --mount=%t/container-mount-namespace/mnt \
${ORIG_EXECSTART} --housekeeping-interval=30s"
name: 90-container-mount-namespace.conf
- contents: |
[Service]
Environment="OPENSHIFT_MAX_HOUSEKEEPING_INTERVAL_DURATION=60s"
Environment="OPENSHIFT_EVICTION_MONITORING_PERIOD_DURATION=30s"
name: 30-kubelet-interval-tuning.conf
name: kubelet.service
21.6.6.3. SCTP
Le protocole SCTP (Stream Control Transmission Protocol) est un protocole clé utilisé dans les applications RAN. Cet objet MachineConfig ajoute le module de noyau SCTP au nœud pour activer ce protocole.
Configuration SCTP recommandée
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: master
name: load-sctp-module
spec:
config:
ignition:
version: 2.2.0
storage:
files:
- contents:
source: data:,
verification: {}
filesystem: root
mode: 420
path: /etc/modprobe.d/sctp-blacklist.conf
- contents:
source: data:text/plain;charset=utf-8,sctp
filesystem: root
mode: 420
path: /etc/modules-load.d/sctp-load.conf
21.6.6.4. Démarrage accéléré des conteneurs
Le MachineConfig CR suivant configure les processus et les conteneurs OpenShift de base pour utiliser tous les cœurs de CPU disponibles lors du démarrage et de l'arrêt du système. Cela accélère la récupération du système lors du démarrage initial et des redémarrages.
Configuration de démarrage recommandée pour les conteneurs accélérés
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: master
name: 04-accelerated-container-startup-master
spec:
config:
ignition:
version: 3.2.0
storage:
files:
- contents:
source: data:text/plain;charset=utf-8;base64,IyEvYmluL2Jhc2gKIwojIFRlbXBvcmFyaWx5IHJlc2V0IHRoZSBjb3JlIHN5c3RlbSBwcm9jZXNzZXMncyBDUFUgYWZmaW5pdHkgdG8gYmUgdW5yZXN0cmljdGVkIHRvIGFjY2VsZXJhdGUgc3RhcnR1cCBhbmQgc2h1dGRvd24KIwojIFRoZSBkZWZhdWx0cyBiZWxvdyBjYW4gYmUgb3ZlcnJpZGRlbiB2aWEgZW52aXJvbm1lbnQgdmFyaWFibGVzCiMKCiMgVGhlIGRlZmF1bHQgc2V0IG9mIGNyaXRpY2FsIHByb2Nlc3NlcyB3aG9zZSBhZmZpbml0eSBzaG91bGQgYmUgdGVtcG9yYXJpbHkgdW5ib3VuZDoKQ1JJVElDQUxfUFJPQ0VTU0VTPSR7Q1JJVElDQUxfUFJPQ0VTU0VTOi0ic3lzdGVtZCBvdnMgY3JpbyBrdWJlbGV0IE5ldHdvcmtNYW5hZ2VyIGNvbm1vbiBkYnVzIn0KCiMgRGVmYXVsdCB3YWl0IHRpbWUgaXMgNjAwcyA9IDEwbToKTUFYSU1VTV9XQUlUX1RJTUU9JHtNQVhJTVVNX1dBSVRfVElNRTotNjAwfQoKIyBEZWZhdWx0IHN0ZWFkeS1zdGF0ZSB0aHJlc2hvbGQgPSAyJQojIEFsbG93ZWQgdmFsdWVzOgojICA0ICAtIGFic29sdXRlIHBvZCBjb3VudCAoKy8tKQojICA0JSAtIHBlcmNlbnQgY2hhbmdlICgrLy0pCiMgIC0xIC0gZGlzYWJsZSB0aGUgc3RlYWR5LXN0YXRlIGNoZWNrClNURUFEWV9TVEFURV9USFJFU0hPTEQ9JHtTVEVBRFlfU1RBVEVfVEhSRVNIT0xEOi0yJX0KCiMgRGVmYXVsdCBzdGVhZHktc3RhdGUgd2luZG93ID0gNjBzCiMgSWYgdGhlIHJ1bm5pbmcgcG9kIGNvdW50IHN0YXlzIHdpdGhpbiB0aGUgZ2l2ZW4gdGhyZXNob2xkIGZvciB0aGlzIHRpbWUKIyBwZXJpb2QsIHJldHVybiBDUFUgdXRpbGl6YXRpb24gdG8gbm9ybWFsIGJlZm9yZSB0aGUgbWF4aW11bSB3YWl0IHRpbWUgaGFzCiMgZXhwaXJlcwpTVEVBRFlfU1RBVEVfV0lORE9XPSR7U1RFQURZX1NUQVRFX1dJTkRPVzotNjB9CgojIERlZmF1bHQgc3RlYWR5LXN0YXRlIGFsbG93cyBhbnkgcG9kIGNvdW50IHRvIGJlICJzdGVhZHkgc3RhdGUiCiMgSW5jcmVhc2luZyB0aGlzIHdpbGwgc2tpcCBhbnkgc3RlYWR5LXN0YXRlIGNoZWNrcyB1bnRpbCB0aGUgY291bnQgcmlzZXMgYWJvdmUKIyB0aGlzIG51bWJlciB0byBhdm9pZCBmYWxzZSBwb3NpdGl2ZXMgaWYgdGhlcmUgYXJlIHNvbWUgcGVyaW9kcyB3aGVyZSB0aGUKIyBjb3VudCBkb2Vzbid0IGluY3JlYXNlIGJ1dCB3ZSBrbm93IHdlIGNhbid0IGJlIGF0IHN0ZWFkeS1zdGF0ZSB5ZXQuClNURUFEWV9TVEFURV9NSU5JTVVNPSR7U1RFQURZX1NUQVRFX01JTklNVU06LTB9CgojIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjCgpLVUJFTEVUX0NQVV9TVEFURT0vdmFyL2xpYi9rdWJlbGV0L2NwdV9tYW5hZ2VyX3N0YXRlCkZVTExfQ1BVX1NUQVRFPS9zeXMvZnMvY2dyb3VwL2NwdXNldC9jcHVzZXQuY3B1cwp1bnJlc3RyaWN0ZWRDcHVzZXQoKSB7CiAgbG9jYWwgY3B1cwogIGlmIFtbIC1lICRLVUJFTEVUX0NQVV9TVEFURSBdXTsgdGhlbgogICAgICBjcHVzPSQoanEgLXIgJy5kZWZhdWx0Q3B1U2V0JyA8JEtVQkVMRVRfQ1BVX1NUQVRFKQogIGZpCiAgaWYgW1sgLXogJGNwdXMgXV07IHRoZW4KICAgICMgZmFsbCBiYWNrIHRvIHVzaW5nIGFsbCBjcHVzIGlmIHRoZSBrdWJlbGV0IHN0YXRlIGlzIG5vdCBjb25maWd1cmVkIHlldAogICAgW1sgLWUgJEZVTExfQ1BVX1NUQVRFIF1dIHx8IHJldHVybiAxCiAgICBjcHVzPSQoPCRGVUxMX0NQVV9TVEFURSkKICBmaQogIGVjaG8gJGNwdXMKfQoKcmVzdHJpY3RlZENwdXNldCgpIHsKICBmb3IgYXJnIGluICQoPC9wcm9jL2NtZGxpbmUpOyBkbwogICAgaWYgW1sgJGFyZyA9fiBec3lzdGVtZC5jcHVfYWZmaW5pdHk9IF1dOyB0aGVuCiAgICAgIGVjaG8gJHthcmcjKj19CiAgICAgIHJldHVybiAwCiAgICBmaQogIGRvbmUKICByZXR1cm4gMQp9CgpnZXRDUFVDb3VudCAoKSB7CiAgbG9jYWwgY3B1c2V0PSIkMSIKICBsb2NhbCBjcHVsaXN0PSgpCiAgbG9jYWwgY3B1cz0wCiAgbG9jYWwgbWluY3B1cz0yCgogIGlmIFtbIC16ICRjcHVzZXQgfHwgJGNwdXNldCA9fiBbXjAtOSwtXSBdXTsgdGhlbgogICAgZWNobyAkbWluY3B1cwogICAgcmV0dXJuIDEKICBmaQoKICBJRlM9JywnIHJlYWQgLXJhIGNwdWxpc3QgPDw8ICRjcHVzZXQKCiAgZm9yIGVsbSBpbiAiJHtjcHVsaXN0W0BdfSI7IGRvCiAgICBpZiBbWyAkZWxtID1+IF5bMC05XSskIF1dOyB0aGVuCiAgICAgICgoIGNwdXMrKyApKQogICAgZWxpZiBbWyAkZWxtID1+IF5bMC05XSstWzAtOV0rJCBdXTsgdGhlbgogICAgICBsb2NhbCBsb3c9MCBoaWdoPTAKICAgICAgSUZTPSctJyByZWFkIGxvdyBoaWdoIDw8PCAkZWxtCiAgICAgICgoIGNwdXMgKz0gaGlnaCAtIGxvdyArIDEgKSkKICAgIGVsc2UKICAgICAgZWNobyAkbWluY3B1cwogICAgICByZXR1cm4gMQogICAgZmkKICBkb25lCgogICMgUmV0dXJuIGEgbWluaW11bSBvZiAyIGNwdXMKICBlY2hvICQoKCBjcHVzID4gJG1pbmNwdXMgPyBjcHVzIDogJG1pbmNwdXMgKSkKICByZXR1cm4gMAp9CgpyZXNldE9WU3RocmVhZHMgKCkgewogIGxvY2FsIGNwdWNvdW50PSIkMSIKICBsb2NhbCBjdXJSZXZhbGlkYXRvcnM9MAogIGxvY2FsIGN1ckhhbmRsZXJzPTAKICBsb2NhbCBkZXNpcmVkUmV2YWxpZGF0b3JzPTAKICBsb2NhbCBkZXNpcmVkSGFuZGxlcnM9MAogIGxvY2FsIHJjPTAKCiAgY3VyUmV2YWxpZGF0b3JzPSQocHMgLVRlbyBwaWQsdGlkLGNvbW0sY21kIHwgZ3JlcCAtZSByZXZhbGlkYXRvciB8IGdyZXAgLWMgb3ZzLXZzd2l0Y2hkKQogIGN1ckhhbmRsZXJzPSQocHMgLVRlbyBwaWQsdGlkLGNvbW0sY21kIHwgZ3JlcCAtZSBoYW5kbGVyIHwgZ3JlcCAtYyBvdnMtdnN3aXRjaGQpCgogICMgQ2FsY3VsYXRlIHRoZSBkZXNpcmVkIG51bWJlciBvZiB0aHJlYWRzIHRoZSBzYW1lIHdheSBPVlMgZG9lcy4KICAjIE9WUyB3aWxsIHNldCB0aGVzZSB0aHJlYWQgY291bnQgYXMgYSBvbmUgc2hvdCBwcm9jZXNzIG9uIHN0YXJ0dXAsIHNvIHdlCiAgIyBoYXZlIHRvIGFkanVzdCB1cCBvciBkb3duIGR1cmluZyB0aGUgYm9vdCB1cCBwcm9jZXNzLiBUaGUgZGVzaXJlZCBvdXRjb21lIGlzCiAgIyB0byBub3QgcmVzdHJpY3QgdGhlIG51bWJlciBvZiB0aHJlYWQgYXQgc3RhcnR1cCB1bnRpbCB3ZSByZWFjaCBhIHN0ZWFkeQogICMgc3RhdGUuICBBdCB3aGljaCBwb2ludCB3ZSBuZWVkIHRvIHJlc2V0IHRoZXNlIGJhc2VkIG9uIG91ciByZXN0cmljdGVkICBzZXQKICAjIG9mIGNvcmVzLgogICMgU2VlIE9WUyBmdW5jdGlvbiB0aGF0IGNhbGN1bGF0ZXMgdGhlc2UgdGhyZWFkIGNvdW50czoKICAjIGh0dHBzOi8vZ2l0aHViLmNvbS9vcGVudnN3aXRjaC9vdnMvYmxvYi9tYXN0ZXIvb2Zwcm90by9vZnByb3RvLWRwaWYtdXBjYWxsLmMjTDYzNQogICgoIGRlc2lyZWRSZXZhbGlkYXRvcnM9JGNwdWNvdW50IC8gNCArIDEgKSkKICAoKCBkZXNpcmVkSGFuZGxlcnM9JGNwdWNvdW50IC0gJGRlc2lyZWRSZXZhbGlkYXRvcnMgKSkKCgogIGlmIFtbICRjdXJSZXZhbGlkYXRvcnMgLW5lICRkZXNpcmVkUmV2YWxpZGF0b3JzIHx8ICRjdXJIYW5kbGVycyAtbmUgJGRlc2lyZWRIYW5kbGVycyBdXTsgdGhlbgoKICAgIGxvZ2dlciAiUmVjb3Zlcnk6IFJlLXNldHRpbmcgT1ZTIHJldmFsaWRhdG9yIHRocmVhZHM6ICR7Y3VyUmV2YWxpZGF0b3JzfSAtPiAke2Rlc2lyZWRSZXZhbGlkYXRvcnN9IgogICAgbG9nZ2VyICJSZWNvdmVyeTogUmUtc2V0dGluZyBPVlMgaGFuZGxlciB0aHJlYWRzOiAke2N1ckhhbmRsZXJzfSAtPiAke2Rlc2lyZWRIYW5kbGVyc30iCgogICAgb3ZzLXZzY3RsIHNldCBcCiAgICAgIE9wZW5fdlN3aXRjaCAuIFwKICAgICAgb3RoZXItY29uZmlnOm4taGFuZGxlci10aHJlYWRzPSR7ZGVzaXJlZEhhbmRsZXJzfSBcCiAgICAgIG90aGVyLWNvbmZpZzpuLXJldmFsaWRhdG9yLXRocmVhZHM9JHtkZXNpcmVkUmV2YWxpZGF0b3JzfQogICAgcmM9JD8KICBmaQoKICByZXR1cm4gJHJjCn0KCnJlc2V0QWZmaW5pdHkoKSB7CiAgbG9jYWwgY3B1c2V0PSIkMSIKICBsb2NhbCBmYWlsY291bnQ9MAogIGxvY2FsIHN1Y2Nlc3Njb3VudD0wCiAgbG9nZ2VyICJSZWNvdmVyeTogU2V0dGluZyBDUFUgYWZmaW5pdHkgZm9yIGNyaXRpY2FsIHByb2Nlc3NlcyBcIiRDUklUSUNBTF9QUk9DRVNTRVNcIiB0byAkY3B1c2V0IgogIGZvciBwcm9jIGluICRDUklUSUNBTF9QUk9DRVNTRVM7IGRvCiAgICBsb2NhbCBwaWRzPSIkKHBncmVwICRwcm9jKSIKICAgIGZvciBwaWQgaW4gJHBpZHM7IGRvCiAgICAgIGxvY2FsIHRhc2tzZXRPdXRwdXQKICAgICAgdGFza3NldE91dHB1dD0iJCh0YXNrc2V0IC1hcGMgIiRjcHVzZXQiICRwaWQgMj4mMSkiCiAgICAgIGlmIFtbICQ/IC1uZSAwIF1dOyB0aGVuCiAgICAgICAgZWNobyAiRVJST1I6ICR0YXNrc2V0T3V0cHV0IgogICAgICAgICgoZmFpbGNvdW50KyspKQogICAgICBlbHNlCiAgICAgICAgKChzdWNjZXNzY291bnQrKykpCiAgICAgIGZpCiAgICBkb25lCiAgZG9uZQoKICByZXNldE9WU3RocmVhZHMgIiQoZ2V0Q1BVQ291bnQgJHtjcHVzZXR9KSIKICBpZiBbWyAkPyAtbmUgMCBdXTsgdGhlbgogICAgKChmYWlsY291bnQrKykpCiAgZWxzZQogICAgKChzdWNjZXNzY291bnQrKykpCiAgZmkKCiAgbG9nZ2VyICJSZWNvdmVyeTogUmUtYWZmaW5lZCAkc3VjY2Vzc2NvdW50IHBpZHMgc3VjY2Vzc2Z1bGx5IgogIGlmIFtbICRmYWlsY291bnQgLWd0IDAgXV07IHRoZW4KICAgIGxvZ2dlciAiUmVjb3Zlcnk6IEZhaWxlZCB0byByZS1hZmZpbmUgJGZhaWxjb3VudCBwcm9jZXNzZXMiCiAgICByZXR1cm4gMQogIGZpCn0KCnNldFVucmVzdHJpY3RlZCgpIHsKICBsb2dnZXIgIlJlY292ZXJ5OiBTZXR0aW5nIGNyaXRpY2FsIHN5c3RlbSBwcm9jZXNzZXMgdG8gaGF2ZSB1bnJlc3RyaWN0ZWQgQ1BVIGFjY2VzcyIKICByZXNldEFmZmluaXR5ICIkKHVucmVzdHJpY3RlZENwdXNldCkiCn0KCnNldFJlc3RyaWN0ZWQoKSB7CiAgbG9nZ2VyICJSZWNvdmVyeTogUmVzZXR0aW5nIGNyaXRpY2FsIHN5c3RlbSBwcm9jZXNzZXMgYmFjayB0byBub3JtYWxseSByZXN0cmljdGVkIGFjY2VzcyIKICByZXNldEFmZmluaXR5ICIkKHJlc3RyaWN0ZWRDcHVzZXQpIgp9CgpjdXJyZW50QWZmaW5pdHkoKSB7CiAgbG9jYWwgcGlkPSIkMSIKICB0YXNrc2V0IC1wYyAkcGlkIHwgYXdrIC1GJzogJyAne3ByaW50ICQyfScKfQoKd2l0aGluKCkgewogIGxvY2FsIGxhc3Q9JDEgY3VycmVudD0kMiB0aHJlc2hvbGQ9JDMKICBsb2NhbCBkZWx0YT0wIHBjaGFuZ2UKICBkZWx0YT0kKCggY3VycmVudCAtIGxhc3QgKSkKICBpZiBbWyAkY3VycmVudCAtZXEgJGxhc3QgXV07IHRoZW4KICAgIHBjaGFuZ2U9MAogIGVsaWYgW1sgJGxhc3QgLWVxIDAgXV07IHRoZW4KICAgIHBjaGFuZ2U9MTAwMDAwMAogIGVsc2UKICAgIHBjaGFuZ2U9JCgoICggJGRlbHRhICogMTAwKSAvIGxhc3QgKSkKICBmaQogIGVjaG8gLW4gImxhc3Q6JGxhc3QgY3VycmVudDokY3VycmVudCBkZWx0YTokZGVsdGEgcGNoYW5nZToke3BjaGFuZ2V9JTogIgogIGxvY2FsIGFic29sdXRlIGxpbWl0CiAgY2FzZSAkdGhyZXNob2xkIGluCiAgICAqJSkKICAgICAgYWJzb2x1dGU9JHtwY2hhbmdlIyMtfSAjIGFic29sdXRlIHZhbHVlCiAgICAgIGxpbWl0PSR7dGhyZXNob2xkJSUlfQogICAgICA7OwogICAgKikKICAgICAgYWJzb2x1dGU9JHtkZWx0YSMjLX0gIyBhYnNvbHV0ZSB2YWx1ZQogICAgICBsaW1pdD0kdGhyZXNob2xkCiAgICAgIDs7CiAgZXNhYwogIGlmIFtbICRhYnNvbHV0ZSAtbGUgJGxpbWl0IF1dOyB0aGVuCiAgICBlY2hvICJ3aXRoaW4gKCsvLSkkdGhyZXNob2xkIgogICAgcmV0dXJuIDAKICBlbHNlCiAgICBlY2hvICJvdXRzaWRlICgrLy0pJHRocmVzaG9sZCIKICAgIHJldHVybiAxCiAgZmkKfQoKc3RlYWR5c3RhdGUoKSB7CiAgbG9jYWwgbGFzdD0kMSBjdXJyZW50PSQyCiAgaWYgW1sgJGxhc3QgLWx0ICRTVEVBRFlfU1RBVEVfTUlOSU1VTSBdXTsgdGhlbgogICAgZWNobyAibGFzdDokbGFzdCBjdXJyZW50OiRjdXJyZW50IFdhaXRpbmcgdG8gcmVhY2ggJFNURUFEWV9TVEFURV9NSU5JTVVNIGJlZm9yZSBjaGVja2luZyBmb3Igc3RlYWR5LXN0YXRlIgogICAgcmV0dXJuIDEKICBmaQogIHdpdGhpbiAkbGFzdCAkY3VycmVudCAkU1RFQURZX1NUQVRFX1RIUkVTSE9MRAp9Cgp3YWl0Rm9yUmVhZHkoKSB7CiAgbG9nZ2VyICJSZWNvdmVyeTogV2FpdGluZyAke01BWElNVU1fV0FJVF9USU1FfXMgZm9yIHRoZSBpbml0aWFsaXphdGlvbiB0byBjb21wbGV0ZSIKICBsb2NhbCBsYXN0U3lzdGVtZENwdXNldD0iJChjdXJyZW50QWZmaW5pdHkgMSkiCiAgbG9jYWwgbGFzdERlc2lyZWRDcHVzZXQ9IiQodW5yZXN0cmljdGVkQ3B1c2V0KSIKICBsb2NhbCB0PTAgcz0xMAogIGxvY2FsIGxhc3RDY291bnQ9MCBjY291bnQ9MCBzdGVhZHlTdGF0ZVRpbWU9MAogIHdoaWxlIFtbICR0IC1sdCAkTUFYSU1VTV9XQUlUX1RJTUUgXV07IGRvCiAgICBzbGVlcCAkcwogICAgKCh0ICs9IHMpKQogICAgIyBSZS1jaGVjayB0aGUgY3VycmVudCBhZmZpbml0eSBvZiBzeXN0ZW1kLCBpbiBjYXNlIHNvbWUgb3RoZXIgcHJvY2VzcyBoYXMgY2hhbmdlZCBpdAogICAgbG9jYWwgc3lzdGVtZENwdXNldD0iJChjdXJyZW50QWZmaW5pdHkgMSkiCiAgICAjIFJlLWNoZWNrIHRoZSB1bnJlc3RyaWN0ZWQgQ3B1c2V0LCBhcyB0aGUgYWxsb3dlZCBzZXQgb2YgdW5yZXNlcnZlZCBjb3JlcyBtYXkgY2hhbmdlIGFzIHBvZHMgYXJlIGFzc2lnbmVkIHRvIGNvcmVzCiAgICBsb2NhbCBkZXNpcmVkQ3B1c2V0PSIkKHVucmVzdHJpY3RlZENwdXNldCkiCiAgICBpZiBbWyAkc3lzdGVtZENwdXNldCAhPSAkbGFzdFN5c3RlbWRDcHVzZXQgfHwgJGxhc3REZXNpcmVkQ3B1c2V0ICE9ICRkZXNpcmVkQ3B1c2V0IF1dOyB0aGVuCiAgICAgIHJlc2V0QWZmaW5pdHkgIiRkZXNpcmVkQ3B1c2V0IgogICAgICBsYXN0U3lzdGVtZENwdXNldD0iJChjdXJyZW50QWZmaW5pdHkgMSkiCiAgICAgIGxhc3REZXNpcmVkQ3B1c2V0PSIkZGVzaXJlZENwdXNldCIKICAgIGZpCgogICAgIyBEZXRlY3Qgc3RlYWR5LXN0YXRlIHBvZCBjb3VudAogICAgY2NvdW50PSQoY3JpY3RsIHBzIHwgd2MgLWwpCiAgICBpZiBzdGVhZHlzdGF0ZSAkbGFzdENjb3VudCAkY2NvdW50OyB0aGVuCiAgICAgICgoc3RlYWR5U3RhdGVUaW1lICs9IHMpKQogICAgICBlY2hvICJTdGVhZHktc3RhdGUgZm9yICR7c3RlYWR5U3RhdGVUaW1lfXMvJHtTVEVBRFlfU1RBVEVfV0lORE9XfXMiCiAgICAgIGlmIFtbICRzdGVhZHlTdGF0ZVRpbWUgLWdlICRTVEVBRFlfU1RBVEVfV0lORE9XIF1dOyB0aGVuCiAgICAgICAgbG9nZ2VyICJSZWNvdmVyeTogU3RlYWR5LXN0YXRlICgrLy0gJFNURUFEWV9TVEFURV9USFJFU0hPTEQpIGZvciAke1NURUFEWV9TVEFURV9XSU5ET1d9czogRG9uZSIKICAgICAgICByZXR1cm4gMAogICAgICBmaQogICAgZWxzZQogICAgICBpZiBbWyAkc3RlYWR5U3RhdGVUaW1lIC1ndCAwIF1dOyB0aGVuCiAgICAgICAgZWNobyAiUmVzZXR0aW5nIHN0ZWFkeS1zdGF0ZSB0aW1lciIKICAgICAgICBzdGVhZHlTdGF0ZVRpbWU9MAogICAgICBmaQogICAgZmkKICAgIGxhc3RDY291bnQ9JGNjb3VudAogIGRvbmUKICBsb2dnZXIgIlJlY292ZXJ5OiBSZWNvdmVyeSBDb21wbGV0ZSBUaW1lb3V0Igp9CgptYWluKCkgewogIGlmICEgdW5yZXN0cmljdGVkQ3B1c2V0ID4mL2Rldi9udWxsOyB0aGVuCiAgICBsb2dnZXIgIlJlY292ZXJ5OiBObyB1bnJlc3RyaWN0ZWQgQ3B1c2V0IGNvdWxkIGJlIGRldGVjdGVkIgogICAgcmV0dXJuIDEKICBmaQoKICBpZiAhIHJlc3RyaWN0ZWRDcHVzZXQgPiYvZGV2L251bGw7IHRoZW4KICAgIGxvZ2dlciAiUmVjb3Zlcnk6IE5vIHJlc3RyaWN0ZWQgQ3B1c2V0IGhhcyBiZWVuIGNvbmZpZ3VyZWQuICBXZSBhcmUgYWxyZWFkeSBydW5uaW5nIHVucmVzdHJpY3RlZC4iCiAgICByZXR1cm4gMAogIGZpCgogICMgRW5zdXJlIHdlIHJlc2V0IHRoZSBDUFUgYWZmaW5pdHkgd2hlbiB3ZSBleGl0IHRoaXMgc2NyaXB0IGZvciBhbnkgcmVhc29uCiAgIyBUaGlzIHdheSBlaXRoZXIgYWZ0ZXIgdGhlIHRpbWVyIGV4cGlyZXMgb3IgYWZ0ZXIgdGhlIHByb2Nlc3MgaXMgaW50ZXJydXB0ZWQKICAjIHZpYSBeQyBvciBTSUdURVJNLCB3ZSByZXR1cm4gdGhpbmdzIGJhY2sgdG8gdGhlIHdheSB0aGV5IHNob3VsZCBiZS4KICB0cmFwIHNldFJlc3RyaWN0ZWQgRVhJVAoKICBsb2dnZXIgIlJlY292ZXJ5OiBSZWNvdmVyeSBNb2RlIFN0YXJ0aW5nIgogIHNldFVucmVzdHJpY3RlZAogIHdhaXRGb3JSZWFkeQp9CgppZiBbWyAiJHtCQVNIX1NPVVJDRVswXX0iID0gIiR7MH0iIF1dOyB0aGVuCiAgbWFpbiAiJHtAfSIKICBleGl0ICQ/CmZpCg==
mode: 493
path: /usr/local/bin/accelerated-container-startup.sh
systemd:
units:
- contents: |
[Unit]
Description=Unlocks more CPUs for critical system processes during container startup
[Service]
Type=simple
ExecStart=/usr/local/bin/accelerated-container-startup.sh
# Maximum wait time is 600s = 10m:
Environment=MAXIMUM_WAIT_TIME=600
# Steady-state threshold = 2%
# Allowed values:
# 4 - absolute pod count (+/-)
# 4% - percent change (+/-)
# -1 - disable the steady-state check
# Note: '%' must be escaped as '%%' in systemd unit files
Environment=STEADY_STATE_THRESHOLD=2%%
# Steady-state window = 120s
# If the running pod count stays within the given threshold for this time
# period, return CPU utilization to normal before the maximum wait time has
# expires
Environment=STEADY_STATE_WINDOW=120
# Steady-state minimum = 40
# Increasing this will skip any steady-state checks until the count rises above
# this number to avoid false positives if there are some periods where the
# count doesn't increase but we know we can't be at steady-state yet.
Environment=STEADY_STATE_MINIMUM=40
[Install]
WantedBy=multi-user.target
enabled: true
name: accelerated-container-startup.service
- contents: |
[Unit]
Description=Unlocks more CPUs for critical system processes during container shutdown
DefaultDependencies=no
[Service]
Type=simple
ExecStart=/usr/local/bin/accelerated-container-startup.sh
# Maximum wait time is 600s = 10m:
Environment=MAXIMUM_WAIT_TIME=600
# Steady-state threshold
# Allowed values:
# 4 - absolute pod count (+/-)
# 4% - percent change (+/-)
# -1 - disable the steady-state check
# Note: '%' must be escaped as '%%' in systemd unit files
Environment=STEADY_STATE_THRESHOLD=-1
# Steady-state window = 60s
# If the running pod count stays within the given threshold for this time
# period, return CPU utilization to normal before the maximum wait time has
# expires
Environment=STEADY_STATE_WINDOW=60
[Install]
WantedBy=shutdown.target reboot.target halt.target
enabled: true
name: accelerated-container-shutdown.service
21.6.6.5. Vidage automatique des crashs du noyau avec kdump
kdump est une fonctionnalité du noyau Linux qui crée un crash dump du noyau lorsque celui-ci se bloque. kdump est activé avec les CR MachineConfig suivants :
Configuration recommandée pour kdump
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: master
name: 06-kdump-enable-master
spec:
config:
ignition:
version: 3.2.0
systemd:
units:
- enabled: true
name: kdump.service
kernelArguments:
- crashkernel=512M
21.6.7. Configurations recommandées pour les clusters après l'installation
Une fois l'installation du cluster terminée, le pipeline ZTP applique les ressources personnalisées (CR) suivantes, nécessaires à l'exécution des charges de travail de l'UD.
Dans GitOps ZTP v4.10 et les versions antérieures, vous devez configurer le démarrage sécurisé de l'UEFI à l'aide d'un CR MachineConfig. Cela n'est plus nécessaire dans GitOps ZTP v4.11 et les versions ultérieures. Dans la version 4.11, vous configurez le démarrage sécurisé UEFI pour les clusters OpenShift à nœud unique à l'aide des CR du profil de performance. Pour plus d'informations, voir Profil de performance.
21.6.7.1. Espaces de noms des opérateurs et groupes d'opérateurs
Les clusters OpenShift à nœud unique qui exécutent des charges de travail DU nécessitent les ressources personnalisées (CR) suivantes : OperatorGroup et Namespace:
- Opérateur de stockage local
- Opérateur forestier
- Opérateur PTP
- Opérateur de réseau SR-IOV
Le YAML suivant résume ces CR :
Configuration recommandée de l'espace de noms de l'opérateur et du groupe d'opérateurs
apiVersion: v1
kind: Namespace
metadata:
annotations:
workload.openshift.io/allowed: management
name: openshift-local-storage
---
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: openshift-local-storage
namespace: openshift-local-storage
spec:
targetNamespaces:
- openshift-local-storage
---
apiVersion: v1
kind: Namespace
metadata:
annotations:
workload.openshift.io/allowed: management
name: openshift-logging
---
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: cluster-logging
namespace: openshift-logging
spec:
targetNamespaces:
- openshift-logging
---
apiVersion: v1
kind: Namespace
metadata:
annotations:
workload.openshift.io/allowed: management
labels:
openshift.io/cluster-monitoring: "true"
name: openshift-ptp
---
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: ptp-operators
namespace: openshift-ptp
spec:
targetNamespaces:
- openshift-ptp
---
apiVersion: v1
kind: Namespace
metadata:
annotations:
workload.openshift.io/allowed: management
name: openshift-sriov-network-operator
---
apiVersion: operators.coreos.com/v1
kind: OperatorGroup
metadata:
name: sriov-network-operators
namespace: openshift-sriov-network-operator
spec:
targetNamespaces:
- openshift-sriov-network-operator
21.6.7.2. Abonnements des opérateurs
Les clusters OpenShift à nœud unique qui exécutent des charges de travail DU nécessitent les CR Subscription suivants. L'abonnement fournit l'emplacement pour télécharger les opérateurs suivants :
- Opérateur de stockage local
- Opérateur forestier
- Opérateur PTP
- Opérateur de réseau SR-IOV
Abonnements recommandés pour les opérateurs
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: cluster-logging namespace: openshift-logging spec: channel: "stable" 1 name: cluster-logging source: redhat-operators sourceNamespace: openshift-marketplace installPlanApproval: Manual 2 --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: local-storage-operator namespace: openshift-local-storage spec: channel: "stable" installPlanApproval: Automatic name: local-storage-operator source: redhat-operators sourceNamespace: openshift-marketplace installPlanApproval: Manual --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: ptp-operator-subscription namespace: openshift-ptp spec: channel: "stable" name: ptp-operator source: redhat-operators sourceNamespace: openshift-marketplace installPlanApproval: Manual --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: sriov-network-operator-subscription namespace: openshift-sriov-network-operator spec: channel: "stable" name: sriov-network-operator source: redhat-operators sourceNamespace: openshift-marketplace installPlanApproval: Manual
- 1
- Indiquez le canal à partir duquel l'opérateur doit être reçu.
stableest le canal recommandé. - 2
- Spécifiez
ManualouAutomatic. En modeAutomatic, l'opérateur se met automatiquement à jour avec les dernières versions du canal au fur et à mesure qu'elles sont disponibles dans le registre. En modeManual, les nouvelles versions de l'opérateur ne sont installées qu'après avoir été explicitement approuvées.
21.6.7.3. Journalisation des clusters et transmission des journaux
Les clusters OpenShift à nœud unique qui exécutent des charges de travail DU nécessitent la journalisation et le transfert de journaux pour le débogage. L'exemple YAML suivant illustre les CR ClusterLogging et ClusterLogForwarder nécessaires.
Configuration recommandée de la journalisation et de la transmission des journaux pour les clusters
apiVersion: logging.openshift.io/v1 kind: ClusterLogging 1 metadata: name: instance namespace: openshift-logging spec: collection: logs: fluentd: {} type: fluentd curation: type: "curator" curator: schedule: "30 3 * * *" managementState: Managed --- apiVersion: logging.openshift.io/v1 kind: ClusterLogForwarder 2 metadata: name: instance namespace: openshift-logging spec: inputs: - infrastructure: {} name: infra-logs outputs: - name: kafka-open type: kafka url: tcp://10.46.55.190:9092/test 3 pipelines: - inputRefs: - audit name: audit-logs outputRefs: - kafka-open - inputRefs: - infrastructure name: infrastructure-logs outputRefs: - kafka-open
21.6.7.4. Profil de performance
Les clusters OpenShift à nœud unique qui exécutent des charges de travail DU nécessitent un profil de performance Node Tuning Operator pour utiliser les capacités et les services de l'hôte en temps réel.
Dans les versions antérieures d'OpenShift Container Platform, l'opérateur Performance Addon était utilisé pour mettre en œuvre un réglage automatique afin d'obtenir des performances de faible latence pour les applications OpenShift. Dans OpenShift Container Platform 4.11 et les versions ultérieures, cette fonctionnalité fait partie de l'opérateur Node Tuning.
L'exemple suivant PerformanceProfile CR illustre la configuration requise du cluster.
Configuration recommandée du profil de performance
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: openshift-node-performance-profile 1 spec: additionalKernelArgs: - "rcupdate.rcu_normal_after_boot=0" - "efi=runtime" 2 cpu: isolated: 2-51,54-103 3 reserved: 0-1,52-53 4 hugepages: defaultHugepagesSize: 1G pages: - count: 32 5 size: 1G 6 node: 0 7 machineConfigPoolSelector: pools.operator.machineconfiguration.openshift.io/master: "" nodeSelector: node-role.kubernetes.io/master: "" numa: topologyPolicy: "restricted" realTimeKernel: enabled: true 8
- 1
- Assurez-vous que la valeur de
namecorrespond à celle spécifiée dans le champspec.profile.datadeTunedPerformancePatch.yamlet dans le champstatus.configuration.source.namedevalidatorCRs/informDuValidator.yaml. - 2
- Configure le démarrage sécurisé UEFI pour l'hôte du cluster.
- 3
- Définissez les CPU isolés. Assurez-vous que toutes les paires Hyper-Threading correspondent.Important
Les pools de CPU réservés et isolés ne doivent pas se chevaucher et doivent couvrir tous les cœurs disponibles. Les cœurs de CPU qui ne sont pas pris en compte entraînent un comportement indéfini dans le système.
- 4
- Définissez les unités centrales réservées. Lorsque le partitionnement de la charge de travail est activé, les processus système, les threads du noyau et les threads du conteneur système sont limités à ces unités centrales. Toutes les unités centrales qui ne sont pas isolées doivent être réservées.
- 5
- Définir le nombre de pages énormes.
- 6
- Définir la taille de la grande page.
- 7
- Définissez
nodecomme étant le nœud NUMA où leshugepagessont alloués. - 8
- Définissez
enabledàtruepour installer le noyau Linux en temps réel.
21.6.7.5. PTP
Les clusters OpenShift à nœud unique utilisent le Precision Time Protocol (PTP) pour la synchronisation de l'heure du réseau. L'exemple suivant PtpConfig CR illustre la configuration esclave PTP requise.
Configuration PTP recommandée
apiVersion: ptp.openshift.io/v1
kind: PtpConfig
metadata:
name: du-ptp-slave
namespace: openshift-ptp
spec:
profile:
- interface: ens5f0 1
name: slave
phc2sysOpts: -a -r -n 24
ptp4lConf: |
[global]
#
# Default Data Set
#
twoStepFlag 1
slaveOnly 0
priority1 128
priority2 128
domainNumber 24
#utc_offset 37
clockClass 248
clockAccuracy 0xFE
offsetScaledLogVariance 0xFFFF
free_running 0
freq_est_interval 1
dscp_event 0
dscp_general 0
dataset_comparison ieee1588
G.8275.defaultDS.localPriority 128
#
# Port Data Set
#
logAnnounceInterval -3
logSyncInterval -4
logMinDelayReqInterval -4
logMinPdelayReqInterval -4
announceReceiptTimeout 3
syncReceiptTimeout 0
delayAsymmetry 0
fault_reset_interval 4
neighborPropDelayThresh 20000000
masterOnly 0
G.8275.portDS.localPriority 128
#
# Run time options
#
assume_two_step 0
logging_level 6
path_trace_enabled 0
follow_up_info 0
hybrid_e2e 0
inhibit_multicast_service 0
net_sync_monitor 0
tc_spanning_tree 0
tx_timestamp_timeout 1
unicast_listen 0
unicast_master_table 0
unicast_req_duration 3600
use_syslog 1
verbose 0
summary_interval 0
kernel_leap 1
check_fup_sync 0
#
# Servo Options
#
pi_proportional_const 0.0
pi_integral_const 0.0
pi_proportional_scale 0.0
pi_proportional_exponent -0.3
pi_proportional_norm_max 0.7
pi_integral_scale 0.0
pi_integral_exponent 0.4
pi_integral_norm_max 0.3
step_threshold 2.0
first_step_threshold 0.00002
max_frequency 900000000
clock_servo pi
sanity_freq_limit 200000000
ntpshm_segment 0
#
# Transport options
#
transportSpecific 0x0
ptp_dst_mac 01:1B:19:00:00:00
p2p_dst_mac 01:80:C2:00:00:0E
udp_ttl 1
udp6_scope 0x0E
uds_address /var/run/ptp4l
#
# Default interface options
#
clock_type OC
network_transport L2
delay_mechanism E2E
time_stamping hardware
tsproc_mode filter
delay_filter moving_median
delay_filter_length 10
egressLatency 0
ingressLatency 0
boundary_clock_jbod 0
#
# Clock description
#
productDescription ;;
revisionData ;;
manufacturerIdentity 00:00:00
userDescription ;
timeSource 0xA0
ptp4lOpts: -2 -s --summary_interval -4
recommend:
- match:
- nodeLabel: node-role.kubernetes.io/master
priority: 4
profile: slave
- 1
- Définit l'interface utilisée pour recevoir le signal d'horloge PTP.
21.6.7.6. Profil accordé étendu
Les clusters OpenShift à nœud unique qui exécutent des charges de travail DU nécessitent des configurations de réglage des performances supplémentaires nécessaires pour les charges de travail hautes performances. L'exemple suivant Tuned CR étend le profil Tuned:
Configuration recommandée du profil Tuned étendu
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: performance-patch
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Configuration changes profile inherited from performance created tuned
include=openshift-node-performance-openshift-node-performance-profile
[bootloader]
cmdline_crash=nohz_full=2-51,54-103
[sysctl]
kernel.timer_migration=1
[scheduler]
group.ice-ptp=0:f:10:*:ice-ptp.*
[service]
service.stalld=start,enable
service.chronyd=stop,disable
name: performance-patch
recommend:
- machineConfigLabels:
machineconfiguration.openshift.io/role: master
priority: 19
profile: performance-patch
21.6.7.7. SR-IOV
La virtualisation des E/S à racine unique (SR-IOV) est couramment utilisée pour activer les réseaux fronthaul et midhaul. L'exemple YAML suivant configure la SR-IOV pour un cluster OpenShift à nœud unique.
Configuration SR-IOV recommandée
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovOperatorConfig
metadata:
name: default
namespace: openshift-sriov-network-operator
spec:
configDaemonNodeSelector:
node-role.kubernetes.io/master: ""
disableDrain: true
enableInjector: true
enableOperatorWebhook: true
---
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetwork
metadata:
name: sriov-nw-du-mh
namespace: openshift-sriov-network-operator
spec:
networkNamespace: openshift-sriov-network-operator
resourceName: du_mh
vlan: 150 1
---
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: sriov-nnp-du-mh
namespace: openshift-sriov-network-operator
spec:
deviceType: vfio-pci 2
isRdma: false
nicSelector:
pfNames:
- ens7f0 3
nodeSelector:
node-role.kubernetes.io/master: ""
numVfs: 8 4
priority: 10
resourceName: du_mh
---
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetwork
metadata:
name: sriov-nw-du-fh
namespace: openshift-sriov-network-operator
spec:
networkNamespace: openshift-sriov-network-operator
resourceName: du_fh
vlan: 140 5
---
apiVersion: sriovnetwork.openshift.io/v1
kind: SriovNetworkNodePolicy
metadata:
name: sriov-nnp-du-fh
namespace: openshift-sriov-network-operator
spec:
deviceType: netdevice 6
isRdma: true
nicSelector:
pfNames:
- ens5f0 7
nodeSelector:
node-role.kubernetes.io/master: ""
numVfs: 8 8
priority: 10
resourceName: du_fh
- 1
- Spécifie le VLAN pour le réseau intermédiaire.
- 2
- Sélectionnez
vfio-pciounetdevice, selon le cas. - 3
- Spécifie l'interface connectée au réseau intermédiaire.
- 4
- Spécifie le nombre de VFs pour le réseau midhaul.
- 5
- Le VLAN pour le réseau frontal.
- 6
- Sélectionnez
vfio-pciounetdevice, selon le cas. - 7
- Spécifie l'interface connectée au réseau fronthaul.
- 8
- Spécifie le nombre de VFs pour le réseau fronthaul.
21.6.7.8. Opérateur de console
L'opérateur de console installe et maintient la console web sur un cluster. Lorsque le nœud est géré de manière centralisée, l'opérateur n'est pas nécessaire et libère de l'espace pour les charges de travail des applications. L'exemple de ressource personnalisée (CR) suivant ( Console ) désactive la console.
Configuration recommandée de la console
apiVersion: operator.openshift.io/v1
kind: Console
metadata:
annotations:
include.release.openshift.io/ibm-cloud-managed: "false"
include.release.openshift.io/self-managed-high-availability: "false"
include.release.openshift.io/single-node-developer: "false"
release.openshift.io/create-only: "true"
name: cluster
spec:
logLevel: Normal
managementState: Removed
operatorLogLevel: Normal
21.6.7.9. Grafana et Alertmanager
Les clusters OpenShift à nœud unique qui exécutent des charges de travail DU nécessitent des ressources CPU réduites consommées par les composants de surveillance d'OpenShift Container Platform. La ressource personnalisée (CR) suivante ConfigMap désactive Grafana et Alertmanager.
Configuration recommandée pour la surveillance des clusters
apiVersion: v1
kind: ConfigMap
metadata:
name: cluster-monitoring-config
namespace: openshift-monitoring
data:
config.yaml: |
grafana:
enabled: false
alertmanagerMain:
enabled: false
prometheusK8s:
retention: 24h
21.6.7.10. Diagnostic du réseau
Les clusters OpenShift à nœud unique qui exécutent des charges de travail DU nécessitent moins de contrôles de connectivité réseau inter-pods pour réduire la charge supplémentaire créée par ces pods. La ressource personnalisée (CR) suivante désactive ces contrôles.
Configuration recommandée pour le diagnostic du réseau
apiVersion: operator.openshift.io/v1 kind: Network metadata: name: cluster spec: disableNetworkDiagnostics: true
Ressources supplémentaires
21.7. Valider le réglage d'un cluster OpenShift à nœud unique pour les charges de travail des applications vDU
Avant de pouvoir déployer des applications d'unités virtuelles distribuées (vDU), vous devez régler et configurer le microprogramme de l'hôte du cluster et divers autres paramètres de configuration du cluster. Utilisez les informations suivantes pour valider la configuration de la grappe afin de prendre en charge les charges de travail vDU.
Ressources supplémentaires
- Pour plus d'informations sur les clusters OpenShift à nœud unique adaptés aux déploiements d'applications vDU, voir Configuration de référence pour le déploiement de vDU sur OpenShift à nœud unique.
21.7.1. Configuration recommandée du micrologiciel pour les hôtes de la grappe vDU
Utilisez le tableau suivant comme base pour configurer le firmware de l'hôte du cluster pour les applications vDU fonctionnant sur OpenShift Container Platform 4.12.
Le tableau suivant est une recommandation générale pour la configuration du micrologiciel de l'hôte du cluster vDU. Les paramètres exacts du micrologiciel dépendront de vos besoins et de votre plate-forme matérielle spécifique. La configuration automatique du firmware n'est pas gérée par le pipeline de provisionnement zero touch.
Tableau 21.7. Paramètres recommandés pour le micrologiciel de l'hôte de la grappe
| Réglage du micrologiciel | Configuration | Description |
|---|---|---|
| HyperTransport (HT) | Activé | Le bus HyperTransport (HT) est une technologie de bus développée par AMD. HT fournit un lien à grande vitesse entre les composants de la mémoire hôte et les autres périphériques du système. |
| UEFI | Activé | Activer le démarrage à partir de l'UEFI pour l'hôte vDU. |
| Politique de puissance et de performance de l'unité centrale | Performances | Définissez la politique de puissance et de performance de l'unité centrale pour optimiser le système en termes de performance plutôt que d'efficacité énergétique. |
| Mise à l'échelle de la fréquence Uncore | Handicapés | Désactivez l'option Uncore Frequency Scaling pour éviter que la tension et la fréquence des parties non centrales de l'unité centrale ne soient réglées indépendamment. |
| Fréquence Uncore | Maximum | Règle les parties non essentielles de l'unité centrale, telles que le cache et le contrôleur de mémoire, à leur fréquence de fonctionnement maximale possible. |
| Performance Limite P | Handicapés | Désactiver la limite de performance P pour empêcher la coordination de la fréquence Uncore des processeurs. |
| Technologie Intel® SpeedStep améliorée | Activé | Activez Enhanced Intel SpeedStep pour permettre au système d'ajuster dynamiquement la tension du processeur et la fréquence du cœur, ce qui réduit la consommation d'énergie et la production de chaleur dans l'hôte. |
| Technologie Intel® Turbo Boost | Activé | Activez la technologie Turbo Boost pour les processeurs basés sur Intel afin d'autoriser automatiquement les cœurs du processeur à fonctionner plus rapidement que la fréquence de fonctionnement nominale s'ils fonctionnent en dessous des limites de puissance, de courant et de température spécifiées. |
| TDP configurable par Intel | Activé | Active la puissance de conception thermique (TDP) pour le CPU. |
| Niveau TDP configurable | Niveau 2 | Le niveau TDP définit la consommation d'énergie de l'unité centrale requise pour une performance donnée. Le niveau TDP 2 permet au CPU d'atteindre le niveau de performance le plus stable au prix de la consommation d'énergie. |
| Turbo à haut rendement énergétique | Handicapés | Désactiver le Turbo écoénergétique pour empêcher le processeur d'utiliser une stratégie basée sur l'efficacité énergétique. |
| Matériel P-States | Activé ou désactivé |
Activer les états P contrôlés par le système d'exploitation pour permettre des configurations d'économie d'énergie. Désactiver |
| Paquet C-State | État C0/C1 | Utilisez les états C0 ou C1 pour mettre le processeur dans un état totalement actif (C0) ou pour arrêter les horloges internes du processeur fonctionnant dans le logiciel (C1). |
| C1E | Handicapés | CPU Enhanced Halt (C1E) est une fonction d'économie d'énergie des puces Intel. La désactivation de C1E empêche le système d'exploitation d'envoyer une commande d'arrêt au processeur lorsqu'il est inactif. |
| Processeur C6 | Handicapés | L'économie d'énergie C6 est une fonction du processeur qui désactive automatiquement les cœurs et la mémoire cache inactifs du processeur. La désactivation de C6 améliore les performances du système. |
| Regroupement sous-NUMA | Handicapés | Le clustering Sub-NUMA divise les cœurs de processeur, le cache et la mémoire en plusieurs domaines NUMA. La désactivation de cette option peut améliorer les performances des charges de travail sensibles à la latence. |
Activer les paramètres SR-IOV et VT-d globaux dans le micrologiciel de l'hôte. Ces paramètres sont pertinents pour les environnements bare-metal.
Activez à la fois C-states et P-States contrôlé par le système d'exploitation pour permettre une gestion de l'alimentation par pod.
21.7.2. Configurations de cluster recommandées pour l'exécution des applications vDU
Les clusters qui exécutent des applications d'unités distribuées virtualisées (vDU) nécessitent une configuration hautement réglée et optimisée. Les informations suivantes décrivent les différents éléments nécessaires à la prise en charge des charges de travail vDU dans les clusters OpenShift Container Platform 4.12.
21.7.2.1. CRs MachineConfig recommandés pour les clusters
Vérifiez que les ressources personnalisées (CR) MachineConfig que vous avez extraites du conteneur ztp-site-generate sont appliquées dans le cluster. Les CR se trouvent dans le dossier out/source-crs/extra-manifest/ extrait.
Les CR MachineConfig suivants du conteneur ztp-site-generate configurent l'hôte du cluster :
Tableau 21.8. CRs MachineConfig recommandés
| Nom de fichier CR | Description |
|---|---|
|
|
Configure le partitionnement de la charge de travail pour le cluster. Appliquez ce |
|
|
Charge le module SCTP du noyau. Ces CR |
|
| Configure l'espace de noms de montage du conteneur et la configuration de Kubelet. |
|
| Configure le démarrage accéléré pour le cluster. |
|
|
Configure |
Ressources supplémentaires
21.7.2.2. Opérateurs de clusters recommandés
Les opérateurs suivants sont nécessaires pour les clusters exécutant des applications d'unités distribuées virtualisées (vDU) et font partie de la configuration de référence de base :
- Node Tuning Operator (NTO). NTO regroupe des fonctionnalités qui étaient auparavant fournies par le Performance Addon Operator, qui fait désormais partie de NTO.
- Opérateur PTP
- Opérateur de réseau SR-IOV
- Opérateur de journalisation Red Hat OpenShift
- Opérateur de stockage local
21.7.2.3. Configuration recommandée du noyau de la grappe
Utilisez toujours la dernière version du noyau temps réel prise en charge dans votre cluster. Veillez à appliquer les configurations suivantes dans le cluster :
Assurez-vous que les adresses
additionalKernelArgssuivantes sont définies dans le profil de performance du cluster :spec: additionalKernelArgs: - "rcupdate.rcu_normal_after_boot=0" - "efi=runtime"
Assurez-vous que le profil
performance-patchdans la CRTunedconfigure le jeu d'isolation CPU correct qui correspond au jeu de CPUisolateddans la CRPerformanceProfileassociée, par exemple :spec: profile: - name: performance-patch # The 'include' line must match the associated PerformanceProfile name # And the cmdline_crash CPU set must match the 'isolated' set in the associated PerformanceProfile data: | [main] summary=Configuration changes profile inherited from performance created tuned include=openshift-node-performance-openshift-node-performance-profile [bootloader] cmdline_crash=nohz_full=2-51,54-103 1 [sysctl] kernel.timer_migration=1 [scheduler] group.ice-ptp=0:f:10:*:ice-ptp.* [service] service.stalld=start,enable service.chronyd=stop,disable- 1
- La liste des CPU dépend de la configuration matérielle de l'hôte, en particulier du nombre de CPU disponibles dans le système et de la topologie des CPU.
21.7.2.4. Vérification de la version du noyau temps réel
Utilisez toujours la dernière version du noyau temps réel dans vos clusters OpenShift Container Platform. Si vous n'êtes pas sûr de la version du noyau utilisée dans le cluster, vous pouvez comparer la version actuelle du noyau en temps réel à la version release à l'aide de la procédure suivante.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous êtes connecté en tant qu'utilisateur avec des privilèges
cluster-admin. -
Vous avez installé
podman.
Procédure
Exécutez la commande suivante pour obtenir la version du cluster :
$ OCP_VERSION=$(oc get clusterversion version -o jsonpath='{.status.desired.version}{"\n"}')Obtenir le numéro SHA de l'image de la version :
$ DTK_IMAGE=$(oc adm release info --image-for=driver-toolkit quay.io/openshift-release-dev/ocp-release:$OCP_VERSION-x86_64)
Exécutez le conteneur d'image de version et extrayez la version du noyau qui est fournie avec la version actuelle du cluster :
$ podman run --rm $DTK_IMAGE rpm -qa | grep 'kernel-rt-core-' | sed 's#kernel-rt-core-##'
Exemple de sortie
4.18.0-305.49.1.rt7.121.el8_4.x86_64
Il s'agit de la version par défaut du noyau en temps réel qui est livrée avec la version.
NoteLe noyau temps réel est désigné par la chaîne
.rtdans la version du noyau.
Vérification
Vérifiez que la version du noyau indiquée pour la version actuelle de la grappe correspond au noyau en temps réel qui s'exécute dans la grappe. Exécutez les commandes suivantes pour vérifier la version du noyau en temps réel en cours d'exécution :
Ouvrez une connexion shell à distance au nœud de cluster :
oc debug node/<node_name>
Vérifier la version du noyau temps réel :
sh-4.4# uname -r
Exemple de sortie
4.18.0-305.49.1.rt7.121.el8_4.x86_64
21.7.3. Vérification de l'application des configurations recommandées pour les clusters
Vous pouvez vérifier que les clusters exécutent la bonne configuration. La procédure suivante décrit comment vérifier les différentes configurations requises pour déployer une application DU dans les clusters OpenShift Container Platform 4.12.
Conditions préalables
- Vous avez déployé un cluster et l'avez optimisé pour les charges de travail vDU.
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté en tant qu'utilisateur avec les privilèges
cluster-admin.
Procédure
Vérifiez que les sources OperatorHub par défaut sont désactivées. Exécutez la commande suivante :
$ oc get operatorhub cluster -o yaml
Exemple de sortie
spec: disableAllDefaultSources: trueVérifiez que toutes les ressources
CatalogSourcerequises sont annotées pour le partitionnement de la charge de travail (PreferredDuringScheduling) en exécutant la commande suivante :$ oc get catalogsource -A -o jsonpath='{range .items[*]}{.metadata.name}{" -- "}{.metadata.annotations.target\.workload\.openshift\.io/management}{"\n"}{end}'Exemple de sortie
certified-operators -- {"effect": "PreferredDuringScheduling"} community-operators -- {"effect": "PreferredDuringScheduling"} ran-operators 1 redhat-marketplace -- {"effect": "PreferredDuringScheduling"} redhat-operators -- {"effect": "PreferredDuringScheduling"}- 1
CatalogSourceles ressources qui ne sont pas annotées sont également renvoyées. Dans cet exemple, la ressourceran-operatorsCatalogSourcen'est pas annotée et n'a pas l'annotationPreferredDuringScheduling.
NoteDans un cluster vDU correctement configuré, une seule source de catalogue annotée est répertoriée.
Vérifiez que tous les espaces de noms d'opérateurs OpenShift Container Platform applicables sont annotés pour le partitionnement de la charge de travail. Cela inclut tous les opérateurs installés avec le noyau d'OpenShift Container Platform et l'ensemble des opérateurs supplémentaires inclus dans la configuration de réglage DU de référence. Exécutez la commande suivante :
$ oc get namespaces -A -o jsonpath='{range .items[*]}{.metadata.name}{" -- "}{.metadata.annotations.workload\.openshift\.io/allowed}{"\n"}{end}'Exemple de sortie
default -- openshift-apiserver -- management openshift-apiserver-operator -- management openshift-authentication -- management openshift-authentication-operator -- management
ImportantLes opérateurs supplémentaires ne doivent pas être annotés pour le partitionnement de la charge de travail. Dans la sortie de la commande précédente, les opérateurs supplémentaires doivent être listés sans aucune valeur à droite du séparateur
--.Vérifiez que la configuration de
ClusterLoggingest correcte. Exécutez les commandes suivantes :Validez que les journaux d'entrée et de sortie appropriés sont configurés :
$ oc get -n openshift-logging ClusterLogForwarder instance -o yaml
Exemple de sortie
apiVersion: logging.openshift.io/v1 kind: ClusterLogForwarder metadata: creationTimestamp: "2022-07-19T21:51:41Z" generation: 1 name: instance namespace: openshift-logging resourceVersion: "1030342" uid: 8c1a842d-80c5-447a-9150-40350bdf40f0 spec: inputs: - infrastructure: {} name: infra-logs outputs: - name: kafka-open type: kafka url: tcp://10.46.55.190:9092/test pipelines: - inputRefs: - audit name: audit-logs outputRefs: - kafka-open - inputRefs: - infrastructure name: infrastructure-logs outputRefs: - kafka-open ...Vérifiez que le calendrier de curation est adapté à votre application :
$ oc get -n openshift-logging clusterloggings.logging.openshift.io instance -o yaml
Exemple de sortie
apiVersion: logging.openshift.io/v1 kind: ClusterLogging metadata: creationTimestamp: "2022-07-07T18:22:56Z" generation: 1 name: instance namespace: openshift-logging resourceVersion: "235796" uid: ef67b9b8-0e65-4a10-88ff-ec06922ea796 spec: collection: logs: fluentd: {} type: fluentd curation: curator: schedule: 30 3 * * * type: curator managementState: Managed ...
Vérifiez que la console web est désactivée (
managementState: Removed) en exécutant la commande suivante :$ oc get consoles.operator.openshift.io cluster -o jsonpath="{ .spec.managementState }"Exemple de sortie
Supprimé
Vérifiez que
chronydest désactivé sur le nœud de cluster en exécutant les commandes suivantes :oc debug node/<node_name>
Vérifiez l'état de
chronydsur le nœud :sh-4.4# chroot /host
sh-4.4# systemctl status chronyd
Exemple de sortie
● chronyd.service - NTP client/server Loaded: loaded (/usr/lib/systemd/system/chronyd.service; disabled; vendor preset: enabled) Active: inactive (dead) Docs: man:chronyd(8) man:chrony.conf(5)Vérifiez que l'interface PTP est bien synchronisée avec l'horloge primaire en utilisant une connexion shell à distance au conteneur
linuxptp-daemonet à l'outil PTP Management Client (pmc) :Définissez la variable
$PTP_POD_NAMEavec le nom du modulelinuxptp-daemonen exécutant la commande suivante :$ PTP_POD_NAME=$(oc get pods -n openshift-ptp -l app=linuxptp-daemon -o name)
Exécutez la commande suivante pour vérifier l'état de synchronisation du dispositif PTP :
$ oc -n openshift-ptp rsh -c linuxptp-daemon-container ${PTP_POD_NAME} pmc -u -f /var/run/ptp4l.0.config -b 0 'GET PORT_DATA_SET'Exemple de sortie
sending: GET PORT_DATA_SET 3cecef.fffe.7a7020-1 seq 0 RESPONSE MANAGEMENT PORT_DATA_SET portIdentity 3cecef.fffe.7a7020-1 portState SLAVE logMinDelayReqInterval -4 peerMeanPathDelay 0 logAnnounceInterval 1 announceReceiptTimeout 3 logSyncInterval 0 delayMechanism 1 logMinPdelayReqInterval 0 versionNumber 2 3cecef.fffe.7a7020-2 seq 0 RESPONSE MANAGEMENT PORT_DATA_SET portIdentity 3cecef.fffe.7a7020-2 portState LISTENING logMinDelayReqInterval 0 peerMeanPathDelay 0 logAnnounceInterval 1 announceReceiptTimeout 3 logSyncInterval 0 delayMechanism 1 logMinPdelayReqInterval 0 versionNumber 2Exécutez la commande suivante
pmcpour vérifier l'état de l'horloge PTP :$ oc -n openshift-ptp rsh -c linuxptp-daemon-container ${PTP_POD_NAME} pmc -u -f /var/run/ptp4l.0.config -b 0 'GET TIME_STATUS_NP'Exemple de sortie
sending: GET TIME_STATUS_NP 3cecef.fffe.7a7020-0 seq 0 RESPONSE MANAGEMENT TIME_STATUS_NP master_offset 10 1 ingress_time 1657275432697400530 cumulativeScaledRateOffset +0.000000000 scaledLastGmPhaseChange 0 gmTimeBaseIndicator 0 lastGmPhaseChange 0x0000'0000000000000000.0000 gmPresent true 2 gmIdentity 3c2c30.ffff.670e00Vérifiez que la valeur attendue de
master offsetcorrespondant à la valeur de/var/run/ptp4l.0.configse trouve dans le journal delinuxptp-daemon-container:$ oc logs $PTP_POD_NAME -n openshift-ptp -c linuxptp-daemon-container
Exemple de sortie
phc2sys[56020.341]: [ptp4l.1.config] CLOCK_REALTIME phc offset -1731092 s2 freq -1546242 delay 497 ptp4l[56020.390]: [ptp4l.1.config] master offset -2 s2 freq -5863 path delay 541 ptp4l[56020.390]: [ptp4l.0.config] master offset -8 s2 freq -10699 path delay 533
Vérifiez que la configuration du SR-IOV est correcte en exécutant les commandes suivantes :
Vérifiez que la valeur
disableDrainde la ressourceSriovOperatorConfigest définie surtrue:$ oc get sriovoperatorconfig -n openshift-sriov-network-operator default -o jsonpath="{.spec.disableDrain}{'\n'}"Exemple de sortie
true
Vérifiez que l'état de synchronisation de
SriovNetworkNodeStateestSucceededen exécutant la commande suivante :$ oc get SriovNetworkNodeStates -n openshift-sriov-network-operator -o jsonpath="{.items[*].status.syncStatus}{'\n'}"Exemple de sortie
Succeeded
Vérifier que le nombre et la configuration attendus des fonctions virtuelles (
Vfs) sous chaque interface configurée pour SR-IOV sont présents et corrects dans le champ.status.interfaces. Par exemple :$ oc get SriovNetworkNodeStates -n openshift-sriov-network-operator -o yaml
Exemple de sortie
apiVersion: v1 items: - apiVersion: sriovnetwork.openshift.io/v1 kind: SriovNetworkNodeState ... status: interfaces: ... - Vfs: - deviceID: 154c driver: vfio-pci pciAddress: 0000:3b:0a.0 vendor: "8086" vfID: 0 - deviceID: 154c driver: vfio-pci pciAddress: 0000:3b:0a.1 vendor: "8086" vfID: 1 - deviceID: 154c driver: vfio-pci pciAddress: 0000:3b:0a.2 vendor: "8086" vfID: 2 - deviceID: 154c driver: vfio-pci pciAddress: 0000:3b:0a.3 vendor: "8086" vfID: 3 - deviceID: 154c driver: vfio-pci pciAddress: 0000:3b:0a.4 vendor: "8086" vfID: 4 - deviceID: 154c driver: vfio-pci pciAddress: 0000:3b:0a.5 vendor: "8086" vfID: 5 - deviceID: 154c driver: vfio-pci pciAddress: 0000:3b:0a.6 vendor: "8086" vfID: 6 - deviceID: 154c driver: vfio-pci pciAddress: 0000:3b:0a.7 vendor: "8086" vfID: 7
Vérifiez que le profil de performance du cluster est correct. Les sections
cpuethugepagesvarient en fonction de votre configuration matérielle. Exécutez la commande suivante :$ oc get PerformanceProfile openshift-node-performance-profile -o yaml
Exemple de sortie
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: creationTimestamp: "2022-07-19T21:51:31Z" finalizers: - foreground-deletion generation: 1 name: openshift-node-performance-profile resourceVersion: "33558" uid: 217958c0-9122-4c62-9d4d-fdc27c31118c spec: additionalKernelArgs: - idle=poll - rcupdate.rcu_normal_after_boot=0 - efi=runtime cpu: isolated: 2-51,54-103 reserved: 0-1,52-53 hugepages: defaultHugepagesSize: 1G pages: - count: 32 size: 1G machineConfigPoolSelector: pools.operator.machineconfiguration.openshift.io/master: "" net: userLevelNetworking: true nodeSelector: node-role.kubernetes.io/master: "" numa: topologyPolicy: restricted realTimeKernel: enabled: true status: conditions: - lastHeartbeatTime: "2022-07-19T21:51:31Z" lastTransitionTime: "2022-07-19T21:51:31Z" status: "True" type: Available - lastHeartbeatTime: "2022-07-19T21:51:31Z" lastTransitionTime: "2022-07-19T21:51:31Z" status: "True" type: Upgradeable - lastHeartbeatTime: "2022-07-19T21:51:31Z" lastTransitionTime: "2022-07-19T21:51:31Z" status: "False" type: Progressing - lastHeartbeatTime: "2022-07-19T21:51:31Z" lastTransitionTime: "2022-07-19T21:51:31Z" status: "False" type: Degraded runtimeClass: performance-openshift-node-performance-profile tuned: openshift-cluster-node-tuning-operator/openshift-node-performance-openshift-node-performance-profileNoteLes paramètres du processeur dépendent du nombre de cœurs disponibles sur le serveur et doivent être alignés sur les paramètres de partitionnement de la charge de travail. La configuration de
hugepagesdépend du serveur et de l'application.Vérifiez que le site
PerformanceProfilea été appliqué avec succès au cluster en exécutant la commande suivante :$ oc get performanceprofile openshift-node-performance-profile -o jsonpath="{range .status.conditions[*]}{ @.type }{' -- '}{@.status}{'\n'}{end}"Exemple de sortie
Available -- True Upgradeable -- True Progressing -- False Degraded -- False
Vérifiez les paramètres du correctif de performance
Tuneden exécutant la commande suivante :$ oc get tuneds.tuned.openshift.io -n openshift-cluster-node-tuning-operator performance-patch -o yaml
Exemple de sortie
apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: creationTimestamp: "2022-07-18T10:33:52Z" generation: 1 name: performance-patch namespace: openshift-cluster-node-tuning-operator resourceVersion: "34024" uid: f9799811-f744-4179-bf00-32d4436c08fd spec: profile: - data: | [main] summary=Configuration changes profile inherited from performance created tuned include=openshift-node-performance-openshift-node-performance-profile [bootloader] cmdline_crash=nohz_full=2-23,26-47 1 [sysctl] kernel.timer_migration=1 [scheduler] group.ice-ptp=0:f:10:*:ice-ptp.* [service] service.stalld=start,enable service.chronyd=stop,disable name: performance-patch recommend: - machineConfigLabels: machineconfiguration.openshift.io/role: master priority: 19 profile: performance-patch- 1
- La liste des processeurs dans
cmdline=nohz_full=variera en fonction de votre configuration matérielle.
Vérifiez que les diagnostics de mise en réseau du cluster sont désactivés en exécutant la commande suivante :
$ oc get networks.operator.openshift.io cluster -o jsonpath='{.spec.disableNetworkDiagnostics}'Exemple de sortie
true
Vérifiez que l'intervalle de maintenance de
Kubeletest réglé sur un taux plus lent. Ce paramètre est défini dans la configuration de la machinecontainerMountNS. Exécutez la commande suivante :$ oc describe machineconfig container-mount-namespace-and-kubelet-conf-master | grep OPENSHIFT_MAX_HOUSEKEEPING_INTERVAL_DURATION
Exemple de sortie
Environment="OPENSHIFT_MAX_HOUSEKEEPING_INTERVAL_DURATION=60s"
Vérifiez que Grafana et
alertManagerMainsont désactivés et que la période de rétention de Prometheus est fixée à 24 heures en exécutant la commande suivante :$ oc get configmap cluster-monitoring-config -n openshift-monitoring -o jsonpath="{ .data.config\.yaml }"Exemple de sortie
grafana: enabled: false alertmanagerMain: enabled: false prometheusK8s: retention: 24h
Utilisez les commandes suivantes pour vérifier que les routes Grafana et
alertManagerMainne sont pas trouvées dans le cluster :$ oc get route -n openshift-monitoring alertmanager-main
$ oc get route -n openshift-monitoring grafana
Les deux requêtes devraient renvoyer des messages à l'adresse
Error from server (NotFound).
Vérifiez qu'il y a un minimum de 4 CPUs alloués comme
reservedpour chacun des arguments de ligne de commandePerformanceProfile,Tunedperformance-patch, workload partitioning, et kernel en exécutant la commande suivante :$ oc get performanceprofile -o jsonpath="{ .items[0].spec.cpu.reserved }"Exemple de sortie
0-3
NoteEn fonction de votre charge de travail, vous pouvez avoir besoin d'allouer des unités centrales réservées supplémentaires.
21.8. Configuration avancée des clusters gérés avec les ressources SiteConfig
Vous pouvez utiliser les ressources personnalisées (CR) de SiteConfig pour déployer des fonctionnalités et des configurations personnalisées dans vos clusters gérés au moment de l'installation.
21.8.1. Personnaliser les manifestes d'installation supplémentaires dans le pipeline ZTP GitOps
Vous pouvez définir un ensemble de manifestes supplémentaires à inclure dans la phase d'installation du pipeline GitOps ZTP (Zero Touch Provisioning). Ces manifestes sont liés aux ressources personnalisées (CR) de SiteConfig et sont appliqués au cluster lors de l'installation. L'inclusion de MachineConfig CRs au moment de l'installation rend le processus d'installation plus efficace.
Conditions préalables
- Créez un dépôt Git où vous gérez les données de configuration de votre site personnalisé. Le dépôt doit être accessible depuis le cluster hub et être défini comme dépôt source pour l'application Argo CD.
Procédure
- Créer un ensemble de manifestes CR supplémentaires que le pipeline ZTP utilise pour personnaliser l'installation des clusters.
Dans votre répertoire personnalisé
/siteconfig, créez un dossier/extra-manifestpour vos manifestes supplémentaires. L'exemple suivant illustre un exemple de/siteconfigavec un dossier/extra-manifest:siteconfig ├── site1-sno-du.yaml ├── site2-standard-du.yaml └── extra-manifest └── 01-example-machine-config.yaml-
Ajoutez vos CR de manifestes supplémentaires personnalisés au répertoire
siteconfig/extra-manifest. Dans votre CR
SiteConfig, saisissez le nom du répertoire dans le champextraManifestPath, par exemple :clusters: - clusterName: "example-sno" networkType: "OVNKubernetes" extraManifestPath: extra-manifest
-
Sauvegardez les CRs
SiteConfiget/extra-manifestet mettez-les dans le repo de configuration du site.
Le pipeline ZTP ajoute les CR du répertoire /extra-manifest à l'ensemble par défaut des manifestes supplémentaires lors du provisionnement de la grappe.
21.8.2. Filtrer les ressources personnalisées à l'aide des filtres SiteConfig
En utilisant des filtres, vous pouvez facilement personnaliser les ressources personnalisées (CR) de SiteConfig pour inclure ou exclure d'autres CR à utiliser dans la phase d'installation du pipeline GitOps de zero touch provisioning (ZTP).
Vous pouvez spécifier une valeur inclusionDefault de include ou exclude pour le CR SiteConfig, ainsi qu'une liste des CR RAN extraManifest spécifiques que vous souhaitez inclure ou exclure. En définissant inclusionDefault comme include, le pipeline ZTP applique tous les fichiers contenus dans /source-crs/extra-manifest pendant l'installation. Le réglage de inclusionDefault à exclude fait l'inverse.
Vous pouvez exclure des CR individuels du dossier /source-crs/extra-manifest qui sont autrement inclus par défaut. L'exemple suivant configure un CR personnalisé à nœud unique OpenShift SiteConfig pour exclure le CR /source-crs/extra-manifest/03-sctp-machine-config-worker.yaml au moment de l'installation.
D'autres scénarios de filtrage facultatifs sont également décrits.
Conditions préalables
- Vous avez configuré le cluster du concentrateur pour générer les CR d'installation et de stratégie nécessaires.
- Vous avez créé un dépôt Git dans lequel vous gérez les données de configuration de votre site personnalisé. Le référentiel doit être accessible depuis le cluster hub et être défini comme référentiel source pour l'application Argo CD.
Procédure
Pour empêcher le pipeline ZTP d'appliquer le fichier
03-sctp-machine-config-worker.yamlCR, appliquez le YAML suivant dans leSiteConfigCR :apiVersion: ran.openshift.io/v1 kind: SiteConfig metadata: name: "site1-sno-du" namespace: "site1-sno-du" spec: baseDomain: "example.com" pullSecretRef: name: "assisted-deployment-pull-secret" clusterImageSetNameRef: "openshift-4.12" sshPublicKey: "<ssh_public_key>" clusters: - clusterName: "site1-sno-du" extraManifests: filter: exclude: - 03-sctp-machine-config-worker.yamlLe pipeline ZTP ne tient pas compte de la CR
03-sctp-machine-config-worker.yamllors de l'installation. Tous les autres CR de/source-crs/extra-manifestsont appliqués.Enregistrez le CR
SiteConfiget transférez les modifications dans le référentiel de configuration du site.Le pipeline ZTP surveille et ajuste les CR qu'il applique en fonction des instructions du filtre
SiteConfig.Facultatif : Pour éviter que le pipeline ZTP n'applique toutes les CR
/source-crs/extra-manifestpendant l'installation du cluster, appliquez le YAML suivant dans la CRSiteConfig:- clusterName: "site1-sno-du" extraManifests: filter: inclusionDefault: excludeFacultatif : Pour exclure tous les CR de
/source-crs/extra-manifestRAN et inclure à la place un fichier CR personnalisé pendant l'installation, modifiez le CR personnalisé deSiteConfigpour définir le dossier des manifestes personnalisés et le fichierinclude, par exemple :clusters: - clusterName: "site1-sno-du" extraManifestPath: "<custom_manifest_folder>" 1 extraManifests: filter: inclusionDefault: exclude 2 include: - custom-sctp-machine-config-worker.yaml
- 1
- Remplacez
<custom_manifest_folder>par le nom du dossier qui contient les CR de l'installation personnalisée, par exemple,user-custom-manifest/. - 2
- Définissez
inclusionDefaultsurexcludepour éviter que le pipeline ZTP n'applique les fichiers contenus dans/source-crs/extra-manifestlors de l'installation.
L'exemple suivant illustre la structure du dossier personnalisé :
siteconfig ├── site1-sno-du.yaml └── user-custom-manifest └── custom-sctp-machine-config-worker.yaml
21.9. Configuration avancée des clusters gérés avec les ressources PolicyGenTemplate
Vous pouvez utiliser les CR PolicyGenTemplate pour déployer des fonctionnalités personnalisées dans vos clusters gérés.
21.9.1. Déploiement de modifications supplémentaires dans les clusters
Si vous souhaitez modifier la configuration du cluster en dehors de la configuration de base du pipeline ZTP de GitOps, trois options s'offrent à vous :
- Appliquer la configuration supplémentaire une fois que le pipeline ZTP est terminé
- Lorsque le déploiement du pipeline ZTP de GitOps est terminé, le cluster déployé est prêt pour les charges de travail des applications. À ce stade, vous pouvez installer des opérateurs supplémentaires et appliquer des configurations spécifiques à vos besoins. Assurez-vous que les configurations supplémentaires n'affectent pas négativement les performances de la plateforme ou le budget CPU alloué.
- Ajouter du contenu à la bibliothèque ZTP
- Les ressources personnalisées (CR) de base que vous déployez avec le pipeline ZTP de GitOps peuvent être complétées par du contenu personnalisé selon les besoins.
- Créer des manifestes supplémentaires pour l'installation du cluster
- Les manifestes supplémentaires sont appliqués pendant l'installation et rendent le processus d'installation plus efficace.
Fournir des CR source supplémentaires ou modifier des CR source existants peut avoir un impact significatif sur la performance ou le profil CPU d'OpenShift Container Platform.
Ressources supplémentaires
- Voir Personnaliser les manifestes d'installation supplémentaires dans le pipeline ZTP GitOps pour plus d'informations sur l'ajout de manifestes supplémentaires.
21.9.2. Utilisation des CR PolicyGenTemplate pour remplacer le contenu des CR sources
PolicyGenTemplate les ressources personnalisées (CR) vous permettent de superposer des détails de configuration supplémentaires aux CR de base fournis avec le plugin GitOps dans le conteneur ztp-site-generate. Vous pouvez considérer les CR PolicyGenTemplate comme une fusion logique ou un correctif de la CR de base. Utilisez les CR PolicyGenTemplate pour mettre à jour un seul champ du CR de base, ou pour superposer l'ensemble du contenu du CR de base. Vous pouvez mettre à jour des valeurs et insérer des champs qui ne figurent pas dans le CR de base.
L'exemple de procédure suivant décrit comment mettre à jour les champs du CR PerformanceProfile généré pour la configuration de référence sur la base du CR PolicyGenTemplate dans le fichier group-du-sno-ranGen.yaml. Utilisez cette procédure comme base pour modifier d'autres parties de PolicyGenTemplate en fonction de vos besoins.
Conditions préalables
- Créez un dépôt Git où vous gérez les données de configuration de votre site personnalisé. Le dépôt doit être accessible depuis le cluster hub et être défini comme dépôt source pour Argo CD.
Procédure
Examinez le CR source de référence à la recherche de contenu existant. Vous pouvez examiner les CR source répertoriés dans la référence
PolicyGenTemplateCR en les extrayant du conteneur ZTP (Zero Touch Provisioning).Créez un dossier
/out:$ mkdir -p ./out
Extraire les CR source :
$ podman run --log-driver=none --rm registry.redhat.io/openshift4/ztp-site-generate-rhel8:v4.12.1 extract /home/ztp --tar | tar x -C ./out
Examinez le document de référence
PerformanceProfileCR à l'adresse./out/source-crs/PerformanceProfile.yaml:apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: $name annotations: ran.openshift.io/ztp-deploy-wave: "10" spec: additionalKernelArgs: - "idle=poll" - "rcupdate.rcu_normal_after_boot=0" cpu: isolated: $isolated reserved: $reserved hugepages: defaultHugepagesSize: $defaultHugepagesSize pages: - size: $size count: $count node: $node machineConfigPoolSelector: pools.operator.machineconfiguration.openshift.io/$mcp: "" net: userLevelNetworking: true nodeSelector: node-role.kubernetes.io/$mcp: '' numa: topologyPolicy: "restricted" realTimeKernel: enabled: trueNoteTous les champs du CR source qui contiennent
$…sont supprimés du CR généré s'ils ne sont pas fournis dans le CRPolicyGenTemplate.Mettez à jour l'entrée
PolicyGenTemplatepourPerformanceProfiledans le fichier de référencegroup-du-sno-ranGen.yaml. L'exemple suivant de strophePolicyGenTemplateCR fournit les spécifications appropriées de l'unité centrale, définit la configuration dehugepageset ajoute un nouveau champ qui définitgloballyDisableIrqLoadBalancingcomme faux.- fileName: PerformanceProfile.yaml policyName: "config-policy" metadata: name: openshift-node-performance-profile spec: cpu: # These must be tailored for the specific hardware platform isolated: "2-19,22-39" reserved: "0-1,20-21" hugepages: defaultHugepagesSize: 1G pages: - size: 1G count: 10 globallyDisableIrqLoadBalancing: false-
Commencer le changement
PolicyGenTemplatedans Git, puis pousser vers le dépôt Git surveillé par l'application GitOps ZTP argo CD.
Exemple de sortie
L'application ZTP génère une politique RHACM qui contient la CR PerformanceProfile générée. Le contenu de ce CR est obtenu en fusionnant les contenus metadata et spec de l'entrée PerformanceProfile dans le PolicyGenTemplate sur le CR source. Le CR résultant a le contenu suivant :
---
apiVersion: performance.openshift.io/v2
kind: PerformanceProfile
metadata:
name: openshift-node-performance-profile
spec:
additionalKernelArgs:
- idle=poll
- rcupdate.rcu_normal_after_boot=0
cpu:
isolated: 2-19,22-39
reserved: 0-1,20-21
globallyDisableIrqLoadBalancing: false
hugepages:
defaultHugepagesSize: 1G
pages:
- count: 10
size: 1G
machineConfigPoolSelector:
pools.operator.machineconfiguration.openshift.io/master: ""
net:
userLevelNetworking: true
nodeSelector:
node-role.kubernetes.io/master: ""
numa:
topologyPolicy: restricted
realTimeKernel:
enabled: true
Dans le dossier /source-crs que vous extrayez du conteneur ztp-site-generate, la syntaxe $ n'est pas utilisée pour la substitution de modèle comme le suggère la syntaxe. Au contraire, si l'outil policyGen voit le préfixe $ pour une chaîne et que vous ne spécifiez pas de valeur pour ce champ dans le CR PolicyGenTemplate correspondant, le champ est entièrement omis du CR de sortie.
Une exception à cette règle est la variable $mcp dans les fichiers YAML /source-crs, qui est remplacée par la valeur spécifiée pour mcp dans le CR PolicyGenTemplate. Par exemple, dans example/policygentemplates/group-du-standard-ranGen.yaml, la valeur de mcp est worker:
spec:
bindingRules:
group-du-standard: ""
mcp: "worker"
L'outil policyGen remplace les instances de $mcp par worker dans les CR de sortie.
21.9.3. Ajouter un nouveau contenu au pipeline ZTP de GitOps
Les CR source du conteneur de générateur de site ZTP de GitOps fournissent un ensemble de fonctionnalités critiques et de paramètres de réglage des nœuds pour les applications d'unités distribuées (UD) du RAN. Ils sont appliqués aux clusters que vous déployez avec ZTP. Pour ajouter ou modifier des CR source existants dans le conteneur ztp-site-generate, reconstruisez le conteneur ztp-site-generate et mettez-le à la disposition du cluster concentrateur, généralement à partir du registre déconnecté associé au cluster concentrateur. Tout CR valide de OpenShift Container Platform peut être ajouté.
Suivez la procédure suivante pour ajouter un nouveau contenu au pipeline ZTP.
Procédure
Créez un répertoire contenant un fichier Containerfile et les fichiers YAML du CR source que vous souhaitez inclure dans le conteneur
ztp-site-generatemis à jour, par exemple :ztp-update/ ├── example-cr1.yaml ├── example-cr2.yaml └── ztp-update.in
Ajoutez le contenu suivant au fichier de conteneurs
ztp-update.in:FROM registry.redhat.io/openshift4/ztp-site-generate-rhel8:v4.12 ADD example-cr2.yaml /kustomize/plugin/ran.openshift.io/v1/policygentemplate/source-crs/ ADD example-cr1.yaml /kustomize/plugin/ran.openshift.io/v1/policygentemplate/source-crs/
Ouvrez un terminal dans le dossier
ztp-update/et reconstruisez le conteneur :$ podman build -t ztp-site-generate-rhel8-custom:v4.12-custom-1
Pousser l'image du conteneur construit vers votre registre déconnecté, par exemple :
$ podman push localhost/ztp-site-generate-rhel8-custom:v4.12-custom-1 registry.example.com:5000/ztp-site-generate-rhel8-custom:v4.12-custom-1
Patch de l'instance Argo CD sur le cluster hub pour pointer vers l'image de conteneur nouvellement construite :
$ oc patch -n openshift-gitops argocd openshift-gitops --type=json -p '[{"op": "replace", "path":"/spec/repo/initContainers/0/image", "value": "registry.example.com:5000/ztp-site-generate-rhel8-custom:v4.12-custom-1"} ]'Lorsque l'instance Argo CD est corrigée, le pod
openshift-gitops-repo-serverredémarre automatiquement.
Vérification
Vérifiez que le nouveau pod
openshift-gitops-repo-servera terminé son initialisation et que le pod repo précédent est terminé :$ oc get pods -n openshift-gitops | grep openshift-gitops-repo-server
Exemple de sortie
openshift-gitops-server-7df86f9774-db682 1/1 Running 1 28s
Vous devez attendre que le nouveau pod
openshift-gitops-repo-serverait terminé son initialisation et que le pod précédent soit terminé pour que le contenu de l'image de conteneur nouvellement ajoutée soit disponible.
Ressources supplémentaires
-
Alternativement, vous pouvez patcher l'instance ArgoCD comme décrit dans Configuration du cluster hub avec ArgoCD en modifiant
argocd-openshift-gitops-patch.jsonavec une imageinitContainermise à jour avant d'appliquer le fichier patch.
21.9.4. Configuration des délais d'évaluation de la conformité des politiques pour les CR PolicyGenTemplate
Utilisez Red Hat Advanced Cluster Management (RHACM) installé sur un cluster hub pour surveiller et signaler si vos clusters gérés sont conformes aux stratégies appliquées. RHACM utilise des modèles de politiques pour appliquer des contrôleurs de politiques et des politiques prédéfinis. Les contrôleurs de politiques sont des instances de définition de ressources personnalisées (CRD) Kubernetes.
Vous pouvez remplacer les intervalles d'évaluation des politiques par défaut par des ressources personnalisées (CR) sur le site PolicyGenTemplate. Vous configurez les paramètres de durée qui définissent combien de temps une CR ConfigurationPolicy peut rester dans un état de conformité ou de non-conformité à la politique avant que RHACM ne réévalue les politiques de cluster appliquées.
Le générateur de politiques ZTP (zero touch provisioning) génère des politiques CR ConfigurationPolicy avec des intervalles d'évaluation prédéfinis. La valeur par défaut de l'état noncompliant est de 10 secondes. La valeur par défaut de l'état compliant est de 10 minutes. Pour désactiver l'intervalle d'évaluation, définissez la valeur sur never.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté au cluster hub en tant qu'utilisateur avec les privilèges
cluster-admin. - Vous avez créé un dépôt Git dans lequel vous gérez les données de configuration de votre site personnalisé.
Procédure
Pour configurer l'intervalle d'évaluation de toutes les politiques dans une CR
PolicyGenTemplate, ajoutezevaluationIntervalau champspec, puis définissez les valeurscompliantetnoncompliantappropriées. Par exemple :spec: evaluationInterval: compliant: 30m noncompliant: 20sPour configurer l'intervalle d'évaluation de l'objet
spec.sourceFilesdans un CRPolicyGenTemplate, ajoutezevaluationIntervalau champsourceFiles, par exemple :spec: sourceFiles: - fileName: SriovSubscription.yaml policyName: "sriov-sub-policy" evaluationInterval: compliant: never noncompliant: 10s-
Commencez les fichiers
PolicyGenTemplateCRs dans le dépôt Git et apportez vos modifications.
Vérification
Vérifiez que les stratégies des clusters de rayons gérés sont contrôlées aux intervalles prévus.
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-adminsur le cluster géré. Obtenez les pods qui sont en cours d'exécution dans l'espace de noms
open-cluster-management-agent-addon. Exécutez la commande suivante :$ oc get pods -n open-cluster-management-agent-addon
Exemple de sortie
NAME READY STATUS RESTARTS AGE config-policy-controller-858b894c68-v4xdb 1/1 Running 22 (5d8h ago) 10d
Vérifiez que les politiques appliquées sont évaluées à l'intervalle prévu dans les journaux du pod
config-policy-controller:$ oc logs -n open-cluster-management-agent-addon config-policy-controller-858b894c68-v4xdb
Exemple de sortie
2022-05-10T15:10:25.280Z info configuration-policy-controller controllers/configurationpolicy_controller.go:166 Skipping the policy evaluation due to the policy not reaching the evaluation interval {"policy": "compute-1-config-policy-config"} 2022-05-10T15:10:25.280Z info configuration-policy-controller controllers/configurationpolicy_controller.go:166 Skipping the policy evaluation due to the policy not reaching the evaluation interval {"policy": "compute-1-common-compute-1-catalog-policy-config"}
21.9.5. Signalisation de l'achèvement du déploiement d'un cluster ZTP avec des politiques d'information du validateur
Créez une politique d'information du validateur qui signale la fin de l'installation et de la configuration du cluster déployé dans le cadre du Zero Touch Provisioning (ZTP). Cette politique peut être utilisée pour les déploiements de clusters OpenShift à un nœud, de clusters à trois nœuds et de clusters standard.
Procédure
Créez une ressource personnalisée (CR) autonome
PolicyGenTemplatequi contient le fichier sourcevalidatorCRs/informDuValidator.yaml. Vous n'avez besoin que d'une CRPolicyGenTemplateautonome pour chaque type de cluster. Par exemple, cette CR applique une politique d'information du validateur pour les clusters OpenShift à nœud unique :Exemple de politique d'information de validateur de cluster à nœud unique CR (group-du-sno-validator-ranGen.yaml)
apiVersion: ran.openshift.io/v1 kind: PolicyGenTemplate metadata: name: "group-du-sno-validator" 1 namespace: "ztp-group" 2 spec: bindingRules: group-du-sno: "" 3 bindingExcludedRules: ztp-done: "" 4 mcp: "master" 5 sourceFiles: - fileName: validatorCRs/informDuValidator.yaml remediationAction: inform 6 policyName: "du-policy" 7
- 1
- Le nom de l'objet
PolicyGenTemplates. Ce nom est également utilisé dans les noms des objetsplacementBinding,placementRule, etpolicyqui sont créés dans l'objetnamespace. - 2
- Cette valeur doit correspondre à celle de
namespaceutilisée dans le groupePolicyGenTemplates. - 3
- L'étiquette
group-du-*définie dansbindingRulesdoit exister dans les fichiersSiteConfig. - 4
- Le label défini dans
bindingExcludedRulesdoit être "ztp-done:`". Le labelztp-doneest utilisé en coordination avec le Topology Aware Lifecycle Manager. - 5
mcpdéfinit l'objetMachineConfigPoolutilisé dans le fichier sourcevalidatorCRs/informDuValidator.yaml. Il doit s'agir demasterpour les déploiements de clusters à un ou trois nœuds et deworkerpour les déploiements de clusters standard.- 6
- Facultatif. La valeur par défaut est
inform. - 7
- Cette valeur fait partie du nom de la stratégie RHACM générée. La stratégie de validation générée pour l'exemple d'un seul nœud est
group-du-sno-validator-du-policy.
-
Commencez le fichier
PolicyGenTemplateCR dans votre dépôt Git et transférez les modifications.
Ressources supplémentaires
21.9.6. Configuration des événements rapides PTP à l'aide des CR PolicyGenTemplate
Vous pouvez configurer les événements rapides PTP pour les clusters vRAN qui sont déployés à l'aide du pipeline GitOps Zero Touch Provisioning (ZTP). Utilisez les ressources personnalisées (CR) de PolicyGenTemplate comme base pour créer une hiérarchie de fichiers de configuration adaptés aux exigences spécifiques de votre site.
Conditions préalables
- Créez un dépôt Git dans lequel vous gérez les données de configuration de votre site personnalisé.
Procédure
Ajoutez le YAML suivant à
.spec.sourceFilesdans le fichiercommon-ranGen.yamlpour configurer l'opérateur AMQP :#AMQ interconnect operator for fast events - fileName: AmqSubscriptionNS.yaml policyName: "subscriptions-policy" - fileName: AmqSubscriptionOperGroup.yaml policyName: "subscriptions-policy" - fileName: AmqSubscription.yaml policyName: "subscriptions-policy"
Appliquez les modifications suivantes à
PolicyGenTemplateaux fichiersgroup-du-3node-ranGen.yaml,group-du-sno-ranGen.yamlougroup-du-standard-ranGen.yamlen fonction de vos besoins :Dans
.sourceFiles, ajoutez le fichierPtpOperatorConfigCR qui configure l'hôte de transport AMQ àconfig-policy:- fileName: PtpOperatorConfigForEvent.yaml policyName: "config-policy"
Configurez les pages
linuxptpetphc2syspour le type d'horloge PTP et l'interface. Par exemple, ajoutez la strophe suivante à.sourceFiles:- fileName: PtpConfigSlave.yaml 1 policyName: "config-policy" metadata: name: "du-ptp-slave" spec: profile: - name: "slave" interface: "ens5f1" 2 ptp4lOpts: "-2 -s --summary_interval -4" 3 phc2sysOpts: "-a -r -m -n 24 -N 8 -R 16" 4 ptpClockThreshold: 5 holdOverTimeout: 30 #secs maxOffsetThreshold: 100 #nano secs minOffsetThreshold: -100 #nano secs
- 1
- Il peut s'agir de
PtpConfigMaster.yaml,PtpConfigSlave.yaml, ouPtpConfigSlaveCvl.yamlen fonction de vos besoins.PtpConfigSlaveCvl.yamlconfigure les serviceslinuxptppour un NIC Intel E810 Columbiaville. Pour les configurations basées surgroup-du-sno-ranGen.yamlougroup-du-3node-ranGen.yaml, utilisezPtpConfigSlave.yaml. - 2
- Nom de l'interface spécifique au dispositif.
- 3
- Vous devez ajouter la valeur
--summary_interval -4àptp4lOptsdans.spec.sourceFiles.spec.profilepour activer les événements rapides PTP. - 4
- Valeurs requises
phc2sysOpts.-mimprime des messages àstdout.linuxptp-daemonDaemonSetanalyse les journaux et génère des métriques Prometheus. - 5
- Facultatif. Si la strophe
ptpClockThresholdn'est pas présente, des valeurs par défaut sont utilisées pour les champsptpClockThreshold. La strophe indique les valeurs par défaut deptpClockThreshold. Les valeurs deptpClockThresholdconfigurent le délai de déclenchement des événements PTP après la déconnexion de l'horloge maître PTP.holdOverTimeoutest la valeur de temps en secondes avant que l'état de l'événement de l'horloge PTP ne passe àFREERUNlorsque l'horloge maître PTP est déconnectée. Les paramètresmaxOffsetThresholdetminOffsetThresholdconfigurent des valeurs de décalage en nanosecondes qui se comparent aux valeurs deCLOCK_REALTIME(phc2sys) ou au décalage du maître (ptp4l). Lorsque la valeur de décalageptp4louphc2sysest en dehors de cette plage, l'état de l'horloge PTP est réglé surFREERUN. Lorsque la valeur de décalage est comprise dans cette plage, l'état de l'horloge PTP est réglé surLOCKED.
Appliquez les modifications suivantes
PolicyGenTemplateaux fichiers YAML de votre site, par exempleexample-sno-site.yaml:Dans
.sourceFiles, ajoutez le fichierInterconnectCR qui configure le routeur AMQ àconfig-policy:- fileName: AmqInstance.yaml policyName: "config-policy"
- Fusionnez tous les autres changements et fichiers nécessaires avec votre référentiel de site personnalisé.
- Transférez les modifications dans le référentiel de configuration de votre site pour déployer les événements rapides PTP sur de nouveaux sites à l'aide de GitOps ZTP.
Ressources supplémentaires
- Pour plus d'informations sur l'installation de l'opérateur d'interconnexion AMQ, voir Installation du bus de messagerie AMQ.
21.9.7. Configuration de l'opérateur de registre d'images pour la mise en cache locale des images
OpenShift Container Platform gère la mise en cache des images à l'aide d'un registre local. Dans les cas d'utilisation de l'edge computing, les clusters sont souvent soumis à des restrictions de bande passante lorsqu'ils communiquent avec des registres d'images centralisés, ce qui peut entraîner de longs temps de téléchargement des images.
De longs temps de téléchargement sont inévitables lors du déploiement initial. Avec le temps, CRI-O risque d'effacer le répertoire /var/lib/containers/storage en cas d'arrêt inattendu. Pour remédier aux longs temps de téléchargement des images, vous pouvez créer un registre d'images local sur les clusters gérés à distance à l'aide de GitOps ZTP. Cette solution est utile dans les scénarios d'Edge computing où les clusters sont déployés à la périphérie du réseau.
Avant de pouvoir configurer le registre d'images local avec GitOps ZTP, vous devez configurer le partitionnement des disques dans le CR SiteConfig que vous utilisez pour installer le cluster géré à distance. Après l'installation, vous configurez le registre d'images local à l'aide d'un CR PolicyGenTemplate. Ensuite, le pipeline ZTP crée des CR de volume persistant (PV) et de revendication de volume persistant (PVC) et corrige la configuration imageregistry.
Le registre d'images local ne peut être utilisé que pour les images d'applications utilisateur et ne peut pas être utilisé pour les images d'opérateurs OpenShift Container Platform ou Operator Lifecycle Manager.
Ressources supplémentaires
- Installation du bus de messagerie AMQ
- Pour plus d'informations sur les registres d'images de conteneurs, voir OpenShift image registry overview.
21.9.8. Configuration des événements bare-metal avec les CR PolicyGenTemplate
21.9.8.1. Configurer le partitionnement des disques avec SiteConfig
Configurer le partitionnement du disque pour un cluster géré à l'aide d'un CR SiteConfig et du ZTP GitOps. Les détails de la partition du disque dans le CR SiteConfig doivent correspondre au disque sous-jacent.
Utilisez des noms persistants pour les périphériques afin d'éviter que les noms de périphériques tels que /dev/sda et /dev/sdb ne soient échangés à chaque redémarrage. Vous pouvez utiliser rootDeviceHints pour choisir le périphérique de démarrage et utiliser ensuite le même périphérique pour d'autres partitionnements.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté au cluster hub en tant qu'utilisateur avec les privilèges
cluster-admin. - Vous avez créé un dépôt Git dans lequel vous gérez les données de configuration de votre site personnalisé pour l'utiliser avec GitOps Zero Touch Provisioning (ZTP).
Procédure
Ajoutez le fichier YAML suivant, qui décrit le partitionnement du disque hôte, au fichier
SiteConfigCR que vous utilisez pour installer le cluster géré :nodes: rootDeviceHints: wwn: "0x62cea7f05c98c2002708a0a22ff480ea" diskPartition: - device: /dev/disk/by-id/wwn-0x62cea7f05c98c2002708a0a22ff480ea 1 partitions: - mount_point: /var/imageregistry size: 102500 2 start: 344844 3- 1
- Ce paramètre dépend du matériel. Il peut s'agir d'un numéro de série ou d'un nom d'appareil. La valeur doit correspondre à la valeur définie pour
rootDeviceHints. - 2
- La valeur minimale pour
sizeest de 102500 MiB. - 3
- La valeur minimale pour
startest de 25000 MiB. La valeur totale desizeetstartne doit pas dépasser la taille du disque, sinon l'installation échouera.
-
Sauvegardez le CR
SiteConfiget mettez-le dans le répertoire de configuration du site.
Le pipeline ZTP approvisionne le cluster à l'aide de SiteConfig CR et configure la partition du disque.
21.9.8.2. Configuration du registre d'images à l'aide des CR PolicyGenTemplate
Utilisez les CR PolicyGenTemplate (PGT) pour appliquer les CR nécessaires à la configuration du registre d'images et à la correction de la configuration imageregistry.
Conditions préalables
- Vous avez configuré une partition de disque dans le cluster géré.
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté au cluster hub en tant qu'utilisateur avec les privilèges
cluster-admin. - Vous avez créé un dépôt Git dans lequel vous gérez les données de configuration de votre site personnalisé pour l'utiliser avec GitOps Zero Touch Provisioning (ZTP).
Procédure
Configurez la classe de stockage, la revendication de volume persistant, le volume persistant et la configuration du registre d'images dans le CR
PolicyGenTemplateapproprié. Par exemple, pour configurer un site individuel, ajoutez le fichier YAML suivant au fichierexample-sno-site.yaml:sourceFiles: # storage class - fileName: StorageClass.yaml policyName: "sc-for-image-registry" metadata: name: image-registry-sc annotations: ran.openshift.io/ztp-deploy-wave: "100" 1 # persistent volume claim - fileName: StoragePVC.yaml policyName: "pvc-for-image-registry" metadata: name: image-registry-pvc namespace: openshift-image-registry annotations: ran.openshift.io/ztp-deploy-wave: "100" spec: accessModes: - ReadWriteMany resources: requests: storage: 100Gi storageClassName: image-registry-sc volumeMode: Filesystem # persistent volume - fileName: ImageRegistryPV.yaml 2 policyName: "pv-for-image-registry" metadata: annotations: ran.openshift.io/ztp-deploy-wave: "100" - fileName: ImageRegistryConfig.yaml policyName: "config-for-image-registry" complianceType: musthave metadata: annotations: ran.openshift.io/ztp-deploy-wave: "100" spec: storage: pvc: claim: "image-registry-pvc"- 1
- Définissez la valeur appropriée pour
ztp-deploy-waveselon que vous configurez les registres d'images au niveau du site, du commun ou du groupe.ztp-deploy-wave: "100"convient au développement ou aux tests car il vous permet de regrouper les fichiers source référencés. - 2
- Dans
ImageRegistryPV.yaml, assurez-vous que le champspec.local.pathest défini à/var/imageregistrypour correspondre à la valeur définie pour le champmount_pointdans le CRSiteConfig.
ImportantNe définissez pas
complianceType: mustonlyhavepour la configuration- fileName: ImageRegistryConfig.yaml. Cela peut faire échouer le déploiement du pod de registre.-
Commencer le changement
PolicyGenTemplatedans Git, puis pousser vers le dépôt Git surveillé par l'application GitOps ZTP ArgoCD.
Vérification
Suivez les étapes suivantes pour résoudre les erreurs du registre d'images local sur les clusters gérés :
Vérifiez que la connexion au registre est réussie lorsque vous êtes connecté au cluster géré. Exécutez les commandes suivantes :
Exporter le nom du cluster géré :
$ cluster=<nom_du_cluster_géré>
Obtenir les détails du cluster géré
kubeconfig:$ oc get secret -n $cluster $cluster-admin-password -o jsonpath='{.data.password}' | base64 -d > kubeadmin-password-$clusterTélécharger et exporter le cluster
kubeconfig:$ oc get secret -n $cluster $cluster-admin-kubeconfig -o jsonpath='{.data.kubeconfig}' | base64 -d > kubeconfig-$cluster && export KUBECONFIG=./kubeconfig-$cluster- Vérifiez l'accès au registre d'images à partir du cluster géré. Voir "Accès au registre".
Vérifiez que le CRD
Configde l'instance du groupeimageregistry.operator.openshift.ione signale pas d'erreurs. Exécutez la commande suivante en vous connectant au cluster géré :$ oc get image.config.openshift.io cluster -o yaml
Exemple de sortie
apiVersion: config.openshift.io/v1 kind: Image metadata: annotations: include.release.openshift.io/ibm-cloud-managed: "true" include.release.openshift.io/self-managed-high-availability: "true" include.release.openshift.io/single-node-developer: "true" release.openshift.io/create-only: "true" creationTimestamp: "2021-10-08T19:02:39Z" generation: 5 name: cluster resourceVersion: "688678648" uid: 0406521b-39c0-4cda-ba75-873697da75a4 spec: additionalTrustedCA: name: acm-iceVérifiez que le site
PersistentVolumeClaimdu cluster géré contient des données. Exécutez la commande suivante en vous connectant au cluster géré :$ oc get pv image-registry-sc
Vérifiez que le pod
registry*est en cours d'exécution et qu'il se trouve dans l'espace de nomsopenshift-image-registry.$ oc get pods -n openshift-image-registry | grep registry*
Exemple de sortie
cluster-image-registry-operator-68f5c9c589-42cfg 1/1 Running 0 8d image-registry-5f8987879-6nx6h 1/1 Running 0 8d
Vérifiez que la partition du disque sur le cluster géré est correcte :
Ouvrez un shell de débogage sur le cluster géré :
$ oc debug node/sno-1.example.com
Exécutez
lsblkpour vérifier les partitions du disque hôte :sh-4.4# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 446.6G 0 disk |-sda1 8:1 0 1M 0 part |-sda2 8:2 0 127M 0 part |-sda3 8:3 0 384M 0 part /boot |-sda4 8:4 0 336.3G 0 part /sysroot `-sda5 8:5 0 100.1G 0 part /var/imageregistry 1 sdb 8:16 0 446.6G 0 disk sr0 11:0 1 104M 0 rom- 1
/var/imageregistryindique que le disque est correctement partitionné.
Ressources supplémentaires
21.9.9. Configuration de la surveillance des événements sur le système nu à l'aide des CR PolicyGenTemplate
Vous pouvez configurer des événements matériels bare-metal pour les clusters vRAN qui sont déployés à l'aide du pipeline Zero Touch Provisioning (ZTP) de GitOps.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Créez un dépôt Git dans lequel vous gérez les données de configuration de votre site personnalisé.
Procédure
Pour configurer l'opérateur d'interconnexion AMQ et l'opérateur de relais d'événements Bare Metal, ajoutez le fichier YAML suivant à
spec.sourceFilesdans le fichiercommon-ranGen.yaml:# AMQ interconnect operator for fast events - fileName: AmqSubscriptionNS.yaml policyName: "subscriptions-policy" - fileName: AmqSubscriptionOperGroup.yaml policyName: "subscriptions-policy" - fileName: AmqSubscription.yaml policyName: "subscriptions-policy" # Bare Metal Event Rely operator - fileName: BareMetalEventRelaySubscriptionNS.yaml policyName: "subscriptions-policy" - fileName: BareMetalEventRelaySubscriptionOperGroup.yaml policyName: "subscriptions-policy" - fileName: BareMetalEventRelaySubscription.yaml policyName: "subscriptions-policy"
Ajoutez le CR
Interconnectà.spec.sourceFilesdans le fichier de configuration du site, par exemple le fichierexample-sno-site.yaml:- fileName: AmqInstance.yaml policyName: "config-policy"
Ajoutez le CR
HardwareEventàspec.sourceFilesdans votre fichier de configuration de groupe spécifique, par exemple dans le fichiergroup-du-sno-ranGen.yaml:- fileName: HardwareEvent.yaml policyName: "config-policy" spec: nodeSelector: {} transportHost: "amqp://<amq_interconnect_name>.<amq_interconnect_namespace>.svc.cluster.local" 1 logLevel: "info"- 1
- L'URL
transportHostest composée des CR AMQ Interconnect existantsnameetnamespace. Par exemple, danstransportHost: "amqp://amq-router.amq-router.svc.cluster.local", les AMQ Interconnectnameetnamespacesont tous deux définis suramq-router.
NoteChaque contrôleur de gestion de carte de base (BMC) ne nécessite qu'une seule ressource
HardwareEvent.-
Validez le changement
PolicyGenTemplatedans Git, puis transférez les changements dans le référentiel de configuration de votre site pour déployer la surveillance des événements sur de nouveaux sites à l'aide du protocole ZTP de GitOps. Créez le Secret Redfish en exécutant la commande suivante :
$ oc -n openshift-bare-metal-events create secret generic redfish-basic-auth \ --from-literal=username=<bmc_username> --from-literal=password=<bmc_password> \ --from-literal=hostaddr="<bmc_host_ip_addr>"
Ressources supplémentaires
- Pour plus d'informations sur l'installation de Bare Metal Event Relay, voir Installation de Bare Metal Event Relay à l'aide de l'interface CLI.
Ressources supplémentaires
- Pour plus d'informations sur la création du nom d'utilisateur, du mot de passe et de l'adresse IP de l'hôte pour le secret BMC, voir Création des CR d'événement et de secret bare-metal.
21.9.10. Utilisation de modèles de concentrateurs dans les CR PolicyGenTemplate
Topology Aware Lifecycle Manager prend en charge les fonctions partielles du modèle de cluster de hub de Red Hat Advanced Cluster Management (RHACM) dans les politiques de configuration utilisées avec GitOps ZTP.
Les modèles de grappes côté hub vous permettent de définir des politiques de configuration qui peuvent être dynamiquement adaptées aux grappes cibles. Il n'est donc pas nécessaire de créer des politiques distinctes pour de nombreux clusters ayant des configurations similaires mais des valeurs différentes.
Les modèles de politique sont limités au même espace de noms que celui dans lequel la politique est définie. Cela signifie que vous devez créer les objets référencés dans le modèle de hub dans le même espace de noms que celui où la politique est créée.
Les fonctions de modèle de concentrateur suivantes sont disponibles pour une utilisation dans GitOps ZTP avec TALM :
fromConfigmaprenvoie la valeur de la clé de données fournie dans la ressource nomméeConfigMap.NoteLa taille des CR
ConfigMapest limitée à 1 MiB. La taille effective des CRConfigMapest encore limitée par l'annotationlast-applied-configuration. Pour éviter la limite delast-applied-configuration, ajoutez l'annotation suivante au modèleConfigMap:argocd.argoproj.io/sync-options: Replace=true
-
base64encrenvoie la valeur encodée en base64 de la chaîne d'entrée -
base64decrenvoie la valeur décodée de la chaîne d'entrée encodée en base64 -
indentrenvoie la chaîne d'entrée avec les espaces d'indentation ajoutés -
autoindentrenvoie la chaîne d'entrée avec des espaces d'indentation ajoutés en fonction de l'espacement utilisé dans le modèle parent -
toIntconvertit et renvoie la valeur entière de la valeur d'entrée -
toBoolconvertit la chaîne d'entrée en une valeur booléenne et renvoie la valeur booléenne
Diverses fonctions de la communauté Open source sont également disponibles pour une utilisation avec GitOps ZTP.
Ressources supplémentaires
21.9.10.1. Exemples de modèles de concentrateurs
Les exemples de code suivants sont des modèles de concentrateur valides. Chacun de ces modèles renvoie des valeurs provenant du CR ConfigMap portant le nom test-config dans l'espace de noms default.
Renvoie la valeur avec la clé
common-key:{{hub fromConfigMap "default" "test-config" "common-key" hub}}Renvoie une chaîne en utilisant la valeur concaténée du champ
.ManagedClusterNameet la chaîne-name:{{hub fromConfigMap "default" "test-config" (printf "%s-name" .ManagedClusterName) hub}}Crée et renvoie une valeur booléenne à partir de la valeur concaténée du champ
.ManagedClusterNameet de la chaîne de caractères-name:{{hub fromConfigMap "default" "test-config" (printf "%s-name" .ManagedClusterName) | toBool hub}}Crée et renvoie une valeur entière à partir de la valeur concaténée du champ
.ManagedClusterNameet de la chaîne de caractères-name:{{hub (printf "%s-name" .ManagedClusterName) | fromConfigMap "default" "test-config" | toInt hub}}
21.9.10.2. Spécification des cartes réseau de l'hôte dans les CR de PolicyGenTemplate de site avec des modèles de cluster de concentrateurs
Vous pouvez gérer les NIC des hôtes dans un seul CR ConfigMap et utiliser les modèles de cluster de hub pour remplir les valeurs NIC personnalisées dans les polices générées qui sont appliquées aux hôtes du cluster. L'utilisation de modèles de cluster de concentrateurs dans les CR PolicyGenTemplate (PGT) signifie qu'il n'est pas nécessaire de créer plusieurs CR PGT pour chaque site.
L'exemple suivant vous montre comment utiliser un seul CR ConfigMap pour gérer les NIC des hôtes du cluster et les appliquer au cluster en tant que polices en utilisant un seul CR de site PolicyGenTemplate.
Lorsque vous utilisez la fonction fromConfigmap, la variable printf n'est disponible que pour les champs clés de la ressource modèle data. Vous ne pouvez pas l'utiliser pour les champs name et namespace.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté au cluster hub en tant qu'utilisateur avec les privilèges
cluster-admin. - Vous avez créé un dépôt Git dans lequel vous gérez les données de configuration de votre site personnalisé. Le dépôt doit être accessible depuis le cluster hub et être défini comme dépôt source pour l'application GitOps ZTP ArgoCD.
Procédure
Créez une ressource
ConfigMapqui décrit les cartes réseau d'un groupe d'hôtes. Par exemple :apiVersion: v1 kind: ConfigMap metadata: name: sriovdata namespace: ztp-site annotations: argocd.argoproj.io/sync-options: Replace=true 1 data: example-sno-du_fh-numVfs: "8" example-sno-du_fh-pf: ens1f0 example-sno-du_fh-priority: "10" example-sno-du_fh-vlan: "140" example-sno-du_mh-numVfs: "8" example-sno-du_mh-pf: ens3f0 example-sno-du_mh-priority: "10" example-sno-du_mh-vlan: "150"- 1
- L'annotation
argocd.argoproj.io/sync-optionsn'est requise que si le siteConfigMapa une taille supérieure à 1 Mio.
NoteLe site
ConfigMapdoit se trouver dans le même espace de noms que la politique pour laquelle la substitution du modèle de concentrateur a été effectuée.-
Commencer le CR
ConfigMapdans Git, puis le pousser vers le dépôt Git contrôlé par l'application Argo CD. Créez une PGT CR de site qui utilise des modèles pour extraire les données requises de l'objet
ConfigMap. En voici un exemple :apiVersion: ran.openshift.io/v1 kind: PolicyGenTemplate metadata: name: "site" namespace: "ztp-site" spec: remediationAction: inform bindingRules: group-du-sno: "" mcp: "master" sourceFiles: - fileName: SriovNetwork.yaml policyName: "config-policy" metadata: name: "sriov-nw-du-fh" spec: resourceName: du_fh vlan: '{{hub fromConfigMap "ztp-site" "sriovdata" (printf "%s-du_fh-vlan" .ManagedClusterName) | toInt hub}}' - fileName: SriovNetworkNodePolicy.yaml policyName: "config-policy" metadata: name: "sriov-nnp-du-fh" spec: deviceType: netdevice isRdma: true nicSelector: pfNames: - '{{hub fromConfigMap "ztp-site" "sriovdata" (printf "%s-du_fh-pf" .ManagedClusterName) | autoindent hub}}' numVfs: '{{hub fromConfigMap "ztp-site" "sriovdata" (printf "%s-du_fh-numVfs" .ManagedClusterName) | toInt hub}}' priority: '{{hub fromConfigMap "ztp-site" "sriovdata" (printf "%s-du_fh-priority" .ManagedClusterName) | toInt hub}}' resourceName: du_fh - fileName: SriovNetwork.yaml policyName: "config-policy" metadata: name: "sriov-nw-du-mh" spec: resourceName: du_mh vlan: '{{hub fromConfigMap "ztp-site" "sriovdata" (printf "%s-du_mh-vlan" .ManagedClusterName) | toInt hub}}' - fileName: SriovNetworkNodePolicy.yaml policyName: "config-policy" metadata: name: "sriov-nnp-du-mh" spec: deviceType: vfio-pci isRdma: false nicSelector: pfNames: - '{{hub fromConfigMap "ztp-site" "sriovdata" (printf "%s-du_mh-pf" .ManagedClusterName) hub}}' numVfs: '{{hub fromConfigMap "ztp-site" "sriovdata" (printf "%s-du_mh-numVfs" .ManagedClusterName) | toInt hub}}' priority: '{{hub fromConfigMap "ztp-site" "sriovdata" (printf "%s-du_mh-priority" .ManagedClusterName) | toInt hub}}' resourceName: du_mhCommencer le site
PolicyGenTemplateCR dans Git et le pousser vers le dépôt Git qui est surveillé par l'application ArgoCD.NoteLes modifications ultérieures apportées à la CR
ConfigMapréférencée ne sont pas automatiquement synchronisées avec les politiques appliquées. Vous devez synchroniser manuellement les nouvelles modifications deConfigMappour mettre à jour les PolicyGenTemplate CR existants. Voir "Synchronisation des nouvelles modifications du ConfigMap avec les CR PolicyGenTemplate existantes".
21.9.10.3. Spécification des ID de VLAN dans les CR de groupe PolicyGenTemplate avec les modèles de cluster de hub
Vous pouvez gérer les ID de VLAN pour les clusters gérés dans un seul ConfigMap CR et utiliser les modèles de cluster de hub pour remplir les ID de VLAN dans les polices générées qui sont appliquées aux clusters.
L'exemple suivant montre comment gérer les ID VLAN dans un seul ConfigMap CR et les appliquer dans des polices de cluster individuelles en utilisant un seul PolicyGenTemplate group CR.
Lorsque vous utilisez la fonction fromConfigmap, la variable printf n'est disponible que pour les champs clés de la ressource modèle data. Vous ne pouvez pas l'utiliser pour les champs name et namespace.
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté au cluster hub en tant qu'utilisateur avec les privilèges
cluster-admin. - Vous avez créé un dépôt Git où vous gérez les données de configuration de votre site personnalisé. Le dépôt doit être accessible depuis le cluster hub et être défini comme dépôt source pour l'application Argo CD.
Procédure
Créez un CR
ConfigMapqui décrit les ID VLAN pour un groupe d'hôtes du cluster. Par exemple :apiVersion: v1 kind: ConfigMap metadata: name: site-data namespace: ztp-group annotations: argocd.argoproj.io/sync-options: Replace=true 1 data: site-1-vlan: "101" site-2-vlan: "234"- 1
- L'annotation
argocd.argoproj.io/sync-optionsn'est requise que si le siteConfigMapa une taille supérieure à 1 Mio.
NoteLe site
ConfigMapdoit se trouver dans le même espace de noms que la politique pour laquelle la substitution du modèle de concentrateur a été effectuée.-
Commencer le CR
ConfigMapdans Git, puis le pousser vers le dépôt Git contrôlé par l'application Argo CD. Créez un groupe PGT CR qui utilise un modèle de concentrateur pour extraire les ID VLAN requis de l'objet
ConfigMap. Par exemple, ajoutez l'extrait YAML suivant au groupe PGT CR :- fileName: SriovNetwork.yaml policyName: "config-policy" metadata: name: "sriov-nw-du-mh" annotations: ran.openshift.io/ztp-deploy-wave: "10" spec: resourceName: du_mh vlan: '{{hub fromConfigMap "" "site-data" (printf "%s-vlan" .ManagedClusterName) | toInt hub}}'Commencer le groupe
PolicyGenTemplateCR dans Git, puis pousser vers le dépôt Git surveillé par l'application Argo CD.NoteLes modifications ultérieures apportées à la CR
ConfigMapréférencée ne sont pas automatiquement synchronisées avec les politiques appliquées. Vous devez synchroniser manuellement les nouvelles modifications deConfigMappour mettre à jour les PolicyGenTemplate CR existants. Voir "Synchronisation des nouvelles modifications du ConfigMap avec les CR PolicyGenTemplate existantes".
21.9.10.4. Synchronisation des nouveaux changements de ConfigMap avec les CR de PolicyGenTemplate existants
Conditions préalables
-
Vous avez installé l'OpenShift CLI (
oc). -
Vous vous êtes connecté au cluster hub en tant qu'utilisateur avec les privilèges
cluster-admin. -
Vous avez créé un CR
PolicyGenTemplatequi tire des informations d'un CRConfigMapà l'aide de modèles de grappes de nœuds.
Procédure
-
Mettez à jour le contenu de votre
ConfigMapCR, et appliquez les changements dans le cluster hub. Pour synchroniser le contenu de la CR
ConfigMapmise à jour avec la politique déployée, effectuez l'une des opérations suivantes :Option 1 : Supprimer la politique existante. ArgoCD utilise la commande
PolicyGenTemplateCR pour recréer immédiatement la politique supprimée. Par exemple, exécutez la commande suivante :oc delete policy <policy_name> -n <policy_namespace> $ oc delete policy <policy_name>
Option 2 : Appliquer une annotation spéciale
policy.open-cluster-management.io/trigger-updateà la police avec une valeur différente à chaque fois que vous mettez à jour le siteConfigMap. Par exemple :$ oc annotate policy <policy_name> -n <policy_namespace> policy.open-cluster-management.io/trigger-update="1"
NoteVous devez appliquer la politique mise à jour pour que les modifications soient prises en compte. Pour plus d'informations, voir Annotation spéciale pour le retraitement.
Facultatif : si elle existe, supprimez la CR
ClusterGroupUpdatequi contient la politique. Par exemple :oc delete clustergroupupgrade <cgu_name> -n <cgu_namespace>
Créez un nouveau CR
ClusterGroupUpdatequi inclut la politique à appliquer avec les changements mis à jour deConfigMap. Par exemple, ajoutez le fichier YAML suivant au fichiercgr-example.yaml:apiVersion: ran.openshift.io/v1alpha1 kind: ClusterGroupUpgrade metadata: name: <cgr_name> namespace: <policy_namespace> spec: managedPolicies: - <managed_policy> enable: true clusters: - <managed_cluster_1> - <managed_cluster_2> remediationStrategy: maxConcurrency: 2 timeout: 240Appliquer la politique mise à jour :
$ oc apply -f cgr-example.yaml
21.10. Mise à jour des clusters gérés avec le Topology Aware Lifecycle Manager
Vous pouvez utiliser le Topology Aware Lifecycle Manager (TALM) pour gérer le cycle de vie du logiciel des clusters gérés par OpenShift Container Platform. TALM utilise les stratégies de Red Hat Advanced Cluster Management (RHACM) pour effectuer des modifications sur les clusters cibles.
Ressources supplémentaires
- Pour plus d'informations sur le gestionnaire de cycle de vie Topology Aware, voir À propos du gestionnaire de cycle de vie Topology Aware.
21.10.1. Mise à jour des clusters dans un environnement déconnecté
Vous pouvez mettre à niveau les clusters gérés et les opérateurs des clusters gérés que vous avez déployés à l'aide de GitOps ZTP et de Topology Aware Lifecycle Manager (TALM).
21.10.1.1. Mise en place de l'environnement
TALM peut effectuer des mises à jour de la plateforme et de l'opérateur.
Vous devez mettre en miroir l'image de la plate-forme et les images de l'opérateur que vous souhaitez mettre à jour dans votre registre miroir avant de pouvoir utiliser TALM pour mettre à jour vos clusters déconnectés. Effectuez les étapes suivantes pour créer un miroir des images :
Pour les mises à jour de la plate-forme, vous devez effectuer les étapes suivantes :
Mettre en miroir le référentiel d'images OpenShift Container Platform souhaité. Assurez-vous que l'image de la plateforme souhaitée est mise en miroir en suivant la procédure " Mirroring the OpenShift Container Platform image repository " (Mise en miroir du référentiel d'images OpenShift Container Platform) dont le lien se trouve dans les Ressources supplémentaires. Enregistrez le contenu de la section
imageContentSourcesdans le fichierimageContentSources.yaml:Exemple de sortie
imageContentSources: - mirrors: - mirror-ocp-registry.ibmcloud.io.cpak:5000/openshift-release-dev/openshift4 source: quay.io/openshift-release-dev/ocp-release - mirrors: - mirror-ocp-registry.ibmcloud.io.cpak:5000/openshift-release-dev/openshift4 source: quay.io/openshift-release-dev/ocp-v4.0-art-dev
Enregistrez la signature de l'image de la plate-forme souhaitée qui a été mise en miroir. Vous devez ajouter la signature de l'image à la CR
PolicyGenTemplatepour les mises à jour de la plate-forme. Pour obtenir la signature de l'image, procédez comme suit :Spécifiez le tag OpenShift Container Platform souhaité en exécutant la commande suivante :
oCP_RELEASE_NUMBER=<release_version>
Spécifiez l'architecture du serveur en exécutant la commande suivante :
aRCHITECTURE=<server_architecture>
Obtenez le résumé de l'image de la version de Quay en exécutant la commande suivante
$ DIGEST="$(oc adm release info quay.io/openshift-release-dev/ocp-release:${OCP_RELEASE_NUMBER}-${ARCHITECTURE} | sed -n 's/Pull From: .*@//p')"Définissez l'algorithme de résumé en exécutant la commande suivante :
$ DIGEST_ALGO="${DIGEST%%:*}"Définissez la signature numérique en exécutant la commande suivante :
$ DIGEST_ENCODED="${DIGEST#*:}"Obtenez la signature de l'image à partir du site web mirror.openshift.com en exécutant la commande suivante :
$ SIGNATURE_BASE64=$(curl -s "https://mirror.openshift.com/pub/openshift-v4/signatures/openshift/release/${DIGEST_ALGO}=${DIGEST_ENCODED}/signature-1" | base64 -w0 && echo)Enregistrez la signature de l'image dans le fichier
checksum-<OCP_RELEASE_NUMBER>.yamlen exécutant les commandes suivantes :$ cat >checksum-${OCP_RELEASE_NUMBER}.yaml <<EOF ${DIGEST_ALGO}-${DIGEST_ENCODED}: ${SIGNATURE_BASE64} EOF
Préparer le graphique de mise à jour. Vous avez deux options pour préparer le graphique de mise à jour :
Utiliser le service de mise à jour OpenShift.
Pour plus d'informations sur la mise en place du graphe sur le hub cluster, voir Déployer l'opérateur pour OpenShift Update Service et Construire le conteneur init de données du graphe.
Faites une copie locale du graphe en amont. Hébergez le graphique de mise à jour sur un serveur
httpouhttpsdans l'environnement déconnecté qui a accès au cluster géré. Pour télécharger le graphe de mise à jour, utilisez la commande suivante :$ curl -s https://api.openshift.com/api/upgrades_info/v1/graph?channel=stable-4.12 -o ~/upgrade-graph_stable-4.12
Pour les mises à jour de l'opérateur, vous devez effectuer la tâche suivante :
- Mettre en miroir les catalogues de l'opérateur. Assurez-vous que les images d'opérateur souhaitées sont mises en miroir en suivant la procédure décrite dans la section "Mise en miroir des catalogues d'opérateur pour utilisation avec des clusters déconnectés".
Ressources supplémentaires
- Pour plus d'informations sur la mise à jour de ZTP, voir Mise à jour de GitOps ZTP.
- Pour plus d'informations sur la mise en miroir d'un référentiel d'images OpenShift Container Platform, voir Mise en miroir du référentiel d'images OpenShift Container Platform.
- Pour plus d'informations sur la mise en miroir des catalogues d'opérateurs pour les clusters déconnectés, voir Mise en miroir des catalogues d'opérateurs pour une utilisation avec des clusters déconnectés.
- Pour plus d'informations sur la préparation de l'environnement déconnecté et la mise en miroir du référentiel d'images souhaité, voir Préparation de l'environnement déconnecté.
- Pour plus d'informations sur les canaux de mise à jour et les versions, voir Comprendre les canaux de mise à jour et les versions.
21.10.1.2. Mise à jour de la plate-forme
Vous pouvez effectuer une mise à jour de la plate-forme avec le TALM.
Conditions préalables
- Installez le gestionnaire de cycle de vie Topology Aware (TALM).
- Mettre à jour ZTP avec la dernière version.
- Approvisionnez un ou plusieurs clusters gérés avec ZTP.
- Mettez en miroir le référentiel d'images souhaité.
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Créer des stratégies RHACM dans le cluster hub.
Procédure
Créer un CR
PolicyGenTemplatepour la mise à jour de la plateforme :Enregistrez le contenu suivant du CR
PolicyGenTemplatedans le fichierdu-upgrade.yaml.Exemple de
PolicyGenTemplatepour la mise à jour de la plate-formeapiVersion: ran.openshift.io/v1 kind: PolicyGenTemplate metadata: name: "du-upgrade" namespace: "ztp-group-du-sno" spec: bindingRules: group-du-sno: "" mcp: "master" remediationAction: inform sourceFiles: - fileName: ImageSignature.yaml 1 policyName: "platform-upgrade-prep" binaryData: ${DIGEST_ALGO}-${DIGEST_ENCODED}: ${SIGNATURE_BASE64} 2 - fileName: DisconnectedICSP.yaml policyName: "platform-upgrade-prep" metadata: name: disconnected-internal-icsp-for-ocp spec: repositoryDigestMirrors: 3 - mirrors: - quay-intern.example.com/ocp4/openshift-release-dev source: quay.io/openshift-release-dev/ocp-release - mirrors: - quay-intern.example.com/ocp4/openshift-release-dev source: quay.io/openshift-release-dev/ocp-v4.0-art-dev - fileName: ClusterVersion.yaml 4 policyName: "platform-upgrade-prep" metadata: name: version annotations: ran.openshift.io/ztp-deploy-wave: "1" spec: channel: "stable-4.12" upstream: http://upgrade.example.com/images/upgrade-graph_stable-4.12 - fileName: ClusterVersion.yaml 5 policyName: "platform-upgrade" metadata: name: version spec: channel: "stable-4.12" upstream: http://upgrade.example.com/images/upgrade-graph_stable-4.12 desiredUpdate: version: 4.12.4 status: history: - version: 4.12.4 state: "Completed"- 1
- Le CR
ConfigMapcontient la signature de l'image de la version souhaitée à mettre à jour. - 2
- Affiche la signature de l'image de la version d'OpenShift Container Platform souhaitée. Obtenez la signature à partir du fichier
checksum-${OCP_RELASE_NUMBER}.yamlque vous avez enregistré en suivant les procédures de la section " Configuration de l'environnement ". - 3
- Affiche le dépôt miroir qui contient l'image OpenShift Container Platform souhaitée. Obtenez les miroirs à partir du fichier
imageContentSources.yamlque vous avez enregistré en suivant les procédures de la section " Configuration de l'environnement ". - 4
- Indique le CR
ClusterVersionà mettre à jour en amont. - 5
- Indique le CR
ClusterVersionpour déclencher la mise à jour. Les champschannel,upstream, etdesiredVersionsont tous nécessaires pour la mise en cache des images.
La CR
PolicyGenTemplategénère deux politiques :-
La politique
du-upgrade-platform-upgrade-prepprépare la mise à jour de la plate-forme. Elle crée le CRConfigMappour la signature d'image de version souhaitée, crée la source de contenu d'image du référentiel d'images de version en miroir et met à jour la version du cluster avec le canal de mise à jour souhaité et le graphique de mise à jour accessible par le cluster géré dans l'environnement déconnecté. -
La politique
du-upgrade-platform-upgradeest utilisée pour effectuer la mise à niveau de la plate-forme.
Ajoutez le contenu du fichier
du-upgrade.yamlau fichierkustomization.yamlsitué dans le dépôt ZTP Git pour les CRPolicyGenTemplateet transférez les modifications dans le dépôt Git.ArgoCD extrait les modifications du référentiel Git et génère les politiques sur le cluster hub.
Vérifiez les politiques créées en exécutant la commande suivante :
$ oc get policies -A | grep platform-upgrade
Appliquer les ressources de mise à jour requises avant de lancer la mise à jour de la plateforme avec le TALM.
Enregistrez le contenu du fichier
platform-upgrade-prepClusterUpgradeGroupCR avec la stratégiedu-upgrade-platform-upgrade-prepet les clusters gérés cibles dans le fichiercgu-platform-upgrade-prep.yml, comme indiqué dans l'exemple suivant :apiVersion: ran.openshift.io/v1alpha1 kind: ClusterGroupUpgrade metadata: name: cgu-platform-upgrade-prep namespace: default spec: managedPolicies: - du-upgrade-platform-upgrade-prep clusters: - spoke1 remediationStrategy: maxConcurrency: 1 enable: trueAppliquez la politique au cluster hub en exécutant la commande suivante :
$ oc apply -f cgu-platform-upgrade-prep.yml
Surveillez le processus de mise à jour. Une fois la mise à jour terminée, assurez-vous que la politique est conforme en exécutant la commande suivante :
$ oc get policies --all-namespaces
Créez le CR
ClusterGroupUpdatepour la mise à jour de la plate-forme avec le champspec.enabledéfini surfalse.Enregistrez le contenu de la mise à jour de la plate-forme
ClusterGroupUpdateCR avec la stratégiedu-upgrade-platform-upgradeet les clusters cibles dans le fichiercgu-platform-upgrade.yml, comme indiqué dans l'exemple suivant :apiVersion: ran.openshift.io/v1alpha1 kind: ClusterGroupUpgrade metadata: name: cgu-platform-upgrade namespace: default spec: managedPolicies: - du-upgrade-platform-upgrade preCaching: false clusters: - spoke1 remediationStrategy: maxConcurrency: 1 enable: falseAppliquez le CR
ClusterGroupUpdateau cluster du concentrateur en exécutant la commande suivante :$ oc apply -f cgu-platform-upgrade.yml
Facultatif : Prémettre en cache les images pour la mise à jour de la plateforme.
Activez la mise en cache préalable dans le CR
ClusterGroupUpdateen exécutant la commande suivante :$ oc --namespace=default patch clustergroupupgrade.ran.openshift.io/cgu-platform-upgrade \ --patch '{"spec":{"preCaching": true}}' --type=mergeSurveillez le processus de mise à jour et attendez la fin de la mise en cache. Vérifiez l'état de la mise en cache préalable en exécutant la commande suivante sur le cluster du concentrateur :
$ oc get cgu cgu-platform-upgrade -o jsonpath='{.status.precaching.status}'
Lancer la mise à jour de la plate-forme :
Activez la stratégie
cgu-platform-upgradeet désactivez la mise en cache préalable en exécutant la commande suivante :$ oc --namespace=default patch clustergroupupgrade.ran.openshift.io/cgu-platform-upgrade \ --patch '{"spec":{"enable":true, "preCaching": false}}' --type=mergeSurveillez le processus. Une fois le processus terminé, assurez-vous que la politique est conforme en exécutant la commande suivante :
$ oc get policies --all-namespaces
Ressources supplémentaires
- Pour plus d'informations sur la mise en miroir des images dans un environnement déconnecté, voir Préparation de l'environnement déconnecté.
21.10.1.3. Mise à jour de l'opérateur
Vous pouvez effectuer une mise à jour de l'opérateur avec le TALM.
Conditions préalables
- Installez le gestionnaire de cycle de vie Topology Aware (TALM).
- Mettre à jour ZTP avec la dernière version.
- Approvisionnez un ou plusieurs clusters gérés avec ZTP.
- Miroir de l'image d'index souhaitée, des images de la liasse et de toutes les images de l'opérateur référencées dans les images de la liasse.
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Créer des stratégies RHACM dans le cluster hub.
Procédure
Mettre à jour le CR
PolicyGenTemplatepour la mise à jour de l'opérateur.Mettez à jour le CR
du-upgradePolicyGenTemplateavec le contenu supplémentaire suivant dans le fichierdu-upgrade.yaml:apiVersion: ran.openshift.io/v1 kind: PolicyGenTemplate metadata: name: "du-upgrade" namespace: "ztp-group-du-sno" spec: bindingRules: group-du-sno: "" mcp: "master" remediationAction: inform sourceFiles: - fileName: DefaultCatsrc.yaml remediationAction: inform policyName: "operator-catsrc-policy" metadata: name: redhat-operators spec: displayName: Red Hat Operators Catalog image: registry.example.com:5000/olm/redhat-operators:v4.12 1 updateStrategy: 2 registryPoll: interval: 1h- 1
- L'URL de l'image d'index contient les images de l'opérateur souhaitées. Si les images d'index sont toujours poussées vers le même nom d'image et la même balise, cette modification n'est pas nécessaire.
- 2
- Le champ
registryPoll.intervalpermet de définir la fréquence à laquelle le gestionnaire du cycle de vie de l'opérateur (OLM) interroge l'image d'index pour les nouvelles versions de l'opérateur. Cette modification n'est pas nécessaire si une nouvelle balise d'image d'index est toujours insérée pour les mises à jour des opérateurs des flux y et z. Le champregistryPoll.intervalpeut être défini sur un intervalle plus court pour accélérer la mise à jour, mais les intervalles plus courts augmentent la charge de calcul. Pour y remédier, vous pouvez rétablir la valeur par défaut du champregistryPoll.intervalune fois la mise à jour terminée.
Cette mise à jour génère une politique,
du-upgrade-operator-catsrc-policy, pour mettre à jour la source du catalogueredhat-operatorsavec les nouvelles images d'index qui contiennent les images d'opérateurs souhaitées.NoteSi vous souhaitez utiliser la mise en cache préalable des images pour les opérateurs et qu'il existe des opérateurs provenant d'une source de catalogue autre que
redhat-operators, vous devez effectuer les tâches suivantes :- Préparez une stratégie de source de catalogue distincte avec la nouvelle image d'index ou la mise à jour de l'intervalle d'interrogation du registre pour la source de catalogue différente.
- Préparer une politique d'abonnement distincte pour les opérateurs souhaités qui proviennent d'une source de catalogue différente.
Par exemple, l'opérateur SRIOV-FEC souhaité est disponible dans la source de catalogue
certified-operators. Pour mettre à jour la source du catalogue et l'abonnement à l'opérateur, ajoutez le contenu suivant pour générer deux politiques,du-upgrade-fec-catsrc-policyetdu-upgrade-subscriptions-fec-policy:apiVersion: ran.openshift.io/v1 kind: PolicyGenTemplate metadata: name: "du-upgrade" namespace: "ztp-group-du-sno" spec: bindingRules: group-du-sno: "" mcp: "master" remediationAction: inform sourceFiles: … - fileName: DefaultCatsrc.yaml remediationAction: inform policyName: "fec-catsrc-policy" metadata: name: certified-operators spec: displayName: Intel SRIOV-FEC Operator image: registry.example.com:5000/olm/far-edge-sriov-fec:v4.10 updateStrategy: registryPoll: interval: 10m - fileName: AcceleratorsSubscription.yaml policyName: "subscriptions-fec-policy" spec: channel: "stable" source: certified-operatorsSupprime les canaux d'abonnement spécifiés dans le CR commun
PolicyGenTemplate, s'ils existent. Les canaux d'abonnement par défaut de l'image ZTP sont utilisés pour la mise à jour.NoteLe canal par défaut pour les opérateurs appliqués par l'intermédiaire de ZTP 4.12 est
stable, à l'exception deperformance-addon-operator. À partir de OpenShift Container Platform 4.11, la fonctionnalitéperformance-addon-operatora été déplacée versnode-tuning-operator. Pour la version 4.10, le canal par défaut pour PAO estv4.10. Vous pouvez également spécifier les canaux par défaut dans le CR communPolicyGenTemplate.Pousser les mises à jour de
PolicyGenTemplateCRs vers le dépôt ZTP Git.ArgoCD extrait les modifications du référentiel Git et génère les politiques sur le cluster hub.
Vérifiez les politiques créées en exécutant la commande suivante :
$ oc get policies -A | grep -E "catsrc-policy|subscription"
Appliquez les mises à jour nécessaires du catalogue avant de lancer la mise à jour de l'opérateur.
Enregistrez le contenu du CR
ClusterGroupUpgradenomméoperator-upgrade-prepavec les stratégies source du catalogue et les clusters gérés cibles dans le fichiercgu-operator-upgrade-prep.yml:apiVersion: ran.openshift.io/v1alpha1 kind: ClusterGroupUpgrade metadata: name: cgu-operator-upgrade-prep namespace: default spec: clusters: - spoke1 enable: true managedPolicies: - du-upgrade-operator-catsrc-policy remediationStrategy: maxConcurrency: 1Appliquez la politique au cluster hub en exécutant la commande suivante :
$ oc apply -f cgu-operator-upgrade-prep.yml
Surveillez le processus de mise à jour. Une fois la mise à jour terminée, assurez-vous que la politique est conforme en exécutant la commande suivante :
$ oc get policies -A | grep -E "catsrc-policy"
Créez le CR
ClusterGroupUpgradepour la mise à jour de l'opérateur avec le champspec.enabledéfini surfalse.Enregistrez le contenu de la mise à jour de l'opérateur
ClusterGroupUpgradeCR avec la stratégiedu-upgrade-operator-catsrc-policyet les stratégies d'abonnement créées à partir des clusters communsPolicyGenTemplateet cibles dans le fichiercgu-operator-upgrade.yml, comme indiqué dans l'exemple suivant :apiVersion: ran.openshift.io/v1alpha1 kind: ClusterGroupUpgrade metadata: name: cgu-operator-upgrade namespace: default spec: managedPolicies: - du-upgrade-operator-catsrc-policy 1 - common-subscriptions-policy 2 preCaching: false clusters: - spoke1 remediationStrategy: maxConcurrency: 1 enable: false
- 1
- La politique est nécessaire à la fonction de mise en cache préalable des images pour récupérer les images de l'opérateur à partir de la source du catalogue.
- 2
- La politique contient des abonnements d'opérateurs. Si vous avez suivi la structure et le contenu de la référence
PolicyGenTemplates, tous les abonnements des opérateurs sont regroupés dans la politiquecommon-subscriptions-policy.
NoteUn CR
ClusterGroupUpgradene peut pré-cacher que les images des opérateurs souhaités définis dans la politique d'abonnement à partir d'une source de catalogue incluse dans le CRClusterGroupUpgrade. Si les opérateurs souhaités proviennent de différentes sources de catalogue, comme dans l'exemple de l'opérateur SRIOV-FEC, un autre CRClusterGroupUpgradedoit être créé avec les politiquesdu-upgrade-fec-catsrc-policyetdu-upgrade-subscriptions-fec-policypour la mise en cache et la mise à jour des images de l'opérateur SRIOV-FEC.Appliquez le CR
ClusterGroupUpgradeau cluster du concentrateur en exécutant la commande suivante :$ oc apply -f cgu-operator-upgrade.yml
Facultatif : Prémettre en cache les images pour la mise à jour de l'opérateur.
Avant de commencer la mise en cache des images, vérifiez que la politique d'abonnement est bien
NonCompliantà ce stade en exécutant la commande suivante :$ oc get policy common-subscriptions-policy -n <policy_namespace>
Exemple de sortie
NAME REMEDIATION ACTION COMPLIANCE STATE AGE common-subscriptions-policy inform NonCompliant 27d
Activez la mise en cache préalable dans le CR
ClusterGroupUpgradeen exécutant la commande suivante :$ oc --namespace=default patch clustergroupupgrade.ran.openshift.io/cgu-operator-upgrade \ --patch '{"spec":{"preCaching": true}}' --type=mergeSurveillez le processus et attendez la fin de la mise en cache. Vérifiez l'état de la mise en cache préalable en exécutant la commande suivante sur le cluster géré :
$ oc get cgu cgu-operator-upgrade -o jsonpath='{.status.precaching.status}'Vérifiez que la mise en cache est terminée avant de lancer la mise à jour en exécutant la commande suivante :
$ oc get cgu -n default cgu-operator-upgrade -ojsonpath='{.status.conditions}' | jqExemple de sortie
[ { "lastTransitionTime": "2022-03-08T20:49:08.000Z", "message": "The ClusterGroupUpgrade CR is not enabled", "reason": "UpgradeNotStarted", "status": "False", "type": "Ready" }, { "lastTransitionTime": "2022-03-08T20:55:30.000Z", "message": "Precaching is completed", "reason": "PrecachingCompleted", "status": "True", "type": "PrecachingDone" } ]
Lancer la mise à jour de l'opérateur.
Activez le
cgu-operator-upgradeClusterGroupUpgradeCR et désactivez la mise en cache préalable pour lancer la mise à jour de l'opérateur en exécutant la commande suivante :$ oc --namespace=default patch clustergroupupgrade.ran.openshift.io/cgu-operator-upgrade \ --patch '{"spec":{"enable":true, "preCaching": false}}' --type=mergeSurveillez le processus. Une fois le processus terminé, assurez-vous que la politique est conforme en exécutant la commande suivante :
$ oc get policies --all-namespaces
Ressources supplémentaires
- Pour plus d'informations sur la mise à jour de GitOps ZTP, voir Mise à jour de GitOps ZTP.
21.10.1.4. Réalisation conjointe d'une mise à jour de la plate-forme et d'une mise à jour de l'opérateur
Vous pouvez effectuer une mise à jour de la plate-forme et de l'opérateur en même temps.
Conditions préalables
- Installez le gestionnaire de cycle de vie Topology Aware (TALM).
- Mettre à jour ZTP avec la dernière version.
- Approvisionnez un ou plusieurs clusters gérés avec ZTP.
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin. - Créer des stratégies RHACM dans le cluster hub.
Procédure
-
Créez le CR
PolicyGenTemplatepour les mises à jour en suivant les étapes décrites dans les sections "Effectuer une mise à jour de la plate-forme" et "Effectuer une mise à jour de l'opérateur". Appliquer les travaux préparatoires pour la plateforme et la mise à jour de l'opérateur.
Enregistrez le contenu du fichier
ClusterGroupUpgradeCR avec les politiques de préparation des mises à jour de la plate-forme, les mises à jour de la source du catalogue et les clusters cibles dans le fichiercgu-platform-operator-upgrade-prep.yml, par exemple :apiVersion: ran.openshift.io/v1alpha1 kind: ClusterGroupUpgrade metadata: name: cgu-platform-operator-upgrade-prep namespace: default spec: managedPolicies: - du-upgrade-platform-upgrade-prep - du-upgrade-operator-catsrc-policy clusterSelector: - group-du-sno remediationStrategy: maxConcurrency: 10 enable: trueAppliquez le fichier
cgu-platform-operator-upgrade-prep.ymlau cluster hub en exécutant la commande suivante :$ oc apply -f cgu-platform-operator-upgrade-prep.yml
Surveillez le processus. Une fois le processus terminé, assurez-vous que la politique est conforme en exécutant la commande suivante :
$ oc get policies --all-namespaces
Créez le CR
ClusterGroupUpdatepour la plate-forme et la mise à jour de l'opérateur avec le champspec.enableréglé surfalse.Enregistrez le contenu de la plateforme et de la mise à jour de l'opérateur
ClusterGroupUpdateCR avec les politiques et les clusters cibles dans le fichiercgu-platform-operator-upgrade.yml, comme indiqué dans l'exemple suivant :apiVersion: ran.openshift.io/v1alpha1 kind: ClusterGroupUpgrade metadata: name: cgu-du-upgrade namespace: default spec: managedPolicies: - du-upgrade-platform-upgrade 1 - du-upgrade-operator-catsrc-policy 2 - common-subscriptions-policy 3 preCaching: true clusterSelector: - group-du-sno remediationStrategy: maxConcurrency: 1 enable: false
- 1
- Il s'agit de la politique de mise à jour de la plateforme.
- 2
- Il s'agit de la stratégie contenant les informations de source du catalogue pour les opérateurs à mettre à jour. Elle est nécessaire pour que la fonction de mise en cache préalable détermine les images d'opérateurs à télécharger sur le cluster géré.
- 3
- Il s'agit de la politique de mise à jour des opérateurs.
Appliquez le fichier
cgu-platform-operator-upgrade.ymlau cluster hub en exécutant la commande suivante :$ oc apply -f cgu-platform-operator-upgrade.yml
Facultatif : Pré-cachez les images pour la plateforme et la mise à jour de l'opérateur.
Activez la mise en cache préalable dans le CR
ClusterGroupUpgradeen exécutant la commande suivante :$ oc --namespace=default patch clustergroupupgrade.ran.openshift.io/cgu-du-upgrade \ --patch '{"spec":{"preCaching": true}}' --type=mergeSurveillez le processus de mise à jour et attendez la fin de la mise en cache. Vérifiez l'état de la mise en cache préalable en exécutant la commande suivante sur le cluster géré :
$ oc get jobs,pods -n openshift-talm-pre-cache
Vérifiez que la mise en cache est terminée avant de lancer la mise à jour en exécutant la commande suivante :
$ oc get cgu cgu-du-upgrade -ojsonpath='{.status.conditions}'
Démarrer la plateforme et la mise à jour de l'opérateur.
Activez le
cgu-du-upgradeClusterGroupUpgradeCR pour démarrer la plateforme et la mise à jour de l'opérateur en exécutant la commande suivante :$ oc --namespace=default patch clustergroupupgrade.ran.openshift.io/cgu-du-upgrade \ --patch '{"spec":{"enable":true, "preCaching": false}}' --type=mergeSurveillez le processus. Une fois le processus terminé, assurez-vous que la politique est conforme en exécutant la commande suivante :
$ oc get policies --all-namespaces
NoteLes CR pour les mises à jour de la plate-forme et de l'opérateur peuvent être créés dès le début en configurant le paramètre
spec.enable: true. Dans ce cas, la mise à jour démarre immédiatement après la fin de la mise en cache préalable et il n'est pas nécessaire d'activer manuellement le CR.La mise en cache préalable et la mise à jour créent des ressources supplémentaires, telles que des stratégies, des liaisons de placement, des règles de placement, des actions de cluster géré et des vues de cluster géré, afin de faciliter l'exécution des procédures. La définition du champ
afterCompletion.deleteObjectssurtruesupprime toutes ces ressources une fois les mises à jour terminées.
21.10.1.5. Suppression des abonnements Performance Addon Operator des clusters déployés
Dans les versions antérieures d'OpenShift Container Platform, l'opérateur Performance Addon fournissait un réglage automatique des performances à faible latence pour les applications. Dans OpenShift Container Platform 4.11 ou ultérieure, ces fonctions font partie de l'opérateur Node Tuning.
N'installez pas l'opérateur Performance Addon sur des clusters exécutant OpenShift Container Platform 4.11 ou une version ultérieure. Si vous mettez à niveau vers OpenShift Container Platform 4.11 ou une version ultérieure, l'opérateur Node Tuning supprime automatiquement l'opérateur Performance Addon.
Vous devez supprimer toutes les stratégies qui créent des abonnements à Performance Addon Operator afin d'empêcher la réinstallation de l'opérateur.
Le profil DU de référence inclut l'opérateur Performance Addon dans le CR PolicyGenTemplate common-ranGen.yaml . Pour supprimer l'abonnement des clusters gérés déployés, vous devez mettre à jour common-ranGen.yaml.
Si vous installez Performance Addon Operator 4.10.3-5 ou une version ultérieure sur OpenShift Container Platform 4.11 ou une version ultérieure, Performance Addon Operator détecte la version du cluster et se met automatiquement en hibernation pour éviter d'interférer avec les fonctions de Node Tuning Operator. Cependant, pour garantir des performances optimales, supprimez le Performance Addon Operator de vos clusters OpenShift Container Platform 4.11.
Conditions préalables
- Créez un dépôt Git où vous gérez les données de configuration de votre site personnalisé. Le dépôt doit être accessible depuis le cluster hub et être défini comme dépôt source pour ArgoCD.
- Mise à jour vers OpenShift Container Platform 4.11 ou une version ultérieure.
-
Connectez-vous en tant qu'utilisateur disposant des privilèges
cluster-admin.
Procédure
Remplacez
complianceTypeparmustnothavepour l'espace de noms Performance Addon Operator, le groupe Operator et l'abonnement dans le fichiercommon-ranGen.yaml.- fileName: PaoSubscriptionNS.yaml policyName: "subscriptions-policy" complianceType: mustnothave - fileName: PaoSubscriptionOperGroup.yaml policyName: "subscriptions-policy" complianceType: mustnothave - fileName: PaoSubscription.yaml policyName: "subscriptions-policy" complianceType: mustnothave-
Fusionnez les modifications avec votre référentiel de site personnalisé et attendez que l'application ArgoCD synchronise les modifications avec le cluster du concentrateur. Le statut de la politique
common-subscriptions-policydevientNon-Compliant. - Appliquez la modification à vos clusters cibles à l'aide du gestionnaire de cycle de vie Topology Aware. Pour plus d'informations sur le déploiement des modifications de configuration, voir la section "Ressources supplémentaires".
Surveillez le processus. Lorsque le statut de la politique
common-subscriptions-policypour un cluster cible estCompliant, l'opérateur Performance Addon a été supprimé du cluster. Obtenez le statut decommon-subscriptions-policyen exécutant la commande suivante :$ oc get policy -n ztp-common common-subscriptions-policy
-
Supprimer l'espace de noms de l'opérateur Performance Addon, le groupe d'opérateurs et les CR d'abonnement de
.spec.sourceFilesdans le fichiercommon-ranGen.yaml. - Fusionnez les modifications avec votre référentiel de site personnalisé et attendez que l'application ArgoCD synchronise les modifications avec le cluster du concentrateur. La politique reste conforme.
21.10.2. À propos de la création automatique de ClusterGroupUpgrade CR pour ZTP
TALM dispose d'un contrôleur appelé ManagedClusterForCGU qui surveille l'état Ready des CR ManagedCluster sur le cluster hub et crée les CR ClusterGroupUpgrade pour le ZTP (zero touch provisioning).
Pour tout cluster géré dans l'état Ready sans étiquette "ztp-done" appliquée, le contrôleur ManagedClusterForCGU crée automatiquement un CR ClusterGroupUpgrade dans l'espace de noms ztp-install avec ses politiques RHACM associées qui sont créées pendant le processus ZTP. Le TALM remédie ensuite à l'ensemble des politiques de configuration répertoriées dans le CR ClusterGroupUpgrade auto-créé pour pousser les CR de configuration vers le cluster géré.
Si le cluster géré n'a pas de politiques liées lorsque le cluster devient Ready, aucun CR ClusterGroupUpgrade n'est créé.
Exemple d'un CR ClusterGroupUpgrade auto-créé pour ZTP
apiVersion: ran.openshift.io/v1alpha1
kind: ClusterGroupUpgrade
metadata:
generation: 1
name: spoke1
namespace: ztp-install
ownerReferences:
- apiVersion: cluster.open-cluster-management.io/v1
blockOwnerDeletion: true
controller: true
kind: ManagedCluster
name: spoke1
uid: 98fdb9b2-51ee-4ee7-8f57-a84f7f35b9d5
resourceVersion: "46666836"
uid: b8be9cd2-764f-4a62-87d6-6b767852c7da
spec:
actions:
afterCompletion:
addClusterLabels:
ztp-done: "" 1
deleteClusterLabels:
ztp-running: ""
deleteObjects: true
beforeEnable:
addClusterLabels:
ztp-running: "" 2
clusters:
- spoke1
enable: true
managedPolicies:
- common-spoke1-config-policy
- common-spoke1-subscriptions-policy
- group-spoke1-config-policy
- spoke1-config-policy
- group-spoke1-validator-du-policy
preCaching: false
remediationStrategy:
maxConcurrency: 1
timeout: 240
21.11. Mise à jour de GitOps ZTP
Vous pouvez mettre à jour l'infrastructure Gitops zero touch provisioning (ZTP) indépendamment du cluster hub, de Red Hat Advanced Cluster Management (RHACM) et des clusters OpenShift Container Platform gérés.
Vous pouvez mettre à jour l'opérateur Red Hat OpenShift GitOps lorsque de nouvelles versions sont disponibles. Lorsque vous mettez à jour le plugin GitOps ZTP, examinez les fichiers mis à jour dans la configuration de référence et assurez-vous que les changements répondent à vos besoins.
21.11.1. Vue d'ensemble du processus de mise à jour ZTP de GitOps
Vous pouvez mettre à jour GitOps zero touch provisioning (ZTP) pour un hub cluster pleinement opérationnel utilisant une version antérieure de l'infrastructure GitOps ZTP. Le processus de mise à jour évite l'impact sur les clusters gérés.
Toute modification des paramètres de politique, y compris l'ajout de contenu recommandé, entraîne une mise à jour des politiques qui doit être déployée sur les clusters gérés et réconciliée.
À un niveau élevé, la stratégie de mise à jour de l'infrastructure ZTP de GitOps est la suivante :
-
Étiqueter tous les groupes existants avec l'étiquette
ztp-done. - Arrêter les applications ArgoCD.
- Installer les nouveaux outils ZTP de GitOps.
- Mettre à jour le contenu requis et les changements optionnels dans le dépôt Git.
- Mettre à jour et redémarrer la configuration de l'application.
21.11.2. Préparation de la mise à niveau
Utilisez la procédure suivante pour préparer votre site à la mise à niveau GitOps zero touch provisioning (ZTP).
Procédure
- Obtenir la dernière version du conteneur GitOps ZTP qui contient les ressources personnalisées (CR) utilisées pour configurer Red Hat OpenShift GitOps pour une utilisation avec GitOps ZTP.
Extrayez le répertoire
argocd/deploymentà l'aide des commandes suivantes :$ mkdir -p ./update
$ podman run --log-driver=none --rm registry.redhat.io/openshift4/ztp-site-generate-rhel8:v4.12 extract /home/ztp --tar | tar x -C ./update
Le répertoire
/updatecontient les sous-répertoires suivants :-
update/extra-manifestcontient les fichiers CR source que le CRSiteConfigutilise pour générer le manifeste supplémentaireconfigMap. -
update/source-crscontient les fichiers CR source que le CRPolicyGenTemplateutilise pour générer les stratégies de Red Hat Advanced Cluster Management (RHACM). -
update/argocd/deploymentcontient des correctifs et des fichiers YAML à appliquer sur le cluster hub pour l'étape suivante de cette procédure. -
update/argocd/example: contient des exemples de fichiersSiteConfigetPolicyGenTemplatequi représentent la configuration recommandée.
-
Mettez à jour les fichiers
clusters-app.yamletpolicies-app.yamlpour refléter le nom de vos applications et l'URL, la branche et le chemin de votre dépôt Git.Si la mise à niveau inclut des changements qui entraînent des politiques obsolètes, ces dernières doivent être supprimées avant d'effectuer la mise à niveau.
Diffuser les changements entre les CR de configuration et de déploiement dans le dossier
/updateet le repo Git où vous gérez les CR de votre flotte de sites. Appliquez et poussez les changements requis dans le référentiel de votre site.ImportantLorsque vous mettez à jour GitOps ZTP vers la dernière version, vous devez appliquer les changements du répertoire
update/argocd/deploymentau dépôt de votre site. N'utilisez pas d'anciennes versions des fichiersargocd/deployment/.
21.11.3. Labellisation des clusters existants
Pour s'assurer que les clusters existants ne sont pas touchés par les mises à jour de l'outil, apposez l'étiquette ztp-done sur tous les clusters gérés existants.
Cette procédure s'applique uniquement à la mise à jour des clusters qui n'ont pas été provisionnés avec Topology Aware Lifecycle Manager (TALM). Les clusters provisionnés avec TALM sont automatiquement étiquetés avec ztp-done.
Procédure
Trouvez un sélecteur d'étiquettes qui répertorie les clusters gérés qui ont été déployés avec le zero touch provisioning (ZTP), comme
local-cluster!=true:$ oc get managedcluster -l 'local-cluster!=true'
Assurez-vous que la liste obtenue contient tous les clusters gérés qui ont été déployés avec ZTP, puis utilisez ce sélecteur pour ajouter l'étiquette
ztp-done:$ oc label managedcluster -l 'local-cluster!=true' ztp-done=
21.11.4. Arrêt des applications ZTP existantes de GitOps
La suppression des applications existantes permet de s'assurer que les modifications apportées au contenu existant dans le dépôt Git ne sont pas déployées tant que la nouvelle version des outils n'est pas disponible.
Utilisez les fichiers d'application du répertoire deployment. Si vous avez utilisé des noms personnalisés pour les applications, mettez d'abord à jour les noms dans ces fichiers.
Procédure
Effectuer une suppression non cascadée sur l'application
clusterspour laisser toutes les ressources générées en place :$ oc delete -f update/argocd/deployment/clusters-app.yaml
Effectuez une suppression en cascade sur l'application
policiespour supprimer toutes les politiques précédentes :$ oc patch -f policies-app.yaml -p '{"metadata": {"finalizers": ["resources-finalizer.argocd.argoproj.io"]}}' --type merge$ oc delete -f update/argocd/deployment/policies-app.yaml
21.11.5. Changements requis dans le dépôt Git
Lors de la mise à niveau du conteneur ztp-site-generate d'une version antérieure de GitOps ZTP vers la version 4.10 ou une version ultérieure, le contenu du référentiel Git doit répondre à des exigences supplémentaires. Le contenu existant du référentiel doit être mis à jour pour refléter ces changements.
Apportez les modifications nécessaires aux fichiers
PolicyGenTemplate:Tous les fichiers
PolicyGenTemplatedoivent être créés dans unNamespacepréfixé parztp. Cela garantit que l'application GitOps zero touch provisioning (ZTP) est en mesure de gérer les CR de politique générés par GitOps ZTP sans entrer en conflit avec la façon dont Red Hat Advanced Cluster Management (RHACM) gère les politiques en interne.Ajouter le fichier
kustomization.yamlau référentiel :Tous les CR
SiteConfigetPolicyGenTemplatedoivent être inclus dans un fichierkustomization.yamlsous leurs arborescences respectives. Par exemple :├── policygentemplates │ ├── site1-ns.yaml │ ├── site1.yaml │ ├── site2-ns.yaml │ ├── site2.yaml │ ├── common-ns.yaml │ ├── common-ranGen.yaml │ ├── group-du-sno-ranGen-ns.yaml │ ├── group-du-sno-ranGen.yaml │ └── kustomization.yaml └── siteconfig ├── site1.yaml ├── site2.yaml └── kustomization.yamlNoteLes fichiers énumérés dans les sections
generatordoivent contenir uniquement les CRSiteConfigouPolicyGenTemplate. Si vos fichiers YAML existants contiennent d'autres CR, par exempleNamespace, ces autres CR doivent être extraits dans des fichiers séparés et répertoriés dans la sectionresources.Le fichier de personnalisation
PolicyGenTemplatedoit contenir tous les fichiers YAMLPolicyGenTemplatedans la sectiongeneratoret les CRNamespacedans la sectionresources. Par exemple :apiVersion: kustomize.config.k8s.io/v1beta1 kind: Kustomization generators: - common-ranGen.yaml - group-du-sno-ranGen.yaml - site1.yaml - site2.yaml resources: - common-ns.yaml - group-du-sno-ranGen-ns.yaml - site1-ns.yaml - site2-ns.yaml
Le fichier de personnalisation
SiteConfigdoit contenir tous les fichiers YAMLSiteConfigdans la sectiongeneratoret tout autre CR dans les ressources :apiVersion: kustomize.config.k8s.io/v1beta1 kind: Kustomization generators: - site1.yaml - site2.yaml
Supprimer les fichiers
pre-sync.yamletpost-sync.yaml.Dans OpenShift Container Platform 4.10 et plus, les fichiers
pre-sync.yamletpost-sync.yamlne sont plus nécessaires. Le CRupdate/deployment/kustomization.yamlgère le déploiement des politiques sur le cluster hub.NoteIl existe un ensemble de fichiers
pre-sync.yamletpost-sync.yamlsous les arbresSiteConfigetPolicyGenTemplate.Examiner et intégrer les modifications recommandées
Chaque version peut inclure des changements supplémentaires recommandés pour la configuration appliquée aux clusters déployés. Généralement, ces changements permettent de réduire l'utilisation du processeur par la plateforme OpenShift, d'ajouter des fonctionnalités ou d'améliorer le réglage de la plateforme.
Examinez les CR de référence
SiteConfigetPolicyGenTemplateapplicables aux types de clusters de votre réseau. Ces exemples se trouvent dans le répertoireargocd/exampleextrait du conteneur ZTP GitOps.
21.11.6. Installation des nouvelles applications ZTP de GitOps
En utilisant le répertoire argocd/deployment extrait, et après avoir vérifié que les applications pointent vers le dépôt Git de votre site, appliquez le contenu complet du répertoire de déploiement. L'application du contenu complet du répertoire garantit que toutes les ressources nécessaires aux applications sont correctement configurées.
Procédure
Pour patcher l'instance ArgoCD dans le cluster hub en utilisant le fichier patch que vous avez précédemment extrait dans le répertoire
update/argocd/deployment/, entrez la commande suivante :$ oc patch argocd openshift-gitops \ -n openshift-gitops --type=merge \ --patch-file update/argocd/deployment/argocd-openshift-gitops-patch.json
Pour appliquer le contenu du répertoire
argocd/deployment, entrez la commande suivante :$ oc apply -k update/argocd/deployment
21.11.7. Déploiement des changements de configuration de GitOps ZTP
Si des changements de configuration ont été inclus dans la mise à niveau en raison de la mise en œuvre des changements recommandés, le processus de mise à niveau entraîne un ensemble de CR de politiques sur le cluster concentrateur dans l'état Non-Compliant. Avec le conteneur ZTP GitOps v4.10 et les versions ultérieures ztp-site-generate, ces politiques sont définies en mode inform et ne sont pas poussées vers les clusters gérés sans une étape supplémentaire de la part de l'utilisateur. Cela permet de gérer les changements potentiellement perturbateurs apportés aux clusters en termes de moment où les changements sont effectués, par exemple, au cours d'une fenêtre de maintenance, et de nombre de clusters mis à jour simultanément.
Pour déployer les changements, créez un ou plusieurs CR ClusterGroupUpgrade comme indiqué dans la documentation TALM. Le CR doit contenir la liste des politiques Non-Compliant que vous souhaitez appliquer aux clusters gérés, ainsi qu'une liste ou un sélecteur des clusters à inclure dans la mise à jour.
Ressources supplémentaires
- Pour plus d'informations sur le Topology Aware Lifecycle Manager (TALM), voir À propos de la configuration du Topology Aware Lifecycle Manager.
-
Pour plus d'informations sur la création des CR
ClusterGroupUpgrade, voir À propos du CR ClusterGroupUpgrade auto-créé pour ZTP.
21.12. Extension des clusters OpenShift à nœud unique avec GitOps ZTP
Vous pouvez étendre les clusters OpenShift à nœud unique avec GitOps ZTP. Lorsque vous ajoutez des nœuds de travail aux clusters OpenShift à nœud unique, le cluster OpenShift à nœud unique d'origine conserve le rôle de nœud du plan de contrôle. L'ajout de nœuds de travail ne nécessite aucun temps d'arrêt pour le cluster OpenShift à nœud unique existant.
Bien qu'il n'y ait pas de limite spécifiée sur le nombre de nœuds de travail que vous pouvez ajouter à un cluster OpenShift à nœud unique, vous devez réévaluer l'allocation de CPU réservée sur le nœud de plan de contrôle pour les nœuds de travail supplémentaires.
Si vous avez besoin d'un partitionnement de la charge de travail sur le nœud de travail, vous devez déployer et remédier aux stratégies de cluster gérées sur le cluster du concentrateur avant d'installer le nœud. De cette façon, les objets MachineConfig de partitionnement de la charge de travail sont rendus et associés au pool de configuration de la machine worker avant que le flux de travail ZTP de GitOps n'applique le fichier d'allumage MachineConfig au nœud de travailleur.
Il est recommandé de remédier d'abord aux stratégies, puis d'installer le nœud de travail. Si vous créez les manifestes de partitionnement de la charge de travail après avoir installé le nœud de travail, vous devez drainer le nœud manuellement et supprimer tous les modules gérés par les ensembles de démons. Lorsque les ensembles de démons de gestion créent les nouveaux modules, ceux-ci sont soumis au processus de partitionnement de la charge de travail.
L'ajout de nœuds de travail à des clusters OpenShift à nœud unique avec GitOps ZTP est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
Ressources supplémentaires
- Pour plus d'informations sur les clusters OpenShift à nœud unique adaptés aux déploiements d'applications vDU, voir Configuration de référence pour le déploiement de vDU sur OpenShift à nœud unique.
- Pour plus d'informations sur les nœuds de travail, voir Ajouter des nœuds de travail aux clusters OpenShift à nœud unique.
21.12.1. Application de profils au nœud de travail
Vous pouvez configurer le nœud de travail supplémentaire avec un profil DU.
Vous pouvez appliquer un profil d'unité distribuée (DU) RAN à la grappe de nœuds de travailleur à l'aide des ressources ZTP GitOps communes, de groupe et spécifiques au site PolicyGenTemplate. Le pipeline ZTP GitOps lié à l'application ArgoCD policies comprend les CR suivants que vous trouverez dans le dossier out/argocd/example/policygentemplates lorsque vous extrayez le conteneur ztp-site-generate:
-
common-ranGen.yaml -
group-du-sno-ranGen.yaml -
example-sno-site.yaml -
ns.yaml -
kustomization.yaml
La configuration du profil d'UD sur le nœud de travail est considérée comme une mise à niveau. Pour lancer le flux de mise à niveau, vous devez mettre à jour les stratégies existantes ou en créer de nouvelles. Ensuite, vous devez créer un CR ClusterGroupUpgrade pour réconcilier les stratégies dans le groupe de clusters.
21.12.2. (Facultatif) Assurer la compatibilité des sélecteurs des démons PTP et SR-IOV
Si le profil DU a été déployé à l'aide du plugin GitOps ZTP version 4.11 ou antérieure, les opérateurs PTP et SR-IOV peuvent être configurés pour placer les démons uniquement sur les nœuds étiquetés comme master. Cette configuration empêche les démons PTP et SR-IOV de fonctionner sur le nœud de travail. Si les sélecteurs de nœuds des démons PTP et SR-IOV sont mal configurés sur votre système, vous devez modifier les démons avant de procéder à la configuration du profil de l'UD travailleur.
Procédure
Vérifiez les paramètres du sélecteur de nœud du démon de l'opérateur PTP sur l'un des clusters de rayons :
$ oc get ptpoperatorconfig/default -n openshift-ptp -ojsonpath='{.spec}' | jqExemple de sortie pour l'opérateur PTP
{\i1}"daemonNodeSelector":{\i1}"node-role.kubernetes.io/master":{\i1}"\N- \N"\N"\N"}} 1- 1
- Si le sélecteur de nœud est défini sur
master, le rayon a été déployé avec la version du plugin ZTP qui nécessite des modifications.
Vérifiez les paramètres du sélecteur de nœud démon de l'opérateur SR-IOV sur l'un des clusters de rayons :
$ oc get sriovoperatorconfig/default -n \ openshift-sriov-network-operator -ojsonpath='{.spec}' | jqExemple de sortie pour l'opérateur SR-IOV
{\aemonNodeSelector":{"node-role.kubernetes.io/worker":\N"\N"},\N "disableDrain":false,\N "enableInjector":true,\N "enableOperatorWebhook":true} 1- 1
- Si le sélecteur de nœud est défini sur
master, le rayon a été déployé avec la version du plugin ZTP qui nécessite des modifications.
Dans la stratégie de groupe, ajoutez les entrées
complianceTypeetspecsuivantes :spec: - fileName: PtpOperatorConfig.yaml policyName: "config-policy" complianceType: mustonlyhave spec: daemonNodeSelector: node-role.kubernetes.io/worker: "" - fileName: SriovOperatorConfig.yaml policyName: "config-policy" complianceType: mustonlyhave spec: configDaemonNodeSelector: node-role.kubernetes.io/worker: ""ImportantLa modification du champ
daemonNodeSelectorentraîne une perte temporaire de synchronisation PTP et une perte de connectivité SR-IOV.- Commencer les changements dans Git, puis pousser vers le dépôt Git surveillé par l'application GitOps ZTP ArgoCD.
21.12.3. Compatibilité des sélecteurs de nœuds PTP et SR-IOV
Les ressources de configuration PTP et les stratégies de nœuds de réseau SR-IOV utilisent node-role.kubernetes.io/master: "" comme sélecteur de nœuds. Si les nœuds de travail supplémentaires ont la même configuration de carte réseau que le nœud du plan de contrôle, les stratégies utilisées pour configurer le nœud du plan de contrôle peuvent être réutilisées pour les nœuds de travail. Toutefois, le sélecteur de nœud doit être modifié pour sélectionner les deux types de nœuds, par exemple avec l'étiquette "node-role.kubernetes.io/worker".
21.12.4. Utilisation des CR PolicyGenTemplate pour appliquer des politiques aux nœuds de travailleur
Vous pouvez créer des règles pour les nœuds de travail.
Procédure
Créez le modèle de politique suivant :
apiVersion: ran.openshift.io/v1 kind: PolicyGenTemplate metadata: name: "example-sno-workers" namespace: "example-sno" spec: bindingRules: sites: "example-sno" 1 mcp: "worker" 2 sourceFiles: - fileName: MachineConfigGeneric.yaml 3 policyName: "config-policy" metadata: labels: machineconfiguration.openshift.io/role: worker name: enable-workload-partitioning spec: config: storage: files: - contents: source: data:text/plain;charset=utf-8;base64,W2NyaW8ucnVudGltZS53b3JrbG9hZHMubWFuYWdlbWVudF0KYWN0aXZhdGlvbl9hbm5vdGF0aW9uID0gInRhcmdldC53b3JrbG9hZC5vcGVuc2hpZnQuaW8vbWFuYWdlbWVudCIKYW5ub3RhdGlvbl9wcmVmaXggPSAicmVzb3VyY2VzLndvcmtsb2FkLm9wZW5zaGlmdC5pbyIKcmVzb3VyY2VzID0geyAiY3B1c2hhcmVzIiA9IDAsICJjcHVzZXQiID0gIjAtMyIgfQo= mode: 420 overwrite: true path: /etc/crio/crio.conf.d/01-workload-partitioning user: name: root - contents: source: data:text/plain;charset=utf-8;base64,ewogICJtYW5hZ2VtZW50IjogewogICAgImNwdXNldCI6ICIwLTMiCiAgfQp9Cg== mode: 420 overwrite: true path: /etc/kubernetes/openshift-workload-pinning user: name: root - fileName: PerformanceProfile.yaml policyName: "config-policy" metadata: name: openshift-worker-node-performance-profile spec: cpu: 4 isolated: "4-47" reserved: "0-3" hugepages: defaultHugepagesSize: 1G pages: - size: 1G count: 32 realTimeKernel: enabled: true - fileName: TunedPerformancePatch.yaml policyName: "config-policy" metadata: name: performance-patch-worker spec: profile: - name: performance-patch-worker data: | [main] summary=Configuration changes profile inherited from performance created tuned include=openshift-node-performance-openshift-worker-node-performance-profile [bootloader] cmdline_crash=nohz_full=4-47 5 [sysctl] kernel.timer_migration=1 [scheduler] group.ice-ptp=0:f:10:*:ice-ptp.* [service] service.stalld=start,enable service.chronyd=stop,disable recommend: - profile: performance-patch-worker- 1
- Les politiques sont appliquées à tous les clusters portant cette étiquette.
- 2
- Le champ
MCPdoit être défini commeworker. - 3
- Ce CR générique
MachineConfigest utilisé pour configurer le partitionnement de la charge de travail sur le nœud de travail. - 4
- Les champs
cpu.isolatedetcpu.reserveddoivent être configurés pour chaque plate-forme matérielle. - 5
- L'ensemble d'unités centrales
cmdline_crashdoit correspondre à l'ensemble d'unités centralescpu.isolateddans la sectionPerformanceProfile.
Un CR générique
MachineConfigest utilisé pour configurer le partitionnement de la charge de travail sur le nœud de travail. Vous pouvez générer le contenu des fichiers de configurationcrioetkubelet.-
Ajoutez le modèle de politique créé au dépôt Git surveillé par l'application ArgoCD
policies. -
Ajouter la politique dans le fichier
kustomization.yaml. - Commencer les changements dans Git, puis pousser vers le dépôt Git surveillé par l'application GitOps ZTP ArgoCD.
Pour remédier aux nouvelles politiques dans votre cluster de rayons, créez une ressource personnalisée TALM :
$ cat <<EOF | oc apply -f - apiVersion: ran.openshift.io/v1alpha1 kind: ClusterGroupUpgrade metadata: name: example-sno-worker-policies namespace: default spec: backup: false clusters: - example-sno enable: true managedPolicies: - group-du-sno-config-policy - example-sno-workers-config-policy - example-sno-config-policy preCaching: false remediationStrategy: maxConcurrency: 1 EOF
21.12.5. Ajouter des nœuds de travail à des clusters OpenShift à nœud unique avec GitOps ZTP
Vous pouvez ajouter un ou plusieurs nœuds de travail à des clusters OpenShift à nœud unique existants afin d'augmenter les ressources CPU disponibles dans le cluster.
Conditions préalables
- Installer et configurer RHACM 2.6 ou version ultérieure dans un cluster de hub bare-metal OpenShift Container Platform 4.11 ou version ultérieure
- Installer Topology Aware Lifecycle Manager dans le cluster hub
- Installer Red Hat OpenShift GitOps dans le cluster hub
-
Utilisez l'image du conteneur GitOps ZTP
ztp-site-generateversion 4.12 ou ultérieure - Déployer un cluster OpenShift géré à un seul nœud avec GitOps ZTP
- Configurer la gestion centrale de l'infrastructure comme décrit dans la documentation RHACM
-
Configurer le DNS desservant le cluster pour résoudre le point de terminaison de l'API interne
api-int.<cluster_name>.<base_domain>
Procédure
Si vous avez déployé votre cluster en utilisant le manifeste
example-sno.yamlSiteConfig, ajoutez votre nouveau nœud de travail à la listespec.clusters['example-sno'].nodes:nodes: - hostName: "example-node2.example.com" role: "worker" bmcAddress: "idrac-virtualmedia+https://[1111:2222:3333:4444::bbbb:1]/redfish/v1/Systems/System.Embedded.1" bmcCredentialsName: name: "example-node2-bmh-secret" bootMACAddress: "AA:BB:CC:DD:EE:11" bootMode: "UEFI" nodeNetwork: interfaces: - name: eno1 macAddress: "AA:BB:CC:DD:EE:11" config: interfaces: - name: eno1 type: ethernet state: up macAddress: "AA:BB:CC:DD:EE:11" ipv4: enabled: false ipv6: enabled: true address: - ip: 1111:2222:3333:4444::1 prefix-length: 64 dns-resolver: config: search: - example.com server: - 1111:2222:3333:4444::2 routes: config: - destination: ::/0 next-hop-interface: eno1 next-hop-address: 1111:2222:3333:4444::1 table-id: 254Créez un secret d'authentification BMC pour le nouvel hôte, référencé par le champ
bmcCredentialsNamedans la sectionspec.nodesde votre fichierSiteConfig:apiVersion: v1 data: password: "password" username: "username" kind: Secret metadata: name: "example-node2-bmh-secret" namespace: example-sno type: Opaque
Commencer les changements dans Git, puis pousser vers le dépôt Git qui est surveillé par l'application GitOps ZTP ArgoCD.
Lorsque l'application ArgoCD
clusterse synchronise, deux nouveaux manifestes apparaissent sur le hub cluster généré par le plugin ZTP :-
BareMetalHost NMStateConfigImportantLe champ
cpusetne doit pas être configuré pour le nœud de travail. Le partitionnement de la charge de travail pour les nœuds de travail est ajouté par le biais de stratégies de gestion une fois l'installation du nœud terminée.
-
Vérification
Vous pouvez contrôler le processus d'installation de plusieurs manières.
Vérifiez que les images de préprovisionnement sont créées en exécutant la commande suivante :
$ oc get ppimg -n example-sno
Exemple de sortie
NAMESPACE NAME READY REASON example-sno example-sno True ImageCreated example-sno example-node2 True ImageCreated
Vérifier l'état des hôtes nus :
$ oc get bmh -n example-sno
Exemple de sortie
NAME STATE CONSUMER ONLINE ERROR AGE example-sno provisioned true 69m example-node2 provisioning true 4m50s 1- 1
- L'état
provisioningindique que l'amorçage du nœud à partir du support d'installation est en cours.
Contrôler en permanence le processus d'installation :
Observez le processus d'installation de l'agent en exécutant la commande suivante :
$ oc get agent -n example-sno --watch
Exemple de sortie
NAME CLUSTER APPROVED ROLE STAGE 671bc05d-5358-8940-ec12-d9ad22804faa example-sno true master Done [...] 14fd821b-a35d-9cba-7978-00ddf535ff37 example-sno true worker Starting installation 14fd821b-a35d-9cba-7978-00ddf535ff37 example-sno true worker Installing 14fd821b-a35d-9cba-7978-00ddf535ff37 example-sno true worker Writing image to disk [...] 14fd821b-a35d-9cba-7978-00ddf535ff37 example-sno true worker Waiting for control plane [...] 14fd821b-a35d-9cba-7978-00ddf535ff37 example-sno true worker Rebooting 14fd821b-a35d-9cba-7978-00ddf535ff37 example-sno true worker Done
Lorsque l'installation du nœud de travailleur est terminée, les certificats du nœud de travailleur sont approuvés automatiquement. À ce stade, le nœud de travailleur apparaît dans l'état
ManagedClusterInfo. Exécutez la commande suivante pour voir l'état :$ oc get managedclusterinfo/example-sno -n example-sno -o \ jsonpath='{range .status.nodeList[*]}{.name}{"\t"}{.conditions}{"\t"}{.labels}{"\n"}{end}'Exemple de sortie
example-sno [{"status":"True","type":"Ready"}] {"node-role.kubernetes.io/master":"","node-role.kubernetes.io/worker":""} example-node2 [{"status":"True","type":"Ready"}] {"node-role.kubernetes.io/worker":""}
21.13. Mise en cache préalable des images pour les déploiements OpenShift à nœud unique
Dans les environnements où la bande passante est limitée et où vous utilisez la solution GitOps zero touch provisioning (ZTP) pour déployer un grand nombre de clusters, vous souhaitez éviter de télécharger toutes les images nécessaires au démarrage et à l'installation d'OpenShift Container Platform. La bande passante limitée sur les sites OpenShift distants à un seul nœud peut entraîner des délais de déploiement trop longs. L'outil factory-precaching-cli vous permet de pré-stager les serveurs avant de les envoyer au site distant pour le provisionnement ZTP.
L'outil factory-precaching-cli effectue les opérations suivantes :
- Télécharge l'image RHCOS rootfs nécessaire au démarrage de l'ISO minimale.
-
Crée une partition à partir du disque d'installation sous le nom de
data. - Formate le disque en xfs.
- Crée une partition de données GUID Partition Table (GPT) à la fin du disque, la taille de la partition étant configurable par l'outil.
- Copie les images de conteneurs nécessaires à l'installation d'OpenShift Container Platform.
- Copie les images de conteneurs requises par ZTP pour installer OpenShift Container Platform.
- Facultatif : Copie les opérateurs du jour 2 dans la partition.
L'outil factory-precaching-cli est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas leur utilisation en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
21.13.1. Obtenir l'outil factory-precaching-cli
Le binaire Go de l'outil factory-precaching-cli est disponible publiquement dans l'image conteneur des outils Telco RAN. Le binaire Go de l'outil factory-precaching-cli dans l'image du conteneur est exécuté sur le serveur exécutant une image RHCOS live à l'aide de podman. Si vous travaillez dans un environnement déconnecté ou si vous disposez d'un registre privé, vous devez y copier l'image afin de pouvoir la télécharger sur le serveur.
Procédure
Tirez l'image de l'outil factory-precaching-cli en exécutant la commande suivante :
# podman pull quay.io/openshift-kni/telco-ran-tools:latest
Vérification
Pour vérifier que l'outil est disponible, interrogez la version actuelle du binaire Go de l'outil factory-precaching-cli :
# podman run quay.io/openshift-kni/telco-ran-tools:latest -- factory-precaching-cli -v
Exemple de sortie
factory-precaching-cli version 20221018.120852+main.feecf17
21.13.2. Démarrage à partir d'une image live du système d'exploitation
Vous pouvez utiliser l'outil factory-precaching-cli pour démarrer les serveurs lorsqu'un seul disque est disponible et qu'un lecteur de disque externe ne peut pas être connecté au serveur.
RHCOS exige que le disque ne soit pas utilisé lorsqu'il est sur le point d'être écrit avec une image RHCOS.
En fonction du matériel du serveur, vous pouvez monter l'ISO live RHCOS sur le serveur vierge en utilisant l'une des méthodes suivantes :
- Utilisation de l'outil Dell RACADM sur un serveur Dell.
- Utilisation de l'outil HPONCFG sur un serveur HP.
- Utilisation de l'API Redfish BMC.
Il est recommandé d'automatiser la procédure de montage. Pour automatiser la procédure, vous devez extraire les images requises et les héberger sur un serveur HTTP local.
Conditions préalables
- Vous avez mis l'hôte sous tension.
- Vous disposez d'une connectivité réseau avec l'hôte.
Cet exemple de procédure utilise l'API Redfish BMC pour monter l'ISO live RHCOS.
Monter l'ISO live RHCOS :
Vérifier l'état des supports virtuels :
$ curl --globoff -H "Content-Type: application/json" -H \ "Accept: application/json" -k -X GET --user ${username_password} \ https://$BMC_ADDRESS/redfish/v1/Managers/Self/VirtualMedia/1 | python -m json.toolMonter le fichier ISO en tant que support virtuel :
$ curl --globoff -L -w "%{http_code} %{url_effective}\\n" -ku ${username_password} -H "Content-Type: application/json" -H "Accept: application/json" -d '{"Image": "http://[$HTTPd_IP]/RHCOS-live.iso"}' -X POST https://$BMC_ADDRESS/redfish/v1/Managers/Self/VirtualMedia/1/Actions/VirtualMedia.InsertMediaDéfinir l'ordre de démarrage pour démarrer une seule fois à partir du support virtuel :
$ curl --globoff -L -w "%{http_code} %{url_effective}\\n" -ku ${username_password} -H "Content-Type: application/json" -H "Accept: application/json" -d '{"Boot":{ "BootSourceOverrideEnabled": "Once", "BootSourceOverrideTarget": "Cd", "BootSourceOverrideMode": "UEFI"}}' -X PATCH https://$BMC_ADDRESS/redfish/v1/Systems/Self
- Redémarrez et assurez-vous que le serveur démarre à partir d'un support virtuel.
Ressources supplémentaires
-
Pour plus d'informations sur l'utilitaire
butane, voir À propos de Butane. - Pour plus d'informations sur la création d'une ISO RHCOS personnalisée, voir Création d'une ISO RHCOS personnalisée pour l'accès au serveur distant.
- Pour plus d'informations sur l'utilisation de l'outil Dell RACADM, voir Integrated Dell Remote Access Controller 9 RACADM CLI Guide.
- Pour plus d'informations sur l'utilisation de l'outil HPONCFG, voir Utilisation de HPONCFG.
- Pour plus d'informations sur l'utilisation de l'API BMC Redfish, voir Démarrer à partir d'une image ISO hébergée par HTTP à l'aide de l'API Redfish.
21.13.3. Partitionnement du disque
Pour exécuter le processus complet de pré-cache, vous devez démarrer à partir d'une ISO vivante et utiliser l'outil factory-precaching-cli à partir d'une image de conteneur pour partitionner et pré-cacher tous les artefacts nécessaires.
Un live ISO ou RHCOS live ISO est nécessaire car le disque ne doit pas être utilisé lorsque le système d'exploitation (RHCOS) est écrit sur le périphérique pendant le provisionnement. Cette procédure permet également d'activer des serveurs à disque unique.
Conditions préalables
- Vous avez un disque qui n'est pas partitionné.
-
Vous avez accès à l'image
quay.io/openshift-kni/telco-ran-tools:latest. - Vous disposez de suffisamment d'espace de stockage pour installer OpenShift Container Platform et mettre en pré-cache les images requises.
Procédure
Vérifier que le disque est dégagé :
# lsblk
Exemple de sortie
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT loop0 7:0 0 93.8G 0 loop /run/ephemeral loop1 7:1 0 897.3M 1 loop /sysroot sr0 11:0 1 999M 0 rom /run/media/iso nvme0n1 259:1 0 1.5T 0 disk
Effacer toutes les signatures de système de fichiers, de RAID ou de table de partition de l'appareil :
# wipefs -a /dev/nvme0n1
Exemple de sortie
/dev/nvme0n1: 8 bytes were erased at offset 0x00000200 (gpt): 45 46 49 20 50 41 52 54 /dev/nvme0n1: 8 bytes were erased at offset 0x1749a955e00 (gpt): 45 46 49 20 50 41 52 54 /dev/nvme0n1: 2 bytes were erased at offset 0x000001fe (PMBR): 55 aa
L'outil échoue si le disque n'est pas vide car il utilise la partition numéro 1 du périphérique pour la mise en cache des artefacts.
21.13.3.1. Création de la partition
Une fois que le périphérique est prêt, vous créez une partition unique et une table de partition GPT. La partition est automatiquement étiquetée comme data et créée à la fin du périphérique. Dans le cas contraire, la partition sera remplacée par la partition coreos-installer.
L'adresse coreos-installer exige que la partition soit créée à la fin du périphérique et qu'elle soit étiquetée comme data. Ces deux conditions sont nécessaires pour sauvegarder la partition lors de l'écriture de l'image RHCOS sur le disque.
Conditions préalables
-
Le conteneur doit fonctionner en tant que
privilegeden raison du formatage des périphériques hôtes. -
Vous devez monter le dossier
/devpour que le processus puisse être exécuté à l'intérieur du conteneur.
Procédure
Dans l'exemple suivant, la taille de la partition est de 250 GiB afin de permettre la mise en cache préalable du profil de l'UD pour les opérateurs du jour 2.
Exécutez le conteneur en tant que
privilegedet partitionnez le disque :# podman run -v /dev:/dev --privileged \ --rm quay.io/openshift-kni/telco-ran-tools:latest -- \ factory-precaching-cli partition \ 1 -d /dev/nvme0n1 \ 2 -s 250 3
Vérifier les informations de stockage :
# lsblk
Exemple de sortie
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT loop0 7:0 0 93.8G 0 loop /run/ephemeral loop1 7:1 0 897.3M 1 loop /sysroot sr0 11:0 1 999M 0 rom /run/media/iso nvme0n1 259:1 0 1.5T 0 disk └─nvme0n1p1 259:3 0 250G 0 part
Vérification
Vous devez vérifier que les conditions suivantes sont remplies :
- Le périphérique possède une table de partition GPT
- La partition utilise les secteurs les plus récents de l'appareil.
-
La partition est correctement étiquetée comme
data.
Interroger l'état du disque pour vérifier que le disque est partitionné comme prévu :
# gdisk -l /dev/nvme0n1
Exemple de sortie
GPT fdisk (gdisk) version 1.0.3 Partition table scan: MBR: protective BSD: not present APM: not present GPT: present Found valid GPT with protective MBR; using GPT. Disk /dev/nvme0n1: 3125627568 sectors, 1.5 TiB Model: Dell Express Flash PM1725b 1.6TB SFF Sector size (logical/physical): 512/512 bytes Disk identifier (GUID): CB5A9D44-9B3C-4174-A5C1-C64957910B61 Partition table holds up to 128 entries Main partition table begins at sector 2 and ends at sector 33 First usable sector is 34, last usable sector is 3125627534 Partitions will be aligned on 2048-sector boundaries Total free space is 2601338846 sectors (1.2 TiB) Number Start (sector) End (sector) Size Code Name 1 2601338880 3125627534 250.0 GiB 8300 data
21.13.3.2. Montage de la cloison
Après avoir vérifié que le disque est correctement partitionné, vous pouvez monter le périphérique sur /mnt.
Il est recommandé de monter l'appareil sur /mnt car ce point de montage est utilisé lors de la préparation du ZTP.
Vérifiez que la partition est formatée comme
xfs:# lsblk -f /dev/nvme0n1
Exemple de sortie
NAME FSTYPE LABEL UUID MOUNTPOINT nvme0n1 └─nvme0n1p1 xfs 1bee8ea4-d6cf-4339-b690-a76594794071
Monter la partition :
# mount /dev/nvme0n1p1 /mnt/
Vérification
Vérifiez que la partition est montée :
# lsblk
Exemple de sortie
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT loop0 7:0 0 93.8G 0 loop /run/ephemeral loop1 7:1 0 897.3M 1 loop /sysroot sr0 11:0 1 999M 0 rom /run/media/iso nvme0n1 259:1 0 1.5T 0 disk └─nvme0n1p1 259:2 0 250G 0 part /var/mnt 1- 1
- Le point de montage est
/var/mntcar le dossier/mntdans le RHCOS est un lien vers/var/mnt.
21.13.4. Téléchargement des images
L'outil factory-precaching-cli vous permet de télécharger les images suivantes sur votre serveur partitionné :
- Images de la plate-forme OpenShift Container
- Images de l'opérateur incluses dans le profil de l'unité distribuée (DU) pour les sites RAN 5G
- Images d'opérateurs provenant de registres déconnectés
La liste des images d'opérateurs disponibles peut varier selon les versions d'OpenShift Container Platform.
21.13.4.1. Téléchargement avec des travailleurs parallèles
L'outil factory-precaching-cli utilise des travailleurs parallèles pour télécharger plusieurs images simultanément. Vous pouvez configurer le nombre de travailleurs avec l'option --parallel ou -p. Le nombre par défaut est fixé à 80 % des processeurs disponibles sur le serveur.
Votre shell de connexion peut être limité à un sous-ensemble de CPU, ce qui réduit les CPU disponibles pour le conteneur. Pour lever cette restriction, vous pouvez faire précéder vos commandes de taskset 0xffffffff, par exemple :
# taskset 0xffffffff podman run --rm quay.io/openshift-kni/telco-ran-tools:latest factory-precaching-cli download --help
21.13.4.2. Préparation du téléchargement des images OpenShift Container Platform
Pour télécharger des images de conteneurs OpenShift Container Platform, vous devez connaître la version du moteur multicluster (MCE). Lorsque vous utilisez le drapeau --du-profile, vous devez également spécifier la version de Red Hat Advanced Cluster Management (RHACM) fonctionnant dans le hub cluster qui va provisionner l'OpenShift à nœud unique.
Conditions préalables
- Vous avez installé RHACM et MCE.
- Vous avez partitionné le périphérique de stockage.
- Vous disposez de suffisamment d'espace pour les images sur le périphérique partitionné.
- Vous avez connecté le serveur bare-metal à l'Internet.
- Vous avez un secret de tirage valide.
Procédure
Vérifiez la version de RHACM et de MCE en exécutant les commandes suivantes dans le cluster hub :
$ oc get csv -A | grep -i advanced-cluster-management
Exemple de sortie
open-cluster-management advanced-cluster-management.v2.6.3 Advanced Cluster Management for Kubernetes 2.6.3 advanced-cluster-management.v2.6.3 Succeeded
$ oc get csv -A | grep -i multicluster-engine
Exemple de sortie
multicluster-engine cluster-group-upgrades-operator.v0.0.3 cluster-group-upgrades-operator 0.0.3 Pending multicluster-engine multicluster-engine.v2.1.4 multicluster engine for Kubernetes 2.1.4 multicluster-engine.v2.0.3 Succeeded multicluster-engine openshift-gitops-operator.v1.5.7 Red Hat OpenShift GitOps 1.5.7 openshift-gitops-operator.v1.5.6-0.1664915551.p Succeeded multicluster-engine openshift-pipelines-operator-rh.v1.6.4 Red Hat OpenShift Pipelines 1.6.4 openshift-pipelines-operator-rh.v1.6.3 Succeeded
Pour accéder au registre des conteneurs, copiez un secret d'extraction valide sur le serveur à installer :
Créez le dossier
.docker:$ mkdir /root/.docker
Copiez le tirage valide du fichier
config.jsondans le dossier.docker/précédemment créé :$ cp config.json /root/.docker/config.json 1- 1
/root/.docker/config.jsonest le chemin par défaut oùpodmanvérifie les identifiants de connexion au registre.
Si vous utilisez un registre différent pour extraire les artefacts requis, vous devez copier le secret d'extraction approprié. Si le registre local utilise TLS, vous devez également inclure les certificats du registre.
21.13.4.3. Télécharger les images d'OpenShift Container Platform
L'outil factory-precaching-cli permet de pré-cacher toutes les images de conteneurs nécessaires au provisionnement d'une version spécifique d'OpenShift Container Platform.
Procédure
Pré-cachez la version en exécutant la commande suivante :
# podman run -v /mnt:/mnt -v /root/.docker:/root/.docker --privileged --rm quay.io/openshift-kni/telco-ran-tools -- \ factory-precaching-cli download \ 1 -r 4.12.0 \ 2 --acm-version 2.6.3 \ 3 --mce-version 2.1.4 \ 4 -f /mnt \ 5 --img quay.io/custom/repository 6
- 1
- Spécifie la fonction de téléchargement de l'outil factory-precaching-cli.
- 2
- Définit la version d'OpenShift Container Platform.
- 3
- Définit la version de RHACM.
- 4
- Définit la version du MCE.
- 5
- Définit le dossier dans lequel vous souhaitez télécharger les images sur le disque.
- 6
- Facultatif. Définit le référentiel dans lequel vous stockez vos images supplémentaires. Ces images sont téléchargées et mises en cache sur le disque.
Exemple de sortie
Generated /mnt/imageset.yaml Generating list of pre-cached artifacts... Processing artifact [1/176]: ocp-v4.0-art-dev@sha256_6ac2b96bf4899c01a87366fd0feae9f57b1b61878e3b5823da0c3f34f707fbf5 Processing artifact [2/176]: ocp-v4.0-art-dev@sha256_f48b68d5960ba903a0d018a10544ae08db5802e21c2fa5615a14fc58b1c1657c Processing artifact [3/176]: ocp-v4.0-art-dev@sha256_a480390e91b1c07e10091c3da2257180654f6b2a735a4ad4c3b69dbdb77bbc06 Processing artifact [4/176]: ocp-v4.0-art-dev@sha256_ecc5d8dbd77e326dba6594ff8c2d091eefbc4d90c963a9a85b0b2f0e6155f995 Processing artifact [5/176]: ocp-v4.0-art-dev@sha256_274b6d561558a2f54db08ea96df9892315bb773fc203b1dbcea418d20f4c7ad1 Processing artifact [6/176]: ocp-v4.0-art-dev@sha256_e142bf5020f5ca0d1bdda0026bf97f89b72d21a97c9cc2dc71bf85050e822bbf ... Processing artifact [175/176]: ocp-v4.0-art-dev@sha256_16cd7eda26f0fb0fc965a589e1e96ff8577e560fcd14f06b5fda1643036ed6c8 Processing artifact [176/176]: ocp-v4.0-art-dev@sha256_cf4d862b4a4170d4f611b39d06c31c97658e309724f9788e155999ae51e7188f ... Summary: Release: 4.12.0 Hub Version: 2.6.3 ACM Version: 2.6.3 MCE Version: 2.1.4 Include DU Profile: No Workers: 83
Vérification
Vérifiez que toutes les images sont compressées dans le dossier cible du serveur :
$ ls -l /mnt 1- 1
- Il est recommandé de mettre les images en pré-cache dans le dossier
/mnt.
Exemple de sortie
-rw-r--r--. 1 root root 136352323 Oct 31 15:19 ocp-v4.0-art-dev@sha256_edec37e7cd8b1611d0031d45e7958361c65e2005f145b471a8108f1b54316c07.tgz -rw-r--r--. 1 root root 156092894 Oct 31 15:33 ocp-v4.0-art-dev@sha256_ee51b062b9c3c9f4fe77bd5b3cc9a3b12355d040119a1434425a824f137c61a9.tgz -rw-r--r--. 1 root root 172297800 Oct 31 15:29 ocp-v4.0-art-dev@sha256_ef23d9057c367a36e4a5c4877d23ee097a731e1186ed28a26c8d21501cd82718.tgz -rw-r--r--. 1 root root 171539614 Oct 31 15:23 ocp-v4.0-art-dev@sha256_f0497bb63ef6834a619d4208be9da459510df697596b891c0c633da144dbb025.tgz -rw-r--r--. 1 root root 160399150 Oct 31 15:20 ocp-v4.0-art-dev@sha256_f0c339da117cde44c9aae8d0bd054bceb6f19fdb191928f6912a703182330ac2.tgz -rw-r--r--. 1 root root 175962005 Oct 31 15:17 ocp-v4.0-art-dev@sha256_f19dd2e80fb41ef31d62bb8c08b339c50d193fdb10fc39cc15b353cbbfeb9b24.tgz -rw-r--r--. 1 root root 174942008 Oct 31 15:33 ocp-v4.0-art-dev@sha256_f1dbb81fa1aa724e96dd2b296b855ff52a565fbef003d08030d63590ae6454df.tgz -rw-r--r--. 1 root root 246693315 Oct 31 15:31 ocp-v4.0-art-dev@sha256_f44dcf2c94e4fd843cbbf9b11128df2ba856cd813786e42e3da1fdfb0f6ddd01.tgz -rw-r--r--. 1 root root 170148293 Oct 31 15:00 ocp-v4.0-art-dev@sha256_f48b68d5960ba903a0d018a10544ae08db5802e21c2fa5615a14fc58b1c1657c.tgz -rw-r--r--. 1 root root 168899617 Oct 31 15:16 ocp-v4.0-art-dev@sha256_f5099b0989120a8d08a963601214b5c5cb23417a707a8624b7eb52ab788a7f75.tgz -rw-r--r--. 1 root root 176592362 Oct 31 15:05 ocp-v4.0-art-dev@sha256_f68c0e6f5e17b0b0f7ab2d4c39559ea89f900751e64b97cb42311a478338d9c3.tgz -rw-r--r--. 1 root root 157937478 Oct 31 15:37 ocp-v4.0-art-dev@sha256_f7ba33a6a9db9cfc4b0ab0f368569e19b9fa08f4c01a0d5f6a243d61ab781bd8.tgz -rw-r--r--. 1 root root 145535253 Oct 31 15:26 ocp-v4.0-art-dev@sha256_f8f098911d670287826e9499806553f7a1dd3e2b5332abbec740008c36e84de5.tgz -rw-r--r--. 1 root root 158048761 Oct 31 15:40 ocp-v4.0-art-dev@sha256_f914228ddbb99120986262168a705903a9f49724ffa958bb4bf12b2ec1d7fb47.tgz -rw-r--r--. 1 root root 167914526 Oct 31 15:37 ocp-v4.0-art-dev@sha256_fa3ca9401c7a9efda0502240aeb8d3ae2d239d38890454f17fe5158b62305010.tgz -rw-r--r--. 1 root root 164432422 Oct 31 15:24 ocp-v4.0-art-dev@sha256_fc4783b446c70df30b3120685254b40ce13ba6a2b0bf8fb1645f116cf6a392f1.tgz -rw-r--r--. 1 root root 306643814 Oct 31 15:11 troubleshoot@sha256_b86b8aea29a818a9c22944fd18243fa0347c7a2bf1ad8864113ff2bb2d8e0726.tgz
21.13.4.4. Téléchargement des images de l'opérateur
Vous pouvez également mettre en pré-cache les opérateurs Day-2 utilisés dans la configuration du cluster 5G Radio Access Network (RAN) Distributed Unit (DU). Les opérateurs Day-2 dépendent de la version installée d'OpenShift Container Platform.
Vous devez inclure les versions du hub RHACM et de l'opérateur MCE en utilisant les drapeaux --acm-version et --mce-version afin que l'outil factory-precaching-cli puisse pré-cacher les images de conteneurs appropriées pour les opérateurs RHACM et MCE.
Procédure
Prémettre en cache les images de l'opérateur :
# podman run -v /mnt:/mnt -v /root/.docker:/root/.docker --privileged --rm quay.io/openshift-kni/telco-ran-tools:latest -- factory-precaching-cli download \ 1 -r 4.12.0 \ 2 --acm-version 2.6.3 \ 3 --mce-version 2.1.4 \ 4 -f /mnt \ 5 --img quay.io/custom/repository 6 --du-profile -s 7
- 1
- Spécifie la fonction de téléchargement de l'outil factory-precaching-cli.
- 2
- Définit la version d'OpenShift Container Platform.
- 3
- Définit la version de RHACM.
- 4
- Définit la version du MCE.
- 5
- Définit le dossier dans lequel vous souhaitez télécharger les images sur le disque.
- 6
- Facultatif. Définit le référentiel dans lequel vous stockez vos images supplémentaires. Ces images sont téléchargées et mises en cache sur le disque.
- 7
- Spécifie la mise en cache préalable des opérateurs inclus dans la configuration de l'UD.
Exemple de sortie
Generated /mnt/imageset.yaml Generating list of pre-cached artifacts... Processing artifact [1/379]: ocp-v4.0-art-dev@sha256_7753a8d9dd5974be8c90649aadd7c914a3d8a1f1e016774c7ac7c9422e9f9958 Processing artifact [2/379]: ose-kube-rbac-proxy@sha256_c27a7c01e5968aff16b6bb6670423f992d1a1de1a16e7e260d12908d3322431c Processing artifact [3/379]: ocp-v4.0-art-dev@sha256_370e47a14c798ca3f8707a38b28cfc28114f492bb35fe1112e55d1eb51022c99 ... Processing artifact [378/379]: ose-local-storage-operator@sha256_0c81c2b79f79307305e51ce9d3837657cf9ba5866194e464b4d1b299f85034d0 Processing artifact [379/379]: multicluster-operators-channel-rhel8@sha256_c10f6bbb84fe36e05816e873a72188018856ad6aac6cc16271a1b3966f73ceb3 ... Summary: Release: 4.12.0 Hub Version: 2.6.3 ACM Version: 2.6.3 MCE Version: 2.1.4 Include DU Profile: Yes Workers: 83
21.13.4.5. Mise en cache d'images personnalisées dans des environnements déconnectés
L'argument --generate-imageset arrête l'outil factory-precaching-cli après que la ressource personnalisée (CR) ImageSetConfiguration a été générée. Cela vous permet de personnaliser la CR ImageSetConfiguration avant de télécharger des images. Après avoir personnalisé la CR, vous pouvez utiliser l'argument --skip-imageset pour télécharger les images que vous avez spécifiées dans la CR ImageSetConfiguration.
Vous pouvez personnaliser le ImageSetConfiguration CR de la manière suivante :
- Ajouter des opérateurs et des images supplémentaires
- Supprimer les opérateurs et les images supplémentaires
- Modifier les sources de l'opérateur et du catalogue pour les remplacer par des registres locaux ou déconnectés
Procédure
Prémettre les images en cache :
# podman run -v /mnt:/mnt -v /root/.docker:/root/.docker --privileged --rm quay.io/openshift-kni/telco-ran-tools:latest -- factory-precaching-cli download \ 1 -r 4.12.0 \ 2 --acm-version 2.6.3 \ 3 --mce-version 2.1.4 \ 4 -f /mnt \ 5 --img quay.io/custom/repository 6 --du-profile -s \ 7 --generate-imageset 8
- 1
- Spécifie la fonction de téléchargement de l'outil factory-precaching-cli.
- 2
- Définit la version d'OpenShift Container Platform.
- 3
- Définit la version de RHACM.
- 4
- Définit la version du MCE.
- 5
- Définit le dossier dans lequel vous souhaitez télécharger les images sur le disque.
- 6
- Facultatif. Définit le référentiel dans lequel vous stockez vos images supplémentaires. Ces images sont téléchargées et mises en cache sur le disque.
- 7
- Spécifie la mise en cache préalable des opérateurs inclus dans la configuration de l'UD.
- 8
- L'argument
--generate-imagesetgénère uniquement le CRImageSetConfiguration, ce qui vous permet de personnaliser le CR.
Exemple de sortie
Generated /mnt/imageset.yaml
Exemple ImageSetConfiguration CR
apiVersion: mirror.openshift.io/v1alpha2 kind: ImageSetConfiguration mirror: platform: channels: - name: stable-4.12 minVersion: 4.12.0 1 maxVersion: 4.12.0 additionalImages: - name: quay.io/custom/repository operators: - catalog: registry.redhat.io/redhat/redhat-operator-index:v4.12 packages: - name: advanced-cluster-management 2 channels: - name: 'release-2.6' minVersion: 2.6.3 maxVersion: 2.6.3 - name: multicluster-engine 3 channels: - name: 'stable-2.1' minVersion: 2.1.4 maxVersion: 2.1.4 - name: local-storage-operator 4 channels: - name: 'stable' - name: ptp-operator 5 channels: - name: 'stable' - name: sriov-network-operator 6 channels: - name: 'stable' - name: cluster-logging 7 channels: - name: 'stable' - name: lvms-operator 8 channels: - name: 'stable-4.12' - name: amq7-interconnect-operator 9 channels: - name: '1.10.x' - name: bare-metal-event-relay 10 channels: - name: 'stable' - catalog: registry.redhat.io/redhat/certified-operator-index:v4.12 packages: - name: sriov-fec 11 channels: - name: 'stable'Personnaliser la ressource du catalogue dans le CR :
apiVersion: mirror.openshift.io/v1alpha2 kind: ImageSetConfiguration mirror: platform: [...] operators: - catalog: eko4.cloud.lab.eng.bos.redhat.com:8443/redhat/certified-operator-index:v4.12 packages: - name: sriov-fec channels: - name: 'stable'Lorsque vous téléchargez des images en utilisant un registre local ou déconnecté, vous devez d'abord ajouter des certificats pour les registres dont vous voulez extraire le contenu.
Pour éviter toute erreur, copiez le certificat de registre dans votre serveur :
# cp /tmp/eko4-ca.crt /etc/pki/ca-trust/source/anchors/.
Ensuite, mettez à jour la liste de confiance des certificats :
# update-ca-trust
Monter le dossier de l'hôte
/etc/pkidans l'image factory-cli :# podman run -v /mnt:/mnt -v /root/.docker:/root/.docker -v /etc/pki:/etc/pki --privileged --rm quay.io/openshift-kni/telco-ran-tools:latest -- \ factory-precaching-cli download \ 1 -r 4.12.0 \ 2 --acm-version 2.6.3 \ 3 --mce-version 2.1.4 \ 4 -f /mnt \ 5 --img quay.io/custom/repository 6 --du-profile -s \ 7 --skip-imageset 8
- 1
- Spécifie la fonction de téléchargement de l'outil factory-precaching-cli.
- 2
- Définit la version d'OpenShift Container Platform.
- 3
- Définit la version de RHACM.
- 4
- Définit la version du MCE.
- 5
- Définit le dossier dans lequel vous souhaitez télécharger les images sur le disque.
- 6
- Facultatif. Définit le référentiel dans lequel vous stockez vos images supplémentaires. Ces images sont téléchargées et mises en cache sur le disque.
- 7
- Spécifie la mise en cache préalable des opérateurs inclus dans la configuration de l'UD.
- 8
- L'argument
--skip-imagesetvous permet de télécharger les images que vous avez spécifiées dans votre CR personnaliséImageSetConfiguration.
Télécharger les images sans générer un nouveau CR
imageSetConfiguration:# podman run -v /mnt:/mnt -v /root/.docker:/root/.docker --privileged --rm quay.io/openshift-kni/telco-ran-tools:latest -- factory-precaching-cli download -r 4.12.0 \ --acm-version 2.6.3 --mce-version 2.1.4 -f /mnt \ --img quay.io/custom/repository \ --du-profile -s \ --skip-imageset
Ressources supplémentaires
- Pour accéder aux registres Red Hat en ligne, voir Outils de personnalisation de l'installation d'OpenShift.
- Pour plus d'informations sur l'utilisation du moteur multicluster, voir À propos du cycle de vie des clusters avec l'opérateur du moteur multicluster.
21.13.5. Mise en cache préalable des images dans ZTP
Le manifeste SiteConfig définit comment un cluster OpenShift doit être installé et configuré. Dans le flux de travail de provisionnement ZTP, l'outil factory-precaching-cli requiert les champs supplémentaires suivants dans le manifeste SiteConfig:
-
clusters.ignitionConfigOverride -
nodes.installerArgs -
nodes.ignitionConfigOverride
Exemple de SiteConfig avec des champs supplémentaires
apiVersion: ran.openshift.io/v1
kind: SiteConfig
metadata:
name: "example-5g-lab"
namespace: "example-5g-lab"
spec:
baseDomain: "example.domain.redhat.com"
pullSecretRef:
name: "assisted-deployment-pull-secret"
clusterImageSetNameRef: "img4.9.10-x86-64-appsub"
sshPublicKey: "ssh-rsa ..."
clusters:
- clusterName: "sno-worker-0"
clusterImageSetNameRef: "eko4-img4.11.5-x86-64-appsub"
clusterLabels:
group-du-sno: ""
common-411: true
sites : "example-5g-lab"
vendor: "OpenShift"
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
machineNetwork:
- cidr: 10.19.32.192/26
serviceNetwork:
- 172.30.0.0/16
networkType: "OVNKubernetes"
additionalNTPSources:
- clock.corp.redhat.com
ignitionConfigOverride: '{"ignition":{"version":"3.1.0"},"systemd":{"units":[{"name":"var-mnt.mount","enabled":true,"contents":"[Unit]\nDescription=Mount partition with artifacts\nBefore=precache-images.service\nBindsTo=precache-images.service\nStopWhenUnneeded=true\n\n[Mount]\nWhat=/dev/disk/by-partlabel/data\nWhere=/var/mnt\nType=xfs\nTimeoutSec=30\n\n[Install]\nRequiredBy=precache-images.service"},{"name":"precache-images.service","enabled":true,"contents":"[Unit]\nDescription=Extracts the precached images in discovery stage\nAfter=var-mnt.mount\nBefore=agent.service\n\n[Service]\nType=oneshot\nUser=root\nWorkingDirectory=/var/mnt\nExecStart=bash /usr/local/bin/extract-ai.sh\n#TimeoutStopSec=30\n\n[Install]\nWantedBy=multi-user.target default.target\nWantedBy=agent.service"}]},"storage":{"files":[{"overwrite":true,"path":"/usr/local/bin/extract-ai.sh","mode":755,"user":{"name":"root"},"contents":{"source":"data:,%23%21%2Fbin%2Fbash%0A%0AFOLDER%3D%22%24%7BFOLDER%3A-%24%28pwd%29%7D%22%0AOCP_RELEASE_LIST%3D%22%24%7BOCP_RELEASE_LIST%3A-ai-images.txt%7D%22%0ABINARY_FOLDER%3D%2Fvar%2Fmnt%0A%0Apushd%20%24FOLDER%0A%0Atotal_copies%3D%24%28sort%20-u%20%24BINARY_FOLDER%2F%24OCP_RELEASE_LIST%20%7C%20wc%20-l%29%20%20%23%20Required%20to%20keep%20track%20of%20the%20pull%20task%20vs%20total%0Acurrent_copy%3D1%0A%0Awhile%20read%20-r%20line%3B%0Ado%0A%20%20uri%3D%24%28echo%20%22%24line%22%20%7C%20awk%20%27%7Bprint%241%7D%27%29%0A%20%20%23tar%3D%24%28echo%20%22%24line%22%20%7C%20awk%20%27%7Bprint%242%7D%27%29%0A%20%20podman%20image%20exists%20%24uri%0A%20%20if%20%5B%5B%20%24%3F%20-eq%200%20%5D%5D%3B%20then%0A%20%20%20%20%20%20echo%20%22Skipping%20existing%20image%20%24tar%22%0A%20%20%20%20%20%20echo%20%22Copying%20%24%7Buri%7D%20%5B%24%7Bcurrent_copy%7D%2F%24%7Btotal_copies%7D%5D%22%0A%20%20%20%20%20%20current_copy%3D%24%28%28current_copy%20%2B%201%29%29%0A%20%20%20%20%20%20continue%0A%20%20fi%0A%20%20tar%3D%24%28echo%20%22%24uri%22%20%7C%20%20rev%20%7C%20cut%20-d%20%22%2F%22%20-f1%20%7C%20rev%20%7C%20tr%20%22%3A%22%20%22_%22%29%0A%20%20tar%20zxvf%20%24%7Btar%7D.tgz%0A%20%20if%20%5B%20%24%3F%20-eq%200%20%5D%3B%20then%20rm%20-f%20%24%7Btar%7D.gz%3B%20fi%0A%20%20echo%20%22Copying%20%24%7Buri%7D%20%5B%24%7Bcurrent_copy%7D%2F%24%7Btotal_copies%7D%5D%22%0A%20%20skopeo%20copy%20dir%3A%2F%2F%24%28pwd%29%2F%24%7Btar%7D%20containers-storage%3A%24%7Buri%7D%0A%20%20if%20%5B%20%24%3F%20-eq%200%20%5D%3B%20then%20rm%20-rf%20%24%7Btar%7D%3B%20current_copy%3D%24%28%28current_copy%20%2B%201%29%29%3B%20fi%0Adone%20%3C%20%24%7BBINARY_FOLDER%7D%2F%24%7BOCP_RELEASE_LIST%7D%0A%0A%23%20workaround%20while%20https%3A%2F%2Fgithub.com%2Fopenshift%2Fassisted-service%2Fpull%2F3546%0A%23cp%20%2Fvar%2Fmnt%2Fmodified-rhcos-4.10.3-x86_64-metal.x86_64.raw.gz%20%2Fvar%2Ftmp%2F.%0A%0Aexit%200"}},{"overwrite":true,"path":"/usr/local/bin/agent-fix-bz1964591","mode":755,"user":{"name":"root"},"contents":{"source":"data:,%23%21%2Fusr%2Fbin%2Fsh%0A%0A%23%20This%20script%20is%20a%20workaround%20for%20bugzilla%201964591%20where%20symlinks%20inside%20%2Fvar%2Flib%2Fcontainers%2F%20get%0A%23%20corrupted%20under%20some%20circumstances.%0A%23%0A%23%20In%20order%20to%20let%20agent.service%20start%20correctly%20we%20are%20checking%20here%20whether%20the%20requested%0A%23%20container%20image%20exists%20and%20in%20case%20%22podman%20images%22%20returns%20an%20error%20we%20try%20removing%20the%20faulty%0A%23%20image.%0A%23%0A%23%20In%20such%20a%20scenario%20agent.service%20will%20detect%20the%20image%20is%20not%20present%20and%20pull%20it%20again.%20In%20case%0A%23%20the%20image%20is%20present%20and%20can%20be%20detected%20correctly%2C%20no%20any%20action%20is%20required.%0A%0AIMAGE%3D%24%28echo%20%241%20%7C%20sed%20%27s%2F%3A.%2A%2F%2F%27%29%0Apodman%20image%20exists%20%24IMAGE%20%7C%7C%20echo%20%22already%20loaded%22%20%7C%7C%20echo%20%22need%20to%20be%20pulled%22%0A%23podman%20images%20%7C%20grep%20%24IMAGE%20%7C%7C%20podman%20rmi%20--force%20%241%20%7C%7C%20true"}}]}}'
nodes:
- hostName: "snonode.sno-worker-0.example.domain.redhat.com"
role: "master"
bmcAddress: "idrac-virtualmedia+https://10.19.28.53/redfish/v1/Systems/System.Embedded.1"
bmcCredentialsName:
name: "worker0-bmh-secret"
bootMACAddress: "e4:43:4b:bd:90:46"
bootMode: "UEFI"
rootDeviceHints:
deviceName: /dev/nvme0n1
cpuset: "0-1,40-41"
installerArgs: '["--save-partlabel", "data"]'
ignitionConfigOverride: '{"ignition":{"version":"3.1.0"},"systemd":{"units":[{"name":"var-mnt.mount","enabled":true,"contents":"[Unit]\nDescription=Mount partition with artifacts\nBefore=precache-ocp-images.service\nBindsTo=precache-ocp-images.service\nStopWhenUnneeded=true\n\n[Mount]\nWhat=/dev/disk/by-partlabel/data\nWhere=/var/mnt\nType=xfs\nTimeoutSec=30\n\n[Install]\nRequiredBy=precache-ocp-images.service"},{"name":"precache-ocp-images.service","enabled":true,"contents":"[Unit]\nDescription=Extracts the precached OCP images into containers storage\nAfter=var-mnt.mount\nBefore=machine-config-daemon-pull.service nodeip-configuration.service\n\n[Service]\nType=oneshot\nUser=root\nWorkingDirectory=/var/mnt\nExecStart=bash /usr/local/bin/extract-ocp.sh\nTimeoutStopSec=60\n\n[Install]\nWantedBy=multi-user.target"}]},"storage":{"files":[{"overwrite":true,"path":"/usr/local/bin/extract-ocp.sh","mode":755,"user":{"name":"root"},"contents":{"source":"data:,%23%21%2Fbin%2Fbash%0A%0AFOLDER%3D%22%24%7BFOLDER%3A-%24%28pwd%29%7D%22%0AOCP_RELEASE_LIST%3D%22%24%7BOCP_RELEASE_LIST%3A-ocp-images.txt%7D%22%0ABINARY_FOLDER%3D%2Fvar%2Fmnt%0A%0Apushd%20%24FOLDER%0A%0Atotal_copies%3D%24%28sort%20-u%20%24BINARY_FOLDER%2F%24OCP_RELEASE_LIST%20%7C%20wc%20-l%29%20%20%23%20Required%20to%20keep%20track%20of%20the%20pull%20task%20vs%20total%0Acurrent_copy%3D1%0A%0Awhile%20read%20-r%20line%3B%0Ado%0A%20%20uri%3D%24%28echo%20%22%24line%22%20%7C%20awk%20%27%7Bprint%241%7D%27%29%0A%20%20%23tar%3D%24%28echo%20%22%24line%22%20%7C%20awk%20%27%7Bprint%242%7D%27%29%0A%20%20podman%20image%20exists%20%24uri%0A%20%20if%20%5B%5B%20%24%3F%20-eq%200%20%5D%5D%3B%20then%0A%20%20%20%20%20%20echo%20%22Skipping%20existing%20image%20%24tar%22%0A%20%20%20%20%20%20echo%20%22Copying%20%24%7Buri%7D%20%5B%24%7Bcurrent_copy%7D%2F%24%7Btotal_copies%7D%5D%22%0A%20%20%20%20%20%20current_copy%3D%24%28%28current_copy%20%2B%201%29%29%0A%20%20%20%20%20%20continue%0A%20%20fi%0A%20%20tar%3D%24%28echo%20%22%24uri%22%20%7C%20%20rev%20%7C%20cut%20-d%20%22%2F%22%20-f1%20%7C%20rev%20%7C%20tr%20%22%3A%22%20%22_%22%29%0A%20%20tar%20zxvf%20%24%7Btar%7D.tgz%0A%20%20if%20%5B%20%24%3F%20-eq%200%20%5D%3B%20then%20rm%20-f%20%24%7Btar%7D.gz%3B%20fi%0A%20%20echo%20%22Copying%20%24%7Buri%7D%20%5B%24%7Bcurrent_copy%7D%2F%24%7Btotal_copies%7D%5D%22%0A%20%20skopeo%20copy%20dir%3A%2F%2F%24%28pwd%29%2F%24%7Btar%7D%20containers-storage%3A%24%7Buri%7D%0A%20%20if%20%5B%20%24%3F%20-eq%200%20%5D%3B%20then%20rm%20-rf%20%24%7Btar%7D%3B%20current_copy%3D%24%28%28current_copy%20%2B%201%29%29%3B%20fi%0Adone%20%3C%20%24%7BBINARY_FOLDER%7D%2F%24%7BOCP_RELEASE_LIST%7D%0A%0Aexit%200"}}]}}'
nodeNetwork:
config:
interfaces:
- name: ens1f0
type: ethernet
state: up
macAddress: "AA:BB:CC:11:22:33"
ipv4:
enabled: true
dhcp: true
ipv6:
enabled: false
interfaces:
- name: "ens1f0"
macAddress: "AA:BB:CC:11:22:33"
21.13.5.1. Comprendre le champ clusters.ignitionConfigOverride
Le champ clusters.ignitionConfigOverride ajoute une configuration au format Ignition pendant la phase de découverte ZTP. La configuration inclut les services systemd dans l'ISO monté sur un support virtuel. De cette manière, les scripts font partie de l'ISO live RHCOS de découverte et peuvent être utilisés pour charger les images de l'installateur assisté (AI).
systemdservices-
Les services
systemdsontvar-mnt.mountetprecache-images.services. Le serviceprecache-images.servicedépend de la partition de disque qui doit être montée dans/var/mntpar l'unitévar-mnt.mount. Le service appelle un script appeléextract-ai.sh. extract-ai.sh-
Le script
extract-ai.shextrait et charge les images requises de la partition du disque vers le conteneur de stockage local. Lorsque le script se termine avec succès, vous pouvez utiliser les images localement. agent-fix-bz1964591-
Le script
agent-fix-bz1964591est une solution de contournement pour un problème lié à AI. Pour empêcher AI de supprimer les images, ce qui peut obligeragent.serviceà les extraire à nouveau du registre, le scriptagent-fix-bz1964591vérifie si les images de conteneur demandées existent.
21.13.5.2. Comprendre le champ nodes.installerArgs
Le champ nodes.installerArgs vous permet de configurer la façon dont l'utilitaire coreos-installer écrit l'ISO live RHCOS sur le disque. Vous devez indiquer de sauvegarder la partition du disque intitulée data car les artefacts sauvegardés dans la partition data sont nécessaires lors de l'étape d'installation d'OpenShift Container Platform.
Les paramètres supplémentaires sont transmis directement à l'utilitaire coreos-installer qui écrit le RHCOS live sur le disque. Au prochain redémarrage, le système d'exploitation démarre à partir du disque.
Vous pouvez transmettre plusieurs options à l'utilitaire coreos-installer:
OPTIONS:
...
-u, --image-url <URL>
Manually specify the image URL
-f, --image-file <path>
Manually specify a local image file
-i, --ignition-file <path>
Embed an Ignition config from a file
-I, --ignition-url <URL>
Embed an Ignition config from a URL
...
--save-partlabel <lx>...
Save partitions with this label glob
--save-partindex <id>...
Save partitions with this number or range
...
--insecure-ignition
Allow Ignition URL without HTTPS or hash21.13.5.3. Comprendre le champ nodes.ignitionConfigOverride
De manière similaire à clusters.ignitionConfigOverride, le champ nodes.ignitionConfigOverride permet d'ajouter des configurations au format Ignition à l'utilitaire coreos-installer, mais au stade de l'installation d'OpenShift Container Platform. Lorsque le RHCOS est écrit sur le disque, la configuration supplémentaire incluse dans l'ISO de découverte ZTP n'est plus disponible. Pendant la phase de découverte, la configuration supplémentaire est stockée dans la mémoire de l'OS live.
À ce stade, le nombre d'images de conteneurs extraites et chargées est plus important qu'à l'étape de découverte. En fonction de la version d'OpenShift Container Platform et de l'installation ou non des Day-2 Operators, le temps d'installation peut varier.
Au stade de l'installation, les services var-mnt.mount et precache-ocp.services systemd sont utilisés.
precache-ocp.serviceLe service
precache-ocp.servicedépend de la partition de disque qui doit être montée dans/var/mntpar l'unitévar-mnt.mount. Le serviceprecache-ocp.serviceappelle un script appeléextract-ocp.sh.ImportantPour extraire toutes les images avant l'installation d'OpenShift Container Platform, vous devez exécuter
precache-ocp.serviceavant d'exécuter les servicesmachine-config-daemon-pull.serviceetnodeip-configuration.service.extract-ocp.sh-
Le script
extract-ocp.shextrait et charge les images requises de la partition du disque vers le conteneur de stockage local. Lorsque le script se termine avec succès, vous pouvez utiliser les images localement.
Lorsque vous avez téléchargé le site SiteConfig et les ressources personnalisées (CR) PolicyGenTemplates facultatives sur le dépôt Git, qu'Argo CD surveille, vous pouvez démarrer le flux de travail ZTP en synchronisant les CR avec le cluster du hub.
21.13.6. Résolution de problèmes
21.13.6.1. Le catalogue rendu n'est pas valide
Lorsque vous téléchargez des images en utilisant un registre local ou déconnecté, vous pouvez rencontrer l'erreur The rendered catalog is invalid. Cela signifie qu'il vous manque les certificats du nouveau registre dont vous voulez extraire le contenu.
L'image de l'outil factory-precaching-cli est construite sur une image UBI RHEL. Les chemins et emplacements des certificats sont les mêmes sur RHCOS.
Exemple d'erreur
Generating list of pre-cached artifacts... error: unable to run command oc-mirror -c /mnt/imageset.yaml file:///tmp/fp-cli-3218002584/mirror --ignore-history --dry-run: Creating directory: /tmp/fp-cli-3218002584/mirror/oc-mirror-workspace/src/publish Creating directory: /tmp/fp-cli-3218002584/mirror/oc-mirror-workspace/src/v2 Creating directory: /tmp/fp-cli-3218002584/mirror/oc-mirror-workspace/src/charts Creating directory: /tmp/fp-cli-3218002584/mirror/oc-mirror-workspace/src/release-signatures backend is not configured in /mnt/imageset.yaml, using stateless mode backend is not configured in /mnt/imageset.yaml, using stateless mode No metadata detected, creating new workspace level=info msg=trying next host error=failed to do request: Head "https://eko4.cloud.lab.eng.bos.redhat.com:8443/v2/redhat/redhat-operator-index/manifests/v4.11": x509: certificate signed by unknown authority host=eko4.cloud.lab.eng.bos.redhat.com:8443 The rendered catalog is invalid. Run "oc-mirror list operators --catalog CATALOG-NAME --package PACKAGE-NAME" for more information. error: error rendering new refs: render reference "eko4.cloud.lab.eng.bos.redhat.com:8443/redhat/redhat-operator-index:v4.11": error resolving name : failed to do request: Head "https://eko4.cloud.lab.eng.bos.redhat.com:8443/v2/redhat/redhat-operator-index/manifests/v4.11": x509: certificate signed by unknown authority
Procédure
Copiez le certificat de registre dans votre serveur :
# cp /tmp/eko4-ca.crt /etc/pki/ca-trust/source/anchors/.
Mettre à jour la liste de confiance des certificats :
# update-ca-trust
Monter le dossier de l'hôte
/etc/pkidans l'image factory-cli :# podman run -v /mnt:/mnt -v /root/.docker:/root/.docker -v /etc/pki:/etc/pki --privileged -it --rm quay.io/openshift-kni/telco-ran-tools:latest -- \ factory-precaching-cli download -r 4.11.5 --acm-version 2.5.4 \ --mce-version 2.0.4 -f /mnt \--img quay.io/custom/repository --du-profile -s --skip-imageset