
Boîte à outils de migration pour conteneurs
Migration vers OpenShift Container Platform 4
Résumé
Chapitre 1. À propos de Migration Toolkit for Containers
Le Migration Toolkit for Containers (MTC) vous permet de migrer des charges de travail d'applications avec état entre les clusters d'OpenShift Container Platform 4 à la granularité d'un espace de noms.
Si vous migrez depuis OpenShift Container Platform 3, voir À propos de la migration d'OpenShift Container Platform 3 vers 4 et Installer l'opérateur Legacy Migration Toolkit for Containers sur OpenShift Container Platform 3.
Vous pouvez migrer des applications au sein d'un même cluster ou entre clusters en utilisant la migration d'état.
MTC fournit une console Web et une API, en fonction des ressources personnalisées de Kubernetes, pour vous aider à contrôler la migration et à minimiser les temps d’arrêt des applications.
La console MTC est installée par défaut sur le cluster cible. Vous pouvez configurer le Migration Toolkit for Containers Operator pour qu'il installe la console sur un cluster distant.
Voir Options de migration avancées pour plus d'informations sur les sujets suivants :
- Automatiser votre migration avec les crochets de migration et l'API MTC.
- Configuration de votre plan de migration pour exclure des ressources, prendre en charge les migrations à grande échelle et activer le redimensionnement automatique des PV pour la migration directe des volumes.
1.1. Terminologie
Tableau 1.1. Terminologie MTC
| Terme | Définition |
|---|---|
| Cluster source | Cluster à partir duquel les applications sont migrées. |
| Cluster de destination[1] | Cluster vers lequel les applications sont migrées. |
| Un référentiel de réplication | Stockage d’objets utilisé pour la copie d’images, de volumes et d’objets Kubernetes pendant la migration indirecte ou pour des objets Kubernetes pendant la migration directe de volumes ou d’images. Le référentiel de réplication doit être accessible à tous les clusters. |
| Cluster hôte |
Cluster sur lequel le pod Le cluster hôte n’a pas besoin d’une route de registre exposée pour la migration directe des images. |
| Cluster distant | Un cluster distant est généralement le cluster source, mais ce n’est pas obligatoire.
Un cluster distant nécessite une ressource personnalisée Un cluster distant nécessite une route de registre sécurisée exposée pour la migration directe des images. |
| Migration indirecte | Les images, volumes et objets Kubernetes sont copiés du cluster source vers le référentiel de réplication, puis du référentiel de réplication vers le cluster de destination. |
| Migration directe des volumes | Les volumes persistants sont copiés directement du cluster source vers le cluster de destination. |
| Migration directe des images | Les images sont copiées directement du cluster source vers le cluster de destination. |
| Migration par étapes | Les données sont copiées vers le cluster de destination sans arrêter l’application. Le fait d’exécuter plusieurs fois une migration par étapes réduit la durée de la migration à basculement. |
| Migration à basculement | L’application est arrêtée sur le cluster source et ses ressources sont migrées vers le cluster de destination. |
| Migration d’état | L'état de l'application est migré en copiant les demandes de volumes persistants spécifiques vers le cluster de destination. |
| Migration de retour | La migration de retour annule une migration terminée. |
1 Appelez le cluster cible dans la console Web MTC.
1.2. Flux de travail MTC
Vous pouvez migrer des ressources Kubernetes, des données de volumes persistants et des images de conteneurs internes vers OpenShift Container Platform 4.12 en utilisant la console web Migration Toolkit for Containers (MTC) ou l'API Kubernetes.
MTC fait migrer les ressources suivantes :
- Un espace de nommage spécifié dans un plan de migration.
Des ressources délimitées par l’espace de nommage : lorsque MTC migre un espace de nommage, il migre l’ensemble des objets et ressources qui y sont associés, comme les services ou les pods. De plus, si une ressource qui existe dans l’espace de nommage, mais pas au niveau du cluster, dépend d’une ressource existant au niveau du cluster, MTC migre les deux.
Par exemple, une contrainte de contexte de sécurité (SCC) est une ressource qui existe au niveau du cluster et un compte de service (SA) est une ressource qui existe au niveau de l'espace de noms. Si un SA existe dans un espace de noms que le MTC migre, le MTC localise automatiquement tous les SCC qui sont liés au SA et migre également ces SCC. De même, le CTM migre les volumes persistants qui sont liés aux revendications de volumes persistants de l'espace de noms.
NoteEn fonction de la ressource, il se peut que les ressources délimitées par le cluster doivent faire l’objet d’une migration manuelle.
- Ressources personnalisées (CR) et définitions de ressources personnalisées (CRD) : MTC migre automatiquement les CR et CRD au niveau de l’espace de nommage.
La procédure de migration d’une application à l’aide de la console Web MTC comprend les étapes suivantes :
Installez l’opérateur Migration Toolkit for Containers sur tous les clusters.
Vous pouvez installer l’opérateur Migration Toolkit for Containers dans un environnement restreint avec un accès Internet limité, voire aucun accès Internet. Les clusters source et cible doivent disposer d’un accès réseau entre eux et vers un registre miroir.
Configurez le référentiel de réplication, un stockage d’objets intermédiaire que MTC utilise pour la migration des données.
Les clusters source et cible doivent disposer d’un accès réseau au référentiel de réplication pendant la migration. Si vous utilisez un serveur mandateur, vous devez le configurer pour qu’il autorise le trafic réseau entre le référentiel de réplication et les clusters.
- Ajoutez le cluster source à la console Web MTC.
- Ajoutez le référentiel de réplication à la console Web MTC.
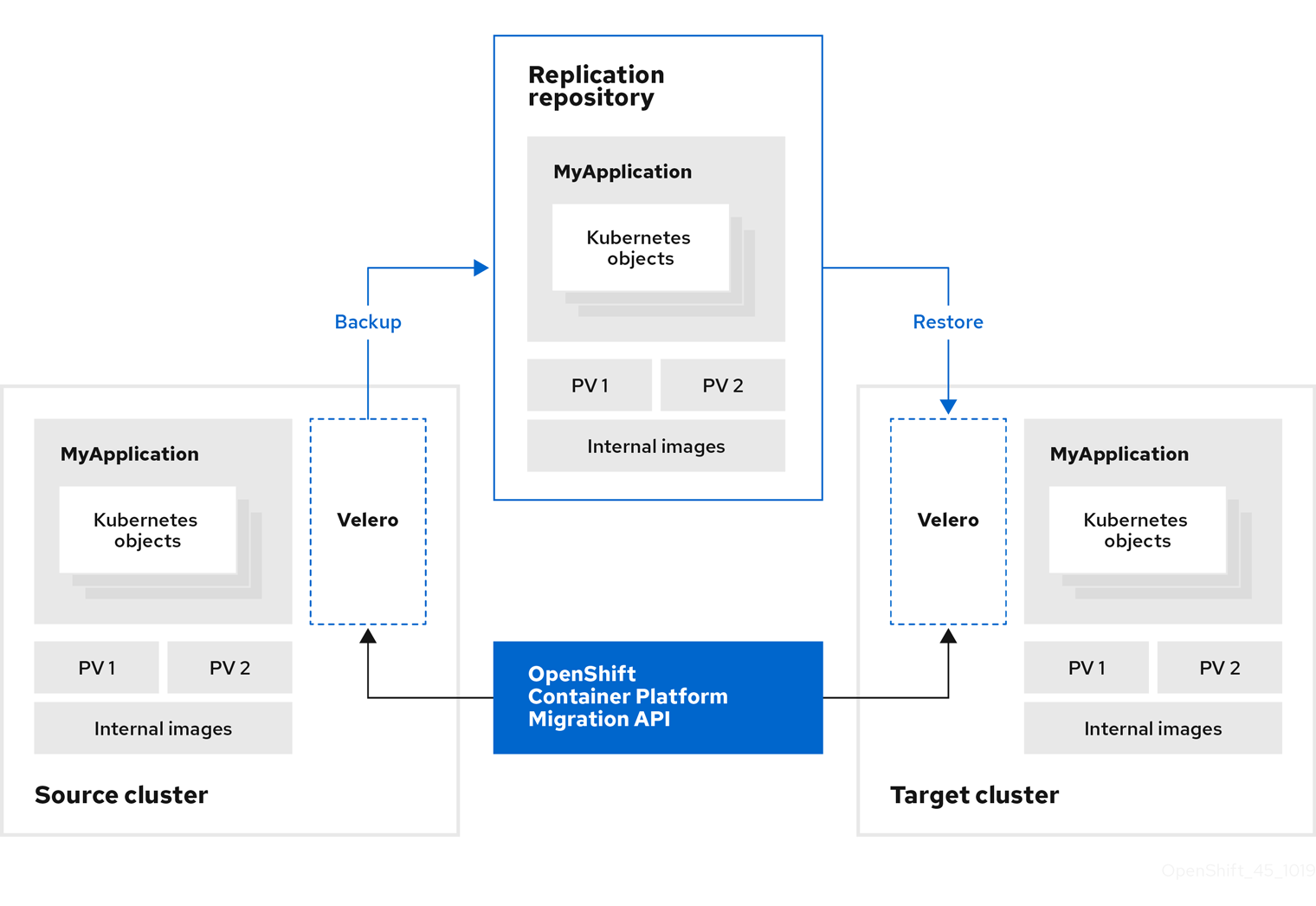
Créez un plan de migration, avec l’une des options de migration de données suivantes :
Copy : MTC copie les données du cluster source vers le référentiel de réplication, et du référentiel de réplication vers le cluster cible.
NoteSi vous utilisez la migration directe d’images ou de volumes, les images ou les volumes sont copiés directement du cluster source vers le cluster cible.
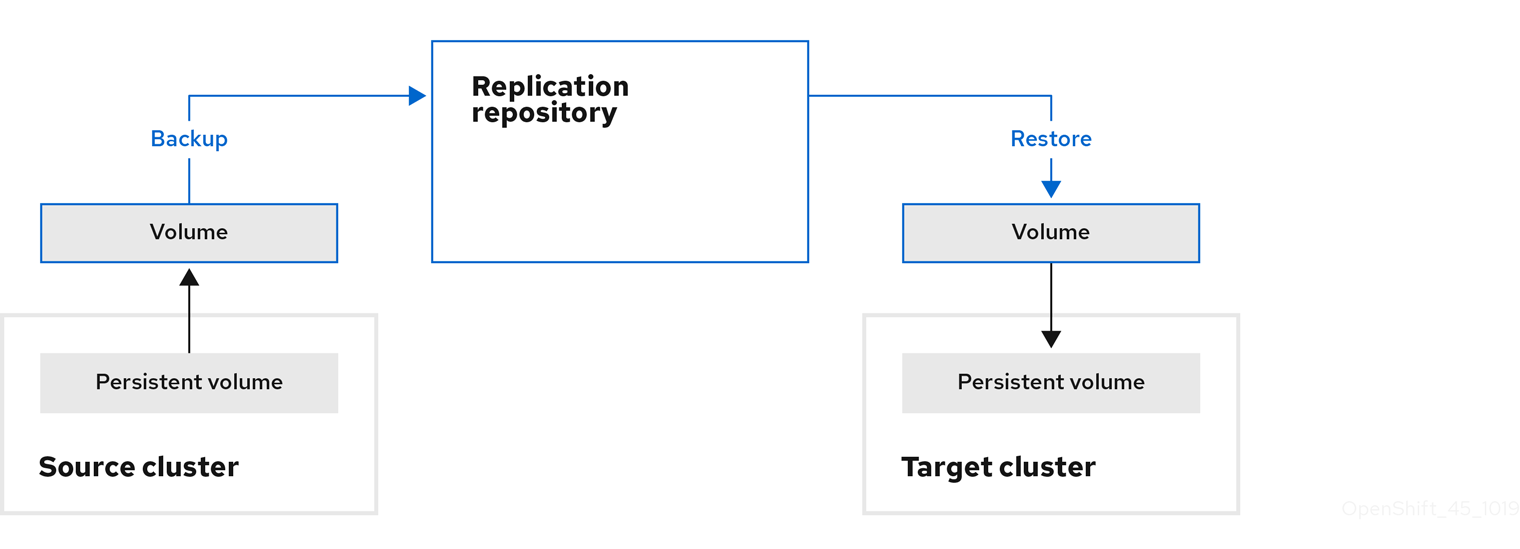
Move : MTC démonte un volume distant (NFS, par exemple) du cluster source, crée une ressource PV sur le cluster cible pointant vers le volume distant, puis monte le volume distant sur le cluster cible. Les applications qui s’exécutent sur le cluster cible utilisent le même volume distant que celui qui était utilisé par le cluster source. Le volume distant doit être accessible aux clusters source et cible.
NoteBien que le référentiel de réplication n’apparaisse pas dans ce diagramme, il est requis dans le cadre de la migration.

Exécutez le plan de migration, avec l’une des options suivantes :
L’option Stage copie les données vers le cluster cible sans arrêter l’application.
Une migration par étapes peut être exécutée plusieurs fois afin que la plupart des données soient copiées sur la cible avant la migration. L’exécution d’une ou plusieurs migrations par étapes réduit la durée de la migration à basculement.
L’option Cutover arrête l’application sur le cluster source et déplace les ressources vers le cluster cible.
Facultatif : vous pouvez décocher la case Halt transactions on the source cluster during migration.
1.3. À propos des méthodes de copie des données
Migration Toolkit for Containers (MTC) prend en charge les méthodes de copie des données de cliché et du système de fichiers pour faire migrer les données du cluster source vers le cluster cible. Vous pouvez choisir une méthode adaptée à votre environnement et prise en charge par votre fournisseur de stockage.
1.3.1. Méthode de copie du système de fichiers
MTC copie les fichiers de données du cluster source vers le référentiel de réplication, et de là vers le cluster cible.
La méthode de copie du système de fichiers utilise Restic pour la migration indirecte ou Rsync pour la migration directe des volumes.
Tableau 1.2. Résumé de la méthode de copie du système de fichiers
| Avantages | Limites |
|---|---|
|
|
La migration des PV Restic et Rsync suppose que les PV pris en charge sont uniquement volumeMode=filesystem. L'utilisation de volumeMode=Block pour la migration du système de fichiers est prise en charge par not.
1.3.2. Méthode de copie de cliché
MTC copie un cliché des données du cluster source dans le référentiel de réplication d’un fournisseur de cloud. Les données sont restaurées sur le cluster cible.
La méthode de copie de cliché peut être utilisée avec Amazon Web Services, Google Cloud Provider et Microsoft Azure.
Tableau 1.3. Résumé de la méthode de copie de cliché
| Avantages | Limites |
|---|---|
|
|
1.4. Migration directe d’images et de volumes
Vous pouvez utiliser la migration directe d’images (DIM) et la migration directe de volumes (DVM) pour faire migrer directement des images et des données du cluster source vers le cluster cible.
Si vous exécutez DVM avec des nœuds situés dans des zones de disponibilité différentes, la migration risque d’échouer, car les pods migrés ne peuvent pas accéder à la revendication de volume persistant.
DIM et DVM présentent des avantages significatifs en termes de performances, car les étapes intermédiaires de sauvegarde des fichiers du cluster source vers le référentiel de réplication et de restauration des fichiers du référentiel de réplication vers le cluster cible sont ignorées. Les données sont transférées avec Rsync.
DIM et DVM présentent d’autres conditions préalables.
Chapitre 2. Notes de publication de Migration Toolkit for Containers
Les notes de version de Migration Toolkit for Containers (MTC) décrivent les nouvelles fonctionnalités et améliorations, les fonctionnalités obsolètes et les problèmes connus.
Le MTC vous permet de migrer les charges de travail des applications entre les clusters OpenShift Container Platform à la granularité d'un espace de noms.
Vous pouvez migrer d'OpenShift Container Platform 3 à 4.12 et entre les clusters d'OpenShift Container Platform 4.
MTC fournit une console Web et une API, en fonction des ressources personnalisées de Kubernetes, pour vous aider à contrôler la migration et à minimiser les temps d’arrêt des applications.
Pour plus d'informations sur la politique de support pour MTC, voir OpenShift Application and Cluster Migration Solutions, part of the Red Hat OpenShift Container Platform Life Cycle Policy.
2.1. Notes de publication de Migration Toolkit for Containers 1.7
2.1.1. Nouvelles fonctionnalités et améliorations
Cette version comporte les nouvelles fonctionnalités et améliorations suivantes :
- L'opérateur Migration Toolkit for Containers (MTC) dépend maintenant de l'opérateur OpenShift API for Data Protection (OADP). Lorsque vous installez l'opérateur MTC, le gestionnaire du cycle de vie de l'opérateur (OLM) installe automatiquement l'opérateur OADP dans le même espace de noms.
-
Vous pouvez migrer d'un cluster source situé derrière un pare-feu vers un cluster de destination basé sur le cloud en établissant un tunnel réseau entre les deux clusters à l'aide de la commande
crane tunnel-api. - Conversion des classes de stockage dans la console web MTC : Vous pouvez convertir la classe de stockage d'un volume persistant (PV) en le migrant au sein du même cluster.
2.1.2. Problèmes connus
Cette version présente les problèmes connus suivants :
-
MigPlanla ressource personnalisée n'affiche pas d'avertissement lorsqu'un AWS gp2 PVC n'a pas d'espace disponible. (BZ#1963927) - Les transferts de données directs et indirects ne fonctionnent pas si le stockage de destination est un PV provisionné dynamiquement par AWS Elastic File System (EFS). Cela est dû aux limitations du pilote AWS EFS Container Storage Interface (CSI). (BZ#2085097)
- Le stockage en bloc pour IBM Cloud doit se trouver dans la même zone de disponibilité. Voir la FAQ IBM sur le stockage de blocs pour le cloud privé virtuel.
2.2. Notes de publication de Migration Toolkit for Containers 1.6
2.2.1. Nouvelles fonctionnalités et améliorations
Cette version comporte les nouvelles fonctionnalités et améliorations suivantes :
- Migration d'état : Vous pouvez effectuer des migrations répétables, uniquement d'état, en sélectionnant des réclamations de volumes persistants (PVC) spécifiques.
- \Notification "Nouvelle version de l'opérateur disponible" : La page Clusters de la console web MTC affiche une notification lorsqu'un nouvel opérateur de Migration Toolkit for Containers est disponible.
2.2.2. Fonctionnalités obsolètes
Les fonctionnalités suivantes sont obsolètes :
- La version 1.4 du MTC n'est plus prise en charge.
2.2.3. Problèmes connus
Cette version présente les problèmes connus suivants :
-
Sur OpenShift Container Platform 3.10, le pod
MigrationControllerprend trop de temps à redémarrer. Le rapport Bugzilla contient une solution de contournement. (BZ#1986796) -
Stageles pods échouent lors de la migration directe de volume à partir d'un cluster source OpenShift Container Platform classique sur IBM Cloud. Le plugin de stockage en bloc IBM ne permet pas de monter le même volume sur plusieurs pods du même nœud. Par conséquent, les PVC ne peuvent pas être montés sur les pods Rsync et sur les pods d'application simultanément. Pour résoudre ce problème, arrêtez les pods d'application avant la migration. (BZ#1887526) -
MigPlanla ressource personnalisée n'affiche pas d'avertissement lorsqu'un AWS gp2 PVC n'a pas d'espace disponible. (BZ#1963927) - Le stockage en bloc pour IBM Cloud doit se trouver dans la même zone de disponibilité. Voir la FAQ IBM sur le stockage de blocs pour le cloud privé virtuel.
2.3. Notes de publication de Migration Toolkit for Containers 1.5
2.3.1. Nouvelles fonctionnalités et améliorations
Cette version comporte les nouvelles fonctionnalités et améliorations suivantes :
- L'arbre Migration resource sur la page Migration details de la console web a été amélioré avec des ressources supplémentaires, des événements Kubernetes et des informations d'état en direct pour la surveillance et le débogage des migrations.
- La console web peut prendre en charge des centaines de plans de migration.
- Un espace de noms source peut être mappé à un espace de noms cible différent dans un plan de migration. Auparavant, l'espace de noms source était associé à un espace de noms cible portant le même nom.
- Les phases d'accrochage et les informations sur l'état sont affichées dans la console web au cours d'une migration.
- Le nombre de tentatives Rsync est affiché dans la console web pendant la migration directe de volumes.
- Le redimensionnement du volume persistant (PV) peut être activé pour la migration directe de volumes afin de garantir que le cluster cible ne manque pas d'espace disque.
- Le seuil qui déclenche le redimensionnement des PV est configurable. Auparavant, le redimensionnement des PV se produisait lorsque l'utilisation du disque dépassait 97 %.
- Velero a été mis à jour à la version 1.6, qui apporte de nombreuses corrections et améliorations.
- Les clients Kubernetes mis en cache peuvent être activés pour améliorer les performances.
2.3.2. Fonctionnalités obsolètes
Les fonctionnalités suivantes sont obsolètes :
- Les versions 1.2 et 1.3 de MTC ne sont plus prises en charge.
-
La procédure de mise à jour des API obsolètes a été supprimée de la section "troubleshooting" de la documentation car la commande
oc convertest obsolète.
2.3.3. Problèmes connus
Cette version présente les problèmes connus suivants :
-
Le stockage Microsoft Azure est indisponible si vous créez plus de 400 plans de migration. La ressource personnalisée
MigStorageaffiche le message suivant :The request is being throttled as the limit has been reached for operation type. (BZ#1977226) - Si une migration échoue, le plan de migration ne conserve pas les paramètres personnalisés de volume persistant (PV) pour les pods mis en veille. Vous devez annuler manuellement la migration, supprimer le plan de migration et en créer un nouveau avec vos paramètres de volume persistant. (BZ#1784899)
-
Le redimensionnement des PV ne fonctionne pas comme prévu pour le stockage AWS gp2 à moins que la valeur de
pv_resizing_thresholdsoit égale ou supérieure à 42 %. (BZ#1973148) Le redimensionnement des PV ne fonctionne pas avec les clusters sources OpenShift Container Platform 3.7 et 3.9 dans les scénarios suivants :
- L'application a été installée après l'installation de MTC.
Un pod d'application a été reprogrammé sur un autre nœud après l'installation de MTC.
OpenShift Container Platform 3.7 et 3.9 ne prend pas en charge la fonctionnalité Mount Propagation qui permet à Velero de monter automatiquement les PV dans le pod
Restic. La ressource personnalisée (CR)MigAnalyticne parvient pas à collecter les données PV du podResticet signale les ressources comme étant0. La CRMigPlanaffiche un état similaire à ce qui suit :Exemple de sortie
status: conditions: - category: Warn lastTransitionTime: 2021-07-15T04:11:44Z message: Failed gathering extended PV usage information for PVs [nginx-logs nginx-html], please see MigAnalytic openshift-migration/ocp-24706-basicvolmig-migplan-1626319591-szwd6 for details reason: FailedRunningDf status: "True" type: ExtendedPVAnalysisFailedPour activer le redimensionnement des PV, vous pouvez redémarrer manuellement le daemonset Restic sur le cluster source ou redémarrer les pods
Resticsur les mêmes nœuds que l'application. Si vous ne redémarrez pas Restic, vous pouvez exécuter la migration de volume directe sans redimensionnement de PV. (BZ#1982729)
2.3.4. Modifications techniques
Cette version comporte les modifications techniques suivantes :
- L'ancien Migration Toolkit for Containers Operator version 1.5.1 est installé manuellement sur OpenShift Container Platform versions 3.7 à 4.5.
- Le Migration Toolkit for Containers Operator version 1.5.1 est installé sur OpenShift Container Platform versions 4.6 et ultérieures à l'aide de l'Operator Lifecycle Manager.
Chapitre 3. Installation de Migration Toolkit for Containers
Vous pouvez installer le Migration Toolkit for Containers (MTC) sur OpenShift Container Platform 4.
Pour installer MTC sur OpenShift Container Platform 3, voir Installation de l'opérateur Legacy Migration Toolkit for Containers sur OpenShift Container Platform 3.
Par défaut, la console web MTC et le pod Migration Controller s'exécutent sur le cluster cible. Vous pouvez configurer le manifeste de ressources personnalisé Migration Controller pour exécuter la console web MTC et le module Migration Controller sur un cluster distant.
Après avoir installé MTC, vous devez configurer un stockage d’objets à utiliser comme référentiel de réplication.
Pour désinstaller MTC, voir Désinstallation de MTC et suppression des ressources.
3.1. Instructions relatives à la compatibilité
Vous devez installer l’opérateur Migration Toolkit for Containers (MTC) compatible avec votre version d’OpenShift Container Platform.
Définitions
- ancienne plate-forme
- OpenShift Container Platform 4.5 et antérieures.
- plate-forme moderne
- OpenShift Container Platform 4.6 et plus.
- opérateur historique
- L'opérateur MTC est conçu pour les plates-formes existantes.
- opérateur moderne
- L'opérateur MTC est conçu pour les plateformes modernes.
- groupe de contrôle
- Le cluster qui exécute le contrôleur MTC et l'interface graphique.
- groupe distant
- Un cluster source ou destination pour une migration qui exécute Velero. Le cluster de contrôle communique avec les clusters distants via l'API Velero pour piloter les migrations.
Tableau 3.1. Compatibilité MTC : Migration à partir d'une plateforme existante
| OpenShift Container Platform 4.5 ou version antérieure | OpenShift Container Platform 4.6 ou version ultérieure | |
|---|---|---|
| Version stable de MTC | MTC 1.7.z
Opérateur Legacy 1.7 : Installer manuellement avec le fichier Important Ce cluster ne peut pas être le cluster de contrôle. | MTC 1.7.z
Installer avec OLM, canal |
Il existe des cas limites dans lesquels des restrictions de réseau empêchent les clusters modernes de se connecter à d'autres clusters impliqués dans la migration. Par exemple, lors de la migration d'un cluster OpenShift Container Platform 3.11 sur site vers un cluster OpenShift Container Platform moderne dans le cloud, où le cluster moderne ne peut pas se connecter au cluster OpenShift Container Platform 3.11.
Avec MTC 1.7, si l'un des clusters distants ne peut pas communiquer avec le cluster de contrôle en raison de restrictions réseau, utilisez la commande crane tunnel-api.
Avec la version stable de MTC, bien que vous deviez toujours désigner le cluster le plus moderne comme cluster de contrôle, dans ce cas précis, il est possible de désigner le cluster hérité comme cluster de contrôle et de pousser les charges de travail vers le cluster distant.
3.2. Installation de l'opérateur Legacy Migration Toolkit for Containers sur OpenShift Container Platform 4.2 à 4.5
Vous pouvez installer manuellement l'ancien Migration Toolkit for Containers Operator sur OpenShift Container Platform versions 4.2 à 4.5.
Conditions préalables
-
Vous devez être connecté en tant qu’utilisateur avec les privilèges
cluster-adminsur tous les clusters. -
Vous devez avoir accès à
registry.redhat.io. -
Il faut que
podmansoit installé.
Procédure
Connectez-vous à
registry.redhat.ioavec vos informations d’identification du Portail Client de Red Hat :$ sudo podman login registry.redhat.io
Téléchargez le fichier
operator.ymlen entrant la commande suivante :$ sudo podman cp $(sudo podman create \ registry.redhat.io/rhmtc/openshift-migration-legacy-rhel8-operator:v1.7):/operator.yml ./
Téléchargez le fichier
controller.ymlen entrant la commande suivante :$ sudo podman cp $(sudo podman create \ registry.redhat.io/rhmtc/openshift-migration-legacy-rhel8-operator:v1.7):/controller.yml ./
- Connectez-vous à votre cluster source OpenShift Container Platform.
Vérifiez que le cluster peut s’authentifier auprès de
registry.redhat.io:$ oc run test --image registry.redhat.io/ubi8 --command sleep infinity
Créer l’objet « Migration Toolkit for Containers Operator » :
$ oc create -f operator.yml
Exemple de sortie
namespace/openshift-migration created rolebinding.rbac.authorization.k8s.io/system:deployers created serviceaccount/migration-operator created customresourcedefinition.apiextensions.k8s.io/migrationcontrollers.migration.openshift.io created role.rbac.authorization.k8s.io/migration-operator created rolebinding.rbac.authorization.k8s.io/migration-operator created clusterrolebinding.rbac.authorization.k8s.io/migration-operator created deployment.apps/migration-operator created Error from server (AlreadyExists): error when creating "./operator.yml": rolebindings.rbac.authorization.k8s.io "system:image-builders" already exists 1 Error from server (AlreadyExists): error when creating "./operator.yml": rolebindings.rbac.authorization.k8s.io "system:image-pullers" already exists- 1
- Vous pouvez ignorer les messages
Error from server (AlreadyExists). Ils sont causés par le Migration Toolkit for Containers Operator qui crée des ressources pour des versions antérieures d'OpenShift Container Platform 4 qui sont fournies dans des versions ultérieures.
Créez l’objet
MigrationController:$ oc create -f controller.yml
Vérifiez que les pods MTC sont en cours d’exécution :
$ oc get pods -n openshift-migration
3.3. Installation de l'opérateur Migration Toolkit for Containers sur OpenShift Container Platform 4.12
Vous installez le Migration Toolkit for Containers Operator sur OpenShift Container Platform 4.12 en utilisant le Operator Lifecycle Manager.
Conditions préalables
-
Vous devez être connecté en tant qu’utilisateur avec les privilèges
cluster-adminsur tous les clusters.
Procédure
- Dans la console Web OpenShift Container Platform, cliquez sur Operators → OperatorHub.
- Utilisez le champ Filter by keyword pour rechercher Migration Toolkit for Containers Operator.
- Sélectionnez Migration Toolkit for Containers Operator et cliquez ensuite sur Install.
Cliquez sur Install.
Sur la page Installed Operators, Migration Toolkit for Containers Operator apparaît dans le projet openshift-migration avec l’état Succeeded.
- Cliquez sur Migration Toolkit for Containers Operator.
- Sous Provided APIs, recherchez la vignette Migration Controller et cliquez ensuite sur Create Instance.
- Cliquez sur Create.
- Cliquez sur Workloads → Pods pour vérifier que les pods MTC sont bien en cours d’exécution.
3.4. Configuration du proxy
Dans le cas d’OpenShift Container Platform 4.1 et versions antérieures, vous devez configurer les proxies dans le manifeste de la ressource personnalisée (CR) MigrationController après avoir installé l’opérateur Migration Toolkit for Containers, car ces versions ne prennent pas en charge un objet proxy à l’échelle du cluster.
Pour OpenShift Container Platform 4.2 à 4.12, le Migration Toolkit for Containers (MTC) hérite des paramètres de proxy à l'échelle du cluster. Vous pouvez modifier les paramètres du proxy si vous souhaitez remplacer les paramètres du proxy à l'échelle du cluster.
3.4.1. Migration directe des volumes
La migration directe des volumes (DVM) a été introduite dans MTC 1.4.2. DVM ne prend en charge qu'un seul proxy. Le cluster source ne peut pas accéder à la route du cluster cible si ce dernier se trouve également derrière un proxy.
Si vous souhaitez effectuer un DVM à partir d'un cluster source situé derrière un proxy, vous devez configurer un proxy TCP qui fonctionne au niveau de la couche transport et transmet les connexions SSL de manière transparente sans les décrypter et les recrypter à l'aide de leurs propres certificats SSL. Un proxy Stunnel est un exemple de ce type de proxy.
3.4.1.1. Configuration du proxy TCP pour le DVM
Vous pouvez établir une connexion directe entre le cluster source et le cluster cible via un proxy TCP et configurer la variable stunnel_tcp_proxy dans le CR MigrationController pour utiliser le proxy :
apiVersion: migration.openshift.io/v1alpha1 kind: MigrationController metadata: name: migration-controller namespace: openshift-migration spec: [...] stunnel_tcp_proxy: http://username:password@ip:port
La migration directe de volume (DVM) ne prend en charge que l'authentification de base pour le proxy. En outre, la DVM ne fonctionne que derrière des proxys qui peuvent tunneliser une connexion TCP de manière transparente. Les mandataires HTTP/HTTPS en mode man-in-the-middle ne fonctionnent pas. Les proxys existants à l'échelle du cluster peuvent ne pas prendre en charge ce comportement. Par conséquent, les paramètres du proxy pour DVM sont intentionnellement différents de la configuration habituelle du proxy dans MTC.
3.4.1.2. Pourquoi utiliser un proxy TCP plutôt qu'un proxy HTTP/HTTPS ?
Vous pouvez activer DVM en exécutant Rsync entre le cluster source et le cluster cible via une route OpenShift. Le trafic est chiffré à l'aide de Stunnel, un proxy TCP. Le Stunnel fonctionnant sur le cluster source initie une connexion TLS avec le Stunnel cible et transfère les données sur un canal crypté.
Les proxys HTTP/HTTPS à l'échelle du cluster dans OpenShift sont généralement configurés en mode man-in-the-middle où ils négocient leur propre session TLS avec les serveurs extérieurs. Cependant, cela ne fonctionne pas avec Stunnel. Stunnel exige que sa session TLS ne soit pas modifiée par le proxy, faisant essentiellement du proxy un tunnel transparent qui transmet simplement la connexion TCP telle quelle. Vous devez donc utiliser un proxy TCP.
3.4.1.3. Problème connu
La migration échoue avec l'erreur Upgrade request required
Le contrôleur de migration utilise le protocole SPDY pour exécuter des commandes dans des modules distants. Si le cluster distant se trouve derrière un proxy ou un pare-feu qui ne prend pas en charge le protocole SPDY, le contrôleur de migration ne parvient pas à exécuter les commandes à distance. La migration échoue avec le message d'erreur Upgrade request required. Solution : Utilisez un proxy qui prend en charge le protocole SPDY.
Outre la prise en charge du protocole SPDY, le proxy ou le pare-feu doit également transmettre l'en-tête HTTP Upgrade au serveur API. Le client utilise cet en-tête pour ouvrir une connexion websocket avec le serveur API. Si l'en-tête Upgrade est bloqué par le proxy ou le pare-feu, la migration échoue avec le message d'erreur Upgrade request required. Solution : Assurez-vous que le proxy transmet l'en-tête Upgrade.
3.4.2. Optimiser les politiques de réseau pour les migrations
OpenShift prend en charge la restriction du trafic vers ou depuis les pods à l'aide de NetworkPolicy ou EgressFirewalls en fonction du plugin réseau utilisé par le cluster. Si l'un des espaces de noms source impliqués dans une migration utilise de tels mécanismes pour restreindre le trafic réseau vers les pods, les restrictions peuvent par inadvertance arrêter le trafic vers les pods Rsync pendant la migration.
Les pods Rsync fonctionnant sur les clusters source et cible doivent se connecter l'un à l'autre via une route OpenShift. Les objets NetworkPolicy ou EgressNetworkPolicy existants peuvent être configurés pour exempter automatiquement les pods Rsync de ces restrictions de trafic.
3.4.2.1. Configuration de la politique de réseau
3.4.2.1.1. Trafic de sortie des pods Rsync
Vous pouvez utiliser les étiquettes uniques des modules Rsync pour autoriser le trafic sortant de ces modules si la configuration de NetworkPolicy dans les espaces de noms source ou destination bloque ce type de trafic. La stratégie suivante autorise le trafic de sortie all à partir des modules Rsync dans l'espace de noms :
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-egress-from-rsync-pods
spec:
podSelector:
matchLabels:
owner: directvolumemigration
app: directvolumemigration-rsync-transfer
egress:
- {}
policyTypes:
- Egress3.4.2.1.2. Trafic entrant vers les pods Rsync
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-egress-from-rsync-pods
spec:
podSelector:
matchLabels:
owner: directvolumemigration
app: directvolumemigration-rsync-transfer
ingress:
- {}
policyTypes:
- Ingress3.4.2.2. Configuration de la politique de réseau EgressNetworkPolicy
L'objet EgressNetworkPolicy ou Egress Firewalls sont des constructions OpenShift conçues pour bloquer le trafic de sortie du cluster.
Contrairement à l'objet NetworkPolicy, le pare-feu Egress fonctionne au niveau du projet car il s'applique à tous les modules de l'espace de noms. Par conséquent, les étiquettes uniques des pods Rsync n'exemptent pas uniquement les pods Rsync des restrictions. Cependant, vous pouvez ajouter les plages CIDR du cluster source ou cible à la règle Allow de la politique afin qu'une connexion directe puisse être établie entre deux clusters.
En fonction du cluster dans lequel le pare-feu de sortie est présent, vous pouvez ajouter la plage CIDR de l'autre cluster pour autoriser le trafic de sortie entre les deux :
apiVersion: network.openshift.io/v1
kind: EgressNetworkPolicy
metadata:
name: test-egress-policy
namespace: <namespace>
spec:
egress:
- to:
cidrSelector: <cidr_of_source_or_target_cluster>
type: Deny3.4.2.3. Choix d'autres points d'arrivée pour le transfert de données
Par défaut, DVM utilise une route OpenShift Container Platform comme point final pour transférer les données PV vers les clusters de destination. Vous pouvez choisir un autre type de point d'extrémité pris en charge, si les topologies de cluster le permettent.
Pour chaque cluster, vous pouvez configurer un point de terminaison en définissant la variable rsync_endpoint_type sur le cluster destination approprié dans votre MigrationController CR :
apiVersion: migration.openshift.io/v1alpha1 kind: MigrationController metadata: name: migration-controller namespace: openshift-migration spec: [...] rsync_endpoint_type: [NodePort|ClusterIP|Route]
3.4.2.4. Configuration de groupes supplémentaires pour les pods Rsync
Lorsque vos PVC utilisent un stockage partagé, vous pouvez configurer l'accès à ce stockage en ajoutant des groupes supplémentaires aux définitions de pods Rsync afin que les pods autorisent l'accès :
Tableau 3.2. Groupes supplémentaires pour les pods Rsync
| Variable | Type | Défaut | Description |
|---|---|---|---|
|
| chaîne de caractères | Non défini | Liste séparée par des virgules des groupes supplémentaires pour les pods Rsync source |
|
| chaîne de caractères | Non défini | Liste de groupes supplémentaires séparés par des virgules pour les pods Rsync cibles |
Exemple d'utilisation
Le CR MigrationController peut être mis à jour pour définir les valeurs de ces groupes supplémentaires :
spec: src_supplemental_groups: "1000,2000" target_supplemental_groups: "2000,3000"
3.4.3. Configuration des proxies
Conditions préalables
-
Vous devez être connecté en tant qu’utilisateur avec les privilèges
cluster-adminsur tous les clusters.
Procédure
Procurez-vous le manifeste du CR
MigrationController:$ oc get migrationcontroller <migration_controller> -n openshift-migration
Mettez à jour les paramètres du proxy :
apiVersion: migration.openshift.io/v1alpha1 kind: MigrationController metadata: name: <migration_controller> namespace: openshift-migration ... spec: stunnel_tcp_proxy: http://<username>:<password>@<ip>:<port> 1 noProxy: example.com 2
Faites précéder un domaine du signe
.pour ne faire correspondre que les sous-domaines. Par exemple,.y.comcorrespond àx.y.com, mais pas ày.com. Utilisez*pour ignorer le proxy pour toutes les destinations. Si vous mettez à l’échelle des workers qui ne sont pas inclus dans le réseau défini par le champnetworking.machineNetwork[].cidrà partir de la configuration d’installation, vous devez les ajouter à cette liste pour éviter les problèmes de connexion.Ce champ est ignoré si ni le champ
httpProxyni le champhttpsProxyne sont définis.-
Enregistrez le manifeste en tant que
migration-controller.yaml. Appliquez le manifeste mis à jour :
$ oc replace -f migration-controller.yaml -n openshift-migration
Pour plus d'informations, voir Configuration du proxy pour l'ensemble du cluster.
3.4.4. Exécuter Rsync en tant que root ou non-root
Cette section s'applique uniquement lorsque vous travaillez avec l'API OpenShift, et non avec la console web.
Les environnements OpenShift ont le contrôleur PodSecurityAdmission activé par défaut. Ce contrôleur exige des administrateurs de cluster qu'ils appliquent les normes de sécurité des pods au moyen d'étiquettes d'espace de noms. Toutes les charges de travail du cluster sont censées exécuter l'un des niveaux de normes de sécurité pods suivants : Privileged Baseline ou Restricted. Chaque cluster dispose de son propre ensemble de règles par défaut.
Pour garantir la réussite du transfert de données dans tous les environnements, Migration Toolkit for Containers (MTC) 1.7.5 a introduit des changements dans les pods Rsync, notamment l'exécution des pods Rsync en tant qu'utilisateur non root par défaut. Cela garantit que le transfert de données est possible même pour les charges de travail qui ne nécessitent pas nécessairement des privilèges plus élevés. Cette modification a été apportée parce qu'il est préférable d'exécuter les charges de travail avec le niveau de privilèges le plus bas possible.
3.4.4.1. Remplacer manuellement l'opération non racine par défaut pour le transfert de données
Bien que l'exécution des pods Rsync en tant qu'utilisateur non root fonctionne dans la plupart des cas, le transfert de données peut échouer lorsque vous exécutez des charges de travail en tant qu'utilisateur root du côté de la source. MTC propose deux façons de remplacer manuellement l'opération non-root par défaut pour le transfert de données :
- Configurer toutes les migrations pour exécuter un pod Rsync en tant que root sur le cluster de destination pour toutes les migrations.
- Exécuter un pod Rsync en tant que root sur le cluster de destination par migration.
Dans les deux cas, vous devez définir les étiquettes suivantes du côté source de tous les espaces de noms qui exécutent des charges de travail avec des privilèges plus élevés avant la migration : enforce, audit, et warn.
Pour en savoir plus sur l'admission à la sécurité des pods et la définition des valeurs des étiquettes, voir Contrôle de la synchronisation de l'admission à la sécurité des pods.
3.4.4.2. Configurer le MigrationController CR en tant que root ou non-root pour toutes les migrations
Par défaut, Rsync s'exécute en tant que non-root.
Sur le cluster de destination, vous pouvez configurer le CR MigrationController pour qu'il exécute Rsync en tant que root.
Procédure
Configurez le CR
MigrationControllercomme suit :apiVersion: migration.openshift.io/v1alpha1 kind: MigrationController metadata: name: migration-controller namespace: openshift-migration spec: [...] migration_rsync_privileged: true
Cette configuration s'appliquera à toutes les migrations futures.
3.4.4.3. Configurer le CR MigMigration en tant que root ou non-root par migration
Sur le cluster de destination, vous pouvez configurer le CR MigMigration pour qu'il exécute Rsync en tant que root ou non-root, avec les options non-root suivantes :
- En tant qu'identifiant d'utilisateur spécifique (UID)
- En tant qu'identifiant de groupe spécifique (GID)
Procédure
Pour exécuter Rsync en tant que root, configurez le CR
MigMigrationselon cet exemple :apiVersion: migration.openshift.io/v1alpha1 kind: MigMigration metadata: name: migration-controller namespace: openshift-migration spec: [...] runAsRoot: true
Pour exécuter Rsync en tant qu'identifiant d'utilisateur (UID) ou de groupe (GID) spécifique, configurez le CR
MigMigrationselon cet exemple :apiVersion: migration.openshift.io/v1alpha1 kind: MigMigration metadata: name: migration-controller namespace: openshift-migration spec: [...] runAsUser: 10010001 runAsGroup: 3
3.5. Configuration d’un référentiel de réplication
Vous devez configurer un stockage d’objets à utiliser comme référentiel de réplication. Migration Toolkit for Containers (MTC) copie les données du cluster source vers le référentiel de réplication, puis du référentiel de réplication vers le cluster cible.
MTC prend en charge les méthodes de copie de données du système de fichiers et des instantanés pour la migration des données du cluster source vers le cluster cible. Sélectionnez une méthode adaptée à votre environnement et prise en charge par votre fournisseur de stockage.
MTC prend en charge les fournisseurs de stockage suivants :
- Passerelle d'objets multicloud
- Services Web d'Amazon S3
- Google Cloud Platform
- Blob Microsoft Azure
- Stockage d’objets S3 générique ; Minio ou Ceph S3, par exemple
3.5.1. Conditions préalables
- Tous les clusters doivent disposer d’un accès réseau ininterrompu au référentiel de réplication.
- Si vous utilisez un serveur mandateur avec un référentiel de réplication hébergé en interne, vous devez vous assurer que le proxy autorise l’accès au référentiel de réplication.
3.5.2. Récupération des informations d’identification de Multicloud Object Gateway
Vous devez récupérer les informations d’identification de Multicloud Object Gateway (MCG) et le point d’accès S3 afin de configurer MCG comme référentiel de réplication pour Migration Toolkit for Containers (MTC). Vous devez récupérer les informations d’identification de Multicloud Object Gateway (MCG) afin de créer une ressource personnalisée (CR) Secret pour OADP (OpenShift API for Data Protection).
MCG est un composant d'OpenShift Data Foundation.
Conditions préalables
- Vous devez déployer OpenShift Data Foundation en utilisant le guide de déploiement OpenShift Data Foundation approprié.
Procédure
Obtenez le point de terminaison S3,
AWS_ACCESS_KEY_IDetAWS_SECRET_ACCESS_KEYen exécutant la commandedescribesur la ressource personnaliséeNooBaa.Vous utilisez ces informations d’identification pour ajouter MCG comme référentiel de réplication.
3.5.3. Configuration d’Amazon Web Services
Vous configurez le stockage d’objets Amazon Web Services (AWS) S3 comme référentiel de réplication pour Migration Toolkit for Containers (MTC).
Conditions préalables
- Il faut que la CLI AWS soit déjà installée.
- Le compartiment de stockage AWS S3 doit être accessible aux clusters source et cible.
Si vous utilisez la méthode de copie de cliché :
- Vous devez avoir accès à EC2 Elastic Block Storage (EBS).
- Les clusters source et cible doivent se trouver dans la même région.
- Les clusters source et cible doivent avoir la même classe de stockage.
- La classe de stockage doit être compatible avec les instantanés.
Procédure
Définissez la variable
BUCKET:$ BUCKET=<your_bucket>
Définissez la variable
REGION:$ REGION=<your_region>
Créez un compartiment AWS S3 :
$ aws s3api create-bucket \ --bucket $BUCKET \ --region $REGION \ --create-bucket-configuration LocationConstraint=$REGION 1- 1
us-east-1ne prend pas en charge la contrainte d’emplacement (LocationConstraint). Si votre région estus-east-1, omettez--create-bucket-configuration LocationConstraint=$REGION.
Créez un utilisateur IAM :
$ aws iam create-user --user-name velero 1- 1
- Si vous souhaitez utiliser Velero pour sauvegarder plusieurs clusters avec plusieurs compartiments S3, créez un nom d’utilisateur unique pour chaque cluster.
Créez un fichier
velero-policy.json:$ cat > velero-policy.json <<EOF { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:DescribeVolumes", "ec2:DescribeSnapshots", "ec2:CreateTags", "ec2:CreateVolume", "ec2:CreateSnapshot", "ec2:DeleteSnapshot" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:DeleteObject", "s3:PutObject", "s3:AbortMultipartUpload", "s3:ListMultipartUploadParts" ], "Resource": [ "arn:aws:s3:::${BUCKET}/*" ] }, { "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:GetBucketLocation", "s3:ListBucketMultipartUploads" ], "Resource": [ "arn:aws:s3:::${BUCKET}" ] } ] } EOFAttachez les politiques pour donner à l'utilisateur
veleroles permissions minimales nécessaires :$ aws iam put-user-policy \ --user-name velero \ --policy-name velero \ --policy-document file://velero-policy.json
Créez une clé d’accès pour l’utilisateur
velero:$ aws iam create-access-key --user-name velero
Exemple de sortie
{ "AccessKey": { "UserName": "velero", "Status": "Active", "CreateDate": "2017-07-31T22:24:41.576Z", "SecretAccessKey": <AWS_SECRET_ACCESS_KEY>, "AccessKeyId": <AWS_ACCESS_KEY_ID> } }Enregistrez
AWS_SECRET_ACCESS_KEYetAWS_ACCESS_KEY_ID. Vous utilisez les informations d’identification pour ajouter AWS comme référentiel de réplication.
3.5.4. Configuration de Google Cloud Platform
Vous configurez un compartiment de stockage Google Cloud Platform (GCP) comme référentiel de réplication pour Migration Toolkit for Containers (MTC).
Conditions préalables
-
Il faut que les outils CLI
gcloudetgsutilsoient déjà installés. Pour plus d’informations, consultez la documentation de Google Cloud. - Le compartiment de stockage GCP doit être accessible aux clusters source et cible.
Si vous utilisez la méthode de copie de cliché :
- Les clusters source et cible doivent se trouver dans la même région.
- Les clusters source et cible doivent avoir la même classe de stockage.
- La classe de stockage doit être compatible avec les instantanés.
Procédure
Connectez-vous à GCP :
$ gcloud auth login
Définissez la variable
BUCKET:$ BUCKET=<bucket> 1- 1
- Indiquez le nom de votre compartiment.
Créez le compartiment de stockage :
$ gsutil mb gs://$BUCKET/
Définissez la variable
PROJECT_IDsur votre projet actif :$ PROJECT_ID=$(gcloud config get-value project)
Créez un compte de service :
$ gcloud iam service-accounts create velero \ --display-name "Velero service account"Répertoriez vos comptes de service :
$ gcloud iam service-accounts list
Définissez la variable
SERVICE_ACCOUNT_EMAILpour qu’elle corresponde à sa valeuremail:$ SERVICE_ACCOUNT_EMAIL=$(gcloud iam service-accounts list \ --filter="displayName:Velero service account" \ --format 'value(email)')Attachez les politiques pour donner à l'utilisateur
veleroles permissions minimales nécessaires :$ ROLE_PERMISSIONS=( compute.disks.get compute.disks.create compute.disks.createSnapshot compute.snapshots.get compute.snapshots.create compute.snapshots.useReadOnly compute.snapshots.delete compute.zones.get )Créez le rôle personnalisé
velero.server:$ gcloud iam roles create velero.server \ --project $PROJECT_ID \ --title "Velero Server" \ --permissions "$(IFS=","; echo "${ROLE_PERMISSIONS[*]}")"Ajoutez une liaison de stratégie IAM au projet :
$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member serviceAccount:$SERVICE_ACCOUNT_EMAIL \ --role projects/$PROJECT_ID/roles/velero.serverMettez à jour le compte de service IAM :
$ gsutil iam ch serviceAccount:$SERVICE_ACCOUNT_EMAIL:objectAdmin gs://${BUCKET}Enregistrez les clés du compte de service IAM dans le fichier
credentials-velerodu répertoire actuel :$ gcloud iam service-accounts keys create credentials-velero \ --iam-account $SERVICE_ACCOUNT_EMAILVous utilisez le fichier
credentials-veleropour ajouter GCP comme référentiel de réplication.
3.5.5. Configuration de Microsoft Azure
Vous configurez un conteneur de stockage Microsoft Azure Blob comme référentiel de réplication pour Migration Toolkit for Containers (MTC).
Conditions préalables
- Il faut que la CLI Azure soit déjà installée.
- Le conteneur de stockage Azure Blob doit être accessible aux clusters source et cible.
Si vous utilisez la méthode de copie de cliché :
- Les clusters source et cible doivent se trouver dans la même région.
- Les clusters source et cible doivent avoir la même classe de stockage.
- La classe de stockage doit être compatible avec les instantanés.
Procédure
Connectez-vous à Azure :
$ az login
Définissez la variable
AZURE_RESOURCE_GROUP:$ AZURE_RESOURCE_GROUP=Velero_Backups
Créez un groupe de ressources Azure :
$ az group create -n $AZURE_RESOURCE_GROUP --location CentralUS 1- 1
- Indiquez votre emplacement.
Définissez la variable
AZURE_STORAGE_ACCOUNT_ID:$ AZURE_STORAGE_ACCOUNT_ID="velero$(uuidgen | cut -d '-' -f5 | tr '[A-Z]' '[a-z]')"
Créez un compte de stockage Azure :
$ az storage account create \ --name $AZURE_STORAGE_ACCOUNT_ID \ --resource-group $AZURE_RESOURCE_GROUP \ --sku Standard_GRS \ --encryption-services blob \ --https-only true \ --kind BlobStorage \ --access-tier HotDéfinissez la variable
BLOB_CONTAINER:$ BLOB_CONTAINER=velero
Créez un conteneur de stockage Azure Blob :
$ az storage container create \ -n $BLOB_CONTAINER \ --public-access off \ --account-name $AZURE_STORAGE_ACCOUNT_ID
Créez des informations d’identification et un principal de service pour
velero:$ AZURE_SUBSCRIPTION_ID=`az account list --query '[?isDefault].id' -o tsv` \ AZURE_TENANT_ID=`az account list --query '[?isDefault].tenantId' -o tsv` \ AZURE_CLIENT_SECRET=`az ad sp create-for-rbac --name "velero" \ --role "Contributor" --query 'password' -o tsv` \ AZURE_CLIENT_ID=`az ad sp list --display-name "velero" \ --query '[0].appId' -o tsv`
Enregistrez les informations d’identification du principal du service dans le fichier
credentials-velero:$ cat << EOF > ./credentials-velero AZURE_SUBSCRIPTION_ID=${AZURE_SUBSCRIPTION_ID} AZURE_TENANT_ID=${AZURE_TENANT_ID} AZURE_CLIENT_ID=${AZURE_CLIENT_ID} AZURE_CLIENT_SECRET=${AZURE_CLIENT_SECRET} AZURE_RESOURCE_GROUP=${AZURE_RESOURCE_GROUP} AZURE_CLOUD_NAME=AzurePublicCloud EOFVous utilisez le fichier
credentials-veleropour ajouter Azure comme référentiel de réplication.
3.5.6. Ressources supplémentaires
3.6. Désinstallation de MTC et suppression de ressources
Vous pouvez désinstaller Migration Toolkit for Containers (MTC) et supprimer ses ressources afin de nettoyer le cluster.
La suppression des CRD velero entraîne la suppression de Velero du cluster.
Conditions préalables
-
Vous devez être connecté en tant qu’utilisateur avec les privilèges
cluster-admin.
Procédure
Supprimez la ressource personnalisée (CR)
MigrationControllersur tous les clusters :$ oc delete migrationcontroller <migration_controller>
- Désinstallez l’opérateur Migration Toolkit for Containers sur OpenShift Container Platform 4 en utilisant Operator Lifecycle Manager.
Supprimez les ressources délimitées par le cluster sur tous les clusters en exécutant les commandes suivantes :
Définitions de ressources personnalisées (CRD)
migration:$ oc delete $(oc get crds -o name | grep 'migration.openshift.io')
CRD
velero:$ oc delete $(oc get crds -o name | grep 'velero')
Rôles de cluster
migration:$ oc delete $(oc get clusterroles -o name | grep 'migration.openshift.io')
Rôle de cluster
migration-operator:$ oc delete clusterrole migration-operator
Rôles de cluster
velero:$ oc delete $(oc get clusterroles -o name | grep 'velero')
Liaisons de rôles de cluster
migration:$ oc delete $(oc get clusterrolebindings -o name | grep 'migration.openshift.io')
Liaisons de rôles de cluster
migration-operator:$ oc delete clusterrolebindings migration-operator
Liaisons de rôles de cluster
velero:$ oc delete $(oc get clusterrolebindings -o name | grep 'velero')
Chapitre 4. Installation de Migration Toolkit for Containers dans un environnement réseau restreint
Vous pouvez installer le Migration Toolkit for Containers (MTC) sur OpenShift Container Platform 4 dans un environnement réseau restreint en effectuant les procédures suivantes :
Créer un catalogue d'opérateurs en miroir.
Ce processus crée un fichier
mapping.txt, qui contient le mappage entre l'imageregistry.redhat.ioet votre image de registre miroir. Le fichiermapping.txtest nécessaire pour installer l'opérateur legacy Migration Toolkit for Containers sur un cluster source OpenShift Container Platform 4.2 à 4.5.Installez l'opérateur Migration Toolkit for Containers sur le cluster cible OpenShift Container Platform 4.12 en utilisant Operator Lifecycle Manager.
Par défaut, la console web MTC et le pod
Migration Controllers'exécutent sur le cluster cible. Vous pouvez configurer le manifeste de ressources personnaliséMigration Controllerpour exécuter la console web MTC et le moduleMigration Controllersur un cluster distant.Installez le Migration Toolkit for Containers Operator sur le cluster source :
- OpenShift Container Platform 4.6 ou version ultérieure : Installez l'opérateur Migration Toolkit for Containers en utilisant Operator Lifecycle Manager.
- OpenShift Container Platform 4.2 à 4.5 : Installez l'ancien Migration Toolkit for Containers Operator à partir de l'interface de ligne de commande.
- Configurez le stockage d’objets à utiliser comme référentiel de réplication.
Pour installer MTC sur OpenShift Container Platform 3, voir Installation de l'ancien opérateur Migration Toolkit for Containers sur OpenShift Container Platform 3.
Pour désinstaller MTC, voir Désinstallation de MTC et suppression des ressources.
4.1. Instructions relatives à la compatibilité
Vous devez installer l’opérateur Migration Toolkit for Containers (MTC) compatible avec votre version d’OpenShift Container Platform.
Définitions
- ancienne plate-forme
- OpenShift Container Platform 4.5 et antérieures.
- plate-forme moderne
- OpenShift Container Platform 4.6 et plus.
- opérateur historique
- L'opérateur MTC est conçu pour les plates-formes existantes.
- opérateur moderne
- L'opérateur MTC est conçu pour les plateformes modernes.
- groupe de contrôle
- Le cluster qui exécute le contrôleur MTC et l'interface graphique.
- groupe distant
- Un cluster source ou destination pour une migration qui exécute Velero. Le cluster de contrôle communique avec les clusters distants via l'API Velero pour piloter les migrations.
Tableau 4.1. Compatibilité MTC : Migration à partir d'une plateforme existante
| OpenShift Container Platform 4.5 ou version antérieure | OpenShift Container Platform 4.6 ou version ultérieure | |
|---|---|---|
| Version stable de MTC | MTC 1.7.z
Opérateur Legacy 1.7 : Installer manuellement avec le fichier Important Ce cluster ne peut pas être le cluster de contrôle. | MTC 1.7.z
Installer avec OLM, canal |
Il existe des cas limites dans lesquels des restrictions de réseau empêchent les clusters modernes de se connecter à d'autres clusters impliqués dans la migration. Par exemple, lors de la migration d'un cluster OpenShift Container Platform 3.11 sur site vers un cluster OpenShift Container Platform moderne dans le cloud, où le cluster moderne ne peut pas se connecter au cluster OpenShift Container Platform 3.11.
Avec MTC 1.7, si l'un des clusters distants ne peut pas communiquer avec le cluster de contrôle en raison de restrictions réseau, utilisez la commande crane tunnel-api.
Avec la version stable de MTC, bien que vous deviez toujours désigner le cluster le plus moderne comme cluster de contrôle, dans ce cas précis, il est possible de désigner le cluster hérité comme cluster de contrôle et de pousser les charges de travail vers le cluster distant.
4.2. Installation de l'opérateur Migration Toolkit for Containers sur OpenShift Container Platform 4.12
Vous installez le Migration Toolkit for Containers Operator sur OpenShift Container Platform 4.12 en utilisant le Operator Lifecycle Manager.
Conditions préalables
-
Vous devez être connecté en tant qu’utilisateur avec les privilèges
cluster-adminsur tous les clusters. - Vous devez créer un catalogue opérateur à partir d’une image miroir dans un registre local.
Procédure
- Dans la console Web OpenShift Container Platform, cliquez sur Operators → OperatorHub.
- Utilisez le champ Filter by keyword pour rechercher Migration Toolkit for Containers Operator.
- Sélectionnez Migration Toolkit for Containers Operator et cliquez ensuite sur Install.
Cliquez sur Install.
Sur la page Installed Operators, Migration Toolkit for Containers Operator apparaît dans le projet openshift-migration avec l’état Succeeded.
- Cliquez sur Migration Toolkit for Containers Operator.
- Sous Provided APIs, recherchez la vignette Migration Controller et cliquez ensuite sur Create Instance.
- Cliquez sur Create.
- Cliquez sur Workloads → Pods pour vérifier que les pods MTC sont bien en cours d’exécution.
4.3. Installation de l'opérateur Legacy Migration Toolkit for Containers sur OpenShift Container Platform 4.2 à 4.5
Vous pouvez installer manuellement l'ancien Migration Toolkit for Containers Operator sur OpenShift Container Platform versions 4.2 à 4.5.
Conditions préalables
-
Vous devez être connecté en tant qu’utilisateur avec les privilèges
cluster-adminsur tous les clusters. -
Vous devez avoir accès à
registry.redhat.io. -
Il faut que
podmansoit installé. -
Vous devez disposer d’un poste de travail Linux avec un accès réseau pour pouvoir télécharger des fichiers à partir de
registry.redhat.io. - Vous devez créer une image miroir du catalogue opérateur.
- Vous devez installer le Migration Toolkit for Containers Operator à partir du catalogue Operator miroité sur OpenShift Container Platform 4.12.
Procédure
Connectez-vous à
registry.redhat.ioavec vos informations d’identification du Portail Client de Red Hat :$ sudo podman login registry.redhat.io
Téléchargez le fichier
operator.ymlen entrant la commande suivante :$ sudo podman cp $(sudo podman create \ registry.redhat.io/rhmtc/openshift-migration-legacy-rhel8-operator:v1.7):/operator.yml ./
Téléchargez le fichier
controller.ymlen entrant la commande suivante :$ sudo podman cp $(sudo podman create \ registry.redhat.io/rhmtc/openshift-migration-legacy-rhel8-operator:v1.7):/controller.yml ./
Exécutez la commande suivante pour obtenir le mappage de l’image de l’opérateur :
$ grep openshift-migration-legacy-rhel8-operator ./mapping.txt | grep rhmtc
Le fichier
mapping.txta été créé lorsque vous avez mis en miroir le catalogue opérateur. La sortie illustre le mappage entre l’imageregistry.redhat.ioet votre image de registre miroir.Exemple de sortie
registry.redhat.io/rhmtc/openshift-migration-legacy-rhel8-operator@sha256:468a6126f73b1ee12085ca53a312d1f96ef5a2ca03442bcb63724af5e2614e8a=<registry.apps.example.com>/rhmtc/openshift-migration-legacy-rhel8-operator
Mettez à jour les valeurs
imagepour les conteneursansibleetoperator, ainsi que la valeurREGISTRYdans le fichieroperator.yml:containers: - name: ansible image: <registry.apps.example.com>/rhmtc/openshift-migration-legacy-rhel8-operator@sha256:<468a6126f73b1ee12085ca53a312d1f96ef5a2ca03442bcb63724af5e2614e8a> 1 ... - name: operator image: <registry.apps.example.com>/rhmtc/openshift-migration-legacy-rhel8-operator@sha256:<468a6126f73b1ee12085ca53a312d1f96ef5a2ca03442bcb63724af5e2614e8a> 2 ... env: - name: REGISTRY value: <registry.apps.example.com> 3- Connectez-vous à votre cluster source OpenShift Container Platform.
Créer l’objet « Migration Toolkit for Containers Operator » :
$ oc create -f operator.yml
Exemple de sortie
namespace/openshift-migration created rolebinding.rbac.authorization.k8s.io/system:deployers created serviceaccount/migration-operator created customresourcedefinition.apiextensions.k8s.io/migrationcontrollers.migration.openshift.io created role.rbac.authorization.k8s.io/migration-operator created rolebinding.rbac.authorization.k8s.io/migration-operator created clusterrolebinding.rbac.authorization.k8s.io/migration-operator created deployment.apps/migration-operator created Error from server (AlreadyExists): error when creating "./operator.yml": rolebindings.rbac.authorization.k8s.io "system:image-builders" already exists 1 Error from server (AlreadyExists): error when creating "./operator.yml": rolebindings.rbac.authorization.k8s.io "system:image-pullers" already exists- 1
- Vous pouvez ignorer les messages
Error from server (AlreadyExists). Ils sont causés par le Migration Toolkit for Containers Operator qui crée des ressources pour des versions antérieures d'OpenShift Container Platform 4 qui sont fournies dans des versions ultérieures.
Créez l’objet
MigrationController:$ oc create -f controller.yml
Vérifiez que les pods MTC sont en cours d’exécution :
$ oc get pods -n openshift-migration
4.4. Configuration du proxy
Dans le cas d’OpenShift Container Platform 4.1 et versions antérieures, vous devez configurer les proxies dans le manifeste de la ressource personnalisée (CR) MigrationController après avoir installé l’opérateur Migration Toolkit for Containers, car ces versions ne prennent pas en charge un objet proxy à l’échelle du cluster.
Pour OpenShift Container Platform 4.2 à 4.12, le Migration Toolkit for Containers (MTC) hérite des paramètres de proxy à l'échelle du cluster. Vous pouvez modifier les paramètres du proxy si vous souhaitez remplacer les paramètres du proxy à l'échelle du cluster.
4.4.1. Migration directe des volumes
La migration directe des volumes (DVM) a été introduite dans MTC 1.4.2. DVM ne prend en charge qu'un seul proxy. Le cluster source ne peut pas accéder à la route du cluster cible si ce dernier se trouve également derrière un proxy.
Si vous souhaitez effectuer un DVM à partir d'un cluster source situé derrière un proxy, vous devez configurer un proxy TCP qui fonctionne au niveau de la couche transport et transmet les connexions SSL de manière transparente sans les décrypter et les recrypter à l'aide de leurs propres certificats SSL. Un proxy Stunnel est un exemple de ce type de proxy.
4.4.1.1. Configuration du proxy TCP pour le DVM
Vous pouvez établir une connexion directe entre le cluster source et le cluster cible via un proxy TCP et configurer la variable stunnel_tcp_proxy dans le CR MigrationController pour utiliser le proxy :
apiVersion: migration.openshift.io/v1alpha1 kind: MigrationController metadata: name: migration-controller namespace: openshift-migration spec: [...] stunnel_tcp_proxy: http://username:password@ip:port
La migration directe de volume (DVM) ne prend en charge que l'authentification de base pour le proxy. En outre, la DVM ne fonctionne que derrière des proxys qui peuvent tunneliser une connexion TCP de manière transparente. Les mandataires HTTP/HTTPS en mode man-in-the-middle ne fonctionnent pas. Les proxys existants à l'échelle du cluster peuvent ne pas prendre en charge ce comportement. Par conséquent, les paramètres du proxy pour DVM sont intentionnellement différents de la configuration habituelle du proxy dans MTC.
4.4.1.2. Pourquoi utiliser un proxy TCP plutôt qu'un proxy HTTP/HTTPS ?
Vous pouvez activer DVM en exécutant Rsync entre le cluster source et le cluster cible via une route OpenShift. Le trafic est chiffré à l'aide de Stunnel, un proxy TCP. Le Stunnel fonctionnant sur le cluster source initie une connexion TLS avec le Stunnel cible et transfère les données sur un canal crypté.
Les proxys HTTP/HTTPS à l'échelle du cluster dans OpenShift sont généralement configurés en mode man-in-the-middle où ils négocient leur propre session TLS avec les serveurs extérieurs. Cependant, cela ne fonctionne pas avec Stunnel. Stunnel exige que sa session TLS ne soit pas modifiée par le proxy, faisant essentiellement du proxy un tunnel transparent qui transmet simplement la connexion TCP telle quelle. Vous devez donc utiliser un proxy TCP.
4.4.1.3. Problème connu
La migration échoue avec l'erreur Upgrade request required
Le contrôleur de migration utilise le protocole SPDY pour exécuter des commandes dans des modules distants. Si le cluster distant se trouve derrière un proxy ou un pare-feu qui ne prend pas en charge le protocole SPDY, le contrôleur de migration ne parvient pas à exécuter les commandes à distance. La migration échoue avec le message d'erreur Upgrade request required. Solution : Utilisez un proxy qui prend en charge le protocole SPDY.
Outre la prise en charge du protocole SPDY, le proxy ou le pare-feu doit également transmettre l'en-tête HTTP Upgrade au serveur API. Le client utilise cet en-tête pour ouvrir une connexion websocket avec le serveur API. Si l'en-tête Upgrade est bloqué par le proxy ou le pare-feu, la migration échoue avec le message d'erreur Upgrade request required. Solution : Assurez-vous que le proxy transmet l'en-tête Upgrade.
4.4.2. Optimiser les politiques de réseau pour les migrations
OpenShift prend en charge la restriction du trafic vers ou depuis les pods à l'aide de NetworkPolicy ou EgressFirewalls en fonction du plugin réseau utilisé par le cluster. Si l'un des espaces de noms source impliqués dans une migration utilise de tels mécanismes pour restreindre le trafic réseau vers les pods, les restrictions peuvent par inadvertance arrêter le trafic vers les pods Rsync pendant la migration.
Les pods Rsync fonctionnant sur les clusters source et cible doivent se connecter l'un à l'autre via une route OpenShift. Les objets NetworkPolicy ou EgressNetworkPolicy existants peuvent être configurés pour exempter automatiquement les pods Rsync de ces restrictions de trafic.
4.4.2.1. Configuration de la politique de réseau
4.4.2.1.1. Trafic de sortie des pods Rsync
Vous pouvez utiliser les étiquettes uniques des modules Rsync pour autoriser le trafic sortant de ces modules si la configuration de NetworkPolicy dans les espaces de noms source ou destination bloque ce type de trafic. La stratégie suivante autorise le trafic de sortie all à partir des modules Rsync dans l'espace de noms :
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-egress-from-rsync-pods
spec:
podSelector:
matchLabels:
owner: directvolumemigration
app: directvolumemigration-rsync-transfer
egress:
- {}
policyTypes:
- Egress4.4.2.1.2. Trafic entrant vers les pods Rsync
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-egress-from-rsync-pods
spec:
podSelector:
matchLabels:
owner: directvolumemigration
app: directvolumemigration-rsync-transfer
ingress:
- {}
policyTypes:
- Ingress4.4.2.2. Configuration de la politique de réseau EgressNetworkPolicy
L'objet EgressNetworkPolicy ou Egress Firewalls sont des constructions OpenShift conçues pour bloquer le trafic de sortie du cluster.
Contrairement à l'objet NetworkPolicy, le pare-feu Egress fonctionne au niveau du projet car il s'applique à tous les modules de l'espace de noms. Par conséquent, les étiquettes uniques des pods Rsync n'exemptent pas uniquement les pods Rsync des restrictions. Cependant, vous pouvez ajouter les plages CIDR du cluster source ou cible à la règle Allow de la politique afin qu'une connexion directe puisse être établie entre deux clusters.
En fonction du cluster dans lequel le pare-feu de sortie est présent, vous pouvez ajouter la plage CIDR de l'autre cluster pour autoriser le trafic de sortie entre les deux :
apiVersion: network.openshift.io/v1
kind: EgressNetworkPolicy
metadata:
name: test-egress-policy
namespace: <namespace>
spec:
egress:
- to:
cidrSelector: <cidr_of_source_or_target_cluster>
type: Deny4.4.2.3. Choix d'autres points d'arrivée pour le transfert de données
Par défaut, DVM utilise une route OpenShift Container Platform comme point final pour transférer les données PV vers les clusters de destination. Vous pouvez choisir un autre type de point d'extrémité pris en charge, si les topologies de cluster le permettent.
Pour chaque cluster, vous pouvez configurer un point de terminaison en définissant la variable rsync_endpoint_type sur le cluster destination approprié dans votre MigrationController CR :
apiVersion: migration.openshift.io/v1alpha1 kind: MigrationController metadata: name: migration-controller namespace: openshift-migration spec: [...] rsync_endpoint_type: [NodePort|ClusterIP|Route]
4.4.2.4. Configuration de groupes supplémentaires pour les pods Rsync
Lorsque vos PVC utilisent un stockage partagé, vous pouvez configurer l'accès à ce stockage en ajoutant des groupes supplémentaires aux définitions de pods Rsync afin que les pods autorisent l'accès :
Tableau 4.2. Groupes supplémentaires pour les pods Rsync
| Variable | Type | Défaut | Description |
|---|---|---|---|
|
| chaîne de caractères | Non défini | Liste séparée par des virgules des groupes supplémentaires pour les pods Rsync source |
|
| chaîne de caractères | Non défini | Liste de groupes supplémentaires séparés par des virgules pour les pods Rsync cibles |
Exemple d'utilisation
Le CR MigrationController peut être mis à jour pour définir les valeurs de ces groupes supplémentaires :
spec: src_supplemental_groups: "1000,2000" target_supplemental_groups: "2000,3000"
4.4.3. Configuration des proxies
Conditions préalables
-
Vous devez être connecté en tant qu’utilisateur avec les privilèges
cluster-adminsur tous les clusters.
Procédure
Procurez-vous le manifeste du CR
MigrationController:$ oc get migrationcontroller <migration_controller> -n openshift-migration
Mettez à jour les paramètres du proxy :
apiVersion: migration.openshift.io/v1alpha1 kind: MigrationController metadata: name: <migration_controller> namespace: openshift-migration ... spec: stunnel_tcp_proxy: http://<username>:<password>@<ip>:<port> 1 noProxy: example.com 2
Faites précéder un domaine du signe
.pour ne faire correspondre que les sous-domaines. Par exemple,.y.comcorrespond àx.y.com, mais pas ày.com. Utilisez*pour ignorer le proxy pour toutes les destinations. Si vous mettez à l’échelle des workers qui ne sont pas inclus dans le réseau défini par le champnetworking.machineNetwork[].cidrà partir de la configuration d’installation, vous devez les ajouter à cette liste pour éviter les problèmes de connexion.Ce champ est ignoré si ni le champ
httpProxyni le champhttpsProxyne sont définis.-
Enregistrez le manifeste en tant que
migration-controller.yaml. Appliquez le manifeste mis à jour :
$ oc replace -f migration-controller.yaml -n openshift-migration
Pour plus d'informations, voir Configuration du proxy pour l'ensemble du cluster.
4.5. Exécuter Rsync en tant que root ou non-root
Cette section s'applique uniquement lorsque vous travaillez avec l'API OpenShift, et non avec la console web.
Les environnements OpenShift ont le contrôleur PodSecurityAdmission activé par défaut. Ce contrôleur exige des administrateurs de cluster qu'ils appliquent les normes de sécurité des pods au moyen d'étiquettes d'espace de noms. Toutes les charges de travail du cluster sont censées exécuter l'un des niveaux de normes de sécurité pods suivants : Privileged Baseline ou Restricted. Chaque cluster dispose de son propre ensemble de règles par défaut.
Pour garantir la réussite du transfert de données dans tous les environnements, Migration Toolkit for Containers (MTC) 1.7.5 a introduit des changements dans les pods Rsync, notamment l'exécution des pods Rsync en tant qu'utilisateur non root par défaut. Cela garantit que le transfert de données est possible même pour les charges de travail qui ne nécessitent pas nécessairement des privilèges plus élevés. Cette modification a été apportée parce qu'il est préférable d'exécuter les charges de travail avec le niveau de privilèges le plus bas possible.
Remplacer manuellement l'opération non root par défaut pour le transfert de données
Bien que l'exécution des pods Rsync en tant qu'utilisateur non root fonctionne dans la plupart des cas, le transfert de données peut échouer lorsque vous exécutez des charges de travail en tant qu'utilisateur root du côté de la source. MTC propose deux façons de remplacer manuellement l'opération non-root par défaut pour le transfert de données :
- Configurer toutes les migrations pour exécuter un pod Rsync en tant que root sur le cluster de destination pour toutes les migrations.
- Exécuter un pod Rsync en tant que root sur le cluster de destination par migration.
Dans les deux cas, vous devez définir les étiquettes suivantes du côté source de tous les espaces de noms qui exécutent des charges de travail avec des privilèges plus élevés avant la migration : enforce, audit, et warn.
Pour en savoir plus sur l'admission à la sécurité des pods et la définition des valeurs des étiquettes, voir Contrôle de la synchronisation de l'admission à la sécurité des pods.
4.5.1. Configurer le MigrationController CR en tant que root ou non-root pour toutes les migrations
Par défaut, Rsync s'exécute en tant que non-root.
Sur le cluster de destination, vous pouvez configurer le CR MigrationController pour qu'il exécute Rsync en tant que root.
Procédure
Configurez le CR
MigrationControllercomme suit :apiVersion: migration.openshift.io/v1alpha1 kind: MigrationController metadata: name: migration-controller namespace: openshift-migration spec: [...] migration_rsync_privileged: true
Cette configuration s'appliquera à toutes les migrations futures.
4.5.2. Configurer le CR MigMigration en tant que root ou non-root par migration
Sur le cluster de destination, vous pouvez configurer le CR MigMigration pour qu'il exécute Rsync en tant que root ou non-root, avec les options non-root suivantes :
- En tant qu'identifiant d'utilisateur spécifique (UID)
- En tant qu'identifiant de groupe spécifique (GID)
Procédure
Pour exécuter Rsync en tant que root, configurez le CR
MigMigrationselon cet exemple :apiVersion: migration.openshift.io/v1alpha1 kind: MigMigration metadata: name: migration-controller namespace: openshift-migration spec: [...] runAsRoot: true
Pour exécuter Rsync en tant qu'identifiant d'utilisateur (UID) ou de groupe (GID) spécifique, configurez le CR
MigMigrationselon cet exemple :apiVersion: migration.openshift.io/v1alpha1 kind: MigMigration metadata: name: migration-controller namespace: openshift-migration spec: [...] runAsUser: 10010001 runAsGroup: 3
4.6. Configuration d’un référentiel de réplication
Multicloud Object Gateway est la seule option prise en charge pour un environnement réseau restreint.
MTC prend en charge les méthodes de copie de données du système de fichiers et des instantanés pour la migration des données du cluster source vers le cluster cible. Vous pouvez sélectionner une méthode adaptée à votre environnement et prise en charge par votre fournisseur de stockage.
4.6.1. Conditions préalables
- Tous les clusters doivent disposer d’un accès réseau ininterrompu au référentiel de réplication.
- Si vous utilisez un serveur mandateur avec un référentiel de réplication hébergé en interne, vous devez vous assurer que le proxy autorise l’accès au référentiel de réplication.
4.6.2. Récupération des informations d’identification de Multicloud Object Gateway
Vous devez récupérer les informations d’identification de Multicloud Object Gateway (MCG) afin de créer une ressource personnalisée (CR) Secret pour OADP (OpenShift API for Data Protection).
MCG est un composant d'OpenShift Data Foundation.
Conditions préalables
- Vous devez déployer OpenShift Data Foundation en utilisant le guide de déploiement OpenShift Data Foundation approprié.
Procédure
-
Obtenez le point de terminaison S3,
AWS_ACCESS_KEY_IDetAWS_SECRET_ACCESS_KEYen exécutant la commandedescribesur la ressource personnaliséeNooBaa.
4.6.3. Ressources supplémentaires
- Disconnected environment dans la documentation de Red Hat OpenShift Data Foundation.
- Flux de travail du CTM
- A propos des méthodes de copie de données
- Ajouter un référentiel de réplication à la console web MTC
4.7. Désinstallation de MTC et suppression de ressources
Vous pouvez désinstaller Migration Toolkit for Containers (MTC) et supprimer ses ressources afin de nettoyer le cluster.
La suppression des CRD velero entraîne la suppression de Velero du cluster.
Conditions préalables
-
Vous devez être connecté en tant qu’utilisateur avec les privilèges
cluster-admin.
Procédure
Supprimez la ressource personnalisée (CR)
MigrationControllersur tous les clusters :$ oc delete migrationcontroller <migration_controller>
- Désinstallez l’opérateur Migration Toolkit for Containers sur OpenShift Container Platform 4 en utilisant Operator Lifecycle Manager.
Supprimez les ressources délimitées par le cluster sur tous les clusters en exécutant les commandes suivantes :
Définitions de ressources personnalisées (CRD)
migration:$ oc delete $(oc get crds -o name | grep 'migration.openshift.io')
CRD
velero:$ oc delete $(oc get crds -o name | grep 'velero')
Rôles de cluster
migration:$ oc delete $(oc get clusterroles -o name | grep 'migration.openshift.io')
Rôle de cluster
migration-operator:$ oc delete clusterrole migration-operator
Rôles de cluster
velero:$ oc delete $(oc get clusterroles -o name | grep 'velero')
Liaisons de rôles de cluster
migration:$ oc delete $(oc get clusterrolebindings -o name | grep 'migration.openshift.io')
Liaisons de rôles de cluster
migration-operator:$ oc delete clusterrolebindings migration-operator
Liaisons de rôles de cluster
velero:$ oc delete $(oc get clusterrolebindings -o name | grep 'velero')
Chapitre 5. Mise à niveau de Migration Toolkit for Containers
Vous pouvez mettre à niveau le Migration Toolkit for Containers (MTC) sur OpenShift Container Platform 4.12 en utilisant Operator Lifecycle Manager.
Vous pouvez mettre à jour MTC sur OpenShift Container Platform 4.5, et les versions antérieures, en réinstallant l'ancien Migration Toolkit for Containers Operator.
Si vous effectuez une mise à niveau à partir de MTC version 1.3, vous devez effectuer une procédure supplémentaire pour mettre à jour la ressource personnalisée (CR) MigPlan.
5.1. Mise à jour du Migration Toolkit for Containers sur OpenShift Container Platform 4.12
Vous pouvez mettre à niveau le Migration Toolkit for Containers (MTC) sur OpenShift Container Platform 4.12 en utilisant le Operator Lifecycle Manager.
Conditions préalables
-
Vous devez être connecté en tant qu’utilisateur avec les privilèges
cluster-admin.
Procédure
Dans la console OpenShift Container Platform, accédez à Operators → Installed Operators.
L’état Upgrade available est affiché pour les opérateurs ayant une mise à niveau en attente.
- Cliquez sur Migration Toolkit for Containers Operator.
- Cliquez sur l’onglet Subscription. Toute mise à niveau nécessitant une approbation est affichée en regard de Upgrade Status. Par exemple, 1 requires approval peut être affiché.
- Cliquez sur 1 requires approval, puis sur Preview Install Plan.
- Passez en revue les ressources qui sont répertoriées comme disponibles pour la mise à niveau, puis cliquez sur Approve.
- Accédez à nouveau à la page Operators → Installed Operators pour surveiller la progression de la mise à niveau. Lorsque vous avez terminé, le statut passe à Succeeded et Up to date.
- Cliquez sur Workloads → Pods pour vérifier que les pods MTC sont bien en cours d’exécution.
5.2. Mise à jour du Migration Toolkit for Containers sur OpenShift Container Platform versions 4.2 à 4.5
Vous pouvez mettre à niveau Migration Toolkit for Containers (MTC) sur OpenShift Container Platform versions 4.2 à 4.5 en installant manuellement l'ancien Migration Toolkit for Containers Operator.
Conditions préalables
-
Vous devez être connecté en tant qu’utilisateur avec les privilèges
cluster-admin. -
Vous devez avoir accès à
registry.redhat.io. -
Il faut que
podmansoit installé.
Procédure
Connectez-vous à
registry.redhat.ioavec vos identifiants du portail client Red Hat en entrant la commande suivante :$ sudo podman login registry.redhat.io
Téléchargez le fichier
operator.ymlen entrant la commande suivante :$ sudo podman cp $(sudo podman create \ registry.redhat.io/rhmtc/openshift-migration-legacy-rhel8-operator:v1.7):/operator.yml ./
Remplacez l'opérateur de Migration Toolkit for Containers en entrant la commande suivante :
$ oc replace --force -f operator.yml
Faites passer le déploiement de
migration-operatorà0pour arrêter le déploiement en entrant la commande suivante :$ oc scale -n openshift-migration --replicas=0 deployment/migration-operator
Mettez à l'échelle le déploiement de
migration-operatorà1pour démarrer le déploiement et appliquer les modifications en entrant la commande suivante :$ oc scale -n openshift-migration --replicas=1 deployment/migration-operator
Vérifiez que le site
migration-operatora été mis à niveau en entrant la commande suivante :$ oc -o yaml -n openshift-migration get deployment/migration-operator | grep image: | awk -F ":" '{ print $NF }'Téléchargez le fichier
controller.ymlen entrant la commande suivante :$ sudo podman cp $(sudo podman create \ registry.redhat.io/rhmtc/openshift-migration-legacy-rhel8-operator:v1.7):/controller.yml ./
Créez l'objet
migration-controlleren entrant la commande suivante :$ oc create -f controller.yml
Vérifiez que les modules MTC fonctionnent en entrant la commande suivante :
$ oc get pods -n openshift-migration
5.3. Mise à niveau de MTC 1.3 vers 1.7
Si vous mettez à niveau la version 1.3.x de Migration Toolkit for Containers (MTC) vers la version 1.7, vous devez mettre à jour le manifeste de ressources personnalisées (CR) MigPlan sur le cluster sur lequel le pod MigrationController s'exécute.
Étant donné que les paramètres indirectImageMigration et indirectVolumeMigration n’existent pas dans MTC 1.3, leur valeur par défaut dans la version 1.4 est false, ce qui signifie que la migration directe des images et des volumes est activée. Étant donné que les exigences de migration directe ne sont pas remplies, le plan de migration ne peut pas atteindre l’état Ready, sauf si les valeurs de ces paramètres sont définies sur true.
Conditions préalables
-
Vous devez être connecté en tant qu’utilisateur avec les privilèges
cluster-admin.
Procédure
-
Connectez-vous au cluster sur lequel le pod
MigrationControllerest en cours d’exécution. Obtenez le manifeste du CR
MigPlan:$ oc get migplan <migplan> -o yaml -n openshift-migration
Mettez à jour les valeurs des paramètres suivants et enregistrez le fichier en tant que
migplan.yaml:... spec: indirectImageMigration: true indirectVolumeMigration: true
Remplacez le manifeste du CR
MigPlanpour appliquer les modifications :$ oc replace -f migplan.yaml -n openshift-migration
Obtenez le manifeste du CR
MigPlanmis à jour pour vérifier les modifications :$ oc get migplan <migplan> -o yaml -n openshift-migration
Chapitre 6. Listes de contrôle de prémigration
Avant de migrer vos charges de travail d’application avec Migration Toolkit for Containers (MTC), consultez les listes de contrôle suivantes.
6.1. Liste de contrôle de la santé du groupe
- ❏ Les clusters répondent à la configuration matérielle minimale requise pour la plateforme et la méthode d'installation spécifiques, par exemple, sur du métal nu.
- ❏ Tous les prérequis du MTC sont satisfaits.
- ❏ Tous les nœuds disposent d’un abonnement actif à OpenShift Container Platform.
- ❏ Vous avez vérifié la santé du nœud.
- ❏ Le fournisseur d'identité fonctionne.
- ❏ Le réseau de migration a un débit minimum de 10 Gbit/s.
❏ Les clusters disposent de ressources suffisantes pour la migration.
NoteLes clusters ont besoin de mémoire, de processeurs et d’espace de stockage supplémentaires pour exécuter une migration en plus des charges de travail normales. Les besoins réels en ressources dépendent du nombre de ressources Kubernetes en cours de migration dans un seul plan. Vous devez tester les migrations dans un environnement hors production afin d’estimer les besoins en ressources.
-
❏ Les performances des disques etcd des clusters ont été vérifiées avec
fio.
6.2. Liste de contrôle du groupe source
❏ Vous avez vérifié les volumes persistants (PV) avec des configurations anormales bloqués dans un état Terminating en exécutant la commande suivante :
$ oc get pv
❏ Vous avez recherché des pods ayant un état autre que Running (En cours d’exécution) ou Completed (Terminé) en exécutant la commande suivante :
$ oc get pods --all-namespaces | egrep -v 'Running | Completed'
❏ Vous avez recherché des pods ayant un nombre élevé de redémarrages en exécutant la commande suivante :
$ oc get pods --all-namespaces --field-selector=status.phase=Running \ -o json | jq '.items[]|select(any( .status.containerStatuses[]; \ .restartCount > 3))|.metadata.name'
Même si les pods sont dans l’état Running (En cours d’exécution), un nombre élevé de redémarrages peut indiquer des problèmes sous-jacents.
- les certificats de cluster sont valides pour la durée du processus de migration.
❏ Vous avez recherché des demandes de signature de certificat en attente en exécutant la commande suivante :
$ oc get csr -A | grep pending -i
- ❏ Le registre utilise un type de stockage recommandé.
- ❏ Vous pouvez lire et écrire des images dans le registre.
- ❏ Le cluster etcd est sain.
- ❏ Le temps de réponse moyen du serveur API sur le cluster source est inférieur à 50 ms.
6.3. Liste de contrôle des groupes cibles
- ❏ Le cluster dispose de la configuration réseau et des autorisations correctes pour accéder aux services externes ; par exemple, des bases de données, des référentiels de code source, des registres d’images de conteneur et des outils CI/CD.
- ❏ Les services et applications externes qui utilisent les services fournis par le cluster disposent de la configuration réseau et des autorisations correctes pour accéder au cluster.
- ❏ Les dépendances internes de l’image de conteneur sont respectées.
- ❏ Le cluster cible et le référentiel de réplication disposent d’un espace de stockage suffisant.
Chapitre 7. Considérations relatives au réseau
Passez en revue les stratégies de redirection du trafic réseau des applications après la migration.
7.1. Considérations relatives au DNS
Le domaine DNS du cluster cible est différent de celui du cluster source. Par défaut, les applications obtiennent les noms de domaine complets (FQDN) du cluster cible après la migration.
Pour conserver le domaine DNS source des applications migrées, sélectionnez l’une des deux options décrites ci-dessous.
7.1.1. Isoler le domaine DNS du cluster cible des clients
Vous pouvez autoriser les demandes des clients envoyées au domaine DNS du cluster source à atteindre le domaine DNS du cluster cible sans exposer ce dernier aux clients.
Procédure
- Placez un composant réseau extérieur, tel qu’un équilibreur de charge d’application ou un proxy inverse, entre les clients et le cluster cible.
- Mettez à jour le nom de domaine complet de l’application sur le cluster source dans le serveur DNS pour renvoyer l’adresse IP du composant réseau extérieur.
- Configurez le composant réseau de manière à envoyer les demandes reçues pour l’application dans le domaine source à l’équilibreur de charge dans le domaine du cluster cible.
-
Créez un enregistrement DNS générique pour le domaine
*.apps.source.example.comqui pointe vers l’adresse IP de l’équilibreur de charge du cluster source. - Créez un enregistrement DNS pour chaque application qui pointe vers l’adresse IP du composant réseau extérieur devant le cluster cible. Un enregistrement DNS spécifique a une priorité plus élevée qu’un enregistrement générique, de sorte qu’aucun conflit ne survient lorsque le nom de domaine complet de l’application est résolu.
- Le composant réseau extérieur doit mettre fin à toutes les connexions TLS sécurisées. Si les connexions passent par l’équilibreur de charge du cluster cible, le nom de domaine complet de l’application cible est exposé au client et des erreurs de certificat se produisent.
- Les applications ne doivent pas renvoyer aux clients des liens faisant référence au domaine du cluster cible. Sinon, certaines parties de l’application risquent de ne pas se charger ou de ne pas fonctionner correctement.
7.1.2. Configuration du cluster cible pour accepter le domaine DNS source
Vous pouvez configurer le cluster cible pour qu’il accepte les demandes portant sur une application migrée dans le domaine DNS du cluster source.
Procédure
Pour l’accès HTTP non sécurisé et l’accès HTTPS sécurisé, procédez comme suit :
Créez, dans le projet du cluster cible, une route configurée pour accepter les demandes adressées au nom de domaine complet (FQDN) de l’application dans le cluster source :
$ oc expose svc <app1-svc> --hostname <app1.apps.source.example.com> \ -n <app1-namespace>
Avec cette nouvelle route, le serveur accepte toute demande portant sur ce FQDN et l’envoie aux pods d’application correspondants. En outre, lorsque vous migrez l’application, une autre route est créée dans le domaine du cluster cible. Les demandes atteignent l’application migrée en utilisant l’un de ces noms d’hôte.
Créez un enregistrement DNS avec votre fournisseur DNS qui fait pointer le FQDN de l’application dans le cluster source vers l’adresse IP de l’équilibreur de charge par défaut du cluster cible. Cela permettra de rediriger le trafic de votre cluster source vers votre cluster cible.
Le FQDN de l’application est résolu sur l’équilibreur de charge du cluster cible. Le routeur du contrôleur d'entrée par défaut accepte les demandes pour ce FQDN car une route pour ce nom d'hôte est exposée.
Pour un accès HTTPS sécurisé, effectuez l’étape supplémentaire suivante :
- Remplacez le certificat x509 du contrôleur d'entrée par défaut créé pendant le processus d'installation par un certificat personnalisé.
Configurez ce certificat de manière à inclure les domaines DNS génériques pour les clusters source et cible dans le champ
subjectAltName.Le nouveau certificat est valide pour sécuriser les connexions effectuées à l’aide de l’un des domaines DNS.
Ressources supplémentaires
- Pour plus d'informations, voir Remplacement du certificat d'entrée par défaut.
7.2. Stratégies de redirection du trafic réseau
Après une migration réussie, vous devez rediriger le trafic réseau de vos applications sans état du cluster source vers le cluster cible.
Les stratégies de redirection du trafic réseau reposent sur les hypothèses suivantes :
- Les pods d’application s’exécutent à la fois sur les clusters source et cible.
- Chaque application est associée à une route qui contient le nom d’hôte du cluster source.
- La route avec le nom d’hôte du cluster source contient un certificat d’autorité de certification (CA).
- Pour le protocole HTTPS, le certificat CA du routeur cible contient un autre nom d’objet pour l’enregistrement DNS générique du cluster source.
Prenez en considération les stratégies suivantes et choisissez celle qui répond à vos objectifs.
Redirection de l’intégralité du trafic réseau pour toutes les applications en même temps
Modifiez l’enregistrement DNS générique du cluster source pour qu’il pointe vers l’adresse IP virtuelle (VIP) du routeur du cluster cible.
Cette stratégie convient pour les applications simples ou les petites migrations.
Redirection du trafic réseau pour des applications individuelles
Créez un enregistrement DNS pour chaque application en faisant pointer l’hôte du cluster source vers l’adresse VIP du routeur du cluster cible. Cet enregistrement DNS a la priorité sur l’enregistrement DNS générique du cluster source.
Redirection progressive du trafic réseau pour les applications individuelles
- Créez un proxy capable de rediriger le trafic à la fois vers l’adresse VIP du routeur de cluster source et vers l’adresse VIP du routeur de cluster cible, et ce, pour chaque application.
- Créez un enregistrement DNS pour chaque application en faisant pointer le nom d’hôte du cluster source vers le proxy.
- Configurez l’entrée proxy de l’application de manière à acheminer un certain pourcentage du trafic vers l’adresse VIP du routeur de cluster cible et le reste du trafic vers l’adresse VIP du routeur de cluster source.
- Augmentez progressivement le pourcentage du trafic acheminé vers l’adresse VIP du routeur de cluster cible jusqu’à ce que tout le trafic réseau soit redirigé.
Redirection du trafic basée sur l’utilisateur pour des applications individuelles
Cette stratégie vous permet de filtrer les en-têtes TCP/IP des demandes des utilisateurs portant sur la redirection du trafic réseau pour des groupes d’utilisateurs prédéfinis. Vous pouvez ainsi tester le processus de redirection sur des populations spécifiques d’utilisateurs avant de rediriger l’ensemble du trafic réseau.
- Créez un proxy capable de rediriger le trafic à la fois vers l’adresse VIP du routeur de cluster source et vers l’adresse VIP du routeur de cluster cible, et ce, pour chaque application.
- Créez un enregistrement DNS pour chaque application en faisant pointer le nom d’hôte du cluster source vers le proxy.
-
Configurez l’entrée proxy de l’application de manière à acheminer le trafic correspondant à un modèle d’en-tête donné, tel que
test customers, vers l’adresse VIP du routeur de cluster cible et le reste du trafic vers l’adresse VIP du routeur de cluster source. - Redirigez le trafic vers l’adresse VIP du routeur de cluster cible par étapes jusqu’à ce que tout le trafic se trouve sur l’adresse VIP du routeur de cluster cible.
Chapitre 8. Migration de vos applications
Vous pouvez migrer vos applications en utilisant la console web Migration Toolkit for Containers (MTC) ou la ligne de commande.
La plupart des ressources délimitées par le cluster ne sont pas encore gérées par MTC. Si vos applications nécessitent des ressources de ce type, vous devrez peut-être les créer manuellement sur le cluster cible.
Vous pouvez utiliser la migration par étapes et la migration à basculement pour migrer une application entre des clusters :
- La migration par étapes copie les données du cluster source vers le cluster cible sans arrêter l’application. Vous pouvez exécuter une migration par étapes à plusieurs reprises afin de réduire la durée de la migration à basculement.
- La migration à basculement arrête les transactions sur le cluster source et déplace les ressources vers le cluster cible.
Vous pouvez utiliser la migration d’état pour migrer l’état d’une application :
- La migration d'état copie les réclamations de volumes persistants (PVC) sélectionnées.
- Vous pouvez utiliser la migration d’état pour migrer un espace de nommage au sein d’un même cluster.
Pendant la migration, Migration Toolkit for Containers (MTC) conserve les annotations d’espace de nommage suivantes :
-
openshift.io/sa.scc.mcs -
openshift.io/sa.scc.supplemental-groups openshift.io/sa.scc.uid-rangeCes annotations conservent la plage d’UID. De cette façon, vous avez la garantie que les conteneurs conservent leurs autorisations de système de fichiers sur le cluster cible. Il existe un risque que les UID migrés fassent double emploi avec les UID d’un espace de nommage existant ou futur sur le cluster cible.
8.1. Conditions préalables à la migration
-
Vous devez être connecté en tant qu’utilisateur avec les privilèges
cluster-adminsur tous les clusters.
Migration directe des images
- Vous devez vous assurer que le registre d'images OpenShift sécurisé du cluster source est exposé.
- Vous devez créer une route vers le registre exposé.
Migration directe des volumes
- Si vos clusters utilisent des proxies, vous devez configurer un proxy TCP Stunnel.
Clusters
- Le cluster source doit être mis à niveau vers la dernière version de MTC z-stream.
- La version de MTC doit être la même sur tous les clusters.
Réseau
- Les clusters disposent d’un accès réseau illimité entre eux et au référentiel de réplication.
-
Si vous copiez les volumes persistants avec
move, les clusters doivent disposer d’un accès réseau illimité aux volumes distants. Vous devez activer les ports suivants sur un cluster OpenShift Container Platform 4 :
-
6443(serveur d’API) -
443(routes) -
53(DNS)
-
-
Vous devez activer le port
443sur le référentiel de réplication si vous utilisez le protocole TLS.
Volumes persistants (PV)
- Les volumes persistants doivent être valides.
- Les volumes persistants doivent être liés à des revendications de volumes persistants.
Si vous utilisez des clichés pour copier les PV, des conditions préalables supplémentaires s’appliquent :
- Le fournisseur de services en nuage doit prendre en charge les instantanés.
- Les PV doivent avoir le même fournisseur de cloud.
- Les PV doivent se trouver dans la même région géographique.
- Les PV doivent avoir la même classe de stockage.
8.2. Migration de vos applications en utilisant la console Web MTC
Vous pouvez configurer des clusters et un référentiel de réplication à l’aide de la console Web MTC. Vous pouvez ensuite créer et exécuter un plan de migration.
8.2.1. Lancement de la console Web MTC
Vous pouvez lancer la console Web MTC (Migration Toolkit for Containers) dans un navigateur.
Conditions préalables
- La console Web MTC doit disposer d’un accès réseau à la console Web OpenShift Container Platform.
- La console Web MTC doit disposer d’un accès réseau au serveur d’autorisation OAuth.
Procédure
- Connectez-vous au cluster OpenShift Container Platform sur lequel vous avez installé MTC.
Saisissez la commande suivante pour obtenir l’URL de la console Web MTC :
$ oc get -n openshift-migration route/migration -o go-template='https://{{ .spec.host }}'La sortie ressemble à ce qui suit :
https://migration-openshift-migration.apps.cluster.openshift.com.Ouvrez un navigateur et accédez à la console Web MTC.
NoteSi vous essayez d’accéder à la console Web MTC immédiatement après avoir installé l’opérateur Migration Toolkit for Containers, il se peut que la console ne se charge pas, car l’opérateur est toujours en train de configurer le cluster. Attendez quelques minutes, puis réessayez.
- Si vous utilisez des certificats CA auto-signés, vous serez invité à accepter le certificat CA du serveur d’API du cluster source. La page Web vous guide dans le processus d’acceptation des certificats restants.
- Connectez-vous à l’aide de votre nom d’utilisateur et de votre mot de passe OpenShift Container Platform.
8.2.2. Ajout d’un cluster à la console Web MTC
Vous pouvez ajouter un cluster à la console Web MTC (Migration Toolkit for Containers).
Conditions préalables
Si vous utilisez des clichés Azure pour copier des données :
- Vous devez spécifier le nom du groupe de ressources Azure pour le cluster.
- Les clusters doivent se trouver dans le même groupe de ressources Azure.
- Les clusters doivent se trouver au même emplacement géographique.
- Si vous utilisez la migration directe des images, vous devez exposer une route vers le registre des images du cluster source.
Procédure
- Connectez-vous au cluster.
Procurez-vous le token du compte du service
migration-controller:$ oc sa get-token migration-controller -n openshift-migration
Exemple de sortie
eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJtaWciLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlY3JldC5uYW1lIjoibWlnLXRva2VuLWs4dDJyIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6Im1pZyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6ImE1YjFiYWMwLWMxYmYtMTFlOS05Y2NiLTAyOWRmODYwYjMwOCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDptaWc6bWlnIn0.xqeeAINK7UXpdRqAtOj70qhBJPeMwmgLomV9iFxr5RoqUgKchZRG2J2rkqmPm6vr7K-cm7ibD1IBpdQJCcVDuoHYsFgV4mp9vgOfn9osSDp2TGikwNz4Az95e81xnjVUmzh-NjDsEpw71DH92iHV_xt2sTwtzftS49LpPW2LjrV0evtNBP_t_RfskdArt5VSv25eORl7zScqfe1CiMkcVbf2UqACQjo3LbkpfN26HAioO2oH0ECPiRzT0Xyh-KwFutJLS9Xgghyw-LD9kPKcE_xbbJ9Y4Rqajh7WdPYuB0Jd9DPVrslmzK-F6cgHHYoZEv0SvLQi-PO0rpDrcjOEQQ
- Dans la console Web MTC, cliquez sur Clusters.
- Cliquez sur Add cluster.
Renseignez les champs suivants :
-
Cluster name : le nom du cluster peut contenir des lettres minuscules (
a-z) et des chiffres (0-9). Il ne doit pas contenir d’espaces ni de caractères internationaux. -
URL : indiquez l’URL du serveur d’API ;
https://<www.example.com>:8443, par exemple. -
Service account token : collez le token du compte de service
migration-controller. Exposed route host to image registry : si vous utilisez la migration directe d’images, spécifiez la route exposée vers le registre d’images du cluster source.
Pour créer la route, exécutez la commande suivante :
Pour OpenShift Container Platform 3 :
$ oc create route passthrough --service=docker-registry --port=5000 -n default
Pour OpenShift Container Platform 4 :
$ oc create route passthrough --service=image-registry --port=5000 -n openshift-image-registry
- Azure Cluster : vous devez sélectionner cette option si vous utilisez des clichés Azure pour copier vos données.
- Azure resource group : ce champ est affiché si l’option Azure Cluster est sélectionnée. Spécifiez le groupe de ressources Azure.
- Require SSL verification : (facultatif) sélectionnez cette option pour vérifier les connexions SSL au cluster.
- CA bundle file : ce champ est affiché si l’option Require SSL verification est sélectionnée. Si vous avez créé un fichier de groupement de certificats CA personnalisé pour les certificats auto-signés, cliquez sur Browse, sélectionnez le fichier en question, puis envoyez-le.
-
Cluster name : le nom du cluster peut contenir des lettres minuscules (
Cliquez sur Add cluster.
Le cluster apparaît dans la liste Clusters.
8.2.3. Ajout d’un référentiel de réplication à la console Web MTC
Vous pouvez ajouter un stockage d’objets en tant que référentiel de réplication à la console Web MTC (Migration Toolkit for Containers).
MTC prend en charge les fournisseurs de stockage suivants :
- Amazon Web Services (AWS) S3
- Multi-Cloud Object Gateway (MCG)
- Stockage d’objets S3 générique ; Minio ou Ceph S3, par exemple
- Google Cloud Provider (GCP)
- Microsoft Azure Blob
Conditions préalables
- Vous devez configurer le stockage d’objets en tant que référentiel de réplication.
Procédure
- Dans la console Web MTC, cliquez sur Replication repositories.
- Cliquez sur Add repository.
Sélectionnez un type de fournisseur de stockage (Storage provider type) et renseignez les champs suivants :
AWS pour les fournisseurs S3, y compris AWS et MCG :
- Replication repository name : indiquez le nom du référentiel de réplication dans la console Web MTC.
- S3 bucket name : indiquez le nom du compartiment S3.
- S3 bucket region : indiquez la région du compartiment S3. Requis pour AWS S3. Facultatif pour certains fournisseurs S3. Consultez la documentation du produit de votre fournisseur S3 pour connaître les valeurs attendues.
-
S3 endpoint : indiquez l’URL du service S3, et non du compartiment ;
https://<s3-storage.apps.cluster.com>, par exemple. Requis pour un fournisseur S3 générique. Vous devez utiliser le préfixehttps://. -
S3 provider access key : indiquez la clé
<AWS_SECRET_ACCESS_KEY>pour AWS ou la clé d’accès du fournisseur S3 pour MCG et les autres fournisseurs S3. -
S3 provider secret access key : indiquez la clé
<AWS_ACCESS_KEY_ID>pour AWS ou la clé d’accès secrète du fournisseur S3 pour MCG et les autres fournisseurs S3. - Require SSL verification : désactivez cette case à cocher si vous utilisez un fournisseur S3 générique.
- Si vous avez créé un fichier de groupement de certificats CA personnalisé pour les certificats auto-signés, cliquez sur Browse et accédez ensuite au fichier codé en Base64.
GCP :
- Replication repository name : indiquez le nom du référentiel de réplication dans la console Web MTC.
- GCP bucket name : indiquez le nom du compartiment GCP.
-
GCP credential JSON blob : indiquez la chaîne dans le fichier
credentials-velero.
Azure :
- Replication repository name : indiquez le nom du référentiel de réplication dans la console Web MTC.
- Azure resource group : indiquez le groupe de ressources du stockage d’objets blob Azure.
- Azure storage account name: indiquez le nom du compte de stockage d’objets blob Azure.
-
Azure credentials - INI file contents : indiquez la chaîne dans le fichier
credentials-velero.
- Cliquez sur Add repository et attendez la validation de la connexion.
Cliquez sur Close.
Le nouveau référentiel apparaît dans la liste Replication repositories.
8.2.4. Création d’un plan de migration dans la console Web MTC
Vous pouvez créer un plan de migration dans la console Web MTC (Migration Toolkit for Containers).
Conditions préalables
-
Vous devez être connecté en tant qu’utilisateur avec les privilèges
cluster-adminsur tous les clusters. - Vous devez vous assurer que la même version de MTC est installée sur tous les clusters.
- Vous devez ajouter les clusters et le référentiel de réplication à la console Web MTC.
- Si vous souhaitez utiliser la méthode de copie des données move pour migrer un volume persistant (PV), les clusters source et cible doivent disposer d’un accès réseau ininterrompu au volume distant.
-
Si vous souhaitez utiliser la migration directe des images, vous devez indiquer la route exposée vers le registre d’images du cluster source. Pour ce faire, vous pouvez utiliser la console Web MTC ou mettre à jour le manifeste de la ressource personnalisée
MigCluster.
Procédure
- Dans la console Web MTC, cliquez sur Migration plans.
- Cliquez sur Add migration plan.
Saisissez le nom du plan dans le champ Plan name.
Le nom du plan de migration ne doit pas dépasser 253 caractères alphanumériques minuscules (
a-z, 0-9), ni contenir d’espaces ou de traits de soulignement (_).- Sélectionnez un cluster source, un cluster cible et un référentiel dans les champs appropriés.
- Cliquez sur Next.
- Sélectionnez les projets à faire migrer.
- Facultatif : cliquez sur l’icône d’édition en regard d’un projet pour modifier l’espace de nommage cible.
- Cliquez sur Next.
Sélectionnez un type de migration pour chaque volume persistant (PV) :
- L’option Copy copie les données du PV d’un cluster source vers le référentiel de réplication, puis restaure les données sur un nouveau PV, avec des caractéristiques similaires, dans le cluster cible.
- L’option Move démonte un volume distant (NFS, par exemple) du cluster source, crée une ressource PV sur le cluster cible pointant vers le volume distant, puis monte le volume distant sur le cluster cible. Les applications qui s’exécutent sur le cluster cible utilisent le même volume distant que celui qui était utilisé par le cluster source.
- Cliquez sur Next.
Sélectionnez une méthode de copie (Copy method) pour chaque PV :
- La méthode Snapshot copy sauvegarde et restaure les données à l’aide de la fonctionnalité de cliché du fournisseur de cloud. Elle est nettement plus rapide que la méthode Filesystem copy.
La méthode Filesystem copy sauvegarde les fichiers sur le cluster source et les restaure sur le cluster cible.
La méthode de copie du système de fichiers est requise pour la migration directe des volumes.
- Vous pouvez sélectionner Verify copy pour vérifier les données migrées avec la méthode Filesystem copy. La vérification des données s’effectue en générant une somme de contrôle pour chaque fichier source et en vérifiant la somme de contrôle après la restauration. La vérification des données réduit sensiblement les performances.
Sélectionnez une classe de stockage cible (Target storage class).
Si vous avez sélectionné Filesystem copy, vous pouvez modifier la classe de stockage cible.
- Cliquez sur Next.
Sur la page Migration options, l’option Direct image migration est sélectionnée si vous avez spécifié une route de registre d’images exposée pour le cluster source. L’option Direct PV migration est sélectionnée si vous migrez des données avec la méthode Filesystem copy.
Les options de migration directe copient les images et les fichiers directement du cluster source vers le cluster cible. Cette option s’avère beaucoup plus rapide que la copie d’images et de fichiers du cluster source vers le référentiel de réplication, puis du référentiel de réplication vers le cluster cible.
- Cliquez sur Next.
Facultatif : cliquez sur Add Hook pour ajouter un script automatique au plan de migration.
Un script automatique exécute un code personnalisé. Vous pouvez ajouter jusqu’à quatre scripts automatiques à un seul plan de migration. Chaque script automatique est exécuté pendant une étape de migration différente.
- Saisissez le nom du script automatique à afficher dans la console Web.
- Si le script automatique est un playbook Ansible, sélectionnez Ansible playbook, puis cliquez sur Browse pour télécharger le playbook ou collez le contenu du playbook dans le champ.
- Facultatif : indiquez une image d’exécution Ansible si vous n’utilisez pas l’image de script automatique par défaut.
Si le script automatique n’est pas un playbook Ansible, sélectionnez Custom container image, et indiquez le nom et le chemin de l’image.
Une image de conteneur personnalisée peut inclure des playbooks Ansible.
- Sélectionnez Source cluster ou Target cluster.
- Saisissez le nom et l’espace de nommage du compte de service dans les champs Service account name et Service account namespace, respectivement.
Sélectionnez l’étape de migration pour le script automatique :
- preBackup : avant la sauvegarde de la charge de travail de l’application sur le cluster source
- postBackup : après la sauvegarde de la charge de travail de l’application sur le cluster source
- preRestore : avant la restauration de la charge de travail de l’application sur le cluster cible
- postRestore : après la restauration de la charge de travail de l’application sur le cluster cible
- Cliquez sur Add.
Cliquez sur Finish.
Le plan de migration est affiché dans la liste Migration plans.
Ressources supplémentaires pour les méthodes de copie de volumes persistants
8.2.5. Exécution d’un plan de migration dans la console Web MTC
Vous pouvez migrer des applications et des données avec le plan de migration que vous avez créé dans la console Web MTC (Migration Toolkit for Containers).
Lors de la migration, MTC définit la stratégie de récupération des volumes persistants (PV) migrés sur Retain sur le cluster cible.
La ressource personnalisée Backup contient une annotation PVOriginalReclaimPolicy qui indique la stratégie de récupération d’origine. Vous pouvez restaurer manuellement la stratégie de récupération des PV migrés.
Conditions préalables
La console Web MTC doit contenir les éléments suivants :
-
Un cluster source dans l’état
Ready -
Un cluster cible dans un l’état
Ready - Un référentiel de réplication
- Un plan de migration valide
Procédure
- Connectez-vous à la console Web MTC et cliquez sur Migration plans.
Cliquez sur le menu Options
 à côté d'un plan de migration et sélectionnez l'une des options suivantes sous Migration:
à côté d'un plan de migration et sélectionnez l'une des options suivantes sous Migration:
- Stage copie les données du cluster source vers le cluster cible sans arrêter l’application.
Cutover arrête les transactions sur le cluster source et déplace les ressources vers le cluster cible.
Facultatif : dans la boîte de dialogue Cutover migration, vous pouvez désactiver la case à cocher Halt transactions on the source cluster during migration.
State copie les réclamations de volumes persistants (PVC) sélectionnées.
ImportantN’utilisez pas la migration d’état pour migrer un espace de nommage entre des clusters. Utilisez plutôt la migration par étapes ou à basculement.
- Sélectionnez une ou plusieurs PVC dans la boîte de dialogue State migration et cliquez ensuite sur Migrate.
Une fois la migration terminée, vérifiez que l’application a été migrée correctement dans la console Web OpenShift Container Platform :
- Cliquez sur Home → Projects.
- Cliquez sur le projet migré pour afficher son état.
- Dans la section Routes, cliquez sur Location pour vérifier que l’application fonctionne correctement, le cas échéant.
- Cliquez sur Workloads → Pods pour vérifier que les pods s’exécutent dans l’espace de nommage migré.
- Cliquez sur Storage → Persistent volumes pour vérifier que les volumes persistants migrés ont été mis en service correctement.
Chapitre 9. Options de migration avancées
Vous pouvez automatiser vos migrations et modifier les ressources personnalisées MigPlan et MigrationController afin d’effectuer des migrations à grande échelle et d’améliorer les performances.
9.1. Terminologie
Tableau 9.1. Terminologie MTC
| Terme | Définition |
|---|---|
| Cluster source | Cluster à partir duquel les applications sont migrées. |
| Cluster de destination[1] | Cluster vers lequel les applications sont migrées. |
| Un référentiel de réplication | Stockage d’objets utilisé pour la copie d’images, de volumes et d’objets Kubernetes pendant la migration indirecte ou pour des objets Kubernetes pendant la migration directe de volumes ou d’images. Le référentiel de réplication doit être accessible à tous les clusters. |
| Cluster hôte |
Cluster sur lequel le pod Le cluster hôte n’a pas besoin d’une route de registre exposée pour la migration directe des images. |
| Cluster distant | Un cluster distant est généralement le cluster source, mais ce n’est pas obligatoire.
Un cluster distant nécessite une ressource personnalisée Un cluster distant nécessite une route de registre sécurisée exposée pour la migration directe des images. |
| Migration indirecte | Les images, volumes et objets Kubernetes sont copiés du cluster source vers le référentiel de réplication, puis du référentiel de réplication vers le cluster de destination. |
| Migration directe des volumes | Les volumes persistants sont copiés directement du cluster source vers le cluster de destination. |
| Migration directe des images | Les images sont copiées directement du cluster source vers le cluster de destination. |
| Migration par étapes | Les données sont copiées vers le cluster de destination sans arrêter l’application. Le fait d’exécuter plusieurs fois une migration par étapes réduit la durée de la migration à basculement. |
| Migration à basculement | L’application est arrêtée sur le cluster source et ses ressources sont migrées vers le cluster de destination. |
| Migration d’état | L'état de l'application est migré en copiant les demandes de volumes persistants spécifiques vers le cluster de destination. |
| Migration de retour | La migration de retour annule une migration terminée. |
1 Appelez le cluster cible dans la console Web MTC.
9.2. Migration d’applications à l’aide de la ligne de commande
Vous pouvez migrer des applications avec l’API MTC en utilisant l’interface de ligne de commande (CLI) afin d’automatiser la migration.
9.2.1. Conditions préalables à la migration
-
Vous devez être connecté en tant qu’utilisateur avec les privilèges
cluster-adminsur tous les clusters.
Migration directe des images
- Vous devez vous assurer que le registre d'images OpenShift sécurisé du cluster source est exposé.
- Vous devez créer une route vers le registre exposé.
Migration directe des volumes
- Si vos clusters utilisent des proxies, vous devez configurer un proxy TCP Stunnel.
Clusters
- Le cluster source doit être mis à niveau vers la dernière version de MTC z-stream.
- La version de MTC doit être la même sur tous les clusters.
Réseau
- Les clusters disposent d’un accès réseau illimité entre eux et au référentiel de réplication.
-
Si vous copiez les volumes persistants avec
move, les clusters doivent disposer d’un accès réseau illimité aux volumes distants. Vous devez activer les ports suivants sur un cluster OpenShift Container Platform 4 :
-
6443(serveur d’API) -
443(routes) -
53(DNS)
-
-
Vous devez activer le port
443sur le référentiel de réplication si vous utilisez le protocole TLS.
Volumes persistants (PV)
- Les volumes persistants doivent être valides.
- Les volumes persistants doivent être liés à des revendications de volumes persistants.
Si vous utilisez des clichés pour copier les PV, des conditions préalables supplémentaires s’appliquent :
- Le fournisseur de services en nuage doit prendre en charge les instantanés.
- Les PV doivent avoir le même fournisseur de cloud.
- Les PV doivent se trouver dans la même région géographique.
- Les PV doivent avoir la même classe de stockage.
9.2.2. Création d’une route de registre pour la migration directe d’images
Pour la migration directe d'images, vous devez créer une route vers le registre d'images OpenShift exposé sur tous les clusters distants.
Conditions préalables
Le registre d'images OpenShift doit être exposé au trafic externe sur tous les clusters distants.
Le registre OpenShift Container Platform 4 est exposé par défaut.
Procédure
Pour créer une route vers un registre OpenShift Container Platform 4, exécutez la commande suivante :
$ oc create route passthrough --service=image-registry -n openshift-image-registry
9.2.3. Configuration du proxy
Dans le cas d’OpenShift Container Platform 4.1 et versions antérieures, vous devez configurer les proxies dans le manifeste de la ressource personnalisée (CR) MigrationController après avoir installé l’opérateur Migration Toolkit for Containers, car ces versions ne prennent pas en charge un objet proxy à l’échelle du cluster.
Pour OpenShift Container Platform 4.2 à 4.12, le Migration Toolkit for Containers (MTC) hérite des paramètres de proxy à l'échelle du cluster. Vous pouvez modifier les paramètres du proxy si vous souhaitez remplacer les paramètres du proxy à l'échelle du cluster.
9.2.3.1. Migration directe des volumes
La migration directe des volumes (DVM) a été introduite dans MTC 1.4.2. DVM ne prend en charge qu'un seul proxy. Le cluster source ne peut pas accéder à la route du cluster cible si ce dernier se trouve également derrière un proxy.
Si vous souhaitez effectuer un DVM à partir d'un cluster source situé derrière un proxy, vous devez configurer un proxy TCP qui fonctionne au niveau de la couche transport et transmet les connexions SSL de manière transparente sans les décrypter et les recrypter à l'aide de leurs propres certificats SSL. Un proxy Stunnel est un exemple de ce type de proxy.
9.2.3.1.1. Configuration du proxy TCP pour le DVM
Vous pouvez établir une connexion directe entre le cluster source et le cluster cible via un proxy TCP et configurer la variable stunnel_tcp_proxy dans le CR MigrationController pour utiliser le proxy :
apiVersion: migration.openshift.io/v1alpha1 kind: MigrationController metadata: name: migration-controller namespace: openshift-migration spec: [...] stunnel_tcp_proxy: http://username:password@ip:port
La migration directe de volume (DVM) ne prend en charge que l'authentification de base pour le proxy. En outre, la DVM ne fonctionne que derrière des proxys qui peuvent tunneliser une connexion TCP de manière transparente. Les mandataires HTTP/HTTPS en mode man-in-the-middle ne fonctionnent pas. Les proxys existants à l'échelle du cluster peuvent ne pas prendre en charge ce comportement. Par conséquent, les paramètres du proxy pour DVM sont intentionnellement différents de la configuration habituelle du proxy dans MTC.
9.2.3.1.2. Pourquoi utiliser un proxy TCP plutôt qu'un proxy HTTP/HTTPS ?
Vous pouvez activer DVM en exécutant Rsync entre le cluster source et le cluster cible via une route OpenShift. Le trafic est chiffré à l'aide de Stunnel, un proxy TCP. Le Stunnel fonctionnant sur le cluster source initie une connexion TLS avec le Stunnel cible et transfère les données sur un canal crypté.
Les proxys HTTP/HTTPS à l'échelle du cluster dans OpenShift sont généralement configurés en mode man-in-the-middle où ils négocient leur propre session TLS avec les serveurs extérieurs. Cependant, cela ne fonctionne pas avec Stunnel. Stunnel exige que sa session TLS ne soit pas modifiée par le proxy, faisant essentiellement du proxy un tunnel transparent qui transmet simplement la connexion TCP telle quelle. Vous devez donc utiliser un proxy TCP.
9.2.3.1.3. Problème connu
La migration échoue avec l'erreur Upgrade request required
Le contrôleur de migration utilise le protocole SPDY pour exécuter des commandes dans des modules distants. Si le cluster distant se trouve derrière un proxy ou un pare-feu qui ne prend pas en charge le protocole SPDY, le contrôleur de migration ne parvient pas à exécuter les commandes à distance. La migration échoue avec le message d'erreur Upgrade request required. Solution : Utilisez un proxy qui prend en charge le protocole SPDY.
Outre la prise en charge du protocole SPDY, le proxy ou le pare-feu doit également transmettre l'en-tête HTTP Upgrade au serveur API. Le client utilise cet en-tête pour ouvrir une connexion websocket avec le serveur API. Si l'en-tête Upgrade est bloqué par le proxy ou le pare-feu, la migration échoue avec le message d'erreur Upgrade request required. Solution : Assurez-vous que le proxy transmet l'en-tête Upgrade.
9.2.3.2. Optimiser les politiques de réseau pour les migrations
OpenShift prend en charge la restriction du trafic vers ou depuis les pods à l'aide de NetworkPolicy ou EgressFirewalls en fonction du plugin réseau utilisé par le cluster. Si l'un des espaces de noms source impliqués dans une migration utilise de tels mécanismes pour restreindre le trafic réseau vers les pods, les restrictions peuvent par inadvertance arrêter le trafic vers les pods Rsync pendant la migration.
Les pods Rsync fonctionnant sur les clusters source et cible doivent se connecter l'un à l'autre via une route OpenShift. Les objets NetworkPolicy ou EgressNetworkPolicy existants peuvent être configurés pour exempter automatiquement les pods Rsync de ces restrictions de trafic.
9.2.3.2.1. Configuration de la politique de réseau
9.2.3.2.1.1. Trafic de sortie des pods Rsync
Vous pouvez utiliser les étiquettes uniques des modules Rsync pour autoriser le trafic sortant de ces modules si la configuration de NetworkPolicy dans les espaces de noms source ou destination bloque ce type de trafic. La stratégie suivante autorise le trafic de sortie all à partir des modules Rsync dans l'espace de noms :
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-egress-from-rsync-pods
spec:
podSelector:
matchLabels:
owner: directvolumemigration
app: directvolumemigration-rsync-transfer
egress:
- {}
policyTypes:
- Egress9.2.3.2.1.2. Trafic entrant vers les pods Rsync
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-all-egress-from-rsync-pods
spec:
podSelector:
matchLabels:
owner: directvolumemigration
app: directvolumemigration-rsync-transfer
ingress:
- {}
policyTypes:
- Ingress9.2.3.2.2. Configuration de la politique de réseau EgressNetworkPolicy
L'objet EgressNetworkPolicy ou Egress Firewalls sont des constructions OpenShift conçues pour bloquer le trafic de sortie du cluster.
Contrairement à l'objet NetworkPolicy, le pare-feu Egress fonctionne au niveau du projet car il s'applique à tous les modules de l'espace de noms. Par conséquent, les étiquettes uniques des pods Rsync n'exemptent pas uniquement les pods Rsync des restrictions. Cependant, vous pouvez ajouter les plages CIDR du cluster source ou cible à la règle Allow de la politique afin qu'une connexion directe puisse être établie entre deux clusters.
En fonction du cluster dans lequel le pare-feu de sortie est présent, vous pouvez ajouter la plage CIDR de l'autre cluster pour autoriser le trafic de sortie entre les deux :
apiVersion: network.openshift.io/v1
kind: EgressNetworkPolicy
metadata:
name: test-egress-policy
namespace: <namespace>
spec:
egress:
- to:
cidrSelector: <cidr_of_source_or_target_cluster>
type: Deny9.2.3.2.3. Choix d'autres points d'arrivée pour le transfert de données
Par défaut, DVM utilise une route OpenShift Container Platform comme point final pour transférer les données PV vers les clusters de destination. Vous pouvez choisir un autre type de point d'extrémité pris en charge, si les topologies de cluster le permettent.
Pour chaque cluster, vous pouvez configurer un point de terminaison en définissant la variable rsync_endpoint_type sur le cluster destination approprié dans votre MigrationController CR :
apiVersion: migration.openshift.io/v1alpha1 kind: MigrationController metadata: name: migration-controller namespace: openshift-migration spec: [...] rsync_endpoint_type: [NodePort|ClusterIP|Route]
9.2.3.2.4. Configuration de groupes supplémentaires pour les pods Rsync
Lorsque vos PVC utilisent un stockage partagé, vous pouvez configurer l'accès à ce stockage en ajoutant des groupes supplémentaires aux définitions de pods Rsync afin que les pods autorisent l'accès :
Tableau 9.2. Groupes supplémentaires pour les pods Rsync
| Variable | Type | Défaut | Description |
|---|---|---|---|
|
| chaîne de caractères | Non défini | Liste séparée par des virgules des groupes supplémentaires pour les pods Rsync source |
|
| chaîne de caractères | Non défini | Liste de groupes supplémentaires séparés par des virgules pour les pods Rsync cibles |
Exemple d'utilisation
Le CR MigrationController peut être mis à jour pour définir les valeurs de ces groupes supplémentaires :
spec: src_supplemental_groups: "1000,2000" target_supplemental_groups: "2000,3000"
9.2.3.3. Configuration des proxies
Conditions préalables
-
Vous devez être connecté en tant qu’utilisateur avec les privilèges
cluster-adminsur tous les clusters.
Procédure
Procurez-vous le manifeste du CR
MigrationController:$ oc get migrationcontroller <migration_controller> -n openshift-migration
Mettez à jour les paramètres du proxy :
apiVersion: migration.openshift.io/v1alpha1 kind: MigrationController metadata: name: <migration_controller> namespace: openshift-migration ... spec: stunnel_tcp_proxy: http://<username>:<password>@<ip>:<port> 1 noProxy: example.com 2
Faites précéder un domaine du signe
.pour ne faire correspondre que les sous-domaines. Par exemple,.y.comcorrespond àx.y.com, mais pas ày.com. Utilisez*pour ignorer le proxy pour toutes les destinations. Si vous mettez à l’échelle des workers qui ne sont pas inclus dans le réseau défini par le champnetworking.machineNetwork[].cidrà partir de la configuration d’installation, vous devez les ajouter à cette liste pour éviter les problèmes de connexion.Ce champ est ignoré si ni le champ
httpProxyni le champhttpsProxyne sont définis.-
Enregistrez le manifeste en tant que
migration-controller.yaml. Appliquez le manifeste mis à jour :
$ oc replace -f migration-controller.yaml -n openshift-migration
9.2.4. Migration d’une application à l’aide de l’API MTC
Vous pouvez migrer une application à partir de la ligne de commande en utilisant l’API Migration Toolkit for Containers (MTC).
Procédure
Créez un manifeste de CR
MigClusterpour le cluster hôte :$ cat << EOF | oc apply -f - apiVersion: migration.openshift.io/v1alpha1 kind: MigCluster metadata: name: <host_cluster> namespace: openshift-migration spec: isHostCluster: true EOF
Créez un manifeste d’objets
Secretpour chaque cluster distant :$ cat << EOF | oc apply -f - apiVersion: v1 kind: Secret metadata: name: <cluster_secret> namespace: openshift-config type: Opaque data: saToken: <sa_token> 1 EOF- 1
- Indiquez le token de compte de service (SA)
migration-controllercodé en base64 du cluster distant. Vous pouvez obtenir le token en exécutant la commande suivante :
$ oc sa get-token migration-controller -n openshift-migration | base64 -w 0
Créez un manifeste de CR
MigClusterpour chaque cluster distant :$ cat << EOF | oc apply -f - apiVersion: migration.openshift.io/v1alpha1 kind: MigCluster metadata: name: <remote_cluster> 1 namespace: openshift-migration spec: exposedRegistryPath: <exposed_registry_route> 2 insecure: false 3 isHostCluster: false serviceAccountSecretRef: name: <remote_cluster_secret> 4 namespace: openshift-config url: <remote_cluster_url> 5 EOF
- 1
- Indiquez la ressource personnalisée
Clusterdu cluster distant. - 2
- Facultatif : pour la migration directe d’images, indiquez la route de registre exposée.
- 3
- La vérification SSL est activée si la valeur est définie sur
false. Les certificats CA ne sont pas requis ni vérifiés si la valeur est définie surtrue. - 4
- Indiquez l’objet
Secretdu cluster distant. - 5
- Indiquez l’URL du cluster distant.
Vérifiez que tous les clusters sont dans l’état
Ready:$ oc describe cluster <cluster>
Créez un manifeste d’objets
Secretpour le référentiel de réplication :$ cat << EOF | oc apply -f - apiVersion: v1 kind: Secret metadata: namespace: openshift-config name: <migstorage_creds> type: Opaque data: aws-access-key-id: <key_id_base64> 1 aws-secret-access-key: <secret_key_base64> 2 EOF
Les informations d’identification AWS sont codées en base64 par défaut. Pour les autres fournisseurs de stockage, vous devez coder vos informations d’identification en exécutant la commande suivante avec chaque clé :
$ echo -n "<key>" | base64 -w 0 1- 1
- Indiquez l’ID de la clé ou la clé secrète. Les deux clés doivent être codées en base64.
Créez un manifeste de CR
MigStoragepour le référentiel de réplication :$ cat << EOF | oc apply -f - apiVersion: migration.openshift.io/v1alpha1 kind: MigStorage metadata: name: <migstorage> namespace: openshift-migration spec: backupStorageConfig: awsBucketName: <bucket> 1 credsSecretRef: name: <storage_secret> 2 namespace: openshift-config backupStorageProvider: <storage_provider> 3 volumeSnapshotConfig: credsSecretRef: name: <storage_secret> 4 namespace: openshift-config volumeSnapshotProvider: <storage_provider> 5 EOF- 1
- Indiquez le nom du compartiment.
- 2
- Indiquez la ressource personnalisée
Secretsdu stockage d’objets. Vous devez vous assurer que les informations d’identification stockées dans la ressource personnaliséeSecretsdu stockage d’objets sont correctes. - 3
- Indiquez le fournisseur de stockage.
- 4
- Facultatif : si vous copiez des données en utilisant des clichés, indiquez la ressource personnalisée
Secretsdu stockage d’objets. Vous devez vous assurer que les informations d’identification stockées dans la ressource personnaliséeSecretsdu stockage d’objets sont correctes. - 5
- Facultatif : si vous copiez des données en utilisant des clichés, indiquez le fournisseur de stockage.
Vérifiez que la ressource personnalisée
MigStoragese trouve dans l’étatReady:$ oc describe migstorage <migstorage>
Créez un manifeste de CR
MigPlan:$ cat << EOF | oc apply -f - apiVersion: migration.openshift.io/v1alpha1 kind: MigPlan metadata: name: <migplan> namespace: openshift-migration spec: destMigClusterRef: name: <host_cluster> namespace: openshift-migration indirectImageMigration: true 1 indirectVolumeMigration: true 2 migStorageRef: name: <migstorage> 3 namespace: openshift-migration namespaces: - <source_namespace_1> 4 - <source_namespace_2> - <source_namespace_3>:<destination_namespace> 5 srcMigClusterRef: name: <remote_cluster> 6 namespace: openshift-migration EOF- 1
- La migration directe des images est activée si la valeur est définie sur
false. - 2
- La migration directe des volumes est activée si la valeur est définie sur
false. - 3
- Indiquez le nom de l’instance CR
MigStorage. - 4
- Indiquez un ou plusieurs espaces de nommage sources. Par défaut, l’espace de nommage de destination porte le même nom.
- 5
- Indiquez un espace de nommage de destination s’il est différent de l’espace de nommage source.
- 6
- Indiquez le nom de l’instance
MigClusterdu cluster source.
Vérifiez que l’instance
MigPlanse trouve dans l’étatReady:$ oc describe migplan <migplan> -n openshift-migration
Créez un manifeste de CR
MigMigrationpour lancer la migration définie dans l’instanceMigPlan:$ cat << EOF | oc apply -f - apiVersion: migration.openshift.io/v1alpha1 kind: MigMigration metadata: name: <migmigration> namespace: openshift-migration spec: migPlanRef: name: <migplan> 1 namespace: openshift-migration quiescePods: true 2 stage: false 3 rollback: false 4 EOF- 1
- Indiquez le nom de la ressource personnalisée
MigPlan. - 2
- Les pods sur le cluster source sont arrêtés avant la migration si la valeur est définie sur
true. - 3
- Une migration par étapes, qui copie la plupart des données sans arrêter l’application, est effectuée si la valeur est définie sur
true. - 4
- Une migration terminée est annulée si la valeur est définie sur
true.
Vérifiez la migration en observant la progression de la ressource personnalisée
MigMigration:$ oc watch migmigration <migmigration> -n openshift-migration
La sortie se présente comme suit :
Exemple de sortie
Name: c8b034c0-6567-11eb-9a4f-0bc004db0fbc Namespace: openshift-migration Labels: migration.openshift.io/migplan-name=django Annotations: openshift.io/touch: e99f9083-6567-11eb-8420-0a580a81020c API Version: migration.openshift.io/v1alpha1 Kind: MigMigration ... Spec: Mig Plan Ref: Name: migplan Namespace: openshift-migration Stage: false Status: Conditions: Category: Advisory Last Transition Time: 2021-02-02T15:04:09Z Message: Step: 19/47 Reason: InitialBackupCreated Status: True Type: Running Category: Required Last Transition Time: 2021-02-02T15:03:19Z Message: The migration is ready. Status: True Type: Ready Category: Required Durable: true Last Transition Time: 2021-02-02T15:04:05Z Message: The migration registries are healthy. Status: True Type: RegistriesHealthy Itinerary: Final Observed Digest: 7fae9d21f15979c71ddc7dd075cb97061895caac5b936d92fae967019ab616d5 Phase: InitialBackupCreated Pipeline: Completed: 2021-02-02T15:04:07Z Message: Completed Name: Prepare Started: 2021-02-02T15:03:18Z Message: Waiting for initial Velero backup to complete. Name: Backup Phase: InitialBackupCreated Progress: Backup openshift-migration/c8b034c0-6567-11eb-9a4f-0bc004db0fbc-wpc44: 0 out of estimated total of 0 objects backed up (5s) Started: 2021-02-02T15:04:07Z Message: Not started Name: StageBackup Message: Not started Name: StageRestore Message: Not started Name: DirectImage Message: Not started Name: DirectVolume Message: Not started Name: Restore Message: Not started Name: Cleanup Start Timestamp: 2021-02-02T15:03:18Z Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Running 57s migmigration_controller Step: 2/47 Normal Running 57s migmigration_controller Step: 3/47 Normal Running 57s (x3 over 57s) migmigration_controller Step: 4/47 Normal Running 54s migmigration_controller Step: 5/47 Normal Running 54s migmigration_controller Step: 6/47 Normal Running 52s (x2 over 53s) migmigration_controller Step: 7/47 Normal Running 51s (x2 over 51s) migmigration_controller Step: 8/47 Normal Ready 50s (x12 over 57s) migmigration_controller The migration is ready. Normal Running 50s migmigration_controller Step: 9/47 Normal Running 50s migmigration_controller Step: 10/47
9.2.5. Migration d’état
Vous pouvez effectuer des migrations répétables, uniquement d'état, en utilisant Migration Toolkit for Containers (MTC) pour migrer les réclamations de volumes persistants (PVC) qui constituent l'état d'une application. Vous migrez des PVC spécifiés en excluant d'autres PVC du plan de migration. Vous pouvez mapper les PVC pour vous assurer que les PVC source et cible sont synchronisés. Les données des volumes persistants (PV) sont copiées sur le cluster cible. Les références PV ne sont pas déplacées et les pods d'application continuent de fonctionner sur le cluster source.
La migration d'état est spécifiquement conçue pour être utilisée en conjonction avec des mécanismes de CD externes, tels que OpenShift Gitops. Vous pouvez migrer les manifestes d'application à l'aide de GitOps tout en migrant l'état à l'aide de MTC.
Si vous disposez d’un pipeline CI/CD, vous pouvez migrer les composants sans état en les déployant sur le cluster cible. Ensuite, vous pouvez migrer les composants avec état en utilisant MTC.
Vous pouvez effectuer une migration d’état entre des clusters ou au sein d’un même cluster.
La migration d’état ne fait migrer que les composants qui constituent l’état d’une application. Si vous souhaitez migrer un espace de nommage complet, utilisez la migration par étapes ou à basculement.
Conditions préalables
-
L'état de l'application sur le cluster source est conservé dans
PersistentVolumesprovisionné viaPersistentVolumeClaims. - Les manifestes de l'application sont disponibles dans un référentiel central accessible à partir des clusters source et cible.
Procédure
Migrer les données des volumes persistants du cluster source vers le cluster cible.
Vous pouvez effectuer cette étape autant de fois que nécessaire. L'application source continue de fonctionner.
Mettre en pause l'application source.
Vous pouvez le faire en définissant les répliques des ressources de charge de travail à
0, soit directement sur le cluster source, soit en mettant à jour les manifestes dans GitHub et en resynchronisant l'application Argo CD.Cloner les manifestes de l'application sur le cluster cible.
Vous pouvez utiliser Argo CD pour cloner les manifestes d'application sur le cluster cible.
Migrer les données de volume restantes de la source vers le cluster cible.
Migrer toutes les nouvelles données créées par l'application au cours du processus de migration des états en effectuant une migration finale des données.
- Si l'application clonée est en état d'arrêt, il faut l'arrêter.
- Basculer l'enregistrement DNS vers le cluster cible pour rediriger le trafic utilisateur vers l'application migrée.
MTC 1.6 ne peut pas mettre les applications en veille automatiquement lors de la migration des états. Il ne peut migrer que les données PV. Par conséquent, vous devez utiliser vos mécanismes CD pour la mise en veille ou l'arrêt des applications.
MTC 1.7 introduit les flux explicites Stage et Cutover. Vous pouvez utiliser la mise en scène pour effectuer des transferts de données initiaux autant de fois que nécessaire. Vous pouvez ensuite procéder à un basculement, au cours duquel les applications sources sont mises en veille automatiquement.
Conditions préalables
-
L'état de l'application sur le cluster source est conservé dans
PersistentVolumesprovisionné viaPersistentVolumeClaims. - Les manifestes de l'application sont disponibles dans un référentiel central accessible à partir des clusters source et cible.
Procédure
Migrer les données des volumes persistants du cluster source vers le cluster cible.
Vous pouvez effectuer cette étape autant de fois que nécessaire. L'application source continue de fonctionner.
Mettre en pause l'application source.
Vous pouvez le faire en définissant les répliques des ressources de charge de travail à
0, soit directement sur le cluster source, soit en mettant à jour les manifestes dans GitHub et en resynchronisant l'application Argo CD.Cloner les manifestes de l'application sur le cluster cible.
Vous pouvez utiliser Argo CD pour cloner les manifestes d'application sur le cluster cible.
Migrer les données de volume restantes de la source vers le cluster cible.
Migrer toutes les nouvelles données créées par l'application au cours du processus de migration des états en effectuant une migration finale des données.
- Si l'application clonée est en état d'arrêt, il faut l'arrêter.
- Basculer l'enregistrement DNS vers le cluster cible pour rediriger le trafic utilisateur vers l'application migrée.
MTC 1.6 ne peut pas mettre les applications en veille automatiquement lors de la migration des états. Il ne peut migrer que les données PV. Par conséquent, vous devez utiliser vos mécanismes CD pour la mise en veille ou l'arrêt des applications.
MTC 1.7 introduit les flux explicites Stage et Cutover. Vous pouvez utiliser la mise en scène pour effectuer des transferts de données initiaux autant de fois que nécessaire. Vous pouvez ensuite procéder à un basculement, au cours duquel les applications sources sont mises en veille automatiquement.
Ressources supplémentaires
- Voir Exclure des PVC de la migration pour sélectionner des PVC pour la migration d'état.
- Voir Mappage des PVC pour migrer les données PV source vers des PVC provisionnés sur le cluster de destination.
- Voir Migrer les objets Kubernetes pour migrer les objets Kubernetes qui constituent l'état d'une application.
9.3. Scripts de migration automatiques
Vous pouvez ajouter jusqu’à quatre scripts de migration automatiques à un seul plan de migration, chaque script s’exécutant alors lors d’une phase différente de la migration. Les scripts de migration automatiques exécutent des tâches telles que la personnalisation de la quiescence des applications, la migration manuelle des types de données non pris en charge et la mise à jour des applications après la migration.
Un script de migration automatique s’exécute sur un cluster source ou cible lors de l’une des étapes de migration suivantes :
-
PreBackup: avant la sauvegarde des ressources sur le cluster source. -
PostBackup: après la sauvegarde des ressources sur le cluster source. -
PreRestore: avant la restauration des ressources sur le cluster cible. -
PostRestore: après la restauration des ressources sur le cluster cible.
Vous pouvez créer un script automatique en créant un playbook Ansible qui s’exécute avec l’image Ansible par défaut ou avec un conteneur de scripts automatiques personnalisé.
Playbook Ansible
Le playbook Ansible est monté sur un conteneur de scripts automatiques en tant qu’objet ConfigMap. Ce conteneur s’exécute comme une tâche, en utilisant le cluster, le compte de service et l’espace de nommage spécifiés dans la ressource personnalisée MigPlan. L’exécution de la tâche se poursuit jusqu’à ce que la limite par défaut de 6 tentatives soit atteinte ou que l’opération soit terminée correctement. L’opération se poursuit même si le pod initial est évincé ou supprimé.
L'image d'exécution Ansible par défaut est registry.redhat.io/rhmtc/openshift-migration-hook-runner-rhel7:1.7. Cette image est basée sur l’image Ansible Runner et inclut python-openshift pour les ressources Ansible Kubernetes, ainsi qu’un binaire oc mis à jour.
Conteneur de scripts automatiques personnalisé
Vous pouvez utiliser un conteneur de scripts automatiques personnalisé au lieu de l’image Ansible par défaut.
9.3.1. Écriture d’un playbook Ansible pour un script de migration automatique
Vous pouvez écrire un playbook Ansible à utiliser comme script de migration automatique. Le script automatique est ajouté à un plan de migration en utilisant la console Web MTC ou en spécifiant des valeurs pour les paramètres spec.hooks dans le manifeste de la ressource personnalisée (CR) MigPlan.
Le playbook Ansible est monté sur un conteneur de scripts automatiques en tant qu’objet ConfigMap. Ce conteneur s’exécute comme une tâche, en utilisant le cluster, le compte de service et l’espace de nommage spécifiés dans la ressource personnalisée MigPlan. Le conteneur de scripts automatiques utilise un token de compte de service spécifié afin que les tâches ne doivent pas être authentifiées avant leur exécution dans le cluster.
9.3.1.1. Modules Ansible
Vous pouvez utiliser le module Ansible shell pour exécuter des commandes oc.
Exemple de module shell
- hosts: localhost
gather_facts: false
tasks:
- name: get pod name
shell: oc get po --all-namespaces
Vous pouvez utiliser des modules kubernetes.core, tels que k8s_info, pour interagir avec les ressources Kubernetes.
Exemple de module k8s_facts
- hosts: localhost
gather_facts: false
tasks:
- name: Get pod
k8s_info:
kind: pods
api: v1
namespace: openshift-migration
name: "{{ lookup( 'env', 'HOSTNAME') }}"
register: pods
- name: Print pod name
debug:
msg: "{{ pods.resources[0].metadata.name }}"
Vous pouvez utiliser le module fail pour produire un état de sortie non nul dans les cas où un tel état ne serait normalement pas produit, garantissant ainsi la détection du succès ou de l’échec d’un script automatique. Les scripts automatiques s’exécutent comme des tâches, et leur état de réussite ou d’échec est basé sur l’état de sortie du conteneur de tâches.
Exemple de module fail
- hosts: localhost
gather_facts: false
tasks:
- name: Set a boolean
set_fact:
do_fail: true
- name: "fail"
fail:
msg: "Cause a failure"
when: do_fail
9.3.1.2. Variables d’environnement
Le nom du CR MigPlan et les espaces de noms de la migration sont transmis en tant que variables d'environnement au conteneur de crochets. Ces variables sont accessibles à l'aide du plugin lookup.
Exemples de variables d’environnement
- hosts: localhost
gather_facts: false
tasks:
- set_fact:
namespaces: "{{ (lookup( 'env', 'MIGRATION_NAMESPACES')).split(',') }}"
- debug:
msg: "{{ item }}"
with_items: "{{ namespaces }}"
- debug:
msg: "{{ lookup( 'env', 'MIGRATION_PLAN_NAME') }}"
9.4. Options du plan de migration
Vous pouvez exclure, modifier et mapper des composants dans la ressource personnalisée (CR) MigPlan.
9.4.1. Exclusion de ressources
Vous pouvez exclure des ressources (comme des flux d’images, des volumes persistants ou des abonnements) d’un plan de migration Migration Toolkit for Containers (MTC) afin de réduire la charge des ressources à migrer, ou pour migrer des images ou des PV avec un autre outil.
Par défaut, MTC exclut les ressources du catalogue de services et les ressources OLM (Operator Lifecycle Manager) de la migration. Ces ressources font partie du groupe d’API du catalogue de services et du groupe d’API OLM, dont aucune n’est prise en charge pour la migration actuellement.
Procédure
Modifiez le manifeste de ressources personnalisées
MigrationController:$ oc edit migrationcontroller <migration_controller> -n openshift-migration
Mettez à jour la section
specen ajoutant des paramètres pour exclure des ressources spécifiques. Pour les ressources qui ne disposent pas de leurs propres paramètres d'exclusion, ajoutez le paramètreadditional_excluded_resources:apiVersion: migration.openshift.io/v1alpha1 kind: MigrationController metadata: name: migration-controller namespace: openshift-migration spec: disable_image_migration: true 1 disable_pv_migration: true 2 additional_excluded_resources: 3 - resource1 - resource2 ...
- 1
- Ajoutez
disable_image_migration: truepour exclure les flux d’images de la migration.imagestreamsest ajouté à la liste desressources excluesdansmain.ymllorsque le podMigrationControllerredémarre. - 2
- Ajoutez
disable_pv_migration: truepour exclure les volumes persistants du plan de migration.persistentvolumesetpersistentvolumeclaimssont ajoutés à la listeexcluded_resourcesdansmain.ymllorsque le podMigrationControllerredémarre. La désactivation de la migration des volumes persistants désactive également leur découverte lorsque vous créez le plan de migration. - 3
- Vous pouvez ajouter les ressources OpenShift Container Platform que vous souhaitez exclure à la liste
additional_excluded_resources.
-
Attendez deux minutes pour que le pod
MigrationControllerredémarre afin que les modifications soient appliquées. Vérifiez que la ressource est exclue :
$ oc get deployment -n openshift-migration migration-controller -o yaml | grep EXCLUDED_RESOURCES -A1
La sortie contient les ressources exclues :
Exemple de sortie
name: EXCLUDED_RESOURCES value: resource1,resource2,imagetags,templateinstances,clusterserviceversions,packagemanifests,subscriptions,servicebrokers,servicebindings,serviceclasses,serviceinstances,serviceplans,imagestreams,persistentvolumes,persistentvolumeclaims
9.4.2. Mappage des espaces de nommage
Si vous mappez des espaces de nommage dans la ressource personnalisée (CR) MigPlan, vous devez vous assurer qu’ils ne sont pas dupliqués sur les clusters source ou de destination, car les plages UID et GID des espaces de nommage sont copiées pendant la migration.
Deux espaces de nommage source mappés sur le même espace de nommage de destination
spec:
namespaces:
- namespace_2
- namespace_1:namespace_2
Si vous souhaitez que l’espace de nommage source soit mappé sur un espace de nommage du même nom, il n’est pas nécessaire de créer un mappage. Par défaut, les espaces de nommage source et cible ont le même nom.
Mappage incorrect des espaces de nommage
spec:
namespaces:
- namespace_1:namespace_1
Référence correcte à l’espace de nommage
spec:
namespaces:
- namespace_1
9.4.3. Exclusion des revendications de volumes persistants (PVC)
Pour sélectionner des revendications de volumes persistants (PVC) pour la migration d’état, vous devez exclure celles que vous ne souhaitez pas migrer. Pour exclure des PVC, définissez le paramètre spec.persistentVolumes.pvc.selection.action de la ressource personnalisée (CR) MigPlan après la découverte des volumes persistants (PV).
Conditions préalables
-
La ressource personnalisée
MigPlanse trouve dans l’étatReady.
Procédure
Ajoutez le paramètre
spec.persistentVolumes.pvc.selection.actionà la ressource personnaliséeMigPlanet définissez-le surskip:apiVersion: migration.openshift.io/v1alpha1 kind: MigPlan metadata: name: <migplan> namespace: openshift-migration spec: ... persistentVolumes: - capacity: 10Gi name: <pv_name> pvc: ... selection: action: skip
9.4.4. Mappage de revendications de volumes persistants
Vous pouvez migrer les données de volume persistant (PV) du cluster source vers des revendications de volumes persistants (PVC) qui ont déjà été mises en service dans le cluster de destination de la ressource personnalisée MigPlan en mappant les PVC. Ce mappage garantit la synchronisation des PVC de destination des applications migrées avec les PVC sources.
Pour mapper les PVC, mettez à jour le paramètre spec.persistentVolumes.pvc.name dans la ressource personnalisée (CR) MigPlan après la découverte des volumes persistants.
Conditions préalables
-
La ressource personnalisée
MigPlanse trouve dans l’étatReady.
Procédure
Mettre à jour le paramètre
spec.persistentVolumes.pvc.namedans la ressource personnaliséeMigPlan:apiVersion: migration.openshift.io/v1alpha1 kind: MigPlan metadata: name: <migplan> namespace: openshift-migration spec: ... persistentVolumes: - capacity: 10Gi name: <pv_name> pvc: name: <source_pvc>:<destination_pvc> 1- 1
- Spécifiez la PVC sur le cluster source et celle sur le cluster de destination. Si la PVC de destination n’existe pas, elle sera créée. Vous pouvez utiliser ce mappage pour renommer la PVC lors de la migration.
9.4.5. Modification des attributs des volumes persistants
Une fois que vous avez créé une ressource personnalisée (CR) MigPlan, la CR MigrationController découvre les volumes persistants (PV). Le bloc spec.persistentVolumes et le bloc status.destStorageClasses sont ajoutés à la ressource personnalisée MigPlan.
Vous pouvez modifier les valeurs du bloc spec.persistentVolumes.selection. Si vous modifiez les valeurs en dehors du bloc spec.persistentVolumes.selection, elles sont écrasées lorsque la CR MigPlan est rapprochée par la CR MigrationController.
La valeur par défaut du paramètre spec.persistentVolumes.selection.storageClass est déterminée par la logique suivante :
-
Si le volume persistant du cluster source est Gluster ou NFS, la valeur par défaut est soit
cephfs, pouraccessMode: ReadWriteMany, soitcephrbd, pouraccessMode: ReadWriteOnce. -
Si le volume persistant n’est ni Gluster ni NFS ou si
cephfsoucephrbdn’est pas disponible, la valeur par défaut est une classe de stockage pour le même fournisseur. - Si une classe de stockage pour le même fournisseur n’est pas disponible, la valeur par défaut est la classe de stockage par défaut du cluster de destination.
Vous pouvez remplacer la valeur storageClass par la valeur de n’importe quel paramètre name dans le bloc status.destStorageClasses de la ressource personnalisée MigPlan.
Si la valeur storageClass est vide, aucune classe de stockage ne sera associée au volume persistant après la migration. Cette option est appropriée si, par exemple, vous voulez déplacer le volume persistant vers un volume NFS sur le cluster de destination.
Conditions préalables
-
La ressource personnalisée
MigPlanse trouve dans l’étatReady.
Procédure
Modifiez les valeurs
spec.persistentVolumes.selectiondans la ressource personnaliséeMigPlan:apiVersion: migration.openshift.io/v1alpha1 kind: MigPlan metadata: name: <migplan> namespace: openshift-migration spec: persistentVolumes: - capacity: 10Gi name: pvc-095a6559-b27f-11eb-b27f-021bddcaf6e4 proposedCapacity: 10Gi pvc: accessModes: - ReadWriteMany hasReference: true name: mysql namespace: mysql-persistent selection: action: <copy> 1 copyMethod: <filesystem> 2 verify: true 3 storageClass: <gp2> 4 accessMode: <ReadWriteMany> 5 storageClass: cephfs- 1
- Les valeurs autorisées sont
move,copyetskip. Si une seule action est prise en charge, cette action est la valeur par défaut. Si plusieurs actions sont prises en charge, la valeur par défaut estcopy. - 2
- Les valeurs autorisées sont
snapshotetfilesystem. La valeur par défaut estfilesystem. - 3
- Le paramètre
verifyest affiché si vous sélectionnez l’option de vérification pour la copie du système de fichiers dans la console Web MTC. Vous pouvez le définir surfalse. - 4
- Vous pouvez remplacer la valeur par défaut par la valeur de n’importe quel paramètre
namedans le blocstatus.destStorageClassesde la ressource personnaliséeMigPlan. Si aucune valeur n’est spécifiée, aucune classe de stockage ne sera associée au volume persistant après la migration. - 5
- Les valeurs autorisées sont
ReadWriteOnceetReadWriteMany. Si cette valeur n’est pas spécifiée, la valeur par défaut est le mode d’accès du PVC du cluster source. Vous ne pouvez modifier le mode d’accès que dans la ressource personnaliséeMigPlan. Vous ne pouvez pas le modifier en utilisant la console Web MTC.
9.4.6. Conversion des classes de stockage dans la console web MTC
Vous pouvez convertir la classe de stockage d'un volume persistant (PV) en le migrant au sein du même cluster. Pour ce faire, vous devez créer et exécuter un plan de migration dans la console web Migration Toolkit for Containers (MTC).
Conditions préalables
-
Vous devez être connecté en tant qu'utilisateur disposant des privilèges
cluster-adminsur le cluster sur lequel MTC est exécuté. - Vous devez ajouter le cluster à la console web MTC.
Procédure
- Dans le volet de navigation de gauche de la console web OpenShift Container Platform, cliquez sur Projects.
Dans la liste des projets, cliquez sur votre projet.
La page Project details s'ouvre.
- Cliquez sur le nom DeploymentConfig. Notez le nom du pod en cours d'exécution.
- Ouvrez l'onglet YAML du projet. Trouvez les PV et notez les noms de leurs réclamations de volume persistantes (PVC) correspondantes.
- Dans la console Web MTC, cliquez sur Migration plans.
- Cliquez sur Add migration plan.
Saisissez le nom du plan dans le champ Plan name.
Le nom du plan de migration doit contenir de 3 à 63 caractères alphanumériques minuscules (
a-z, 0-9) et ne doit pas contenir d'espaces ni de traits de soulignement (_).- Dans le menu Migration type, sélectionnez Storage class conversion.
- Dans la liste Source cluster, sélectionnez le cluster souhaité pour la conversion de la classe de stockage.
Cliquez sur Next.
La page Namespaces s'ouvre.
- Sélectionnez le projet souhaité.
Cliquez sur Next.
La page Persistent volumes s'ouvre. La page affiche les PV du projet, tous sélectionnés par défaut.
- Pour chaque PV, sélectionnez la classe de stockage cible souhaitée.
Cliquez sur Next.
L'assistant valide le nouveau plan de migration et indique qu'il est prêt.
Cliquez sur Close.
Le nouveau plan apparaît sur la page Migration plans.
Pour lancer la conversion, cliquez sur le menu des options du nouveau plan.
Sous Migrations, deux options sont affichées, Stage et Cutover.
NoteLa migration de basculement met à jour les références PVC dans les applications.
La migration d'étape ne met pas à jour les références PVC dans les applications.
Sélectionnez l'option souhaitée.
Selon l'option choisie, la notification Stage migration ou Cutover migration apparaît.
Cliquez sur Migrate.
Selon l'option choisie, le message Stage started ou Cutover started apparaît.
Pour connaître l'état de la migration en cours, cliquez sur le numéro dans la colonne Migrations.
La page Migrations s'ouvre.
Pour obtenir plus de détails sur la migration en cours et suivre sa progression, sélectionnez la migration dans la colonne Type.
La page Migration details s'ouvre. Lorsque la migration progresse jusqu'à l'étape DirectVolume et que l'état de l'étape devient
Running Rsync Pods to migrate Persistent Volume data, vous pouvez cliquer sur View details et voir l'état détaillé des copies.- Dans le fil d'Ariane, cliquez sur Stage ou Cutover et attendez que toutes les étapes soient terminées.
Ouvrez l'onglet PersistentVolumeClaims de la console web OpenShift Container Platform.
Vous pouvez voir de nouveaux PVC avec les noms des PVC initiaux mais se terminant par
new, qui utilisent la classe de stockage cible.- Dans le volet de navigation de gauche, cliquez sur Pods. Constatez que le pod de votre projet fonctionne à nouveau.
Ressources supplémentaires
-
Pour plus d'informations sur les actions
moveetcopy, voir le flux de travail MTC. -
Pour plus de détails sur l'action
skip, voir Exclusion des PVC de la migration. - Pour plus d'informations sur les méthodes de copie du système de fichiers et des instantanés, voir À propos des méthodes de copie de données.
9.4.7. Effectuer une migration d'état des objets Kubernetes à l'aide de l'API MTC
Après avoir migré toutes les données PV, vous pouvez utiliser l'API Migration Toolkit for Containers (MTC) pour effectuer une migration d'état unique des objets Kubernetes qui constituent une application.
Pour ce faire, vous configurez les champs de ressources personnalisées (CR) MigPlan pour fournir une liste de ressources Kubernetes avec un sélecteur d'étiquettes supplémentaire pour filtrer davantage ces ressources, puis vous effectuez une migration en créant une CR MigMigration. La ressource MigPlan est fermée après la migration.
La sélection des ressources Kubernetes est une fonctionnalité réservée à l'API. Vous devez mettre à jour la CR MigPlan et créer une CR MigMigration pour elle à l'aide de la CLI. La console web MTC ne prend pas en charge la migration des objets Kubernetes.
Après la migration, le paramètre closed de la CR MigPlan est défini sur true. Vous ne pouvez pas créer une autre CR MigMigration pour cette CR MigPlan.
Vous ajoutez des objets Kubernetes à la CR MigPlan en utilisant l’une des options suivantes :
-
Ajout des objets Kubernetes à la section
includedResources. Lorsque le champincludedResourcesest spécifié dans le CRMigPlan, le plan prend une liste degroup-kinden entrée. Seules les ressources présentes dans la liste sont incluses dans la migration. -
Ajout du paramètre facultatif
labelSelectorpour filtrer les ressourcesincludedResourcesdans le champMigPlan. Lorsque ce champ est spécifié, seules les ressources correspondant au sélecteur d'étiquette sont incluses dans la migration. Par exemple, vous pouvez filtrer une liste de ressourcesSecretetConfigMapen utilisant l'étiquetteapp: frontendcomme filtre.
Procédure
Mettez à jour le CR
MigPlanpour inclure les ressources Kubernetes et, éventuellement, pour filtrer les ressources incluses en ajoutant le paramètrelabelSelector:Pour mettre à jour le CR
MigPlanafin d'inclure les ressources Kubernetes :apiVersion: migration.openshift.io/v1alpha1 kind: MigPlan metadata: name: <migplan> namespace: openshift-migration spec: includedResources: - kind: <kind> 1 group: "" - kind: <kind> group: ""- 1
- Indiquez l’objet Kubernetes ;
SecretouConfigMap, par exemple.
Facultatif : Pour filtrer les ressources incluses en ajoutant le paramètre
labelSelector:apiVersion: migration.openshift.io/v1alpha1 kind: MigPlan metadata: name: <migplan> namespace: openshift-migration spec: includedResources: - kind: <kind> 1 group: "" - kind: <kind> group: "" ... labelSelector: matchLabels: <label> 2
Créer un CR
MigMigrationpour migrer les ressources Kubernetes sélectionnées. Vérifiez que le bon siteMigPlanest référencé dansmigPlanRef:apiVersion: migration.openshift.io/v1alpha1 kind: MigMigration metadata: generateName: <migplan> namespace: openshift-migration spec: migPlanRef: name: <migplan> namespace: openshift-migration stage: false
9.5. Options du contrôleur de migration
Vous pouvez modifier les limites du plan de migration, activer le redimensionnement de volumes persistants ou activer les clients Kubernetes en cache dans la ressource personnalisée (CR) MigrationController pour les migrations à grande échelle et pour améliorer les performances.
9.5.1. Augmentation des limites pour les migrations à grande échelle
Vous pouvez augmenter les limites des objets de migration et des ressources du conteneur pour les migrations à grande échelle avec Migration Toolkit for Containers (MTC).
Vous devez tester ces modifications avant d’effectuer une migration dans un environnement de production.
Procédure
Modifiez le manifeste de la ressource personnalisée (CR)
MigrationController:$ oc edit migrationcontroller -n openshift-migration
Mettez à jour les paramètres suivants :
... mig_controller_limits_cpu: "1" 1 mig_controller_limits_memory: "10Gi" 2 ... mig_controller_requests_cpu: "100m" 3 mig_controller_requests_memory: "350Mi" 4 ... mig_pv_limit: 100 5 mig_pod_limit: 100 6 mig_namespace_limit: 10 7 ...
- 1
- Spécifie le nombre de processeurs disponibles pour la CR
MigrationController. - 2
- Spécifie la quantité de mémoire disponible pour la CR
MigrationController. - 3
- Spécifie le nombre d’unités centrales disponibles pour les demandes de CR
MigrationController.100mreprésente 0,1 unité centrale (100 * 1e-3). - 4
- Spécifie la quantité de mémoire disponible pour les demandes de CR
MigrationController. - 5
- Spécifie le nombre de volumes persistants qui peuvent être migrés.
- 6
- Spécifie le nombre de pods qui peuvent être migrés.
- 7
- Spécifie le nombre n’espaces de nommage qui peuvent être migrés.
Créez un plan de migration qui utilise les paramètres mis à jour pour vérifier les modifications.
Si votre plan de migration dépasse les limites de CR
MigrationController, la console MTC affiche un message d’avertissement lorsque vous enregistrez le plan.
9.5.2. Activation du redimensionnement des volumes persistants pour la migration directe des volumes
Vous pouvez activer le redimensionnement des volumes persistants (PV) pour la migration directe des volumes pour éviter de manquer d’espace disque sur le cluster de destination.
Lorsque l’utilisation du disque d’un PV atteint un niveau configuré, la ressource personnalisée (CR) MigrationController compare la capacité de stockage demandée d’une revendication de volume persistant (PVC) à sa capacité allouée réelle. Ensuite, il calcule l’espace requis sur le cluster de destination.
Un paramètre pv_resizing_threshold détermine à quel moment le redimensionnement des PV est utilisé. Le seuil par défaut est de 3%. Cela signifie que le redimensionnement des PV se produit lorsque l’utilisation du disque d’un PV est supérieure à 97%. Vous pouvez augmenter ce seuil afin que le redimensionnement des PV se produise à un niveau d’utilisation du disque plus faible.
La capacité de la PVC est calculée selon les critères suivants :
-
Si la capacité de stockage demandée (
spec.resources.requests.storage) de la PVC n’est pas égale à sa capacité mise en service réelle (status.capacity.storage), c’est la valeur la plus élevée qui est utilisée. - Si un volume persistant est mis en service via une PVC et qu’il est modifié par la suite, de sorte que ses capacités de PV et de PVC ne correspondent plus, c’est la valeur la plus élevée qui est utilisée.
Conditions préalables
-
Les PVC doivent être attachées à un ou plusieurs pods en cours d’exécution pour que la ressource personnalisée
MigrationControllerpuisse exécuter des commandes.
Procédure
- Connectez-vous au cluster hôte.
Activez le redimensionnement des PV en appliquant un correctif à la ressource personnalisée
MigrationController:$ oc patch migrationcontroller migration-controller -p '{"spec":{"enable_dvm_pv_resizing":true}}' \ 1 --type='merge' -n openshift-migration- 1
- Définissez la valeur sur
falsepour désactiver le redimensionnement des PV.
Facultatif : mettez à jour le paramètre
pv_resizing_thresholdpour augmenter le seuil :$ oc patch migrationcontroller migration-controller -p '{"spec":{"pv_resizing_threshold":41}}' \ 1 --type='merge' -n openshift-migration- 1
- La valeur par défaut est
3.
Lorsque le seuil est dépassé, le message d’état suivant est affiché dans l’état de la ressource personnalisée
MigPlan:status: conditions: ... - category: Warn durable: true lastTransitionTime: "2021-06-17T08:57:01Z" message: 'Capacity of the following volumes will be automatically adjusted to avoid disk capacity issues in the target cluster: [pvc-b800eb7b-cf3b-11eb-a3f7-0eae3e0555f3]' reason: Done status: "False" type: PvCapacityAdjustmentRequiredNotePour le stockage AWS gp2, ce message n’apparaît que si la valeur
pv_resizing_thresholdest supérieure ou égale à 42 % en raison de la manière dont gp2 calcule l’utilisation et la taille des volumes. (BZ#1973148)
9.5.3. Activation des clients Kubernetes en cache
Vous pouvez activer les clients Kubernetes mis en cache dans la ressource personnalisée (CR) MigrationController pour améliorer les performances pendant la migration. L’avantage le plus important en termes de performances se manifeste lors de la migration entre des clusters situés dans des régions différentes ou avec une latence importante du réseau.
Cependant, dans le cas des tâches déléguées (comme la sauvegarde Rsync pour la migration directe des volumes ou la sauvegarde et la restauration Velero), il n’y a pas d’amélioration des performances avec les clients en cache.
Les clients en cache ont besoin de plus de mémoire, car la CR MigrationController met en cache toutes les ressources API nécessaires pour interagir avec les CR MigCluster. Les demandes qui sont normalement envoyées au serveur d’API sont redirigées vers le cache à la place. Le cache surveille le serveur d’API pour les mises à jour.
Vous pouvez augmenter les limites de mémoire et les demandes de la CR MigrationController si des erreurs OOMKilled se produisent après avoir activé les clients en cache.
Procédure
Activez les clients en cache en exécutant la commande suivante :
$ oc -n openshift-migration patch migrationcontroller migration-controller --type=json --patch \ '[{ "op": "replace", "path": "/spec/mig_controller_enable_cache", "value": true}]'Facultatif : augmentez les limites de mémoire de la CR
MigrationControlleren exécutant la commande suivante :$ oc -n openshift-migration patch migrationcontroller migration-controller --type=json --patch \ '[{ "op": "replace", "path": "/spec/mig_controller_limits_memory", "value": <10Gi>}]'Facultatif : augmentez le nombre de requêtes de mémoire
MigrationControllerCR en exécutant la commande suivante :$ oc -n openshift-migration patch migrationcontroller migration-controller --type=json --patch \ '[{ "op": "replace", "path": "/spec/mig_controller_requests_memory", "value": <350Mi>}]'
Chapitre 10. Résolution de problèmes
Cette section décrit les ressources permettant de résoudre les problèmes affectant Migration Toolkit for Containers (MTC).
Pour les problèmes connus, voir les notes de mise à jour de MTC.
10.1. Flux de travail MTC
Vous pouvez migrer des ressources Kubernetes, des données de volumes persistants et des images de conteneurs internes vers OpenShift Container Platform 4.12 en utilisant la console web Migration Toolkit for Containers (MTC) ou l'API Kubernetes.
MTC fait migrer les ressources suivantes :
- Un espace de nommage spécifié dans un plan de migration.
Des ressources délimitées par l’espace de nommage : lorsque MTC migre un espace de nommage, il migre l’ensemble des objets et ressources qui y sont associés, comme les services ou les pods. De plus, si une ressource qui existe dans l’espace de nommage, mais pas au niveau du cluster, dépend d’une ressource existant au niveau du cluster, MTC migre les deux.
Par exemple, une contrainte de contexte de sécurité (SCC) est une ressource qui existe au niveau du cluster et un compte de service (SA) est une ressource qui existe au niveau de l'espace de noms. Si un SA existe dans un espace de noms que le MTC migre, le MTC localise automatiquement tous les SCC qui sont liés au SA et migre également ces SCC. De même, le CTM migre les volumes persistants qui sont liés aux revendications de volumes persistants de l'espace de noms.
NoteEn fonction de la ressource, il se peut que les ressources délimitées par le cluster doivent faire l’objet d’une migration manuelle.
- Ressources personnalisées (CR) et définitions de ressources personnalisées (CRD) : MTC migre automatiquement les CR et CRD au niveau de l’espace de nommage.
La procédure de migration d’une application à l’aide de la console Web MTC comprend les étapes suivantes :
Installez l’opérateur Migration Toolkit for Containers sur tous les clusters.
Vous pouvez installer l’opérateur Migration Toolkit for Containers dans un environnement restreint avec un accès Internet limité, voire aucun accès Internet. Les clusters source et cible doivent disposer d’un accès réseau entre eux et vers un registre miroir.
Configurez le référentiel de réplication, un stockage d’objets intermédiaire que MTC utilise pour la migration des données.
Les clusters source et cible doivent disposer d’un accès réseau au référentiel de réplication pendant la migration. Si vous utilisez un serveur mandateur, vous devez le configurer pour qu’il autorise le trafic réseau entre le référentiel de réplication et les clusters.
- Ajoutez le cluster source à la console Web MTC.
- Ajoutez le référentiel de réplication à la console Web MTC.
Créez un plan de migration, avec l’une des options de migration de données suivantes :
Copy : MTC copie les données du cluster source vers le référentiel de réplication, et du référentiel de réplication vers le cluster cible.
NoteSi vous utilisez la migration directe d’images ou de volumes, les images ou les volumes sont copiés directement du cluster source vers le cluster cible.
Move : MTC démonte un volume distant (NFS, par exemple) du cluster source, crée une ressource PV sur le cluster cible pointant vers le volume distant, puis monte le volume distant sur le cluster cible. Les applications qui s’exécutent sur le cluster cible utilisent le même volume distant que celui qui était utilisé par le cluster source. Le volume distant doit être accessible aux clusters source et cible.
NoteBien que le référentiel de réplication n’apparaisse pas dans ce diagramme, il est requis dans le cadre de la migration.
Exécutez le plan de migration, avec l’une des options suivantes :
L’option Stage copie les données vers le cluster cible sans arrêter l’application.
Une migration par étapes peut être exécutée plusieurs fois afin que la plupart des données soient copiées sur la cible avant la migration. L’exécution d’une ou plusieurs migrations par étapes réduit la durée de la migration à basculement.
L’option Cutover arrête l’application sur le cluster source et déplace les ressources vers le cluster cible.
Facultatif : vous pouvez décocher la case Halt transactions on the source cluster during migration.
À propos des ressources personnalisées de MTC
Migration Toolkit for Containers (MTC) crée les ressources personnalisées (CR) suivantes :
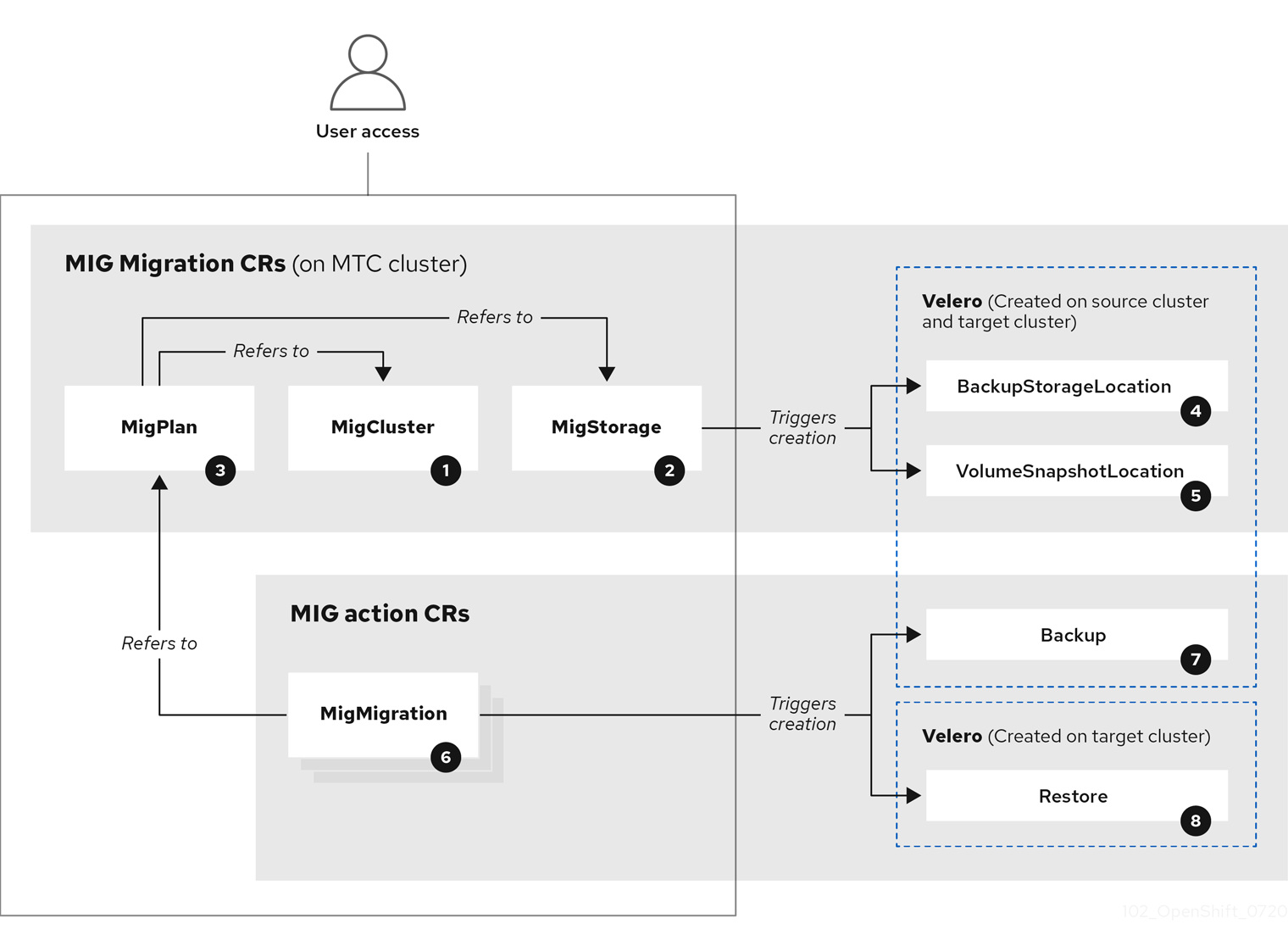
![]() MigCluster (configuration, cluster MTC) : Définition du cluster
MigCluster (configuration, cluster MTC) : Définition du cluster
![]() MigStorage (configuration, cluster MTC) : Définition du stockage
MigStorage (configuration, cluster MTC) : Définition du stockage
![]() MigPlan (configuration, cluster MTC) : Plan de migration
MigPlan (configuration, cluster MTC) : Plan de migration
La CR MigPlan décrit les clusters source et cible, le référentiel de réplication et les espaces de nommage en cours de migration. Elle est associée à 0, 1 ou plusieurs CR MigMigration.
La suppression d’une CR MigPlan supprime les CR MigMigration associées.
![]() BackupStorageLocation (configuration, cluster MTC) : Emplacement des objets de sauvegarde
BackupStorageLocation (configuration, cluster MTC) : Emplacement des objets de sauvegarde Velero
![]() VolumeSnapshotLocation (configuration, cluster MTC) : Emplacement des instantanés de volume
VolumeSnapshotLocation (configuration, cluster MTC) : Emplacement des instantanés de volume Velero
![]() MigMigration (action, cluster MTC) : Migration, créée chaque fois que vous mettez en scène ou migrez des données. Chaque CR
MigMigration (action, cluster MTC) : Migration, créée chaque fois que vous mettez en scène ou migrez des données. Chaque CR MigMigration est associé à un CR MigPlan.
![]() Sauvegarde (action, cluster source) : Lorsque vous exécutez un plan de migration, le CR
Sauvegarde (action, cluster source) : Lorsque vous exécutez un plan de migration, le CR MigMigration crée deux CR de sauvegarde Velero sur chaque cluster source :
- CR de sauvegarde n°1 pour les objets Kubernetes
- CR de sauvegarde n°2 pour les données de volume persistant
![]() Restauration (action, cluster cible) : Lorsque vous exécutez un plan de migration, le CR
Restauration (action, cluster cible) : Lorsque vous exécutez un plan de migration, le CR MigMigration crée deux CR de restauration Velero sur le cluster cible :
- CR de restauration n°1 (à l’aide de la CR de sauvegarde n°2) pour les données de volume persistant
- CR de restauration n°2 (à l’aide de la CR de sauvegarde n°1) pour les objets Kubernetes
10.2. Manifestes de ressources personnalisées MTC
Migration Toolkit for Containers (MTC) utilise les manifestes de ressources personnalisées (CR) suivants pour faire migrer les applications.
10.2.1. DirectImageMigration
La CR DirectImageMigration copie directement les images du cluster source vers le cluster de destination.
apiVersion: migration.openshift.io/v1alpha1
kind: DirectImageMigration
metadata:
labels:
controller-tools.k8s.io: "1.0"
name: <direct_image_migration>
spec:
srcMigClusterRef:
name: <source_cluster>
namespace: openshift-migration
destMigClusterRef:
name: <destination_cluster>
namespace: openshift-migration
namespaces: 1
- <source_namespace_1>
- <source_namespace_2>:<destination_namespace_3> 210.2.2. DirectImageStreamMigration
La CR DirectImageStreamMigration copie directement les références de flux d’images du cluster source vers le cluster de destination.
apiVersion: migration.openshift.io/v1alpha1
kind: DirectImageStreamMigration
metadata:
labels:
controller-tools.k8s.io: "1.0"
name: <direct_image_stream_migration>
spec:
srcMigClusterRef:
name: <source_cluster>
namespace: openshift-migration
destMigClusterRef:
name: <destination_cluster>
namespace: openshift-migration
imageStreamRef:
name: <image_stream>
namespace: <source_image_stream_namespace>
destNamespace: <destination_image_stream_namespace>10.2.3. DirectVolumeMigration
La CR DirectVolumeMigration copie directement les volumes persistants (PV) du cluster source vers le cluster de destination.
apiVersion: migration.openshift.io/v1alpha1 kind: DirectVolumeMigration metadata: name: <direct_volume_migration> namespace: openshift-migration spec: createDestinationNamespaces: false 1 deleteProgressReportingCRs: false 2 destMigClusterRef: name: <host_cluster> 3 namespace: openshift-migration persistentVolumeClaims: - name: <pvc> 4 namespace: <pvc_namespace> srcMigClusterRef: name: <source_cluster> namespace: openshift-migration
- 1
- Défini sur
truepour créer des espaces de nommage pour les PV sur le cluster de destination. - 2
- Défini sur
truepour supprimer les CRDirectVolumeMigrationProgressaprès la migration. La valeur par défaut estfalseafin que les CRDirectVolumeMigrationProgresssoient conservés pour la résolution des problèmes. - 3
- Mettez à jour le nom du cluster si le cluster de destination n’est pas le cluster hôte.
- 4
- Indiquez une ou plusieurs PVC à migrer.
10.2.4. DirectVolumeMigrationProgress
La CR DirectVolumeMigrationProgress affiche la progression de la CR DirectVolumeMigration.
apiVersion: migration.openshift.io/v1alpha1
kind: DirectVolumeMigrationProgress
metadata:
labels:
controller-tools.k8s.io: "1.0"
name: <direct_volume_migration_progress>
spec:
clusterRef:
name: <source_cluster>
namespace: openshift-migration
podRef:
name: <rsync_pod>
namespace: openshift-migration10.2.5. MigAnalytic
La CR MigAnalytic collecte le nombre d’images, les ressources Kubernetes et la capacité du volume persistant (PV) à partir d’une CR MigPlan associée.
Vous pouvez configurer les données qu’elle collecte.
apiVersion: migration.openshift.io/v1alpha1
kind: MigAnalytic
metadata:
annotations:
migplan: <migplan>
name: <miganalytic>
namespace: openshift-migration
labels:
migplan: <migplan>
spec:
analyzeImageCount: true 1
analyzeK8SResources: true 2
analyzePVCapacity: true 3
listImages: false 4
listImagesLimit: 50 5
migPlanRef:
name: <migplan>
namespace: openshift-migration- 1
- Facultatif : renvoie le nombre d’images.
- 2
- Facultatif : renvoie le numéro, le type et la version de l’API des ressources Kubernetes.
- 3
- Facultatif : renvoie la capacité du volume persistant (PV).
- 4
- Renvoie une liste de noms d’images. La valeur par défaut est
falseafin que la sortie ne soit pas excessivement longue. - 5
- Facultatif : indiquez le nombre maximum de noms d’images à renvoyer si
listImagesest défini surtrue.
10.2.6. MigCluster
La CR MigCluster définit un cluster hôte, local ou distant.
apiVersion: migration.openshift.io/v1alpha1
kind: MigCluster
metadata:
labels:
controller-tools.k8s.io: "1.0"
name: <host_cluster> 1
namespace: openshift-migration
spec:
isHostCluster: true 2
# The 'azureResourceGroup' parameter is relevant only for Microsoft Azure.
azureResourceGroup: <azure_resource_group> 3
caBundle: <ca_bundle_base64> 4
insecure: false 5
refresh: false 6
# The 'restartRestic' parameter is relevant for a source cluster.
restartRestic: true 7
# The following parameters are relevant for a remote cluster.
exposedRegistryPath: <registry_route> 8
url: <destination_cluster_url> 9
serviceAccountSecretRef:
name: <source_secret> 10
namespace: openshift-config- 1
- Mettez à jour le nom du cluster si le pod
migration-controllern’est pas en cours d’exécution sur ce cluster. - 2
- Le pod
migration-controllers’exécute sur ce cluster si la valeur est définie surtrue. - 3
- Microsoft Azure uniquement : indiquez le groupe de ressources.
- 4
- Facultatif : si vous avez créé un fichier de groupement de certificats pour les certificats CA auto-signés et si la valeur du paramètre
insecureestfalse, spécifiez le fichier de groupement de certificats codé en Base64. - 5
- Définissez la valeur sur
truepour désactiver la vérification SSL. - 6
- Définissez la valeur sur
truepour valider le cluster. - 7
- Définissez la valeur sur
truepour redémarrer les podsResticsur le cluster source après la création des podsStage. - 8
- Uniquement pour le cluster distant et la migration directe d’images : indiquez le chemin du registre sécurisé exposé.
- 9
- Cluster distant uniquement : indiquez l’URL.
- 10
- Cluster distant uniquement : indiquez le nom de l’objet
Secret.
10.2.7. MigHook
La ressource personnalisée (CR) MigHook définit un script de migration automatique qui exécute un code personnalisé à une étape spécifique de la migration. Vous pouvez créer jusqu’à quatre scripts de ce type. Chaque script automatique s’exécute au cours d’une phase différente de la migration.
Vous pouvez configurer le nom du script automatique, la durée d’exécution, une image personnalisée et le cluster où le script en question sera exécuté.
Les phases de migration et les espaces de nommage des scripts automatiques sont configurés dans la CR MigPlan.
apiVersion: migration.openshift.io/v1alpha1 kind: MigHook metadata: generateName: <hook_name_prefix> 1 name: <mighook> 2 namespace: openshift-migration spec: activeDeadlineSeconds: 1800 3 custom: false 4 image: <hook_image> 5 playbook: <ansible_playbook_base64> 6 targetCluster: source 7
- 1
- Facultatif : un hachage unique est ajouté à la valeur de ce paramètre afin que chaque script de migration automatique ait un nom unique. Il n’est pas nécessaire de spécifier la valeur du paramètre
name. - 2
- Indiquez le nom du script de migration automatique, à moins que vous ne spécifiiez la valeur du paramètre
generateName. - 3
- Facultatif : indiquez le nombre maximum de secondes pendant lesquelles un script automatique peut être exécuté. La valeur par défaut est
1800. - 4
- Le script automatique est une image personnalisée si la valeur est définie sur
true. L’image personnalisée peut inclure Ansible ou être écrite dans un autre langage de programmation. - 5
- Spécifiez l’image personnalisée ;
quay.io/konveyor/hook-runner:latest, par exemple. Requis si le paramètrecustomest défini surtrue. - 6
- Playbook Ansible codé en base64. Requis si le paramètre
customest défini surfalse. - 7
- Indiquez le cluster sur lequel le script automatique sera exécuté. La valeur valide est
sourceoudestination.
10.2.8. MigMigration
La CR MigMigration exécute une CR MigPlan.
Vous pouvez configurer une CR MigMigration pour exécuter une migration par étapes ou incrémentielle, pour annuler une migration en cours ou pour annuler une migration terminée.
apiVersion: migration.openshift.io/v1alpha1
kind: MigMigration
metadata:
labels:
controller-tools.k8s.io: "1.0"
name: <migmigration>
namespace: openshift-migration
spec:
canceled: false 1
rollback: false 2
stage: false 3
quiescePods: true 4
keepAnnotations: true 5
verify: false 6
migPlanRef:
name: <migplan>
namespace: openshift-migration- 1
- Défini sur
truepour annuler une migration en cours. - 2
- Défini sur
truepour annuler une migration terminée. - 3
- Défini sur
truepour exécuter une migration par étapes. Les données sont copiées de manière incrémentielle et les pods du cluster source ne sont pas arrêtés. - 4
- Défini sur
truepour arrêter l’application pendant la migration. Les pods du cluster source sont mis à l’échelle sur0après l’étapeBackup. - 5
- Défini sur
truepour conserver les étiquettes et les annotations appliquées pendant la migration. - 6
- Défini sur
truepour s’assurer que l’état des pods migrés sur le cluster de destination est vérifié et pour renvoyer les noms des pods qui ne se trouvent pas dans l’étatRunning.
10.2.9. MigPlan
La CR MigPlan définit les paramètres d’un plan de migration.
Vous pouvez configurer des espaces de nommage de destination, des phases de script automatique et une migration directe ou indirecte.
Par défaut, l’espace de nommage de destination porte le même nom que l’espace de nommage source. Si vous configurez un espace de nommage de destination différent, vous devez vous assurer que les espaces de nommage ne sont pas dupliqués sur les clusters source ou de destination, car les plages UID et GID sont copiées pendant la migration.
apiVersion: migration.openshift.io/v1alpha1
kind: MigPlan
metadata:
labels:
controller-tools.k8s.io: "1.0"
name: <migplan>
namespace: openshift-migration
spec:
closed: false 1
srcMigClusterRef:
name: <source_cluster>
namespace: openshift-migration
destMigClusterRef:
name: <destination_cluster>
namespace: openshift-migration
hooks: 2
- executionNamespace: <namespace> 3
phase: <migration_phase> 4
reference:
name: <hook> 5
namespace: <hook_namespace> 6
serviceAccount: <service_account> 7
indirectImageMigration: true 8
indirectVolumeMigration: false 9
migStorageRef:
name: <migstorage>
namespace: openshift-migration
namespaces:
- <source_namespace_1> 10
- <source_namespace_2>
- <source_namespace_3>:<destination_namespace_4> 11
refresh: false 12- 1
- La migration est terminée si le paramètre est défini sur
true. Vous ne pouvez pas créer une autre CRMigMigrationpour cette CRMigPlan. - 2
- Facultatif : vous pouvez spécifier jusqu’à quatre scripts de migration automatiques. Chaque script automatique doit être exécuté pendant une phase différente de la migration.
- 3
- Facultatif : indiquez l’espace de nommage dans lequel le script automatique sera exécuté.
- 4
- Facultatif : indiquez la phase de migration au cours de laquelle un script automatique s’exécute. Un script automatique peut être affecté à une seule phase. Les valeurs valides sont
PreBackup,PostBackup,PreRestoreetPostRestore. - 5
- Facultatif : indiquez le nom de la CR
MigHook. - 6
- Facultatif : indiquez l’espace de nommage de la CR
MigHook. - 7
- Facultatif : indiquez un compte de service avec les privilèges
cluster-admin. - 8
- La migration directe des images est désactivée si le paramètre est défini sur
true. Les images sont copiées du cluster source vers le référentiel de réplication et du référentiel de réplication vers le cluster de destination. - 9
- La migration directe des volumes est désactivée si le paramètre est défini sur
true. Les volumes persistants (PV) sont copiés du cluster source vers le référentiel de réplication et du référentiel de réplication vers le cluster de destination. - 10
- Indiquez un ou plusieurs espaces de nommage sources. Si vous ne spécifiez que l’espace de nommage source, l’espace de nommage de destination est le même.
- 11
- Indiquez l’espace de nommage de destination s’il est différent de l’espace source.
- 12
- La CR
MigPlanest validée si le paramètre est défini surtrue.
10.2.10. MigStorage
La CR MigStorage décrit le stockage d’objets pour le référentiel de réplication.
Amazon Web Services (AWS), Microsoft Azure, Google Cloud Storage, Multi-Cloud Object Gateway et le stockage cloud générique compatible S3 sont pris en charge.
AWS et la méthode de copie de cliché ont des paramètres supplémentaires.
apiVersion: migration.openshift.io/v1alpha1
kind: MigStorage
metadata:
labels:
controller-tools.k8s.io: "1.0"
name: <migstorage>
namespace: openshift-migration
spec:
backupStorageProvider: <backup_storage_provider> 1
volumeSnapshotProvider: <snapshot_storage_provider> 2
backupStorageConfig:
awsBucketName: <bucket> 3
awsRegion: <region> 4
credsSecretRef:
namespace: openshift-config
name: <storage_secret> 5
awsKmsKeyId: <key_id> 6
awsPublicUrl: <public_url> 7
awsSignatureVersion: <signature_version> 8
volumeSnapshotConfig:
awsRegion: <region> 9
credsSecretRef:
namespace: openshift-config
name: <storage_secret> 10
refresh: false 11- 1
- Indiquez le fournisseur de stockage.
- 2
- Méthode de copie de cliché uniquement : indiquez le fournisseur de stockage.
- 3
- AWS uniquement : indiquez le nom du compartiment.
- 4
- AWS uniquement : indiquez la région du compartiment ;
us-east-1, par exemple. - 5
- Indiquez le nom de l’objet
Secretque vous avez créé pour le stockage. - 6
- AWS uniquement : si vous utilisez AWS Key Management Service (AWS KMS), indiquez l’identifiant unique de la clé.
- 7
- AWS uniquement : si vous avez accordé un accès public au compartiment AWS, indiquez son URL.
- 8
- AWS uniquement : indiquez la version de la signature AWS pour l’authentification des demandes adressées au compartiment ;
4, par exemple. - 9
- Méthode de copie de cliché uniquement : indiquez la région géographique des clusters.
- 10
- Méthode de copie de cliché uniquement : indiquez le nom de l’objet
Secretque vous avez créé pour le stockage. - 11
- Définissez la valeur sur
truepour valider le cluster.
10.3. Journaux et outils de débogage
Cette section décrit les journaux et outils de débogage que vous pouvez utiliser dans le cadre de la résolution des problèmes.
10.3.1. Affichage des ressources du plan de migration
Vous pouvez afficher les ressources du plan de migration pour surveiller une migration en cours ou pour résoudre un échec de migration en utilisant la console Web MTC et l’interface de ligne de commande (CLI).
Procédure
- Dans la console Web MTC, cliquez sur Migration Plans.
- Cliquez sur le numéro Migrations en regard d’un plan de migration pour afficher la page Migrations.
- Cliquez sur une migration pour en afficher les détails (Migration details).
Développez Migration resources pour afficher les ressources de migration et leur état dans une arborescence.
NotePour résoudre un échec de migration, commencez par une ressource de haut niveau qui a échoué, puis descendez dans l’arborescence vers les ressources de niveau inférieur.
Cliquez sur le menu Options
à côté d'une ressource et sélectionnez l'une des options suivantes :
La commande Copy
oc describecopie la commande dans votre presse-papiers.Connectez-vous au cluster concerné, puis exécutez la commande.
Les conditions et les événements de la ressource sont affichés au format YAML.
La commande Copy
oc logscopie la commande dans votre presse-papiers.Connectez-vous au cluster concerné, puis exécutez la commande.
Si la ressource prend en charge le filtrage des journaux, un journal filtré est affiché.
View JSON affiche les données de la ressource au format JSON dans un navigateur Web.
Les données sont les mêmes que celles de la sortie de la commande
oc get <resource>.
10.3.2. Consultation d’un journal de plan de migration
Vous pouvez consulter un journal agrégé pour un plan de migration. Utilisez la console Web MTC pour copier une commande dans le presse-papiers, puis exécutez la commande à partir de l’interface de ligne de commande (CLI).
La commande affiche les journaux filtrés des pods suivants :
-
Migration Controller -
Velero -
Restic -
Rsync -
Stunnel -
Registry
Procédure
- Dans la console Web MTC, cliquez sur Migration Plans.
- Cliquez sur le numéro Migrations en regard d’un plan de migration.
- Cliquez sur View logs.
-
Cliquez sur l’icône Copier pour copier la commande
oc logsdans votre presse-papiers. Connectez-vous au cluster concerné et saisissez la commande dans la CLI.
Le journal agrégé relatif au plan de migration est affiché.
10.3.3. Utilisation du lecteur de journaux de migration
Vous pouvez utiliser le lecteur de journaux de migration pour afficher une vue unique et filtrée de l’ensemble des journaux de migration.
Procédure
Procurez-vous le pod
mig-log-reader:$ oc -n openshift-migration get pods | grep log
Saisissez la commande suivante pour afficher un seul journal de migration :
$ oc -n openshift-migration logs -f <mig-log-reader-pod> -c color 1- 1
- L’option
-c plainaffiche le journal sans couleurs.
10.3.4. Accès aux métriques de performance
La ressource personnalisée (CR) MigrationController enregistre les métriques et les transfère dans le stockage de surveillance sur le cluster. Vous pouvez interroger les métriques en utilisant le langage PromQL (Prometheus Query Language) pour diagnostiquer les problèmes de performance de la migration. Toutes les métriques sont réinitialisées au redémarrage du pod Migration Controller.
Vous pouvez accéder aux métriques de performance et exécuter des requêtes en utilisant la console Web OpenShift Container Platform.
Procédure
- Dans la console Web OpenShift Container Platform, cliquez sur Observe → Metrics.
Saisissez une requête PromQL, sélectionnez une fenêtre temporelle à afficher, puis cliquez sur Run Queries.
Si votre navigateur Web n’affiche pas tous les résultats, utilisez la console Prometheus.
10.3.4.1. Métriques fournies
La ressource personnalisée (CR) MigrationController fournit des métriques pour le compte CR MigMigration et pour ses demandes API.
10.3.4.1.1. cam_app_workload_migrations
Cette métrique est un décompte des CR MigMigration au fil du temps. Il est utile de la consulter en même temps que les métriques mtc_client_request_count et mtc_client_request_elapsed pour assembler les informations sur les demandes API aux changements d’état de migration. Cette métrique est incluse dans Telemetry.
Tableau 10.1. Métrique cam_app_workload_migrations
| Nom de l’étiquette utilisable dans une requête | Exemples de valeurs d’étiquette | Description de l’étiquette |
|---|---|---|
| status |
|
État de la CR |
| type | stage, final |
Type de la CR |
10.3.4.1.2. mtc_client_request_count
Cette métrique est un nombre cumulé des demandes API Kubernetes émises par MigrationController. Elle n’est pas incluse dans Telemetry.
Tableau 10.2. Métrique mtc_client_request_count
| Nom de l’étiquette utilisable dans une requête | Exemples de valeurs d’étiquette | Description de l’étiquette |
|---|---|---|
| cluster |
| Cluster sur lequel la demande a été émise |
| component |
| API du sous-contrôleur qui a émis la demande |
| function |
| Fonction à partir de laquelle la demande a été émise |
| kind |
| Type Kubernetes pour lequel la demande a été émise |
10.3.4.1.3. mtc_client_request_elapsed
Cette métrique est une latence cumulée, en millisecondes, des demandes API Kubernetes émises par MigrationController. Elle n’est pas incluse dans Telemetry.
Tableau 10.3. Métrique mtc_client_request_elapsed
| Nom de l’étiquette utilisable dans une requête | Exemples de valeurs d’étiquette | Description de l’étiquette |
|---|---|---|
| cluster |
| Cluster sur lequel la demande a été émise |
| component |
| API du sous-contrôleur qui a émis la demande |
| function |
| Fonction à partir de laquelle la demande a été émise |
| kind |
| Ressource Kubernetes pour laquelle la demande a été émise |
10.3.4.1.4. Requêtes utiles
Le tableau ci-dessous présente quelques requêtes utiles qui peuvent être utilisées pour surveiller les performances.
Tableau 10.4. Requêtes utiles
| Requête | Description |
|---|---|
|
| Nombre de demandes API émises, triées par type |
|
| Nombre total de demandes API émises |
|
| Latence des demandes API, classées par type |
|
| Latence totale des demandes API |
|
| Latence moyenne des demandes API |
|
| Latence moyenne des demandes API, triées par type |
|
| Nombre de migrations en cours, multiplié par 100 pour une visualisation plus facile parallèlement au nombre de demandes |
10.3.5. Utilisation de l’outil must-gather
Vous pouvez collecter des journaux, des métriques et des informations sur les ressources MTC personnalisées en utilisant l’outil must-gather.
Les données must-gather doivent être jointes à tous les dossiers client.
Vous pouvez collecter des données sur une période d’une heure ou de 24 heures et les visualiser à l’aide de la console Prometheus.
Conditions préalables
-
Vous devez être connecté au cluster OpenShift Container Platform en tant qu’utilisateur avec le rôle
cluster-admin. -
Il faut que la CLI OpenShift (
oc) soit installée.
Procédure
-
Accédez au répertoire dans lequel vous souhaitez stocker les données
must-gather. Exécutez la commande
oc adm must-gatherpour l’une des options de collecte de données suivantes :Pour collecter les données relatives à l’heure écoulée :
$ oc adm must-gather --image=registry.redhat.io/rhmtc/openshift-migration-must-gather-rhel8:v1.7
Les données sont enregistrées en tant que
must-gather/must-gather.tar.gz. Vous pouvez envoyer ce fichier dans un dossier d’assistance sur le Portail Client de Red Hat.Pour collecter les données des dernières 24 heures :
$ oc adm must-gather --image=registry.redhat.io/rhmtc/openshift-migration-must-gather-rhel8:v1.7 \ -- /usr/bin/gather_metrics_dump
Cette opération peut prendre beaucoup de temps. Les données sont enregistrées sous le nom
must-gather/metrics/prom_data.tar.gz.
Visualisation des données de métrique à l’aide de la console Prometheus
Vous pouvez visualiser les données de métrique à l’aide de la console Prometheus.
Procédure
Décompressez le fichier
prom_data.tar.gz:$ tar -xvzf must-gather/metrics/prom_data.tar.gz
Créez une instance Prometheus locale :
$ make prometheus-run
La commande produit l’URL Prometheus.
Sortie
Started Prometheus on http://localhost:9090
- Démarrez un navigateur Web et accédez à l’URL pour afficher les données à l’aide de la console Web Prometheus.
Après avoir consulté les données, supprimez l’instance Prometheus, ainsi que les données :
$ make prometheus-cleanup
10.3.6. Débogage des ressources Velero avec l’outil CLI Velero
Vous pouvez déboguer les ressources personnalisées (CR) Backup et Restore, et récupérer les journaux avec l’outil CLI Velero.
L’outil CLI Velero fournit des informations plus détaillées que l’outil CLI OpenShift.
Syntaxe
Utilisez la commande oc exec pour exécuter une commande CLI Velero :
$ oc -n openshift-migration exec deployment/velero -c velero -- ./velero \ <backup_restore_cr> <command> <cr_name>
Exemple :
$ oc -n openshift-migration exec deployment/velero -c velero -- ./velero \ backup describe 0e44ae00-5dc3-11eb-9ca8-df7e5254778b-2d8ql
Option d’aide
Utilisez l’option velero --help pour répertorier toutes les commandes CLI de Velero :
$ oc -n openshift-migration exec deployment/velero -c velero -- ./velero \ --help
Commande describe
Utilisez la commande velero describe pour récupérer un résumé des avertissements et des erreurs associés à une ressource personnalisée (CR) Backup ou Restore.
$ oc -n openshift-migration exec deployment/velero -c velero -- ./velero \ <backup_restore_cr> describe <cr_name>
Exemple :
$ oc -n openshift-migration exec deployment/velero -c velero -- ./velero \ backup describe 0e44ae00-5dc3-11eb-9ca8-df7e5254778b-2d8ql
Commande logs
Utilisez la commande velero logs pour récupérer les journaux d’une ressource personnalisée (CR) Backup ou Restore.
$ oc -n openshift-migration exec deployment/velero -c velero -- ./velero \ <backup_restore_cr> logs <cr_name>
Exemple :
$ oc -n openshift-migration exec deployment/velero -c velero -- ./velero \ restore logs ccc7c2d0-6017-11eb-afab-85d0007f5a19-x4lbf
10.3.7. Résolution d’un échec de migration partiel
Vous pouvez déboguer un message d’avertissement concernant un échec de migration partiel en utilisant la CLI Velero afin d’examiner les journaux de ressources personnalisées (CR) Restore.
Un échec partiel se produit lorsque Velero rencontre un problème qui n’entraîne pas l’échec de la migration. Par exemple, s’il manque une définition de ressource personnalisée (CRD) ou s’il y a une différence entre les versions de CRD sur les clusters source et cible, la migration se termine, mais la ressource personnalisée n’est pas créée sur le cluster cible.
Velero enregistre le problème comme un échec partiel et traite ensuite le reste des objets dans la ressource personnalisée Backup.
Procédure
Vérifiez l’état d’une CR
MigMigration:$ oc get migmigration <migmigration> -o yaml
Exemple de sortie
status: conditions: - category: Warn durable: true lastTransitionTime: "2021-01-26T20:48:40Z" message: 'Final Restore openshift-migration/ccc7c2d0-6017-11eb-afab-85d0007f5a19-x4lbf: partially failed on destination cluster' status: "True" type: VeleroFinalRestorePartiallyFailed - category: Advisory durable: true lastTransitionTime: "2021-01-26T20:48:42Z" message: The migration has completed with warnings, please look at `Warn` conditions. reason: Completed status: "True" type: SucceededWithWarningsVérifiez l’état de la CR
Restoreen utilisant la commande Velerodescribe:$ oc -n {namespace} exec deployment/velero -c velero -- ./velero \ restore describe <restore>Exemple de sortie
Phase: PartiallyFailed (run 'velero restore logs ccc7c2d0-6017-11eb-afab-85d0007f5a19-x4lbf' for more information) Errors: Velero: <none> Cluster: <none> Namespaces: migration-example: error restoring example.com/migration-example/migration-example: the server could not find the requested resourceVérifiez les journaux de la CR
Restoreen utilisant la commande Velerologs:$ oc -n {namespace} exec deployment/velero -c velero -- ./velero \ restore logs <restore>Exemple de sortie
time="2021-01-26T20:48:37Z" level=info msg="Attempting to restore migration-example: migration-example" logSource="pkg/restore/restore.go:1107" restore=openshift-migration/ccc7c2d0-6017-11eb-afab-85d0007f5a19-x4lbf time="2021-01-26T20:48:37Z" level=info msg="error restoring migration-example: the server could not find the requested resource" logSource="pkg/restore/restore.go:1170" restore=openshift-migration/ccc7c2d0-6017-11eb-afab-85d0007f5a19-x4lbf
Le message d’erreur du journal de la CR
Restore(the server could not find the requested resource) indique la cause de l’échec partiel de la migration.
10.3.8. Utilisation des ressources MTC personnalisées pour la résolution des problèmes
Vous pouvez vérifier les ressources personnalisées (CR) MTC ( Migration Toolkit for Containers) suivantes pour résoudre l’échec d’une migration :
-
MigCluster -
MigStorage -
MigPlan BackupStorageLocationLa CR
BackupStorageLocationcontient une étiquettemigrationcontrollerpermettant d’identifier l’instance MTC qui a créé la CR :labels: migrationcontroller: ebe13bee-c803-47d0-a9e9-83f380328b93VolumeSnapshotLocationLa CR
VolumeSnapshotLocationcontient une étiquettemigrationcontrollerpermettant d’identifier l’instance MTC qui a créé la CR :labels: migrationcontroller: ebe13bee-c803-47d0-a9e9-83f380328b93-
MigMigration BackupMTC définit la stratégie de récupération des volumes persistants (PV) migrés sur
Retainsur le cluster cible. La CRBackupcontient une annotationopenshift.io/orig-reclaim-policyqui indique la stratégie de récupération d’origine. Vous pouvez restaurer manuellement la stratégie de récupération des PV migrés.-
Restore
Procédure
Répertoriez les CR
MigMigrationdans l’espace de nommageopenshift-migration:$ oc get migmigration -n openshift-migration
Exemple de sortie
NAME AGE 88435fe0-c9f8-11e9-85e6-5d593ce65e10 6m42s
Inspectez la CR
MigMigration:$ oc describe migmigration 88435fe0-c9f8-11e9-85e6-5d593ce65e10 -n openshift-migration
La sortie est semblable aux exemples suivants.
Exemple de sortie MigMigration
name: 88435fe0-c9f8-11e9-85e6-5d593ce65e10
namespace: openshift-migration
labels: <none>
annotations: touch: 3b48b543-b53e-4e44-9d34-33563f0f8147
apiVersion: migration.openshift.io/v1alpha1
kind: MigMigration
metadata:
creationTimestamp: 2019-08-29T01:01:29Z
generation: 20
resourceVersion: 88179
selfLink: /apis/migration.openshift.io/v1alpha1/namespaces/openshift-migration/migmigrations/88435fe0-c9f8-11e9-85e6-5d593ce65e10
uid: 8886de4c-c9f8-11e9-95ad-0205fe66cbb6
spec:
migPlanRef:
name: socks-shop-mig-plan
namespace: openshift-migration
quiescePods: true
stage: false
status:
conditions:
category: Advisory
durable: True
lastTransitionTime: 2019-08-29T01:03:40Z
message: The migration has completed successfully.
reason: Completed
status: True
type: Succeeded
phase: Completed
startTimestamp: 2019-08-29T01:01:29Z
events: <none>
Exemple de sortie de la CR backup Velero n°2 qui décrit les données de volume persistant (PV)
apiVersion: velero.io/v1
kind: Backup
metadata:
annotations:
openshift.io/migrate-copy-phase: final
openshift.io/migrate-quiesce-pods: "true"
openshift.io/migration-registry: 172.30.105.179:5000
openshift.io/migration-registry-dir: /socks-shop-mig-plan-registry-44dd3bd5-c9f8-11e9-95ad-0205fe66cbb6
openshift.io/orig-reclaim-policy: delete
creationTimestamp: "2019-08-29T01:03:15Z"
generateName: 88435fe0-c9f8-11e9-85e6-5d593ce65e10-
generation: 1
labels:
app.kubernetes.io/part-of: migration
migmigration: 8886de4c-c9f8-11e9-95ad-0205fe66cbb6
migration-stage-backup: 8886de4c-c9f8-11e9-95ad-0205fe66cbb6
velero.io/storage-location: myrepo-vpzq9
name: 88435fe0-c9f8-11e9-85e6-5d593ce65e10-59gb7
namespace: openshift-migration
resourceVersion: "87313"
selfLink: /apis/velero.io/v1/namespaces/openshift-migration/backups/88435fe0-c9f8-11e9-85e6-5d593ce65e10-59gb7
uid: c80dbbc0-c9f8-11e9-95ad-0205fe66cbb6
spec:
excludedNamespaces: []
excludedResources: []
hooks:
resources: []
includeClusterResources: null
includedNamespaces:
- sock-shop
includedResources:
- persistentvolumes
- persistentvolumeclaims
- namespaces
- imagestreams
- imagestreamtags
- secrets
- configmaps
- pods
labelSelector:
matchLabels:
migration-included-stage-backup: 8886de4c-c9f8-11e9-95ad-0205fe66cbb6
storageLocation: myrepo-vpzq9
ttl: 720h0m0s
volumeSnapshotLocations:
- myrepo-wv6fx
status:
completionTimestamp: "2019-08-29T01:02:36Z"
errors: 0
expiration: "2019-09-28T01:02:35Z"
phase: Completed
startTimestamp: "2019-08-29T01:02:35Z"
validationErrors: null
version: 1
volumeSnapshotsAttempted: 0
volumeSnapshotsCompleted: 0
warnings: 0
Exemple de sortie de la CR restore Velero n°2 qui décrit les ressources Kubernetes
apiVersion: velero.io/v1
kind: Restore
metadata:
annotations:
openshift.io/migrate-copy-phase: final
openshift.io/migrate-quiesce-pods: "true"
openshift.io/migration-registry: 172.30.90.187:5000
openshift.io/migration-registry-dir: /socks-shop-mig-plan-registry-36f54ca7-c925-11e9-825a-06fa9fb68c88
creationTimestamp: "2019-08-28T00:09:49Z"
generateName: e13a1b60-c927-11e9-9555-d129df7f3b96-
generation: 3
labels:
app.kubernetes.io/part-of: migration
migmigration: e18252c9-c927-11e9-825a-06fa9fb68c88
migration-final-restore: e18252c9-c927-11e9-825a-06fa9fb68c88
name: e13a1b60-c927-11e9-9555-d129df7f3b96-gb8nx
namespace: openshift-migration
resourceVersion: "82329"
selfLink: /apis/velero.io/v1/namespaces/openshift-migration/restores/e13a1b60-c927-11e9-9555-d129df7f3b96-gb8nx
uid: 26983ec0-c928-11e9-825a-06fa9fb68c88
spec:
backupName: e13a1b60-c927-11e9-9555-d129df7f3b96-sz24f
excludedNamespaces: null
excludedResources:
- nodes
- events
- events.events.k8s.io
- backups.velero.io
- restores.velero.io
- resticrepositories.velero.io
includedNamespaces: null
includedResources: null
namespaceMapping: null
restorePVs: true
status:
errors: 0
failureReason: ""
phase: Completed
validationErrors: null
warnings: 15
10.4. Préoccupations et problèmes courants
Cette section décrit les préoccupations et problèmes courants qui peuvent entraîner des problèmes au cours de la migration.
10.4.1. La migration directe des volumes ne se termine pas
Si la migration directe des volumes ne se termine pas, il se peut que le cluster cible n’ait pas les mêmes annotations node-selector que le cluster source.
Migration Toolkit for Containers (MTC) fait migrer les espaces de nommage avec toutes les annotations afin de conserver les contraintes du contexte de sécurité et les exigences en termes de planification. Pendant la migration directe des volumes, MTC crée des pods de transfert Rsync sur le cluster cible dans les espaces de nommage qui ont été migrés depuis le cluster source. Si un espace de nommage de cluster cible ne possède pas les mêmes annotations que l’espace de nommage de cluster source, les pods de transfert Rsync ne peuvent pas être planifiés. Les pods Rsync restent dans l’état Pending.
Vous pouvez identifier et corriger ce problème en procédant comme suit.
Procédure
Vérifiez l’état de la CR
MigMigration:$ oc describe migmigration <pod> -n openshift-migration
La sortie comprend le message d’état suivant :
Exemple de sortie
Some or all transfer pods are not running for more than 10 mins on destination cluster
Sur le cluster source, procurez-vous les détails d’un espace de nommage migré :
$ oc get namespace <namespace> -o yaml 1- 1
- Indiquez l’espace de nommage migré.
Sur le cluster cible, modifiez l’espace de nommage migré :
$ oc edit namespace <namespace>
Ajoutez les annotations
openshift.io/node-selectormanquantes à l’espace de nommage migré comme dans l’exemple suivant :apiVersion: v1 kind: Namespace metadata: annotations: openshift.io/node-selector: "region=east" ...- Exécutez à nouveau le plan de migration.
10.4.2. Messages d’erreur et résolutions
Cette section décrit les messages d’erreur courants que vous pouvez rencontrer avec Migration Toolkit for Containers (MTC), ainsi que la façon de résoudre les causes sous-jacentes.
10.4.2.1. Erreur de certificat CA affichée lors du premier accès à la console MTC
Si un message CA certificate error s’affiche la première fois que vous essayez d’accéder à la console MTC, cela est probablement dû à l’utilisation de certificats CA auto-signés dans l’un des clusters.
Pour résoudre ce problème, accédez à l’URL oauth-authorization-server affichée dans le message d’erreur et acceptez le certificat. Pour résoudre ce problème de façon permanente, ajoutez le certificat au magasin de confiance de votre navigateur Web.
Si un message Unauthorized s’affiche après l’acceptation du certificat, accédez à la console MTC et actualisez la page Web.
10.4.2.2. Erreur de timeout OAuth dans la console MTC
Si un message connection has timed out s’affiche dans la console MTC après l’acceptation d’un certificat auto-signé, les causes sont probablement les suivantes :
- Interruption de l’accès réseau au serveur OAuth
- Interruption de l’accès réseau à la console OpenShift Container Platform
-
Configuration du proxy qui bloque l’accès à l’URL
oauth-authorization-server. Pour plus d’informations, reportez-vous à l’article MTC console inaccessible because of OAuth timeout error (Console MTC inaccessible en raison d’une erreur de timeout OAuth).
Pour déterminer la cause du timeout :
- Examinez la page Web de la console MTC à l’aide de l’inspecteur Web d’un navigateur.
-
Recherchez des erreurs dans le journal du pod
Migration UI.
10.4.2.3. Erreur de certificat signé par une autorité inconnue
Si vous utilisez un certificat auto-signé pour sécuriser un cluster ou un référentiel de réplication pour Migration Toolkit for Containers (MTC), il se peut que la vérification du certificat échoue avec le message d’erreur suivant : Certificate signed by unknown authority.
Vous pouvez créer un fichier de regroupement de certificats CA personnalisé et l’envoyer dans la console Web MTC lorsque vous ajoutez un cluster ou un référentiel de réplication.
Procédure
Téléchargez un certificat CA à partir d’un point d’accès distant et enregistrez-le en tant que fichier de regroupement CA :
$ echo -n | openssl s_client -connect <host_FQDN>:<port> \ 1 | sed -ne '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/p' > <ca_bundle.cert> 2
10.4.2.4. Erreurs d’emplacement de stockage de sauvegarde dans le journal du pod Velero
Si une ressource personnalisée Velero Backup contient une référence à un emplacement de stockage de sauvegarde qui n’existe pas, il se peut que le journal du pod Velero affiche les messages d’erreur suivants :
$ oc logs <Velero_Pod> -n openshift-migration
Exemple de sortie
level=error msg="Error checking repository for stale locks" error="error getting backup storage location: BackupStorageLocation.velero.io \"ts-dpa-1\" not found" error.file="/remote-source/src/github.com/vmware-tanzu/velero/pkg/restic/repository_manager.go:259"
Vous pouvez ignorer ces messages d’erreur. Un emplacement de stockage de sauvegarde manquant ne peut pas faire échouer une migration.
10.4.2.5. Erreur de timeout de sauvegarde du volume du pod dans le journal du pod Velero
Si une migration échoue en raison d’un timeout de Restic, l’erreur suivante est affichée dans le journal du pod Velero.
level=error msg="Error backing up item" backup=velero/monitoring error="timed out waiting for all PodVolumeBackups to complete" error.file="/go/src/github.com/heptio/velero/pkg/restic/backupper.go:165" error.function="github.com/heptio/velero/pkg/restic.(*backupper).BackupPodVolumes" group=v1
La valeur par défaut de restic_timeout est d’une heure. Vous pouvez augmenter ce paramètre pour les migrations de grande envergure, en gardant à l’esprit qu’une valeur plus élevée peut retarder le renvoi de messages d’erreur.
Procédure
- Dans la console Web OpenShift Container Platform, accédez à Operators → Installed Operators.
- Cliquez sur Migration Toolkit for Containers Operator.
- Dans l’onglet MigrationController, cliquez sur migration-controller.
Dans l’onglet YAML, mettez à jour la valeur du paramètre suivant :
spec: restic_timeout: 1h 1- 1
- Les unités valides sont
h(heures),m(minutes) ets(secondes) ;3h30m15s, par exemple.
- Cliquez sur Save.
10.4.2.6. Erreurs de vérification Restic dans la ressource personnalisée MigMigration
Si la vérification des données échoue lors de la migration d’un volume persistant avec la méthode de copie des données du système de fichiers, l’erreur suivante s’affiche dans la CR MigMigration.
Exemple de sortie
status:
conditions:
- category: Warn
durable: true
lastTransitionTime: 2020-04-16T20:35:16Z
message: There were verify errors found in 1 Restic volume restores. See restore `<registry-example-migration-rvwcm>`
for details 1
status: "True"
type: ResticVerifyErrors 2
Une erreur de vérification des données n’entraîne pas l’échec du processus de migration.
Vous pouvez vérifier la CR Restore pour identifier la source de l’erreur de vérification des données.
Procédure
- Connectez-vous au cluster cible.
Visualisez la CR
Restore:$ oc describe <registry-example-migration-rvwcm> -n openshift-migration
La sortie identifie le volume persistant avec des erreurs
PodVolumeRestore.Exemple de sortie
status: phase: Completed podVolumeRestoreErrors: - kind: PodVolumeRestore name: <registry-example-migration-rvwcm-98t49> namespace: openshift-migration podVolumeRestoreResticErrors: - kind: PodVolumeRestore name: <registry-example-migration-rvwcm-98t49> namespace: openshift-migrationAffichez la CR
PodVolumeRestore:$ oc describe <migration-example-rvwcm-98t49>
La sortie identifie le pod
Resticqui a enregistré les erreurs.Exemple de sortie
completionTimestamp: 2020-05-01T20:49:12Z errors: 1 resticErrors: 1 ... resticPod: <restic-nr2v5>
Consultez le journal du pod
Resticpour localiser les erreurs :$ oc logs -f <restic-nr2v5>
10.4.2.7. Erreur d’autorisation Restic lors de la migration d’un stockage NFS avec la fonction root_squash activée
Si vous migrez des données à partir d’un stockage NFS et que la fonction root_squash est activée, Restic est mappé sur nfsnobody et n’a pas l’autorisation d’effectuer la migration. L’erreur suivante est affichée dans le journal du pod Restic.
Exemple de sortie
backup=openshift-migration/<backup_id> controller=pod-volume-backup error="fork/exec /usr/bin/restic: permission denied" error.file="/go/src/github.com/vmware-tanzu/velero/pkg/controller/pod_volume_backup_controller.go:280" error.function="github.com/vmware-tanzu/velero/pkg/controller.(*podVolumeBackupController).processBackup" logSource="pkg/controller/pod_volume_backup_controller.go:280" name=<backup_id> namespace=openshift-migration
Vous pouvez résoudre ce problème en créant un groupe supplémentaire pour Restic et en ajoutant l’ID du groupe au manifeste de CR MigrationController.
Procédure
- Créez un groupe supplémentaire pour Restic sur le stockage NFS.
-
Définissez le bit
setgidsur les répertoires NFS afin que la propriété du groupe soit héritée. Ajoutez le paramètre
restic_supplemental_groupsau manifeste de CRMigrationControllersur les clusters source et cible :spec: restic_supplemental_groups: <group_id> 1- 1
- Indiquez l’ID du groupe supplémentaire.
-
Attendez que les pods
Resticredémarrent pour que les modifications soient appliquées.
10.5. Annulation d’une migration
Vous pouvez annuler une migration en utilisant la console Web MTC ou la CLI.
Vous pouvez également annuler une migration manuellement.
10.5.1. Annulation d’une migration à l’aide de la console Web MTC
Vous pouvez annuler une migration en utilisant la console Web MTC (Migration Toolkit for Containers).
Les ressources suivantes restent dans les espaces de nommage migrés en vue du débogage après l’échec d’une migration directe de volumes (DVM) :
- Objets ConfigMap (clusters source et de destination)
-
Objets
Secret(clusters source et de destination) -
CR
Rsync(cluster source)
Ces ressources n’affectent pas l’annulation. Vous pouvez les supprimer manuellement.
Si, par la suite, vous exécutez le même plan de migration avec succès, les ressources de la migration qui a échoué seront automatiquement supprimées.
Si votre application a été arrêtée au cours d’une migration qui a échoué, vous devez annuler la migration pour éviter une corruption des données dans le volume persistant.
L’annulation n’est pas nécessaire si l’application n’a pas été arrêtée pendant la migration, car l’application d’origine est toujours en cours d’exécution sur le cluster source.
Procédure
- Dans la console Web MTC, cliquez sur Migration plans.
-
Cliquez sur le menu Options
à côté d'un plan de migration et sélectionnez Rollback sous Migration.
Cliquez sur Rollback et attendez que le processus d’annulation soit terminé.
Dans les détails du plan de migration, le message Rollback succeeded est affiché.
Vérifiez que l’annulation a réussi dans la console Web OpenShift Container Platform du cluster source :
- Cliquez sur Home → Projects.
- Cliquez sur le projet migré pour afficher son état.
- Dans la section Routes, cliquez sur Location pour vérifier que l’application fonctionne correctement, le cas échéant.
- Cliquez sur Workloads → Pods pour vérifier que les pods s’exécutent dans l’espace de nommage migré.
- Cliquez sur Storage → Persistent volumes pour vérifier que le volume persistant migré est correctement mis en service.
10.5.2. Annulation d’une migration à partir de l’interface de ligne de commande
Vous pouvez annuler une migration en créant une ressource personnalisée (CR) MigMigration à partir de l’interface de ligne de commande.
Les ressources suivantes restent dans les espaces de nommage migrés en vue du débogage après l’échec d’une migration directe de volumes (DVM) :
- Objets ConfigMap (clusters source et de destination)
-
Objets
Secret(clusters source et de destination) -
CR
Rsync(cluster source)
Ces ressources n’affectent pas l’annulation. Vous pouvez les supprimer manuellement.
Si, par la suite, vous exécutez le même plan de migration avec succès, les ressources de la migration qui a échoué seront automatiquement supprimées.
Si votre application a été arrêtée au cours d’une migration qui a échoué, vous devez annuler la migration pour éviter une corruption des données dans le volume persistant.
L’annulation n’est pas nécessaire si l’application n’a pas été arrêtée pendant la migration, car l’application d’origine est toujours en cours d’exécution sur le cluster source.
Procédure
Créez une CR
MigMigrationsur la base de l’exemple suivant :$ cat << EOF | oc apply -f - apiVersion: migration.openshift.io/v1alpha1 kind: MigMigration metadata: labels: controller-tools.k8s.io: "1.0" name: <migmigration> namespace: openshift-migration spec: ... rollback: true ... migPlanRef: name: <migplan> 1 namespace: openshift-migration EOF- 1
- Indiquez le nom de la CR
MigPlanassociée.
- Dans la console Web MTC, vérifiez que les ressources de projet ayant fait l’objet d’une migration ont été supprimées du cluster cible.
- Vérifiez que les ressources migrées sont présentes dans le cluster source et que l’application est en cours d’exécution.
10.5.3. Annulation manuelle d’une migration
Vous pouvez annuler manuellement une migration qui a échoué en supprimant les pods stage et en réactivant l’application.
Si vous exécutez le même plan de migration avec succès, les ressources de la migration qui a échoué sont automatiquement supprimées.
Les ressources suivantes restent dans les espaces de nommage migrés après l’échec d’une migration directe des volumes (DVM) :
- Objets ConfigMap (clusters source et de destination)
-
Objets
Secret(clusters source et de destination) -
CR
Rsync(cluster source)
Ces ressources n’affectent pas l’annulation. Vous pouvez les supprimer manuellement.
Procédure
Supprimez les pods
stagesur tous les clusters :$ oc delete $(oc get pods -l migration.openshift.io/is-stage-pod -n <namespace>) 1- 1
- Espaces de nommage spécifiés dans la CR
MigPlan.
Réactivez l’application sur le cluster source en dimensionnant les réplicas sur leur nombre d’avant la migration :
$ oc scale deployment <deployment> --replicas=<premigration_replicas>
L’annotation
migration.openshift.io/preQuiesceReplicasdans la CRDeploymentaffiche le nombre de réplicas d’avant la migration :apiVersion: extensions/v1beta1 kind: Deployment metadata: annotations: deployment.kubernetes.io/revision: "1" migration.openshift.io/preQuiesceReplicas: "1"Vérifiez que les pods d’application sont en cours d’exécution sur le cluster source :
$ oc get pod -n <namespace>