
Gestion des machines
Ajout et maintenance de machines en grappe
Résumé
Chapitre 1. Aperçu de la gestion des machines
Vous pouvez utiliser la gestion des machines pour travailler de manière flexible avec l'infrastructure sous-jacente telle que Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP), Red Hat OpenStack Platform (RHOSP), Red Hat Virtualization (RHV) et VMware vSphere pour gérer le cluster OpenShift Container Platform. Vous pouvez contrôler le cluster et effectuer une mise à l'échelle automatique, telle que la mise à l'échelle vers le haut et vers le bas du cluster en fonction de politiques de charge de travail spécifiques.
Il est important d'avoir un cluster qui s'adapte à l'évolution des charges de travail. Le cluster OpenShift Container Platform peut évoluer horizontalement vers le haut ou vers le bas lorsque la charge augmente ou diminue.
La gestion des machines est mise en œuvre sous la forme d'une définition de ressource personnalisée (CRD). Un objet CRD définit un nouvel objet unique Kind dans le cluster et permet au serveur API Kubernetes de gérer l'ensemble du cycle de vie de l'objet.
L'opérateur API Machine provisionne les ressources suivantes :
-
MachineSet -
Machine -
ClusterAutoscaler -
MachineAutoscaler -
MachineHealthCheck
1.1. Vue d'ensemble de l'API Machine
L'API Machine est une combinaison de ressources primaires basées sur le projet Cluster API en amont et de ressources OpenShift Container Platform personnalisées.
Pour les clusters OpenShift Container Platform 4.12, l'API Machine effectue toutes les actions de gestion du provisionnement de l'hôte du nœud une fois l'installation du cluster terminée. Grâce à ce système, OpenShift Container Platform 4.12 offre une méthode de provisionnement élastique et dynamique au-dessus d'une infrastructure de cloud public ou privé.
Les deux principales ressources sont les suivantes
- Machines
-
Unité fondamentale décrivant l'hôte d'un nœud. Une machine possède une spécification
providerSpec, qui décrit les types de nœuds de calcul proposés par les différentes plateformes de cloud computing. Par exemple, un type de machine pour un nœud de travail sur Amazon Web Services (AWS) peut définir un type de machine spécifique et les métadonnées requises. - Jeux de machines
MachineSetles ressources sont des groupes de machines de calcul. Les ensembles de machines de calcul sont aux machines de calcul ce que les ensembles de répliques sont aux pods. Si vous avez besoin de plus de machines de calcul ou si vous devez les réduire, vous modifiez le champreplicasde la ressourceMachineSetpour répondre à vos besoins en matière de calcul.AvertissementLes machines du plan de contrôle ne peuvent pas être gérées par des ensembles de machines de calcul.
Les ensembles de machines du plan de contrôle fournissent des capacités de gestion pour les machines du plan de contrôle prises en charge qui sont similaires à celles que les ensembles de machines de calcul fournissent pour les machines de calcul.
Pour plus d'informations, voir "Gestion des machines du plan de contrôle".
Les ressources personnalisées suivantes ajoutent des capacités supplémentaires à votre cluster :
- Machine autoscaler
La ressource
MachineAutoscalermet automatiquement à l'échelle les machines de calcul dans un nuage. Vous pouvez définir les limites minimales et maximales de mise à l'échelle pour les nœuds d'un ensemble de machines de calcul spécifié, et l'autoscaler de machines maintient cette plage de nœuds.L'objet
MachineAutoscalerprend effet après l'existence d'un objetClusterAutoscaler. Les ressourcesClusterAutoscaleretMachineAutoscalersont mises à disposition par l'objetClusterAutoscalerOperator.- Cluster autoscaler
Cette ressource est basée sur le projet de cluster autoscaler en amont. Dans l'implémentation d'OpenShift Container Platform, elle est intégrée à l'API Machine en étendant l'API compute machine set. Vous pouvez utiliser le cluster autoscaler pour gérer votre cluster de la manière suivante :
- Définir des limites d'échelle à l'échelle du cluster pour les ressources telles que les cœurs, les nœuds, la mémoire et les GPU
- Définir la priorité afin que le cluster donne la priorité aux pods et que de nouveaux nœuds ne soient pas mis en ligne pour des pods moins importants
- Définir la politique de mise à l'échelle de manière à pouvoir augmenter les nœuds mais pas les diminuer
- Bilan de santé de la machine
-
La ressource
MachineHealthCheckdétecte lorsqu'une machine n'est pas saine, la supprime et, sur les plates-formes prises en charge, crée une nouvelle machine.
Dans OpenShift Container Platform version 3.11, il n'était pas possible de déployer facilement une architecture multizone car le cluster ne gérait pas le provisionnement des machines. À partir de la version 4.1 d'OpenShift Container Platform, ce processus est plus facile. Chaque ensemble de machines de calcul est limité à une seule zone, de sorte que le programme d'installation envoie des ensembles de machines de calcul à travers les zones de disponibilité en votre nom. Ainsi, comme votre calcul est dynamique, et en cas de défaillance d'une zone, vous disposez toujours d'une zone pour rééquilibrer vos machines. Dans les régions Azure globales qui ne disposent pas de plusieurs zones de disponibilité, vous pouvez utiliser des ensembles de machines pour garantir une haute disponibilité. L'autoscaler assure l'équilibrage du meilleur effort pendant toute la durée de vie d'un cluster.
1.2. Gestion des machines de calcul
En tant qu'administrateur de cluster, vous pouvez effectuer les actions suivantes :
Créez un ensemble de machines de calcul pour les fournisseurs de cloud suivants :
- Modifier manuellement un ensemble de machines de calcul en ajoutant ou en supprimant une machine de l'ensemble de machines de calcul.
-
Modifier un ensemble de machines de calcul via le fichier de configuration YAML
MachineSet. - Supprimer une machine.
- Créer des ensembles de machines de calcul pour l'infrastructure.
- Configurer et déployer un contrôle de l'état des machines pour réparer automatiquement les machines endommagées dans un pool de machines.
1.3. Gestion des machines du plan de contrôle
En tant qu'administrateur de cluster, vous pouvez effectuer les actions suivantes :
Mettez à jour votre configuration de plan de contrôle avec un jeu de machines de plan de contrôle pour les fournisseurs de cloud suivants :
- Configurer et déployer un contrôle de l'état des machines pour récupérer automatiquement les machines du plan de contrôle qui ne sont pas en bon état.
1.4. Appliquer l'autoscaling à un cluster OpenShift Container Platform
Vous pouvez faire évoluer automatiquement votre cluster OpenShift Container Platform pour garantir la flexibilité nécessaire à l'évolution des charges de travail. Pour faire évoluer automatiquement votre cluster, vous devez d'abord déployer un autoscaler de cluster, puis un autoscaler de machine pour chaque ensemble de machines de calcul.
- Les cluster autoscaler augmente ou diminue la taille du cluster en fonction des besoins de déploiement.
- L'option machine autoscaler ajuste le nombre de machines dans les ensembles de machines de calcul que vous déployez dans votre cluster OpenShift Container Platform.
1.5. Ajout de machines de calcul sur l'infrastructure fournie par l'utilisateur
L'infrastructure fournie par l'utilisateur est un environnement dans lequel vous pouvez déployer une infrastructure telle que des ressources de calcul, de réseau et de stockage qui hébergent OpenShift Container Platform. Vous pouvez ajouter des machines de calcul à un cluster sur une infrastructure fournie par l'utilisateur pendant ou après le processus d'installation.
1.6. Ajout de machines de calcul RHEL à votre cluster
En tant qu'administrateur de cluster, vous pouvez effectuer les actions suivantes :
- Ajoutez des machines de calcul Red Hat Enterprise Linux (RHEL), également connues sous le nom de machines de travail, à un cluster d'infrastructure provisionné par l'utilisateur ou à un cluster d'infrastructure provisionné par l'installation.
- Ajouter des machines de calcul Red Hat Enterprise Linux (RHEL) à un cluster existant.
Chapitre 2. Gérer les machines de calcul avec l'API Machine
2.1. Création d'un ensemble de machines de calcul sur Alibaba Cloud
Vous pouvez créer un ensemble de machines de calcul différent pour répondre à un objectif spécifique dans votre cluster OpenShift Container Platform sur Alibaba Cloud. Par exemple, vous pouvez créer des ensembles de machines d'infrastructure et des machines connexes afin de pouvoir déplacer des charges de travail de support vers les nouvelles machines.
Vous ne pouvez utiliser les fonctionnalités avancées de gestion et de mise à l'échelle des machines que dans les clusters où l'API Machine est opérationnelle. Les clusters dont l'infrastructure est fournie par l'utilisateur nécessitent une validation et une configuration supplémentaires pour utiliser l'API Machine.
Les clusters avec le type de plateforme d'infrastructure none ne peuvent pas utiliser l'API Machine. Cette limitation s'applique même si les machines de calcul attachées au cluster sont installées sur une plateforme qui prend en charge cette fonctionnalité. Ce paramètre ne peut pas être modifié après l'installation.
Pour afficher le type de plateforme de votre cluster, exécutez la commande suivante :
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.1.1. Exemple de YAML pour une machine de calcul définie comme ressource personnalisée sur Alibaba Cloud
Cet exemple YAML définit un ensemble de machines de calcul qui fonctionne dans une zone Alibaba Cloud spécifiée dans une région et crée des nœuds qui sont étiquetés avec node-role.kubernetes.io/<role>: "".
Dans cet exemple, <infrastructure_id> est l'étiquette d'ID d'infrastructure basée sur l'ID de cluster que vous avez défini lors du provisionnement du cluster, et <role> est l'étiquette de nœud à ajouter.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1
machine.openshift.io/cluster-api-machine-role: <role> 2
machine.openshift.io/cluster-api-machine-type: <role> 3
name: <infrastructure_id>-<role>-<zone> 4
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 5
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<zone> 6
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 7
machine.openshift.io/cluster-api-machine-role: <role> 8
machine.openshift.io/cluster-api-machine-type: <role> 9
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<zone> 10
spec:
metadata:
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: machine.openshift.io/v1
credentialsSecret:
name: alibabacloud-credentials
imageId: <image_id> 11
instanceType: <instance_type> 12
kind: AlibabaCloudMachineProviderConfig
ramRoleName: <infrastructure_id>-role-worker 13
regionId: <region> 14
resourceGroup: 15
id: <resource_group_id>
type: ID
securityGroups:
- tags: 16
- Key: Name
Value: <infrastructure_id>-sg-<role>
type: Tags
systemDisk: 17
category: cloud_essd
size: <disk_size>
tag: 18
- Key: kubernetes.io/cluster/<infrastructure_id>
Value: owned
userDataSecret:
name: <user_data_secret> 19
vSwitch:
tags: 20
- Key: Name
Value: <infrastructure_id>-vswitch-<zone>
type: Tags
vpcId: ""
zoneId: <zone> 21- 1 5 7
- Spécifiez l'ID d'infrastructure qui est basé sur l'ID de cluster que vous avez défini lorsque vous avez provisionné le cluster. Si l'OpenShift CLI (
oc) est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 8 9
- Spécifiez l'étiquette de nœud à ajouter.
- 4 6 10
- Spécifiez l'ID de l'infrastructure, l'étiquette du nœud et la zone.
- 11
- Spécifiez l'image à utiliser. Utilisez une image provenant d'un jeu de machines de calcul par défaut existant pour le cluster.
- 12
- Spécifiez le type d'instance que vous souhaitez utiliser pour l'ensemble de machines de calcul.
- 13
- Spécifiez le nom du rôle RAM à utiliser pour le jeu de machines de calcul. Utilisez la valeur indiquée par le programme d'installation dans le jeu de machines de calcul par défaut.
- 14
- Spécifiez la région où placer les machines.
- 15
- Spécifiez le groupe et le type de ressources pour le cluster. Vous pouvez utiliser la valeur indiquée par le programme d'installation dans le jeu de machines de calcul par défaut ou en spécifier une autre.
- 16 18 20
- Spécifiez les balises à utiliser pour l'ensemble de machines de calcul. Au minimum, vous devez inclure les balises présentées dans cet exemple, avec les valeurs appropriées pour votre cluster. Vous pouvez inclure des balises supplémentaires, y compris les balises que le programme d'installation ajoute à l'ensemble de machines de calcul par défaut qu'il crée, si nécessaire.
- 17
- Spécifiez le type et la taille du disque racine. Utilisez la valeur
categoryque le programme d'installation renseigne dans le jeu de machines de calcul par défaut qu'il crée. Si nécessaire, indiquez une valeur différente en gigaoctets poursize. - 19
- Spécifiez le nom du secret dans le fichier YAML des données utilisateur qui se trouve dans l'espace de noms
openshift-machine-api. Utilisez la valeur indiquée par le programme d'installation dans le jeu de machines de calcul par défaut. - 21
- Indiquez la zone de votre région où placer les machines. Assurez-vous que votre région prend en charge la zone que vous spécifiez.
2.1.1.1. Paramètres définis par la machine pour les statistiques d'utilisation du nuage Alibaba
Les ensembles de machines de calcul par défaut que le programme d'installation crée pour les clusters Alibaba Cloud incluent des valeurs de balises non essentielles qu'Alibaba Cloud utilise en interne pour suivre les statistiques d'utilisation. Ces balises sont renseignées dans les paramètres securityGroups, tag, et vSwitch de la liste spec.template.spec.providerSpec.value.
Lorsque vous créez des ensembles de machines de calcul pour déployer des machines supplémentaires, vous devez inclure les balises Kubernetes requises. Les balises de statistiques d'utilisation sont appliquées par défaut, même si elles ne sont pas spécifiées dans les ensembles de machines de calcul que vous créez. Vous pouvez également inclure des balises supplémentaires si nécessaire.
Les extraits YAML suivants indiquent quelles balises des ensembles de machines de calcul par défaut sont facultatives et lesquelles sont obligatoires.
Tags dans spec.template.spec.providerSpec.value.securityGroups
spec:
template:
spec:
providerSpec:
value:
securityGroups:
- tags:
- Key: kubernetes.io/cluster/<infrastructure_id> 1
Value: owned
- Key: GISV
Value: ocp
- Key: sigs.k8s.io/cloud-provider-alibaba/origin 2
Value: ocp
- Key: Name
Value: <infrastructure_id>-sg-<role> 3
type: Tags
- 1 2
- Facultatif : Cette balise est appliquée même si elle n'est pas spécifiée dans le jeu de machines de calcul.
- 3
- Required.
où :
-
<infrastructure_id>est l'ID de l'infrastructure qui est basé sur l'ID du cluster que vous avez défini lorsque vous avez approvisionné le cluster. -
<role>est l'étiquette de nœud à ajouter.
-
Tags dans spec.template.spec.providerSpec.value.tag
spec:
template:
spec:
providerSpec:
value:
tag:
- Key: kubernetes.io/cluster/<infrastructure_id> 1
Value: owned
- Key: GISV 2
Value: ocp
- Key: sigs.k8s.io/cloud-provider-alibaba/origin 3
Value: ocp
Tags dans spec.template.spec.providerSpec.value.vSwitch
spec:
template:
spec:
providerSpec:
value:
vSwitch:
tags:
- Key: kubernetes.io/cluster/<infrastructure_id> 1
Value: owned
- Key: GISV 2
Value: ocp
- Key: sigs.k8s.io/cloud-provider-alibaba/origin 3
Value: ocp
- Key: Name
Value: <infrastructure_id>-vswitch-<zone> 4
type: Tags
- 1 2 3
- Facultatif : Cette balise est appliquée même si elle n'est pas spécifiée dans le jeu de machines de calcul.
- 4
- Required.
où :
-
<infrastructure_id>est l'ID de l'infrastructure qui est basé sur l'ID du cluster que vous avez défini lorsque vous avez approvisionné le cluster. -
<zone>est la zone de votre région où placer les machines.
-
2.1.2. Création d'un ensemble de machines de calcul
En plus des ensembles de machines de calcul créés par le programme d'installation, vous pouvez créer vos propres ensembles pour gérer dynamiquement les ressources de calcul des machines pour les charges de travail spécifiques de votre choix.
Conditions préalables
- Déployer un cluster OpenShift Container Platform.
-
Installez le CLI OpenShift (
oc). -
Connectez-vous à
ocen tant qu'utilisateur disposant de l'autorisationcluster-admin.
Procédure
Créez un nouveau fichier YAML contenant l'échantillon de ressources personnalisées (CR) de l'ensemble de machines de calcul et nommé
<file_name>.yaml.Veillez à définir les valeurs des paramètres
<clusterID>et<role>.Facultatif : si vous n'êtes pas sûr de la valeur à définir pour un champ spécifique, vous pouvez vérifier un ensemble de machines de calcul existant dans votre cluster.
Pour répertorier les ensembles de machines de calcul de votre cluster, exécutez la commande suivante :
$ oc get machinesets -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Pour afficher les valeurs d'une ressource personnalisée (CR) d'un ensemble de machines de calcul spécifique, exécutez la commande suivante :
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml
Exemple de sortie
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1 name: <infrastructure_id>-<role> 2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec: 3 ...- 1
- L'ID de l'infrastructure du cluster.
- 2
- Une étiquette de nœud par défaut.Note
Pour les clusters disposant d'une infrastructure fournie par l'utilisateur, un ensemble de machines de calcul ne peut créer que des machines de type
workeretinfra. - 3
- Les valeurs de la section
<providerSpec>du CR de l'ensemble de machines de calcul sont spécifiques à la plate-forme. Pour plus d'informations sur les paramètres<providerSpec>dans le CR, consultez l'exemple de configuration du CR de l'ensemble de machines de calcul pour votre fournisseur.
Créez un CR
MachineSeten exécutant la commande suivante :oc create -f <nom_du_fichier>.yaml
Vérification
Affichez la liste des ensembles de machines de calcul en exécutant la commande suivante :
$ oc get machineset -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Lorsque le nouveau jeu de machines de calcul est disponible, les valeurs
DESIREDetCURRENTcorrespondent. Si le jeu de machines de calcul n'est pas disponible, attendez quelques minutes et exécutez à nouveau la commande.
2.2. Création d'un ensemble de machines de calcul sur AWS
Vous pouvez créer un ensemble de machines de calcul différent pour répondre à un objectif spécifique dans votre cluster OpenShift Container Platform sur Amazon Web Services (AWS). Par exemple, vous pouvez créer des jeux de machines d'infrastructure et des machines connexes afin de pouvoir déplacer des charges de travail de support vers les nouvelles machines.
Vous ne pouvez utiliser les fonctionnalités avancées de gestion et de mise à l'échelle des machines que dans les clusters où l'API Machine est opérationnelle. Les clusters dont l'infrastructure est fournie par l'utilisateur nécessitent une validation et une configuration supplémentaires pour utiliser l'API Machine.
Les clusters avec le type de plateforme d'infrastructure none ne peuvent pas utiliser l'API Machine. Cette limitation s'applique même si les machines de calcul attachées au cluster sont installées sur une plateforme qui prend en charge cette fonctionnalité. Ce paramètre ne peut pas être modifié après l'installation.
Pour afficher le type de plateforme de votre cluster, exécutez la commande suivante :
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.2.1. Exemple de YAML pour une ressource personnalisée d'un ensemble de machines de calcul sur AWS
Cet exemple YAML définit un ensemble de machines de calcul qui fonctionne dans la zone us-east-1a Amazon Web Services (AWS) et crée des nœuds étiquetés avec node-role.kubernetes.io/<role>: "".
Dans cet exemple, <infrastructure_id> est l'étiquette d'ID d'infrastructure basée sur l'ID de cluster que vous avez défini lors du provisionnement du cluster, et <role> est l'étiquette de nœud à ajouter.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1
name: <infrastructure_id>-<role>-<zone> 2
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 3
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<zone> 4
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 5
machine.openshift.io/cluster-api-machine-role: <role> 6
machine.openshift.io/cluster-api-machine-type: <role> 7
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<zone> 8
spec:
metadata:
labels:
node-role.kubernetes.io/<role>: "" 9
providerSpec:
value:
ami:
id: ami-046fe691f52a953f9 10
apiVersion: awsproviderconfig.openshift.io/v1beta1
blockDevices:
- ebs:
iops: 0
volumeSize: 120
volumeType: gp2
credentialsSecret:
name: aws-cloud-credentials
deviceIndex: 0
iamInstanceProfile:
id: <infrastructure_id>-worker-profile 11
instanceType: m6i.large
kind: AWSMachineProviderConfig
placement:
availabilityZone: <zone> 12
region: <region> 13
securityGroups:
- filters:
- name: tag:Name
values:
- <infrastructure_id>-worker-sg 14
subnet:
filters:
- name: tag:Name
values:
- <infrastructure_id>-private-<zone> 15
tags:
- name: kubernetes.io/cluster/<infrastructure_id> 16
value: owned
- name: <custom_tag_name> 17
value: <custom_tag_value> 18
userDataSecret:
name: worker-user-data- 1 3 5 11 14 16
- Spécifiez l'ID d'infrastructure qui est basé sur l'ID de cluster que vous avez défini lorsque vous avez provisionné le cluster. Si le CLI OpenShift est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 4 8
- Spécifiez l'ID de l'infrastructure, l'étiquette du nœud de rôle et la zone.
- 6 7 9
- Spécifiez l'étiquette du nœud de rôle à ajouter.
- 10
- Spécifiez une image de machine Amazon (AMI) Red Hat Enterprise Linux CoreOS (RHCOS) valide pour votre zone AWS pour vos nœuds OpenShift Container Platform. Si vous souhaitez utiliser une image AWS Marketplace, vous devez compléter l'abonnement à OpenShift Container Platform depuis AWS Marketplace afin d'obtenir un identifiant AMI pour votre région.
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.ami.id}{"\n"}' \ get machineset/<infrastructure_id>-<role>-<zone> - 17 18
- Optionnel : Spécifiez des données de balises personnalisées pour votre cluster. Par exemple, vous pouvez ajouter une adresse électronique de contact pour l'administration en spécifiant une paire
name:valuedeEmail:admin-email@example.com.NoteDes balises personnalisées peuvent également être spécifiées lors de l'installation dans le fichier
install-config.yml. Si le fichierinstall-config.ymlet le jeu de machines comprennent une balise avec les mêmes donnéesname, la valeur de la balise du jeu de machines est prioritaire sur la valeur de la balise dans le fichierinstall-config.yml. - 12
- Spécifiez la zone, par exemple,
us-east-1a. - 13
- Précisez la région, par exemple
us-east-1. - 15
- Spécifiez l'ID de l'infrastructure et la zone.
2.2.2. Création d'un ensemble de machines de calcul
En plus des ensembles de machines de calcul créés par le programme d'installation, vous pouvez créer vos propres ensembles pour gérer dynamiquement les ressources de calcul des machines pour les charges de travail spécifiques de votre choix.
Conditions préalables
- Déployer un cluster OpenShift Container Platform.
-
Installez le CLI OpenShift (
oc). -
Connectez-vous à
ocen tant qu'utilisateur disposant de l'autorisationcluster-admin.
Procédure
Créez un nouveau fichier YAML contenant l'échantillon de ressources personnalisées (CR) de l'ensemble de machines de calcul et nommé
<file_name>.yaml.Veillez à définir les valeurs des paramètres
<clusterID>et<role>.Facultatif : si vous n'êtes pas sûr de la valeur à définir pour un champ spécifique, vous pouvez vérifier un ensemble de machines de calcul existant dans votre cluster.
Pour répertorier les ensembles de machines de calcul de votre cluster, exécutez la commande suivante :
$ oc get machinesets -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Pour afficher les valeurs d'une ressource personnalisée (CR) d'un ensemble de machines de calcul spécifique, exécutez la commande suivante :
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml
Exemple de sortie
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1 name: <infrastructure_id>-<role> 2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec: 3 ...- 1
- L'ID de l'infrastructure du cluster.
- 2
- Une étiquette de nœud par défaut.Note
Pour les clusters disposant d'une infrastructure fournie par l'utilisateur, un ensemble de machines de calcul ne peut créer que des machines de type
workeretinfra. - 3
- Les valeurs de la section
<providerSpec>du CR de l'ensemble de machines de calcul sont spécifiques à la plate-forme. Pour plus d'informations sur les paramètres<providerSpec>dans le CR, consultez l'exemple de configuration du CR de l'ensemble de machines de calcul pour votre fournisseur.
Créez un CR
MachineSeten exécutant la commande suivante :oc create -f <nom_du_fichier>.yaml
- Si vous avez besoin d'ensembles de machines de calcul dans d'autres zones de disponibilité, répétez ce processus pour créer d'autres ensembles de machines de calcul.
Vérification
Affichez la liste des ensembles de machines de calcul en exécutant la commande suivante :
$ oc get machineset -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Lorsque le nouveau jeu de machines de calcul est disponible, les valeurs
DESIREDetCURRENTcorrespondent. Si le jeu de machines de calcul n'est pas disponible, attendez quelques minutes et exécutez à nouveau la commande.
2.2.3. Options du jeu de machines pour le service de métadonnées de l'instance Amazon EC2
Vous pouvez utiliser des jeux de machines pour créer des machines qui utilisent une version spécifique du service de métadonnées d'instance Amazon EC2 (IMDS). Les jeux de machines peuvent créer des machines qui autorisent l'utilisation d'IMDSv1 et d'IMDSv2 ou des machines qui requièrent l'utilisation d'IMDSv2.
Pour modifier la configuration IMDS des machines existantes, modifiez le fichier YAML de l'ensemble de machines qui gère ces machines. Pour déployer de nouvelles machines de calcul avec votre configuration IMDS préférée, créez un fichier YAML d'ensemble de machine de calcul avec les valeurs appropriées.
Avant de configurer un jeu de machines pour créer des machines nécessitant IMDSv2, assurez-vous que toutes les charges de travail qui interagissent avec le service de métadonnées AWS prennent en charge IMDSv2.
2.2.3.1. Configuration de l'IMDS à l'aide de jeux de machines
Vous pouvez spécifier si l'utilisation d'IMDSv2 est requise en ajoutant ou en modifiant la valeur de metadataServiceOptions.authentication dans le fichier YAML de l'ensemble de machines pour vos machines.
Procédure
Ajoutez ou modifiez les lignes suivantes sous le champ
providerSpec:providerSpec: value: metadataServiceOptions: authentication: Required 1- 1
- Pour exiger IMDSv2, définissez la valeur du paramètre sur
Required. Pour autoriser l'utilisation de IMDSv1 et IMDSv2, définissez la valeur du paramètre surOptional. Si aucune valeur n'est spécifiée, IMDSv1 et IMDSv2 sont tous deux autorisés.
2.2.4. Jeux de machines qui déploient des machines en tant qu'instances dédiées
Vous pouvez créer un ensemble de machines fonctionnant sur AWS qui déploie des machines en tant qu'instances dédiées. Les instances dédiées s'exécutent dans un nuage privé virtuel (VPC) sur du matériel dédié à un seul client. Ces instances Amazon EC2 sont physiquement isolées au niveau du matériel hôte. L'isolement des instances dédiées se produit même si les instances appartiennent à différents comptes AWS liés à un seul compte payeur. Toutefois, d'autres instances non dédiées peuvent partager le matériel avec les instances dédiées si elles appartiennent au même compte AWS.
Les instances avec une location publique ou dédiée sont prises en charge par l'API Machine. Les instances en mode public s'exécutent sur du matériel partagé. La location publique est la location par défaut. Les instances avec une location dédiée s'exécutent sur du matériel à locataire unique.
2.2.4.1. Création d'instances dédiées à l'aide d'ensembles de machines
Vous pouvez exécuter une machine qui est soutenue par une Instance Dédiée en utilisant l'intégration API Machine. Définissez le champ tenancy dans votre fichier YAML machine set pour lancer une Dedicated Instance sur AWS.
Procédure
Spécifiez une location dédiée dans le champ
providerSpec:providerSpec: placement: tenancy: dedicated
2.2.5. Jeux de machines qui déploient des machines en tant qu'instances Spot
Vous pouvez réaliser des économies en créant un ensemble de machines de calcul fonctionnant sur AWS qui déploie des machines en tant qu'instances Spot non garanties. Les instances Spot utilisent la capacité AWS EC2 inutilisée et sont moins chères que les instances à la demande. Vous pouvez utiliser les instances Spot pour des charges de travail qui peuvent tolérer des interruptions, telles que les charges de travail par lots ou sans état, évolutives horizontalement.
AWS EC2 peut mettre fin à une instance Spot à tout moment. AWS donne un avertissement de deux minutes à l'utilisateur lorsqu'une interruption se produit. OpenShift Container Platform commence à supprimer les charges de travail des instances concernées lorsque AWS émet l'avertissement de résiliation.
Des interruptions peuvent se produire lors de l'utilisation des Instances Spot pour les raisons suivantes :
- Le prix de l'instance dépasse votre prix maximum
- La demande d'instances Spot augmente
- L'offre d'Instances Spot diminue
Lorsqu'AWS met fin à une instance, un gestionnaire de fin s'exécutant sur le nœud Spot Instance supprime la ressource machine. Pour satisfaire la quantité de l'ensemble de machines de calcul replicas, l'ensemble de machines de calcul crée une machine qui demande une instance Spot.
2.2.5.1. Création d'instances Spot en utilisant des ensembles de machines de calcul
Vous pouvez lancer une instance Spot sur AWS en ajoutant spotMarketOptions à votre fichier YAML d'ensemble de machines de calcul.
Procédure
Ajoutez la ligne suivante sous le champ
providerSpec:providerSpec: value: spotMarketOptions: {}Vous pouvez éventuellement définir le champ
spotMarketOptions.maxPricepour limiter le coût de l'instance Spot. Par exemple, vous pouvez définirmaxPrice: '2.50'.Si l'adresse
maxPriceest définie, cette valeur est utilisée comme prix spot maximum horaire. Si elle n'est pas définie, le prix maximum est fixé par défaut au prix de l'instance à la demande.NoteIl est fortement recommandé d'utiliser le prix On-Demand par défaut comme valeur
maxPriceet de ne pas définir le prix maximum pour les Instances Spot.
2.2.6. Ajouter un nœud GPU à un cluster OpenShift Container Platform existant
Vous pouvez copier et modifier la configuration d'un ensemble de machines de calcul par défaut pour créer un ensemble de machines et des machines compatibles avec le GPU pour le fournisseur de cloud AWS EC2.
Le tableau suivant énumère les types d'instance validés :
| Instance type | Accélérateur GPU NVIDIA | Nombre maximal de GPU | L'architecture |
|---|---|---|---|
|
| A100 | 8 | x86 |
|
| T4 | 1 | x86 |
Procédure
Affichez les nœuds, les machines et les jeux de machines existants en exécutant la commande suivante. Notez que chaque nœud est une instance d'une définition de machine avec une région AWS et un rôle OpenShift Container Platform spécifiques.
$ oc get nodes
Exemple de sortie
NAME STATUS ROLES AGE VERSION ip-10-0-52-50.us-east-2.compute.internal Ready worker 3d17h v1.25.4+86bd4ff ip-10-0-58-24.us-east-2.compute.internal Ready control-plane,master 3d17h v1.25.4+86bd4ff ip-10-0-68-148.us-east-2.compute.internal Ready worker 3d17h v1.25.4+86bd4ff ip-10-0-68-68.us-east-2.compute.internal Ready control-plane,master 3d17h v1.25.4+86bd4ff ip-10-0-72-170.us-east-2.compute.internal Ready control-plane,master 3d17h v1.25.4+86bd4ff ip-10-0-74-50.us-east-2.compute.internal Ready worker 3d17h v1.25.4+86bd4ff
Affichez les machines et les ensembles de machines qui existent dans l'espace de noms
openshift-machine-apien exécutant la commande suivante. Chaque ensemble de machines de calcul est associé à une zone de disponibilité différente dans la région AWS. Le programme d'installation équilibre automatiquement la charge des machines de calcul entre les zones de disponibilité.$ oc get machinesets -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE preserve-dsoc12r4-ktjfc-worker-us-east-2a 1 1 1 1 3d11h preserve-dsoc12r4-ktjfc-worker-us-east-2b 2 2 2 2 3d11h
Affichez les machines qui existent dans l'espace de noms
openshift-machine-apien exécutant la commande suivante. Pour l'instant, il n'y a qu'une machine de calcul par ensemble de machines, bien qu'un ensemble de machines de calcul puisse être mis à l'échelle pour ajouter un nœud dans une région et une zone particulières.$ oc get machines -n openshift-machine-api | grep worker
Exemple de sortie
preserve-dsoc12r4-ktjfc-worker-us-east-2a-dts8r Running m5.xlarge us-east-2 us-east-2a 3d11h preserve-dsoc12r4-ktjfc-worker-us-east-2b-dkv7w Running m5.xlarge us-east-2 us-east-2b 3d11h preserve-dsoc12r4-ktjfc-worker-us-east-2b-k58cw Running m5.xlarge us-east-2 us-east-2b 3d11h
Faites une copie de l'une des définitions de compute
MachineSetexistantes et générez le résultat dans un fichier JSON en exécutant la commande suivante. Ce fichier servira de base à la définition de l'ensemble de machines de calcul compatibles avec le GPU.$ oc get machineset preserve-dsoc12r4-ktjfc-worker-us-east-2a -n openshift-machine-api -o json > <output_file.json>
Modifiez le fichier JSON et apportez les modifications suivantes à la nouvelle définition
MachineSet:-
Remplacez
workerpargpu. Ce sera le nom du nouveau jeu de machines. Changez le type d'instance de la nouvelle définition
MachineSeteng4dn, qui inclut un GPU NVIDIA Tesla T4. Pour en savoir plus sur les types d'instance AWSg4dn, voir Calcul accéléré.$ jq .spec.template.spec.providerSpec.value.instanceType preserve-dsoc12r4-ktjfc-worker-gpu-us-east-2a.json "g4dn.xlarge"
Le fichier
<output_file.json>est enregistré sous le nom depreserve-dsoc12r4-ktjfc-worker-gpu-us-east-2a.json.
-
Remplacez
Mettez à jour les champs suivants dans
preserve-dsoc12r4-ktjfc-worker-gpu-us-east-2a.json:-
.metadata.nameà un nom contenantgpu. -
.spec.selector.matchLabels["machine.openshift.io/cluster-api-machineset"]pour correspondre au nouveau site.metadata.name. -
.spec.template.metadata.labels["machine.openshift.io/cluster-api-machineset"]pour correspondre au nouveau site.metadata.name. -
.spec.template.spec.providerSpec.value.instanceTypeà l'adresseg4dn.xlarge.
-
Pour vérifier vos modifications, exécutez la commande suivante :
diffde la définition originale du calcul et de la nouvelle définition du nœud compatible avec le GPU :$ oc -n openshift-machine-api get preserve-dsoc12r4-ktjfc-worker-us-east-2a -o json | diff preserve-dsoc12r4-ktjfc-worker-gpu-us-east-2a.json -
Exemple de sortie
10c10 < "name": "preserve-dsoc12r4-ktjfc-worker-gpu-us-east-2a", --- > "name": "preserve-dsoc12r4-ktjfc-worker-us-east-2a", 21c21 < "machine.openshift.io/cluster-api-machineset": "preserve-dsoc12r4-ktjfc-worker-gpu-us-east-2a" --- > "machine.openshift.io/cluster-api-machineset": "preserve-dsoc12r4-ktjfc-worker-us-east-2a" 31c31 < "machine.openshift.io/cluster-api-machineset": "preserve-dsoc12r4-ktjfc-worker-gpu-us-east-2a" --- > "machine.openshift.io/cluster-api-machineset": "preserve-dsoc12r4-ktjfc-worker-us-east-2a" 60c60 < "instanceType": "g4dn.xlarge", --- > "instanceType": "m5.xlarge",
Créez l'ensemble de machines de calcul compatibles avec le GPU à partir de la définition en exécutant la commande suivante :
$ oc create -f preserve-dsoc12r4-ktjfc-worker-gpu-us-east-2a.json
Exemple de sortie
machineset.machine.openshift.io/preserve-dsoc12r4-ktjfc-worker-gpu-us-east-2a created
Vérification
Affichez le jeu de machines que vous avez créé en exécutant la commande suivante :
$ oc -n openshift-machine-api get machinesets | grep gpu
Le nombre de répliques de MachineSet étant fixé à
1, un nouvel objetMachineest créé automatiquement.Exemple de sortie
preserve-dsoc12r4-ktjfc-worker-gpu-us-east-2a 1 1 1 1 4m21s
Affichez l'objet
Machinecréé par le jeu de machines en exécutant la commande suivante :$ oc -n openshift-machine-api get machines | grep gpu
Exemple de sortie
preserve-dsoc12r4-ktjfc-worker-gpu-us-east-2a running g4dn.xlarge us-east-2 us-east-2a 4m36s
Notez qu'il n'est pas nécessaire de spécifier un espace de noms pour le nœud. La définition du nœud est limitée à la grappe.
2.2.7. Déploiement de l'opérateur de découverte de fonctionnalités des nœuds
Une fois le nœud compatible avec le GPU créé, vous devez le découvrir afin de pouvoir le planifier. Pour ce faire, installez l'opérateur NFD (Node Feature Discovery). L'opérateur NFD identifie les caractéristiques des dispositifs matériels dans les nœuds. Il résout le problème général de l'identification et du catalogage des ressources matérielles dans les nœuds d'infrastructure afin qu'elles puissent être mises à la disposition d'OpenShift Container Platform.
Procédure
- Installez l'opérateur de découverte de fonctionnalités Node à partir de OperatorHub dans la console OpenShift Container Platform.
-
Après avoir installé l'opérateur NFD dans OperatorHub, sélectionnez Node Feature Discovery dans la liste des opérateurs installés et sélectionnez Create instance. Ceci installe les pods
nfd-masteretnfd-worker, un podnfd-workerpour chaque nœud de calcul, dans l'espace de nomsopenshift-nfd. Vérifiez que l'opérateur est installé et fonctionne en exécutant la commande suivante :
$ oc get pods -n openshift-nfd
Exemple de sortie
NAME READY STATUS RESTARTS AGE nfd-controller-manager-8646fcbb65-x5qgk 2/2 Running 7 (8h ago) 1d
- Recherchez l'Oerator installé dans la console et sélectionnez Create Node Feature Discovery.
-
Sélectionnez Create pour créer une ressource personnalisée NFD. Cela crée des pods NFD dans l'espace de noms
openshift-nfdqui interrogent les nœuds OpenShift Container Platform à la recherche de ressources matérielles et les cataloguent.
Vérification
Après une construction réussie, vérifiez qu'un pod NFD fonctionne sur chaque nœud en exécutant la commande suivante :
$ oc get pods -n openshift-nfd
Exemple de sortie
NAME READY STATUS RESTARTS AGE nfd-controller-manager-8646fcbb65-x5qgk 2/2 Running 7 (8h ago) 12d nfd-master-769656c4cb-w9vrv 1/1 Running 0 12d nfd-worker-qjxb2 1/1 Running 3 (3d14h ago) 12d nfd-worker-xtz9b 1/1 Running 5 (3d14h ago) 12d
L'opérateur NFD utilise les identifiants PCI des fournisseurs pour identifier le matériel dans un nœud. NVIDIA utilise l'ID PCI
10de.Affichez le GPU NVIDIA découvert par l'opérateur NFD en exécutant la commande suivante :
$ oc describe node ip-10-0-132-138.us-east-2.compute.internal | egrep 'Roles|pci'
Exemple de sortie
Roles: worker feature.node.kubernetes.io/pci-1013.present=true feature.node.kubernetes.io/pci-10de.present=true feature.node.kubernetes.io/pci-1d0f.present=true
10deapparaît dans la liste des caractéristiques du nœud compatible avec le GPU. Cela signifie que l'opérateur NFD a correctement identifié le nœud de l'ensemble de machines équipé d'un GPU.
2.3. Création d'un ensemble de machines de calcul sur Azure
Vous pouvez créer un ensemble de machines de calcul différent pour répondre à un besoin spécifique dans votre cluster OpenShift Container Platform sur Microsoft Azure. Par exemple, vous pouvez créer des jeux de machines d'infrastructure et des machines connexes afin de pouvoir déplacer des charges de travail de support vers les nouvelles machines.
Vous ne pouvez utiliser les fonctionnalités avancées de gestion et de mise à l'échelle des machines que dans les clusters où l'API Machine est opérationnelle. Les clusters dont l'infrastructure est fournie par l'utilisateur nécessitent une validation et une configuration supplémentaires pour utiliser l'API Machine.
Les clusters avec le type de plateforme d'infrastructure none ne peuvent pas utiliser l'API Machine. Cette limitation s'applique même si les machines de calcul attachées au cluster sont installées sur une plateforme qui prend en charge cette fonctionnalité. Ce paramètre ne peut pas être modifié après l'installation.
Pour afficher le type de plateforme de votre cluster, exécutez la commande suivante :
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.3.1. Exemple de YAML pour une ressource personnalisée d'un ensemble de machines de calcul sur Azure
Cet exemple YAML définit un ensemble de machines de calcul qui fonctionne dans la zone 1 Microsoft Azure d'une région et crée des nœuds étiquetés avec node-role.kubernetes.io/<role>: "".
Dans cet exemple, <infrastructure_id> est l'étiquette d'ID d'infrastructure basée sur l'ID de cluster que vous avez défini lors du provisionnement du cluster, et <role> est l'étiquette de nœud à ajouter.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1
machine.openshift.io/cluster-api-machine-role: <role> 2
machine.openshift.io/cluster-api-machine-type: <role> 3
name: <infrastructure_id>-<role>-<region> 4
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 5
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<region> 6
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 7
machine.openshift.io/cluster-api-machine-role: <role> 8
machine.openshift.io/cluster-api-machine-type: <role> 9
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<region> 10
spec:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-machineset: <machineset_name> 11
node-role.kubernetes.io/<role>: "" 12
providerSpec:
value:
apiVersion: azureproviderconfig.openshift.io/v1beta1
credentialsSecret:
name: azure-cloud-credentials
namespace: openshift-machine-api
image: 13
offer: ""
publisher: ""
resourceID: /resourceGroups/<infrastructure_id>-rg/providers/Microsoft.Compute/images/<infrastructure_id> 14
sku: ""
version: ""
internalLoadBalancer: ""
kind: AzureMachineProviderSpec
location: <region> 15
managedIdentity: <infrastructure_id>-identity 16
metadata:
creationTimestamp: null
natRule: null
networkResourceGroup: ""
osDisk:
diskSizeGB: 128
managedDisk:
storageAccountType: Premium_LRS
osType: Linux
publicIP: false
publicLoadBalancer: ""
resourceGroup: <infrastructure_id>-rg 17
sshPrivateKey: ""
sshPublicKey: ""
tags:
- name: <custom_tag_name> 18
value: <custom_tag_value> 19
subnet: <infrastructure_id>-<role>-subnet 20 21
userDataSecret:
name: worker-user-data 22
vmSize: Standard_D4s_v3
vnet: <infrastructure_id>-vnet 23
zone: "1" 24- 1 5 7 16 17 20 23
- Spécifiez l'ID d'infrastructure qui est basé sur l'ID de cluster que vous avez défini lorsque vous avez provisionné le cluster. Si le CLI OpenShift est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure clusterVous pouvez obtenir le sous-réseau en exécutant la commande suivante :
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.subnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1Vous pouvez obtenir le vnet en exécutant la commande suivante :
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.vnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1 - 2 3 8 9 12 21 22
- Spécifiez l'étiquette de nœud à ajouter.
- 4 6 10
- Spécifiez l'ID de l'infrastructure, l'étiquette du nœud et la région.
- 11
- Facultatif : Spécifiez le nom de l'ensemble de machines de calcul pour activer l'utilisation des ensembles de disponibilité. Ce paramètre ne s'applique qu'aux nouvelles machines de calcul.
- 13
- Spécifiez les détails de l'image pour votre ensemble de machines de calcul. Si vous souhaitez utiliser une image Azure Marketplace, voir "Sélection d'une image Azure Marketplace".
- 14
- Spécifiez une image compatible avec votre type d'instance. Les images Hyper-V de génération V2 créées par le programme d'installation ont un suffixe
-gen2, tandis que les images V1 portent le même nom sans suffixe. - 15
- Spécifiez la région où placer les machines.
- 24
- Indiquez la zone de votre région où placer les machines. Assurez-vous que votre région prend en charge la zone que vous spécifiez.
- 18 19
- Optionnel : Spécifiez des balises personnalisées dans votre jeu de machines. Indiquez le nom de la balise dans le champ
<custom_tag_name>et la valeur de la balise correspondante dans le champ<custom_tag_value>.
2.3.2. Création d'un ensemble de machines de calcul
En plus des ensembles de machines de calcul créés par le programme d'installation, vous pouvez créer vos propres ensembles pour gérer dynamiquement les ressources de calcul des machines pour les charges de travail spécifiques de votre choix.
Conditions préalables
- Déployer un cluster OpenShift Container Platform.
-
Installez le CLI OpenShift (
oc). -
Connectez-vous à
ocen tant qu'utilisateur disposant de l'autorisationcluster-admin.
Procédure
Créez un nouveau fichier YAML contenant l'échantillon de ressources personnalisées (CR) de l'ensemble de machines de calcul et nommé
<file_name>.yaml.Veillez à définir les valeurs des paramètres
<clusterID>et<role>.Facultatif : si vous n'êtes pas sûr de la valeur à définir pour un champ spécifique, vous pouvez vérifier un ensemble de machines de calcul existant dans votre cluster.
Pour répertorier les ensembles de machines de calcul de votre cluster, exécutez la commande suivante :
$ oc get machinesets -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Pour afficher les valeurs d'une ressource personnalisée (CR) d'un ensemble de machines de calcul spécifique, exécutez la commande suivante :
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml
Exemple de sortie
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1 name: <infrastructure_id>-<role> 2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec: 3 ...- 1
- L'ID de l'infrastructure du cluster.
- 2
- Une étiquette de nœud par défaut.Note
Pour les clusters disposant d'une infrastructure fournie par l'utilisateur, un ensemble de machines de calcul ne peut créer que des machines de type
workeretinfra. - 3
- Les valeurs de la section
<providerSpec>du CR de l'ensemble de machines de calcul sont spécifiques à la plate-forme. Pour plus d'informations sur les paramètres<providerSpec>dans le CR, consultez l'exemple de configuration du CR de l'ensemble de machines de calcul pour votre fournisseur.
Créez un CR
MachineSeten exécutant la commande suivante :oc create -f <nom_du_fichier>.yaml
Vérification
Affichez la liste des ensembles de machines de calcul en exécutant la commande suivante :
$ oc get machineset -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Lorsque le nouveau jeu de machines de calcul est disponible, les valeurs
DESIREDetCURRENTcorrespondent. Si le jeu de machines de calcul n'est pas disponible, attendez quelques minutes et exécutez à nouveau la commande.
2.3.3. Selecting an Azure Marketplace image
Vous pouvez créer un jeu de machines fonctionnant sur Azure qui déploie des machines utilisant l'offre Azure Marketplace. Pour utiliser cette offre, vous devez d'abord obtenir l'image Azure Marketplace. Lorsque vous obtenez votre image, tenez compte des éléments suivants :
-
While the images are the same, the Azure Marketplace publisher is different depending on your region. If you are located in North America, specify
redhatas the publisher. If you are located in EMEA, specifyredhat-limitedas the publisher. -
The offer includes a
rh-ocp-workerSKU and arh-ocp-worker-gen1SKU. Therh-ocp-workerSKU represents a Hyper-V generation version 2 VM image. The default instance types used in OpenShift Container Platform are version 2 compatible. If you plan to use an instance type that is only version 1 compatible, use the image associated with therh-ocp-worker-gen1SKU. Therh-ocp-worker-gen1SKU represents a Hyper-V version 1 VM image.
Installing images with the Azure marketplace is not supported on clusters with arm64 instances.
Conditions préalables
-
You have installed the Azure CLI client
(az). - Your Azure account is entitled for the offer and you have logged into this account with the Azure CLI client.
Procédure
Display all of the available OpenShift Container Platform images by running one of the following commands:
North America:
$ az vm image list --all --offer rh-ocp-worker --publisher redhat -o table
Exemple de sortie
Offer Publisher Sku Urn Version ------------- -------------- ------------------ -------------------------------------------------------------- -------------- rh-ocp-worker RedHat rh-ocp-worker RedHat:rh-ocp-worker:rh-ocpworker:4.8.2021122100 4.8.2021122100 rh-ocp-worker RedHat rh-ocp-worker-gen1 RedHat:rh-ocp-worker:rh-ocp-worker-gen1:4.8.2021122100 4.8.2021122100
EMEA:
$ az vm image list --all --offer rh-ocp-worker --publisher redhat-limited -o table
Exemple de sortie
Offer Publisher Sku Urn Version ------------- -------------- ------------------ -------------------------------------------------------------- -------------- rh-ocp-worker redhat-limited rh-ocp-worker redhat-limited:rh-ocp-worker:rh-ocp-worker:4.8.2021122100 4.8.2021122100 rh-ocp-worker redhat-limited rh-ocp-worker-gen1 redhat-limited:rh-ocp-worker:rh-ocp-worker-gen1:4.8.2021122100 4.8.2021122100
NoteRegardless of the version of OpenShift Container Platform that you install, the correct version of the Azure Marketplace image to use is 4.8. If required, your VMs are automatically upgraded as part of the installation process.
Inspect the image for your offer by running one of the following commands:
North America:
$ az vm image show --urn redhat:rh-ocp-worker:rh-ocp-worker:<version>
EMEA:
$ az vm image show --urn redhat-limited:rh-ocp-worker:rh-ocp-worker:<version>
Review the terms of the offer by running one of the following commands:
North America:
$ az vm image terms show --urn redhat:rh-ocp-worker:rh-ocp-worker:<version>
EMEA:
$ az vm image terms show --urn redhat-limited:rh-ocp-worker:rh-ocp-worker:<version>
Accept the terms of the offering by running one of the following commands:
North America:
$ az vm image terms accept --urn redhat:rh-ocp-worker:rh-ocp-worker:<version>
EMEA:
$ az vm image terms accept --urn redhat-limited:rh-ocp-worker:rh-ocp-worker:<version>
-
Enregistrez les détails de l'image de votre offre, en particulier les valeurs de
publisher,offer,skuetversion. Ajoutez les paramètres suivants à la section
providerSpecde votre fichier YAML de configuration de la machine en utilisant les détails de l'image pour votre offre :Exemple de valeurs d'image
providerSpecpour les machines Azure MarketplaceproviderSpec: value: image: offer: rh-ocp-worker publisher: redhat resourceID: "" sku: rh-ocp-worker type: MarketplaceWithPlan version: 4.8.2021122100
2.3.4. Activation des diagnostics de démarrage Azure
Vous pouvez activer les diagnostics de démarrage sur les machines Azure créées par votre jeu de machines.
Conditions préalables
- Disposer d'un cluster Microsoft Azure existant.
Procédure
Ajoutez la configuration
diagnosticsapplicable à votre type de stockage au champproviderSpecde votre fichier YAML machine set :Pour un compte de stockage géré par Azure :
providerSpec: diagnostics: boot: storageAccountType: AzureManaged 1- 1
- Spécifie un compte de stockage Azure Managed.
Pour un compte de stockage Azure non géré :
providerSpec: diagnostics: boot: storageAccountType: CustomerManaged 1 customerManaged: storageAccountURI: https://<storage-account>.blob.core.windows.net 2NoteSeul le service de données Azure Blob Storage est pris en charge.
Vérification
- Sur le portail Microsoft Azure, consultez la page Boot diagnostics pour une machine déployée par le jeu de machines et vérifiez que vous pouvez voir les journaux de série pour la machine.
2.3.5. Jeux de machines qui déploient des machines en tant que VM Spot
Vous pouvez réaliser des économies en créant un ensemble de machines de calcul fonctionnant sur Azure qui déploie des machines en tant que VM Spot non garanties. Les VM Spot utilisent la capacité inutilisée d'Azure et sont moins coûteuses que les VM standard. Vous pouvez utiliser les Spot VM pour les charges de travail qui peuvent tolérer des interruptions, telles que les charges de travail par lots ou sans état, évolutives horizontalement.
Azure peut mettre fin à une VM Spot à tout moment. Azure donne un avertissement de 30 secondes à l'utilisateur lorsqu'une interruption se produit. OpenShift Container Platform commence à supprimer les charges de travail des instances concernées lorsque Azure émet l'avertissement de résiliation.
Des interruptions peuvent se produire lors de l'utilisation des VM Spot pour les raisons suivantes :
- Le prix de l'instance dépasse votre prix maximum
- L'offre de machines virtuelles Spot diminue
- Azure a besoin d'un retour de capacité
Lorsqu'Azure met fin à une instance, un gestionnaire de fin s'exécutant sur le nœud Spot VM supprime la ressource machine. Pour satisfaire la quantité de l'ensemble de machines de calcul replicas, l'ensemble de machines de calcul crée une machine qui demande une VM Spot.
2.3.5.1. Création de machines virtuelles Spot à l'aide d'ensembles de machines de calcul
Vous pouvez lancer une VM Spot sur Azure en ajoutant spotVMOptions à votre fichier YAML d'ensemble de machine de calcul.
Procédure
Ajoutez la ligne suivante sous le champ
providerSpec:providerSpec: value: spotVMOptions: {}Vous pouvez éventuellement définir le champ
spotVMOptions.maxPricepour limiter le coût de la VM Spot. Par exemple, vous pouvez définirmaxPrice: '0.98765'. Si le champmaxPriceest défini, cette valeur est utilisée comme prix maximum horaire de la VM Spot. S'il n'est pas défini, le prix maximum est fixé par défaut à-1et les frais sont portés au prix standard de la VM.Azure plafonne les prix des VM Spot au prix standard. Azure n'expulsera pas une instance en raison de la tarification si l'instance est configurée avec le prix par défaut
maxPrice. Cependant, une instance peut toujours être expulsée en raison de restrictions de capacité.
Il est fortement recommandé d'utiliser le prix standard par défaut des VM comme valeur maxPrice et de ne pas fixer le prix maximum pour les VM Spot.
2.3.6. Jeux de machines qui déploient des machines sur des disques d'OS éphémères
Vous pouvez créer un ensemble de machines de calcul fonctionnant sur Azure qui déploie des machines sur des disques OS éphémères. Les disques OS éphémères utilisent la capacité locale des VM plutôt que le stockage Azure distant. Cette configuration n'entraîne donc aucun coût supplémentaire et offre une latence réduite pour la lecture, l'écriture et la réimagerie.
Ressources complémentaires
- Pour plus d'informations, consultez la documentation Microsoft Azure sur les disques d'exploitation éphémères pour les machines virtuelles Azure.
2.3.6.1. Création de machines sur des disques OS éphémères à l'aide d'ensembles de machines de calcul
Vous pouvez lancer des machines sur des disques OS éphémères sur Azure en modifiant votre fichier YAML d'ensemble de machine de calcul.
Conditions préalables
- Disposer d'un cluster Microsoft Azure existant.
Procédure
Modifiez la ressource personnalisée (CR) en exécutant la commande suivante :
oc edit machineset <machine-set-name> $ oc edit machineset <machine-set-name>
où
<machine-set-name>est l'ensemble de machines de calcul que vous souhaitez provisionner sur des disques OS éphémères.Ajoutez ce qui suit au champ
providerSpec:providerSpec: value: ... osDisk: ... diskSettings: 1 ephemeralStorageLocation: Local 2 cachingType: ReadOnly 3 managedDisk: storageAccountType: Standard_LRS 4 ...ImportantL'implémentation de la prise en charge des disques OS éphémères dans OpenShift Container Platform ne prend en charge que le type de placement
CacheDisk. Ne modifiez pas le paramètre de configurationplacement.Créez un ensemble de machines de calcul en utilisant la configuration mise à jour :
oc create -f <machine-set-config>.yaml
Vérification
-
Sur le portail Microsoft Azure, consultez la page Overview pour une machine déployée par l'ensemble de machines de calcul et vérifiez que le champ
Ephemeral OS diskest défini surOS cache placement.
2.3.7. Jeux de machines qui déploient des machines avec des disques ultra comme disques de données
Vous pouvez créer un jeu de machines fonctionnant sur Azure qui déploie des machines avec des ultra-disques. Les disques ultra sont des systèmes de stockage haute performance destinés à être utilisés avec les charges de travail les plus exigeantes.
Vous pouvez également créer une revendication de volume persistant (PVC) qui se lie dynamiquement à une classe de stockage soutenue par des disques Azure ultra et les monte sur des pods.
Les disques de données ne permettent pas de spécifier le débit ou l'IOPS du disque. Vous pouvez configurer ces propriétés en utilisant des PVC.
Ressources complémentaires
2.3.7.1. Création de machines avec ultra-disques à l'aide de jeux de machines
Vous pouvez déployer des machines avec des ultra-disques sur Azure en modifiant votre fichier YAML de configuration des machines.
Conditions préalables
- Disposer d'un cluster Microsoft Azure existant.
Procédure
Créez un secret personnalisé dans l'espace de noms
openshift-machine-apien utilisant le secret de donnéesworkeren exécutant la commande suivante :$ oc -n openshift-machine-api \ get secret <role>-user-data \ 1 --template='{{index .data.userData | base64decode}}' | jq > userData.txt 2
Dans un éditeur de texte, ouvrez le fichier
userData.txtet localisez le caractère final}dans le fichier.-
Sur la ligne immédiatement précédente, ajouter un
,. Créez une nouvelle ligne après le site
,et ajoutez les détails de configuration suivants :"storage": { "disks": [ 1 { "device": "/dev/disk/azure/scsi1/lun0", 2 "partitions": [ 3 { "label": "lun0p1", 4 "sizeMiB": 1024, 5 "startMiB": 0 } ] } ], "filesystems": [ 6 { "device": "/dev/disk/by-partlabel/lun0p1", "format": "xfs", "path": "/var/lib/lun0p1" } ] }, "systemd": { "units": [ 7 { "contents": "[Unit]\nBefore=local-fs.target\n[Mount]\nWhere=/var/lib/lun0p1\nWhat=/dev/disk/by-partlabel/lun0p1\nOptions=defaults,pquota\n[Install]\nWantedBy=local-fs.target\n", 8 "enabled": true, "name": "var-lib-lun0p1.mount" } ] }- 1
- Les détails de configuration du disque que vous souhaitez attacher à un nœud en tant qu'ultra disque.
- 2
- Indiquez la valeur
lundéfinie dans la strophedataDisksdu jeu de machines que vous utilisez. Par exemple, si le jeu de machines contientlun: 0, indiquezlun0. Vous pouvez initialiser plusieurs disques de données en spécifiant plusieurs entrées"disks"dans ce fichier de configuration. Si vous spécifiez plusieurs entrées"disks", assurez-vous que la valeurlunde chaque entrée correspond à la valeur du jeu de machines. - 3
- Les détails de la configuration d'une nouvelle partition sur le disque.
- 4
- Indiquez un nom pour la partition. Il peut être utile d'utiliser des noms hiérarchiques, tels que
lun0p1pour la première partition delun0. - 5
- Indiquez la taille totale en Mo de la partition.
- 6
- Spécifiez le système de fichiers à utiliser lors du formatage d'une partition. Utilisez l'étiquette de partition pour spécifier la partition.
- 7
- Indiquez une unité
systemdpour monter la partition au démarrage. Utilisez l'étiquette de partition pour spécifier la partition. Vous pouvez créer plusieurs partitions en spécifiant plusieurs entrées"partitions"dans ce fichier de configuration. Si vous spécifiez plusieurs entrées"partitions", vous devez spécifier une unitésystemdpour chacune d'entre elles. - 8
- Pour
Where, spécifiez la valeur destorage.filesystems.path. PourWhat, spécifiez la valeur destorage.filesystems.device.
-
Sur la ligne immédiatement précédente, ajouter un
Extrayez la valeur du modèle de désactivation dans un fichier appelé
disableTemplating.txten exécutant la commande suivante :$ oc -n openshift-machine-api get secret <role>-user-data \ 1 --template='{{index .data.disableTemplating | base64decode}}' | jq > disableTemplating.txt- 1
- Remplacer
<role>parworker.
Combinez les fichiers
userData.txtetdisableTemplating.txtpour créer un fichier de données secrètes en exécutant la commande suivante :$ oc -n openshift-machine-api create secret generic <role>-user-data-x5 \ 1 --from-file=userData=userData.txt \ --from-file=disableTemplating=disableTemplating.txt- 1
- Pour
<role>-user-data-x5, indiquez le nom du secret. Remplacez<role>parworker.
Copiez une ressource personnalisée (CR) Azure
MachineSetexistante et modifiez-la en exécutant la commande suivante :oc edit machineset <machine-set-name> $ oc edit machineset <machine-set-name>
où
<machine-set-name>est l'ensemble de machines que vous voulez provisionner avec des ultra-disques.Ajouter les lignes suivantes aux endroits indiqués :
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet spec: template: spec: metadata: labels: disk: ultrassd 1 providerSpec: value: ultraSSDCapability: Enabled 2 dataDisks: 3 - nameSuffix: ultrassd lun: 0 diskSizeGB: 4 deletionPolicy: Delete cachingType: None managedDisk: storageAccountType: UltraSSD_LRS userDataSecret: name: <role>-user-data-x5 4- 1
- Indiquez une étiquette à utiliser pour sélectionner un nœud créé par ce jeu de machines. Cette procédure utilise
disk.ultrassdpour cette valeur. - 2 3
- Ces lignes permettent d'utiliser des disques ultra. Pour
dataDisks, inclure la strophe entière. - 4
- Spécifiez le secret des données de l'utilisateur créé précédemment. Remplacez
<role>parworker.
Créez un jeu de machines à l'aide de la configuration mise à jour en exécutant la commande suivante :
oc create -f <machine-set-name>.yaml
Vérification
Validez la création des machines en exécutant la commande suivante :
$ oc get machines
Les machines doivent être dans l'état
Running.Pour une machine en cours d'exécution et à laquelle un nœud est attaché, validez la partition en exécutant la commande suivante :
$ oc debug node/<node-name> -- chroot /host lsblk
Dans cette commande,
oc debug node/<node-name>démarre un shell de débogage sur le nœud<node-name>et transmet une commande à--. La commande passéechroot /hostpermet d'accéder aux binaires du système d'exploitation hôte sous-jacent, etlsblkmontre les périphériques de bloc attachés à la machine du système d'exploitation hôte.
Prochaines étapes
Pour utiliser un ultra disque à partir d'un pod, créez une charge de travail qui utilise le point de montage. Créez un fichier YAML similaire à l'exemple suivant :
apiVersion: v1 kind: Pod metadata: name: ssd-benchmark1 spec: containers: - name: ssd-benchmark1 image: nginx ports: - containerPort: 80 name: "http-server" volumeMounts: - name: lun0p1 mountPath: "/tmp" volumes: - name: lun0p1 hostPath: path: /var/lib/lun0p1 type: DirectoryOrCreate nodeSelector: disktype: ultrassd
2.3.7.2. Ressources de dépannage pour les ensembles de machines qui activent les ultra-disques
Utilisez les informations de cette section pour comprendre et résoudre les problèmes que vous pourriez rencontrer.
2.3.7.2.1. Configuration incorrecte de l'ultra disque
Si une configuration incorrecte du paramètre ultraSSDCapability est spécifiée dans le jeu de machines, le provisionnement de la machine échoue.
Par exemple, si le paramètre ultraSSDCapability est défini sur Disabled, mais qu'un disque ultra est spécifié dans le paramètre dataDisks, le message d'erreur suivant apparaît :
StorageAccountType UltraSSD_LRS can be used only when additionalCapabilities.ultraSSDEnabled is set.
- Pour résoudre ce problème, vérifiez que la configuration de votre jeu de machines est correcte.
2.3.7.2.2. Paramètres de disque non pris en charge
Si une région, une zone de disponibilité ou une taille d'instance qui n'est pas compatible avec les disques ultra est spécifiée dans le jeu de machines, le provisionnement de la machine échoue. Vérifiez les journaux pour le message d'erreur suivant :
failed to create vm <machine_name> : failure sending request for machine <machine_name> : cannot create vm : compute.VirtualMachinesClient#CreateOrUpdate : Échec de l'envoi de la requête : StatusCode=400 -- Erreur d'origine : Code="BadRequest" Message="Le type de compte de stockage 'UltraSSD_LRS' n'est pas pris en charge <more_information_about_why>."
- Pour résoudre ce problème, vérifiez que vous utilisez cette fonctionnalité dans un environnement pris en charge et que la configuration de votre jeu de machines est correcte.
2.3.7.2.3. Impossible de supprimer des disques
Si la suppression des ultra-disques en tant que disques de données ne fonctionne pas comme prévu, les machines sont supprimées et les disques de données sont orphelins. Vous devez supprimer les disques orphelins manuellement si vous le souhaitez.
2.3.8. Activation des clés de chiffrement gérées par le client pour un ensemble de machines
Vous pouvez fournir une clé de chiffrement à Azure pour chiffrer les données sur les disques gérés au repos. Vous pouvez activer le chiffrement côté serveur avec des clés gérées par le client en utilisant l'API Machine.
Un Azure Key Vault, un ensemble de chiffrement de disque et une clé de chiffrement sont nécessaires pour utiliser une clé gérée par le client. Le jeu de chiffrement de disque doit se trouver dans un groupe de ressources auquel le Cloud Credential Operator (CCO) a accordé des autorisations. Si ce n'est pas le cas, un rôle de lecteur supplémentaire doit être accordé à l'ensemble de chiffrement de disque.
Conditions préalables
Procédure
Configurez le cryptage du disque dans le champ
providerSpecde votre fichier YAML de configuration de la machine. Par exemple :providerSpec: value: osDisk: diskSizeGB: 128 managedDisk: diskEncryptionSet: id: /subscriptions/<subscription_id>/resourceGroups/<resource_group_name>/providers/Microsoft.Compute/diskEncryptionSets/<disk_encryption_set_name> storageAccountType: Premium_LRS
Ressources complémentaires
2.3.9. Mise en réseau accélérée pour les machines virtuelles Microsoft Azure
Accelerated Networking utilise la virtualisation d'E/S à racine unique (SR-IOV) pour fournir aux VM Microsoft Azure un chemin plus direct vers le commutateur. Les performances du réseau s'en trouvent améliorées. Cette fonctionnalité peut être activée pendant ou après l'installation.
2.3.9.1. Limitations
Tenez compte des limitations suivantes lorsque vous décidez d'utiliser ou non la mise en réseau accélérée :
- La mise en réseau accélérée n'est prise en charge que sur les clusters où l'API Machine est opérationnelle.
Bien que la configuration minimale requise pour un nœud de travail Azure soit de deux vCPU, Accelerated Networking nécessite une taille de VM Azure comprenant au moins quatre vCPU. Pour répondre à cette exigence, vous pouvez modifier la valeur de
vmSizedans votre jeu de machines. Pour plus d'informations sur les tailles de VM Azure, consultez la documentation Microsoft Azure.
- Lorsque cette fonctionnalité est activée sur un cluster Azure existant, seuls les nœuds nouvellement provisionnés sont concernés. Les nœuds en cours d'exécution ne sont pas rapprochés. Pour activer la fonctionnalité sur tous les nœuds, vous devez remplacer chaque machine existante. Cette opération peut être effectuée pour chaque machine individuellement, ou en réduisant le nombre de réplicas à zéro, puis en l'augmentant jusqu'au nombre de réplicas souhaité.
2.3.10. Ajouter un nœud GPU à un cluster OpenShift Container Platform existant
Vous pouvez copier et modifier la configuration d'un ensemble de machines de calcul par défaut pour créer un ensemble de machines et des machines compatibles avec le GPU pour le fournisseur de cloud Azure.
Le tableau suivant énumère les types d'instance validés :
| vmSize | Accélérateur GPU NVIDIA | Nombre maximal de GPU | L'architecture |
|---|---|---|---|
|
| V100 | 4 | x86 |
|
| T4 | 1 | x86 |
|
| A100 | 8 | x86 |
Par défaut, les abonnements Azure n'ont pas de quota pour les types d'instances Azure avec GPU. Les clients doivent demander une augmentation de quota pour les familles d'instances Azure listées ci-dessus.
Procédure
Affichez les machines et les ensembles de machines qui existent dans l'espace de noms
openshift-machine-apien exécutant la commande suivante. Chaque ensemble de machines de calcul est associé à une zone de disponibilité différente dans la région Azure. Le programme d'installation équilibre automatiquement la charge des machines de calcul entre les zones de disponibilité.$ oc get machineset -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE myclustername-worker-centralus1 1 1 1 1 6h9m myclustername-worker-centralus2 1 1 1 1 6h9m myclustername-worker-centralus3 1 1 1 1 6h9m
Faites une copie de l'une des définitions de compute
MachineSetexistantes et produisez le résultat dans un fichier YAML en exécutant la commande suivante. Ce fichier servira de base à la définition de l'ensemble de machines de calcul compatibles avec le GPU.$ oc get machineset -n openshift-machine-api myclustername-worker-centralus1 -o yaml > machineset-azure.yaml
Voir le contenu du jeu de machines :
$ cat machineset-azure.yaml
Exemple de fichier
machineset-azure.yamlapiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: annotations: machine.openshift.io/GPU: "0" machine.openshift.io/memoryMb: "16384" machine.openshift.io/vCPU: "4" creationTimestamp: "2023-02-06T14:08:19Z" generation: 1 labels: machine.openshift.io/cluster-api-cluster: myclustername machine.openshift.io/cluster-api-machine-role: worker machine.openshift.io/cluster-api-machine-type: worker name: myclustername-worker-centralus1 namespace: openshift-machine-api resourceVersion: "23601" uid: acd56e0c-7612-473a-ae37-8704f34b80de spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: myclustername machine.openshift.io/cluster-api-machineset: myclustername-worker-centralus1 template: metadata: labels: machine.openshift.io/cluster-api-cluster: myclustername machine.openshift.io/cluster-api-machine-role: worker machine.openshift.io/cluster-api-machine-type: worker machine.openshift.io/cluster-api-machineset: myclustername-worker-centralus1 spec: lifecycleHooks: {} metadata: {} providerSpec: value: acceleratedNetworking: true apiVersion: machine.openshift.io/v1beta1 credentialsSecret: name: azure-cloud-credentials namespace: openshift-machine-api diagnostics: {} image: offer: "" publisher: "" resourceID: /resourceGroups/myclustername-rg/providers/Microsoft.Compute/galleries/gallery_myclustername_n6n4r/images/myclustername-gen2/versions/latest sku: "" version: "" kind: AzureMachineProviderSpec location: centralus managedIdentity: myclustername-identity metadata: creationTimestamp: null networkResourceGroup: myclustername-rg osDisk: diskSettings: {} diskSizeGB: 128 managedDisk: storageAccountType: Premium_LRS osType: Linux publicIP: false publicLoadBalancer: myclustername resourceGroup: myclustername-rg spotVMOptions: {} subnet: myclustername-worker-subnet userDataSecret: name: worker-user-data vmSize: Standard_D4s_v3 vnet: myclustername-vnet zone: "1" status: availableReplicas: 1 fullyLabeledReplicas: 1 observedGeneration: 1 readyReplicas: 1 replicas: 1Faites une copie du fichier
machineset-azure.yamlen exécutant la commande suivante :$ cp machineset-azure.yaml machineset-azure-gpu.yaml
Mettez à jour les champs suivants dans
machineset-azure-gpu.yaml:-
Remplacer
.metadata.namepar un nom contenantgpu. -
Modifier
.spec.selector.matchLabels["machine.openshift.io/cluster-api-machineset"]pour qu'il corresponde au nouveau nom .metadata. -
Modifier
.spec.template.metadata.labels["machine.openshift.io/cluster-api-machineset"]pour qu'il corresponde au nouveau.metadata.name. Remplacer
.spec.template.spec.providerSpec.value.vmSizeparStandard_NC4as_T4_v3.Exemple de fichier
machineset-azure-gpu.yamlapiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: annotations: machine.openshift.io/GPU: "1" machine.openshift.io/memoryMb: "28672" machine.openshift.io/vCPU: "4" creationTimestamp: "2023-02-06T20:27:12Z" generation: 1 labels: machine.openshift.io/cluster-api-cluster: myclustername machine.openshift.io/cluster-api-machine-role: worker machine.openshift.io/cluster-api-machine-type: worker name: myclustername-nc4ast4-gpu-worker-centralus1 namespace: openshift-machine-api resourceVersion: "166285" uid: 4eedce7f-6a57-4abe-b529-031140f02ffa spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: myclustername machine.openshift.io/cluster-api-machineset: myclustername-nc4ast4-gpu-worker-centralus1 template: metadata: labels: machine.openshift.io/cluster-api-cluster: myclustername machine.openshift.io/cluster-api-machine-role: worker machine.openshift.io/cluster-api-machine-type: worker machine.openshift.io/cluster-api-machineset: myclustername-nc4ast4-gpu-worker-centralus1 spec: lifecycleHooks: {} metadata: {} providerSpec: value: acceleratedNetworking: true apiVersion: machine.openshift.io/v1beta1 credentialsSecret: name: azure-cloud-credentials namespace: openshift-machine-api diagnostics: {} image: offer: "" publisher: "" resourceID: /resourceGroups/myclustername-rg/providers/Microsoft.Compute/galleries/gallery_myclustername_n6n4r/images/myclustername-gen2/versions/latest sku: "" version: "" kind: AzureMachineProviderSpec location: centralus managedIdentity: myclustername-identity metadata: creationTimestamp: null networkResourceGroup: myclustername-rg osDisk: diskSettings: {} diskSizeGB: 128 managedDisk: storageAccountType: Premium_LRS osType: Linux publicIP: false publicLoadBalancer: myclustername resourceGroup: myclustername-rg spotVMOptions: {} subnet: myclustername-worker-subnet userDataSecret: name: worker-user-data vmSize: Standard_NC4as_T4_v3 vnet: myclustername-vnet zone: "1" status: availableReplicas: 1 fullyLabeledReplicas: 1 observedGeneration: 1 readyReplicas: 1 replicas: 1
-
Remplacer
Pour vérifier vos modifications, exécutez la commande suivante :
diffde la définition originale du calcul et de la nouvelle définition du nœud compatible avec le GPU :$ diff machineset-azure.yaml machineset-azure-gpu.yaml
Exemple de sortie
14c14 < name: myclustername-worker-centralus1 --- > name: myclustername-nc4ast4-gpu-worker-centralus1 23c23 < machine.openshift.io/cluster-api-machineset: myclustername-worker-centralus1 --- > machine.openshift.io/cluster-api-machineset: myclustername-nc4ast4-gpu-worker-centralus1 30c30 < machine.openshift.io/cluster-api-machineset: myclustername-worker-centralus1 --- > machine.openshift.io/cluster-api-machineset: myclustername-nc4ast4-gpu-worker-centralus1 67c67 < vmSize: Standard_D4s_v3 --- > vmSize: Standard_NC4as_T4_v3
Créez l'ensemble de machines de calcul compatibles avec le GPU à partir du fichier de définition en exécutant la commande suivante :
$ oc create -f machineset-azure-gpu.yaml
Exemple de sortie
machineset.machine.openshift.io/myclustername-nc4ast4-gpu-worker-centralus1 created
Affichez les machines et les ensembles de machines qui existent dans l'espace de noms
openshift-machine-apien exécutant la commande suivante. Chaque ensemble de machines de calcul est associé à une zone de disponibilité différente dans la région Azure. Le programme d'installation équilibre automatiquement la charge des machines de calcul entre les zones de disponibilité.$ oc get machineset -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE clustername-n6n4r-nc4ast4-gpu-worker-centralus1 1 1 1 1 122m clustername-n6n4r-worker-centralus1 1 1 1 1 8h clustername-n6n4r-worker-centralus2 1 1 1 1 8h clustername-n6n4r-worker-centralus3 1 1 1 1 8h
Affichez les machines qui existent dans l'espace de noms
openshift-machine-apien exécutant la commande suivante. Vous ne pouvez configurer qu'une machine de calcul par ensemble, mais vous pouvez faire évoluer un ensemble de machines de calcul pour ajouter un nœud dans une région et une zone particulières.$ oc get machines -n openshift-machine-api
Exemple de sortie
NAME PHASE TYPE REGION ZONE AGE myclustername-master-0 Running Standard_D8s_v3 centralus 2 6h40m myclustername-master-1 Running Standard_D8s_v3 centralus 1 6h40m myclustername-master-2 Running Standard_D8s_v3 centralus 3 6h40m myclustername-nc4ast4-gpu-worker-centralus1-w9bqn Running centralus 1 21m myclustername-worker-centralus1-rbh6b Running Standard_D4s_v3 centralus 1 6h38m myclustername-worker-centralus2-dbz7w Running Standard_D4s_v3 centralus 2 6h38m myclustername-worker-centralus3-p9b8c Running Standard_D4s_v3 centralus 3 6h38m
Affichez les nœuds, les machines et les jeux de machines existants en exécutant la commande suivante. Notez que chaque nœud est une instance d'une définition de machine avec une région Azure et un rôle OpenShift Container Platform spécifiques.
$ oc get nodes
Exemple de sortie
NAME STATUS ROLES AGE VERSION myclustername-master-0 Ready control-plane,master 6h39m v1.25.4+a34b9e9 myclustername-master-1 Ready control-plane,master 6h41m v1.25.4+a34b9e9 myclustername-master-2 Ready control-plane,master 6h39m v1.25.4+a34b9e9 myclustername-nc4ast4-gpu-worker-centralus1-w9bqn Ready worker 14m v1.25.4+a34b9e9 myclustername-worker-centralus1-rbh6b Ready worker 6h29m v1.25.4+a34b9e9 myclustername-worker-centralus2-dbz7w Ready worker 6h29m v1.25.4+a34b9e9 myclustername-worker-centralus3-p9b8c Ready worker 6h31m v1.25.4+a34b9e9
Afficher la liste des ensembles de machines de calcul :
$ oc get machineset -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE myclustername-worker-centralus1 1 1 1 1 8h myclustername-worker-centralus2 1 1 1 1 8h myclustername-worker-centralus3 1 1 1 1 8h
Créez l'ensemble de machines de calcul compatibles avec le GPU à partir du fichier de définition en exécutant la commande suivante :
$ oc create -f machineset-azure-gpu.yaml
Afficher la liste des ensembles de machines de calcul :
oc get machineset -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE myclustername-nc4ast4-gpu-worker-centralus1 1 1 1 1 121m myclustername-worker-centralus1 1 1 1 1 8h myclustername-worker-centralus2 1 1 1 1 8h myclustername-worker-centralus3 1 1 1 1 8h
Vérification
Affichez le jeu de machines que vous avez créé en exécutant la commande suivante :
$ oc get machineset -n openshift-machine-api | grep gpu
Le nombre de répliques de MachineSet étant fixé à
1, un nouvel objetMachineest créé automatiquement.Exemple de sortie
myclustername-nc4ast4-gpu-worker-centralus1 1 1 1 1 121m
Affichez l'objet
Machinecréé par le jeu de machines en exécutant la commande suivante :$ oc -n openshift-machine-api get machines | grep gpu
Exemple de sortie
myclustername-nc4ast4-gpu-worker-centralus1-w9bqn Running Standard_NC4as_T4_v3 centralus 1 21m
Il n'est pas nécessaire de spécifier un espace de noms pour le nœud. La définition du nœud est limitée à la grappe.
2.3.11. Déploiement de l'opérateur de découverte de fonctionnalités des nœuds
Une fois le nœud compatible avec le GPU créé, vous devez le découvrir afin de pouvoir le planifier. Pour ce faire, installez l'opérateur NFD (Node Feature Discovery). L'opérateur NFD identifie les caractéristiques des dispositifs matériels dans les nœuds. Il résout le problème général de l'identification et du catalogage des ressources matérielles dans les nœuds d'infrastructure afin qu'elles puissent être mises à la disposition d'OpenShift Container Platform.
Procédure
- Installez l'opérateur de découverte de fonctionnalités Node à partir de OperatorHub dans la console OpenShift Container Platform.
-
Après avoir installé l'opérateur NFD dans OperatorHub, sélectionnez Node Feature Discovery dans la liste des opérateurs installés et sélectionnez Create instance. Ceci installe les pods
nfd-masteretnfd-worker, un podnfd-workerpour chaque nœud de calcul, dans l'espace de nomsopenshift-nfd. Vérifiez que l'opérateur est installé et fonctionne en exécutant la commande suivante :
$ oc get pods -n openshift-nfd
Exemple de sortie
NAME READY STATUS RESTARTS AGE nfd-controller-manager-8646fcbb65-x5qgk 2/2 Running 7 (8h ago) 1d
- Recherchez l'Oerator installé dans la console et sélectionnez Create Node Feature Discovery.
-
Sélectionnez Create pour créer une ressource personnalisée NFD. Cela crée des pods NFD dans l'espace de noms
openshift-nfdqui interrogent les nœuds OpenShift Container Platform à la recherche de ressources matérielles et les cataloguent.
Vérification
Après une construction réussie, vérifiez qu'un pod NFD fonctionne sur chaque nœud en exécutant la commande suivante :
$ oc get pods -n openshift-nfd
Exemple de sortie
NAME READY STATUS RESTARTS AGE nfd-controller-manager-8646fcbb65-x5qgk 2/2 Running 7 (8h ago) 12d nfd-master-769656c4cb-w9vrv 1/1 Running 0 12d nfd-worker-qjxb2 1/1 Running 3 (3d14h ago) 12d nfd-worker-xtz9b 1/1 Running 5 (3d14h ago) 12d
L'opérateur NFD utilise les identifiants PCI des fournisseurs pour identifier le matériel dans un nœud. NVIDIA utilise l'ID PCI
10de.Affichez le GPU NVIDIA découvert par l'opérateur NFD en exécutant la commande suivante :
$ oc describe node ip-10-0-132-138.us-east-2.compute.internal | egrep 'Roles|pci'
Exemple de sortie
Roles: worker feature.node.kubernetes.io/pci-1013.present=true feature.node.kubernetes.io/pci-10de.present=true feature.node.kubernetes.io/pci-1d0f.present=true
10deapparaît dans la liste des caractéristiques du nœud compatible avec le GPU. Cela signifie que l'opérateur NFD a correctement identifié le nœud de l'ensemble de machines équipé d'un GPU.
Ressources complémentaires
2.3.11.1. Activation de l'Accelerated Networking sur un cluster Microsoft Azure existant
Vous pouvez activer Accelerated Networking sur Azure en ajoutant acceleratedNetworking à votre fichier YAML machine set.
Conditions préalables
- Disposer d'un cluster Microsoft Azure existant où l'API Machine est opérationnelle.
Procédure
Ajoutez ce qui suit au champ
providerSpec:providerSpec: value: acceleratedNetworking: true 1 vmSize: <azure-vm-size> 2- 1
- This line enables Accelerated Networking.
- 2
- Specify an Azure VM size that includes at least four vCPUs. For information about VM sizes, see Microsoft Azure documentation.
Prochaines étapes
- Pour activer la fonctionnalité sur les nœuds en cours d'exécution, vous devez remplacer chaque machine existante. Cette opération peut être effectuée pour chaque machine individuellement, ou en réduisant les répliques à zéro, puis en les augmentant jusqu'au nombre de répliques souhaité.
Vérification
-
Sur le portail Microsoft Azure, consultez la page des paramètres Networking pour une machine approvisionnée par le jeu de machines et vérifiez que le champ
Accelerated networkingest défini surEnabled.
Ressources complémentaires
2.4. Création d'un ensemble de machines de calcul sur Azure Stack Hub
Vous pouvez créer un ensemble de machines de calcul différent pour répondre à un objectif spécifique dans votre cluster OpenShift Container Platform sur Microsoft Azure Stack Hub. Par exemple, vous pouvez créer des ensembles de machines d'infrastructure et des machines connexes afin de pouvoir déplacer des charges de travail de support vers les nouvelles machines.
Vous ne pouvez utiliser les fonctionnalités avancées de gestion et de mise à l'échelle des machines que dans les clusters où l'API Machine est opérationnelle. Les clusters dont l'infrastructure est fournie par l'utilisateur nécessitent une validation et une configuration supplémentaires pour utiliser l'API Machine.
Les clusters avec le type de plateforme d'infrastructure none ne peuvent pas utiliser l'API Machine. Cette limitation s'applique même si les machines de calcul attachées au cluster sont installées sur une plateforme qui prend en charge cette fonctionnalité. Ce paramètre ne peut pas être modifié après l'installation.
Pour afficher le type de plateforme de votre cluster, exécutez la commande suivante :
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.4.1. Exemple de YAML pour une ressource personnalisée d'un ensemble de machines de calcul sur Azure Stack Hub
Cet exemple YAML définit un ensemble de machines de calcul qui fonctionne dans la zone 1 Microsoft Azure d'une région et crée des nœuds étiquetés avec node-role.kubernetes.io/<role>: "".
Dans cet exemple, <infrastructure_id> est l'étiquette d'ID d'infrastructure basée sur l'ID de cluster que vous avez défini lors du provisionnement du cluster, et <role> est l'étiquette de nœud à ajouter.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1
machine.openshift.io/cluster-api-machine-role: <role> 2
machine.openshift.io/cluster-api-machine-type: <role> 3
name: <infrastructure_id>-<role>-<region> 4
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 5
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<region> 6
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 7
machine.openshift.io/cluster-api-machine-role: <role> 8
machine.openshift.io/cluster-api-machine-type: <role> 9
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<region> 10
spec:
metadata:
creationTimestamp: null
labels:
node-role.kubernetes.io/<role>: "" 11
providerSpec:
value:
apiVersion: machine.openshift.io/v1beta1
availabilitySet: <availability_set> 12
credentialsSecret:
name: azure-cloud-credentials
namespace: openshift-machine-api
image:
offer: ""
publisher: ""
resourceID: /resourceGroups/<infrastructure_id>-rg/providers/Microsoft.Compute/images/<infrastructure_id> 13
sku: ""
version: ""
internalLoadBalancer: ""
kind: AzureMachineProviderSpec
location: <region> 14
managedIdentity: <infrastructure_id>-identity 15
metadata:
creationTimestamp: null
natRule: null
networkResourceGroup: ""
osDisk:
diskSizeGB: 128
managedDisk:
storageAccountType: Premium_LRS
osType: Linux
publicIP: false
publicLoadBalancer: ""
resourceGroup: <infrastructure_id>-rg 16
sshPrivateKey: ""
sshPublicKey: ""
subnet: <infrastructure_id>-<role>-subnet 17 18
userDataSecret:
name: worker-user-data 19
vmSize: Standard_DS4_v2
vnet: <infrastructure_id>-vnet 20
zone: "1" 21- 1 5 7 13 15 16 17 20
- Spécifiez l'ID d'infrastructure qui est basé sur l'ID de cluster que vous avez défini lorsque vous avez provisionné le cluster. Si le CLI OpenShift est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure clusterVous pouvez obtenir le sous-réseau en exécutant la commande suivante :
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.subnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1Vous pouvez obtenir le vnet en exécutant la commande suivante :
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.vnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1 - 2 3 8 9 11 18 19
- Spécifiez l'étiquette de nœud à ajouter.
- 4 6 10
- Spécifiez l'ID de l'infrastructure, l'étiquette du nœud et la région.
- 14
- Spécifiez la région où placer les machines.
- 21
- Indiquez la zone de votre région où placer les machines. Assurez-vous que votre région prend en charge la zone que vous spécifiez.
- 12
- Spécifiez l'ensemble de disponibilité pour le cluster.
2.4.2. Création d'un ensemble de machines de calcul
En plus des ensembles de machines de calcul créés par le programme d'installation, vous pouvez créer vos propres ensembles pour gérer dynamiquement les ressources de calcul des machines pour les charges de travail spécifiques de votre choix.
Conditions préalables
- Déployer un cluster OpenShift Container Platform.
-
Installez le CLI OpenShift (
oc). -
Connectez-vous à
ocen tant qu'utilisateur disposant de l'autorisationcluster-admin. - Créer un ensemble de disponibilité dans lequel déployer les machines de calcul Azure Stack Hub.
Procédure
Créez un nouveau fichier YAML contenant l'échantillon de ressources personnalisées (CR) de l'ensemble de machines de calcul et nommé
<file_name>.yaml.Veillez à définir les valeurs des paramètres
<availabilitySet>,<clusterID>et<role>.Facultatif : si vous n'êtes pas sûr de la valeur à définir pour un champ spécifique, vous pouvez vérifier un ensemble de machines de calcul existant dans votre cluster.
Pour répertorier les ensembles de machines de calcul de votre cluster, exécutez la commande suivante :
$ oc get machinesets -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Pour afficher les valeurs d'une ressource personnalisée (CR) d'un ensemble de machines de calcul spécifique, exécutez la commande suivante :
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml
Exemple de sortie
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1 name: <infrastructure_id>-<role> 2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec: 3 ...- 1
- L'ID de l'infrastructure du cluster.
- 2
- Une étiquette de nœud par défaut.Note
Pour les clusters disposant d'une infrastructure fournie par l'utilisateur, un ensemble de machines de calcul ne peut créer que des machines de type
workeretinfra. - 3
- Les valeurs de la section
<providerSpec>du CR de l'ensemble de machines de calcul sont spécifiques à la plate-forme. Pour plus d'informations sur les paramètres<providerSpec>dans le CR, consultez l'exemple de configuration du CR de l'ensemble de machines de calcul pour votre fournisseur.
Créez un CR
MachineSeten exécutant la commande suivante :oc create -f <nom_du_fichier>.yaml
Vérification
Affichez la liste des ensembles de machines de calcul en exécutant la commande suivante :
$ oc get machineset -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Lorsque le nouveau jeu de machines de calcul est disponible, les valeurs
DESIREDetCURRENTcorrespondent. Si le jeu de machines de calcul n'est pas disponible, attendez quelques minutes et exécutez à nouveau la commande.
2.4.3. Activation des diagnostics de démarrage Azure
Vous pouvez activer les diagnostics de démarrage sur les machines Azure créées par votre jeu de machines.
Conditions préalables
- Disposer d'un cluster Microsoft Azure Stack Hub existant.
Procédure
Ajoutez la configuration
diagnosticsapplicable à votre type de stockage au champproviderSpecde votre fichier YAML machine set :Pour un compte de stockage géré par Azure :
providerSpec: diagnostics: boot: storageAccountType: AzureManaged 1- 1
- Spécifie un compte de stockage Azure Managed.
Pour un compte de stockage Azure non géré :
providerSpec: diagnostics: boot: storageAccountType: CustomerManaged 1 customerManaged: storageAccountURI: https://<storage-account>.blob.core.windows.net 2NoteSeul le service de données Azure Blob Storage est pris en charge.
Vérification
- Sur le portail Microsoft Azure, consultez la page Boot diagnostics pour une machine déployée par le jeu de machines et vérifiez que vous pouvez voir les journaux de série pour la machine.
2.4.4. Activation des clés de chiffrement gérées par le client pour un ensemble de machines
Vous pouvez fournir une clé de chiffrement à Azure pour chiffrer les données sur les disques gérés au repos. Vous pouvez activer le chiffrement côté serveur avec des clés gérées par le client en utilisant l'API Machine.
Un Azure Key Vault, un ensemble de chiffrement de disque et une clé de chiffrement sont nécessaires pour utiliser une clé gérée par le client. Le jeu de chiffrement de disque doit se trouver dans un groupe de ressources auquel le Cloud Credential Operator (CCO) a accordé des autorisations. Si ce n'est pas le cas, un rôle de lecteur supplémentaire doit être accordé à l'ensemble de chiffrement de disque.
Conditions préalables
Procédure
Configurez le cryptage du disque dans le champ
providerSpecde votre fichier YAML de configuration de la machine. Par exemple :providerSpec: value: osDisk: diskSizeGB: 128 managedDisk: diskEncryptionSet: id: /subscriptions/<subscription_id>/resourceGroups/<resource_group_name>/providers/Microsoft.Compute/diskEncryptionSets/<disk_encryption_set_name> storageAccountType: Premium_LRS
Ressources complémentaires
2.5. Création d'un ensemble de machines de calcul sur GCP
Vous pouvez créer un ensemble de machines de calcul différent pour répondre à un besoin spécifique dans votre cluster OpenShift Container Platform sur Google Cloud Platform (GCP). Par exemple, vous pouvez créer des jeux de machines d'infrastructure et des machines connexes afin de pouvoir déplacer des charges de travail de support vers les nouvelles machines.
Vous ne pouvez utiliser les fonctionnalités avancées de gestion et de mise à l'échelle des machines que dans les clusters où l'API Machine est opérationnelle. Les clusters dont l'infrastructure est fournie par l'utilisateur nécessitent une validation et une configuration supplémentaires pour utiliser l'API Machine.
Les clusters avec le type de plateforme d'infrastructure none ne peuvent pas utiliser l'API Machine. Cette limitation s'applique même si les machines de calcul attachées au cluster sont installées sur une plateforme qui prend en charge cette fonctionnalité. Ce paramètre ne peut pas être modifié après l'installation.
Pour afficher le type de plateforme de votre cluster, exécutez la commande suivante :
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.5.1. Exemple de YAML pour une ressource personnalisée d'une machine de calcul sur GCP
Cet exemple YAML définit un ensemble de machines de calcul qui fonctionne dans Google Cloud Platform (GCP) et crée des nœuds étiquetés avec node-role.kubernetes.io/<role>: "".
Dans cet exemple, <infrastructure_id> est l'étiquette d'ID d'infrastructure basée sur l'ID de cluster que vous avez défini lors du provisionnement du cluster, et <role> est l'étiquette de nœud à ajouter.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1
name: <infrastructure_id>-w-a
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-w-a
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <role> 2
machine.openshift.io/cluster-api-machine-type: <role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-w-a
spec:
metadata:
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: gcpprovider.openshift.io/v1beta1
canIPForward: false
credentialsSecret:
name: gcp-cloud-credentials
deletionProtection: false
disks:
- autoDelete: true
boot: true
image: <path_to_image> 3
labels: null
sizeGb: 128
type: pd-ssd
gcpMetadata: 4
- key: <custom_metadata_key>
value: <custom_metadata_value>
kind: GCPMachineProviderSpec
machineType: n1-standard-4
metadata:
creationTimestamp: null
networkInterfaces:
- network: <infrastructure_id>-network
subnetwork: <infrastructure_id>-worker-subnet
projectID: <project_name> 5
region: us-central1
serviceAccounts:
- email: <infrastructure_id>-w@<project_name>.iam.gserviceaccount.com
scopes:
- https://www.googleapis.com/auth/cloud-platform
tags:
- <infrastructure_id>-worker
userDataSecret:
name: worker-user-data
zone: us-central1-a- 1
- Pour
<infrastructure_id>, spécifiez l'ID d'infrastructure qui est basé sur l'ID de cluster que vous avez défini lorsque vous avez provisionné le cluster. Si le CLI OpenShift est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2
- Pour
<node>, indiquez l'étiquette de nœud à ajouter. - 3
- Spécifiez le chemin d'accès à l'image utilisée dans les ensembles de machines de calcul actuels. Si le CLI OpenShift est installé, vous pouvez obtenir le chemin d'accès à l'image en exécutant la commande suivante :
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.disks[0].image}{"\n"}' \ get machineset/<infrastructure_id>-worker-aTo use a GCP Marketplace image, specify the offer to use:
-
OpenShift Container Platform:
https://www.googleapis.com/compute/v1/projects/redhat-marketplace-public/global/images/redhat-coreos-ocp-48-x86-64-202210040145 -
OpenShift Platform Plus:
https://www.googleapis.com/compute/v1/projects/redhat-marketplace-public/global/images/redhat-coreos-opp-48-x86-64-202206140145 -
OpenShift Kubernetes Engine:
https://www.googleapis.com/compute/v1/projects/redhat-marketplace-public/global/images/redhat-coreos-oke-48-x86-64-202206140145
-
OpenShift Container Platform:
- 4
- Facultatif : Spécifiez des métadonnées personnalisées sous la forme d'une paire
key:value. Pour des exemples de cas d'utilisation, voir la documentation GCP pour la définition de métadonnées personnalisées. - 5
- Pour
<project_name>, indiquez le nom du projet GCP que vous utilisez pour votre cluster.
2.5.2. Création d'un ensemble de machines de calcul
En plus des ensembles de machines de calcul créés par le programme d'installation, vous pouvez créer vos propres ensembles pour gérer dynamiquement les ressources de calcul des machines pour les charges de travail spécifiques de votre choix.
Conditions préalables
- Déployer un cluster OpenShift Container Platform.
-
Installez le CLI OpenShift (
oc). -
Connectez-vous à
ocen tant qu'utilisateur disposant de l'autorisationcluster-admin.
Procédure
Créez un nouveau fichier YAML contenant l'échantillon de ressources personnalisées (CR) de l'ensemble de machines de calcul et nommé
<file_name>.yaml.Veillez à définir les valeurs des paramètres
<clusterID>et<role>.Facultatif : si vous n'êtes pas sûr de la valeur à définir pour un champ spécifique, vous pouvez vérifier un ensemble de machines de calcul existant dans votre cluster.
Pour répertorier les ensembles de machines de calcul de votre cluster, exécutez la commande suivante :
$ oc get machinesets -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Pour afficher les valeurs d'une ressource personnalisée (CR) d'un ensemble de machines de calcul spécifique, exécutez la commande suivante :
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml
Exemple de sortie
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1 name: <infrastructure_id>-<role> 2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec: 3 ...- 1
- L'ID de l'infrastructure du cluster.
- 2
- Une étiquette de nœud par défaut.Note
Pour les clusters disposant d'une infrastructure fournie par l'utilisateur, un ensemble de machines de calcul ne peut créer que des machines de type
workeretinfra. - 3
- Les valeurs de la section
<providerSpec>du CR de l'ensemble de machines de calcul sont spécifiques à la plate-forme. Pour plus d'informations sur les paramètres<providerSpec>dans le CR, consultez l'exemple de configuration du CR de l'ensemble de machines de calcul pour votre fournisseur.
Créez un CR
MachineSeten exécutant la commande suivante :oc create -f <nom_du_fichier>.yaml
Vérification
Affichez la liste des ensembles de machines de calcul en exécutant la commande suivante :
$ oc get machineset -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Lorsque le nouveau jeu de machines de calcul est disponible, les valeurs
DESIREDetCURRENTcorrespondent. Si le jeu de machines de calcul n'est pas disponible, attendez quelques minutes et exécutez à nouveau la commande.
2.5.3. Configuration des types de disques persistants à l'aide d'ensembles de machines de calcul
Vous pouvez configurer le type de disque persistant sur lequel un ensemble de machines de calcul déploie des machines en modifiant le fichier YAML de l'ensemble de machines de calcul.
Pour plus d'informations sur les types de disques persistants, la compatibilité, la disponibilité régionale et les limitations, voir la documentation GCP Compute Engine sur les disques persistants.
Procédure
- Dans un éditeur de texte, ouvrez le fichier YAML d'un ensemble de machines de calcul existant ou créez-en un nouveau.
Modifiez la ligne suivante sous le champ
providerSpec:providerSpec: value: disks: type: <pd-disk-type> 1- 1
- Indiquez le type de disque persistant. Les valeurs valides sont
pd-ssd,pd-standard, etpd-balanced. La valeur par défaut estpd-standard.
Vérification
-
Dans la console Google Cloud, examinez les détails d'une machine déployée par l'ensemble de machines de calcul et vérifiez que le champ
Typecorrespond au type de disque configuré.
2.5.4. Jeux de machines qui déploient des machines en tant qu'instances VM préemptibles
Vous pouvez réduire les coûts en créant un ensemble de machines de calcul fonctionnant sur GCP qui déploie des machines en tant qu'instances VM préemptibles non garanties. Les instances VM préemptibles utilisent la capacité excédentaire de Compute Engine et sont moins coûteuses que les instances normales. Vous pouvez utiliser les instances VM préemptibles pour les charges de travail qui peuvent tolérer des interruptions, telles que les charges de travail évolutives horizontalement, par lots ou sans état.
Le moteur de calcul GCP peut mettre fin à une instance de VM préemptible à tout moment. Compute Engine envoie un avis de préemption à l'utilisateur indiquant qu'une interruption se produira dans 30 secondes. OpenShift Container Platform commence à supprimer les charges de travail des instances concernées lorsque Compute Engine émet l'avis de préemption. Un signal ACPI G3 Mechanical Off est envoyé au système d'exploitation après 30 secondes si l'instance n'est pas arrêtée. L'instance VM préemptible est ensuite transférée à l'état TERMINATED par Compute Engine.
Des interruptions peuvent se produire lors de l'utilisation d'instances VM préemptibles pour les raisons suivantes :
- Il y a un événement lié au système ou à la maintenance
- L'offre d'instances de VM préemptibles diminue
- L'instance atteint la fin de la période de 24 heures allouée pour les instances VM préemptibles
Lorsque GCP met fin à une instance, un gestionnaire de fin s'exécutant sur le nœud d'instance VM préemptible supprime la ressource machine. Pour satisfaire la quantité de l'ensemble de machines de calcul replicas, l'ensemble de machines de calcul crée une machine qui demande une instance de VM préemptible.
2.5.4.1. Créer des instances de VM préemptibles en utilisant des ensembles de machines de calcul
Vous pouvez lancer une instance de VM préemptible sur GCP en ajoutant preemptible à votre fichier YAML de configuration de machine de calcul.
Procédure
Ajoutez la ligne suivante sous le champ
providerSpec:providerSpec: value: preemptible: trueSi
preemptibleest défini surtrue, la machine est étiquetée commeinterruptable-instanceaprès le lancement de l'instance.
2.5.5. Activation des clés de chiffrement gérées par le client pour un ensemble de machines de calcul
Google Cloud Platform (GCP) Compute Engine permet aux utilisateurs de fournir une clé de chiffrement pour chiffrer les données sur les disques au repos. La clé est utilisée pour chiffrer la clé de chiffrement des données, et non pour chiffrer les données du client. Par défaut, Compute Engine chiffre ces données en utilisant les clés Compute Engine.
Vous pouvez activer le cryptage avec une clé gérée par le client en utilisant l'API Machine. Vous devez d'abord créer une clé KMS et attribuer les autorisations correctes à un compte de service. Le nom de la clé KMS, le nom du porte-clés et l'emplacement sont nécessaires pour permettre à un compte de service d'utiliser votre clé.
Si vous ne souhaitez pas utiliser un compte de service dédié pour le chiffrement du KMS, le compte de service par défaut du Compute Engine est utilisé à la place. Vous devez autoriser le compte de service par défaut à accéder aux clés si vous n'utilisez pas de compte de service dédié. Le nom du compte de service par défaut du moteur de calcul suit le modèle service-<project_number>@compute-system.iam.gserviceaccount.com.
Procédure
Exécutez la commande suivante avec le nom de votre clé KMS, le nom de l'anneau de clés et l'emplacement pour permettre à un compte de service spécifique d'utiliser votre clé KMS et pour accorder au compte de service le rôle IAM correct :
gcloud kms keys add-iam-policy-binding <key_name> \ --keyring <key_ring_name> \ --location <key_ring_location> \ --member "serviceAccount:service-<project_number>@compute-system.iam.gserviceaccount.com” \ --role roles/cloudkms.cryptoKeyEncrypterDecrypter
Configurez la clé de chiffrement dans le champ
providerSpecdu fichier YAML de votre machine de calcul. Par exemple :providerSpec: value: # ... disks: - type: # ... encryptionKey: kmsKey: name: machine-encryption-key 1 keyRing: openshift-encrpytion-ring 2 location: global 3 projectID: openshift-gcp-project 4 kmsKeyServiceAccount: openshift-service-account@openshift-gcp-project.iam.gserviceaccount.com 5- 1
- Nom de la clé de chiffrement gérée par le client et utilisée pour le chiffrement du disque.
- 2
- Le nom du porte-clés KMS auquel la clé KMS appartient.
- 3
- Emplacement du GCP dans lequel se trouve le trousseau de clés KMS.
- 4
- Facultatif : L'ID du projet dans lequel le porte-clés KMS existe. Si aucun ID de projet n'est défini, l'ensemble de machines de calcul
projectIDdans lequel l'ensemble de machines de calcul a été créé est utilisé. - 5
- Facultatif : Le compte de service utilisé pour la demande de chiffrement de la clé KMS donnée. Si aucun compte de service n'est défini, le compte de service par défaut du Compute Engine est utilisé.
Après la création d'une nouvelle machine à l'aide de la configuration actualisée de l'objet
providerSpec, la clé de chiffrement du disque est chiffrée avec la clé KMS.
2.5.6. Activation de la prise en charge du GPU pour un ensemble de machines de calcul
Google Cloud Platform (GCP) Compute Engine permet aux utilisateurs d'ajouter des GPU aux instances de machines virtuelles. Les charges de travail qui bénéficient d'un accès aux ressources GPU peuvent être plus performantes sur les machines de calcul avec cette fonctionnalité activée. OpenShift Container Platform sur GCP prend en charge les modèles de GPU NVIDIA dans les séries de machines A2 et N1.
Tableau 2.1. Configurations GPU prises en charge
| Nom du modèle | Type de GPU | Types de machines [1] |
|---|---|---|
| NVIDIA A100 |
|
|
| NVIDIA K80 |
|
|
| NVIDIA P100 |
| |
| NVIDIA P4 |
| |
| NVIDIA T4 |
| |
| NVIDIA V100 |
|
- Pour plus d'informations sur les types de machines, y compris les spécifications, la compatibilité, la disponibilité régionale et les limitations, voir la documentation GCP Compute Engine sur la série de machines N1, la série de machines A2 et la disponibilité des régions et zones GPU.
Vous pouvez définir le GPU pris en charge à utiliser pour une instance à l'aide de l'API Machine.
Vous pouvez configurer les machines de la série N1 pour qu'elles soient déployées avec l'un des types de GPU pris en charge. Les machines de la série A2 sont livrées avec des GPU associés et ne peuvent pas utiliser d'accélérateurs invités.
Les GPU pour les charges de travail graphiques ne sont pas pris en charge.
Procédure
- Dans un éditeur de texte, ouvrez le fichier YAML d'un ensemble de machines de calcul existant ou créez-en un nouveau.
Spécifiez une configuration GPU dans le champ
providerSpecdu fichier YAML de votre machine de calcul. Voir les exemples suivants de configurations valides :Exemple de configuration pour la série de machines A2 :
providerSpec: value: machineType: a2-highgpu-1g 1 onHostMaintenance: Terminate 2 restartPolicy: Always 3- 1
- Spécifiez le type de machine. Assurez-vous que le type de machine est inclus dans la série de machines A2.
- 2
- Lorsque vous utilisez le support GPU, vous devez définir
onHostMaintenancesurTerminate. - 3
- Spécifiez la politique de redémarrage pour les machines déployées par l'ensemble de machines de calcul. Les valeurs autorisées sont
AlwaysouNever.
Exemple de configuration pour la série de machines N1 :
providerSpec: value: gpus: - count: 1 1 type: nvidia-tesla-p100 2 machineType: n1-standard-1 3 onHostMaintenance: Terminate 4 restartPolicy: Always 5- 1
- Spécifiez le nombre de GPU à attacher à la machine.
- 2
- Spécifiez le type de GPU à attacher à la machine. Assurez-vous que le type de machine et le type de GPU sont compatibles.
- 3
- Spécifiez le type de machine. Assurez-vous que le type de machine et le type de GPU sont compatibles.
- 4
- Lorsque vous utilisez le support GPU, vous devez définir
onHostMaintenancesurTerminate. - 5
- Spécifiez la politique de redémarrage pour les machines déployées par l'ensemble de machines de calcul. Les valeurs autorisées sont
AlwaysouNever.
2.5.7. Ajouter un nœud GPU à un cluster OpenShift Container Platform existant
Vous pouvez copier et modifier la configuration d'un ensemble de machines de calcul par défaut pour créer un ensemble de machines et des machines compatibles avec le GPU pour le fournisseur de cloud GCP.
Le tableau suivant énumère les types d'instance validés :
| Instance type | Accélérateur GPU NVIDIA | Nombre maximal de GPU | L'architecture |
|---|---|---|---|
|
| A100 | 1 | x86 |
|
| T4 | 1 | x86 |
Procédure
-
Faire une copie d'un site existant
MachineSet. -
Dans la nouvelle copie, modifiez le jeu de machines
namedansmetadata.nameet dans les deux instances demachine.openshift.io/cluster-api-machineset. Modifiez le type d'instance pour ajouter les deux lignes suivantes à la nouvelle copie de
MachineSet:machineType: a2-highgpu-1g onHostMaintenance: Terminate
Exemple de fichier
a2-highgpu-1g.json{ "apiVersion": "machine.openshift.io/v1beta1", "kind": "MachineSet", "metadata": { "annotations": { "machine.openshift.io/GPU": "0", "machine.openshift.io/memoryMb": "16384", "machine.openshift.io/vCPU": "4" }, "creationTimestamp": "2023-01-13T17:11:02Z", "generation": 1, "labels": { "machine.openshift.io/cluster-api-cluster": "myclustername-2pt9p" }, "name": "myclustername-2pt9p-worker-gpu-a", "namespace": "openshift-machine-api", "resourceVersion": "20185", "uid": "2daf4712-733e-4399-b4b4-d43cb1ed32bd" }, "spec": { "replicas": 1, "selector": { "matchLabels": { "machine.openshift.io/cluster-api-cluster": "myclustername-2pt9p", "machine.openshift.io/cluster-api-machineset": "myclustername-2pt9p-worker-gpu-a" } }, "template": { "metadata": { "labels": { "machine.openshift.io/cluster-api-cluster": "myclustername-2pt9p", "machine.openshift.io/cluster-api-machine-role": "worker", "machine.openshift.io/cluster-api-machine-type": "worker", "machine.openshift.io/cluster-api-machineset": "myclustername-2pt9p-worker-gpu-a" } }, "spec": { "lifecycleHooks": {}, "metadata": {}, "providerSpec": { "value": { "apiVersion": "machine.openshift.io/v1beta1", "canIPForward": false, "credentialsSecret": { "name": "gcp-cloud-credentials" }, "deletionProtection": false, "disks": [ { "autoDelete": true, "boot": true, "image": "projects/rhcos-cloud/global/images/rhcos-412-86-202212081411-0-gcp-x86-64", "labels": null, "sizeGb": 128, "type": "pd-ssd" } ], "kind": "GCPMachineProviderSpec", "machineType": "a2-highgpu-1g", "onHostMaintenance": "Terminate", "metadata": { "creationTimestamp": null }, "networkInterfaces": [ { "network": "myclustername-2pt9p-network", "subnetwork": "myclustername-2pt9p-worker-subnet" } ], "preemptible": true, "projectID": "myteam", "region": "us-central1", "serviceAccounts": [ { "email": "myclustername-2pt9p-w@myteam.iam.gserviceaccount.com", "scopes": [ "https://www.googleapis.com/auth/cloud-platform" ] } ], "tags": [ "myclustername-2pt9p-worker" ], "userDataSecret": { "name": "worker-user-data" }, "zone": "us-central1-a" } } } } }, "status": { "availableReplicas": 1, "fullyLabeledReplicas": 1, "observedGeneration": 1, "readyReplicas": 1, "replicas": 1 } }Affichez les nœuds, les machines et les ensembles de machines existants en exécutant la commande suivante. Notez que chaque nœud est une instance d'une définition de machine avec une région GCP spécifique et un rôle OpenShift Container Platform.
$ oc get nodes
Exemple de sortie
NAME STATUS ROLES AGE VERSION myclustername-2pt9p-master-0.c.openshift-qe.internal Ready control-plane,master 8h v1.25.4+77bec7a myclustername-2pt9p-master-1.c.openshift-qe.internal Ready control-plane,master 8h v1.25.4+77bec7a myclustername-2pt9p-master-2.c.openshift-qe.internal Ready control-plane,master 8h v1.25.4+77bec7a myclustername-2pt9p-worker-a-mxtnz.c.openshift-qe.internal Ready worker 8h v1.25.4+77bec7a myclustername-2pt9p-worker-b-9pzzn.c.openshift-qe.internal Ready worker 8h v1.25.4+77bec7a myclustername-2pt9p-worker-c-6pbg6.c.openshift-qe.internal Ready worker 8h v1.25.4+77bec7a myclustername-2pt9p-worker-gpu-a-wxcr6.c.openshift-qe.internal Ready worker 4h35m v1.25.4+77bec7a
Affichez les machines et les ensembles de machines qui existent dans l'espace de noms
openshift-machine-apien exécutant la commande suivante. Chaque ensemble de machines de calcul est associé à une zone de disponibilité différente dans la région GCP. Le programme d'installation équilibre automatiquement la charge des machines de calcul entre les zones de disponibilité.$ oc get machinesets -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE myclustername-2pt9p-worker-a 1 1 1 1 8h myclustername-2pt9p-worker-b 1 1 1 1 8h myclustername-2pt9p-worker-c 1 1 8h myclustername-2pt9p-worker-f 0 0 8h
Affichez les machines qui existent dans l'espace de noms
openshift-machine-apien exécutant la commande suivante. Vous ne pouvez configurer qu'une machine de calcul par ensemble, mais vous pouvez faire évoluer un ensemble de machines de calcul pour ajouter un nœud dans une région et une zone particulières.$ oc get machines -n openshift-machine-api | grep worker
Exemple de sortie
myclustername-2pt9p-worker-a-mxtnz Running n2-standard-4 us-central1 us-central1-a 8h myclustername-2pt9p-worker-b-9pzzn Running n2-standard-4 us-central1 us-central1-b 8h myclustername-2pt9p-worker-c-6pbg6 Running n2-standard-4 us-central1 us-central1-c 8h
Faites une copie de l'une des définitions de compute
MachineSetexistantes et générez le résultat dans un fichier JSON en exécutant la commande suivante. Ce fichier servira de base à la définition de l'ensemble de machines de calcul compatibles avec le GPU.$ oc get machineset myclustername-2pt9p-worker-a -n openshift-machine-api -o json > <output_file.json>
Modifiez le fichier JSON pour apporter les changements suivants à la nouvelle définition
MachineSet:-
Renommez l'ensemble de machines
nameen insérant la sous-chaînegpudansmetadata.nameet dans les deux instances demachine.openshift.io/cluster-api-machineset. Remplacer
machineTypede la nouvelle définition deMachineSetpara2-highgpu-1g, qui inclut un GPU NVIDIA A100.jq .spec.template.spec.providerSpec.value.machineType ocp_4.12_machineset-a2-highgpu-1g.json "a2-highgpu-1g"
Le fichier
<output_file.json>est enregistré sous le nom deocp_4.12_machineset-a2-highgpu-1g.json.
-
Renommez l'ensemble de machines
Mettez à jour les champs suivants dans
ocp_4.12_machineset-a2-highgpu-1g.json:-
Remplacer
.metadata.namepar un nom contenantgpu. -
Modifier
.spec.selector.matchLabels["machine.openshift.io/cluster-api-machineset"]pour qu'il corresponde au nouveau.metadata.name. -
Modifier
.spec.template.metadata.labels["machine.openshift.io/cluster-api-machineset"]pour qu'il corresponde au nouveau.metadata.name. -
Remplacer
.spec.template.spec.providerSpec.value.MachineTypepara2-highgpu-1g. Ajouter la ligne suivante sous
machineType: ``OnHostMaintenance'' : "Terminer". Par exemple :"machineType": "a2-highgpu-1g", "onHostMaintenance": "Terminate",
-
Remplacer
Pour vérifier vos modifications, exécutez la commande suivante :
diffde la définition originale du calcul et de la nouvelle définition du nœud compatible avec le GPU :$ oc get machineset/myclustername-2pt9p-worker-a -n openshift-machine-api -o json | diff ocp_4.12_machineset-a2-highgpu-1g.json -
Exemple de sortie
15c15 < "name": "myclustername-2pt9p-worker-gpu-a", --- > "name": "myclustername-2pt9p-worker-a", 25c25 < "machine.openshift.io/cluster-api-machineset": "myclustername-2pt9p-worker-gpu-a" --- > "machine.openshift.io/cluster-api-machineset": "myclustername-2pt9p-worker-a" 34c34 < "machine.openshift.io/cluster-api-machineset": "myclustername-2pt9p-worker-gpu-a" --- > "machine.openshift.io/cluster-api-machineset": "myclustername-2pt9p-worker-a" 59,60c59 < "machineType": "a2-highgpu-1g", < "onHostMaintenance": "Terminate", --- > "machineType": "n2-standard-4",
Créez l'ensemble de machines de calcul compatibles avec le GPU à partir du fichier de définition en exécutant la commande suivante :
$ oc create -f ocp_4.12_machineset-a2-highgpu-1g.json
Exemple de sortie
machineset.machine.openshift.io/myclustername-2pt9p-worker-gpu-a created
Vérification
Affichez le jeu de machines que vous avez créé en exécutant la commande suivante :
$ oc -n openshift-machine-api get machinesets | grep gpu
Le nombre de répliques de MachineSet étant fixé à
1, un nouvel objetMachineest créé automatiquement.Exemple de sortie
myclustername-2pt9p-worker-gpu-a 1 1 1 1 5h24m
Affichez l'objet
Machinecréé par le jeu de machines en exécutant la commande suivante :$ oc -n openshift-machine-api get machines | grep gpu
Exemple de sortie
myclustername-2pt9p-worker-gpu-a-wxcr6 Running a2-highgpu-1g us-central1 us-central1-a 5h25m
Notez qu'il n'est pas nécessaire de spécifier un espace de noms pour le nœud. La définition du nœud est limitée à la grappe.
2.5.8. Déploiement de l'opérateur de découverte de fonctionnalités des nœuds
Une fois le nœud compatible avec le GPU créé, vous devez le découvrir afin de pouvoir le planifier. Pour ce faire, installez l'opérateur NFD (Node Feature Discovery). L'opérateur NFD identifie les caractéristiques des dispositifs matériels dans les nœuds. Il résout le problème général de l'identification et du catalogage des ressources matérielles dans les nœuds d'infrastructure afin qu'elles puissent être mises à la disposition d'OpenShift Container Platform.
Procédure
- Installez l'opérateur de découverte de fonctionnalités Node à partir de OperatorHub dans la console OpenShift Container Platform.
-
Après avoir installé l'opérateur NFD dans OperatorHub, sélectionnez Node Feature Discovery dans la liste des opérateurs installés et sélectionnez Create instance. Ceci installe les pods
nfd-masteretnfd-worker, un podnfd-workerpour chaque nœud de calcul, dans l'espace de nomsopenshift-nfd. Vérifiez que l'opérateur est installé et fonctionne en exécutant la commande suivante :
$ oc get pods -n openshift-nfd
Exemple de sortie
NAME READY STATUS RESTARTS AGE nfd-controller-manager-8646fcbb65-x5qgk 2/2 Running 7 (8h ago) 1d
- Recherchez l'Oerator installé dans la console et sélectionnez Create Node Feature Discovery.
-
Sélectionnez Create pour créer une ressource personnalisée NFD. Cela crée des pods NFD dans l'espace de noms
openshift-nfdqui interrogent les nœuds OpenShift Container Platform à la recherche de ressources matérielles et les cataloguent.
Vérification
Après une construction réussie, vérifiez qu'un pod NFD fonctionne sur chaque nœud en exécutant la commande suivante :
$ oc get pods -n openshift-nfd
Exemple de sortie
NAME READY STATUS RESTARTS AGE nfd-controller-manager-8646fcbb65-x5qgk 2/2 Running 7 (8h ago) 12d nfd-master-769656c4cb-w9vrv 1/1 Running 0 12d nfd-worker-qjxb2 1/1 Running 3 (3d14h ago) 12d nfd-worker-xtz9b 1/1 Running 5 (3d14h ago) 12d
L'opérateur NFD utilise les identifiants PCI des fournisseurs pour identifier le matériel dans un nœud. NVIDIA utilise l'ID PCI
10de.Affichez le GPU NVIDIA découvert par l'opérateur NFD en exécutant la commande suivante :
$ oc describe node ip-10-0-132-138.us-east-2.compute.internal | egrep 'Roles|pci'
Exemple de sortie
Roles: worker feature.node.kubernetes.io/pci-1013.present=true feature.node.kubernetes.io/pci-10de.present=true feature.node.kubernetes.io/pci-1d0f.present=true
10deapparaît dans la liste des caractéristiques du nœud compatible avec le GPU. Cela signifie que l'opérateur NFD a correctement identifié le nœud de l'ensemble de machines équipé d'un GPU.
2.6. Création d'un ensemble de machines de calcul sur IBM Cloud
Vous pouvez créer un ensemble de machines de calcul différent pour répondre à un objectif spécifique dans votre cluster OpenShift Container Platform sur IBM Cloud. Par exemple, vous pouvez créer des jeux de machines d'infrastructure et des machines connexes afin de pouvoir déplacer des charges de travail de support vers les nouvelles machines.
Vous ne pouvez utiliser les fonctionnalités avancées de gestion et de mise à l'échelle des machines que dans les clusters où l'API Machine est opérationnelle. Les clusters dont l'infrastructure est fournie par l'utilisateur nécessitent une validation et une configuration supplémentaires pour utiliser l'API Machine.
Les clusters avec le type de plateforme d'infrastructure none ne peuvent pas utiliser l'API Machine. Cette limitation s'applique même si les machines de calcul attachées au cluster sont installées sur une plateforme qui prend en charge cette fonctionnalité. Ce paramètre ne peut pas être modifié après l'installation.
Pour afficher le type de plateforme de votre cluster, exécutez la commande suivante :
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.6.1. Exemple de YAML pour une ressource personnalisée d'un ensemble de machines de calcul sur IBM Cloud
Cet exemple YAML définit un ensemble de machines de calcul qui s'exécute dans une zone IBM Cloud spécifiée dans une région et crée des nœuds étiquetés avec node-role.kubernetes.io/<role>: "".
Dans cet exemple, <infrastructure_id> est l'étiquette d'ID d'infrastructure basée sur l'ID de cluster que vous avez défini lors du provisionnement du cluster, et <role> est l'étiquette de nœud à ajouter.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1
machine.openshift.io/cluster-api-machine-role: <role> 2
machine.openshift.io/cluster-api-machine-type: <role> 3
name: <infrastructure_id>-<role>-<region> 4
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 5
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<region> 6
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 7
machine.openshift.io/cluster-api-machine-role: <role> 8
machine.openshift.io/cluster-api-machine-type: <role> 9
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<region> 10
spec:
metadata:
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: ibmcloudproviderconfig.openshift.io/v1beta1
credentialsSecret:
name: ibmcloud-credentials
image: <infrastructure_id>-rhcos 11
kind: IBMCloudMachineProviderSpec
primaryNetworkInterface:
securityGroups:
- <infrastructure_id>-sg-cluster-wide
- <infrastructure_id>-sg-openshift-net
subnet: <infrastructure_id>-subnet-compute-<zone> 12
profile: <instance_profile> 13
region: <region> 14
resourceGroup: <resource_group> 15
userDataSecret:
name: <role>-user-data 16
vpc: <vpc_name> 17
zone: <zone> 18- 1 5 7
- L'ID de l'infrastructure qui est basé sur l'ID du cluster que vous avez défini lorsque vous avez provisionné le cluster. Si le CLI OpenShift est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 8 9 16
- L'étiquette de nœud à ajouter.
- 4 6 10
- L'ID de l'infrastructure, l'étiquette du nœud et la région.
- 11
- L'image personnalisée de Red Hat Enterprise Linux CoreOS (RHCOS) qui a été utilisée pour l'installation du cluster.
- 12
- L'ID d'infrastructure et la zone de votre région où placer les machines. Assurez-vous que votre région prend en charge la zone que vous spécifiez.
- 13
- Spécifiez le profil de l'instance IBM Cloud.
- 14
- Spécifiez la région où placer les machines.
- 15
- Le groupe de ressources dans lequel les ressources de la machine sont placées. Il s'agit soit d'un groupe de ressources existant spécifié au moment de l'installation, soit d'un groupe de ressources créé par l'installateur et nommé en fonction de l'identifiant de l'infrastructure.
- 17
- Le nom du VPC.
- 18
- Indiquez la zone de votre région où placer les machines. Assurez-vous que votre région prend en charge la zone que vous spécifiez.
2.6.2. Création d'un ensemble de machines de calcul
En plus des ensembles de machines de calcul créés par le programme d'installation, vous pouvez créer vos propres ensembles pour gérer dynamiquement les ressources de calcul des machines pour les charges de travail spécifiques de votre choix.
Conditions préalables
- Déployer un cluster OpenShift Container Platform.
-
Installez le CLI OpenShift (
oc). -
Connectez-vous à
ocen tant qu'utilisateur disposant de l'autorisationcluster-admin.
Procédure
Créez un nouveau fichier YAML contenant l'échantillon de ressources personnalisées (CR) de l'ensemble de machines de calcul et nommé
<file_name>.yaml.Veillez à définir les valeurs des paramètres
<clusterID>et<role>.Facultatif : si vous n'êtes pas sûr de la valeur à définir pour un champ spécifique, vous pouvez vérifier un ensemble de machines de calcul existant dans votre cluster.
Pour répertorier les ensembles de machines de calcul de votre cluster, exécutez la commande suivante :
$ oc get machinesets -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Pour afficher les valeurs d'une ressource personnalisée (CR) d'un ensemble de machines de calcul spécifique, exécutez la commande suivante :
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml
Exemple de sortie
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1 name: <infrastructure_id>-<role> 2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec: 3 ...- 1
- L'ID de l'infrastructure du cluster.
- 2
- Une étiquette de nœud par défaut.Note
Pour les clusters disposant d'une infrastructure fournie par l'utilisateur, un ensemble de machines de calcul ne peut créer que des machines de type
workeretinfra. - 3
- Les valeurs de la section
<providerSpec>du CR de l'ensemble de machines de calcul sont spécifiques à la plate-forme. Pour plus d'informations sur les paramètres<providerSpec>dans le CR, consultez l'exemple de configuration du CR de l'ensemble de machines de calcul pour votre fournisseur.
Créez un CR
MachineSeten exécutant la commande suivante :oc create -f <nom_du_fichier>.yaml
Vérification
Affichez la liste des ensembles de machines de calcul en exécutant la commande suivante :
$ oc get machineset -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Lorsque le nouveau jeu de machines de calcul est disponible, les valeurs
DESIREDetCURRENTcorrespondent. Si le jeu de machines de calcul n'est pas disponible, attendez quelques minutes et exécutez à nouveau la commande.
2.7. Création d'un ensemble de machines de calcul sur Nutanix
Vous pouvez créer un ensemble de machines de calcul différent pour servir un objectif spécifique dans votre cluster OpenShift Container Platform sur Nutanix. Par exemple, vous pouvez créer des ensembles de machines d'infrastructure et des machines connexes afin de pouvoir déplacer des charges de travail de support vers les nouvelles machines.
Vous ne pouvez utiliser les fonctionnalités avancées de gestion et de mise à l'échelle des machines que dans les clusters où l'API Machine est opérationnelle. Les clusters dont l'infrastructure est fournie par l'utilisateur nécessitent une validation et une configuration supplémentaires pour utiliser l'API Machine.
Les clusters avec le type de plateforme d'infrastructure none ne peuvent pas utiliser l'API Machine. Cette limitation s'applique même si les machines de calcul attachées au cluster sont installées sur une plateforme qui prend en charge cette fonctionnalité. Ce paramètre ne peut pas être modifié après l'installation.
Pour afficher le type de plateforme de votre cluster, exécutez la commande suivante :
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.7.1. Exemple de YAML pour une ressource personnalisée compute machine set sur Nutanix
Cet exemple YAML définit un ensemble de machines Nutanix qui crée des nœuds étiquetés avec node-role.kubernetes.io/<role>: "".
Dans cet exemple, <infrastructure_id> est l'étiquette d'ID d'infrastructure basée sur l'ID de cluster que vous avez défini lors du provisionnement du cluster, et <role> est l'étiquette de nœud à ajouter.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1
machine.openshift.io/cluster-api-machine-role: <role> 2
machine.openshift.io/cluster-api-machine-type: <role> 3
name: <infrastructure_id>-<role>-<zone> 4
namespace: openshift-machine-api
annotations: 5
machine.openshift.io/memoryMb: "16384"
machine.openshift.io/vCPU: "4"
spec:
replicas: 3
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 6
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<zone> 7
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 8
machine.openshift.io/cluster-api-machine-role: <role> 9
machine.openshift.io/cluster-api-machine-type: <role> 10
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role>-<zone> 11
spec:
metadata:
labels:
node-role.kubernetes.io/<role>: ""
providerSpec:
value:
apiVersion: machine.openshift.io/v1
cluster:
type: uuid
uuid: <cluster_uuid>
credentialsSecret:
name: nutanix-creds-secret
image:
name: <infrastructure_id>-rhcos 12
type: name
kind: NutanixMachineProviderConfig
memorySize: 16Gi 13
subnets:
- type: uuid
uuid: <subnet_uuid>
systemDiskSize: 120Gi 14
userDataSecret:
name: <user_data_secret> 15
vcpuSockets: 4 16
vcpusPerSocket: 1 17- 1 6 8
- Spécifiez l'ID d'infrastructure qui est basé sur l'ID de cluster que vous avez défini lorsque vous avez provisionné le cluster. Si l'OpenShift CLI (
oc) est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 9 10
- Spécifiez l'étiquette de nœud à ajouter.
- 4 7 11
- Spécifiez l'ID de l'infrastructure, l'étiquette du nœud et la zone.
- 5
- Annotations pour le cluster autoscaler.
- 12
- Spécifiez l'image à utiliser. Utilisez une image provenant d'un jeu de machines de calcul par défaut existant pour le cluster.
- 13
- Spécifiez la quantité de mémoire pour le cluster en Gi.
- 14
- Spécifiez la taille du disque système en Gi.
- 15
- Spécifiez le nom du secret dans le fichier YAML des données utilisateur qui se trouve dans l'espace de noms
openshift-machine-api. Utilisez la valeur indiquée par le programme d'installation dans le jeu de machines de calcul par défaut. - 16
- Spécifiez le nombre de sockets vCPU.
- 17
- Spécifiez le nombre de vCPU par socket.
2.7.2. Création d'un ensemble de machines de calcul
En plus des ensembles de machines de calcul créés par le programme d'installation, vous pouvez créer vos propres ensembles pour gérer dynamiquement les ressources de calcul des machines pour les charges de travail spécifiques de votre choix.
Conditions préalables
- Déployer un cluster OpenShift Container Platform.
-
Installez le CLI OpenShift (
oc). -
Connectez-vous à
ocen tant qu'utilisateur disposant de l'autorisationcluster-admin.
Procédure
Créez un nouveau fichier YAML contenant l'échantillon de ressources personnalisées (CR) de l'ensemble de machines de calcul et nommé
<file_name>.yaml.Veillez à définir les valeurs des paramètres
<clusterID>et<role>.Facultatif : si vous n'êtes pas sûr de la valeur à définir pour un champ spécifique, vous pouvez vérifier un ensemble de machines de calcul existant dans votre cluster.
Pour répertorier les ensembles de machines de calcul de votre cluster, exécutez la commande suivante :
$ oc get machinesets -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Pour afficher les valeurs d'une ressource personnalisée (CR) d'un ensemble de machines de calcul spécifique, exécutez la commande suivante :
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml
Exemple de sortie
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1 name: <infrastructure_id>-<role> 2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec: 3 ...- 1
- L'ID de l'infrastructure du cluster.
- 2
- Une étiquette de nœud par défaut.Note
Pour les clusters disposant d'une infrastructure fournie par l'utilisateur, un ensemble de machines de calcul ne peut créer que des machines de type
workeretinfra. - 3
- Les valeurs de la section
<providerSpec>du CR de l'ensemble de machines de calcul sont spécifiques à la plate-forme. Pour plus d'informations sur les paramètres<providerSpec>dans le CR, consultez l'exemple de configuration du CR de l'ensemble de machines de calcul pour votre fournisseur.
Créez un CR
MachineSeten exécutant la commande suivante :oc create -f <nom_du_fichier>.yaml
Vérification
Affichez la liste des ensembles de machines de calcul en exécutant la commande suivante :
$ oc get machineset -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Lorsque le nouveau jeu de machines de calcul est disponible, les valeurs
DESIREDetCURRENTcorrespondent. Si le jeu de machines de calcul n'est pas disponible, attendez quelques minutes et exécutez à nouveau la commande.
2.8. Créer un ensemble de machines de calcul sur OpenStack
Vous pouvez créer un ensemble de machines de calcul différent pour servir un objectif spécifique dans votre cluster OpenShift Container Platform sur Red Hat OpenStack Platform (RHOSP). Par exemple, vous pouvez créer des jeux de machines d'infrastructure et des machines connexes afin de pouvoir déplacer des charges de travail de support vers les nouvelles machines.
Vous ne pouvez utiliser les fonctionnalités avancées de gestion et de mise à l'échelle des machines que dans les clusters où l'API Machine est opérationnelle. Les clusters dont l'infrastructure est fournie par l'utilisateur nécessitent une validation et une configuration supplémentaires pour utiliser l'API Machine.
Les clusters avec le type de plateforme d'infrastructure none ne peuvent pas utiliser l'API Machine. Cette limitation s'applique même si les machines de calcul attachées au cluster sont installées sur une plateforme qui prend en charge cette fonctionnalité. Ce paramètre ne peut pas être modifié après l'installation.
Pour afficher le type de plateforme de votre cluster, exécutez la commande suivante :
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.8.1. Exemple de YAML pour une ressource personnalisée d'une machine de calcul sur RHOSP
Cet exemple YAML définit un ensemble de machines de calcul qui fonctionne sur Red Hat OpenStack Platform (RHOSP) et crée des nœuds qui sont étiquetés avec node-role.kubernetes.io/<role>: "".
Dans cet exemple, <infrastructure_id> est l'étiquette d'ID d'infrastructure basée sur l'ID de cluster que vous avez défini lors du provisionnement du cluster, et <role> est l'étiquette de nœud à ajouter.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1
machine.openshift.io/cluster-api-machine-role: <role> 2
machine.openshift.io/cluster-api-machine-type: <role> 3
name: <infrastructure_id>-<role> 4
namespace: openshift-machine-api
spec:
replicas: <number_of_replicas>
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 5
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> 6
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 7
machine.openshift.io/cluster-api-machine-role: <role> 8
machine.openshift.io/cluster-api-machine-type: <role> 9
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> 10
spec:
providerSpec:
value:
apiVersion: openstackproviderconfig.openshift.io/v1alpha1
cloudName: openstack
cloudsSecret:
name: openstack-cloud-credentials
namespace: openshift-machine-api
flavor: <nova_flavor>
image: <glance_image_name_or_location>
serverGroupID: <optional_UUID_of_server_group> 11
kind: OpenstackProviderSpec
networks: 12
- filter: {}
subnets:
- filter:
name: <subnet_name>
tags: openshiftClusterID=<infrastructure_id> 13
primarySubnet: <rhosp_subnet_UUID> 14
securityGroups:
- filter: {}
name: <infrastructure_id>-worker 15
serverMetadata:
Name: <infrastructure_id>-worker 16
openshiftClusterID: <infrastructure_id> 17
tags:
- openshiftClusterID=<infrastructure_id> 18
trunk: true
userDataSecret:
name: worker-user-data 19
availabilityZone: <optional_openstack_availability_zone>- 1 5 7 13 15 16 17 18
- Spécifiez l'ID d'infrastructure qui est basé sur l'ID de cluster que vous avez défini lorsque vous avez provisionné le cluster. Si le CLI OpenShift est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 8 9 19
- Spécifiez l'étiquette de nœud à ajouter.
- 4 6 10
- Spécifiez l'ID de l'infrastructure et l'étiquette du nœud.
- 11
- Pour définir une stratégie de groupe de serveurs pour le jeu de machines, entrez la valeur renvoyée lors de la création d'un groupe de serveurs. Pour la plupart des déploiements, les stratégies
anti-affinityousoft-anti-affinitysont recommandées. - 12
- Nécessaire pour les déploiements sur plusieurs réseaux. Pour spécifier plusieurs réseaux, ajoutez une autre entrée dans le tableau des réseaux. Vous devez également inclure le réseau utilisé comme valeur
primarySubnet. - 14
- Indiquez le sous-réseau RHOSP sur lequel vous souhaitez que les points d'extrémité des nœuds soient publiés. En général, il s'agit du même sous-réseau que celui utilisé comme valeur de
machinesSubnetdans le fichierinstall-config.yaml.
2.8.2. Exemple de YAML pour une ressource personnalisée d'un ensemble de machines de calcul qui utilise SR-IOV sur RHOSP
Si vous avez configuré votre cluster pour la virtualisation des E/S à racine unique (SR-IOV), vous pouvez créer des ensembles de machines de calcul qui utilisent cette technologie.
Cet exemple YAML définit un ensemble de machines de calcul qui utilise les réseaux SR-IOV. Les nœuds qu'il crée sont étiquetés avec des symboles node-role.openshift.io/<node_role>: ""
Dans cet exemple, infrastructure_id est l'étiquette d'ID d'infrastructure basée sur l'ID de cluster que vous avez défini lors du provisionnement du cluster, et node_role est l'étiquette de nœud à ajouter.
L'exemple suppose deux réseaux SR-IOV nommés "radio" et "uplink". Les réseaux sont utilisés dans les définitions de port de la liste spec.template.spec.providerSpec.value.ports.
Seuls les paramètres spécifiques aux déploiements SR-IOV sont décrits dans cet exemple. Pour consulter un exemple plus général, voir "Sample YAML for a compute machine set custom resource on RHOSP".
Exemple d'un ensemble de machines de calcul utilisant les réseaux SR-IOV
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <node_role>
machine.openshift.io/cluster-api-machine-type: <node_role>
name: <infrastructure_id>-<node_role>
namespace: openshift-machine-api
spec:
replicas: <number_of_replicas>
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<node_role>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <node_role>
machine.openshift.io/cluster-api-machine-type: <node_role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<node_role>
spec:
metadata:
providerSpec:
value:
apiVersion: openstackproviderconfig.openshift.io/v1alpha1
cloudName: openstack
cloudsSecret:
name: openstack-cloud-credentials
namespace: openshift-machine-api
flavor: <nova_flavor>
image: <glance_image_name_or_location>
serverGroupID: <optional_UUID_of_server_group>
kind: OpenstackProviderSpec
networks:
- subnets:
- UUID: <machines_subnet_UUID>
ports:
- networkID: <radio_network_UUID> 1
nameSuffix: radio
fixedIPs:
- subnetID: <radio_subnet_UUID> 2
tags:
- sriov
- radio
vnicType: direct 3
portSecurity: false 4
- networkID: <uplink_network_UUID> 5
nameSuffix: uplink
fixedIPs:
- subnetID: <uplink_subnet_UUID> 6
tags:
- sriov
- uplink
vnicType: direct 7
portSecurity: false 8
primarySubnet: <machines_subnet_UUID>
securityGroups:
- filter: {}
name: <infrastructure_id>-<node_role>
serverMetadata:
Name: <infrastructure_id>-<node_role>
openshiftClusterID: <infrastructure_id>
tags:
- openshiftClusterID=<infrastructure_id>
trunk: true
userDataSecret:
name: <node_role>-user-data
availabilityZone: <optional_openstack_availability_zone>
- 1 5
- Entrez un UUID de réseau pour chaque port.
- 2 6
- Entrez un UUID de sous-réseau pour chaque port.
- 3 7
- La valeur du paramètre
vnicTypedoit êtredirectpour chaque port. - 4 8
- La valeur du paramètre
portSecuritydoit êtrefalsepour chaque port.Vous ne pouvez pas définir de groupes de sécurité ni de paires d'adresses autorisées pour les ports lorsque la sécurité des ports est désactivée. La définition de groupes de sécurité sur l'instance applique les groupes à tous les ports qui lui sont attachés.
Après avoir déployé des machines de calcul compatibles avec SR-IOV, vous devez les étiqueter en tant que telles. Par exemple, à partir d'une ligne de commande, entrez :
$ oc label node <NODE_NAME> feature.node.kubernetes.io/network-sriov.capable="true"
Le trunking est activé pour les ports créés par des entrées dans les listes de réseaux et de sous-réseaux. Les noms des ports créés à partir de ces listes suivent le modèle <machine_name>-<nameSuffix>. Le champ nameSuffix est obligatoire dans les définitions de port.
Vous pouvez activer le trunking pour chaque port.
En option, vous pouvez ajouter des balises aux ports dans le cadre de leurs listes tags.
Ressources complémentaires
2.8.3. Exemple de YAML pour les déploiements SR-IOV où la sécurité des ports est désactivée
Pour créer des ports de virtualisation d'E/S à racine unique (SR-IOV) sur un réseau dont la sécurité des ports est désactivée, définissez un ensemble de machines de calcul qui inclut les ports en tant qu'éléments de la liste spec.template.spec.providerSpec.value.ports. Cette différence par rapport à l'ensemble de machines de calcul SR-IOV standard est due à la configuration automatique des groupes de sécurité et des paires d'adresses autorisées qui se produit pour les ports créés à l'aide des interfaces de réseau et de sous-réseau.
Les ports que vous définissez pour les sous-réseaux de machines sont nécessaires :
- Paires d'adresses autorisées pour l'API et les ports IP virtuels d'entrée
- Le groupe de sécurité informatique
- Rattachement au réseau et au sous-réseau des machines
Seuls les paramètres spécifiques aux déploiements SR-IOV où la sécurité des ports est désactivée sont décrits dans cet exemple. Pour consulter un exemple plus général, voir "Sample YAML for a compute machine set custom resource that uses SR-IOV on RHOSP".
Exemple d'un ensemble de machines de calcul utilisant des réseaux SR-IOV et dont la sécurité des ports est désactivée
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <node_role>
machine.openshift.io/cluster-api-machine-type: <node_role>
name: <infrastructure_id>-<node_role>
namespace: openshift-machine-api
spec:
replicas: <number_of_replicas>
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<node_role>
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <node_role>
machine.openshift.io/cluster-api-machine-type: <node_role>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<node_role>
spec:
metadata: {}
providerSpec:
value:
apiVersion: openstackproviderconfig.openshift.io/v1alpha1
cloudName: openstack
cloudsSecret:
name: openstack-cloud-credentials
namespace: openshift-machine-api
flavor: <nova_flavor>
image: <glance_image_name_or_location>
kind: OpenstackProviderSpec
ports:
- allowedAddressPairs: 1
- ipAddress: <API_VIP_port_IP>
- ipAddress: <ingress_VIP_port_IP>
fixedIPs:
- subnetID: <machines_subnet_UUID> 2
nameSuffix: nodes
networkID: <machines_network_UUID> 3
securityGroups:
- <compute_security_group_UUID> 4
- networkID: <SRIOV_network_UUID>
nameSuffix: sriov
fixedIPs:
- subnetID: <SRIOV_subnet_UUID>
tags:
- sriov
vnicType: direct
portSecurity: False
primarySubnet: <machines_subnet_UUID>
serverMetadata:
Name: <infrastructure_ID>-<node_role>
openshiftClusterID: <infrastructure_id>
tags:
- openshiftClusterID=<infrastructure_id>
trunk: false
userDataSecret:
name: worker-user-data
Le trunking est activé pour les ports créés par des entrées dans les listes de réseaux et de sous-réseaux. Les noms des ports créés à partir de ces listes suivent le modèle <machine_name>-<nameSuffix>. Le champ nameSuffix est obligatoire dans les définitions de port.
Vous pouvez activer le trunking pour chaque port.
En option, vous pouvez ajouter des balises aux ports dans le cadre de leurs listes tags.
Si votre cluster utilise Kuryr et que le réseau RHOSP SR-IOV a désactivé la sécurité des ports, le port primaire pour les machines de calcul doit avoir :
-
La valeur du paramètre
spec.template.spec.providerSpec.value.networks.portSecurityEnabledest fixée àfalse. -
Pour chaque sous-réseau, la valeur du paramètre
spec.template.spec.providerSpec.value.networks.subnets.portSecurityEnabledest fixée àfalse. -
La valeur de
spec.template.spec.providerSpec.value.securityGroupsest fixée à vide :[].
Exemple de section d'un ensemble de machines de calcul pour un cluster sur Kuryr qui utilise SR-IOV et dont la sécurité des ports est désactivée
...
networks:
- subnets:
- uuid: <machines_subnet_UUID>
portSecurityEnabled: false
portSecurityEnabled: false
securityGroups: []
...
Dans ce cas, vous pouvez appliquer le groupe de sécurité informatique à l'interface principale de la VM après la création de la VM. Par exemple, à partir d'une ligne de commande :
$ openstack port set --enable-port-security --security-group <infrastructure_id>-<node_role> <main_port_ID>
Après avoir déployé des machines de calcul compatibles avec SR-IOV, vous devez les étiqueter en tant que telles. Par exemple, à partir d'une ligne de commande, entrez :
$ oc label node <NODE_NAME> feature.node.kubernetes.io/network-sriov.capable="true"
2.8.4. Création d'un ensemble de machines de calcul
En plus des ensembles de machines de calcul créés par le programme d'installation, vous pouvez créer vos propres ensembles pour gérer dynamiquement les ressources de calcul des machines pour les charges de travail spécifiques de votre choix.
Conditions préalables
- Déployer un cluster OpenShift Container Platform.
-
Installez le CLI OpenShift (
oc). -
Connectez-vous à
ocen tant qu'utilisateur disposant de l'autorisationcluster-admin.
Procédure
Créez un nouveau fichier YAML contenant l'échantillon de ressources personnalisées (CR) de l'ensemble de machines de calcul et nommé
<file_name>.yaml.Veillez à définir les valeurs des paramètres
<clusterID>et<role>.Facultatif : si vous n'êtes pas sûr de la valeur à définir pour un champ spécifique, vous pouvez vérifier un ensemble de machines de calcul existant dans votre cluster.
Pour répertorier les ensembles de machines de calcul de votre cluster, exécutez la commande suivante :
$ oc get machinesets -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Pour afficher les valeurs d'une ressource personnalisée (CR) d'un ensemble de machines de calcul spécifique, exécutez la commande suivante :
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml
Exemple de sortie
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1 name: <infrastructure_id>-<role> 2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec: 3 ...- 1
- L'ID de l'infrastructure du cluster.
- 2
- Une étiquette de nœud par défaut.Note
Pour les clusters disposant d'une infrastructure fournie par l'utilisateur, un ensemble de machines de calcul ne peut créer que des machines de type
workeretinfra. - 3
- Les valeurs de la section
<providerSpec>du CR de l'ensemble de machines de calcul sont spécifiques à la plate-forme. Pour plus d'informations sur les paramètres<providerSpec>dans le CR, consultez l'exemple de configuration du CR de l'ensemble de machines de calcul pour votre fournisseur.
Créez un CR
MachineSeten exécutant la commande suivante :oc create -f <nom_du_fichier>.yaml
Vérification
Affichez la liste des ensembles de machines de calcul en exécutant la commande suivante :
$ oc get machineset -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Lorsque le nouveau jeu de machines de calcul est disponible, les valeurs
DESIREDetCURRENTcorrespondent. Si le jeu de machines de calcul n'est pas disponible, attendez quelques minutes et exécutez à nouveau la commande.
2.9. Création d'un ensemble de machines de calcul sur RHV
Vous pouvez créer un ensemble de machines de calcul différent pour répondre à un objectif spécifique dans votre cluster OpenShift Container Platform sur Red Hat Virtualization (RHV). Par exemple, vous pouvez créer des jeux de machines d'infrastructure et des machines connexes afin de pouvoir déplacer les charges de travail de support vers les nouvelles machines.
Vous ne pouvez utiliser les fonctionnalités avancées de gestion et de mise à l'échelle des machines que dans les clusters où l'API Machine est opérationnelle. Les clusters dont l'infrastructure est fournie par l'utilisateur nécessitent une validation et une configuration supplémentaires pour utiliser l'API Machine.
Les clusters avec le type de plateforme d'infrastructure none ne peuvent pas utiliser l'API Machine. Cette limitation s'applique même si les machines de calcul attachées au cluster sont installées sur une plateforme qui prend en charge cette fonctionnalité. Ce paramètre ne peut pas être modifié après l'installation.
Pour afficher le type de plateforme de votre cluster, exécutez la commande suivante :
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.9.1. Exemple de YAML pour une ressource personnalisée d'une machine de calcul sur RHV
Cet exemple YAML définit un ensemble de machines de calcul fonctionnant sur RHV et crée des nœuds étiquetés avec node-role.kubernetes.io/<node_role>: "".
Dans cet exemple, <infrastructure_id> est l'étiquette d'ID d'infrastructure basée sur l'ID de cluster que vous avez défini lors du provisionnement du cluster, et <role> est l'étiquette de nœud à ajouter.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1
machine.openshift.io/cluster-api-machine-role: <role> 2
machine.openshift.io/cluster-api-machine-type: <role> 3
name: <infrastructure_id>-<role> 4
namespace: openshift-machine-api
spec:
replicas: <number_of_replicas> 5
Selector: 6
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 7
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> 8
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 9
machine.openshift.io/cluster-api-machine-role: <role> 10
machine.openshift.io/cluster-api-machine-type: <role> 11
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> 12
spec:
metadata:
labels:
node-role.kubernetes.io/<role>: "" 13
providerSpec:
value:
apiVersion: ovirtproviderconfig.machine.openshift.io/v1beta1
cluster_id: <ovirt_cluster_id> 14
template_name: <ovirt_template_name> 15
sparse: <boolean_value> 16
format: <raw_or_cow> 17
cpu: 18
sockets: <number_of_sockets> 19
cores: <number_of_cores> 20
threads: <number_of_threads> 21
memory_mb: <memory_size> 22
guaranteed_memory_mb: <memory_size> 23
os_disk: 24
size_gb: <disk_size> 25
storage_domain_id: <storage_domain_UUID> 26
network_interfaces: 27
vnic_profile_id: <vnic_profile_id> 28
credentialsSecret:
name: ovirt-credentials 29
kind: OvirtMachineProviderSpec
type: <workload_type> 30
auto_pinning_policy: <auto_pinning_policy> 31
hugepages: <hugepages> 32
affinityGroupsNames:
- compute 33
userDataSecret:
name: worker-user-data- 1 7 9
- Spécifiez l'ID d'infrastructure qui est basé sur l'ID de cluster que vous avez défini lorsque vous avez provisionné le cluster. Si l'OpenShift CLI (
oc) est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 10 11 13
- Spécifiez l'étiquette de nœud à ajouter.
- 4 8 12
- Spécifiez l'ID de l'infrastructure et l'étiquette du nœud. L'ensemble de ces deux chaînes ne peut dépasser 35 caractères.
- 5
- Indiquez le nombre de machines à créer.
- 6
- Sélecteur pour les machines.
- 14
- Spécifiez l'UUID du cluster RHV auquel appartient cette instance de VM.
- 15
- Spécifiez le modèle de VM RHV à utiliser pour créer la machine.
- 16
- Setting this option to
falseenables preallocation of disks. The default istrue. Settingsparsetotruewithformatset torawis not available for block storage domains. Therawformat writes the entire virtual disk to the underlying physical disk. - 17
- Can be set to
coworraw. The default iscow. Thecowformat is optimized for virtual machines.NotePreallocating disks on file storage domains writes zeroes to the file. This might not actually preallocate disks depending on the underlying storage.
- 18
- Facultatif : Le champ CPU contient la configuration du CPU, y compris les sockets, les cœurs et les threads.
- 19
- Facultatif : Spécifiez le nombre de sockets pour une VM.
- 20
- Facultatif : Spécifiez le nombre de cœurs par socket.
- 21
- Facultatif : Spécifiez le nombre de threads par cœur.
- 22
- Facultatif : Spécifiez la taille de la mémoire d'une VM en MiB.
- 23
- Facultatif : Spécifiez la taille de la mémoire garantie d'une machine virtuelle en MiB. Il s'agit de la quantité de mémoire qui est garantie de ne pas être drainée par le mécanisme de ballonnement. Pour plus d'informations, voir Explication des paramètres de ballonnement et d'optimisation de la mémoire.Note
Si vous utilisez une version antérieure à RHV 4.4.8, voir Exigences de mémoire garantie pour OpenShift sur les clusters Red Hat Virtualization.
- 24
- Facultatif : Disque racine du nœud.
- 25
- Facultatif : Spécifiez la taille du disque de démarrage en GiB.
- 26
- Facultatif : Indiquez l'UUID du domaine de stockage pour les disques du nœud de calcul. Si aucune valeur n'est fournie, le nœud de calcul est créé sur le même domaine de stockage que les nœuds de contrôle. (par défaut)
- 27
- Facultatif : Liste des interfaces réseau de la VM. Si vous incluez ce paramètre, OpenShift Container Platform écarte toutes les interfaces réseau du modèle et en crée de nouvelles.
- 28
- Facultatif : Spécifiez l'ID du profil vNIC.
- 29
- Indiquez le nom de l'objet secret qui contient les informations d'identification RHV.
- 30
- Facultatif : Spécifiez le type de charge de travail pour lequel l'instance est optimisée. Cette valeur affecte le paramètre
RHV VM. Valeurs prises en charge :desktop,server(par défaut),high_performance.high_performanceaméliore les performances de la VM. Il existe des limitations, par exemple, vous ne pouvez pas accéder à la VM avec une console graphique. Pour plus d'informations, voir Configuration de machines virtuelles, de modèles et de pools haute performance sur Virtual Machine Management Guide. - 31
- Facultatif : AutoPinningPolicy définit la stratégie qui définit automatiquement les paramètres CPU et NUMA, y compris l'épinglage sur l'hôte pour cette instance. Valeurs prises en charge :
none,resize_and_pin. Pour plus d'informations, voir Définition des nœuds NUMA à l'adresse Virtual Machine Management Guide. - 32
- Facultatif : Hugepages est la taille en KiB pour définir les hugepages dans une VM. Valeurs prises en charge :
2048ou1048576. Pour plus d'informations, voir Configuration des pages volumineuses sur le site Virtual Machine Management Guide. - 33
- Facultatif : Une liste de noms de groupes d'affinité à appliquer aux machines virtuelles. Les groupes d'affinité doivent exister dans oVirt.
Étant donné que RHV utilise un modèle lors de la création d'une VM, si vous ne spécifiez pas de valeur pour un paramètre facultatif, RHV utilise la valeur de ce paramètre qui est spécifiée dans le modèle.
2.9.2. Création d'un ensemble de machines de calcul
En plus des ensembles de machines de calcul créés par le programme d'installation, vous pouvez créer vos propres ensembles pour gérer dynamiquement les ressources de calcul des machines pour les charges de travail spécifiques de votre choix.
Conditions préalables
- Déployer un cluster OpenShift Container Platform.
-
Installez le CLI OpenShift (
oc). -
Connectez-vous à
ocen tant qu'utilisateur disposant de l'autorisationcluster-admin.
Procédure
Créez un nouveau fichier YAML contenant l'échantillon de ressources personnalisées (CR) de l'ensemble de machines de calcul et nommé
<file_name>.yaml.Veillez à définir les valeurs des paramètres
<clusterID>et<role>.Facultatif : si vous n'êtes pas sûr de la valeur à définir pour un champ spécifique, vous pouvez vérifier un ensemble de machines de calcul existant dans votre cluster.
Pour répertorier les ensembles de machines de calcul de votre cluster, exécutez la commande suivante :
$ oc get machinesets -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Pour afficher les valeurs d'une ressource personnalisée (CR) d'un ensemble de machines de calcul spécifique, exécutez la commande suivante :
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml
Exemple de sortie
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1 name: <infrastructure_id>-<role> 2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec: 3 ...- 1
- L'ID de l'infrastructure du cluster.
- 2
- Une étiquette de nœud par défaut.Note
Pour les clusters disposant d'une infrastructure fournie par l'utilisateur, un ensemble de machines de calcul ne peut créer que des machines de type
workeretinfra. - 3
- Les valeurs de la section
<providerSpec>du CR de l'ensemble de machines de calcul sont spécifiques à la plate-forme. Pour plus d'informations sur les paramètres<providerSpec>dans le CR, consultez l'exemple de configuration du CR de l'ensemble de machines de calcul pour votre fournisseur.
Créez un CR
MachineSeten exécutant la commande suivante :oc create -f <nom_du_fichier>.yaml
Vérification
Affichez la liste des ensembles de machines de calcul en exécutant la commande suivante :
$ oc get machineset -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Lorsque le nouveau jeu de machines de calcul est disponible, les valeurs
DESIREDetCURRENTcorrespondent. Si le jeu de machines de calcul n'est pas disponible, attendez quelques minutes et exécutez à nouveau la commande.
2.10. Création d'un ensemble de machines de calcul sur vSphere
Vous pouvez créer un ensemble de machines de calcul différent pour répondre à un objectif spécifique dans votre cluster OpenShift Container Platform sur VMware vSphere. Par exemple, vous pouvez créer des jeux de machines d'infrastructure et des machines connexes afin de pouvoir déplacer des charges de travail de support vers les nouvelles machines.
Vous ne pouvez utiliser les fonctionnalités avancées de gestion et de mise à l'échelle des machines que dans les clusters où l'API Machine est opérationnelle. Les clusters dont l'infrastructure est fournie par l'utilisateur nécessitent une validation et une configuration supplémentaires pour utiliser l'API Machine.
Les clusters avec le type de plateforme d'infrastructure none ne peuvent pas utiliser l'API Machine. Cette limitation s'applique même si les machines de calcul attachées au cluster sont installées sur une plateforme qui prend en charge cette fonctionnalité. Ce paramètre ne peut pas être modifié après l'installation.
Pour afficher le type de plateforme de votre cluster, exécutez la commande suivante :
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'2.10.1. Exemple de YAML pour une ressource personnalisée d'un ensemble de machines de calcul sur vSphere
Cet exemple YAML définit un ensemble de machines de calcul qui fonctionne sur VMware vSphere et crée des nœuds étiquetés avec node-role.kubernetes.io/<role>: "".
Dans cet exemple, <infrastructure_id> est l'étiquette d'ID d'infrastructure basée sur l'ID de cluster que vous avez défini lors du provisionnement du cluster, et <role> est l'étiquette de nœud à ajouter.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1
name: <infrastructure_id>-<role> 2
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 3
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> 4
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 5
machine.openshift.io/cluster-api-machine-role: <role> 6
machine.openshift.io/cluster-api-machine-type: <role> 7
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> 8
spec:
metadata:
creationTimestamp: null
labels:
node-role.kubernetes.io/<role>: "" 9
providerSpec:
value:
apiVersion: vsphereprovider.openshift.io/v1beta1
credentialsSecret:
name: vsphere-cloud-credentials
diskGiB: 120
kind: VSphereMachineProviderSpec
memoryMiB: 8192
metadata:
creationTimestamp: null
network:
devices:
- networkName: "<vm_network_name>" 10
numCPUs: 4
numCoresPerSocket: 1
snapshot: ""
template: <vm_template_name> 11
userDataSecret:
name: worker-user-data
workspace:
datacenter: <vcenter_datacenter_name> 12
datastore: <vcenter_datastore_name> 13
folder: <vcenter_vm_folder_path> 14
resourcepool: <vsphere_resource_pool> 15
server: <vcenter_server_ip> 16- 1 3 5
- Spécifiez l'ID d'infrastructure qui est basé sur l'ID de cluster que vous avez défini lorsque vous avez provisionné le cluster. Si l'OpenShift CLI (
oc) est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 4 8
- Spécifiez l'ID de l'infrastructure et l'étiquette du nœud.
- 6 7 9
- Spécifiez l'étiquette de nœud à ajouter.
- 10
- Indiquez le réseau VM vSphere sur lequel déployer l'ensemble de machines de calcul. Ce réseau VM doit se trouver là où d'autres machines de calcul résident dans le cluster.
- 11
- Spécifiez le modèle de VM vSphere à utiliser, par exemple
user-5ddjd-rhcos. - 12
- Spécifiez le centre de données vCenter sur lequel déployer l'ensemble de machines de calcul.
- 13
- Spécifiez le Datastore vCenter sur lequel déployer l'ensemble de machines de calcul.
- 14
- Indiquez le chemin d'accès au dossier vSphere VM dans vCenter, par exemple
/dc1/vm/user-inst-5ddjd. - 15
- Spécifiez le pool de ressources vSphere pour vos machines virtuelles.
- 16
- Spécifiez l'IP du serveur vCenter ou le nom de domaine complet.
2.10.2. Privilèges vCenter minimaux requis pour la gestion des ensembles de machines de calcul
Pour gérer les ensembles de machines de calcul dans un cluster OpenShift Container Platform sur vCenter, vous devez utiliser un compte disposant des privilèges nécessaires pour lire, créer et supprimer les ressources requises. L'utilisation d'un compte disposant de privilèges administratifs globaux est le moyen le plus simple d'accéder à toutes les autorisations nécessaires.
Si vous ne pouvez pas utiliser un compte avec des privilèges administratifs globaux, vous devez créer des rôles pour accorder les privilèges minimums requis. Le tableau suivant répertorie les rôles et privilèges vCenter minimaux requis pour créer, mettre à l'échelle et supprimer des ensembles de machines de calcul et pour supprimer des machines dans votre cluster OpenShift Container Platform.
Exemple 2.1. Rôles et privilèges vCenter minimaux requis pour la gestion des ensembles de machines de calcul
| vSphere object for role | When required | Privilèges requis |
|---|---|---|
| vSphere vCenter | Always |
|
| vSphere vCenter Cluster | Always |
|
| vSphere Datastore | Always |
|
| vSphere Port Group | Always |
|
| Virtual Machine Folder | Always |
|
| vSphere vCenter Datacenter | If the installation program creates the virtual machine folder |
|
|
1 Les autorisations | ||
Le tableau suivant détaille les autorisations et les paramètres de propagation requis pour la gestion des ensembles de machines de calcul.
Exemple 2.2. Required permissions and propagation settings
| vSphere object | Type de dossier | Propagate to children | Permissions required |
|---|---|---|---|
| vSphere vCenter | Always | Pas nécessaire | Listed required privileges |
| vSphere vCenter Datacenter | Existing folder | Pas nécessaire |
|
| Installation program creates the folder | Exigée | Listed required privileges | |
| vSphere vCenter Cluster | Always | Exigée | Listed required privileges |
| vSphere vCenter Datastore | Always | Pas nécessaire | Listed required privileges |
| vSphere Switch | Always | Pas nécessaire |
|
| vSphere Port Group | Always | Pas nécessaire | Listed required privileges |
| vSphere vCenter Virtual Machine Folder | Existing folder | Exigée | Listed required privileges |
For more information about creating an account with only the required privileges, see vSphere Permissions and User Management Tasks in the vSphere documentation.
2.10.3. Exigences pour les grappes dont l'infrastructure est fournie par l'utilisateur afin d'utiliser des ensembles de machines de calcul
Pour utiliser des ensembles de machines de calcul sur des clusters disposant d'une infrastructure fournie par l'utilisateur, vous devez vous assurer que la configuration de votre cluster prend en charge l'utilisation de l'API Machine.
Obtention de l'identifiant de l'infrastructure
Pour créer des ensembles de machines de calcul, vous devez être en mesure de fournir l'identifiant d'infrastructure de votre cluster.
Procédure
Pour obtenir l'identifiant d'infrastructure de votre cluster, exécutez la commande suivante :
$ oc get infrastructure cluster -o jsonpath='{.status.infrastructureName}'
Satisfaire aux exigences en matière d'accréditation vSphere
Pour utiliser les ensembles de machines de calcul, l'API Machine doit pouvoir interagir avec vCenter. Les informations d'identification qui autorisent les composants de l'API Machine à interagir avec vCenter doivent exister dans un secret de l'espace de noms openshift-machine-api.
Procédure
Pour déterminer si les informations d'identification requises existent, exécutez la commande suivante :
$ oc get secret \ -n openshift-machine-api vsphere-cloud-credentials \ -o go-template='{{range $k,$v := .data}}{{printf "%s: " $k}}{{if not $v}}{{$v}}{{else}}{{$v | base64decode}}{{end}}{{"\n"}}{{end}}'Exemple de sortie
<vcenter-server>.password=<openshift-user-password> <vcenter-server>.username=<openshift-user>
où
<vcenter-server>est l'adresse IP ou le nom de domaine entièrement qualifié (FQDN) du serveur vCenter et<openshift-user>et<openshift-user-password>sont les informations d'identification de l'administrateur OpenShift Container Platform à utiliser.Si le secret n'existe pas, créez-le en exécutant la commande suivante :
$ oc create secret generic vsphere-cloud-credentials \ -n openshift-machine-api \ --from-literal=<vcenter-server>.username=<openshift-user> --from-literal=<vcenter-server>.password=<openshift-user-password>
Satisfaire aux exigences de configuration d'Ignition
Le provisionnement des machines virtuelles (VM) nécessite une configuration Ignition valide. La configuration Ignition contient l'adresse machine-config-server et un ensemble de confiance système pour obtenir d'autres configurations Ignition auprès de l'opérateur Machine Config.
Par défaut, cette configuration est stockée dans le secret worker-user-data de l'espace de noms machine-api-operator. Les ensembles de machines de calcul font référence au secret pendant le processus de création de la machine.
Procédure
Pour déterminer si le secret requis existe, exécutez la commande suivante :
$ oc get secret \ -n openshift-machine-api worker-user-data \ -o go-template='{{range $k,$v := .data}}{{printf "%s: " $k}}{{if not $v}}{{$v}}{{else}}{{$v | base64decode}}{{end}}{{"\n"}}{{end}}'Exemple de sortie
disableTemplating: false userData: 1 { "ignition": { ... }, ... }- 1
- La sortie complète est omise ici, mais devrait avoir ce format.
Si le secret n'existe pas, créez-le en exécutant la commande suivante :
$ oc create secret generic worker-user-data \ -n openshift-machine-api \ --from-file=<installation_directory>/worker.ign
où
<installation_directory>est le répertoire qui a été utilisé pour stocker vos ressources d'installation lors de l'installation du cluster.
2.10.4. Création d'un ensemble de machines de calcul
En plus des ensembles de machines de calcul créés par le programme d'installation, vous pouvez créer vos propres ensembles pour gérer dynamiquement les ressources de calcul des machines pour les charges de travail spécifiques de votre choix.
Les clusters installés avec une infrastructure fournie par l'utilisateur ont une pile réseau différente de celle des clusters dont l'infrastructure est fournie par le programme d'installation. En raison de cette différence, la gestion automatique de l'équilibreur de charge n'est pas prise en charge sur les clusters dotés d'une infrastructure fournie par l'utilisateur. Pour ces clusters, un ensemble de machines de calcul ne peut créer que des machines de type worker et infra.
Conditions préalables
- Déployer un cluster OpenShift Container Platform.
-
Installez le CLI OpenShift (
oc). -
Connectez-vous à
ocen tant qu'utilisateur disposant de l'autorisationcluster-admin. - Disposer des autorisations nécessaires pour déployer des machines virtuelles dans votre instance vCenter et avoir l'accès requis au magasin de données spécifié.
- Si votre cluster utilise une infrastructure fournie par l'utilisateur, vous avez satisfait aux exigences spécifiques de l'API Machine pour cette configuration.
Procédure
Créez un nouveau fichier YAML contenant l'échantillon de ressources personnalisées (CR) de l'ensemble de machines de calcul et nommé
<file_name>.yaml.Veillez à définir les valeurs des paramètres
<clusterID>et<role>.Facultatif : si vous n'êtes pas sûr de la valeur à définir pour un champ spécifique, vous pouvez vérifier un ensemble de machines de calcul existant dans votre cluster.
Pour répertorier les ensembles de machines de calcul de votre cluster, exécutez la commande suivante :
$ oc get machinesets -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Pour afficher les valeurs d'une ressource personnalisée (CR) d'un ensemble de machines de calcul spécifique, exécutez la commande suivante :
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml
Exemple de sortie
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1 name: <infrastructure_id>-<role> 2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec: 3 ...- 1
- L'ID de l'infrastructure du cluster.
- 2
- Une étiquette de nœud par défaut.Note
Pour les clusters disposant d'une infrastructure fournie par l'utilisateur, un ensemble de machines de calcul ne peut créer que des machines de type
workeretinfra. - 3
- Les valeurs de la section
<providerSpec>du CR de l'ensemble de machines de calcul sont spécifiques à la plate-forme. Pour plus d'informations sur les paramètres<providerSpec>dans le CR, consultez l'exemple de configuration du CR de l'ensemble de machines de calcul pour votre fournisseur.
Si vous créez un ensemble de machines de calcul pour un cluster qui dispose d'une infrastructure fournie par l'utilisateur, notez les valeurs importantes suivantes :
Exemple de valeurs vSphere
providerSpecapiVersion: machine.openshift.io/v1beta1 kind: MachineSet ... template: ... spec: providerSpec: value: apiVersion: machine.openshift.io/v1beta1 credentialsSecret: name: vsphere-cloud-credentials 1 diskGiB: 120 kind: VSphereMachineProviderSpec memoryMiB: 16384 network: devices: - networkName: "<vm_network_name>" numCPUs: 4 numCoresPerSocket: 4 snapshot: "" template: <vm_template_name> 2 userDataSecret: name: worker-user-data 3 workspace: datacenter: <vcenter_datacenter_name> datastore: <vcenter_datastore_name> folder: <vcenter_vm_folder_path> resourcepool: <vsphere_resource_pool> server: <vcenter_server_address> 4- 1
- Le nom du secret dans l'espace de noms
openshift-machine-apiqui contient les informations d'identification vCenter requises. - 2
- Le nom du modèle de VM RHCOS pour votre cluster qui a été créé lors de l'installation.
- 3
- Le nom du secret dans l'espace de noms
openshift-machine-apiqui contient les informations d'identification requises pour la configuration d'Ignition. - 4
- L'adresse IP ou le nom de domaine complet (FQDN) du serveur vCenter.
Créez un CR
MachineSeten exécutant la commande suivante :oc create -f <nom_du_fichier>.yaml
Vérification
Affichez la liste des ensembles de machines de calcul en exécutant la commande suivante :
$ oc get machineset -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Lorsque le nouveau jeu de machines de calcul est disponible, les valeurs
DESIREDetCURRENTcorrespondent. Si le jeu de machines de calcul n'est pas disponible, attendez quelques minutes et exécutez à nouveau la commande.
Chapitre 3. Mise à l'échelle manuelle d'un ensemble de machines de calcul
Vous pouvez ajouter ou supprimer une instance d'une machine dans un ensemble de machines de calcul.
Si vous devez modifier des aspects d'un ensemble de machines de calcul en dehors de la mise à l'échelle, consultez la section Modifier un ensemble de machines de calcul.
3.1. Conditions préalables
-
Si vous avez activé le proxy à l'échelle du cluster et mis à l'échelle des machines de calcul non incluses dans
networking.machineNetwork[].cidrà partir de la configuration d'installation, vous devez ajouter les machines de calcul au champnoProxyde l'objet Proxy afin d'éviter les problèmes de connexion.
Vous ne pouvez utiliser les fonctionnalités avancées de gestion et de mise à l'échelle des machines que dans les clusters où l'API Machine est opérationnelle. Les clusters dont l'infrastructure est fournie par l'utilisateur nécessitent une validation et une configuration supplémentaires pour utiliser l'API Machine.
Les clusters avec le type de plateforme d'infrastructure none ne peuvent pas utiliser l'API Machine. Cette limitation s'applique même si les machines de calcul attachées au cluster sont installées sur une plateforme qui prend en charge cette fonctionnalité. Ce paramètre ne peut pas être modifié après l'installation.
Pour afficher le type de plateforme de votre cluster, exécutez la commande suivante :
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'3.2. Mise à l'échelle manuelle d'un ensemble de machines de calcul
Pour ajouter ou supprimer une instance d'une machine dans un ensemble de machines de calcul, vous pouvez mettre à l'échelle manuellement l'ensemble de machines de calcul.
Ce guide s'applique aux installations d'infrastructure entièrement automatisées et fournies par l'installateur. Les installations d'infrastructure personnalisées et fournies par l'utilisateur n'ont pas d'ensembles de machines de calcul.
Conditions préalables
-
Installer un cluster OpenShift Container Platform et la ligne de commande
oc. -
Connectez-vous à
ocen tant qu'utilisateur disposant de l'autorisationcluster-admin.
Procédure
Affichez les ensembles de machines de calcul qui se trouvent dans le cluster en exécutant la commande suivante :
$ oc get machinesets -n openshift-machine-api
Les ensembles de machines de calcul sont répertoriés sous la forme de
<clusterid>-worker-<aws-region-az>.Affichez les machines de calcul qui se trouvent dans le cluster en exécutant la commande suivante :
$ oc get machine -n openshift-machine-api
Définissez l'annotation sur la machine de calcul que vous souhaitez supprimer en exécutant la commande suivante :
$ oc annotate machine/<machine_name> -n openshift-machine-api machine.openshift.io/delete-machine="true"
Mettez à l'échelle l'ensemble de machines de calcul en exécutant l'une des commandes suivantes :
$ oc scale --replicas=2 machineset <machineset> -n openshift-machine-api
Ou bien :
$ oc edit machineset <machineset> -n openshift-machine-api
AstuceVous pouvez également appliquer le YAML suivant pour mettre à l'échelle l'ensemble des machines de calcul :
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machineset> namespace: openshift-machine-api spec: replicas: 2
Vous pouvez augmenter ou diminuer le nombre de machines de calcul. Il faut quelques minutes pour que les nouvelles machines soient disponibles.
ImportantPar défaut, le contrôleur de machine tente de drainer le nœud soutenu par la machine jusqu'à ce qu'il y parvienne. Dans certaines situations, comme dans le cas d'un budget de perturbation de pods mal configuré, l'opération de vidange peut ne pas aboutir. Si l'opération de vidange échoue, le contrôleur de machine ne peut pas procéder au retrait de la machine.
Vous pouvez éviter de vider le nœud en annotant
machine.openshift.io/exclude-node-drainingdans une machine spécifique.
Vérification
Vérifiez la suppression de la machine prévue en exécutant la commande suivante :
$ oc get machines
3.3. Politique de suppression des ensembles de machines de calcul
Random, Newest, et Oldest sont les trois options de suppression prises en charge. La valeur par défaut est Random, ce qui signifie que des machines aléatoires sont choisies et supprimées lorsque des machines de calcul à échelle réduite sont mises hors service. La politique de suppression peut être définie en fonction du cas d'utilisation en modifiant l'ensemble particulier de machines de calcul :
spec: deletePolicy: <delete_policy> replicas: <desired_replica_count>
Des machines spécifiques peuvent également être supprimées en priorité en ajoutant l'annotation machine.openshift.io/delete-machine=true à la machine concernée, quelle que soit la politique de suppression.
Par défaut, les pods de routeur de OpenShift Container Platform sont déployés sur des workers. Comme le routeur est nécessaire pour accéder à certaines ressources du cluster, notamment la console Web, ne mettez pas à l'échelle l'ensemble de machines de calcul de l'ouvrier à l'adresse 0 à moins de déplacer d'abord les pods de routeur.
Les ensembles de machines de calcul personnalisés peuvent être utilisés pour des cas d'utilisation exigeant que des services s'exécutent sur des nœuds spécifiques et que ces services soient ignorés par le contrôleur lorsque les ensembles de machines de calcul travailleurs sont réduits. Cela permet d'éviter les interruptions de service.
3.4. Ressources complémentaires
Chapitre 4. Modifier un ensemble de machines de calcul
Vous pouvez modifier un ensemble de machines de calcul, par exemple en ajoutant des étiquettes, en changeant le type d'instance ou en modifiant le stockage des blocs.
Sur Red Hat Virtualization (RHV), vous pouvez également modifier un ensemble de machines de calcul pour provisionner de nouveaux nœuds sur un domaine de stockage différent.
Si vous devez mettre à l'échelle un ensemble de machines de calcul sans effectuer d'autres modifications, consultez la section Mise à l'échelle manuelle d'un ensemble de machines de calcul.
4.1. Modifier un ensemble de machines de calcul
Pour apporter des modifications à un ensemble de machines de calcul, modifiez le fichier YAML MachineSet. Ensuite, supprimez toutes les machines associées à l'ensemble de machines de calcul en supprimant chaque machine ou en réduisant l'ensemble de machines de calcul à 0 réplicas. Ensuite, réduisez les réplicas au nombre souhaité. Les modifications apportées à un ensemble de machines de calcul n'affectent pas les machines existantes.
Si vous devez mettre à l'échelle un ensemble de machines de calcul sans faire d'autres changements, vous n'avez pas besoin de supprimer les machines.
Par défaut, les pods de routeur de OpenShift Container Platform sont déployés sur des travailleurs. Le routeur étant nécessaire pour accéder à certaines ressources du cluster, notamment la console Web, ne mettez pas à l'échelle l'ensemble de machines de calcul à l'adresse 0 à moins de relocaliser d'abord les pods de routeur.
Conditions préalables
-
Installer un cluster OpenShift Container Platform et la ligne de commande
oc. -
Connectez-vous à
ocen tant qu'utilisateur disposant de l'autorisationcluster-admin.
Procédure
Modifiez le jeu de machines de calcul en exécutant la commande suivante :
$ oc edit machineset <machineset> -n openshift-machine-api
Réduisez l'ensemble de la machine de calcul à
0en exécutant l'une des commandes suivantes :$ oc scale --replicas=0 machineset <machineset> -n openshift-machine-api
Ou bien :
$ oc edit machineset <machineset> -n openshift-machine-api
AstuceVous pouvez également appliquer le YAML suivant pour mettre à l'échelle l'ensemble des machines de calcul :
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machineset> namespace: openshift-machine-api spec: replicas: 0
Attendez que les machines soient retirées.
Augmentez la taille de l'ensemble de machines de calcul si nécessaire en exécutant l'une des commandes suivantes :
$ oc scale --replicas=2 machineset <machineset> -n openshift-machine-api
Ou bien :
$ oc edit machineset <machineset> -n openshift-machine-api
AstuceVous pouvez également appliquer le YAML suivant pour mettre à l'échelle l'ensemble des machines de calcul :
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machineset> namespace: openshift-machine-api spec: replicas: 2
Attendez que les machines démarrent. Les nouvelles machines contiennent les modifications que vous avez apportées à l'ensemble de machines de calcul.
Ressources complémentaires
4.2. Migration des nœuds vers un domaine de stockage différent sur RHV
Vous pouvez migrer le plan de contrôle d'OpenShift Container Platform et les nœuds de calcul vers un domaine de stockage différent dans un cluster Red Hat Virtualization (RHV).
4.2.1. Migration des nœuds de calcul vers un domaine de stockage différent dans RHV
Conditions préalables
- Vous êtes connecté au Manager.
- Vous avez le nom du domaine de stockage cible.
Procédure
Identifiez le modèle de machine virtuelle en exécutant la commande suivante :
$ oc get -o jsonpath='{.items[0].spec.template.spec.providerSpec.value.template_name}{"\n"}' machineset -ACréez une nouvelle machine virtuelle dans le Gestionnaire, basée sur le modèle que vous avez identifié. Laissez tous les autres paramètres inchangés. Pour plus de détails, reportez-vous à la section Créer une machine virtuelle basée sur un modèle dans Red Hat Virtualization Virtual Machine Management Guide.
AstuceIl n'est pas nécessaire de démarrer la nouvelle machine virtuelle.
- Créez un nouveau modèle à partir de la nouvelle machine virtuelle. Spécifiez le domaine de stockage cible sous Target. Pour plus de détails, reportez-vous à la section Créer un modèle dans Red Hat Virtualization Virtual Machine Management Guide.
Ajouter un nouvel ensemble de machines de calcul au cluster OpenShift Container Platform avec le nouveau modèle.
Obtenez les détails de l'ensemble de machines de calcul actuel en exécutant la commande suivante :
$ oc get machineset -o yaml
Utilisez ces informations pour créer un ensemble de machines de calcul. Pour plus d'informations, voir Creating a compute machine set.
Entrez le nouveau nom du modèle de machine virtuelle dans le champ template_name. Utilisez le même nom de modèle que vous avez utilisé dans la boîte de dialogue New template dans le Gestionnaire.
- Notez les noms des anciens et des nouveaux ensembles de machines de calcul. Vous devrez vous y référer dans les étapes suivantes.
Migrer les charges de travail.
Mettez à l'échelle le nouvel ensemble de machines de calcul. Pour plus d'informations sur la mise à l'échelle manuelle des jeux de machines de calcul, voir Scaling a compute machine set manually.
OpenShift Container Platform déplace les pods vers un travailleur disponible lorsque l'ancienne machine est supprimée.
- Réduire la taille de l'ancien ensemble de machines de calcul.
Supprimez l'ancien jeu de machines de calcul en exécutant la commande suivante :
oc delete machineset <machineset-name>
4.2.2. Migration des nœuds du plan de contrôle vers un domaine de stockage différent sur RHV
OpenShift Container Platform ne gère pas les nœuds de plan de contrôle, ils sont donc plus faciles à migrer que les nœuds de calcul. Vous pouvez les migrer comme n'importe quelle autre machine virtuelle sur Red Hat Virtualization (RHV).
Effectuez cette procédure pour chaque nœud séparément.
Conditions préalables
- Vous êtes connecté au Manager.
- Vous avez identifié les nœuds du plan de contrôle. Ils sont étiquetés master dans le gestionnaire.
Procédure
- Sélectionnez la machine virtuelle intitulée master.
- Arrêtez la machine virtuelle.
- Cliquez sur l'onglet Disks.
- Cliquez sur le disque de la machine virtuelle.
-
Cliquez sur More Actions
 et sélectionnez Move.
et sélectionnez Move.
- Sélectionnez le domaine de stockage cible et attendez la fin du processus de migration.
- Démarrer la machine virtuelle.
Vérifiez que le cluster OpenShift Container Platform est stable :
$ oc get nodes
La sortie doit afficher le nœud avec le statut
Ready.- Répétez cette procédure pour chaque nœud du plan de contrôle.
Chapitre 5. Suppression d'une machine
Vous pouvez supprimer une machine spécifique.
5.1. Suppression d'une machine spécifique
Vous pouvez supprimer une machine spécifique.
Ne supprimez pas une machine du plan de contrôle à moins que votre cluster n'utilise un jeu de machines du plan de contrôle.
Conditions préalables
- Installer un cluster OpenShift Container Platform.
-
Installez le CLI OpenShift (
oc). -
Connectez-vous à
ocen tant qu'utilisateur disposant de l'autorisationcluster-admin.
Procédure
Affichez les machines qui se trouvent dans le cluster en exécutant la commande suivante :
$ oc get machine -n openshift-machine-api
La sortie de la commande contient une liste de machines au format
<clusterid>-<role>-<cloud_region>.- Identifiez la machine que vous souhaitez supprimer.
Supprimez la machine en exécutant la commande suivante :
$ oc delete machine <machine> -n openshift-machine-api
ImportantPar défaut, le contrôleur de machine tente de drainer le nœud soutenu par la machine jusqu'à ce qu'il y parvienne. Dans certaines situations, comme dans le cas d'un budget de perturbation de pods mal configuré, l'opération de vidange peut ne pas aboutir. Si l'opération de vidange échoue, le contrôleur de machine ne peut pas procéder au retrait de la machine.
Vous pouvez éviter de vider le nœud en annotant
machine.openshift.io/exclude-node-drainingdans une machine spécifique.Si la machine que vous supprimez appartient à un ensemble de machines, une nouvelle machine est immédiatement créée pour satisfaire le nombre de répliques spécifié.
5.2. Crochets de cycle de vie pour la phase de suppression de la machine
Les crochets du cycle de vie d'une machine sont des points du cycle de vie de réconciliation d'une machine où le processus normal du cycle de vie peut être interrompu. Dans la phase de la machine Deleting, ces interruptions permettent aux composants de modifier le processus de suppression de la machine.
5.2.1. Terminologie et définitions
Pour comprendre le comportement des crochets de cycle de vie pour la phase de suppression de la machine, vous devez comprendre les concepts suivants :
- Rapprochement
- La réconciliation est le processus par lequel un contrôleur tente de faire correspondre l'état réel du cluster et des objets qu'il comprend aux exigences d'une spécification d'objet.
- Contrôleur de machine
Le contrôleur de machine gère le cycle de vie de réconciliation d'une machine. Pour les machines sur des plateformes cloud, le contrôleur de machine est la combinaison d'un contrôleur OpenShift Container Platform et d'un actionneur spécifique à la plateforme du fournisseur cloud.
Dans le cadre de la suppression d'une machine, le contrôleur de machine effectue les actions suivantes :
- Drainer le nœud qui est soutenu par la machine.
- Supprimer l'instance de machine du fournisseur de services en nuage.
-
Supprimer l'objet
Node.
- Crochet de cycle de vie
Un point défini dans le cycle de vie de réconciliation d'un objet où le processus normal du cycle de vie peut être interrompu. Les composants peuvent utiliser un crochet de cycle de vie pour injecter des changements dans le processus afin d'obtenir un résultat souhaité.
Il y a deux crochets de cycle de vie dans la phase de la machine
Deleting:
-
preDraindoivent être résolus avant que le nœud soutenu par la machine puisse être vidé. -
preTerminatedoivent être résolus avant que l'instance puisse être retirée du fournisseur d'infrastructure.
- Contrôleur de mise en œuvre des crochets
Un contrôleur, autre que le contrôleur de la machine, qui peut interagir avec un crochet de cycle de vie. Un contrôleur qui met en œuvre un crochet peut effectuer une ou plusieurs des actions suivantes :
- Ajouter un crochet de cycle de vie.
- Répondre à un crochet du cycle de vie.
- Supprimer un crochet de cycle de vie.
Chaque crochet du cycle de vie a un seul contrôleur qui met en œuvre le crochet, mais un contrôleur qui met en œuvre le crochet peut gérer un ou plusieurs crochets.
5.2.2. Ordre de traitement de l'effacement des machines
Dans OpenShift Container Platform 4.12, il y a deux crochets de cycle de vie pour la phase de suppression de la machine : preDrain et preTerminate. Lorsque tous les crochets pour un point de cycle de vie donné sont supprimés, la réconciliation se poursuit normalement.
Figure 5.1. Flux de suppression des machines
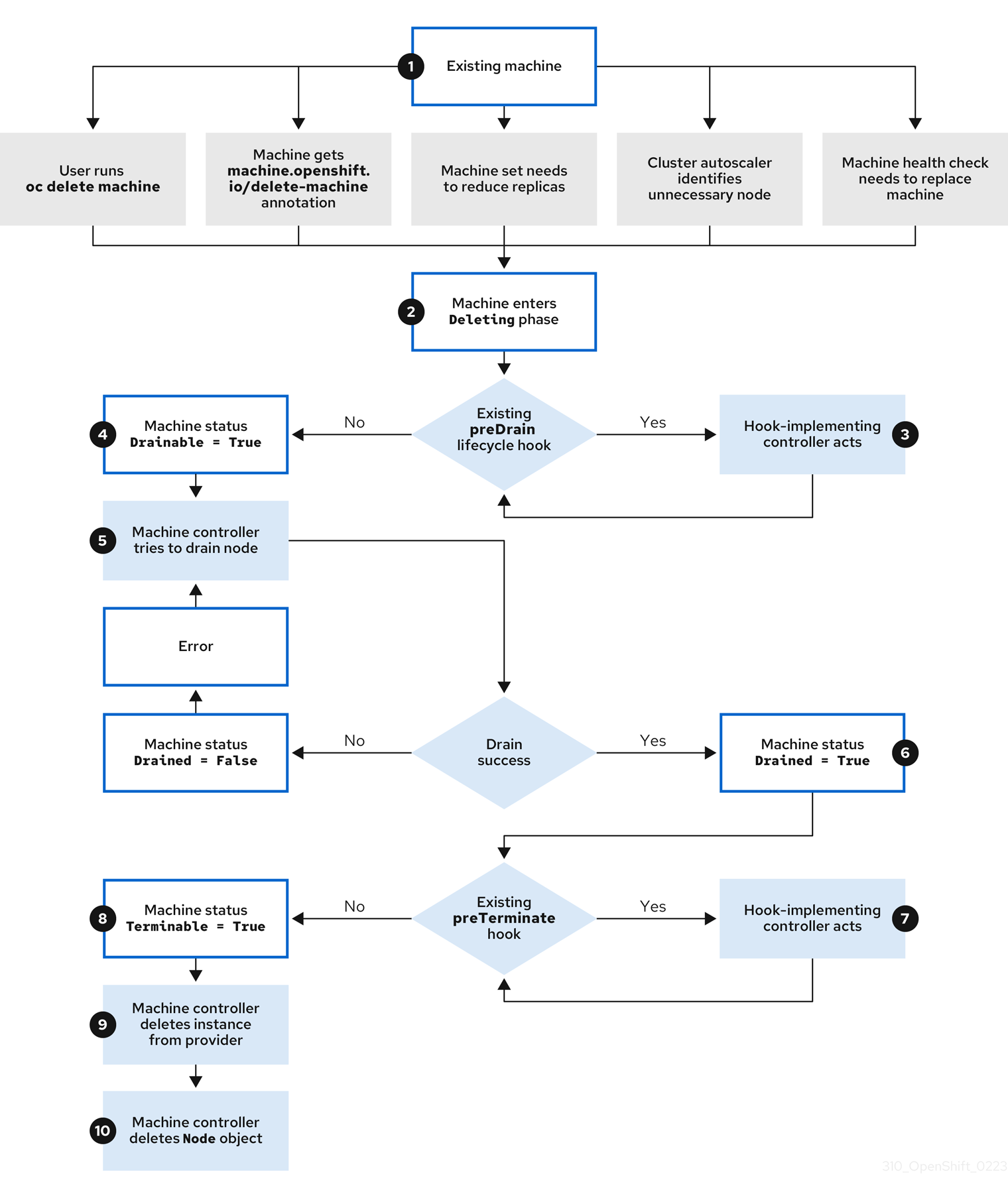
La phase de la machine Deleting se déroule dans l'ordre suivant :
Une machine existante est destinée à être supprimée pour l'une des raisons suivantes :
-
Un utilisateur disposant des autorisations
cluster-adminutilise la commandeoc delete machine. -
La machine reçoit une annotation
machine.openshift.io/delete-machine. - L'ensemble de machines qui gère la machine la marque pour suppression afin de réduire le nombre de répliques dans le cadre de la réconciliation.
- L'autoscaler de cluster identifie un nœud qui n'est pas nécessaire pour répondre aux besoins de déploiement du cluster.
- Un contrôle de l'état d'une machine est configuré pour remplacer une machine qui n'est pas en bon état.
-
Un utilisateur disposant des autorisations
-
La machine entre dans la phase
Deleting, au cours de laquelle elle est marquée pour suppression mais reste présente dans l'API. S'il existe un crochet de cycle de vie
preDrain, le contrôleur qui le gère effectue l'action spécifiée.Jusqu'à ce que tous les crochets du cycle de vie
preDrainsoient satisfaits, la condition d'état de la machineDrainableest fixée àFalse.-
Il n'y a pas de crochets de cycle de vie
preDrainnon résolus et la condition d'état de la machineDrainableest réglée surTrue. Le contrôleur de machine tente de drainer le nœud qui est soutenu par la machine.
-
Si la vidange échoue,
Drainedest défini surFalseet le contrôleur de machine tente de vidanger à nouveau le nœud. -
Si la vidange réussit,
DraineddevientTrue.
-
Si la vidange échoue,
-
La condition d'état de la machine
Drainedest réglée surTrue. S'il existe un crochet de cycle de vie
preTerminate, le contrôleur qui le gère effectue l'action spécifiée.Jusqu'à ce que tous les crochets du cycle de vie
preTerminatesoient satisfaits, la condition d'état de la machineTerminableest fixée àFalse.-
Il n'y a pas de crochets de cycle de vie
preTerminatenon résolus et la condition d'état de la machineTerminableest réglée surTrue. - Le contrôleur de machine supprime l'instance du fournisseur d'infrastructure.
-
Le contrôleur de machine supprime l'objet
Node.
5.2.3. Configuration du crochet du cycle de vie de la suppression
Les extraits YAML suivants illustrent le format et l'emplacement des configurations de crochets de cycle de vie de suppression dans un jeu de machines :
Extrait YAML d'un crochet de cycle de vie preDrain
apiVersion: machine.openshift.io/v1beta1
kind: Machine
metadata:
...
spec:
lifecycleHooks:
preDrain:
- name: <hook-name> 1
owner: <hook-owner> 2
...
Extrait YAML d'un crochet de cycle de vie preTerminate
apiVersion: machine.openshift.io/v1beta1
kind: Machine
metadata:
...
spec:
lifecycleHooks:
preTerminate:
- name: <hook-name> 1
owner: <hook-owner> 2
...
Exemple de configuration d'un crochet de cycle de vie
L'exemple suivant montre la mise en œuvre de plusieurs crochets de cycle de vie fictifs qui interrompent le processus de suppression de la machine :
Exemple de configuration pour les crochets de cycle de vie
apiVersion: machine.openshift.io/v1beta1
kind: Machine
metadata:
...
spec:
lifecycleHooks:
preDrain: 1
- name: MigrateImportantApp
owner: my-app-migration-controller
preTerminate: 2
- name: BackupFileSystem
owner: my-backup-controller
- name: CloudProviderSpecialCase
owner: my-custom-storage-detach-controller 3
- name: WaitForStorageDetach
owner: my-custom-storage-detach-controller
...
- 1
- Une strophe de crochet de cycle de vie
preDrainqui contient un seul crochet de cycle de vie. - 2
- Une strophe de crochet de cycle de vie
preTerminatequi contient trois crochets de cycle de vie. - 3
- Un contrôleur de mise en œuvre de crochets qui gère deux crochets de cycle de vie
preTerminate:CloudProviderSpecialCaseetWaitForStorageDetach.
5.2.4. Exemples de crochets de cycle de vie de suppression de machine pour les développeurs d'opérateurs
Les opérateurs peuvent utiliser les crochets de cycle de vie pour la phase de suppression des machines afin de modifier le processus de suppression des machines. Les exemples suivants montrent comment un opérateur peut utiliser cette fonctionnalité :
Exemples de cas d'utilisation de preDrain lifecycle hooks
- Remplacer les machines de manière proactive
-
Un opérateur peut utiliser un crochet de cycle de vie
preDrainpour s'assurer qu'une machine de remplacement est créée et jointe avec succès au cluster avant de supprimer l'instance d'une machine supprimée. Cela peut atténuer l'impact des perturbations pendant le remplacement de la machine ou des instances de remplacement qui ne s'initialisent pas rapidement. - Mise en œuvre d'une logique de vidange personnalisée
Un opérateur peut utiliser un crochet de cycle de vie
preDrainpour remplacer la logique de vidange du contrôleur de machine par un contrôleur de vidange différent. En remplaçant la logique de vidange, l'opérateur aura plus de flexibilité et de contrôle sur le cycle de vie des charges de travail sur chaque nœud.Par exemple, les bibliothèques de vidange du contrôleur de machine ne prennent pas en charge la commande, mais un fournisseur de vidange personnalisé pourrait fournir cette fonctionnalité. En utilisant un fournisseur de vidange personnalisé, un opérateur peut donner la priorité au déplacement des applications critiques avant de vidanger le nœud afin de minimiser les interruptions de service dans les cas où la capacité du cluster est limitée.
Exemples de cas d'utilisation de preTerminate lifecycle hooks
- Vérification du détachement du stockage
-
Un opérateur peut utiliser un crochet de cycle de vie
preTerminatepour s'assurer que le stockage attaché à une machine est détaché avant que la machine ne soit retirée du fournisseur d'infrastructure. - Améliorer la fiabilité des journaux
Après la vidange d'un nœud, le démon de l'exportateur de journaux a besoin d'un certain temps pour synchroniser les journaux avec le système de journalisation centralisé.
Un opérateur de journalisation peut utiliser un crochet de cycle de vie
preTerminatepour ajouter un délai entre la vidange du nœud et la suppression de la machine du fournisseur d'infrastructure. Ce délai donne à l'opérateur le temps de s'assurer que les principales charges de travail sont supprimées et qu'elles n'alimentent plus l'historique des journaux. Lorsqu'aucune nouvelle donnée n'est ajoutée à l'historique des journaux, l'exportateur de journaux peut rattraper le processus de synchronisation, garantissant ainsi que tous les journaux d'application sont capturés.
5.2.5. Protection du quorum à l'aide de crochets de cycle de vie de la machine
Pour les clusters OpenShift Container Platform qui utilisent l'opérateur API Machine, l'opérateur etcd utilise des crochets de cycle de vie pour la phase de suppression de la machine afin de mettre en œuvre un mécanisme de protection du quorum.
En utilisant un crochet de cycle de vie preDrain, l'opérateur etcd peut contrôler quand les pods sur une machine de plan de contrôle sont vidés et supprimés. Pour protéger le quorum etcd, l'opérateur etcd empêche la suppression d'un membre etcd jusqu'à ce qu'il migre ce membre sur un nouveau nœud dans le cluster.
Ce mécanisme permet à l'opérateur etcd de contrôler précisément les membres du quorum etcd et à l'opérateur Machine API de créer et de supprimer en toute sécurité des machines du plan de contrôle sans connaissance opérationnelle spécifique du cluster etcd.
5.2.5.1. Suppression du plan de contrôle avec ordre de traitement de la protection du quorum
Lorsqu'une machine de plan de contrôle est remplacée dans une grappe qui utilise un ensemble de machines de plan de contrôle, la grappe a temporairement quatre machines de plan de contrôle. Lorsque le quatrième nœud de plan de contrôle rejoint la grappe, l'opérateur etcd démarre un nouveau membre etcd sur le nœud de remplacement. Lorsque l'opérateur etcd observe que l'ancienne machine de plan de contrôle est marquée pour suppression, il arrête le membre etcd sur l'ancien nœud et promeut le membre etcd de remplacement pour qu'il rejoigne le quorum de la grappe.
La phase de la machine du plan de contrôle Deleting se déroule dans l'ordre suivant :
- Une machine du plan de contrôle doit être supprimée.
-
La machine du plan de contrôle entre dans la phase
Deleting. Pour satisfaire le crochet de cycle de vie
preDrain, l'opérateur etcd entreprend les actions suivantes :-
L'opérateur etcd attend qu'une quatrième machine de plan de contrôle soit ajoutée au cluster en tant que membre etcd. Ce nouveau membre etcd a l'état
Runningmais pasreadyjusqu'à ce qu'il reçoive la mise à jour complète de la base de données de la part du leader etcd. - Lorsque le nouveau membre etcd reçoit la mise à jour complète de la base de données, l'opérateur etcd promeut le nouveau membre etcd en tant que membre votant et supprime l'ancien membre etcd du cluster.
Une fois cette transition terminée, l'ancien pod etcd et ses données peuvent être supprimés en toute sécurité, et le crochet de cycle de vie
preDrainest donc supprimé.-
L'opérateur etcd attend qu'une quatrième machine de plan de contrôle soit ajoutée au cluster en tant que membre etcd. Ce nouveau membre etcd a l'état
-
La condition d'état de la machine du plan de contrôle
Drainableest réglée surTrue. Le contrôleur de machine tente de drainer le nœud qui est soutenu par la machine du plan de contrôle.
-
Si la vidange échoue,
Drainedest défini surFalseet le contrôleur de machine tente de vidanger à nouveau le nœud. -
Si la vidange réussit,
DraineddevientTrue.
-
Si la vidange échoue,
-
La condition d'état de la machine du plan de contrôle
Drainedest réglée surTrue. -
Si aucun autre opérateur n'a ajouté un crochet de cycle de vie
preTerminate, la condition d'état de la machine du plan de contrôleTerminabledevientTrue. - Le contrôleur de machine supprime l'instance du fournisseur d'infrastructure.
-
Le contrôleur de machine supprime l'objet
Node.
Extrait YAML démontrant la protection du quorum etcd preDrain lifecycle hook
apiVersion: machine.openshift.io/v1beta1
kind: Machine
metadata:
...
spec:
lifecycleHooks:
preDrain:
- name: EtcdQuorumOperator 1
owner: clusteroperator/etcd 2
...
5.3. Ressources complémentaires
Chapitre 6. Appliquer l'autoscaling à un cluster OpenShift Container Platform
L'application de l'autoscaling à un cluster OpenShift Container Platform implique le déploiement d'un autoscaler de cluster, puis le déploiement d'autoscalers de machine pour chaque type de machine dans votre cluster.
Vous ne pouvez configurer l'autoscaler de cluster que dans les clusters où l'API machine est opérationnelle.
6.1. À propos de l'autoscaler de cluster
L'autoscaler de cluster ajuste la taille d'un cluster OpenShift Container Platform pour répondre à ses besoins de déploiement actuels. Il utilise des arguments déclaratifs, de type Kubernetes, pour fournir une gestion de l'infrastructure qui ne repose pas sur des objets d'un fournisseur de cloud spécifique. L'autoscaler de cluster a une portée de cluster et n'est pas associé à un espace de noms particulier.
L'autoscaler de cluster augmente la taille du cluster lorsque des pods ne parviennent pas à être planifiés sur l'un des nœuds de travail actuels en raison de ressources insuffisantes ou lorsqu'un autre nœud est nécessaire pour répondre aux besoins de déploiement. L'autoscaler de cluster n'augmente pas les ressources du cluster au-delà des limites que vous avez spécifiées.
L'autoscaler de cluster calcule la mémoire totale, le CPU et le GPU sur tous les nœuds du cluster, même s'il ne gère pas les nœuds du plan de contrôle. Ces valeurs ne sont pas axées sur une seule machine. Il s'agit d'une agrégation de toutes les ressources de l'ensemble de la grappe. Par exemple, si vous définissez la limite maximale des ressources mémoire, l'autoscaler de la grappe inclut tous les nœuds de la grappe lors du calcul de l'utilisation actuelle de la mémoire. Ce calcul est ensuite utilisé pour déterminer si l'autoscaler de cluster a la capacité d'ajouter des ressources de travailleur supplémentaires.
Assurez-vous que la valeur maxNodesTotal dans la définition de la ressource ClusterAutoscaler que vous créez est suffisamment grande pour tenir compte du nombre total possible de machines dans votre cluster. Cette valeur doit englober le nombre de machines du plan de contrôle et le nombre possible de machines de calcul vers lesquelles vous pourriez évoluer.
Toutes les 10 secondes, l'autoscaler de cluster vérifie quels sont les nœuds inutiles dans le cluster et les supprime. L'autoscaler de cluster considère qu'un nœud doit être supprimé si les conditions suivantes sont remplies :
-
L'utilisation du nœud est inférieure au seuil node utilization level pour la grappe. Le niveau d'utilisation du nœud est la somme des ressources demandées divisée par les ressources allouées au nœud. Si vous ne spécifiez pas de valeur dans la ressource personnalisée
ClusterAutoscaler, l'autoscaler de cluster utilise une valeur par défaut de0.5, ce qui correspond à une utilisation de 50 %. - L'autoscaler de cluster peut déplacer tous les pods en cours d'exécution sur le nœud vers les autres nœuds. Le planificateur Kubernetes est responsable de la planification des pods sur les nœuds.
- L'autoscaler de cluster n'a pas d'annotation de réduction d'échelle désactivée.
Si les types de pods suivants sont présents sur un nœud, l'autoscaler de cluster ne supprimera pas le nœud :
- Les pods dont les budgets de perturbation des pods (PDB) sont restrictifs.
- Les pods du système Kube qui ne s'exécutent pas par défaut sur le nœud.
- Les pods du système Kube qui n'ont pas de PDB ou qui ont un PDB trop restrictif.
- Pods qui ne sont pas soutenus par un objet contrôleur tel qu'un déploiement, un ensemble de répliques ou un ensemble avec état.
- Pods avec stockage local.
- Pods qui ne peuvent pas être déplacés ailleurs en raison d'un manque de ressources, de sélecteurs de nœuds ou d'affinités incompatibles, d'anti-affinités correspondantes, etc.
-
À moins qu'ils n'aient également une annotation
"cluster-autoscaler.kubernetes.io/safe-to-evict": "true", les pods qui ont une annotation"cluster-autoscaler.kubernetes.io/safe-to-evict": "false".
Par exemple, vous fixez la limite maximale de l'unité centrale à 64 cœurs et configurez l'autoscaler de cluster pour qu'il ne crée que des machines dotées de 8 cœurs chacune. Si votre cluster commence avec 30 cœurs, l'autoscaler de cluster peut ajouter jusqu'à 4 nœuds supplémentaires avec 32 cœurs, pour un total de 62.
Si vous configurez l'autoscaler de cluster, des restrictions d'utilisation supplémentaires s'appliquent :
- Ne modifiez pas directement les nœuds faisant partie de groupes de nœuds à mise à l'échelle automatique. Tous les nœuds d'un même groupe de nœuds ont la même capacité et les mêmes étiquettes et exécutent les mêmes pods système.
- Spécifiez les requêtes pour vos pods.
- Si vous devez éviter que des pods soient supprimés trop rapidement, configurez des PDB appropriés.
- Confirmez que le quota de votre fournisseur de cloud est suffisamment important pour prendre en charge les pools de nœuds maximums que vous configurez.
- N'exécutez pas d'autoscalers de groupes de nœuds supplémentaires, en particulier ceux proposés par votre fournisseur de cloud.
L'autoscaler de pods horizontaux (HPA) et l'autoscaler de clusters modifient les ressources du cluster de différentes manières. Le HPA modifie le nombre de répliques du déploiement ou de l'ensemble de répliques en fonction de la charge CPU actuelle. Si la charge augmente, le HPA crée de nouvelles répliques, quelle que soit la quantité de ressources disponibles pour la grappe. S'il n'y a pas assez de ressources, l'autoscaler du cluster ajoute des ressources pour que les pods créés par l'HPA puissent fonctionner. Si la charge diminue, l'APH arrête certaines répliques. Si cette action entraîne une sous-utilisation ou un vide complet de certains nœuds, l'autoscaler de cluster supprime les nœuds inutiles.
L'autoscaler de cluster prend en compte les priorités des pods. La fonction de priorité et de préemption des pods permet de planifier les pods en fonction des priorités si le cluster ne dispose pas de suffisamment de ressources, mais l'autoscaler de cluster garantit que le cluster dispose des ressources nécessaires pour faire fonctionner tous les pods. Pour respecter l'intention des deux fonctionnalités, l'autoscaler de cluster inclut une fonction de coupure de priorité. Vous pouvez utiliser cette coupure pour planifier les pods "best-effort", qui n'entraînent pas l'augmentation des ressources par l'autoscaler de cluster, mais qui s'exécutent uniquement lorsque des ressources sont disponibles.
Les modules dont la priorité est inférieure à la valeur limite n'entraînent pas l'augmentation de la taille du cluster et n'empêchent pas la réduction de la taille du cluster. Aucun nouveau nœud n'est ajouté pour exécuter les pods, et les nœuds exécutant ces pods peuvent être supprimés pour libérer des ressources.
La mise à l'échelle automatique du cluster est prise en charge pour les plates-formes qui disposent d'une API machine.
6.2. Configuration de l'autoscaler de cluster
Tout d'abord, déployez le cluster autoscaler pour gérer la mise à l'échelle automatique des ressources dans votre cluster OpenShift Container Platform.
Étant donné que l'autoscaler de cluster s'applique à l'ensemble du cluster, vous ne pouvez créer qu'un seul autoscaler de cluster pour le cluster.
6.2.1. Définition de la ressource ClusterAutoscaler
Cette définition de ressource ClusterAutoscaler montre les paramètres et les valeurs d'exemple pour l'autoscaler de cluster.
apiVersion: "autoscaling.openshift.io/v1" kind: "ClusterAutoscaler" metadata: name: "default" spec: podPriorityThreshold: -10 1 resourceLimits: maxNodesTotal: 24 2 cores: min: 8 3 max: 128 4 memory: min: 4 5 max: 256 6 gpus: - type: nvidia.com/gpu 7 min: 0 8 max: 16 9 - type: amd.com/gpu min: 0 max: 4 logVerbosity: 4 10 scaleDown: 11 enabled: true 12 delayAfterAdd: 10m 13 delayAfterDelete: 5m 14 delayAfterFailure: 30s 15 unneededTime: 5m 16 utilizationThreshold: "0.4" 17
- 1
- Spécifiez la priorité qu'un pod doit dépasser pour que l'autoscaler de cluster déploie des nœuds supplémentaires. Entrez une valeur entière de 32 bits. La valeur
podPriorityThresholdest comparée à la valeurPriorityClassque vous attribuez à chaque module. - 2
- Indiquez le nombre maximal de nœuds à déployer. Cette valeur correspond au nombre total de machines déployées dans votre cluster, et pas seulement à celles que l'autoscaler contrôle. Veillez à ce que cette valeur soit suffisamment importante pour prendre en compte toutes les machines de calcul et du plan de contrôle, ainsi que le nombre total de répliques spécifié dans les ressources
MachineAutoscaler. - 3
- Spécifiez le nombre minimum de cœurs à déployer dans le cluster.
- 4
- Spécifiez le nombre maximum de cœurs à déployer dans le cluster.
- 5
- Spécifiez la quantité minimale de mémoire, en GiB, dans le cluster.
- 6
- Spécifiez la quantité maximale de mémoire, en GiB, dans le cluster.
- 7
- Facultatif : Spécifiez le type de nœud GPU à déployer. Seuls
nvidia.com/gpuetamd.com/gpusont des types valides. - 8
- Spécifiez le nombre minimum de GPU à déployer dans le cluster.
- 9
- Spécifiez le nombre maximum de GPU à déployer dans le cluster.
- 10
- Spécifiez le niveau de verbosité de la journalisation entre
0et10. Les seuils de niveau de journalisation suivants sont fournis à titre indicatif :-
1(par défaut) Informations de base sur les modifications. -
4: Verbosité au niveau du débogage pour résoudre les problèmes typiques. -
9: Informations de débogage étendues au niveau du protocole.
Si vous ne spécifiez pas de valeur, la valeur par défaut de
1est utilisée. -
- 11
- Dans cette section, vous pouvez spécifier la période d'attente pour chaque action en utilisant n'importe quel intervalle ParseDuration valide, y compris
ns,us,ms,s,m, eth. - 12
- Indiquez si l'autoscaler de cluster peut supprimer les nœuds inutiles.
- 13
- Facultatif : Spécifiez le délai d'attente avant la suppression d'un nœud après qu'un nœud ait été récemment added. Si vous ne spécifiez pas de valeur, la valeur par défaut de
10mest utilisée. - 14
- Facultatif : Spécifiez le délai d'attente avant la suppression d'un nœud après qu'un nœud ait été récemment deleted. Si vous ne spécifiez pas de valeur, la valeur par défaut de
0sest utilisée. - 15
- Facultatif : Indiquez le délai d'attente avant la suppression d'un nœud après un échec de mise à l'échelle. Si vous n'indiquez pas de valeur, la valeur par défaut de
3mest utilisée. - 16
- Facultatif : Spécifiez la période avant qu'un nœud inutile ne soit éligible à la suppression. Si vous ne spécifiez pas de valeur, la valeur par défaut de
10mest utilisée.<17> Facultatif : Indiquez l'adresse node utilization level en dessous de laquelle un nœud inutile peut être supprimé. Le niveau d'utilisation du nœud correspond à la somme des ressources demandées divisée par les ressources allouées au nœud et doit être supérieur à"0"et inférieur à"1". Si vous n'indiquez pas de valeur, l'autoscaler de cluster utilise la valeur par défaut"0.5", qui correspond à une utilisation de 50 %. Cette valeur doit être exprimée sous la forme d'une chaîne de caractères.
Lors d'une opération de mise à l'échelle, l'autoscaler de cluster reste dans les plages définies dans la définition de la ressource ClusterAutoscaler, comme le nombre minimum et maximum de cœurs à déployer ou la quantité de mémoire dans le cluster. Cependant, l'autoscaler de cluster ne corrige pas les valeurs actuelles de votre cluster pour qu'elles soient comprises dans ces plages.
Les valeurs minimales et maximales des CPU, de la mémoire et des GPU sont déterminées en calculant ces ressources sur tous les nœuds de la grappe, même si l'autoscaler de grappe ne gère pas les nœuds. Par exemple, les nœuds du plan de contrôle sont pris en compte dans la mémoire totale de la grappe, même si l'autoscaler de la grappe ne gère pas les nœuds du plan de contrôle.
6.2.2. Déploiement du cluster autoscaler
Pour déployer le cluster autoscaler, vous créez une instance de la ressource ClusterAutoscaler.
Procédure
-
Créer un fichier YAML pour la ressource
ClusterAutoscalerqui contient la définition de la ressource personnalisée. Créer la ressource dans le cluster :
$ oc create -f <filename>.yaml 1- 1
<filename>est le nom du fichier de ressources que vous avez personnalisé.
6.3. Prochaines étapes
- Après avoir configuré l'autoscaler de cluster, vous devez configurer au moins un autoscaler de machine.
6.4. À propos de l'autoscaler de la machine
L'autoscaler de machines ajuste le nombre de machines dans les ensembles de machines de calcul que vous déployez dans un cluster OpenShift Container Platform. Vous pouvez mettre à l'échelle à la fois l'ensemble de machines de calcul par défaut worker et tout autre ensemble de machines de calcul que vous créez. L'autoscaler de machines crée plus de machines lorsque le cluster manque de ressources pour prendre en charge plus de déploiements. Toute modification des valeurs dans les ressources MachineAutoscaler, telles que le nombre minimum ou maximum d'instances, est immédiatement appliquée à l'ensemble de machines de calcul qu'elle cible.
Vous devez déployer un autoscaler de machines pour que l'autoscaler de clusters puisse mettre à l'échelle vos machines. L'autoscaler de cluster utilise les annotations sur les ensembles de machines de calcul que l'autoscaler de machine définit pour déterminer les ressources qu'il peut mettre à l'échelle. Si vous définissez un autoscaler de cluster sans définir également des autoscalers de machines, l'autoscaler de cluster ne mettra jamais votre cluster à l'échelle.
6.5. Configuration des autoscalers de la machine
Après avoir déployé l'autoscaler de cluster, déployez les ressources MachineAutoscaler qui référencent les ensembles de machines de calcul utilisés pour la mise à l'échelle du cluster.
Vous devez déployer au moins une ressource MachineAutoscaler après avoir déployé la ressource ClusterAutoscaler.
Vous devez configurer des ressources distinctes pour chaque ensemble de machines de calcul. N'oubliez pas que les ensembles de machines de calcul sont différents dans chaque région, alors réfléchissez à la possibilité d'activer la mise à l'échelle des machines dans plusieurs régions. L'ensemble de machines de calcul que vous mettez à l'échelle doit contenir au moins une machine.
6.5.1. Définition de la ressource MachineAutoscaler
Cette définition de la ressource MachineAutoscaler montre les paramètres et les valeurs d'exemple pour l'autoscaler de la machine.
apiVersion: "autoscaling.openshift.io/v1beta1" kind: "MachineAutoscaler" metadata: name: "worker-us-east-1a" 1 namespace: "openshift-machine-api" spec: minReplicas: 1 2 maxReplicas: 12 3 scaleTargetRef: 4 apiVersion: machine.openshift.io/v1beta1 kind: MachineSet 5 name: worker-us-east-1a 6
- 1
- Spécifiez le nom de l'autoscaler de machine. Pour faciliter l'identification de l'ensemble de machines de calcul que cet autoscaler de machine met à l'échelle, spécifiez ou incluez le nom de l'ensemble de machines de calcul à mettre à l'échelle. Le nom de l'ensemble de machines de calcul prend la forme suivante :
<clusterid>-<machineset>-<region>. - 2
- Indiquez le nombre minimum de machines du type spécifié qui doivent rester dans la zone spécifiée après que l'autoscaler de cluster a initié la mise à l'échelle du cluster. En cas d'exécution sur AWS, GCP, Azure, RHOSP ou vSphere, cette valeur peut être définie sur
0. Pour les autres fournisseurs, ne définissez pas cette valeur sur0.Vous pouvez réaliser des économies en définissant cette valeur sur
0pour des cas d'utilisation tels que l'exécution de matériel coûteux ou à usage limité utilisé pour des charges de travail spécialisées, ou en mettant à l'échelle un ensemble de machines de calcul avec des machines de très grande taille. L'autoscaler de cluster réduit l'ensemble de machines de calcul à zéro si les machines ne sont pas utilisées.ImportantNe définissez pas la valeur
spec.minReplicassur0pour les trois ensembles de machines de calcul qui sont créés pendant le processus d'installation d'OpenShift Container Platform pour une infrastructure provisionnée par l'installateur. - 3
- Indiquez le nombre maximum de machines du type spécifié que l'autoscaler de cluster peut déployer dans la zone spécifiée après avoir initié la mise à l'échelle du cluster. Assurez-vous que la valeur
maxNodesTotaldans la définition de la ressourceClusterAutoscalerest suffisamment grande pour permettre à l'autoscaler de machines de déployer ce nombre de machines. - 4
- Dans cette section, indiquez les valeurs qui décrivent l'ensemble des machines de calcul existantes à mettre à l'échelle.
- 5
- La valeur du paramètre
kindest toujoursMachineSet. - 6
- La valeur
namedoit correspondre au nom d'un ensemble de machines de calcul existant, comme indiqué dans la valeur du paramètremetadata.name.
6.5.2. Déploiement de la machine autoscaler
Pour déployer la machine autoscaler, vous créez une instance de la ressource MachineAutoscaler.
Procédure
-
Créer un fichier YAML pour la ressource
MachineAutoscalerqui contient la définition de la ressource personnalisée. Créer la ressource dans le cluster :
$ oc create -f <filename>.yaml 1- 1
<filename>est le nom du fichier de ressources que vous avez personnalisé.
6.6. Ressources complémentaires
- Pour plus d'informations sur la priorité des pods, voir Inclure la priorité des pods dans les décisions de planification des pods dans OpenShift Container Platform.
Chapitre 7. Création de jeux de machines d'infrastructure
Vous ne pouvez utiliser les fonctionnalités avancées de gestion et de mise à l'échelle des machines que dans les clusters où l'API Machine est opérationnelle. Les clusters dont l'infrastructure est fournie par l'utilisateur nécessitent une validation et une configuration supplémentaires pour utiliser l'API Machine.
Les clusters avec le type de plateforme d'infrastructure none ne peuvent pas utiliser l'API Machine. Cette limitation s'applique même si les machines de calcul attachées au cluster sont installées sur une plateforme qui prend en charge cette fonctionnalité. Ce paramètre ne peut pas être modifié après l'installation.
Pour afficher le type de plateforme de votre cluster, exécutez la commande suivante :
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'Vous pouvez utiliser les jeux de machines d'infrastructure pour créer des machines qui hébergent uniquement des composants d'infrastructure, tels que le routeur par défaut, le registre intégré d'images de conteneurs et les composants pour les métriques et la surveillance des clusters. Ces machines d'infrastructure ne sont pas comptabilisées dans le nombre total d'abonnements requis pour faire fonctionner l'environnement.
Dans un déploiement de production, il est recommandé de déployer au moins trois ensembles de machines pour contenir les composants de l'infrastructure. OpenShift Logging et Red Hat OpenShift Service Mesh déploient tous deux Elasticsearch, qui nécessite l'installation de trois instances sur différents nœuds. Chacun de ces nœuds peut être déployé dans différentes zones de disponibilité pour une haute disponibilité. Cette configuration nécessite trois ensembles de machines différents, un pour chaque zone de disponibilité. Dans les régions Azure globales qui ne disposent pas de plusieurs zones de disponibilité, vous pouvez utiliser des ensembles de machines pour garantir une haute disponibilité.
7.1. Composants de l'infrastructure OpenShift Container Platform
Les charges de travail d'infrastructure suivantes ne donnent pas lieu à des abonnements de travailleurs OpenShift Container Platform :
- Les services du plan de contrôle de Kubernetes et d'OpenShift Container Platform qui s'exécutent sur des maîtres
- Le routeur par défaut
- Le registre intégré des images de conteneurs
- Le contrôleur d'entrée basé sur HAProxy
- Le service de collecte ou de surveillance des données de la grappe, y compris les composants permettant de surveiller les projets définis par l'utilisateur
- Journalisation agrégée des clusters
- Courtiers en services
- Red Hat Quay
- Red Hat OpenShift Data Foundation
- Red Hat Advanced Cluster Manager
- Red Hat Advanced Cluster Security pour Kubernetes
- Red Hat OpenShift GitOps
- Red Hat OpenShift Pipelines
Tout nœud qui exécute un autre conteneur, pod ou composant est un nœud de travail que votre abonnement doit couvrir.
Pour plus d'informations sur les nœuds d'infrastructure et les composants qui peuvent être exécutés sur les nœuds d'infrastructure, consultez la section "Red Hat OpenShift control plane and infrastructure nodes" dans le document OpenShift sizing and subscription guide for enterprise Kubernetes (Guide de dimensionnement et d'abonnement pour Kubernetes d'entreprise ).
Pour créer un nœud d'infrastructure, vous pouvez utiliser un jeu de machines, étiqueter le nœud ou utiliser un pool de configuration de machines.
7.2. Création de jeux de machines d'infrastructure pour les environnements de production
Dans un déploiement de production, il est recommandé de déployer au moins trois ensembles de machines de calcul pour contenir les composants de l'infrastructure. OpenShift Logging et Red Hat OpenShift Service Mesh déploient tous deux Elasticsearch, qui nécessite l'installation de trois instances sur différents nœuds. Chacun de ces nœuds peut être déployé dans différentes zones de disponibilité pour une haute disponibilité. Une telle configuration nécessite trois ensembles de machines de calcul différents, un pour chaque zone de disponibilité. Dans les régions Azure globales qui ne disposent pas de plusieurs zones de disponibilité, vous pouvez utiliser des ensembles de machines de calcul pour garantir une haute disponibilité.
7.2.1. Création d'ensembles de machines d'infrastructure pour différents nuages
Utilisez l'exemple de machine de calcul pour votre nuage.
7.2.1.1. Exemple de YAML pour une machine de calcul définie comme ressource personnalisée sur Alibaba Cloud
Cet exemple YAML définit un ensemble de machines de calcul qui s'exécute dans une zone Alibaba Cloud spécifiée dans une région et crée des nœuds étiquetés avec node-role.kubernetes.io/infra: "".
Dans cet exemple, <infrastructure_id> est l'étiquette d'ID d'infrastructure basée sur l'ID de cluster que vous avez défini lors du provisionnement du cluster, et <infra> est l'étiquette de nœud à ajouter.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1
machine.openshift.io/cluster-api-machine-role: <infra> 2
machine.openshift.io/cluster-api-machine-type: <infra> 3
name: <infrastructure_id>-<infra>-<zone> 4
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 5
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<infra>-<zone> 6
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 7
machine.openshift.io/cluster-api-machine-role: <infra> 8
machine.openshift.io/cluster-api-machine-type: <infra> 9
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<infra>-<zone> 10
spec:
metadata:
labels:
node-role.kubernetes.io/infra: ""
providerSpec:
value:
apiVersion: machine.openshift.io/v1
credentialsSecret:
name: alibabacloud-credentials
imageId: <image_id> 11
instanceType: <instance_type> 12
kind: AlibabaCloudMachineProviderConfig
ramRoleName: <infrastructure_id>-role-worker 13
regionId: <region> 14
resourceGroup: 15
id: <resource_group_id>
type: ID
securityGroups:
- tags: 16
- Key: Name
Value: <infrastructure_id>-sg-<role>
type: Tags
systemDisk: 17
category: cloud_essd
size: <disk_size>
tag: 18
- Key: kubernetes.io/cluster/<infrastructure_id>
Value: owned
userDataSecret:
name: <user_data_secret> 19
vSwitch:
tags: 20
- Key: Name
Value: <infrastructure_id>-vswitch-<zone>
type: Tags
vpcId: ""
zoneId: <zone> 21
taints: 22
- key: node-role.kubernetes.io/infra
effect: NoSchedule- 1 5 7
- Spécifiez l'ID d'infrastructure qui est basé sur l'ID de cluster que vous avez défini lorsque vous avez provisionné le cluster. Si l'OpenShift CLI (
oc) est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 8 9
- Indiquez l'étiquette du nœud
<infra>. - 4 6 10
- Spécifiez l'ID de l'infrastructure, l'étiquette du nœud
<infra>et la zone. - 11
- Spécifiez l'image à utiliser. Utilisez une image provenant d'un jeu de machines de calcul par défaut existant pour le cluster.
- 12
- Spécifiez le type d'instance que vous souhaitez utiliser pour l'ensemble de machines de calcul.
- 13
- Spécifiez le nom du rôle RAM à utiliser pour le jeu de machines de calcul. Utilisez la valeur indiquée par le programme d'installation dans le jeu de machines de calcul par défaut.
- 14
- Spécifiez la région où placer les machines.
- 15
- Spécifiez le groupe et le type de ressources pour le cluster. Vous pouvez utiliser la valeur indiquée par le programme d'installation dans le jeu de machines de calcul par défaut ou en spécifier une autre.
- 16 18 20
- Spécifiez les balises à utiliser pour l'ensemble de machines de calcul. Au minimum, vous devez inclure les balises présentées dans cet exemple, avec les valeurs appropriées pour votre cluster. Vous pouvez inclure des balises supplémentaires, y compris les balises que le programme d'installation ajoute à l'ensemble de machines de calcul par défaut qu'il crée, si nécessaire.
- 17
- Spécifiez le type et la taille du disque racine. Utilisez la valeur
categoryque le programme d'installation renseigne dans le jeu de machines de calcul par défaut qu'il crée. Si nécessaire, indiquez une valeur différente en gigaoctets poursize. - 19
- Spécifiez le nom du secret dans le fichier YAML des données utilisateur qui se trouve dans l'espace de noms
openshift-machine-api. Utilisez la valeur indiquée par le programme d'installation dans le jeu de machines de calcul par défaut. - 21
- Indiquez la zone de votre région où placer les machines. Assurez-vous que votre région prend en charge la zone que vous spécifiez.
- 22
- Spécifiez une erreur pour empêcher les charges de travail utilisateur d'être planifiées sur les nœuds infra.
Paramètres définis par la machine pour les statistiques d'utilisation du nuage Alibaba
Les ensembles de machines de calcul par défaut que le programme d'installation crée pour les clusters Alibaba Cloud incluent des valeurs de balises non essentielles qu'Alibaba Cloud utilise en interne pour suivre les statistiques d'utilisation. Ces balises sont renseignées dans les paramètres securityGroups, tag, et vSwitch de la liste spec.template.spec.providerSpec.value.
Lorsque vous créez des ensembles de machines de calcul pour déployer des machines supplémentaires, vous devez inclure les balises Kubernetes requises. Les balises de statistiques d'utilisation sont appliquées par défaut, même si elles ne sont pas spécifiées dans les ensembles de machines de calcul que vous créez. Vous pouvez également inclure des balises supplémentaires si nécessaire.
Les extraits YAML suivants indiquent quelles balises des ensembles de machines de calcul par défaut sont facultatives et lesquelles sont obligatoires.
Tags dans spec.template.spec.providerSpec.value.securityGroups
spec:
template:
spec:
providerSpec:
value:
securityGroups:
- tags:
- Key: kubernetes.io/cluster/<infrastructure_id> 1
Value: owned
- Key: GISV
Value: ocp
- Key: sigs.k8s.io/cloud-provider-alibaba/origin 2
Value: ocp
- Key: Name
Value: <infrastructure_id>-sg-<role> 3
type: Tags
- 1 2
- Facultatif : Cette balise est appliquée même si elle n'est pas spécifiée dans le jeu de machines de calcul.
- 3
- Required.
où :
-
<infrastructure_id>est l'ID de l'infrastructure qui est basé sur l'ID du cluster que vous avez défini lorsque vous avez approvisionné le cluster. -
<role>est l'étiquette de nœud à ajouter.
-
Tags dans spec.template.spec.providerSpec.value.tag
spec:
template:
spec:
providerSpec:
value:
tag:
- Key: kubernetes.io/cluster/<infrastructure_id> 1
Value: owned
- Key: GISV 2
Value: ocp
- Key: sigs.k8s.io/cloud-provider-alibaba/origin 3
Value: ocp
Tags dans spec.template.spec.providerSpec.value.vSwitch
spec:
template:
spec:
providerSpec:
value:
vSwitch:
tags:
- Key: kubernetes.io/cluster/<infrastructure_id> 1
Value: owned
- Key: GISV 2
Value: ocp
- Key: sigs.k8s.io/cloud-provider-alibaba/origin 3
Value: ocp
- Key: Name
Value: <infrastructure_id>-vswitch-<zone> 4
type: Tags
- 1 2 3
- Facultatif : Cette balise est appliquée même si elle n'est pas spécifiée dans le jeu de machines de calcul.
- 4
- Required.
où :
-
<infrastructure_id>est l'ID de l'infrastructure qui est basé sur l'ID du cluster que vous avez défini lorsque vous avez approvisionné le cluster. -
<zone>est la zone de votre région où placer les machines.
-
7.2.1.2. Exemple de YAML pour une ressource personnalisée d'un ensemble de machines de calcul sur AWS
Cet exemple YAML définit un ensemble de machines de calcul qui fonctionne dans la zone us-east-1a Amazon Web Services (AWS) et crée des nœuds étiquetés avec node-role.kubernetes.io/infra: "".
Dans cet exemple, <infrastructure_id> est l'étiquette d'ID d'infrastructure basée sur l'ID de cluster que vous avez défini lors du provisionnement du cluster, et <infra> est l'étiquette de nœud à ajouter.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1
name: <infrastructure_id>-infra-<zone> 2
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 3
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra-<zone> 4
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 5
machine.openshift.io/cluster-api-machine-role: infra 6
machine.openshift.io/cluster-api-machine-type: infra 7
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra-<zone> 8
spec:
metadata:
labels:
node-role.kubernetes.io/infra: "" 9
providerSpec:
value:
ami:
id: ami-046fe691f52a953f9 10
apiVersion: awsproviderconfig.openshift.io/v1beta1
blockDevices:
- ebs:
iops: 0
volumeSize: 120
volumeType: gp2
credentialsSecret:
name: aws-cloud-credentials
deviceIndex: 0
iamInstanceProfile:
id: <infrastructure_id>-worker-profile 11
instanceType: m6i.large
kind: AWSMachineProviderConfig
placement:
availabilityZone: <zone> 12
region: <region> 13
securityGroups:
- filters:
- name: tag:Name
values:
- <infrastructure_id>-worker-sg 14
subnet:
filters:
- name: tag:Name
values:
- <infrastructure_id>-private-<zone> 15
tags:
- name: kubernetes.io/cluster/<infrastructure_id> 16
value: owned
- name: <custom_tag_name> 17
value: <custom_tag_value> 18
userDataSecret:
name: worker-user-data
taints: 19
- key: node-role.kubernetes.io/infra
effect: NoSchedule- 1 3 5 11 14 16
- Spécifiez l'ID d'infrastructure qui est basé sur l'ID de cluster que vous avez défini lorsque vous avez provisionné le cluster. Si le CLI OpenShift est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 4 8
- Spécifiez l'ID de l'infrastructure, l'étiquette du nœud de rôle
infraet la zone. - 6 7 9
- Indiquez l'étiquette du nœud de rôle
infra. - 10
- Spécifiez une image de machine Amazon (AMI) Red Hat Enterprise Linux CoreOS (RHCOS) valide pour votre zone AWS pour vos nœuds OpenShift Container Platform. Si vous souhaitez utiliser une image AWS Marketplace, vous devez compléter l'abonnement à OpenShift Container Platform depuis AWS Marketplace afin d'obtenir un identifiant AMI pour votre région.
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.ami.id}{"\n"}' \ get machineset/<infrastructure_id>-<role>-<zone> - 17 18
- Optionnel : Spécifiez des données de balises personnalisées pour votre cluster. Par exemple, vous pouvez ajouter une adresse électronique de contact pour l'administration en spécifiant une paire
name:valuedeEmail:admin-email@example.com.NoteDes balises personnalisées peuvent également être spécifiées lors de l'installation dans le fichier
install-config.yml. Si le fichierinstall-config.ymlet le jeu de machines comprennent une balise avec les mêmes donnéesname, la valeur de la balise du jeu de machines est prioritaire sur la valeur de la balise dans le fichierinstall-config.yml. - 12
- Spécifiez la zone, par exemple,
us-east-1a. - 13
- Précisez la région, par exemple
us-east-1. - 15
- Spécifiez l'ID de l'infrastructure et la zone.
- 19
- Spécifiez une erreur pour empêcher les charges de travail utilisateur d'être planifiées sur les nœuds infra.
Les ensembles de machines fonctionnant sur AWS prennent en charge les Instances Spot non garanties. Vous pouvez réaliser des économies en utilisant des Instances Spot à un prix inférieur à celui des Instances On-Demand sur AWS. Configurez les Instances Spot en ajoutant spotMarketOptions au fichier YAML MachineSet.
7.2.1.3. Exemple de YAML pour une ressource personnalisée d'un ensemble de machines de calcul sur Azure
Cet exemple YAML définit un ensemble de machines de calcul qui s'exécute dans la zone 1 Microsoft Azure d'une région et crée des nœuds étiquetés avec node-role.kubernetes.io/infra: "".
Dans cet exemple, <infrastructure_id> est l'étiquette d'ID d'infrastructure basée sur l'ID de cluster que vous avez défini lors du provisionnement du cluster, et <infra> est l'étiquette de nœud à ajouter.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1
machine.openshift.io/cluster-api-machine-role: <infra> 2
machine.openshift.io/cluster-api-machine-type: <infra> 3
name: <infrastructure_id>-infra-<region> 4
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 5
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra-<region> 6
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 7
machine.openshift.io/cluster-api-machine-role: <infra> 8
machine.openshift.io/cluster-api-machine-type: <infra> 9
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra-<region> 10
spec:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-machineset: <machineset_name> 11
node-role.kubernetes.io/infra: "" 12
providerSpec:
value:
apiVersion: azureproviderconfig.openshift.io/v1beta1
credentialsSecret:
name: azure-cloud-credentials
namespace: openshift-machine-api
image: 13
offer: ""
publisher: ""
resourceID: /resourceGroups/<infrastructure_id>-rg/providers/Microsoft.Compute/images/<infrastructure_id> 14
sku: ""
version: ""
internalLoadBalancer: ""
kind: AzureMachineProviderSpec
location: <region> 15
managedIdentity: <infrastructure_id>-identity 16
metadata:
creationTimestamp: null
natRule: null
networkResourceGroup: ""
osDisk:
diskSizeGB: 128
managedDisk:
storageAccountType: Premium_LRS
osType: Linux
publicIP: false
publicLoadBalancer: ""
resourceGroup: <infrastructure_id>-rg 17
sshPrivateKey: ""
sshPublicKey: ""
tags:
- name: <custom_tag_name> 18
value: <custom_tag_value> 19
subnet: <infrastructure_id>-<role>-subnet 20 21
userDataSecret:
name: worker-user-data 22
vmSize: Standard_D4s_v3
vnet: <infrastructure_id>-vnet 23
zone: "1" 24
taints: 25
- key: node-role.kubernetes.io/infra
effect: NoSchedule- 1 5 7 16 17 20 23
- Spécifiez l'ID d'infrastructure qui est basé sur l'ID de cluster que vous avez défini lorsque vous avez provisionné le cluster. Si le CLI OpenShift est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure clusterVous pouvez obtenir le sous-réseau en exécutant la commande suivante :
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.subnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1Vous pouvez obtenir le vnet en exécutant la commande suivante :
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.vnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1 - 2 3 8 9 12 21 22
- Indiquez l'étiquette du nœud
<infra>. - 4 6 10
- Spécifiez l'ID de l'infrastructure, l'étiquette du nœud
<infra>et la région. - 11
- Facultatif : Spécifiez le nom de l'ensemble de machines de calcul pour activer l'utilisation des ensembles de disponibilité. Ce paramètre ne s'applique qu'aux nouvelles machines de calcul.
- 13
- Spécifiez les détails de l'image pour votre ensemble de machines de calcul. Si vous souhaitez utiliser une image Azure Marketplace, voir "Sélection d'une image Azure Marketplace".
- 14
- Spécifiez une image compatible avec votre type d'instance. Les images Hyper-V de génération V2 créées par le programme d'installation ont un suffixe
-gen2, tandis que les images V1 portent le même nom sans suffixe. - 15
- Spécifiez la région où placer les machines.
- 24
- Indiquez la zone de votre région où placer les machines. Assurez-vous que votre région prend en charge la zone que vous spécifiez.
- 18 19
- Optionnel : Spécifiez des balises personnalisées dans votre jeu de machines. Indiquez le nom de la balise dans le champ
<custom_tag_name>et la valeur de la balise correspondante dans le champ<custom_tag_value>. - 25
- Spécifiez une erreur pour empêcher les charges de travail utilisateur d'être planifiées sur les nœuds infra.
Les ensembles de machines fonctionnant sur Azure prennent en charge les VM Spot non garanties. Vous pouvez réaliser des économies en utilisant des VM Spot à un prix inférieur à celui des VM standard sur Azure. Vous pouvez configurer les VM Spot en ajoutant spotVMOptions au fichier YAML MachineSet.
Ressources complémentaires
7.2.1.4. Exemple de YAML pour une ressource personnalisée d'un ensemble de machines de calcul sur Azure Stack Hub
Cet exemple YAML définit un ensemble de machines de calcul qui s'exécute dans la zone 1 Microsoft Azure d'une région et crée des nœuds étiquetés avec node-role.kubernetes.io/infra: "".
Dans cet exemple, <infrastructure_id> est l'étiquette d'ID d'infrastructure basée sur l'ID de cluster que vous avez défini lors du provisionnement du cluster, et <infra> est l'étiquette de nœud à ajouter.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1
machine.openshift.io/cluster-api-machine-role: <infra> 2
machine.openshift.io/cluster-api-machine-type: <infra> 3
name: <infrastructure_id>-infra-<region> 4
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 5
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra-<region> 6
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 7
machine.openshift.io/cluster-api-machine-role: <infra> 8
machine.openshift.io/cluster-api-machine-type: <infra> 9
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra-<region> 10
spec:
metadata:
creationTimestamp: null
labels:
node-role.kubernetes.io/infra: "" 11
taints: 12
- key: node-role.kubernetes.io/infra
effect: NoSchedule
providerSpec:
value:
apiVersion: machine.openshift.io/v1beta1
availabilitySet: <availability_set> 13
credentialsSecret:
name: azure-cloud-credentials
namespace: openshift-machine-api
image:
offer: ""
publisher: ""
resourceID: /resourceGroups/<infrastructure_id>-rg/providers/Microsoft.Compute/images/<infrastructure_id> 14
sku: ""
version: ""
internalLoadBalancer: ""
kind: AzureMachineProviderSpec
location: <region> 15
managedIdentity: <infrastructure_id>-identity 16
metadata:
creationTimestamp: null
natRule: null
networkResourceGroup: ""
osDisk:
diskSizeGB: 128
managedDisk:
storageAccountType: Premium_LRS
osType: Linux
publicIP: false
publicLoadBalancer: ""
resourceGroup: <infrastructure_id>-rg 17
sshPrivateKey: ""
sshPublicKey: ""
subnet: <infrastructure_id>-<role>-subnet 18 19
userDataSecret:
name: worker-user-data 20
vmSize: Standard_DS4_v2
vnet: <infrastructure_id>-vnet 21
zone: "1" 22- 1 5 7 14 16 17 18 21
- Spécifiez l'ID d'infrastructure qui est basé sur l'ID de cluster que vous avez défini lorsque vous avez provisionné le cluster. Si le CLI OpenShift est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure clusterVous pouvez obtenir le sous-réseau en exécutant la commande suivante :
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.subnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1Vous pouvez obtenir le vnet en exécutant la commande suivante :
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.vnet}{"\n"}' \ get machineset/<infrastructure_id>-worker-centralus1 - 2 3 8 9 11 19 20
- Indiquez l'étiquette du nœud
<infra>. - 4 6 10
- Spécifiez l'ID de l'infrastructure, l'étiquette du nœud
<infra>et la région. - 12
- Spécifiez une erreur pour empêcher les charges de travail utilisateur d'être planifiées sur les nœuds infra.
- 15
- Spécifiez la région où placer les machines.
- 13
- Spécifiez l'ensemble de disponibilité pour le cluster.
- 22
- Indiquez la zone de votre région où placer les machines. Assurez-vous que votre région prend en charge la zone que vous spécifiez.
Les ensembles de machines fonctionnant sur Azure Stack Hub ne prennent pas en charge les VM Spot non garanties.
7.2.1.5. Exemple de YAML pour une ressource personnalisée d'un ensemble de machines de calcul sur IBM Cloud
Cet exemple YAML définit un ensemble de machines de calcul qui s'exécute dans une zone IBM Cloud spécifiée dans une région et crée des nœuds étiquetés avec node-role.kubernetes.io/infra: "".
Dans cet exemple, <infrastructure_id> est l'étiquette d'ID d'infrastructure basée sur l'ID de cluster que vous avez défini lors du provisionnement du cluster, et <infra> est l'étiquette de nœud à ajouter.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1
machine.openshift.io/cluster-api-machine-role: <infra> 2
machine.openshift.io/cluster-api-machine-type: <infra> 3
name: <infrastructure_id>-<infra>-<region> 4
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 5
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<infra>-<region> 6
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 7
machine.openshift.io/cluster-api-machine-role: <infra> 8
machine.openshift.io/cluster-api-machine-type: <infra> 9
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<infra>-<region> 10
spec:
metadata:
labels:
node-role.kubernetes.io/infra: ""
providerSpec:
value:
apiVersion: ibmcloudproviderconfig.openshift.io/v1beta1
credentialsSecret:
name: ibmcloud-credentials
image: <infrastructure_id>-rhcos 11
kind: IBMCloudMachineProviderSpec
primaryNetworkInterface:
securityGroups:
- <infrastructure_id>-sg-cluster-wide
- <infrastructure_id>-sg-openshift-net
subnet: <infrastructure_id>-subnet-compute-<zone> 12
profile: <instance_profile> 13
region: <region> 14
resourceGroup: <resource_group> 15
userDataSecret:
name: <role>-user-data 16
vpc: <vpc_name> 17
zone: <zone> 18
taints: 19
- key: node-role.kubernetes.io/infra
effect: NoSchedule- 1 5 7
- L'ID de l'infrastructure qui est basé sur l'ID du cluster que vous avez défini lorsque vous avez provisionné le cluster. Si le CLI OpenShift est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 8 9 16
- L'étiquette du nœud
<infra>. - 4 6 10
- L'ID de l'infrastructure, l'étiquette du nœud
<infra>et la région. - 11
- L'image personnalisée de Red Hat Enterprise Linux CoreOS (RHCOS) qui a été utilisée pour l'installation du cluster.
- 12
- L'ID d'infrastructure et la zone de votre région où placer les machines. Assurez-vous que votre région prend en charge la zone que vous spécifiez.
- 13
- Spécifiez le profil de l'instance IBM Cloud.
- 14
- Spécifiez la région où placer les machines.
- 15
- Le groupe de ressources dans lequel les ressources de la machine sont placées. Il s'agit soit d'un groupe de ressources existant spécifié au moment de l'installation, soit d'un groupe de ressources créé par l'installateur et nommé en fonction de l'identifiant de l'infrastructure.
- 17
- Le nom du VPC.
- 18
- Indiquez la zone de votre région où placer les machines. Assurez-vous que votre région prend en charge la zone que vous spécifiez.
- 19
- L'altération pour empêcher les charges de travail des utilisateurs d'être programmées sur les nœuds infra.
7.2.1.6. Exemple de YAML pour une ressource personnalisée d'une machine de calcul sur GCP
Cet exemple YAML définit un ensemble de machines de calcul qui fonctionne dans Google Cloud Platform (GCP) et crée des nœuds étiquetés avec node-role.kubernetes.io/infra: "".
Dans cet exemple, <infrastructure_id> est l'étiquette d'ID d'infrastructure basée sur l'ID de cluster que vous avez défini lors du provisionnement du cluster, et <infra> est l'étiquette de nœud à ajouter.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1
name: <infrastructure_id>-w-a
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-w-a
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id>
machine.openshift.io/cluster-api-machine-role: <infra> 2
machine.openshift.io/cluster-api-machine-type: <infra>
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-w-a
spec:
metadata:
labels:
node-role.kubernetes.io/infra: ""
providerSpec:
value:
apiVersion: gcpprovider.openshift.io/v1beta1
canIPForward: false
credentialsSecret:
name: gcp-cloud-credentials
deletionProtection: false
disks:
- autoDelete: true
boot: true
image: <path_to_image> 3
labels: null
sizeGb: 128
type: pd-ssd
gcpMetadata: 4
- key: <custom_metadata_key>
value: <custom_metadata_value>
kind: GCPMachineProviderSpec
machineType: n1-standard-4
metadata:
creationTimestamp: null
networkInterfaces:
- network: <infrastructure_id>-network
subnetwork: <infrastructure_id>-worker-subnet
projectID: <project_name> 5
region: us-central1
serviceAccounts:
- email: <infrastructure_id>-w@<project_name>.iam.gserviceaccount.com
scopes:
- https://www.googleapis.com/auth/cloud-platform
tags:
- <infrastructure_id>-worker
userDataSecret:
name: worker-user-data
zone: us-central1-a
taints: 6
- key: node-role.kubernetes.io/infra
effect: NoSchedule- 1
- Pour
<infrastructure_id>, spécifiez l'ID d'infrastructure qui est basé sur l'ID de cluster que vous avez défini lorsque vous avez provisionné le cluster. Si le CLI OpenShift est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2
- Pour
<infra>, indiquez l'étiquette du nœud<infra>. - 3
- Spécifiez le chemin d'accès à l'image utilisée dans les ensembles de machines de calcul actuels. Si le CLI OpenShift est installé, vous pouvez obtenir le chemin d'accès à l'image en exécutant la commande suivante :
$ oc -n openshift-machine-api \ -o jsonpath='{.spec.template.spec.providerSpec.value.disks[0].image}{"\n"}' \ get machineset/<infrastructure_id>-worker-aTo use a GCP Marketplace image, specify the offer to use:
-
OpenShift Container Platform:
https://www.googleapis.com/compute/v1/projects/redhat-marketplace-public/global/images/redhat-coreos-ocp-48-x86-64-202210040145 -
OpenShift Platform Plus:
https://www.googleapis.com/compute/v1/projects/redhat-marketplace-public/global/images/redhat-coreos-opp-48-x86-64-202206140145 -
OpenShift Kubernetes Engine:
https://www.googleapis.com/compute/v1/projects/redhat-marketplace-public/global/images/redhat-coreos-oke-48-x86-64-202206140145
-
OpenShift Container Platform:
- 4
- Facultatif : Spécifiez des métadonnées personnalisées sous la forme d'une paire
key:value. Pour des exemples de cas d'utilisation, voir la documentation GCP pour la définition de métadonnées personnalisées. - 5
- Pour
<project_name>, indiquez le nom du projet GCP que vous utilisez pour votre cluster. - 6
- Spécifiez une erreur pour empêcher les charges de travail utilisateur d'être planifiées sur les nœuds infra.
Les ensembles de machines fonctionnant sur GCP prennent en charge les instances VM préemptibles non garanties. Vous pouvez réaliser des économies en utilisant des instances VM préemptibles à un prix inférieur à celui des instances normales sur GCP. Vous pouvez configurer les instances VM pr éemptibles en ajoutant preemptible au fichier YAML MachineSet.
7.2.1.7. Exemple de YAML pour une ressource personnalisée compute machine set sur Nutanix
Cet exemple YAML définit un ensemble de machines de calcul Nutanix qui crée des nœuds étiquetés avec node-role.kubernetes.io/infra: "".
Dans cet exemple, <infrastructure_id> est l'étiquette d'ID d'infrastructure basée sur l'ID de cluster que vous avez défini lors du provisionnement du cluster, et <infra> est l'étiquette de nœud à ajouter.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1
machine.openshift.io/cluster-api-machine-role: <infra> 2
machine.openshift.io/cluster-api-machine-type: <infra> 3
name: <infrastructure_id>-<infra>-<zone> 4
namespace: openshift-machine-api
annotations: 5
machine.openshift.io/memoryMb: "16384"
machine.openshift.io/vCPU: "4"
spec:
replicas: 3
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 6
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<infra>-<zone> 7
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 8
machine.openshift.io/cluster-api-machine-role: <infra> 9
machine.openshift.io/cluster-api-machine-type: <infra> 10
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<infra>-<zone> 11
spec:
metadata:
labels:
node-role.kubernetes.io/infra: ""
providerSpec:
value:
apiVersion: machine.openshift.io/v1
cluster:
type: uuid
uuid: <cluster_uuid>
credentialsSecret:
name: nutanix-creds-secret
image:
name: <infrastructure_id>-rhcos 12
type: name
kind: NutanixMachineProviderConfig
memorySize: 16Gi 13
subnets:
- type: uuid
uuid: <subnet_uuid>
systemDiskSize: 120Gi 14
userDataSecret:
name: <user_data_secret> 15
vcpuSockets: 4 16
vcpusPerSocket: 1 17
taints: 18
- key: node-role.kubernetes.io/infra
effect: NoSchedule- 1 6 8
- Spécifiez l'ID d'infrastructure qui est basé sur l'ID de cluster que vous avez défini lorsque vous avez provisionné le cluster. Si l'OpenShift CLI (
oc) est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 9 10
- Indiquez l'étiquette du nœud
<infra>. - 4 7 11
- Spécifiez l'ID de l'infrastructure, l'étiquette du nœud
<infra>et la zone. - 5
- Annotations pour le cluster autoscaler.
- 12
- Spécifiez l'image à utiliser. Utilisez une image provenant d'un jeu de machines de calcul par défaut existant pour le cluster.
- 13
- Spécifiez la quantité de mémoire pour le cluster en Gi.
- 14
- Spécifiez la taille du disque système en Gi.
- 15
- Spécifiez le nom du secret dans le fichier YAML des données utilisateur qui se trouve dans l'espace de noms
openshift-machine-api. Utilisez la valeur indiquée par le programme d'installation dans le jeu de machines de calcul par défaut. - 16
- Spécifiez le nombre de sockets vCPU.
- 17
- Spécifiez le nombre de vCPU par socket.
- 18
- Spécifiez une erreur pour empêcher les charges de travail utilisateur d'être planifiées sur les nœuds infra.
7.2.1.8. Exemple de YAML pour une ressource personnalisée d'une machine de calcul sur RHOSP
Cet exemple YAML définit un ensemble de machines de calcul qui fonctionne sur Red Hat OpenStack Platform (RHOSP) et crée des nœuds qui sont étiquetés avec node-role.kubernetes.io/infra: "".
Dans cet exemple, <infrastructure_id> est l'étiquette d'ID d'infrastructure basée sur l'ID de cluster que vous avez défini lors du provisionnement du cluster, et <infra> est l'étiquette de nœud à ajouter.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1
machine.openshift.io/cluster-api-machine-role: <infra> 2
machine.openshift.io/cluster-api-machine-type: <infra> 3
name: <infrastructure_id>-infra 4
namespace: openshift-machine-api
spec:
replicas: <number_of_replicas>
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 5
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra 6
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 7
machine.openshift.io/cluster-api-machine-role: <infra> 8
machine.openshift.io/cluster-api-machine-type: <infra> 9
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra 10
spec:
metadata:
creationTimestamp: null
labels:
node-role.kubernetes.io/infra: ""
taints: 11
- key: node-role.kubernetes.io/infra
effect: NoSchedule
providerSpec:
value:
apiVersion: openstackproviderconfig.openshift.io/v1alpha1
cloudName: openstack
cloudsSecret:
name: openstack-cloud-credentials
namespace: openshift-machine-api
flavor: <nova_flavor>
image: <glance_image_name_or_location>
serverGroupID: <optional_UUID_of_server_group> 12
kind: OpenstackProviderSpec
networks: 13
- filter: {}
subnets:
- filter:
name: <subnet_name>
tags: openshiftClusterID=<infrastructure_id> 14
primarySubnet: <rhosp_subnet_UUID> 15
securityGroups:
- filter: {}
name: <infrastructure_id>-worker 16
serverMetadata:
Name: <infrastructure_id>-worker 17
openshiftClusterID: <infrastructure_id> 18
tags:
- openshiftClusterID=<infrastructure_id> 19
trunk: true
userDataSecret:
name: worker-user-data 20
availabilityZone: <optional_openstack_availability_zone>- 1 5 7 14 16 17 18 19
- Spécifiez l'ID d'infrastructure qui est basé sur l'ID de cluster que vous avez défini lorsque vous avez provisionné le cluster. Si le CLI OpenShift est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 8 9 20
- Indiquez l'étiquette du nœud
<infra>. - 4 6 10
- Spécifiez l'ID de l'infrastructure et l'étiquette du nœud
<infra>. - 11
- Spécifiez une erreur pour empêcher les charges de travail utilisateur d'être planifiées sur les nœuds infra.
- 12
- Pour définir une stratégie de groupe de serveurs pour le jeu de machines, entrez la valeur renvoyée lors de la création d'un groupe de serveurs. Pour la plupart des déploiements, les stratégies
anti-affinityousoft-anti-affinitysont recommandées. - 13
- Requis pour les déploiements sur plusieurs réseaux. En cas de déploiement sur plusieurs réseaux, cette liste doit inclure le réseau utilisé comme valeur
primarySubnet. - 15
- Indiquez le sous-réseau RHOSP sur lequel vous souhaitez que les points d'extrémité des nœuds soient publiés. En général, il s'agit du même sous-réseau que celui utilisé comme valeur de
machinesSubnetdans le fichierinstall-config.yaml.
7.2.1.9. Exemple de YAML pour une ressource personnalisée d'une machine de calcul sur RHV
Cet exemple YAML définit un ensemble de machines de calcul fonctionnant sur RHV et crée des nœuds étiquetés avec node-role.kubernetes.io/<node_role>: "".
Dans cet exemple, <infrastructure_id> est l'étiquette d'ID d'infrastructure basée sur l'ID de cluster que vous avez défini lors du provisionnement du cluster, et <role> est l'étiquette de nœud à ajouter.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1
machine.openshift.io/cluster-api-machine-role: <role> 2
machine.openshift.io/cluster-api-machine-type: <role> 3
name: <infrastructure_id>-<role> 4
namespace: openshift-machine-api
spec:
replicas: <number_of_replicas> 5
Selector: 6
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 7
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> 8
template:
metadata:
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 9
machine.openshift.io/cluster-api-machine-role: <role> 10
machine.openshift.io/cluster-api-machine-type: <role> 11
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> 12
spec:
metadata:
labels:
node-role.kubernetes.io/<role>: "" 13
providerSpec:
value:
apiVersion: ovirtproviderconfig.machine.openshift.io/v1beta1
cluster_id: <ovirt_cluster_id> 14
template_name: <ovirt_template_name> 15
sparse: <boolean_value> 16
format: <raw_or_cow> 17
cpu: 18
sockets: <number_of_sockets> 19
cores: <number_of_cores> 20
threads: <number_of_threads> 21
memory_mb: <memory_size> 22
guaranteed_memory_mb: <memory_size> 23
os_disk: 24
size_gb: <disk_size> 25
storage_domain_id: <storage_domain_UUID> 26
network_interfaces: 27
vnic_profile_id: <vnic_profile_id> 28
credentialsSecret:
name: ovirt-credentials 29
kind: OvirtMachineProviderSpec
type: <workload_type> 30
auto_pinning_policy: <auto_pinning_policy> 31
hugepages: <hugepages> 32
affinityGroupsNames:
- compute 33
userDataSecret:
name: worker-user-data- 1 7 9
- Spécifiez l'ID d'infrastructure qui est basé sur l'ID de cluster que vous avez défini lorsque vous avez provisionné le cluster. Si l'OpenShift CLI (
oc) est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 3 10 11 13
- Spécifiez l'étiquette de nœud à ajouter.
- 4 8 12
- Spécifiez l'ID de l'infrastructure et l'étiquette du nœud. L'ensemble de ces deux chaînes ne peut dépasser 35 caractères.
- 5
- Indiquez le nombre de machines à créer.
- 6
- Sélecteur pour les machines.
- 14
- Spécifiez l'UUID du cluster RHV auquel appartient cette instance de VM.
- 15
- Spécifiez le modèle de VM RHV à utiliser pour créer la machine.
- 16
- Setting this option to
falseenables preallocation of disks. The default istrue. Settingsparsetotruewithformatset torawis not available for block storage domains. Therawformat writes the entire virtual disk to the underlying physical disk. - 17
- Can be set to
coworraw. The default iscow. Thecowformat is optimized for virtual machines.NotePreallocating disks on file storage domains writes zeroes to the file. This might not actually preallocate disks depending on the underlying storage.
- 18
- Facultatif : Le champ CPU contient la configuration du CPU, y compris les sockets, les cœurs et les threads.
- 19
- Facultatif : Spécifiez le nombre de sockets pour une VM.
- 20
- Facultatif : Spécifiez le nombre de cœurs par socket.
- 21
- Facultatif : Spécifiez le nombre de threads par cœur.
- 22
- Facultatif : Spécifiez la taille de la mémoire d'une VM en MiB.
- 23
- Facultatif : Spécifiez la taille de la mémoire garantie d'une machine virtuelle en MiB. Il s'agit de la quantité de mémoire qui est garantie de ne pas être drainée par le mécanisme de ballonnement. Pour plus d'informations, voir Explication des paramètres de ballonnement et d'optimisation de la mémoire.Note
Si vous utilisez une version antérieure à RHV 4.4.8, voir Exigences de mémoire garantie pour OpenShift sur les clusters Red Hat Virtualization.
- 24
- Facultatif : Disque racine du nœud.
- 25
- Facultatif : Spécifiez la taille du disque de démarrage en GiB.
- 26
- Facultatif : Indiquez l'UUID du domaine de stockage pour les disques du nœud de calcul. Si aucune valeur n'est fournie, le nœud de calcul est créé sur le même domaine de stockage que les nœuds de contrôle. (par défaut)
- 27
- Facultatif : Liste des interfaces réseau de la VM. Si vous incluez ce paramètre, OpenShift Container Platform écarte toutes les interfaces réseau du modèle et en crée de nouvelles.
- 28
- Facultatif : Spécifiez l'ID du profil vNIC.
- 29
- Indiquez le nom de l'objet secret qui contient les informations d'identification RHV.
- 30
- Facultatif : Spécifiez le type de charge de travail pour lequel l'instance est optimisée. Cette valeur affecte le paramètre
RHV VM. Valeurs prises en charge :desktop,server(par défaut),high_performance.high_performanceaméliore les performances de la VM. Il existe des limitations, par exemple, vous ne pouvez pas accéder à la VM avec une console graphique. Pour plus d'informations, voir Configuration de machines virtuelles, de modèles et de pools haute performance sur Virtual Machine Management Guide. - 31
- Facultatif : AutoPinningPolicy définit la stratégie qui définit automatiquement les paramètres CPU et NUMA, y compris l'épinglage sur l'hôte pour cette instance. Valeurs prises en charge :
none,resize_and_pin. Pour plus d'informations, voir Définition des nœuds NUMA à l'adresse Virtual Machine Management Guide. - 32
- Facultatif : Hugepages est la taille en KiB pour définir les hugepages dans une VM. Valeurs prises en charge :
2048ou1048576. Pour plus d'informations, voir Configuration des pages volumineuses sur le site Virtual Machine Management Guide. - 33
- Facultatif : Une liste de noms de groupes d'affinité à appliquer aux machines virtuelles. Les groupes d'affinité doivent exister dans oVirt.
Étant donné que RHV utilise un modèle lors de la création d'une VM, si vous ne spécifiez pas de valeur pour un paramètre facultatif, RHV utilise la valeur de ce paramètre qui est spécifiée dans le modèle.
7.2.1.10. Exemple de YAML pour une ressource personnalisée d'un ensemble de machines de calcul sur vSphere
Cet exemple YAML définit un ensemble de machines de calcul qui fonctionne sur VMware vSphere et crée des nœuds étiquetés avec node-role.kubernetes.io/infra: "".
Dans cet exemple, <infrastructure_id> est l'étiquette d'ID d'infrastructure basée sur l'ID de cluster que vous avez défini lors du provisionnement du cluster, et <infra> est l'étiquette de nœud à ajouter.
apiVersion: machine.openshift.io/v1beta1
kind: MachineSet
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1
name: <infrastructure_id>-infra 2
namespace: openshift-machine-api
spec:
replicas: 1
selector:
matchLabels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 3
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra 4
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: <infrastructure_id> 5
machine.openshift.io/cluster-api-machine-role: <infra> 6
machine.openshift.io/cluster-api-machine-type: <infra> 7
machine.openshift.io/cluster-api-machineset: <infrastructure_id>-infra 8
spec:
metadata:
creationTimestamp: null
labels:
node-role.kubernetes.io/infra: "" 9
taints: 10
- key: node-role.kubernetes.io/infra
effect: NoSchedule
providerSpec:
value:
apiVersion: vsphereprovider.openshift.io/v1beta1
credentialsSecret:
name: vsphere-cloud-credentials
diskGiB: 120
kind: VSphereMachineProviderSpec
memoryMiB: 8192
metadata:
creationTimestamp: null
network:
devices:
- networkName: "<vm_network_name>" 11
numCPUs: 4
numCoresPerSocket: 1
snapshot: ""
template: <vm_template_name> 12
userDataSecret:
name: worker-user-data
workspace:
datacenter: <vcenter_datacenter_name> 13
datastore: <vcenter_datastore_name> 14
folder: <vcenter_vm_folder_path> 15
resourcepool: <vsphere_resource_pool> 16
server: <vcenter_server_ip> 17- 1 3 5
- Spécifiez l'ID d'infrastructure qui est basé sur l'ID de cluster que vous avez défini lorsque vous avez provisionné le cluster. Si l'OpenShift CLI (
oc) est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2 4 8
- Spécifiez l'ID de l'infrastructure et l'étiquette du nœud
<infra>. - 6 7 9
- Indiquez l'étiquette du nœud
<infra>. - 10
- Spécifiez une erreur pour empêcher les charges de travail utilisateur d'être planifiées sur les nœuds infra.
- 11
- Indiquez le réseau VM vSphere sur lequel déployer l'ensemble de machines de calcul. Ce réseau VM doit se trouver là où d'autres machines de calcul résident dans le cluster.
- 12
- Spécifiez le modèle de VM vSphere à utiliser, par exemple
user-5ddjd-rhcos. - 13
- Spécifiez le centre de données vCenter sur lequel déployer l'ensemble de machines de calcul.
- 14
- Spécifiez le Datastore vCenter sur lequel déployer l'ensemble de machines de calcul.
- 15
- Indiquez le chemin d'accès au dossier vSphere VM dans vCenter, par exemple
/dc1/vm/user-inst-5ddjd. - 16
- Spécifiez le pool de ressources vSphere pour vos machines virtuelles.
- 17
- Spécifiez l'IP du serveur vCenter ou le nom de domaine complet.
7.2.2. Création d'un ensemble de machines de calcul
En plus des ensembles de machines de calcul créés par le programme d'installation, vous pouvez créer vos propres ensembles pour gérer dynamiquement les ressources de calcul des machines pour les charges de travail spécifiques de votre choix.
Conditions préalables
- Déployer un cluster OpenShift Container Platform.
-
Installez le CLI OpenShift (
oc). -
Connectez-vous à
ocen tant qu'utilisateur disposant de l'autorisationcluster-admin.
Procédure
Créez un nouveau fichier YAML contenant l'échantillon de ressources personnalisées (CR) de l'ensemble de machines de calcul et nommé
<file_name>.yaml.Veillez à définir les valeurs des paramètres
<clusterID>et<role>.Facultatif : si vous n'êtes pas sûr de la valeur à définir pour un champ spécifique, vous pouvez vérifier un ensemble de machines de calcul existant dans votre cluster.
Pour répertorier les ensembles de machines de calcul de votre cluster, exécutez la commande suivante :
$ oc get machinesets -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Pour afficher les valeurs d'une ressource personnalisée (CR) d'un ensemble de machines de calcul spécifique, exécutez la commande suivante :
$ oc get machineset <machineset_name> \ -n openshift-machine-api -o yaml
Exemple de sortie
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> 1 name: <infrastructure_id>-<role> 2 namespace: openshift-machine-api spec: replicas: 1 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> template: metadata: labels: machine.openshift.io/cluster-api-cluster: <infrastructure_id> machine.openshift.io/cluster-api-machine-role: <role> machine.openshift.io/cluster-api-machine-type: <role> machine.openshift.io/cluster-api-machineset: <infrastructure_id>-<role> spec: providerSpec: 3 ...- 1
- L'ID de l'infrastructure du cluster.
- 2
- Une étiquette de nœud par défaut.Note
Pour les clusters disposant d'une infrastructure fournie par l'utilisateur, un ensemble de machines de calcul ne peut créer que des machines de type
workeretinfra. - 3
- Les valeurs de la section
<providerSpec>du CR de l'ensemble de machines de calcul sont spécifiques à la plate-forme. Pour plus d'informations sur les paramètres<providerSpec>dans le CR, consultez l'exemple de configuration du CR de l'ensemble de machines de calcul pour votre fournisseur.
Créez un CR
MachineSeten exécutant la commande suivante :oc create -f <nom_du_fichier>.yaml
Vérification
Affichez la liste des ensembles de machines de calcul en exécutant la commande suivante :
$ oc get machineset -n openshift-machine-api
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-infra-us-east-1a 1 1 1 1 11m agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Lorsque le nouveau jeu de machines de calcul est disponible, les valeurs
DESIREDetCURRENTcorrespondent. Si le jeu de machines de calcul n'est pas disponible, attendez quelques minutes et exécutez à nouveau la commande.
7.2.3. Création d'un nœud d'infrastructure
Voir Création de jeux de machines d'infrastructure pour les environnements d'infrastructure fournis par l'installateur ou pour tout cluster dont les nœuds du plan de contrôle sont gérés par l'API des machines.
Les exigences du cluster imposent le provisionnement de l'infrastructure, également appelée infra nodes. Le programme d'installation ne fournit des provisions que pour le plan de contrôle et les nœuds de travail. Les nœuds de travail peuvent être désignés comme nœuds d'infrastructure ou nœuds d'application, également appelés app, par le biais de l'étiquetage.
Procédure
Ajoutez une étiquette au nœud de travailleur que vous voulez utiliser comme nœud d'application :
$ oc label node <node-name> node-role.kubernetes.io/app=""
Ajoutez une étiquette aux nœuds de travailleur que vous souhaitez utiliser comme nœuds d'infrastructure :
$ oc label node <node-name> node-role.kubernetes.io/infra=""
Vérifiez si les nœuds concernés ont désormais les rôles
infraetapp:$ oc get nodes
Créer un sélecteur de nœuds par défaut pour l'ensemble du cluster. Le sélecteur de nœuds par défaut est appliqué aux modules créés dans tous les espaces de noms. Cela crée une intersection avec tous les sélecteurs de nœuds existants sur un pod, ce qui contraint davantage le sélecteur du pod.
ImportantSi la clé du sélecteur de nœuds par défaut est en conflit avec la clé de l'étiquette d'un pod, le sélecteur de nœuds par défaut n'est pas appliqué.
Cependant, ne définissez pas un sélecteur de nœud par défaut qui pourrait rendre un module non ordonnançable. Par exemple, si le sélecteur de nœud par défaut est défini sur un rôle de nœud spécifique, tel que
node-role.kubernetes.io/infra="", alors que l'étiquette d'un module est définie sur un rôle de nœud différent, tel quenode-role.kubernetes.io/master="", le module risque de ne plus être ordonnançable. C'est pourquoi il convient d'être prudent lorsque l'on définit le sélecteur de nœuds par défaut sur des rôles de nœuds spécifiques.Vous pouvez également utiliser un sélecteur de nœud de projet pour éviter les conflits de clés de sélecteur de nœud à l'échelle du cluster.
Modifiez l'objet
Scheduler:$ oc edit scheduler cluster
Ajoutez le champ
defaultNodeSelectoravec le sélecteur de nœud approprié :apiVersion: config.openshift.io/v1 kind: Scheduler metadata: name: cluster ... spec: defaultNodeSelector: topology.kubernetes.io/region=us-east-1 1 ...- 1
- Cet exemple de sélecteur de nœuds déploie par défaut les pods sur les nœuds de la région
us-east-1.
- Enregistrez le fichier pour appliquer les modifications.
Vous pouvez maintenant déplacer les ressources d'infrastructure vers les nœuds infra nouvellement étiquetés.
Ressources complémentaires
7.2.4. Création d'un pool de configuration pour les machines d'infrastructure
Si vous avez besoin que les machines d'infrastructure aient des configurations dédiées, vous devez créer un pool d'infrastructure.
Procédure
Ajoutez une étiquette au nœud que vous souhaitez affecter comme nœud infra avec une étiquette spécifique :
$ oc label node <node_name> <label>
$ oc label node ci-ln-n8mqwr2-f76d1-xscn2-worker-c-6fmtx node-role.kubernetes.io/infra=
Créez un pool de configuration de machine qui contient à la fois le rôle de travailleur et votre rôle personnalisé en tant que sélecteur de configuration de machine :
$ cat infra.mcp.yaml
Exemple de sortie
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: infra spec: machineConfigSelector: matchExpressions: - {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,infra]} 1 nodeSelector: matchLabels: node-role.kubernetes.io/infra: "" 2NoteLes pools de configuration machine personnalisés héritent des configurations machine du pool de travail. Les pools personnalisés utilisent n'importe quelle configuration de machine ciblée pour le pool de travailleur, mais ajoutent la possibilité de déployer également des changements qui sont ciblés uniquement sur le pool personnalisé. Étant donné qu'un pool personnalisé hérite des ressources du pool de travail, toute modification apportée au pool de travail affecte également le pool personnalisé.
Après avoir obtenu le fichier YAML, vous pouvez créer le pool de configuration de la machine :
$ oc create -f infra.mcp.yaml
Vérifier les configurations des machines pour s'assurer que la configuration de l'infrastructure a été rendue avec succès :
$ oc get machineconfig
Exemple de sortie
NAME GENERATEDBYCONTROLLER IGNITIONVERSION CREATED 00-master 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 00-worker 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-master-container-runtime 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-master-kubelet 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-worker-container-runtime 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 01-worker-kubelet 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 99-master-1ae2a1e0-a115-11e9-8f14-005056899d54-registries 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 99-master-ssh 3.2.0 31d 99-worker-1ae64748-a115-11e9-8f14-005056899d54-registries 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 31d 99-worker-ssh 3.2.0 31d rendered-infra-4e48906dca84ee702959c71a53ee80e7 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 23m rendered-master-072d4b2da7f88162636902b074e9e28e 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-master-3e88ec72aed3886dec061df60d16d1af 02c07496ba0417b3e12b78fb32baf6293d314f79 3.2.0 31d rendered-master-419bee7de96134963a15fdf9dd473b25 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 17d rendered-master-53f5c91c7661708adce18739cc0f40fb 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 13d rendered-master-a6a357ec18e5bce7f5ac426fc7c5ffcd 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 7d3h rendered-master-dc7f874ec77fc4b969674204332da037 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-worker-1a75960c52ad18ff5dfa6674eb7e533d 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-worker-2640531be11ba43c61d72e82dc634ce6 5b6fb8349a29735e48446d435962dec4547d3090 3.2.0 31d rendered-worker-4e48906dca84ee702959c71a53ee80e7 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 7d3h rendered-worker-4f110718fe88e5f349987854a1147755 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 17d rendered-worker-afc758e194d6188677eb837842d3b379 02c07496ba0417b3e12b78fb32baf6293d314f79 3.2.0 31d rendered-worker-daa08cc1e8f5fcdeba24de60cd955cc3 365c1cfd14de5b0e3b85e0fc815b0060f36ab955 3.2.0 13d
Vous devriez voir une nouvelle configuration de machine, avec le préfixe
rendered-infra-*.Facultatif : Pour déployer les modifications apportées à un pool personnalisé, créez une configuration de machine qui utilise le nom du pool personnalisé comme étiquette, par exemple
infra. Notez que cette opération n'est pas obligatoire et qu'elle n'est présentée qu'à des fins didactiques. De cette manière, vous pouvez appliquer toutes les configurations personnalisées spécifiques à vos nœuds infra.NoteAprès avoir créé le nouveau pool de configuration machine, le MCO génère une nouvelle configuration rendue pour ce pool, et les nœuds associés à ce pool redémarrent pour appliquer la nouvelle configuration.
Créer une configuration de machine :
$ cat infra.mc.yaml
Exemple de sortie
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: name: 51-infra labels: machineconfiguration.openshift.io/role: infra 1 spec: config: ignition: version: 3.2.0 storage: files: - path: /etc/infratest mode: 0644 contents: source: data:,infra- 1
- Ajoutez l'étiquette que vous avez ajoutée au nœud en tant que
nodeSelector.
Appliquer la configuration de la machine aux nœuds infra-étiquetés :
$ oc create -f infra.mc.yaml
Confirmez que le pool de configuration de votre nouvelle machine est disponible :
$ oc get mcp
Exemple de sortie
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE infra rendered-infra-60e35c2e99f42d976e084fa94da4d0fc True False False 1 1 1 0 4m20s master rendered-master-9360fdb895d4c131c7c4bebbae099c90 True False False 3 3 3 0 91m worker rendered-worker-60e35c2e99f42d976e084fa94da4d0fc True False False 2 2 2 0 91m
Dans cet exemple, un nœud de travailleur a été transformé en nœud d'infrastructure.
Ressources complémentaires
- Voir Gestion de la configuration des nœuds avec les pools de configuration de machines pour plus d'informations sur le regroupement de machines infra dans un pool personnalisé.
7.3. Affectation des ressources de l'ensemble de machines aux nœuds d'infrastructure
Après avoir créé un jeu de machines d'infrastructure, les rôles worker et infra sont appliqués aux nouveaux nœuds d'infrastructure. Les nœuds auxquels le rôle infra est appliqué ne sont pas pris en compte dans le nombre total d'abonnements requis pour faire fonctionner l'environnement, même si le rôle worker est également appliqué.
Cependant, un nœud infra étant affecté en tant que travailleur, il est possible que des charges de travail utilisateur soient affectées par inadvertance à un nœud infra. Pour éviter cela, vous pouvez appliquer une taint au nœud infra et des tolérances pour les pods que vous souhaitez contrôler.
7.3.1. Lier les charges de travail des nœuds d'infrastructure à l'aide de taches et de tolérances
Si vous disposez d'un nœud infra auquel les rôles infra et worker ont été attribués, vous devez configurer le nœud de manière à ce que les charges de travail utilisateur ne lui soient pas affectées.
Il est recommandé de conserver le double label infra,worker créé pour les nœuds infra et d'utiliser les taints et les tolérances pour gérer les nœuds sur lesquels les charges de travail des utilisateurs sont planifiées. Si vous supprimez le label worker du nœud, vous devez créer un pool personnalisé pour le gérer. Un nœud doté d'une étiquette autre que master ou worker n'est pas reconnu par le MCO sans pool personnalisé. Le maintien de l'étiquette worker permet au nœud d'être géré par le pool de configuration de la machine de travail par défaut, s'il n'existe aucun pool personnalisé qui sélectionne l'étiquette personnalisée. Le label infra indique au cluster qu'il ne compte pas dans le nombre total d'abonnements.
Conditions préalables
-
Configurez des objets
MachineSetsupplémentaires dans votre cluster OpenShift Container Platform.
Procédure
Ajouter une tare au nœud infra pour empêcher la programmation des charges de travail des utilisateurs sur ce nœud :
Déterminer si le nœud est contaminé :
oc describe nodes <node_name>
Exemple de sortie
oc describe node ci-ln-iyhx092-f76d1-nvdfm-worker-b-wln2l Name: ci-ln-iyhx092-f76d1-nvdfm-worker-b-wln2l Roles: worker ... Taints: node-role.kubernetes.io/infra:NoSchedule ...
Cet exemple montre que le nœud a une tare. Vous pouvez procéder à l'ajout d'une tolérance à votre pod à l'étape suivante.
Si vous n'avez pas configuré une taint pour empêcher la planification des charges de travail des utilisateurs sur cette taint :
$ oc adm taint nodes <node_name> <key>=<value>:<effect>
Par exemple :
$ oc adm taint nodes node1 node-role.kubernetes.io/infra=reserved:NoExecute
AstuceVous pouvez également appliquer le YAML suivant pour ajouter l'altération :
kind: Node apiVersion: v1 metadata: name: <node_name> labels: ... spec: taints: - key: node-role.kubernetes.io/infra effect: NoExecute value: reserved ...Cet exemple place une taint sur
node1qui a la clénode-role.kubernetes.io/infraet l'effet de taintNoSchedule. Les nœuds avec l'effetNoSchedulene planifient que les pods qui tolèrent l'altération, mais permettent aux pods existants de rester planifiés sur le nœud.NoteSi un planificateur est utilisé, les pods violant les taints de nœuds peuvent être expulsés du cluster.
Ajoutez des tolérances pour les configurations de pods que vous souhaitez planifier sur le nœud infra, comme le routeur, le registre et les charges de travail de surveillance. Ajoutez le code suivant à la spécification de l'objet
Pod:tolerations: - effect: NoExecute 1 key: node-role.kubernetes.io/infra 2 operator: Exists 3 value: reserved 4
- 1
- Spécifiez l'effet que vous avez ajouté au nœud.
- 2
- Spécifiez la clé que vous avez ajoutée au nœud.
- 3
- Spécifiez l'opérateur
Existspour exiger la présence d'une taint avec la clénode-role.kubernetes.io/infrasur le nœud. - 4
- Spécifiez la valeur de la paire clé-valeur taint que vous avez ajoutée au nœud.
Cette tolérance correspond à l'altération créée par la commande
oc adm taint. Un pod avec cette tolérance peut être programmé sur le nœud infra.NoteIl n'est pas toujours possible de déplacer les modules d'un opérateur installé via OLM vers un nœud infra. La possibilité de déplacer les pods d'un opérateur dépend de la configuration de chaque opérateur.
- Programmer le pod sur le nœud infra à l'aide d'un planificateur. Voir la documentation de Controlling pod placement onto nodes pour plus de détails.
Ressources complémentaires
- Voir Contrôle du placement des pods à l'aide de l'ordonnanceur pour des informations générales sur la planification d'un pod sur un nœud.
- Voir Déplacer des ressources vers des ensembles de machines d'infrastructure pour obtenir des instructions sur la planification de pods vers des nœuds d'infrastructure.
7.4. Déplacement de ressources vers des ensembles de machines d'infrastructure
Certaines ressources d'infrastructure sont déployées par défaut dans votre cluster. Vous pouvez les déplacer vers les ensembles de machines d'infrastructure que vous avez créés en ajoutant le sélecteur de nœuds d'infrastructure, comme indiqué :
spec:
nodePlacement: 1
nodeSelector:
matchLabels:
node-role.kubernetes.io/infra: ""
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/infra
value: reserved
- effect: NoExecute
key: node-role.kubernetes.io/infra
value: reserved- 1
- Ajoutez un paramètre
nodeSelectoravec la valeur appropriée au composant que vous souhaitez déplacer. Vous pouvez utiliser unnodeSelectordans le format indiqué ou utiliser des paires<key>: <value>, en fonction de la valeur spécifiée pour le nœud. Si vous avez ajouté une tare au nœud de l'infrasructure, ajoutez également une tolérance correspondante.
En appliquant un sélecteur de nœud spécifique à tous les composants de l'infrastructure, OpenShift Container Platform planifie ces charges de travail sur les nœuds portant ce label.
7.4.1. Déplacement du routeur
Vous pouvez déployer le module de routeur sur un ensemble de machines de calcul différent. Par défaut, le module est déployé sur un nœud de travail.
Conditions préalables
- Configurez des ensembles de machines de calcul supplémentaires dans votre cluster OpenShift Container Platform.
Procédure
Voir la ressource personnalisée
IngressControllerpour l'opérateur de routeur :$ oc get ingresscontroller default -n openshift-ingress-operator -o yaml
La sortie de la commande ressemble au texte suivant :
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: creationTimestamp: 2019-04-18T12:35:39Z finalizers: - ingresscontroller.operator.openshift.io/finalizer-ingresscontroller generation: 1 name: default namespace: openshift-ingress-operator resourceVersion: "11341" selfLink: /apis/operator.openshift.io/v1/namespaces/openshift-ingress-operator/ingresscontrollers/default uid: 79509e05-61d6-11e9-bc55-02ce4781844a spec: {} status: availableReplicas: 2 conditions: - lastTransitionTime: 2019-04-18T12:36:15Z status: "True" type: Available domain: apps.<cluster>.example.com endpointPublishingStrategy: type: LoadBalancerService selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller=defaultModifiez la ressource
ingresscontrolleret changez la ressourcenodeSelectorpour qu'elle utilise l'étiquetteinfra:$ oc edit ingresscontroller default -n openshift-ingress-operator
spec: nodePlacement: nodeSelector: 1 matchLabels: node-role.kubernetes.io/infra: "" tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved - effect: NoExecute key: node-role.kubernetes.io/infra value: reserved- 1
- Ajoutez un paramètre
nodeSelectoravec la valeur appropriée au composant que vous souhaitez déplacer. Vous pouvez utiliser unnodeSelectorau format indiqué ou des paires<key>: <value>, en fonction de la valeur spécifiée pour le nœud. Si vous avez ajouté une taint au nœud d'infrastructure, ajoutez également une tolérance correspondante.
Confirmez que le pod routeur est en cours d'exécution sur le nœud
infra.Affichez la liste des modules de routeur et notez le nom du nœud du module en cours d'exécution :
$ oc get pod -n openshift-ingress -o wide
Exemple de sortie
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES router-default-86798b4b5d-bdlvd 1/1 Running 0 28s 10.130.2.4 ip-10-0-217-226.ec2.internal <none> <none> router-default-955d875f4-255g8 0/1 Terminating 0 19h 10.129.2.4 ip-10-0-148-172.ec2.internal <none> <none>
Dans cet exemple, le pod en cours d'exécution se trouve sur le nœud
ip-10-0-217-226.ec2.internal.Visualiser l'état du nœud du pod en cours d'exécution :
oc get node <node_name> 1- 1
- Spécifiez l'adresse
<node_name>que vous avez obtenue à partir de la liste des pods.
Exemple de sortie
NAME STATUS ROLES AGE VERSION ip-10-0-217-226.ec2.internal Ready infra,worker 17h v1.25.0
Comme la liste des rôles comprend
infra, le pod est exécuté sur le bon nœud.
7.4.2. Déplacement du registre par défaut
Vous configurez l'opérateur de registre pour qu'il déploie ses pods sur différents nœuds.
Conditions préalables
- Configurez des ensembles de machines de calcul supplémentaires dans votre cluster OpenShift Container Platform.
Procédure
Voir l'objet
config/instance:$ oc get configs.imageregistry.operator.openshift.io/cluster -o yaml
Exemple de sortie
apiVersion: imageregistry.operator.openshift.io/v1 kind: Config metadata: creationTimestamp: 2019-02-05T13:52:05Z finalizers: - imageregistry.operator.openshift.io/finalizer generation: 1 name: cluster resourceVersion: "56174" selfLink: /apis/imageregistry.operator.openshift.io/v1/configs/cluster uid: 36fd3724-294d-11e9-a524-12ffeee2931b spec: httpSecret: d9a012ccd117b1e6616ceccb2c3bb66a5fed1b5e481623 logging: 2 managementState: Managed proxy: {} replicas: 1 requests: read: {} write: {} storage: s3: bucket: image-registry-us-east-1-c92e88cad85b48ec8b312344dff03c82-392c region: us-east-1 status: ...Modifiez l'objet
config/instance:$ oc edit configs.imageregistry.operator.openshift.io/cluster
spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - podAffinityTerm: namespaces: - openshift-image-registry topologyKey: kubernetes.io/hostname weight: 100 logLevel: Normal managementState: Managed nodeSelector: 1 node-role.kubernetes.io/infra: "" tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved - effect: NoExecute key: node-role.kubernetes.io/infra value: reserved- 1
- Ajoutez un paramètre
nodeSelectoravec la valeur appropriée au composant que vous souhaitez déplacer. Vous pouvez utiliser unnodeSelectordans le format indiqué ou utiliser des paires<key>: <value>, en fonction de la valeur spécifiée pour le nœud. Si vous avez ajouté une tare au nœud de l'infrasructure, ajoutez également une tolérance correspondante.
Vérifiez que le pod de registre a été déplacé vers le nœud d'infrastructure.
Exécutez la commande suivante pour identifier le nœud où se trouve le module de registre :
$ oc get pods -o wide -n openshift-image-registry
Confirmez que le nœud a l'étiquette que vous avez spécifiée :
oc describe node <node_name>
Examinez la sortie de la commande et confirmez que
node-role.kubernetes.io/infrafigure dans la listeLABELS.
7.4.3. Déplacement de la solution de surveillance
La pile de surveillance comprend plusieurs composants, notamment Prometheus, Thanos Querier et Alertmanager. L'opérateur de surveillance des clusters gère cette pile. Pour redéployer la pile de surveillance sur les nœuds d'infrastructure, vous pouvez créer et appliquer une carte de configuration personnalisée.
Procédure
Modifiez la carte de configuration
cluster-monitoring-configet changez la cartenodeSelectorpour qu'elle utilise le labelinfra:$ oc edit configmap cluster-monitoring-config -n openshift-monitoring
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: |+ alertmanagerMain: nodeSelector: 1 node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute prometheusK8s: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute prometheusOperator: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute k8sPrometheusAdapter: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute kubeStateMetrics: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute telemeterClient: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute openshiftStateMetrics: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute thanosQuerier: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute- 1
- Ajoutez un paramètre
nodeSelectoravec la valeur appropriée au composant que vous souhaitez déplacer. Vous pouvez utiliser unnodeSelectordans le format indiqué ou utiliser des paires<key>: <value>, en fonction de la valeur spécifiée pour le nœud. Si vous avez ajouté une tare au nœud de l'infrasructure, ajoutez également une tolérance correspondante.
Observez le déplacement des modules de surveillance vers les nouvelles machines :
$ watch 'oc get pod -n openshift-monitoring -o wide'
Si un composant n'a pas été déplacé vers le nœud
infra, supprimez le pod contenant ce composant :oc delete pod -n openshift-monitoring <pod>
Le composant du module supprimé est recréé sur le nœud
infra.
7.4.4. Déplacer les ressources de journalisation d'OpenShift
Vous pouvez configurer le Cluster Logging Operator pour déployer les pods des composants du sous-système de journalisation, tels qu'Elasticsearch et Kibana, sur différents nœuds. Vous ne pouvez pas déplacer le pod Cluster Logging Operator de son emplacement d'installation.
Par exemple, vous pouvez déplacer les pods Elasticsearch vers un nœud distinct en raison des exigences élevées en matière de CPU, de mémoire et de disque.
Conditions préalables
- Les opérateurs Red Hat OpenShift Logging et Elasticsearch doivent être installés. Ces fonctionnalités ne sont pas installées par défaut.
Procédure
Modifiez la ressource personnalisée (CR)
ClusterLoggingdans le projetopenshift-logging:$ oc edit ClusterLogging instance
apiVersion: logging.openshift.io/v1 kind: ClusterLogging ... spec: collection: logs: fluentd: resources: null type: fluentd logStore: elasticsearch: nodeCount: 3 nodeSelector: 1 node-role.kubernetes.io/infra: '' tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved - effect: NoExecute key: node-role.kubernetes.io/infra value: reserved redundancyPolicy: SingleRedundancy resources: limits: cpu: 500m memory: 16Gi requests: cpu: 500m memory: 16Gi storage: {} type: elasticsearch managementState: Managed visualization: kibana: nodeSelector: 2 node-role.kubernetes.io/infra: '' tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved - effect: NoExecute key: node-role.kubernetes.io/infra value: reserved proxy: resources: null replicas: 1 resources: null type: kibana ...- 1 2
- Ajoutez un paramètre
nodeSelectoravec la valeur appropriée au composant que vous souhaitez déplacer. Vous pouvez utiliser unnodeSelectordans le format indiqué ou utiliser des paires<key>: <value>, en fonction de la valeur spécifiée pour le nœud. Si vous avez ajouté une tare au nœud de l'infrasructure, ajoutez également une tolérance correspondante.
Vérification
Pour vérifier qu'un composant a été déplacé, vous pouvez utiliser la commande oc get pod -o wide.
Par exemple :
Vous souhaitez déplacer le pod Kibana du nœud
ip-10-0-147-79.us-east-2.compute.internal:$ oc get pod kibana-5b8bdf44f9-ccpq9 -o wide
Exemple de sortie
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kibana-5b8bdf44f9-ccpq9 2/2 Running 0 27s 10.129.2.18 ip-10-0-147-79.us-east-2.compute.internal <none> <none>
Vous souhaitez déplacer le pod Kibana vers le nœud
ip-10-0-139-48.us-east-2.compute.internal, un nœud d'infrastructure dédié :$ oc get nodes
Exemple de sortie
NAME STATUS ROLES AGE VERSION ip-10-0-133-216.us-east-2.compute.internal Ready master 60m v1.25.0 ip-10-0-139-146.us-east-2.compute.internal Ready master 60m v1.25.0 ip-10-0-139-192.us-east-2.compute.internal Ready worker 51m v1.25.0 ip-10-0-139-241.us-east-2.compute.internal Ready worker 51m v1.25.0 ip-10-0-147-79.us-east-2.compute.internal Ready worker 51m v1.25.0 ip-10-0-152-241.us-east-2.compute.internal Ready master 60m v1.25.0 ip-10-0-139-48.us-east-2.compute.internal Ready infra 51m v1.25.0
Notez que le nœud a une étiquette
node-role.kubernetes.io/infra: '':$ oc get node ip-10-0-139-48.us-east-2.compute.internal -o yaml
Exemple de sortie
kind: Node apiVersion: v1 metadata: name: ip-10-0-139-48.us-east-2.compute.internal selfLink: /api/v1/nodes/ip-10-0-139-48.us-east-2.compute.internal uid: 62038aa9-661f-41d7-ba93-b5f1b6ef8751 resourceVersion: '39083' creationTimestamp: '2020-04-13T19:07:55Z' labels: node-role.kubernetes.io/infra: '' ...Pour déplacer le pod Kibana, modifiez le CR
ClusterLoggingpour ajouter un sélecteur de nœud :apiVersion: logging.openshift.io/v1 kind: ClusterLogging ... spec: ... visualization: kibana: nodeSelector: 1 node-role.kubernetes.io/infra: '' proxy: resources: null replicas: 1 resources: null type: kibana- 1
- Ajouter un sélecteur de nœud correspondant à l'étiquette de la spécification du nœud.
Après avoir sauvegardé le CR, le pod Kibana actuel est terminé et le nouveau pod est déployé :
$ oc get pods
Exemple de sortie
NAME READY STATUS RESTARTS AGE cluster-logging-operator-84d98649c4-zb9g7 1/1 Running 0 29m elasticsearch-cdm-hwv01pf7-1-56588f554f-kpmlg 2/2 Running 0 28m elasticsearch-cdm-hwv01pf7-2-84c877d75d-75wqj 2/2 Running 0 28m elasticsearch-cdm-hwv01pf7-3-f5d95b87b-4nx78 2/2 Running 0 28m fluentd-42dzz 1/1 Running 0 28m fluentd-d74rq 1/1 Running 0 28m fluentd-m5vr9 1/1 Running 0 28m fluentd-nkxl7 1/1 Running 0 28m fluentd-pdvqb 1/1 Running 0 28m fluentd-tflh6 1/1 Running 0 28m kibana-5b8bdf44f9-ccpq9 2/2 Terminating 0 4m11s kibana-7d85dcffc8-bfpfp 2/2 Running 0 33s
Le nouveau pod se trouve sur le nœud
ip-10-0-139-48.us-east-2.compute.internal:$ oc get pod kibana-7d85dcffc8-bfpfp -o wide
Exemple de sortie
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kibana-7d85dcffc8-bfpfp 2/2 Running 0 43s 10.131.0.22 ip-10-0-139-48.us-east-2.compute.internal <none> <none>
Après quelques instants, le pod Kibana original est retiré.
$ oc get pods
Exemple de sortie
NAME READY STATUS RESTARTS AGE cluster-logging-operator-84d98649c4-zb9g7 1/1 Running 0 30m elasticsearch-cdm-hwv01pf7-1-56588f554f-kpmlg 2/2 Running 0 29m elasticsearch-cdm-hwv01pf7-2-84c877d75d-75wqj 2/2 Running 0 29m elasticsearch-cdm-hwv01pf7-3-f5d95b87b-4nx78 2/2 Running 0 29m fluentd-42dzz 1/1 Running 0 29m fluentd-d74rq 1/1 Running 0 29m fluentd-m5vr9 1/1 Running 0 29m fluentd-nkxl7 1/1 Running 0 29m fluentd-pdvqb 1/1 Running 0 29m fluentd-tflh6 1/1 Running 0 29m kibana-7d85dcffc8-bfpfp 2/2 Running 0 62s
Ressources complémentaires
- Voir la documentation de surveillance pour les instructions générales sur le déplacement des composants d'OpenShift Container Platform.
Chapitre 8. Ajouter des machines de calcul RHEL à un cluster OpenShift Container Platform
Dans OpenShift Container Platform, vous pouvez ajouter des machines de calcul Red Hat Enterprise Linux (RHEL) à un cluster d'infrastructure fourni par l'utilisateur ou à un cluster d'infrastructure fourni par l'installation sur l'architecture x86_64. Vous pouvez utiliser RHEL comme système d'exploitation uniquement sur les machines de calcul.
8.1. À propos de l'ajout de nœuds de calcul RHEL à un cluster
Dans OpenShift Container Platform 4.12, vous avez la possibilité d'utiliser des machines Red Hat Enterprise Linux (RHEL) comme machines de calcul dans votre cluster si vous utilisez une installation d'infrastructure fournie par l'utilisateur sur l'architecture x86_64. Vous devez utiliser des machines Red Hat Enterprise Linux CoreOS (RHCOS) pour les machines du plan de contrôle dans votre cluster.
Si vous choisissez d'utiliser des machines de calcul RHEL dans votre cluster, vous êtes responsable de la gestion et de la maintenance de l'ensemble du cycle de vie du système d'exploitation. Vous devez effectuer les mises à jour du système, appliquer les correctifs et effectuer toutes les autres tâches requises.
- Étant donné que la suppression d'OpenShift Container Platform d'une machine du cluster nécessite la destruction du système d'exploitation, vous devez utiliser du matériel dédié pour toutes les machines RHEL que vous ajoutez au cluster.
- La mémoire swap est désactivée sur toutes les machines RHEL que vous ajoutez à votre cluster OpenShift Container Platform. Vous ne pouvez pas activer la mémoire swap sur ces machines.
Vous devez ajouter toutes les machines de calcul RHEL au cluster après avoir initialisé le plan de contrôle.
8.2. Configuration requise pour les nœuds de calcul RHEL
Les machines de calcul Red Hat Enterprise Linux (RHEL) hôtes de votre environnement OpenShift Container Platform doivent répondre aux spécifications matérielles minimales et aux exigences de niveau système suivantes :
- Vous devez avoir un abonnement OpenShift Container Platform actif sur votre compte Red Hat. Si ce n'est pas le cas, contactez votre représentant commercial pour plus d'informations.
- Les environnements de production doivent fournir des machines de calcul pour prendre en charge les charges de travail prévues. En tant qu'administrateur de cluster, vous devez calculer la charge de travail prévue et ajouter environ 10 % de frais généraux. Pour les environnements de production, allouez suffisamment de ressources pour que la défaillance d'un hôte de nœud n'affecte pas votre capacité maximale.
Chaque système doit répondre aux exigences matérielles suivantes :
- Système physique ou virtuel, ou instance fonctionnant sur un IaaS public ou privé.
Système d'exploitation de base : RHEL 8.6 ou 8.7 avec l'option d'installation "Minimal".
ImportantL'ajout de machines de calcul RHEL 7 à un cluster OpenShift Container Platform n'est pas pris en charge.
Si vous disposez de machines de calcul RHEL 7 qui étaient prises en charge dans une version antérieure d'OpenShift Container Platform, vous ne pouvez pas les mettre à niveau vers RHEL 8. Vous devez déployer de nouveaux hôtes RHEL 8, et les anciens hôtes RHEL 7 doivent être supprimés. Voir la section "Suppression des nœuds" pour plus d'informations.
Pour obtenir la liste la plus récente des fonctionnalités majeures qui ont été dépréciées ou supprimées dans OpenShift Container Platform, consultez la section Deprecated and removed features des notes de version d'OpenShift Container Platform.
- Si vous avez déployé OpenShift Container Platform en mode FIPS, vous devez activer FIPS sur la machine RHEL avant de la démarrer. Voir Installation d'un système RHEL 8 avec le mode FIPS activé dans la documentation RHEL 8.
The use of FIPS Validated / Modules in Process cryptographic libraries is only supported on OpenShift Container Platform deployments on the x86_64 architecture.
- NetworkManager 1.0 ou version ultérieure.
- 1 vCPU.
- Minimum 8 Go de RAM.
-
Minimum 15 Go d'espace sur le disque dur pour le système de fichiers contenant
/var/. -
Minimum 1 Go d'espace sur le disque dur pour le système de fichiers contenant
/usr/local/bin/. Au moins 1 Go d'espace sur le disque dur pour le système de fichiers contenant son répertoire temporaire. Le répertoire temporaire du système est déterminé selon les règles définies dans le module tempfile de la bibliothèque standard Python.
-
Chaque système doit répondre aux exigences supplémentaires de votre fournisseur de système. Par exemple, si vous avez installé votre cluster sur VMware vSphere, vos disques doivent être configurés conformément à ses directives de stockage et l'attribut
disk.enableUUID=truedoit être défini. - Chaque système doit pouvoir accéder aux points d'extrémité de l'API du cluster en utilisant des noms d'hôtes résolubles dans le DNS. Tout contrôle d'accès à la sécurité du réseau en place doit permettre l'accès du système aux points d'extrémité du service API de la grappe.
-
Chaque système doit répondre aux exigences supplémentaires de votre fournisseur de système. Par exemple, si vous avez installé votre cluster sur VMware vSphere, vos disques doivent être configurés conformément à ses directives de stockage et l'attribut
Ressources complémentaires
8.2.1. Certificate signing requests management
Because your cluster has limited access to automatic machine management when you use infrastructure that you provision, you must provide a mechanism for approving cluster certificate signing requests (CSRs) after installation. The kube-controller-manager only approves the kubelet client CSRs. The machine-approver cannot guarantee the validity of a serving certificate that is requested by using kubelet credentials because it cannot confirm that the correct machine issued the request. You must determine and implement a method of verifying the validity of the kubelet serving certificate requests and approving them.
8.3. Préparation d'une image pour votre nuage
Les Amazon Machine Images (AMI) sont nécessaires car les différents formats d'images ne peuvent pas être utilisés directement par AWS. Vous pouvez utiliser les AMI fournies par Red Hat ou importer manuellement vos propres images. L'AMI doit exister avant que l'instance EC2 puisse être provisionnée. Vous aurez besoin d'un identifiant AMI valide afin que la version RHEL correcte nécessaire pour les machines de calcul soit sélectionnée.
8.3.1. Liste des dernières images RHEL disponibles sur AWS
Les identifiants AMI correspondent aux images de démarrage natives pour AWS. Étant donné qu'une AMI doit exister avant que l'instance EC2 ne soit provisionnée, vous devez connaître l'ID AMI avant de procéder à la configuration. L'interface de ligne de commande (CLI) AWS est utilisée pour répertorier les ID d'images Red Hat Enterprise Linux (RHEL) disponibles.
Conditions préalables
- You have installed the AWS CLI.
Procédure
Utilisez cette commande pour répertorier les Amazon Machine Images (AMI) RHEL 8.4 :
$ aws ec2 describe-images --owners 309956199498 \ 1 --query 'sort_by(Images, &CreationDate)[*].[CreationDate,Name,ImageId]' \ 2 --filters "Name=name,Values=RHEL-8.4*" \ 3 --region us-east-1 \ 4 --output table 5
- 1
- L'option de commande
--ownersaffiche les images Red Hat basées sur l'ID de compte309956199498.ImportantCet identifiant de compte est nécessaire pour afficher les identifiants AMI des images fournies par Red Hat.
- 2
- L'option de commande
--querydéfinit la manière dont les images sont triées à l'aide des paramètres'sort_by(Images, &CreationDate)[*].[CreationDate,Name,ImageId]'. Dans ce cas, les images sont triées par date de création et le tableau est structuré de manière à indiquer la date de création, le nom de l'image et les identifiants AMI. - 3
- L'option de commande
--filterdéfinit la version de RHEL à afficher. Dans cet exemple, comme le filtre est défini par"Name=name,Values=RHEL-8.4*", les AMI RHEL 8.4 sont affichées. - 4
- L'option de commande
--regiondéfinit la région dans laquelle un AMI est stocké. - 5
- L'option de commande
--outputdéfinit la manière dont les résultats sont affichés.
Lors de la création d'une machine de calcul RHEL pour AWS, assurez-vous que l'AMI est RHEL 8.4 ou 8.5.
Exemple de sortie
------------------------------------------------------------------------------------------------------------ | DescribeImages | +---------------------------+-----------------------------------------------------+------------------------+ | 2021-03-18T14:23:11.000Z | RHEL-8.4.0_HVM_BETA-20210309-x86_64-1-Hourly2-GP2 | ami-07eeb4db5f7e5a8fb | | 2021-03-18T14:38:28.000Z | RHEL-8.4.0_HVM_BETA-20210309-arm64-1-Hourly2-GP2 | ami-069d22ec49577d4bf | | 2021-05-18T19:06:34.000Z | RHEL-8.4.0_HVM-20210504-arm64-2-Hourly2-GP2 | ami-01fc429821bf1f4b4 | | 2021-05-18T20:09:47.000Z | RHEL-8.4.0_HVM-20210504-x86_64-2-Hourly2-GP2 | ami-0b0af3577fe5e3532 | +---------------------------+-----------------------------------------------------+------------------------+
Ressources complémentaires
- Vous pouvez également importer manuellement des images RHEL sur AWS.
8.4. Préparation de la machine pour l'exécution du cahier de jeu
Avant d'ajouter des machines de calcul qui utilisent Red Hat Enterprise Linux (RHEL) comme système d'exploitation à un cluster OpenShift Container Platform 4.12, vous devez préparer une machine RHEL 8 pour exécuter un playbook Ansible qui ajoute le nouveau nœud au cluster. Cette machine ne fait pas partie du cluster mais doit pouvoir y accéder.
Conditions préalables
-
Installez le CLI OpenShift (
oc) sur la machine sur laquelle vous exécutez le playbook. -
Connectez-vous en tant qu'utilisateur disposant de l'autorisation
cluster-admin.
Procédure
-
Assurez-vous que le fichier
kubeconfigpour le cluster et le programme d'installation que vous avez utilisé pour installer le cluster se trouvent sur l'ordinateur RHEL 8. Pour ce faire, vous pouvez utiliser la même machine que celle que vous avez utilisée pour installer le cluster. - Configurez la machine pour accéder à tous les hôtes RHEL que vous prévoyez d'utiliser comme machines de calcul. Vous pouvez utiliser n'importe quelle méthode autorisée par votre entreprise, y compris un bastion avec un proxy SSH ou un VPN.
Configurez un utilisateur sur la machine sur laquelle vous exécutez le playbook et qui dispose d'un accès SSH à tous les hôtes RHEL.
ImportantSi vous utilisez l'authentification par clé SSH, vous devez gérer la clé avec un agent SSH.
Si ce n'est pas déjà fait, enregistrez la machine auprès du RHSM et associez-lui un pool avec un abonnement
OpenShift:Enregistrer la machine auprès du RHSM :
# subscription-manager register --username=<user_name> --password=<password>
Tirer les dernières données d'abonnement du RHSM :
# subscription-manager refresh
Liste des abonnements disponibles :
# subscription-manager list --available --matches '*OpenShift*'
Dans la sortie de la commande précédente, trouvez l'ID du pool pour un abonnement à OpenShift Container Platform et attachez-le :
# subscription-manager attach --pool=<pool_id>
Activer les dépôts requis par OpenShift Container Platform 4.12 :
# subscription-manager repos \ --enable="rhel-8-for-x86_64-baseos-rpms" \ --enable="rhel-8-for-x86_64-appstream-rpms" \ --enable="rhocp-4.12-for-rhel-8-x86_64-rpms"Installez les paquets nécessaires, y compris
openshift-ansible:# yum install openshift-ansible openshift-clients jq
Le paquet
openshift-ansiblefournit des utilitaires de programme d'installation et attire d'autres paquets dont vous avez besoin pour ajouter un nœud de calcul RHEL à votre cluster, tels qu'Ansible, les playbooks et les fichiers de configuration associés. Le paquetopenshift-clientsfournit la CLIoc, et le paquetjqaméliore l'affichage de la sortie JSON sur votre ligne de commande.
8.5. Préparation d'un nœud de calcul RHEL
Avant d'ajouter une machine Red Hat Enterprise Linux (RHEL) à votre cluster OpenShift Container Platform, vous devez enregistrer chaque hôte auprès du gestionnaire d'abonnements Red Hat (RHSM), attacher un abonnement OpenShift Container Platform actif et activer les référentiels requis.
Sur chaque hôte, s'enregistrer auprès du RHSM :
# subscription-manager register --username=<user_name> --password=<password>
Tirer les dernières données d'abonnement du RHSM :
# subscription-manager refresh
Liste des abonnements disponibles :
# subscription-manager list --available --matches '*OpenShift*'
Dans la sortie de la commande précédente, trouvez l'ID du pool pour un abonnement à OpenShift Container Platform et attachez-le :
# subscription-manager attach --pool=<pool_id>
Désactiver tous les dépôts yum :
Désactiver tous les dépôts RHSM activés :
# subscription-manager repos --disable="*"
Dressez la liste des dépôts yum restants et notez leur nom sous
repo id, le cas échéant :# yum repolist
Utilisez
yum-config-managerpour désactiver les autres dépôts yum :# yum-config-manager --disable <repo_id>
Vous pouvez également désactiver tous les dépôts :
# yum-config-manager --disable \*
Notez que cette opération peut prendre quelques minutes si vous avez un grand nombre de référentiels disponibles
Activez uniquement les dépôts requis par OpenShift Container Platform 4.12 :
# subscription-manager repos \ --enable="rhel-8-for-x86_64-baseos-rpms" \ --enable="rhel-8-for-x86_64-appstream-rpms" \ --enable="rhocp-4.12-for-rhel-8-x86_64-rpms" \ --enable="fast-datapath-for-rhel-8-x86_64-rpms"Arrêtez et désactivez firewalld sur l'hôte :
# systemctl disable --now firewalld.service
NoteVous ne devez pas activer firewalld par la suite. Si vous le faites, vous ne pourrez pas accéder aux logs de OpenShift Container Platform sur le worker.
8.6. Attacher les permissions de rôle à l'instance RHEL dans AWS
En utilisant la console Amazon IAM dans votre navigateur, vous pouvez sélectionner les rôles nécessaires et les attribuer à un nœud de travail.
Procédure
- Dans la console AWS IAM, créez le rôle IAM de votre choix.
- Attachez le rôle IAM au nœud de travailleur souhaité.
Ressources complémentaires
8.7. Marquage d'un nœud de travail RHEL en tant que propriété ou partage
Un cluster utilise la valeur de la balise kubernetes.io/cluster/<clusterid>,Value=(owned|shared) pour déterminer la durée de vie des ressources liées au cluster AWS.
-
La valeur de la balise
owneddoit être ajoutée si la ressource doit être détruite dans le cadre de la destruction du cluster. -
La valeur de la balise
shareddoit être ajoutée si la ressource continue d'exister après la destruction du cluster. Cette balise indique que le cluster utilise cette ressource, mais qu'il existe un propriétaire distinct pour cette ressource.
Procédure
-
Avec les machines de calcul RHEL, l'instance de travailleur RHEL doit être étiquetée avec
kubernetes.io/cluster/<clusterid>=ownedoukubernetes.io/cluster/<cluster-id>=shared.
Ne marquez pas tous les groupes de sécurité existants avec la balise kubernetes.io/cluster/<name>,Value=<clusterid>, ou l'Elastic Load Balancing (ELB) ne sera pas en mesure de créer un équilibreur de charge.
8.8. Ajout d'une machine de calcul RHEL à votre cluster
Vous pouvez ajouter des machines de calcul qui utilisent Red Hat Enterprise Linux comme système d'exploitation à un cluster OpenShift Container Platform 4.12.
Conditions préalables
- Vous avez installé les paquets requis et effectué la configuration nécessaire sur la machine sur laquelle vous exécutez le playbook.
- Vous avez préparé les hôtes RHEL pour l'installation.
Procédure
Effectuez les étapes suivantes sur la machine que vous avez préparée pour exécuter le manuel de jeu :
Créez un fichier d'inventaire Ansible nommé
/<path>/inventory/hostsqui définit les hôtes de votre machine de calcul et les variables requises :[all:vars] ansible_user=root 1 #ansible_become=True 2 openshift_kubeconfig_path="~/.kube/config" 3 [new_workers] 4 mycluster-rhel8-0.example.com mycluster-rhel8-1.example.com
- 1
- Indiquez le nom de l'utilisateur qui exécute les tâches Ansible sur les ordinateurs distants.
- 2
- Si vous ne spécifiez pas
rootpouransible_user, vous devez définiransible_becomepourTrueet attribuer à l'utilisateur les autorisations sudo. - 3
- Indiquez le chemin et le nom du fichier
kubeconfigpour votre cluster. - 4
- Dressez la liste de chaque machine RHEL à ajouter à votre cluster. Vous devez fournir le nom de domaine complet pour chaque hôte. Ce nom est le nom d'hôte que le cluster utilise pour accéder à la machine. Définissez donc le nom public ou privé correct pour accéder à la machine.
Naviguez jusqu'au répertoire du playbook Ansible :
$ cd /usr/share/ansible/openshift-ansible
Exécutez le manuel de jeu :
$ ansible-playbook -i /<path>/inventory/hosts playbooks/scaleup.yml 1- 1
- Pour
<path>, indiquez le chemin d'accès au fichier d'inventaire Ansible que vous avez créé.
8.9. Approving the certificate signing requests for your machines
When you add machines to a cluster, two pending certificate signing requests (CSRs) are generated for each machine that you added. You must confirm that these CSRs are approved or, if necessary, approve them yourself. The client requests must be approved first, followed by the server requests.
Conditions préalables
- You added machines to your cluster.
Procédure
Confirm that the cluster recognizes the machines:
$ oc get nodes
Exemple de sortie
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.25.0 master-1 Ready master 63m v1.25.0 master-2 Ready master 64m v1.25.0
The output lists all of the machines that you created.
NoteThe preceding output might not include the compute nodes, also known as worker nodes, until some CSRs are approved.
Review the pending CSRs and ensure that you see the client requests with the
PendingorApprovedstatus for each machine that you added to the cluster:$ oc get csr
Exemple de sortie
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...
In this example, two machines are joining the cluster. You might see more approved CSRs in the list.
If the CSRs were not approved, after all of the pending CSRs for the machines you added are in
Pendingstatus, approve the CSRs for your cluster machines:NoteBecause the CSRs rotate automatically, approve your CSRs within an hour of adding the machines to the cluster. If you do not approve them within an hour, the certificates will rotate, and more than two certificates will be present for each node. You must approve all of these certificates. After the client CSR is approved, the Kubelet creates a secondary CSR for the serving certificate, which requires manual approval. Then, subsequent serving certificate renewal requests are automatically approved by the
machine-approverif the Kubelet requests a new certificate with identical parameters.NoteFor clusters running on platforms that are not machine API enabled, such as bare metal and other user-provisioned infrastructure, you must implement a method of automatically approving the kubelet serving certificate requests (CSRs). If a request is not approved, then the
oc exec,oc rsh, andoc logscommands cannot succeed, because a serving certificate is required when the API server connects to the kubelet. Any operation that contacts the Kubelet endpoint requires this certificate approval to be in place. The method must watch for new CSRs, confirm that the CSR was submitted by thenode-bootstrapperservice account in thesystem:nodeorsystem:admingroups, and confirm the identity of the node.To approve them individually, run the following command for each valid CSR:
$ oc adm certificate approve <csr_name> 1- 1
<csr_name>est le nom d'un CSR figurant dans la liste des CSR actuels.
To approve all pending CSRs, run the following command:
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approveNoteSome Operators might not become available until some CSRs are approved.
Now that your client requests are approved, you must review the server requests for each machine that you added to the cluster:
$ oc get csr
Exemple de sortie
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...
If the remaining CSRs are not approved, and are in the
Pendingstatus, approve the CSRs for your cluster machines:To approve them individually, run the following command for each valid CSR:
$ oc adm certificate approve <csr_name> 1- 1
<csr_name>est le nom d'un CSR figurant dans la liste des CSR actuels.
To approve all pending CSRs, run the following command:
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
After all client and server CSRs have been approved, the machines have the
Readystatus. Verify this by running the following command:$ oc get nodes
Exemple de sortie
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.25.0 master-1 Ready master 73m v1.25.0 master-2 Ready master 74m v1.25.0 worker-0 Ready worker 11m v1.25.0 worker-1 Ready worker 11m v1.25.0
NoteIt can take a few minutes after approval of the server CSRs for the machines to transition to the
Readystatus.
Informations complémentaires
- For more information on CSRs, see Certificate Signing Requests.
8.10. Paramètres requis pour le fichier hosts d'Ansible
Vous devez définir les paramètres suivants dans le fichier hosts Ansible avant d'ajouter des machines de calcul Red Hat Enterprise Linux (RHEL) à votre cluster.
| Paramètres | Description | Valeurs |
|---|---|---|
|
| L'utilisateur SSH qui permet une authentification basée sur SSH sans mot de passe. Si vous utilisez l'authentification par clé SSH, vous devez gérer la clé avec un agent SSH. |
Un nom d'utilisateur sur le système. La valeur par défaut est |
|
|
Si les valeurs de |
|
|
|
Spécifie un chemin et un nom de fichier vers un répertoire local qui contient le fichier | Le chemin et le nom du fichier de configuration. |
8.10.1. Optionnel : Suppression des machines de calcul RHCOS d'un cluster
Après avoir ajouté les machines de calcul Red Hat Enterprise Linux (RHEL) à votre cluster, vous pouvez éventuellement supprimer les machines de calcul Red Hat Enterprise Linux CoreOS (RHCOS) afin de libérer des ressources.
Conditions préalables
- Vous avez ajouté des machines de calcul RHEL à votre cluster.
Procédure
Affichez la liste des machines et enregistrez les noms des nœuds des machines de calcul RHCOS :
$ oc get nodes -o wide
Pour chaque machine de calcul RHCOS, supprimer le nœud :
Marquez le nœud comme non ordonnançable en exécutant la commande
oc adm cordon:$ oc adm cordon <node_name> 1- 1
- Indiquez le nom du nœud de l'une des machines de calcul RHCOS.
Égoutter toutes les gousses du nœud :
oc adm drain <node_name> --force --delete-emptydir-data --ignore-daemonsets 1- 1
- Indiquez le nom du nœud de la machine de calcul RHCOS que vous avez isolée.
Supprimer le nœud :
oc delete nodes <node_name> $ oc delete nodes <node_name> 1- 1
- Indiquez le nom du nœud de la machine de calcul RHCOS que vous avez drainée.
Examinez la liste des machines de calcul pour vous assurer que seuls les nœuds RHEL sont conservés :
$ oc get nodes -o wide
- Supprimez les machines RHCOS de l'équilibreur de charge pour les machines de calcul de votre cluster. Vous pouvez supprimer les machines virtuelles ou réimager le matériel physique des machines de calcul RHCOS.
Chapitre 9. Ajouter des machines de calcul RHEL à un cluster OpenShift Container Platform
Si votre cluster OpenShift Container Platform comprend déjà des machines de calcul Red Hat Enterprise Linux (RHEL), qui sont également connues sous le nom de machines de travail, vous pouvez y ajouter d'autres machines de calcul RHEL.
9.1. À propos de l'ajout de nœuds de calcul RHEL à un cluster
Dans OpenShift Container Platform 4.12, vous avez la possibilité d'utiliser des machines Red Hat Enterprise Linux (RHEL) comme machines de calcul dans votre cluster si vous utilisez une installation d'infrastructure fournie par l'utilisateur sur l'architecture x86_64. Vous devez utiliser des machines Red Hat Enterprise Linux CoreOS (RHCOS) pour les machines du plan de contrôle dans votre cluster.
Si vous choisissez d'utiliser des machines de calcul RHEL dans votre cluster, vous êtes responsable de la gestion et de la maintenance de l'ensemble du cycle de vie du système d'exploitation. Vous devez effectuer les mises à jour du système, appliquer les correctifs et effectuer toutes les autres tâches requises.
- Étant donné que la suppression d'OpenShift Container Platform d'une machine du cluster nécessite la destruction du système d'exploitation, vous devez utiliser du matériel dédié pour toutes les machines RHEL que vous ajoutez au cluster.
- La mémoire swap est désactivée sur toutes les machines RHEL que vous ajoutez à votre cluster OpenShift Container Platform. Vous ne pouvez pas activer la mémoire swap sur ces machines.
Vous devez ajouter toutes les machines de calcul RHEL au cluster après avoir initialisé le plan de contrôle.
9.2. Configuration requise pour les nœuds de calcul RHEL
Les machines de calcul Red Hat Enterprise Linux (RHEL) hôtes de votre environnement OpenShift Container Platform doivent répondre aux spécifications matérielles minimales et aux exigences de niveau système suivantes :
- Vous devez avoir un abonnement OpenShift Container Platform actif sur votre compte Red Hat. Si ce n'est pas le cas, contactez votre représentant commercial pour plus d'informations.
- Les environnements de production doivent fournir des machines de calcul pour prendre en charge les charges de travail prévues. En tant qu'administrateur de cluster, vous devez calculer la charge de travail prévue et ajouter environ 10 % de frais généraux. Pour les environnements de production, allouez suffisamment de ressources pour que la défaillance d'un hôte de nœud n'affecte pas votre capacité maximale.
Chaque système doit répondre aux exigences matérielles suivantes :
- Système physique ou virtuel, ou instance fonctionnant sur un IaaS public ou privé.
Système d'exploitation de base : RHEL 8.6 ou 8.7 avec l'option d'installation "Minimal".
ImportantL'ajout de machines de calcul RHEL 7 à un cluster OpenShift Container Platform n'est pas pris en charge.
Si vous disposez de machines de calcul RHEL 7 qui étaient prises en charge dans une version antérieure d'OpenShift Container Platform, vous ne pouvez pas les mettre à niveau vers RHEL 8. Vous devez déployer de nouveaux hôtes RHEL 8, et les anciens hôtes RHEL 7 doivent être supprimés. Voir la section "Suppression des nœuds" pour plus d'informations.
Pour obtenir la liste la plus récente des fonctionnalités majeures qui ont été dépréciées ou supprimées dans OpenShift Container Platform, consultez la section Deprecated and removed features des notes de version d'OpenShift Container Platform.
- Si vous avez déployé OpenShift Container Platform en mode FIPS, vous devez activer FIPS sur la machine RHEL avant de la démarrer. Voir Installation d'un système RHEL 8 avec le mode FIPS activé dans la documentation RHEL 8.
The use of FIPS Validated / Modules in Process cryptographic libraries is only supported on OpenShift Container Platform deployments on the x86_64 architecture.
- NetworkManager 1.0 ou version ultérieure.
- 1 vCPU.
- Minimum 8 Go de RAM.
-
Minimum 15 Go d'espace sur le disque dur pour le système de fichiers contenant
/var/. -
Minimum 1 Go d'espace sur le disque dur pour le système de fichiers contenant
/usr/local/bin/. Au moins 1 Go d'espace sur le disque dur pour le système de fichiers contenant son répertoire temporaire. Le répertoire temporaire du système est déterminé selon les règles définies dans le module tempfile de la bibliothèque standard Python.
-
Chaque système doit répondre aux exigences supplémentaires de votre fournisseur de système. Par exemple, si vous avez installé votre cluster sur VMware vSphere, vos disques doivent être configurés conformément à ses directives de stockage et l'attribut
disk.enableUUID=truedoit être défini. - Chaque système doit pouvoir accéder aux points d'extrémité de l'API du cluster en utilisant des noms d'hôtes résolubles dans le DNS. Tout contrôle d'accès à la sécurité du réseau en place doit permettre l'accès du système aux points d'extrémité du service API de la grappe.
-
Chaque système doit répondre aux exigences supplémentaires de votre fournisseur de système. Par exemple, si vous avez installé votre cluster sur VMware vSphere, vos disques doivent être configurés conformément à ses directives de stockage et l'attribut
Ressources complémentaires
9.2.1. Certificate signing requests management
Because your cluster has limited access to automatic machine management when you use infrastructure that you provision, you must provide a mechanism for approving cluster certificate signing requests (CSRs) after installation. The kube-controller-manager only approves the kubelet client CSRs. The machine-approver cannot guarantee the validity of a serving certificate that is requested by using kubelet credentials because it cannot confirm that the correct machine issued the request. You must determine and implement a method of verifying the validity of the kubelet serving certificate requests and approving them.
9.3. Préparation d'une image pour votre nuage
Les Amazon Machine Images (AMI) sont nécessaires car les différents formats d'images ne peuvent pas être utilisés directement par AWS. Vous pouvez utiliser les AMI fournies par Red Hat ou importer manuellement vos propres images. L'AMI doit exister avant que l'instance EC2 puisse être provisionnée. Vous devez répertorier les identifiants AMI afin que la version RHEL correcte requise pour les machines de calcul soit sélectionnée.
9.3.1. Liste des dernières images RHEL disponibles sur AWS
Les identifiants AMI correspondent aux images de démarrage natives pour AWS. Étant donné qu'une AMI doit exister avant que l'instance EC2 ne soit provisionnée, vous devez connaître l'ID AMI avant de procéder à la configuration. L'interface de ligne de commande (CLI) AWS est utilisée pour répertorier les ID d'images Red Hat Enterprise Linux (RHEL) disponibles.
Conditions préalables
- You have installed the AWS CLI.
Procédure
Utilisez cette commande pour répertorier les Amazon Machine Images (AMI) RHEL 8.4 :
$ aws ec2 describe-images --owners 309956199498 \ 1 --query 'sort_by(Images, &CreationDate)[*].[CreationDate,Name,ImageId]' \ 2 --filters "Name=name,Values=RHEL-8.4*" \ 3 --region us-east-1 \ 4 --output table 5
- 1
- L'option de commande
--ownersaffiche les images Red Hat basées sur l'ID de compte309956199498.ImportantCet identifiant de compte est nécessaire pour afficher les identifiants AMI des images fournies par Red Hat.
- 2
- L'option de commande
--querydéfinit la manière dont les images sont triées à l'aide des paramètres'sort_by(Images, &CreationDate)[*].[CreationDate,Name,ImageId]'. Dans ce cas, les images sont triées par date de création et le tableau est structuré de manière à indiquer la date de création, le nom de l'image et les identifiants AMI. - 3
- L'option de commande
--filterdéfinit la version de RHEL à afficher. Dans cet exemple, comme le filtre est défini par"Name=name,Values=RHEL-8.4*", les AMI RHEL 8.4 sont affichées. - 4
- L'option de commande
--regiondéfinit la région dans laquelle un AMI est stocké. - 5
- L'option de commande
--outputdéfinit la manière dont les résultats sont affichés.
Lors de la création d'une machine de calcul RHEL pour AWS, assurez-vous que l'AMI est RHEL 8.4 ou 8.5.
Exemple de sortie
------------------------------------------------------------------------------------------------------------ | DescribeImages | +---------------------------+-----------------------------------------------------+------------------------+ | 2021-03-18T14:23:11.000Z | RHEL-8.4.0_HVM_BETA-20210309-x86_64-1-Hourly2-GP2 | ami-07eeb4db5f7e5a8fb | | 2021-03-18T14:38:28.000Z | RHEL-8.4.0_HVM_BETA-20210309-arm64-1-Hourly2-GP2 | ami-069d22ec49577d4bf | | 2021-05-18T19:06:34.000Z | RHEL-8.4.0_HVM-20210504-arm64-2-Hourly2-GP2 | ami-01fc429821bf1f4b4 | | 2021-05-18T20:09:47.000Z | RHEL-8.4.0_HVM-20210504-x86_64-2-Hourly2-GP2 | ami-0b0af3577fe5e3532 | +---------------------------+-----------------------------------------------------+------------------------+
Ressources complémentaires
- Vous pouvez également importer manuellement des images RHEL sur AWS.
9.4. Préparation d'un nœud de calcul RHEL
Avant d'ajouter une machine Red Hat Enterprise Linux (RHEL) à votre cluster OpenShift Container Platform, vous devez enregistrer chaque hôte auprès du gestionnaire d'abonnements Red Hat (RHSM), attacher un abonnement OpenShift Container Platform actif et activer les référentiels requis.
Sur chaque hôte, s'enregistrer auprès du RHSM :
# subscription-manager register --username=<user_name> --password=<password>
Tirer les dernières données d'abonnement du RHSM :
# subscription-manager refresh
Liste des abonnements disponibles :
# subscription-manager list --available --matches '*OpenShift*'
Dans la sortie de la commande précédente, trouvez l'ID du pool pour un abonnement à OpenShift Container Platform et attachez-le :
# subscription-manager attach --pool=<pool_id>
Désactiver tous les dépôts yum :
Désactiver tous les dépôts RHSM activés :
# subscription-manager repos --disable="*"
Dressez la liste des dépôts yum restants et notez leur nom sous
repo id, le cas échéant :# yum repolist
Utilisez
yum-config-managerpour désactiver les autres dépôts yum :# yum-config-manager --disable <repo_id>
Vous pouvez également désactiver tous les dépôts :
# yum-config-manager --disable \*
Notez que cette opération peut prendre quelques minutes si vous avez un grand nombre de référentiels disponibles
Activez uniquement les dépôts requis par OpenShift Container Platform 4.12 :
# subscription-manager repos \ --enable="rhel-8-for-x86_64-baseos-rpms" \ --enable="rhel-8-for-x86_64-appstream-rpms" \ --enable="rhocp-4.12-for-rhel-8-x86_64-rpms" \ --enable="fast-datapath-for-rhel-8-x86_64-rpms"Arrêtez et désactivez firewalld sur l'hôte :
# systemctl disable --now firewalld.service
NoteVous ne devez pas activer firewalld par la suite. Si vous le faites, vous ne pourrez pas accéder aux logs de OpenShift Container Platform sur le worker.
9.5. Attacher les permissions de rôle à l'instance RHEL dans AWS
En utilisant la console Amazon IAM dans votre navigateur, vous pouvez sélectionner les rôles nécessaires et les attribuer à un nœud de travail.
Procédure
- Dans la console AWS IAM, créez le rôle IAM de votre choix.
- Attachez le rôle IAM au nœud de travailleur souhaité.
Ressources complémentaires
9.6. Marquage d'un nœud de travail RHEL en tant que propriété ou partage
Un cluster utilise la valeur de la balise kubernetes.io/cluster/<clusterid>,Value=(owned|shared) pour déterminer la durée de vie des ressources liées au cluster AWS.
-
La valeur de la balise
owneddoit être ajoutée si la ressource doit être détruite dans le cadre de la destruction du cluster. -
La valeur de la balise
shareddoit être ajoutée si la ressource continue d'exister après la destruction du cluster. Cette balise indique que le cluster utilise cette ressource, mais qu'il existe un propriétaire distinct pour cette ressource.
Procédure
-
Avec les machines de calcul RHEL, l'instance de travailleur RHEL doit être étiquetée avec
kubernetes.io/cluster/<clusterid>=ownedoukubernetes.io/cluster/<cluster-id>=shared.
Ne marquez pas tous les groupes de sécurité existants avec la balise kubernetes.io/cluster/<name>,Value=<clusterid>, ou l'Elastic Load Balancing (ELB) ne sera pas en mesure de créer un équilibreur de charge.
9.7. Ajout de machines de calcul RHEL à votre cluster
Vous pouvez ajouter plus de machines de calcul qui utilisent Red Hat Enterprise Linux (RHEL) comme système d'exploitation à un cluster OpenShift Container Platform 4.12.
Conditions préalables
- Votre cluster OpenShift Container Platform contient déjà des nœuds de calcul RHEL.
-
Le fichier
hostsque vous avez utilisé pour ajouter les premières machines de calcul RHEL à votre cluster se trouve sur la machine que vous utilisez pour exécuter le playbook. - La machine sur laquelle vous exécutez le manuel de jeu doit pouvoir accéder à tous les hôtes RHEL. Vous pouvez utiliser toute méthode autorisée par votre entreprise, y compris un bastion avec un proxy SSH ou un VPN.
-
Le fichier
kubeconfigpour le cluster et le programme d'installation que vous avez utilisé pour installer le cluster se trouvent sur la machine que vous utilisez pour exécuter le playbook. - Vous devez préparer les hôtes RHEL pour l'installation.
- Configurez un utilisateur sur la machine sur laquelle vous exécutez le playbook et qui dispose d'un accès SSH à tous les hôtes RHEL.
- Si vous utilisez l'authentification par clé SSH, vous devez gérer la clé avec un agent SSH.
-
Installez le CLI OpenShift (
oc) sur la machine sur laquelle vous exécutez le playbook.
Procédure
-
Ouvrez le fichier d'inventaire Ansible à l'adresse
/<path>/inventory/hostsqui définit les hôtes de votre machine de calcul et les variables requises. -
Renommez la section
[new_workers]du fichier en[workers]. Ajoutez une section
[new_workers]au fichier et définissez les noms de domaine pleinement qualifiés pour chaque nouvel hôte. Le fichier ressemble à l'exemple suivant :[all:vars] ansible_user=root #ansible_become=True openshift_kubeconfig_path="~/.kube/config" [workers] mycluster-rhel8-0.example.com mycluster-rhel8-1.example.com [new_workers] mycluster-rhel8-2.example.com mycluster-rhel8-3.example.com
Dans cet exemple, les machines
mycluster-rhel8-0.example.cometmycluster-rhel8-1.example.comsont dans le cluster et vous ajoutez les machinesmycluster-rhel8-2.example.cometmycluster-rhel8-3.example.com.Naviguez jusqu'au répertoire du playbook Ansible :
$ cd /usr/share/ansible/openshift-ansible
Exécutez le manuel de mise à l'échelle :
$ ansible-playbook -i /<path>/inventory/hosts playbooks/scaleup.yml 1- 1
- Pour
<path>, indiquez le chemin d'accès au fichier d'inventaire Ansible que vous avez créé.
9.8. Approving the certificate signing requests for your machines
When you add machines to a cluster, two pending certificate signing requests (CSRs) are generated for each machine that you added. You must confirm that these CSRs are approved or, if necessary, approve them yourself. The client requests must be approved first, followed by the server requests.
Conditions préalables
- You added machines to your cluster.
Procédure
Confirm that the cluster recognizes the machines:
$ oc get nodes
Exemple de sortie
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.25.0 master-1 Ready master 63m v1.25.0 master-2 Ready master 64m v1.25.0
The output lists all of the machines that you created.
NoteThe preceding output might not include the compute nodes, also known as worker nodes, until some CSRs are approved.
Review the pending CSRs and ensure that you see the client requests with the
PendingorApprovedstatus for each machine that you added to the cluster:$ oc get csr
Exemple de sortie
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...
In this example, two machines are joining the cluster. You might see more approved CSRs in the list.
If the CSRs were not approved, after all of the pending CSRs for the machines you added are in
Pendingstatus, approve the CSRs for your cluster machines:NoteBecause the CSRs rotate automatically, approve your CSRs within an hour of adding the machines to the cluster. If you do not approve them within an hour, the certificates will rotate, and more than two certificates will be present for each node. You must approve all of these certificates. After the client CSR is approved, the Kubelet creates a secondary CSR for the serving certificate, which requires manual approval. Then, subsequent serving certificate renewal requests are automatically approved by the
machine-approverif the Kubelet requests a new certificate with identical parameters.NoteFor clusters running on platforms that are not machine API enabled, such as bare metal and other user-provisioned infrastructure, you must implement a method of automatically approving the kubelet serving certificate requests (CSRs). If a request is not approved, then the
oc exec,oc rsh, andoc logscommands cannot succeed, because a serving certificate is required when the API server connects to the kubelet. Any operation that contacts the Kubelet endpoint requires this certificate approval to be in place. The method must watch for new CSRs, confirm that the CSR was submitted by thenode-bootstrapperservice account in thesystem:nodeorsystem:admingroups, and confirm the identity of the node.To approve them individually, run the following command for each valid CSR:
$ oc adm certificate approve <csr_name> 1- 1
<csr_name>est le nom d'un CSR figurant dans la liste des CSR actuels.
To approve all pending CSRs, run the following command:
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approveNoteSome Operators might not become available until some CSRs are approved.
Now that your client requests are approved, you must review the server requests for each machine that you added to the cluster:
$ oc get csr
Exemple de sortie
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...
If the remaining CSRs are not approved, and are in the
Pendingstatus, approve the CSRs for your cluster machines:To approve them individually, run the following command for each valid CSR:
$ oc adm certificate approve <csr_name> 1- 1
<csr_name>est le nom d'un CSR figurant dans la liste des CSR actuels.
To approve all pending CSRs, run the following command:
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
After all client and server CSRs have been approved, the machines have the
Readystatus. Verify this by running the following command:$ oc get nodes
Exemple de sortie
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.25.0 master-1 Ready master 73m v1.25.0 master-2 Ready master 74m v1.25.0 worker-0 Ready worker 11m v1.25.0 worker-1 Ready worker 11m v1.25.0
NoteIt can take a few minutes after approval of the server CSRs for the machines to transition to the
Readystatus.
Informations complémentaires
- For more information on CSRs, see Certificate Signing Requests.
9.9. Paramètres requis pour le fichier hosts d'Ansible
Vous devez définir les paramètres suivants dans le fichier hosts Ansible avant d'ajouter des machines de calcul Red Hat Enterprise Linux (RHEL) à votre cluster.
| Paramètres | Description | Valeurs |
|---|---|---|
|
| L'utilisateur SSH qui permet une authentification basée sur SSH sans mot de passe. Si vous utilisez l'authentification par clé SSH, vous devez gérer la clé avec un agent SSH. |
Un nom d'utilisateur sur le système. La valeur par défaut est |
|
|
Si les valeurs de |
|
|
|
Spécifie un chemin et un nom de fichier vers un répertoire local qui contient le fichier | Le chemin et le nom du fichier de configuration. |
Chapitre 10. Gérer manuellement l'infrastructure fournie par l'utilisateur
10.1. Ajouter manuellement des machines de calcul à des grappes avec une infrastructure fournie par l'utilisateur
Vous pouvez ajouter des machines de calcul à un cluster sur une infrastructure fournie par l'utilisateur soit dans le cadre du processus d'installation, soit après l'installation. Le processus de post-installation nécessite certains des mêmes fichiers de configuration et paramètres que ceux utilisés lors de l'installation.
10.1.1. Ajouter des machines de calcul à Amazon Web Services
Pour ajouter des machines de calcul à votre cluster OpenShift Container Platform sur Amazon Web Services (AWS), voir Ajouter des machines de calcul à AWS à l'aide des modèles CloudFormation.
10.1.2. Ajouter des machines de calcul à Microsoft Azure
Pour ajouter des machines de calcul à votre cluster OpenShift Container Platform sur Microsoft Azure, voir Créer des machines de travail supplémentaires dans Azure.
10.1.3. Ajouter des machines de calcul à Azure Stack Hub
Pour ajouter des machines de calcul à votre cluster OpenShift Container Platform sur Azure Stack Hub, voir Création de machines de travail supplémentaires dans Azure Stack Hub.
10.1.4. Ajout de machines de calcul à Google Cloud Platform
Pour ajouter des machines de calcul à votre cluster OpenShift Container Platform sur Google Cloud Platform (GCP), voir Création de machines de travail supplémentaires dans GCP.
10.1.5. Ajouter des machines de calcul à vSphere
Vous pouvez utiliser des ensembles de machines de calcul pour automatiser la création de machines de calcul supplémentaires pour votre cluster OpenShift Container Platform sur vSphere.
Pour ajouter manuellement des machines de calcul à votre cluster, voir Ajouter manuellement des machines de calcul à vSphere.
10.1.6. Ajouter des machines de calcul à RHV
Pour ajouter des machines de calcul à votre cluster OpenShift Container Platform sur RHV, voir Ajouter des machines de calcul à RHV.
10.1.7. Ajouter des machines de calcul à du métal nu
Pour ajouter des machines de calcul à votre cluster OpenShift Container Platform sur bare metal, voir Ajouter des machines de calcul à bare metal.
10.2. Ajouter des machines de calcul à AWS en utilisant des modèles CloudFormation
Vous pouvez ajouter d'autres machines de calcul à votre cluster OpenShift Container Platform sur Amazon Web Services (AWS) que vous avez créé à l'aide des modèles CloudFormation types.
10.2.1. Conditions préalables
- Vous avez installé votre cluster sur AWS en utilisant les modèles AWS CloudFormation fournis.
- Vous disposez du fichier JSON et du modèle CloudFormation que vous avez utilisés pour créer les machines de calcul lors de l'installation du cluster. Si vous n'avez pas ces fichiers, vous devez les recréer en suivant les instructions de la procédure d'installation.
10.2.2. Ajouter des machines de calcul à votre cluster AWS en utilisant les modèles CloudFormation
Vous pouvez ajouter d'autres machines de calcul à votre cluster OpenShift Container Platform sur Amazon Web Services (AWS) que vous avez créé à l'aide des modèles CloudFormation types.
Le modèle CloudFormation crée une pile qui représente une machine de calcul. Vous devez créer une pile pour chaque machine de calcul.
Si vous n'utilisez pas le modèle CloudFormation fourni pour créer vos nœuds de calcul, vous devez consulter les informations fournies et créer manuellement l'infrastructure. Si votre cluster ne s'initialise pas correctement, vous devrez peut-être contacter l'assistance de Red Hat avec vos journaux d'installation.
Conditions préalables
- Vous avez installé un cluster OpenShift Container Platform en utilisant des modèles CloudFormation et vous avez accès au fichier JSON et au modèle CloudFormation que vous avez utilisé pour créer les machines de calcul lors de l'installation du cluster.
- Vous avez installé l'AWS CLI.
Procédure
Créer une autre pile de calcul.
Lancer le modèle :
$ aws cloudformation create-stack --stack-name <name> \ 1 --template-body file://<template>.yaml \ 2 --parameters file://<parameters>.json 3
- 1
<name>est le nom de la pile CloudFormation, par exemplecluster-workers. Vous devez fournir le nom de cette pile si vous supprimez le cluster.- 2
<template>is the relative path to and name of the CloudFormation template YAML file that you saved.- 3
<parameters>is the relative path to and name of the CloudFormation parameters JSON file.
Confirm that the template components exist:
$ aws cloudformation describe-stacks --stack-name <name>
- Continuez à créer des piles de calcul jusqu'à ce que vous ayez créé suffisamment de machines de calcul pour votre cluster.
10.2.3. Approving the certificate signing requests for your machines
When you add machines to a cluster, two pending certificate signing requests (CSRs) are generated for each machine that you added. You must confirm that these CSRs are approved or, if necessary, approve them yourself. The client requests must be approved first, followed by the server requests.
Conditions préalables
- You added machines to your cluster.
Procédure
Confirm that the cluster recognizes the machines:
$ oc get nodes
Exemple de sortie
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.25.0 master-1 Ready master 63m v1.25.0 master-2 Ready master 64m v1.25.0
The output lists all of the machines that you created.
NoteThe preceding output might not include the compute nodes, also known as worker nodes, until some CSRs are approved.
Review the pending CSRs and ensure that you see the client requests with the
PendingorApprovedstatus for each machine that you added to the cluster:$ oc get csr
Exemple de sortie
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...
In this example, two machines are joining the cluster. You might see more approved CSRs in the list.
If the CSRs were not approved, after all of the pending CSRs for the machines you added are in
Pendingstatus, approve the CSRs for your cluster machines:NoteBecause the CSRs rotate automatically, approve your CSRs within an hour of adding the machines to the cluster. If you do not approve them within an hour, the certificates will rotate, and more than two certificates will be present for each node. You must approve all of these certificates. After the client CSR is approved, the Kubelet creates a secondary CSR for the serving certificate, which requires manual approval. Then, subsequent serving certificate renewal requests are automatically approved by the
machine-approverif the Kubelet requests a new certificate with identical parameters.NoteFor clusters running on platforms that are not machine API enabled, such as bare metal and other user-provisioned infrastructure, you must implement a method of automatically approving the kubelet serving certificate requests (CSRs). If a request is not approved, then the
oc exec,oc rsh, andoc logscommands cannot succeed, because a serving certificate is required when the API server connects to the kubelet. Any operation that contacts the Kubelet endpoint requires this certificate approval to be in place. The method must watch for new CSRs, confirm that the CSR was submitted by thenode-bootstrapperservice account in thesystem:nodeorsystem:admingroups, and confirm the identity of the node.To approve them individually, run the following command for each valid CSR:
$ oc adm certificate approve <csr_name> 1- 1
<csr_name>est le nom d'un CSR figurant dans la liste des CSR actuels.
To approve all pending CSRs, run the following command:
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approveNoteSome Operators might not become available until some CSRs are approved.
Now that your client requests are approved, you must review the server requests for each machine that you added to the cluster:
$ oc get csr
Exemple de sortie
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...
If the remaining CSRs are not approved, and are in the
Pendingstatus, approve the CSRs for your cluster machines:To approve them individually, run the following command for each valid CSR:
$ oc adm certificate approve <csr_name> 1- 1
<csr_name>est le nom d'un CSR figurant dans la liste des CSR actuels.
To approve all pending CSRs, run the following command:
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
After all client and server CSRs have been approved, the machines have the
Readystatus. Verify this by running the following command:$ oc get nodes
Exemple de sortie
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.25.0 master-1 Ready master 73m v1.25.0 master-2 Ready master 74m v1.25.0 worker-0 Ready worker 11m v1.25.0 worker-1 Ready worker 11m v1.25.0
NoteIt can take a few minutes after approval of the server CSRs for the machines to transition to the
Readystatus.
Informations complémentaires
- For more information on CSRs, see Certificate Signing Requests.
10.3. Ajouter manuellement des machines de calcul à vSphere
Vous pouvez ajouter manuellement des machines de calcul à votre cluster OpenShift Container Platform sur VMware vSphere.
Vous pouvez également utiliser des ensembles de machines de calcul pour automatiser la création de machines de calcul VMware vSphere supplémentaires pour votre cluster.
10.3.1. Conditions préalables
- Vous avez installé un cluster sur vSphere.
- Vous disposez des supports d'installation et des images Red Hat Enterprise Linux CoreOS (RHCOS) que vous avez utilisés pour créer votre cluster. Si vous ne disposez pas de ces fichiers, vous devez les obtenir en suivant les instructions de la procédure d'installation.
Si vous n'avez pas accès aux images Red Hat Enterprise Linux CoreOS (RHCOS) qui ont été utilisées pour créer votre cluster, vous pouvez ajouter des machines de calcul à votre cluster OpenShift Container Platform avec des versions plus récentes des images Red Hat Enterprise Linux CoreOS (RHCOS). Pour obtenir des instructions, voir L'ajout de nouveaux nœuds au cluster UPI échoue après la mise à niveau vers OpenShift 4.6 .
10.3.2. Adding more compute machines to a cluster in vSphere
You can add more compute machines to a user-provisioned OpenShift Container Platform cluster on VMware vSphere.
Conditions préalables
- Obtain the base64-encoded Ignition file for your compute machines.
- You have access to the vSphere template that you created for your cluster.
Procédure
After the template deploys, deploy a VM for a machine in the cluster.
- Right-click the template’s name and click Clone → Clone to Virtual Machine.
On the Select a name and folder tab, specify a name for the VM. You might include the machine type in the name, such as
compute-1.NoteEnsure that all virtual machine names across a vSphere installation are unique.
- On the Select a name and folder tab, select the name of the folder that you created for the cluster.
- On the Select a compute resource tab, select the name of a host in your datacenter.
- Optional: On the Select storage tab, customize the storage options.
- On the Select clone options, select Customize this virtual machine’s hardware.
On the Customize hardware tab, click VM Options → Advanced.
- From the Latency Sensitivity list, select High.
Click Edit Configuration, and on the Configuration Parameters window, click Add Configuration Params. Define the following parameter names and values:
-
guestinfo.ignition.config.data: Paste the contents of the base64-encoded compute Ignition config file for this machine type. -
guestinfo.ignition.config.data.encoding: Specifybase64. -
disk.EnableUUID: SpecifyTRUE.
-
- In the Virtual Hardware panel of the Customize hardware tab, modify the specified values as required. Ensure that the amount of RAM, CPU, and disk storage meets the minimum requirements for the machine type. Also, make sure to select the correct network under Add network adapter if there are multiple networks available.
- Complete the configuration and power on the VM.
- Continue to create more compute machines for your cluster.
10.3.3. Approving the certificate signing requests for your machines
When you add machines to a cluster, two pending certificate signing requests (CSRs) are generated for each machine that you added. You must confirm that these CSRs are approved or, if necessary, approve them yourself. The client requests must be approved first, followed by the server requests.
Conditions préalables
- You added machines to your cluster.
Procédure
Confirm that the cluster recognizes the machines:
$ oc get nodes
Exemple de sortie
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.25.0 master-1 Ready master 63m v1.25.0 master-2 Ready master 64m v1.25.0
The output lists all of the machines that you created.
NoteThe preceding output might not include the compute nodes, also known as worker nodes, until some CSRs are approved.
Review the pending CSRs and ensure that you see the client requests with the
PendingorApprovedstatus for each machine that you added to the cluster:$ oc get csr
Exemple de sortie
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...
In this example, two machines are joining the cluster. You might see more approved CSRs in the list.
If the CSRs were not approved, after all of the pending CSRs for the machines you added are in
Pendingstatus, approve the CSRs for your cluster machines:NoteBecause the CSRs rotate automatically, approve your CSRs within an hour of adding the machines to the cluster. If you do not approve them within an hour, the certificates will rotate, and more than two certificates will be present for each node. You must approve all of these certificates. After the client CSR is approved, the Kubelet creates a secondary CSR for the serving certificate, which requires manual approval. Then, subsequent serving certificate renewal requests are automatically approved by the
machine-approverif the Kubelet requests a new certificate with identical parameters.NoteFor clusters running on platforms that are not machine API enabled, such as bare metal and other user-provisioned infrastructure, you must implement a method of automatically approving the kubelet serving certificate requests (CSRs). If a request is not approved, then the
oc exec,oc rsh, andoc logscommands cannot succeed, because a serving certificate is required when the API server connects to the kubelet. Any operation that contacts the Kubelet endpoint requires this certificate approval to be in place. The method must watch for new CSRs, confirm that the CSR was submitted by thenode-bootstrapperservice account in thesystem:nodeorsystem:admingroups, and confirm the identity of the node.To approve them individually, run the following command for each valid CSR:
$ oc adm certificate approve <csr_name> 1- 1
<csr_name>est le nom d'un CSR figurant dans la liste des CSR actuels.
To approve all pending CSRs, run the following command:
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approveNoteSome Operators might not become available until some CSRs are approved.
Now that your client requests are approved, you must review the server requests for each machine that you added to the cluster:
$ oc get csr
Exemple de sortie
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...
If the remaining CSRs are not approved, and are in the
Pendingstatus, approve the CSRs for your cluster machines:To approve them individually, run the following command for each valid CSR:
$ oc adm certificate approve <csr_name> 1- 1
<csr_name>est le nom d'un CSR figurant dans la liste des CSR actuels.
To approve all pending CSRs, run the following command:
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
After all client and server CSRs have been approved, the machines have the
Readystatus. Verify this by running the following command:$ oc get nodes
Exemple de sortie
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.25.0 master-1 Ready master 73m v1.25.0 master-2 Ready master 74m v1.25.0 worker-0 Ready worker 11m v1.25.0 worker-1 Ready worker 11m v1.25.0
NoteIt can take a few minutes after approval of the server CSRs for the machines to transition to the
Readystatus.
Informations complémentaires
- For more information on CSRs, see Certificate Signing Requests.
10.4. Ajouter des machines de calcul à un cluster sur RHV
Dans la version 4.12 d'OpenShift Container Platform, vous pouvez ajouter des machines de calcul à un cluster OpenShift Container Platform provisionné par l'utilisateur sur RHV.
Conditions préalables
- Vous avez installé un cluster sur RHV avec une infrastructure fournie par l'utilisateur.
10.4.1. Ajouter des machines de calcul à un cluster sur RHV
Procédure
-
Modifiez le fichier
inventory.ymlpour y inclure les nouveaux travailleurs. Exécutez le playbook Ansible
create-templates-and-vmspour créer les disques et les machines virtuelles :$ ansible-playbook -i inventory.yml create-templates-and-vms.yml
Exécutez le playbook Ansible
workers.ymlpour démarrer les machines virtuelles :$ ansible-playbook -i inventory.yml workers.yml
Les CSR des nouveaux travailleurs qui rejoignent le cluster doivent être approuvées par l'administrateur. La commande suivante permet d'approuver toutes les demandes en attente :
$ oc get csr -ojson | jq -r '.items[] | select(.status == {} ) | .metadata.name' | xargs oc adm certificate approve
10.5. Ajouter des machines de calcul à du métal nu
Vous pouvez ajouter des machines de calcul à votre cluster OpenShift Container Platform sur du métal nu.
10.5.1. Conditions préalables
- Vous avez installé un cluster sur du métal nu.
- Vous disposez des supports d'installation et des images Red Hat Enterprise Linux CoreOS (RHCOS) que vous avez utilisés pour créer votre cluster. Si vous ne disposez pas de ces fichiers, vous devez les obtenir en suivant les instructions de la procédure d'installation.
- Si un serveur DHCP est disponible pour votre infrastructure fournie par l'utilisateur, vous avez ajouté les détails des machines de calcul supplémentaires à votre configuration de serveur DHCP. Il s'agit d'une adresse IP persistante, d'informations sur le serveur DNS et d'un nom d'hôte pour chaque machine.
- Vous avez mis à jour votre configuration DNS pour inclure le nom de l'enregistrement et l'adresse IP de chaque machine de calcul que vous ajoutez. Vous avez validé que la recherche DNS et la recherche DNS inverse se résolvent correctement.
Si vous n'avez pas accès aux images Red Hat Enterprise Linux CoreOS (RHCOS) qui ont été utilisées pour créer votre cluster, vous pouvez ajouter des machines de calcul à votre cluster OpenShift Container Platform avec des versions plus récentes des images Red Hat Enterprise Linux CoreOS (RHCOS). Pour obtenir des instructions, voir L'ajout de nouveaux nœuds au cluster UPI échoue après la mise à niveau vers OpenShift 4.6 .
10.5.2. Création de machines Red Hat Enterprise Linux CoreOS (RHCOS)
Avant d'ajouter des machines de calcul à un cluster installé sur une infrastructure bare metal, vous devez créer des machines RHCOS à utiliser. Vous pouvez utiliser une image ISO ou un démarrage PXE en réseau pour créer les machines.
Vous devez utiliser la même image ISO que celle que vous avez utilisée pour installer un cluster pour déployer tous les nouveaux nœuds d'un cluster. Il est recommandé d'utiliser le même fichier de configuration Ignition. Les nœuds se mettent automatiquement à niveau lors du premier démarrage avant d'exécuter les charges de travail. Vous pouvez ajouter des nœuds avant ou après la mise à niveau.
10.5.2.1. Création d'autres machines RHCOS à l'aide d'une image ISO
Vous pouvez créer davantage de machines de calcul Red Hat Enterprise Linux CoreOS (RHCOS) pour votre cluster bare metal en utilisant une image ISO pour créer les machines.
Conditions préalables
- Obtenez l'URL du fichier de configuration Ignition pour les machines de calcul de votre cluster. Vous avez téléchargé ce fichier sur votre serveur HTTP lors de l'installation.
Procédure
Utilisez le fichier ISO pour installer RHCOS sur d'autres machines de calcul. Utilisez la même méthode que lorsque vous avez créé des machines avant d'installer le cluster :
- Burn the ISO image to a disk and boot it directly.
- Utiliser la redirection ISO avec une interface LOM.
Démarrer l'image ISO RHCOS sans spécifier d'options ni interrompre la séquence de démarrage en direct. Attendez que le programme d'installation démarre à l'invite de l'interpréteur de commandes dans l'environnement réel RHCOS.
NoteVous pouvez interrompre le processus de démarrage de l'installation RHCOS pour ajouter des arguments au noyau. Cependant, pour cette procédure ISO, vous devez utiliser la commande
coreos-installercomme indiqué dans les étapes suivantes, au lieu d'ajouter des arguments au noyau.Run the
coreos-installercommand and specify the options that meet your installation requirements. At a minimum, you must specify the URL that points to the Ignition config file for the node type, and the device that you are installing to:$ sudo coreos-installer install --ignition-url=http://<HTTP_server>/<node_type>.ign <device> --ignition-hash=sha512-<digest> 12
- 1
- You must run the
coreos-installercommand by usingsudo, because thecoreuser does not have the required root privileges to perform the installation. - 2
- The
--ignition-hashoption is required when the Ignition config file is obtained through an HTTP URL to validate the authenticity of the Ignition config file on the cluster node.<digest>is the Ignition config file SHA512 digest obtained in a preceding step.
NoteIf you want to provide your Ignition config files through an HTTPS server that uses TLS, you can add the internal certificate authority (CA) to the system trust store before running
coreos-installer.The following example initializes a bootstrap node installation to the
/dev/sdadevice. The Ignition config file for the bootstrap node is obtained from an HTTP web server with the IP address 192.168.1.2:$ sudo coreos-installer install --ignition-url=http://192.168.1.2:80/installation_directory/bootstrap.ign /dev/sda --ignition-hash=sha512-a5a2d43879223273c9b60af66b44202a1d1248fc01cf156c46d4a79f552b6bad47bc8cc78ddf0116e80c59d2ea9e32ba53bc807afbca581aa059311def2c3e3b
Monitor the progress of the RHCOS installation on the console of the machine.
ImportantAssurez-vous que l'installation est réussie sur chaque nœud avant de commencer l'installation d'OpenShift Container Platform. L'observation du processus d'installation peut également aider à déterminer la cause des problèmes d'installation du RHCOS qui pourraient survenir.
- Continue to create more compute machines for your cluster.
10.5.2.2. Création d'autres machines RHCOS par démarrage PXE ou iPXE
Vous pouvez créer davantage de machines de calcul Red Hat Enterprise Linux CoreOS (RHCOS) pour votre cluster bare metal en utilisant le démarrage PXE ou iPXE.
Conditions préalables
- Obtenez l'URL du fichier de configuration Ignition pour les machines de calcul de votre cluster. Vous avez téléchargé ce fichier sur votre serveur HTTP lors de l'installation.
-
Obtenez les URL de l'image ISO RHCOS, du BIOS métallique compressé, de
kernelet deinitramfsque vous avez téléchargés sur votre serveur HTTP lors de l'installation du cluster. - Vous avez accès à l'infrastructure de démarrage PXE que vous avez utilisée pour créer les machines de votre cluster OpenShift Container Platform lors de l'installation. Les machines doivent démarrer à partir de leurs disques locaux après l'installation de RHCOS.
-
Si vous utilisez l'UEFI, vous avez accès au fichier
grub.confque vous avez modifié lors de l'installation d'OpenShift Container Platform.
Procédure
Confirmez que votre installation PXE ou iPXE pour les images RHCOS est correcte.
Pour PXE :
DEFAULT pxeboot TIMEOUT 20 PROMPT 0 LABEL pxeboot KERNEL http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture> 1 APPEND initrd=http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img 2- 1
- Indiquez l'emplacement du fichier live
kernelque vous avez téléchargé sur votre serveur HTTP. - 2
- Indiquez l'emplacement des fichiers RHCOS que vous avez téléchargés sur votre serveur HTTP. La valeur du paramètre
initrdcorrespond à l'emplacement du fichierinitramfs, la valeur du paramètrecoreos.inst.ignition_urlcorrespond à l'emplacement du fichier de configuration Ignition et la valeur du paramètrecoreos.live.rootfs_urlcorrespond à l'emplacement du fichierrootfs. Les paramètrescoreos.inst.ignition_urletcoreos.live.rootfs_urlne prennent en charge que HTTP et HTTPS.
Cette configuration ne permet pas l'accès à la console série sur les machines dotées d'une console graphique. Pour configurer une console différente, ajoutez un ou plusieurs arguments console= à la ligne APPEND. Par exemple, ajoutez console=tty0 console=ttyS0 pour définir le premier port série du PC comme console primaire et la console graphique comme console secondaire. Pour plus d'informations, reportez-vous à Comment configurer un terminal série et/ou une console dans Red Hat Enterprise Linux ?
Pour iPXE :
kernel http://<HTTP_server>/rhcos-<version>-live-kernel-<architecture> initrd=main coreos.inst.install_dev=/dev/sda coreos.inst.ignition_url=http://<HTTP_server>/worker.ign coreos.live.rootfs_url=http://<HTTP_server>/rhcos-<version>-live-rootfs.<architecture>.img 1 initrd --name main http://<HTTP_server>/rhcos-<version>-live-initramfs.<architecture>.img 2
- 1
- Spécifiez l'emplacement des fichiers RHCOS que vous avez téléchargés sur votre serveur HTTP. La valeur du paramètre
kernelcorrespond à l'emplacement du fichierkernel, l'argumentinitrd=mainest nécessaire pour le démarrage sur les systèmes UEFI, la valeur du paramètrecoreos.inst.ignition_urlcorrespond à l'emplacement du fichier de configuration Ignition worker et la valeur du paramètrecoreos.live.rootfs_urlcorrespond à l'emplacement du fichierrootfslive. Les paramètrescoreos.inst.ignition_urletcoreos.live.rootfs_urlne prennent en charge que les protocoles HTTP et HTTPS. - 2
- Specify the location of the
initramfsfile that you uploaded to your HTTP server.
Cette configuration ne permet pas l'accès à la console série sur les machines dotées d'une console graphique. Pour configurer une console différente, ajoutez un ou plusieurs arguments console= à la ligne kernel. Par exemple, ajoutez console=tty0 console=ttyS0 pour définir le premier port série du PC comme console primaire et la console graphique comme console secondaire. Pour plus d'informations, reportez-vous à Comment configurer un terminal série et/ou une console dans Red Hat Enterprise Linux ?
- Utilisez l'infrastructure PXE ou iPXE pour créer les machines de calcul nécessaires à votre cluster.
10.5.3. Approving the certificate signing requests for your machines
When you add machines to a cluster, two pending certificate signing requests (CSRs) are generated for each machine that you added. You must confirm that these CSRs are approved or, if necessary, approve them yourself. The client requests must be approved first, followed by the server requests.
Conditions préalables
- You added machines to your cluster.
Procédure
Confirm that the cluster recognizes the machines:
$ oc get nodes
Exemple de sortie
NAME STATUS ROLES AGE VERSION master-0 Ready master 63m v1.25.0 master-1 Ready master 63m v1.25.0 master-2 Ready master 64m v1.25.0
The output lists all of the machines that you created.
NoteThe preceding output might not include the compute nodes, also known as worker nodes, until some CSRs are approved.
Review the pending CSRs and ensure that you see the client requests with the
PendingorApprovedstatus for each machine that you added to the cluster:$ oc get csr
Exemple de sortie
NAME AGE REQUESTOR CONDITION csr-8b2br 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending csr-8vnps 15m system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...
In this example, two machines are joining the cluster. You might see more approved CSRs in the list.
If the CSRs were not approved, after all of the pending CSRs for the machines you added are in
Pendingstatus, approve the CSRs for your cluster machines:NoteBecause the CSRs rotate automatically, approve your CSRs within an hour of adding the machines to the cluster. If you do not approve them within an hour, the certificates will rotate, and more than two certificates will be present for each node. You must approve all of these certificates. After the client CSR is approved, the Kubelet creates a secondary CSR for the serving certificate, which requires manual approval. Then, subsequent serving certificate renewal requests are automatically approved by the
machine-approverif the Kubelet requests a new certificate with identical parameters.NoteFor clusters running on platforms that are not machine API enabled, such as bare metal and other user-provisioned infrastructure, you must implement a method of automatically approving the kubelet serving certificate requests (CSRs). If a request is not approved, then the
oc exec,oc rsh, andoc logscommands cannot succeed, because a serving certificate is required when the API server connects to the kubelet. Any operation that contacts the Kubelet endpoint requires this certificate approval to be in place. The method must watch for new CSRs, confirm that the CSR was submitted by thenode-bootstrapperservice account in thesystem:nodeorsystem:admingroups, and confirm the identity of the node.To approve them individually, run the following command for each valid CSR:
$ oc adm certificate approve <csr_name> 1- 1
<csr_name>est le nom d'un CSR figurant dans la liste des CSR actuels.
To approve all pending CSRs, run the following command:
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs --no-run-if-empty oc adm certificate approveNoteSome Operators might not become available until some CSRs are approved.
Now that your client requests are approved, you must review the server requests for each machine that you added to the cluster:
$ oc get csr
Exemple de sortie
NAME AGE REQUESTOR CONDITION csr-bfd72 5m26s system:node:ip-10-0-50-126.us-east-2.compute.internal Pending csr-c57lv 5m26s system:node:ip-10-0-95-157.us-east-2.compute.internal Pending ...
If the remaining CSRs are not approved, and are in the
Pendingstatus, approve the CSRs for your cluster machines:To approve them individually, run the following command for each valid CSR:
$ oc adm certificate approve <csr_name> 1- 1
<csr_name>est le nom d'un CSR figurant dans la liste des CSR actuels.
To approve all pending CSRs, run the following command:
$ oc get csr -o go-template='{{range .items}}{{if not .status}}{{.metadata.name}}{{"\n"}}{{end}}{{end}}' | xargs oc adm certificate approve
After all client and server CSRs have been approved, the machines have the
Readystatus. Verify this by running the following command:$ oc get nodes
Exemple de sortie
NAME STATUS ROLES AGE VERSION master-0 Ready master 73m v1.25.0 master-1 Ready master 73m v1.25.0 master-2 Ready master 74m v1.25.0 worker-0 Ready worker 11m v1.25.0 worker-1 Ready worker 11m v1.25.0
NoteIt can take a few minutes after approval of the server CSRs for the machines to transition to the
Readystatus.
Informations complémentaires
- For more information on CSRs, see Certificate Signing Requests.
Chapitre 11. Gérer les machines avec l'API Cluster
La gestion des machines avec l'API de cluster est une fonctionnalité d'aperçu technologique uniquement. Les fonctionnalités de l'aperçu technologique ne sont pas prises en charge par les accords de niveau de service (SLA) de production de Red Hat et peuvent ne pas être complètes sur le plan fonctionnel. Red Hat ne recommande pas de les utiliser en production. Ces fonctionnalités offrent un accès anticipé aux fonctionnalités des produits à venir, ce qui permet aux clients de tester les fonctionnalités et de fournir un retour d'information pendant le processus de développement.
Pour plus d'informations sur la portée de l'assistance des fonctionnalités de l'aperçu technologique de Red Hat, voir Portée de l'assistance des fonctionnalités de l'aperçu technologique.
L'API Cl uster est un projet en amont intégré à OpenShift Container Platform en tant qu'aperçu technologique pour les clusters Amazon Web Services (AWS) et Google Cloud Platform (GCP). Vous pouvez utiliser l'API Cluster pour créer et gérer des ensembles de machines de calcul et des machines dans votre cluster OpenShift Container Platform. Cette fonctionnalité s'ajoute à la gestion des machines à l'aide de l'API Machine ou constitue une alternative à cette dernière.
Pour les clusters OpenShift Container Platform 4.12, vous pouvez utiliser l'API Cluster pour effectuer des actions de gestion du provisionnement de l'hôte du nœud une fois l'installation du cluster terminée. Ce système permet une méthode de provisionnement élastique et dynamique au-dessus de l'infrastructure de cloud public ou privé.
Avec l'API Cluster Technology Preview, vous pouvez créer des machines de calcul et des ensembles de machines de calcul sur les clusters d'OpenShift Container Platform pour les fournisseurs pris en charge. Vous pouvez également explorer les fonctionnalités permises par cette implémentation qui pourraient ne pas être disponibles avec l'API Machine.
Avantages
En utilisant l'API Cluster, les utilisateurs et les développeurs d'OpenShift Container Platform peuvent bénéficier des avantages suivants :
- L'option d'utiliser les fournisseurs d'infrastructure de l'API Cluster de la communauté en amont qui pourraient ne pas être pris en charge par l'API Machine.
- La possibilité de collaborer avec des tiers qui assurent la maintenance des contrôleurs de machines pour les fournisseurs d'infrastructure.
- La possibilité d'utiliser le même ensemble d'outils Kubernetes pour la gestion de l'infrastructure dans OpenShift Container Platform.
- La possibilité de créer des ensembles de machines de calcul à l'aide de l'API Cluster qui prennent en charge des fonctionnalités qui ne sont pas disponibles avec l'API Machine.
Limitations
L'utilisation de l'API Cluster pour gérer les machines est une fonctionnalité de l'aperçu technologique et présente les limitations suivantes :
- Seuls les clusters AWS et GCP sont pris en charge.
-
Pour utiliser cette fonctionnalité, vous devez activer le portail de fonctionnalités
ClusterAPIEnableddans l'ensemble de fonctionnalitésTechPreviewNoUpgrade. L'activation de cet ensemble de fonctionnalités ne peut être annulée et empêche les mises à jour mineures de la version. - Vous devez créer manuellement les ressources primaires dont l'API de cluster a besoin.
- Les machines du plan de contrôle ne peuvent pas être gérées par l'API Cluster.
- La migration des ensembles de machines de calcul existants créés par l'API Machine vers des ensembles de machines de calcul de l'API Cluster n'est pas prise en charge.
- Il n'y a pas de parité totale des fonctionnalités avec l'API Machine.
11.1. Architecture de l'API de la grappe
L'intégration par OpenShift Container Platform de l'API Cluster en amont est mise en œuvre et gérée par l'opérateur CAPI Cluster. L'Opérateur CAPI Cluster et ses opérandes sont provisionnés dans l'espace de noms openshift-cluster-api, contrairement à l'API Machine, qui utilise l'espace de noms openshift-machine-api.
11.1.1. L'opérateur CAPI du cluster
L'opérateur Cluster CAPI est un opérateur OpenShift Container Platform qui maintient le cycle de vie des ressources Cluster API. Cet opérateur est responsable de toutes les tâches administratives liées au déploiement du projet Cluster API au sein d'un cluster OpenShift Container Platform.
Si une grappe est correctement configurée pour permettre l'utilisation de l'API de grappe, l'opérateur CAPI de grappe installe l'opérateur API de grappe sur la grappe.
L'opérateur CAPI de cluster est distinct de l'opérateur API de cluster en amont.
Pour plus d'informations, voir l'entrée relative à l'opérateur CAPI de cluster dans le contenu Cluster Operators reference.
11.1.2. Ressources primaires
L'API Cluster est composée des ressources primaires suivantes. Pour l'aperçu technologique de cette fonctionnalité, vous devez créer ces ressources manuellement dans l'espace de noms openshift-cluster-api.
- Groupement d'entreprises
- Unité fondamentale qui représente un cluster géré par l'API Cluster.
- Infrastructure
- Une ressource spécifique au fournisseur qui définit les propriétés partagées par tous les ensembles de machines de calcul dans le cluster, telles que la région et les sous-réseaux.
- Modèle de machine
- Un modèle spécifique au fournisseur qui définit les propriétés des machines qu'un ensemble de machines de calcul crée.
- Ensemble de machines
Un groupe de machines.
Les jeux de machines de calcul sont aux machines ce que les jeux de répliques sont aux pods. Si vous avez besoin de plus de machines ou si vous devez les réduire, vous modifiez le champ
replicasde l'ensemble de machines de calcul pour répondre à vos besoins de calcul.Avec l'API Cluster, un ensemble de machines de calcul fait référence à un objet
Clusteret à un modèle de machine spécifique au fournisseur.- Machine
Unité fondamentale décrivant l'hôte d'un nœud.
L'API Cluster crée des machines sur la base de la configuration du modèle de machine.
Ressources complémentaires
11.2. Exemples de fichiers YAML
Pour l'aperçu technologique de l'API de cluster, vous devez créer manuellement les ressources primaires dont l'API de cluster a besoin. Les exemples de fichiers YAML de cette section montrent comment faire fonctionner ces ressources ensemble et configurer les paramètres des machines qu'elles créent en fonction de votre environnement.
11.2.1. Exemple de YAML pour une ressource de cluster de l'API Cluster
La ressource cluster définit le nom et le fournisseur d'infrastructure pour le cluster et est gérée par l'API Cluster. Cette ressource a la même structure pour tous les fournisseurs.
apiVersion: cluster.x-k8s.io/v1beta1 kind: Cluster metadata: name: <cluster_name> 1 namespace: openshift-cluster-api spec: infrastructureRef: apiVersion: infrastructure.cluster.x-k8s.io/v1beta1 kind: <infrastructure_kind> 2 name: <cluster_name> 3 namespace: openshift-cluster-api
Les autres ressources de l'API Cluster sont spécifiques à chaque fournisseur. Reportez-vous aux exemples de fichiers YAML pour votre cluster :
11.2.2. Exemples de fichiers YAML pour la configuration des clusters Amazon Web Services
Certaines ressources de l'API Cluster sont spécifiques à un fournisseur. Les exemples de fichiers YAML de cette section présentent des configurations pour un cluster Amazon Web Services (AWS).
11.2.2.1. Exemple de YAML pour une ressource d'infrastructure Cluster API sur Amazon Web Services
La ressource d'infrastructure est spécifique au fournisseur et définit des propriétés qui sont partagées par tous les ensembles de machines de calcul dans le cluster, telles que la région et les sous-réseaux. L'ensemble de machines de calcul fait référence à cette ressource lorsqu'il crée des machines.
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1 kind: AWSCluster 1 metadata: name: <cluster_name> 2 namespace: openshift-cluster-api spec: region: <region> 3
11.2.2.2. Exemple de YAML pour une ressource modèle de machine Cluster API sur Amazon Web Services
La ressource modèle de machine est spécifique au fournisseur et définit les propriétés de base des machines qu'un ensemble de machines de calcul crée. L'ensemble de machines de calcul fait référence à ce modèle lorsqu'il crée des machines.
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha4 kind: AWSMachineTemplate 1 metadata: name: <template_name> 2 namespace: openshift-cluster-api spec: template: spec: 3 uncompressedUserData: true iamInstanceProfile: .... instanceType: m5.large cloudInit: insecureSkipSecretsManager: true ami: id: .... subnet: filters: - name: tag:Name values: - ... additionalSecurityGroups: - filters: - name: tag:Name values: - ...
11.2.2.3. Exemple de YAML pour un ensemble de machines de calcul Cluster API sur Amazon Web Services
La ressource Ensemble de machines de calcul définit des propriétés supplémentaires pour les machines qu'elle crée. Le jeu de machines de calcul fait également référence à la ressource d'infrastructure et au modèle de machine lors de la création de machines.
apiVersion: cluster.x-k8s.io/v1alpha4 kind: MachineSet metadata: name: <machine_set_name> 1 namespace: openshift-cluster-api spec: clusterName: <cluster_name> 2 replicas: 1 selector: matchLabels: test: example template: metadata: labels: test: example spec: bootstrap: dataSecretName: worker-user-data 3 clusterName: <cluster_name> 4 infrastructureRef: apiVersion: infrastructure.cluster.x-k8s.io/v1alpha4 kind: AWSMachineTemplate 5 name: <cluster_name> 6
- 1
- Spécifiez un nom pour l'ensemble de machines de calcul.
- 2 4 6
- Specify the name of the cluster.
- 3
- Pour l'API Cluster Technology Preview, l'opérateur peut utiliser le secret des données de l'utilisateur du travailleur à partir de l'espace de noms
openshift-machine-api. - 5
- Indiquez le type de modèle de machine. Cette valeur doit correspondre à celle de votre plate-forme.
11.2.3. Exemples de fichiers YAML pour la configuration des clusters Google Cloud Platform
Certaines ressources de l'API Cluster sont spécifiques à un fournisseur. Les exemples de fichiers YAML de cette section présentent des configurations pour un cluster Google Cloud Platform (GCP).
11.2.3.1. Exemple de YAML pour une ressource d'infrastructure Cluster API sur Google Cloud Platform
La ressource d'infrastructure est spécifique au fournisseur et définit des propriétés qui sont partagées par tous les ensembles de machines de calcul dans le cluster, telles que la région et les sous-réseaux. L'ensemble de machines de calcul fait référence à cette ressource lorsqu'il crée des machines.
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1 kind: GCPCluster 1 metadata: name: <cluster_name> 2 spec: network: name: <cluster_name>-network 3 project: <project> 4 region: <region> 5
11.2.3.2. Exemple de YAML pour une ressource de modèle de machine Cluster API sur Google Cloud Platform
La ressource modèle de machine est spécifique au fournisseur et définit les propriétés de base des machines qu'un ensemble de machines de calcul crée. L'ensemble de machines de calcul fait référence à ce modèle lorsqu'il crée des machines.
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1 kind: GCPMachineTemplate 1 metadata: name: <template_name> 2 namespace: openshift-cluster-api spec: template: spec: 3 rootDeviceType: pd-ssd rootDeviceSize: 128 instanceType: n1-standard-4 image: projects/rhcos-cloud/global/images/rhcos-411-85-202203181601-0-gcp-x86-64 subnet: <cluster_name>-worker-subnet serviceAccounts: email: <service_account_email_address> scopes: - https://www.googleapis.com/auth/cloud-platform additionalLabels: kubernetes-io-cluster-<cluster_name>: owned additionalNetworkTags: - <cluster_name>-worker ipForwarding: Disabled
11.2.3.3. Exemple de YAML pour une ressource d'ensemble de machines de calcul Cluster API sur Google Cloud Platform
La ressource Ensemble de machines de calcul définit des propriétés supplémentaires pour les machines qu'elle crée. Le jeu de machines de calcul fait également référence à la ressource d'infrastructure et au modèle de machine lors de la création de machines.
apiVersion: cluster.x-k8s.io/v1beta1 kind: MachineSet metadata: name: <machine_set_name> 1 namespace: openshift-cluster-api spec: clusterName: <cluster_name> 2 replicas: 1 selector: matchLabels: test: test template: metadata: labels: test: test spec: bootstrap: dataSecretName: worker-user-data 3 clusterName: <cluster_name> 4 infrastructureRef: apiVersion: infrastructure.cluster.x-k8s.io/v1beta1 kind: GCPMachineTemplate 5 name: <machine_set_name> 6 failureDomain: <failure_domain> 7
- 1 6
- Spécifiez un nom pour l'ensemble de machines de calcul.
- 2 4
- Specify the name of the cluster.
- 3
- Pour l'API Cluster Technology Preview, l'opérateur peut utiliser le secret des données de l'utilisateur du travailleur à partir de l'espace de noms
openshift-machine-api. - 5
- Indiquez le type de modèle de machine. Cette valeur doit correspondre à celle de votre plate-forme.
- 7
- Spécifiez le domaine de défaillance dans la région GCP.
11.3. Création d'un ensemble de machines de calcul Cluster API
Vous pouvez créer des ensembles de machines de calcul qui utilisent l'API de cluster pour gérer dynamiquement les ressources de calcul des machines pour des charges de travail spécifiques de votre choix.
Conditions préalables
- Déployer un cluster OpenShift Container Platform.
- Activer l'utilisation de l'API Cluster.
-
Installez le CLI OpenShift (
oc). -
Connectez-vous à
ocen tant qu'utilisateur disposant de l'autorisationcluster-admin.
Procédure
Créez un fichier YAML contenant la ressource personnalisée (CR) du cluster et nommé
<cluster_resource_file>.yaml.Si vous n'êtes pas sûr de la valeur à définir pour le paramètre
<cluster_name>, vous pouvez vérifier la valeur d'un ensemble de machines de calcul Machine API existant dans votre cluster.Pour répertorier les ensembles de machines de calcul de l'API Machine, exécutez la commande suivante :
$ oc get machinesets -n openshift-machine-api 1- 1
- Spécifiez l'espace de noms
openshift-machine-api.
Exemple de sortie
NAME DESIRED CURRENT READY AVAILABLE AGE agl030519-vplxk-worker-us-east-1a 1 1 1 1 55m agl030519-vplxk-worker-us-east-1b 1 1 1 1 55m agl030519-vplxk-worker-us-east-1c 1 1 1 1 55m agl030519-vplxk-worker-us-east-1d 0 0 55m agl030519-vplxk-worker-us-east-1e 0 0 55m agl030519-vplxk-worker-us-east-1f 0 0 55m
Pour afficher le contenu d'un ensemble de machines de calcul CR spécifique, exécutez la commande suivante :
$ oc get machineset <machineset_name> \ -n openshift-machine-api \ -o yaml
Exemple de sortie
... template: metadata: labels: machine.openshift.io/cluster-api-cluster: agl030519-vplxk 1 machine.openshift.io/cluster-api-machine-role: worker machine.openshift.io/cluster-api-machine-type: worker machine.openshift.io/cluster-api-machineset: agl030519-vplxk-worker-us-east-1a ...- 1
- L'ID du cluster, que vous utilisez pour le paramètre
<cluster_name>.
Créez le cluster CR en exécutant la commande suivante :
oc create -f <cluster_resource_file>.yaml
Vérification
Pour confirmer que le cluster CR est créé, exécutez la commande suivante :
$ oc get cluster
Exemple de sortie
NAME PHASE AGE VERSION <cluster_name> Provisioning 4h6m
-
Créez un fichier YAML contenant le CR de l'infrastructure et nommé
<infrastructure_resource_file>.yaml. Créez l'infrastructure CR en exécutant la commande suivante :
oc create -f <infrastructure_resource_file>.yaml
Vérification
Pour confirmer que le CR d'infrastructure est créé, exécutez la commande suivante :
oc get <infrastructure_kind>
où
<infrastructure_kind>est la valeur correspondant à votre plate-forme.Exemple de sortie
NAME CLUSTER READY VPC BASTION IP <cluster_name> <cluster_name> true
-
Créez un fichier YAML contenant le modèle de machine CR et nommé
<machine_template_resource_file>.yaml. Créez le modèle de machine CR en exécutant la commande suivante :
oc create -f <machine_template_resource_file>.yaml
Vérification
Pour confirmer que le modèle de machine CR est créé, exécutez la commande suivante :
oc get <machine_template_kind>
où
<machine_template_kind>est la valeur correspondant à votre plate-forme.Exemple de sortie
NAME AGE <template_name> 77m
-
Créez un fichier YAML contenant l'ensemble de machines de calcul CR et nommé
<machine_set_resource_file>.yaml. Créez l'ensemble de machines de calcul CR en exécutant la commande suivante :
oc create -f <machine_set_resource_file>.yaml
Vérification
Pour confirmer que l'ensemble de machines de calcul CR est créé, exécutez la commande suivante :
oc get machineset -n openshift-cluster-api 1- 1
- Spécifiez l'espace de noms
openshift-cluster-api.
Exemple de sortie
NAME CLUSTER REPLICAS READY AVAILABLE AGE VERSION <machine_set_name> <cluster_name> 1 1 1 17m
Lorsque le nouveau jeu de machines de calcul est disponible, les valeurs
REPLICASetAVAILABLEcorrespondent. Si le jeu de machines de calcul n'est pas disponible, attendez quelques minutes et exécutez à nouveau la commande.
Vérification
Pour vérifier que l'ensemble de machines de calcul crée des machines selon la configuration souhaitée, vous pouvez consulter les listes de machines et de nœuds dans le cluster.
Pour afficher la liste des machines Cluster API, exécutez la commande suivante :
oc get machine -n openshift-cluster-api 1- 1
- Spécifiez l'espace de noms
openshift-cluster-api.
Exemple de sortie
NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION <machine_set_name>-<string_id> <cluster_name> <ip_address>.<region>.compute.internal <provider_id> Running 8m23s
Pour afficher la liste des nœuds, exécutez la commande suivante :
$ oc get node
Exemple de sortie
NAME STATUS ROLES AGE VERSION <ip_address_1>.<region>.compute.internal Ready worker 5h14m v1.25.0 <ip_address_2>.<region>.compute.internal Ready master 5h19m v1.25.0 <ip_address_3>.<region>.compute.internal Ready worker 7m v1.25.0
11.4. Dépannage des clusters qui utilisent l'API Cluster
Utilisez les informations de cette section pour comprendre et résoudre les problèmes que vous pourriez rencontrer. En règle générale, les étapes de dépannage des problèmes liés à l'API Cluster sont similaires à celles des problèmes liés à l'API Machine.
L'opérateur CAPI de cluster et ses opérandes sont fournis dans l'espace de noms openshift-cluster-api, tandis que l'API de machine utilise l'espace de noms openshift-machine-api. Lorsque vous utilisez les commandes oc qui font référence à un espace de noms, veillez à faire référence au bon espace de noms.
11.4.1. Les commandes CLI renvoient les machines de l'API Cluster
Pour les clusters qui utilisent l'API Cluster, les commandes oc telles que oc get machine renvoient des résultats pour les machines de l'API Cluster. Comme la lettre c précède la lettre m dans l'ordre alphabétique, les machines de l'API Cluster apparaissent dans les résultats avant les machines de l'API Machine.
Pour ne répertorier que les machines de l'API Machine, utilisez le nom complet
machines.machine.openshift.iolors de l'exécution de la commandeoc get machine:$ oc get machines.machine.openshift.io
Pour ne répertorier que les machines Cluster API, utilisez le nom complet
machines.cluster.x-k8s.iolors de l'exécution de la commandeoc get machine:$ oc get machines.cluster.x-k8s.io
Chapitre 12. Gestion des machines du plan de contrôle
12.1. A propos des jeux de machines à plan de contrôle
Avec les jeux de machines du plan de contrôle, vous pouvez automatiser la gestion des ressources des machines du plan de contrôle au sein de votre cluster OpenShift Container Platform.
Les ensembles de machines du plan de contrôle ne peuvent pas gérer les machines de calcul, et les ensembles de machines de calcul ne peuvent pas gérer les machines du plan de contrôle.
Les jeux de machines du plan de contrôle offrent aux machines du plan de contrôle des capacités de gestion similaires à celles que les jeux de machines de calcul offrent aux machines de calcul. Toutefois, ces deux types de jeux de machines sont des ressources personnalisées distinctes définies dans l'API Machine et présentent plusieurs différences fondamentales dans leur architecture et leur fonctionnalité.
12.1.1. Vue d'ensemble de l'opérateur de l'ensemble de la machine Control Plane
Le Control Plane Machine Set Operator utilise la ressource personnalisée (CR) ControlPlaneMachineSet pour automatiser la gestion des ressources machine du plan de contrôle au sein de votre cluster OpenShift Container Platform.
Lorsque l'état de l'ensemble des machines du plan de contrôle de la grappe est défini sur Active, l'opérateur s'assure que la grappe dispose du nombre correct de machines du plan de contrôle avec la configuration spécifiée. Cela permet d'automatiser le remplacement des machines du plan de contrôle dégradées et le déploiement des modifications apportées au plan de contrôle.
Un cluster n'a qu'un seul jeu de machines du plan de contrôle, et l'opérateur ne gère que les objets de l'espace de noms openshift-machine-api.
12.1.2. Limitations
Le régleur de machine à plan de contrôle est soumis aux limitations suivantes :
-
L'opérateur nécessite que l'opérateur API Machine soit opérationnel et n'est donc pas pris en charge sur les clusters avec des machines provisionnées manuellement. Lors de l'installation d'un cluster OpenShift Container Platform avec des machines provisionnées manuellement pour une plateforme qui crée une ressource personnalisée (CR)
ControlPlaneMachineSetgénérée activement, vous devez supprimer les fichiers manifestes Kubernetes qui définissent l'ensemble de machines du plan de contrôle comme indiqué dans le processus d'installation. - Seuls les clusters Amazon Web Services (AWS), Microsoft Azure et VMware vSphere sont pris en charge.
- Seuls les clusters avec trois machines de plan de contrôle sont pris en charge.
- La mise à l'échelle horizontale du plan de contrôle n'est pas prise en charge.
- Le déploiement des machines du plan de contrôle Azure sur des disques OS éphémères augmente le risque de perte de données et n'est pas pris en charge.
Le déploiement de machines de plan de contrôle en tant qu'instances AWS Spot ou VM Azure Spot n'est pas pris en charge.
ImportantLa tentative de déploiement des machines du plan de contrôle en tant qu'instances AWS Spot ou VM Azure Spot peut entraîner la perte du quorum etcd dans le cluster. Un cluster qui perd simultanément toutes les machines du plan de contrôle est irrécupérable.
- Il n'est pas possible de modifier le jeu de machines du plan de contrôle pendant ou avant l'installation. Vous ne devez modifier le jeu de machines du plan de contrôle qu'après l'installation.
12.1.3. Ressources complémentaires
12.2. Premiers pas avec les jeux de machines pour les plans de contrôle
Le processus de démarrage des jeux de machines du plan de contrôle dépend de l'état de la ressource personnalisée (CR) ControlPlaneMachineSet dans votre cluster.
- Clusters avec un CR généré actif
- Les clusters qui ont un CR généré avec un état actif utilisent la machine du plan de contrôle définie par défaut. Aucune action de l'administrateur n'est requise.
- Clusters avec un CR généré inactif
- Pour les clusters qui incluent une CR générée inactive, vous devez revoir la configuration de la CR et l'activer.
- Groupes sans CR généré
- Pour les clusters qui n'incluent pas de CR généré, vous devez créer et activer un CR avec la configuration appropriée pour votre cluster.
Si vous n'êtes pas sûr de l'état de la CR ControlPlaneMachineSet dans votre cluster, vous pouvez vérifier l'état de la CR.
12.2.1. Fournisseurs de services en nuage pris en charge
Dans OpenShift Container Platform 4.12, les jeux de machines du plan de contrôle sont pris en charge pour les clusters Amazon Web Services (AWS), Microsoft Azure et VMware vSphere.
L'état de l'ensemble des machines du plan de contrôle après l'installation dépend de votre fournisseur de cloud et de la version d'OpenShift Container Platform que vous avez installée sur votre cluster.
Tableau 12.1. Mise en œuvre de l'ensemble des machines du plan de contrôle pour OpenShift Container Platform 4.12
| Fournisseur d'informatique en nuage | Actif par défaut | CR généré | CR manuel nécessaire |
|---|---|---|---|
| Amazon Web Services (AWS) | X [1] | X | |
| Microsoft Azure | X | ||
| VMware vSphere | X |
- Les clusters AWS mis à niveau vers la version 4.12 à partir d'une version antérieure nécessitent une activation CR.
12.2.2. Vérification de l'état des ressources personnalisées de l'ensemble des machines du plan de contrôle
Vous pouvez vérifier l'existence et l'état de la ressource personnalisée (CR) ControlPlaneMachineSet.
Procédure
Déterminez l'état de la CR en exécutant la commande suivante :
$ oc get controlplanemachineset.machine.openshift.io cluster \ --namespace openshift-machine-api
-
Un résultat de
Activeindique que la CRControlPlaneMachineSetexiste et est activée. Aucune action de l'administrateur n'est requise. -
Un résultat de
Inactiveindique qu'une CRControlPlaneMachineSetexiste mais qu'elle n'est pas activée. -
Un résultat de
NotFoundindique qu'il n'existe pas de CRControlPlaneMachineSet.
-
Un résultat de
Prochaines étapes
Pour utiliser le jeu de machines du plan de contrôle, vous devez vous assurer qu'il existe un CR ControlPlaneMachineSet avec les paramètres corrects pour votre cluster.
- Si votre cluster dispose d'un CR existant, vous devez vérifier que la configuration du CR est correcte pour votre cluster.
- Si votre cluster n'a pas de CR existant, vous devez en créer un avec la configuration correcte pour votre cluster.
12.2.3. Activation de la ressource personnalisée de l'ensemble des machines du plan de contrôle
Pour utiliser le jeu de machines du plan de contrôle, vous devez vous assurer qu'il existe une ressource personnalisée (CR) ControlPlaneMachineSet avec les paramètres corrects pour votre cluster. Sur un cluster avec une CR générée, vous devez vérifier que la configuration de la CR est correcte pour votre cluster et l'activer.
Pour plus d'informations sur les paramètres du CR, voir "Control plane machine set configuration".
Procédure
Affichez la configuration du CR en exécutant la commande suivante :
$ oc --namespace openshift-machine-api edit controlplanemachineset.machine.openshift.io cluster
- Modifiez les valeurs des champs qui ne correspondent pas à la configuration de votre cluster.
Lorsque la configuration est correcte, activez la CR en définissant le champ
.spec.statesurActiveet en enregistrant vos modifications.ImportantPour activer la RC, vous devez remplacer le champ
.spec.stateparActivedans la même sessionoc editque celle que vous utilisez pour mettre à jour la configuration de la RC. Si la RC est sauvegardée avec l'étatInactive, le générateur de jeux de machines du plan de contrôle réinitialise la RC à ses paramètres d'origine.
Ressources complémentaires
12.2.4. Création d'une ressource personnalisée du jeu de machines du plan de contrôle
Pour utiliser le jeu de machines du plan de contrôle, vous devez vous assurer qu'il existe une ressource personnalisée (CR) ControlPlaneMachineSet avec les paramètres corrects pour votre cluster. Sur un cluster sans CR générée, vous devez créer la CR manuellement et l'activer.
Pour plus d'informations sur la structure et les paramètres de la CR, voir "Control plane machine set configuration".
Procédure
Créez un fichier YAML en utilisant le modèle suivant :
Modèle de fichier YAML du jeu de machines du plan de contrôle CR
apiVersion: machine.openshift.io/v1 kind: ControlPlaneMachineSet metadata: name: cluster namespace: openshift-machine-api spec: replicas: 3 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <cluster_id> 1 machine.openshift.io/cluster-api-machine-role: master machine.openshift.io/cluster-api-machine-type: master state: Active 2 strategy: type: RollingUpdate 3 template: machineType: machines_v1beta1_machine_openshift_io machines_v1beta1_machine_openshift_io: failureDomains: platform: <platform> 4 <platform_failure_domains> 5 metadata: labels: machine.openshift.io/cluster-api-cluster: <cluster_id> 6 machine.openshift.io/cluster-api-machine-role: master machine.openshift.io/cluster-api-machine-type: master spec: providerSpec: value: <platform_provider_spec> 7- 1
- Spécifiez l'ID d'infrastructure basé sur l'ID de cluster que vous avez défini lors du provisionnement du cluster. Vous devez spécifier cette valeur lorsque vous créez un CR
ControlPlaneMachineSet. Si l'OpenShift CLI (oc) est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 2
- Indiquer l'état de l'opérateur. Lorsque l'état est
Inactive, l'opérateur n'est pas opérationnel. Vous pouvez activer l'opérateur en définissant la valeurActive.ImportantAvant d'activer le CR, vous devez vous assurer que sa configuration est adaptée aux besoins de votre cluster.
- 3
- Spécifie la stratégie de mise à jour pour le cluster. Les valeurs autorisées sont
OnDeleteetRollingUpdate. La valeur par défaut estRollingUpdate. - 4
- Indiquez le nom de la plate-forme de votre fournisseur de cloud. Les valeurs autorisées sont
AWS,Azure, etVSphere. - 5
- Ajoutez la configuration
<platform_failure_domains>pour le cluster. Le format et les valeurs de cette section sont spécifiques au fournisseur. Pour plus d'informations, consultez l'exemple de configuration du domaine de défaillance de votre fournisseur de cloud.NoteVMware vSphere ne prend pas en charge les domaines de défaillance. Pour les clusters vSphere, remplacez
<platform_failure_domains>par un paramètrefailureDomains:vide. - 6
- Spécifiez l'ID de l'infrastructure.
- 7
- Ajoutez la configuration
<platform_provider_spec>pour le cluster. Le format et les valeurs de cette section sont spécifiques au fournisseur. Pour plus d'informations, consultez l'exemple de spécification de votre fournisseur de cloud.
- Reportez-vous à l'exemple de YAML pour un jeu de machines du plan de contrôle CR et complétez votre fichier avec des valeurs adaptées à la configuration de votre cluster.
- Reportez-vous à l'exemple de configuration du domaine de défaillance et à l'exemple de spécification du fournisseur pour votre fournisseur de cloud et mettez à jour ces sections de votre fichier avec les valeurs appropriées.
-
Lorsque la configuration est correcte, activez la CR en définissant le champ
.spec.statesurActiveet en enregistrant vos modifications. Créez le CR à partir de votre fichier YAML en exécutant la commande suivante :
oc create -f <control_plane_machine_set>.yaml
où
<control_plane_machine_set>est le nom du fichier YAML qui contient la configuration du CR.
Ressources complémentaires
12.3. Configuration de l'ensemble des machines du plan de contrôle
Ces exemples de fichiers YAML et de snippets illustrent la structure de base d'une ressource personnalisée (CR) d'un ensemble de machines du plan de contrôle, ainsi que des échantillons spécifiques à la plate-forme pour les configurations du domaine de défaillance et de la spécification du fournisseur.
12.3.1. Exemple de YAML pour une ressource personnalisée d'un ensemble de machines de plan de contrôle
La base du ControlPlaneMachineSet CR est structurée de la même manière pour toutes les plateformes.
Exemple de fichier YAML ControlPlaneMachineSet CR
apiVersion: machine.openshift.io/v1 kind: ControlPlaneMachineSet metadata: name: cluster 1 namespace: openshift-machine-api spec: replicas: 3 2 selector: matchLabels: machine.openshift.io/cluster-api-cluster: <cluster_id> 3 machine.openshift.io/cluster-api-machine-role: master machine.openshift.io/cluster-api-machine-type: master state: Active 4 strategy: type: RollingUpdate 5 template: machineType: machines_v1beta1_machine_openshift_io machines_v1beta1_machine_openshift_io: failureDomains: platform: <platform> 6 <platform_failure_domains> 7 metadata: labels: machine.openshift.io/cluster-api-cluster: <cluster_id> machine.openshift.io/cluster-api-machine-role: master machine.openshift.io/cluster-api-machine-type: master spec: providerSpec: value: <platform_provider_spec> 8
- 1
- Spécifie le nom du CR
ControlPlaneMachineSet, qui estcluster. Ne pas modifier cette valeur. - 2
- Spécifie le nombre de machines du plan de contrôle. Seuls les clusters avec trois machines de plan de contrôle sont pris en charge, la valeur
replicasest donc3. La mise à l'échelle horizontale n'est pas prise en charge. Ne modifiez pas cette valeur. - 3
- Spécifie l'ID de l'infrastructure qui est basé sur l'ID du cluster que vous avez défini lors du provisionnement du cluster. Vous devez spécifier cette valeur lorsque vous créez un CR
ControlPlaneMachineSet. Si l'OpenShift CLI (oc) est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure cluster - 4
- Spécifie l'état de l'opérateur. Lorsque l'état est
Inactive, l'opérateur n'est pas opérationnel. Vous pouvez activer l'opérateur en réglant la valeur surActive.ImportantAvant d'activer l'Opérateur, vous devez vous assurer que la configuration de
ControlPlaneMachineSetCR est correcte pour les besoins de votre cluster. Pour plus d'informations sur l'activation de l'Opérateur d'ensemble de machines du plan de contrôle, voir "Getting started with control plane machine sets". - 5
- Spécifie la stratégie de mise à jour pour le cluster. Les valeurs autorisées sont
OnDeleteetRollingUpdate. La valeur par défaut estRollingUpdate. Pour plus d'informations sur les stratégies de mise à jour, voir "Mise à jour de la configuration du plan de contrôle". - 6
- Indique le nom de la plate-forme du fournisseur de cloud. Ne pas modifier cette valeur.
- 7
- Spécifie la configuration de
<platform_failure_domains>pour le cluster. Le format et les valeurs de cette section sont spécifiques au fournisseur. Pour plus d'informations, consultez l'exemple de configuration du domaine de défaillance de votre fournisseur de cloud.NoteVMware vSphere ne prend pas en charge les domaines de défaillance.
- 8
- Spécifie la configuration de
<platform_provider_spec>pour le cluster. Le format et les valeurs de cette section sont spécifiques au fournisseur. Pour plus d'informations, consultez l'exemple de spécification de votre fournisseur de cloud.
Ressources complémentaires
Configuration spécifique au fournisseur
Les sections <platform_provider_spec> et <platform_failure_domains> des ressources du jeu de machines du plan de contrôle sont spécifiques au fournisseur. Reportez-vous à l'exemple YAML pour votre cluster :
12.3.2. Exemple de YAML pour la configuration des clusters Amazon Web Services
Certaines sections de l'ensemble de machines du plan de contrôle CR sont spécifiques au fournisseur. Les exemples YAML de cette section montrent des configurations de domaine de défaillance et de spécification de fournisseur pour un cluster Amazon Web Services (AWS).
12.3.2.1. Exemple de configuration d'un domaine de défaillance AWS
Le concept d'ensemble de machines du plan de contrôle d'un domaine de défaillance est analogue au concept existant d'AWS d'un domaine de défaillance Availability Zone (AZ). Le CR ControlPlaneMachineSet répartit les machines du plan de contrôle sur plusieurs domaines de défaillance lorsque cela est possible.
Lors de la configuration des domaines de défaillance AWS dans le jeu de machines du plan de contrôle, vous devez spécifier le nom de la zone de disponibilité et le sous-réseau à utiliser.
Exemples de valeurs de domaine de défaillance AWS
failureDomains:
aws:
- placement:
availabilityZone: <aws_zone_a> 1
subnet: 2
filters:
- name: tag:Name
values:
- <cluster_id>-private-<aws_zone_a> 3
type: Filters 4
- placement:
availabilityZone: <aws_zone_b> 5
subnet:
filters:
- name: tag:Name
values:
- <cluster_id>-private-<aws_zone_b> 6
type: Filters
platform: AWS 7
- 1
- Spécifie une zone de disponibilité AWS pour le premier domaine de défaillance.
- 2
- Spécifie une configuration de sous-réseau. Dans cet exemple, le type de sous-réseau est
Filters, il y a donc une strophefilters. - 3
- Spécifie le nom du sous-réseau pour le premier domaine de défaillance, en utilisant l'ID d'infrastructure et la zone de disponibilité AWS.
- 4
- Spécifie le type de sous-réseau. Les valeurs autorisées sont :
ARN,FiltersetID. La valeur par défaut estFilters. - 5
- Spécifie le nom du sous-réseau pour un domaine de défaillance supplémentaire, en utilisant l'ID de l'infrastructure et la zone de disponibilité AWS.
- 6
- Spécifie l'ID d'infrastructure du cluster et la zone de disponibilité AWS pour le domaine de défaillance supplémentaire.
- 7
- Indique le nom de la plate-forme du fournisseur de cloud. Ne pas modifier cette valeur.
12.3.2.2. Exemple de spécification d'un fournisseur AWS
Lorsque vous créez un jeu de machines du plan de contrôle pour un cluster existant, la spécification du fournisseur doit correspondre à la configuration providerSpec dans le CR du plan de contrôle machine créé par le programme d'installation. Vous pouvez omettre tout champ défini dans la section du domaine de défaillance du CR.
Dans l'exemple suivant, <cluster_id> est l'ID de l'infrastructure qui est basé sur l'ID du cluster que vous avez défini lorsque vous avez provisionné le cluster. Si le CLI OpenShift est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure clusterExemples de valeurs AWS providerSpec
providerSpec:
value:
ami:
id: ami-<ami_id_string> 1
apiVersion: machine.openshift.io/v1beta1
blockDevices:
- ebs: 2
encrypted: true
iops: 0
kmsKey:
arn: ""
volumeSize: 120
volumeType: gp3
credentialsSecret:
name: aws-cloud-credentials 3
deviceIndex: 0
iamInstanceProfile:
id: <cluster_id>-master-profile 4
instanceType: m6i.xlarge 5
kind: AWSMachineProviderConfig 6
loadBalancers: 7
- name: <cluster_id>-int
type: network
- name: <cluster_id>-ext
type: network
metadata:
creationTimestamp: null
metadataServiceOptions: {}
placement: 8
region: <region> 9
securityGroups:
- filters:
- name: tag:Name
values:
- <cluster_id>-master-sg 10
subnet: {} 11
userDataSecret:
name: master-user-data 12
- 1
- Spécifie l'ID de l'Amazon Machine Images (AMI) de Red Hat Enterprise Linux CoreOS (RHCOS) pour le cluster. L'AMI doit appartenir à la même région que le cluster. Si vous souhaitez utiliser une image AWS Marketplace, vous devez compléter l'abonnement à OpenShift Container Platform depuis AWS Marketplace pour obtenir un ID AMI pour votre région.
- 2
- Spécifie la configuration d'un volume EBS crypté.
- 3
- Spécifie le nom secret de la grappe. Ne pas modifier cette valeur.
- 4
- Spécifie le profil de l'instance AWS Identity and Access Management (IAM). Ne pas modifier cette valeur.
- 5
- Spécifie le type d'instance AWS pour le plan de contrôle.
- 6
- Spécifie le type de plateforme du fournisseur de cloud. Ne pas modifier cette valeur.
- 7
- Spécifie les équilibreurs de charge internes (
int) et externes (ext) pour le cluster. - 8
- Ce paramètre est configuré dans le domaine de défaillance et est affiché ici avec une valeur vide. Si une valeur spécifiée pour ce paramètre diffère de la valeur du domaine de défaillance, l'opérateur la remplace par la valeur du domaine de défaillance.
- 9
- Spécifie la région AWS pour le cluster.
- 10
- Spécifie le groupe de sécurité des machines du plan de contrôle.
- 11
- Ce paramètre est configuré dans le domaine de défaillance et est affiché ici avec une valeur vide. Si une valeur spécifiée pour ce paramètre diffère de la valeur du domaine de défaillance, l'opérateur la remplace par la valeur du domaine de défaillance.
- 12
- Spécifie le secret des données utilisateur du plan de contrôle. Ne pas modifier cette valeur.
Ressources complémentaires
12.3.3. Exemple de YAML pour la configuration des clusters Microsoft Azure
Certaines sections de l'ensemble de machines du plan de contrôle CR sont spécifiques au fournisseur. Les exemples YAML de cette section montrent des configurations de domaine de défaillance et de spécification de fournisseur pour un cluster Azure.
12.3.3.1. Exemple de configuration d'un domaine de défaillance Azure
Le concept d'ensemble de machines du plan de contrôle d'un domaine de défaillance est analogue au concept Azure existant d'un domaine de défaillance Azure availability zone. La CR ControlPlaneMachineSet répartit les machines du plan de contrôle sur plusieurs domaines de défaillance lorsque cela est possible.
Lors de la configuration des domaines de défaillance Azure dans le jeu de machines du plan de contrôle, vous devez spécifier le nom de la zone de disponibilité.
Exemple de valeurs de domaine de défaillance Azure
failureDomains: azure: 1 - zone: "1" - zone: "2" - zone: "3" platform: Azure 2
12.3.3.2. Exemple de spécification d'un fournisseur Azure
Lorsque vous créez un jeu de machines du plan de contrôle pour un cluster existant, la spécification du fournisseur doit correspondre à la configuration providerSpec dans le CR du plan de contrôle Machine créé par le programme d'installation. Vous pouvez omettre tout champ défini dans la section du domaine de défaillance du CR.
Dans l'exemple suivant, <cluster_id> est l'ID de l'infrastructure qui est basé sur l'ID du cluster que vous avez défini lorsque vous avez provisionné le cluster. Si le CLI OpenShift est installé, vous pouvez obtenir l'ID d'infrastructure en exécutant la commande suivante :
$ oc get -o jsonpath='{.status.infrastructureName}{"\n"}' infrastructure clusterExemples de valeurs Azure providerSpec
providerSpec:
value:
acceleratedNetworking: true
apiVersion: machine.openshift.io/v1beta1
credentialsSecret:
name: azure-cloud-credentials 1
namespace: openshift-machine-api
diagnostics: {}
image: 2
offer: ""
publisher: ""
resourceID: /resourceGroups/<cluster_id>-rg/providers/Microsoft.Compute/galleries/gallery_<cluster_id>/images/<cluster_id>-gen2/versions/412.86.20220930 3
sku: ""
version: ""
internalLoadBalancer: <cluster_id>-internal 4
kind: AzureMachineProviderSpec 5
location: <region> 6
managedIdentity: <cluster_id>-identity
metadata:
creationTimestamp: null
name: <cluster_id>
networkResourceGroup: <cluster_id>-rg
osDisk: 7
diskSettings: {}
diskSizeGB: 1024
managedDisk:
storageAccountType: Premium_LRS
osType: Linux
publicIP: false
publicLoadBalancer: <cluster_id> 8
resourceGroup: <cluster_id>-rg
subnet: <cluster_id>-master-subnet 9
userDataSecret:
name: master-user-data 10
vmSize: Standard_D8s_v3
vnet: <cluster_id>-vnet
zone: "" 11
- 1
- Spécifie le nom secret de la grappe. Ne pas modifier cette valeur.
- 2
- Spécifie les détails de l'image pour le jeu de machines du plan de contrôle.
- 3
- Spécifie une image compatible avec votre type d'instance. Les images Hyper-V de génération V2 créées par le programme d'installation ont un suffixe
-gen2, tandis que les images V1 portent le même nom sans suffixe. - 4
- Spécifie l'équilibreur de charge interne pour le plan de contrôle. Ce champ peut ne pas être préconfiguré, mais il est requis dans les CR
ControlPlaneMachineSetetMachinedu plan de contrôle. - 5
- Spécifie le type de plateforme du fournisseur de cloud. Ne pas modifier cette valeur.
- 6
- Spécifie la région dans laquelle placer les machines du plan de contrôle.
- 7
- Spécifie la configuration du disque pour le plan de contrôle.
- 8
- Spécifie l'équilibreur de charge public pour le plan de contrôle.
- 9
- Spécifie le sous-réseau pour le plan de contrôle.
- 10
- Spécifie le secret des données utilisateur du plan de contrôle. Ne pas modifier cette valeur.
- 11
- Ce paramètre est configuré dans le domaine de défaillance et est affiché ici avec une valeur vide. Si une valeur spécifiée pour ce paramètre diffère de la valeur du domaine de défaillance, l'opérateur la remplace par la valeur du domaine de défaillance.
Ressources complémentaires
12.3.4. Exemple de YAML pour la configuration des clusters VMware vSphere
Certaines sections de l'ensemble de machines du plan de contrôle CR sont spécifiques au fournisseur. L'exemple YAML de cette section montre une configuration de spécification de fournisseur pour un cluster VMware vSphere.
12.3.4.1. Exemple de spécification d'un fournisseur vSphere
Lorsque vous créez un jeu de machines du plan de contrôle pour un cluster existant, la spécification du fournisseur doit correspondre à la configuration providerSpec dans le CR du plan de contrôle machine créé par le programme d'installation.
Exemples de valeurs vSphere providerSpec
providerSpec:
value:
apiVersion: machine.openshift.io/v1beta1
credentialsSecret:
name: vsphere-cloud-credentials 1
diskGiB: 120 2
kind: VSphereMachineProviderSpec 3
memoryMiB: 16384 4
metadata:
creationTimestamp: null
network: 5
devices:
- networkName: <vm_network_name>
numCPUs: 4 6
numCoresPerSocket: 4 7
snapshot: ""
template: <vm_template_name> 8
userDataSecret:
name: master-user-data 9
workspace:
datacenter: <vcenter_datacenter_name> 10
datastore: <vcenter_datastore_name> 11
folder: <path_to_vcenter_vm_folder> 12
resourcePool: <vsphere_resource_pool> 13
server: <vcenter_server_ip> 14
- 1
- Spécifie le nom secret de la grappe. Ne pas modifier cette valeur.
- 2
- Spécifie la taille du disque VM pour les machines du plan de contrôle.
- 3
- Spécifie le type de plateforme du fournisseur de cloud. Ne pas modifier cette valeur.
- 4
- Spécifie la mémoire allouée aux machines du plan de contrôle.
- 5
- Spécifie le réseau sur lequel le plan de contrôle est déployé.
- 6
- Spécifie le nombre de CPU alloués aux machines du plan de contrôle.
- 7
- Spécifie le nombre de cœurs pour chaque unité centrale du plan de contrôle.
- 8
- Spécifie le modèle de VM vSphere à utiliser, tel que
user-5ddjd-rhcos. - 9
- Spécifie le secret des données utilisateur du plan de contrôle. Ne pas modifier cette valeur.
- 10
- Spécifie le centre de données vCenter pour le plan de contrôle.
- 11
- Spécifie le Datastore vCenter pour le plan de contrôle.
- 12
- Spécifie le chemin d'accès au dossier vSphere VM dans vCenter, tel que
/dc1/vm/user-inst-5ddjd. - 13
- Spécifie le pool de ressources vSphere pour vos machines virtuelles.
- 14
- Spécifie l'IP du serveur vCenter ou son nom de domaine complet.
12.4. Gestion des machines du plan de contrôle avec des ensembles de machines du plan de contrôle
Les jeux de machines du plan de contrôle automatisent plusieurs aspects essentiels de la gestion du plan de contrôle.
12.4.1. Mise à jour de la configuration du plan de contrôle
Vous pouvez modifier la configuration des machines dans le plan de contrôle en mettant à jour la spécification dans la ressource personnalisée (CR) de l'ensemble de machines du plan de contrôle.
L'opérateur du jeu de machines du plan de contrôle surveille les machines du plan de contrôle et compare leur configuration avec les spécifications du CR du jeu de machines du plan de contrôle. En cas de divergence entre les spécifications du RC et la configuration d'une machine du plan de contrôle, l'opérateur marque cette machine du plan de contrôle pour qu'elle soit remplacée.
Pour plus d'informations sur les paramètres du CR, voir "Control plane machine set configuration".
Conditions préalables
- Votre cluster dispose d'un opérateur de plateau de contrôle activé et opérationnel.
Procédure
Modifiez le jeu de machines CR de votre plan de contrôle en exécutant la commande suivante :
$ oc edit controlplanemachineset.machine.openshift.io cluster \ -n openshift-machine-api
- Modifiez les valeurs des champs que vous souhaitez mettre à jour dans la configuration de votre cluster.
- Enregistrez vos modifications.
Prochaines étapes
-
Pour les clusters qui utilisent la stratégie de mise à jour par défaut
RollingUpdate, les modifications apportées à la configuration du plan de contrôle sont propagées automatiquement. -
Pour les clusters configurés pour utiliser la stratégie de mise à jour
OnDelete, vous devez remplacer manuellement les machines du plan de contrôle.
12.4.1.1. Mise à jour automatique de la configuration du plan de contrôle
Vous pouvez utiliser la stratégie de mise à jour RollingUpdate pour propager automatiquement les changements dans la configuration de votre plan de contrôle.
Pour les clusters qui utilisent la stratégie de mise à jour par défaut RollingUpdate, l'opérateur crée une machine de plan de contrôle de remplacement avec la configuration spécifiée dans le CR. Lorsque la machine de plan de contrôle de remplacement est prête, l'opérateur supprime la machine de plan de contrôle marquée pour le remplacement. La machine de remplacement rejoint alors le plan de contrôle.
Si plusieurs machines du plan de contrôle sont marquées pour être remplacées, l'opérateur répète ce processus de remplacement une machine à la fois jusqu'à ce que chaque machine soit remplacée.
12.4.1.2. Tester les modifications apportées à la configuration du plan de contrôle
Vous pouvez utiliser la stratégie de mise à jour OnDelete pour tester les modifications apportées à la configuration de votre plan de contrôle. Avec cette stratégie de mise à jour, vous remplacez manuellement les machines du plan de contrôle. Le remplacement manuel des machines vous permet de tester les modifications apportées à votre configuration sur une seule machine avant d'appliquer les changements à plus grande échelle.
Pour les clusters configurés pour utiliser la stratégie de mise à jour OnDelete, l'opérateur crée une machine de plan de contrôle de remplacement lorsque vous supprimez une machine existante. Lorsque la machine de remplacement du plan de contrôle est prête, l'opérateur etcd autorise la suppression de la machine existante. La machine de remplacement rejoint alors le plan de contrôle.
Si plusieurs machines du plan de contrôle sont supprimées, l'opérateur crée simultanément toutes les machines de remplacement nécessaires.
12.4.2. Activation des fonctionnalités d'Amazon Web Services pour les machines du plan de contrôle
Vous pouvez activer les fonctionnalités Amazon Web Services (AWS) sur les machines du plan de contrôle en modifiant la configuration de votre jeu de machines du plan de contrôle. Lorsque vous enregistrez une mise à jour de l'ensemble de machines du plan de contrôle, l'opérateur de l'ensemble de machines du plan de contrôle met à jour les machines du plan de contrôle conformément à la stratégie de mise à jour que vous avez configurée.
12.4.2.1. Limiter le serveur API au domaine privé
Après avoir déployé un cluster sur Amazon Web Services (AWS), vous pouvez reconfigurer le serveur API pour qu'il n'utilise que la zone privée.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Avoir accès à la console web en tant qu'utilisateur avec les privilèges
admin.
Procédure
Dans le portail web ou la console de votre fournisseur de cloud, effectuez les actions suivantes :
Localisez et supprimez le composant d'équilibreur de charge approprié :
- Pour AWS, supprimez l'équilibreur de charge externe. L'entrée API DNS dans la zone privée pointe déjà vers l'équilibreur de charge interne, qui utilise une configuration identique, de sorte qu'il n'est pas nécessaire de modifier l'équilibreur de charge interne.
-
Supprimez l'entrée DNS
api.$clustername.$yourdomaindans la zone publique.
Supprimez les équilibreurs de charge externes en supprimant les lignes suivantes dans la ressource personnalisée control plane machine set :
providerSpec: value: loadBalancers: - name: lk4pj-ext 1 type: network 2 - name: lk4pj-int type: network
12.4.2.2. Modifier le type d'instance Amazon Web Services à l'aide d'un jeu de machines du plan de contrôle
Vous pouvez modifier le type d'instance Amazon Web Services (AWS) que vos machines du plan de contrôle utilisent en mettant à jour la spécification dans la ressource personnalisée (CR) de l'ensemble de machines du plan de contrôle.
Conditions préalables
- Votre cluster AWS utilise un jeu de machines de plan de contrôle.
Procédure
Modifiez la ligne suivante sous le champ
providerSpec:providerSpec: value: ... instanceType: <compatible_aws_instance_type> 1- 1
- Spécifiez un type d'instance AWS plus important avec la même base que la sélection précédente. Par exemple, vous pouvez remplacer
m6i.xlargeparm6i.2xlargeoum6i.4xlarge.
- Enregistrez vos modifications.
12.4.2.3. Options du jeu de machines pour le service de métadonnées de l'instance Amazon EC2
Vous pouvez utiliser des jeux de machines pour créer des machines qui utilisent une version spécifique du service de métadonnées d'instance Amazon EC2 (IMDS). Les jeux de machines peuvent créer des machines qui autorisent l'utilisation d'IMDSv1 et d'IMDSv2 ou des machines qui requièrent l'utilisation d'IMDSv2.
Pour modifier la configuration de l'IMDS pour les machines existantes, modifiez le fichier YAML de l'ensemble de machines qui gère ces machines.
Avant de configurer un jeu de machines pour créer des machines nécessitant IMDSv2, assurez-vous que toutes les charges de travail qui interagissent avec le service de métadonnées AWS prennent en charge IMDSv2.
12.4.2.3.1. Configuration de l'IMDS à l'aide de jeux de machines
Vous pouvez spécifier si l'utilisation d'IMDSv2 est requise en ajoutant ou en modifiant la valeur de metadataServiceOptions.authentication dans le fichier YAML de l'ensemble de machines pour vos machines.
Procédure
Ajoutez ou modifiez les lignes suivantes sous le champ
providerSpec:providerSpec: value: metadataServiceOptions: authentication: Required 1- 1
- Pour exiger IMDSv2, définissez la valeur du paramètre sur
Required. Pour autoriser l'utilisation de IMDSv1 et IMDSv2, définissez la valeur du paramètre surOptional. Si aucune valeur n'est spécifiée, IMDSv1 et IMDSv2 sont tous deux autorisés.
12.4.2.4. Jeux de machines qui déploient des machines en tant qu'instances dédiées
Vous pouvez créer un ensemble de machines fonctionnant sur AWS qui déploie des machines en tant qu'instances dédiées. Les instances dédiées s'exécutent dans un nuage privé virtuel (VPC) sur du matériel dédié à un seul client. Ces instances Amazon EC2 sont physiquement isolées au niveau du matériel hôte. L'isolement des instances dédiées se produit même si les instances appartiennent à différents comptes AWS liés à un seul compte payeur. Toutefois, d'autres instances non dédiées peuvent partager le matériel avec les instances dédiées si elles appartiennent au même compte AWS.
Les instances avec une location publique ou dédiée sont prises en charge par l'API Machine. Les instances en mode public s'exécutent sur du matériel partagé. La location publique est la location par défaut. Les instances avec une location dédiée s'exécutent sur du matériel à locataire unique.
12.4.2.4.1. Création d'instances dédiées à l'aide d'ensembles de machines
Vous pouvez exécuter une machine qui est soutenue par une Instance Dédiée en utilisant l'intégration API Machine. Définissez le champ tenancy dans votre fichier YAML machine set pour lancer une Dedicated Instance sur AWS.
Procédure
Spécifiez une location dédiée dans le champ
providerSpec:providerSpec: placement: tenancy: dedicated
12.4.3. Activation des fonctionnalités de Microsoft Azure pour les machines du plan de contrôle
Vous pouvez activer les fonctionnalités Microsoft Azure sur les machines du plan de contrôle en modifiant la configuration de votre jeu de machines du plan de contrôle. Lorsque vous enregistrez une mise à jour de l'ensemble de machines du plan de contrôle, l'opérateur de l'ensemble de machines du plan de contrôle met à jour les machines du plan de contrôle conformément à la stratégie de mise à jour que vous avez configurée.
12.4.3.1. Limiter le serveur API au domaine privé
Après avoir déployé un cluster sur Microsoft Azure, vous pouvez reconfigurer le serveur API pour qu'il n'utilise que la zone privée.
Conditions préalables
-
Installez le CLI OpenShift (
oc). -
Avoir accès à la console web en tant qu'utilisateur avec les privilèges
admin.
Procédure
Dans le portail web ou la console de votre fournisseur de cloud, effectuez les actions suivantes :
Localisez et supprimez le composant d'équilibreur de charge approprié :
-
Pour Azure, supprimez la règle
api-internalpour l'équilibreur de charge.
-
Pour Azure, supprimez la règle
-
Supprimez l'entrée DNS
api.$clustername.$yourdomaindans la zone publique.
Supprimez les équilibreurs de charge externes en supprimant les lignes suivantes dans la ressource personnalisée control plane machine set :
providerSpec: value: loadBalancers: - name: lk4pj-ext 1 type: network 2 - name: lk4pj-int type: network
12.4.3.2. Selecting an Azure Marketplace image
Vous pouvez créer un jeu de machines fonctionnant sur Azure qui déploie des machines utilisant l'offre Azure Marketplace. Pour utiliser cette offre, vous devez d'abord obtenir l'image Azure Marketplace. Lorsque vous obtenez votre image, tenez compte des éléments suivants :
-
While the images are the same, the Azure Marketplace publisher is different depending on your region. If you are located in North America, specify
redhatas the publisher. If you are located in EMEA, specifyredhat-limitedas the publisher. -
The offer includes a
rh-ocp-workerSKU and arh-ocp-worker-gen1SKU. Therh-ocp-workerSKU represents a Hyper-V generation version 2 VM image. The default instance types used in OpenShift Container Platform are version 2 compatible. If you plan to use an instance type that is only version 1 compatible, use the image associated with therh-ocp-worker-gen1SKU. Therh-ocp-worker-gen1SKU represents a Hyper-V version 1 VM image.
Installing images with the Azure marketplace is not supported on clusters with arm64 instances.
Conditions préalables
-
You have installed the Azure CLI client
(az). - Your Azure account is entitled for the offer and you have logged into this account with the Azure CLI client.
Procédure
Display all of the available OpenShift Container Platform images by running one of the following commands:
North America:
$ az vm image list --all --offer rh-ocp-worker --publisher redhat -o table
Exemple de sortie
Offer Publisher Sku Urn Version ------------- -------------- ------------------ -------------------------------------------------------------- -------------- rh-ocp-worker RedHat rh-ocp-worker RedHat:rh-ocp-worker:rh-ocpworker:4.8.2021122100 4.8.2021122100 rh-ocp-worker RedHat rh-ocp-worker-gen1 RedHat:rh-ocp-worker:rh-ocp-worker-gen1:4.8.2021122100 4.8.2021122100
EMEA:
$ az vm image list --all --offer rh-ocp-worker --publisher redhat-limited -o table
Exemple de sortie
Offer Publisher Sku Urn Version ------------- -------------- ------------------ -------------------------------------------------------------- -------------- rh-ocp-worker redhat-limited rh-ocp-worker redhat-limited:rh-ocp-worker:rh-ocp-worker:4.8.2021122100 4.8.2021122100 rh-ocp-worker redhat-limited rh-ocp-worker-gen1 redhat-limited:rh-ocp-worker:rh-ocp-worker-gen1:4.8.2021122100 4.8.2021122100
NoteRegardless of the version of OpenShift Container Platform that you install, the correct version of the Azure Marketplace image to use is 4.8. If required, your VMs are automatically upgraded as part of the installation process.
Inspect the image for your offer by running one of the following commands:
North America:
$ az vm image show --urn redhat:rh-ocp-worker:rh-ocp-worker:<version>
EMEA:
$ az vm image show --urn redhat-limited:rh-ocp-worker:rh-ocp-worker:<version>
Review the terms of the offer by running one of the following commands:
North America:
$ az vm image terms show --urn redhat:rh-ocp-worker:rh-ocp-worker:<version>
EMEA:
$ az vm image terms show --urn redhat-limited:rh-ocp-worker:rh-ocp-worker:<version>
Accept the terms of the offering by running one of the following commands:
North America:
$ az vm image terms accept --urn redhat:rh-ocp-worker:rh-ocp-worker:<version>
EMEA:
$ az vm image terms accept --urn redhat-limited:rh-ocp-worker:rh-ocp-worker:<version>
-
Enregistrez les détails de l'image de votre offre, en particulier les valeurs de
publisher,offer,skuetversion. Ajoutez les paramètres suivants à la section
providerSpecde votre fichier YAML de configuration de la machine en utilisant les détails de l'image pour votre offre :Exemple de valeurs d'image
providerSpecpour les machines Azure MarketplaceproviderSpec: value: image: offer: rh-ocp-worker publisher: redhat resourceID: "" sku: rh-ocp-worker type: MarketplaceWithPlan version: 4.8.2021122100
12.4.3.3. Activation des diagnostics de démarrage Azure
Vous pouvez activer les diagnostics de démarrage sur les machines Azure créées par votre jeu de machines.
Conditions préalables
- Disposer d'un cluster Microsoft Azure existant.
Procédure
Ajoutez la configuration
diagnosticsapplicable à votre type de stockage au champproviderSpecde votre fichier YAML machine set :Pour un compte de stockage géré par Azure :
providerSpec: diagnostics: boot: storageAccountType: AzureManaged 1- 1
- Spécifie un compte de stockage Azure Managed.
Pour un compte de stockage Azure non géré :
providerSpec: diagnostics: boot: storageAccountType: CustomerManaged 1 customerManaged: storageAccountURI: https://<storage-account>.blob.core.windows.net 2NoteSeul le service de données Azure Blob Storage est pris en charge.
Vérification
- Sur le portail Microsoft Azure, consultez la page Boot diagnostics pour une machine déployée par le jeu de machines et vérifiez que vous pouvez voir les journaux de série pour la machine.
12.4.3.4. Jeux de machines qui déploient des machines avec des disques ultra comme disques de données
Vous pouvez créer un jeu de machines fonctionnant sur Azure qui déploie des machines avec des ultra-disques. Les disques ultra sont des systèmes de stockage haute performance destinés à être utilisés avec les charges de travail les plus exigeantes.
Ressources complémentaires
12.4.3.4.1. Création de machines avec ultra-disques à l'aide de jeux de machines
Vous pouvez déployer des machines avec des ultra-disques sur Azure en modifiant votre fichier YAML de configuration des machines.
Conditions préalables
- Disposer d'un cluster Microsoft Azure existant.
Procédure
Créez un secret personnalisé dans l'espace de noms
openshift-machine-apien utilisant le secret de donnéesmasteren exécutant la commande suivante :$ oc -n openshift-machine-api \ get secret <role>-user-data \ 1 --template='{{index .data.userData | base64decode}}' | jq > userData.txt 2
Dans un éditeur de texte, ouvrez le fichier
userData.txtet localisez le caractère final}dans le fichier.-
Sur la ligne immédiatement précédente, ajouter un
,. Créez une nouvelle ligne après le site
,et ajoutez les détails de configuration suivants :"storage": { "disks": [ 1 { "device": "/dev/disk/azure/scsi1/lun0", 2 "partitions": [ 3 { "label": "lun0p1", 4 "sizeMiB": 1024, 5 "startMiB": 0 } ] } ], "filesystems": [ 6 { "device": "/dev/disk/by-partlabel/lun0p1", "format": "xfs", "path": "/var/lib/lun0p1" } ] }, "systemd": { "units": [ 7 { "contents": "[Unit]\nBefore=local-fs.target\n[Mount]\nWhere=/var/lib/lun0p1\nWhat=/dev/disk/by-partlabel/lun0p1\nOptions=defaults,pquota\n[Install]\nWantedBy=local-fs.target\n", 8 "enabled": true, "name": "var-lib-lun0p1.mount" } ] }- 1
- Les détails de configuration du disque que vous souhaitez attacher à un nœud en tant qu'ultra disque.
- 2
- Indiquez la valeur
lundéfinie dans la strophedataDisksdu jeu de machines que vous utilisez. Par exemple, si le jeu de machines contientlun: 0, indiquezlun0. Vous pouvez initialiser plusieurs disques de données en spécifiant plusieurs entrées"disks"dans ce fichier de configuration. Si vous spécifiez plusieurs entrées"disks", assurez-vous que la valeurlunde chaque entrée correspond à la valeur du jeu de machines. - 3
- Les détails de la configuration d'une nouvelle partition sur le disque.
- 4
- Indiquez un nom pour la partition. Il peut être utile d'utiliser des noms hiérarchiques, tels que
lun0p1pour la première partition delun0. - 5
- Indiquez la taille totale en Mo de la partition.
- 6
- Spécifiez le système de fichiers à utiliser lors du formatage d'une partition. Utilisez l'étiquette de partition pour spécifier la partition.
- 7
- Indiquez une unité
systemdpour monter la partition au démarrage. Utilisez l'étiquette de partition pour spécifier la partition. Vous pouvez créer plusieurs partitions en spécifiant plusieurs entrées"partitions"dans ce fichier de configuration. Si vous spécifiez plusieurs entrées"partitions", vous devez spécifier une unitésystemdpour chacune d'entre elles. - 8
- Pour
Where, spécifiez la valeur destorage.filesystems.path. PourWhat, spécifiez la valeur destorage.filesystems.device.
-
Sur la ligne immédiatement précédente, ajouter un
Extrayez la valeur du modèle de désactivation dans un fichier appelé
disableTemplating.txten exécutant la commande suivante :$ oc -n openshift-machine-api get secret <role>-user-data \ 1 --template='{{index .data.disableTemplating | base64decode}}' | jq > disableTemplating.txt- 1
- Remplacer
<role>parmaster.
Combinez les fichiers
userData.txtetdisableTemplating.txtpour créer un fichier de données secrètes en exécutant la commande suivante :$ oc -n openshift-machine-api create secret generic <role>-user-data-x5 \ 1 --from-file=userData=userData.txt \ --from-file=disableTemplating=disableTemplating.txt- 1
- Pour
<role>-user-data-x5, indiquez le nom du secret. Remplacez<role>parmaster.
Modifiez le jeu de machines CR de votre plan de contrôle en exécutant la commande suivante :
$ oc --namespace openshift-machine-api edit controlplanemachineset.machine.openshift.io cluster
Ajouter les lignes suivantes aux endroits indiqués :
apiVersion: machine.openshift.io/v1beta1 kind: ControlPlaneMachineSet spec: template: spec: metadata: labels: disk: ultrassd 1 providerSpec: value: ultraSSDCapability: Enabled 2 dataDisks: 3 - nameSuffix: ultrassd lun: 0 diskSizeGB: 4 deletionPolicy: Delete cachingType: None managedDisk: storageAccountType: UltraSSD_LRS userDataSecret: name: <role>-user-data-x5 4- 1
- Indiquez une étiquette à utiliser pour sélectionner un nœud créé par ce jeu de machines. Cette procédure utilise
disk.ultrassdpour cette valeur. - 2 3
- Ces lignes permettent d'utiliser des disques ultra. Pour
dataDisks, inclure la strophe entière. - 4
- Spécifiez le secret des données de l'utilisateur créé précédemment. Remplacez
<role>parmaster.
Enregistrez vos modifications.
-
Pour les clusters qui utilisent la stratégie de mise à jour par défaut
RollingUpdate, l'opérateur propage automatiquement les modifications à votre configuration du plan de contrôle. -
Pour les clusters configurés pour utiliser la stratégie de mise à jour
OnDelete, vous devez remplacer manuellement les machines du plan de contrôle.
-
Pour les clusters qui utilisent la stratégie de mise à jour par défaut
Vérification
Validez la création des machines en exécutant la commande suivante :
$ oc get machines
Les machines doivent être dans l'état
Running.Pour une machine en cours d'exécution et à laquelle un nœud est attaché, validez la partition en exécutant la commande suivante :
$ oc debug node/<node-name> -- chroot /host lsblk
Dans cette commande,
oc debug node/<node-name>démarre un shell de débogage sur le nœud<node-name>et transmet une commande à--. La commande passéechroot /hostpermet d'accéder aux binaires du système d'exploitation hôte sous-jacent, etlsblkmontre les périphériques de bloc attachés à la machine du système d'exploitation hôte.
Prochaines étapes
- Pour utiliser un ultra disque sur le plan de contrôle, reconfigurez votre charge de travail pour utiliser le point de montage de l'ultra disque du plan de contrôle.
12.4.3.4.2. Ressources de dépannage pour les ensembles de machines qui activent les ultra-disques
Utilisez les informations de cette section pour comprendre et résoudre les problèmes que vous pourriez rencontrer.
12.4.3.4.2.1. Configuration incorrecte de l'ultra disque
Si une configuration incorrecte du paramètre ultraSSDCapability est spécifiée dans le jeu de machines, le provisionnement de la machine échoue.
Par exemple, si le paramètre ultraSSDCapability est défini sur Disabled, mais qu'un disque ultra est spécifié dans le paramètre dataDisks, le message d'erreur suivant apparaît :
StorageAccountType UltraSSD_LRS can be used only when additionalCapabilities.ultraSSDEnabled is set.
- Pour résoudre ce problème, vérifiez que la configuration de votre jeu de machines est correcte.
12.4.3.4.2.2. Paramètres de disque non pris en charge
Si une région, une zone de disponibilité ou une taille d'instance qui n'est pas compatible avec les disques ultra est spécifiée dans le jeu de machines, le provisionnement de la machine échoue. Vérifiez les journaux pour le message d'erreur suivant :
failed to create vm <machine_name> : failure sending request for machine <machine_name> : cannot create vm : compute.VirtualMachinesClient#CreateOrUpdate : Échec de l'envoi de la requête : StatusCode=400 -- Erreur d'origine : Code="BadRequest" Message="Le type de compte de stockage 'UltraSSD_LRS' n'est pas pris en charge <more_information_about_why>."
- Pour résoudre ce problème, vérifiez que vous utilisez cette fonctionnalité dans un environnement pris en charge et que la configuration de votre jeu de machines est correcte.
12.4.3.4.2.3. Impossible de supprimer des disques
Si la suppression des ultra-disques en tant que disques de données ne fonctionne pas comme prévu, les machines sont supprimées et les disques de données sont orphelins. Vous devez supprimer les disques orphelins manuellement si vous le souhaitez.
12.4.3.5. Activation des clés de chiffrement gérées par le client pour un ensemble de machines
Vous pouvez fournir une clé de chiffrement à Azure pour chiffrer les données sur les disques gérés au repos. Vous pouvez activer le chiffrement côté serveur avec des clés gérées par le client en utilisant l'API Machine.
Un Azure Key Vault, un ensemble de chiffrement de disque et une clé de chiffrement sont nécessaires pour utiliser une clé gérée par le client. Le jeu de chiffrement de disque doit se trouver dans un groupe de ressources auquel le Cloud Credential Operator (CCO) a accordé des autorisations. Si ce n'est pas le cas, un rôle de lecteur supplémentaire doit être accordé à l'ensemble de chiffrement de disque.
Conditions préalables
Procédure
Configurez le cryptage du disque dans le champ
providerSpecde votre fichier YAML de configuration de la machine. Par exemple :providerSpec: value: osDisk: diskSizeGB: 128 managedDisk: diskEncryptionSet: id: /subscriptions/<subscription_id>/resourceGroups/<resource_group_name>/providers/Microsoft.Compute/diskEncryptionSets/<disk_encryption_set_name> storageAccountType: Premium_LRS
Ressources complémentaires
12.4.3.6. Mise en réseau accélérée pour les machines virtuelles Microsoft Azure
Accelerated Networking utilise la virtualisation d'E/S à racine unique (SR-IOV) pour fournir aux VM Microsoft Azure un chemin plus direct vers le commutateur. Les performances du réseau s'en trouvent améliorées. Cette fonctionnalité peut être activée après l'installation.
12.4.3.6.1. Limitations
Tenez compte des limitations suivantes lorsque vous décidez d'utiliser ou non la mise en réseau accélérée :
- La mise en réseau accélérée n'est prise en charge que sur les clusters où l'API Machine est opérationnelle.
Accelerated Networking nécessite une taille de VM Azure comprenant au moins quatre vCPU. Pour répondre à cette exigence, vous pouvez modifier la valeur de
vmSizedans votre jeu de machines. Pour plus d'informations sur les tailles de VM Azure, consultez la documentation Microsoft Azure.
12.4.3.6.2. Activation de l'Accelerated Networking sur un cluster Microsoft Azure existant
Vous pouvez activer Accelerated Networking sur Azure en ajoutant acceleratedNetworking à votre fichier YAML machine set.
Conditions préalables
- Disposer d'un cluster Microsoft Azure existant où l'API Machine est opérationnelle.
Procédure
Ajoutez ce qui suit au champ
providerSpec:providerSpec: value: acceleratedNetworking: true 1 vmSize: <azure-vm-size> 2- 1
- This line enables Accelerated Networking.
- 2
- Specify an Azure VM size that includes at least four vCPUs. For information about VM sizes, see Microsoft Azure documentation.
Vérification
-
Sur le portail Microsoft Azure, consultez la page des paramètres Networking pour une machine approvisionnée par le jeu de machines et vérifiez que le champ
Accelerated networkingest défini surEnabled.
12.5. Résilience et récupération du plan de contrôle
Vous pouvez utiliser le jeu de machines du plan de contrôle pour améliorer la résilience du plan de contrôle de votre cluster OpenShift Container Platform.
12.5.1. Haute disponibilité et tolérance aux pannes avec domaines de défaillance
Dans la mesure du possible, le jeu de machines du plan de contrôle répartit les machines du plan de contrôle sur plusieurs domaines de défaillance. Cette configuration assure une haute disponibilité et une tolérance aux pannes au sein du plan de contrôle. Cette stratégie peut aider à protéger le plan de contrôle lorsque des problèmes surviennent au sein du fournisseur d'infrastructure.
12.5.1.1. Support et configuration de la plateforme du domaine de défaillance
Le concept d'ensemble de machines du plan de contrôle d'un domaine de défaillance est analogue aux concepts existants sur les fournisseurs de nuages. Toutes les plateformes ne prennent pas en charge l'utilisation des domaines de défaillance.
Tableau 12.2. Matrice de support du domaine de défaillance
| Fournisseur d'informatique en nuage | Prise en charge des domaines de défaillance | Nomenclature des prestataires |
|---|---|---|
| Amazon Web Services (AWS) | X | |
| Microsoft Azure | X | |
| VMware vSphere | Sans objet |
La configuration du domaine de défaillance dans la ressource personnalisée (CR) du jeu de machines du plan de contrôle est spécifique à la plate-forme. Pour plus d'informations sur les paramètres du domaine de défaillance dans la CR, consultez l'exemple de configuration du domaine de défaillance de votre fournisseur.
12.5.1.2. Équilibrage des machines du plan de contrôle
L'ensemble de machines du plan de contrôle équilibre les machines du plan de contrôle dans les domaines de défaillance spécifiés dans la ressource personnalisée (CR).
Dans la mesure du possible, l'ensemble des machines du plan de contrôle utilise chaque domaine de défaillance de manière égale afin de garantir une tolérance aux pannes appropriée. S'il y a moins de domaines de panne que de machines du plan de contrôle, les domaines de panne sont sélectionnés pour être réutilisés dans l'ordre alphabétique des noms. Pour les clusters dont aucun domaine de panne n'est spécifié, toutes les machines du plan de contrôle sont placées dans un seul domaine de panne.
Certaines modifications apportées à la configuration des domaines de panne entraînent le rééquilibrage des machines du plan de contrôle par l'ensemble de machines du plan de contrôle. Par exemple, si vous ajoutez des domaines de panne à un cluster comportant moins de domaines de panne que de machines du plan de contrôle, le jeu de machines du plan de contrôle rééquilibre les machines sur tous les domaines de panne disponibles.
12.5.2. Récupération des machines du plan de contrôle défaillantes
L'opérateur de jeu de machines du plan de contrôle automatise la récupération des machines du plan de contrôle. Lorsqu'une machine du plan de contrôle est supprimée, l'opérateur crée une machine de remplacement avec la configuration spécifiée dans la ressource personnalisée (CR) ControlPlaneMachineSet.
Pour les clusters qui utilisent des jeux de machines du plan de contrôle, vous pouvez configurer un contrôle de l'état des machines. Le contrôle de l'état des machines supprime les machines du plan de contrôle qui ne sont pas en bonne santé afin qu'elles soient remplacées.
Si vous configurez une ressource MachineHealthCheck pour le plan de contrôle, définissez la valeur de maxUnhealthy sur 1.
Cette configuration garantit que le contrôle de l'état des machines ne prend aucune mesure lorsque plusieurs machines du plan de contrôle semblent être en mauvaise santé. Plusieurs machines de plan de contrôle malsaines peuvent indiquer que le cluster etcd est dégradé ou qu'une opération de mise à l'échelle visant à remplacer une machine défaillante est en cours.
Si le cluster etcd est dégradé, une intervention manuelle peut être nécessaire. Si une opération de mise à l'échelle est en cours, le bilan de santé de la machine doit permettre de la terminer.
Ressources complémentaires
12.5.3. Protection du quorum à l'aide de crochets de cycle de vie de la machine
Pour les clusters OpenShift Container Platform qui utilisent l'opérateur API Machine, l'opérateur etcd utilise des crochets de cycle de vie pour la phase de suppression de la machine afin de mettre en œuvre un mécanisme de protection du quorum.
En utilisant un crochet de cycle de vie preDrain, l'opérateur etcd peut contrôler quand les pods sur une machine de plan de contrôle sont vidés et supprimés. Pour protéger le quorum etcd, l'opérateur etcd empêche la suppression d'un membre etcd jusqu'à ce qu'il migre ce membre sur un nouveau nœud dans le cluster.
Ce mécanisme permet à l'opérateur etcd de contrôler précisément les membres du quorum etcd et à l'opérateur Machine API de créer et de supprimer en toute sécurité des machines du plan de contrôle sans connaissance opérationnelle spécifique du cluster etcd.
12.5.3.1. Suppression du plan de contrôle avec ordre de traitement de la protection du quorum
Lorsqu'une machine de plan de contrôle est remplacée dans une grappe qui utilise un ensemble de machines de plan de contrôle, la grappe a temporairement quatre machines de plan de contrôle. Lorsque le quatrième nœud de plan de contrôle rejoint la grappe, l'opérateur etcd démarre un nouveau membre etcd sur le nœud de remplacement. Lorsque l'opérateur etcd observe que l'ancienne machine de plan de contrôle est marquée pour suppression, il arrête le membre etcd sur l'ancien nœud et promeut le membre etcd de remplacement pour qu'il rejoigne le quorum de la grappe.
La phase de la machine du plan de contrôle Deleting se déroule dans l'ordre suivant :
- Une machine du plan de contrôle doit être supprimée.
-
La machine du plan de contrôle entre dans la phase
Deleting. Pour satisfaire le crochet de cycle de vie
preDrain, l'opérateur etcd entreprend les actions suivantes :-
L'opérateur etcd attend qu'une quatrième machine de plan de contrôle soit ajoutée au cluster en tant que membre etcd. Ce nouveau membre etcd a l'état
Runningmais pasreadyjusqu'à ce qu'il reçoive la mise à jour complète de la base de données de la part du leader etcd. - Lorsque le nouveau membre etcd reçoit la mise à jour complète de la base de données, l'opérateur etcd promeut le nouveau membre etcd en tant que membre votant et supprime l'ancien membre etcd du cluster.
Une fois cette transition terminée, l'ancien pod etcd et ses données peuvent être supprimés en toute sécurité, et le crochet de cycle de vie
preDrainest donc supprimé.-
L'opérateur etcd attend qu'une quatrième machine de plan de contrôle soit ajoutée au cluster en tant que membre etcd. Ce nouveau membre etcd a l'état
-
La condition d'état de la machine du plan de contrôle
Drainableest réglée surTrue. Le contrôleur de machine tente de drainer le nœud qui est soutenu par la machine du plan de contrôle.
-
Si la vidange échoue,
Drainedest défini surFalseet le contrôleur de machine tente de vidanger à nouveau le nœud. -
Si la vidange réussit,
DraineddevientTrue.
-
Si la vidange échoue,
-
La condition d'état de la machine du plan de contrôle
Drainedest réglée surTrue. -
Si aucun autre opérateur n'a ajouté un crochet de cycle de vie
preTerminate, la condition d'état de la machine du plan de contrôleTerminabledevientTrue. - Le contrôleur de machine supprime l'instance du fournisseur d'infrastructure.
-
Le contrôleur de machine supprime l'objet
Node.
Extrait YAML démontrant la protection du quorum etcd preDrain lifecycle hook
apiVersion: machine.openshift.io/v1beta1
kind: Machine
metadata:
...
spec:
lifecycleHooks:
preDrain:
- name: EtcdQuorumOperator 1
owner: clusteroperator/etcd 2
...
Ressources complémentaires
12.6. Dépannage de l'ensemble de machines du plan de contrôle
Utilisez les informations de cette section pour comprendre et résoudre les problèmes que vous pourriez rencontrer.
12.6.1. Vérification de l'état des ressources personnalisées de l'ensemble des machines du plan de contrôle
Vous pouvez vérifier l'existence et l'état de la ressource personnalisée (CR) ControlPlaneMachineSet.
Procédure
Déterminez l'état de la CR en exécutant la commande suivante :
$ oc get controlplanemachineset.machine.openshift.io cluster \ --namespace openshift-machine-api
-
Un résultat de
Activeindique que la CRControlPlaneMachineSetexiste et est activée. Aucune action de l'administrateur n'est requise. -
Un résultat de
Inactiveindique qu'une CRControlPlaneMachineSetexiste mais qu'elle n'est pas activée. -
Un résultat de
NotFoundindique qu'il n'existe pas de CRControlPlaneMachineSet.
-
Un résultat de
Prochaines étapes
Pour utiliser le jeu de machines du plan de contrôle, vous devez vous assurer qu'il existe un CR ControlPlaneMachineSet avec les paramètres corrects pour votre cluster.
- Si votre cluster dispose d'un CR existant, vous devez vérifier que la configuration du CR est correcte pour votre cluster.
- Si votre cluster n'a pas de CR existant, vous devez en créer un avec la configuration correcte pour votre cluster.
12.6.2. Ajouter un équilibreur de charge interne Azure manquant
Le paramètre internalLoadBalancer est requis dans les ressources personnalisées (CR) ControlPlaneMachineSet et Machine du plan de contrôle pour Azure. Si ce paramètre n'est pas préconfiguré sur votre cluster, vous devez l'ajouter aux deux CR.
Pour plus d'informations sur l'emplacement de ce paramètre dans la spécification du fournisseur Azure, voir l'exemple de spécification du fournisseur Azure. L'emplacement dans le plan de contrôle Machine CR est similaire.
Procédure
Dressez la liste des machines du plan de contrôle de votre cluster en exécutant la commande suivante :
$ oc get machines \ -l machine.openshift.io/cluster-api-machine-role==master \ -n openshift-machine-api
Pour chaque machine du plan de contrôle, modifiez le CR en exécutant la commande suivante :
oc edit machine <control_plane_machine_name> $ oc edit machine <control_plane_machine_name>
-
Ajoutez le paramètre
internalLoadBalanceravec les détails corrects pour votre cluster et enregistrez vos modifications. Modifiez le jeu de machines CR de votre plan de contrôle en exécutant la commande suivante :
$ oc edit controlplanemachineset.machine.openshift.io cluster \ -n openshift-machine-api
-
Ajoutez le paramètre
internalLoadBalanceravec les détails corrects pour votre cluster et enregistrez vos modifications.
Prochaines étapes
-
Pour les clusters qui utilisent la stratégie de mise à jour par défaut
RollingUpdate, l'opérateur propage automatiquement les modifications à votre configuration du plan de contrôle. -
Pour les clusters configurés pour utiliser la stratégie de mise à jour
OnDelete, vous devez remplacer manuellement les machines du plan de contrôle.
Ressources complémentaires
12.6.3. Récupération d'un opérateur etcd dégradé
Certaines situations peuvent entraîner une dégradation de l'opérateur etcd.
Par exemple, lors de la remédiation, le bilan de santé de la machine peut supprimer une machine du plan de contrôle qui héberge etcd. Si le membre etcd n'est pas joignable à ce moment-là, l'opérateur etcd est dégradé.
Lorsque l'opérateur etcd est dégradé, une intervention manuelle est nécessaire pour forcer l'opérateur à retirer le membre défaillant et restaurer l'état du cluster.
Procédure
Dressez la liste des machines du plan de contrôle de votre cluster en exécutant la commande suivante :
$ oc get machines \ -l machine.openshift.io/cluster-api-machine-role==master \ -n openshift-machine-api \ -o wide
L'une des conditions suivantes peut indiquer une défaillance de la machine du plan de contrôle :
-
La valeur
STATEeststopped. -
La valeur
PHASEestFailed. -
La valeur
PHASEestDeletingpendant plus de dix minutes.
ImportantAvant de continuer, assurez-vous que votre cluster dispose de deux machines de plan de contrôle saines. L'exécution des actions de cette procédure sur plus d'une machine de plan de contrôle risque de perdre le quorum etcd et peut entraîner une perte de données.
Si vous avez perdu la majorité de vos hôtes du plan de contrôle, ce qui entraîne la perte du quorum etcd, vous devez suivre la procédure de reprise après sinistre "Restauration d'un état antérieur du cluster" au lieu de cette procédure.
-
La valeur
Modifiez le CR de la machine du plan de contrôle défaillant en exécutant la commande suivante :
oc edit machine <control_plane_machine_name> $ oc edit machine <control_plane_machine_name>
Supprimez le contenu du paramètre
lifecycleHooksde la machine du plan de contrôle défaillante et enregistrez vos modifications.L'opérateur etcd retire la machine défaillante du cluster et peut alors ajouter de nouveaux membres etcd en toute sécurité.
Ressources complémentaires
12.7. Désactivation du jeu de machines du plan de contrôle
Le champ .spec.state d'une ressource personnalisée (CR) ControlPlaneMachineSet activée ne peut pas être modifié de Active à Inactive. Pour désactiver l'ensemble de machines du plan de contrôle, vous devez supprimer la CR afin qu'elle soit retirée du cluster.
Lorsque vous supprimez le CR, l'opérateur de l'ensemble de machines du plan de contrôle effectue des opérations de nettoyage et désactive l'ensemble de machines du plan de contrôle. L'opérateur supprime ensuite le CR du cluster et crée un ensemble de machines de plan de contrôle inactif avec les paramètres par défaut.
12.7.1. Suppression du jeu de machines du plan de contrôle
Pour arrêter de gérer les machines du plan de contrôle avec le jeu de machines du plan de contrôle sur votre cluster, vous devez supprimer la ressource personnalisée (CR) ControlPlaneMachineSet.
Procédure
Supprimez le jeu de machines du plan de contrôle CR en exécutant la commande suivante :
$ oc delete controlplanemachineset.machine.openshift.io cluster \ -n openshift-machine-api
Vérification
-
Vérifiez l'état de la ressource personnalisée de l'ensemble de machines du plan de contrôle. Un résultat de
Inactiveindique que le processus de retrait et de remplacement est réussi. Une CRControlPlaneMachineSetexiste mais n'est pas activée.
12.7.2. Vérification de l'état des ressources personnalisées de l'ensemble des machines du plan de contrôle
Vous pouvez vérifier l'existence et l'état de la ressource personnalisée (CR) ControlPlaneMachineSet.
Procédure
Déterminez l'état de la CR en exécutant la commande suivante :
$ oc get controlplanemachineset.machine.openshift.io cluster \ --namespace openshift-machine-api
-
Un résultat de
Activeindique que la CRControlPlaneMachineSetexiste et est activée. Aucune action de l'administrateur n'est requise. -
Un résultat de
Inactiveindique qu'une CRControlPlaneMachineSetexiste mais qu'elle n'est pas activée. -
Un résultat de
NotFoundindique qu'il n'existe pas de CRControlPlaneMachineSet.
-
Un résultat de
12.7.3. Réactivation du jeu de machines du plan de contrôle
Pour réactiver le jeu de machines du plan de contrôle, vous devez vous assurer que la configuration du CR est correcte pour votre cluster et l'activer.
Ressources complémentaires
Chapitre 13. Déploiement des contrôles de santé des machines
Vous pouvez configurer et déployer un contrôle de l'état des machines pour réparer automatiquement les machines endommagées dans un pool de machines.
Vous ne pouvez utiliser les fonctionnalités avancées de gestion et de mise à l'échelle des machines que dans les clusters où l'API Machine est opérationnelle. Les clusters dont l'infrastructure est fournie par l'utilisateur nécessitent une validation et une configuration supplémentaires pour utiliser l'API Machine.
Les clusters avec le type de plateforme d'infrastructure none ne peuvent pas utiliser l'API Machine. Cette limitation s'applique même si les machines de calcul attachées au cluster sont installées sur une plateforme qui prend en charge cette fonctionnalité. Ce paramètre ne peut pas être modifié après l'installation.
Pour afficher le type de plateforme de votre cluster, exécutez la commande suivante :
$ oc get infrastructure cluster -o jsonpath='{.status.platform}'13.1. À propos des contrôles de santé des machines
Vous ne pouvez appliquer un contrôle de l'état des machines qu'aux machines du plan de contrôle des clusters qui utilisent des jeux de machines du plan de contrôle.
Pour surveiller l'état des machines, créez une ressource afin de définir la configuration d'un contrôleur. Définissez une condition à vérifier, telle que le maintien de l'état NotReady pendant cinq minutes ou l'affichage d'une condition permanente dans le détecteur de problèmes de nœuds, ainsi qu'une étiquette pour l'ensemble des machines à surveiller.
Le contrôleur qui observe une ressource MachineHealthCheck vérifie la condition définie. Si une machine échoue au contrôle de santé, elle est automatiquement supprimée et une autre est créée pour la remplacer. Lorsqu'une machine est supprimée, un événement machine deleted s'affiche.
Pour limiter l'impact perturbateur de la suppression des machines, le contrôleur ne draine et ne supprime qu'un seul nœud à la fois. S'il y a plus de machines malsaines que le seuil maxUnhealthy ne le permet dans le groupe de machines ciblées, la remédiation s'arrête et permet donc une intervention manuelle.
Les délais d'attente doivent être étudiés avec soin, en tenant compte de la charge de travail et des besoins.
- Les délais d'attente prolongés peuvent entraîner de longues périodes d'indisponibilité de la charge de travail sur la machine en état d'insalubrité.
-
Des délais trop courts peuvent entraîner une boucle de remédiation. Par exemple, le délai de vérification de l'état de
NotReadydoit être suffisamment long pour permettre à la machine de terminer le processus de démarrage.
Pour arrêter le contrôle, retirez la ressource.
13.1.1. Limitations lors du déploiement des contrôles de santé des machines
Il y a des limites à prendre en compte avant de déployer un bilan de santé machine :
- Seules les machines appartenant à un jeu de machines sont remédiées par un bilan de santé de la machine.
- Si le nœud d'une machine est supprimé du cluster, un contrôle de santé de la machine considère que la machine n'est pas en bonne santé et y remédie immédiatement.
-
Si le nœud correspondant à une machine ne rejoint pas le cluster après le
nodeStartupTimeout, la machine est remédiée. -
Une machine est remédiée immédiatement si la phase de ressource
MachineestFailed.
13.2. Exemple de ressource MachineHealthCheck
La ressource MachineHealthCheck pour tous les types d'installation basés sur le cloud, et autre que bare metal, ressemble au fichier YAML suivant :
apiVersion: machine.openshift.io/v1beta1 kind: MachineHealthCheck metadata: name: example 1 namespace: openshift-machine-api spec: selector: matchLabels: machine.openshift.io/cluster-api-machine-role: <role> 2 machine.openshift.io/cluster-api-machine-type: <role> 3 machine.openshift.io/cluster-api-machineset: <cluster_name>-<label>-<zone> 4 unhealthyConditions: - type: "Ready" timeout: "300s" 5 status: "False" - type: "Ready" timeout: "300s" 6 status: "Unknown" maxUnhealthy: "40%" 7 nodeStartupTimeout: "10m" 8
- 1
- Indiquez le nom du bilan de santé de la machine à déployer.
- 2 3
- Spécifiez une étiquette pour le pool de machines que vous souhaitez vérifier.
- 4
- Indiquez le jeu de machines à suivre au format
<cluster_name>-<label>-<zone>. Par exemple,prod-node-us-east-1a. - 5 6
- Spécifiez la durée du délai d'attente pour une condition de nœud. Si une condition est remplie pendant la durée du délai, la machine sera remédiée. Les délais d'attente prolongés peuvent entraîner de longues périodes d'indisponibilité pour une charge de travail sur une machine en mauvais état.
- 7
- Spécifiez le nombre de machines autorisées à être assainies simultanément dans le pool ciblé. Il peut s'agir d'un pourcentage ou d'un nombre entier. Si le nombre de machines malsaines dépasse la limite fixée par
maxUnhealthy, la remédiation n'est pas effectuée. - 8
- Spécifiez le délai d'attente pour qu'un contrôle de l'état de santé d'une machine attende qu'un nœud rejoigne la grappe avant qu'une machine ne soit considérée comme étant en mauvais état.
Le site matchLabels n'est qu'un exemple ; vous devez définir vos groupes de machines en fonction de vos besoins spécifiques.
13.2.1. Court-circuitage du contrôle de santé de la machine remédiation
Le court-circuitage garantit que les contrôles de santé des machines ne remédient aux machines que lorsque le cluster est sain. Le court-circuitage est configuré via le champ maxUnhealthy de la ressource MachineHealthCheck.
Si l'utilisateur définit une valeur pour le champ maxUnhealthy, avant de remédier à des machines, MachineHealthCheck compare la valeur de maxUnhealthy avec le nombre de machines dans son pool cible qu'il a déterminé comme n'étant pas en bonne santé. La remédiation n'est pas effectuée si le nombre de machines malsaines dépasse la limite fixée par maxUnhealthy.
Si maxUnhealthy n'est pas défini, la valeur par défaut est 100% et les machines sont remédiées quel que soit l'état du cluster.
La valeur appropriée de maxUnhealthy dépend de l'échelle du cluster que vous déployez et du nombre de machines couvertes par MachineHealthCheck. Par exemple, vous pouvez utiliser la valeur maxUnhealthy pour couvrir plusieurs ensembles de machines de calcul dans plusieurs zones de disponibilité, de sorte que si vous perdez une zone entière, votre paramètre maxUnhealthy empêche toute autre remédiation au sein du cluster. Dans les régions Azure globales qui ne disposent pas de plusieurs zones de disponibilité, vous pouvez utiliser des ensembles de disponibilité pour assurer une haute disponibilité.
Si vous configurez une ressource MachineHealthCheck pour le plan de contrôle, définissez la valeur de maxUnhealthy sur 1.
Cette configuration garantit que le contrôle de l'état des machines ne prend aucune mesure lorsque plusieurs machines du plan de contrôle semblent être en mauvaise santé. Plusieurs machines de plan de contrôle malsaines peuvent indiquer que le cluster etcd est dégradé ou qu'une opération de mise à l'échelle visant à remplacer une machine défaillante est en cours.
Si le cluster etcd est dégradé, une intervention manuelle peut être nécessaire. Si une opération de mise à l'échelle est en cours, le bilan de santé de la machine doit permettre de la terminer.
Le champ maxUnhealthy peut être défini comme un nombre entier ou un pourcentage. Il existe différentes implémentations de remédiation en fonction de la valeur de maxUnhealthy.
13.2.1.1. Réglage de l'insalubrité maximale par l'utilisation d'une valeur absolue
Si maxUnhealthy est défini sur 2:
- La remédiation sera effectuée si 2 nœuds ou moins sont malsains
- La remédiation ne sera pas effectuée si 3 nœuds ou plus sont malsains
Ces valeurs sont indépendantes du nombre de machines contrôlées par le bilan de santé.
13.2.1.2. Fixation de l'insalubrité maximale à l'aide de pourcentages
Si maxUnhealthy est défini sur 40% et qu'il y a 25 machines en cours de vérification :
- La remédiation sera effectuée si 10 nœuds ou moins sont malsains
- La remédiation ne sera pas effectuée si 11 nœuds ou plus sont malsains
Si maxUnhealthy est défini sur 40% et qu'il y a 6 machines en cours de contrôle :
- La remédiation sera effectuée si 2 nœuds ou moins sont malsains
- La remédiation ne sera pas effectuée si 3 nœuds ou plus sont malsains
Le nombre de machines autorisé est arrondi à la baisse lorsque le pourcentage de machines maxUnhealthy contrôlées n'est pas un nombre entier.
13.3. Création d'une ressource pour le bilan de santé d'une machine
Vous pouvez créer une ressource MachineHealthCheck pour les ensembles de machines de votre cluster.
Vous ne pouvez appliquer un contrôle de l'état des machines qu'aux machines du plan de contrôle des clusters qui utilisent des jeux de machines du plan de contrôle.
Conditions préalables
-
Installer l'interface de ligne de commande
oc.
Procédure
-
Créez un fichier
healthcheck.ymlqui contient la définition du contrôle de l'état de santé de votre machine. Appliquez le fichier
healthcheck.ymlà votre cluster :$ oc apply -f healthcheck.yml
Vous pouvez configurer et déployer un contrôle de l'état des machines pour détecter et réparer les nœuds métalliques nus qui ne sont pas en bon état.
13.4. A propos de la remédiation basée sur l'énergie du métal nu
Dans un cluster bare metal, la remédiation des nœuds est essentielle pour assurer la santé globale du cluster. La remédiation physique d'un cluster peut s'avérer difficile et tout retard dans la mise en état de sécurité ou de fonctionnement de la machine augmente la durée pendant laquelle le cluster reste dans un état dégradé, ainsi que le risque que des défaillances ultérieures mettent le cluster hors ligne. La remédiation basée sur l'énergie permet de relever ces défis.
Au lieu de reprovisionner les nœuds, la remédiation basée sur l'alimentation utilise un contrôleur d'alimentation pour mettre hors tension un nœud inopérant. Ce type de remédiation est également appelé "power fencing".
OpenShift Container Platform utilise le contrôleur MachineHealthCheck pour détecter les nœuds bare metal défectueux. La remédiation basée sur la puissance est rapide et redémarre les nœuds défectueux au lieu de les retirer du cluster.
La remédiation basée sur l'énergie offre les possibilités suivantes :
- Permet la récupération des nœuds du plan de contrôle
- Réduit le risque de perte de données dans les environnements hyperconvergés
- Réduction des temps d'arrêt liés à la récupération des machines physiques
13.4.1. MachineHealthChecks sur le métal nu
La suppression d'une machine sur un cluster bare metal déclenche le reprovisionnement d'un hôte bare metal. Habituellement, le reprovisionnement d'un hôte bare metal est un processus long, au cours duquel le cluster manque de ressources de calcul et les applications peuvent être interrompues. Pour changer le processus de remédiation par défaut de la suppression de la machine au cycle d'alimentation de l'hôte, annotez la ressource MachineHealthCheck avec l'annotation machine.openshift.io/remediation-strategy: external-baremetal.
Une fois l'annotation définie, les machines insalubres sont mises hors tension à l'aide des informations d'identification BMC.
13.4.2. Comprendre le processus de remédiation
Le processus de remédiation se déroule comme suit :
- Le contrôleur MachineHealthCheck (MHC) détecte qu'un nœud n'est pas sain.
- Le MHC informe le contrôleur de la machine nue qui demande la mise hors tension du nœud en mauvais état.
- Après la mise hors tension, le nœud est supprimé, ce qui permet à la grappe de reprogrammer la charge de travail concernée sur d'autres nœuds.
- Le contrôleur de la machine nue demande à mettre le nœud sous tension.
- Une fois que le nœud est opérationnel, il se réenregistre auprès de la grappe, ce qui entraîne la création d'un nouveau nœud.
- Une fois le nœud recréé, le contrôleur de machine bare metal restaure les annotations et les étiquettes qui existaient sur le nœud malsain avant sa suppression.
Si les opérations d'alimentation n'ont pas abouti, le contrôleur de la machine bare metal déclenche le reprovisionnement du nœud malsain, sauf s'il s'agit d'un nœud de plan de contrôle ou d'un nœud provisionné de manière externe.
13.4.3. Création d'une ressource MachineHealthCheck pour le bare metal
Conditions préalables
- OpenShift Container Platform est installé à l'aide d'une infrastructure fournie par l'installateur (IPI).
- Accès aux informations d'identification du contrôleur de gestion de la carte de base (BMC) (ou accès BMC à chaque nœud)
- Accès réseau à l'interface BMC du nœud malade.
Procédure
-
Créez un fichier
healthcheck.yamlqui contient la définition du contrôle de l'état de santé de votre machine. -
Appliquez le fichier
healthcheck.yamlà votre cluster à l'aide de la commande suivante :
$ oc apply -f healthcheck.yaml
Exemple de ressource MachineHealthCheck pour le métal nu
apiVersion: machine.openshift.io/v1beta1 kind: MachineHealthCheck metadata: name: example 1 namespace: openshift-machine-api annotations: machine.openshift.io/remediation-strategy: external-baremetal 2 spec: selector: matchLabels: machine.openshift.io/cluster-api-machine-role: <role> 3 machine.openshift.io/cluster-api-machine-type: <role> 4 machine.openshift.io/cluster-api-machineset: <cluster_name>-<label>-<zone> 5 unhealthyConditions: - type: "Ready" timeout: "300s" 6 status: "False" - type: "Ready" timeout: "300s" 7 status: "Unknown" maxUnhealthy: "40%" 8 nodeStartupTimeout: "10m" 9
- 1
- Indiquez le nom du bilan de santé de la machine à déployer.
- 2
- Pour les clusters bare metal, vous devez inclure l'annotation
machine.openshift.io/remediation-strategy: external-baremetaldans la sectionannotationspour activer la remédiation par cycle d'alimentation. Avec cette stratégie de remédiation, les hôtes malsains sont redémarrés au lieu d'être retirés du cluster. - 3 4
- Spécifiez une étiquette pour le pool de machines que vous souhaitez vérifier.
- 5
- Spécifiez le jeu de machines de calcul à suivre au format
<cluster_name>-<label>-<zone>. Par exemple,prod-node-us-east-1a. - 6 7
- Indiquez la durée du délai d'attente pour la condition de nœud. Si la condition est remplie pendant la durée du délai, la machine sera remédiée. Les délais d'attente prolongés peuvent entraîner de longues périodes d'indisponibilité pour une charge de travail sur une machine en mauvais état.
- 8
- Spécifiez le nombre de machines autorisées à être assainies simultanément dans le pool ciblé. Il peut s'agir d'un pourcentage ou d'un nombre entier. Si le nombre de machines malsaines dépasse la limite fixée par
maxUnhealthy, la remédiation n'est pas effectuée. - 9
- Spécifiez le délai d'attente pour qu'un contrôle de l'état de santé d'une machine attende qu'un nœud rejoigne la grappe avant qu'une machine ne soit considérée comme étant en mauvais état.
Le site matchLabels n'est qu'un exemple ; vous devez définir vos groupes de machines en fonction de vos besoins spécifiques.
Pour résoudre un problème lié à la remédiation basée sur l'alimentation, vérifiez les points suivants :
- Vous avez accès à la BMC.
- BMC est connecté au nœud du plan de contrôle responsable de l'exécution de la tâche de remédiation.