
Guide d'administration et de configuration
À utiliser dans Red Hat JBoss Enterprise Application Platform 6
Résumé
Chapitre 1. Introduction
1.1. Red Hat JBoss Enterprise Application Platform 6 (JBoss EAP 6)
1.2. Les fonctionnalités de JBoss EAP 6
Tableau 1.1. Fonctionnalités 6.1.0
| Fonctionnalité | Description |
|---|---|
| Certification Java | Implémentation certifiée des spécifications de JBoss Enterprise Application Platform 6 Full Profil et Web Profile. |
| Domaine géré |
|
| Console de gestion et Management CLI | Il y a de nouvelles interfaces pour gérer le domaine ou serveur autonome. Il n'est nul besoin de modifier les fichiers de configuration XML à la main. Le Management CLI offre également un mode lot, ce qui signifie que vous pourrez scripter et automatiser les tâches de gestion. |
| La disposition du répertoire est simplifiée | Le répertoire modules/ contient maintenant les modules du serveur d'application, au lieu d'utiliser les répertoires communs et spécifiques au serveur lib/. Les répertoires domain/ et standalone/ contiennent les artefacts et les fichiers de configuration pour le domaine et pour les déploiements autonomes. |
| Mécanisme de chargement de classes modulaire | Les modules sont chargés et déchargés à la demande pour plus de performance et de sécurité et des démarrages et redémarrages plus rapides. |
| Gestion de Sources de données simplifiée | Les pilotes de base de données peuvent être déployés comme tout autre service. En plus, les sources de données sont créées et gérées directement dans la Console de gestion ou le Management CLI. |
| Temps de démarrage et d'arrêt optimisés | JBoss EAP 6 utilise moins de ressources et est extrêmement efficace au niveau de l'utilisation des ressources. Surtout utile aux développeurs. |
1.3. JBoss EAP 6 Operating Modes
1.4. Les serveurs autonomes
1.5. Les Domaines gérés
domain.sh ou domain.bat est exécuté. Contrairement au contrôleur de domaine, les contrôleurs hôtes sont configurés pour lui déléguer des tâches de gestion de domaine. Le contrôleur hôte de chaque hôte interagit avec le contrôleur de domaine pour vérifier le cycle de vie des instances du serveur d'application exécutées sur son hôte et pour aider le contrôleur de domaine à les gérer. Chaque hôte peut contenir plusieurs groupes de serveurs. Un groupe de serveurs est un ensemble d'instances de serveurs sur lequel JBoss EAP 6 est installé et étant configurées comme une seule et même entité. Etant donné que le contrôleur de domaine gère la configuration et les applications déployées sur les groupes de serveurs, chaque serveur de groupe de serveurs partage la même configuration et les mêmes déploiements.
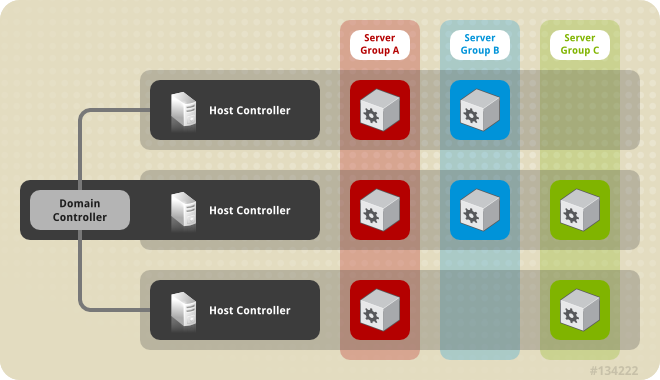
Figure 1.1. Représentation graphique d'un domaine géré
1.6. Contrôleur de domaine
- maintenir la politique centrale de gestion du domaine
- s'assurer que tous les contrôleurs soient mis au courant de leurs contenus actuels
- assister tous les contrôleurs pour que toutes les instances en cours de JBoss EAP 6 soient configurées suivant cette politique
domain/configuration/domain.xml, dans le fichier d'installation JBoss EAP 6 non compressé, sur le système de fichiers de l'hôte du contrôleur de domaines.
domain/configuration/ du contrôleur hôte qui est destiné à être exécuté comme contrôleur de domaine. Ce fichier n'est pas obligatoire pour les installations sur les contrôleurs hôtes non destinés à être conçus comme contrôleur de domaine. Cependant, la présence d'un fichier domain.xml sur un tel serveur ne nuit pas. Le fichier domain.xml contient la configuration des divers profils qui peuvent être configurés pour exécuter sur les instances de serveur d'un domaine. Une configuration de profil inclut la configuration détaillée des différents sous-systèmes qui composent un profil. La configuration de domaine inclut également la définition des groupes de sockets et la définition des groupes de serveurs.
1.7. Échecs de Contrôleurs de domaines
1.8. Contrôleur hôte
domain.sh ou domain.bat script est exécuté sur un hôte. La responsabilité primaire d'un contrôleur hôte est la gestion de serveur. Il délègue des tâches de gestion de domaine et est responsable de lancer et d'arrêter les processus de serveurs d'applications individuels qui s'exécutent sur son hôte. Il interagit avec le contrôleur de domaines pour gérer la communication entre les serveurs et le contrôleur de domaines. Plusieurs contrôleurs hôte d'un domaine peuvent interagir avec un contrôleur de domaine unique. Par conséquent, tous les contrôleurs hôtes et les instances de serveurs exécutant en mode de domaine unique peuvent avoir un contrôleur de domaine unique et doivent appartenir au même domaine.
domain/configuration/host.xml situé dans le fichier d'installation de JBoss EAP 6 décompressé sur le système de fichiers de son hôte. Le fichier host.xml contient les informations de configuration suivantes spécifiques à l'hôte particulier :
- Énumère les noms des instances de JBoss EAP 6 censées être exécutées à partir de l'installation.
- Une des configurations suivantes :
- la façon dont le contrôleur hôte contacte le contrôleur de domaines pour s'enregistrer et pour accéder à la configuration de domaine
- la façon de rechercher et contacter un contrôleur de domaines éloigné
- comment le contrôleur d'hôtes doit se persuader lui-même d'agir en tant que contrôleur de domaines
- Configuration d'éléments spécifiques à l'installation physique locale. Ainsi, les définitions d'interfaces nommées déclarées dans domain.xml peuvent être mappées vers une adresse IP spécifique à une machine dans host.xml. Les noms de chemins d'accès abstraits de domain.xml peuvent être mappés vers les chemins d'accès d'host.xml.
1.9. Les groupes de serveurs
<server-group name="main-server-group" profile="default"> <socket-binding-group ref="standard-sockets"/> <deployments> <deployment name="foo.war_v1" runtime-name="foo.war"/> <deployment name="bar.ear" runtime-name="bar.ear"/> </deployments> </server-group>
- nom : le nom du groupe de serveurs
- profil : le nom du profil du groupe de serveurs
- socket-binding-group : le nom du groupe de liaisons de sockets par défaut à utiliser pour les serveurs dans le groupe. Ce nom peut être remplacé sur la base d'un serveur à la fois dans host.xml. Si le nom socket-binding-group n'est pas fourni dans l'élément server-group, il doit être donné pour chaque serveur dans le fichier host.xml.
- deployments : le contenu de déploiement à déployer sur les serveurs du groupe
- system-properties : les propriétés système à définir sur les serveurs du groupe
- jvm : les paramètres de configuration par défaut de tous les serveurs du groupe. Le contrôleur hôte fait fusionner ces paramètres dans n'importe quelle configuration fournie par host.xml pour établir les paramètres à utiliser dans la JVM du serveur.
1.10. Profils JBoss EAP 6
Chapitre 2. Gestion de serveurs d'applications
2.1. Démarrer et stopper JBoss EAP 6
2.1.1. Démarrer JBoss EAP 6
2.1.2. Démarrez JBoss EAP 6 comme un serveur autonome
Cette rubrique couvre toutes les étapes à couvrir pour démarrer JBoss EAP 6 en tant que serveur autonome.
Procédure 2.1. Démarrer le Service de plate-forme comme serveur autonome.
Dans Red Hat Enterprise Linux.
Exécuter la commande suivante :EAP_HOME/bin/standalone.shDans Microsoft Windows Server
Exécuter la commande suivante :EAP_HOME\bin\standalone.batOption : indiquer les paramètres supplémentaires.
Pour imprimer une liste de paramètres supplémentaires à passer aux scripts de démarrage, utiliser le paramètre-h.
L'instance de serveur autonome JBoss EAP 6 démarre.
2.1.3. Démarrez JBoss EAP 6 comme domaine géré
Le contrôleur de domaines doit être démarré avant qu'un serveur esclave ne démarre dans des groupes de serveurs du domaine. Utiliser cette procédure sur le contrôleur de domaine pour commencer, puis, sur chaque contrôleur d'hôte associé et sur chaque hôte associé.
Procédure 2.2. Démarrer le Service de plate-forme comme serveur géré
Dans Red Hat Enterprise Linux.
Exécutez la commande :EAP_HOME/bin/domain.shDans Microsoft Windows Server
Exécutez la commande :EAP_HOME\bin\domain.batEn option : passez des paramètres supplémentaires au script de démarrage.
Pour obtenir une liste de paramètres que vous pourrez passer au script de démarrage, utilisez le paramètre-h.
L'instance de domaine géré de JBoss EAP 6 démarre.
2.1.4. Démarrez JBoss EAP 6 avec une configuration différente
Prérequis
- Avant d'utiliser un fichier de configuration alternatif, préparez-le à l'aide de la configuration par défaut comme modèle. Pour un domaine géré, le fichier de configuration doit être placé dans
EAP_HOME/domain/configuration/. Pour les serveurs autonomes, le fichier de configuration devra être mis dans le répertoireEAP_HOME/standalone/configuration/.
Note
EAP_HOME/docs/examples/configs/. Utiliser ces exemples pour activer des fonctionnalités supplémentaires, comme clustering ou l'API XTS de Transactions.
Procédure 2.3. Démarrage de l'instance par une configuration différente
Serveur autonome
Pour un domaine autonome, fournir le nom du fichier de configuration comme option du paramètre--server-config. Le fichier de configuration doit se trouver dans le répertoireEAP_HOME/standalone/configuration/, et vous devez indiquer le chemin d'accès du fichier de ce répertoire.Exemple 2.1. Utiliser un fichier de configuration alternatif pour un Serveur autonome Red Hat Enterprise Linux.
[user@host bin]$
./standalone.sh --server-config=standalone-alternate.xmlCet exemple utilise le fichier de configurationEAP_HOME/standalone/configuration/standalone-alternate.xml.Exemple 2.2. Utiliser un fichier de configuration alternatif pour un Serveur autonome Microsoft Windows.
C:\EAP_HOME\bin>
standalone.bat --server-config=standalone-alternate.xmlCet exemple utilise le fichier de configurationEAP_HOME/standalone/configuration/standalone-alternate.xml.Domaine géré
Pour un domaine géré, fournir le nom du fichier de configuration comme option du paramètre--domain-config. Le fichier de configuration se trouve dans le répertoireEAP_HOME/domain/configuration/, et vous devez indiquer le chemin d'accès de ce répertoire.Exemple 2.3. Utilisation d'un fichier de configuration alternatif pour un Domaine géré dans Red Hat Enterprise Linux
[user@host bin]$
./domain.sh --domain-config=domain-alternate.xmlCet exemple utilise le fichier de configurationEAP_HOME/domain/configuration/domain-alternate.xml.Exemple 2.4. Utilisation d'un fichier de configuration alternatif pour un Domaine géré dans un serveur Microsoft Windows
C:\EAP_HOME\bin>
domain.bat --domain-config=domain-alternate.xmlCet exemple utilise le fichier de configurationEAP_HOME\domain\configuration\domain-alternate.xml.
La plateforme JBoss Enterprise Application Platform est maintenant en cours d'exécution, avec votre fichier de configuration alternatif.
2.1.5. Stopper le serveur JBoss EAP 6
Note
Procédure 2.4. Stopper une instance autonome de JBoss EAP 6
Stopper une instance qui a été démarrée de façon interactive à partir d'une invite de commande.
Appuyez surCtrl-Cdans le terminal où JBoss EAP 6 exécute.Stopper une instance qui a démarré en tant que service de système d'exploitation.
Suivant votre système d'exploitation, utiliser une des procédures suivantes :Red Hat Enterprise Linux
Dans Red Hat Enterprise Linux, si vous avez écrit un script de service, utiliser sa fonctionstop. Cela devra être inscrit dans le script. Ensuite, vous pourrez utiliserservice scriptname stop, avec scriptname comme nom de script.Microsoft Windows Server
Dans Microsoft Windows, utiliser la commandenet service, ou bien faites cesser le service à partir de l'applet Services qui se trouve dans le Panneau de contrôle.
Stopper une instance qui exécute en arrière-plan (Red Hat Enterprise Linux)
- Cherchez l'instance dans la liste de processus. Une option consiste à exécuter la commande
ps aux |grep "[j]ava -server". Cela renverra un résultat pour chaque instance de JBoss EAP 6 en cours d'exécution sur la machine locale. - Envoyer au processus le signal
TERM, en exécutantkill process_ID, avec process_ID comme numéro de deuxième champ de la commandeps auxci-dessus.
Chacune de ces solutions ferme la plate-forme JBoss EAP 6 nettement, ce qui fait qu'aucune donnée n'est perdue.
2.1.6. Référence aux variables et arguments à passer à l'exécution du serveur
standalone.xml, domain.xml et host.xml. Cela peut comprendre le démarrage du serveur par un ensemble de liaisons de sockets différent ou une configuration secondaire. Vous pourrez accéder à une liste des paramètres disponibles en passant la variable d'assistance au démarrage.
Exemple 2.5.
-h ou --help en plus. Les résultats de cette variable d'assistance sont expliqués dans le tableau ci-dessous.
[localhost bin]$ standalone.sh -hTableau 2.1. Tableau des arguments et variables du temps d'exécution
| Argument ou Variable | Description |
|---|---|
| --admin-only | Définir le type d'exécution du serveur à ADMIN_ONLY. Cela le fera ouvrir les interfaces administratives et il pourra ainsi accepter les ordres de gestion, mais il ne pourra pas démarrer d'autres services de runtime ou accepter les demandes de l'utilisateur final. |
| -b=<value> | Définir la propriété système jboss.bind.address à la valeur donnée. |
| -b <value> | Définir la propriété système jboss.bind.address à la valeur donnée. |
| -b<interface>=<value> | Définir la propriété système jboss.bind.address.<interface> à la valeur donnée. |
| -c=<config> | Nommer le fichier de configuration du serveur à utiliser. La valeur par défaut est standalone.xml. |
| -c <config> | Nommer le fichier de configuration du serveur à utiliser. La valeur par défaut est standalone.xml. |
| --debug [<port>] | Activer le mode de débogage par un argument en option qui indique le port. Ne fonctionne que si le script de lancement le supporte. |
| -D<name>[=<value>] | Définir une propriété système. |
| -h | Afficher le message d'assistance et sortir. |
| --help | Afficher le message d'assistance et sortir. |
| --read-only-server-config=<config> | Nom du fichier de configuration du serveur à utiliser. Cela diffère de '--server-config' et '-c' en ce que le fichier d'origine n'est jamais écrasé. |
| -P=<url> | Télécharger les propriétés système de l'URL donné. |
| -P <url> | Télécharger les propriétés système de l'URL donné. |
| --properties=<url> | Télécharger les propriétés système de l'URL donné. |
| -S<name>[=<value>] | Définir une propriété de sécurité. |
| --server-config=<config> | Nommer le fichier de configuration du serveur à utiliser. La valeur par défaut est standalone.xml. |
| -u=<value> | Définir la propriété système jboss.default.multicast.address à la valeur donnée. |
| -u <value> | Définir la propriété système jboss.default.multicast.address à la valeur donnée. |
| -V | Afficher la version du serveur d'application et sortir. |
| -v | Afficher la version du serveur d'application et sortir. |
| --version | Afficher la version du serveur d'application et sortir. |
2.2. Démarrer et arrêter les serveurs
2.2.1. Démarrer et arrêter les serveurs par le Management CLI
Vous pouvez démarrer une instance de serveur autonome par les scripts de ligne de commande, et le fermer par le Management CLI par la commande shutdown. Si vous avez besoin de l'instance par la suite, exécuter le processus de démarrage à nouveau selon les instructions dans Section 2.1.2, « Démarrez JBoss EAP 6 comme un serveur autonome ».
Exemple 2.6. Démarrer et arrêter une instance de serveur autonome par le Management CLI
[standalone@localhost:9999 /] shutdown
Si vous exécutez un Domaine géré, la Console de gestion va vous permettre de démarrer ou de stopper sélectivement des serveurs spécifiques pour ce domaine. Cela inclut les groupes de serveurs dans tout le domaine, ainsi que les instances de serveur spécifiques sur un hôte.
Exemple 2.7. Stopper un Hôte de serveur dans un Domaine géré via un Management CLI
shutdown est utilisée pour fermer un hôte de Domaine Géré déclaré. Cette exemple stoppe un hôte de serveur nommé master en déclarant le nom d'instance avant d'appeler l'opération de fermeture. Utiliser la touche tab pour aider à la complétion de chaînes et pour exposer des variables visibles comme les valeurs hôtes disponibles.
[domain@localhost:9999 /] /host=master:shutdown
Exemple 2.8. Stopper un Hôte de serveur dans un Domaine géré via un Management CLI
main-server-group en déclarant le groupe avant les opérations start et stop. Utilisez la touche tab pour aider à la complétion de chaînes et pour exposer des variables visibles comme les valeurs de nom de groupe de serveur disponible.
[domain@localhost:9999 /] /server-group=main-server-group:start-servers
[domain@localhost:9999 /] /server-group=main-server-group:stop-servers
Exemple 2.9. Démarrer et stopper une instance de serveur dans un Domaine géré via un Management CLI
server-one sur l'hôte master en déclarant la configuration de l'hôte et du serveur avant d'invoquer les opérations start et stop. Utilisez la touche tab pour aider à la complétion de chaînes et pour exposer des variables visibles comme les valeurs de configuration de l'hôte et du serveur.
[domain@localhost:9999 /] /host=master/server-config=server-one:start
[domain@localhost:9999 /] /host=master/server-config=server-one:stop
2.2.2. Démarrer un serveur par la Console de gestion
Prérequis
Procédure 2.5. Démarrer le serveur
Naviguer dans Server Instances dans la Console de gestion
- Sélectionner l'onglet Runtime en haut de la console.
Sélectionner un serveur
À partir de la liste Server Instances, sélectionner le serveur que vous souhaitez démarrer. Les serveurs qui sont en cours d'exécution sont indiqués.En plaçant le curseur sur une instance de cette liste, vous verrez vos options en bleu sous Détails du serveur.Cliquer sur le bouton
Pour démarrer une instance, cliquer surStart Serverquand vous verrez ce texte. Une boîte de dialogue de confirmation va s'ouvrir. Cliquer sur le bouton pour démarrer le serveur.
Le serveur sélectionné démarre et exécute.
2.2.3. Stopper un serveur qui utilise une Console de gestion
Prérequis
Procédure 2.6. Stopper un serveur qui utilise une Console de gestion
Naviguez dans Hôtes, groupes et instances de serveur dans la Console de gestion
- Sélectionner l'onglet Runtime en haut de la console. Les instances de serveur disponibles seront affichées sur le tableau général de l'onglet Topologie.
Sélectionner un serveur
À partir de la liste Server Instances, sélectionner le serveur que vous souhaitez stopper. Les serveurs qui sont en cours d'exécution sont indiqués.Cliquer sur le texte .
Cliquer sur le texte qui apparaît quand vous bougez la souris sur l'entrée serveur. Une boîte de dialogue de confirmation apparaîtra.- Cliquer sur le bouton pour arrêter le serveur.
Le serveur sélectionné est stoppé.
2.3. Chemins d'accès aux systèmes de fichiers
2.3.1. Chemins d'accès aux systèmes de fichiers
domain.xml, host.xml et standalone.xml incluent tous une section où les chemins d'accès peuvent être déclarés. D'autres sections de la configuration peuvent ensuite référencer ces chemins par leur nom logique, évitant la déclaration du chemin d'accès absolu pour chaque instance. Cela bénéficie aux efforts de configuration et d'administration car cela permet à des configurations hôtes spécifiques de résoudre des noms logiques universels.
jboss.server.log.dir qui pointe vers le répertoire log du serveur.
Exemple 2.10. Exemple de chemin d'accès relatif du répertoire de logging
<file relative-to="jboss.server.log.dir" path="server.log"/>
Tableau 2.2. Chemins d'accès standard
| Valeur | Description |
|---|---|
jboss.home.dir | Le répertoire root de la distribution JBoss EAP 6. |
user.home | Le répertoire d'accueil de l'utilisateur. |
user.dir | Le répertoire de travail actuel de l'utilisateur |
java.home | Le répertoire d'installation de Java |
jboss.server.base.dir | Le répertoire root d'une instance de serveur individuel. |
jboss.server.data.dir | Le répertoire que le serveur va utiliser pour le stockage de fichier de données persistantes. |
jboss.server.config.dir | Le répertoire qui contient la configuration du serveur. |
jboss.server.log.dir | Le répertoire que le serveur va utiliser pour le stockage de fichier de journalisation. |
jboss.server.temp.dir | Le répertoire que le serveur va utiliser pour le stockage de fichier temporaires. |
jboss.controller.temp.dir | Le répertoire que le contrôleur hôte va utiliser pour le stockage de fichier temporaires. |
path dans leur fichier de configuration. L'exemple suivant indique la nouvelle déclaration de chemin relatif qui se rapporte au répertoire root de l'instance du serveur individuel.
Exemple 2.11. Format d'un chemin relatif
<path name="examplename" path="example/path" relative-to="jboss.server.data.dir"/>
Tableau 2.3. Attributs de chemin d'accès
| Attribut | Description |
|---|---|
name | Le nom du chemin d'accès. |
path | Le chemin d'accès du système de fichier. Considéré comme chemin absolu, à moins que l'attribut relative-to ne soit spécifié, dans lequel cas, la valeur sera traitée comme étant relative à ce chemin. |
relative-to | Un attribut optionnel qui indique le nom d'un autre nom ancienement nommé, ou bien qui correspond à un chemin standard défini par le système. |
path (chemin) d'un fichier de configuration domain.xml ne requiert que le nom de l'attribut. Il n'a pas besoin d'inclure des informations sur le chemin du système de fichiers, comme le montre l'exemple suivant.
Exemple 2.12. Exemple de chemin de domaine
<path name="example"/>
exemple auquel les autres parties de la configuration du domain.xml peuvent faire référence. L'emplacement du système de fichiers courant déclaré par l'exemple est spécifique aux fichiers de configuration host.xml respectifs des instances de l'hôte qui se joignent aux groupes de domaine. Si cette approche est utilisée, il doit y avoir un élément de chemin dans l'host.xml de chaque machine, qui indique le chemin du système de fichier.
Exemple 2.13. Exemple de chemin d'hôte
<path name="example" path="path/to/example" />
path d'un fichier standalone.xml doit inclure la spécification du chemin d'accès du système de fichier.
2.4. Historique du fichier de configuration
2.4.1. Fichiers de configuration de JBoss EAP 6
Tableau 2.4. Emplacements de Fichiers de configuration
| Mode du serveur | Emplacement | But |
|---|---|---|
| domain.xml | EAP_HOME/domain/configuration/domain.xml | Il s'agit du fichier de configuration principal d'un domaine géré. Seul le master du domaine lit ce fichier. Il peut être supprimé pour les autres membres du domaine. |
| host.xml | EAP_HOME/domain/configuration/host.xml | Ce fichier contient les détails de configuration spécifiques à un hôte physique dans un domaine géré, tels que les interfaces réseau, les liaisons de sockets, le nom de l'hôte et d'autres détails spécifiques à l'hôte. Le fichier host.xml contient toutes les fonctionnalités de hôte-master.xml et hôte-slave.xml, qui sont décrits ci-dessous. Ce fichier n'est pas présent pour les serveurs autonomes. |
| host-master.xml | EAP_HOME/domain/configuration/host-master.xml | Ce fichier inclut tous les détails de configuration nécessaires pour exécuter un serveur en tant que serveur maître de domaine géré. Ce fichier n'est pas présent dans les serveurs autonomes. |
| host-slave.xml | EAP_HOME/domain/configuration/host-slave.xml | Ce fichier inclut tous les détails de configuration nécessaires pour exécuter un serveur en tant que serveur esclave de domaine géré. Ce fichier n'est pas présent dans les serveurs autonomes. |
| standalone.xml | EAP_HOME/standalone/configuration/standalone.xml | C'est le fichier de configuration par défaut pour un serveur autonome. Il contient toutes les informations sur le serveur autonome, y compris les sous-systèmes, réseautage, déploiements, les liaisons de sockets et autres détails configurables. Cette configuration est utilisée automatiquement lorsque vous démarrez votre serveur autonome. |
| standalone-full.xml | EAP_HOME/standalone/configuration/standalone-full.xml | Il s'agit d'un exemple de configuration pour un serveur autonome. Il prend en charge chaque sous-système possible à l'exception de ceux destinés à la haute disponibilité. Pour l'utiliser, arrêtez votre serveur et redémarrez à l'aide de la commande suivante : EAP_HOME/bin/standalone.sh -c standalone-full.xml |
| standalone-ha.xml | EAP_HOME/standalone/configuration/standalone-ha.xml | Cet exemple de fichier de configuration active tous les sous-systèmes par défaut et ajoute les mod_cluster et les sous-systèmes JGroups pour un serveur autonome, afin qu'il puisse participer à un cluster de haute disponibilité ou d'équilibrage de la charge. Ce fichier n'est pas applicable à un domaine géré. Pour utiliser cette configuration, arrêtez votre serveur et redémarrez le à l'aide de la commande suivante : EAP_HOME/bin/standalone.sh -c standalone-ha.xml |
| standalone-full-ha.xml | EAP_HOME/standalone/configuration/standalone-full-ha.xml | Il s'agit d'un exemple de configuration pour un serveur autonome. Il prend en charge chaque sous-système possible incluant ceux destinés à la haute disponibilité. Pour l'utiliser, arrêtez votre serveur et redémarrez à l'aide de la commande suivante : EAP_HOME/bin/standalone.sh -c standalone-full-ha.xml |
2.4.2. Historique du fichier de configuration
standalone.xml, ainsi que les fichiers domain.xml et host.xml. Alors que ces fichiers sont modifiables directement, la méthode recommandée consiste à configurer le modèle de serveur d'applications par les opérations de gestion disponibles, y compris Management CLI et la Console de gestion.
2.4.3. Démarrer le serveur par une ancienne configuration
standalone.xml. Le même concept s'applique à un domaine géré par domain.xml et host.xml respectivement.
- Identifier la version de sauvegarde que vous souhaitez démarrer. Cet exemple va rappeler l'instance de modèle de serveur qui précédait la première modification qui a lieu suite à un démarrage réussi.
EAP_HOME/configuration/standalone_xml_history/current/standalone.v1.xml - Démarrer le serveur par cette configuration du modèle de sauvegarde en passant le nom de fichier relatif sous
jboss.server.config.dir.EAP_HOME/bin/standalone.sh --server-config=standalone_xml_history/current/standalone.v1.xml
Le serveur d'applications démarre par la configuration sélectionnée.
2.4.4. Sauvegarder un snapshot de configuration par le Management CLI
Les snapshots représentent une copie d'un moment précis d'une configuration de serveur en cours. Ces copies peuvent être sauvegardées et chargées par l'administrateur.
standalone.xml, mais le même processus s'applique aux fichiers de configuration domain.xml et host.xml.
Procédure 2.7. Télécharger un Snapshot de configuration et Sauvegardez-le
Sauvegarde d'un snapshot
Exécuter l'opérationtake-snapshotpour acquérir une copie de la configuration du serveur.[standalone@localhost:9999 /] :take-snapshot { "outcome" => "success", "result" => "/home/User/EAP_HOME/standalone/configuration/standalone_xml_history/snapshot/20110630-172258657standalone.xml"
Un snapshot de la configuration du serveur en cours a été sauvegardé.
2.4.5. Charger un Snapshot de Configuration avec le Management CLI.
standalone.xml, mais le même processus s'applique aux fichiers domain.xml et host.xml.
Procédure 2.8. Télécharger un snapshot de configuration
- Identifier le snapshot à télécharger. Cet exemple va rappeler le fichier suivant du répertoire de snapshots. Le chemin par défaut des fichiers de snapshot est le suivant.
EAP_HOME/standalone/configuration/standalone_xml_history/snapshot/20110812-191301472standalone.xml
Les snapshots sont exprimés par leurs chemins relatifs, selon lesquels l'exemple ci-dessus peut être écrit ainsi.jboss.server.config.dir/standalone_xml_history/snapshot/20110812-191301472standalone.xml
- Démarrer le serveur par le snapshot de configuration sélectionné en passant le nom du fichier.
EAP_HOME/bin/standalone.sh --server-config=standalone_xml_history/snapshot/20110913-164449522standalone.xml
Le serveur démarre à nouveau avec la configuration sélectionnée dans le snapshot téléchargé.
2.4.6. Supprimer un snapshot de configuration par le Management CLI
standalone.xml, mais le même processus s'applique aux fichiers domain.xml et host.xml.
Procédure 2.9. Supprimer un snapshot particulier
- Identifier le snapshot à effacer. Cet exemple va effacer le fichier suivant du répertoire de snapshots.
EAP_HOME/standalone/configuration/standalone_xml_history/snapshot/20110630-165714239standalone.xml
- Exécuter la commande
:delete-snapshotpour supprimer un snapshot particulier, en spécifiant le nom du snapshot comme dans l'exemple ci-dessous.[standalone@localhost:9999 /]
:delete-snapshot(name="20110630-165714239standalone.xml"){"outcome" => "success"}
Le snapshot a été supprimé.
Procédure 2.10. Supprimer tous les snapshots
- Exécuter la commande
:delete-snapshot(name="all")pour supprimer tous les snapshots comme dans l'exemple ci-dessous.[standalone@localhost:9999 /]
:delete-snapshot(name="all"){"outcome" => "success"}
Tous les snapshots ont été supprimés.
2.4.7. Lister tous les snapshots de configuration par le Management CLI
standalone.xml, mais le même processus s'applique aux fichiers domain.xml et host.xml.
Procédure 2.11. Lister tous les snapshots de configuration
Lister tous les snapshots
Lister tous les snapshots sauvegardés en exécutant la commande:list-snapshots.[standalone@localhost:9999 /]
:list-snapshots{ "outcome" => "success", "result" => { "directory" => "/home/hostname/EAP_HOME/standalone/configuration/standalone_xml_history/snapshot", "names" => [ "20110818-133719699standalone.xml", "20110809-141225039standalone.xml", "20110802-152010683standalone.xml", "20110808-161118457standalone.xml", "20110912-151949212standalone.xml", "20110804-162951670standalone.xml" ] } }
Les snapshots sont listés.
Chapitre 3. Interfaces de gestion
3.1. Gestion du serveur d'applications
3.2. Les API (de l'anglais Application Programming Interfaces) de Gestion
JBoss EAP 6 offre trois approches différentes pour configurer et gérer des serveurs, étant à la fois une interface web, un client de ligne de commande et un ensemble de fichiers de configuration XML. Tandis que les méthodes recommandées pour la modification du fichier de configuration incluent la Console de Gestion et Management CLI, les modifications de configuration de la part des trois sont toujours synchronisées à travers les différentes vues et sont conservées dans les fichiers XML. Notez que les modifications apportées aux fichiers de configuration XML pendant l'exécution d'une instance de serveur seront remplacées par le modèle de serveur.
La Console de gestion est un exemple d'interface web construite avec Google Web Toolkit (GWT). La Console de gestion communique avec le serveur à l'aide de l'interface de gestion HTTP. Le point de terminaison HTTP API est le point d'entrée pour les clients de gestion basés sur le protocole HTTP, pour s'intégrer à la couche de gestion. Il utilise un protocole JSON encodé et un API de style RPC de-typed, pour décrire et exécuter des opérations de gestion en fonction d'un domaine géré ou d'un serveur autonome. L'API HTTP est utilisé par la console web, mais offre aussi des possibilités d'intégration pour un large éventail d'autres clients.
Exemple 3.1. Exemple de fichier de configuration HTTP API
<management-interfaces>
[...]
<http-interface security-realm="ManagementRealm">
<socket-binding http="management-http"/>
</http-interface>
</management-interfaces>
Tableau 3.1. Les URL d'accès à la Console de gestion
| URL | Description |
|---|---|
http://localhost:9990/console | Le Console de gestion accédée par l'hôte local, qui contrôle la configuration du Domaine géré. |
http://hostname:9990/console | La Console de gestion accédée à distance, qui nomme l'hôte et qui contrôle la configuration du Domaine géré. |
http://hostname:9990/management | Le HTTP Management API exécute sur le même port que la Console de gestion, affiche les mêmes valeurs et attributs bruts exposés à l'API. |
Le Management CLI est un exemple d'outil d'API Natif. Cet outil de gestion est disponible à une instance de Serveur autonome ou à un Domaine, permettant ainsi à un utilisateur de se connecter à une instance du Serveur autonome ou au Contrôleur du domaine, et d'exécuter des opérations de gestion rendues disponibles par le modèle de gestion de-types.
Exemple 3.2. Exemple de fichier de configuration d'API natif
<management-interfaces>
<native-interface security-realm="ManagementRealm">
<socket-binding native="management-native"/>
</native-interface>
[...]
</management-interfaces>
3.3. Console de gestion et Management CLI
3.4. La console de gestion
3.4.1. Console de gestion
3.4.2. Se conncecter à la console de gestion
Prérequis
- JBoss EAP doit être en cours d'exécution.
Procédure 3.1. Se conncecter à la console de gestion
Naviguer vers la page de démarrage de la console de gestion
Naviguer vers la console de gestion. L'emplacement par défaut est http://localhost:9990/console/, où le port 9990 est prédéfini comme liaison de socket de console de gestion.Se conncecter à la console de gestion
Saisir le nom d'utilisateur et le mot de passe du compte que vous avez déjà créé pour vous connecter à l'écran de connexion de la console de gestion.
Figure 3.1. Écran de connexion de la console de gestion
Résultat
- Domaine géré
- Serveur autonome
3.4.3. Changer la Langue de la Console de management
Langues prises en charge
- Allemand (de)
- Chinois simplifié (zn-Hans)
- Portugais brézilien (pt-BR)
- Français (fr)
- Espagnol (es)
- Japonais (ja)
Procédure 3.2. Changer la Langue de la Console de management basée-web
Connectez-vous à la Console de management.
Connectez-vous à la Console de management basée web.Ouvrir le dialogue de configuration.
Dans le coin gauche de l'écran, il y a une étiquette Settings de configuration. Cliquer sur cette étiquette pour ouvrir les paramètres de configuration de la Console de management.Sélectionner la langue désirée.
Sélectionner la langue désirée à partir de la case Locale. Puis sélectionner Save. Une autre case explicative vous demande de charger à nouveau l'application. Cliquer sur Confirm. Réactualiser votre navigateur pour pouvoir utiliser les nouveaux paramètres régionaux (Locale).
3.4.4. Configurer un Serveur par la Console de gestion
Prérequis
Procédure 3.3. Configurer le Serveur
Naviguer dans le panneau Server Configurations qui se trouve dans la Console de gestion
- Sélectionner l'onglet Hosts en haut de la console. Les instances de serveur disponibles s'afficheront sur un tableau.
Modifier la configuration du serveur
- Sélectionner l'instance de serveur à partir du tableau Available Server Configurations.
- Sélectionner le bouton qui se trouve en dessous de la liste de serveurs.
- Procédez avec les changements des attributs de configuration.
- Sélectionnez le bouton qui se trouve en dessous de la liste du serveurs.
La configuration du serveur a changé, et prendra effet la prochaine fois que le serveur démarre.
3.4.5. Ajouter un déploiement dans une Console de gestion
Procédure 3.4. Ajouter et vérifier un déploiement
Naviguez dans le panneau Manage Deployments de la Console de gestion.
- Sélectionner l'onglet Runtime en haut de la console.
- Pour un serveur autonome, il vous faudra étendre l'élément de menu qui se trouve à gauche de la console et sélectionner . Pour un domaine géré, étendre l'élément de menu qui se trouve à gauche de la console, et sélectionner .
Le panneau Manage Deployments apparaît.Ajouter le contenu du déploiement.
Sélectionner le bouton dans l'onglet Content Repository. Une boîte de dialogue Create Deployment apparaîtra.Choisissez un fichier à déployer
Dans la boîte de dialogue, sélectionner le bouton . Cherchez le fichier que vous souhaitez déployer, et sélectionnez-le en vue de son chargement. Sélectionner le bouton pour continuer une fois que le fichier a été sélectionné.Vérifier les noms de déploiement
Vérifier le nom du déploiement et le nom du runtime qui apparaît dans la boîte de dialogue Create Deployments. Sélectionner le bouton pour charger le fichier une fois que les noms auront été vérifiés.
Le contenu sélectionné est téléchargé dans le serveur et est maintenant prêt à être déployé.
3.4.6. Créer un nouveau serveur dans la Console de management
Prérequis
Procédure 3.5. Créer une nouvelle configuration de serveur
Naviguez sur la page Server Configuration qui se trouve dans la Console de management
Sélectionnez l'onglet Server qui se trouve en haut et à droite de la console.Créer une nouvelle configuration
- Sélectionner le bouton qui se trouve en haut du panneau Server Configuration.
- Modifier les paramètres de base du serveur dans la boîte de dialogue Create Server Configuration.
- Cliquez sur le bouton pour enregistrer la nouvelle configuration de votre serveur.
Le nouveau serveur créé est listé dans Server Configurations.
3.4.7. Modifier les Niveaux de journalisation par défaut en utilisant la Console de gestion
Procédure 3.6. Modifier les niveaux de journalisation
Naviguez dans le panneau Logging de la Console de gestion.
- Si vous travaillez dans un domaine géré, sélectionner l'onglet Profiles en haut de la console, puis, sélectionnez le profil qui convient dans la liste déroulante à gauche de la console.
- Pour une domaine géré ou un serveur autonome, sélectionner → à partir du menu qui se trouve à gauche de la console et cliquer sur Logging.
- Cliquer sur l'onglet Log Categories en haut de la console.
Modifier les informations du créateur du journal
Modifer les informations des entrées du tableau Log Categories.- Sélectionner une entrée dans le tableau Log Categories, puis sélectionner le bouton dans la section Details ci-dessous.
- Définir le niveau de journalisation de la catégorie dans la zone déroulante Log Level. Sélectionner le bouton quand c'est fait.
Les niveaux de journalisation des catégories qui conviennent sont maintenant mis à jour.
3.4.8. Créer un nouveau groupe de service dans la Console de gestion
Procédure 3.7. Configurer et Ajouter un groupe de serveurs
Rendez-vous dans la vue Server Groups
Sélectionner l'onglet Hosts en haut et à droite.- Sélectionner l'onglet Server Groups dans le menu Server dans la colonne de gauche.
Ajouter un groupe de serveurs
Cliquer sur le bouton pour ajouter un nouveau groupe de serveurs.Configurer le groupe de serveurs
- Saisir un nom pour le groupe de serveurs
- Sélectionner le profil dans lequel vous souhaitez ajouter le groupe de serveurs.
- Sélectionner la liaison de socket dans laquelle vous souhaitez ajouter le groupe de serveurs.
- Sélectionner le bouton Save pour sauvegarder le nouveau groupe.
Le nouveau groupe de serveurs est visible dans la Console de gestion.
3.5. L'interface CLI
3.5.1. Gestion par interface en ligne de commande (CLI)
3.5.2. Lancement du Management CLI
Conditions préalables :
Procédure 3.8. Lancement du CLI dans Linux ou Windows
Lancement du CLI dans Linux
Exécutez le fichierEAP_HOME/bin/jboss-cli.shen saisissant ce qui suit dans la ligne de commande :$ EAP_HOME/bin/jboss-cli.sh
Lancement du CLI dans Windows
Exécutez le fichierEAP_HOME/bin/jboss-cli.baten cliquant deux fois, ou en saisissant ce qui suit dans la ligne de commande :C:\>EAP_HOME\bin\jboss-cli.bat
3.5.3. Quitter le Management CLI
Procédure 3.9. Quitter le Management CLI
Exécutez la commande
quitAvec le Management CLI, saisir la commandequit:[domain@localhost:9999 /]
quitClosed connection to localhost:9999
3.5.4. Se connecter à une instance de serveur géré par le Management CLI
Procédure 3.10. Se connecter à une instance de serveur gérée
Exécutez la commande
connectAvec Management CLI, saisir la commandeconnect:[disconnected /]
connectConnected to domain controller at localhost:9999- Sinon, pour vous connecter à un serveur géré quand on démarre le Management CLI sur le système Linux, utiliser le paramètre
--connect:$
EAP_HOME/bin/jboss-cli.sh --connect - Le paramètre
--connectpeut être utilisé pour indiquer l'hôte et le port du serveur. Pour connecter l'adresse192.168.0.1à la valeur du port9999ce qui suit s'applique :$
EAP_HOME/bin/jboss-cli.sh --connect --controller=192.168.0.1:9999
3.5.5. Comment obtenir de l'aide avec le Management CLI
L'interface de gestion CLI dispose d'une boîte de dialogue d'assistance avec des options générales et des options sensibles au contexte. Les commandes d'assistance dépendant du contexte de l'opération nécessitent une connexion à un contrôleur de domaine ou à un serveur autonome. Ces commandes ne seront pas affichées dans la liste, sauf si la connexion a été établie.
Procédure 3.11. Aide au niveau options Générales et options Sensibles au contexte
Exécuter la commande
helpAvec le Management CLI, saisir la commandehelp:[standalone@localhost:9999 /]
helpObtenez de l'aide au niveau sensibilité du contexte
Avec le Management CLI, saisir la commande étenduehelp -commands:[standalone@localhost:9999 /]
help --commands- Pour plus d'informations sur une commande particulière, exécuter la commande
helpavec comme argument'--help'.[standalone@localhost:9999 /]
deploy --help
L'information d'assistance du CLI s'affichera.
3.5.6. Utiliser le Management CLI en Mode par lot
Le traitement par lot permet à un certain nombre de requêtes d'être groupées par séquences et exécutées ensemble par unité. Si une des demandes opérationnelles d'une séquence échoue, tout le groupe d'opérations sera annulé.
Prérequis
Procédure 3.12. Commandes et opérations en mode par lot
Saisir un mode par lot
Saisir le mode par lot par la commandebatch.[standalone@localhost:9999 /] batch [standalone@localhost:9999 / #]
Le mode par lot est indiqué par le signe (#) dans l'invite.Ajouter les demandes opérationnelles au lot
Une fois que vous serez en mode par lot, saisir les demandes opérationnelles comme d'habitude. Les demandes opérationnelles sont ajoutées au lot dans l'ordre de saisie.Voir Section 3.5.8, « Utiliser les opérations et les commandes du Management CLI » pour obtenir des informations sur la façon de formater les demandes opérationnelles.Exécuter le lot
Une fois que toute la séquence de demandes opérationnelles est saisie, exécuter le lot avec la commanderun-batch.[standalone@localhost:9999 / #] run-batch The batch executed successfully.
Voir Section 3.5.7, « Commandes CLI Mode Lot » pour obtenir une liste complète des commandes disponibles pour pouvoir travailler avec des lots.Les commandes de lots sont stockées dans des fichiers externes
Les commandes fréquemment exécutées peuvent être stockées dans un fichier texte externe et être chargées en passant le chemin d'accès complet au fichier comme argument à la commandebatchou exécutées directement en étant un argument à la commanderun-batch.Vous pouvez créer un fichier de commande lot avec l'éditeur de texte. Chaque commande doit figurer sur une ligne par elle-même et la CLI doit être en mesure d'y accéder.La commande suivante chargera un fichiermyscript.txten mode lot. Toutes les commandes de ce fichier seront alors être prêtes à la modification ou à la suppression. De nouvelles commandes pourront être ajoutées. Les modifications effectuées au cours de cette session de lot ne persistera pas dans le fichiermyscript.txt.[standalone@localhost:9999 /] batch --file=myscript.txt
Ce qui suit exécutera instantanément les commandes lot stockées dans le fichiermyscript.txt[standalone@localhost:9999 /] run-batch --file=myscript.txt
La séquence de demandes opérationnelles saisies est effectuée sous forme de lot.
3.5.7. Commandes CLI Mode Lot
Tableau 3.2. Commandes CLI Mode Lot
| Command Name | Description |
|---|---|
| list-batch | Liste des commandes et des opérations du lot en cours. |
| edit-batch-line line-number edited-command | Modifier une ligne du lot en cours en donnant un numéro de ligne à modifier et la commande modidiée. Exemple : edit-batch-line 2 data-source disable --name=ExampleDS. |
| move-batch-line fromline toline | Réorganiser les lignes dans le lot en spécifiant le numéro de ligne à déplacer comme premier argument et sa nouvelle position comme deuxième argument. Exemple : move-batch-line 3 1. |
| remove-batch-line linenumber | Supprimer la commande de lot à la ligne indiquée. Exemple : remove-batch-line 3. |
| holdback-batch [batchname] |
Vous pouvez reporter à plus tard ou stocker un lot en cours à l'aide de cette commande. Utilisez cette option si vous voulez soudainement exécuter quelque chose dans la CLI en dehors du lot. Pour revenir à ce lot en attente, tapez simplement
batch à nouveau à la ligne de commande CLI.
Si vous fournissez un nom de lot en utilisant la commande
holdback-batch, le lot sera stocké sous ce nom. Pour retourner au lot nommé, utilisez la commande batch batchname. L'appel de la commande batch sans un nom de lot va commencer un nouveau lot (sans nom). Il peut y avoir qu'un seul lot suspendu sans nom.
Pour voir une liste de tous les lots suspendus, utiliser la commande
batch -l.
|
| discard-batch | Rejète le lot actif en cours. |
3.5.8. Utiliser les opérations et les commandes du Management CLI
Prérequis
Procédure 3.13. Créer, configurer et exécuter les requêtes
Construire la demande opérationnelle
Les demandes opérationnelles facilitent une interaction de bas niveau dans le modèle de gestion. Il s'agit d'une façon contrôlée de modifier les configurations du serveur. Une demande opérationnelle se présente en trois parties :- une adresse, avec une barre oblique devant (
/). - un nom d'opération, avec deux points (
:). - un groupe optionnel de paramètres, entre parenthèses (
()).
Déterminer l'adresse
La configuration est présentée sous forme de ressources auxquelles s'adresser et de façon hiérarchique. Chaque noeud de ressources procure un groupe différent d'opérations. Une adresse utilise la syntaxe suivante :/node-type=node-name
- node-type correspond au type de noeud de ressource. Cela correspond à un nom d'élément dans la configuration XML.
- node-name correspond au nom du nœud. Cela correspond à l'attribut
nomde l'élément dans la configuration XML. - Séparer chaque niveau de l'arborescence de ressources par une barre oblique (
/).
Voir les fichiers de configuration XML pour déterminer l'adresse qui convient. Le fichierEAP_HOME/standalone/configuration/standalone.xmlcontient la configuration d'un serveur autonome et les fichiersEAP_HOME/domain/configuration/domain.xmletEAP_HOME/domain/configuration/host.xmlcontiennent la configuration d'un domaine géré.Exemple 3.3. Exemple d'adresses d'opérations
Pour procéder à une opération dans le sous-système de journalisation, utiliser l'adresse suivante dans la demande opérationnelle :/subsystem=logging
Pour effectuer une opération sur la source de données Java, utiliser l'adresse suivante dans la demande opérationnelle :/subsystem=datasources/data-source=java
Déterminer l'opération
Les opérations diffèrent avec chaque type de nœud de ressource. Une opération utilise la syntaxe suivante ::operation-name
- operation-name correspond au nom de l'opération à demander.
Utiliser l'opérationread-operation-namessur une adresse de ressources d'un serveur autonome pour lister les opérations disponibles.Exemple 3.4. Opérations disponibles
Pour énumérer toutes les opérations disponibles du sous-système de journalisation, saisir la requête suivante dans une serveur autonome :[standalone@localhost:9999 /] /subsystem=logging:read-operation-names { "outcome" => "success", "result" => [ "add", "read-attribute", "read-children-names", "read-children-resources", "read-children-types", "read-operation-description", "read-operation-names", "read-resource", "read-resource-description", "remove", "undefine-attribute", "whoami", "write-attribute" ] }Déterminer un paramètre
Chaque opération a sans doute besoin de paramètres différents.Les paramètres utilisent la syntaxe suivante :(parameter-name=parameter-value)
- parameter-name correspond au nom du paramètre.
- parameter-value correspond à la valeur du paramètre.
- Les différents paramètres sont séparés par des virgules (
,).
Afin de déterminer les paramètres qui conviennent, exécutez la commanderead-operation-descriptionsur un nœud de ressource, en faisant passer le nom de l'opération en tant que paramètre. Voir Exemple 3.5, « Déterminer les paramètres des opérations » pour plus de détails.Exemple 3.5. Déterminer les paramètres des opérations
Afin de déterminer les paramètres qui conviennent pour l'opérationread-children-typessur le sous-système de journalisation, saisir la commanderead-operation-descriptioncomme suit :[standalone@localhost:9999 /] /subsystem=logging:read-operation-description(name=read-children-types) { "outcome" => "success", "result" => { "operation-name" => "read-children-types", "description" => "Gets the type names of all the children under the selected resource", "reply-properties" => { "type" => LIST, "description" => "The children types", "value-type" => STRING }, "read-only" => true } }
Saisir toute la demande opérationnelle
Une fois que l'adresse, l'opération et tous les paramètres auront été sélectionnés, saisir la demande opérationnelle complète.Exemple 3.6. Exemple de demande opérationnelle
[standalone@localhost:9999 /]
/subsystem=web/connector=http:read-resource(recursive=true)
L'interface de gestion effectue la demande opérationnelle sur la configuration du serveur.
3.5.9. Références de Commandes de Management CLI
La section Section 3.5.5, « Comment obtenir de l'aide avec le Management CLI » décrit comment accéder aux fonctionnalités d'assistance du Management CLI. L'interface de gestion dispose d'une boîte de dialogue d'assistance avec des options générales et des options sensibles au contexte. Les commandes d'assistance dépendant du contexte de l'opération nécessitent une connexion à un contrôleur de domaine ou à un serveur autonome. Ces commandes ne seront pas affichées dans la liste, sauf si la connexion a été établie.
Tableau 3.3.
| Commande | Description |
|---|---|
batch | Démarrer le mode par lot en créant un nouveau lot ou, selon les lots existants retenus, réactiver l'un d'entre eux. Si il n'y a pas de lot existant retenu, cette commande sans argument va commencer un nouveau lot .S'il y a un lot sans nom existant retenu, cette commande le réactivera. S'il y a des lots existants retenus, mais avec nom, il peuvent être activés en exécutant cette commande avec ce nom comme argument. |
cd | Change le chemin du nœud en cours à l'argument. Le chemin du nœud en cours est utilisé comme adresse pour les requêtes opérationnelles qui ne contiennent pas la partie adresse. Si une opération n'inclut pas d'adresse, l'adresse incluse sera considérée comme relative au chemin du nœud en cours. Le chemin du nœud en cours peut finir en type de nœud. Dans ce cas, exécuter une opération en spécifiant un nom de nœud est suffisant, comme logging:read-resource. |
clear | Efface l'écran |
command | Vous permet d'ajouter, de supprimer ou de lister des commandes existantes de type standard. Une commande de type standard est une commande qui est assignée à un type de nœud spécifique et qui vous permet d'effectuer une opération disponible à une instance de ce type. Elle vous permet de modifier n'importe quelle propriété exposée par le type de n'importe quelle instance existante. |
connect | Connecte le contrôleur à l'hôte et au port spécifiés. |
connection-factory | Définit une usine de connexions |
data-source | Gère les configurations de sources de données JDBC dans le sous-système de la source de données. |
deploy | Déploie l'application désignée par le chemin d'accès au fichier ou bien, active une application qui est pré-existante, mais désactivée dans le référentiel. Si elle est exécutée sans argument, cette commande énumérera tous les déploiements existants. |
help | Affiche le message d'assistance. Peut être utilisé avec l'argument --commands pour fournir aux commandes données des résultats sensibles au contexte. |
history | Affiche l'historique en mémoire de la commande CLI et affiche un statut pour savoir si l'expansion de l'historique est activée ou non. Peut être utilisé avec des arguments pour effacer, désactiver, ou activer l'expansion de l'historique selon les besoins. |
jms-queue | Définit une file d'attente JMS dans le sous-système de messagerie. |
jms-topic | Définit un topic dans le sous-système de messagerie. |
ls | Lister les contenus du chemin d'accès au nœud. Par défaut, le résultat est imprimé dans des colonnes qui utilisent toute la largeur du terminal. Utiliser -l affichera les résultats sur la base d'un nom par ligne. |
pwd | Affiche le chemin d'accès du nœud pour le nœud en cours |
quit | Termine l'interface de ligne de commande. |
read-attribute | Affiche la valeur et, suivant les arguments, la description de l'attribut d'une ressource gérée. |
read-operation | Affiche la description d'une opération particulière, ou bien liste toutes les opérations si aucune n'est spécifiée. |
undeploy | Annule une demande lorsque celle-ci est exécutée avec le nom de l'application prévue. Peut être exécuté avec des arguments pour supprimer également l'application du référentiel. Imprime la liste de tous les déploiements existants si exécutée sans application spécifiée. |
version | Affiche la version de serveur d'application et les informations d'environnement. |
xa-data-source | Gére la configuration de la source de données JDBC XA du sous-système de la source de données. |
3.5.10. Référence aux Opérations de Management CLI
Les opérations du Management CLI peuvent être exposées par l'opération read-operation-names décrite dans la rubrique Section 3.6.5, « Afficher les Noms de l'opération en utilisant le Management CLI ». Les descriptions des opérations peuvent être exposées par l'opération read-operation-descriptions décrite dans la rubrique Section 3.6.4, « Affiche une description d'opération en utilisant le Management CLI ».
Tableau 3.4. Les opérations de Management CLI
| Nom de l'opération | Description |
|---|---|
add-namespace | Ajoute un mappage de préfixe d'espace-nom à la mappe d'attribut d'espace-nom. |
add-schema-location | Ajoute un schéma de mappage d'emplacement à la mappe d'attribut schema-locations. |
delete-snapshot | Efface un snapshot de la configuration serveur dans le répertoire de snapshots. |
full-replace-deployment | Ajoute le contenu précédemment téléchargé déploiement à la liste de contenu disponible, remplace le contenu existant du même nom dans le runtime et supprime le contenu remplacé dans la liste de contenu disponible. Voir lien pour plus de renseignements. |
list-snapshots | Liste les snapshots de la configuration du serveur sauvegardée dans le répertoire des snapshots. |
read-attribute | Affiche la valeur d'un attribut d'une ressource sélectionnée. |
read-children-names | Affiche le nom de tous les enfants d'une ressource donnée ayant le type donné. |
read-children-resources | Affiche des informations sur tous les enfants d'une ressource d'un type donné. |
read-children-types | Affiche les noms de types de tous les enfants pour la ressource sélectionnée. |
read-config-as-xml | Lit la configuration actuelle et l'affiche en format XML. |
read-operation-description | Affiche les détails d'une opération de la ressource donnée. |
read-operation-names | Affiche les noms de toutes les opérations de la ressource donnée. |
read-resource | Affiche les valeurs des attributs d'un modèle de ressource avec des informations complètes ou de base sur n'importe quelle ressource enfant. |
read-resource-description | Indique la description des attributs d'une ressource, les types de dépendants et les opérations. |
reload | Charge le serveur à nouveau en fermant tous les services et en redémarrant. |
remove-namespace | Supprime un mappage de préfixe d'espace-nom à la mappe d'attribut d'espace-nom. |
remove-schema-location | Supprime un schéma de mappage d'emplacement à la mappe d'attribut schema-locations. |
replace-deployment | Remplace le contenu existant du runtime par un contenu nouveau. Le nouveau contenu doit avoir été chargé auparavant dans le référentiel du contenu de déploiement. |
resolve-expression | Opération qui accepte une expression comme entrée ou un string pouvant être compris comme une expression, et résolu en fonction du système locale de propriétés et des variables d'environnement. |
resolve-internet-address | Prend un ensemble de critères de résolution d'interface et trouve une adresse IP sur une machine locale qui correspond au critère, ou échoue si aucune adresse IP correspondante n'est trouvée. |
server-set-restart-required | Met le serveur en mode «restart-required» |
shutdown | Ferme le serveur via un appel à System.exit(0). |
start-servers | Démarre tous les serveurs configurés dans un Domaine géré qui n'est pas actuellement en cours d'exécution. |
stop-servers | Arrête tous les serveurs actuellement en cours d'exécution dans un Domaine géré. |
take-snapshot | Prend un snapshot de la configuration du serveur et la sauvegarde dans le répertoire des snapshots. |
upload-deployment-bytes | Indique si le contenu de déploiement du tableau d'octets inclus doit être ajouté au référentiel du contenu de déploiement. Notez que cette opération n'indique pas que le contenu doive être déployé au runtime. |
upload-deployment-stream | Indique si le contenu de déploiement disponible dans l'index des flux entrants doit être ajouté au référentiel du contenu de déploiement. Notez que cette opération n'indique pas que le contenu doive être déployé au runtime. |
upload-deployment-url | Indique si le contenu de déploiement disponible dans l'URL doit être ajouté au référentiel du contenu de déploiement. Notez que cette opération n'indique pas que le contenu doive être déployé au runtime. |
validate-address | Valide l'adresse de l'opération |
write-attribute | Indique la valeur d'un attribut d'une ressource sélectionnée. |
3.6. Opérations de l'interface CLI
3.6.1. Afficher les attributs d'une ressource par le Management CLI
L'opération read-attribute est une opération globale utilisée pour lire la valeur d'exécution d'un attribut sélectionné. Peut être utilisée pour exposer uniquement les valeurs qui ont été définies par l'utilisateur, en ignorant toute valeur par défaut ou non définie. Les propriétés de la requête incluent les paramètres suivants.
Propriétés de requêtes
name- Le nom de l'attribut pour obtenir la valeur sous la ressource sélectionnée.
include-defaults- Un paramètre booléen qui peut être défini à
falsepour limiter les résultats de l'opération aux attributs qui ont été définis par l'utilisateur uniquement, et ignorer les valeurs par défaut.
Procédure 3.14. Affiche la valeur de runtime en cours pour un attribut sélectionné.
Exécuter l'opération
read-attributeÀ partir du Management CLI, utiliser l'opérationread-attributepour afficher la valeur d'un attribut de ressource. Pour plus d'informations sur les requêtes d'informations, voir le sujet Section 3.5.8, « Utiliser les opérations et les commandes du Management CLI ».[standalone@localhost:9999 /]
:read-attribute(name=name-of-attribute)
read-attribute est la possibilité d'exposer la valeur d'exécution actuelle d'un attribut spécifique. Des résultats similaires peuvent être obtenus avec l'opération read-attribute, mais seulement avec l'addition de la propriété de requête include-runtime, et uniquement dans le cadre d'une liste de toutes les ressources disponibles pour ce nœud. L'opération read-attribute est destinée aux requêtes d'attribut précises, comme le montre l'exemple suivant.
Exemple 3.7. Exécuter l'opération read-attribute pour exposer l'IP d'interface publique.
read-attribute pour renvoyer la valeur exacte dans le runtime en cours.
[standalone@localhost:9999 /] /interface=public:read-attribute(name=resolved-address)
{
"outcome" => "success",
"result" => "127.0.0.1"
}
resolved-address est une valeur de runtime, donc il ne s'affiche pas dans les résultats de l'opération read-resource standard.
[standalone@localhost:9999 /] /interface=public:read-resource
{
"outcome" => "success",
"result" => {
"any" => undefined,
"any-address" => undefined,
"any-ipv4-address" => undefined,
"any-ipv6-address" => undefined,
"inet-address" => expression "${jboss.bind.address:127.0.0.1}",
"link-local-address" => undefined,
"loopback" => undefined,
"loopback-address" => undefined,
"multicast" => undefined,
"name" => "public",
"nic" => undefined,
"nic-match" => undefined,
"not" => undefined,
"point-to-point" => undefined,
"public-address" => undefined,
"site-local-address" => undefined,
"subnet-match" => undefined,
"up" => undefined,
"virtual" => undefined
}
}
resolved-address ou des autres valeurs de runtime, vous devrez utiliser la propriété de requête include-runtime.
[standalone@localhost:9999 /] /interface=public:read-resource(include-runtime=true)
{
"outcome" => "success",
"result" => {
"any" => undefined,
"any-address" => undefined,
"any-ipv4-address" => undefined,
"any-ipv6-address" => undefined,
"inet-address" => expression "${jboss.bind.address:127.0.0.1}",
"link-local-address" => undefined,
"loopback" => undefined,
"loopback-address" => undefined,
"multicast" => undefined,
"name" => "public",
"nic" => undefined,
"nic-match" => undefined,
"not" => undefined,
"point-to-point" => undefined,
"public-address" => undefined,
"resolved-address" => "127.0.0.1",
"site-local-address" => undefined,
"subnet-match" => undefined,
"up" => undefined,
"virtual" => undefined
}
}
La valeur de l'attribut du runtime en cours est affichée.
3.6.2. Afficher l'utilisateur qui est actif dans le Management CLI
L'opération whoami est une opération globale utilisée pour identifier les attributs de l'utilisateur actif. L'opération expose l'identité de nom d'utilisateur et le domaine qui leur est attribué. L'opération whoami est utile pour les administrateurs qui gèrent plusieurs comptes d'utilisateurs dans plusieurs domaines, ou pour aider à assurer le suivi des utilisateurs actifs à travers les instances de domaine avec plusieurs sessions de terminal et les comptes utilisateurs.
Procédure 3.15. Affiche l'utilisateur qui est actif dans le Management CLI par l'opération whoami
Exécuter l'opération
whoamiÀ partir du Management CLI, utiliser l'opérationwhoamipour afficher le compte utilisateur actif.[standalone@localhost:9999 /]
:whoamiL'exemple suivant utilise la commandewhoamidans une instance de serveur autonome pour montrer que l'utilisateur actif est leusername, et que l'utilisateur est assigné au domaineManagementRealm.Exemple 3.8. Utiliser la commande
whoamidans une instance autonome[standalone@localhost:9999 /]:whoami { "outcome" => "success", "result" => {"identity" => { "username" => "username", "realm" => "ManagementRealm" }} }
Votre compte d'utilisateur actif en cours est affiché
3.6.3. Affiche les informations Système et Serveur dans le Management CLI
Procédure 3.16. Affiche les informations Système et Serveur dans le Management CLI
Exécuter la commande
versionÀ partir du Management CLI, saisir la commandeversion:[domain@localhost:9999 /]
version
Les informations sur la version de votre serveur d'applications et sur votre environnement s'afficheront.
3.6.4. Affiche une description d'opération en utilisant le Management CLI
Procédure 3.17. Éxécuter la commande de Management CLI suivante
Exécuter l'opération
read-operation-descriptionÀ partir du Management CLI, utiliserread-operation-descriptionpour afficher des informations sur l'opération. L'opération requiert des paramètres supplémentaires dans le format d'une paire clé-valeur pour indiquer quelle opération afficher. Pour plus d'informations sur les requêtes d'informations, voir le sujet Section 3.5.8, « Utiliser les opérations et les commandes du Management CLI ».[standalone@localhost:9999 /]
:read-operation-description(name=name-of-operation)
Exemple 3.9. Afficher la description de l'opération «list-snapshots»
list-snapshots.
[standalone@localhost:9999 /] :read-operation-description(name=list-snapshots)
{
"outcome" => "success",
"result" => {
"operation-name" => "list-snapshots",
"description" => "Lists the snapshots",
"request-properties" => {},
"reply-properties" => {
"type" => OBJECT,
"value-type" => {
"directory" => {
"type" => STRING,
"description" => "The directory where the snapshots are stored",
"expressions-allowed" => false,
"required" => true,
"nillable" => false,
"min-length" => 1L,
"max-length" => 2147483647L
},
"names" => {
"type" => LIST,
"description" => "The names of the snapshots within the snapshots directory",
"expressions-allowed" => false,
"required" => true,
"nillable" => false,
"value-type" => STRING
}
}
},
"access-constraints" => {"sensitive" => {"snapshots" => {"type" => "core"}}},
"read-only" => false
}
}
La description est affichée pour l'opération choisie.
3.6.5. Afficher les Noms de l'opération en utilisant le Management CLI
Procédure 3.18. Éxécuter la commande de Management CLI suivante
Exécuter l'opération
read-operation-namesÀ partir du Management CLI, utiliser l'opérationread-operation-namespour afficher les noms des opérations disponibles. Pour plus d'informations sur les requêtes d'informations, voir le sujet Section 3.5.8, « Utiliser les opérations et les commandes du Management CLI ».[standalone@localhost:9999 /]
:read-operation-names
Exemple 3.10. Afficher les noms de l'opération en utilisant le Management CLI
read-operation-names.
[standalone@localhost:9999 /]:read-operation-names
{
"outcome" => "success",
"result" => [
"add-namespace",
"add-schema-location",
"delete-snapshot",
"full-replace-deployment",
"list-snapshots",
"read-attribute",
"read-children-names",
"read-children-resources",
"read-children-types",
"read-config-as-xml",
"read-operation-description",
"read-operation-names",
"read-resource",
"read-resource-description",
"reload",
"remove-namespace",
"remove-schema-location",
"replace-deployment",
"resolve-expression",
"resolve-internet-address",
"server-set-restart-required",
"shutdown",
"take-snapshot",
"undefine-attribute",
"upload-deployment-bytes",
"upload-deployment-stream",
"upload-deployment-url",
"validate-address",
"validate-operation",
"whoami",
"write-attribute"
]
}Les noms d'opérations disponibles sont affichés.
3.6.6. Afficher les ressources disponibles en utilisant le Management CLI
L'opération read-resource est une opération globale utilisée pour lire la valeur des ressources. Peut être utilisée pour exposer des informations complètes ou de base sur les ressources des nœuds en cours ou des nœuds enfants, ainsi qu'un ensemble de propriétés de requêtes qui peuvent étendre ou limiter l'étendue des résultats de l'opération. Les propriétés de la requête incluent les paramètres suivants.
Propriétés de requêtes
recursive- Pour savoir si on doit inclure récursivement des informations complètes sur les ressources enfant.
recursive-depth- La précision des informations de ressources enfant incluses
proxies- Si on doit inclure des ressources éloignées pour une recherche récursive. Par exemple, si on doit inclure les ressources niveau hôte à partir des Contrôleurs Hôtes esclave pour une demande de Contrôleur de domaines.
include-runtime- Si on doit inclure des attributs de runtime dans la réponse, comme des valeurs d'attributs qui ne proviennent pas de la configuration persistante. Cette propriété de requête est définie sur false par défaut.
include-defaults- Une propriété de demande booléenne qui sert à activer ou à désactiver la lecture des attributs par défaut. Si définie sur false, seuls les attributs définis par l'utilisateur seront renvoyés, ignorant ainsi ceux qui sont non définis.
Procédure 3.19. Éxécuter la commande de Management CLI suivante
Exécuter l'opération
read-resourceAvec le Management CLI, faites l'opérationread-resourcepour afficher les ressources disponibles.[standalone@localhost:9999 /]
:read-resourceL'exemple suivant vous montre comment il est possible d'utiliser l'opérationread-resourcedans une instance de serveur autonome pour exposer les informations de ressources générales. Les résultats ressemblent au fichier de configurationstandalone.xml, qui affiche les ressources de système, les extensions, les interfaces et les sous-systèmes installés ou configurés pour l'instance du serveur. Ces résultats peuvent être interrogés directement.Exemple 3.11. Exécuter l'opération
read-resourceniveau racine[standalone@localhost:9999 /]:read-resource { "outcome" => "success", "result" => { "deployment" => undefined, "deployment-overlay" => undefined, "management-major-version" => 1, "management-micro-version" => 0, "management-minor-version" => 4, "name" => "longgrass", "namespaces" => [], "product-name" => "EAP", "product-version" => "6.1.0.GA", "release-codename" => "Janus", "release-version" => "7.2.0.Final-redhat-3", "schema-locations" => [], "system-property" => undefined, "core-service" => { "management" => undefined, "service-container" => undefined, "server-environment" => undefined, "platform-mbean" => undefined }, "extension" => { "org.jboss.as.clustering.infinispan" => undefined, "org.jboss.as.connector" => undefined, "org.jboss.as.deployment-scanner" => undefined, "org.jboss.as.ee" => undefined, "org.jboss.as.ejb3" => undefined, "org.jboss.as.jaxrs" => undefined, "org.jboss.as.jdr" => undefined, "org.jboss.as.jmx" => undefined, "org.jboss.as.jpa" => undefined, "org.jboss.as.jsf" => undefined, "org.jboss.as.logging" => undefined, "org.jboss.as.mail" => undefined, "org.jboss.as.naming" => undefined, "org.jboss.as.pojo" => undefined, "org.jboss.as.remoting" => undefined, "org.jboss.as.sar" => undefined, "org.jboss.as.security" => undefined, "org.jboss.as.threads" => undefined, "org.jboss.as.transactions" => undefined, "org.jboss.as.web" => undefined, "org.jboss.as.webservices" => undefined, "org.jboss.as.weld" => undefined }, "interface" => { "management" => undefined, "public" => undefined, "unsecure" => undefined }, "path" => { "jboss.server.temp.dir" => undefined, "user.home" => undefined, "jboss.server.base.dir" => undefined, "java.home" => undefined, "user.dir" => undefined, "jboss.server.data.dir" => undefined, "jboss.home.dir" => undefined, "jboss.server.log.dir" => undefined, "jboss.server.config.dir" => undefined, "jboss.controller.temp.dir" => undefined }, "socket-binding-group" => {"standard-sockets" => undefined}, "subsystem" => { "logging" => undefined, "datasources" => undefined, "deployment-scanner" => undefined, "ee" => undefined, "ejb3" => undefined, "infinispan" => undefined, "jaxrs" => undefined, "jca" => undefined, "jdr" => undefined, "jmx" => undefined, "jpa" => undefined, "jsf" => undefined, "mail" => undefined, "naming" => undefined, "pojo" => undefined, "remoting" => undefined, "resource-adapters" => undefined, "sar" => undefined, "security" => undefined, "threads" => undefined, "transactions" => undefined, "web" => undefined, "webservices" => undefined, "weld" => undefined } } }Exécuter l'opération
read-resourcepour un nœud enfantL'opérationread-resourcepeut être exécutée pour chercher les nœuds enfants à partir de la racine. La structure de l'opération commence par définir le nœud à exposer, puis s'ajoute à l'opération pour exécuter à ses côtés.[standalone@localhost:9999 /]
/subsystem=web/connector=http:read-resourceDans l'exemple suivant, on peut exposer des informations de ressources spécifiques sur un composant de sous-système en redirigeant l'opérationread-resourcevers un nœud de sous-système web particulier.Exemple 3.12. Exposer les ressources de nœud enfant à partir d'un nœud racine
[standalone@localhost:9999 /] /subsystem=web/connector=http:read-resource { "outcome" => "success", "result" => { "configuration" => undefined, "enable-lookups" => false, "enabled" => true, "executor" => undefined, "max-connections" => undefined, "max-post-size" => 2097152, "max-save-post-size" => 4096, "name" => "http", "protocol" => "HTTP/1.1", "proxy-name" => undefined, "proxy-port" => undefined, "redirect-port" => 443, "scheme" => "http", "secure" => false, "socket-binding" => "http", "ssl" => undefined, "virtual-server" => undefined } }Les mêmes résultats sont possibles en utilisant la commandecdpour naviguer dans les nœuds enfants et en exécutant l'opérationread-resourcedirectement.Exemple 3.13. Exposer les ressources de nœud enfant en changeant de répertoire
[standalone@localhost:9999 /] cd subsystem=web
[standalone@localhost:9999 subsystem=web] cd connector=http
[standalone@localhost:9999 connector=http] :read-resource { "outcome" => "success", "result" => { "configuration" => undefined, "enable-lookups" => false, "enabled" => true, "executor" => undefined, "max-connections" => undefined, "max-post-size" => 2097152, "max-save-post-size" => 4096, "name" => "http", "protocol" => "HTTP/1.1", "proxy-name" => undefined, "proxy-port" => undefined, "redirect-port" => 443, "scheme" => "http", "secure" => false, "socket-binding" => "http", "ssl" => undefined, "virtual-server" => undefined } }Utiliser le paramètre récursif pour inclure des valeurs actives dans les résultats
Le paramètre récursif peut être utilisé pour exposer les valeurs de tous les attributs, y compris les valeurs non persistantes, celles qui sont passées au démarrage, ou les autres attributs normalement actifs du modèle d'exécution.[standalone@localhost:9999 /]
/interface=public:read-resource(include-runtime=true)Par rapport à l'exemple précédent, l'inclusion de la propriété de requêteinclude-runtimeexpose des attributs actifs supplémentaires, comme des octets envoyés ou des octets reçus par le connecteur HTTP.Exemple 3.14. Exposer des valeurs actives et supplémentaires par le paramètre
include-runtime[standalone@localhost:9999 /] /subsystem=web/connector=http:read-resource(include-runtime=true) { "outcome" => "success", "result" => { "any" => undefined, "any-address" => undefined, "any-ipv4-address" => undefined, "any-ipv6-address" => undefined, "inet-address" => expression "${jboss.bind.address:127.0.0.1}", "link-local-address" => undefined, "loopback" => undefined, "loopback-address" => undefined, "multicast" => undefined, "name" => "public", "nic" => undefined, "nic-match" => undefined, "not" => undefined, "point-to-point" => undefined, "public-address" => undefined, "resolved-address" => "127.0.0.1", "site-local-address" => undefined, "subnet-match" => undefined, "up" => undefined, "virtual" => undefined } }
3.6.7. Afficher les descriptions de ressources disponibles en utilisant le Management CLI
Procédure 3.20. Éxécuter la commande de Management CLI suivante
Exécuter l'opération
read-resource-descriptionÀ partir du Management CLI, utiliser l'opérationread-resource-descriptionpour lire et afficher les noms des ressources disponibles. Pour plus d'informations sur les requêtes d'opérations, voir le sujet Section 3.5.8, « Utiliser les opérations et les commandes du Management CLI ».[standalone@localhost:9999 /]
:read-resource-descriptionUtiliser les paramètres en option
L'opérationread-resource-descriptionautorise l'utilisation de paramètres supplémentaires.- Utiliser le paramètre
operationspour inclure les descriptions des opérations de la ressource.[standalone@localhost:9999 /]
:read-resource-description(operations=true) - Utiliser le paramètre
inheritedpour inclure ou pour exclure des descriptions des opérations héritées de ressource. L'état par défaut est true.[standalone@localhost:9999 /]
:read-resource-description(inherited=false) - Utiliser le paramètre
recursivepour inclure les descriptions récursives des ressources dépendantes.[standalone@localhost:9999 /]
:read-resource-description(recursive=true) - Utiliser le paramètre
localepour obtenir la description des ressources. Si « null », la locale régionale par défaut sera utilisée.[standalone@localhost:9999 /]
:read-resource-description(locale=true)
Les descriptions des ressources disponibles sont affichées.
3.6.8. Charger à nouveau le serveur d'applications à l'aide du Management CLI
Procédure 3.21. Charger à nouveau le serveur d'applications
Exécuter l'opération
reloadÀ partir du Management CLI, utiliser l'opérationreloadpour fermer le serveur via l'appel de systèmeSystem.exit(0). Pour plus d'informations sur les demandes d'opérations, voir le sujet Section 3.5.8, « Utiliser les opérations et les commandes du Management CLI ».[standalone@localhost:9999 /]
:reload{"outcome" => "success"}
Le serveur d'applications charge à nouveau en fermant tout d'abord tous les services et en démarrant le runtime à nouveau. Le Management CLI reconnecte automatiquement.
3.6.9. Fermer le serveur d'applications à l'aide du Management CLI
Procédure 3.22. Fermer le Serveur d'applications
Exécuter l'opération
shutdown- À partir du Management CLI, utiliser l'opération
shutdownpour fermer le serveur via l'appel de systèmeSystem.exit(0). Pour plus d'informations sur les requêtes d'opérations, voir le sujet Section 3.5.8, « Utiliser les opérations et les commandes du Management CLI ».- En mode autonome, utiliser la commande suivante :
[standalone@localhost:9999 /]
:shutdown - En mode domaine, utiliser la commande suivante avec le nom d'hôte qui convient :
[domain@localhost:9999 /]
/host=master:shutdown
- Pour vous connecter à une instance CLI détachée et pour fermer le serveur, exécuter la commande suivante :
jboss-cli.sh --connect command=:shutdown
- Pour vous connecter à une instance CLI éloignée et pour fermer le serveur, exécuter la commande suivante :
[disconnected /] connect IP_ADDRESS Connected to IP_ADDRESS:PORT_NUMBER [192.168.1.10:9999 /] :shutdown
Remplacer l'IP_ADDRESS par l'adresse IP de votre instance.
Le serveur d'applications se ferme. Le Management CLI sera déconnecté car le runtime n'est pas disponible.
3.6.10. Configurer un attribut à l'aide du Management CLI
L'opération write-attribute est une opération globale utilisée pour écrire ou modifier un attribut de la ressource sélectionnée. Vous pouvez utiliser l'opération pour rendre les modifications persistantes ou pour modifier les paramètres de configuration de vos instances de serveur géré. Les propriétés de la requête incluent les paramètres suivants.
Propriétés de requêtes
name- Le nom de l'attribut pour définir la valeur sous la ressource sélectionnée.
value- La valeur désirée de l'attribut sous la ressource sélectionnée. Peut être « null » si le modèle sous-jacent supporte des valeurs « null ».
Procédure 3.23. Configurer un attribut de ressource à l'aide du Management CLI
Exécuter l'opération
write-attributeÀ partir du Management CLI, utiliser l'opérationwrite-attributepour modifier la valeur d'un attribut de ressource. L'opération peut être exécutée dans le nœud dépendant de la ressource, ou bien dans le nœud root du Management CLI où le chemin de ressource complet est spécifié.
Exemple 3.15. Désactiver le scanner de déploiement par l'opération write-attribute
write-attribute pour désactiver le scanner de déploiement. L'opération est exécutée à partir d'un nœud root, en utilisant l'onglet de complétion de tâche pour pouvoir peupler le chemin de ressources qui convient.
[standalone@localhost:9999 /] /subsystem=deployment-scanner/scanner=default:write-attribute(name=scan-enabled,value=false)
{"outcome" => "success"}
read-attribute.
[standalone@localhost:9999 /] /subsystem=deployment-scanner/scanner=default:read-attribute(name=scan-enabled)
{
"outcome" => "success",
"result" => false
}
read-resource. Dans l'exemple suivant, cette configuration particulière vous montre que l'attribut scan-enabled est maintenant défini à false.
[standalone@localhost:9999 /] /subsystem=deployment-scanner/scanner=default:read-resource
{
"outcome" => "success",
"result" => {
"auto-deploy-exploded" => false,
"auto-deploy-xml" => true,
"auto-deploy-zipped" => true,
"deployment-timeout" => 600,
"path" => "deployments",
"relative-to" => "jboss.server.base.dir",
"scan-enabled" => false,
"scan-interval" => 5000
}
}
L'attribut de ressource est mis à jour.
3.7. Historique des commandes de l'interface CLI
3.7.1. Utiliser l'Historique de commande à l'aide du Management CLI.
.jboss-cli-history. Le fichier de l'historique est configuré par défaut pour enregistrer un maximum de 500 commandes CLI.
history elle-même renverra l'historique de la session en cours, ou si accompagnée d'arguments, elle pourra désactiver, activer ou supprimer l'historique de la mémoire de session. Le Management CLI vous donne également la possibilité d'utiliser les flèches de votre clavier pour naviguer dans l'historique des commandes et des opérations.
Fonctions de l'historique du Management CLI
3.7.2. Afficher l'Historique de commandes à l'aide du Management CLI.
Procédure 3.24. Afficher l'Historique de commandes à l'aide du Management CLI.
Exécuter la commande
historyÀ partir du Management CLI, saisir la commandehistory:[standalone@localhost:9999 /]
history
L'historique de la commande CLI stocké en mémoire depuis le démarrage du CLI ou la commande de suppression de l'historique est affiché.
3.7.3. Effacer l'Historique de commandes à l'aide du Management CLI.
Procédure 3.25. Effacer l'Historique de commandes à l'aide du Management CLI.
Exécuter la commande
history --clearÀ partir du Management CLI, saisir la commandeversion:[standalone@localhost:9999 /]
history --clear
L'historique des commandes enregistré depuis le démarrage du CLI est supprimé de la mémoire de session. L'historique de la commande est toujours présent dans le fichier .jboss-cli-history qui est sauvegardé dans le répertoire d'accueil de l'utilisateur.
3.7.4. Désactiver l'Historique de commandes à l'aide du Management CLI.
Procédure 3.26. Désactiver l'Historique de commandes à l'aide du Management CLI.
Exécuter la commande
history --disableÀ partir du Management CLI, saisir la commandehistory --disable:[standalone@localhost:9999 /]
history --disable
Les commandes passées dans le CLI ne seront pas enregistrées dans la mémoire ou dans un fichier .jboss-cli-history sauvegardé dans le répertoire d'accueil de l'utilisateur.
3.7.5. Activer l'Historique de commandes à l'aide du Management CLI.
Procédure 3.27. Activer l'Historique de commandes à l'aide du Management CLI.
Exécuter la commande
history --enableÀ partir du Management CLI, saisir la commandehistory --enable:[standalone@localhost:9999 /]
history --enable
Les commandes passées dans le CLI seront enregistrées dans la mémoire ou dans un fichier .jboss-cli-history sauvegardé dans le répertoire d'accueil de l'utilisateur.
3.8. La journalisation d'auditing de l'interface de gestion
3.8.1. La Journalisation d'auditing de l'interface de gestion
Note
3.8.2. Activer la Journalisation d'auditing de l'interface de gestion par le Management CLI
/core-service=management/access=audit/logger=audit-log:write-attribute(name=enabled,value=true)
3.8.3. Formateur pour la Journalisation d'auditing de l'interface de gestion
Tableau 3.5. Champs de formateur JSON
| Attribut | Description |
|---|---|
| include-date | Valeur booléenne qui définit si l'horodatage est oui ou non inclus dans les archives log formatées. |
| date-separator | Chaîne contenant des caractères pour séparer la date du reste des messages log formatés. Sera ignoré si include-date=false. |
| date-format | Format de date utilisé pour les horodatages compris par java.text.SimpleDateFormat. Ignoré si include-date=false. |
| compact | Si défini sur true, formatera le JSON sur une seule ligne. Il y a sans doute encore des valeurs contenant de nouvelles lignes, donc s'il est important pour vous d'avoir l'enregistrement total sur une seule ligne, définir escape-new-line ou escape-control-characters à true. |
| escape-control-characters | Si défini sur true, échapera tous les caractères de contrôle (entrées ASCII à valeur décimales < 32) avec le code ASCII en octale ; par exemple, une nouvelle ligne devient '#012'. Si défini sur true, remplacera escape-new-line=false. |
| escape-new-line | Si défini sur true, échappera toutes les nouvelles lignes avec le code ASCII en octale, comme par exemple "#012". |
3.8.4. Gestionnaire de fichiers de journalisation de l'auditing de l'interface de gestion
Tableau 3.6. Champs de journalisation d'audit de Gestionnaire de fichiers.
| Attribut | Description | Lecture seule |
|---|---|---|
| formateur | Le nom d'un formateur JSON à utiliser pour formater les enregistrements de journalisation. | False |
| path | Le chemin d'accès du fichier de journalisation de l'auditing | False |
| relative-to | Le nom d'un chemin d'accès déjà nommé, ou d'un des chemins standard fournis par le système. Si relative-to est donné, la valeur de l'attribut du chemin d'accès sera traité comme relative au chemin spécifié par cet attribut. | False |
| failure-count | Le nombre d'échecs de journalisation depuis l'initialisation du gestionnaire. | True |
| max-failure-count | Le nombre maximum d'échecs de journalisation avant de désactiver ce gestionnaire. | False |
| disabled-due-to-failure | true si ce gestionnaire était désactivé à cause des échecs de journalisation. | True |
3.8.5. Gestionnaire de fichier Syslog de journalisation de l'auditing de l'interface de gestion
- http://www.ietf.org/rfc/rfc3164.txt
- http://www.ietf.org/rfc/rfc5424.txt
- http://www.ietf.org/rfc/rfc6587.txt
Tableau 3.7. Champs de Gestionnaire Syslog
| Champ | Description | Lecture seule |
|---|---|---|
| formateur | Le nom du formateur à utiliser pour formater les enregistrements de journalisation. | False |
| failure-count | Le nombre d'échecs de journalisation depuis l'initialisation du gestionnaire | True |
| max-failure-count | Le nombre maximum d'échecs de journalisation avant de désactiver ce gestionnaire. | False |
| disabled-due-to-failure | True si ce gestionnaire était désactivé à cause des échecs de journalisation. | True |
| syslog-format | Format Syslog: RFC-5424 ou RFC-3164. | False |
| max-length | La taille maximum d'un message de journalisation (en octets), comprenant l'en-tête. Si non défini, la valeur par défaut sera de 1024 octets si le syslog-format est RFC3164, ou 2048 octets si le syslog-format est RFC5424. | False. |
| truncate | Indique si un message doit ou non tronquer le message quand la longueur en octets est supérieure à la longueur maximale. Si la valeur est définie sur false, les messages seront divisés et envoyés avec les mêmes valeurs d'en-tête. | False |
3.8.6. Activer la Journalisation d'auditing de l'interface de gestion par le Serveur Syslog.
Note
/host=HOST_NAME aux commandes /core-service si vous devez appliquer les changements à un domaine géré.
Procédure 3.28. Activer la Journalisation sur un Serveur Syslog
Créer un Gestionnaire Syslog nommé
msyslog[standalone@localhost:9999 /]batch [standalone@localhost:9999 /]/core-service=management/access=audit/syslog-handler=mysyslog:add(formatter=json-formatter) [standalone@localhost:9999 /]/core-service=management/access=audit/syslog-handler=mysyslog/protocol=udp:add(host=localhost,port=514) [standalone@localhost:9999 /]run-batch
Ajouter une référence au Gestionnaire Syslog.
[standalone@localhost:9999 /]/core-service=management/access=audit/logger=audit-log/handler=mysyslog:add
Les entrées de journalisation de l'auditing de l'interface de gestion sont alors enregistrées sur le serveur syslog.
3.8.7. Options de Journalisation d'auditing de l'interface de gestion
Options de configuration
- log-boot
- Si défini sur
true, quand on démarre le serveur, les opérations de gestion seront incluses dans le log d'auditing, sinonfalse. Notons que la valeur par défaut est false. - log-read-only
- Si défini sur
true, toutes les opérations d'auditing seront journalisées. Si défini surfalse, seules les opérations qui changeront le modèle seront journalisées. La valeur par défaut est : false.
3.8.8. Champs de Journalisation d'auditing de l'interface de gestion
Tableau 3.8. Champs de Journalisation d'auditing de l'interface de gestion
| Nom de champ | Description |
|---|---|
| type | Peut avoir pour valeur core, indiquant ainsi qu'il s'agit d'une opération de gestion, ou jmx indiquant une provenance de sous-système JMX (voir le sous-système JMX pour la configuration de la Journalisation de l'auditing du sous-système JMX). |
| r/o | true si l'opération ne modifie pas le modèle de gestion, sinon false. |
| booting | true si l'opération a été exécutée à l'amorçage, false si elle a été exécutée une fois que le serveur était en route. |
| version | Numéro de version de l'instance JBoss EAP. |
| user | Nom d'utilisateur de l'utilisateur authentifié. Si l'opération a été journalisée via le CLI sur le même ordinateur que le serveur en cours d'exécution, l'utilisateur spécial $local sera utilisé. |
| domainUUID | Identifiant pour relier toutes les opérations tandis qu'elles sont propagées du contrôleur de domaines vers ses serveurs, ses contrôleurs hôtes, et ses serveurs de contrôleurs hôtes esclaves. |
| access | Cela peut avoir une des valeurs suivantes : NATIVE, HTTP, JMX. NATIVE - l'opération provient de l'interface de gestion native, par exemple le CLI. HTTP - l'opération provient de l'interface HTTP de domaine, par exemple la Console d'administration. JMX - l'opération provient du sous-système de JMX. Voir JMX pour savoir comment configurer la journalisation del'auditing pour JMX. |
| remote-address | l'adresse du client qui exécute l'opération. |
| success | true si l'opération a réussi, false si non. |
| ops | Les opérations en cours. Liste des opérations sérialisées dans JSON. Au démarrage, cela correspondra à toutes les opérations résultant du traitement XML. Une fois démarré, la liste contiendra normalement une seule entrée. |
Chapitre 4. Gestion des utilisateurs
4.1. Création d'utilisateur
4.1.1. Ajouter Utilisateur pour les Interfaces de gestion
Les Interfaces de gestion sont sécurisées par défaut dans JBoss EAP 6 car il n'y a aucun compte utilisateur initialement disponible, sauf si vous avez installé la plateforme à l'aide de l'installateur graphique. Il s'agit d'une précaution de sécurité pour empêcher les violations de sécurité des systèmes distants pour cause d'erreur de configuration simple. L'accès non-HTTP local est protégé par un mécanisme SASL, avec une négociation qui passe entre le client et le serveur chaque fois que le client se connecte pour la première fois à partir de l'hôte local.
Note
Procédure 4.1. Créer l'utilisateur administratif d'origine pour les interfaces de gestion distantes
Invoquer le script
add-user.shouadd-user.batscript.Passez au répertoireEAP_HOME/bin/. Invoquer le script qui convient à votre système d'exploitation.- Red Hat Enterprise Linux
[user@host bin]$./add-user.sh- Microsoft Windows Server
C:\bin>add-user.bat
Choisissez d'utiliser un utilisateur Management.
Appuyer sur ENTER pour sélectionner l'optionapour ajouter un utilisateur Management. Cet utilisateur sera ajouté au domaineManagementRealmet il sera autorisé à effectuer des opérations de gestion par la Management Console basée web ou par le Management CLI basé sur la ligne de commande. Autre alternative,b, ajoutera l'utilisateur au domaineApplicationRealm, et ne fournit aucune permission particulière. Ce domaine est fourni pour être utilisé avec des applications.Saisir le nom d'utilisateur et le mot de passe que vous souhaitez.
Quand on vous y invite, saisir le nom d'utilisateur et le nom de passe. On vous demandera de saisir le mot de passe une seconde fois pour confirmer.Saisissez les informations sur votre groupe.
Ajouter le groupe ou les groupes auxquels l'utilisateur appartient. Si l'utilisateur appartient à plusieurs groupes, saisir une liste séparée par des virgules. Laisser vide s'il n'y a pas de groupes pour l'utilisateur.Vérifier les informations et confirmer.
On vous invitera à confirmer les informations. Quand vous serez satisfait, saisiryes.Décidez si l'utilisateur représente une instance de serveur de JBoss EAP 6 à distance.
En plus des administrateurs, un autre type d'utilisateur qui a parfois besoin d'être ajouté à JBoss EAP 6 dans le domaineManagementRealmest un utilisateur qui représente une autre instance de JBoss EAP 6, et qui a besoin d'être authentifié pour rejoindre un groupement en tant que membre. L'invite suivante vous permet de désigner votre utilisateur supplémentaire dans ce but. Si vous sélectionnezyes, on vous donnera une valeursecretde hachage, qui représentera le mot de passe de l'utilisateur, que vous aurez besoin d'ajouter dans un fichier de configuration différent. Dans le but de cette tâche, répondrenoà cette question.Saisir des utilisateurs supplémentaires.
Vous pouvez saisir des utilisateurs supplémentaires si vous le souhaitez, en répétant la procédure. Vous pouvez également les ajouter à tout moment sur un système en cours d'exécution. Au lieu de choisir le domaine de sécurité par défaut, vous pouvez ajouter des utilisateurs d'autres domaines afin d'ajuster leurs autorisations.Créer des utilisateurs en mode non interactif.
Vous pouvez créer des utilisateurs en mode non interactif, en l'indiquant dans chaque paramètre de ligne de commande. Cette approche n'est pas recommandée sur les systèmes partagés, parce que les mots de passe seront visibles dans les fichiers de journalisation (log) et dans les fichiers d'historique. La syntaxe de la commande, pour le domaine de gestion, est la suivante :[user@host bin]$./add-user.sh usernamepasswordPour utiliser le domaine d'application, utiliser le paramètre-a.[user@host bin]$./add-user.sh -a usernamepassword- Vous pouvez supprimer la sortie normale du script add-user en passant le paramètre
--silent. Cela s'applique uniquement si un minimum de paramètres,nom d'utilisateuretmot de passe, ont été indiqués. Le message d'erreur apparaîtra toujours.
Tout utilisateur que vous ajoutez est activé dans les domaines de sécurité que vous avez indiqués. Les utilisateurs actifs dans le domaine ManagementRealm sont en mesure de gérer la plateforme JBoss EAP 6 à partir de systèmes éloignés.
Voir également :
4.1.2. Passer des Arguments au script add-user de la Gestion Utilisateur
add-user.sh ou add-user.bat interactivement ou vous pouvez passer des arguments par la ligne de commande. Cette section décrit les options qui se présentent pour passer des arguments de ligne de commande au script add-user.
add-user.sh ou add-user.bat, consulter Section 4.1.3, « Arguments de commande Add-user » .
add-user.sh ou add-user.bat, consulter Section 4.1.5, « Exemples de lignes de commande de script Add-user » .
4.1.3. Arguments de commande Add-user
add-user.sh ou add-user.bat.
Tableau 4.1. Arguments de commande Add-user
| Argument de ligne de commande | Valeur d'argument | Description |
|---|---|---|
|
-a
|
N/A
|
Cet argument demande de créer un utilisateur dans le domaine de l'application. S'il est omis, un utilisateur sera créé par défaut dans le domaine de gestion.
|
|
-dc
|
DOMAIN_CONFIGURATION_DIRECTORY
|
Cet argument spécifie le répertoire de configuration de domaine qui contient les fichiers de propriétés. S'il est omis, le répertoire par défaut sera
EAP_HOME/domain/configuration/.
|
|
-sc
|
SERVER_CONFIGURATION_DIRECTORY
|
Cet argument spécifie un répertoire de configuration de serveur autonome différent qui contient les fichiers de propriétés. S'il est omis, le répertoire par défaut sera
EAP_HOME/standalone/configuration/.
|
|
-up
--user-properties
|
USER_PROPERTIES_FILE
|
Cet argument spécifie le nom d'un autre fichier de propriétés utilisateur. Il peut correspondre à un chemin absolu ou il peut correspondre à un nom de fichier utilisé en conjonction avec l'argument
-sc ou -dc qui spécifie le répertoire de configuration alternatif.
|
|
-g
--group
|
GROUP_LIST
|
Une liste séparée par des virgules de groupes à assigner à cet utilisateur.
|
|
-gp
--group-properties
|
GROUP_PROPERTIES_FILE
|
Cet argument spécifie le nom d'un autre fichier de propriétés de groupe. Il peut correspondre à un chemin absolu ou il peut correspondre à un nom de fichier utilisé en conjonction avec l'argument
-sc ou -dc qui spécifie le répertoire de configuration alternatif.
|
|
-p
--password
|
PASSWORD
|
Le mot de passe utilisateur. Le mot de passe doit remplir les critères suivants :
|
|
-u
--user
|
USER_NAME
|
Le nom de l'utilisateur.
|
|
-r
--realm
|
REALM_NAME
|
Le nom du domaine utilisé pour sécuriser les interfaces de gestion. S'il est omis, la valeur par défaut sera "ManagementRealm".
|
|
-s
--silent
|
N/A
|
Exécuter le script add-user sans sortie vers la console.
|
|
-h
--help
|
N/A
|
Afficher les informations d'utilisation du script add--user.
|
4.1.4. Spécifier des Fichiers de Propriétés alternatifs pour les Informations de Gestion des Utilisateurs
Par défaut, les informations utilisateur et rôle créés à l'aide du script add-user.sh ou Add-user.bat sont stockées dans des fichiers de propriétés situés dans le répertoire de configuration de serveur. Les informations de configuration du serveur sont stockées dans le répertoire EAP_HOME/standalone/configuration/ et les informations de configuration de domaine sont stockées dans le répertoire EAP_HOME/domaine/configuration/. Cette rubrique décrit comment substituer les noms de fichier et emplacements par défaut.
Procédure 4.2. Spécifier des Fichiers de Propriétés alternatifs
- Pour spécifier un autre répertoire pour la configuration du serveur, utilisez l'argument
-sc. Cet argument spécifie un autre répertoire qui contiendra les fichiers de propriétés de configuration de serveur. - Pour spécifier un répertoire alternatif de configuration de domaine, utiliser l'argument
-dc. Cet argument spécifie un répertoire alternatif qui contient les fichiers de propriétés de configuration de domaines. - Pour spécifier un fichier de configuration utilisateur différent, utiliser l'argument
-upou--user-properties. Peut correspondre à un chemin complet ou à un nom de fichier utilisé en conjonction avec-scou-dcspécifiant le répertoire de configuration alternatif. - Pour spécifier un fichier de configuration groupe différent, utiliser l'argument
-upou--group-properties. Peut correspondre à un chemin complet ou à un nom de fichier utilisé en conjonction avec-scou-dcspécifiant le répertoire de configuration alternatif.
Note
add-user a pour but d'opérer sur des fichiers de propriétés existants. Tout fichier de propriété alternatif spécifié dans un argument de ligne de commande devra sortir ou vous verrez l'erreur suivante :
JBAS015234: No appusers.properties files found
4.1.5. Exemples de lignes de commande de script Add-user
add-user.sh ou add-user.bat. À moins que cela soit notifié, ces commandes supposent la configuration d'un serveur autonome.
Exemple 4.1. Créer un utilisateur qui appartienne à un groupe unique en utilisant les fichiers de propriétés par défaut.
EAP_HOME/bin/add-user.sh -a -u 'appuser1' -p 'password1!' -g 'guest'- L'utilisateur
appuser1est ajouté aux fichiers de propriétés suivantes par défaut qui contiennent les informations utilisateur.EAP_HOME/standalone/configuration/application-users.propertiesEAP_HOME/domain/configuration/application-users.properties
- L'utilisateur
appuser1ayant pour groupeguestest ajouté aux fichiers de propriétés suivantes par défaut qui contiennent les informations utilisateur.EAP_HOME/standalone/configuration/application-roles.propertiesEAP_HOME/domain/configuration/application-roles.properties
Exemple 4.2. Créer un utilisateur qui appartienne à plusieurs groupes en utilisant les fichiers de propriétés par défaut.
EAP_HOME/bin/add-user.sh -a -u 'appuser1' -p 'password1!' -g 'guest,app1group,app2group'- L'utilisateur
appuser1est ajouté aux fichiers de propriétés suivantes par défaut qui contiennent les informations utilisateur.EAP_HOME/standalone/configuration/application-users.propertiesEAP_HOME/domain/configuration/application-users.properties
- L'utilisateur
appuser1ayant pour groupesguest,app1group, etapp2groupest ajouté aux fichiers de propriétés suivantes par défaut qui contiennent les informations utilisateur.EAP_HOME/standalone/configuration/application-roles.propertiesEAP_HOME/domain/configuration/application-roles.properties
Exemple 4.3. Créer un utilisateur ayant des privilèges admin dans le domaine par défaut en utilisant les fichiers de propriétés par défaut.
EAP_HOME/bin/add-user.sh -u 'adminuser1' -p 'password1!' -g 'admin'- L'utilisateur
adminuser1est ajouté aux fichiers de propriétés suivantes par défaut qui contiennent les informations utilisateur.EAP_HOME/standalone/configuration/mgmt-users.propertiesEAP_HOME/domain/configuration/mgmt-users.properties
- L'utilisateur
adminuser1ayant pour groupeadminest ajouté aux fichiers de propriétés suivantes par défaut qui contiennent les informations utilisateur.EAP_HOME/standalone/configuration/mgmt-groups.propertiesEAP_HOME/domain/configuration/mgmt-groups.properties
Exemple 4.4. Créer un utilisateur qui appartienne à un groupe unique en utilisant des fichiers de propriétés alternatifs pour stocker des informations.
EAP_HOME/bin/add-user.sh -a -u appuser1 -p password1! -g app1group -sc /home/someusername/userconfigs/ -up appusers.properties -gp appgroups.properties - L'utilisateur
appuser1est ajouté aux fichiers de propriétés suivantes et ce fichier est maintenant le fichier par défaut qui contient les informations utilisateur./home/someusername/userconfigs/appusers.properties
- L'utilisateur
appuser1ayant pour groupeapp1groupest ajouté aux fichiers de propriétés suivantes et ce fichier est maintenant le fichier par défaut qui contient les informations utilisateur./home/someusername/userconfigs/appgroups.properties
Chapitre 5. Réseau et configuration de port
5.1. Interfaces
5.1.1. Les interfaces
domain.xml, host.xml et standalone.xml comprennent tous des déclarations d'interface. Les critères de déclaration peuvent référencer une adresse générique ou spécifier un ensemble de caractéristiques qu'une interface ou une adresse doit avoir pour pouvoir établir une correspondance valide. Les exemples suivants illustrent plusieurs configurations possibles de déclarations d'interface, généralement définies soit dans le fichier de configuration standalone.xml ou host.xml. Cela permet à des groupes d'hôtes distants de maintenir leurs propres attributs d'interfaces spécifiques, tout en permettant une référence aux groupes d'interfaces dans le fichier de configuration domain.xml du contrôleur de domaine.
inet-address indiquée pour le groupes de noms relatifs management et public.
Exemple 5.1. Un groupe d'interfaces créé avec une adresse inet
<interfaces> <interface name="management"> <inet-address value="127.0.0.1"/> </interface> <interface name="public"> <inet-address value="127.0.0.1"/> </interface> </interfaces>
any-address pour déclarer une adresse générique.
Exemple 5.2. Un groupe global créé avec une déclaration générique
<interface name="global"> <!-- Use the wild-card address --> <any-address/> </interface>
externe.
Exemple 5.3. Un groupe externe créé avec un NIC
<interface name="external"> <nic name="eth0"/> </interface>
Exemple 5.4. Un groupe par défaut créé avec des valeurs conditionnelles spécifiques
<interface name="default">
<!-- Match any interface/address on the right subnet if it's
up, supports multicast, and isn't point-to-point -->
<subnet-match value="192.168.0.0/16"/>
<up/>
<multicast/>
<not>
<point-to-point/>
</not>
</interface>
5.1.2. Configurer les interfaces
standalone.xml et host.xml offrent trois interfaces nommées avec jetons d'interfaces relatives pour chacune. Vous pouvez utiliser la Console de gestion ou le Management CLI pour configurer des attributs et valeurs supplémentaires indiquées dans le tableau ci-dessous. Vous pouvez également remplacer les liaisons d'interfaces relatives par des valeurs spécifiques selon les besoins. Notez que si vous le faites, vous serez incapable de passer une valeur d'interface en cours d'exécution de serveur, car -b peut seulement substituer une valeur relative.
Exemple 5.5. Configuration d'interface par défaut
<interfaces>
<interface name="management">
<inet-address value="${jboss.bind.address.management:127.0.0.1}"/>
</interface>
<interface name="public">
<inet-address value="${jboss.bind.address:127.0.0.1}"/>
</interface>
<interface name="unsecure">
<inet-address value="${jboss.bind.address.unsecure:127.0.0.1}"/>
</interface>
</interfaces>
Tableau 5.1. Attributs et valeurs d'interface
| Élément d'interface | Description |
|---|---|
any | Élément vide de type exclusion d'adresse, utilisé pour forcer le critère de sélection. |
any-address | Élément vide indiquant que les sockets qui utilisent cette interface doivent être liés à une adresse générique. L'adresse générique IPv6 (::) sera utilisée à moins que la propriété système java.net.preferIpV4Stack soit définie sur true, dans lequel cas, l'adresse générique (0.0.0.0) IPv4 sera utilisée. Si un socket est lié à une adresse anylocal IPv6 sur une machine dual-stack, il pourra accepter le trafic IPv6 et IPv4 ; si lié à l'adresse IPv4 anylocal (mappées IPv4), il ne peut accepter que le trafic IPv4. |
any-ipv4-address | Élément vide indiquant que les sockets qui utilisent cette interface doivent être liés à une adresse générique (0.0.0.0) IPv4. |
any-ipv6-address | Élément vide indiquant que les sockets qui utilisent cette interface doivent être liés à une adresse générique (::). IPv6. |
inet-address | Soit une adresse IP en notation à points IPV6 ou IPV4, ou un nom d'hôte qui puisse être résolu. |
link-local-address | Élément vide indiquant qu'une partie du critère de sélection d'une interface doit si oui ou non il a une adresse associée local-link. |
loopback | Élément vide indiquant qu'une partie du critère de sélection d'une interface est de savoir s'il s'agit oui ou non d'une interface de loopback. |
loopback-address | Une adresse de loopback qui ne peut pas réellement être configurée sur l'interface de loopback de la machine. Diffère d'inet-addressType car la valeur donnée sera utilisée même si aucune carte réseau possédant l'adresse IP associée ne peut être trouvée. |
multicast | Élément vide indiquant qu'une partie du critère de sélection d'une interface doit être si oui ou non il y a un support multi-diffusion. |
nic | Le nom d'une interface de réseau (e.g. eth0, eth1, lo). |
nic-match | Une expression standard à laquelle faire correspondre les noms des interfaces de réseau disponibles sur la machine pour trouver une interface qui convienne. |
not | Élément vide de type exclusion d'adresse, utilisé pour forcer le critère de sélection. |
point-to-point | Élément vide indiquant qu'une partie du critère de sélection d'une interface doit être si elle a oui ou non une interface d'un point à un autre. |
public-address | Élément vide indiquant qu'une partie du critère de sélection d'une interface doit être si elle a oui ou non une adresse publiquement routable. |
site-local-address | Élément vide indiquant qu'une partie du critère de sélection d'une interface doit être ou non une adresse associée à à son site-local |
subnet-match | Une adresse IP réseau et le nombre de bits dans le préfixe de réseau de l'adresse, sous la forme « / » ; par exemple"192.168.0.0/16". |
up | Élément vide indiquant qu'une partie du critère de sélection d'une interface est active ou non. |
virtual | Élément vide indiquant qu'une partie du critère de sélection d'une interface doit être ou non une interface virtuelle. |
Configuration des attributs d'une interface
Sélectionner le Management CLI ou la Console de gestion pour configurer vos attributs d'interface selon les besoins.Configurer les attributs d'interface par le Management CLI
Utiliser le Management CLI pour ajouter de nouvelles interfaces et pour écrire des nouvelles valeurs dans dans les attributs de l'interface.Ajouter une nouvelle interface
Utiliser l'opérationadd(ajouter) pour créer une nouvelle interface selon les besoins. Vous pouvez exécuter cette commande à partir de la racine de la session de Management CLI, qui, dans l'exemple suivant, crée un nouveau titre de nom d'interface interfacename, avecinet-addressdéclaré ainsi 12.0.0.2./interface=interfacename/:add(inet-address=12.0.0.2)
Modifier les attributs d'une interface
Utiliser l'opérationwritepour écrire une nouvelle valeur dans un attribut. Vous pouvez utiliser l'onglet de complétion pour terminer la chaîne de commande en cours, ainsi que pour exposer les attributs disponibles. L'exemple suivant met à jour la valeur de l'inet-addressà 12.0.0.8/interface=interfacename/:write(inet-address=12.0.0.8)
Modifier les attributs d'une interface
Confirmer que les valeurs ont changé en exécutantread-resourceaccompagné du paramètreinclude-runtime=truepour exposer toutes les valeurs actives en cours du modèle de serveur.[standalone@localhost:9999 interface=public]
:read-resource(include-runtime=true)
Configurer les attributs d'interface par la Console de gestion
Utiliser la Console de gestion pour ajouter des nouvelles interfaces et pour écrire des nouvelles valeurs dans les attributs de l'interface.Connectez-vous à la Console de gestion.
Connectez-vous à la Console de gestion de votre instance de Serveur autonome ou Managed Domain (Domaine géré).Si vous utilisez le Managed Domain, sélectionner le profil qui convient.
Sélectionner l'onglet Profiles en haut à droite, puis sélectionner le profil qui convient à partir du menu Profile en haut et à gauche de l'écran suivant.Sélectionner l'item Interfaces à partir du menu de navigation.
Sélectionner l'item de menu Interfaces à partir du menu de navigation.Ajouter une nouvelle interface
- Cliquer sur le bouton (ajouter).
- Saisir les valeurs qui conviennent pour les Name (Nom), Inet Address (Adresse Inet) et Address Wildcard (Adresse générique).
- Cliquer sur le bouton pour terminer.
Modifier les attributs d'une interface
- Sélectionner l'interface à modifier et cliquer sur le bouton .
- Saisir les valeurs qui conviennent pour les Name (Nom), Inet Address (Adresse Inet) et Address Wildcard (Adresse générique).
- Cliquer sur le bouton pour terminer.
5.2. Groupes de liaisons de sockets
5.2.1. Groupes de liaisons de sockets
domain.xml et standalone.xml. D'autres sections de la configuration peuvent alors faire référence à ces sockets par leur nom logique, plutôt que d'avoir à inclure tous les détails de la configuration de socket. Cela permet de référencer des configurations de sockets relatives qui peuvent varier sur des machines différentes.
Exemple 5.6. Liaisons de sockets par défaut pour la configuration du serveur autonome.
standalone.xml sont groupés sous standard-sockets. Ce groupe est aussi référencé dans l'interface publique , en utilisant la même méthodologie de référencement logique.
<socket-binding-group name="standard-sockets" default-interface="public">
<socket-binding name="http" port="8080"/>
<socket-binding name="https" port="8443"/>
<socket-binding name="jacorb" port="3528"/>
<socket-binding name="jacorb-ssl" port="3529"/>
<socket-binding name="jmx-connector-registry" port="1090" interface="management"/>
<socket-binding name="jmx-connector-server" port="1091" interface="management"/>
<socket-binding name="jndi" port="1099"/>
<socket-binding name="messaging" port="5445"/>
<socket-binding name="messaging-throughput" port="5455"/>
<socket-binding name="osgi-http" port="8090" interface="management"/>
<socket-binding name="remoting" port="4447"/>
<socket-binding name="txn-recovery-environment" port="4712"/>
<socket-binding name="txn-status-manager" port="4713"/>
</socket-binding-group>
Exemple 5.7. Liaisons de sockets par défaut pour la configuration du serveur autonome.
domain.xml contiennent quatre groupes : standard-sockets, ha-sockets, full-sockets et full-ha-sockets. Ces groupes sont également référencés dans une interface appelée public.
<socket-binding-groups>
<socket-binding-group name="standard-sockets" default-interface="public">
<!-- Needed for server groups using the 'default' profile -->
<socket-binding name="ajp" port="8009"/>
<socket-binding name="http" port="8080"/>
<socket-binding name="https" port="8443"/>
<socket-binding name="osgi-http" interface="management" port="8090"/>
<socket-binding name="remoting" port="4447"/>
<socket-binding name="txn-recovery-environment" port="4712"/>
<socket-binding name="txn-status-manager" port="4713"/>
<outbound-socket-binding name="mail-smtp">
<remote-destination host="localhost" port="25"/>
</outbound-socket-binding>
</socket-binding-group>
<socket-binding-group name="ha-sockets" default-interface="public">
<!-- Needed for server groups using the 'ha' profile -->
<socket-binding name="ajp" port="8009"/>
<socket-binding name="http" port="8080"/>
<socket-binding name="https" port="8443"/>
<socket-binding name="jgroups-mping" port="0" multicast-address="${jboss.default.multicast.address:230.0.0.4}" multicast-port="45700"/>
<socket-binding name="jgroups-tcp" port="7600"/>
<socket-binding name="jgroups-tcp-fd" port="57600"/>
<socket-binding name="jgroups-udp" port="55200" multicast-address="${jboss.default.multicast.address:230.0.0.4}" multicast-port="45688"/>
<socket-binding name="jgroups-udp-fd" port="54200"/>
<socket-binding name="modcluster" port="0" multicast-address="224.0.1.105" multicast-port="23364"/>
<socket-binding name="osgi-http" interface="management" port="8090"/>
<socket-binding name="remoting" port="4447"/>
<socket-binding name="txn-recovery-environment" port="4712"/>
<socket-binding name="txn-status-manager" port="4713"/>
<outbound-socket-binding name="mail-smtp">
<remote-destination host="localhost" port="25"/>
</outbound-socket-binding>
</socket-binding-group>
<socket-binding-group name="full-sockets" default-interface="public">
<!-- Needed for server groups using the 'full' profile -->
<socket-binding name="ajp" port="8009"/>
<socket-binding name="http" port="8080"/>
<socket-binding name="https" port="8443"/>
<socket-binding name="jacorb" interface="unsecure" port="3528"/>
<socket-binding name="jacorb-ssl" interface="unsecure" port="3529"/>
<socket-binding name="messaging" port="5445"/>
<socket-binding name="messaging-group" port="0" multicast-address="${jboss.messaging.group.address:231.7.7.7}" multicast-port="${jboss.messaging.group.port:9876}"/>
<socket-binding name="messaging-throughput" port="5455"/>
<socket-binding name="osgi-http" interface="management" port="8090"/>
<socket-binding name="remoting" port="4447"/>
<socket-binding name="txn-recovery-environment" port="4712"/>
<socket-binding name="txn-status-manager" port="4713"/>
<outbound-socket-binding name="mail-smtp">
<remote-destination host="localhost" port="25"/>
</outbound-socket-binding>
</socket-binding-group>
<socket-binding-group name="full-ha-sockets" default-interface="public">
<!-- Needed for server groups using the 'full-ha' profile -->
<socket-binding name="ajp" port="8009"/>
<socket-binding name="http" port="8080"/>
<socket-binding name="https" port="8443"/>
<socket-binding name="jacorb" interface="unsecure" port="3528"/>
<socket-binding name="jacorb-ssl" interface="unsecure" port="3529"/>
<socket-binding name="jgroups-mping" port="0" multicast-address="${jboss.default.multicast.address:230.0.0.4}" multicast-port="45700"/>
<socket-binding name="jgroups-tcp" port="7600"/>
<socket-binding name="jgroups-tcp-fd" port="57600"/>
<socket-binding name="jgroups-udp" port="55200" multicast-address="${jboss.default.multicast.address:230.0.0.4}" multicast-port="45688"/>
<socket-binding name="jgroups-udp-fd" port="54200"/>
<socket-binding name="messaging" port="5445"/>
<socket-binding name="messaging-group" port="0" multicast-address="${jboss.messaging.group.address:231.7.7.7}" multicast-port="${jboss.messaging.group.port:9876}"/>
<socket-binding name="messaging-throughput" port="5455"/>
<socket-binding name="modcluster" port="0" multicast-address="224.0.1.105" multicast-port="23364"/>
<socket-binding name="osgi-http" interface="management" port="8090"/>
<socket-binding name="remoting" port="4447"/>
<socket-binding name="txn-recovery-environment" port="4712"/>
<socket-binding name="txn-status-manager" port="4713"/>
<outbound-socket-binding name="mail-smtp">
<remote-destination host="localhost" port="25"/>
</outbound-socket-binding>
</socket-binding-group>
</socket-binding-groups>
standalone.xml et domain.xml du répertoire de l'application. La méthode recommandée pour gérer les liaisons consiste à utiliser la Console de gestion ou le Management CLI. Les avantages d'utiliser la Console de gestion est l'interface utilisateur graphique avec une écran de Groupe de liaisons de sockets dédié dans la section Configuration générale . Le Management CLI propose un API et un flux de travail basés ligne de commande qui permet le traitement par lots et l'utilisation de scripts aux niveaux supérieurs et inférieurs de la configuration de serveur d'applications. Les deux interfaces permettent la persistance des modifications ou bien leur enregistrement dans la configuration du serveur.
5.2.2. Configurer les liaisons de sockets
standard-sockets, et ne peut pas créer de groupes supplémentaires. À la place, vous pouvez créer des fichiers de configuration de serveur autonome alternatif. Pour le domaine géré cependant, vous pouvez créer des groupes de liaisons de sockets et configurer les liaisons de socket qu'ils contiennent selon vos besoins. Le tableau suivant montre les attributs disponibles pour chaque liaison de sockets.
Tableau 5.2. Attributs de liaisons de sockets
| Composant | Description | Rôle |
|---|---|---|
| Nom | Nom logique de la configuration de socket qui doit être utilisée ailleurs dans la configuration. | Requis |
| Port | Port de base auquel un socket basé sur cette configuration doit être lié. Notez que les serveurs peuvent être configurés pour substituer cette valeur de base en appliquant une incrémentation ou décrémentation à toutes les valeurs de port. | Requis |
| Interface | Nom logique de l'interface à laquelle un socket basé sur cette configuration doit être lié. Si non défini, la valeur de l'attribut "default-interface" du groupe de liaison de sockets enveloppant servira. | Option |
| Adresse multi-diffusion | Si le socket doit être utilisé en multi-diffusion, c'est l'adresse multi-diffusion qu'il vous faut. | Option |
| Port multi-diffusion | Lié au cycle de vie de la conversation. Le scope de la conversation correspond aux longueurs de la requête et de la session, et est contrôlé par l'application. | Option |
| Port fixe | Si les contextes ne correspondent pas à vos besoins, vous pourrez définir des scopes personnalisés. | Option |
Configurer des liaisons de sockets dans des Groupes de liaisons de sockets
Sélectionner le Management CLI ou la Console de gestion pour configurer vos liaisons de sockets selon les besoins.Configurer les liaisons de sockets par le Management CLI
Sélectionner le Management CLI pour configurer les liaisons de sockets.Ajouter un nouvelle liaison de sockets
Utiliser l'opérationadd(ajouter) pour créer une nouvelle configuration d'adresse si nécessaire. Vous pouvez exécuter cette commande à partir de la racine de la session de Management CLI, qui, dans l'exemple suivant, crée une nouvelle liaison de sockets intitulée newsocket, avec un attributportdéclaré comme 1234. Les exemples s'appliquent à la fois pour la modification des serveurs autonomes et des serveurs gérés sur la liaison de socketsstandard-socketscomme montré ci-dessous.[domain@localhost:9999 /] /socket-binding-group=standard-sockets/socket-binding=newsocket/:add(port=1234)
Modifier les attributs de modèle
Utiliser l'opérationwrite-attributepour écrire une nouvelle valeur dans un attribut. Vous pouvez utiliser l'onglet de complétion pour aider à compléter la chaîne de commande que vous saisissez, et pour exposer les attributs disponibles. L'exemple suivant met à jour la valeurportà 2020[domain@localhost:9999 /] /socket-binding-group=standard-sockets/socket-binding=newsocket/:write-attribute(name=port,value=2020)
Confirmer les attributs de modèle
Confirmer que les valeurs ont changé en exécutantread-resourceaccompagné du paramètreinclude-runtime=truepour exposer toutes les valeurs actives en cours du modèle de serveur.[domain@localhost:9999 /] /socket-binding-group=standard-sockets/socket-binding=newsocket/:read-resource
Configurer les liaisons de sockets par la Console de gestion
Utiliser le Management CLI pour configurer les liaisons de sockets.Connectez-vous à la Console de gestion.
Connectez-vous à la Console de gestion de votre domaine géré ou de votre serveur autonome.Sélectionner le Profile tab
Sélectionner l'onglet Profiles en haut et à droite.Sélectionner l'élément Socket Binding à partir du menu de navigation.
Sélectionner l'élément de menu Socket Binding à partir du menu de navigation. Si vous utilisez un domaine géré, sélectionner le groupe désiré dans le menu Socket Binding Groups.Ajouter un nouvelle liaison de sockets
- Cliquer sur le bouton (ajouter).
- Saisir les valeurs qui conviennent pour les Name (Nom), Port (Port) et Binding Group (Groupe de liaisons).
- Cliquer sur le bouton pour terminer.
Modifier les attributs d'une interface
- Sélectionner la liaison de sockets à modifier et cliquer sur le bouton .
- Saisir les valeurs qui conviennent pour les Name (Nom), Interface (Interface) etr Port (Port).
- Cliquer sur le bouton pour terminer.
5.2.3. Ports de réseau utilisés par JBoss EAP 6
- Le fait que vos groupes de serveurs utilisent le groupe de liaisons de sockets par défaut, ou un groupe de liaisons de sockets personnalisé.
- Des exigences de vos déploiements individuels.
Note
Groupes de liaison de socket par défaut
full-ha-socketsfull-socketsha-socketsstandard-sockets
Tableau 5.3. Référence aux Groupes de liaison de socket par défaut
| Nom | Port | Port Multidiffusion | Description | full-ha-sockets | full-sockets | ha-socket | standard-socket |
|---|---|---|---|---|---|---|---|
ajp | 8009 | Protocole Apache JServ. Utilisé pour le clustering HTTP et pour l'équilibrage des charges. | Oui | Oui | Oui | Oui | |
http | 8080 | Le port par défaut des applications déployées. | Oui | Oui | Oui | Oui | |
https | 8443 | Connexion cryptée-SSL entre les applications déployées et les clients. | Oui | Oui | Oui | Oui | |
jacorb | 3528 | Services CORBA pour les transactions JTS et autres services dépendants-ORB. | Oui | Oui | Non | Non | |
jacorb-ssl | 3529 | Services CORBA cryptés-SSL. | Oui | Oui | Non | Non | |
jgroups-diagnostics | 7500 | Multidiffusion. Utilisé pour découverte de pair dans les groupements HA. Non configurable par les Interfaces de gestion. | Oui | Non | Oui | Non | |
jgroups-mping | 45700 | Multicast. Utilisé pour découvrir l'appartenance de groupe d'origine dans un cluster HA. | Oui | Non | Oui | Non | |
jgroups-tcp | 7600 | Découverte de pairs unicast dans les groupements HA avec TCP. | Oui | Non | Oui | Non | |
jgroups-tcp-fd | 57600 | Utilisé pour la détection des échecs en TCP. | Oui | Non | Oui | Non | |
jgroups-udp | 55200 | 45688 | Découverte de pairs unicast dans les groupements HA avec UDP. | Oui | Non | Oui | Non |
jgroups-udp-fd | 54200 | Utilisé pour la détection des échecs par UDP. | Oui | Non | Oui | Non | |
messaging | 5445 | Service JMS. | Oui | Oui | Non | Non | |
messaging-group | Référencé par la diffusion HornetQ JMS et les groupes Discovery | Oui | Oui | Non | Non | ||
messaging-throughput | 5455 | Utilisé par JMS à distance. | Oui | Oui | Non | Non | |
mod_cluster | 23364 | Port multidiffusion pour la communication entre JBoss EAP 6 et l'équilibreur de charges HTTP. | Oui | Non | Oui | Non | |
osgi-http | 8090 | Utilisé par les composants internes qui utilisent le sous-système OSGi. Non configurable par les Interfaces de gestion. | Oui | Oui | Oui | Oui | |
remoting | 4447 | Utilisé pour l'invocation EJB. | Oui | Oui | Oui | Oui | |
txn-recovery-environment | 4712 | Gestionnaire de recouvrement des transactions JTA. | Oui | Oui | Oui | Oui | |
txn-status-manager | 4713 | Gestionnaire des transactions JTA / JTS. | Oui | Oui | Oui | Oui |
En plus des groupes de liaisons de socket, chaque contrôleur d'hôte ouvre deux ports supplémentaires pour la gestion :
- 9990 - Le port de Console de gestion
- 9999 - Le port utilisé par la Console de gestion et par le Management API
5.2.4. Valeurs de décalage des ports pour les Groupes de liaison de sockets par défaut
5.2.5. Configurer les Port Offset (valeurs de décalages de ports)
Configurer les Port Offset (valeurs de décalages de ports)
Sélectionner le Management CLI ou la Console de gestion pour configurer vos ports offsets.Configurer Port Offsets par le Management CLI
Sélectionner le Management CLI pour configurer vos ports offsets.Modifier les Ports Offsets
Utiliser l'opérationwrite-attributpour écrire une nouvelle valeur référence de port. L'exemple suivant met à jour la valeur dusocket-binding-port-offsetde server-two à 250. Ce serveur est membre du groupe hôte local par défaut. Un redémarrage est nécessaire pour que les modifications puissent prendre effet.[domain@localhost:9999 /] /host=master/server-config=server-two/:write-attribute(name=socket-binding-port-offset,value=250)
Confirmer les attributs de Port Offset
Confirmer que les valeurs ont changé en exécutantread-resourceaccompagné du paramètreinclude-runtime=truepour exposer toutes les valeurs actives en cours du modèle de serveur.[domain@localhost:9999 /] /host=master/server-config=server-two/:read-resource(include-runtime=true)
Configurer Port Offsets par la Console de Management
Sélectionner la Console de Management pour configurer vos ports offsets.Connectez-vous à la Console de gestion.
Connectez-vous à la Console de gestion de votre domaine géré.Sélectionner l'onglet Hosts
Sélectionner l'onglet Hosts en haut et à droite.Modifier les attributs de Port Offset
- Sélectionner le serveur dans la section
Configuration Nameet cliquer sur le bouton . - Saisir les valeurs que vous désirez dans le champ Port Offset.
- Cliquer sur le bouton pour terminer.
5.3. IPv6
5.3.1. Configurer les Préférences de JVM Stack d'IPv6 Networking
- Résumé
- Cette section couvre l'activation du réseau IPv6 de l'installation JBoss EAP 6
Procédure 5.1. Désactiver la propriété IPv4 Stack Java
- Ouvrir le fichier qui convient à l'installation :
Pour le serveur autonome :
OuvrirEAP_HOME/bin/standalone.conf.Pour un domaine géré :
OuvrirEAP_HOME/bin/domain.conf.
- Modifier la propriété IPv4 Stack Java à false :
-Djava.net.preferIPv4Stack=false
Par exemple :# Specify options to pass to the Java VM. # if [ "x$JAVA_OPTS" = "x" ]; then JAVA_OPTS="-Xms64m -Xmx512m -XX:MaxPermSize=256m -Djava.net.preferIPv4Stack=false -Dorg.jboss.resolver.warning=true -Dsun.rmi.dgc.client.gcInterval=3600000 -Dsun.rmi.dgc.server.gcInterval=3600000 -Djava.net.preferIPv6Addresses=true" fi
5.3.2. Configurer les déclarations d'interface du réseautage IPv6
Suivre ces étapes de configuration de l'adresse inet d'interface dans IPv6 par défaut:
Prérequis
Procédure 5.2. Configurer l'interface du réseautage IPv6
- Cliquer sur l'onglet Profile qui se trouve en haut et à droite de la console.
- Sélectionner l'option Interfaces qui se trouve sous General Configuration.
- Sélectionner l'interface réseau nommée à configurer.
- Cliquer sur le bouton .
- Définir l'adresse inet à :
${jboss.bind.address.management:[ADDRESS]} - Cliquez sur le bouton pour enregistrer les modifications.
- Démarrer le serveur à nouveau pour implémenter les changements.
5.3.3. Configurer les Préférences JVM Stacks des adresses IPv6
- Résumé
- Cette rubrique couvre la configuration de l'installation de JBoss EAP 6 pour qu'elle préfère les adresses IPv6 dans les fichiers de configuration.
Procédure 5.3. Configuration de l'installation JBoss EAP 6 pour qu'elle préfère les adresses IPv6
- Ouvrir le fichier qui convient à l'installation :
Pour le serveur autonome :
OuvrirEAP_HOME/bin/standalone.conf.Pour un domaine géré :
OuvrirEAP_HOME/bin/domain.conf.
- Ajouter la propriété Java suivante aux options de la Java VM
-Djava.net.preferIPv6Addresses=true
Par exemple :# Specify options to pass to the Java VM. # if [ "x$JAVA_OPTS" = "x" ]; then JAVA_OPTS="-Xms64m -Xmx512m -XX:MaxPermSize=256m -Djava.net.preferIPv4Stack=false -Dorg.jboss.resolver.warning=true -Dsun.rmi.dgc.client.gcInterval=3600000 -Dsun.rmi.dgc.server.gcInterval=3600000 -Djava.net.preferIPv6Addresses=true" fi
Chapitre 6. Gestion des sources de données
6.1. Introduction
6.1.1. JDBC
6.1.2. Bases de données supportées par JBoss EAP 6
6.1.3. Types de sources de données
les sources de données et les sources de données XA.
6.1.4. L'exemple de source de données
Avertissement
6.1.5. Déploiement des fichiers -ds.xml
*-ds.xml était requis dans le répertoire de déploiement de la configuration du serveur. Les fichiers *-ds.xml peuvent toujours être déployés dans JBoss EAP 6, suivant le schéma de sources de données 1.1 disponible sous Schemas : http://www.ironjacamar.org/documentation.html.
Avertissement
Important
*-ds.xml.
6.2. Pilotes JDBC
6.2.1. Installer un pilote JDBC avec la console de gestion
Avant que votre application puisse se connecter à une source de données JDBC, vos pilotes JDBC du fournisseur de votre source de données doivent être installés dans un endroit où JBoss EAP 6 puisse les utiliser. JBoss EAP 6 vous permettra de déployer ces pilotes comme tout autre déploiement. Cela signifie que vous pouvez les déployer sur plusieurs serveurs dans un groupe de serveurs, si vous utilisez un domaine géré.
Note
Vous devrez remplir les conditions suivantes avant de pouvoir effectuer cette tâche :
- Télécharger le pilote JDBC de votre fournisseur de base de données.
Procédure 6.1. Déployer le pilote JDBC
Accéder à la console de gestion
Déployez le fichier JAR dans votre serveur ou groupe de serveurs.
Si vous utilisez un domaine géré, déployez le fichier JAR dans un groupe de serveurs. Sinon, déployez-le sur votre serveur. Voir Section 9.2.2, « Déployer une application par la Console de gestion ».
Le pilote JDBC est déployé, et est disponible pour vos applications.
6.2.2. Installer un pilote JDBC comme core module
Vous devrez remplir les conditions suivantes avant de pouvoir effectuer cette tâche :
- Télécharger le pilote JDBC de votre base de données fournisseur. Voici les adresses de téléchargement pour le pilote JDBC : Section 6.2.3, « Adresses des téléchargements de pilotes JDBC ».
- En extraire l'archive
Procédure 6.2. Installer un pilote JDBC comme core module
- Créer une structure de chemin d'accès de fichier sous le répertoire
EAP_HOME/modules/. Ainsi, pour un pilote MySQL JDBC, créer une structure de répertoire comme suit :EAP_HOME/modules/com/mysql/main/. - Copier le pilote JDBC dans le sous-répertoire
main/. - Dans le sous-répertoire
main/, créer un fichiermodule.xmlressemblant à l'exemple qui se trouve Section 7.1.1, « Modules ». LemoduleXSD est défini dans le fichierEAP_HOME/docs/schema/module-1_2.xsd. - Démarrer le serveur.
- Démarrer l'interface CLI.
- Exécuter la commande CLI suivante pour ajouter le module de pilote JDBC comme pilote :
/subsystem=datasources/jdbc-driver=DRIVER_NAME:add(driver-name=DRIVER_NAME,driver-module-name=MODULE_NAME,driver-xa-datasource-class-name=XA_DATASOURCE_CLASS_NAME)
Exemple 6.1. Exemple de Commande CLI
/subsystem=datasources/jdbc-driver=mysql:add(driver-name=mysql,driver-module-name=com.mysql,driver-xa-datasource-class-name=com.mysql.jdbc.jdbc2.optional.MysqlXADataSource)
Le pilote JDBC est maintenant installé et configuré comme core module. Il est maintenant prêt à être référencé par les sources de données d'application.
6.2.3. Adresses des téléchargements de pilotes JDBC
Tableau 6.1. Adresses des téléchargements du pilote JDBC
| Fournisseur | Adresse de téléchargement |
|---|---|
| MySQL | |
| PostgreSQL | |
| Oracle | |
| IBM | |
| Sybase | |
| Microsoft |
6.2.4. Accès aux Classes Spécifiques du fournisseur
Cette section couvre les étapes à suivre pour utiliser les classes spécifiques JDBC. Cela est utile quand une application a besoin d'utiliser une fonctionnalité spécifique à un fournisseur ne faisant pas partie de l'API JDBC.
Avertissement
Important
Important
Procédure 6.3. Ajouter une dépendance à l'application
Configurer le fichier
MANIFEST.MF- Ouvrir le fichier
META-INF/MANIFEST.MFde l'application dans un éditeur de texte. - Ajouter une dépendance au module JDBC et sauvegarder le fichier.
Dépendences : MODULE_NAME
Exemple 6.2. Exemple de dépendance
Dépendences: com.mysql
Créer un fichier
jboss-deployment-structure.xmlCréer un fichierjboss-deployment-structure.xmldans le dossierMETA-INF/ouWEB-INFde l'application.Exemple 6.3. Exemple de fichier
jboss-deployment-structure.xml<jboss-deployment-structure> <deployment> <dependencies> <module name="com.mysql" /> </dependencies> </deployment> </jboss-deployment-structure>
Exemple 6.4. Accède à l'API spécifique du fournisseur
import java.sql.Connection; import org.jboss.jca.adapters.jdbc.WrappedConnection; Connection c = ds.getConnection(); WrappedConnection wc = (WrappedConnection)c; com.mysql.jdbc.Connection mc = wc.getUnderlyingConnection();
6.3. Sources de données non-XA
6.3.1. Créer une source de données Non-XA avec les Interfaces de gestion
Cette section explique les étapes à suivre pour créer une source de données non-XA, en utilisant la Console de gestion ou le Management CLI.
Prérequis
- Le serveur JBoss EAP 6 doit être en cours d'exécution
Note
Procédure 6.4. Créer une Source de données par le Management CLI ou la Console de gestion
Management CLI
- Lancer l'outil CLI et connectez-vous à votre serveur.
- Exécuter la commande suivante pour créer une source de données non-XA, et configurer les variables comme il se doit :
data-source add --name=DATASOURCE_NAME --jndi-name=JNDI_NAME --driver-name=DRIVER_NAME --connection-url=CONNECTION_URL
- Activer la source de données :
data-source enable --name=DATASOURCE_NAME
Console de gestion
- Connectez-vous à la Console de gestion.
Naviguez dans le panneau Datasources qui se trouve dans la Console de gestion
Mode autonome
Sélectionner l'onglet Profile en haut de la console.Mode Domaine
- Sélectionner l'onglet Profiles en haut de la console.
- Sélectionner le profil qui convient à partir du menu déroulant en haut à gauche.
- Étendre le menu qui se trouve à gauche de la console.
- Sélectionner → à partir du menu à gauche de la console.
Créer une nouvelle source de données
- Sélectionner le bouton qui se trouve en haut du panneau Datasources.
- Saisir les attributs de la nouvelle source de données de l'assistant Create Datasource et appuyez sur .
- Saisir les informations sur le pilote JDBC dans l'assistant Create Datasource et appuyez sur .
- Saisir les paramètres de connexion dans l'assistant Create Datasource et appuyez sur .
La source de données non-Xa a été ajoutée au serveur. Elle est maintenant visible dans le fichier standalone.xml ou le fichier domain.xml, ainsi que dans les interfaces de gestion.
6.3.2. Modifier une source de données Non-XA avec les Interfaces de gestion
Cette section explique les étapes à suivre pour modifier une source de données non-XA, en utilisant la Console de gestion ou le Management CLI.
Prérequis
Note
jta soit défini à true.
Procédure 6.5. Modifier une Source de données non-XA
Management CLI
- Utiliser la commande
write-attributepour configurer un attribut de source de données :/subsystem=datasources/data-source=DATASOURCE_NAME:write-attribute(name=ATTRIBUTE_NAME,value=ATTRIBUTE_VALUE)
- Charger à nouveau le serveur pour confirmer les changements :
:reload
Console de gestion
Naviguez dans le panneau Datasources qui se trouve dans la Console de gestion
Mode autonome
Sélectionner l'onglet Profile en haut de la console.Mode Domaine
- Sélectionner l'onglet Profiles en haut de la console.
- Sélectionner le profil qui convient à partir du menu déroulant en haut à gauche.
- Étendre le menu qui se trouve à gauche de la console.
- Sélectionner → à partir du menu à gauche de la console.
Modifier la source de données
- Sélectionner la source de données qui convient à partir de la liste Available Datasources. Les attributs de la source de données sont affichés dans le panneau Attributes ci-dessous.
- Sélectionner le bouton pour modifier les attributs de la source de données.
- Modifier les attributs de la source de données et sélectionner le bouton quand c'est fait.
La source de données non-Xa a été configurée. Elle est maintenant visible dans le fichier standalone.xml ou le fichier domain.xml, ainsi que dans les interfaces de gestion.
- Pour créer une nouvelle source de données. voir : Section 6.3.1, « Créer une source de données Non-XA avec les Interfaces de gestion ».
- Pour supprimer la source de données, voir Section 6.3.3, « Supprimer une source de données Non-XA avec les Interfaces de gestion ».
6.3.3. Supprimer une source de données Non-XA avec les Interfaces de gestion
Ce sujet couvre les étapes requises pour supprimer une source de données non-XA de JBoss EAP 6, en utilisant la Console de gestion ou le Management CLI.
Prérequis
Procédure 6.6. Supprimer un source de données non-XA
Management CLI
- Exécuter la commande suivante pour supprimer une source de données non-XA :
data-source remove --name=DATASOURCE_NAME
Console de gestion
Naviguer dans le panneau Datasources qui se trouve dans la Console de gestion
Mode autonome
Sélectionner l'onglet Profile en haut de la console.Mode Domaine
- Sélectionner l'onglet Profiles en haut de la console.
- Sélectionner le profil qui convient à partir du menu déroulant en haut à gauche.
- Étendre le menu qui se trouve à gauche de la console.
- Sélectionner → à partir du menu à gauche de la console.
- Sélectionner la source de données enregistrée à supprimer, et cliquer sur le bouton qui se trouve en haut et à droite de la console.
La source de données non-XA a été supprimée dans le serveur.
- Pour créer une nouvelle source de données, voir : Section 6.3.1, « Créer une source de données Non-XA avec les Interfaces de gestion ».
6.4. Sources de données XA
6.4.1. Créer une source de données XA avec les Interfaces de gestion
Conditions préalables :
Cette section explique les étapes à suivre pour créer une source de données XA, en utilisant la Console de gestion ou le Management CLI.
Note
Procédure 6.7. Créer une source de données XA en utilisant le Management CLI ou la Console de gestion
Management CLI
- Exécuter la commande suivante pour créer une source de données XA, et configurer les variables comme il se doit:
xa-data-source add --name=XA_DATASOURCE_NAME --jndi-name=JNDI_NAME --driver-name=DRIVER_NAME --xa-datasource-class=XA_DATASOURCE_CLASS
Configurer les propriétés de la source de données XA
Définir le nom du serveur
Exécuter la commande suivante pour configurer le nom du serveur de l'hôte :/subsystem=datasources/xa-data-source=XA_DATASOURCE_NAME/xa-datasource-properties=ServerName:add(value=HOSTNAME)
Définir le nom de la base de données
Exécuter la commande suivante pour configurer le nom de la base de données :/subsystem=datasources/xa-data-source=XA_DATASOURCE_NAME/xa-datasource-properties=DatabaseName:add(value=DATABASE_NAME)
- Activer la source de données :
xa-data-source enable --name=XA_DATASOURCE_NAME
Console de gestion
Naviguez dans le panneau Datasources qui se trouve dans la Console de gestion
Mode autonome
Sélectionner l'onglet Profile en haut de la console.Mode Domaine
- Sélectionner l'onglet Profiles en haut de la console.
- Sélectionner le profil qui convient à partir du menu déroulant en haut à gauche.
- Étendre le menu qui se trouve à gauche de la console.
- Sélectionner → à partir du menu à gauche de la console.
- Sélectionner l'onglet XA Datasource.
Créer une nouvelle source de données XA
- Sélectionner le bouton qui se trouve en haut du panneau Datasources.
- Saisir les attributs de la nouvelle source de données XA de l'assistant Create XA Datasource et appuyez sur .
- Saisir les informations sur le pilote JDBC dans l'assistant Create XA Datasource et appuyez sur .
- Modifier les propriétés et appuyer sur .
- Saisir les paramètres de connexion dans l'assistant Create XA Datasource et appuyer sur .
La source de données XA a été ajoutée au serveur. Elle est maintenant visible dans le fichier standalone.xml ou le fichier domain.xml, ainsi que dans les interfaces de gestion.
Voir également :
6.4.2. Modifier une base de données XA par les interfaces de gestion
Cette section explique les étapes à suivre pour modifier une source de données XA, en utilisant la Console de gestion ou le Management CLI.
Prérequis
Procédure 6.8. Modifier une source de données XA en utilisant le Management CLI ou la Console de gestion
Management CLI
Configurer les attributs de source de données XA
Utiliser la commandewrite-attributepour configurer un attribut de source de données :/subsystem=datasources/xa-data-source=XA_DATASOURCE_NAME:write-attribute(name=ATTRIBUTE_NAME,value=ATTRIBUTE_VALUE)
Configurer les propriétés de la source de données XA
Exécuter la commande suivante pour configurer une sous-ressource de source de données XA :/subsystem=datasources/xa-data-source=DATASOURCE_NAME/xa-datasource-properties=PROPERTY_NAME:add(value=PROPERTY_VALUE)
- Charger à nouveau le serveur pour confirmer les changements :
:reload
Console de gestion
Naviguez dans le panneau Datasources qui se trouve dans la Console de gestion
Mode autonome
Sélectionner l'onglet Profile en haut de la console.Mode Domaine
- Sélectionner l'onglet Profiles en haut de la console.
- Sélectionner le profil qui convient à partir du menu déroulant en haut à gauche.
- Étendre le menu qui se trouve à gauche de la console.
- Sélectionner → à partir du menu à gauche de la console.
- Sélectionner l'onglet XA Datasource.
Modifier la source de données
- Sélectionner la source de données XA qui convient à partir de la liste Available XA Datasources. Les attributs de la source de données XA sont affichés dans le panneau Attributes ci-dessous.
- Sélectionner le bouton pour modifier les attributs de la source de données.
- Modifier les attributs de la source de données XA et sélectionner le bouton quand c'est fait.
La source de données XA a été configurée. Les changements sont maintenant visibles dans le fichier standalone.xml ou le fichier domain.xml, ainsi que dans les interfaces de gestion.
- Pour créer une nouvelle source de données, voir : Section 6.4.1, « Créer une source de données XA avec les Interfaces de gestion ».
- Pour supprimer la source de données, voir Section 6.4.3, « Supprimer une source de données XA avec les Interfaces de gestion ».
6.4.3. Supprimer une source de données XA avec les Interfaces de gestion
Ce sujet couvre les étapes requises pour supprimer une source de données XA de JBoss EAP 6, en utilisant la Console de gestion ou le Management CLI.
Prérequis
Procédure 6.9. Supprimer une source de données XA en utilisant le Management CLI ou la Console de gestion
Management CLI
- Exécuter la commande suivante pour supprimer une source de données :
xa-data-source remove --name=XA_DATASOURCE_NAME
Console de gestion
Naviguer dans le panneau Datasources qui se trouve dans la Console de gestion
Mode autonome
Sélectionner l'onglet Profile en haut de la console.Mode Domaine
- Sélectionner l'onglet Profiles en haut de la console.
- Sélectionner le profil qui convient à partir du menu déroulant en haut à gauche.
- Étendre le menu qui se trouve à gauche de la console.
- Sélectionner → à partir du menu à gauche de la console.
- Sélectionner l'onglet XA Datasource.
- Sélectionner la source de données XA enregistrée à supprimer, et cliquer sur le bouton qui se trouve en haut et à droite de la console.
La source de données XA a été supprimée dans le serveur.
- Pour ajouter une nouvelle source de données, voir : Section 6.4.1, « Créer une source de données XA avec les Interfaces de gestion ».
6.4.4. XA Recovery
6.4.4.1. Les modules de recouvrement XA
com.arjuna.ats.jta.recovery.XAResourceRecovery.
6.4.4.2. Configurer les modules de recouvrement
Tableau 6.2. Attributs de configuration générale
| Attribut | Description |
|---|---|
| recovery-username |
Le nom d'utilisateur qui doit être utilisé par le module de recouvrement pour se connecter à la ressource de recouvrement.
|
| recovery-password |
Le mot de passe qui doit être utilisé par le module de recouvrement pour se connecter à la ressource de recouvrement.
|
| recovery-security-domain |
Le domaine de sécurité qui doit être utilisé par le module de recouvrement pour se connecter à la ressource de recouvrement.
|
| recovery-plugin-class-name |
Si vous devez utiliser un module de recouvrement personnalisé, définissez cet attribut au nom complet de classe du module. Le module doit étendre la classe
com.arjuna.ats.jta.recovery.XAResourceRecovery.
|
| recovery-plugin-properties |
Si vous utilisez un module de récupération personnalisée qui requiert des propriétés à définir, définissez cet attribut à la liste de paires key=value séparée par des virgules pour les propriétés.
|
Informations de configuration spécifiques au fournisseur
- Oracle
- Si la source de données Oracle n'est pas configurée correctement, vous apercevrez sans doute les erreurs suivantes dans votre sortie de journalisation :
WARN [com.arjuna.ats.jta.logging.loggerI18N] [com.arjuna.ats.internal.jta.recovery.xarecovery1] Local XARecoveryModule.xaRecovery got XA exception javax.transaction.xa.XAException, XAException.XAER_RMERR
Pour résoudre cette erreur, veillez à ce que l'utilisateur Oracle configuré dansrecovery-usernameait bien accès aux tableaux utiles au recouvrement. L'énoncé SQL suivant affiche les attributions d'instances correctes Oracle 11g ou Oracle 10g R2 corrigées pour le bogue 5945463 d'Oracle.GRANT SELECT ON sys.dba_pending_transactions TO recovery-username; GRANT SELECT ON sys.pending_trans$ TO recovery-username; GRANT SELECT ON sys.dba_2pc_pending TO recovery-username; GRANT EXECUTE ON sys.dbms_xa TO recovery-username;
Si vous utilisez une version Oracle 11g antérieure à 11g, modifier l'énoncé finalEXECUTEainsi:GRANT EXECUTE ON sys.dbms_system TO recovery-username;
- PostgreSQL
- Voir la documentation PostgreSQL pour obtenir des instructions sur la façon d'activer des transactions (ex. XA) préparées. La version 8.4-701 du pilote JDBC de PostgreSQL a un bogue dans
org.postgresql.xa.PGXAConnectionqui empêche le recouvrement dans certaines situations. Cela a été résolu dans les nouvelles versions. - MySQL
- Basé sur http://bugs.mysql.com/bug.php?id=12161, le recouvrement de transactions XA ne fonctionnait pas dans certaines versions de MySQL 5. Cela a été corrigé dans MySQL 6.1. Voir l'URL du bogue ou la documentation MySQL pour obtenir davantage d'informations.
- IBM DB2
- IBM DB2 s'attend à ce que la méthode
XAResource.recoversoit appelée uniquement pendant la phase de resynchronisation désignée qui se produit lorsque le serveur d'applications est redémarré après un accident ou une panne. Il s'agit d'une décision de conception pour l'implémentation de DB2, qui est en dehors du dessein de cette documentation.
6.5. Sécurité des bases de données
6.5.1. Sécurité des bases de données
- Domaines de sécurité : Section 10.6.1, « Les domaines de sécurité ».
Exemple 6.5. Exemple de domaine de sécurité
<security> <security-domain>mySecurityDomain</security-domain> </security>
Exemple 6.6. Exemple de mots de passe
<security>
<user-name>admin</user-name>
<password>${VAULT::ds_ExampleDS::password::N2NhZDYzOTMtNWE0OS00ZGQ0LWE4MmEtMWNlMDMyNDdmNmI2TElORV9CUkVBS3ZhdWx0}</password>
</security>
6.6. Configuration des sources de données
6.6.1. Paramètres de source de données
Tableau 6.3. Les paramètres de source de données communs aux sources XA ou non-XA
| Paramètre | Description |
|---|---|
| jndi-name | Le nom JNDI unique pour la source de données. |
| pool-name | Le nom du pool de gestion de la source de données. |
| activé | Indique si la source de données est activée. |
| use-java-context |
Indique si on doit relier la source de données au JNDI global.
|
| spy |
Activer la fonctionnalité
spy sur la couche JDBC. Cela journalisera tout le trafic JDBC dans la source de données. Le paramètre logging-category doit également être défini à org.jboss.jdbc.
|
| use-ccm | Activer le gestionnaire de connexion cache. |
| new-connection-sql | Un énoncé SQL qui exécute quand la connexion est ajoutée au pool de connexion. |
| transaction-isolation |
Un parmi :
|
| url-delimiter | Le délimiteur d'URLs d'une connexion url pour les bases de données clusterisées HA (Haute disponibilité). |
| url-selector-strategy-class-name | Une classe qui implémente l'interface org.jboss.jca.adapters.jdbc.URLSelectorStrategy. |
| sécurité |
Contient des éléments dépendants en tant que paramètres de sécurité. Voir Tableau 6.8, « Paramètres de sécurité ».
|
| validation |
Contient des éléments dépendants en tant que paramètres de validation. Voir Tableau 6.9, « Paramètres de validation ».
|
| timeout |
Contient des éléments dépendants en tant que paramètres de timeout. Voir Tableau 6.10, « Paramètres de timeout ».
|
| énoncé |
Contient des éléments dépendants en tant que paramètres d'énoncés. Voir Tableau 6.11, « Paramètres d'instruction ».
|
Tableau 6.4. Paramètres de source de données non-xa
| Paramètre | Description |
|---|---|
| jta | Active l'intégration JTA pour les sources de données non-XA. Ne s'applique pas aux sources de données XA. |
| connection-url | L'URL de connexion du pilote JDBC. |
| driver-class | Le nom complet de la classe de pilote JDBC. |
| connection-property |
Propriétés de connexions arbitraires passées à la méthode
Driver.connect(url,props). Chaque connection-property indique une paire name/value. Le nom de la propriété provient du nom, et la valeur provient du contenu de l'élément.
|
| pool |
Contient des éléments dépendants en tant que paramètres de pooling. Voir Tableau 6.6, « Les paramètres de pool communs aux sources XA ou non-XA ».
|
Tableau 6.5. Paramètres de source de données XA
| Paramètre | Description |
|---|---|
| xa-datasource-property |
Une propriété pour assigner la classe d'implémentation
XADataSource. Spécifiée par name=value. Si une méthode setter existe, dans le format setName, la propriété sera définie en appelant une méthode setter sous le format setName(value).
|
| xa-datasource-class |
Le nom complet de la classe d'implémentation de
javax.sql.XADataSource.
|
| pilote |
Unique référence au module de chargeur de classe qui contient le pilote JDBC. Le format accepté est driverName#majorVersion.minorVersion.
|
| xa-pool |
Contient des éléments dépendants en tant que paramètres de pooling. Voir Tableau 6.6, « Les paramètres de pool communs aux sources XA ou non-XA » et Tableau 6.7, « Paramètres du pool XA »
|
| recouvrement |
Contient des éléments dépendants en tant que paramètres de recouvrement. Voir Tableau 6.12, « Paramètres de recouvrement ».
|
Tableau 6.6. Les paramètres de pool communs aux sources XA ou non-XA
| Paramètre | Description |
|---|---|
| min-pool-size | Le nombre minimum de connexions contenues par un pool. |
| max-pool-size | Le nombre maximum de connexions qu'un pool peut contenir |
| Pré-remplissage | Indique si l'on doit essayer de pré-remplir un pool de connexion. Un élément vide indique une valeur true. La valeur par défaut est false. |
| use-strict-min | Indique si la taille du pool est stricte. false par défaut. |
| flush-strategy |
Indique si le pool est vidé en cas d'erreur. Les valeurs acceptées sont :
La valeur par défaut est
FailingConnectionOnly.
|
| allow-multiple-users | Indique si plusieurs utilisateurs pourront avoir accès à la source de données par la méthode getConnection(user, password), et si les types de pools internes ont une influence sur ce comportement. |
Tableau 6.7. Paramètres du pool XA
| Paramètre | Description |
|---|---|
| is-same-rm-override | Indique si la classe javax.transaction.xa.XAResource.isSameRM(XAResource) retourne true ou false. |
| entrelacement | Indique si on doit activer l'entrelacement pour les fabriques de connexion XA. |
| no-tx-separate-pools | Indique si on doit créer des sous-répertoires distincts pour chaque contexte. Cela est nécessaire pour les sources de données Oracle, qui ne permettent pas aux connexions XA d'être utilisées à la fois à l'intérieur et à l'extérieur d'une transaction de JTA |
| pad-xid | Indique si on doit remplir le Xid. |
| wrap-xa-resource |
Indique si on doit inclure XAResource dans une instance
org.jboss.tm.XAResourceWrapper.
|
Tableau 6.8. Paramètres de sécurité
| Paramètre | Description |
|---|---|
| user-name | Le nom d'utilisation pour créer une nouvelle connexion. |
| mot de passe | Le mot de passe à utiliser pour créer une nouvelle connexion |
| security-domain | Contient le nom d'un gestionnaire de sécurité JAAS, qui gère l'authentification. Ce nom correspond à l'attribut application-policy/name de la configuration de connexion JAAS. |
| reauth-plugin | Définit un plugin d'authentification à nouveau pour la ré authentification de connexions physiques. |
Tableau 6.9. Paramètres de validation
| Paramètre | Description |
|---|---|
| valid-connection-checker |
Une mise en œuvre d'interface
org.jboss.jca.adaptors.jdbc.ValidConnectionChecker qui fournit une méthode SQLException.isValidConnection(Connection e) pour valider une connexion. Une exception signifie que la connexion est détruite. Cela remplace le paramètre check-valid-connection-sql s'il est présent.
|
| check-valid-connection-sql | Un énoncé SQL pour vérifier la validité d'un pool de connexion. Peut être appelé quand une connexion gérée est tirée d'un pool. |
| validate-on-match |
Indique si la validation de niveau de connexion est exécutée lorsqu'une fabrique de connexions essaie de correspondre à une connexion gérée pour un ensemble donné.
Spécifier « true » pour
Validate-on-match n'est généralement pas effectué conjointement avec la spécification « true » de background-validation. Validate-on-match est nécessaire lorsqu'un client doit avoir une connexion validée avant l'utilisation. Ce paramètre est true par défaut.
|
| background-validation |
Indique que les connexions sont validées sur un thread d'arrière-plan. La validation de l'arrière-plan (Background validation) est une optimisation de performance lorsque non utilisé avec
validate-on-match. Si Validate-on-match est sur true, l'utilisation de background-validation pourrait entraîner des contrôles redondants. La validation de l'arrière-plan pourrait provoquer une mauvaise connexion (une connexion qui irait mal entre le moment de l'analyse de validation et avant d'être donnée au client), l'application cliente doit par conséquent tenir compte de cette possibilité.
|
| background-validation-millis | La durée, en millisecondes, pendant laquelle la validation d'arrière-plan exécute. |
| use-fast-fail |
Si défini sur true, échoue une allocation de connexion lors de la première tentative, si la connexion est non valide. La valeur par défaut est
false.
|
| stale-connection-checker |
Une instance de
org.jboss.jca.adapters.jdbc.StaleConnectionChecker qui produit une méthode booléenne isStaleConnection(SQLException e). Si cette méthode renvoie un true, l'exception sera contenue dans org.jboss.jca.adapters.jdbc.StaleConnectionException, qui correspond à une sous-classe de SQLException.
|
| exception-sorter |
Une instance de
org.jboss.jca.adapters.jdbc.ExceptionSorter qui fournit une méthode booléenne isExceptionFatal(SQLException e). Cette méthode validera si une exception est envoyée à toutes les instances d'un javax.resource.spi.ConnectionEventListener en tant que message connectionErrorOccurred.
|
Tableau 6.10. Paramètres de timeout
| Paramètre | Description |
|---|---|
| use-try-lock | Utiliser tryLock() au lieu de lock(). Vous essayerez ainsi d'obtenir un verrou pour le nombre de secondes configurées, avant le timeout, au lieu d'échouer immédiatement quand le verrou n'est pas disponible. La valeur par défaut est de 60 secondes. Par exemple, pour définir un timeout de 5 minutes, définir <use-try-lock>300</use-try-lock>. |
| blocking-timeout-millis | La durée maximale, en millisecondes, de blocage lorsque vous attendez une connexion. Après que ce délai soit dépassé, une exception sera levée. Cela bloque uniquement pendant que vous attendez un permis de connexion et ne lève pas d'exception si la création d'une nouvelle connexion prend beaucoup de temps. Par défaut, 30000, qui correspond à 30 secondes. |
| idle-timeout-minutes |
La durée maximale, en minutes, avant qu'une connexion inactive soit fermée. La durée maximale réelle dépend de la durée d'analyse de l'idleRemover, qui correspond à la moitié du plus petit
idle-timeout-minutes de n'importe quel pool.
|
| set-tx-query-timeout |
Indique si on doit définir le timeout d'interrogation par rapport au temps qui reste avant le timeout de transaction. Si aucune transaction n'existe, on utilisera le timeout de recherche qui a été configuré. La valeur par défaut est
false.
|
| query-timeout | Timeout pour les recherches, en secondes. La valeur par défaut est « no timeout ». |
| allocation-retry | Le nombre de tentatives de connexion avant d'envoyer une connexion. La valeur par défaut est 0, pour qu'une exception puisse être envoyée à la première défaillance. |
| allocation-retry-wait-millis |
Le temps, en millisecondes, qu'il faut attendre avant de retenter d'allouer une connexion. La valeur par défaut est 5 000, soit 5 secondes.
|
| xa-resource-timeout |
Si la valeur est non nulle, elle passe à la méthode
XAResource.setTransactionTimeout.
|
Tableau 6.11. Paramètres d'instruction
| Paramètre | Description |
|---|---|
| track-statements |
Indique si l'on doit vérifier les instructions non fermées lorsqu'une connexion est renvoyée à un pool ou qu'une instruction est retournée dans le cache d'instruction préparée. Si false, les instructions ne seront pas suivies.
Valeurs valides
|
| prepared-statement-cache-size | Le nombre d'instructions préparées par connexion, dans le cache LRU (le moins souvent utilisé récemment). |
| share-prepared-statements |
Indique si le fait de demander la même instruction deux fois sans la fermer utilise la même instruction préparée sous-jacente. La valeur par défaut est
false.
|
Tableau 6.12. Paramètres de recouvrement
| Paramètre | Description |
|---|---|
| recover-credential | Une paire nom d'utilisateur/mot de passe ou domaine de sécurité pour le recouvrement. |
| recover-plugin |
Une mise en œuvre de la classe
org.jboss.jca.core.spi.recoveryRecoveryPlugin à utiliser pour le recouvrement.
|
6.6.2. Les URL de connexion de sources de données
Tableau 6.13.
| Source de données | URL de connexion |
|---|---|
| PostgreSQL | jdbc:postgresql://SERVER_NAME:PORT/DATABASE_NAME |
| MySQL | jdbc:mysql://SERVER_NAME:PORT/DATABASE_NAME |
| Oracle | jdbc:oracle:thin:@ORACLE_HOST:PORT:ORACLE_SID |
| IBM DB2 | jdbc:db2://SERVER_NAME:PORT/DATABASE_NAME |
| Microsoft SQLServer | jdbc:microsoft:sqlserver://SERVER_NAME:PORT;DatabaseName=DATABASE_NAME |
6.6.3. Extensions de sources de données
Tableau 6.14. Extensions de sources de données
| Extension de sources de données | Paramètre de configuration | Description |
|---|---|---|
| org.jboss.jca.adapters.jdbc.spi.ExceptionSorter | <exception-sorter> | Vérifie si SQLException est fatal pour la connexion sur laquelle l'exception a été lancée |
| org.jboss.jca.adapters.jdbc.spi.StaleConnection | <stale-connection-checker> | Wraps stale SQLExceptions in a org.jboss.jca.adapters.jdbc.StaleConnectionException |
| org.jboss.jca.adapters.jdbc.spi.ValidConnection | <valid-connection-checker> | Vérifie si une connexion est valide pour être utilisée par l'application |
Implémentations des extensions
- Générique
- org.jboss.jca.adapters.jdbc.extensions.novendor.NullExceptionSorter
- org.jboss.jca.adapters.jdbc.extensions.novendor.NullStaleConnectionChecker
- org.jboss.jca.adapters.jdbc.extensions.novendor.NullValidConnectionChecker
- org.jboss.jca.adapters.jdbc.extensions.novendor.JDBC4ValidConnectionChecker
- PostgreSQL
- org.jboss.jca.adapters.jdbc.extensions.postgres.PostgreSQLExceptionSorter
- org.jboss.jca.adapters.jdbc.extensions.postgres.PostgreSQLValidConnectionChecker
- MySQL
- org.jboss.jca.adapters.jdbc.extensions.mysql.MySQLExceptionSorter
- org.jboss.jca.adapters.jdbc.extensions.mysql.MySQLReplicationValidConnectionChecker
- org.jboss.jca.adapters.jdbc.extensions.mysql.MySQLValidConnectionChecker
- IBM DB2
- org.jboss.jca.adapters.jdbc.extensions.db2.DB2ExceptionSorter
- org.jboss.jca.adapters.jdbc.extensions.db2.DB2StaleConnectionChecker
- org.jboss.jca.adapters.jdbc.extensions.db2.DB2ValidConnectionChecker
- Sybase
- org.jboss.jca.adapters.jdbc.extensions.sybase.SybaseExceptionSorter
- org.jboss.jca.adapters.jdbc.extensions.sybase.SybaseValidConnectionChecker
- Microsoft SQLServer
- org.jboss.jca.adapters.jdbc.extensions.mssql.MSSQLValidConnectionChecker
- Oracle
- org.jboss.jca.adapters.jdbc.extensions.oracle.OracleExceptionSorter
- org.jboss.jca.adapters.jdbc.extensions.oracle.OracleExceptionSorter
- org.jboss.jca.adapters.jdbc.extensions.oracle.OracleValidConnectionChecker
6.6.4. Voir les statistiques de sources de données
jdbc et pool qui utilisent des versions modifiées des commandes ci-dessous :
Procédure 6.10.
/subsystem=datasources/data-source=ExampleDS/statistics=jdbc:read-resource(include-runtime=true)
/subsystem=datasources/data-source=ExampleDS/statistics=pool:read-resource(include-runtime=true)
Note
include-runtime=true et à ce que tous les statistiques soient en runtime uniquement et la valeur par défaut est false.
6.6.5. Statistiques de bases de données
Le tableau suivant montre une liste des statistiques principaux de sources de données pris en charge :
Tableau 6.15. Statistiques principaux
| Nom | Description |
|---|---|
ActiveCount |
Le nombre de connexions actives. Chacune de ces connexions est soit utilisée par une application, ou disponible via pool
|
AvailableCount |
Le nombre de connexions disponibles dans le pool
|
AverageBlockingTime |
Le durée moyenne passée à bloquer l'obtention d'un verrou exclusif sur le pool. La valeur est en millisecondes.
|
AverageCreationTime |
Le durée moyenne passée à créer une connexion. La valeur est en millisecondes.
|
CreatedCount |
Le nombre de connexions créées.
|
DestroyedCount |
Le nombre de connexions détruites.
|
InUseCount |
Le nombre de connexions actuellement utilisées.
|
MaxCreationTime |
La durée maximum pour créer une connexion. La valeur est en millisecondes.
|
MaxUsedCount |
Le nombre maximum de connexions utilisées
|
MaxWaitCount |
Le nombre maximum de requêtes attendant une connexion en même temps.
|
MaxWaitTime |
Le durée maximum à attendre un verrou exclusif sur le pool.
|
TimedOut |
Le nombre de connexions expirées
|
TotalBlockingTime |
Le durée à attendre un verrou exclusif sur le pool. La valeur est en millisecondes.
|
TotalCreationTime |
La durée passée à créer des connexions. La valeur est en millisecondes.
|
WaitCount |
Le nombre de requêtes en attente de connexion.
|
Le tableau suivant montre une liste des statistiques JDBC de sources de données pris en charge :
Tableau 6.16. Statistiques JDBC
| Nom | Description |
|---|---|
PreparedStatementCacheAccessCount |
Le nombre de fois qu'un cache d'énoncé a été accédé.
|
PreparedStatementCacheAddCount |
Le nombre d'énoncés ajoutés au cache de l'énoncé.
|
PreparedStatementCacheCurrentSize |
Le nombre d'énoncés préparés et que l'on peut appeler, actuellement mis en cache dans un cache d'énoncé.
|
PreparedStatementCacheDeleteCount |
Le nombre d'énoncés rejetés du cache.
|
PreparedStatementCacheHitCount |
Le nombre de fois que des énoncés de cache ont été utilisés.
|
PreparedStatementCacheMissCount |
Le nombre de fois qu'une requête d'énoncé a pu être réglée par un énoncé d'un cache.
|
6.7. Exemples de sources de données
6.7.1. L'exemple de source de données PostgreSQL
Exemple 6.7.
<datasources>
<datasource jndi-name="java:jboss/PostgresDS" pool-name="PostgresDS">
<connection-url>jdbc:postgresql://localhost:5432/postgresdb</connection-url>
<driver>postgresql</driver>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.postgres.PostgreSQLValidConnectionChecker"></valid-connection-checker>
<exception-sorter class-name="org.jboss.jca.adapters.jdbc.extensions.postgres.PostgreSQLExceptionSorter"></exception-sorter>
</validation>
</datasource>
<drivers>
<driver name="postgresql" module="org.postgresql">
<xa-datasource-class>org.postgresql.xa.PGXADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>
module.xml pour la source de données PostgreSQL ci-dessus.
<module xmlns="urn:jboss:module:1.1" name="org.postgresql">
<resources>
<resource-root path="postgresql-9.1-902.jdbc4.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>
6.7.2. Exemple de source de données PostgreSQL XA
Exemple 6.8.
<datasources>
<xa-datasource jndi-name="java:jboss/PostgresXADS" pool-name="PostgresXADS">
<driver>postgresql</driver>
<xa-datasource-property name="ServerName">localhost</xa-datasource-property>
<xa-datasource-property name="PortNumber">5432</xa-datasource-property>
<xa-datasource-property name="DatabaseName">postgresdb</xa-datasource-property>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.postgres.PostgreSQLValidConnectionChecker">
</valid-connection-checker>
<exception-sorter class-name="org.jboss.jca.adapters.jdbc.extensions.postgres.PostgreSQLExceptionSorter">
</exception-sorter>
</validation>
</xa-datasource>
<drivers>
<driver name="postgresql" module="org.postgresql">
<xa-datasource-class>org.postgresql.xa.PGXADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>
module.xml pour la source de données PostgreSQL XA ci-dessus.
<module xmlns="urn:jboss:module:1.1" name="org.postgresql">
<resources>
<resource-root path="postgresql-9.1-902.jdbc4.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>
6.7.3. Exemple de source de données MySQL
Exemple 6.9.
<datasources>
<datasource jndi-name="java:jboss/MySqlDS" pool-name="MySqlDS">
<connection-url>jdbc:mysql://mysql-localhost:3306/jbossdb</connection-url>
<driver>mysql</driver>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.mysql.MySQLValidConnectionChecker"></valid-connection-checker>
<exception-sorter class-name="org.jboss.jca.adapters.jdbc.extensions.mysql.MySQLExceptionSorter"></exception-sorter>
</validation>
</datasource>
<drivers>
<driver name="mysql" module="com.mysql">
<xa-datasource-class>com.mysql.jdbc.jdbc2.optional.MysqlXADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>
module.xml pour la source de données MySQL ci-dessus.
<module xmlns="urn:jboss:module:1.1" name="com.mysql">
<resources>
<resource-root path="mysql-connector-java-5.0.8-bin.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>
6.7.4. Exemple de source de données MySQL XA
Exemple 6.10.
<datasources>
<xa-datasource jndi-name="java:jboss/MysqlXADS" pool-name="MysqlXADS">
<driver>mysql</driver>
<xa-datasource-property name="ServerName">localhost</xa-datasource-property>
<xa-datasource-property name="DatabaseName">mysqldb</xa-datasource-property>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.mysql.MySQLValidConnectionChecker"></valid-connection-checker>
<exception-sorter class-name="org.jboss.jca.adapters.jdbc.extensions.mysql.MySQLExceptionSorter"></exception-sorter>
</validation>
</xa-datasource>
<drivers>
<driver name="mysql" module="com.mysql">
<xa-datasource-class>com.mysql.jdbc.jdbc2.optional.MysqlXADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>
module.xml pour la source de données MySQL XA ci-dessus.
<module xmlns="urn:jboss:module:1.1" name="com.mysql">
<resources>
<resource-root path="mysql-connector-java-5.0.8-bin.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>
6.7.5. L'exemple de source de données Oracle
Note
Exemple 6.11.
<datasources>
<datasource jndi-name="java:/OracleDS" pool-name="OracleDS">
<connection-url>jdbc:oracle:thin:@localhost:1521:XE</connection-url>
<driver>oracle</driver>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.oracle.OracleValidConnectionChecker"></valid-connection-checker>
<stale-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.oracle.OracleStaleConnectionChecker"></stale-connection-checker>
<exception-sorter class-name="org.jboss.jca.adapters.jdbc.extensions.oracle.OracleExceptionSorter"></exception-sorter>
</validation>
</datasource>
<drivers>
<driver name="oracle" module="com.oracle">
<xa-datasource-class>oracle.jdbc.xa.client.OracleXADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>
module.xml pour la source de données Oracle ci-dessus.
<module xmlns="urn:jboss:module:1.1" name="com.oracle">
<resources>
<resource-root path="ojdbc6.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>
6.7.6. Exemple de Source de données d'Oracle XA
Note
Important
user est une valeur définir par l'utilisateur pour pouvoir se connecter à partir de JBoss à Oracle :
- GRANT SELECT ON sys.dba_pending_transactions TO user;
- GRANT SELECT ON sys.pending_trans$ TO user;
- GRANT SELECT ON sys.dba_2pc_pending TO user;
- GRANT EXECUTE ON sys.dbms_xa TO user; (If using Oracle 10g R2 (patched) or Oracle 11g)OUGRANT EXECUTE ON sys.dbms_system TO user; (If using an unpatched Oracle version prior to 11g)
Exemple 6.12.
<datasources>
<xa-datasource jndi-name="java:/XAOracleDS" pool-name="XAOracleDS">
<driver>oracle</driver>
<xa-datasource-property name="URL">jdbc:oracle:oci8:@tc</xa-datasource-property>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<xa-pool>
<is-same-rm-override>false</is-same-rm-override>
<no-tx-separate-pools />
</xa-pool>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.oracle.OracleValidConnectionChecker"></valid-connection-checker>
<stale-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.oracle.OracleStaleConnectionChecker"></stale-connection-checker>
<exception-sorter class-name="org.jboss.jca.adapters.jdbc.extensions.oracle.OracleExceptionSorter"></exception-sorter>
</validation>
</xa-datasource>
<drivers>
<driver name="oracle" module="com.oracle">
<xa-datasource-class>oracle.jdbc.xa.client.OracleXADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>
module.xml pour la source de données Oracle XA ci-dessus.
<module xmlns="urn:jboss:module:1.1" name="com.oracle">
<resources>
<resource-root path="ojdbc6.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>
6.7.7. Exemple de source de données Microsoft SQLServer
Exemple 6.13.
<datasources>
<datasource jndi-name="java:/MSSQLDS" pool-name="MSSQLDS">
<connection-url>jdbc:microsoft:sqlserver://localhost:1433;DatabaseName=MyDatabase</connection-url>
<driver>sqlserver</driver>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.mssql.MSSQLValidConnectionChecker"></valid-connection-checker>
</validation>
</datasource>
<drivers>
<driver name="sqlserver" module="com.microsoft">
<xa-datasource-class>com.microsoft.sqlserver.jdbc.SQLServerXADataSource</xa-datasource-class>
</driver>
</datasources>
module.xml pour la source de données Microsoft SQLServer ci-dessus.
<module xmlns="urn:jboss:module:1.1" name="com.microsoft">
<resources>
<resource-root path="sqljdbc4.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>
6.7.8. Exemple de source de données Microsoft SQLServer XA
Exemple 6.14.
<datasources>
<xa-datasource jndi-name="java:/MSSQLXADS" pool-name="MSSQLXADS">
<driver>sqlserver</driver>
<xa-datasource-property name="ServerName">localhost</xa-datasource-property>
<xa-datasource-property name="DatabaseName">mssqldb</xa-datasource-property>
<xa-datasource-property name="SelectMethod">cursor</xa-datasource-property>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<xa-pool>
<is-same-rm-override>false</is-same-rm-override>
</xa-pool>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.mssql.MSSQLValidConnectionChecker"></valid-connection-checker>
</validation>
</xa-datasource>
<drivers>
<driver name="sqlserver" module="com.microsoft">
<xa-datasource-class>com.microsoft.sqlserver.jdbc.SQLServerXADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>
module.xml pour la source de données Microsoft SQLServer XA ci-dessus.
<module xmlns="urn:jboss:module:1.1" name="com.microsoft">
<resources>
<resource-root path="sqljdbc4.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>
6.7.9. Exemple de source de données IBM DB2
Exemple 6.15.
<datasources>
<datasource jndi-name="java:/DB2DS" pool-name="DB2DS">
<connection-url>jdbc:db2:ibmdb2db</connection-url>
<driver>ibmdb2</driver>
<pool>
<min-pool-size>0</min-pool-size>
<max-pool-size>50</max-pool-size>
</pool>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.db2.DB2ValidConnectionChecker"></valid-connection-checker>
<stale-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.db2.DB2StaleConnectionChecker"></stale-connection-checker>
<exception-sorter class-name="org.jboss.jca.adapters.jdbc.extensions.db2.DB2ExceptionSorter"></exception-sorter>
</validation>
</datasource>
<drivers>
<driver name="ibmdb2" module="com.ibm">
<xa-datasource-class>com.ibm.db2.jdbc.DB2XADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>
module.xml pour la source de données IBM DB2 ci-dessus.
<module xmlns="urn:jboss:module:1.1" name="com.ibm">
<resources>
<resource-root path="db2jcc.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>
6.7.10. Exemple de source de données IBM DB2 XA
Exemple 6.16.
<datasources>
<xa-datasource jndi-name="java:/DB2XADS" pool-name="DB2XADS">
<driver>ibmdb2</driver>
<xa-datasource-property name="DatabaseName">ibmdb2db</xa-datasource-property>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<xa-pool>
<is-same-rm-override>false</is-same-rm-override>
</xa-pool>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.db2.DB2ValidConnectionChecker"></valid-connection-checker>
<stale-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.db2.DB2StaleConnectionChecker"></stale-connection-checker>
<exception-sorter class-name="org.jboss.jca.adapters.jdbc.extensions.db2.DB2ExceptionSorter"></exception-sorter>
</validation>
<recovery>
<recover-plugin class-name="org.jboss.jca.core.recovery.ConfigurableRecoveryPlugin">
<config-property name="EnableIsValid">false</config-property>
<config-property name="IsValidOverride">false</config-property>
<config-property name="EnableClose">false</config-property>
</recover-plugin>
</recovery>
</xa-datasource>
<drivers>
<driver name="ibmdb2" module="com.ibm">
<xa-datasource-class>com.ibm.db2.jcc.DB2XADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>
module.xml pour la source de données IBM DB2 XA ci-dessus.
<module xmlns="urn:jboss:module:1.1" name="com.ibm">
<resources>
<resource-root path="db2jcc.jar"/>
<resource-root path="db2jcc_license_cisuz.jar"/>
<resource-root path="db2jcc_license_cu.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>
6.7.11. L'exemple de source de données Sybase
Exemple 6.17.
<datasources>
<datasource jndi-name="java:jboss/SybaseDB" pool-name="SybaseDB" enabled="true">
<connection-url>jdbc:sybase:Tds:localhost:5000/DATABASE?JCONNECT_VERSION=6</connection-url>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.sybase.SybaseValidConnectionChecker"></valid-connection-checker>
<exception-sorter class-name="org.jboss.jca.adapters.jdbc.extensions.sybase.SybaseExceptionSorter"></exception-sorter>
</validation>
</datasource>
<drivers>
<driver name="sybase" module="com.sybase">
<datasource-class>com.sybase.jdbc2.jdbc.SybDataSource</datasource-class>
<xa-datasource-class>com.sybase.jdbc3.jdbc.SybXADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>
module.xml pour la source de données Sybase ci-dessus.
<module xmlns="urn:jboss:module:1.1" name="com.sybase">
<resources>
<resource-root path="jconn2.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>
6.7.12. L'exemple de source de données Sybase
Exemple 6.18.
<datasources>
<xa-datasource jndi-name="java:jboss/SybaseXADS" pool-name="SybaseXADS" enabled="true">
<xa-datasource-property name="NetworkProtocol">Tds</xa-datasource-property>
<xa-datasource-property name="ServerName">myserver</xa-datasource-property>
<xa-datasource-property name="PortNumber">4100</xa-datasource-property>
<xa-datasource-property name="DatabaseName">mydatabase</xa-datasource-property>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.sybase.SybaseValidConnectionChecker"></valid-connection-checker>
<exception-sorter class-name="org.jboss.jca.adapters.jdbc.extensions.sybase.SybaseExceptionSorter"></exception-sorter>
</validation>
</xa-datasource>
<drivers>
<driver name="sybase" module="com.sybase">
<datasource-class>com.sybase.jdbc2.jdbc.SybDataSource</datasource-class>
<xa-datasource-class>com.sybase.jdbc3.jdbc.SybXADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>
module.xml pour la source de données Sybase XA ci-dessus.
<module xmlns="urn:jboss:module:1.1" name="com.sybase">
<resources>
<resource-root path="jconn2.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>
Chapitre 7. Configuration des modules
7.1. Introduction
7.1.1. Modules
- Modules statiques
- Les modules statiques sont prédéfinis dans le répertoire
EAP_HOME/modules/du serveur d'application. Chaque sous-répertoire représente un module et contient un ou plusieurs fichiers JAR et un fichier de configuration (module.xml). Le nom de ce module est défini dans le fichiermodule.xml. Toutes les API fournies par le serveur d'application sont fournies en tant que modules statiques, comme les API Java EE ainsi que d'autres API comme JBoss Logging.Exemple 7.1. Exemple de fichier module.xml
<?xml version="1.0" encoding="UTF-8"?> <module xmlns="urn:jboss:module:1.0" name="com.mysql"> <resources> <resource-root path="mysql-connector-java-5.1.15.jar"/> </resources> <dependencies> <module name="javax.api"/> <module name="javax.transaction.api"/> </dependencies> </module>Le nom du module,com.mysql, doit correspondre à la structure du répertoire du module.La création de modules statiques personnalisés peut être utile si plusieurs applications sont déployées sur un même serveur utilisant les mêmes bibliothèques de tierce partie. Au lieu d'un regroupement de ces bibliothèques pour chaque application, un module contenant ces bibliothèques peut être créé et installé par l'administrateur JBoss. Les applications peuvent ensuite déclarer une dépendance explicite sur les modules statiques personnalisés. - Modules dynamiques
- Les modules dynamiques sont créés et chargés par le serveur d'application pour chaque déploiement JAR ou WAR (ou sous-déploiement d'un EAR). Le nom d'un module dynamique est dérivé du nom de l'archive déployée. Comme les déploiements sont chargés sous forme de modules, ils peuvent configurer des dépendances et peuvent être utilisés comme dépendances par d'autres déploiements.
7.1.2. Modules globaux
7.1.3. Les dépendances de modules
Exemple 7.2. Les dépendances de module
- Le Module A déclare une dépendance explicite sur le Module C, ou bien
- Le Module B exporte ses dépendances sur le Module C.
7.1.4. Isolement du chargeur de classes d'un sous-déploiement
7.2. Désactiver l'isolement de module de sous-déploiement pour tous les déploiements
Avertissement
Arrêter le serveur
Arrêter le serveur JBoss EAP.Ouvrir le fichier de configuration du serveur
Ouvrir le fichier de configuration du serveur dans un éditeur de texteCe fichier sera différent pour un domaine géré ou un serveur autonome. De plus, des emplacements et des noms de fichier non-défauts peuvent être utilisés. Les fichiers de configuration par défaut sontdomain/configuration/domain.xmletstandalone/configuration/standalone.xmlpour les domaines gérés et les serveurs autonomes respectivement.Chercher la configuration de sous-système EE
Chercher la configuration de sous-système EE. L'élément<profile>du fichier de configuration contient plusieurs éléments du sous-système. L'élément du sous-système a comme espace-nom deurn:jboss:domain:ee:1.0.<profile> ... <subsystem xmlns="urn:jboss:domain:ee:1.0" /> ...
La configuration par défaut a une balise en fermeture automatique unique mais une configuration personnalisée peut avoir des balises d'ouverture ou de fermeture distinctes (éventuellement avec d'autres éléments à l'intérieur) comme ceci :<subsystem xmlns="urn:jboss:domain:ee:1.0" ></subsystem>
Remplacer les balises en fermeture automatique si nécessaire
Si l'élément de sous-système EE est une balise en fermeture automatique unique, remplacez-la par les balises d'ouverture ou de fermeture qui conviennent ainsi :<subsystem xmlns="urn:jboss:domain:ee:1.0" ></subsystem>
Ajouter l'élément ear-deployments-isolated
Ajouter l'élémentear-subdeployments-isolatedcomme dépendant de l'élément du sous-système EE et ajouter le contenu defalsecomme suit :<subsystem xmlns="urn:jboss:domain:ee:1.0" ><ear-subdeployments-isolated>false</ear-subdeployments-isolated></subsystem>
Démarrer le serveur
Lancer à nouveau le serveur JBoss EAP pour qu'il commence à exécuter avec la nouvelle configuration.
Le serveur va maintenant exécuter avec l'isolement de module de sous-déploiement désactivé pour tous les déploiements.
7.3. Ajouter un module à tous les déploiements
Prérequis
- Vous devez connaître le nom des modules qui ont été ajoutés comme modules globaux. Voir Section 7.4.1, « Les modules inclus » pour obtenir la liste des modules statiques inclus dans JBoss EAP 6. Si le module est dans un autre déploiement, voir Section 7.4.2, « Nommage de modules dynamiques » pour déterminer le nom du module.
Procédure 7.1. Ajouter un module à la liste des modules globaux
- Connectez-vous à la console de gestion. Section 3.4.2, « Se conncecter à la console de gestion »
- Naviguez dans le panneau EE Subsystem.
Mode autonome
Sélectionner l'onglet Profile qui se trouve en haut de la console.Mode Domaine
- Sélectionner l'onglet Profiles qui se trouve en haut de la console.
- Sélectionner le profil qui convient à partir du menu déroulant en haut à gauche.
- Étendre le menu qui se trouve à gauche de la console.
- Sélectionner → à partir du menu à gauche de la console.
- Cliquer sur le bouton dans la section Subsystem Defaults. La boîte de dialogue Create Module apparaîtra.
- Saisir alors le nom du module et le slot de module, en option.
- Cliquer sur le bouton pour ajouter le nouveau module global, ou bien cliquer sur le lien pour annuler.
- Si vous cliquez sur le bouton , la boîte de dialogue va se fermer et le module spécifié sera ajouté à la liste des modules globaux.
- Si vous cliquez sur le bouton , la boîte de dialogue se fermera et il n'y aura aucun changement.
Les modules ajoutés à la liste des modules globaux seront ajoutés en tant que dépendances à chaque déploiement.
7.4. Référence
7.4.1. Les modules inclus
asm.asmch.qos.cal10ncom.google.guavacom.h2database.h2com.sun.jsf-implcom.sun.jsf-implcom.sun.xml.bindcom.sun.xml.messaging.saajgnu.getoptjavaee.apijavax.activation.apijavax.annotation.apijavax.apijavax.ejb.apijavax.el.apijavax.enterprise.apijavax.enterprise.deploy.apijavax.faces.apijavax.faces.apijavax.inject.apijavax.interceptor.apijavax.jms.apijavax.jws.apijavax.mail.apijavax.management.j2ee.apijavax.persistence.apijavax.resource.apijavax.rmi.apijavax.security.auth.message.apijavax.security.jacc.apijavax.servlet.apijavax.servlet.jsp.apijavax.servlet.jstl.apijavax.transaction.apijavax.validation.apijavax.ws.rs.apijavax.wsdl4j.apijavax.xml.bind.apijavax.xml.jaxp-providerjavax.xml.registry.apijavax.xml.rpc.apijavax.xml.soap.apijavax.xml.stream.apijavax.xml.ws.apijlinenet.sourceforge.cssparsernet.sourceforge.htmlunitnet.sourceforge.nekohtmlnu.xomorg.antlrorg.apache.antorg.apache.commons.beanutilsorg.apache.commons.cliorg.apache.commons.codecorg.apache.commons.collectionsorg.apache.commons.ioorg.apache.commons.langorg.apache.commons.loggingorg.apache.commons.poolorg.apache.cxforg.apache.httpcomponentsorg.apache.james.mime4jorg.apache.log4jorg.apache.neethiorg.apache.santuario.xmlsecorg.apache.velocityorg.apache.ws.scoutorg.apache.ws.securityorg.apache.ws.xmlschemaorg.apache.xalanorg.apache.xercesorg.apache.xml-resolverorg.codehaus.jackson.jackson-core-aslorg.codehaus.jackson.jackson-jaxrsorg.codehaus.jackson.jackson-mapper-aslorg.codehaus.jackson.jackson-xcorg.codehaus.woodstoxorg.dom4jorg.hibernateorg.hibernate.enversorg.hibernate.infinispanorg.hibernate.validatororg.hornetqorg.hornetq.raorg.infinispanorg.infinispan.cachestore.jdbcorg.infinispan.cachestore.remoteorg.infinispan.client.hotrodorg.jacorborg.javassistorg.jaxenorg.jboss.as.aggregateorg.jboss.as.appclientorg.jboss.as.cliorg.jboss.as.clustering.apiorg.jboss.as.clustering.commonorg.jboss.as.clustering.ejb3.infinispanorg.jboss.as.clustering.implorg.jboss.as.clustering.infinispanorg.jboss.as.clustering.jgroupsorg.jboss.as.clustering.serviceorg.jboss.as.clustering.singletonorg.jboss.as.clustering.web.infinispanorg.jboss.as.clustering.web.spiorg.jboss.as.cmporg.jboss.as.connectororg.jboss.as.consoleorg.jboss.as.controllerorg.jboss.as.controller-clientorg.jboss.as.deployment-repositoryorg.jboss.as.deployment-scannerorg.jboss.as.domain-add-userorg.jboss.as.domain-http-error-contextorg.jboss.as.domain-http-interfaceorg.jboss.as.domain-managementorg.jboss.as.eeorg.jboss.as.ee.deploymentorg.jboss.as.ejb3org.jboss.as.embeddedorg.jboss.as.host-controllerorg.jboss.as.jacorborg.jboss.as.jaxrorg.jboss.as.jaxrsorg.jboss.as.jdrorg.jboss.as.jmxorg.jboss.as.jpaorg.jboss.as.jpa.hibernateorg.jboss.as.jpa.hibernateorg.jboss.as.jpa.hibernate.infinispanorg.jboss.as.jpa.openjpaorg.jboss.as.jpa.spiorg.jboss.as.jpa.utilorg.jboss.as.jsr77org.jboss.as.loggingorg.jboss.as.mailorg.jboss.as.management-client-contentorg.jboss.as.messagingorg.jboss.as.modclusterorg.jboss.as.namingorg.jboss.as.networkorg.jboss.as.osgiorg.jboss.as.platform-mbeanorg.jboss.as.pojoorg.jboss.as.process-controllerorg.jboss.as.protocolorg.jboss.as.remotingorg.jboss.as.sarorg.jboss.as.securityorg.jboss.as.serverorg.jboss.as.standaloneorg.jboss.as.threadsorg.jboss.as.transactionsorg.jboss.as.weborg.jboss.as.webservicesorg.jboss.as.webservices.server.integrationorg.jboss.as.webservices.server.jaxrpc-integrationorg.jboss.as.weldorg.jboss.as.xtsorg.jboss.classfilewriterorg.jboss.com.sun.httpserverorg.jboss.common-coreorg.jboss.dmrorg.jboss.ejb-clientorg.jboss.ejb3org.jboss.iiop-clientorg.jboss.integration.ext-contentorg.jboss.interceptororg.jboss.interceptor.spiorg.jboss.invocationorg.jboss.ironjacamar.apiorg.jboss.ironjacamar.implorg.jboss.ironjacamar.jdbcadaptersorg.jboss.jandexorg.jboss.jaxbintrosorg.jboss.jboss-transaction-spiorg.jboss.jsfunit.coreorg.jboss.jtsorg.jboss.jts.integrationorg.jboss.loggingorg.jboss.logmanagerorg.jboss.logmanager.log4jorg.jboss.marshallingorg.jboss.marshalling.riverorg.jboss.metadataorg.jboss.modulesorg.jboss.mscorg.jboss.nettyorg.jboss.osgi.deploymentorg.jboss.osgi.frameworkorg.jboss.osgi.resolverorg.jboss.osgi.spiorg.jboss.osgi.vfsorg.jboss.remoting3org.jboss.resteasy.resteasy-atom-providerorg.jboss.resteasy.resteasy-cdiorg.jboss.resteasy.resteasy-jackson-providerorg.jboss.resteasy.resteasy-jaxb-providerorg.jboss.resteasy.resteasy-jaxrsorg.jboss.resteasy.resteasy-jsapiorg.jboss.resteasy.resteasy-multipart-providerorg.jboss.saslorg.jboss.security.negotiationorg.jboss.security.xacmlorg.jboss.shrinkwrap.coreorg.jboss.staxmapperorg.jboss.stdioorg.jboss.threadsorg.jboss.vfsorg.jboss.weld.apiorg.jboss.weld.coreorg.jboss.weld.spiorg.jboss.ws.apiorg.jboss.ws.commonorg.jboss.ws.cxf.jbossws-cxf-clientorg.jboss.ws.cxf.jbossws-cxf-factoriesorg.jboss.ws.cxf.jbossws-cxf-serverorg.jboss.ws.cxf.jbossws-cxf-transports-httpserverorg.jboss.ws.jaxws-clientorg.jboss.ws.jaxws-jboss-httpserver-httpspiorg.jboss.ws.native.jbossws-native-coreorg.jboss.ws.native.jbossws-native-factoriesorg.jboss.ws.native.jbossws-native-servicesorg.jboss.ws.saaj-implorg.jboss.ws.spiorg.jboss.ws.tools.commonorg.jboss.ws.tools.wsconsumeorg.jboss.ws.tools.wsprovideorg.jboss.xborg.jboss.xnioorg.jboss.xnio.nioorg.jboss.xtsorg.jdomorg.jgroupsorg.joda.timeorg.junitorg.omg.apiorg.osgi.coreorg.picketboxorg.picketlinkorg.python.jython.standaloneorg.scannotation.scannotationorg.slf4jorg.slf4j.extorg.slf4j.implorg.slf4j.jcl-over-slf4jorg.w3c.css.sacsun.jdk
7.4.2. Nommage de modules dynamiques
- Les déploiements des fichiers WAR et JAR sont nommés selon le format suivant :
deployment.DEPLOYMENT_NAME
Par exemple,inventory.waretstore.jarauront les mêmes noms de module quedeployment.inventory.waretdeployment.store.jarrespectivement. - Les sous-déploiements des archives Enterprise sont nommés selon le format suivant :
deployment.EAR_NAME.SUBDEPLOYMENT_NAME
Ainsi, le sous-déploiementreports.war, qui se trouve dans l'archive enterpriseaccounts.ear, aura le nom de module dudeployment.accounts.ear.reports.war.
Chapitre 8. Valves globales
8.1. Valves
8.2. Valves globales
8.3. Les valves d'authentification
org.apache.catalina.authenticator.AuthenticatorBase et elle remplace la méthode authenticate()
8.4. Installation d'une Valve globale
Prérequis :
- La valve doit déjà avoir été créée et empaquetée dans un fichier JAR.
- Un fichier
module.xmldoit déjà avoir été créé pour le module.Voir Section 7.1.1, « Modules » pour un exemple de fichiermodule.xml.
Procédure 8.1. Installer un Module Global
Créer un répertoire d'installation de module
Vous devrez créer un répertoire pour le module à installer dans le répertoire de modules du serveur d'applications.EAP_HOME/modules/system/layers/base/MODULENAME/main
$ mkdir -P /usr/share/jboss/modules/system/layers/base/MyValveModule/main
Copier les fichiers
Copier le JAR et les fichiersmodule.xmldans le répertoire créé dans l'étape 1.$ cp MyValves.jar modules.xml /usr/share/jboss/modules/system/layers/base/MyValveModule/main
8.5. Configuration d'une Valve globale
Procédure 8.2. Configuration d'une Valve globale
Activer la Valve
Utiliser l'opérationaddpour ajouter une nouvelle saisie Valve./subsystem=web/valve=VALVENAME:add(module="MODULENAME",class-name="CLASSNAME")
Vous devrez indiquer les valeurs suivantes :VALVENAME, le nom utilisé pour cette valve dans la configuration de l'application.MODULENAME, le module qui contient la valeur en cours de configuration.CLASSNAME, le nom de classe de la valve spécifique dans le module.
/subsystem=web/valve=clientlimiter:add(module="clientlimitermodule",class-name="org.jboss.samplevalves.restrictedUserAgentsValve")
En option : spécifier les paramètres
Si la valve a des paramètres de configuration, spécifier les dans l'opérationadd-param./subsystem=web/valve=testvalve:add-param(param-name="NAME", param-value="VALUE")
/subsystem=web/valve=testvalve:add-param( param-name="restricteduseragents", param-value="^.*MS Web Services Client Protocol.*$" )
Chapitre 9. Déploiement d'applications
9.1. Les déploiements d'applications
Administration
Management CLI
Développement
Scanner de déploiement
9.2. Déployer avec la console de gestion
9.2.1. Gérer le déploiement d'une application à l'aide de la Console de gestion
9.2.2. Déployer une application par la Console de gestion
Prérequis
Procédure 9.1. Déployer une application par la Console de gestion
Naviguer dans le panneau Manage Deployments de la Console de gestion.
- Sélectionner l'onglet Runtime en haut de la console.
- Déplier le menu
DomainouStandalone(s'il ne l'est pas déjà). - Sélectionner l'option Manage Deployments à partir du menu à gauche de la console.
Déployer une application
La méthode de déploiement variera suivant que vous déployez dans une instance de serveur autonome ou dans un domaine géré.Déployer dans une instance de serveur autonome.
Le tableau Available Deployment Content affiche tous les déploiements d'applications disponibles et leurs statuts.Activer l'application dans une instance de serveur autonome
Cliquer sur le bouton du tableau Deployments pour activer le déploiement de l'application.Confirmer
Cliquer sur le bouton pour confirmer que l'application puisse être activée dans l'instance du serveur.
Déployer dans un domaine géré.
La section Deployment Content contient un tableau Content Repository qui affiche tous les déploiements d'applications et leurs statuts.Activer l'application dans un domaine géré
Cliquer sur le bouton dans le tableau Content Repository.Sélectionner les groupes de serveurs
Cocher les cases pour chaque groupe de serveurs dans lesquels vous souhaitez ajouter l'application et cliquer sur le bouton pour continuer.Confirmer
Cliquer sur l'onglet Server Group Deployments pour afficher le tableau Server Groups. Votre application sera maintenant déployée dans les groupes de serveurs que vous avez sélectionnés.
L'application est déployée sur le serveur qui convient ou dans le groupe de serveurs qui convient.
9.2.3. Retirer le déploiement d'une application à l'aide de la Console de gestion
Prérequis
Procédure 9.2. Retirer le déploiement d'une application à l'aide de la Console de gestion
Naviguer dans le panneau Manage Deployments de la Console de gestion.
- Sélectionner l'onglet Runtime en haut de la console.
- Déplier le menu
DomainouStandalone(s'il ne l'est pas déjà). - Sélectionner l'option Manage Deployments à partir du menu à gauche de la console.
Supprimer le déploiement d'une application
La méthode de suppression du déploiement variera suivant que vous déployez dans une instance de serveur autonome ou dans un domaine géré.Supprimer le déploiement d'une instance de serveur autonome.
Le tableau Available Deployment Content affiche tous les déploiements d'applications disponibles et leurs statuts.Désactiver l'application dans une instance de serveur autonome
Cliquer sur le bouton du tableau Deployments pour désactiver le déploiement de l'application.Confirmez que vous souhaitez désactiver l'application
Cliquer sur le bouton pour confirmer que l'application puisse être désactivée dans l'instance du serveur.
Supprimer le déploiement à partir d'un domaine géré
La section Deployment Content contient un tableau Content Repository. Available Deployment Content affiche tous les déploiements d'applications disponibles et leurs statuts.Désactiver l'application dans un domaine géré
Cliquer sur l'onglet Server Groups pour afficher les groupes de serveurs et le statut de leurs applications déployées.Sélectionner le groupe de serveurs
Cliquer sur le nom du serveur dans le tableau Server Group pour supprimer un déploiement.Désactiver l'application à partir du serveur sélectionné
Cliquer sur le bouton pour désactiver l'application d'un serveur sélectionné.Confirmez que vous souhaitez désactiver l'application
Cliquer sur le bouton pour confirmer que l'application puisse être désactivée dans l'instance du serveur.Répéter la suppression du déploiement pour les groupes de serveurs qui restent.
Répéter au besoin pour d'autres groupes de serveur. Le statut de l'application est confirmé pour chaque groupe de serveurs dans le tableau Deployments.
L'application n'est pas déployée à partir d'un serveur qui convient ou d'un groupe de serveurs.
9.3. Déployer part l'interface de commandes CLI
9.3.1. Gérer le déploiement d'une application à l'aide du Management CLI
9.3.2. Déployer une application dans un domaine géré à l'aide du Management CLI
Prérequis
Procédure 9.3. Déployer une application dans un domaine géré
Exécuter la commande
deployPar l'intermédiaire du Management CLI, saisir la commandedeployainsi que le chemin d'accès vers le déploiement de l'application. Inclure le paramètre--all-server-groupsafin de déployer tous les groupes de serveurs.[domain@localhost:9999 /]
deploy /path/to/test-application.war --all-server-groups- Sinon, définir des groupes de serveurs particuliers de déploiement avec le paramètre
--server-groups.[domain@localhost:9999 /]
deploy /path/to/test-application.war --server-groups=server_group_1,server_group_2
Veuillez noter qu'un déploiement réussi ne crée pas de sortie vers le CLI.
L'application indiquée est maintenant déployée dans un groupe de serveurs de votre domaine géré.
9.3.3. Supprimer le déploiement d'une application dans un domaine géré à l'aide du Management CLI
Prérequis
Procédure 9.4. Supprimer le déploiement d'une application dans un domaine géré
Exécuter la commande
undeployPar l'intermédiaire du Management CLI, saisir la commandeundeployainsi que le nom de fichier du déploiement de l'application. On peut retirer le déploiement de l'application à partir de n'importe quel groupe de serveur dans lequel elle a été déployée à l'origine en ajoutant le paramètre--all-relevant-server-groups.[domain@localhost:9999 /]undeploytest-application.war--all-relevant-server-groupsVeuillez noter qu'une suppression de déploiement réussie ne crée pas de sortie vers le CLI.
L'application spécifiée n'est plus déployée maintenant.
9.3.4. Déployer une application dans une Serveur autonome à l'aide du Management CLI
Prérequis
Procédure 9.5. Déployer une application dans un serveur autonome
Exécuter la commande
deployAvec Management CLI, saisir la commandedeployavec le chemin d'accès vers le déploiement de l'application.[standalone@localhost:9999 /]
deploy /path/to/test-application.warVeuillez noter qu'un déploiement réussi ne crée pas de sortie vers le CLI.
L'application indiquée est maintenant déployée dans un serveur autonome.
9.3.5. Supprimer le déploiement d'une application dans un serveur autonome à l'aide du Management CLI
Prérequis
Procédure 9.6. Supprimer le déploiement d'une application dans un serveur autonome
Exécuter la commande
undeployAvec Management CLI, saisir la commandeundeployavec le nom du fichier du déploiement de l'application.[standalone@localhost:9999 /]
undeploy test-application.warVeuillez noter qu'une suppression de déploiement réussie ne crée pas de sortie vers le CLI.
L'application spécifiée n'est désormais plus déployée.
9.4. Déployer avec le scanneur de déploiement
9.4.1. Gérer le déploiement d'applications dans le scanneur de déploiement
9.4.2. Déployer une application dans une instance de serveur autonome par un scanneur de déploiement
Prérequis
Cette tâche présente une méthode de déploiement des applications dans une instance de serveur autonome par le scanneur de déploiement. Comme il est indiqué dans la section Section 9.1, « Les déploiements d'applications », cette méthode est retenue pour la commodité des développeurs, où les méthodes de Management Console ou de Management CLI sont recommandées pour la gestion des applications dans les environnements de production.
Procédure 9.7. Utiliser le scanneur de déploiement pour déployer les applications.
Copier le contenu dans le dossier de déploiement
Copier le fichier de l'application dans un dossier de déploiement qui se situeEAP_HOME/standalone/deployments/.Modes d'analyses de déploiements
Le déploiement d'une application varie entre un mode d'analyse de déploiement manuel ou automatique.Déploiement automatique
Le scanneur de déploiement saisit un changement d'état d'un dossier et crée un fichier de marquage, comme expliqué dans la section Section 9.4.5, « Référence pour les fichiers de marquage de scanneur de déploiement ».Déploiement manuel
Le scanneur de déploiement a besoin d'un fichier de marqueurs pour déclencher le processus de déploiement. L'exemple suivant utilise la commande Unixtouchpour créer un nouveau fichier.dodeploy.Exemple 9.1. Déploiement par la commande
touch[user@host bin]$
touch$EAP_HOME/standalone/deployments/example.war.dodeploy
Le fichier de l'application est déployé sur le serveur d'applications. Un fichier de marquage est créé dans le dossier de déploiement pour indiquer la réussite du déploiement, et l'application est marquée comme Enabled dans la console de gestion.
Exemple 9.2. Contenu du dossier de déploiement après le déploiement.
example.war example.war.deployed
9.4.3. Supprimer le déploiement d'une application dans une instance de serveur autonome par un scanneur de déploiement
Prérequis
Cette tâche présente une méthode de retrait de déploiement d'applications en provenance d'une instance de serveur autonome qui ont été déployées par le scanneur de déploiement. Comme il est indiqué dans la section Section 9.1, « Les déploiements d'applications », cette méthode est retenue pour la commodité des développeurs, où les méthodes de Management Console ou de Management CLI sont recommandées pour la gestion des applications dans les environnements de production.
Note
Procédure 9.8. Retirer le déploiement d'une application à l'aide d'une des méthodes suivantes
Supprimer le déploiement de l'application
Il existe deux méthodes pour supprimer un déploiement d'application suivant que vous souhaitiez supprimer l'application d'un dossier de déploiement ou bien que vous souhaitiez uniquement modifier son statut de déploiement.Retirer un déploiement par suppression du fichier de marquage
Supprimer le fichier de marquageexample.war.deployedde l'application qui est déployée pour commencer le retrait de déploiement de l'application du runtime.- Résultat
- Le scanneur de déploiement retire l'application et crée un fichier de marquage
example.war.undeployed. L'application demeure dans le dossier de déploiement.
Retirer le déploiement en supprimant l'application
Supprimer l'application depuis le répertoire de déploiement pour encourager le scanneur de déploiement à commencer le retrait du déploiement de l'application du runtime.- Résultat
- Le scanneur de déploiement retire l'application et crée un fichier de marquage
filename.filetype.undeployed. L'application n'est plus présente dans le dossier de déploiement.
Le fichier de l'application n'est plus déployé dans le serveur d'applications et n'est plus visible dans l'écran Deployments de la Console de gestion.
9.4.4. Redéploiement d'une application dans une instance de serveur autonome par le scanneur de déploiement
Prérequis
Cette tâche présente une méthode de retrait de déploiement d'applications dans une instance de serveur autonome qui a été déployée par le scanneur de déploiement. Comme il est indiqué dans la section Section 9.1, « Les déploiements d'applications », cette méthode est retenue pour la commodité des développeurs, où les méthodes de Management Console ou de Management CLI sont recommandées pour la gestion des applications dans les environnements de production.
Procédure 9.9. Déployer à nouveau une application dans un serveur autonome
Redéploiement de l'application
Il existe trois méthodes possibles pour redéployer une application déployée par le scanner de déploiement. Ces méthodes déclenchent le scanneur de déploiement pour initier un cycle de déploiement, et peuvent être choisies en fonction des préférences personnelles.Redéploiement par modification du fichier de marquage
Déclencher le redéploiement du scanneur de déploiement en modifiant l'horodatage d'accès du fichier. Dans l'exemple Linux suivant, on utilise une commande Unixtouch.Exemple 9.3. Redéployer par la commande Unix
touch[user@host bin]$
touchEAP_HOME/standalone/deployments/example.war.dodeployRésultatLe scanneur de déploiement a détecté un changement dans le fichier de marquage et a déployé à nouveau l'application. Un nouveau fichier de marquage
.deployedremplace le précédent.Déployer à nouveau en créant un nouveau fichier de marquage
.dodeployDéclencher le redéploiement du scanneur de déploiement en créant un nouveau fichier de marquage.dodeploy. Voir les instructions de déploiement du manuel qui se trouvent dans Section 9.4.2, « Déployer une application dans une instance de serveur autonome par un scanneur de déploiement ».Déployer à nouveau en supprimant le fichier de marquage
Comme décrit dans Section 9.4.5, « Référence pour les fichiers de marquage de scanneur de déploiement », la suppression du fichier de marquage.deployedva déclencher un retrait de déploiement et créera un marqueur.undeployed. Supprimer le marqueur de suppression de déploiement déclenchera le cycle de déploiement à nouveau. Voir Section 9.4.3, « Supprimer le déploiement d'une application dans une instance de serveur autonome par un scanneur de déploiement » pour obtenir des informations supplémentaires.
Le fichier de l'application est déployé à nouveau.
9.4.5. Référence pour les fichiers de marquage de scanneur de déploiement
Les fichiers de marquage font partie du sous-système du scanneur de déploiement. Ces fichiers indiquent le statut d'une application dans un répertoire de déploiement de l'instance du serveur autonome. Un fichier de marquage a le même nom que l'application, avec un suffixe de fichier qui indique l'état du déploiement de l'application. Le tableau suivant définit les types et les réponses de chaque fichier de marquage.
Exemple 9.4. Exemple de fichier de marquage
testapplication.war.
testapplication.war.deployedTableau 9.1. Définitions de types de fichiers de marquage
| Suffixe du nom de fichier | Origine | Description |
|---|---|---|
.dodeploy | Utilisateur généré | Indique que le contenu doit être déployé ou redéployé dans le runtime. |
.skipdeploy | Utilisateur généré | Désactive l'autodéploiement d'une application si présent. Utile pour bloquer temporairement l'auto-déploiement d'un contenu explosé, empêchant ainsi le risque de modifications de contenu imcomplètes d'être rendues live. Peut être utile pour le contenu compressé, bien que le scanneur détecte les changements en cours dans le contenu compressé et attend qu'ils soient terminés. |
.isdeploying | Système généré | Indique l'initiation du déploiement. Le fichier de marquage sera effacé quand le processus de déploiement sera complété. |
.deployed | Système généré | Indique que le contenu a été déployé. Le déploiement du contenu sera supprimé si le fichier est effacé. |
.failed | Système généré | Indique les échecs de déploiement. Le fichier de marquage contient des informations sur la cause de l'échec. Si le fichier de marquage est supprimé, le contenu sera rendu visible dans l'auto-déploiement à nouveau. |
.isundeploying | Système généré | Indique une réponse suite à la suppression d'un fichier .deployed. Le déploiement du contenu sera supprimé et le marqueur sera effacé automatiquement dès complétion. |
.undeployed | Système généré | Indique si le contenu a été déployé. La suppression du fichier de marquage n'a pas d'impact sur le re-déploiement du contenu. |
.pending | Système généré | Indique que les instructions de déploiement devront être envoyées au serveur suite à la résolution d'un problème qui a été detecté. Ce marqueur sert de blocage de déploiement global. Le scanneur ne demandera pas au serveur de déployer ou de supprimer un déploiement de contenu tant que cette condition existe. |
9.4.6. Référence pour attributs de scanneur de déploiement
write-attribute. Pour plus d'informations sur les options de configuration, se référer à la section suivante Section 9.4.8, « Configurer le scanneur de déploiement avec le Management CLI ».
Tableau 9.2. Attributs de scanneur de déploiement
| Nom | Description | Type | Valeur par défaut |
|---|---|---|---|
auto-deploy-exploded | Permet le déploiement automatique d'un contenu éclaté sans nécessiter un fichier de marquage .dodeploy. Recommandé pour les scénarios de développement de base uniquement pour empêcher le déploiement d'applications éclatées de se produire lors de changements du développeur ou du système d'exploitation. | Booléen | False |
auto-deploy-xml | Autorise le déploiement automatique d'un contenu XML sans besoin de fichier de marquage .dodeploy. | Booléen | True |
auto-deploy-zipped | Autorise le déploiement automatique d'un contenu compressé sans besoin de fichier de marquage .dodeploy. | Booléen | True |
deployment-timeout | La durée nécessaire en secondes pour que le scanneur de déploiement puisse permettre un déploiement avant annulation. | Long | 600 |
path | Définit le chemin du système de fichier à scanner. Si l'attribut relative-to est spécifié, la valeur path agira comme un ajout relatif à ce répertoire ou chemin d'acccès. | String | déploiements |
relative-to | Référence à un chemin de système de fichier défini dans la section paths du fichier de configuration XML du serveur. | String | jboss.server.base.dir |
scan-enabled | Autorise le scanning automatique des applications par scan-interval au démarrage. | Booléen | True |
scan-interval | L'intervalle en millisecondes entre les balayages de référentiels. Une valeur inférieure à 1 empêche le scanneur d'opérer au démarrage. | Int | 5000 |
9.4.7. Configurer le scanneur de déploiement
9.4.8. Configurer le scanneur de déploiement avec le Management CLI
Bien qu'il existe plusieurs méthodes de configuration du scanneur de déploiement, le Management CLI permet d'exposer et de modifier les attributs par l'utilisation de batch scripts ou en temps réel. Vous pouvez modifier le comportement du scanneur de déploiement par l'utilisation de l'attribut lecture read-attribute et des opérations de ligne de commande write-attribute. Davantage d'informations sur les attributs de scanneur de déploiement sont définis dans la rubrique .
standalone.xml.
<subsystem xmlns="urn:jboss:domain:deployment-scanner:1.1">
<deployment-scanner path="deployments" relative-to="jboss.server.base.dir" scan-interval="5000"/>
</subsystem>
Procédure 9.10. Configurer le scanneur de déploiement
Déterminer les attributs de scanner de déploiement à configurer
Pour configurer le scanneur de déploiement par le Management CLI, vous devrez tout d'abord exposer les noms d'attribut qui conviennent. Vous pouvez faire cela grâce à l'opérationread-resourcesau nœud root, ou bien par la commandecdpour passer au nœud dépendant du sous-système. Vous pouvez également afficher les attributs par la commandelsà ce niveau.Exposer les attributs de scanneur de déploiement par l'opération
read-resourceUtiliser l'opérationread-resourcepour exposer les attributs définis par la ressource de scanneur de déploiement par défaut.[standalone@localhost:9999 /]/subsystem=deployment-scanner/scanner=default:read-resource { "outcome" => "success", "result" => { "auto-deploy-exploded" => false, "auto-deploy-xml" => true, "auto-deploy-zipped" => true, "deployment-timeout" => 600, "path" => "deployments", "relative-to" => "jboss.server.base.dir", "scan-enabled" => true, "scan-interval" => 5000 } }Exposer les attributs de scanneur de déploiement par la commande
lsUtiliser la commandelsavec l'argument-len option pour afficher une table de résultats qui incluent des attributs de nœud, des valeurs et types de sous-système. Vous pouvez en apprendre davantage sur la commandelset ses arguments en exposant l'entréels --help. Pour plus d'informations sur le menu help du Management CLI, voir la section Section 3.5.5, « Comment obtenir de l'aide avec le Management CLI ».[standalone@localhost:9999 /] ls -l /subsystem=deployment-scanner/scanner=default ATTRIBUTE VALUE TYPE auto-deploy-exploded false BOOLEAN auto-deploy-xml true BOOLEAN auto-deploy-zipped true BOOLEAN deployment-timeout 600 LONG path deployments STRING relative-to jboss.server.base.dir STRING scan-enabled true BOOLEAN scan-interval 5000 INT
Configurer le scanneur de déploiement par l'opération
write-attributeUne fois que vous avez déterminé le nom de l'attribut à modifier, utiliser la commandewrite-attributepour spécifier le nom de l'attribut et la nouvelle valeur à indiquer. Les exemples suivants sont tous exécutés au niveau du nœud dépendant, qui peut être accédé en utilisant la commandecdet la saisie semi-automatique via la touche TAB pour passer au nœud de scanneur par défaut.[standalone@localhost:9999 /] cd subsystem=deployment-scanner/scanner=default
Active le déploiement automatique du contenu explosé.
Utiliser l'opérationwrite-attributepour activer le déploiement automatique du contenu d'application explosé.[standalone@localhost:9999 scanner=default] :write-attribute(name=auto-deploy-exploded,value=true) {"outcome" => "success"}Désactiver le déploiement automatique du contenu XML
Utiliser l'opérationwrite-attributepour désactiver le déploiement automatique du contenu d'application explosé.[standalone@localhost:9999 scanner=default] :write-attribute(name=auto-deploy-xml,value=false) {"outcome" => "success"}Désactiver le déploiement automatique du contenu compressé
Utiliser la commandewrite-attributepour désactiver le déploiement automatique du contenu d'applications compressé.[standalone@localhost:9999 scanner=default] :write-attribute(name=auto-deploy-zipped,value=false) {"outcome" => "success"}Configurer l'attribut du chemin d'accès
Utiliser l'opérationwrite-attributepour modifier l'attribut de chemin d'accès, pour substituer la valeur de l'exemplenewpathnamepar un nouveau nom de chemin d'accès que le scanneur de déploiement puisse surveiller. Notez que le serveur aura besoin que le nouveau chargement prenne effet.[standalone@localhost:9999 scanner=default] :write-attribute(name=path,value=newpathname) { "outcome" => "success", "response-headers" => { "operation-requires-reload" => true, "process-state" => "reload-required" } }Configurer l'attribut du chemin relatif
Utiliser l'opérationwrite-attributepour modifier la référence relative du chemin du système de fichier ainsi définie dans la section des chemins d'accès du fichier de configuration XML. Notez que le serveur aura besoin que le nouveau chargement prenne effet.[standalone@localhost:9999 scanner=default] :write-attribute(name=relative-to,value=new.relative.dir) { "outcome" => "success", "response-headers" => { "operation-requires-reload" => true, "process-state" => "reload-required" } }Désactiver le scanneur de déploiement
Utiliser l'opérationwrite-attributepour désactiver le scanneur de déploiement en définissant la valeurscan-enabledà false.[standalone@localhost:9999 scanner=default] :write-attribute(name=scan-enabled,value=false) {"outcome" => "success"}Changer l'intervalle de balayage
Utiliser l'opérationwrite-attributepour modifier l'intervalle de balayage de 5 000 millisecondes à 10 000 millisecondes.[standalone@localhost:9999 scanner=default] :write-attribute(name=scan-interval,value=10000) {"outcome" => "success"}
Vos modifications de configuration sont sauvegardées dans le scanneur de déploiement.
9.5. Déployer avec Maven
9.5.1. Gestion du déploiement d'applications dans Maven
9.5.2. Déployer une application dans Maven
Prérequis
Cette tâche vous montre une méthode pour déployer des applications dans Maven. L'exemple fourni utilise l'application jboss-as-helloworld.war qui se trouve dans la collection Jboss EAP 6 Quickstarts. Le projet helloworld contient un fichier POM qui initialise le jboss-as-maven-plugin. Ce plugin fournit des simples opérations pour déployer ou supprimer le déploiement d'applications vers ou en provenance du serveur d'applications.
Procédure 9.11. Déployer une application dans Maven.
Exécuter la commande de déploiement de Maven dans une session de terminal
Ouvrir la session de terminal et naviguez dans le répertoire qui contient les exemples Quickstart.- Exécuter la commande de déploiement Maven pour déployer l'application. Si l'application est déjà en cours d'exécution, elle sera déployée à nouveau.
[localhost]$ mvn package jboss-as:deploy
Confirmer le déploiement de l'application
Voir le résultat dans la fenêtre du terminal
Le déploiement peut être confirmé si vous regardez les entrées de journalisation de l'opération dans la fenêtre du terminal.Exemple 9.5. Confirmation Maven pour l'application helloworld
[INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESSFUL [INFO] ------------------------------------------------------------------------ [INFO] Total time: 3 seconds [INFO] Finished at: Mon Oct 10 17:22:05 EST 2011 [INFO] Final Memory: 21M/343M [INFO] ------------------------------------------------------------------------
Voir les résultats dans la fenêtre du terminal du serveur
Le déploiement peut également être confirmé dans le flux de statut de l'instance du serveur d'applications actives.Exemple 9.6. Confirmation du serveur d'applications pour l'application helloworld
17:22:04,922 INFO [org.jboss.as.server.deployment] (pool-1-thread-3) Contenu ajouté dans /home/username/EAP_HOME/standalone/data/content/2c/39607b0c8dbc6a36585f72866c1bcfc951f3ff/content 17:22:04,924 INFO [org.jboss.as.server.deployment] (MSC service thread 1-1) Starting deployment of "jboss-as-helloworld.war" 17:22:04,954 INFO [org.jboss.weld] (MSC service thread 1-3) Processing CDI deployment: jboss-as-helloworld.war 17:22:04,973 INFO [org.jboss.weld] (MSC service thread 1-2) Starting Services for CDI deployment: jboss-as-helloworld.war 17:22:04,979 INFO [org.jboss.weld] (MSC service thread 1-4) Starting weld service 17:22:05,051 INFO [org.jboss.web] (MSC service thread 1-2) registering web context: /jboss-as-helloworld 17:22:05,064 INFO [org.jboss.as.server.controller] (pool-1-thread-3) Deployed "jboss-as-helloworld.war"
L'application est déployée dans le serveur d'applications.
9.5.3. Supprimer le déploiement d'une application dans Maven
Prérequis
Cette tâche vous montre une méthode pour supprimer le déploiement des applications dans Maven. L'exemple fourni utilise l'application jboss-as-helloworld.war qui se trouve dans la collection Jboss EAP 6 Quickstarts. Le projet helloworld contient un fichier POM qui initialise le jboss-as-maven-plugin. Ce plugin fournit des simples opérations pour déployer ou supprimer le déploiement d'applications vers ou en provenance du serveur d'applications.
Procédure 9.12. Supprimer un déploiement d'application dans Maven
Exécuter la commande de déploiement de Maven dans une session de terminal
Ouvrir la session de terminal et naviguez dans le répertoire qui contient les exemples Quickstart.Exemple 9.7. Passes au répertoire d'application helloworld
[localhost]$ cd /path/to/EAP_Quickstarts/helloworld
- Exécuter la commande de suppression de déploiement.
[localhost]$ mvn jboss-as:undeploy
Confirmer la suppression du déploiement de l'application
Voir le résultat dans la fenêtre du terminal
La suppression du déploiement peut être confirmée si on observe les entrées de journalisation de la fenêtre de terminal.Exemple 9.8. Confirmation Maven pour l'application helloworld
[INFO] ------------------------------------------------------------------------ [INFO] Building JBoss AS Quickstarts: Helloworld [INFO] task-segment: [jboss-as:undeploy] [INFO] ------------------------------------------------------------------------ [INFO] [jboss-as:undeploy {execution: default-cli}] [INFO] Executing goal undeploy for /home/username/EAP_Quickstarts/helloworld/target/jboss-as-helloworld.war on server localhost (127.0.0.1) port 9999. Oct 10, 2011 5:33:02 PM org.jboss.remoting3.EndpointImpl <clinit> INFO: JBoss Remoting version 3.2.0.Beta2 Oct 10, 2011 5:33:02 PM org.xnio.Xnio <clinit> INFO: XNIO Version 3.0.0.Beta2 Oct 10, 2011 5:33:02 PM org.xnio.nio.NioXnio <clinit> INFO: XNIO NIO Implementation Version 3.0.0.Beta2 [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESSFUL [INFO] ------------------------------------------------------------------------ [INFO] Total time: 1 second [INFO] Finished at: Mon Oct 10 17:33:02 EST 2011 [INFO] Final Memory: 11M/212M [INFO] ------------------------------------------------------------------------Voir les résultats dans la fenêtre du terminal du serveur
La suppression du déploiement peut également être confirmée dans le flux de statut de l'instance du serveur d'applications d'applications actives.Exemple 9.9. Confirmation du serveur d'applications pour l'application helloworld
17:33:02,334 INFO [org.jboss.weld] (MSC service thread 1-3) Stopping weld service 17:33:02,342 INFO [org.jboss.as.server.deployment] (MSC service thread 1-3) Stopped deployment jboss-as-helloworld.war in 15ms 17:33:02,352 INFO [org.jboss.as.server.controller] (pool-1-thread-5) Undeployed "jboss-as-helloworld.war"
La suppression du déploiement de l'application provient du serveur d'applications.
9.6. Contrôler l'ordre des Applications déployées dans JBoss EAP 6
Procédure 9.13. Contrôle de l'ordre de déploiement dans EAP 6.0.X
- Crée des scripts CLI qui déploient et retirent les déploiements d'applications dans un ordre séquentiel quand le serveur est à l'Arrêt/Démarrage.
- CLI prend également en charge le concept de mode batch qui permet de grouper les commandes et les opérations et les exécuter ensemble comme une unité atomique. Si au moins une des commandes ou opérations échoue, toutes les autres commandes et opérations exécutées avec succès dans le lot seront annulées.
Procédure 9.14. Contrôler l'ordre de déploiement dans EAP 6.1.X
- Créer (s'il n'existe pas encore) un fichier
jboss-all.xmldans le dossierapp.ear/META-INFoùapp.earest l'archive d'application qui dépend d'une autre archive d'application à déployer avant. - Effectuer une saisie
jboss-deployment-dependenciesdans ce fichier comme indiqué ci-dessous. Notez que dans la liste ci-dessous,framework.earest l'application de dépendance qui doit être déployée avant que l'archive d'applicationapp.earne le soit.<jboss umlns="urn:jboss:1.0"> <jboss-deployment-dependencies xmlns="urn:jboss:deployment-dependencies:1.0"> <dependency name="framework.ear" /> </jboss-deployment-dependencies> </jboss>
9.7. Remplacement du descripteur de déploiement
Procédure 9.15. Remplacer le descripteur de déploiement en utilisant le Management CLI
app.war et que vous souhaitez remplacer son fichier WEB-INF/web.xml avec un autre fichier web.xml situé dans /home/user/web.xml.
- Ajouter une superposition de déploiement (deployment overlay) et y ajouter du contenu. Vous pouvez y parvenir de deux façons :
Utilisation d'une arborescence DMR
/deployment-overlay=myoverlay:add/deployment-overlay=myoverlay/content=WEB-INF\/web.xml:add(content={url=file:///home/user/web.xml})Si vous le souhaitez, vous pouvez ajouter des règles de contenu en utilisant le deuxième code.
Utilisation des méthodes de facilité
deployment-overlay add --name=myoverlay --content=WEB-INF/web.xml=/home/user/web.xml
Lier la superposition à une archive de déploiement
deployment-overlay link --name=myoverlay --deployments=app.warVous pouvez spécifier plusieurs noms d'archives séparés par des virgules./deployment-overlay=myoverlay/deployment=app.war:addVeuillez noter que le nom d'archive de déploiement n'a pas besoin d'exister sur le serveur pour l'instant. Vous devez indiquer le nom, mais il ne sera pas encore lié à un déploiement.
Déployer à nouveau l'application
/deployment=app.war:redeploy
Chapitre 10. Sécuriser JBoss EAP 6
10.1. La sécurité du sous-système
Si le mode de sujet deep copy est désactivé (par défaut), la copie d'une structure de données de sécurité se réfère à l'original uniquement au lieu de copier toute la structure de données. Ce comportement est plus efficace, mais enclin à la corruption des données si plusieurs threads possédant la même identité effacent le sujet lors d'un vidage ou d'une déconnexion.
Vous pouvez définir des propriétés de sécurité dans tout le système, qui sont appliquées à la classe java.security.Security class.
Un domaine de sécurité est un ensemble de configuration de sécurité déclarative Java Authentication and Authorization Service (JAAS) qu'une ou plusieurs applications utilisent pour contrôler l'authentification, l'autorisation, l'auditing de et le mapping. Trois domaines de sécurité sont inclus par défaut: jboss-ejb-policy, jboss-web-policy, et other. Vous pouvez créer autant de domaines de sécurité que vous souhaitez pour accommoder les besoins de vos applications.
10.2. Structure du sous-système de sécurité
Exemple 10.1. Exemple de configuration de sous-système de sécurité
<subsystem xmlns="urn:jboss:domain:security:1.2">
<security-management>
...
</security-management>
<security-domains>
<security-domain name="other" cache-type="default">
<authentication>
<login-module code="Remoting" flag="optional">
<module-option name="password-stacking" value="useFirstPass"/>
</login-module>
<login-module code="RealmUsersRoles" flag="required">
<module-option name="usersProperties" value="${jboss.domain.config.dir}/application-users.properties"/>
<module-option name="rolesProperties" value="${jboss.domain.config.dir}/application-roles.properties"/>
<module-option name="realm" value="ApplicationRealm"/>
<module-option name="password-stacking" value="useFirstPass"/>
</login-module>
</authentication>
</security-domain>
<security-domain name="jboss-web-policy" cache-type="default">
<authorization>
<policy-module code="Delegating" flag="required"/>
</authorization>
</security-domain>
<security-domain name="jboss-ejb-policy" cache-type="default">
<authorization>
<policy-module code="Delegating" flag="required"/>
</authorization>
</security-domain>
</security-domains>
<vault>
...
</vault>
</subsystem>
<security-management>, <subject-factory> et <security-properties> ne sont pas présents dans la configuration par défaut. Les éléments <subject-factory> et <security-properties> ont été désapprouvés sur JBoss EAP 6.1 et versions ultérieures.
10.3. Configurer le sous-système de sécurité
- <security-management>
- Cette section remplace les comportements de haut niveau du sous-système de sécurité. Chaque paramètre est optionnel. Il est rare de modifier ces paramètres sauf pour le mode de sujet Deep Copy.
Option Description deep-copy-subject-mode Indiquez si l'on doit copier ou lier les tokens de sécurité pour la sécurité des threads.authentication-manager-class-name Indiquer un nom de classe d'implémentation AthentificationManager alternatif à utiliser.authorization-manager-class-name Indiquer un nom de classe d'implémentation AthorizationManager alternatif à utiliser.audit-manager-class-name Indiquer un nom de classe d'implémentation Audit Manager alternatif à utiliser.identity-trust-manager-class-name Indiquer un nom de classe d'implémentation IdentityTrustManager alternatif à utiliser.mapping-manager-class-name Indiquer le nom de classe d'implémentation MappingManager à utiliser. - <subject-factory>
- La fabrique de sujets contrôle la création d'instances de sujets. Elle utilise sans doute le gestionnaire d'authentification pour vérifier l'appelant. L'utilisation principale du sujet est la création d'un sujet par les composants JCA. Il est rare que l'on ait besoin de modifier la fabrique de sujets.
- <security-domains>
- Un élément de conteneur qui contient plusieurs domaines de sécurité. Un domaine de sécurité peut contenir des informations sur des modules d'authentification, d'autorisation, de mappage, et d'auditing, ainsi qu'une autorisation JASPI et une configuration JSSE. Votre application indique ainsi un domaine de sécurité pour gérer ses informations de sécurité.
- <security-properties>
- Contient des noms et valeurs définis dans la classe java.security.Security
10.4. Mode de sujet Deep Copy
10.5. Activer le Mode de sujet Deep Copy
Procédure 10.1. Activer le mode de sécurité Deep Copy à partir de la Console de gestion
Connectez-vous à la Console de gestion.
La console de gestion est normalement disponible à par un URL commme http://127.0.0.1:9990/. Ajuster cette valeur pour qu'elle corresponde à vos besoins.Domaine géré : sélectionner le profil qui convient.
Dans un domaine géré, le sous-système de sécurité est configuré par profil, ou vous pouvez activer ou désactiver le mode de sécurité Deep Copy pour chacun, de manière indépendante.Pour sélectionner un profil, cliquer sur Profiles en haut et à droite de l'affichage console, puis sélectionner le profil que vous souhaitez modifier à partir de la case de sélection Profile en haut et à gauche.Ouvrir le menu de configuration Security Subsystem.
Étendre l'item de menu Security à droite de la console de gestion, puis cliquer sur le lien Security Subsystem.Modifier deep-copy-subject-mode.
Cliquer sur le bouton . Cocher la case qui se trouve à côté de Deep Copy Subjects: pour activer le mode Copier Sujet (copy subject).
Si vous préférez utiliser le Management CLI pour activer cette option, utiliser une des commandes suivantes.
Exemple 10.2. Domaine géré
/profile=full/subsystem=security:write-attribute(name=deep-copy-subject-mode,value=TRUE)
Exemple 10.3. Serveur autonome
/subsystem=security:write-attribute(name=deep-copy-subject-mode,value=TRUE)
10.6. Domaines de sécurité
10.6.1. Les domaines de sécurité
10.6.2. Picketbox
- Section 10.6.5, « L'autorisation » et contrôle d'accès
- Section 10.6.9, « Security Mapping » des principaux, rôles et attributs
10.6.3. Authentification
10.6.4. Configurer l'authentification dans un Domaine de sécurité
Procédure 10.2. Configurer l'authentification dans un Domaine de sécurité
Ouvrir l'affichage détaillé du domaine de sécurité.
Cliquer sur l'étiquette Profiles en haut et à droite de la console de gestion. Dans un domaine géré, sélectionner le profil à modifier à partir de la case de sélection Profile en haut et à gauche de l'affichage du profil. Cliquer sur l'item de menu Security sur la gauche, et cliquer sur Security Domains à partir du menu déroulant. Cliquer sur le lien View pour obtenir le domaine de sécurité que vous souhaitez modifier.Naviguer dans la configuration du sous-système d'authentification.
Cliquer sur l'étiquette Authentification en haut de l'affichage s'il n'a pas déjà été sélectionné.La zone de configuration est divisée en deux : Login Modules et Details. Le module de connexion est l'unité de base de configuration. Un domaine de sécurité peut inclure plusieurs polices d'autorisation, et chacune peut inclure plusieurs attributs et options.Ajouter un module de connexion
Cliquer sur le bouton Add pour ajouter un module de police d'authentification JAAS. Remplir les informations pour votre module. Le Code est le nom de classe de votre module. Les Flags contrôlent la façon dont le module est lié à d'autres modules de polices d'authentification du même domaine de sécurité.Explication des indicateursLa spécification Java Enterprise Edition 6 fournit l'explication suivante sur les marqueurs des modules de sécurité. La liste suivante provient de http://docs.oracle.com/javase/6/docs/technotes/guides/security/jaas/JAASRefGuide.html#AppendixA. Consulter ce document pour obtenir des informations plus détaillées.
Marqueur Détails requis Le LoginModule est requis pour la réussite. En cas de réussite ou d'échec, l'autorisation continuera son chemin dans la liste du LoginModule.pré-requis Le LoginModule est requis pour la réussite. En cas de succès, l'authentification continue vers le bas de la liste LoginModule. En cas d'échec, le contrôle est renvoyé immédiatement à l'application (l'authentification ne continue pas son chemin le long de la liste LoginModule).suffisant The LoginModule n'est pas nécessaire pour aboutir. S'il ne réussit pas, le contrôle retourne immédiatement à l'application (l'authentification ne se déroule pas vers le bas de la liste LoginModule). S'il échoue, l'authentification se poursuit vers le bas de la liste LoginModule.option Le LoginModule n'est pas requis pour la réussite. En cas de réussite ou d'échec, l'autorisation continuera son chemin dans la liste du LoginModule.Une fois que vous aurez ajouté votre module, vous pourrez modifier son Code ou ses Flags (indicateurs) en cliquant sur le bouton dans la section Details de l'écran. Veillez à ce que l'onglet Attributes soit bien sélectionné.Option : ajouter ou supprimer un module
Pour ajouter des options à votre module, cliquer sur leurs entrées dans la liste Login Modules, et sélectionner l'onglet Module Options dans la section Details qui se trouve en bas de la page. Cliquer sur le bouton , et fournir la clé et la valeur de l'option. Utiliser le bouton pour supprimer l'option.
Votre module d'authentification est ajouté au domaine de sécurité, et est rendu disponible immédiatement auprès des applications qui utilisent le domaine de sécurité.
jboss.security.security_domain
Par défaut, chaque module de connexion défini dans un domaine de sécurité a l'option de module jboss.security.security_domain ajoutée automatiquement. Cette option cause des problèmes avec les modules de connexion, qui vérifient que seules les options connues soient définies. Le module de connexion Kerberos d'IBM com.ibm.security.auth.module.Krb5LoginModule est l'un d'entre eux.
true en démarrant la plate-forme JBoss EAP 6. Ajouter ce qui suit pour démarrer les paramètres.
-Djboss.security.disable.secdomain.option=true
10.6.5. L'autorisation
10.6.6. Configurer l'autorisation pour un domaine de sécurité
Procédure 10.3. Configurer l'autorisation pour un domaine de sécurité
Ouvrir l'affichage détaillé du domaine de sécurité.
Cliquer sur l'étiquette Profiles en haut et à droite de la console de gestion. Dans un domaine géré, sélectionner le profil à modifier à partir de la case de sélection Profile en haut et à gauche de l'affichage du profil. Cliquer sur l'item de menu Security sur la gauche, et cliquer sur Security Domains à partir du menu déroulant. Cliquer sur le lien View pour obtenir le domaine de sécurité que vous souhaitez modifier.Naviguer dans la configuration du sous-système d'autorisation.
Cliquer sur l'étiquette Authorization en haut de l'affichage si elle n'a pas déjà été sélectionnée.La zone de configuration est divisée en deux: Policies et Details. Le module de connexion est l'unité de base de configuration. Un domaine de sécurité peut inclure plusieurs polices d'autorisation, et chacune d'elle peut inclure plusieurs attributs ou options.Ajouter une police.
Cliquer sur le bouton Add pour ajouter un module de police d'autorisation JAAS. Remplir les informations pour votre module. Le Code est le nom de classe de votre module. Les Flags contrôlent la façon dont le module est lié à d'autres modules de polices d'autorisation du même domaine de sécurité.Explication des indicateursLa spécification Java Enterprise Edition 6 fournit l'explication suivante sur les marqueurs des modules de sécurité. La liste suivante provient de http://docs.oracle.com/javase/6/docs/technotes/guides/security/jaas/JAASRefGuide.html#AppendixA. Consulter ce document pour obtenir des informations plus détaillées.
Marqueur Détails requis Le LoginModule est requis pour la réussite. En cas de réussite ou d'échec, l'autorisation continuera son chemin dans la liste du LoginModule.pré-requis Le LoginModule est requis pour la réussite. En cas de succès, l'autorisation continue vers le bas de la liste LoginModule. En cas d'échec, le contrôle est renvoyé immédiatement à l'application (l'autorisation ne continue pas son chemin le long de la liste LoginModule).suffisant The LoginModule n'est pas nécessaire pour aboutir. S'il ne réussit pas, le contrôle retourne immédiatement à l'application (l'autorisation ne se déroule pas vers le bas de la liste LoginModule). S'il échoue, l'authentification se poursuit vers le bas de la liste LoginModule.option Le LoginModule n'est pas requis pour la réussite. En cas de réussite ou d'échec, l'autorisation continuera son chemin dans la liste du LoginModule.Une fois que vous aurez ajouté votre module, vous pourrez modifier son Code ou ses Flags (indicateurs) en cliquant sur le bouton dans la section Details de l'écran. Veillez à ce que l'onglet Attributes soit bien sélectionné.Option : ajouter, éditer, ou supprimer un module
Si vous avez besoin d'ajouter des options à votre module, cliquer sur leurs entrées dans la liste Login Modules, et sélectionner l'onglet Module Options dans la section Details qui se trouve en bas de la page. Cliquer sur le bouton , et fournir la clé et la valeur de l'option. Pour la modifier, cliquer sur la clé et modifier. Utiliser le bouton pour supprimer l'option.
Votre module de police de sécurité est ajouté au domaine de sécurité, et est rendu disponible immédiatement auprès des applications qui utilisent le domaine de sécurité.
10.6.7. Security Auditing
10.6.8. Configurer Security Auditing
Procédure 10.4. Configurer Security Auditing pour un domaine de sécurité
Ouvrir l'affichage détaillé du domaine de sécurité.
Cliquer sur l'étiquette Profiles en haut et à droite de la console de gestion. Dans un domaine autonome, l'onglet est intitulé Profile. Dans un domaine géré, sélectionner le profil à modifier à partir de la case de sélection Profile en haut et à gauche de l'affichage du profil. Cliquer sur l'item de menu Security sur la gauche, et cliquer sur Security Domains à partir du menu déroulant. Cliquer sur le lien View pour obtenir le domaine de sécurité que vous souhaitez modifier.Naviguer dans la configuration du sous-système Auditing.
Cliquer sur l'étiquette Audit en haut de l'affichage si elle n'a pas déjà été sélectionnée.La zone de configuration est divisée en deux : Provider Modules et Details. Le module de fournisseur est l'unité de base de configuration. Un domaine de sécurité peut inclure plusieurs polices d'autorisation, et chacune peut inclure plusieurs attributs et options.Ajouter un module de fournisseur.
Cliquer sur le bouton Add pour ajouter un module de fournisseur. Remplir la section Code avec le nom de classe du module du fournisseur.Une fois que vous aurez ajouté votre module, vous pourrez modifier son Code en cliquant sur le bouton dans la section Details de l'écran. Veillez à ce que l'onglet Attributes soit bien sélectionné.Vérifier que le module fonctionne
Le but d'un module d'auditing est d'offrir un moyen de surveiller les événements dans le sous-système de sécurité. Ce monitoring peut être réalisé sous la forme d'écriture dans un fichier de journalisation, des notifications email ou autre mécanisme d'audit mesurable.Par exemple, JBoss EAP 6 inclut le moduleLogAuditProviderpar défaut. S'il est activé par les étapes décrites ci-dessus, ce module d'audit écrira des notifications de sécurité dans un fichieraudit.logqui se situe dans le sous-dossierlogdu répertoireEAP_HOME.Pour vérifier si les étapes ci-dessus fonctionnent dans le contexteLogAuditProvider, procédez à une action qui risque de déclencher une notification, puis vérifier le fichier de journalisation de l'audit.Pour obtenir une liste complète des Modules Security Auditing Provider, voir : Section 11.4, « Modules Security Auditing Provider inclus »Option : ajouter, éditer, ou supprimer un module
Si vous avez besoin d'ajouter des options à votre module, cliquer sur leurs entrées dans la liste Module, et sélectionner l'onglet Module Options dans la section Details de la page. Cliquer sur le bouton , et fournir la clé et la valeur de l'option. Pour modifier une option existante, la supprimer en cliquant sur l'étiquette , et l'ajouter à nouveau grâce aux options qui conviennent en cliquant sur le bouton .
Votre module d'audit de sécurité est ajouté au domaine de sécurité, et est rendu disponible immédiatement auprès des applications qui utilisent le domaine de sécurité.
10.6.9. Security Mapping
10.6.10. Configurer le Security Mapping dans un domaine de sécurité
Procédure 10.5. Configurer le Mappage de sécurité pour un Domaine de sécurité
Ouvrir l'affichage détaillé du domaine de sécurité.
Cliquer sur l'étiquette Profiles en haut et à droite de la console de gestion. Dans un domaine autonome, l'onglet est intitulé Profile. Dans un domaine géré, sélectionner le profile à modifier à partir de la case de sélection Profile en haut et à gauche de l'affichage du profil. Cliquer sur l'item de menu Security sur la gauche, et cliquer sur Security Domains à partir du menu déroulant. Cliquer sur le lien View pour obtenir le domaine de sécurité que vous souhaitez modifier.Naviguer dans la configuration du sous-système de Mapping
Cliquer sur l'étiquette Mapping en haut de l'affichage si elle n'a pas déjà été sélectionnée.La zone de configuration est divisée en deux : Modules et Details. Le module de connexion est l'unité de base de configuration. Un domaine de sécurité peut inclure plusieurs polices de mapping, et chacune peut inclure plusieurs attributs et options.Ajouter un module.
Cliquer sur le bouton Add pour ajouter un module de police de mapping. Remplir les informations pour votre module. Le Code est le nom de classe du module. Le champ Type se rapporte au type de mapping effectué par ce module. Les valeurs autorisées sont les suivantes : principal, rôle, attribut ou identifiant.Une fois que vous aurez ajouté votre module, vous pourrez modifier son Code ou ses Type en cliquant sur le bouton dans la section Details de l'écran. Veillez à ce que l'onglet Attributes soit bien sélectionné.Option : ajouter, éditer ou supprimer un module
Pour ajouter des options à votre module, cliquer sur leurs entrées dans la liste Modules, et sélectionner l'onglet Module Options dans la section Details. Cliquer sur le bouton , et fournir la clé et la valeur de l'option. Pour modifier une option existante, la supprimer en cliquant sur l'étiquette Remove, et ajouter la nouvelle valeur. Utiliser le bouton pour supprimer une option.
Votre module de mappage de sécurité est ajouté au domaine de sécurité, et est rendu disponible immédiatement auprès des applications qui utilisent le domaine de sécurité.
10.6.11. Utiliser un domaine de sécurité dans votre application
Pour utiliser un domaine de sécurité dans votre application, vous devez tout d'abord configurer le domaine dans le fichier de configuration du serveur ou dans le fichier de descripteur de l'application. Ensuite, vous devez ajouter les annotations requises à l'EJB qui l'utilisent. Cette rubrique décrit les étapes requises pour utiliser un domaine de sécurité dans votre application.
Avertissement
Procédure 10.6. Configurez votre application pour qu'elle puisse utiliser un domaine de sécurité
Définir le domaine de sécurité
Vous pouvez définir le domaine de sécurité soit dans le fichier de configuration du serveur, soit dans le fichier du descripteur de l'application.Configurez le domaine de sécurité dans le fichier de configuration du serveur
Le domaine de sécurité est configuré dans le sous-système desécuritédu fichier de configuration du serveur. Si l'instance de JBoss EAP 6 s'exécute dans un domaine géré, il s'agira du fichierdomain/configuration/domain.xml. Si l'instance de JBoss EAP 6 s'exécute comme un serveur autonome, ce sera le fichierstandalone/configuration/standalone.xml.Les domaines de sécuritéother,jboss-web-policy, etjboss-ejb-policysont fournis par défaut dans JBoss EAP 6. L'exemple XML suivant a été copié à partir du sous-système desécuritédans le fichier de configuration du serveur.<subsystem xmlns="urn:jboss:domain:security:1.2"> <security-domains> <security-domain name="other" cache-type="default"> <authentication> <login-module code="Remoting" flag="optional"> <module-option name="password-stacking" value="useFirstPass"/> </login-module> <login-module code="RealmDirect" flag="required"> <module-option name="password-stacking" value="useFirstPass"/> </login-module> </authentication> </security-domain> <security-domain name="jboss-web-policy" cache-type="default"> <authorization> <policy-module code="Delegating" flag="required"/> </authorization> </security-domain> <security-domain name="jboss-ejb-policy" cache-type="default"> <authorization> <policy-module code="Delegating" flag="required"/> </authorization> </security-domain> </security-domains> </subsystem>Vous pouvez configurer des domaines de sécurité supplémentaires selon les besoins par la console de gestion ou par l'interface CLI.Configurer le domaine de sécurité dans le fichier de descripteur de l'application.
Le domaine de sécurité est spécifié dans l'élément enfant<security-domain>de l'élément<jboss-web>du fichierWEB-INF/jboss-web.xmlde l'application. L'exemple suivant configure un domaine de sécurité nommémy-domain.<jboss-web> <security-domain>my-domain</security-domain> </jboss-web>Il s'agit d'une des configurations que vous pouvez indiquer dans le descripteurWEB-INF/jboss-web.xml.
Ajoutez l'annotation requise à l'EJB.
Vous pouvez configurer la sécurité dans EJB par les annotations@SecurityDomainet@RolesAllowed. L'exemple de code EJB suivant limite l'accès au domaine de sécuritéotheraux utilisateurs ayant pour rôleguest(invité).package example.ejb3; import java.security.Principal; import javax.annotation.Resource; import javax.annotation.security.RolesAllowed; import javax.ejb.SessionContext; import javax.ejb.Stateless; import org.jboss.ejb3.annotation.SecurityDomain; /** * Simple secured EJB using EJB security annotations * Allow access to "other" security domain by users in a "guest" role. */ @Stateless @RolesAllowed({ "guest" }) @SecurityDomain("other") public class SecuredEJB { // Inject the Session Context @Resource private SessionContext ctx; /** * Secured EJB method using security annotations */ public String getSecurityInfo() { // Session context injected using the resource annotation Principal principal = ctx.getCallerPrincipal(); return principal.toString(); } }Pour obtenir des exemples de code supplémentaires, voir le quickstartejb-securitydans le package JBoss EAP 6 Quickstarts disponible à partir du portail clients de Red Hat.
10.6.12. Java Authorization Contract for Containers (JACC)
10.6.12.1. Java Authorization Contract for Containers (JACC)
10.6.12.2. Configurer la sécurité JACC (Java Authorization Contract for Containers)
jboss-web.xml pour y inclure les paramètres qu'il faut.
Pour ajouter JACC au domaine de sécurité, ajouter la police d'autorisation JACC à la pile d'autorisations du domaine de sécurité, avec l'indicateur requis. Voici un exemple de domaine de sécurité avec support JACC. Cependant, le domaine de sécurité est configuré dans la console de gestion ou Management CLI, plutôt que directement dans le code XML.
<security-domain name="jacc" cache-type="default">
<authentication>
<login-module code="UsersRoles" flag="required">
</login-module>
</authentication>
<authorization>
<policy-module code="JACC" flag="required"/>
</authorization>
</security-domain>
Le fichier jboss-web.xml se trouve dans META-INF/ ou dans le répertoire WEB-INF/ de votre déploiement, et contient des ajouts ou remplacements de configuration spécifique JBoss pour le conteneur web. Pour utiliser votre domaine de sécurité activé-JACC, vous devrez inclure l'élément <security-domain>, et aussi définir l'élément <use-jboss-authorization> sur true. L'application suivante est configurée correctement pour pouvoir utiliser le domaine de sécurité JACC ci-dessus.
<jboss-web>
<security-domain>jacc</security-domain>
<use-jboss-authorization>true</use-jboss-authorization>
</jboss-web>
La façon de configurer les EJB pour qu'ils utilisent un domaine de sécurité et pour qu'ils utilisent JACC diffère des applications Web. Pour un EJB, vous pouvez déclarer des method permissions (permissions de méthode) sur une méthode ou sur un groupe de méthodes, dans le descripteur ejb-jar.xml. Dans l'élément <ejb-jar>, chaque élément <method-permission> dépendant contient des informations sur les rôles JACC. Voir l'exemple de configuration pour plus d'informations. La classe EJBMethodPermission fait partie de l'API Java Enterprise Edition 6, et est documentée dans http://docs.oracle.com/javaee/6/api/javax/security/jacc/EJBMethodPermission.html.
Exemple 10.4. Exemple de permissions de méthode JACC dans un EJB
<ejb-jar>
<method-permission>
<description>The employee and temp-employee roles may access any method of the EmployeeService bean </description>
<role-name>employee</role-name>
<role-name>temp-employee</role-name>
<method>
<ejb-name>EmployeeService</ejb-name>
<method-name>*</method-name>
</method>
</method-permission>
</ejb-jar>
jboss-ejb3.xml qui se trouve dans l'élément enfant <security>. En plus du domaine de sécurité, vous pouvez également spécifier le run-as principal, qui change le principal que l'EJB exécute.
Exemple 10.5. Exemple de déclaration de domaine de sécurité dans un EJB
<security> <ejb-name>*</ejb-name> <security-domain>myDomain</security-domain> <run-as-principal>myPrincipal</run-as-principal> </security>
10.6.13. JASPI (Java Authentication SPI for Containers)
10.6.13.1. Sécurité Java Authentication SPI pour Conteneurs (JASPI)
10.6.13.2. Configuration de la sécurité Java Authentication SPI pour conteneurs (JASPI)
<authentication-jaspi> à votre domaine de sécurité. La configuration est similaire à celle d'un module d'authentification standard, mais les éléments de module de login sont inclus dans l'élément <login-module-stack>. La structure de configuration est la suivante :
Exemple 10.6. Structure de l'élément authentication-jaspi
<authentication-jaspi> <login-module-stack name="..."> <login-module code="..." flag="..."> <module-option name="..." value="..."/> </login-module> </login-module-stack> <auth-module code="..." login-module-stack-ref="..."> <module-option name="..." value="..."/> </auth-module> </authentication-jaspi>
EAP_HOME/domain/configuration/domain.xml ou dans le fichier EAP_HOME/standalone/configuration/standalone.xml.
10.7. Sécurité dans l'interface de gestion
10.7.1. Configuration Sécurité Utilisateur par défaut
Toutes les interfaces de gestion de JBoss EAP 6 sont sécurisées par défaut. Cette sécurité existe sous deux formes :
- Les interfaces locales sont sécurisées par un contrat SASL entre des clients locaux et le serveur auquel ils se connectent. Ce mécanisme de sécurité repose sur la capacité du client à accéder au système de fichiers local. C'est parce que l'accès au système de fichiers local permettrait au client d'ajouter un utilisateur ou encore de modifier la configuration pour déjouer les autres mécanismes de sécurité. Cela est conforme au principe selon lequel si l'accès physique au système de fichiers est réussi, les autres mécanismes de sécurité sont superflus. Le mécanisme passe par quatre étapes :
Note
L'accès HTTP est considéré comme éloigné, même si vous vous connectez à l'hôte local par HTTP.- Le client envoie un message au serveur incluant une requête pour authentifier le mécanisme SASL local.
- Le serveur génère un token unique, qu'il écrit dans un fichier unique, et envoie un message au client avec le chemin d'accès fichier complet.
- Le client lit le token dans le fichier et l'envoie au serveur, pour vérifier qu'il a l'accès local au système de fichiers.
- Le serveur vérifie le token et efface le fichier.
- Les clients distants, y compris HTTP, utilisent une sécurité basée domaine. Le domaine par défaut qui comprend les autorisations pour configurer la plate-forme JBoss EAP 6 à distance en utilisant les interfaces de gestion est
ManagementRealm. Un script est fourni pour vous permettre d'ajouter des utilisateurs à ce domaine (ou à des domaines que vous créez). Pour plus d'informations sur la façon d'ajouter des utilisateurs, voir le chapitre Getting Started de JBoss EAP 6 Installation Guide. Pour chaque utilisateur, le nom d'utilisateur, un mot de passe haché et le domaine sont stockés dans un fichier.- Domaine géré
EAP_HOME/domain/configuration/mgmt-users.properties- Serveur autonome
EAP_HOME/standalone/configuration/mgmt-users.properties
Même si les contenus demgmt-users.propertiessont masqués, le fichier doit toujours être considéré comme un fichier sensible. Il est recommandé qu'il soit défini sur le mode de fichier600, qui ne donne aucun accès autre que l'accès en lecture et écriture au propriétaire du fichier.
10.7.2. Aperçu Général de la Configuration de l'Interface de Gestion avancée
EAP_HOME/domain/configuration/host.xml ou EAP_HOME/standalone/configuration/standalone.xml contrôle l'interface réseau à laquelle se relie le processus contrôleur hôte, les types d'interfaces de gestion qui sont disponibles à tous, et quel type de système d'authentification est utilisé pour authentifier les utilisateurs sur chaque interface. Cette rubrique explique comment configurer les interfaces de gestion en fonction de votre environnement.
<management avec plusieurs attributs configurables, et les trois éléments enfants configurables suivants. Les domaines de sécurité et les connexions sortantes sont définies chacune pour commencer, puis appliquées aux interfaces de gestion en tant qu'attributs.
<security-realms><outbound-connections><management-interfaces>
Le domaine de sécurité est chargé de l'authentification et de permettre aux utilisateurs autorisés d'administrer JBoss EAP 6 via l'API de gestion, le Management CLI ou la Console de gestion basée-web.
ManagementRealm et ApplicationRealm. Chacun de ces domaines de sécurité utilise un fichier -users.properties pour stocker les utilisateurs et les mots de passe de hachage, et -roles.properties pour stocker les correspondances entre les utilisateurs et les rôles. Un support est également inclus pour le domaine de sécurité activé-LDAP.
Note
Certains domaines de sécurité se connectent à des interfaces externes, comme un serveur LDAP. Une connexion sortante définit la manière d'établir cette connexion. Un type de connexion prédéfinie, la connexion ldap-connection, définit tous les attributs obligatoires et facultatifs pour se connecter au serveur LDAP et vérifier les informations d'identification.
Une interface de gestion comprend des propriétés sur la façon de connecter et configurer JBoss EAP. Ces informations comprennent l'interface réseau nommée, le port, le domaine de sécurité et autres informations configurables sur l'interface. Deux interfaces sont incluses dans une installation par défaut :
http-interfaceest la configuration de la console de gestion basée-web.native-interfaceest la configuration pour la Management CLI en ligne de commande et l'API de gestion Rest-like.
10.7.3. LDAP
10.7.4. Utiliser LDAP pour vous authentifier auprès des interfaces de Gestion
- Créer une connexion sortante au serveur LDAP.
- Créer un domaine de sécurité activé-LDAP.
- Référencer le nouveau domaine de sécurité dans l'interface de Gestion.
La connexion sortante LDAP autorise les attributs suivants :
Tableau 10.1. Attributs d'une Connexion sortante LDAP
| Attribut | Requis | Description |
|---|---|---|
| url | oui |
L'adresse URL du serveur de répertoire.
|
| search-dn | oui |
Le nom unique (DN) de l'utilisateur autorisé à effectuer des recherches.
|
| search-credentials | oui |
Le mot de passe de l'utilisateur autorisé à effectuer des recherches.
|
| initial-context-factory | non |
L'usine de contexte initiale à utiliser quand on établit une connexion. Valeur par défaut
com.sun.jndi.ldap.LdapCtxFactory.
|
| security-realm | non |
Domaine de sécurité à référencer pour obtenir un
SSLContext configuré pour établir la connexion.
|
Exemple 10.7. Ajouter une connexion sortante LDAP
- Search DN:
cn=search,dc=acme,dc=com - Search Credential:
myPass - URL:
ldap://127.0.0.1:389
/host=master/core-service=management/security-realm=ldap_security_realm:add
/host=master/core-service=management/ldap-connection=ldap_connection/:add(search-credential=myPass,url=ldap://127.0.0.1:389,search-dn="cn=search,dc=acme,dc=com")
Les Interfaces de gestion peuvent authentifier sur le serveur LDAP au lieu des domaines de sécurité basés propriété-fichier et configurés par défaut. L'authentificateur LDAP fonctionne en établissant tout d'abord une connexion au serveur de répertoires distant. Il effectue ensuite une recherche en utilisant le nom d'utilisateur que l'utilisateur a transmis au système d'authentification, afin de trouver le nom unique complet (DN) du dossier LDAP. Une nouvelle connexion est alors établie, utilisant le DN de l'utilisateur comme information d'identification et mot de passe fournis par l'utilisateur. Si cette authentification au serveur LDAP réussit, le DN est considéré comme valide.
- connection
- Le nom de la connexion définie dans
<outbound-connections>à utiliser pour se connecter au répertoire LDAP. - base-dn
- Le nom unique (DN) du contexte pour commencer à chercher l'utilisateur.
- recursive
- Indique si la recherche doit être récursive dans toute l'arborescence de répertoires LDAP, ou si l'on doit rechercher uniquement le contexte spécifié. La valeur par défaut est
false. - user-dn
- Attribut de l'utilisateur qui détient le nom unique (DN). Utilisé par la suite pour tester l'authentification. Valeur par défaut
dn. - Soit
username-filterouadvanced-filter, comme élément enfant. - Le
username-filterutilise un attribut unique nomméattribute, dont la valeur correspond au nom de l'attribut LDAP qui contient le nom d'utilisateur, commeuserNameousambaAccountName.Leadvanced-filterprend un attribut unique nomméfilter, qui contient une recherche de filtre en syntaxe LDAP standard. Veillez à bien échapper les caractères&en commutant à& amp;. Voici un exemple de filtre :(&(sAMAccountName={0})(memberOf=cn=admin,cn=users,dc=acme,dc=com))Après avoir échappé un caractère esperluette, le filtre apparaîtra ainsi :(&(sAMAccountName={0})(memberOf=cn=admin,cn=users,dc=acme,dc=com))
Exemple 10.8. XML représentant un Domaine de sécurité activé-LDAP
- connection -
ldap_connection - base-dn -
cn=users,dc=acme,dc=com. - username-filter -
attribute="sambaAccountName"
<security-realm name="ldap_security_realm">
<authentication>
<ldap connection="ldap_connection" base-dn="cn=users,dc=acme,dc=com">
<username-filter attribute="sambaAccountName" />
</ldap>
</authentication>
</security-realm>
Avertissement
Exemple 10.9. Ajout d'un Domaine de sécurité LDAP
/host=master/core-service=management/security-realm=ldap_security_realm/authentication=ldap:add(base-dn="DC=mycompany,DC=org", recursive=true, username-attribute="MyAccountName", connection="ldap_connection")
Après avoir créé un domaine de sécurité, vous devez le référencer dans la configuration de votre interface de gestion. L'interface de gestion utilisera le domaine de sécurité pour l'authentification HTTP digest.
Exemple 10.10. Ajouter le Domaine de sécurité à l'interface HTTP
/host=master/core-service=management/management-interface=http-interface/:write-attribute(name=security-realm,value=ldap-security-realm)
Pour configurer un hôte dans un domaine géré pour s'authentifier sur Active Directory de Microsoft, suivre cette procédure, qui crée un domaine de sécurité et mappe les rôles aux groupes Active Directory, par l'authentification JAAS. Cette procédure est nécessaire parce que Microsoft Active Directory autorise la liaison avec un mot de passe vide. Cette procédure empêche l'utilisation d'un mot de passe vide dans la plate-forme d'applications.
master.
Ajouter un nouveau
<security-realm>nomméldap_security_realm, et le configurer pour qu'il puisse utiliser JAAS.Les commandes CLI suivantes ajoutent le domaine de sécurité, puis définissent son mécanisme d'authentification. Modifier le nom de l'hôte selon les besoins./host=master/core-service=management/security-realm=ldap_security_realm/:add
/host=master/core-service=management/security-realm=ldap_security_realm/authentication=jaas/:add(name=managementLDAPDomain)
Configurer
<http-interface>pour utiliser le nouveau domaine de sécurité.La commande de Management CLI suivante configure l'interface HTTP./host=master/core-service=management/management-interface=http-interface/:write-attribute(name=security-realm,value=ldap_security_realm)
Configurer JBoss Enterprise Application Platform pour ajouter une configuration JAAS personnalisée à ses paramètres de démarrage (start-up).
Modifier le fichierEAP_HOME /bin/domain.conf. Rechercher la variableHOST_CONTROLLER_JAVA_OPTSpuis y ajouter des directives pour la JVM, qui sont nécessaires avant le démarrage de JBoss Enterprise Application Platform. Voici un exemple du contenu par défaut de ce paramètre :HOST_CONTROLLER_JAVA_OPTS="$JAVA_OPTS"
Ajouter la directive suivante à la ligne :-Djava.security.auth.login.config=/opt/jboss-eap-6.0/domain/configuration/jaas.conf"La ligne modifiée ressemble à ceci :-Djava.security.auth.login.config=/opt/jboss-eap-6.0/domain/configuration/jaas.conf"
Ajouter le module de connexion aux options de module.
Dans le même fichier, chercher la ligne contenant ce qui suit :JBOSS_MODULES_SYSTEM_PKGS="org.jboss.byteman"
Modifier cette ligne pour qu'elle ressemble à ceci. Veillez à ne pas insérer d'espaces supplémentaires.JBOSS_MODULES_SYSTEM_PKGS="org.jboss.byteman,com.sun.security.auth.login"
Sauvegarder et fermer le fichierdomain.conf.Créer la configuration JAAS qui sera ajoutée au chemin de classe.
Créer un nouveau fichier à l'emplacement suivant :EAP_HOME/domain/configuration/jaas.confLe fichier doit contenir ce qui suit. Modifier les paramètres pour qu'ils correspondent à votre environnement.managementLDAPDomain { org.jboss.security.auth.spi.LdapExtLoginModule required java.naming.factory.initial="com.sun.jndi.ldap.LdapCtxFactory" java.naming.provider.url="ldap://your_active_directory_host:389" java.naming.security.authentication="simple" bindDN="cn=Administrator,cn=users,dc=domain,dc=your_company,dc=com" bindCredential="password" baseCtxDN="cn=users,dc=domain,dc=redhat,dc=com" baseFilter="(&(sAMAccountName={0})(|(memberOf=cn=Domain Guests,cn=Users,dc=domain,dc=acme,dc=com)(memberOf=cn=Domain Admins,cn=Users,dc=domain,dc=acme,dc=com)))" allowEmptyPasswords="false" rolesCtxDN="cn=users,dc=domain,dc=acme,dc=com" roleFilter="(cn=no such group)" searchScope="SUBTREE_SCOPE"; };- Redémarrer JBoss Enterprise Application Platform et votre interface HTTP utilisera le serveur LDAP pour l'authentification.
10.7.5. Désactiver l'interface de gestion HTTP
Note
console-enabled de l'interface HTTP à false, au lieu de désactiver l'interface complètement.
/host=master/core-service=management/management-interface=http-interface/:write-attribute(name=console-enabled,value=false)
Exemple 10.11. Lire la configuration de l'interface HTTP
/host=master/core-service=management/management-interface=http-interface/:read-resource(recursive=true,proxies=false,include-runtime=false,include-defaults=true)
{
"outcome" => "success",
"result" => {
"console-enabled" => true,
"interface" => "management",
"port" => expression "${jboss.management.http.port:9990}",
"secure-port" => undefined,
"security-realm" => "ManagementRealm"
}
}
Exemple 10.12. Supprimer l'interface HTTP
/host=master/core-service=management/management-interface=http-interface/:remove
Exemple 10.13. Recréer l'Interface HTTP
/host=master/core-service=management/management-interface=http-interface:add(console-enabled=true,interface=management,port="${jboss.management.http.port:9990}",security-realm=ManagementRealm)10.7.6. Supprimer l'authentification silencieuse du domaine de sécurité par défaut.
L'installation par défaut de JBoss EAP 6 contient une méthode d'authentification silencieuse pour un utilisateur de Management CLI local. Cela donne à l'utilisateur local la possibilité d'accéder au Management CLI sans authentification par nom d'utilisateur ou mot de passe. Cette fonctionnalité est activée dans un but pratique et pour faciliter l'exécution des scripts de Management CLI sans exiger l'authentification des utilisateurs locaux. Cette méthode est considérée comme une fonctionnalité utile étant donné que l'accès à la configuration locale donne généralement aussi à l'utilisateur la possibilité d'ajouter ses propres informations d'utilisateur ou sinon la possibilité de désactiver les contrôles de sécurité.
local dans la section security-realm du fichier de configuration. S'applique à la fois à standalone.xml pour une instance de serveur autonome, ou à host.xml pour un domaine géré. Vous ne devez envisager de supprimer l'élément local que si vous comprenez l'impact que ceci peut avoir sur la configuration de votre serveur particulier.
local visible dans l'exemple suivant.
Exemple 10.14. Exemple d'élément local dans security-realm
<security-realms>
<security-realm name="ManagementRealm">
<authentication>
<local default-user="$local"/>
<properties path="mgmt-users.properties" relative-to="jboss.server.config.dir"/>
</authentication>
</security-realm>
<security-realm name="ApplicationRealm">
<authentication>
<local default-user="$local" allowed-users="*"/>
<properties path="application-users.properties" relative-to="jboss.server.config.dir"/>
</authentication>
<authorization>
<properties path="application-roles.properties" relative-to="jboss.server.config.dir"/>
</authorization>
</security-realm>
</security-realms>
Conditions préalables
Procédure 10.7. Supprimer l'authentification silencieuse du domaine de sécurité par défaut.
Supprimer l'authentification silencieuse par l'interface CLI
Supprimer l'élémentlocaldu Domaine de gestion et du Domaine d'applications comme requis.- Supprimer l'élément
localdu Domaine de gestion.Pour les serveurs autonomes
/core-service=management/security-realm=ManagementRealm/authentication=local:remove
Pour les domaines gérés
/host=HOST_NAME/core-service=management/security-realm=ManagementRealm/authentication=local:remove
- Supprimer l'élément
localdu Domaine d'applications.Pour les serveurs autonomes
/core-service=management/security-realm=ApplicationRealm/authentication=local:remove
Pour les domaines gérés
/host=HOST_NAME/core-service=management/security-realm=ApplicationRealm/authentication=local:remove
L'authentification silencieuse est retirée du ManagementRealm et de l'ApplicationRealm.
10.7.7. Désactiver l'accès à distance du Sous-système JMX
/profil=default. Pour un serveur autonome, retirer complètement cette partie de la commande.
Note
Exemple 10.15. Supprimer le Connecteur distant du Sous-système JMX
/profile=default/subsystem=jmx/remoting-connector=jmx/:remove
Exemple 10.16. Supprimer le Sous-système JMX
/profile=default/subsystem=jmx/:remove
10.7.8. Configurer les Domaines de sécurité pour les Interfaces de gestion
Cet exemple montre la configuration par défaut du domaine de sécurité du ManagementRealm. Il utilise un fichier mgmt-users.properties qui contient ses informations de configuration.
Exemple 10.17. ManagementRealm par défaut
/host=master/core-service=management/security-realm=ManagementRealm/:read-resource(recursive=true,proxies=false,include-runtime=false,include-defaults=true)
{
"outcome" => "success",
"result" => {
"authorization" => undefined,
"server-identity" => undefined,
"authentication" => {"properties" => {
"path" => "mgmt-users.properties",
"plain-text" => false,
"relative-to" => "jboss.domain.config.dir"
}}
}
}
Les commandes suivantes créent un nouveau domaine de sécurité nommé TestRealm et définissent le répertoire du fichier de propriétés qui conviennent.
Exemple 10.18. Rédaction d'un domaine de sécurité
/host=master/core-service=management/security-realm=TestRealm/:add/host=master/core-service=management/security-realm=TestRealm/authentication=properties/:add(path=TestUsers.properties, relative-to=jboss.domain.config.dir)
Après avoir ajouté un domaine de sécurité, l'utiliser comme référence à l'interface de gestion.
Exemple 10.19. Ajouter un Domaine de sécurité à une Interface de gestion
/host=master/core-service=management/management-interface=http-interface/:write-attribute(security-realm=TestRealm)
10.8. Activer les interfaces de gestion par le contrôle d'accès basé rôle
10.8.1. Les RBAC (Role-Based Access Control)
10.8.2. Les RBAC (Role-Based Access Control) dans le GUI et le CLI
- La Console de gestion
- Dans la Console de gestion, certains contrôles et vues sont désactivés (en gris) ou invisibles selon les permissions du rôle qui vous est assigné.Si vous n'avez pas de permission Lecture pour un attribut de ressource, cet attribut apparaîtra en blanc sur la console. Par exemple, la plupart des rôles ne peuvent pas lire les champs Nom d'utilisateur ou Mot de passe des sources de données.Si vous n'avez pas de permission Écriture sur un attribut de ressource, cet attribut sera désactivé (grisé) dans le formulaire de modification de la ressource. Si vous n'avez pas du tout de permission Écriture sur la ressource, le bouton de modification de la ressource ne s'affichera pas.Si vous n'avez pas les permissions nécessaires pour accéder à une ressource ou à un attribut (c'est « non adressable » pour votre rôle) et cela ne vous apparaîtra pas dans la console. L'accès contrôle système lui-même qui est uniquement visible par quelques rôles par défaut en est un exemple.
- Management API
- Les utilisateurs de l'outil
jboss-cli.shou directement de l'API rencontreront un comportement légèrement différent dans l'API lorsque RBAC est activé.Les ressources et les attributs qui ne peuvent être lus sont filtrés des résultats. Si les éléments filtrés sont adressables par le rôle, leurs noms seront répertoriés en tant quefiltered-attributesdans la sectionresponse-headersdu résultat. Si une ressource ou un attribut n'est pas adressable par le rôle, il n'apparaîtra pas du tout.Toute tentative d'accès à une ressource non adressable résultera par l'erreur : « resource not found ».Si un utilisateur tente d'écrire ou de lire une ressource qu'il peut adresser, mais qu'il n'a pas les permissions de lecture ou d'écriture qui conviennent, une erreur "Permission Denied" apparaîtra.
10.8.3. Schémas d'authentification supportés
username/password, client certificate, et local user.
- Username/Password
- Les utilisateurs sont authentifiés par une combinaison de nom d'utilisation et de mot de passe qui sont ensuite vérifiés par le fichier
mgmt-users.properties, ou via un serveur LDAP. - Client Certificate
- Utilisation du Trust Store
- Utilisateur local
jboss-cli.shauthentifie automatiquement en tant que Local User si le serveur exécute sur la même machine. Par défaut, Local User est un membre du groupeSuperUser.
mgmt-users.properties ou par un serveur LDAP, ces systèmes peuvent fournir des informations de groupes d'utilisateur. Cette information peut également servir à JBoss EAP pour attribuer des rôles aux utilisateurs.
10.8.4. Les rôles standard
- Monitor
- Les utilisateurs du rôle Monitor ont le plus petit nombre de permissions et ne peuvent lire que la configuration ou l'état du serveur en cours. Ce rôle est destiné aux utilisateurs qui ont besoin de vérifier et reporter la performance du serveur.Les Monitors ne peuvent pas modifier la configuration du serveur, et ne peuvent pas accéder aux données ou opérations confidentielles.
- Operator
- Le rôle Operator étend le rôle Monitor en ajoutant la possibilité de modifier l'état d'exécution du serveur. Cela signifie que les opérateurs peuvent recharger et arrêter le serveur, ainsi que suspendre et reprendre les destinations JMS. Le rôle Operator est idéal pour les utilisateurs responsables des hôtes physiques ou virtuels du serveur d'applications, puisqu'ils peuvent s'assurer ainsi que les serveurs puissent être arrêtés, redémarrés ou corrigés si nécessaire.Le opérateurs ne peuvent pas modifier la configuration du serveur ou accéder à des données ou opérations confidentielles.
- Maintainer
- Le rôle Maintainer a le droit de visualiser et modifier l'état d'exécution et toute la configuration à l'exception des données sensibles et des opérations. Le rôle du mainteneur est un rôle d'usage général qui n'a pas accès aux données sensibles et aux opérations. Le rôle Maintainer permet aux utilisateurs de bénéficier d'un accès presque total d'administration du serveur, sans donner à ces utilisateurs l'accès aux mots de passe ou autres informations sensibles.Le mainteneurs ne peuvent pas accéder à des données ou opérations sensibles.
- Administrator
- Le rôle Administrator a un accès illimité aux ressources et opérations sur le serveur sauf sur le système d'enregistrement d'audit. L'administrateur est le seul rôle (excepté SuperUser) qui a accès à des données sensibles et aux opérations. Ce rôle peut également configurer le système de contrôle d'accès. Le rôle Administrator n'est requis que lorsque vous manipulez des données sensibles ou configurez les utilisateurs et les rôles.
- SuperUser
- Le rôle SuperUser a un accès illimité aux ressources et opérations sur le serveur, y compris au système d'enregistrement d'audit. Ce rôle est équivalent aux rôles d'utilisateurs administrateurs des versions plus anciennes de JBoss EAP 6 (6.0 et 6.1). Si RBAC est désactivé, tous les utilisateurs de management auront une permission équivalente à celle d'un rôle SuperUser.
- Deployer
- Le rôle Deployer a les mêmes permissions que Monitor, mais peut modifier la configuration et l'état des déploiements ou n'importe quel autre type de ressource activée en tant que ressource d'application.
- Auditor
- Le rôle Auditor possède toutes les permissions du rôle Monitor et peut également voir (mais pas modifier) les données sensibles. Il a aussi accès au système de journalisation de l'auditing. Le rôle Auditor est le seul rôle en dehors de SuperUser qui puisse accéder au système de journalisation de l'auditing.Les auditeurs ne peuvent pas modifier les données ou les ressources sensibles. Seul l'accès lecture est permis.
10.8.5. Les Permissions de rôle
Tableau 10.2. Matrice de permissions de rôle
|
Monitor
|
Operator
|
Maintainer
|
Deployer
|
Auditor
|
Administrator
|
SuperUser
| |
|
Lecture Config et État
|
X
|
X
|
X
|
X
|
X
|
X
|
X
|
|
Lire Données sensibles [2]
|
X
|
X
|
X
| ||||
|
Modifier Données sensibles [2]
|
X
|
X
| |||||
|
Lire/Modifer Audit Log
|
X
|
X
| |||||
|
Modifier État du Runtime
|
X
|
X
|
X[1]
|
X
|
X
| ||
|
Modifier Config persistante
|
X
|
X[1]
|
X
|
X
| |||
|
Lire/Modifier Contrôle d'accès
|
X
|
X
|
10.8.6. Contraintes
- Contraintes d'application
- Les contraintes d'application définissent des ensembles de ressources et des attributs qui sont accessibles aux utilisateurs du rôle chargé du déploiement (Deployer). Par défaut, la seule Contrainte d'application activée est la principale qui inclut des déploiements, des superpositions de déploiement. Les contraintes d'application sont également incluses (mais pas activées par défaut) pour les sources de données, connexion, mail, messagerie, nommage, adaptateurs de ressources et sécurité. Ces contraintes permettent aux utilisateurs de Deployer, non seulement de déployer des applications mais également de configurer et de maintenir les ressources requises par ces applications.La configuration de contraintes d'applications se trouve dans l'API de gestion à l'adresse suivante :
/core-service=management/access=authorization/constraint=application-classification. - Contraintes de sensibilité
- Les contraintes de confidentialité définissent des ressources considérées comme « sensibles ». Une ressource sensible est généralement de nature secrète, comme un mot de passe, ou une information qui puisse avoir de graves répercussions sur le fonctionnement du serveur, comme le networking, la configuration de la JVM ou les propriétés système. Le système de contrôle d'accès lui-même est aussi considéré comme sensible.Les seuls rôles autorisés à écrire dans les ressources sensibles sont Administrateur et Superutilisateur. Le rôle Auditeur est seulement capable de lire les ressources confidentielles. Aucun autre rôle ne peut avoir accès.La configuration de contraintes de sensibilité se trouve dans l'API de gestion à l'adresse suivante :
/core-service=management/access=authorization/constraint=sensitivity-classification. - Contrainte d'expression d'archivage sécurisé
- Une contrainte d'expression d'archivage sécurisé détermine si la lecture ou l'écriture d'expressions d'archivage sécurisé est considéré comme une opération sensible. Par défaut, les deux sont sensibles.La configuration de contraintes d'expression d'archivage sécurisé se trouve dans l'API de gestion à l'adresse suivante :
/core-service=management/access=authorization/constraint=vault-expression.
10.8.7. JMX et RBAC (Role-Based Access Control)
- L'API de gestion de JBoss EAP 6 est exposé comme JMX Management Beans. Ces Management Beans sont appelés « core mbeans » et leur accès est contrôlé et filtré exactement de la même façon que l'API de gestion sous-jacent lui-même.
- Le sous-système JMX est configuré avec des permissions d'écriture « sensibles ». Cela signifie que seuls les utilisateurs avec les rôles Administrateur et Superutilisateur peuvent apporter des modifications à ce sous-système. Les utilisateurs avec le rôle Auditeur peuvent aussi lire cette configuration du sous-système.
- Par défaut, les beans de gestion enregistrés par des applications déployées et des services (non-core mbeans) sont accessibles par tous les utilisateurs de gestion, mais seuls les utilisateurs ayant un rôle Maintenance, Opérateur, Administrateur, Superutilisateur peuvent écrire dessus.
10.8.8. Configurer le RBAC (Role-Based Access Control)
10.8.8.1. Aperçu des tâches de configuration RBAC
- Voir et configurer les rôles assignés (ou exclus) pour chaque utilisateur
- Voir et configurer les rôles assignés (ou exclus) pour chaque groupe
- Voir Appartenance Utilisateur et Groupe par Rôle.
- Configurer Appartenance par défaut pour un rôle.
- Créer un scoped rôle
- Activer et désactiver RBAC
- Modifier la police de combinaison de permissions
- Configurer les contraintes de sensibilité des ressources et des ressources d'applications
10.8.8.2. Activer le RBAC (Role-Based Access Control)
simple à rbac. Cela peut être fait en utilisant l'outil jboss-cli.sh, ou en modifiant la configuration du serveur XML du fichier si le serveur est hors ligne. Quand RBAC est désactivé ou activé sur un serveur en cours d'exécution, la configuration du serveur doit être rechargée avant de prendre effet.
jboss-cli.sh est exécuté par le rôle SuperUser s'il est exécuté dans la même machine que le serveur.
Procédure 10.8. Activer RBAC
- Pour activer RBAC avec
jboss-cli.shutiliser l'opérationwrite-attributede la ressource d'autorisation d'accès, pour définir la valeur de l'attribut provider àrbac/core-service=management/access=authorization:write-attribute(name=provider, value=rbac)
[standalone@localhost:9999 /] /core-service=management/access=authorization:write-attribute(name=provider, value=rbac) { "outcome" => "success", "response-headers" => { "operation-requires-reload" => true, "process-state" => "reload-required" } } [standalone@localhost:9999 /] /:reload { "outcome" => "success", "result" => undefined } [standalone@localhost:9999 /]
Procédure 10.9. Désactiver RBAC
- Pour désactiver RBAC avec
jboss-cli.shutiliser l'opérationwrite-attributede la ressource d'autorisation d'accès pour définir la valeur de l'attribut provider àsimple/core-service=management/access=authorization:write-attribute(name=provider, value=simple)
[standalone@localhost:9999 /] /core-service=management/access=authorization:write-attribute(name=provider, value=simple) { "outcome" => "success", "response-headers" => { "operation-requires-reload" => true, "process-state" => "reload-required" } } [standalone@localhost:9999 /] /:reload { "outcome" => "success", "result" => undefined } [standalone@localhost:9999 /]
provider de l'élément de contrôle d'accès de l'élément de gestion. Définissez la valeur rbac sur « activé » et simple sur « désactivé ».
<management>
<access-control provider="rbac">
<role-mapping>
<role name="SuperUser">
<include>
<user name="$local"/>
</include>
</role>
</role-mapping>
</access-control>
</management>
10.8.8.3. Modifier la police de combinaison de permissions
permissive ou rejecting. La valeur par défaut est permissive.
permissive, si un rôle est assigné à l'utilisateur pour permettre une action, alors l'action sera autorisée.
rejecting est sélectionné, si plusieurs rôle sont assignés à l'utilisateur pour permettre une action, alors l'action ne sera pas autorisée.
jboss-cli.sh lorsque la police est définie sur rejecting.
permission-combination-policy soit permissive ou rejecting. Cela peut être fait par l'outil jboss-cli.sh, ou en modifiant la configuration du serveur XML du fichier si le serveur est hors ligne.
Procédure 10.10. Définir la police de combinaison de permissions
- Effectuer l'opération
write-attributede la ressource d'autorisation d'accès pour définir l'attributpermission-combination-policyau nom de la police requise./core-service=management/access=authorization:write-attribute(name=permission-combination-policy, value=POLICYNAME)
Les noms de police valide sont « rejecting » ou « permissive ».[standalone@localhost:9999 /] /core-service=management/access=authorization:write-attribute(name=permission-combination-policy, value=rejecting) {"outcome" => "success"} [standalone@localhost:9999 access=authorization]
permission-combination-policy de l'élément de contrôle d'accès.
<access-control provider="rbac" permission-combination-policy="rejecting">
<role-mapping>
<role name="SuperUser">
<include>
<user name="$local"/>
</include>
</role>
</role-mapping>
</access-control>
10.8.9. Gestion des rôles
10.8.9.1. Appartenance à un rôle
- L'utilisateur est :
- listé comme utilisateur à inclure dans le rôle, ou
- un membre d'un groupe qui est listé pour être inclus dans le rôle.
- L'utilisateur n'est pas :
- listé comme utilisateur à exclure du rôle, ou
- un membre d'un groupe qui est listé pour être exclus du rôle.
jboss-cli.sh.
10.8.9.2. Configurer Attribution de Rôle Utilisateur
jboss-cli.sh. Cette section explique uniquement comment utiliser la Console de gestion.
- Connectez-vous à la Console de gestion.
- Cliquer sur l'onglet Administration.
- Déployer l'élément Contrôle d'accès (Access Control) sur la gauche et sélectionner Attribution de rôles (Role Assignment).
- Sélectionner l'onglet Utilisateurs (USERS).
Figure 10.1. Instantané de Gestion de rôle dans la Console de gestion
Procédure 10.11. Créer une nouvelle attribution de rôle pour l'utilisateur
- Connexion à la Console de gestion.
- Naviguer vers l'onglet Utilisateur de la section Attribution de rôles.
- Cliquer sur le bouton Add en haut et à droite de la liste d'utilisateur. Le dialogue Ajouter Utilisateur (Add User) apparaîtra.
Figure 10.2. Boîte de dialogue Ajouter Utilisateur (Add User)
- Vous devez préciser un nom d'utilisateur, ou domaine si possible.
- Définir le type de menu à inclure ou à exclure.
- Cliquer la case des rôles à inclure ou à exclure. Vous pouvez utiliser la clé de contrôle (clé de commande OSX) pour cocher les divers items.
- Cliquer Sauvegarde.Si cela réussit, la boîte de dialogue Ajouter un utilisateur se ferme, et la liste des utilisateurs sera mise à jour pour refléter les modifications apportées. En cas d'échec, un message « Impossible d'enregistrer l'attribution de rôle » s'affichera.
Procédure 10.12. Mise à jour d'une attribution de rôle pour un utilisateur
- Connexion à la Console de gestion.
- Naviguer vers l'onglet Utilisateur de la section Attribution de rôles.
- Sélectionner un utilisateur dans la liste.
- Cliquer sur le bouton Édit. Le panneau de sélection est alors en mode Édit.
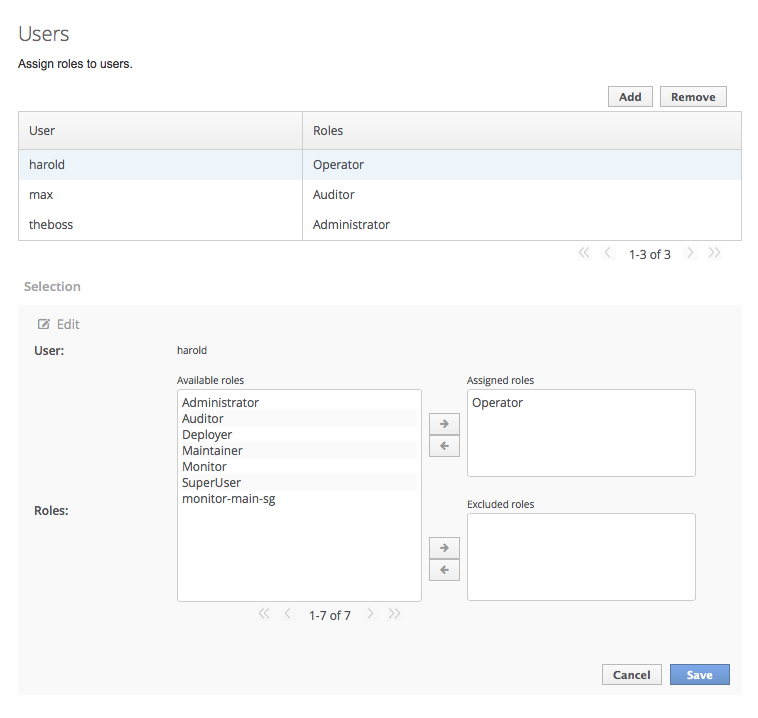
Figure 10.3. Sélection Vue Édit
Vous pourrez ici ajouter ou supprimer les rôles assignés pour exclus pour l'utilisateur.- Pour ajouter un rôle assigné, sélectionner le rôle requis de la liste de rôles disponibles sur la gauche et cliquer sur le bouton avec une flèche pointant sur la droite qui se trouve à côté de la liste de rôles assignés. Le rôle se déplacera alors depuis la liste de rôles disponibles vers la liste de rôles assignés.
- Pour supprimer un rôle assigné, sélectionner le rôle requis de la liste de rôles assignés sur la droite et cliquer sur le bouton avec une flèche pointant sur la gauche qui se trouve à côté de la liste de rôles assignés. Le rôle se déplacera alors depuis la liste de rôles assignés vers la liste de rôles disponibles.
- Pour ajouter un rôle exclus, sélectionner le rôle requis de la liste de rôles disponibles sur la gauche et cliquer sur le bouton avec une flèche pointant sur la droite qui se trouve à côté de la liste de rôles exclus. Le rôle se déplacera alors depuis la liste de rôles disponibles vers la liste de rôles exclus.
- Pour supprimer un rôle exclus, sélectionner le rôle requis de la liste de rôles assignés sur la droite et cliquer sur le bouton avec une flèche pointant sur la gauche qui se trouve à côté de la liste de rôles exclus. Le rôle se déplacera alors depuis la liste de rôles exclus vers la liste de rôles disponibles.
- Cliquer Sauvegarde.Si cela réussit, la vue Édit se ferme, et la liste des utilisateurs sera mise à jour pour refléter les modifications apportées. En cas d'échec, un message « Impossible d'enregistrer l'attribution de rôle » s'affichera.
Procédure 10.13. Suppression d'une attribution de rôle pour un utilisateur
- Connexion à la Console de gestion.
- Naviguer vers l'onglet Utilisateur de la section Attribution de rôles.
- Sélectionner un utilisateur dans la liste.
- Cliquer sur le bouton Suppression (Remove). La boîte de dialogue Suppression d'attribution de rôle (Remove Role Assignment) apparaîtra.
- Cliquez sur le bouton oui pour confirmer.Si cela réussit, l'utilisateur n'apparaîtra plus sur la liste d'attributions de rôle d'utilisateur.
Important
10.8.9.3. Configurer Attribution de Rôle Utilisateur avec jboss-cli.sh
jboss-cli.sh. Cette section explique uniquement comment utiliser jboss-cli.sh.
/core-service=management/access=authorization en tant qu'éléments role-mapping.
Procédure 10.14. Affichage de la Configuration Attribution de rôles
- Utiliser l'opération :read-children-names pour obtenir une liste complète des rôles configurés :
/core-service=management/access=authorization:read-children-names(child-type=role-mapping)
[standalone@localhost:9999 access=authorization] :read-children-names(child-type=role-mapping) { "outcome" => "success", "result" => [ "ADMINISTRATOR", "DEPLOYER", "MAINTAINER", "MONITOR", "OPERATOR", "SuperUser" ] } - Utiliser l'opération
read-resourced'un mappage de rôle (role-mapping) pour obtenir toutes les informations sur un rôle particulier :/core-service=management/access=authorization/role-mapping=ROLENAME:read-resource(recursive=true)
[standalone@localhost:9999 access=authorization] ./role-mapping=ADMINISTRATOR:read-resource(recursive=true) { "outcome" => "success", "result" => { "include-all" => false, "exclude" => undefined, "include" => { "user-theboss" => { "name" => "theboss", "realm" => undefined, "type" => "USER" }, "user-harold" => { "name" => "harold", "realm" => undefined, "type" => "USER" }, "group-SysOps" => { "name" => "SysOps", "realm" => undefined, "type" => "GROUP" } } } } [standalone@localhost:9999 access=authorization]
Procédure 10.15. Ajouter un nouveau rôle
- Utiliser l'opération
addpour ajouter une nouvelle configuration de rôle./core-service=management/access=authorization/role-mapping=ROLENAME:add
ROLENAME est le nom du rôle du nouveau mappage.[standalone@localhost:9999 access=authorization] ./role-mapping=AUDITOR:add {"outcome" => "success"} [standalone@localhost:9999 access=authorization]
Procédure 10.16. Ajouter un Utilisateur comme inclus dans un rôle
- Utiliser l'opération
addpour ajouter une entrée d'utilisateur dans la liste d'inclusions du rôle./core-service=management/access=authorization/role-mapping=ROLENAME/include=ALIAS:add(name=USERNAME, type=USER)
ROLENAME est le nom du rôle en cours de configuration.ALIASest un nom unique pour ce mappage. Red Hat recommande d'utiliser une convention de mappage pour tous les alias commeuser-USERNAME.USERNAME est le nom de l'utilisateur entrain d'être ajouté à la liste des inclusions.[standalone@localhost:9999 access=authorization] ./role-mapping=AUDITOR/include=user-max:add(name=max, type=USER) {"outcome" => "success"} [standalone@localhost:9999 access=authorization]
Procédure 10.17. Ajouter un Utilisateur comme exclus dans un rôle
- Utiliser l'opération
addpour ajouter une entrée d'utilisateur dans la liste d'exclusions du rôle./core-service=management/access=authorization/role-mapping=ROLENAME/exclude=ALIAS:add(name=USERNAME, type=USER)
ROLENAME est le nom du rôle en cours de configuration.USERNAME est le nom de l'utilisateur ajouté à la liste des exclusions.ALIASest un nom unique pour ce mappage. Red Hat recommande d'utiliser une convention de mappage pour tous les alias commeuser-USERNAME.[standalone@localhost:9999 access=authorization] ./role-mapping=AUDITOR/exclude=user-max:add(name=max, type=USER) {"outcome" => "success"} [standalone@localhost:9999 access=authorization]
Procédure 10.18. Configuration Suppression d'un rôle d'utilisateur d'inclusion
- Utiliser l'opération
removepour supprimer la saisie./core-service=management/access=authorization/role-mapping=ROLENAME/include=ALIAS:remove
ROLENAME est le nom du rôle en cours de configurationALIASest un nom unique pour ce mappage. Red Hat recommande d'utiliser une convention de mappage pour tous les alias commeuser-USERNAME.[standalone@localhost:9999 access=authorization] ./role-mapping=AUDITOR/include=user-max:remove {"outcome" => "success"} [standalone@localhost:9999 access=authorization]Supprimer l'utilisateur de la liste d'inclusions ne permet pas de supprimer l'utilisateur du système, ni ne garantit que le rôle ne sera pas assigné à l'utilisateur. Le rôle peut être assigné sur la base de l'appartenance à un groupe.
Procédure 10.19. Configuration Suppression d'un rôle d'utilisateur d'exclusion
- Utiliser l'opération
removepour supprimer la saisie./core-service=management/access=authorization/role-mapping=ROLENAME/exclude=ALIAS:remove
ROLENAME est le nom du rôle en cours de configuration.ALIASest un nom unique pour ce mappage. Red Hat recommande d'utiliser une convention de mappage pour tous les alias commeuser-USERNAME.[standalone@localhost:9999 access=authorization] ./role-mapping=AUDITOR/exclude=user-max:remove {"outcome" => "success"} [standalone@localhost:9999 access=authorization]Supprimer l'utilisateur de la liste d'exclusions ne permet pas de supprimer l'utilisateur du système, ni ne garantit que le rôle puisse être assigné à l'utilisateur. Le rôle peut être assigné sur la base de l'appartenance à un groupe.
10.8.9.4. Groupes Utilisateurs et Rôles
mgmt-users.properties ou d'un serveur LDAP peuvent être membres des groupes d'utilisateurs. Un groupe d'utilisateurs est une étiquette arbitraire qui peut être assignée à un ou plusieurs utilisateurs.
mgmt-users.properties, l'information groupe est stockée dans le fichier de mgmt-groups.properties. Lorsque vous utilisez LDAP, l'information groupe est stockée dans le serveur LDAP et maintenue par les responsables du serveur LDAP.
10.8.9.5. Configurer Attribution de rôles de groupe
jboss-cli.sh. Cette section explique uniquement comment utiliser la Console de gestion.
- Connectez-vous à la Console de gestion.
- Cliquer sur l'onglet Administration.
- Déployer l'élément Contrôle d'accès (Access Control) sur la gauche et sélectionner Attribution de rôles (Role Assignment).
- Sélectionner l'onglet Groupes (GROUPS).
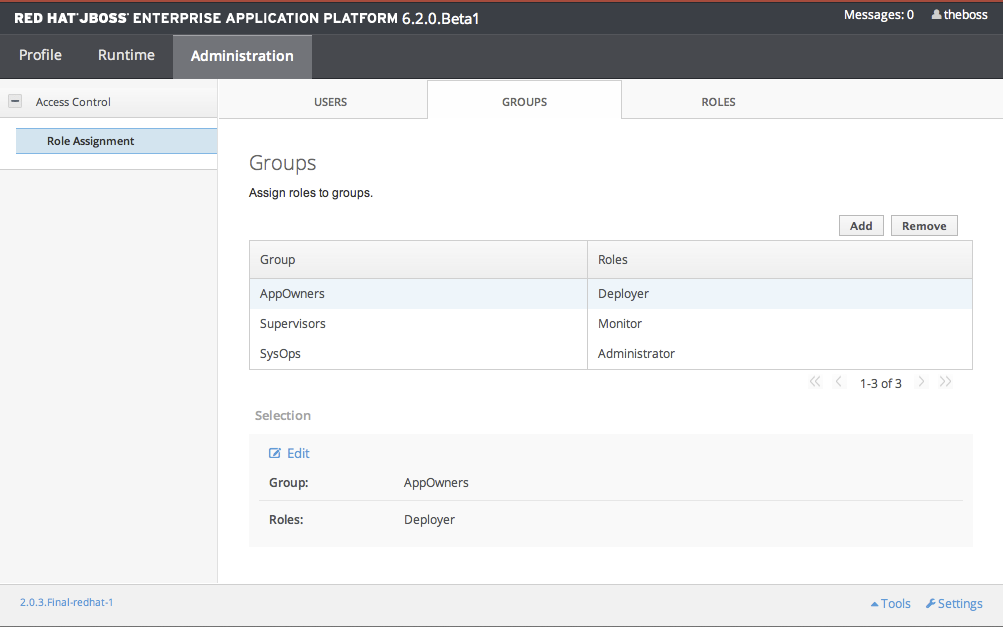
Figure 10.4. Gestion de rôle de groupe dans la Console de gestion
Procédure 10.20. Créer une nouvelle attribution de rôle pour un groupe
- Connectez-vous à la Console de gestion
- Naviguer vers l'onglet Groupes de la section Attribution de rôles.
- Cliquer sur le bouton Add en haut et à droite de la liste d'utilisateur. Le dialogue Ajouter Utilisateur (Add User) apparaîtra.
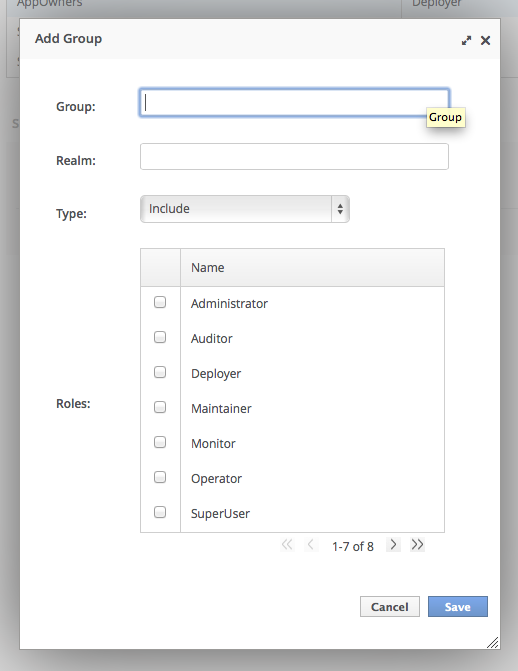
Figure 10.5. Ajouter le dialogue de groupe
- Vous devez préciser un nom de groupe, et domaine si possible.
- Définir le type de menu à inclure ou à exclure.
- Cliquer la case des rôles à inclure ou à exclure. Vous pouvez utiliser la clé de contrôle (clé de commande OSX) pour cocher les divers items.
- Cliquer Sauvegarde.Si cela réussit, la boîte de dialogue Ajouter un groupe se ferme, et la liste des groupes sera mise à jour pour refléter les modifications apportées. En cas d'échec, un message « Impossible d'enregistrer l'attribution de rôle » s'affichera.
Procédure 10.21. Mise à jour d'une attribution de rôle pour un groupe
- Connexion à la Console de gestion.
- Naviguer vers l'onglet Groupes de la section Attribution de rôles.
- Sélectionner un groupe dans la liste.
- Cliquer sur le bouton Édit. La vue de sélection est alors en mode Édit.
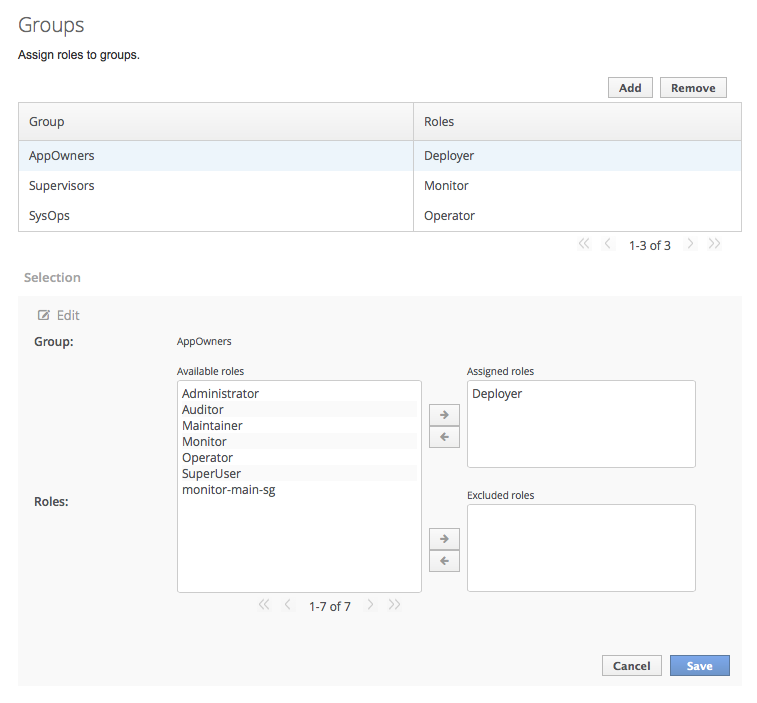
Figure 10.6. Sélection Vue Mode Édition
Vous pourrez ici ajouter ou supprimer les rôles assignés ou exclus du groupe :- Pour ajouter un rôle assigné, sélectionner le rôle requis de la liste de rôles disponibles sur la gauche et cliquer sur le bouton avec une flèche pointant sur la droite qui se trouve à côté de la liste de rôles assignés. Le rôle se déplacera alors depuis la liste de rôles disponibles vers la liste de rôles assignés.
- Pour supprimer un rôle assigné, sélectionner le rôle requis de la liste de rôles assignés sur la droite et cliquer sur le bouton avec une flèche pointant sur la gauche qui se trouve à côté de la liste de rôles assignés. Le rôle se déplacera alors depuis la liste de rôles assignés vers la liste de rôles disponibles.
- Pour ajouter un rôle exclus, sélectionner le rôle requis de la liste de rôles disponibles sur la gauche et cliquer sur le bouton avec une flèche pointant sur la droite qui se trouve à côté de la liste de rôles exclus. Le rôle se déplacera alors depuis la liste de rôles disponibles vers la liste de rôles exclus.
- Pour supprimer un rôle exclus, sélectionner le rôle requis de la liste de rôles assignés sur la droite et cliquer sur le bouton avec une flèche pointant sur la gauche qui se trouve à côté de la liste de rôles exclus. Le rôle se déplacera alors depuis la liste de rôles exclus vers la liste de rôles disponibles.
- Cliquer Sauvegarde.Si cela réussit, la vue Édit se ferme, et la liste des groupes sera mise à jour pour refléter les modifications apportées. En cas d'échec, un message « Impossible d'enregistrer l'attribution de rôle » s'affichera.
Procédure 10.22. Supprimer une attribution de rôle pour un groupe
- Connexion à la Console de gestion.
- Naviguer vers l'onglet Groupes de la section Attribution de rôles.
- Sélectionner un groupe dans la liste.
- Cliquer sur le bouton Suppression (Remove). La boîte de dialogue Suppression d'attribution de rôle (Remove Role Assignment) apparaîtra.
- Cliquez sur le bouton oui pour confirmer.Si cela réussit, le rôle n'apparaîtra plus sur la liste d'attributions de rôle d'utilisateur.La suppression du groupe de la liste d'attribution de rôles ne retire pas l'utilisateur du système, ni ne garantit qu'aucun rôle ne sera assigné aux membres de ce groupe. Chaque membre du groupe peut encore avoir un rôle qui lui soit directement assigné.
10.8.9.6. Configurer Attribution de rôles de groupe avec jboss-cli.sh
jboss-cli.sh. Cette section explique uniquement comment utiliser l'outil jboss-cli.sh.
/core-service=management/access=authorization en tant qu'éléments de mappage.
Procédure 10.23. Affichage de la Configuration Attribution de rôles de groupe
- Utiliser l'opération
read-children-namespour obtenir une liste complète des rôles configurés :/core-service=management/access=authorization:read-children-names(child-type=role-mapping)
[standalone@localhost:9999 access=authorization] :read-children-names(child-type=role-mapping) { "outcome" => "success", "result" => [ "ADMINISTRATOR", "DEPLOYER", "MAINTAINER", "MONITOR", "OPERATOR", "SuperUser" ] } - Utiliser l'opération
read-resourced'un mappage de rôle (role-mapping) pour obtenir toutes les informations sur un rôle particulier :/core-service=management/access=authorization/role-mapping=ROLENAME:read-resource(recursive=true)
[standalone@localhost:9999 access=authorization] ./role-mapping=ADMINISTRATOR:read-resource(recursive=true) { "outcome" => "success", "result" => { "include-all" => false, "exclude" => undefined, "include" => { "user-theboss" => { "name" => "theboss", "realm" => undefined, "type" => "USER" }, "user-harold" => { "name" => "harold", "realm" => undefined, "type" => "USER" }, "group-SysOps" => { "name" => "SysOps", "realm" => undefined, "type" => "GROUP" } } } } [standalone@localhost:9999 access=authorization]
Procédure 10.24. Ajouter un nouveau rôle
- Utiliser l'opération
addpour ajouter une nouvelle configuration de rôle./core-service=management/access=authorization/role-mapping=ROLENAME:add
[standalone@localhost:9999 access=authorization] ./role-mapping=AUDITOR:add {"outcome" => "success"} [standalone@localhost:9999 access=authorization]
Procédure 10.25. Ajouter un Groupe comme inclus dans un rôle
- Utiliser l'opération
addpour ajouter une entrée de Groupe dans la liste d'inclusions du rôle./core-service=management/access=authorization/role-mapping=ROLENAME/include=ALIAS:add(name=GROUPNAME, type=GROUP)
ROLENAME est le nom du rôle en cours de configuration.GROUPNAME est le nom du groupe entrain d'être ajouté à la liste des inclusions.ALIASest un nom unique pour ce mappage. Red Hat recommande d'utiliser une convention de mappage pour tous les alias commegroup-GROUPNAME.[standalone@localhost:9999 access=authorization] ./role-mapping=AUDITOR/include=group-investigators:add(name=investigators, type=GROUP) {"outcome" => "success"} [standalone@localhost:9999 access=authorization]
Procédure 10.26. Ajouter un groupe comme exclus dans un rôle
- Utiliser l'opération
addpour ajouter une entrée de Groupe dans la liste d'exclusions du rôle./core-service=management/access=authorization/role-mapping=ROLENAME/exclude=ALIAS:add(name=GROUPNAME, type=GROUP)
ROLENAME est le nom du rôle en cours de configurationGROUPNAME est le nom du groupe entrain d'être ajouté à la liste des inclusionsALIASest un nom unique pour ce mappage. Red Hat recommande d'utiliser une convention de mappage pour tous les alias commegroup-GROUPNAME.[standalone@localhost:9999 access=authorization] ./role-mapping=AUDITOR/exclude=group-supervisors:add(name=supervisors, type=USER) {"outcome" => "success"} [standalone@localhost:9999 access=authorization]
Procédure 10.27. Configuration Suppression d'un rôle de groupe
- Utiliser l'opération
removepour supprimer la saisie./core-service=management/access=authorization/role-mapping=ROLENAME/include=ALIAS:remove
ROLENAME est le nom du rôle en cours de configurationALIASest un nom unique pour ce mappage. Red Hat recommande d'utiliser une convention de mappage pour tous les alias commegroup-GROUPNAME.[standalone@localhost:9999 access=authorization] ./role-mapping=AUDITOR/include=group-investigators:remove {"outcome" => "success"} [standalone@localhost:9999 access=authorization]Supprimer le groupe de la liste d'inclusions ne permet pas de supprimer le groupe du système, ni ne garantit que le rôle ne sera pas assigné à des utilisateurs de ce groupe. Le rôle peut être assigné à des utilisateurs du groupe individuellement.
Procédure 10.28. Supprimer une entrée d'exclusion de groupe d'utilisateurs
- Utiliser l'opération
removepour supprimer la saisie./core-service=management/access=authorization/role-mapping=ROLENAME/exclude=ALIAS:remove
ROLENAME est le nom du rôle en cours de configuration.ALIASest un nom unique pour ce mappage. Red Hat recommande d'utiliser une convention de mappage pour tous les alias commegroup-GROUPNAME.[standalone@localhost:9999 access=authorization] ./role-mapping=AUDITOR/exclude=group-supervisors:remove {"outcome" => "success"} [standalone@localhost:9999 access=authorization]Supprimer le groupe de la liste d'exclusions ne permet pas de supprimer le groupe du système, ni ne garantit que le rôle ne va pas être assigné à des membres du groupe. Les rôles peuvent être exclus sur la base de l'appartenance à un groupe.
10.8.9.7. Autorisation et Chargement de groupes avec LDAP
<authorization>
<ldap connection="...">
<username-to-dn> <!-- OPTIONAL -->
<!-- Only one of the following. -->
<username-is-dn />
<username-filter base-dn="..." recursive="..." user-dn-attribute="..." attribute="..." />
<advanced-filter base-dn="..." recursive="..." user-dn-attribute="..." filter="..." />
</username-to-dn>
<group-search group-name="..." iterative="..." group-dn-attribute="..." group-name-attribute="..." >
<!-- One of the following -->
<group-to-principal base-dn="..." recursive="..." search-by="...">
<membership-filter principal-attribute="..." />
</group-to-principal>
<principal-to-group group-attribute="..." />
</group-search>
</ldap>
</authorization>
Important
username-to-dn
username-to-dn indique comment elle est définie. Cet élément est uniquement nécessaire si ce qui suit est true :
- L'étape d'authentification n'a pas eu lieu avec LDAP.
- La recherche de groupe utilise le nom unique pendant la recherche.
- 1:1 username-to-dn
- Il s'agit de la forme de configuration de base et elle est utilisée pour spécifier que le nom d'utilisateur saisi par l'utilisateur éloigné est en fait le nom unique de l'utilisateur.
<username-to-dn> <username-is-dn /> </username-to-dn>
Comme cela définit un mappage 1:1, il n'y a pas de configuration supplémentaire possible. - username-filter
- La prochaine option est très semblable à la simple option décrite ci-dessus dans l'étape d'authentification. Tout simplement, un attribut est spécifié et on recherche une correspondance avec le nom d'utilisateur fourni.
<username-to-dn> <username-filter base-dn="dc=people,dc=harold,dc=example,dc=com" recursive="false" attribute="sn" user-dn-attribute="dn" /> </username-to-dn>Les attributs qui peuvent être définis sont les suivants :base-dn: le nom unique du contexte pour commencer la recherche.recursive: indique si la recherche va s'étendre à des sous-contextes. La valeur par défaut estfalse.attribute: l'attribut de l'entrée de l'utilisateur à faire correspondre avec le nom d'utilisateur fourni. La valeur par défaut estuid.user-dn-attribute: l'attribut à lire pour obtenir les noms uniques d'utilisateurs. La valeur par défaut estdn.
- advanced-filter
- L'option finale est de spécifier un filtre avancé. Comme dans la section authentification, c'est l'opportunité d'utiliser un filtre personnalisé pour trouver le nom unique de l'utilisateur.
<username-to-dn> <advanced-filter base-dn="dc=people,dc=harold,dc=example,dc=com" recursive="false" filter="sAMAccountName={0}" user-dn-attribute="dn" /> </username-to-dn>Pour les attributs qui correspondent à celles du username-filter, le sens et les valeurs par défaut sont les mêmes, donc je ne vais pas les énumérer ici et cela laisse un nouvel attribut :filter: filtre personnalisé utilisé pour chercher une entrée d'utilisateur quand le nom d'utilisateur est substitué dans l'espace réservé{0}
Important
Le code XML doit rester valide une fois que le filtre est défini donc si des caractères spéciaux comme&sont utilisés, assurez-vous que la forme qui convient soit utilisée. Par exemple& amp ;pour le caractère&.
La recherche Groupe
Exemple 10.20. Principal à Groupe - Exemple LDIF
TestUserOne, qui est membre de GroupOne, GroupOne est alors à son tour membre de GroupFive. L'appartenance au groupe est démontrée par l'utilisation d'un attribut memberOf qui est défini sur le nom unique du groupe dont l'utilisateur est membre.
memberOf définis, un pour chaque groupe dont l'utilisateur est un membre direct.
dn: uid=TestUserOne,ou=users,dc=principal-to-group,dc=example,dc=org objectClass: extensibleObject objectClass: top objectClass: groupMember objectClass: inetOrgPerson objectClass: uidObject objectClass: person objectClass: organizationalPerson cn: Test User One sn: Test User One uid: TestUserOne distinguishedName: uid=TestUserOne,ou=users,dc=principal-to-group,dc=example,dc=org memberOf: uid=GroupOne,ou=groups,dc=principal-to-group,dc=example,dc=org memberOf: uid=Slashy/Group,ou=groups,dc=principal-to-group,dc=example,dc=org userPassword:: e1NTSEF9WFpURzhLVjc4WVZBQUJNbEI3Ym96UVAva0RTNlFNWUpLOTdTMUE9PQ== dn: uid=GroupOne,ou=groups,dc=principal-to-group,dc=example,dc=org objectClass: extensibleObject objectClass: top objectClass: groupMember objectClass: group objectClass: uidObject uid: GroupOne distinguishedName: uid=GroupOne,ou=groups,dc=principal-to-group,dc=example,dc=org memberOf: uid=GroupFive,ou=subgroups,ou=groups,dc=principal-to-group,dc=example,dc=org dn: uid=GroupFive,ou=subgroups,ou=groups,dc=principal-to-group,dc=example,dc=org objectClass: extensibleObject objectClass: top objectClass: groupMember objectClass: group objectClass: uidObject uid: GroupFive distinguishedName: uid=GroupFive,ou=subgroups,ou=groups,dc=principal-to-group,dc=example,dc=org
Exemple 10.21. Groupe à Principal - Exemple LDIF
TestUserOne qui est un membre de GroupOne, qui est à son tour membre de GroupFive - cependant dans ce cas, c'est un attribut uniqueMember du groupe à l'utilisateur utilisé pour la référence croisée.
dn: uid=TestUserOne,ou=users,dc=group-to-principal,dc=example,dc=org objectClass: top objectClass: inetOrgPerson objectClass: uidObject objectClass: person objectClass: organizationalPerson cn: Test User One sn: Test User One uid: TestUserOne userPassword:: e1NTSEF9SjR0OTRDR1ltaHc1VVZQOEJvbXhUYjl1dkFVd1lQTmRLSEdzaWc9PQ== dn: uid=GroupOne,ou=groups,dc=group-to-principal,dc=example,dc=org objectClass: top objectClass: groupOfUniqueNames objectClass: uidObject cn: Group One uid: GroupOne uniqueMember: uid=TestUserOne,ou=users,dc=group-to-principal,dc=example,dc=org dn: uid=GroupFive,ou=subgroups,ou=groups,dc=group-to-principal,dc=example,dc=org objectClass: top objectClass: groupOfUniqueNames objectClass: uidObject cn: Group Five uid: GroupFive uniqueMember: uid=TestUserFive,ou=users,dc=group-to-principal,dc=example,dc=org uniqueMember: uid=GroupOne,ou=groups,dc=group-to-principal,dc=example,dc=org
Recherche de groupe standard
<group-search group-name="..." iterative="..." group-dn-attribute="..." group-name-attribute="..." >
...
</group-search>
group-name: cet attribut est utilisé pour indiquer le formulaire qui doit être utilisé pour le nom de groupe retourné comme liste de groupes dont l'utilisateur est membre, cela peut être sous la simple forme de nom du groupe ou le nom unique du groupe, si le nom unique est nécessaire, cet attribut peut être défini àDISTINGUISHED_NAME. Valeur par défautSIMPLE.itérative: cet attribut est utilisé pour indiquer si après avoir identifié les groupes qui appartiennent à un utilisateur, on doit rechercher également de manière itérative basée sur les groupes afin d'identifier quels groupes appartiennent à quels groupes. Si la recherche itérative est activée, nous continuons jusqu'à ce que nous rejoignions un groupe qui ne soit pas membre si aucun autre groupe ou cycle est détecté. Par défaut,false.
Important
group-dn-attribute: sur une entrée pour un groupe dont l'attribut est son nom unique. La valeur par défaut estdn.group-name-attribute: sur une entrée pour un groupe dont l'attribut est son simple nom. La valeur par défautuid.
Exemple 10.22. Configuration d'exemple de Principal à Groupe
memberOf de l'utilisateur.
<authorization>
<ldap connection="LocalLdap">
<username-to-dn>
<username-filter base-dn="ou=users,dc=principal-to-group,dc=example,dc=org" recursive="false" attribute="uid" user-dn-attribute="dn" />
</username-to-dn>
<group-search group-name="SIMPLE" iterative="true" group-dn-attribute="dn" group-name-attribute="uid">
<principal-to-group group-attribute="memberOf" />
</group-search>
</ldap>
</authorization>
principal-to-group a été ajouté avec un seul attribut.
group-attribute: le nom de l'attribut sur l'entrée d'utilisateur qui correspond au nom unique du groupe qui appartient à l'utilisateur. La valeur par défautmemberOf.
Exemple 10.23. Configuration d'exemple de Groupe à Principal
<authorization>
<ldap connection="LocalLdap">
<username-to-dn>
<username-filter base-dn="ou=users,dc=group-to-principal,dc=example,dc=org" recursive="false" attribute="uid" user-dn-attribute="dn" />
</username-to-dn>
<group-search group-name="SIMPLE" iterative="true" group-dn-attribute="dn" group-name-attribute="uid">
<group-to-principal base-dn="ou=groups,dc=group-to-principal,dc=example,dc=org" recursive="true" search-by="DISTINGUISHED_NAME">
<membership-filter principal-attribute="uniqueMember" />
</group-to-principal>
</group-search>
</ldap>
</authorization>
group-to-principal est ajouté ici. Cet élément est utilisé pour définir comment les recherches de groupes qui référencent l'entrée de l'utilisateur seront exécutées. Les attributs suivants sont définis :
base-dn: le nom unique du contexte à utiliser pour commencer la recherche.recursive: indique si les sous-contextes peuvent également être recherchés. La valeur par défaut estfalse.search-by: Le forme du nom de rôle utilisé dans les recherches. Valeurs validesSIMPLEetDISTINGUISHED_NAME. Valeur par défautDISTINGUISHED_NAME.
principal-attribute: le nom de l'attribut d'entrée de groupe qui référence l'entrée utilisateur. La valeur par défaut estmember.
10.8.9.8. Scoped Rôles
- Un nom unique.
- Qui correspond aux rôles standards sur lesquels il est basé.
- S'il s'applique au Groupes de serveurs ou aux Hôtes
- La liste des groupes de serveurs ou hôtes auxquels il est limité.
- Si tous les utilisateurs sont inclus automatiquement. La valeur par défaut sera false.
- Rôles Host-scoped
- Un rôle non host-scoped limite les permissions de ce rôle à un ou plusieurs hôtes. Cela signifie que l'accès est donné aux arborescences de ressources
/host=*/qui conviennent, mais les ressources spécifiques à d'autres hôtes sont cachées. - Rôles Server-Group-scoped
- Un rôle server-group-scoped limite les permissions de ce rôle à un ou plusieurs groupes de serveurs. De plus, les permissions de rôle seront appliquées également au profil, groupe de liaison de socket, config du serveur et aux ressources de serveur qui sont associées avec les groupes de serveur spécifiés. Toutes les ressources secondaires à l'intérieur qui ne sont pas liées de manière logique au groupe de serveurs ne seront pas visibles par l'utilisateur.
10.8.9.9. Création de Rôles scoped
- Connectez-vous à la console de gestion
- Cliquer sur l'onglet Administration
- Étendre l'élément Contrôle d'accès sur la gauche et sélectionner Attribution de rôles.
- Sélectionner l'onglet ROLES, puis l'onglet Scoped roles à l'intérieur.
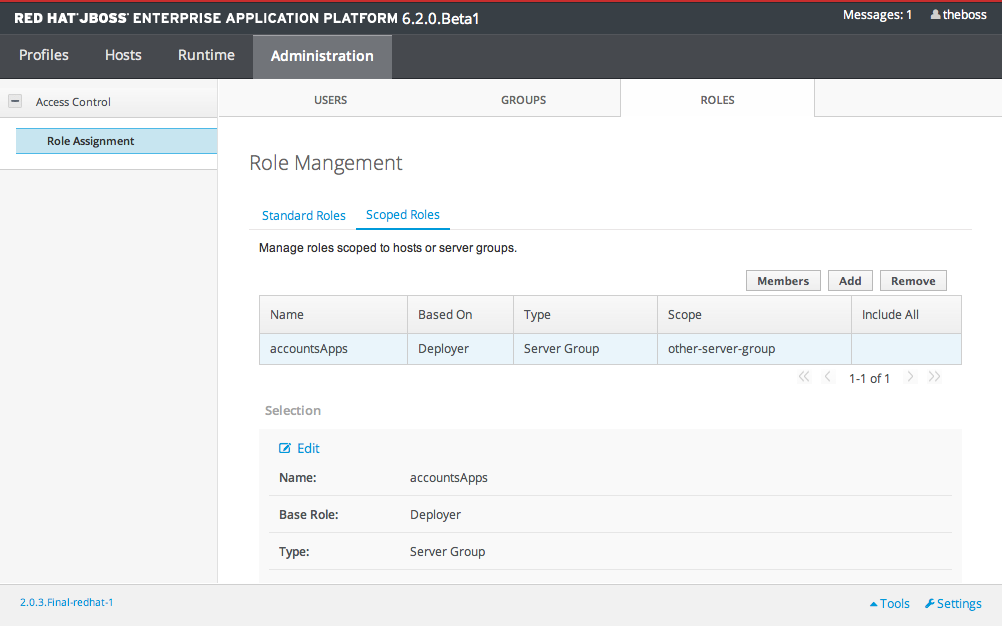
Figure 10.7. Configuration des Scoped roles dans la Console de gestion.
Procédure 10.29. Ajouter un Nouveau Scoped role
- Connectez-vous à la console de gestion
- Naviguez vers la partie Scoped roles de l'onglet Rôles.
- Cliquer sur le bouton Ajouter. La boîte de dialogues Ajouter apparaîtra.
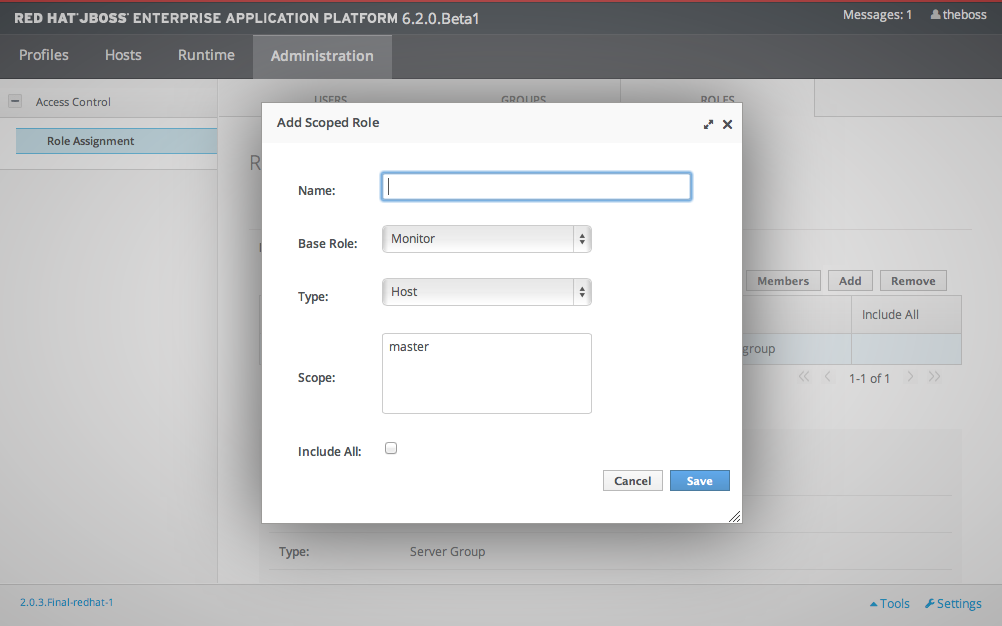
Figure 10.8. Ajouter la boite de dialogues Scoped role.
- Indiquer les détails suivants :
- Name, le nom unique du nouveau scoped role.
- Base Role, le rôle sur lequel ce rôle basera sa permission.
- Type, indique si ce rôle sera limité à des hôtes ou groupes de serveurs.
- Scope, la liste d'hôtes ou de groupes de serveurs auxquels le rôle est limité. Vous pouvez sélectionner plusieurs entrées.
- Include All, indique si le rôle doit automatiquement inclure tous les utilisateurs. La valeur par défaut est non.
- Cliquer sur le bouton de Sauvegarde. La boîte de dialogue se fermera et le rôle nouvellement créé apparaîtra dans le tableau.
Procédure 10.30. Modifier un Scoped Role.
- Connectez-vous à la console de gestion
- Naviguer dans la partie Scoped roles de l'onglet Rôles.
- Cliquer sur le scoped role que vous souhaitez modifier dans le tableau. Les détails de ce rôle apparaissent dans le Panneau de sélection qui se trouve sous le tableau.
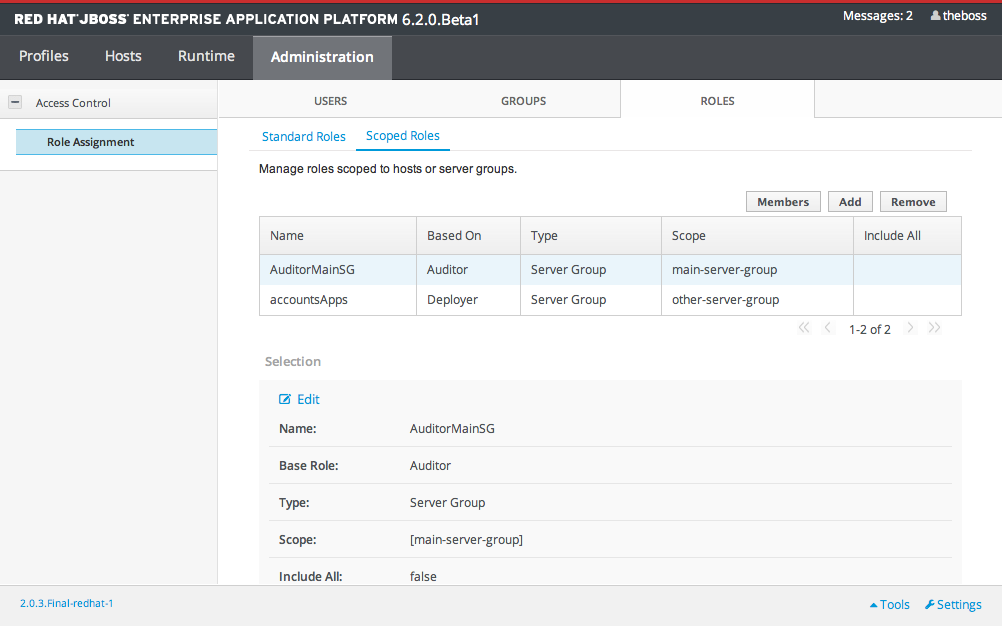
Figure 10.9. Rôle sélectionné.
- Cliquer sur le lien Modifier du Panneau de sélection. Le panneau de sélection passera alors en mode d'édition.
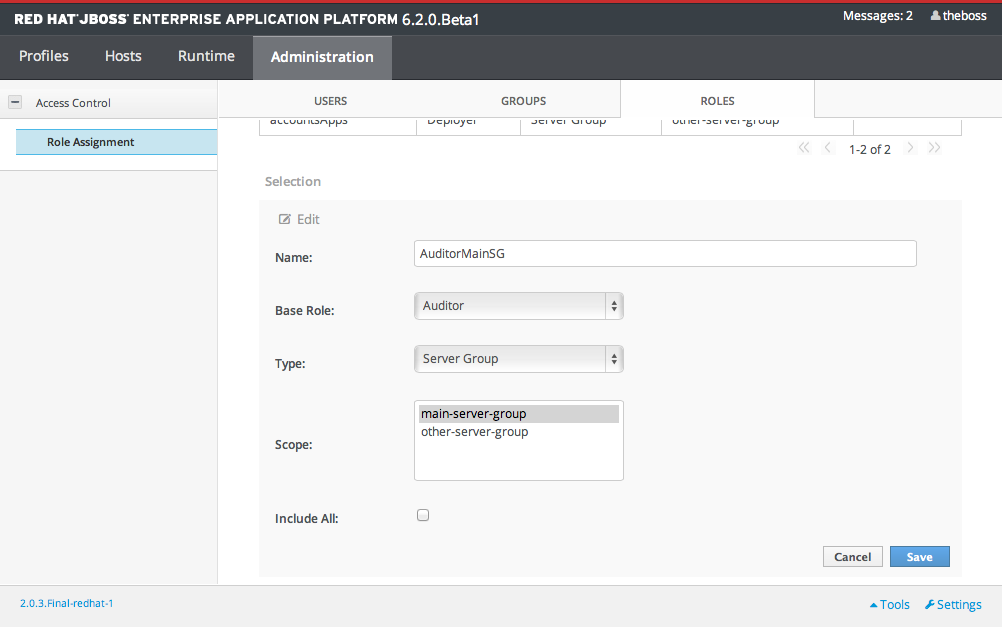
Figure 10.10. Panneau de sélection en Mode édition.
- Mettre à jour les informations que vous souhaitez modifier et cliquer sur le bouton Sauvegarde. Le Panneau de sélection retourne à son état précédent. Le panneau de sélection et le tableau afficheront les informations nouvellement mises à jour.
Procédure 10.31. Afficher les membres scoped role
- Connectez-vous à la console de gestion
- Naviguer dans la partie Scoped roles de l'onglet Rôles.
- Cliquer sur le scoped role du tableau dont vous souhaitez voir les membres, puis cliquer sur le bouton Membres. La boîte de dialogue Rôles de membres apparaîtra. Elle nous affichera les utilisateurs et les groupes qui sont inclus ou exclus du rôle.
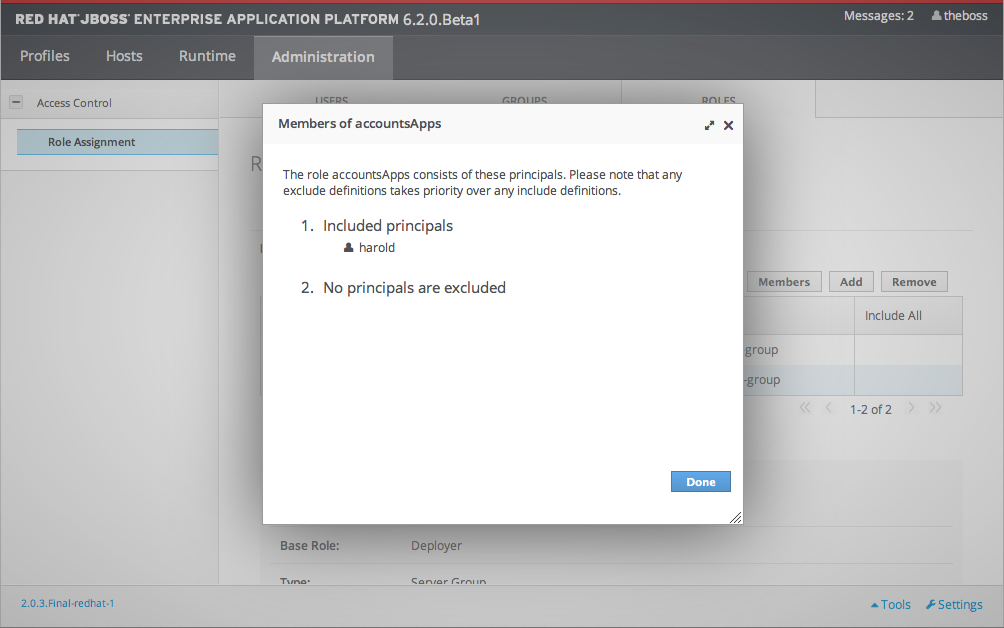
Figure 10.11. Dialogue Appartenance à un rôle
- Cliquer sur le bouton Terminé quand vous aurez fini de consulter cette information.
Procédure 10.32. Supprimer un Scoped Role.
Important
- Connectez-vous à la console de gestion
- Naviguer dans la partie Scoped roles de l'onglet Rôles.
- Sélectionner le scoped role à supprimer du tableau.
- Cliquer sur le bouton Suppression. La boîte de dialogue Suppression Scoped Role apparaîtra.
- Cliquer sur le bouton Confirmer. La boîte de dialogue se fermera et le rôle sera supprimé.
10.8.10. Configurer les contraintes
10.8.10.1. Configurer les contraintes de sensibilité
/core-service=management/access=authorization/constraint=sensitivity-classification.
classification. Les classifications sont ensuite regroupées en types. Il existe 39 catégories incluses qui sont regroupées en 13 types.
write-attribut permet de paramétrer les attributs configured-requires-read, configured-requires-write, ou configured-requires-addressable. Pour rendre ce type d'opération sensible, définir la valeur de l'attribut à true, sinon, pour le rendre non sensible, le définir à la valeur false. Par défaut, ces attributs ne sont pas définis et les valeurs default-requires-read, default-requires-write, et default-requires-addressable seront utilisées. Une fois que l'attribut est configuré, ce sera cette valeur qui sera utilisée à la place de la valeur par défaut. Impossible de modifier les valeurs par défaut.
Exemple 10.24. Comment rendre les propriétés système des opérations sensibles.
[domain@localhost:9999 /] cd /core-service=management/access=authorization/constraint=sensitivity-classification/type=core/classification=system-property
[domain@localhost:9999 classification=system-property] :write-attribute(name=configured-requires-read, value=true)
{
"outcome" => "success",
"result" => undefined,
"server-groups" => {"main-server-group" => {"host" => {"master" => {
"server-one" => {"response" => {"outcome" => "success"}},
"server-two" => {"response" => {"outcome" => "success"}}
}}}}
}
[domain@localhost:9999 classification=system-property] :read-resource
{
"outcome" => "success",
"result" => {
"configured-requires-addressable" => undefined,
"configured-requires-read" => true,
"configured-requires-write" => undefined,
"default-requires-addressable" => false,
"default-requires-read" => false,
"default-requires-write" => true,
"applies-to" => {
"/host=master/system-property=*" => undefined,
"/host=master/core-service=platform-mbean/type=runtime" => undefined,
"/server-group=*/system-property=*" => undefined,
"/host=master/server-config=*/system-property=*" => undefined,
"/host=master" => undefined,
"/system-property=*" => undefined,
"/" => undefined
}
}
}
[domain@localhost:9999 classification=system-property]
Tableau 10.3. Résultats des configurations de contraintes de sensibilité
| Valeur | requires-read | requires-write | requires-addressable |
|---|---|---|---|
true
|
L'opération lecture est sensible.
Seuls les rôles Auditeur, Administrateur, ou SuperUtilisateur peuvent lire.
|
L'opération écriture est sensible.
Seuls les Administrateurs et les SuperUtilisateurs peuvent écrire.
|
L'opération Adressage est sensible.
Seuls les rôles Auditeur, Administrateur, ou SuperUtilisateur peuvent adresser.
|
false
|
L'opération lecture n'est pas sensible.
Tous les utilisateurs de gestion peuvent lire.
|
L'opération écriture n'est pas sensible.
Seuls les rôles Mainteneur, Administrateur, ou SuperUtilisateur peuvent écrire. Les Déployeurs peuvent également écrire la ressource dans une ressource d'applications.
|
L'opération Adressage n'est pas sensible.
Tous les utilisateurs de gestion peuvent adresser.
|
10.8.10.2. Configurer les contraintes des ressources d'applications
/core-service=management/access=authorization/constraint=application-classification/.
classification. Les classifications sont ensuite regroupées en types. Il existe 14 catégories incluses qui sont regroupées en 8 types. Chaque classification comporte un élément applies-to qui correspond à une liste de modèles de chemins d'accès de ressources auxquels s'applique la configuration de la classification.
core. Core inclut des déploiements, des superpositions de déploiement et des opérations de déploiement.
write-attribute permet de définir l'attribut configured-application attribute de la classification sur true. Pour désactiver une ressource d'application, définir cet attribut sur false. Par défaut, ces attributs ne sont pas définis et la valeur default-application attribute sera utilisée. La valeur par défaut ne peut pas être changée
Exemple 10.25. Activer la classification des ressources d'application logger-profile
[domain@localhost:9999 /] cd /core-service=management/access=authorization/constraint=application-classification/type=logging/classification=logging-profile
[domain@localhost:9999 classification=logging-profile] :write-attribute(name=configured-application, value=true)
{
"outcome" => "success",
"result" => undefined,
"server-groups" => {"main-server-group" => {"host" => {"master" => {
"server-one" => {"response" => {"outcome" => "success"}},
"server-two" => {"response" => {"outcome" => "success"}}
}}}}
}
[domain@localhost:9999 classification=logging-profile] :read-resource
{
"outcome" => "success",
"result" => {
"configured-application" => true,
"default-application" => false,
"applies-to" => {"/profile=*/subsystem=logging/logging-profile=*" => undefined}
}
}
[domain@localhost:9999 classification=logging-profile]
Important
10.8.10.3. Configuration de contraintes d'expressions d'archivage sécurisé
/core-service=management/access=authorization/constraint=vault-expression.
write-attribute pour définir les attributs de configured-requires-write et configured-requires-read à true ou false. Par défaut, celles-ci ne sont pas définies et les valeurs default-requires-read et default-requires-write sont utilisées. Impossible de modifier les valeurs par défaut.
Exemple 10.26. Comment rendre l'écriture d'expressions d'archivage une opération non sensible
[domain@localhost:9999 /] cd /core-service=management/access=authorization/constraint=vault-expression
[domain@localhost:9999 constraint=vault-expression] :write-attribute(name=configured-requires-write, value=false)
{
"outcome" => "success",
"result" => undefined,
"server-groups" => {"main-server-group" => {"host" => {"master" => {
"server-one" => {"response" => {"outcome" => "success"}},
"server-two" => {"response" => {"outcome" => "success"}}
}}}}
}
[domain@localhost:9999 constraint=vault-expression] :read-resource
{
"outcome" => "success",
"result" => {
"configured-requires-read" => undefined,
"configured-requires-write" => false,
"default-requires-read" => true,
"default-requires-write" => true
}
}
[domain@localhost:9999 constraint=vault-expression]
Tableau 10.4. Résultats des configurations de contraintes d'expressions d'archivage sécurisé
| Valeur | requires-read | requires-write |
|---|---|---|
true
|
L'opération lecture est sensible.
Seuls les rôles Auditeur, Administrateur, ou SuperUtilisateur peuvent lire.
|
L'opération écriture est sensible.
Seuls les Administrateurs et les SuperUtilisateurs peuvent écrire.
|
false
|
L'opération lecture n'est pas sensible.
Tous les utilisateurs de gestion peuvent lire.
|
L'opération écriture n'est pas sensible.
Les rôles Moniteur, Administrateur, ou SuperUtilisateur peuvent écrire. Les Déployeurs peuvent également écrire si l'expression d'archivage de sécurité est dans une ressource d'applications.
|
10.8.11. Références de contraintes
10.8.11.1. Références de contraintes des ressources d'applications
Type: core
- Classification: deployment-overlay
- default: true
CHEMIN Attributs Opérations /deployment-overlay=*/deployment=*/upload-deployment-stream, full-replace-deployment, upload-deployment-url, upload-deployment-bytes
Type: datasources
- Classification: datasource
- default: false
CHEMIN Attributs Opérations /deployment=*/subdeployment=*/subsystem=datasources/data-source=*/subsystem=datasources/data-source=*/subsystem=datasources/data-source=ExampleDS/deployment=*/subsystem=datasources/data-source=*
- Classification: jdbc-driver
- default: false
CHEMIN Attributs Opérations /subsystem=datasources/jdbc-driver=*
- Classification: xa-data-source
- default: false
CHEMIN Attributs Opérations /subsystem=datasources/xa-data-source=*/deployment=*/subsystem=datasources/xa-data-source=*/deployment=*/subdeployment=*/subsystem=datasources/xa-data-source=*
Type: logging
- Classification: logger
- default: false
CHEMIN Attributs Opérations /subsystem=logging/logger=*/subsystem=logging/logging-profile=*/logger=*
- Classification: logging-profile
- default: false
CHEMIN Attributs Opérations /subsystem=logging/logging-profile=*
Type: mail
- Classification: mail-session
- default: false
CHEMIN Attributs Opérations /subsystem=mail/mail-session=*
Type: naming
- Classification: binding
- default: false
CHEMIN Attributs Opérations /subsystem=naming/binding=*
Type: resource-adapters
- Classification: resource-adapters
- default: false
CHEMIN Attributs Opérations /subsystem=resource-adapters/resource-adapter=*
Type: security
- Classification: security-domain
- default: false
CHEMIN Attributs Opérations /subsystem=security/security-domain=*
10.8.11.2. Références de contraintes de sensibilité
Type: core
- Classification: access-control
- requires-addressable: true
- requires-read: true
- requires-write: true
CHEMIN attributs opérations /core-service=management/access=authorization/subsystem=jmxnon-core-mbean-sensitivity
- Classification: credential
- requires-addressable: false
- requires-read: true
- requires-write: true
CHEMIN attributs opérations /subsystem=mail/mail-session=*/server=pop3username , password/subsystem=mail/mail-session=*/server=imapnom d'utilisateur, mot de passe/subsystem=datasources/xa-data-source=*user-name, recovery-username, password, recovery-password/subsystem=mail/mail-session=*/custom=*nom d'utilisateur, mot de passe/subsystem=datasources/data-source=*"Nom d'utilisateur, mot de passe/subsystem=remoting/remote-outbound-connection=*"nom d'utilisateur/subsystem=mail/mail-session=*/server=smtpusername , password/subsystem=web/connector=*/configuration=sslkey-alias, password/subsystem=resource-adapters/resource-adapter=*/connection-definitions=*"recovery-username, recovery-password
- Classification: domain-controller
- requires-addressable: false
- requires-read: false
- requires-write: true
CHEMIN attributs opérations
- Classification: domain-names
- requires-addressable: false
- requires-read: false
- requires-write: true
CHEMIN attributs opérations
- Classification: extensions
- requires-addressable: false
- requires-read: false
- requires-write: true
CHEMIN attributs opérations /extension=*
- Classification: jvm
- requires-addressable: false
- requires-read: false
- requires-write: true
CHEMIN attributs opérations /core-service=platform-mbean/type=runtimeinput-arguments, boot-class-path, class-path, boot-class-path-supported, library-path
- Classification: management-interfaces
- requires-addressable: false
- requires-read: false
- requires-write: true
CHEMIN attributs opérations /core-service=management/management-interface=native-interface/core-service=management/management-interface=http-interface
- Classification: module-loading
- requires-addressable: false
- requires-read: false
- requires-write: true
CHEMIN attributs opérations /core-service=module-loading
- Classification: patching
- requires-addressable: false
- requires-read: false
- requires-write: true
CHEMIN attributs opérations /core-service=patching/addon=*/core-service=patching/layer=*"/core-service=patching
- Classification: read-whole-config
- requires-addressable: false
- requires-read: true
- requires-write: true
CHEMIN attributs opérations /read-config-as-xml
- Classification: security-domain
- requires-addressable: true
- requires-read: true
- requires-write: true
CHEMIN attributs opérations /subsystem=security/security-domain=*
- Classification: security-domain-ref
- requires-addressable: true
- requires-read: true
- requires-write: true
CHEMIN attributs opérations /subsystem=datasources/xa-data-source=*security-domain/subsystem=datasources/data-source=*security-domain/subsystem=ejb3default-security-domain/subsystem=resource-adapters/resource-adapter=*/connection-definitions=*security-domain, recovery-security-domain, security-application, security-domain-and-application
- Classification: security-realm
- requires-addressable: true
- requires-read: true
- requires-write: true
CHEMIN attributs opérations /core-service=management/security-realm=*
- Classification: security-realm-ref
- requires-addressable: true
- requires-read: true
- requires-write: true
CHEMIN attributs opérations /subsystem=remoting/connector=*security-realm/core-service=management/management-interface=native-interfacesecurity-realm/core-service=management/management-interface=http-interfacesecurity-realm/subsystem=remoting/remote-outbound-connection=*security-realm
- Classification: security-vault
- requires-addressable: false
- requires-read: false
- requires-write: true
CHEMIN attributs opérations /core-service=vault
- Classification: service-container
- requires-addressable: false
- requires-read: false
- requires-write: true
CHEMIN attributs opérations /core-service=service-container
- Classification: snapshots
- requires-addressable: false
- requires-read: false
- requires-write: false
CHEMIN attributs opérations /take-snapshot, list-snapshots, delete-snapshot
- Classification: socket-binding-ref
- requires-addressable: false
- requires-read: false
- requires-write: false
CHEMIN attributs opérations /subsystem=mail/mail-session=*/server=pop3outbound-socket-binding-ref/subsystem=mail/mail-session=*/server=imapoutbound-socket-binding-ref/subsystem=remoting/connector=*socket-binding/subsystem=web/connector=*socket-binding/subsystem=remoting/local-outbound-connection=*outbound-socket-binding-ref/socket-binding-group=*/local-destination-outbound-socket-binding=*socket-binding-ref/subsystem=remoting/remote-outbound-connection=*outbound-socket-binding-ref/subsystem=mail/mail-session=*/server=smtpoutbound-socket-binding-ref/subsystem=transactionsprocess-id-socket-binding, status-socket-binding, socket-binding
- Classification: socket-config
- requires-addressable: false
- requires-read: false
- requires-write: true
CHEMIN attributs opérations /interface=*resolve-internet-address/core-service=management/management-interface=native-interfaceport, interface, socket-binding/socket-binding-group=*/core-service=management/management-interface=http-interfaceport, secure-port, interface, secure-socket-binding, socket-binding/resolve-internet-address/subsystem=transactionsprocess-id-socket-max-ports
- Classification: system-property
- requires-addressable: false
- requires-read: false
- requires-write: true
CHEMIN attributs opérations /core-service=platform-mbean/type=runtimesystem-properties/system-property=*/resolve-expression
Type: datasources
- Classification: data-source-security
- requires-addressable: false
- requires-read: true
- requires-write: true
CHEMIN attributs opérations /subsystem=datasources/xa-data-source=*user-name, security-domain, password/subsystem=datasources/data-source=*user-name, security-domain, password
Type: jdr
- Classification: jdr
- requires-addressable: false
- requires-read: false
- requires-write: true
CHEMIN attributs opérations /subsystem=jdrgenerate-jdr-report
Type: jmx
- Classification: jmx
- requires-addressable: false
- requires-read: false
- requires-write: true
CHEMIN attributs opérations /subsystem=jmx
Type: mail
- Classification: mail-server-security
- requires-addressable: false
- requires-read: false
- requires-write: true
CHEMIN attributs opérations /subsystem=mail/mail-session=*/server=pop3username, tls, ssl, password/subsystem=mail/mail-session=*/server=imapusername, tls, ssl, password/subsystem=mail/mail-session=*/custom=*username, tls, ssl, password/subsystem=mail/mail-session=*/server=smtpusername, tls, ssl, password
Type: naming
- Classification: jndi-view
- requires-addressable: false
- requires-read: true
- requires-write: true
CHEMIN attributs opérations /subsystem=namingjndi-view
- Classification: naming-binding
- requires-addressable: false
- requires-read: false
- requires-write: false
CHEMIN attributs opérations /subsystem=naming/binding=*
Type: remoting
- Classification: remoting-security
- requires-addressable: false
- requires-read: true
- requires-write: true
CHEMIN attributs opérations /subsystem=remoting/connector=*authentication-provider, security-realm/subsystem=remoting/remote-outbound-connection=*username, security-realm/subsystem=remoting/connector=*/security=sasl
Type: resource-adapters
- Classification: resource-adapter-security
- requires-addressable: false
- requires-read: true
- requires-write: true
CHEMIN attributs opérations /subsystem=resource-adapters/resource-adapter=*/connection-definitions=*security-domain, recovery-username, recovery-security-domain, security-application, security-domain-and-application, recovery-password
Type: security
- Classification: misc-security
- requires-addressable: false
- requires-read: true
- requires-write: true
CHEMIN attributs opérations /subsystem=securitydeep-copy-subject-mode
Type: web
- Classification: web-access-log
- requires-addressable: false
- requires-read: false
- requires-write: false
CHEMIN attributs opérations /subsystem=web/virtual-server=*/configuration=access-log
- Classification: web-connector
- requires-addressable: false
- requires-read: false
- requires-write: false
CHEMIN attributs opérations /subsystem=web/connector=*
- Classification: web-ssl
- requires-addressable: false
- requires-read: true
- requires-write: true
CHEMIN attributs opérations /subsystem=web/connector=*/configuration=ssl
- Classification: web-sso
- requires-addressable: false
- requires-read: true
- requires-write: true
CHEMIN attributs opérations /subsystem=web/virtual-server=*/configuration=sso
- Classification: web-valve
- requires-addressable: false
- requires-read: false
- requires-write: false
CHEMIN attributs opérations /subsystem=web/valve=*
10.9. Sécurité de réseau
10.9.1. Sécuriser les interfaces de gestion
Dans un environnement de test, il est de pratique courante de faire fonctionner JBoss EAP 6 sans couche de sécurité sur les interfaces de gestion, composées de la Console de gestion, du Management CLI ou autre implémentation de l'API. Cela permet des changements rapides de développement et de configuration.
10.9.2. Indiquer l'interface de réseau que JBoss EAP 6 utilise
Isoler les services afin qu'ils soient accessibles uniquement aux clients qui en ont besoin augmente la sécurité de votre réseau. JBoss EAP 6 comprend deux interfaces dans sa configuration par défaut, qui se lient à l'IP adresse 127.0.0.1 ou localhost, par défaut. Une des interfaces est appelée gestion et est utilisée par la Console de gestion, CLI et API. L'autre est appelé public et est utilisé pour déployer des applications. Ces interfaces ne sont pas spéciales ou importantes, mais sont fournies comme point de départ.
management utilise les ports 9990 et 9999 par défaut, et l'interface public utilise le port 8080, ou le port 8443 avec HTTPS.
Avertissement
Stopper le serveur JBoss EAP 6
Stopper JBoss EAP 6 en envoyant une interruption de manière appropriée pour votre système d'exploitation. Si vous exécutez JBoss EAP 6 comme une application de premier plan, il suffit d'appuyer sur Ctrl+C.Démarrer JBoss EAP 6 à nouveau, en spécifiant l'adresse de liaison.
Utiliser l'argument de ligne de commande-bpour démarrer JBoss EAP 6 sur une interface particulière.Exemple 10.27. Indiquer l'interface publique.
EAP_HOME/bin/domain.sh -b 10.1.1.1
Exemple 10.28. Indiquer l'interface de gestion.
EAP_HOME/bin/domain.sh -bmanagement=10.1.1.1
Exemple 10.29. Indiquer des adresses différentes pour chaque interface.
EAP_HOME/bin/domain.sh -bmanagement=127.0.0.1 -b 10.1.1.1
Exemple 10.30. Lier l'interface publique à toutes les interfaces de réseau.
EAP_HOME/bin/domain.sh -b 0.0.0.0
-b pour spécifier une adresse IP en cours d'exécution, donc ce n'est pas recommandé. Si vous décidez de le faire, n'oubliez pas de stopper JBoss EAP 6 complètement avant d'éditer le fichier XML.
10.9.3. Ports de réseau utilisés par JBoss EAP 6
- Le fait que vos groupes de serveurs utilisent le groupe de liaisons de sockets par défaut, ou un groupe de liaisons de sockets personnalisé.
- Des exigences de vos déploiements individuels.
Note
Groupes de liaison de socket par défaut
full-ha-socketsfull-socketsha-socketsstandard-sockets
Tableau 10.5. Référence aux Groupes de liaison de socket par défaut
| Nom | Port | Port Multidiffusion | Description | full-ha-sockets | full-sockets | ha-socket | standard-socket |
|---|---|---|---|---|---|---|---|
ajp | 8009 | Protocole Apache JServ. Utilisé pour le clustering HTTP et pour l'équilibrage des charges. | Oui | Oui | Oui | Oui | |
http | 8080 | Le port par défaut des applications déployées. | Oui | Oui | Oui | Oui | |
https | 8443 | Connexion cryptée-SSL entre les applications déployées et les clients. | Oui | Oui | Oui | Oui | |
jacorb | 3528 | Services CORBA pour les transactions JTS et autres services dépendants-ORB. | Oui | Oui | Non | Non | |
jacorb-ssl | 3529 | Services CORBA cryptés-SSL. | Oui | Oui | Non | Non | |
jgroups-diagnostics | 7500 | Multidiffusion. Utilisé pour découverte de pair dans les groupements HA. Non configurable par les Interfaces de gestion. | Oui | Non | Oui | Non | |
jgroups-mping | 45700 | Multicast. Utilisé pour découvrir l'appartenance de groupe d'origine dans un cluster HA. | Oui | Non | Oui | Non | |
jgroups-tcp | 7600 | Découverte de pairs unicast dans les groupements HA avec TCP. | Oui | Non | Oui | Non | |
jgroups-tcp-fd | 57600 | Utilisé pour la détection des échecs en TCP. | Oui | Non | Oui | Non | |
jgroups-udp | 55200 | 45688 | Découverte de pairs unicast dans les groupements HA avec UDP. | Oui | Non | Oui | Non |
jgroups-udp-fd | 54200 | Utilisé pour la détection des échecs par UDP. | Oui | Non | Oui | Non | |
messaging | 5445 | Service JMS. | Oui | Oui | Non | Non | |
messaging-group | Référencé par la diffusion HornetQ JMS et les groupes Discovery | Oui | Oui | Non | Non | ||
messaging-throughput | 5455 | Utilisé par JMS à distance. | Oui | Oui | Non | Non | |
mod_cluster | 23364 | Port multidiffusion pour la communication entre JBoss EAP 6 et l'équilibreur de charges HTTP. | Oui | Non | Oui | Non | |
osgi-http | 8090 | Utilisé par les composants internes qui utilisent le sous-système OSGi. Non configurable par les Interfaces de gestion. | Oui | Oui | Oui | Oui | |
remoting | 4447 | Utilisé pour l'invocation EJB. | Oui | Oui | Oui | Oui | |
txn-recovery-environment | 4712 | Gestionnaire de recouvrement des transactions JTA. | Oui | Oui | Oui | Oui | |
txn-status-manager | 4713 | Gestionnaire des transactions JTA / JTS. | Oui | Oui | Oui | Oui |
En plus des groupes de liaisons de socket, chaque contrôleur d'hôte ouvre deux ports supplémentaires pour la gestion :
- 9990 - Le port de Console de gestion
- 9999 - Le port utilisé par la Console de gestion et par le Management API
10.9.4. Configurer les pare-feux de réseau pour qu'ils fonctionnent avec JBoss EAP 6
La plupart des environnements de production utilisent des pare-feux dans le cadre d'une stratégie globale de sécurité réseau. Si vous avez besoin que plusieurs instances de serveur puissent communiquer entre eux ou avec des services externes tels que des serveurs web ou des bases de données, votre pare-feu doit en tenir compte. Un pare-feu bien géré ouvre uniquement les ports qui sont nécessaires à l'opération et limite l'accès aux ports pour des adresses IP, des sous-réseaux et protocoles réseau spécifiques.
Prérequis
- Déterminer les ports que vous souhaitez ouvrir.
- Vous devez avoir une bonne compréhension de vos logiciels de pare-feux. Cette procédure utilise la commande
system-config-firewallde Red Hat Enterprise Linux 6. Microsoft Windows Server inclut un pare-feu intégré, et plusieurs solutions de pare-feux de tierce partie existent pour chaque plate-forme.
Cette procédure configure un pare-feu dans un environnement qui comprend les hypothèses suivantes :
- Le système d'exploitation est Red Hat Enterprise Linux 6
- JBoss EAP 6 exécute sur l'hôte
10.1.1.2. En option, le serveur peut avoir son propre pare-feu. - Le serveur du pare-feu de réseau exécute sur l'hôte
10.1.1.1sur l'interfaceeth0, et possède une interface externeeth1. - Le trafic de réseau devra être redirigé vers le port 5445 (port utilisé par JMS) renvoyé sur JBoss EAP 6. Le trafic ne doit pas pouvoir transiter par le pare-feu du réseau.
Procédure 10.33. Gérer les pare-feux de réseau pour qu'ils soient opérationnels dans JBoss EAP 6
Connectez-vous à la Console de gestion.
Connectez-vous à la Console de gestion. Par défaut, elle exécute sur http://localhost:9990/console/.Déterminer les liaisons de socket utilisées par le groupe de liaisons de socket.
Cliquer sur l'étiquette Profiles qui se trouve en haut et à droite de la Console de gestion. Sur la gauche de l'écran, vous verrez une série de menus. Le titre en bas du menu est General Configuration (Configuration générale). Cliquer sur Socket Binding sous ce titre. L'écran Socket Binding Declarations apparaîtra. Pour commencer, vous verrez le groupestandard-sockets. Vous pourrez choisir un autre groupe en le sélectionnant à partir de la case mixte à droite.Note
Si vous utilisez un serveur autonome, il ne possédera qu'un seul groupe de liaisons de socket.La liste de noms de sockets et des ports apparaît, avec huit valeurs par page. Vous pourrez naviguer entre les pages grâce à la flèche de navigation en dessous du tableau.Déterminer les ports que vous souhaitez ouvrir.
Suivant la fonction d'un port particulier, et suivant les besoins de votre environnement, certains ports devront sans doute être ouverts sur votre pare-feu.Configurer votre pare-feu pour rediriger le trafic réseau vers la plateforme JBoss EAP 6.
Procéder à ces étapes de configuration de votre pare-feu de réseau pour permettre au trafic de se diriger vers le port désiré.- Connectez-vous au pare-feu de votre machine, et accéder à cette commande, en tant qu'utilisateur root.
- Saisir la commande
system-config-firewallpour lancer l'utilitaire de configuration du pare-feu. Un GUI ou Utilitaire de ligne de commande opérera selon la façon dont vous êtes connecté au système de pare-feu. Cette tâche assume que vous êtes connecté via SSH et que vous utilisez l'interface de ligne de commande. - Utiliser la clé TAB de votre clavier pour naviguer vers le bouton , puis appuyer sur la clé ENTER. L'écranTrusted Services apparaîtra.
- Ne changez aucune valeur, mais utilisez la clé TAB pour naviguer vers le bouton , puis, appuyer sur ENTER pour aller vers le prochain écran. L'écran Other Ports apparaîtra.
- Utiliser la clé TAB pour naviguer vers le bouton <Add>, puis appuyer sur la clé ENTER. L'écran Port and Protocol apparaîtra.
- Saisir
5445dans le champ Port / Port Range, puis utiliser la clé TAB pour vous rendre dans le champ Protocol, puis saisirtcp. Utiliser la clé TAB pour naviguer vers le bouton , puis appuyer sur ENTER. - Utiliser la clé TAB pour naviguer vers le bouton jusqu'à atteindre l'écran Port Forwarding.
- Utiliser la clé TAB pour naviguer vers le bouton <Add>, puis appuyer sur la clé ENTER.
- Remplir les valeurs suivantes pour définir la redirection de port vers port 5445.
- Interface source: eth1
- Protocol: tcp
- Port / Port Range: 5445
- Destination IP address: 10.1.1.2
- Port / Port Range: 5445
Utiliser la clé TAB pour naviguer vers le bouton , puis appuyer sur la clé ENTER. - Utiliser la clé TAB pour naviguer vers le bouton , puis appuyer sur la clé ENTER.
- Utiliser la clé TAB pour naviguer vers le bouton , puis appuyer sur ENTER. Pour appliquer les changements, lire la notice d'avertissement, puis appuyer sur .
Configurer un pare-feu sur votre hôte de plateforme JBoss EAP 6.
Certaines organisations choisissent de configurer un pare-feu sur le serveur JBoss EAP 6 lui-même et de fermer tous les ports qui ne sont pas utiles à son fonctionnement. Voir Section 10.9.3, « Ports de réseau utilisés par JBoss EAP 6 » pour déterminer quels ports ouvrir, puis fermer le reste. La configuration par défaut de Red Hat Enterprise Linux 6 ferme tous les ports sauf 22 (utilisé pour Secure Shell (SSH) et 5353 (utilisé pour la multi-diffusion DNS). Si vous configurez les ports, assurez-vous que vous avez un accès physique à votre serveur pour ne pas, par inadvertance, vous verrouiller vous-même.
Votre pare-feu est configuré pour renvoyer le trafic vers votre serveur JBoss EAP 6 interne, de la façon dont vous avez spécifié dans la configuration de votre pare-feu. Si vous avez choisi d'activer un pare-feu sur votre serveur JBoss Enterprise Application Platform 6, tous les ports seront fermés sauf ceux nécessaires à l'exécution de vos applications.
10.10. Java Security Manager
10.10.1. Java Security Manager
Le gestionnaire de sécurité Java est une classe qui gère la limite extérieure de la sandbox Java Virtual Machine (JVM), contrôlant ainsi comment le code qui est exécuté dans la JVM peut interagir avec les ressources à l'extérieur de la machine virtuelle Java. Lorsque le gestionnaire de sécurité Java est activé, l'API Java vérifie avec le gestionnaire de sécurité pour approbation avant d'exécuter une vaste gamme d'opérations potentiellement dangereuses.
10.10.2. Exécuter JBoss EAP 6 dans le Java Security Manager
domain.sh ou standalone.sh. La procédure suivante va vous guider à travers les étapes de configuration de votre instance pour exécuter au sein d'une stratégie Java Security Manager.
Conditions préalables
- Avant de suivre cette procédure, vous devrez rédiger une stratégie de sécurité, en utilisant la commande
policytoolcomprise dans votre Java Development Kit (JDK). Cette procédure assume que votre stratégie se trouve dansEAP_HOME/bin/server.policy. Sinon, vous pouvez écrire la stratégie de sécurité à l'aide d'un éditeur de texte et la sauvegarder commeEAP_HOME/bin/server.policy. - Le domaine ou le serveur autonome doivent être tout à fait arrêtés avant d'éditer un fichier de configuration quelconque.
Procédure 10.34. Configurer le gestionnaire de sécurité dans JBoss EAP 6
Ouvrir le fichier de configuration.
Ouvrir le fichier de configuration pour le modifier. Ce fichier se trouve dans un de ces emplacements, suivant que vous utilisiez un domaine géré ou un serveur autonome. Il ne s'agit pas du fichier exécutable utilisé pour démarrer le serveur ou le domaine.Domaine géré
EAP_HOME/bin/domain.confServeur autonome
EAP_HOME/bin/standalone.conf
Ajouter les options Java au fichier.
Pour s'assurer que les options Java soient bien utilisées, ajouter les au bloc de code qui commence par :if [ "x$JAVA_OPTS" = "x" ]; then
Vous pourrez modifier la valeur de-Djava.security.policypour spécifier l'emplacement exact de votre police de sécurité. Il doit être contenu sur une ligne seulement, sans retour à la ligne. Vous pouvez modifier-Djava.security.debugpour journaliser des informations, en indiquant leur niveau de débogage. La plus verbeuse estaccess,policyetaccess:failure.JAVA_OPTS="$JAVA_OPTS -Djava.security.manager -Djboss.home.dir=$PWD/.. -Djava.security.policy==$PWD/server.policy -Djava.security.debug=access:failure"
Démarrer le domaine ou le serveur.
Démarrer le domaine ou le serveur en tant que normal.
10.10.3. Polices du Java Security Manager
Un jeu d'autorisations définies pour les différentes classes du code. Le gestionnaire de sécurité Java examine les requêtes en provenance des applications en fonction de la politique de sécurité. Si une action est autorisée par la politique, le gestionnaire de sécurité permettra que l'action ait lieu. Si l'action n'est pas autorisée par la police, le gestionnaire de sécurité refusera cette action. La stratégie de sécurité peut définir des autorisations basées sur l'emplacement du code ou sur la signature du code.
java.security.manager et java.security.policy.
10.10.4. Écrire une politique pour le Java Security Manager
Il y a une application nommée policytool dans la plupart des distributions JDK et JRE, ayant pour but la modification ou la création de politiques de sécurité pour le Java Security Manager. Vous trouverez des informations sur policytool dans http://docs.oracle.com/javase/6/docs/technotes/tools/.
Une politique de sécurité consiste en les éléments de configuration suivants :
- CodeBase
- L'emplacement de l'URL (à l'exclusion des informations sur l'hôte ou le domaine) d'où viennent les codes. Ce paramètre est en option.
- SignedBy
- L'alias est utilisé dans le fichier de clés pour référencer le signataire dont la clé privée a été utilisée pour signer le code. Cela peut être une valeur unique ou une liste séparée par des virgules. Ce paramètre est facultatif. Si omis, la présence ou l'absence de signature n'a aucun impact sur le gestionnaire de sécurité Java.
- Principaux
- Une liste de paires de principal_type/principal_name, qui doivent se trouver dans l'ensemble Principal du thread en cours d'exécution. L'entrée Principal est facultative. S'il est omis, il signifie « n'importe quel principal »
- Permissions
- Une permission est l'accès qui est accordé au code. De nombreuses autorisations sont fournies dans le cadre de la spécification Java Enterprise Edition 6 (Java EE 6). Ce document couvre uniquement les autorisations supplémentaires qui sont fournies par JBoss EAP 6.
Procédure 10.35. Définir une politique pour le Java Security Manager
Démarrer
policytool.Démarrer l'outilpolicytoold'une des façons suivantes.Red Hat Enterprise Linux
À partir de votre GUI ou invite de commande, exécuter/usr/bin/policytool.Microsoft Windows Server
Exécuterpolicytool.exeà partir du menu de Démarrage (Start) ou à partir debin\de votre installation Java. L'emplacement peut varier.
Créer une politique.
Pour créer une politique, sélectionner . Ajouter les paramètres dont vous aurez besoin, et cliquer sur .Modifier une politique existante
Sélectionner la police à partir d'une liste de politiques existantes, et sélectionner le bouton . Modifier les paramètres suivant les besoins.Supprimer une politique existante.
Sélectionner la politique à partir d'une liste de politiques existantes, et sélectionner le bouton .
Permission spécifique à JBoss EAP 6
- org.jboss.security.SecurityAssociation.getPrincipalInfo
- Donne accès aux méthodes
org.jboss.security.SecurityAssociation.getPrincipal()etgetCredential(). Le risque encouru avec cette permission est que l'on peut voir le thread de l'appelant et ses détails d'authentification. - org.jboss.security.SecurityAssociation.getSubject
- Donne accès à la méthode
org.jboss.security.SecurityAssociation.getSubject(). - org.jboss.security.SecurityAssociation.setPrincipalInfo
- Donne accès aux méthodes
org.jboss.security.SecurityAssociation.setPrincipal(),setCredential(),setSubject(),pushSubjectContext(), etpopSubjectContext(). Le risque encouru avec cette permission est que l'on peut voir le thread de l'appelant et ses détails d'authentification. - org.jboss.security.SecurityAssociation.setServer
- Donne accès aux méthodes
org.jboss.security.SecurityAssociation.setPrincipal(). Le risque encouru avec cette permission est que l'on peut activer ou désactiver le stockage multi-thread de l'appelant principal et ses détails d'authentification. - org.jboss.security.SecurityAssociation.setRunAsRole
- Donne accès aux méthodes
org.jboss.security.SecurityAssociation.pushRunAsRole(),popRunAsRole(),pushRunAsIdentity(), etpopRunAsIdentity(). Le risque encouru avec cette permission est que l'on peut voir le thread de l'appelant et ses détails d'authentification. - org.jboss.security.SecurityAssociation.accessContextInfo
- Donne accès aux méthodes
org.jboss.security.SecurityAssociation.accessContextInfo(), etaccessContextInfo(). Cela vous permet les actions set et get pour définir et obtenir les informations de sécurité. - org.jboss.naming.JndiPermission
- Fournit des permissions spéciales pour les fichiers et répertoires d'un chemin d'accès JNDI spécifié, ou bien de façon récursive pour tous les fichiers et sous-répertoires. Une JndiPermission consiste en un nom de chemin et un ensemble de permissions valides liées au fichier ou répertoire.Les permissions disponibles sont les suivantes :
- bind
- rebind
- unbind
- lookup
- list
- listBindings
- createSubcontext
- all
Les noms de chemin d'accès se terminant par/*indiquent que les permissions indiquées s'appliquent à tous les fichiers et répertoires de nom du chemin. Les noms de chemin se terminant par/-indiquent des permissions récursives vers tous les fichiers et sous-directoires du nom du chemin. Les noms de chemins consistants avec le token <<ALL BINDINGS>> correspondent à n'importe quel fichier du répertoire. - org.jboss.security.srp.SRPPermission
- Une classe de permissions personnalisées pour protéger l'accès à des informations sensibles SRP comme la clé de session privée et la clé privée. Cette autorisation n'a pas toutes les actions définies. La cible de
getSessionKey()donne accès à la clé de session privée qui résulte de la négociation SRP. L'accès à cette clé permet de chiffrer et de déchiffrer les messages qui ont été chiffrés avec la clé de session. - org.hibernate.secure.HibernatePermission
- Cette classe de permissions fournit des permissions de base pour sécuriser les sessions Hibernate. La cible de cette propriété est le nom de l'entité. Les actions disponibles sont les suivantes :
- insérer
- supprimer
- update
- lecture
- * (all)
- org.jboss.metadata.spi.stack.MetaDataStackPermission
- Fournit une classe de permission personnalisée pour contrôler la façon dont les appelants interagissent avec la pile de métadonnées. Les permissions disponibles sont les suivantes :
- modifier
- push (vers la pile)
- pop (de la pile)
- peek (dans la pile)
- * (all)
- org.jboss.config.spi.ConfigurationPermission
- Sécurise la mise en place des propriétés de configuration. Définit uniquement les noms des cibles, mais aucune action. Les cibles pour cette propriété incluent :
- <property name> (la propriété que ce code a la permission de définir)
- * (all properties)
- org.jboss.kernel.KernelPermission
- Sécurise l'accès à la configuration du noyau. Définit uniquement les noms des cibles, mais aucune action. Les cibles pour cette propriété incluent :
- access (à la configuration du noyau)
- configure (implique accès)
- * (all)
- org.jboss.kernel.plugins.util.KernelLocatorPermission
- Sécurise l'accès au noyau. Définit uniquement les noms des cibles, mais aucune action. Les cibles pour cette propriété incluent :
- noyau
- * (all)
10.10.5. Débogage des politiques du gestionnaire de sécurité
java.security.debug configure le niveau des informations liées à la sécurité qui ont été reportées. La commande java -Djava.security.debug=help vous produira de l'aide avec l'ensemble complet des options de débogage. Définir le niveau de débogage à all est utile quand on résout un échec lié à la sécurité dont la cause est inconnue, mais en général, cela produit trop d'informations. Une valeur par défaut utile et raisonnable est access:failure.
Procédure 10.36. Activer le débogage général
Cette procédure permettra un bon niveau de sécurité général pour les informations de débogage liées à la sécurité.
Ajouter la ligne suivante au fichier de configuration du serveur.- Si l'instance de JBoss EAP 6 exécute sur une domaine géré, la ligne sera ajoutée au fichier
bin/domain.confde Linux ou au fichierbin/domain.conf.batde Windows. - Si l'instance de JBoss EAP exécute sur une domaine autonome, la ligne sera ajoutée au fichier
bin/standalone.confde Linux ou au fichierbin/standalone.conf.batde Windows.
Linux
JAVA_OPTS="$JAVA_OPTS -Djava.security.debug=access:failure"
Windows
JAVA_OPTS="%JAVA_OPTS% -Djava.security.debug=access:failure"
Un niveau général d'informations de débogage lié à la sécurité a été activé.
10.11. Sécurité des applications
10.11.1. Activer/Désactiver un remplacement de propriété basé descripteur
Le contrôle précis du remplacement de propriété de descripteur a été introduit dans jboss-as-ee_1_1.xsd. Cette tâche couvre les étapes requises pour configurer le remplacement de propriété basé descripteur.
Conditions préalables
- Si défini à
true, les remplacements de propriété sont activés. - Si défini à
false, les remplacements de propriété sont désactivés.
Procédure 10.37. jboss-descriptor-property-replacement
jboss-descriptor-property-replacement est utilisé pour activer ou désactiver le remplacement de propriété dans les descripteurs suivants :
jboss-ejb3.xmljboss-app.xmljboss-web.xml*-jms.xml*-ds.xml
jboss-descriptor-property-replacement est true.
- À l'aide de l'interface CLI, exécuter la commande suivante pour déterminer la valeur de
jboss-descriptor-property-replacement:/subsystem=ee:read-attribute(name="jboss-descriptor-property-replacement")
- Exécuter la commande suivante pour configurer le comportement :
/subsystem=ee:write-attribute(name="jboss-descriptor-property-replacement",value=VALUE)
Procédure 10.38. spec-descriptor-property-replacement
spec-descriptor-property-replacement est utilisé pour activer ou désactiver le remplacement de propriété dans les descripteurs suivants :
ejb-jar.xmlpersistence.xml
spec-descriptor-property-replacement est false.
- À l'aide de l'interface CLI, exécuter la commande suivante pour confirmer la valeur de
spec-descriptor-property-replacement:/subsystem=ee:read-attribute(name="spec-descriptor-property-replacement")
- Exécuter la commande suivante pour configurer le comportement :
/subsystem=ee:write-attribute(name="spec-descriptor-property-replacement",value=VALUE)
Les indicateurs de remplacement de propriété basé descripteur ont bien été configurés.
10.12. Encodage SSL
10.12.1. Implémentation du cryptage SSL pour le serveur de JBoss EAP 6.
De nombreuses applications web requièrent une connexion cryptée-SSL entre les clients et le serveur, connue sous le nom de connexion HTTPS. Vous pouvez utiliser cette procédure pour activer HTTPS sur votre serveur ou groupe de serveurs.
Prérequis
- Vous aurez besoin d'un ensemble de clés de cryptage SSL et d'un certificat de cryptage SSL. Vous pourrez vous les procurer par l'intermédiaire d'une autorité de signature de certificats. Pour générer les clés de cryptage par les utilitaires de Red Hat Enterprise Linux, voir Section 10.12.2, « Générer une clé de cryptage SSL et un certificat ».
- Vous devrez connaitre les informations suivantes sur votre environnement et sur votre installation :
- Le nom complet du répertoire et le chemin d'accès à vos fichiers de certificats
- Le mot de passe de cryptage pour vos clés de cryptage.
- Vous devrez exécuter le Management CLI et le connecter à votre contrôleur de domaine ou à votre serveur autonome.
Note
/profile=default du début d'une commande de Management CLI.
Procédure 10.39. Configurer le JBoss Web Server pour qu'il puisse utiliser HTTPS
Ajouter un nouveau connecteur HTTPS.
Exécuter la commande de Management CLI suivante, en changeant le profil comme il se doit. Cela va créer un nouveau connecteur sécurisé, nomméHTTPS, qui utilise le protocolehttps, la liaison de sockethttps(ayant comme valeur par défaut8443), et qui est définie pour être sécurisée.Exemple 10.31. Commande de Management CLI
/profile=default/subsystem=web/connector=HTTPS/:add(socket-binding=https,scheme=https,protocol=HTTP/1.1,secure=true)
Configurer le certificat de cryptage SSL et les clés.
Exécutez les commandes CLI suivantes pour configurer votre certificat SSL, en remplaçant vos propres valeurs par celles de l'exemple. Cet exemple suppose que le keystore est copié dans le répertoire de configuration du serveur, qui estEAP_HOME/domain/configuration/pour un domaine géré.Exemple 10.32. Commande de Management CLI
/profile=default/subsystem=web/connector=HTTPS/ssl=configuration:add(name=https,certificate-key-file="${jboss.server.config.dir}/keystore.jks",password=SECRET, key-alias=KEY_ALIAS)Pour obtenir une liste complète des paramètres que vous pouvez définir pour les propriétés SSL du connecteur, voir Section 10.12.3, « Référence de connecteur SSL ».Déployer une application.
Déployer une application dans un groupe de serveurs qui utilise le profil que vous avez configuré. Si vous utilisez un serveur autonome, déployer une application sur votre serveur. Les demandes HTTP en sa direction utilisent la nouvelle connexion cryptée-SSL.
10.12.2. Générer une clé de cryptage SSL et un certificat
Prérequis
- La commande
keytooldoit être disponible. Elle est fournie par le Java Development Kit. Dans Red Hat Enterprise Linux, OpenJDK installe cette commande à l'emplacement suivant/usr/bin/keytool. - Comprendre la syntaxe et les paramètres de la commande
keytool. Cette procédure utilise des instructions extrêmement génériques, car des discussions plus sophistiquées sur les spécificités des certificats SSL ou sur la commandekeytoolsont hors de portée de cette documentation.
Procédure 10.40. Générer une clé de cryptage SSL et un certificat
Générer un keystore avec des clés privées et des clés publiques.
Exécuter la commande suivante pour générer un keystore nomméserver.keystoreayant comme aliasjbossdans votre répertoire actuel.keytool -genkeypair -alias jboss -keyalg RSA -keystore server.keystore -storepass mykeystorepass --dname "CN=jsmith,OU=Engineering,O=mycompany.com,L=Raleigh,S=NC,C=US"
Le tableau suivant décrit les paramètres utilisés avec la commande « keytool ».Paramètre Description -genkeypairLa commande keytoolqui génère une paire de clés contenant une clé publique et une clé privée.-aliasL'alias est pour le keystore. Cette valeur est arbitraire, mais l'alias jbossest la valeur par défaut utilisée par le serveur JBoss Web.-keyalgL'algorithme de création de paires de clés. Dans ce cas, c'est RSA.-keystoreLe nom et l'emplacement du fichier keystore. L'emplacement par défaut est le répertoire en cours. Le nom que vous choisissez est arbitraire. Dans ce cas, il s'agit du fichier nommé server.keystore.-storepassCe mot de passe est utilisé pour authentifier le keystore, et pour que la clé puisse être lue. Le mot de passe doit contenir au moins 6 caractères de long et doit être fourni quand on accède au keystore. Dans un tel cas, on utilise mykeystorepass. Si vous omettez ce paramètre, on vous demandera de le saisir quand vous exécuterez la commande.-keypassIl s'agit du mot de passe pour la clé.Note
À cause d'une limitation d'implémentation, il doit correspondre à celui du mot de passe du store.--dnameUne chaîne avec des guillemets qui décrit le nom distinct de la clé, comme par exemple : "CN=jsmith,OU=Engineering,O=mycompany.com,L=Raleigh,C=US". Cette chaîne est une compilation des composants suivants : CN- Le nom commun ou le nom d'hôte. Si le nom d'hôte est "jsmith.mycompany.com", leCNsera "jsmith".OU- L'unité organisationnelle, par exemple "Engineering"O- Le nom de l'organisation, par exemple "mycompany.com".L- La localité, par exemple "Raleigh" ou "London"S- L'état ou la province, par exemple "NC". Ce paramètres est optionnel.C- Les 2 lettres d'un code pays, par exemple "US" ou "UK".
Quand vous exécuterez la commande ci-dessus, on vous demandera les informations suivantes :- Si vous n'utilisiez pas le paramètre
-storepasssur la ligne de commande, on vous demandera de saisir le mot de passe du keystore. Saisir le nouveau mot de passe à la seconde invite. - Si vous n'utilisiez pas le paramètre
-keypasssur la ligne de commande, on vous demandera de saisir le mot de passe de la clé. Appuyez sur Enter pour le définir à la même valeur que celle du mot de passe du keystore.
Quand la commande s'achèvera, le fichierserver.keystorecontiendra la clé unique avec l'aliasjboss.Vérifier la clé.
Vérifier que la clé fonctionne correctement en utilisant la commande suivante.keytool -list -keystore server.keystore
On vous demande le mot de passe du keystore. Les contenus du keystore sont affichés (dans ce cas, il s'agit d'une simple clé nomméejboss). Notez le type de la cléjboss, qui estkeyEntry. Cela indique que le keystore contient à la fois une entrée publique et une entrée privée pour cette clé.Créer une demande de signature de certificat.
Exécutez la commande suivante pour générer une demande de signature de certificat en utilisant la clé publique du keystore que vous avez créé dans la 1ere étape.keytool -certreq -keyalg RSA -alias jboss -keystore server.keystore -file certreq.csr
On vous demandera le mot de passe pour pouvoir authentifier le keystore. La commandekeytoolcrée alors une nouvelle demande de signature de certificat nomméecertreq.csrdans le répertoire en cours d'utilisation.Tester la demande de signature de certificat nouvellement générée.
Tester les contenus du certificat avec la commande suivante :openssl req -in certreq.csr -noout -text
Les détails du certificat apparaissent.En option : soumettre votre demande de signature de certificat à une autorité de certification (AC).
Une Autorité de Certification (AC) authentifie votre certificat pour qu'il soit considéré de confiance par des clients de tierce partie. L'AC vous a produit un certificat signé, et en option, vous a peut être fourni un ou plusieurs certificats intermédiaires.Option : exporter un certificat auto-signé du keystore.
Si vous n'en avez besoin que dans un but de test ou en interne, vous pourrez utiliser un certificat auto-signé. Vous pourrez en exporter un, créé dans la première étape, en provenance du keystore, comme suit :keytool -export -alias jboss -keystore server.keystore -file server.crt
On vous demande un mot de passe pour pouvoir s'authentifier au keystore. Un certificat auto-signé, intituléserver.crt, a été créé dans le répertoire en cours d'utilisation.Importer le certificat signé avec tout certificat intermédiaire.
Importer chaque certificat, dans l'ordre dans lequel l'AC vous le demande. Pour chaque AC que vous importez, remplacerintermediate.caouserver.crtpar le nom du fichier. Si vos certificats ne sont pas fournis dans des fichiers séparés, créer un fichier séparé pour chaque certificat, et coller leur contenu dans le fichier.Note
Votre certificat signé et les clés de ce certificat sont des ressources de valeur. Soyez vigilant sur la façon dont vous les transportez entre les serveurs.keytool -import -keystore server.keystore -alias intermediateCA -file intermediate.ca
keytool -import -alias jboss -keystore server.keystore -file server.crt
Testez que vos certificats soient bien importés avec succès.
Exécuter la commande suivante, et saisir le mot de passe de keystore quand on vous le demandera. Les contenus de votre keystore sont affichés, et les certificats font partie de la liste.keytool -list -keystore server.keystore
Votre certificat signé est maintenant inclus dans votre keystore et est prêt à l'utilisation pour crypter les connexions SSL, y compris les communications au serveur web HTTPS.
10.12.3. Référence de connecteur SSL
par défaut. Changer le nom du profil à celui que vous souhaitez configurer, pour un domaine géré, ou omettre la portion /profile=default de la commande, pour un serveur autonome.
Tableau 10.6. Attributs de connecteurs SSL
| Attribut | Description | Commande CLI |
|---|---|---|
| name |
Le nom d'affichage du connecteur SSL
|
/profile=default/subsystem=web/connector=HTTPS/ssl=configuration/:write-attribute(name=name,value=https) |
| verify-client |
Définir à
true pour obtenir une chaîne de certificat valide de la part d'un client avant d'accepter une connexion. Définir à want si vous voulez que la pile SSL demande un certificat de client, mais ne pas l'échouer si celui-ci n'est pas présenté. Définir à false (la valeur par défaut) si vous ne souhaitez pas demander de chaîne de certificat, à moins que le client ne demande une ressource protégée par une contrainte de sécurité qui utilise l'authentification de CLIENT-CERT.
|
/profile=default/subsystem=web/connector=HTTPS/ssl=configuration/:write-attribute(name=verify-client,value=want) |
| verify-depth |
Le nombre maximal d'émetteurs de certificats intermédiaires vérifiés avant de décider que les clients n'ont pas de certificat valide. La valeur par défaut est
10.
|
/profile=default/subsystem=web/connector=HTTPS/ssl=configuration/:write-attribute(name=verify-depth,value=10) |
| certificate-key-file |
Le chemin d'accès complet et nom de fichier du keystore où le certificat de serveur signé est stocké. Avec le cryptage JSSE, ce fichier de certificat sera le seul, tandis que OpenSSL utilise plusieurs fichiers. La valeur par défaut est le fichier
.keystore dans le répertoire home de l'utilisateur exécutant JBoss EAP 6. Si votre keystoreType n'utilise pas de fichier, définissez le paramètre en chaîne vide.
|
/profile=default/subsystem=web/connector=HTTPS/ssl=configuration/:write-attribute(name=certificate-key-file,value=../domain/configuration/server.keystore) |
| certificate-file |
Si vous utilisez un cryptage OpenSSL, définir la valeur de ce paramètre au chemin d'accès du fichier qui contient le certificat de serveur.
|
/profile=default/subsystem=web/connector=HTTPS/ssl=configuration/:write-attribute(name=certificate-file,value=server.crt) |
| password |
Le mot de passe pour le trustore et le keystore à la fois. Dans l'exemple suivant, remplacer PASSWORD par votre propre mot de passe.
|
/profile=default/subsystem=web/connector=HTTPS/ssl=configuration/:write-attribute(name=password,value=PASSWORD) |
| protocol |
La version de protocole SSL à utiliser. Les valeurs prises en charge comprennent
SSLv2, SSLv3, TLSv1, SSLv2+SSLv3, et ALL. La valeur par défaut est ALL.
|
/profile=default/subsystem=web/connector=HTTPS/ssl=configuration/:write-attribute(name=protocol,value=ALL) |
| cipher-suite |
Une liste séparée par des virgules des algorithmes de cryptage autorisés. La valeur par défaut JVM pour JSSE contient des algorithmes de chiffrement faibles, qui ne doivent pas être utilisés. L'exemple répertorie uniquement les deux algorithmes de chiffrement possibles, mais des exemples concrets en utiliseront probablement plus.
|
/profile=default/subsystem=web/connector=HTTPS/ssl=configuration/:write-attribute(name=cipher-suite, value="TLS_RSA_WITH_AES_128_CBC_SHA,TLS_RSA_WITH_AES_256_CBC_SHA") |
| key-alias |
L'alias utilisé pour le certificat de serveur dans le keystore. Dans l'exemple suivant, remplacer KEY_ALIAS par l'alias de votre certificat.
|
/profile=default/subsystem=web/connector=HTTPS/ssl=configuration/:write-attribute(name=key-alias,value=KEY_ALIAS) |
| truststore-type |
Le type de truststore. Il existe différents types de keystores, dont
PKCS12 et le JKS standard de Java.
|
/profile=default/subsystem=web/connector=HTTPS/ssl=configuration/:write-attribute(name=truststore-type,value=jks) |
| keystore-type |
Le type de keystore. Il existe différents types de keystores, dont
PKCS12 et le JKS standard de Java.
|
/profile=default/subsystem=web/connector=HTTPS/ssl=configuration/:write-attribute(name=keystore-type,value=jks) |
| ca-certificate-file |
Le fichier contenant les certificats CA. Il s'agit du
truststoreFile, dans le cas de JSSE, et il utilise le même mot de passe que le keystore. Le fichier ca-certificate-file est utilisé pour valider les certificats de clients.
|
/profile=default/subsystem=web/connector=HTTPS/ssl=configuration/:write-attribute(name=certificate-file,value=ca.crt) |
| ca-certificate-password |
Le mot de passe de certificat pour le
ca-certificate-file. Dans l'exemple ci-dessous, remplacer MASKED_PASSWORD par votre propre mot de passe masqué.
|
/profile=default/subsystem=web/connector=HTTPS/ssl=configuration/:write-attribute(name=ca-certificate-password,value=MASKED_PASSWORD) |
| ca-revocation-url |
Un fichier ou URL qui contient la liste de révocations. Se réfère au
crlFile pour JSSE ou au SSLCARevocationFile pour SSL.
|
/profile=default/subsystem=web/connector=HTTPS/ssl=configuration/:write-attribute(name=ca-revocation-url,value=ca.crl) |
| session-cache-size |
La taille du cache SSLSession. Cet attribut s'applique uniquement aux connecteurs JSSE. La valeur par défaut est
0, qui indique une taille cache illimitée.
|
/profile=default/subsystem=web/connector=HTTPS/ssl=configuration/:write-attribute(name=session-cache-size,value=100) |
| session-timeout |
Le nombre de secondes avant qu'une SSLSession n'expire. Cet attribut s'applique uniquement aux connecteurs JSSE. La valeur par défaut est
86400 secondes, ce qui correspond à 24 heures.
|
/profile=default/subsystem=web/connector=HTTPS/ssl=configuration/:write-attribute(name=session-timeout,value=43200) |
10.13. L'archivage sécurisé des mots de passe pour les strings de nature confidentielle
10.13.1. Sécurisation des chaînes confidentielles des fichiers en texte clair
Avertissement
java.io.IOException: com.sun.crypto.provider.SealedObjectForKeyProtector
10.13.2. Créer un Keystore Java pour stocker des strings sensibles
Prérequis
- La commande
keytooldoit être disponible. Elle est fournie par le Java Runtime Environment (JRE). Chercher le chemin du fichier. Se trouve à l'emplacement suivant/usr/bin/keytooldans Red Hat Enterprise Linux.
Procédure 10.41. Installation du Java Keystore
Créer un répertoire pour stocker votre keystore et autres informations cryptées.
Créer un répertoire qui contiendra votre keystore et autres informations pertinentes. Le reste de cette procédure assume que le répertoire est/home/USER/vault/.Déterminer les paramètres à utiliser avec
keytool.Déterminer les paramètres suivants :- alias
- L'alias est un identificateur unique pour l'archivage sécurisé ou autres données stockées dans le keystore. L'alias dans l'exemple de commande à la fin de cette procédure est
vault(archivage sécurisé). Les alias sont insensibles à la casse. - keyalg
- L'algorithme à utiliser pour le cryptage. Dans cette procédure, l'exemple utilise
RSA. Consultez la documentation de votre JRE et de votre système d'exploitation pour étudier vos possibilités. - keysize
- La taille d'une clé de cryptage impacte sur la difficulté de décrypter au seul moyen de la force brutale. Dans cette procédure, l'exemple utilise
1024. Pour plus d'informations sur les valeurs appropriées, voir la documentation distribuée aveckeytool. - keystore
- Le keystore est une base de données qui contient des informations chiffrées et des informations sur la façon de déchiffrer. Si vous ne spécifiez pas de keystore, le keystore par défaut à utiliser est un fichier appelé
.keystoredans votre répertoire personnel. La première fois que vous ajoutez des données dans un keystore, il sera créé. L'exemple de cette procédure utilise le keystorevault.keystore.
La commande dukeytoola plusieurs options. Consulter la documentation de votre JRE ou de votre système d'exploitation pour obtenir plus d'informations.Détermine les réponses aux questions que la commande
keystorevous demandera.Lekeystorea besoin des informations suivantes pour remplir l'entrée du keytore :- Mot de passe du keystore
- Lorsque vous créez un keystore, vous devez définir un mot de passe. Pour pouvoir travailler dans keystore dans le futur, vous devez fournir le mot de passe. Créer un mot de passe dont vous vous souviendrez. Le keystore est sécurisé par son mot de passe et par la sécurité du système d'exploitation et du système de fichiers où il se trouve.
- Mot de passe clé (en option)
- En plus du mot de passe du keystore, vous pouvez indiquer un mot de passe pour chaque clé contenue. Pour utiliser une clé, le mot de passe doit être donné à chaque utilisation. Normalement, cette fonction n'est pas utilisée.
- Prénom et nom de famille
- Cela, ainsi que le reste de l'information dans la liste, aide à identifier la clé de façon unique et à la placer dans une hiérarchie par rapport aux autres clés. Il ne doit pas nécessairement correspondre à un nom, mais doit être composé de deux mots et doit être unique à une clé. L'exemple dans cette procédure utilise
Admninistrateur Comptabilité. En terme de répertoires, cela devient le nom commun du certificat. - Unité organisationnelle
- Il s'agit d'un mot unique d'identification qui utilise le certificat. Il se peut que ce soit l'application ou l'unité commerciale. L'exemple de cette procédure utilise
enterprise_application_platform. Normalement, tous les keystores utilisés par un groupe ou une application utilisent la même unité organisationnelle. - Organisation
- Il s'agit normalement d'une représentation de votre nom d'organisation en un seul mot. Demeure constant à travers tous les certificats qui sont utilisés par une organisation. Cet exemple utilise
MyOrganization. - Ville ou municipalité
- Votre ville.
- État ou province
- Votre état ou province, ou l'équivalent pour votre localité.
- Pays
- Le code pays en deux lettres.
Ces informations vont créer ensemble une hiérarchie de vos keystores et certificats, qui garantira qu'ils utilisent une structure de nommage consistante, et unique.Exécuter la commande
keytool, en fournissant les informations que vous avez collectées.Exemple 10.33. Exemple d'entrée et de sortie de la commande
keystore$ keytool -genseckey -alias vault -storetype jceks -keyalg AES -keysize 128 -storepass vault22 -keypass vault22 -keystore /home/USER/vault/vault.keystore Enter keystore password: vault22 Re-enter new password:vault22 What is your first and last name? [Unknown]:
Accounting AdministratorWhat is the name of your organizational unit? [Unknown]:AccountingServicesWhat is the name of your organization? [Unknown]:MyOrganizationWhat is the name of your City or Locality? [Unknown]:RaleighWhat is the name of your State or Province? [Unknown]:NCWhat is the two-letter country code for this unit? [Unknown]:USIs CN=Accounting Administrator, OU=AccountingServices, O=MyOrganization, L=Raleigh, ST=NC, C=US correct? [no]:yesEnter key password for <vault> (RETURN if same as keystore password):
Un fichier nommé vault.keystore est créé dans le répertoire /home/USER/vault/. Il stocke une clé simple, nommée vault, qui sera utilisée pour stocker des strings cryptés, comme des mots de passe, pour la plateforme JBoss EAP 6.
10.13.3. Masquer le mot de passe du keystore et initialiser le mot de passe de l'archivage de sécurité
Prérequis
- L'application
EAP_HOME/bin/vault.shdoit pouvoir être accessible via l'interface de ligne de commande.
Exécuter la commande
vault.sh.ExécuterEAP_HOME/bin/vault.sh. Démarrer une nouvelle session interactive en tapant0.Saisir le nom du répertoire où les fichiers cryptés seront stockés.
Ce répertoire doit être raisonnablement sécurisé, mais JBoss EAP 6 doit pouvoir y accéder. Si vous suivez Section 10.13.2, « Créer un Keystore Java pour stocker des strings sensibles », votre keystore sera dans un répertoire nommévault/dans votre répertoire de base (home). Cet exemple utilise le répertoire/home/USER/vault/.Note
N'oubliez pas d'inclure la barre oblique finale dans le nom du répertoire. Soit/ou\, selon votre système d'exploitation.Saisir le nom de votre keystore.
Saisir le nom complet vers le fichier de keystore. Cet exemple utilise/home/USER/vault/vault.keystore.Crypter le mot de passe du keystore.
Les étapes suivantes vous servent à crypter le mot de passe du keystore, afin que vous puissiez l'utiliser dans les applications et les fichiers de configuration en toute sécuritéSaisir le mot de passe du keystore.
Quand vous y serez invité, saisir le mot de passe du keystore.Saisir une valeur salt.
Entrez une valeur salt de 8 caractères. La valeur salt, ainsi que le nombre d'itérations (ci-dessous), sont utilisés pour créer la valeur de hachageSaisir le nombre d'itérations.
Saisir un nombre pour le nombre d'itérations.Notez les informations de mot de passe masqué.
Le mot de passe masqué, salt et le nombre d'itérations sont imprimés en sortie standard. Prenez-en note dans un endroit sûr. Un attaquant pourrait les utiliser pour déchiffrer le mot de passe.Saisir un alias pour l'archivage de sécurité.
Quand on vous y invite, saisir un alias pour l'archivage de sécurité. Si vous suivez Section 10.13.2, « Créer un Keystore Java pour stocker des strings sensibles » pour créer votre archivage de sécurité, l'alias seravault.
Sortir de la console interactive.
Saisir2pour sortir de la console interactive.
Votre mot de passe de keystore est masqué afin de pouvoir être utilisé dans les fichiers de configuration et de déploiement. De plus, votre archivage de sécurité est complètement configuré et prêt à l'utilisation.
10.13.4. Configurer JBoss EAP pour qu'il utilise l'archivage sécurisé des mots de passe
Avant de masquer les mots de passe et d'autres attributs sensibles dans les fichiers de configuration, vous devez sensibiliser JBoss EAP 6 à l'archivage sécurisé des mots de passe qui les stocke et les déchiffre. Actuellement, cela vous oblige à arrêter Enterprise Application Platform et à modifier la configuration directement.
Prérequis
Procédure 10.42. Assigner un mot de passe d'archivage sécurisé.
Déterminer les valeurs qui conviennent pour la commande.
Déterminer les valeurs pour les paramètres suivants, déterminés par les commandes utilisées pour créer le keystore lui-même. Pour obtenir des informations sur la façon de créer un keystore, voir les sujets suivants : Section 10.13.2, « Créer un Keystore Java pour stocker des strings sensibles » et Section 10.13.3, « Masquer le mot de passe du keystore et initialiser le mot de passe de l'archivage de sécurité ».Paramètre Description KEYSTORE_URL Le chemin d'accès ou URI du fichier keystore, qui s'appelle normalementvault.keystoreKEYSTORE_PASSWORD Le mot de passe utilisé pour accéder au keystore. Cette valeur devrait être masquée.KEYSTORE_ALIAS Le nom du keystore.SALT Le salt utilisé pour crypter et décrypter les valeurs de keystore.ITERATION_COUNT Le nombre de fois que l'algorithme de chiffrement est exécuté.ENC_FILE_DIR Le chemin d'accès au répertoire à partir duquel les commandes de keystore sont exécutées. Normalement, le répertoire contient les mots de passe sécurisés.hôte (domaine géré uniquement) Le nom de l'hôte que vous configurezUtiliser le Management CLI pour activer les mots de passe sécurisés.
Exécutez une des commandes suivantes, selon que vous utilisez un domaine géré ou une configuration de serveur autonome. Substituez les valeurs de la commande par celles de la première étape de cette procédure.Note
Si vous utilisez Microsoft Windows Server, remplacer chaque caractère de/dans un chemin d'accès de nom de fichier ou de répertoire par quatre caractères\. C'est parce qu'il faut deux caractères\, chacun échappé. Cela n'a pas besoin d'être fait pour les autres caractères/.Domaine géré
/host=YOUR_HOST/core-service=vault:add(vault-options=[("KEYSTORE_URL" => "PATH_TO_KEYSTORE"), ("KEYSTORE_PASSWORD" => "MASKED_PASSWORD"), ("KEYSTORE_ALIAS" => "ALIAS"), ("SALT" => "SALT"),("ITERATION_COUNT" => "ITERATION_COUNT"), ("ENC_FILE_DIR" => "ENC_FILE_DIR")])Serveur autonome
/core-service=vault:add(vault-options=[("KEYSTORE_URL" => "PATH_TO_KEYSTORE"), ("KEYSTORE_PASSWORD" => "MASKED_PASSWORD"), ("KEYSTORE_ALIAS" => "ALIAS"), ("SALT" => "SALT"),("ITERATION_COUNT" => "ITERATION_COUNT"), ("ENC_FILE_DIR" => "ENC_FILE_DIR")])
Ce qui suit est un exemple de la commande avec des valeurs hypothétiques :/core-service=vault:add(vault-options=[("KEYSTORE_URL" => "/home/user/vault/vault.keystore"), ("KEYSTORE_PASSWORD" => "MASK-3y28rCZlcKR"), ("KEYSTORE_ALIAS" => "vault"), ("SALT" => "12438567"),("ITERATION_COUNT" => "50"), ("ENC_FILE_DIR" => "/home/user/vault/")])
JBoss EAP 6 est configuré pour décrypter les strings masqués par l'intermédiaire de l'archivage sécurisé de mots de passe. Pour ajouter des strings à l'archivage sécurisé, et les utiliser dans votre configuration, voir la section suivante : Section 10.13.5, « Stocker et résoudre des strings sensibles cryptés du Keystore Java. ».
10.13.5. Stocker et résoudre des strings sensibles cryptés du Keystore Java.
En comptant les mots de passe et les autres strings sensibles, les fichiers de configuration en texte brut ne sont pas sécurisés. JBoss EAP 6 inclut la capacité de stocker et d'utiliser les valeurs masquées dans les fichiers de configuration, et d'utiliser ces valeurs masquées dans les fichiers de configuration.
Prérequis
- L'application
EAP_HOME/bin/vault.shdoit pouvoir être accessible via l'interface de ligne de commande.
Procédure 10.43. Installation du Java Keystore
Exécuter la commande
vault.sh.ExécuterEAP_HOME/bin/vault.sh. Démarrer une nouvelle session interactive en tapant0.Saisir le nom du répertoire où les fichiers cryptés seront stockés.
Si vous suivez Section 10.13.2, « Créer un Keystore Java pour stocker des strings sensibles », votre keystore sera dans un répertoire nommévault/de votre répertoire de base. Dans la plupart des cas, il est logique de stocker toutes vos informations cryptées au même endroit dans le keystore. Cet exemple utilise le répertoire/home/USER/vault/.Note
N'oubliez pas d'inclure la barre oblique finale dans le nom du répertoire. Soit/ou\, selon votre système d'exploitation.Saisir le nom de votre keystore.
Saisir le nom complet vers le fichier de keystore. Cet exemple utilise/home/USER/vault/vault.keystore.Saisir le mot de passe du keystore, le nom de l'archivage sécurisé, salt, et le nombre d'itérations.
Quand vous y êtes invité, saisir le mot de passe du keystore, le nom de l'archivage sécurisé, salt, et le nombre d'itérations.Sélectionner l'option de stockage d'un mot de passe.
Sélectionner l'option0de stockage d'un mot de passe ou autre string sensible.Saisir la valeur.
Une fois que vous y êtes invité, saisir la valeur deux fois. Si les valeurs ne correspondent pas, vous serez invité à essayer à nouveau.Saisir le bloc d'archivage sécurisé.
Saisir le bloc d'archivage sécurisé, qui est un conteneur pour les attributs qui ont trait à la même ressource. Un exemple de nom d'attribut seraitds_ExampleDS. Cela fera partie de la référence à la chaîne cryptée, dans votre source de données ou autre définition de service.Saisir le nom de l'attribut.
Saisir le nom de l'attribut que vous stockez. Exemple de nom d'attributpassword.RésultatUn message comme celui qui suit montre que l'attribut a été sauvegardé.
Valeur de l'attribut pour (ds_ExampleDS, password) sauvegardé
Notez les informations pour ce string crypté.
Un message s'affiche sur la sortie standard, montrant le bloc d'archivage sécurisé, le nom de l'attribut, la clé partagée et des conseils sur l'utilisation du string dans votre configuration. Prendre note de ces informations dans un emplacement sécurisé. Voici un exemple de sortie.******************************************** Vault Block:ds_ExampleDS Attribute Name:password Configuration should be done as follows: VAULT::ds_ExampleDS::password::1 ********************************************
Utiliser le string crypté dans votre configuration.
Utiliser le string de l'étape de configuration précédente, à la place du string en texte brut. Une source de données utilisant le mot de passe crypté ci-dessus, est montrée ci-dessous.... <subsystem xmlns="urn:jboss:domain:datasources:1.0"> <datasources> <datasource jndi-name="java:jboss/datasources/ExampleDS" enabled="true" use-java-context="true" pool-name="H2DS"> <connection-url>jdbc:h2:mem:test;DB_CLOSE_DELAY=-1</connection-url> <driver>h2</driver> <pool></pool> <security> <user-name>sa</user-name> <password>${VAULT::ds_ExampleDS::password::1}</password> </security> </datasource> <drivers> <driver name="h2" module="com.h2database.h2"> <xa-datasource-class>org.h2.jdbcx.JdbcDataSource</xa-datasource-class> </driver> </drivers> </datasources> </subsystem> ...Vous pouvez utiliser un string crypté n'importe où dans votre fichier de configuration autonome ou de domaine pour lequel les expressions sont autorisées.Note
Pour vérifier si les expressions sont utilisées dans un sous-système particulier, exécuter la commande CLI suivante sur ce sous-système :/host=master/core-service=management/security-realm=TestRealm:read-resource-description(recursive=true)
À partir du résultat de cette commande, chercher la valeur du paramètreexpressions-allowed. Si 'true', vous pourrez utiliser des expressions dans la configuration de ce sous-système particulier.Une fois que vous aurez mis votre string dans le keystore, utiliser la syntaxe suivante pour remplacer tout string en texte claire par un texte crypté.${VAULT::<replaceable>VAULT_BLOCK</replaceable>::<replaceable>ATTRIBUTE_NAME</replaceable>::<replaceable>ENCRYPTED_VALUE</replaceable>}Voici un exemple de valeur réelle, où le bloc d'archivage sécurisé estds_ExampleDSet l'attribut estpassword.<password>${VAULT::ds_ExampleDS::password::1}</password>
10.13.6. Stocker et résoudre des strings sensibles de vos applications
Les éléments de configuration de la plate-forme JBoss EAP 6 prennent en charge la capacité de régler les chaînes cryptées en fonction des valeurs stockées dans Java Keystore, via le mécanisme Security Vault. Vous pouvez ajouter le support pour cette fonctionnalité à vos propres applications.
Avant d'effectuer cette procédure, assurez-vous que le répertoire pour stocker vos fichiers dans le Security Vault existe bien. Qu'importe où vous les placez, tant que l'utilisateur qui exécute JBoss EAP 6 dispose de l'autorisation de lire et écrire des fichiers. Cet exemple situe le répertoire vault/ dans le répertoire /home/USER/vault/. Le Security Vault lui-même correspond à un fichier nommé vault.keystore qui se trouve dans le répertoire vault/.
Exemple 10.34. Ajout du string de mot de passe au Security Vault
EAP_HOME/bin/vault.sh. La série de commandes et réponses est incluse dans la session suivante. Les valeurs saisies par l'utilisateur apparaîtront clairement. Certaines sorties seront supprimées pour le formatage. Dans Microsoft Windows, le nom de la commande est vault.bat. Notez que dans Microsoft Windows, les chemins d'accès au fichier utilisent le caractère \ comme séparateur de répertoire, et non pas le caractère /.
[user@host bin]$ ./vault.sh ********************************** **** JBoss Vault ******** ********************************** Please enter a Digit:: 0: Start Interactive Session 1: Remove Interactive Session 2: Exit0Starting an interactive session Enter directory to store encrypted files:/home/user/vault/Enter Keystore URL:/home/user/vault/vault.keystoreEnter Keystore password:...Enter Keystore password again:...Values match Enter 8 character salt:12345678Enter iteration count as a number (Eg: 44):25Enter Keystore Alias:vaultVault is initialized and ready for use Handshake with Vault complete Please enter a Digit:: 0: Store a password 1: Check whether password exists 2: Exit0Task: Store a password Please enter attribute value:saPlease enter attribute value again:saValues match Enter Vault Block:DSEnter Attribute Name:thePassAttribute Value for (DS, thePass) saved Please make note of the following: ******************************************** Vault Block:DS Attribute Name:thePass Configuration should be done as follows: VAULT::DS::thePass::1 ******************************************** Please enter a Digit:: 0: Store a password 1: Check whether password exists 2: Exit2
VAULT.
Exemple 10.35. Servlet qui utilise un mot de passe Vaulted
package vaulterror.web;
import java.io.IOException;
import java.io.Writer;
import javax.annotation.Resource;
import javax.annotation.sql.DataSourceDefinition;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.sql.DataSource;
/*@DataSourceDefinition(
name = "java:jboss/datasources/LoginDS",
user = "sa",
password = "sa",
className = "org.h2.jdbcx.JdbcDataSource",
url = "jdbc:h2:tcp://localhost/mem:test"
)*/
@DataSourceDefinition(
name = "java:jboss/datasources/LoginDS",
user = "sa",
password = "VAULT::DS::thePass::1",
className = "org.h2.jdbcx.JdbcDataSource",
url = "jdbc:h2:tcp://localhost/mem:test"
)
@WebServlet(name = "MyTestServlet", urlPatterns = { "/my/" }, loadOnStartup = 1)
public class MyTestServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
@Resource(lookup = "java:jboss/datasources/LoginDS")
private DataSource ds;
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
Writer writer = resp.getWriter();
writer.write((ds != null) + "");
}
}
10.14. Encodage se conformant à FIPS 140-2
10.14.1. Conformité FIPS 140-2
10.14.2. Mots de passe conformes FIPS 140-2
- Une longueur minimale de sept (7) caractères.
- Il doit inclure des caractères d'au moins trois (3) des classes de caractères suivantes :
- chiffres ASCII,
- minuscules ASCII,
- Majuscules ASCII,
- non alphanumériques ASCII, et
- non-ASCII.
10.14.3. Active la Cryptography FIPS 140-2 pour SSL dans Red Hat Enterprise Linux 6
Pré-requis
- Red Hat Enterprise Linux 6 doit déjà être configuré pour être configuré en conformité avec FIPS 140-2. Voir https://access.redhat.com/knowledge/solutions/137833.
Procédure 10.44. Voir Conformité Cryptographie FIPS 140-2 pour SSL
Créer la base de données
Créer la base de données NSS dans un répertoire qui appartienne à l'utilisateurjboss.$ mkdir -p /usr/share/jboss-as/nssdb $ chown jboss /usr/share/jboss-as/nssdb $ modutil -create -dbdir /usr/share/jboss-as/nssdb
Créer un fichier de configuration NSS
Créer un nouveau fichier texte ayant comme nomnss_pkcsll_fips.cfgdans le répertoire/usr/share/jboss-asavec le contenu suivant :name = nss-fips nssLibraryDirectory=/usr/lib64 nssSecmodDirectory=/usr/share/jboss-as/nssdb nssModule = fips
Le fichier de configuration NSS doit spécifier :- un nom,
- le répertoire où se trouve la bibliothèque, et
- le répertoire où la base de données NSS a été créée selon l'étape 1.
Si vous n'êtes pas sur une version 64bit de Red Hat Enterprise Linux 6, alors définirnssLibraryDirectoryà/usr/libà la place de/usr/lib64.Activer le fournisseur SunPKCS11
Modifier le fichier de configurationjava.securityde votre JRE ($JAVA_HOME/jre/lib/security/java.security) et ajouter la ligne suivante :security.provider.1=sun.security.pkcs11.SunPKCS11 /usr/share/jboss-as/nss_pkcsll_fips.cfg
Notez que le fichier de configuration spécifié sur cette ligne est le fichier créé à l'étape 2.Toute autre lignesecurity.provider.Xde ce fichier devra posséder la valeur X +1 pour que la priorité soit donnée à ce fournisseur.Activer le mode FIPS pour la bibliothèque NSS
Exécutez la commandemodutilcomme indiqué pour activer le mode FIPS :modutil -fips true -dbdir /usr/share/jboss-as/nssdb
Notez que le répertoire indiqué ici est le répertoire créé à l'étape 1.Vous aurez sans doute une erreur de bibliothèque à ce niveau, ce qui vous oblige à régénérer les signatures de bibliothèques sur certains des objets NSS partagés.Modifier le mot de passe du token FIPS
Définir le mot de passe du token FIPS par la commande suivante. Notez que le nom du token doit correspondre àNSS FIPS 140-2 Certificate DB.modutil -changepw "
NSS FIPS 140-2 Certificate DB" -dbdir /usr/share/jboss-as/nssdbLe mot de passe utilisé pour le token FIPS doit être un mot de passe conforme FIPS.Créer le certificat grâce aux outils NSS
Saisir la commande suivante pour créer un certificat par les outils NSS.certutil -S -k rsa -n jbossweb -t "u,u,u" -x -s "CN=localhost, OU=MYOU, O=MYORG, L=MYCITY, ST=MYSTATE, C=MY" -d /usr/share/jboss-as/nssdb
Configurer le connecteur HTTPS pour utiliser le keystore PKCS11
Ajouter un connecteur HTTPS par la commande suivante dans JBoss CLI :/subsystem=web/connector=https/:add(socket-binding=https,scheme=https,protocol=HTTP/1.1,secure=true)
Puis, ajouter la configuration SSL par la commande suivante, en remplaçant PASSWORD par le mot de passe conforme FIPS de l'étape 5./subsystem=web/connector=https/ssl=configuration:add(name=https,password=PASSWORD,keystore-type=PCKS11, cipher-suite="SSL_RSA_WITH_3DES_EDE_CBC_SHA,SSL_DHE_RSA_WITH_3DES_EDE_CBC_SHA, TLS_RSA_WITH_AES_128_CBC_SHA,TLS_DHE_DSS_WITH_AES_128_CBC_SHA, TLS_DHE_RSA_WITH_AES_128_CBC_SHA,TLS_RSA_WITH_AES_256_CBC_SHA, TLS_DHE_DSS_WITH_AES_256_CBC_SHA,TLS_DHE_RSA_WITH_AES_256_CBC_SHA, TLS_ECDH_ECDSA_WITH_3DES_EDE_CBC_SHA,TLS_ECDH_ECDSA_WITH_AES_128_CBC_SHA, TLS_ECDH_ECDSA_WITH_AES_256_CBC_SHA,TLS_ECDHE_ECDSA_WITH_3DES_EDE_CBC_SHA, TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA,TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA, TLS_ECDH_RSA_WITH_3DES_EDE_CBC_SHA,TLS_ECDH_RSA_WITH_AES_128_CBC_SHA, TLS_ECDH_RSA_WITH_AES_256_CBC_SHA,TLS_ECDHE_RSA_WITH_3DES_EDE_CBC_SHA, TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA,TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA, TLS_ECDH_anon_WITH_3DES_EDE_CBC_SHA,TLS_ECDH_anon_WITH_AES_128_CBC_SHA, TLS_ECDH_anon_WITH_AES_256_CBC_SHA")
Vérifier
Vérifier que la JVM puisse lire la clé privée du keystore PKCS11 en exécutant la commande suivante :keytool -list -storetype pkcs11
Exemple 10.36. Configuration XML du connecteur HTTPS avec conformité FIPS 140-2
<connector name="https" protocol="HTTP/1.1" scheme="https" socket-binding="https" secure="true">
<ssl name="https" password="****"
cipher-suite="SSL_RSA_WITH_3DES_EDE_CBC_SHA,SSL_DHE_RSA_WITH_3DES_EDE_CBC_SHA,
TLS_RSA_WITH_AES_128_CBC_SHA, TLS_DHE_DSS_WITH_AES_128_CBC_SHA,
TLS_DHE_RSA_WITH_AES_128_CBC_SHA,TLS_RSA_WITH_AES_256_CBC_SHA,
TLS_DHE_DSS_WITH_AES_256_CBC_SHA,TLS_DHE_RSA_WITH_AES_256_CBC_SHA,
TLS_ECDH_ECDSA_WITH_3DES_EDE_CBC_SHA,TLS_ECDH_ECDSA_WITH_AES_128_CBC_SHA,
TLS_ECDH_ECDSA_WITH_AES_256_CBC_SHA,TLS_ECDHE_ECDSA_WITH_3DES_EDE_CBC_SHA,
TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA,TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA,
TLS_ECDH_RSA_WITH_3DES_EDE_CBC_SHA,TLS_ECDH_RSA_WITH_AES_128_CBC_SHA,
TLS_ECDH_RSA_WITH_AES_256_CBC_SHA,TLS_ECDHE_RSA_WITH_3DES_EDE_CBC_SHA,
TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA,TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA,
TLS_ECDH_anon_WITH_3DES_EDE_CBC_SHA,TLS_ECDH_anon_WITH_AES_128_CBC_SHA,
TLS_ECDH_anon_WITH_AES_256_CBC_SHA"
keystore-type="PKCS11"/>
</connector>
cipher-suite a des sauts de ligne insérés pour faciliter la lecture.
Chapitre 11. Référence à l'administration de la sécurité
11.1. Modules d'authentification inclus
Role dans le nom de Code
Code ou le nom complet (package) pour vous référer au module.
Modules d'authentification
Tableau 11.1. Client
| Code | Client
|
| Class | org.jboss.security.ClientLoginModule
|
| Description |
Ce module de connexion est conçu pour établir l'identité de l'appelant et les informations d'identification lorsque JBoss EAP agit en tant que client. Il ne doit jamais servir sous forme de domaine de sécurité pour l'authentification serveur.
|
Tableau 11.2. Options de Modules Client
| Option | Type | Par défaut | Description |
|---|---|---|---|
multi-threaded | true ou false
| false
|
Définir la valeur sur true si chaque thread possède son propre stockage d'informations d'identification et principal. La valeur false pour indiquer que tous les threads de la machine virtuelle partagent la même identité et informations d'identification.
|
password-stacking
| useFirstPass ou false
| false
|
Définir la valeur sur useFirstPass pour indiquer que ce module de connexion doit rechercher les informations stockées dans le LoginContext à utiliser comme identité. Cette option peut être utilisée lorsque vous empilez les autres modules de connexion avec celui-ci.
|
restore-login-identity
| true ou false
| false
|
Définir sur true si l'identité et les informations d'identification du début de la méthode login() doivent être restaurées une fois que la méthode logout() est invoquée.
|
Tableau 11.3. Certificate
| Code | Certificate
|
| Class | org.jboss.security.auth.spi.BaseCertLoginModule
|
| Description |
Ce module de connexion est conçu pour authentifier les utilisateurs basés sur des
X509 Certificates. Un cas d'utilisation pour ceci est l'authentification CLIENT-CERT d'une application web.
|
Tableau 11.4. Options de module Certificate
| Option | Type | Par défaut | Description |
|---|---|---|---|
securityDomain
| chaîne |
aucun
|
Nom du domaine de sécurité qui possède la configuration JSSE du truststore qui contient les certificats approuvés.
|
verifier
| Class |
aucun
|
Le nom de classe du
org.jboss.security.auth.certs.X509CertificateVerifier à utiliser pour vérifier le certificat de connexion.
|
Tableau 11.5. CertificateUsers
| Code | CertificateUsers
|
| Class | org.jboss.security.auth.spi.UsersRolesLoginModule
|
| Description |
Utilise deux ressources de propriété. La première mappe les noms d'utilisateur aux mots de passe, et la seconde mappe les noms d'utilisateurs aux rôles.
|
Tableau 11.6. Options de module CertificateUsers
| Option | Type | Par défaut | Description |
|---|---|---|---|
unauthenticatedIdentity
| Une chaîne |
aucun
|
Définit le nom principal devant être affecté aux demandes qui ne contiennent aucune information d'authentification. Cela peut permettre à des servlets non protégés d'appeler des méthodes sur EJB ne nécessitant pas un rôle spécifique. Un tel principal ne possédera aucun rôle associé et ne pourra accéder qu'aux méthodes EJB ou EJB non sécurisées associées à la contrainte de
permission non contrôlée.
|
password-stacking
| useFirstPass ou false
| false
|
Définir la valeur sur
useFirstPass pour indiquer que ce module de connexion doit rechercher les informations stockées dans le LoginContext à utiliser comme identité. Cette option peut être utilisée lorsque vous empilez les autres modules de connexion avec celui-ci.
|
hashAlgorithm | Une chaîne |
aucun
|
Le nom de l'algorithme
java.security.MessageDigest à utiliser pour hacher le mot de passe. Il n'y a pas de valeur par défaut pour cette option, donc vous devez la définir explicitement pour permettre le hachage. Quand hashAlgorithm est spécifié, le mot de passe en texte clair obtenu de CallbackHandler sera haché avant de passer à UsernamePasswordLoginModule.validatePassword comme argument d'inputPassword. Le expectedPassword stocké dans le fichier users.properties doit être haché de façon similaire. Voir http://docs.oracle.com/javase/6/docs/api/java/security/MessageDigest.html pour obtenir des informations sur java.security.MessageDigest
|
hashEncoding
| base64 ou hex
| base64
|
Le format du string du mot de passe haché, si
hashAlgorithm est défini également.
|
hashCharset
| Une chaîne |
Le codage par défaut défini dans l'environnement du conteneur.
|
Le codage utilisé pour convertir le mot de passe de texte en clair en un tableau d'octets.
|
usersProperties
|
Le chemin d'accès complet et le nom d'une ressource ou d'un fichier de propriétés
| users.properties
|
Le fichier qui contient les mappages entre les utilisateurs et les mots de passe. Chaque propriété du fichier a le format
username=password.
|
rolesProperties
| Le chemin d'accès complet et le nom d'une ressource ou d'un fichier de propriétés | roles.properties
|
Le fichier qui contient les mappages entre les utilisateurs et les rôles. Chaque propriété du fichier a le format
username=role1,role2,...,roleN
|
ignorePasswordCase
| true ou false
| false
|
Si la comparaison de mot de passe doit ignorer la casse. Ceci est utile pour le codage de mots de passe hachés quand le mot de passe haché n'est pas significatif.
|
principalClass
| Un nom de classe complet. |
aucun
|
Une classe d'implémentation de
Principalcontenant un constructeur qui prend l'argument du String comme nom de principal.
|
roleGroupSeparator
|
Un seul caractère
| . (un seul point)
|
Le caractère utilisé pour séparer le nom d'utilisateur du nom de groupe de rôle dans le fichier
rolesGroup.
|
defaultUsersProperties
| chaîne | defaultUsers.properties
|
Nom de la ressource ou du fichier où se replier si le fichier usersProperties est introuvable.
|
defaultRolesProperties
| chaîne | defaultRoles.properties
|
Nom de la ressource ou du fichier où se replier si le fichier
rolesProperties est introuvable.
|
hashUserPassword
| true ou false
| true
|
Indique si on doit hacher le mot de passe entré par l'utilisateur, lorsqu'
hashAlgorithm est indiqué. La valeur par défaut est true.
|
hashStorePassword
| true ou false
| true
|
Indique le mot de passe de store retourné quand le
getUsersPassword() doit être haché, quand hashAlgorithm est spécifié.
|
digestCallback
| Un nom de classe complet. |
aucun
|
Le nom de classe de l'implémentation
org.jboss.crypto.digest.DigestCallback qui inclut le contenu pre/post digest comme les valeurs salt. Utilisé uniquement si l'hashAlgorithm est spécifié.
|
storeDigestCallback
| Un nom de classe complet. |
aucun
|
Le nom de classe de l'implémentation
org.jboss.crypto.digest.DigestCallback qui inclut le contenu pre/post digest comme les valeurs salt pour hacher le mot de passe du store. Utilisé uniquement si l'hashStoreAlgorithm est sur true et si hashAlgorithm est spécifié.
|
callback.option.STRING
| Divers | aucun |
Toutes les options ayant comme préfixe
callback.option. sont passées à la méthode DigestCallback.init(Map). Le nom d'utilisateur entré est toujours passé par l'option javax.security.auth.login.name, et le mot de passe input/store password est passé par l'option javax.security.auth.login.password au digestCallback ou au storeDigestCallback.
|
Tableau 11.7. CertificateRoles
| Code | CertificateRoles
|
| Class | org.jboss.security.auth.spi.CertRolesLoginModule
|
| Description |
Ce module de connexion étend le module de connexion de certificat pour ajouter des fonctions de mappage de rôle à partir d'un fichier de propriétés. Il prend les mêmes options que le module de connexion du certificat et ajoute les options suivantes.
|
Tableau 11.8. Options de module CertificateRoles
| Option | Type | Par défaut | Description |
|---|---|---|---|
rolesProperties
| Une chaîne | roles.properties
|
Le nom de la ressource ou du fichier contenant les rôles à attribuer à chaque utilisateur. Le fichier de propriétés de rôle doit être sous format nom d'utilisateur=role1,role2, où le nom d'utilisateur est le nom unique du certificat, sans signe égal
= ou espace blanc. L'exemple suivant est dans le bon format :
CN\=unit-tests-client,\ OU\=Red\ Hat\ Inc.,\ O\=Red\ Hat\ Inc.,\ ST\=North\ Carolina,\ C\=US=JBossAdmin |
defaultRolesProperties
| Une chaîne | defaultRoles.properties
|
Nom de la ressource ou du fichier où se replier si le fichier
rolesProperties est introuvable.
|
roleGroupSeparator
| Un seul caractère | . (un seul point)
|
Le caractère à utiliser comme séparateur de groupe rôle dans le fichier de
roleProperties
|
Tableau 11.9. Database
| Code | Database |
| Class | org.jboss.security.auth.spi.DatabaseServerLoginModule
|
| Description |
Un module de connexion basé-JDBC supportant le mappage de rôle et l'authentification. Basé sur deux tables logiques, avec les définitions suivantes.
|
Tableau 11.10. Database Module Options
| Option | Type | Par défaut | Description |
|---|---|---|---|
dsJndiName
| Ressource JNDI |
aucun
|
Le nom de la ressource JNDI qui store les informations d'authentification. Cette option est requise.
|
principalsQuery
| Énoncé SQL | select Password from Principals where PrincipalID=?
|
La requête SQL préparée pour obtenir les informations sur le principal.
|
rolesQuery
| Énoncé SQL | select Role, RoleGroup from Roles where PrincipalID=?
|
Enoncé SQL préparé en vue d'obtenir les informations concernant les rôles. Il doit être équivalent à
select Role, RoleGroup from Roles where PrincipalID=?, avec Role comme nom de rôle et la valeur de la colonne RoleGroup doit toujours être Roles avec un R majuscule ou CallerPrincipal.
|
Tableau 11.11. DatabaseCertificate
| Code | DatabaseCertificate
|
| Class | org.jboss.security.auth.spi.DatabaseCertLoginModule
|
| Description |
Ce module de connexion étend le module de connexion de certificat pour ajouter des fonctions de mappage de rôle d'une table de bases de données. Il possède les mêmes options mais aussi ces options supplémentaires :
|
Tableau 11.12. DatabaseCertificate Module Options
| Option | Type | Par défaut | Description |
|---|---|---|---|
dsJndiName
| Ressource JNDI | |
Le nom de la ressource JNDI qui store les informations d'authentification. Cette option est requise.
|
rolesQuery
| Énoncé SQL | select Role,RoleGroup from Roles where PrincipalID=?
|
Enoncé SQL préparé en vue d'exécuter pour mapper les rôles. Doit être équivalent à
select Role, RoleGroup from Roles where PrincipalID=?, avec Role comme nom de rôle et la valeur de la colonne RoleGroup doit toujours être Roles avec un R majuscule ou CallerPrincipal.
|
suspendResume
| true ou false
| true
|
Indique si une transaction JTA existante doit être suspendue pendant les opérations de base de données.
|
Tableau 11.13. Identity
| Code | Identity
|
| Class | org.jboss.security.auth.spi.IdentityLoginModule
|
| Description |
Associe le principal spécifié dans les options de module avec n'importe quel sujet authentifié dans le module. Le type de classe de principal utilisée est
org.jboss.security.SimplePrincipal.. Si aucune option de principal n'est spécifiée, on utilisera un principal ayant pour nom guest.
|
Tableau 11.14. Options de module Identity
| Option | Type | Par défaut | Description |
|---|---|---|---|
principal
| Une chaîne | guest
|
Le nom à utiliser pour le principal.
|
roles
| Une liste de strings séparée par des virgules |
aucun
|
Une liste de rôles séparée par des virgules qui sera assignée au sujet.
|
Tableau 11.15. Ldap
| Code | Ldap
|
| Class | org.jboss.security.auth.spi.LdapLoginModule
|
| Description |
Authentifie sur un serveur LDAP, lorsque le nom d'utilisateur et le mot de passe sont stockés dans un serveur LDAP qui est accessible à l'aide d'un fournisseur LDAP JNDI. Bon nombre des options ne sont pas requises, car elles sont déterminées par le fournisseur LDAP ou l'environnement.
|
Tableau 11.16. Options de module Ldap
| Option | Type | Par défaut | Description |
|---|---|---|---|
java.naming.factory.initial
| class name | com.sun.jndi.ldap.LdapCtxFactory
|
Nom de classe de l'implémentation
InitialContextFactory.
|
java.naming.provider.url
| ldap:// URL
|
aucun
|
URL pour le serveur LDAP
|
java.naming.security.authentication
| none, simple, ou le nom d'un mécanisme SASL
| simple
|
Le niveau de sécurité à utiliser pour la liaison avec le serveur LDAP.
|
java.naming.security.protocol
| Protocole de transport |
Si non spécifié, déterminé par le fournisseur.
|
Le protocole de transport à utiliser pour l'accès sécurisé, comme SSL.
|
java.naming.security.principal
| Une chaîne |
aucun
|
Le nom du principal permettant d'authentifier l'appelant vers le service. Il est construit à partir des autres propriétés décrites ci-dessous.
|
java.naming.security.credentials
| Un type d'information d'identification |
aucun
|
Le type d'information d'identification utilisée par le schéma d'authentification. Exemples : mot de passe haché, mot de passe de texte clair, clé ou certificat. Si cette propriété n'est pas spécifiée, le comportement est déterminé par le fournisseur de service.
|
principalDNPrefix
| Une chaîne |
aucun
|
Préfixe ajouté au nom d'utilisateur pour former le DN de l'utilisateur. Vous pouvez demander à l'utilisateur un nom d'utilisateur et créer le nom de domaine DN complet en utilisant
principalDNPrefix et principalDNSuffix.
|
principalDNSuffix
| chaîne | |
Suffixe ajouté au nom d'utilisateur pour former le DN de l'utilisateur. Vous pouvez demander à l'utilisateur un nom d'utilisateur et créer le nom de domaine DN complet en utilisant
principalDNPrefix et principalDNSuffix.
|
useObjectCredential
| true ou false
|
false
|
Si les informations d'identification doivent être obtenues sous forme d'objet opaque à l'aide du type de Callback
org.jboss.security.auth.callback.ObjectCallback plutôt que comme mot de passe char[] utilisant un JAAS PasswordCallback. Cela permet de passer les informations d'identification non-char[] au serveur Ldap.
|
rolesCtxDN
| DN complet |
aucun
|
Le DN complet pour le contexte à chercher pour les rôles d'utilisateur.
|
userRolesCtxDNAttributeName
|
Attribut
|
aucun
|
L'attribut dans l'objet utilisateur qui contient le nom unique DN pour que le contexte rechercher des rôles d'utilisateur. Cela diffère de
rolesCtxDN dans ce contexte de recherche car les rôles d'un utilisateur peuvent être uniques pour chaque utilisateur.
|
roleAttributeID
| Attribut | roles
|
Nom de l'attribut qui contient les rôles d'utilisateur.
|
roleAttributeIsDN
| true ou false
| false
|
Indique si le
roleAttributeID contient le nom de domaine complet d'un objet de rôle. Si false, le nom de rôle est tiré de la valeur de l'attribut roleNameAttributeId du nom de contexte. Certains schémas de répertoire, tel que Active Directory, requièrent que cet attribut soit défini à true.
|
roleNameAttributeID
| Attribut | group
|
Nom de l'attribut du contexte de
roleCtxDN qui contient le nom de rôle. Si la propriété roleAttributeIsDN est définie sur true, cette propriété sera utilisée pour rechercher l'attribut de nom de l'objet rôle.
|
uidAttributeID
| Attribut | uid
|
Nom de l'attribut qui contient le
UserRolesAttributeDN correspondant à l'ID d'utilisateur. Utilisé pour localiser les rôles d'utilisateur.
|
matchOnUserDN
| true ou false
| false
|
Si la recherche de rôles d'utilisateur doit correspondre au DN de l'utilisateur entièrement distinct ou au nom d'utilisateur uniquement. Si
true, l'userDN complet sera utilisé comme valeur de correspondance. Si false, seul le nom d'utilisateur sera utilisé comme valeur de correspondance pour l'attribut UserRolesAttributeDN.
|
allownEmptyPasswords
| true ou false
| true
|
Indique si on doit autoriser les mots de passe vides. La plupart des serveurs LDAP traitent les mots de passe vides comme des tentatives de connexion anonymes. Pour rejeter les mots de passe vides, définir à false.
|
Tableau 11.17. LdapExtended
| Code | LdapExtended
|
| Class | org.jboss.security.auth.spi.LdapExtLoginModule
|
| Description |
Une autre implémentation de module de connexion LDAP qui utilise les recherches pour localiser l'utilisateur de liaisons et rôles associés. La requête de rôles suit récursivement les noms de domaines DN pour naviguer dans une structure de rôles hiérarchique. Il utilise les mêmes options
java.naming que le module Ldap, et utilise les options suivantes à la place des autres options du module Ldap.
L'authentification a lieu en 2 étapes :
|
Tableau 11.18. Options de module LdapExtended
| Option | Type | Par défaut | Description |
|---|---|---|---|
baseCtxDN
| DN complet |
aucun
|
Le DN fixe de contexte de niveau supérieur pour commencer la recherche utilisateur.
|
bindDN
| DN complet |
aucun
|
Le DN utilisé pour la liaison au serveur LDAP pour les requêtes d'utilisateurs et de rôles. Ce nom unique a besoin d'autorisations de lecture et de recherche pour les valeurs
baseCtxDN et rolesCtxDN.
|
bindCredential
| Un string, parfois crypté |
aucun
|
Mots de passe stockés en tant que texte brut pour le
bindDN, ou chargés en externe par la commande EXT. Ce mot de passe peut être crypté par le mécanisme d'archivage sécurisé. Vous pourrez utiliser les formats suivants :
Reportez-vous à la rubrique suivante pour en savoir plus sur le cryptage des chaînes sensibles : Section 10.13.2, « Créer un Keystore Java pour stocker des strings sensibles »
|
baseFilter
| String de filtre LDAP |
aucun
|
Un filtre de recherche permettant de localiser le contexte de l'utilisateur à authentifier. L'entrée username ou userDN obtenue à partir du rappel de module de connexion est substitué dans le filtre à chaque fois qu'une expression
{0} est utilisée. Un exemple de filtre de recherche est (uid={0}).
|
rolesCtxDN
| DN complet |
aucun
|
Le DN fixe du contexte pour rechercher des rôles d'utilisateur. Ce n'est pas le DN où les rôles se trouvent, mais le DN où les objets contenant les rôles d'utilisateur se trouvent. Par exemple, dans un serveur Active Directory de Microsoft, c'est le DN où le compte d'utilisateur se trouve.
|
roleFilter
| String de filtre LDAP | |
Un filtre de recherche permettant de localiser les rôles associés à l'utilisateur authentifié. L'entrée user ou userDN obtenue à partir du rappel de module de connexion est substitué dans le filtre à chaque fois qu'une expression
{0} est utilisée. L'utilisateurDN (userDN) authentifié sera substitué dans le filtre à chaque fois qu'un {1} est utilisé. Un exemple de filtre de recherche qui correspond au nom d'utilisateur d'entrée serait (member={0}). Un autre correspondant au userDN authentifié pourrait être (member={1}).
|
roleAttributeIsDN | true ou false
| false
|
Indique si le
roleAttributeID contient le nom de domaine complet d'un objet de rôle. Si false, le nom de rôle est tiré de la valeur de l'attribut roleNameAttributeId du nom de contexte. Certains schémas de répertoire, tel que Active Directory, requièrent que cet attribut soit défini à true.
|
defaultRole
|
Un nom de rôle.
|
aucun
|
Un rôle inclus pour tous les utilisateurs authentifiés
|
parseRoleNameFromDN
| true ou false
| false
|
Un indicateur qui signale si le DN retourné par une requête contient le roleNameAttributeID. Si la valeur est
true, le DN est vérifié pour le roleNameATtributeID. Si la valeur est false, le DN n'est pas coché pour le roleNameAttributeID. Cet indicateur peut améliorer les performances des requêtes LDAP.
|
parseUsername
| true ou false
| false
|
Un indicateur qui signale si le DN doit être vérifié niveau nom d'utilisateur. Si la valeur est
true, le DN est vérifié niveau nom d'utilisateur. Si la valeur est false, le DN n'est pas vérifié au niveau nom d'utilisateur. Cet option peut à la fois être utilisée pour usernameBeginString et usernameEndString.
|
usernameBeginString
|
une chaîne
|
aucun
|
Définit le string qui doit être supprimé au début du DN pour révéler le nom d'utilisateur. Cette option est utilisée avec
usernameEndString.
|
usernameEndString
|
une chaîne
|
aucun
|
Définit le string qui doit être supprimé à la fin du DN pour révéler le nom d'utilisateur. Cette option est utilisée avec
userBeginString.
|
roleNameAttributeID
| Attribut | group
|
Nom de l'attribut du contexte de
roleCtxDN qui contient le nom de rôle. Si la propriété roleAttributeIsDN est définie sur true, cette propriété sera utilisée pour rechercher l'attribut de nom de l'objet rôle.
|
distinguishedNameAttribute
| Attribut | distinguishedName
|
Le nom de l'attribut dans l'entrée de l'utilisateur qui contient le nom unique de l'utilisateur. Ceci peut être nécessaire si le DN de l'utilisateur lui-même contient des caractères spéciaux (barre oblique inverse par exemple) qui empêchent le mappage de l'utilisateur. Si l'attribut n'existe pas, le DN de l'entrée sera utilisé.
|
roleRecursion
| Un entier relatif | 0
|
Le nombre de niveaux de récursivité de la recherche de rôle dans un contexte de correspondance donné. Désactiver la récursivité en attribuant le paramètre
0.
|
searchTimeLimit
| Un entier relatif | 10000 (10 seconds)
|
Timeout en millisecondes pour les recherches utilisateur/rôle.
|
searchScope
|
Un parmi :
OBJECT_SCOPE, ONELEVEL_SCOPE, SUBTREE_SCOPE
| SUBTREE_SCOPE
|
Étendue à utiliser.
|
allownEmptyPasswords
| true ou false
| true
|
Indique si on doit autoriser les mots de passe vides. La plupart des serveurs LDAP traitent les mots de passe vides comme des tentatives de connexion anonymes. Pour rejeter les mots de passe vides, définir à false.
|
Tableau 11.19. RoleMapping
| Code | RoleMapping
|
| Class | org.jboss.security.auth.spi.RoleMappingLoginModule
|
| Description |
Mappe un rôle qui est le résultat final du processus d'authentification de manière déclarative. Ce module doit être marqué comme étant
optionnel quand vous y ajoutez le domaine de sécurité.
|
Tableau 11.20. Options de module RoleMapping
| Option | Type | Par défaut | Description |
|---|---|---|---|
rolesProperties
| Le chemin d'accès complet et le nom d'une ressource ou d'un fichier de propriétés | roles.properties
|
Nom de la ressource ou du fichier de propriétés qui mappe les rôles aux rôles de remplacement. Le format est
original_role=role1,role2,role3
|
replaceRole
| true ou false
| false
|
Indique si on doit ajouter les rôles en cours, ou les remplacer par les rôles mappés. Sont remplacés si définis sur
true.
|
Tableau 11.21. RunAs
| Code | RunAs
|
| Class | Class: org.jboss.security.auth.spi.RunAsLoginModule
|
| Description |
Un module d'assistance qui pousse un rôle
run as dans la pile pour la durée de la phase d'authentification de la connexion, et qui extrait le rôle run as de la pile soit dans la phase commit ou abort. Ce module de connexion fournit un rôle pour les autres modules de connexion qui doivent accéder aux ressources sécurisées afin d'effectuer leur authentification, par exemple un module de connexion qui accède à un EJB sécurisé. RunAsLoginModule doit être configuré avant que les modules de connexion qui ont besoin d'un rôle run as soient mis en place.
|
Tableau 11.22. Options RunAs
| Option | Type | Par défaut | Description |
|---|---|---|---|
roleName
| Un nom de rôle. | nobody
|
Le nom de rôle à utiliser comme rôle
run as pendant la phase de connexion.
|
Tableau 11.23. Simple
| Code | Simple
|
| Class | org.jboss.security.auth.spi.SimpleServerLoginModule
|
| Description |
Module d'installation rapide de sécurité pour les tests. Implémente ce simple algorithme :
|
Simple Module Options
Le module Simple n'a pas d'options.
Tableau 11.24. ConfiguredIdentity
| Code | ConfiguredIdentity
|
| Class | org.picketbox.datasource.security.ConfiguredIdentityLoginModule
|
| Description |
Associe le principal spécifié dans les options du module avec n'importe quel sujet authentifié dans le module. Le type de classe du Principal classe est
org.jboss.security.SimplePrincipal.
|
Tableau 11.25. ConfiguredIdentity Module Options
| Option | Type | Par défaut | Description |
|---|---|---|---|
principal
| Nom d'un principal. | none
|
Le principal qui sera associé avec n'importe quel sujet authentifié dans le module.
|
Tableau 11.26. SecureIdentity
| Code | SecureIdentity
|
| Class | org.picketbox.datasource.security.SecureIdentityLoginModule
|
| Description |
Ce module est fourni à des fins d'héritage. Il permet de crypter un mot de passe et ensuite d'utiliser le mot de passe crypté avec un principal statique. Si votre application utilise
SecureIdentity, envisager plutôt d'utiliser un mécanisme d'archivage sécurisé de mot de passe.
|
Tableau 11.27. Options de module SecureIdentity
| Option | Type | Par défaut | Description |
|---|---|---|---|
username
| chaîne | aucun | Le nom d'utilisateur pour l'authentification. |
password
| string encodé | aucun |
Le mot de passe à utiliser pour l'authentification. Pour crypter le mot de passe, utilisez le module directement dans la ligne de commande.
Coller le résultat de cette commande dans le champ d'option de module.
|
managedConnectionFactoryName
| Une ressource JCA | aucun |
Le nom de la fabrique de connexions JCA à utiliser pour votre source de données.
|
Tableau 11.28. PropertiesUsers
| Code | PropertiesUsers
|
| Class | org.jboss.security.auth.spi.PropertiesUsersLoginModule
|
| Description |
Utilise un fichier de propriétés pour stocker les noms d'utilisateur et mots de passe pour l'authentification. Aucune autorisation (correspondance de rôle) n'est fournie. Ce module convient seulement pour les tests.
|
Tableau 11.29. SimpleUsers
| Code | SimpleUsers
|
| Class | org.jboss.security.auth.spi.SimpleUsersLoginModule
|
| Description |
Ce module de connexion stocke le nom d'utilisateur et le mot de passe en texte clair dans un fichier de propriétés de Java. Il est inclus pour les essais uniquement et n'est pas approprié pour un environnement de production.
|
Tableau 11.30. Options de module SimpleUsers
| Option | Type | Par défaut | Description |
|---|---|---|---|
username
| chaîne | aucun | Le nom d'utilisateur pour l'authentification. |
password
| chaîne | aucun | Le nom d'utilisateur en texte clair pour l'authentification. |
Tableau 11.31. LdapUsers
| Code | LdapUsers
|
| Class | org.jboss.security.auth.spi.LdapUsersLoginModule
|
| Description |
Le module
LdapUsers est remplacé par les modules ExtendedLDAP et AdvancedLdap.
|
Tableau 11.32. Kerberos
| Code | Kerberos
|
| Class | com.sun.security.auth.module.Krb5LoginModule
|
| Description |
Effectue l'authentification de connexion Kerberos avec GSSAPI. Ce module fait partie de la structure de sécurité de l'API fourni par Sun Microsystems. Vous trouverez des informations à ce sujet dans http://docs.oracle.com/javase/1.4.2/docs/guide/security/jaas/spec/com/sun/security/auth/module/Krb5LoginModule.html. Ce module devra être mis en correspondance avec un autre module qui gère les mappages d'authentification et de rôles.
|
Tableau 11.33. Options de module Kerberos
| Option | Type | Par défaut | Description |
|---|---|---|---|
storekey
| true ou false
| false |
Indique si on doit ajouter
KerberosKey dans les informations d'authentification privées du sujet.
|
doNotPrompt
| true ou false
| false |
Si défini sur
true, l'utilisateur n'aura pas besoin de mot de passe.
|
useTicketCache
|
Valeur booléenne de
. true ou false
| false |
Si défini sur
true, le GTG sera obtenu à partir du cache du ticket. Si défini sur false, le cache du ticket ne sera pas utilisé.
|
ticketcache
| Un fichier ou une ressource qui représente un cache de ticket Kerberos. |
La valeur par défaut dépend du système d'exploitation que vous utilisez.
| Emplacement du ticketcache. |
useKeyTab
| true ou false
| false | Indique si on doit obtenir la clé du principal à partir d'un keytab. |
keytab
| Un fichier ou une ressource représentant un onglet de clé Kerberos. |
L'emplacement du fichier de configuration Kerberos du système d'exploitation, ou
/home/user/krb5.keytab
| Emplacement du fichier keytab. |
principal
| Une chaîne | aucun |
Le nom du principal. Cela peut être un simple nom d'utilisateur ou un nom de service tel que
host/testserver.acme.com. Utiliser cela au lieu d'obtenir le principal d'un fichier keytab, ou lorsque le fichier keytab contient plus d'un principal.
|
useFirstPass
| true ou false
| false |
Indique si on doit extraire le nom d'utilisateur et le mot de passe de l'état partagé du module à l'aide de
javax.security.auth.login.name et de javax.security.auth.login.password comme clés. Si l'authentification échoue, il n'y aura pas de nouvelle tentative.
|
tryFirstPass
| true ou false
| false |
Identique à
useFirstPass, mais si l'authentification échoue, le module utilise le CallbackHandler pour récupérer un nouveau nom d'utilisateur et mot de passe. Si la seconde authentification échoue, l'échec sera signalé à l'application appelante.
|
storePass
| true ou false
| false |
Indique si on doit stocker le nom d'utilisateur et le mot de passe de l'état partagé du module. N'a pas lieu si les clés existent déjà dans l'état partagé, ou si l'authentification a échoué.
|
clearPass
| true ou false
| false |
Définir à
true pour supprimer le nom de l'utilisateur et le mot de passe de l'état partagé une fois que les deux phases d'authentification sont terminées.
|
Tableau 11.34. SPNEGOUsers
| Code | SPNEGOUsers
|
| Class | org.jboss.security.negotiation.spnego.SPNEGOLoginModule
|
| Description |
Effectue l'authentification de connexion SPNEGO vers un serveur Microsoft Active Directory ou autre environnement qui supporte SPNEGO. SPNEGO peut également transporter les informations d'identification de Kerberos. Ce module a besoin de fonctionner en parallèle à un autre module qui gère l'authentification et le mappage des rôles.
|
Tableau 11.35. Options de module SPNEGO
| Option | Type | Par défaut | Description |
|---|---|---|---|
storeKey
| true ou false
| false
|
Indique si on doit stocker la clé ou non.
|
useKeyTab
| true ou false
| false
|
Indique si on doit utiliser un keytab.
|
principal
|
String représentant un principal d'authentification.
|
aucun
|
Le nom du principal pour l'authentification.
|
keyTab
|
Un fichier ou une ressource représentant un keytab.
| none
|
L'emplacement d'un keytab.
|
doNotPrompt
| true ou false
| false
|
Si on doit demander un mot de passe.
|
debug
| true ou false
| false
|
Indique si on doit enregistrer plus de messages verbeux pour pouvoir déboguer.
|
Tableau 11.36. AdvancedLdap
| Code | AdvancedLdap |
| Class | org.jboss.security.negotiation.AdvancedLdapLoginModule
|
| Description |
Module qui fournit davantage de fonctionnalité, comme SASL et l'utilisation d'un domaine de sécurité JAAS.
|
Tableau 11.37. Options de module AdvancedLdap
| Option | Type | Par défaut | Description |
|---|---|---|---|
bindAuthentication
|
chaîne
|
aucun
|
Le type d'authentification SASL à utiliser pour se lier au serveur de répertoires.
|
java.naming.provider.url
| string
|
aucun
|
L'URI du serveur de répertoires.
|
baseCtxDN
|
DN (Nom Distinctif) complet
|
aucun
|
Le nom distinctif à utiliser comme base pour les recherches.
|
baseFilter
|
Chaîne représentant un filtre de recherche LDAP
|
aucun
|
Le filtre à utiliser pour réduire les résultats des recherches.
|
roleAttributeID
|
Chaîne représentant un attribut LDAP
|
aucun
|
L'attribut LDAP qui contient les noms des rôles d'autorisation.
|
roleAttributeIsDN
| true ou false
| false
|
Indique si l'attribut de rôle est un Nom Distinctif (DN).
|
roleNameAttributeID
|
Chaîne représentant un attribut LDAP
|
aucun
|
L'attribut contenu dans
RoleAttributeId qui contient lui-même l'attribut de rôle.
|
recurseRoles
| true ou false
| false
|
Indique si on doit chercher récursivement des rôles dans
RoleAttributeId.
|
Tableau 11.38. AdvancedADLdap
| Code | AdvancedADLdap |
| Class | org.jboss.security.negotiation.AdvancedADLoginModule
|
| Description |
Ce module étend le module de connexion
AdvancedLdap, et ajoute des paramètres supplémentaires utiles au répertoire Microsoft Active Directory.
|
Tableau 11.39. UsersRoles
| Code | UsersRoles |
| Class | org.jboss.security.auth.spi.UsersRolesLoginModul
|
| Description |
Un module de connexion supportant des utilisateurs multiples et des rôles utilisateur stockés dans deux fichiers de propriétés différents.
|
Tableau 11.40. Options de module UsersRoles
| Option | Type | Par défaut | Description |
|---|---|---|---|
usersProperties
|
Chemin d'accès à un fichier ou à une ressource.
| users.properties
|
Fichier ou ressource qui contient les mappages d'utilisateur aux mots de passe. Le format du fichier est
user=hashed-password
|
rolesProperties
|
Chemin d'accès à un fichier ou à une ressource.
| roles.properties
|
Fichier ou ressource qui contient les mappages d'utilisateur aux rôles. Le format du fichier est
username=role1,role2,role3
|
password-stacking
| useFirstPass ou false
| false
|
La valeur de
useFirstPass indique si ce module de connexion doit tout d'abord rechercher les informations stockées dans le LoginContext à utiliser comme identité. Cette option peut être utilisée lorsque vous empilez les autres modules de connexion avec celui-ci.
|
hashAlgorithm
|
Chaîne représentant un algorithme de hachage de mot de passe.
| none
|
Le nom de l'algorithme
java.security.MessageDigest à utiliser pour hacher le mot de passe. Il n'y a pas de valeur par défaut pour cette option, donc vous devez la définir explicitement pour permettre le hachage. Quand hashAlgorithm est spécifié, le mot de passe en texte clair obtenu de CallbackHandler sera haché avant d'être passé à UsernamePasswordLoginModule.validatePassword comme argument inputPassword. Le mot de passe stocké dans le fichier users.properties doit être haché de façon similaire.
|
hashEncoding
| base64 ou hex
| base64
|
Le format du string du mot de passe haché, si hashAlgorithm est défini également.
|
hashCharset
|
Une chaîne
|
Le codage par défaut défini dans l'environnement runtime du conteneur.
|
Le codage utilisé pour convertir le mot de passe de texte en clair en un tableau d'octets.
|
unauthenticatedIdentity
|
Un nom de principal
|
aucun
|
Définit le nom principal affecté aux demandes qui ne contiennent aucune information d'authentification. Cela peut permettre à des servlets non protégés d'appeler des méthodes sur EJB ne nécessitant pas un rôle spécifique. Un tel principal ne possédera aucun rôle associé et ne pourra accéder qu'aux méthodes EJB ou EJB non sécurisées associées à la contrainte de
permission non contrôlée.
|
Les modules d'authentification sont des implémentations de javax.security.auth.spi.LoginModule. Reportez-vous à la documentation de l'API pour plus d'informations sur la création d'un module d'authentification personnalisé.
11.2. Modules d'autorisation inclus
| Code | Class |
|---|---|
| DenyAll | org.jboss.security.authorization.modules.AllDenyAuthorizationModule |
| PermitAll | org.jboss.security.authorization.modules.AllPermitAuthorizationModule |
| Delegating | org.jboss.security.authorization.modules.DelegatingAuthorizationModule |
| Web | org.jboss.security.authorization.modules.WebAuthorizationModule |
| JACC | org.jboss.security.authorization.modules.JACCAuthorizationModule |
11.3. Modules de sécurité inclus
| Code | Class |
|---|---|
| PropertiesRoles | org.jboss.security.mapping.providers.role.PropertiesRolesMappingProvider |
| SimpleRoles | org.jboss.security.mapping.providers.role.SimpleRolesMappingProvider |
| DeploymentRoles | org.jboss.security.mapping.providers.DeploymentRolesMappingProvider |
| DatabaseRoles | org.jboss.security.mapping.providers.role.DatabaseRolesMappingProvider |
| LdapRoles | org.jboss.security.mapping.providers.role.LdapRolesMappingProvider |
11.4. Modules Security Auditing Provider inclus
| Code | Class |
|---|---|
| LogAuditProvider | org.jboss.security.audit.providers.LogAuditProvider |
Chapitre 12. Configuration de sous-système
12.1. Aperçu Configuration Sous-système
JBoss EAP 6 utilise une configuration simplifiée, avec un fichier de configuration par domaine ou par serveur autonome. Dans un domaine autonome, un fichier distinct existe pour chaque contrôleur hôte également. Les modifications apportées à la configuration persistent automatiquement, donc le XML ne doit pas être édité manuellement. La configuration est scannée et automatiquement remplacée par l'API de gestion. La ligne de commande du Management CLI et la Console de gestion basée-web permettent de configurer chaque aspect de JBoss EAP 6.
EAP_HOME/domain/configuration/domain.xml pour un domaine géré ou EAP_HOME/standalone/configuration/standalone.xml pour un serveur autonome. La plupart des sous-systèmes incluent les détails de configuration configurés par l'intermédiaire de descripteurs de déploiements dans les versions précédentes de JBoss EAP.
Chaque configuration de sous-système est définie dans un schéma XML. Les schémas de configuration se trouvent dans le répertoire EAP_HOME/docs/schema/ de votre installation.
Sous-systèmes simples
ee– implémentation Java EE 6 APIejb– sous-système Enterprise JavaBeans (EJB)jaxrs– l'API JAX-RS API, fourni par RESTeasy.sar– le sous-système qui supporte Service Archives.threads– le sous-système qui supporte le traitement des threads.weld– l'API Contexts and Dependency Injection, fourni par Weld.
Chapitre 13. Le sous-système de journalisation
13.1. Introduction
13.1.1. Logging (Journalisation)
13.1.2. Frameworks de journalisations d'applications pris en charge par JBoss LogManager
- JBoss Logging - inclus avec JBoss EAP 6
- Apache Commons Logging - http://commons.apache.org/logging/
- Simple Logging Facade dans Java (SLF4J) - http://www.slf4j.org/
- Apache log4j - http://logging.apache.org/log4j/1.2/
- Java SE Logging (java.util.logging) - http://download.oracle.com/javase/6/docs/api/java/util/logging/package-summary.html
13.1.3. Configuration du journal d'amorçage
logging.properties. Ce fichier est un fichier standard de propriétés Java qui peut être modifié à l'aide d'un éditeur de texte. Chaque ligne du fichier possède le format property=value.
logging.properties se trouvera soit dans EAP_HOME/domain/configuration/logging.properties ou EAP_HOME/standalone/configuration/logging.properties.
13.1.4. Emplacements de fichiers de journalisation par défaut
Tableau 13.1. Fichier de journalisation par défaut d'un serveur autonome
| Fichier journal | Description |
|---|---|
EAP_HOME/standalone/log/server.log |
Le journal du serveur. Contient les messages de journalisation de serveur, dont les messages de démarrage de serveur.
|
Tableau 13.2. Fichiers de journalisation par défaut d'un domaine géré
| Fichier journal | Description |
|---|---|
EAP_HOME/domain/log/host-controller.log |
Journal d'amorçage du contrôleur hôte. Contient les messages de journalisation liés au démarrage du contrôleur hôte.
|
EAP_HOME/domain/log/process-controller.log |
Journal d'amorçage du contrôleur de processus. Contient les messages de journalisation liés au démarrage du contrôleur de processus.
|
EAP_HOME/domain/servers/SERVERNAME/log/server.log |
Le journal du serveur pour le serveur nommé. Contient les messages de journalisation de ce serveur, dont les messages de démarrage de serveur.
|
13.1.5. Filtre les expressions de journalisation
Avertissement
13.1.6. Niveaux de journalisation
TRACE, DEBOG, INFO, ATTENTION, ERREUR et FATAL.
ATTENTION enregistrera uniquement les messages des niveaux ATTENTION, ERREUR et FATAL.
13.1.7. Niveaux de journalisation pris en charge
Tableau 13.3. Niveaux de journalisation pris en charge
| Niveau de journalisation | Valeur | Description |
|---|---|---|
| FINESSE MAX | 300 |
-
|
| PLUS FIN | 400 |
-
|
| TRACE | 400 |
Utilisé pour des messages qui fournissent des informations détaillées sur l'état d'exécution d'une application. Les messages de journalisation
TRACE sont habituellement capturés lors du débogage d'une application uniquement.
|
| DEBUG | 500 |
Utilisé pour des messages qui indiquent des demandes individuelles de progrès ou des activités d'une application. Les messages de journalisation
DEBUG ne sont habituellement capturés que lors du débogage d'une application.
|
| FINESSE | 500 |
-
|
| CONFIG | 700 |
-
|
| INFO | 800 |
Utilisé pour des messages qui indiquent la progression globale de l'application. Souvent utilisé pour le démarrage de l'application, la fermeture et autres événements majeurs de cycle de vie.
|
| AVERTISSEMENT | 900 |
Utilisé pour indiquer une situation qui n'est pas en erreur, mais n'est pas considérée comme idéale. Peut indiquer des circonstances qui peuvent entraîner des erreurs dans le futur.
|
| ATTENTION | 900 |
-
|
| ERREUR | 1000 |
Utiliser pour indiquer une erreur qui s'est produite et qui puisse empêcher l'activité actuelle ou la demande de se remplir, mais qui n'empêchera pas l'application d'exécuter.
|
| SÉVÈRE | 1000 |
-
|
| FATAL | 1100 |
Utiliser pour indiquer les événements qui pourraient entraîner des défaillances de services critiques ou la fermeture de l'application, ou qui pourraient entraîner la fermeture de la plateforme JBoss EAP 6.
|
13.1.8. Catégories de journalisation
13.1.9. Root Logger
server.log. On prénomme parfois ce fichier : journal du serveur (server log).
13.1.10. Gestionnaires de journaux
Console, File, Periodic, Size, Async et Custom.
13.1.11. Types de gestionnaires de journalisation
- Console
- Les gestionnaires de journaux de console écrivent des messages du journalisation soit dans le système d'exploitation hôte (stdout) ou dans le flux d'erreurs standard (stderr). Ces messages sont affichés lorsque JBoss EAP 6 est exécuté à partir d'une invite de ligne de commande. Les messages d'un gestionnaire de journal de Console ne sont pas enregistrés à moins que le système d'exploitation ne soit spécifiquement configuré pour capturer stdout ou stderr.
- Fichier
- Les gestionnaires de journaux de fichiers sont les gestionnaires de journalisation les plus simples, qui écrivent les messages de journalisation dans un fichier spécifique.
- Périodique
- Les gestionnaires de journaux périodiques écrivent des messages de journalisation dans un fichier nommé jusqu'à ce qu'une certaine durée se soit écoulée. Une fois que cette période a expiré, le fichier est nommé à nouveau en rajoutant l'horodatage et le gestionnaire continue d'écrire dans un fichier de journalisation nouvellement créée avec le nom d'origine.
- Taille
- Les gestionnaires de journaux de Taille écrivent les messages de journalisation dans un fichier jusqu'à ce que le fichier atteigne une taille spécifiée. Lorsque le fichier atteint une taille donnée, il est renommé avec un préfixe numérique et le gestionnaire continue d'écrire dans un fichier journal récemment créé avec le nom d'origine. Chaque gestionnaire de journaux de Taille doit spécifier le nombre maximal de fichiers contenus de cette façon.
- Async
- Les gestionnaires de journaux async sont des gestionnaires de journaux wrapper qui fournissent un comportement asynchrone pour un ou plusieurs autres gestionnaires de journaux. Ils sont utiles pour les gestionnaires de journaux qui pourraient avoir une latence élevée ou autres problèmes de performances comme l'écriture d'un fichier journal à un système de fichiers réseau.
- Personnalisé
- Les gestionnaires d'informations personnalisées vous permettent de configurer de nouveaux types de gestionnaires de journaux mis en place. Un gestionnaire personnalisé doit être implémenté comme classe Java qui s'étend
java.util.logging.Handleret doit être contenu dans un module. - syslog
- Les gestionnaires de syslog peuvent être utilisés pour envoyer des messages à un serveur de journalisation à distance. Cela permet à plusieurs applications d'envoyer leurs messages de journalisation au même serveur, où ils peuvent être analysés en même temps.
13.1.12. Log Formatters
java.util.Formatter.
%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n , crée des messages de journalisation qui ressemblent à ceci :
15:53:26,546 INFO [org.jboss.as] (Controller Boot Thread) JBAS015951: Admin console listening on http://127.0.0.1:9990
13.1.13. Syntaxe de Formateur de journaux
Tableau 13.4. Syntaxe de Formateur de journaux
| Symbole | Description |
|---|---|
%c | La catégorie de l'événement de journalisation |
%p | Le niveau de saisie de la journalisation (info/déboggage/etc) |
%P | Le niveau localisé de la saisie de journalisation |
%d | Les date/heure (yyyy-MM-dd HH:mm:ss,SSS form) |
%r | L'heure relative (en millisecondes depuis l'initialisation de la journalisation) |
%z | Le réseau horaire |
%k | Une clé de ressource de journalisation (utilisée pour la localisation de messages de journalisation) |
%m | Le message de journalisation (avec trace d'exception) |
%s | Le simple message de journalisation (sans trace d'exception) |
%e | Exception stack trace (sans informations sur les modules étendus) |
%E | Exception stack trace (avec informations sur les modules étendus) |
%t | Le nom du thread en cours |
%n | Un caractère de nouvelle ligne |
%C | La classe du code appelant la méthode de journalisation (lente) |
%F | Le nom de fichier de la classe appelant la méthode de journalisation (lente) |
%l | L'emplacement d'origine du code appelant la méthode de journalisation (lente) |
%L | Le numéro de ligne du code appelant la méthode de journalisation (lente) |
%M | La méthode du code appelant la méthode de journalisation (lente) |
%x | Log4J Nested Diagnostic Context |
%X | Log4J Message Diagnostic Context |
%% | Un pourcentage (caractère d'échappement) |
13.2. Configurer la journalisation par la Console de gestion
- Connectez-vous à la console de gestion
- Naviguez dans la configuration du sous-système de logging. Cette étape varie suivant qu'il s'agisse de serveurs qui s'exécutent sur les serveurs autonomes ou des serveurs exécutant dans un domaine géré.
Serveur autonome
Cliquer sur Profil, étendre Core dans le panneau Profile, puis cliquer sur Logging.Domaine géré
Cliquer sur Profil, sélectionner le Profil à modifier, étendre Core, puis cliquer sur Logging.
- Modifier le niveau de journalisation.
- Ajouter et supprimer des log handlers.
- Ajouter et supprimer les catégories de journalisation.
- Modifier les propriétés de catégories.
- Ajouter et supprimer les log handlers d'une catégorie.
- Ajouter de nouveaux handlers.
- Configurer les handlers.
13.3. Configuration de logging dans le CLI
13.3.1. Configurer le Root Logger par le CLI
- Ajouter des Log Handler au Root Logger.
- Afficher la configuration du Root Logger.
- Modifier le niveau de journalisation.
- Supprimer des Log Handler du Root Logger.
Important
/subsystem=logging/logging-profile=NAME/ au lieu de /subsystem=logging/.
- Ajouter un Log Handler au Root Logger
- Utiliser l'opération
root-logger-assign-handleravec la syntaxe suivante HANDLER dans le nom du gestionnaire de journalisation (Log Hangler) à ajouter./subsystem=logging/root-logger=ROOT:root-logger-assign-handler(name="HANDLER")
Le gestionnaire de journalisation doit avoir déjà été créé avant qu'il puisse être ajouté au Root Logger.Exemple 13.1. Root Logger root-logger-assign-handler operation
[standalone@localhost:9999 /] /subsystem=logging/root-logger=ROOT:root-logger-assign-handler(name="AccountsNFSAsync") {"outcome" => "success"} [standalone@localhost:9999 /] - Afficher le contenu de la configuration du Root Logger
- Utiliser l'opération
read-resourceavec la syntaxe suivante./subsystem=logging/root-logger=ROOT:read-resource
Exemple 13.2. Opération Root Logger «read-resource»
[standalone@localhost:9999 /] /subsystem=logging/root-logger=ROOT:read-resource { "outcome" => "success", "result" => { "filter" => {"match" => "names"}, "handlers" => [ "CONSOLE", "FILE" ], "level" => "INFO" } } - Définir le niveau de journalisation du Root Logger
- Utiliser l'opération
write-attributeavec la syntaxe suivante avec LEVEL indiquant les niveaux de journalisation pris en charge./subsystem=logging/root-logger=ROOT:write-attribute(name="level", value="LEVEL")
Exemple 13.3. L'opération «write-attribute» du Root Logger pour définir le niveau de journalisation
[standalone@localhost:9999 /] /subsystem=logging/root-logger=ROOT:write-attribute(name="level", value="DEBUG") {"outcome" => "success"} [standalone@localhost:9999 /] - Supprimer un Log Handler du Root Logger
- Utiliser
root-logger-unassign-handleravec la syntaxe suivante, avec HANDLER comme nom du gestionnaire de journalisation à supprimer./subsystem=logging/root-logger=ROOT:root-logger-unassign-handler(name="HANDLER")
Exemple 13.4. Supprimer un Log Handler
[standalone@localhost:9999 /] /subsystem=logging/root-logger=ROOT:root-logger-unassign-handler(name="AccountsNFSAsync") {"outcome" => "success"} [standalone@localhost:9999 /]
13.3.2. Configurer une Catégorie dans l'interface CLI
- Ajouter une nouvelle catégorie de journalisation :
- Afficher la configuration d'une catégorie de journalisation.
- Définir un niveau de journalisation.
- Ajouter des Log Handlers à une catégorie de journalisation.
- Supprimer des Log Handlers d'une catégorie de journalisation.
- Supprimer une catégorie de journalisation.
Important
/subsystem=logging/logging-profile=NAME/ au lieu de /subsystem=logging/.
- Ajouter une catégorie de journalisation
- Utiliser l'opération
addavec la syntaxe suivante. Remplacer CATEGORY par la catégorie à ajouter./subsystem=logging/logger=CATEGORY:add
Exemple 13.5. Ajouter une nouvelle catégorie de journalisation
[standalone@localhost:9999 /] /subsystem=logging/logger=com.company.accounts.rec:add {"outcome" => "success"} [standalone@localhost:9999 /] - Afficher une configuration de catégorie de journalisation
- Utiliser l'opération
read-resourceavec la syntaxe suivante. Remplacer CATEGORY par le nom de la catégorie./subsystem=logging/logger=CATEGORY:read-resource
Exemple 13.6. Opération de lecture de ressource de la catégorie de journalisation
[standalone@localhost:9999 /] /subsystem=logging/logger=org.apache.tomcat.util.modeler:read-resource { "outcome" => "success", "result" => { "filter" => undefined, "handlers" => undefined, "level" => "WARN", "use-parent-handlers" => true } } [standalone@localhost:9999 /] - Définir le niveau de journalisation.
- Utiliser l'opération
write-attributeavec la syntaxe suivante. Remplacer CATEGORY par le nom de la catégorie de journalisation et LEVEL par le niveau de journalisation à définir./subsystem=logging/logger=CATEGORY:write-attribute(name="level", value="LEVEL")
Exemple 13.7. Définir un niveau de journalisation
[standalone@localhost:9999 /] /subsystem=logging/logger=com.company.accounts.rec:write-attribute(name="level", value="DEBUG") {"outcome" => "success"} [standalone@localhost:9999 /] - Définir la Catégorie de journalisation pour utiliser le Log Handler du Root Logger.
- Utiliser l'opération
write-attributeavec la syntaxe suivante. Remplacer CATEGORY par le nom de la catégorie de journalisation. Remplacer BOOLEAN par true pour cette catégorie de journalisation pour utiliser les handlers du Root Logger. Le remplacer par false s'il doit utiliser ses propres handlers./subsystem=logging/logger=CATEGORY:write-attribute(name="use-parent-handlers", value="BOOLEAN")
Exemple 13.8. Configurer use-parent-handlers
[standalone@localhost:9999 /] /subsystem=logging/logger=com.company.accounts.rec:write-attribute(name="use-parent-handlers", value="true") {"outcome" => "success"} [standalone@localhost:9999 /] - Ajouter un Log Handler à une catégorie de journalisation.
- Utiliser l'opération
assign-handleravec la syntaxe suivante. Remplacer CATEGORY par la catégorie à ajouter et HANDLER par le nom du handler à ajouter./subsystem=logging/logger=CATEGORY:assign-handler(name="HANDLER")
Le Log Handler doit déjà avoir été créé avant de l'ajouter au Root Handler.Exemple 13.9. Ajouter un Log Handler
[standalone@localhost:9999 /] /subsystem=logging/logger=com.company.accounts.rec:assign-handler(name="AccountsNFSAsync") {"outcome" => "success"} [standalone@localhost:9999 /] - Supprimer un Log Handler d'une catégorie de journalisation
- Utiliser l'opération
unassign-handleravec la syntaxe suivante. Remplacer CATEGORY par le nom de la catégorie à HANDLER par le nom du Log Handler à supprimer./subsystem=logging/logger=CATEGORY:unassign-handler(name="HANDLER")
Exemple 13.10. Supprimer un Log Handler
[standalone@localhost:9999 /] /subsystem=logging/root-logger=ROOT:root-logger-unassign-handler(name="AccountsNFSAsync") {"outcome" => "success"} [standalone@localhost:9999 /] - Supprimer une catégorie
- Utiliser l'opération
removeavec la syntaxe suivante. Remplacer CATEGORY par le nom de la catégorie à supprimer./subsystem=logging/logger=CATEGORY:remove
Exemple 13.11. Supprimer une catégorie de journalisation
[standalone@localhost:9999 /] /subsystem=logging/logger=com.company.accounts.rec:remove {"outcome" => "success"} [standalone@localhost:9999 /]
13.3.3. Configurer un Log Handler de console dans le CLI
- Ajouter un nouveau Log Handler de console.
- Afficher la configuration d'un Log Handler de console.
- Définir le niveau de journalisation du handler.
- Définir la cible de la sortie du handler.
- Définir la codification utilisée pour la sortie du handler.
- Définir le formateur utilisé pour la sortie du handler.
- Définir si le handler utilise autoflush ou non.
- Supprimer un handler de journalisation de console.
Important
/subsystem=logging/logging-profile=NAME/ au lieu de /subsystem=logging/.
- Ajouter un Log Handler de console
- Utiliser l'opération
addavec la syntaxe suivante. Remplacer HANDLER par le nom du gestionnaire de journalisation (Log Hangler) de la console à ajouter./subsystem=logging/console-handler=HANDLER:add
Exemple 13.12. Ajouter un Log Handler de console
[standalone@localhost:9999 /] /subsystem=logging/console-handler=ERRORCONSOLE:add {"outcome" => "success"} [standalone@localhost:9999 /] - Afficher une configuration de Log Handler de journalisation de la console
- Utiliser l'opération
read-resourceavec la syntaxe suivante. Remplacer HANDLER par le nom du Log Handler de la console./subsystem=logging/console-handler=HANDLER:read-resource
Exemple 13.13. Afficher une configuration de Log Handler de journalisation de la console
[standalone@localhost:9999 /] /subsystem=logging/console-handler=CONSOLE:read-resource { "outcome" => "success", "result" => { "autoflush" => true, "encoding" => undefined, "filter" => undefined, "formatter" => "%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n", "level" => "INFO", "target" => "System.out" } } [standalone@localhost:9999 /] - Définir le Niveau de journalisation
- Utiliser l'opération
change-log-levelavec la syntaxe suivante. Remplacer HANDLER par le nom du Log Handler de la console et LEVEL par le niveau de journalisation à définir./subsystem=logging/console-handler=HANDLER:change-log-level(level="LEVEL")
Exemple 13.14. Définir le Niveau de journalisation
[standalone@localhost:9999 /] /subsystem=logging/console-handler=ERRORCONSOLE:change-log-level(level="TRACE") {"outcome" => "success"} [standalone@localhost:9999 /] - Définir la cible
- Utiliser l'opération
write-attributeavec la syntaxe suivante. Remplacer HANDLER par le nom du Log Handler de la console et TARGET parSystem.errouSystem.outpour le flux Erreurs système ou le flux Standard out./subsystem=logging/console-handler=HANDLER:write-attribute(name="target", value="TARGET")
Exemple 13.15. Définir la cible
[standalone@localhost:9999 /] /subsystem=logging/console-handler=ERRORCONSOLE:write-attribute(name="target", value="System.err") {"outcome" => "success"} [standalone@localhost:9999 /] - Définir le Codage
- Utiliser l'opération
write-attributeavec la syntaxe suivante. Remplacer HANDLER par le nom du Log Handler de la console et ENCODING par le nom de codification du caractère qui convient./subsystem=logging/console-handler=HANDLER:write-attribute(name="encoding", value="ENCODING")
Exemple 13.16. Définir le Codage
[standalone@localhost:9999 /] /subsystem=logging/console-handler=ERRORCONSOLE:write-attribute(name="encoding", value="utf-8") {"outcome" => "success"} [standalone@localhost:9999 /] - Définir Formateur
- Utiliser l'opération
write-attributeavec la syntaxe suivante. Remplacer HANDLER par le nom du Log Handler de la console et FORMAT par le string de formateur requis./subsystem=logging/console-handler=HANDLER:write-attribute(name="formatter", value="FORMAT")
Exemple 13.17. Définir Formateur
[standalone@localhost:9999 /] /subsystem=logging/console-handler=ERRORCONSOLE:write-attribute(name="formatter", value="%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n") {"outcome" => "success"} [standalone@localhost:9999 /] - Définir Auto Flush
- Utiliser l'opération
write-attributeavec la syntaxe suivante. Remplacer HANDLER par le nom du Log Handler de la console et BOOLEAN partruesi le handler doit écrire sa sortie immédiatement./subsystem=logging/console-handler=HANDLER:write-attribute(name="autoflush", value="BOOLEAN")
Exemple 13.18. Définir Auto Flush
[standalone@localhost:9999 /] /subsystem=logging/console-handler=ERRORCONSOLE:write-attribute(name="autoflush", value="true") {"outcome" => "success"} [standalone@localhost:9999 /] - Supprimer un Log Handler de console
- Utiliser l'opération
removeavec la syntaxe suivante. Remplacer HANDLER par le nom du Log Handler de la console à supprimer./subsystem=logging/console-handler=HANDLER:remove
Exemple 13.19. Supprimer un Log Handler de console
[standalone@localhost:9999 /] /subsystem=logging/console-handler=ERRORCONSOLE:remove {"outcome" => "success"} [standalone@localhost:9999 /]
13.3.4. Configurer un Log Handler de fichiers dans le CLI
- Ajouter un nouveau Log Handler de fichiers.
- Afficher la configuration d'un Log Handler de fichiers
- Définir le niveau de journalisation du handler.
- Définir le comportement d'ajout du handler.
- Définir si le handler utilise autoflush ou non.
- Définir la codification utilisée pour la sortie du handler.
- Indiquer le fichier dans lequel le Log Handler écrit.
- Définir le formateur utilisé pour la sortie du handler.
- Supprimer un Log Handler de fichiers.
Important
/subsystem=logging/logging-profile=NAME/ au lieu de /subsystem=logging/.
- Ajouter un Log Handler de fichiers
- Utiliser l'opération
addavec la syntaxe suivante. Remplacer PATH par le nom du fichier dans lequel le log est écrit. Remplacer DIR par le nom du répertoire dans lequel le fichier se trouve. La valeur DIR peut correspondre à une variable de chemin./subsystem=logging/file-handler=HANDLER:add(file={"path"=>"PATH", "relative-to"=>"DIR"})Exemple 13.20. Ajouter un Log Handler de fichiers
[standalone@localhost:9999 /] /subsystem=logging/file-handler=accounts_log:add(file={"path"=>"accounts.log", "relative-to"=>"jboss.server.log.dir"}) {"outcome" => "success"} [standalone@localhost:9999 /] - Afficher une configuration de Log Handler de fichiers
- Utiliser l'opération
read-resourceavec la syntaxe suivante. Remplacer HANDLER par le nom du Log Handler de fichiers./subsystem=logging/file-handler=HANDLER:read-resource
Exemple 13.21. Utiliser l'opération read-resource
[standalone@localhost:9999 /] /subsystem=logging/file-handler=accounts_log:read-resource { "outcome" => "success", "result" => { "append" => true, "autoflush" => true, "encoding" => undefined, "file" => { "path" => "accounts.log", "relative-to" => "jboss.server.log.dir" }, "filter" => undefined, "formatter" => "%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n", "level" => undefined } } [standalone@localhost:9999 /] - Définir Niveau de journalisation
- Utiliser l'opération
change-log-levelavec la syntaxe suivante. Remplacer HANDLER par le nom du Log Handler de fichiers et LEVEL par le niveau de journalisation à définir./subsystem=logging/file-handler=HANDLER:change-log-level(level="LEVEL")
Exemple 13.22. Changer le niveau de journalisation
/subsystem=logging/file-handler=accounts_log:change-log-level(level="DEBUG") {"outcome" => "success"} [standalone@localhost:9999 /] - Définir le comportement d'ajout
- Utiliser l'opération
write-attributeavec la syntaxe suivante. Remplacer HANDLER par le nom du Log Handler de fichiers. Remplacer BOOLÉEN par false si vous souhaitez qu'un nouveau fichier de journalisation soit créé à chaque fois qu'un serveur d'applications est lancé. Remplacer BOOLÉEN partruesi le serveur d'applications doit continuer à utiliser le même fichier./subsystem=logging/file-handler=HANDLER:write-attribute(name="append", value="BOOLEAN")
Exemple 13.23. Changer la propriété d'ajout
[standalone@localhost:9999 /] /subsystem=logging/file-handler=accounts_log:write-attribute(name="append", value="true") { "outcome" => "success", "response-headers" => { "operation-requires-reload" => true, "process-state" => "reload-required" } } [standalone@localhost:9999 /]JBoss EAP 6 doit démarrer à nouveau pour prendre effet. - Définir Auto Flush
- Utiliser l'opération
write-attributeavec la syntaxe suivante. Remplacer HANDLER par le nom du Log Handler de fichiers et BOOLEAN partruesi le handler doit écrire sa sortie immédiatement./subsystem=logging/file-handler=HANDLER:write-attribute(name="autoflush", value="BOOLEAN")
Exemple 13.24. Changer la propriété autoflush
[standalone@localhost:9999 /] /subsystem=logging/file-handler=accounts_log:write-attribute(name="autoflush", value="false") { "outcome" => "success", "response-headers" => {"process-state" => "reload-required"} } [standalone@localhost:9999 /]JBoss EAP 6 doit démarrer à nouveau pour prendre effet. - Définir le Codage
- Utiliser l'opération
write-attributeavec la syntaxe suivante. Remplacer HANDLER par le nom du Log Handler de fichiers et ENCODING par le nom de codification du caractère qui convient./subsystem=logging/file-handler=HANDLER:write-attribute(name="encoding", value="ENCODING")
Exemple 13.25. Définir le Codage
[standalone@localhost:9999 /] /subsystem=logging/file-handler=accounts_log:write-attribute(name="encoding", value="utf-8") {"outcome" => "success"} [standalone@localhost:9999 /] - Changer le fichier dans lequel le Log Handler écrit.
- Utiliser l'opération
change-fileavec la syntaxe suivante. Remplacer PATH par le nom du fichier dans lequel le log est écrit. Remplacer DIR par le nom du répertoire dans lequel le fichier se trouve. La valeur DIR peut correspondre à une variable de chemin./subsystem=logging/file-handler=HANDLER:change-file(file={"path"=>"PATH", "relative-to"=>"DIR"})Exemple 13.26. Changer le fichier dans lequel le Log Handler écrit.
[standalone@localhost:9999 /] /subsystem=logging/file-handler=accounts_log:change-file(file={"path"=>"accounts-debug.log", "relative-to"=>"jboss.server.log.dir"}) {"outcome" => "success"} [standalone@localhost:9999 /] - Définir Formateur
- Utiliser l'opération
write-attributeavec la syntaxe suivante. Remplacer HANDLER par le nom du Log Handler de fichiers et FORMAT par le string de formateur requis./subsystem=logging/file-handler=HANDLER:write-attribute(name="formatter", value="FORMAT")
Exemple 13.27. Définir Formateur
[standalone@localhost:9999 /] /subsystem=logging/file-handler=accounts-log:write-attribute(name="formatter", value="%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n") {"outcome" => "success"} [standalone@localhost:9999 /] - Supprimer un Log Handler de fichiers.
- Utiliser l'opération
removeavec la syntaxe suivante. Remplacer HANDLER par le nom du Log Handler de fichiers à supprimer./subsystem=logging/file-handler=HANDLER:remove
Exemple 13.28. Supprimer un Log Handler de fichiers.
[standalone@localhost:9999 /] /subsystem=logging/file-handler=accounts_log:remove {"outcome" => "success"} [standalone@localhost:9999 /]Un Log Handler ne peut être supprimé que s'il ne peut pas être référencé par une catégorie de journalisation ou par un Log Handler async.
13.3.5. Configurer un Log Handler périodique dans le CLI
- Ajouter un nouveau Log Handler périodique.
- Afficher la configuration d'un Log Handler périodique
- Définir le niveau de journalisation du handler.
- Définir le comportement d'ajout du handler.
- Définir si le handler utilise autoflush ou non.
- Définir la codification utilisée pour la sortie du handler.
- Indiquer le fichier dans lequel le Log Handler écrit.
- Définir le formateur utilisé pour la sortie du handler.
- Définir le suffixe pour les journaux en rotation
- Supprimer un Log Handler périodique
Important
/subsystem=logging/logging-profile=NAME/ au lieu de /subsystem=logging/.
- Ajouter un nouveau Log Handler périodique en rotation.
- Utiliser l'opération
addavec la syntaxe suivante./subsystem=logging/periodic-rotating-file-handler=HANDLER:add(file={"path"=>"PATH", "relative-to"=>"DIR"}, suffix="SUFFIX")Remplacer HANDLER par le nom du Log Handler. Remplacer PATH par le nom du fichier dans lequel le log est écrit. Remplacer DIR par le nom du répertoire dans lequel le fichier se trouve. La valeur DIR peut correspondre à une variable de chemin. Remplacer SUFFIX par le suffixe de rotation de fichiers à utiliser.Exemple 13.29. Créer un nouvel handler
[standalone@localhost:9999 /] /subsystem=logging/periodic-rotating-file-handler=HOURLY_DEBUG:add(file={"path"=>"daily-debug.log", "relative-to"=>"jboss.server.log.dir"}, suffix=".yyyy.MM.dd") {"outcome" => "success"} [standalone@localhost:9999 /] - Afficher une configuration de Log Handler de fichiers en rotation périodique
- Utiliser l'opération
read-resourceavec la syntaxe suivante./subsystem=logging/periodic-rotating-file-handler=HANDLER:read-resource
Remplacer HANDLER par le nom du Log Handler.Exemple 13.30. Utiliser l'opération read-resource
[standalone@localhost:9999 /] /subsystem=logging/periodic-rotating-file-handler=HOURLY_DEBUG:read-resource { "outcome" => "success", "result" => { "append" => true, "autoflush" => true, "encoding" => undefined, "file" => { "path" => "daily-debug.log", "relative-to" => "jboss.server.log.dir" }, "filter" => undefined, "formatter" => "%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n", "level" => undefined } } [standalone@localhost:9999 /] - Définir Niveau de journalisation
- Utiliser l'opération
change-log-levelavec la syntaxe suivante./subsystem=logging/periodic-rotating-file-handler=HANDLER:change-log-level(level="LEVEL")
Remplacer HANDLER par le nom du Log Handler périodique et LEVEL par le niveau de journalisation à définir.Exemple 13.31. Définir le niveau de journalisation
[standalone@localhost:9999 /] /subsystem=logging/periodic-rotating-file-handler=HOURLY_DEBUG:change-log-level(level="DEBUG") {"outcome" => "success"} [standalone@localhost:9999 /] - Définir le comportement d'ajout
- Utiliser l'opération
write-attributeavec la syntaxe suivante./subsystem=logging/periodic-rotating-handler=HANDLER:write-attribute(name="append", value="BOOLEAN")
Remplacer HANDLER par le nom du Log Handler périodique. Remplacer BOOLÉEN parfalsesi vous souhaitez qu'un nouveau fichier de journalisation soit créé à chaque fois qu'un serveur d'applications est lancé. Remplacer BOOLÉEN partruesi le serveur d'applications doit continuer à utiliser le même fichier.JBoss EAP 6 doit démarrer à nouveau pour prendre effet.Exemple 13.32. Définir le comportement d'ajout
[standalone@localhost:9999 /] /subsystem=logging/periodic-rotating-file-handler=HOURLY_DEBUG:write-attribute(name="append", value="true") { "outcome" => "success", "response-headers" => { "operation-requires-reload" => true, "process-state" => "reload-required" } } [standalone@localhost:9999 /] - Définir Auto Flush
- Utiliser l'opération
write-attributeavec la syntaxe suivante./subsystem=logging/periodic-rotating-file-handler=HANDLER:write-attribute(name="autoflush", value="BOOLEAN")
Remplacer HANDLER par le nom du Log Handler périodique et BOOLEAN partruesi le handler doit écrire sa sortie immédiatement.JBoss EAP 6 doit démarrer à nouveau pour prendre effet.Exemple 13.33. Définir le comportement Auto Flush
[standalone@localhost:9999 /] /subsystem=logging/periodic-rotating-file-handler=HOURLY_DEBUG:write-attribute(name="autoflush", value="false") { "outcome" => "success", "response-headers" => {"process-state" => "reload-required"} } [standalone@localhost:9999 /] - Définir le Codage
- Utiliser l'opération
write-attributeavec la syntaxe suivante./subsystem=logging/periodic-rotating-file-handler=HANDLER:write-attribute(name="encoding", value="ENCODING")
Remplacer HANDLER par le nom du Log Handler périodique et ENCODING par le nom de codification du caractère qui convient.Exemple 13.34. Définir le Codage
[standalone@localhost:9999 /] /subsystem=logging/periodic-rotating-file-handler=HOURLY_DEBUG:write-attribute(name="encoding", value="utf-8") {"outcome" => "success"} [standalone@localhost:9999 /] - Changer le fichier dans lequel le Log Handler écrit.
- Utiliser l'opération
change-fileavec la syntaxe suivante./subsystem=logging/periodic-rotating-file-handler=HANDLER:change-file(file={"path"=>"PATH", "relative-to"=>"DIR"})Remplacer HANDLER par le nom du Log Handler périodique. Remplacer PATH par le nom du fichier dans lequel le log est écrit. Remplacer DIR par le nom du répertoire dans lequel le fichier se trouve. La valeur DIR peut correspondre à une variable de chemin.Exemple 13.35. Changer le fichier dans lequel le Log Handler écrit.
[standalone@localhost:9999 /] /subsystem=logging/periodic-rotating-file-handler=HOURLY_DEBUG:change-file(file={"path"=>"daily-debug.log", "relative-to"=>"jboss.server.log.dir"}) {"outcome" => "success"} [standalone@localhost:9999 /] - Définir Formateur
- Utiliser l'opération
write-attributeavec la syntaxe suivante./subsystem=logging/periodic-rotating-file-handler=HANDLER:write-attribute(name="formatter", value="FORMAT")
Remplacer HANDLER par le nom du Log Handler périodique et FORMAT par le string de formateur à définir.Exemple 13.36. Définir Formateur
[standalone@localhost:9999 /] /subsystem=logging/periodic-rotating-file-handler=HOURLY_DEBUG:write-attribute(name="formatter", value="%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n") {"outcome" => "success"} [standalone@localhost:9999 /] - Définir le suffixe pour les journaux en rotation
- Utiliser l'opération
write-attributeavec la syntaxe suivante./subsystem=logging/periodic-rotating-file-handler=HANDLER:write-attribute(name="suffix", value="SUFFIX")
Remplacer HANDLER par le nom du Log Handler et SUFFIX par le string de suffixe à définir.Exemple 13.37.
[standalone@localhost:9999 /] /subsystem=logging/periodic-rotating-file-handler=HOURLY_DEBUG:write-attribute(name="suffix", value=".yyyy-MM-dd-HH") {"outcome" => "success"} [standalone@localhost:9999 /] - Supprimer un Log Handler périodique
- Utiliser l'opération
removeavec la syntaxe suivante./subsystem=logging/periodic-rotating-file-handler=HANDLER:remove
Remplacer HANDLER par le nom du Log Handler périodique.Exemple 13.38. Supprimer un Log Handler périodique
[standalone@localhost:9999 /] /subsystem=logging/periodic-rotating-file-handler=HOURLY_DEBUG:remove {"outcome" => "success"} [standalone@localhost:9999 /]
13.3.6. Configurer un Log Handler Taille dans le CLI
- Ajouter un nouveau Log Handler
- Afficher la configuration du Log Handler
- Définir le niveau de journalisation du handler.
- Définir le comportement d'ajout du handler.
- Définir si le handler utilise autoflush ou non.
- Définir la codification utilisée pour la sortie du handler.
- Indiquer le fichier dans lequel le Log Handler écrit.
- Définir le formateur utilisé pour la sortie du handler.
- Définir la taille maximum de chaque fichier de journalisation
- Définir le nombre maximum de journaux de sauvegarde à conserver
- Supprimer un Log Handler.
Important
/subsystem=logging/logging-profile=NAME/ au lieu de /subsystem=logging/.
- Ajouter un nouveau Log Handler
- Utiliser l'opération
addavec la syntaxe suivante./subsystem=logging/size-rotating-file-handler=HANDLER:add(file={"path"=>"PATH", "relative-to"=>"DIR"})Remplacer HANDLER par le nom du Log Handler. Remplacer PATH par le nom du fichier dans lequel le log est écrit. Remplacer DIR par le nom du répertoire dans lequel le fichier se trouve. La valeur DIR peut correspondre à une variable de chemin.Exemple 13.39. Ajouter un nouveau Log Handler
[standalone@localhost:9999 /] /subsystem=logging/size-rotating-file-handler=ACCOUNTS_TRACE:add(file={"path"=>"accounts_trace.log", "relative-to"=>"jboss.server.log.dir"}) {"outcome" => "success"} [standalone@localhost:9999 /] - Afficher la configuration du Log Handler
- Utiliser l'opération
read-resourceavec la syntaxe suivante./subsystem=logging/size-rotating-file-handler=HANDLER:read-resource
Remplacer HANDLER par le nom du Log Handler.Exemple 13.40. Afficher la configuration du Log Handler
[standalone@localhost:9999 /] /subsystem=logging/size-rotating-file-handler=ACCOUNTS_TRACE:read-resource { "outcome" => "success", "result" => { "append" => true, "autoflush" => true, "encoding" => undefined, "file" => { "path" => "accounts_trace.log", "relative-to" => "jboss.server.log.dir" }, "filter" => undefined, "formatter" => "%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n", "level" => undefined, "max-backup-index" => 1, "rotate-size" => "2m" } } [standalone@localhost:9999 /] - Définir le niveau de journalisation du handler
- Utiliser l'opération
change-log-levelavec la syntaxe suivante./subsystem=logging/size-rotating-file-handler=HANDLER:change-log-level(level="LEVEL")
Remplacer HANDLER par le nom du Log Handler et LEVEL par le niveau de journalisation à définir.Exemple 13.41. Définir le niveau de journalisation du handler
[standalone@localhost:9999 /] /subsystem=logging/size-rotating-file-handler=ACCOUNTS_TRACE:change-log-level(level="TRACE") {"outcome" => "success"} [standalone@localhost:9999 /] - Définir le comportement d'ajout du handler.
- Utiliser l'opération
write-attributeavec la syntaxe suivante./subsystem=logging/size-rotating-file-handler=HANDLER:write-attribute(name="append", value="BOOLEAN")
Remplacer HANDLER par le nom du Log Handler. Remplacer BOOLÉEN parfalsesi vous souhaitez qu'un nouveau fichier de journalisation soit créé à chaque fois qu'un serveur d'applications est lancé. Remplacer BOOLÉEN partruesi le serveur d'applications doit continuer à utiliser le même fichier.JBoss EAP 6 doit démarrer à nouveau pour prendre effet.Exemple 13.42. Définir le comportement d'ajout du handler.
[standalone@localhost:9999 /] /subsystem=logging/size-rotating-file-handler=ACCOUNTS_TRACE:write-attribute(name="append", value="true") { "outcome" => "success", "response-headers" => { "operation-requires-reload" => true, "process-state" => "reload-required" } } [standalone@localhost:9999 /] - Définir si le handler utilise autoflush ou non
- Utiliser l'opération
write-attributeavec la syntaxe suivante./subsystem=logging/size-rotating-file-handler=HANDLER:write-attribute(name="autoflush", value="BOOLEAN")
Remplacer HANDLER par le nom du Log Handler et BOOLEAN partruesi le handler doit écrire sa sortie immédiatement.Exemple 13.43. Définir si le handler utilise autoflush ou non
[standalone@localhost:9999 /] /subsystem=logging/size-rotating-file-handler=ACCOUNTS_TRACE:write-attribute(name="autoflush", value="true") {"outcome" => "success"} [standalone@localhost:9999 /] - Définir la codification utilisée pour la sortie du handler
- Utiliser l'opération
write-attributeavec la syntaxe suivante./subsystem=logging/size-rotating-file-handler=HANDLER:write-attribute(name="encoding", value="ENCODING")
Remplacer HANDLER par le nom du Log Handler et ENCODING par le nom de codification du caractère qui convient.Exemple 13.44. Définir la codification utilisée pour la sortie du handler
[standalone@localhost:9999 /] /subsystem=logging/size-rotating-file-handler=ACCOUNTS_TRACE:write-attribute(name="encoding", value="utf-8") {"outcome" => "success"} [standalone@localhost:9999 /] - Indiquer le fichier dans lequel le Log Handler écrit
- Utiliser l'opération
change-fileavec la syntaxe suivante./subsystem=logging/size-rotating-file-handler=HANDLER:change-file(file={"path"=>"PATH", "relative-to"=>"DIR"})Remplacer HANDLER par le nom du Log Handler. Remplacer PATH par le nom du fichier dans lequel le log est écrit. Remplacer DIR par le nom du répertoire dans lequel le fichier se trouve. La valeur DIR peut correspondre à une variable de chemin.Exemple 13.45. Indiquer le fichier dans lequel le Log Handler écrit
[standalone@localhost:9999 /] /subsystem=logging/size-rotating-file-handler=ACCOUNTS_TRACE:change-file(file={"path"=>"accounts_trace.log", "relative-to"=>"jboss.server.log.dir"}) {"outcome" => "success"} [standalone@localhost:9999 /] - Définir le formateur utilisé pour la sortie du handler.
- Utiliser l'opération
write-attributeavec la syntaxe suivante./subsystem=logging/size-rotating-file-handler=HANDLER:write-attribute(name="formatter", value="FORMATTER")
Remplacer HANDLER par le nom du Log Handler et FORMAT par le string de formateur à définir.Exemple 13.46. Définir le formateur utilisé pour la sortie du handler.
[standalone@localhost:9999 /] /subsystem=logging/size-rotating-file-handler=ACCOUNTS_TRACE:write-attribute(name="formatter", value="%d{HH:mm:ss,SSS} %-5p (%c) [%t] %s%E%n") {"outcome" => "success"} [standalone@localhost:9999 /] - Définir la taille maximum de chaque fichier de journalisation
- Utiliser l'opération
write-attributeavec la syntaxe suivante./subsystem=logging/size-rotating-file-handler=HANDLER:write-attribute(name="rotate-size", value="SIZE")
Remplacer HANDLER par le nom du Log Handler et SIZE par la taille de fichier maximum.Exemple 13.47. Définir la taille maximum de chaque fichier de journalisation
[standalone@localhost:9999 /] /subsystem=logging/size-rotating-file-handler=ACCOUNTS_TRACE:write-attribute(name="rotate-size", value="50m") {"outcome" => "success"} [standalone@localhost:9999 /] - Définir le nombre maximum de journaux de sauvegarde à conserver
- Utiliser l'opération
write-attributeavec la syntaxe suivante./subsystem=logging/size-rotating-file-handler=HANDLER:write-attribute(name="max-backup-index", value="NUMBER")
Remplacer HANDLER par le nom du Log Handler et NUMBER par le nombre de fichiers de journalisation à conserver.Exemple 13.48. Définir le nombre maximum de journaux de sauvegarde à conserver
[standalone@localhost:9999 /] /subsystem=logging/size-rotating-file-handler=ACCOUNTS_TRACE:write-attribute(name="max-backup-index", value="5") {"outcome" => "success"} [standalone@localhost:9999 /] - Supprimer un Log Handler
- Utiliser l'opération
removeavec la syntaxe suivante./subsystem=logging/size-rotating-file-handler=HANDLER:remove
Remplacer HANDLER par le nom du Log Handler.Exemple 13.49. Supprimer un Log Handler
[standalone@localhost:9999 /] /subsystem=logging/size-rotating-file-handler=ACCOUNTS_TRACE:remove {"outcome" => "success"} [standalone@localhost:9999 /]
13.3.7. Configurer un Log Handler Async dans le CLI
- Ajouter un nouveau Log Handler async
- Afficher la configuration d'un Log Handler async
- Modifier le niveau de journalisation
- Définir la longueur de la file d'attente
- Définir l'action de dépassement
- Ajouter les sous-handlers
- Supprimer les sous-handlers
- Supprimer un sous-handler async
Important
/subsystem=logging/logging-profile=NAME/ au lieu de /subsystem=logging/.
- Ajouter un nouveau Log Handler async
- Utiliser l'opération
addavec la syntaxe suivante./subsystem=logging/async-handler=HANDLER:add(queue-length="LENGTH")
Remplacer HANDLER par le nom du Log Handler et LENGTH par la valeur du nombre maximum de requêtes de journalisation pouvant tenir dans une file d'attente.Exemple 13.50.
[standalone@localhost:9999 /] /subsystem=logging/async-handler=NFS_LOGS:add(queue-length="10") {"outcome" => "success"} [standalone@localhost:9999 /] - Afficher la configuration d'un Log Handler async
- Utiliser l'opération
read-resourceavec la syntaxe suivante./subsystem=logging/async-handler=HANDLER:read-resource
Remplacer HANDLER par le nom du Log Handler.Exemple 13.51.
[standalone@localhost:9999 /] /subsystem=logging/async-handler=NFS_LOGS:read-resource { "outcome" => "success", "result" => { "encoding" => undefined, "filter" => undefined, "formatter" => "%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n", "level" => undefined, "overflow-action" => "BLOCK", "queue-length" => "50", "subhandlers" => undefined } } [standalone@localhost:9999 /] - Modifier le niveau de journalisation
- Utiliser l'opération
change-log-levelavec la syntaxe suivante./subsystem=logging/async-handler=HANDLER:change-log-level(level="LEVEL")
Remplacer HANDLER par le nom du Log Handler et LEVEL par le niveau de journalisation à définir.Exemple 13.52.
[standalone@localhost:9999 /] /subsystem=logging/async-handler=NFS_LOGS:change-log-level(level="INFO") {"outcome" => "success"} [standalone@localhost:9999 /] - Définir la longueur de la file d'attente
- Utiliser l'opération
write-attributeavec la syntaxe suivante./subsystem=logging/async-handler=HANDLER:write-attribute(name="queue-length", value="LENGTH")
Remplacer HANDLER par le nom du Log Handler et LENGTH par la valeur du nombre maximum de requêtes de journalisation pouvant tenir dans une file d'attente.JBoss EAP 6 doit démarrer à nouveau pour prendre effet.Exemple 13.53.
[standalone@localhost:9999 /] /subsystem=logging/async-handler=NFS_LOGS:write-attribute(name="queue-length", value="150") { "outcome" => "success", "response-headers" => { "operation-requires-reload" => true, "process-state" => "reload-required" } } [standalone@localhost:9999 /] - Définir l'action de dépassement
- Utiliser l'opération
write-attributeavec la syntaxe suivante./subsystem=logging/async-handler=HANDLER:write-attribute(name="overflow-action", value="ACTION")
Remplacer HANDLER par le nom du Log Handler et ACTION par DISCARD ou BLOCK.Exemple 13.54.
[standalone@localhost:9999 /] /subsystem=logging/async-handler=NFS_LOGS:write-attribute(name="overflow-action", value="DISCARD") {"outcome" => "success"} [standalone@localhost:9999 /] - Ajouter les sous-handlers
- Utiliser l'opération
assign-subhandleravec la syntaxe suivante./subsystem=logging/async-handler=HANDLER:assign-subhandler(name="SUBHANDLER")
Remplacer HANDLER par le nom du Log Handler et SUBHANDLER par le nom du Log Handler qui doit être ajouté comme sous-handler de ce handler asynch.Exemple 13.55.
[standalone@localhost:9999 /] /subsystem=logging/async-handler=NFS_LOGS:assign-subhandler(name="NFS_FILE") {"outcome" => "success"} [standalone@localhost:9999 /] - Supprimer les sous-handlers
- Utiliser l'opération
unassign-subhandleravec la syntaxe suivante./subsystem=logging/async-handler=HANDLER:unassign-subhandler(name="SUBHANDLER")
Remplacer HANDLER par le nom du Log Handler et SUBHANDLER par le nom du Log Handler qui doit être supprimé.Exemple 13.56.
[standalone@localhost:9999 /] /subsystem=logging/async-handler=NFS_LOGS:unassign-subhandler(name="NFS_FILE") {"outcome" => "success"} [standalone@localhost:9999 /] - Supprimer un sous-handler async
- Utiliser l'opération
removeavec la syntaxe suivante./subsystem=logging/async-handler=HANDLER:remove
Remplacer HANDLER par le nom du Log Handler.Exemple 13.57.
[standalone@localhost:9999 /] /subsystem=logging/async-handler=NFS_LOGS:remove {"outcome" => "success"} [standalone@localhost:9999 /]
13.3.8. Configurer un Gestionnaire syslog
- Accès et permissions correctes pour le Management CLI.
Procédure 13.1. Ajouter un gestionnaire syslog
- Exécuter la commande suivante pour ajouter un gestionnaire syslog :
/subsystem=logging/syslog-handler=HANDLER_NAME:add
Procédure 13.2. Configurer un Gestionnaire syslog
- Exécuter la commande suivante pour configurer un attribut de gestionnaire syslog :
/subsystem=logging/syslog-handler=HANDLER_NAME:write-attribute(name=ATTRIBUTE_NAME,value=ATTRIBUTE_VALUE)
Procédure 13.3. Supprimer un gestionnaire syslog
- Exécuter la commande suivante pour supprimer un gestionnaire syslog existant :
/subsystem=logging/syslog-handler=HANDLER_NAME:remove
Tableau 13.5. Titre de Table
| Attribut | Description | Valeur par défaut |
|---|---|---|
| Important | Le port que le serveur syslog écoute. | 514 |
| app-name | Le nom de l'application utilisé lors du formatage du message dans le format RFC5424. | vide |
| activé | Si défini sur true, le gestionnaire sera activé et fonctionnera normalement. Si défini sur false, le gestionnaire sera ignoré lors du traitement des messages de journalisation. | true |
| level | Le niveau de journalisation indiquant quels niveaux de message seront journalisés. Les niveaux de message inférieurs seront supprimés. | TOUS |
| aménagement | Tel que défini par RFC-5424 et RFC-3164 | niveau utilisateur |
| adresse serveur | L'adresse du serveur syslog | localhost |
| hostname | Le nom de l'hôte à partir duquel les messages sont envoyés. | vide |
| syslog-format | Formate le message de journalisation selon la spécification RFC. | RFC5424 |
| Le nom | nom du gestionnaire | vide |
13.4. Profils de journalisation
13.4.1. Profils de journalisation
Important
- Un nom unique. Ceci est requis.
- N'importe quel nombre de Log Handlers.
- N'importe quelle catégorie log.
- Un root logger maximum.
Important
13.4.2. Créer un nouveau Profil de journalisation par le CLI
/subsystem=logging/logging-profile=NAME:add
13.4.3. Créer un Profil de journalisation par le CLI
- Le chemin de configuration root est
/subsystem=logging/logging-profile=NAME - Un profil de journalisation ne peut pas contenir d'autres profils de journalisation.
Exemple 13.58. Créer et Configurer un Profil de journalisation
- Créer le profil :
/subsystem=logging/logging-profile=accounts-app-profile:add
- Créer gestionnaire de fichiers
/subsystem=logging/logging-profile=accounts-app-profile/file-handler=ejb-trace-file:add(file={path=>"ejb-trace.log", "relative-to"=>"jboss.server.log.dir"})/subsystem=logging/logging-profile=accounts-app-profile/file-handler=ejb-trace-file:change-log-level(level="DEBUG")
- Créer une catégorie de logger
/subsystem=logging/logging-profile=accounts-app-profile/logger=com.company.accounts.ejbs:add(level=TRACE)
- Assigner un gestionnaire de fichiers à une catégorie
/subsystem=logging/logging-profile=accounts-app-profile/logger=com.company.accounts.ejbs:assign-handler(name="ejb-trace-file")
13.4.4. Spécifier un profil de journalisation dans une application
MANIFEST.MF.
Pré-requis :
- Vous devez connaître le nom du profil de journalisation qui a été défini sur le serveur pour cette application. Demandez à votre administrateur de systèmes le nom du profil à utiliser.
Procédure 13.4. Ajouter une configuration de profil de journalisation à une application
Modifier
MANIFEST.MFSi votre application ne possède pas de fichierMANIFEST.MF: le créer avec le contenu suivant, en remplaçant NAME par le nom de profil qui convient.Manifest-Version: 1.0 Logging-Profile: NAMESi votre application contient déjà un fichierMANIFEST.MF: ajouter la ligne suivante, en remplaçant NAME par le nom du profil qui convient.Logging-Profile: NAME
Note
maven-war-plugin, vous pourrez mettre votre fichier MANIFEST.MF dans src/main/resources/META-INF/ et ajouter la configuration suivante à votre fichier pom.xml.
<plugin>
<artifactId>maven-war-plugin</artifactId>
<configuration>
<archive>
<manifestFile>src/main/resources/META-INF/MANIFEST.MF</manifestFile>
</archive>
</configuration>
</plugin>
13.4.5. Exemple de Configuration de Profil de journalisation
MANIFEST.MF de l'application.
- Le Nom est
accounts-app-profile. - La Catégorie de journalisation est
com.company.accounts.ejbs. - Le niveau de journalisations est
TRACE. - Le Log Handler est un gestionnaire de fichiers qui utilise
ejb-trace.log.
Exemple 13.59. Session CLI
localhost:bin user$ ./jboss-cli.sh -c
[standalone@localhost:9999 /] /subsystem=logging/logging-profile=accounts-app-profile:add
{"outcome" => "success"}
[standalone@localhost:9999 /] /subsystem=logging/logging-profile=accounts-app-profile/file-handler=ejb-trace-file:add(file={path=>"ejb-trace.log", "relative-to"=>"jboss.server.log.dir"})
{"outcome" => "success"}
[standalone@localhost:9999 /] /subsystem=logging/logging-profile=accounts-app-profile/file-handler=ejb-trace-file:change-log-level(level="DEBUG")
{"outcome" => "success"}
[standalone@localhost:9999 /] /subsystem=logging/logging-profile=accounts-app-profile/logger=com.company.accounts.ejbs:add(level=TRACE)
{"outcome" => "success"}
[standalone@localhost:9999 /] /subsystem=logging/logging-profile=accounts-app-profile/logger=com.company.accounts.ejbs:assign-handler(name="ejb-trace-file")
{"outcome" => "success"}
[standalone@localhost:9999 /]Exemple 13.60. Configuration XML
<logging-profiles>
<logging-profile name="accounts-app-profile">
<file-handler name="ejb-trace-file">
<level name="DEBUG"/>
<file relative-to="jboss.server.log.dir" path="ejb-trace.log"/>
</file-handler>
<logger category="com.company.accounts.ejbs">
<level name="TRACE"/>
<handlers>
<handler name="ejb-trace-file"/>
</handlers>
</logger>
</logging-profile>
</logging-profiles>
Exemple 13.61. Fichier Application MANIFEST.MF
Manifest-Version: 1.0 Logging-Profile: accounts-app-profile
13.5. Propriétés de la configuration de journalisation
13.5.1. Propriétés Root Logger
Tableau 13.6. Propriétés Root Logger
| Propriété | Datatype | Description |
|---|---|---|
| level | String |
Le niveau maximum de messages log que le root logger souhaite enregistrer.
|
| handlers | String[] |
Une liste des log handlers utilisés par le root logger.
|
| filter-spec | String |
Expression qui définit un filtre. L'expression suivante définit un filtre qui ne correspond pas à un modèle :
not(match("JBAS.*"))
|
13.5.2. Propriétés de catégorie de journalisation
Tableau 13.7. Propriétés de catégorie de journalisation
| Propriété | Datatype | Description |
|---|---|---|
| niveau | String |
Le niveau maximum de messages log que le root logger souhaite enregistrer.
|
| handlers | String[] |
Une liste des log handlers utilisés par le root logger.
|
| use-parent-handlers | Booléen |
Si défini sur true, cette catégorie utilisera les Log handlers du Root logger en plus des handlers assignés.
|
| catégorie | String |
La catégorie de journalisation à partir de laquelle les messages de journalisation seront capturés.
|
| filter-spec | String |
Expression qui définit un filtre. L'expression suivante définit un filtre qui ne correspond pas à un modèle :
not(match("JBAS.*"))
|
13.5.3. Propriétés de Log Handlers de console
Tableau 13.8. Propriétés de Log Handlers de console
| Propriété | Datatype | Description |
|---|---|---|
| level | String |
Le niveau maximum de messages de journalisation que le Log Handler enregistre.
|
| encoding | String |
Définir la codification utilisée pour la sortie.
|
| formatter | String |
Le formateur de journalisation utilisé par ce Log Handler.
|
| target | String |
Le flux de sortie du système vers lequel la sortie du Log Handler se dirige. Peut correspondre à System.err ou System.out pour le flux d'erreurs système ou standard out stream respectivement.
|
| autoflush | Booléen |
Si défini sur true, les messages de journalisation seront envoyés vers la cible des handlers immédiatement après la réception.
|
| Le nom | String |
L'identifiant unique de ce Log Handler.
|
| activé | Booléen |
Si défini sur
true, le gestionnaire sera activé et fonctionnera normalement. Si défini sur false, le gestionnaire sera ignoré lors du traitement des messages de journalisation.
|
| filter-spec | String |
Expression qui définit un filtre. L'expression suivante définit un filtre qui ne correspond pas à un modèle :
not(match("JBAS.*"))
|
13.5.4. Propriétés de Log Handlers de fichiers
Tableau 13.9. Propriétés de Log Handlers de fichiers
| Propriété | Datatype | Description |
|---|---|---|
| level | String |
Le niveau maximum de messages de journalisation que le Log Handler enregistre.
|
| encoding | String |
Définir la codification utilisée pour la sortie.
|
| formatter | String |
Le formateur de journalisation utilisé par ce Log Handler.
|
| append | Booléen |
Si la valeur est true alors tous les messages rédigés par ce gestionnaire seront ajoutés au fichier si celui-ci existe déjà. Si la valeur est false, un nouveau fichier sera créé chaque fois que le serveur d'applications est lancé. Les modifications à
append nécessitent un redémarrage du serveur pour qu'elles soient prises en compte.
|
| autoflush | Booléen |
Si définis sur true, les messages de journalisation seront envoyés au fichier assigné aux handlers dès réception. Les changements à
autoflush nécessitent un redémarrage de serveur pour pouvoir prendre effet.
|
| Le nom | String |
L'identifiant unique de ce Log Handler.
|
| fichier | Objet |
L'objet qui représente le fichier dans lequel la sortie de ce Log Handler est écrite. Il contient deux propriétés de configuration,
relative-to et path.
|
| relative-to | String |
C'est une propriété de l'objet fichier qui correspond au répertoire où le fichier journal est écrit. Les variables de chemin d'accès de fichier JBoss EAP 6 peuvent être indiquées ici. La variable
jboss.server.log.dir pointe vers le répertoire log/ du serveur.
|
| path | String |
C'est une propriété de l'objet fichier qui correspond au nom du fichier où seront écrit les messages du journal. C'est un nom de chemin d'accès relatif qui est ajouté à la valeur de la propriété
relative-to pour déterminer le chemin d'accès complet.
|
| activé | Booléen |
Si défini à
true, le gestionnaire sera activé et fonctionnera normalement. Si défini sur false, le gestionnaire sera ignoré lors du traitement des messages de journalisation.
|
| filter-spec | String |
Expression qui définit un filtre. L'expression suivante définit un filtre qui ne correspond pas à un modèle :
not(match("JBAS.*"))
|
13.5.5. Propriétés de Log Handlers périodiques
Tableau 13.10. Propriétés de Log Handlers périodiques
| Property | Datatype | Description |
|---|---|---|
| append | Boolean |
Si la valeur est true alors tous les messages rédigés par ce gestionnaire seront ajoutés au fichier si celui-ci existe déjà. Si la valeur est false, un nouveau fichier sera créé chaque fois que le serveur d'applications est lancé. Les modifications à «append» (ajout) nécessitent un redémarrage du serveur pour qu'elles soient prises en compte.
|
| autoflush | Boolean |
Si définis sur true, les messages de journalisation seront envoyés au fichier assigné aux handlers dès réception. Les changements à « autoflush » nécessitent un redémarrage de serveur pour pouvoir prendre effet.
|
| encoding | String |
Définir la codification utilisée pour la sortie.
|
| formatter | String |
Le formateur de journalisation utilisé par ce Log Handler.
|
| level | String |
Le niveau maximum de messages de journalisation que le Log Handler enregistre.
|
| name | String |
L'identifiant unique de ce Log Handler.
|
| fichier | Object |
L'objet qui représente le fichier dans lequel la sortie de ce Log Handler est écrite. Il contient deux propriétés de configuration,
relative-to et path.
|
| relative-to | String |
C'est une propriété de l'objet fichier qui correspond au répertoire où le fichier journal est écrit. Les variables de chemin d'accès peuvent être indiquées ici. La variable
jboss.server.log.dir pointe vers le répertoire log/ du serveur.
|
| path | String |
C'est une propriété de l'objet fichier qui correspond au nom du fichier où seront écrits les messages du journal. C'est un nom de chemin d'accès relatif qui est ajouté à la valeur de la propriété
relative-to pour déterminer le chemin d'accès complet.
|
| suffix | String |
Cette chaîne est ajoutée au nom de fichier des journaux en rotation et sert à déterminer la fréquence de rotation. Le format du suffixe est un point (.) suivi d'une date de chaîne qui est analysable par la classe
Ijava.text.SimpleDateFormat. Le journal est mis en rotation sur la base de la plus petite unité de temps définie par le suffixe. Par exemple, le suffixe .yyyy-MM-dd se traduira par rotation quotidienne du log ou journal.
|
| activé | Boolean |
Si défini à
true, le gestionnaire sera activé et fonctionnera normalement. Si défini sur false, le gestionnaire sera ignoré lors du traitement des messages de journalisation.
|
| filter-spec | String |
Expression qui définit un filtre. L'expression suivante définit un filtre qui ne correspond pas à un modèle :
not(match("JBAS.*"))
|
13.5.6. Propriétés de Log Handlers de Taille
Tableau 13.11. Propriétés de Log Handlers de Taille
| Propriété | Datatype | Description |
|---|---|---|
| append | Booléen |
Si la valeur est true alors tous les messages rédigés par ce gestionnaire seront ajoutés au fichier si celui-ci existe déjà. Si la valeur est false, un nouveau fichier sera créé chaque fois que le serveur d'applications est lancé. Les modifications apportées à « append » (ajout) nécessitent un redémarrage du serveur pour qu'elles soient prises en compte.
|
| autoflush | Booléen |
Si définis sur true, les messages de journalisation seront envoyés au fichier assigné aux handlers dès réception. Les modifications apportées à « append » (ajout) nécessitent un redémarrage de serveur pour pouvoir prendre effet.
|
| encoding | String |
Définir la codification utilisée pour la sortie.
|
| formatter | String |
Le formateur de journalisation utilisé par ce Log Handler.
|
| level | String |
Le niveau maximum de messages de journalisation que le Log Handler enregistre.
|
| Le nom | String |
L'identifiant unique de ce Log Handler.
|
| fichier | Objet |
L'objet qui représente le fichier dans lequel la sortie de ce Log Handler est écrite. Il contient deux propriétés de configuration,
relative-to et path.
|
| relative-to | String |
C'est une propriété de l'objet fichier qui correspond au répertoire où le fichier journal est écrit. Les variables de chemin d'accès peuvent être indiquées ici. La variable
jboss.server.log.dir pointe vers le répertoire log/ du serveur.
|
| path | String |
C'est une propriété de l'objet fichier qui correspond au nom du fichier où seront écrits les messages du journal. C'est un nom de chemin d'accès relatif qui est ajouté à la valeur de la propriété
relative-to pour déterminer le chemin d'accès complet.
|
| rotate-size | Integer |
La taille maximale que le fichier journal peut atteindre avant qu'il soit mis en rotation. Un seul caractère ajouté au nombre indique les unités de taille :
b pour bytes, k pour kilobytes, m pour megabytes, g pour gigabytes. Par ex. 50m pour 50 megabytes.
|
| max-backup-index | Integer |
Le nombre maximum de journaux en rotation conservés. Quand ce nombre est atteint, le journal le plus ancien est utilisé à nouveau.
|
| activé | Booléen |
Si défini sur
true, le gestionnaire sera activé et fonctionnera normalement. Si défini sur false, le gestionnaire sera ignoré lors du traitement des messages de journalisation.
|
| filter-spec | String |
Expression qui définit un filtre. L'expression suivante définit un filtre qui ne correspond pas à un modèle :
not(match("JBAS.*"))
|
| rotate-on-boot | Booléen |
Si la valeur est
true, un nouveau fichier de journalisation sera créé au redémarrage du serveur. La valeur par défaut est false.
|
13.5.7. Propriétés de Log Handlers Async
Tableau 13.12. Propriétés de Log Handlers Async
| Property | Datatype | Description |
|---|---|---|
| level | String |
Le niveau maximum de messages de journalisation que le Log Handler enregistre.
|
| name | String |
L'identifiant unique de ce Log Handler.
|
| queue-length | Integer |
Nombre maximal de messages de journalisation gardés par le handler en attendant que les sub-handlers répondent.
|
| overflow-action | String |
La façon dont ce handler répond quand sa file d'attente est dépassée. Peut être défini sur
BLOCK ou DISCARD. BLOCK fait patienter l'application de journalisation jusqu'à ce qu'il y ait suffisamment d'espace disponible dans la file d'attente. C'est le même comportement qu'avec un handler non-async. DISCARD permet à l'application de journalisation de continuer, mais le message de journalisation sera effacé.
|
| subhandlers | String[] |
Il s'agit de la liste de Log Handlers à laquelle cet handler async passe ses messages log.
|
| enabled | Booléen |
Si défini sur
true, le gestionnaire sera activé et fonctionnera normalement. Si défini sur false, le gestionnaire sera ignoré lors du traitement des messages de journalisation.
|
| filter-spec | String |
Expression qui définit un filtre. L'expression suivante définit un filtre qui ne correspond pas à un modèle :
not(match("JBAS.*"))
|
13.6. Exemple de configuration XML de logging
13.6.1. Échantillon de Configuration XML pour Root Logger
<subsystem xmlns="urn:jboss:domain:logging:1.2">
<root-logger>
<level name="INFO"/>
<handlers>
<handler name="CONSOLE"/>
<handler name="FILE"/>
</handlers>
</root-logger>
</subsystem>
13.6.2. Échantillon de Configuration XML pour une Catégorie de journalisation
<subsystem xmlns="urn:jboss:domain:logging:1.2">
<logger category="com.company.accounts.rec">
<handlers>
<handler name="accounts-rec"/>
</handlers>
</logger>
</subsystem>
13.6.3. Échantillon de Configuration XML pour un Log Handler de console
<subsystem xmlns="urn:jboss:domain:logging:1.2">
<console-handler name="CONSOLE">
<level name="INFO"/>
<formatter>
<pattern-formatter pattern="%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n"/>
</formatter>
</console-handler>
</subsystem>
13.6.4. Échantillon de Configuration XML pour un Gestionnaire de journalisation ou Log Handler de fichiers
<file-handler name="accounts-rec-trail" autoflush="true">
<level name="INFO"/>
<file relative-to="jboss.server.log.dir" path="accounts-rec-trail.log"/>
<append value="true"/>
</file-handler>
13.6.5. Échantillon de Configuration XML pour un Log Handler périodique
<periodic-rotating-file-handler name="FILE">
<formatter>
<pattern-formatter pattern="%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n"/>
</formatter>
<file relative-to="jboss.server.log.dir" path="server.log"/>
<suffix value=".yyyy-MM-dd"/>
<append value="true"/>
</periodic-rotating-file-handler>
13.6.6. Échantillon de Configuration XML pour un Log Handler de Taille
<size-rotating-file-handler name="accounts_debug" autoflush="false"> <level name="DEBUG"/> <file relative-to="jboss.server.log.dir" path="accounts-debug.log"/> <rotate-size value="500k"/> <max-backup-index value="5"/> <append value="true"/> </size-rotating-file-handler>
13.6.7. Échantillon de Configuration XML pour un Log Handler Async
<async-handler name="Async_NFS_handlers">
<level name="INFO"/>
<queue-length value="512"/>
<overflow-action value="block"/>
<subhandlers>
<handler name="FILE"/>
<handler name="accounts-record"/>
</subhandlers>
</async-handler>
Chapitre 14. JVM
14.1. JVM
14.1.1. Paramètres de configuration de JVM
host.xml et domain.xml, et ils sont déterminés par les composants de contrôleur de domaine chargés de lancer et d'arrêter le processus du serveur. Dans une instance de serveur autonome, les processus de démarrage de serveur peuvent passer des paramètres de ligne de commande au démarrage. Ceux-ci peuvent être déclarés depuis la ligne de commande ou via l'écran de Propriétés système dans la Console de gestion.
Une caractéristique importante du domaine géré est la possibilité de définir des paramètres de la JVM à plusieurs niveaux. Vous pouvez configurer les paramètres de JVM personnalisés au niveau de l'hôte, par groupe de serveurs, ou par instance de serveur. Les éléments enfants plus spécialisés remplacent la configuration parent, permettant la déclaration des configurations de serveur spécifique sans nécessiter d'exclusions au niveau groupe ou hôte. Cela permet également la configuration parent d'être héritée par les autres niveaux jusqu'à ce que les paramètres soient déclarés dans les fichiers de configuration ou transmis pendant le runtime.
Exemple 14.1. Les paramètres de configuration JVM du fichier de configuration du domaine
domain.xml.
<server-groups>
<server-group name="main-server-group" profile="default">
<jvm name="default">
<heap size="64m" max-size="512m"/>
</jvm>
<socket-binding-group ref="standard-sockets"/>
</server-group>
<server-group name="other-server-group" profile="default">
<jvm name="default">
<heap size="64m" max-size="512m"/>
</jvm>
<socket-binding-group ref="standard-sockets"/>
</server-group>
</server-groups>
main-server-group déclare une taille de segment de 64 mégaoctets et une taille de segment maximale de 512 méga-octets. N'importe quel serveur qui appartient à ce groupe héritera de ces paramètres. Vous pouvez modifier ces paramètres pour le groupe dans son ensemble, par hôte ou serveur individuel.
Exemple 14.2. Les paramètres de configuration du domaine dans le fichier de configuration de l'hôte
host.xml.
<servers>
<server name="server-one" group="main-server-group" auto-start="true">
<jvm name="default"/>
</server>
<server name="server-two" group="main-server-group" auto-start="true">
<jvm name="default">
<heap size="64m" max-size="256m"/>
</jvm>
<socket-binding-group ref="standard-sockets" port-offset="150"/>
</server>
<server name="server-three" group="other-server-group" auto-start="false">
<socket-binding-group ref="standard-sockets" port-offset="250"/>
</server>
</servers>
server-two appartient au groupe de serveurs nommé main-server-group, qui hérite les paramètres du groupe de JVM par défaut. Dans l'exemple précédent, la taille du segment principal de main-server-group a été fixée à 512 méga-octets. En déclarant une taille de segment basse de 256 mégaoctets, server-two peut substituer les paramètres de domain.xml pour ajuster les performances comme vous le souhaitez.
Les paramètres de JVM pour des instances de serveurs autonomes peuvent être déclarés pendant l'exécution en définissant la variable d'environnement JAVA_OPTS avant de démarrer le serveur. Un exemple de définition de la variable d'environnement JAVA_OPTS en ligne de commande Linux est :
[user@host bin]$ export JAVA_OPTS="-Xmx1024M"
C:\> set JAVA_OPTS="Xmx1024M"
standalone.conf qui se trouve dans le dossier EAP_HOME/bin, contenant des exemples d'options à passer à la JVM.
14.1.2. Afficher le statut JVM dans la Console de gestion
Prérequis
Tableau 14.1. Attributs de Statut JVM
| Type | Description |
|---|---|
| Max | Le montant de mémoire maximal en octets pouvant être utilisés pour la gestion de la mémoire. |
| Utilisé | Le montant de mémoire utilisé en méga octets. |
| Validé | Le montant de mémoire en octets alloué à l'utilisation de la machine virtuelle Java. |
| Init | Le montant de mémoire en octets que la machine virtuelle Java a demandé au départ au système d'exploitation pour la gestion de la mémoire. |
Procédure 14.1. Afficher le statut JVM dans la Console de gestion
Afficher le statut de la JVM
Vous pouvez afficher le statut de la JVM dans l'instance de serveur autonome ou dans un domaine géré.Affichage du statut de la JVM pour une instance de serveur autonome
Sélectionner du menu sur l'écran de .Afficher le statut de la JVM d'un domaine géré
Sélectionner le statut de la JVM à partir du menu Statut de domaine sur l'écran Runtime.- Le domaine géré peut rendre visibles toutes les instances de serveur dans le groupe de serveurs, mais ne vous permettra d'afficher qu'un seul serveur à la fois en sélectionnant dans le menu serveur. Pour afficher le statut des autres serveurs dans votre groupe de serveurs, cliquez sur le menu déroulant en haut à gauche de l'écran pour sélectionner à partir de l'hôte et des serveurs affichés dans votre groupe et cliquez sur le bouton pour charger les résultats.
Le statut des paramètres de configuration de la JVM de l'instance de serveur est affiché.
Chapitre 15. Sous-système web
15.1. Configurer le Sous-système Web
Pour configurer le sous-système de Web à l'aide de la Console de gestion sur le web, cliquer sur l'onglet Profile(s) en haut à droite. Pour un domaine géré, sélectionner le profil de serveur que vous souhaitez configurer dans la boîte de sélection de Profil en haut à gauche. Développer le menu de Subsystems, puis le menu Web. Chaque partie configurable du sous-système Web est montré.
Note
ha ou full-ha, dans un domaine géré, ou si vous démarrez votre serveur autonome avec le profil standalone-ha ou standalone-full-ha. La configuration mod_cluster est abordée dans Section 16.5.2, « Configurer le sous-système mod_cluster ».
Pour configurer le conteneur JSP, les connecteurs HTTP et des serveurs virtuels HTTP, cliquer sur l'entrée de menu Servlet/HTTP. Cliquer sur le bouton Edit pour modifier une valeur. Cliquer sur le bouton Advanced pour afficher les options avancées. Les options sont expliquées ci-dessous. Les options pour les serveurs virtuels et les connecteurs HTTP figurent dans des tableaux distincts.
Tableau 15.1. Options de configuration Servlet/HTTP
| Option | Description | Commande CLI |
|---|---|---|
| Désactivé ? |
Si défini sur
true, le conteneur Java ServerPages (JSP) sera désactivé. Valeur par défaut false. Utile si vous n'utilisez pas les pages Java ServerPages (JSPs).
|
/profile=full-ha/subsystem=web/configuration=jsp-configuration/:write-attribute(name=disabled,value=false) |
| Développement ? |
Si sur true, active Development Mode, qui produit davantage d'informations verbeuses de débogage. Valeur par défaut
false.
|
/profile=full-ha/subsystem=web/configuration=jsp-configuration/:write-attribute(name=development,value=false) |
| Garder Générés ? |
Cliquer sur Advanced pour voir cette option, si elle est cachée. Si sur
true garde les servlets générés. Activé par défaut.
|
/profile=full-ha/subsystem=web/configuration=jsp-configuration/:write-attribute(name=keep-generated,value=true) |
| Vérifier l'intervalle ? |
Cliquer sur Advanced pour voir cette option, si elle est cachée. Valeur en secondes qui détermine la fréquence des vérifications de mises à jour JSP par un processus en arrière-plan. La valeur par défaut est
0.
|
/profile=full-ha/subsystem=web/configuration=jsp-configuration/:write-attribute(name=check-interval,value=0) |
| Afficher Source ? |
Cliquer sur Advanced pour voir cette option, si elle est cachée. Si sur
true, le fragment de source JSP est affiché quand une erreur d'exécution a lieu. La valeur par défaut est true.
|
/profile=full-ha/subsystem=web/configuration=jsp-configuration/:write-attribute(name=display-source-fragment,value=true) |
mod_cluster, mod_jk, mod_proxy, ISAPI, et NSAPI pour l'équilibrage des charges et pour le clustering HA. Pour configurer un connecteur, sélectionner l'onglet Connectors et cliquer sur Add. Pour supprimer un connecteur, le sélectionner et cliquer sur Remove. Pour modifier un connecteur, le sélectionner et cliquer sur Edit.
Exemple 15.1. Créer un Nouveau connecteur
/profile=full-ha/subsystem=web/connector=ajp/:add(socket-binding=ajp,scheme=http,protocol=AJP/1.3,secure=false,name=ajp,max-post-size=2097152,enabled=true,enable-lookups=false,redirect-port=8433,max-save-post-size=4096)
Tableau 15.2. Options de connecteur
| Option | Description | Commande CLI |
|---|---|---|
| Nom |
Un nom unique de connecteur, à but d'affichage.
|
/profile=full-ha/subsystem=web/connector=ajp/:read-attribute(name=name) |
| Liaisons de sockets |
La liaison de socket nommée à laquelle le connecteur doit se lier. La liaison de socket est un mappage entre un nom de socket et un port réseau. Les liaisons de socket sont configurées pour chaque serveur autonome, ou par l'intermédiaire de groupes de liaison de socket dans un domaine géré. Un groupe de liaisons de sockets est appliqué à un groupe de serveurs.
|
/profile=full-ha/subsystem=web/connector=ajp/:write-attribute(name=socket-binding,value=ajp) |
| Schéma |
Le schéma de connecteur web, comme HTTP ou HTTPS.
|
/profile=full-ha/subsystem=web/connector=ajp/:write-attribute(name=scheme,value=http) |
| Protocole |
Le protocole de connecteur web à utiliser, comme AJP ou HTTP.
|
/profile=full-ha/subsystem=web/connector=ajp/:write-attribute(name=protocol,value=AJP/1.3) |
| Activé |
Indique si le connecteur web connecté est activé.
|
/profile=full-ha/subsystem=web/connector=ajp/:write-attribute(name=enabled,value=true) |
Exemple 15.2. Ajouter un nouveau serveur virtuel
/profile=full-ha/subsystem=web/virtual-server=default-host/:add(enable-welcome-root=true,default-web-module=ROOT.war,alias=["localhost","example.com"],name=default-host)
Tableau 15.3. Options de serveurs virtuels
| Option | Description | Commande CLI |
|---|---|---|
| Nom |
Nom unique de serveur virtuel, à but d'affichage.
| |
| Alias |
Une liste de noms d'hôtes qui doivent correspondre à ce serveur virtuel. Dans la Console de management, utiliser un nom d'hôte par ligne.
|
/profile=full-ha/subsystem=web/virtual-server=default-host/:write-attribute(name=alias,value=["localhost","example.com"]) |
| Module par défaut |
Le module dont l'application web doit être déployée au nœud racine de ce serveur virtuel et qui sera affiché quand aucun répertoire n'est donné par la requête HTTP.
|
/profile=full-ha/subsystem=web/virtual-server=default-host/:write-attribute(name=default-web-module,value=ROOT.war) |
Pour configurer les options de services web, cliquer sur Web Services. Les options sont expliquées dans le tableau ci-dessous.
Tableau 15.4. Options de configuration des services web
| Option | Description | Commande CLI |
|---|---|---|
| Modifier l'adresse WSDL |
Indique si l'adresse WSDL peut être modifiée par les applications. Valeur par défaut
true.
|
/profile=full-ha/subsystem=webservices/:write-attribute(name=modify-wsdl-address,value=true) |
| Hôte WSDL |
Le contrat WSDL d'un Service Web JAX-WS inclut un élément <soap:address> qui pointe vers l'emplacement du point de terminaison. Si la valeur de <soap:address> est un URL valide, elle n'est pas remplacée à moins que
modify-wsdl-adress soit défini à la valeur true. Si la valeur de <soap:address> n'est pas un URL valide, elle est remplacée en utilisant les valeurs wsdl-host et wsdl-port ou wsdl-secure-port. Si wsdl-host est défini sur jbossws.undefined.host, l'adresse hôte de l'auteur de la demande est utilisée lorsque <soap:address> est réécrite. Par défaut, ${jboss.bind.address:127.0.0.1}, qui utilise 127.0.0.1 si aucune adresse de liaison est spécifiée lors du démarrage de JBoss EAP 6.
|
/profile=full-ha/subsystem=webservices/:write-attribute(name=wsdl-host,value=127.0.0.1) |
| Port WSDL |
Le port non-sécurisé utilisé pour écrire à nouveau l'adresse SOAP. Si définie sur
0 (défaut), le port sera identifié en demandant la liste des connecteurs installés.
|
/profile=full-ha/subsystem=webservices/:write-attribute(name=wsdl-port,value=80) |
| Port sécurisé WSDL |
Le port sécurisé utilisé pour écrire à nouveau l'adresse SOAP. Si définie sur
0 (défaut), le port sera identifié en demandant la liste des connecteurs installés.
|
/profile=full-ha/subsystem=webservices/:write-attribute(name=wsdl-secure-port,value=443) |
15.2. Remplacer l'application web Welcome par défaut
Procédure 15.1. Remplacer l'application web Welcome par défaut par votre propre application web
Désactiver l'application Welcome
Utiliser le script de Management CLIEAP_HOME/bin/jboss-cli.shpour exécuter la commande suivante. Vous aurez sans doute besoin de modifier un profil de domaine géré, ou retirer une portion de la commande/profile=defaultdu serveur autonome./profile=default/subsystem=web/virtual-server=default-host:write-attribute(name=enable-welcome-root,value=false)
Configurer votre application web par le contexte root.
Afin de configurer votre application web, pour qu'elle utilise (/) comme adresse URL, modifier son fichierjboss-web.xml, qui se trouve dans le répertoireMETA-INF/ouWEB-INF/. Remplacer sa directive<context-root>par une autre qui ressemble à ce qui suit.<jboss-web> <context-root>/</context-root> </jboss-web>Déployer votre application.
Déployer votre application pour le groupe de serveurs ou le serveur que vous avez modifié lors de la première étape. L'application est maintenant disponible surhttp://SERVER_URL:PORT/.
Chapitre 16. HTTP clustering et équilibrage des charges
16.1. Introduction
16.1.1. Clusters de Haute disponibilité et Clusters d'équilibrage des charges
- Les instances du serveur d'applications
- Les applications web, lorsqu'elles sont utilisées en conjonction avec le serveur interne JBoss Web, Apache HTTPD, Microsoft IIS ou Oracle iPlanet Web Server.
- Les EJB (Enterprise JavaBeans) avec, ou sans état
- Mécanismes Single Sign On (SSO)
- Cache distribué
- Sessions HTTP
- Les services JMS et les MDB (Messages Driven Beans)
16.1.2. Composants pouvant bénéficier de la haute disponibilité (HA)
Plusieurs instances de JBoss EAP 6 (exécutant en tant que serveur autonome) ou les membres d'un groupe de serveurs (exécutant en tant que domaine géré) peuvent être configurés pour être hautement disponibles. Cela signifie que si une instance ou un membre est arrêté ou disparaît du groupement, sa charge de travail sera déplacée vers un père. La charge de travail peut être gérée de manière à fournir une fonctionnalité d'équilibrage de la charge, afin que les serveurs ou les groupes de serveurs avec des ressources plus ou moins supérieures puissent prendre une part plus importante de la charge de travail, ou qu'une capacité supplémentaire puisse être ajoutée pendant les périodes de forte charge.
Le serveur web lui-même peut être groupé pour HA, à l'aide d'un des mécanismes d'équilibrage de charge compatible. Le plus souple est le connecteur mod_cluster, qui est intégré dans le conteneur de JBoss EAP. Les autres possibilités incluent les connecteurs Apache mod_jk ou mod_proxy, ou les connecteurs ISAPI et NSAPI.
Les application déployées peuvent être rendues HA (Highly Available) à cause de la spécification Java Enterprise Edition 6 (Java EE 6). Les EJB de session avec ou sans état peuvent être clusterisées, de façon à ce que si le nœud impliqué dans le travail disparaît, un autre nœud prendra sa place, et dans le cas de beans de session avec état, préserveront l'état.
16.1.3. Connecteurs HTTP - Aperçu général
Tableau 16.1. Caractéristiques et contraintes des connecteurs HTTP
| Connecteur | Web server | Systèmes d'exploitation pris en charge | Protocoles pris en charge | S'adapte au statut de déploiement | Prend en charge une sticky session |
|---|---|---|---|---|---|
| mod_cluster | JBoss Enterprise Web Server HTTPD, Native HTTPD (Red Hat Enterprise Linux, Hewlett-Packard HP-UX) | Red Hat Enterprise Linux, Microsoft Windows Server, Oracle Solaris, Hewlett-Packard HP-UX | HTTP, HTTPS, AJP | Oui. Détecte le déploiement et l'annulation du déploiement d'applications et décide dynamiquement s'il faut diriger les demandes clients vers un serveur basé sur la question de savoir si l'application est déployée sur ce serveur. | Oui |
| mod_jk | JBoss Enterprise Web Server HTTPD, Native HTTPD (Red Hat Enterprise Linux, Hewlett-Packard HP-UX) | Red Hat Enterprise Linux, Microsoft Windows Server, Oracle Solaris, Hewlett-Packard HP-UX | AJP | Non. Redirige les demandes des clients vers le conteneur tant que le conteneur est disponible, quel que soit le statut de l'application. | Oui |
| mod_proxy | JBoss Enterprise Web Server HTTPD | Red Hat Enterprise Linux, Microsoft Windows Server, Oracle Solaris | HTTP, HTTPS, AJP | Non. Redirige les demandes des clients vers le conteneur tant que le conteneur est disponible, quel que soit le statut de l'application. | Oui |
| ISAPI | Microsoft IIS | Microsoft Windows Server | AJP | Non. Redirige les demandes des clients vers le conteneur tant que le conteneur est disponible, quel que soit le statut de l'application. | Oui |
| NSAPI | Oracle iPlanet Web Server | Oracle Solaris | AJP | Non. Redirige les demandes des clients vers le conteneur tant que le conteneur est disponible, quel que soit le statut de l'application. | Oui |
Pour en savoir plus sur les connecteurs HTTP
16.1.4. Nœud de worker
Un worker node, connu sous le simple nom de node, est un serveur JBoss EAP 6 qui accepte des requêtes d'un ou plusieurs serveurs HTTPD faisant face au client. JBoss EAP 6 peut accepter des requêtes de son propre HTTPD, c'est à dire le HTTPD fourni avec JBoss Enterprise Web Server, Apache HTTPD, Microsoft IIS, ou Oracle iPlanet Web Server (ancien Netscape Web Server).
Un nœud de cluster est un membre d'un groupement de serveurs. Un tel cluster peut être en équilibrage de charge, en haute disponibilité, ou les deux. Dans un cluster d'équilibrage de charge, un gestionnaire central distribue également la charge de travail parmi ses nœuds, par mesure d'égalité suivant la situation particulière. Dans un cluster de haute disponibilité (HA), certains nœuds travaillent activement, tandis que d'autres sont en attente d'intervenir si un des nœuds actifs quitte le cluster.
16.2. Configuration de connecteur
16.2.1. Définir les pools de thread pour HTTP Connector in JBoss EAP 6
Les pools de threads de JBoss EAP 6 peuvent être partagés entre les différents éléments à l'aide du modèle Executor. Ces pools peuvent être partagés non seulement par les différents connecteurs (HTTP), mais aussi par d'autres composants de JBoss EAP 6 qui prennent en charge le modèle Executor. Obtenir le pool de threads de connecteurs HTTP qui corresponde à vos exigences de performance web actuel est un art délicat et nécessite une étroite surveillance du pool de threads en cours et des exigences de charge web en cours ou anticipées. Dans cette tâche, vous allez apprendre à définir un pool de threads de connecteur HTTP en utilisant le modèle Executor. Vous apprendrez comment définir cela en utilisant à la fois l'interface par ligne de commande et en modifiant le fichier de configuration XML.
Procédure 16.1. Installation d'un pool de threads pour un connecteur HTTP
Définir une usine de threads
Ouvrir votre fichier de configuration (standalone.xmlsi vous modifiez un serveur autonome oudomain.xmlsi vous modifiez une configuration basée domaine. Ce fichier se trouve dans le dossierEAP_HOME/standalone/configurationou dansEAP_HOME/domain/configuration).Ajouter l'entrée de sous-système suivante, en modifiant les valeurs en fonction de vos besoins de serveur.<subsystem xmlns="urn:jboss:domain:threads:1.0"> <thread-factory name="http-connector-factory" thread-name-pattern="HTTP-%t" priority="9" group-name="uq-thread-pool"/> </subsystem>Si vous préférez utiliser le CLI pour cette tâche, alors exécutez la commande suivante dans une invite de commande CLI :[standalone@localhost:9999 /] ./subsystem=threads/thread-factory=http-connector-factory:add(thread-name-pattern="HTTP-%t", priority="9", group-name="uq-thread-pool")
Créer un exécuteur
Vous pouvez utiliser une des six classes d'exécuteur intégrées pour qu'elle agisse en tant qu'exécuteur pour cette usine :unbounded-queue-thread-pool,bounded-queue-thread-pool,blocking-bounded-queue-thread-pool,queueless-thread-pool,blocking-queueless-thread-pooletscheduled-thread-pool.Dans cet exemple, nous utiliseronsunbounded-queue-thread-poolcomme exécuteur. Modifier les valeurs des paramètresmax-threadsetkeepalive-timeselon les besoins de votre serveur.<unbounded-queue-thread-pool name="uq-thread-pool"> <thread-factory name="http-connector-factory" /> <max-threads count="10" /> <keepalive-time time="30" unit="seconds" /> </unbounded-queue-thread-pool>
Ou bien, si vous préférez utiliser le CLI :[standalone@localhost:9999 /] ./subsystem=threads/unbounded-queue-thread-pool=uq-thread-pool:add(thread-factory="http-connector-factory", keepalive-time={time=30, unit="seconds"}, max-threads=30)Forcez le connecteur web HTTP à utiliser ce pool de threads
Dans le même fichier de configurations, cherchez l'élément de connecteur HTTP dans le sous-système web et modifiez-le en utilisant le pool de threads défini dans les étapes suivantes.<connector name="http" protocol="HTTP/1.1" scheme="http" socket-binding="http" executor="uq-thread-pool" />
Si vous préférez utiliser le CLI :[standalone@localhost:9999 /] ./subsystem=web/connector=http:write-attribute(name=executor, value="uq-thread-pool")
Redémarrer le serveur
Redémarrer le serveur (autonome ou domaine) pour que les changements puissent prendre effet. Utiliser les commandes CLI suivantes pour confirmer si les changements des étapes ci-dessus ont eu lieu :[standalone@localhost:9999 /] ./subsystem=threads:read-resource(recursive=true) { "outcome" => "success", "result" => { "blocking-bounded-queue-thread-pool" => undefined, "blocking-queueless-thread-pool" => undefined, "bounded-queue-thread-pool" => undefined, "queueless-thread-pool" => undefined, "scheduled-thread-pool" => undefined, "thread-factory" => {"http-connector-factory" => { "group-name" => "uq-thread-pool", "name" => "http-connector-factory", "priority" => 9, "thread-name-pattern" => "HTTP-%t" }}, "unbounded-queue-thread-pool" => {"uq-thread-pool" => { "keepalive-time" => { "time" => 30L, "unit" => "SECONDS" }, "max-threads" => 30, "name" => "uq-thread-pool", "thread-factory" => "http-connector-factory" }} } } [standalone@localhost:9999 /] ./subsystem=web/connector=http:read-resource(recursive=true) { "outcome" => "success", "result" => { "configuration" => undefined, "enable-lookups" => false, "enabled" => true, "executor" => "uq-thread-pool", "max-connections" => undefined, "max-post-size" => 2097152, "max-save-post-size" => 4096, "name" => "http", "protocol" => "HTTP/1.1", "proxy-name" => undefined, "proxy-port" => undefined, "redirect-port" => 443, "scheme" => "http", "secure" => false, "socket-binding" => "http", "ssl" => undefined, "virtual-server" => undefined } }
Vous avez pu créer une usine de threads et un exécuteur, tout en modifiant votre Connecteur HTTP pour qu'il utilise ce pool de threads.
16.3. Configuration HTTP
16.3.1. HTTP Autonome
16.3.2. Installer Apache HTTPD inclus avec JBoss EAP 6
Prérequis
- Vous aurez besoin d'un accès administrateur ou root pour compléter cette tâche.
- L'APR (Apache Portability Runtime) doit être installé. Sous Red Hat Enterprise Linux, installer l'un des packages suivants :
apr-develouapr-util-devel. Si vous utilisez un système d'exploitation différent, merci de vous reporter au site internet de Apache Portability Runtime à l'adresse http://apr.apache.org/ pour installer les packages requis.
Procédure 16.2. Installer Apache HTTPD
Naviguer dans la liste des téléchargements de JBoss EAP de votre plateforme dans le Portail de Services Clients de Red Hat.
Vous connecter au Portail de service à la clientèle de Red Hat à l'adresse suivante https://access.redhat.com. Grâce aux menus en haut de la page, sélectionner Downloads, JBoss Enterprise Middleware, Downloads. Sélectionner Application Platform à partir de la listeProduct. Sélectionner la version de JBoss EAP pour voir les téléchargements disponibles pour cette version.Sélectionner le binaire HTTPD de la liste.
Chercher le binaire HTTPD pour votre système d'exploitation et votre architecture. Cliquer sur le lien Download. Un fichier ZIP qui contient la distribution HTTPD se télécharge dans votre ordinateur.Extraire le ZIP dans le système où le binaire HTTPD exécutera.
Extraire le fichier ZIP sur votre serveur préféré à un emplacement temporaire. Le fichier ZIP contiendra le répertoirehttpdsous le dossier jboss-ews-version-number. Copier le dossierhttpdet le placer à l'intérieur du répertoire où vous avez installé JBoss EAP 6, couramment appelé EAP_HOME.Votre HTTPD se trouvera dans le répertoireEAP_HOME/httpd/. Vous pouvez maintenant utiliser cet emplacement pour HTTPD_HOME, comme dans les autres documentations JBoss EAP 6.Exécuter le script Post-installation et créer un utilisateur apache et des comptes de groupe.
A l'invite du shell, passer sur le compte utilisateur root, naviguer vers le répertoireEAP_HOME/httpdet exécuter la commande suivante :./.postinstall
Ensuite, vérifier si un utilisateur appelé apache existe sur le système en exécutant la commande suivante :id apache
Si l'utilisateur n'existe pas, il devra être ajouté avec l'utilisateur approprié. Pour cela, exécuter la commande suivante :/usr/sbin/groupadd -g 91 -r apache 2> /dev/null || : /usr/sbin/useradd -c "Apache" -u 48 \ -s /sbin/nologin -r apache 2> /dev/null || :
Une fois complété, si l'utilisateurapachecompte exécuter le service httpd, la propriété des répertoires HTTP devra être changée pour indiquer ceci :chown -R apache:apache httpd
Pour vérifier que les commandes ci-dessus ont été exécutées avec succès, vérifier que l'utilisateurapachepossède une permission d'exécution pour le chemin d'installation du serveur HTTP.ls -l
Le résultat doit correspondre à cela :drwxrwxr-- 11 apache apache 4096 Feb 14 06:52 httpd
Configuration du HTTPD.
Passer au nouveau compte utilisateur en utilisant la commande suivante :sudo su apache
Puis configurer HTTPD comme utilisateurapachepour répondre aux besoins de votre organisation. Vous pouvez utiliser la documentation disponible à partir de la Apache Foundation à l'adresse http://httpd.apache.org/ pour un guide général.Démarrer le HTTPD.
Démarrer le HTTPD par la commande suivante :EAP_HOME/httpd/sbin/apachectl start
Stopper le HTTPD.
Pour stopper le HTTP, lancer la commande suivante :EAP_HOME/httpd/sbin/apachectl stop
16.3.3. Installer le Apache HTTPD dans Red Hat Enterprise Linux avec JBoss EAP 6 (RPM)
Prérequis
- Vous aurez besoin d'un accès administrateur ou root pour compléter cette tâche.
- L'APR (Apache Portability Runtime) doit être installé. Sous Red Hat Enterprise Linux, installer l'un des packages suivants :
apr-develouapr-util-devel. Si vous utilisez un système d'exploitation différent, merci de vous reporter au site internet de Apache Portability Runtime à l'adresse http://apr.apache.org/ pour installer les packages requis. - Un abonnement actif aux canaux BaseOS sur le Red Hat Network.
- Installer HTTPD avec la commande suivante :
yum install httpd
16.3.4. Configuration mod_cluster sur httpd
mod_cluster est un équilibreur de charges basé httpd. Il utilise un réseau de communication pour envoyer des requêtes de httpd vers un groupe de noeuds de serveur d'application. Les dérivatifs suivants peuvent être définis pour configurer mod cluster sur httpd.
Note
Tableau 16.2. Dérivatifs mod_cluster
| Dérivatif | Description | Valeurs |
|---|---|---|
| CreateBalancers | Définit comment les équilibreurs de charge sont créés dans les hôtes virtuels httpd. Cela active les directives comme : ProxyPass /balancer://mycluster1/. |
0: Créer tous les hôtes virtuels httpd
1: Ne pas créer d'équilibreurs (vous aurez besoin d'un ProxyPass ou d'un ProxyMatch au moins pour définir les noms des équilibreurs)
2: Ne créer que le serveur principal
Par défaut: 2
Si vous utilisez la valeur 1, n'oubliez pas de configurer l'équilibreur dans la directive ProxyPass, car la valeur par défaut correspond à une session sticky vide. De plus
nofailover=Off et les valeurs reçues via message MCMP CONFIG sont ignorées.
|
| UseAlias | Vérifier que l'alias corresponde bien au nom du serveur. |
0: Ignorer les alias
1: Vérifier les alias
Par défaut : 0
|
| LBstatusRecalTime | Intervalle d'équilibrage de charge (en secondes) de la logique pour recalculer le statut d'un nœud. |
Par défaut : 5 secondes
|
| WaitForRemove | Durée en secondes avant qu'un nœud supprimé soit oublié par httpd. |
Par défaut : 10 secondes
|
| ProxyPassMatch/ProxyPass |
ProxyPassMatch et ProxyPass sont des directives mod_proxy qui, quand on utilise
! (à la place de l'url de back-end), évitent un proxy inverse sur le chemin d'accès. Utilisé pour autoriser httpd à fournir des informations statiques comme des images. Ainsi,
ProxyPassMatch ^(/.*\.gif)$ !
L'exemple ci-dessus permet à httpd de servir les fichiers .gif directement.
|
Le contexte d'une directive mod_manager est l'hôte virtuel dans tous les cas, sauf contre indication. Le contexte server config implique que la directive doit se trouver en dehors d'une configuration de l'hôte virtuel. Si tel n'est pas le cas, un message erreur apparaîtra et httpd ne démarrera pas.
Tableau 16.3. Dérivatifs mod_manager
| Dérivatif | Description | Valeurs |
|---|---|---|
| EnableMCPMReceive | Autorise l'hôte virtuel à recevoir MCPM des noeuds. Inclure EnableMCPMReceive dans la configuration httpd pour permettre au mod_cluster de fonctionner. Le sauvegarder dans l'hôte virtuel de configuration advertise. | |
| MemManagerFile |
Le nom de base pour les noms que mod_manager utilise pour stocker la configuration, générer des clés pour mémoire partagée ou fichiers verrouillés. Ce doit être un nom de chemin d'accès absolu ; les répertoires seront créés si nécessaire. Il est recommandé que ces fichiers soient placés sur un lecteur local et non pas en NFS share.
Context: config serveur
| $server_root/logs/
|
| Maxcontext | Le nombre maximum de contextes pris en charge par mod_cluster
Context: config serveur
|
Par défaut: 100
|
| Maxnode | Le nombre maximum de nœuds supportés par le mod_cluster.
Context: config serveur
|
Par défaut: 20
|
| Maxhost | Le nombre maximum d'hôtes (alias) supportés par mod_cluster. Inclut également le nombre maximum d'équilibreurs de charge.
Context: config serveur
| 10 |
| Maxsessionid |
Le nombre d'ID de session actifs stockés afin de procurer le nombre de sessions actives du gestionnaire mod_cluster-manager. Une session est inactive quand mod_cluster ne reçoit aucune information de la session pendant 5 minutes.
Context: config serveur
Ce champ est à but de démonstration et débogage uniquement.
| 0: la logique n'est pas activée. |
| MaxMCMPMaxMessSize | Taille maximum des messages MCMP en provenance d'autres directives max | Calculé sur la base d'autres directives max. Min: 1024 |
| ManagerBalancerName | Le nom que l'équilibreur des charges utilise quand JBoss AS/JBossWeb/Tomcat ne fournit pas de nom d'équilibreur. | mycluster
|
| PersistSlots | Indique à mod_slotmem de persister les nœuds, les alias et les contextes dans des fichiers.
Context: config serveur
| Off |
| CheckNonce | Contrôle de la vérification de la valeur unique avec le gestionnaire mod_cluster=manager. |
on/off
Par défaut : on - Nonce checked
|
| AllowDisplay | Contrôle des affichages supplémentaires sur la page principale du mod_cluster-manager. |
on/off
Par défaut : off - only version is displayed
|
| AllowCmd | Autorise les commandes qui utilisent l'URL mod_cluster-manager. |
on/off
Par défaut: on - Commands allowed
|
| ReduceDisplay | Réduit le montant d'informations affichées sur la page principale de mod_cluster-manager, afin qu'un plus grand nombre de noeuds puissent être affichés sur la page. |
on/off
Default: off - full information is displayed
|
| SetHandler mod_cluster-manager |
Affiche des informations sur le nœud que mod_cluster voit dans le cluster. L'information comprend des informations génériques et compte aussi le nombre de sessions actives.
<Location /mod_cluster-manager> SetHandler mod_cluster-manager Order deny,allow Allow from 127.0.0.1 </Location> |
on/off
Default : off
|
Note
16.3.5. Utiliser un HTTPD externe comme Web frontal pour les applications JBoss EAP 6.
Pour comprendre les raisons d'utiliser un service HTTPD externe comme le serveur web frontal, et pour connaître les avantages et inconvénients des différents connecteurs HTTP pris en charge par JBoss EAP 6, consulter Section 16.1.3, « Connecteurs HTTP - Aperçu général ». Dans certaines situations, vous pouvez utiliser l'HTTPD de votre système d'exploitation. Sinon, vous pouvez utiliser l'HTTPD qui est fourni par le serveur JBoss Enterprise Web.
16.3.6. Configurer JBoss EAP 6 pour accepter des requêtes en provenance d'HTTPD externe
JBoss EAP 6 n'a pas besoin de savoir de quel proxy elle accepte les requêtes, uniquement le port et le protocole. Ce n'est pas le cas pour mod_cluster, qui est davantage lié à la configuration de JBoss EAP 6. En revanche, les tâches suivantes fonctionnent pour mod_jk, mod_proxy, ISAPI, et NSAPI. Substituer les protocoles et les ports que vous aurez besoin de configurer par ceux des exemples.
mod_cluster, consulter Section 16.5.6, « Configurer un nœud de worker de mod_cluster ».
Prérequis
- Vous devrez être connecté au Management CLI ou à la Console de gestion pour effectuer cette tâche. Les étapes précises utilisent le Management CLI, mais la même procédure de base est utilisée dans la Console de gestion.
- Vous aurez besoin d'une liste des protocoles que vous devrez utiliser, que ce soit HTTP, HTTPS ou AJP.
Procédure 16.3. Modifier la configuration et ajouter les liaisons de socket
Configurer les propriétés de système
jvmRouteetuseJKPar défaut, le jvmRoute est sur la même valeur que le nom du serveur. Si vous avez besoin de le personnaliser, vous pouvez utiliser une commande semblable à la suivante. Remplacer ou supprimer la partie de la commande/profile=ha, en fonction du profil ou si vous utilisiez un serveur autonome. Remplacez la chaîneCUSTOM_ROUTE_NAMEpar votre nom jvmRoute personnalisé.[user@localhost:9999 /]
/profile=ha/subsystem=web:write-attribute(name="instance-id",value="CUSTOM_ROUTE_NAME")ActiveruseJKen la définissant surtruegrâce à la commande suivante :[user@localhost:9999 /]
/system-property=UseJK/:add(value=true)Lister les connecteurs disponibles dans le sous-sytème.
Note
Cette étape est nécessaire uniquement si vous n'utilisez pas la configurationautonome-ha.xmlpour un serveur autonome, ou les profilshaoufull-had'un groupe de serveurs dans un domaine géré. Ces configurations ont déjà tous les connecteurs nécessaires.Pour qu'un service externe HTTPD puisse se connecter au serveur web de JBoss EAP 6, le sous-système web doit avoir un connecteur. Chaque protocole a besoin de son propre connecteur, lié à un groupe de sockets.Pour avoir la liste des connecteurs actuellement disponibles, lancer la commande suivante :[standalone@localhost:9999 /]
/subsystem=web:read-children-names(child-type=connector)S'il n'y a aucune ligne sur le connecteur dont vous avez besoin (HTTP, HTTPS, AJP), vous devrez ajouter un connecteur.Lire la configuration d'un connecteur.
Pour voir les détails de configuration d'un connecteur, vous pourrez lire sa configuration. La commande suivante lit la configuration du connecteur AJP. Les autres connecteurs ont des sorties de configuration semblables.[standalone@localhost:9999 /]
/subsystem=web/connector=ajp:read-resource(recursive=true){ "outcome" => "success", "result" => { "enable-lookups" => false, "enabled" => true, "max-post-size" => 2097152, "max-save-post-size" => 4096, "protocol" => "AJP/1.3", "redirect-port" => 8443, "scheme" => "http", "secure" => false, "socket-binding" => "ajp", "ssl" => undefined, "virtual-server" => undefined } }Ajouter les connecteurs utiles au sous-système web.
Pour ajouter un connecteur au sous-système web, il doit y avoir une liaison de sockets. La liaison de sockets est ajoutée au groupe de liaisons de sockets utilisées par votre serveur ou groupe de serveurs. Les étapes suivantes supposent que votre groupe de serveurs estserver-group-oneet que votre groupe de liaisons de sockets eststandard-sockets.Ajouter une liaison au groupe de liaisons de sockets.
Pour ajouter un groupe de liaison de sockets, lancer la commande suivante, en remplaçant le protocole et le port par ceux dont vous avez besoin.[standalone@localhost:9999 /]
/socket-binding-group=standard-sockets/socket-binding=ajp:add(port=8009)Ajouter la liaison de sockets au sous-système web.
Lancer la commande suivante pour ajouter un connecteur au sous-système web, en substituant le nom de liaison de socket et le protocole par ceux que vous avez besoin.[standalone@localhost:9999 /]
/subsystem=web/connector=ajp:add(socket-binding=ajp, protocol="AJP/1.3", enabled=true, scheme="http")
16.4. Clustering
16.4.1. Utiliser la Communication TCP pour le sous-système de clusterisation
TCPPING à votre configuration et l'utiliser comme mécanisme par défaut. Ces options de configuration sont disponibles en ligne de commandes avec le Management CLI.
mod_cluster utilise également la communication UDP par défaut, et vous pouvez opter pour TCP également.
16.4.2. Configurer le sous-système JGroup pour Utilisation TCP
mod_cluster pour qu'il puisse utiliser TCP également, consulter Section 16.4.3, « Désactiver les annonces dans le sous-système mod_cluster. ».
Exécuter le Management CLI
Lancer la Management CLI, avec la commandeEAP_HOME/bin/jboss-cli.shdans Linux ou bien la commandeEAP_HOME\bin\jboss-cli.batdans le serveur Microsoft Windows. Saisirconnectpour connecter le contrôleur de domaine sur l'hôte local, ouconnect IP_ADDRESSpour vous connecter à un contrôleur de domaines sur un serveur éloigné.Modifier le script suivant selon votre environnement.
Copier le script suivant dans un éditeur de texte. Si vous utilisez un profil différent sur un domaine géré, changer le nom du profil. Si vous utilisez un serveur autonome, supprimer la portion/profile=full-hades commandes. Modifier les propriétés figurant au bas de la commande comme suit. Chacune de ces propriétés est facultative.- initial_hosts
- Une liste des hôtes considérés comme connus, séparés par des virgules sera à votre disposition pour rechercher l'adhésion de départ.
- port_range
- Si vous le souhaitez, vous pouvez attribuer une plage de ports. Si vous affectez une plage de ports de 2, et que le port initial est 7600, alors TCPPING tentera de contacter chaque hôte sur les ports 7600-7601. Cette propriété est facultative.
- timeout
- Une valeur de timeout facultative, en millisecondes, pour les membres d'un cluster.
- num_initial_members
- Le nombre de nœuds avant qu'un cluster soit considéré comme complet. Cette propriété est facultative.
cd /profile=full-ha/subsystem=jgroups ./stack=tcpping:add cd stack=tcpping ./transport=TRANSPORT:add(type=TCP,socket-binding=jgroups-tcp) :add-protocol(type=TCPPING) :add-protocol(type=MERGE2) :add-protocol(type=FD_SOCK,socket-binding=jgroups-tcp-fd) :add-protocol(type=FD) :add-protocol(type=VERIFY_SUSPECT) :add-protocol(type=BARRIER) :add-protocol(type=pbcast.NAKACK) :add-protocol(type=UNICAST2) :add-protocol(type=pbcast.STABLE) :add-protocol(type=pbcast.GMS) :add-protocol(type=UFC) :add-protocol(type=MFC) :add-protocol(type=FRAG2) :add-protocol(type=RSVP) cd protocol=TCPPING ./property=initial_hosts/:add(value="HostA[7600],HostB[7600]") ./property=port_range/:add(value=0) ./property=timeout/:add(value=3000) ./property=num_initial_members/:add(value=3) cd ../.. :write-attribute(name=default-stack,value=tcpping)
Exécuter le script en mode lot.
Avertissement
Les serveurs qui exécutent le profil devront être fermés avant de pouvoir exécuter le fichier de commandes.Sur invitation du Management CLI, saisirbatchet appuyer sur la touche Enter. L'invite change pour inclure un signe (#) pour indiquer que vous êtes en mode lot. Cela vous permet d'entrer une série de commandes. Si l'une d'entre elles venait à échouer, toute l'opération serait annulée.Coller le script modifié de l'étape précédente, ajouter une nouvelle ligne supplémentaire à la fin. Saisirrun-batchpour exécuter le lot. Une fois que toutes les commandes sont exécutées, le messageThe batch executed successfullyapparaîtra.
La pile TCPPING est maintenant disponible pour les sous-systèmes JGroups. Si elle est utilisée, le sous-système JGroups utilisera TCP pour toute la communication de réseau. Pour configurer le sous-système mod_cluster à utiliser TCP également, consulter Section 16.4.3, « Désactiver les annonces dans le sous-système mod_cluster. ».
16.4.3. Désactiver les annonces dans le sous-système mod_cluster.
mod_cluster utilise l'UDP multidiffusion pour annoncer sa présence aux workers d'arrière-plan. Si vous le souhaitez, vous pouvez désactiver les annonces. Utiliser la procédure suivante pour configurer ce comportement.
Procédure 16.4.
Modifier la configuration HTTPD.
Modifier la configuration HTTPD pour désactiver la publicité serveur et pour utiliser un proxy à la place. La liste de proxys est configurée sur le worker, et contient tous les serveurs HTTPS activés-mod_clusterauxquels le worker peut parler.La configuration demod_clusterpour le serveur HTTPD se trouve généralement dans le répertoire/etc/httpd/ouetc/httpd/au sein de l'installation de HTTPD, s'il est installé dans un emplacement non standard. Reportez-vous à Section 16.5.3, « Installer le Module mod cluster dans Apache HTTPD ou dans JBoss Enterprise Web Server HTTPD (ZIP) » et Section 16.5.5, « Configurer les propriétés Server Advertisement de votre HTTPD activé par un cluster » pour plus d'informations sur le fichier lui-même. Ouvrez le fichier contenant l'hôte virtuel qui écoute les requêtes MCPM (à l'aide de la directiveEnableMCPMReceive) et désactiver le serveur d'annonces en remplaçant la directiveServerAdvertisecomme suit.ServerAdvertise Off
Désactiver les annonces dans le sous-système
mod_clusterde JBoss EAP 6, et fournir une liste de proxys.Vous pouvez désactiver les annonces du sous-systèmemod_clusteret fournir une liste de proxys, en utilisant la console de gestion basée web ou le Management CLI de lignes de commande. La liste de proxys est utile car le sous-systèmemod_clusterne sera pas en mesure de découvrir les proxys automatiquement si les annonces sont désactivées.Console de gestion
- Si vous utilisez un domaine géré, vous ne pourrez uniquement configurer que
mod_clusterdans les profils où il est activé, tels quehaetfull-ha. - Connectez-vous à la Console de gestion et sélectionner l'étiquette Profiles en haut et à droite de l'écran. Si vous utilisez un domaine géré, sélectionner le profil
haoufull-haà partir de la boîte de sélection Profiles en haut et à gauche de la page Profiles. - Cliquer sur le menu Subsystems pour l'étendre. Étendre le sous-menu Web, et sélectionner Modcluster.
- Cliquez sur le bouton Edit en haut, pour modifier les options qui s'appliquent à tout le sous-système
mod_cluster. Modifiez la valeur de Advertise surfalse. Utilisez le bouton Save pour enregistrer les paramètres. - Cliquez sur l'onglet Proxies près du bas de l'écran. Cliquez sur le bouton Edit dans la sous-page de Proxies et entrez une liste de serveurs proxys. La syntaxe correcte est une liste séparée par des virgules de chaînes
HOSTNAME:PORT, semblable à la suivante.10.33.144.3:6666,10.33.144.1:6666
Cliquez sur le bouton Save pour enregistrer les modifications.
Management CLI
Les deux commandes de Management CLI suivantes créent la même configuration que les instructions de la Console de gestion ci-dessus. Elles supposent que vous exécutez un domaine géré et que votre groupe de serveurs utilise le profilfull-ha. Si vous utilisez un profil différent, modifiez son nom dans les commandes. Si vous utilisez un serveur autonome à l'aide du profilstandalone-haprofil, supprimez la portion/profile=full-hades commandes./profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=advertise,value=false) /profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=proxy-list,value="10.33.144.3:6666,10.33.144.1:6666")
L'équilibreur HTTPD n'annonce plus sa présence aux nœuds de worker et la multidiffusion UDP n'est plus utilisée.
16.5. Web, Connecteurs HTTP, et HTTP Clustering
16.5.1. Le connecteur HTTP mod_cluster
- mod_cluster Management Protocol (MCMP) est un lien supplémentaire entre les nœuds de serveur d'applications et httpd, utilisé par les nœuds de serveur d'applications pour transmettre des facteurs d'équilibrage des charges côté serveur et des événements de cycle de vie de retour vers le conteneur web via un ensemble personnalisé de méthodes HTTP.
- La configuration dynamique des proxies HTTPD permet à JBoss EAP 6 de s'adapter sur le champ, sans besoin de configuration supplémentaire.
- Les serveurs d'application se chargent des calculs de factorisation d'équilibre des charges.
- mod_cluster offre un contrôle précis du cycle de vie. Chaque serveur transmet tout événement de cycle de vie du contexte d'application web au proxy, l'informant de démarrer ou d'arrêter les demandes de routage dans un contexte donné du serveur. Ceci empêche les utilisateurs finaux de voir les erreurs 404 en raison des ressources non disponibles.
- AJP, HTTP ou HTTPS avec mod_cluster et Apache HTTP peuvent être utilisés.
16.5.2. Configurer le sous-système mod_cluster
mod_cluster sont disponibles dans la zone de configuration du sous-système Web. Cliquer sur l'onglet Profiles en haut à gauche. Si vous utilisez un domaine géré, sélectionnez le bon profil pour configurer dans la boîte de sélection de Profile en haut et à droite. Par défaut, les profils ha et full-ha ont le sous-système mod_cluster activé. Si vous utilisez un serveur autonome, vous devez utiliser le profil standalone-ha ou standalone-full-ha pour démarrer le serveur. Cliquer sur l'élément Web dans le menu de gauche et choisissez mod_cluster dans le sous-menu. Les options sont expliquées dans les tableaux ci-dessous. La configuration générale est indiquée en premier, suivie de la configuration de sessions, les contextes web, proxy, SSL et réseautage. Chacune d'elles possède son propre onglet dans l'écran de configuration de mod_cluster
Note
ha et full-ha pour un domaine géré, ou standalone-ha et standalone-full-ha pour un serveur autonome.
Tableau 16.4. Options de configuration mod_cluster
| Option | Description | Commande CLI |
|---|---|---|
| Groupe d'équilibrage des charges |
Si non nulles, les requêtes devront être envoyées vers un groupe d'équilibrage de charges sur l'équilibreur de charges. Laisser cet espace vide si vous ne souhaitez pas utiliser ces groupes d'équilibrage des charges.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=load-balancing-group,value=myGroup) |
| Équilibreur |
Le nom de l'équilibreur. Doit correspondre à la configuration du proxy HTTPD.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=balancer,value=myBalancer) |
| Socket Advertise |
Le nom de la liaison de sockets à utiliser pour les annonces de cluster.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=advertise-socket,value=modcluster) |
| Clé Sécurité Advertise |
Une chaîne contenant la clé de sécurité à annonce.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=advertise-security-key,value=myKey) |
| Advertise |
Indique si les annonces sont activées. Valeur par défaut
true.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=advertise,value=true) |
Tableau 16.5. Options de configuration de session mod_cluster
| Option | Description | Commande CLI |
|---|---|---|
| Sticky Session |
Si vous souhaitez utiliser des sessions pour les demandes. Cela signifie qu'après que le client ait établi une connexion sur un nœud de cluster spécifique, leur transmission ultérieure est routée vers ce même nœud à moins qu'il ne soit plus disponible. La valeur par défaut est
true, qui est le paramètre recommandé.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=sticky-session,value=true) |
| Sticky Session Force |
Si sur
true, la demande ne sera pas redirigée vers un nouveau nœud de cluster si son nœud initial n'est plus disponible. Au lieu de cela, elle échouera. La valeur par défaut est false.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=sticky-session-force,value=false) |
| Sticky Session Remove |
Supprime les informations de session en cas d'échec. Désactivé par défaut.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=sticky-session-remove,value=false) |
Tableau 16.6. Options de configuration de contexte web mod_cluster
| Option | Description | Commande CLI |
|---|---|---|
| Auto Enable Contexts |
Si on doit ajouter de nouveaux contextes à
mod_cluster par défaut ou non. La valeur par défaut true. Si vous modifiez la valeur par défaut et que vous devez activer le contexte manuellement, l'application web peut activer son contexte à l'aide de la méthode MBean enable(), ou via le gestionnaire mod_cluster, une application web qui s'exécute sur le serveur proxy HTTPD, sur un hôte virtuel nommé ou le port qui est spécifié dans la configuration de cet HTTPD.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=auto-enable-contexts,value=true) |
| Excluded Contexts |
Une liste séparée par des virgules de contextes que
mod_cluster doit ignorer. Si aucun hôte n'est indiqué, l'hôte est censé être localhost. ROOT indique le contexte racine de l'application web. La valeur par défaut est ROOT,invoker,jbossws,juddi,console.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=excluded-contexts,value="ROOT,invoker,jbossws,juddi,console") |
Tableau 16.7. Options de configuration proxy de mod_cluster
| Option | Description | Commande CLI |
|---|---|---|
| Proxy URL |
Si défini, cette valeur sera ajoutée à l'URL des commandes MCMP.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=proxy-url,value=myhost) |
| Proxy List |
Une liste séparée par des virgules des adresses proxy HTTPD, dans le format
hostname:port. Ceci indique la liste des serveurs proxy avec lesquels le processus de mod_cluster va tenter de communiquer au départ.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=proxy-list,value="127.0.0.1,127.0.0.2") |
mod_cluster
Par défaut, la communication mod_cluster a lieu sur un lien HTTP crypté. Si vous définissez le schéma du connecteur à HTTPS (voir Tableau 16.5, « Options de configuration de session mod_cluster »), les paramètres ci-dessous indiquent à mod_cluster où trouver les informations pour encoder la connexion.
Tableau 16.8. Options de configuration SSL de mod_cluster
| Option | Description | Commande CLI |
|---|---|---|
| ssl |
Indique si on doit activer SSL. Valeur par défaut
false.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/ssl=configuration/:write-attribute(name=ssl,value=true) |
| Clé Alias |
Clé alias choisie quand le certificat est créé.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/ssl=configuration/:write-attribute(name=key-alias,value=jboss) |
| Key Store |
L'emplacement où le keystore garde les certificats clients
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/ssl=configuration/:write-attribute(name=key-store,value=System.getProperty("user.home") + "/.keystore")
|
| Key Store Type |
Le type de keystore
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/ssl=configuration/:write-attribute(name=key-store-type,value=JKS) |
| Key Store Provider |
Le fournisseur de keystore
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/ssl=configuration/:write-attribute(name=key-store-provider,value=IBMJCE) |
| Mot de passe |
Mot de passe choisi quand le certificat est créé.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/ssl=configuration/:write-attribute(name=password,value=changeit) |
| Trust Algorithm |
L'algorithme de la fabrique de gestionnaire de confiance
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/ssl=configuration/:write-attribute(name=trust-algorithm,value=PKIX) |
| Cert File |
L'emplacement du fichier de certificats.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/ssl=configuration/:write-attribute(name=ca-certificate-file,value=${user.home}/jboss.crt)
|
| CRL File |
Fichier de la liste de révocation du certificat.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/ssl=configuration/:write-attribute(name=ca-crl-file,value=${user.home}/jboss.crl)
|
| Max Certificate Length |
La longueur maximum du certificat contenue dans le trust store. Valeur par défaut 5.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/ssl=configuration/:write-attribute(name=trust-max-cert-length,value=5) |
| Key File |
L'emplacement du fichier clé du certificat.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/ssl=configuration/:write-attribute(name=certificate-key-file,value=${user.home}/.keystore)
|
| Cipher Suite |
La suite cipher d'encodage autorisée.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/ssl=configuration/:write-attribute(name=cipher-suite,value=ALL) |
| Certificate Encoding Algorithms |
L'algorithme de la fabrique de gestionnaire de clés.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/ssl=configuration/:write-attribute(name=encoding-algorithms,value=ALL) |
| Revocation URL |
L'URL de la liste de révocation de l'autorité de certificat
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/ssl=configuration/:write-attribute(name=ca-revocation-url,value=jboss.crl) |
| Protocole |
Les protocoles SSL activés.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/ssl=configuration/:write-attribute(name=protocol,value=SSLv3) |
mod_cluster
Les options de réseautage de mod_cluster contrôlent des comportements de timeout différents pour des types de services variés avec lesquels le service mod_cluster communique.
Tableau 16.9. Options de configuration de réseautage de mod_cluster
| Option | Description | Commande CLI |
|---|---|---|
| Node Timeout |
Timeout (en secondes) des connexions de proxy vers un nœud. C'est que le temps
mod_cluster attendra la réponse de dorsal avant de retourner l'erreur. Cela correspond au délai d'attente dans la documentation de mod_proxy de travailleur. La valeur -1 n'indique aucun délai d'attente. Notez que mod_cluster utilise toujours un cping/cpong avant d'adresser une demande et la valeur connectiontimeout utilisée par mod_cluster est la valeur de ping.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=node-timeout,value=-1) |
| Socket Timeout |
Nombre de millisecondes pendant lesquelles patienter avant d'obtenir une réponse d'un proxy httpd à des commandes MCMP avant le timeout, et indiquer erreur de proxy.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=socket-timeout,value=20) |
| Stop Context Timeout |
Durée, mesurée dans les unités spécifiées par stopContextTimeoutUnit, pendant laquelle attendre l'arrêt net d'un contexte (fin des demandes en attente pour un contexte distribuable; ou destruction/expiration des sessions actives pour un contexte non distribuable).
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=stop-context-timeout,value=10) |
| Session Draining Strategy |
Indique si on doit drainer les sessions avant de retirer le déploiement d'une application web.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=session-draining-strategy,value=DEFAULT) |
| Max Attempts |
Nombre de fois qu'un proxy HTTPD va tenter d'envoyer une requête donnée à un worker avant d'abandonner. La valeur minimale est
1, ce qui signifie essayer une seule fois. La valeur par défaut du module mod_proxy est également 1, ce qui signifie qu'aucune nouvelle tentative ne se produit.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=max-attempts,value=1) |
| Flush Packets |
Indique si on doit activer le vidage des paquets dans le serveur HTTPD. Valeur par défaut
false.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=flush-packets,value=false) |
| Flush Wait |
Durée, en secondes, pendant laquelle on doit attendre le vidage des paquets dans le serveur HTTPD. Une valeur
-1. A value of -1 indique une attente indéfinie avant de vider les paquets.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=flush-wait,value=-1) |
| Ping |
Durée, en secondes, pendant laquelle attendre un réponse au ping d'un noeud de cluster. Valeur par défaut
10 secondes.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=ping,value=10) |
| SMAX |
Le nombre de soft connexions inactives maximales (le même que
smax dans la documentation du module de worker mod_proxy). La valeur maximale dépend de la configuration de thread httpd et peut être ThreadsPerChild ou 1.
|
profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=smax,value=ThreadsPerChild) |
| TTL |
Time To live (en secondes) pour les connexions inactives au dessus de smax, la valeur par défaut est 60
Quand
nodeTimeout n'est pas défini, le Proxy de la directive ProxyTimeout est utilisé. Si ProxyTimeout n'est pas défini, alors le Timeout sera utilisé. La valeur par défaut est de 300 secondes. nodeTimeout, ProxyTimeout, et Timeout sont définis au niveau socket.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=ttl,value=-1) |
| Node Timeout |
La durée d'attente, en secondes, pour le traitement d'une requête par un processus de travail de serveur HTTPD externe. Par défaut,
-1, ce qui signifie que mod_cluster attend indéfiniment la requête traitée par le worker HTTPD.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=node-timeout,value=-1) |
mod_cluster
Les options de configuration de mod_cluster suivantes ne sont pas disponibles dans la Console de gestion basée web, et ne peuvent être uniquement définies qu'en utilisant le Management CLI en ligne de commandes.
1, et répartit uniformément les travaux sans prendre en compte un algorithme d'équilibrage de charges. Pour l'ajouter, utilisez la commande CLI suivante : /profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/simple-load-provider:add
busyness (niveau d'activité) comme facteur déterminant. Vous trouverez ci-dessous la liste des facteurs possibles. Vous pouvez également créer votre propre fournisseur de charge en fonction de votre propre environnement. Les options suivantes du fournisseur de charge dynamique peuvent être modifiées. Notez que vous pouvez avoir plus d'un facteur (métrique) à tout moment. Il vous sufira de les ajouter par l'interface CLI.
:add-metric(type=cpu)
Tableau 16.10. Options Load provider dynamque de mod_cluster
| Option | Description | Commande CLI |
|---|---|---|
| Decay |
Le facteur par lequel les métriques historiques se désintègrent de façon significative.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/dynamic-load-provider=configuration/:write-attribute(name=decay,value=2) |
| Historique |
Le nombre d'enregistrements de métriques de charge historique à considérer pour déterminer la charge.
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/dynamic-load-provider=configuration/:write-attribute(name=history,value=9) |
| Métrique de charge |
Le seule métrique de charge inclus dans le fournisseur de charge dynamique de JBoss EAP 6 est
busyness (niveau d'activité), qui tente d'envoyer chaque nouvelle requête au worker le moins occupé. Vous pouvez définir la capacité de votre worker (1 indique une capacité de 100 %) et le poids accordé au métrique de busyness global. .
|
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/dynamic-load-provider=configuration/load-metric=busyness/:write-attribute(name=capacity,value=1.0) /profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/dynamic-load-provider=configuration/load-metric=busyness/:write-attribute(name=type,value=busyness) /profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/dynamic-load-provider=configuration/load-metric=busyness/:write-attribute(name=weight,value=1) |
Algorithmes de métriques de charge
- cpu
- Le métrique de charge cpu utilise la charge CPU moyenne pour déterminer quel nœud de cluster reçoit la charge de travail suivante.
- mem
- Le métrique de charge mem utilise la mémoire native RAM comme facteur de charge. L'utilisation de ce métrique est déconseillée car elle fournit une valeur qui inclut les tampons et le cache. C'est donc toujours un chiffre très faible sur chaque système décent pourvu d'une bonne gestion de mémoire.
- heap
- La métrique de charge de tas utilise l'usage de tas pour déterminer quel cluster reçoit la charge de travail suivante.
- sessions
- Le métrique de charge de session utilise le nombre de sessions actives comme métrique.
- requêtes
- Le métrique de charge de requêtes utilise le nombre de requêtes en provenance des clients pour déterminer quel nœud de cluster reçoit la charge de travail suivante. Par exemple, capacité 1000 signifie que 1000 requêtes/s est considéré comme une « pleine charge ».
- send-traffic
- Le métrique de charge send-traffic (trafic envoyé) utilise le volume de trafic envoyé à partir d'un nœud de worker vers les clients. Par ex. une capacité par défaut de 512 indique que le nœud doit être considéré en pleine charge, si le trafic sortant moyen est 512 KB/s ou supérieur.
- receive-traffic
- Le métrique de charge receive-traffic (réception de trafic) utilise le volume de trafic envoyé vers le nœud de worker en provenance des clients. Par ex. une capacité par défaut de 1024 indique que le nœud doit être considéré en pleine charge, si le trafic entrant moyen est 1024 KB/s ou supérieur.
- busyness
- Ce métrique représente le nombre de threads d'une pool de threads en train de répondre à des requêtes.
Exemple 16.1. Définir un métrique d'équilibrage de charges
/profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/dynamic-load-provider=configuration/load-metric=cpu/:write-attribute(name="weight",value="3")
16.5.3. Installer le Module mod cluster dans Apache HTTPD ou dans JBoss Enterprise Web Server HTTPD (ZIP)
Prérequis
- Pour cette tâche, vous devrez utiliser Apache HTTPD installé dans Red Hat Enterprise Linux 6, ou JBoss Enterprise Web Server, ou encore HTTPD autonome comme composant de JBoss EAP 6 à télécharger séparément.
- Si vous avez besoin d'installer Apache HTTPD dans Red Hat Enterprise Linux 6, utiliser les instructions dans Red Hat Enterprise Linux 6 Deployment Guide, qui sont disponibles à partir de https://access.redhat.com/site/documentation/.
- Si vous avez besoin d'installer HTTPD autonome en tant que composant téléchargeable de JBoss EAP 6, consulter Section 16.3.2, « Installer Apache HTTPD inclus avec JBoss EAP 6 ».
- Si vous avez besoin d'installer le serveur JBoss Enterprise Web Server, utiliser les instructions dans JBoss Enterprise Web Server Installation Guide, qui sont disponibles à partir de https://access.redhat.com/site/documentation/.
- Télécharger le package Webserver Connecter Natives pour votre système d'exploitation et architecture depuis le portail client de Red Hat à https://access.redhat.com. Ce paquet contient les modules HTTPD mod_cluster binaires précompilés pour votre système d'exploitation. Après avoir extrait l'archive, les modules se trouvent dans le répertoire
modules/native/lib/httpd/modules/.Le répertoireetc/contient quelques exemples de fichiers de configuration et le répertoireshare/contient une documentation supplémentaire. - Vous devez être connectés avec des privilèges administratifs (root).
Procédure 16.5. Installer le Module mod cluster
Déterminer l'emplacement de votre configuration HTTPD
Votre emplacement de configuration HTTPD sera différent selon que vous utilisez Apache HTTPD de Red Hat Enterprise Linux, HTTPD autonome inclus comme composant séparé téléchargeabl dans JBoss EAP 6 ou HTTPD disponible dans JBoss Enterprise Web Server. C'est l'une des trois options suivantes qui sera mentionnée au cours de cette tâche sous le nom HTTPD_HOME.- Apache HTTPD -
/etc/httpd/ - JBoss EAP 6 HTTPD - Cet emplacement est choisi par vous-même sur la base des exigences de votre infrastructure.
- JBoss Enterprise Web Server HTTPD -
EWS_HOME/httpd/
Copier les modules dans le répertoire de modules HTTPD.
Copier les quatre modules (les fichiers qui se terminent par.so) à partir du répertoiremodules/native/lib/httpd/modules/de l'archive extraite Webserver Natives vers le répertoireHTTPD_HOME/modules/.Pour JBoss Enterprise Web Server, désactiver le module
mod_proxy_balancer.Si vous utilisez JBoss Enterprise Web Server, le modulemod_proxy_balancersera activé par défaut. Il est incompatible avec mod cluster. Pour le désactiver, modifierHTTPD_HOME/conf/httpd.confet décommenter la ligne suivante en mettant le symbole#(hachage) devant la ligne qui charge le module. La ligne apparaîtra sans le commentaire, puis avec, comme ci-dessous.LoadModule proxy_balancer_module modules/mod_proxy_balancer.so
# LoadModule proxy_balancer_module modules/mod_proxy_balancer.so
Sauvegarder et fermer le fichier.Configurer le module mod cluster.
L'archive Webserver Natives contient un échantillon de fichiermod_cluster.conf(modules/system/layers/base/native/etc/httpd/conf). Ce fichier peut être utilisé comme guide ou copié et modifié pour créer un fichierHTTPD_HOME/httpd/conf.d/JBoss_HTTP.conf.Note
L'utilisation du nomJBoss_HTTP.confest une convention arbitraire de ce document. le fichier de configuration sera chargé, indépendemment de son nom, s'il est enregistré dans le répertoireconf.d/avec l'extension.conf.Ajouter l'entrée suivante à votre fichier de configuration :LoadModule slotmem_module modules/mod_slotmem.so LoadModule manager_module modules/mod_manager.so LoadModule proxy_cluster_module modules/mod_proxy_cluster.so LoadModule advertise_module modules/mod_advertise.so
Cela oblige Apache HTTPD à charger les modules dontmod_clustera besoin automatiquement pour fonctionner.Créer un proxy de listener de serveur.
Continuer à éditerHTTPD_HOME/httpd/conf/JBoss_HTTP.confet ajouter la configuration minimale suivante, en remplaçant les valeurs en lettres majuscules par des valeurs adaptées à votre système.Listen IP_ADDRESS:PORT <VirtualHost IP_ADDRESS:PORT> <Location /> Order deny,allow Deny from all Allow from *.MYDOMAIN.COM </Location> KeepAliveTimeout 60 MaxKeepAliveRequests 0 EnableMCPMReceive On ManagerBalancerName mycluster ServerAdvertise On </VirtualHost>Ces directives créent un nouveau serveur virtuel qui écoute sur le portIP_ADDRESS:PORT, permet des connexions deMYDOMAIN.COMet se présente comme un équilibreur de charge du nommycluster. Ces directives sont traitées en détail dans la documentation pour le serveur Web Apache Server. Pour en savoir plus sur les directivesServerAdvertiseetEnableMCPMReceiveou les implications des annonces de serveur, reportez-vous à Section 16.5.5, « Configurer les propriétés Server Advertisement de votre HTTPD activé par un cluster ».Enregistrer le fichier et sortir.Redémarrer le HTTPD.
La façon de redémarrer HTTPD dépend de savoir si vous utilisez Apache HTTPD de Red Hat Enterprise Linux ou le HTTDP inclus dans JBoss Enterprise Web Server. Choisir une des deux méthodes ci-dessous.Red Hat Enterprise Linux 6 Apache HTTPD
Exécuter la commande suivante :[root@host]#
service httpd restartJBoss Enterprise Web Server HTTPD
JBoss Enterprise Web Server exécute à la fois sur Red Hat Enterprise Linux et Microsoft Windows Server. La méthode de redémarrage du HTTPD est différente pour chacun.Red Hat Enterprise Linux
Dans Red Hat Enterprise Linux, JBoss Enterprise Web Server installe son HTTPD en tant que service. Pour redémarrer HTTPD, lancer les deux commandes suivantes :[root@host ~]# service httpd stop[root@host ~]# service httpd startMicrosoft Windows Server
Lancer les commandes suivantes dans une invite de commande avec des privilèges administratifs :C:\> net stop httpdC:\> net start httpd
Apache HTTPD est maintenant configuré comme équilibreur de charges, et peut fonctionner avec le sous-système mod_cluster qui exécute sur JBoss EAP 6. Pour configurer JBoss EAP 6 pour qu'il soit au fait de mod_cluster, consulter Section 16.5.6, « Configurer un nœud de worker de mod_cluster ».
16.5.4. Installer le Module mod cluster dans Apache HTTPD ou dans JBoss Enterprise Web Server HTTPD (RPM)
Prérequis
- Pour cette tâche, vous devrez utiliser Apache HTTPD installé dans Red Hat Enterprise Linux 6, ou JBoss Enterprise Web Server, ou encore HTTPD autonome comme composant de JBoss EAP 6 à télécharger séparément.
- Si vous avez besoin d'installer Apache HTTPD dans Red Hat Enterprise Linux 6, utiliser les instructions dans Red Hat Enterprise Linux 6 Deployment Guide, qui sont disponibles à partir de https://access.redhat.com/site/documentation/.
- Si vous avez besoin d'installer HTTPD autonome en tant que composant téléchargeable de JBoss EAP 6, consulter Section 16.3.2, « Installer Apache HTTPD inclus avec JBoss EAP 6 ».
- Si vous avez besoin d'installer le serveur JBoss Enterprise Web Server, utiliser les instructions dans JBoss Enterprise Web Server Installation Guide, qui sont disponibles à partir de https://access.redhat.com/site/documentation/.
- Vous devez être connectés avec des privilèges administratifs (root).
- Vous devez posséder un abonnement actif au canal RHN
jbappplatform-6-ARCH-server-VERS-rpm.
- Instaler le package
mod_cluster-nativeavec YUM :yum install mod_cluster-native
- HTTPD 2.2.15:
- Si vous choisissez de rester sur HTTPD 2.2.15, vous devez désactiver le module
mod_proxy_balancerchargé par défaut en commentant la ligneLoadModule proxy_balancer_moduledans le fichier httpd.conf.Vous pouvez modifier le fichier manuellement ou utiliser la commande suivante :sed -i 's/^LoadModule proxy_balancer_module/#LoadModule proxy_balancer_module/;s/$//' /etc/httpd/conf/httpd.conf
- Si vous choisissez d'effectuer une mise à niveau vers HTTPD 2.2.22, installer la dernière version avec la commande suivante :
yum install httpd
- Afin de lancer le service HTTPD au démarrage, exécuter la commande suivante :
ajout service httpd
- Démarrer l'équilibreur mod_cluster par la commande suivante :
lancement service httpd
16.5.5. Configurer les propriétés Server Advertisement de votre HTTPD activé par un cluster
Pour obtenir des instructions sur la façon de configurer votre HTTPD pour qu'il interagisse avec l'équilibreur de charges, consulter Section 16.5.3, « Installer le Module mod cluster dans Apache HTTPD ou dans JBoss Enterprise Web Server HTTPD (ZIP) ». L'élément de configuration server advertisement requiert davantage d'explications.
httpd.conf associé à votre instance d'HTTPD Apache. Il s'agit le plus souvent de /etc/httpd/conf/httpd.conf dans Red Hat Enterprise Linux, ou peut-être le répertoire etc/ de votre instance HTTPD Apache autonome.
Procédure 16.6. Modifier le fichier httpd.conf et implémenter les changements
Désactivez le paramètre
AdvertiseFrequency, s'il existe.Si vous voyez une ligne qui ressemble à ceci dans votre énoncé<VirtualHost>, dé-commenter cette ligne en ajoutant un signe#devant le premier caractère. La valeur ne devra pas correspondre à5.AdvertiseFrequency 5
Ajouter la directive qui permet de désactiver Server Advertisement.
Ajouter la directive suivante dans l'énoncé<VirtualHost>afin de désactiver Server Advertisement.ServerAdvertise Off
Actionner la possibilité de recevoir des messages MCPM.
Ajouter la directive suivante pour permettre au serveur HTTPD de recevoir des messages MCPM de la part des worker nodes.EnableMCPMReceive On
Redémarrer le serveur HTTPD.
Redémarrer le serveur HTTPD en lançant une des commandes suivantes, selon que vous utilisez Red Hat Enterprise Linux ou Microsoft Windows Server.Red Hat Enterprise Linux
[root@host ]# service httpd restart
Microsoft Windows Server
C:\> net service http C:\> net service httpd start
Le démon HTTPD n'annonce plus l'adresse IP et le port de votre serveur proxy mod_cluster. Pour l'annoncer, vous devez configurer vos worker nodes pour qu'ils utilisent une adresse statique et un port pour communiquer avec le proxy. Consulter Section 16.5.6, « Configurer un nœud de worker de mod_cluster » pour plus de détails.
16.5.6. Configurer un nœud de worker de mod_cluster
Un worker node de mod_cluster se compose d'un serveur JBoss EAP. Ce serveur peut faire partie d'un groupe de serveurs dans un domaine géré ou un serveur autonome. Un processus distinct s'exécute sur JBoss EAP, qui gère tous les nœuds du cluster. C'est ce qu'on appelle le master. Pour plus d'informations conceptuelles sur les worker nodes, consulter Section 16.1.4, « Nœud de worker ». Pour une vue d'ensemble de l'équilibrage de la charge HTTPD, consulter Section 16.1.3, « Connecteurs HTTP - Aperçu général ».
mod_cluster. Pour configurer le sous-système mod_cluster, reportez-vous à Configure the mod_cluster Subsystem dans Administration and Configuration Guide. Chaque nœud de worker est configuré séparément, alors répétez cette procédure pour chaque nœud que vous souhaitez ajouter au cluster.
Configuration d'un nœud de worker
- Si vous utilisez un serveur autonome, il devra être démarré par le profil
standalone-ha. - Si vous utilisez un domaine géré, votre groupe de serveurs devra utiliser le profil
haoufull-ha, et le groupe de liaisons de socketsha-socketsoufull-ha-sockets. JBoss EAP 6 est fourni avec un groupe de serveurs à clusterisation activée, nomméother-server-groupqui remplit ces prérequis.
Note
/profile=full-ha des commandes.
Procédure 16.7. Configurez un nœud de worker
Configurez les interfaces de réseau
Les interfaces de réseau ont toutes la valeur127.0.0.1par défaut. Chaque hôte physique, qui accueille un serveur autonome ou bien un ou plusieurs serveurs au sein d'un groupe de serveurs, a besoin de ses interfaces configurées pour utiliser son adresse IP, que les autres serveurs peuvent apercevoir.Pour changer l'adresse IP d'un hôte de JBoss EAP 6, vous devrez le fermer et modifier son fichier de configuration directement. C'est parce que l'API de gestion qui actionne la console de gestion et le CLI dépendent d'une adresse de gestion stable.Suivez ces étapes pour changer l'adresse IP sur chaque serveur de votre cluster par votre adresse IP publique de master.- Fermer le serveur complètement.
- Modifier soit
host.xml, qui se trouve dansEAP_HOME/domain/configuration/pour un domaine géré, ou bien le fichierstandalone-ha.xml, qui se trouve dansEAP_HOME/standalone/configuration/pour un serveur autonome. - Chercher l'élément
<interfaces>. Il y a trois interfaces configurées. Ces interfaces sontmanagement,public, etunsecured. Pour chacune d'entre elles, changer la valeur127.0.0.1à l'adresse IP externe de l'hôte. - Pour les hôtes qui participent à un domaine géré, mais qui ne sont pas master, localiser l'élément
<host. Notez qu'il n'a pas de symbole de fermeture>, car il contient des attributs. Modifiez la valeur de son nom d'attributmasterpar un nom unique, avec un nom différent par esclave. Ce nom servira aussi à l'esclave pour identifier au cluster, donc notez bien ceci. - Pour les hôtes nouvellement configurés qui ont besoin de rejoindre un domaine géré, chercher l'élément
<domain-controller>. Dé-commenter ou supprimer l'élément<local />, et ajouter la ligne suivante, en changeant l'adresse IP (X.X.X.X) par l'adresse du contrôleur de domaine. Cette étape ne s'applique pas à un serveur autonome.<remote host="X.X.X.X" port="${jboss.domain.master.port:9999}" security-realm="ManagementRealm"/> - Enregistrer le fichier et sortir.
Configurez l'authentification pour chaque serveur esclave.
Chaque serveur esclave a besoin d'un nom d'utilisateur et d'un mot de passe créé dans leManagementRealmdu contrôleur de domaine ou du master autonome. Sur le contrôleur de domaine ou sur le master autonome, exécutez la commandeEAP_HOME/bin/add-user.sh. Ajoutez un utilisateur avec le même nom d'utilisateur comme esclave auManagementRealm. Quand on vous demandera si cet utilisateur doit s'authentifier auprès d'une instance de JBoss AS externe, répondezOui. Vous trouverez un exemple de l'entrée et de la sortie de la commande ci-dessous, pour un esclave appeléslave1, et un mot de passechangeme.user:bin user$ ./add-user.sh What type of user do you wish to add? a) Management User (mgmt-users.properties) b) Application User (application-users.properties) (a):
aEnter the details of the new user to add. Realm (ManagementRealm) : Username :slave1Password :changemeRe-enter Password :changemeAbout to add user 'slave1' for realm 'ManagementRealm' Is this correct yes/no?yesAdded user 'slave1' to file '/home/user/jboss-eap-6.0/standalone/configuration/mgmt-users.properties' Added user 'slave1' to file '/home/user/jboss-eap-6.0/domain/configuration/mgmt-users.properties' Is this new user going to be used for one AS process to connect to another AS process e.g. slave domain controller? yes/no? yes To represent the user add the following to the server-identities definition <secret value="Y2hhbmdlbWU=" />Copiez l'élément codé-Base64
<secret>à partir de la sortieadd-user.sh.Si vous prévoyez de spécifier un mot de passe codé Base64 pour l'authentification, copiez l'élément<secret>à partir de la dernière ligne de la sortieadd-user.shcar vous en aurez besoin à l'étape suivante.Modifiez le domaine de sécurité de l'hôte esclave pour la nouvelle authentification.
- Réouvrir le fichier
host.xmloustandalone-ha.xmlde l'hôte esclave. - Chercher l'élément
<security-realms>. C'est là où vous pourrez configurer le domaine de sécurité. - Vous pourrez spécifier la valeur secrète d'une des manières suivantes :
Spécifier le mot de passe codé Base64 dans le fichier de configuration.
- Ajouter le bloc suivant de code XML sous la ligne
<security-realm name="ManagementRealm">,<server-identities> <secret value="Y2hhbmdlbWU="/> </server-identities> - Remplacer "Y2hhbmdlbWU=" par la valeur secrète retournée de la sortie
add-user.shlors de l'étape précédente.
Configurez l'hôte pour obtenir un mot de passe de l'archivage sécurisé.
- Utilisez le script
vault.shpour générer un mot de passe masqué. Cela génèrera une chaîne comme la suivante :VAULT::secret::password::ODVmYmJjNGMtZDU2ZC00YmNlLWE4ODMtZjQ1NWNmNDU4ZDc1TElORV9CUkVBS3ZhdWx0.Vous pourrez trouver plus d'informations sur l'archivage sécurisé dans Password Vaults de la section Sensitive Strings de ce guide, ici : Section 10.13.1, « Sécurisation des chaînes confidentielles des fichiers en texte clair ». - Ajouter le bloc de code XML suivant directement sous la ligne
<security-realm name="ManagementRealm">.<server-identities> <secret value="${VAULT::secret::password::ODVmYmJjNGMtZDU2ZC00YmNlLWE4ODMtZjQ1NWNmNDU4ZDc1TElORV9CUkVBS3ZhdWx0}"/> </server-identities>Veillez à remplacer la valeur secrète par le mot de passe masqué généré lors de l'étape précédente.Note
Quand vous créez un mot de passe dans l'archivage sécurisé, celui-ci devra être spécifié en texte brut, et non pas codé Base64.
Spécifiez le mot de passe en tant que propriété système.
- Ajouter le bloc de code XML suivant sous la ligne
<security-realm name="ManagementRealm"><server-identities> <secret value="${server.identity.password}"/> </server-identities> - Quand vous spécifiez le mot de passe en tant que propriété système, vous pouvez configurer l'hôte d'une des manières suivantes :
- Démarrez le serveur en saisissant le mot de passe en texte brut comme argument de ligne de commande, comme par exemple :
-Dserver.identity.password=changeme
Note
Le mot de passe doit être saisi en texte brut et sera visible par quiconque lance la commandeps -ef. - Mettez le mot de passe dans un fichier de propriétés et passez l'URL du fichier de propriétés sous forme d'argument de ligne de commande.
- Ajoutez la paire clé/valeur à un fichier de propriétés. Par exemple :
server.identity.password=changeme
- Démarrez le serveur par les arguments de ligne de commande
--properties=URL_TO_PROPERTIES_FILE
.
- Sauvegarder et sortir du fichier.
Redémarrez le serveur.
L'esclave va maintenant authentifier le master en utilisant son nom d'hôte comme nom d'utilisateur et le string codifié comme mot de passe.
Votre serveur autonome, ou les serveurs au sein d'un groupe de serveurs d'un domaine géré, sont désormais configurés en tant que worker nodes du mod_cluster. Si vous déployez une application en cluster, ses sessions seront répliquées sur tous les nœuds de cluster de basculement, et seront en mesure d'accepter les demandes provenant d'un serveur HTTPD externe ou d'un équilibreur de charges. Chaque nœud du cluster détecte les autres nœuds à l'aide d'automatic discovery, par défaut. Pour configurer la détection automatique et les autres paramètres spécifiques du sous-système mod_cluster, reportez-vous à Section 16.5.2, « Configurer le sous-système mod_cluster ». Pour configurer le serveur Apache HTTPD, reportez-vous à Section 16.3.5, « Utiliser un HTTPD externe comme Web frontal pour les applications JBoss EAP 6. ».
16.5.7. Migration du trafic entre les clusters
Après avoir créé un nouveau cluster avec JBoss EAP 6, vous souhaitez sans doute migrer le trafic d'un ancien cluster vers un nouveau dans le cadre d'un processus de mise à niveau. Au cours de cette tâche, vous verrez la stratégie qui peut être utilisée pour migrer ce trafic avec un minimum de temps mort.
Prérequis
- Nouvelle installation de cluster : Section 16.5.2, « Configurer le sous-système
mod_cluster» (Nous appellerons ce cluster : NOUVEAU Cluster). - Une ancienne installation de cluster a été rendue obsolète (Nous appellerons ce cluster : ANCIEN Cluster).
Procédure 16.8. Mise à niveau du processus pour les clusters
- Installez votre nouveau cluster en suivant les étapes décrites dans les prérequis.
- Pour les NOUVEAUX et VIEUX Cluster à la fois, assurez-vous que l'option de configuration
sticky-sessionest définie surtrue(surtruepar défaut). L'activation de cette option signifie que toutes les nouvelles demandes présentées à un nœud de cluster dans un de ces clusters continuera d'aller vers ce nœud./profile=full-ha/subsystem=modcluster/mod-cluster-config=configuration/:write-attribute(name=sticky-session,value=true)
- Ajouter les nœuds dans le NOUVEAU Cluster à la configuration de mod_cluster individuellement à l'aide du processus décrit ici: Section 16.5.6, « Configurer un nœud de worker de mod_cluster »
- Configurer l'équilibrage de la charge (mod_cluster) pour arrêter les contextes individuels dans l'ANCIEN Cluster. L'arrêt des contextes (par opposition à leur désactivation) dans l'ANCIEN Cluster permettra aux contextes individuels de s'arrêter gracieusement (et éventuellement à un arrêt total). Les sessions existantes seront toujours servies, mais aucune nouvelle session ne sera dirigée vers ces nœuds. Les contextes arrêtés peuvent prendre plusieurs minutes ou même plusieurs heures pour s'arrêter.Vous pouvez utiliser le CLI suivant pour stopper un contexte. Remplacer les valeurs de paramètre par des valeurs adaptées à votre environnement.
[standalone@localhost:9999 subsystem=modcluster] :stop-context(context=/myapp, virtualhost=default-host, waittime=50)
Vous avez effectué la mise à niveau de JBoss EAP 6 Cluster avec succès.
16.6. Apache mod_jk
16.6.1. Le connecteur Apache mod_jk HTTP
mod_jk est un connecteur HTTP fourni aux clients qui en ont besoin pour des raisons de compatibilité. Apache mod_jk fournit un équilibrage des charges et fait partie des jboss-eap-native-webserver-connectors contenus dans JBoss Web Container. Pour les plateformes prises en charge, consulter https://access.redhat.com/site/articles/111663. Le connecteur mod_jk est maintenu par Apache, et sa documentation se trouve à l'adresse http://tomcat.apache.org/connectors-doc/.
mod_cluster, un serveur proxy Apache ne connaît pas le statut des déploiements sur les serveurs ou groupes de serveurs, et ne peut donc pas ajuster les envois et lieux de travail en fonction du statut.
mod_cluster, mod_jk communique à travers le protocole AJP 1.3.
Note
mod_cluster est un équilibreur de charges plus avancé que mod_jk. mod_cluster fournit toute la fonctionnalité de mod_jk et quelques fonctionnalités supplémentaires. Pour plus d'informations sur mod_cluster, consulter Section 16.5.1, « Le connecteur HTTP mod_cluster ».
Prochaine étape : configurer la plateforme JBoss EAP 6 pour qu'elle puisse participer à un groupe d'équilibrage des charges mod_jk
16.6.2. Configurer JBoss EAP 6 pour qu'il communique avec Apache Mod_jk
Le connecteur mod_jk HTTP possède un simple composant, le module mod_jk.so, qui est chargé par le démon HTTPD. Ce module reçoit les demandes des clients et les transfère vers le conteneur, en l'occurrence JBoss EAP 6. JBoss EAP 6 doit également être configuré pour accepter ces demandes et envoyer leurs réponses vers le démon HTTPD.
- Dans un domaine géré, dans les groupes de serveurs qui utilisent les profils
haetfull-ha, et le groupe de liaisons de socketshaoufull-ha. Le groupe de serveursother-server-groupest configuré correctement dans une installation par défaut. - Dans un serveur autonome, les profils
standalone-haetstandalone-full-hasont configurés pour les configurations en cluster. Pour démarrer le serveur autonome avec un de ces profils, lancer la commande ci-dessous, à partir du répertoireEAP_HOME/. Remplacer par le nom de profil approprié.[user@host bin]$
./bin/standalone.sh --server-config=standalone-ha.xml
16.6.3. Installer le Module_jk_mod dans Apache HTTPD Server (ZIP)
Prérequis
- Pour cette tâche, vous devrez utiliser Apache HTTPD installé dans un environnement pris en charge ou l'Apache HTTP installé sur JBoss Enterprise Web Server. Notez que l'Apache HTTP installé dans JBoss Enterprise Web Server fait partie de la distribution JBoss Enterprise Web Server fait partie de la distribution JBoss EAP 6.
- Si vous devez installer Apache HTTP Server, utilisez les instructions qui se trouvent dans Red Hat Enterprise Linux Deployment Guide, disponible dans https://access.redhat.com/site/documentation/.
- Si vous avez besoin d'installer le serveur JBoss Enterprise Web Server, utiliser les instructions dans JBoss Enterprise Web Server Installation Guide, qui sont disponibles à partir de https://access.redhat.com/site/documentation/.
- Si vous utilisez le serveur Apache HTTP, télécharger le package JBoss EAP 6 Native Components pour votre plate-forme du portail client de Red Hat à https://access.redhat.com. Ce paquet contient les mod_cluster et mod_jk binaires précompilés pour Red Hat Enterprise Linux. Si vous utilisez JBoss Enterprise Web Server, il comprend déjà le binaire pour mod_jk.
- Vous devez être connectés avec des privilèges administratifs (root).
Procédure 16.9. Installer le Module mod cluster
Configurer le module mod_jk.
- Créer un nouveau fichier nommé
HTTPD_HOME/conf.d/mod-jk.confet y ajouter ce qui suit.Note
La directiveJkMountindique quels URL Apache doivent transférer au module mod_jk. Sur la base de la configuration de la directive, mod_jk transfère l'URL reçu aux conteneurs de servlet qui conviennent.Pour servir le contenu directement, et n'utiliser que l'équilibreur de charges que pour les applicatins Java, le chemin URL doit être/application/*. Pour utiliser mod_jk en tant qu'équilibreur des charges, utiliser la valeur/*, pour transférer tous les URL au mod_jk.# Load mod_jk module # Specify the filename of the mod_jk lib LoadModule jk_module modules/mod_jk.so # Where to find workers.properties JkWorkersFile conf/workers.properties # Where to put jk logs JkLogFile logs/mod_jk.log # Set the jk log level [debug/error/info] JkLogLevel info # Select the log format JkLogStampFormat "[%a %b %d %H:%M:%S %Y]" # JkOptions indicates to send SSK KEY SIZE JkOptions +ForwardKeySize +ForwardURICompat -ForwardDirectories # JkRequestLogFormat JkRequestLogFormat "%w %V %T" # Mount your applications # The default setting only sends Java application data to mod_jk. # Use the commented-out line to send all URLs through mod_jk. # JkMount /* loadbalancer JkMount /application/* loadbalancer # Add shared memory. # This directive is present with 1.2.10 and # later versions of mod_jk, and is needed for # for load balancing to work properly JkShmFile logs/jk.shm # Add jkstatus for managing runtime data <Location /jkstatus/> JkMount status Order deny,allow Deny from all Allow from 127.0.0.1 </Location>
Observer les valeurs et vérifier qu'elles sont raisonnables pour votre installation. Quand vous serez satisfait, sauvegarder le fichier. Spécifier une directive JKMountFile
En plus de la directive JKMount demod-jk.conf, vous pourrez spécifier un fichier qui contient des modèles URL multiples à transférer au mod_jk.- Ajouter ce qui suit au fichier
HTTPD_HOME/conf/mod-jk.conf:# You can use external file for mount points. # It will be checked for updates each 60 seconds. # The format of the file is: /url=worker # /examples/*=loadbalancer JkMountFile conf/uriworkermap.properties
- Créer un nouveau fichier intitulé
HTTPD_HOME/conf/uriworkermap.properties, avec une ligne pour chaque modèle URL à faire correspondre. L'exemple suivant montre des exemples de syntaxe pour ce fichier.# Simple worker configuration file /*=loadbalancer
Copy le fichier mod_jk.so dans le répertoire de modules HTTPD
Note
Utile uniquement si votre HTTPD n'a pas demod_jk.sodans son répertoiremodules/. Vous pourrez éviter cette étape si vous utilisez le serveur Apache HTTPD inclus, un téléchargement de JBoss EAP 6.Extraire le paquet Native Web Server Connectors ZIP. Localiser le fichiermod_jk.sosoit dans le répertoireEAP_HOME/modules/native/lib/httpd/modules/ou le répertoireEAP_HOME/modules/native/lib64/httpd/modules/suivant que votre système d'exploitation est de 32-bit ou de 64-bit.Copier le fichier dans le répertoireHTTPD_HOME/modules/.
Configurer les noeuds de worker mod_jk.
- Créer un nouveau fichier nommé
HTTPD_HOME/conf/workers.properties. Utiliser l'exemple suivant comme point de départ, et modifier le fichier selon vos besoins.# Define list of workers that will be used # for mapping requests worker.list=loadbalancer,status # Define Node1 # modify the host as your host IP or DNS name. worker.node1.port=8009 worker.node1.host=node1.mydomain.com worker.node1.type=ajp13 worker.node1.ping_mode=A worker.node1.lbfactor=1 # Define Node2 # modify the host as your host IP or DNS name. worker.node2.port=8009 worker.node2.host=node2.mydomain.com worker.node2.type=ajp13 worker.node2.ping_mode=A worker.node2.lbfactor=1 # Load-balancing behavior worker.loadbalancer.type=lb worker.loadbalancer.balance_workers=node1,node2 worker.loadbalancer.sticky_session=1 # Status worker for managing load balancer worker.status.type=status
Pour obtenir une description détaillée de la syntaxe du fichierworkers.properties, et pour obtenir des options de configuration avancées, consulter Section 16.6.5, « Référence de configuration des Apache Mod_jk Workers ».
Redémarrer le HTTPD.
La façon de redémarrer HTTPD dépend de savoir si vous utilisez Apache HTTPD de Red Hat Enterprise Linux ou le HTTDP inclus dans JBoss Enterprise Web Server. Choisir une des deux méthodes ci-dessous.Apache HTTPD de Red Hat Enterprise Linux
Exécuter la commande suivante :[root@host]#
service httpd restartJBoss Enterprise Web Server HTTPD
JBoss Enterprise Web Server exécute à la fois sur Red Hat Enterprise Linux et Microsoft Windows Server. La méthode de redémarrage du HTTPD est différente pour chacun.Red Hat Enterprise Linux, installé avec RPM
Dans Red Hat Enterprise Linux, JBoss Enterprise Web Server installe son HTTPD en tant que service. Pour redémarrer HTTPD, lancer les deux commandes suivantes :[root@host ~]# service httpd stop [root@host ~]# service httpd start
Red Hat Enterprise Linux, installé avec ZIP
Si vous avez installé JBoss Enterprise Web Server HTTPD à partir d'une archive ZIP, utiliser la commandeapachectlpour redémarrer HTTPD. Remplacer EWS_HOME par le répertoire où vous avez décompressé JBoss Enterprise Web Server HTTPD.[root@host ~]# EWS_HOME/httpd/sbin/apachectl restart
Microsoft Windows Server
Lancer les commandes suivantes dans une invite de commande avec des privilèges administratifs :C:\> net stop Apache2.2 C:\> net start Apache2.2
Solaris
Lancer les commandes suivantes dans l'invite de commandes avec des permissions admin. Remplacer EWS_HOME par le répertoire où vous avez décompressé JBoss Enterprise Web Server HTTPD.[root@host ~] EWS_HOME/httpd/sbin/apachectl restart
Apache HTTPD est maintenant configuré pour pouvoir utiliser l'équilibreur de charges de mod_jk. Pour configurer JBoss EAP 6 pour qu'il soit au fait de mod_jk, consulter Section 16.3.6, « Configurer JBoss EAP 6 pour accepter des requêtes en provenance d'HTTPD externe ».
16.6.4. Installer le Module_jk_mod dans Apache HTTPD Server (RPM)
Prérequis
- Pour cette tâche, vous devrez utiliser Apache HTTPD installé dans un environnement pris en charge ou l'Apache HTTP installé sur JBoss Enterprise Web Server. Notez que l'Apache HTTP installé dans JBoss Enterprise Web Server fait partie de la distribution JBoss Enterprise Web Server fait partie de la distribution JBoss EAP 6.
- Si vous devez installer Apache HTTP Server, utilisez les instructions qui se trouvent dans Red Hat Enterprise Linux Deployment Guide, disponible dans https://access.redhat.com/site/documentation/.
- Si vous avez besoin d'installer le serveur JBoss Enterprise Web Server, utiliser les instructions dans JBoss Enterprise Web Server Installation Guide, qui sont disponibles à partir de https://access.redhat.com/site/documentation/.
- Vous devez être connectés avec des privilèges administratifs (root).
Procédure 16.10. Red Hat Enterprise Linux 5: mod_jk with Apache HTTP Server 2.2.3
- Installer mod_jk-ap22 1.2.37 et ses dépendances mod_perl de
jbappplatform-6-*-server-5-rpm:yum install mod_jk
- Option : Copier l'exemple de fichiers de configuration à utiliser :
cp /usr/share/doc/mod_jk-ap22-1.2.37/mod_jk.conf.sample /etc/httpd/conf.d/mod_jk.conf
cp /usr/share/doc/mod_jk-ap22-1.2.37/workers.properties.sample /etc/httpd/conf/workers.properties
Ces fichiers devront être modifiés pour pouvoir correspondre à vos besoins. - Démarrer le serveur :
service httpd start
Note
Cannot load /etc/httpd/modules/mod_jk.so into server: /etc/httpd/modules/mod_jk.so: undefined symbol: ap_get_server_description
/etc/httpd/conf.d/mod_jk.conf :
<IfModule !perl_module>
LoadModule perl_module modules/mod_perl.so
</IfModule>
LoadModule jk_module modules/mod_jk.so
Procédure 16.11. Red Hat Enterprise Linux 5: mod_jk with JBoss EAP Apache HTTP Server 2.2.22
- Installer à la fois mod_jk et le dernier Apache HTTP Server 2.2.22 fourni par le canal
jbappplatform-6-*-server-5-rpmà l'aide de cette commande :yum install mod_jk httpd
- Option : Copier l'exemple de fichiers de configuration à utiliser :
cp /usr/share/doc/mod_jk-ap22-1.2.37/mod_jk.conf.sample /etc/httpd/conf.d/mod_jk.conf
cp /usr/share/doc/mod_jk-ap22-1.2.37/workers.properties.sample /etc/httpd/conf/workers.properties
Ces fichiers devront être modifiés pour pouvoir correspondre à vos besoins. - Démarrer le serveur :
service httpd start
Procédure 16.12. Red Hat Enterprise Linux 6: mod_jk et JBoss EAP Apache HTTP Server 2.2.22
- Installer mod_jk-ap22 1.2.37 et le package Apache HTTP Server 2.2.22 httpd du canal
jbappplatform-6-*-server-6-rpm(tous les versions existantes doivent être mises à jour) :yum install mod_jk httpd
- Option : Copier l'exemple de fichiers de configuration à utiliser :
cp /usr/share/doc/mod_jk-ap22-1.2.37/mod_jk.conf.sample /etc/httpd/conf.d/mod_jk.conf
cp /usr/share/doc/mod_jk-ap22-1.2.37/workers.properties.sample /etc/httpd/conf/workers.properties
Ces fichiers devront être modifiés pour pouvoir correspondre à vos besoins. - Démarrer le serveur :
service httpd start
Procédure 16.13. Red Hat Enterprise Linux 6: mod_jk with Apache HTTP Server 2.2.15
- Installer mod_jk with Apache HTTP Server 2.2.15 par la commande suivante :
yum install mod_jk
- Option : Copier l'exemple de fichiers de configuration à utiliser :
cp /usr/share/doc/mod_jk-ap22-1.2.37/mod_jk.conf.sample /etc/httpd/conf.d/mod_jk.conf
cp /usr/share/doc/mod_jk-ap22-1.2.37/workers.properties.sample /etc/httpd/conf/workers.properties
Ces fichiers devront être modifiés pour pouvoir correspondre à vos besoins. - Démarrer le serveur :
service httpd start
16.6.5. Référence de configuration des Apache Mod_jk Workers
workers.properties définit le comportement des noeuds de workers à qui mod_jk passe les requêtes de clients. Dans Red Hat Enterprise Linux, le fichier se trouve dans /etc/httpd/conf/workers.properties. Le fichier workers.properties définit où les différents conteneurs de servlet se trouvent, et la façon dont la charge de travail doit être distribuée parmi eux.
worker.WORKER_NAME.DIRECTIVE, avec WORKER_NAME comme nom unique de worker, et DIRECTIVE comme paramètre de configuration à appliquer au worker.
Les modèles de noeuds spécifient les paramètres par défaut par noeud. Vous pouvez remplacer le modèle contenu dans le paramètre de nœud lui-même. Vous pouvez voir un exemple de modèle de nœud dans Exemple 16.2, « Exemple de fichier workers.properties ».
Tableau 16.11. Propriétés globales
| Propriété | Description |
|---|---|
| worker.list | La liste des noms de worker utilisés par mod_jk. Ces workers sont prêts à recevoir des requêtes. |
Tableau 16.12. Propriétés per-worker
| Propriété | Description |
|---|---|
| type |
Le type de worker. Le type par défaut est
ajp13. Autres valeurs possibles ajp14, lb, status.
Pour plus d'informations sur ces directives, voir la référence de protocole Apache Tomcat Connector AJP à http://tomcat.apache.org/connectors-doc/ajp/ajpv13a.html.
|
| balance_workers |
Spécifie les nœuds de worker que l'équilibreur de charges doit gérer. Vous pouvez utiliser la directive plusieurs fois pour un même équilibrage de charge. Il se compose d'une liste séparée par des virgules des noms de workers. Ceci est défini par worker, et non pas par nœud. Elle affecte tous les nœuds équilibrés par ce type de worker.
|
| sticky_session |
Indique si les demandes d'une même session sont toujours acheminées vers le même worker. La valeur par défaut est
0, ce qui signifie que les sticky sessions sont désactivées. Pour activer des sticky sessions, définir à 1. Les sticky sessions doivent habituellement être activées, à moins que toutes vos demandes soient vraiment stateless. Ceci est défini par worker, et non pas par nœud. Affecte tous les nœuds équilibrés par ce type de worker.
|
Tableau 16.13. Propriétés per-node
| Propriété | Description |
|---|---|
| host |
Le nom d'hôte ou l'adresse IP du worker. Le noeud de worker doit supporter la pile de protocole
ajp. La valeur par défaut est localhost.
|
| Important |
Le numéro de port de l'instance de serveur éloigné qui écoute les requêtes de protocoles définis. La valeur par défaut est
8009, qui correspond au port d'écoute des workers AJP13. La valeur par défaut des workers AJP14 est 8011.
|
| ping_mode |
Les conditions dans lesquelles les connexions sont interrogées pour le statut du réseau. La sonde utilise un paquet AJP13 vide pour CPing et s'attend à un CPong en réponse. Spécifier les conditions à l'aide d'une combinaison d'indicateurs de la directive. Les indicateurs ne sont pas séparés par une virgule ou un espace blanc. Le ping_mode peut être n'importe quelle combinaison de
C, P, I, ou A.
|
| ping_timeout, connect_timeout, prepost_timeout, connection_ping_interval |
Les valeurs de timeout pour les paramètres de sonde de connexion ci-dessus. La valeur est spécifiée en millisecondes, et la valeur par défaut pour
ping_timeout est de 10000.
|
| lbfactor |
Spécifie le facteur d'équilibrage des charge d'un worker individuel et ne s'applique qu'à un worker membre d'un équilibreur de charge. Ceci est utile pour donner à un serveur plus puissant, une charge de travail supplémentaire. Pour donner à un worker 3 fois la charge de la valeur par défaut, définir cette valeur à
3: worker.my_worker.lbfactor=3
|
Exemple 16.2. Exemple de fichier workers.properties
worker.list=node1, node2, node3
worker.balancer1.sticky_sessions=1
worker.balancer1.balance_workers=node1
worker.balancer2.sticky_session=1
worker.balancer2.balance_workers=node2,node3
worker.nodetemplate.type=ajp13
worker.nodetemplate.port=8009
worker.node1.template=nodetemplate
worker.node1.host=localhost
worker.node1.ping_mode=CI
worker.node1.connection_ping_interval=9000
worker.node1.lbfactor=1
worker.node2.template=nodetemplate
worker.node2.host=192.168.1.1
worker.node2.ping_mode=A
worker.node3.template=nodetemplate
worker.node3.host=192.168.1.2
16.7. Apache mod_proxy
16.7.1. Le connecteur Apache mod_proxy HTTP
mod_proxy et mod_jk. Pour en savoir plus sur mod_jk, consulter Section 16.6.1, « Le connecteur Apache mod_jk HTTP ». La plate-forme JBoss EAP 6 prend en charge l'utilisation de l'un d'entre eux, bien que mod_cluster, le connecteur HTTP de JBoss, couple plus étroitement JBoss EAP 6 et le démon HTTP, et est le connecteur HTTP recommandé. Reportez-vous à Section 16.1.3, « Connecteurs HTTP - Aperçu général » pour une vue d'ensemble des connecteurs HTTP pris en charge, y compris les avantages et les inconvénients.
mod_jk, mod_proxy supporte les connexions via les protocoles HTTP et HTTPS. Chacun d'eux aussi en charge le protocole AJP.
mod_proxy peut être configuré en autonome ou en configurations d'équilibrage de charge, et il prend en charge la notion de sticky sessions.
mod_proxy nécessite que JBoss EAP 6 ait le connecteur web HTTP, HTTPS ou AJP configuré. Cela fait partie du sous-système web. Consulter Section 15.1, « Configurer le Sous-système Web » pour obtenir des informations sur la façon de configurer le sous-système web.
16.7.2. Installer Mod_proxy HTTP Connector dans Apache HTTPD
mod_proxy est un module d'équilibrage de charges fourni par Apache. Cette tâche présente une configuration de base. Pour plus d'informations sur la configuration avancée, ou pour plus de détails, reportez-vous à la documentation Apache mod_proxy à https://httpd.apache.org/docs/2.2/mod/mod_proxy.html. Pour plus d'informations sur mod_proxy d'une perspective JBoss EAP 6, consulter Section 16.7.1, « Le connecteur Apache mod_proxy HTTP » et Section 16.1.3, « Connecteurs HTTP - Aperçu général ».
Prérequis
- JBoss Enterprise Web Server HTTPD ou Apache HTTP doivent être installés. Un Serveur Apache HTTP autonome est fourni séparément dans le portail clients Red Hat à https://access.redhat.com, dans la zone de téléchargement de JBoss EAP 6. Voir Section 16.3.2, « Installer Apache HTTPD inclus avec JBoss EAP 6 » pour obtenir des informations sur le démon HTTP si vous souhaitez l'utiliser.
- Les modules
mod_proxydoivent être installés. Apache HTTPD est généralement livré avec les modulesmod_proxydéjà inclus. C'est le cas sur Red Hat Enterprise Linux et sur le serveur Apache HTTP qui vient avec le serveur Web de JBoss Enterprise. - Vous devez avoir les permissions
rootou administrateur pour pouvoir modifier la configuration de Serveur Apache HTTP. - Dans notre exemple, on assume que JBoss EAP 6 est configuré avec le connecteur web HTTP ou HTTPS. Cela fait partie de la configuration du sous-système web. Voir Section 15.1, « Configurer le Sous-système Web » pour obtenir des informations sur la façon de configurer le sous-système web.
Activer les modules
mod_proxydans le démon HTTP.Recherchez les lignes suivantes dans votre fichierHTTPD_HOME/conf/httpd.conf. Si elles ne sont pas présentes, ajoutez-les en bas. Si elles sont présentes, mais que les lignes commencent par un caractère de commentaire (#), supprimer le caractère. Enregistrez le fichier par la suite. Habituellement, les modules sont déjà présents et activés.LoadModule proxy_module modules/mod_proxy.so LoadModule proxy_balancer_module modules/mod_proxy_balancer.so LoadModule proxy_http_module modules/mod_proxy_http.so # Uncomment these to proxy FTP or HTTPS #LoadModule proxy_ftp_module modules/mod_proxy_ftp.so #LoadModule proxy_connect_module modules/mod_proxy_connect.so
Ajouter un proxy non équilibreur de charges.
Ajouter la configuration suivante à votre fichierHTTPD_HOME/conf/httpd.conf, directement sous une directive<VirtualHost>que vous possédez sans doute. Remplacer les valeurs par des valeurs appropriées à votre installation.Cet exemple utilise un hôte virtuel. Voir la nouvelle étape pour utiliser la configuration HTTPD par défaut.<VirtualHost *:80> # Your domain name ServerName Domain_NAME_HERE ProxyPreserveHost On # The IP and port of JBoss EAP 6 # These represent the default values, if your HTTPD is on the same host # as your JBoss EAP 6 managed domain or server ProxyPass / http://localhost:8080/ ProxyPassReverse / http://localhost:8080/ # The location of the HTML files, and access control information DocumentRoot /var/www <Directory /var/www> Options -Indexes Order allow,deny Allow from all </Directory> </VirtualHost>
Après avoir appliqué vos changements, sauvegarder le fichier.Ajouter le proxy d'équilibrage des charges.
Pour utilisermod_proxycomme équilibreur de charges, et pour envoyer du travail à des serveurs multiples de JBoss EAP 6, ajouter la configuration suivante à votre fichierHTTPD_HOME/conf/httpd.conf. Remplacer les par les valeurs qui correspondent à votre environnement.<Proxy balancer://mycluster> Order deny,allow Allow from all # Add each JBoss Enterprise Application Server by IP address and port. # If the route values are unique like this, one node will not fail over to the other. BalancerMember http://192.168.1.1:8080 route=node1 BalancerMember http://192.168.1.2:8180 route=node2 </Proxy> <VirtualHost *:80> # Your domain name ServerName YOUR_DOMAIN_NAME ProxyPreserveHost On ProxyPass / balancer://mycluster/ # The location of the HTML files, and access control information DocumentRoot /var/www <Directory /var/www> Options -Indexes Order allow,deny Allow from all </Directory> </VirtualHost>
Les exemples ci-dessus communiquent tous par le protocole HTTP. Vous pouvez également utiliser les protocoles AJP ou HTTPS si vous chargez les modulesmod_proxy. Voir lamod_proxydocumentation http://httpd.apache.org/docs/2.2/mod/mod_proxy.html pour plus d'informations.Activer les sticky sessions.
Sticky sessions signifie que si la demande d'un client va initialement à un nœud spécifique de JBoss EAP 6, toutes les demandes futures seront envoyés au même nœud, sauf si le nœud n'est plus disponible. C'est presque toujours le comportement correct.Pour activer des sticky sessions dumod_proxy, ajoutez le paramètrestickysessionà l'énoncéProxyPass. Cet exemple montre également d'autres paramètres que vous pouvez utiliser. Reportez-vous à documentationmod_proxyApache à http://httpd.apache.org/docs/2.2/mod/mod_proxy.html pour plus d'informations à leur sujet.ProxyPass /MyApp balancer://mycluster stickysession=JSESSIONID lbmethod=bytraffic nofailover=Off
Redémarrer le HTTPD.
Redémarrez le serveur HTTPD pour que les modifications prennent effet.
Votre HTTPD est configuré pour utiliser le mod_proxy pour envoyer des demandes de client aux serveurs ou clusters de JBoss EAP 6, en configuration standard ou équilibrage de charge. Pour configurer la plate-forme JBoss EAP 6 pour répondre à ces demandes, reportez-vous à Section 16.3.6, « Configurer JBoss EAP 6 pour accepter des requêtes en provenance d'HTTPD externe ».
16.8. Microsoft ISAPI
16.8.1. Internet Server API (ISAPI) HTTP Connector
16.8.2. Configurer Microsoft IIS pour qu'il puisse utiliser le re-directionneur ISAPI Redirector
Prérequis
- Assurez-vous que vous utilisez un système d'exploitation pris en charge et installez le serveur IIS. Se référer à https://access.redhat.com/site/articles/111663 pour obtenir une liste des configurations prises en charge.
- Télécharger le package JBoss Native Components de Microsoft Windows, à partir du Portail Clients dans https://access.redhat.com. Naviguez dans Downloads, puis JBoss Enterprise Middleware, puis Application Platform.. Choisir soit
i386ou bienx86_64. Décompresser le fichier, qui inclut «ISAPI redirect DLL» dans le répertoirejboss-eap-6.0/modules/native/sbin/.Extraire le fichier zip de composants natifs et copier son contenu dans le répertoiresbin\vers une location sur votre serveur. Le reste de cette tâche assume que vous utilisezC:\connectors\.
Procédure 16.14. Configurer le IIS Redirector à l'aide du IIS Manager (IIS 7)
- Ouvrir le IIS Manager en claiquant sur → , puis, saisissez
inetmgr. - Dans le panneau de vue d'aroborescence, développer IIS 7.
- Cliquer à deux fois sur ISAPI and CGI Registrations pour l'ouvrir sous forme d'une fenêtre séparée.
- Dans le panneau Actions, cliquer sur Add. La fenêtre Add ISAPI or CGI Restriction s'ouvrira.
- Indiquer les valeurs suivantes :
- ISAPI or CGI Path:
c:\connectors\isapi_redirect.dll - Description:
jboss - Allow extension path to execute: sélectionner la case à cocher.
- Cliquer sur OK pour fermer la fenêtre Add ISAPI or CGI Restriction.
Définir un répertoire virtuel JBoss Native
- Cliquer à droite sur Default Web Site, puis cliquer sur Add Virtual Directory. La fenêtre Add Virtual Directory va s'ouvrir.
- Indiquer les valeurs suivantes pour ajouter un répertoire virtuel :
- Alias:
jboss - Physical Path:
C:\connectors\
- Cliquer sur OK pour sauvegarder les valeurs et fermer la fenêtre Add Virtual Directory.
Définir un filtre JBoss Native ISAPI Redirect
- Dans le panneau de vue d'arborescence, développer → .
- Cliquer à deux fois sur Filtres ISAPI. L'affichage ISAPI Filters Features apparaîtra.
- Dans le panneau Actions, cliquer sur Add. La fenêtre Add ISAPI Filter s'ouvrira.
- Indiquer les valeurs suivantes dans la fenêtre Add ISAPI Filter:
- Filter name:
jboss - Executable:
C:\connectors\isapi_redirect.dll
- Cliquer OK pour sauvegarder les valeurs et pour fermer la fenêtre Add ISAPI Filters.
Activer le handler ISAPI-dll
- Cliquer deux fois sur l'élément IIS 7 qui se trouve sur le panneau d'affichage: IIS 7 Home Features View s'ouvrira.
- Cliquer deux fois sur Handler Mappings: Handler Mappings Features View s'ouvrira.
- Dans la liste déroulante modifiable Group by sélectionner State, les Handler Mappings s'affichent dans Enabled and Disabled Groups.
- Trouver ISAPI-dll. S'il se trouve dans le groupe Disabled, cliquer à droite, et sélectionner Edit Feature Permissions.
- Activer les permissions suivantes :
- Read
- Script
- Execute
- Cliquer sur OK pour sauvegarder les valeurs, et fermer la fenêtre Edit Feature Permissions.
Microsoft IIS est maintenant configuré pour utiliser le re-directeur ISAPI Redirector. Ensuite, Section 16.3.6, « Configurer JBoss EAP 6 pour accepter des requêtes en provenance d'HTTPD externe », puis Section 16.8.3, « Configurer ISAPI Redirector pour qu'il envoie des requêtes de clients à la plate-forme JBoss EAP 6 » ou Section 16.8.4, « Configurer ISAPI Redirector pour qu'il équilibre des requêtes de clients entre des serveurs multiples de la plate-forme JBoss EAP 6 ».
16.8.3. Configurer ISAPI Redirector pour qu'il envoie des requêtes de clients à la plate-forme JBoss EAP 6
Cette tâche configure un groupe de serveurs de JBoss EAP 6 pour qu'ils puissent accepter les demandes du redirecteur ISAPI. Il n'inclut pas la configuration d'équilibrage de charge ou de haute disponibilité avec basculement. Si vous avez besoin de ces fonctionnalités, reportez-vous à Section 16.8.4, « Configurer ISAPI Redirector pour qu'il équilibre des requêtes de clients entre des serveurs multiples de la plate-forme JBoss EAP 6 ».
Conditions préalables
- Vous aurez besoin d'un accès administrateur pour accéder au serveur IIS
Procédure 16.15. Modifier les fichiers de propriété et configurer la redirection
Créer un répertoire pour stocker la journalisation, les fichiers de propriété, et les fichiers de verrouillage.
Le reste de cette procédure suppose que vous utilisez le répertoireC:\connectors\à cet effet. Si vous utilisez un autre répertoire, modifier les instructions en conséquence.Créer le fichier
isapi_redirect.properties.Créer un nouveau fichier intituléC:\connectors\isapi_redirect.properties. Copier les contenus suivants dans le fichier.# Configuration file for the ISAPI Redirector # Extension uri definition extension_uri=/jboss/isapi_redirect.dll # Full path to the log file for the ISAPI Redirector log_file=c:\connectors\isapi_redirect.log # Log level (debug, info, warn, error or trace) # Use debug only testing phase, for production switch to info log_level=debug # Full path to the workers.properties file worker_file=c:\connectors\workers.properties # Full path to the uriworkermap.properties file worker_mount_file=c:\connectors\uriworkermap.properties #Full path to the rewrite.properties file rewrite_rule_file=c:\connectors\rewrite.properties
Si vous ne souhaitez pas utiliser un fichierrewrite.properties, dé-commentez la dernière ligne en plaçant un caractère#au début de la ligne. Voir Étape 5 pour plus d'informations.Créer le fichier
uriworkermap.propertiesLe fichieruriworkermap.propertiescontient les mappages entre les URL de l'application déployée et quel worker gère leurs demandes vers eux. Le fichier d'exemple suivant illustre la syntaxe du fichier. Placez votre fichieruriworkermap.propertiesdansC:\connectors\.# images and css files for path /status are provided by worker01 /status=worker01 /images/*=worker01 /css/*=worker01 # Path /web-console is provided by worker02 # IIS (customized) error page is used for http errors with number greater or equal to 400 # css files are provided by worker01 /web-console/*=worker02;use_server_errors=400 /web-console/css/*=worker01 # Example of exclusion from mapping, logo.gif won't be displayed # !/web-console/images/logo.gif=* # Requests to /app-01 or /app-01/something will be routed to worker01 /app-01|/*=worker01 # Requests to /app-02 or /app-02/something will be routed to worker02 /app-02|/*=worker02
Créer le fichier
workers.properties.Le fichierworkers.propertiescontient des définitions de mappage entre les étiquettes de workers et les instances de serveur. Le fichier d'exemple suivant illustre la syntaxe du fichier. Placez ce fichier dans le répertoireC:\connectors\.# An entry that lists all the workers defined worker.list=worker01, worker02 # Entries that define the host and port associated with these workers # First JBoss EAP 6 server definition, port 8009 is standard port for AJP in EAP worker.worker01.host=127.0.0.1 worker.worker01.port=8009 worker.worker01.type=ajp13 # Second JBoss EAP 6 server definition worker.worker02.host= 127.0.0.100 worker.worker02.port=8009 worker.worker02.type=ajp13
Créer le fichier
rewrite.properties.Le fichierrewrite.propertiescontient des dispositions relatives aux demandes spécifiques de réécriture d'URL simple pour certaines applications. Le chemin d'accès de réécriture est spécifié à l'aide de paires nom / valeur, comme illustré dans l'exemple ci-dessous. Placez ce fichier dans le répertoireC:\connectors\.#Simple example # Images are accessible under abc path /app-01/abc/=/app-01/images/
Redémarrer le serveur IIS.
Redémarrer votre serveur IIS par les commandesnet stopetnet start.C:\> net stop was /Y C:\> net start w3svc
Le serveur IIS est configuré pour envoyer des demandes de clients à des serveurs spécifiques de JBoss EAP 6 que vous aurez configurés, sur une base spécifique à l'application.
16.8.4. Configurer ISAPI Redirector pour qu'il équilibre des requêtes de clients entre des serveurs multiples de la plate-forme JBoss EAP 6
Cette configuration équilibre les requêtes des clients entre les serveurs de JBoss EAP 6 que vous spécifiez. Si vous préférez envoyer des demandes de client à des serveurs JBoss EAP 6 spécifiques sur une base «par-déploiement», reportez-vous plutôt à Section 16.8.3, « Configurer ISAPI Redirector pour qu'il envoie des requêtes de clients à la plate-forme JBoss EAP 6 ».
Prérequis
- Vous aurez besoin d'un accès administrateur pour accéder au serveur IIS.
Procédure 16.16. Équilibrage des requêtes de clients entre des serveurs multiples.
Créer un répertoire pour stocker la journalisation, les fichiers de propriété, et les fichiers de verrouillage.
Le reste de cette procédure suppose que vous utilisez le répertoireC:\connectors\à cet effet. Si vous utilisez un autre répertoire, modifier les instructions en conséquence.Créer le fichier
isapi_redirect.properties.Créer un nouveau fichier intituléC:\connectors\isapi_redirect.properties. Copier les contenus suivants dans le fichier.# Configuration file for the ISAPI Redirector # Extension uri definition extension_uri=C:\connectors\isapi_redirect.dll # Full path to the log file for the ISAPI Redirector log_file==c:\connectors\isapi_redirect.log # Log level (debug, info, warn, error or trace) # Use debug only testing phase, for production switch to info log_level=debug # Full path to the workers.properties file worker_file=c:\connectors\workers.properties # Full path to the uriworkermap.properties file worker_mount_file=c:\connectors\uriworkermap.properties #OPTIONAL: Full path to the rewrite.properties file rewrite_rule_file=c:\connectors\rewrite.properties
Si vous ne souhaitez pas utiliser un fichierrewrite.properties, dé-commentez la dernière ligne en plaçant un caractère#au début de la ligne. Voir Étape 5 pour plus d'informations.Créer le fichier
uriworkermap.properties.Le fichieruriworkermap.propertiescontient les mappages entre les URL de l'application déployée et quel worker gère les demandes à leur intention. Le fichier exemple suivant illustre la syntaxe du fichier, avec une configuration d'équilibrage de charge. Le caractère générique (*) envoie toutes les requêtes de divers sous-répertoires d'URL vers l'équilibreur de charges nommérouter. La configuration de l'équilibreur de charges est couverte dans Étape 4.Mettez votre fichieruriworkermap.propertiesdansC:\connectors\.# images, css files, path /status and /web-console will be # provided by nodes defined in the load-balancer called "router" /css/*=router /images/*=router /status=router /web-console|/*=router # Example of exclusion from mapping, logo.gif won't be displayed !/web-console/images/logo.gif=* # Requests to /app-01 and /app-02 will be routed to nodes defined # in the load-balancer called "router" /app-01|/*=router /app-02|/*=router # mapping for management console, nodes in cluster can be enabled or disabled here /jkmanager|/*=status
Créer le fichier
workers.properties.Le fichierworkers.propertiescontient les définitions de mappage entre les étiquettes de workers et les instances de serveur. Le fichier exemple suivant illustre la syntaxe du fichier. L'équilibrage de charge est configuré vers la fin du fichier, et comprend les workersworker01etworker02. Le fichierworkers.propertiessuit la syntaxe du même fichier que celui utilisé pour la configuration d'Apache mod_jk. Pour plus d'informations sur la syntaxe du fichierworkers.properties, reportez-vous à Section 16.6.5, « Référence de configuration des Apache Mod_jk Workers ».Mettez ce fichier dans le répertoireC:\connectors\.# The advanced router LB worker worker.list=router,status # First EAP server definition, port 8009 is standard port for AJP in EAP # # lbfactor defines how much the worker will be used. # The higher the number, the more requests are served # lbfactor is useful when one machine is more powerful # ping_mode=A – all possible probes will be used to determine that # connections are still working worker.worker01.port=8009 worker.worker01.host=127.0.0.1 worker.worker01.type=ajp13 worker.worker01.ping_mode=A worker.worker01.socket_timeout=10 worker.worker01.lbfactor=3 # Second EAP server definition worker.worker02.port=8009 worker.worker02.host= 127.0.0.100 worker.worker02.type=ajp13 worker.worker02.ping_mode=A worker.worker02.socket_timeout=10 worker.worker02.lbfactor=1 # Define the LB worker worker.router.type=lb worker.router.balance_workers=worker01,worker02 # Define the status worker for jkmanager worker.status.type=status
Créer le fichier
rewrite.properties.Le fichierrewrite.propertiescontient des dispositions relatives aux demandes spécifiques de réécriture d'URL simple pour certaines applications. Le chemin d'accès de réécriture est spécifié à l'aide de paires nom / valeur, comme illustré dans l'exemple ci-dessous. Placez ce fichier dans le répertoireC:\connectors\.#Simple example # Images are accessible under abc path /app-01/abc/=/app-01/images/
Redémarrer le serveur IIS.
Redémarrer votre serveur IIS par les commandesnet stopetnet start.C:\> net stop was /Y C:\> net start w3svc
Le serveur IIS est configuré pour envoyer des demandes de clients à des serveurs de JBoss EAP 6 référencés dans le fichier workers.properties, équilibrant la charge équitablement à travers les serveurs.
16.9. Oracle NSAPI
16.9.1. Netscape Server API (NSAPI) HTTP Connector
16.9.2. Configurer le connecteur NSAPI dans Oracle Solaris
Le connecteur NSAPI est un module qui exécute dans le serveur Oracle iPlanet Web Server.
Prérequis
- Votre serveur exécute Oracle Solaris 10 ou supérieur, soit en architecture 32-bit ou 64-bit.
- Oracle iPlanet Web Server 7.0.15 ou versions supérieures pour architectures Intel, ou 7.0 14 ou versions supérieures pour les architectures SPARC, est installé ou configuré, indépendamment du connecteur NSAPI.
- La plate-forme JBoss EAP 6 est installée et configurée sur chaque serveur qui servira en tant que noeud de worker. Voir Section 16.3.6, « Configurer JBoss EAP 6 pour accepter des requêtes en provenance d'HTTPD externe ».
- Le package JBoss Native Components ZIP peut être téléchargé à partir du Portail Clients à https://access.redhat.com.
Procédure 16.17. Extraire et Installer le connecteur NSAPI
Extraire le package JBoss Native Components.
Le reste de cette procédure assume que le répertoirelib/orlib64/du package de Native Components est extrait d'un répertoire nomméconnectors/qui se trouve dans/opt/oracle/webserver7/config/. Pour le reste de cette procédure, ce répertoire sera identifié comme IPLANET_CONFIG. Si votre répertoire de configuration Oracle iPlanet est différent, ou si vous exécutez Oracle iPlanet Web Server 6, modifier la procédure en fonction.Désactiver les mappages du servlet.
Ouvrir le fichierIPLANET_CONFIG/default.web.xmlet chercher la section avec l'en-têteBuilt In Server Mappings. Désactiver les mappages pour les trois servlets suivantes, en les enveloppant entre lignes de commentaire XML (<!--et-->).- défaut
- invoker
- jsp
L'exemple de configuration suivant montre les mappages désactivés.<!-- ============== Built In Servlet Mappings =============== --> <!-- The servlet mappings for the built in servlets defined above. --> <!-- The mapping for the default servlet --> <!--servlet-mapping> <servlet-name>default</servlet-name> <url-pattern>/</url-pattern> </servlet-mapping--> <!-- The mapping for the invoker servlet --> <!--servlet-mapping> <servlet-name>invoker</servlet-name> <url-pattern>/servlet/*</url-pattern> </servlet-mapping--> <!-- The mapping for the JSP servlet --> <!--servlet-mapping> <servlet-name>jsp</servlet-name> <url-pattern>*.jsp</url-pattern> </servlet-mapping-->
Sauvegarder et sortir du fichier.Configurer iPlanet Web Server pour qu'il puisse charger le module de connecteur NSAPI.
Ajouter les lignes suivantes à la fin de ce fichierIPLANET_CONFIG/magnus.conf, en modifiant les chemins de fichiers pour qu'ils s'accordent avec votre configuration. Ces lignes définissent l'emplacement du modulensapi_redirector.so, ainsi que celle du fichierworkers.properties, qui liste les noeuds de worker et leurs propriétés.Init fn="load-modules" funcs="jk_init,jk_service" shlib="IPLANET_CONFIG/connectors/lib/nsapi_redirector.so" shlib_flags="(global|now)" Init fn="jk_init" worker_file="IPLANET_CONFIG/connectors/workers.properties" log_level="debug" log_file="IPLANET_CONFIG/config/connectors/nsapi.log" shm_file="IPLANET_CONFIG/conf/connectors/jk_shm"
La configuration ci-dessus est basée sur une architecture 32-bit. Si vous utilisez 64-bit Solaris, changez le stringlib/nsapi_redirector.soenlib64/nsapi_redirector.so.Sauvegarder et sortir du fichier.Configurer le connecteur NSAPI
Vous pouvez configurer le connecteur NSAPI pour une configuration de base, avec aucun équilibrage des charges, ou une configuration d'équilibrage de des charges. Choisissez l'une des options suivantes, après quoi votre configuration sera terminée
16.9.3. Configurer NSAPI en connecteur de base HTTP
Cette tâche configure le connecteur NSAPI à rediriger les demandes des clients aux serveurs JBoss EAP 6 sans aucun équilibrage de charge ou basculement. La redirection se fait sur la base d'un déploiement (est donc basé-URL). Pour une configuration d'équilibrage des charges, consultez Section 16.9.4, « Configurer NSAPI en tant que Cluster d'équilibrage des charges » à la place.
Prérequis
- Vous devez compléter Section 16.9.2, « Configurer le connecteur NSAPI dans Oracle Solaris » avant de continuer avec la tâche suivante.
Procédure 16.18. Installer le connecteur HHP de base
Définir les chemins URL pour redirection vers les serveurs de la plate-forme JBoss EAP 6.
Note
DansIPLANET_CONFIG/obj.conf, les espaces ne sont pas autorisés en début de ligne, sauf quand la ligne est en continuation de la ligne précédente.Modifier le fichierIPLANET_CONFIG/obj.conf. Chercher la section qui commence par<Object name="default">, et ajouter chaque modèle d'URL à son correspondant, sous le format montré dans le fichier exemple ci-dessous. Le stringjknsapifait référence au connecteur HTTP qui sera défini dans la prochaine étape. L'exemple montre comment utiliser les caractères génériques pour la correspondance de modèles.<Object name="default"> [...] NameTrans fn="assign-name" from="/status" name="jknsapi" NameTrans fn="assign-name" from="/images(|/*)" name="jknsapi" NameTrans fn="assign-name" from="/css(|/*)" name="jknsapi" NameTrans fn="assign-name" from="/nc(|/*)" name="jknsapi" NameTrans fn="assign-name" from="/jmx-console(|/*)" name="jknsapi" </Object>
Définir le worker qui sert chaque chemin d'accès.
Continuer à modifier le fichierIPLANET_CONFIG/obj.conf. Ajouter ce qui suit directement après la balise de fermeture de la section que vous venez de finir d'éditer :</Object>.<Object name="jknsapi"> ObjectType fn=force-type type=text/plain Service fn="jk_service" worker="worker01" path="/status" Service fn="jk_service" worker="worker02" path="/nc(/*)" Service fn="jk_service" worker="worker01" </Object>
L'exemple ci-dessus redirige les requêtes vers le chemin URL/statuset le worker nomméworker01, et tous les URL en-dessous/nc/vers le workerworker02. La troisième ligne indique que tous les URL assignés à l'objetjknsapiqui n'ont pas de correspondance avec les lignes précédentes sont servis àworker01.Sauvegarder et sortir du fichier.Définir les workers et leurs attributs.
Créer un fichier intituléworkers.propertiesdans le répertoireIPLANET_CONFIG/connectors/# An entry that lists all the workers defined worker.list=worker01, worker02 # Entries that define the host and port associated with these workers worker.worker01.host=127.0.0.1 worker.worker01.port=8009 worker.worker01.type=ajp13 worker.worker02.host=127.0.0.100 worker.worker02.port=8009 worker.worker02.type=ajp13
Le fichierworkers.propertiesutilise la même syntaxe qu'Apache mod_jk. Pour obtenir plus d'informations sur les options disponibles, voir Section 16.6.5, « Référence de configuration des Apache Mod_jk Workers ».Sauvegarder et sortir du fichier.Redémarrer le serveur iPlanet Web Server.
Lancer les commandes suivantes pour redémarrer le serveur iPlanet Web Server.IPLANET_CONFIG/../bin/stopserv IPLANET_CONFIG/../bin/startserv
iPlanet Web Server envoie maintenant les requêtes clients aux URL que vous avez configurées vers les déploiements de JBoss EAP 6.
16.9.4. Configurer NSAPI en tant que Cluster d'équilibrage des charges
Cette tâche configure le connecteur NSAPI à rediriger les demandes des clients aux serveurs JBoss EAP 6 dans une configuration d'équilibrage des charges. Pour utiliser NSAPI comme simple connecteur HTTP sans équilibrage des charges, voir Section 16.9.3, « Configurer NSAPI en connecteur de base HTTP ».
Prérequis
- Vous devez compléter Section 16.9.2, « Configurer le connecteur NSAPI dans Oracle Solaris » avant de continuer avec la tâche suivante.
Procédure 16.19. Configurer le connecteur pour l'équilibrage des charges
Définir les chemins URL pour redirection vers les serveurs de la plate-forme JBoss EAP 6.
Note
DansIPLANET_CONFIG/obj.conf, les espaces ne sont pas autorisés en début de ligne, sauf quand la ligne est en continuation de la ligne précédente.Modifier le fichierIPLANET_CONFIG/obj.conf. Chercher la section qui commence par<Object name="default">, et ajouter chaque modèle d'URL à son correspondant, sous le format montré dans le fichier exemple ci-dessous. Le stringjknsapifait référence au connecteur HTTP qui sera défini dans la prochaine étape. L'exemple montre comment utiliser les caractères génériques pour la correspondance de modèles.<Object name="default"> [...] NameTrans fn="assign-name" from="/status" name="jknsapi" NameTrans fn="assign-name" from="/images(|/*)" name="jknsapi" NameTrans fn="assign-name" from="/css(|/*)" name="jknsapi" NameTrans fn="assign-name" from="/nc(|/*)" name="jknsapi" NameTrans fn="assign-name" from="/jmx-console(|/*)" name="jknsapi" NameTrans fn="assign-name" from="/jkmanager/*" name="jknsapi" </Object>
Définir le worker qui sert chaque chemin d'accès.
Continuer à modifier le fichierIPLANET_CONFIG/obj.conf. Ajouter ce qui suit directement après la balise de fermeture de la section que vous venez de finir d'éditer dans l'étape précédente (</Object>), et modifiez là suivant vos besoins :<Object name="jknsapi"> ObjectType fn=force-type type=text/plain Service fn="jk_service" worker="status" path="/jkmanager(/*)" Service fn="jk_service" worker="router" </Object>
Cet objetjksnapidéfinit les noeuds de worker utilisés pour servir chaque chemin relié au mappagename="jksnapi"de l'objetdefault. Tout sauf les URL correspondant à/jkmanager/*sont redirigés au worker nommérouter.Définir les workers et leurs attributs.
Créer un fichier intituléworkers.propertiesdans le répertoireIPLANET_CONFIG/connector/# The advanced router LB worker # A list of each worker worker.list=router,status # First JBoss EAP server # (worker node) definition. # Port 8009 is the standard port for AJP # worker.worker01.port=8009 worker.worker01.host=127.0.0.1 worker.worker01.type=ajp13 worker.worker01.ping_mode=A worker.worker01.socket_timeout=10 worker.worker01.lbfactor=3 # Second JBoss EAP server worker.worker02.port=8009 worker.worker02.host=127.0.0.100 worker.worker02.type=ajp13 worker.worker02.ping_mode=A worker.worker02.socket_timeout=10 worker.worker02.lbfactor=1 # Define the load-balancer called "router" worker.router.type=lb worker.router.balance_workers=worker01,worker02 # Define the status worker worker.status.type=status
Le fichierworkers.propertiesutilise la même syntaxe qu'Apache mod_jk. Pour obtenir plus d'informations sur les options disponibles, voir Section 16.6.5, « Référence de configuration des Apache Mod_jk Workers ».Sauvegarder et sortir du fichier.Redémarrer le serveur iPlanet Web Server.
Choisir une des procédures suivantes, suivant que vous souhaitez exécuter iPlanet Web Server 6.1 ou 7.0.iPlanet Web Server 6.1
IPLANET_CONFIG/../stop IPLANET_CONFIG/../start
iPlanet Web Server 7.0
IPLANET_CONFIG/../bin/stopserv IPLANET_CONFIG/../bin/startserv
iPlanet Web Server redirige les modèles d'URL que vous avez configurés à vos serveurs JBoss EAP 6 dans une configuration d'équilibrage des charges.
Chapitre 17. Messagerie
17.1. Introduction
17.1.1. HornetQ
17.1.2. Java Messaging Service (JMS)
17.1.3. Styles de messagerie pris en compte
- Modèle de file d'attente de messages
- Le modèle de file d'attente de message consiste à envoyer un message à une file d'attente. Une fois dans la file d'attente, le message est normalement rendu persistant pour en garantir sa livraison. Une fois que le message s'est déplacé dans la file, le système de messagerie le livre à un consommateur de messages. Le consommateur de messages accuse réception de la livraison du message une fois qu'il a été traité.En messagerie PPP, le modèle de file d'attente de messagerie autorise plusieurs consommateurs pour une même file d'attente, mais chaque message ne peut être reçu que par un seul consommateur.
- Modèle Publish-Subscribe
- Le modèle Publish-Subscribe permet à plusieurs émetteurs d'envoyer des messages vers une seule entité sur le serveur. Cette entité est connue sous le nom de "topic". Chaque topic peut être traité par plusieurs consommateurs, ce que l'on appelle des "abonnements" (ou "subscriptions" en anglais)Chaque abonnement reçoit une copie des messages envoyés au topic. La différence avec le modèle de file d'attente de messages, c'est que chaque message n'est consommé que par un seul consommateur.Les abonnements qui sont durables conservent une copie de chaque message envoyé à ce topic jusqu'à ce que l'abonné les consomme. Ces copies sont conservées même en cas d'un redémarrage du serveur. Les abonnements non durables durent le temps de la connexion qui les a créés.
17.2. Accepteurs et Connecteurs
Accepteurs et Connecteurs
Acceptor- Un accepteur définit quels types de connections sont acceptées par le serveur HornetQ.
Connector- Un connecteur définit comment se connecter au serveur HornetQ, et est utilisé par le client HornetQ.
Invm et Netty
Invm- Invm est un acronyme pour Intra Virtual Machine. Peut être utilisé quand le client et le serveur exécutent en même temps dans la même JVM.
Netty- Le nom d'un porjet JBoss. Doit être utilisé quand le client et le serveur exécutent dans les JVM différentes.
standalone.xml et domain.xml. Vous pouvez utiliser la Console de gestion ou de la CLI de gestion pour les définir
Exemple 17.1. Exemple de configuration du connecteur et de l'accepteur par défaut
<connectors>
<netty-connector name="netty" socket-binding="messaging"/>
<netty-connector name="netty-throughput" socket-binding="messaging-throughput">
<param key="batch-delay" value="50"/>
</netty-connector>
<in-vm-connector name="in-vm" server-id="0"/>
</connectors>
<acceptors>
<netty-acceptor name="netty" socket-binding="messaging"/>
<netty-acceptor name="netty-throughput" socket-binding="messaging-throughput">
<param key="batch-delay" value="50"/>
<param key="direct-deliver" value="false"/>
</netty-acceptor>
<in-vm-acceptor name="in-vm" server-id="0"/>
</acceptors>
17.3. Les ponts
17.4. JNDI (Java Naming and Directory Interface)
17.5. Travailler avec des messages volumineux
17.6. Configuration
17.6.1. Configurer le Serveur JMS
EAP_HOME/domain/configuration/domain.xml des serveurs du domaine, ou dans le fichier EAP_HOME/standalone/configuration/standalone.xml des serveurs autonomes.
<subsystem xmlns="urn:jboss:domain:messaging:1.3"> contient toute la configuration JMS. Ajouter toute instance ConnectionFactory, Queue, ou Topic requise pour le JNDI.
Activer le sous-système JMS dans JBoss EAP 6
Dans l'élément<extensions>, vérifier que la ligne suivante est bien présente et n'est pas dé-commentée :<extension module="org.jboss.as.messaging"/>
Ajouter le sous-système JMS de base.
Si le sous-système de Messagerie n'est pas présent dans votre fichier de configuration, ajoutez-le.- Cherchez le
<profile>qui correspond à celui que vous utilisez, et chercher sa balise de<subsystems>. - Ajouter une nouvelle ligne sous la balise
<subsystems>. Coller ceci à l'intérieur :<subsystem xmlns="urn:jboss:domain:messaging:1.3"> </subsystem>
Toutes les configurations supplémentaires pourront être ajoutées à la ligne vide ci-dessus.
Ajouter la configuration de base à JMS.
<journal-file-size>102400</journal-file-size> <journal-min-files>2</journal-min-files> <journal-type>NIO</journal-type> <!-- disable messaging persistence --> <persistence-enabled>false</persistence-enabled>
Personnaliser les valeurs ci-dessus pour qu'elles correspondent à vos besoins.Avertissement
La valeur dejournal-file-sizedoit être plus élevée que celle de la taille du message envoyé au serveur, ou bien le serveur ne pourra pas stocker le message.Ajouter les instances de fabrique de connexion à HornetQ
Le client utilise un objetConnectionFactoryJMS pour faire des connexions au serveur. Pour ajouter un objet de fabrique de connexion JMS à HornetQ, inclure une simple balise<jms-connection-factories>et un élément<connection-factory>pour chaque fabrique de connexion comme suit :<subsystem xmlns="urn:jboss:domain:messaging:1.3"> ... <jms-connection-factories> <connection-factory name="myConnectionFactory"> <connectors> <connector-ref connector-name="netty"/> </connectors> <entries> <entry name="/ConnectionFactory"/> </entries> </connection-factory> </jms-connection-factories> ... </subsystem>Configurer le connecteur
nettyLa fabrique de connexion JMS utilise un connecteurnetty. Il s'agit d'une référence à un objet de connecteur déployé dans le fichier de configuration du serveur. L'objet de connecteur détermine le transport et les paramètres utilisés pour vous connecter au serveur.Pour configurer le connecteurnetty, inclure les paramètres suivants :<subsystem xmlns="urn:jboss:domain:messaging:1.3"> ... <connectors> <netty-connector name="netty" socket-binding="messaging"/> <netty-connector name="netty-throughput" socket-binding="messaging-throughput"> <param key="batch-delay" value="50"/> </netty-connector> <in-vm-connector name="in-vm" server-id="0"/> </connectors> ... </subsystem>Le connecteur référence les liaisons de socket demessaginget demessaging-throughput. La liaison de socket demessagingutilise le port 5445, et la liaison de socketmessaging-throughpututilise le port 5455. Veillez à ce que les liaisons de socket suivantes sont présentes dans l'élément<socket-binding-groups>:<socket-binding-groups> ... <socket-binding-group ... > <socket-binding name="messaging" port="5445"/> <socket-binding name="messaging-throughput" port="5455"/> ... </socket-binding-group> ... </socket-binding-groups>Ajouter les instances de file d'attente à HornetQ
Il y a quatre façons de configurer les instances de files d'attente (ou destinations JMS) pour HornetQ.- Utiliser la Console de gestionPour utiliser la Console de gestion, le serveur devra être démarré sous le mode
Message-Enabled. Vous y parviendrez en utilisant l'option-cet en forçant l'utilisation du fichier de configurationstandalone-full.xml(pour les serveurs autonomes). Ainsi, en mode autonome, ce qui suit démarrera le serveur en mode activation de message../standalone.sh -c standalone-full.xml
Une fois que le serveur a démarré, connectez-vous à la Console de gestion et naviguez dans: Profile → Messaging → Destinations → default → View, puis, cliquer sur le bouton Ajouter pour saisir les détails de la destination JMS. - Utiliser le Management CLI:Tout d'abord, connectez-vous au Management CLI:
bin/jboss-cli.sh --connect
Puis, passez au sous-système de messagerie :cd /subsystem=messaging/hornetq-server=default
Finalement, exécuter une opération Ajouter, en remplaçant les exemples de valeurs données ci-dessous avec les vôtres :./jms-queue=testQueue:add(durable=false,entries=["java:jboss/exported/jms/queue/test"])
- Créer un fichier de configuration JMS et y ajouter le dossier de déploiementsCommencer à créer un fichier de configuration JMS: example-jms.xml. Ajouter y les entrées suivantes, en remplaçant les valeurs avec les vôtres.
<?xml version="1.0" encoding="UTF-8"?> <messaging-deployment xmlns="urn:jboss:messaging-deployment:1.0"> <hornetq-server> <jms-destinations> <jms-queue name="testQueue"> <entry name="queue/test"/> <entry name="java:jboss/exported/jms/queue/test"/> </jms-queue> <jms-topic name="testTopic"> <entry name="topic/test"/> <entry name="java:jboss/exported/jms/topic/test"/> </jms-topic> </jms-destinations> </hornetq-server> </messaging-deployment>Sauvegardez ce fichier dans le dossier de déploiements et faire un déploiement. - Ajouter les entrées dans le fichier de configuration de JBoss EAP 6.En utilisant standalone-full.xml comme exemple, chercher le sous-système de messagerie dans ce fichier.
<subsystem xmlns="urn:jboss:domain:messaging:1.3">
Ajoutez y les entrées suivantes, encore une fois, en remplaçant les valeurs de l'exemple avec les vôtres. Vous devez ajouter ces entrées après la balise de fin </jms-connection-factories> mais avant l'élément </hornetq-server> :<jms-destinations> <jms-queue name="testQueue"> <entry name="queue/test"/> <entry name="java:jboss/exported/jms/queue/test"/> </jms-queue> <jms-topic name="testTopic"> <entry name="topic/test"/> <entry name="java:jboss/exported/jms/topic/test"/> </jms-topic> </jms-destinations>
Procéder à une configuration supplémentaire
Si vous avez besoin de davantage de paramètres de configuration, revoir DTD dansEAP_HOME/docs/schema/jboss-messaging_1_3.xsd.
17.6.2. Configuration des paramètres de l'adresse JMS
<address-settings>.
Les adresses en syntaxe wildcard peuvent être utilisées pour faire correspondre plusieurs adresses similaires avec une seule instruction, ce qui est semblable à la façon dont nombreux systèmes utilisent le caractère astérisque (*) pour faire correspondre plusieurs fichiers ou chaînes avec une seule recherche. Les caractères suivants ont une signification particulière dans un énoncé wildcard.
Tableau 17.1. Syntaxe Wildcard JMS
| Caractère | Description |
|---|---|
| . (point simple) | Marque l'espace entre les mots au sein d'une expression wildcard. |
| # (symbole de hachage) | Fait correspondre une séquence de zéros ou de plusieurs mots. |
| * (un astérisque) | Faire correspondre à un mot unique. |
Tableau 17.2. Exemples de JMS Wildcards
| Exemple | Description |
|---|---|
| news.europe.# |
Correspond à
news.europe, news.europe.sport, news.europe.politic, mais pas à news.usa ou europe.
|
| news. |
Correspond à
news.europe mais pas à news.europe.sport.
|
| news.*.sport |
Correspond à
news.europe.sport et news.usa.sport, mais pas à news.europe.politics.
|
Exemple 17.2. Configuration des paramètres d'adresse par défaut
<address-settings>
<!--default for catch all-->
<address-setting match="#">
<dead-letter-address>jms.queue.DLQ</dead-letter-address>
<expiry-address>jms.queue.ExpiryQueue</expiry-address>
<redelivery-delay>0</redelivery-delay>
<max-size-bytes>10485760</max-size-bytes>
<address-full-policy>BLOCK</address-full-policy>
<message-counter-history-day-limit>10</message-counter-history-day-limit>
</address-setting>
</address-settings>
Tableau 17.3. Description de la configuration des paramètres de l'adresse JMS
| Élément | Description | Valeur par défaut | Type |
|---|---|---|---|
address-full-policy
|
Détermine ce qui se passe quand une adresse dont la max-size-bytes est spécifiée, est remplie.
|
PAGE
|
STRING
|
dead-letter-address
|
Si une adresse de lettres mortes est spécifiée, les messages seront déplacés vers l'adresse de lettres mortes si les tentatives de livraison
max-livraison-tentatives ont échoué. Dans le cas contraire, ces messages non remis sont ignorés. Les caractères génériques (wildcard) sont autorisés.
|
jms.queue.DLQ
|
STRING
|
expiry-address
|
Si l'adresse d'expiration est présente, les messages expirés seront envoyés à l'adresse ou aux adresses correspondantes, au lieu d'être jetés. Les caractères génériques (wildcards) sont autorisés.
|
jms.queue.ExpiryQueue
|
STRING
|
last-value-queue
|
Définit si une file d'attente utilise uniquement les dernières valeurs ou non.
|
false
|
BOOLÉEN
|
max-delivery-attempts
|
Le nombre max de tentatives d'envoi d'un message avant qu'il soit envoyés à
dead-letter-address ou qu'il soit ignoré.
|
10
|
INT
|
max-size-bytes
|
La taille maximum d'octets.
|
10485760L
|
LONG
|
message-counter-history-day-limit
|
Limite en Jour de l'historique du compteur de messages.
|
10
|
INT
|
page-max-cache-size
|
Le nombre de pages de fichiers à conserver en mémoire pour optimiser IO en cours de navigation de pagination.
|
5
|
INT
|
page-size-bytes
|
La taille de pagination.
|
5
|
INT
|
redelivery-delay
|
La durée entre les tentatives de re-livraison, exprimée en millisecondes. Si défini sur la valeur
0, les tentatives de re-livraison auront lieu indéfiniment.
|
0L
|
LONG
|
redistribution-delay
|
Définit la durée à attendre lorsque le dernier consommateur est fermé dans une file d'attente avant de pouvoir redistribuer des messages.
|
-1L
|
LONG
|
send-to-dla-on-no-route
|
Un paramètre pour une adresse qui définit la condition d'un message non acheminé vers une file d'attente pour qu'il soit envoyé à la place vers une file d'attente des messages morts ou DLA (de l'anglais Dead Letter Queue) indiquée pour cette adresse.
|
false
|
BOOLÉEN
|
Configurer les paramètres de l'adresse et les attributs du modèle
Choisir le Management CLI ou la Console de Management pour configurer vos attributs de modèle selon les besoins.Configurer les paramètres de l'adresse par le Management CLI
Utiliser le Management CLI pour configurer les paramètres de l'adresse.Ajouter un nouveau Modèle
Utiliser l'opérationaddpour créer un nouveau paramètre d'adresse, si nécessaire. Vous pouvez exécuter cette commande à partir de la racine de la session de Management CLI, qui, dans les exemples suivants, crée un nouveau modèle ou motif intitulé patternname, avec un attributmax-delivery-attemptsdéclaré à 5. Voici des exemples pour les modifications sur le serveur autonome et le domaine géré pour le profilfull.[domain@localhost:9999 /] /profile=full/subsystem=messaging/hornetq-server=default/address-setting=patternname/:add(max-delivery-attempts=5)
[standalone@localhost:9999 /] /subsystem=messaging/hornetq-server=default/address-setting=patternname/:add(max-delivery-attempts=5)
Modifier les attributs de modèle
Utiliser l'opérationwritepour écrire une nouvelle valeur dans un attribut. Vous pouvez utiliser l'onglet de complétion pour terminer la chaîne de commande en cours, ainsi que pour exposer les attributs disponibles. L'exemple suivant met à jour la valeur demax-delivery-attemptsà 10[domain@localhost:9999 /] /profile=full/subsystem=messaging/hornetq-server=default/address-setting=patternname/:write-attribute(name=max-delivery-attempts,value=10)
[standalone@localhost:9999 /] /subsystem=messaging/hornetq-server=default/address-setting=patternname/:write-attribute(name=max-delivery-attempts,value=10)
Confirmer les attributs de modèle
Confirmer que les valeurs ont changé en exécutantread-resourceaccompagné du paramètreinclude-runtime=truepour exposer toutes les valeurs actives en cours du modèle de serveur.[domain@localhost:9999 /] /profile=full/subsystem=messaging/hornetq-server=default/address-setting=patternname/:read-resource
[standalone@localhost:9999 /] /subsystem=messaging/hornetq-server=default/address-setting=patternname/:read-resource
Configurer les paramètres de l'adresse par la Console de gestion
Utiliser la Console de gestion pour configurer les paramètres de l'adresse.Connectez-vous à la Console de gestion.
Connectez-vous à la Console de gestion de votre domaine géré ou de votre serveur autonome.Si vous utilisez le Domaine géré, sélectionner le profil qui convient.
Sélectionner l'onglet Profiles en haut à droite, puis sélectionner le profil qui convient à partir du menu Profile en haut et à gauche de l'écran suivant. Seuls les profilsfulletfull-haont le sous-systèmemessagingactivé.Sélectionner l'item Messaging à partir du menu de navigation.
Étendre l'item de menu Messaging à partir du menu de navigation, et cliquer sur Destinations.Voir le fournisseur JMS.
Une liste de fournisseurs JMS s'affiche. Dans la configuration par défaut, on ne voit que le fournisseur pardefault. Cliquer sur le lien View pour afficher les paramètres de ce fournisseur en détail.Voir les paramètre de configuration de l'adresse.
Cliquer sur l'onglet Addressing. Ensuite, vous pourrez soit ajouter un nouveau modèle en cliquant sur le bouton , ou en modifiant un modèle existant en cliquant sur son nom et en cliquant sur le bouton .Configurer les options.
Si vous ajoutez un modèle, le champ Pattern s'en référera au paramètrematchde l'élémentaddress-setting. Vous pourrez aussi modifier Dead Letter Address, Expiry Address, Redelivery Delay, et Max Delivery Attempts. Les autres options doivent être configurées par la Management CLI.
17.6.3. Configurer la Messagerie dans HornetQ
standalone.xml ou domain.xml. Cependant, il est utile de se familiariser avec les composants de messagerie des fichiers de configuration par défaut, où les exemples de documentation utilisant des outils de gestion donnent des extraits de fichiers de configuration comme référence.
17.6.4. Configurer la re-livraison différée
La re-livraison différée est définie dans l'élément <redelivery-delay>, qui est un élément dépendant de l'élément de configuration <address-setting> de la configuration du sous-système JMS (Java Messaging Service).
<!-- delay redelivery of messages for 5s --> <address-setting match="jms.queue.exampleQueue"> <redelivery-delay>5000</redelivery-delay> </address-setting>
<redelivery-delay> est défini à 0, il n'y aura pas de livraison à nouveau. Les caractères génériques (wildcards) peuvent être utilisés sur l'élément <address-setting-match> pour configurer la livraison à nouveau des adresses qui correspondent au(x) caractère(s) générique(s).
17.6.5. Configurer les adresses de lettres mortes
Une adresse de lettre morte est définie dans l'élément <address-setting> de configuration du sous-système de JMS (Java Messaging Service).
<!-- undelivered messages in exampleQueue will be sent to the dead letter address deadLetterQueue after 3 unsuccessful delivery attempts --> <address-setting match="jms.queue.exampleQueue"> <dead-letter-address>jms.queue.deadLetterQueue</dead-letter-address> <max-delivery-attempts>3</max-delivery-attempts> </address-setting>
<dead-letter-address> n'est pas spécifié, les messages sont supprimés au bout de <max-delivery-attempts> envois. Par défaut, les messages sont envoyés 10 fois. Si vous définissez <max-delivery-attempts> à -1 vous autorisez un nombre d'envois indéterminé. Ainsi, une lettre morte peut être définie globalement pour un ensemble d'adresses correspondantes et vous pouvez définir <max-delivery-attempts> à -1 pour qu'une adresse particulière soit configurée sur un nombre d'envois indéfini. Les astérisques peuvent aussi être utilisés pour faire correspondre à un ensemble d'adresses particulier.
17.6.6. Configurer les adresses d'expiration de messages
Les adresses d'expiration de messages sont définies dans la configuration address-setting de JMS (Java Messaging Service). Ainsi :
<!-- expired messages in exampleQueue will be sent to the expiry address expiryQueue --> <address-setting match="jms.queue.exampleQueue"> <expiry-address>jms.queue.expiryQueue</expiry-address> </address-setting>
Les wildcards peuvent être utilisées pour que plusieurs adresses similaires puissent être reconnues en un seul énoncé, de la même façon dont de nombreux systèmes utilisent les astérisques (*) pour faire correspondre des fichiers ou strings multiples en une seule recherche. Les caractères suivants sont une signification particulière dans un énoncé wildcard.
Tableau 17.4. Syntaxe Wildcard JMS
| Caractère | Description |
|---|---|
| . (point simple) | Marque l'espace entre les mots au sein d'une expression wildcard. |
| # (a pound or hash symbol) | Fait correspondre une séquence de zéros ou de plusieurs mots. |
| * (un astérisque) | Faire correspondre à un mot unique. |
Tableau 17.5. Exemples de JMS Wildcards
| Exemple | Description |
|---|---|
| news.europe.# |
Correspond à
news.europe, news.europe.sport, news.europe.politic, mais pas à news.usa ou europe.
|
| news. |
Correspond à
news.europe mais pas à news.europe.sport.
|
| news.*.sport |
Correspond à
news.europe.sport et news.usa.sport, mais pas à news.europe.politics.
|
17.6.7. Référence pour les attributs de configuration d'HornetQ
read-resource.
Exemple 17.3. Exemple
[standalone@localhost:9999 /] /subsystem=messaging/hornetq-server=default:read-resource
Tableau 17.6. Attributs HornetQ
| Attribut | Exemple de valeur | Type |
|---|---|---|
allow-failback | true | BOOLÉEN |
async-connection-execution-enabled | true | BOOLÉEN |
backup | false | BOOLÉEN |
cluster-password | somethingsecure | STRING |
mask-password | true | BOOLÉEN |
cluster-user | HORNETQ.CLUSTER.ADMIN.USER | STRING |
clustered | false | BOOLÉEN |
connection-ttl-override | -1 | LONG |
create-bindings-dir | true | BOOLÉEN |
create-journal-dir | true | BOOLÉEN |
failback-delay | 5000 | LONG |
failover-on-shutdown | false | BOOLÉEN |
id-cache-size | 2000 | INT |
jmx-domain | org.hornetq | STRING |
jmx-management-enabled | false | BOOLÉEN |
journal-buffer-size | 100 | LONG |
journal-buffer-timeout | 100 | LONG |
journal-compact-min-files | 10 | INT |
journal-compact-percentage | 30 | INT |
journal-file-size | 102400 | LONG |
journal-max-io | 1 | INT |
journal-min-files | 2 | INT |
journal-sync-non-transactional | true | BOOLÉEN |
journal-sync-transactional | true | BOOLÉEN |
journal-type | ASYNCIO | STRING |
live-connector-ref | référence | STRING |
log-journal-write-rate | false | BOOLÉEN |
management-address | jms.queue.hornetq.management | STRING |
management-notification-address | hornetq.notifications | STRING |
memory-measure-interval | -1 | LONG |
memory-warning-threshold | 25 | INT |
message-counter-enabled | false | BOOLÉEN |
message-counter-max-day-history | 10 | INT |
message-counter-sample-period | 10000 | LONG |
message-expiry-scan-period | 30000 | LONG |
message-expiry-thread-priority | 3 | INT |
page-max-concurrent-io | 5 | INT |
perf-blast-pages | -1 | INT |
persist-delivery-count-before-delivery | false | BOOLÉEN |
persist-id-cache | true | BOOLÉEN |
persistence-enabled | true | BOOLÉEN |
remoting-interceptors | Non défini | LIST |
run-sync-speed-test | false | BOOLÉEN |
scheduled-thread-pool-max-size | 5 | INT |
security-domain | autre | STRING |
security-enabled | true | BOOLÉEN |
security-invalidation-interval | 10000 | LONG |
server-dump-interval | -1 | LONG |
shared-store | true | BOOLÉEN |
started | true | BOOLÉEN |
thread-pool-max-size | 30 | INT |
transaction-timeout | 300000 | LONG |
transaction-timeout-scan-period | 1000 | LONG |
version | 2.2.16.Final (HQ_2_2_16_FINAL, 122) | STRING |
wild-card-routing-enabled | true | BOOLÉEN |
Avertissement
journal-file-size doit être plus élevée que celle de la taille du message envoyé au serveur, ou bien le serveur ne pourra pas stocker le message.
17.6.8. Définir l'expiration des messages
Avec Hornet Core API, l'expiration peut être définie directement sur le message. Par exemple :
// message will expire in 5000ms from now message.setExpiration(System.currentTimeMillis() + 5000);
MessageProducer
JMS MessageProducer inclut un paramètre TimeToLive qui contrôle l'expiration de message du message qu'il envoie :
// messages sent by this producer will be retained for 5s (5000ms) before expiration producer.setTimeToLive(5000);
- _HQ_ORIG_ADDRESS
- _HQ_ACTUAL_EXPIRY
17.7. Persistance
17.7.1. Persistance dans HornetQ
- Java New I/O (NIO)Utilise Java NIO pour l'interface avec le système de fichiers. Cela donne une excellence performance et exécute sur n'importe quelle plate-forme avec Java 6 ou un runtime plus récent.
- Linux Asynchronous IO (AIO)Utilise un encapsuleur de code natif pour parler à la bibliothèque d'e/s asynchrone Linux (AIO). Avec AIO, HornetQ reçoit un message lorsque les données ont été rendues persistantes. Cette commande supprime le besoin de synchronisation explicite. AIO fournira généralement une meilleure performance que Java NIO, mais nécessite le noyau Linux 2.6 ou version ultérieur et le paquet libaio.AIO nécessite également les systèmes de fichiers ext2, ext3, ext4, jfs or xfs.
- bindings journalStocke les données relatives à des liaisons, y compris l'ensemble des files d'attente déployées sur le serveur et leurs attributs. Il stocke également des données comme les compteurs de séquence ID. Le journal de liaisons est toujours un journal NIO, car il a généralement un débit faible en comparaison au journal de messages.Les fichiers de ce journal ont comme préfixe hornetq-bindings. Chaque fichier a des extensions de liaison. La taille du fichier est de 1048576 octets, et le fichier se trouve dans le dossier de liaisons.
- JMS journalStocke toutes les données liées à JMS, comme les files d'attente JMS, les sujets ou fabriques de connexions et toutes les liaisons JNDI de ces ressources. Toute ressource JMS créée avec l'API de gestion sont persistées dans ce journal. Toutes les ressources configurées par des fichiers de configuration ne le sont pas. Ce journal n'est créé que si JMS est utilisé.
- message journalStocke toutes les données liées à des messages, y compris les messages eux-mêmes et les duplicate-id caches. Par défaut, HornetQ utiliser AIO pour son journal. Si AIO est disponible, il retombera automatiquement sur NIO.
17.8. Haute disponibilité
17.8.2. High-availability (HA) Failover
Important
Important
17.8.3. Déploiements sur les serveurs de sauvegarde HornetQ
17.9. Réplication de messages
17.9.1. La réplication de messages HornetQ
Avertissement
backup-group-name a été défini dans le fichier hornetq-configuration.xml. Un serveur de sauvegarde se connectera à un serveur live qui partage le même nom de groupe uniquement. En l'absence de ce paramètre, un serveur de sauvegarde va essayer de se connecter à un serveur live.
17.9.2. Configurer les Serveurs HornetQ pour la Réplication
hornetq-configuration.xml pour qu'ils aient :
<shared-store>false</shared-store>
.
.
.
<cluster-connections>
<cluster-connection name="my-cluster">
...
</cluster-connection>
</cluster-connections>
<backup>true</backup>
<connectors>
<connector name="nameOfConfiguredLiveServerConnector">
<factory-class>
org.hornetq.core.remoting.impl.netty.NettyConnectorFactory
</factory-class>
<param key="port" value="5445"/>
</connector>
<!-- a real configuration could have more connectors here -->
<connectors>
Chapitre 18. Sous-système de transaction
18.1. Configuration de sous-système de transaction
18.1.1. Configuration des transactions
Les procédures suivantes vous montrent comment configurer le sous-système de transactions de JBoss EAP 6.
18.1.2. Configurer le Transaction Manager (TM) (ou gestionnaire de transactions)
default, il se peut que vous ayez à modifier les étapes et les commandes de la manière suivante.
Notes sur les commandes d'exemple
- Pour la console de gestion, le profil par défaut
defaultest celui qui sera sélectionné quand vous vous connectez. Si vous souhaitez modifier la configuration du gestionnaire de transactions (TM) dans un autre profile, sélectionnez votre profile à la place, et non pasdefault, pour chaque instruction.De même, substituez votre profil à la place du profil par défautdefaultpour les commandes CLI de l'exemple. - Si vous utilisez un serveur autonome, un seul profil existe. Ignorer toute instruction pour choisir un profil spécifique. Dans les commandes CLI, retirer la partie
/profile=defaultdes commandes d'échantillon.
Note
transactions doit être activé. Il est activé par défaut, et il faut pour cela qu'un certain nombre d'autres sous-systèmes fonctionnent correctement, donc il est improbable qu'il soit désactivé.
Pour configurer le TM à l'aide de la Console de gestion sur le web, sélectionnez l'onglet Runtime de la liste dans la partie supérieure gauche de l'écran de la console de gestion. Si vous utilisez un domaine géré, vous avez le choix de plusieurs profils. Choisir le bon profil de la boîte de sélection dans la partie supérieure droite de l'écran Profils. Étendez le menu Container, et sélectionnez Transactions.
Dans l'interface CLI, vous pouvez configurer le TM en utilisant une série de commandes. Les commandes commencent toutes par /profile=default/subsystem=transactions/ pour un domaine géré avec default de profil, ou par /subsystem=transactions pour un serveur autonome.
Tableau 18.1. Options de configuration du TM
| Option | Description | CLI Command |
|---|---|---|
|
Activer les statistiques
|
Indique s'il faut activer les statistiques de transaction. Ces statistiques se trouvent dans la console de gestion dans la section Subsystem Metrics de l'onglet Runtime.
| /profile=default/subsystem=transactions/:write-attribute(name=enable-statistics,value=true)
|
|
Délai d'attente par défaut
|
Délai d'attente de transaction par défaut. La valeur par défaut est de
300 secondes. Vous pouvez la remplacer par programmation, sur la base d'une transaction.
| /profile=default/subsystem=transactions/:write-attribute(name=default-timeout,value=300)
|
|
Chemin
|
Le chemin d'accès relatif ou absolu du système de fichiers dans lequel le cœur du gestionnaire de transactions stocke les données. Par défaut, la valeur est un chemin d'accès relatif à la valeur de l'attribut
relative-to. Le chemin est utilisé pour sauvegarder l'ID du processus quand la balise process-id (ou le process-id-uuid CLI attribute) sont utilisés.
| /profile=default/subsystem=transactions/:write-attribute(name=path,value=var)
|
|
Relatif à
|
Fait référence une configuration de chemin global dans le modèle du domaine. La valeur par défaut correspond au répertoire de données de JBoss EAP 6, qui correspond à la valeur de la propriété
jboss.server.data.dir, dont la valeur par défaut est EAP_HOME/domain/data/ pour un domaine géré, ou EAP_HOME/standalone/data/ pour une instance de serveur autonome. La valeur de l'attribut path du gestionnaire de transactions est relative à ce chemin.
| /profile=default/subsystem=transactions/:write-attribute(name=relative-to,value=jboss.server.data.dir)
|
|
Chemin de Store Objet
|
Un chemin de système de fichiers relatif ou absolu où le store objet TM stocke des données. Relatif, par défaut, à la valeur du paramètre
object-store-relative-to.
| /profile=default/subsystem=transactions/:write-attribute(name=object-store-path,value=tx-object-store)
|
|
Chemin de Store Objet Relatif à
|
Fait référence une configuration de chemin global dans le modèle du domaine. La valeur par défaut correspond au répertoire de données de JBoss EAP 6, qui correspond à la valeur de la propriété
jboss.server.data.dir, ayant comme valeur par défaut EAP_HOME/domain/data/ pour un domaine géré, ou EAP_HOME/standalone/data/ pour une instance de serveur autonome. La valeur de l'attribut path de l'attribut du gestinnaire de transactions est relative à ce chemin.
| /profile=default/subsystem=transactions/:write-attribute(name=object-store-relative-to,value=jboss.server.data.dir)
|
|
Liaisons de sockets
|
Indique le nom de la liaison du socket utilisé par le gestionnaire de transactions pour la récupération et la création des identificateurs de transactions, lorsque le mécanisme du socket est utilisé. Se référer à
processus-id-socket-max-ports pour plus d'informations sur la génération de l'identificateur unique. Les liaisons de socket sont spécifiées par le groupe de serveurs dans l'onglet Server de la console de gestion.
| /profile=default/subsystem=transactions/:write-attribute(name=socket-binding,value=txn-recovery-environment)
|
|
Listener de recouvrement
|
Indique si oui ou non le processus de recouvrement de transactions doit écouter au socket de réseau. La valeur par défaut est
false.
| /profile=default/subsystem=transactions/:write-attribute(name=recovery-listener,value=false)
|
Tableau 18.2. Options de configuration du TM avancées
| Option | Description | CLI Command |
|---|---|---|
|
jts
|
Indique si l'on doit utiliser les transactions Java Transaction Service (JTS). La valeur par défaut est
false, qui utilise des transactions JTA uniquement.
| /profile=default/subsystem=transactions/:write-attribute(name=jts,value=false)
|
|
Identificateur de nœud
|
L'identifiant de nœud pour le service JTS. Ce dernier doit être unique pour le service JTS, parce que le gestionnaire de transactions l'utilise pour la récupération.
| /profile=default/subsystem=transactions/:write-attribute(name=node-identifier,value=1)
|
|
process-id-socket-max-ports
|
Le gestionnaire de transactions crée un identifiant unique pour chaque journal des transactions. Deux mécanismes différents sont fournis pour générer des identificateurs uniques : un mécanisme basé sur le socket et un mécanisme fondé sur l'identificateur de processus du processus.
Dans le cas de l'identifiant basé-socket, le socket est ouvert et son numéro de port est utilisé pour l'identifiant. Si le port est déjà utilisé, on cherchera le port suivant jusqu'à ce qu'un port libre soit trouvé. Les
processus-id-socket-max-ports représentent le nombre maximal de sockets que le TM va essayer avant d'abandonner. La valeur par défaut est 10.
| /profile=default/subsystem=transactions/:write-attribute(name=process-id-socket-max-ports,value=10)
|
|
process-id-uuid
|
Définir à
true avec un identifiant de processus pour créer un identifiant unique pour chaque transaction. Sinon, le mécanisme basé socket sera utilisé. La valeur par défaut est true. Se référer à process-id-socket-max-ports pour obtenir davantage d'informations.
| /profile=default/subsystem=transactions/:write-attribute(name=process-id-uuid,value=true)
|
|
use-hornetq-store
|
Utiliser les mécanismes de stockage journalisés de HornetQ au lieu du stockage basé sur des fichiers, pour les journaux de transactions. Ceci est désactivé par défaut, mais peut améliorer les performances I/O. Il n'est pas recommandé pour les transactions JTS sur les gestionnaires de transactions séparés .
| /profile=default/subsystem=transactions/:write-attribute(name=use-hornetq-store,value=false)
|
18.1.3. Configurez votre base de données pour utiliser les Transactions JTA
Cette tâche vous montre comment activer JTA (Java Transactions API) sur votre source de données.
Vous devez remplir les conditions suivantes avant de continuer cette tâche :
- Votre base de données ou autre ressource devra supporter JTA. Dans le doute, veuillez consulter la documentation.
- Créer une source de données. Veuillez vous référer à Section 6.3.1, « Créer une source de données Non-XA avec les Interfaces de gestion ».
- Stopper le serveur JBoss EAP 6
- Obtenir un accès pour pouvoir éditer les fichiers de configuration directement, dans un éditeur de texte.
Procédure 18.1. Configurer la Source de données pour utiliser les Transactions JTA.
Ouvrir le fichier de configuration dans l'éditeur de texte.
Selon si vous exécutez JBoss EAP 6 sur un domaine géré ou un serveur autonome, votre fichier de configuration ne se trouvera pas au même endroit.Domaine géré
Le fichier de configuration par défaut d'un domaine géré se trouve dansEAP_HOME/domain/configuration/domain.xmlpour Red Hat Enterprise Linux, etEAP_HOME\domain\configuration\domain.xmlpour Microsoft Windows Server.Serveur autonome
Le fichier de configuration par défaut d'un serveur autonome se trouve dansEAP_HOME/standalone/configuration/domain.xmlpour Red Hat Enterprise Linux, etEAP_HOME\standalone\configuration\domain.xmlpour Microsoft Windows Server.
Chercher la balise
<datasource>qui correspond à votre source de données.La source de données aura un attributjndi-namecorrespondant à celui que vous aviez indiqué quand vous l'avez créée. Par exemple, la source de données ExampleDS ressemble à ceci :<datasource jndi-name="java:jboss/datasources/ExampleDS" pool-name="H2DS" enabled="true" jta="true" use-java-context="true" use-ccm="true">
Définir l'attribut
jtaàtrue.Ajouter l'élément suivant au contenu de votre balise<datasource>, tel qu'il apparaît à l'étape précédente :jta="true"Sauvegarder le fichier de configuration.
Sauvegarder le fichier de configuration et sortir de l'éditeur de texte.Démarrer JBoss EAP 6.
Relancer le serveur JBoss EAP 6.
JBoss EAP 6 démarre, et votre source de données est configurée pour utiliser les transactions JTA.
18.1.4. Configuration d'une source de données XA
Pour pouvoir ajouter une source de données XA, vous devrez vous connecter à la console de gestion. Voir Section 3.4.2, « Se conncecter à la console de gestion » pour plus d'informations.
Ajouter une nouvelle source de données.
Ajouter une nouvelle source de données à la plateforme JBoss EAP 6. Suivre les instructions qui se trouvent dans Section 6.3.1, « Créer une source de données Non-XA avec les Interfaces de gestion », puis, cliquer sur l'onglet XA Datasource en haut.Configurer les propriétés supplémentaires suivant les besoins.
Tous les paramètres de la source de données se trouvent dans Section 6.6.1, « Paramètres de source de données ».
Votre source de données XA est configurée et prête à l'utilisation.
18.1.5. Messages de journalisation de transactions
DEBUG pour le logger de transaction. Pour un débogage détaillé, utiliser le niveau de journalisation TRACE. Veuillez consulter Section 18.1.6, « Configurer la journalisation des sous-systèmes de transactions » pour plus d'informations sur la configuration du logger de transaction.
TRACE. Vous trouverez ci-dessous quelques-uns des messages les plus courants. Cette liste n'est pas exhaustive, il se peut que vous rencontriez d'autres messages.
Tableau 18.3. Changement d'état de transaction
| Début de transaction |
Quand une transaction commence, le code suivant s'exécute :
com.arjuna.ats.arjuna.coordinator.BasicAction::Begin:1342 tsLogger.logger.trace("BasicAction::Begin() for action-id "+ get_uid());
|
| Validation de transaction |
Quand une transaction est validée, le code suivant s'exécute :
com.arjuna.ats.arjuna.coordinator.BasicAction::End:1342 tsLogger.logger.trace("BasicAction::End() for action-id "+ get_uid());
|
| Restauration de transaction |
Quand une transaction est restaurée, le code suivant s'exécute :
com.arjuna.ats.arjuna.coordinator.BasicAction::Abort:1575 tsLogger.logger.trace("BasicAction::Abort() for action-id "+ get_uid());
|
| Délai d'expiration de transaction |
Quand une transaction expire, le code suivant s'exécute :
com.arjuna.ats.arjuna.coordinator.TransactionReaper::doCancellations:349 tsLogger.logger.trace("Reaper Worker " + Thread.currentThread() + " attempting to cancel " + e._control.get_uid());
Vous verrez ensuite le même thread restaurer la transaction comme montré ci-dessus.
|
18.1.6. Configurer la journalisation des sous-systèmes de transactions
Utiliser cette procédure pour contrôler la quantité d'informations enregistrées sur les transactions, indépendamment des autres paramètres de journalisation dans JBoss EAP 6. La procédure montre comment procéder dans la console de gestion sur le web. La commande de gestion CLI est donnée par la suite.
Procédure 18.2. Configurer le Transaction Logger par la console de gestion
Naviguer vers la zone de configuration de la journalisation
Dans la console de gestion, cliquer sur l'onglet Profiles en haut et à gauche de l'écran. Si vous utilisez un domaine géré, fermer le profil du serveur que vous souhaitez configurer, à partir de la case de sélection Profile qui se trouve en haut et à droite.Dérouler le menu Core, et cliquer sur l'étiquette Logging.Modifier les attributs de
com.arjuna.Cliquer sur le bouton Edit dans la section Details qui se situe en bas de la page. Vous pourrez ajouter ici les informations de journalisation spécifiques à la classe. La classecom.arjunaest déjà présente. Vous pourrez modifier le niveau de journalisation et décider si vous souhaitez utiliser les gestionnaires parents.- Niveau de journalisation
- Le niveau de journalisation est
WARNpar défaut. Comme les transactions peuvent produire une grande quantité de messages de journalisation, la signification des niveaux de journalisation standard est légèrement différente pour le Transaction Logger. En général, les messages avec des niveaux de gravité moins élevés que le niveau choisi sont ignorés.Niveaux de journalisation des transactions, du plus au moins détaillé.
- TRACE
- DEBUG
- INFO
- WARN
- ERROR
- FAILURE
- Utiliser les gestionnaires parents
- Indique si l'enregistreur d'événements doit envoyer ses sorties vers l'enregistreur d'événements parent. Le comportement par défaut est
true.
- Les changements prennent effet immédiatement.
18.2. Administration des transactions
18.2.1. Naviguer et gérer les transactions
log-store. Une opération API nommée probe lit les journaux de transactions et crée un noeud pour chaque journal. Vous pouvez invoquer la commande probe manuellement, quand vous souhaitez réactualiser le log-store. Il est normal pour les journaux de transactions d'apparaître ou de disparaître rapidement.
Exemple 18.1. Réactualiser le Log Store
default dans un domaine géré. Dans le cas d'un serveur autonome, supprimer profile=default de la commande.
/profile=default/subsystem=transactions/log-store=log-store/:probe
Exemple 18.2. Voir toutes les transactions préparées
ls de système de fichier.
ls /profile=default/subsystem=transactions/log-store=log-store/transactions
Gérer une transaction
- Voir des attributs de transaction.
- Pour voir des informations sur une transaction, comme son nom JNDI, son nom de produit EIS ou sa version, ou statut, utiliser la commande CLI
:read-resource./profile=default/subsystem=transactions/log-store=log-store/transactions=0\:ffff7f000001\:-b66efc2\:4f9e6f8f\:9:read-resource
- Voir tous les participants d'une transaction.
- Chaque journal de transaction contient un élément enfant nommé
participants. Utiliser la commande CLIread-resourceCLI sur cet élément pour voir les participants des transactions. Les participants sont identifiés par leurs noms JNDI./profile=default/subsystem=transactions/log-store=log-store/transactions=0\:ffff7f000001\:-b66efc2\:4f9e6f8f\:9/participants=java\:\/JmsXA:read-resource
Le résultat devrait ressembler à ceci :{ "outcome" => "success", "result" => { "eis-product-name" => "HornetQ", "eis-product-version" => "2.0", "jndi-name" => "java:/JmsXA", "status" => "HEURISTIC", "type" => "/StateManager/AbstractRecord/XAResourceRecord" } }Le statut du résultat affiché ici est dans un étatHEURISTICet est susceptible d'être recouvert. Voir Recouvrement d'une transaction. pour plus d'informations. - Supprimer une transaction.
- Chaque journal de transaction supporte une opération
:deletepour effacer l'enregistrement qui représente la transaction./profile=default/subsystem=transactions/log-store=log-store/transactions=0\:ffff7f000001\:-b66efc2\:4f9e6f8f\:9:delete
- Recouvrement d'une transaction.
- Chaque journal de transaction supporte le recouvrement par la commande CLI
:recover.Recouvrement des transactions heuristiques et des participants
- Si le statut de la transaction est
HEURISTIC, l'opération de recouvrement change l'état enPREPAREet déclenche un recouvrement. - Si l'un des participants de la transaction est heuristique, l'opération de recouvrement tente de reprendre l'opération
commit(validation) à nouveau. En cas de succès, le participant est retiré du journal des transactions. Vous pouvez vérifier cela en exécutant à nouveau l'opération:probesur lelog-storeet en vérifiant que le participant n'est plus inscrit. Si c'est le dernier participant, la transaction sera également supprimée.
- Réactualiser le statut de la transaction qui a besoin d'être recouvrée.
- Si une transaction a besoin d'être recouvrée, vous pourrez utiliser la commande CLI
:refreshpour vous assurer qu'elle a toujours besoin d'être recouvrée, avant de tenter le recouvrement./profile=default/subsystem=transactions/log-store=log-store/transactions=0\:ffff7f000001\:-b66efc2\:4f9e6f8f\:9:refresh
Si les statistiques de TM (Transaction Manager) sont activées, vous pouvez consulter les statistiques à propos du Gestionnaire de Transactions et du sous-système de transactions. Veuillez consulter Section 18.1.2, « Configurer le Transaction Manager (TM) (ou gestionnaire de transactions) » pour plus d'informations sur l'activation des statistiques de TM.
Tableau 18.4. Les statistiques de sous-système de transaction
| Statistique | Description | Commande CLI |
|---|---|---|
| Total |
Le nombre total de transactions exécutées par le gestionnaire de transactions sur ce serveur.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-transactions,include-defaults=true) |
| Validé |
Le nombre de transactions validées exécutées par le gestionnaire de transactions sur ce serveur.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-committed-transactions,include-defaults=true) |
| Abandonné |
Le nombre de transactions interrompues exécutées par le gestionnaire de transactions sur ce serveur.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-aborted-transactions,include-defaults=true) |
| Délai expiré |
Le nombre de transactions expirées exécutées par le gestionnaire de transactions sur ce serveur.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-timed-out-transactions,include-defaults=true) |
| Heuristiques |
Pas disponible dans la Console de Gestion. Nombre de transactions dans un état heuristique.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-heuristics,include-defaults=true) |
| Transactions In-Flight |
Pas disponible dans la console de gestion. Nombre de transactions commencées mais pas encore achevées.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-inflight-transactions,include-defaults=true) |
| Origine de l'échec - Applications |
Le nombre de transactions échouées dont l'origine de l'échec était une application.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-application-rollbacks,include-defaults=true) |
| Origine de l'échec - Ressources |
Le nombre de transactions échouées dont l'origine de l'échec était une ressource.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-resource-rollbacks,include-defaults=true) |
18.3. Références de transactions
18.3.1. Erreurs et exceptions pour les transactions JBoss
UserTransaction, voir la spécification UserTransaction API dans http://download.oracle.com/javaee/1.3/api/javax/transaction/UserTransaction.html.
18.3.2. Limitations de JTA Clustering
18.4. Configuration ORB
18.4.1. A propos de CORBA (Common Object Request Broker Architecture)
18.4.2. Configurer l'ORB pour les transactions JTS
Note
full et full-ha uniquement. Dans un serveur autonome, il est disponible uniquement quand vous utilisez les configurations standalone-full.xml ou standalone-full-ha.xml.
Procédure 18.3. Configurer l'ORB par la console de gestion
Voir les paramètres de configuration du profil.
Sélectionnez Profiles (domaine géré) ou Profile (serveur autonome) dans la partie supérieure droite de la console de gestion. Si vous utilisez un domaine géré, sélectionnez soit le profil full ou full-ha à partir de la boîte de dialogue de sélection en haut à gauche.Modifier les paramètres Initialisateurs
Étendre le menu Sous-système sur la gauche, si nécessaire. Étendre le sous-menu Conteneur et cliquer sur JacORB.Sur le formulaire qui apparaît sur l'écran principal, sélectionner l'onglet Initialisateur, et cliquer sur le bouton Modofier.Activer les intercepteurs de sécurité en configurant la valeur de Security àactive.Pour activer ORB sur JTS, définir la valeur des Intercepteurs de transations àactive, au lieu de la valeur par défautspec.Voir le lien Besoin d'aide ? sur le formulaire pour accéder à des explications sur ces valeurs. Cliquer sur Sauvegarde quand vous aurez fini de modifier les valeurs.Configuration ORB avancée
Voir les autres sections du formulaire pour les options de configuration avancées. Chaque section inclut un lien Besoin d'aide ? avec des informations détaillées sur les paramètres.
Vous pouvez configurer chaque aspect de l'ORB à l'aide du Management CLI. Les commandes suivantes configurent les initialisateurs aux mêmes valeurs que celles de la procédure ci-dessus, pour la console de gestion. Il s'agit de la configuration minimale pour l'ORB, si utilisé avec JTS.
/profile=full des commandes.
Exemple 18.3. Activer les intercepteurs de sécurité
/profile=full/subsystem=jacorb/:write-attribute(name=security,value=on)
Exemple 18.4. Activer l'ORB pour JTS
/profile=full/subsystem=jacorb/:write-attribute(name=transactions,value=on)
Exemple 18.5. Activer les transactions dans le sous-système JacORB
/profile=full/subsystem=jacorb/:write-attribute(name=transactions,value=on)
Exemple 18.6. Activer JTS dans le sous-système de transactions
/subsystem=transactions:write-attribute(name=jts,value=true)
18.5. JDBC Object Store Support
18.5.1. JDBC Store de Transactions
- Définir
use-jdbc-storeàtrue./subsystem=transactions:write-attribute(name=use-jdbc-store, value=true)
- Définir
jdbc-store-datasourceau nom JNDI pour la source de données à utiliser./subsystem=transactions:write-attribute(name=jdbc-store-datasource, value=java:jboss/datasources/TransDS)
Tableau 18.5. Propriétés des StoresJDBC de transactions
| Propriété | Description |
|---|---|
use-jdbc-store
|
Le définir à true pour activer le store JDBC de transactions.
|
jdbc-store-datasource
|
Le nom JNDI de la source de données JDBC utilisée pour le stockage.
|
jdbc-action-store-drop-table
|
Supprimez et recréez les tables de stores d'actions lors du lancement. En option, par défaut « false ».
|
jdbc-action-store-table-prefix
|
Le préfixe des noms de tables de stores d'actions. En option.
|
jdbc-communication-store-drop-table
|
Supprimez et recréez les tables de stores de communications lors du lancement. En option, par défaut « false ».
|
jdbc-communication-store-table-prefix
|
Le préfixe des noms de tables de stores de communications. En option.
|
jdbc-state-store-drop-table
|
Supprimez et recréez les tables de stores d'états lors du lancement. En option, par défaut « false ».
|
jdbc-state-store-table-prefix
|
Le préfixe des noms de tables de stores d'états. En option.
|
Chapitre 19. Sous-système de messagerie
19.1. Utiliser des transports personnalisés dans les sous-systèmes de messagerie
outbound-socket-binding-ref qui fait référence à une liaison de socket de mail sortante et qui est défini par l'adresse d'hôte et le numéro de port.
outbound-socket-binding-ref et autorisent les formats de propriétés d'hôte personnalisés.
Procédure 19.1.
- Ajouter une nouvelle session mail. La commande ci-dessous créer une nouvelle session nommée mySession et définit JNDI à
java:jboss/mail/MySession:/subsystem=mail/mail-session=mySession:add(jndi-name=java:jboss/mail/MySession)
- Ajouter une liaison de socket sortante. La commande ci-dessous ajoute une liaison de socket nommée
my-smtp-bindingqui pointe verslocalhost:25./socket-binding-group=standard-sockets/remote-destination-outbound-socket-binding=my-smtp-binding:add(host=localhost, port=25)
- Ajouter un serveur SMTP avec
outbind-socket-binding-ref. La commande suivante ajoute un SMTP nommémy-smtp-bindinget définit un nom d'utilisateur, un mot de passe et une configuration TLS./subsystem=mail/mail-session=mySession/server=smtp:add(outbound-socket-binding-ref= my-smtp-binding, username=user, password=pass, tls=true)
- Répéter ce processus pour POP3 et IMAP :
/socket-binding-group=standard-sockets/remote-destination-outbound-socket-binding=my-pop3-binding:add(host=localhost, port=110)
/subsystem=mail/mail-session=mySession/server=pop3:add(outbound-socket-binding-ref=my-pop3-binding, username=user, password=pass)
/socket-binding-group=standard-sockets/remote-destination-outbound-socket-binding=my-imap-binding:add(host=localhost, port=143)
/subsystem=mail/mail-session=mySession/server=imap:add(outbound-socket-binding-ref=my-imap-binding, username=user, password=pass)
- Pour utiliser un serveur personnalisé, créer un nouveau serveur mail personnalisé sans la liaison de socket sortante (comme c'est optionnel) et fournir à la place l'information hôte comme faisant partie des propriétés.
/subsystem=mail/mail-session=mySession/custom=myCustomServer:add(username=user,password=pass, properties={"host" => "myhost", "my-property" =>"value"})Lorsque vous définissez les protocoles personnalisés, n'importe quel nom de propriété qui contient un point (.) est considéré comme un nom complet et est passé tel qu'il est fourni. N'importe quel autre format (my-property, par exemple) sera traduit dans le format suivant :mail. server-name.my-property.
<subsystem xmlns="urn:jboss:domain:mail:1.1">
<mail-session jndi-name="java:/Mail" from="user.name@domain.org">
<smtp-server outbound-socket-binding-ref="mail-smtp" tls="true">
<login name="user" password="password"/>
</smtp-server>
<pop3-server outbound-socket-binding-ref="mail-pop3"/>
<imap-server outbound-socket-binding-ref="mail-imap">
<login name="nobody" password="password"/>
</imap-server>
</mail-session>
<mail-session debug="true" jndi-name="java:jboss/mail/Default">
<smtp-server outbound-socket-binding-ref="mail-smtp"/>
</mail-session>
<mail-session debug="true" jndi-name="java:jboss/mail/Custom">
<custom-server name="smtp">
<login name="username" password="password"/>
<property name="host" value="mail.example.com"/>
</custom-server>
<custom-server name="pop3" outbound-socket-binding-ref="mail-pop3">
<property name="custom_prop" value="some-custom-prop-value"/>
<property name="some.fully.qualified.property" value="fully-qualified-prop-name"/>
</custom-server>
</mail-session>
<mail-session debug="true" jndi-name="java:jboss/mail/Custom2">
<custom-server name="pop3" outbound-socket-binding-ref="mail-pop3">
<property name="custom_prop" value="some-custom-prop-value"/>
</custom-server>
</mail-session>
</subsystem>
Chapitre 20. Enterprise JavaBeans
20.1. Introduction
20.1.1. Entreprise JavaBeans
20.1.2. Enterprise JavaBeans pour Administrateurs
- Cliquer sur le lien Profile qui se trouve en haut et à droite pour changer de vue de Profil.
- Veillez à ce que le menu Profile soit développé sur la flèche qui se trouve à côté de l'étiquette.
- Cliquer sur Container pour le développer, puis cliquer sur EJB 3.
- Cliquer sur le lien Profile qui se trouve en haut pour changer de vue de Profil.
- Veillez à ce que le menu Subsystèmes soit développé sur la flèche qui se trouve à côté de l'étiquette.
- Sélectionner le profile que vous modifiez à partir du menu Profile.
- Cliquer sur Container pour le développer, puis cliquer sur EJB 3.
20.1.3. Beans Enterprise
Important
20.1.4. Session Beans
20.1.5. Message-Driven Beans
20.2. Configurer les bean pools
20.2.1. Bean Pools
20.2.2. Créer un Bean Pool
Procédure 20.1. Créer un Bean Pool par la console de gestion
- Connectez-vous à la Console de gestion. Voir Section 3.4.2, « Se conncecter à la console de gestion ».
- Cliquer sur en haut à droite, puis développer l'item dans le panneau de Profil sur la gauche, et sélectionner . Puis sélectionner l'onglet dans le panneau principal.
- Cliquer sur le bouton . Le dialogue Add EJB3 Bean Pools apparaîtra.
- Donnez les informations requises, les valeurs de Name, Max Pool Size, Timeout et l'unité de Timeout.
- Cliquer sur le bouton pour sauvegarder le nouveau Bean Pool ou cliquer sur le lien Cancel pour faire cesser la procédure.
- Si vous cliquer sur le bouton , le dialogue se fermera et le nouveau Bean Pool apparaîtra dans la liste.
- Si vous cliquez sur , le dialogue se fermera et aucun autre Bean Pool ne sera créé.
Procédure 20.2. Créer un Bean Pool par le CLI
- Lancer l'outil CLI et connectez-vous à votre serveur. Voir Section 3.5.4, « Se connecter à une instance de serveur géré par le Management CLI ».
- Utiliser l'opération
addavec la syntaxe suivante./subsystem=ejb3/strict-max-bean-instance-pool=BEANPOOLNAME:add(max-pool-size=MAXSIZE, timeout=TIMEOUT, timeout-unit="UNIT")
- Remplacer BEANPOOLNAME par le nom requis de Bean Pool.
- Remplacer MAXSIZE par le nom requis de Bean Pool.
- Remplacer TIMEOUT
- Remplacer UNIT par l'unité de temps requise. Les valeurs permises sont les suivantes :
NANOSECONDS,MICROSECONDS,MILLISECONDS,SECONDS,MINUTES,HOURS, etDAYS.
- Utiliser l'opération
read-resourcepour confirmer la création d'un Bean Pool./subsystem=ejb3/strict-max-bean-instance-pool=BEANPOOLNAME:read-resource
Exemple 20.1. Créer un Bean Pool par la CLI
[standalone@localhost:9999 /] /subsystem=ejb3/strict-max-bean-instance-pool=ACCTS_BEAN_POOL:add(max-pool-size=500, timeout=5000, timeout-unit="SECONDS")
{"outcome" => "success"}
[standalone@localhost:9999 /]Exemple 20.2. Exemple de configuration XML
<subsystem xmlns="urn:jboss:domain:ejb3:1.2">
<pools>
<bean-instance-pools>
<strict-max-pool name="slsb-strict-max-pool" max-pool-size="20"
instance-acquisition-timeout="5"
instance-acquisition-timeout-unit="MINUTES" />
<strict-max-pool name="mdb-strict-max-pool" max-pool-size="20"
instance-acquisition-timeout="5"
instance-acquisition-timeout-unit="MINUTES" />
</bean-instance-pools>
</pools>
</subsystem>
20.2.3. Supprimer un Bean Pool
Prérequis :
- La Bean Pool que vous souhaitez supprimer ne peut pas être en cours d'utilisation. Consulter Section 20.2.5, « Assigner des Bean Pools aux Beans de session et aux Beans basés messages » pour vérifier qu'elle n'est pas en cours d'utilisation.
Procédure 20.3. Supprimer un Bean Pool par la Console de management
- Connectez-vous à la Console de gestion. Voir Section 3.4.2, « Se conncecter à la console de gestion ».
- Cliquer sur en haut à droite, puis développer l'item dans le panneau de Profil sur la gauche, et sélectionner . Puis sélectionner l'onglet dans le panneau principal.
- Cliquer sur le Bean Pool que vous souhaiter supprimer de la liste.
- Cliquer sur le bouton . La boîte de dialogue Remove Item apparaîtra.
- Cliquer sur le bouton pour confirmer la suppression ou cliquer sur le lien pour abandonner l'opération.Si vous cliquer sur le bouton , le dialogue se fermera et le Bean Pool sera supprimé et retiré de la liste.Si vous cliquez sur le bouton Cancel, la boîte de dialogue se fermera et il n'y aura aucun changement.
Procédure 20.4. Supprimer un Bean Pool par le CLI
- Lancer l'outil CLI et connectez-vous à votre serveur. Voir Section 3.5.4, « Se connecter à une instance de serveur géré par le Management CLI ».
- Utiliser l'opération
removeavec la syntaxe suivante./subsystem=ejb3/strict-max-bean-instance-pool=BEANPOOLNAME:remove
- Remplacer BEANPOOLNAME par le nom requis de Bean Pool.
Exemple 20.3. Supprimer un Bean Pool par le CLI
[standalone@localhost:9999 /] /subsystem=ejb3/strict-max-bean-instance-pool=ACCTS_BEAN_POOL:remove
{"outcome" => "success"}
[standalone@localhost:9999 /]20.2.4. Modifier un Bean Pool
Procédure 20.5. Modifier un Bean Pool par la Console de management
- Connectez-vous à la Console de gestion. Section 3.4.2, « Se conncecter à la console de gestion »
- Cliquer sur en haut à droite, puis développer l'item dans le panneau de Profil sur la gauche, et sélectionner . Puis sélectionner l'onglet dans le panneau principal.
- Cliquer sur le Bean Pool que vous souhaiter modifier dans la liste.
- Cliquer sur le bouton . Le champ de la zone Details est maintenant modifiable.
- Modifier les informations que vous souhaitez. Seules les valeurs de Max Pool Size, Timeout, et l'unité de Timeout peuvent être modifiés.
- Cliquer sur le bouton si les changements vous conviennent, ou bien, cliquer sur le lien Cancel si vous souhaitez ignorer les changements.Si vous cliquez sur le bouton , la zone Details sera à nouveau une zone non modifiable et le Bean Pool sera mis à jour avec les nouvelles informations.Si vous cliquez sur le lien Cancel, la zone Details sera à nouveau une zone non modifiable et aucun changement n'aura lieu.
Procédure 20.6. Modifier un Bean Pool par le CLI
- Lancer l'outil CLI et connectez-vous à votre serveur. Voir Section 3.5.4, « Se connecter à une instance de serveur géré par le Management CLI ».
- Utiliser l'opération
write-attributeavec la syntaxe suivante pour chaque attribut du Bean Pool à modifier./subsystem=ejb3/strict-max-bean-instance-pool=BEANPOOLNAME:write-attribute(name="ATTRIBUTE", value="VALUE")
- Remplacer BEANPOOLNAME par le nom requis de Bean Pool.
- Remplacer ATTRIBUTE par le nom de l'attribut à modifier. Les attributs ne pouvant pas être modifiés de cette façon sont
max-pool-size,timeout, ettimeout-unit. - Remplacer VALUE par la valeur requise de l'attribut.
- Utiliser l'opération
read-resourcepour confirmer les changements au Bean Pool./subsystem=ejb3/strict-max-bean-instance-pool=BEANPOOLNAME:read-resource
Exemple 20.4. Définir la Valeur de timeout d'un Bean Pool par le CLI
[standalone@localhost:9999 /] /subsystem=ejb3/strict-max-bean-instance-pool=HSBeanPool:write-attribute(name="timeout", value="1500")
{"outcome" => "success"}
[standalone@localhost:9999 /]20.2.5. Assigner des Bean Pools aux Beans de session et aux Beans basés messages
slsb-strict-max-pool et mdb-strict-max-pool pour les Stateless sessions beans et les Beans basés-messages respectivement.
Procédure 20.7. Allouer des Bean Pools pour les Session beans ou pour les Beans basés-message par la Console de gestion.
- Connectez-vous à la Console de gestion. Section 3.4.2, « Se conncecter à la console de gestion »
- Naviguer vers le panneau de Configuration de conteneurs EJB3.
- Cliquer sur le bouton . Le champ de la zone Details est maintenant modifiable.
- Sélectionner le Bean Pool à utiliser pour chaque type de bean à partir de la combo-box appropriée.
- Cliquer sur le bouton si les changements vous conviennent, ou bien, cliquer sur le lien Cancel si vous souhaitez ignorer les changements.
- La zone Détails sera maintenant modifiable et affichera la sélection Bean Pool qui convient.
Procédure 20.8. Allouer des Bean Pools pour les Session beans ou pour les Beans basés-message par le CLI.
- Lancer l'outil CLI et connectez-vous à votre serveur. Voir Section 3.5.4, « Se connecter à une instance de serveur géré par le Management CLI ».
- Utiliser l'opération
write-attributeavec la syntaxe suivante./subsystem=ejb3:write-attribute(name="BEANTYPE", value="BEANPOOL")
- Remplacer BEANTYPE par
default-mdb-instance-poolpour les bean basés-messages oudefault-slsb-instance-poolpour les stateless sessions beans. - Remplacer BEANPOOL par le nom du Bean Pool à assigner.
- Utiliser l'opération
read-resourcepour confirmer les changements./subsystem=ejb3:read-resource
Exemple 20.5. Assigner un Bean Pool pour les Session beans par le CLI
[standalone@localhost:9999 /] /subsystem=ejb3:write-attribute(name="default-slsb-instance-pool", value="LV_SLSB_POOL")
{"outcome" => "success"}
[standalone@localhost:9999 /]Exemple 20.6. Exemple de configuration XML
<subsystem xmlns="urn:jboss:domain:ejb3:1.2">
<session-bean>
<stateless>
<bean-instance-pool-ref pool-name="slsb-strict-max-pool"/>
</stateless>
<stateful default-access-timeout="5000" cache-ref="simple"/>
<singleton default-access-timeout="5000"/>
</session-bean>
<mdb>
<resource-adapter-ref resource-adapter-name="hornetq-ra"/>
<bean-instance-pool-ref pool-name="mdb-strict-max-pool"/>
</mdb>
</subsystem>
20.3. Configurer les EJB thread pools
20.3.1. Enterprise Bean Thread Pools
20.3.2. Créer un Thread Pool
Procédure 20.9. Créer un Thread Pool EJB par la Console de gestion
- Connectez-vous à la Console de gestion. Section 3.4.2, « Se conncecter à la console de gestion »
- Cliquer sur en haut à droite, puis développer l'item dans le panneau de Profil sur la gauche, et sélectionner . Puis sélectionner l'onglet dans le panneau principal.
- Cliquer sur le bouton . Le dialogue Add EJB3 Thread Pools apparaîtra.
- Donnez les informations requises, les valeurs de Name, Max Threads, et Keep-Alive Timeout.
- Cliquer sur le bouton pour sauvegarder le nouveau thread pool ou cliquer sur le lien pour annuler la procédure.
- Si vous cliquez sur le bouton , le dialogue disparaîtra et le nouveau Pool Thread apparaîtra dans la liste.
- Si vous cliquez sur , le dialogue se fermera et aucun autre Thread Pool ne sera créé.
Procédure 20.10. Créer un Thread Pool par le CLI
- Lancer l'outil CLI et connectez-vous à votre serveur. Voir Section 3.5.4, « Se connecter à une instance de serveur géré par le Management CLI ».
- Utiliser l'opération
addavec la syntaxe suivante./subsystem=ejb3/thread-pool=THREADPOOLNAME:add(max-threads=MAXSIZE, keepalive-time={"time"=>"TIME", "unit"=>UNIT"})- Remplacer BEANPOOLNAME par le nom requis de Thread Pool.
- Remplacer MAXSIZE par la taille maximum de thread Pool.
- Remplacer UNIT par l'unité de temps requise de «keep-alive time». Les valeurs permises sont les suivantes :
NANOSECONDS,MICROSECONDS,MILLISECONDS,SECONDS,MINUTES,HOURS, etDAYS. - Remplacer TIME par la valeur (entier relatif) du «keep-alive time». Cette valeur doit correspondre à un nombre d'unités UNIT.
- Utiliser l'opération
read-resourcepour confirmer la création d'un Bean Pool./subsystem=ejb3/strict-max-bean-instance-pool=THREADPOOLNAME:read-resource
Exemple 20.7. Créer un Thread Pool par le CLI
[standalone@localhost:9999 /] /subsystem=ejb3/thread-pool=testmepool:add(max-threads=50, keepalive-time={"time"=>"150", "unit"=>"SECONDS"})
{"outcome" => "success"}
[standalone@localhost:9999 /]Exemple 20.8. Exemple de configuration XML
<subsystem xmlns="urn:jboss:domain:ejb3:1.2">
<thread-pools>
<thread-pool name="default" max-threads="20" keepalive-time="150"/>
</thread-pools>
</subsystem>
20.3.3. Supprimer le Thread Pool
Prérequis
- La Thread Pool que vous souhaitez supprimer ne peut pas être en cours d'utilisation. Voir les tâches suivantes pour vérifier que le thread pool n'est pas en cours d'utilisation :
Procédure 20.11. Supprimer un Thread Pool EJB par la Console de management
- Connectez-vous à la console de management. Section 3.4.2, « Se conncecter à la console de gestion ».
- Cliquer sur en haut à droite, puis développer l'élément dans le panneau de Profil sur la gauche, et sélectionner . Puis sélectionner l'onglet dans le panneau principal.
- Cliquer sur le Thread Pool que vous souhaiter supprimer de la liste.
- Cliquer sur le bouton . La boîte de dialogue Remove Item apparaît.
- Cliquer sur le bouton pour confirmer la suppression ou cliquer sur le lien pour abandonner l'opération.Si vous cliquer sur le bouton , le dialogue se fermera et le Thread Pool sera supprimé et retiré de la liste.Si vous cliquez sur le bouton , la boîte de dialogue se fermera et il n'y aura aucun changement.
Procédure 20.12. Supprimer un Thread Pool par le CLI
- Lancer l'outil CLI et connectez-vous à votre serveur. Voir Section 3.5.4, « Se connecter à une instance de serveur géré par le Management CLI ».
- Utiliser l'opération
removeavec la syntaxe suivante./subsystem=ejb3/thread-pool=THREADPOOLNAME:remove
- Remplacer THREADPOOLNAME par le nom requis de Thread Pool.
Exemple 20.9. Supprimer un Thread Pool par le CLI
[standalone@localhost:9999 /] /subsystem=ejb3/thread-pool=ACCTS_THREADS:remove
{"outcome" => "success"}
[standalone@localhost:9999 /]20.3.4. Modifier un Thread Pool
Procédure 20.13. Modifier un Thread Pool par la Console de management
Login
Connectez-vous à la Console de gestion.Naviguez dans l'onglet EJB3 Thread Pools
Cliquer sur en haut à droite, puis développer l'item dans le panneau de Profil sur la gauche, et sélectionner . Puis sélectionner l'onglet dans le panneau principal.Sélectionner le Thread Pool à modifier
Sélectionner le Thread Pool que vous souhaiter supprimer de la liste.Cliquer sur le bouton Edit
Les champs et les espaces réservés aux détails sont maintenant modifiables.Modifier Détails
Modifier les détails que vous souhaitez modifier. Vous ne pourrez modifier que les valeurs suivantes :Thread Factory,Max Threads,Keepalive Timeout, etKeepalive Timeout Unit.Sauvegarder ou Annuler
Cliquer sur le bouton si les changements vous conviennent, ou bien, cliquer sur le lien Cancel si vous souhaitez ignorer les changements.
Procédure 20.14. Modifier un Thread Pool par le CLI
- Lancer l'outil CLI et connectez-vous à votre serveur. Voir Section 3.5.4, « Se connecter à une instance de serveur géré par le Management CLI ».
- Utiliser l'opération
write_attributeavec la syntaxe suivante pour chaque attribut du Thread Pool à modifier./subsystem=ejb3/thread-pool=THREADPOOLNAME:write-attribute(name="ATTRIBUTE", value="VALUE")
- Remplacer THREADPOOLNAME par le nom requis de Thread Pool.
- Remplacer ATTRIBUTE par le nom de l'attribut à modifier. Les attributs ne pouvant pas être modifiés de cette façon sont
keepalive-time,max-thread, etthread-factory. - Remplacer VALUE par la valeur requise de l'attribut.
- Utiliser l'opération
read-resourcepour confirmer les changements au Thread Pool./subsystem=ejb3/thread-pool=THREADPOOLNAME:read-resource
Important
keepalive-time par le CLI, la valeur requise correspond à une représentations d'objet. La syntaxe sera la suivante :
/subsystem=ejb3/thread-pool=THREADPOOLNAME:write-attribute(name="keepalive-time", value={"time" => "VALUE","unit" => "UNIT"}Exemple 20.10. Définir la Valeur maximum Maxsize d'un Thread Pool par le CLI
[standalone@localhost:9999 /] /subsystem=ejb3/thread-pool=HSThreads:write-attribute(name="max-threads", value="50")
{"outcome" => "success"}
[standalone@localhost:9999 /]Exemple 20.11. Définir la valeur de temps keepalive-time d'un Thread Pool par le CLI
[standalone@localhost:9999 /] /subsystem=ejb3/thread-pool=HSThreads:write-attribute(name="keepalive-time", value={"time"=>"150"})
{"outcome" => "success"}
[standalone@localhost:9999 /]20.4. Configurer les session beans
20.4.1. Session Bean Access Timeout
@javax.ejb.AccessTimeout sur la méthode.
20.4.2. Définir les valeurs de timeout d'accès aux beans de session par défaut
Procédure 20.15. Définir les valeurs de timeout d'accès aux beans de session par défaut par la Console de gestion
- Connectez-vous à la Console de gestion. Voir Section 3.4.2, « Se conncecter à la console de gestion ».
- Cliquer sur en haut à droite, puis développer l'item dans le panneau de Profil sur la gauche, et sélectionner . Puis sélectionner l'onglet dans le panneau principal.
- Cliquer sur le bouton . Le champ de la zone Details est maintenant modifiable.
- Saisir les valeurs qui conviennent dans Stateful Access Timeout et/ou dans les cases de texte Singleton Access Timeout.
- Cliquer sur le bouton si les changements vous conviennent, ou bien, cliquer sur le lien Cancel si vous souhaitez ignorer les changements.
- La zone de Details sera alors non modifiable et affichera les valeurs de timeout qui conviennent.
Procédure 20.16. Définir les valeurs de timeout d'accès aux beans de session par le CLI.
- Lancer l'outil CLI et connectez-vous à votre serveur. Voir Section 3.5.4, « Se connecter à une instance de serveur géré par le Management CLI ».
- Utiliser l'opération
write-attributeavec la syntaxe suivante./subsystem=ejb3:write-attribute(name="BEANTYPE", value=TIME)
- Remplacer BEANTYPE par
default-stateful-bean-access-timeoutpour les sessions beans Stateful, oudefault-singleton-bean-access-timeoutpour les sessions bean Singleton. - Remplacer TIME par la valeur de timeout qui convient.
- Utiliser l'opération
read-resourcepour confirmer les changements./subsystem=ejb3:read-resource
Exemple 20.12. Définir la valeur de timeout d'accès aux beans Stateful par le CLI à 9000.
[standalone@localhost:9999 /] /subsystem=ejb3:write-attribute(name="default-stateful-bean-access-timeout", value=9000)
{"outcome" => "success"}
[standalone@localhost:9999 /]Exemple 20.13. Exemple de configuration XML
<subsystem xmlns="urn:jboss:domain:ejb3:1.2">
<session-bean>
<stateless>
<bean-instance-pool-ref pool-name="slsb-strict-max-pool"/>
</stateless>
<stateful default-access-timeout="5000" cache-ref="simple"/>
<singleton default-access-timeout="5000"/>
</session-bean>
</subsystem>
20.5. Configurer les message-driven beans
20.5.1. Définir l'Adaptateur de ressources par défaut des Beans basés-messages
hornetq-ra.
Procédure 20.17. Définir l'adaptateur de ressources par défaut pour les beans basés-messages par la Console de gestion.
- Connectez-vous à la Console de gestion. Section 3.4.2, « Se conncecter à la console de gestion »
- Cliquer sur en haut à droite, puis développer l'item dans le panneau de Profil sur la gauche, et sélectionner . Puis sélectionner l'onglet dans le panneau principal.
- Cliquer sur le bouton . Le champ de la zone Details est maintenant modifiable.
- Saisir le nom de l'adaptateur de la ressource à utiliser dans la case de texte Default Resource Adapter.
- Cliquer sur le bouton si les changements vous conviennent, ou bien, cliquer sur le lien Cancel si vous souhaitez ignorer les changements.
- La zone Details sera alors non modifiable et affichera le nom d'adaptateur de ressources qui convient.
Procédure 20.18. Définir l'adaptateur de ressources par défaut pour les beans basés-messages par le CLI
- Lancer l'outil CLI et connectez-vous à votre serveur. Voir Section 3.5.4, « Se connecter à une instance de serveur géré par le Management CLI ».
- Utiliser l'opération
write-attributeavec la syntaxe suivante./subsystem=ejb3:write-attribute(name="default-resource-adapter-name", value="RESOURCE-ADAPTER")
Remplacer RESOURCE-ADAPTER par le nom de l'adaptateur de ressources à utiliser. - Utiliser l'opération
read-resourcepour confirmer les changements./subsystem=ejb3:read-resource
Exemple 20.14. Définir l'adaptateur de ressources par défaut pour les beans basés-messages par le CLI
[standalone@localhost:9999 subsystem=ejb3] /subsystem=ejb3:write-attribute(name="default-resource-adapter-name", value="EDIS-RA")
{"outcome" => "success"}
[standalone@localhost:9999 subsystem=ejb3]Exemple 20.15. Exemple de configuration XML
<subsystem xmlns="urn:jboss:domain:ejb3:1.2">
<mdb>
<resource-adapter-ref resource-adapter-name="hornetq-ra"/>
<bean-instance-pool-ref pool-name="mdb-strict-max-pool"/>
</mdb>
</subsystem>
20.6. Configurer le service EJB3 Timer
20.6.1. Service de minuterie EJB3
20.6.2. Configurer le Service de la minuterie EJB3
Procédure 20.19. Configurer le Service du timer EJB3
Login
Connectez-vous à la Console de gestion.Ouvrir l'onglet de Service de minuterie
Cliquer sur en haut à droite, puis développer l'élément dans le panneau de Profil sur la gauche, et sélectionner . Puis sélectionner l'onglet dans le panneau principal, puis l'onglet .Saisir le Mode Édition
Cliquer sur le bouton Édit. Les champs seront alors modifiables.Effectuer les changements requis.
Vous pouvez sélectionner un Thread Pool EJB3 différent pour le Service de minuterie si les Thread Pools supplémentaires sont été configurés, et vous pouvez changer le répertoire utilisé pour sauvegarder les données du Service de minuterie. La configuration de répertoire de données du Service de minuterie comprend deux valeurs:Path, le répertoire qui contient les données, etRelative To, le répertoire qui contientPath. Par défautRelative Toest défini à une variable de chemin de système de fichiers.Sauvegarder ou Annuler
Cliquer sur le bouton si les changements vous conviennent, ou bien, cliquer sur le lien Cancel si vous souhaitez ignorer les changements.
20.7. Configurer le service d'invocation asynchrone EJB
20.7.1. EJB3 Service d'invocations asynchrones
20.7.2. Configurer le Thread Pool du Service d'invocations asynchrones EJB3
Procédure 20.20. Configurerhttp://francegourmet.com.au/product-category/snails-and-mushrooms/
Login
Connectez-vous à la Console de gestion.Ouvrir l'onglet Async Service
Cliquer sur en haut à droite, étendre l'item dans le panneau Profile qui se trouve sur la gauche et sélectionner . Sélectionner l'onglet à partir du panneau principal, puis l'onglet .Saisir le Mode Édition
Cliquer sur le bouton . Les champs sont alors modifiables.Sélectionner le Thread Pool
Sélectionner le Thread Pool à utiliser à partir de la liste. Le Thread Pool devra déjà avoir été créé.Sauvegarder ou Annuler
Cliquer sur le bouton si les changements vous conviennent, ou bien, cliquer sur le lien si vous souhaitez ignorer les changements.
20.8. Configurer EJB3 Remote Invocation Service
20.8.1. EJB3 Remote Service
20.8.2. Configurer EJB3 Remote Service
Procédure 20.21. Configurer EJB3 Remote Service
Login
Connectez-vous à la Console de gestion.Ouverture de l'onglet Remote Service
Cliquer sur en haut à droite, puis développer l'élément dans le panneau de Profil sur la gauche, et sélectionner . Puis sélectionner l'onglet dans le panneau principal, puis l'onglet .Saisir le Mode Édition
Cliquer sur le bouton Édit. Les champs seront alors modifiables.Effectuer les changements requis.
Vous pouvez sélectionner un EJB3 Thread Pool différent pour Remote Service si les Thread Pools supplémentaires ont été configurés. Vous pouvez changer le connecteur utilisé pour enregistrer le Canal EJB Remoting.Sauvegarder ou Annuler
Cliquer sur le bouton si les changements vous conviennent, ou bien, cliquer sur le lien Cancel si vous souhaitez ignorer les changements.
20.9. Configurer les EJB 2.x Entity Beans
20.9.1. EJB Entity Beans
20.9.2. Container-Managed Persistence
20.9.3. Activer EJB 2.x Container-Managed Persistence
org.jboss.as.cmp. CMP est activé par défaut dans le domaine géré et dans la configuration complète du serveur autonome, par ex. standalone-full.xml.
org.jboss.as.cmp à la liste d'extensions actives dans le fichier de configuration du serveur.
<extensions>
<extension module="org.jboss.as.cmp"/>
</extensions>
org.jboss.as.cmp.
20.9.4. Configurer EJB 2.x Container-Managed Persistence
- Les générateurs de clés basés-UUID
- Un générateur de clés basé-UUID crée des clés qui utilisent un Identifiant Unique Universel (UUI). Les générateurs de clés UUID ont besoin uniquement d'avoir un nom unique; ils n'ont pas d'autre configuration.Les générateurs de clés basé-UUID peuvent être ajoutés par le CLI avec la syntaxe suivante.
/subsystem=cmp/uuid-keygenerator=UNIQUE_NAME:add
Exemple 20.16. Ajouter le générateur de clés UUID
Pour ajouter un générateur de clés basé-UUID ayant pour nomuuid_identities, utiliser cette commande CLI :/subsystem=cmp/uuid-keygenerator=uuid_identities:add
La configuration XML créée par cette commande est :<subsystem xmlns="urn:jboss:domain:cmp:1.0"> <key-generators> <uuid name="uuid_identities" /> </key-generators> </subsystem> - Générateurs de clés HiLo
- Les générateurs de clés HiLo utilisent une base de données pour créer et stocker des clés d'identité des entités. Le générateur de clés HiLo doivent posséder des noms uniques et sont configurés avec des propriétés qui indiquent la source de données utilisée pour stocker les données, ainsi que les noms du tableau et colonnes qui stockent les clés.Les générateurs de clés HiLo peuvent être ajoutés par le CLI grâce à la syntaxe de commande suivante:
/subsystem=cmp/hilo-keygenerator=UNIQUE_NAME/:add(property=value, property=value, ...)
Exemple 20.17. Ajouter un générateur de clés HiLo
/subsystem=cmp/hilo-keygenerator=DB_KEYS/:add(create-table=false,data-source=java:jboss/datasources/ExampleDS,drop-table=false,id-column=cmp_key_ids,select-hi-ddl=select max(cmp_key_ids) from cmp_key_seq,sequence-column=cmp_key_seq,table-name=cmp-keys))
La configuration XML créée par cette commande est :<subsystem xmlns="urn:jboss:domain:cmp:1.0"> <key-generators> <hilo name="DB_KEYS"> <create-table>false</create-table> <data-source>java:jboss/datasources/ExampleDS</data-source> <drop-table>false</drop-table> <id-column>cmp_key_ids</id-column> <select-hi-ddl>select max(cmp_key_ids) from cmp_key_seq</select-hi-ddl> <sequence-column>cmp_key_seq</sequence-column> <table-name>cmp-keys</table-name> </hilo> </key-generators> </subsystem>
20.9.5. Les propriétés de sous-système CMP pour les Générateurs de clés HiLo
Tableau 20.1. Les propriétés de sous-système CMP pour les Générateurs de clés HiLo
| Propriété | Type des données | Description |
|---|---|---|
block-size | long |
-
|
create-table | booléen |
Si défini sur
TRUE, le tableau table-name sera créé avec le contenu create-table-ddl si le tableau n'est pas trouvé.
|
create-table-ddl | chaîne |
Les commandes DDL utilisées pour créer le tableau spécifié dans
table-name si on ne create-table est défini à TRUE.
|
data-source | token |
La source de données utilisée pour se connecter à la base de données.
|
drop-table | booléen |
-
|
id-column | token |
-
|
select-hi-ddl | chaîne | La commande SQL qui retournera la plus grande clé actuellement stockée. |
sequence-column | token |
-
|
sequence-name | token |
-
|
table-name | token |
Nom de la table utilisée pour stocker les informations sur les clés
|
Chapitre 21. Java Connector Architecture (JCA)
21.1. Introduction
21.1.1. Java EE Connector API (JCA)
21.1.2. Java Connector Architecture (JCA)
- connections
- transactions
- sécurité
- cycle de vie
- Instances de travail
- Flux interne de transactions
- Flux interne de messages
21.1.3. Adaptateurs de ressources
21.2. Configuration du sous-système Java Connector Architecture (JCA)
- Validation d'archive
- Ce paramétrage indique si la validation d'archivage doit avoir lieu sur les unités de déploiement.
- Le tableau suivant décrit les attributs que vous pouvez définir pour la validation d'archivage.
Tableau 21.1. Attributs de validation d'archivage
Attribut Valeur par défaut Description enabledtrue Indique si la validation d'archivage est activée.fail-on-errortrue Indique si un rapport d'erreur de validation d'archivage a fait échouer le développement.fail-on-warnfalse Indique si un rapport d'avertissement de validation d'archivage a fait échouer le développement. - Si une archive n'implémente pas la spécification Java EE Connector Architecture correctement, et que la validation d'archivage est activée, un message d'erreur s'affichera pendant le déploiement pour décrire le problème, comme par exemple :
Severity: ERROR Section: 19.4.2 Description: A ResourceAdapter must implement a "public int hashCode()" method. Code: com.mycompany.myproject.ResourceAdapterImpl Severity: ERROR Section: 19.4.2 Description: A ResourceAdapter must implement a "public boolean equals(Object)" method. Code: com.mycompany.myproject.ResourceAdapterImpl
- Si la validation d'archivage n'est pas spécifiée, on la considérera comme présente et l'attribut
enabledaura comme valeur true par défaut.
- Validation de bean
- Ce paramètre indique si la validation de bean (JSR-303) aura lieu sur les unités de déploiement.
- Le tableau ci-dessous décrit les attributs que vous pouvez déterminer pour la validation de bean.
Tableau 21.2. Attributs de validation de bean
Attribut Valeur par défaut Description enabledtrue Indique si la validation de bean est activée. - Si la validation de bean n'est pas spécifiée, on la considérera comme présente et l'attribut
enabledaura comme valeur true par défaut.
- Work Managers
- Il y a deux types de Work Managers :
- Work Manager par défaut
- Le Work Manager par défaut et ses Thread Pools.
- Work Manager personnalisé
- Une définition de Work Manager et ses Thread Pools.
- Le tableau suivant décrit les attributs que vous pouvez définir pour les Work Managers.
Tableau 21.3. Attributs de Work Managers
Attribut Description nameIndique le nom du Work Manager. Requis pour les Work Managers personnalisés.short-running-threadsThread Pool pour les instances Work standards. Chaque Work Manager a un Thread Pool à exécution courte.long-running-threadsLes instances Work de Thread pool de JCA 1.6 qui définissentLONG_RUNNING. Chaque Work Manager peut avoir un Thread pool de longue durée en option. - Le tableau ci-dessous décrit les attributs que vous pouvez définir pour les Thread pools de Work Managers.
Tableau 21.4. Attributs de Thread pool
Attribut Description allow-core-timeoutParamètre booléen qui détermine quels threads principaux risquent d'expirer. La valeur par défaut est false.core-threadsLa taille du pool de threads. Doit être inférieure à la taille de pool de threads maximum.queue-lengthLa longueur maximum de la file d'attente.max-threadTaille de pool de threads maximum.keepalive-timeIndique le durée pendant laquelle les threads de pool doivent être conservés après avoir complété leur tâche.thread-factoryRéférence à la fabrique de threads.
- Bootstrap Contexts
- Utilisé pour définir les contextes de bootstapping (démarrage) personnalisés.
- Le tableau suivant décrit les attributs à définir pour les contextes de bootstraping.
Tableau 21.5. Attributs de contexte de bootstrapping
Attribut Description nameIndique le nom du contexte de bootstrappingworkmanagerIndique le nom du Work Manager à utiliser dans ce contexte.
- Gestionnaire de connexion mis en cache
- Utilisé pour déboguer les connexions et pour supporter l'inscription tardive d'une connexion dans une transaction, pour vérifier leur bonne utilisation et fonctionnement.
- Le tableau suivant décrit les attributs que vous pouvez définir pour le manager de connexions mis en cache.
Tableau 21.6. Attributs de manager de connexion mis en cache
Attribut Valeur par défaut Description debugfalse Sorties avertissement en cas d'échec de fermeture explicite des connexionserrorfalse Envoie une exception en cas d'échec de fermeture explicite des connexions.
Procédure 21.1. Configurer le sous-système JCA par la Console de gestion
- Le sous-système JCA de JBoss EAP 6 peut être configuré dans la Console de gestion. Les options de configuration de JCA sont situées dans des endroits légèrement différents dans la Console de gestion, selon la façon dont le serveur est exécuté.
- Si le serveur exécute ne autonome, suivre les étapes suivantes :
- Cliquer sur le lien Profile qui se trouve en haut et à droite de la vue Profile.
- Veillez à ce que la section Profile du panneau de navigation à gauche soit développée.
- Cliquer sur Connector pour l'étendre, puis cliquer sur JCA.
- Si le serveur exécute dans le cadre d'une Managed Domain, suivre les étapes suivantes :
- Cliquer sur le lien Profile qui se trouve en haut et à droite de la vue Profile
- Sélectionner le profil que vous souhaitez modifier à partir du menu Profile en haut du panneau de navigation sur la gauche.
- Cliquer sur Connector pour l'étendre, puis cliquer sur JCA.
- Configurer les paramètres du sous-système JCA à l'aide des trois onglets.
Config courante
L'onglet Common Config contient des paramètres pour le gestionnaire de connexions en cache, la validation de l'archive et la validation de bean (JSR-303). Chacun d'entre eux est contenu dans son onglet propre. Ces réglages peuvent être changés en ouvrant l'onglet correspondant, en cliquant sur le bouton Edit, en effectuant les changements nécessaires et puis en cliquant sur le bouton Save de sauvegarde.
Figure 21.1. Configuration commune JCA
Work Managers
L'onglet Work Manager contient la liste des Work Managers (gestionnaires de travail) configurés. Les nouveaux Work Managers peuvent être ajoutés, supprimés, et leurs pools de threads configurés ici. Chaque Work Manager peut avoir un pool de threads à exécution courte et un pool de threads de longue durée en option.
Figure 21.2. Work Managers
Les attributs de pools de threads peuvent être configurés ici :
Figure 21.3. Work Manager Thread Pools
Bootstrap Contexts
L'onglet Bootstrap Contexts contient la liste des contextes d'amorçage configurés. De nouveaux objets de contexte d'amorçage peuvent être ajoutés, supprimés ou configurés. Un Work Manager doit être assigné à chaque contexte de Bootstrap.
Figure 21.4. Bootstrap Contexts
21.3. Déployer un adaptateur de ressources
Procédure 21.2. Déployer un adaptateur de ressources par la Management CLI
- Ouvrir une invite de commande de votre système d'exploitation.
- Connectez-vous au Management CLI.
- Dans Linux, saisir ce qui suit au niveau de la ligne de commande :
$ EAP_HOME/bin/jboss-cli.sh --connect $ Connected to standalone controller at localhost:9999
- Dans Windows, saisir ce qui suit au niveau de la ligne de commande :
C:\>EAP_HOME\bin\jboss-cli.bat --connect C:\> Connected to standalone controller at localhost:9999
- Déployer l'adaptateur de ressources.
- Pour déployer l'adaptateur de ressources dans un serveur autonome, saisir ce qui suit dans une ligne de commande :
$ deploy path/to/resource-adapter-name.rar
- Pour déployer l'adaptateur de ressources dans tous les serveurs d'un domaine géré, saisir ce qui suit dans une ligne de commande :
$ deploy path/to/resource-adapter-name.rar --all-server-groups
Procédure 21.3. Déployer un adaptateur de ressources par la Console de gestion basée-web
- Démarrer votre serveur JBoss EAP 6
- Si vous n'avez pas encore ajouté d'utilisateur de gestion, ajoutez-en un maintenant. Pour plus d'informations, voir le chapitre Getting Started du Guide d'installation de JBoss EAP 6. Section 4.1.1, « Ajouter Utilisateur pour les Interfaces de gestion »
- Ouvrez un navigateur web et naviguez dans la Console de management. L'emplacement par défaut est http://localhost:9990/console/. Pour plus d'informations sur la Console de management, voir Section 3.4.2, « Se conncecter à la console de gestion ».
- Cliquer sur le lien Runtime qui se trouve en haut et à droite pour passer à la vue de Runtime, puis choisir Manage Deployments dans le panneau de navigation de gauche, et cliquer sur (Ajouter Contenu) en haut et à droite.
- Naviguer dans l'archive d'adaptateur de ressources et le sélectionner. Puis, cliquer sur le bouton .
- Vérifier les noms de déploiement, puis cliquer sur le bouton .
- L'archive d'adaptateur de ressources devrait maintenant s'afficher dans la liste dans un état désactivé. Cliquer sur le lien Enable pour l'activer.
- Un dialogue vous demande "êtes-vous certain?" que vous souhaitez activer le RAR listé. Cliquer sur . L'archive d'adaptateur de déploiement devrait maintenant afficher
Enabled.
Procédure 21.4. Déployer un adaptateur de ressources manuellement
- Copier l'archive d'adaptateur de ressources dans le répertoire des déploiements de serveur,
- Pour un serveur autonome, copier l'archive d'adptateur de ressources dans le répertoire
EAP_HOME/standalone/deployments/. - Pour un domaine géré, copier l'archive d'adptateur de ressources dans le répertoire
EAP_HOME/domain/deployments/du contrôleur de domaine.
21.4. Configuration d'un adaptateur de ressources déployées
Note
[standalone@localhost:9999 /]. Ne PAS saisir le texte qui se trouve à l'intérieur des accolades. Voici la sortie que vous devriez apercevoir comme résultat, ainsi, {"outcome" => "success"}.
Procédure 21.5. Configurer un adaptateur de ressources par le Management CLI
- Ouvrir une invite de commande de votre système d'exploitation.
- Connectez-vous au Management CLI.
- Dans Linux, saisir ce qui suit au niveau de la ligne de commande :
$ EAP_HOME/bin/jboss-cli.sh --connect
Vous devriez voir le résultat de sortie suivant :$ Connected to standalone controller at localhost:9999
- Dans Windows, saisir ce qui suit au niveau de la ligne de commande :
C:\>EAP_HOME\bin\jboss-cli.bat --connect
Vous devriez voir le résultat de sortie suivant :C:\> Connected to standalone controller at localhost:9999
- Ajouter la configuration d'adaptateur de ressource.
[standalone@localhost:9999 /] /subsystem=resource-adapters/resource-adapter=eis.rar:add(archive=eis.rar, transaction-support=XATransaction) {"outcome" => "success"} - Configurer la <config-property>
serverniveau adaptateur de ressources.[standalone@localhost:9999 /] /subsystem=resource-adapters/resource-adapter=eis.rar/config-properties=server/:add(value=localhost) {"outcome" => "success"} - Configurer la <config-property>
portniveau adaptateur de ressources[standalone@localhost:9999 /] /subsystem=resource-adapters/resource-adapter=eis.rar/config-properties=port/:add(value=9000) {"outcome" => "success"} - Ajouter une définition de connexion à la fabrique de connexions gérées.
[standalone@localhost:9999 /] /subsystem=resource-adapters/resource-adapter=eis.rar/connection-definitions=cfName:add(class-name=com.acme.eis.ra.EISManagedConnectionFactory, jndi-name=java:/eis/AcmeConnectionFactory) {"outcome" => "success"} - Configurer <config-property>
portniveau usine de connexions gérées.[standalone@localhost:9999 /] /subsystem=resource-adapters/resource-adapter=eis.rar/connection-definitions=cfName/config-properties=name/:add(value=Acme Inc) {"outcome" => "success"} - Ajouter un objet admin.
[standalone@localhost:9999 /] /subsystem=resource-adapters/resource-adapter=eis.rar/admin-objects=aoName:add(class-name=com.acme.eis.ra.EISAdminObjectImpl, jndi-name=java:/eis/AcmeAdminObject) {"outcome" => "success"} - Configurer la propriété
thresholdde l'objet admin.[standalone@localhost:9999 /] /subsystem=resource-adapters/resource-adapter=eis.rar/admin-objects=aoName/config-properties=threshold/:add(value=10) {"outcome" => "success"} - Activer l'adaptateur de ressource.
[standalone@localhost:9999 /] /subsystem=resource-adapters/resource-adapter=eis.rar:activate {"outcome" => "success"} - Voir l'adaptateur de ressources nouvellement configuré et activé.
[standalone@localhost:9999 /] /subsystem=resource-adapters/resource-adapter=eis.rar:read-resource(recursive=true) { "outcome" => "success", "result" => { "archive" => "eis.rar", "beanvalidationgroups" => undefined, "bootstrap-context" => undefined, "transaction-support" => "XATransaction", "admin-objects" => {"aoName" => { "class-name" => "com.acme.eis.ra.EISAdminObjectImpl", "enabled" => true, "jndi-name" => "java:/eis/AcmeAdminObject", "use-java-context" => true, "config-properties" => {"threshold" => {"value" => 10}} }}, "config-properties" => { "server" => {"value" => "localhost"}, "port" => {"value" => 9000} }, "connection-definitions" => {"cfName" => { "allocation-retry" => undefined, "allocation-retry-wait-millis" => undefined, "background-validation" => false, "background-validation-millis" => undefined, "blocking-timeout-wait-millis" => undefined, "class-name" => "com.acme.eis.ra.EISManagedConnectionFactory", "enabled" => true, "flush-strategy" => "FailingConnectionOnly", "idle-timeout-minutes" => undefined, "interleaving" => false, "jndi-name" => "java:/eis/AcmeConnectionFactory", "max-pool-size" => 20, "min-pool-size" => 0, "no-recovery" => undefined, "no-tx-separate-pool" => false, "pad-xid" => false, "pool-prefill" => false, "pool-use-strict-min" => false, "recovery-password" => undefined, "recovery-plugin-class-name" => undefined, "recovery-plugin-properties" => undefined, "recovery-security-domain" => undefined, "recovery-username" => undefined, "same-rm-override" => undefined, "security-application" => undefined, "security-domain" => undefined, "security-domain-and-application" => undefined, "use-ccm" => true, "use-fast-fail" => false, "use-java-context" => true, "use-try-lock" => undefined, "wrap-xa-resource" => true, "xa-resource-timeout" => undefined, "config-properties" => {"name" => {"value" => "Acme Inc"}} }} } }
Procédure 21.6. Configurer un adaptateur de ressources par la Console de gestion basée-web
- Démarrer votre serveur JBoss EAP 6
- Si vous n'avez pas encore ajouté d'utilisateur, ajoutez-en un maintenant. Pour plus d'informations, voir le chapitre Getting Started du Guide d'installation de JBoss EAP 6.
- Ouvrir un navigateur web et naviguez dans la Console de gestion. L'emplacement par défaut est http://localhost:9990/console/. Pour plus d'informations sur la Console de gestion, voir Section 3.4.2, « Se conncecter à la console de gestion ».
- Cliquer sur le lien Runtime pour passer à la vue Profile, puis choisir Resource Adapters dans le panneau de navigation de gauche, et cliquer sur (Ajouter).
- Saisir le nom de l'archive et choisir le type de transaction
XATransactionà partir du menu déroulant TX:. Ensuite, cliquer sur . - Sélectionner l'onglet Properties, puis cliquer sur pour ajouter des propriétés d'adaptateur de ressources.
- Saisir le
serveurpour le Name (nom) et le nom d'ĥôte, par exemplelocalhost, pour la valeur Value. Puis cliquer sur pour sauvegarder la propriété. - Saisir le
portpour le Name (nom) et le nom d'ĥôte, par exemple9000, pour la valeur Value. Puis cliquer sur pour sauvegarder la propriété. - Les propriétés
serveretportapparaissent maintenant dans le panneau Properties. Cliquer sur le lien View (Vue) sous la colonne Option pour l'adaptateur de ressources listées pour visualiser les définitions de connexion or Connection Definitions. - Cliquer sur Add en haut et à droite de la page pour ajouter une définiton de connexion.
- Saisir le JNDI Name et le nom de classe complet de la Connection Class. Puis cliquer sur .
- Cliquer sur pour saisir la Key (clé) et la Value pour cette définition de connexion.
- Cliquer sur le champ
namedans la colonne Key pour autoriser la saisie des données sur ce champ. Saisir le nom de propriété et appuyer sur Entrée pour ce champ. Cliquer sur le champvaluedans la colonne Value pour activer la saisie sur ce champ. Saisir la valeur de la propriété et appuyer sur Entrée une fois que c'est fait. Puis, cliquer sur pour sauvegarder la propriété. - La définition de connexion est terminée, mais non activée. Cliquer sur le bouton pour activer la définition de connexion.
- Un dialogue vous demande "Souhaitez-vous réellement modifier la définition de connexion?" du nom JNDI. Cliquer sur . La définition de connexion devrait maintenant afficher
Enabled(activée). - Cliquer sur l'onglet Admin Objects qui se trouve dans la partie supérieure de la page pour créer et configurer des objets admin. Puis, cliquer sur .
- Saisir le JNDI Name et le nom de classe Class Name complet de l'objet admin. Puis cliquer sur .
- Sélectionner l'onglet Properties, puis cliquer sur pour ajouter des propriétés d'objet admin.
- Saisir une propriété de configuration d'objet admin, comme par exemple la limite
threshold, dans le champ Name (nom). Saisir la valeur de la propriété de configuration, comme par exemple10, pour la valeur Value. Puis cliquer sur pour sauvegarder la propriété. - L'objet admin est maintenant complété, mais non actif. CLiquer sur pour activer l'objet admin.
- Un dialogue vous demande "Souhaitez-vous réellement modifier l'Objet admin?" du nom JNDI. Cliquer sur . L'objet admin devrait maintenant afficher
Enabled(activé). - Vous devez charger à nouveau la configuration du serveur pour terminer ce processus. Cliquer sur le lien Runtime pour passer à la vue de Runtime, puis choisir Configuration dans le panneau de navigation de gauche, et cliquer sur (Charger à nouveau).
- Un dialogue vous demande « Souhaitez-vous charger à nouveau la configuration du serveur ? » pour le serveur indiqué ? Cliquer sur . La configuration du serveur sera à jour.
Procédure 21.7. Configurer un adaptateur de ressources manuellement
- Stopper le serveur JBoss EAP 6.
Important
Vous devez interrompre le serveur avant de modifier le fichier de configuration du serveur pour que votre changement puisse être persisté au redémarrage du serveur. - Ouvrir le fichier de configuration du serveur pour l'éditing.
- Pour les serveurs autonomes, il s'agit du fichier
EAP_HOME/standalone/configuration/standalone.xml. - Si vous exécutez dans un domaine géré, il s'agira du fichier
EAP_HOME/domain/configuration/domain.xml.
- Chercher le sous-système
urn:jboss:domain:resource-adaptersdans le fichier de configuration. - Il n'y a pas d'adaptateurs de ressources définis pour ce système. Veuillez commencer par remplacer :
<subsystem xmlns="urn:jboss:domain:resource-adapters:1.1"/>
par ceci :<subsystem xmlns="urn:jboss:domain:resource-adapters:1.1"> <resource-adapters> <!-- <resource-adapter> configuration listed below --> </resource-adapters> </subsystem> - Remplacer la configuration
<!-- <resource-adapter> listée ci-dessous -->par la définition XML de l'adaptateur de ressources. Ce qui suit représente la représentation XML de la configuration de l'adaptateur de ressources créé par le Management CLI et la Console de gestion basée-web décrite ci-dessus.<resource-adapter> <archive> eis.rar </archive> <transaction-support>XATransaction</transaction-support> <config-property name="server"> localhost </config-property> <config-property name="port"> 9000 </config-property> <connection-definitions> <connection-definition class-name="com.acme.eis.ra.EISManagedConnectionFactory" jndi-name="java:/eis/AcmeConnectionFactory" pool-name="java:/eis/AcmeConnectionFactory"> <config-property name="name"> Acme Inc </config-property> </connection-definition> </connection-definitions> <admin-objects> <admin-object class-name="com.acme.eis.ra.EISAdminObjectImpl" jndi-name="java:/eis/AcmeAdminObject" pool-name="java:/eis/AcmeAdminObject"> <config-property name="threshold"> 10 </config-property> </admin-object> </admin-objects> </resource-adapter> Démarrer ler serveur
Lancer à nouveau le serveur JBoss EAP 6 pour qu'il commence à exécuter avec la nouvelle configuration.
21.5. Référence de description d'adaptateur de ressources
Tableau 21.7. Éléments principaux
| Élément | Description |
|---|---|
bean-validation-groups | Indique le groupe de validation du bean qui doit être utilisé |
bootstrap-context | Indique le nom unique du contexte de bootstrapping qui doit être utilisé |
config-property | Config-property spécifie les propriétés de configuration de l'adaptateur de ressources. |
transaction-support | Indique le type de transactions pris en charge par l'adaptateur de ressources. La valeurs valides sont : NoTransaction, LocalTransaction, XATransaction |
connection-definitions | Indique les définitions de connexion |
admin-objects | Indique les objets d'administration |
Tableau 21.8. Éléments de groupes de validation de beans
| Élément | Description |
|---|---|
bean-validation-group | Indique le nom de classe complet d'un groupe de validation de beans devant être utilisé pour la validation. |
Tableau 21.9. Définition de connexion / attributs d'objets admin
| Attribut | Description |
|---|---|
class-name | Indique le nom de classe complet d'une usine de connexions gérée ou d'un objet admin |
jndi-name | Indique le nom JNDI |
enabled | L'objet doit-il être activé ? |
use-java-context | Indique si on doit utiliser un contexte java:/ JNDI |
pool-name | Indique le nom de pool de l'objet |
use-ccm | Active le gestionnaire de connexion mis en cache |
Tableau 21.10. Éléments de définition de connexion
| Élément | Description |
|---|---|
config-property | Config-property spécifie les propriétés de configuration de l'usine de connexions. |
pool | Indique les paramètres de pooling |
xa-pool | Indique les paramètres de pooling XA |
security | Indique les paramètres de sécurité |
timeout | Indique les paramètres de timeout |
validation | Indique les paramètres de validation |
recovery | Indique les paramètres de recouvrement XA |
Tableau 21.11. Éléments de pooling
| Élément | Description |
|---|---|
min-pool-size | L'élément min-pool-size indique le nombre minimal de connexions qu'un pool peut contenir. Celles-ci ne sont pas créées tant que l'on ne connaît pas le sujet de la demande de connexion. La valeur par défaut est 0 |
max-pool-size | L'élément max-pool-size indique le nombre maximal de connexions d'un pool. On ne pourra pas créer plus de connexions que ce nombre indiqué pour chaque sub-pool. Cette valeur par défaut est à 20. |
prefill | Indique si l'on doit essayer de pré-remplir le pool de connexion. La valeur par défaut est false. |
use-strict-min | Indique si la min-pool-size doit être considérée sérieusement. La valeur par défaut est false. |
flush-strategy | Indique comment le pool doit être vidé en cas d'erreur. Les valeurs valides sont FailingConnectionOnly (default), IdleConnections, EntirePool |
Tableau 21.12. Éléments de pool XA
| Élément | Description |
|---|---|
min-pool-size | L'élément min-pool-size indique le nombre minimal de connexions qu'un pool peut contenir. Celles-ci ne sont pas créées tant que l'on ne connaît pas le sujet de la demande de connexion. La valeur par défaut est 0 |
max-pool-size | L'élément max-pool-size indique le nombre maximal de connexions d'un pool. On ne pourra pas créer plus de connexions que ce nombre indiqué pour chaque sub-pool. Cette valeur par défaut est à 20. |
prefill | Indique si l'on doit essayer de pré-remplir le pool de connexion. La valeur par défaut est false. |
use-strict-min | Indique si la min-pool-size doit être considérée sérieusement. La valeur par défaut est false. |
flush-strategy | Indique comment le pool doit être vidé en cas d'erreur. Les valeurs valides sont FailingConnectionOnly (default), IdleConnections, EntirePool |
is-same-rm-override | L'élément is-same-rm-override element permet de définir inconditionnellement si javax.transaction.xa.XAResource.isSameRM(XAResource) doit renvoyer true ou false |
interleaving | Élément qui permet ou non l'entrelacement des usines de connexions XA |
no-tx-separate-pools | Oracle n'aime pas que les connexions XA soient utilisées à la fois à l'intérieur et à l'extérieur d'une connexion JTA. Pour résoudre ce problème, vous pourrez créer des sub-pools pour ces contextes différents. |
pad-xid | Est-ce que le Xid doit être mis en tampon ? |
wrap-xa-resource | Est-ce que les instances XAResource doivent être encapsulées dans une instance org.jboss.tm.XAResourceWrapper |
Tableau 21.13. Éléments de sécurité
| Élément | Description |
|---|---|
application | Indique si les paramètres de sécurité fournis comme getConnection(user, pw) sont utilisés pour distinguer les connexions d'un pool. |
security-domain | Indique si des Sujets (de domaine de sécurité) sont utilisés pour distinguer les connexions d'un pool. Le contenu du domaine de sécurité correspond au nom du gestionnaire de sécurité JAAS qui gère l'authentification. Ce nom est en corrélation à l'attribut « JAAS login-config.xml descriptor application-policy/name ». |
security-domain-and-application | Indique que les paramètres de l'application fournis, par exemple, à partir de getConnection (utilisateur, pw)) ou que le Sujet (du domaine de la sécurité) soient utilisés pour distinguer les connexions du pool. Le contenu du domaine de sécurité est le nom du gestionnaire de sécurité JAAS qui gère l'authentification. Ce nom correspond à l'attribut « JAAS login-config.xml descriptor application-policy/name ». |
Tableau 21.14. Éléments de timeout
| Élément | Description |
|---|---|
blocking-timeout-millis | L'élément « blocking-timeout-millis » indique la durée maximale en millisecondes de blocage pendant que vous attendez une connexion, avant de lever une exception. Notez que cela bloque uniquement pendant que vous attendez un permis de connexion, et ne soulèvera pas d'exception si la création d'une nouvelle connexion prend un temps excessivement long. La valeur par défaut est 30000 (30 secondes). |
idle-timeout-minutes | Les éléments idle-timeout-minutes indiquent la durée maximum, en minutes, avant qu'une connexion inutile puisse être fermée. La durée maximum dépend du temps de balayage de l'idleRemover, qui correspond à la moitié du temps « idle-timeout-minutes » le plus petit de n'importe quel pool. |
allocation-retry | Cet élément de tentative d'allocation indique le nombre de fois que l'on doit allouer un connexion avant de lancer une exception. La valeur par défaut est 0. |
allocation-retry-wait-millis | Le temps, en millisecondes, qu'il faut attendre avant de retenter d'allouer une connexion. La valeur par défaut est 5 000, soit 5 secondes. |
xa-resource-timeout | Passé à XAResource.setTransactionTimeout(). La valeur par défaut est 0 sans invoquer le setter. Indiqué en secondes. |
Tableau 21.15. Éléments de validation
| Élément | Description |
|---|---|
background-validation | Élément pour spécifier que les connexions doivent être validées en arrière-plan plutôt qu'avant utilisation |
background-validation-minutes | L'élément « background-validation-minutes » indique la durée, en minutes, d'exécution de la validation d'arrière-plan. |
use-fast-fail | Indique s'il y a échec d'allocation de connexion à la première connexion si invalide (true) ou s'il y a de nouvelles tentatives jusqu'à ce que le pool soit épuisé de tout essai de connexion possible (false). La valeur par défaut est false. |
Tableau 21.16. Éléments d'objets admin
| Élément | Description |
|---|---|
config-property | Spécifie une propriété de configuration d'objet d'administration. |
Tableau 21.17. Éléments de recouvrement
| Élément | Description |
|---|---|
recover-credential | Indique la paire nom / mot de passe ou le domaine de sécurité qui doit être utilisé pour le recouvrement. |
recover-plugin | Spécifie l'implémentation de org.jboss.jca.core.spi.recovery.RecoveryPlugin class. |
jboss-as-resource-adapters_1_0.xsd et http://www.ironjacamar.org/doc/schema/ironjacamar_1_0.xsd pour l'activation automatique.
21.6. Affichages des statistiques de connexion
deployment=name.rar.
/subsystem afin d'être accessible à partir de tout rar non défini dans les configurations de fichiers standalone.xml ou domain.xml.
Exemple 21.1.
/deployment=example.rar/subsystem=resource-adapters/statistics=statistics/connection-definitions=java\:\/testMe:read-resource(include-runtime=true)
Note
include-runtime=true et à ce que tous les statistiques soient en runtime uniquement et la valeur par défaut est false.
21.7. Statistiques d'adaptateur de ressources
Le tableau suivant contient une liste de statistiques principaux d'adaptateurs de ressources pris en charge :
Tableau 21.18. Statistiques principaux
| Nom | Description |
|---|---|
ActiveCount |
Le nombre de connexions actives. Chacune de ces connexions est soit utilisée par une application, ou disponible via pool
|
AvailableCount |
Le nombre de connexions disponibles dans le pool
|
AverageBlockingTime |
Le durée moyenne passée à bloquer l'obtention d'un verrou exclusif sur le pool. La valeur est en millisecondes.
|
AverageCreationTime |
Le durée moyenne passée à créer une connexion. La valeur est en millisecondes.
|
CreatedCount |
Le nombre de connexions créées.
|
DestroyedCount |
Le nombre de connexions détruites.
|
InUseCount |
Le nombre de connexions actuellement utilisées.
|
MaxCreationTime |
La durée maximum pour créer une connexion. La valeur est en millisecondes.
|
MaxUsedCount |
Le nombre maximum de connexions utilisées
|
MaxWaitCount |
Le nombre maximum de requêtes attendant une connexion en même temps.
|
MaxWaitTime |
Le durée maximum à attendre un verrou exclusif sur le pool.
|
TimedOut |
Le nombre de connexions expirées
|
TotalBlockingTime |
Le durée à attendre un verrou exclusif sur le pool. La valeur est en millisecondes.
|
TotalCreationTime |
La durée passée à créer des connexions. La valeur est en millisecondes.
|
WaitCount |
Le nombre de requêtes en attente de connexion.
|
21.8. Déployer l'adaptateur de ressources WebSphere MQ
WebSphere MQ est un logiciel de messagerie Oriented Middleware (MOM) d'IBM qui permet à des applications sur des systèmes distribués à communiquer entre eux. Ceci est accompli grâce à l'utilisation des messages et des files d'attente de messages. WebSphere MQ est chargé de remettre des messages à des files d'attente de messages et pour transférer des données à d'autres gestionnaires de file d'attente à l'aide de canaux de message. Pour plus d'informations sur WebSphere MQ, voir WebSphere MQ.
Cette section couvre les étapes à suivre pour déployer et configurer l'adaptateur de ressource Websphere MQ dans JBoss EAP 6. Cela peut se faire manuellement en modifiant les fichiers de configuration, par le Management CLI, ou par la Console de gestion basée-web.
Avant de démarrer, vous devrez vérifier votre version d'adaptateur de ressource WebSphere MQ et comprendre certaines propriétés de configuration de WebSphere MQ.
- L'adaptateur de ressources WebSphere MQ est fourni en tant que fichier RAR (Resource Archive) nommé
wmq.jmsra-VERSION.rar. Vous devrez utiliser la version7.0.1.7ou version supérieure. - Vous devez connaître les valeurs des propriétés de configuration Websphere MQ suivantes. Voir la documentation de produit WebSphere MQ pour obtenir des détails sur ces propriétés.
- MQ.QUEUE.MANAGER: le nom du gestionnaires de files d'attentes de WebSphere MQ
- MQ.HOST.NAME: le nom d'hôte utilisé pour se connecter au gestionnaire de files d'attente de WebSphere MQ
- MQ.CHANNEL.NAME: le canal de serveur utilisé pour se connecter au gestionnaire de files d'attente de WebSphere MQ
- MQ.QUEUE.NAME: le nom de la file d'attente de destination
- MQ.PORT: le port utilisé pour se connecter au gestionnaire de files d'attente de WebSphere MQ
- MQ.CLIENT: le type de transport
- Pour les connexions sortantes, vous devrez vous familiariser avec la propriété de configuration suivante :
- MQ.CONNECTIONFACTORY.NAME: le nom de l'instance d'usine de connexion qui fournit la connexion vers le système à distance.
Note
Procédure 21.8. Déployer l'adaptateur de ressources manuellement
- Si vous avez besoin d'un support de transactions avec l'adaptateur de ressources de WebSphereMQ, vous devrez re-paquager l'archive
wmq.jmsra-VERSION.rarpour qu'elle incluemqetclient.jar. Vous devrez utiliser la commande suivante :[user@host ~]$
Soyez certain de remplacer VERSION par le numéro de version correct.jar -uf wmq.jmsra-VERSION.rar mqetclient.jar - Copier le fichier
wmq.jmsra-VERSION.rardans le répertoireEAP_HOME/standalone/deployments/. - Ajouter l'adaptateur de ressources au fichier de configuration du serveur.
- Ouvrir le fichier
EAP_HOME/standalone/configuration/standalone-full.xmldans un éditeur. - Chercher le sous-système
urn:jboss:domain:resource-adaptersdans le fichier de configuration. - Il n'y a pas d'adaptateurs de ressources définis pour ce système. Veuillez commencer par remplacer :
<subsystem xmlns="urn:jboss:domain:resource-adapters:1.1"/>
par ceci :<subsystem xmlns="urn:jboss:domain:resource-adapters:1.1"> <resource-adapters> <!-- <resource-adapter> configuration listed below --> </resource-adapters> </subsystem> - La configuration de l'adaptateur de ressources dépend de si vous avez besoin de la restauration et du support de transactions. Si vous n'avez pas besoin de support de transaction, choisissez la première étape de configuration ci-dessous. Si vous avez besoin de support de transaction, choisissez la deuxième étape de la configuration.
- Pour les déploiements non transactionnels, veuillez remplacer la configuration
<!-- <resource-adapter> listée ci-dessous -->par ce qui suit :<resource-adapter> <archive> wmq.jmsra-VERSION.rar </archive> <transaction-support>NoTransaction</transaction-support> <connection-definitions> <connection-definition class-name="com.ibm.mq.connector.outbound.ManagedConnectionFactoryImpl" jndi-name="java:jboss/MQ.CONNECTIONFACTORY.NAME" pool-name="MQ.CONNECTIONFACTORY.NAME"> <config-property name="channel"> MQ.CHANNEL.NAME </config-property> <config-property name="transportType"> MQ.CLIENT </config-property> <config-property name="queueManager"> MQ.QUEUE.MANAGER </config-property> <security> <security-domain>MySecurityDomain</security-domain> </security> </connection-definition> </connection-definitions> <admin-objects> <admin-object class-name="com.ibm.mq.connector.outbound.MQQueueProxy" jndi-name="java:jboss/MQ.QUEUE.NAME" pool-name="MQ.QUEUE.NAME"> <config-property name="baseQueueName"> MQ.QUEUE.NAME </config-property> </admin-object> </admin-objects> </resource-adapter>Soyez certain de remplacer VERSION par le numéro de version correct qui se trouve dans le nom du RAR. - Pour les déploiements transactionnels, veuillez remplacer la configuration
<!-- <resource-adapter> listée ci-dessous -->par ce qui suit :<resource-adapter> <archive> wmq.jmsra-VERSION.rar </archive> <transaction-support>XATransaction</transaction-support> <connection-definitions> <connection-definition class-name="com.ibm.mq.connector.outbound.ManagedConnectionFactoryImpl" jndi-name="java:jboss/MQ.CONNECTIONFACTORY.NAME" pool-name="MQ.CONNECTIONFACTORY.NAME"> <config-property name="channel"> MQ.CHANNEL.NAME </config-property> <config-property name="transportType"> MQ.CLIENT </config-property> <config-property name="queueManager"> MQ.QUEUE.MANAGER </config-property> <security> <security-domain>MySecurityDomain</security-domain> </security> <recovery> <recover-credential> <user-name>USER_NAME</user-name> <password>PASSWORD</password> </recover-credential> </recovery> </connection-definition> </connection-definitions> <admin-objects> <admin-object class-name="com.ibm.mq.connector.outbound.MQQueueProxy" jndi-name="java:jboss/MQ.QUEUE.NAME" pool-name="MQ.QUEUE.NAME"> <config-property name="baseQueueName"> MQ.QUEUE.NAME </config-property> </admin-object> </admin-objects> </resource-adapter>Soyez certain de remplacer VERSION par le numéro de version correct qui se trouve dans le nom du RAR. Vous devrez également remplacer USER_NAME et PASSWORD avec le nom et le mot de passe valides.Note
Pour supporter les transactions, l'élément <transaction-support> a été défini àXATransaction. Pour supporter XA recovery, l'élément <recovery> a été ajouté à une définition de connexion.
- Si vous souhaitez changer le fournisseur par défaut en système de messagerie EJB3 dans JBoss EAP 6 de HornetQ vers WebSphere MQ, modifier le sous-système
urn:jboss:domain:ejb3:1.2comme suit :Remplacer :<mdb> <resource-adapter-ref resource-adapter-name="hornetq-ra"/> <bean-instance-pool-ref pool-name="mdb-strict-max-pool"/> </mdb>par :<mdb> <resource-adapter-ref resource-adapter-name="wmq.jmsra-VERSION.rar"/> <bean-instance-pool-ref pool-name="mdb-strict-max-pool"/> </mdb>Soyez certain de remplacer VERSION par le numéro de version correct qui se trouve dans le nom du RAR.
Procédure 21.9. Modifier le code MDB pour utiliser l'adaptateur de ressources
- Configurer ActivationConfigProperty et ResourceAdapter du code MDB comme suit :
@MessageDriven( name="WebSphereMQMDB", activationConfig = { @ActivationConfigProperty(propertyName = "destinationType",propertyValue = "javax.jms.Queue"), @ActivationConfigProperty(propertyName = "useJNDI", propertyValue = "false"), @ActivationConfigProperty(propertyName = "hostName", propertyValue = "MQ.HOST.NAME"), @ActivationConfigProperty(propertyName = "port", propertyValue = "MQ.PORT"), @ActivationConfigProperty(propertyName = "channel", propertyValue = "MQ.CHANNEL.NAME"), @ActivationConfigProperty(propertyName = "queueManager", propertyValue = "MQ.QUEUE.MANAGER"), @ActivationConfigProperty(propertyName = "destination", propertyValue = "MQ.QUEUE.NAME"), @ActivationConfigProperty(propertyName = "transportType", propertyValue = "MQ.CLIENT") }) @ResourceAdapter(value = "wmq.jmsra-VERSION.rar") @TransactionAttribute(TransactionAttributeType.NOT_SUPPORTED) public class WebSphereMQMDB implements MessageListener { }Soyez certain de remplacer VERSION par le numéro de version correct qui se trouve dans le nom du RAR.
21.9. Configurer un Adaptateur de ressources JMS standard à utiliser avec un Fournisseur JMS de tierce partie
JBoss EAP 6 peut être configuré pour fonctionner avec des fournisseurs tiers de JMS, cependant tous les fournisseurs JMS ne produisent pas un adaptateur de ressources JMS JCA pour l'intégration avec les plateformes d'applications Java. Cette procédure couvre les étapes requises pour configurer l'adaptateur de ressources JMS générique inclus dans JBoss EAP 6 pour se connecter à un fournisseur JMS. Dans cette procédure, Tibco EMS 6.3 est utilisé comme un exemple de fournisseur JMS, mais d'autres fournisseurs JMS peuvent avoir besoin d'une configuration différente.
Important
Cette procédure suppose qu'un serveur de fournisseur JMS est déjà configuré et prêt à l'emploi. Les binaires nécessaires à l'implémentation du fournisseur JMS seront nécessaires. Vous devez également connaître les valeurs des propriétés de fournisseur JMS suivantes :
- PROVIDER_HOST:PROVIDER_PORT: le nom d'hôte et le numéro de port du serveur de fournisseur JMS.
- PROVIDER_CONNECTION_FACTORY: le nom de l'usine de connexions du JMS fourni.
- PROVIDER_QUEUE, PROVIDER_TOPIC: les noms des files d'attente et des sujets de fournisseurs JMS qui doivent être utilisés.
Procédure 21.10. Configuration d'un Adaptateur de ressources générique JMS
- Créer une implémentation
ObjectFactorypour la liaison de files d'attentes et de sujets JNDI :- En utilisant le code ci-dessous comme modèle, remplacer les informations serveur par les valeurs de serveur du fournisseur JMS.
import java.util.Hashtable; import java.util.Properties; public class RemoteJMSObjectFactory implements ObjectFactory { private Context context = null; public RemoteJMSObjectFactory() { } public Object getObjectInstance(Object obj, Name name, Context nameCtx, Hashtable<?, ?> environment) throws Exception { try { String jndi = (String) obj; final Properties env = new Properties(); env.put(Context.INITIAL_CONTEXT_FACTORY, "com.tibco.tibjms.naming.TibjmsInitialContextFactory"); env.put(Context.URL_PKG_PREFIXES, "com.tibco.tibjms.naming"); env.put(Context.PROVIDER_URL, "tcp://TIBCO_HOST:TIBCO_PORT"); context = new InitialContext(env); Object o = context.lookup(jndi); return o; } catch (NamingException e) { e.printStackTrace(); throw e; } } } - Compiler le code ci-dessus, et sauvegarder le fichier de classe résultant dans un fichier JAR nommé
remoteJMSObjectFactory.jar
- Créer un module
genericjmspour votre instance JBoss EAP 6 :- Créer la structure de répertoire suivante :
EAP_HOME/modules/system/layers/base/org/jboss/genericjms/provider/main - Copier le fichier
remoteJMSObjectFactory.jardansEAP_HOME/modules/system/layers/base/org/jboss/genericjms/provider/main - Copier les binaires requis pour l'implémentation JMS du fournisseur dans
EAP_HOME/modules/system/layers/base/org/jboss/genericjms/provider/main. Pour Tibco EMS, les binaires requis sonttibjms.jarettibcrypt.jardu répertoire/libde l'installation Tibco. - Créer un fichier
module.xmldansEAP_HOME/modules/system/layers/base/org/jboss/genericjms/provider/maincomme ci-dessous, en énumérant les fichiers JAR des étapes précédentes comme ressources :<module xmlns="urn:jboss:module:1.1" name="org.jboss.genericjms.provider"> <resources> <resource-root path="tibjms.jar"/> <resource-root path="tibcrypt.jar"/> <resource-root path="remoteJMSObjectFactory.jar"/> </resources> <dependencies> <module name="javax.api"/> <module name="javax.jms.api"/> </dependencies> </module>
- Ajouter le module JMS générique comme une dépendance pour tous les déploiements en tant que modules globaux.
Note
Dans cette procédure,EAP_HOME/standalone/configuration/standalone-full.xmlest utilisé comme fichier de configuration JBoss EAP 6.DansEAP_HOME/standalone/configuration/standalone-full.xml, sous<subsystem xmlns="urn:jboss:domain:ee:1.1">,ajouter:<global-modules> <module name="org.jboss.genericjms.provider" slot="main"/> <module name="org.jboss.common-core" slot="main"/> </global-modules>
- Remplacer l'adaptateur de ressources HornetQ par défaut par l'adaptateur de ressources générique.Dans
EAP_HOME/standalone/configuration/standalone-full.xml, remplacer<subsystem xmlns="urn:jboss:domain:ejb3:1.4"> <mdb>, par:<mdb> <resource-adapter-ref resource-adapter-name="org.jboss.genericjms"/> <bean-instance-pool-ref pool-name="mdb-strict-max-pool"/> </mdb>
- Ajouter les liaisons pour vos files d'attente et sujets JMS en tant qu'objets selon les besoins.Dans
EAP_HOME/standalone/configuration/standalone-full.xml, under<subsystem xmlns="urn:jboss:domain:naming:1.3">, ajouter les liaisons, remplaçant PROVIDER_QUEUE et PROVIDER_TOPIC selonles besoins :<bindings> <object-factory name="PROVIDER_QUEUE" module="org.jboss.genericjms.provider" class="org.jboss.qa.RemoteJMSObjectFactory"/> <object-factory name="PROVIDER_TOPIC" module="org.jboss.genericjms.provider" class="org.jboss.qa.RemoteJMSObjectFactory"/> </bindings>
- Dans
EAP_HOME/standalone/configuration/standalone-full.xml, ajouter la configuration d'adaptateur de ressources générique dans<subsystem xmlns="urn:jboss:domain:resource-adapters:1.1">.Remplacer PROVIDER_CONNECTION_FACTORY, PROVIDER_HOST, et PROVIDER_PORT par les valeurs du fournisseur JMS.<resource-adapters> <resource-adapter id="org.jboss.genericjms"> <module slot="main" id="org.jboss.genericjms"/> <transaction-support>NoTransaction</transaction-support> <connection-definitions> <connection-definition class-name="org.jboss.resource.adapter.jms.JmsManagedConnectionFactory" jndi-name="java:/jms/PROVIDER_CONNECTION_FACTORY" pool-name="PROVIDER_CONNECTION_FACTORY"> <config-property name="JndiParameters"> java.naming.factory.initial=com.tibco.tibjms.naming.TibjmsInitialContextFactory;java.naming.provider.url=tcp://PROVIDER_HOST:PROVIDER_PORT </config-property> <config-property name="ConnectionFactory"> PROVIDER_CONNECTION_FACTORY </config-property> <security> <application/> </security> </connection-definition> </connection-definitions> </resource-adapter> </resource-adapters>
L'adaptateur de ressources JMS est maintenant configuré et prêt à l'utilisation.
@MessageDriven(activationConfig = {
@ActivationConfigProperty(propertyName = "destinationType", propertyValue = "javax.jms.Queue"),
@ActivationConfigProperty(propertyName = "jndiProperties", propertyValue = "java.naming.factory.initial=com.tibco.tibjms.naming.TibjmsInitialContextFactory;java.naming.provider.url=tcp://PROVIDER_HOST:PROVIDER_PORT")
@ActivationConfigProperty(propertyName = "destination", propertyValue = "PROVIDER_QUEUE"),
@ActivationConfigProperty(propertyName = "connectionFactory", propertyValue = "PROVIDER_CONNECTION_FACTORY"),
})
@ResourceAdapter("generic-jms-ra.rar")
public class SampleMdb implements MessageListener {
@Override
public void onMessage(Message message) {
}
}
Chapitre 22. Déployer JBoss EAP 6 dans Amazon EC2
22.1. Introduction
22.1.1. Amazon EC2
22.1.2. Amazon Machine Instances (AMIs)
22.1.3. JBoss Cloud Access
22.1.4. Fonctionnalités de JBoss Cloud Access
- Red Hat Enterprise Linux 6
- JBoss EAP 6
- L'agent JBoss Operations Network (JON) 3
- Mises à jour de produit par les RPM par l'intermédiaire de l'infrastructure de mise à jour de Red Hat.
Important
22.1.5. Types d'instances Amazon EC2 prises en charge
Tableau 22.1. Types d'instances Amazon EC2 prises en charge
| Type d'instance | Description |
|---|---|
| Instance standard |
Les instances standard sont des environnements d'ordre général ayant un ratio de mémoire-à-CPU équilibré.
|
| Instance de mémoire élevée |
Les Instances de mémoire élevée possède davantage de mémoire allouée que les Instances standard. Les Instances de mémoire élevée conviennent aux applications à haut débit telles que les bases de données ou les applications de mise en cache de mémoire.
|
| Instance Haut CPU |
Les Instance Haut CPU ont davantage de ressources CPU allouées que de mémoire et conviennent à des débits moindres mais à des applications intensives en CPU.
|
Important
Micro (t1.micro) ne convient pas au déploiement de la plateforme JBoss EAP 6.
22.1.6. AMI Red Hat pris en charge
RHEL-osversion-JBEAP-6.0.0-arch-creationdate
6.2.
x86_64 ou i386.
20120501.
RHEL-6.2-JBEAP-6.0.0-x86_64-20120501.
22.2. Déployer JBoss EAP 6 dans Amazon EC2
22.2.1. Aperçu du déploiement de JBoss EAP 6 sur Amazon EC2
- Red Hat Enterprise Linux 6, https://access.redhat.com/site/documentation/Red_Hat_Enterprise_Linux/.
- Amazon Web Services, http://aws.amazon.com/documentation/.
22.2.2. JBoss EAP 6 non clusterisée
22.2.2.1. Instances non-clusterisées
22.2.2.2. Instances non clusterisées
22.2.2.2.1. Lancer l'instance de JBoss EAP 6 non clusterisée
Ce sujet couvre les étapes requises pour lancer une instance de JBoss EAP 6 non clusterisée sur Red Hat AMI (Amazon Machine Image).
Prérequis
- Pour un AMI Red Hat qui convient, consulter Section 22.1.6, « AMI Red Hat pris en charge ».
- Groupe de sécurité pré-configuré qui autorise les requêtes entrantes sur les ports 22, 8080, et 9990 au moins.
Procédure 22.1. Lancer une instance non clusterisée de JBoss EAP 6 sur Red Hat AMI (Amazon Machine Image).
- Configurer le champ
User Data. Les paramètres configurables sont disponibles ici : Section 22.4.1, « Paramètres de configuration permanente », Section 22.4.2, « Paramètres de scripts personnalisés ».Exemple 22.1. Exemple de champ de données utilisateur
L'exemple montre le champ de données utilisateur d'une instance JBoss EAP 6 non clusterisée. Le mot de passe de l'utilisateuradmina été défini àadminpwd.JBOSSAS_ADMIN_PASSWORD=adminpwd JBOSS_IP=0.0.0.0 #listen on all IPs and interfaces # In production, access to these ports needs to be restricted for security reasons PORTS_ALLOWED="9990 9443" cat> $USER_SCRIPT << "EOF" # Get the application to be deployed from an Internet URL # mkdir -p /usr/share/java/jboss-ec2-eap-applications # wget https://<your secure storage hostname>/<path>/<app name>.war -O /usr/share/java/jboss-ec2-eap-applications/<app name>.war # Create a file of CLI commands to be executed after starting the server cat> $USER_CLI_COMMANDS << "EOC" # deploy /usr/share/java/jboss-ec2-eap-applications/<app name>.war EOC EOF
Pour les instances de production
Pour une instance de production, ajouter la ligne suivante sous la ligneUSER_SCRIPTdu champUser Datapour que les mises à jour de sécurité s'appliquent à l'amorçage.yum -y update
Note
yum -y updatesoit être exécuté régulièrement, pour appliquer les correctifs de sécurité et les améliorations.- Lancement de l'instance AMI Red Hat
Une instance non clusterisée de JBoss EAP 6 a été configurée, et lancée sur un AMI Red Hat.
22.2.2.2.2. Déployer une Application sur une instance de JBoss EAP 6 non clusterisée
Ce sujet couvre le déploiement d'une application sur une instance de JBoss EAP 6 sur un AMI Red Hat.
Déploiement d'un exemple d'application
Ajouter les lignes suivantes au champUser Data:# Deploy the sample application from the local filesystem deploy --force /usr/share/java/jboss-ec2-eap-samples/hello.war
Exemple 22.2. Champs de données d'utilisateur avec l'exemple d'application
Cet exemple utilise l'exemple d'application fourni sur l'AMI Red Hat. Il inclut également une configuration de base d'une instance non clusterisée de JBoss EAP 6. Le mot de passeadminde l'utilisateur a été défini àadminpwd.JBOSSAS_ADMIN_PASSWORD=adminpwd JBOSS_IP=0.0.0.0 #listen on all IPs and interfaces # In production, access to these ports needs to be restricted for security reasons PORTS_ALLOWED="9990 9443" cat> $USER_SCRIPT << "EOF" # Create a file of CLI commands to be executed after starting the server cat> $USER_CLI_COMMANDS << "EOC" # Deploy the sample application from the local filesystem deploy --force /usr/share/java/jboss-ec2-eap-samples/hello.war EOC EOF
Déployer une application personnalisée
Ajouter les lignes suivantes au champUser Data(données utilisateur), pour configurer le nom de l'URL de l'application :# Get the application to be deployed from an Internet URL mkdir -p /usr/share/java/jboss-ec2-eap-applications wget https://<your secure storage hostname>/<path>/<app name>.war -O /usr/share/java/jboss-ec2-eap-applications/<app name>.war
Exemple 22.3. Exemple de champ de données utilisateur avec application personnalisée
Cet exemple utilise une application nomméeMyApp, et inclut une configuration de base pour une instance JBoss EAP 6 non clusterisée. Le mot de passeadminde l'utilisateur a été défini àadminpwd.JBOSSAS_ADMIN_PASSWORD=adminpwd JBOSS_IP=0.0.0.0 #listen on all IPs and interfaces # In production, access to these ports needs to be restricted for security reasons PORTS_ALLOWED="9990 9443" cat> $USER_SCRIPT << "EOF" # Get the application to be deployed from an Internet URL mkdir -p /usr/share/java/jboss-ec2-eap-applications wget https://PATH_TO_MYAPP/MyApp.war -O /usr/share/java/jboss-ec2-eap-applications/MyApp.war # Create a file of CLI commands to be executed after starting the server cat> $USER_CLI_COMMANDS << "EOC" deploy /usr/share/java/jboss-ec2-eap-applications/MyApp.war EOC EOF
- Lancement de l'instance AMI Red Hat
L'application a été déployée avec succès dans JBoss EAP 6.
22.2.2.2.3. Lancer l'instance de JBoss EAP 6 non clusterisée
Cette rubrique couvre les étapes nécessaires pour tester la plateforme non clusterisée de JBoss EAP 6.
Procédure 22.2. Vérifier que l'instance de JBoss EAP 6 non clusterisée exécute correctement
- Déterminer le
Public DNSde l'instance, qui se situe dans le panneau d'informations de l'instance. - Naviguer dans
http://<public-DNS>:8080. - Confirmer que la page d'accueil de JBoss EAP apparaît, y compris le lien vers la Console admin. Si la page d'accueil n'est pas disponible, consulter : Section 22.5.1, « Résolution de problèmes dans Amazon EC2 ».
- Cliquer sur l'hyperlien Admin Console.
- Se connecter :
- Nom d'utilisateur :
admin - Mot de passe : Spécifié dans le champ
User Dataici : Section 22.2.2.2.1, « Lancer l'instance de JBoss EAP 6 non clusterisée ».
Tester l'exemple d'application
Naviguer danshttp://<public-DNS>:8080/hellopour tester que l'exemple d'application exécute avec succès. Le texteHello World!doit apparaître dans le navigateur. Si le texte n'apparait pas, voir : Section 22.5.1, « Résolution de problèmes dans Amazon EC2 ».- Se déconnecter de la console admin de JBoss EAP.
L'instance de JBoss EAP 6 exécute correctement.
22.2.2.3. Domaines gérés non clusterisés
22.2.2.3.1. Lancer une instance pour qu'elle serve en tant que Contrôleur de domaine
Cette rubrique couvre les étapes requises pour lancer un domaine géré non clusterisé de JBoss EAP 6 sur une AMI Red Hat (Amazon Machine Image)
Prérequis
- Pour un AMI Red Hat qui convient, consulter Section 22.1.6, « AMI Red Hat pris en charge ».
Procédure 22.3. Lancer un domaine géré de JBoss EAP 6 non clusterisé sur AMI Red Hat
- Dans l'onglet Groupe de sécurité, veillez bien à ce que tout le trafic soit autorisé. Les capacités de pare-feu intégrées de Red Hat Enterprise Linux peuvent être utilisées pour restreindre l'accès si nécessaire.
- Définir le sous-réseau public du VPC à running.
- Sélectionner un IP statique.
- Configurer le champ
User Data. Les paramètres configurables sont disponibles ici : Section 22.4.1, « Paramètres de configuration permanente », Section 22.4.2, « Paramètres de scripts personnalisés ».Exemple 22.4. Exemple de champ de données utilisateur
L'exemple montre le champ de données utilisateur d'un domaine géré de JBoss EAP 6 non clusterisé. Le mot de passe de l'utilisateuradmina été défini suradmin.## password that will be used by slave host controllers to connect to the domain controller JBOSSAS_ADMIN_PASSWORD=admin ## subnet prefix this machine is connected to SUBNET=10.0.0. #### to run the example no modifications below should be needed #### JBOSS_DOMAIN_CONTROLLER=true PORTS_ALLOWED="9999 9990 9443" JBOSS_IP=`hostname | sed -e 's/ip-//' -e 'y/-/./'` #listen on public/private EC2 IP address cat > $USER_SCRIPT << "EOF" ## Get the application to be deployed from an Internet URL # mkdir -p /usr/share/java/jboss-ec2-eap-applications # wget https://<your secure storage hostname>/<path>/<app name>.war -O /usr/share/java/jboss-ec2-eap-applications/<app name>.war ## Create a file of CLI commands to be executed after starting the server cat> $USER_CLI_COMMANDS << "EOC" # Add the modcluster subsystem to the default profile to set up a proxy /profile=default/subsystem=web/connector=ajp:add(name=ajp,protocol=AJP/1.3,scheme=http,socket-binding=ajp) /:composite(steps=[ {"operation" => "add", "address" => [ ("profile" => "default"), ("subsystem" => "modcluster") ] },{ "operation" => "add", "address" => [ ("profile" => "default"), ("subsystem" => "modcluster"), ("mod-cluster-config" => "configuration") ], "advertise" => "false", "proxy-list" => "${jboss.modcluster.proxyList}", "connector" => "ajp"}, { "operation" => "add", "address" => [ ("profile" => "default"), ("subsystem" => "modcluster"), ("mod-cluster-config" => "configuration"), ("dynamic-load-provider" => "configuration") ]}, { "operation" => "add", "address" => [ ("profile" => "default"), ("subsystem" => "modcluster"), ("mod-cluster-config" => "configuration"), ("dynamic-load-provider" => "configuration"), ("load-metric" => "busyness")], "type" => "busyness"} ]) # Deploy the sample application from the local filesystem deploy /usr/share/java/jboss-ec2-eap-samples/hello.war --server-groups=main-server-group EOC ## this will workaround the problem that in a VPC, instance hostnames are not resolvable echo -e "127.0.0.1\tlocalhost.localdomain localhost" > /etc/hosts echo -e "::1\tlocalhost6.localdomain6 localhost6" >> /etc/hosts for (( i=1 ; i<255 ; i++ )); do echo -e "$SUBNET$i\tip-${SUBNET//./-}$i" ; done >> /etc/hosts EOF Pour les instances de production
Pour une instance de production, ajouter la ligne suivante sous la ligneUSER_SCRIPTdu champUser Datapour que les mises à jour de sécurité s'appliquent à l'amorçage.yum -y update
Note
yum -y updatedoit être exécuté régulièrement pour appliquer les correctifs de sécurité et les améliorations.- Lancement de l'instance AMI Red Hat
Un domaine géré non clusterisé de JBoss EAP 6 a été configuré, et lancé sur une AMI Red Hat.
22.2.2.3.2. Lancer une ou plusieurs instances pour qu'elles servent en tant que contrôleurs d'hôtes
Cette rubrique couvre les étapes requises pour lancer une ou plusieurs instances de JBoss EAP 6 en tant que contrôleurs d'hôtes non clusterisée sur Red Hat AMI (Amazon Machine Image).
Prérequis
- Configurer et lancer le contrôleur de domaine non clusterisé. Consulter Section 22.2.2.3.1, « Lancer une instance pour qu'elle serve en tant que Contrôleur de domaine » .
Procédure 22.4. Lancer les contrôleurs d'hôte
- Sélectionner un AMI.
- Définir le nombre d'instances que vous souhaitez (le nombre de contrôleurs hôtes esclaves)
- Sélectionner le VPC et le type d'instance.
- Cliquer sur le Groupe de sécurité.
- Veillez à ce que tout le trafic en provenance du sous-système de JBoss EAP 6 soit autorisé.
- Définir les autres restrictions suivant les besoins.
- Ajouter ce qui suit dans le champ User Data :
## mod cluster proxy addresses MOD_CLUSTER_PROXY_LIST=10.0.0.4:7654 ## host controller setup JBOSS_DOMAIN_MASTER_ADDRESS=10.0.0.5 JBOSS_HOST_PASSWORD=<password for slave host controllers> ## subnet prefix this machine is connected to SUBNET=10.0.1. #### to run the example no modifications below should be needed #### JBOSS_HOST_USERNAME=admin PORTS_ALLOWED="1024:65535" JBOSS_IP=`hostname | sed -e 's/ip-//' -e 'y/-/./'` #listen on public/private EC2 IP address cat > $USER_SCRIPT << "EOF" ## Server instance configuration sed -i "s/other-server-group/main-server-group/" $JBOSS_CONFIG_DIR/$JBOSS_HOST_CONFIG ## this will workaround the problem that in a VPC, instance hostnames are not resolvable echo -e "127.0.0.1\tlocalhost.localdomain localhost" > /etc/hosts echo -e "::1\tlocalhost6.localdomain6 localhost6" >> /etc/hosts for (( i=1 ; i<255 ; i++ )); do echo -e "$SUBNET$i\tip-${SUBNET//./-}$i" ; done >> /etc/hosts EOF Pour les instances de production
Pour une instance de production, ajouter la ligne suivante sous la ligneUSER_SCRIPTdu champUser Datapour que les mises à jour de sécurité s'appliquent à l'amorçage.yum -y update
Note
yum -y updatedoit être exécuté régulièrement, pour appliquer les correctifs de sécurité et les améliorations.- Lancement de l'instance AMI Red Hat
Les contrôleurs d'hôtes non clusterisés de JBoss EAP 6 ont été configurés, et lancés sur une AMI Red Hat.
22.2.2.3.3. Tester le domaine géré de JBoss EAP 6 non clusterisée
Cette rubrique couvre les étapes requises pour tester le domaine géré non clusterisé de JBoss EAP 6 sur une AMI Red Hat (Amazon Machine Image)
Prérequis
- Configurer et lancer le contrôleur de domaine. Consulter Section 22.2.2.3.1, « Lancer une instance pour qu'elle serve en tant que Contrôleur de domaine » .
- Configurer et lancer les contrôleurs d'hôte. Consulter Section 22.2.2.3.2, « Lancer une ou plusieurs instances pour qu'elles servent en tant que contrôleurs d'hôtes » .
Procédure 22.5. Tester le Serveur Web
- Naviguer dans
http://ELASTIC_IP_OF_APACHE_HTTPDavec un navigateur pour confirmer que le serveur web exécute avec succès.
Procédure 22.6. Tester le contrôleur de domaine
- Naviguer dans
http://ELASTIC_IP_OF_DOMAIN_CONTROLLER:9990/console - Connectez-vous en utilisant le nom d'utilisateur
adminet le mot de passe spécifiés dans le champ Données d'utilisateur pour le Contrôleur de domaine et la Page d'accueil de la console admin du domaine géré s'affichera (http://ELASTIC_IP_OF_DOMAIN_CONTROLLER:9990/console/App.html#server-instances). - Cliquer sur l'étiquette du serveur en haut et à droite de l'écran, et sélectionner un contrôleur d'hôtes dans le menu déroulant d'Hôtes en haut et à gauche de l'écran.
- Vérifier que chaque contrôleur d'hôte ait deux configurations de serveurs nommées respectivement
server-oneetserver-twoqui appartiennent toutes deux aumain-server-group. - Se déconnecter de la console admin de JBoss EAP.
Procédure 22.7. Tester les contrôleurs d'hôte
- Naviguer dans
http://ELASTIC_IP_OF_APACHE_HTTPD/hellopour tester que l'exemple d'application exécute. Le texteHello World!devrait apparaître dans le navigateur.Si le texte n'est pas visible, voir : Section 18.5.1, "About Troubleshooting Amazon EC2". - Se connecter à l'instance Apache HTTPD :
$ ssh -L7654:localhost:7654 ELASTIC_IP_OF_APACHE_HTTPD
- Naviguer dans
http://localhost:7654/mod_cluster-managerpour confirmer que toutes les instances exécutent correctement.
Le serveur web de JBoss EAP 6, le contrôleur de domaine, et les contrôleurs hôtes exécutent correctement sur une AMI Red Hat.
22.2.3. JBoss EAP 6 clusterisé
22.2.3.1. Instances clusterisées
standalone-ec2-ha.xml et standalone-mod_cluster-ec2-ha.xml. Chacun de ces fichiers de configuration fournit du clustering sans multidiffusion car Amazon EC2 ne prend pas en charge la multidiffusion. Cela se fait par monodiffusion TCP pour les communications de clusters et S3_PING comme protocole de découverte. La configuration autonome-mod_cluster-ec2-ha.xml fournit également un enregistrement simple par les proxys de mod_cluster.
domain-ec2.xml fournit deux profils à utiliser dans les domaines gérés clusterisés : ec2-ha, et mod_cluster-ec2-ha.
22.2.3.2. Créer une instance de base de données de service de bases de données relationnelles.
Cette rubrique couvre les étapes nécessaires pour créer une instance de base de données de service de bases de données relationnelles, en utilisant MySQL comme exemple.
Avertissement
Important
Procédure 22.8. Créer une instance de base de données de service de bases de données relationnelles.
- Cliquer sur le RDS de la console AWS.
- Abonnez-vous au service si nécessaire.
- Cliquer sur Launch DB instance.
- Cliquer sur MySQL.
- Sélectionner une version, comme
5.5.12. - Sélectionner small instance.
- Veillez à ce que Multi-AZ Deployment et Auto upgrade soient désactivés:
off. - Définir Storage à
5GB. - Définir le nom d'utilisateur et le mot de passe de l'administrateur de système et cliquer sur le bouton .
- Sélectionner un nom de base de données à créer avec l'instance, et cliquer sur .
- Désactiver les back-ups et la maintenance, si nécessaire.
- Confirmer les paramètres.
La base de données est alors créée. Elle s'initialisera et sera prête à l'utilisation dans quelques minutes.
22.2.3.3. Clouds privés virtuels
22.2.3.4. Créer un VPC (Virtual Private Cloud)
Cette rubrique décrit les étapes requises pour créer un cloud privé virtuel, en prenant comme exemple une base de données externe au VPC. Vos stratégies de sécurité peuvent exiger la connexion à la base de données à crypter. Veuillez consulter RDS FAQ d'Amazon pour plus d'informations sur le cryptage des connexions de base de données.
Important
- Aller dans l'onglet VPC de la console AWS.
- Abonnez-vous au service si nécessaire.
- Cliquer sur "Create new VPC".
- Séelctionner un VPC avec un sous-système public et un privé.
- Définir le sous-système public à
10.0.0.0/24. - Définir le sous-système privé à
10.0.1.0/24.
- Aller dans Elastic IPs.
- Créer un IP élastique pour que l'instance mod_cluster proxy/NAT puisse l'utiliser.
- Aller dans Security groups et créer un groupe de sécurité pour autoriser le trafic entrant et sortant.
- Aller sur les ACL de réseau
- Créer un ACL pour autoriser le trafic entrant et sortant.
- Créer un ACL pour autoriser le trafic vers et depuis les ports TCP
22,8009,8080,8443,9443,9990et16163uniquement.
Le Cloud privé virtuel (VPC) a été créé.
22.2.3.5. Lancer une instance Apache HTTPD pour qu'elle serve en tant que proxy de mod_cluster et d'instance NAT pour le VPC
Cette section couvre toutes les étapes requises pour lancer une instance Apache HTTPD qui puisse servir de proxy mod_cluster et d'instance NAT au Virtuel Private Cloud.
Prérequis
Procédure 22.9. Lancer une instance Apache HTTPD pour qu'elle serve en tant que proxy de mod_cluster et d'instance NAT pour le VPC
- Créer un IP élastique pour cette instance.
- Sélectionnez un AMI.
- Allez dans le Security Group et autoriser tout le trafic (utiliser les capacités de pare-feu intégrées de Red Hat Enterprise Linux pour restreindre l'accès si nécessaire).
- Choisir "
running" dans le sous-système public du VPC. - Sélectionner un IP statique (comme par ex
10.0.0.4). - Mettez ce qui suit dans le champ User Data:
JBOSSCONF=disabled cat > $USER_SCRIPT << "EOS" echo 1 > /proc/sys/net/ipv4/ip_forward echo 0 > /proc/sys/net/ipv4/conf/all/rp_filter echo 0 > /proc/sys/net/ipv4/conf/eth0/rp_filter iptables -I INPUT 4 -s 10.0.1.0/24 -p tcp --dport 7654 -j ACCEPT iptables -I INPUT 4 -p tcp --dport 80 -j ACCEPT iptables -I FORWARD -m state --state RELATED,ESTABLISHED -j ACCEPT iptables -I FORWARD -s 10.0.1.0/24 -j ACCEPT iptables -t nat -A POSTROUTING -o eth0 ! -s 10.0.0.4 -j MASQUERADE # balancer module incompatible with mod_cluster sed -i -e 's/LoadModule proxy_balancer_module/#\0/' /etc/httpd/conf/httpd.conf cat > /etc/httpd/conf.d/mod_cluster.conf << "EOF" #LoadModule proxy_module modules/mod_proxy.so #LoadModule proxy_ajp_module modules/mod_proxy_ajp.so LoadModule slotmem_module modules/mod_slotmem.so LoadModule manager_module modules/mod_manager.so LoadModule proxy_cluster_module modules/mod_proxy_cluster.so LoadModule advertise_module modules/mod_advertise.so Listen 7654 # workaround JBPAPP-4557 MemManagerFile /var/cache/mod_proxy/manager <VirtualHost *:7654> <Location /mod_cluster-manager> SetHandler mod_cluster-manager Order deny,allow Deny from all Allow from 127.0.0.1 </Location> <Location /> Order deny,allow Deny from all Allow from 10. Allow from 127.0.0.1 </Location> KeepAliveTimeout 60 MaxKeepAliveRequests 0 ManagerBalancerName mycluster ServerAdvertise Off EnableMCPMReceive On </VirtualHost> EOF echo "`hostname | sed -e 's/ip-//' -e 'y/-/./'` `hostname`" >> /etc/hosts semanage port -a -t http_port_t -p tcp 7654 #add port in the apache port list for the below to work setsebool -P httpd_can_network_relay 1 #for mod_proxy_cluster to work chcon -t httpd_config_t -u system_u /etc/httpd/conf.d/mod_cluster.conf #### Uncomment the following line when launching a managed domain #### # setsebool -P httpd_can_network_connect 1 service httpd start EOS - Décochez la case Amazon EC2 cloud source/destination pour cette instance pour qu'elle puisse agir en tant que router.
- Cliquer à droite sur l'instance Apache HTTPD et sélectionner "Change Source/Dest check".
- Cliquer sur Yes, Disable.
- Créer un IP élastique pour cette instance.
L'instance Apache HTTPD aura été lancée avec succès.
22.2.3.6. Configurer le routage par défaut du sous-système privé VPC
Cette rubrique couvre les étapes requises pour configurer le routage par défaut du sous-système privé VPC. Les noeuds de cluster de JBoss EAP 6 exécuteront dans le sous-système privé du VPC, mais les noeuds de cluster ont besoin d'un accès internet pour la connectivité S3. Un routage par défaut doit être défini pour aller dans l'instance NAT.
Procédure 22.10. Configurer le routage par défaut du sous-système privé VPC
- Naviguer dans l'instance Apache HTTPD de la console Amazon AWS.
- Naviguer dans → .
- Cliquer sur le tableau de routage utilisé par le sous-système privé.
- Dans le champ de nouveau routage, saisir
0.0.0.0/0. - Cliquer sur "Select a target".
- Sélectionner "
Enter Instance ID". - Choisir l'ID de l'instance Apache HTTPD en cours d'exécution.
Le routage par défaut a été configurée correctement pour le sous-système VPC.
22.2.3.7. IAM (Identity and Access Management)
22.2.3.8. Configurer l'installation IAM
Cette rubrique couvre les étapes de configuration requises pour installer IAM pour les instances de JBoss EAP 6. Le protocole S3_PING utilise Bucket S3 pour découvrir d'autres membres du cluster. La version 3.0.x de JGroups a besoin d'un compte d'accès Amazon AWS et de clés secrètes pour s'authentifier dans le service S3.
Procédure 22.11. Configurer l'installation IAM
- Aller dans l'onglet IAM de la Console AWS.
- Cliquer sur users (utilisateurs).
- Sélectionner Create New Users (Créer Nouveaux Utilisateurs).
- Choisir un nom, et veillez à ce que l'option Generate an access key for each User (Générer une clé d'accès pour chaque utilisateur) soit cochée.
- Sélectionner Download credentials, et les sauvegarder dans un emplacement sécurisé.
- Fermer la fenêtre.
- Cliquer sur un utilisateur nouvellement créé.
- Prenez note de la valeur de
User ARM. Cette valeur est requise pour configurer Bucket S3, et est documenté ici: Section 22.2.3.10, « Configurer l'installation S3 Bucket ».
Le compte IAM a été créé avec succès.
22.2.3.9. S3 Bucket
22.2.3.10. Configurer l'installation S3 Bucket
Cette rubrique couvre les étapes nécessaires pour configurer une nouvelle S3 Bucket.
Procédure 22.12. Configurer l'installation S3 Bucket
- Ouvrir l'onglet S3 dans la console AWS.
- Cliquer sur Créer Bucket.
- Choisir un nom pour la Bucket et cliquer sur (Créer).
Note
Les noms de Bucket sont uniques dans tout S3. Les noms ne peuvent pas être réutilisés. - Cliquer à droite sur la nouvelle Bucket et sélectionner Properties (propriétés).
- Cliquer sur Add bucket policy (ajouter la règle de bucket) dans l'onglet de permissions.
- Cliquer sur New policy (Nouvelle police) pour ouvrir l'assistant de création de police.
- Copier le texte suivant dans la nouvelle police, en remplaçant
arn:aws:iam::05555555555:user/jbosscluster*par la valeur définie ici : Section 22.2.3.8, « Configurer l'installation IAM ». Changer les deux instances declusterbucket123au nom de Bucket défini dans l'étape 3 de cette procédure.{ "Version": "2008-10-17", "Id": "Policy1312228794320", "Statement": [ { "Sid": "Stmt1312228781799", "Effect": "Allow", "Principal": { "AWS": [ "arn:aws:iam::055555555555:user/jbosscluster" ] }, "Action": [ "s3:ListBucketVersions", "s3:GetObjectVersion", "s3:ListBucket", "s3:PutBucketVersioning", "s3:DeleteObject", "s3:DeleteObjectVersion", "s3:GetObject", "s3:ListBucketMultipartUploads", "s3:ListMultipartUploadParts", "s3:PutObject", "s3:GetBucketVersioning" ], "Resource": [ "arn:aws:s3:::clusterbucket123/*", "arn:aws:s3:::clusterbucket123" ] } ] }
Une nouvelle Bucket a maintenant été créée, et configurée avec succès.
22.2.3.11. Instances clusterisées
22.2.3.11.1. Lancer les AMI de JBoss EAP 6 clusterisée
Cette rubrique couvre les étapes requises pour lancer les AMI JBoss EAP 6.
Prérequis
Avertissement
JBOSS_CLUSTER_ID pour obtenir des informations sur la façon d'effectuer ce travail de configuration de façon fiable : Section 22.4.1, « Paramètres de configuration permanente ».
Important
Avertissement
Procédure 22.13. Lancer les AMI de JBoss EAP 6 clusterisée
- Sélectionner un AMI.
- Définir le nombre d'instances voulues (la taille du cluster).
- Sélectionner le VPC et le type d'instance.
- Cliquer sur le groupe Security Group.
- Veillez à ce que tout le trafic en provenance du cluster JBoss EAP 6 soit autorisé.
- Définir les autres restriction suivant les besoins.
- Ajouter ce qui suit dans le champ User Data :
Exemple 22.5. Exemple de champ de données utilisateur
## mod cluster proxy addresses MOD_CLUSTER_PROXY_LIST=10.0.0.4:7654 ## clustering setup JBOSS_JGROUPS_S3_PING_SECRET_ACCESS_KEY=<your secret key> JBOSS_JGROUPS_S3_PING_ACCESS_KEY=<your access key> JBOSS_JGROUPS_S3_PING_BUCKET=<your bucket name> ## password to access admin console JBOSSAS_ADMIN_PASSWORD=<your password for opening admin console> ## database credentials configuration JAVA_OPTS="$JAVA_OPTS -Ddb.host=instancename.something.rds.amazonaws.com -Ddb.database=mydatabase -Ddb.user=<user> -Ddb.passwd=<pass>" ## subnet prefix this machine is connected to SUBNET=10.0.1. #### to run the example no modifications below should be needed #### PORTS_ALLOWED="1024:65535" JBOSS_IP=`hostname | sed -e 's/ip-//' -e 'y/-/./'` #listen on public/private EC2 IP address cat > $USER_SCRIPT << "EOF" ## Get the application to be deployed from an Internet URL # mkdir -p /usr/share/java/jboss-ec2-eap-applications # wget https://<your secure storage hostname>/<path>/<app name>.war -O /usr/share/java/jboss-ec2-eap-applications/<app name>.war ## install the JDBC driver as a core module yum -y install mysql-connector-java mkdir -p /usr/share/jbossas/modules/com/mysql/main cp -v /usr/share/java/mysql-connector-java-*.jar /usr/share/jbossas/modules/com/mysql/main/mysql-connector-java.jar cat > /usr/share/jbossas/modules/com/mysql/main/module.xml <<"EOM" <?xml version="1.0" encoding="UTF-8"?> <module xmlns="urn:jboss:module:1.0" name="com.mysql"> <resources> <resource-root path="mysql-connector-java.jar"/> </resources> <dependencies> <module name="javax.api"/> </dependencies> </module> EOM cat > $USER_CLI_COMMANDS << "EOC" ## Deploy sample application from local filesystem deploy --force /usr/share/java/jboss-ec2-eap-samples/cluster-demo.war ## ExampleDS configuration for MySQL database data-source remove --name=ExampleDS /subsystem=datasources/jdbc-driver=mysql:add(driver-name="mysql",driver-module-name="com.mysql") data-source add --name=ExampleDS --connection-url="jdbc:mysql://${db.host}:3306/${db.database}" --jndi-name=java:jboss/datasources/ExampleDS --driver-name=mysql --user-name="${db.user}" --password="${db.passwd}" /subsystem=datasources/data-source=ExampleDS:enable /subsystem=datasources/data-source=ExampleDS:test-connection-in-pool EOC ## this will workaround the problem that in a VPC, instance hostnames are not resolvable echo -e "127.0.0.1\tlocalhost.localdomain localhost" > /etc/hosts echo -e "::1\tlocalhost6.localdomain6 localhost6" >> /etc/hosts for (( i=1 ; i<255 ; i++ )); do echo -e "$SUBNET$i\tip-${SUBNET//./-}$i" ; done >> /etc/hosts EOF
Les AMI JBoss EAP 6 clusterisés ont été configurées et lancées avec succès.
22.2.3.11.2. Lancer l'instance de JBoss EAP 6 clusterisée
Cette rubrique couvre les étapes pour s'assurer que les instances de la plateforme clusterisée de JBoss EAP 6 6 exécutent correctement.
Procédure 22.14. Tester l'instance clusterisée
- Naviguez dans http://ELASTIC_IP_OF_APACHE_HTTPD pour confirmer que le serveur web exécute correctement.
Tester les noeuds clusterisés
- Naviguez dans http://ELASTIC_IP_OF_APACHE_HTTPD/cluster-demo/put.jsp.
- Vérifier que l'un des noeuds de cluster journalise le message suivant :
Putting date now
- Stopper le noeud de cluster qui a journalisé le message dans l'étape précédente.
- Naviguez dans http://ELASTIC_IP_OF_APACHE_HTTPD/cluster-demo/get.jsp.
- Vérifier que l'heure indiquée est la même que l'heure PUT (mise) par
put.jspà l'étape 2-a. - Vérifier que l'un des noeuds de cluster en cours d'exécution journalise le message suivant :
Obtenir la date maintenant
- Démarrer à nouveau le noeud clusterisé qui est arrêté.
- Connectez-vous à l'instance Apache HTTPD :
ssh -L7654:localhost:7654 <ELASTIC_IP_OF_APACHE_HTTPD>
- Naviguez dans http://localhost:7654/mod_cluster-manager pour confirmer que toutes les instances exécutent correctement.
L'instance clustrisée de JBoss EAP 6 a été testée, et il a été confirmé qu'elle exécutait correctement.
22.2.3.12. Domaines gérés clusterisés
22.2.3.12.1. Lancer une instance pour qu'elle serve en tant que Contrôleur de domaine de cluster
Cette rubrique couvre les étapes requises pour lancer un domaine géré clusterisé de JBoss EAP 6 sur une AMI Red Hat (Amazon Machine Image)
Prérequis
- Pour un AMI Red Hat qui convient, consulter Section 22.1.6, « AMI Red Hat pris en charge » .
Procédure 22.15. Lancer un contrôleur de domaine clusterisé
- Créer un IP élastique pour cette instance.
- Sélectionner un AMI.
- Allez dans le Groupe de sécurité et autoriser tout le trafic (utiliser les capacités de pare-feu intégrées de Red Hat Enterprise Linux pour restreindre l'accès si nécessaire).
- Choisir "running" dans le sous-système public du VPC.
- Sélectionner un IP statique (comme par ex 10.0.0.5).
- Mettez ce qui suit dans le champ User Data :
## mod cluster proxy addresses MOD_CLUSTER_PROXY_LIST=10.0.0.4:7654 ## password that will be used by slave host controllers to connect to the domain controller JBOSSAS_ADMIN_PASSWORD=<password for slave host controllers> ## subnet prefix this machine is connected to SUBNET=10.0.0. #### to run the example no modifications below should be needed #### JBOSS_DOMAIN_CONTROLLER=true PORTS_ALLOWED="9999 9990 9443" JBOSS_IP=`hostname | sed -e 's/ip-//' -e 'y/-/./'` #listen on public/private EC2 IP address cat > $USER_SCRIPT << "EOF" ## Get the application to be deployed from an Internet URL # mkdir -p /usr/share/java/jboss-ec2-eap-applications # wget https://<your secure storage hostname>/<path>/<app name>.war -O /usr/share/java/jboss-ec2-eap-applications/<app name>.war ## Install the JDBC driver as a core module yum -y install mysql-connector-java mkdir -p /usr/share/jbossas/modules/com/mysql/main cp -v /usr/share/java/mysql-connector-java-*.jar /usr/share/jbossas/modules/com/mysql/main/mysql-connector-java.jar cat > /usr/share/jbossas/modules/com/mysql/main/module.xml <<"EOM" <?xml version="1.0" encoding="UTF-8"?> <module xmlns="urn:jboss:module:1.0" name="com.mysql"> <resources> <resource-root path="mysql-connector-java.jar"/> </resources> <dependencies> <module name="javax.api"/> </dependencies> </module> EOM cat > $USER_CLI_COMMANDS << "EOC" ## Deploy the sample application from the local filesystem deploy /usr/share/java/jboss-ec2-eap-samples/cluster-demo.war --server-groups=other-server-group ## ExampleDS configuration for MySQL database data-source --profile=mod_cluster-ec2-ha remove --name=ExampleDS /profile=mod_cluster-ec2-ha/subsystem=datasources/jdbc-driver=mysql:add(driver-name="mysql",driver-module-name="com.mysql") data-source --profile=mod_cluster-ec2-ha add --name=ExampleDS --connection-url="jdbc:mysql://${db.host}:3306/${db.database}" --jndi-name=java:jboss/datasources/ExampleDS --driver-name=mysql --user-name="${db.user}" --password="${db.passwd}" /profile=mod_cluster-ec2-ha/subsystem=datasources/data-source=ExampleDS:enable EOC ## this will workaround the problem that in a VPC, instance hostnames are not resolvable echo -e "127.0.0.1\tlocalhost.localdomain localhost" > /etc/hosts echo -e "::1\tlocalhost6.localdomain6 localhost6" >> /etc/hosts for (( i=1 ; i<255 ; i++ )); do echo -e "$SUBNET$i\tip-${SUBNET//./-}$i" ; done >> /etc/hosts EOF Pour les instances de production
Pour une instance de production, ajouter la ligne suivante sous la ligneUSER_SCRIPTdu champUser Datapour que les mises à jour de sécurité s'appliquent à l'amorçage.yum -y update
Note
yum -y updatesoit être exécuté régulièrement, pour appliquer les correctifs de sécurité et les améliorations.- Lancement de l'instance AMI Red Hat
Un domaine géré clusterisé de JBoss EAP 6 a été configuré, et lancé sur une AMI Red Hat.
22.2.3.12.2. Lancer une ou plusieurs instances pour qu'elles servent en tant que contrôleurs d'hôtes de cluster
Cette rubrique couvre les étapes requises pour lancer une ou plusieurs instances de JBoss EAP 6 en tant que contrôleurs d'hôtes clusterisés sur une AMI de Red Hat (Amazon Machine Image).
Prérequis
- Configurer et lancer le contrôleur de domaine clusterisé. Consulter Section 22.2.3.12.1, « Lancer une instance pour qu'elle serve en tant que Contrôleur de domaine de cluster » .
Procédure 22.16. Lancer les contrôleurs d'hôte
- Sélectionner une AMI.
- Définir le nombre d'instances que vous souhaitez (le nombre de contrôleurs hôtes esclaves)
- Sélectionner le VPC et le type d'instance.
- Cliquer sur le Groupe de sécurité.
- Veillez à ce que tout le trafic en provenance du cluster JBoss EAP 6 soit autorisé.
- Définir les autres restriction suivant les besoins.
- Ajouter ce qui suit dans le champ User Data :
## mod cluster proxy addresses MOD_CLUSTER_PROXY_LIST=10.0.0.4:7654 ## clustering setup JBOSS_JGROUPS_S3_PING_SECRET_ACCESS_KEY=<your secret key> JBOSS_JGROUPS_S3_PING_ACCESS_KEY=<your access key> JBOSS_JGROUPS_S3_PING_BUCKET=<your bucket name> ## host controller setup JBOSS_DOMAIN_MASTER_ADDRESS=10.0.0.5 JBOSS_HOST_PASSWORD=<password for slave host controllers> ## database credentials configuration JAVA_OPTS="$JAVA_OPTS -Ddb.host=instancename.something.rds.amazonaws.com -Ddb.database=mydatabase -Ddb.user=<user> -Ddb.passwd=<pass>" ## subnet prefix this machine is connected to SUBNET=10.0.1. #### to run the example no modifications below should be needed #### JBOSS_HOST_USERNAME=admin PORTS_ALLOWED="1024:65535" JBOSS_IP=`hostname | sed -e 's/ip-//' -e 'y/-/./'` #listen on public/private EC2 IP address cat > $USER_SCRIPT << "EOF" ## Server instance configuration sed -i "s/main-server-group/other-server-group/" $JBOSS_CONFIG_DIR/$JBOSS_HOST_CONFIG ## install the JDBC driver as a core module yum -y install mysql-connector-java mkdir -p /usr/share/jbossas/modules/com/mysql/main cp -v /usr/share/java/mysql-connector-java-*.jar /usr/share/jbossas/modules/com/mysql/main/mysql-connector-java.jar cat > /usr/share/jbossas/modules/com/mysql/main/module.xml <<"EOM" <?xml version="1.0" encoding="UTF-8"?> <module xmlns="urn:jboss:module:1.0" name="com.mysql"> <resources> <resource-root path="mysql-connector-java.jar"/> </resources> <dependencies> <module name="javax.api"/> </dependencies> </module> EOM ## this will workaround the problem that in a VPC, instance hostnames are not resolvable echo -e "127.0.0.1\tlocalhost.localdomain localhost" > /etc/hosts echo -e "::1\tlocalhost6.localdomain6 localhost6" >> /etc/hosts for (( i=1 ; i<255 ; i++ )); do echo -e "$SUBNET$i\tip-${SUBNET//./-}$i" ; done >> /etc/hosts EOF Pour les instances de production
Pour une instance de production, ajouter la ligne suivante sous la ligneUSER_SCRIPTdu champUser Datapour que les mises à jour de sécurité s'appliquent à l'amorçage.yum -y update
Note
yum -y updatesoit être exécuté régulièrement, pour appliquer les correctifs de sécurité et les améliorations.- Lancement de l'instance AMI Red Hat
Les contrôleurs d'hôtes clusterisés de JBoss EAP 6 ont été configurés, et lancés sur une AMI Red Hat.
22.2.3.12.3. Tester le domaine géré de JBoss EAP 6 clusterisée
Cette rubrique couvre les étapes requises pour tester le domaine géré clusterisé de JBoss EAP 6 sur une AMI Red Hat (Amazon Machine Image)
Prérequis
- Configurer et lancer le contrôleur de domaine clusterisé. Consulter Section 22.2.3.12.1, « Lancer une instance pour qu'elle serve en tant que Contrôleur de domaine de cluster » .
- Configurer et lancer les contrôleurs d'hôte de cluster. Consulter Section 22.2.3.12.2, « Lancer une ou plusieurs instances pour qu'elles servent en tant que contrôleurs d'hôtes de cluster » .
Procédure 22.17. Tester l'instance Apache HTTPD
- Naviguer dans
http://ELASTIC_IP_OF_APACHE_HTTPDavec un navigateur pour confirmer que le serveur web exécute avec succès.
Procédure 22.18. Tester le contrôleur de domaine
- Naviguer dans
http://ELASTIC_IP_OF_DOMAIN_CONTROLLER:9990/console - Connectez-vous en utilisant le nom d'utilisateur
adminet le mot de passe spécifiés dans le champ Données d'utilisateur pour le Contrôleur de domaine. Une fois connecté, la Page d'accueil de la console admin d'un domaine géré s'affichera (http://ELASTIC_IP_OF_DOMAIN_CONTROLLER:9990/console/App.html#server-instances). - Cliquer sur l'étiquette du serveur en haut et à droite de l'écran, et sélectionner un contrôleur d'hôtes dans le menu déroulant d'Hôtes en haut et à gauche de l'écran.
- Vérifier que ce contrôleur d'hôte ait deux configurations de serveurs nommées respectivement
server-oneetserver-twoet vérifier qu'elles appartiennent toutes deux àother-server-group.
Procédure 22.19. Tester les contrôleurs d'hôte
- Naviguez dans
http://ELASTIC_IP_OF_APACHE_HTTPD/cluster-demo/put.jsp. - Vérifier que l'un des contrôleurs d'hôte journalise le message suivant :
Putting date now. - Stopper l'instance du serveur qui a journalisé le message dans l'étape précédente (voir la Section 2.8.3, Stopper un serveur par la Console de gestion).
- Naviguez dans
http://ELASTIC_IP_OF_APACHE_HTTPD/cluster-demo/get.jsp. - Vérifier que l'heure indiquée est la même que l'heure
PUT(mise) parput.jspà l'étape 2-a. - Vérifier que l'une des instances de serveur en cours d'exécution journalise le message suivant :
Getting date now. - Re-démarrer l'instance du serveur arrêtée (voir la Section 2.8.3, Stopper un serveur par la Console de gestion).
- Connectez-vous à l'instance d'Apache HTTPD.
$ ssh -L7654:localhost:7654 ELASTIC_IP_OF_APACHE_HTTPD
- Naviguez dans
http://localhost:7654/mod_cluster-managerpour confirmer que toutes les instances exécutent correctement.
Le serveur web de JBoss EAP 6, le contrôleur de domaine, et les contrôleurs hôtes exécutent correctement sur une AMI de Red Hat.
22.3. Mettre en place le monitoring dans JBoss Operations Network (JON)
22.3.1. AMI Monitoring
Figure 22.1. La connectivité du serveur JON
22.3.2. Prérequis de connectivité
22.3.3. Network Address Translation (NAT)
rhq.communications.connector.* du fichier de configuration de agent-configuration.xml
22.3.4. Amazon EC2 et DNS
22.3.5. Routing dans EC2
source/destination checking activée par défaut. Cette fonction supprime tous les paquets envoyés au serveur qui ont une destination séparée de l'adresse IP de la machine. Si la solution VPN sélectionnée pour la connexion des agents au serveur JON inclut un routeur, cette fonctionnalité devra être désactivée pour le ou les serveur(s) agissant en tant que routeurs ou passerelles VPN. Ce paramètre de configuration est accessible via la console d'Amazon AWS. La désactivation de source/destination checking est également requise dans un Cloud privé virtuel (VPC).
- Quand vous créez un VPC, évitez d'allouer des adresses déjà utilisées dans le réseau privé afin d'éviter les problèmes de connectivité.
- Si une instance a besoin d'accéder à des ressources locales de zone disponible, veillez à ce que les adresses privées Amazon EC2 soient utilisées et que les trafic ne soit pas dirigé par le VPN.
- Si une instance d'Amazon EC2 a accès à un petit sous-ensemble d'adresses de réseau privé d'entreprise (par exemple les serveurs JON uniquement), seules ces adresses devront être acheminées par le VPN. Cela augmente la sécurité et réduit les chances de collision d'espaces d'adresse de réseau privé et Amazon EC2.
22.3.6. Quitter ou Re-démarrer JON
JON_AGENT_ADDR dans /etc/sysconfig/jon-agent-ec2 pour refléter la nouvelle adresse IP, puis redémarrez l'agent.
22.3.7. Configurer une instance pour vous enregistrer dans le Réseau d'opérations de JBoss.
- Dans JBoss EAP 6, ajouter ceci dans le champ User Data (Données utilisateur).
JON_SERVER_ADDR=jon2.it.example.com ## if instance not already configured to resolve its hostname JON_AGENT_ADDR=`ip addr show dev eth0 primary to 0/0 | sed -n 's#.*inet \([0-9.]\+\)/.*#\1#p'` PORTS_ALLOWED=16163 # insert other JON options when necessary, see Appendix I
22.4. Configuration du script utilisateur
22.4.1. Paramètres de configuration permanente
Les paramètres suivants peuvent être utilisés pour influencer la configuration et les opérations de JBoss EAP 6. Leur contenu se trouve dans /etc/sysconfig/jbossas et /etc/sysconfig/jon-agent-ec2.
Tableau 22.2. Paramètres configurables
| Nom | Description | Par défaut |
|---|---|---|
| JBOSS_JGROUPS_S3_PING_ACCESS_KEY | Clé d'accès de compte utilisateur Amazon AWS pour S3_PING Discovery quand on utilise le clustering. | N/A |
| JBOSS_JGROUPS_S3_PING_SECRET_ACCESS_KEY | Clé d'accès secrète au compte utilisateur Amazon AWS | N/A |
| JBOSS_JGROUPS_S3_PING_BUCKET | Amazon S3 Bucket à utiliser dans S3_PING Discovery. | N/A |
| JBOSS_CLUSTER_ID |
ID des noeuds de membres d'un groupement. Utilisé uniquement pour le clustering. Les valeurs acceptées sont (dans l'ordre) :
| Dernier octet de l'adresse IP d'eth0 |
| MOD_CLUSTER_PROXY_LIST | Liste délimitée par des virgules d'IP/Noms d'hôte de proxies mod_cluster si mod_cluster doit être utilisé. | N/A |
| PORTS_ALLOWED | Liste des ports entrants qui seront utilisés par le pare-feu en plus des ports par défaut. | N/A |
| JBOSSAS_ADMIN_PASSWORD | Mot de passe pour l'utilisateur admin. | N/A |
| JON_SERVER_ADDR | IP ou Nom d'hôte du serveur JON dans lequel s'enregistrer. Uniquement utilisé pour l'enregistrement, ensuite, l'agent peut communiquer avec les autres serveurs dans le groupement JON. | N/A |
| JON_SERVER_PORT | Port utilisé par l'agent pour communiquer avec le serveur. | 7080 |
| JON_AGENT_NAME | Nom de l'agent JON, doit être unique. | ID de l'instance |
| JON_AGENT_PORT | Port que l'agent écoute. | 16163 |
| JON_AGENT_ADDR | Adresse IP à laquelle l'agent JON est relié. Utilisé quand le serveur a plus d'une adresse publique, (par ex VPN). | L'agent JON choisit l'IP ou le nom d'hôte local par défaut. |
| JON_AGENT_OPTS | Propriétés de système d'agent JON supplémentaire pouvant être utilisé pour configurer SSL, NAT et d'autres paramètres avancés. | N/A |
| JBOSS_SERVER_CONFIG |
Nom du fichier de configuraiton de serveur JBoss EAP à utiliser. Si JBOSS_DOMAIN_CONTROLLER=true, alors
domain-ec2.xml sera utilisé. Sinon :
| standalone.xml, standalone-full.xml, standalone-ec2-ha.xml, standalone-mod_cluser-ec2-ha.xml, domain-ec2.xml suivant les autres paramètres. |
| JAVA_OPTS | Valeurs personnalisées à ajouter à la variable avant que JBoss EAP 6 démarre. | JAVA_OPTS est créé à partir de valeurs appartenant à d'autres paramètres. |
| JBOSS_IP | Adresse IP à laquelle le serveur est lié. | 127.0.0.1 |
| JBOSSCONF | Le nom du profil de JBoss EAP 6 pour démarrer. Pour empêcher JBoss EAP 6 de démarrer, JBOSSCONF peut être défini à disabled | standalone |
|
JBOSS_DOMAIN_CONTROLLER
|
Indique si cette instance exécute ou non comme contrôleur de domaine.
| false
|
|
JBOSS_DOMAIN_MASTER_ADDRESS
|
Adresse IP de contrôleur de domaine distant.
|
N/A
|
|
JBOSS_HOST_NAME
|
Le nom d'hôte logique (du domaine). Doit être un nom séparé.
|
La valeur de la variable d'environnement HOSTNAME.
|
|
JBOSS_HOST_USERNAME
|
Le nom d'utilisateur du contrôleur d'hôte doit être utilisé quand on enregistre dans le contrôleur de domaine. Si non fourni, le JBOSS_HOST_NAME sera utilisé à la place.
|
JBOSS_HOST_NAME
|
|
JBOSS_HOST_PASSWORD
|
Le mot de passe que le contrôleur d'hôte doit utiliser quand il s'enregistre avec le contrôleur de domaine.
|
N/A
|
|
JBOSS_HOST_CONFIG
|
Si JBOSS_DOMAIN_CONTROLLER=true, alors
host-master.xml sera utilisé. Si JBOSS_DOMAIN_MASTER_ADDRESS est présent, alors host-slave.xml sera utilisé.
| host-master.xml ou host-slave.xml, suivant les autres paramètres.
|
22.4.2. Paramètres de scripts personnalisés
Les paramètres suivants peuvent être utilisés dans la section de personnalisation utlisateur du champ User Data:.
Tableau 22.3. Paramètres configurables
| Nom | Description |
|---|---|
|
JBOSS_DEPLOY_DIR
|
Déployer le répertoire du profil actif (par exemple,
/var/lib/jbossas/standalone/deployments/). Les archives déployables de ce répertoire seront déployées. Red Hat recommande d'utiliser la Console de gestion ou le CLI pour gérer les déploiements au lieu d'utiliser le répertoire de déploiement.
|
|
JBOSS_CONFIG_DIR
|
Répertoire de config du profile actif (par exemple,
/var/lib/jbossas/standalone/configuration).
|
|
JBOSS_HOST_CONFIG
|
Nom du fichier de configuration de l'hôte actif (par exemple,
host-master.xml). Red Hat conseille d'utiliser la Console de gestion ou le CLI pour configurer le serveur au lieu d'éditer le fichier de configuration.
|
|
JBOSS_SERVER_CONFIG
|
Nom du fichier de configuration du serveur actif (par exemple,
standalone-ec2-ha.xml). Red Hat conseille d'utiliser la Console de gestion ou le CLI pour configurer le serveur au lieu d'éditer le fichier de configuration.
|
|
USER_SCRIPT
|
Chemin d'accès au script de configuration personnalisé disponible avant de trouver la configuraiton user-data.
|
|
USER_CLI_COMMANDS
|
Chemin d'accès à un fichier personnalisé des commandes CLI, disponible avant de trouver la configuration user-data.
|
22.5. Résolution de problèmes
22.5.1. Résolution de problèmes dans Amazon EC2
22.5.2. Information de diagnostique
/var/log/jboss_user-data.outest la sortie du script init de jboss-ec2-eap et du script de configuration personnalisée utilisateur./var/cache/jboss-ec2-eap/contient les données utilisateur réelles, le script personnalisé, et les commandes CLI utilisées au démarrage de l'instance./var/logcontient également tous les journaux collectés au démarrage de la machine, JBoss EAP 6, httpd et la plupart des autres services.
Annexe A. Références supplémentaires
A.1. Télécharger les fichiers du portail des clients de Red Hat
Prérequis
- Avant de commencer cette tâche, vous aurez besoin d'un compte de Portail Clients. Rendez-vous dans https://access.redhat.com et cliquer sur le lien Register qui se trouve en haut et à droite pour créer un compte.
Procédure A.1. Connectez-vous et téléchargez les fichiers du Portail Clients de Red Hat
- Aller dans http://access.redhat.com et cliquer sur le lien Log in en haut et à gauche. Saisir vos identifiants, et cliquer sur Log In.Résultat
Vous êtes connecté dans RHN et on vous renvoie à la page web principale à https://access.redhat.com.
Rendez-vous à la page Downloads page.
Utiliser une des options de pour aller dans la page Downloads.- Cliquer sur le lien Downloads qui se trouve en haut de la barre de navigation.
- Rendez-vous directement dans https://access.redhat.com/downloads/.
Sélectionner le produit et la version à télécharge.
Utiliser une de ces méthodes pour choisir le produit et la version qui conviennent à télécharger.- Procéder une étape à la fois.
- Chercher votre produit à partir de la zône de recherche qui se trouve en haut et à droite de l'écran.
Télécharger le fichier qui convient pour votre système d'exploitation et la méthode d'installation de votre choix.
Suivant le produit, vous aurez le choix entre un installateur natif, un RPM ou une archive Zip suivant le système d'exploitation et l'architecture. Cliquer soit sur le nom de fichier ou sur le lien Download à droite du fichier que vous souhaitez télécharger.
Le fichier sera téléchargé dans votre ordinateur.
A.2. Configurer le JDK par défaut dans Red Hat Enterprise Linux
alternatives.
Important
Note
Prérequis
- Pour compléter cette tâche, vous devrez avoir l'accès super utilisateur, soit en connexion directe, ou par la commande
sudo.
Procédure A.2. Configurer le JDK par défaut
Déterminez les chemins qui vous conviennent le mieux pour vos binaires
javaetjavac.Vous pouvez utiliser la commanderpm -ql packagename |grep binpour trouver les emplacements des binaires installés à partir des RPM. Les locations par défaut des binairesjavaetjavacdes systèmes Red Hat Enterprise Linux 32-bit sont les suivantes :Tableau A.1. Emplacements par défaut des binaires
javaetjavacJDK Chemin OpenJDK 1.6 /usr/lib/jvm/jre-1.6.0-openjdk/bin/java/usr/lib/jvm/java-1.6.0-openjdk/bin/javacOracle JDK 1.6 /usr/lib/jvm/jre-1.6.0-sun/bin/java/usr/lib/jvm/java-1.6.0-sun/bin/javacDéfinir chaque solution alternative
Exécutez les commandes suivantes pour que votre système utilisejavaetjavac:/usr/sbin/alternatives --config javaou/usr/sbin/alternatives --config javac. Suivez les instructions sur l'écran.Option: définir un choix alternatif
java_sdk_1.6.0.Si vous souhaitez utiliser Oracle JDK, vous devrez configurer la solution alternativejava_sdk_1.6.0.également. Utiliser la commande suivante :/usr/sbin/alternatives --config java_sdk_1.6.0. Le chemin d'accès qui convient est normalement/usr/lib/jvm/java-1.6.0-sun. Vous pourrez faire une liste de fichiers pour vérifier.
Le JDK alternatif est sélectionné et actif.
Annexe B. Historique de révisions
| Historique des versions | |||
|---|---|---|---|
| Version 2.0-27.1 | Wed Aug 26 2015 | ||
| |||
| Version 2.0-27 | Monday April 07 2014 | ||
| |||