
Guide de développement
À utiliser dans Red Hat JBoss Enterprise Application Platform 6
Résumé
Preface
Chapitre 1. Introduction au développement d'applications
1.1. Introduction
1.1.1. Red Hat JBoss Enterprise Application Platform 6 (JBoss EAP 6)
1.2. Pré-requis
1.2.1. Familiarisez vous avec Java Enterprise Edition 6
1.2.1.1. Les Profils EE 6
1.2.1.2. Web Profil de Java Enterprise Edition 6
Pré-requis de Java EE 6 Web Profile
- Java Platform, Enterprise Edition 6
Technologies Java Web
- Servlet 3.0 (JSR 315)
- JSP 2.2 et Expression Language (EL) 1.2
- JavaServer Faces (JSF) 2.0 (JSR 314)
- Java Standard Tag Library (JSTL) for JSP 1.2
- Débogage du support pour les autres langages 1.0 (JSR 45)
Enterprise Application Technologies
- Contexts and Dependency Injection (CDI) (JSR 299)
- Injection de dépendance dans Java (JSR 330)
- Enterprise JavaBeans 3.1 Lite (JSR 318)
- Java Persistence API 2.0 (JSR 317)
- Annotations communes de la Plateforme Java 1.1 (JSR 250)
- Java Transaction API (JTA) 1.1 (JSR 907)
- Bean Validation (JSR 303)
1.2.1.3. Java Enterprise Edition 6 Full Profile
Items inclus dans EE 6 Full Profile
- EJB 3.1 (not Lite) (JSR 318)
- Java EE Connector Architecture 1.6 (JSR 322)
- Java Message Service (JMS) API 1.1 (JSR 914)
- JavaMail 1.4 (JSR 919)
Technologies Service Web
- Jax-RS RESTful Web Services 1.1 (JSR 311)
- Implémentation d'Enterprise Web Services 1.3 (JSR 109)
- JAX-WS Java API for XML-Based Web Services 2.2 (JSR 224)
- Java Architecture pour XML Binding (JAXB) 2.2 (JSR 222)
- Web Services Metadata pour Java Platform (JSR 181)
- Les API Java pour XML-based RPC 1.1 (JSR 101)
- Les API Java pour XML Messaging 1.3 (JSR 67)
- Java API pour les Registres XML (JAXR) 1.0 (JSR 93)
Technologies de Gestion et de Sécurité
- Interface Fournisseur Service Java Authentification pour Conteneurs 1.0 (JSR 196)
- Contrat Java Authentication Contract pour les Conteneurs 1.3 (JSR 115)
- Déploiement Application Java EE 1.2 (JSR 88)
- J2EE Management 1.1 (JSR 77)
1.2.2. Les modules et le système de chargement de la nouvelle classe modulaire de JBoss EAP 6.
1.2.2.1. Modules
- Modules statiques
- Les modules statiques sont prédéfinis dans le répertoire
EAP_HOME/modules/du serveur d'application. Chaque sous-répertoire représente un module et contient un ou plusieurs fichiers JAR et un fichier de configuration (module.xml). Le nom de ce module est défini dans le fichiermodule.xml. Toutes les API fournies par le serveur d'application sont fournies en tant que modules statiques, comme les API Java EE ainsi que d'autres API comme JBoss Logging.Exemple 1.1. Exemple de fichier module.xml
<?xml version="1.0" encoding="UTF-8"?> <module xmlns="urn:jboss:module:1.0" name="com.mysql"> <resources> <resource-root path="mysql-connector-java-5.1.15.jar"/> </resources> <dependencies> <module name="javax.api"/> <module name="javax.transaction.api"/> </dependencies> </module>Le nom du module,com.mysql, doit correspondre à la structure du répertoire du module.La création de modules statiques personnalisés peut être utile si plusieurs applications sont déployées sur un même serveur utilisant les mêmes bibliothèques de tierce partie. Au lieu d'un regroupement de ces bibliothèques pour chaque application, un module contenant ces bibliothèques peut être créé et installé par l'administrateur JBoss. Les applications peuvent ensuite déclarer une dépendance explicite sur les modules statiques personnalisés. - Modules dynamiques
- Les modules dynamiques sont créés et chargés par le serveur d'application pour chaque déploiement JAR ou WAR (ou sous-déploiement d'un EAR). Le nom d'un module dynamique est dérivé du nom de l'archive déployée. Comme les déploiements sont chargés sous forme de modules, ils peuvent configurer des dépendances et peuvent être utilisés comme dépendances par d'autres déploiements.
1.2.2.2. Chargement des classes et Modules
1.3. Installer l'environnement de développement
1.3.1. Télécharger et installer JBoss Developer Studio
1.3.1.1. Installation de JBoss Developer Studio
1.3.1.2. Téléchargez JBoss Developer Studio 5
- Visitez https://access.redhat.com/.
- Sélectionner → → .
- Sélectionnez JBoss Developer Studio depuis la liste déroulante.
- Sélectionnez la version appropriée et cliquez sur .
1.3.1.3. Installer JBoss Developer Studio 5
Procédure 1.1. Installer JBoss Developer Studio 5
- Ouvrir un terminal.
- Aller dans le répertoire qui contient le fichier téléchargé
.jar. - Exécuter la commande suivante pour lancer le GUI d'installation.
java -jar jbdevstudio-build_version.jar
- Cliquer sur pour commencer le processus d'installation.
- Sélectionner J'accepte les conditions de licence et cliquer sur .
- Ajuster le chemin d'accès de l'installation et cliquer sur .
Note
Si le dossier de chemin d'installation n'existe pas, vous verrez une invite. Cliquer alors sur pour créer le dossier. - Choisir une JVM, ou bien conserver la JVM sélectionnée par défaut, et cliquer sur .
- Ajouter une plateforme d'applications disponible, et cliquer sur .
- Vérifier les informations d'installation et cliquer sur .
- Cliquer sur une fois le processus d'installation terminé.
- Configurer les raccourcis bureau pour JBoss Developer Studio et cliquer sur .
- Cliquer sur le bouton .
1.3.1.4. Démarrer JBoss Developer Studio
Procédure 1.2. Commande pour lancer JBoss Developer Studio
- Ouvrir un terminal.
- Aller dans le répertoire d'installation.
- Lancer la commande suivante pour démarrer JBoss Developer Studio :
[localhost]$ ./jbdevstudio
1.3.1.5. Ajouter le serveur de JBoss EAP 6 au JBoss Developer Studio
Procédure 1.3. Ajouter le serveur
- Ouvrir l'onglet Serveurs. S'il n'y a pas d'onglet Serveurs, l'ajouter au panneau comme suit :
- Cliquer sur → → .
- Sélectionner Serveurs à partir du dossier Serveur et cliquer sur .
- Cliquer sur le lien nouvel assistant de serveur ou bien cliquer à droite dans le panneau vide sur serveur, et sélectionner → .

Figure 1.1. Ajouter un nouveau serveur - Aucun serveur disponible
- Étendre JBoss Enterprise Middleware et choisir . Puis, cliquer sur .
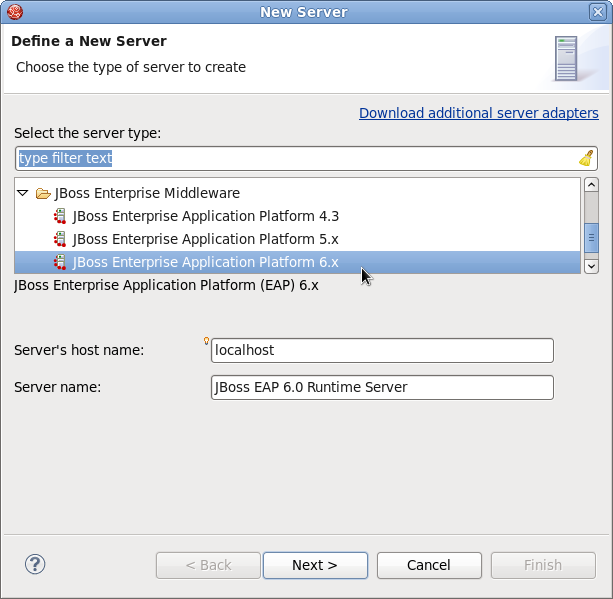
Figure 1.2. Choisir le type de serveur
- Cliquer sur et naviguez vers l'emplacement d'installation de JBoss EAP 6. Puis, cliquer sur .
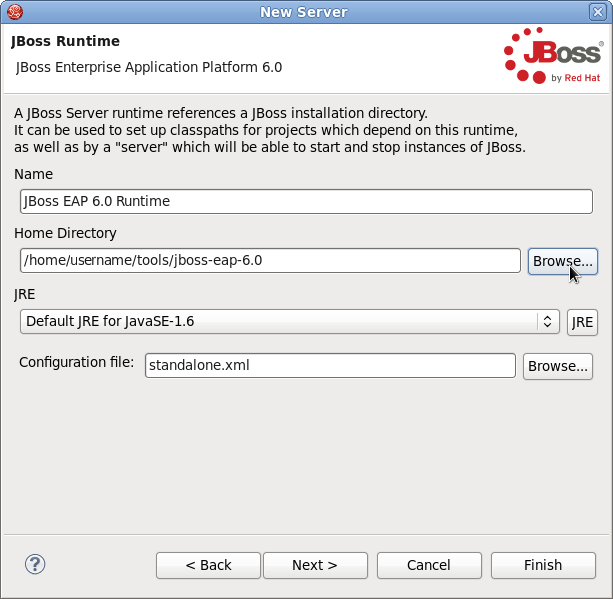
Figure 1.3. Naviguer vers l'installation du serveur
- Sur cet écran, vous définissez le comportement de serveur. Vous pouvez démarrer le serveur manuellement ou laisser JBoss Developer Studio le gérer pour vous. Vous pouvez également définir un serveur distant pour le déploiement et déterminer si vous souhaitez exposer le port de gestion pour ce serveur, par exemple, si vous avez besoin de le connecter en utilisant JMX. Dans cet exemple, supposons que le serveur est local et que vous souhaitiez que JBoss Developer Studio gère votre serveur sans que vous ayiez besoin de vérifier quoi que ce soit. Cliquer sur .
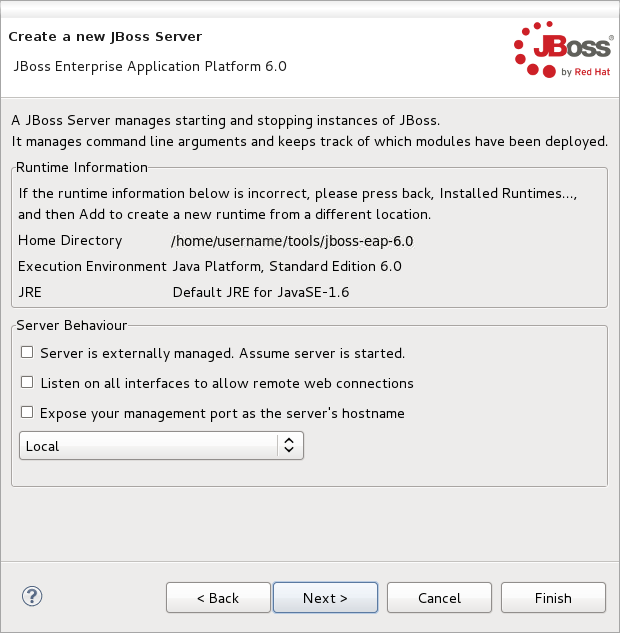
Figure 1.4. Définir le nouveau comportement du serveur de JBoss
- Cet écran vous permet de configurer les projets existants pour le nouveau serveur. Puisque vous n'avez pas de projets à ce stade, cliquez sur .
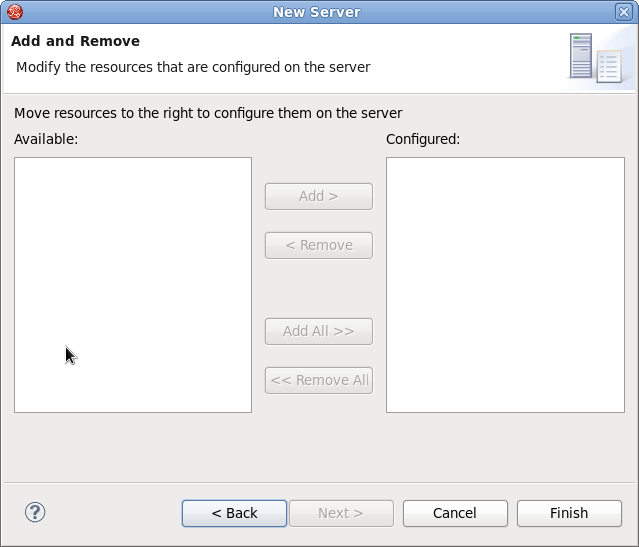
Figure 1.5. Modifier les ressources dans le nouveau serveur de JBoss
Le serveur de JBoss Enterprise Application Server 6.0 Runtime est listé dans l'onglet Serveurs.
Figure 1.6. Le server apparaît sur la liste de serveurs
1.4. Exécuter votre première application
1.4.1. Remplacer l'application web Welcome par défaut
Procédure 1.4. Remplacer l'application web Welcome par défaut par votre propre application web
Désactiver l'application Welcome
Utiliser le script de Management CLIEAP_HOME/bin/jboss-cli.shpour exécuter la commande suivante. Vous aurez sans doute besoin de modifier un profil de domaine géré, ou retirer une portion de la commande/profile=defaultdu serveur autonome./profile=default/subsystem=web/virtual-server=default-host:write-attribute(name=enable-welcome-root,value=false)
Configurer votre application web par le contexte root.
Afin de configurer votre application web, pour qu'elle utilise (/) comme adresse URL, modifier son fichierjboss-web.xml, qui se trouve dans le répertoireMETA-INF/ouWEB-INF/. Remplacer sa directive<context-root>par une autre qui ressemble à ce qui suit.<jboss-web> <context-root>/</context-root> </jboss-web>Déployer votre application.
Déployer votre application pour le groupe de serveurs ou le serveur que vous avez modifié lors de la première étape. L'application est maintenant disponible surhttp://SERVER_URL:PORT/.
1.4.2. Télécharger les exemples de codes Quickstart
1.4.2.1. Accès aux Quickstarts
JBoss EAP 6 contient une série d'exemples quickstart conçus pour aider les utilisateurs à commencer à rédiger des applications en utilisant les technologies Java EE 6.
Prérequis
- Maven 3.0.0 ou versions plus récentes. Pour en savoir plus sur l'installation de Maven, veuillez consulter http://maven.apache.org/download.html.
- Le référentiel JBoss EAP 6.2 Maven est disponible en ligne, donc il n'est pas utile de le télécharger ou de l'installer localement. Si vous envisagez de l'utiliser en ligne, passer à l'étape suivante. Si vous préférez l'installer dans un référentiel local, consulter : Section 2.2.3, « Installer le référentiel Maven de JBoss EAP 6 localement ».
Procédure 1.5. Télécharger les Quickstarts
- Ouvrir un navigateur web, et accéder à cet URL: https://access.redhat.com/jbossnetwork/restricted/listSoftware.html?product=appplatform.
- Trouver "Quickstarts" dans la liste.
- Cliquer sur le bouton pour télécharger un fichier ZIP contenant les exemples.
- Décompresser l'archive dans un répertoire de votre choix.
Les exemples de Java EE Quickstart ont été téléchargés et décompressés. Veuillez consulter le fichier README.md dans le répertoire supérieur des archives Quickstart pour des instructions concernant le déploiement de chaque quickstart.
1.4.3. Exécuter les Quickstarts
1.4.3.1. Exécuter les Quickstarts (Démarrages rapides) dans JBoss Developer Studio
Procédure 1.6. Importer les Quickstarts dans JBoss Developer Studio
- Si vous ne l'avez pas encore fait, configurez le référentiel Maven de JBoss EAP en utilisant les paramètres de Maven Section 2.3.2, « Configurer le référentiel JBoss EAP 6 Platform Maven Repository par les paramètres de configuration de Maven ».
- Démarrer JBoss Developer Studio.
- À partir du menu, sélectionner → .
- Dans la liste sélectionnée, choisir → , puis cliquer sur .
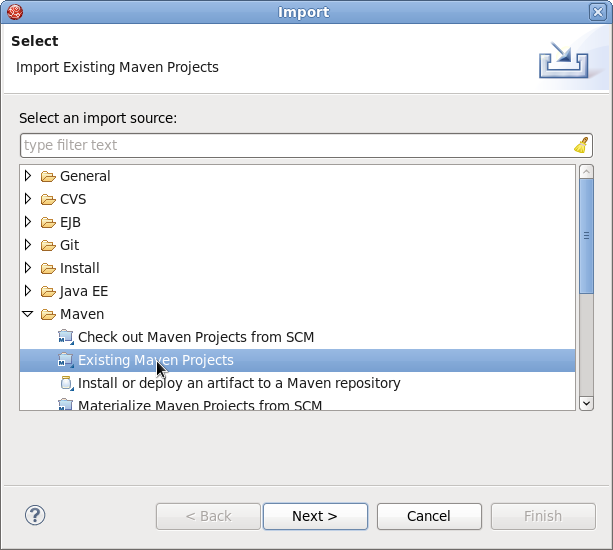
Figure 1.7. Importer les projets Maven existants
- Naviguer vers le répertoire du quickstart que vous souhaitez importer et cliquer sur . La zone de liste Projets verra apparaître le fichier
pom.xmldu projet quickstart sélectionné.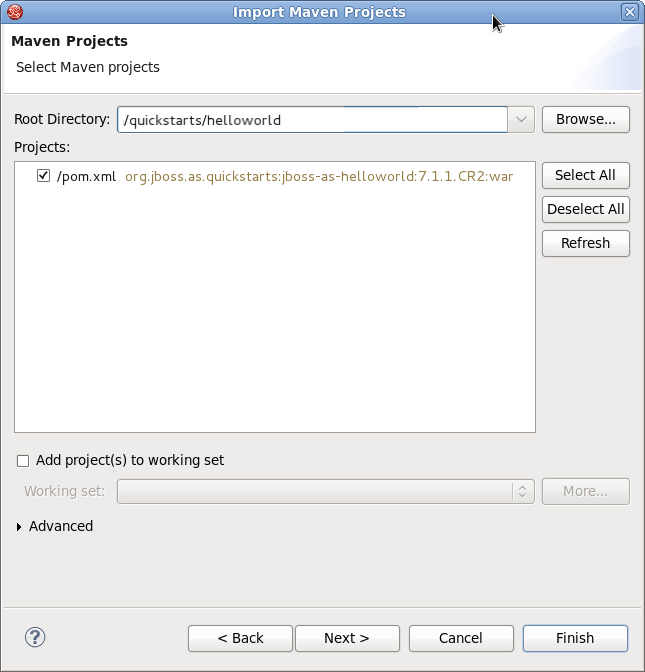
Figure 1.8. Sélectionner les projets Maven
- Cliquer sur , puis .
Procédure 1.7. Générer et déployer le Quickstart helloworld
helloworld est un des quickstarts les plus simples et représente une bonne façon de vérifier que le serveur JBoss est configuré et exécute correctement.
- Ouvrir l'onglet Serveurs. Pour l'ajouter dans le panneau :
- Cliquer sur → → .
- Sélectionner Servers à partir du dossier Serveur et cliquer sur .
- Cliquer avec le bouton droit de la souris sur helloworld dans l'onglet Project Explorer, puis sélectionner → .
- Sélectionner le serveur JBoss EAP 6.0 Runtime Server et cliquer sur . Cela devrait déployer le Quickstart
helloworlddu serveur JBoss. - Afficher la console du serveur. Vous devriez apercevoir le message suivant :
JBAS018210: Register web context: /jboss-helloworld JBAS018559: Deployed "jboss-helloworld.war" (runtime-name : "jboss-helloworld.war")
Le contexte web enregistré se rajoute àhttp://localhost:8080pour fournir l'URL utilisé pour accéder à l'application qui est déployée. - Pour vérifier que le Quickstart
helloworlda été déployé correctement dans le serveur JBoss, ouvrir le navigateur web, et accéder à l'application dans l'URL: http://localhost:8080/jboss-helloworld
1.4.3.2. Exécuter les Quickstarts par la Ligne de commande
Procédure 1.8. Générer et déployer les Quickstarts par la Ligne de commande
Vérifier le fichier
READMEqui se trouve dans le répertoire racine des quickstarts.Ce fichier contient des informations générales sur les prérequis de systèmes, sur la façon de configurer Maven, comment ajouter des utilisateurs, et comment exécuter les Quickstarts. Lisez attentivement avant de commencer.Il contient également un tableau qui répertorie les Quickstarts disponibles. Le tableau répertorie chaque nom de Quickstart et chaque technologie dont il s'agit. Il y a une brève description pour chaque Quickstart et une indication du niveau d'expérience requis pour l'installer. Pour des informations plus détaillées, cliquez sur le nom du Quickstart.Certains Quickstarts sont conçus pour améliorer ou étendre d'autres Quickstarts. Ils sont indiqués dans la colonnePrérequis. Si un Quickstart est associé à une liste de prérequis, vous devrez les installer avant d'utiliser le Quickstart.Certains Quickstart ont besoin de l'installation et de la configuraiton des composants optionnels. Ne pas installer ces composants à moins que le Quickstart ne l'exige.Exécuter le Quickstart
helloworldLe Quickstarthelloworldest l'un des Quickstarts les plus simples, et représente un bon moyen de vérifier si le serveur JBoss est configuré et exécute correctement. Ouvrir le fichierREADMEdans la racine du Quickstarthelloworld. Il contient des instructions détaillées sur la façon de construire et de déployer le Quickstart et d'accéder à l'application en cours.Exécuter d'autres Quickstarts.
Suivre les instructions dans le fichierREADMEqui se trouve dans le dossier racine de chaque Quickstart pour exécuter l'exemple.
1.4.4. Revoir les tutoriels Quickstart
1.4.4.1. Découvrir le Quickstart HelloWorld
Le Quickstart helloworld vous montre comment déployer un simple Servlet dans la plateforme JBoss EAP 6. La logique commerciale comprend un service fourni sous forme de bean CDI (Contexts and Dependency Injection) qui est injecté dans le Servlet. Ce Quickstart est très simple. Tout ce qu'il se contente de faire est d'imprimer "Hello World" dans une page web. C'est une bonne façon de savoir si vous avez bien configuré et démarré votre serveur.
Procédure 1.9. Importer le quickstart helloworld dans JBoss Developer Studio
- Si vous ne l'avez pas encore fait, configurez le référentiel Maven de JBoss EAP en utilisant les paramètres de Maven Section 2.3.2, « Configurer le référentiel JBoss EAP 6 Platform Maven Repository par les paramètres de configuration de Maven ».
- Si vous ne l'avez pas encore fait, installez JBoss Developer Studio Section 1.3.1.3, « Installer JBoss Developer Studio 5 ».
- À partir du menu, sélectionner → .
- Dans la liste sélectionnée, choisir → , puis cliquer sur .
Figure 1.9. Importer les projets Maven existants
- Naviguer dans le répertoire
QUICKSTART_HOME/quickstart/helloworld/et cliquer sur le bouton . La case qui contient la liste Projets contient le fichierpom.xmlqui vient du projet Quickstart helloworld.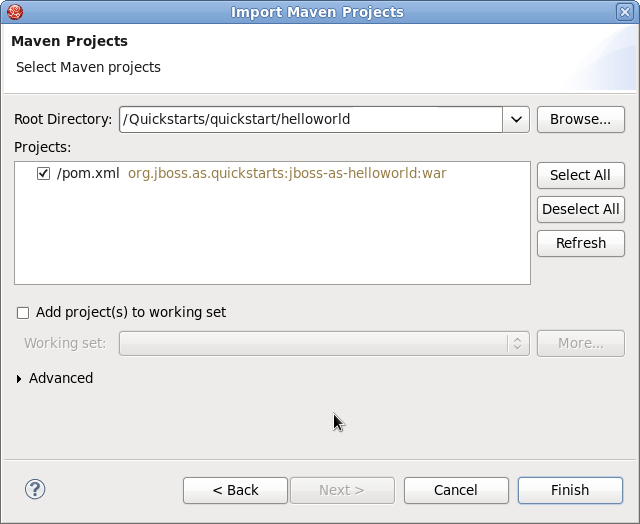
Figure 1.10. Sélectionner les projets Maven
- Cliquer sur .
Procédure 1.10. Générer et déployer le Quickstart helloworld
- Si vous n'avez pas encore configuré JBoss Developer Studio pour JBoss EAP 6, vous devez Section 1.3.1.5, « Ajouter le serveur de JBoss EAP 6 au JBoss Developer Studio ».
- Cliquer avec le bouton droit de la souris sur jboss-as-helloworld sur l'onglet Project Explorer, puis sélectionner → .
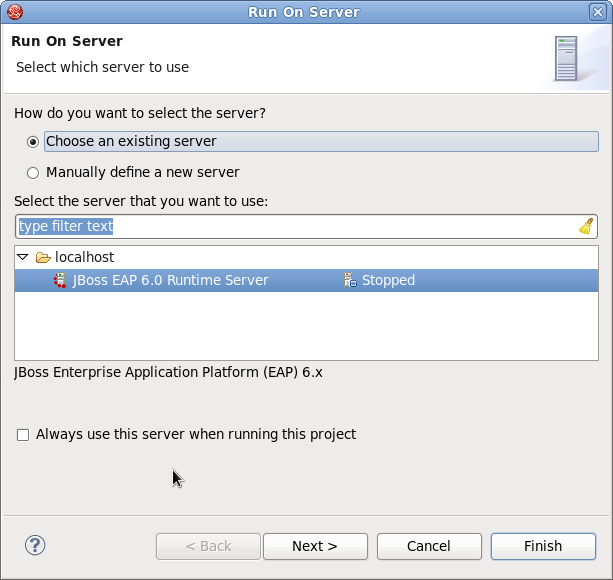
Figure 1.11. Exécuter sur le serveur
- Sélectionner le serveur JBoss EAP 6.0 Runtime Server et cliquer sur . Cela déployera le Quickstart helloworld du serveur JBoss.
- Pour vérifier que le quickstart helloworld a bien été déployé dans le serveur JBoss, ouvrir le navigateur web et accéder à l'application par le lien URL suivant : http://localhost:8080/jboss-as-helloworld
Procédure 1.11. Observer la structure du répertoire
QUICKSTART_HOME/helloworld. Le Quickstart helloworld comprend un Servlet et un bean CDI. Il comprend également un fichier beans.xml qui indique à JBoss EAP 6 comment trouver des beans pour cette application et comment activer le CDI.
- Le fichier
beans.xmlse trouve dans le dossierWEB-INF/qui se trouve dans le répertoiresrc/main/webapp/du Quickstart. - Le répertoire
src/main/webapp/inclut également un fichierindex.htmlqui utilise une simple réactualisation meta pour rediriger le navigateur de l'utilisateur vers le Servlet, qui se trouve à http://localhost:8080/jboss-as-helloworld/HelloWorld. - Tous les fichiers de configuration de cet exemple se trouvent dans
WEB-INF/, qui se trouve dans le répertoiresrc/main/webapp/de l'exemple. - Notez que le Quickstart n'a pas même besoin d'un fichier
web.xml!
Procédure 1.12. Examiner le code
Vérifier le code HelloWorldServlet
Le fichierHelloWorldServlet.javase trouve dans le répertoiresrc/main/java/org/jboss/as/quickstarts/helloworld/. Le Servlet envoie les informations dans le navigateur.27. @WebServlet("/HelloWorld") 28. public class HelloWorldServlet extends HttpServlet { 29. 30. static String PAGE_HEADER = "<html><head /><body>"; 31. 32. static String PAGE_FOOTER = "</body></html>"; 33. 34. @Inject 35. HelloService helloService; 36. 37. @Override 38. protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { 39. PrintWriter writer = resp.getWriter(); 40. writer.println(PAGE_HEADER); 41. writer.println("<h1>" + helloService.createHelloMessage("World") + "</h1>"); 42. writer.println(PAGE_FOOTER); 43. writer.close(); 44. } 45. 46. }Tableau 1.1. Infos HelloWorldServlet
Ligne Note 27 Avant Java EE 6, on utilisait un fichier XML pour enregistrer les Servlets. C'est bien plus clean. Tout ce qu'il vous reste à faire est d'ajouter l'annotation @WebServletet de fournir un mappage vers un URL qui est utilisé pour accéder au serveur.30-32 Chaque page web a besoin d'HTML formé correctement. Ce Quickstart utilise les Strings statiques pour écrire les sorties minimum de l'en-tête et du pied de page. 34-35 Ces lignes injectent le bean CDI HelloService, qui génère le message réel. Tant que nous ne changeons les API de HelloService, cette approche nous permet de modifier l'implémentation de HelloService à une date ultérieure sans changer l'affichage. 41 Cette ligne appelle le service pour générer le message "Hello World", et l'écrire dans la requête HTTP. Vérifier le code HelloService
Le fichierHelloService.javase trouve dans le répertoiresrc/main/java/org/jboss/as/quickstarts/helloworld/. Ce service est très simple. Il renvoie un message. Nul besoin d'enregistrement d'annotation ou XML.9. public class HelloService { 10. 11. String createHelloMessage(String name) { 12. return "Hello " + name + "!"; 32. } 33. } 34.
1.4.4.2. Découvrir le Quickstart numberguess
Ce Quickstart vous montre comment créer et déployer une simple application de JBoss EAP 6. Cette application ne persiste pas n'importe quelle information. Les informations sont affichées par JSF, et la logique métier est encapsulée dans deux beans CDI. Dans le Quickstart numberguess, vous obtenez 10 tentatives pour deviner un nombre entre 1 et 100. Après chaque tentative, on vous indique si votre estimation est trop élevée ou trop faible.
QUICKSTART_HOME/numberguess. Le Quickstart hnumberguess comprend un certain nombre de beans, des fichiers de configuration et des affichages Facelets (JSF), tout cela dans un package de module WAR.
Procédure 1.13. Importer le quickstart numberguess dans JBoss Developer Studio
- Si vous ne l'avez pas encore fait, effectuer les procédures suivantes : Section 1.3.1.3, « Installer JBoss Developer Studio 5 »
- À partir du menu, sélectionner → .
- Dans la liste sélectionnée, choisir → , puis cliquer sur .
Figure 1.12. Importer les projets Maven existants
- Naviguer dans le répertoire
QUICKSTART_HOME/quickstart/numberguess/et cliquer sur le bouton . La case qui contient la liste Projets contient le fichierpom.xmlqui vient du projet Quickstart helloworld. - Cliquer sur .
Procédure 1.14. Générer et déployer le Quickstart numberguess
- Si vous n'avez pas encore configuré JBoss Developer Studio pour JBoss EAP 6, vous devez faire la chose suivante : Section 1.3.1.5, « Ajouter le serveur de JBoss EAP 6 au JBoss Developer Studio ».
- Cliquer avec le bouton droit de la souris sur jboss-as-numberguess sur l'onglet Project Explorer, puis sélectionner → .
- Sélectionner le serveur JBoss EAP 6.0 Runtime Server et cliquer sur . Cela déployera le Quickstart numberguess du serveur JBoss.
- Pour vérifier que le quickstart numberguess a bien été déployé dans le serveur JBoss, ouvrir le navigateur web et accéder à l'application en cliquant sur cet URL : http://localhost:8080/jboss-as-numberguess
Procédure 1.15. Examiner les fichiers de configuration
WEB-INF/, qui se trouvent dans le répertoire src/main/webapp/ du Quickstart.
Voir le fichier faces-config
Ce Quickstart utilise la version de JSF 2.0 defaces-config.xml. Une version normalisée de Facelets correspond au gestionnaire d'affichage par défaut de JSF 2.0, donc il n'y a par vraiment grand chose à configurer. JBoss EAP 6 va au-delà de Java EE ici. Il va automatiquement configurer JSF pour vous, si vous incluez ce fichier de configuration. En conséquence, la configuration ne consistera uniquement en l'élément racine :03. <faces-config version="2.0" 04. xmlns="http://java.sun.com/xml/ns/javaee" 05. xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 06. xsi:schemaLocation=" 07. http://java.sun.com/xml/ns/javaee> 08. http://java.sun.com/xml/ns/javaee/web-facesconfig_2_0.xsd"> 09. 10. </faces-config>
Voir le fichier beans.xml
Il y a également un fichierbeans.xmlqui indique à JBoss EAP 6 de chercher des beans dans cette application et d'activer le CDI.Il n'y a pas de fichier web.xml
Notez que le Quickstart n'a pas même besoin d'un fichierweb.xml!
Procédure 1.16. Examiner le code JSF
.xhtml pour les fichiers source, mais s'occupe des vues rendues par l'extension .jsf.
Examiner le code home.xhtml
Le fichierhome.xhtmlse trouve dans le répertoiresrc/main/webapp/.03. <html xmlns="http://www.w3.org/1999/xhtml" 04. xmlns:ui="http://java.sun.com/jsf/facelets" 05. xmlns:h="http://java.sun.com/jsf/html" 06. xmlns:f="http://java.sun.com/jsf/core"> 07. 08. <head> 09. <meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1" /> 10. <title>Numberguess</title> 11. </head> 12. 13. <body> 14. <div id="content"> 15. <h1>Guess a number...</h1> 16. <h:form id="numberGuess"> 17. 18. <!-- Feedback for the user on their guess --> 19. <div style="color: red"> 20. <h:messages id="messages" globalOnly="false" /> 21. <h:outputText id="Higher" value="Higher!" 22. rendered="#{game.number gt game.guess and game.guess ne 0}" /> 23. <h:outputText id="Lower" value="Lower!" 24. rendered="#{game.number lt game.guess and game.guess ne 0}" /> 25. </div> 26. 27. <!-- Instructions for the user --> 28. <div> 29. I'm thinking of a number between <span 30. id="numberGuess:smallest">#{game.smallest}</span> and <span 31. id="numberGuess:biggest">#{game.biggest}</span>. You have 32. #{game.remainingGuesses} guesses remaining. 33. </div> 34. 35. <!-- Input box for the users guess, plus a button to submit, and reset --> 36. <!-- These are bound using EL to our CDI beans --> 37. <div> 38. Your guess: 39. <h:inputText id="inputGuess" value="#{game.guess}" 40. required="true" size="3" 41. disabled="#{game.number eq game.guess}" 42. validator="#{game.validateNumberRange}" /> 43. <h:commandButton id="guessButton" value="Guess" 44. action="#{game.check}" 45. disabled="#{game.number eq game.guess}" /> 46. </div> 47. <div> 48. <h:commandButton id="restartButton" value="Reset" 49. action="#{game.reset}" immediate="true" /> 50. </div> 51. </h:form> 52. 53. </div> 54. 55. <br style="clear: both" /> 56. 57. </body> 58. </html>Tableau 1.2. Infos JSF
Ligne Note 20-24 Voici les messages qui peuvent être envoyés par l'utilisateur : "Higher!" et "Lower!" 29-32 Au fur et à mesure que l'utilisateur devine, l'étendue des nombres qu'ils devinent se rétrécit. Cette phrase change pour s'assurer qu'ils connaissent la portée d'une tentative valide. 38-42 Ce champ d'entrée est lié à une propriété de bean qui utilise une expression de valeur. 42 On utilise une liaison de validateur pour s'assurer que l'utilisateur ne mette pas le nombre qu'il devine en dehors de la limite. Si le validateur n'était pas présent, l'utilisateur peut deviner un nombre en dehors de la limite. 43-45 Il doit y avoir un moyen pour que l'utilisateur envoie le nombre qu'il devine au serveur. Ici, on associe une méthode d'action sur le bean.
Procédure 1.17. Examiner les fichiers de classe
src/main/java/org/jboss/as/quickstarts/numberguess/. :a déclaration de paquet et les importations ont été exclues de ces listings. La liste complète se trouve dans le code source du Quickstart.
Vérifier le code du qualificateur Random.java
Un qualificateur est utilisé pour supprimer l'ambiguïté entre deux beans, qui sont tous deux admissibles pour l'injection selon leur type. Pour plus d'informations sur les qualificateurs, voir Section 9.2.3.3, « Utiliser un qualificateur pour résoudre une injection ambiguë »Le qualificateur@Randomest utilisé pour injecter un nombre au hasard.21. @Target({ TYPE, METHOD, PARAMETER, FIELD }) 22. @Retention(RUNTIME) 23. @Documented 24. @Qualifier 25. public @interface Random { 26. 27. }Vérifier le code du qualificateur MaxNumber.java
Lequalificateur@MaxNumberest utilisé pour injecter le nombre maximum autorisé.21. @Target({ TYPE, METHOD, PARAMETER, FIELD }) 22. @Retention(RUNTIME) 23. @Documented 24. @Qualifier 25. public @interface MaxNumber { 26. 27. }Vérifier le code du générateur
La classeGeneratorest chargé de créer le nombre aléatoire par une méthode de producteur. Elle indique également le nombre maximum possible par une méthode de producteur. Cette classe reste dans la portée de l'application, donc, vous n'obtenez pas un nombre différent au hasard à chaque fois.28. @ApplicationScoped 29. public class Generator implements Serializable { 30. private static final long serialVersionUID = -7213673465118041882L; 31. 32. private java.util.Random random = new java.util.Random(System.currentTimeMillis()); 33. 34. private int maxNumber = 100; 35. 36. java.util.Random getRandom() { 37. return random; 38. } 39. 40. @Produces 41. @Random 42. int next() { 43. // a number between 1 and 100 44. return getRandom().nextInt(maxNumber - 1) + 1; 45. } 46. 47. @Produces 48. @MaxNumber 49. int getMaxNumber() { 50. return maxNumber; 51. } 52. }Vérifier le code Game
La classe session scopedGameest le point d'entrée principal de l'application. Elle est là pour initialiser et réinitialiser le jeu, pour capturer et valider la tentative de numéro de l'utilisateur, et afin de fournir un commentaire de retour à l'utilisateur avec unFacesMessage. Elle utilise une méthode de cycle de vie de post-construction pour initialiser le jeu, en tirant un nombre au hasard du bean@Random Instance<Integer>.Notez l'annotation @Named dans la classe. Cette annotation est uniquement requise quand on veut rendre le bean accessible à une vue JSF via Expression Language (EL), et dans ce cas#{game}.035. @Named 036. @SessionScoped 037. public class Game implements Serializable { 038. 039. private static final long serialVersionUID = 991300443278089016L; 040. 041. /** 042. * The number that the user needs to guess 043. */ 044. private int number; 045. 046. /** 047. * The users latest guess 048. */ 049. private int guess; 050. 051. /** 052. * The smallest number guessed so far (so we can track the valid guess range). 053. */ 054. private int smallest; 055. 056. /** 057. * The largest number guessed so far 058. */ 059. private int biggest; 060. 061. /** 062. * The number of guesses remaining 063. */ 064. private int remainingGuesses; 065. 066. /** 067. * The maximum number we should ask them to guess 068. */ 069. @Inject 070. @MaxNumber 071. private int maxNumber; 072. 073. /** 074. * The random number to guess 075. */ 076. @Inject 077. @Random 078. Instance<Integer> randomNumber; 079. 080. public Game() { 081. } 082. 083. public int getNumber() { 084. return number; 085. } 086. 087. public int getGuess() { 088. return guess; 089. } 090. 091. public void setGuess(int guess) { 092. this.guess = guess; 093. } 094. 095. public int getSmallest() { 096. return smallest; 097. } 098. 099. public int getBiggest() { 100. return biggest; 101. } 102. 103. public int getRemainingGuesses() { 104. return remainingGuesses; 105. } 106. 107. /** 108. * Check whether the current guess is correct, and update the biggest/smallest guesses as needed. 109. * Give feedback to the user if they are correct. 110. */ 111. public void check() { 112. if (guess > number) { 113. biggest = guess - 1; 114. } else if (guess < number) { 115. smallest = guess + 1; 116. } else if (guess == number) { 117. FacesContext.getCurrentInstance().addMessage(null, new FacesMessage("Correct!")); 118. } 119. remainingGuesses--; 120. } 121. 122. /** 123. * Reset the game, by putting all values back to their defaults, and getting a new random number. 124. * We also call this method when the user starts playing for the first time using 125. * {@linkplain PostConstruct @PostConstruct} to set the initial values. 126. */ 127. @PostConstruct 128. public void reset() { 129. this.smallest = 0; 130. this.guess = 0; 131. this.remainingGuesses = 10; 132. this.biggest = maxNumber; 133. this.number = randomNumber.get(); 134. } 135. 136. /** 137. * A JSF validation method which checks whether the guess is valid. It might not be valid because 138. * there are no guesses left, or because the guess is not in range. 139. * 140. */ 141. public void validateNumberRange(FacesContext context, UIComponent toValidate, Object value) { 142. if (remainingGuesses <= 0) { 143. FacesMessage message = new FacesMessage("No guesses left!"); 144. context.addMessage(toValidate.getClientId(context), message); 145. ((UIInput) toValidate).setValid(false); 146. return; 147. } 148. int input = (Integer) value; 149. 150. if (input < smallest || input > biggest) { 151. ((UIInput) toValidate).setValid(false); 152. 153. FacesMessage message = new FacesMessage("Invalid guess"); 154. context.addMessage(toValidate.getClientId(context), message); 155. } 156. } 157. }
Chapitre 2. Guide Maven
2.1. Pour en savoir plus sur Maven
2.1.1. Le référentiel Maven
http:// pour un référentiel sur un serveur HTTP ou file:// pour un référentiel de serveur de fichiers. Un référentiel local correspond à un téléchargement cache des artefacts à partir d'un référentiel distant.
2.1.2. Le fichier POM Maven
pom.xml requiert certaines options de configuration définissant la valeur par défaut. Voir Section 2.1.3, « Prérequis minimum pour un fichier POM Maven » pour plus de détails.
pom.xml est disponible sur le lien http://maven.apache.org/maven-v4_0_0.xsd.
2.1.3. Prérequis minimum pour un fichier POM Maven
Les prérequis minimum pour un fichier pom.xml sont les suivants :
- project root
- modelVersion
- groupId - l'id du groupe du projet
- artifactId - l'id de l'artifact (projet)
- version - la version de l'artifact dans le groupe spécifié
Un fichier pom.xml de base devrait resssembler à ceci :
<project> <modelVersion>4.0.0</modelVersion> <groupId>com.jboss.app</groupId> <artifactId>my-app</artifactId> <version>1</version> </project>
2.1.4. Le fichier des configurations de Maven
settings.xml contient des informations de configuration spécifiques à l'utilisateur pour Maven. Il contient des informations qui ne devraient pas être distribuées dans le fichier pom.xml, comme l'identité du dévelopeur, l'information sur le proxy, l'emplacement du référentiel local, et autres paramètres propres à un utilisateur.
settings.xml.
- Dans l'installation Maven
- Le fichier de configuration se trouve dans le répertoire
M2_HOME/conf/. On les appelle les paramètresglobaux. Le fichier de configuration Maven par défaut est un modèle qui peut être copié et utilisé comme point de départ pour le fichier des paramètres utilisateur. - Dans l'installation de l'utilisateur
- Le fichier de configuration se trouve dans le répertoire
USER_HOME/.m2/. Si les fichierssettings.xmlet Maven existent tous les deux, leurs contenus seront fusionnés. S'il y a une intersection, le fichier utilisateursettings.xmlaura priorité.
settings.xml Maven :
<?xml version="1.0" encoding="UTF-8"?>
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd">
<profiles>
<!-- Configure the JBoss EAP Maven repository -->
<profile>
<id>jboss-eap-maven-repository</id>
<repositories>
<repository>
<id>jboss-eap</id>
<url>file:///path/to/repo/jboss-eap-6.0-maven-repository</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>jboss-eap-maven-plugin-repository</id>
<url>file:///path/to/repo/jboss-eap-6.0-maven-repository</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
</pluginRepositories>
</profile>
</profiles>
<activeProfiles>
<!-- Optionally, make the repository active by default -->
<activeProfile>jboss-eap-maven-repository</activeProfile>
</activeProfiles>
</settings>
settings.xml à l'adresse suivante http://maven.apache.org/xsd/settings-1.0.0.xsd.
2.2. Installer le Référentiel JBoss Maven et Maven
2.2.1. Télécharger et installer Maven
- Aller dans Apache Maven Project - Download Maven et télécharger la dernière distribution de votre système d'exploitation.
- Voir la documentation Maven pour les informations sur le façon de télécharger et installer Apache Maven sur votre système d'exploitation.
2.2.2. Installer le référentiel Maven de JBoss EAP 6
2.2.3. Installer le référentiel Maven de JBoss EAP 6 localement
Le référentiel de JBoss EAP 6.2 Maven est disponible en ligne. Il n'est pas donc nécessaire de le télécharger et de l'installer localement. Toutefois, si vous préférez installer le référentiel JBoss EAP Maven localement, il y a trois façons de procéder : sur votre système de fichiers local, sur le serveur Web Apache, ou avec un gestionnaire de référentiel Maven. Cet exemple couvre les étapes pour télécharger le référentiel JBoss EAP 6 Maven sur le système de fichiers local. Cette option est facile à configurer et vous permet d'obtenir d'être opérationnel rapidement sur votre ordinateur local. Il peut vous aider à vous familiariser à l'utilisation de Maven pour le développement, mais n'est pas recommandé pour les environnements de production en équipes.
Procédure 2.1. Télécharger et installer le référentiel Maven de JBoss EAP 6 sur le système de fichier local.
- Ouvrir un navigateur web, et accéder à cet URL: https://access.redhat.com/jbossnetwork/restricted/listSoftware.html?product=appplatform.
- Chercher "Red Hat JBoss Enterprise Application Platform 6.2.0 Maven Repository" dans la liste.
- Cliquer sur le bouton pour télécharger un fichier
.zipcontenant le référentiel. - Décompresser le fichier dans le même répertoire sur votre système de fichiers local dans un répertoire de votre choix.
Ceci crée un répertoire de référentiel Maven appelé jboss-eap-6.2.0.maven-repository.
Important
settings.xml de Maven. Chaque référentiel local doit être configuré dans sa propre balise <repository>.
Important
repository/ cache, qui se situe sous le répertoire .m2/ avant de tenter d'utiliser le nouveau répertoire Maven.
2.2.4. Installer le référentiel Maven de JBoss EAP 6 à utiliser avec Appache httpd
Il vous faut configurer Apache httpd. Voir la documentation Apache HTTP Server Project pour obtenir des instructions.
Procédure 2.2. Télécharger l'archive ZIP du Référentiel Maven de JBoss EAP 6
- Ouvrir un navigateur web, et accéder à cet URL: https://access.redhat.com/jbossnetwork/restricted/listSoftware.html?product=appplatform.
- Chercher "Red Hat JBoss Enterprise Application Platform 6.2.0 Maven Repository" dans la liste.
- Cliquer sur le bouton pour télécharger un fichier
.zipcontenant le référentiel. - Décompresser les fichiers dans un répertoire qui soit accessible au serveur Apache.
- Configurer Apache pour lui donner la permission écriture et pour permettre la navigation dans le répertoire créé.
Cela permet à un environnement multi-utilisateurs d'accéder à un référentiel Maven sur Apache httpd.
Note
2.2.5. Installer le référentiel Maven de JBoss EAP 6 en utilisant le gestionnaire de référentiels Nexus Maven
Procédure 2.3. Télécharger l'archive ZIP du référentiel Maven de JBoss EAP 6
- Ouvrir un navigateur web, et accéder à cet URL: https://access.redhat.com/jbossnetwork/restricted/listSoftware.html?product=appplatform.
- Chercher "Red Hat JBoss Enterprise Application Platform 6.2.0 Maven Repository" dans la liste.
- Cliquer sur le bouton pour télécharger un fichier
.zipcontenant le référentiel. - Décompresser les fichiers dans un répertoire de votre choix.
Procédure 2.4. Ajouter le référentiel Maven de JBoss EAP 6 en utilisant le gestionnaire de référentiels Nexus Maven
- Connectez-vous à Nexus en tant qu'administrateur.
- Sélectionner la section Référentiels à partir du menu → qui se trouve à gauche du gestionnaire de référentiels.
- Cliquer sur le menu déroulant Ajouter..., puis sélectionner Référentiel hébergé.
- Donner un nom et une ID au nouveau référentiel.
- Saisir le chemin du disque qui mène au référentiel décompressé dans le champ d'emplacement Remplacement du stockage local.
- Continuer si vous souhaitez que l'artéfact soit disponible dans un groupe de référentiels. Ne pas continuer avec cette procédure si ce n'est pas ce que vous souhaitez.
- Sélectionner le groupe de référentiels.
- Cliquer sur l'onglet Configurer.
- Déplacez le nouveau référentiel JBoss Maven de la liste Référentiels disponibles vers la liste Référentiels de groupes ordonnancés sur la gauche.
Note
Notez que l'ordre de cette liste détermine la priorité de recherche d'artefacts Maven.
Le référentiel est configuré par le gestionnaire de référentiels Maven Nexus.
2.2.6. Gestionnaires de référentiels Maven
- Ils donnent la possibilité de configurer des proxys entre votre organisation et des référentiels Maven à distance, ce qui offre un grand nombre d'avantages, parmi lesquels des déploiements plus rapides et plus efficaces et un meilleur niveau de contrôle sur ce qui est téléchargé par Maven.
- Ils fournissent des destinations de déploiement pour les artefacts que vous aurez vous-même générés, permettant ainsi une collaboration entre différentes équipes de développement au sein d'une organisation.
Gestionnaires de référentiels Maven les plus communément utilisés
- Sonatype Nexus
- Voir Sonatype Nexus: Manage Artifacts pour obtenir plus d'informations sur Nexus.
- Artifactory
- Voir Artifactory Open Source pour obtenir plus d'informations sur Artifactory.
- Apache Archiva
- Voir Apache Archiva: The Build Artifact Repository Manager pour obtenir plus d'informations sur Apache Archiva.
2.3. Utiliser le Référentiel Maven
2.3.1. Configurer le référentiel Maven de JBoss EAP
Il existe deux approches pour amener Maven à utiliser le référentiel Maven de JBoss EAP 6 dans votre projet :
- Vous pouvez configurer les référentiels dans les paramètres globaux ou d'utilisateur de Maven.
- Vous pouvez configurer les référentiels dans le fichier POM du projet.
Procédure 2.5. Configurer les paramètres Maven pour qu'ils utilisent le référentiel Maven de JBoss EAP 6
Configurer le référentiel Maven par les paramètres Maven
Nous vous conseillons cette dernière approche. Les paramètres Maven utilisés avec un gestionnaire de référentiel ou un référentiel sur un serveur partagé offrent un meilleur contrôle et une meilleure gestion des projets. Les paramètres offrent également la capacité d'utiliser un miroir alternatif pour rediriger toutes les demandes de recherche pour un référentiel spécifique vers un gestionnaire de référentiel sans changer les fichiers du projet. Pour plus d'informations concernant les miroirs, veuillez consulter http://maven.apache.org/guides/mini/guide-mirror-settings.html.Cette méthode de configuration s'applique à tous les projets Maven, tant que le fichier POM du projet ne contient pas de configuration de référentiel.Configurer le référentiel Maven pour qu'il utilise le fichier POM du projet.
Cette méthode de configuration est généralement déconseillée. Si vous décidez de configurer des référentiels dans le fichier POM de votre projet, planifiez de manière prudente et souvenez-vous que cela pourrait ralentir votre build et que vous pourriez vous retrouver avec des artefacts ne provenant pas du référentiel attendu.Note
Dans le cas d'une entreprise, où un gestionnaire de référentiel est généralement utilisé, Maven doit interroger tous les artefacts pour tous les projets en utilisant ce gestionnaire. Maven utilise tous les référentiels déclarés pour trouver les artéfacts manquants. Par conséquent, s'il ne peut trouver ce qu'il cherche, il pourra le chercher dans la centrale de référentiels (définie dans le fichier POM parent intégré). Pour remplacer cet emplacement central, vous pouvez ajouter une définition aveccentralde manière à ce que la centrale de référentiels devienne également votre gestionnaire de référentiel. Cela fonctionne bien avec les projets établis, mais pose un problème pour les projets vierges ou récents puisque cela crée une dépendance cyclique.Les fichiers POM inclus de manière transitive représentent également un problème avec ce type de configuration. Maven doit interroger ces référentiels externes pour trouver les artefacts manquants. Non seulement cela ralentira votre build, mais vous fera également perdre le contrôle sur la provenance de vos artefacts et risquera d'endommager votre build.Cette méthode de configuration remplace les configuration utilisateur et globales pour le projet configuré.
2.3.2. Configurer le référentiel JBoss EAP 6 Platform Maven Repository par les paramètres de configuration de Maven
- Vous pouvez modifier les paramètres Maven. Cela amène Maven à utiliser la configuration à travers tous les projets.
- Vous pouvez configurer le fichier POM du projet. Cela limite la configuration au projet particulier.
Note
- Système de fichiers
- file:///path/to/repo/jboss-eap-6.x-maven-repository
- Apache Web Server
- http://intranet.acme.com/jboss-eap-6.x-maven-repository/
- Gestionnaire de référentiel Nexus
- https://intranet.acme.com/nexus/content/repositories/jboss-eap-6.x-maven-repository
Procédure 2.6. Configurer Maven par les paramètres fournis dans les exemples Quickstart
settings.xml configuré pour utiliser le référentiel JBoss EAP 6.2 Maven en ligne. Il s'agit de l'approche la plus simple.
- Cette procédure remplace le fichier de configuration Maven existant, donc vous devrez sauvegarder le fichier
settings.xmlMaven existant.- Chercher le répertoire d'installation Maven qui corresponde à votre système d'exploitation. Il se trouve normalement dans le répertoire
USER_HOME/.m2/.- Dans Linux ou Mac, c'est:
~/.m2/ - Pour Windows, c'est :
\Documents and Settings\USER_NAME\.m2\ou\Users\USER_NAME\.m2\
- Si vous avez un fichier
USER_HOME/.m2/settings.xmlexistant, renommer le et faire une copie de sauvegarde afin de pouvoir le restaurer plus tard.
- Télécharger et décompresser les exemples quickstart fournis dans JBoss EAP 6.2. Pour plus d'informations, voir la section Download the Quickstart Code Examples du Development Guide dans JBoss EAP 6 à https://access.redhat.com/site/documentation/JBoss_Enterprise_Application_Platform/.
- Copier le fichier
QUICKSTART_HOME/settings.xmldans le répertoireUSER_HOME/.m2/. - Si vous modifiez le fichier
settings.xmltandis que JBoss Developer Studio est en cours d'exécution, suivre la procédure ci-dessous intitulée Refresh the JBoss Developer Studio User Settings.
Procédure 2.7. Modifier et configurer les paramètres Maven manuellement pour qu'ils utilisent le référentiel Maven de JBoss EAP 6.2 en ligne
- Chercher le répertoire d'installation Maven qui corresponde à votre système d'exploitation. Il se trouve normalement dans le répertoire
USER_HOME/.m2/.- Dans Linux ou Mac, c'est
~/.m2/ - Pour Windows, c'est
\Documents and Settings\USER_NAME\.m2\ou\Users\USER_NAME\.m2\
- Si vous ne trouvez pas de fichier
settings.xml, copier le fichiersettings.xmldu répertoireUSER_HOME/.m2/conf/dans le répertoireUSER_HOME/.m2/. - Copier l'XML suivant dans l'élément
<profiles>du fichier.<!-- Configure the JBoss GA Maven repository --> <profile> <id>jboss-ga-repository</id> <repositories> <repository> <id>jboss-ga-repository</id> <url>http://maven.repository.redhat.com/techpreview/all</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>false</enabled> </snapshots> </repository> </repositories> <pluginRepositories> <pluginRepository> <id>jboss-ga-plugin-repository</id> <url>http://maven.repository.redhat.com/techpreview/all</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>false</enabled> </snapshots> </pluginRepository> </pluginRepositories> </profile> <!-- Configure the JBoss Early Access Maven repository --> <profile> <id>jboss-earlyaccess-repository</id> <repositories> <repository> <id>jboss-earlyaccess-repository</id> <url>http://maven.repository.redhat.com/earlyaccess/all/</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>false</enabled> </snapshots> </repository> </repositories> <pluginRepositories> <pluginRepository> <id>jboss-earlyaccess-plugin-repository</id> <url>http://maven.repository.redhat.com/earlyaccess/all/</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>false</enabled> </snapshots> </pluginRepository> </pluginRepositories> </profile>Copier l'XML suivant dans l'élément<activeProfiles>desettings.xml.<activeProfile>jboss-ga-repository</activeProfile> <activeProfile>jboss-earlyaccess-repository</activeProfile>
- Si vous modifiez le fichier
settings.xmltandis que JBoss Developer Studio est en cours d'exécution, suivre la procédure ci-dessous intitulée Refresh the JBoss Developer Studio User Settings.
Procédure 2.8. Configurer les paramètres pour pouvoir utiliser un référentiel JBoss EAP installé localement
- Chercher le répertoire d'installation Maven qui corresponde à votre système d'exploitation. Il se trouve normalement dans le répertoire
USER_HOME/.m2/.- Dans Linux ou Mac, c'est
~/.m2/ - Pour Windows, c'est
\Documents and Settings\USER_NAME\.m2\ou\Users\USER_NAME\.m2\
- Si vous ne trouvez pas de fichier
settings.xml, copier le fichiersettings.xmldu répertoireUSER_HOME/.m2/conf/dans le répertoireUSER_HOME/.m2/. - Copier l'XML suivant dans l'élément
<profiles>du fichiersettings.xml. Veillez bien à changer l'<url>au bon emplacement de référentiel.<profile> <id>jboss-eap-repository</id> <repositories> <repository> <id>jboss-eap-repository</id> <name>JBoss EAP Maven Repository</name> <url>file:///path/to/repo/jboss-eap-6.x-maven-repository</url> <layout>default</layout> <releases> <enabled>true</enabled> <updatePolicy>never</updatePolicy> </releases> <snapshots> <enabled>false</enabled> <updatePolicy>never</updatePolicy> </snapshots> </repository> </repositories> <pluginRepositories> <pluginRepository> <id>jboss-eap-repository-group</id> <name>JBoss EAP Maven Repository</name> <url> file:///path/to/repo/jboss-eap-6.x-maven-repository </url> <layout>default</layout> <releases> <enabled>true</enabled> <updatePolicy>never</updatePolicy> </releases> <snapshots> <enabled>false</enabled> <updatePolicy>never</updatePolicy> </snapshots> </pluginRepository> </pluginRepositories> </profile>Copier l'XML suivant dans l'élément<activeProfiles>desettings.xml.<activeProfile>jboss-eap-repository</activeProfile>
- Si vous modifiez le fichier
settings.xmltandis que JBoss Developer Studio est en cours d'exécution, suivre la procédure ci-dessous intitulée Refresh the JBoss Developer Studio User Settings.
Procédure 2.9. Réactualiser les paramètres de configuration de l'utilisateur JBoss Developer Studio
settings.xml tandis que JBoss Developer Studio est en cours d'exécution, vous devrez réactualiser les paramètres de configuration de l'utilisateur.
- À partir du menu, sélectionner → .
- Dans la fenêtre Window Préférences, étendre Maven et sélectionner Paramètres de configuration utilisateur.
- Cliquer sur le bouton pour réactualiser les configurations utilisateur de Maven dans JBoss Developer Studio.
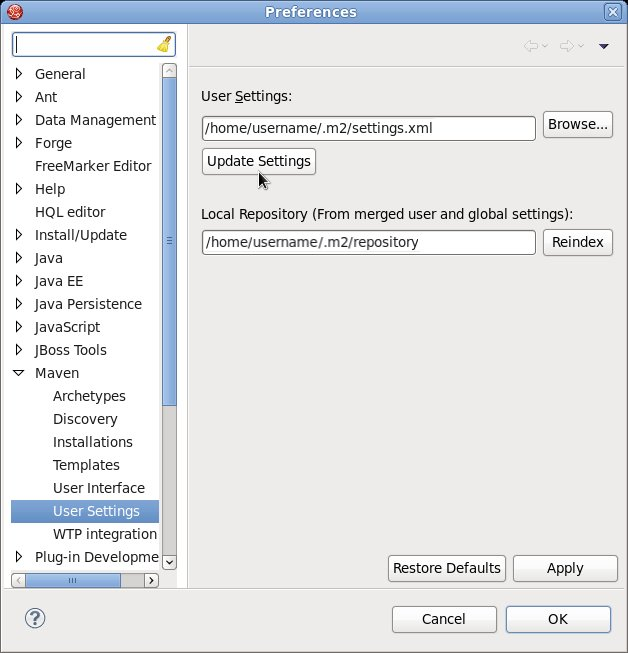
Figure 2.1. Mise à jour des paramètres de configuration de l'utilisateur Maven
Important
- Missing artifact ARTIFACT_NAME
- [ERROR] Failed to execute goal on project PROJECT_NAME; Could not resolve dependencies for PROJECT_NAME
~/.m2/repository/ subdirectory on Linux, or the %SystemDrive%\Users\USERNAME\.m2\repository\ subdirectory on Windows.
2.3.3. Configurer le référentiel JBoss EAP 6 Platform Maven Repository par le Projet POM
- Vous pouvez modifier les paramètres Maven.
- Vous pouvez configurer le fichier POM du projet.
pom.xml. Cette méthode de configuration remplace les configurations Utilisateur et Globales.
Note
central de manière à ce que la centrale de référentiels devienne également votre gestionnaire de référentiel. Cela fonctionne bien avec les projets établis, mais pose un problème pour les projets vierges ou récents puisque cela crée une dépendance cyclique.
Note
- Système de fichiers
file:///path/to/repo/jboss-eap-6.0.0-maven-repository- Apache Web Server
http://intranet.acme.com/jboss-eap-6.0.0-maven-repository/- Gestionnaire de référentiel Nexus
https://intranet.acme.com/nexus/content/repositories/jboss-eap-6.0.0-maven-repository
- Ouvrir le fichier
pom.xmlde votre projet dans un éditeur de texte. - Ajouter la configuration du référentiel suivant. S'il y a déjà une configuration
<repositories>qui se trouve dans le fichier, lui ajouter l'élément<repository>. Veillez bien à modifier l'<url>pour qu'il corresponde bien à l'emplacement du référentiel.<repositories> <repository> <id>jboss-eap-repository-group</id> <name>JBoss EAP Maven Repository</name> <url>file:///path/to/repo/jboss-eap-6.0.0-maven-repository/</url> <layout>default</layout> <releases> <enabled>true</enabled> <updatePolicy>never</updatePolicy> </releases> <snapshots> <enabled>true</enabled> <updatePolicy>never</updatePolicy> </snapshots> </repository> </repositories> - Ajouter la configuration de référentiel de plug-in suivante. S'il existe déjà une configuration
<pluginRepositories>dans le fichier, lui ajouter l'élément<pluginRepository>.<pluginRepositories> <pluginRepository> <id>jboss-eap-repository-group</id> <name>JBoss EAP Maven Repository</name> <url>file:///path/to/repo/jboss-eap-6.0.0-maven-repository/</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>true</enabled> </snapshots> </pluginRepository> </pluginRepositories>
2.3.4. Gestion des dépendances du projet
pom.xml (POM) qui indique les versions de toutes les dépendances d'exécution d'un module donné. Les dépendances de versions sont listées dans la section de gestion des dépendances du fichier.
groupId:artifactId:version (GAV) à la section de gestion des dépendances du fichier pom.xml du projet et en spécifiant <scope>import</scope> et les valeurs de l'élément <type>pom</type>.
Note
fournie. C'est parce que ces classes sont fournies par le serveur d'applications en cours d'exécution et qu'il n'est pas nécessaire de les empaqueter avec l'application utilisateur.
Artéfacts Maven pris en charge
-redhat, par exemple 1.0.0-redhat-1.
pom.xml de configuration de build garantit que le build utilise l'artefact binaire correct pour la génération de builds locaux et pour le testing. Notez qu'un artefact avec une version -redhat ne fait pas nécessairement partie de l'API public prise en charge et peut changer à l'avenir au cours des révisions. Pour plus d'informations sur l'API public pris en charge, voir la documentation JavaDoc incluse dans la sortie.
<dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-core</artifact> <version>4.2.6.Final-redhat-1</version> <scope>provided</scope> </dependency>Notez que l'exemple ci-dessus contient une valeur pour le champ
<version/>. Cependant, il est recommandé d'utiliser la gestion des dépendances Maven pour configurer les versions de dépendances.
Gestion des dépendances
<dependencyManagement>
<dependencies>
...
<dependency>
<groupId>org.jboss.bom</groupId>
<artifactId>eap6-supported-artifacts</artifactId>
<version>6.2.0.GA</version>
<type>pom</type>
<scope>import</scope>
</dependency>
...
</dependencies>
</dependencyManagement>
JBoss JavaEE Specs Bom de nomenclature
jboss-javaee-6.0 contient les JAR de spécification JAVA EE utilisés dans JBoss EAP.
3.0.2.Final-redhat-x de la NOMENCL jboss-javaee-6.0.
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.jboss.spec</groupId>
<artifactId>jboss-javaee-6.0</artifactId>
<version>3.0.2.Final-redhat-x</version>
<type>pom</type>
<scope>import</scope>
</dependency>
...
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.jboss.spec.javax.servlet</groupId>
<artifactId>jboss-servlet-api_3.0_spec</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.jboss.spec.javax.servlet.jsp</groupId>
<artifactId>jboss-jsp-api_2.2_spec</artifactId>
<scope>provided</scope>
</dependency>
...
</dependencies>
Les nomenclatures JBoss EAP BOM et les Quickstarts
Tableau 2.1. Nomenclatures JBoss BOM utilisées par les Quickstarts
| IdArtéfact Maven | Description |
|---|---|
| jboss-javaee-6.0-with-hibernate | Cette nomenclature BOM s'appuie sur le profil BOM complet de Java EE, ajoutant des projets communautaires Hibernate ORM, Hibernate Search et Hibernate Validator. Elle fournit également des projets d'outil tel que Hibernate JPA Model Gen et le processeur Hibernate Validator Annotation. |
| jboss-javaee-6.0-with-hibernate3 | Cette nomenclature BOM s'appuie sur le profil BOM complet de Java EE, ajoutant des projets communautaires Hibernate 3 ORM, Hibernate Entity Manager (JPA 1.0) et Hibernate Validator. |
| jboss-javaee-6.0-with-logging | Cette nomenclature BOM s'appuie sur le profil BOM complet de Java EE, ajoutant JBoss Logging Tools et Log4 framework. |
| jboss-javaee-6.0-with-osgi | Cette nomenclature BOM s'appuie sur le profil BOM complet de Java EE, ajoutant OSGI. |
| jboss-javaee-6.0-with-resteasy | Cette nomenclature BOM s'appuie sur le profil BOM complet de Java EE, ajoutant RESTEasy |
| jboss-javaee-6.0-with-security | Cette nomenclature BOM s'appuie sur le profil BOM complet de Java EE, ajoutant Picketlink. |
| jboss-javaee-6.0-with-tools | Cette nomenclature BOM s'appuie sur le profil BOM complet de Java EE, ajoutant Arquillian à l'ensemble. Elle procure également une version de JUnit et de TestNG conseillés pour l'utilisation avec Arquillian. |
| jboss-javaee-6.0-with-transactions | Cette nomenclature BOM inclut un gestionnaire de transactions de classe mondiale. Utiliser les API JBossTS pour pouvoir profiter de toutes ses fonctionnalités. |
6.2.0.GA de la nomemclature BOM jboss-javaee-6.0-with-hibernate.
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.jboss.bom.eap</groupId>
<artifactId>jboss-javaee-6.0-with-hibernate</artifactId>
<version>6.2.0.GA</version>
<type>pom</type>
<scope>import</scope>
</dependency>
...
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<scope>provided</scope>
</dependency>
...
</dependencies>
JBoss Client BOMs
jboss-as-ejb-client-bom et jboss-as-jms-client-bom.
7.3.0.Final-redhat-x du client jboss-as-ejb-client-bom BOM.
<dependencies>
<dependency>
<groupId>org.jboss.as</groupId>
<artifactId>jboss-as-ejb-client-bom</artifactId>
<version>7.3.0.Final-redhat-x</version>
<type>pom</type>
</dependency>
...l
</dependencies>
Cet exemple utilise la version 7.3.0.Final-redhat-x du client BOM jboss-as-jms-client-bom.
<dependencies>
<dependency>
<groupId>org.jboss.as</groupId>
<artifactId>jboss-as-jms-client-bom</artifactId>
<version>7.3.0.Final-redhat-x</version>
<type>pom</type>
</dependency>
...
</dependencies>
2.4. Mise à niveau du référentiel Maven
2.4.1. Appliquer un correctif dans le répertoire Maven local
Un rréférentiel Maven stocke des bibliothèques Java, des plug-ins et autres objets nécessaires pour compiler et déployer des applications JBoss EAP. Le référentiel de JBoss EAP est disponible en ligne ou en fichier ZIP téléchargé. Si vous utilisez le référentiel hébergé publiquement, les mises à jour seront appliquées automatiquement. Toutefois, si vous téléchargez et installez le repository Maven localement, vous serez chargé d'appliquer les mises à jour vous-même. Chaque fois qu'un correctif sera disponible dans JBoss EAP, un correctif correspondant sera fourni pour le référentiel JBoss EAP Maven. Ce correctif est disponible sous la forme d'un fichier ZIP incrémentiel qui est décompressé dans le référentiel local existant. Le fichier ZIP contient des nouveaux fichiers JAR et POM. Il n'écrase pas les JAR existants, ni ne les supprime, donc il n'y a aucune exigence de restauration.
unzip.
Pré-requis
- Accès valide et abonnement au Portail Clients de Red Hat.
- Le fichier Red Hat JBoss Enterprise Application Platform 6.3.0 Maven Repository ZIP, téléchargé et installé localement.
Procédure 2.10. Mise à jour du Référentiel Maven
- Ouvrir un navigateur et connectez-vous dans https://access.redhat.com.
- Sélectionner du menu en haut de la page.
- Chercher
Red Hat JBoss Middlewareet cliquer sur le bouton . - Sélectionner Plate-forme d'applications à partir du menu déroulant Produit qui se trouve sur l'écran suivant.
- Sélectionner la version qui convient de JBoss EAP à partir du menu déroulant Version qui apparaît sur l'écran, puis cliquer sur Correctifs.
- Chercher
Red Hat JBoss Enterprise Application Platform 6.2 CPx Incremental Maven Repositorydans la liste et cliquer sur . - Vous êtes invités à sauvegarder le fichier ZIP dans un répertoire de votre choix. Sélectionner un répertoire et sauvegardez le fichier.
- Chercher le chemin d'accès vers le répertoire JBoss EAP dont il s'agit dans les commandes ci-dessous, sous EAP_MAVEN_REPOSITORY_PATH, correspondant à votre système d'exploitation. Pour obtenir plus d'informations sur la façon d'installer le référentiel Maven sur le système de fichiers local, voir Section 2.2.3, « Installer le référentiel Maven de JBoss EAP 6 localement ».
- Décompresser le fichier de correctifs Maven dans le répertoire d'installation de JBoss EAP 6.2.x.
- Dans Linux, ouvrir un terminal et saisir la commande suivante :
[standalone@localhost:9999 /]
unzip -o jboss-eap-6.2.x-incremental-maven-repository.zip -dEAP_MAVEN_REPOSITORY_PATH - Dans Windows, utiliser l'utilitaire pour extraire le fichier ZIP pour le mettre dans la racine du répertoire
EAP_MAVEN_REPOSITORY_PATH.
Le référentiel Maven installé localement est mis à jour au dernier correctif.
Chapitre 3. Chargement de classes modulaire et modules
3.1. Introduction
3.1.1. Chargement des classes et Modules
3.1.2. Chargement des classes
3.1.3. Modules
- Modules statiques
- Les modules statiques sont prédéfinis dans le répertoire
EAP_HOME/modules/du serveur d'application. Chaque sous-répertoire représente un module et contient un ou plusieurs fichiers JAR et un fichier de configuration (module.xml). Le nom de ce module est défini dans le fichiermodule.xml. Toutes les API fournies par le serveur d'application sont fournies en tant que modules statiques, comme les API Java EE ainsi que d'autres API comme JBoss Logging.Exemple 3.1. Exemple de fichier module.xml
<?xml version="1.0" encoding="UTF-8"?> <module xmlns="urn:jboss:module:1.0" name="com.mysql"> <resources> <resource-root path="mysql-connector-java-5.1.15.jar"/> </resources> <dependencies> <module name="javax.api"/> <module name="javax.transaction.api"/> </dependencies> </module>Le nom du module,com.mysql, doit correspondre à la structure du répertoire du module.La création de modules statiques personnalisés peut être utile si plusieurs applications sont déployées sur un même serveur utilisant les mêmes bibliothèques de tierce partie. Au lieu d'un regroupement de ces bibliothèques pour chaque application, un module contenant ces bibliothèques peut être créé et installé par l'administrateur JBoss. Les applications peuvent ensuite déclarer une dépendance explicite sur les modules statiques personnalisés. - Modules dynamiques
- Les modules dynamiques sont créés et chargés par le serveur d'application pour chaque déploiement JAR ou WAR (ou sous-déploiement d'un EAR). Le nom d'un module dynamique est dérivé du nom de l'archive déployée. Comme les déploiements sont chargés sous forme de modules, ils peuvent configurer des dépendances et peuvent être utilisés comme dépendances par d'autres déploiements.
3.1.4. Les dépendances de modules
Exemple 3.2. Les dépendances de module
- Le Module A déclare une dépendance explicite sur le Module C, ou bien
- Le Module B exporte ses dépendances sur le Module C.
3.1.5. Chargement des classes dans les déploiements
- Déploiement WAR
- Un déploiement WAR est un simple module. Les classes du répertoire
WEB-INF/libsont considérées de la même manière que celles du répertoireWEB-INF/classes. Toutes les classes empaquetées dans le war seront téléchargées par le même chargeur de classes. - Déploiement EAR
- Les déploiements EAR sont faits de plus d'un module. La définition de ces modules suit ces règles :
- Le répertoire
lib/du EAR est un simple module nommé le module parent. - Chaque déploiement WAR du EAR est un module simple.
- Chaque déploiement EJB JAR du EAR est un simple module.
Les modules de sous-déploiement (les déploiements WAR et JAR dans EAR) ont une dépendance automatique sur le module parent. Cependant ils n'ont pas de dépendance automatique l'un sur l'autre. Ceci est appelé l'isolement du sous-déploiement et peut être désactivé par déploiement ou pour le serveur de toute l'application dans son ensemble.Les dépendances explicites entre les modules de sous-déploiement peuvent être ajoutées par les mêmes moyens, tout comme tout autre module.
3.1.6. Précédence pour le chargement des classes
- Dépendances implicites.Voici les dépendances qui sont ajoutées automatiquement par JBoss EAP 6, comme les API JAVA EE. Ces dépendances ont la plus haute précédence de chargeur de classe car ils contiennent des API et des fonctionnalités communes qui sont fournies par JBoss EAP 6.Voir Section 3.8.1, « Dépendances de modules implicites » pour obtenir des détails sur chaque dépendance implicite.
- Dépendances explicitesIl s'agit de dépendances qui sont ajoutées manuellement dans la configuration de l'application. Cela peut être fait à l'aide du fichier d'application
MANIFEST.MFou du nouveau fichier du descripteur de déploiement en option de JBossjboss-deployment-structure.xml.Voir Section 3.2, « Ajouter une dépendance de module explicite à un déploiement » pour apprendre comment ajouter des dépendances explicites. - Ressources locales.Fichiers de classe empaquetées à l'intérieur du déploiement lui-même, par ex. les répertoires
WEB-INF/classesouWEB-INF/libd'un fichier WAR. - Dépendances inter-déploiement.Ce sont des dépendances sur les autres déploiements d'un déploiement EAR. Cela peut inclure des classes du répertoire
libdu EAR ou des classes des autres jars EJB.
3.1.7. Nommage de modules dynamiques
- Les déploiements des fichiers WAR et JAR sont nommés selon le format suivant :
deployment.DEPLOYMENT_NAME
Par exemple,inventory.waretstore.jarauront les mêmes noms de module quedeployment.inventory.waretdeployment.store.jarrespectivement. - Les sous-déploiements des archives Enterprise sont nommés selon le format suivant :
deployment.EAR_NAME.SUBDEPLOYMENT_NAME
Ainsi, le sous-déploiementreports.war, qui se trouve dans l'archive enterpriseaccounts.ear, aura le nom de module dudeployment.accounts.ear.reports.war.
3.1.8. jboss-deployment-structure.xml
jboss-deployment-structure.xml est un descripteur de déploiement optionnel de JBoss EAP 6. Ce descripteur de déploiement fournit un contrôle pour le chargement de classes dans le déploiement.
EAP_HOME/docs/schema/jboss-deployment-structure-1_2.xsd
3.2. Ajouter une dépendance de module explicite à un déploiement
Prérequis
- Vous devez déjà avoir un projet de logiciel qui fonctionne, et auquel vous souhaitez ajouter une dépendance de module.
- Vous devez connaître le nom du module qui est ajouté comme dépendance. Voir Section 3.8.2, « Les modules inclus » pour obtenir la liste des modules statiques inclus dans JBoss EAP 6. Si le module correspond à un autre déploiement, voir Section 3.1.7, « Nommage de modules dynamiques » pour déterminer le nom du module.
- Par l'ajout d'entrées dans le fichier
MANIFEST.MFdu déploiement. - Par l'ajout d'entrées dans le descripteur de déploiement
jboss-deployment-structure.xml.
Procédure 3.1. Par l'ajout d'une configuration de dépendance à MANIFEST.MF
MANIFEST.MF. Voir Section 3.3, « Générer des entrées MANIFEST.MF en utilisant Maven ».
Ajouter le fichier
MANIFEST.MFSi le projet ne possède pas de fichierMANIFEST.MF, créer un fichier nomméMANIFEST.MF. Pour une application web (WAR), ajouter ce fichier au répertoireMETA-INF. Pour une archive EJB (JAR), l'ajouter au répertoireMETA-INF.Ajouter une entrée de dépendance
Ajouter une entrée de dépendance au fichierMANIFEST.MFavec une liste de noms de modules de dépendance séparés par des virgules.Dépendances : org.javassist, org.apache.velocity
Option: rendre une dépendance optionnelle
On peut rendre une dépendance optionnelle an ajoutantoptionalau nom du module de l'entrée de dépendance.Dépendances : org.javassist optional, org.apache.velocity
Option : export d'une dépendance
On peut exporter une dépendance en ajoutantexportau nom du module de l'entrée de dépendance.Dépendences : org.javassist, org.apache.velocity export
Procédure 3.2. Ajouter une configuration de dépendance à jboss-deployment-structure.xml
Ajouter
jboss-deployment-structure.xmlSi l'application n'a pas de fichierjboss-deployment-structure.xml, créer un nouveau fichier nomméjboss-deployment-structure.xmlet l'ajouter au projet. Ce fichier est un fichier XML ayant l'élément racine de<jboss-deployment-structure>.<jboss-deployment-structure> </jboss-deployment-structure>
Pour une application web (WAR), ajouter ce fichier au répertoireWEB-INF. Pour une archive EJB (JAR), l'ajouter au répertoireMETA-INF.Ajouter une section de dépendances
Créer un élément<deployment>à l'intérieur de la racine du document et un élément<dependencies>également.Ajouter les éléments du module
Dans le nœud de dépendances, ajouter un élément de module pour chaque dépendance du module. Définir l'attributnameau nom du module.<module name="org.javassist" />
Option: rendre une dépendance optionnelle
On peut rendre une dépendance optionnelle en ajoutant l'attributoptionalà l'entrée du module, avec la valeurTRUE. La valeur par défaut de cet attribut estFALSE.<module name="org.javassist" optional="TRUE" />
Option : export d'une dépendance
On peut exporter une dépendance en ajoutant l'attributoptionalà l'entrée du module, avec la valeurTRUE. La valeur par défaut de cet attribut estFALSE.<module name="org.javassist" export="TRUE" />
Exemple 3.3. jboss-deployment-structure.xml avec deux dépendances
<jboss-deployment-structure>
<deployment>
<dependencies>
<module name="org.javassist" />
<module name="org.apache.velocity" export="TRUE" />
</dependencies>
</deployment>
</jboss-deployment-structure>
3.3. Générer des entrées MANIFEST.MF en utilisant Maven
MANIFEST.MF avec une entrée Dependencies. Ce procédé ne génère pas automatiquement la liste de dépendances, il crée seulement le fichier MANIFEST.MF avec les informations spécifiées dans le fichier pom.xml.
Prérequis
- Vous devez déjà posséder un projet Maven en cours
- Le projet Maven doit utiliser l'un des plug-ins JAR, EJB, ou WAR (
maven-jar-plugin,maven-ejb-plugin,maven-war-plugin). - Vous devez connaître le nom des dépendances de module du projet. Voir Section 3.8.2, « Les modules inclus » pour obtenir la liste des modules statiques inclus dans JBoss EAP 6. Si le module est dans un autre déploiement, voir Section 3.1.7, « Nommage de modules dynamiques » pour déterminer le nom du module.
Procédure 3.3. Générer un fichier MANIFEST.MF contenant des dépendances de module.
Ajouter une Configuration
Ajouter la configuration suivante à la configuration du plug-in de l'empaquetage dans le fichierpom.xmldu projet.<configuration> <archive> <manifestEntries> <Dependencies></Dependencies> </manifestEntries> </archive> </configuration>Dépendances de la Liste
Ajouter la liste des dépendances de module dans l'élement <Dependencies> . Utiliser le même format utilisé lors de l'ajout des dépendances dans leMANIFEST.MF. Veuillez consulter Section 3.2, « Ajouter une dépendance de module explicite à un déploiement » pour plus d'informations concernant ce format.<Dependencies>org.javassist, org.apache.velocity</Dependencies>
Construire le projet
Construire le projet en utilisant l'objectif d'assemblage de Maven.[Localhost ]$ mvn assembly:assembly
MANIFEST.MF avec les dépendances de module spécifiées.
Exemple 3.4. Dépendances de module configurées dans pom.xml
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-war-plugin</artifactId>
<configuration>
<archive>
<manifestEntries>
<Dependencies>org.javassist, org.apache.velocity</Dependencies>
</manifestEntries>
</archive>
</configuration>
</plugin>
</plugins>
3.4. Empêcher qu'un module soit chargé implicitement
Prérequis
- Vous devez déjà avoir un projet informatique qui fonctionne et dont vous souhaitez exclure une dépendance.
- Vous devez connaître le nom du module à exclure. Voir Section 3.8.1, « Dépendances de modules implicites » pour obtenir une liste des dépendances implicites et de leurs conditions.
Procédure 3.4. Ajouter une configuration d'exclusion de dépendances de jboss-deployment-structure.xml
- Si l'application n'a pas de fichier
jboss-deployment-structure.xml, créer un nouveau fichier intituléjboss-deployment-structure.xmlet ajoutez-le au projet. Ce fichier est un fichier XML ayant comme élément root<jboss-deployment-structure>.<jboss-deployment-structure> </jboss-deployment-structure>
Pour une application web (WAR), ajouter ce fichier au répertoireWEB-INF. Pour une archive EJB (JAR), l'ajouter au répertoireMETA-INF. - Créer un élément
<deployment>dans la racine de l'élément et un<exclusions>à l'intérieur.<deployment> <exclusions> </exclusions> </deployment>
- Dans l'élément d'exclusion, ajouter un élément
<module>pour chaque module à exclure. Définir l'attributnameau nom du module.<module name="org.javassist" />
Exemple 3.5. Exclusion de deux modules
<jboss-deployment-structure>
<deployment>
<exclusions>
<module name="org.javassist" />
<module name="org.dom4j" />
</exclusions>
</deployment>
</jboss-deployment-structure>
3.5. Exclure un sous-système d'un déploiement
Ce sujet traite des étapes nécessaires pour exclure un sous-système d'un déploiement. Pour ce faire, il convient de modifier le fichier de configuration jboss-deployment-structure.xml. Le fait d'exclure un sous-système crée le même effet que de le retirer, sauf qu'il ne s'applique qu'à un seul déploiement.
Procédure 3.5. Exclure un sous-système
- Ouvrir le fichier
jboss-deployment-structure.xmldans un éditeur de texte. - Ajouter le XML suivant dans les balises de <deployment> :
<exclude-subsystems> <subsystem name="SUBSYSTEM_NAME" /> </exclude-subsystems>
- Enregistrer le fichier
jboss-deployment-structure.xml
Le sous-système a bien été exclus. Les processeurs d'unité de déploiement du sous-système n'exécuteront plus sur le déploiement.
Exemple 3.6. Exemple d'un fichier jboss-deployment-structure.xml.
<jboss-deployment-structure xmlns="urn:jboss:deployment-structure:1.2">
<ear-subdeployments-isolated>true</ear-subdeployments-isolated>
<deployment>
<exclude-subsystems>
<subsystem name="resteasy" />
</exclude-subsystems>
<exclusions>
<module name="org.javassist" />
</exclusions>
<dependencies>
<module name="deployment.javassist.proxy" />
<module name="deployment.myjavassist" />
<module name="myservicemodule" services="import"/>
</dependencies>
<resources>
<resource-root path="my-library.jar" />
</resources>
</deployment>
<sub-deployment name="myapp.war">
<dependencies>
<module name="deployment.myear.ear.myejbjar.jar" />
</dependencies>
<local-last value="true" />
</sub-deployment>
<module name="deployment.myjavassist" >
<resources>
<resource-root path="javassist.jar" >
<filter>
<exclude path="javassist/util/proxy" />
</filter>
</resource-root>
</resources>
</module>
<module name="deployment.javassist.proxy" >
<dependencies>
<module name="org.javassist" >
<imports>
<include path="javassist/util/proxy" />
<exclude path="/**" />
</imports>
</module>
</dependencies>
</module>
</jboss-deployment-structure>
3.6. Utiliser le chargeur de classes par programmation dans un développement
3.6.1. Chargement des classes et des ressources par programmation dans le déploiement.
- Charger une classe en utilisant la méthode Class.forName() Method
- Vous pouvez utiliser la méthode
Class.forName()pour charger ou initialiser les classes par programmation. Cette méthode comprend deux signatures.La signature à trois arguments est la méthode recommandée pour charger une classe par programmation. Cette signature vous permet de contrôler si vous souhaitez que la classe cible soit initialisée pendant le chargement. Il est également plus efficace d'obtenir et de fournir le chargeur de classe parce que la JVM n'a pas besoin d'examiner la pile des appels pour déterminer quel chargeur de classe utiliser. En supposant que la classe contenant le code se nomme- Class.forName(String className)
- Cette signature ne prend en compte qu'un seul paramètre, le nom de la classe que vous devez charger. Avec cette méthode de signature, la classe est chargée par le chargeur de classes et initialise la classe nouvellement chargée par défaut.
- Class.forName(String className, boolean initialize, ClassLoader loader)
- Cette signature s'attend à recevoir trois paramètres : le nom de la classe, une valeur booléenne qui indique si on doit initialiser la classe, et le ClassLoader qui doit charger la classe.
CurrentClass, vous pourrez obtenir le chargeur de classes de la classe par la méthodeCurrent.class.getClassLoader().L'exemple suivant donne un exemple de chargeur de classes qui puisse charger et initialiser la classeTargetClass:Exemple 3.7. Fournir un chargeur de classes pour télécharger et initialiser les TargetClass.
Class<?> targetClass = Class.forName("com.myorg.util.TargetClass", true, CurrentClass.class.getClassLoader()); - Chercher toutes les ressources avec un Prénom
- Si vous connaissez le nom ou le chemin de la ressource, la meilleure façon de la charger directement serait d'utiliser la classe JDK ou l'API Classloader.
- Charger une seule ressource
- Pour charger une seule ressource qui se trouve dans le même répertoire que votre classe ou dans une autre classe de votre déploiement, vous pouvez utiliser la méthode
Class.getResourceAsStream().Exemple 3.8. Charger une seule ressource dans votre déploiement.
InputStream inputStream = CurrentClass.class.getResourceAsStream("targetResourceName"); - Charger toutes les instances en une ressource unique
- Pour charger toutes les instances d'une même ressource qui sont visibles par le chargeur de classe de votre déploiement, utilisez la méthode
Class.getClassLoader retourne ().getResources(String resourceName), oùresourceNameest le chemin d'accès qualifié complet de la ressource. Cette méthode retourne une énumération de tous les objetsURLpour les ressources accessibles par le chargeur de classe du prénom donné. Vous pouvez ensuite parcourir le tableau des URL pour ouvrir chaque flux à l'aide de la méthodeopenStream().Exemple 3.9. Charger toutes les instances d'une ressource et itérer le résultat.
Enumeration<URL> urls = CurrentClass.class.getClassLoader().getResources("full/path/to/resource"); while (urls.hasMoreElements()) { URL url = urls.nextElement(); InputStream inputStream = null; try { inputStream = url.openStream(); // Process the inputStream ... } catch(IOException ioException) { // Handle the error } finally { if (inputStream != null) { try { inputStream.close(); } catch (Exception e) { // ignore } } } }Note
Comme les instances URL sont chargées à partir du stockage local, il n'est pas utile d'utiliseropenConnection()ou méthodes semblables. Les flux sont plus faciles à utiliser et minimisent la complexité du code.
- Charger un fichier de classe à partir d'un chargeur de classes
- Si une classe a déjà été chargée, vous pouvez charger le fichier de classe qui correspond à cette classe en utilisant la syntaxe suivante :Si la classe n'a pas encore été chargée, vous devrez utiliser le chargeur de classes et en interpréter le chemin d'accès :
Exemple 3.10. Charger un fichier de classe déjà chargée.
InputStream inputStream = CurrentClass.class.getResourceAsStream(TargetClass.class.getSimpleName() + ".class");
Exemple 3.11. Charger un fichier de classe d'une classe qui n'a pas été chargée.
String className = "com.myorg.util.TargetClass" InputStream inputStream = CurrentClass.class.getClassLoader().getResourceAsStream(className.replace('.', '/') + ".class");
3.6.2. Itérer les ressources par programmation dans un déploiement.
MANIFEST.MF:
Dépendences: org.jboss.modulesIl est important de noter que malgré que ces API fournissent une flexibilité grandissante, ils exécuteront bien plus lentement qu'une recherche de chemin d'accès directe.
- Lister les ressources du déploiement et de toutes les importations.
- Il y a des moments où il n'est pas possible de rechercher des ressources par le chemin exact. Par exemple, le chemin d'accès exact n'est peut être pas connu ou vous devrez peut-être examiner plus d'un fichier dans un chemin d'accès donné. Dans ce cas, la bibliothèque de modules de JBoss fournit plusieurs API pour une itération de toutes les ressources de déploiement. Vous pouvez parcourir les ressources dans un déploiement en utilisant une des deux méthodes.
- Itérer toutes les ressources qui se trouvent dans un seul module
- La méthode
ModuleClassLoader.iterateResources()itère toutes les ressources au sein de ce chargeur de classes de module. Cette méthode accepte deux arguments : le nom du répertoire de départ à rechercher et une valeur booléenne qui spécifie s'il doit agir récursivement dans les sous-répertoires.L'exemple suivant montre comment on obtient le ModuleClassLoader ou l'itérateur pour les ressources qui se trouvent dans le répertoirebin/, récursivement dans les sous-répertoires.L'itérateur résultant peut être utilisé pour examiner chaque ressource correspondante et pour chercher son nom et sa taille (si disponible), pour ouvrir une transmission à lire, ou pour obtenir l'URL d'une ressource.Exemple 3.12. Chercher les ressources du répertoire "bin" récursivement dans les sous-répertoires.
ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Iterator<Resource> mclResources = moduleClassLoader.iterateResources("bin",true); - Itérer toutes les ressources qui se trouvent dans un seul module et dans les ressources importées
- La méthode
Module.iterateResources()itère toutes les ressources au sein de ce chargeur de classes de module, y compris les ressources qui sont importées dans le module. Cette méthode renvoie un ensemble beaucoup plus vaste que la méthode précédente. Cette méthode requiert un argument: un filtre qui rétrécit le résultat à un modèle spécifique. Alternativement, les PathFilters.acceptAll() peuvent être fournis pour retourner l'ensemble.Exemple 3.13. Chercher toutes les ressources de ce module, y compris les importations.
ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Module module = moduleClassLoader.getModule(); Iterator<Resource> moduleResources = module.iterateResources(PathFilters.acceptAll());
- Chercher toutes les ressources qui correspondent à un modèle particulier
- Si vous avez besoin de trouver des ressources spécifiques dans votre déploiement ou dans son importation complète, vous devrez filtrer l'itération de la ressource. Les API de filtrage de JBoss Modules peuvent vous donner plusieurs outils pour y parvenir.
- Examiner toutes les dépendances
- Si vous devez examiner l'ensemble des dépendances, vous pouvez utiliser le paramètre
PathFilterde la méthodeModule.iterateResources()pour vérifier le nom de chaque ressource et trouver une correspondance. - Examiner les dépendances de déploiement
- Si vous devez regarder uniquement dans le déploiement, utilisez la méthode
ModuleClassLoader.iterateResources(). Toutefois, vous devez utiliser des méthodes supplémentaires pour filtrer l'itérateur qui en résulte. La méthodePathFilters.filtered()peut fournir une vue filtrée d'un itérateur de ressources dans ce cas. La classePathFilterscomprend plusieurs méthodes statiques pour créer et composer des filtres qui remplissent des fonctions diverses, y compris la recherche de chemins dépendants ou des correspondances exactes, ou encore correspondant à un motif "glob" Ant-style.
- Exemples de codes supplémentaires pour filtrer les ressources
- Les exemples suivants démontrent comment filtrer les ressources sur la base de critères différents.
Exemple 3.14. Trouver tous les noms qui comprennent "messages.properties" dans votre déploiement.
ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Iterator<Resource> mclResources = PathFilters.filtered(PathFilters.match("**/messages.properties"), moduleClassLoader.iterateResources("", true));Exemple 3.15. Trouver tous les noms qui comprennent "messages.properties" dans votre déploiement et dans vos importations.
ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Module module = moduleClassLoader.getModule(); Iterator<Resource> moduleResources = module.iterateResources(PathFilters.match("**/message.properties));Exemple 3.16. Trouver tous les fichiers qui se trouvent dans tout répertoire nommé "my-resources" de votre déploiement.
ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Iterator<Resource> mclResources = PathFilters.filtered(PathFilters.match("**/my-resources/**"), moduleClassLoader.iterateResources("", true));Exemple 3.17. Trouver tous les fichiers nommés "messages.properties" dans votre déploiement et dans vos importations.
ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Module module = moduleClassLoader.getModule(); Iterator<Resource> moduleResources = module.iterateResources(PathFilters.any(PathFilters.match("**/messages"), PathFilters.match("**/errors"));Exemple 3.18. Trouver tous les fichiers qui se trouvent dans un package spécifique de votre déploiement.
ModuleClassLoader moduleClassLoader = (ModuleClassLoader) TargetClass.class.getClassLoader(); Iterator<Resource> mclResources = moduleClassLoader.iterateResources("path/form/of/packagename", false);
3.7. Chargement de classe et sous-déploiements
3.7.1. Chargement de classes et de modules dans les EAR (Archives Enterprise)
- Chaque sous-déploiement WAR ou EJB JAR est un module.
- Le contenu du répertoire
lib/de la racine de l'archive EAR est un module. On l'appelle un module parent.
- Les sous-déploiements WAR possédent des dépendances implicites sur le module parent et sur tout sous-déploiement JAR EJB.
- Les sous-déploiements EJB JAR possédent des dépendances implicites sur le module parent et sur tout sous-déploiement JAR EJB.
Important
Class-Path dans le fichier MANIFEST.MF de chaque sous-déploiement.
3.7.2. Isolement du chargeur de classes d'un sous-déploiement
3.7.3. Désactiver l'isolement du chargeur de classes d'un sous-déploiement dans un EAR
Important
Ajouter le fichier du descripteur de déploiement
Ajouter le fichier de descripteur de déploiementjboss-deployment-structure.xmlau répertoireMETA-INFdu EAR s'il n'existe pas déjà et ajouter le contenu suivant :<jboss-deployment-structure> </jboss-deployment-structure>
Ajouter l'élément
<ear-subdeployments-isolated>Ajouter l'élément<ear-subdeployments-isolated>au fichierjboss-deployment-structure.xmls'il n'existe pas déjà dans le contenu defalse.<ear-subdeployments-isolated>false</ear-subdeployments-isolated>
L'isolement de chargeur de classe de sous-déploiement sera maintenant désactivé pour le déploiement de cet EAR. Cela signifie que les sous-déploiements du EAR auront des dépendances automatiques sur chacun des sous-déploiements non-WAR.
3.8. Référence
3.8.1. Dépendances de modules implicites
Tableau 3.1. Dépendances de modules implicites
| Sous-système | Modules toujours ajoutés | Modules ajoutés conditionnellement | Conditions |
|---|---|---|---|
| Serveur principal |
|
-
|
-
|
| Sous-système EE |
|
-
|
-
|
| Sous-système EJB3 |
-
|
|
La présence de
ejb-jar.xml à des emplacements valides dans le déploiement, tel que mentionné dans les spécifications Java EE 6 ou la présence d'EJB basés sur annotations (par exemple @Stateless, @Stateful, @MessageDriven, etc)
|
| Sous-système JAX-RS (Resteasy) |
|
| La présence d'annotations JAX-RS dans le déploiement |
| Sous-système JCA |
|
| Si le déploiement correspond à un déploiement (RAR) d'adaptateur de ressources. |
| Sous-système JPA (Hibernate) |
|
| La présence de l'annotation @PersistenceUnit ou @PersistenceContext, <persistence-unit-ref> ou encore <persistence-context-ref> dans un descripteur de déploiement. |
| Sous-système SAR |
-
|
| Le déploiement correspond à une archive SAR |
| Sous-système de sécurité |
|
-
|
-
|
| Sous-système Web |
-
|
| Le déploiement correspond à une archive WAR. JavaServer Faces(JSF) est ajouté uniquement si utilisé. |
| Sous-système de Services Web |
|
-
|
-
|
| Sous-système Weld (CDI) |
-
|
| Si un fichier beans.xml est détecté dans le déploiement |
3.8.2. Les modules inclus
asm.asmch.qos.cal10ncom.google.guavacom.h2database.h2com.sun.jsf-implcom.sun.jsf-implcom.sun.xml.bindcom.sun.xml.messaging.saajgnu.getoptjavaee.apijavax.activation.apijavax.annotation.apijavax.apijavax.ejb.apijavax.el.apijavax.enterprise.apijavax.enterprise.deploy.apijavax.faces.apijavax.faces.apijavax.inject.apijavax.interceptor.apijavax.jms.apijavax.jws.apijavax.mail.apijavax.management.j2ee.apijavax.persistence.apijavax.resource.apijavax.rmi.apijavax.security.auth.message.apijavax.security.jacc.apijavax.servlet.apijavax.servlet.jsp.apijavax.servlet.jstl.apijavax.transaction.apijavax.validation.apijavax.ws.rs.apijavax.wsdl4j.apijavax.xml.bind.apijavax.xml.jaxp-providerjavax.xml.registry.apijavax.xml.rpc.apijavax.xml.soap.apijavax.xml.stream.apijavax.xml.ws.apijlinenet.sourceforge.cssparsernet.sourceforge.htmlunitnet.sourceforge.nekohtmlnu.xomorg.antlrorg.apache.antorg.apache.commons.beanutilsorg.apache.commons.cliorg.apache.commons.codecorg.apache.commons.collectionsorg.apache.commons.ioorg.apache.commons.langorg.apache.commons.loggingorg.apache.commons.poolorg.apache.cxforg.apache.httpcomponentsorg.apache.james.mime4jorg.apache.log4jorg.apache.neethiorg.apache.santuario.xmlsecorg.apache.velocityorg.apache.ws.scoutorg.apache.ws.securityorg.apache.ws.xmlschemaorg.apache.xalanorg.apache.xercesorg.apache.xml-resolverorg.codehaus.jackson.jackson-core-aslorg.codehaus.jackson.jackson-jaxrsorg.codehaus.jackson.jackson-mapper-aslorg.codehaus.jackson.jackson-xcorg.codehaus.woodstoxorg.dom4jorg.hibernateorg.hibernate.enversorg.hibernate.infinispanorg.hibernate.validatororg.hornetqorg.hornetq.raorg.infinispanorg.infinispan.cachestore.jdbcorg.infinispan.cachestore.remoteorg.infinispan.client.hotrodorg.jacorborg.javassistorg.jaxenorg.jboss.as.aggregateorg.jboss.as.appclientorg.jboss.as.cliorg.jboss.as.clustering.apiorg.jboss.as.clustering.commonorg.jboss.as.clustering.ejb3.infinispanorg.jboss.as.clustering.implorg.jboss.as.clustering.infinispanorg.jboss.as.clustering.jgroupsorg.jboss.as.clustering.serviceorg.jboss.as.clustering.singletonorg.jboss.as.clustering.web.infinispanorg.jboss.as.clustering.web.spiorg.jboss.as.cmporg.jboss.as.connectororg.jboss.as.consoleorg.jboss.as.controllerorg.jboss.as.controller-clientorg.jboss.as.deployment-repositoryorg.jboss.as.deployment-scannerorg.jboss.as.domain-add-userorg.jboss.as.domain-http-error-contextorg.jboss.as.domain-http-interfaceorg.jboss.as.domain-managementorg.jboss.as.eeorg.jboss.as.ee.deploymentorg.jboss.as.ejb3org.jboss.as.embeddedorg.jboss.as.host-controllerorg.jboss.as.jacorborg.jboss.as.jaxrorg.jboss.as.jaxrsorg.jboss.as.jdrorg.jboss.as.jmxorg.jboss.as.jpaorg.jboss.as.jpa.hibernateorg.jboss.as.jpa.hibernateorg.jboss.as.jpa.hibernate.infinispanorg.jboss.as.jpa.openjpaorg.jboss.as.jpa.spiorg.jboss.as.jpa.utilorg.jboss.as.jsr77org.jboss.as.loggingorg.jboss.as.mailorg.jboss.as.management-client-contentorg.jboss.as.messagingorg.jboss.as.modclusterorg.jboss.as.namingorg.jboss.as.networkorg.jboss.as.osgiorg.jboss.as.platform-mbeanorg.jboss.as.pojoorg.jboss.as.process-controllerorg.jboss.as.protocolorg.jboss.as.remotingorg.jboss.as.sarorg.jboss.as.securityorg.jboss.as.serverorg.jboss.as.standaloneorg.jboss.as.threadsorg.jboss.as.transactionsorg.jboss.as.weborg.jboss.as.webservicesorg.jboss.as.webservices.server.integrationorg.jboss.as.webservices.server.jaxrpc-integrationorg.jboss.as.weldorg.jboss.as.xtsorg.jboss.classfilewriterorg.jboss.com.sun.httpserverorg.jboss.common-coreorg.jboss.dmrorg.jboss.ejb-clientorg.jboss.ejb3org.jboss.iiop-clientorg.jboss.integration.ext-contentorg.jboss.interceptororg.jboss.interceptor.spiorg.jboss.invocationorg.jboss.ironjacamar.apiorg.jboss.ironjacamar.implorg.jboss.ironjacamar.jdbcadaptersorg.jboss.jandexorg.jboss.jaxbintrosorg.jboss.jboss-transaction-spiorg.jboss.jsfunit.coreorg.jboss.jtsorg.jboss.jts.integrationorg.jboss.loggingorg.jboss.logmanagerorg.jboss.logmanager.log4jorg.jboss.marshallingorg.jboss.marshalling.riverorg.jboss.metadataorg.jboss.modulesorg.jboss.mscorg.jboss.nettyorg.jboss.osgi.deploymentorg.jboss.osgi.frameworkorg.jboss.osgi.resolverorg.jboss.osgi.spiorg.jboss.osgi.vfsorg.jboss.remoting3org.jboss.resteasy.resteasy-atom-providerorg.jboss.resteasy.resteasy-cdiorg.jboss.resteasy.resteasy-jackson-providerorg.jboss.resteasy.resteasy-jaxb-providerorg.jboss.resteasy.resteasy-jaxrsorg.jboss.resteasy.resteasy-jsapiorg.jboss.resteasy.resteasy-multipart-providerorg.jboss.saslorg.jboss.security.negotiationorg.jboss.security.xacmlorg.jboss.shrinkwrap.coreorg.jboss.staxmapperorg.jboss.stdioorg.jboss.threadsorg.jboss.vfsorg.jboss.weld.apiorg.jboss.weld.coreorg.jboss.weld.spiorg.jboss.ws.apiorg.jboss.ws.commonorg.jboss.ws.cxf.jbossws-cxf-clientorg.jboss.ws.cxf.jbossws-cxf-factoriesorg.jboss.ws.cxf.jbossws-cxf-serverorg.jboss.ws.cxf.jbossws-cxf-transports-httpserverorg.jboss.ws.jaxws-clientorg.jboss.ws.jaxws-jboss-httpserver-httpspiorg.jboss.ws.native.jbossws-native-coreorg.jboss.ws.native.jbossws-native-factoriesorg.jboss.ws.native.jbossws-native-servicesorg.jboss.ws.saaj-implorg.jboss.ws.spiorg.jboss.ws.tools.commonorg.jboss.ws.tools.wsconsumeorg.jboss.ws.tools.wsprovideorg.jboss.xborg.jboss.xnioorg.jboss.xnio.nioorg.jboss.xtsorg.jdomorg.jgroupsorg.joda.timeorg.junitorg.omg.apiorg.osgi.coreorg.picketboxorg.picketlinkorg.python.jython.standaloneorg.scannotation.scannotationorg.slf4jorg.slf4j.extorg.slf4j.implorg.slf4j.jcl-over-slf4jorg.w3c.css.sacsun.jdk
3.8.3. Référence de descripteur de déploiement de structure de déploiement de JBoss
- Définition des dépendances de modules explicites.
- Empêcher les dépendances implicites spécifiques de charger.
- Définir des modules supplémentaires à partir des ressources de ce déploiement.
- Modifier le comportement de l'isolation du sous-déploiement dand ce déploiement EAR.
- Ajouter des racines de ressources supplémentaires à un EAR.
Chapitre 4. Valves globales
4.1. Valves
4.2. Valves globales
4.3. Les valves d'authentification
org.apache.catalina.authenticator.AuthenticatorBase et elle remplace la méthode authenticate()
4.4. Configurer une application web pour utiliser une valve.
jboss-web.xml.
Important
Prérequis
- La valve doit être créée et incluse dans le chemin de classe de l'application. Pour ce faire, il convient de l'inclure dans le fichier WAR de l'application ou dans tout autre module ajouté comme dépendance. Les exemples de tels modules comprennent un module statique installé sur le serveur ou un fichier JAR dans le répertoire
lib/d'une archive EAR si le WAR est déployé dans un EAR. - L'application doit inclure un descripteur de déploiement de
jboss-web.xml.
Procédure 4.1. Configurer une application pour une valve locale.
Ajouter un élément de Valve
Ajouter un élément de valve avec les attributs de nom et de nom de classe au fichierjboss-web.xmlde l'application. Le nom est un identifiant unique pour la valve et la classe de nom est le nom de la classe de valve.<valve> <class-name>VALVECLASSNAME</class-name> </valve>Paramètres spécifiques
Si la valve possède des paramètres configurables, ajouter un élément enfantparamà l'élément valve pour chaque paramètre, en spécifiant leur nom et leur valeur.<param name="PARAMNAME" value = "VALUE" />
Exemple 4.1. Configuration valve jboss-web.xml
<valve>
<class-name="org.jboss.samplevalves.restrictedUserAgentsValve">
<param name="restricteduseragents" value = "^.*MS Web Services Client Protocol.*$" />
</valve>
4.5. Configurer une application web pour qu'elle utilise une valve d'authentification
web.xml de l'application. Dans le cas le plus simple, la configuration web.xml revient à utiliser une authentification BASIC sauf que l'élément enfant auth-method de login-config est défini sous le nom de la valve qui effectue la configuration.
Prérequis
- La valve d'authentification devrait déjà être créée.
- Si la valve d'authentification est une valve globale, cette dernière devrait déjà être installée et configurée, et il vous convient de connaître le nom sous laquelle elle a été configurée.
- Informez-vous du nom de domaine de la zone de sécurité que l'application utilise.
Procédure 4.2. Configurer une application pour utiliser une valve d'authentification
Configurer la valve
L'utilisation d'une valve locale nécessite une configuration dans le descripteur de déploiementjboss-web.xmldes applications. Voir Section 4.4, « Configurer une application web pour utiliser une valve. ».Cela n'est pas nécessaire pour l'utilisation d'une valve globale.Ajouter une configuration de sécurité à web.xml.
Ajouter la configuration de sécurité au fichier web.xml pour votre application en utilisant les éléments standards tels que la contrainte de sécurité, la configuration de l'identifiant et le rôle de la sécurité. Dans l'élément de configuration de l'identifiant, définir la valeur de la méthode d'identification en tant que nom de la valve d'identification. L'élément de nom de la zone doit également être défini en tant que nom de la zone de sécurité de JBoss utilisée par l'application.<login-config> <auth-method>VALVE_NAME</auth-method> <realm-name>REALM_NAME</realm-name> </login-config>
4.6. Créer une valve personnalisée
Procédure 4.3. Créer une valve personnalisée
Créer la classe Valve
Créer une sous-classe deorg.apache.catalina.valves.ValveBase.package org.jboss.samplevalves; import org.apache.catalina.valves.ValveBase; import org.apache.catalina.connector.Request; import org.apache.catalina.connector.Response; public class restrictedUserAgentsValve extends ValveBase { }Mettre en place la méthode d'invocation
La méthodeinvoke()est utilisée lorsque la valve est exécutée dans la pipeline. Les objets de requête et de réponse sont considérés comme des paramètres. Effectuer tout procédé et modification de requête et réponse ici.public void invoke(Request request, Response response) { }Invoquer la prochaine étape de pipeline
La dernière étape que la méthode d'invocation doit effectuer est d'invoquer l'étape suivante de la pipeline et de transmettre les objets de requête et de réponse modifiés, en utilisant la méthodegetNext().invoke().getNext().invoke(request, response);
Option : indiquer les paramètres
Si la valve doit être configurable, activer cette option en ajoutant un paramètre. Pour ce faire, il convient d'ajouter une variable d'instance et une méthode setter pour chaque paramètre.private String restrictedUserAgents = null; public void setRestricteduseragents(String mystring) { this.restrictedUserAgents = mystring; }
Exemple 4.2. Échantillon de valve personnalisée
package org.jboss.samplevalves;
import java.io.IOException;
import java.util.regex.Pattern;
import javax.servlet.ServletException;
import org.apache.catalina.valves.ValveBase;
import org.apache.catalina.connector.Request;
import org.apache.catalina.connector.Response;
public class restrictedUserAgentsValve extends ValveBase
{
private String restrictedUserAgents = null;
public void setRestricteduseragents(String mystring)
{
this.restrictedUserAgents = mystring;
}
public void invoke(Request request, Response response) throws IOException, ServletException
{
String agent = request.getHeader("User-Agent");
System.out.println("user-agent: " + agent + " : " + restrictedUserAgents);
if (Pattern.matches(restrictedUserAgents, agent))
{
System.out.println("user-agent: " + agent + " matches: " + restrictedUserAgents);
response.addHeader("Connection", "close");
}
getNext().invoke(request, response);
}
}
Chapitre 5. La journalisation pour les développeurs
5.1. Introduction
5.1.1. Journalisation
5.1.2. Frameworks de journalisations d'applications pris en charge par JBoss LogManager
- JBoss Logging - inclus avec JBoss EAP 6
- Apache Commons Logging - http://commons.apache.org/logging/
- Simple Logging Facade dans Java (SLF4J) - http://www.slf4j.org/
- Apache log4j - http://logging.apache.org/log4j/1.2/
- Java SE Logging (java.util.logging) - http://download.oracle.com/javase/6/docs/api/java/util/logging/package-summary.html
5.1.3. Niveaux de journalisation
TRACE, DEBOG, INFO, ATTENTION, ERREUR et FATAL.
ATTENTION enregistrera uniquement les messages des niveaux ATTENTION, ERREUR et FATAL.
5.1.4. Niveaux de journalisation pris en charge
Tableau 5.1. Niveaux de journalisation pris en charge
| Niveau de journalisation | Valeur | Description |
|---|---|---|
| FINESSE MAX | 300 |
-
|
| PLUS FIN | 400 |
-
|
| TRACE | 400 |
Utilisé pour des messages qui fournissent des informations détaillées sur l'état d'exécution d'une application. Les messages de journalisation
TRACE sont habituellement capturés lors du débogage d'une application uniquement.
|
| DEBUG | 500 |
Utilisé pour des messages qui indiquent des demandes individuelles de progrès ou des activités d'une application. Les messages de journalisation
DEBUG ne sont habituellement capturés que lors du débogage d'une application.
|
| FINESSE | 500 |
-
|
| CONFIG | 700 |
-
|
| INFO | 800 |
Utilisé pour des messages qui indiquent la progression globale de l'application. Souvent utilisé pour le démarrage de l'application, la fermeture et autres événements majeurs de cycle de vie.
|
| AVERTISSEMENT | 900 |
Utilisé pour indiquer une situation qui n'est pas en erreur, mais n'est pas considérée comme idéale. Peut indiquer des circonstances qui peuvent entraîner des erreurs dans le futur.
|
| ATTENTION | 900 |
-
|
| ERREUR | 1000 |
Utiliser pour indiquer une erreur qui s'est produite et qui puisse empêcher l'activité actuelle ou la demande de se remplir, mais qui n'empêchera pas l'application d'exécuter.
|
| SÉVÈRE | 1000 |
-
|
| FATAL | 1100 |
Utiliser pour indiquer les événements qui pourraient entraîner des défaillances de services critiques ou la fermeture de l'application, ou qui pourraient entraîner la fermeture de la plateforme JBoss EAP 6.
|
5.1.5. Emplacements de fichiers de journalisation par défaut
Tableau 5.2. Fichier de journalisation par défaut d'un serveur autonome
| Fichier journal | Description |
|---|---|
EAP_HOME/standalone/log/server.log |
Le journal du serveur. Contient les messages de journalisation de serveur, dont les messages de démarrage de serveur.
|
Tableau 5.3. Fichiers de journalisation par défaut d'un domaine géré
| Fichier journal | Description |
|---|---|
EAP_HOME/domain/log/host-controller.log |
Journal d'amorçage du contrôleur hôte. Contient les messages de journalisation liés au démarrage du contrôleur hôte.
|
EAP_HOME/domain/log/process-controller.log |
Journal d'amorçage du contrôleur de processus. Contient les messages de journalisation liés au démarrage du contrôleur de processus.
|
EAP_HOME/domain/servers/SERVERNAME/log/server.log |
Le journal du serveur pour le serveur nommé. Contient les messages de journalisation de ce serveur, dont les messages de démarrage de serveur.
|
5.2. Journalisation dans le JBoss Logging Framework
5.2.1. JBoss Logging
5.2.2. Fonctionnalités de JBoss Logging
- Fournit un enregistreur d'événements de saisie ("typed") facile d'utilisation.
- Support total pour l'internationalisation et la localisation. Les traducteurs travaillent sur des lots de messages dans des fichiers de propriétés, tandis que les développeurs peuvent travailler sur des interfaces et annotations.
- Outils « buid-time » pour générer les enregistreurs d'événements en saisie pour la production, et la génération runtime d'enregistreurs d'événements pour le développement.
5.2.3. Ajouter une journalisation à une application par JBoss Logging
org.jboss.logging.Logger) et utiliser la méthode appropriée de cet objet. Cette tâche décrit les étapes nécessaires pour ajouter un support pour ceci à votre application.
Prérequis
- Si vous utilisez Maven en tant que système de build, il convient que le projet soit déjà configuré pour inclure le référentiel JBoss Maven. Voir Section 2.3.2, « Configurer le référentiel JBoss EAP 6 Platform Maven Repository par les paramètres de configuration de Maven »
- Les fichiers JAR de JBoss Logging doivent se trouver dans le chemin d'accès de génération de vos applications. La façon dont vous procédez dépendra de votre décision de générer votre application avec JBoss Developer Studio ou avec Maven.
- Quand vous générez avec JBoss Developer Studio vous pouvez procéder en sélectionnant Project -> Properties à partir du menu JBoss Developer Studio, en sélectionnant Targeted Runtimes et en veillant bien à vérifier le temps d'exécution de JBoss EAP 6.
- Quand vous générez avec Maven, vous pouvez procéder en ajoutant la configuration de dépendance suivante au fichier
pom.xmlde votre projet.<dependency> <groupId>org.jboss.logging</groupId> <artifactId>jboss-logging</artifactId> <version>3.1.2.GA-redhat-1</version> <scope>provided</scope> </dependency>
Vous n'avez pas besoin d'inclure les JAR de l'application générée car JBoss EAP 6 les fournit aux applications qui sont déployées.
Ajouter Imports
Ajouter les déclarations d'importation des espace-noms de classe JBoss Logging que vous allez utiliser. Vous devrez importer au minimumimport org.jboss.logging.Logger.import org.jboss.logging.Logger;
Créer un objet Logger
Créer une instance deorg.jboss.logging.Loggeret l'initialiser en utilisant la méthode statiqueLogger.getLogger(Class). Red Hat vous recommande de la créer en tant que variable à instance unique pour chaque classe.private static final Logger LOGGER = Logger.getLogger(HelloWorld.class);
Ajouter les messages de journalisation
Ajouter des appels aux méthodes de l'objetLoggerà votre code, là où vous souhaitez qu'il envoie des messages. L'objetLoggercomprend un certain nombre de méthodes contenant des paramètres différents suivant les types de messages. Les plus faciles à utiliser sont les suivants :debog(message objet)info(message objet)erreur(message objet)trace(message objet)fatal(message objet)Ces méthodes envoient un message de journalisation avec le niveau de journalisation correspondant et le paramètremessagecomme string.LOGGER.error("Configuration file not found.");Pour obtenir une liste complète des méthodes JBoss Logging, consulter le packageorg.jboss.loggingdans JBoss EAP 6 API Documentation.
Exemple 5.1. Utilisation de JBoss Logging quand on ouvre un fichier de propriétés
import org.jboss.logging.Logger;
public class LocalSystemConfig
{
private static final Logger LOGGER = Logger.getLogger(LocalSystemConfig.class);
public Properties openCustomProperties(String configname) throws CustomConfigFileNotFoundException
{
Properties props = new Properties();
try
{
LOGGER.info("Loading custom configuration from "+configname);
props.load(new FileInputStream(configname));
}
catch(IOException e) //catch exception in case properties file does not exist
{
LOGGER.error("Custom configuration file ("+configname+") not found. Using defaults.");
throw new CustomConfigFileNotFoundException(configname);
}
return props;
}
5.3. Profils de journalisation
5.3.1. Profils de journalisation
Important
- Un nom unique. Ceci est requis.
- N'importe quel nombre de Log Handlers.
- N'importe quelle catégorie log.
- Un root logger maximum.
Important
5.3.2. Spécifier un profil de journalisation dans une application
MANIFEST.MF.
Pré-requis :
- Vous devez connaître le nom du profil de journalisation qui a été défini sur le serveur pour cette application. Demandez à votre administrateur de systèmes le nom du profil à utiliser.
Procédure 5.1. Ajouter une configuration de profil de journalisation à une application
Modifier
MANIFEST.MFSi votre application ne possède pas de fichierMANIFEST.MF: le créer avec le contenu suivant, en remplaçant NAME par le nom de profil qui convient.Manifest-Version: 1.0 Logging-Profile: NAMESi votre application contient déjà un fichierMANIFEST.MF: ajouter la ligne suivante, en remplaçant NAME par le nom du profil qui convient.Logging-Profile: NAME
Note
maven-war-plugin, vous pourrez mettre votre fichier MANIFEST.MF dans src/main/resources/META-INF/ et ajouter la configuration suivante à votre fichier pom.xml.
<plugin>
<artifactId>maven-war-plugin</artifactId>
<configuration>
<archive>
<manifestFile>src/main/resources/META-INF/MANIFEST.MF</manifestFile>
</archive>
</configuration>
</plugin>
Chapitre 6. Internationalisation et localisation
6.1. Introduction
6.1.1. Internationalisation
6.1.2. Localisation
6.2. Outils JBoss Logging
6.2.1. Aperçu
6.2.1.1. JBoss Logging Tools - Internationalisation et Localisation
org.jboss.logging. Il n'est pas nécessaire d'implémenter les interfaces, JBoss Logging Tools le fait au moment de la compilation. Une fois définies, vous pouvez utiliser ces méthodes pour enregistrer des messages ou d'obtenir des objets d'exception dans votre code.
6.2.1.2. JBoss Logging Tools Quickstart
logging-tools, contient un simple projet Maven qui démontre les fonctionnalités de JBoss Logging Tools. A été utilisé extensivement dans cette documentation pour les exemples de code.
6.2.1.3. Message Logger
@org.jboss.logging.MessageLogger.
6.2.1.4. Lot de messages
@org.jboss.logging.MessageBundle.
6.2.1.5. Messages de journalisation internationalisés
@LogMessage et @Message et spécifier le message de journalisation en utilisant l'attribut de la valeur de @Message. Les messages de journalisation internationalisés sont localisés en fournissant des traductions dans un fichier de propriétés.
6.2.1.6. Exceptions internationalisées
6.2.1.7. Messages internationalisés
6.2.1.8. Fichiers de propriétés de traduction
6.2.1.9. Codes de projets de JBoss Logging Tools
projectCode de l'annotation @MessageLogger.
6.2.1.10. Ids de messages de JBoss Logging Tools
id de l'annotation @Message.
6.2.2. Création de loggers, de messages ou d'exceptions internationalisés
6.2.2.1. Créer des messages log internationalisés
logging-tools pour trouver un exemple complet.
Prérequis :
- Vous devez déjà posséder un projet Maven en cours. Voir Section 6.2.6.1, « Configuration Maven JBoss Logging Tools ».
- Le projet doit avoir la configuration Maven qui convient pour JBoss Logging Tools.
Procédure 6.1. Créer un lot de messages log internationalisés
Créer une interface de Message Logger
Ajouter une interface Java à votre projet pour contenir les définitions de messages log. Définir l'interface de façon descriptive pour les messages log qui seront définis à l'intérieur.L'interface de messages log ont les prérequis suivants :- Doit être annotée par
@org.jboss.logging.MessageLogger. - Doit étendre
org.jboss.logging.BasicLogger. - L'interface doit définir un champ qui est un Logger typed quiimpléemnte cette interface. Procédez par la méthode
getMessageLogger()deorg.jboss.logging.Logger.
package com.company.accounts.loggers; import org.jboss.logging.BasicLogger; import org.jboss.logging.Logger; import org.jboss.logging.MessageLogger; @MessageLogger(projectCode="") interface AccountsLogger extends BasicLogger { AccountsLogger LOGGER = Logger.getMessageLogger( AccountsLogger.class, AccountsLogger.class.getPackage().getName() ); }Ajouter les définitions de méthode
Ajouter une définition de méthode à l'interface de chaque message log. Nommez chaque méthode descriptivement par rapport au message log qu'elle représente.Chaque méthode a les prérequis suivants :- La méthode doit renvoyer
void. - La méthode doit être annotée par
@org.jboss.logging.LogMessage. - La méthode doit être annotée par
@org.jboss.logging.Message. - L'attribut de
@org.jboss.logging.Messagecontient le message log par défaut. Il s'agit du message qui est utilisé s'il n'y a pas de traduction.
@LogMessage @Message(value = "Customer query failed, Database not available.") void customerQueryFailDBClosed();
Le niveau de journalisation par défaut estINFO.Invoquer les méthodes
Ajouter les appels aux méthodes d'interface dans votre code là où les messages doivent être journalisés. Il n'est pas utile de créer des implémentations des interfaces, le processeur d'annotations le fait pour vous quand le projet est compilé.AccountsLogger.LOGGER.customerQueryFailDBClosed();
Les loggers personnalisés sont des sous-classes de BasicLogger, donc les méthodes de journalisation deBasicLogger(debug(),error()etc) peuvent également être utilisées. Il n'est pas utile de créer d'autres loggers pour enregistrer les messages non internationalisés.AccountsLogger.LOGGER.error("Invalid query syntax.");
6.2.2.2. Créer et utiliser des messages internationalisés
logging-tools pour trouver un exemple complet.
Prérequis
- Vous avez un projet Maven utilisant le référentiel JBoss EAP 6. Voir Section 2.3.2, « Configurer le référentiel JBoss EAP 6 Platform Maven Repository par les paramètres de configuration de Maven ».
- La configuration Maven requise pour JBoss Logging Tools a été ajoutée. Voir Section 6.2.6.1, « Configuration Maven JBoss Logging Tools ».
Procédure 6.2. Créer et utiliser des messages internationalisés
Créer une interface pour les exceptions.
JBoss Logging Tools définit les messages internationalisés dans les interfaces. Nommer chaque interface de manière descriptive pour les messages qui seront définis à l'intérieur.L'interface possède les prérequis suivants :- Elle doit être déclarée publique
- Elle doit être annotée par
@org.jboss.logging.MessageBundle. - L'interface doit définir un champ qui corresponde à un lot de messages du même type que l'interface.
@MessageBundle(projectCode="") public interface GreetingMessageBundle { GreetingMessageBundle MESSAGES = Messages.getBundle(GreetingMessageBundle.class); }Ajouter les définitions de méthode
Ajouter une définition de méthode dans l'interface de chaque message.Chaque méthode a les prérequis suivants :- Elle doit renvoyer un objet de type
String. - La méthode doit être annotée par
@org.jboss.logging.Message. - L'attribut
@org.jboss.logging.Messagedoit être défini à la valeur par défaut du message. Il s'agit du message qui est utilisé si aucune traduction n'est disponible.
@Message(value = "Hello world.") String helloworldString();
Méthodes d'invocation
Invoquer les méthodes d'interface dans votre application quand vous aurez besoin d'obtenir le message.System.console.out.println(helloworldString());
6.2.2.3. Créer des exceptions personnalisées
logging-tools pour trouver un exemple complet.
Procédure 6.3. Créer et utiliser des exceptions internationalisées
Ajouter une configuration JBoss Logging Tools
Ajouter la configuration de projet qui convient pour prendre en charge JBoss Logging Tools. Voir Section 6.2.6.1, « Configuration Maven JBoss Logging Tools »Créer une interface pour les exceptions.
JBoss Logging Tools définit les exceptions internationalisées dans les interfaces. Nommer chaque interface de façon descriptive pour les exceptions qui seront décrites à l'intérieur.L'interface possède les prérequis suivants :- Elle doit être déclarée
public. - Elle doit être annotée par
@org.jboss.logging.MessageBundle. - L'interface doit définir un champ qui correspond à un lot de messages du même type que l'interface.
@MessageBundle(projectCode="") public interface ExceptionBundle { ExceptionBundle EXCEPTIONS = Messages.getBundle(ExceptionBundle.class); }Ajouter les définitions de méthode
Ajouter un définition de méthode à l'interface pour chaque exception. Nommez chaque méthode de façon descriptive pour chaque exception qu'elle représente.Chaque méthode a les prérequis suivants :- Elle doit renvoyer un objet du type
Exceptionou bien un sous-type deException. - La méthode doit être annotée par
@org.jboss.logging.Message. - L'attribut de
@org.jboss.logging.Messagedoit être défini à la valeur du message d'exception par défaut. Il s'agit du message qui est utilisé s'il n'y a pas de traduction. - Si l'exception est retournée à un constructeur qui nécessite des paramètres en plus d'une chaîne de message, alors ces paramètres doivent être fournis dans la définition de méthode à l'aide de l'annotation
@param. Les paramètres doivent être du même type et même ordre que le constructeur.
@Message(value = "The config file could not be opened.") IOException configFileAccessError(); @Message(id = 13230, value = "Date string '%s' was invalid.") ParseException dateWasInvalid(String dateString, @Param int errorOffset);
Méthodes d'invocation
Invoquer les méthodes d'interface de votre code quand vous devrez obtenir une des exceptions. Les méthodes ne lancent pas d'exceptions, elles envoient l'objet d'exception que vous pourrez alors envoyer vous-même.try { propsInFile=new File(configname); props.load(new FileInputStream(propsInFile)); } catch(IOException ioex) //in case props file does not exist { throw ExceptionBundle.EXCEPTIONS.configFileAccessError(); }
6.2.3. Localisation de loggers, messages ou exceptions internationalisés
6.2.3.1. Générer des nouveaux fichiers de propriétés de traduction avec Maven
logging-tools pour trouver un exemple complet.
Prérequis :
- Vous devez déjà posséder un projet Maven en cours.
- Le projet devra avoir été configuré pour JBoss Logging Tools.
- Le projet doit contenir une ou plusieurs interfaces qui définissent des exceptions ou des messages de journalisation internationalisés
Procédure 6.4. Générer des nouveaux fichiers de propriétés de traduction avec Maven
Ajouter la configuration Maven
Ajouter l'argument de compilateur-AgenereatedTranslationFilePathà la configuration du plug-in du compilateur Maven et lui assigner le chemin d'accès où les nouveaux fichiers devront être créés.<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>2.3.2</version> <configuration> <source>1.6</source> <target>1.6</target> <compilerArgument> -AgeneratedTranslationFilesPath=${project.basedir}/target/generated-translation-files </compilerArgument> <showDeprecation>true</showDeprecation> </configuration> </plugin>La configuration ci-dessus va créer des nouveaux fichiers dans le répertoiretarget/generated-translation-filesde votre projet Maven.Créer votre projet
Créer votre projet en utilisant Maven.[Localhost]$ mvn compile
@MessageBundle ou @MessageLogger. Les nouveaux fichiers sont créés dans un sous-répertoire qui correspond au package Java dans lequel chaque interface est déclarée.
InterfaceName comme nom d'interface pour laquelle ce fichier a été créé : InterfaceName.i18n_locale_COUNTRY_VARIANT.properties.
6.2.3.2. Traduire un logger, une exception ou un message internationalisé
logging-tools pour trouver un exemple complet.
Prérequis
- Vous devez déjà posséder un projet Maven en cours
- Le projet devra avoir été configuré pour JBoss Logging Tools.
- Le projet devra contenir une ou plusieurs interfaces qui définissent les exceptions ou message log d'internationalisation.
- Le projet devra être configuré pour générer des fichiers de propriétés modèles.
Procédure 6.5. Traduire un message, une exception ou un message internationalisé
Créer des fichiers de propriétés modèles
Exécuter la commandemvn compilepour créer les modèles de fichiers de propriétés de traduction.Ajouter le fichier modèle à votre projet.
Copier le modèle des interfaces que vous souhaitez traduire depuis le répertoire où elles ont été créées dans le répertoiresrc/main/resourcesde votre projet. Les fichiers de propriétés doivent figurer dans le même package des interfaces qu'ils traduisent.Renommer le fichier modèle copié
Renommer la copie du fichier modèle selon la traduction qu'il contient. Par exemple,GreeterLogger.i18n_fr_FR.properties.Traduire le contenu du modèle
Modifier le nouveau fichier de propriétés de traduction de manière à contenir la traduction appropriée.# Level: Logger.Level.INFO # Message: Hello message sent. logHelloMessageSent=Bonjour message envoyé.
Répéter les étapes deux, trois et quatre pour chaque traduction de chaque lot exécuté.
target/generated-sources/annotations/.
6.2.4. Personnalisation des messages de journalisation internationalisés
6.2.4.1. Ajouter les ids de messages et les codes de projets aux messages de journalisation
logging-tools pour trouver un exemple complet.
Prérequis
- Vous devez déjà posséder un projet avec des messages de journalisation internationalisés. Voir Section 6.2.2.1, « Créer des messages log internationalisés ».
- Vous devrez connaître le code de projet que vous utilisez. Vous pouvez utiliser un code de projet simple, ou en définir un différent pour chaque interface.
Procédure 6.6. Ajouter les ids et les codes de projets aux messages de journalisation
Indiquer le code de projet de l'interface.
Indiquer le code du projet par l'attribut projectCode de l'annotation@MessageLoggerqui est attachée à une interface de logger personnalisée. Tous les messages définis dans l'interface utiliseront ce code de projet.@MessageLogger(projectCode="ACCNTS") interface AccountsLogger extends BasicLogger { }Indiquer les ids de messages
Indiquer un id de message pour chaque message qui utilise un attribut id de l'annotation @Message liée à la méthode qui définit le message.@LogMessage @Message(id=43, value = "Customer query failed, Database not available.") void customerQueryFailDBClosed();
10:55:50,638 INFO [com.company.accounts.ejb] (MSC service thread 1-4) ACCNTS000043: Customer query failed, Database not available.
6.2.4.2. Indiquer le niveau de journalisation d'un message
INFO. Un niveau de journalisation différent peut être indiqué avec l'attribut level de l'annotation @LogMessage jointe à la méthode de journalisation.
Procédure 6.7. Indiquer le niveau de journalisation d'un message
Indiquer l'attribut du niveau
Ajouter l'attributlevelà l'annotation de@LogMessagede la définition de la méthode de message de journalisation.Allouer un niveau de journalisation
Allouer l'attributlevelà la valeur du niveau de journalisation de ce message. Les valeurs valides delevelsont les six constantes énumérées définies dansorg.jboss.logging.Logger.Level:DEBUG,ERROR,FATAL,INFO,TRACE, etWARN.Import org.jboss.logging.Logger.Level; @LogMessage(level=Level.ERROR) @Message(value = "Customer query failed, Database not available.") void customerQueryFailDBClosed();
ERROR.
10:55:50,638 ERROR [com.company.app.Main] (MSC service thread 1-4) Customer query failed, Database not available.
6.2.4.3. Personnaliser les messages de journalisation par des paramètres
Procédure 6.8. Personnaliser les messages de journalisation avec les paramètres
Ajouter des paramètres à la définition de la méthode
Les paramètres d'un type donné peuvent être ajoutés à la définition de la méthode. Quel que soit le type, la représentation String du paramètre est ce qui est affiché dans le message.Ajouter les références de paramètre dans le message de journalisation
Les références peuvent utiliser des indexations explicites ou ordinaires.- Pour utiliser des indexes ordinaires, insérer les caractères
%sdans la chaîne de message où vous souhaitez voir apparaître chaque paramètre. Le premier%sinsèrera le premier paramètre, le deuxième insèrera le deuxième paramètre, et ainsi de suite. - Pour les indexations explicites, insérer les caractères
%{#}dans le message où # correspond au numéro du paramètre que vous souhaitez apercevoir.
Important
Exemple 6.1. Paramètres de messages qui utilisent des indexations ordinaires.
@LogMessage(level=Logger.Level.DEBUG) @Message(id=2, value="Customer query failed, customerid:%s, user:%s") void customerLookupFailed(Long customerid, String username);
Exemple 6.2. Paramètres de messages qui utilisent des indexations explicites
@LogMessage(level=Logger.Level.DEBUG)
@Message(id=2, value="Customer query failed, customerid:%{1}, user:%{2}")
void customerLookupFailed(Long customerid, String username);
6.2.4.4. Indiquer une exception comme cause d'un message de journalisation
Throwable ou d'une de ses sous-classes et doit être marqué par l'annotation @Cause . Ce paramètre ne peut pas être référencé dans le message de journal comme les autres paramètres et il s'affiche à la suite du message de journalisation.
Procédure 6.9. Indiquer une exception comme cause d'un message de journalisation
Ajouter le paramètre
Ajouter un paramètreThrowableou une sous-classe à la méthode.@Message(id=404, value="Loading configuration failed. Config file:%s") void loadConfigFailed(Exception ex, File file);
Ajouter l'annotation
Ajouter l'annotation@Causeau paramètre.import org.jboss.logging.Cause @Message(value = "Loading configuration failed. Config file: %s") void loadConfigFailed(@Cause Exception ex, File file);
Invoquer la méthode
Quand la méthode est invoquée dans votre code, un objet du type qui convient devra être passé et sera affiché à la suite du message de journalisation.try { confFile=new File(filename); props.load(new FileInputStream(confFile)); } catch(Exception ex) //in case properties file cannot be read { ConfigLogger.LOGGER.loadConfigFailed(ex, filename); }Vous trouverez ci-dessous la sortie des extraits de code ci-dessus, si le code à lancé une exception de typeFileNotFoundException.10:50:14,675 INFO [com.company.app.Main] (MSC service thread 1-3) Loading configuration failed. Config file: customised.properties java.io.FileNotFoundException: customised.properties (No such file or directory) at java.io.FileInputStream.open(Native Method) at java.io.FileInputStream.<init>(FileInputStream.java:120) at com.company.app.demo.Main.openCustomProperties(Main.java:70) at com.company.app.Main.go(Main.java:53) at com.company.app.Main.main(Main.java:43)
6.2.5. Personnalisation des exceptions internationalisées
6.2.5.1. Ajouter les ids et les codes de projets aux messages d'exceptions
Prérequis
- Vous devrez déjà avoir un projet avec des exceptions internationalisées. Voir Section 6.2.2.3, « Créer des exceptions personnalisées ».
- Vous devrez connaître le code de projet que vous utilisez. Vous pouvez utiliser un code de projet simple, ou en définir un différent pour chaque interface.
Procédure 6.10. Ajouter les ids et les codes de projets aux messages d'exceptions
Indiquer un code de projet
Indiquer le code de projet en utilisant l'attributprojectCodede l'annotation@MessageBundleattachée à une interface de lot d'exceptions. Tous les messages qui sont définis dans l'interface utiliseront ce code de projet.@MessageBundle(projectCode="ACCTS") interface ExceptionBundle { ExceptionBundle EXCEPTIONS = Messages.getBundle(ExceptionBundle.class); }Indiquer les ID de messages
Indiquer l'id de message pour chaque exception en utilisant l'attributidde l'annotation@Messageassociée à la méthode qui définit l'exception.@Message(id=143, value = "The config file could not be opened.") IOException configFileAccessError();
Important
Exemple 6.3. Créer des exceptions internationalisées
@MessageBundle(projectCode="ACCTS")
interface ExceptionBundle
{
ExceptionBundle EXCEPTIONS = Messages.getBundle(ExceptionBundle.class);
@Message(id=143, value = "The config file could not be opened.")
IOException configFileAccessError();
}
throw ExceptionBundle.EXCEPTIONS.configFileAccessError();
Exception in thread "main" java.io.IOException: ACCTS000143: The config file could not be opened. at com.company.accounts.Main.openCustomProperties(Main.java:78) at com.company.accounts.Main.go(Main.java:53) at com.company.accounts.Main.main(Main.java:43)
6.2.5.2. Personnaliser les messages d'exception avec des paramètres
Procédure 6.11. Personnaliser les messages d'exception avec les paramètres
Ajouter des paramètres à la définition de la méthode
Les paramètres d'un type donné peuvent être ajoutés à la définition de la méthode. Quel que soit le type, la représentationStringdu paramètre est ce qui est affiché dans le message.Ajouter les références de paramètre au message d'exception
Les références peuvent utiliser des indexations explicites ou ordinaires.- Pour utiliser des indexations ordinaires, insérer les caractères
%sdans la chaîne de message où vous souhaitez voir apparaître chaque paramètre. Le premier%sinsèrera le premier paramètre, le deuxième insèrera le deuxième paramètre, et ainsi de suite. - Pour les indexations explicites, insérer les caractères
%{#}dans le message où#correspond au numéro du paramètres que vous souhaitez apercevoir.
L'utilisation des indexations explicites permet aux références de paramètre du message d'être dans un ordre différent que celui défini dans la méthode. C'est important pour les messages traduits qui peuvent nécessiter un ordonnancement des paramètres différent.
Important
@Cause n'est pas inclus dans le nombre de paramètres.
Exemple 6.4. Utilisation des indexations ordinaires
@Message(id=143, value = "The config file %s could not be opened.") IOException configFileAccessError(File config);
Exemple 6.5. Utilisation des indexations explicites
@Message(id=143, value = "The config file %{1} could not be opened.")
IOException configFileAccessError(File config);
6.2.5.3. Indiquer une exception comme cause d'une autre exception
Procédure 6.12. Indiquer une exception comme « cause » d'une autre exception
Ajouter le paramètre
Ajouter un paramètreThrowableou une sous-classe à la méthode.@Message(id=328, value = "Error calculating: %s.") ArithmeticException calculationError(Throwable cause, String msg);
Ajouter l'annotation
Ajouter l'annotation@Causeau paramètre.import org.jboss.logging.Cause @Message(id=328, value = "Error calculating: %s.") ArithmeticException calculationError(@Cause Throwable cause, String msg);
Invoquer la méthode
Invoquer la méthode d'interface pour obtenir un objet d'exception. Le cas d'utilisation le plus commun est de lancer une exception à partir d'un bloc catch en utilisant l'exception récupérée comme « cause ».try { ... } catch(Exception ex) { throw ExceptionBundle.EXCEPTIONS.calculationError( ex, "calculating payment due per day"); }
Exemple 6.6. Indiquer une exception comme « cause » d'une autre exception
@MessageBundle(projectCode = "TPS")
interface CalcExceptionBundle
{
CalcExceptionBundle EXCEPTIONS = Messages.getBundle(CalcExceptionBundle.class);
@Message(id=328, value = "Error calculating: %s.")
ArithmeticException calcError(@Cause Throwable cause, String value);
}
int totalDue = 5;
int daysToPay = 0;
int amountPerDay;
try
{
amountPerDay = totalDue/daysToPay;
}
catch (Exception ex)
{
throw CalcExceptionBundle.EXCEPTIONS.calcError(ex, "payments per day");
}
Exception in thread "main" java.lang.ArithmeticException: TPS000328: Error calculating: payments per day. at com.company.accounts.Main.go(Main.java:58) at com.company.accounts.Main.main(Main.java:43) Caused by: java.lang.ArithmeticException: / by zero at com.company.accounts.Main.go(Main.java:54) ... 1 more
6.2.6. Référence
6.2.6.1. Configuration Maven JBoss Logging Tools
pom.xml :
logging-tools pour obtenir un exemple de fichier pom.xml complet.
- Le référentiel JBoss Maven Repository doit être activé pour le projet. Voir Section 2.3.2, « Configurer le référentiel JBoss EAP 6 Platform Maven Repository par les paramètres de configuration de Maven ».
- Les dépendances Maven de
jboss-loggingetjboss-logging-processordoivent être ajoutées. Les deux dépendances sont disponibles sur JBoss EAP 6, ainsi l'étendue de chaque dépendance peut être définie commeprovidedtel qu'il a été montré.<dependency> <groupId>org.jboss.logging</groupId> <artifactId>jboss-logging-processor</artifactId> <version>1.0.0.Final</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.jboss.logging</groupId> <artifactId>jboss-logging</artifactId> <version>3.1.0.GA</version> <scope>provided</scope> </dependency>
- Le
maven-compiler-plugindoit utiliser au minimum la version2.2et être configuré pour la cible et les sources générées de1.6.<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>2.3.2</version> <configuration> <source>1.6</source> <target>1.6</target> </configuration> </plugin>
6.2.6.2. Format de fichier de propriétés de traduction
key=value simple, orienté-ligne, décrit dans la documentation java.util.Properties class, http://docs.oracle.com/javase/6/docs/api/java/util/Properties.html.
InterfaceName.i18n_locale_COUNTRY_VARIANT.properties
InterfaceNameest le nom de l'interface où les traductions s'appliquent.locale,COUNTRY, etVARIANTidentifient les paramètres régionaux correspondant à la traduction.localeetCOUNTRYindiquent la langue et le pays en utilisant respectivement les codes Langues et Pays ISO-639 et ISO-3166.COUNTRYest optionnel.VARIANTest un identifiant optionnel pouvant être utilisé pour identifier les traductions qui ne s'appliquent qu'à un système d'exploitation ou navigateur en particulier.
Exemple 6.7. Échantillon de fichier de propriétés de traductions
GreeterService.i18n_fr_FR_POSIX.properties.
# Level: Logger.Level.INFO # Message: Hello message sent. logHelloMessageSent=Bonjour message envoyé.
6.2.6.3. Références aux annotations de JBoss Logging Tools
Tableau 6.1. Annotations de JBoss Logging Tools
| Annotation | Cible | Description | Attributs |
|---|---|---|---|
@MessageBundle | Interface |
Définit l'interface en tant que Lot de Messages
| projectCode |
@MessageLogger | Interface |
Définit l'interface en tant que Message Logger
| projectCode |
@Message | Méthode |
Peut être utilisé dans les Lots de Messages et Message Loggers. Dans un Message Logger, définit une méthode comme étant un logger localisé. Dans un Lot de Messages, définit la méthode comme étant une méthode qui renvoie une Chaîne localisées ou un objet d'Exception.
| value, id |
@LogMessage | Méthode |
Définit une méthode dans un Message Logger comme étant une méthode de logging.
| level (default INFO) |
@Cause | Paramètre |
Définit un paramètre comme étant un paramètre faisant passer une exception en tant que cause d'un Message Log ou autre exception.
| - |
@Param | Paramètre |
Définit un paramètre comme étant un paramètre passé au constructeur d'une Exception.
| - |
Chapitre 7. Enterprise JavaBeans
7.1. Introduction
7.1.1. Entreprise JavaBeans
7.1.2. Groupe de fonctionnalités EJB 3.1
- Session Beans
- Message Driven Beans
- Vues non-interfaces
- interfaces locales
- interfaces distantes
- services web JAX-WS
- services web JAX-RS
- Service de minuterie
- Appels asynchrones
- Intercepteurs
- Interopérabilité RMI/IIOP
- Support de transaction
- Sécurité
- API intégrable
- Entity Beans (persistance gérée-bean et conteneur))
- Vues client Entity Beans EJB 2.1
- EJB Query Language (EJB QL)
- Services Web basés JAX-RPC (points de terminaison et vues client)
7.1.3. EJB 3.1 Lite
- ne supportant que les fonctionnalités qui sont utiles pour les applications-web, et
- en permettant aux EJB d'être déployés dans le même fichier WAR sous forme d'application web.
7.1.4. Fonctionnalités EJB 3.1 Lite
- Session Beans sans état, avec état, et singleton
- Interfaces commerciales locales et beans "sans interface"
- Intercepteurs
- Transactions gérées-conteneur et gérées-bean
- Sécurité déclarative et programmatique
- API intégrable
- Interfaces éloignées
- Intéropérabilité RMI-IIOP
- Points de terminaison de Services Web JAX-WS
- Service de minuterie EJB
- Invocations de session beans asynchrones
- Message-driven beans
7.1.5. Beans Enterprise
Important
7.1.6. Écriture des beans Enterprise
7.1.7. Interfaces Métier de Session Bean
7.1.7.1. Interfaces de métier Bean Enterprise
7.1.7.2. Interfaces de métier locales EJB
7.1.7.3. Interfaces métier à distance EJB
7.1.7.4. Beans EJB No-interface
7.2. Créer des projets Enterprise Bean
7.2.1. Créer un projet d'archives EJB avec le Studio JBoss Developer
Prérequis
- Un serveur et un temps d'exécution du serveur ont été établis pour JBoss EAP 6.
Procédure 7.1. Créer un projet EJB avec le Studio JBoss Developer
Créer un nouveau projet
Pour ouvrir l'Assistant New EJB Project, naviguer jusqu'au menu , sélectionner puis .
Figure 7.1. Assistant New EJB Project
Détails
Fournir les informations suivantes :- Nom du projet.Il s'agira du nom du projet qui apparaît dans JBoss Developer Studio, et également le nom du fichier par défaut du fichier JAR déployé.
- Emplacement du projetLe répertoire où les fichiers du projet seront sauvegardés. La valeur par défaut est un répertoire qui se trouve dans l'espace de travail en cours.
- Runtime cible.Il s'agit du runtime de serveur utilisé pour le projet. Il devra être défini au même runtime JBoss EAP 6, qui est utilisé par le serveur dans lequel vous souhaitez déployer.
- Version de module EJB. Il s'agit de la version de la spécification EJB avec laquelle vos beans enterprise devront se conformer. Red Hat recommande que vous utilisiez
3.1. - Configuration. Cela vous permet d'ajuster les fonctionnalités prises en charge par votre projet. Utiliser la configuration par défaut pour le runtime que vous avez sélectionné.
Cliquer sur pour continuer.Java Build Configuration
Cet écran vous permet de personnaliser les répertoires qui contiennent les fichiers source de Java et le répertoire où les résultats de la génération se trouvent.Conservez cette configuration sans y apporter aucun changement et cliquer sur le bouton .Paramétrage du Module EJB
Cocher la case Générer descripteur de déploiement ejb-jar.xml si un descripteur de déploiement est requis. Le descripteur de déploiement est une option dans EJB 3.1, et peut être rajouté plus tard si nécessaire.Cliquer sur le bouton et le projet sera créé. Il s'affichera dans Project Explorer.
Figure 7.2. Nouveau projet EJB créé dans Project Explorer
Ajouter l'artifact généré dans le serveur en vue du déploiement
Ouvrir le dialogue Ajouter et Supprimer en cliquant à droite sur le serveur dans lequel vous souhaitez générer l'artefact dans l'onglet serveur, et sélectionner 'Ajouter et Supprimer'.Sélectionner la ressource à déployer à partir de la colonne Disponible et cliquer sur le bouton . La ressource sera déplacée dans la colonne Configurer, Cliquer sur pour fermer le dialogue.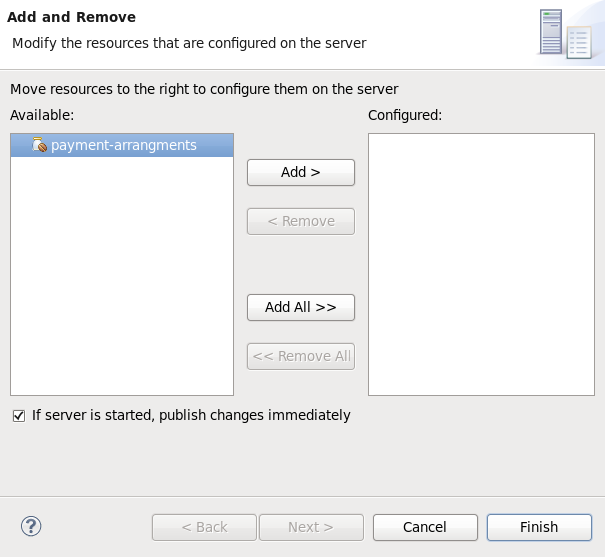
Figure 7.3. Ajouter et Supprimer le dialogue
Vous avez maintenant un Projet EJB dans JBoss Developer Studio pouvant être construit et déployé pour un serveur spécifique.
7.2.2. Créer un projet EJB Archive dans Maven.
Prérequis :
- Maven est déjà installé.
- Vous comprenez les bases d'utilisation de Maven.
Procédure 7.2. Créer un projet EJB Archive dans Maven
Créer le projet Maven
Un projet EJB peut être créé en utilisant le système archétype de Maven et l'archétypeejb-javaee6. Pour ce faire, exécuter la commandemvnavec les paramètres suivants :mvn archetype:generate -DarchetypeGroupId=org.codehaus.mojo.archetypes -DarchetypeArtifactId=ejb-javaee6
Maven vous demandera legroupId, leartifactId, laversionet lepackagede votre projet.[localhost]$ mvn archetype:generate -DarchetypeGroupId=org.codehaus.mojo.archetypes -DarchetypeArtifactId=ejb-javaee6 [INFO] Scanning for projects... [INFO] [INFO] ------------------------------------------------------------------------ [INFO] Building Maven Stub Project (No POM) 1 [INFO] ------------------------------------------------------------------------ [INFO] [INFO] >>> maven-archetype-plugin:2.0:generate (default-cli) @ standalone-pom >>> [INFO] [INFO] <<< maven-archetype-plugin:2.0:generate (default-cli) @ standalone-pom <<< [INFO] [INFO] --- maven-archetype-plugin:2.0:generate (default-cli) @ standalone-pom --- [INFO] Generating project in Interactive mode [INFO] Archetype [org.codehaus.mojo.archetypes:ejb-javaee6:1.5] found in catalog remote Define value for property 'groupId': : com.shinysparkly Define value for property 'artifactId': : payment-arrangments Define value for property 'version': 1.0-SNAPSHOT: : Define value for property 'package': com.shinysparkly: : Confirm properties configuration: groupId: com.company artifactId: payment-arrangments version: 1.0-SNAPSHOT package: com.company.collections Y: : [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 32.440s [INFO] Finished at: Mon Oct 31 10:11:12 EST 2011 [INFO] Final Memory: 7M/81M [INFO] ------------------------------------------------------------------------ [localhost]$
Ajouter vos beans enterprise
Ecrire vos beans enterprise et les ajouter au projet sous le répertoiresrc/main/javadans le sous-répertoire approprié pour le paquetage du bean.Créer votre projet
Pour construire ce projet, exécuter la commandemvn packagedans le même répertoire que le fichierpom.xml. Cela compilera les classes Java et empaquettera le fichier JAR. Le fichier JAR construit se nommeartifactId-version.jaret se trouve dans le répertoiretarget/.
7.2.3. Créer un projet EAR contenant un projet EJB
Prérequis
- Un serveur et runtime de serveur pour JBoss EAP 6 a été installé. Veuillez vous référer à Section 1.3.1.5, « Ajouter le serveur de JBoss EAP 6 au JBoss Developer Studio ».
Procédure 7.3. Créer un projet EAR contenant un projet EJB
Ouvrir le nouvel Assistant de Projet de l'Application EAR.
Naviguer vers le menu , sélectionner , puis et l'assistant Nouveau Projet apparaîtra. Sélectionner et cliquer sur le bouton .
Figure 7.4. Nouvel Assistant de Projet de l'Application EAR.
Fournir des Informations
Fournir les informations suivantes :- Nom du projet.En plus d'être le nom du projet qui apparaît dans le JBoss Developer Studio, c'est également le nom de fichier par défaut pour le fichier EAR déployé.
- Emplacement du ProjetLe répertoire où les fichiers du projet seront sauvegardés. La valeur par défaut est un répertoire qui se trouve dans l'espace de travail en cours.
- Runtime cible.Il s'agit du runtime de serveur utilisé pour le projet. Il devra être défini au même runtime JBoss EAP 6, qui est utilisé par le serveur dans lequel vous souhaitez déployer.
- Version EAR.C'est la version des spécifications de Java Enterprise Edition auquel votre projet devra se conformer. Red Hat recommande d'en utiliser
6. - Configuration. Cela vous permet d'ajuster les fonctionnalités prises en charge par votre projet. Utiliser la configuration par défaut pour le runtime que vous avez sélectionné.
Cliquer sur pour continuer.Ajouter un nouveau module EJB.
Les nouveaux Modules peuvent être ajoutés à partir de la page Enterprise Application de l'assistant. Pour ajouter un nouveau Projet EJB en tant que module, veuillez suivre les étapes suivantes :Ajouter un nouveau Module EJB.
Cliquer sur , décocher la case Créer Modules par Défaut, sélectionner Enterprise Java Bean et cliquer sur . L'assistant Nouveau Projet EJB apparaîtra.Créer un Projet EJB.
L'assistant Nouveau Projet EJB est le même que l'assistant utilisé pour créer de nouveaux projets EJB autonomes et est décrit dans Section 7.2.1, « Créer un projet d'archives EJB avec le Studio JBoss Developer ».Les détails minimales requis pour créer le project sont les suivants :- Nom du Projet
- Runtime de la cible
- Version Module EJB
- Configuration
Toutes les autres étapes de l'assistant sont optionnelles. Cliquer sur pour finir de créer le Projet EJB.
Le Projet EJB tout juste créé est listé dans les dépendances du module Java EE et la case est cochée.Optionnel : ajouter un descripteur de déploiement application.xml
Cocher la case Générer descripteur de déploiement d'application.xml le cas échéant.Cliquer sur Finish
Deux nouveaux projets vont apparaître, le projet EJB et le projet EAR.Ajouter l'artifact généré dans le serveur en vue du déploiement
Ouvrir la boîte de dialogue Ajouter et Supprimer en cliquant avec le bouton droit de la souris, dans l'onglet Serveurs, sur le serveur dans lequel vous souhaitez déployer l'artéfact de la build dans l'onglet serveur, et sélectionner .Sélectionner la ressource EAR à déployer depuis la colonne Disponible et cliquer sur le bouton . La ressource sera déplacée vers la colonne Configuré. Cliquer sur pour fermer la boîte de dialogue.
Figure 7.5. Ajouter et Supprimer le dialogue
Vous avez maintenant un Projet d'Application Enterprise avec un Projet EJB membre. Celui-ci se créera et se déploiera vers le serveur indiqué en tant que déploiement EAR unique contenant un sous-déploiement EJB.
7.2.4. Ajouter un descripteur de déploiement à un projet EJB
Prérequis :
- Vous avez un projet EJB dans JBoss Developer Studio auquel vous souhaitez ajouter un descripteur de déploiement EJB.
Procédure 7.4. Ajouter un descripteur de déploiement à un projet EJB.
Ouvrir le projet
Ouvrir le projet dans JBoss Developer Studio.Ajouter un descipteur de déploiement
Cliquer à droite sur le dossier Descripteur de déploiement dans la vue du projet et sélectionner .
Figure 7.6. Ajouter un descripteur de déploiement
ejb-jar.xml, sera créé dans ejbModule/META-INF/. Cliquer deux fois dans le dossier Descripteur de déploiement dans la vue du projet, ce qui permettra d'ouvrir ce fichier également.
7.3. Session Beans
7.3.1. Session Beans
7.3.2. Stateless Session Beans
7.3.3. Stateful Session Beans
7.3.4. Singleton Session Beans
7.3.5. Ajouter des Session Beans à un projet dans JBoss Developer Studio
Prérequis :
- Vous avec un EJB ou Dynamic Web Project dans JBoss Developer Studio auquel vous souhaitez ajouter un ou plusieurs session beans.
Procédure 7.5. Ajouter des Session Beans à un projet dans JBoss Developer Studio
Ouvrir le projet
Ouvrir le projet dans JBoss Developer Studio.Ouvrir l'assistant "Create EJB 3.x Session Bean" (Créer EJB 3.x Session Bean)
Pour ouvrir l'assistant Créer EJB 3.x Session Bean, naviguer dans le menu , et sélectionner , puis .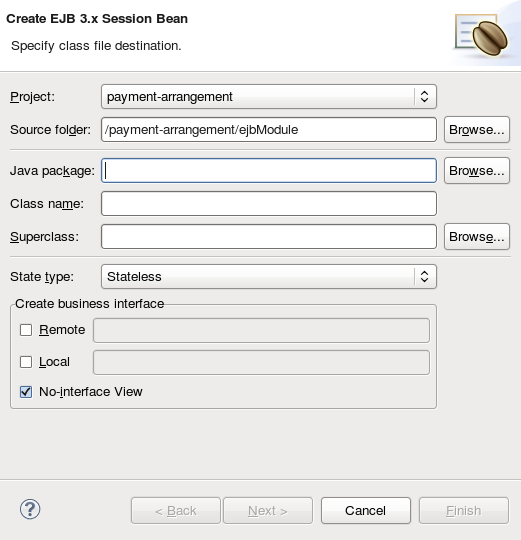
Figure 7.7. Créer un assistant EJB 3.x Session Bean
Indiquer les informations de classe
Donner les informations suivantes :- ProjetVerifier que le projet qui convient a bien été sélectionné.
- Dossier sourceIl s'agit du dossier dans lequel les fichiers source de Java seront créés. Cela n'a pas normalement besoin d'être changé.
- PackageIndiquer le package auquel cette classe appartient.
- Nom de la classeIndiquer le nom de la classe qui représentera le session bean.
- SuperclassLa classe de session bean peut hériter d'une Superclass. Indiquer ici si votre session a une Superclass.
- Type d'étatIndiquer le type d'état du session bean: stateless, stateful, ou singleton.
- Interfaces commercialesPar défaut, la case No-interface est cochée, donc aucune interface ne sera créée. Cocher les cases des interfaces que vous souhaitez définir et ajuster les noms si nécessaire.Nous vous rappelons que les beans Enterprise d'un WAR (Web Archive) ne supportent qu'EJB 3.1 Lite, et que cela n'inclut pas les interfaces commerciales distantes.
Cliquez sur .Informations spécifiques aux Session Bean
Vous pouvez saisir des informations supplémentaires ici pour personnaliser encore plus le session bean. Vous n'avez pas besoin de changer quoi que ce soit ici.Les items que vous pouvez changer sont :- Nom de bean.
- Nom mappé.
- Type de transaction (géré conteneur ou géré bean).
- On peut fournir des interfaces supplémentaires que le bean doit implémenter.
- Vous pouvez également spécifier des interfaces EJB 2.x Home et Component si nécessaire.
Terminer
Cliquer sur le bouton et le nouveau session bean sera créé, et ajouté au projet. Les fichiers de toute nouvelle interface commerciale seront également créés, s'ils ont été spécifiés.
Figure 7.8. Nouveau Session Bean dans JBoss Developer Studio
7.4. Message-Driven Beans
7.4.1. Message-Driven Beans
7.4.2. Adaptateurs de ressources
7.4.3. Créer un Message-Driven Bean basé JMS dans JBoss Developer Studio
Prérequis :
- Vous devrez avoir un projet existant ouvert dans JBoss Developer Studio.
- Vous devrez connaître le nom et le type de la destination JMS que le bean écoutera.
- Le support pour JMS (Java Messaging Service) doit être autorisé dans la configuration JBoss EAP 6 dans laquelle ce bean sera déployé.
Procédure 7.6. Ajouter un Message-Driven Bean basé JMS dans JBoss Developer Studio.
Ouvrir l'assistant Créer EJB 3.x Message-Driven Bean
Aller à → → . Sélectionner EJB/Message-Driven Bean (EJB 3.x) et cliquer sur le bouton .
Figure 7.9. Créer l'assistant Message-Driven Bean EJB 3.x
Indiquer les détails de la destination de fichier de classe
Il existe trois ensembles de détails à indiquer pour la classe de bean : le Projet, la classe Java et le message de destination.- Projet
- Si plusieurs projets existent dans Espace de travail, assurez-vous que le bon projet est sélectionné dans le menu .
- Le dossier où le fichier source du nouveau bean sera créé est
ejbModulesous le répertoire du projet sélectionné. Ne peut être changé que pour répondre à des cas particuliers.
- Classe Java
- Les champs obligatoires sont les suivants : Package Java et nom de classe.
- Il n'est pas nécessaire de fournir une Superclasse à moins que la logique commerciale de votre application ne l'exige.
- Destination du message
- Voici les informations à fournir pour un Message-Driven Bean basé JMS :
- Nom de Destination. C'est la file d'attente ou le nom du sujet qui contient les messages auxquels le Bean répondra.
- La case JMS est sélectionnée par défaut. Veuillez ne pas la changer.
- Définir Type de destination comme File d'attente ou Sujet tel qu'il vous est demandé.
Cliquer sur le bouton .Saisir les informations spécifiques aux Message-Driven Bean
Les valeurs par défaut sont appropriées pour un Message-Driven Bean basé JMS utilisant des transactions gérées conteneur.- Changer le type de transaction à Bean si le Bean doit utiliser des transactions gérées bean.
- Changer le nom du Bean s'il est demandé un nom de bean différent du nom de classe.
- L'interface JMS Message Listener sera déjà listée. Vous n'aurez pas besoin d'ajouter ou de supprimer des interfaces, à moins qu'elles soient spécifiques à votre logique commerciale d'applications.
- Laisser les cases décochées pour créer les méthodes stub sélectionnées.
Cliquer sur le bouton .
onMessage(). Une fenêtre d'édition de JBoss Developer Studio est apparue avec le fichier correspondant.
7.5. Invoquer les Session Beans
7.5.1. Invoquer un session bean à distance avec JNDI
ejb-remote contient des projets Maven qui démontrent cette fonctionnalité. Le Quickstart contient des projets à la fois pour le déploiement des session beans et pour le client distant. Les exemples de code ci-dessous sont extraits du projet du client distant.
Pré-requis
- Vous devez déjà avoir un projet Maven créé, prêt à l'utilisation.
- La configuration du référentiel JBoss EAP 6 Maven a déjà été ajoutée.
- Les session beans que vous souhaitez invoquer sont déjà déployés.
- Les session beans déployés implémentent les interfaces commerciales éloignées.
- Les interfaces commerciales éloignées des session beans sont disponibles sous forme de dépendance de Maven. Si les interfaces commerciales éloignées ne sont disponibles que sous forme de fichier JAR, alors il est recommandé d'ajouter le JAR à votre référentiel Maven comme un artefact. Reportez-vous à la documentation de Maven pour obtenir des directives
install:install-file, http://maven.apache.org/plugins/maven-install-plugin/usage.html - Vous aurez besoin de connaître le nom d'hôte et le port JNDI du serveur qui hébergent les session beans.
Procédure 7.7. Ajouter une configuration de projet Maven pour l'invocation à distance des session beans
Ajouter les dépendances de projet utiles
Lepom.xmldu projet doit être mis à jour pour pouvoir inclure les dépendances nécessaires.Ajouter le fichier
jboss-ejb-client.propertiesL'API du client JBoss EJB s'attend à trouver un fichier dans le root du projet nomméjboss-ejb-client.propertiesqui contient les informations de connexion aux services JNDI. Ajouter ce fichier au répertoiresrc/main/resources/de votre projet avec le contenu suivant.# In the following line, set SSL_ENABLED to true for SSL remote.connectionprovider.create.options.org.xnio.Options.SSL_ENABLED=false remote.connections=default # Uncomment the following line to set SSL_STARTTLS to true for SSL # remote.connection.default.connect.options.org.xnio.Options.SSL_STARTTLS=true remote.connection.default.host=localhost remote.connection.default.port = 4447 remote.connection.default.connect.options.org.xnio.Options.SASL_POLICY_NOANONYMOUS=false # Add any of the following SASL options if required # remote.connection.default.connect.options.org.xnio.Options.SASL_POLICY_NOANONYMOUS=false # remote.connection.default.connect.options.org.xnio.Options.SASL_POLICY_NOPLAINTEXT=false # remote.connection.default.connect.options.org.xnio.Options.SASL_DISALLOWED_MECHANISMS=JBOSS-LOCAL-USER
Changer le nom d'hôte et le port pour qu'ils correspondent au serveur.4447est le numéro de port par défaut. Pour une connexion sécurisée, définir la ligneSSL_ENABLEDàtrueet dé-commenter la ligneSSL_STARTTLS. L'interface éloignée du conteneur supporte les connexions sécurisées et non sécurisées en utilisant le même port.Ajouter des dépendances aux interfaces commerciales à distance.
Ajouter les dépendances Maven aupom.xmlaux interfaces commerciales éloignées des session beans.<dependency> <groupId>org.jboss.as.quickstarts</groupId> <artifactId>jboss-as-ejb-remote-server-side</artifactId> <type>ejb-client</type> <version>${project.version}</version> </dependency>
Procédure 7.8. Obtenez un Bean Proxy par JNDI et invoquer les méthodes du Bean
Exceptions vérifiées par Handle
Deux des méthodes utilisées dans le code suivant (InitialContext()etlookup()) ont une exception vérifiée du typejavax.naming.NamingException. Ces appels de méthode doivent soit être contenus dans un bloc try/catch qui intercepteNamingExceptionou dans une méthode déclarée pour lancerNamingException. Le Quickstartejb-remoteutilise la seconde technique.Créer un contexte JNDI
Un objet de contexte JNDI fournit le mécanisme pour demander les ressources dans le serveur. Créer un contexte JNDI avec le code suivant :final Hashtable jndiProperties = new Hashtable(); jndiProperties.put(Context.URL_PKG_PREFIXES, "org.jboss.ejb.client.naming"); final Context context = new InitialContext(jndiProperties);
Les propriétés de connexion du service JNDI sont lues à partir du fichierjboss-ejb-client.properties.Utiliser la méthode JNDI Context's lookup() pour obtenir un Bean Proxy
Invoquer le méthodelookup()du bean proxy et lui faire passer le nom JNDI du session bean dont vous avez besoin. Un objet sera renvoyé et il devra correspondre au type de méthode d'interface commerciale qui contient les méthodes que vous souhaitez invoquer.final RemoteCalculator statelessRemoteCalculator = (RemoteCalculator) context.lookup( "ejb:/jboss-as-ejb-remote-server-side/CalculatorBean!" + RemoteCalculator.class.getName());Les noms de session bean JNDI sont définis par une syntaxe particulière. Pour plus d'informations, consulter Section 7.8.1, « Référence de nommage EJB JNDI » .Méthodes d'invocation
Maintenant que vous avez un objet bean proxy, vous pouvez invoquer n'importe quelle méthode qui contient l'interface commerciale distante.int a = 204; int b = 340; System.out.println("Adding " + a + " and " + b + " via the remote stateless calculator deployed on the server"); int sum = statelessRemoteCalculator.add(a, b); System.out.println("Remote calculator returned sum = " + sum);Le proxy bean transmet la demande d'invocation de méthode au bean de session sur le serveur, où elle est exécutée. Le résultat est retourné au proxy bean qui, ensuite, le retourne à l'appelant. La communication entre le proxy bean et le bean de session distant est transparente à l'appelant.
7.5.2. Contextes Client EJB
- Un client à distance, exécuté comme application Java autonome.
- Un client à distance, exécuté dans une autre instance de JBoss EAP 6.
7.5.3. Considérations lors de l'utilisation d'un Contexte EJB Unique
Vous devez considérer les prérequis de votre application lors de l'utilisation d'un contexte client EJB unique avec des clients à distance autonomes. Pour plus d'informations sur les différents types de clients à distance, veuillez consulter : Section 7.5.2, « Contextes Client EJB » .
Un client autonome à distance possède généralement un seul contexte client EJB sauvegardé par n'importe quel nombre de récepteurs EJB. Voici un exemple d'application client à distance autonome :
public class MyApplication {
public static void main(String args[]) {
final javax.naming.Context ctxOne = new javax.naming.InitialContext();
final MyBeanInterface beanOne = ctxOne.lookup("ejb:app/module/distinct/bean!interface");
beanOne.doSomething();
...
}
}
jboss-ejb-client.properties, utilisé pour installer le contexte client EJB et les récepteurs EJB. Cette configuration comprend également les informations de sécurité, qui sont ensuite utilisées pour créer le récepteur EJB qui relie le serveur JBoss EAP 6. Quand le code ci-dessus est invoqué,l'API client EJB recherche le contexte client EJB, qui est ensuite utilisé pour sélectionner le récepteur EJB qui recevra et traitera la requête d'invocation EJB. Dans ce cas, il n'y a que le contexte client EJB unique, donc ce contexte est utilisé par le code ci-dessus pour invoquer le bean. La procédure pour invoquer un bean de session à distance en utilisant JNDI est décrite plus en détails ici : Section 7.5.1, « Invoquer un session bean à distance avec JNDI » .
Une application d'utilisateur pourrait vouloir invoquer un bean plus d'une fois, mais se connecter au serveur JBoss EAp 6 en utilisant différentes informations de sécurité. Voici un exemple d'une application client à distance autonome qui invoque deux fois le même bean :
public class MyApplication {
public static void main(String args[]) {
// Use the "foo" security credential connect to the server and invoke this bean instance
final javax.naming.Context ctxOne = new javax.naming.InitialContext();
final MyBeanInterface beanOne = ctxOne.lookup("ejb:app/module/distinct/bean!interface");
beanOne.doSomething();
...
// Use the "bar" security credential to connect to the server and invoke this bean instance
final javax.naming.Context ctxTwo = new javax.naming.InitialContext();
final MyBeanInterface beanTwo = ctxTwo.lookup("ejb:app/module/distinct/bean!interface");
beanTwo.doSomething();
...
}
}
Les Contextes Client EJB étendus offrent une solution à ce problème. Ils offrent un plus grand contrôle sur les contextes client EJB et leurs contextes JNDI associés, qui sont généralement utilisés pour les invocations EJB. Pour plus d'informations sur les Contextes Client EJB de l'étendue, veuillez consulter Section 7.5.4, « Utiliser des Contextes Client EJB étendus » et Section 7.5.5, « Configurer les EJB en utilisant un Contexte Client EJB Scoped » .
7.5.4. Utiliser des Contextes Client EJB étendus
Pour invoquer un EJB dans les versions antérieures de JBoss EAP 6, il faut généralement créer un contexte JNDI et lui passer le PROVIDER_URL, qui indique le serveur de cible. Toute invocation faite sur les proxys EJB recherchées en utilisant ce contexte JNDI finiraient sur ce serveur. Avec les contextes client EJB étendus, les applications utilisateur contrôlent quel récepteur EJB est utilisé pour une invocation spécifique.
Avant l'introduction des contextes client EJB étendus, le contexte était généralement étendu à l'application client. Les contextes client étendus autorisent maintenant les contextes client EJB à être étendus avec les contextes JNDI. Voici un exemple d'une application client autonome à distance qui invoque le même bean deux fois en utilisant un contexte client EJB étendu.
public class MyApplication {
public static void main(String args[]) {
// Use the "foo" security credential connect to the server and invoke this bean instance
final Properties ejbClientContextPropsOne = getPropsForEJBClientContextOne():
final javax.naming.Context ctxOne = new javax.naming.InitialContext(ejbClientContextPropsOne);
final MyBeanInterface beanOne = ctxOne.lookup("ejb:app/module/distinct/bean!interface");
beanOne.doSomething();
...
ctxOne.close();
// Use the "bar" security credential to connect to the server and invoke this bean instance
final Properties ejbClientContextPropsTwo = getPropsForEJBClientContextTwo():
final javax.naming.Context ctxTwo = new javax.naming.InitialContext(ejbClientContextPropsTwo);
final MyBeanInterface beanTwo = ctxTwo.lookup("ejb:app/module/distinct/bean!interface");
beanTwo.doSomething();
...
ctxTwo.close();
}
}
jboss-ejb-client.properties. Pour étendre le contexte client EJB au contexte JNDI, il faut également indiquer la propriété org.jboss.ejb.client.scoped.context et définir sa valeur sur true. Cette propriété notifie à l'API client EJB qu'il doit créer un contexte client EJB, sauvegardé par des récepteurs EJB, et que le contexte créé doit ensuite être étendu ou visible uniquement au contexte JNDI qui l'a créé. Tout proxy EJB recherché ou invoqué en utilisant ce contexte JNDI ne connaîtra que le contexte client EJB associé à ce contexte JNDI. Les autres contextes JNDI utilisés par l'application pour rechercher ou invoquer des EJB ne reconnaîtra pas les autres contextes client EJB étendus.
org.jboss.ejb.client.scoped.context et ne sont pas étendus vers un contexte client EJB, utiliseront le comportement par défaut, qui utilise le contexte client EJB existant normalement attaché à l'application entière.
Note
InitialContext lorsqu'il n'est plus utile. Lorsque l'InitialContext est fermé, les ressources sont libérées immédiatement. Les proxys qui y sont liés ne sont plus valides et tout invocation soulèvera une exception. Une mauvaise fermeture du InitialContext peut entraîner les problèmes de ressource ou de performance.
7.5.5. Configurer les EJB en utilisant un Contexte Client EJB Scoped
Les EJB peuvent être configurés en utilisant un contexte scoped basé mappe. Cela est possible en complétant par programmation une mappe Properties en utilisant les propriétés standards trouvées dans jboss-ejb-client.properties, en indiquant true pour la propriété org.jboss.ejb.client.scoped.context, et en passant les propriétés sur la création InitialContext.
Procédure 7.9. Configurer un EJB en utilisant un contexte scoped basé mappage
Configurer les propriétés
Configurer les propriétés client EJB par programmation, en indiquant le même ensemble de propriétés utilisées dans le fichierjboss-ejb-client.propertiesstandard. Pour activer le contexte étendu, vous devez indiquer la propriétéorg.jboss.ejb.client.scoped.contextet configurer sa valeur commetrue. Voici un exemple de configuration des propriétés par programmation :// Configure EJB Client properties for the InitialContext Properties ejbClientContextProps = new Properties(); ejbClientContextProps.put(“remote.connections”,”name1”); ejbClientContextProps.put(“remote.connection.name1.host”,”localhost”); ejbClientContextProps.put(“remote.connection.name1.port”,”4447”); // Property to enable scoped EJB client context which will be tied to the JNDI context ejbClientContextProps.put("org.jboss.ejb.client.scoped.context", “true”);Passer les propriétés en création de contexte
// Create the context using the configured properties InitialContext ic = new InitialContext(ejbClientContextProps); MySLSB bean = ic.lookup("ejb:myapp/ejb//MySLSBBean!" + MySLSB.class.getName());
- Les contextes générés par les proxys EJB de recherche sont liés par ce contexte étendu et n'utilisent que les paramètres de connexion appropriés. Cela permet de créer différents contextes pour accéder aux données au sein d'une application client ou pour accéder aux serveurs de manière indépendante en utilisant différents logins.
- Dans le client, le
InitialContextétendu et le proxy étendu sont tous les deux transférés vers les threads, permettant à chaque thread de fonctionner avec le contexte donné. Il est également possible de transférer le proxy vers de multiples threads qui peuvent l'utiliser simultanément. - Le contexte étendu proxy EJB est sérialisé sur l'appel distant, puis désérialisé sur le serveur. Lorsqu'il est désérialisé, les informations de contexte étendu sont supprimées et il retourne à son état par défaut. Si le proxy désérialisé est utilisé sur le serveur distant, c-a-d s'il n'a plus le contexte étendu utilisé lors de sa création, cela peut provoquer une erreur
EJBCLIENT000025ou éventuellement appeler une cible indésirable en utilisant le nom de l'EJB.
7.5.6. Propriétés Client EJB
Les tableaux suivants énumèrent les propriétés pouvant être configurées par programmation ou dans le fichier jboss-ejb-client.properties.
Le tableau suivant énumère les propriétés valides pour la bibliothèque entière au sein de la même étendue.
Tableau 7.1. Propriétés globales
| Nom de propriété | Description |
|---|---|
endpoint.name |
Nom du point de terminaison du client. Si pas configuré, sa valeur par défaut sera
client-endpoint.
Cela peut s'avérer utile pour distinguer différentes configurations de point de terminaison puisque le nom de thread comprend cette propriété.
|
remote.connectionprovider.create.options.org.xnio.Options.SSL_ENABLED |
Valeur booléenne qui indique si le protocole SSL est activé pour toutes les connexions.
|
deployment.node.selector |
Nom complet de l'implémentation de
org.jboss.ejb.client.DeploymentNodeSelector.
Ceci est utilisé pour équilibrer les charges de l'invocation des EJB.
|
invocation.timeout |
Délai pour la liaison EJB ou le cycle requête/réponse de l'invocation de la méthode. Valeur exprimée en millisecondes.
L'invocation de toute méthode lève une
java.util.concurrent.TimeoutException si l'exécution prend plus de temps que la période de délai. L'exécution se termine et le serveur n'est pas interrompu.
|
reconnect.tasks.timeout |
Délai des tâches de reconnexion de l'arrière-plan. Valeur exprimée en millisecondes.
Si des connexions sont éteintes, la prochaine invocation EJB de client utilisera un algorithme pour décider si une reconnexion est nécessaire pour trouver le bon nœud.
|
org.jboss.ejb.client.scoped.context |
Valeur booléenne indiquant s'il faut activer le contexte client EJB d'étendue. La valeur par défaut est
false.
Si défini comme
true, le client EJB utilisera le contexte étendu lié au contexte JNDI. Sinon, le contexte de client EJB utilisera la sélecteur global dans le JVM pour déterminer les propriétés utilisées pour appeler l'hôte et l'EJB à distance.
|
Les propriétés de connexion commencent par le préfixe remote.connection.CONNECTION_NAME où le CONNECTION_NAME est un identifiant local utilisé uniquement pour identifier la connexion de manière exclusive.
Tableau 7.2. Propriétés de connexion
| Nom de propriété | Description |
|---|---|
remote.connections |
Liste de
connection-names actifs séparés par des virgules. Chaque connexion est configurée sous ce nom.
|
|
Nom d'hôte ou IP de cette connexion
|
|
Port de la connexion. La valeur par défaut est 4447.
|
|
Nom d'utilisateur utilisé pour authentifier la sécurité de connexion.
|
|
Mot de passe utilisé pour authentifier l'utilisateur.
|
|
Période de délai de la connexion initiale. Après cela, la tâche de reconnexion vérifiera périodiquement si la connexion peut être établie. Valeur exprimée en millisecondes.
|
|
Nom complet de la classe
CallbackHandler. Sera utilisé pour établir la connexion et ne peut être changé tant que la connexion sera ouverte.
|
channel.options.org.jboss.remoting3.RemotingOptions.MAX_OUTBOUND_MESSAGES
|
Valeur entière indiquant le nombre maximale de requêtes sortantes. La valeur par défaut est 80.
Il n'y a qu'une connexion entre le client (JVM) et le serveur pour gérer les invocations.
|
connect.options.org.xnio.Options.SASL_POLICY_NOANONYMOUS
|
Valeur booléenne déterminant si les identifiants doivent être fournis par le client pour réussir la connexion. La valeur par défaut est
true.
Si défini comme
true, le client doit fournir les identifiants. Si défini comme false, l'invocation est autorisée tant que le connecteur à distance ne demande pas un domaine de sécurité.
|
connect.options.org.xnio.Options.SASL_DISALLOWED_MECHANISMS
|
Désactive certains mécanismes SASL utilisés pour l'authentification pendant la création de la connexion.
JBOSS_LOCAL_USER signifie que le mécanisme d'authentification silencieuse, utilisé lorsque le client et le serveur sont sur la même machine, est désactivé.
|
connect.options.org.xnio.Options.SASL_POLICY_NOPLAINTEXT
|
Valeur booléenne qui active ou désactive l'utilisation de messages de texte brut pendant l'authentification. Si JAAS est utilisé, il doit être défini comme « false » pour autoriser un mot de passe de texte brut.
|
connect.options.org.xnio.Options.SSL_ENABLED
|
Valeur booléenne indiquant si le protocole SSL est activé pour cette connexion.
|
connect.options.org.jboss.remoting3.RemotingOptions.HEARTBEAT_INTERVAL
|
Intervalle pour envoyer une pulsation entre le client et le serveur afin de prévenir les fermetures automatiques, dans le cas d'un pare-feu par exemple. Valeur exprimée en millisecondes.
|
Si la connexion initiale se connecte à un environnement clusterisé, la topologie du cluster est reçue de manière automatique et asynchrone. Ces propriétés sont utilisées pour se connecter à chaque membre reçu. Chaque propriété commence avec le préfixe remote.cluster.CLUSTER_NAME où le CLUSTER_NAME se réfère à la configuration du sous-système Infinispan du serveur associé.
Tableau 7.3. Propriétés de Cluster
| Nom de propriété | Description |
|---|---|
clusternode.selector
|
Le nom complet de l'implémentation de
org.jboss.ejb.client.ClusterNodeSelector.
Cette classe, plutôt que
org.jboss.ejb.clientDeploymentNodeSelector, est utilisée pour équilibrer la charge des invocations EJB dans un environnement clusterisé. Si le cluster est complètement arrêté, l'invocation échouera avec comme message No ejb receiver available.
|
channel.options.org.jboss.remoting3.RemotingOptions.MAX_OUTBOUND_MESSAGES
|
Valeur entière indiquant le nombre maximale de requêtes sortantes pouvant être faites au cluster entier.
|
node.NODE_NAME. channel.options.org.jboss.remoting3.RemotingOptions.MAX_OUTBOUND_MESSAGES
|
Valeur entière indiquant le nombre maximale de requêtes sortantes pouvant être faites à ce nœud de cluster spécifique.
|
7.6. Intercepteurs de conteneurs
7.6.1. Intercepteurs de conteneurs
ejb-jar.xml pour la version 3.1 du descripteur de déploiement ejb-jar.
Les intercepteurs de conteneur configurés pour un EJB sont garantis d'être exécutés avant que le JBoss EAP 6.1 ne fournisse des intercepteurs de sécurité, des intercepteurs de gestion de transaction ou autres intercepteurs fournis par le serveur. Cela permet aux intercepteurs de conteneurs spécifiques à l'application de traiter ou de configurer des données de contexte pertinentes avant l'invocation.
Bien que les intercepteurs de conteneur soient modélisés pour pouvoir ressembler aux intercepteurs de Java EE, il y a quelques différences dans la sémantique de l'API. Par exemple, il est illégal pour les intercepteurs de conteneur d'invoquer la méthode javax.interceptor.InvocationContext.getTarget() parce que ces intercepteurs sont invoqués bien avant que les composants EJB ne soient configurés ou instanciés.
7.6.2. Créer une classe d'intercepteur de conteneur
Les classes d'intercepteur de conteneur sont de simples POJO (Plain Old Java Objects). Ils utilisent @javax.annotation.AroundInvoke pour marquer la méthode qui devra être invoquée lors de l'invocation du bean.
iAmAround de l'invocation :
Exemple 7.1. Exemple de Classe d'intercepteur de Conteneur
public class ClassLevelContainerInterceptor {
@AroundInvoke
private Object iAmAround(final InvocationContext invocationContext) throws Exception {
return this.getClass().getName() + " " + invocationContext.proceed();
}
}
jboss-ejb3.xml ici: Section 7.6.3, « Configurer un intercepteur de conteneur ».
7.6.3. Configurer un intercepteur de conteneur
Les intercepteurs de conteneurs utilisent les bibliothèques d'intercepteur J2EE standard, ce qui signifie qu'ils utilisent les mêmes éléments XSD que ceux qui sont autorisés dans le fichier ejb-jar.xml pour la version 3.1 du descripteur de déploiement ejb-jar. Comme ils se reposent sur les bibliothèques standard d'interceptor Jave EE, les intercepteurs de conteneur peuvent uniquement être configurés à l'aide de descripteurs de déploiement. Cela a été conçu pour que les applications n'exigent pas une annotation spécifique de JBoss ou autre dépendance de bibliothèque. Pour plus d'informations sur les intercepteurs de conteneur, voir : Section 7.6.1, « Intercepteurs de conteneurs ».
Procédure 7.10. Créer le fichier de descripteur pour configurer l'intercepteur de conteneur
- Créer un fichier
jboss-ejb3.xmldans le répertoireMETA-INFdu déploiement EJB. - Configurer les éléments de l'intercepteur du conteneur dans le fichier du descripteur.
- Utiliser l'espace-nom
urn:container-interceptors:1.0pour indiquer la configuration des éléments de l'intercepteur du conteneur. - Utiliser l'élément
<container-interceptors>pour indiquer les intercepteurs du conteneur. - Utiliser les éléments
<interceptor-binding>pour relier l'intercepteur du conteneur aux EJB. Les intercepteurs peuvent être reliés d'une des manières suivantes :- Relier l'intercepteur à tous les EJB du déploiement par le caractère générique
*. - Relier l'intercepteur au niveau bean individuel par le nom spécifique de l'EJB.
- Relier l'intercepteur au niveau de méthode spécifique des EJB.
Note
Ces éléments sont configurés par EJB 3.1 XSD de la même façon que pour les intercepteurs Java EE.
- Vérifier les exemples d'éléments ci-dessus dans le fichier de descripteur suivant.
Exemple 7.2. jboss-ejb3.xml
<jboss xmlns="http://www.jboss.com/xml/ns/javaee" xmlns:jee="http://java.sun.com/xml/ns/javaee" xmlns:ci ="urn:container-interceptors:1.0"> <jee:assembly-descriptor> <ci:container-interceptors> <!-- Default interceptor --> <jee:interceptor-binding> <ejb-name>*</ejb-name> <interceptor-class>org.jboss.as.test.integration.ejb.container.interceptor.ContainerInterceptorOne</interceptor-class> </jee:interceptor-binding> <!-- Class level container-interceptor --> <jee:interceptor-binding> <ejb-name>AnotherFlowTrackingBean</ejb-name> <interceptor-class>org.jboss.as.test.integration.ejb.container.interceptor.ClassLevelContainerInterceptor</interceptor-class> </jee:interceptor-binding> <!-- Method specific container-interceptor --> <jee:interceptor-binding> <ejb-name>AnotherFlowTrackingBean</ejb-name> <interceptor-class>org.jboss.as.test.integration.ejb.container.interceptor.MethodSpecificContainerInterceptor</interceptor-class> <method> <method-name>echoWithMethodSpecificContainerInterceptor</method-name> </method> </jee:interceptor-binding> <!-- container interceptors in a specific order --> <jee:interceptor-binding> <ejb-name>AnotherFlowTrackingBean</ejb-name> <interceptor-order> <interceptor-class>org.jboss.as.test.integration.ejb.container.interceptor.ClassLevelContainerInterceptor</interceptor-class> <interceptor-class>org.jboss.as.test.integration.ejb.container.interceptor.MethodSpecificContainerInterceptor</interceptor-class> <interceptor-class>org.jboss.as.test.integration.ejb.container.interceptor.ContainerInterceptorOne</interceptor-class> </interceptor-order> <method> <method-name>echoInSpecificOrderOfContainerInterceptors</method-name> </method> </jee:interceptor-binding> </ci:container-interceptors> </jee:assembly-descriptor> </jboss>L'XSD de l'espace-nomurn:container-interceptors:1.0se trouve dansEAP_HOME/docs/schema/jboss-ejb-container-interceptors_1_0.xsd.
7.6.4. Modifier l'identité du contexte de sécurité
Par défaut, lorsque vous effectuez un appel distant à un EJB déployé sur le serveur d'applications, la connexion au serveur est authentifiée et toute demande reçue via cette connexion sera exécutée tant qu'identité qui a authentifié la connexion. Cela est vrai pour les appels client-serveur et serveur-serveur. Si vous avez besoin d'utiliser différentes identités de la part d'un même client, vous devrez normalement ouvrir des connexions multiples au serveur afin que chacune d'entre elles soient authentifiée en tant qu'identité différente. Plutôt que d'ouvrir plusieurs connexions de client, vous pouvez donner l'autorisation à l'utilisateur authentifié d'exécuter une requête sous un nom différent.
ejb-security-interceptors pour obtenir un exemple complet. Les exemples de code suivants sont des versions abrégées du code du Quickstart.
Procédure 7.11. Modifier l'identité du contexte de sécurité
Créer l'intercepteur côté client
Cet intercepteur doit implémenterorg.jboss.ejb.client.EJBClientInterceptor. L'intercepteur doit passer l'identité requise par le mappage de données contextuelles, par l'intermédiaire d'un appelEJBClientInvocationContext.getContextData(). Voici un exemple de code d'intercepteur côté client :public class ClientSecurityInterceptor implements EJBClientInterceptor { public void handleInvocation(EJBClientInvocationContext context) throws Exception { Principal currentPrincipal = SecurityActions.securityContextGetPrincipal(); if (currentPrincipal != null) { Map<String, Object> contextData = context.getContextData(); contextData.put(ServerSecurityInterceptor.DELEGATED_USER_KEY, currentPrincipal.getName()); } context.sendRequest(); } public Object handleInvocationResult(EJBClientInvocationContext context) throws Exception { return context.getResult(); } }Les applications utilisateur peuvent alors se connecter à l'intercepteur dans leEJBClientContextpar l'un des moyens suivants :Par programmation
Par cette approche, vous appelez l'APIorg.jboss.ejb.client.EJBClientContext.registerInterceptor(int order, EJBClientInterceptor interceptor)et passezorderet l'instanceinterceptor. Leorderest utilisé pour déterminer où exactement cetinterceptorest placé dans la chaîne d'intercepteur du client.Mécanisme ServiceLoader
Cette approche nécessite la création d'un fichierMETA-INF/services/org.jboss.ejb.client.EJBClientInterceptoret le placer ou le conditionneur dans le chemin de classe de l'application client. Les règles du fichier sont dictées par le Java ServiceLoader Mechanism. Ce fichier devrait contenir, dans chaque ligne distincte, le nom de classe qualifié complet de l'implémentation d'intercepteur de client EJB. Les classes d'intercepteur de client EJB doivent être disponibles dans le chemin de classe. Les intercepteurs de client EJB ajoutés en utilisant le mécanisme deServiceLoadersont ajoutés à la fin de la chaîne d'intercepteur de client, dans l'ordre dans lequel ils se trouvent dans le chemin de classe (classpath). Le démarrage rapide ou quickstartejb-security-interceptorsutilise cette approche.
Créer et configurer l'intercepteur du conteneur côté serveur
Les classes d'intercepteur de conteneur sont de simples Plain Old Java Objects (POJOs). Elles utilisent@javax.annotation.AroundInvokepour marquer la méthode qui sera invoquée lors de l'invocation sur le bean. Pour plus d'informations sur les intercepteurs de conteneur, consulter : Section 7.6.1, « Intercepteurs de conteneurs ».Créer l'intercepteur de conteneur
Cet intercepteur reçoit leInvocationContexten même temps que l'identité et demande le changement. Ce qui suit est une version modifiée de l'exemple de code :public class ServerSecurityInterceptor { private static final Logger logger = Logger.getLogger(ServerSecurityInterceptor.class); static final String DELEGATED_USER_KEY = ServerSecurityInterceptor.class.getName() + ".DelegationUser"; @AroundInvoke public Object aroundInvoke(final InvocationContext invocationContext) throws Exception { Principal desiredUser = null; RealmUser connectionUser = null; Map<String, Object> contextData = invocationContext.getContextData(); if (contextData.containsKey(DELEGATED_USER_KEY)) { desiredUser = new SimplePrincipal((String) contextData.get(DELEGATED_USER_KEY)); Connection con = SecurityActions.remotingContextGetConnection(); if (con != null) { UserInfo userInfo = con.getUserInfo(); if (userInfo instanceof SubjectUserInfo) { SubjectUserInfo sinfo = (SubjectUserInfo) userInfo; for (Principal current : sinfo.getPrincipals()) { if (current instanceof RealmUser) { connectionUser = (RealmUser) current; break; } } } } else { throw new IllegalStateException("Delegation user requested but no user on connection found."); } } SecurityContext cachedSecurityContext = null; boolean contextSet = false; try { if (desiredUser != null && connectionUser != null && (desiredUser.getName().equals(connectionUser.getName()) == false)) { // The final part of this check is to verify that the change does actually indicate a change in user. try { // We have been requested to switch user and have successfully identified the user from the connection // so now we attempt the switch. cachedSecurityContext = SecurityActions.securityContextSetPrincipalInfo(desiredUser, new OuterUserCredential(connectionUser)); // keep track that we switched the security context contextSet = true; SecurityActions.remotingContextClear(); } catch (Exception e) { logger.error("Failed to switch security context for user", e); // Don't propagate the exception stacktrace back to the client for security reasons throw new EJBAccessException("Unable to attempt switching of user."); } } return invocationContext.proceed(); } finally { // switch back to original security context if (contextSet) { SecurityActions.securityContextSet(cachedSecurityContext); } } } }Note
L'exemple de code ci-dessus utilise deux classes, org.jboss.as.controller.security.SubjectUserInfo et org.jboss.as.domain.management.security.RealmUser, qui font partie de l'API privée de JBoss EAP. Une API publique deviendra disponible dans la version EAP 6.3 et les classes privées seront obsolètes, mais ces classes seront entretenues et rendues disponible pendant toute la durée du cycle de version EAP 6.x.Configurer l'intercepteur de conteneur
Pour plus d'informations sur la façon de configurer les intercepteurs de conteneurs côté serveur, consulter : Section 7.6.3, « Configurer un intercepteur de conteneur ».
JAAS LoginModule
Ce composant doit vérifier que l'utilisateur est en mesure d'exécuter les requêtes suivant l'identité de la requête. Les exemples de code suivants indiquent les méthodes de login et de validation :@SuppressWarnings("unchecked") @Override public boolean login() throws LoginException { if (super.login() == true) { log.debug("super.login()==true"); return true; } // Time to see if this is a delegation request. NameCallback ncb = new NameCallback("Username:"); ObjectCallback ocb = new ObjectCallback("Password:"); try { callbackHandler.handle(new Callback[] { ncb, ocb }); } catch (Exception e) { if (e instanceof RuntimeException) { throw (RuntimeException) e; } return false; // If the CallbackHandler can not handle the required callbacks then no chance. } String name = ncb.getName(); Object credential = ocb.getCredential(); if (credential instanceof OuterUserCredential) { // This credential type will only be seen for a delegation request, if not seen then the request is not for us. if (delegationAcceptable(name, (OuterUserCredential) credential)) { identity = new SimplePrincipal(name); if (getUseFirstPass()) { String userName = identity.getName(); if (log.isDebugEnabled()) log.debug("Storing username '" + userName + "' and empty password"); // Add the username and an empty password to the shared state map sharedState.put("javax.security.auth.login.name", identity); sharedState.put("javax.security.auth.login.password", ""); } loginOk = true; return true; } } return false; // Attempted login but not successful. }protected boolean delegationAcceptable(String requestedUser, OuterUserCredential connectionUser) { if (delegationMappings == null) { return false; } String[] allowedMappings = loadPropertyValue(connectionUser.getName(), connectionUser.getRealm()); if (allowedMappings.length == 1 && "*".equals(allowedMappings[1])) { // A wild card mapping was found. return true; } for (String current : allowedMappings) { if (requestedUser.equals(current)) { return true; } } return false; }
README pour obtenir des instructions complètes et des informations détaillées sur le code.
7.6.5. Sécurité supplémentaire pour l'authentification EJB
Par défaut, lorsque vous effectuez un appel distant à un EJB déployé sur le serveur d'applications, la connexion au serveur est authentifiée et toute demande reçue via cette connexion est exécutée en utilisant les informations d'identification qui ont authentifié la connexion. L'authentification au niveau de la connexion dépend des capacités des mécanismes sous-jacents SASL (Simple Authentication and Security Layer). Plutôt que d'écrire des mécanismes SASL personnalisés, vous pouvez ouvrir et authentifier une connexion au serveur, puis plus tard ajouter les jetons de sécurité supplémentaires avant d'appeler un EJB. Cette rubrique décrit comment passer des informations supplémentaires sur la connexion existante du client pour l'authentification de l'EJB.
Procédure 7.12. Information de sécurité pour l'authentification EJB
Créer l'intercepteur côté client
Cet intercepteur doit implémenterorg.jboss.ejb.client.EJBClientInterceptor. L'intercepteur doit passer le token de sécurité supplémentaire par le mappage de données contextuelles, par l'intermédiaire d'un appelEJBClientInvocationContext.getContextData(). Voici un exemple de code d'intercepteur côté client qui crée un token de sécurité supplémentaire :public class ClientSecurityInterceptor implements EJBClientInterceptor { public void handleInvocation(EJBClientInvocationContext context) throws Exception { Object credential = SecurityActions.securityContextGetCredential(); if (credential != null && credential instanceof PasswordPlusCredential) { PasswordPlusCredential ppCredential = (PasswordPlusCredential) credential; Map<String, Object> contextData = context.getContextData(); contextData.put(ServerSecurityInterceptor.SECURITY_TOKEN_KEY, ppCredential.getAuthToken()); } context.sendRequest(); } public Object handleInvocationResult(EJBClientInvocationContext context) throws Exception { return context.getResult(); } }Pour obtenir des informations sur la façon de connecter l'intercepteur client dans une application, voir Section 7.6.6, « Utiliser un intercepteur côté client dans une application ».Créer et configurer l'intercepteur du conteneur côté serveur
Les classes d'intercepteur de conteneur sont de simples Plain Old Java Objects (POJOs). Elles utilisent@javax.annotation.AroundInvokepour marquer la méthode qui est invoquée lors de l'invocation sur le bean. Pour plus d'informations sur les intercepteurs de conteneur, consulter : Section 7.6.1, « Intercepteurs de conteneurs ».Créer l'intercepteur de conteneur
Cet intercepteur récupère le jeton d'authentification de sécurité du contexte et le passe au domaine JAAS (Java Authentication and Autorisation Service) pour vérification. Voici un exemple de code d'intercepteur de conteneur :public class ServerSecurityInterceptor { private static final Logger logger = Logger.getLogger(ServerSecurityInterceptor.class); static final String SECURITY_TOKEN_KEY = ServerSecurityInterceptor.class.getName() + ".SecurityToken"; @AroundInvoke public Object aroundInvoke(final InvocationContext invocationContext) throws Exception { Principal userPrincipal = null; RealmUser connectionUser = null; String authToken = null; Map<String, Object> contextData = invocationContext.getContextData(); if (contextData.containsKey(SECURITY_TOKEN_KEY)) { authToken = (String) contextData.get(SECURITY_TOKEN_KEY); Connection con = SecurityActions.remotingContextGetConnection(); if (con != null) { UserInfo userInfo = con.getUserInfo(); if (userInfo instanceof SubjectUserInfo) { SubjectUserInfo sinfo = (SubjectUserInfo) userInfo; for (Principal current : sinfo.getPrincipals()) { if (current instanceof RealmUser) { connectionUser = (RealmUser) current; break; } } } userPrincipal = new SimplePrincipal(connectionUser.getName()); } else { throw new IllegalStateException("Token authentication requested but no user on connection found."); } } SecurityContext cachedSecurityContext = null; boolean contextSet = false; try { if (userPrincipal != null && connectionUser != null && authToken != null) { try { // We have been requested to use an authentication token // so now we attempt the switch. cachedSecurityContext = SecurityActions.securityContextSetPrincipalCredential(userPrincipal, new OuterUserPlusCredential(connectionUser, authToken)); // keep track that we switched the security context contextSet = true; SecurityActions.remotingContextClear(); } catch (Exception e) { logger.error("Failed to switch security context for user", e); // Don't propagate the exception stacktrace back to the client for security reasons throw new EJBAccessException("Unable to attempt switching of user."); } } return invocationContext.proceed(); } finally { // switch back to original security context if (contextSet) { SecurityActions.securityContextSet(cachedSecurityContext); } } } }Note
L'exemple de code ci-dessus utilise deux classes, org.jboss.as.controller.security.SubjectUserInfo et org.jboss.as.domain.management.security.RealmUser, qui font partie de l'API privée de JBoss EAP. Une API publique sera rendue disponible dans la version EAP 6.3 et les classes privées seront obsolètes, mais ces classes seront entretenues et rendues disponible pendant toute la durée du cycle de version EAP 6.x.Configurer l'intercepteur du conteneur
Pour plus d'informations sur la façon de configurer les intercepteurs de conteneurs côté serveur, consulter: Section 7.6.3, « Configurer un intercepteur de conteneur ».
Créer le JAAS LoginModule
Ce module personnalisé exécute l'authentification à l'aide de l'information de la connexion authentifiée existante ainsi qu'à l'aide qu'un jeton de sécurité supplémentaire. Voici un exemple de code qui utilise le jeton de sécurité supplémentaire et qui exécute l'authentification :public class SaslPlusLoginModule extends AbstractServerLoginModule { private static final String ADDITIONAL_SECRET_PROPERTIES = "additionalSecretProperties"; private static final String DEFAULT_AS_PROPERTIES = "additional-secret.properties"; private Properties additionalSecrets; private Principal identity; @Override public void initialize(Subject subject, CallbackHandler callbackHandler, Map<String, ?> sharedState, Map<String, ?> options) { addValidOptions(new String[] { ADDITIONAL_SECRET_PROPERTIES }); super.initialize(subject, callbackHandler, sharedState, options); // Load the properties that contain the additional security tokens String propertiesName; if (options.containsKey(ADDITIONAL_SECRET_PROPERTIES)) { propertiesName = (String) options.get(ADDITIONAL_SECRET_PROPERTIES); } else { propertiesName = DEFAULT_AS_PROPERTIES; } try { additionalSecrets = SecurityActions.loadProperties(propertiesName); } catch (IOException e) { throw new IllegalArgumentException(String.format("Unable to load properties '%s'", propertiesName), e); } } @Override public boolean login() throws LoginException { if (super.login() == true) { log.debug("super.login()==true"); return true; } // Time to see if this is a delegation request. NameCallback ncb = new NameCallback("Username:"); ObjectCallback ocb = new ObjectCallback("Password:"); try { callbackHandler.handle(new Callback[] { ncb, ocb }); } catch (Exception e) { if (e instanceof RuntimeException) { throw (RuntimeException) e; } return false; // If the CallbackHandler can not handle the required callbacks then no chance. } String name = ncb.getName(); Object credential = ocb.getCredential(); if (credential instanceof OuterUserPlusCredential) { OuterUserPlusCredential oupc = (OuterUserPlusCredential) credential; if (verify(name, oupc.getName(), oupc.getAuthToken())) { identity = new SimplePrincipal(name); if (getUseFirstPass()) { String userName = identity.getName(); if (log.isDebugEnabled()) log.debug("Storing username '" + userName + "' and empty password"); // Add the username and an empty password to the shared state map sharedState.put("javax.security.auth.login.name", identity); sharedState.put("javax.security.auth.login.password", oupc); } loginOk = true; return true; } } return false; // Attempted login but not successful. } private boolean verify(final String authName, final String connectionUser, final String authToken) { // For the purpose of this quick start we are not supporting switching users, this login module is validation an // additional security token for a user that has already passed the sasl process. return authName.equals(connectionUser) && authToken.equals(additionalSecrets.getProperty(authName)); } @Override protected Principal getIdentity() { return identity; } @Override protected Group[] getRoleSets() throws LoginException { Group roles = new SimpleGroup("Roles"); Group callerPrincipal = new SimpleGroup("CallerPrincipal"); Group[] groups = { roles, callerPrincipal }; callerPrincipal.addMember(getIdentity()); return groups; } }Ajouter le LoginModule personnalisé à la chaîne
Vous devez ajouter le nouveau LoginModule personnalisé à l'endroit qui convient dans la chaîne pour qu'il soit invoqué dans le bon ordre. Dans cet exemple, leSaslPlusLoginModuledoit être mis dans la chaîne avant le LoginModule qui charge les rôles par l'optionpassword-stacking.Configurer l'ordonnancement du LoginModule par le Management CLI
Ce qui suit est un exemple de commandes de Management CLI qui enchaînent leSaslPlusLoginModulepersonnalisé avant le LoginModuleRealmDirectqui définit l'optionpassword-stacking.
Pour plus d'informations sur le Management CLI, voir le chapitre intitulé Management Interfaces du guide Administration and Configuration Guide de JBoss EAP 6 qui se trouve sur le Portail Clients https://access.redhat.com/site/documentation/JBoss_Enterprise_Application_Platform/[standalone@localhost:9999 /] ./subsystem=security/security-domain=quickstart-domain:add(cache-type=default)[standalone@localhost:9999 /] ./subsystem=security/security-domain=quickstart-domain/authentication=classic:add[standalone@localhost:9999 /] ./subsystem=security/security-domain=quickstart-domain/authentication=classic/login-module=DelegationLoginModule:add(code=org.jboss.as.quickstarts.ejb_security_plus.SaslPlusLoginModule,flag=optional,module-options={password-stacking=useFirstPass})[standalone@localhost:9999 /] ./subsystem=security/security-domain=quickstart-domain/authentication=classic/login-module=RealmDirect:add(code=RealmDirect,flag=required,module-options={password-stacking=useFirstPass})Configurer l'ordonnancement du LoginModule manuellement
Ce qui suit est un exemple de XML qui configure l'ordonnancement du LoginModule dans le sous-système desecuritydu fichier de configuration du serveur. LeSaslPlusLoginModuledoit précéder le LoginModuleRealmDirectpour qu'il puisse vérifier l'utilisateur distant avant que les rôles utilisateurs ne soient chargés et l'optionpassword-stackingdéfinie.<security-domain name="quickstart-domain" cache-type="default"> <authentication> <login-module code="org.jboss.as.quickstarts.ejb_security_plus.SaslPlusLoginModule" flag="required"> <module-option name="password-stacking" value="useFirstPass"/> </login-module> <login-module code="RealmDirect" flag="required"> <module-option name="password-stacking" value="useFirstPass"/> </login-module> </authentication> </security-domain>
Créer le client distant
Dans l'exemple de code suivant, on assume que le fichieradditional-secret.propertiesauquel accède le JAAS LoginModule ci-dessus contient la propriété suivante :quickstartUser=7f5cc521-5061-4a5b-b814-bdc37f021acc
Le code suivant montre comment créer un token de sécurité et comment le définir avant l'appel EJB. Le token secret est codé en dur dans des buts de démonstration uniquement. Ce client se contente d'afficher les résultats sur la console.import static org.jboss.as.quickstarts.ejb_security_plus.EJBUtil.lookupSecuredEJB; public class RemoteClient { /** * @param args */ public static void main(String[] args) throws Exception { SimplePrincipal principal = new SimplePrincipal("quickstartUser"); Object credential = new PasswordPlusCredential("quickstartPwd1!".toCharArray(), "7f5cc521-5061-4a5b-b814-bdc37f021acc"); SecurityActions.securityContextSetPrincipalCredential(principal, credential); SecuredEJBRemote secured = lookupSecuredEJB(); System.out.println(secured.getPrincipalInformation()); } }
7.6.6. Utiliser un intercepteur côté client dans une application
Vous pouvez connecter un intercepteur côté client dans une application par programmation ou en utilisant un mécanisme ServiceLoader. La procédure suivante décrit les deux méthodes.
Procédure 7.13. Connecter l'intercepteur
Par programmation
Par cette approche, vous appelez l'APIorg.jboss.ejb.client.EJBClientContext.registerInterceptor(int order, EJBClientInterceptor interceptor)et passez l'instanceorderet l'instanceinterceptor. L'instanceorderest utilisé pour déterminer où exactement cetinterceptorest placé dans la chaîne d'intercepteur du client.Mécanisme ServiceLoader
Cette approche nécessite la création d'un fichierMETA-INF/services/org.jboss.ejb.client.EJBClientInterceptoret le placer ou le conditionner dans le chemin de classe de l'application client. Les règles du fichier sont dictées par le Java ServiceLoader Mechanism. Ce fichier devrait contenir, dans chaque ligne distincte, le nom de classe qualifié complet de l'implémentation d'intercepteur de client EJB. Les classes d'intercepteur de client EJB doivent être disponibles dans le chemin de classe. Les intercepteurs de client EJB ajoutés en utilisant le mécanisme deServiceLoadersont ajoutés à la fin de la chaîne d'intercepteur de client, dans l'ordre dans lequel ils se trouvent dans le chemin de classe.
7.7. JavaBeans Enterprise clusterisés
7.7.1. JavaBeans clusterisées (EJB)
Note
7.8. Référence
7.8.1. Référence de nommage EJB JNDI
ejb:<appName>/<moduleName>/<distinctName>/<beanName>!<viewClassName>?stateful
<appName>- Si le fichier JAR du session bean a été déployé dans une EAR, alors voici le nom de cette EAR. Par défaut, le nom d'un EAR correspond à son nom de fichier sans le suffixe
.ear. Le nom de l'application peut également être remplacé dans son fichierapplication.xml. Si le bean de session n'est pas déployé dans un EAR, laisser le vide. <moduleName>- Le nom du module correspond au nom du fichier dans lequel le session bean est déployé. Par défaut, le nom du fichier JAR correspond à son nom de fichier sans le suffixe
.jar. Le nom du module peut également être remplacé par leejb-jar.xmldu JAR. <distinctName>- JBoss EAP 6 permet à chaque déploiement de spécifier un nom distinct en option. Si le déploiement n'a pas de nom distinct, laisser le vide.
<beanName>- Le nom du bean est le nom de classe de la session bean à invoquer.
<viewClassName>- Le nom de classe de vue est le nom de classe complet de l'interface distante de l'interface distante. Inclut le nom du package de l'interface.
?stateful- Le suffixe
?statefulest requis quand le nom JNDI se réfère à un bean de session stateful. Non inclus dans d'autres types de bean.
7.8.2. Résolution de référence EJB
@EJB et @Resource. Veuillez noter qu'XML remplace toujours les annotations, mais que les mêmes règles s'appliquent.
Règles pour les annotations @EJB
- L'annotation
@EJBpossède également un attributmappedName(). La spécification le considère comme une métadonnée spécifique au fournisseur tandis que JBoss reconnaitmappedName()en tant que nom JNDI global du EJB que vous référencez. Si vous avez indiqué unmappedName(), alors tous les autres attributs seront ignorés et ce nom JNDI global sera utilisé comme liaison. - Si vous indiquez
@EJBsans attributs définis :@EJB ProcessPayment myEjbref;
Alors les règles suivantes vont s'appliquer :- Le jar EJB du bean de référencement est analysé pour trouver un EJB avec l'interface, utilisée dans l'injection
@EJB. S'il existe plus d'un EJB qui publie la même interface commerciale, alors une exception apparaîtra. S'il n'y a qu'un seul bean dans cette interface, alors celui-là sera utilisé. - Chercher l'EAR des EJB qui publient cette interface. S'il y a des doubles, alors il y aura une exception. Sinon le bean correspondant sera renvoyé.
- Chercher globalement dans le runtime de JBoss un EJB de cette interface. Une fois de plus, s'il y a des doubles, il y aura une exception.
@EJB.beanName()correspond à<ejb-link>. Si lebeanName()est défini, il vous faudra utiliser le même algorithme que@EJBsans attribut défini mis à partbeanName()comme une clé de la recherche. Il existe une exception à cette règle si vous utilisez la syntaxe ejb-link '#'. La syntaxe '#' vous permettra de mettre un chemin d'accès relatif dans un jar de l'EJB qui contient l'EJB de référencement. Reportez-vous à la spécification EJB 3.1 pour plus de détails.
7.8.3. Dépendances de projet pour les clients EJB distants
Tableau 7.4. Dépendances Maven pour les clients EJB
| GroupID | ArtifactID |
|---|---|
| org.jboss.spec | jboss-javaee-6.0 |
| org.jboss.as | jboss-as-ejb-client-bom |
| org.jboss.spec.javax.transaction | jboss-transaction-api_1.1_spec |
| org.jboss.spec.javax.ejb | jboss-ejb-api_3.1_spec |
| org.jboss | jboss-ejb-client |
| org.jboss.xnio | xnio-api |
| org.jboss.xnio | xnio-nio |
| org.jboss.remoting3 | jboss-remoting |
| org.jboss.sasl | jboss-sasl |
| org.jboss.marshalling | jboss-marshalling-river |
jboss-javaee-6.0 et jboss-as-ejb-client-bom, ces dépendances doivent être ajoutées à la section <dependencies> du fichier pom.xml.
jboss-javaee-6.0 et jboss-as-ejb-client-bom doivent être ajoutées à la section <dependencyManagement> du fichier pom.xml avec l'étendue de import.
Note
artifactID peuvent être modifiées. Veuillez consulter le référentiel Maven pour connaître la version la plus récente.
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.jboss.spec</groupId>
<artifactId>jboss-javaee-6.0</artifactId>
<version>3.0.0.Final-redhat-1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.jboss.as</groupId>
<artifactId>jboss-as-ejb-client-bom</artifactId>
<version>7.1.1.Final-redhat-1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
remote-ejb/client/pom.xml pour obtenir un exemple complet de configuration de dépendance pour une invocation de session bean éloignée.
7.8.4. Référence de descripteur de déploiement jboss-ejb3.xml
jboss-ejb3.xml est un descripteur de déploiement personnalisé pouvant être utilisé dans un JAR EJB ou des archives WAR. Dans une archive JAR EJB il doit être situé dans le répertoire META-INF/. Dans une archive WAR, il doit être situé dans le répertoire WEB-INF/.
ejb-jar.xml, qui utilise les mêmes espace-noms et qui fournit des espace-noms supplémentaires. Les contenus de jboss-ejb3.xml sont mergés avec les contenus de ejb-jar.xml, et les items jboss-ejb3.xml ont la priorité.
jboss-ejb3.xml. Voir http://java.sun.com/xml/ns/javaee/ pour la documentation sur les espace-noms standard.
http://www.jboss.com/xml/ns/javaee.
Espace-nom de descripteur d'assemblage
<assembly-descriptor> . Ils peuvent être utilisés pour appliquer leur configuration à un simple bean, ou à tous les beans du déploiement en utilisant \* comme ejb-name.
- Espace-nom de clustering :
urn:clustering:1.0 xmlns:c="urn:clustering:1.0"
Cela vous permet de marquer les EJB comme étant clusterisés. Il s'agit du descripteur de déploiement équivalent au@org.jboss.ejb3.annotation.Clustered.<c:clustering> <ejb-name>DDBasedClusteredSFSB</ejb-name> <c:clustered>true</c:clustered> </c:clustering>
- L'espace-nom de sécurité (
urn:security) xmlns:s="urn:security"
Cela vous permet de définir le domaine de sécurité et le principal prétendant pour l'EJB.<s:security> <ejb-name>*</ejb-name> <s:security-domain>myDomain</s:security-domain> <s:run-as-principal>myPrincipal</s:run-as-principal> </s:security>
- L'espace-nom d'adaptateur de ressource :
urn:resource-adapter-binding xmlns:r="urn:resource-adapter-binding"
Cela vous permet de définir l'adaptateur de ressource d'un Message-Driven Bean.<r:resource-adapter-binding> <ejb-name>*</ejb-name> <r:resource-adapter-name>myResourceAdaptor</r:resource-adapter-name> </r:resource-adapter-binding>
- L'espace-nom IIOP :
urn:iiop xmlns:u="urn:iiop"
L'espace-nom IIOP est l'endroit où les paramètres IIOP sont configurés.- L'espace-nom du pool :
urn:ejb-pool:1.0 xmlns:p="urn:ejb-pool:1.0"
Cela vous permet de sélectionner le pool qui est utilisé par les stateless session beans ou par les Message-Driven Beans. Les pools sont définis dans la configuration du serveur.<p:pool> <ejb-name>*</ejb-name> <p:bean-instance-pool-ref>my-pool</p:bean-instance-pool-ref> </p:pool>
- L'espace-nom du cache :
urn:ejb-cache:1.0 xmlns:c="urn:ejb-cache:1.0"
Cela vous permet de sélectionner le cache qui est utilisé par les stateful session beans inclus. Les caches sont définis dans la configuration du serveur.<c:cache> <ejb-name>*</ejb-name> <c:cache-ref>my-cache</c:cache-ref> </c:cache>
Exemple 7.3. Fichier exemple de jboss-ejb3.xml
<?xml version="1.1" encoding="UTF-8"?>
<jboss:ejb-jar xmlns:jboss="http://www.jboss.com/xml/ns/javaee"
xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:c="urn:clustering:1.0"
xsi:schemaLocation="http://www.jboss.com/xml/ns/javaee http://www.jboss.org/j2ee/schema/jboss-ejb3-2_0.xsd http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/ejb-jar_3_1.xsd"
version="3.1"
impl-version="2.0">
<enterprise-beans>
<message-driven>
<ejb-name>ReplyingMDB</ejb-name>
<ejb-class>org.jboss.as.test.integration.ejb.mdb.messagedestination.ReplyingMDB</ejb-class>
<activation-config>
<activation-config-property>
<activation-config-property-name>destination</activation-config-property-name>
<activation-config-property-value>java:jboss/mdbtest/messageDestinationQueue
</activation-config-property-value>
</activation-config-property>
</activation-config>
</message-driven>
</enterprise-beans>
<assembly-descriptor>
<c:clustering>
<ejb-name>DDBasedClusteredSFSB</ejb-name>
<c:clustered>true</c:clustered>
</c:clustering>
</assembly-descriptor>
</jboss:ejb-jar>
Chapitre 8. Clustering dans les applications web
8.1. Réplique de session
8.1.1. La réplique de session HTTP
8.1.2. Cache de Session Web
standalone-ha.xml, ou les profils de domaine gérés ha ou full-ha. Les éléments les plus couramment configurés sont le mode cache et le nombre de propriétaires de cache pour un cache distribué.
Le mode cache peut être REPL (par défaut) ou DIST.
- REPL
- Le mode
REPLreproduit tout le cache un nœud sur deux dans le cluster. Cela constitue l'option la plus sûre, mais elle introduit aussi plus de surcharge de temps. - DIST
- Le mode
DISTest semblable au buddy mode fourni dans les exécutions précédentes. Il réduit la surcharge de temps en répartissant le cache entre le nombre de nœuds indiqués dans le paramètreowners. Ce nombre de propriétaires est défini par défaut sur2.
Le paramètre owners contrôle combien de nœuds de clusters détiennent des duplicatas de la session. La valeur par défaut est 2.
8.1.3. Configurer le Cache de session web
REPL. Si vous souhaitez utiliser le mode DIST, exécutez les deux commandes suivantes dans le Management CLI. Si vous utilisez un profil différent, changez le nom de profil dans les commandes. Si vous utilisez un serveur autonome, retirez la partie /profile=ha des commandes.
Procédure 8.1. Configurer le Cache de session web
Modifier le mode cache par défaut en
DIST./profile=ha/subsystem=infinispan/cache-container=web/:write-attribute(name=default-cache,value=dist)
Définir le nombre de propriétaires de cache distribué.
La commande suivante définit5propriétaires. La valeur par défaut est2./profile=ha/subsystem=infinispan/cache-container=web/distributed-cache=dist/:write-attribute(name=owners,value=5)
Modifier le mode cache par défaut en
REPL./profile=ha/subsystem=infinispan/cache-container=web/:write-attribute(name=default-cache,value=repl)
Relancer le serveur
Après avoir modifié le mode cache du web, vous devez relancer le serveur.
Votre serveur est configuré pour une copie de session. Pour utiliser une copie de session dans vos propres applications, veuillez vous référer au sujet suivant : Section 8.1.4, « Activer la copie de session pour votre application ».
8.1.4. Activer la copie de session pour votre application
Pour profiter des fonctionnalités HA (High Availability) de JBoss EAP 6, configurer votre application de manière à ce qu'elle soit distribuable. Cette procédure vous montrera comment y parvenir puis vous expliquera certaines options de configuration avancées que vous pourrez utiliser.
Procédure 8.2. Rendez votre Application Distribuable
Prérequis : indiquer que votre application est distribuable
Si votre application n'apparaît pas comme distribuable, ses sessions ne seront jamais distribuées. Ajouter l'élément<distributable />dans la balise<web-app>du fichier descriptifweb.xmlde votre application. Voici un exemple :Exemple 8.1. Configuration minimum pour une application distribuable
<?xml version="1.0"?> <web-app xmlns="http://java.sun.com/xml/ns/j2ee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd" version="2.4"> <distributable/> </web-app>Modifier le comportement de réplication par défaut si vous le souhaitez.
Si vous souhaitez changer une des valeurs qui affectent la réplique de session, vous pouvez les changer dans l'élément<replication-config>qui est un dépendant de l'élément<jboss-web>. Pour un exemple donné, ne l'inclure que si vous souhaitez remplacer les valeurs par défaut. L'exemple suivant énumère tous les paramètres par défaut, et est suivi d'un tableau qui explique les options les plus fréquemment modifiées.Exemple 8.2. Valeurs
<replication-config>par défaut<!DOCTYPE jboss-web PUBLIC "-//JBoss//DTD Web Application 5.0//EN" "http://www.jboss.org/j2ee/dtd/jboss-web_5_0.dtd"> <jboss-web> <replication-config> <cache-name>custom-session-cache</cache-name> <replication-trigger>SET</replication-trigger> <replication-granularity>ATTRIBUTE</replication-granularity> <use-jk>false</use-jk> <max-unreplicated-interval>30</max-unreplicated-interval> <snapshot-mode>INSTANT</snapshot-mode> <snapshot-interval>1000</snapshot-interval> <session-notification-policy>com.example.CustomSessionNotificationPolicy</session-notification-policy> </replication-config> </jboss-web>
Tableau 8.1. Options communes pour la réplique de session
|
Option
|
Description
|
|---|---|
<replication-trigger>
|
Contrôle quelles conditions doivent déclencher la réplication de données de session dans l'ensemble du cluster. Cette option est utile, quand un objet mutable stocké comme attribut de session est accessible à partir de la session, le conteneur n'a aucun moyen évident de savoir si l'objet a été modifié et s'il doit être reproduit, sauf si la méthode
setAttribute() est appelée directement.
Valeurs valides pour
Quelle que soit la configuration, vous pourrez toujours déclencher la réplication de session en appelant
setAttribute().
|
<replication-granularity>
|
Détermine la granularité des données répliquées. La valeur par défaut est
SESSION, mais peut être définie à ATTRIBUTE à la place, pour augmenter la performance dans les sessions où la plupart des attributs restent inchangés.
|
Tableau 8.2. Options les moins communément modifiées pour les réplications de session
|
Option
|
Description
|
|---|---|
<useJK>
|
Présumons qu'un équilibreur de charge tel que
mod_cluster, mod_jk, ou mod_proxy soit utilisé. La valeur par défaut est false. Si définie comme true, le conteneur examine l'ID de session associé à chaque requête et remplace la partie jvmRoute de l'ID de session s'il y a un basculement.
|
<max-unreplicated-interval>
|
Le plus grand intervalle (en secondes) à attendre après une session avant de déclencher une réplication d'un horodateur de session, même s'il est considéré comme inchangé. Cela permet aux nœuds de cluster d'être informés de l'horodateur de chaque session et aux sessions non répliquées de ne pas expirer de manière incorrecte pendant un basculement. Cela vous permet également de vous fier à une valeur correcte pour les appels à méthode
HttpSession.getLastAccessedTime() pendant un baculement.
Par défaut, aucune valeur n'est indiquée. Cela signifie que la configuration
jvmRoute du conteneur détermine si le basculement JK est utilisé. Une valeur 0 entraîne une réplication de l'horodateur à chaque accès à la session. Une valeur -1 n'entraîne une réplication de l'horodateur seulement si une autre activité pendant la requête entraîne une réplication. Une valeur positive supérieure à HttpSession.getMaxInactiveInterval() est traitée comme une erreur de configuration et convertie à 0.
|
<snapshot-mode>
|
Indique quand les sessions sont répliquées vers d'autres nœuds. La valeur par défaut est
INSTANT et l'autre valeur possible est INTERVAL.
En mode
INSTANT, les modifications sont répliquées à la fin d'une requête, au moyen du thread de traitement des requêtes. L'option <snapshot-interval> est ignorée.
En mode
INTERVAL, une tâche d'arrière-plan s'exécute à l'intervalle indiqué par <snapshot-interval>, et réplique les sessions modifiées.
|
<snapshot-interval>
|
L'intervalle, en millisecondes, pendant lequel les sessions modifiées doivent être répliquées si elles utilisent
INTERVAL pour la valeur de <snapshot-mode>.
|
<session-notification-policy>
|
Nom complet de la classe de l'implémentation de l'interface
ClusteredSessionNotificationPolicy qui contrôle si les notifications de spécification servlet sont émises vers un HttpSessionListener, HttpSessionAttributeListener, ou HttpSessionBindingListener enregistré.
|
8.2. Passivation et activation HttpSession
8.2.1. La passivation et l'activation de session HTTP
- Quand le conteneur réclame la création d'une nouvelle session, si le nombre de sessions actives en cours dépasse une limite configurable, le serveur tentera de passiver certaines sessions pour faire de la place à une nouvelle.
- De façon périodique, à un intervalle précis configuré, une tâche d'arrière-plan vérifiera si les sessions doivent être passivées.
- Quand une application web est déployée et qu'une copie de sauvegarde de sessions actives sur d'autres serveurs est acquise par le gestionnaire de session de l'application web récemment déployée, les sessions peuvent être passivées.
- La session n'a pas été utilisée pendant une durée plus longue qu'une période d'inactivité configurable maximale.
- Le nombre de sessions actives dépasse un maximum configurable et la session n'a pas été utilisée pendant une durée plus longue qu'une période d'inactivité configurable maximale.
8.2.2. Configurer la passivation HttpSession dans votre application
La Passivation HttpSession est configurée dans le fichier WEB_INF/jboss-web.xml ou META_INF/jboss-web.xml de votre application.
Exemple 8.3. Exemple de fichier jboss-web.xml
<!DOCTYPE jboss-web PUBLIC
"-//JBoss//DTD Web Application 5.0//EN"
"http://www.jboss.org/j2ee/dtd/jboss-web_5_0.dtd">
<jboss-web version="6.0"
xmlns="http://www.jboss.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.jboss.com/xml/ns/javaee http://www.jboss.org/j2ee/schema/jboss-web_6_0.xsd">
<max-active-sessions>20</max-active-sessions>
<passivation-config>
<use-session-passivation>true</use-session-passivation>
<passivation-min-idle-time>60</passivation-min-idle-time>
<passivation-max-idle-time>600</passivation-max-idle-time>
</passivation-config>
</jboss-web>
Éléments de configuration de passivation
<max-active-sessions>- Nombre maximal de sessions actives autorisé. Si le nombre de sessions gérées par le gestionnaire de sessions dépasse cette valeur et que la passivation est activée, ce dépassement sera passivé sur la base du
<passivation-min-idle-time>configuré. Ensuite, si le nombre de sessions actives dépasse toujours cette limite, les tentatives de création de nouvelles sessions échoueront. La valeur par défaut de-1ne définit aucune limite quant au nombre maximal de sessions actives. <passivation-config>- Cet élément contient le reste des paramètres de configuration de passivation, en tant qu'éléments enfants.
<passivation-config> Eléments enfants
<use-session-passivation>- Si oui ou non la passivation de session doit être utilisée. La valeur par défaut est
false. <passivation-min-idle-time>- La durée minimum, en secondes, pendant laquelle une session doit être inactive avant que le conteneur n'envisage de la passiver de manière à réduire le nombre de sessions actives pour être conforme à la valeur définie par les max-active-sessions. La valeur par défaut
-1empêche les sessions d'être passivée avant que le temps<passivation-max-idle-time>ne se soit écoulé. Les valeurs -1 ou supérieures sont déconseillées si<max-active-sessions>est configuré. <passivation-max-idle-time>- La durée maximum, en secondes, pendant laquelle une session peut être inactive avant que le conteneur ne tente de la passiver pour économiser de la mémoire. La passivation de ces sessions aura lieu, que le nombre de sessions actives excède
<max-active-sessions>ou pas. Cette valeur doit être inférieure à la configuration<session-timeout>dans le fichierweb.xml. La valeur par défaut-1désactive la passivation selon l'inactivité maximum.
Note
<max-active-sessions>. Le nombre de sessions répliquées à partir d'autres nœuds dépend également de si le mode cache REPL ou DIST est désactivé. Dans le mode cache REPL, chaque session est répliquée vers chaque nœud. Dans le mode cache DIST, chaque session n'est répliquée que vers le nombre de nœuds indiqué par le paramètre owner. Veuillez vous référer à Section 8.1.2, « Cache de Session Web » et Section 8.1.3, « Configurer le Cache de session web » pour plus de renseignements sur la configuration des modes cache de session.
REPL, chaque nœud peut stocker 800 sessions en mémoire. Avec le mode cache DIST désactivé, et la configuration owners définie par défaut sur 2, chaque nœud stocke 200 sessions en mémoire.
8.3. Domaine du cookie
8.3.1. Le domaine du cookie
/. Cela signifie que seul l'hôte d'origine peut lire le contenu d'un cookie. Le fait de configurer un domaine de cookie particulier rend le contenu du cookie disponible à un plus grand nombre d'hôtes. Pour configurer le domaine de cookie, veuillez vous référer à Section 8.3.2, « Configurer le domaine du cookie ».
8.3.2. Configurer le domaine du cookie
http://app1.xyz.com et http://app2.xyz.com à partager un contexte SSO, même si ces applications fonctionnent sur des serveurs différents dans un cluster ou si l'hôte virtuel avec lequel ils sont associés possède plusieurs alias.
Exemple 8.4. Exemple de configuration de domaine de cookie
<Valve className="org.jboss.web.tomcat.service.sso.ClusteredSingleSignOn"
cookieDomain="xyz.com" />
8.4. Implémenter un HA Singleton
Dans JBoss EAP 5, les archives HA Singleton ont été déployées dans le répertoire deploy-hasingleton/ distinct d'autres déploiements. Cela a été fait pour empêcher le déploiement automatique et pour veiller à ce que le service HASingletonDeployer contrôle le déploiement et déploie les archives uniquement sur le nœud maître du cluster. Il y n'avait aucune fonctionnalité de déploiement à chaud, ce redéploiement exigeait un redémarrage du serveur. Aussi, si le nœud maître échouait nécessitant un autre nœud pour prendre le relais de nœud maître, le service singleton devait passer par le processus de déploiement complet afin de fournir le service.
Procédure 8.3. Implémenter un Service HA Singleton
Rédiger une application de Service HA Singleton
Vous trouverez ci-dessous un exemple simple de Service intégré dans le Decorater du SingletonService qui puisse être déployé en tant que service singleton.Créer un service singleton
Vous trouverez ci-dessous un exemple simple de service singleton.package com.mycompany.hasingleton.service.ejb; import java.util.concurrent.atomic.AtomicBoolean; import java.util.logging.Logger; import org.jboss.as.server.ServerEnvironment; import org.jboss.msc.inject.Injector; import org.jboss.msc.service.Service; import org.jboss.msc.service.ServiceName; import org.jboss.msc.service.StartContext; import org.jboss.msc.service.StartException; import org.jboss.msc.service.StopContext; import org.jboss.msc.value.InjectedValue; /** * @author <a href="mailto:wfink@redhat.com">Wolf-Dieter Fink</a> */ public class EnvironmentService implements Service<String> { private static final Logger LOGGER = Logger.getLogger(EnvironmentService.class.getCanonicalName()); public static final ServiceName SINGLETON_SERVICE_NAME = ServiceName.JBOSS.append("quickstart", "ha", "singleton"); /** * A flag whether the service is started. */ private final AtomicBoolean started = new AtomicBoolean(false); private String nodeName; private final InjectedValue<ServerEnvironment> env = new InjectedValue<ServerEnvironment>(); public Injector<ServerEnvironment> getEnvInjector() { return this.env; } /** * @return the name of the server node */ public String getValue() throws IllegalStateException, IllegalArgumentException { if (!started.get()) { throw new IllegalStateException("The service '" + this.getClass().getName() + "' is not ready!"); } return this.nodeName; } public void start(StartContext arg0) throws StartException { if (!started.compareAndSet(false, true)) { throw new StartException("The service is still started!"); } LOGGER.info("Start service '" + this.getClass().getName() + "'"); this.nodeName = this.env.getValue().getNodeName(); } public void stop(StopContext arg0) { if (!started.compareAndSet(true, false)) { LOGGER.warning("The service '" + this.getClass().getName() + "' is not active!"); } else { LOGGER.info("Stop service '" + this.getClass().getName() + "'"); } } }Créer un EJB singleton pour démarrer le service en tant que SingletonService au démarrage du serveur.
La liste suivante est un exemple d'EJB singleton qui démarre un SingletonService au démarrage d'un serveur :package com.mycompany.hasingleton.service.ejb; import java.util.Collection; import java.util.EnumSet; import javax.annotation.PostConstruct; import javax.annotation.PreDestroy; import javax.ejb.Singleton; import javax.ejb.Startup; import org.jboss.as.clustering.singleton.SingletonService; import org.jboss.as.server.CurrentServiceContainer; import org.jboss.as.server.ServerEnvironment; import org.jboss.as.server.ServerEnvironmentService; import org.jboss.msc.service.AbstractServiceListener; import org.jboss.msc.service.ServiceController; import org.jboss.msc.service.ServiceController.Transition; import org.jboss.msc.service.ServiceListener; import org.slf4j.Logger; import org.slf4j.LoggerFactory; /** * A Singleton EJB to create the SingletonService during startup. * * @author <a href="mailto:wfink@redhat.com">Wolf-Dieter Fink</a> */ @Singleton @Startup public class StartupSingleton { private static final Logger LOGGER = LoggerFactory.getLogger(StartupSingleton.class); /** * Create the Service and wait until it is started.<br/> * Will log a message if the service will not start in 10sec. */ @PostConstruct protected void startup() { LOGGER.info("StartupSingleton will be initialized!"); EnvironmentService service = new EnvironmentService(); SingletonService<String> singleton = new SingletonService<String>(service, EnvironmentService.SINGLETON_SERVICE_NAME); // if there is a node where the Singleton should deployed the election policy might set, // otherwise the JGroups coordinator will start it //singleton.setElectionPolicy(new PreferredSingletonElectionPolicy(new NamePreference("node2/cluster"), new SimpleSingletonElectionPolicy())); ServiceController<String> controller = singleton.build(CurrentServiceContainer.getServiceContainer()) .addDependency(ServerEnvironmentService.SERVICE_NAME, ServerEnvironment.class, service.getEnvInjector()) .install(); controller.setMode(ServiceController.Mode.ACTIVE); try { wait(controller, EnumSet.of(ServiceController.State.DOWN, ServiceController.State.STARTING), ServiceController.State.UP); LOGGER.info("StartupSingleton has started the Service"); } catch (IllegalStateException e) { LOGGER.warn("Singleton Service {} not started, are you sure to start in a cluster (HA) environment?",EnvironmentService.SINGLETON_SERVICE_NAME); } } /** * Remove the service during undeploy or shutdown */ @PreDestroy protected void destroy() { LOGGER.info("StartupSingleton will be removed!"); ServiceController<?> controller = CurrentServiceContainer.getServiceContainer().getRequiredService(EnvironmentService.SINGLETON_SERVICE_NAME); controller.setMode(ServiceController.Mode.REMOVE); try { wait(controller, EnumSet.of(ServiceController.State.UP, ServiceController.State.STOPPING, ServiceController.State.DOWN), ServiceController.State.REMOVED); } catch (IllegalStateException e) { LOGGER.warn("Singleton Service {} has not be stopped correctly!",EnvironmentService.SINGLETON_SERVICE_NAME); } } private static <T> void wait(ServiceController<T> controller, Collection<ServiceController.State> expectedStates, ServiceController.State targetState) { if (controller.getState() != targetState) { ServiceListener<T> listener = new NotifyingServiceListener<T>(); controller.addListener(listener); try { synchronized (controller) { int maxRetry = 2; while (expectedStates.contains(controller.getState()) && maxRetry > 0) { LOGGER.info("Service controller state is {}, waiting for transition to {}", new Object[] {controller.getState(), targetState}); controller.wait(5000); maxRetry--; } } } catch (InterruptedException e) { LOGGER.warn("Wait on startup is interrupted!"); Thread.currentThread().interrupt(); } controller.removeListener(listener); ServiceController.State state = controller.getState(); LOGGER.info("Service controller state is now {}",state); if (state != targetState) { throw new IllegalStateException(String.format("Failed to wait for state to transition to %s. Current state is %s", targetState, state), controller.getStartException()); } } } private static class NotifyingServiceListener<T> extends AbstractServiceListener<T> { @Override public void transition(ServiceController<? extends T> controller, Transition transition) { synchronized (controller) { controller.notify(); } } } }Créer un Stateless Session Bean pour accéder au service à partir d'un client.
Voici un exemple de Stateless Session Bean qui accède au service à partir d'un client :package com.mycompany.hasingleton.service.ejb; import javax.ejb.Stateless; import org.jboss.as.server.CurrentServiceContainer; import org.jboss.msc.service.ServiceController; import org.slf4j.Logger; import org.slf4j.LoggerFactory; /** * A simple SLSB to access the internal SingletonService. * * @author <a href="mailto:wfink@redhat.com">Wolf-Dieter Fink</a> */ @Stateless public class ServiceAccessBean implements ServiceAccess { private static final Logger LOGGER = LoggerFactory.getLogger(ServiceAccessBean.class); public String getNodeNameOfService() { LOGGER.info("getNodeNameOfService() is called()"); ServiceController<?> service = CurrentServiceContainer.getServiceContainer().getService( EnvironmentService.SINGLETON_SERVICE_NAME); LOGGER.debug("SERVICE {}", service); if (service != null) { return (String) service.getValue(); } else { throw new IllegalStateException("Service '" + EnvironmentService.SINGLETON_SERVICE_NAME + "' not found!"); } } }Créer une interface de logique commerciale pour le SingletonService.
Voici un exemple d'interface de logique commerciale pour le SingletonService.package com.mycompany.hasingleton.service.ejb; import javax.ejb.Remote; /** * Business interface to access the SingletonService via this EJB * * @author <a href="mailto:wfink@redhat.com">Wolf-Dieter Fink</a> */ @Remote public interface ServiceAccess { public abstract String getNodeNameOfService(); }
Démarrez chaque instance de JBoss EAP 6 avec le clustering activé.
La méthode d'activation du clustering dépend si les serveurs exécutent en autonome ou en domaine géré.Activer le clustering pour les serveurs qui exécutent dans un domaine géré.
Vous pourrez utiliserle Management CLI, ou bien, vous pourrez éditer le fichier de configuration manuellement pour activer le clustering.Activer le clustering par le Management CLI.
Démarrer votre contrôleur de domaine.
Ouvrir une invite de commande de votre système d'exploitation.
Connectez vous au Management CLI en faisant passer l'adresse IP du contrôleur de domaine ou le nom DNS.
Dans cet exemple, considérons que l'adresse IP du contrôleur du domaine est192.168.0.14.- Dans Linux, saisir ce qui suit au niveau de la ligne de commande :
$ EAP_HOME/bin/jboss-cli.sh --connect --controller=192.168.0.14
- Dans Windows, saisir ce qui suit au niveau de la ligne de commande :
C:\>EAP_HOME\bin\jboss-cli.bat --connect --controller=192.168.0.14
Vous devriez voir apparaître le résultat suivant :Connected to domain controller at 192.168.0.14
Ajouter le groupe de serveurs
main-server.[domain@192.168.0.14:9999 /] /server-group=main-server-group:add(profile="ha",socket-binding-group="ha-sockets") { "outcome" => "success", "result" => undefined, "server-groups" => undefined }Créer un serveur nommé
server-oneet ajoutez-le au groupe de serveursmain-server.[domain@192.168.0.14:9999 /] /host=station14Host2/server-config=server-one:add(group=main-server-group,auto-start=false) { "outcome" => "success", "result" => undefined }Configurer la JVM pour le groupe de serveurs
main-server.[domain@192.168.0.14:9999 /] /server-group=main-server-group/jvm=default:add(heap-size=64m,max-heap-size=512m) { "outcome" => "success", "result" => undefined, "server-groups" => undefined }Créer un serveur nommé
server-one, mettez-le dans un groupe de serveurs séparés et définir son Port Offset à 100.[domain@192.168.0.14:9999 /] /host=station14Host2/server-config=server-two:add(group=distinct2,socket-binding-port-offset=100) { "outcome" => "success", "result" => undefined }
Activer le clustering en modifiant manuellement les fichiers de configuration du serveur.
Stopper le serveur JBoss EAP 6.
Important
Vous devez interrompre le serveur avant de modifier le fichier de configuration du serveur pour que votre changement puisse être persisté au redémarrage du serveur.Ouvrir le fichier de configuration
domain.xmlpour modifierDésignez un groupe de serveurs qui puisse utiliser le profilhaet le groupe de liaisons de socketsha-socketscomme suit :<server-groups> <server-group name="main-server-group" profile="ha"> <jvm name="default"> <heap size="64m" max-size="512m"/> </jvm> <socket-binding-group ref="ha-sockets"/> </server-group> </server-groups>Ouvrir le fichier de configuration
host.xmlpour modifierÉditez le fichier comme suit :<servers> <server name="server-one" group="main-server-group" auto-start="false"/> <server name="server-two" group="distinct2"> <socket-bindings port-offset="100"/> </server> <servers>Démarrer le serveur :
- Dans Linux, tapez :
EAP_HOME/bin/domain.sh - Dans Microsoft Windows, tapez :
EAP_HOME\bin\domain.bat
Activer le clustering pour les serveurs autonomes
Pour activer le clustering dans les serveurs autonomes, démarrer le serveur par le nom du nœud et le fichier de configurationstandalone-ha.xmlcomme ce qui suit :- Dans Linux, saisir :
EAP_HOME/bin/standalone.sh --server-config=standalone-ha.xml -Djboss.node.name=UNIQUE_NODE_NAME - Dans Microsoft Windows, saisir :
EAP_HOME\bin\standalone.bat --server-config=standalone-ha.xml -Djboss.node.name=UNIQUE_NODE_NAME
Note
Pour éviter les conflits de ports quand on exécute plusieurs serveurs sur une machine, configurez le fichierstandalone-ha.xmlpour que chaque instance de serveur puisse se lier à une interface séparée. Sinon, vous pourrez démarrer les instances de serveurs suivants par une référence de port, par l'argument suivant, ou similaire, dans votre ligne de commande :-Djboss.socket.binding.port-offset=100.Déployer l'application dans les serveurs
Si vous utilisez Maven pour déployer votre application, utiliser la commande Maven pour vous déployer dans le serveur qui exécute sur les ports par défaut :mvn clean install jboss-as:deployPour déployer des serveurs supplémentaires, indiquer le nom du serveur et le numéro de port dans la ligne de commande :mvn clean package jboss-as:deploy -Ddeploy.hostname=localhost -Ddeploy.port=10099
Chapitre 9. CDI
9.1. CDI
9.1.1. CDI
9.1.2. CDI (Contexts and Dependency Injection)
9.1.3. Avantages de CDI
- CDI simplifie et rétrécit votre base code en remplaçant des gros morceaux de code par des annotations.
- CDI est flexible, ce qui vous permet de désactiver ou d'activer des injections et des événements, d'utiliser des autres beans, ou d'injecter des objets non-CDI facilement.
- Il est facile d'utiliser votre ancien code avec CDI. Vous n'avez qu'à y inclure un
beans.xmldans votre répertoireMETA-INF/ouWEB-INF/. Le fichier peut être vide. - CDI simplifie le packaging et les déploiements, et réduit le montant d'XML que vous aurez besoin d'ajouter à vos déploiements.
- CDI propose une gestion du cycle de vie par contexte. Vous pouvez lier des injections aux requêtes, sessions, conversations, ou contextes personnalisés.
- CDI propose un injection de dépendance type-safe, qui est plus sécurisée et facile à débogger qu'une injection basée string.
- CDI découple les intercepteurs des beans.
- CDI fournit une notification d'événements complexe.
9.1.4. Injection de Dépendance de Type-safe
9.1.5. Relation entre Weld, Seam 2, Seam 3, et JavaServer Faces
9.2. Utiliser CDI
9.2.1. Premières étapes
9.2.1.1. Activer CDI
Le CDI (Contexts and Dependency Injection) est l'une des technologies de base de la JBoss EAP 6, et est activé par défaut. Si, pour une raison ou une autre, il était désactivé et que vous souhaitiez l'activer, veuillez suivre le procédé suivant :
Procédure 9.1. Activer CDI dans JBoss EAP 6
Vérifier si les informations du sous-système sont dé-commentées dans le fichier de configuration.
On peut désactiver un sous-système en dé-commentant la section qui convient dans les fichiers de configurationdomain.xmloustandalone.xml, ou en supprimant la section qui convient.Pour trouver le sous-système dansEAP_HOME/domain/configuration/domain.xmlouEAP_HOME/standalone/configuration/standalone.xml, le chercher dans les strings suivants. S'il existe, il se trouve dans la section <extensions>.<extension module="org.jboss.as.weld"/>
La ligne suivante doit se trouver dans le profil que vous utilisez. Les profils se trouvent dans des éléments de <profile> dans la section <profiles>.<subsystem xmlns="urn:jboss:domain:weld:1.0"/>
Avant de modifier un fichier, arrêter JBoss EAP 6.
JBoss EAP 6 modifie les fichiers de configuration pendant le temps d'exécution, vous devez donc arrêter le serveur avant de modifier directement les fichiers de configuration.Modifer le fichier de configuration pour restaurer le sous-système CDI.
Si le sous-système CDI est dé-commenté, supprimer les commentaires.S'il était supprimé totalement, le restaurer en ajoutant cette ligne au fichier dans une nouvelle ligne directement au dessus de la balise </extensions> :<extension module="org.jboss.as.weld"/>
- Vous devez également ajouter la ligne suivante dans le profil concerné qui se trouve dans la section <profiles>.
<subsystem xmlns="urn:jboss:domain:weld:1.0"/>
Démarrer à nouveau JBoss EAP 6.
Démarrer JBoss EAP 6 avec votre configuration mise à jour.
JBoss EAP 6 démarre avec le sous-système CDI activé.
9.2.2. Utiliser CDI pour développer une application
9.2.2.1. Utiliser CDI pour développer une application
Le CDI (Contexts and Dependency Injection) vous offre une très grande flexibilité pour développer des applications, réutiliser des codes, adapter votre code au déploiement ou à l'exécution et tester des unités. JBoss EAP 6 comprend Weld, l'implémentation de référence de CDI. Ces tâches vous montrent comment utiliser CDI dans vos applications enterprise.
9.2.2.2. CDI avec le code existant
beans.xml dans le répertoire META-INF/ ou WEB-INF/ de votre archive. Ce fichier peut rester vide.
Procédure 9.2. Utiliser les anciens beans dans les applications CDI
Groupez vos beans dans une archive.
Groupez vos beans dans une archive JAR ou WAR.Inclure un fichier
beans.xmldans votre archive.Mettez un fichierbeans.xmldans votre répertoire d'archive JARMETA-INF/ou d'archive WARWEB-INF/. Ce fichier peut rester vide.
Vous pouvez utiliser ces beans avec CDI. Le conteneur peut créer et détruire des instances de vos beans et les associer à un contexte désigné, les injecter dans les autres beans, les utiliser dans des expressions EL, les spécialiser par des annotations de qualifier et y ajouter des intercepteurs et des décorateurs, sans aucune modification de votre code existant. Dans certains cas, vous devrez peut-être ajouter des annotations.
9.2.2.3. Exclure les beans du processus de balayage
Une des caractéristiques de Weld, l'implémentation de CDI de JBoss EAP 6, est la possibilité d'exclure des classes de balayage de votre archive, d'avoir des événements de cycle de vie conteneur émis, et déployés comme beans. Cela ne fait pas partie de la spécification JSR-299.
Exemple 9.1. Exclure des packages de votre bean.
- Le premier exclut toutes les classes Swing.
- Le second exclut les classes Google Web Toolkit id le Google Web Toolkit n'est pas installé.
- Le troisième exclut les classes qui finissent dans la chaîne
Blether(en utilisant une expression régulière), si la propriété de système verbosity est définie commelow. - Le quatrième exclut les classes JSF (Java Server Faces) si les classes Wicket sont présentes et la propriété de système viewlayer n'est pas définie.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:weld="http://jboss.org/schema/weld/beans"
xsi:schemaLocation="
http://java.sun.com/xml/ns/javaee http://docs.jboss.org/cdi/beans_1_0.xsd
http://jboss.org/schema/weld/beans http://jboss.org/schema/weld/beans_1_1.xsd">
<weld:scan>
<!-- Don't deploy the classes for the swing app! -->
<weld:exclude name="com.acme.swing.**" />
<!-- Don't include GWT support if GWT is not installed -->
<weld:exclude name="com.acme.gwt.**">
<weld:if-class-available name="!com.google.GWT"/>
</weld:exclude>
<!--
Exclude classes which end in Blether if the system property verbosity is set to low
i.e.
java ... -Dverbosity=low
-->
<weld:exclude pattern="^(.*)Blether$">
<weld:if-system-property name="verbosity" value="low"/>
</weld:exclude>
<!--
Don't include JSF support if Wicket classes are present, and the viewlayer system
property is not set
-->
<weld:exclude name="com.acme.jsf.**">
<weld:if-class-available name="org.apache.wicket.Wicket"/>
<weld:if-system-property name="!viewlayer"/>
</weld:exclude>
</weld:scan>
</beans>
9.2.2.4. Utiliser une injection pour étendre une implémentation
Vous pouvez utiliser une injection pour ajouter ou modifier une caractéristique de votre code existant. Cet exemple vous montre comment ajouter une capacité de traduction à une classe existante. La traduction est une caractéristique hypothétique et la façon dont elle est implémentée dans cet exemple est pseudo-code, et elle est fournie à titre illustratif uniquement.
buildPhrase. La méthode buildPhrase utilise le nom d'une ville comme paramètre et crée une formule telle que "Welcome to Boston". Votre objectif est de créer une version de cette classe Welcome pouvant traduire cette formule d'accueil dans une autre langue.
Exemple 9.2. Injecter un Bean Translator dans la classe Welcome.
Translator hypothétique dans la classe Welcome. L'objet Translator peut être un bean sans état EJB ou un autre type de bean, pouvant traduire des phrases d'une langue à une autre. Ainsi, le Translator est utilisé pour traduire la formule d'accueil complète, sans avoir à modifier la classe Welcome d'origine. Le Translator est injecté avant que la méthode buildPhrase ne soit implémentée.
public class TranslatingWelcome extends Welcome {
@Inject Translator translator;
public String buildPhrase(String city) {
return translator.translate("Welcome to " + city + "!");
}
...
}
9.2.3. Dépendances ambigues ou non satisfaites
9.2.3.1. Dépendances ambigües et non-satisfaites
- Il résout les annotations de qualificateur sur tous les beans qui implémentent le bean d'un point d'injection.
- Il filre les beans désactivés. Les beans désactivés sont des beans @Alternative qui ne sont pas explicitement activés.
9.2.3.2. Qualificateurs
Exemple 9.3. Définit les qualificateurs @Synchronous et @Asynchronous
@Qualifier
@Retention(RUNTIME)
@Target({TYPE, METHOD, FIELD, PARAMETER})
public @interface Synchronous {}
@Qualifier
@Retention(RUNTIME)
@Target({TYPE, METHOD, FIELD, PARAMETER})
public @interface Asynchronous {}
Exemple 9.4. Utiliser les qualificateurs @Synchronous et @Asynchronous
@Synchronous
public class SynchronousPaymentProcessor implements PaymentProcessor {
public void process(Payment payment) { ... }
}
@Asynchronous
public class AsynchronousPaymentProcessor implements PaymentProcessor {
public void process(Payment payment) { ... }
}
9.2.3.3. Utiliser un qualificateur pour résoudre une injection ambiguë
Cette tâche indique une injection ambiguë et la retire par un qualificateur. Pour en savoir plus sur les injections ambiguës, voir Section 9.2.3.1, « Dépendances ambigües et non-satisfaites ».
Exemple 9.5. Injections ambiguës
Welcome, une qui traduit, et l'autre non. Dans cette situation, l'injection ci-dessous est ambiguë et a besoin d'être spécifiée pour qu'on puisse utiliser la classe de traduction Welcome.
public class Greeter {
private Welcome welcome;
@Inject
void init(Welcome welcome) {
this.welcome = welcome;
}
...
}
Procédure 9.3. Résoudre une injection ambiguë avec un qualificateur
Créer une annotation de qualificateur nommée
@Translating.@Qualifier @Retention(RUNTIME) @Target({TYPE,METHOD,FIELD,PARAMETERS}) public @interface Translating{}Annoter votre classe
Welcomepar l'annotation@Translating.@Translating public class TranslatingWelcome extends Welcome { @Inject Translator translator; public String buildPhrase(String city) { return translator.translate("Welcome to " + city + "!"); } ... }Demander la classe de traduction
Welcomedans votre injection.Vous devez demander une implémentation explicitement qualifiée, qui ressemble au modèle de la méthode de fabrique. L'ambiguité se résout au point d'injection.public class Greeter { private Welcome welcome; @Inject void init(@Translating Welcome welcome) { this.welcome = welcome; } public void welcomeVisitors() { System.out.println(welcome.buildPhrase("San Francisco")); } }
TranslatingWelcome est utilisé, et il n'y a pas d'ambiguité.
9.2.4. Beans gérés
9.2.4.1. Les beans gérés
9.2.4.2. Types de Classes qui ne sont pas des Beans
@ManagedBean, mais en CDI cela n'est pas nécessaire. Conformément à la spécification, le conteneur CDI traite n'importe quelle classe qui remplit les conditions suivantes en tant que bean géré :
- Il s'agit d'une classe interne non-statique
- Il ne s'agit pas d'une classe concrète, ou bien elle est annotée par
@Decorator - Elle n'est pas annotée par une annotation définie par un composant EJB, ni déclarée comme classe bean EJB dans
ejb-jar.xml. - Elle n'implémente pas l'interface
javax.enterprise.inject.spi.Extension. - Possède un constructeur sans paramètre ou un constructeur annoté avec
@Inject.
9.2.4.3. Utiliser CDI pour injecter un objet dans un bean
META-INF/beans.xml ou WEB-INF/beans.xml, chaque objet de votre déploiement peut être injecté par CDI.
Injecter un objet dans n'importe quelle partie de bean par l'annotation
@Inject.Pour obtenir une instance de classe, dans votre bean, annotez ce champ avec@Inject.Exemple 9.6. Injecter une instance
TextTranslatordans unTranslateControllerpublic class TranslateController { @Inject TextTranslator textTranslator; ...Utiliser les méthodes de l'objet injecté
Vous pouvez directement utiliser les méthodes de vos objets injectés. Partez du principe queTextTranslatorpossède une méthodetranslate.Exemple 9.7. Utiliser les méthodes de l'objet injecté
// in TranslateController class public void translate() { translation = textTranslator.translate(inputText); }Utiliser l'injection dans le contructeur d'un bean
Vous pouvez injecter des objets dans le constructeur d'un bean, ou bien, vous pouvez utiliser une fabrique ou un localisateur de service pour les créer.Exemple 9.8. Utiliser l'injection pour la construction d'un bean
public class TextTranslator { private SentenceParser sentenceParser; private Translator sentenceTranslator; @Inject TextTranslator(SentenceParser sentenceParser, Translator sentenceTranslator) { this.sentenceParser = sentenceParser; this.sentenceTranslator = sentenceTranslator; } // Methods of the TextTranslator class ... }Utiliser l'interface
Instance(<T>)pour obtenir les instances de façon programmatique.L'interfaceInstancepeut renvoyer une instance de TextTranslator si paramétrée par le type de bean.Exemple 9.9. Obtenir une instance par programmation
@Inject Instance<TextTranslator> textTranslatorInstance; ... public void translate() { textTranslatorInstance.get().translate(inputText); }
Lorsque vous injectez un objet dans un bean, toutes les méthodes et les propriétés de l'objet sont disponibles pour votre bean. Si vous injectez dans le constructeur de votre bean, les instances des objets injectés sont créés quand le constructeur de votre bean est appelé, à moins que l'injection ne fasse référence à une instance qui existe déjà. Par exemple, une nouvelle instance ne serait pas créée si vous injectiez un bean basé-session pendant la durée de la session.
9.2.5. Contextes, Scopes et Dépendances
9.2.5.1. Contextes et scopes
@RequestScoped, @SessionScoped, et @ConversationScope.
9.2.5.2. Contexte disponibles
Tableau 9.1. Contextes disponibles
| Contexte | Description |
|---|---|
| @Dependent | Le bean est lié au cycle de vie du bean qui contient la référence. |
| @ApplicationScoped | Lié au cycle de vie de l'application. |
| @RequestScoped | Lié au cycle de vie de la requête. |
| @SessionScoped | Lié au cycle de vie de la session. |
| @ConversationScoped | Lié au cycle de vie de la conversation. Le scope de la conversation correspond aux longueurs de la requête et de la session, et est contrôlé par l'application. |
| Scopes personnalisés | Si les contextes ne correspondent pas à vos besoins, vous pourrez définir des scopes personnalisés. |
9.2.6. Cycle de vie d'un bean
9.2.6.1. Gestion du cycle de vie d'un bean
Cette tâche vous montre comment sauvegarder un bean pendant la durée de vie d'une requête. Il existe plusieurs autres scopes, et vous pouvez définir vos propres scopes.
@Dependent. Cela veut dire que le cycle de vie du bean dépend du cycle de vie du bean qui contient la référence. Pour plus d'informations, voir Section 9.2.5.1, « Contextes et scopes ».
Procédure 9.4. Gestion du cycle de vie d'un bean
Annoter le bean par le scope qui correspond au scope désiré.
@RequestScoped @Named("greeter") public class GreeterBean { private Welcome welcome; private String city; // getter & setter not shown @Inject void init(Welcome welcome) { this.welcome = welcome; } public void welcomeVisitors() { System.out.println(welcome.buildPhrase(city)); } }Quand votre bean est utilisé dans la vue JSF, il contient un état.
<h:form> <h:inputText value="#{greeter.city}"/> <h:commandButton value="Welcome visitors" action="#{greeter.welcomeVisitors}"/> </h:form>
Votre bean est sauvegardé dans le contexte lié au scope que vous spécifiez, et dure aussi longtemps que le scope est applicable.
9.2.6.2. Utilisation d'une méthode Producer
Cette tâche vous montre comment utiliser les méthodes Producer pour créer un certain nombre d'objets qui ne sont pas des beans, pour l'injection.
Exemple 9.10. Utiliser une méthode Producer au lieu d'une méthode Alternative, pour permettre le polymorphisme suite au déploiement.
@Preferred dans l'exemple donné est une annotation qualifiante. Pour plus d'informations sur les qualificateurs, veuillez vous référer à : Section 9.2.3.2, « Qualificateurs ».
@SessionScoped
public class Preferences implements Serializable {
private PaymentStrategyType paymentStrategy;
...
@Produces @Preferred
public PaymentStrategy getPaymentStrategy() {
switch (paymentStrategy) {
case CREDIT_CARD: return new CreditCardPaymentStrategy();
case CHECK: return new CheckPaymentStrategy();
default: return null;
}
}
}
@Inject @Preferred PaymentStrategy paymentStrategy;
Exemple 9.11. Assigner un scope à une méthode Producer
@Dependent. Si vous attribuez une étendue à un bean, celle-ci est destinée au contexte approprié. La méthode Producer dans cet exemple n'est appelée qu'une fois par session.
@Produces @Preferred @SessionScoped
public PaymentStrategy getPaymentStrategy() {
...
}
Exemple 9.12. Utiliser une injection à l'intérieur d'une méthode Producer
@Produces @Preferred @SessionScoped
public PaymentStrategy getPaymentStrategy(CreditCardPaymentStrategy ccps,
CheckPaymentStrategy cps ) {
switch (paymentStrategy) {
case CREDIT_CARD: return ccps;
case CHEQUE: return cps;
default: return null;
}
}
Note
Les méthodes Producer vous permettent d'injecter des objets non-bean et de changer votre code de façon dynamique.
9.2.7. Beans nommés et beans alternatifs
9.2.7.1. Named Beans
@Named. Nommer un bean vous permet de l'utiliser directement dans JSF (Java Server Faces).
@Named prend un paramètre optionnel, qui correspond au nom du bean. Si le paramètre est omis, le nom du bean en minuscules sera utilisé.
9.2.7.2. Utilisation des Named Beans
Utiliser l'annotation
@Namedpour assigner un nom à un bean.@Named("greeter") public class GreeterBean { private Welcome welcome; @Inject void init (Welcome welcome) { this.welcome = welcome; } public void welcomeVisitors() { System.out.println(welcome.buildPhrase("San Francisco")); } }Le nom du bean en soi est une option. Si vous l'oubliez, le bean sera nommé par rapport à son nom de classe, avec la première lettre en non capitale. Dans l'exemple ci-dessus, le nom par défaut serait doncgreeterBean.Utiliser le bean nommé dans une vue JSF
<h:form> <h:commandButton value="Welcome visitors" action="#{greeter.welcomeVisitors}"/> </h:form>
Votre bean nommé correspond à une action dans le contrôle de votre vue JSF, et à un minimum de code.
9.2.7.3. Beans Alternative
Exemple 9.13. Définition d'alternatif
@Alternative @Synchronous @Asynchronous
public class MockPaymentProcessor implements PaymentProcessor {
public void process(Payment payment) { ... }
}
beans.xml.
9.2.7.4. Remplacer une injection par une alternative
Les beans Alternative vous permettent de remplacer des beans existants. On peut les concevoir comme un moyen d'ajouter une classe qui remplit le même rôle, mais qui fonctionne différemment. Ils sont désactivés par défaut. Cette tâche vous montre comment indiquer et activer une alternative.
Procédure 9.5. Remplacer une injection
TranslatingWelcome dans votre projet, mais que vous souhaitez la remplacer par une "fausse" classe TranslatingWelcome. Cela serait le cas pour un déploiement test, où le vrai bean Translator ne peut être utilisé.
Définir l'alternative.
@Alternative @Translating public class MockTranslatingWelcome extends Welcome { public String buildPhrase(string city) { return "Bienvenue à " + city + "!"); } }Substituer l'alternative.
Pour activer l'implémentation de substitution, ajouter le nom complet de la classe à votre fichierMETA-INF/beans.xmlouWEB-INF/beans.xml.<beans> <alternatives> <class>com.acme.MockTranslatingWelcome</class> </alternatives> </beans>
L'implémentation alternative est maintenant utilisée à la place de l'implémentation d'origine.
9.2.8. Stérétypes
9.2.8.1. Stéréotypes
- scope par défaut
- un groupe de liaisons d'intercepteur
- tous les beans avec un stéréotype ont des noms EL de bean par défaut
- tous les beans avec un stéréotype sont des alternatifs
@Named, tout bean sur lequel elle se trouve, a un nom de bean par défaut. Le bean peut remplacer ce nom id l'annotation @Named est directement spécifiée sur le bean. Pour plus d'informations sur les beans nommés, voir Section 9.2.7.1, « Named Beans ».
9.2.8.2. Utilisation des stéréotypes
Sans les stéréotypes, les annotations peuvent devenir encombrées. Cette tâche vous montre comment utiliser les stéréotypes pour réduire l'encombrement et simplifier votre code. Pour plus d'informations sur ce que sont les stéréotypes, voir Section 9.2.8.1, « Stéréotypes ».
Exemple 9.14. Encombrement d'annotation
@Secure
@Transactional
@RequestScoped
@Named
public class AccountManager {
public boolean transfer(Account a, Account b) {
...
}
}
Procédure 9.6. Définition et utilisation des stéréotypes
Définir le stéréotype
@Secure @Transactional @RequestScoped @Named @Stereotype @Retention(RUNTIME) @Target(TYPE) public @interface BusinessComponent { ... }Utilisation d'un stéréotype.
@BusinessComponent public class AccountManager { public boolean transfer(Account a, Account b) { ... } }
Les stéréotypes rationalisent et simplifient votre code.
9.2.9. Méthodes Observer
9.2.9.1. Méthodes Observer
9.2.9.2. Appliquer et observer des événements
Exemple 9.15. Appliquer un événement
public class AccountManager {
@Inject Event<Withdrawal> event;
public boolean transfer(Account a, Account b) {
...
event.fire(new Withdrawal(a));
}
}
Exemple 9.16. Appliquer un événement par un qualificateur
public class AccountManager {
@Inject @Suspicious Event <Withdrawal> event;
public boolean transfer(Account a, Account b) {
...
event.fire(new Withdrawal(a));
}
}
Exemple 9.17. Observer un événement
@Observes.
public class AccountObserver {
void checkTran(@Observes Withdrawal w) {
...
}
}
Exemple 9.18. Oberver un événement qualifié
public class AccountObserver {
void checkTran(@Observes @Suspicious Withdrawal w) {
...
}
}
9.2.10. Intercepteurs
9.2.10.1. Les intercepteurs
Points d'interception
- Interception de méthodes commerciales
- Un intercepteur de méthode commeciale s'applique aux invocations de méthodes du bean par les clients du bean.
- Interception de lifecycle callback
- Un intercepteur de lifecycle callback s'applique aux invocations de lifecycle callback par le conteneur.
- Interception de méthode de timeout
- Un intercepteur de méthode de timeout s'applique aux invocations de métodes d'EJB timeout par le conteneur.
9.2.10.2. Utiliser les intercepteurs dans CDI
Exemple 9.19. Intercepteurs sans CDI
- Le bean doit indiquer l'implémentation de l'intercepteur directement.
- Chaque bean de l'application doit indiquer l'ensemble des intercepteurs dans l'ordre qui convient. Cela fait que l'ajout ou le retrait d'intercepteurs sur la base d'une application prend beaucoup de temps et comporte un risque d'erreur non négligeable.
@Interceptors({
SecurityInterceptor.class,
TransactionInterceptor.class,
LoggingInterceptor.class
})
@Stateful public class BusinessComponent {
...
}
Procédure 9.7. Utiliser les intercepteurs dans CDI
Définir le type de liaison d'intercepteur
@InterceptorBinding @Retention(RUNTIME) @Target({TYPE, METHOD}) public @interface Secure {}Marquer l'implémentation de l'intercepteur
@Secure @Interceptor public class SecurityInterceptor { @AroundInvoke public Object aroundInvoke(InvocationContext ctx) throws Exception { // enforce security ... return ctx.proceed(); } }Utiliser l'intercepteur dans votre code commercial.
@Secure public class AccountManager { public boolean transfer(Account a, Account b) { ... } }Activer l'intercepteur dans votre déploiement, en l'ajoutant à votre fichier
META-INF/beans.xmlouWEB-INF/beans.xml.<beans> <interceptors> <class>com.acme.SecurityInterceptor</class> <class>com.acme.TransactionInterceptor</class> </interceptors> </beans>Les intercepteurs sont appliqués dans l'ordre indiqué.
CDI simplifie votre code d'intercepteur et simplifie l'application de votre code commercial.
9.2.11. Les décorateurs
@Decorator.
Exemple 9.20. Exemple de décorateur
@Decorator
public abstract class LargeTransactionDecorator
implements Account {
@Inject @Delegate @Any Account account;
@PersistenceContext EntityManager em;
public void withdraw(BigDecimal amount) {
...
}
public void deposit(BigDecimal amount);
...
}
}
9.2.12. Extensions portables
- intégration par les moteurs de Business Process Management
- intégration aux frameworks de tierce partie comme Spring, Seam, GWT ou Wicket
- nouvelle technologie basée sur le modèle de programmation CDI
- En fournissant ainsi ses propres beans, intercepteurs et décorateurs au conteneur
- En injectant des dépendances dans ses propres objets en utilisant le service d'injections de dépendances
- En fournissant une implémentation de contexte pour un scope personnalisé
- En augmentant ou en remplaçant les métadonnées basées annotation par les métadonnées d'autres sources
9.2.13. Proxies Beans
9.2.13.1. Proxys Bean
Problèmes d'injection de dépendance, qui sont résolus en utilisant les proxys.
- Performance - les proxys sont bien plus rapides que l'injection de dépendance, donc vous pouvez les utiliser dans des beans qui requièrent une haute performance.
- Thread safety - les proxys envoient des requêtes vers l'instance de bean qui convient, même quand plusieurs threads accèdent à un bean en même temps.
Classes qui ne peuvent pas être mises en proxy
- Types Primitives ou Tableaux
- Classes
finalou qui possèdent une méthodefinal - Classes qui ont un constructeur non-privé par défaut
9.2.13.2. Utiliser un Proxy ou une Injection
Un proxy est utilisé pour l'injection quand les cycles de vie des beans sont différents les uns des autres. Le proxy est une sous-classe du bean qui est créée au moment de l'exécution et qui remplace toutes les méthodes non privées de la classe de bean. Le serveur proxy transmet l'invocation sur l'instance réelle du bean.
PaymentProcessor n'est pas injectée directement dans Shop. À la place, un proxy est injecté, et quand la méthode processPayment() est appelée, le proxy cherche l'instance de bean courante PaymentProcessor et appelle la méthode processPayment() dessus.
Exemple 9.21. Injection de proxy
@ConversationScoped
class PaymentProcessor
{
public void processPayment(int amount)
{
System.out.println("I'm taking $" + amount);
}
}
@ApplicationScoped
public class Shop
{
@Inject
PaymentProcessor paymentProcessor;
public void buyStuff()
{
paymentProcessor.processPayment(100);
}
}
Chapitre 10. Java Transaction API (JTA)
10.1. Aperçu
10.1.1. Java Transactions API (JTA)
Ces topics vous donnent des explications de base sur l'API Java Transactions (JTA).
10.2. Concepts de transactions
10.2.1. Transactions
10.2.2. Les propriétés ACID de transactions
Atomicity, Consistency, Isolation, et Durability. Cette terminologie est normalement utilisée dans le contexte de bases de données ou d'opérations transactionnelles.
Définitions ACID
- Atomicité
- Pour qu'une transaction soit atomique, tous les membres de la transaction doivent prendre la même décision. Ils doivent soit tous valider, soit tous se retirer. Si l'atomicité est cassée, ce qui en résultera s'appelle un heuristic outcome..
- Homogénéité
- Homogénéité signifie que les données écrites dans la base de données doivent être valides, en terme de schéma de base de données. La base de donnée et les autres sources de données doivent toujours être dans un état consistant. Par exemple, un état inconsistant pourrait correspondre à un champ dans lequel la moitié des données sont écrites avant qu'une opération n'échoue. Dans le cas d'un état consistant, toutes les données sont écrites, et l'écriture est retirée si incomplète.
- Isolation
- Isolation signifie que les données ajoutées à l'opération doivent être verrouillées avant toute modification, pour ne pas que les processus modifient les données au delà de la portée de la transaction en question.
- Durabilité
- Durabilité signifie qu'en cas d'échec externe, après que les membres d'une transaction aient été instruits de valider, tous les membres seront disponibles pour continuer la validation de la transaction quand l'échec sera résolu. Cette défaillance est sans doute liée au matériel, logiciels, réseau, ou tout autre système impliqué.
10.2.3. Coordinateur de transactions ou Gestionnaire de transactions
10.2.4. Participants d'une transaction.
10.2.5. JTA (Java Transactions API)
10.2.6. JTS (Java Transaction Service)
Note
10.2.7. Sources de Données XA et Transactions XA
10.2.8. La Récupération XA
10.2.9. Le protocole de validation en 2-Phases
Au cours de la première phase, les participants à la transaction indiquent au coordinateur de transaction s'ils sont en mesure de valider la transaction ou bien, ils devront la retirer.
Dans la deuxième phase, le coordinateur de transactions prend la décision à savoir si l'opération globale doit être validée ou bien, retirée. Si l'un des participants ne peut pas valider, la transaction sera retirée. Sinon, l'opération peut être validée. Le coordinateur dirige les opérations et en notifie le coordinateur quand les décisions sont prises. À ce moment-là, la transaction est terminée.
10.2.10. Les délais d'attente de transactions
10.2.11. Les transactions distribuées
10.2.12. API de Portabilité ORB
Classes API de la Portabilité ORB
com.arjuna.orbportability.orbcom.arjuna.orbportability.oa
10.2.13. Transactions imbriquées
Les avantages des transactions imbriquées
- Isolation des erreurs
- Si une sous-transaction s'annule, par exemple parce qu'un objet utilisé échoue, la transaction englobante ne nécessite pas d'être annulée.
- Modularité
- Si une transaction est déjà associée à un appel quand une nouvelle transaction commence, la nouvelle transaction sera imbriquée à l'intérieur. Dès lors, si vous savez qu'un objet requiert des transactions, vous pouvez les imbriquer dans l'objet. Si les méthodes de l'objet sont invoquées sans une transaction client, alors les transactions de l'objet sont de niveau supérieur. Sinon, elles sont imbriquées dans l'étendue des transactions du client. De la même manière, un client n'a pas besoin de savoir si un objet est transactionnel. Il peut commencer sa propre transaction.
10.3. Optimisations de transactions
10.3.1. Optimisations de transactions
Le sous-système de transactions de JBoss EAP 6 inclut plusieurs optimisations dont vous pouvez tirer avantage pour vos applications.
10.3.2. Optimisation LRCO pour une validation en 1 phase (1 PC)
10.3.3. Optimisation Presumed-Abort
10.3.4. Optimisation Lecture-seule
10.4. Résultats de transactions
10.4.1. Résultats de transactions
- Roll-back
- Si un participant à une transaction ne peut pas effectuer une validation, ou si le coordinateur de transaction ne peut pas indiquer aux participants de valider, la transaction sera annulée. Voir Section 10.4.3, « Transactions Roll-Back » pour plus d'informations.
- Valider
- Si chaque participant à une transaction peut valider, le coordinateur de transactions leur indique comment procéder, Voir Section 10.4.2, « Transactions de validation » pour plus d'informations.
- Résultat heuristique
- Si certains participants à une transaction valident, et que d'autres annulent, on parle de résultat heuristique. Les résultats heuristiques dérivent d'interventions humaines. Voir Section 10.4.4, « Résultats heuristiques » pour plus d'informations.
10.4.2. Transactions de validation
10.4.3. Transactions Roll-Back
10.4.4. Résultats heuristiques
- Rollback heuristique
- L'opération de validation a échoué car certains ou tous les participants ont abandonné la transaction.
- Validation heuristique
- Une opération de tentative de restauration a échoué, car tous les participants ont validé unilatéralement. Cela peut se produire si, par exemple, le coordinateur est en mesure de préparer correctement la transaction, mais décide alors de l'annuler en raison d'une défaillance de son côté, comme un oubli de mettre à jour son journal. Dans l'intervalle, les participants peuvent décider de valider.
- Mixed heuristiques
- Certains participants ont validé et d'autres ont abandonné
- Danger heuristique
- Le résultat de certaines mises à jour est inconnu. Pour les connus, ils ont soit tous été validés ou annulés.
10.4.5. Erreurs et exceptions pour les transactions JBoss
UserTransaction, voir la spécification UserTransaction API dans http://download.oracle.com/javaee/1.3/api/javax/transaction/UserTransaction.html.
10.5. Aperçu sur les transactions JTA
10.5.1. JTA (Java Transactions API)
10.5.2. Cycle de vie d'une transaction JTA
Votre application démarre une nouvelle transaction
Pour démarrer une transaction, votre application doit obtenir une instance de la classeUserTransactiondu JNDI ou bien, s'il s'agit d'un EJB, en provenance d'une annotation. L'interfaceUserTransactioncomprend des méthodes pour commencer, valider, ou annuler des transactions au plus haut niveau. Les transactions nouvellement créées sont associées automatiquement à leur thread invoquant. Les transactions imbriquées ne sont pas supportées dans JTA, donc toutes les transactions sont des transactions au plus haut niveau.En appelantUserTransaction.begin(), on commence une nouvelle transaction. Toute ressource qui est utilisée après cela sera associée à la transaction. S'il y a plus plus d'une seule ressource listée, votre transaction devient une transaction XA, et participera au protocole de validation en deux temps.Votre application modifie son état.
Dans l'étape suivante, votre transaction effectue son travail et précède aux changements d'état.Votre application décide de valider ou de s'annuler
Quand votre application a fini de changer d'état, elle décide si elle doit valider ou s'annuler. Elle appelle la méthode qui convient. Elle appelleUserTransaction.commit()ouUserTransaction.rollback(). C'est quand le protocole en deux phases (2PC) a lieu si vous avez listé plus d'une ressource. Section 10.2.9, « Le protocole de validation en 2-Phases »Le gestionnaire de transactions supprime la transaction des archives.
Après la validation ou l'annulation, le gestionnaire de transactions nettoie ses archives et supprime les informations sur votre transaction.
Le recouvrement d'échec a lieu automatiquement. Si une ressource, un participant à une transaction, ou un serveur d'applications est disponible, le gestionnaire de transactions s'occupe du recouvrement quand l'échec sous-jacent est résolu.
10.6. Configuration de sous-système de transaction
10.6.1. Configuration des transactions
Les procédures suivantes vous montrent comment configurer le sous-système de transactions de JBoss EAP 6.
10.6.2. Configuration de source de données transactionnelle
10.6.2.1. Configurez votre base de données pour utiliser les Transactions JTA
Cette tâche vous montre comment activer JTA (Java Transactions API) sur votre source de données.
Vous devez remplir les conditions suivantes avant de continuer cette tâche :
- Votre base de données ou autre ressource devra supporter JTA. Dans le doute, veuillez consulter la documentation.
- Créer une source de données. Veuillez vous référer à Section 10.6.2.4, « Créer une source de données Non-XA avec les interfaces de gestion ».
- Stopper le serveur JBoss EAP 6
- Obtenir un accès pour pouvoir éditer les fichiers de configuration directement, dans un éditeur de texte.
Procédure 10.1. Configurer la Source de données pour utiliser les Transactions JTA.
Ouvrir le fichier de configuration dans l'éditeur de texte.
Selon si vous exécutez JBoss EAP 6 sur un domaine géré ou un serveur autonome, votre fichier de configuration ne se trouvera pas au même endroit.Domaine géré
Le fichier de configuration par défaut d'un domaine géré se trouve dansEAP_HOME/domain/configuration/domain.xmlpour Red Hat Enterprise Linux, etEAP_HOME\domain\configuration\domain.xmlpour Microsoft Windows Server.Serveur autonome
Le fichier de configuration par défaut d'un serveur autonome se trouve dansEAP_HOME/standalone/configuration/domain.xmlpour Red Hat Enterprise Linux, etEAP_HOME\standalone\configuration\domain.xmlpour Microsoft Windows Server.
Chercher la balise
<datasource>qui correspond à votre source de données.La source de données aura un attributjndi-namecorrespondant à celui que vous aviez indiqué quand vous l'avez créée. Par exemple, la source de données ExampleDS ressemble à ceci :<datasource jndi-name="java:jboss/datasources/ExampleDS" pool-name="H2DS" enabled="true" jta="true" use-java-context="true" use-ccm="true">
Définir l'attribut
jtaàtrue.Ajouter l'élément suivant au contenu de votre balise<datasource>, tel qu'il apparaît à l'étape précédente :jta="true"Sauvegarder le fichier de configuration.
Sauvegarder le fichier de configuration et sortir de l'éditeur de texte.Démarrer JBoss EAP 6.
Relancer le serveur JBoss EAP 6.
JBoss EAP 6 démarre, et votre source de données est configurée pour utiliser les transactions JTA.
10.6.2.2. Configuration d'une source de données XA
Pour pouvoir ajouter une source de données XA, vous devrez vous connecter à la console de gestion. Voir Section 10.6.2.3, « Se conncecter à la console de gestion » pour plus d'informations.
Ajouter une nouvelle source de données.
Ajouter une nouvelle source de données à la plateforme JBoss EAP 6. Suivre les instructions qui se trouvent dans Section 10.6.2.4, « Créer une source de données Non-XA avec les interfaces de gestion », puis, cliquer sur l'onglet XA Datasource en haut.Configurer les propriétés supplémentaires suivant les besoins.
Tous les paramètres de la source de données se trouvent dans Section 10.6.2.5, « Paramètres de source de données ».
Votre source de données XA est configurée et prête à l'utilisation.
10.6.2.3. Se conncecter à la console de gestion
Prérequis
- JBoss EAP doit être en cours d'exécution.
Procédure 10.2. Se conncecter à la console de gestion
Naviguer vers la page de démarrage de la console de gestion
Naviguer vers la console de gestion. L'emplacement par défaut est http://localhost:9990/console/, où le port 9990 est prédéfini comme liaison de socket de console de gestion.Se conncecter à la console de gestion
Saisir le nom d'utilisateur et le mot de passe du compte que vous avez déjà créé pour vous connecter à l'écran de connexion de la console de gestion.
Figure 10.1. Écran de connexion de la console de gestion
Résultat
- Domaine géré
- Serveur autonome
10.6.2.4. Créer une source de données Non-XA avec les interfaces de gestion
Cette section explique les étapes à suivre pour créer une source de données non-XA, en utilisant la console de gestion ou le Management CLI.
Prérequis
- Le serveur JBoss EAP 6 doit être en cours d'exécution.
Note
Procédure 10.3. Créer une source de données en utilisant le Management CLI ou la console de gestion
Management CLI
- Lancer l'outil CLI et connectez-vous à votre serveur.
- Exécuter la commande suivante pour créer une source de données non-XA, et configurer les variables comme il se doit :
data-source add --name=DATASOURCE_NAME --jndi-name=JNDI_NAME --driver-name=DRIVER_NAME --connection-url=CONNECTION_URL
- Activer la source de données :
data-source enable --name=DATASOURCE_NAME
Console de gestion
- Connectez-vous à la Console de gestion.
Naviguez dans le panneau Datasources qui se trouve dans la console de gestion
Mode autonome
Sélectionnez l'onglet Profil qui se trouve en haut et à droite de la console.Mode Domaine
- Sélectionnez l'onglet Profiles qui se trouve en haut et à droite de la console.
- Sélectionner le profil qui convient à partir du menu déroulant en haut à gauche.
- Étendre le menu qui se trouve à gauche de la console.
- Sélectionner → à partir du menu à gauche de la console.
Figure 10.2. Panneau de sources de données
Créer une nouvelle source de données
- Sélectionner le bouton qui se trouve en haut du panneau Datasources.
- Saisir les attributs de la nouvelle source de données de l'assistant Create Datasource et appuyez sur .
- Saisir les informations sur le pilote JDBC dans l'assistant Create Datasource et appuyez sur .
- Saisir les paramètres de connexion dans l'assistant Create Datasource et appuyez sur .
La source de données non-Xa a été ajoutée au serveur. Elle est maintenant visible dans le fichier standalone.xml ou le fichier domain.xml, ainsi que dans les interfaces de gestion.
10.6.2.5. Paramètres de source de données
Tableau 10.1. Les paramètres de source de données communs aux sources XA ou non-XA
| Paramètre | Description |
|---|---|
| jndi-name | Le nom JNDI unique pour la source de données. |
| pool-name | Le nom du pool de gestion de la source de données. |
| activé | Indique si la source de données est activée. |
| use-java-context |
Indique si on doit relier la source de données au JNDI global.
|
| spy |
Activer la fonctionnalité
spy sur la couche JDBC. Cela journalisera tout le trafic JDBC dans la source de données. Le paramètre logging-category doit également être défini à org.jboss.jdbc.
|
| use-ccm | Activer le gestionnaire de connexion cache. |
| new-connection-sql | Un énoncé SQL qui exécute quand la connexion est ajoutée au pool de connexion. |
| transaction-isolation |
Un parmi :
|
| url-delimiter | Le délimiteur d'URLs d'une connexion url pour les bases de données clusterisées HA (Haute disponibilité). |
| url-selector-strategy-class-name | Une classe qui implémente l'interface org.jboss.jca.adapters.jdbc.URLSelectorStrategy. |
| sécurité |
Contient des éléments dépendants en tant que paramètres de sécurité. Voir Tableau 10.6, « Paramètres de sécurité ».
|
| validation |
Contient des éléments dépendants en tant que paramètres de validation. Voir Tableau 10.7, « Paramètres de validation ».
|
| timeout |
Contient des éléments dépendants en tant que paramètres de timeout. Voir Tableau 10.8, « Paramètres de timeout ».
|
| énoncé |
Contient des éléments dépendants en tant que paramètres d'énoncés. Voir Tableau 10.9, « Paramètres d'instruction ».
|
Tableau 10.2. Paramètres de source de données non-xa
| Paramètre | Description |
|---|---|
| jta | Active l'intégration JTA pour les sources de données non-XA. Ne s'applique pas aux sources de données XA. |
| connection-url | L'URL de connexion du pilote JDBC. |
| driver-class | Le nom complet de la classe de pilote JDBC. |
| connection-property |
Propriétés de connexions arbitraires passées à la méthode
Driver.connect(url,props). Chaque connection-property indique une paire name/value. Le nom de la propriété provient du nom, et la valeur provient du contenu de l'élément.
|
| pool |
Contient des éléments dépendants en tant que paramètres de pooling. Voir Tableau 10.4, « Les paramètres de pool communs aux sources XA ou non-XA ».
|
Tableau 10.3. Paramètres de source de données XA
| Paramètre | Description |
|---|---|
| xa-datasource-property |
Une propriété pour assigner la classe d'implémentation
XADataSource. Spécifiée par name=value. Si une méthode setter existe, dans le format setName, la propriété sera définie en appelant une méthode setter sous le format setName(value).
|
| xa-datasource-class |
Le nom complet de la classe d'implémentation de
javax.sql.XADataSource.
|
| pilote |
Unique référence au module de chargeur de classe qui contient le pilote JDBC. Le format accepté est driverName#majorVersion.minorVersion.
|
| xa-pool |
Contient des éléments dépendants en tant que paramètres de pooling. Voir Tableau 10.4, « Les paramètres de pool communs aux sources XA ou non-XA » et Tableau 10.5, « Paramètres du pool XA »
|
| recouvrement |
Contient des éléments dépendants en tant que paramètres de recouvrement. Voir Tableau 10.10, « Paramètres de recouvrement ».
|
Tableau 10.4. Les paramètres de pool communs aux sources XA ou non-XA
| Paramètre | Description |
|---|---|
| min-pool-size | Le nombre minimum de connexions contenues par un pool. |
| max-pool-size | Le nombre maximum de connexions qu'un pool peut contenir |
| Pré-remplissage | Indique si l'on doit essayer de pré-remplir un pool de connexion. Un élément vide indique une valeur true. La valeur par défaut est false. |
| use-strict-min | Indique si la taille du pool est stricte. false par défaut. |
| flush-strategy |
Indique si le pool est vidé en cas d'erreur. Les valeurs acceptées sont :
La valeur par défaut est
FailingConnectionOnly.
|
| allow-multiple-users | Indique si plusieurs utilisateurs pourront avoir accès à la source de données par la méthode getConnection(user, password), et si les types de pools internes ont une influence sur ce comportement. |
Tableau 10.5. Paramètres du pool XA
| Paramètre | Description |
|---|---|
| is-same-rm-override | Indique si la classe javax.transaction.xa.XAResource.isSameRM(XAResource) retourne true ou false. |
| entrelacement | Indique si on doit activer l'entrelacement pour les fabriques de connexion XA. |
| no-tx-separate-pools | Indique si on doit créer des sous-répertoires distincts pour chaque contexte. Cela est nécessaire pour les sources de données Oracle, qui ne permettent pas aux connexions XA d'être utilisées à la fois à l'intérieur et à l'extérieur d'une transaction de JTA |
| pad-xid | Indique si on doit remplir le Xid. |
| wrap-xa-resource |
Indique si on doit inclure XAResource dans une instance
org.jboss.tm.XAResourceWrapper.
|
Tableau 10.6. Paramètres de sécurité
| Paramètre | Description |
|---|---|
| user-name | Le nom d'utilisation pour créer une nouvelle connexion. |
| mot de passe | Le mot de passe à utiliser pour créer une nouvelle connexion |
| security-domain | Contient le nom d'un gestionnaire de sécurité JAAS, qui gère l'authentification. Ce nom correspond à l'attribut application-policy/name de la configuration de connexion JAAS. |
| reauth-plugin | Définit un plugin d'authentification à nouveau pour la ré authentification de connexions physiques. |
Tableau 10.7. Paramètres de validation
| Paramètre | Description |
|---|---|
| valid-connection-checker |
Une mise en œuvre d'interface
org.jboss.jca.adaptors.jdbc.ValidConnectionChecker qui fournit une méthode SQLException.isValidConnection(Connection e) pour valider une connexion. Une exception signifie que la connexion est détruite. Cela remplace le paramètre check-valid-connection-sql s'il est présent.
|
| check-valid-connection-sql | Un énoncé SQL pour vérifier la validité d'un pool de connexion. Peut être appelé quand une connexion gérée est tirée d'un pool. |
| validate-on-match |
Indique si la validation de niveau de connexion est exécutée lorsqu'une fabrique de connexions essaie de correspondre à une connexion gérée pour un ensemble donné.
Spécifier « true » pour
Validate-on-match n'est généralement pas effectué conjointement avec la spécification « true » de background-validation. Validate-on-match est nécessaire lorsqu'un client doit avoir une connexion validée avant l'utilisation. Ce paramètre est true par défaut.
|
| background-validation |
Indique que les connexions sont validées sur un thread d'arrière-plan. La validation de l'arrière-plan (Background validation) est une optimisation de performance lorsque non utilisé avec
validate-on-match. Si Validate-on-match est sur true, l'utilisation de background-validation pourrait entraîner des contrôles redondants. La validation de l'arrière-plan pourrait provoquer une mauvaise connexion (une connexion qui irait mal entre le moment de l'analyse de validation et avant d'être donnée au client), l'application cliente doit par conséquent tenir compte de cette possibilité.
|
| background-validation-millis | La durée, en millisecondes, pendant laquelle la validation d'arrière-plan exécute. |
| use-fast-fail |
Si défini sur true, échoue une allocation de connexion lors de la première tentative, si la connexion est non valide. La valeur par défaut est
false.
|
| stale-connection-checker |
Une instance de
org.jboss.jca.adapters.jdbc.StaleConnectionChecker qui produit une méthode booléenne isStaleConnection(SQLException e). Si cette méthode renvoie un true, l'exception sera contenue dans org.jboss.jca.adapters.jdbc.StaleConnectionException, qui correspond à une sous-classe de SQLException.
|
| exception-sorter |
Une instance de
org.jboss.jca.adapters.jdbc.ExceptionSorter qui fournit une méthode booléenne isExceptionFatal(SQLException e). Cette méthode validera si une exception est envoyée à toutes les instances d'un javax.resource.spi.ConnectionEventListener en tant que message connectionErrorOccurred.
|
Tableau 10.8. Paramètres de timeout
| Paramètre | Description |
|---|---|
| use-try-lock | Utiliser tryLock() au lieu de lock(). Vous essayerez ainsi d'obtenir un verrou pour le nombre de secondes configurées, avant le timeout, au lieu d'échouer immédiatement quand le verrou n'est pas disponible. La valeur par défaut est de 60 secondes. Par exemple, pour définir un timeout de 5 minutes, définir <use-try-lock>300</use-try-lock>. |
| blocking-timeout-millis | La durée maximale, en millisecondes, de blocage lorsque vous attendez une connexion. Après que ce délai soit dépassé, une exception sera levée. Cela bloque uniquement pendant que vous attendez un permis de connexion et ne lève pas d'exception si la création d'une nouvelle connexion prend beaucoup de temps. Par défaut, 30000, qui correspond à 30 secondes. |
| idle-timeout-minutes |
La durée maximale, en minutes, avant qu'une connexion inactive soit fermée. La durée maximale réelle dépend de la durée d'analyse de l'idleRemover, qui correspond à la moitié du plus petit
idle-timeout-minutes de n'importe quel pool.
|
| set-tx-query-timeout |
Indique si on doit définir le timeout d'interrogation par rapport au temps qui reste avant le timeout de transaction. Si aucune transaction n'existe, on utilisera le timeout de recherche qui a été configuré. La valeur par défaut est
false.
|
| query-timeout | Timeout pour les recherches, en secondes. La valeur par défaut est « no timeout ». |
| allocation-retry | Le nombre de tentatives de connexion avant d'envoyer une connexion. La valeur par défaut est 0, pour qu'une exception puisse être envoyée à la première défaillance. |
| allocation-retry-wait-millis |
Le temps, en millisecondes, qu'il faut attendre avant de retenter d'allouer une connexion. La valeur par défaut est 5 000, soit 5 secondes.
|
| xa-resource-timeout |
Si la valeur est non nulle, elle passe à la méthode
XAResource.setTransactionTimeout.
|
Tableau 10.9. Paramètres d'instruction
| Paramètre | Description |
|---|---|
| track-statements |
Indique si l'on doit vérifier les instructions non fermées lorsqu'une connexion est renvoyée à un pool ou qu'une instruction est retournée dans le cache d'instruction préparée. Si false, les instructions ne seront pas suivies.
Valeurs valides
|
| prepared-statement-cache-size | Le nombre d'instructions préparées par connexion, dans le cache LRU (le moins souvent utilisé récemment). |
| share-prepared-statements |
Indique si le fait de demander la même instruction deux fois sans la fermer utilise la même instruction préparée sous-jacente. La valeur par défaut est
false.
|
Tableau 10.10. Paramètres de recouvrement
| Paramètre | Description |
|---|---|
| recover-credential | Une paire nom d'utilisateur/mot de passe ou domaine de sécurité pour le recouvrement. |
| recover-plugin |
Une mise en œuvre de la classe
org.jboss.jca.core.spi.recoveryRecoveryPlugin à utiliser pour le recouvrement.
|
10.6.3. Journalisation des transactions
10.6.3.1. Messages de journalisation de transactions
DEBUG pour le logger de transaction. Pour un débogage détaillé, utiliser le niveau de journalisation TRACE. Veuillez consulter Section 10.6.3.2, « Configurer la journalisation des sous-systèmes de transactions » pour plus d'informations sur la configuration du logger de transaction.
TRACE. Vous trouverez ci-dessous quelques-uns des messages les plus courants. Cette liste n'est pas exhaustive, il se peut que vous rencontriez d'autres messages.
Tableau 10.11. Changement d'état de transaction
| Début de transaction |
Quand une transaction commence, le code suivant s'exécute :
com.arjuna.ats.arjuna.coordinator.BasicAction::Begin:1342 tsLogger.logger.trace("BasicAction::Begin() for action-id "+ get_uid());
|
| Validation de transaction |
Quand une transaction est validée, le code suivant s'exécute :
com.arjuna.ats.arjuna.coordinator.BasicAction::End:1342 tsLogger.logger.trace("BasicAction::End() for action-id "+ get_uid());
|
| Restauration de transaction |
Quand une transaction est restaurée, le code suivant s'exécute :
com.arjuna.ats.arjuna.coordinator.BasicAction::Abort:1575 tsLogger.logger.trace("BasicAction::Abort() for action-id "+ get_uid());
|
| Délai d'expiration de transaction |
Quand une transaction expire, le code suivant s'exécute :
com.arjuna.ats.arjuna.coordinator.TransactionReaper::doCancellations:349 tsLogger.logger.trace("Reaper Worker " + Thread.currentThread() + " attempting to cancel " + e._control.get_uid());
Vous verrez ensuite le même thread restaurer la transaction comme montré ci-dessus.
|
10.6.3.2. Configurer la journalisation des sous-systèmes de transactions
Utiliser cette procédure pour contrôler la quantité d'informations enregistrées sur les transactions, indépendamment des autres paramètres de journalisation dans JBoss EAP 6. La procédure montre comment procéder dans la console de gestion sur le web. La commande de gestion CLI est donnée par la suite.
Procédure 10.4. Configurer le Transaction Logger par la console de gestion
Naviguer vers la zone de configuration de la journalisation
Dans la console de gestion, cliquer sur l'onglet Profiles en haut et à gauche de l'écran. Si vous utilisez un domaine géré, fermer le profil du serveur que vous souhaitez configurer, à partir de la case de sélection Profile qui se trouve en haut et à droite.Dérouler le menu Core, et cliquer sur l'étiquette Logging.Modifier les attributs de
com.arjuna.Cliquer sur le bouton Edit dans la section Details qui se situe en bas de la page. Vous pourrez ajouter ici les informations de journalisation spécifiques à la classe. La classecom.arjunaest déjà présente. Vous pourrez modifier le niveau de journalisation et décider si vous souhaitez utiliser les gestionnaires parents.- Niveau de journalisation
- Le niveau de journalisation est
WARNpar défaut. Comme les transactions peuvent produire une grande quantité de messages de journalisation, la signification des niveaux de journalisation standard est légèrement différente pour le Transaction Logger. En général, les messages avec des niveaux de gravité moins élevés que le niveau choisi sont ignorés.Niveaux de journalisation des transactions, du plus au moins détaillé.
- TRACE
- DEBUG
- INFO
- WARN
- ERROR
- FAILURE
- Utiliser les gestionnaires parents
- Indique si l'enregistreur d'événements doit envoyer ses sorties vers l'enregistreur d'événements parent. Le comportement par défaut est
true.
- Les changements prennent effet immédiatement.
10.6.3.3. Naviguer et gérer les transactions
log-store. Une opération API nommée probe lit les journaux de transactions et crée un noeud pour chaque journal. Vous pouvez invoquer la commande probe manuellement, quand vous souhaitez réactualiser le log-store. Il est normal pour les journaux de transactions d'apparaître ou de disparaître rapidement.
Exemple 10.1. Réactualiser le Log Store
default dans un domaine géré. Dans le cas d'un serveur autonome, supprimer profile=default de la commande.
/profile=default/subsystem=transactions/log-store=log-store/:probe
Exemple 10.2. Voir toutes les transactions préparées
ls de système de fichier.
ls /profile=default/subsystem=transactions/log-store=log-store/transactions
Gérer une transaction
- Voir des attributs de transaction.
- Pour voir des informations sur une transaction, comme son nom JNDI, son nom de produit EIS ou sa version, ou statut, utiliser la commande CLI
:read-resource./profile=default/subsystem=transactions/log-store=log-store/transactions=0\:ffff7f000001\:-b66efc2\:4f9e6f8f\:9:read-resource
- Voir tous les participants d'une transaction.
- Chaque journal de transaction contient un élément enfant nommé
participants. Utiliser la commande CLIread-resourceCLI sur cet élément pour voir les participants des transactions. Les participants sont identifiés par leurs noms JNDI./profile=default/subsystem=transactions/log-store=log-store/transactions=0\:ffff7f000001\:-b66efc2\:4f9e6f8f\:9/participants=java\:\/JmsXA:read-resource
Le résultat devrait ressembler à ceci :{ "outcome" => "success", "result" => { "eis-product-name" => "HornetQ", "eis-product-version" => "2.0", "jndi-name" => "java:/JmsXA", "status" => "HEURISTIC", "type" => "/StateManager/AbstractRecord/XAResourceRecord" } }Le statut du résultat affiché ici est dans un étatHEURISTICet est susceptible d'être recouvert. Voir Recouvrement d'une transaction. pour plus d'informations. - Supprimer une transaction.
- Chaque journal de transaction supporte une opération
:deletepour effacer l'enregistrement qui représente la transaction./profile=default/subsystem=transactions/log-store=log-store/transactions=0\:ffff7f000001\:-b66efc2\:4f9e6f8f\:9:delete
- Recouvrement d'une transaction.
- Chaque journal de transaction supporte le recouvrement par la commande CLI
:recover.Recouvrement des transactions heuristiques et des participants
- Si le statut de la transaction est
HEURISTIC, l'opération de recouvrement change l'état enPREPAREet déclenche un recouvrement. - Si l'un des participants de la transaction est heuristique, l'opération de recouvrement tente de reprendre l'opération
commit(validation) à nouveau. En cas de succès, le participant est retiré du journal des transactions. Vous pouvez vérifier cela en exécutant à nouveau l'opération:probesur lelog-storeet en vérifiant que le participant n'est plus inscrit. Si c'est le dernier participant, la transaction sera également supprimée.
- Réactualiser le statut de la transaction qui a besoin d'être recouvrée.
- Si une transaction a besoin d'être recouvrée, vous pourrez utiliser la commande CLI
:refreshpour vous assurer qu'elle a toujours besoin d'être recouvrée, avant de tenter le recouvrement./profile=default/subsystem=transactions/log-store=log-store/transactions=0\:ffff7f000001\:-b66efc2\:4f9e6f8f\:9:refresh
Si les statistiques de TM (Transaction Manager) sont activées, vous pouvez consulter les statistiques à propos du Gestionnaire de Transactions et du sous-système de transactions. Veuillez consulter Section 10.7.8.2, « Configurer le Transaction Manager (TM) ou Gestionnaire de transactions » pour plus d'informations sur l'activation des statistiques de TM.
Tableau 10.12. Les statistiques de sous-système de transaction
| Statistique | Description | Commande CLI |
|---|---|---|
| Total |
Le nombre total de transactions exécutées par le gestionnaire de transactions sur ce serveur.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-transactions,include-defaults=true) |
| Validé |
Le nombre de transactions validées exécutées par le gestionnaire de transactions sur ce serveur.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-committed-transactions,include-defaults=true) |
| Abandonné |
Le nombre de transactions interrompues exécutées par le gestionnaire de transactions sur ce serveur.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-aborted-transactions,include-defaults=true) |
| Délai expiré |
Le nombre de transactions expirées exécutées par le gestionnaire de transactions sur ce serveur.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-timed-out-transactions,include-defaults=true) |
| Heuristiques |
Pas disponible dans la Console de Gestion. Nombre de transactions dans un état heuristique.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-heuristics,include-defaults=true) |
| Transactions In-Flight |
Pas disponible dans la console de gestion. Nombre de transactions commencées mais pas encore achevées.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-inflight-transactions,include-defaults=true) |
| Origine de l'échec - Applications |
Le nombre de transactions échouées dont l'origine de l'échec était une application.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-application-rollbacks,include-defaults=true) |
| Origine de l'échec - Ressources |
Le nombre de transactions échouées dont l'origine de l'échec était une ressource.
|
/host=master/server=server-one/subsystem=transactions/:read-attribute(name=number-of-resource-rollbacks,include-defaults=true) |
10.7. Utiliser les transactions JTA
10.7.1. Transactions JTA
Les procédures suivantes sont utiles quand vous aurez besoin d'utiliser des transactions dans votre application.
10.7.2. Transactions de contrôle
Cette liste de procédures expose les différentes façons de contrôler les transactions dans vos applications utilisant les API JTA ou JTS.
10.7.3. Démarrer une transaction
Dans une transaction distribuée, les participants à la transaction se trouvent dans des applications séparées sur de multiples serveurs. Si un participant rejoint une transaction déjà existante, plutôt que de créer un nouveau contexte de transaction, les deux (ou plus) participants qui partagent le contexte participent à une transaction distribuée. Pour utiliser une transaction distribuée, vous devez configurer l'ORB. Veuillez consulter la section ORB Configuration du Administration and Configuration Guide pour plus d'informations sur la configuration ORB.
Obtenez une instance de
UserTransaction.Vous pouvez obtenir une instance par JNDI, injection, ou un EjbContext d'EJB, si l'EJB utilise des transactions gérées-bean, par l'annotation@TransactionManagement(TransactionManagementType.BEAN).JNDI
new InitialContext().lookup("java:comp/UserTransaction")Injection
@Resource UserTransaction userTransaction;
EjbContext
EjbContext.getUserTransaction()
Appeler
UserTransaction.begin()une fois connecté à votre source de données.... try { System.out.println("\nCreating connection to database: "+url); stmt = conn.createStatement(); // non-tx statement try { System.out.println("Starting top-level transaction."); userTransaction.begin(); stmtx = conn.createStatement(); // will be a tx-statement ... } }
L'un des avantages des EJB est que le conteneur gère toutes les transactions. Si vous avez configuré l'ORB, le conteneur gérera les transactions distribuées pour vous.
La transaction est lancée. Toute utilisation de votre source de données sera transactionnelle jusqu'à ce que vous validiez ou annuliez la transaction.
Note
10.7.4. Transactions imbriquées
prepare et une phase commit ou abort. Ce type de transaction imbriquée peut mener à des résultats incohérents, comme un coordinateur de sous-transaction en cours de validation qui découvre qu'une ressource ne peut être validée. Il se peut que le coordinateur ne puisse être capable de dire aux ressources validées de s'interrompre, causant ainsi un résultat heuristique. Cette transaction stricte imbriquée OTS est disponible via l'interface CosTransactions::SubtransactionAwareResource.
ArjunaOTS::ArjunaSubtranAwareResource. Il est poussé par un protocole de validation à deux phases à chaque fois qu'une transaction imbriquée est validée.
10.7.5. Valider une transaction
Vous devez démarrer une transaction avant de pouvoir la valider. Pour plus d'informations sur le démarrage d'une transaction, veuillez consulter Section 10.7.3, « Démarrer une transaction ».
Appeler la méthode
commit()surUserTransaction.Lorsque vous appelez la méthodecommit()surUserTransaction, le gestionnaire de transactions tente de valider la transaction.@Inject private UserTransaction userTransaction; public void updateTable(String key, String value) EntityManager entityManager = entityManagerFactory.createEntityManager(); try { userTransaction.begin(): <!-- Perform some data manipulation using entityManager --> ... // Commit the transaction userTransaction.commit(); } catch (Exception ex) { <!-- Log message or notify Web page --> ... try { userTransaction.rollback(); } catch (SystemException se) { throw new RuntimeException(se); } throw new RuntimeException(e); } finally { entityManager.close(); } }Si vous utilisez des CMT (Container Managed Transactions), vous n'avez pas besoin de valider manuellement.
Si vous configurez votre bean pour qu'il puisse utiliser des transactions gérées conteneur, le conteneur devra gérer le cyle de vie des transactions pour vous sur la base d'annotations que vous aurez configurées dans le code.
Votre source de données valide et votre transaction se termine, ou une exception est lancée.
Note
10.7.6. Annuler une transaction
Vous devez démarrer une transaction avant de pouvoir la supprimer. Pour plus d'informations sur le démarrage d'une transaction, veuillez consulter Section 10.7.3, « Démarrer une transaction ».
Appeler la méthode
rollback()surUserTransaction.Lorsque vous appelez la méthoderollback()surUserTransaction, le gestionnaire de transactions tentera de valider la transaction.@Inject private UserTransaction userTransaction; public void updateTable(String key, String value) EntityManager entityManager = entityManagerFactory.createEntityManager(); try { userTransaction.begin(): <!-- Perform some data manipulation using entityManager --> ... // Commit the transaction userTransaction.commit(); } catch (Exception ex) { <!-- Log message or notify Web page --> ... try { userTransaction.rollback(); } catch (SystemException se) { throw new RuntimeException(se); } throw new RuntimeException(e); } finally { entityManager.close(); } }Si vous utilisez des CMT (Container Managed Transactions), vous n'avez pas besoin de supprimer la transaction manuellement.
Si vous configurez votre bean pour qu'il puisse utiliser des transactions gérées conteneur, le conteneur devra gérer le cyle de vie des transactions pour vous sur la base d'annotations que vous aurez configurées dans le code.
Votre transaction est annulée par le gestionnaire de transactions.
Note
10.7.7. Gérer un résultat heuristique dans une transaction
Procédure 10.5. Gérer un résultat heuristique dans une transaction
Déterminer la cause
En général, la cause d'un résultat heuristique pour une transaction est qu'un gestionnaire de ressources a promis qu'il pourrait commettre ou annuler, et il n'a pas pu remplir sa promesse. Cela pouvait être dû à un problème avec un composant de tierce partie, la couche d'intégration entre le composant tiers et la plate-forme EAP 6 ou bien la plate-forme JBoss EAP 6 elle-même.De loin, les deux causes les plus communes d'erreurs heuristiques sont des erreurs temporaires situées dans l'environnement ou des erreurs de code liées aux gestionnaires de ressources.Solution aux échecs temporaires de l'environnement
Normalement, s'il y a un échec temporaire dans votre environnement, vous le saurez avant d'être au courant de l'erreur heuristique. Il peut s'agir d'une défaillance de réseau ou de matériel, d'une erreur de base de données, d'une panne de courant, d'un hôte ou de tout autre cause.En cas de résultat heuristique ayant lieu dans un environnement de test, au cours de test de stress, cela vous fournit des informations sur les points faibles de votre environnement.Avertissement
La plate-forme JBoss EAP 6 restaurera automatiquement les transactions qui ne sont pas dans un état heuristique au moment de la défaillance, mais elle ne tentera pas de restaurer les transactions heuristiques.Contacter les fournisseurs de gestionnaires de ressources
Si vous n'expérimentez aucun échec évident dans votre environnement, ou si le résultat heuristique est facilement reproductible, c'est probablement une erreur de codage. Contacter les fournisseurs de tierce partie pour savoir si une solution est disponible. Si vous pensez que le problème est dans le gestionnaire de transactions de la plate-forme JBoss EAP 6 elle-même, veuillez prendre contact avec Red Hat Global Support Services.Dans un environnement de test, supprimer les logs et démarrez à nouveau la plate-forme JBoss EAP 6.
Dans un environnement de test, ou bien dans les cas où vous ne vous souciez pas de l'intégrité des données, le fait de supprimer les journaux des transactions et de redémarrer la plate-forme JBoss EAP 6 se débarrasse du résultat heuristique. Les journaux des transactions sont situés dansEAP_HOME/standalone/data/tx-object-store/pour les serveurs autonomes, ou dansEAP_HOME/domain/servers/SERVER_NAME/data/tx-object-storepour les domaines gérés, par défaut. Dans le cas d'un domaine géré, SERVER_NAME se rapporte au nom du serveur individuel qui participe à un groupe de serveurs.Résoudre le résultat à la main
Le processus de résolution de résultat à la main dépend des circonstances particulières de l'incident. Normalement, vous aurez besoin de procéder aux étapes suivantes, en les appliquant à votre situation.- Identifier les gestionnaires de ressources impliqués.
- Examiner l'état dans le gestionnaire de transactions et dans les gestionnaires de ressources.
- Forcer manuellement le nettoyage des journaux et la reconciliation des données dans un ou plusieurs des composants impliqués.
La façon dont procéder à ces étapes sont au delà de la portée de ce document.
10.7.8. Temps d'expiration des transactions
10.7.8.1. Les délais d'attente de transactions
10.7.8.2. Configurer le Transaction Manager (TM) ou Gestionnaire de transactions
default, il se peut que vous ayez à modifier les étapes et les commandes de la manière suivante.
Notes sur les commandes d'exemple
- Pour la console de gestion, le profil par défaut
defaultest celui qui sera sélectionné quand vous vous connectez. Si vous souhaitez modifier la configuration du Transaction Manager dans un autre profile, sélectionnez votre profile à la place, et non pasdefault, pour chaque instruction.De même, substituez votre profil à la place du profil par défautdefaultpour les commandes CLI de l'exemple. - Si vous utilisez un Serveur Autonome, un seul profil existe. Ignorer toute instruction pour choisir un profil spécifique. Dans les commandes CLI, retirer la partie
/profile=defaultdes commandes d'échantillon.
Note
transactions doit être activé. Il est activé par défaut, et il faut pour cela qu'un certain nombre d'autres sous-systèmes fonctionnent correctement, donc il est improbable qu'il soit désactivé.
Pour configurer le TM à l'aide de la Console de gestion sur le web, sélectionnez l'onglet Runtime de la liste dans la partie supérieure gauche de l'écran de la console de gestion. Si vous utilisez un domaine géré, vous avez le choix de plusieurs profils. Choisir le bon profil de la boîte de sélection dans la partie supérieure droite de l'écran Profils. Étendez le menu Container, et sélectionnez Transactions.
Dans le Management CLI, vous pouvez configurer le TM en utilisant une série de commandes. Les commandes commencent toutes par /profile=default/subsystem=transactions/ pour un domaine géré avec default de profil, ou par /subsystem=transactions pour un serveur autonome.
Tableau 10.13. Options de configuration de la TM
| Option | Description | Commande CLI |
|---|---|---|
|
Activer les statistiques
|
Indique s'il faut activer les statistiques de transaction. Ces statistiques se trouvent dans la console de gestion dans la section Subsystem Metrics de l'onglet Runtime.
| /profile=default/subsystem=transactions/:write-attribute(name=enable-statistics,value=true)
|
|
Activer le statut TSM
|
Indique si l'on doit activer le service de gestion du statut de transaction (TSM), qui est utilisé pour le recouvrement hors-processus.
| /profile=default/subsystem=transactions/:write-attribute(name=enable-tsm-status,value=false)
|
|
Délai d'attente par défaut
|
Délai d'attente de transaction par défaut. La valeur par défaut est de
300 secondes. Vous pouvez la remplacer par programmation, sur la base d'une transaction.
| /profile=default/subsystem=transactions/:write-attribute(name=default-timeout,value=300)
|
|
Chemin
|
Le chemin d'accès relatif ou absolu du système de fichiers dans lequel le cœur du gestionnaire de transactions stocke les données. Par défaut, la valeur est un chemin d'accès relatif à la valeur de l'attribut
relative-to.
| /profile=default/subsystem=transactions/:write-attribute(name=path,value=var)
|
|
Relatif à
|
Référence une configuration de chemin global dans le modèle du domaine. La valeur par défaut correspond au répertoire de données de JBoss EAP 6, qui correspond à la valeur de la propriété
jboss.server.data.dir, et qui a pour valeur par défaut EAP_HOME/domain/data/ pour un Domaine Géré, ou EAP_HOME/standalone/data/ pour une instance de Serveur Autonome. La valeur de l'attribut TM du chemin path est relative à ce chemin. Utiliser une chaîne vide pour désactiver le comportement par défaut et forcer la valeur de l'attribut du chemin path qui doit être traité comme un chemin absolu.
| /profile=default/subsystem=transactions/:write-attribute(name=relative-to,value=jboss.server.data.dir)
|
|
Chemin de Store Objet
|
Un chemin de système de fichiers relatif ou absolu où le store objet TM stocke des données. Relatif, par défaut, à la valeur du paramètre
object-store-relative-to.
| /profile=default/subsystem=transactions/:write-attribute(name=object-store-path,value=tx-object-store)
|
|
Chemin de Store Objet Relatif à
|
Référence une configuration de chemin global dans le modèle du domaine. La valeur par défaut correspond au répertoire de données de JBoss EAP 6, qui correspond à la valeur de la propriété
jboss.server.data.dir, et qui a pour valeur par défaut EAP_HOME/domain/data/ pour un Domaine Géré, ou EAP_HOME/standalone/data/ pour une instance de Serveur Autonome. La valeur de l'attribut TM du chemin path est relative à ce chemin. Utiliser une chaîne vide pour désactiver le comportement par défaut et forcer la valeur de l'attribut du chemin path qui doit être traité comme un chemin absolu.
| /profile=default/subsystem=transactions/:write-attribute(name=object-store-relative-to,value=jboss.server.data.dir)
|
|
Liaisons de sockets
|
Indique le nom de la liaison du socket utilisé par le gestionnaire de transactions pour la récupération et la création des identificateurs de transactions, lorsque le mécanisme du socket est utilisé. Se référer à
processus-id-socket-max-ports pour plus d'informations sur la génération de l'identificateur unique. Les liaisons de socket sont spécifiées par le groupe de serveurs dans l'onglet Serveur de la console de gestion.
| /profile=default/subsystem=transactions/:write-attribute(name=socket-binding,value=txn-recovery-environment)
|
|
Liaison de socket de statut
|
Indique la liaison de socket à utiliser pour le gestionnaire de statuts de transactions.
| /profile=default/subsystem=transactions/:write-attribute(name=status-socket-binding,value=txn-status-manager)
|
|
Listener de recouvrement
|
Indique si oui ou non le processus de recouvrement de transaction doit écouter au socket de réseau. La valeur par défaut est
false.
| /profile=default/subsystem=transactions/:write-attribute(name=recovery-listener,value=false)
|
Tableau 10.14. Options de configuration TM avancées
| Option | Description | Commande CLI |
|---|---|---|
|
jts
|
Indique si l'on doit utiliser les transactions Java Transaction Service (JTS). La valeur par défaut est
false, qui utilise des transactions JTA uniquement.
| /profile=default/subsystem=transactions/:write-attribute(name=jts,value=false)
|
|
Identifiant de nœud
|
L'identifiant de nœud pour le service JTS. Ce dernier doit être unique pour le service JTS, parce que le gestionnaire de transactions l'utilise pour la récupération.
| /profile=default/subsystem=transactions/:write-attribute(name=node-identifier,value=1)
|
|
process-id-socket-max-ports
|
Le gestionnaire de transactions crée un identifiant unique pour chaque journal des transactions. Deux mécanismes différents sont fournis pour générer des identificateurs uniques : un mécanisme basé sur le socket et un mécanisme fondé sur l'identificateur de processus du processus.
Dans le cas de l'identifiant basé-socket, le socket est ouvert et son numéro de port est utilisé pour l'identifiant. Si le port est déjà utilisé, on cherchera le port suivant, jusqu'à ce qu'un port libre soit trouvé. Les
processus-id-socket-max-ports représentent le nombre maximal de sockets que le TM va essayer avant d'abandonner. La valeur par défaut est 10.
| /profile=default/subsystem=transactions/:write-attribute(name=process-id-socket-max-ports,value=10)
|
|
process-id-uuid
|
Définir à
true avec un identifiant de processus pour créer un identifiant unique pour chaque transaction. Sinon, le mécanisme basé socket sera utilisé. La valeur par défaut est true. Se référer à process-id-socket-max-ports pour obtenir davantage d'informations.
| /profile=default/subsystem=transactions/:write-attribute(name=process-id-uuid,value=true)
|
|
use-hornetq-store
|
Utiliser les mécanismes de stockage journalisés de HornetQ au lieu du stockage basé sur des fichiers, pour les journaux de transactions. Ceci est désactivé par défaut, mais peut améliorer les performances I/O. Il n'est pas recommandé pour les transactions JTS sur les gestionnaires de transactions séparés .
| /profile=default/subsystem=transactions/:write-attribute(name=use-hornetq-store,value=false)
|
10.7.9. Gestion des erreurs de transactions JTA
10.7.9.1. Erreurs de transactions
Note
Ce type d'erreur se manifeste souvent quand Hibernate n'est pas en mesure d'obtenir une connexion de base de données pour le chargement différé. Si cela survient fréquemment, vous pourrez augmenter la valeur du temps d'expiration. Voir Section 10.7.8.2, « Configurer le Transaction Manager (TM) ou Gestionnaire de transactions ».
NotSupportedException
L'exception NotSupportedException indique habituellement que vous avez tenté d'insérer une transaction JTA, et que ce n'est pas pris en charge. Si vous n'étiez pas en train d'essayer d'insérer une transaction, il est probable qu'une autre transaction a commencé dans une tâche de pool de threads, mais a terminé la tâche sans suspendre, ni mettre fin à la transaction.
UserTransaction , qui s'en occupe automatiquement. Si tel est le cas, il y a peut-être un problème dans le framework.
TransactionManager ou Transactions directement, considérez le comportement suivant lors de la validation ou de l'annulation d'une transaction. Si votre code utilise les méthodes du TransactionManager pour contrôler vos transactions, la validation ou l'annulation d'une transaction dissociera la transaction du thread actuel. Toutefois, si votre code utilise les méthodes Transaction , l'opération peut être pas associée au thread en cours d'exécution, et il faudra la dissocier de son thread manuellement, avant de la retourner au pool de threads.
Cette erreur a lieu si vous essayez d'enlister une seconde ressource non-XA dans une transaction. Si vous avez besoin de ressources multiples pour une transaction, elles doivent être XA.
10.8. Configuration ORB
10.8.1. A propos de CORBA (Common Object Request Broker Architecture)
10.8.2. Configurer l'ORB pour les transactions JTS
Note
full et full-ha uniquement. Dans un serveur autonome, il est disponible uniquement quand vous utilisez les configurations standalone-full.xml ou standalone-full-ha.xml.
Procédure 10.6. Configurer l'ORB par la console de gestion
Voir les paramètres de configuration du profil.
Sélectionnez Profiles (domaine géré) ou Profile (serveur autonome) dans la partie supérieure droite de la console de gestion. Si vous utilisez un domaine géré, sélectionnez soit le profil full ou full-ha à partir de la boîte de dialogue de sélection en haut à gauche.Modifier les paramètres Initialisateurs
Étendre le menu Sous-système sur la gauche, si nécessaire. Étendre le sous-menu Conteneur et cliquer sur JacORB.Sur le formulaire qui apparaît sur l'écran principal, sélectionner l'onglet Initialisateur, et cliquer sur le bouton Modofier.Activer les intercepteurs de sécurité en configurant la valeur de Security àactive.Pour activer ORB sur JTS, définir la valeur des Intercepteurs de transations àactive, au lieu de la valeur par défautspec.Voir le lien Besoin d'aide ? sur le formulaire pour accéder à des explications sur ces valeurs. Cliquer sur Sauvegarde quand vous aurez fini de modifier les valeurs.Configuration ORB avancée
Voir les autres sections du formulaire pour les options de configuration avancées. Chaque section inclut un lien Besoin d'aide ? avec des informations détaillées sur les paramètres.
Vous pouvez configurer chaque aspect de l'ORB à l'aide du Management CLI. Les commandes suivantes configurent les initialisateurs aux mêmes valeurs que celles de la procédure ci-dessus, pour la console de gestion. Il s'agit de la configuration minimale pour l'ORB, si utilisé avec JTS.
/profile=full des commandes.
Exemple 10.3. Activer les intercepteurs de sécurité
/profile=full/subsystem=jacorb/:write-attribute(name=security,value=on)
Exemple 10.4. Activer l'ORB pour JTS
/profile=full/subsystem=jacorb/:write-attribute(name=transactions,value=on)
Exemple 10.5. Activer les transactions dans le sous-système JacORB
/profile=full/subsystem=jacorb/:write-attribute(name=transactions,value=on)
Exemple 10.6. Activer JTS dans le sous-système de transactions
/subsystem=transactions:write-attribute(name=jts,value=true)
10.9. Références de transactions
10.9.1. Erreurs et exceptions pour les transactions JBoss
UserTransaction, voir la spécification UserTransaction API dans http://download.oracle.com/javaee/1.3/api/javax/transaction/UserTransaction.html.
10.9.2. Limitations de JTA Clustering
10.9.3. Exemple de transaction JTA
Exemple 10.7. Exemple de transaction JTA
public class JDBCExample {
public static void main (String[] args) {
Context ctx = new InitialContext();
// Change these two lines to suit your environment.
DataSource ds = (DataSource)ctx.lookup("jdbc/ExampleDS");
Connection conn = ds.getConnection("testuser", "testpwd");
Statement stmt = null; // Non-transactional statement
Statement stmtx = null; // Transactional statement
Properties dbProperties = new Properties();
// Get a UserTransaction
UserTransaction txn = new InitialContext().lookup("java:comp/UserTransaction");
try {
stmt = conn.createStatement(); // non-tx statement
// Check the database connection.
try {
stmt.executeUpdate("DROP TABLE test_table");
stmt.executeUpdate("DROP TABLE test_table2");
}
catch (Exception e) {
// assume not in database.
}
try {
stmt.executeUpdate("CREATE TABLE test_table (a INTEGER,b INTEGER)");
stmt.executeUpdate("CREATE TABLE test_table2 (a INTEGER,b INTEGER)");
}
catch (Exception e) {
}
try {
System.out.println("Starting top-level transaction.");
txn.begin();
stmtx = conn.createStatement(); // will be a tx-statement
// First, we try to roll back changes
System.out.println("\nAdding entries to table 1.");
stmtx.executeUpdate("INSERT INTO test_table (a, b) VALUES (1,2)");
ResultSet res1 = null;
System.out.println("\nInspecting table 1.");
res1 = stmtx.executeQuery("SELECT * FROM test_table");
while (res1.next()) {
System.out.println("Column 1: "+res1.getInt(1));
System.out.println("Column 2: "+res1.getInt(2));
}
System.out.println("\nAdding entries to table 2.");
stmtx.executeUpdate("INSERT INTO test_table2 (a, b) VALUES (3,4)");
res1 = stmtx.executeQuery("SELECT * FROM test_table2");
System.out.println("\nInspecting table 2.");
while (res1.next()) {
System.out.println("Column 1: "+res1.getInt(1));
System.out.println("Column 2: "+res1.getInt(2));
}
System.out.print("\nNow attempting to rollback changes.");
txn.rollback();
// Next, we try to commit changes
txn.begin();
stmtx = conn.createStatement();
ResultSet res2 = null;
System.out.println("\nNow checking state of table 1.");
res2 = stmtx.executeQuery("SELECT * FROM test_table");
while (res2.next()) {
System.out.println("Column 1: "+res2.getInt(1));
System.out.println("Column 2: "+res2.getInt(2));
}
System.out.println("\nNow checking state of table 2.");
stmtx = conn.createStatement();
res2 = stmtx.executeQuery("SELECT * FROM test_table2");
while (res2.next()) {
System.out.println("Column 1: "+res2.getInt(1));
System.out.println("Column 2: "+res2.getInt(2));
}
txn.commit();
}
catch (Exception ex) {
ex.printStackTrace();
System.exit(0);
}
}
catch (Exception sysEx) {
sysEx.printStackTrace();
System.exit(0);
}
}
}
10.9.4. Documentation API pour JBoss Transactions JTA
Chapitre 11. Hibernate
11.1. Hibernate Core
11.2. Java Persistence API (JPA)
11.2.1. JPA
bean-validation, greeter, et kitchensink : Section 1.4.2.1, « Accès aux Quickstarts ».
11.2.2. Hibernate EntityManager
11.2.3. Guide de départ
11.2.3.1. Créer un projet JPA dans JBoss Developer Studio
Cet exemple indique les étapes à effectuer pour créer un projet JPA dans JBoss Developer Studio.
Procédure 11.1. Créer un projet JPA dans JBoss Developer Studio
- Dans la fenêtre JBoss Developer Studio, cliquer sur → → .
- Dans la boîte de dialogue du projet, taper le nom du projet.

- Sélectionner un runtime cible depuis le menu déroulant.
- Si aucun runtime cible n'est disponible, cliquer sur .
- Trouver le Dossier JBoss Community dans la liste.
- Sélectionner JBoss Enterprise Application Platform 6.x Runtime

- Cliquer sur .
- Dans le champ Répertoire Personnel, cliquer sur pour définir le dossier source JBoss EAP comme Répertoire Personnel.

- Cliquer sur .
- Cliquer sur .
- Laisser les dossiers source sur la fenêtre de chemin de build en mode défaut, et cliquer sur .
- Dans le menu déroulant de la Plateforme, vous assurer que Hibernate (JPA 2.x) est sélectionné.
- Cliquer sur .
- Si cela vous est demandé, choisissez si vous souhaitez ouvrir la fenêtre de perspective JPA.
11.2.3.2. Créer le fichier de paramètres de persistance dans JBoss Developer Studio
Ce sujet couvre le processus de création du fichier persistence.xml dans un projet Java qui utilise JBoss Developer Studio.
Procédure 11.2. Créer et configurer un nouveau fichier de configuration de persistance
- Ouvrir un projet EJB 3.x dans JBoss Developer Studio.
- Cliquer à droite sur le répertoire racine du projet dans le panneau Project Explorer
- Sélectionner → .
- Sélectionner Fichier XML à partir du dossier XML et cliquer sur .
- Sélectionner le dossier
ejbModule/META-INFcomme répertoire parent. - Nommer le fichier
persistence.xmlet cliquer sur . - Sélectionner Créer fichier XML à partir d'un fichier de schéma XML et cliquer sur .
- Sélectionner http://java.sun.com/xml/ns/persistence/persistence_2.0.xsd dans la liste Sélectionner une entrée de Catalogue XML et cliquer sur .

- Cliquer sur pour créer le fichier.
- Résultat :
- Le fichier
persistence.xmla été créé dans le dossierMETA-INF/et est prêt pour la configuration. Un exemple de fichier se trouve ici : Section 11.2.3.3, « Exemple de fichier de configuration de persistance »
11.2.3.3. Exemple de fichier de configuration de persistance
Exemple 11.1. persistence.xml
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd"
version="2.0">
<persistence-unit name="example" transaction-type="JTA">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>java:jboss/datasources/ExampleDS</jta-data-source>
<mapping-file>ormap.xml</mapping-file>
<jar-file>TestApp.jar</jar-file>
<class>org.test.Test</class>
<shared-cache-mode>NONE</shared-cache-mode>
<validation-mode>CALLBACK</validation-mode>
<properties>
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>
<property name="hibernate.hbm2ddl.auto" value="create-drop"/>
</properties>
</persistence-unit>
</persistence>
11.2.3.4. Créer le fichier de configuration Hibernate dans JBoss Developer Studio
Ce sujet traite du procédé à suivre pour créer le fichier hibernate.cfg.xml dans un Projet Java en utilisant JBoss Developer Studio.
Procédure 11.3. Créer un nouveau fichier de Configuration Hibernate
- Ouvrir un projet Java dans JBoss Developer Studio
- Cliquer à droite sur le répertoire racine du projet dans le panneau Project Explorer
- Sélectionner → .
- Sélectionner Fichier de configuration Hibernate depuis le dossier Hibernate et cliquer sur .
- Sélectionner le répertoire
src/et cliquer sur . - Configurer :
- Nom de la fabrique à Session
- Dialecte de base de données
- Classe pilote
- URL de connexion
- Nom d'utilisateur
- Mot de passe
- Cliquer sur pour créer le fichier.
- Résultat :
- Le fichier
hibernate.cfg.xmla été créé dans le dossiersrc/. Un exemple de fichier est disponible ici : Section 11.2.3.5, « Exemple de fichier de configuration Hibernate ».
11.2.3.5. Exemple de fichier de configuration Hibernate
Exemple 11.2. hibernate.cfg.xml
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- Datasource Name -->
<property name="connection.datasource">ExampleDS</property>
<!-- SQL dialect -->
<property name="dialect">org.hibernate.dialect.H2Dialect</property>
<!-- Enable Hibernate's automatic session context management -->
<property name="current_session_context_class">thread</property>
<!-- Disable the second-level cache -->
<property name="cache.provider_class">org.hibernate.cache.NoCacheProvider</property>
<!-- Echo all executed SQL to stdout -->
<property name="show_sql">true</property>
<!-- Drop and re-create the database schema on startup -->
<property name="hbm2ddl.auto">update</property>
<mapping resource="org/hibernate/tutorial/domain/Event.hbm.xml"/>
</session-factory>
</hibernate-configuration>
11.2.4. Configuration
11.2.4.1. Propriétés de configuration de Hibernate
Tableau 11.1. Propriétés
| Nom de propriété | Description |
|---|---|
| hibernate.dialect |
Le nom de classe d'un
org.hibernate.dialect.Dialect Hibernate. Permet à Hibernate de générer SQL optimisé pour une base de données relative particulière.
Dans la plupart des cas, Hibernate pourra choisir la mise en œuvre
org.hibernate.dialect.Dialect correcte, selon les JDBC metadata renvoyées par le pilote JDBC.
|
| hibernate.show_sql |
Booléen. Écrit toutes les déclarations SQL à la console. C'est une alternative pour définir la catégorie du journal
org.hibernate.SQL sur debug.
|
| hibernate.format_sql |
Booléen. Mettre en forme le SQL dans le journal et la console.
|
| hibernate.default_schema |
Qualifie les noms de tableaux non qualifiés avec le schéma/espace tableau donné dans le SQL généré.
|
| hibernate.default_catalog |
Qualifie les noms de tableaux non qualifiés avec le catalogue donné dans le SQL généré.
|
| hibernate.session_factory_name |
Le
org.hibernate.SessionFactory sera automatiquement lié à ce nom dans JNDI après avoir été créé. Par exemple, jndi/composite/name.
|
| hibernate.max_fetch_depth |
Définit une "profondeur" maximum pour l'arborescence de récupération de la jointure externe pour les associations à fin unique (un-à-un, plusieurs-à-un). Un
0 désactive la récupération de jointure externe par défaut. La valeur recommandée se situe entre 0 et 3.
|
| hibernate.default_batch_fetch_size |
Définit une taille par défaut pour la récupération en lot d'associations de Hibernate. Les valeurs recommandées sont
4, 8, et 16.
|
| hibernate.default_entity_mode |
Définit un mode par défaut pour la réprésentation d'entité pour toutes les sessions ouvertes à partir de
SessionFactory. Les valeurs comprennent : dynamic-map, dom4j, pojo.
|
| hibernate.order_updates |
Booléen. Oblige Hibernate à ordonner les mises à jour SQL par la valeur clé principale des éléments mis à jour. Cela se traduira en un nombre inférieur de blocages de transactions dans des systèmes hautement simultanés.
|
| hibernate.generate_statistics |
Booléen. Si autorisé, Hibernate va collecter les statistiques utiles pour le réglage de performance.
|
| hibernate.use_identifier_rollback |
Booléen. Si autorisé, les propriétés d'identifiant générées seront restaurées à leur valeur par défaut lorsque les objets sont supprimés.
|
| hibernate.use_sql_comments |
Booléen. Si activé, Hibernate génèrera des commentaires à l'intérieur de SQL, pour faciliter de débogage. La valeur par défaut est
false.
|
| hibernate.id.new_generator_mappings |
Booléen. Cette propriété est appropriée lorsque
@GeneratedValue est utilisée. Elle indique si les nouvelles implémentations IdentifierGenerator sont utilisées pour javax.persistence.GenerationType.AUTO, javax.persistence.GenerationType.TABLE et javax.persistence.GenerationType.SEQUENCE. La valeur par défaut est true.
|
Important
hibernate.id.new_generator_mappings, les nouvelles applications devront garder la valeur par défaut true. Les applications existantes qui utilisent Hibernate 3.3.x devront sans doute modifier cette valeur à false pour continuer à utiliser un objet de séquence ou un générateur basé-table et pour maintenir la compatibilité rétro-active.
11.2.4.2. Hibernate JDBC et Propriétés de Connexion
Tableau 11.2. Propriétés
| Nom de propriété | Description |
|---|---|
| hibernate.jdbc.fetch_size |
Valeur non nulle qui détermine la taille de récupération JDBC (appelle
Statement.setFetchSize()).
|
| hibernate.jdbc.batch_size |
Une valeur non nulle active l'utilisation des mises à jour de lots de JDBC2 par Hibernate. Les valeurs recommandées se situent entre
5 et 30.
|
| hibernate.jdbc.batch_versioned_data |
Booléen. Définir cette propriété sur
true si le pilote JDBC renvoie des nombres de lignes corrects avec executeBatch(). Hibernate utilisera ensuite un DML en lot pour les données versionnées automatiquement. La valeur par défaut est false.
|
| hibernate.jdbc.factory_class |
Sélectionner un
org.hibernate.jdbc.Batcher personnalisé. La plupart des applications n'auront pas besoin de cette propriété de configuration.
|
| hibernate.jdbc.use_scrollable_resultset |
Booléen. Active l'utilisation des ensembles de résultats déroulants de JDBC2 par Hibernate. Cette propriété n'est nécessaire que lorsque l'on utilise des connexions JDBC fournies par l'utilisateur. Sans quoi, Hibernate utilise des métadonnées de connexion.
|
| hibernate.jdbc.use_streams_for_binary |
Booléen. Ceci est une propriété de niveau système. Utiliser les flux lors de l'écriture/la lecture de types
binary ou serializable depuis/vers JDBC.
|
| hibernate.jdbc.use_get_generated_keys |
Booléen. Active l'utilisation de JDBC3
PreparedStatement.getGeneratedKeys() pour récupérer les cléfs générées en mode natif après insertion. Requiert le pilote JDBC3+ et JRE1.4+. Défini sur false si le pilote JDBC rencontre des problèmes avec les générateurs d'identifiants Hibernate. Par défaut, il tente de déterminer les capacités du pilote en utilisant les métadonnées de connexion.
|
| hibernate.connection.provider_class |
Le nom de classe d'un
org.hibernate.connection.ConnectionProvider personnalisé qui fournit des connexions JDBC à Hibernate.
|
| hibernate.connection.isolation |
Définit le niveau d'isolation des transactions JDBC. Vérifier
java.sql.Connection pour des valeurs compréhensibles, mais veuillez noter que la plupart des bases de données ne prennent pas en charge tous les niveaux d'isolation et que quelques unes définissent des isolations additionnelles, non-standard. Les valeurs standard sont 1, 2, 4, 8.
|
| hibernate.connection.autocommit |
Booléen. Cette propriété n'est pas recommandée à l'utilisation. Active l'autovalidation pour les connexions « en commun » de JDBC.
|
| hibernate.connection.release_mode |
Indique à quel moment Hibernate devra diffuser les connexions JDBC. Par défaut, une connexion JDBC est maintenue jusqu'à ce que la session soit explicitement fermée ou déconnectée. La valeur par défaut
auto choisira after_statement pour les stratégies de transaction JTA et CMT, et after_transaction pour la stratégie de transaction JDBC.
Les valeurs disponibles sont
auto (par défaut) | on_close | after_transaction | after_statement.
Ce paramètre n'affecte que les
Sessions renvoyées depuis SessionFactory.openSession. Pour les Sessions obtenues par SessionFactory.getCurrentSession, l'implémentation CurrentSessionContext configurée pour l'utilisation contrôle le mode de publication de connexion pour ces Sessions.
|
| hibernate.connection.<propertyName> |
Passer la propriété JDBC <propertyName> à
DriverManager.getConnection().
|
| hibernate.jndi.<propertyName> |
Passer la proriété <propertyName> à
InitialContextFactory de JNDI.
|
11.2.4.3. Propriétés d'Hibernate Cache
Tableau 11.3. Propriétés
| Nom de propriété | Description |
|---|---|
hibernate.cache.provider_class |
Le nom de classe d'un
CacheProvider personnalisé.
|
hibernate.cache.use_minimal_puts |
Booléen. Optimise l'opération cache de second niveau pour minimiser les écritures, au détriment de lectures plus fréquentes. Cette configuration est surtout utile pour les caches clusterisés et, dans Hibernate 3, est activée par défaut pour les implémentations cache clusterisées.
|
hibernate.cache.use_query_cache |
Booléen. Active le cache de recherche. Les recherches individuelles doivent toujours être définies comme cachables.
|
hibernate.cache.use_second_level_cache |
Booléen. Utilisé pour désactiver totalement le cache de second niveau, qui est activé par défaut pour les classes qui spécifient un mappage
<cache>.
|
hibernate.cache.query_cache_factory |
Le nom de classe d'une interface
QueryCache personnalisée. La valeur par défaut est le StandardQueryCache intégré.
|
hibernate.cache.region_prefix |
Un préfixe à utiliser pour les noms régionaux de cache de second niveau.
|
hibernate.cache.use_structured_entries |
Booléen. Force Hibernate à stocker des données dans un cache de second niveau dans un format plus amical pour l'utilisateur.
|
hibernate.cache.default_cache_concurrency_strategy |
Configuration utilisée pour donner le nom de la statégie qu'il faut
org.hibernate.annotations.CacheConcurrencyStrategy quand @Cacheable ou @Cache sont utilisés. @Cache(strategy="..") est utilisé pour remplacer cette valeur par défaut.
|
11.2.4.4. Propriétés de transaction Hibernate
Tableau 11.4. Propriétés
| Nom de propriété | Description |
|---|---|
hibernate.transaction.factory_class |
Le nom de classe d'une
TransactionFactory à utiliser avec l'API de Transaction de Hibernate. Valeur par défaut : JDBCTransactionFactory.
|
jta.UserTransaction |
Un nom JNDI utilisé par
JTATransactionFactory pour obtenir la UserTransaction JTA depuis le serveur d'applications.
|
hibernate.transaction.manager_lookup_class |
Le nom de classe d'une
TransactionManagerLookup. Requis lorsque la mise en cache de niveau JVM est activée ou lorsque le générateur hilo est utilisé dans un environnement JTA.
|
hibernate.transaction.flush_before_completion |
Booléen. Si activé, la session sera automatiquement vidée avant la phase d'achèvement de la transaction. Une gestion de contexte de session automatique et intégrée est préférée.
|
hibernate.transaction.auto_close_session |
Booléen. Si activé, la session sera automatiquement fermée après la phase d'achèvement de la transaction. Une gestion de contexte de session automatique et intégrée est préférable.
|
11.2.4.5. Propriétés Hibernate diverses
Tableau 11.5. Propriétés
| Nom de propriété | Description |
|---|---|
hibernate.current_session_context_class |
Fournit une stratégie personnalisée pour l'étendue de la
Session « actuelle ». Les valeurs comprennent jta | thread | managed | custom.Class.
|
hibernate.query.factory_class |
Choisir l'implémentation de l'analyseur de HQL :
org.hibernate.hql.internal.ast.ASTQueryTranslatorFactory ou org.hibernate.hql.internal.classic.ClassicQueryTranslatorFactory.
|
hibernate.query.substitutions |
Utilisé pour mapper à partir de jetons dans les requêtes Hibernate aux jetons SQL (les jetons peuvent avoir un nom fonctionnel ou littéral). Par exemple,
hqlLiteral=SQL_LITERAL, hqlFunction=SQLFUNC.
|
hibernate.hbm2ddl.auto |
Valide ou exporte automatiquement le schéma DDL vers la base de données quand la
SessionFactory est créée. Avec create-drop, le schéma de base de données sera déposé lorsque la SessionFactory est fermée explicitement. Les options de valeur de propriété sont validate | update | create | create-drop
|
hibernate.hbm2ddl.import_files |
Les noms séparés par des virgules des fichiers optionnels contenant des déclarations SQL DML exécutées pendant la création de
SessionFactory. Cela est utile pour tester ou démontrer. Par exemple, en ajoutant des déclarations INSERT, la base de données peut être remplie avec un lot minimum de données quand elle est déployée. Exemple de valeur : /humans.sql,/dogs.sql.
L'ordre de fichier compte, puisque les déclarations d'un fichier donné sont exécutées avant la déclaration du fichier suivant. Ces déclarations ne sont exécutées que si le schéma est créé (c'est-à-dire si
hibernate.hbm2ddl.auto est défini comme create ou create-drop).
|
hibernate.hbm2ddl.import_files_sql_extractor |
Le nom de classe d'un
ImportSqlCommandExtractor personnalisé. Valeur par défaut de SingleLineSqlCommandExtractor intégré. Cela est utile pour implémenter un analyseur dédié qui extrait une déclaration unique de SQL depuis chaque fichier d'importation. Hibernate fournit également MultipleLinesSqlCommandExtractor, qui prend en charge des instructions/commentaires et des chaînes citées réparties sur de multiples lignes (point-virgule obligatoire à la fin de chaque déclaration).
|
hibernate.bytecode.use_reflection_optimizer |
Booléen. Ceci est une propriété de niveau système, qui ne peut pas être définie dans le fichier
hibernate.cfg.xml. Elle permet l'utilisation de la manipulation bytecode au lieu de la réflexion d'exécution. La réflexion peut parfois être utile lors de la résolution de problèmes. Hibernate requiert toujours soit CGLIB ou javassist même si l'optimizer est éteint.
|
hibernate.bytecode.provider |
Javassist et cglib peuvent tous les deux être utilisés comme moteurs de manipulation de byte. La valeur par défaut est
javassist. La valeur de propriété est soit javassist soit cglib.
|
11.2.4.6. Dialectes SQL Hibernate
Important
hibernate.dialect devrait être définie sur la sous-classe org.hibernate.dialect.Dialect correcte pour la base de données de l'application. Si un dialecte est indiqué, Hibernate utilisera des valeurs par défaut raisonnables pour quelques unes des autres propriétés. Cela signifie qu'elles n'ont pas besoin d'être spécifiées manuellement.
Tableau 11.6. Dialectes SQL (hibernate.dialect)
| RDBMS | Dialecte |
|---|---|
| DB2 | org.hibernate.dialect.DB2Dialect |
| DB2 AS/400 | org.hibernate.dialect.DB2400Dialect |
| DB2 OS390 | org.hibernate.dialect.DB2390Dialect |
| Firebird | org.hibernate.dialect.FirebirdDialect |
| FrontBase | org.hibernate.dialect.FrontbaseDialect |
| H2 Database | org.hibernate.dialect.H2Dialect |
| HypersonicSQL | org.hibernate.dialect.HSQLDialect |
| Informix | org.hibernate.dialect.InformixDialect |
| Ingres | org.hibernate.dialect.IngresDialect |
| Interbase | org.hibernate.dialect.InterbaseDialect |
| Mckoi SQL | org.hibernate.dialect.MckoiDialect |
| Microsoft SQL Server 2000 | org.hibernate.dialect.SQLServerDialect |
| Microsoft SQL Server 2005 | org.hibernate.dialect.SQLServer2005Dialect |
| Microsoft SQL Server 2008 | org.hibernate.dialect.SQLServer2008Dialect |
| Microsoft SQL Server 2012 | org.hibernate.dialect.SQLServer2008Dialect |
| MySQL5 | org.hibernate.dialect.MySQL5Dialect |
| MySQL5 avec InnoDB | org.hibernate.dialect.MySQL5InnoDBDialect |
| MySQL avec MyISAM | org.hibernate.dialect.MySQLMyISAMDialect |
| Oracle (toute version) | org.hibernate.dialect.OracleDialect |
| Oracle 9i | org.hibernate.dialect.Oracle9iDialect |
| Oracle 10g | org.hibernate.dialect.Oracle10gDialect |
| Oracle 11g | org.hibernate.dialect.Oracle10gDialect |
| Pointbase | org.hibernate.dialect.PointbaseDialect |
| PostgreSQL | org.hibernate.dialect.PostgreSQLDialect |
| PostgreSQL 9.2 | org.hibernate.dialect.PostgreSQL82Dialect |
| Postgres Plus Advanced Server | org.hibernate.dialect.PostgresPlusDialect |
| Progress | org.hibernate.dialect.ProgressDialect |
| SAP DB | org.hibernate.dialect.SAPDBDialect |
| Sybase | org.hibernate.dialect.SybaseASE15Dialect |
| Sybase 15.7 | org.hibernate.dialect.SybaseASE157Dialect |
| Sybase Anywhere | org.hibernate.dialect.SybaseAnywhereDialect |
11.2.5. Caches de second niveau
11.2.5.1. Les caches de second niveau
- Web Session Clustering
- Stateful Session Bean Clustering
- SSO Clustering
- Cache de second niveau d'Hibernate
11.2.5.2. Configurer un cache de second niveau pour Hibernate
Procédure 11.4. Créer et modifier le fichier hibernate.cfg.xml
Créer le fichier hibernate.cfg.xml
Créer le fichierhibernate.cfg.xmldans le chemin de classe du déploiement. Pour plus de détails, voir Section 11.2.3.4, « Créer le fichier de configuration Hibernate dans JBoss Developer Studio » .- Ajouter ces lignes d'XML au fichier
hibernate.cfg.xmlde votre application. Le XML doit être à l'intérieur des balises <session-factory>:<property name="hibernate.cache.use_second_level_cache">true</property> <property name="hibernate.cache.use_query_cache">true</property>
- Ajouter un élément ci-dessous à la section <session-factory> de votre fichier
hibernate.cfg.xml:Si le CacheManager Infinispan est lié au JNDI :
<property name="hibernate.cache.region.factory_class"> org.hibernate.cache.infinispan.JndiInfinispanRegionFactory </property> <property name="hibernate.cache.infinispan.cachemanager"> java:CacheManager </property>Si le CacheManager Infinispan est autonome :
<property name="hibernate.cache.region.factory_class"> org.hibernate.cache.infinispan.InfinispanRegionFactory </property>
Infinispan est configuré au second niveau de cache dans Hibernate.
11.3. Annotations Hibernate
11.3.1. Annotations Hibernate
Tableau 11.7. Annotations définies d'Hibernate
| Annotation | Description |
|---|---|
| AccessType | Type d'accès de propriété |
| Tous | Définit une association ToOne pointant vers plusieurs types d'entités. L'association du type d'entité correspondant se fait à travers une colonne discriminatoire de métadonnées. Ce type de mappage devrait seulement être marginal. |
| AnyMetaDef | Définit les métadonnées @Any et @manyToAny. |
| AnyMedaDefs | Définit les ensembles de métadonnées @Any et @ManyToAny. Peut être défini au niveau d'entité ou de paquetage. |
| BatchSize | Taille de lot pour chargement SQL. |
| Cache | Ajouter une stratégie de mise en cache à une entité root ou une collection. |
| Cascade | Appliquer une stratégie de cascade sur une association |
| Check | Contraintes de vérification SQL arbitraires qui peuvent être définies aux niveaux de classe, de propriété ou de collection. |
| Columns | Prend en charge une gamme de colonnes. Utile pour les mappages de type utilisateur de composant. |
| ColumnTransformer | Expression SQL personnalisée utilisée pour lire la valeur depuis et écrire une valeur vers une colonne. Utiliser pour le chargement/enregistrement d'objet direct ainsi que les requêtes. L'expression de lecture doit contenir exactement un "?" pour la valeur. |
| ColumnTransformers | Annotation plurielle pour @ColumnTransformer. Utile lorsque plus d'une colonne utilise ce comportement. |
| DiscriminatorFormula | Formule discriminatoire à placer à l'entité de root. |
| DiscriminatorOptions | Annotation optionnelle pour exprimer les propriétés discriminatoires spécifiques à Hibernate. |
| Entity | Prolonge l'entité avec les caractéristiques Hibernate. |
| Fetch | Définit la stratégie de récupération utilisée pour l'association donnée. |
| FetchProfile | Définit le profil de stratégie de récupération |
| FetchProfiles | Annotation plurielle pour @FetchProfile. |
| Filter | Ajoute des filtres à une entité ou une entité de cible d'une collection. |
| FilterDef | Définition de Filtre. |
| FilterDefs | Gamme de définitions de filtre. |
| FilterJoinTable | Ajoute des filtres pour une collection rejoindre une table |
| FilterJoinTables | Ajoute de multiples @FilterJoinTable à une collection |
| Filters | Ajoute de multiples @Filters. |
| Formula | A utiliser comme remplacement pour @Column dans la plupart des emplacements. La formule doit être un fragment SQL valide. |
| Generated | Cette propriété annotée est générée par la base de données. |
| GenericGenerator | Annotation de générateur décrivant toute sorte de générateur Hibernate d'une manière non-typée. |
| GenericGenerators | Gamme de définitions de générateur génériques. |
| Immutable |
Marque une Entité ou une Collection comme immuable. Si aucune annotation, l'élément est mutable.
Une entité immuable peut ne pas être mise à jour par l'application. Les mises à jour vers une entité immuable seront ignorées, mais aucune exception ne sera levée.
Placer @Immutable sur une collection rend la collection immuable, ce qui signifie que les additions et suppressions vers et depuis la collection ne sont pas autorisées. Une HibernateException est levée dans ce cas.
|
| Index | Définit un indice de base de données. |
| JoinFormula | A utiliser comme remplacement pour @JoinColumn dans la plupart des emplacements. La formule doit être un fragment SQL valable. |
| LazyCollection | Définit le statut lazy d'une collection |
| LazyToOne | Définit le statut lazy d'une association ToOne (c'est-à-dire OneToOne or ManyToOne). |
| Loader | Ecrase la méthode FIND par défaut de Hibernate. |
| ManyToAny | Définit une association ToMany en indiquant différent types d'entité. L'association du type d'entité correspondant se fait à travers une colonne discriminatoire de métadonnées. Ce type de mappage devrait seulement être marginal. |
| MapKeyType | Définit le type de clé d'une mappe persistante. |
| MetaValue | Représente une valeur discriminatoire associée à un type d'entité donné. |
| NamedNativeQueries | Prolonge les NamedNativeQueries pour maintenir les objets NamedNativeQuery de Hibernate. |
| NamedNativeQuery | Prolonge la NamedNativeQuery avec les caractéristiques Hibernate. |
| NamedQueries | Etend les NamedQueries pour maintenir les objets NamedQuery de Hibernate. |
| NamedQuery | Prolonge NamedQuery avec les caractéristiques Hibernate. |
| IdNaturel | Indique que la propriété fait partie de l'identifiant naturel de l'entité. |
| NotFound | Action à accomplir lorsqu'un élément est introuvable dans une association. |
| OnDelete | Stratégie à utiliser pour la suppression de collections, de tableaux ou de sous-classes jointes. OnDelete des tableaux secondaires n'est pas actuellement pris en charge. |
| OptimisticLock | Indique si une modification de la propriété annotée déclenchera une incrémentation de version d'entité. Si l'annotation n'est pas présente, la propriété est impliquée dans la stratégie de verrouillage optimiste (par défaut). |
| OptimisticLocking | Utilisé pour définir le style de verrouillage optimiste à appliquer à une entité. Dans une hiérarchie, seulement valide sur l'entité de root. |
| OrderBy | Ordonner une collection en utilisant l'ordre SQL (pas l'ordre HSL). |
| ParamDef | Une définition de paramètre. |
| Paramètre | Modèle clé/valeur |
| Parent | Renvoie la référence de la propriété en tant que pointeur vers le propriétaire (en général l'entité propriétaire). |
| Persister | Indique un persister personnalisé |
| Polymorphisme | Utilisé pour définir le type de polymorphisme qu'Hibernate appliquera aux hiérarchies d'entité. |
| Proxy | Configuration proxy et lazy d'une classe particulière. |
| RowId | Prend en charge les caractéristiques de mappage ROWID de Hibernate |
| Tri | Tri de collection (tri de niveau Java). |
| Source | Annotation optionnelle conjointement avec les propriétés de Version et de version Timestamp. La valeur d'annotation décide de l'endroit où timestamp est généré. |
| SQLDelete | Ecrase la méthode DELETE par défaut de Hibernate. |
| SQLDeleteAll | Ecrase la méthode DELETE ALL par défaut de Hibernate. |
| SQLInsert | Remplace la méthode INSERT INTO par défaut de Hibernate. |
| SQLUpdate | Remplace la méthode UPDATE par défaut de Hibernate. |
| Subselect | Mappe une entité immuable et en lecture seule vers une expression sous-sélection SQL donnée. |
| Synchronize | S'assure qu'auto-flush fonctionne correctement et que les requêtes concernant l'entité dérivée ne renvoient pas des données obsolètes. Principalement utilisé avec Subselect. |
| Table | Information complémentaire d'une table primaire ou secondaire |
| Tables | Annotation plurielle de Table |
| Cible | Définit une source explicite et évite la résolution de réflexion et de génériques. |
| Tuplizer | Définit un tuplizer pour une entité ou un composant. |
| Tuplizers | Définit un ensemble de tuplizers pour une entité ou un composant. |
| Type | Type Hibernate. |
| TypeDef | Définition d'un type Hibernate |
| TypeDefs | Gamme de définition de Type Hibernate |
| Where | Clause Where à ajouter à l'élément Entité ou entité de cible d'une collection. La clause est écrite en SQL. |
| WhereJoinTable | Clause Where à ajouter à la collection joindre une table. La clause est écrite en SQL. |
11.4. Langage de recherche Hibernate
11.4.1. Langage de recherche d'Hibernate
11.4.2. Déclarations HQL
SELECT, UPDATE, DELETE, et INSERT. La déclaration INSERT de HQL n'a pas d'équivalent dans JPQL.
Important
UPDATE ou DELETE est exécutée.
Tableau 11.8. Déclarations HQL
| Déclaration | Description |
|---|---|
SELECT |
Le BNF pour les déclarations
SELECT dans HQL est :
select_statement :: =
[select_clause]
from_clause
[where_clause]
[groupby_clause]
[having_clause]
[orderby_clause]
La déclaration
SELECT de HQL la plus simple qui soit est sous la forme :
from com.acme.Cat |
UDPATE | Le BNF pour la déclaration UPDATE dans HQL est le même que dans JPQL. |
DELETE | Le BNF pour les déclarations DELETE dans HQL est le même que dans JPQL. |
11.4.3. La déclaration INSERT
INSERT. Il n'existe pas d'équivalent JPQL. Le BNF d'une déclaration INSERT HQL est :
insert_statement ::= insert_clause select_statement insert_clause ::= INSERT INTO entity_name (attribute_list) attribute_list ::= state_field[, state_field ]*
attribute_list est analogue à la column specification dans la déclaration INSERT de SQL. Pour les entités impliquées dans un héritage mappé, seuls les attributs définis directement sur l'entité nommée peuvent être utilisés dans la attribute_list. Les propriétés de sur-classe ne sont pas autorisées et les propriétés de sous-classe sont inutiles. En d'autres termes, les déclarations INSERT sont, par nature, non-polymorphes.
Avertissement
select_statement peut être n'importe quelle requête sélectionnée HQL valide, avec l'avertissement que les types de renvoi doivent correspondre aux types attendus par l'insertion. Actuellement, cela est vérifié lors de la compilation de requêtes plutôt que de permettre une vérification reléguée à la base de données. Cela pourrait causer des problèmes entre les types Hibernate qui sont equivalent et non pas equal. Par exemple, cela pourrait entraîner des problèmes avec des incompatibilités entre un attribut mappé en tant que org.hibernate.type.DateType et un attribut défini en tant que org.hibernate.type.TimestampType, bien que la base de données puisse ne pas faire la distinction ou puisse être capable de traiter la conversion.
attribute_list, dans quel cas sa valeur sera prise à partir de l'expression sélectionnée correspondante, ou l'omettre à partir de la attribute_list, dans quel cas une valeur générée est utilisée. Cette dernière option n'est disponible que lors de l'utilisation de générateurs d'identifiants qui opèrent « dans la base de données ». Tenter d'utiliser cette option avec n'importe quel générateur de type « en mémoire » causera une exception en cours de traitement.
attribute_list, dans quel cas sa valeur sera prise à partir des expressions sélectionnées correspondantes, ou l'omettre à partir de la attribute_list dans quel cas la seed value définie par le org.hibernate.type.VersionType correspondant est utilisé.
Exemple 11.3. Exemple d'énoncé de requêtes INSERT
String hqlInsert = "insert into DelinquentAccount (id, name) select c.id, c.name from Customer c where ..."; int createdEntities = s.createQuery( hqlInsert ).executeUpdate();
11.4.4. La clause FROM
FROM est chargée de définir l'étendue des types de modèles objets disponibles au reste de la requête. Elle est également chargée de définir toutes les « variables d'identification » disponibles au reste de la requête.
11.4.5. La clause WITH
WITH pour qualifier les conditions de jointure. Cela est spécifique à HQL. JPQL ne définit pas cette fonctionnalité.
Exemple 11.4. Exemple de jointure with-clause
select distinct c
from Customer c
left join c.orders o
with o.value > 5000.00
with clause font partie de on clause dans le SQL généré contrairement aux autres requêtes dans cette section où les conditions HQL/JPQL font partie de la where clause dans le SQL généré. La différence dans cet exemple en particulier n'est sûrement pas très importante. Le with clause est quelques fois nécessaire pour des requêtes plus compliquées.
11.4.6. Mises à jour, Insertions et Suppressions en bloc
Avertissement
( UPDATE | DELETE ) FROM? EntityName (WHERE where_conditions)?.
Note
FROM et le WHERE Clause sont optionnels.
Exemple 11.5. Exemple de déclaration de mise à jour en bloc
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
String hqlUpdate = "update Company set name = :newName where name = :oldName";
int updatedEntities = s.createQuery( hqlUpdate )
.setString( "newName", newName )
.setString( "oldName", oldName )
.executeUpdate();
tx.commit();
session.close();
Exemple 11.6. Exemple de déclaration de suppression en bloc
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
String hqlDelete = "delete Company where name = :oldName";
int deletedEntities = s.createQuery( hqlDelete )
.setString( "oldName", oldName )
.executeUpdate();
tx.commit();
session.close();
int renvoyées par la méthode Query.executeUpdate() indique le nombre d'entités qui se trouvent dans la base de données et qui sont affectées par l'opération.
Company (entreprises) qui contiennent oldName dans le tableau, mais aussi dans les tableaux de liaisons. Donc, un tableau d'entreprises (Companies) qui se trouve dans une relation BiDirectionelle ManyToMany avec un tableau d'employés (Employee) perdrait des lignes dans le tableau de liaison correspondant Company_Employee suite à l'exécution de l'exemple précédent.
int deletedEntries ci-dessus contiendra le nombre de lignes affectées par cette opération, y compris les lignes qui se trouvent dans les tableaux de liaisons.
INSERT INTO EntityName properties_list select_statement.
Note
Exemple 11.7. Exemple de déclaration d'insertion en bloc
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
String hqlInsert = "insert into Account (id, name) select c.id, c.name from Customer c where ...";
int createdEntities = s.createQuery( hqlInsert )
.executeUpdate();
tx.commit();
session.close();
id via SELECT, un ID sera généré, tant que la base de données sous-jacente prend en charge les clés générées automatiquement. La valeur de retour de cette opération d'insertion en bloc est le nombre d'entrées créées dans la base de données.
11.4.7. Références de collection
Exemple 11.8. Exemple de références de collection
select c
from Customer c
join c.orders o
join o.lineItems l
join l.product p
where o.status = 'pending'
and p.status = 'backorder'
// alternate syntax
select c
from Customer c,
in(c.orders) o,
in(o.lineItems) l
join l.product p
where o.status = 'pending'
and p.status = 'backorder'
o fait référence au type de modèle de variable Order qui correspond au type d'éléments de l'association Customer#orders.
IN. Les deux formes sont équivalentes. La forme choisie par une application est tout simplement une question de goût.
11.4.8. Expressions de chemins qualifiées
Tableau 11.9. Expressions de chemins
| Expression | Description |
|---|---|
VALUE |
Correspond à la valeur de la collection. C'est équivalent à ne pas spécifier de qualificateur. Utile pour démontrer une intention. Valide pour n'importe quel type de référence collection-valued.
|
INDEX |
Selon les règles HQL, ceci est valable pour les mappages et pour les listes qui spécifient une annotation
javax.persistence.OrderColumn pour désigner la clé de Mappage ou la position de la Liste (aka la valeur OrderColumn). JPQL toutefois réserve ceci pour une utilisation dans la case Liste et ajoute la clé dans la case Mappage. Les applications intéressées par la transférabilité des fournisseurs JPA doivent tenir compte de cette distinction.
|
KEY |
Uniquement valide pour le mappage. Se réfère à la clé de mappage. Si la clé elle-même est une entité, elle peut naviguer davantage.
|
ENTRY |
Uniquement valide pour les mappages. Voir le tuple (combinaison d'une clé et de sa valeur) logique du Mappagev
java.util.Map.Entry. ENTRY n'est valide qu'en tant que chemin final et uniquement pour la clause sélectionnée.
|
Exemple 11.9. Exemple de références de collection qualifiée
// Product.images is a Map<String,String> : key = a name, value = file path
// select all the image file paths (the map value) for Product#123
select i
from Product p
join p.images i
where p.id = 123
// same as above
select value(i)
from Product p
join p.images i
where p.id = 123
// select all the image names (the map key) for Product#123
select key(i)
from Product p
join p.images i
where p.id = 123
// select all the image names and file paths (the 'Map.Entry') for Product#123
select entry(i)
from Product p
join p.images i
where p.id = 123
// total the value of the initial line items for all orders for a customer
select sum( li.amount )
from Customer c
join c.orders o
join o.lineItems li
where c.id = 123
and index(li) = 1
11.4.9. Fonctions scalaires
11.4.10. Fonctions standardisées HQL
Tableau 11.10. Fonctions standardisées HQL
| Fonction | Description |
|---|---|
BIT_LENGTH |
Renvoie la longueur des données binaires.
|
CAST |
Effectue une transcription SQL. La cible de transcription doit désigner le type de mappage Hibernate à utiliser. Voir le chapitre sur les types de données pour obtenir plus d'informations.
|
EXTRACT |
Effectue une extraction SQL sur les valeurs Heure/Date. L'extraction soutire une partie de la valeur (l'année, par exemple). Voir les formes d'abréviation ci-dessous.
|
SECOND |
Abréviation pour extraire une Seconde.
|
MINUTE |
Forme d'abréviation pour extraire une Minute.
|
HOUR |
Abréviation pour extraire une Heure.
|
DAY |
Abréviation pour extraire un Jour.
|
MONTH |
Abréviation pour extraire un Mois.
|
YEAR |
Abréviation pour extraire une Année.
|
STR |
Abréviation pour la conversion d'une valeur en caractère.
|
addSqlFunction de org.hibernate.cfg.Configuration
11.4.11. Opération de concaténation
CONCAT). N'est pas défini par JPQL, donc les applications portables doivent éviter de l'utiliser. L'opérateur de concaténation vient d'un opérateur de concaténation SQL - ||.
Exemple 11.10. Exemple d'opération de concaténation
select 'Mr. ' || c.name.first || ' ' || c.name.last from Customer c where c.gender = Gender.MALE
11.4.12. Instanciation dynamique
Exemple 11.11. Exemple d'instanciation dynamique - Constructor
select new Family( mother, mate, offspr )
from DomesticCat as mother
join mother.mate as mate
left join mother.kittens as offspr
Exemple 11.12. Exemple d'instanciation dynamique - List
select new list(mother, offspr, mate.name)
from DomesticCat as mother
inner join mother.mate as mate
left outer join mother.kittens as offspr
Exemple 11.13. Exemple d'instanciation dynamique - Mappe
select new map( mother as mother, offspr as offspr, mate as mate )
from DomesticCat as mother
inner join mother.mate as mate
left outer join mother.kittens as offspr
select new map( max(c.bodyWeight) as max, min(c.bodyWeight) as min, count(*) as n )
from Cat cxt"/>
11.4.13. Prédicats HQL
TRUE ou FALSE, bien que les comparaison booléènnes comportant des NULL résolvent les UNKNOWN.
Prédicats HQL
- Prédicat Nullness
- Cherchez une valeur nulle et sans effet. Peut s'appliquer à des références d'attributs de base, à des références d'entité et à des paramètres. De plus, HQL permet une application à des types de composants/intégrables.
Exemple 11.14. Exemples de vérification de Nullness
// select everyone with an associated address select p from Person p where p.address is not null // select everyone without an associated address select p from Person p where p.address is null
- Prédicat Like
- Procède à une comparaison d'équivalence entre des valeurs de chaîne. La syntaxe est la suivante :
like_expression ::= string_expression [NOT] LIKE pattern_value [ESCAPE escape_character]
Les sémantiques suivent l'expression Like SQL. Lapattern_valueest un modèle qui tente de correspondre à l'expression de chaînestring_expression. Tout comme pour l'expresion «like» SQL, le modèle oupattern_valuepeut utiliser "_" et "%" comme caractères génériques. Les significations sont les mêmes. "_" correspond à n'importe quel caractère unique. "%" correspond à un certain nombre de caractères.Le caractèreescapeoptionnel est utilisé pour spécifier un caractère d'échappement en combinaison à ce qui est impliqué par "_" ou "%" dans le modèle oupattern_value. Ceci est utile quand on doit chercher des modèles contenant des "_" ou des "%".Exemple 11.15. Exemples de prédicats «Like»
select p from Person p where p.name like '%Schmidt' select p from Person p where p.name not like 'Jingleheimmer%' // find any with name starting with "sp_" select sp from StoredProcedureMetadata sp where sp.name like 'sp|_%' escape '|'
- Prédicat Between
- Ressemble à l'expression SQL
BETWEEN. Détermine qu'une valeur est entre 2 autres valeurs. Tous les opérandes doivent avoir des types comparables.Exemple 11.16. Exemples de prédicats «Between»
select p from Customer c join c.paymentHistory p where c.id = 123 and index(p) between 0 and 9 select c from Customer c where c.president.dateOfBirth between {d '1945-01-01'} and {d '1965-01-01'} select o from Order o where o.total between 500 and 5000 select p from Person p where p.name between 'A' and 'E'
11.4.14. Comparaisons relationnelles
Exemple 11.17. Exemples de comparaisons relationnelles
// numeric comparison
select c
from Customer c
where c.chiefExecutive.age < 30
// string comparison
select c
from Customer c
where c.name = 'Acme'
// datetime comparison
select c
from Customer c
where c.inceptionDate < {d '2000-01-01'}
// enum comparison
select c
from Customer c
where c.chiefExecutive.gender = com.acme.Gender.MALE
// boolean comparison
select c
from Customer c
where c.sendEmail = true
// entity type comparison
select p
from Payment p
where type(p) = WireTransferPayment
// entity value comparison
select c
from Customer c
where c.chiefExecutive = c.chiefTechnologist
ALL, ANY, SOME. SOME et ANY sont synonymes.
ALL passe à true si la comparaison est true pour toutes les valeurs qui se trouvent dans le résultat de la sous-requête. Passe à false si le résultat de la sous-requête est vide.
Exemple 11.18. Exemple de qualificateur de comparaison de sous-requête ALL
// select all players that scored at least 3 points // in every game. select p from Player p where 3 > all ( select spg.points from StatsPerGame spg where spg.player = p )
ANY/SOME passe à true si la comparaison est true pour toutes les valeurs qui se trouvent dans le résultat de la sous-requête. Passe à false si le résultat de la sous-requête est vide.
11.4.15. Prédicat IN
IN effectue une vérification pour savoir si une valeur donnée fait partie de la liste des valeurs. Sa syntaxe est la suivante :
in_expression ::= single_valued_expression
[NOT] IN single_valued_list
single_valued_list ::= constructor_expression |
(subquery) |
collection_valued_input_parameter
constructor_expression ::= (expression[, expression]*)
single_valued_expression et des valeurs individuelles qui se trouvent dans la liste single_valued_list doivent être consistantes. JPQL limite les types valides ici à des chaînes, des valeurs numériques, date, heure, heure/date, et enum. Dans JPQL, single_valued_expression ne peut se référer qu'à des :
- "state fields", son terme pour attributs simples. Cela exclut en particulier les attributs composants/intégrés et associations.
- expression de type d'entité.
single_valued_expression peut désigner un bien plus large éventail de types d'expression. Les association de valeurs simples sont autorisées, ainsi que les attributs composant/intégré, bien que cette fonctionnalité dépend du niveau de soutien pour le tuple ou pour la «syntaxe de constructeur de valeur de ligne» dans la base de données sous-jacente. En outre, les HQL ne limitent pas le type de valeur en aucune façon, bien que les développeurs d'applications doivent être conscients que les différents types peuvent encourir un soutien limité basé sur le fournisseur de base de données sous-jacent. C'est en grande partie la raison des limitations JPQL
constructor_expression et collection_valued_input_parameter, la liste des valeurs ne doit pas rester vide; elle doit contenir une valeur au moins.
Exemple 11.19. Exemples de prédicat
select p
from Payment p
where type(p) in (CreditCardPayment, WireTransferPayment)
select c
from Customer c
where c.hqAddress.state in ('TX', 'OK', 'LA', 'NM')
select c
from Customer c
where c.hqAddress.state in ?
select c
from Customer c
where c.hqAddress.state in (
select dm.state
from DeliveryMetadata dm
where dm.salesTax is not null
)
// Not JPQL compliant!
select c
from Customer c
where c.name in (
('John','Doe'),
('Jane','Doe')
)
// Not JPQL compliant!
select c
from Customer c
where c.chiefExecutive in (
select p
from Person p
where ...
)
11.4.16. SQL Ordering
ORDER BY est utilisée pour spécifier les valeurs sélectionnées à utiliser pour ordonnancer le résultat. Les types d'expressions considérées comme valides pour la clause order-by sont les suivantes :
- state fields
- attributs composant/intégré
- expressions scalaires comme les opérations arithmétiques, les fonctions, etc.
- variable d'identification déclarée dans la clause Select pour n'importe quel type d'expression antérieure.
ASC (ascendant) ou DESC (descendant) pour indiquer la direction d'ordonnancement désirée.
Exemple 11.20. Exemple Order-by
// legal because p.name is implicitly part of p
select p
from Person p
order by p.name
select c.id, sum( o.total ) as t
from Order o
inner join o.customer c
group by c.id
order by t
11.5. Services Hibernate
11.5.1. Les services Hibernate
11.5.2. Contrats de service
org.hibernate.service.Service. Hibernate l'utilise en interne pour des raisons de sécurité de base.
org.hibernate.service.spi.Startable et org.hibernate.service.spi.Stoppable pour recevoir des notifications de démarrage ou d'arrêt. Il existe un autre service en option org.hibernate.service.spi.Manageable que marque le service comme étant gérable dans le JMX dans la mesure où l'intégration JMX est activée.
11.5.3. Types de dépendances de service
- @
org.hibernate.service.spi.InjectService - Toute méthode de classe d'implémentation de service qui accepte un seul paramètre et qui est annotée par @
InjectServiceest considérée comme réclamant une injection de la part d'un autre service.Par défaut, le type du paramètre de méthode doit correspondre au rôle de service à injecter. Si le type de paramètre est différent du rôle de service, l'attributserviceRoleduInjectServicedevra être utilisé pour nommer explicitement le rôle.Les services injectés sont requis par défaut, c'est à dire que le démarrage échouera si un service dépendant nommé est manquant. Si le service injecté est optionnel, l'attributrequisd'InjectServicedevra être déclaréfalse(la valeur par défaut esttrue). org.hibernate.service.spi.ServiceRegistryAwareService- La seconde approche est une approche pull pour laquelle le service implémente l'interface de service optionnelle
org.hibernate.service.spi.ServiceRegistryAwareServicequi déclare une méthodeinjectServicesunique.En cours de démarrage, Hibernate injectera leorg.hibernate.service.ServiceRegistrylui-même dans les services qui implémentent cette interface. Le service peut alors utiliser la référenceServiceRegistrypour trouver les services additionnels dont il pourrait avoir besoin.
11.5.4. Le ServiceRegistry
11.5.4.1. Le ServiceRegistry
org.hibernate.service.ServiceRegistry. Le but principal d'un registre de service est de contenir, de gérer et de donner accès aux services.
org.hibernate.service.ServiceRegistryBuilder pour créer une instance org.hibernate.service.ServiceRegistry.
Exemple 11.21. Utiliser ServiceRegistryBuilder pour créer un ServiceRegistry
ServiceRegistryBuilder registryBuilder = new ServiceRegistryBuilder( bootstrapServiceRegistry );
ServiceRegistry serviceRegistry = registryBuilder.buildServiceRegistry();
11.5.5. Services personnalisés
11.5.5.1. Services personnalisés
org.hibernate.service.ServiceRegistry est créé, il est considéré comme immuable. Les services eux-mêmes pourraient accepter une reconfiguration, mais ici, l'immuabilité signifie un ajout/remplacement des services. Et donc, un autre rôle assuré par org.hibernate.service.ServiceRegistryBuilder est de permettre de peaufiner des services qui figureront dans le org.hibernate.service.ServiceRegistry qu'il génère.
org.hibernate.service.ServiceRegistryBuilder à propos de services personnalisés.
- Implémenter une classe
org.hibernate.service.spi.BasicServiceInitiatorpour contrôler la construction sur demande de la classe du service et y ajouter leorg.hibernate.service.ServiceRegistryBuildervia sa méthodeaddInitiator. - Il vous suffit d'instancier la classe de service et de l'ajouter au
org.hibernate.service.ServiceRegistryBuildervia sa méthodeaddService.
Exemple 11.22. Utiliser ServiceRegistryBuilder pour remplacer un service existant par un service personnalisé
ServiceRegistryBuilder registryBuilder = new ServiceRegistryBuilder( bootstrapServiceRegistry );
serviceRegistryBuilder.addService( JdbcServices.class, new FakeJdbcService() );
ServiceRegistry serviceRegistry = registryBuilder.buildServiceRegistry();
public class FakeJdbcService implements JdbcServices{
@Override
public ConnectionProvider getConnectionProvider() {
return null;
}
@Override
public Dialect getDialect() {
return null;
}
@Override
public SqlStatementLogger getSqlStatementLogger() {
return null;
}
@Override
public SqlExceptionHelper getSqlExceptionHelper() {
return null;
}
@Override
public ExtractedDatabaseMetaData getExtractedMetaDataSupport() {
return null;
}
@Override
public LobCreator getLobCreator(LobCreationContext lobCreationContext) {
return null;
}
@Override
public ResultSetWrapper getResultSetWrapper() {
return null;
}
@Override
public JdbcEnvironment getJdbcEnvironment() {
return null;
}
}
11.5.6. Le registre Bootstrap
11.5.6.1. Le registre Boot-strap
ClassLoaderService qui en est un parfait exemple. Même la résolution des fichiers de configuration doit avoir accès aux services de chargement de classes (resource look ups). C'est le registre racine (sans parent) en conditions normales d'utilisation.
org.hibernate.service.BootstrapServiceRegistryBuilder.
11.5.6.2. Utilisation de BootstrapServiceRegistryBuilder
Exemple 11.23. Utilisation de BootstrapServiceRegistryBuilder
BootstrapServiceRegistry bootstrapServiceRegistry = new BootstrapServiceRegistryBuilder()
// pass in org.hibernate.integrator.spi.Integrator instances which are not
// auto-discovered (for whatever reason) but which should be included
.with( anExplicitIntegrator )
// pass in a class-loader Hibernate should use to load application classes
.withApplicationClassLoader( anExplicitClassLoaderForApplicationClasses )
// pass in a class-loader Hibernate should use to load resources
.withResourceClassLoader( anExplicitClassLoaderForResources )
// see BootstrapServiceRegistryBuilder for rest of available methods
...
// finally, build the bootstrap registry with all the above options
.build();
11.5.6.3. Les services BootstrapRegistry
org.hibernate.service.classloading.spi.ClassLoaderService
- la capacité de localiser des classes d'application
- la capacité de localiser des classes d'intégration
- la capacité de localiser des ressources (fichiers de propriétés, fichiers xml, etc.)
- la capacité à charger
java.util.ServiceLoader
Note
org.hibernate.integrator.spi.IntegratorService
java.util.ServiceLoader fournie par org.hibernate.service.classloading.spi.ClassLoaderService pour découvrir les implémentations du contrat org.hibernate.integrator.spi.Integrator.
/META-INF/services/org.hibernate.integrator.spi.Integrator et de le rendre disponible sur le chemin de classe. java.util.ServiceLoader couvre le format de ce fichier en détails, et surtout dresse une liste des classes par FQN qui implémentent le org.hibernate.integrator.spi.Integrator un par ligne.
11.5.7. Le registre SessionFactory
11.5.7.1. Le registre SessionFactory
org.hibernate.SessionFactory donnée, les instances de service de ce groupe appartiennent explicitement à une org.hibernate.SessionFactory unique.
org.hibernate.SessionFactory pour pouvoir être initiées. Ce registre spécial est org.hibernate.service.spi.SessionFactoryServiceRegistry
11.5.7.2. Services SessionFactory
org.hibernate.event.service.spi.EventListenerRegistry
- Description
- Service pour gérer les listeners d'événements
- Initiateur
org.hibernate.event.service.internal.EventListenerServiceInitiator- Implémentations
org.hibernate.event.service.internal.EventListenerRegistryImpl
11.5.8. Intégrateurs
11.5.8.1. Intégrateurs
org.hibernate.integrator.spi.Integrator a pour but de procurer un simple moyen de permettre aux développeurs de raccrocher un processus de création de SessionFactory en état de fonctionnement. L'interface org.hibernate.integrator.spi.Integrator définit 2 méthodes intéressantes: integrate permet de se joindre à un processus de création; disintegrate nous permet de raccrocher la fermeture de la SessionFactory.
Note
org.hibernate.integrator.spi.Integrator, une forme surchargée de integrate qui accepte un org.hibernate.metamodel.source.MetadataImplementor à la place d'une org.hibernate.cfg.Configuration. Cette forme a pour dessein d'être utilisée avec le nouveau code de méta modèle qui devra est opérationnel dans 5.0.
11.5.8.2. Cas d'utilisation d'Integrator
org.hibernate.integrator.spi.Integrator actuellement consistent à enregistrer des listeners d'événements et de fournir des services (voir org.hibernate.integrator.spi.ServiceContributingIntegrator). Dans 5.0, nous espérons étendre ceci afin de permettre de modifier les méta modèles qui décrivent le mappage entre les modèles relationnels et les objets.
Exemple 11.24. Enregistrement des listeners d'événements
public class MyIntegrator implements org.hibernate.integrator.spi.Integrator {
public void integrate(
Configuration configuration,
SessionFactoryImplementor sessionFactory,
SessionFactoryServiceRegistry serviceRegistry) {
// As you might expect, an EventListenerRegistry is the thing with which event listeners are registered It is a
// service so we look it up using the service registry
final EventListenerRegistry eventListenerRegistry = serviceRegistry.getService( EventListenerRegistry.class );
// If you wish to have custom determination and handling of "duplicate" listeners, you would have to add an
// implementation of the org.hibernate.event.service.spi.DuplicationStrategy contract like this
eventListenerRegistry.addDuplicationStrategy( myDuplicationStrategy );
// EventListenerRegistry defines 3 ways to register listeners:
// 1) This form overrides any existing registrations with
eventListenerRegistry.setListeners( EventType.AUTO_FLUSH, myCompleteSetOfListeners );
// 2) This form adds the specified listener(s) to the beginning of the listener chain
eventListenerRegistry.prependListeners( EventType.AUTO_FLUSH, myListenersToBeCalledFirst );
// 3) This form adds the specified listener(s) to the end of the listener chain
eventListenerRegistry.appendListeners( EventType.AUTO_FLUSH, myListenersToBeCalledLast );
}
}
11.6. Validation d'un bean
11.6.1. Validation Bean
bean-validation quickstart example: Section 1.4.2.1, « Accès aux Quickstarts ».
11.6.2. Hibernate Validator
11.6.3. Contraintes de validation
11.6.3.1. Les contraintes de validation
11.6.3.2. Créer une annotation de contrainte dans JBoss Developer Studio
Cette tâche couvre le processus de création d'une annotation de contrainte dans JBoss Developer Studio, à utiliser dans une application Java.
Procédure 11.5. Créer une annotation de contrainte
- Ouvrir un projet Java dans JBoss Developer Studio
Créer un ensemble de données
Une annotation de contrainte requiert un ensemble de données qui définissent les valeurs qui conviennent.- Cliquer à droite sur le dossier racine du projet dans le panneau Project Explorer.
- Sélectionner → .
- Configurer les éléments suivants :
- Package :
- Nom :
- Cliquer sur le bouton pour ajouter des interfaces selon les besoins.
- Cliquer sur pour créer le fichier.
- Ajouter un ensemble de valeurs à l'ensemble de données et cliquer sur .
Exemple 11.25. Exemple d'ensemble de données
package com.example; public enum CaseMode { UPPER, LOWER; }Créer le fichier Annotation
Créer une nouvelle classe Java. Pour les détails, consulter Section 11.6.3.3, « Créer une nouvelle classe Java dans JBoss Developer Studio ».- Configurez l'annotation de la contrainte et cliquer sur .
Exemple 11.26. Exemple de fichier d'annotation de contrainte
package com.mycompany; import static java.lang.annotation.ElementType.*; import static java.lang.annotation.RetentionPolicy.*; import java.lang.annotation.Documented; import java.lang.annotation.Retention; import java.lang.annotation.Target; import javax.validation.Constraint; import javax.validation.Payload; @Target( { METHOD, FIELD, ANNOTATION_TYPE }) @Retention(RUNTIME) @Constraint(validatedBy = CheckCaseValidator.class) @Documented public @interface CheckCase { String message() default "{com.mycompany.constraints.checkcase}"; Class<?>[] groups() default {}; Class<? extends Payload>[] payload() default {}; CaseMode value(); }
- Résultat
- Une annotation de contrainte personnalisée possédant un ensemble de valeurs possibles a été créé, prêt à l'utilisation dans le projet Java.
11.6.3.3. Créer une nouvelle classe Java dans JBoss Developer Studio
Ce sujet couvre le processus de création d'une classe Java dans un projet Java qui utilise JBoss Developer Studio.
Procédure 11.6. Créer une nouvelle classe Java
- Cliquer à droite sur le dossier racine du projet dans le panneau Project Explorer.
- Sélectionner → .
- Configurer les éléments suivants :
- Package:
- Nom:
Option: ajouter une interface
- Cliquer sur
- Rechercher le nom de l'interface
- Sélectionner l'interface qui convient.
- Répéter les étapes 2 et 3 pour chaque interface requise.
- Cliquer sur .
- Cliquer sur pour créer le fichier.
- Résultat
- Une nouvelle Classe Java a maintenant été créée dans le projet, prête à la configuration.
11.6.3.4. Contraintes d'Hibernate Validator
Tableau 11.11. Contraintes intégrées
| Annotation | + | Vérification du runtime | Impact des métadonnées Hibernate |
|---|---|---|---|
| @Length(min=, max=) | propriété (String) | Vérifier si la longueur de la chaîne de caractères correspond à la plage. | La colonne sera définie à la longueur maximum. |
| @Max(value=) | propriété (numérique ou représentation par chaîne d'un numérique) | Vérifiez si la valeur est inférieure ou égale à la valeur maximum. | Ajouter un contrôle sur la colonne. |
| @Min(value=) | propriété (numérique ou représentation par chaîne d'un numérique) | Vérifier si la valeur est supérieure ou égale à la valeur minimale. | Ajouter un contrôle sur la colonne. |
| @NotNull | propriété | Vérifier si la valeur est non nulle. | Colonne(s) non nulles. |
| @NotEmpty | propriété | Vérifier si la chaîne est non nulle ou vide. Vérifier si la connexion est non nulle ou vide. | Colonne(s) non nulles (pour Chaîne). |
| @Past | propriété (date ou calendrier) | Vérifier si la date est dans le passé. | Ajouter un contrôle sur la colonne. |
| @Future | propriété (date ou calendrier) | Vérifier si la date est dans le futur. | Aucun(e). |
| @Pattern(regex="regexp", flag=) or @Patterns( {@Pattern(...)} ) | propriété (String) | Vérifier si la propriété correspond à une expression standard avec un indicateur de correspondance (voir java.util.regex.Pattern). | Aucun(e). |
| @Range(min=, max=) | propriété (numérique ou représentation par chaîne d'un numérique) | Vérifier si la valeur est comprise entre la valeur minimum et la valeur maximum (comprise). | Ajouter un contrôle sur la colonne. |
| @Size(min=, max=) | propriété (tableau, collection, mappe) | Vérifier si la taille de l'élément est comprise entre la valeur minimum et la valeur maximum (comprise). | Aucun(e). |
| @AssertFalse | propriété | Vérifier si la méthode évalue à false (utile pour les contraintes en code et non pas sous forme d'annotations). | Aucun(e). |
| @AssertTrue | propriété | Vérifier si la méthode évalue à true (utile pour les contraintes en code et non pas sous forme d'annotations). | Aucun(e). |
| @Valid | propriété (objet) | Procède à une validation récursive de l'objet associé. Si l'objet correspond à une collection ou à un tableau, les éléments seront validés de façon récursive. Si l'objet est une mappe, les éléments correspondant à la valeur seront validés de façon récursive. | Aucun(e). |
| propriété (String) | Vérifier si la chaîne de caractères est bien conforme à la spécification de l'adresse email. | Aucun(e). | |
| @CreditCardNumber | propriété (String) | Vérifier si la chaîne de caractères correspond à un numéro de carte de crédit formaté (dérivatif de l'algorithme Luhn). | Aucun(e). |
| @Digits(integerDigits=1) | propriété (numérique ou représentation par chaîne d'un numérique) | Vérifier si la propriété est un numéro qui comprend un maximum de integerDigits chiffres et fractionalDigits chiffres sous forme de fraction. | Définit la précision et l'échelle de la colonne. |
| @EAN | propriété (String) | Vérifie si la chaîne correspond à un code UPC-A ou EAN formaté comme il faut. | Aucun(e). |
11.6.4. Configuration
11.6.4.1. Exemple de fichier de configuration de validation
Exemple 11.27. validation.xml
<validation-config xmlns="http://jboss.org/xml/ns/javax/validation/configuration"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://jboss.org/xml/ns/javax/validation/configuration">
<default-provider>
org.hibernate.validator.HibernateValidator
</default-provider>
<message-interpolator>
org.hibernate.validator.messageinterpolation.ResourceBundleMessageInterpolator
</message-interpolator>
<constraint-validator-factory>
org.hibernate.validator.engine.ConstraintValidatorFactoryImpl
</constraint-validator-factory>
<constraint-mapping>
/constraints-example.xml
</constraint-mapping>
<property name="prop1">value1</property>
<property name="prop2">value2</property>
</validation-config>
11.7. Envers
11.7.1. Hibernate Envers
@Audited, et ils stockent l'historique des modifications apportées à l'entité. Les données peuvent ensuite être récupérées et interrogées.
- vérifier tous les mappages définis par la spécification JPA,
- vérifier tous les mappages qui étendent la spécification JPA,
- vérifier toules les entités mappées ou qui utilisent l'API Hibernate natif
- journaliser des données pour chaque révision par l'intermédiaire d'une entité de révision, et
- interroger les données historiques.
11.7.2. Audit de classes persistantes
@Audited . Quand l'annotation s'applique à une classe, un tableau est créé, et ce tableau stocke l'historique de révision de l'entité.
11.7.3. Stratégies d'auditing
11.7.3.1. Stratégies d'auditing
- Stratégie d'audit par défaut
- Cette stratégie persiste les données d'audit avec la révision de départ. Pour chaque ligne insérée, mise à jour ou effacée dans un tableau audité, une ou plusieurs lignes seront insérées dans les tableaux d'audit, avec la révision de départ de sa validité.Les lignes des tableaux d'audit ne sont jamais mises à jour suite à une insertion. Les demandes d'informations d'audit utilisent des sous-requêtes pour sélectionner les lignes qui s'appliquent aux tableaux d'audit, et qui sont lentes et difficiles à indexer.
- Stratégie d'audit de validité
- Cette stratégie stocke la révision de départ, ainsi que la révision de fin de l'information d'audit. Pour chaque rangée insérée, mise à jour ou effacée dans un tableau audité, un ou plusieurs rangées seront insérées dans les tableaux d'audit, avec la révision de départ de sa validité.En même temps, le champ de révision de fin des lignes d'audit précédentes (si disponible) est défini pour cette révision. Les demandes d'informations d'audit peuvent ensuite utiliser entre révision de départ ou de fin, à la place des sous-requêtes. Cela signifie que persister les informations d'audit est un peu plus lent à cause des mises à jour supplémentaires, mais la récupération d'informations d'audit est beaucoup plus rapide.Cela peut également être amélioré en ajoutant des indices supplémentaires.
11.7.3.2. Définir la stratégie d'auditing
Il y a deux stratégies d'auditing prises en charge par JBoss EAP 6 : la stratégie d'audit de validité ou la stratégie d'audit par défaut. Cette tâche couvre les étapes nécessaires requises pour définir la stratégie d'auditing d'une application.
Procédure 11.7. Définir une stratégie d'auditing
- Configurer la propriété
org.hibernate.envers.audit_strategyqui se trouve dans le ficherpersistence.xmlde l'application. Si la propriété est définie dans le fichierpersistence.xml, alors la stratégie d'audit par défaut sera utilisée.Exemple 11.28. Définir la stratégie d'auditing par défaut
<property name="org.hibernate.envers.audit_strategy" value="org.hibernate.envers.strategy.DefaultAuditStrategy"/>
Exemple 11.29. Définir la stratégie d'auditing de validité
<property name="org.hibernate.envers.audit_strategy" value="org.hibernate.envers.strategy.ValidityAuditStrategy"/>
11.7.4. Introduction à l'auditing d'entités
11.7.4.1. Ajouter une support d'auditing à une entité JPA
Procédure 11.8. Ajouter une support d'auditing à une entité JPA
- Configurer les paramètres d'auditing disponible qui conviennent au déploiement : Section 11.7.5.1, « Configurer les paramètres Envers ».
- Ouvrir l'entité JPA à auditer.
- Importer l'interface
org.hibernate.envers.Audited. - Appliquer l'annotation
@Auditedà chaque champ ou propriété à auditer, ou l'appliquer une seule fois à toute la classe.Exemple 11.30. Audit de deux champs
import org.hibernate.envers.Audited; import javax.persistence.Entity; import javax.persistence.Id; import javax.persistence.GeneratedValue; import javax.persistence.Column; @Entity public class Person { @Id @GeneratedValue private int id; @Audited private String name; private String surname; @ManyToOne @Audited private Address address; // add getters, setters, constructors, equals and hashCode here }Exemple 11.31. Audit d'une classe complète
import org.hibernate.envers.Audited; import javax.persistence.Entity; import javax.persistence.Id; import javax.persistence.GeneratedValue; import javax.persistence.Column; @Entity @Audited public class Person { @Id @GeneratedValue private int id; private String name; private String surname; @ManyToOne private Address address; // add getters, setters, constructors, equals and hashCode here }
L'entité JPA a été configurée pour l'auditing. Un tableau intitulé Entity_AUD sera créé pour stocker les changements historiques.
11.7.5. Configuration
11.7.5.1. Configurer les paramètres Envers
Procédure 11.9. Configurer les paramètres Envers
- Ouvrir le fichier
persistence.xmlde l'application. - Ajouter, supprimer ou configurer les propriétés Envers selon les besoins. Pour obtenir une liste complète des propriétés disponibles, consulter Section 11.7.5.4, « Propriétés de configuration Envers ».
Exemple 11.32. Exemples de paramètres Envers
<persistence-unit name="mypc">
<description>Persistence Unit.</description>
<jta-data-source>java:jboss/datasources/ExampleDS</jta-data-source>
<shared-cache-mode>ENABLE_SELECTIVE</shared-cache-mode>
<properties>
<property name="hibernate.hbm2ddl.auto" value="create-drop" />
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.cache.use_second_level_cache" value="true" />
<property name="hibernate.cache.use_query_cache" value="true" />
<property name="hibernate.generate_statistics" value="true" />
<property name="org.hibernate.envers.versionsTableSuffix" value="_V" />
<property name="org.hibernate.envers.revisionFieldName" value="ver_rev" />
</properties>
</persistence-unit>
- Résultat
- L'auditing a été configuré pour toutes les entités JPA de l'application.
11.7.5.2. Activer ou désactiver l'auditing en cours d'exécution
Cette tâche couvre les étapes de configuration requises pour activer/désactiver l'auditing de version d'entité en cours d'exécution.
Procédure 11.10. Activer/désactiver l'auditing
- Sous-classe la classe
AuditEventListener. - Remplace les méthodes suivantes appelées sur les événements Hibernate :
- onPostInsert
- onPostUpdate
- onPostDelete
- onPreUpdateCollection
- onPreRemoveCollection
- onPostRecreateCollection
- Spécifie la sous-classe comme listener des événements.
- Détermine si le changement doit être vérifié.
- Passe l'appel à la sur-classe si le changement doit être vérifié.
11.7.5.3. Configurer l'auditing conditionnel.
Hibernate Envers persiste les données d'auditing en réaction à certains événements, en utilisant une série de listeners d'événements. Ces listeners sont enregistrés automatiquement si le jar Envers est sur le chemin de classe. Cette tâche couvre les étapes requises pour mettre en place l'auditing conditionnel, en remplaçant certains listeners d'événements Envers.
Procédure 11.11. Implémentation de l'Auditing conditionnel
- Définir la propriété Hibernate
hibernate.listeners.envers.autoRegisterà false dans le fichierpersistence.xml. - Sous-classer chaque listener d'événement à remplacer. Mettez la logique d'auditing conditionnel dans la sous-classe, et appeler la super méthode si on doit procéder à l'auditing.
- Créer une implémentation personnalisée de
org.hibernate.integrator.spi.Integrator, semblable àorg.hibernate.envers.event.EnversIntegrator. Utiliser les sous-classes de listeners d'événements créées à la deuxième étape, à la place des classes par défaut. - Ajouter un fichier
META-INF/services/org.hibernate.integrator.spi.Integratorau jar. Ce fichier doit contenir le nom complet de la classe qui implémente d'interface.
L'auditing conditionnel alors est configuré, remplaçant ainsi les listeners d'événements Envers par défaut.
11.7.5.4. Propriétés de configuration Envers
Tableau 11.12. Paramètres de configuration du Versioning de données d'entité
| Nom de propriété | Valeur par défaut | Description |
|---|---|---|
|
org.hibernate.envers.audit_table_prefix
| |
String attaché au nom d'une entité auditée, pour créer le nom de l'entité qui contiendra l'audit en formation.
|
|
org.hibernate.envers.audit_table_suffix
|
_AUD
|
String attaché au nom d'une entité auditée, pour créer le nom de l'entité qui contiendra l'audit en formation. Par exemple, si une entité ayant comme nom de tableau
Person est auditée, Envers créera un tableau nommé Person_AUD pour stocker les données historiques.
|
|
org.hibernate.envers.revision_field_name
|
REV
|
Le nom du champ qui contient le numéro de révision dans l'entité d'audit.
|
|
org.hibernate.envers.revision_type_field_name
|
REVTYPE
|
Le nom du champ de l'entité d'audit qui contient le type de révision. Les types actuels de révision possibles sont :
add, mod et del.
|
|
org.hibernate.envers.revision_on_collection_change
|
true
|
Cette propriété indique si une révision doit être créée si un champ relationnel qui n'appartient à personne change. Il peut s'agir d'une collection d'une relation one-to-many, ou bien du champ qui utilise l'attribut
mappedBy dans une relation one-to-one.
|
|
org.hibernate.envers.do_not_audit_optimistic_locking_field
|
true
|
Si true, les propriétés utilisées pour le verrouillage optimiste (annoté par
@Version) sera exclus automatiquement de l'audit.
|
|
org.hibernate.envers.store_data_at_delete
|
false
|
Cette propriété définit si oui ou non les données d'entité doivent être stockées dans la révision lorsque l'entité est supprimée, au lieu de l'ID uniquement, avec toutes les autres propriétés marquées comme null. Ce n'est pas généralement nécessaire, car les données sont présentes dans l'avant dernière révision. Parfois, il est plus facile et plus efficace d'y accéder dans la dernière révision. Cependant, cela signifie que les données de l'entité contenues avant suppression apparaissent deux fois.
|
|
org.hibernate.envers.default_schema
|
null (comme dans les tableaux normaux)
|
Le nom de schéma par défaut utilisé pour les tableaux d'audit. Peut être substitué à l'aide de l'annotation
@AuditTable(schema="..."). Si absent, le schéma sera le même que le schéma des tableaux normaux.
|
|
org.hibernate.envers.default_catalog
|
null (comme dans les tableaux normaux)
|
Le nom de catalogue par défaut qui doit être utilisé dans les tableaux d'audit. Peut être substitué par l'annotation
@AuditTable(catalog="..."). Si non présent, le catalogue sera le même que le catalogue des tableaux normaux.
|
|
org.hibernate.envers.audit_strategy
|
org.hibernate.envers.strategy.DefaultAuditStrategy
|
Cette propriété définit la stratégie d'auditing qui doit être utilisée lors de la persistance des données d'audit. Par défaut, seule la révision où une entité a été modifiée est stockée. Alternativement,
org.hibernate.envers.strategy.ValidityAuditStrategy stocke la révision du départ et révision de la fin. Ceux-ci définissent ensemble quand une ligne d'auditing est valide.
|
|
org.hibernate.envers.audit_strategy_validity_end_rev_field_name
|
REVEND
|
Le nom de la colonne qui contiendra le dernier numéro de révision dans les entités d'auditing. Cette propriété n'est valide que si la stratégie d'auditing de validité est utilisée.
|
|
org.hibernate.envers.audit_strategy_validity_store_revend_timestamp
|
false
|
Cette propriété définit si l'horodatage du dernier numéro de révision des dernières données valides doit être conservé en plus de la dernière révision elle-même. Ceci est utile pour pouvoir purger les archives d'audit sur une base de données relationnelle en utilisant le partitionnement de la table. Le partitionnement exige une colonne qui existe dans la table. Cette propriété n'est évaluée que si la
ValidityAuditStrategy est utilisée
|
|
org.hibernate.envers.audit_strategy_validity_revend_timestamp_field_name
|
REVEND_TSTMP
|
Nom de la colonne d'horodatage de la dernière révision au moment où les données étaient encore valides. Utilisé uniquement si
ValidityAuditStrategy est utilisé, et si org.hibernate.envers.audit_strategy_validity_store_revend_timestamp évalue sur true.
|
11.7.6. Recherches
11.7.6.1. Suppression de l'information d'auditing
Hibernate Envers fournit une fonctionnalité qui permet d'extraire des informations d'audit par des requêtes. Cette section vous donne des exemples de telles requêtes.
Note
live, car elles impliquent des sous-sélections en corrélation.
Exemple 11.33. Chercher des entités d'une classe pour une révision donnée
AuditQuery query = getAuditReader()
.createQuery()
.forEntitiesAtRevision(MyEntity.class, revisionNumber);
AuditEntity. La recherche ci-dessous ne sélectionne que des entités dont la propriété nom est égale à John:
query.add(AuditEntity.property("name").eq("John"));
query.add(AuditEntity.property("address").eq(relatedEntityInstance));
// or
query.add(AuditEntity.relatedId("address").eq(relatedEntityId));
List personsAtAddress = getAuditReader().createQuery()
.forEntitiesAtRevision(Person.class, 12)
.addOrder(AuditEntity.property("surname").desc())
.add(AuditEntity.relatedId("address").eq(addressId))
.setFirstResult(4)
.setMaxResults(2)
.getResultList();
Exemple 11.34. Chercher les révisions de demandes pour lesquelles les entités d'une classe donnée ont changé
AuditQuery query = getAuditReader().createQuery()
.forRevisionsOfEntity(MyEntity.class, false, true);
AuditEntity.revisionNumber()- Spécifie les contraintes, les projections et l'ordre en considération desquels l'entité auditée a été modifiée dans le numéro de révision.
AuditEntity.revisionProperty(propertyName)- Spécifier les contraintes, les projections et l'ordre de l'entité de révision sur une propriété , correspondants à la révision dans laquelle l'entité auditée a été modifiée.
AuditEntity.revisionType()- Fournit des accès au type de révision (ADD, MOD, DEL).
MyEntity, ayant pour ID entityId a changé, après le numéro de révision 42 :
Number revision = (Number) getAuditReader().createQuery()
.forRevisionsOfEntity(MyEntity.class, false, true)
.setProjection(AuditEntity.revisionNumber().min())
.add(AuditEntity.id().eq(entityId))
.add(AuditEntity.revisionNumber().gt(42))
.getSingleResult();
actualDate d'une entité donnée est supérieure à une valeur donnée, mais aussi petite que possible :
Number revision = (Number) getAuditReader().createQuery()
.forRevisionsOfEntity(MyEntity.class, false, true)
// We are only interested in the first revision
.setProjection(AuditEntity.revisionNumber().min())
.add(AuditEntity.property("actualDate").minimize()
.add(AuditEntity.property("actualDate").ge(givenDate))
.add(AuditEntity.id().eq(givenEntityId)))
.getSingleResult();
minimize() et maximize() renvoient un critère, auquel des contraintes peuvent être ajoutées, et qui doit être respecté par les entités avec des propriétés maximisées/minimisées.
selectEntitiesOnly- Ce paramètre n'est valide que lorsqu'une projection explicite n'est pas définie.Si true, le résultat de la recherche correspondra à une liste d'entités qui ont changé lors de révisions satisfaisant les contraintes spécifiées.Si false, le résultat correspondra à une liste de trois tableaux d'éléments. Le premier élément correspondra à l'instance d'entité modifiée. Le second correspondra à une entité qui contient les données de révision. Si aucune entité personnalisée n'est utilisée, alors on aura une instance de
DefaultRevisionEntity. Le troisième tableau d'éléments correspondra au type de révision (ADD, MOD, DEL). selectDeletedEntities- Ce paramètre indique si les révisions dans lesquelles les entités ont été supprimées doivent être incluses dans les résultats. Si true, les entités auront le type de révision
DEL, et tous les champs, à part l'id, auront pour valeurnull.
Exemple 11.35. Chercher les révisions d'une entité qui ont pu modifier une propriété donnée
MyEntity pour une id donnée, quand la propriété actualDate a été modifiée.
AuditQuery query = getAuditReader().createQuery()
.forRevisionsOfEntity(MyEntity.class, false, true)
.add(AuditEntity.id().eq(id));
.add(AuditEntity.property("actualDate").hasChanged())
hasChanged peut être combinée à des critères supplémentaires. La recherche ci-dessous renvoie une coupe horizontale de MyEntity au moment où le revisionNumber est créé. Ce sera limité aux révisions qui ont modifié prop1, et non pas prop2.
AuditQuery query = getAuditReader().createQuery()
.forEntitiesAtRevision(MyEntity.class, revisionNumber)
.add(AuditEntity.property("prop1").hasChanged())
.add(AuditEntity.property("prop2").hasNotChanged());
MyEntities modifiées dans le revisionNumber avec prop1 modifié et prop2 intact. »
forEntitiesModifiedAtRevision :
AuditQuery query = getAuditReader().createQuery()
.forEntitiesModifiedAtRevision(MyEntity.class, revisionNumber)
.add(AuditEntity.property("prop1").hasChanged())
.add(AuditEntity.property("prop2").hasNotChanged());
Exemple 11.36. Recherche d'entités modifiées dans une révision donnée
Set<Pair<String, Class>> modifiedEntityTypes = getAuditReader()
.getCrossTypeRevisionChangesReader().findEntityTypes(revisionNumber);
org.hibernate.envers.CrossTypeRevisionChangesReader:
List<Object> findEntities(Number)- Retourne des instantanés de toutes les entités d'auditing changées (ajoutées, mises à jour et supprimées) dans une révision donnée. Exécute des requêtes SQL
n + 1, oùnest un nombre de classes d'entités différentes modifiées dans la révision spécifiée. List<Object> findEntities(Number, RevisionType)- Retourne des instantanés de toutes les entités d'auditing changées (ajoutées, mises à jour et supprimées) dans une révision donnée filtrée par type de modification. Exécute des requêtes SQL
n + 1, oùnest un nombre de classes d'entités différentes modifiées dans la révision spécifiée. Map<RevisionType, List<Object>> findEntitiesGroupByRevisionType(Number)- Retourne une carte contenant les listes des instantanés d'entité regroupés par opération de modification (ajout, mise à jour et suppression). Exécute des requêtes SQL
3n + 1, oùnest un nombre de classes d'entités différentes modifiées au cours de la révision spécifiée.
11.8. Réglage de la performance
11.8.1. Algorithmes de chargement de lots alternatifs
- Niveau Par classeLors du chargement de données sur un niveau par classe, Hibernate, requiert la taille de lot de l'association à pré-charger lorsqu'il est interrogé. Par exemple, imaginons que lors de l'exécution, vous ayez 30 instances d'un objet
voiturechargées dans la session. Chaque objetvoitureappartient à un objetpropriétaire. Si vous deviez parcourir tous les objetsvoitureet appeler leurs propriétaires, par un chargementdifféré(lazy loading), Hibernate émettra 30 instructions select - une pour chaque propriétaire. Il s'agit d'un goulot d'étranglement de performance.À la place, vous pouvez dire à Hibernate de charger à l'avance le prochain lot de propriétaires avant qu'ils aient été interrogés par une requête. Quand un objetowner(propriétaire) est interrogé, Hibernate interrogera ces objets à plusieurs reprises dans le même énoncé SELECT.Le nombre d'objetsowner(propriétaire) à interroger à l'avance dépend du paramètrebatch-sizespécifié en cours de configuration :<class name="owner" batch-size="10"></class>
Cela indique à Hibernate d'interroger au moins 10 objetsownerau cas où ils seraient nécessaires dans un avenir proche. Lorsqu'un utilisateur interroge le propriétaireownerdecar A, le propriétaireownerdecar Bpeut déjà avoir été chargé dans un lot de chargement. Lorsque l'utilisateur a besoin du propriétaireownerdecar B, au lieu d'aller à la base de données (et émettre une instruction SELECT), la valeur peut être récupérée de la session en cours.En plus du paramètrebatch-size, Hibernate 4.2.0 a introduit un nouvel élément de configuration pour améliorer la performance de chargement de lots. La configuration s'appelleBatch Fetch Styleet est spécifiée par le paramètrehibernate.batch_fetch_style.Il existe trois styles d'extraction de lots pris en charge : LEGACY, PADDED et DYNAMIC. Pour spécifier le style, utiliserorg.hibernate.cfg.AvailableSettings#BATCH_FETCH_STYLE.- LEGACY : dans le style hérité de chargement, une série de tailles de lots pré-construits basé
ArrayHelper.getBatchSizes(int)sont utilisées. Les lots sont chargés à l'aide de la taille de lot de pré-construction suivante à partir du nombre d'identificateurs existants pouvant être mis en lot.En continuant avec l'exemple suivant, ayant une taillebatch-sizede 30, les tailles de lot pré-construits sont [30, 15, 10, 9, 8, 7, .., 1]. Si l'on tente de mettre en lots 29 identifiants, on obtiendra des lots de 15, 10 et 4. Il y aura 3 requêtes SQL correspondantes, chacune chargeant 15, 10 et 4 propriétaires de la base de données. - PADDED - similaire au style de chargement de classes LEGACY. Utilise toujours des tailles de lots pré-construits, mais utilise la taille de lot supérieure et remplit les espaces réservés de l'identifiant supplémentaire.Tout comme dans l'exemple ci-dessus, si 30 objets propriétaires doivent être initialisés, il ne pourra y avoir qu'une demande exécutée dans la base de données.Cependant, si 29 objets propriétaires doivent être initialisés, Hibernate n'exécutera qu'un seul énoncé select SQL de taille de lot 30, avec l'espace supplémentaire rempli par un identifiant répété.
- Dynamic - bien que toujours conforme à la limitation de la taille des lots, ce style de chargement dynamiquement de lots construit son énoncé SQL SELECT à l'aide du nombre réel d'objets à charger.Par exemple, pour 30 objets propriétaires, et une taille de lot maximale de 30, un appel pour récupérer 30 objets propriétaires entraînera une instruction SQL SELECT. Un appel pour récupérer 35 se traduira en deux énoncés SQL, ayant pour taille de lot 30 et 5, respectivement. Hibernate modifiera dynamiquement le second énoncé SQL pour maintenir à 5, le nombre requis, tout en restant sous la restriction de 30 pour la taille des lots. C'est différent de la version PADDED, car le deuxième SQL ne sera pas PADDED et à la différence du style LEGACY, il n'y a pas de taille fixe pour le second énoncé SQL - le second SQL est créé dynamiquement.Pour une requête inférieure à 30 identifiants, ce style ne chargera de façon dynamique que le nombre d'identifiants requis.
- Niveau Par collectionHibernate peut aussi mettre en lots des collections de chargement, en respectant la taille ou les styles des lots d'extraction suivant la liste de la section par-classe ci-dessus.Pour inverser l'exemple utilisé dans la section précédente, considérons que vous deviez charger tous les objets
car(voiture) appartenant à chaque objetowner(propriétaire). Si 10 objets propriétaireownersont chargés dans la session en cours, itérer tous les propriétaires va générer 10 énoncés SELECT, un pour chaque appel de méthode àgetCars(). Si vous activez l'extraction de lot pour la collection de voitures dans le mappage du propriétaire, Hibernate pourra chercher ces collections à l'avance, comme illustré ci-dessous.<class name="Owner"><set name="cars" batch-size="5"></set></class>
Donc, avec une taille de lotbatch-sizeégale à 5 et en utilisant le style de lot hérité, Hibernate chargera 5 collections dans deux énoncés SELECT.
11.8.2. Mise en cache de second niveau d'objets de référence pour les données non mutables
hibernate.cache.use_reference_entries à true. Par défaut, hibernate.cache.use_reference_entries est défini à false.
hibernate.cache.use_reference_entries a pour valeur true, un objet de données immuables qui n'a pas d'associations n'est pas copié dans le cache de second niveau, et seulement sa référence y sera stockée.
Avertissement
hibernate.cache.use_reference_entries a pour valeur true, un objet de données immuables qui possède des associations sera copié dans le cache de second niveau.
Chapitre 12. Services Web JAX-RS
12.1. JAX-RS
helloworld-rs, jax-rs-client, et kitchensink quickstart: Section 1.4.2.1, « Accès aux Quickstarts ».
12.2. RESTEasy
12.3. Services Web RESTful
12.4. Annotations définies RESTEasy
Tableau 12.1. Annotations JAX-RS/RESTEasy
| Annotation | Utilisation |
|---|---|
ClientResponseType | Il s'agit d'une annotation que vous pouvez ajouter à une interface de client RESTEasy qui a un type de renvoi Réponse. |
ContentEncoding | Méta annotation qui indique un Contenet-Encoding à appliquer par l'annotation annotée. |
DecorateTypes | Doit être mis sur une classe DecoratorProcessor pour spécifier les types pris en charge. |
Decorator | Méta annotation à mettre dans une autre annotation qui déclenche décoration. |
Form | Peut être utilisé comme objet de valeur pour les requêtes/réponses entrantes/sortantes. |
StringParameterUnmarshallerBinder | Méta annotation à mettre dans une autre annotation qui déclenche un StringParameterUnmarshaller à appliquer à un injecteur d'annotation basé chaîne. |
Cache | Définit l'en-tête Cache-Control de réponse automatiquement. |
NoCache | Définit la réponse Cache-Control à "nocache". |
ServerCached | Indique que la réponse à cette méthode jax-rs devrait être mise en cache sur le serveur. |
ClientInterceptor | Identifie un intercepteur en tant qu'intercepteur côté client. |
DecoderPrecedence | Cet intercepteur est un décodeur Content_Encoding. |
EncoderPrecedence | Cet intercepteur est un encodeur Content_Encoding. |
HeaderDecoratorPrecedence | Les intercepteurs HeaderDecoratorPrecedence doivent toujours venir en premier car ils décorent une réponse (sur le serveur), ou une réquête sortante (sur le client) avec des en-têtes spéciaux définis utilisateur. |
RedirectPrecedence | Doivent être mis dans un PreProcessInterceptor. |
SecurityPrecedence | Doivent être mis dans un PreProcessInterceptor. |
ServerInterceptor | Identifie un intercepteur en tant qu'intercepteur côté client. |
NoJackson | Mis sur une classe, un paramètre, un champ ou une métode quand vous ne souhaitez pas déclencher un fournisseur Jackson. |
ImageWriterParams | Annotation qu'une classe de ressource peut utiliser pour passer des paramètres au IIOImageProvider. |
DoNotUseJAXBProvider | Mettre ceci sur une classe ou sur un paramètre quand vous ne souhaitez pas utiliser le MessageBodyReader/Writer JAXB, mais que vous avez à la place un fournisseur plus spécifique que vous souhaitez utliser pour marshaler le type. |
Formatted | Formate la sortie XNL par des indentations et des nouvelles lignes. Il s'agit d'un Decorateur JAXB. |
IgnoreMediaTypes | Mis sur un type, une méthode, un paramètre ou un champ pour indiquer au JAXRS de ne pas utiliser de fournisseur JAXB pour une certain type de media. |
Stylesheet | Indique un en-tête de feuille de style XML. |
Wrapped | Mettre ceci sur une méthode ou un paramètre quand vous souhaitez marshaller ou démarshaller une collection ou un tableau d'objets JAXB. |
WrappedMap | Mettre ceci sur une méthode ou un paramètre quand vous souhaitez marshaller ou démarshaller une mappe d'objets JAXB. |
XmlHeader | Définit un en-tête XML de document renvoyé. |
BadgerFish | Un JSONConfig. |
Mapped | Un JSONConfig. |
XmlNsMap | Un JSONToXml. |
MultipartForm | Peut être utilisé comme objet de valeur pour les requêtes/réponses entrantes/sortantes d'un type de mime multipart/form-data. |
PartType | Doit être utilisé en conjonction avec des fournisseurs Multipart quand on écrit une liste ou un mappage de type multipart/*. |
XopWithMultipartRelated | Cette annotation peut être utilisée pour traiter/produire des messages XOP entrants/sortants (packagés comme multipart/related) vers/en provenance d'objets annotés JAXB. |
After | Utilisée pour ajouter un attribut d'expiration quand on signe ou comme contrôle. |
Signed | Annotation pratique qui déclenche la signature d'une requête ou d'une réponse utilisant la spécification DOSETA. |
Verify | Vérification d'une signature entrante spécifiée dans un en-tête de signature. |
12.5. Configuration RESTEasy
12.5.1. Paramètres de configuration RESTEasy
Tableau 12.2. Éléments
| Nom d'option | Valeur par défaut | Description |
|---|---|---|
| resteasy.servlet.mapping.prefix | Pas de valeur par défaut | Si le modèle d'url du mappage de servlet Resteasy n'est pas /*. |
| resteasy.scan | false | Scanner automatiquement les jars WEB-INF/lib et le répertoire WEB-INF/classes pour @Provider et les classes de ressource JAX-RS (@Path, @GET, @POST etc..) à la fois et les enregistrer. |
| resteasy.scan.providers | false | Scanner les classes @Provider et les enregistrer. |
| resteasy.scan.resources | false | Scanner les classes de ressources JAX-RS. |
| resteasy.providers | pas de valeur par défaut | Une liste de noms de classes @Provider complètes que vous souhaitez enregistrer délimitée par des virgules. |
| resteasy.use.builtin.providers | true | Indique si on doit ou non enregistrer les classes @Provider intégrées, par défaut. |
| resteasy.resources | Pas de valeur par défaut | Une liste de noms de classes de ressources JAX-RS complètes que vous souhaitez enregistrer délimitée par des virgules. |
| resteasy.jndi.resources | Pas de valeur par défaut | Une liste délimitée par des virgules de noms JNDI qui référencent des objets que vous souhaitez enregistrer comme ressources JAX-RS. |
| javax.ws.rs.Application | Pas de valeur par défaut | Nom qualifié de classe d'application à amorcer en spec portable. |
| resteasy.media.type.mappings | Pas de valeur par défaut | Remplace le besoin d'un en-tête Accept par mappage des extensions de noms de fichier (comme .xml ou .txt) avec un type de media. Utilisé quand le client n'est pas en mesure d'utiliser un en-tête Accept pour choisir une représentation (par ex. un navigateur). |
| resteasy.language.mappings | Pas de valeur par défaut | Remplace le besoin d'un en-tête Accept-Language par mappage des extensions de noms de fichier (comme .en ou .fr) avec une langue. Utilisé quand le client n'est pas en mesure d'utiliser un en-tête Accept-Language pour choisir une représentation (par ex. un navigateur). |
Important
resteasy.scan.* du fichier web.xml seront ignorées, et tous les composants annotés JAX-RS seront scannés automatiquement.
12.6. JAX-RS Web Service Security
12.6.1. Activer la sécurité basée-rôle pour RESTEasy JAX-RS Web Service
RESTEasy supporte les annotations @RolesAllowed, @PermitAll, et @DenyAll sur les méthodes JAX-RS. Cependant, il ne reconnaît pas ces annotations par défaut. Suivre les étapes suivantes pour configurer le fichier web.xml et pour activer la sécurité basée-rôle.
Avertissement
Procédure 12.1. Activer la sécurité basée-rôle pour RESTEasy JAX-RS Web Service
- Ouvrir le fichier
web.xmlde l'application dans l'éditeur de textes. - Ajouter le <context-param> suivant au fichier, dans les balises
web-app:<context-param> <param-name>resteasy.role.based.security</param-name> <param-value>true</param-value> </context-param> - Déclarer tous les rôles utilisés dans le fichier RESTEasy JAX-RS WAR file, en utilisant les balises de <security-role>:
<security-role><role-name>ROLE_NAME</role-name></security-role><security-role><role-name>ROLE_NAME</role-name></security-role> - Autorise l'accès à tous les URL gérés par le runtime JAX-RS pour tous les rôles :
<security-constraint><web-resource-collection><web-resource-name>Resteasy</web-resource-name><url-pattern>/PATH</url-pattern></web-resource-collection><auth-constraint><role-name>ROLE_NAME</role-name><role-name>ROLE_NAME</role-name></auth-constraint></security-constraint>
La sécurité basée rôle à été activée dans l'application, avec un certain nombre de rôles définis.
Exemple 12.1. Exemple de configuration de sécurité basée rôles
<web-app>
<context-param>
<param-name>resteasy.role.based.security</param-name>
<param-value>true</param-value>
</context-param>
<servlet-mapping>
<servlet-name>Resteasy</servlet-name>
<url-pattern>/*</url-pattern>
</servlet-mapping>
<security-constraint>
<web-resource-collection>
<web-resource-name>Resteasy</web-resource-name>
<url-pattern>/security</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>admin</role-name>
<role-name>user</role-name>
</auth-constraint>
</security-constraint>
<security-role>
<role-name>admin</role-name>
</security-role>
<security-role>
<role-name>user</role-name>
</security-role>
</web-app>
12.6.2. Sécuriser un service JAX-RS Web par des annotations
Cette rubrique couvre les étapes à parcourir pour sécuriser un service JAX-RS Web par les annotations de sécurité supportées.
Procédure 12.2. Sécuriser un service JAX-RS Web par des annotations de sécurité supportées.
- Activer la sécurité basée-rôle. Pour plus d'informations, voir Section 12.6.1, « Activer la sécurité basée-rôle pour RESTEasy JAX-RS Web Service ».
- Ajouter des annotations de sécurité au service JAX-RS Web. RESTEasy supporte les annotations suivantes :
- @RolesAllowed
- Définit les rôles qui peuvent accéder à la méthode. Tous les rôles doivent être définis dans le fichier
web.xml. - @PermitAll
- Autorise tous les rôles définis dans le fichier
web.xmlà accéder à la méthode. - @DenyAll
- Refuse tout accès à la méthode.
12.7. RESTEasy Logging
12.7.1. JAX-RS Web Service Logging
- Si log4j est dans le chemin de classe de l'application, log4j sera utilisé.
- Si slf4j est dans le chemin de classe de l'application, slf4j sera utilisé.
- java.util.logging est la valeur par défaut si ni log4j ni slf4j sont dans le chemin de classe.
- Si le param de contexte de servlet resteasy.logger.type est défini à java.util.logging, log4j, ou slf4j remplaceront le comportement par défaut.
12.7.2. Catégories de journalisation définies dans RESTEasy
Tableau 12.3. Catégories
| Catégorie | Fonction |
|---|---|
org.jboss.resteasy.core | Journalise toutes les activités par l'implémentation RESEasy principale. |
org.jboss.resteasy.plugins.providers | Journalise toutes les activités par les fournisseurs d'entité RESTEasy. |
org.jboss.resteasy.plugins.server | Journalise tous les activités par l'implémentation RESEasy. |
org.jboss.resteasy.specimpl | Journalise toutes les activités par les classes d'implémentation JAX-RS. |
org.jboss.resteasy.mock | Journalise les activités par le framework factice RESTEasy. |
12.8. Gestion des exceptions
12.8.1. Créer un mappeur d'exceptions
Les mappeurs d'exceptions sont des composants fournis par des applications, personnalisés qui interceptent les exceptions lancées et qui écrivent des réponses HTTP spécifiques.
Exemple 12.2. Mappeur d'exceptions
ExceptionMapper .
@Provider
public class EJBExceptionMapper implements ExceptionMapper<javax.ejb.EJBException>
{
Response toResponse(EJBException exception) {
return Response.status(500).build();
}
}
web.xml sous le paramètre de contexte resteasy.providers, ou bien renvoyez-le par programmation via la classe ResteasyProviderFactory.
12.8.2. Exceptions RESTEasy lancées en interne
Tableau 12.4. Liste des exceptions
| Exception | Code HTTP | Description |
|---|---|---|
| BadRequestException | 400 | Échec de la requête. La requête n'a pas été formatée correctement, ou il y a eu un problème lors de son traitement. |
| UnauthorizedException | 401 | Non autorisé. Exception de sécurité envoyée si vous utilisez la sécurité basée rôle annotée RESTEasy. |
| InternalServerErrorException | 500 | Erreur interne de serveur. |
| MethodNotAllowedException | 405 | Il n'y a pas de méthode JAX-RS pour la ressource qui peut gérer l'opération HTTP invoquée. |
| NotAcceptableException | 406 | Il n'y a pas de méthode JAX-RS qui puisse produire les types de media listés dans l'en-tête Accept |
| NotFoundException | 404 | Il n'y a pas de méthode JAX-RS qui serve le chemin/la ressource de la requête. |
| ReaderException | 400 | Toutes les exceptions envoyées, à partir des MessageBodyWriters sont incluses dans cette exception. S'il n'y a pas de ExceptionMapper dans l'exception, ou si l'exception n'est pas une WebApplicationException , alors RESTEasy renverra un code 400 par défaut. |
| WriterException | 500 | Toutes les exceptions envoyées, à partir des MessageBodyWriters sont incluses dans cette exception. S'il n'y a pas de ExceptionMapper dans l'exception, ou si l'exception n'est pas une WebApplicationException , alors RESTEasy renverra un code 400 par défaut. |
| JAXBUnmarshalException | 400 | Les fournisseurs JAXB (XML et Jettison) envoient cette exception sur les lectures. Peuvent correspondre à des wrapping JAXBExceptions. Cette classe s'étend à ReaderException. |
| JAXBMarshalException | 500 | Les fournisseurs JAXB (XML et Jettison) envoient cette exception sur les lectures. Peuvent correspondre à des wrapping JAXBExceptions. Cette classe s'étend à WriterException. |
| ApplicationException | N/A | Encapsule toutes les exceptions levées à partir du code d'application. Fonctionne de la même façon que InvocationTargetException. S'il y a un ExceptionMapper pour l'exception encapsulée, elle sera utilisée pour traiter la demande |
| Échec | N/A | Erreur RESTEasy interne. Non journalisée. |
| LoggableFailure | N/A | Erreur RESTEasy interne. Journalisée. |
| DefaultOptionsMethodException | N/A | Si l'utilisateur invoque HTTP OPTIONS et qu'il n'y a pas de méthode JAX-RS, RESTEasy fournira un comportement par défaut en lançant cette exception. |
12.9. Intercepteurs RESTEasy
12.9.1. Interception des invocations JAX-RS
RESTEasy peut intercepter les invocations JAX-RS et les re-router vers des objets style listener que l'on appelle des intercepteurs. Cette section couvre les descriptions de quatre types d'intercepteurs.
Exemple 12.3. MessageBodyReader/Writer Interceptors
@Provider, ainsi que par @ServerInterceptor ou @ClientInterceptor, de façon à ce que RESTEasy sache s'il doit les ajouter ou non à la liste d'intercepteurs.
MessageBodyReader.readFrom() ou de MessageBodyWriter.writeTo(). Ils peuvent être utilisés pour encapsuler les flux d'entrée ou de sortie.
public interface MessageBodyReaderInterceptor
{
Object read(MessageBodyReaderContext context) throws IOException, WebApplicationException;
}
public interface MessageBodyWriterInterceptor
{
void write(MessageBodyWriterContext context) throws IOException, WebApplicationException;
}
MessageBodyReaderContext.proceed() ou MessageBodyWriterContext.proceed() est appelé pour aller vers le prochain intercepteur, ou, s'il n'y a plus d'intercepteur à invoquer, la méthode readFrom() ou writeTo() du MessageBodyReader ou du MessageBodyWriter. Cette encapsulation permet aux objets d'être modifiés avant d'aller vers le Reader ou Writer, puis d'être nettoyés, après proceed().
@Provider
@ServerInterceptor
public class MyHeaderDecorator implements MessageBodyWriterInterceptor {
public void write(MessageBodyWriterContext context) throws IOException, WebApplicationException
{
context.getHeaders().add("My-Header", "custom");
context.proceed();
}
}
Exemple 12.4. PreProcessInterceptor
public interface PreProcessInterceptor
{
ServerResponse preProcess(HttpRequest request, ResourceMethod method) throws Failure, WebApplicationException;
}
preProcess() renvoie une ServerResponse, alors la méthode JAX-RS sous-jacente ne sera pas invoquée, et le runtime traitera la réponse et retournera au client. Si la méthode preProcess() ne renvoie pas une ServerResponse, la méthode JAX-RS sous-jacente sera alors invoquée.
Exemple 12.5. PostProcessInterceptors
public interface PostProcessInterceptor
{
void postProcess(ServerResponse response);
}
Exemple 12.6. ClientExecutionInterceptors
@ClientInterceptor et @Provider. Ces intercepteurs sont exécutés après que le MessageBodyWriter, et que le ClientRequest aient été créés côté client.
public interface ClientExecutionInterceptor
{
ClientResponse execute(ClientExecutionContext ctx) throws Exception;
}
public interface ClientExecutionContext
{
ClientRequest getRequest();
ClientResponse proceed() throws Exception;
}
12.9.2. Lier un intercepteur à une méthode JAX-RS
Par défaut, tous les intercepteurs sont invoqués pour chaque requête. L'interface AcceptedByMethod peut être implémentée pour préciser ce comportement.
Exemple 12.7. Exemple de liaison d'intercepteurs
accept() pour les intercepteurs qui implémentent l'interface AcceptedByMethod. Si la méthode renvoie true, l'intercepteur sera ajouté à la chaîne d'appel de la méthode JAX-RS; sinon, il sera ignoré avec cette méthode.
accept() détermine si l'annotation @GET est présente dans la méthode JAX-RS. Si tel est le cas, l'intercepteur sera appliqué à la chaîne d'appel de la méthode.
@Provider
@ServerInterceptor
public class MyHeaderDecorator implements MessageBodyWriterInterceptor, AcceptedByMethod {
public boolean accept(Class declaring, Method method) {
return method.isAnnotationPresent(GET.class);
}
public void write(MessageBodyWriterContext context) throws IOException, WebApplicationException
{
context.getHeaders().add("My-Header", "custom");
context.proceed();
}
}
12.9.3. Enregistrer un intercepteur
Cette section couvre la façon dont on doit enregistrer un intercepteur RESTEasy JAX-RS dans une application.
Procédure 12.3. Enregistrer un intercepteur
- Pour enregistrer un intercepteur, listez-le dans le fichier
web.xmlsous le paramètre de contexteresteasy.providers, ou bien renvoyez-le sous forme de classe ou d'objet dansApplication.getClasses()ouApplication.getSingletons()
12.9.4. Familles de précédence d'intercepteur
12.9.4.1. Familles de précédence d'intercepteur
Les intercepteurs peuvent être sensibles à l'ordre dans lequel ils sont invoqués. Mettre les intercepteurs de groupes RESTEasy en familles pour faciliter l'ordonnancement. Cette section couvre les familles de précédence d'intercepteurs intégrés et les intercepteurs associés à chaque famille.
- SECURITY
- Les intercepteurs SECURITY sont normalement des PreProcessInterceptors. Ils sont invoqués en premier car on ne doit pas faire grand chose avant que l'invocation soit autorisée.
- HEADER_DECORATOR
- Les intercepteurs HEADER_DECORATOR ajoutent des en-têtes à une réponse ou à une requête sortante. Ils suivent les intercepteurs de sécurité car les en-têtes ajoutés peuvent affecter le comportement des autres familles d'intercepteurs.
- ENCODER
- Les intercepteurs ENCODER changent l'OutputStream. Par exemple, l'intercepteur GZIP crée un GZIPOutputStream pour envelopper l'outputStream réel pour la compression.
- REDIRECT
- Les intercepteurs REDIRECT sont normalement utilisés dans PreProcessInterceptors, car ils peuvent router à nouveau la demande et éviter ainsi totalement la méthode JAX-RS.
- DECODER
- Les intercepteurs DECODER englobent l'IutputStream. Par exemple, le décodeur d'intercepteur GZIP englobe le GZIPInputStream.
12.9.4.2. Définissez une famille de précédence d'intercepteurs personnalisée
Les familles de précédence personnalisées peuvent être créées ou enregistrées dans le fichier web.xml. Ce sujet couvre des exemples des paramètres de contexte disponibles pour définir les familles de précédence d'intercepteurs.
Exemple 12.8. resteasy.append.interceptor.precedence
resteasy.append.interceptor.precedence rajoute la nouvelle famille de précédence à la liste de famille de précédent par défaut.
<context-param>
<param-name>resteasy.append.interceptor.precedence</param-name>
<param-value>CUSTOM_PRECEDENCE_FAMILY</param-value>
</context-param>
Exemple 12.9. resteasy.interceptor.before.precedence
resteasy.interceptor.before.precedence définit la famille de précédence par défaut exécutée avant la famille personnalisée. La valeur du paramètre est sous la forme DEFAULT_PRECEDENCE_FAMILY/CUSTOM_PRECEDENCE_FAMILY, délimitée par un ':'.
<context-param>
<param-name>resteasy.interceptor.before.precedence</param-name>
<param-value>DEFAULT_PRECEDENCE_FAMILY : CUSTOM_PRECEDENCE_FAMILY</param-value>
</context-param>
Exemple 12.10. resteasy.interceptor.after.precedence
resteasy.interceptor.after.precedence définit la famille de précédence par défaut exécutée après la famille personnalisée. La valeur du paramètre est sous la forme DEFAULT_PRECEDENCE_FAMILY/CUSTOM_PRECEDENCE_FAMILY, délimitée par un :.
<context-param>
<param-name>resteasy.interceptor.after.precedence</param-name>
<param-value>DEFAULT_PRECEDENCE_FAMILY : CUSTOM_PRECEDENCE_FAMILY</param-value>
</context-param>
12.10. Annotations basées chaîne
12.10.1. Conversion des annotations basées @*Param en objects
@*Param JAX-RS,@PathParam et @FormParam incluses, sont représentées par des chaînes dans une requête HTTP brut. Ces types de paramètres injectés peuvent être convertis en objets si ces objets ont une méthode valueOf(String) statique ou un constructeur qui prend un paramètre String.
@Provider commerciales pour effectuer cette conversion pour les classes qui n'ont ni de méthode valueOf(String) statique, ni de constructeur de string.
Exemple 12.11. StringConverter
import org.jboss.resteasy.client.ProxyFactory;
import org.jboss.resteasy.spi.StringConverter;
import org.jboss.resteasy.test.BaseResourceTest;
import org.junit.Assert;
import org.junit.Before;
import org.junit.Test;
import javax.ws.rs.HeaderParam;
import javax.ws.rs.MatrixParam;
import javax.ws.rs.PUT;
import javax.ws.rs.Path;
import javax.ws.rs.PathParam;
import javax.ws.rs.QueryParam;
import javax.ws.rs.ext.Provider;
public class StringConverterTest extends BaseResourceTest
{
public static class POJO
{
private String name;
public String getName()
{
return name;
}
public void setName(String name)
{
this.name = name;
}
}
@Provider
public static class POJOConverter implements StringConverter<POJO>
{
public POJO fromString(String str)
{
System.out.println("FROM STRNG: " + str);
POJO pojo = new POJO();
pojo.setName(str);
return pojo;
}
public String toString(POJO value)
{
return value.getName();
}
}
@Path("/")
public static class MyResource
{
@Path("{pojo}")
@PUT
public void put(@QueryParam("pojo")POJO q, @PathParam("pojo")POJO pp,
@MatrixParam("pojo")POJO mp, @HeaderParam("pojo")POJO hp)
{
Assert.assertEquals(q.getName(), "pojo");
Assert.assertEquals(pp.getName(), "pojo");
Assert.assertEquals(mp.getName(), "pojo");
Assert.assertEquals(hp.getName(), "pojo");
}
}
@Before
public void setUp() throws Exception
{
dispatcher.getProviderFactory().addStringConverter(POJOConverter.class);
dispatcher.getRegistry().addPerRequestResource(MyResource.class);
}
@Path("/")
public static interface MyClient
{
@Path("{pojo}")
@PUT
void put(@QueryParam("pojo")POJO q, @PathParam("pojo")POJO pp,
@MatrixParam("pojo")POJO mp, @HeaderParam("pojo")POJO hp);
}
@Test
public void testIt() throws Exception
{
MyClient client = ProxyFactory.create(MyClient.class, "http://localhost:8081");
POJO pojo = new POJO();
pojo.setName("pojo");
client.put(pojo, pojo, pojo, pojo);
}
}
Exemple 12.12. StringParameterUnmarshaller
StringParameterUnmarshaller est sensible aux annotations placées sur le paramètre ou le champ sur lesquels vous injectez. Il est créé par injecteur. La méthode setAnnotations() est appelée par resteasy pour initialiser l'unmarshaller.
org.jboss.resteasy.annotations.StringsParameterUnmarshallerBinder.
java.util.Date basé @PathParam.
public class StringParamUnmarshallerTest extends BaseResourceTest
{
@Retention(RetentionPolicy.RUNTIME)
@StringParameterUnmarshallerBinder(DateFormatter.class)
public @interface DateFormat
{
String value();
}
public static class DateFormatter implements StringParameterUnmarshaller<Date>
{
private SimpleDateFormat formatter;
public void setAnnotations(Annotation[] annotations)
{
DateFormat format = FindAnnotation.findAnnotation(annotations, DateFormat.class);
formatter = new SimpleDateFormat(format.value());
}
public Date fromString(String str)
{
try
{
return formatter.parse(str);
}
catch (ParseException e)
{
throw new RuntimeException(e);
}
}
}
@Path("/datetest")
public static class Service
{
@GET
@Produces("text/plain")
@Path("/{date}")
public String get(@PathParam("date") @DateFormat("MM-dd-yyyy") Date date)
{
System.out.println(date);
Calendar c = Calendar.getInstance();
c.setTime(date);
Assert.assertEquals(3, c.get(Calendar.MONTH));
Assert.assertEquals(23, c.get(Calendar.DAY_OF_MONTH));
Assert.assertEquals(1977, c.get(Calendar.YEAR));
return date.toString();
}
}
@BeforeClass
public static void setup() throws Exception
{
addPerRequestResource(Service.class);
}
@Test
public void testMe() throws Exception
{
ClientRequest request = new ClientRequest(generateURL("/datetest/04-23-1977"));
System.out.println(request.getTarget(String.class));
}
}
12.11. Configuration des extensions de fichiers
12.11.1. Mapper les extensions de fichiers avec les types de media dans le fichier web.xml
Certains clients, comme les navigateurs, ne peuvent pas utiliser les en-têtes Accept et Accept-Language pour négocier le type de média de la représentation ou la langue. RESTEasy peut mapper des suffixes de noms de fichier aux langues et types de médias pour régler ce problème. Procédez comme suit pour mapper les types de media avec les extensions de fichier, dans le fichier web.xml
Procédure 12.4. Mapper des types de media avec les extensions de fichiers
- Ouvrir le fichier
web.xmlde l'application dans l'éditeur de textes. - Ajouter le paramètre de contexte
resteasy.media.type.mappingsau fichier, dans les balisesweb-app:<context-param> <param-name>resteasy.media.type.mappings</param-name> </context-param> - Configurer les valeurs des paramètres. Les mappages forment une liste délimitée par des virgules. Chaque mappage est délimité par un
::Exemple 12.13. Exemple de mappage
<context-param> <param-name>resteasy.media.type.mappings</param-name> <param-value>html : text/html, json : application/json, xml : application/xml</param-value> </context-param>
12.11.2. Mapper les extensions de fichiers vers les Langues dans le fichier web.xml
Certains clients, comme les navigateurs, ne peuvent pas utiliser les en-têtes Accept et Accept-Language pour négocier le type de média de la représentation ou la langue. RESTEasy peut mapper des suffixes de noms de fichier aux langues et types de médias pour régler ce problème. Procédez comme suit pour mapper les langues avec les extensions de fichier, dans le fichier web.xml
Procédure 12.5. Mapper les extensions de fichiers vers les Langues dans le fichier web.xml
- Ouvrir le fichier
web.xmlde l'application dans un éditeur de texte. - Ajouter le paramètre de contexte
resteasy.language.mappingsau fichier, dans les balisesweb-app:<context-param> <param-name>resteasy.language.mappings</param-name> </context-param> - Configurer les valeurs de paramètres. Les mappages forment une liste délimitée par des virgules. Chaque mappage est délimité par un
::Exemple 12.14. Exemple de mappage
<context-param> <param-name>resteasy.language.mappings</param-name> <param-value> en : en-US, es : es, fr : fr</param-name> </context-param>
12.11.3. Types de media supportés par RESTEasy
Tableau 12.5. Types de media
| Type de media | Type Java |
|---|---|
| application/*+xml, text/*+xml, application/*+json, application/*+fastinfoset, application/atom+* | Classes annotées JaxB |
| application/*+xml, text/*+xml | org.w3c.dom.Document |
| */* | java.lang.String |
| */* | java.io.InputStream |
| text/brut | primtives, java.lang.String, ou tout type qui possède un contructeur de String, ou une méthode valueOf(String) pour les entrées et toString() pour les sorties |
| */* | javax.activation.DataSource |
| */* | byte[] |
| */* | java.io.File |
| application/x-www-form-urlencoded | javax.ws.rs.core.MultivaluedMap |
12.12. API JavaScript RESTEasy
12.12.1. API JavaScript RESTEasy
Exemple 12.15. Simple exemple d'API JavaScript JAX-RS
@Path("/")
public interface X{
@GET
public String Y();
@PUT
public void Z(String entity);
}
var X = {
Y : function(params){...},
Z : function(params){...}
};
12.12.2. Activation du Servlet API JavaScript RESTEasy
L'API JavaScript RESTEasy n'est pas activé par défaut. Suivre les étapes suivantes en utilisant le fichier web.xml.
Procédure 12.6. Modifier web.xml pour activer l'API RESTEasy JavaScript
- Ouvrir le fichier
web.xmlde l'application dans l'éditeur de textes. - Ajouter la configuration suivante dans le fichier, dans les balises
web-app:<servlet><servlet-name>RESTEasy JSAPI</servlet-name><servlet-class>org.jboss.resteasy.jsapi.JSAPIServlet</servlet-class></servlet><servlet-mapping><servlet-name>RESTEasy JSAPI</servlet-name><url-pattern>/URL</url-pattern></servlet-mapping>
12.12.3. Paramètres de l'API JavaScript RESTEasy
Tableau 12.6. Propriétés des paramètres
| Propriété | Valeur par défaut | Description |
|---|---|---|
| $entity | L'entité pour envoyer une requête PUT ou POST. | |
| $contentType | Type MIME de l'entité de contenu envoyée comme en-tête de type de contenu ou Content-Type. Déterminé par l'annotation @Consumes. | |
| $accepts | */* | Types MIME de l'entité envoyés comme en-tête de Accept. Déterminé par l'annotation @Provides. |
| $callback | Définir à une fonction (httpCode, xmlHttpRequest, value) pour un appel asynchrone. Si non présent, l'appel sera synchronisé et renverra une valeur. | |
| $apiURL | Définit la base de l'URI du point de terminaison JAX-RS, sans la dernière barre oblique. | |
| $username | Si le nom d'utilisateur ou le mot de passe sont définis, ils seront utilisés comme informations d'authentification pour la demande. | |
| $password | Si le nom d'utilisateur ou le mot de passe sont définis, ils seront utilisés comme informations d'authentification pour la demande. |
12.12.4. Créer des requêtes AJAX par l'API JavaScript
L'API JavaScript RESTEasy peut être utilisé pour créer des requêtes manuellement. Cette section couvre des exemples de ce comportement.
Exemple 12.16. L'Objet REST
// Change the base URL used by the API:
REST.apiURL = "http://api.service.com";
// log everything in a div element
REST.log = function(text){
jQuery("#log-div").append(text);
};
- apiURL
- Défini par défaut à l'URL root JAX-RS. Utilisé par chaque fonction d'API Client JavaScript lors de la création de requêtes.
- log
- Définir à une fonction(string) pour pouvoir recevoir les logs d'API Client RESTEasy. Cela est utile si vous souhaitez déboguer votre API Client ou mettre les logs là où vous pouvez les voir.
Exemple 12.17. La classe REST.Request
var r = new REST.Request();
r.setURI("http://api.service.com/orders/23/json");
r.setMethod("PUT");
r.setContentType("application/json");
r.setEntity({id: "23"});
r.addMatrixParameter("JSESSIONID", "12309812378123");
r.execute(function(status, request, entity){
log("Response is "+status);
});
12.12.5. Membres de la classe REST.Request
Tableau 12.7. Classe REST.Request
| Membre | Description |
|---|---|
| execute(callback) | Exécute la requête avec toutes les informations définies pour l'objet en cours. La valeur est passée à la fonction de rappel de l'argument optionnel, et n'est pas renvoyée. |
| setAccepts(acceptHeader) | Définit l'en-tête de la requête Accept. Par défaut */*. |
| setCredentials(username, password) | Définit les informations d'identification de la requête. |
| setEntity(entity) | Définit les informations d'identification de l'entité. |
| setContentType(contentTypeHeader) | Définit l'en-tête de la requête Type de contenu |
| setURI(uri) | Définit l'URI de la requête. Doit correspondre à un URI absolu. |
| setMethod(method) | Définit la méthode de requête. GET par défaut. |
| setAsync(async) | Contrôle si la requête doit être asynchrone. True par défaut. |
| addCookie(name, value) | Définit le cookie donnée dans le document en cours quand on exécute la requête. Sera persistant dans le navigateur. |
| addQueryParameter(name, value) | Ajoute un paramètre d'interrogation à la partie de requête URI. |
| addMatrixParameter(name, value) | Ajoute un paramètre de matrix (paramètre de chemin d'accès) au dernier segment de l'URI de la requête. |
| addHeader(nom, valeur) | Ajoute un en-tête de requête. |
12.13. RESTEasy Asynchronous Job Service
12.13.1. Service Job Asynchrone RESTEasy
12.13.2. Activer le Service de jobs asynchrones
Procédure 12.7. Modifier le fichier web.xml
- Activer le Service de jobs asynchrones dans le fichier
web.xml:<context-param> <param-name>resteasy.async.job.service.enabled</param-name> <param-value>true</param-value> </context-param>
Le service de jobs asynchrones a été activé. Pour les options de configuration, consulter : Section 12.13.4, « Paramètres de configuration de Service Job Asynchrone ».
12.13.3. Configurer les Jobs asynchrones avec RESTEasy
Cette section couvre des exemples de paramètres de recherche de jobs asynchrones avec RESTEasy.
Avertissement
web.xml à la place.
Important
Exemple 12.18. Le paramètre Asynch
asynch est utilisé pour exécuter des invocations en arrière-plan. Une réponse 202 Accepted est retourné, ainsi que d'un en-tête d'emplacement avec un URL pointant vers la réponse de la méthode de base.
POST http://example.com/myservice?asynch=true
HTTP/1.1 202 Accepted Location: http://example.com/asynch/jobs/3332334
/asynch/jobs/{job-id}?wait={millisconds}|nowait=true- GET renvoie la méthode de ressources JAX-RS invoquée comme réponse si le job est complété. Si le job n'a pas été complété, ce GET renverra un code de réponse 202 Accepted. L'invocation de GET ne supprime pas le job; peut être appelé à plusieurs reprises.
- POST procède à une lecture de la réponse du job et supprime le job s'il est terminé.
- DELETE est appelé pour nettoyer manuellement la file d'attente du job.
Note
Quand la file d'attente du job est pleine, il expulsera job le plus ancien de la mémoire automatiquement, sans avoir besoin d'appeler DELETE.
Exemple 12.19. Wait / Nowait
wait et nowait. Si le paramètre wait n'est pas spécifié, l'opération aura par défaut nowait=true, et n'attendra pas si le job n'est pas terminé. Le paramètre wait est défini en millisecondes.
POST http://example.com/asynch/jobs/122?wait=3000
Exemple 12.20. Le Paramètre Oneway
oneway.
POST http://example.com/myservice?oneway=true
12.13.4. Paramètres de configuration de Service Job Asynchrone
Le tableau suivant donne des informations sur la paramètres contextuels configurables du Service Job Asynchrone. Ces paramètres sont configurés dans le fichier web.xml.
Tableau 12.8. Paramètres de configuration
| Paramètre | Description |
|---|---|
| resteasy.async.job.service.max.job.results | Nombre de résultats de jobs qui peuvent être conservés en toute harmonie à un moment donné. La valeur par défaut est 100. |
| resteasy.async.job.service.max.wait | Temps d'attente maximum quand un client interroge un job. La valeur par défaut est 300000. |
| resteasy.async.job.service.thread.pool.size | Taille de thread pool des threads d'arrière-plan qui exécutent le job. La valeur par défaut est 100. |
| resteasy.async.job.service.base.path | Définit le chemin de base des URI de job. La valeur par défaut est /asynch/jobs |
Exemple 12.21. Exemple de configuration de jobs asynchrones
<web-app>
<context-param>
<param-name>resteasy.async.job.service.enabled</param-name>
<param-value>true</param-value>
</context-param>
<context-param>
<param-name>resteasy.async.job.service.max.job.results</param-name>
<param-value>100</param-value>
</context-param>
<context-param>
<param-name>resteasy.async.job.service.max.wait</param-name>
<param-value>300000</param-value>
</context-param>
<context-param>
<param-name>resteasy.async.job.service.thread.pool.size</param-name>
<param-value>100</param-value>
</context-param>
<context-param>
<param-name>resteasy.async.job.service.base.path</param-name>
<param-value>/asynch/jobs</param-value>
</context-param>
<listener>
<listener-class>
org.jboss.resteasy.plugins.server.servlet.ResteasyBootstrap
</listener-class>
</listener>
<servlet>
<servlet-name>Resteasy</servlet-name>
<servlet-class>
org.jboss.resteasy.plugins.server.servlet.HttpServletDispatcher
</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>Resteasy</servlet-name>
<url-pattern>/*</url-pattern>
</servlet-mapping>
</web-app>
12.14. RESTEasy JAXB
12.14.1. Créer un décorateur JAXB
Les fournisseurs JAXB de RESTEasy ont une manière enfichable de décorer des Instances Marshaller ou Unmarshaller. Il y a une annotation qui est créée soit par un Marshaller, soit par un Unmarshaller. Cette section couvre toutes les étapes pour créer un décorateur JAXB dans RESTEasy.
Procédure 12.8. Créer un décorateur JAXB dans RESTEasy
Créer la classe de processeur
- Créer une classe qui implémente DecoratorProcessor<Target, Annotation>. La cible sera soit une classe de Marshaller ou Unmarshaller JAXB. L'annotation est créée dans la seconde étape.
- Annoter la classe par @DecorateTypes, et déclarer les Types MIME que le décorateur doit décorer.
- Définir les propriétés ou les valeurs au sein de la fonction
decorate.
Exemple 12.22. Exemple de classe de processeur
import org.jboss.resteasy.core.interception.DecoratorProcessor; import org.jboss.resteasy.annotations.DecorateTypes; import javax.xml.bind.Marshaller; import javax.xml.bind.PropertyException; import javax.ws.rs.core.MediaType; import javax.ws.rs.Produces; import java.lang.annotation.Annotation; @DecorateTypes({"text/*+xml", "application/*+xml"}) public class PrettyProcessor implements DecoratorProcessor<Marshaller, Pretty> { public Marshaller decorate(Marshaller target, Pretty annotation, Class type, Annotation[] annotations, MediaType mediaType) { target.setProperty(Marshaller.JAXB_FORMATTED_OUTPUT, Boolean.TRUE); } }Créer une annotation
- Créer une interface personnalisée annotée par @Decorator.
- Déclarer le processeur ou la cible de l'annotation @Decorator. Le processeur est créé dans la première étape. La cible sera soit la classe Marshaller JAXB ou la classe Unmarshaller JAXB.
Exemple 12.23. Exemple d'annotation
import org.jboss.resteasy.annotations.Decorator; @Target({ElementType.TYPE, ElementType.METHOD, ElementType.PARAMETER, ElementType.FIELD}) @Retention(RetentionPolicy.RUNTIME) @Decorator(processor = PrettyProcessor.class, target = Marshaller.class) public @interface Pretty {}- Ajouter l'annotation créée dans une fonction dans la seconde étape de façon à ce que l'entrée ou la sortie soit décorée quand elle sera mise en ordre.
Le décorateur JAXB a été créé et sera appliqué au sein du service web JAX-RS.
12.15. RESTEasy Atom Support
12.15.1. Fournissseur et API Atom
org.jboss.resteasy.plugins.providers.atom. RESTEasy utilise JAXB pour marshaller et démarshaller l'API. Le fournisseur est basé JAXB, et ne se limite pas à envoyer des objets Atom par XML. Tous les fournisseurs JAXB que RESTEasy contient peuvent être réutilisés par le fournisseur et l'API Atom, y compris JSON. Voir Javadocs pour obtenir plus d'informations sur l'API.
Chapitre 13. Services Web JAX-WS
13.1. Services Web JAX-WS
WS-Notification, WS-Addressing, WS-Policy, WS-Security et WS-Trust. Ils communiquent à l'aide d'un XML spécialisé appelé Simple Object Access Protocol (SOAP), qui définit une architecture de message et le message de formats.
WebService et WebMethod.
webservices.
Les JBoss EAP Quickstarts incluent plusieurs applications JAX-WS Web Services qui fonctionnent correctement. Exemples :
- wsat-simple
- wsba-coordinator-completion-simple
- wsba-participant-completion-simple
13.2. Configurer le sous-système webservices
webservices, qui contrôle le comportement des Services Web déployés dans JBoss EAP 6. La commande pour modifier chaque élément dans le script de gestion CLI (EAP_HOME /bin/jboss-cli.sh ou EAP_HOME /bin/jboss-cli.bat) est fournie. Supprimer la partie de la commande / Profil = default pour un serveur autonome, ou la modifier pour effectuer un changement au sous-système pour un profil différent sur un domaine géré.
Vous pouvez écrire à nouveau l'élément <soap:address> dans les contrats WSDL endpoint-published. Cette solution peut être utilisée pour contrôler l'adresse du serveur qui est publiée aux clients pour chaque point de terminaison. Chacun des éléments suivants en option peuvent être modifiés pour satisfaire vos besoins. La modification de ces éléments exige un redémarrage du serveur.
Tableau 13.1. Éléments de configuration pour les adresses de points de terminaison publiés.
| Élément | Description | Commande CLI |
|---|---|---|
| modify-wsdl-address |
Indique s'il faut toujours modifier l'adresse WSDL. Si true, le contenu de
< adresse:soap > sera toujours remplacé. Si false, le contenu de < adresse:soap > sera remplacé seulement si ce n'est pas une URL valide. Les valeurs utilisées seront wsdl-host, wsdl-port, et wsdl-secure-port décrit ci-dessous.
| /profile=default/subsystem=webservices/:write-attribute(name=modify-wsdl-address,value=true)
|
| wsdl-host |
Le nom d'hôte / adresse IP à utiliser pour écrire à nouveau
<soap:address>. Si wsdl-host est défini au string jbossws.undefined.host, l'hôte du demandeur sera utilisé quand on écrit à nouveau une <soap:address>.
| /profile=default/subsystem=webservices/:write-attribute(name=wsdl-host,value=10.1.1.1) |
| wsdl-port | Entier relatif qui définit explicitement le port HTTP qui sera utilisé pour écrire à nouveau l'adresse SOAP. Si non défini, le port HTTP peut être identifié en cherchant la liste de connecteurs HTTP installés. | /profile=default/subsystem=webservices/:write-attribute(name=wsdl-port,value=8080)
|
| wsdl-secure-port | Entier relatif qui définit explicitement le port HTTPS qui sera utilisé pour écrire à nouveau l'adresse SOAP. Si non défini, le port HTTPS peut être identifié en cherchant la liste de connecteurs HTTPS installés. | /profile=default/subsystem=webservices/:write-attribute(name=wsdl-secure-port,value=8443)
|
Vous pouvez définir des configurations de points de terminaison qui peuvent être référencées par les implémentations de points de terminaison. Une des façons dont cela puisse être utilisé consiste à ajouter un gestionnaire donné à n'importe quel point de terminaison WS, pour lequel il est indiqué une configuration de point de terminaison donnée avec l'annotation @org.jboss.ws.api.annotation.EndpointConfig.
Standard-Endpoint-Config par défaut. Il existe également une configuration Recording-Endpoint-Config personnalisée, également incluse. Cela vous donne un exemple de gestionnaire d'enregistrement. La Standard-Endpoint-Config est utilisée automatiquement pour tout point de terminaison non associé à une autre configuration.
Standard-Endpoint-Config par le Management CLI, il suffit d'utiliser la commande suivante :
/profile=default/subsystem=webservices/endpoint-config=Standard-Endpoint-Config/:read-resource(recursive=true,proxies=false,include-runtime=false,include-defaults=true)
La configuration d'un point de terminaison, à laquelle on fait référence ainsi endpoint-config dans l'API de gestion, inclut post-handler-chain, post-handler-chain et quelques propriétés qui sont appliquées à un point de terminaison particulier. Les commandes suivantes lisent et ajoutent un point de config.
Exemple 13.1. Lecture d'une config de point de terminaison
/profile=default/subsystem=webservices/endpoint-config=Recording-Endpoint-Config:read-resource
Exemple 13.2. Ajout d'une config de point de terminaison
/profile=default/subsystem=webservices/endpoint-config=My-Endpoint-Config:add
Chaque config de point de terminaison peut être associée à des chaînes de gestionnaires PRE ou POST. Chaque chaîne de gestionnaire peut inclure des gestionnaires conformes à JAXWS. Pour les messages sortants, les gestionnaires de chaînes de gestionnaires PRE sont exécutés avant tout gestionnaire attaché aux points de terminaison, à l'aide de moyens JAXWS standards, comme avec l'annotation @HandlerChain. Les gestionnaires de chaînes de POST handler sont exécutés après les gestionnaires de points de terminaison habituels. Pour les messages entrants, c'est l'opposé. JAX-WS est une API standard pour les services basés XML, et est documenté à l'adresse suivante http://jcp.org/en/jsr/detail?id=224.
protocol-binding, qui définit les protocoles qui déclenchent le démarrage de la chaîne.
Exemple 13.3. Lecture d'une chaîne de gestionnaire
/profile=default/subsystem=webservices/endpoint-config=Recording-Endpoint-Config/pre-handler-chain=recording-handlers:read-resource
Exemple 13.4. Ajouter un chaîne de gestionnaire
/profile=default/subsystem=webservices/endpoint-config=My-Endpoint-Config/post-handler-chain=my-handlers:add(protocol-bindings="##SOAP11_HTTP")
Un gestionnaire JAXWS est un <gestionnaire> d'élément dépendant, qui se trouve à l'intérieur d'une chaîne de gestionnaire. Le gestionnaire prend un attribut de classe , qui est le nom de classe complet de la classe du gestionnaire. Quand le point de terminaison est déployé, une instance de cette classe sera créée pour chaque déploiement référençant. Le chargeur de classes de déploiement ou le chargeur de classes du module org.jboss.as.webservices.server.integration doivent pouvoir charger la classe de gestionnaire.
Exemple 13.5. Lecture d'un gestionnaire
/profile=default/subsystem=webservices/endpoint-config=Recording-Endpoint-Config/pre-handler-chain=recording-handlers/handler=RecordingHandler:read-resource
Exemple 13.6. Ajout d'un gestionnaire
/profile=default/subsystem=webservices/endpoint-config=My-Endpoint-Config/post-handler-chain=my-handlers/handler=foo-handler:add(class="org.jboss.ws.common.invocation.RecordingServerHandler")
Vous pouvez afficher des informations d'exécution sur les Services Web, tels que le contexte web et l'URL WSDL, en interrogeant les points de terminaison eux-mêmes. Vous pouvez utiliser le caractère de * pour interroger tous les points de terminaison à la fois. Les deux annotations suivantes montrent la commande pour un serveur dans un domaine géré, puis pour un serveur autonome.
Exemple 13.7. Voir les informations de Runtime sur tous les points de terminaison d'un serveur dans un domaine géré.
server-one qui se trouve sur l'hôte physique master d'un domaine géré.
/host=master/server=server-one/deployment="*"/subsystem=webservices/endpoint="*":read-resource
Exemple 13.8. Voir les informations de Runtime sur tous les points de terminaison d'un serveur dans un domaine autonome
server-one qui se trouve sur l'hôte physique nommé master.
/host=master/server=server-one/deployment="*"/subsystem=webservices/endpoint="*":read-resource
Exemple 13.9. Exemple d'information de point de terminaison
{
"outcome" => "success",
"result" => [{
"address" => [
("deployment" => "jaxws-samples-handlerchain.war"),
("subsystem" => "webservices"),
("endpoint" => "jaxws-samples-handlerchain:TestService")
],
"outcome" => "success",
"result" => {
"class" => "org.jboss.test.ws.jaxws.samples.handlerchain.EndpointImpl",
"context" => "jaxws-samples-handlerchain",
"name" => "TestService",
"type" => "JAXWS_JSE",
"wsdl-url" => "http://localhost:8080/jaxws-samples-handlerchain?wsdl"
}
}]
}
13.3. Ponts de terminaison de services web JAX-WS
13.3.1. Les points de terminaison de Services Web JAX-WS
Un service web doit se conformer aux pré-requis de l'API JAXWS et à la spécification des métadonnées des services web qui se trouvent dans http://www.jcp.org/en/jsr/summary?id=181. Une implémentation valide devra remplir les critères suivants:
- Contenir une annotation
javax.jws.WebService. - Tous les paramètres de méthode et les types de renvoi doivent être compatibles avec la spécification JAXB 2.0, JSR-222. Voir http://www.jcp.org/en/jsr/summary?id=222 pour plus d'informations.
Exemple 13.10. Exemple de point de terminaison POJO
@WebService
@SOAPBinding(style = SOAPBinding.Style.RPC)
public class JSEBean01
{
@WebMethod
public String echo(String input)
{
...
}
}
Exemple 13.11. Exemple de point de terminaison de Services Web
<web-app ...>
<servlet>
<servlet-name>TestService</servlet-name>
<servlet-class>org.jboss.test.ws.jaxws.samples.jsr181pojo.JSEBean01</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>TestService</servlet-name>
<url-pattern>/*</url-pattern>
</servlet-mapping>
</web-app>
Exemple 13.12. Exposer un point de terminaison dans un EJB
@Stateless
@Remote(EJB3RemoteInterface.class)
@RemoteBinding(jndiBinding = "/ejb3/EJB3EndpointInterface")
@WebService
@SOAPBinding(style = SOAPBinding.Style.RPC)
public class EJB3Bean01 implements EJB3RemoteInterface
{
@WebMethod
public String echo(String input)
{
...
}
}
Les services JAX-WS implémentent généralement une interface de point de terminaison de service Java (SEI), qui peut être mappée à partir d'un type de port WSDL, soit directement ou à l'aide d'annotations. Ce SEI fournit une abstraction de haut niveau qui masque les détails entre les objets Java et leurs représentations XML. Toutefois, dans certains cas, les services doivent pouvoir opérer au niveau du message XML. L'interface de point de terminaison Provider (fournisseur) fournit cette fonctionnalité aux Services Web qui l'implémentent.
Une fois que vous aurez déployé votre Service Web, vous pourrez consommer le WSDL pour créer les stubs de composants qui seront à la base de votre application. Votre application pourra alors accéder au point de terminaison et faire son travail.
Les JBoss EAP Quickstarts incluent plusieurs applications JAX-WS Web Services qui fonctionnent correctement. Exemples :
- wsat-simple
- wsba-coordinator-completion-simple
- wsba-participant-completion-simple
13.3.2. Écrire et déployer un point de terminaison de Service Web JAX-WS
Cette rubrique décrit le développement d'un simple point de terminaison du service JAX-WS, qui est le composant côté serveur qui répond aux demandes des clients JAX-WS et publie la définition WSDL pour lui-même. Pour plus d'informations sur les points de terminaison de service JAX-WS, consulter Section 13.5.2, « Référence API Commun JAX-WS » et la documentation de l'API en format Javadoc distribuée dans JBoss EAP 6.
Un service web doit se conformer aux pré-requis de l'API JAXWS et à la spécification des métadonnées des services web qui se trouvent dans http://www.jcp.org/en/jsr/summary?id=181. Une implémentation valide devra remplir les critères suivants :
- Doit contenir l'annotation
javax.jws.WebService. - Tous les paramètres de méthode et les types de renvoi doivent être compatibles avec la spécification JAXB 2.0, JSR-222. Voir http://www.jcp.org/en/jsr/summary?id=222 pour plus d'informations.
Exemple 13.13. Exemple d'implémentation de service
package org.jboss.test.ws.jaxws.samples.retail.profile;
import javax.ejb.Stateless;
import javax.jws.WebService;
import javax.jws.WebMethod;
import javax.jws.soap.SOAPBinding;
@Stateless
@WebService(
name="ProfileMgmt",
targetNamespace = "http://org.jboss.ws/samples/retail/profile",
serviceName = "ProfileMgmtService")
@SOAPBinding(parameterStyle = SOAPBinding.ParameterStyle.BARE)
public class ProfileMgmtBean {
@WebMethod
public DiscountResponse getCustomerDiscount(DiscountRequest request) {
return new DiscountResponse(request.getCustomer(), 10.00);
}
}
Exemple 13.14. Exemple de charge XML
DiscountRequest utilisée par le bean ProfileMgmtBean dans l'exemple précédent. Les annotations sont incluses par souci de verbosité. Normalement, les valeurs par défaut JAXB sont raisonnables et n'ont pas besoin d'être spécifiées.
package org.jboss.test.ws.jaxws.samples.retail.profile;
import javax.xml.bind.annotation.XmlAccessType;
import javax.xml.bind.annotation.XmlAccessorType;
import javax.xml.bind.annotation.XmlType;
import org.jboss.test.ws.jaxws.samples.retail.Customer;
@XmlAccessorType(XmlAccessType.FIELD)
@XmlType( (1)
name = "discountRequest",
namespace="http://org.jboss.ws/samples/retail/profile",
propOrder = { "customer" }
)
public class DiscountRequest {
protected Customer customer;
public DiscountRequest() {
}
public DiscountRequest(Customer customer) {
this.customer = customer;
}
public Customer getCustomer() {
return customer;
}
public void setCustomer(Customer value) {
this.customer = value;
}
}
La classe d'implémentation est encapsulée dans un déploiement de JAR. Toutes les métadonnées requises pour le déploiement proviennent des annotations qui se trouvent sur la classe d'implémentation et l'interface de point de terminaison de service. Déployer le JAR à l'aide du Management CLI ou de l'Interface de gestion, et le point de terminaison HTTP sera créé automatiquement.
Exemple 13.15. Exemple de structure JAR pour un déploiement de service web
[user@host ~]$ jar -tf jaxws-samples-retail.jar
org/jboss/test/ws/jaxws/samples/retail/profile/DiscountRequest.class
org/jboss/test/ws/jaxws/samples/retail/profile/DiscountResponse.class
org/jboss/test/ws/jaxws/samples/retail/profile/ObjectFactory.class
org/jboss/test/ws/jaxws/samples/retail/profile/ProfileMgmt.class
org/jboss/test/ws/jaxws/samples/retail/profile/ProfileMgmtBean.class
org/jboss/test/ws/jaxws/samples/retail/profile/ProfileMgmtService.class
org/jboss/test/ws/jaxws/samples/retail/profile/package-info.class
13.4. Clients du service JAX-WS Web
13.4.1. Consommer et accéder à un Service Web JAX-WS
- Créer les artefacts client.
- Construire un service stub.
- Accéder au point de terminaison.
Avant de pouvoir créer des artefacts client, vous devrez créer votre contrat WSDL. Le contrat WSDL suivant est utilisé dans les exemples présentés dans le reste de cette section.
Exemple 13.16. Exemple de contrat WSDL
<definitions
name='ProfileMgmtService'
targetNamespace='http://org.jboss.ws/samples/retail/profile'
xmlns='http://schemas.xmlsoap.org/wsdl/'
xmlns:ns1='http://org.jboss.ws/samples/retail'
xmlns:soap='http://schemas.xmlsoap.org/wsdl/soap/'
xmlns:tns='http://org.jboss.ws/samples/retail/profile'
xmlns:xsd='http://www.w3.org/2001/XMLSchema'>
<types>
<xs:schema targetNamespace='http://org.jboss.ws/samples/retail'
version='1.0' xmlns:xs='http://www.w3.org/2001/XMLSchema'>
<xs:complexType name='customer'>
<xs:sequence>
<xs:element minOccurs='0' name='creditCardDetails' type='xs:string'/>
<xs:element minOccurs='0' name='firstName' type='xs:string'/>
<xs:element minOccurs='0' name='lastName' type='xs:string'/>
</xs:sequence>
</xs:complexType>
</xs:schema>
<xs:schema
targetNamespace='http://org.jboss.ws/samples/retail/profile'
version='1.0'
xmlns:ns1='http://org.jboss.ws/samples/retail'
xmlns:tns='http://org.jboss.ws/samples/retail/profile'
xmlns:xs='http://www.w3.org/2001/XMLSchema'>
<xs:import namespace='http://org.jboss.ws/samples/retail'/>
<xs:element name='getCustomerDiscount'
nillable='true' type='tns:discountRequest'/>
<xs:element name='getCustomerDiscountResponse'
nillable='true' type='tns:discountResponse'/>
<xs:complexType name='discountRequest'>
<xs:sequence>
<xs:element minOccurs='0' name='customer' type='ns1:customer'/>
</xs:sequence>
</xs:complexType>
<xs:complexType name='discountResponse'>
<xs:sequence>
<xs:element minOccurs='0' name='customer' type='ns1:customer'/>
<xs:element name='discount' type='xs:double'/>
</xs:sequence>
</xs:complexType>
</xs:schema>
</types>
<message name='ProfileMgmt_getCustomerDiscount'>
<part element='tns:getCustomerDiscount' name='getCustomerDiscount'/>
</message>
<message name='ProfileMgmt_getCustomerDiscountResponse'>
<part element='tns:getCustomerDiscountResponse'
name='getCustomerDiscountResponse'/>
</message>
<portType name='ProfileMgmt'>
<operation name='getCustomerDiscount'
parameterOrder='getCustomerDiscount'>
<input message='tns:ProfileMgmt_getCustomerDiscount'/>
<output message='tns:ProfileMgmt_getCustomerDiscountResponse'/>
</operation>
</portType>
<binding name='ProfileMgmtBinding' type='tns:ProfileMgmt'>
<soap:binding style='document'
transport='http://schemas.xmlsoap.org/soap/http'/>
<operation name='getCustomerDiscount'>
<soap:operation soapAction=''/>
<input>
<soap:body use='literal'/>
</input>
<output>
<soap:body use='literal'/>
</output>
</operation>
</binding>
<service name='ProfileMgmtService'>
<port binding='tns:ProfileMgmtBinding' name='ProfileMgmtPort'>
<soap:address
location='SERVER:PORT/jaxws-samples-retail/ProfileMgmtBean'/>
</port>
</service>
</definitions>
Note
wsconsume.sh ou wsconsume.bat est utilisé pour consommer le contrat abstrait (WSDL) et produire les classes Java annotées et les sources optionnelles qui le définissent. La commande se trouve dans le répertoire EAP_HOME/bin/ de l'installation JBoss EAP 6.
Exemple 13.17. Syntaxe de la commande wsconsume.sh
[user@host bin]$ ./wsconsume.sh --help
WSConsumeTask is a cmd line tool that generates portable JAX-WS artifacts from a WSDL file.
usage: org.jboss.ws.tools.cmd.WSConsume [options] <wsdl-url>
options:
-h, --help Show this help message
-b, --binding=<file> One or more JAX-WS or JAXB binding files
-k, --keep Keep/Generate Java source
-c --catalog=<file> Oasis XML Catalog file for entity resolution
-p --package=<name> The target package for generated source
-w --wsdlLocation=<loc> Value to use for @WebService.wsdlLocation
-o, --output=<directory> The directory to put generated artifacts
-s, --source=<directory> The directory to put Java source
-t, --target=<2.0|2.1|2.2> The JAX-WS specification target
-q, --quiet Be somewhat more quiet
-v, --verbose Show full exception stack traces
-l, --load-consumer Load the consumer and exit (debug utility)
-e, --extension Enable SOAP 1.2 binding extension
-a, --additionalHeaders Enable processing of implicit SOAP headers
-n, --nocompile Do not compile generated sources
.java listés dans la sortie, à partir du fichier ProfileMgmtService.wsdl. Les sources utilisent la structure de répertoire du package, qui est spécifié par le commutateur -p.
[user@host bin]$ wsconsume.sh -k -p org.jboss.test.ws.jaxws.samples.retail.profile ProfileMgmtService.wsdl
output/org/jboss/test/ws/jaxws/samples/retail/profile/Customer.java
output/org/jboss/test/ws/jaxws/samples/retail/profile/DiscountRequest.java
output/org/jboss/test/ws/jaxws/samples/retail/profile/DiscountResponse.java
output/org/jboss/test/ws/jaxws/samples/retail/profile/ObjectFactory.java
output/org/jboss/test/ws/jaxws/samples/retail/profile/ProfileMgmt.java
output/org/jboss/test/ws/jaxws/samples/retail/profile/ProfileMgmtService.java
output/org/jboss/test/ws/jaxws/samples/retail/profile/package-info.java
output/org/jboss/test/ws/jaxws/samples/retail/profile/Customer.class
output/org/jboss/test/ws/jaxws/samples/retail/profile/DiscountRequest.class
output/org/jboss/test/ws/jaxws/samples/retail/profile/DiscountResponse.class
output/org/jboss/test/ws/jaxws/samples/retail/profile/ObjectFactory.class
output/org/jboss/test/ws/jaxws/samples/retail/profile/ProfileMgmt.class
output/org/jboss/test/ws/jaxws/samples/retail/profile/ProfileMgmtService.class
output/org/jboss/test/ws/jaxws/samples/retail/profile/package-info.class
.java et les fichiers .class compilés sont générés dans le répertoire output/ qui se trouve dans le répertoire où vous exécutez la commande.
Tableau 13.2. Descriptions d'artefacts créés par wsconsume.sh
| Fichier | Description |
|---|---|
ProfileMgmt.java
|
Interface de point de terminaison de service.
|
Customer.java
|
Personnaliser le type de données.
|
Discount*.java
|
Personnaliser les types de données.
|
ObjectFactory.java
|
Référentiel JAXB XML.
|
package-info.java
|
Annotations de package JAXB.
|
ProfileMgmtService.java
|
Usine de connexions.
|
wsconsume.sh génère tous les types de données personnalisés (classes JAXB annotées), l'interface de point de terminaison de service et une classe de fabrique de services. Ces artefacts sont utilisés pour créer les implémentations web service clients.
Les clients de service Web permet d'abstraire les détails d'un appel de service web distant stubs de service. Pour une application cliente, une invocation WS ressemble à une invocation de tout autre composant de l'entreprise. Dans ce cas, l'interface de point de terminaison de service agit comme l'interface de l'entreprise, et une classe de fabrique de service n'est pas utilisée pour sa construction comme une ébauche de service.
Exemple 13.18. Créer un Service Stub et accéder à un point de terminaison
wsconsume.sh pour construire le stub de service. Enfin, le stub peut être utilisé comme le serait toute autre interface commerciale.
import javax.xml.ws.Service;
[...]
Service service = Service.create(
new URL("http://example.org/service?wsdl"),
new QName("MyService")
);
ProfileMgmt profileMgmt = service.getPort(ProfileMgmt.class);
// Use the service stub in your application
13.4.2. Développer une application client JAX-WS
Service
- Aperçu
- Un
Serviceest une abstraction qui représente un service WSDL. Un service WSDL est une collection de ports liés les uns aux autres, dont chacun comprend un type de port lié à un protocole particulier et une adresse de point de terminaison particulière.Généralement, le service est créé quand le reste des stubs du composant sont générés à partir d'un contrat WSDL existant. Le contrat WSDL est disponible via l'URL WSDL du point de terminaison déployé, ou peut être créé à partir de la source de point de terminaison à l'aide de la commandewsprovide.shdans le répertoire de/bin/ EAP_HOME.On appelle cela une utilisation statique. Dans un tel cas, vous créez des instances de la classeService, créée elle-même comme un des composants stubs.Vous pouvez également créer le service manuellement, par la méthodeService.create. On appelle cela une utilisation dynamic. - Utilisation
- Cas d'utilisation static
- Le cas d'utilisation statique pour un client JAX-WS suppose que vous ayez déjà un contrat WSDL. Ceci peut être généré par un outil externe ou généré à l'aide des annotations JAX-WS qui conviennent lorsque vous créez votre point de terminaison de JAX-WS.Pour générer vos stubs de composants, vous pouvez utiliser le script
wsconsume.shouwsconsume.batinclus dansEAP_HOME/bin/. Ce script prend le WSDL URL ou fichier en tant que paramètre, et génère de nombreux fichiers structurés dans un arborescence de répertoires. La source et les fichiers de classe représentant votreServices'appellentCLASSNAME_Service.javaetCLASSNAME_Service.class, respectivement.La classe d'implémentation générée possède deux constructeurs publics, un sans argument et un avec deux arguments. Les deux arguments représentent respectivement l'emplacement WSDL (unjava.net.URL) et le nom du service (unjavax.xml.namespace.QName).Le constructeur sans argument est celui qui est le plus souvent utilisé. Dans ce cas, l'emplacement WSDL et le nom du service sont ceux que l'on trouve dans le fichier WSDL. Ceux-ci sont définis implicitement à partir de l'annotation@WebServiceClientqui décore la classe générée.Exemple 13.19. Exemple de classe de service générée
@WebServiceClient(name="StockQuoteService", targetNamespace="http://example.com/stocks", wsdlLocation="http://example.com/stocks.wsdl") public class StockQuoteService extends javax.xml.ws.Service { public StockQuoteService() { super(new URL("http://example.com/stocks.wsdl"), new QName("http://example.com/stocks", "StockQuoteService")); } public StockQuoteService(String wsdlLocation, QName serviceName) { super(wsdlLocation, serviceName); } ... } - Cas d'utilisation dynamic
- Dans un cas d'utilisation dynamic, aucun stub n'est généré automatiquement. Au lieu de cela, le client de service web utilise la méthode
Service.createpour créer des instances deService. Le fragment de code suivant illustre ce processus.Exemple 13.20. Création de service manuellement
URL wsdlLocation = new URL("http://example.org/my.wsdl"); QName serviceName = new QName("http://example.org/sample", "MyService"); Service service = Service.create(wsdlLocation, serviceName);
- Handler Resolver
- JAX-WS fournit un framework plug-in flexible pour des modules de traitement des messages, appelés gestionnaires. Ces gestionnaires étendent les fonctionnalités d'un système de runtime JAX-WS. Une instance de
Servicedonnera accès à unHandlerResolvergrâce à une paire de méthodesgetHandlerResolveretsetHandlerResolverqui peuvent configurer un ensemble de gestionnaires sur la base de service, de port ou de protocole.Lorsqu'une instance deServicecrée un proxy ou une instanceDispatch, le Handler Resolver enregistré dans le service crée la chaîne de gestionnaires requise. Les changements ultérieurs apportés au Handler Resolver qui sont configurés pour une instance deServicen'affectent pas les gestionnaires sur proxies préalablement créés ou les instances deDispatch. - Exécuteur
- Les instances de
Servicepeuvent être configurées par unjava.util.concurrent.Executor.Executorinvoque les callbacks asynchrones demandés par l'application. Les méthodessetExecutoretgetExecutordeServicepeuvent modifier et extraire l'Executorconfiguré pour un service.
Un dynamic proxy est une instance de proxy de client utilisant une des méthodes getPort fournie par le Service. Le portName indique le nom du port WSDL que le service utilise. La serviceEndpointInterface indique l'interface du point de terminaison du service prise en charge par l'instance du proxy dynamique créé.
Exemple 13.21. Méthodes getPort
public <T> T getPort(QName portName, Class<T> serviceEndpointInterface) public <T> T getPort(Class<T> serviceEndpointInterface)
wsconsume.sh qui interprète le WSDL et qui, à partir de cela, crée des classes Java.
Exemple 13.22. Revoie le Port d'un Service
@WebServiceClient(name = "TestEndpointService", targetNamespace = "http://org.jboss.ws/wsref",
wsdlLocation = "http://localhost.localdomain:8080/jaxws-samples-webserviceref?wsdl")
public class TestEndpointService extends Service
{
...
public TestEndpointService(URL wsdlLocation, QName serviceName) {
super(wsdlLocation, serviceName);
}
@WebEndpoint(name = "TestEndpointPort")
public TestEndpoint getTestEndpointPort()
{
return (TestEndpoint)super.getPort(TESTENDPOINTPORT, TestEndpoint.class);
}
}
@WebServiceRef
L'annotation @WebServiceRef déclare une référence à un Service Web. Elle suit un modèle de ressource indiqué par l'annotation javax.annotation.Resource définie dans http://www.jcp.org/en/jsr/summary?id=250.
Cas d'utilisateur @WebServiceRef
- Vous pouvez l'utiliser pour définir une référence dont le type est une classe de
Servicegénérée. Dans ce cas, l'élément de valeur et le type font tous deux référence au type de classe deServicegénéré. En outre, si le type de référence peut être déduit grâce au champ ou à la déclaration de méthode à laquelle l'annotation est s'applique, les éléments de type et de valeur peuvent (mais n'y sont pas tenus) avoir la valeur par défaut deObject.class. Si le type ne peut pas être déduit, alors l'élément au moins doit être présent, avec une valeur par défaut. - Vous pouvez l'utiliser pour définir une référence de type SEI. Dans ce cas, l'élément de type peut (mais pas forcément) se présenter avec sa valeur par défaut si le type de référence peut être déduit de la déclaration de champ ou de méthode annotée. Toutefois, l'élément de valeur doit toujours être présent et faire référence à un type de classe de service généré, qui est un sous-type de
javax.xml.ws.Service. L'élémentwsdlLocation, s'il est présent, substitue les informations d'emplacement WSDL spécifiées dans l'annotation@WebServicede la classe de service générée référencée.Exemple 13.23. Exemples de
@WebServiceRefpublic class EJB3Client implements EJB3Remote { @WebServiceRef public TestEndpointService service4; @WebServiceRef public TestEndpoint port3;
Les Services Web XML utilisent des messages XML pour la communication entre le point de terminaison, qui est déployé dans le conteneur Java EE, et tous les clients. Les messages XML utilisent un langage XML appelé Simple Object Access Protocol (SOAP). L'API JAX-WS fournit les mécanismes pour que le point de terminaison et les clients àpuissent chacun être en mesure d'envoyer et de recevoir des messages SOAP et de convertir les messages SOAP en Java et vice versa. Cela s'appelle marshalling et unmarshalling.
Dispatch fournit cette fonctionnalité. Dispatch opère dans un des deux modes d'utilisation, qui sont identifiés par l'une des constantes suivantes.
javax.xml.ws.Service.Mode.MESSAGE- Ce mode ordonne aux applications clientes de travailler directement avec les structures de message qui sont spécifiques au protocole. Si utilisé avec une liaison de protocole SOAP, une application cliente fonctionne directement avec un message SOAP.javax.xml.ws.Service.Mode.PAYLOAD- ce mode amène le client à travailler avec la charge elle-même. Par exemple, s'il est utilisé avec une liaison de protocole SOAP, une application cliente travaillera alors avec le contenu SOAP plutôt qu'avec l'intégralité du message SOAP.
Dispatch est une API de bas niveau qui exige des clients de structurer les messages ou les charges en XML, avec une adhérence stricte aux normes du protocole individuel et une connaissance approfondie de la structure de message ou de la charge. Dispatch est une classe générique qui prend en charge l'entrée et la sortie des messages ou des charges de message de n'importe quel type.
Exemple 13.24. Dispatch Usage
Service service = Service.create(wsdlURL, serviceName); Dispatch dispatch = service.createDispatch(portName, StreamSource.class, Mode.PAYLOAD); String payload = "<ns1:ping xmlns:ns1='http://oneway.samples.jaxws.ws.test.jboss.org/'/>"; dispatch.invokeOneWay(new StreamSource(new StringReader(payload))); payload = "<ns1:feedback xmlns:ns1='http://oneway.samples.jaxws.ws.test.jboss.org/'/>"; Source retObj = (Source)dispatch.invoke(new StreamSource(new StringReader(payload)));
L'interface BindingProvider représente un composant qui fournit une liaison de protocole que les clients peuvent utiliser. Elle est implémentée et étendue par l'interface Dispatch.
BindingProvider peuvent fournir des possibilités d'opérations asynchrones. Comme les opérations asynchrones, les invocations sont découplées de l'instance BindingProvider au moment de l'invocation. Le contexte de réponse n'est pas mis à jour lorsque l'opération est terminée. Au lieu de cela, un contexte de réponse distinct est mis à disposition à l'aide de l'interface de réponse.
Exemple 13.25. Invocation asynchrone
public void testInvokeAsync() throws Exception
{
URL wsdlURL = new URL("http://" + getServerHost() + ":8080/jaxws-samples-asynchronous?wsdl");
QName serviceName = new QName(targetNS, "TestEndpointService");
Service service = Service.create(wsdlURL, serviceName);
TestEndpoint port = service.getPort(TestEndpoint.class);
Response response = port.echoAsync("Async");
// access future
String retStr = (String) response.get();
assertEquals("Async", retStr);
}
@Oneway
L'annotation @Oneway indique que la méthode web donnée ne prend un message d'entrée mais ne renvoie aucun message de sortie. Habituellement, une méthode @Oneway renvoie le thread de contrôle à l'application appelante avant l'exécution de la méthode commerciale.
Exemple 13.26. Exemple d'invocation @Oneway
@WebService (name="PingEndpoint")
@SOAPBinding(style = SOAPBinding.Style.RPC)
public class PingEndpointImpl
{
private static String feedback;
@WebMethod
@Oneway
public void ping()
{
log.info("ping");
feedback = "ok";
}
@WebMethod
public String feedback()
{
log.info("feedback");
return feedback;
}
}
Il y a deux propriétés qui contrôlent le comportement du délai d'expiration de la connexion HTTP et le délai d'attente d'un client qui attend de recevoir un message. Le premier est javax.xml.ws.client.connectionTimeout et le second est javax.xml.ws.client.receiveTimeout. Chacun est exprimé en millisecondes, et la syntaxe correcte est indiquée ci-dessous.
Exemple 13.27. Configuration de timeout JAX-WS
public void testConfigureTimeout() throws Exception
{
//Set timeout until a connection is established
((BindingProvider)port).getRequestContext().put("javax.xml.ws.client.connectionTimeout", "6000");
//Set timeout until the response is received
((BindingProvider) port).getRequestContext().put("javax.xml.ws.client.receiveTimeout", "1000");
port.echo("testTimeout");
}
13.5. Référence de développement JAX-WS
13.5.1. Activation de WS-Addressing (Web Services Addressing)
Prérequis
- Votre application doit posséder un service JAX-WS et une configuration client.
Procédure 13.1. Annoter et mettre à jour le code client
Annoter le point de terminaison du service
Ajouter l'annotation@Addressingau code du point de terminaison de l'application.Exemple 13.28. annotation
@AddressingCet exemple montre un point de terminaison normal avec l'ajout de l'annotation@Addressing.package org.jboss.test.ws.jaxws.samples.wsa; import javax.jws.WebService; import javax.xml.ws.soap.Addressing; @WebService ( portName = "AddressingServicePort", serviceName = "AddressingService", wsdlLocation = "WEB-INF/wsdl/AddressingService.wsdl", targetNamespace = "http://www.jboss.org/jbossws/ws-extensions/wsaddressing", endpointInterface = "org.jboss.test.ws.jaxws.samples.wsa.ServiceIface" ) @Addressing(enabled=true, required=true) public class ServiceImpl implements ServiceIface { public String sayHello() { return "Hello World!"; } }Mise à jour du code client
Mettez à jour le code client dans l'application pour configurer WS-Addressing.Exemple 13.29. La configuration client pour WS-Addressing
Cet exemple montre un client JAX-WS mis à jour pour configurer WS-Addressing.package org.jboss.test.ws.jaxws.samples.wsa; import java.net.URL; import javax.xml.namespace.QName; import javax.xml.ws.Service; import javax.xml.ws.soap.AddressingFeature; public final class AddressingTestCase { private final String serviceURL = "http://localhost:8080/jaxws-samples-wsa/AddressingService"; public static void main(String[] args) throws Exception { // construct proxy QName serviceName = new QName("http://www.jboss.org/jbossws/ws-extensions/wsaddressing", "AddressingService"); URL wsdlURL = new URL(serviceURL + "?wsdl"); Service service = Service.create(wsdlURL, serviceName); ServiceIface proxy = (ServiceIface)service.getPort(ServiceIface.class, new AddressingFeature()); // invoke method proxy.sayHello(); } }
Le client et le point de terminaison communiquent maintenant avec WS-Addressing.
13.5.2. Référence API Commun JAX-WS
Le framework de gestionnaires est implémenté par une liaison de protocole de JAX-WS dans le runtime du client et le point de terminaison, qui est le composant de serveur. Les proxies et les instances Dispatch, connus collectivement en tant que fournisseurs de liaison, chacun utilisant des liaisons de protocole pour lier leur fonctionnalité abstraite à des protocoles spécifiques.
Types de gestionnaires de messages
- Gestionnaire logique
- Les gestionnaires logiques n'opèrent que sur des propriétés de contexte de messages et sur des charges utiles de messages. Les gestionnaires logiques sont libérés des protocoles et ne peuvent pas affecter les parties d'un message qui soient spécifiques à un protocole. Les gestionnaires logiques implémentent l'interface
javax.xml.ws.handler.LogicalHandler. - Gestionnaire de protocoles
- Les gestionnaires de protocoles fonctionnent sur les propriétés de contexte de message et les messages de protocole spécifique. Les gestionnaires de protocoles sont spécifiques à un protocole particulier et peuvent accéder et modifier les aspects spécifiques d'un protocole de message. Les gestionnaires de protocoles implémentent une interface dérivée de
javax.xml.ws.handler.Handler except javax.xml.ws.handler.LogicalHandler. - Gestionnaire de points de terminaison
- Sur un point de terminaison de service, les gestionnaires sont définis à l'aide de l'annotation
@HandlerChain. L'emplacement du fichier de chaîne de gestionnaires peut être soit unjava.net.URLabsolu dansexternalFormou un chemin d'accès relatif du fichier source ou du fichier de classe.Exemple 13.30. Exemple de gestionnaire de points de terminaison
@WebService @HandlerChain(file = "jaxws-server-source-handlers.xml") public class SOAPEndpointSourceImpl { ... } - Service Client Handler
- Sur un client JAX-WS, les gestionnaires sont définis soit en utilisant l'annotation
@HandlerChain, comme dans les points de terminaison de service, soit de façon dynamique, à l'aide de l'API JAX-WS.Exemple 13.31. Définir un Service Client Handler par une API
Service service = Service.create(wsdlURL, serviceName); Endpoint port = (Endpoint)service.getPort(Endpoint.class); BindingProvider bindingProvider = (BindingProvider)port; List<Handler> handlerChain = new ArrayList<Handler>(); handlerChain.add(new LogHandler()); handlerChain.add(new AuthorizationHandler()); handlerChain.add(new RoutingHandler()); bindingProvider.getBinding().setHandlerChain(handlerChain);L'appel à la méthodesetHandlerChainest requis.
L'interface MessageContext est une super interface pour tous les contextes de message JAX-WS. Elle étend Map <String,Object> de méthodes et des constantes supplémentaires pour gérer un ensemble de propriétés qui permettent aux gestionnaires d'une chaîne de gestionnaires de partager l'état connexe de traitement. Par exemple, un gestionnaire peut utiliser la méthode put pour insérer une propriété dans le contexte du message. Un ou plusieurs autres gestionnaires de la chaîne de gestionnaires peuvent obtenir par la suite le message via la méthode get.
APPLICATION ou GESTIONNAIRE. Toutes les propriétés sont disponibles pour tous les gestionnaires d'une instance d'un modèle d'échange de messages ou MEP (de l'anglais Message Exchange Pattern) d'un point de terminaison particulier. Par exemple, si un gestionnaire logique met une propriété dans le contexte du message, cette propriété sera également disponible à tous les gestionnaires de protocole dans la chaîne au cours de l'exécution d'une instance MEP.
Note
APPLICATION sont également rendues disponibles en tant qu'applications clients et implémentations de point de terminaison de services. Le defaultscope d'un propriété est HANDLER par défaut.
- Contexte de message logique
- Lorsque les gestionnaires logiques sont invoqués, ils reçoivent un contexte de message de type
LogicalMessageContext. LeLogicalMessageContextétendMessageContextpar des méthodes qui récupèrent et modifient la charge du message. Il ne donne pas accès aux aspects spécifiques au protocole d'un message. Une liaison de protocole définit quels composants d'un message sont disponibles via un contexte logique message. Un gestionnaire logique déployé dans une liaison SOAP peut accéder au contenu du corps SOAP, mais pas aux en-têtes SOAP. En revanche, la liaison XML/HTTP définit qu'un gestionnaire de logique accède à l'entière charge XML d'un message. - Contexte de message SOAP
- Quand les gestionnaires SOAP sont invoqués, ils reçoivent un
SOAPMessageContext. LeSOAPMessageContextétendMessageContextpar des méthodes qui obtiennent et modifient la charge du message SOAP.
Une application peut lever une SOAPFaultException ou une exception spécifique à l'application utilisateur. Dans ce dernier cas, les wrapper beans de faute requis seront générés en cours d'exécution s'ils ne font pas déjà partie du déploiement.
Exemple 13.32. Exemple de gestion des fautes
public void throwSoapFaultException()
{
SOAPFactory factory = SOAPFactory.newInstance();
SOAPFault fault = factory.createFault("this is a fault string!", new QName("http://foo", "FooCode"));
fault.setFaultActor("mr.actor");
fault.addDetail().addChildElement("test");
throw new SOAPFaultException(fault);
}
public void throwApplicationException() throws UserException
{
throw new UserException("validation", 123, "Some validation error");
}
Les annotations disponibles via JAX-WS API sont définies dans JSR-224, que l'on peut trouver à l'adresse suivante http://www.jcp.org/en/jsr/detail?id=224. Ces annotations sont dans le package javax.xml.ws.
javax.jws.
Chapitre 14. Identité au sein d'applications
14.1. Concepts de base
14.1.1. Chiffrement
14.1.2. Les domaines de sécurité
14.1.3. Cryptage SSL
14.1.4. Sécurité déclarative
14.2. Sécurité basée-rôle pour les applications
14.2.1. La sécurité des applications
14.2.2. Authentification
14.2.3. L'autorisation
14.2.4. Security Auditing
14.2.5. Security Mapping
14.2.6. Security Extension Architecture
La première partie de l'infrastructure est l'API JAAS. JAAS est un framework additionnel qui procure une couche d'abstraction entre l'infrastructure de sécurité et votre application.
org.jboss.security.plugins.JaasSecurityManager, qui implémente les interfaces AuthenticationManager et RealmMapping. JaasSecurityManager s'intègre dans les couches de conteneur EJB et web, basées sur l'élément <security-domain> du descripteur de déploiement du composant correspondant.
JaasSecurityManagerService
Le service MBean JaasSecurityManagerService s'occupe des gestionnaires de la sécurité. Bien que son nom commence par Jaas, les gestionnaires de sécurité qu'il gère n'ont pas besoin pas d'utiliser JAAS dans leur implémentation. Le nom reflète le fait que l'implémentation de gestionnaire de sécurité par défaut est le JaasSecurityManager
JaasSecurityManagerService est d'externaliser la mise en œuvre du gestionnaire de sécurité. Vous pouvez modifier la mise en œuvre du gestionnaire de sécurité en fournissant une implémentation alternative des interfaces AuthenticationManager et RealmMapping.
JaasSecurityManagerService est de fournir une implémentation javax.naming.spi.ObjectFactory JNDI pour permettre une gestion simple de la liaison dépourvue de code entre le nom JNDI et l'implémentation du gestionnaire de sécurité, sans code. Pour activer la sécurité, spécifiez le nom JNDI de l'implémentation du gestionnaire de sécurité par l'intermédiaire de l'élément de descripteur de déploiement <security-domain>.
JaasSecurityManagerService relie un next naming system reference, qui se nomme lui-même comme ObjectFactory JNDI sous le nom java:/jaas. Cela permet à une convention de nommage de la forme java:/jaas/XYZ à correspondre à la valeur de l'élément <security-domain>, et l'instance du gestionnaire de sécurité du domaine de sécurité XYZ sera créée selon les besoins, en créant une instance de la classe spécifiée par l'attribut SecurityManagerClassName par l'intermédiaire d'un constructeur qui prendra le nom du domaine de sécurité.
Note
java:/jaas à votre descripteur de déploiement. Vous pouvez le faire, pour les raisons de compatibilité rétroactive, mais ce sera ignoré.
org.jboss.security.plugins.JaasSecurityDomain est une extension de JaasSecurityManager, qui ajoute la notion de KeyStore, de KeyManagerFactory et de TrustManagerFactory pour SSL et autres cas d'utilisation cryptographique.
Pour plus d'informations, et pour obtenir des exemples pratiques de l'architecture de sécurité en action, voir Section 14.2.8, « Java Authentication et Authorization Service (JAAS) ».
14.2.7. Java Authentication et Authorization Service (JAAS)
14.2.8. Java Authentication et Authorization Service (JAAS)
Les groupes de serveurs (dans un domaine géré) et les serveurs (dans un serveur autonome) comprennent la configuration des domaines de la sécurité. Un domaine de sécurité comprend des informations sur une combinaison d'authentification, autorisation, mapping et modules, avec détails de configuration. Une application spécifie quel domaine de sécurité est exigé, par son nom, dans son fichier jboss-web.xml.
Une configuration spécifique à une application a lieu dans un ou plusieurs fichiers.
Tableau 14.1. Fichiers de configuration spécifique à une application
| Fichier | Description |
|---|---|
| ejb-jar.xml |
Le descripteur de déploiement pour une application Enterprise JavaBeans (EJB), situé dans le répertoire
META-INF de l'EJB. Utiliser le fichier ejb-jar.xml pour préciser les rôles et les mapper aux principaux, au niveau de l'application. Vous pouvez également limiter certaines méthodes et classes spécifiques à certains rôles. Également utilisé pour les autres configurations EJB spécifiques non liées à la sécurité.
|
| web.xml |
Le descripteur de déploiement pour une application web en Java Enterprise Edition (EE). Utilisez le fichier
web.xml pour déclarer le domaine de sécurité que l'application utilise pour l'authentification et l'autorisation, ainsi que les contraintes de transport et ressources, comme limiter les types de demandes HTTP autorisées. Vous pouvez également configurer l'authentification basée-web dans ce fichier. Utilisé également pour d'autre configurations spécifiques à l'application non liées à la sécurité.
|
| jboss-ejb3.xml |
Contient des extensions au descripteur
ejb-jar.xml spécifiques à JBoss.
|
| jboss-web.xml |
Contient des extensions au descripteur
web.xml spécifiques à JBoss.
|
Note
ejb-jar.xml et web.xml sont définis dans la spécification Java Enterprise Edition (Java EE). Le fichier jboss-ejb3.xml fournit des extensions spécifiques à JBoss pour le fichier ejb-jar.xml, et le fichier jboss-web.xml fournit des extensions spécifiques à JBoss pour le fichier web.xml.
Java Authentication and Authorization Service (JAAS) est un cadre de sécurité au niveau utilisateur pour les applications Java, utilisant des modules d'authentification enfichables (PAM). Il est intégré dans le Java Runtime Environment (JRE). Dans JBoss EAP 6, le composant côté conteneur est le MBean org.jboss.security.plugins.JaasSecurityManager. Il fournit les implémentations par défaut des interfaces AuthenticationManager et RealmMapping.
JaasSecurityManager utilise les packages JAAS pour implémenter le comportement d'interface AuthenticationManager et RealmMapping. En particulier, son comportement découle de l'exécution des instances de modules de connexion qui sont configurées dans le domaine de sécurité assigné au JaasSecurityManager. Les modules de connexion implémentent l'authentification principale du domaine de sécurité et le comportement de mappage de rôle. Vous pouvez utiliser le JaasSecurityManager à travers tous les domaines de la sécurité en assignant des configurations de modules de connexion différentes pour les domaines.
EJBHome. L'EJB a déjà été déployé dans le serveur et ses méthodes d'interface EJBHome ont déjà été sécurisées par les éléments <method-permission> qui se trouvent dans le descripteur ejb-jar.xml. Utilise le domaine de sécurité jwdomain, qui est indiqué dans l'élément <security-domain> du fichier jboss-ejb3.xml. L'image ci-dessous indique les étapes qui seront expliquées par la suite.
Figure 14.1. Étapes d'une invocation de méthode EJB sécurisée
- Le client effectue une connexion JAAS pour établir le principal et les informations d'identification pour l'authentification. Correspond à Client Side Login dans le schéma. Peut être exécuté via JNDI.Pour effectuer une connexion JAAS, vous devez créer une instance de LoginContext et y indiquer le nom de la configuration à utiliser. Ici, le nom de configuration est
other. Cette connexion unique associe la connexion principale et les informations d'identification à toutes les invocations de méthode EJB. Le processus n'authentifie pas forcément l'utilisateur. La nature de la connexion côté client dépend de la configuration du module de connexion que le client utilise. Dans cet exemple, l'entrée de configurationothercôté client utilise le module de connexionClientLoginModule. Ce module lie le nom d'utilisateur et le mot de passe à la couche d'invocation EJB pour une authentification ultérieure sur le serveur. L'identité du client n'est pas authentifiée sur le client. - Le client obtient la méthode
EJBHomeet l'invoque sur le serveur. L'invocation inclut les arguments de la méthode adoptée par le client, ainsi que l'identité de l'utilisateur et les informations d'identification de la connexion JAAS de côté client. - Sur le serveur, l'intercepteur de sécurité authentifie l'utilisateur qui a invoqué la méthode. Cela nécessite une autre connexion JAAS.
- Le domaine de sécurité ci-dessous détermine le choix des modules de connexion. Le nom du domaine de sécurité est passé au constructeur
LoginContexten tant que nom de configuration de la connexion. Le domaine de sécurité des EJB estjwdomain. Si l'authentification JAAS est réussie, un sujet JAAS sera créé. Un sujet JAAS comprend un PrincipalSet avec les détails suivants :- Une instance
java.security.Principalqui correspond à l'identité du client en provenance de l'environnement de sécurité du déploiement. - Un groupe
java.security.acl.GroupappeléRoles, qui contient les noms de rôles du domaine d'application de l'utilisateur. Les objets de typeorg.jboss.security.SimplePrincipalreprésentent les noms de rôles. Ces rôles valident l'accès aux méthodes EJB suivant les contraintes deejb-jar.xmlet de l'implémentation de la méthodeEJBContext.isCallerInRole(String). - Un
java.security.acl.Groupoptionnel nomméCallerPrincipal, contenant un seulorg.jboss.security.SimplePrincipalqui correspond à l'identité de l'appelant du domaine de l'application. Le membre du groupe CallerPrincipal correspond à la valeur renvoyée par la méthodeEJBContext.getCallerPrincipal(). Ce mappage permet au Principal de l'environnement de sécurité professionnel de se mapper à un Principal connu de l'application. En l'absence d'un mappage CallerPrincipal, le principal opérationnel est le même que le principal du domaine d'application.
- Le serveur vérifie que l'utilisateur qui appelle la méthode EJB a la permission de le faire. Cette autorisation requiert les étapes suivantes :
- Obtenir les noms des rôles autorisés à accéder à la méthode EJB à partir du conteneur EJB. Les noms de rôles sont déterminés par les éléments <role-name> de tous les éléments <method-permission> du descripteur
ejb-jar.xmlqui contiennent la méthode invoquée. - Si aucun des rôles n'a été attribué, ou si la méthode est spécifiée dans un élément de la liste d'exclusion, l'accès à la méthode sera refusé. Sinon, la méthode
doesUserHaveRolesera appelée dans le gestionnaire de sécurité par l'intercepteur de sécurité pour vérifier si l'appelant possède l'un des noms de rôles assignés. Cette méthode effectue une itération dans les noms de rôles et vérifie si le groupeSubject Rolesde l'utilisateur authentifié contient un SimplePrincipal avec le nom de rôle assigné. L'accès est autorisé si un nom de rôle est membre du groupe Rôles. L'accès est refusé si aucun des noms de rôles n'est membre. - Si l'EJB utilise un proxy de sécurité personnalisé, l'invocation de méthode sera déléguée au proxy. Si le proxy de sécurité refuse l'accès à l'appelant, elle lève une exception
java.lang.SecurityException. Sinon, l'accès à la méthode EJB sera autorisé et l'invocation de méthode passera au prochain intercepteur de conteneur. Le SecurityProxyInterceptor s'occupe de ce contrôle et cet intercepteur n'est pas affiché. - Pour les demandes de connexion web, le serveur web vérifie les contraintes de sécurité définies dans
web.xmlqui correspondent à la ressource demandée et à la méthode HTTP à laquelle on a accédé.S'il existe une contrainte pour la demande, le serveur web appelle le JaasSecurityManager pour effectuer l'authentification du principal, qui assure à son tour veille à ce que les rôles d'utilisateur soient associés à cet objet principal.
14.2.9. Utiliser un domaine de sécurité dans votre application
Pour utiliser un domaine de sécurité dans votre application, vous devez tout d'abord configurer le domaine dans le fichier de configuration du serveur ou dans le fichier de descripteur de l'application. Ensuite, vous devez ajouter les annotations requises à l'EJB qui l'utilisent. Cette rubrique décrit les étapes requises pour utiliser un domaine de sécurité dans votre application.
Procédure 14.1. Configurer votre application pour qu'elle puisse utiliser un Domaine de sécurité
Définir le domaine de sécurité
Vous pouvez définir le domaine de sécurité soit dans le fichier de configuration du serveur, soit dans le fichier du descripteur de l'application.Configurer le domaine de sécurité dans le fichier de configuration du serveur
Le domaine de sécurité est configuré dans le sous-système desécuritédu fichier de configuration du serveur. Si l'instance de JBoss EAP 6 s'exécute dans un domaine géré, il s'agira du fichierdomain/configuration/domain.xml. Si l'instance de JBoss EAP 6 s'exécute comme un serveur autonome, ce sera le fichierstandalone/configuration/standalone.xml.Les domaines de sécuritéother,jboss-web-policy, etjboss-ejb-policysont fournis par défaut dans JBoss EAP 6. L'exemple XML suivant a été copié à partir du sous-système desécuritédans le fichier de configuration du serveur.<subsystem xmlns="urn:jboss:domain:security:1.2"> <security-domains> <security-domain name="other" cache-type="default"> <authentication> <login-module code="Remoting" flag="optional"> <module-option name="password-stacking" value="useFirstPass"/> </login-module> <login-module code="RealmDirect" flag="required"> <module-option name="password-stacking" value="useFirstPass"/> </login-module> </authentication> </security-domain> <security-domain name="jboss-web-policy" cache-type="default"> <authorization> <policy-module code="Delegating" flag="required"/> </authorization> </security-domain> <security-domain name="jboss-ejb-policy" cache-type="default"> <authorization> <policy-module code="Delegating" flag="required"/> </authorization> </security-domain> </security-domains> </subsystem>Vous pouvez configurer des domaines de sécurité supplémentaires selon les besoins par la console de gestion ou par le Management CLI.Configurer le domaine de sécurité dans le fichier de descripteur de l'application.
Le domaine de sécurité est spécifié dans l'élément enfant<security-domain>de l'élément<jboss-web>du fichierWEB-INF/jboss-web.xmlde l'application. L'exemple suivant configure un domaine de sécurité nommémy-domain.<jboss-web> <security-domain>my-domain</security-domain> </jboss-web>Il s'agit d'une des configurations que vous pouvez indiquer dans le descripteurWEB-INF/jboss-web.xml.
Ajouter l'annotation requise à l'EJB.
Vous pouvez configurer la sécurité dans EJB par les annotations@SecurityDomainet@RolesAllowed. L'exemple de code EJB suivant limite l'accès au domaine de sécuritéotheraux utilisateurs ayant pour rôleguest(invité).package example.ejb3; import java.security.Principal; import javax.annotation.Resource; import javax.annotation.security.RolesAllowed; import javax.ejb.SessionContext; import javax.ejb.Stateless; import org.jboss.ejb3.annotation.SecurityDomain; /** * Simple secured EJB using EJB security annotations * Allow access to "other" security domain by users in a "guest" role. */ @Stateless @RolesAllowed({ "guest" }) @SecurityDomain("other") public class SecuredEJB { // Inject the Session Context @Resource private SessionContext ctx; /** * Secured EJB method using security annotations */ public String getSecurityInfo() { // Session context injected using the resource annotation Principal principal = ctx.getCallerPrincipal(); return principal.toString(); } }Pour obtenir des exemples de code supplémentaires, voirejb-securityQuickstart dans le package JBoss EAP 6 Quickstarts disponible à partir du Portail Clients Red Hat.
14.2.10. Utilisation de la sécurité basée-rôle dans les Servlets
jboss-web.xml du WAR.
Avant d'utiliser la sécurité basée-rôles dans une servlet, le domaine de sécurité utilisé pour authentifier et autoriser l'accès doit être configuré sur la plateforme JBoss EAP 6.
Procédure 14.2. Ajout de la sécurité basée-rôle dans les servlets
Ajout de mappages entre les types d'URL et les servlets.
Utiliser les éléments<servlet-mapping>du fichierweb.xmlpour mapper les servlets individuels à des types d'URL. L'exemple suivant mappe le serveur nomméDisplayOpResultau type d'URL/DisplayOpResult.<servlet-mapping> <servlet-name>DisplayOpResult</servlet-name> <url-pattern>/DisplayOpResult</url-pattern> </servlet-mapping>Ajout des contraintes de sécurité aux types d'URL.
Pour mapper le type d'URL avec une contrainte de sécurité, utilisez un<security-constraint>. L'exemple suivant limite l'accès d'un type d'URL/DisplayOpResultafin qu'il soit accessible aux principaux ayant pour rôleeap_admin. Le rôle doit être présent dans le domaine de sécurité.<security-constraint> <display-name>Restrict access to role eap_admin</display-name> <web-resource-collection> <web-resource-name>Restrict access to role eap_admin</web-resource-name> <url-pattern>/DisplayOpResult/*</url-pattern> </web-resource-collection> <auth-constraint> <role-name>eap_admin</role-name> </auth-constraint> </security-constraint> <security-role> <role-name>eap_admin</role-name> </security-role> <login-config> <auth-method>BASIC</auth-method> </login-config>Vous aurez besoin d'indiquer la méthode d'authentification, qui peut être une des suivantes :BASIC, FORM, DIGEST, CLIENT-CERT, SPNEGO.. Cet exemple utilise l'authentificationBASIC.Indiquer le domaine de sécurité et le fichier
jboss-web.xmldu WAR.Ajouter le domaine de sécurité au fichierjboss-Web.xmldu WAR afin de connecter les servlets au domaine de la sécurité configuré sachant comment authentifier et autoriser les principaux selon les contraintes de sécurité. L'exemple suivant utilise le domaine de sécurité appeléacme_domain.<jboss-web> ... <security-domain>acme_domain</security-domain> ... </jboss-web>
Exemple 14.1. Exemple web.xml avec la sécurité basée rôle configurée.
<web-app xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd"
version="3.0">
<display-name>Use Role-Based Security In Servlets</display-name>
<welcome-file-list>
<welcome-file>/index.jsp</welcome-file>
</welcome-file-list>
<servlet-mapping>
<servlet-name>DisplayOpResult</servlet-name>
<url-pattern>/DisplayOpResult</url-pattern>
</servlet-mapping>
<security-constraint>
<display-name>Restrict access to role eap_admin</display-name>
<web-resource-collection>
<web-resource-name>Restrict access to role eap_admin</web-resource-name>
<url-pattern>/DisplayOpResult/*</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>eap_admin</role-name>
</auth-constraint>
</security-constraint>
<security-role>
<role-name>eap_admin</role-name>
</security-role>
<login-config>
<auth-method>BASIC</auth-method>
</login-config>
</web-app>
14.2.11. Utilisation d'une authentification système de tierce partie pour votre application
Note
context.xml. Les valves sont configurées directement dans le descripteur jboss-web.xml à la place. Le fichier context.xml peut maintenant être ignoré.
Exemple 14.2. Valve d'authentification de base
<jboss-web>
<valve>
<class-name>org.jboss.security.negotiation.NegotiationAuthenticator</class-name>
</valve>
</jboss-web>
Exemple 14.3. Personnaliser une valve avec des attributs d'en-tête
<jboss-web>
<valve>
<class-name>org.jboss.web.tomcat.security.GenericHeaderAuthenticator</class-name>
<param>
<param-name>httpHeaderForSSOAuth</param-name>
<param-value>sm_ssoid,ct-remote-user,HTTP_OBLIX_UID</param-value>
</param>
<param>
<param-name>sessionCookieForSSOAuth</param-name>
<param-value>SMSESSION,CTSESSION,ObSSOCookie</param-value>
</param>
</valve>
</jboss-web>
Rédiger vous-même votre authentificateur est en dehors de la portée de ce document. Cependant, le code Java suivant est fourni comme exemple.
Exemple 14.4. GenericHeaderAuthenticator.java
/*
* JBoss, Home of Professional Open Source.
* Copyright 2006, Red Hat Middleware LLC, and individual contributors
* as indicated by the @author tags. See the copyright.txt file in the
* distribution for a full listing of individual contributors.
*
* This is free software; you can redistribute it and/or modify it
* under the terms of the GNU Lesser General Public License as
* published by the Free Software Foundation; either version 2.1 of
* the License, or (at your option) any later version.
*
* This software is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
* Lesser General Public License for more details.
*
* You should have received a copy of the GNU Lesser General Public
* License along with this software; if not, write to the Free
* Software Foundation, Inc., 51 Franklin St, Fifth Floor, Boston, MA
* 02110-1301 USA, or see the FSF site: http://www.fsf.org.
*/
package org.jboss.web.tomcat.security;
import java.io.IOException;
import java.security.Principal;
import java.util.StringTokenizer;
import javax.management.JMException;
import javax.management.ObjectName;
import javax.servlet.http.Cookie;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.catalina.Realm;
import org.apache.catalina.Session;
import org.apache.catalina.authenticator.Constants;
import org.apache.catalina.connector.Request;
import org.apache.catalina.connector.Response;
import org.apache.catalina.deploy.LoginConfig;
import org.jboss.logging.Logger;
import org.jboss.as.web.security.ExtendedFormAuthenticator;
/**
* JBAS-2283: Provide custom header based authentication support
*
* Header Authenticator that deals with userid from the request header Requires
* two attributes configured on the Tomcat Service - one for the http header
* denoting the authenticated identity and the other is the SESSION cookie
*
* @author <a href="mailto:Anil.Saldhana@jboss.org">Anil Saldhana</a>
* @author <a href="mailto:sguilhen@redhat.com">Stefan Guilhen</a>
* @version $Revision$
* @since Sep 11, 2006
*/
public class GenericHeaderAuthenticator extends ExtendedFormAuthenticator {
protected static Logger log = Logger
.getLogger(GenericHeaderAuthenticator.class);
protected boolean trace = log.isTraceEnabled();
// JBAS-4804: GenericHeaderAuthenticator injection of ssoid and
// sessioncookie name.
private String httpHeaderForSSOAuth = null;
private String sessionCookieForSSOAuth = null;
/**
* <p>
* Obtain the value of the <code>httpHeaderForSSOAuth</code> attribute. This
* attribute is used to indicate the request header ids that have to be
* checked in order to retrieve the SSO identity set by a third party
* security system.
* </p>
*
* @return a <code>String</code> containing the value of the
* <code>httpHeaderForSSOAuth</code> attribute.
*/
public String getHttpHeaderForSSOAuth() {
return httpHeaderForSSOAuth;
}
/**
* <p>
* Set the value of the <code>httpHeaderForSSOAuth</code> attribute. This
* attribute is used to indicate the request header ids that have to be
* checked in order to retrieve the SSO identity set by a third party
* security system.
* </p>
*
* @param httpHeaderForSSOAuth
* a <code>String</code> containing the value of the
* <code>httpHeaderForSSOAuth</code> attribute.
*/
public void setHttpHeaderForSSOAuth(String httpHeaderForSSOAuth) {
this.httpHeaderForSSOAuth = httpHeaderForSSOAuth;
}
/**
* <p>
* Obtain the value of the <code>sessionCookieForSSOAuth</code> attribute.
* This attribute is used to indicate the names of the SSO cookies that may
* be present in the request object.
* </p>
*
* @return a <code>String</code> containing the names (separated by a
* <code>','</code>) of the SSO cookies that may have been set by a
* third party security system in the request.
*/
public String getSessionCookieForSSOAuth() {
return sessionCookieForSSOAuth;
}
/**
* <p>
* Set the value of the <code>sessionCookieForSSOAuth</code> attribute. This
* attribute is used to indicate the names of the SSO cookies that may be
* present in the request object.
* </p>
*
* @param sessionCookieForSSOAuth
* a <code>String</code> containing the names (separated by a
* <code>','</code>) of the SSO cookies that may have been set by
* a third party security system in the request.
*/
public void setSessionCookieForSSOAuth(String sessionCookieForSSOAuth) {
this.sessionCookieForSSOAuth = sessionCookieForSSOAuth;
}
/**
* <p>
* Creates an instance of <code>GenericHeaderAuthenticator</code>.
* </p>
*/
public GenericHeaderAuthenticator() {
super();
}
public boolean authenticate(Request request, HttpServletResponse response,
LoginConfig config) throws IOException {
log.trace("Authenticating user");
Principal principal = request.getUserPrincipal();
if (principal != null) {
if (trace)
log.trace("Already authenticated '" + principal.getName() + "'");
return true;
}
Realm realm = context.getRealm();
Session session = request.getSessionInternal(true);
String username = getUserId(request);
String password = getSessionCookie(request);
// Check if there is sso id as well as sessionkey
if (username == null || password == null) {
log.trace("Username is null or password(sessionkey) is null:fallback to form auth");
return super.authenticate(request, response, config);
}
principal = realm.authenticate(username, password);
if (principal == null) {
forwardToErrorPage(request, response, config);
return false;
}
session.setNote(Constants.SESS_USERNAME_NOTE, username);
session.setNote(Constants.SESS_PASSWORD_NOTE, password);
request.setUserPrincipal(principal);
register(request, response, principal, HttpServletRequest.FORM_AUTH,
username, password);
return true;
}
/**
* Get the username from the request header
*
* @param request
* @return
*/
protected String getUserId(Request request) {
String ssoid = null;
// We can have a comma-separated ids
String ids = "";
try {
ids = this.getIdentityHeaderId();
} catch (JMException e) {
if (trace)
log.trace("getUserId exception", e);
}
if (ids == null || ids.length() == 0)
throw new IllegalStateException(
"Http headers configuration in tomcat service missing");
StringTokenizer st = new StringTokenizer(ids, ",");
while (st.hasMoreTokens()) {
ssoid = request.getHeader(st.nextToken());
if (ssoid != null)
break;
}
if (trace)
log.trace("SSOID-" + ssoid);
return ssoid;
}
/**
* Obtain the session cookie from the request
*
* @param request
* @return
*/
protected String getSessionCookie(Request request) {
Cookie[] cookies = request.getCookies();
log.trace("Cookies:" + cookies);
int numCookies = cookies != null ? cookies.length : 0;
// We can have comma-separated ids
String ids = "";
try {
ids = this.getSessionCookieId();
log.trace("Session Cookie Ids=" + ids);
} catch (JMException e) {
if (trace)
log.trace("checkSessionCookie exception", e);
}
if (ids == null || ids.length() == 0)
throw new IllegalStateException(
"Session cookies configuration in tomcat service missing");
StringTokenizer st = new StringTokenizer(ids, ",");
while (st.hasMoreTokens()) {
String cookieToken = st.nextToken();
String val = getCookieValue(cookies, numCookies, cookieToken);
if (val != null)
return val;
}
if (trace)
log.trace("Session Cookie not found");
return null;
}
/**
* Get the configured header identity id in the tomcat service
*
* @return
* @throws JMException
*/
protected String getIdentityHeaderId() throws JMException {
if (this.httpHeaderForSSOAuth != null)
return this.httpHeaderForSSOAuth;
return (String) mserver.getAttribute(new ObjectName(
"jboss.web:service=WebServer"), "HttpHeaderForSSOAuth");
}
/**
* Get the configured session cookie id in the tomcat service
*
* @return
* @throws JMException
*/
protected String getSessionCookieId() throws JMException {
if (this.sessionCookieForSSOAuth != null)
return this.sessionCookieForSSOAuth;
return (String) mserver.getAttribute(new ObjectName(
"jboss.web:service=WebServer"), "SessionCookieForSSOAuth");
}
/**
* Get the value of a cookie if the name matches the token
*
* @param cookies
* array of cookies
* @param numCookies
* number of cookies in the array
* @param token
* Key
* @return value of cookie
*/
protected String getCookieValue(Cookie[] cookies, int numCookies,
String token) {
for (int i = 0; i < numCookies; i++) {
Cookie cookie = cookies[i];
log.trace("Matching cookieToken:" + token + " with cookie name="
+ cookie.getName());
if (token.equals(cookie.getName())) {
if (trace)
log.trace("Cookie-" + token + " value=" + cookie.getValue());
return cookie.getValue();
}
}
return null;
}
}
14.3. Domaines de sécurité
14.3.1. Domaines de sécurité
ManagementRealmstocke les informations d'authentification pour l'API de gestion, qui fournit les fonctionnalités pour le Management CLI et la Console de gestion sur le web. Il fournit un système d'authentification pour gérer JBoss EAP 6 . Vous pouvez également utiliser leManagementRealmsi votre application a besoin des mêmes règles commerciales que vous utilisez pour l'API de gestion, lors de son authentification.ApplicationRealmstocke l'utilisateur, le mot de passe et les informations de rôle pour les applications Web et les EJB.
REALM-users.propertiesstocke les mots de passe et les mots de passe hachés.REALM-users.propertiesstocke les mappages user-to-role.
domain/configuration/ et standalone/configuration/. Les fichiers sont inscrits simultanément par la commande add-user.sh ou add-user.bat. Quand vous exécutez la commande, la première décision est de décider dans quel domaine ajouter votre premier utilisateur.
14.3.2. Ajout d'un domaine de sécurité
Exécuter le Management CLI
Démarrer par la commandejboss-cli.shoujboss-cli.batet connectez-vous au serveur.Créer le nouveau domaine de sécurité lui-même.
Exécutez la commande suivante pour créer un nouveau domaine de sécurité nomméMyDomainRealmsur un contrôleur de domaine ou sur un serveur autonome./host=master/core-service=management/security-realm=MyDomainRealm:add()
Créer les références du fichier de propriétés qui stocke les informations sur le nouveau rôle.
Exécuter la commande suivante pour créer un pointeur au fichier nommémyfile.properties, qui contiendra les propriétés attachées au nouveau rôle.Note
Le fichier de propriétés nouvellement créées n'est pas géré par les scriptsadd-user.shetadd-user.batinclus. Il devra être administré en externe./host=master/core-service=management/security-realm=MyDomainRealm/authentication=properties:add(path=myfile.properties)
Votre nouveau domaine de sécurité est créé. Lorsque vous ajoutez des utilisateurs et des rôles à ce nouveau domaine, l'information va être stockée dans un fichier séparé des domaines de sécurité par défaut. Vous pouvez gérer ce nouveau fichier à l'aide de vos propres applications ou procédures.
14.3.3. Ajout d'un utilisateur à un domaine de sécurité
Éxécuter la commande
add-user.shouadd-user.bat.Ouvrez un terminal (shell) et changez de répertoireEAP_HOME/bin/. Si vous exécutez Red Hat Enterprise Linux ou un autre système d'exploitation style UNIX, exécutezadd-user.sh. Si vous exécutez sur un serveur Microsoft Windows, exécutezadd-user.bat.Choisissez d'ajouter un utilisateur de gestion ou un utilisateur d'application.
Pour cette procédure, saisirbpour ajouter un utilisateur d'application.Choisir le domaine dans lequel l'utilisateur sera ajouté.
Par défaut, le seul domaine disponible estApplicationRealm. Si vous avez ajouté un domaine personnalisé, vous pouvez saisir son nom à la place.Saisir le nom d'utilisateur, le mot de passe et les rôles lorsque vous y serez invité.
Saisir le nom d'utilisateur, le mot de passe et les rôles lorsque vous y serez invité. Vérifiez votre choix en tapantyes, ounopour annuler les changements. Les changements sont inscrits dans les fichiers de propriétés du domaine de sécurité.
14.4. Sécurité des applications EJB
14.4.1. Identité Sécurité
14.4.1.1. L'identité de sécurité EJB
<security-identity> qui se trouve dans la configuration de la sécurité. Il s'agit d'une référence à l'identité qu'un autre EJB doit utiliser quand il invoque des méthodes ou des composants.
<use-caller-identity> sera présente, et dans le second cas, la balise <run-as> sera utilisée.
14.4.1.2. Définir l'identité de sécurité d'un EJB
Exemple 14.5. Définir l'identité de sécurité d'un EJB pour que ce soit la même que celle de l'appelant
<security-identity>.
<ejb-jar> <enterprise-beans> <session> <ejb-name>ASessionBean</ejb-name> <!-- ... --> <security-identity> <use-caller-identity/> </security-identity> </session> <!-- ... --> </enterprise-beans> </ejb-jar>
Exemple 14.6. Définir l'idendité de sécurité d'un EJB à un rôle spécifique
<run-as> et les balises <role-name> dans la balise <security-identity>.
<ejb-jar> <enterprise-beans> <session> <ejb-name>RunAsBean</ejb-name> <!-- ... --> <security-identity> <run-as> <description>A private internal role</description> <role-name>InternalRole</role-name> </run-as> </security-identity> </session> </enterprise-beans> <!-- ... --> </ejb-jar>
<run-as>, un principal nommé anonymous est assigné aux appels sortants. Pour assigner un autre principal, utiliser <run-as-principal>.
<session>
<ejb-name>RunAsBean</ejb-name>
<security-identity>
<run-as-principal>internal</run-as-principal>
</security-identity>
</session>
Note
<run-as> et <run-as-principal> à l'intérieur d'un élément de servlet.
Voir également :
14.4.2. Permissions de méthodes EJB
14.4.2.1. Permissions de méthodes EJB
<method-permisison>. Cette déclaration définit les rôles qui sont autorisés à appeler des méthodes de l'interface EJB. Vous pouvez définir des permissions pour les combinaisons suivantes :
- Toutes les méthodes d'interface de composant ou d'accueil de l'EJB nommé
- Une méthode spécifiée d'interface de composant ou d'accueil de l'EJB nommé
- Une méthode spécifiée à l'intérieur d'un ensemble de méthodes avec un nom surchargé
14.4.2.2. Utilisation des permissions de méthodes EJB
L'élément <method-permission> définit les roles logiques qui peuvent accéder aux méthodes EJB définies par les éléments <method>. Un certain nombre d'exemples expliquent la syntaxe XML. Plusieurs énoncés de method-permission peuvent être présents, et avoir un effet cumulatif. L'élément <method-permission> est un dépendant de l'élément <assembly-descriptor> du descripteur <ejb-jar>.
Exemple 14.7. Permet aux rôles d'accéder à toutes les méthodes d'un EJB
<method-permission>
<description>The employee and temp-employee roles may access any method
of the EmployeeService bean </description>
<role-name>employee</role-name>
<role-name>temp-employee</role-name>
<method>
<ejb-name>EmployeeService</ejb-name>
<method-name>*</method-name>
</method>
</method-permission>
Exemple 14.8. Permet aux rôles d'accéder uniquement à des méthodes spécifiques d'un EJB, et de déterminer quels paramètres de méthode peuvent être passés.
<method-permission> <description>The employee role may access the findByPrimaryKey, getEmployeeInfo, and the updateEmployeeInfo(String) method of the AcmePayroll bean </description> <role-name>employee</role-name> <method> <ejb-name>AcmePayroll</ejb-name> <method-name>findByPrimaryKey</method-name> </method> <method> <ejb-name>AcmePayroll</ejb-name> <method-name>getEmployeeInfo</method-name> </method> <method> <ejb-name>AcmePayroll</ejb-name> <method-name>updateEmployeeInfo</method-name> <method-params> <method-param>java.lang.String</method-param> </method-params> </method> </method-permission>
Exemple 14.9. Permet à n'importe quel utilisateur authentifié d'accéder aux méthodes des EJB
<unchecked/> permet à un utilisateur authentifié d'utiliser les méthodes spécifiées.
<method-permission> <description>Any authenticated user may access any method of the EmployeeServiceHelp bean</description> <unchecked/> <method> <ejb-name>EmployeeServiceHelp</ejb-name> <method-name>*</method-name> </method> </method-permission>
Exemple 14.10. Exclut totalement certaines méthodes EJB à l'utilisation
<exclude-list> <description>No fireTheCTO methods of the EmployeeFiring bean may be used in this deployment</description> <method> <ejb-name>EmployeeFiring</ejb-name> <method-name>fireTheCTO</method-name> </method> </exclude-list>
Exemple 14.11. Un <assembly-descriptor> complet contenant plusieurs blocs de <method-permission>
<ejb-jar>
<assembly-descriptor>
<method-permission>
<description>The employee and temp-employee roles may access any
method of the EmployeeService bean </description>
<role-name>employee</role-name>
<role-name>temp-employee</role-name>
<method>
<ejb-name>EmployeeService</ejb-name>
<method-name>*</method-name>
</method>
</method-permission>
<method-permission>
<description>The employee role may access the findByPrimaryKey,
getEmployeeInfo, and the updateEmployeeInfo(String) method of
the AcmePayroll bean </description>
<role-name>employee</role-name>
<method>
<ejb-name>AcmePayroll</ejb-name>
<method-name>findByPrimaryKey</method-name>
</method>
<method>
<ejb-name>AcmePayroll</ejb-name>
<method-name>getEmployeeInfo</method-name>
</method>
<method>
<ejb-name>AcmePayroll</ejb-name>
<method-name>updateEmployeeInfo</method-name>
<method-params>
<method-param>java.lang.String</method-param>
</method-params>
</method>
</method-permission>
<method-permission>
<description>The admin role may access any method of the
EmployeeServiceAdmin bean </description>
<role-name>admin</role-name>
<method>
<ejb-name>EmployeeServiceAdmin</ejb-name>
<method-name>*</method-name>
</method>
</method-permission>
<method-permission>
<description>Any authenticated user may access any method of the
EmployeeServiceHelp bean</description>
<unchecked/>
<method>
<ejb-name>EmployeeServiceHelp</ejb-name>
<method-name>*</method-name>
</method>
</method-permission>
<exclude-list>
<description>No fireTheCTO methods of the EmployeeFiring bean may be
used in this deployment</description>
<method>
<ejb-name>EmployeeFiring</ejb-name>
<method-name>fireTheCTO</method-name>
</method>
</exclude-list>
</assembly-descriptor>
</ejb-jar>
14.4.3. Annotations de sécurité EJB
14.4.3.1. Les annotations de sécurité EJB
- @DeclareRoles
- Déclare quels rôles sont disponibles.
- @RolesAllowed, @PermitAll, @DenyAll
- Indique quelles permissions de méthodes sont autorisées. Pour obtenir des informations sur les permissions de méthode, voir Section 14.4.2.1, « Permissions de méthodes EJB ».
- @RunAs
- Configure l'identification de sécurité propagée d'un composant.
14.4.3.2. Utilisation des annotations de sécurité EJB
Vous pouvez utiliser deux descripteurs XML ou des annotations pour contrôler quels rôles de sécurité sont en mesure d'appeler des méthodes dans votre Enterprise JavaBeans (EJB). Pour plus d'informations sur l'utilisation des descripteurs XML, reportez-vous à Section 14.4.2.2, « Utilisation des permissions de méthodes EJB ».
Annotations pour contrôler les permissions de sécurité des EJB
- @DeclareRoles
- Utiliser @DeclareRoles pour déterminer sur quels rôles de sécurité vérifier les permissions. Si aucun @DeclareRoles n'est présent, la liste sera édifié automatiquement à partir de l'annotation @RolesAllowed.
- @SecurityDomain
- Indique le domaine de sécurité à utiliser pour l'EJB. Si l'EJB est annoté pour autorisation avec
@RolesAllowed, l'autorisation ne s'appliquera que si l'EJB est annoté par un domaine de sécurité. - @RolesAllowed, @PermitAll, @DenyAll
- Utiliser @RolesAllowed pour lister les rôles autorisés pour accéder à une méthode ou à des méthodes. Utiliser @PermitAll ou @DenyAll pour permettre ou refuser à tous les roles d'utiliser une méthode ou des méthodes.
- @RunAs
- Utiliser @RunAs pour spécifier un rôle permanent pour une méthode.
Exemple 14.12. Exemple d'annotations de sécurité
@Stateless
@RolesAllowed({"admin"})
@SecurityDomain("other")
public class WelcomeEJB implements Welcome {
@PermitAll
public String WelcomeEveryone(String msg) {
return "Welcome to " + msg;
}
@RunAs("tempemployee")
public String GoodBye(String msg) {
return "Goodbye, " + msg;
}
public String GoodbyeAdmin(String msg) {
return "See you later, " + msg;
}
}
WelcomeEveryone. La méthode GoodBye exécute sous la forme du rôle tempemployee pour les appels. Seul le rôle admin peut accéder à la méthode GoodbyeAdmin, ou à toute autre méthode sans annotation de sécurité.
14.4.4. Accès à distance aux EJB
14.4.4.1. Remote Method Access
Types de services pris en charge
- Socket / Secure Socket
- RMI / RMI sur SSL
- HTTP / HTTPS
- Servlet / Secure Servlet
- Bisocket / Secure Bisocket
Le système Remoting d'accès distant fournit également des services de marshalling et unmarshalling de données. Le marshaling de données désigne la capacité de déplacer en toute sécurité des données au-delà des limites de réseau et de la plate-forme, afin qu'un système séparé puisse effectuer des tâches dessus. Le travail est ensuite renvoyé vers le système d'origine et se comporte comme s'il avait eu lieu localement.
Lorsque vous créez une application cliente qui utilise Remoting, vous indiquez à votre application de communiquer avec le serveur en la configurant pour qu'elle utilise un type spécial de localisateur de ressources appelé un InvokerLocator, qui est une chaîne simple avec un format de type URL. Le serveur écoute les requêtes des ressources distantes sur un connecteur, qui est configuré comme faisant partie du sous-système remoting. Le connecteur transmet la demande à un ServerInvocationHandler configuré. Chaque ServerInvocationHandler implémente une méthode invoke(InvocationRequest) qui sait comment gérer la demande.
Couches de framework JBoss Remoting
- L'utilisateur interagit avec la couche externe. Côté client, la couche externe est la classe
Client, qui envoie des requêtes d'invocation. Côté serveur, c'est InvocationHandler, mis en œuvre par l'utilisateur, qui reçoit des demandes d'invocation. - Le transport est contrôlé par la couche d'invocateur.
- La couche inférieure contient le marshaller et le unmarshaller, qui convertit les formats de données en formats de transmission.
14.4.4.2. Remoting Callbacks
InvocationRequest au client. Votre code côté serveur fonctionne de la même façon que le rappel soit synchrone ou asynchrone. Seul le client a besoin de connaître la différence. InvocationRequest du serveur envoie un responseObject au client. Il s'agit de la charge que le client a demandé. C'est peut-être une réponse directe à une demande ou à une notification d'événement.
m_listeners. Il contient une liste de tous les listeners qui ont été ajoutés à votre server handler. L'interface du ServerInvocationHandler inclut des méthodes qui vous permettent de gérer cette liste.
org.jboss.remoting.InvokerCallbackHandler, qui traite les données de callback. Après l'implémentation du callback handler, soit vous vous ajoutez vous-même, en tant que listener de «pull callback», ou bien, vous installez un serveur de callbacks pour un «push callback».
Pour un «pull callback», votre client s'ajoute à la liste du serveur des listeners à l'aide de la méthode Client.addListener(). Ensuite, il interroge le serveur périodiquement au sujet de l'exécution synchrone des données de callback. Ce sondage est effectué à l'aide de Client.getCallbacks().
Un «push callback» requiert que votre application cliente exécute elle-même son propre InvocationHandler. Pour ce faire, vous devez exécuter un service Remoting sur le client lui-même. Ceci s'appelle un callback server. Le callback server accepte les requêtes entrantes de façon asynchrone et les traite pour l'auteur de la demande (dans ce cas, le serveur). Pour inscrire le callback server de votre client avec le serveur principal, passez l'argument InvokerLocator du callback server comme deuxième argument à la méthode addListener.
14.4.4.3. Remoting Server Detection
14.4.4.4. Configurer le sous-système de JBoss Remoting
JBoss Remoting a trois éléments configurables de niveau supérieur : le pool de worker threads, un ou plusieurs connecteurs et une série de lien URI locaux et distants. Cette rubrique propose une explication pour chaque élément configurable, des exemples de commandes CLI pour savoir comment configurer chaque élément et un exemple XML d'un sous-système entièrement configuré. Cette configuration s'applique uniquement au serveur. La plupart des gens n'auront pas à configurer le sous-système de communication à distance, sauf s'ils utilisent des connecteurs personnalisés pour leurs propres applications. Les applications qui agissent comme des clients Remoting, comme les EJB, nécessitent une configuration distincte pour se connecter à un connecteur spécifique.
Note
Les commandes CLI sont formulées pour un domaine géré, lorsque vous configurez le profil par défaut. Pour configurer un profil différent, changez-en le nom. Pour un serveur autonome, omettre la section /profile=default de la commande.
Il y a un certain nombre d'aspects de configuration qui sont en dehors du sous-système remoting :
- Network Interface
- L'interface de réseau qui est utilisée par le sous-système
remotingest l'interfaceunsecuredéfinie dansdomain/configuration/domain.xmlou dansstandalone/configuration/standalone.xml.<interfaces> <interface name="management"/> <interface name="public"/> <interface name="unsecure"/> </interfaces>La définition par-hôte de l'interfaceunsecureest définie danshost.xmldans le même répertoire quedomain.xmloustandalone.xml. Cette interface est également utilisée par plusieurs autres sous-systèmes. Soyez vigilants quand vous la modifierez.<interfaces> <interface name="management"> <inet-address value="${jboss.bind.address.management:127.0.0.1}"/> </interface> <interface name="public"> <inet-address value="${jboss.bind.address:127.0.0.1}"/> </interface> <interface name="unsecure"> <!-- Used for IIOP sockets in the standard configuration. To secure JacORB you need to setup SSL --> <inet-address value="${jboss.bind.address.unsecure:127.0.0.1}"/> </interface> </interfaces> - socket-binding
- La liaison-socket par défaut utilisée par le sous-système
remotingse lie au port TCP 4777. Reportez-vous à la documentation sur les liaisons de socket et de groupes de liaisons de socket pour plus d'informations si vous avez besoin de procéder à une modification. - Remoting Connector Reference pour EJB
- Le sous-système EJB contient une référence vers le connecteur à distance pour les invocations de méthodes à distance. Voici la configuration par défaut :
<remote connector-ref="remoting-connector" thread-pool-name="default"/> - Configuration du transport sécurisé
- Les transports à distance (Remoting) utilisent StartTLS pour avoir une connexion sécurisée (HTTPS, Secure Servlet, etc.) si le client le demande. La même liaison de socket (port réseau) est utilisée pour les connexions sécurisées et non sécurisées, donc aucune configuration côté serveur supplémentaire n'est nécessaire. Le client demande le transport sécurisé ou non sécurisé, tel que le dictent ses besoins. Les composants JBoss EAP 6 qui utilisent Remoting, tels que les fournisseur JMS, EJB et ORB exigent des interfaces sécurisées par défaut.
Avertissement
Un Worker Thread Pool est un ensemble de threads qui peuvent traiter les tâches qui arrivent par les connecteurs Remoting. Il s'agit d'un seul élément <worker-thread-pool>, et nécessite un certain nombre d'attributs. Régler ces attributs si vous avez des timeouts de réseau, ou si vous devez limiter l'utilisation de la mémoire. Les conseils varient suivant la situation dans laquelle vous vous trouvez. Contacter Red Hat Global Support Services pour obtenir davantage d'informations.
Tableau 14.2. Attributs de Worker Thread Pool
| Attribut | Description | Commande CLI |
|---|---|---|
| read-threads |
Le nombre de read-threads à créer pour le worker à distance. La valeur par défaut est
1.
| /profile=default/subsystem=remoting/:write-attribute(name=worker-read-threads,value=1)
|
| write-threads |
Le nombre de write-threads à créer pour le worker à distance. La valeur par défaut est
1.
| /profile=default/subsystem=remoting/:write-attribute(name=worker-write-threads,value=1)
|
| task-keepalive |
Le nombre de millisecondes pour conserver les threads de tâche de workers à distance non-core vivants. La valeur par défaut est
60.
| /profile=default/subsystem=remoting/:write-attribute(name=worker-task-keepalive,value=60)
|
| task-max-threads |
Le nombre de maximum de threads pour le Worker Task Thread Pool distant. La valeur par défaut est
60.
| /profile=default/subsystem=remoting/:write-attribute(name=worker-task-max-threads,value=16)
|
| task-core-threads |
Le nombre de threads principaux pour le Worker Task Thread Pool distant. La valeur par défaut est
4.
| /profile=default/subsystem=remoting/:write-attribute(name=worker-task-core-threads,value=4)
|
| task-limit |
Le nombre de maximum de tâches de worker distantes. La valeur par défaut est
16384.
| /profile=default/subsystem=remoting/:write-attribute(name=worker-task-limit,value=16384)
|
Le connecteur est le principal élément de configuration de Remoting (d'accès à distance). Les connecteurs multiples sont autorisés. Chacun se compose d'un élément <connector> avec plusieurs sous-éléments, ainsi que quelques attributs possibles. Le connecteur par défaut est utilisé par plusieurs sous-systèmes de JBoss EAP 6. Des paramètres spécifiques pour les éléments et les attributs de vos connecteurs personnalisés dépendent de vos applications, donc contactez Red Hat Global Support Services pour plus d'informations.
Tableau 14.3. Attributs de connecteur
| Attribut | Description | Commande CLI |
|---|---|---|
| socket-binding | Le nom de la liaison de socket à utiliser pour ce connecteur. | /profile=default/subsystem=remoting/connector=remoting-connector/:write-attribute(name=socket-binding,value=remoting)
|
| authentication-provider |
Le module JASPIC (de l'anglais Java Authentication Service Provider Interface for Containers) à utiliser avec ce connecteur. Le module doit être dans le chemin de classes.
| /profile=default/subsystem=remoting/connector=remoting-connector/:write-attribute(name=authentication-provider,value=myProvider)
|
| security-realm |
En option. Le domaine de la sécurité qui contient les utilisateurs, mots de passe et les rôles de votre application. Un EJB ou une Application Web peut authentifier sur un domaine de sécurité.
ApplicationRealm est disponible dans une installation de JBoss EAP 6 par défaut.
| /profile=default/subsystem=remoting/connector=remoting-connector/:write-attribute(name=security-realm,value=ApplicationRealm)
|
Tableau 14.4. Éléments de connecteur
| Attribut | Description | Commande CLI |
|---|---|---|
| sasl |
Élément englobant des mécanismes d'authentification SASL (Simple Authentication and Security Layer)
| N/A
|
| propriétés |
Contient un ou plusieurs éléments
<property>, contenant chacun un attribut name et un attribut value optionnel.
| /profile=default/subsystem=remoting/connector=remoting-connector/property=myProp/:add(value=myPropValue)
|
Vous pouvez spécifier trois types différents d'attribut de connexion sortante :
- Connexion sortante vers un URI.
- Connexion sortante locale – se connectant à une ressource locale, comme un socket.
- Connexion sortante à distance – se connectant à une ressource à distance et s'authentifiant par l'intermédiaire d'un domaine de sécurité.
<outbound-connections>. Chacun de ces types de connexion prend un attribut outbound-socket-binding-ref. La connexion sortante-prend un attribut uri. La connexion sortante à prend les attributs facultatifs username (nom d'utilisateur) et security-realm (domaine de sécurité) à utiliser pour l'autorisation.
Tableau 14.5. Éléments de connexion sortante
| Attribut | Description | Commande CLI |
|---|---|---|
| outbound-connection | Connexion sortante standard | /profile=default/subsystem=remoting/outbound-connection=my-connection/:add(uri=http://my-connection)
|
| local-outbound-connection | Connexion sortante en schéma implicite local:// URI. | /profile=default/subsystem=remoting/local-outbound-connection=my-connection/:add(outbound-socket-binding-ref=remoting2)
|
| remote-outbound-connection |
Connexions sortantes en schéma remote:// URI, utilisant l'authentification de base/digest avec domaine de sécurité.
| /profile=default/subsystem=remoting/remote-outbound-connection=my-connection/:add(outbound-socket-binding-ref=remoting,username=myUser,security-realm=ApplicationRealm)
|
Avant de définir des éléments enfants SASL, vous devez créer l'élément SASL initial. Utiliser la commande suivante :
/profile=default/subsystem=remoting/connector=remoting-connector/security=sasl:add
| Attribut | Description | Commande CLI |
|---|---|---|
| include-mechanisms |
Contient un attribut
value, qui correspond à une liste de mécanismes SASL séparés par des espaces.
|
/profile=default/subsystem=remoting/connector=remoting-connector/security=sasl:write-attribute(name=include-mechanisms,value=["DIGEST","PLAIN","GSSAPI"]) |
| qop |
Contient un attribut
value, qui correspond à une liste de valeurs de protection SASL séparées par des espaces, en ordre décroissant de préférence.
|
/profile=default/subsystem=remoting/connector=remoting-connector/security=sasl:write-attribute(name=qop,value=["auth"]) |
| puissance |
Contient un attribut
value, qui correspond à une liste de valeurs de puissance cipher SASL séparées par des espaces, en ordre décroissant de préférence.
|
/profile=default/subsystem=remoting/connector=remoting-connector/security=sasl:write-attribute(name=strength,value=["medium"]) |
| reuse-session |
Contient un attribut
value, qui correspond à une valeur booléenne. Si sur true, tente de réutiliser les sessions.
|
/profile=default/subsystem=remoting/connector=remoting-connector/security=sasl:write-attribute(name=reuse-session,value=false) |
| server-auth |
Contient un attribut
value, qui correspond à une valeur booléenne. Si sur true, le serveur s'authentifie auprès du client.
|
/profile=default/subsystem=remoting/connector=remoting-connector/security=sasl:write-attribute(name=server-auth,value=false) |
| politique |
Un élément clôturé qui contient zéro ou plusieurs des éléments suivants, prenant chacun une seule
valeur.
|
/profile=default/subsystem=remoting/connector=remoting-connector/security=sasl/sasl-policy=policy:add /profile=default/subsystem=remoting/connector=remoting-connector/security=sasl/sasl-policy=policy:write-attribute(name=forward-secrecy,value=true) /profile=default/subsystem=remoting/connector=remoting-connector/security=sasl/sasl-policy=policy:write-attribute(name=no-active,value=false) /profile=default/subsystem=remoting/connector=remoting-connector/security=sasl/sasl-policy=policy:write-attribute(name=no-anonymous,value=false) /profile=default/subsystem=remoting/connector=remoting-connector/security=sasl/sasl-policy=policy:write-attribute(name=no-dictionary,value=true) /profile=default/subsystem=remoting/connector=remoting-connector/security=sasl/sasl-policy=policy:write-attribute(name=no-plain-text,value=false) /profile=default/subsystem=remoting/connector=remoting-connector/security=sasl/sasl-policy=policy:write-attribute(name=pass-credentials,value=true) |
| propriétés |
Contient un ou plusieurs éléments
<property>, contenant chacun un attribut name et un attribut value optionnel.
|
/profile=default/subsystem=remoting/connector=remoting-connector/security=sasl/property=myprop:add(value=1) /profile=default/subsystem=remoting/connector=remoting-connector/security=sasl/property=myprop2:add(value=2) |
Exemple 14.13. Exemples de configurations
<subsystem xmlns="urn:jboss:domain:remoting:1.1">
<connector name="remoting-connector" socket-binding="remoting" security-realm="ApplicationRealm"/>
</subsystem>
<subsystem xmlns="urn:jboss:domain:remoting:1.1">
<worker-thread-pool read-threads="1" task-keepalive="60' task-max-threads="16" task-core-thread="4" task-limit="16384" write-threads="1" />
<connector name="remoting-connector" socket-binding="remoting" security-realm="ApplicationRealm">
<sasl>
<include-mechanisms value="GSSAPI PLAIN DIGEST-MD5" />
<qop value="auth" />
<strength value="medium" />
<reuse-session value="false" />
<server-auth value="false" />
<policy>
<forward-secrecy value="true" />
<no-active value="false" />
<no-anonymous value="false" />
<no-dictionary value="true" />
<no-plain-text value="false" />
<pass-credentials value="true" />
</policy>
<properties>
<property name="myprop1" value="1" />
<property name="myprop2" value="2" />
</properties>
</sasl>
<authentication-provider name="myprovider" />
<properties>
<property name="myprop3" value="propValue" />
</properties>
</connector>
<outbound-connections>
<outbound-connection name="my-outbound-connection" uri="http://myhost:7777/"/>
<remote-outbound-connection name="my-remote-connection" outbound-socket-binding-ref="my-remote-socket" username="myUser" security-realm="ApplicationRealm"/>
<local-outbound-connection name="myLocalConnection" outbound-socket-binding-ref="my-outbound-socket"/>
</outbound-connections>
</subsystem>
Aspects de la configuration non encore documentés
- JNDI et Détection automatique multi diffusion
14.4.4.5. Utilisation des domaines de sécurité avec les clients EJB distants
- Ajouter un nouveau domaine de sécurité au contrôleur de domaine ou au serveur autonome.
- Ajoutez les paramètres suivants au fichier
jboss-ejb-client.properties, qui est dans le chemin de classes de l'application. Cet exemple suppose que la connexion est appeléepar défautpar les autres paramètres qui se trouvent dans le fichier.remote.connection.default.username=appuser remote.connection.default.password=apppassword
- Créer un connecteur Remoting personnalisé sur le domaine ou sur le serveur autonome qui utilise le nouveau domaine de sécurité.
- Déployer votre EJB dans le groupe de serveur configuré pour utiliser le profil avec le connecteur Remoting personnalisé, ou dans le serveur autonome si vous n'utilisez pas de domaine géré.
14.4.4.6. Ajout d'un domaine de sécurité
Exécuter le Management CLI
Démarrer par la commandejboss-cli.shoujboss-cli.batet connectez-vous au serveur.Créer le nouveau domaine de sécurité lui-même.
Exécutez la commande suivante pour créer un nouveau domaine de sécurité nomméMyDomainRealmsur un contrôleur de domaine ou sur un serveur autonome./host=master/core-service=management/security-realm=MyDomainRealm:add()
Créer les références du fichier de propriétés qui stocke les informations sur le nouveau rôle.
Exécuter la commande suivante pour créer un pointeur au fichier nommémyfile.properties, qui contiendra les propriétés attachées au nouveau rôle.Note
Le fichier de propriétés nouvellement créées n'est pas géré par les scriptsadd-user.shetadd-user.batinclus. Il devra être administré en externe./host=master/core-service=management/security-realm=MyDomainRealm/authentication=properties:add(path=myfile.properties)
Votre nouveau domaine de sécurité est créé. Lorsque vous ajoutez des utilisateurs et des rôles à ce nouveau domaine, l'information va être stockée dans un fichier séparé des domaines de sécurité par défaut. Vous pouvez gérer ce nouveau fichier à l'aide de vos propres applications ou procédures.
14.4.4.7. Ajout d'un utilisateur à un domaine de sécurité
Éxécuter la commande
add-user.shouadd-user.bat.Ouvrez un terminal (shell) et changez de répertoireEAP_HOME/bin/. Si vous exécutez Red Hat Enterprise Linux ou un autre système d'exploitation style UNIX, exécutezadd-user.sh. Si vous exécutez sur un serveur Microsoft Windows, exécutezadd-user.bat.Choisissez d'ajouter un utilisateur de gestion ou un utilisateur d'application.
Pour cette procédure, saisirbpour ajouter un utilisateur d'application.Choisir le domaine dans lequel l'utilisateur sera ajouté.
Par défaut, le seul domaine disponible estApplicationRealm. Si vous avez ajouté un domaine personnalisé, vous pouvez saisir son nom à la place.Saisir le nom d'utilisateur, le mot de passe et les rôles lorsque vous y serez invité.
Saisir le nom d'utilisateur, le mot de passe et les rôles lorsque vous y serez invité. Vérifiez votre choix en tapantyes, ounopour annuler les changements. Les changements sont inscrits dans les fichiers de propriétés du domaine de sécurité.
14.4.4.8. Accès EJB à distance utilisant le cryptage SSL
14.5. Sécurité Application JAX-RS
14.5.1. Activer la sécurité basée-rôle pour RESTEasy JAX-RS Web Service
RESTEasy supporte les annotations @RolesAllowed, @PermitAll, et @DenyAll sur les méthodes JAX-RS. Cependant, il ne reconnaît pas ces annotations par défaut. Suivre les étapes suivantes pour configurer le fichier web.xml et pour activer la sécurité basée-rôle.
Avertissement
Procédure 14.3. Activer la sécurité basée-rôle pour RESTEasy JAX-RS Web Service
- Ouvrir le fichier
web.xmlde l'application dans l'éditeur de textes. - Ajouter le <context-param> suivant au fichier, dans les balises
web-app:<context-param> <param-name>resteasy.role.based.security</param-name> <param-value>true</param-value> </context-param> - Déclarer tous les rôles utilisés dans le fichier RESTEasy JAX-RS WAR file, en utilisant les balises de <security-role>:
<security-role><role-name>ROLE_NAME</role-name></security-role><security-role><role-name>ROLE_NAME</role-name></security-role> - Autorise l'accès à tous les URL gérés par le runtime JAX-RS pour tous les rôles :
<security-constraint><web-resource-collection><web-resource-name>Resteasy</web-resource-name><url-pattern>/PATH</url-pattern></web-resource-collection><auth-constraint><role-name>ROLE_NAME</role-name><role-name>ROLE_NAME</role-name></auth-constraint></security-constraint>
La sécurité basée rôle à été activée dans l'application, avec un certain nombre de rôles définis.
Exemple 14.14. Exemple de configuration de sécurité basée rôles
<web-app>
<context-param>
<param-name>resteasy.role.based.security</param-name>
<param-value>true</param-value>
</context-param>
<servlet-mapping>
<servlet-name>Resteasy</servlet-name>
<url-pattern>/*</url-pattern>
</servlet-mapping>
<security-constraint>
<web-resource-collection>
<web-resource-name>Resteasy</web-resource-name>
<url-pattern>/security</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>admin</role-name>
<role-name>user</role-name>
</auth-constraint>
</security-constraint>
<security-role>
<role-name>admin</role-name>
</security-role>
<security-role>
<role-name>user</role-name>
</security-role>
</web-app>
14.5.2. Sécuriser un service JAX-RS Web par des annotations
Cette rubrique couvre les étapes à parcourir pour sécuriser un service JAX-RS Web par les annotations de sécurité supportées.
Procédure 14.4. Sécuriser un service JAX-RS Web par des annotations de sécurité supportées.
- Activer la sécurité basée-rôle. Pour plus d'informations, voir Section 14.5.1, « Activer la sécurité basée-rôle pour RESTEasy JAX-RS Web Service ».
- Ajouter des annotations de sécurité au service JAX-RS Web. RESTEasy supporte les annotations suivantes :
- @RolesAllowed
- Définit les rôles qui peuvent accéder à la méthode. Tous les rôles doivent être définis dans le fichier
web.xml. - @PermitAll
- Autorise tous les rôles définis dans le fichier
web.xmlà accéder à la méthode. - @DenyAll
- Refuse tout accès à la méthode.
14.6. Protocole mots de passes distants sécurisés
14.6.1. Protocole pour mots de passes distants sécurisés (SRP pour Secure Remote Password)
Ce document décrit un mécanisme d'authentification de réseau à cryptage puissant connu comme le nom de protocole SRP (Secure Remote Password). Ce mécanisme est approprié pour négocier des connexions sécurisées avec un mot de passe fourni par l'utilisateur, tout en éliminant les problèmes de sécurité traditionnellement associés à des mots de passe réutilisables. Ce système effectue également un échange de clés sécurisée dans le processus d'authentification, ce qui permet à ce que des couches de sécurité (protection de la vie privée et/ou de l'intégrité) soient activées lors de la session. Il n'est nul besoin de serveurs de clés de confiance ou d'infrastructures de certificats, et les clients ne sont pas tenus de stocker ou de gérer des clés à long terme. SRP offre des avantages tant au niveau de la sécurité qu'au niveau déploiement sur les techniques existantes de stimulation / réponse, ce qui en fait un remplacement idéal pour les besoins d'authentification de mots de passe sécurisés.
14.6.2. Configuration du protocole SRP (Secure Remote Password)
SRPVerifierStore. Vous trouverez des informations sur l'implémentation à Implémentation SRPVerifierStore.
Procédure 14.5. Intégrer le store de mots de passe existant
Créer un store d'informations de mots de passe hachés.
Si vos mots de passe sont déjà stockés sous une forme hachée irréversible, vous aurez besoin de faire cela sur la base utilisateur.Vous pouvez implémenter unsetUserVerifier(String, VerifierInfo)en tant que méthode noOp, ou d'une méthode qui envoie une exception signifiant que le store est en lecture-seule.Créer l'interface SRPVerifierStore.
Créer une implémentation d'interfaceSRPVerifierStorepersonnalisée qui puisse obtenirVerifierInfodu store que vous avez créé.LeverifyUserChallenge(String, Object)peut servir à intégrer des schémas basés token de matériel existant comme SafeWord ou Radius dans l'algorithme SRP. Cette méthode d'interface est appelée uniquement lorsque la configuration SRPLoginModule du client spécifie l'option hasAuxChallenge.Créer le MBean JNDI.
Créer un MBean qui expose l'interfaceSRPVerifierStoredisponible à JNDI, et expose tous les paramètres configurables requis.Le serviceorg.jboss.security.srp.SRPVerifierStoreServicepar défaut vous permet d'implémenter ceci. Vous pouvez également implémenter le MBean par une implémentation de fichier de propriétés Java duSRPVerifierStore.
L'implémentation par défaut de l'interface SRPVerifierStore n'est pas recommandée pour les systèmes de production, car elle exige que toutes les informations de hachage de mot de passe soient disponibles sous forme de fichier d'objets sérialisés.
SRPVerifierStore fournit un accès à l'objet SRPVerifierStore.VerifierInfo pour un nom d'utilisateur donné. La méthode getUserVerifier(String) est appelée par le SRPService au départ d'une session SRP utilisateur pour obtenir les paramètres requis par l'algorithme SRP.
Éléments d'un Objet VerifierInfo
- nom d'utilisateur
- Le nom d'utilisateur ou l'ID utilisateur pour s'authentifier
- verifier
- Un hachage unidirectionnel du mot de passe que l'utilisateur saisit comme preuve d'identité. La classe
org.jboss.security.Utilinclut une méthodecalculateVerifierqui exécute l'algorithme de hachage de mot de passe. Le mot de passe de sortie prend la formeH(salt | H(username | password)), oùHest la fonction de hachage sécurisée SHA, telle que définie par RFC2945. Le nom d'utilisateur est converti d'une chaîne en un byte [] en utilisant le codage UTF-8. - salt
- Un nombre aléatoire utilisé pour augmenter la difficulté d'une attaque de force brute de dictionnaire sur la base de données de mot de passe de vérification dans le cas où la base de données soit compromise. La valeur doit être générée à partir d'un algorithme de cryptage fort composé de nombres aléatoires lorsque le mot de passe en texte clair existant de l'utilisateur est haché.
- g
- Le générateur primitif d'algorithme SRP. Cela peut être un paramètre fixe bien connu plutôt qu'un paramètre par utilisateur. La classe d'utilitaire de
org.jboss.security.srp.SRPConffournit plusieurs paramètres pourg, avec une valeur par défaut appropriée obtenue par l'intermédiaire deSRPConf.getDefaultParams().g(). - N
- SRP algorithm safe-prime modulus. Cela peut être un paramètre fixe bien connu, plutôt qu'un paramètre par utilisateur. La classe d'utilitaire de
org.jboss.security.srp.SRPConffournit plusieurs paramètres pour «N», y compris un bon nombre de valeurs par défaut obtenues viaSRPConf.getDefaultParams().N().
Exemple 14.15. L'interface SRPVerifierStore
package org.jboss.security.srp;
import java.io.IOException;
import java.io.Serializable;
import java.security.KeyException;
public interface SRPVerifierStore
{
public static class VerifierInfo implements Serializable
{
public String username;
public byte[] salt;
public byte[] g;
public byte[] N;
}
public VerifierInfo getUserVerifier(String username)
throws KeyException, IOException;
public void setUserVerifier(String username, VerifierInfo info)
throws IOException;
public void verifyUserChallenge(String username, Object auxChallenge)
throws SecurityException;
}
14.7. L'archivage sécurisé des mots de passe pour les strings de nature confidentielle
14.7.1. Sécurisation des chaînes confidentielles des fichiers en texte clair
Avertissement
java.io.IOException: com.sun.crypto.provider.SealedObjectForKeyProtector
14.7.2. Créer un Keystore Java pour stocker des strings sensibles
Prérequis
- La commande
keytooldoit être disponible. Elle est fournie par le Java Runtime Environment (JRE). Chercher le chemin du fichier. Se trouve à l'emplacement suivant/usr/bin/keytooldans Red Hat Enterprise Linux.
Procédure 14.6. Installation du Java Keystore
Créer un répertoire pour stocker votre keystore et autres informations cryptées.
Créer un répertoire qui contiendra votre keystore et autres informations pertinentes. Le reste de cette procédure assume que le répertoire est/home/USER/vault/.Déterminer les paramètres à utiliser avec
keytool.Déterminer les paramètres suivants :- alias
- L'alias est un identificateur unique pour l'archivage sécurisé ou autres données stockées dans le keystore. L'alias dans l'exemple de commande à la fin de cette procédure est
vault(archivage sécurisé). Les alias sont insensibles à la casse. - keyalg
- L'algorithme à utiliser pour le cryptage. Dans cette procédure, l'exemple utilise
RSA. Consultez la documentation de votre JRE et de votre système d'exploitation pour étudier vos possibilités. - keysize
- La taille d'une clé de cryptage impacte sur la difficulté de décrypter au seul moyen de la force brutale. Dans cette procédure, l'exemple utilise
1024. Pour plus d'informations sur les valeurs appropriées, voir la documentation distribuée aveckeytool. - keystore
- Le keystore est une base de données qui contient des informations chiffrées et des informations sur la façon de déchiffrer. Si vous ne spécifiez pas de keystore, le keystore par défaut à utiliser est un fichier appelé
.keystoredans votre répertoire personnel. La première fois que vous ajoutez des données dans un keystore, il sera créé. L'exemple de cette procédure utilise le keystorevault.keystore.
La commande dukeytoola plusieurs options. Consulter la documentation de votre JRE ou de votre système d'exploitation pour obtenir plus d'informations.Détermine les réponses aux questions que la commande
keystorevous demandera.Lekeystorea besoin des informations suivantes pour remplir l'entrée du keytore :- Mot de passe du keystore
- Lorsque vous créez un keystore, vous devez définir un mot de passe. Pour pouvoir travailler dans keystore dans le futur, vous devez fournir le mot de passe. Créer un mot de passe dont vous vous souviendrez. Le keystore est sécurisé par son mot de passe et par la sécurité du système d'exploitation et du système de fichiers où il se trouve.
- Mot de passe clé (en option)
- En plus du mot de passe du keystore, vous pouvez indiquer un mot de passe pour chaque clé contenue. Pour utiliser une clé, le mot de passe doit être donné à chaque utilisation. Normalement, cette fonction n'est pas utilisée.
- Prénom et nom de famille
- Cela, ainsi que le reste de l'information dans la liste, aide à identifier la clé de façon unique et à la placer dans une hiérarchie par rapport aux autres clés. Il ne doit pas nécessairement correspondre à un nom, mais doit être composé de deux mots et doit être unique à une clé. L'exemple dans cette procédure utilise
Admninistrateur Comptabilité. En terme de répertoires, cela devient le nom commun du certificat. - Unité organisationnelle
- Il s'agit d'un mot unique d'identification qui utilise le certificat. Il se peut que ce soit l'application ou l'unité commerciale. L'exemple de cette procédure utilise
enterprise_application_platform. Normalement, tous les keystores utilisés par un groupe ou une application utilisent la même unité organisationnelle. - Organisation
- Il s'agit normalement d'une représentation de votre nom d'organisation en un seul mot. Demeure constant à travers tous les certificats qui sont utilisés par une organisation. Cet exemple utilise
MyOrganization. - Ville ou municipalité
- Votre ville.
- État ou province
- Votre état ou province, ou l'équivalent pour votre localité.
- Pays
- Le code pays en deux lettres.
Ces informations vont créer ensemble une hiérarchie de vos keystores et certificats, qui garantira qu'ils utilisent une structure de nommage consistante, et unique.Exécuter la commande
keytool, en fournissant les informations que vous avez collectées.Exemple 14.16. Exemple d'entrée et de sortie de la commande
keystore$ keytool -genseckey -alias vault -storetype jceks -keyalg AES -keysize 128 -storepass vault22 -keypass vault22 -keystore /home/USER/vault/vault.keystore Enter keystore password: vault22 Re-enter new password:vault22 What is your first and last name? [Unknown]:
Accounting AdministratorWhat is the name of your organizational unit? [Unknown]:AccountingServicesWhat is the name of your organization? [Unknown]:MyOrganizationWhat is the name of your City or Locality? [Unknown]:RaleighWhat is the name of your State or Province? [Unknown]:NCWhat is the two-letter country code for this unit? [Unknown]:USIs CN=Accounting Administrator, OU=AccountingServices, O=MyOrganization, L=Raleigh, ST=NC, C=US correct? [no]:yesEnter key password for <vault> (RETURN if same as keystore password):
Un fichier nommé vault.keystore est créé dans le répertoire /home/USER/vault/. Il stocke une clé simple, nommée vault, qui sera utilisée pour stocker des strings cryptés, comme des mots de passe, pour la plateforme JBoss EAP 6.
14.7.3. Masquer le mot de passe du keystore et initialiser le mot de passe de l'archivage de sécurité
Prérequis
- L'application
EAP_HOME/bin/vault.shdoit pouvoir être accessible via l'interface de ligne de commande.
Exécuter la commande
vault.sh.ExécuterEAP_HOME/bin/vault.sh. Démarrer une nouvelle session interactive en tapant0.Saisir le nom du répertoire où les fichiers cryptés seront stockés.
Ce répertoire doit être raisonnablement sécurisé, mais JBoss EAP 6 doit pouvoir y accéder. Si vous suivez Section 14.7.2, « Créer un Keystore Java pour stocker des strings sensibles », votre keystore sera dans un répertoire nommévault/dans votre répertoire de base (home). Cet exemple utilise le répertoire/home/USER/vault/.Note
N'oubliez pas d'inclure la barre oblique finale dans le nom du répertoire. Soit/ou\, selon votre système d'exploitation.Saisir le nom de votre keystore.
Saisir le nom complet vers le fichier de keystore. Cet exemple utilise/home/USER/vault/vault.keystore.Crypter le mot de passe du keystore.
Les étapes suivantes vous servent à crypter le mot de passe du keystore, afin que vous puissiez l'utiliser dans les applications et les fichiers de configuration en toute sécuritéSaisir le mot de passe du keystore.
Quand vous y serez invité, saisir le mot de passe du keystore.Saisir une valeur salt.
Entrez une valeur salt de 8 caractères. La valeur salt, ainsi que le nombre d'itérations (ci-dessous), sont utilisés pour créer la valeur de hachageSaisir le nombre d'itérations.
Saisir un nombre pour le nombre d'itérations.Notez les informations de mot de passe masqué.
Le mot de passe masqué, salt et le nombre d'itérations sont imprimés en sortie standard. Prenez-en note dans un endroit sûr. Un attaquant pourrait les utiliser pour déchiffrer le mot de passe.Saisir un alias pour l'archivage de sécurité.
Quand on vous y invite, saisir un alias pour l'archivage de sécurité. Si vous suivez Section 14.7.2, « Créer un Keystore Java pour stocker des strings sensibles » pour créer votre archivage de sécurité, l'alias seravault.
Sortir de la console interactive.
Saisir2pour sortir de la console interactive.
Votre mot de passe de keystore est masqué afin de pouvoir être utilisé dans les fichiers de configuration et de déploiement. De plus, votre archivage de sécurité est complètement configuré et prêt à l'utilisation.
14.7.4. Configurer JBoss EAP pour qu'il utilise l'archivage sécurisé des mots de passe
Avant de masquer les mots de passe et d'autres attributs sensibles dans les fichiers de configuration, vous devez sensibiliser JBoss EAP 6 à l'archivage sécurisé des mots de passe qui les stocke et les déchiffre. Actuellement, cela vous oblige à arrêter Enterprise Application Platform et à modifier la configuration directement.
Prérequis
Procédure 14.7. Assigner un mot de passe d'archivage sécurisé.
Déterminer les valeurs qui conviennent pour la commande.
Déterminer les valeurs pour les paramètres suivants, déterminés par les commandes utilisées pour créer le keystore lui-même. Pour obtenir des informations sur la façon de créer un keystore, voir les sujets suivants : Section 14.7.2, « Créer un Keystore Java pour stocker des strings sensibles » et Section 14.7.3, « Masquer le mot de passe du keystore et initialiser le mot de passe de l'archivage de sécurité ».Paramètre Description KEYSTORE_URL Le chemin d'accès ou URI du fichier keystore, qui s'appelle normalementvault.keystoreKEYSTORE_PASSWORD Le mot de passe utilisé pour accéder au keystore. Cette valeur devrait être masquée.KEYSTORE_ALIAS Le nom du keystore.SALT Le salt utilisé pour crypter et décrypter les valeurs de keystore.ITERATION_COUNT Le nombre de fois que l'algorithme de chiffrement est exécuté.ENC_FILE_DIR Le chemin d'accès au répertoire à partir duquel les commandes de keystore sont exécutées. Normalement, le répertoire contient les mots de passe sécurisés.hôte (domaine géré uniquement) Le nom de l'hôte que vous configurezUtiliser le Management CLI pour activer les mots de passe sécurisés.
Exécutez une des commandes suivantes, selon que vous utilisez un domaine géré ou une configuration de serveur autonome. Substituez les valeurs de la commande par celles de la première étape de cette procédure.Note
Si vous utilisez Microsoft Windows Server, remplacer chaque caractère de/dans un chemin d'accès de nom de fichier ou de répertoire par quatre caractères\. C'est parce qu'il faut deux caractères\, chacun échappé. Cela n'a pas besoin d'être fait pour les autres caractères/.Domaine géré
/host=YOUR_HOST/core-service=vault:add(vault-options=[("KEYSTORE_URL" => "PATH_TO_KEYSTORE"), ("KEYSTORE_PASSWORD" => "MASKED_PASSWORD"), ("KEYSTORE_ALIAS" => "ALIAS"), ("SALT" => "SALT"),("ITERATION_COUNT" => "ITERATION_COUNT"), ("ENC_FILE_DIR" => "ENC_FILE_DIR")])Serveur autonome
/core-service=vault:add(vault-options=[("KEYSTORE_URL" => "PATH_TO_KEYSTORE"), ("KEYSTORE_PASSWORD" => "MASKED_PASSWORD"), ("KEYSTORE_ALIAS" => "ALIAS"), ("SALT" => "SALT"),("ITERATION_COUNT" => "ITERATION_COUNT"), ("ENC_FILE_DIR" => "ENC_FILE_DIR")])
Ce qui suit est un exemple de la commande avec des valeurs hypothétiques :/core-service=vault:add(vault-options=[("KEYSTORE_URL" => "/home/user/vault/vault.keystore"), ("KEYSTORE_PASSWORD" => "MASK-3y28rCZlcKR"), ("KEYSTORE_ALIAS" => "vault"), ("SALT" => "12438567"),("ITERATION_COUNT" => "50"), ("ENC_FILE_DIR" => "/home/user/vault/")])
JBoss EAP 6 est configuré pour décrypter les strings masqués par l'intermédiaire de l'archivage sécurisé de mots de passe. Pour ajouter des strings à l'archivage sécurisé, et les utiliser dans votre configuration, voir la section suivante : Section 14.7.5, « Stocker et résoudre des strings sensibles cryptés du Keystore Java. ».
14.7.5. Stocker et résoudre des strings sensibles cryptés du Keystore Java.
En comptant les mots de passe et les autres strings sensibles, les fichiers de configuration en texte brut ne sont pas sécurisés. JBoss EAP 6 inclut la capacité de stocker et d'utiliser les valeurs masquées dans les fichiers de configuration, et d'utiliser ces valeurs masquées dans les fichiers de configuration.
Prérequis
- L'application
EAP_HOME/bin/vault.shdoit pouvoir être accessible via l'interface de ligne de commande.
Procédure 14.8. Installation du Java Keystore
Exécuter la commande
vault.sh.ExécuterEAP_HOME/bin/vault.sh. Démarrer une nouvelle session interactive en tapant0.Saisir le nom du répertoire où les fichiers cryptés seront stockés.
Si vous suivez Section 14.7.2, « Créer un Keystore Java pour stocker des strings sensibles », votre keystore sera dans un répertoire nommévault/de votre répertoire de base. Dans la plupart des cas, il est logique de stocker toutes vos informations cryptées au même endroit dans le keystore. Cet exemple utilise le répertoire/home/USER/vault/.Note
N'oubliez pas d'inclure la barre oblique finale dans le nom du répertoire. Soit/ou\, selon votre système d'exploitation.Saisir le nom de votre keystore.
Saisir le nom complet vers le fichier de keystore. Cet exemple utilise/home/USER/vault/vault.keystore.Saisir le mot de passe du keystore, le nom de l'archivage sécurisé, salt, et le nombre d'itérations.
Quand vous y êtes invité, saisir le mot de passe du keystore, le nom de l'archivage sécurisé, salt, et le nombre d'itérations.Sélectionner l'option de stockage d'un mot de passe.
Sélectionner l'option0de stockage d'un mot de passe ou autre string sensible.Saisir la valeur.
Une fois que vous y êtes invité, saisir la valeur deux fois. Si les valeurs ne correspondent pas, vous serez invité à essayer à nouveau.Saisir le bloc d'archivage sécurisé.
Saisir le bloc d'archivage sécurisé, qui est un conteneur pour les attributs qui ont trait à la même ressource. Un exemple de nom d'attribut seraitds_ExampleDS. Cela fera partie de la référence à la chaîne cryptée, dans votre source de données ou autre définition de service.Saisir le nom de l'attribut.
Saisir le nom de l'attribut que vous stockez. Exemple de nom d'attributpassword.RésultatUn message comme celui qui suit montre que l'attribut a été sauvegardé.
Valeur de l'attribut pour (ds_ExampleDS, password) sauvegardé
Notez les informations pour ce string crypté.
Un message s'affiche sur la sortie standard, montrant le bloc d'archivage sécurisé, le nom de l'attribut, la clé partagée et des conseils sur l'utilisation du string dans votre configuration. Prendre note de ces informations dans un emplacement sécurisé. Voici un exemple de sortie.******************************************** Vault Block:ds_ExampleDS Attribute Name:password Configuration should be done as follows: VAULT::ds_ExampleDS::password::1 ********************************************
Utiliser le string crypté dans votre configuration.
Utiliser le string de l'étape de configuration précédente, à la place du string en texte brut. Une source de données utilisant le mot de passe crypté ci-dessus, est montrée ci-dessous.... <subsystem xmlns="urn:jboss:domain:datasources:1.0"> <datasources> <datasource jndi-name="java:jboss/datasources/ExampleDS" enabled="true" use-java-context="true" pool-name="H2DS"> <connection-url>jdbc:h2:mem:test;DB_CLOSE_DELAY=-1</connection-url> <driver>h2</driver> <pool></pool> <security> <user-name>sa</user-name> <password>${VAULT::ds_ExampleDS::password::1}</password> </security> </datasource> <drivers> <driver name="h2" module="com.h2database.h2"> <xa-datasource-class>org.h2.jdbcx.JdbcDataSource</xa-datasource-class> </driver> </drivers> </datasources> </subsystem> ...Vous pouvez utiliser un string crypté n'importe où dans votre fichier de configuration autonome ou de domaine pour lequel les expressions sont autorisées.Note
Pour vérifier si les expressions sont utilisées dans un sous-système particulier, exécuter la commande CLI suivante sur ce sous-système :/host=master/core-service=management/security-realm=TestRealm:read-resource-description(recursive=true)
À partir du résultat de cette commande, chercher la valeur du paramètreexpressions-allowed. Si 'true', vous pourrez utiliser des expressions dans la configuration de ce sous-système particulier.Une fois que vous aurez mis votre string dans le keystore, utiliser la syntaxe suivante pour remplacer tout string en texte claire par un texte crypté.${VAULT::<replaceable>VAULT_BLOCK</replaceable>::<replaceable>ATTRIBUTE_NAME</replaceable>::<replaceable>ENCRYPTED_VALUE</replaceable>}Voici un exemple de valeur réelle, où le bloc d'archivage sécurisé estds_ExampleDSet l'attribut estpassword.<password>${VAULT::ds_ExampleDS::password::1}</password>
14.7.6. Stocker et résoudre des strings sensibles de vos applications
Les éléments de configuration de la plate-forme JBoss EAP 6 prennent en charge la capacité de régler les chaînes cryptées en fonction des valeurs stockées dans Java Keystore, via le mécanisme Security Vault. Vous pouvez ajouter le support pour cette fonctionnalité à vos propres applications.
Avant d'effectuer cette procédure, assurez-vous que le répertoire pour stocker vos fichiers dans le Security Vault existe bien. Qu'importe où vous les placez, tant que l'utilisateur qui exécute JBoss EAP 6 dispose de l'autorisation de lire et écrire des fichiers. Cet exemple situe le répertoire vault/ dans le répertoire /home/USER/vault/. Le Security Vault lui-même correspond à un fichier nommé vault.keystore qui se trouve dans le répertoire vault/.
Exemple 14.17. Ajout du string de mot de passe au Security Vault
EAP_HOME/bin/vault.sh. La série de commandes et réponses est incluse dans la session suivante. Les valeurs saisies par l'utilisateur apparaîtront clairement. Certaines sorties seront supprimées pour le formatage. Dans Microsoft Windows, le nom de la commande est vault.bat. Notez que dans Microsoft Windows, les chemins d'accès au fichier utilisent le caractère \ comme séparateur de répertoire, et non pas le caractère /.
[user@host bin]$ ./vault.sh ********************************** **** JBoss Vault ******** ********************************** Please enter a Digit:: 0: Start Interactive Session 1: Remove Interactive Session 2: Exit0Starting an interactive session Enter directory to store encrypted files:/home/user/vault/Enter Keystore URL:/home/user/vault/vault.keystoreEnter Keystore password:...Enter Keystore password again:...Values match Enter 8 character salt:12345678Enter iteration count as a number (Eg: 44):25Enter Keystore Alias:vaultVault is initialized and ready for use Handshake with Vault complete Please enter a Digit:: 0: Store a password 1: Check whether password exists 2: Exit0Task: Store a password Please enter attribute value:saPlease enter attribute value again:saValues match Enter Vault Block:DSEnter Attribute Name:thePassAttribute Value for (DS, thePass) saved Please make note of the following: ******************************************** Vault Block:DS Attribute Name:thePass Configuration should be done as follows: VAULT::DS::thePass::1 ******************************************** Please enter a Digit:: 0: Store a password 1: Check whether password exists 2: Exit2
VAULT.
Exemple 14.18. Servlet qui utilise un mot de passe Vaulted
package vaulterror.web;
import java.io.IOException;
import java.io.Writer;
import javax.annotation.Resource;
import javax.annotation.sql.DataSourceDefinition;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.sql.DataSource;
/*@DataSourceDefinition(
name = "java:jboss/datasources/LoginDS",
user = "sa",
password = "sa",
className = "org.h2.jdbcx.JdbcDataSource",
url = "jdbc:h2:tcp://localhost/mem:test"
)*/
@DataSourceDefinition(
name = "java:jboss/datasources/LoginDS",
user = "sa",
password = "VAULT::DS::thePass::1",
className = "org.h2.jdbcx.JdbcDataSource",
url = "jdbc:h2:tcp://localhost/mem:test"
)
@WebServlet(name = "MyTestServlet", urlPatterns = { "/my/" }, loadOnStartup = 1)
public class MyTestServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
@Resource(lookup = "java:jboss/datasources/LoginDS")
private DataSource ds;
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
Writer writer = resp.getWriter();
writer.write((ds != null) + "");
}
}
14.8. Java Authorization Contract for Containers (JACC)
14.8.1. Java Authorization Contract for Containers (JACC)
14.8.2. Configurer la sécurité JACC (Java Authorization Contract for Containers)
jboss-web.xml pour y inclure les paramètres qu'il faut.
Pour ajouter JACC au domaine de sécurité, ajouter la police d'autorisation JACC à la pile d'autorisations du domaine de sécurité, avec l'indicateur requis. Voici un exemple de domaine de sécurité avec support JACC. Cependant, le domaine de sécurité est configuré dans la console de gestion ou Management CLI, plutôt que directement dans le code XML.
<security-domain name="jacc" cache-type="default">
<authentication>
<login-module code="UsersRoles" flag="required">
</login-module>
</authentication>
<authorization>
<policy-module code="JACC" flag="required"/>
</authorization>
</security-domain>
Le fichier jboss-web.xml se trouve dans META-INF/ ou dans le répertoire WEB-INF/ de votre déploiement, et contient des ajouts ou remplacements de configuration spécifique JBoss pour le conteneur web. Pour utiliser votre domaine de sécurité activé-JACC, vous devrez inclure l'élément <security-domain>, et aussi définir l'élément <use-jboss-authorization> sur true. L'application suivante est configurée correctement pour pouvoir utiliser le domaine de sécurité JACC ci-dessus.
<jboss-web>
<security-domain>jacc</security-domain>
<use-jboss-authorization>true</use-jboss-authorization>
</jboss-web>
La façon de configurer les EJB pour qu'ils utilisent un domaine de sécurité et pour qu'ils utilisent JACC diffère des applications Web. Pour un EJB, vous pouvez déclarer des method permissions (permissions de méthode) sur une méthode ou sur un groupe de méthodes, dans le descripteur ejb-jar.xml. Dans l'élément <ejb-jar>, chaque élément <method-permission> dépendant contient des informations sur les rôles JACC. Voir l'exemple de configuration pour plus d'informations. La classe EJBMethodPermission fait partie de l'API Java Enterprise Edition 6, et est documentée dans http://docs.oracle.com/javaee/6/api/javax/security/jacc/EJBMethodPermission.html.
Exemple 14.19. Exemple de permissions de méthode JACC dans un EJB
<ejb-jar>
<method-permission>
<description>The employee and temp-employee roles may access any method of the EmployeeService bean </description>
<role-name>employee</role-name>
<role-name>temp-employee</role-name>
<method>
<ejb-name>EmployeeService</ejb-name>
<method-name>*</method-name>
</method>
</method-permission>
</ejb-jar>
jboss-ejb3.xml qui se trouve dans l'élément enfant <security>. En plus du domaine de sécurité, vous pouvez également spécifier le run-as principal, qui change le principal que l'EJB exécute.
Exemple 14.20. Exemple de déclaration de domaine de sécurité dans un EJB
<security> <ejb-name>*</ejb-name> <security-domain>myDomain</security-domain> <run-as-principal>myPrincipal</run-as-principal> </security>
14.9. Java Authentication SPI for Containers (JASPI)
14.9.1. Sécurité Java Authentication SPI pour Conteneurs (JASPI)
14.9.2. Configuration de la sécurité Java Authentication SPI pour conteneurs (JASPI)
<authentication-jaspi> à votre domaine de sécurité. La configuration est similaire à celle d'un module d'authentification standard, mais les éléments de module de login sont inclus dans l'élément <login-module-stack>. La structure de configuration est la suivante :
Exemple 14.21. Structure de l'élément authentication-jaspi
<authentication-jaspi> <login-module-stack name="..."> <login-module code="..." flag="..."> <module-option name="..." value="..."/> </login-module> </login-module-stack> <auth-module code="..." login-module-stack-ref="..."> <module-option name="..." value="..."/> </auth-module> </authentication-jaspi>
EAP_HOME/domain/configuration/domain.xml ou dans le fichier EAP_HOME/standalone/configuration/standalone.xml.
Chapitre 15. Single Sign On (SSO)
15.1. SSO (Single Sign On) pour les applications web
Single Sign On (SSO) autorise l'authentification à une ressource, en vue d'autoriser implicitement l'accès à d'autres ressources.
SSO Non-clusterisé limite le partage des informations d'autorisation pour les applications d'un même hôte virtuel. En outre, il n'y a aucun mécanisme de résilience en cas de défaillance de l'hôte. Les données d'authentification SSO clusterisées peuvent être partagées entre les applications de plusieurs hôtes virtuels et sont résistantes au basculement. De plus, SSO clusterisé est capable de recevoir des demandes d'un équilibreur de charges.
Si une ressource n'est pas protégée, un utilisateur n'a pas besoin de s'authentifier. Si un utilisateur accède à une ressource protégée, l'utilisateur devra s'authentifier.
Les limitations de SSO
- Aucune propagation au-delà des limites de tierce-parties.
- SSO ne peut être utilisé qu'entre des applications déployées au sein de conteneurs JBoss EAP 6.
- Authentification gérée-conteneur uniquement.
- Vous devez utiliser des éléments d'authentification géré-conteneurs, comme
<login-config>dans leweb.xmlde votre application. - Nécessite des cookies.
- SSO se maintient par des cookies de navigateur et la ré-écriture d'URL n'est pas prise en charge.
- Limitations de domaine et de domaine de sécurité
- À moins que le paramètre
requireReauthenticationsoit défini àtrue, toutes les applications web configurées pour la même valve SSO devront partager la même configuration Realm dansweb.xmlet le même domaine de sécurité.Vous pouvez imbriquer l'élément Realm à l'intérieur de l'élément Hôte ou de l'élément Engine environnant, mais pas à l'intérieur d'un élément context.xml pour une des applications web concernéesLe<security-domain>configuré dansjboss-web.xmldoit être consistant à travers toutes les applications web.Toutes les intégrations de sécurité doivent pouvoir accepter les mêmes informations d'autorisation (comme les noms d'utilisateur et mots de passe).
15.2. SSO (Single Sign On) clusterisées pour les applications web
jboss-Web.xml de l'application.
- Apache Tomcat ClusteredSingleSignOn
- Apache Tomcat IDPWebBrowserSSOValve
- SSO basée-SPNEGO de PicketLink
15.3. Choisir l'implémentation SSO qui vous convient
Si votre organisation utilise déjà une authentification basée Kerberos et un système d'autorisation comme Microsoft Active Directory, vos pourrez utiliser les mêmes systèmes pour vous authentifier de façon transparente à vos applications enterprise en cours d'exécution sur JBoss EAP 6.
Si vous avez besoin de propager des informations de sécurité entre des applications qui s'exécutent dans le même groupe de serveurs ou instance, vous pourrez utiliser le SSO non-clusterisé. Cela implique uniquement la configuration de la valve dans le descripteur de jboss-web.xml de votre application.
Si vous avez besoin de propager des informations de sécurité entre des applications qui s'exécutent dans un environnement clusterisé sur plusieurs instances de JBoss EAP 6, vous pourrez utiliser la valve SSO clusterisée. Ce paramètre est configuré dans le fichierjboss-Web.xml de votre application.
15.4. Utilisation de SSO (Single Sign On) pour les applications web
Les fonctionnalités SSO (Single Sign On) sont fournies par les sous-systèmes web et Infinispan. Utiliser cette procédure pour configurer SSO dans les applications web.
Prérequis
- Vous devez avoir un domaine de sécurité configuré qui gère les authentifications et autorisations.
- Le sous-système
infinispandoit être présent. Il se trouve dans le profilcomplet-hapour un domaine géré, ou en utilisant la configurationstandalone-full-ha.xmldans un serveur autonome. - Le
webcache-conteneuret le cache-conteneur SSO doivent chacun être présents. Les exemples de fichiers de configurations contiennent déjà le cache-conteneurweb, et certaines des configurations contiennent déjà le cache-conteneur SSO également. Utilisez les commandes suivantes pour vérifier et activer le cache conteneur SSO. Notez que ces commandes modifient le profilhad'un domaine géré. Vous pouvez modifier les commandes pour utiliser un profil différent, ou supprimer la portion/profile=hade la commande, pour un serveur autonome.Exemple 15.1. Vérifier le cache-conteneur
webLes profils et les configurations mentionnées ci-dessus incluent le cache-conteneurwebpar défaut. Utilisez la commande suivante pour vérifier sa présence. Si vous utilisez un profil différent, remplacez par son nom à la place deha./profile=ha/subsystem=infinispan/cache-container=web/:read-resource(recursive=false,proxies=false,include-runtime=false,include-defaults=true)
Si le résultat affiche unsuccess, le sous-système sera présent. Sinon, vous devrez l'ajouter.Exemple 15.2. Ajouter le cache-conteneur
webUtiliser les trois commandes suivantes pour activer le cache-conteneurwebà votre configuration. Modifier le nom du profil selon le cas, ainsi que les autres paramètres. Ici, les paramètres sont ceux utilisés dans une configuration par défaut./profile=ha/subsystem=infinispan/cache-container=web:add(aliases=["standard-session-cache"],default-cache="repl",module="org.jboss.as.clustering.web.infinispan")
/profile=ha/subsystem=infinispan/cache-container=web/transport=TRANSPORT:add(lock-timeout=60000)
/profile=ha/subsystem=infinispan/cache-container=web/replicated-cache=repl:add(mode="ASYNC",batching=true)
Exemple 15.3. Vérifier le cache-conteneur
SSOÉxécuter la commande de Management CLI suivante :/profile=ha/subsystem=infinispan/cache-container=web/:read-resource(recursive=true,proxies=false,include-runtime=false,include-defaults=true)
Chercher une sortie qui ressemble à ceci :"sso" => {Si vous ne la trouvez pas, le cache-conteneur ne sera pas présent dans votre configuration.Exemple 15.4. Ajouter le cache-conteneur
SSO/profile=ha/subsystem=infinispan/cache-container=web/replicated-cache=sso:add(mode="SYNC", batching=true)
- Le sous-système
webdoit être configuré pour utiliser SSO. La commande suivante active SSO sur le serveur virtuel appelédefault-hostet le domaine de cookiesdomaine.com. Le nom de cache estsso, et une nouvelle authentification est désactivée./profile=ha/subsystem=web/virtual-server=default-host/sso=configuration:add(cache-container="web",cache-name="sso",reauthenticate="false",domain="domain.com")
- Chaque application qui partage les informations SSO doit être configurée pour utiliser le même <security-domain> dans son descripteur de déploiement de
jboss-web.xmlet le même Realm dans son fichier de configurationweb.xml.
SSO clusterisée permet le partage d'authentification entre des hôtes distincts, tandis que ce n'est pas le cas pour SSO non-clusterisée. Les valves SSO en cluster et non clusterisées sont configurées de la même manière, mais SSO clusterisée comprend les paramètres cacheConfig, processExpiresInterval et maxEmptyLife, qui contrôlent la réplication en groupement des données persistantes.
Exemple 15.5. Exemple de configuration SSO clusterisée
tomcat.
<jboss-web> <security-domain>tomcat</security-domain> <valve> <class-name>org.jboss.web.tomcat.service.sso.ClusteredSingleSignOn</class-name> <param> <param-name>maxEmptyLife</param-name> <param-value>900</param-value> </param> </valve> </jboss-web>
Tableau 15.1. Options de configuration SSO
| Option | Description |
|---|---|
| cookieDomain |
Domaine hôte utilisé pour les cookies SSO. La valeur par défaut est
/. Pour permettre à app1.xyz.com et à app2.xyz.com de partager les cookies SSO, vous devrez définir le cookieDomain à xyz.com.
|
| maxEmptyLife |
SSO clusterisée uniquement. Le nombre maximum de secondes qu'une valve SSO sans sessions actives sera utilisable par une demande, avant d'expirer. Une valeur positive permet une manipulation appropriée d'arrêt d'un nœud si c'est le seul avec des sessions actives attachées à la valve. Si maxEmptyLife est défini sur
0, la vanne se terminera en même temps que les copies de la session locale, mais des copies de sauvegarde des sessions, des applications en cluster, seront disponibles à d'autres nœuds du cluster. Si on permet à la vanne à vivre au-delà de la durée de ses sessions gérées, cela donne du temps à l'utilisateur d'effectuer une autre demande qui puisse basculer sur un nœud différent, où il active la copie de sauvegarde de la session. La valeur par défaut, est de 1800 secondes (30 minutes).
|
| processExpiresInterval |
SSO clusterisé uniquement. Le nombre minimum de secondes entre les efforts de la valve pour trouver et invalider des instances SSO qui ont expiré le délai d'attente de
MaxEmptyLife. La valeur par défaut est de 60 (1 minute).
|
| requiresReauthentication |
Si true, chaque requête utilise des informations d'authentification en cache pour authentifier à nouveau le domaine de sécurité. Si false (la valeur par défaut), une cookie SSO valide sera suffisante pour que la valve puisse authentifier chaque nouvelle requête.
|
Une application peut rendre invalide une session en invoquant la méthode javax.servlet.http.HttpSession.invalidate().
15.5. Kerberos
15.6. SPNEGO
15.7. Microsoft Active Directory
- LDAP (Lightweight Directory Access Protocol) stocke les informations utilisateurs, ordinateurs, mots de passe et autres ressources.
- Kerberos procure une authentification sécurisée sur le réseau.
- DNS (Domain Service Name) fournit des mappages entre les adresses IP, les noms d'hôtes et les ordinateurs ou autres périphériques du réseau.
15.8. Configuration de Kerberos ou Microsoft Active Directory Desktop SSO pour les applications web
Pour authentifier vos applications web ou EJB à l'aide de l'authentification basée Kerberos existante de votre organisation et de votre infrastructure d'autorisation, comme Microsoft Active Directory, vous pouvez utiliser les fonctionnalités de JBoss Negotation intégrées dans JBoss EAP 6. Si vous configurez votre application web correctement, une connexion réussie en desktop ou réseau sera suffisante pour vous authentifier en toute transparence dans votre application web, donc aucune invite de connexion supplémentaire ne sera nécessaire.
Il existe des différences notables entre la plateforme JBoss EAP 6 et les versions précédentes :
- Les domaines de sécurité sont configurés centralement, pour chaque profil d'un domaine géré, ou pour chaque serveur autonome. Ils ne font pas partie du déploiement lui-même. Le domaine de sécurité qu'un déploiement doit utiliser est nommé dans le fichier de déploiement
jboss-web.xmloujboss-ejb3.xml. - Les propriétés de sécurité sont configurées dans le cadre du domaine de sécurité, faisant partie de sa configuration centrale. Elles ne font pas partie du déploiement.
- Vous pouvez ne plus remplacer les authentificateurs dans votre déploiement. Toutefois, vous pouvez ajouter une valve NegotiationAuthenticator à votre descripteur
jboss-web.xmlafin d'obtenir le même effet. La valve nécessite toujours les éléments<security-constraint>et<login-config>à définir dans le fichierweb.xml. Ils servent à décider quelles ressources sont sécurisées. Cependant, l'auth-method choisie sera substituée par la valve NegotiationAuthenticator du fichierjboss-web.xml. - Les attributs
CODEdes domaines de sécurité utilisent maintenant un nom simple au lieu d'un nom de classe complet. Le tableau suivant montre les mappages entre les classes utilisées pour JBoss Negotiation, et leurs classes.
Tableau 15.2. Codes de modules de connexion et Noms de classes
| Nom simple | Nom de classe | But |
|---|---|---|
| Kerberos | com.sun.security.auth.module.Krb5LoginModule | Module de connexion Kerberos |
| SPNEGO | org.jboss.security.negotiation.spnego.SPNEGOLoginModule | Le mécanisme qui permet aux applications web de s'authentifier à votre serveur d'authentification Kerberos. |
| AdvancedLdap | org.jboss.security.negotiation.AdvancedLdapLoginModule | Utilisé avec les serveurs LDAP autres que Microsoft Active Directory. |
| AdvancedAdLdap | org.jboss.security.negotiation.AdvancedADLoginModule | Utilisé avec les serveurs Microsoft Active Directory LDAP. |
JBoss Negotiation Toolkit est un outil de débogage que vous pouvez télécharger à partir de https://community.jboss.org/servlet/JiveServlet/download/16876-2-34629/jboss-negotiation-toolkit.war. Il est fourni comme un outil supplémentaire pour vous aider à déboguer et tester les mécanismes d'authentification avant d'introduire votre application en production. C'est un outil non pris en charge, mais considéré comme très utile. Comme SPNEGO, cet outil peut être difficile à configurer pour les applications web.
Procédure 15.1. Installation de l'authentification SSO (Single Sign On) pour les Applications Web ou EJB
Configurer un domaine de sécurité qui représente l'identité de votre serveur. Définir les propriétés système si nécessaire.
Le premier domaine de sécurité authentifie le conteneur lui-même au service de répertoires. Il a besoin d'utiliser un module de connexion qui accepte un type de mécanisme de connexion statique, car un utilisateur réel n'est pas impliqué. Cet exemple utilise une entité de sécurité statique et fait référence à un fichier keytab qui contient les informations d'identification.Le code XML est donné ici dans un but de clarification, mais vous devez utiliser la console de gestion ou le Management CLI pour configurer vos domaines de sécurité.<security-domain name="host" cache-type="default"> <authentication> <login-module code="Kerberos" flag="required"> <module-option name="storeKey" value="true"/> <module-option name="useKeyTab" value="true"/> <module-option name="principal" value="host/testserver@MY_REALM"/> <module-option name="keyTab" value="/home/username/service.keytab"/> <module-option name="doNotPrompt" value="true"/> <module-option name="debug" value="false"/> </login-module> </authentication> </security-domain>Configurer un second domaine de sécurité pour sécuriser l'application web ou les applications. Définir les propriétés système si nécessaire.
Le deuxième domaine de sécurité est utilisé pour authentifier l'utilisateur particulier au serveur d'authentification Kerberos ou SPNEGO. Vous avez besoin d'au moins un module de connexion pour authentifier l'utilisateur et un autre à la recherche de rôles à appliquer à l'utilisateur. Le code XML suivant montre un exemple de domaine de sécurité SPNEGO. Il inclut un module d'autorisation pour mapper les rôles aux utilisateurs individuels. Vous pouvez également utiliser un module de recherche pour les rôles sur le serveur d'authentification lui-même.<security-domain name="SPNEGO" cache-type="default"> <authentication> <!-- Check the username and password --> <login-module code="SPNEGO" flag="requisite"> <module-option name="password-stacking" value="useFirstPass"/> <module-option name="serverSecurityDomain" value="host"/> </login-module> <!-- Search for roles --> <login-module code="UsersRoles" flag="required"> <module-option name="password-stacking" value="useFirstPass" /> <module-option name="usersProperties" value="spnego-users.properties" /> <module-option name="rolesProperties" value="spnego-roles.properties" /> </login-module> </authentication> </security-domain>Spécifier la security-constraint et la login-config dans le fichier
web.xmlLe descripteurweb.xmlcontient des informations sur les contraintes de sécurité et sur la configuration de la connexion. En voici des exemples :<security-constraint> <display-name>Security Constraint on Conversation</display-name> <web-resource-collection> <web-resource-name>examplesWebApp</web-resource-name> <url-pattern>/*</url-pattern> </web-resource-collection> <auth-constraint> <role-name>RequiredRole</role-name> </auth-constraint> </security-constraint> <login-config> <auth-method>SPNEGO</auth-method> <realm-name>SPNEGO</realm-name> </login-config> <security-role> <description> role required to log in to the Application</description> <role-name>RequiredRole</role-name> </security-role>Indiquer le domaine de sécurité et les autres paramètres dans le descripteur
jboss-web.xml.Spécifiez le nom du domaine de la sécurité côté client (l'autre dans cet exemple) dans le descripteurjboss-Web.xmlde votre déploiement, pour obliger votre application à utiliser ce domaine de sécurité.Vous ne pouvez plus remplacer les authentificateurs directement. À la place, vous devez ajouter NegotiationAuthenticator comme valve au descripteurjboss-web.xmlsi nécessaire.<jacc-star-role-allow>vous permet d'utiliser un astérisque (*) pour faire correspondre plusieurs noms de rôles, et est optionnel.<jboss-web> <security-domain>java:/jaas/SPNEGO</security-domain> <valve> <class-name>org.jboss.security.negotiation.NegotiationAuthenticator</class-name> </valve> <jacc-star-role-allow>true</jacc-star-role-allow> </jboss-web>Ajouter une dépendance au
MANIFEST.MFde votre application, pour trouver l'emplacement des classes Negotiation.L'application web a besoin d'une dépendance sur la classeorg.jboss.security.negotiationà ajouter au manifesteMETA-INF/MANIFEST.MFdu déploiement pour pouvoir localiser les classes JBoss Negotiation. Ce qui suit vous montre une entrée formatée correctement.Manifest-Version: 1.0 Build-Jdk: 1.6.0_24 Dependencies: org.jboss.security.negotiation
Votre application web accepte et authentifie les informations d'identification avec Kerberos, Active Directory de Microsoft ou autre service de répertoire compatible SPNEGO. Si l'utilisateur exécute l'application d'un système qui est déjà enregistré dans le service de répertoires, et où les rôles sont déjà appliqués à l'utilisateur, l'application web n'aura pas besoin d'authentification, et les fonctionnalités SSO seront opérationnelles.
Chapitre 16. Références de sécurité pour le développement
16.1. Référence de configuration jboss-web.xml
Le fichier jboss-web.xml se trouve dans WEB-INF ou dans le répertoire META-INF de votre déploiement. Il contient des informations de configuration sur des fonctionnalités que le conteneur JBoss Web ajoute au Servlet 3.0. Les paramètres de configuration spécifiques à la spécification de Servlet 3.0 se trouvent dans web.xml, dans le même répertoire.
jboss-web.xml est l'élément <jboss-web>.
La plupart des paramètres de configuration font correspondre les prérequis définis dans le fichier web.xml de l'application à des ressources locales. Pour plus d'explications sur les paramètres de configuration de web.xml consulter http://docs.oracle.com/cd/E13222_01/wls/docs81/webapp/web_xml.html.
web.xml requiert jdbc/MyDataSource, alors jboss-web.xml fera sans doute correspondre la source de données globale java:/DefaultDS pour remplir ce besoin. Le WAR utilise la source de données globale pour faire correspondre jdbc/MyDataSource.
Tableau 16.1. Attributs de haut niveau communs
| Attribut | Description |
|---|---|
| env-entry |
Un mappage à
env-entry requis par web.xml.
|
| ejb-ref |
Un mappage à
ejb-ref requis par web.xml.
|
| ejb-local-ref |
Un mappage à
ejb-local-ref requis par web.xml.
|
| service-ref |
Un mappage à
service-ref requis par web.xml.
|
| resource-ref |
Un mappage à
resource-ref requis par web.xml.
|
| resource-env-ref |
Un mappage à
resource-env-ref requis par web.xml.
|
| message-destination-ref |
Un mappage à
message-destination-ref requis par web.xml.
|
| persistence-context-ref |
Un mappage à
persistence-context-ref requis par web.xml.
|
| persistence-unit-ref |
Un mappage à
persistence-unit-ref requis par web.xml.
|
| post-construct |
Un mappage à
post-context requis par web.xml.
|
| pre-destroy |
Un mappage à
pre-destroy requis par web.xml.
|
| data-source |
Un mappage à
data-source requis par web.xml.
|
| context-root | Le contexte root de l'application. La valeur par défaut est le nom du déploiement sans le suffixe .war. |
| virtual-host | Le nom de l'hôte virtuel HTTP à partir duquel l'application accepte les requêtes. Se réfère au contenu de l'en-tête de l'Host HTTP. |
| annotation | Décrit une annotation utilisée par l'application. Voir <annotation> pour plus d'informations. |
| listener | Décrit un listener utilisé par l'application. Voir <listener> pour plus d'informations. |
| session-config | Cet élément remplit la même fonction que l'élément <session-config> du fichier web.xml et est inclus dans un but de compatibilité seulement. |
| valve | Décrit une valve utilisée par l'application. Voir <valve> pour plus d'informations. |
| overlay | Le nom d'une couche supplémentaire à ajouter à l'application. |
| security-domain | Le nom du domaine de sécurité utilisé par l'application. Le domaine de sécurité lui-même est configuré à partir de la console de gestion basée web ou le Management CLI. |
| security-role | Cet élément remplit la même fonction que l'élément <session-role> du fichier web.xml et est inclus dans un but de compatibilité seulement. |
| use-jboss-authorization | Si cet élément est présent et contient la valeur non sensible à la casse "true", la pile d'autorisation web JBoss sera utilisée. S'il n'est pas présent ou contient une valeur non "true", alors seuls les mécanismes d'autorisation indiqués dans les spécifications Java Enterprise Edition seront utilisés. Cet élément est nouveau dans JBoss EAP 6. |
| disable-audit | Si cet élément vide est présent, l'auditing de sécurité web sera désactivé. Sinon, il sera activé. L'auditing de sécurité web ne fait pas partie de la spécification Java EE. Cet élément est nouveau dans JBoss EAP 6. |
| disable-cross-context | Si sur false, l'application sera en mesure d'appeler un autre contexte d'application. La valeur par défaut est true. |
Décrit une annotation utilisée par l'application. Le tableau suivant liste les éléments enfants d'une <annotation>.
Tableau 16.2. Éléments de configuration d'une annotation
| Attribut | Description |
|---|---|
| class-name |
Nom de la classe de l'annotation
|
| servlet-security |
L'élément, comme
@ServletSecurity, qui représente la sécurité du servlet.
|
| run-as |
L'élément, comme
@RunAs, qui représente l'information run-as
|
| multi-part |
L'élément, comme
@MultiPart, qui représente l'information multi-part.
|
Décrit un listener. Le tableau suivant liste les éléments enfants d'un <listener>.
Tableau 16.3. Éléments de configuration d'un listener
| Attribut | Description |
|---|---|
| class-name |
Nom de la classe du listener
|
| listener-type |
Liste les éléments de
condition qui indiquent quel sorte de listener ajouter au contexte de l'application. Les choix valides sont les suivants :
|
| module |
Le nom du module qui contient la classe du listener.
|
| param |
Un paramètre. Contient deux éléments enfants,
<param-name> et <param-value>.
|
Décrit une valve de l'application. Contient les mêmes éléments de configuration que <listener>.
16.2. Référence de paramètre de sécurité EJB
Tableau 16.4. Éléments de paramètres de sécurité EJB
| Élément | Description |
|---|---|
<security-identity>
|
Contient des éléments enfants relatifs à l'identité de sécurité d'un EJB.
|
<use-caller-identity />
|
Indique que l'EJB utilise la même identité de sécurité que l'appelant.
|
<run-as>
|
Contient un élément
<role-name>.
|
<run-as-principal>
|
Si présent, indique le principal assigné aux appels sortants. Si non présent, les appels sortants sont assignés à un principal nommé
anonymous.
|
<role-name>
|
Spécifie le role d'exécution de l'EJB.
|
<description>
|
Décrit le role nommé dans
. <role-name>
|
Exemple 16.1. Exemples d'identité de sécurité
<session>.
<ejb-jar>
<enterprise-beans>
<session>
<ejb-name>ASessionBean</ejb-name>
<security-identity>
<use-caller-identity/>
</security-identity>
</session>
<session>
<ejb-name>RunAsBean</ejb-name>
<security-identity>
<run-as>
<description>A private internal role</description>
<role-name>InternalRole</role-name>
</run-as>
</security-identity>
</session>
<session>
<ejb-name>RunAsBean</ejb-name>
<security-identity>
<run-as-principal>internal</run-as-principal>
</security-identity>
</session>
</enterprise-beans>
</ejb-jar>
Chapitre 17. Références supplémentaires
17.1. Types d'archives Java
Tableau 17.1.
| Type d'archive | Extension | But | Exigences pour la structure de répertoire |
|---|---|---|---|
| Archive Java | .jar | Contient les bibliothèques de classes Java. |
Le fichier
META-INF/MANIFEST.MF (optionnel), spécifiant des informations comme quelle classe est la classe principale .
|
| Archive Web | .war |
Contient des fichiers Java Server Pages (JSP), des servlets, et des fichiers XML, en plus des classes et des bibliothèques. Le contenu Archive Web s'appelle aussi Web Application.
|
Le fichier
WEB-INF/web.xml, qui contient des informations sur la structure de l'application web. Il y a également d'autres fichiers présents dans WEB-INF/.
|
| Resource Adapter Archive | .rar |
La structure du répertoire est dans la spécification JCA.
|
Contient un adaptateur de ressources Java Connector Architecture (JCA). S'appelle également un connecteur.
|
| Enterprise Archive | .ear |
Utilisé par Java Enterprise Edition (EE) pour empaqueter un ou plusieurs modules dans une simple archive, pour que les modules puissent être déployés dans le serveur d'applications simultanément. Maven et Ant sont les outils les plus communément utilisés pour générer les archives EAR.
|
Le répertoire
META-INF/ qui contient un ou plusieurs fichiers de descripteurs de déploiement XML.
|
|
N'importe quel type de module.
| |||
| Service Archive | .sar |
Ressemble à une Archive Enterprise, spécifique à Enterprise Application Platform.
|
Répertoire
META-INF/ contenant un fichier jboss-service.xml ou jboss-beans.xml.
|
Annexe A. Revision History
| Historique des versions | |||
|---|---|---|---|
| Version 1.0.0-1 | Wed Jun 18 2014 | ||
| |||