
Red Hat Training
A Red Hat training course is available for RHEL 8
Supervisión y gestión del estado y el rendimiento del sistema
Optimización del rendimiento, la latencia y el consumo de energía del sistema
Resumen
Hacer que el código abierto sea más inclusivo
Red Hat se compromete a sustituir el lenguaje problemático en nuestro código, documentación y propiedades web. Estamos empezando con estos cuatro términos: maestro, esclavo, lista negra y lista blanca. Debido a la enormidad de este esfuerzo, estos cambios se implementarán gradualmente a lo largo de varias versiones próximas. Para más detalles, consulte el mensaje de nuestro CTO Chris Wright.
Proporcionar comentarios sobre la documentación de Red Hat
Agradecemos su opinión sobre nuestra documentación. Por favor, díganos cómo podemos mejorarla. Para ello:
Para comentarios sencillos sobre pasajes concretos:
- Asegúrese de que está viendo la documentación en el formato Multi-page HTML. Además, asegúrese de ver el botón Feedback en la esquina superior derecha del documento.
- Utilice el cursor del ratón para resaltar la parte del texto que desea comentar.
- Haga clic en la ventana emergente Add Feedback que aparece debajo del texto resaltado.
- Siga las instrucciones mostradas.
Para enviar comentarios más complejos, cree un ticket de Bugzilla:
- Vaya al sitio web de Bugzilla.
- Como componente, utilice Documentation.
- Rellene el campo Description con su sugerencia de mejora. Incluya un enlace a la(s) parte(s) pertinente(s) de la documentación.
- Haga clic en Submit Bug.
Capítulo 1. Resumen de las opciones de supervisión del rendimiento
Las siguientes son algunas de las herramientas de monitorización y configuración del rendimiento disponibles en Red Hat Enterprise Linux 8:
-
Performance Co-Pilot (
pcp) se utiliza para supervisar, visualizar, almacenar y analizar las mediciones de rendimiento a nivel de sistema. Permite la supervisión y gestión de datos en tiempo real, así como el registro y la recuperación de datos históricos. Red Hat Enterprise Linux 8 proporciona varias herramientas que se pueden utilizar desde la línea de comandos para supervisar un sistema fuera del nivel de ejecución 5. Las siguientes son las herramientas de línea de comandos incorporadas:
-
topes proporcionado por el paqueteprocps-ng. Ofrece una visión dinámica de los procesos de un sistema en ejecución. Muestra una variedad de información, incluyendo un resumen del sistema y una lista de tareas que están siendo gestionadas por el núcleo de Linux. -
pses proporcionado por el paqueteprocps-ng. Captura una instantánea de un grupo selecto de procesos activos. Por defecto, el grupo examinado se limita a los procesos que son propiedad del usuario actual y que están asociados a la terminal donde se ejecuta el comandops. -
Las estadísticas de la memoria virtual (
vmstat) son proporcionadas por el paqueteprocps-ng. Proporciona informes instantáneos de los procesos del sistema, la memoria, la paginación, la entrada/salida de bloques, las interrupciones y la actividad de la CPU. -
El reportero de actividad del sistema (
sar) es proporcionado por el paquetesysstat. Recoge y reporta información sobre la actividad del sistema que ha ocurrido hasta el momento en el día actual.
-
-
perfutiliza contadores de rendimiento del hardware y puntos de rastreo del kernel para rastrear el impacto de otros comandos y aplicaciones en un sistema. -
bcc-toolsse utiliza para BPF Compiler Collection (BCC). Proporciona más de 100 scriptseBPFque monitorizan las actividades del kernel. Para más información sobre cada una de estas herramientas, consulte la página man que describe cómo utilizarlas y qué funciones realizan. -
turbostates proporcionado por el paquetekernel-tools. Informa sobre la topología del procesador, la frecuencia, las estadísticas de estado de energía en reposo, la temperatura y el uso de energía en los procesadores Intel 64. -
iostates proporcionado por el paquetesysstat. Supervisa e informa sobre la carga de dispositivos de entrada/salida del sistema para ayudar a los administradores a tomar decisiones sobre cómo equilibrar la carga de entrada/salida entre los discos físicos. -
irqbalancedistribuye las interrupciones de hardware entre los procesadores para mejorar el rendimiento del sistema. -
ssimprime información estadística sobre los sockets, permitiendo a los administradores evaluar el rendimiento del dispositivo a lo largo del tiempo. Red Hat recomienda el uso desssobrenetstaten Red Hat Enterprise Linux 8. -
numastates proporcionado por el paquetenumactl. Por defecto,numastatmuestra las estadísticas del sistema NUMA por nodo desde el asignador de memoria del kernel. El rendimiento óptimo se indica con valores altos denuma_hity bajos denuma_miss. -
numades un demonio de gestión automática de afinidad NUMA. Supervisa la topología NUMA y el uso de recursos dentro de un sistema que mejora dinámicamente la asignación de recursos NUMA, la gestión y, por tanto, el rendimiento del sistema. -
SystemTapsupervisa y analiza las actividades del sistema operativo, especialmente las del núcleo. -
valgrindanaliza las aplicaciones ejecutándolas en una CPU sintética e instrumentando el código de la aplicación existente mientras se ejecuta. A continuación, imprime comentarios que identifican claramente cada proceso involucrado en la ejecución de la aplicación en un archivo especificado por el usuario, un descriptor de archivo o un socket de red. También es útil para encontrar fugas de memoria. -
pqoses proporcionado por el paqueteintel-cmt-cat. Supervisa y controla la caché de la CPU y el ancho de banda de la memoria en los procesadores Intel recientes.
Recursos adicionales
-
Para más información, consulte las páginas man de
pcp,top,ps,vmstat,sar,perf,iostat,irqbalance,ss,numastat,numad,valgrind, ypqos. -
Para más información sobre
pcp, consulte la documentación del directorio/usr/share/doc/. -
Para más información sobre el valor
awaity lo que puede causar que sus valores sean altos, vea el artículo de la Base de Conocimiento de Red Hat: ¿Qué significa exactamente el valor \ "await" reportado por iostat?
Capítulo 2. Cómo empezar con Tuned
Como administrador del sistema, puede utilizar la aplicación Tuned para optimizar el perfil de rendimiento de su sistema para una variedad de casos de uso.
2.1. El objetivo de Tuned
Tuned es un servicio que monitoriza tu sistema y optimiza el rendimiento bajo determinadas cargas de trabajo. El núcleo de Tuned es profiles, que ajusta su sistema para diferentes casos de uso.
Tuned se distribuye con una serie de perfiles predefinidos para casos de uso como:
- Alto rendimiento
- Baja latencia
- Ahorro de energía
Es posible modificar las reglas definidas para cada perfil y personalizar la forma de ajustar un dispositivo concreto. Cuando se cambia a otro perfil o se desactiva Tuned, todos los cambios realizados en la configuración del sistema por el perfil anterior vuelven a su estado original.
También puedes configurar Tuned para que reaccione a los cambios en el uso de los dispositivos y ajuste la configuración para mejorar el rendimiento de los dispositivos activos y reducir el consumo de energía de los inactivos.
2.2. Perfiles afinados
Un análisis detallado de un sistema puede llevar mucho tiempo. Tuned ofrece una serie de perfiles predefinidos para casos de uso típicos. También puedes crear, modificar y eliminar perfiles.
Los perfiles proporcionados con Tuned se dividen en las siguientes categorías:
- Perfiles de ahorro de energía
- Perfiles que aumentan el rendimiento
Los perfiles para aumentar el rendimiento incluyen perfiles que se centran en los siguientes aspectos:
- Baja latencia para el almacenamiento y la red
- Alto rendimiento para el almacenamiento y la red
- Rendimiento de la máquina virtual
- Rendimiento del host de virtualización
El perfil por defecto
Durante la instalación, se selecciona automáticamente el mejor perfil para su sistema. Actualmente, el perfil por defecto se selecciona según las siguientes reglas personalizables:
| Medio ambiente | Perfil por defecto | Objetivo |
|---|---|---|
| Nodos de cálculo |
| El mejor rendimiento de la producción |
| Máquinas virtuales |
|
El mejor rendimiento. Si no te interesa el mejor rendimiento, puedes cambiarlo por el perfil |
| Otros casos |
| Rendimiento y consumo de energía equilibrados |
Perfiles fusionados
Como característica experimental, es posible seleccionar más perfiles a la vez. Tuned intentará fusionarlos durante la carga.
Si hay conflictos, la configuración del último perfil especificado tiene prioridad.
Ejemplo 2.1. Bajo consumo de energía en un huésped virtual
El siguiente ejemplo optimiza el sistema para que se ejecute en una máquina virtual para obtener el mejor rendimiento y, al mismo tiempo, lo ajusta para que tenga un bajo consumo de energía, mientras que el bajo consumo de energía es la prioridad:
# tuned-adm profile virtual-guest powersave
La fusión se realiza automáticamente sin comprobar si la combinación de parámetros resultante tiene sentido. En consecuencia, la función podría ajustar algunos parámetros en sentido contrario, lo que podría ser contraproducente: por ejemplo, ajustar el disco para un alto rendimiento mediante el perfil throughput-performance y, al mismo tiempo, ajustar el spindown del disco al valor bajo mediante el perfil spindown-disk.
La ubicación de los perfiles
Tuned almacena los perfiles en los siguientes directorios:
/usr/lib/tuned/-
Los perfiles específicos de la distribución se almacenan en el directorio. Cada perfil tiene su propio directorio. El perfil consiste en el archivo de configuración principal llamado
tuned.conf, y opcionalmente otros archivos, por ejemplo scripts de ayuda. /etc/tuned/-
Si necesita personalizar un perfil, copie el directorio del perfil en el directorio que se utiliza para los perfiles personalizados. Si hay dos perfiles con el mismo nombre, se utiliza el perfil personalizado situado en
/etc/tuned/.
La sintaxis de la configuración del perfil
El archivo tuned.conf puede contener una sección [main] y otras secciones para configurar las instancias del plug-in. Sin embargo, todas las secciones son opcionales.
Las líneas que comienzan con el signo de almohadilla (#) son comentarios.
Recursos adicionales
-
La página de manual
tuned.conf(5).
2.3. Perfiles ajustados distribuidos con RHEL
La siguiente es una lista de perfiles que se instalan con Tuned en Red Hat Enterprise Linux.
Puede haber más perfiles específicos de productos o de terceros en Tuned. Dichos perfiles suelen ser proporcionados por paquetes RPM independientes.
balanced-
El perfil de ahorro de energía por defecto. Pretende ser un compromiso entre el rendimiento y el consumo de energía. Utiliza el autoescalado y el autoajuste siempre que es posible. El único inconveniente es el aumento de la latencia. En la versión actual de Tuned, habilita los plugins de CPU, disco, audio y vídeo, y activa el regulador de CPU
conservative. La opciónradeon_powersaveutiliza el valor dedpm-balancedsi está soportado, de lo contrario se establece enauto. powersaveUn perfil para obtener el máximo rendimiento de ahorro de energía. Puede limitar el rendimiento para minimizar el consumo real de energía. En la versión actual de Tuned, permite la suspensión automática de USB, el ahorro de energía de WiFi y el ahorro de energía de la Gestión de Energía de Enlaces Agresivos (ALPM) para los adaptadores de host SATA. También programa el ahorro de energía de los núcleos múltiples para los sistemas con una baja tasa de despertar y activa el regulador
ondemand. Activa el ahorro de energía de audio AC97 o, dependiendo de tu sistema, el ahorro de energía HDA-Intel con un tiempo de espera de 10 segundos. Si tu sistema contiene una tarjeta gráfica Radeon compatible con KMS activado, el perfil la configura para el ahorro de energía automático. En los ASUS Eee PC, se habilita un Super Hybrid Engine dinámico.NotaEn algunos casos, el perfil
balancedes más eficaz que el perfilpowersave.Considere que hay una cantidad definida de trabajo que debe realizarse, por ejemplo, un archivo de vídeo que debe ser transcodificado. Su máquina puede consumir menos energía si la transcodificación se hace a plena potencia, porque la tarea termina rápidamente, la máquina empieza a estar en reposo y puede pasar automáticamente a modos de ahorro de energía muy eficientes. Por otro lado, si transcodificas el archivo con una máquina estrangulada, la máquina consume menos energía durante la transcodificación, pero el proceso tarda más y la energía total consumida puede ser mayor.
Por ello, el perfil
balancedpuede ser generalmente una mejor opción.throughput-performance-
Un perfil de servidor optimizado para un alto rendimiento. Desactiva los mecanismos de ahorro de energía y activa los ajustes de
sysctlque mejoran el rendimiento del disco y la red IO. El gobernador de la CPU está configurado enperformance. latency-performance-
Un perfil de servidor optimizado para una baja latencia. Desactiva los mecanismos de ahorro de energía y habilita los ajustes de
sysctlque mejoran la latencia. El gobernador de la CPU está configurado enperformancey la CPU está bloqueada en los estados de baja C (por PM QoS). network-latency-
Un perfil para el ajuste de la red de baja latencia. Se basa en el perfil
latency-performance. Además, desactiva las páginas enormes transparentes y el equilibrio NUMA, y ajusta otros parámetros relacionados con la redsysctl. network-throughput-
Un perfil para el ajuste de la red de rendimiento. Se basa en el perfil
throughput-performance. Además, aumenta los búferes de red del núcleo. virtual-guest-
Un perfil diseñado para máquinas virtuales de Red Hat Enterprise Linux 8 y huéspedes de VMWare basado en el perfil
throughput-performanceque, entre otras tareas, disminuye el intercambio de memoria virtual y aumenta los valores de readahead de disco. No desactiva las barreras de disco. virtual-host-
Un perfil diseñado para hosts virtuales basado en el perfil
throughput-performanceque, entre otras tareas, disminuye el swappiness de la memoria virtual, aumenta los valores de readahead del disco y permite un valor más agresivo de writeback de páginas sucias. oracle-
Un perfil optimizado para las cargas de bases de datos Oracle basado en el perfil
throughput-performance. Además, desactiva las páginas enormes transparentes y modifica otros parámetros del kernel relacionados con el rendimiento. Este perfil lo proporciona el paquetetuned-profiles-oracle. desktop-
Un perfil optimizado para ordenadores de sobremesa, basado en el perfil
balanced. Además, permite los autogrupos del programador para mejorar la respuesta de las aplicaciones interactivas. cpu-partitioningEl perfil
cpu-partitioningdivide las CPUs del sistema en CPUs aisladas y de mantenimiento. Para reducir el jitter y las interrupciones en una CPU aislada, el perfil borra la CPU aislada de los procesos del espacio de usuario, los hilos móviles del kernel, los gestores de interrupciones y los temporizadores del kernel.Una CPU de mantenimiento puede ejecutar todos los servicios, procesos de shell e hilos del kernel.
Puede configurar el perfil de
cpu-partitioningen el archivo/etc/tuned/cpu-partitioning-variables.conf. Las opciones de configuración son:isolated_cores=cpu-list-
Enumera las CPUs a aislar. La lista de CPUs aisladas está separada por comas o el usuario puede especificar el rango. Se puede especificar un rango utilizando un guión, como
3-5. Esta opción es obligatoria. Cualquier CPU que falte en esta lista se considera automáticamente una CPU de mantenimiento. no_balance_cores=cpu-list-
Enumera las CPUs que no son consideradas por el kernel durante el balanceo de carga de procesos en todo el sistema. Esta opción es opcional. Suele ser la misma lista que
isolated_cores.
Para más información sobre
cpu-partitioning, consulte la página de manualtuned-profiles-cpu-partitioning(7).postgresql-
Un perfil optimizado para cargas de bases de datos PostgreSQL basado en el perfil
throughput-performance. Además, deshabilita las páginas enormes transparentes y modifica otros parámetros del kernel relacionados con el rendimiento. Este perfil es proporcionado por el paquetetuned-profiles-postgresql.
Perfiles en tiempo real
Los perfiles de tiempo real están pensados para sistemas que ejecutan el kernel de tiempo real. Sin una compilación especial del kernel, no configuran el sistema para que sea en tiempo real. En RHEL, los perfiles están disponibles en repositorios adicionales.
Están disponibles los siguientes perfiles en tiempo real:
realtimeUtilización en sistemas bare-metal en tiempo real.
Proporcionado por el paquete
tuned-profiles-realtime, que está disponible en los repositorios RT o NFV.realtime-virtual-hostUtilizar en un host de virtualización configurado para tiempo real.
Proporcionado por el paquete
tuned-profiles-nfv-host, que está disponible en el repositorio NFV.realtime-virtual-guestUso en un huésped de virtualización configurado para tiempo real.
Proporcionado por el paquete
tuned-profiles-nfv-guest, que está disponible en el repositorio NFV.
2.4. Sintonización estática y dinámica en Tuned
Esta sección explica la diferencia entre las dos categorías de ajuste del sistema que aplica Tuned: static y dynamic.
- Sintonización estática
-
Consiste principalmente en la aplicación de los ajustes predefinidos de
sysctlysysfsy en la activación puntual de varias herramientas de configuración comoethtool. - Sintonización dinámica
Observa cómo se utilizan los distintos componentes del sistema durante todo el tiempo de funcionamiento del mismo. Tuned ajusta la configuración del sistema de forma dinámica basándose en esa información de supervisión.
Por ejemplo, el disco duro se utiliza mucho durante el arranque y el inicio de sesión, pero apenas se usa después, cuando el usuario puede trabajar principalmente con aplicaciones como navegadores web o clientes de correo electrónico. Del mismo modo, la CPU y los dispositivos de red se utilizan de forma diferente en distintos momentos. Tuned supervisa la actividad de estos componentes y reacciona a los cambios en su uso.
Por defecto, el ajuste dinámico está desactivado. Para activarla, edite el archivo
/etc/tuned/tuned-main.confy cambie la opcióndynamic_tuningpor1. A continuación, Tuned analiza periódicamente las estadísticas del sistema y las utiliza para actualizar los ajustes del sistema. Para configurar el intervalo de tiempo en segundos entre estas actualizaciones, utilice la opciónupdate_interval.Los algoritmos de ajuste dinámico implementados actualmente intentan equilibrar el rendimiento y el ahorro de energía, por lo que están desactivados en los perfiles de rendimiento. El ajuste dinámico para plug-ins individuales puede activarse o desactivarse en los perfiles de Tuned.
Ejemplo 2.2. Ajuste estático y dinámico en una estación de trabajo
En una estación de trabajo típica de oficina, la interfaz de red Ethernet está inactiva la mayor parte del tiempo. Sólo entran y salen algunos correos electrónicos o se cargan algunas páginas web.
Para este tipo de cargas, la interfaz de red no tiene que funcionar a toda velocidad todo el tiempo, como lo hace por defecto. Tuned dispone de un complemento de monitorización y ajuste para dispositivos de red que puede detectar esta baja actividad y reducir automáticamente la velocidad de esa interfaz, lo que suele traducirse en un menor consumo de energía.
Si la actividad en la interfaz aumenta durante un periodo de tiempo prolongado, por ejemplo, porque se está descargando una imagen de DVD o se abre un correo electrónico con un archivo adjunto de gran tamaño, Tuned lo detecta y ajusta la velocidad de la interfaz al máximo para ofrecer el mejor rendimiento mientras el nivel de actividad es alto.
Este principio se utiliza también para otros complementos para la CPU y los discos.
2.5. Modo sin demonio ajustado
Puede ejecutar Tuned en el modo no-daemon, que no requiere ninguna memoria residente. En este modo, Tuned aplica la configuración y sale.
Por defecto, el modo no-daemon está desactivado porque en este modo faltan muchas de las funciones de Tuned, entre ellas:
- Soporte de D-Bus
- Soporte de conexión en caliente
- Soporte de retroceso para los ajustes
Para activar el modo no-daemon, incluya la siguiente línea en el archivo /etc/tuned/tuned-main.conf:
daemon = 0
2.6. Instalación y habilitación de Tuned
Este procedimiento instala y habilita la aplicación Tuned, instala los perfiles de Tuned y preestablece un perfil predeterminado de Tuned para su sistema.
Procedimiento
Instale el paquete
tuned:# yum install tuned
Habilite e inicie el servicio
tuned:# systemctl enable --now tuned
Opcionalmente, instale los perfiles de Tuned para los sistemas en tiempo real:
# yum install tuned-profiles-realtime tuned-profiles-nfv
Verifique que el perfil Tuned esté activo y aplicado:
$ tuned-adm active Current active profile: balanced$ tuned-adm verify Verfication succeeded, current system settings match the preset profile. See tuned log file ('/var/log/tuned/tuned.log') for details.
2.7. Listado de perfiles disponibles en Tuned
Este procedimiento enumera todos los perfiles de Tuned que están actualmente disponibles en su sistema.
Procedimiento
Para listar todos los perfiles disponibles de Tuned en su sistema, utilice:
$ tuned-adm list Available profiles: - balanced - General non-specialized tuned profile - desktop - Optimize for the desktop use-case - latency-performance - Optimize for deterministic performance at the cost of increased power consumption - network-latency - Optimize for deterministic performance at the cost of increased power consumption, focused on low latency network performance - network-throughput - Optimize for streaming network throughput, generally only necessary on older CPUs or 40G+ networks - powersave - Optimize for low power consumption - throughput-performance - Broadly applicable tuning that provides excellent performance across a variety of common server workloads - virtual-guest - Optimize for running inside a virtual guest - virtual-host - Optimize for running KVM guests Current active profile: balanced
Para mostrar sólo el perfil actualmente activo, utilice:
$ tuned-adm active Current active profile: balanced
Recursos adicionales
-
La página de manual
tuned-adm(8).
2.8. Cómo establecer un perfil de sintonía
Este procedimiento activa un perfil seleccionado de Tuned en su sistema.
Requisitos previos
-
El servicio
tunedestá funcionando. Consulte Sección 2.6, “Instalación y habilitación de Tuned” para más detalles.
Procedimiento
Opcionalmente, puede dejar que Tuned le recomiende el perfil más adecuado para su sistema:
# tuned-adm recommend balancedActivar un perfil:
# perfil tuned-adm selected-profileTambién puede activar una combinación de varios perfiles:
# perfil tuned-adm profile1 profile2
Ejemplo 2.3. Una máquina virtual optimizada para un bajo consumo de energía
El siguiente ejemplo optimiza el sistema para que se ejecute en una máquina virtual con el mejor rendimiento y al mismo tiempo lo ajusta para que tenga un bajo consumo de energía, mientras que el bajo consumo de energía es la prioridad:
# tuned-adm profile virtual-guest powersave
Vea el perfil activo actual de Tuned en su sistema:
# tuned-adm active Current active profile: selected-profileReinicie el sistema:
# rebote
Pasos de verificación
Compruebe que el perfil Tuned está activo y aplicado:
$ tuned-adm verify Verfication succeeded, current system settings match the preset profile. See tuned log file ('/var/log/tuned/tuned.log') for details.
Recursos adicionales
-
La página de manual
tuned-adm(8)
2.9. Desactivación de Tuned
Este procedimiento desactiva Tuned y restablece todos los ajustes del sistema afectados a su estado original antes de que Tuned los modificara.
Procedimiento
Para desactivar todas las sintonías temporalmente:
# tuned-adm off
Los ajustes se aplican de nuevo tras el reinicio del servicio
tuned.O bien, para detener y desactivar el servicio
tunedde forma permanente:# systemctl disable --now tuned
Recursos adicionales
-
La página de manual
tuned-adm(8).
Capítulo 3. Personalización de los perfiles Tuned
Puede crear o modificar los perfiles de Tuned para optimizar el rendimiento del sistema para su caso de uso previsto.
Requisitos previos
- Instale y active Tuned como se describe en Sección 2.6, “Instalación y habilitación de Tuned”.
3.1. Perfiles afinados
Un análisis detallado de un sistema puede llevar mucho tiempo. Tuned ofrece una serie de perfiles predefinidos para casos de uso típicos. También puedes crear, modificar y eliminar perfiles.
Los perfiles proporcionados con Tuned se dividen en las siguientes categorías:
- Perfiles de ahorro de energía
- Perfiles que aumentan el rendimiento
Los perfiles para aumentar el rendimiento incluyen perfiles que se centran en los siguientes aspectos:
- Baja latencia para el almacenamiento y la red
- Alto rendimiento para el almacenamiento y la red
- Rendimiento de la máquina virtual
- Rendimiento del host de virtualización
El perfil por defecto
Durante la instalación, se selecciona automáticamente el mejor perfil para su sistema. Actualmente, el perfil por defecto se selecciona según las siguientes reglas personalizables:
| Medio ambiente | Perfil por defecto | Objetivo |
|---|---|---|
| Nodos de cálculo |
| El mejor rendimiento de la producción |
| Máquinas virtuales |
|
El mejor rendimiento. Si no te interesa el mejor rendimiento, puedes cambiarlo por el perfil |
| Otros casos |
| Rendimiento y consumo de energía equilibrados |
Perfiles fusionados
Como característica experimental, es posible seleccionar más perfiles a la vez. Tuned intentará fusionarlos durante la carga.
Si hay conflictos, la configuración del último perfil especificado tiene prioridad.
Ejemplo 3.1. Bajo consumo de energía en un huésped virtual
El siguiente ejemplo optimiza el sistema para que se ejecute en una máquina virtual para obtener el mejor rendimiento y, al mismo tiempo, lo ajusta para que tenga un bajo consumo de energía, mientras que el bajo consumo de energía es la prioridad:
# tuned-adm profile virtual-guest powersave
La fusión se realiza automáticamente sin comprobar si la combinación de parámetros resultante tiene sentido. En consecuencia, la función podría ajustar algunos parámetros en sentido contrario, lo que podría ser contraproducente: por ejemplo, ajustar el disco para un alto rendimiento mediante el perfil throughput-performance y, al mismo tiempo, ajustar el spindown del disco al valor bajo mediante el perfil spindown-disk.
La ubicación de los perfiles
Tuned almacena los perfiles en los siguientes directorios:
/usr/lib/tuned/-
Los perfiles específicos de la distribución se almacenan en el directorio. Cada perfil tiene su propio directorio. El perfil consiste en el archivo de configuración principal llamado
tuned.conf, y opcionalmente otros archivos, por ejemplo scripts de ayuda. /etc/tuned/-
Si necesita personalizar un perfil, copie el directorio del perfil en el directorio que se utiliza para los perfiles personalizados. Si hay dos perfiles con el mismo nombre, se utiliza el perfil personalizado situado en
/etc/tuned/.
La sintaxis de la configuración del perfil
El archivo tuned.conf puede contener una sección [main] y otras secciones para configurar las instancias del plug-in. Sin embargo, todas las secciones son opcionales.
Las líneas que comienzan con el signo de almohadilla (#) son comentarios.
Recursos adicionales
-
La página de manual
tuned.conf(5).
3.2. Herencia entre perfiles Tuned
Tuned los perfiles pueden basarse en otros perfiles y modificar sólo algunos aspectos de su perfil principal.
La sección [main] de los perfiles Tuned reconoce la opción include:
[main]
include=parentTodos los ajustes del parent se cargan en este perfil child. En las siguientes secciones, el perfil child puede anular ciertos ajustes heredados del parent o añadir nuevos ajustes que no están presentes en el perfil parent perfil.
Puede crear su propio perfil child en el directorio /etc/tuned/ basándose en un perfil preinstalado en /usr/lib/tuned/ con sólo algunos parámetros ajustados.
Si el parent perfil se actualiza, por ejemplo, tras una actualización de Tuned, los cambios se reflejan en el perfil de child.
Ejemplo 3.2. Un perfil de ahorro de energía basado en el equilibrio
A continuación se muestra un ejemplo de perfil personalizado que amplía el perfil balanced y establece la gestión de energía de enlace agresiva (ALPM) para todos los dispositivos al máximo de ahorro de energía.
[main] include=balanced [scsi_host] alpm=min_power
Recursos adicionales
-
La página de manual
tuned.conf(5)
3.3. Sintonización estática y dinámica en Tuned
Esta sección explica la diferencia entre las dos categorías de ajuste del sistema que aplica Tuned: static y dynamic.
- Sintonización estática
-
Consiste principalmente en la aplicación de los ajustes predefinidos de
sysctlysysfsy en la activación puntual de varias herramientas de configuración comoethtool. - Sintonización dinámica
Observa cómo se utilizan los distintos componentes del sistema durante todo el tiempo de funcionamiento del mismo. Tuned ajusta la configuración del sistema de forma dinámica basándose en esa información de supervisión.
Por ejemplo, el disco duro se utiliza mucho durante el arranque y el inicio de sesión, pero apenas se usa después, cuando el usuario puede trabajar principalmente con aplicaciones como navegadores web o clientes de correo electrónico. Del mismo modo, la CPU y los dispositivos de red se utilizan de forma diferente en distintos momentos. Tuned supervisa la actividad de estos componentes y reacciona a los cambios en su uso.
Por defecto, el ajuste dinámico está desactivado. Para activarla, edite el archivo
/etc/tuned/tuned-main.confy cambie la opcióndynamic_tuningpor1. A continuación, Tuned analiza periódicamente las estadísticas del sistema y las utiliza para actualizar los ajustes del sistema. Para configurar el intervalo de tiempo en segundos entre estas actualizaciones, utilice la opciónupdate_interval.Los algoritmos de ajuste dinámico implementados actualmente intentan equilibrar el rendimiento y el ahorro de energía, por lo que están desactivados en los perfiles de rendimiento. El ajuste dinámico para plug-ins individuales puede activarse o desactivarse en los perfiles de Tuned.
Ejemplo 3.3. Ajuste estático y dinámico en una estación de trabajo
En una estación de trabajo típica de oficina, la interfaz de red Ethernet está inactiva la mayor parte del tiempo. Sólo entran y salen algunos correos electrónicos o se cargan algunas páginas web.
Para este tipo de cargas, la interfaz de red no tiene que funcionar a toda velocidad todo el tiempo, como lo hace por defecto. Tuned dispone de un complemento de monitorización y ajuste para dispositivos de red que puede detectar esta baja actividad y reducir automáticamente la velocidad de esa interfaz, lo que suele traducirse en un menor consumo de energía.
Si la actividad en la interfaz aumenta durante un periodo de tiempo prolongado, por ejemplo, porque se está descargando una imagen de DVD o se abre un correo electrónico con un archivo adjunto de gran tamaño, Tuned lo detecta y ajusta la velocidad de la interfaz al máximo para ofrecer el mejor rendimiento mientras el nivel de actividad es alto.
Este principio se utiliza también para otros complementos para la CPU y los discos.
3.4. Complementos afinados
Los plug-ins son módulos en los perfiles de Tuned que Tuned utiliza para supervisar u optimizar diferentes dispositivos en el sistema.
Tuned utiliza dos tipos de plug-ins:
- plug-ins de monitorización
- plug-ins de afinación
Control de los plug-ins
Los plug-ins de monitorización se utilizan para obtener información de un sistema en funcionamiento. La salida de los plug-ins de monitorización puede ser utilizada por los plug-ins de ajuste para el ajuste dinámico.
Los plug-ins de monitorización se instancian automáticamente siempre que sus métricas sean necesarias para cualquiera de los plug-ins de ajuste habilitados. Si dos plug-ins de ajuste necesitan los mismos datos, sólo se crea una instancia del plug-in de monitorización y se comparten los datos.
Plug-ins de sintonía
Cada plug-in de sintonización sintoniza un subsistema individual y toma varios parámetros que se rellenan a partir de los perfiles sintonizados. Cada subsistema puede tener varios dispositivos, como múltiples CPUs o tarjetas de red, que son manejados por instancias individuales de los plug-ins de ajuste. También se admiten ajustes específicos para dispositivos individuales.
Sintaxis de los plug-ins en los perfiles Tuned
Las secciones que describen las instancias del plug-in tienen el siguiente formato:
[NAME] type=TYPE devices=DEVICES
- NOMBRE
- es el nombre de la instancia del complemento tal y como se utiliza en los registros. Puede ser una cadena arbitraria.
- TIPO
- es el tipo de complemento de afinación.
- DISPOSITIVOS
es la lista de dispositivos que maneja esta instancia de plug-in.
La línea
devicespuede contener una lista, un comodín (*) y la negación (!). Si no hay una líneadevices, todos los dispositivos presentes o posteriormente conectados en el sistema del TYPE son manejados por la instancia del complemento. Esto es lo mismo que utilizar la opcióndevices=*.Ejemplo 3.4. Combinación de dispositivos en bloque con un complemento
El siguiente ejemplo coincide con todos los dispositivos de bloque que empiezan por
sd, comosdaosdb, y no desactiva las barreras en ellos:[data_disk] type=disk devices=sd* disable_barriers=false
El siguiente ejemplo coincide con todos los dispositivos de bloque excepto
sda1ysda2:[data_disk] type=disk devices=!sda1, !sda2 disable_barriers=false
Si no se especifica ninguna instancia de un complemento, el complemento no está activado.
Si el complemento admite más opciones, también pueden especificarse en la sección del complemento. Si no se especifica la opción y no se ha especificado previamente en el complemento incluido, se utiliza el valor por defecto.
Sintaxis breve del plug-in
Si no necesita nombres personalizados para la instancia del complemento y sólo hay una definición de la instancia en su archivo de configuración, Tuned admite la siguiente sintaxis corta:
[TYPE] devices=DEVICES
En este caso, es posible omitir la línea type. La instancia es entonces referida con un nombre, el mismo que el tipo. El ejemplo anterior podría entonces reescribirse en:
Ejemplo 3.5. Correspondencia de los dispositivos de bloque mediante la sintaxis corta
[disk] devices=sdb* disable_barriers=false
Definiciones de plug-in conflictivas en un perfil
Si la misma sección se especifica más de una vez utilizando la opción include, las configuraciones se fusionan. Si no se pueden fusionar debido a un conflicto, la última definición en conflicto anula la configuración anterior. Si no sabe qué se definió anteriormente, puede utilizar la opción booleana replace y establecerla como true. Esto hace que todas las definiciones anteriores con el mismo nombre se sobrescriban y la fusión no se produzca.
También puede desactivar el complemento especificando la opción enabled=false. Esto tiene el mismo efecto que si la instancia nunca se hubiera definido. Desactivar el complemento es útil si está redefiniendo la definición anterior desde la opción include y no quiere que el complemento esté activo en su perfil personalizado.
Funcionalidad no implementada en ningún plug-in
Tuned incluye la capacidad de ejecutar cualquier comando de shell como parte de la activación o desactivación de un perfil de ajuste. Esto permite ampliar los perfiles de Tuned con funcionalidades que aún no se han integrado en Tuned.
Puede especificar comandos de shell arbitrarios utilizando el complemento script.
Recursos adicionales
-
La página de manual
tuned.conf(5)
3.5. Plug-ins disponibles en Tuned
Esta sección enumera todos los plug-ins de monitorización y ajuste disponibles actualmente en Tuned.
Control de los plug-ins
En la actualidad, se han implementado los siguientes complementos de supervisión:
disk- Obtiene la carga del disco (número de operaciones IO) por dispositivo e intervalo de medición.
net- Obtiene la carga de red (número de paquetes transferidos) por tarjeta de red e intervalo de medición.
load- Obtiene la carga de la CPU por CPU e intervalo de medición.
Plug-ins de sintonía
Actualmente, se han implementado los siguientes plug-ins de sintonización. Sólo algunos de estos plug-ins implementan el ajuste dinámico. También se enumeran las opciones que admiten los plug-ins:
cpuEstablece el gobernador de la CPU al valor especificado por la opción
governory cambia dinámicamente la latencia de acceso directo a la memoria (DMA) de la CPU de la calidad del servicio de gestión de la energía (PM QoS) según la carga de la CPU.Si la carga de la CPU es inferior al valor especificado por la opción
load_threshold, la latencia se establece en el valor especificado por la opciónlatency_high, en caso contrario se establece en el valor especificado porlatency_low.También puede forzar la latencia a un valor específico y evitar que siga cambiando dinámicamente. Para ello, establezca la opción
force_latencyen el valor de latencia deseado.eeepc_sheAjusta dinámicamente la velocidad del bus frontal (FSB) en función de la carga de la CPU.
Esta característica se puede encontrar en algunos netbooks y también se conoce como ASUS Super Hybrid Engine (SHE).
Si la carga de la CPU es menor o igual al valor especificado por la opción
load_threshold_powersave, el complemento establece la velocidad del FSB al valor especificado por la opciónshe_powersave. Si la carga de la CPU es mayor o igual al valor especificado por la opciónload_threshold_normal, establece la velocidad del FSB al valor especificado por la opciónshe_normal.La sintonización estática no es compatible y el complemento se desactiva de forma transparente si Tuned no detecta el soporte de hardware para esta función.
net-
Configura la funcionalidad Wake-on-LAN con los valores especificados por la opción
wake_on_lan. Utiliza la misma sintaxis que la utilidadethtool. También cambia dinámicamente la velocidad de la interfaz según la utilización de la misma. sysctlEstablece varios ajustes de
sysctlespecificados por las opciones del plug-in.La sintaxis es
name=value, donde name es el mismo que el nombre proporcionado por la utilidadsysctl.Utilice el plug-in
sysctlsi necesita cambiar los ajustes del sistema que no están cubiertos por otros plug-ins disponibles en Tuned. Si los ajustes están cubiertos por algunos plug-ins específicos, prefiera estos plug-ins.usbEstablece el tiempo de espera de autosuspensión de los dispositivos USB al valor especificado por el parámetro
autosuspend.El valor
0significa que la suspensión automática está desactivada.vmActiva o desactiva las páginas enormes transparentes en función del valor de la opción
transparent_hugepages.Los valores válidos de la opción
transparent_hugepagesson:- "Siempre"
- "nunca"
- "madvise\N"
audioEstablece el tiempo de espera de autosuspensión para los códecs de audio al valor especificado por la opción
timeout.Actualmente, se admiten los códecs
snd_hda_intelysnd_ac97_codec. El valor0significa que la autosuspensión está desactivada. También puede forzar el reinicio del controlador estableciendo la opción booleanareset_controlleratrue.diskEstablece el elevador de disco al valor especificado por la opción
elevator.También se fija:
-
APM al valor especificado por la opción
apm -
Cuántica del programador al valor especificado por la opción
scheduler_quantum -
Tiempo de espera del disco al valor especificado por la opción
spindown -
La cabeza de disco al valor especificado por el parámetro
readahead -
La cabeza de lectura del disco actual a un valor multiplicado por la constante especificada por la opción
readahead_multiply
Además, este plug-in cambia dinámicamente la gestión avanzada de la energía y la configuración del tiempo de espera de la unidad en función de la utilización actual de la unidad. El ajuste dinámico puede controlarse mediante la opción booleana
dynamicy está activado por defecto.-
APM al valor especificado por la opción
scsi_hostOpciones de sintonía para los hosts SCSI.
Establece la gestión de energía de enlace agresiva (ALPM) al valor especificado por la opción
alpm.mounts-
Activa o desactiva las barreras para los montajes según el valor booleano de la opción
disable_barriers. scriptEjecuta un script o binario externo cuando se carga o descarga el perfil. Puede elegir un ejecutable arbitrario.
ImportanteEl plug-in
scriptse proporciona principalmente para la compatibilidad con versiones anteriores. Prefiera otros plug-ins de Tuned si cubren la funcionalidad requerida.Tuned llama al ejecutable con uno de los siguientes argumentos:
-
startal cargar el perfil -
stopal descargar el perfil
Debe implementar correctamente la acción
stopen su ejecutable y revertir todos los ajustes que haya cambiado durante la acciónstart. De lo contrario, el paso de reversión después de cambiar su perfil Tuned no funcionará.Los scripts Bash pueden importar la biblioteca Bash
/usr/lib/tuned/functionsy utilizar las funciones allí definidas. Utilice estas funciones sólo para la funcionalidad que no es proporcionada de forma nativa por Tuned. Si el nombre de una función comienza con un guión bajo, como_wifi_set_power_level, considera que la función es privada y no la uses en tus scripts, porque podría cambiar en el futuro.Especifique la ruta del ejecutable utilizando el parámetro
scripten la configuración del plug-in.Ejemplo 3.6. Ejecución de un script Bash desde un perfil
Para ejecutar un script Bash llamado
script.shque se encuentra en el directorio del perfil, utilice:[script] script=${i:PROFILE_DIR}/script.sh-
sysfsEstablece varios ajustes de
sysfsespecificados por las opciones del plug-in.La sintaxis es
name=value, donde name es la ruta de acceso asysfs.Utilice este plugin en caso de que necesite cambiar algunos ajustes que no están cubiertos por otros plug-ins. Prefiera plug-ins específicos si cubren los ajustes necesarios.
videoEstablece varios niveles de ahorro de energía en las tarjetas de vídeo. Actualmente, sólo son compatibles las tarjetas Radeon.
El nivel de powersave se puede especificar mediante la opción
radeon_powersave. Los valores admitidos son:-
default -
auto -
low -
mid -
high -
dynpm -
dpm-battery -
dpm-balanced -
dpm-perfomance
Para más detalles, consulte www.x.org. Tenga en cuenta que este complemento es experimental y la opción podría cambiar en futuras versiones.
-
bootloaderAñade opciones a la línea de comandos del kernel. Este complemento sólo es compatible con el cargador de arranque GRUB 2.
Se puede especificar una ubicación no estándar del archivo de configuración de GRUB 2 mediante la opción
grub2_cfg_file.Las opciones del kernel se añaden a la configuración actual de GRUB y sus plantillas. Es necesario reiniciar el sistema para que las opciones del kernel surtan efecto.
Si se cambia a otro perfil o se detiene manualmente el servicio
tunedse eliminan las opciones adicionales. Si apagas o reinicias el sistema, las opciones del kernel persisten en el archivogrub.cfg.Las opciones del kernel se pueden especificar con la siguiente sintaxis:
cmdline=arg1 arg2 .. argN
Ejemplo 3.7. Modificación de la línea de comandos del kernel
Por ejemplo, para añadir la opción del núcleo
quieta un perfil Tuned, incluya las siguientes líneas en el archivotuned.conf:[bootloader] cmdline=quiet
El siguiente es un ejemplo de un perfil personalizado que añade la opción
isolcpus=2a la línea de comandos del kernel:[bootloader] cmdline=isolcpus=2
3.6. Variables y funciones integradas en los perfiles Tuned
Las variables y las funciones incorporadas se amplían en tiempo de ejecución cuando se activa un perfil Tuned.
El uso de las variables de Tuned reduce la cantidad de datos necesarios en los perfiles de Tuned. También puede:
- Utilizar varias funciones incorporadas junto con las variables de Tuned
- Crear funciones personalizadas en Python y añadirlas a Tuned en forma de plug-ins
Variables
No hay variables predefinidas en los perfiles de Tuned. Puede definir sus propias variables creando la sección [variables] en un perfil y utilizando la siguiente sintaxis:
[variables] variable_name=value
Para ampliar el valor de una variable en un perfil, utilice la siguiente sintaxis:
${variable_name}Ejemplo 3.8. Aislamiento de los núcleos de la CPU mediante variables
En el siguiente ejemplo, la variable ${isolated_cores} se expande a 1,2; por lo que el kernel arranca con la opción isolcpus=1,2:
[variables]
isolated_cores=1,2
[bootloader]
cmdline=isolcpus=${isolated_cores}
Las variables se pueden especificar en un archivo separado. Por ejemplo, puede añadir las siguientes líneas a tuned.conf:
[variables]
include=/etc/tuned/my-variables.conf
[bootloader]
cmdline=isolcpus=${isolated_cores}
Si añade la opción isolated_cores=1,2 al archivo /etc/tuned/my-variables.conf, el kernel arranca con la opción isolcpus=1,2.
Funciones
Para llamar a una función, utilice la siguiente sintaxis:
${f:function_name:argument_1:argument_2}
Para ampliar la ruta del directorio donde se encuentran el perfil y el archivo tuned.conf, utilice la función PROFILE_DIR, que requiere una sintaxis especial:
${i:PROFILE_DIR}Ejemplo 3.9. Aislamiento de los núcleos de la CPU mediante variables y funciones incorporadas
En el siguiente ejemplo, la variable ${non_isolated_cores} se expande a 0,3-5, y la función incorporada cpulist_invert se llama con el argumento 0,3-5:
[variables]
non_isolated_cores=0,3-5
[bootloader]
cmdline=isolcpus=${f:cpulist_invert:${non_isolated_cores}}
La función cpulist_invert invierte la lista de CPUs. Para una máquina de 6 CPUs, la inversión es 1,2, y el kernel arranca con la opción de línea de comandos isolcpus=1,2.
Recursos adicionales
-
La página de manual
tuned.conf(5)
3.7. Funciones incorporadas disponibles en los perfiles Tuned
Las siguientes funciones incorporadas están disponibles en todos los perfiles de Tuned:
PROFILE_DIR-
Devuelve la ruta del directorio donde se encuentran el perfil y el archivo
tuned.conf. exec- Ejecuta un proceso y devuelve su salida.
assertion- Compara dos argumentos. Si son do not match, la función registra el texto del primer argumento y aborta la carga del perfil.
assertion_non_equal- Compara dos argumentos. Si son match, la función registra el texto del primer argumento y aborta la carga del perfil.
kb2s- Convierte los kilobytes en sectores de disco.
s2kb- Convierte los sectores del disco en kilobytes.
strip- Crea una cadena a partir de todos los argumentos pasados y elimina los espacios en blanco iniciales y finales.
virt_checkComprueba si Tuned se está ejecutando dentro de una máquina virtual (VM) o en el metal desnudo:
- Dentro de una VM, la función devuelve el primer argumento.
- En bare metal, la función devuelve el segundo argumento, incluso en caso de error.
cpulist_invert-
Invierte una lista de CPUs para hacer su complemento. Por ejemplo, en un sistema con 4 CPUs, numeradas del 0 al 3, la inversión de la lista
0,2,3es1. cpulist2hex- Convierte una lista de CPU en una máscara de CPU hexadecimal.
cpulist2hex_invert- Convierte una lista de CPU en una máscara de CPU hexadecimal y la invierte.
hex2cpulist- Convierte una máscara de CPU hexadecimal en una lista de CPU.
cpulist_online- Comprueba si las CPUs de la lista están conectadas. Devuelve la lista que contiene sólo las CPUs en línea.
cpulist_present- Comprueba si las CPUs de la lista están presentes. Devuelve la lista que contiene sólo las CPUs presentes.
cpulist_unpack-
Descompone una lista de CPU en forma de
1-3,4a1,2,3,4. cpulist_pack-
Empaqueta una lista de CPU en forma de
1,2,3,5a1-3,5.
3.8. Creación de nuevos perfiles Tuned
Este procedimiento crea un nuevo perfil Tuned con reglas de rendimiento personalizadas.
Requisitos previos
-
El servicio
tunedestá instalado y funcionando. Consulte Sección 2.6, “Instalación y habilitación de Tuned” para obtener más detalles.
Procedimiento
En el directorio
/etc/tuned/, cree un nuevo directorio con el mismo nombre que el perfil que desea crear:# mkdir /etc/tuned/my-profileEn el nuevo directorio, cree un archivo llamado
tuned.conf. Añada en él una sección[main]y definiciones de plug-in, según sus necesidades.Por ejemplo, véase la configuración del perfil
balanced:[main] summary=General non-specialized tuned profile [cpu] governor=conservative energy_perf_bias=normal [audio] timeout=10 [video] radeon_powersave=dpm-balanced, auto [scsi_host] alpm=medium_power
Para activar el perfil, utilice:
# perfil tuned-adm my-profileCompruebe que el perfil Tuned está activo y que se aplican los ajustes del sistema:
$ tuned-adm active Current active profile: my-profile$ tuned-adm verify Verfication succeeded, current system settings match the preset profile. See tuned log file ('/var/log/tuned/tuned.log') for details.
Recursos adicionales
-
La página de manual
tuned.conf(5)
3.9. Modificación de los perfiles Tuned existentes
Este procedimiento crea un perfil hijo modificado basado en un perfil existente Tuned.
Requisitos previos
-
El servicio
tunedestá instalado y funcionando. Consulte Sección 2.6, “Instalación y habilitación de Tuned” para obtener más detalles.
Procedimiento
En el directorio
/etc/tuned/, cree un nuevo directorio con el mismo nombre que el perfil que desea crear:# mkdir /etc/tuned/modified-profileEn el nuevo directorio, cree un archivo llamado
tuned.conf, y configure la sección[main]como sigue:[main] include=parent-profileSustituya parent-profile por el nombre del perfil que está modificando.
Incluya las modificaciones de su perfil.
Ejemplo 3.10. Disminución de la caducidad en el perfil de rendimiento de la producción
Para utilizar la configuración del perfil
throughput-performancey cambiar el valor devm.swappinessa 5, en lugar del 10 predeterminado, utilice:[main] include=throughput-performance [sysctl] vm.swappiness=5
Para activar el perfil, utilice:
# perfil tuned-adm modified-profileCompruebe que el perfil Tuned está activo y que se aplican los ajustes del sistema:
$ tuned-adm active Current active profile: my-profile$ tuned-adm verify Verfication succeeded, current system settings match the preset profile. See tuned log file ('/var/log/tuned/tuned.log') for details.
Recursos adicionales
-
La página de manual
tuned.conf(5)
3.10. Configuración del programador de discos mediante Tuned
Este procedimiento crea y habilita un perfil Tuned que establece un programador de disco determinado para los dispositivos de bloque seleccionados. La configuración persiste a través de los reinicios del sistema.
En los siguientes comandos y la configuración, reemplazar:
-
device con el nombre del dispositivo de bloque, por ejemplo
sdf -
selected-scheduler con el programador de discos que se desea establecer para el dispositivo, por ejemplo
bfq
Requisitos previos
El servicio
tunedestá instalado y habilitado.Para más detalles, consulte Sección 2.6, “Instalación y habilitación de Tuned”.
Procedimiento
Opcional: Seleccione un perfil existente de Tuned en el que se basará su perfil. Para ver una lista de perfiles disponibles, consulte Sección 2.3, “Perfiles ajustados distribuidos con RHEL”.
Para ver qué perfil está actualmente activo, utilice:
$ tuned-adm active
Cree un nuevo directorio para albergar su perfil de Tuned:
# mkdir /etc/tuned/my-profileBusca el identificador único del sistema del dispositivo de bloque seleccionado:
$ udevadm info --query=property --name=/dev/device | grep -E '(WWN|SERIAL)' ID_WWN=0x5002538d00000000 ID_SERIAL=Generic-_SD_MMC_20120501030900000-0:0 ID_SERIAL_SHORT=20120501030900000
NotaEl comando de este ejemplo devolverá todos los valores identificados como World Wide Name (WWN) o número de serie asociados al dispositivo de bloque especificado. Aunque es preferible utilizar un WWN, el WWN no siempre está disponible para un dispositivo determinado y cualquier valor devuelto por el comando del ejemplo es aceptable para utilizarlo como el device system unique ID.
Cree el
/etc/tuned/my-profile/tuned.confarchivo de configuración. En el archivo, establezca las siguientes opciones:Opcional: Incluir un perfil existente:
[main] include=existing-profileEstablece el programador de discos seleccionado para el dispositivo que coincide con el identificador WWN:
[disk] devices_udev_regex=IDNAME=device system unique id elevator=selected-scheduler
-
Sustituya IDNAME por el nombre del identificador utilizado (por ejemplo,
ID_WWN). -
Sustituya device system unique id por el valor del identificador elegido (por ejemplo,
0x5002538d00000000).
Para hacer coincidir varios dispositivos en la opción
devices_udev_regex, encierre los identificadores entre paréntesis y sepárelos con barras verticales:-
Sustituya IDNAME por el nombre del identificador utilizado (por ejemplo,
devices_udev_regex=(ID_WWN=0x5002538d00000000)|(ID_WWN=0x1234567800000000)
Habilita tu perfil:
# perfil tuned-adm my-profileCompruebe que el perfil Tuned está activo y aplicado:
$ tuned-adm active Current active profile: my-profile$ tuned-adm verify Verification succeeded, current system settings match the preset profile. See tuned log file ('/var/log/tuned/tuned.log') for details.
Recursos adicionales
- Para más información sobre la creación de un perfil Tuned, consulte Capítulo 3, Personalización de los perfiles Tuned.
Capítulo 4. Revisión de un sistema mediante la interfaz del atún
Utilice la herramienta tuna para ajustar los programadores, la prioridad de los hilos, los gestores de IRQ y aislar los núcleos de la CPU y los sockets. Tuna reduce la complejidad de las tareas de ajuste.
4.1. Instalación de la herramienta del atún
La herramienta tuna está diseñada para ser utilizada en un sistema en funcionamiento. Esto permite que las herramientas de medición específicas de la aplicación vean y analicen el rendimiento del sistema inmediatamente después de realizar los cambios.
La herramienta tuna realiza las siguientes operaciones:
- Enumera las CPUs de un sistema
- Enumera las solicitudes de interrupción (IRQ) que se ejecutan actualmente en un sistema
- Cambia la política y la información de prioridad de los hilos
- Muestra las políticas y prioridades actuales de un sistema
Procedimiento
Para instalar la herramienta
tuna:# yum install tuna
Para mostrar las opciones de la CLI disponibles en
tuna:# tuna -h
Recursos adicionales
-
La página de manual
tuna.
4.2. Visualización del estado del sistema mediante la herramienta tuna
Este procedimiento describe cómo ver el estado del sistema utilizando la herramienta de interfaz de línea de comandos (CLI) tuna.
Requisitos previos
- La herramienta de la tuna está instalada. Para más información, consulte Sección 4.1, “Instalación de la herramienta del atún”.
Procedimiento
Para ver las políticas y prioridades actuales:
# tuna --show_threads thread pid SCHED_ rtpri affinity cmd 1 OTHER 0 0,1 init 2 FIFO 99 0 migration/0 3 OTHER 0 0 ksoftirqd/0 4 FIFO 99 0 watchdog/0Para ver un hilo específico correspondiente a un PID o que coincida con un nombre de comando:
# tuna --threads=pid_or_cmd_list --show_threadsEl argumento pid_or_cmd_list es una lista de PIDs o patrones de nombres de comandos separados por comas.
-
Para ajustar las CPUs mediante la CLI
tuna, consulte Sección 4.3, “Ajuste de las CPUs con la herramienta tuna”. -
Para ajustar las IRQs utilizando la herramienta
tuna, consulte Sección 4.4, “Ajuste de las IRQs con la herramienta tuna”. Para guardar la configuración modificada:
# tuna --save=nombredearchivo
Este comando sólo guarda los hilos del kernel que se están ejecutando. Los procesos que no se están ejecutando no se guardan.
Recursos adicionales
-
La página de manual
tuna. -
El comando
tuna -hmuestra las opciones de la CLI disponibles.
4.3. Ajuste de las CPUs con la herramienta tuna
Los comandos de la herramienta tuna pueden dirigirse a CPUs individuales. Usando la herramienta tuna, puedes:
Isolate CPUs- Todas las tareas que se ejecutan en la CPU especificada se mueven a la siguiente CPU disponible. Aislar una CPU hace que no esté disponible eliminándola de la máscara de afinidad de todos los hilos.
Include CPUs- Permite que las tareas se ejecuten en la CPU especificada
Restore CPUs- Restaura la CPU especificada a su configuración anterior.
Este procedimiento describe cómo afinar las CPUs utilizando la CLI de tuna.
Requisitos previos
- La herramienta de la tuna está instalada. Para más información, consulte Sección 4.1, “Instalación de la herramienta del atún”.
Procedimiento
Para especificar la lista de CPUs que se verán afectadas por un comando:
# tuna --cpus=cpu_list [command]
El argumento cpu_list es una lista de números de CPU separados por comas. Por ejemplo,
--cpus=0,2. Las listas de CPU también pueden especificarse en un rango, por ejemplo--cpus=”1-3”que seleccionaría las CPUs 1, 2 y 3.Para añadir una CPU específica a la actual cpu_list, por ejemplo, utilice
--cpus= 0.Sustituya [command] por, por ejemplo,
--isolate.Para aislar una CPU:
# tuna --cpus=cpu_list --isolate
Para incluir una CPU:
# tuna --cpus=cpu_list --include
Para utilizar un sistema con cuatro o más procesadores, muestre cómo hacer que todos los hilos de ssh se ejecuten en la CPU 0 y 1, y todos los hilos de
httpen la CPU 2 y 3:# tuna --cpus=0,1 --threads=ssh\* \ --move --cpus=2,3 --threads=http\* --move
Este comando realiza las siguientes operaciones de forma secuencial:
- Selecciona las CPUs 0 y 1.
-
Selecciona todos los hilos que empiezan por
ssh. - Mueve los hilos seleccionados a las CPUs seleccionadas. Tuna establece la máscara de afinidad de los hilos que comienzan con ssh a las CPUs apropiadas. Las CPUs pueden ser expresadas numéricamente como 0 y 1, en máscara hexadecimal como 0x3, o en binario como 11.
- Restablece la lista de CPUs en 2 y 3.
-
Selecciona todos los hilos que empiezan por
http. -
Mueve los hilos seleccionados a las CPUs especificadas. Tuna establece la máscara de afinidad de los hilos que comienzan con
httpa las CPUs especificadas. Las CPUs pueden expresarse numéricamente como 2 y 3, en máscara hexadecimal como 0xC, o en binario como 1100.
Pasos de verificación
Para mostrar la configuración actual y verificar que los cambios se realizaron como se esperaba:
# tuna --threads=gnome-sc\* --show_threads \ --cpus=0 --move --show_threads --cpus=1 \ --move --show_threads --cpus=+0 --move --show_threads thread ctxt_switches pid SCHED_ rtpri affinity voluntary nonvoluntary cmd 3861 OTHER 0 0,1 33997 58 gnome-screensav thread ctxt_switches pid SCHED_ rtpri affinity voluntary nonvoluntary cmd 3861 OTHER 0 0 33997 58 gnome-screensav thread ctxt_switches pid SCHED_ rtpri affinity voluntary nonvoluntary cmd 3861 OTHER 0 1 33997 58 gnome-screensav thread ctxt_switches pid SCHED_ rtpri affinity voluntary nonvoluntary cmd 3861 OTHER 0 0,1 33997 58 gnome-screensav
Este comando realiza las siguientes operaciones de forma secuencial:
-
Selecciona todos los hilos que comienzan con los hilos de
gnome-sc. - Muestra los hilos seleccionados para que el usuario pueda verificar su máscara de afinidad y su prioridad RT.
- Selecciona la CPU 0.
-
Mueve los hilos de
gnome-sca la CPU especificada, CPU 0. - Muestra el resultado del movimiento.
- Restablece la lista de CPUs en 1.
-
Mueve los hilos de
gnome-sca la CPU especificada, CPU 1. - Muestra el resultado del movimiento.
- Añade la CPU 0 a la lista de CPUs.
-
Mueve los hilos de
gnome-sca las CPUs especificadas, CPUs 0 y 1. - Muestra el resultado del movimiento.
-
Selecciona todos los hilos que comienzan con los hilos de
Recursos adicionales
-
El archivo
/proc/cpuinfo. -
La página de manual
tuna. -
El comando
tuna -hmuestra las opciones de la CLI disponibles.
4.4. Ajuste de las IRQs con la herramienta tuna
El archivo /proc/interrupts registra el número de interrupciones por IRQ, el tipo de interrupción y el nombre del dispositivo que se encuentra en esa IRQ. Este procedimiento describe cómo afinar las IRQs utilizando la herramienta tuna.
Requisitos previos
- La herramienta de la tuna está instalada. Para más información, consulte Sección 4.1, “Instalación de la herramienta del atún”.
Procedimiento
Para ver las IRQs actuales y su afinidad:
# tuna --show_irqs # users affinity 0 timer 0 1 i8042 0 7 parport0 0
Para especificar la lista de IRQs que serán afectadas por un comando:
# tuna --irqs=irq_list [command]
El argumento irq_list es una lista de números IRQ separados por comas o patrones de nombres de usuario.
Sustituya [command] por, por ejemplo,
--isolate.Para mover una interrupción a una CPU especificada:
# tuna --irqs=128 --show_irqs # users affinity 128 iwlwifi 0,1,2,3 # tuna --irqs=128 --cpus=3 --move
Sustituye 128 por el argumento irq_list y 3 por el argumento cpu_list.
El argumento cpu_list es una lista de números de CPU separados por comas, por ejemplo,
--cpus=0,2. Para más información, véase Sección 4.3, “Ajuste de las CPUs con la herramienta tuna”.
Pasos de verificación
Compara el estado de las IRQs seleccionadas antes y después de mover cualquier interrupción a una CPU especificada:
# tuna --irqs=128 --show_irqs # users affinity 128 iwlwifi 3
Recursos adicionales
-
El archivo
/procs/interrupts. -
La página de manual
tuna. -
El comando
tuna -hmuestra las opciones de la CLI disponibles.
Capítulo 5. Supervisión del rendimiento mediante RHEL System Roles
5.1. Introducción a los roles del sistema RHEL
RHEL System Roles es una colección de roles y módulos de Ansible. RHEL System Roles proporciona una interfaz de configuración para gestionar de forma remota varios sistemas RHEL. La interfaz permite gestionar las configuraciones del sistema en varias versiones de RHEL, así como adoptar nuevas versiones principales.
En Red Hat Enterprise Linux 8, la interfaz consta actualmente de los siguientes roles:
- kdump
- red
- selinux
- almacenamiento
- certificado
- kernel_settings
- registro
- métrica
- nbde_client y nbde_server
- timesync
- tlog
Todos estos roles son proporcionados por el paquete rhel-system-roles disponible en el repositorio AppStream.
Recursos adicionales
- Para obtener una visión general de las funciones del sistema RHEL, consulte el artículo de la base de conocimientos de Red Hat Enterprise Linux (RHEL) sobre las funciones del sistema.
-
Para obtener información sobre una función concreta, consulte la documentación en el directorio
/usr/share/doc/rhel-system-roles. Esta documentación se instala automáticamente con el paqueterhel-system-roles.
5.2. Terminología de los roles del sistema RHEL
Puede encontrar los siguientes términos en esta documentación:
Terminología de los roles del sistema
- Libro de jugadas de Ansible
- Los playbooks son el lenguaje de configuración, despliegue y orquestación de Ansible. Pueden describir una política que desea que sus sistemas remotos apliquen, o un conjunto de pasos en un proceso general de TI.
- Nodo de control
- Cualquier máquina con Ansible instalado. Puedes ejecutar comandos y playbooks, invocando /usr/bin/ansible o /usr/bin/ansible-playbook, desde cualquier nodo de control. Puedes usar cualquier ordenador que tenga Python instalado como nodo de control: ordenadores portátiles, escritorios compartidos y servidores pueden ejecutar Ansible. Sin embargo, no puedes usar una máquina Windows como nodo de control. Puedes tener varios nodos de control.
- Inventario
- Una lista de nodos gestionados. Un archivo de inventario también se llama a veces "archivo de host". Su inventario puede especificar información como la dirección IP para cada nodo gestionado. Un inventario también puede organizar los nodos gestionados, creando y anidando grupos para facilitar el escalado. Para obtener más información sobre el inventario, consulte la sección Trabajar con el inventario.
- Nodos gestionados
- Los dispositivos de red, servidores, o ambos, que gestionas con Ansible. Los nodos gestionados también se denominan a veces "hosts". Ansible no se instala en los nodos gestionados.
5.3. Instalación de RHEL System Roles en su sistema
Este párrafo es la introducción del módulo del procedimiento: una breve descripción del procedimiento.
Requisitos previos
- Tiene una suscripción a Red Hat Ansible Engine. Consulte el procedimiento ¿Cómo descargo e instalo Red Hat Ansible Engine?
- Tienes los paquetes de Ansible instalados en el sistema que quieres usar como nodo de control:
Procedimiento
Instale el paquete
rhel-system-rolesen el sistema que desea utilizar como nodo de control:# yum install rhel-system-roles
Si no dispone de una suscripción a Red Hat Ansible Engine, puede utilizar una versión soportada limitada de Red Hat Ansible Engine proporcionada con su suscripción a Red Hat Enterprise Linux. En este caso, siga estos pasos:
Habilite el repositorio del motor Ansible de RHEL:
# subscription-manager refresh # subscription-manager repos --enable ansible-2-for-rhel-8-x86_64-rpms
Instale el motor Ansible:
# yum install ansible
Como resultado, puede crear un libro de jugadas de Ansible.
Recursos adicionales
- Para obtener una visión general de las funciones del sistema RHEL, consulte las funciones del sistema Red Hat Enterprise Linux (RHEL)
- Para obtener información más detallada sobre el uso del comando ansible-playbook, consulte la página man de ansible-playbook.
5.4. Aplicar un papel
El siguiente procedimiento describe cómo aplicar un rol particular.
Requisitos previos
El paquete
rhel-system-rolesestá instalado en el sistema que se quiere utilizar como nodo de control:# yum install rhel-system-rolesEl repositorio del motor Ansible está habilitado y el paquete
ansibleestá instalado en el sistema que desea utilizar como nodo de control. Necesita el paqueteansiblepara ejecutar playbooks que utilicen RHEL System Roles.Si no dispone de una suscripción a Red Hat Ansible Engine, puede utilizar una versión soportada limitada de Red Hat Ansible Engine proporcionada con su suscripción a Red Hat Enterprise Linux. En este caso, siga estos pasos:
Habilite el repositorio del motor Ansible de RHEL:
# subscription-manager refresh # subscription-manager repos --enable ansible-2-for-rhel-8-x86_64-rpms
Instale el motor Ansible:
# yum install ansible
- Si tiene una suscripción a Red Hat Ansible Engine, siga el procedimiento descrito en ¿Cómo descargo e instalo Red Hat Ansible Engine?
Puedes crear un playbook de Ansible.
Los playbooks representan el lenguaje de configuración, despliegue y orquestación de Ansible. Mediante el uso de playbooks, puedes declarar y gestionar configuraciones de máquinas remotas, desplegar múltiples máquinas remotas u orquestar pasos de cualquier proceso manual ordenado.
Un playbook es una lista de uno o más
plays. Cadaplaypuede incluir variables, tareas o roles de Ansible.Los libros de jugadas son legibles para las personas y se expresan en el formato
YAML.Para más información sobre los playbooks, consulte la documentación de Ansible.
Procedimiento
Cree un playbook de Ansible que incluya el rol requerido.
El siguiente ejemplo muestra cómo utilizar los roles a través de la opción
roles:para un determinadoplay:--- - hosts: webservers roles: - rhel-system-roles.network - rhel-system-roles.timesyncPara más información sobre el uso de roles en los playbooks, consulte la documentación de Ansible.
Consulte los ejemplos de Ansible para ver ejemplos de playbooks.
NotaCada rol incluye un archivo README, que documenta cómo usar el rol y los valores de los parámetros soportados. También puede encontrar un ejemplo de libro de jugadas para un rol en particular en el directorio de documentación del rol. Este directorio de documentación se proporciona por defecto con el paquete
rhel-system-roles, y se puede encontrar en la siguiente ubicación:/usr/share/doc/rhel-system-roles/SUBSYSTEM/Sustituya SUBSYSTEM por el nombre del rol requerido, como
selinux,kdump,network,timesync, ostorage.Verifique la sintaxis del libro de jugadas:
#
ansible-playbook --syntax-check name.of.the.playbookEl comando
ansible-playbookofrece una opción--syntax-checkque puede utilizar para verificar la sintaxis de un libro de jugadas.Ejecute el libro de jugadas en los hosts seleccionados ejecutando el comando
ansible-playbook:#
ansible-playbook -i name.of.the.inventory name.of.the.playbookUn inventario es una lista de sistemas con los que trabaja Ansible. Para más información sobre cómo crear un inventario y cómo trabajar con él, consulte la documentación de Ansible.
Si no tiene un inventario, puede crearlo en el momento de ejecutar
ansible-playbook:Si sólo tiene un host de destino contra el que desea ejecutar el libro de jugadas, utilice:
# ansible-playbook -i host1, name.of.the.playbookSi tiene varios hosts de destino contra los que desea ejecutar el libro de jugadas, utilice:
# ansible-playbook -i host1,host2,....,hostn name.of.the.playbook
Recursos adicionales
-
Para obtener información más detallada sobre el uso del comando
ansible-playbook, consulte la página de manualansible-playbook.
5.5. Introducción a la función del sistema de métricas
RHEL System Roles es una colección de roles y módulos de Ansible que proporcionan una interfaz de configuración consistente para gestionar remotamente múltiples sistemas RHEL. El rol de sistema de métricas configura los servicios de análisis de rendimiento para el sistema local y, opcionalmente, incluye una lista de sistemas remotos que deben ser supervisados por el sistema local. El rol de sistema de métricas le permite utilizar pcp para supervisar el rendimiento de sus sistemas sin tener que configurar pcp por separado, ya que la configuración y el despliegue de pcp son gestionados por el libro de jugadas.
Tabla 5.1. Variables de rol del sistema de métricas
| Variable de rol | Descripción | Ejemplo de uso |
|---|---|---|
| metrics_monitored_hosts |
Lista de hosts remotos que serán analizados por el host de destino. Estos hosts tendrán métricas registradas en el host de destino, así que asegúrese de que existe suficiente espacio en disco debajo de |
|
| metrics_retention_days | Configura el número de días de retención de datos de rendimiento antes de su eliminación. |
|
| servicio_gráfico_métrico |
Una bandera booleana que permite que el host se configure con servicios para la visualización de datos de rendimiento a través de |
|
| metrics_query_service |
Un indicador booleano que permite configurar el host con servicios de consulta de series temporales para consultar las métricas registradas de |
|
| metrics_provider |
Especifica qué colector de métricas se utilizará para proporcionar métricas. Actualmente, |
|
Recursos adicionales
-
para obtener detalles sobre los parámetros utilizados en
metrics_connectionse información adicional sobre el rol del sistema de métricas, consulte el archivo/usr/share/ansible/roles/rhel-system-roles.metrics/README.md.
5.6. Uso de la función de sistema de métricas para supervisar su sistema local con visualización
Este procedimiento describe cómo utilizar el rol de sistema RHEL de métricas para supervisar su sistema local y, al mismo tiempo, aprovisionar la visualización de datos a través de grafana.
Requisitos previos
- Tiene instalado Red Hat Ansible Engine en la máquina que desea supervisar.
-
Tiene el paquete
rhel-system-rolesinstalado en la máquina que desea supervisar.
Procedimiento
Configure
localhosten el inventario de/etc/ansible/hostsAnsible añadiendo el siguiente contenido al inventario:localhost ansible_connection=local
Cree un playbook de Ansible con el siguiente contenido:
--- - hosts: localhost vars: metrics_graph_service: yes roles: - rhel-system-roles.metricsEjecute el libro de jugadas de Ansible:
# ansible-playbook name_of_your_playbook.ymlNotaDado que el booleano
metrics_graph_serviceestá configurado con el valor="sí",grafanase instala y aprovisiona automáticamente conpcpañadido como fuente de datos.-
Para ver la visualización de las métricas que se recopilan en su máquina, acceda a la interfaz web
grafanacomo se describe en Acceso a la interfaz web de Grafana.
5.7. Utilizar la función de sistema de métrica para configurar una flota de sistemas individuales que se supervisen a sí mismos
Este procedimiento describe cómo utilizar el rol de sistema de métricas para configurar una flota de máquinas para que se monitoreen a sí mismas.
Requisitos previos
- Tiene instalado Red Hat Ansible Engine en la máquina que desea utilizar para ejecutar el libro de jugadas.
-
Tienes el paquete
rhel-system-rolesinstalado en la máquina que quieres usar para ejecutar el playbook.
Procedimiento
Añada el nombre o la IP de las máquinas que desea supervisar a través del libro de jugadas al archivo de inventario de Ansible
/etc/ansible/hostsbajo un nombre de grupo identificativo encerrado entre paréntesis:[remotes] webserver.example.com database.example.com
Cree un playbook de Ansible con el siguiente contenido:
--- - hosts: remotes vars: metrics_retention_days: 0 roles: - rhel-system-roles.metricsEjecute el libro de jugadas de Ansible:
# ansible-playbook name_of_your_playbook.yml
5.8. Uso del rol de sistema de métrica para supervisar una flota de máquinas de forma centralizada a través de su máquina local
Este procedimiento describe cómo utilizar el rol de sistema de métricas para configurar su máquina local para supervisar de forma centralizada una flota de máquinas, a la vez que proporciona la visualización de los datos a través de grafana y la consulta de los datos a través de redis.
Requisitos previos
- Tiene instalado Red Hat Ansible Engine en la máquina que desea utilizar para ejecutar el libro de jugadas.
-
Tienes el paquete
rhel-system-rolesinstalado en la máquina que quieres usar para ejecutar el playbook.
Procedimiento
Cree un playbook de Ansible con el siguiente contenido:
--- - hosts: localhost vars: metrics_graph_service: yes metrics_query_service: yes metrics_retention_days: 10 metrics_monitored_hosts: ["database.example.com", "webserver.example.com"] roles: - rhel-system-roles.metricsEjecute el libro de jugadas de Ansible:
# ansible-playbook name_of_your_playbook.ymlNotaDado que los booleanos
metrics_graph_serviceymetrics_query_serviceestán configurados con el valor="sí",grafanase instala automáticamente y se aprovisiona conpcpañadido como fuente de datos con el registro de datospcpindexado enredis, lo que permite utilizar el lenguaje de consultapcppara realizar consultas complejas de los datos.-
Para ver la representación gráfica de las métricas que se recopilan de forma centralizada por su máquina y para consultar los datos, acceda a la interfaz web
grafanacomo se describe en Acceso a la interfaz web de Grafana.
Capítulo 6. Supervisión del rendimiento con Performance Co-Pilot
Como administrador del sistema, puede supervisar el rendimiento del sistema utilizando la aplicación Performance Co-Pilot (PCP) en Red Hat Enterprise Linux 8.
6.1. Visión general de la PCP
PCP es un conjunto de herramientas, servicios y bibliotecas para supervisar, visualizar, almacenar y analizar las mediciones de rendimiento del sistema.
Características de la PCP:
- Arquitectura distribuida de peso ligero, que resulta útil durante el análisis centralizado de sistemas complejos.
- Permite el seguimiento y la gestión de datos en tiempo real.
- Permite el registro y la recuperación de datos históricos.
Se pueden añadir métricas de rendimiento utilizando interfaces de Python, Perl, C , y C. Las herramientas de análisis pueden utilizar las API de cliente de Python, C , C directamente, y las aplicaciones web enriquecidas pueden explorar todos los datos de rendimiento disponibles utilizando una interfaz JSON.
Puede analizar los patrones de datos comparando los resultados en vivo con los datos archivados.
La PCP tiene los siguientes componentes:
-
El Daemon Colector de Métricas de Rendimiento (
pmcd) recoge los datos de rendimiento de los Agentes de Dominio de Métricas de Rendimiento instalados (pmda). PMDAs puede ser cargado o descargado individualmente en el sistema y son controlados por el PMCD en el mismo host. -
Diversas herramientas cliente, como
pminfoopmstat, pueden recuperar, visualizar, archivar y procesar estos datos en el mismo host o a través de la red. -
El paquete
pcpproporciona las herramientas de línea de comandos y la funcionalidad subyacente. -
El paquete
pcp-guiproporciona la aplicación gráfica. Instale el paquetepcp-guiejecutando el comandoyum install pcp-gui. Para más información, consulte Sección 6.6, “Rastreo visual de los archivos de registro del PCP con la aplicación PCP Charts ”.
Recursos adicionales
-
El directorio
/usr/share/doc/pcp-doc/. - Sección 6.9, “Herramientas distribuidas con la PCP”.
- El índice de artículos, soluciones, tutoriales y libros blancos de Performance Co-Pilot (PCP) en el Portal del Cliente de Red Hat.
- El artículo de la base de conocimientos de Red Hat " Side-by-side comparison of PCP tools with legacy tools ".
- La documentación de la PCP en sentido ascendente.
6.2. Instalación y habilitación del PCP
Para empezar a utilizar PCP, instale todos los paquetes necesarios y active los servicios de monitorización de PCP.
Procedimiento
Instale el paquete PCP:
# yum install pcp
Habilite e inicie el servicio
pmcden la máquina anfitriona:# systemctl enable pmcd # systemctl start pmcd
Compruebe que el proceso
pmcdse está ejecutando en el host y que el PMDA XFS aparece como habilitado en la configuración:# pcp Performance Co-Pilot configuration on workstation: platform: Linux workstation 4.18.0-80.el8.x86_64 #1 SMP Wed Mar 13 12:02:46 UTC 2019 x86_64 hardware: 12 cpus, 2 disks, 1 node, 36023MB RAM timezone: CEST-2 services: pmcd pmcd: Version 4.3.0-1, 8 agents pmda: root pmcd proc xfs linux mmv kvm jbd2
Recursos adicionales
- Sección 6.9, “Herramientas distribuidas con la PCP”.
- La página man de pmcd.
6.3. Implementación de una configuración mínima de PCP
La configuración mínima de PCP recopila estadísticas de rendimiento en Red Hat Enterprise Linux. La configuración implica añadir el número mínimo de paquetes en un sistema de producción necesario para recopilar datos para su posterior análisis. Puede analizar el archivo tar.gz resultante y el archivo de la salida pmlogger usando varias herramientas PCP y compararlos con otras fuentes de información de rendimiento.
Requisitos previos
- El PCP está instalado. Para más información, consulte Sección 6.2, “Instalación y habilitación del PCP”.
Procedimiento
Actualice la configuración de
pmlogger:# pmlogconf -r /var/lib/pcp/config/pmlogger/config.default
Inicie los servicios
pmcdypmlogger:# systemctl start pmcd.service # systemctl start pmlogger.service
- Ejecute las operaciones necesarias para registrar los datos de rendimiento.
Detenga los servicios
pmcdypmlogger:# systemctl stop pmcd.service # systemctl stop pmlogger.service
Guarde la salida y guárdela en un archivo
tar.gzcuyo nombre se basa en el nombre del host y la fecha y hora actuales:# cd /var/log/pcp/pmlogger/ # tar -czf $(hostname).$(date +%F-%Hh%M).pcp.tar.gz $(hostname)
Extraiga este archivo y analice los datos con las herramientas de PCP.
Recursos adicionales
- Sección 6.9, “Herramientas distribuidas con la PCP”
- Sección 6.8, “Servicios del sistema distribuidos con PCP”
- La página man de pmlogconf.
- La página man de pmlogger.
- La página man de pmcd.
6.4. Registro de datos de rendimiento con pmlogger
Con la herramienta PCP puede registrar los valores de las métricas de rendimiento y reproducirlos posteriormente. Esto le permite realizar un análisis retrospectivo del rendimiento.
Con la herramienta pmlogger, puedes:
- Crear los registros archivados de las métricas seleccionadas en el sistema
- Especificar qué métricas se registran en el sistema y con qué frecuencia
6.4.1. Modificación del archivo de configuración de pmlogger con pmlogconf
Cuando el servicio pmlogger se está ejecutando, PCP registra un conjunto de métricas por defecto en el host. Utilice la utilidad pmlogconf para comprobar la configuración por defecto. Si el archivo de configuración pmlogger no existe, pmlogconf lo crea con unos valores de métrica por defecto.
Requisitos previos
- El PCP está instalado. Para más información, consulte Sección 6.2, “Instalación y habilitación del PCP”.
Procedimiento
Cree o modifique el archivo de configuración de
pmlogger:# pmlogconf -r /var/lib/pcp/config/pmlogger/config.default
-
Siga las indicaciones de
pmlogconfpara activar o desactivar grupos de métricas de rendimiento relacionadas y para controlar el intervalo de registro de cada grupo activado.
Recursos adicionales
- Sección 6.9, “Herramientas distribuidas con la PCP”
- Sección 6.8, “Servicios del sistema distribuidos con PCP”
- La página man de pmlogconf.
- La página man de pmlogger.
6.4.2. Editar manualmente el archivo de configuración de pmlogger
Para crear una configuración de registro a medida con métricas específicas e intervalos determinados, edite manualmente el archivo de configuración pmlogger.
En la configuración manual, puedes:
- Registrar las métricas que no aparecen en la configuración automática.
- Elija las frecuencias de registro personalizadas.
- Añadir PMDA con las métricas de la aplicación.
El archivo de configuración por defecto de pmlogger es /var/lib/pcp/config/pmlogger/config.default. El archivo de configuración especifica qué métricas son registradas por la instancia primaria de registro.
Requisitos previos
- El PCP está instalado. Para más información, consulte Sección 6.2, “Instalación y habilitación del PCP”.
Procedimiento
Abra y edite el archivo
/var/lib/pcp/config/pmlogger/config.defaultpara añadir métricas específicas:# It is safe to make additions from here on ... # log mandatory on every 5 seconds { xfs.write xfs.write_bytes xfs.read xfs.read_bytes } log mandatory on every 10 seconds { xfs.allocs xfs.block_map xfs.transactions xfs.log } [access] disallow * : all; allow localhost : enquire;
Recursos adicionales
6.4.3. Habilitación del servicio pmlogger
El servicio pmlogger debe estar iniciado y habilitado para registrar los valores de las métricas en la máquina local.
Requisitos previos
- El PCP está instalado. Para más información, consulte Sección 6.2, “Instalación y habilitación del PCP”.
Procedimiento
Inicie y active el servicio
pmlogger:# systemctl start pmlogger # systemctl enable pmlogger
Compruebe que el
pmloggerestá activado:# pcp Performance Co-Pilot configuration on workstation: platform: Linux workstation 4.18.0-80.el8.x86_64 #1 SMP Wed Mar 13 12:02:46 UTC 2019 x86_64 hardware: 12 cpus, 2 disks, 1 node, 36023MB RAM timezone: CEST-2 services: pmcd pmcd: Version 4.3.0-1, 8 agents, 1 client pmda: root pmcd proc xfs linux mmv kvm jbd2 pmlogger: primary logger: /var/log/pcp/pmlogger/workstation/20190827.15.54
Recursos adicionales
- Sección 6.9, “Herramientas distribuidas con la PCP”
- Sección 6.8, “Servicios del sistema distribuidos con PCP”
-
El archivo
/var/lib/pcp/config/pmlogger/config.default. - La página man de pmlogger.
6.4.4. Configuración de un sistema de clientes para la recopilación de métricas
Este procedimiento describe cómo configurar un sistema cliente para que un servidor central pueda recoger las métricas de los clientes que ejecutan PCP.
Requisitos previos
- El PCP está instalado. Para más información, consulte Sección 6.2, “Instalación y habilitación del PCP”.
Procedimiento
Instale el paquete
pcp-system-tools:# yum install pcp-system-tools
Configure una dirección IP para
pmcd:# echo "-i 192.168.4.62" >>/etc/pcp/pmcd/pmcd.optionsSustituya 192.168.4.62 por la dirección IP en la que debe escuchar el cliente.
Por defecto,
pmcdestá a la escucha en el localhost.Configure el cortafuegos para añadir la dirección pública
zonede forma permanente:# firewall-cmd --permanent --zone=public --add-port=44321/tcp success # firewall-cmd --reload success
Establece un booleano de SELinux:
# setsebool -P pcp_bind_all_unreserved_ports on
Habilite los servicios
pmcdypmlogger:# systemctl enable pmcd pmlogger # systemctl restart pmcd pmlogger
Pasos de verificación
Verifique si el
pmcdestá escuchando correctamente en la dirección IP configurada:# ss -tlp | grep 44321 LISTEN 0 5 127.0.0.1:44321 0.0.0.0:* users:(("pmcd",pid=151595,fd=6)) LISTEN 0 5 192.168.4.62:44321 0.0.0.0:* users:(("pmcd",pid=151595,fd=0)) LISTEN 0 5 [::1]:44321 [::]:* users:(("pmcd",pid=151595,fd=7))
Recursos adicionales
- Sección 6.9, “Herramientas distribuidas con la PCP”.
- Sección 6.8, “Servicios del sistema distribuidos con PCP”.
-
El archivo
/var/lib/pcp/config/pmlogger/config.default. - La página man de pmlogger.
-
La página de manual
firewall-cmd. -
La página de manual
setsebool. -
La página de manual
ss.
6.4.5. Creación de un servidor central para la recogida de datos
Este procedimiento describe cómo crear un servidor central para recoger las métricas de los clientes que ejecutan PCP.
Requisitos previos
- El PCP está instalado. Para más información, consulte Sección 6.2, “Instalación y habilitación del PCP”.
- El cliente está configurado para la recogida de métricas. Para más información, consulte Sección 6.4.4, “Configuración de un sistema de clientes para la recopilación de métricas”.
Procedimiento
Instale el paquete
pcp-system-tools:# yum install pcp-system-tools
Añade clientes para la supervisión:
# echo "192.168.4.13 n n PCP_LOG_DIR/pmlogger/rhel7u4a -r -T24h10m \ -c config.remote" >> /etc/pcp/pmlogger/control.d/remote # echo "192.168.4.14 n n PCP_LOG_DIR/pmlogger/rhel6u10a -r -T24h10m \ -c config.remote" >> /etc/pcp/pmlogger/control.d/remote # echo "192.168.4.62 n n PCP_LOG_DIR/pmlogger/rhel8u1a -r -T24h10m \ -c config.remote" >> /etc/pcp/pmlogger/control.d/remote
Sustituya 192.168.4.13, 192.168.4.14, y 192.168.4.62 por las direcciones IP de los clientes.
Habilite los servicios
pmcdypmlogger:# systemctl enable pmcd pmlogger # systemctl restart pmcd pmlogger
Pasos de verificación
Asegúrese de que puede acceder al último archivo de cada directorio:
# for i in /var/log/pcp/pmlogger/rhel*/*.0; do pmdumplog -L $i; done Log Label (Log Format Version 2) Performance metrics from host rhel6u10a.local commencing Mon Nov 25 21:55:04.851 2019 ending Mon Nov 25 22:06:04.874 2019 Archive timezone: JST-9 PID for pmlogger: 24002 Log Label (Log Format Version 2) Performance metrics from host rhel7u4a commencing Tue Nov 26 06:49:24.954 2019 ending Tue Nov 26 07:06:24.979 2019 Archive timezone: CET-1 PID for pmlogger: 10941 [..]
Los archivos del directorio
/var/log/pcp/pmlogger/pueden utilizarse para otros análisis y gráficos.
Recursos adicionales
- Sección 6.9, “Herramientas distribuidas con la PCP”.
- Sección 6.8, “Servicios del sistema distribuidos con PCP”.
-
El archivo
/var/lib/pcp/config/pmlogger/config.default. - La página man de pmlogger.
6.4.6. Reproducción de los archivos de registro de PCP con pmdumptext
Después de registrar los datos métricos, puede volver a reproducir los archivos de registro de PCP. Para exportar los registros a archivos de texto e importarlos a hojas de cálculo, utilice las utilidades de PCP como pmdumptext, pmrep, o pmlogsummary.
Con la herramienta pmdumptext, puedes:
- Ver los archivos de registro
- Analizar el archivo de registro PCP seleccionado y exportar los valores en una tabla ASCII
- Extraiga todo el registro del archivo o sólo seleccione los valores de las métricas del registro especificando métricas individuales en la línea de comandos
Requisitos previos
- El PCP está instalado. Para más información, consulte Sección 6.2, “Instalación y habilitación del PCP”.
-
El servicio
pmloggerestá activado. Para más información, consulte Sección 6.4.3, “Habilitación del servicio pmlogger”. Instale el paquete
pcp-gui:# yum install pcp-gui
Procedimiento
Muestra los datos de la métrica:
$ pmdumptext -t 5seconds -H -a 20170605 xfs.perdev.log.writes Time local::xfs.perdev.log.writes["/dev/mapper/fedora-home"] local::xfs.perdev.log.writes["/dev/mapper/fedora-root"] ? 0.000 0.000 none count / second count / second Mon Jun 5 12:28:45 ? ? Mon Jun 5 12:28:50 0.000 0.000 Mon Jun 5 12:28:55 0.200 0.200 Mon Jun 5 12:29:00 6.800 1.000El ejemplo mencionado muestra los datos de la métrica
xfs.perdev.logrecogidos en un archivo en un intervalo de 5 second y muestra todas las cabeceras.
Recursos adicionales
- Sección 6.9, “Herramientas distribuidas con la PCP”
- Sección 6.8, “Servicios del sistema distribuidos con PCP”
- La página de manual de pmdumptext.
- La página man de pmrep.
- La página man de pmlogsummary.
- La página man de pmlogger.
6.5. Monitorización de postfix con pmda-postfix
Este procedimiento describe cómo supervisar las métricas de rendimiento del servidor de correo postfix con pmda-postfix. Ayuda a comprobar cuántos correos electrónicos se reciben por segundo.
Requisitos previos
- El PCP está instalado. Para más información, consulte Sección 6.2, “Instalación y habilitación del PCP”.
-
El servicio
pmloggerestá activado. Para más información, consulte Sección 6.4.3, “Habilitación del servicio pmlogger”.
Procedimiento
Instale los siguientes paquetes:
Instale el
pcp-system-tools:# yum install pcp-system-tools
Instale el paquete
pmda-postfixpara supervisarpostfix:# yum install pcp-pmda-postfix postfix
Instale el demonio de registro:
# yum install rsyslog
Instala el cliente de correo para probarlo:
# yum install mutt
Habilite los servicios
postfixyrsyslog:# systemctl enable postfix rsyslog # systemctl restart postfix rsyslog
Habilitar el booleano SELinux, para que
pmda-postfixpueda acceder a los archivos de registro necesarios:# setsebool -P pcp_read_generic_logs=on
Instale el
PMDA:# cd /var/lib/pcp/pmdas/postfix/ # ./Install Updating the Performance Metrics Name Space (PMNS) ... Terminate PMDA if already installed ... Updating the PMCD control file, and notifying PMCD ... Waiting for pmcd to terminate ... Starting pmcd ... Check postfix metrics have appeared ... 7 metrics and 58 values
Pasos de verificación
Verifique el funcionamiento de
pmda-postfix:echo testmail | mutt root
Verifique las métricas disponibles:
# pminfo postfix postfix.received postfix.sent postfix.queues.incoming postfix.queues.maildrop postfix.queues.hold postfix.queues.deferred postfix.queues.active
Recursos adicionales
- Sección 6.9, “Herramientas distribuidas con la PCP”
- Sección 6.8, “Servicios del sistema distribuidos con PCP”
-
El archivo
/var/lib/pcp/config/pmlogger/config.default. - La página man de pmlogger.
-
La página de manual
rsyslog. -
La página de manual
postfix. -
La página de manual
setsebool.
6.6. Rastreo visual de los archivos de registro del PCP con la aplicación PCP Charts
Después de registrar los datos de las métricas, se pueden reproducir los archivos de registro del PCP en forma de gráficos.
A través de la aplicación PCP Charts, puedes:
- Reproduzca los datos en la aplicación PCP Charts y utilice gráficos para visualizar los datos retrospectivos junto a los datos en vivo del sistema.
- Representar los valores de las métricas de rendimiento en gráficos.
- Visualizar varios gráficos simultáneamente.
Las métricas se obtienen de uno o más hosts en vivo con opciones alternativas para utilizar los datos métricos de los archivos de registro de PCP como fuente de datos históricos.
A continuación se presentan varias formas de personalizar la interfaz de la aplicación PCP Charts para mostrar los datos de las métricas de rendimiento:
- diagrama de líneas
- gráficos de barras
- gráficos de utilización
Requisitos previos
- El PCP está instalado. Para más información, consulte Sección 6.2, “Instalación y habilitación del PCP”.
-
Datos de rendimiento registrados con el
pmlogger. Para más información, véase Sección 6.4, “Registro de datos de rendimiento con pmlogger”. Instale el paquete
pcp-gui:# yum install pcp-gui
Procedimiento
Inicie la aplicación PCP Charts desde la línea de comandos:
# pmchart
La configuración del servidor
pmtimese encuentra en la parte inferior. El botón start y pause le permite controlar:- El intervalo en el que PCP sondea los datos métricos
- La fecha y la hora de las métricas de los datos históricos
- Vaya a File → New Chart para seleccionar la métrica tanto de la máquina local como de las máquinas remotas especificando su nombre o dirección de host. Las opciones de configuración avanzadas incluyen la posibilidad de establecer manualmente los valores de los ejes para el gráfico y de elegir manualmente el color de los gráficos.
Registre las vistas creadas en la aplicación PCP Charts:
A continuación se presentan las opciones para tomar imágenes o grabar las vistas creadas en la aplicación PCP Charts:
- Haga clic en File → Export para guardar una imagen de la vista actual.
- Haga clic en Record → Start para iniciar una grabación. Haga clic en Record → Stop para detener la grabación. Después de detener la grabación, las métricas grabadas se archivan para ser vistas más tarde.
Opcional: En la aplicación PCP Charts, el archivo de configuración principal, conocido como view, permite guardar los metadatos asociados a uno o varios gráficos. Estos metadatos describen todos los aspectos del gráfico, incluyendo las métricas utilizadas y las columnas del gráfico. Guarde la configuración personalizada de view haciendo clic en File → Save View, y cargue la configuración de view más tarde. El siguiente ejemplo del archivo de configuración de la vista de la aplicación PCP Charts describe un gráfico de apilamiento que muestra el número total de bytes leídos y escritos en el sistema de archivos XFS dado
loop1:#kmchart version 1 chart title "Filesystem Throughput /loop1" style stacking antialiasing off plot legend "Read rate" metric xfs.read_bytes instance "loop1" plot legend "Write rate" metric xfs.write_bytes instance "loop1"
Recursos adicionales
- Sección 6.9, “Herramientas distribuidas con la PCP”
- La página man de pmchart.
- La página man de pmtime.
6.7. Análisis del rendimiento del sistema de archivos XFS con PCP
El PMDA de XFS forma parte del paquete pcp y está activado por defecto durante la instalación. Se utiliza para recopilar datos de métricas de rendimiento de los sistemas de archivos XFS en PCP.
6.7.1. Instalación manual de XFS PMDA
Si el PMDA XFS no aparece en la lectura de la configuración del PCP, instale el agente PMDA manualmente.
Procedimiento
Navegue hasta el directorio xfs:
# cd /var/lib/pcp/pmdas/xfs/
Instale el PMDA XFS manualmente:
xfs]# ./Install You will need to choose an appropriate configuration for install of the “xfs” Performance Metrics Domain Agent (PMDA). collector collect performance statistics on this system monitor allow this system to monitor local and/or remote systems both collector and monitor configuration for this system Please enter c(ollector) or m(onitor) or (both) [b] Updating the Performance Metrics Name Space (PMNS) ... Terminate PMDA if already installed ... Updating the PMCD control file, and notifying PMCD ... Waiting for pmcd to terminate ... Starting pmcd ... Check xfs metrics have appeared ... 149 metrics and 149 values
Seleccione el rol PMDA deseado introduciendo
cpara el colector,mpara el monitor, obpara ambos. El script de instalación de PMDA le pide que especifique uno de los siguientes roles de PMDA:-
La función
collectorpermite la recopilación de métricas de rendimiento en el sistema actual La función
monitorpermite al sistema supervisar los sistemas locales, los sistemas remotos o ambosLa opción por defecto es
collectorymonitor, lo que permite que el PMDA XFS funcione correctamente en la mayoría de los escenarios.
-
La función
Recursos adicionales
- Sección 6.9, “Herramientas distribuidas con la PCP”
- La página man de pmcd.
6.7.2. Examinar las métricas de rendimiento de XFS con pminfo
La herramienta pminfo muestra información sobre las métricas de rendimiento disponibles. Este procedimiento muestra una lista de todas las métricas disponibles proporcionadas por el PMDA de XFS.
Requisitos previos
- El PCP está instalado. Para más información, consulte Sección 6.2, “Instalación y habilitación del PCP”.
Procedimiento
Muestra la lista de todas las métricas disponibles proporcionadas por el PMDA de XFS:
# pminfo xfs
Muestra información de las métricas individuales. Los siguientes ejemplos examinan métricas específicas de XFS
readywriteutilizando la herramientapminfo:Muestra una breve descripción de la métrica
xfs.write_bytes:# pminfo --oneline xfs.write_bytes xfs.write_bytes [number of bytes written in XFS file system write operations]
Muestra una descripción larga de la métrica
xfs.read_bytes:# pminfo --helptext xfs.read_bytes xfs.read_bytes Help: This is the number of bytes read via read(2) system calls to files in XFS file systems. It can be used in conjunction with the read_calls count to calculate the average size of the read operations to file in XFS file systems.
Obtenga el valor de rendimiento actual de la métrica
xfs.read_bytes:# pminfo --fetch xfs.read_bytes xfs.read_bytes value 4891346238
Recursos adicionales
- Sección 6.10, “Grupos de métricas PCP para XFS”.
- La página de manual de pminfo.
6.7.3. Restablecimiento de las métricas de rendimiento de XFS con pmstore
Con PCP, puede modificar los valores de ciertas métricas, especialmente si la métrica actúa como variable de control, como la métrica xfs.control.reset. Para modificar el valor de una métrica, utilice la herramienta pmstore.
Requisitos previos
- El PCP está instalado. Para más información, consulte Sección 6.2, “Instalación y habilitación del PCP”.
Procedimiento
Muestra el valor de una métrica:
$ pminfo -f xfs.write xfs.write value 325262Restablece todas las métricas XFS:
# pmstore xfs.control.reset 1 xfs.control.reset old value=0 new value=1
Ver la información después de restablecer la métrica:
$ pminfo --fetch xfs.write xfs.write value 0
Recursos adicionales
- Sección 6.9, “Herramientas distribuidas con la PCP”
- Sección 6.10, “Grupos de métricas PCP para XFS”.
- La página man de pmstore.
- La página de manual de pminfo.
6.7.4. Examen de las métricas XFS disponibles por sistema de archivos
PCP permite a XFS PMDA informar de ciertas métricas XFS por cada uno de los sistemas de archivos XFS montados. Esto facilita la localización de problemas específicos del sistema de archivos montado y la evaluación del rendimiento. El comando pminfo proporciona métricas XFS por dispositivo para cada sistema de archivos XFS montado.
Requisitos previos
- El PCP está instalado. Para más información, consulte Sección 6.2, “Instalación y habilitación del PCP”.
Procedimiento
Obtenga métricas XFS por dispositivo con
pminfo:# pminfo --fetch --oneline xfs.perdev.read xfs.perdev.write xfs.perdev.read [number of XFS file system read operations] inst [0 or "loop1"] value 0 inst [0 or "loop2"] value 0 xfs.perdev.write [number of XFS file system write operations] inst [0 or "loop1"] value 86 inst [0 or "loop2"] value 0
Recursos adicionales
- Sección 6.11, “Grupos de métricas PCP por dispositivo para XFS”.
- La página de manual de pminfo.
6.8. Servicios del sistema distribuidos con PCP
| Nombre | Descripción |
|
| El demonio recolector de métricas de rendimiento (PMCD). |
|
| El motor de inferencia de métricas de rendimiento. |
|
| El registrador de métricas de rendimiento. |
|
| Gestiona una colección de daemons PCP para un conjunto de hosts locales y remotos descubiertos que ejecutan el Performance Metric Collector Daemon (PMCD) según cero o más directorios de configuración. |
|
| El servidor proxy Performance Metric Collector Daemon (PMCD). |
6.9. Herramientas distribuidas con la PCP
| Nombre | Descripción |
|
| Muestra el estado actual de una instalación de Performance Co-Pilot. |
|
| Muestra la ocupación a nivel de sistema de los recursos de hardware más críticos desde el punto de vista del rendimiento: CPU, memoria, disco y red. |
|
|
Muestra las métricas de un sistema a la vez. Para mostrar las métricas de varios sistemas, utilice la opción |
|
| Traza los valores de las métricas de rendimiento disponibles a través de las instalaciones del Co-Piloto de Rendimiento. |
|
| Muestra las métricas de rendimiento del sistema de alto nivel mediante la interfaz de programación de aplicaciones de métricas de rendimiento (PMAPI). |
|
| Recoge y muestra datos a nivel de sistema, ya sea de un sistema en vivo o de un archivo de Performance Co-Pilot. |
|
| Muestra los valores de los parámetros de configuración. |
|
| Muestra los indicadores de control de depuración de Performance Co-Pilot disponibles y sus valores. |
|
| Compara los valores medios de cada métrica en uno o dos archivos, en una ventana de tiempo determinada, en busca de cambios que puedan ser de interés al buscar regresiones de rendimiento. |
|
| Muestra el control, los metadatos, el índice y la información de estado de un archivo de Performance Co-Pilot. |
|
| Muestra los valores de las métricas de rendimiento recogidas en directo o desde un archivo de Performance Co-Pilot. |
|
| Muestra los códigos de error disponibles de Performance Co-Pilot y sus correspondientes mensajes de error. |
|
| Busca servicios de PCP en la red. |
|
| Un motor de inferencia que evalúa periódicamente un conjunto de expresiones aritméticas, lógicas y de reglas. Las métricas se recogen de un sistema en vivo o de un archivo de Performance Co-Pilot. |
|
| Muestra o establece las variables configurables de pmie. |
|
| Muestra información sobre las métricas de rendimiento. Las métricas se recogen de un sistema en vivo o de un archivo de Performance Co-Pilot. |
|
| Informa de las estadísticas de E/S de los dispositivos SCSI (por defecto) o de los dispositivos device-mapper (con la opción -x dm). |
|
| Configura interactivamente las instancias activas de pmlogger. |
|
| Identifica los datos no válidos en un archivo de Performance Co-Pilot. |
|
| Crea y modifica un archivo de configuración de pmlogger. |
|
| Verifica, modifica o repara la etiqueta de un archivo de Performance Co-Pilot. |
|
| Calcula la información estadística sobre las métricas de rendimiento almacenadas en un archivo de Performance Co-Pilot. |
|
| Determina la disponibilidad de las métricas de rendimiento. |
|
| Informes sobre los valores de las métricas de rendimiento seleccionadas, fácilmente personalizables. |
|
| Permite el acceso a los hosts de Performance Co-Pilot a través de un firewall. |
|
| Muestra periódicamente un breve resumen del rendimiento del sistema. |
|
| Modifica los valores de las métricas de rendimiento. |
|
| Proporciona una interfaz de línea de comandos para el agente de dominio de métricas de rendimiento de rastreo (PMDA). |
|
| Muestra el valor actual de una métrica de rendimiento. |
6.10. Grupos de métricas PCP para XFS
| Grupo métrico | Métricas proporcionadas |
|
| Métricas generales de XFS, incluyendo los recuentos de operaciones de lectura y escritura, y los recuentos de bytes de lectura y escritura. Junto con los contadores para el número de veces que los inodos se vacían, se agrupan y el número de fallos en la agrupación. |
|
| Gama de métricas relativas a la asignación de objetos en el sistema de archivos, entre las que se incluyen el número de extensiones y las creaciones y liberaciones de bloques. Búsqueda y comparación del árbol de asignación junto con la creación y eliminación de registros de extensión del btree. |
|
| Las métricas incluyen el número de lecturas/escrituras del mapa de bloques y de borrados de bloques, operaciones de lista de extensión para inserciones, borrados y búsquedas. También los contadores de operaciones de comparación, búsqueda, inserción y eliminación del mapa de bloques. |
|
| Contadores de operaciones de directorio en sistemas de archivos XFS para la creación, eliminación de entradas, recuento de operaciones "getdent". |
|
| Contadores del número de transacciones de metadatos, estos incluyen el recuento del número de transacciones síncronas y asíncronas junto con el número de transacciones vacías. |
|
| Contadores del número de veces que el sistema operativo buscó un inodo XFS en la caché de inodos con diferentes resultados. Cuentan los accesos a la caché, los fallos de la caché, etc. |
|
| Los contadores del número de escrituras en el búfer del registro en los sistemas de archivos XFS incluyen el número de bloques escritos en el disco. También hay métricas para el número de descargas de registros y de anclajes. |
|
| Cuenta el número de bytes de datos de archivo que el deamon de descarga de XFS descarga junto con los contadores del número de búferes que se descargan en el espacio contiguo y no contiguo del disco. |
|
| Cuenta el número de operaciones de obtención, establecimiento, eliminación y listado de atributos en todos los sistemas de archivos XFS. |
|
| Métricas para el funcionamiento de las cuotas en los sistemas de archivos XFS, que incluyen contadores para el número de reclamaciones de cuotas, pérdidas de caché de cuotas, aciertos de caché y reclamaciones de datos de cuotas. |
|
| Gama de métricas relativas a los objetos de búfer de XFS. Los contadores incluyen el número de llamadas a búferes solicitados, bloqueos de búferes con éxito, bloqueos de búferes en espera, miss_locks, miss_retries y golpes de búfer al buscar páginas. |
|
| Métricas relativas a las operaciones del btree XFS. |
|
| Métricas de configuración que se utilizan para restablecer los contadores de métricas para las estadísticas XFS. Las métricas de control se conmutan mediante la herramienta pmstore. |
6.11. Grupos de métricas PCP por dispositivo para XFS
| Grupo métrico | Métricas proporcionadas |
|
| Métricas generales de XFS, incluyendo los recuentos de operaciones de lectura y escritura, y los recuentos de bytes de lectura y escritura. Junto con los contadores para el número de veces que los inodos se vacían, se agrupan y el número de fallos en la agrupación. |
|
| Gama de métricas relativas a la asignación de objetos en el sistema de archivos, entre las que se incluyen el número de extensiones y las creaciones y liberaciones de bloques. Búsqueda y comparación del árbol de asignación junto con la creación y eliminación de registros de extensión del btree. |
|
| Las métricas incluyen el número de lecturas/escrituras del mapa de bloques y de borrados de bloques, operaciones de lista de extensión para inserciones, borrados y búsquedas. También los contadores de operaciones de comparación, búsqueda, inserción y eliminación del mapa de bloques. |
|
| Contadores de operaciones de directorio de los sistemas de archivos XFS para la creación, eliminación de entradas, recuento de operaciones "getdent". |
|
| Contadores del número de transacciones de metadatos, estos incluyen el recuento del número de transacciones síncronas y asíncronas junto con el número de transacciones vacías. |
|
| Contadores del número de veces que el sistema operativo buscó un inodo XFS en la caché de inodos con diferentes resultados. Cuentan los accesos a la caché, los fallos de la caché, etc. |
|
| Los contadores del número de escrituras en el búfer del registro en los sistemas de archivos XFS incluyen el número de bloques escritos en el disco. También hay métricas para el número de descargas de registros y de anclajes. |
|
| Cuenta el número de bytes de datos de archivo que el deamon de descarga de XFS descarga junto con los contadores del número de búferes que se descargan en el espacio contiguo y no contiguo del disco. |
|
| Cuenta el número de operaciones de obtención, establecimiento, eliminación y listado de atributos en todos los sistemas de archivos XFS. |
|
| Métricas para el funcionamiento de las cuotas en los sistemas de archivos XFS, que incluyen contadores para el número de reclamaciones de cuotas, pérdidas de caché de cuotas, aciertos de caché y reclamaciones de datos de cuotas. |
|
| Gama de métricas relativas a los objetos de búfer de XFS. Los contadores incluyen el número de llamadas a búferes solicitados, bloqueos de búferes con éxito, bloqueos de búferes en espera, miss_locks, miss_retries y golpes de búfer al buscar páginas. |
|
| Métricas relativas a las operaciones del btree XFS. |
Capítulo 7. Configuración de la representación gráfica de las métricas de la PCP
Mediante una combinación de redis, pcp, bpftrace, vector y grafana se obtienen gráficos, basados en los datos en vivo o en los datos recogidos por Performance Co-Pilot (PCP). Permite acceder a los gráficos de las métricas del PCP mediante un navegador web.
- El PCP es un marco genérico que recoge, supervisa, analiza y almacena las métricas relacionadas con el rendimiento. Para obtener más información sobre el PCP y sus componentes, consulte Supervisión del rendimiento con Performance Co-Pilot.
-
Redis es un
in-memory-database. Se utiliza para almacenar los datos de los archivos archivados que son fácilmente accesibles para la generación de gráficos por la aplicación Grafana. -
Bpftrace permite acceder a los datos en directo de las fuentes que no están disponibles como datos normales en la página web
pmloggero en los archivos. - Vector proporciona acceso a los datos en vivo, pero no proporciona acceso a los datos del pasado.
-
Grafana genera gráficos que son accesibles desde un navegador. El
grafana-serveres un componente que escucha, por defecto, en todas las interfaces, y proporciona servicios web a los que se accede a través del navegador. El plugingrafana-pcpinteractúa con el protocolopmproxyen el backend.
7.1. Configuración de PCP en un sistema
Este procedimiento describe cómo configurar PCP en un sistema con el paquete pcp-zeroconf. Una vez instalado el paquete pcp-zeroconf, el sistema registra el conjunto de métricas por defecto en ficheros archivados.
Procedimiento
Instale el paquete
pcp-zeroconf:# yum install pcp-zeroconf
Pasos de verificación
Asegúrese de que el servicio
pmloggerestá activo y comienza a archivar las métricas:# pcp | grep pmlogger pmlogger: primary logger: /var/log/pcp/pmlogger/localhost.localdomain/20200401.00.12
Recursos adicionales
-
La página de manual
pmlogger. - Para obtener más información sobre el PCP y sus componentes, consulte Supervisión del rendimiento con Performance Co-Pilot.
7.2. Configuración de un servidor Grafana
Este procedimiento describe cómo configurar un grafana-server. Es un servidor back-end para el dashbaord de Grafana. El componente grafana-server escucha en la interfaz y proporciona servicios web a los que se accede a través del navegador.
Requisitos previos
-
El paquete
pcp-zeroconfestá instalado. Para más información, consulte Sección 7.1, “Configuración de PCP en un sistema”.
Procedimiento
Instale los siguientes paquetes:
# yum install redis grafana grafana-pcp
Reinicie y habilite los siguientes componentes:
# systemctl restart redis pmproxy grafana-server # systemctl enable redis pmproxy grafana-server
Pasos de verificación
Asegúrese de que el
grafana-serverestá escuchando y respondiendo a las peticiones:# ss -ntlp | grep 3000 LISTEN 0 128 *:3000 *:* users:(("grafana-server",pid=19522,fd=7))
Recursos adicionales
-
La página de manual
pmproxy. -
La página de manual
grafana-server.
7.3. Acceso a la interfaz web de Grafana
Este procedimiento describe cómo acceder a la interfaz web de Grafana y generar gráficos utilizando diferentes tipos de fuentes de datos.
Requisitos previos
-
El paquete
pcp-zeroconfestá instalado. Para más información, consulte Sección 7.1, “Configuración de PCP en un sistema”. -
El
grafana-serverestá configurado. Para más información, consulte Sección 7.2, “Configuración de un servidor Grafana”.
Procedimiento
En el sistema cliente, abra un navegador y acceda a
grafana-serveren el puerto3000, utilizando http://192.0.2.0:3000 el enlace.Sustituya 192.0.2.0 por la IP de su máquina.
Para el primer inicio de sesión, introduzca admin en los campos username y password.
Figura 7.1. Página de inicio de sesión de Grafana

- Para crear una cuenta segura, Grafana pide que se establezca una nueva password.
In the pane, hover on the
 configuration icon > click Plugins > in the Filter by name or type, type performance co-pilot > click Performance Co-Pilot plugin and > click Enable to enable the
configuration icon > click Plugins > in the Filter by name or type, type performance co-pilot > click Performance Co-Pilot plugin and > click Enable to enable the grafana-pcpplugin.Figura 7.2. Tablero de mandos de la casa
 Nota
NotaThe top corner of the screen has a similar
 icon, but it controls the general Dashboard settings.
icon, but it controls the general Dashboard settings.
-
Click the
 icon to view the Home Dashboard.
icon to view the Home Dashboard.
En la página Home Dashboard, haga clic en Add data source para añadir las fuentes de datos PCP Redis, PCP bpftrace y PCP Vector.
Para más información sobre cómo añadir las fuentes de datos PCP Redis, PCP bpftrace y PCP Vector, consulte:
-
Optional: In the pane, hover on the
 icon to change the Preferences or to Sign out.
icon to change the Preferences or to Sign out.
Pasos de verificación
Asegúrese de que el plugin Performance Co-Pilot está activado:
# grafana-cli plugins ls | grep performancecopilot-pcp-app performancecopilot-pcp-app @ 1.0.5
Recursos adicionales
-
La página de manual
grafana-cli. -
La página de manual
grafana-server.
7.4. Añadir PCP Redis como fuente de datos
La fuente de datos PCP Redis visualiza todo lo que contiene el archivo y consulta la capacidad de las series temporales que ofrece el lenguaje pmseries. Analiza los datos en varios hosts. Este procedimiento describe cómo añadir PCP Redis como fuente de datos y cómo ver el panel de control con una visión general de las métricas útiles.
Requisitos previos
-
El sitio
grafana-serveres accesible. Para más información, consulte Sección 7.3, “Acceso a la interfaz web de Grafana”.
Procedimiento
Click the
icon > click Add data source > in the Filter by name or type, type redis > and click PCP Redis > in the URL field, accept the given suggestion http://localhost:44322 and > click Save & Test.
Figura 7.3. Añadir PCP Redis en la fuente de datos
In the pane, hover on the
 filter icon > click Manage > in the Filter Dashboard by name, type pcp redis > select PCP Redis Host Overview to see a dashboard with an overview of any useful metrics.
filter icon > click Manage > in the Filter Dashboard by name, type pcp redis > select PCP Redis Host Overview to see a dashboard with an overview of any useful metrics.
Figura 7.4. Descripción del host PCP Redis
In the pane, hover on the
 icon > click Dashboard option > click Add Query > from the Query list, select the PCP Redis and > in the text field of A, enter metric, for example,
icon > click Dashboard option > click Add Query > from the Query list, select the PCP Redis and > in the text field of A, enter metric, for example, kernel.all.loadto visualize the kernel load graph.Figura 7.5. Consulta PCP Redis
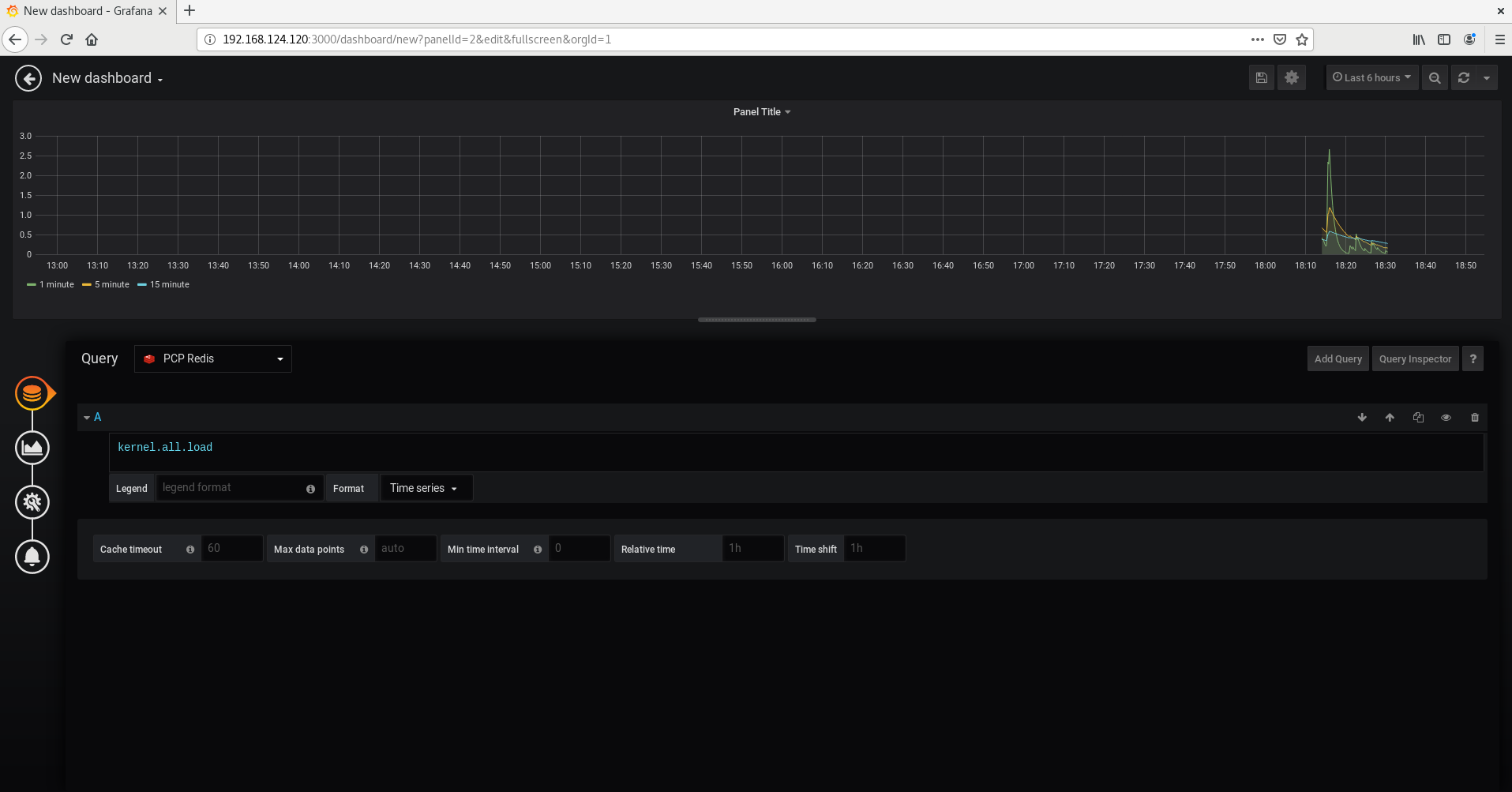
Recursos adicionales
-
La página de manual
pmseries.
7.5. Configuración de la autenticación entre los componentes del PCP
PCP soporta el mecanismo de autenticación scram-sha-256 a través del marco de trabajo de la Capa de Seguridad de Autenticación Simple (SASL). Este procedimiento describe cómo configurar la autenticación utilizando el mecanismo de autenticación scram-sha-256.
A partir de Red Hat Enterprise Linux 8.3, PCP soporta el mecanismo de autenticación scram-sha-256.
Requisitos previos
Instale el marco
saslpara el mecanismo de autenticaciónscram-sha-256:# yum install cyrus-sasl-scram cyrus-sasl-lib
Procedimiento
Especifique el mecanismo de autenticación admitido y la ruta de la base de datos de usuarios en el archivo
pmcd.conf:# vi /etc/sasl2/pmcd.conf mech_list: scram-sha-256 sasldb_path: /etc/pcp/passwd.db
Crear un nuevo usuario:
# useradd -r metricsSustituye metrics por tu nombre de usuario.
Añade el usuario creado en la base de datos de usuarios:
# saslpasswd2 -a pmcd metrics Password: Again (for verification):Establezca los permisos de la base de datos de usuarios:
# chown root:pcp /etc/pcp/passwd.db # chmod 640 /etc/pcp/passwd.db
Reinicie el servicio
pmcd:# systemctl restart pmcd
Pasos de verificación
Verifique la configuración de
sasl:# pminfo -f -h "pcp://127.0.0.1?username=metrics" disk.dev.read Password: disk.dev.read inst [0 or "sda"] value 19540
Recursos adicionales
-
Para más información, consulte las páginas de manual
saslauthd,pminfo, ysha256. - Para obtener más información sobre la configuración de la autenticación entre componentes de PCP en RHEL 8.2, consulte el artículo de la base de conocimientos ¿Cómo puedo configurar la autenticación entre componentes de PCP, como PMDA y pmcd?
7.6. Añadir PCP bpftrace como fuente de datos
El agente bpftrace permite la introspección del sistema mediante los scripts bpftrace, que utiliza el Berkeley Packet Filter mejorado (eBPF) para recopilar métricas del kernel y de los tracepoints del espacio de usuario. Este procedimiento describe cómo añadir el PCP bpftrace como fuente de datos y cómo ver el panel de control con una visión general de cualquier métrica útil.
Requisitos previos
-
El sitio
grafana-serveres accesible. Para más información, consulte Sección 7.3, “Acceso a la interfaz web de Grafana”. -
El mecanismo de autenticación
scram-sha-256está configurado. Para más información, consulte Sección 7.5, “Configuración de la autenticación entre los componentes del PCP”.
Requisitos previos
Instale el paquete
pcp-pmda-bpftrace:# yum install pcp-pmda-bpftrace
Procedimiento
Edite el archivo
bpftrace.confy añada su usuario, que ha creado en Sección 7.5, “Configuración de la autenticación entre los componentes del PCP”:# vi /var/lib/pcp/pmdas/bpftrace/bpftrace.conf [dynamic_scripts] enabled = true auth_enabled = true allowed_users = root,metricsSustituye metrics por tu nombre de usuario.
Instale el
bpftracePMDA:# cd /var/lib/pcp/pmdas/bpftrace/ # ./Install Updating the Performance Metrics Name Space (PMNS) ... Terminate PMDA if already installed ... Updating the PMCD control file, and notifying PMCD ... Check bpftrace metrics have appeared ... 7 metrics and 6 values
El
pmda-bpftraceestá ahora instalado, y sólo puede ser utilizado después de autenticar a su usuario.- Inicie sesión en la interfaz web de Grafana. Para obtener más información, consulte Sección 7.3, “Acceso a la interfaz web de Grafana”.
Click the
icon > click Add data source > in the Filter by name or type, type bpftrace > and click PCP bpftrace > in the URL field, accept the given suggestion http://localhost:44322.
Seleccione la opción > añada las credenciales de usuario creadas en el campo User y Password y > haga clic en Save & Test.
Figura 7.6. Añadir PCP bpftrace en la fuente de datos
In the pane, hover on the
filter icon > click Manage > in the Filter Dashboard by name, type pcp bpftrace > select PCP bpftrace System Analysis to see a dashboard with an overview of useful metrics.
Figura 7.7. Análisis del sistema PCP bpftrace
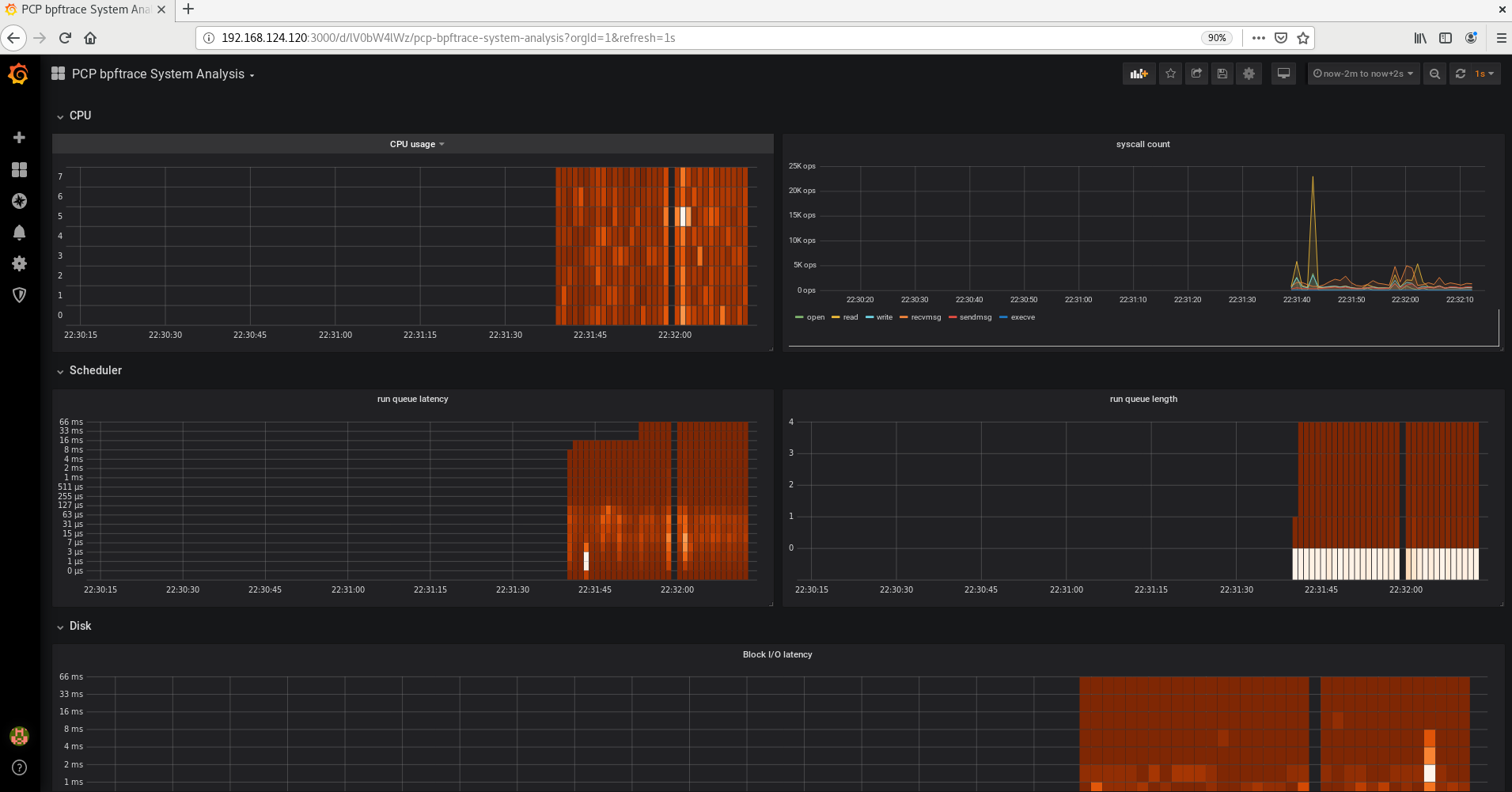
Recursos adicionales
-
La página de manual
pmdabpftrace. -
La página de manual
bpftrace.
7.7. Añadir PCP Vector como fuente de datos
La fuente de datos PCP Vector muestra las métricas en vivo y utiliza las métricas de pcp. Analiza los datos de hosts individuales. Este procedimiento describe cómo añadir un PCP Vector como fuente de datos y cómo ver el panel de control con una visión general de cualquier métrica útil.
Requisitos previos
-
El sitio
grafana-serveres accesible. Para más información, consulte Sección 7.3, “Acceso a la interfaz web de Grafana”.
Procedimiento
Instale el paquete
pcp-pmda-bcc:# yum install pcp-pmda-bcc
Instale el
bccPMDA:# cd /var/lib/pcp/pmdas/bcc # ./Install [Wed Apr 1 00:27:48] pmdabcc(22341) Info: Initializing, currently in 'notready' state. [Wed Apr 1 00:27:48] pmdabcc(22341) Info: Enabled modules: [Wed Apr 1 00:27:48] pmdabcc(22341) Info: ['biolatency', 'sysfork', [...] Updating the Performance Metrics Name Space (PMNS) ... Terminate PMDA if already installed ... Updating the PMCD control file, and notifying PMCD ... Check bcc metrics have appeared ... 1 warnings, 1 metrics and 0 values
- Inicie sesión en la interfaz web de Grafana. Para obtener más información, consulte Sección 7.3, “Acceso a la interfaz web de Grafana”.
Click the
icon > click Add data source > in the Filter by name or type, type vector > and click PCP Vector > in the URL field, accept the given suggestion http://localhost:44322 and > click Save & Test.
Figura 7.8. Añadir el vector PCP en la fuente de datos
In the pane, hover on the
icon > click Manage > in the Filter Dashboard by name, type pcp vector > select PCP Vector Host Overview to see a dashboard with an overview of useful metrics.
Figura 7.9. Visión general del anfitrión vectorial PCP
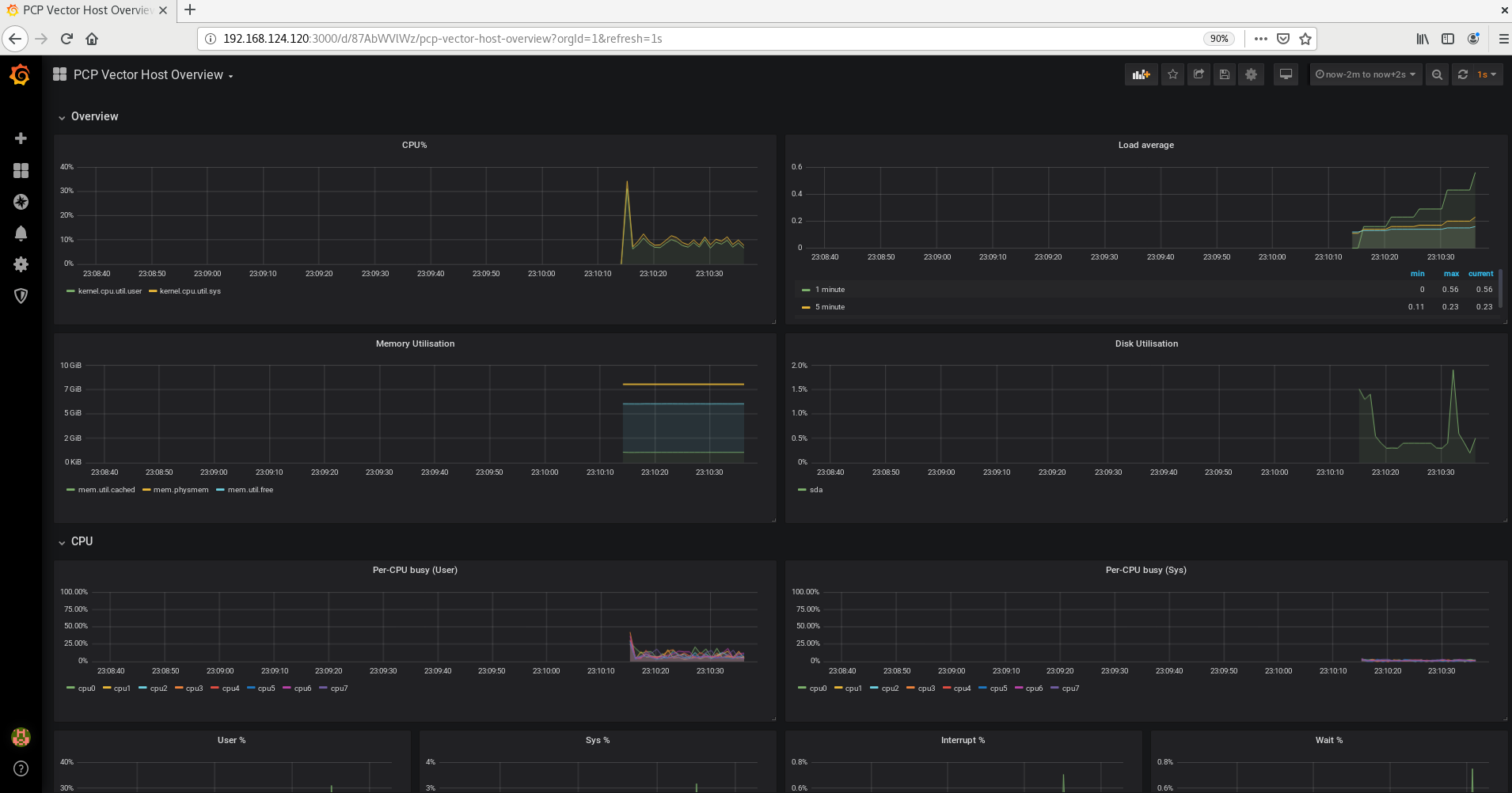
Recursos adicionales
-
La página de manual
pmdabcc.
Capítulo 8. Optimización del rendimiento del sistema mediante la consola web
Aprenda a establecer un perfil de rendimiento en la consola web de RHEL 8 para optimizar el rendimiento del sistema para una tarea seleccionada.
8.1. Opciones de ajuste del rendimiento en la consola web
Red Hat Enterprise Linux 8 proporciona varios perfiles de rendimiento que optimizan el sistema para las siguientes tareas:
- Sistemas que utilizan el escritorio
- Rendimiento de la producción
- Rendimiento de la latencia
- Rendimiento de la red
- Bajo consumo de energía
- Máquinas virtuales
El servicio tuned optimiza las opciones del sistema para ajustarse al perfil seleccionado.
En la consola web, puedes establecer qué perfil de rendimiento utiliza tu sistema.
Recursos adicionales
-
Para más detalles sobre el servicio
tuned, véase Supervisión y gestión del estado y el rendimiento del sistema.
8.2. Establecer un perfil de rendimiento en la consola web
Este procedimiento utiliza la consola web para optimizar el rendimiento del sistema para una tarea seleccionada.
Requisitos previos
La consola web está instalada y accesible.
Para más detalles, véase Instalación de la consola web.
Procedimiento
Inicie sesión en la consola web de RHEL 8.
Para más detalles, consulte Iniciar sesión en la consola web.
- Haga clic en Overview.
En el campo Performance Profile, haga clic en el perfil de rendimiento actual.

- En el cuadro de diálogo Change Performance Profile, cambie el perfil si es necesario.
Haga clic en Change Profile.

Pasos de verificación
- La pestaña Overview muestra ahora el perfil de rendimiento seleccionado.
Capítulo 9. Configuración del programador de discos
El programador de disco es responsable de ordenar las peticiones de E/S enviadas a un dispositivo de almacenamiento.
Puede configurar el programador de varias maneras:
- Configure el programador mediante Tuned, como se describe en Sección 9.6, “Configuración del programador de discos mediante Tuned”
-
Configure el programador mediante
udev, como se describe en Sección 9.7, “Configuración del programador de discos mediante reglas udev” - Cambiar temporalmente el planificador en un sistema en funcionamiento, como se describe en Sección 9.8, “Establecer temporalmente un programador para un disco específico”
9.1. Cambios en el programador de discos en RHEL 8
En RHEL 8, los dispositivos de bloque sólo admiten la programación de colas múltiples. Esto permite que el rendimiento de la capa de bloques escale bien con unidades de estado sólido (SSD) rápidas y sistemas multinúcleo.
Se han eliminado los programadores tradicionales de cola única, que estaban disponibles en RHEL 7 y versiones anteriores.
9.2. Programadores de disco disponibles
Los siguientes programadores de disco de cola múltiple son compatibles con RHEL 8:
none- Implementa un algoritmo de programación FIFO (first-in first-out). Combina las solicitudes en la capa de bloques genéricos a través de una simple caché de último golpe.
mq-deadlineIntenta proporcionar una latencia garantizada para las solicitudes desde el punto en que éstas llegan al planificador.
El planificador de
mq-deadlineclasifica las solicitudes de E/S en cola en un lote de lectura o de escritura y, a continuación, las programa para su ejecución en orden creciente de direccionamiento lógico de bloques (LBA). Por defecto, los lotes de lectura tienen prioridad sobre los de escritura, ya que es más probable que las aplicaciones se bloqueen en las operaciones de E/S de lectura. Después de quemq-deadlineprocese un lote, comprueba cuánto tiempo han estado las operaciones de escritura sin tiempo de procesador y programa el siguiente lote de lectura o de escritura según corresponda.Este planificador es adecuado para la mayoría de los casos de uso, pero sobre todo para aquellos en los que las operaciones de escritura son mayoritariamente asíncronas.
bfqDirigido a sistemas de escritorio y tareas interactivas.
El programador
bfqgarantiza que una sola aplicación nunca utilice todo el ancho de banda. En efecto, el dispositivo de almacenamiento siempre responde como si estuviera inactivo. En su configuración por defecto,bfqse centra en ofrecer la menor latencia en lugar de lograr el máximo rendimiento.bfqse basa en el códigocfq. No concede el disco a cada proceso durante una franja de tiempo fija, sino que asigna al proceso un budget medido en número de sectores.Este programador es adecuado cuando se copian archivos grandes y el sistema no deja de responder en este caso.
kyberEl planificador se ajusta a un objetivo de latencia. Puede configurar las latencias objetivo para las solicitudes de lectura y escritura síncrona.
Este programador es adecuado para dispositivos rápidos, por ejemplo NVMe, SSD u otros dispositivos de baja latencia.
9.3. Diferentes programadores de disco para diferentes casos de uso
Dependiendo de la tarea que realice su sistema, se recomiendan los siguientes programadores de disco como línea de base antes de cualquier tarea de análisis y ajuste:
Tabla 9.1. Programadores de disco para diferentes casos de uso
| Caso de uso | Programador de discos |
|---|---|
| Disco duro tradicional con interfaz SCSI |
Utilice |
| SSD de alto rendimiento o un sistema con CPU con almacenamiento rápido |
Utilice |
| Tareas de escritorio o interactivas |
Utilice |
| Invitado virtual |
Utilice |
9.4. El programador de discos por defecto
Los dispositivos de bloque utilizan el programador de discos por defecto a menos que se especifique otro programador.
Para los dispositivos de bloque non-volatile Memory Express (NVMe) específicamente, el programador por defecto es none y Red Hat recomienda no cambiarlo.
El kernel selecciona un programador de disco por defecto basado en el tipo de dispositivo. El planificador seleccionado automáticamente es normalmente la configuración óptima. Si necesita un planificador diferente, Red Hat recomienda utilizar las reglas de udev o la aplicación Tuned para configurarlo. Compare los dispositivos seleccionados y cambie el planificador sólo para esos dispositivos.
9.5. Determinación del programador de disco activo
Este procedimiento determina qué programador de disco está actualmente activo en un dispositivo de bloque dado.
Procedimiento
Leer el contenido del
/sys/block/device/queue/schedulerarchivo:# cat /sys/block/device/queue/scheduler [mq-deadline] kyber bfq noneEn el nombre del archivo, sustituya device por el nombre del dispositivo de bloque, por ejemplo
sdc.El programador activo aparece entre corchetes (
[ ]).
9.6. Configuración del programador de discos mediante Tuned
Este procedimiento crea y habilita un perfil Tuned que establece un programador de disco determinado para los dispositivos de bloque seleccionados. La configuración persiste a través de los reinicios del sistema.
En los siguientes comandos y la configuración, reemplazar:
-
device con el nombre del dispositivo de bloque, por ejemplo
sdf -
selected-scheduler con el programador de discos que se desea establecer para el dispositivo, por ejemplo
bfq
Requisitos previos
El servicio
tunedestá instalado y habilitado.Para más detalles, consulte Sección 2.6, “Instalación y habilitación de Tuned”.
Procedimiento
Opcional: Seleccione un perfil existente de Tuned en el que se basará su perfil. Para ver una lista de perfiles disponibles, consulte Sección 2.3, “Perfiles ajustados distribuidos con RHEL”.
Para ver qué perfil está actualmente activo, utilice:
$ tuned-adm active
Cree un nuevo directorio para albergar su perfil de Tuned:
# mkdir /etc/tuned/my-profileBusca el identificador único del sistema del dispositivo de bloque seleccionado:
$ udevadm info --query=property --name=/dev/device | grep -E '(WWN|SERIAL)' ID_WWN=0x5002538d00000000 ID_SERIAL=Generic-_SD_MMC_20120501030900000-0:0 ID_SERIAL_SHORT=20120501030900000
NotaEl comando de este ejemplo devolverá todos los valores identificados como World Wide Name (WWN) o número de serie asociados al dispositivo de bloque especificado. Aunque es preferible utilizar un WWN, el WWN no siempre está disponible para un dispositivo determinado y cualquier valor devuelto por el comando del ejemplo es aceptable para utilizarlo como el device system unique ID.
Cree el
/etc/tuned/my-profile/tuned.confarchivo de configuración. En el archivo, establezca las siguientes opciones:Opcional: Incluir un perfil existente:
[main] include=existing-profileEstablece el programador de discos seleccionado para el dispositivo que coincide con el identificador WWN:
[disk] devices_udev_regex=IDNAME=device system unique id elevator=selected-scheduler
-
Sustituya IDNAME por el nombre del identificador utilizado (por ejemplo,
ID_WWN). -
Sustituya device system unique id por el valor del identificador elegido (por ejemplo,
0x5002538d00000000).
Para hacer coincidir varios dispositivos en la opción
devices_udev_regex, encierre los identificadores entre paréntesis y sepárelos con barras verticales:-
Sustituya IDNAME por el nombre del identificador utilizado (por ejemplo,
devices_udev_regex=(ID_WWN=0x5002538d00000000)|(ID_WWN=0x1234567800000000)
Habilita tu perfil:
# perfil tuned-adm my-profileCompruebe que el perfil Tuned está activo y aplicado:
$ tuned-adm active Current active profile: my-profile$ tuned-adm verify Verification succeeded, current system settings match the preset profile. See tuned log file ('/var/log/tuned/tuned.log') for details.
Recursos adicionales
- Para más información sobre la creación de un perfil Tuned, consulte Capítulo 3, Personalización de los perfiles Tuned.
9.7. Configuración del programador de discos mediante reglas udev
Este procedimiento establece un programador de disco determinado para dispositivos de bloque específicos utilizando las reglas de udev. La configuración persiste a través de los reinicios del sistema.
En los siguientes comandos y la configuración, reemplazar:
-
device con el nombre del dispositivo de bloque, por ejemplo
sdf -
selected-scheduler con el programador de discos que se desea establecer para el dispositivo, por ejemplo
bfq
Procedimiento
Encuentra el identificador único del sistema del dispositivo de bloque:
$ udevadm info --name=/dev/device | grep -E '(WWN|SERIAL)' E: ID_WWN=0x5002538d00000000 E: ID_SERIAL=Generic-_SD_MMC_20120501030900000-0:0 E: ID_SERIAL_SHORT=20120501030900000
NotaEl comando de este ejemplo devolverá todos los valores identificados como World Wide Name (WWN) o número de serie asociados al dispositivo de bloque especificado. Aunque es preferible utilizar un WWN, el WWN no siempre está disponible para un dispositivo determinado y cualquier valor devuelto por el comando del ejemplo es aceptable para utilizarlo como el device system unique ID.
Configure la regla
udev. Cree el archivo/etc/udev/rules.d/99-scheduler.rulescon el siguiente contenido:ACTION=="add|change", SUBSYSTEM=="block", ENV{{{}IDNAME}=="device system unique id", ATTR{queue/scheduler}="selected-scheduler"-
Sustituya IDNAME por el nombre del identificador utilizado (por ejemplo,
ID_WWN). -
Sustituya device system unique id por el valor del identificador elegido (por ejemplo,
0x5002538d00000000).
-
Sustituya IDNAME por el nombre del identificador utilizado (por ejemplo,
Recargue las reglas de
udev:# udevadm control --reload-rules
Aplicar la configuración del programador:
# udevadm trigger --type=devices --action=change
Verificar el programador activo:
# cat /sys/block/device/queue/scheduler
9.8. Establecer temporalmente un programador para un disco específico
Este procedimiento establece un programador de disco determinado para dispositivos de bloque específicos. La configuración no persiste a través de los reinicios del sistema.
Procedimiento
Escriba el nombre del programador seleccionado en el
/sys/block/device/queue/schedulerarchivo:# echo selected-scheduler > /sys/block/device/cola/programador
En el nombre del archivo, sustituya device por el nombre del dispositivo de bloque, por ejemplo
sdc.
Pasos de verificación
Compruebe que el programador está activo en el dispositivo:
# cat /sys/block/device/queue/scheduler
Capítulo 10. Ajuste del rendimiento de un servidor Samba
Este capítulo describe qué ajustes pueden mejorar el rendimiento de Samba en ciertas situaciones, y qué ajustes pueden tener un impacto negativo en el rendimiento.
Partes de esta sección han sido adoptadas de la documentación de Performance Tuning publicada en el Wiki de Samba. Licencia: CC BY 4.0. Autores y colaboradores: Ver la pestaña de historia en la página de la Wiki.
Requisitos previos
Samba se configura como servidor de archivos o de impresión
Consulte Uso de Samba como servidor.
10.1. Configuración de la versión del protocolo SMB
Cada nueva versión de SMB añade funciones y mejora el rendimiento del protocolo. Los recientes sistemas operativos Windows y Windows Server siempre admiten la última versión del protocolo. Si Samba también utiliza la última versión del protocolo, los clientes de Windows que se conectan a Samba se benefician de las mejoras de rendimiento. En Samba, el valor por defecto del protocolo máximo del servidor se establece en la última versión estable del protocolo SMB soportada.
Para tener siempre habilitada la última versión estable del protocolo SMB, no configure el parámetro server max protocol. Si establece el parámetro manualmente, tendrá que modificar la configuración con cada nueva versión del protocolo SMB, para tener habilitada la última versión del protocolo.
El siguiente procedimiento explica cómo utilizar el valor por defecto en el parámetro server max protocol.
Procedimiento
-
Eliminar el parámetro
server max protocolde la sección[global]en el archivo/etc/samba/smb.conf. Recargar la configuración de Samba
#
smbcontrol all reload-config
10.3. Ajustes que pueden tener un impacto negativo en el rendimiento
Por defecto, el kernel de Red Hat Enterprise Linux está ajustado para un alto rendimiento de la red. Por ejemplo, el kernel utiliza un mecanismo de auto-ajuste para los tamaños de búfer. El ajuste del parámetro socket options en el archivo /etc/samba/smb.conf anula estos ajustes del kernel. Como resultado, el establecimiento de este parámetro disminuye el rendimiento de la red Samba en la mayoría de los casos.
Para utilizar la configuración optimizada del Kernel, elimine el parámetro socket options de la sección [global] en el sitio web /etc/samba/smb.conf.
Capítulo 11. Optimización del rendimiento de las máquinas virtuales
Las máquinas virtuales (VM) siempre experimentan cierto grado de deterioro del rendimiento en comparación con el host. Las siguientes secciones explican las razones de este deterioro y proporcionan instrucciones sobre cómo minimizar el impacto de la virtualización en el rendimiento en RHEL 8, para que los recursos de su infraestructura de hardware puedan ser utilizados de la manera más eficiente posible.
11.1. Qué influye en el rendimiento de las máquinas virtuales
Las máquinas virtuales se ejecutan como procesos de espacio de usuario en el host. Por lo tanto, el hipervisor tiene que convertir los recursos del sistema del host para que las máquinas virtuales puedan utilizarlos. Como consecuencia, una parte de los recursos es consumida por la conversión, por lo que la VM no puede alcanzar la misma eficiencia de rendimiento que el host.
El impacto de la virtualización en el rendimiento del sistema
Entre las razones más específicas de la pérdida de rendimiento de las máquinas virtuales se encuentran:
- Las CPUs virtuales (vCPUs) se implementan como hilos en el host, manejados por el planificador de Linux.
- Las máquinas virtuales no heredan automáticamente las características de optimización, como NUMA o las páginas enormes, del núcleo anfitrión.
- Los ajustes de E/S del disco y de la red del host pueden tener un impacto significativo en el rendimiento de la máquina virtual.
- El tráfico de red suele viajar a una VM a través de un puente basado en software.
- Dependiendo de los dispositivos anfitriones y sus modelos, puede haber una sobrecarga significativa debido a la emulación de un hardware particular.
La gravedad del impacto de la virtualización en el rendimiento de las máquinas virtuales se ve influida por una serie de factores, entre los que se incluyen:
- El número de máquinas virtuales que se ejecutan simultáneamente.
- La cantidad de dispositivos virtuales utilizados por cada VM.
- Los tipos de dispositivos utilizados por las máquinas virtuales.
Reducción de la pérdida de rendimiento de las máquinas virtuales
RHEL 8 ofrece una serie de funciones que puede utilizar para reducir los efectos negativos de la virtualización sobre el rendimiento. En particular:
-
El servicio
tunedpuede optimizar automáticamente la distribución de recursos y el rendimiento de sus máquinas virtuales. - Elajuste de E/S en bloque puede mejorar el rendimiento de los dispositivos de bloque de la máquina virtual, como los discos.
- El ajuste de NUMA puede aumentar el rendimiento de las vCPU.
- Lared virtual puede optimizarse de varias maneras.
El ajuste del rendimiento de la VM puede tener efectos adversos en otras funciones de virtualización. Por ejemplo, puede dificultar la migración de la VM modificada.
11.2. Optimización del rendimiento de las máquinas virtuales mediante el ajuste
La utilidad tuned es un mecanismo de entrega de perfiles de ajuste que adapta RHEL a determinadas características de la carga de trabajo, como los requisitos de las tareas intensivas de la CPU o la capacidad de respuesta del rendimiento de la red de almacenamiento. Proporciona una serie de perfiles de ajuste preconfigurados para mejorar el rendimiento y reducir el consumo de energía en una serie de casos de uso específicos. Puede editar estos perfiles o crear otros nuevos para crear soluciones de rendimiento adaptadas a su entorno, incluidos los entornos virtualizados.
Red Hat recomienda utilizar los siguientes perfiles cuando se utiliza la virtualización en RHEL 8:
-
Para las máquinas virtuales RHEL 8, utilice el perfil virtual-guest. Se basa en el perfil de aplicación general
throughput-performancepero también disminuye el intercambio de la memoria virtual. - Para los hosts de virtualización RHEL 8, utilice el perfil virtual-host. Esto permite una escritura más agresiva de las páginas de memoria sucias, lo que beneficia el rendimiento del host.
Requisitos previos
-
El servicio
tunedestá instalado y habilitado.
Procedimiento
Para activar un perfil específico de tuned:
Enumera los perfiles disponibles en
tuned.# tuned-adm list Available profiles: - balanced - General non-specialized tuned profile - desktop - Optimize for the desktop use-case [...] - virtual-guest - Optimize for running inside a virtual guest - virtual-host - Optimize for running KVM guests Current active profile: balanced
Optional: Crear un nuevo perfil
tunedo editar un perfil existentetuned.Para más información, consulte la sección de personalización de los perfiles ajustados.
Activar un perfil
tuned.# tuned-adm profile selected-profilePara optimizar un host de virtualización, utilice el perfil virtual-host.
# tuned-adm profile virtual-hostEn un sistema operativo invitado RHEL, utilice el perfil virtual-guest.
# tuned-adm profile virtual-guest
Recursos adicionales
-
Para más información sobre los perfiles de
tunedytuned, consulte Supervisión y gestión del estado y el rendimiento del sistema.
11.3. Configuración de la memoria de la máquina virtual
Para mejorar el rendimiento de una máquina virtual (VM), puede asignar más memoria RAM del host a la VM. Del mismo modo, puede disminuir la cantidad de memoria asignada a una VM para que la memoria del host pueda asignarse a otras VM o tareas.
Para realizar estas acciones, puede utilizar la consola web o la interfaz de línea de comandos.
11.3.1. Añadir y eliminar la memoria de la máquina virtual mediante la consola web
Para mejorar el rendimiento de una máquina virtual (VM) o para liberar los recursos del host que está utilizando, puede utilizar la consola web para ajustar la cantidad de memoria asignada a la VM.
Requisitos previos
El sistema operativo invitado está ejecutando los controladores del globo de memoria. Para verificar que este es el caso:
Asegúrese de que la configuración de la máquina virtual incluye el dispositivo
memballoon:# virsh dumpxml testguest | grep memballoon <memballoon model='virtio'> </memballoon>Si este comando muestra alguna salida y el modelo no está configurado en
none, el dispositivomemballoonestá presente.Asegúrese de que los controladores de balones se ejecutan en el sistema operativo invitado.
- En los huéspedes de Windows, los controladores se instalan como parte del paquete de controladores virtio-win. Para obtener instrucciones, consulte Instalación de controladores KVM paravirtualizados para máquinas virtuales Windows.
-
En los huéspedes de Linux, los controladores suelen estar incluidos por defecto y se activan cuando el dispositivo
memballoonestá presente.
- Para utilizar la consola web para gestionar las máquinas virtuales, instale el complemento VM de la consola web.
Procedimiento
Optional: Obtenga la información sobre la memoria máxima y la memoria actualmente utilizada para una VM. Esto servirá como línea de base para sus cambios, y también para la verificación.
# virsh dominfo testguest Max memory: 2097152 KiB Used memory: 2097152 KiBEn la interfaz de , haga clic en una fila con el nombre de las máquinas virtuales para las que desea ver y ajustar la memoria asignada.
La fila se expande para revelar el panel de Visión General con información básica sobre las máquinas virtuales seleccionadas.
Haga clic en el valor de la línea
Memoryen el panel de visión general.Aparece el diálogo
Memory Adjustment.
Configurar las CPUs virtuales para la VM seleccionada.
Maximum allocation - Establece la cantidad máxima de memoria del host que la VM puede utilizar para sus procesos. El aumento de este valor mejora el potencial de rendimiento de la VM, y la reducción del valor disminuye la huella de rendimiento que la VM tiene en su host.
El ajuste de la asignación máxima de memoria sólo es posible en una máquina virtual apagada.
- Current allocation - Establece la cantidad real de memoria asignada a la VM. Puede ajustar el valor para regular la memoria disponible para la VM para sus procesos. Este valor no puede superar el valor máximo de asignación.
Haga clic en .
Se ajusta la asignación de memoria de la VM.
Recursos adicionales
- Para obtener instrucciones para ajustar la configuración de la memoria de la VM mediante la interfaz de línea de comandos, consulte Sección 11.3.2, “Añadir y eliminar la memoria de la máquina virtual mediante la interfaz de línea de comandos”.
- Para optimizar la forma en que la VM utiliza la memoria asignada, puede modificar su configuración de vCPU. Para más información, consulte Sección 11.5, “Optimización del rendimiento de la CPU de la máquina virtual”.
11.3.2. Añadir y eliminar la memoria de la máquina virtual mediante la interfaz de línea de comandos
Para mejorar el rendimiento de una máquina virtual (VM) o para liberar los recursos del host que está utilizando, puede utilizar la CLI para ajustar la cantidad de memoria asignada a la VM.
Requisitos previos
El sistema operativo invitado está ejecutando los controladores del globo de memoria. Para verificar que este es el caso:
Asegúrese de que la configuración de la máquina virtual incluye el dispositivo
memballoon:# virsh dumpxml testguest | grep memballoon <memballoon model='virtio'> </memballoon>Si este comando muestra alguna salida y el modelo no está configurado en
none, el dispositivomemballoonestá presente.Asegúrese de que los controladores de balones se ejecutan en el sistema operativo invitado.
- En los huéspedes de Windows, los controladores se instalan como parte del paquete de controladores virtio-win. Para obtener instrucciones, consulte Instalación de controladores KVM paravirtualizados para máquinas virtuales Windows.
-
En los huéspedes de Linux, los controladores suelen estar incluidos por defecto y se activan cuando el dispositivo
memballoonestá presente.
Procedimiento
Optional: Obtenga la información sobre la memoria máxima y la memoria actualmente utilizada para una VM. Esto servirá como línea de base para sus cambios, y también para la verificación.
# virsh dominfo testguest Max memory: 2097152 KiB Used memory: 2097152 KiBAjuste la memoria máxima asignada a una VM. Aumentar este valor mejora el potencial de rendimiento de la VM, y reducir el valor disminuye la huella de rendimiento que la VM tiene en su host. Tenga en cuenta que este cambio sólo puede realizarse en una VM apagada, por lo que ajustar una VM en funcionamiento requiere un reinicio para que tenga efecto.
Por ejemplo, para cambiar la memoria máxima que la VM testguest puede utilizar a 4096 MiB:
# virt-xml testguest --edit --memory memory=4096,currentMemory=4096 Domain 'testguest' defined successfully. Changes will take effect after the domain is fully powered off.
Optional: También puede ajustar la memoria utilizada actualmente por la VM, hasta la asignación máxima. Esto regula la carga de memoria que la VM tiene en el host hasta el próximo reinicio, sin cambiar la asignación máxima de la VM.
# virsh setmem testguest --current 2048
Verificación
Confirme que la memoria utilizada por la VM ha sido actualizada:
# virsh dominfo testguest Max memory: 4194304 KiB Used memory: 2097152 KiBOptional: Si ha ajustado la memoria actual de la VM, puede obtener las estadísticas del globo de memoria de la VM para evaluar la eficacia con la que regula el uso de la memoria.
# virsh domstats --balloon testguest Domain: 'testguest' balloon.current=365624 balloon.maximum=4194304 balloon.swap_in=0 balloon.swap_out=0 balloon.major_fault=306 balloon.minor_fault=156117 balloon.unused=3834448 balloon.available=4035008 balloon.usable=3746340 balloon.last-update=1587971682 balloon.disk_caches=75444 balloon.hugetlb_pgalloc=0 balloon.hugetlb_pgfail=0 balloon.rss=1005456
Recursos adicionales
- Para obtener instrucciones para ajustar la configuración de la memoria de la VM mediante la consola web, consulte Sección 11.3.1, “Añadir y eliminar la memoria de la máquina virtual mediante la consola web”.
- Para optimizar la forma en que la VM utiliza la memoria asignada, puede modificar su configuración de vCPU. Para más información, consulte Sección 11.5, “Optimización del rendimiento de la CPU de la máquina virtual”.
11.3.3. Recursos adicionales
Para aumentar la memoria máxima de una VM en ejecución, puede adjuntar un dispositivo de memoria a la VM. Esto también se conoce como memory hot plug. Para más detalles, consulte Adjuntar dispositivos a las máquinas virtuales.
Tenga en cuenta que la eliminación de un dispositivo de memoria de una VM, también conocida como memory hot unplug, no está soportada en RHEL 8 y Red Hat desaconseja su uso.
11.4. Optimización del rendimiento de E/S de las máquinas virtuales
Las capacidades de entrada y salida (E/S) de una máquina virtual (VM) pueden limitar significativamente la eficiencia general de la VM. Para solucionar esto, se puede optimizar la E/S de una VM configurando los parámetros de E/S en bloque.
11.4.1. Ajuste de la E/S en bloque en las máquinas virtuales
Cuando una o varias máquinas virtuales utilizan varios dispositivos de bloque, puede ser importante ajustar la prioridad de E/S de determinados dispositivos virtuales modificando su I/O weights.
Aumentar el peso de E/S de un dispositivo aumenta su prioridad para el ancho de banda de E/S, y por lo tanto le proporciona más recursos del host. Del mismo modo, reducir el peso de un dispositivo hace que consuma menos recursos del host.
El valor de weight de cada dispositivo debe estar dentro del rango de 100 a 1000. Como alternativa, el valor puede ser 0, lo que elimina ese dispositivo de los listados por dispositivo.
Procedimiento
Para visualizar y configurar los parámetros de E/S de bloque de una VM:
Muestra los parámetros actuales de
<blkio>para una VM:# virsh dumpxml VM-name<domain> [...] <blkiotune> <weight>800</weight> <device> <path>/dev/sda</path> <weight>1000</weight> </device> <device> <path>/dev/sdb</path> <weight>500</weight> </device> </blkiotune> [...] </domain>Editar el peso de E/S de un dispositivo especificado:
# virsh blkiotune VM-name --device-weights device, I/O-weightPor ejemplo, lo siguiente cambia el peso del dispositivo /dev/sda en la VM liftrul a 500.
# virsh blkiotune liftbrul --device-weights /dev/sda, 500
11.4.2. Estrangulamiento de E/S de disco en máquinas virtuales
Cuando varias máquinas virtuales se ejecutan simultáneamente, pueden interferir con el rendimiento del sistema mediante el uso excesivo de E/S de disco. El estrangulamiento de E/S de disco en la virtualización KVM proporciona la capacidad de establecer un límite en las solicitudes de E/S de disco enviadas desde las VMs a la máquina anfitriona. Esto puede evitar que una máquina virtual sobreutilice los recursos compartidos y afecte al rendimiento de otras máquinas virtuales.
Para activar el estrangulamiento de E/S de disco, establezca un límite en las solicitudes de E/S de disco enviadas desde cada dispositivo de bloque conectado a las máquinas virtuales a la máquina anfitriona.
Procedimiento
Utilice el comando
virsh domblklistpara listar los nombres de todos los dispositivos de disco en una VM especificada.# virsh domblklist rollin-coal Target Source ------------------------------------------------ vda /var/lib/libvirt/images/rollin-coal.qcow2 sda - sdb /home/horridly-demanding-processes.isoBusque el dispositivo de bloque del host en el que está montado el disco virtual que desea estrangular.
Por ejemplo, si quiere acelerar el disco virtual
sdbdel paso anterior, la siguiente salida muestra que el disco está montado en la partición/dev/nvme0n1p3.$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT zram0 252:0 0 4G 0 disk [SWAP] nvme0n1 259:0 0 238.5G 0 disk ├─nvme0n1p1 259:1 0 600M 0 part /boot/efi ├─nvme0n1p2 259:2 0 1G 0 part /boot └─nvme0n1p3 259:3 0 236.9G 0 part └─luks-a1123911-6f37-463c-b4eb-fxzy1ac12fea 253:0 0 236.9G 0 crypt /homeEstablezca los límites de E/S para el dispositivo de bloque utilizando el comando
virsh blkiotune.# virsh blkiotune VM-name --parameter device,limitEl siguiente ejemplo regula el disco
sdben la VMrollin-coala 1000 operaciones de E/S de lectura y escritura por segundo y a 50 MB por segundo de rendimiento de lectura y escritura.# virsh blkiotune rollin-coal --device-read-iops-sec /dev/nvme0n1p3,1000 --device-write-iops-sec /dev/nvme0n1p3,1000 --device-write-bytes-sec /dev/nvme0n1p3,52428800 --device-read-bytes-sec /dev/nvme0n1p3,52428800
Información adicional
- El estrangulamiento de E/S de disco puede ser útil en varias situaciones, por ejemplo, cuando se ejecutan máquinas virtuales pertenecientes a diferentes clientes en el mismo host, o cuando se dan garantías de calidad de servicio para diferentes máquinas virtuales. El estrangulamiento de E/S de disco también puede utilizarse para simular discos más lentos.
- El estrangulamiento de E/S puede aplicarse de forma independiente a cada dispositivo de bloque conectado a una máquina virtual y admite límites de rendimiento y operaciones de E/S.
-
Red Hat no soporta el uso del comando
virsh blkdeviotunepara configurar el estrangulamiento de E/S en las VMs. Para más información sobre las características no soportadas cuando se usa RHEL 8 como anfitrión de VM, vea Características no soportadas en la virtualización de RHEL 8.
11.4.3. Activación de la cola múltiple virtio-scsi
Al utilizar dispositivos de almacenamiento virtio-scsi en sus máquinas virtuales (VM), la función multi-queue virtio-scsi proporciona un mejor rendimiento y escalabilidad del almacenamiento. Permite que cada CPU virtual (vCPU) tenga una cola y una interrupción separadas para usar sin afectar a otras vCPU.
Procedimiento
Para habilitar el soporte de múltiples colas virtio-scsi para una VM específica, añada lo siguiente a la configuración XML de la VM, donde N es el número total de colas vCPU:
<controller type='scsi' index='0' model='virtio-scsi'> <driver queues='N' /> </controller>
11.5. Optimización del rendimiento de la CPU de la máquina virtual
Al igual que las CPUs físicas en las máquinas anfitrionas, las vCPUs son críticas para el rendimiento de las máquinas virtuales (VM). Como resultado, la optimización de las vCPUs puede tener un impacto significativo en la eficiencia de los recursos de sus VMs. Para optimizar su vCPU:
- Ajuste cuántas CPUs de host se asignan a la VM. Puede hacerlo mediante la CLI o la consola web.
Asegúrese de que el modelo de vCPU está alineado con el modelo de CPU del host. Por ejemplo, para configurar la VM testguest1 para que utilice el modelo de CPU del host:
# virt-xml testguest1 --edit --cpu host-model- Desactivar la fusión de páginas del núcleo (KSM).
Si su máquina anfitriona utiliza acceso no uniforme a la memoria (NUMA), también puede configure NUMA para sus máquinas virtuales. Esto mapea los procesos de la CPU y la memoria del host en los procesos de la CPU y la memoria de la VM lo más cerca posible. En efecto, el ajuste NUMA proporciona a la vCPU un acceso más ágil a la memoria del sistema asignada a la VM, lo que puede mejorar la eficacia del procesamiento de la vCPU.
Para más detalles, consulte Sección 11.5.3, “Configuración de NUMA en una máquina virtual” y Sección 11.5.4, “Ejemplo de escenario de ajuste de rendimiento de vCPU”.
11.5.1. Añadir y eliminar CPUs virtuales mediante la interfaz de línea de comandos
Para aumentar u optimizar el rendimiento de la CPU de una máquina virtual (VM), puede añadir o eliminar CPUs virtuales (vCPUs) asignadas a la VM.
Cuando se realiza en una VM en ejecución, esto también se conoce como vCPU hot plugging y hot unplugging. Sin embargo, tenga en cuenta que la desconexión en caliente de vCPU no está soportada en RHEL 8 y Red Hat desaconseja su uso.
Requisitos previos
Optional: Ver el estado actual de las vCPUs en la VM objetivo. Por ejemplo, para mostrar el número de vCPUs en la VM testguest:
# virsh vcpucount testguest maximum config 4 maximum live 2 current config 2 current live 1Esta salida indica que testguest está usando actualmente 1 vCPU, y se puede conectar en caliente 1 vCPu más para aumentar el rendimiento de la VM. Sin embargo, después de reiniciar, el número de vCPUs que utiliza testguest cambiará a 2, y será posible conectar en caliente 2 vCPUs más.
Procedimiento
Ajusta el número máximo de vCPUs que se pueden adjuntar a una VM, que entra en vigor en el siguiente arranque de la VM.
Por ejemplo, para aumentar el número máximo de vCPU para la VM testguest a 8:
# virsh setvcpus testguest 8 --maximum --configTenga en cuenta que el máximo puede estar limitado por la topología de la CPU, el hardware del host, el hipervisor y otros factores.
Ajuste el número actual de vCPUs adjuntas a una VM, hasta el máximo configurado en el paso anterior. Por ejemplo:
Para aumentar el número de vCPUs adjuntas a la VM testguest en ejecución a 4:
# virsh setvcpus testguest 4 --liveEsto aumenta el rendimiento de la VM y la huella de carga del host de testguest hasta el siguiente arranque de la VM.
Para disminuir permanentemente el número de vCPUs adjuntas a la VM testguest a 1:
# virsh setvcpus testguest 1 --configEsto disminuye el rendimiento de la VM y la huella de carga del host de testguest después del siguiente arranque de la VM. Sin embargo, si es necesario, se pueden conectar en caliente vCPUs adicionales a la VM para aumentar temporalmente su rendimiento.
Verificación
Confirme que el estado actual de vCPU para la VM refleja sus cambios.
# virsh vcpucount testguest maximum config 8 maximum live 4 current config 1 current live 4
Recursos adicionales
- Para obtener información sobre cómo añadir y eliminar vCPUs mediante la consola web, consulte Sección 11.5.2, “Gestión de las CPUs virtuales mediante la consola web”.
11.5.2. Gestión de las CPUs virtuales mediante la consola web
Utilizando la consola web de RHEL 8, puede revisar y configurar las CPUs virtuales utilizadas por las máquinas virtuales (VMs) a las que está conectada la consola web.
Requisitos previos
- Para utilizar la consola web para gestionar las máquinas virtuales, instale el complemento VM de la consola web.
Procedimiento
En la interfaz de , haga clic en una fila con el nombre de las máquinas virtuales para las que desea ver y configurar los parámetros de la CPU virtual.
La fila se expande para revelar el panel de Visión General con información básica sobre las VMs seleccionadas, incluyendo el número de CPUs virtuales, y los controles para apagar y eliminar la VM.
Haga clic en el número de vCPUs en el panel de visión general.
Aparece el diálogo de detalles de la vCPU.
 Nota
NotaLa advertencia en el diálogo de detalles de la vCPU sólo aparece después de cambiar la configuración de la CPU virtual.
Configurar las CPUs virtuales para la VM seleccionada.
vCPU Count - El número de vCPUs actualmente en uso.
NotaEl recuento de vCPU no puede ser mayor que el máximo de vCPU.
- vCPU Maximum - El número máximo de CPUs virtuales que se pueden configurar para la VM. Si este valor es superior a vCPU Count, se pueden adjuntar vCPUs adicionales a la VM.
- Sockets - El número de sockets a exponer a la VM.
- Cores per socket - El número de núcleos para cada socket a exponer a la VM.
Threads per core - El número de hilos para cada núcleo que se exponen a la VM.
Tenga en cuenta que las opciones Sockets, Cores per socket, y Threads per core ajustan la topología de la CPU de la VM. Esto puede ser beneficioso para el rendimiento de la vCPU y puede impactar la funcionalidad de cierto software en el SO huésped. Si su implementación no requiere una configuración diferente, Red Hat recomienda mantener los valores por defecto.
Haga clic en .
Se configuran las CPUs virtuales para la VM.
NotaLos cambios en la configuración de la CPU virtual sólo tienen efecto después de reiniciar la VM.
Recursos adicionales:
- Para obtener información sobre la gestión de las vCPUs mediante la interfaz de línea de comandos, consulte Sección 11.5.1, “Añadir y eliminar CPUs virtuales mediante la interfaz de línea de comandos”.
11.5.3. Configuración de NUMA en una máquina virtual
Los siguientes métodos se pueden utilizar para configurar los ajustes de acceso no uniforme a la memoria (NUMA) de una máquina virtual (VM) en un host RHEL 8.
Requisitos previos
El host es una máquina compatible con NUMA. Para detectar si es así, utilice el comando
virsh nodeinfoy consulte la líneaNUMA cell(s):# virsh nodeinfo CPU model: x86_64 CPU(s): 48 CPU frequency: 1200 MHz CPU socket(s): 1 Core(s) per socket: 12 Thread(s) per core: 2 NUMA cell(s): 2 Memory size: 67012964 KiB
Si el valor de la línea es 2 o mayor, el host es compatible con NUMA.
Procedimiento
Para facilitar su uso, puede establecer la configuración NUMA de una máquina virtual utilizando utilidades y servicios automatizados. Sin embargo, es más probable que la configuración manual de NUMA produzca una mejora significativa del rendimiento.
Automatic methods
Establezca la política NUMA de la máquina virtual en
Preferred. Por ejemplo, para hacerlo para la VM testguest5:# virt-xml testguest5 --edit --vcpus placement=auto # virt-xml testguest5 --edit --numatune mode=preferred
Activar el equilibrio automático de NUMA en el host:
# echo 1 > /proc/sys/kernel/numa_balancingUtilice el comando
numadpara alinear automáticamente la CPU de la VM con los recursos de memoria.# numad
Manual methods
Asigne hilos específicos de vCPU a una CPU de host específica o a un rango de CPUs. Esto también es posible en hosts y máquinas virtuales que no son NUMA, y se recomienda como método seguro para mejorar el rendimiento de las vCPU.
Por ejemplo, los siguientes comandos conectan los hilos de vCPU 0 a 5 de la VM testguest6 a las CPUs anfitrionas 1, 3, 5, 7, 9 y 11, respectivamente:
# virsh vcpupin testguest6 0 1 # virsh vcpupin testguest6 1 3 # virsh vcpupin testguest6 2 5 # virsh vcpupin testguest6 3 7 # virsh vcpupin testguest6 4 9 # virsh vcpupin testguest6 5 11
A continuación, puede comprobar si se ha realizado con éxito:
# virsh vcpupin testguest6 VCPU CPU Affinity ---------------------- 0 1 1 3 2 5 3 7 4 9 5 11Después de fijar los hilos de vCPU, también puede fijar los hilos de proceso de QEMU asociados con una VM específica a una CPU de host específica o a un rango de CPUs. Por ejemplo, los siguientes comandos fijan el hilo de proceso QEMU de testguest6 a las CPUs 13 y 15, y verifican que esto se ha realizado con éxito:
# virsh emulatorpin testguest6 13,15 # virsh emulatorpin testguest6 emulator: CPU Affinity ---------------------------------- *: 13,15
Por último, también puede especificar qué nodos NUMA del host se asignarán específicamente a una determinada VM. Esto puede mejorar el uso de la memoria del host por parte de la vCPU de la VM. Por ejemplo, los siguientes comandos configuran testguest6 para que utilice los nodos NUMA del host 3 a 5, y verifican que esto fue exitoso:
# virsh numatune testguest6 --nodeset 3-5 # virsh numatune testguest6
Recursos adicionales
- Tenga en cuenta que para obtener los mejores resultados de rendimiento, se recomienda utilizar todos los métodos de ajuste manual indicados anteriormente. Para ver un ejemplo de esta configuración, consulte Sección 11.5.4, “Ejemplo de escenario de ajuste de rendimiento de vCPU”.
-
Para ver la configuración NUMA actual de tu sistema, puedes utilizar la utilidad
numastat. Para más detalles sobre el uso denumastat, consulte Sección 11.7, “Herramientas de supervisión del rendimiento de las máquinas virtuales”. - Actualmente no es posible realizar el ajuste NUMA en los hosts IBM Z. Para más información, consulte Cómo difiere la virtualización en IBM Z de AMD64 e Intel 64.
11.5.4. Ejemplo de escenario de ajuste de rendimiento de vCPU
Para obtener el mejor rendimiento posible de la vCPU, Red Hat recomienda utilizar los ajustes manuales vcpupin, emulatorpin, y numatune juntos, por ejemplo como en el siguiente escenario.
Escenario de partida
Su host tiene las siguientes características de hardware:
- 2 nodos NUMA
- 3 núcleos de CPU en cada nodo
- 2 hilos en cada núcleo
La salida de
virsh nodeinfode una máquina de este tipo sería similar:# virsh nodeinfo CPU model: x86_64 CPU(s): 12 CPU frequency: 3661 MHz CPU socket(s): 2 Core(s) per socket: 3 Thread(s) per core: 2 NUMA cell(s): 2 Memory size: 31248692 KiBUsted pretende modificar una VM existente para que tenga 8 vCPUs, lo que significa que no cabrá en un solo nodo NUMA.
Por lo tanto, debes distribuir 4 vCPUs en cada nodo NUMA y hacer que la topología de las vCPUs se parezca lo más posible a la topología del host. Esto significa que las vCPUs que se ejecutan como hilos hermanos de una determinada CPU física deben estar vinculadas a los hilos del host en el mismo núcleo. Para más detalles, consulte la página web Solution:
Solución
Obtenga la información sobre la topología del host:
# virsh capabilitiesLa salida debe incluir una sección similar a la siguiente:
<topology> <cells num="2"> <cell id="0"> <memory unit="KiB">15624346</memory> <pages unit="KiB" size="4">3906086</pages> <pages unit="KiB" size="2048">0</pages> <pages unit="KiB" size="1048576">0</pages> <distances> <sibling id="0" value="10" /> <sibling id="1" value="21" /> </distances> <cpus num="6"> <cpu id="0" socket_id="0" core_id="0" siblings="0,3" /> <cpu id="1" socket_id="0" core_id="1" siblings="1,4" /> <cpu id="2" socket_id="0" core_id="2" siblings="2,5" /> <cpu id="3" socket_id="0" core_id="0" siblings="0,3" /> <cpu id="4" socket_id="0" core_id="1" siblings="1,4" /> <cpu id="5" socket_id="0" core_id="2" siblings="2,5" /> </cpus> </cell> <cell id="1"> <memory unit="KiB">15624346</memory> <pages unit="KiB" size="4">3906086</pages> <pages unit="KiB" size="2048">0</pages> <pages unit="KiB" size="1048576">0</pages> <distances> <sibling id="0" value="21" /> <sibling id="1" value="10" /> </distances> <cpus num="6"> <cpu id="6" socket_id="1" core_id="3" siblings="6,9" /> <cpu id="7" socket_id="1" core_id="4" siblings="7,10" /> <cpu id="8" socket_id="1" core_id="5" siblings="8,11" /> <cpu id="9" socket_id="1" core_id="3" siblings="6,9" /> <cpu id="10" socket_id="1" core_id="4" siblings="7,10" /> <cpu id="11" socket_id="1" core_id="5" siblings="8,11" /> </cpus> </cell> </cells> </topology>- Optional: Pruebe el rendimiento de la VM utilizando las herramientas y utilidades aplicables.
Configurar y montar páginas enormes de 1 GiB en el host:
Añade la siguiente línea a la línea de comandos del kernel del host:
default_hugepagesz=1G hugepagesz=1G
Cree el archivo
/etc/systemd/system/hugetlb-gigantic-pages.servicecon el siguiente contenido:[Unit] Description=HugeTLB Gigantic Pages Reservation DefaultDependencies=no Before=dev-hugepages.mount ConditionPathExists=/sys/devices/system/node ConditionKernelCommandLine=hugepagesz=1G [Service] Type=oneshot RemainAfterExit=yes ExecStart=/etc/systemd/hugetlb-reserve-pages.sh [Install] WantedBy=sysinit.target
Cree el archivo
/etc/systemd/hugetlb-reserve-pages.shcon el siguiente contenido:#!/bin/sh nodes_path=/sys/devices/system/node/ if [ ! -d $nodes_path ]; then echo "ERROR: $nodes_path does not exist" exit 1 fi reserve_pages() { echo $1 > $nodes_path/$2/hugepages/hugepages-1048576kB/nr_hugepages } reserve_pages 4 node1 reserve_pages 4 node2Esto reserva cuatro páginas enormes de 1GiB de node1 y cuatro páginas enormes de 1GiB de node2.
Haga ejecutable el script creado en el paso anterior:
# chmod x /etc/systemd/hugetlb-reserve-pages.shHabilitar la reserva de página enorme en el arranque:
# systemctl enable hugetlb-gigantic-pages
Utilice el comando
virsh editpara editar la configuración XML de la VM que desea optimizar, en este ejemplo super-VM:# virsh edit super-vmAjuste la configuración XML de la VM de la siguiente manera:
-
Configure la VM para utilizar 8 vCPUs estáticas. Utilice el elemento
<vcpu/>para hacerlo. Conecte cada uno de los hilos de la vCPU a los correspondientes hilos de la CPU del host que refleja en la topología. Para ello, utilice los elementos de
<vcpupin/>en la sección<cputune>.Tenga en cuenta que, como se muestra en la utilidad
virsh capabilitiesanterior, los hilos de la CPU del host no están ordenados secuencialmente en sus respectivos núcleos. Además, los hilos de la vCPU deben fijarse en el conjunto más alto de núcleos de host disponibles en el mismo nodo NUMA. Para ver una ilustración de la tabla, consulte la sección Additional Resources a continuación.La configuración XML para los pasos a. y b. puede ser similar a
<cputune> <vcpupin vcpu='0' cpuset='1'/> <vcpupin vcpu='1' cpuset='4'/> <vcpupin vcpu='2' cpuset='2'/> <vcpupin vcpu='3' cpuset='5'/> <vcpupin vcpu='4' cpuset='7'/> <vcpupin vcpu='5' cpuset='10'/> <vcpupin vcpu='6' cpuset='8'/> <vcpupin vcpu='7' cpuset='11'/> <emulatorpin cpuset='6,9'/> </cputune>
Configura la VM para que utilice páginas enormes de 1 GiB:
<memoryBacking> <hugepages> <page size='1' unit='GiB'/> </hugepages> </memoryBacking>Configure los nodos NUMA de la máquina virtual para que utilicen la memoria de los nodos NUMA correspondientes del host. Para ello, utilice los elementos de
<memnode/>en la sección<numatune/>:<numatune> <memory mode="preferred" nodeset="1"/> <memnode cellid="0" mode="strict" nodeset="0"/> <memnode cellid="1" mode="strict" nodeset="1"/> </numatune>
Asegúrese de que el modo de la CPU está configurado en
host-passthrough, y que la CPU utiliza la caché en el modopassthrough:<cpu mode="host-passthrough"> <topology sockets="2" cores="2" threads="2"/> <cache mode="passthrough"/>
-
Configure la VM para utilizar 8 vCPUs estáticas. Utilice el elemento
La configuración XML resultante de la VM debe incluir una sección similar a la siguiente:
[...] <memoryBacking> <hugepages> <page size='1' unit='GiB'/> </hugepages> </memoryBacking> <vcpu placement='static'>8</vcpu> <cputune> <vcpupin vcpu='0' cpuset='1'/> <vcpupin vcpu='1' cpuset='4'/> <vcpupin vcpu='2' cpuset='2'/> <vcpupin vcpu='3' cpuset='5'/> <vcpupin vcpu='4' cpuset='7'/> <vcpupin vcpu='5' cpuset='10'/> <vcpupin vcpu='6' cpuset='8'/> <vcpupin vcpu='7' cpuset='11'/> <emulatorpin cpuset='6,9'/> </cputune> <numatune> <memory mode="preferred" nodeset="1"/> <memnode cellid="0" mode="strict" nodeset="0"/> <memnode cellid="1" mode="strict" nodeset="1"/> </numatune> <cpu mode="host-passthrough"> <topology sockets="2" cores="2" threads="2"/> <cache mode="passthrough"/> <numa> <cell id="0" cpus="0-3" memory="2" unit="GiB"> <distances> <sibling id="0" value="10"/> <sibling id="1" value="21"/> </distances> </cell> <cell id="1" cpus="4-7" memory="2" unit="GiB"> <distances> <sibling id="0" value="21"/> <sibling id="1" value="10"/> </distances> </cell> </numa> </cpu> </domain>- Optional: Pruebe el rendimiento de la VM utilizando las herramientas y utilidades aplicables para evaluar el impacto de la optimización de la VM.
Recursos adicionales
Las siguientes tablas ilustran las conexiones entre las vCPUs y las CPUs anfitrionas a las que deben ser fijadas:
Tabla 11.1. Topología de host
CPU threads
0
3
1
4
2
5
6
9
7
10
8
11
Cores
0
1
2
3
4
5
Sockets
0
1
NUMA nodes
0
1
Tabla 11.2. Topología VM
vCPU threads
0
1
2
3
4
5
6
7
Cores
0
1
2
3
Sockets
0
1
NUMA nodes
0
1
Tabla 11.3. Topología combinada de host y VM
vCPU threads
0
1
2
3
4
5
6
7
Host CPU threads
0
3
1
4
2
5
6
9
7
10
8
11
Cores
0
1
2
3
4
5
Sockets
0
1
NUMA nodes
0
1
En este escenario, hay 2 nodos NUMA y 8 vCPUs. Por lo tanto, 4 hilos de vCPU deben ser fijados a cada nodo.
Además, Red Hat recomienda dejar al menos un hilo de CPU disponible en cada nodo para las operaciones del sistema anfitrión.
Como en este ejemplo, cada nodo NUMA alberga 3 núcleos, cada uno de ellos con 2 hilos de la CPU anfitriona, el conjunto para el nodo 0 se traduce como sigue:
<vcpupin vcpu='0' cpuset='1'/> <vcpupin vcpu='1' cpuset='4'/> <vcpupin vcpu='2' cpuset='2'/> <vcpupin vcpu='3' cpuset='5'/>
11.5.5. Desactivación de la fusión de páginas en el núcleo
Aunque la fusión de la misma página del núcleo (KSM) mejora la densidad de la memoria, aumenta la utilización de la CPU y puede afectar negativamente al rendimiento general dependiendo de la carga de trabajo. En estos casos, puede mejorar el rendimiento de la máquina virtual (VM) desactivando KSM.
Dependiendo de sus necesidades, puede desactivar KSM para una sola sesión o de forma persistente.
Procedimiento
Para desactivar KSM para una sola sesión, utilice la utilidad
systemctlpara detener los serviciosksmyksmtuned.# systemctl stop ksm # systemctl stop ksmtuned
Para desactivar KSM de forma persistente, utilice la utilidad
systemctlpara desactivar los serviciosksmyksmtuned.# systemctl disable ksm Removed /etc/systemd/system/multi-user.target.wants/ksm.service. # systemctl disable ksmtuned Removed /etc/systemd/system/multi-user.target.wants/ksmtuned.service.
Las páginas de memoria compartidas entre máquinas virtuales antes de desactivar el KSM seguirán siendo compartidas. Para dejar de compartir, elimine todas las páginas de PageKSM en el sistema utilizando el siguiente comando:
# echo 2 > /sys/kernel/mm/ksm/run
Después de que las páginas anónimas sustituyan a las páginas KSM, el servicio del kernel khugepaged reconstruirá las hugepages transparentes en la memoria física de la máquina virtual.
11.6. Optimización del rendimiento de la red de máquinas virtuales
Debido a la naturaleza virtual de la tarjeta de interfaz de red (NIC) de una VM, la VM pierde una parte de su ancho de banda de red de host asignado, lo que puede reducir la eficiencia general de la carga de trabajo de la VM. Los siguientes consejos pueden minimizar el impacto negativo de la virtualización en el rendimiento de la NIC virtual (vNIC).
Procedimiento
Utilice cualquiera de los siguientes métodos y observe si tiene un efecto beneficioso en el rendimiento de su red VM:
- Habilitar el módulo vhost_net
En el host, asegúrese de que la función del kernel
vhost_netestá activada:# lsmod | grep vhost vhost_net 32768 1 vhost 53248 1 vhost_net tap 24576 1 vhost_net tun 57344 6 vhost_netSi la salida de este comando está en blanco, active el módulo del kernel
vhost_net:# modprobe vhost_net- Configurar la red virtio de colas múltiples
Para configurar la función multi-queue virtio-net para una VM, utilice el comando
virsh editpara editar la configuración XML de la VM. En el XML, añada lo siguiente a la sección<devices>, y sustituyaNpor el número de vCPUs de la VM, hasta 16:<interface type='network'> <source network='default'/> <model type='virtio'/> <driver name='vhost' queues='N'/> </interface>Si la máquina virtual está funcionando, reiníciela para que los cambios surtan efecto.
- Procesamiento de paquetes de red
En las configuraciones de máquinas virtuales de Linux con una ruta de transmisión larga, la agrupación de paquetes por lotes antes de enviarlos al kernel puede mejorar la utilización de la caché. Para configurar la agrupación de paquetes, utilice el siguiente comando en el host y sustituya tap0 por el nombre de la interfaz de red que utilizan las máquinas virtuales:
# ethtool -C tap0 rx-frames 128- SR-IOV
- Si su NIC de host admite SR-IOV, utilice la asignación de dispositivos SR-IOV para sus vNIC. Para obtener más información, consulte Administración de dispositivos SR-IOV.
Recursos adicionales
- Para obtener información adicional sobre los tipos de conexión de red virtual y consejos de uso, consulte Comprender las redes virtuales.
11.7. Herramientas de supervisión del rendimiento de las máquinas virtuales
Para identificar qué es lo que consume más recursos de la VM y qué aspecto del rendimiento de la VM necesita ser optimizado, se pueden utilizar herramientas de diagnóstico de rendimiento, tanto generales como específicas para la VM.
Herramientas de supervisión del rendimiento del sistema operativo por defecto
Para la evaluación estándar del rendimiento, puede utilizar las utilidades proporcionadas por defecto por sus sistemas operativos anfitrión y huésped:
En su host RHEL 8, como root, utilice la utilidad
topo la aplicación system monitor, y busqueqemuyvirten la salida. Esto muestra la cantidad de recursos del sistema anfitrión que sus máquinas virtuales están consumiendo.-
Si la herramienta de monitorización muestra que alguno de los procesos de
qemuovirtconsume una gran parte de la capacidad de la CPU o de la memoria del host, utilice la utilidadperfpara investigar. Para más detalles, véase más abajo. -
Además, si un proceso de hilo de
vhost_net, llamado por ejemplo vhost_net-1234, se muestra como consumiendo una cantidad excesiva de capacidad de la CPU del host, considere el uso de las características de optimización de la red virtual, comomulti-queue virtio-net.
-
Si la herramienta de monitorización muestra que alguno de los procesos de
En el sistema operativo invitado, utilice las utilidades de rendimiento y las aplicaciones disponibles en el sistema para evaluar qué procesos consumen más recursos del sistema.
-
En los sistemas Linux, puede utilizar la utilidad
top. - En los sistemas Windows, puede utilizar la aplicación Task Manager.
-
En los sistemas Linux, puede utilizar la utilidad
perf kvm
Puede utilizar la utilidad perf para recopilar y analizar estadísticas específicas de la virtualización sobre el rendimiento de su host RHEL 8. Para ello:
En el host, instale el paquete perf:
# yum install perfUtilice el comando
perf kvm statpara mostrar las estadísticas de perfeccionamiento de su host de virtualización:-
Para la monitorización en tiempo real de su hipervisor, utilice el comando
perf kvm stat live. -
Para registrar los datos de perf de su hipervisor durante un periodo de tiempo, active el registro mediante el comando
perf kvm stat record. Una vez cancelado o interrumpido el comando, los datos se guardan en el archivoperf.data.guest, que puede analizarse mediante el comandoperf kvm stat report.
-
Para la monitorización en tiempo real de su hipervisor, utilice el comando
Analice la salida de
perfpara ver los tipos de eventos deVM-EXITy su distribución. Por ejemplo, los eventosPAUSE_INSTRUCTIONdeberían ser poco frecuentes, pero en la siguiente salida, la alta ocurrencia de este evento sugiere que las CPUs del host no están manejando bien las vCPUs en funcionamiento. En tal escenario, considere apagar algunas de sus VMs activas, remover vCPUs de estas VMs, o afinar el rendimiento de las vCPUs.# perf kvm stat report Analyze events for all VMs, all VCPUs: VM-EXIT Samples Samples% Time% Min Time Max Time Avg time EXTERNAL_INTERRUPT 365634 31.59% 18.04% 0.42us 58780.59us 204.08us ( +- 0.99% ) MSR_WRITE 293428 25.35% 0.13% 0.59us 17873.02us 1.80us ( +- 4.63% ) PREEMPTION_TIMER 276162 23.86% 0.23% 0.51us 21396.03us 3.38us ( +- 5.19% ) PAUSE_INSTRUCTION 189375 16.36% 11.75% 0.72us 29655.25us 256.77us ( +- 0.70% ) HLT 20440 1.77% 69.83% 0.62us 79319.41us 14134.56us ( +- 0.79% ) VMCALL 12426 1.07% 0.03% 1.02us 5416.25us 8.77us ( +- 7.36% ) EXCEPTION_NMI 27 0.00% 0.00% 0.69us 1.34us 0.98us ( +- 3.50% ) EPT_MISCONFIG 5 0.00% 0.00% 5.15us 10.85us 7.88us ( +- 11.67% ) Total Samples:1157497, Total events handled time:413728274.66us.Otros tipos de eventos que pueden señalar problemas en la salida de
perf kvm statincluyen:-
INSN_EMULATION- sugiere una configuración subóptima de E/S de la máquina virtual.
-
Para obtener más información sobre el uso de perf para supervisar el rendimiento de la virtualización, consulte la página de manual perf-kvm.
numastat
Para ver la configuración NUMA actual de tu sistema, puedes utilizar la utilidad numastat, que se proporciona al instalar el paquete numactl.
A continuación se muestra un host con 4 VMs en ejecución, cada una de las cuales obtiene memoria de múltiples nodos NUMA. Esto no es óptimo para el rendimiento de las vCPUs, y justifica un ajuste:
# numastat -c qemu-kvm
Per-node process memory usage (in MBs)
PID Node 0 Node 1 Node 2 Node 3 Node 4 Node 5 Node 6 Node 7 Total
--------------- ------ ------ ------ ------ ------ ------ ------ ------ -----
51722 (qemu-kvm) 68 16 357 6936 2 3 147 598 8128
51747 (qemu-kvm) 245 11 5 18 5172 2532 1 92 8076
53736 (qemu-kvm) 62 432 1661 506 4851 136 22 445 8116
53773 (qemu-kvm) 1393 3 1 2 12 0 0 6702 8114
--------------- ------ ------ ------ ------ ------ ------ ------ ------ -----
Total 1769 463 2024 7462 10037 2672 169 7837 32434Por el contrario, a continuación se muestra la memoria proporcionada a cada VM por un único nodo, lo que es significativamente más eficiente.
# numastat -c qemu-kvm
Per-node process memory usage (in MBs)
PID Node 0 Node 1 Node 2 Node 3 Node 4 Node 5 Node 6 Node 7 Total
--------------- ------ ------ ------ ------ ------ ------ ------ ------ -----
51747 (qemu-kvm) 0 0 7 0 8072 0 1 0 8080
53736 (qemu-kvm) 0 0 7 0 0 0 8113 0 8120
53773 (qemu-kvm) 0 0 7 0 0 0 1 8110 8118
59065 (qemu-kvm) 0 0 8050 0 0 0 0 0 8051
--------------- ------ ------ ------ ------ ------ ------ ------ ------ -----
Total 0 0 8072 0 8072 0 8114 8110 32368Capítulo 12. Gestionar el consumo de energía con PowerTOP
Como administrador del sistema, puede utilizar la PowerTOP herramienta para analizar y gestionar el consumo de energía.
12.1. El objetivo de PowerTOP
PowerTOP es un programa que diagnostica los problemas relacionados con el consumo de energía y ofrece sugerencias para prolongar la vida útil de la batería.
La herramienta PowerTOP puede proporcionar una estimación del uso total de energía del sistema y también del uso individual de energía para cada proceso, dispositivo, trabajador del kernel, temporizador y controlador de interrupciones. La herramienta también puede identificar componentes específicos del kernel y de las aplicaciones del espacio de usuario que despiertan con frecuencia la CPU.
Red Hat Enterprise Linux 8 utiliza la versión 2.x de PowerTOP.
12.2. Uso de PowerTOP
Requisitos previos
Para poder utilizar PowerTOPasegúrese de que el paquete
powertopha sido instalado en su sistema:# yum install powertop
12.2.1. Iniciar PowerTOP
Procedimiento
Para ejecutar PowerTOPutilice el siguiente comando:
# powertop
Los ordenadores portátiles deben funcionar con batería cuando se ejecuta el comando powertop.
12.2.2. Calibración de PowerTOP
Procedimiento
En un ordenador portátil, puedes calibrar el motor de estimación de potencia ejecutando el siguiente comando:
# powertop --calibrate
Deje que la calibración termine sin interactuar con la máquina durante el proceso.
La calibración lleva tiempo porque el proceso realiza varias pruebas, pasa por los niveles de brillo y enciende y apaga los dispositivos.
Una vez finalizado el proceso de calibración PowerTOP arranca con normalidad. Deja que funcione durante aproximadamente una hora para recoger los datos.
Cuando se recogen suficientes datos, las cifras de estimación de la potencia aparecen en la primera columna de la tabla de salida.
Tenga en cuenta que powertop --calibrate sólo puede utilizarse en ordenadores portátiles.
12.2.3. Ajuste del intervalo de medición
Por defecto, PowerTOP toma medidas en intervalos de 20 segundos.
Si desea cambiar esta frecuencia de medición, utilice el siguiente procedimiento:
Procedimiento
Ejecute el comando
powertopcon la opción--time:# powertop --time=time in seconds
12.3. Estadísticas de PowerTOP
Mientras se ejecuta, PowerTOP recoge las estadísticas del sistema.
PowerTOPproporciona múltiples pestañas:
-
Overview -
Idle stats -
Frequency stats -
Device stats -
Tunables
Puede utilizar las teclas Tab y Shift Tab para recorrer estas pestañas.
12.3.1. La pestaña "Visión general"
En la pestaña Overview, puede ver una lista de los componentes que envían despertares a la CPU con más frecuencia o que consumen más energía. Los elementos de la pestaña Overview, incluidos los procesos, las interrupciones, los dispositivos y otros recursos, se ordenan según su utilización.
Las columnas adyacentes dentro de la pestaña Overview proporcionan la siguiente información:
- Uso
- Estimación de la potencia de la utilización del recurso.
- Eventos
- Despertares por segundo. El número de wakeups por segundo indica la eficiencia de los servicios o de los dispositivos y drivers del kernel. Un menor número de activaciones significa que se consume menos energía. Los componentes se ordenan según el grado de optimización del uso de la energía.
- Categoría
- Clasificación del componente; como proceso, dispositivo o temporizador.
- Descripción
- Descripción del componente.
Si se calibra correctamente, se muestra también una estimación del consumo de energía para cada elemento de la primera columna.
Aparte de esto, la pestaña Overview incluye la línea con estadísticas resumidas como:
- Consumo total de energía
- Duración restante de la batería (sólo si es aplicable)
- Resumen del total de activaciones por segundo, operaciones de la GPU por segundo y operaciones del sistema de archivos virtuales por segundo
12.3.2. La pestaña de estadísticas de inactividad
La pestaña Idle stats muestra el uso de los estados C para todos los procesadores y núcleos, mientras que la pestaña Frequency stats muestra el uso de los estados P incluyendo el modo Turbo, si es aplicable, para todos los procesadores y núcleos. La duración de los estados C o P es una indicación de lo bien que se ha optimizado el uso de la CPU. Cuanto más tiempo permanezca la CPU en los estados C o P más altos (por ejemplo, C4 es más alto que C3), mejor es la optimización del uso de la CPU. Idealmente, la residencia es del 90% o más en el estado C o P más alto cuando el sistema está inactivo.
12.3.3. La pestaña de estadísticas del dispositivo
La pestaña Device stats proporciona información similar a la pestaña Overview pero sólo para los dispositivos.
12.3.4. Pestaña "Tunables" (sintonizables)
La pestaña Tunables contiene PowerTOPpara optimizar el sistema para un menor consumo de energía.
Utilice las teclas up y down para desplazarse por las sugerencias, y la tecla enter para activar o desactivar la sugerencia.
Figura 12.1. Salida de PowerTOP

Recursos adicionales
Para más detalles sobre PowerTOPconsulte la página de inicio de PowerTOP.
12.4. Generar una salida HTML
Además de la salida de powertop’s en el terminal, también puede generar un informe HTML.
Procedimiento
Ejecute el comando
powertopcon la opción--html:# powertop --html=htmlfile.html
Sustituya el parámetro
htmlfile.htmlpor el nombre deseado para el archivo de salida.
12.5. Optimización del consumo de energía
Para optimizar el consumo de energía, puede utilizar el servicio powertop o la utilidad powertop2tuned.
12.5.1. Optimización del consumo de energía mediante el servicio powertop
Puede utilizar el servicio powertop para activar automáticamente todas las PowerTOP's sugerencias desde la pestaña Tunables en el arranque:
Procedimiento
Habilite el servicio
powertop:# systemctl enable powertop
12.5.2. La utilidad powertop2tuned
La utilidad powertop2tuned permite crear perfiles personalizados Tuned perfiles a partir de PowerTOP sugerencias.
Por defecto, powertop2tuned crea perfiles en el directorio /etc/tuned/, y basa el perfil personalizado en el perfil actualmente seleccionado Tuned actualmente seleccionado. Por razones de seguridad, todos los PowerTOP ajustes se desactivan inicialmente en el nuevo perfil.
Para activar las afinaciones, puedes:
-
Descompóngalos en la página web
/etc/tuned/profile_name/tuned.conf file. Utilice la opción
--enableo-epara generar un nuevo perfil que permita la mayoría de las afinaciones sugeridas por PowerTOP.Algunos ajustes potencialmente problemáticos, como la autosuspensión del USB, están desactivados por defecto y deben ser descomentados manualmente.
12.5.3. Optimización del consumo de energía mediante la utilidad powertop2tuned
Requisitos previos
La utilidad
powertop2tunedestá instalada en el sistema:# yum install tuned-utils
Procedimiento
Cree un perfil personalizado:
# powertop2tuned new_profile_name
Activar el nuevo perfil:
# tuned-adm profile new_profile_name
Información adicional
Para obtener una lista completa de las opciones que admite
powertop2tuned, utilice:$ powertop2tuned --help
12.5.4. Comparación de powertop.service y powertop2tuned
La optimización del consumo de energía con powertop2tuned es preferible a powertop.service por las siguientes razones:
-
La utilidad
powertop2tunedrepresenta la integración de PowerTOP en Tunedque permite beneficiarse de las ventajas de ambas herramientas. -
La utilidad
powertop2tunedpermite un control fino de la sintonía habilitada. -
Con
powertop2tuned, no se habilita automáticamente la sintonía potencialmente peligrosa. -
Con
powertop2tuned, la reversión es posible sin reiniciar.
Capítulo 13. Empezar a trabajar con perf
Como administrador del sistema, puede utilizar la herramienta perf para recoger y analizar los datos de rendimiento de su sistema.
13.1. Introducción al perfeccionamiento
La herramienta de espacio de usuario perf interactúa con el subsistema basado en el kernel Performance Counters for Linux (PCL). perf es una potente herramienta que utiliza la Unidad de Monitorización del Rendimiento (PMU) para medir, registrar y monitorizar una variedad de eventos de hardware y software. perf también soporta tracepoints, kprobes y uprobes.
13.2. Instalación de perf
Este procedimiento instala la herramienta de espacio de usuario perf.
Procedimiento
Instale la herramienta
perf:# yum install perf
13.3. Comandos comunes de perfeccionamiento
Esta sección ofrece una visión general de los comandos más utilizados en perf.
Comandos de perfeccionamiento más utilizados
perf stat- Este comando proporciona estadísticas generales para eventos comunes de rendimiento, incluyendo instrucciones ejecutadas y ciclos de reloj consumidos. Las opciones permiten la selección de eventos distintos a los eventos de medición por defecto.
perf record-
Este comando registra los datos de rendimiento en un archivo,
perf.data, que puede ser analizado posteriormente con el comandoperf report. perf report-
Este comando lee y muestra los datos de rendimiento del archivo
perf.datacreado porperf record. perf list- Este comando lista los eventos disponibles en una máquina en particular. Estos eventos variarán en función de la configuración de hardware y software de monitorización del rendimiento del sistema.
perf top-
Este comando realiza una función similar a la de la utilidad
top. Genera y muestra un perfil de contador de rendimiento en tiempo real. perf trace-
Este comando realiza una función similar a la herramienta
strace. Supervisa las llamadas al sistema utilizadas por un hilo o proceso especificado y todas las señales recibidas por esa aplicación. perf help-
Este comando muestra una lista completa de comandos de
perf.
Recursos adicionales
-
Para enumerar las opciones adicionales de los subcomandos y sus descripciones, añada la opción
-hal comando de destino.
13.4. Perfilado en tiempo real del uso de la CPU con perf top
Puede utilizar el comando perf top para medir el uso de la CPU de diferentes funciones en tiempo real.
Requisitos previos
-
Tiene la herramienta de espacio de usuario
perfinstalada como se describe en Instalación de perf.
13.4.1. La finalidad de la tapa perf
El comando perf top se utiliza para la creación de perfiles del sistema en tiempo real y funciona de forma similar a la utilidad top. Sin embargo, mientras que la utilidad top generalmente le muestra cuánto tiempo de CPU está utilizando un proceso o hilo determinado, perf top le muestra cuánto tiempo de CPU utiliza cada función específica. En su estado por defecto, perf top le informa sobre las funciones que se están utilizando en todas las CPUs, tanto en el espacio del usuario como en el del núcleo. Para utilizar perf top se necesita acceso de root.
13.4.2. Perfilando el uso de la CPU con perf top
Este procedimiento activa perf top y perfila el uso de la CPU en tiempo real.
Requisitos previos
-
Tiene la herramienta de espacio de usuario
perfinstalada como se describe en Instalación de perf. - Tienes acceso a la raíz
Procedimiento
Inicie la interfaz de monitorización
perf top:# perf top
Ejemplo 13.1. Perfeccionamiento de la salida superior
-------------------------------------------------------------------- PerfTop: 20806 irqs/sec kernel:57.3% exact: 100.0% lost: 0/0 drop: 0/0 [4000Hz cycles], (all, 8 CPUs) --------------------------------------------------------------------- Overhead Shared Object Symbol 2.20% [kernel] [k] do_syscall_64 2.17% [kernel] [k] module_get_kallsym 1.49% [kernel] [k] copy_user_enhanced_fast_string 1.37% libpthread-2.29.so [.] __pthread_mutex_lock 1.31% [unknown] [.] 0000000000000000 1.07% [kernel] [k] psi_task_change 1.04% [kernel] [k] switch_mm_irqs_off 0.94% [kernel] [k] __fget 0.74% [kernel] [k] entry_SYSCALL_64 0.69% [kernel] [k] syscall_return_via_sysret 0.69% libxul.so [.] 0x000000000113f9b0 0.67% [kernel] [k] kallsyms_expand_symbol.constprop.0 0.65% firefox [.] moz_xmalloc 0.65% libpthread-2.29.so [.] __pthread_mutex_unlock_usercnt 0.60% firefox [.] free 0.60% libxul.so [.] 0x000000000241d1cd 0.60% [kernel] [k] do_sys_poll 0.58% [kernel] [k] menu_select 0.56% [kernel] [k] _raw_spin_lock_irqsave 0.55% perf [.] 0x00000000002ae0f3
En el ejemplo anterior, la función del núcleo
do_syscall_64es la que más tiempo de CPU utiliza.
Recursos adicionales
-
La página de manual
perf-top(1).
13.4.3. Interpretación de los resultados del perfeccionamiento
- La columna "Sobrecarga"
- Muestra el porcentaje de CPU que está utilizando una función determinada.
- La columna "Objeto compartido"
- Muestra el nombre del programa o la biblioteca que utiliza la función.
- La columna "Símbolo"
-
Muestra el nombre o símbolo de la función. Las funciones ejecutadas en el espacio del núcleo se identifican con
[k]y las funciones ejecutadas en el espacio del usuario se identifican con[.].
13.4.4. Por qué perf muestra algunos nombres de funciones como direcciones de funciones en bruto
Para las funciones del núcleo, perf utiliza la información del archivo /proc/kallsyms para asignar las muestras a sus respectivos nombres de función o símbolos. Para las funciones ejecutadas en el espacio de usuario, sin embargo, es posible que veas las direcciones de las funciones en bruto porque el binario está despojado.
El paquete debuginfo del ejecutable debe estar instalado o, si el ejecutable es una aplicación desarrollada localmente, la aplicación debe compilarse con la información de depuración activada (la opción -g en GCC) para mostrar los nombres de las funciones o los símbolos en tal situación.
Recursos adicionales
13.4.5. Habilitación de los repositorios de depuración y de código fuente
Una instalación estándar de Red Hat Enterprise Linux no habilita los repositorios de depuración y de fuentes. Estos repositorios contienen la información necesaria para depurar los componentes del sistema y medir su rendimiento.
Procedimiento
Habilitar los canales de paquetes de información de origen y de depuración:
# subscription-manager repos --enable rhel-8-for-$(uname -i)-baseos-debug-rpms # subscription-manager repos --enable rhel-8-for-$(uname -i)-baseos-source-rpms # subscription-manager repos --enable rhel-8-for-$(uname -i)-appstream-debug-rpms # subscription-manager repos --enable rhel-8-for-$(uname -i)-appstream-source-rpms
La parte
$(uname -i)se sustituye automáticamente por un valor correspondiente a la arquitectura de su sistema:Nombre de la arquitectura Valor Intel y AMD de 64 bits
x86_64
ARM de 64 bits
aarch64
IBM POWER
ppc64le
IBM Z
s390x
13.4.6. Obtención de paquetes debuginfo para una aplicación o librería usando GDB
La información de depuración es necesaria para depurar el código. Para el código que se instala desde un paquete, el depurador de GNU (GDB) reconoce automáticamente la información de depuración que falta, resuelve el nombre del paquete y proporciona consejos concretos sobre cómo obtener el paquete.
Requisitos previos
- La aplicación o la biblioteca que desea depurar debe estar instalada en el sistema.
-
GDB y la herramienta
debuginfo-installdeben estar instalados en el sistema. Para más detalles, consulte Configuración para depurar aplicaciones. -
Los canales que proporcionan los paquetes
debuginfoydebugsourcedeben estar configurados y habilitados en el sistema.
Procedimiento
Inicie GDB conectado a la aplicación o biblioteca que desea depurar. GDB reconoce automáticamente la información de depuración que falta y sugiere un comando a ejecutar.
$ gdb -q /bin/ls Reading symbols from /bin/ls...Reading symbols from .gnu_debugdata for /usr/bin/ls...(no debugging symbols found)...done. (no debugging symbols found)...done. Missing separate debuginfos, use: dnf debuginfo-install coreutils-8.30-6.el8.x86_64 (gdb)Salir de GDB: escribir q y confirmar con Enter.
(gdb) q
Ejecute el comando sugerido por GDB para instalar los paquetes necesarios de
debuginfo:# dnf debuginfo-install coreutils-8.30-6.el8.x86_64
La herramienta de gestión de paquetes
dnfofrece un resumen de los cambios, pide confirmación y, una vez confirmada, descarga e instala todos los archivos necesarios.-
En caso de que GDB no pueda sugerir el paquete
debuginfo, siga el procedimiento descrito en Obtención de paquetes debuginfo para una aplicación o biblioteca de forma manual.
13.5. Recuento de eventos durante la ejecución del proceso
Puede utilizar el comando perf stat para contar los eventos de hardware y software durante la ejecución del proceso.
Requisitos previos
-
Tiene la herramienta de espacio de usuario
perfinstalada como se describe en Instalación de perf.
13.5.1. El propósito de las estadísticas de perf
El comando perf stat ejecuta un comando especificado, mantiene un recuento de eventos de hardware y software durante la ejecución del comando y genera estadísticas de estos recuentos. Si no se especifica ningún evento, perf stat cuenta un conjunto de eventos comunes de hardware y software.
13.5.2. Recuento de eventos con perf stat
Puede utilizar perf stat para contar las ocurrencias de eventos de hardware y software durante la ejecución de comandos y generar estadísticas de estos recuentos. Por defecto, perf stat funciona en modo por hilo.
Requisitos previos
-
Tiene la herramienta de espacio de usuario
perfinstalada como se describe en Instalación de perf.
Procedimiento
Cuenta los eventos.
Si se ejecuta el comando
perf statsin acceso de root, sólo se contarán los eventos que se produzcan en el espacio de usuario:$ perf stat ls
Ejemplo 13.2. Salida de perf stat ejecutada sin acceso de root
Desktop Documents Downloads Music Pictures Public Templates Videos Performance counter stats for 'ls': 1.28 msec task-clock:u # 0.165 CPUs utilized 0 context-switches:u # 0.000 M/sec 0 cpu-migrations:u # 0.000 K/sec 104 page-faults:u # 0.081 M/sec 1,054,302 cycles:u # 0.823 GHz 1,136,989 instructions:u # 1.08 insn per cycle 228,531 branches:u # 178.447 M/sec 11,331 branch-misses:u # 4.96% of all branches 0.007754312 seconds time elapsed 0.000000000 seconds user 0.007717000 seconds sysComo puede ver en el ejemplo anterior, cuando
perf statse ejecuta sin acceso de root los nombres de los eventos van seguidos de:u, lo que indica que estos eventos se contaron sólo en el espacio de usuario.Para contar tanto los eventos del espacio del usuario como los del espacio del núcleo, debe tener acceso de root cuando ejecute
perf stat:# perf stat ls
Ejemplo 13.3. Salida de perf stat ejecutada con acceso de root
Desktop Documents Downloads Music Pictures Public Templates Videos Performance counter stats for 'ls': 3.09 msec task-clock # 0.119 CPUs utilized 18 context-switches # 0.006 M/sec 3 cpu-migrations # 0.969 K/sec 108 page-faults # 0.035 M/sec 6,576,004 cycles # 2.125 GHz 5,694,223 instructions # 0.87 insn per cycle 1,092,372 branches # 352.960 M/sec 31,515 branch-misses # 2.89% of all branches 0.026020043 seconds time elapsed 0.000000000 seconds user 0.014061000 seconds sysPor defecto,
perf statfunciona en modo por hilo. Para cambiar al conteo de eventos en toda la CPU, pase la opción-aaperf stat. Para contar los eventos de toda la CPU, se necesita acceso de root:# perf stat -a ls
Recursos adicionales
-
La página de manual
perf-stat(1).
13.5.3. Interpretación de las estadísticas de rendimiento
perf stat ejecuta un comando especificado y cuenta las ocurrencias de eventos durante la ejecución de los comandos y muestra las estadísticas de estos recuentos en tres columnas:
- El número de ocurrencias contadas para un evento determinado
- El nombre del evento que se contó
Cuando se dispone de métricas relacionadas, se muestra un ratio o porcentaje después del signo de almohadilla (
#) en la columna de la derecha.-
Por ejemplo, cuando se ejecuta en el modo por defecto,
perf statcuenta tanto los ciclos como las instrucciones y, por tanto, calcula y muestra las instrucciones por ciclo en la columna de la derecha. Puede ver un comportamiento similar con respecto a los fallos de bifurcación como porcentaje de todas las bifurcaciones, ya que ambos eventos se cuentan por defecto.
-
Por ejemplo, cuando se ejecuta en el modo por defecto,
13.5.4. Adjuntar una estadística de perfeccionamiento a un proceso en ejecución
Puede adjuntar perf stat a un proceso en ejecución. Esto indicará a perf stat que cuente las ocurrencias de eventos sólo en los procesos especificados durante la ejecución de un comando.
Requisitos previos
-
Tiene la herramienta de espacio de usuario
perfinstalada como se describe en Instalación de perf.
Procedimiento
Adjuntar
perf stata un proceso en ejecución:$ perf stat -p ID1,ID2 sleep seconds
El ejemplo anterior cuenta los eventos en los procesos con los ID de
ID1yID2durante un periodo de tiempo desecondssegundos, tal y como se indica en el comandosleep.
Recursos adicionales
-
La página de manual
perf-stat(1).
13.6. Registro y análisis de perfiles de rendimiento con perf
La herramienta perf permite registrar los datos de rendimiento y analizarlos posteriormente.
Requisitos previos
-
Tiene la herramienta de espacio de usuario
perfinstalada como se describe en Instalación de perf.
13.6.1. El propósito del registro de perfeccionamiento
El comando perf record muestrea los datos de rendimiento y los almacena en un archivo, perf.data, que puede leerse y visualizarse con otros comandos perf. perf.data se genera en el directorio actual y puede accederse a él en otro momento, posiblemente en una máquina diferente.
Si no se especifica un comando para que perf record grabe durante, lo hará hasta que se detenga manualmente el proceso pulsando Ctrl C. Puedes adjuntar perf record a procesos específicos pasando la opción -p seguida de uno o más IDs de proceso. Puedes ejecutar perf record sin acceso de root, sin embargo, al hacerlo sólo se muestrearán los datos de rendimiento en el espacio de usuario. En el modo por defecto, perf record utiliza los ciclos de la CPU como evento de muestreo y opera en modo por hilo con el modo de herencia activado.
13.6.2. Grabación de un perfil de rendimiento sin acceso a la raíz
Puede utilizar perf record sin acceso a la raíz para muestrear y registrar los datos de rendimiento sólo en el espacio del usuario.
Requisitos previos
-
Tiene la herramienta de espacio de usuario
perfinstalada como se describe en Instalación de perf.
Procedimiento
Toma de muestras y registra los datos de rendimiento:
$ registro de perfeccionamiento commandSustituya
commandcon el comando durante el cual desea muestrear los datos. Si no especifica un comando,perf recordmuestreará los datos hasta que usted lo detenga manualmente pulsando Ctrl+C.
Recursos adicionales
-
La página de manual
perf-record(1).
13.6.3. Grabación de un perfil de rendimiento con acceso root
Puede utilizar perf record con acceso de root para muestrear y registrar datos de rendimiento tanto en el espacio de usuario como en el espacio del núcleo simultáneamente.
Requisitos previos
-
Tiene la herramienta de espacio de usuario
perfinstalada como se describe en Instalación de perf. - Tienes acceso a la raíz.
Procedimiento
Toma de muestras y registra los datos de rendimiento:
# registro de perfeccionamiento commandSustituya
commandcon el comando durante el cual desea muestrear los datos. Si no especifica un comando,perf recordmuestreará los datos hasta que usted lo detenga manualmente pulsando Ctrl+C.
Recursos adicionales
-
La página de manual
perf-record(1).
13.6.4. Grabación de un perfil de rendimiento en modo por CPU
Puede utilizar perf record en el modo por CPU para muestrear y registrar los datos de rendimiento tanto en el espacio del usuario como en el espacio del kernel simultáneamente en todos los hilos de una CPU monitorizada. Por defecto, el modo por CPU monitoriza todas las CPUs en línea.
Requisitos previos
-
La herramienta de espacio de usuario
perfestá instalada. Para más información, consulte Instalación de perf.
Procedimiento
Toma de muestras y registra los datos de rendimiento:
# perf record -a commandSustituya
commandcon el comando durante el cual desea muestrear los datos. Si no especifica un comando,perf recordmuestreará los datos hasta que usted lo detenga manualmente pulsando Ctrl+C.
Recursos adicionales
-
La página de manual
perf-record(1).
13.6.5. Captura de datos del gráfico de llamadas con el registro perf
Puede configurar la herramienta perf record para que registre qué función está llamando a otras funciones en el perfil de rendimiento. Esto ayuda a identificar un cuello de botella si varios procesos están llamando a la misma función.
Requisitos previos
-
La herramienta de espacio de usuario
perfestá instalada. Para más información, consulte Instalación de perf.
Procedimiento
Tome muestras y registre los datos de rendimiento con la opción
--call-graph:$ perf record --call-graph method command
-
Sustituya
commandcon el comando durante el cual desea muestrear los datos. Si no especifica un comando,perf recordmuestreará los datos hasta que usted lo detenga manualmente pulsando Ctrl+C. Sustituya method por uno de los siguientes métodos de desenrollado:
fp-
Utiliza el método del puntero de marco. Dependiendo de la optimización del compilador, como en el caso de los binarios construidos con la opción de GCC
--fomit-frame-pointer, esto puede no ser capaz de desenrollar la pila. dwarf- Utiliza la información de la trama de llamada DWARF para desenrollar la pila.
lbr- Utiliza el hardware del último registro de rama en los procesadores Intel.
-
Sustituya
Recursos adicionales
-
La página de manual
perf-record(1).
13.6.6. Analizar los datos de perfeccionamiento con el informe de perfeccionamiento
Puede utilizar perf report para visualizar y analizar un archivo perf.data.
Requisitos previos
-
La herramienta de espacio de usuario
perfestá instalada. Para más información, consulte Instalación de perf. -
Hay un archivo
perf.dataen el directorio actual. -
Si el archivo
perf.datase creó con acceso de root, deberá ejecutarperf reporttambién con acceso de root.
Procedimiento
Muestra el contenido del archivo
perf.datapara su posterior análisis:# perf report
Ejemplo 13.4. Ejemplo de salida
Samples: 2K of event 'cycles', Event count (approx.): 235462960 Overhead Command Shared Object Symbol 2.36% kswapd0 [kernel.kallsyms] [k] page_vma_mapped_walk 2.13% sssd_kcm libc-2.28.so [.] __memset_avx2_erms 2.13% perf [kernel.kallsyms] [k] smp_call_function_single 1.53% gnome-shell libc-2.28.so [.] __strcmp_avx2 1.17% gnome-shell libglib-2.0.so.0.5600.4 [.] g_hash_table_lookup 0.93% Xorg libc-2.28.so [.] __memmove_avx_unaligned_erms 0.89% gnome-shell libgobject-2.0.so.0.5600.4 [.] g_object_unref 0.87% kswapd0 [kernel.kallsyms] [k] page_referenced_one 0.86% gnome-shell libc-2.28.so [.] __memmove_avx_unaligned_erms 0.83% Xorg [kernel.kallsyms] [k] alloc_vmap_area 0.63% gnome-shell libglib-2.0.so.0.5600.4 [.] g_slice_alloc 0.53% gnome-shell libgirepository-1.0.so.1.0.0 [.] g_base_info_unref 0.53% gnome-shell ld-2.28.so [.] _dl_find_dso_for_object 0.49% kswapd0 [kernel.kallsyms] [k] vma_interval_tree_iter_next 0.48% gnome-shell libpthread-2.28.so [.] __pthread_getspecific 0.47% gnome-shell libgirepository-1.0.so.1.0.0 [.] 0x0000000000013b1d 0.45% gnome-shell libglib-2.0.so.0.5600.4 [.] g_slice_free1 0.45% gnome-shell libgobject-2.0.so.0.5600.4 [.] g_type_check_instance_is_fundamentally_a 0.44% gnome-shell libc-2.28.so [.] malloc 0.41% swapper [kernel.kallsyms] [k] apic_timer_interrupt 0.40% gnome-shell ld-2.28.so [.] _dl_lookup_symbol_x 0.39% kswapd0 [kernel.kallsyms] [k] __raw_callee_save___pv_queued_spin_unlock
Recursos adicionales
-
La página de manual
perf-report(1).
13.6.7. Interpretación de los resultados de los informes de perfeccionamiento
La tabla que se muestra al ejecutar el comando perf report ordena los datos en varias columnas:
- La columna "Gastos generales
- Indica qué porcentaje de las muestras globales se recogieron en esa función concreta.
- La columna "Comando
- Indica en qué proceso se recogieron las muestras.
- La columna "Objeto compartido
- Muestra el nombre de la imagen ELF de la que provienen las muestras (el nombre [kernel.kallsyms] se utiliza cuando las muestras provienen del kernel).
- La columna "Símbolo
- Muestra el nombre o símbolo de la función.
En el modo por defecto, las funciones se clasifican en orden descendente, mostrando primero las que tienen mayor sobrecarga.
13.6.8. Por qué perf muestra algunos nombres de funciones como direcciones de funciones en bruto
Para las funciones del núcleo, perf utiliza la información del archivo /proc/kallsyms para asignar las muestras a sus respectivos nombres de función o símbolos. Para las funciones ejecutadas en el espacio de usuario, sin embargo, es posible que veas las direcciones de las funciones en bruto porque el binario está despojado.
El paquete debuginfo del ejecutable debe estar instalado o, si el ejecutable es una aplicación desarrollada localmente, la aplicación debe compilarse con la información de depuración activada (la opción -g en GCC) para mostrar los nombres de las funciones o los símbolos en tal situación.
Recursos adicionales
No es necesario volver a ejecutar perf record después de instalar el debuginfo asociado a un ejecutable. Basta con volver a ejecutar perf report.
13.6.9. Habilitación de los repositorios de depuración y de código fuente
Una instalación estándar de Red Hat Enterprise Linux no habilita los repositorios de depuración y de fuentes. Estos repositorios contienen la información necesaria para depurar los componentes del sistema y medir su rendimiento.
Procedimiento
Habilitar los canales de paquetes de información de origen y de depuración:
# subscription-manager repos --enable rhel-8-for-$(uname -i)-baseos-debug-rpms # subscription-manager repos --enable rhel-8-for-$(uname -i)-baseos-source-rpms # subscription-manager repos --enable rhel-8-for-$(uname -i)-appstream-debug-rpms # subscription-manager repos --enable rhel-8-for-$(uname -i)-appstream-source-rpms
La parte
$(uname -i)se sustituye automáticamente por un valor correspondiente a la arquitectura de su sistema:Nombre de la arquitectura Valor Intel y AMD de 64 bits
x86_64
ARM de 64 bits
aarch64
IBM POWER
ppc64le
IBM Z
s390x
13.6.10. Obtención de paquetes debuginfo para una aplicación o librería usando GDB
La información de depuración es necesaria para depurar el código. Para el código que se instala desde un paquete, el depurador de GNU (GDB) reconoce automáticamente la información de depuración que falta, resuelve el nombre del paquete y proporciona consejos concretos sobre cómo obtener el paquete.
Requisitos previos
- La aplicación o la biblioteca que desea depurar debe estar instalada en el sistema.
-
GDB y la herramienta
debuginfo-installdeben estar instalados en el sistema. Para más detalles, consulte Configuración para depurar aplicaciones. -
Los canales que proporcionan los paquetes
debuginfoydebugsourcedeben estar configurados y habilitados en el sistema.
Procedimiento
Inicie GDB conectado a la aplicación o biblioteca que desea depurar. GDB reconoce automáticamente la información de depuración que falta y sugiere un comando a ejecutar.
$ gdb -q /bin/ls Reading symbols from /bin/ls...Reading symbols from .gnu_debugdata for /usr/bin/ls...(no debugging symbols found)...done. (no debugging symbols found)...done. Missing separate debuginfos, use: dnf debuginfo-install coreutils-8.30-6.el8.x86_64 (gdb)Salir de GDB: escribir q y confirmar con Enter.
(gdb) q
Ejecute el comando sugerido por GDB para instalar los paquetes necesarios de
debuginfo:# dnf debuginfo-install coreutils-8.30-6.el8.x86_64
La herramienta de gestión de paquetes
dnfofrece un resumen de los cambios, pide confirmación y, una vez confirmada, descarga e instala todos los archivos necesarios.-
En caso de que GDB no pueda sugerir el paquete
debuginfo, siga el procedimiento descrito en Obtención de paquetes debuginfo para una aplicación o biblioteca de forma manual.
Capítulo 14. Monitorización del rendimiento del sistema con perf
Como administrador del sistema, puede utilizar la herramienta perf para recoger y analizar los datos de rendimiento de su sistema.
14.1. Grabación de un perfil de rendimiento en modo por CPU
Puede utilizar perf record en el modo por CPU para muestrear y registrar los datos de rendimiento tanto en el espacio del usuario como en el espacio del kernel simultáneamente en todos los hilos de una CPU monitorizada. Por defecto, el modo por CPU monitoriza todas las CPUs en línea.
Requisitos previos
-
La herramienta de espacio de usuario
perfestá instalada. Para más información, consulte Instalación de perf.
Procedimiento
Toma de muestras y registra los datos de rendimiento:
# perf record -a commandSustituya
commandcon el comando durante el cual desea muestrear los datos. Si no especifica un comando,perf recordmuestreará los datos hasta que usted lo detenga manualmente pulsando Ctrl+C.
Recursos adicionales
-
La página de manual
perf-record(1).
14.2. Captura de datos del gráfico de llamadas con el registro perf
Puede configurar la herramienta perf record para que registre qué función está llamando a otras funciones en el perfil de rendimiento. Esto ayuda a identificar un cuello de botella si varios procesos están llamando a la misma función.
Requisitos previos
-
La herramienta de espacio de usuario
perfestá instalada. Para más información, consulte Instalación de perf.
Procedimiento
Tome muestras y registre los datos de rendimiento con la opción
--call-graph:$ perf record --call-graph method command
-
Sustituya
commandcon el comando durante el cual desea muestrear los datos. Si no especifica un comando,perf recordmuestreará los datos hasta que usted lo detenga manualmente pulsando Ctrl+C. Sustituya method por uno de los siguientes métodos de desenrollado:
fp-
Utiliza el método del puntero de marco. Dependiendo de la optimización del compilador, como en el caso de los binarios construidos con la opción de GCC
--fomit-frame-pointer, esto puede no ser capaz de desenrollar la pila. dwarf- Utiliza la información de la trama de llamada DWARF para desenrollar la pila.
lbr- Utiliza el hardware del último registro de rama en los procesadores Intel.
-
Sustituya
Recursos adicionales
-
La página de manual
perf-record(1).
14.3. Identificar las CPUs ocupadas con perf
Cuando se investigan los problemas de rendimiento de un sistema, se puede utilizar la herramienta perf para identificar las CPU más ocupadas con el fin de centrar los esfuerzos.
14.3.1. Visualización de los eventos de la CPU contabilizados con perf stat
Puede utilizar perf stat para mostrar qué eventos de la CPU se contaron deshabilitando la agregación del recuento de la CPU. Debe contar los eventos en el modo de todo el sistema utilizando la bandera -a para poder utilizar esta funcionalidad.
Requisitos previos
-
La herramienta de espacio de usuario
perfestá instalada. Para más información, consulte Instalación de perf.
Procedimiento
Cuenta los eventos con la agregación del recuento de la CPU desactivada:
# perf stat -a -A sleep secondsEl ejemplo anterior muestra los recuentos de un conjunto predeterminado de eventos comunes de hardware y software registrados durante un período de tiempo de
secondssegundos, según lo dictado por el uso del comandosleep, sobre cada CPU individual en orden ascendente, comenzando conCPU0. Por ello, puede ser útil especificar un evento como los ciclos:# perf stat -a -A -e cycles sleep seconds
14.3.2. Visualización de las muestras de la CPU que se tomaron con el informe de perfeccionamiento
El comando perf record muestrea los datos de rendimiento y almacena estos datos en un archivo perf.data que puede ser leído con el comando perf report. El comando perf record siempre registra en qué CPU se tomaron las muestras. Se puede configurar perf report para que muestre esta información.
Requisitos previos
-
La herramienta de espacio de usuario
perfestá instalada. Para más información, consulte Instalación de perf. -
Hay un archivo
perf.datacreado conperf recorden el directorio actual. Si el archivoperf.datase creó con acceso de root, es necesario ejecutarperf reporttambién con acceso de root.
Procedimiento
Mostrar el contenido del archivo
perf.datapara su posterior análisis mientras se clasifica por CPU:# perf report --sort cpu
Se puede ordenar por CPU y comando para mostrar información más detallada sobre dónde se gasta el tiempo de la CPU:
# perf report --sort cpu,comm
Este ejemplo listará los comandos de todas las CPUs monitoreadas por sobrecarga total en orden descendente de uso de sobrecarga e identificará la CPU en la que se ejecutó el comando.
Recursos adicionales
-
Para obtener más información sobre la grabación de un archivo
perf.data, consulte Grabación y análisis de perfiles de rendimiento con perf.
14.3.3. Visualización de CPUs específicas durante la elaboración de perfiles con perf top
Puede configurar perf top para que muestre las CPUs específicas y su uso relativo mientras perfila su sistema en tiempo real.
Requisitos previos
-
La herramienta de espacio de usuario
perfestá instalada. Para más información, consulte Instalación de perf.
Procedimiento
Inicie la interfaz
perf topmientras clasifica por CPU:# perf top --sort cpu
Este ejemplo listará las CPUs y su respectiva sobrecarga en orden descendente de uso de la sobrecarga en tiempo real.
Se puede ordenar por CPU y por comando para obtener información más detallada de dónde se gasta el tiempo de la CPU:
# perf top --sort cpu,comm
Este ejemplo listará los comandos por el total de gastos generales en orden descendente de uso de gastos generales e identificará la CPU en la que se ejecutó el comando en tiempo real.
14.4. Monitorización de CPUs específicas con perf
Puede configurar la herramienta perf para supervisar sólo las CPUs específicas de interés.
14.4.1. Monitoreo de CPUs específicas con registro de perf y reporte de perf
Puede configurar perf record para que sólo tome muestras de CPUs específicas de interés y analizar el archivo perf.data generado con perf report para su posterior análisis.
Requisitos previos
-
La herramienta de espacio de usuario
perfestá instalada. Para más información, consulte Instalación de perf.
Procedimiento
Muestrear y registrar los datos de rendimiento en las CPUs específicas, generando un archivo
perf.data:Utilizando una lista de CPUs separada por comas:
# perf record -C 0,1 sleep seconds
El ejemplo anterior muestrea y registra datos en las CPUs 0 y 1 durante un periodo de
secondssegundos según lo dictado por el uso del comandosleep.Utilizando una gama de CPUs:
# perf record -C 0-2 sleep seconds
El ejemplo anterior muestrea y registra datos en todas las CPUs desde la CPU 0 a la 2 durante un periodo de
secondssegundos según el uso del comandosleep.
Muestra el contenido del archivo
perf.datapara su posterior análisis:# perf report
Este ejemplo mostrará el contenido de
perf.data. Si está supervisando varias CPUs y quiere saber en qué CPU se tomaron muestras de datos, consulte Visualizar en qué CPU se tomaron muestras con el informe perf.
14.4.2. Visualización de CPUs específicas durante la elaboración de perfiles con perf top
Puede configurar perf top para que muestre las CPUs específicas y su uso relativo mientras perfila su sistema en tiempo real.
Requisitos previos
-
La herramienta de espacio de usuario
perfestá instalada. Para más información, consulte Instalación de perf.
Procedimiento
Inicie la interfaz
perf topmientras clasifica por CPU:# perf top --sort cpu
Este ejemplo listará las CPUs y su respectiva sobrecarga en orden descendente de uso de la sobrecarga en tiempo real.
Se puede ordenar por CPU y por comando para obtener información más detallada de dónde se gasta el tiempo de la CPU:
# perf top --sort cpu,comm
Este ejemplo listará los comandos por el total de gastos generales en orden descendente de uso de gastos generales e identificará la CPU en la que se ejecutó el comando en tiempo real.
14.5. Generación de un archivo perf.data legible en un dispositivo diferente
Puede utilizar la herramienta perf para registrar los datos de rendimiento en un archivo perf.data para analizarlo en otro dispositivo.
Requisitos previos
-
La herramienta de espacio de usuario
perfestá instalada. Para más información, consulte Instalación de perf. -
El paquete del kernel
debuginfoestá instalado. Para más información, consulte Obtener paquetes debuginfo para una aplicación o biblioteca utilizando GDB.
Procedimiento
Capture los datos de rendimiento que le interese investigar más a fondo:
# perf record -a --call-graph fp sleep secondsEste ejemplo generaría un
perf.datasobre todo el sistema durante un periodo desecondssegundos según el uso del comandosleep. También capturaría los datos del gráfico de llamadas utilizando el método del puntero de trama.Generar un fichero de archivo que contenga símbolos de depuración de los datos registrados:
# archivo perf
Pasos de verificación
Compruebe que el fichero de archivo se ha generado en su directorio activo actual:
# ls perf.data*
La salida mostrará todos los archivos del directorio actual que empiecen por
perf.data. El archivo se llamaráperf.data.tar.gzo
perf data.tar.bz2
Recursos adicionales
-
Para obtener más información sobre la grabación de un archivo
perf.data, consulte Grabación y análisis de perfiles de rendimiento con perf. -
Para más información sobre la captura de datos del gráfico de llamadas con
perf record, consulte Captura de datos del gráfico de llamadas con el registro de perf.
14.6. Analizar un archivo perf.data creado en un dispositivo diferente
Puede utilizar la herramienta perf para analizar un archivo perf.data generado en un dispositivo diferente.
Requisitos previos
-
La herramienta de espacio de usuario
perfestá instalada. Para más información, consulte Instalación de perf. -
Un archivo
perf.datay un archivo asociado generado en un dispositivo diferente están presentes en el dispositivo actual que se está utilizando.
Procedimiento
-
Copie tanto el archivo
perf.datacomo el archivo comprimido en su directorio activo actual. Extraiga el archivo en
~/.debug:# mkdir -p ~/.debug # tar xf perf.data.tar.bz2 -C ~/.debugNotaEl archivo también puede llamarse
perf.data.tar.gz.Abra el archivo
perf.datapara su posterior análisis:# perf report
Capítulo 15. Supervisión del rendimiento de las aplicaciones con perf
Esta sección describe cómo utilizar la herramienta perf para supervisar el rendimiento de la aplicación.
15.1. Adjuntar un registro de perfeccionamiento a un proceso en ejecución
Requisitos previos
Puede adjuntar perf record a un proceso en ejecución. Esto indicará a perf record que sólo muestre y registre los datos de rendimiento en los procesos especificados.
Requisitos previos
-
La herramienta de espacio de usuario
perfestá instalada. Para más información, consulte Instalación de perf.
Procedimiento
Adjuntar
perf recorda un proceso en ejecución:$ perf record -p ID1,ID2 sleep seconds
El ejemplo anterior muestra y registra los datos de rendimiento de los procesos con los ID de proceso
ID1yID2durante un periodo de tiempo desecondssegundos según lo dictado por el comandosleep. También puede configurarperfpara registrar eventos en hilos específicos:$ perf record -t ID1,ID2 sleep seconds
NotaCuando se utiliza la bandera
-ty se estipulan los ID de los hilos,perfdesactiva la herencia por defecto. Puedes habilitar la herencia añadiendo la opción--inherit.
15.2. Captura de datos del gráfico de llamadas con el registro perf
Puede configurar la herramienta perf record para que registre qué función está llamando a otras funciones en el perfil de rendimiento. Esto ayuda a identificar un cuello de botella si varios procesos están llamando a la misma función.
Requisitos previos
-
La herramienta de espacio de usuario
perfestá instalada. Para más información, consulte Instalación de perf.
Procedimiento
Tome muestras y registre los datos de rendimiento con la opción
--call-graph:$ perf record --call-graph method command
-
Sustituya
commandcon el comando durante el cual desea muestrear los datos. Si no especifica un comando,perf recordmuestreará los datos hasta que usted lo detenga manualmente pulsando Ctrl+C. Sustituya method por uno de los siguientes métodos de desenrollado:
fp-
Utiliza el método del puntero de marco. Dependiendo de la optimización del compilador, como en el caso de los binarios construidos con la opción de GCC
--fomit-frame-pointer, esto puede no ser capaz de desenrollar la pila. dwarf- Utiliza la información de la trama de llamada DWARF para desenrollar la pila.
lbr- Utiliza el hardware del último registro de rama en los procesadores Intel.
-
Sustituya
Recursos adicionales
-
La página de manual
perf-record(1).
15.3. Analizar los datos de perfeccionamiento con el informe de perfeccionamiento
Puede utilizar perf report para visualizar y analizar un archivo perf.data.
Requisitos previos
-
La herramienta de espacio de usuario
perfestá instalada. Para más información, consulte Instalación de perf. -
Hay un archivo
perf.dataen el directorio actual. -
Si el archivo
perf.datase creó con acceso de root, deberá ejecutarperf reporttambién con acceso de root.
Procedimiento
Muestra el contenido del archivo
perf.datapara su posterior análisis:# perf report
Ejemplo 15.1. Ejemplo de salida
Samples: 2K of event 'cycles', Event count (approx.): 235462960 Overhead Command Shared Object Symbol 2.36% kswapd0 [kernel.kallsyms] [k] page_vma_mapped_walk 2.13% sssd_kcm libc-2.28.so [.] __memset_avx2_erms 2.13% perf [kernel.kallsyms] [k] smp_call_function_single 1.53% gnome-shell libc-2.28.so [.] __strcmp_avx2 1.17% gnome-shell libglib-2.0.so.0.5600.4 [.] g_hash_table_lookup 0.93% Xorg libc-2.28.so [.] __memmove_avx_unaligned_erms 0.89% gnome-shell libgobject-2.0.so.0.5600.4 [.] g_object_unref 0.87% kswapd0 [kernel.kallsyms] [k] page_referenced_one 0.86% gnome-shell libc-2.28.so [.] __memmove_avx_unaligned_erms 0.83% Xorg [kernel.kallsyms] [k] alloc_vmap_area 0.63% gnome-shell libglib-2.0.so.0.5600.4 [.] g_slice_alloc 0.53% gnome-shell libgirepository-1.0.so.1.0.0 [.] g_base_info_unref 0.53% gnome-shell ld-2.28.so [.] _dl_find_dso_for_object 0.49% kswapd0 [kernel.kallsyms] [k] vma_interval_tree_iter_next 0.48% gnome-shell libpthread-2.28.so [.] __pthread_getspecific 0.47% gnome-shell libgirepository-1.0.so.1.0.0 [.] 0x0000000000013b1d 0.45% gnome-shell libglib-2.0.so.0.5600.4 [.] g_slice_free1 0.45% gnome-shell libgobject-2.0.so.0.5600.4 [.] g_type_check_instance_is_fundamentally_a 0.44% gnome-shell libc-2.28.so [.] malloc 0.41% swapper [kernel.kallsyms] [k] apic_timer_interrupt 0.40% gnome-shell ld-2.28.so [.] _dl_lookup_symbol_x 0.39% kswapd0 [kernel.kallsyms] [k] __raw_callee_save___pv_queued_spin_unlock
Recursos adicionales
-
La página de manual
perf-report(1).
Capítulo 16. Perfilando los accesos a la memoria con perf mem
16.1. El propósito de la perf mem
El subcomando mem de la herramienta perf permite el muestreo de los accesos a la memoria (cargas y almacenamientos). El comando perf mem proporciona información sobre la latencia de la memoria, los tipos de accesos a la memoria, las funciones que causan aciertos y fallos en la caché y, mediante el registro del símbolo de datos, las ubicaciones de memoria en las que se producen estos aciertos y fallos.
16.2. Muestreo de acceso a la memoria con perf mem
Puede utilizar perf mem para muestrear los accesos a la memoria de su sistema. El comando toma las mismas opciones que perf record y perf report, así como algunas opciones exclusivas del subcomando mem. Los datos registrados se almacenan en un archivo perf.data en el directorio actual para su posterior análisis.
Requisitos previos
-
Tiene la herramienta de espacio de usuario
perfinstalada como se describe en Instalación de perf.
Procedimiento
Muestrear los accesos a la memoria:
# perf mem record -a sleep secondsEste ejemplo muestrea los accesos a la memoria en todas las CPUs durante un período de seconds segundos, según lo dictado por el comando
sleep. Puede reemplazar el comandosleeppor cualquier comando durante el cual desee muestrear los datos de acceso a la memoria. Por defecto,perf memmuestrea tanto las cargas como los almacenamientos de memoria. Puede seleccionar sólo una operación de memoria utilizando la opción-ty especificando "load" o "store" entreperf memyrecord. Para las cargas, se captura la información sobre el nivel de la jerarquía de memoria, los accesos a la memoria TLB, los snoops del bus y los bloqueos de memoria.Abra el archivo
perf.datapara su análisis:# perf mem report
Si ha utilizado los comandos de ejemplo, la salida es:
Available samples 35k cpu/mem-loads,ldlat=30/P 54k cpu/mem-stores/P
La línea
cpu/mem-loads,ldlat=30/Pdenota los datos recogidos sobre las cargas de memoria y la líneacpu/mem-stores/Pdenota los datos recogidos sobre los almacenes de memoria. Resalte la categoría de interés y pulse Enter para ver los datos:Samples: 35K of event 'cpu/mem-loads,ldlat=30/P', Event count (approx.): 4067062 Overhead Samples Local Weight Memory access Symbol Shared Object Data Symbol Data Object Snoop TLB access Locked 0.07% 29 98 L1 or L1 hit [.] 0x000000000000a255 libspeexdsp.so.1.5.0 [.] 0x00007f697a3cd0f0 anon None L1 or L2 hit No 0.06% 26 97 L1 or L1 hit [.] 0x000000000000a255 libspeexdsp.so.1.5.0 [.] 0x00007f697a3cd0f0 anon None L1 or L2 hit No 0.06% 25 96 L1 or L1 hit [.] 0x000000000000a255 libspeexdsp.so.1.5.0 [.] 0x00007f697a3cd0f0 anon None L1 or L2 hit No 0.06% 1 2325 Uncached or N/A hit [k] pci_azx_readl [kernel.kallsyms] [k] 0xffffb092c06e9084 [kernel.kallsyms] None L1 or L2 hit No 0.06% 1 2247 Uncached or N/A hit [k] pci_azx_readl [kernel.kallsyms] [k] 0xffffb092c06e8164 [kernel.kallsyms] None L1 or L2 hit No 0.05% 1 2166 L1 or L1 hit [.] 0x00000000038140d6 libxul.so [.] 0x00007ffd7b84b4a8 [stack] None L1 or L2 hit No 0.05% 1 2117 Uncached or N/A hit [k] check_for_unclaimed_mmio [kernel.kallsyms] [k] 0xffffb092c1842300 [kernel.kallsyms] None L1 or L2 hit No 0.05% 22 95 L1 or L1 hit [.] 0x000000000000a255 libspeexdsp.so.1.5.0 [.] 0x00007f697a3cd0f0 anon None L1 or L2 hit No 0.05% 1 1898 L1 or L1 hit [.] 0x0000000002a30e07 libxul.so [.] 0x00007f610422e0e0 anon None L1 or L2 hit No 0.05% 1 1878 Uncached or N/A hit [k] pci_azx_readl [kernel.kallsyms] [k] 0xffffb092c06e8164 [kernel.kallsyms] None L2 miss No 0.04% 18 94 L1 or L1 hit [.] 0x000000000000a255 libspeexdsp.so.1.5.0 [.] 0x00007f697a3cd0f0 anon None L1 or L2 hit No 0.04% 1 1593 Local RAM or RAM hit [.] 0x00000000026f907d libxul.so [.] 0x00007f3336d50a80 anon Hit L2 miss No 0.03% 1 1399 L1 or L1 hit [.] 0x00000000037cb5f1 libxul.so [.] 0x00007fbe81ef5d78 libxul.so None L1 or L2 hit No 0.03% 1 1229 LFB or LFB hit [.] 0x0000000002962aad libxul.so [.] 0x00007fb6f1be2b28 anon None L2 miss No 0.03% 1 1202 LFB or LFB hit [.] __pthread_mutex_lock libpthread-2.29.so [.] 0x00007fb75583ef20 anon None L1 or L2 hit No 0.03% 1 1193 Uncached or N/A hit [k] pci_azx_readl [kernel.kallsyms] [k] 0xffffb092c06e9164 [kernel.kallsyms] None L2 miss No 0.03% 1 1191 L1 or L1 hit [k] azx_get_delay_from_lpib [kernel.kallsyms] [k] 0xffffb092ca7efcf0 [kernel.kallsyms] None L1 or L2 hit No
También puede ordenar los resultados para investigar diferentes aspectos de interés al mostrar los datos. Por ejemplo, para ordenar los datos sobre las cargas de memoria por tipo de accesos a la memoria que se producen durante el período de muestreo en orden descendente de la sobrecarga que representan:
# perf mem -t load report --sort=mem
Por ejemplo, la salida puede ser:
Samples: 35K of event 'cpu/mem-loads,ldlat=30/P', Event count (approx.): 40670 Overhead Samples Memory access 31.53% 9725 LFB or LFB hit 29.70% 12201 L1 or L1 hit 23.03% 9725 L3 or L3 hit 12.91% 2316 Local RAM or RAM hit 2.37% 743 L2 or L2 hit 0.34% 9 Uncached or N/A hit 0.10% 69 I/O or N/A hit 0.02% 825 L3 miss
Recursos adicionales
-
Para una explicación de las opciones de comando específicas del subcomando
mem, consulte la página de manualperf-mem(1).
16.3. Interpretación de los resultados del informe perf mem
La tabla que se muestra al ejecutar el comando perf mem report sin ningún modificador ordena los datos en varias columnas:
- La columna "Gastos generales
- Indica el porcentaje de muestras globales recogidas en esa función concreta.
- La columna "Muestras
- Muestra el número de muestras que representa esa fila.
- La columna "Peso local
- Muestra la latencia de acceso en ciclos del núcleo del procesador.
- La columna "Acceso a la memoria
- Muestra el tipo de acceso a la memoria que se ha producido.
- La columna "Símbolo
- Muestra el nombre o símbolo de la función.
- La columna "Objeto compartido
- Muestra el nombre de la imagen ELF de la que provienen las muestras (el nombre [kernel.kallsyms] se utiliza cuando las muestras provienen del kernel).
- La columna "Símbolo de datos
- Muestra la dirección de la posición de memoria a la que se dirige la fila.
A menudo, debido a la asignación dinámica de memoria o al acceso a la memoria de la pila, la columna "Símbolo de datos" mostrará una dirección sin procesar.
- La columna "Snoop"
- Muestra las transacciones del bus.
- La columna "Acceso a la TLB
- Muestra los accesos a la memoria TLB.
- La columna "Bloqueado
- Indica si una función estaba o no bloqueada en memoria.
En el modo por defecto, las funciones se clasifican en orden descendente, mostrando primero las que tienen mayor sobrecarga.
Capítulo 17. Detección de falsas comparticiones con perf c2c
17.1. El objetivo de perf c2c
El subcomando c2c de la herramienta perf permite el análisis de datos compartidos de caché a caché (C2C). Se puede utilizar el comando perf c2c para inspeccionar la contención de las líneas de caché y detectar tanto la compartición verdadera como la falsa.
La contención de líneas de caché se produce cuando un núcleo de procesador en un sistema de multiprocesamiento simétrico (SMP) modifica elementos de datos en la misma línea de caché que está en uso por otros procesadores. Todos los demás procesadores que utilizan esta línea de caché deben invalidar su copia y solicitar una actualizada. Esto puede provocar una degradación del rendimiento.
The perf c2c command provides the following information: * Cache lines where contention has been detected * Processes reading and writing the data * Instructions causing the contention * The Non-Uniform Memory Access (NUMA) nodes involved in the contention
17.2. Falso reparto
La falsa compartición se produce cuando un núcleo de procesador en un sistema de multiprocesamiento simétrico (SMP) modifica elementos de datos en la misma línea de caché que está en uso por otros procesadores para acceder a otros elementos de datos que no están siendo compartidos entre los procesadores. Esta modificación inicial requiere que los otros procesadores que utilizan la línea de caché invaliden su copia y soliciten una actualizada, a pesar de que los procesadores no necesitan, o incluso no tienen necesariamente acceso, a una versión actualizada del elemento de datos modificado.
17.3. Detección de la contención de líneas de caché con perf c2c
Utilice el comando perf c2c para detectar la contención de líneas de caché en un sistema. El comando perf c2c admite las mismas opciones que perf record, así como algunas opciones exclusivas del subcomando c2c. Los datos registrados se almacenan en un archivo perf.data en el directorio actual para su posterior análisis.
Requisitos previos
-
La herramienta de espacio de usuario
perfestá instalada. Para más información, consulte Instalación de perf.
Procedimiento
Utilice
perf c2cpara detectar la contención de las líneas de caché:# perf c2c record -a sleep seconds
Este ejemplo muestrea y registra los datos de contención de líneas de caché en todas las CPUs durante un periodo de
secondssegún lo dictado por el comandosleep. Puede reemplazar el comandosleepcon cualquier comando que desee recopilar datos de contención de líneas de caché.
Recursos adicionales
-
Para una explicación de las opciones de comando específicas del subcomando
c2c, consulte la página de manualperf-c2c(1).
17.4. Visualización de un archivo perf.data grabado con perf c2c record
Requisitos previos
-
La herramienta de espacio de usuario
perfestá instalada. Para más información, consulte Instalación de perf. -
Un archivo
perf.datagrabado con el comandoperf c2cestá disponible en el directorio actual. Para obtener más información, consulte Detección de la contención de líneas de caché con perf c2c.
Procedimiento
Abra el archivo
perf.datapara su posterior análisis:# perf c2c report --stdio
Este comando visualiza el archivo
perf.dataen varios gráficos dentro del terminal:================================================= Trace Event Information ================================================= Total records : 329219 Locked Load/Store Operations : 14654 Load Operations : 69679 Loads - uncacheable : 0 Loads - IO : 0 Loads - Miss : 3972 Loads - no mapping : 0 Load Fill Buffer Hit : 11958 Load L1D hit : 17235 Load L2D hit : 21 Load LLC hit : 14219 Load Local HITM : 3402 Load Remote HITM : 12757 Load Remote HIT : 5295 Load Local DRAM : 976 Load Remote DRAM : 3246 Load MESI State Exclusive : 4222 Load MESI State Shared : 0 Load LLC Misses : 22274 LLC Misses to Local DRAM : 4.4% LLC Misses to Remote DRAM : 14.6% LLC Misses to Remote cache (HIT) : 23.8% LLC Misses to Remote cache (HITM) : 57.3% Store Operations : 259539 Store - uncacheable : 0 Store - no mapping : 11 Store L1D Hit : 256696 Store L1D Miss : 2832 No Page Map Rejects : 2376 Unable to parse data source : 1 ================================================= Global Shared Cache Line Event Information ================================================= Total Shared Cache Lines : 55 Load HITs on shared lines : 55454 Fill Buffer Hits on shared lines : 10635 L1D hits on shared lines : 16415 L2D hits on shared lines : 0 LLC hits on shared lines : 8501 Locked Access on shared lines : 14351 Store HITs on shared lines : 109953 Store L1D hits on shared lines : 109449 Total Merged records : 126112 ================================================= c2c details ================================================= Events : cpu/mem-loads,ldlat=30/P : cpu/mem-stores/P Cachelines sort on : Remote HITMs Cacheline data groupping : offset,pid,iaddr ================================================= Shared Data Cache Line Table ================================================= # # Total Rmt ----- LLC Load Hitm ----- ---- Store Reference ---- --- Load Dram ---- LLC Total ----- Core Load Hit ----- -- LLC Load Hit -- # Index Cacheline records Hitm Total Lcl Rmt Total L1Hit L1Miss Lcl Rmt Ld Miss Loads FB L1 L2 Llc Rmt # ..... .................. ....... ....... ....... ....... ....... ....... ....... ....... ........ ........ ....... ....... ....... ....... ....... ........ ........ # 0 0x602180 149904 77.09% 12103 2269 9834 109504 109036 468 727 2657 13747 40400 5355 16154 0 2875 529 1 0x602100 12128 22.20% 3951 1119 2832 0 0 0 65 200 3749 12128 5096 108 0 2056 652 2 0xffff883ffb6a7e80 260 0.09% 15 3 12 161 161 0 1 1 15 99 25 50 0 6 1 3 0xffffffff81aec000 157 0.07% 9 0 9 1 0 1 0 7 20 156 50 59 0 27 4 4 0xffffffff81e3f540 179 0.06% 9 1 8 117 97 20 0 10 25 62 11 1 0 24 7 ================================================= Shared Cache Line Distribution Pareto ================================================= # # ----- HITM ----- -- Store Refs -- Data address ---------- cycles ---------- cpu Shared # Num Rmt Lcl L1 Hit L1 Miss Offset Pid Code address rmt hitm lcl hitm load cnt Symbol Object Source:Line Node{cpu list} # ..... ....... ....... ....... ....... .................. ....... .................. ........ ........ ........ ........ ................... .................... ........................... .... # ------------------------------------------------------------- 0 9834 2269 109036 468 0x602180 ------------------------------------------------------------- 65.51% 55.88% 75.20% 0.00% 0x0 14604 0x400b4f 27161 26039 26017 9 [.] read_write_func no_false_sharing.exe false_sharing_example.c:144 0{0-1,4} 1{24-25,120} 2{48,54} 3{169} 0.41% 0.35% 0.00% 0.00% 0x0 14604 0x400b56 18088 12601 26671 9 [.] read_write_func no_false_sharing.exe false_sharing_example.c:145 0{0-1,4} 1{24-25,120} 2{48,54} 3{169} 0.00% 0.00% 24.80% 100.00% 0x0 14604 0x400b61 0 0 0 9 [.] read_write_func no_false_sharing.exe false_sharing_example.c:145 0{0-1,4} 1{24-25,120} 2{48,54} 3{169} 7.50% 9.92% 0.00% 0.00% 0x20 14604 0x400ba7 2470 1729 1897 2 [.] read_write_func no_false_sharing.exe false_sharing_example.c:154 1{122} 2{144} 17.61% 20.89% 0.00% 0.00% 0x28 14604 0x400bc1 2294 1575 1649 2 [.] read_write_func no_false_sharing.exe false_sharing_example.c:158 2{53} 3{170} 8.97% 12.96% 0.00% 0.00% 0x30 14604 0x400bdb 2325 1897 1828 2 [.] read_write_func no_false_sharing.exe false_sharing_example.c:162 0{96} 3{171} ------------------------------------------------------------- 1 2832 1119 0 0 0x602100 ------------------------------------------------------------- 29.13% 36.19% 0.00% 0.00% 0x20 14604 0x400bb3 1964 1230 1788 2 [.] read_write_func no_false_sharing.exe false_sharing_example.c:155 1{122} 2{144} 43.68% 34.41% 0.00% 0.00% 0x28 14604 0x400bcd 2274 1566 1793 2 [.] read_write_func no_false_sharing.exe false_sharing_example.c:159 2{53} 3{170} 27.19% 29.40% 0.00% 0.00% 0x30 14604 0x400be7 2045 1247 2011 2 [.] read_write_func no_false_sharing.exe false_sharing_example.c:163 0{96} 3{171}
17.5. Interpretación del informe perf c2c
La visualización que se muestra al ejecutar el comando perf c2c report --stdio clasifica los datos en varias tablas:
- Información sobre eventos de rastreo
-
Esta tabla proporciona un resumen de alto nivel de todas las muestras de carga y almacenamiento, que son recogidas por el comando
perf c2c record. - Información de eventos de la línea de caché global compartida
- Esta tabla proporciona estadísticas sobre las líneas de caché compartidas.
- c2c Detalles
-
Esta tabla proporciona información sobre qué eventos se muestrearon y cómo se organizan los datos de
perf c2c reportdentro de la visualización. - Tabla de líneas de caché de datos compartidos
- Esta tabla proporciona un resumen de una línea para las líneas de caché más calientes en las que se detecta falsa compartición y está ordenada en orden descendente por la cantidad de HITM remotos detectados por línea de caché por defecto.
- Distribución de líneas de caché compartidas Pareto
Estas tablas proporcionan una variedad de información sobre cada línea de caché que experimenta contención:
- Las líneas de caché están numeradas en la columna "NUM", empezando por el 0.
- La dirección virtual de cada línea de caché está contenida en la columna "Dirección de datos Offset" y seguida por el offset en la línea de caché donde se produjeron los diferentes accesos.
- La columna "Pid" contiene el ID del proceso.
- La columna "Dirección del código" contiene la dirección del código del puntero de la instrucción.
- Las columnas bajo la etiqueta "ciclos" muestran las latencias medias de carga.
- La columna "cpu cnt" muestra de cuántas CPUs diferentes provienen las muestras (esencialmente, cuántas CPUs diferentes estaban esperando los datos indexados en esa ubicación dada).
- La columna "Símbolo" muestra el nombre o símbolo de la función.
- La columna "Shared Object" muestra el nombre de la imagen ELF de la que provienen las muestras (el nombre [kernel.kallsyms] se utiliza cuando las muestras provienen del kernel).
- La columna "Fuente:Línea" muestra el archivo fuente y el número de línea.
- La columna "Node{cpu list}" muestra de qué CPUs específicas proceden las muestras de cada nodo.
17.6. Detección de falsas comparticiones con perf c2c
Requisitos previos
-
La herramienta de espacio de usuario
perfestá instalada. Para más información, consulte Instalación de perf. -
Un archivo
perf.datagrabado con el comandoperf c2cestá disponible en el directorio actual. Para obtener más información, consulte Detección de la contención de líneas de caché con perf c2c.
Procedimiento
Abra el archivo
perf.datapara su posterior análisis:# perf c2c report --stdio
Esto abre el archivo
perf.dataen la terminal.En la tabla "Información de eventos de rastreo", localice la fila que contiene los valores de "Faltas de LLC a la caché remota (HITM)":
================================================= Trace Event Information ================================================= Total records : 329219 Locked Load/Store Operations : 14654 Load Operations : 69679 Loads - uncacheable : 0 Loads - IO : 0 Loads - Miss : 3972 Loads - no mapping : 0 Load Fill Buffer Hit : 11958 Load L1D hit : 17235 Load L2D hit : 21 Load LLC hit : 14219 Load Local HITM : 3402 Load Remote HITM : 12757 Load Remote HIT : 5295 Load Local DRAM : 976 Load Remote DRAM : 3246 Load MESI State Exclusive : 4222 Load MESI State Shared : 0 Load LLC Misses : 22274 LLC Misses to Local DRAM : 4.4% LLC Misses to Remote DRAM : 14.6% LLC Misses to Remote cache (HIT) : 23.8% LLC Misses to Remote cache (HITM) : 57.3% Store Operations : 259539 Store - uncacheable : 0 Store - no mapping : 11 Store L1D Hit : 256696 Store L1D Miss : 2832 No Page Map Rejects : 2376 Unable to parse data source : 1El porcentaje en la columna de valores de la fila "LLC Misses to Remote Cache (HITM)\Nrepresenta el porcentaje de misses LLC que se produjeron a través de los nodos NUMA en las líneas de caché modificadas y es un indicador clave de que se ha producido una falsa compartición.
Inspeccione la columna "Rmt" del campo "LLC Load Hitm" de la tabla "Shared Data Cache Line":
================================================= Shared Data Cache Line Table ================================================= # # Total Rmt ----- LLC Load Hitm ----- ---- Store Reference ---- --- Load Dram ---- LLC Total ----- Core Load Hit ----- -- LLC Load Hit -- # Index Cacheline records Hitm Total Lcl Rmt Total L1Hit L1Miss Lcl Rmt Ld Miss Loads FB L1 L2 Llc Rmt # ..... .................. ....... ....... ....... ....... ....... ....... ....... ....... ........ ........ ....... ....... ....... ....... ....... ........ ........ # 0 0x602180 149904 77.09% 12103 2269 9834 109504 109036 468 727 2657 13747 40400 5355 16154 0 2875 529 1 0x602100 12128 22.20% 3951 1119 2832 0 0 0 65 200 3749 12128 5096 108 0 2056 652 2 0xffff883ffb6a7e80 260 0.09% 15 3 12 161 161 0 1 1 15 99 25 50 0 6 1 3 0xffffffff81aec000 157 0.07% 9 0 9 1 0 1 0 7 20 156 50 59 0 27 4 4 0xffffffff81e3f540 179 0.06% 9 1 8 117 97 20 0 10 25 62 11 1 0 24 7Esta tabla está ordenada en forma descendente por la cantidad de HITM remotos detectados por línea de caché. Un número alto en la columna \ "Rmt" de la sección \ "LLC Load Hitm" indica una falsa compartición y requiere una mayor inspección de la línea de caché en la que se produjo para depurar la actividad de falsa compartición.
Capítulo 18. Introducción a los flamegraphs
Como administrador del sistema, puede utilizar flamegraphs para crear visualizaciones de los datos de rendimiento del sistema registrados con la herramienta perf. Como desarrollador de software, puede utilizar flamegraphs para crear visualizaciones de los datos de rendimiento de la aplicación registrados con la herramienta perf.
El muestreo de trazas de pila es una técnica común para perfilar el rendimiento de la CPU con la herramienta perf. Lamentablemente, los resultados del perfilado de las trazas de la pila con perf pueden ser extremadamente verboso y laborioso de analizar. flamegraphs son visualizaciones creadas a partir de los datos registrados con perf para hacer más rápida y fácil la identificación de las rutas de código calientes.
18.1. Instalación de flamegraphs
Para empezar a utilizar flamegraphs, instale el paquete necesario:
Procedimiento
Instale el paquete
flamegraphs:# yum install js-d3-flame-graph
18.2. Creación de flamegrafías en todo el sistema
Este procedimiento describe cómo visualizar los datos de rendimiento registrados en todo un sistema utilizando flamegraphs.
Requisitos previos
-
flamegraphsse instalan tal y como se describe en la instalación de los flamencos. -
La herramienta
perfse instala como se describe en la instalación de perf.
Procedimiento
Registra los datos y crea la visualización:
# perf script flamegraph -a -F 99 sleep 60
Este comando muestrea y registra los datos de rendimiento de todo el sistema durante 60 segundos, tal y como se estipula en el uso del comando
sleep, y luego construye la visualización que se almacenará en el directorio activo actual comoflamegraph.html. El comando muestreará los datos del gráfico de llamadas por defecto y toma los mismos argumentos que la herramientaperf, en este caso particular:-a- Estipula el registro de datos en todo el sistema.
-F- Para ajustar la frecuencia de muestreo por segundo.
Pasos de verificación
Para el análisis, vea el flamograma generado:
# xdg-open flamegraph.html
Este comando abre el flamograma en el navegador por defecto:

18.3. Creación de flamegrafías sobre procesos específicos
Puede utilizar los flamegráficos para visualizar los datos de rendimiento registrados sobre procesos específicos en ejecución.
Requisitos previos
-
flamegraphsse instalan tal y como se describe en la instalación de los flamencos. -
La herramienta
perfse instala como se describe en la instalación de perf.
Procedimiento
Registra los datos y crea la visualización:
# perf script flamegraph -a -F 99 -p
ID1,ID2sleep 60Este comando muestrea y registra los datos de rendimiento de los procesos con los ID de proceso
ID1yID2durante 60 segundos, como se estipula al usar el comandosleep, y luego construye la visualización que se almacenará en el directorio activo actual comoflamegraph.html. El comando muestreará los datos del gráfico de llamadas por defecto y toma los mismos argumentos que la herramientaperf, en este caso particular:-a- Estipula el registro de datos en todo el sistema.
-F- Para ajustar la frecuencia de muestreo por segundo.
-p- Estipular identificaciones de procesos específicos para muestrear y registrar datos.
Pasos de verificación
Para el análisis, vea el flamograma generado:
# xdg-open flamegraph.html
Este comando anterior abre el flamograma en el navegador por defecto:
18.4. Interpretación de los flamogramas
Cada caja del flamegráfico representa una función diferente en la pila. El eje y muestra la profundidad de la pila, siendo la caja superior de cada pila la función que estaba realmente en la CPU y todo lo que está por debajo es la ascendencia. El eje x muestra la población de los datos del gráfico de llamadas muestreado. Los hijos de una pila en una fila determinada se muestran según el número de muestras tomadas de cada función respectiva en orden descendente a lo largo del eje x; el eje x does not representa el paso del tiempo. Cuanto más ancha es una casilla individual, más frecuente era en la CPU o parte de una ascendencia en la CPU en el momento en que se muestrearon los datos.
- IMPORTANTE
-
Las casillas que representan funciones del espacio de usuario pueden ser etiquetadas como Unknown en
flamegraphsporque el binario de la función es despojado. El paquetedebuginfodel ejecutable debe estar instalado o, si el ejecutable es una aplicación desarrollada localmente, la aplicación debe compilarse con información de depuración, la opción-gen GCC, para mostrar los nombres de las funciones o los símbolos en tal situación.
Procedimiento
- Para revelar los nombres de las funciones que no hayan sido mostradas previamente e investigar más a fondo los datos, haga clic en un cuadro dentro del flamegráfico para ampliar la pila en ese lugar determinado:
- Para volver a la vista por defecto del flamograma, haga clic en el botón .
Capítulo 19. Perfiles de asignación de memoria con numastat
Con la herramienta numastat, se pueden mostrar estadísticas sobre las asignaciones de memoria en un sistema. La herramienta numastat muestra los datos de cada nodo NUMA por separado. Puede utilizar esta información para investigar el rendimiento de la memoria de su sistema o la eficacia de diferentes políticas de memoria en su sistema.
19.1. Estadísticas numastat por defecto
Por defecto, la herramienta numastat muestra estadísticas sobre estas categorías de datos para cada nodo NUMA:
numa_hit- El número de páginas que fueron asignadas con éxito a este nodo.
numa_miss-
El número de páginas que se asignaron en este nodo debido a la poca memoria en el nodo previsto. Cada evento
numa_misstiene su correspondiente eventonuma_foreignen otro nodo. numa_foreign-
El número de páginas inicialmente destinadas a este nodo que fueron asignadas a otro nodo en su lugar. Cada evento
numa_foreigntiene su correspondiente eventonuma_missen otro nodo. interleave_hit- El número de páginas de política de intercalación asignadas con éxito a este nodo.
local_node- El número de páginas asignadas con éxito en este nodo por un proceso en este nodo.
other_node- El número de páginas asignadas en este nodo por un proceso en otro nodo.
Los valores altos de numa_hit y los bajos de numa_miss (en relación con los demás) indican un rendimiento óptimo.
19.2. Perfiles de asignación de memoria con numastat
Perfile la asignación de memoria del sistema utilizando la herramienta numastat.
Requisitos previos
-
Tiene instalado el paquete
numactl.
Procedimiento
Perfila la asignación de memoria de tu sistema:
$ numastat node0 node1 numa_hit 76557759 92126519 numa_miss 30772308 30827638 numa_foreign 30827638 30772308 interleave_hit 106507 103832 local_node 76502227 92086995 other_node 30827840 30867162
Recursos adicionales
-
La página de manual
numastat(8).
Capítulo 20. Configurar un sistema operativo para optimizar la utilización de la CPU
Esta sección describe cómo configurar el sistema operativo para optimizar la utilización de la CPU en sus cargas de trabajo.
20.1. Herramientas para supervisar y diagnosticar los problemas del procesador
Las siguientes son las herramientas disponibles en Red Hat Enterprise Linux 8 para supervisar y diagnosticar problemas de rendimiento relacionados con el procesador:
-
turbostatimprime los resultados de los contadores a intervalos especificados para ayudar a los administradores a identificar comportamientos inesperados en los servidores, como el uso excesivo de energía, la imposibilidad de entrar en estados de reposo profundo o la creación innecesaria de interrupciones de gestión del sistema (SMI). -
la utilidad
numactlproporciona una serie de opciones para gestionar la afinidad del procesador y la memoria. El paquetenumactlincluye la bibliotecalibnuma, que ofrece una interfaz de programación sencilla para la política NUMA soportada por el núcleo, y puede utilizarse para un ajuste más preciso que la aplicaciónnumactl. -
numastatmuestra las estadísticas de memoria por nodo NUMA para el sistema operativo y sus procesos, y muestra a los administradores si la memoria de los procesos está repartida por todo el sistema o está centralizada en nodos específicos. Esta herramienta es proporcionada por el paquetenumactl. -
numades un demonio de gestión automática de afinidad NUMA. Supervisa la topología NUMA y el uso de recursos dentro de un sistema para mejorar dinámicamente la asignación y gestión de recursos NUMA. -
/proc/interruptsmuestra el número de solicitud de interrupción (IRQ), el número de solicitudes de interrupción similares gestionadas por cada procesador del sistema, el tipo de interrupción enviada y una lista separada por comas de los dispositivos que responden a la solicitud de interrupción enumerada. la utilidad
pqosestá disponible en el paqueteintel-cmt-cat. Supervisa la caché de la CPU y el ancho de banda de la memoria en los procesadores Intel recientes. Supervisa:- Las instrucciones por ciclo (IPC).
- El recuento de fallos de caché de último nivel.
- El tamaño en kilobytes que el programa que se ejecuta en una determinada CPU ocupa en el LLC.
- El ancho de banda de la memoria local (MBL).
- El ancho de banda de la memoria remota (MBR).
-
x86_energy_perf_policypermite a los administradores definir la importancia relativa del rendimiento y la eficiencia energética. Esta información puede utilizarse para influir en los procesadores que admiten esta característica cuando seleccionan opciones que compensan el rendimiento y la eficiencia energética. -
la herramienta
tasksetes proporcionada por el paqueteutil-linux. Permite a los administradores recuperar y establecer la afinidad de procesador de un proceso en ejecución, o lanzar un proceso con una afinidad de procesador especificada.
Recursos adicionales
-
Para más información, consulte las páginas man de
turbostat,numactl,numastat,numa,numad,pqos,x86_energy_perf_policyytaskset.
20.2. Determinación de la topología del sistema
En la informática moderna, la idea de una CPU es engañosa, ya que la mayoría de los sistemas modernos tienen múltiples procesadores. La topología del sistema es la forma en que estos procesadores están conectados entre sí y con otros recursos del sistema. Esto puede afectar al rendimiento del sistema y de las aplicaciones, así como a las consideraciones de ajuste de un sistema.
20.2.1. Tipos de topología del sistema
A continuación se describen los dos principales tipos de topología utilizados en la informática moderna:
- Topología de multiprocesador simétrico (SMP)
- La topología SMP permite que todos los procesadores accedan a la memoria en el mismo tiempo. Sin embargo, debido a que el acceso a la memoria compartida e igualitaria obliga intrínsecamente a los accesos a la memoria en serie de todas las CPU, las limitaciones de escalado de los sistemas SMP se consideran ahora generalmente inaceptables. Por este motivo, prácticamente todos los sistemas de servidores modernos son máquinas NUMA.
- Topología de acceso no uniforme a la memoria (NUMA)
La topología NUMA se ha desarrollado más recientemente que la topología SMP. En un sistema NUMA, varios procesadores se agrupan físicamente en un socket. Cada zócalo tiene una zona de memoria dedicada y procesadores que tienen acceso local a esa memoria, a los que se denomina colectivamente nodo. Los procesadores de un mismo nodo tienen un acceso de alta velocidad al banco de memoria de ese nodo, y un acceso más lento a los bancos de memoria que no están en su nodo.
Por lo tanto, hay una penalización de rendimiento cuando se accede a la memoria no local. Así, las aplicaciones sensibles al rendimiento en un sistema con topología NUMA deberían acceder a la memoria que se encuentra en el mismo nodo que el procesador que ejecuta la aplicación, y deberían evitar acceder a la memoria remota siempre que sea posible.
Las aplicaciones multihilo que son sensibles al rendimiento pueden beneficiarse de ser configuradas para ejecutarse en un nodo NUMA específico en lugar de un procesador específico. La conveniencia de esto depende de su sistema y de los requisitos de su aplicación. Si varios subprocesos de la aplicación acceden a los mismos datos almacenados en caché, puede ser conveniente configurar esos subprocesos para que se ejecuten en el mismo procesador. Sin embargo, si varios subprocesos que acceden a datos diferentes y los almacenan en caché se ejecutan en el mismo procesador, cada subproceso puede desalojar los datos almacenados en caché a los que accedió un subproceso anterior. Esto significa que cada hilo "echa de menos" la caché y pierde tiempo de ejecución buscando datos de la memoria y reemplazándolos en la caché. Utilice la herramienta
perfpara comprobar si hay un número excesivo de pérdidas de caché.
20.2.2. Visualización de las topologías del sistema
Hay una serie de comandos que ayudan a entender la topología de un sistema. Este procedimiento describe cómo determinar la topología del sistema.
Procedimiento
Para mostrar una visión general de la topología de su sistema:
$ numactl --hardware available: 4 nodes (0-3) node 0 cpus: 0 4 8 12 16 20 24 28 32 36 node 0 size: 65415 MB node 0 free: 43971 MB [...]
Recoger la información sobre la arquitectura de la CPU, como el número de CPUs, hilos, núcleos, sockets y nodos NUMA:
$ lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 40 On-line CPU(s) list: 0-39 Thread(s) per core: 1 Core(s) per socket: 10 Socket(s): 4 NUMA node(s): 4 Vendor ID: GenuineIntel CPU family: 6 Model: 47 Model name: Intel(R) Xeon(R) CPU E7- 4870 @ 2.40GHz Stepping: 2 CPU MHz: 2394.204 BogoMIPS: 4787.85 Virtualization: VT-x L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 30720K NUMA node0 CPU(s): 0,4,8,12,16,20,24,28,32,36 NUMA node1 CPU(s): 2,6,10,14,18,22,26,30,34,38 NUMA node2 CPU(s): 1,5,9,13,17,21,25,29,33,37 NUMA node3 CPU(s): 3,7,11,15,19,23,27,31,35,39
Para ver una representación gráfica de su sistema:
# yum install hwloc-gui # lstopo
Figura 20.1. La salida
lstopo
Para ver el resultado textual detallado:
# yum install hwloc # lstopo-no-graphics Machine (15GB) Package L#0 + L3 L#0 (8192KB) L2 L#0 (256KB) + L1d L#0 (32KB) + L1i L#0 (32KB) + Core L#0 PU L#0 (P#0) PU L#1 (P#4) HostBridge L#0 PCI 8086:5917 GPU L#0 "renderD128" GPU L#1 "controlD64" GPU L#2 "card0" PCIBridge PCI 8086:24fd Net L#3 "wlp61s0" PCIBridge PCI 8086:f1a6 PCI 8086:15d7 Net L#4 "enp0s31f6"
Recursos adicionales
-
Para más información, consulte las páginas de manual
numactl,lscpu, ylstopo.
20.3. Ajuste de la política de programación
En Red Hat Enterprise Linux, la unidad más pequeña de ejecución de procesos se llama hilo. El programador del sistema determina qué procesador ejecuta un hilo y durante cuánto tiempo lo hace. Sin embargo, debido a que la principal preocupación del programador es mantener el sistema ocupado, puede que no programe los hilos de forma óptima para el rendimiento de la aplicación.
Por ejemplo, digamos que una aplicación en un sistema NUMA se está ejecutando en el Nodo A cuando un procesador en el Nodo B está disponible. Para mantener el procesador en el Nodo B ocupado, el programador mueve uno de los hilos de la aplicación al Nodo B. Sin embargo, el hilo de la aplicación sigue necesitando acceso a la memoria en el Nodo A. Pero, esta memoria tardará más en ser accedida porque el hilo se está ejecutando ahora en el Nodo B y la memoria del Nodo A ya no es local para el hilo. Por lo tanto, el hilo puede tardar más en terminar de ejecutarse en el Nodo B de lo que habría tardado en esperar a que un procesador en el Nodo A estuviera disponible, y luego ejecutar el hilo en el nodo original con acceso a la memoria local.
Las aplicaciones sensibles al rendimiento a menudo se benefician de que el diseñador o administrador determine dónde se ejecutan los hilos. El planificador de Linux implementa una serie de políticas de programación que determinan dónde y durante cuánto tiempo se ejecuta un hilo. Las siguientes son las dos categorías principales de políticas de programación:
- Políticas normales: Los hilos normales se utilizan para tareas de prioridad normal.
- Políticas en tiempo real: Las políticas de tiempo real se utilizan para tareas sensibles al tiempo que deben completarse sin interrupciones. Los subprocesos en tiempo real no están sujetos a cortes de tiempo. Esto significa que el hilo se ejecuta hasta que se bloquea, sale, cede voluntariamente o es adelantado por un hilo de mayor prioridad. El hilo en tiempo real de menor prioridad se programa antes que cualquier hilo con una política normal. Para más información, consulte Sección 20.3.1, “Programación de la prioridad estática con SCHED_FIFO” y Sección 20.3.2, “Programación prioritaria por turnos con SCHED_RR”.
20.3.1. Programación de la prioridad estática con SCHED_FIFO
La SCHED_FIFO, también llamada programación de prioridad estática, es una política en tiempo real que define una prioridad fija para cada hilo. Esta política permite a los administradores mejorar el tiempo de respuesta de los eventos y reducir la latencia. Se recomienda no ejecutar esta política durante un periodo de tiempo prolongado para tareas sensibles al tiempo.
Cuando SCHED_FIFO está en uso, el programador escanea la lista de todos los hilos de SCHED_FIFO en orden de prioridad y programa el hilo de mayor prioridad que esté listo para ejecutarse. El nivel de prioridad de un subproceso de SCHED_FIFO puede ser cualquier número entero entre 1 y 99, donde 99 se trata como la prioridad más alta. Red Hat recomienda comenzar con un número más bajo y aumentar la prioridad sólo cuando identifique problemas de latencia.
Debido a que los hilos en tiempo real no están sujetos a la división del tiempo, Red Hat no recomienda establecer una prioridad como 99. Esto mantiene su proceso en el mismo nivel de prioridad que los hilos de migración y de vigilancia; si su hilo entra en un bucle de cálculo y estos hilos se bloquean, no podrán ejecutarse. Los sistemas con un solo procesador acabarán colgándose en esta situación.
Los administradores pueden limitar el ancho de banda de SCHED_FIFO para evitar que los programadores de aplicaciones en tiempo real inicien tareas en tiempo real que acaparen el procesador.
Los siguientes son algunos de los parámetros utilizados en esta política:
/proc/sys/kernel/sched_rt_period_us-
Este parámetro define el periodo de tiempo, en microsegundos, que se considera el cien por cien del ancho de banda del procesador. El valor por defecto es
1000000 μs, o1 second. /proc/sys/kernel/sched_rt_runtime_us-
Este parámetro define el periodo de tiempo, en microsegundos, que se dedica a ejecutar hilos en tiempo real. El valor por defecto es
950000 μs, o0.95 seconds.
20.3.2. Programación prioritaria por turnos con SCHED_RR
La SCHED_RR es una variante round-robin de la SCHED_FIFO. Esta política es útil cuando varios hilos deben ejecutarse con el mismo nivel de prioridad.
Al igual que SCHED_FIFO, SCHED_RR es una política en tiempo real que define una prioridad fija para cada hilo. El programador escanea la lista de todos los hilos SCHED_RR en orden de prioridad y programa el hilo de mayor prioridad que esté listo para ejecutarse. Sin embargo, a diferencia de SCHED_FIFO, los hilos que tienen la misma prioridad se programan en un estilo round-robin dentro de una determinada franja de tiempo.
Puede establecer el valor de esta franja de tiempo en milisegundos con el parámetro del núcleo sched_rr_timeslice_ms en el archivo /proc/sys/kernel/sched_rr_timeslice_ms. El valor más bajo es 1 millisecond.
20.3.3. Programación normal con SCHED_OTHER
La SCHED_OTHER es la política de programación por defecto en Red Hat Enterprise Linux 8. Esta política utiliza el Programador Completamente Justo (CFS) para permitir un acceso justo al procesador a todos los hilos programados con esta política. Esta política es más útil cuando hay un gran número de hilos o cuando el rendimiento de los datos es una prioridad, ya que permite una programación más eficiente de los hilos en el tiempo.
Cuando esta política está en uso, el planificador crea una lista de prioridad dinámica basada en parte en el valor de amabilidad de cada proceso. Los administradores pueden cambiar el valor de amabilidad de un proceso, pero no pueden cambiar la lista de prioridad dinámica del planificador directamente.
20.3.4. Establecer las políticas del programador
Compruebe y ajuste las políticas y prioridades del programador utilizando la herramienta de línea de comandos chrt. Puede iniciar nuevos procesos con las propiedades deseadas, o cambiar las propiedades de un proceso en ejecución. También puede utilizarse para establecer la política en tiempo de ejecución.
Procedimiento
Ver el ID del proceso (PID) de los procesos activos:
# ps
Utilice la opción
--pido-pcon el comandopspara ver los detalles del PID en particular.Compruebe la política de programación, el PID y la prioridad de un proceso concreto:
# chrt -p 468 pid 468's current scheduling policy: SCHED_FIFO pid 468's current scheduling priority: 85 # chrt -p 476 pid 476's current scheduling policy: SCHED_OTHER pid 476's current scheduling priority: 0
Aquí, 468 y 476 son PID de un proceso.
Establecer la política de programación de un proceso:
Por ejemplo, para establecer el proceso con PID 1000 a SCHED_FIFO, con una prioridad de 50:
# chrt -f -p 50 1000Por ejemplo, para establecer el proceso con PID 1000 a SCHED_OTHER, con una prioridad de 0:
# chrt -o -p 0 1000Por ejemplo, para establecer el proceso con PID 1000 a SCHED_RR, con una prioridad de 10:
# chrt -r -p 10 1000Para iniciar una nueva aplicación con una política y una prioridad determinadas, especifique el nombre de la aplicación:
# chrt -f 36 /bin/my-app
Recursos adicionales
-
La página de manual
chrt. - Para más información sobre las opciones de política, véase Opciones de política para el comando chrt.
- Para obtener información sobre la configuración de la política de forma persistente, consulte Sección 20.3.6, “Cambiar la prioridad de los servicios durante el proceso de arranque”.
20.3.5. Opciones de política para el comando chrt
Para establecer la política de programación de un proceso, utilice la opción de comando apropiada:
Tabla 20.1. Opciones de política para el comando chrt
| Opción corta | Opción larga | Descripción |
|---|---|---|
|
|
|
Establecer el horario para |
|
|
|
Establecer el horario para |
|
|
|
Establecer el horario para |
20.3.6. Cambiar la prioridad de los servicios durante el proceso de arranque
Mediante el servicio systemd, es posible establecer prioridades en tiempo real para los servicios lanzados durante el proceso de arranque. El unit configuration directives se utiliza para cambiar la prioridad de un servicio durante el proceso de arranque.
El cambio de prioridad del proceso de arranque se realiza mediante las siguientes directivas en la sección de servicio:
CPUSchedulingPolicy=-
Establece la política de programación de la CPU para los procesos ejecutados. Se utiliza para establecer las políticas
other,fifo, yrr. CPUSchedulingPriority=-
Establece la prioridad de programación de la CPU para los procesos ejecutados. El rango de prioridad disponible depende de la política de programación de la CPU seleccionada. Para las políticas de programación en tiempo real, se puede utilizar un número entero entre
1(prioridad más baja) y99(prioridad más alta).
El siguiente procedimiento describe cómo cambiar la prioridad de un servicio, durante el proceso de arranque, utilizando el servicio mcelog.
Requisitos previos
Instale el paquete ajustado:
# yum install tuned
Habilite e inicie el servicio ajustado:
# systemctl enable --now tuned
Procedimiento
Ver las prioridades de programación de los hilos en ejecución:
# tuna --show_threads thread ctxt_switches pid SCHED_ rtpri affinity voluntary nonvoluntary cmd 1 OTHER 0 0xff 3181 292 systemd 2 OTHER 0 0xff 254 0 kthreadd 3 OTHER 0 0xff 2 0 rcu_gp 4 OTHER 0 0xff 2 0 rcu_par_gp 6 OTHER 0 0 9 0 kworker/0:0H-kblockd 7 OTHER 0 0xff 1301 1 kworker/u16:0-events_unbound 8 OTHER 0 0xff 2 0 mm_percpu_wq 9 OTHER 0 0 266 0 ksoftirqd/0 [...]Cree un archivo de directorio de configuración del servicio
mcelogsuplementario e inserte el nombre de la política y la prioridad en este archivo:# cat <<-EOF > /etc/systemd/system/mcelog.system.d/priority.conf > [SERVICE] CPUSchedulingPolicy=_fifo_ CPUSchedulingPriority=_20_ EOF
Recarga la configuración de los scripts de systemd:
# systemctl daemon-reload
Reinicie el servicio mcelog:
# systemctl restart mcelog
Pasos de verificación
Muestra la prioridad de
mcelogestablecida porsystemdissue:# tuna -t mcelog -P thread ctxt_switches pid SCHED_ rtpri affinity voluntary nonvoluntary cmd 826 FIFO 20 0,1,2,3 13 0 mcelog
Recursos adicionales
-
Para más información, consulte las páginas man de
systemdytuna. - Para más información sobre el rango de prioridad, véase Descripción del rango de prioridad.
20.3.7. Mapa de prioridades
Las prioridades se definen en grupos, con algunos grupos dedicados a determinadas funciones del núcleo.
Tabla 20.2. Descripción del rango de prioridad
| Prioridad | Hilos | Descripción |
|---|---|---|
| 1 | Hilos del núcleo de baja prioridad | Esta prioridad suele reservarse para las tareas que deben estar justo por encima de SCHED_OTHER. |
| 2 - 49 | Disponible para su uso | El rango utilizado para las prioridades típicas de la aplicación. |
| 50 | Valor de hard-IRQ por defecto | |
| 51 - 98 | Hilos de alta prioridad | Utilice este rango para hilos que se ejecutan periódicamente y deben tener tiempos de respuesta rápidos. No utilices este rango para hilos ligados a la CPU, ya que matarás de hambre a las interrupciones. |
| 99 | Perros guardianes y migración | Hilos del sistema que deben ejecutarse con la máxima prioridad. |
20.3.8. perfil de partición del ordenador
El perfil cpu-partitioning se utiliza para aislar las CPUs de las interrupciones a nivel de sistema. Una vez aisladas estas CPUs, se pueden asignar a aplicaciones específicas. Esto es muy útil en entornos de baja latencia o en entornos en los que se desea extraer el máximo rendimiento del hardware.
Este perfil también permite designar CPUs de mantenimiento. Una CPU de mantenimiento se utiliza para ejecutar todos los servicios, demonios, procesos de shell e hilos del kernel.
Puede configurar el perfil cpu-partitioning en el archivo /etc/tuned/cpu-partitioning-variables.conf utilizando las siguientes opciones de configuración:
isolated_cores=cpu-list- Enumera las CPUs a aislar. La lista de CPUs aisladas está separada por comas o se puede especificar un rango usando un guión, como 3-5. Esta opción es obligatoria. Cualquier CPU que falte en esta lista se considera automáticamente una CPU de mantenimiento.
no_balance_cores=cpu-list-
Enumera las CPUs que no son consideradas por el kernel durante el balanceo de carga de procesos en todo el sistema. Esta opción es opcional. Suele ser la misma lista que
isolated_cores.
20.3.9. Recursos adicionales
-
Para más información, consulte las páginas man de
sched,sched_setaffinity,sched_getaffinity,sched_setscheduler,sched_getscheduler,cpuset,tuna,chrt,systemdytuned-profiles-cpu-partitioning.
20.4. Configurar el tiempo de tic del kernel
Por defecto, Red Hat Enterprise Linux 8 utiliza un kernel sin tics, que no interrumpe las CPUs inactivas para reducir el uso de energía y permitir que los nuevos procesadores aprovechen los estados de sueño profundo.
Red Hat Enterprise Linux 8 también ofrece una opción de tickless dinámico, que es útil para cargas de trabajo sensibles a la latencia, como la computación de alto rendimiento o la computación en tiempo real. Por defecto, la opción de tickless dinámico está deshabilitada. Este procedimiento describe cómo habilitar de forma persistente el comportamiento dinámico sin tics.
Procedimiento
Para habilitar el comportamiento dinámico sin tics en ciertos núcleos, especifique esos núcleos en la línea de comandos del kernel con el parámetro
nohz_full. En un sistema de 16 núcleos, añada este parámetro en el archivo/etc/default/grub:nohz_full=1-15
Esto permite un comportamiento dinámico sin tics en los núcleos 1 a 15, trasladando todo el control del tiempo al único núcleo no especificado (núcleo 0).
Para habilitar de forma persistente el comportamiento dinámico "tickless", regenere la configuración de GRUB2 utilizando el archivo por defecto editado. En sistemas con firmware BIOS, ejecute el siguiente comando:
# grub2-mkconfig -o /etc/grub2.cfg
En sistemas con firmware UEFI, ejecute el siguiente comando:
# grub2-mkconfig -o /etc/grub2-efi.cfg
Cuando el sistema arranque, mueva manualmente los hilos de
rcual núcleo no sensible a la latencia, en este caso el núcleo 0:# for i in `pgrep rcu[^c]` ; do taskset -pc 0 $i ; done
-
Opcional: Utilice el parámetro
isolcpusen la línea de comandos del kernel para aislar ciertos núcleos de las tareas del espacio del usuario. Opcional: Establecer la afinidad de la CPU para los hilos del kernel
write-back bdi-flushal núcleo de mantenimiento de la casa:echo 1 > /sys/bus/workqueue/devices/writeback/cpumask
Pasos de verificación
Una vez reiniciado el sistema, verifique si
dynticksestá habilitado:# grep dynticks var/log/dmesg [ 0.000000] NO_HZ: Full dynticks CPUs: 2-5,8-11
Verifique que la configuración dinámica sin tics funciona correctamente:
# perf stat -C 1 -e irq_vectors:local_timer_entry taskset -c 1 stress -t 1 -c 1
Aquí,
stresses un programa que gira en la CPU para1 second.Un posible sustituto de
stresses un script que se ejecuta:while :; do d=1; done
La configuración por defecto del temporizador del kernel muestra 1000 ticks en una CPU ocupada:
# perf stat -C 1 -e irq_vectors:local_timer_entry taskset -c 1 stress -t 1 -c 1 1000 irq_vectors:local_timer_entry
Con el núcleo dinámico sin tics configurado, debería ver 1 tic en su lugar:
# perf stat -C 1 -e irq_vectors:local_timer_entry taskset -c 1 stress -t 1 -c 1 1 irq_vectors:local_timer_entry
Recursos adicionales
-
Para más información, consulte las páginas man de
perfycpuset. - Todo sobre el parámetro de kernel nohz_full Artículo de la base de conocimientos de Red Hat.
- ¿Cómo verificar la lista de "aislados" y "nohz_full"? De la CPU desde sysfs? Artículo de la base de conocimientos de Red Hat.
20.5. Configuración de los sistemas de afinidad de las interrupciones
Una solicitud de interrupción o IRQ es una señal de atención inmediata enviada desde un elemento de hardware a un procesador. A cada dispositivo de un sistema se le asignan uno o más números de IRQ que le permiten enviar interrupciones únicas. Cuando las interrupciones están habilitadas, un procesador que recibe una solicitud de interrupción pausa inmediatamente la ejecución del hilo de aplicación actual para atender la solicitud de interrupción.
Debido a que las interrupciones detienen el funcionamiento normal, las altas tasas de interrupción pueden degradar gravemente el rendimiento del sistema. Es posible reducir el tiempo que tardan las interrupciones configurando la afinidad de las mismas o enviando un número de interrupciones de menor prioridad en un lote (coalescencia de varias interrupciones).
Las solicitudes de interrupción tienen una propiedad de afinidad asociada, smp_affinity, que define los procesadores que manejan la solicitud de interrupción. Para mejorar el rendimiento de la aplicación, asigne la afinidad de la interrupción y la afinidad del proceso al mismo procesador, o a los procesadores del mismo núcleo. Esto permite que los hilos de interrupción y de aplicación especificados compartan líneas de caché.
En los sistemas que soportan la dirección de las interrupciones, la modificación de la propiedad smp_affinity de una solicitud de interrupción configura el hardware de manera que la decisión de atender una interrupción con un procesador en particular se hace a nivel de hardware sin intervención del kernel.
20.5.1. Equilibrar manualmente las interrupciones
Si su BIOS exporta su topología NUMA, el servicio irqbalance puede servir automáticamente las solicitudes de interrupción en el nodo que es local al hardware que solicita el servicio.
Procedimiento
- Compruebe qué dispositivos corresponden a las solicitudes de interrupción que desea configurar.
Busca las especificaciones de hardware de tu plataforma. Comprueba si el chipset de tu sistema soporta la distribución de interrupciones.
- Si lo hace, puede configurar la entrega de interrupciones como se describe en los siguientes pasos. Además, comprueba qué algoritmo utiliza tu chipset para equilibrar las interrupciones. Algunas BIOS tienen opciones para configurar la entrega de interrupciones.
- Si no lo hace, el chipset siempre dirige todas las interrupciones a una única CPU estática. No se puede configurar qué CPU se utiliza.
Compruebe qué modo de controlador de interrupción programable avanzado (APIC) está en uso en su sistema:
$ journalctl --dmesg | grep APIC
Aquí,
-
Si su sistema utiliza un modo distinto a
flat, puede ver una línea similar aSetting APIC routing to physical flat. Si no ve este mensaje, su sistema utiliza el modo
flat.Si su sistema utiliza el modo
x2apic, puede desactivarlo añadiendo la opciónnox2apica la línea de comandos del kernel en la configuraciónbootloader.Sólo el modo plano no físico (
flat) soporta la distribución de interrupciones a múltiples CPUs. Este modo está disponible sólo para sistemas que tienen hasta 8 CPUs.
-
Si su sistema utiliza un modo distinto a
-
Calcule el
smp_affinity mask. Para más información sobre cómo calcular elsmp_affinity mask, véase Sección 20.5.2, “Configuración de la máscara smp_affinity”.
20.5.2. Configuración de la máscara smp_affinity
El valor de smp_affinity se almacena como una máscara de bits hexadecimal que representa a todos los procesadores del sistema. Cada bit configura una CPU diferente. El bit menos significativo es la CPU 0. El valor por defecto de la máscara es f, lo que significa que una petición de interrupción puede ser manejada en cualquier procesador del sistema. Poner este valor a 1 significa que sólo el procesador 0 puede manejar la interrupción.
Procedimiento
En binario, utilice el valor 1 para las CPUs que manejan las interrupciones. Por ejemplo, para que la CPU 0 y la CPU 7 manejen las interrupciones, utilice
0000000010000001como código binario:Tabla 20.3. Bits binarios para CPUs
CPU 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 Binario
0
0
0
0
0
0
0
0
1
0
0
0
0
0
0
1
Convierte el código binario a hexadecimal:
Por ejemplo, para convertir el código binario utilizando Python:
>>> hex(int('0000000010000001', 2)) '0x81'En sistemas con más de 32 procesadores, debe delimitar los valores de
smp_affinitypara grupos discretos de 32 bits. Por ejemplo, si desea que sólo los primeros 32 procesadores de un sistema de 64 procesadores atiendan una solicitud de interrupción, utilice0xffffffff,00000000.El valor de afinidad de la interrupción para una solicitud de interrupción particular se almacena en el archivo asociado
/proc/irq/irq_number/smp_affinity. Establezca la máscarasmp_affinityen este archivo:# echo mask > /proc/irq/irq_number/smp_affinity
20.5.3. Recursos adicionales
-
Para más información, consulte las páginas man de
irqbalance,journalctl, ytaskset.
Capítulo 21. Configuración de RHEL para optimizar el acceso a los recursos de red
Esta sección describe cómo configurar RHEL para que presente un acceso optimizado a los recursos de red en sus cargas de trabajo. Los problemas de rendimiento de la red son a veces el resultado de un mal funcionamiento del hardware o de una infraestructura defectuosa. Resolver estos problemas está fuera del alcance de este documento. El servicio Tuned proporciona una serie de perfiles diferentes para mejorar el rendimiento en una serie de casos de uso específicos:
-
latency-performance -
network-latency -
network-throughput
21.1. Herramientas para supervisar y diagnosticar problemas de rendimiento
Las siguientes son las herramientas disponibles en Red Hat Enterprise Linux 8, que se utilizan para supervisar el rendimiento del sistema y diagnosticar problemas de rendimiento relacionados con el subsistema de red:
-
sses una utilidad de línea de comandos. Imprime información estadística sobre los sockets y permite a los administradores evaluar el rendimiento del dispositivo a lo largo del tiempo. Por defecto,ssmuestra los sockets TCP abiertos que no están a la escucha y que han establecido conexiones. Utilizando las opciones de la línea de comandos, los administradores pueden filtrar las estadísticas sobre sockets específicos. Red Hat recomiendasssobre el obsoletonetstaten Red Hat Enterprise Linux -
la utilidad
ippermite a los administradores gestionar y supervisar rutas, dispositivos, políticas de enrutamiento y túneles. El comandoipmonitor puede supervisar continuamente el estado de los dispositivos, las direcciones y las rutas. Utilice la opción-jpara mostrar la salida en formato JSON, que se puede proporcionar a otras utilidades para automatizar el procesamiento de la información. -
dropwatches una herramienta interactiva, proporcionada por el paquetedropwatch. Supervisa y registra los paquetes que el kernel abandona. -
ethtooles una utilidad que permite a los administradores ver y editar la configuración de las tarjetas de interfaz de red. Utilice esta herramienta para observar las estadísticas, como el número de paquetes perdidos por ese dispositivo, de ciertos dispositivos. Mediante el comandoethtool -S device namecomando, vea el estado de los contadores de un dispositivo específico del dispositivo que desea supervisar. -
El archivo
/proc/net/snmpmuestra los datos que el agentesnmputiliza para la supervisión y gestión de IP, ICMP, TCP y UDP. Examinar este archivo de forma regular ayuda a los administradores a identificar valores inusuales y, por tanto, a identificar posibles problemas de rendimiento. Por ejemplo, un aumento de los errores de entrada UDP (InErrors) en el archivo/proc/net/snmppuede indicar un cuello de botella en la cola de recepción de un socket. -
nstates una herramienta de línea de comandos que monitoriza las estadísticas del kernel SNMP y de la interfaz de red. Esta herramienta lee los datos del archivo/proc/net/snmpe imprime la información en un formato legible para el ser humano. Por defecto, los scripts de
SystemTap, proporcionados por el paquete systemtap-client se instalan en el directorio/usr/share/systemtap/examples/network:-
nettop.stp: Cada 5 segundos, el script muestra una lista de procesos (identificador de proceso y comando) con el número de paquetes enviados y recibidos y la cantidad de datos enviados y recibidos por el proceso durante ese intervalo. -
socket-trace.stp: Instrumenta cada una de las funciones en el archivonet/socket.cdel kernel de Linux, y muestra los datos de rastreo. -
dropwatch.stp: Cada 5 segundos, el script muestra el número de búferes de socket liberados en ubicaciones del kernel. Utilice la opción--all-modulespara ver los nombres simbólicos. -
latencytap.stp: Este script registra el efecto que tienen los diferentes tipos de latencia en uno o más procesos. Imprime una lista de tipos de latencia cada 30 segundos, ordenada en forma descendente por el tiempo total que el proceso o procesos pasaron esperando. Esto puede ser útil para identificar la causa de la latencia del almacenamiento y de la red.
Red Hat recomienda utilizar la opción
--all-modulescon este script para permitir mejor la asignación de eventos de latencia. Por defecto, este script se instala en el directorio/usr/share/systemtap/examples/profiling.-
-
BPF Compiler Collection (BCC) es una biblioteca que facilita la creación de los programas Berkeley Packet Filter extendidos (
eBPF). La principal utilidad de los programas deeBPFes analizar el rendimiento del sistema operativo y el rendimiento de la red sin experimentar problemas de sobrecarga o seguridad.
Recursos adicionales
-
Para más información, consulte las páginas de manual
ss,ethtool,nettop,ip,dropwatchySystemTap. -
El directorio
/usr/share/systemtap/examples/network. -
Para obtener más información sobre la CCC, consulte el archivo
/usr/share/doc/bcc/README.md, que proporciona el sitio webbcc package. - ¿Cómo escribir un script despachador de NetworkManager para aplicar los comandos de ethtool? Solución Red Hat Knowlegebase.
- Configuración de las funciones de descarga de ethtool mediante la secciónNetworkManager.
21.2. Cuellos de botella en la recepción de paquetes
Aunque la pila de red se autooptimiza en gran medida, hay una serie de puntos durante el procesamiento de paquetes de red que pueden convertirse en cuellos de botella y reducir el rendimiento. A continuación se detallan los problemas que pueden provocar cuellos de botella:
The buffer or ring buffer of the network card-
El buffer de hardware puede ser un cuello de botella si el kernel deja caer un gran número de paquetes. Utiliza la utilidad
ethtoolpara monitorizar un sistema en busca de paquetes perdidos. The hardware or software interrupt queues- Las interrupciones pueden aumentar la latencia y la contención del procesador. Para obtener información sobre cómo el procesador maneja las interrupciones, consulte Configuración de sistemas de afinidad de interrupciones.
The socket receive queue of the application-
Un gran número de paquetes que no se copian o por un aumento de los errores de entrada UDP (
InErrors) en el archivo/proc/net/snmp, indica un cuello de botella en la cola de recepción de una aplicación.
Si el búfer del hardware deja caer un gran número de paquetes, las siguientes son las posibles soluciones:
Slow the input traffic- Filtrar el tráfico entrante, reducir el número de grupos de multidifusión unidos o reducir la cantidad de tráfico de difusión para disminuir la velocidad de llenado de la cola.
Resize the hardware buffer queueRedimensionar la cola del buffer de hardware: Reduzca el número de paquetes que se pierden aumentando el tamaño de la cola para que no se desborde tan fácilmente. Puedes modificar los parámetros de
rx/txdel dispositivo de red con el comandoethtool:ethtool --set-ring device-name valueChange the drain rate of the queueDisminuya la velocidad de llenado de la cola filtrando o descartando paquetes antes de que lleguen a la cola, o disminuyendo el peso del dispositivo. Filtra el tráfico entrante o baja el peso del dispositivo de la tarjeta de interfaz de red para ralentizar el tráfico entrante.
El peso del dispositivo se refiere al número de paquetes que un dispositivo puede recibir a la vez en un solo acceso programado del procesador. Se puede aumentar la velocidad de vaciado de una cola incrementando su peso de dispositivo que está controlado por el parámetro del kernel
dev_weight. Para alterar temporalmente este parámetro, cambie el contenido del archivo/proc/sys/net/core/dev_weight, o para alterarlo permanentemente, utilice el comandosysctl, que es proporcionado por el paqueteprocps-ng.Aumentar la longitud de la cola de sockets de la aplicación: Esta suele ser la forma más fácil de mejorar la tasa de drenaje de una cola de sockets, pero es poco probable que sea una solución a largo plazo. Si una cola de sockets recibe una cantidad limitada de tráfico en ráfagas, aumentar la profundidad de la cola de sockets para que coincida con el tamaño de las ráfagas de tráfico puede evitar que se pierdan paquetes. Para aumentar la profundidad de una cola, aumenta el tamaño del buffer de recepción del socket haciendo cualquiera de los siguientes cambios:
-
Aumenta el valor del parámetro
/proc/sys/net/core/rmem_default: Este parámetro controla el tamaño por defecto del buffer de recepción utilizado por los sockets. Este valor debe ser menor o igual que el valor del parámetroproc/sys/net/core/rmem_max. -
Utilice
setsockoptpara configurar un valor mayor deSO_RCVBUF: Este parámetro controla el tamaño máximo en bytes del buffer de recepción de un socket. Utilice la llamada al sistemagetsockoptpara determinar el valor actual del búfer.
-
Aumenta el valor del parámetro
Alterar la tasa de drenaje de una cola suele ser la forma más sencilla de mitigar el bajo rendimiento de la red. Sin embargo, aumentar el número de paquetes que un dispositivo puede recibir a la vez utiliza tiempo adicional del procesador, durante el cual no se pueden programar otros procesos, por lo que esto puede causar otros problemas de rendimiento.
Recursos adicionales
-
Para más información, consulte las páginas de manual
ss,socket, yethtool. -
El archivo
/proc/net/snmp.
21.3. Configurar el sondeo de ocupado
Si el análisis revela una alta latencia, su sistema puede beneficiarse de la recepción de paquetes basada en el sondeo en lugar de en la interrupción.
El sondeo ocupado ayuda a reducir la latencia en la ruta de recepción de la red al permitir que el código de la capa de socket sondee la cola de recepción de un dispositivo de red, y desactiva las interrupciones de la red. Esto elimina los retrasos causados por la interrupción y el cambio de contexto resultante. Sin embargo, también aumenta la utilización de la CPU. El sondeo ocupado también evita que la CPU entre en reposo, lo que puede suponer un consumo adicional de energía. El comportamiento de sondeo ocupado es soportado por todos los controladores de dispositivos.
21.3.1. Habilitación del sondeo ocupado
Por defecto, el sondeo de ocupado está desactivado. Este procedimiento describe cómo habilitar el sondeo de ocupado.
Procedimiento
Asegúrese de que la opción de compilación CONFIG_NET_RX_BUSY_POLL está activada:
# cat /boot/config-$(uname -r) | grep CONFIG_NET_RX_BUSY_POLL CONFIG_NET_RX_BUSY_POLL=y
Habilitar el sondeo de ocupado
Para habilitar el sondeo de ocupado en sockets específicos, establezca el valor del kernel
sysctl.net.core.busy_polla un valor distinto de0:# echo "net.core.busy_poll=50" > /etc/sysctl.d/95-enable-busy-polling-for-sockets.conf # sysctl -p /etc/sysctl.d/95-enable-busy-polling-for-sockets.conf
Este parámetro controla el número de microsegundos de espera de los paquetes en el sondeo del socket y selecciona
syscalls. Red Hat recomienda un valor de50.-
Añade la opción de enchufe
SO_BUSY_POLLal enchufe. Para habilitar el sondeo de ocupado de forma global, establezca en
sysctl.net.core.busy_readun valor distinto de0:# echo "net.core.busy_read=50" > /etc/sysctl.d/95-enable-busy-polling-globally.conf # sysctl -p /etc/sysctl.d/95-enable-busy-polling-globally.conf
El parámetro
net.core.busy_readcontrola el número de microsegundos de espera de los paquetes en la cola del dispositivo para las lecturas de socket. También establece el valor por defecto deSO_BUSY_POLL option. Red Hat recomienda un valor de50para un pequeño número de sockets y un valor de100para un gran número de sockets. Para números extremadamente grandes de sockets, por ejemplo más de varios cientos, utilice la llamada al sistemaepollen su lugar.
Pasos de verificación
Verificar si el sondeo de ocupación está activado
# ethtool -k device | grep "busy-poll" busy-poll: on [fixed] # cat /proc/sys/net/core/busy_read 50
Recursos adicionales
-
Para más información, consulte las páginas de manual
ethtool,socket,sysctl, ysysctl.conf. - Configuración de las funciones de descarga de ethtool mediante la secciónNetworkManager.
21.4. Escalado del lado de la recepción
El Receive-Side Scaling (RSS), también conocido como recepción multicola, distribuye el procesamiento de la recepción de la red entre varias colas de recepción basadas en hardware, lo que permite que el tráfico de red entrante sea procesado por varias CPU. El RSS puede utilizarse para aliviar los cuellos de botella en el procesamiento de las interrupciones de recepción causados por la sobrecarga de una sola CPU, y para reducir la latencia de la red. Por defecto, el RSS está activado.
El número de colas o las CPUs que deben procesar la actividad de la red para el RSS se configuran en el controlador del dispositivo de red correspondiente:
-
Para el controlador
bnx2x, se configura en el parámetronum_queues. -
Para el controlador
sfc, se configura en el parámetrorss_cpus.
En cualquier caso, se suele configurar en el directorio /sys/class/net/device/queues/rx-queue/ donde device es el nombre del dispositivo de red (como enp1s0) y rx-queue es el nombre de la cola de recepción correspondiente.
El demonio irqbalance puede utilizarse junto con RSS para reducir la probabilidad de transferencias de memoria entre nodos y el rebote de líneas de caché. Esto disminuye la latencia del procesamiento de paquetes de red.
21.4.1. Visualización de las colas de peticiones de interrupción
Al configurar el RSS, Red Hat recomienda limitar el número de colas a una por núcleo físico de CPU. Los hiperhilos suelen representarse como núcleos separados en las herramientas de análisis, pero la configuración de colas para todos los núcleos, incluidos los núcleos lógicos como los hiperhilos, no ha demostrado ser beneficiosa para el rendimiento de la red.
Cuando está activado, el RSS distribuye el procesamiento de red de forma equitativa entre las CPUs disponibles, basándose en la cantidad de procesamiento que cada CPU tiene en cola. Sin embargo, utilice los parámetros --show-rxfh-indir y --set-rxfh-indir de la utilidad ethtool, para modificar la forma en que RHEL distribuye la actividad de red, y ponderar ciertos tipos de actividad de red como más importantes que otros.
Este procedimiento describe cómo ver las colas de peticiones de interrupción.
Procedimiento
Para determinar si su tarjeta de interfaz de red es compatible con RSS, compruebe si hay varias colas de solicitud de interrupción asociadas a la interfaz en
/proc/interrupts:# egrep 'CPU|p1p1' /proc/interrupts CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 89: 40187 0 0 0 0 0 IR-PCI-MSI-edge p1p1-0 90: 0 790 0 0 0 0 IR-PCI-MSI-edge p1p1-1 91: 0 0 959 0 0 0 IR-PCI-MSI-edge p1p1-2 92: 0 0 0 3310 0 0 IR-PCI-MSI-edge p1p1-3 93: 0 0 0 0 622 0 IR-PCI-MSI-edge p1p1-4 94: 0 0 0 0 0 2475 IR-PCI-MSI-edge p1p1-5
La salida muestra que el controlador NIC creó 6 colas de recepción para la interfaz
p1p1(p1p1-0hastap1p1-5). También muestra cuántas interrupciones fueron procesadas por cada cola, y qué CPU atendió la interrupción. En este caso, hay 6 colas porque por defecto, este controlador NIC en particular crea una cola por CPU, y este sistema tiene 6 CPUs. Este es un patrón bastante común entre los controladores NIC.Para listar la cola de peticiones de interrupción de un dispositivo PCI con la dirección
0000:01:00.0:# ls -1 /sys/devices/*/*/0000:01:00.0/msi_irqs 101 102 103 104 105 106 107 108 109
21.5. Recibir dirección de paquetes
El Receive Packet Steering (RPS) es similar al RSS en el sentido de que se utiliza para dirigir los paquetes a CPUs específicas para su procesamiento. Sin embargo, el RPS se implementa a nivel de software y ayuda a evitar que la cola de hardware de una única tarjeta de interfaz de red se convierta en un cuello de botella en el tráfico de la red. El RPS tiene varias ventajas sobre el RSS basado en hardware:
- El RPS puede utilizarse con cualquier tarjeta de interfaz de red.
- Es fácil añadir filtros de software a RPS para hacer frente a nuevos protocolos.
- RPS no aumenta la tasa de interrupciones de hardware del dispositivo de red. Sin embargo, sí introduce interrupciones entre procesadores.
El RPS se configura por dispositivo de red y cola de recepción, en el archivo /sys/class/net/device/queues/rx-queue/rps_cpus donde device es el nombre del dispositivo de red, como enp1s0 y rx-queue es el nombre de la cola de recepción apropiada, como rx-0.
El valor por defecto del archivo rps_cpus es 0. Esto desactiva el RPS, y la CPU maneja la interrupción de la red y también procesa el paquete. Para habilitar RPS, configure el archivo rps_cpus apropiado con las CPUs que deben procesar los paquetes del dispositivo de red especificado y la cola de recepción.
Los archivos rps_cpus utilizan mapas de bits de CPU delimitados por comas. Por lo tanto, para permitir que una CPU maneje las interrupciones de la cola de recepción en una interfaz, establezca el valor de sus posiciones en el mapa de bits en 1. Por ejemplo, para manejar las interrupciones con las CPUs 0, 1, 2, y 3, configure el valor de rps_cpus a f, que es el valor hexadecimal de 15. En representación binaria, 15 es 00001111 (1 2 4 8).
En el caso de los dispositivos de red con colas de transmisión únicas, el mejor rendimiento se puede conseguir configurando el RPS para que utilice las CPU en el mismo dominio de memoria. En los sistemas que no son NUMA, esto significa que se pueden utilizar todas las CPUs disponibles. Si la tasa de interrupción de la red es extremadamente alta, excluir la CPU que maneja las interrupciones de la red también puede mejorar el rendimiento.
Para los dispositivos de red con múltiples colas, no suele ser beneficioso configurar tanto RPS como RSS, ya que RSS está configurado para asignar una CPU a cada cola de recepción por defecto. Sin embargo, RPS puede seguir siendo beneficioso si hay menos colas de hardware que CPUs, y RPS está configurado para usar CPUs en el mismo dominio de memoria.
21.6. Dirección de flujo de recepción
Receive Flow Steering (RFS) amplía el comportamiento de RPS para aumentar la tasa de aciertos de la caché de la CPU y reducir así la latencia de la red. Mientras que RPS reenvía los paquetes basándose únicamente en la longitud de la cola, RFS utiliza el back-end de RPS para calcular la CPU más adecuada y, a continuación, reenvía los paquetes basándose en la ubicación de la aplicación que los consume. Esto aumenta la eficiencia de la caché de la CPU.
Los datos recibidos de un solo emisor no se envían a más de una CPU. Si la cantidad de datos recibidos de un solo emisor es mayor que la que puede manejar una sola CPU, configure un tamaño de trama mayor para reducir el número de interrupciones y, por tanto, la cantidad de trabajo de procesamiento para la CPU. Como alternativa, considere las opciones de descarga de NIC o CPUs más rápidas.
Considere la posibilidad de utilizar numactl o taskset junto con RFS para asignar aplicaciones a núcleos, sockets o nodos NUMA específicos. Esto puede ayudar a evitar que los paquetes se procesen fuera de orden.
21.6.1. Activación de la dirección del flujo de recepción
Por defecto, la dirección de flujo de recepción (RFS) está desactivada. Este procedimiento describe cómo habilitar el RFS.
Procedimiento
Establezca el valor del núcleo
net.core.rps_sock_flow_entriesal número máximo esperado de conexiones activas simultáneas:# echo \ "net.core.rps_sock_flow_entries=32768" > /etc/sysctl.d/95-enable-rps.conf
Red Hat recomienda un valor de
32768para cargas de servidor moderadas. Todos los valores introducidos se redondean a la potencia más cercana de2en la práctica.Establece de forma persistente el valor de la
net.core.rps_sock_flow_entries:# sysctl -p /etc/sysctl.d/95-enable-rps.conf
Para establecer temporalmente el valor del
sys/class/net/device/queues/rx-queue/rps_flow_cntal valor del archivo (rps_sock_flow_entries/N), donde N es el número de colas de recepción de un dispositivo:# echo 2048 > /sys/class/net/device/queues/rx-queue/rps_flow_cnt
Sustituya device por el nombre del dispositivo de red que desea configurar (por ejemplo, enp1s0), y rx-queue por la cola de recepción que desea configurar (por ejemplo, rx-0). Sustituya N por el número de colas de recepción configuradas. Por ejemplo, si el
rps_flow_entriesestá configurado como32768y hay16colas de recepción configuradas, elrps_flow_cnt = 32786/16= 2048(es decir,rps_flow_cnt = rps_flow_enties/N).Para los dispositivos de cola única, el valor de
rps_flow_cntes el mismo que el derps_sock_flow_entries.Habilite de forma persistente la RFS en todos los dispositivos de red, cree el archivo
/etc/udev/rules.d/99-persistent-net.rulesy añada el siguiente contenido:SUBSYSTEM=="net", ACTION=="add", RUN{program}+="/bin/bash -c 'for x in /sys/$DEVPATH/queues/rx-*; do echo 2048 > $x/rps_flow_cnt; done'"Opcional: Para activar el RPS en un dispositivo de red específico:
SUBSYSTEM=="net", ACTION=="move", NAME="device name" RUN{program} ="/bin/bash -c 'for x in /sys/$DEVPATH/queues/rx-*; do echo 2048 > $x/rps_flow_cnt; done'"Sustituya device name por el nombre real del dispositivo de red.
Pasos de verificación
Compruebe si la RFS está activada:
# cat /proc/sys/net/core/rps_sock_flow_entries 32768 # cat /sys/class/net/device/queues/rx-queue/rps_flow_cnt 2048
Recursos adicionales
-
Para más información, consulte la página de manual
sysctl.
21.7. RFS acelerado
El RFS acelerado aumenta la velocidad del RFS añadiendo asistencia de hardware. Al igual que la RFS, los paquetes se reenvían en función de la ubicación de la aplicación que los consume. Sin embargo, a diferencia del RFS tradicional, los paquetes se envían directamente a una CPU que es local al hilo que consume los datos:
- ya sea la CPU que está ejecutando la aplicación
- o una CPU local a esa CPU en la jerarquía de la caché
El RFS acelerado sólo está disponible si se cumplen las siguientes condiciones:
-
La NIC debe soportar el RFS acelerado. La RFS acelerada es compatible con las tarjetas que exportan la función
ndo_rx_flow_steer()net_device. Compruebe la hoja de datos de la NIC para asegurarse de que esta función es compatible. -
ntupledebe estar habilitado. Para obtener información sobre cómo habilitar estos filtros, consulte Sección 21.7.1, “Habilitación de los filtros de ntuple”.
Una vez que se cumplen estas condiciones, la asignación de la CPU a la cola se deduce automáticamente basándose en la configuración tradicional del RFS. Es decir, la asignación de la CPU a la cola se deduce en base a las afinidades IRQ configuradas por el controlador para cada cola de recepción. Para más información sobre la activación del RFS tradicional, consulte Sección 21.6.1, “Activación de la dirección del flujo de recepción”.
21.7.1. Habilitación de los filtros de ntuple
Utilice el comando ethtool -k para comprobar si los filtros de ntuple están activados.
Procedimiento
Muestra el estado actual del filtro
ntuple:# ethtool -k enp1s0 | grep ntuple-filters ntuple-filters: offHabilite los filtros de
ntuple:# ethtool -k enp1s0 ntuple on
Si la salida es ntuple-filters: off [fixed], el filtrado ntuple está desactivado y no se puede configurar:
# ethtool -k enp1s0 | grep ntuple-filters
ntuple-filters: off [fixed]Pasos de verificación
Asegúrese de que los filtros de
ntupleestán activados:# ethtool -k enp1s0 | grep ntuple-filters ntuple-filters: on
Recursos adicionales
-
Para más información, consulte la página de manual
ethtool.
Capítulo 22. Configurar un sistema operativo para optimizar el acceso a la memoria
Esta sección describe cómo configurar el sistema operativo para optimizar el acceso a la memoria entre las cargas de trabajo, y las herramientas que puede utilizar para hacerlo.
22.1. Herramientas para supervisar y diagnosticar problemas de memoria del sistema
Las siguientes herramientas están disponibles en Red Hat Enterprise Linux 8 para supervisar el rendimiento del sistema y diagnosticar problemas de rendimiento relacionados con la memoria del sistema:
-
vmstatherramienta, proporcionada por el paqueteprocps-ng, muestra informes de los procesos de un sistema, la memoria, la paginación, la E/S en bloque, las trampas, los discos y la actividad de la CPU. Proporciona un informe instantáneo del promedio de estos eventos desde que la máquina se encendió por última vez, o desde el informe anterior. valgrindes un framework que proporciona instrumentación a los binarios del espacio de usuario. Instale esta herramienta, utilizando el comandoyum install valgrind. Incluye una serie de herramientas, que puede utilizar para perfilar y analizar el rendimiento del programa, tales como:la opción
memcheckes la herramienta por defectovalgrind. Detecta e informa sobre una serie de errores de memoria que pueden ser difíciles de detectar y diagnosticar, como:- Acceso a la memoria que no debería producirse
- Uso de valores no definidos o no inicializados
- Memoria heap liberada incorrectamente
- Superposición de punteros
Fugas de memoria
NotaMemcheck sólo puede informar de estos errores, no puede evitar que se produzcan. Sin embargo,
memcheckregistra un mensaje de error inmediatamente antes de que se produzca el error.
-
cachegrindopción simula la interacción de la aplicación con la jerarquía de caché del sistema y el predictor de bifurcaciones. Recoge estadísticas durante la ejecución de la aplicación y muestra un resumen en la consola. -
massifmide el espacio del montón utilizado por una aplicación específica. Mide tanto el espacio útil como cualquier espacio adicional asignado para propósitos de contabilidad y alineación.
Recursos adicionales
-
Para más información, consulte la página de manual
vmstatyvalgrind. -
Para más información sobre el marco
valgrind, consulte el archivo/usr/share/doc/valgrind-version/valgrind_manual.pdf.
22.2. Resumen de la memoria de un sistema
El Kernel de Linux está diseñado para maximizar la utilización de los recursos de memoria del sistema (RAM). Debido a estas características de diseño, y dependiendo de los requerimientos de memoria de la carga de trabajo, parte de la memoria del sistema está en uso dentro del núcleo en nombre de la carga de trabajo, mientras que una pequeña parte de la memoria está libre. Esta memoria libre se reserva para asignaciones especiales del sistema, y para otros servicios del sistema de baja o alta prioridad. El resto de la memoria del sistema se dedica a la carga de trabajo en sí, y se divide en las dos categorías siguientes:
File memoryLas páginas añadidas en esta categoría representan partes de archivos en almacenamiento permanente. Estas páginas, desde la caché de páginas, pueden ser mapeadas o desmapeadas en los espacios de direcciones de una aplicación. Las aplicaciones pueden mapear archivos en su espacio de direcciones utilizando las llamadas al sistema
mmap, o bien operar sobre los archivos a través de las llamadas al sistema de lectura o escritura de E/S en buffer.Las llamadas al sistema de E/S con búfer, así como las aplicaciones que mapean páginas directamente, pueden reutilizar páginas no mapeadas. En consecuencia, el núcleo almacena estas páginas en la caché, especialmente cuando el sistema no está ejecutando ninguna tarea de uso intensivo de memoria, para evitar volver a realizar costosas operaciones de E/S sobre el mismo conjunto de páginas.
Anonymous memory- Las páginas de esta categoría están en uso por un proceso asignado dinámicamente, o no están relacionadas con archivos en almacenamiento permanente. Este conjunto de páginas respalda las estructuras de control en memoria de cada tarea, como la pila de la aplicación y las áreas del montón.
Figura 22.1. Patrones de uso de la memoria
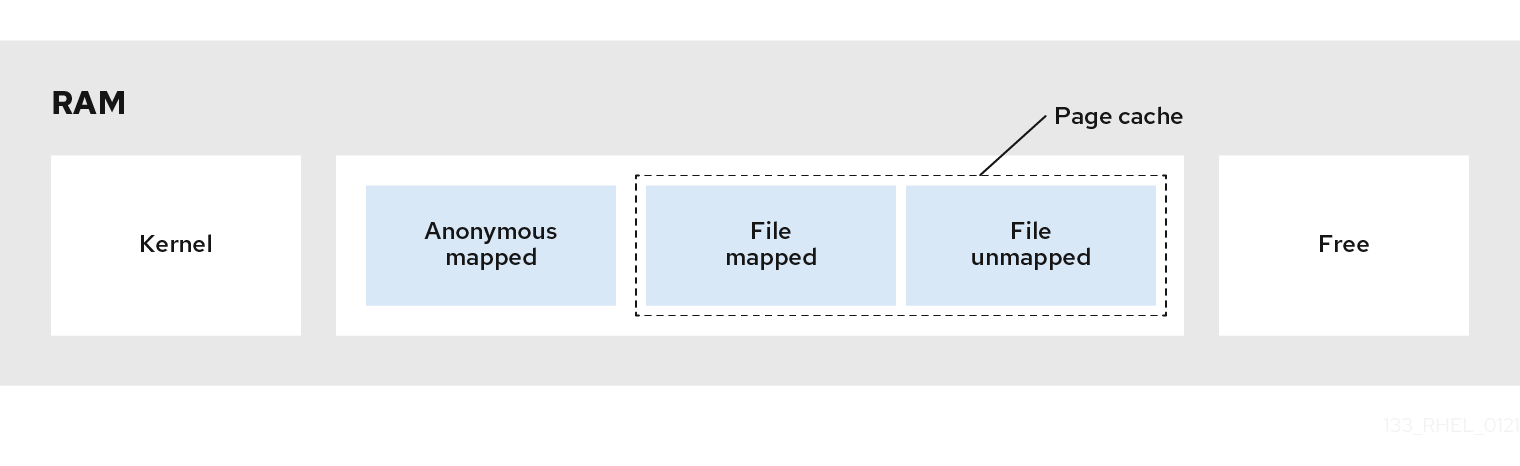
22.3. Optimización de la utilización de la memoria de un sistema
Esta sección proporciona información sobre los parámetros del kernel relacionados con la memoria y cómo puede utilizarlos para mejorar la utilización de la memoria del sistema. Los siguientes son los parámetros del kernel relacionados con la memoria disponibles en Red Hat Enterprise Linux 8:
- Parámetro de memoria virtual. Para más información, consulte Sección 22.3.1, “Parámetros de la memoria virtual”.
- Parámetro del sistema de archivos. Para más información, consulte Sección 22.3.2, “Parámetros del sistema de archivos”.
- Parámetro del núcleo. Para más información, consulte Sección 22.3.3, “Parámetros del núcleo”.
22.3.1. Parámetros de la memoria virtual
Los parámetros de la memoria virtual se encuentran en el directorio /proc/sys/vm a menos que se indique lo contrario.
Los siguientes son los parámetros de memoria virtual disponibles:
vm.dirty_ratio-
Es un valor porcentual. Cuando se modifica este porcentaje de la memoria total del sistema, el sistema comienza a escribir las modificaciones en el disco con la operación
pdflush. El valor por defecto es el 20 por ciento. vm.dirty_background_ratio- Un valor porcentual. Cuando se modifica este porcentaje de la memoria total del sistema, el sistema comienza a escribir las modificaciones en el disco en segundo plano. El valor por defecto es el 10 por ciento.
vm.overcommit_memoryDefine las condiciones que determinan si una solicitud de memoria grande es aceptada o denegada.El valor por defecto es 0.
Por defecto, el kernel realiza un manejo heurístico de la sobrecarga de memoria estimando la cantidad de memoria disponible y fallando las peticiones que son demasiado grandes. Sin embargo, dado que la memoria se asigna utilizando una heurística en lugar de un algoritmo preciso, es posible sobrecargar la memoria con esta configuración.
Ajuste del valor del parámetro
overcommit_memory:- Cuando este parámetro se establece en 1, el kernel no realiza ninguna gestión de sobrecompromiso de memoria. Esto aumenta la posibilidad de sobrecarga de memoria, pero mejora el rendimiento de las tareas que requieren mucha memoria.
-
Cuando este parámetro se establece en 2, el kernel deniega las solicitudes de memoria iguales o mayores que la suma del espacio de intercambio total disponible y el porcentaje de RAM física especificado en
overcommit_ratio. Esto reduce el riesgo de sobrecompromiso de memoria, pero se recomienda sólo para sistemas con áreas de swap mayores que su memoria física.
vm.overcommit_ratio-
Especifica el porcentaje de RAM física que se tiene en cuenta cuando
overcommit_memoryse establece en 2. El valor por defecto es 50. vm.max_map_count- Define el número máximo de áreas del mapa de memoria que puede utilizar un proceso. El valor por defecto es 65530. Aumente este valor si su aplicación necesita más áreas de mapa de memoria.
vm.min_free_kbytesEstablece el tamaño de la reserva de páginas libres. También es responsable de establecer los umbrales
min_page,low_page, yhigh_pageque gobiernan el comportamiento de los algoritmos de recuperación de páginas del núcleo de Linux. También especifica el número mínimo de kilobytes a mantener libres en todo el sistema. Esto calcula un valor específico para cada zona de memoria baja, a cada una de las cuales se le asigna un número de páginas libres reservadas en proporción a su tamaño.Ajuste del valor del parámetro
vm.min_free_kbytes:- Aumentar el valor del parámetro reduce efectivamente la memoria utilizable del conjunto de trabajo de la aplicación. Por lo tanto, es posible que desee utilizarlo sólo para las cargas de trabajo impulsadas por el kernel, donde los búferes de los controladores necesitan ser asignados en contextos atómicos.
Disminuir el valor del parámetro puede hacer que el kernel sea incapaz de atender las peticiones del sistema, si la memoria se vuelve muy disputada en el sistema.
AvisoLos valores extremos pueden ser perjudiciales para el rendimiento del sistema. Establecer
vm.min_free_kbytesa un valor extremadamente bajo impide que el sistema recupere la memoria de forma efectiva, lo que puede provocar caídas del sistema y fallos en el servicio de interrupciones u otros servicios del kernel. Sin embargo, establecervm.min_free_kbytesdemasiado alto aumenta considerablemente la actividad de recuperación del sistema, causando latencia de asignación debido a un falso estado de recuperación directa. Esto puede hacer que el sistema entre en un estado de falta de memoria inmediatamente.El parámetro
vm.min_free_kbytestambién establece una marca de agua de recuperación de página, llamadamin_pages. Esta marca de agua se utiliza como factor para determinar las otras dos marcas de agua de memoria,low_pages, yhigh_pages, que rigen los algoritmos de recuperación de páginas.
/proc/PID/oom_adjEn el caso de que un sistema se quede sin memoria, y el parámetro
panic_on_oomesté fijado en 0, la funciónoom_killermata los procesos, empezando por el proceso que tenga el mayoroom_score, hasta que el sistema se recupere.El parámetro
oom_adjdetermina eloom_scorede un proceso. Este parámetro se establece por identificador de proceso. Un valor de -17 desactiva eloom_killerpara ese proceso. Otros valores válidos van de -16 a 15.
Los procesos creados por un proceso ajustado heredan la oom_score de ese proceso.
vm.swappinessEl valor de swappiness, que va de 0 a 100, controla el grado en que el sistema favorece la recuperación de memoria del pool de memoria anónima, o del pool de memoria caché de páginas.
Ajuste del valor del parámetro
swappiness:- Los valores más altos favorecen a las cargas de trabajo impulsadas por el mapeo de archivos, mientras que intercambian la memoria anónima de RAM de los procesos a los que se accede menos activamente. Esto es útil para los servidores de archivos o aplicaciones de streaming que dependen de los datos, de los archivos en el almacenamiento, para residir en la memoria para reducir la latencia de E/S para las solicitudes de servicio.
Los valores bajos favorecen las cargas de trabajo de mapeo anónimo mientras se recupera la caché de páginas (memoria de mapeo de archivos). Esta configuración es útil para las aplicaciones que no dependen en gran medida de la información del sistema de archivos, y utilizan en gran medida la memoria privada y asignada dinámicamente, como las aplicaciones matemáticas y de cálculo numérico, y algunos supervisores de virtualización de hardware como QEMU.
El valor por defecto del parámetro
vm.swappinesses 30.AvisoConfigurando el
vm.swappinessa0evita agresivamente el intercambio de memoria anónima a un disco, esto incrementa el riesgo de que los procesos sean eliminados por la funciónoom_killercuando se encuentran bajo cargas de trabajo intensivas de memoria o E/S.
Recursos adicionales
-
Para más información, consulte la página de manual
sysctl. - Para más información sobre cómo configurar estos parámetros de forma temporal y persistente, consulte Sección 22.3.4, “Configuración de los parámetros del núcleo relacionados con la memoria”.
22.3.2. Parámetros del sistema de archivos
Los parámetros del sistema de archivos se encuentran en el directorio /proc/sys/fs. Los siguientes son los parámetros del sistema de archivos disponibles:
aio-max-nr- Define el número máximo permitido de eventos en todos los contextos de entrada/salida asíncronos activos. El valor por defecto es 65536, y la modificación de este valor no preasigna ni redimensiona ninguna estructura de datos del kernel.
file-maxDetermina el número máximo de manejadores de archivos para todo el sistema. El valor por defecto en Red Hat Enterprise Linux 8 es 8192 o una décima parte de las páginas de memoria libres disponibles en el momento de iniciar el kernel, lo que sea mayor.
El aumento de este valor puede resolver los errores causados por la falta de manejadores de archivos disponibles.
Recursos adicionales
-
Para más información, consulte la página de manual
sysctl.
22.3.3. Parámetros del núcleo
Los valores por defecto de los parámetros del kernel se encuentran en el directorio /proc/sys/kernel/. Estos valores son calculados por el kernel en el momento del arranque en función de los recursos disponibles del sistema.
Los siguientes son los parámetros del kernel disponibles que se utilizan para establecer los límites de las llamadas al sistema msg* y shm* System V IPC (sysvipc):
msgmax-
Define el tamaño máximo permitido en bytes de cualquier mensaje individual en una cola de mensajes. Este valor no debe exceder el tamaño de la cola (
msgmnb). Utilice el comandosysctl msgmaxpara determinar el valor actual demsgmaxen su sistema. msgmnb-
Define el tamaño máximo en bytes de una cola de mensajes. Utilice el comando
sysctl msgmnbpara determinar el valor actual demsgmnben su sistema. msgmni-
Define el número máximo de identificadores de cola de mensajes, y por tanto el número máximo de colas. Utilice el comando
sysctl msgmnipara determinar el valor actual demsgmnien su sistema. shmall-
Define la cantidad total de páginas de memoria compartida que se pueden utilizar en el sistema a la vez. Por ejemplo, una página es de 4096 bytes en la arquitectura AMD64 e Intel 64. Utilice el comando
sysctl shmallpara determinar el valor actual deshmallen su sistema. shmmax-
Define el tamaño máximo en bytes de un único segmento de memoria compartida permitido por el kernel. Utilice el comando
sysctl shmmaxpara determinar el valor actual deshmmaxen su sistema. shmmni- Define el número máximo de segmentos de memoria compartida en todo el sistema. El valor por defecto es 4096 en todos los sistemas.
Recursos adicionales
-
Para más información, consulte la página de manual
sysvipcysysctl.
Capítulo 23. Configurar páginas enormes
La memoria física se gestiona en trozos de tamaño fijo llamados páginas. En la arquitectura x86_64, soportada por Red Hat Enterprise Linux 8, el tamaño por defecto de una página de memoria es de 4 KB. Este tamaño de página por defecto ha demostrado ser adecuado para sistemas operativos de propósito general, como Red Hat Enterprise Linux, que soporta muchos tipos diferentes de cargas de trabajo.
Sin embargo, algunas aplicaciones específicas pueden beneficiarse del uso de tamaños de página mayores en determinados casos. Por ejemplo, una aplicación que trabaje con un conjunto de datos grande y relativamente fijo de cientos de megabytes o incluso decenas de gigabytes puede tener problemas de rendimiento si utiliza páginas de 4 KB. Tales conjuntos de datos pueden requerir una enorme cantidad de páginas de 4 KB, lo que puede provocar una sobrecarga en el sistema operativo y la CPU.
Esta sección proporciona información sobre las enormes páginas disponibles en Red Hat Enterprise Linux 8 y cómo puede configurarlas.
23.1. Características disponibles de la página enorme
Con Red Hat Enterprise Linux 8, puede utilizar páginas enormes para aplicaciones que trabajan con grandes conjuntos de datos y mejorar el rendimiento de dichas aplicaciones.
Los siguientes son los métodos de página enorme, que son soportados en Red Hat Enterprise Linux 8:
HugeTLB pagesLas páginas HugeTLB también se denominan páginas enormes estáticas. Hay dos formas de reservar páginas HugeTLB:
- En el momento del arranque: Aumenta la posibilidad de éxito porque la memoria aún no se ha fragmentado de forma significativa. Sin embargo, en las máquinas NUMA, el número de páginas se divide automáticamente entre los nodos NUMA. Para más información sobre los parámetros que influyen en el comportamiento de las páginas HugeTLB en el momento del arranque, consulte Sección 23.2, “Parámetros para reservar páginas HugeTLB en el momento del arranque” y sobre cómo utilizar estos parámetros para configurar las páginas HugeTLB en el momento del arranque, consulte Sección 23.4, “Configuración de HugeTLB en el arranque”.
- En tiempo de ejecución: Permite reservar las páginas enormes por nodo NUMA. Si la reserva en tiempo de ejecución se realiza lo antes posible en el proceso de arranque, la probabilidad de fragmentación de la memoria es menor. Para obtener más información sobre los parámetros que influyen en el comportamiento de las páginas HugeTLB en tiempo de ejecución, consulte Sección 23.3, “Parámetros para reservar páginas HugeTLB en tiempo de ejecución” y sobre cómo utilizar estos parámetros para configurar las páginas HugeTLB en tiempo de ejecución, consulte Sección 23.5, “Configuración de HugeTLB en tiempo de ejecución”.
Transparent HugePages (THP)Con THP, el kernel asigna automáticamente las páginas enormes a los procesos y, por tanto, no es necesario reservar manualmente las páginas enormes estáticas. A continuación se muestran los dos modos de funcionamiento de THP:
-
system-wide: Aquí, el kernel intenta asignar páginas enormes a un proceso siempre que sea posible asignar las páginas enormes y el proceso esté utilizando una zona de memoria virtual contigua grande. per-process: Aquí, el kernel sólo asigna páginas enormes a las áreas de memoria de los procesos individuales que puede especificar utilizando la llamada al sistemamadvise().NotaLa función THP sólo admite páginas de 2 MB.
Para obtener información sobre cómo activar y desactivar el THP, consulte Sección 23.6, “Habilitación de hugepages transparentes” y Sección 23.7, “Desactivación de hugepages transparentes”.
-
23.2. Parámetros para reservar páginas HugeTLB en el momento del arranque
Utilice los siguientes parámetros para influir en el comportamiento de la página HugeTLB en el momento del arranque:
Tabla 23.1. Parámetros utilizados para configurar las páginas HugeTLB en el momento del arranque
| Parámetro | Descripción | Valor por defecto |
|---|---|---|
|
| Define el número de páginas enormes persistentes configuradas en el kernel en el momento del arranque. En un sistema NUMA, las páginas enormes, que tienen este parámetro definido, se dividen por igual entre los nodos.
Puede asignar páginas enormes a nodos específicos en tiempo de ejecución cambiando el valor de los nodos en el archivo | El valor por defecto es 0.
Para actualizar este valor en el arranque, cambie el valor de este parámetro en el archivo |
|
| Define el tamaño de las páginas enormes persistentes configuradas en el kernel en el momento del arranque. | Los valores válidos son 2 MB y 1 GB. El valor por defecto es 2 MB. |
|
| Define el tamaño por defecto de las páginas enormes persistentes configuradas en el kernel en el momento del arranque. | Los valores válidos son 2 MB y 1 GB. El valor por defecto es 2 MB. |
23.3. Parámetros para reservar páginas HugeTLB en tiempo de ejecución
Utilice los siguientes parámetros para influir en el comportamiento de la página HugeTLB en tiempo de ejecución:
Tabla 23.2. Parámetros utilizados para configurar las páginas HugeTLB en tiempo de ejecución
| Parámetro | Descripción | Nombre del archivo |
|---|---|---|
|
| Define el número de páginas enormes de un tamaño determinado asignadas a un nodo NUMA específico. |
|
|
| Define el número máximo de páginas enormes adicionales que pueden ser creadas y utilizadas por el sistema a través de la sobrecompromiso de memoria. Escribir cualquier valor distinto de cero en este archivo indica que el sistema obtiene ese número de páginas enormes del pool de páginas normales del kernel si el pool de páginas enormes persistente se agota. A medida que estas páginas enormes sobrantes quedan sin usar, se liberan y se devuelven a la reserva de páginas normales del núcleo. |
|
23.4. Configuración de HugeTLB en el arranque
El tamaño de las páginas que soporta el subsistema HugeTLB depende de la arquitectura. La arquitectura x86_64 soporta páginas enormes de 2 MB y páginas gigantes de 1 GB.
Este procedimiento describe cómo reservar una página de 1 GB en el momento del arranque.
Procedimiento
Cree un pool HugeTLB para páginas de 1 GB añadiendo la siguiente línea a las opciones de línea de comandos del kernel en el archivo
/etc/default/grubcomo root:default_hugepagesz=1G hugepagesz=1G
Regenerar la configuración de
GRUB2utilizando el archivo por defecto editado:Si su sistema utiliza el firmware de la BIOS, ejecute el siguiente comando:
# grub2-mkconfig -o /boot/grub2/grub.cfg
Si su sistema utiliza el marco UEFI, ejecute el siguiente comando:
# grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
Cree un nuevo archivo llamado
hugetlb-gigantic-pages.serviceen el directorio/usr/lib/systemd/system/y añada el siguiente contenido:[Unit] Description=HugeTLB Gigantic Pages Reservation DefaultDependencies=no Before=dev-hugepages.mount ConditionPathExists=/sys/devices/system/node ConditionKernelCommandLine=hugepagesz=1G [Service] Type=oneshot RemainAfterExit=yes ExecStart=/usr/lib/systemd/hugetlb-reserve-pages.sh [Install] WantedBy=sysinit.target
Cree un nuevo archivo llamado
hugetlb-reserve-pages.shen el directorio/usr/lib/systemd/y añada el siguiente contenido:Al añadir el siguiente contenido, sustituya number_of_pages por el número de páginas de 1GB que desea reservar, y node por el nombre del nodo en el que se van a reservar estas páginas.
#!/bin/sh nodes_path=/sys/devices/system/node/ if [ ! -d $nodes_path ]; then echo "ERROR: $nodes_path does not exist" exit 1 fi reserve_pages() { echo $1 > $nodes_path/$2/hugepages/hugepages-1048576kB/nr_hugepages } reserve_pages number_of_pages nodePor ejemplo, para reservar dos páginas de 1GB en node0 y una página de 1GB en node1, sustituya number_of_pages por 2 para node0 y 1 para node1:
reserve_pages 2 node0 reserve_pages 1 node1
Crear un script ejecutable:
# chmod x /usr/lib/systemd/hugetlb-reserve-pages.sh
Habilitar la reserva de arranque anticipado:
# systemctl enable hugetlb-gigantic-pages
-
Puedes intentar reservar más páginas de 1GB en tiempo de ejecución escribiendo en
nr_hugepagesen cualquier momento. Sin embargo, estas reservas pueden fallar debido a la fragmentación de la memoria. La forma más fiable de reservar páginas de 1GB es usando este scripthugetlb-reserve-pages.sh, que se ejecuta antes durante el arranque. - Reservar páginas enormes estáticas puede reducir efectivamente la cantidad de memoria disponible para el sistema, y evita que éste utilice adecuadamente toda su capacidad de memoria. Aunque una reserva de páginas enormes reservadas del tamaño adecuado puede ser beneficiosa para las aplicaciones que la utilizan, una reserva de páginas enormes reservadas sobredimensionada o no utilizada acabará siendo perjudicial para el rendimiento general del sistema. Al establecer un pool de páginas enormes reservadas, asegúrese de que el sistema puede utilizar correctamente toda su capacidad de memoria.
Recursos adicionales
-
Para más información, consulte la documentación pertinente del núcleo, que se instala en el archivo
/usr/share/doc/kernel-doc-kernel_version/Documentation/vm/hugetlbpage.txt. -
Para más información, consulte la página de manual
systemd.service.
23.5. Configuración de HugeTLB en tiempo de ejecución
Este procedimiento describe cómo añadir veinte páginas enormes de 2048 kB a node2.
Procedimiento
Muestra las estadísticas de la memoria:
# numastat -cm | egrep 'Node|Huge' Node 0 Node 1 Node 2 Node 3 Total add AnonHugePages 0 2 0 8 10 HugePages_Total 0 0 0 0 0 HugePages_Free 0 0 0 0 0 HugePages_Surp 0 0 0 0 0Añade el número de páginas enormes de un tamaño especificado al nodo:
# echo 20 > /sys/devices/system/node2/hugepages/hugepages-2048kB/nr_hugepages
Para reservar páginas en función de sus necesidades, sustituya:
- 20 con el número de páginas enormes que desea reservar,
- 2048kB con el tamaño de las enormes páginas,
- node2 con el nodo en el que desea reservar las páginas.
Pasos de verificación
Asegúrese de que el número de páginas enormes se añade:
# numastat -cm | egrep 'Node|Huge' Node 0 Node 1 Node 2 Node 3 Total AnonHugePages 0 2 0 8 10 HugePages_Total 0 0 40 0 40 HugePages_Free 0 0 40 0 40 HugePages_Surp 0 0 0 0 0
Recursos adicionales
-
Para más información, consulte la página de manual
numastat.
23.6. Habilitación de hugepages transparentes
THP está habilitado por defecto en Red Hat Enterprise Linux 8. Sin embargo, puede habilitar o deshabilitar THP. Este procedimiento describe cómo habilitar THP.
Procedimiento
Compruebe el estado actual del THP:
# cat /sys/kernel/mm/transparent_hugepage/enabled
Habilita el THP:
# echo always > /sys/kernel/mm/transparent_hugepage/enabled
Para evitar que las aplicaciones asignen más recursos de memoria de los necesarios, desactive las páginas enormes transparentes en todo el sistema y habilítelas sólo para las aplicaciones que lo soliciten explícitamente a través de la página
madvise:# echo madvise > /sys/kernel/mm/transparent_hugepage/enabled
A veces, proporcionar una baja latencia a las asignaciones de corta duración tiene mayor prioridad que conseguir inmediatamente el mejor rendimiento con las asignaciones de larga duración. En estos casos, se puede desactivar la compactación directa dejando activada la THP.
La compactación directa es una compactación de memoria sincrónica durante la asignación de la página enorme. Desactivar la compactación directa no proporciona ninguna garantía de ahorro de memoria, pero puede disminuir el riesgo de mayores latencias durante los fallos de página frecuentes. Tenga en cuenta que si la carga de trabajo se beneficia significativamente de THP, el rendimiento disminuye. Desactivar la compactación directa:
# echo madvise > /sys/kernel/mm/transparent_hugepage/defrag
Recursos adicionales
-
Para más información, consulte la página de manual
madvise.
23.7. Desactivación de hugepages transparentes
THP está habilitado por defecto en Red Hat Enterprise Linux 8. Sin embargo, puede habilitar o deshabilitar THP.Este procedimiento describe cómo deshabilitar THP.
Procedimiento
Compruebe el estado actual del THP:
# cat /sys/kernel/mm/transparent_hugepage/enabled
Desactivar el THP:
# echo never > /sys/kernel/mm/transparent_hugepage/enabled
23.8. Impacto del tamaño de la página en el tamaño de la memoria intermedia de traducción
La lectura de las asignaciones de direcciones de la tabla de páginas consume mucho tiempo y recursos, por lo que las CPUs están construidas con una caché para las direcciones utilizadas recientemente, llamada Translation Lookaside Buffer (TLB). Sin embargo, el TLB por defecto sólo puede almacenar en caché un cierto número de asignaciones de direcciones.
Si un mapeo de direcciones solicitado no está en la TLB, lo que se llama un fallo de la TLB, el sistema todavía necesita leer la tabla de páginas para determinar el mapeo de direcciones físicas a virtuales. Debido a la relación entre los requisitos de memoria de la aplicación y el tamaño de las páginas utilizadas para almacenar en caché las asignaciones de direcciones, las aplicaciones con grandes requisitos de memoria tienen más probabilidades de sufrir una degradación del rendimiento debido a los fallos de la TLB que las aplicaciones con requisitos mínimos de memoria. Por lo tanto, es importante evitar los fallos de la TLB siempre que sea posible.
Las funciones HugeTLB y Transparent Huge Page permiten a las aplicaciones utilizar páginas de más de 4 KB. Esto permite que las direcciones almacenadas en la TLB hagan referencia a más memoria, lo que reduce los fallos de la TLB y mejora el rendimiento de la aplicación.
Capítulo 24. Cómo empezar con SystemTap
Como administrador del sistema, puede utilizar SystemTap para identificar las causas subyacentes de un error o problema de rendimiento en un sistema Linux en funcionamiento.
Como desarrollador de aplicaciones, puede utilizar SystemTap para supervisar en detalle cómo se comporta su aplicación dentro del sistema Linux.
24.1. El objetivo de SystemTap
SystemTap es una herramienta de rastreo y sondeo que puede utilizar para estudiar y supervisar las actividades de su sistema operativo (en particular, el kernel) con todo detalle. SystemTap proporciona información similar a la salida de herramientas como netstat, ps, top, y iostat. Sin embargo, SystemTap ofrece más opciones de filtrado y análisis de la información recogida. En los scripts de SystemTap, se especifica la información que SystemTap recopila.
SystemTap pretende complementar el conjunto de herramientas de monitorización de Linux existentes proporcionando a los usuarios la infraestructura necesaria para realizar un seguimiento de la actividad del núcleo y combinando esta capacidad con dos atributos:
- Flexibility
- el marco de trabajo de SystemTap le permite desarrollar scripts simples para investigar y monitorear una amplia variedad de funciones del kernel, llamadas al sistema y otros eventos que ocurren en el espacio del kernel. Con esto, SystemTap no es tanto una herramienta como un sistema que le permite desarrollar sus propias herramientas forenses y de monitorización específicas del kernel.
- Ease-of-Use
- SystemTap permite supervisar la actividad del kernel sin tener que recompilar el kernel o reiniciar el sistema.
24.2. Implantación de SystemTap
Para utilizar SystemTap, debe instalar los paquetes asociados de SystemTap y del núcleo.
24.2.1. Habilitación de los repositorios de depuración y de código fuente
Una instalación estándar de Red Hat Enterprise Linux no habilita los repositorios de depuración y de fuentes. Estos repositorios contienen la información necesaria para depurar los componentes del sistema y medir su rendimiento.
Procedimiento
Habilitar los canales de paquetes de información de origen y de depuración:
# subscription-manager repos --enable rhel-8-for-$(uname -i)-baseos-debug-rpms # subscription-manager repos --enable rhel-8-for-$(uname -i)-baseos-source-rpms # subscription-manager repos --enable rhel-8-for-$(uname -i)-appstream-debug-rpms # subscription-manager repos --enable rhel-8-for-$(uname -i)-appstream-source-rpms
La parte
$(uname -i)se sustituye automáticamente por un valor correspondiente a la arquitectura de su sistema:Nombre de la arquitectura Valor Intel y AMD de 64 bits
x86_64
ARM de 64 bits
aarch64
IBM POWER
ppc64le
IBM Z
s390x
24.2.2. Instalación de SystemTap
Para empezar a utilizar SystemTap, instale los paquetes necesarios. Para utilizar SystemTap en más de un núcleo cuando un sistema tiene varios núcleos instalados, instale los correspondientes paquetes del núcleo necesarios para la versión del núcleo each.
Requisitos previos
- Ha habilitado los repositorios de depuración como se describe en Activación de los repositorios de depuración y de origen.
Procedimiento
Instale los paquetes SystemTap necesarios:
# yum install systemtap
Instale los paquetes del kernel necesarios:
Utilizando
stap-prep:# stap-prep
Si
stap-prepno funciona, instale manualmente los paquetes del kernel necesarios:# yum install kernel-debuginfo-$(uname -r) kernel-debuginfo-common-$(uname -i)-$(uname -r) kernel-devel-$(uname -r)
$(uname -i)se sustituye automáticamente por la plataforma de hardware de su sistema y$(uname -r)se sustituye automáticamente por la versión de su kernel en ejecución.
Pasos de verificación
Si el núcleo que se va a sondear con SystemTap está actualmente en uso, compruebe si su instalación se ha realizado correctamente:
# stap -v -e 'probe kernel.function(\ "vfs_read") {printf(\ "read performed\n"); exit()}'Un despliegue exitoso de SystemTap resulta en una salida similar a la siguiente:
Pass 1: parsed user script and 45 library script(s) in 340usr/0sys/358real ms. Pass 2: analyzed script: 1 probe(s), 1 function(s), 0 embed(s), 0 global(s) in 290usr/260sys/568real ms. Pass 3: translated to C into "/tmp/stapiArgLX/stap_e5886fa50499994e6a87aacdc43cd392_399.c" in 490usr/430sys/938real ms. Pass 4: compiled C into "stap_e5886fa50499994e6a87aacdc43cd392_399.ko" in 3310usr/430sys/3714real ms. Pass 5: starting run. 1 read performed 2 Pass 5: run completed in 10usr/40sys/73real ms. 3
Las tres últimas líneas de salida (que comienzan con
Pass 5) indican que:
24.3. Instrumentación cruzada de SystemTap
24.3.1. Instrumentación cruzada SystemTap
Cuando se ejecuta un script de SystemTap, se construye un módulo del kernel a partir de ese script. A continuación, SystemTap carga el módulo en el kernel.
Normalmente, los scripts de SystemTap sólo pueden ejecutarse en los sistemas en los que se ha desplegado SystemTap. Para ejecutar SystemTap en diez sistemas, es necesario desplegar SystemTap en todos esos sistemas. En algunos casos, esto puede no ser factible ni deseado. Por ejemplo, la política de la empresa puede prohibir la instalación de paquetes que proporcionen compiladores o información de depuración en máquinas específicas, lo que impedirá el despliegue de SystemTap.
Para evitarlo, utilice cross-instrumentation. La instrumentación cruzada es el proceso de generar módulos de instrumentación de SystemTap a partir de un script de SystemTap en un sistema para ser utilizado en otro sistema. Este proceso ofrece las siguientes ventajas:
- Los paquetes de información del kernel para varias máquinas pueden instalarse en una sola máquina anfitriona.
Los errores de empaquetado del kernel pueden impedirlo. En estos casos, los paquetes kernel-debuginfo y kernel-devel para los host system y target system deben coincidir. Si esto ocurre, informe del error en https://bugzilla.redhat.com/.
-
Cada target machine sólo necesita instalar un paquete para utilizar el módulo de instrumentación SystemTap generado:
systemtap-runtime.
El host system debe tener la misma arquitectura y ejecutar la misma distribución de Linux que el target system para que el instrumentation module construido funcione.
- instrumentation module
- El módulo del núcleo construido a partir de un script de SystemTap; el módulo de SystemTap se construye en el host system, y se cargará en el target kernel del target system.
- host system
- El sistema en el que se compilan los módulos de instrumentación (a partir de los scripts de SystemTap), que se cargarán en target systems.
- target system
- El sistema en el que se está construyendo el instrumentation module (desde los scripts de SystemTap).
- target kernel
- El núcleo del target system. Este es el núcleo que carga y ejecuta el instrumentation module.
24.3.2. Inicialización de la instrumentación cruzada de SystemTap
Inicie la instrumentación cruzada de SystemTap para construir módulos de instrumentación de SystemTap desde un script de SystemTap en un sistema y utilizarlos en otro sistema que no tenga SystemTap completamente desplegado.
Requisitos previos
- SystemTap se instala en host system como se describe en Instalación de SystemTap.
- Tanto host system como target system tienen la misma arquitectura.
- Tanto host system como target system están ejecutando la misma versión principal de Red Hat Enterprise Linux (como Red Hat Enterprise Linux 8), pero can están ejecutando diferentes versiones menores (como 8.1 y 8.2).
Los errores de empaquetado del kernel pueden impedir que se instalen varios paquetes kernel-debuginfo y kernel-devel en un mismo sistema. En estos casos, la versión menor de host system y target system debe coincidir. Si esto ocurre, informe del error en https://bugzilla.redhat.com/.
Procedimiento
Determine el núcleo que se ejecuta en cada target system:
$ uname -r
Repita este paso para cada target system.
Instale el paquete necesario para ejecutar los módulos precompilados en cada target system:
# yum install systemtap-runtime
- En el host system, instale el target kernel y los paquetes relacionados para cada target system por el método descrito en la instalación de SystemTap.
Construir un módulo de instrumentación en el host system, copiarlo y ejecutarlo en el target system tampoco:
Utilizando la implementación remota:
# stap --remote target_system script
Este comando implementa remotamente el script especificado en el target system. Debe asegurarse de que se puede realizar una conexión SSH a la target system desde la host system para que esto tenga éxito.
Manualmente:
Construya el módulo de instrumentación en la página web host system:
# stap -r kernel_version script -m module_name -p 4
Aquí, kernel_version se refiere a la versión de target kernel determinada en el paso 1, script se refiere al script que se convertirá en un instrumentation module, y module_name es el nombre deseado del instrumentation module. La opción
-p4indica a SystemTap que no cargue ni ejecute el módulo compilado.Una vez compilado el instrumentation module, cópielo en el sistema de destino y cárguelo con el siguiente comando:
# staprun module_name.koNotaLa ejecución de un módulo precompilado sólo requiere el paquete
systemtap-runtime.
24.4. Ejecución de scripts de SystemTap
24.4.1. Privilegios para ejecutar SystemTap
La ejecución de los scripts de SystemTap requiere privilegios elevados del sistema pero, en algunos casos, los usuarios sin privilegios pueden necesitar ejecutar la instrumentación de SystemTap en su máquina.
Para permitir que los usuarios ejecuten SystemTap sin acceso root, añada usuarios a both de estos grupos de usuarios:
stapdevLos miembros de este grupo pueden utilizar
stappara ejecutar scripts de SystemTap, ostaprunpara ejecutar módulos de instrumentación de SystemTap.La ejecución de
stapimplica la compilación de los scripts de SystemTap en módulos del kernel y su carga en el mismo. Esto requiere privilegios elevados en el sistema, que se conceden a los miembros destapdev. Lamentablemente, estos privilegios también otorgan acceso efectivo de root a los miembros destapdev. Por lo tanto, sólo se debe conceder la membresía del grupostapdeva los usuarios a los que se les puede confiar el acceso a la raíz.stapusr-
Los miembros de este grupo sólo pueden utilizar
staprunpara ejecutar los módulos de instrumentación de SystemTap. Además, sólo pueden ejecutar esos módulos desde el directorio/lib/modules/kernel_version/systemtap/directorio. Este directorio debe ser propiedad sólo del usuario root, y sólo debe poder ser escrito por el usuario root.
24.4.2. Ejecución de scripts de SystemTap
Puede ejecutar los scripts de SystemTap desde la entrada estándar o desde un archivo.
Los scripts de ejemplo que se distribuyen con la instalación de SystemTap se encuentran en el directorio /usr/share/systemtap/examples.
Requisitos previos
- SystemTap y los paquetes del núcleo necesarios asociados se instalan como se describe en la instalación de SystemTap.
Para ejecutar los scripts de SystemTap como un usuario normal, añada el usuario a los grupos de SystemTap:
# usermod --append --groups stapdev,stapusr user-name
Procedimiento
Ejecute el script SystemTap:
Desde la entrada estándar:
# echo \ "probe timer.s(1) {exit()}" | stap -Este comando indica a
stapque ejecute el script pasado porechoa la entrada estándar. Para añadir opciones astap, insértelas antes del carácter-. Por ejemplo, para que los resultados de este comando sean más detallados, el comando es:# echo \ "probe timer.s(1) {exit()}" | stap -v -De un archivo:
# stap file_name
Capítulo 25. Análisis del rendimiento del sistema con BPF Compiler Collection
Como administrador del sistema, utilice la biblioteca BPF Compiler Collection (BCC) para crear herramientas que le permitan analizar el rendimiento de su sistema operativo Linux y recopilar información, que podría ser difícil de obtener a través de otras interfaces.
25.1. Una introducción a BCC
BPF Compiler Collection (BCC) es una biblioteca que facilita la creación de los programas Berkeley Packet Filter (eBPF) ampliados. La principal utilidad de los programas eBPF es analizar el rendimiento del sistema operativo y el rendimiento de la red sin experimentar problemas de sobrecarga o seguridad.
BCC elimina la necesidad de que los usuarios conozcan detalles técnicos profundos de eBPF, y proporciona muchos puntos de partida listos para usar, como el paquete bcc-tools con programas de eBPF precreados.
Los programas eBPF se activan en eventos, como la E/S de disco, las conexiones TCP y la creación de procesos. Es poco probable que los programas provoquen el bloqueo del kernel, bucles o que dejen de responder, ya que se ejecutan en una máquina virtual segura en el kernel.
25.2. Instalación del paquete bcc-tools
Esta sección describe cómo instalar el paquete bcc-tools, que también instala la biblioteca BPF Compiler Collection (BCC) como dependencia.
Requisitos previos
- Un activo Red Hat Enterprise Linux subscription
-
Un enabled repository que contiene el paquete
bcc-tools - Núcleo actualizado
- Permisos de raíz.
Procedimiento
Instalar
bcc-tools:#yum install bcc-toolsLas herramientas BCC se instalan en el directorio
/usr/share/bcc/tools/.Opcionalmente, inspeccione las herramientas:
#ll /usr/share/bcc/tools/... -rwxr-xr-x. 1 root root 4198 Dec 14 17:53 dcsnoop -rwxr-xr-x. 1 root root 3931 Dec 14 17:53 dcstat -rwxr-xr-x. 1 root root 20040 Dec 14 17:53 deadlock_detector -rw-r--r--. 1 root root 7105 Dec 14 17:53 deadlock_detector.c drwxr-xr-x. 3 root root 8192 Mar 11 10:28 doc -rwxr-xr-x. 1 root root 7588 Dec 14 17:53 execsnoop -rwxr-xr-x. 1 root root 6373 Dec 14 17:53 ext4dist -rwxr-xr-x. 1 root root 10401 Dec 14 17:53 ext4slower ...El directorio
docde la lista anterior contiene la documentación de cada herramienta.
25.3. Utilización de determinadas herramientas bcc para el análisis del rendimiento
Esta sección describe cómo utilizar ciertos programas precreados de la biblioteca BPF Compiler Collection (BCC) para analizar de forma eficiente y segura el rendimiento del sistema en base a cada evento. El conjunto de programas precreados en la biblioteca BCC puede servir de ejemplo para la creación de programas adicionales.
Requisitos previos
- Biblioteca BCC instalada
- Permisos de la raíz
Uso de execsnoop para examinar los procesos del sistema
Ejecute el programa
execsnoopen un terminal:# /usr/share/bcc/tools/execsnoopEn otro terminal ejecutar por ejemplo:
$ ls /usr/share/bcc/tools/doc/Lo anterior crea un proceso de corta duración del comando
ls.El terminal que ejecuta
execsnoopmuestra una salida similar a la siguiente:PCOMM PID PPID RET ARGS ls 8382 8287 0 /usr/bin/ls --color=auto /usr/share/bcc/tools/doc/ sed 8385 8383 0 /usr/bin/sed s/^ *[0-9]\+ *// ...
El programa
execsnoopimprime una línea de salida por cada nuevo proceso, que consume recursos del sistema. Incluso detecta procesos de programas que se ejecutan muy poco tiempo, comols, y la mayoría de las herramientas de monitorización no los registrarían.La salida de
execsnoopmuestra los siguientes campos:-
PCOMM - El nombre del proceso padre. (
ls) -
PID - El ID del proceso. (
8382) -
PPID - El ID del proceso padre. (
8287) -
RET - El valor de retorno de la llamada al sistema
exec()(0), que carga el código del programa en nuevos procesos. - ARGS - La ubicación del programa iniciado con argumentos.
-
PCOMM - El nombre del proceso padre. (
Para ver más detalles, ejemplos y opciones de execsnoop, consulte el archivo /usr/share/bcc/tools/doc/execsnoop_example.txt.
Para más información sobre exec(), consulte las páginas del manual exec(3).
Uso de opensnoop para rastrear qué archivos abre un comando
Ejecute el programa
opensnoopen un terminal:# /usr/share/bcc/tools/opensnoop -n unameLo anterior imprime la salida para los archivos, que son abiertos sólo por el proceso del comando
uname.En otra terminal ejecutar:
$ unameEl comando anterior abre ciertos archivos, que se capturan en el siguiente paso.
El terminal que ejecuta
opensnoopmuestra una salida similar a la siguiente:PID COMM FD ERR PATH 8596 uname 3 0 /etc/ld.so.cache 8596 uname 3 0 /lib64/libc.so.6 8596 uname 3 0 /usr/lib/locale/locale-archive ...
El programa
opensnoopvigila la llamada al sistemaopen()en todo el sistema, e imprime una línea de salida para cada archivo queunameintentó abrir en el camino.La salida de
opensnoopmuestra los siguientes campos:-
PID - El ID del proceso. (
8596) -
COMM - El nombre del proceso. (
uname) -
FD - El descriptor del archivo - un valor que
open()devuelve para referirse al archivo abierto. (3) - ERR - Cualquier error.
PATH - La ubicación de los archivos que
open()intentó abrir.Si un comando intenta leer un archivo inexistente, la columna
FDdevuelve-1y la columnaERRimprime un valor correspondiente al error en cuestión. Como resultado,opensnooppuede ayudarle a identificar una aplicación que no se comporta correctamente.
-
PID - El ID del proceso. (
Para ver más detalles, ejemplos y opciones de opensnoop, consulte el archivo /usr/share/bcc/tools/doc/opensnoop_example.txt.
Para más información sobre open(), consulte las páginas del manual open(2).
Uso de biotop para examinar las operaciones de E/S en el disco
Ejecute el programa
biotopen un terminal:# /usr/share/bcc/tools/biotop 30El comando permite supervisar los procesos principales, que realizan operaciones de E/S en el disco. El argumento asegura que el comando producirá un resumen de 30 segundos.
NotaSi no se proporciona ningún argumento, la pantalla de salida se actualiza por defecto cada 1 segundo.
En otro terminal ejecute por ejemplo :
# dd if=/dev/vda of=/dev/zeroEl comando anterior lee el contenido del dispositivo de disco duro local y escribe la salida en el archivo
/dev/zero. Este paso genera cierto tráfico de E/S para ilustrarbiotop.El terminal que ejecuta
biotopmuestra una salida similar a la siguiente:PID COMM D MAJ MIN DISK I/O Kbytes AVGms 9568 dd R 252 0 vda 16294 14440636.0 3.69 48 kswapd0 W 252 0 vda 1763 120696.0 1.65 7571 gnome-shell R 252 0 vda 834 83612.0 0.33 1891 gnome-shell R 252 0 vda 1379 19792.0 0.15 7515 Xorg R 252 0 vda 280 9940.0 0.28 7579 llvmpipe-1 R 252 0 vda 228 6928.0 0.19 9515 gnome-control-c R 252 0 vda 62 6444.0 0.43 8112 gnome-terminal- R 252 0 vda 67 2572.0 1.54 7807 gnome-software R 252 0 vda 31 2336.0 0.73 9578 awk R 252 0 vda 17 2228.0 0.66 7578 llvmpipe-0 R 252 0 vda 156 2204.0 0.07 9581 pgrep R 252 0 vda 58 1748.0 0.42 7531 InputThread R 252 0 vda 30 1200.0 0.48 7504 gdbus R 252 0 vda 3 1164.0 0.30 1983 llvmpipe-1 R 252 0 vda 39 724.0 0.08 1982 llvmpipe-0 R 252 0 vda 36 652.0 0.06 ...
La salida de
biotopmuestra los siguientes campos:-
PID - El ID del proceso. (
9568) -
COMM - El nombre del proceso. (
dd) -
DISK - El disco que realiza las operaciones de lectura. (
vda) - I/O - El número de operaciones de lectura realizadas. (16294)
- Kbytes - La cantidad de Kbytes alcanzados por las operaciones de lectura. (14,440,636)
- AVGms - El tiempo medio de E/S de las operaciones de lectura. (3.69)
-
PID - El ID del proceso. (
Para ver más detalles, ejemplos y opciones de biotop, consulte el archivo /usr/share/bcc/tools/doc/biotop_example.txt.
Para más información sobre dd, consulte las páginas del manual dd(1).
Uso de xfsslower para exponer operaciones del sistema de archivos inesperadamente lentas
Ejecute el programa
xfssloweren un terminal:# /usr/share/bcc/tools/xfsslower 1El comando anterior mide el tiempo que el sistema de archivos XFS emplea en realizar operaciones de lectura, escritura, apertura o sincronización (
fsync). El argumento1asegura que el programa muestra sólo las operaciones que son más lentas que 1 ms.NotaCuando no se proporcionan argumentos,
xfsslowermuestra por defecto las operaciones más lentas de 10 ms.En otro terminal ejecute, por ejemplo, lo siguiente:
$ vim textEl comando anterior crea un archivo de texto en el editor
vimpara iniciar cierta interacción con el sistema de archivos XFS.El terminal que ejecuta
xfsslowermuestra algo similar al guardar el archivo del paso anterior:TIME COMM PID T BYTES OFF_KB LAT(ms) FILENAME 13:07:14 b'bash' 4754 R 256 0 7.11 b'vim' 13:07:14 b'vim' 4754 R 832 0 4.03 b'libgpm.so.2.1.0' 13:07:14 b'vim' 4754 R 32 20 1.04 b'libgpm.so.2.1.0' 13:07:14 b'vim' 4754 R 1982 0 2.30 b'vimrc' 13:07:14 b'vim' 4754 R 1393 0 2.52 b'getscriptPlugin.vim' 13:07:45 b'vim' 4754 S 0 0 6.71 b'text' 13:07:45 b'pool' 2588 R 16 0 5.58 b'text' ...
Cada línea de arriba representa una operación en el sistema de archivos, que tomó más tiempo que un determinado umbral.
xfssloweres bueno para exponer posibles problemas del sistema de archivos, que pueden tomar la forma de operaciones inesperadamente lentas.La salida de
xfsslowermuestra los siguientes campos:-
COMM - El nombre del proceso. (
b’bash') T - El tipo de operación. (
R)- Read
- Write
- Sync
- OFF_KB - El desplazamiento del archivo en KB. (0)
- FILENAME - El archivo que se está leyendo, escribiendo o sincronizando.
-
COMM - El nombre del proceso. (
Para ver más detalles, ejemplos y opciones de xfsslower, consulte el archivo /usr/share/bcc/tools/doc/xfsslower_example.txt.
Para más información sobre fsync, consulte las páginas del manual fsync(2).