
Red Hat Training
A Red Hat training course is available for RHEL 8
Gestión de dispositivos de almacenamiento
Implantación y configuración del almacenamiento de un solo nodo en Red Hat Enterprise Linux 8
Resumen
Hacer que el código abierto sea más inclusivo
Red Hat se compromete a sustituir el lenguaje problemático en nuestro código, documentación y propiedades web. Estamos empezando con estos cuatro términos: maestro, esclavo, lista negra y lista blanca. Debido a la enormidad de este esfuerzo, estos cambios se implementarán gradualmente a lo largo de varias versiones próximas. Para más detalles, consulte el mensaje de nuestro CTO Chris Wright.
Proporcionar comentarios sobre la documentación de Red Hat
Agradecemos su opinión sobre nuestra documentación. Por favor, díganos cómo podemos mejorarla. Para ello:
Para comentarios sencillos sobre pasajes concretos:
- Asegúrese de que está viendo la documentación en el formato Multi-page HTML. Además, asegúrese de ver el botón Feedback en la esquina superior derecha del documento.
- Utilice el cursor del ratón para resaltar la parte del texto que desea comentar.
- Haga clic en la ventana emergente Add Feedback que aparece debajo del texto resaltado.
- Siga las instrucciones mostradas.
Para enviar comentarios más complejos, cree un ticket de Bugzilla:
- Vaya al sitio web de Bugzilla.
- Como componente, utilice Documentation.
- Rellene el campo Description con su sugerencia de mejora. Incluya un enlace a la(s) parte(s) pertinente(s) de la documentación.
- Haga clic en Submit Bug.
Capítulo 1. Resumen de las opciones de almacenamiento disponibles
Este capítulo describe los tipos de almacenamiento que están disponibles en Red Hat Enterprise Linux 8. Red Hat Enterprise Linux ofrece una variedad de opciones para gestionar el almacenamiento local y para conectarse al almacenamiento remoto. Figura 1.1, “Diagrama de almacenamiento de alto nivel de Red Hat Enterprise Linux” describe las diferentes opciones de almacenamiento:
Figura 1.1. Diagrama de almacenamiento de alto nivel de Red Hat Enterprise Linux
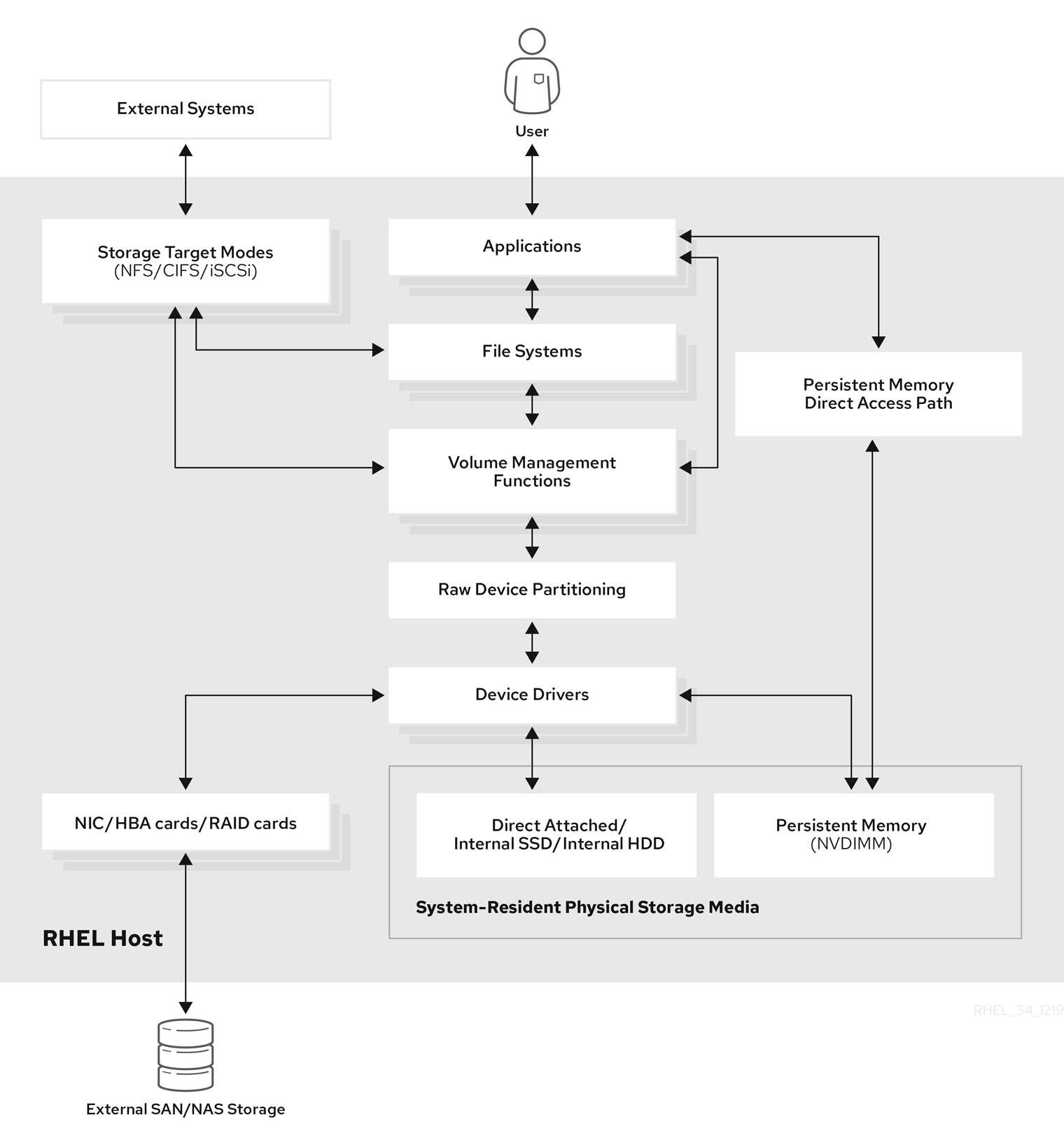
1.1. Opciones de almacenamiento local
A continuación se muestran las opciones de almacenamiento local disponibles en Red Hat Enterprise Linux 8:
- Administración básica de discos
Usando parted y fdisk, puedes crear, modificar, borrar y ver las particiones. A continuación se muestran las normas de distribución de las particiones:
- Registro de arranque maestro (MBR)
- Se utiliza con ordenadores basados en BIOS. Puede crear particiones primarias, extendidas y lógicas.
- Tabla de partición GUID (GPT)
- Utiliza un identificador único global (GUID) y proporciona un GUID único de disco y de partición.
Para cifrar la partición, puede utilizar la configuración de clave unificada de Linux en formato de disco (LUKS). Para encriptar la partición, seleccione la opción durante la instalación y se le pedirá que introduzca la frase de contraseña. Esta frase de contraseña desbloquea la clave de cifrado.
- Opciones de consumo de almacenamiento
- Gestión de los módulos de memoria doble en línea no volátil (NVDIMM)
- Es una combinación de memoria y almacenamiento. Puede habilitar y gestionar varios tipos de almacenamiento en los dispositivos NVDIMM conectados a su sistema.
- Gestión del almacenamiento en bloque
- Los datos se almacenan en forma de bloques en los que cada bloque tiene un identificador único.
- Almacenamiento de archivos
- Los datos se almacenan a nivel de archivo en el sistema local. Se puede acceder a estos datos localmente utilizando XFS (por defecto) o ext4, y a través de una red utilizando NFS y SMB.
- Volúmenes lógicos
- Gestor de volúmenes lógicos (LVM)
Crea dispositivos lógicos a partir de dispositivos físicos. El volumen lógico (LV) es una combinación de los volúmenes físicos (PV) y los grupos de volúmenes (VG). La configuración de LVM incluye:
- Creación de PV desde los discos duros.
- Creación de VG a partir de la PV.
- Creación de LV a partir del VG asignando puntos de montaje al LV.
- Optimizador virtual de datos (VDO)
Se utiliza para la reducción de datos mediante el uso de la deduplicación, la compresión y el thin provisioning. El uso de LV por debajo de VDO ayuda en:
- Ampliación del volumen de VDO
- Extensión del volumen VDO en varios dispositivos
- Sistemas de archivos locales
- XFS
- El sistema de archivos por defecto de RHEL.
- Ext4
- Un sistema de archivos heredado.
- Stratis
- Está disponible como Technology Preview. Stratis es un sistema híbrido de gestión del almacenamiento local de usuario y núcleo que admite funciones de almacenamiento avanzadas.
1.2. Opciones de almacenamiento remoto
A continuación se muestran las opciones de almacenamiento remoto disponibles en Red Hat Enterprise Linux 8:
- Opciones de conectividad de almacenamiento
- iSCSI
- RHEL 8 utiliza la herramienta targetcli para añadir, eliminar, ver y supervisar las interconexiones de almacenamiento iSCSI.
- Canal de fibra (FC)
Red Hat Enterprise Linux 8 proporciona los siguientes controladores nativos de canal de fibra:
-
lpfc -
qla2xxx -
Zfcp
-
- Memoria no volátil Express (NVMe)
Una interfaz que permite a la utilidad de software del host comunicarse con las unidades de estado sólido. Utilice los siguientes tipos de transporte de tejido para configurar NVMe sobre tejidos:
- NVMe sobre tejidos utilizando el Acceso Directo a Memoria Remota (RDMA).
- NVMe sobre telas utilizando Fibre Channel (FC)
- Device Mapper multipathing (DM Multipath)
- Permite configurar múltiples rutas de E/S entre nodos de servidor y matrices de almacenamiento en un único dispositivo. Estas rutas de E/S son conexiones físicas de SAN que pueden incluir cables, conmutadores y controladores independientes.
- Sistema de archivos en red
- NFS
- SMB
1.3. Solución en clúster del sistema de archivos GFS2
El sistema de archivos Red Hat Global File System 2 (GFS2) es un sistema de archivos de cluster simétrico de 64 bits que proporciona un espacio de nombres compartido y gestiona la coherencia entre múltiples nodos que comparten un dispositivo de bloques común. Un sistema de archivos GFS2 pretende ofrecer un conjunto de características lo más parecido posible a un sistema de archivos local y, al mismo tiempo, reforzar la coherencia total del clúster entre los nodos. Para lograrlo, los nodos emplean un esquema de bloqueo en todo el clúster para los recursos del sistema de archivos. Este esquema de bloqueo utiliza protocolos de comunicación como TCP/IP para intercambiar información de bloqueo.
En algunos casos, la API del sistema de archivos de Linux no permite que la naturaleza agrupada de GFS2 sea totalmente transparente; por ejemplo, los programas que utilizan bloqueos POSIX en GFS2 deben evitar el uso de la función GETLK ya que, en un entorno agrupado, el ID del proceso puede corresponder a un nodo diferente del clúster. Sin embargo, en la mayoría de los casos, la funcionalidad de un sistema de archivos GFS2 es idéntica a la de un sistema de archivos local.
El complemento de almacenamiento resistente de Red Hat Enterprise Linux (RHEL) proporciona GFS2 y depende del complemento de alta disponibilidad de RHEL para proporcionar la gestión de clústeres que requiere GFS2.
El módulo del kernel gfs2.ko implementa el sistema de archivos GFS2 y se carga en los nodos de cluster GFS2.
Para obtener el mejor rendimiento de GFS2, es importante tener en cuenta las consideraciones de rendimiento que se derivan del diseño subyacente. Al igual que un sistema de archivos local, GFS2 se basa en la caché de páginas para mejorar el rendimiento mediante el almacenamiento en caché local de los datos más utilizados. Para mantener la coherencia entre los nodos del clúster, el control de la caché lo proporciona la máquina de estado glock.
Recursos adicionales
- Para obtener más información sobre los sistemas de archivos GFS2, consulte la documentación Configuración de los sistemas de archivos GFS2.
1.4. Soluciones agrupadas
Esta sección proporciona una visión general de las opciones en clúster como Red Hat Gluster Storage (RHGS) o Red Hat Ceph Storage (RHCS).
1.4.1. Opción de Red Hat Gluster Storage
Red Hat Gluster Storage (RHGS) es una plataforma de almacenamiento definida por software. Agrega recursos de almacenamiento en disco de múltiples servidores en un único espacio de nombres global. GlusterFS es un sistema de archivos distribuido de código abierto. Es adecuado para soluciones en la nube e híbridas.
GlusterFS se compone de diferentes tipos de volumen, que son la base de GlusterFS y proporcionan diferentes requisitos. El volumen es una colección de los ladrillos, que son el espacio de almacenamiento en sí.
Los siguientes son los tipos de volumen GlusterFS:
- Distributed GlusterFS volume es el volumen por defecto. En este caso cada archivo se almacena en un ladrillo y no puede ser compartido entre diferentes ladrillos.
- el tipoReplicated GlusterFS volume mantiene las réplicas de los datos. En este caso, si un ladrillo falla, el usuario puede seguir accediendo a los datos.
- Distributed replicated GlusterFS volume es un volumen híbrido que distribuye réplicas en un gran número de sistemas. Es adecuado para el entorno en el que los requisitos para escalar el almacenamiento y la alta fiabilidad son críticos.
Recursos adicionales
- Para más información sobre RHGS, consulte el Manual de administración del almacenamiento gluster de Red Hat.
1.4.2. Opción de Red Hat Ceph Storage
Red Hat Ceph Storage (RHCS) es una plataforma de almacenamiento escalable, abierta y definida por software que combina la versión más estable del sistema de almacenamiento Ceph con una plataforma de gestión Ceph, utilidades de implantación y servicios de soporte.
Red Hat Ceph Storage está diseñado para la infraestructura de nube y el almacenamiento de objetos a escala web. Los clústeres de Red Hat Ceph Storage constan de los siguientes tipos de nodos:
- Nodo de administración de Red Hat Ceph Storage Ansible
Este tipo de nodo actúa como lo hacía el nodo tradicional de administración de Ceph en las versiones anteriores de Red Hat Ceph Storage. Este tipo de nodo proporciona las siguientes funciones:
- Gestión centralizada del clúster de almacenamiento
- Los archivos de configuración y las claves de Ceph
- Opcionalmente, repositorios locales para instalar Ceph en nodos que no pueden acceder a Internet por razones de seguridad
- Monitorear los nodos
Cada nodo monitor ejecuta el demonio monitor (
ceph-mon), que mantiene una copia maestra del mapa del cluster. El mapa del cluster incluye la topología del cluster. Un cliente que se conecta al clúster Ceph recupera la copia actual del mapa del clúster desde el monitor, lo que permite al cliente leer y escribir datos en el clúster.ImportanteCeph puede funcionar con un solo monitor; sin embargo, para asegurar una alta disponibilidad en un cluster de producción, Red Hat sólo soportará implementaciones con al menos tres nodos de monitorización. Red Hat recomienda desplegar un total de 5 monitores Ceph para clusters de almacenamiento que superen los 750 OSD.
- Nodos OSD
Cada nodo de Dispositivo de Almacenamiento de Objetos (OSD) ejecuta el demonio Ceph OSD (
ceph-osd), que interactúa con los discos lógicos conectados al nodo. Ceph almacena los datos en estos nodos OSD.Ceph puede funcionar con muy pocos nodos OSD, que por defecto son tres, pero los clusters de producción obtienen un mejor rendimiento a partir de escalas modestas, por ejemplo 50 OSD en un cluster de almacenamiento. Lo ideal es que un clúster Ceph tenga varios nodos OSD, lo que permite crear dominios de fallo aislados mediante la creación del mapa CRUSH.
- Nodos MDS
-
Cada nodo del Servidor de Metadatos (MDS) ejecuta el demonio MDS (
ceph-mds), que gestiona los metadatos relacionados con los archivos almacenados en el Sistema de Archivos Ceph (CephFS). El demonio MDS también coordina el acceso al clúster compartido. - Nodo de la pasarela de objetos
-
El nodo Ceph Object Gateway ejecuta el demonio Ceph RADOS Gateway (
ceph-radosgw), y es una interfaz de almacenamiento de objetos construida sobrelibradospara proporcionar a las aplicaciones una puerta de enlace RESTful a los clusters de almacenamiento Ceph. El Ceph Object Gateway soporta dos interfaces: - S3
- Proporciona la funcionalidad de almacenamiento de objetos con una interfaz que es compatible con un gran subconjunto de la API RESTful de Amazon S3.
- Swift
- Proporciona funcionalidad de almacenamiento de objetos con una interfaz que es compatible con un gran subconjunto de la API de OpenStack Swift.
Recursos adicionales
- Para más información sobre RHCS, consulte la documentación de Red Hat Ceph Storage.
Capítulo 2. Gestión del almacenamiento local mediante los roles de sistema de RHEL
Para gestionar LVM y sistemas de archivos locales (FS) mediante Ansible, puede utilizar el rol storage, que es uno de los roles de sistema RHEL disponibles en RHEL 8.
El uso del rol storage le permite automatizar la administración de sistemas de archivos en discos y volúmenes lógicos en múltiples máquinas y en todas las versiones de RHEL a partir de RHEL 7.7.
Para más información sobre los Roles del Sistema RHEL y cómo aplicarlos, vea Introducción a los Roles del Sistema RHEL.
2.1. Introducción a la función de almacenamiento
La función storage puede gestionar:
- Sistemas de archivos en discos que no han sido particionados
- Grupos de volúmenes LVM completos, incluyendo sus volúmenes lógicos y sistemas de archivos
Con el rol storage puede realizar las siguientes tareas:
- Crear un sistema de archivos
- Eliminar un sistema de archivos
- Montar un sistema de archivos
- Desmontar un sistema de archivos
- Crear grupos de volúmenes LVM
- Eliminar grupos de volúmenes LVM
- Crear volúmenes lógicos
- Eliminar volúmenes lógicos
- Crear volúmenes RAID
- Eliminar volúmenes RAID
- Crear pools LVM con RAID
- Eliminar pools LVM con RAID
2.2. Parámetros que identifican un dispositivo de almacenamiento en el rol de sistema de almacenamiento
La configuración de su rol en storage afecta sólo a los sistemas de archivos, volúmenes y pools que se enumeran en las siguientes variables.
storage_volumesLista de sistemas de archivos en todos los discos no particionados que se van a gestionar.
Actualmente, las particiones no son compatibles.
storage_poolsLista de piscinas a gestionar.
Actualmente el único tipo de pool soportado es LVM. Con LVM, los pools representan grupos de volúmenes (VGs). Bajo cada pool hay una lista de volúmenes que deben ser gestionados por el rol. Con LVM, cada volumen corresponde a un volumen lógico (LV) con un sistema de archivos.
2.3. Ejemplo de playbook de Ansible para crear un sistema de archivos XFS en un dispositivo de bloques
Esta sección proporciona un ejemplo de libro de jugadas de Ansible. Este libro de jugadas aplica el rol storage para crear un sistema de archivos XFS en un dispositivo de bloques utilizando los parámetros predeterminados.
El rol storage puede crear un sistema de archivos sólo en un disco entero no particionado o en un volumen lógico (LV). No puede crear el sistema de archivos en una partición.
Ejemplo 2.1. Un playbook que crea XFS en /dev/sdb
---
- hosts: all
vars:
storage_volumes:
- name: barefs
type: disk
disks:
- sdb
fs_type: xfs
roles:
- rhel-system-roles.storage-
El nombre del volumen (
barefsen el ejemplo) es actualmente arbitrario. El rolstorageidentifica el volumen por el dispositivo de disco listado bajo el atributodisks:. -
Puede omitir la línea
fs_type: xfsporque XFS es el sistema de archivos por defecto en RHEL 8. Para crear el sistema de archivos en un LV, proporcione la configuración de LVM bajo el atributo
disks:, incluyendo el grupo de volúmenes que lo rodea. Para obtener más detalles, consulte Ejemplo de libro de jugadas de Ansible para gestionar volúmenes lógicos.No proporcione la ruta de acceso al dispositivo LV.
Recursos adicionales
-
Para más detalles sobre los parámetros utilizados en el rol de sistema
storage, consulte el archivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
2.4. Ejemplo de playbook de Ansible para montar persistentemente un sistema de archivos
Esta sección proporciona un ejemplo de libro de jugadas de Ansible. Este libro de jugadas aplica el rol storage para montar de forma inmediata y persistente un sistema de archivos XFS.
Ejemplo 2.2. Un playbook que monta un sistema de archivos en /dev/sdb a /mnt/data
---
- hosts: all
vars:
storage_volumes:
- name: barefs
type: disk
disks:
- sdb
fs_type: xfs
mount_point: /mnt/data
roles:
- rhel-system-roles.storage-
Este libro de jugadas añade el sistema de archivos al archivo
/etc/fstab, y monta el sistema de archivos inmediatamente. -
Si el sistema de archivos del dispositivo
/dev/sdbo el directorio del punto de montaje no existen, el libro de jugadas los crea.
Recursos adicionales
-
Para más detalles sobre los parámetros utilizados en el rol de sistema
storage, consulte el archivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
2.5. Ejemplo de libro de jugadas de Ansible para gestionar volúmenes lógicos
Esta sección proporciona un ejemplo de libro de jugadas de Ansible. Este libro de jugadas aplica el rol storage para crear un volumen lógico LVM en un grupo de volúmenes.
Ejemplo 2.3. Un libro de jugadas que crea un volumen lógico mylv en el grupo de volúmenes myvg
- hosts: all
vars:
storage_pools:
- name: myvg
disks:
- sda
- sdb
- sdc
volumes:
- name: mylv
size: 2G
fs_type: ext4
mount_point: /mnt
roles:
- rhel-system-roles.storageEl grupo de volúmenes
myvgestá formado por los siguientes discos:-
/dev/sda -
/dev/sdb -
/dev/sdc
-
-
Si el grupo de volumen
myvgya existe, el libro de jugadas añade el volumen lógico al grupo de volumen. -
Si el grupo de volumen
myvgno existe, el libro de jugadas lo crea. -
El libro de jugadas crea un sistema de archivos Ext4 en el volumen lógico
mylv, y monta persistentemente el sistema de archivos en/mnt.
Recursos adicionales
-
Para más detalles sobre los parámetros utilizados en el rol de sistema
storage, consulte el archivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
2.6. Ejemplo de libro de jugadas de Ansible para activar el descarte de bloques en línea
Esta sección proporciona un ejemplo de libro de jugadas de Ansible. Este libro de jugadas aplica el rol storage para montar un sistema de archivos XFS con el descarte de bloques en línea activado.
Ejemplo 2.4. Un libro de jugadas que permite descartar bloques en línea en /mnt/data/
---
- hosts: all
vars:
storage_volumes:
- name: barefs
type: disk
disks:
- sdb
fs_type: xfs
mount_point: /mnt/data
mount_options: discard
roles:
- rhel-system-roles.storageRecursos adicionales
- Este libro de jugadas también realiza todas las operaciones del ejemplo de montaje persistente descrito en Sección 2.4, “Ejemplo de playbook de Ansible para montar persistentemente un sistema de archivos”.
-
Para más detalles sobre los parámetros utilizados en el rol de sistema
storage, consulte el archivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
2.7. Ejemplo de playbook Ansible para crear y montar un sistema de archivos Ext4
Esta sección proporciona un ejemplo de libro de jugadas de Ansible. Este libro de jugadas aplica el rol storage para crear y montar un sistema de archivos Ext4.
Ejemplo 2.5. Un playbook que crea Ext4 en /dev/sdb y lo monta en /mnt/data
---
- hosts: all
vars:
storage_volumes:
- name: barefs
type: disk
disks:
- sdb
fs_type: ext4
fs_label: label-name
mount_point: /mnt/data
roles:
- rhel-system-roles.storage-
El libro de jugadas crea el sistema de archivos en el disco
/dev/sdb. -
El libro de jugadas monta persistentemente el sistema de archivos en el directorio
/mnt/datadirectorio. -
La etiqueta del sistema de archivos es
label-name.
Recursos adicionales
-
Para más detalles sobre los parámetros utilizados en el rol de sistema
storage, consulte el archivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
2.8. Ejemplo de playbook de Ansible para crear y montar un sistema de archivos ext3
Esta sección proporciona un ejemplo de libro de jugadas de Ansible. Este libro de jugadas aplica el rol storage para crear y montar un sistema de archivos Ext3.
Ejemplo 2.6. Un playbook que crea Ext3 en /dev/sdb y lo monta en /mnt/data
---
- hosts: all
vars:
storage_volumes:
- name: barefs
type: disk
disks:
- sdb
fs_type: ext3
fs_label: label-name
mount_point: /mnt/data
roles:
- rhel-system-roles.storage-
El libro de jugadas crea el sistema de archivos en el disco
/dev/sdb. -
El libro de jugadas monta persistentemente el sistema de archivos en el directorio
/mnt/datadirectorio. -
La etiqueta del sistema de archivos es
label-name.
Recursos adicionales
-
Para más detalles sobre los parámetros utilizados en el rol de sistema
storage, consulte el archivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
2.9. Configuración de un volumen RAID mediante el rol de sistema de almacenamiento
Con el rol de sistema storage, puede configurar un volumen RAID en RHEL utilizando Red Hat Ansible Automation Platform. En esta sección aprenderá a configurar un playbook de Ansible con los parámetros disponibles para configurar un volumen RAID que se adapte a sus necesidades.
Requisitos previos
Tiene instalado Red Hat Ansible Engine en el sistema desde el que desea ejecutar el libro de jugadas.
NotaNo es necesario tener Red Hat Ansible Automation Platform instalado en los sistemas en los que se desea implementar la solución
storage.-
Tienes el paquete
rhel-system-rolesinstalado en el sistema desde el que quieres ejecutar el playbook. -
Tienes un archivo de inventario que detalla los sistemas en los que quieres desplegar un volumen RAID usando el rol de sistema
storage.
Procedimiento
Cree un nuevo
playbook.ymlarchivo con el siguiente contenido:- hosts: all vars: storage_safe_mode: false storage_volumes: - name: data type: raid disks: [sdd, sde, sdf, sdg] raid_level: raid0 raid_chunk_size: 32 KiB mount_point: /mnt/data state: present roles: - name: rhel-system-roles.storageAvisoLos nombres de los dispositivos pueden cambiar en determinadas circunstancias; por ejemplo, cuando se añade un nuevo disco a un sistema. Por lo tanto, para evitar la pérdida de datos, no se recomienda utilizar nombres de discos específicos en el libro de jugadas.
Opcional. Verificar la sintaxis del libro de jugadas.
# ansible-playbook --syntax-check playbook.ymlEjecute el libro de jugadas en su archivo de inventario:
# ansible-playbook -i inventory.file /path/to/file/playbook.yml
Recursos adicionales
- Para obtener más información sobre RAID, consulte Gestión de RAID.
-
Para obtener detalles sobre los parámetros utilizados en el rol del sistema de almacenamiento, consulte el archivo
/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
2.10. Configuración de un pool LVM con RAID utilizando el rol de sistema de almacenamiento
Con el rol de sistema storage, puede configurar un pool LVM con RAID en RHEL utilizando Red Hat Ansible Automation Platform. En esta sección aprenderá a configurar un playbook Ansible con los parámetros disponibles para configurar un pool LVM con RAID.
Requisitos previos
Tiene instalado Red Hat Ansible Engine en el sistema desde el que desea ejecutar el libro de jugadas.
NotaNo es necesario tener Red Hat Ansible Automation Platform instalado en los sistemas en los que se desea implementar la solución
storage.-
Tienes el paquete
rhel-system-rolesinstalado en el sistema desde el que quieres ejecutar el playbook. -
Tienes un archivo de inventario que detalla los sistemas en los que quieres configurar un pool LVM con RAID utilizando el rol de sistema
storage.
Procedimiento
Cree un nuevo
playbook.ymlarchivo con el siguiente contenido:- hosts: all vars: storage_safe_mode: false storage_pools: - name: my_pool type: lvm disks: [sdh, sdi] raid_level: raid1 volumes: - name: my_pool size: "1 GiB" mount_point: "/mnt/app/shared" fs_type: xfs state: present roles: - name: rhel-system-roles.storageNotaPara crear un pool LVM con RAID, debes especificar el tipo de RAID utilizando el parámetro
raid_level.Opcional. Verificar la sintaxis del libro de jugadas.
# ansible-playbook --syntax-check playbook.ymlEjecute el libro de jugadas en su archivo de inventario:
# ansible-playbook -i inventory.file /path/to/file/playbook.yml
Recursos adicionales
- Para obtener más información sobre RAID, consulte Gestión de RAID.
-
Para obtener detalles sobre los parámetros utilizados en el rol del sistema de almacenamiento, consulte el archivo
/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
2.11. Creación de un volumen encriptado LUKS utilizando el rol de almacenamiento
Puede utilizar el rol storage para crear y configurar un volumen encriptado con LUKS ejecutando un playbook de Ansible.
Requisitos previos
Tiene instalado Red Hat Ansible Engine en el sistema desde el que desea ejecutar el libro de jugadas.
NotaNo es necesario tener Red Hat Ansible Automation Platform instalado en los sistemas en los que se desea crear el volumen.
-
Tiene el paquete
rhel-system-rolesinstalado en el controlador Ansible. - Dispone de un archivo de inventario en el que se detallan los sistemas en los que desea desplegar un volumen encriptado LUKS mediante el rol de sistema de almacenamiento.
Procedimiento
Cree un nuevo
playbook.ymlarchivo con el siguiente contenido:- hosts: all vars: storage_volumes: - name: barefs type: disk disks: - sdb fs_type: xfs fs_label: label-name mount_point: /mnt/data encryption: true encryption_password: your-password roles: - rhel-system-roles.storageOpcional. Verificar la sintaxis del libro de jugadas:
# ansible-playbook --syntax-check playbook.ymlEjecute el libro de jugadas en su archivo de inventario:
# ansible-playbook -i inventory.file /path/to/file/playbook.yml
Recursos adicionales
- Para más información sobre LUKS, véase 17. Cifrado de dispositivos de bloque mediante LUKS..
-
Para más detalles sobre los parámetros utilizados en el rol de sistema
storage, consulte el archivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
Recursos adicionales
Para más información, instale el paquete
rhel-system-rolesy consulte los siguientes directorios:-
/usr/share/doc/rhel-system-roles/storage/ -
/usr/share/ansible/roles/rhel-system-roles.storage/
-
Capítulo 3. Cómo empezar con las particiones
Como administrador del sistema, puede utilizar los siguientes procedimientos para crear, eliminar y modificar varios tipos de particiones de disco.
Para obtener una visión general de las ventajas y desventajas de utilizar particiones en dispositivos de bloque, consulte el siguiente artículo de KBase: https://access.redhat.com/solutions/163853.
3.1. Visualización de la tabla de particiones
Como administrador del sistema, puede mostrar la tabla de particiones de un dispositivo de bloque para ver la disposición de las particiones y los detalles sobre las particiones individuales.
3.1.1. Visualización de la tabla de particiones con parted
Este procedimiento describe cómo ver la tabla de particiones en un dispositivo de bloque utilizando la utilidad parted.
Procedimiento
Inicie el shell interactivo
parted:# parted block-device-
Sustituya block-device por la ruta del dispositivo que desea examinar: por ejemplo,
/dev/sda.
-
Sustituya block-device por la ruta del dispositivo que desea examinar: por ejemplo,
Ver la tabla de particiones:
Impresión (parcial)
Opcionalmente, utilice el siguiente comando para cambiar a otro dispositivo que desee examinar a continuación:
(separado) seleccionar block-device
Recursos adicionales
-
La página de manual
parted(8).
3.1.2. Ejemplo de salida de parted print
Esta sección proporciona un ejemplo de salida del comando print en el shell parted y describe los campos de la salida.
Ejemplo 3.1. Salida del comando print
Model: ATA SAMSUNG MZNLN256 (scsi) Disk /dev/sda: 256GB Sector size (logical/physical): 512B/512B Partition Table: msdos Disk Flags: Number Start End Size Type File system Flags 1 1049kB 269MB 268MB primary xfs boot 2 269MB 34.6GB 34.4GB primary 3 34.6GB 45.4GB 10.7GB primary 4 45.4GB 256GB 211GB extended 5 45.4GB 256GB 211GB logical
A continuación se describen los campos:
Model: ATA SAMSUNG MZNLN256 (scsi)- El tipo de disco, el fabricante, el número de modelo y la interfaz.
Disk /dev/sda: 256GB- La ruta del archivo al dispositivo de bloque y la capacidad de almacenamiento.
Partition Table: msdos- El tipo de etiqueta del disco.
Number-
El número de la partición. Por ejemplo, la partición con número menor 1 corresponde a
/dev/sda1. StartyEnd- La ubicación en el dispositivo donde comienza y termina la partición.
Type- Los tipos válidos son metadatos, libre, primario, extendido o lógico.
File system-
El tipo de sistema de archivos. Si el campo
File systemde un dispositivo no muestra ningún valor, significa que su tipo de sistema de archivos es desconocido. La utilidadpartedno puede reconocer el sistema de archivos de los dispositivos cifrados. Flags-
Enumera las banderas establecidas para la partición. Las banderas disponibles son
boot,root,swap,hidden,raid,lvm, olba.
3.2. Creación de una tabla de particiones en un disco
Como administrador del sistema, puede formatear un dispositivo de bloque con diferentes tipos de tablas de partición para permitir el uso de particiones en el dispositivo.
Al formatear un dispositivo de bloque con una tabla de particiones se borran todos los datos almacenados en el dispositivo.
3.2.1. Consideraciones antes de modificar las particiones de un disco
Esta sección enumera los puntos clave a tener en cuenta antes de crear, eliminar o redimensionar las particiones.
Esta sección no cubre la tabla de particiones DASD, que es específica de la arquitectura IBM Z. Para obtener información sobre DASD, consulte:
- Configuración de una instancia de Linux en IBM Z
- El artículo Lo que debe saber sobre DASD en el Centro de Conocimiento de IBM
El número máximo de particiones
El número de particiones en un dispositivo está limitado por el tipo de tabla de particiones:
En un dispositivo formateado con la tabla de particiones Master Boot Record (MBR), puede tener cualquiera de los dos:
- Hasta cuatro particiones primarias, o
- Hasta tres particiones primarias, una partición extendida y múltiples particiones lógicas dentro de la extendida.
-
En un dispositivo formateado con el GUID Partition Table (GPT), el número máximo de particiones es 128. Aunque la especificación GPT permite más particiones aumentando el área reservada para la tabla de particiones, la práctica común utilizada por la utilidad
partedes limitarla a un área suficiente para 128 particiones.
Red Hat recomienda que, a menos que tenga una razón para hacer lo contrario, debería at least crear las siguientes particiones: swap, /boot/, y / (raíz).
El tamaño máximo de una partición
El tamaño de una partición en un dispositivo está limitado por el tipo de tabla de particiones:
- En un dispositivo formateado con la tabla de particiones Master Boot Record (MBR), el tamaño máximo es de 2TiB.
- En un dispositivo formateado con el GUID Partition Table (GPT), el tamaño máximo es de 8ZiB.
Si quieres crear una partición mayor de 2TiB, el disco debe estar formateado con GPT.
Alineación de tamaños
La utilidad parted le permite especificar el tamaño de la partición utilizando varios sufijos diferentes:
- MiB, GiB o TiB
Tamaño expresado en potencias de 2.
- El punto inicial de la partición se alinea con el sector exacto especificado por el tamaño.
- El punto final se alinea con el tamaño especificado menos 1 sector.
- MB, GB o TB
Tamaño expresado en potencias de 10.
El punto inicial y final se alinea dentro de la mitad de la unidad especificada: por ejemplo, ±500KB cuando se utiliza el sufijo MB.
3.2.2. Comparación de los tipos de tablas de partición
Esta sección compara las propiedades de los diferentes tipos de tablas de partición que se pueden crear en un dispositivo de bloque.
Tabla 3.1. Tipos de tablas de partición
| Tabla de partición | Número máximo de particiones | Tamaño máximo de la partición |
|---|---|---|
| Registro de arranque maestro (MBR) | 4 primarios, o 3 primarios y 12 lógicos dentro de una partición extendida | 2TiB |
| Tabla de partición GUID (GPT) | 128 | 8ZiB |
3.2.3. Particiones de disco MBR
Los diagramas de este capítulo muestran que la tabla de particiones está separada del disco real. Sin embargo, esto no es del todo exacto. En realidad, la tabla de particiones se almacena al principio del disco, antes de cualquier sistema de archivos o datos de usuario, pero para mayor claridad, están separados en los siguientes diagramas.
Figura 3.1. Disco con tabla de partición MBR
Como muestra el diagrama anterior, la tabla de particiones se divide en cuatro secciones de cuatro particiones primarias. Una partición primaria es una partición en un disco duro que sólo puede contener una unidad lógica (o sección). Cada sección puede contener la información necesaria para definir una sola partición, lo que significa que la tabla de particiones no puede definir más de cuatro particiones.
Cada entrada de la tabla de particiones contiene varias características importantes de la partición:
- Los puntos del disco donde comienza y termina la partición.
- Si la partición es active. Sólo se puede marcar una partición como active.
- El tipo de partición.
Los puntos inicial y final definen el tamaño de la partición y su ubicación en el disco. El indicador "activo" es utilizado por los cargadores de arranque de algunos sistemas operativos. En otras palabras, el sistema operativo en la partición que está marcada como "activa" es arrancado, en este caso.
El tipo es un número que identifica el uso previsto de la partición. Algunos sistemas operativos utilizan el tipo de partición para denotar un tipo de sistema de archivos específico, para marcar la partición como asociada a un sistema operativo concreto, para indicar que la partición contiene un sistema operativo de arranque, o alguna combinación de las tres.
El siguiente diagrama muestra un ejemplo de una unidad con una sola partición:
Figura 3.2. Disco con una sola partición
La única partición en este ejemplo está etiquetada como DOS. Esta etiqueta muestra el tipo de partición, siendo DOS una de las más comunes.
3.2.4. Particiones MBR extendidas
En caso de que cuatro particiones sean insuficientes para sus necesidades, puede utilizar las particiones extendidas para crear particiones adicionales. Puede hacerlo configurando el tipo de partición como "Extendida".
Una partición extendida es como una unidad de disco en sí misma - tiene su propia tabla de particiones, que apunta a una o más particiones (ahora llamadas particiones lógicas, en contraposición a las cuatro particiones primarias), contenidas completamente dentro de la propia partición extendida. El siguiente diagrama muestra una unidad de disco con una partición primaria y una partición extendida que contiene dos particiones lógicas (junto con algo de espacio libre sin particionar):
Figura 3.3. Disco con una partición MBR primaria y otra extendida
Como esta figura implica, hay una diferencia entre las particiones primarias y las lógicas - sólo puede haber hasta cuatro particiones primarias y extendidas, pero no hay un límite fijo para el número de particiones lógicas que pueden existir. Sin embargo, debido a la forma en que se accede a las particiones en Linux, no se pueden definir más de 15 particiones lógicas en una sola unidad de disco.
3.2.5. Tipos de partición MBR
La siguiente tabla muestra una lista de algunos de los tipos de partición MBR más utilizados y los números hexadecimales utilizados para representarlos.
Tabla 3.2. Tipos de partición MBR
| MBR partition type | Value | MBR partition type | Value |
| Vacío | 00 | Novell Netware 386 | 65 |
| DOS 12-bit FAT | 01 | PIC/IX | 75 |
| Raíz de XENIX | O2 | Antiguo MINIX | 80 |
| XENIX usr | O3 | Linux/MINUX | 81 |
| DOS 16 bits ⇐32M | 04 | Intercambio en Linux | 82 |
| Extendido | 05 | Linux nativo | 83 |
| DOS 16 bits >=32 | 06 | Linux ampliado | 85 |
| OS/2 HPFS | 07 | Amoeba | 93 |
| AIX | 08 | Amoeba BBT | 94 |
| AIX de arranque | 09 | BSD/386 | a5 |
| Gestor de arranque de OS/2 | 0a | OpenBSD | a6 |
| Win95 FAT32 | 0b | NEXTSTEP | a7 |
| Win95 FAT32 (LBA) | 0c | BSDI fs | b7 |
| Win95 FAT16 (LBA) | 0e | Intercambio BSDI | b8 |
| Win95 Extended (LBA) | 0f | Syrinx | c7 |
| Venix 80286 | 40 | CP/M | db |
| Novell | 51 | Acceso al DOS | e1 |
| Bota PRep | 41 | DOS R/O | e3 |
| GNU HURD | 63 | DOS secundario | f2 |
| Novell Netware 286 | 64 | BBT | ff |
3.2.6. Tabla de partición GUID
La tabla de partición GUID (GPT) es un esquema de partición basado en el uso de un identificador único global (GUID). La GPT se desarrolló para hacer frente a las limitaciones de la tabla de partición MBR, especialmente con el limitado espacio de almacenamiento máximo direccionable de un disco. A diferencia de MBR, que no puede direccionar un almacenamiento mayor de 2 TiB (equivalente a unos 2,2 TB), GPT se utiliza con discos duros de mayor tamaño; el tamaño máximo direccionable del disco es de 2,2 ZiB. Además, GPT, por defecto, permite crear hasta 128 particiones primarias. Este número puede ampliarse asignando más espacio a la tabla de particiones.
Una GPT tiene tipos de partición basados en GUIDs. Tenga en cuenta que ciertas particiones requieren un GUID específico. Por ejemplo, la partición del sistema para los cargadores de arranque EFI requiere el GUID C12A7328-F81F-11D2-BA4B-00A0C93EC93B.
Los discos GPT utilizan el direccionamiento lógico de bloques (LBA) y la disposición de las particiones es la siguiente:
- Para mantener la compatibilidad con los discos MBR, el primer sector (LBA 0) de GPT está reservado para los datos de MBR y se llama "MBR protector".
- La cabecera GPT primaria comienza en el segundo bloque lógico (LBA 1) del dispositivo. La cabecera contiene el GUID del disco, la ubicación de la tabla de particiones primaria, la ubicación de la cabecera GPT secundaria, y las sumas de comprobación CRC32 de sí misma y de la tabla de particiones primaria. También especifica el número de entradas de partición en la tabla.
- La GPT primaria incluye, por defecto 128 entradas de partición, cada una con un tamaño de entrada de 128 bytes, su GUID de tipo de partición y su GUID de partición única.
- La GPT secundaria es idéntica a la GPT primaria. Se utiliza principalmente como una tabla de respaldo para la recuperación en caso de que la tabla de partición primaria se corrompa.
- La cabecera secundaria de GPT se encuentra en el último sector lógico del disco y puede utilizarse para recuperar la información de GPT en caso de que la cabecera primaria esté dañada. Contiene el GUID del disco, la ubicación de la tabla de particiones secundarias y la cabecera GPT primaria, las sumas de comprobación CRC32 de sí mismo y de la tabla de particiones secundarias, y el número de posibles entradas de partición.
Figura 3.4. Disco con una tabla de partición GUID
Debe haber una partición de arranque de la BIOS para que el gestor de arranque se instale con éxito en un disco que contenga una tabla de particiones GPT (GUID). Esto incluye los discos inicializados por Anaconda. Si el disco ya contiene una partición de arranque del BIOS, se puede reutilizar.
3.2.7. Creación de una tabla de particiones en un disco con partición
Este procedimiento describe cómo formatear un dispositivo de bloque con una tabla de particiones utilizando la utilidad parted.
Procedimiento
Inicie el shell interactivo
parted:# parted block-device-
Sustituya block-device por la ruta del dispositivo en el que desea crear una tabla de particiones: por ejemplo,
/dev/sda.
-
Sustituya block-device por la ruta del dispositivo en el que desea crear una tabla de particiones: por ejemplo,
Determine si ya existe una tabla de particiones en el dispositivo:
Impresión (parcial)
Si el dispositivo ya contiene particiones, se eliminarán en los siguientes pasos.
Cree la nueva tabla de partición:
(parted) mklabel table-typeSustituya table-type por el tipo de tabla de partición deseado:
-
msdospara MBR -
gptpara GPT
-
Ejemplo 3.2. Creación de una tabla GPT
Por ejemplo, para crear una tabla GPT en el disco, utilice:
(parted) mklabel gpt
Los cambios empiezan a producirse en cuanto se introduce este comando, así que revísalo antes de ejecutarlo.
Ver la tabla de particiones para confirmar que la tabla de particiones existe:
Impresión (parcial)
Salga del shell
parted:(separada) dejar de fumar
Recursos adicionales
-
La página de manual
parted(8).
Próximos pasos
- Crear particiones en el dispositivo. Consulte Sección 3.3, “Crear una partición” para obtener más detalles.
3.3. Crear una partición
Como administrador del sistema, puedes crear nuevas particiones en un disco.
3.3.1. Consideraciones antes de modificar las particiones de un disco
Esta sección enumera los puntos clave a tener en cuenta antes de crear, eliminar o redimensionar las particiones.
Esta sección no cubre la tabla de particiones DASD, que es específica de la arquitectura IBM Z. Para obtener información sobre DASD, consulte:
- Configuración de una instancia de Linux en IBM Z
- El artículo Lo que debe saber sobre DASD en el Centro de Conocimiento de IBM
El número máximo de particiones
El número de particiones en un dispositivo está limitado por el tipo de tabla de particiones:
En un dispositivo formateado con la tabla de particiones Master Boot Record (MBR), puede tener cualquiera de los dos:
- Hasta cuatro particiones primarias, o
- Hasta tres particiones primarias, una partición extendida y múltiples particiones lógicas dentro de la extendida.
-
En un dispositivo formateado con el GUID Partition Table (GPT), el número máximo de particiones es 128. Aunque la especificación GPT permite más particiones aumentando el área reservada para la tabla de particiones, la práctica común utilizada por la utilidad
partedes limitarla a un área suficiente para 128 particiones.
Red Hat recomienda que, a menos que tenga una razón para hacer lo contrario, debería at least crear las siguientes particiones: swap, /boot/, y / (raíz).
El tamaño máximo de una partición
El tamaño de una partición en un dispositivo está limitado por el tipo de tabla de particiones:
- En un dispositivo formateado con la tabla de particiones Master Boot Record (MBR), el tamaño máximo es de 2TiB.
- En un dispositivo formateado con el GUID Partition Table (GPT), el tamaño máximo es de 8ZiB.
Si quieres crear una partición mayor de 2TiB, el disco debe estar formateado con GPT.
Alineación de tamaños
La utilidad parted le permite especificar el tamaño de la partición utilizando varios sufijos diferentes:
- MiB, GiB o TiB
Tamaño expresado en potencias de 2.
- El punto inicial de la partición se alinea con el sector exacto especificado por el tamaño.
- El punto final se alinea con el tamaño especificado menos 1 sector.
- MB, GB o TB
Tamaño expresado en potencias de 10.
El punto inicial y final se alinea dentro de la mitad de la unidad especificada: por ejemplo, ±500KB cuando se utiliza el sufijo MB.
3.3.2. Tipos de partición
Esta sección describe diferentes atributos que especifican el tipo de una partición.
Tipos de partición o banderas
El tipo de partición, o bandera, es utilizado por un sistema en ejecución sólo en raras ocasiones. Sin embargo, el tipo de partición es importante para los generadores sobre la marcha, como systemd-gpt-auto-generator, que utilizan el tipo de partición para, por ejemplo, identificar y montar automáticamente los dispositivos.
-
La utilidad
partedproporciona cierto control de los tipos de partición mediante la asignación del tipo de partición a flags. La utilidad parted sólo puede manejar ciertos tipos de partición: por ejemplo LVM, swap o RAID. -
La utilidad
fdiskadmite toda la gama de tipos de partición especificando códigos hexadecimales.
Tipo de sistema de archivos de la partición
La utilidad parted acepta opcionalmente un argumento de tipo de sistema de archivos al crear una partición. El valor se utiliza para:
- Establecer las banderas de la partición en MBR, o
-
Establezca el tipo de UUID de la partición en GPT. Por ejemplo, los tipos de sistema de archivos
swap,fat, ohfsestablecen diferentes GUIDs. El valor por defecto es el GUID de datos de Linux.
El argumento no modifica el sistema de archivos de la partición de ninguna manera. Sólo diferencia entre las banderas o GUIDs soportados.
Se admiten los siguientes tipos de sistemas de archivos:
-
xfs -
ext2 -
ext3 -
ext4 -
fat16 -
fat32 -
hfs -
hfs -
linux-swap -
ntfs -
reiserfs
3.3.3. Esquema de nomenclatura de las particiones
Red Hat Enterprise Linux utiliza un esquema de nomenclatura basado en archivos, con nombres de archivos en forma de /dev/xxyN.
Los nombres de dispositivos y particiones tienen la siguiente estructura:
/dev/-
Este es el nombre del directorio en el que se encuentran todos los archivos del dispositivo. Como las particiones se colocan en los discos duros, y los discos duros son dispositivos, los archivos que representan todas las posibles particiones se encuentran en
/dev. xx-
Las dos primeras letras del nombre de las particiones indican el tipo de dispositivo en el que se encuentra la partición, normalmente
sd. y-
Esta letra indica en qué dispositivo se encuentra la partición. Por ejemplo,
/dev/sdapara el primer disco duro,/dev/sdbpara el segundo, y así sucesivamente. En sistemas con más de 26 discos, puede utilizar más letras. Por ejemplo,/dev/sdaa1. N-
La letra final indica el número que representa la partición. Las cuatro primeras particiones (primarias o extendidas) están numeradas de
1a4. Las particiones lógicas comienzan en5. Por ejemplo,/dev/sda3es la tercera partición primaria o extendida en el primer disco duro, y/dev/sdb6es la segunda partición lógica en el segundo disco duro. La numeración de las particiones de la unidad sólo se aplica a las tablas de partición MBR. Tenga en cuenta que N no siempre significa partición.
Incluso si Red Hat Enterprise Linux puede identificar y referirse a all tipos de particiones de disco, podría no ser capaz de leer el sistema de archivos y por lo tanto acceder a los datos almacenados en cada tipo de partición. Sin embargo, en muchos casos, es posible acceder con éxito a los datos de una partición dedicada a otro sistema operativo.
3.3.4. Puntos de montaje y particiones de disco
En Red Hat Enterprise Linux, cada partición se utiliza para formar parte del almacenamiento necesario para soportar un único conjunto de archivos y directorios. Esto se hace utilizando el proceso conocido como mounting, que asocia una partición con un directorio. El montaje de una partición hace que su almacenamiento esté disponible a partir del directorio especificado, conocido como mount point.
Por ejemplo, si la partición /dev/sda5 está montada en /usr/, eso significaría que todos los archivos y directorios bajo /usr/ residen físicamente en /dev/sda5. Así, el archivo /usr/share/doc/FAQ/txt/Linux-FAQ se almacenaría en /dev/sda5, mientras que el archivo /etc/gdm/custom.conf no.
Continuando con el ejemplo, también es posible que uno o más directorios por debajo de /usr/ sean puntos de montaje para otras particiones. Por ejemplo, una partición /dev/sda7 podría ser montada en /usr/local, lo que significa que /usr/local/man/whatis residiría entonces en /dev/sda7 en lugar de /dev/sda5.
3.3.5. Creación de una partición con parted
Este procedimiento describe cómo crear una nueva partición en un dispositivo de bloque utilizando la utilidad parted.
Requisitos previos
- Hay una tabla de particiones en el disco. Para obtener detalles sobre cómo formatear el disco, consulte Sección 3.2, “Creación de una tabla de particiones en un disco”.
- Si la partición que quiere crear es mayor de 2TiB, el disco debe estar formateado con la tabla de particiones GUID (GPT).
Procedimiento
Inicie el shell interactivo
parted:# parted block-device-
Sustituya block-device por la ruta del dispositivo en el que desea crear una partición: por ejemplo,
/dev/sda.
-
Sustituya block-device por la ruta del dispositivo en el que desea crear una partición: por ejemplo,
Vea la tabla de particiones actual para determinar si hay suficiente espacio libre:
Impresión (parcial)
- Si no hay suficiente espacio libre, puede redimensionar una partición existente. Para más información, consulte Sección 3.5, “Cambiar el tamaño de una partición”.
A partir de la tabla de particiones, determinar:
- Los puntos inicial y final de la nueva partición
- En MBR, qué tipo de partición debe ser.
Crea la nueva partición:
(parted) mkpart part-type name fs-type start end
-
Sustituya part-type con
primary,logical, oextendeden base a lo que haya decidido de la tabla de particiones. Esto se aplica sólo a la tabla de particiones MBR. - Sustituya name con un nombre de partición arbitrario. Esto es necesario para las tablas de partición GPT.
-
Sustituir fs-type por cualquiera de los siguientes:
xfs,ext2,ext3,ext4,fat16,fat32,hfs,hfs,linux-swap,ntfs, oreiserfs. El parámetro fs-type es opcional. Tenga en cuenta quepartedno crea el sistema de archivos en la partición. -
Sustituya start y end con los tamaños que determinan los puntos inicial y final de la partición, contando desde el principio del disco. Puede utilizar sufijos de tamaño, como
512MiB,20GiB, o1.5TiB. El tamaño por defecto es de megabytes.
Ejemplo 3.3. Creación de una pequeña partición primaria
Por ejemplo, para crear una partición primaria de 1024MiB hasta 2048MiB en una tabla MBR, utilice:
(parted) mkpart primary 1024MiB 2048MiB
Los cambios empiezan a producirse en cuanto se introduce este comando, así que revísalo antes de ejecutarlo.
-
Sustituya part-type con
Vea la tabla de particiones para confirmar que la partición creada está en la tabla de particiones con el tipo de partición, el tipo de sistema de archivos y el tamaño correctos:
Impresión (parcial)
Salga del shell
parted:(separada) dejar de fumar
Utilice el siguiente comando para esperar a que el sistema registre el nuevo nodo de dispositivo:
# udevadm settle
Verifique que el kernel reconoce la nueva partición:
# cat /proc/partitions
Recursos adicionales
-
La página de manual
parted(8).
3.3.6. Establecer un tipo de partición con fdisk
Este procedimiento describe cómo establecer un tipo de partición, o bandera, utilizando la utilidad fdisk.
Requisitos previos
- Hay una partición en el disco.
Procedimiento
Inicie el shell interactivo
fdisk:# fdisk block-device-
Sustituya block-device por la ruta del dispositivo en el que desea establecer un tipo de partición: por ejemplo,
/dev/sda.
-
Sustituya block-device por la ruta del dispositivo en el que desea establecer un tipo de partición: por ejemplo,
Ver la tabla de particiones actual para determinar el número de partición menor:
Comando (m de ayuda) printPuede ver el tipo de partición actual en la columna
Typey su correspondiente ID de tipo en la columnaId.Introduzca el comando de tipo de partición y seleccione una partición utilizando su número menor:
Command (m for help): type Partition number (1,2,3 default 3): 2
Opcionalmente, enumera los códigos hexadecimales disponibles:
Código hexadecimal (escriba L para listar todos los códigos) LEstablezca el tipo de partición:
Código hexadecimal (escriba L para listar todos los códigos) 8eEscriba sus cambios y salga del shell
fdisk:Command (m for help): write The partition table has been altered. Syncing disks.Verifique los cambios:
# fdisk --list block-device
3.4. Eliminar una partición
Como administrador del sistema, puede eliminar una partición de disco que ya no se utilice para liberar espacio en el disco.
Al eliminar una partición se borran todos los datos almacenados en ella.
3.4.1. Consideraciones antes de modificar las particiones de un disco
Esta sección enumera los puntos clave a tener en cuenta antes de crear, eliminar o redimensionar las particiones.
Esta sección no cubre la tabla de particiones DASD, que es específica de la arquitectura IBM Z. Para obtener información sobre DASD, consulte:
- Configuración de una instancia de Linux en IBM Z
- El artículo Lo que debe saber sobre DASD en el Centro de Conocimiento de IBM
El número máximo de particiones
El número de particiones en un dispositivo está limitado por el tipo de tabla de particiones:
En un dispositivo formateado con la tabla de particiones Master Boot Record (MBR), puede tener cualquiera de los dos:
- Hasta cuatro particiones primarias, o
- Hasta tres particiones primarias, una partición extendida y múltiples particiones lógicas dentro de la extendida.
-
En un dispositivo formateado con el GUID Partition Table (GPT), el número máximo de particiones es 128. Aunque la especificación GPT permite más particiones aumentando el área reservada para la tabla de particiones, la práctica común utilizada por la utilidad
partedes limitarla a un área suficiente para 128 particiones.
Red Hat recomienda que, a menos que tenga una razón para hacer lo contrario, debería at least crear las siguientes particiones: swap, /boot/, y / (raíz).
El tamaño máximo de una partición
El tamaño de una partición en un dispositivo está limitado por el tipo de tabla de particiones:
- En un dispositivo formateado con la tabla de particiones Master Boot Record (MBR), el tamaño máximo es de 2TiB.
- En un dispositivo formateado con el GUID Partition Table (GPT), el tamaño máximo es de 8ZiB.
Si quieres crear una partición mayor de 2TiB, el disco debe estar formateado con GPT.
Alineación de tamaños
La utilidad parted le permite especificar el tamaño de la partición utilizando varios sufijos diferentes:
- MiB, GiB o TiB
Tamaño expresado en potencias de 2.
- El punto inicial de la partición se alinea con el sector exacto especificado por el tamaño.
- El punto final se alinea con el tamaño especificado menos 1 sector.
- MB, GB o TB
Tamaño expresado en potencias de 10.
El punto inicial y final se alinea dentro de la mitad de la unidad especificada: por ejemplo, ±500KB cuando se utiliza el sufijo MB.
3.4.2. Eliminación de una partición con parted
Este procedimiento describe cómo eliminar una partición de disco utilizando la utilidad parted.
Procedimiento
Inicie el shell interactivo
parted:# parted block-device-
Sustituya block-device por la ruta del dispositivo en el que desea eliminar una partición: por ejemplo,
/dev/sda.
-
Sustituya block-device por la ruta del dispositivo en el que desea eliminar una partición: por ejemplo,
Ver la tabla de particiones actual para determinar el número menor de la partición a eliminar:
Impresión (parcial)
Retire la partición:
(separado) rm minor-number-
Sustituya minor-number por el número menor de la partición que desea eliminar: por ejemplo,
3.
Los cambios empiezan a producirse en cuanto se introduce este comando, así que revísalo antes de ejecutarlo.
-
Sustituya minor-number por el número menor de la partición que desea eliminar: por ejemplo,
Confirme que la partición se ha eliminado de la tabla de particiones:
Impresión (parcial)
Salga del shell
parted:(separada) dejar de fumar
Verifique que el kernel sabe que la partición ha sido eliminada:
# cat /proc/partitions
-
Elimine la partición del archivo
/etc/fstabsi está presente. Encuentre la línea que declara la partición eliminada, y elimínela del archivo. Regenere las unidades de montaje para que su sistema registre la nueva configuración de
/etc/fstab:# systemctl daemon-reload
Si ha eliminado una partición swap o ha eliminado partes de LVM, elimine todas las referencias a la partición de la línea de comandos del kernel en el archivo
/etc/default/gruby regenere la configuración de GRUB:En un sistema basado en BIOS:
# grub2-mkconfig --output=/etc/grub2.cfg
En un sistema basado en UEFI:
# grub2-mkconfig --output=/etc/grub2-efi.cfg
Para registrar los cambios en el sistema de arranque temprano, reconstruya el sistema de archivos
initramfs:# dracut --force --verbose
Recursos adicionales
-
La página de manual
parted(8)
3.5. Cambiar el tamaño de una partición
Como administrador del sistema, puede ampliar una partición para utilizar el espacio de disco no utilizado, o reducir una partición para utilizar su capacidad para diferentes propósitos.
3.5.1. Consideraciones antes de modificar las particiones de un disco
Esta sección enumera los puntos clave a tener en cuenta antes de crear, eliminar o redimensionar las particiones.
Esta sección no cubre la tabla de particiones DASD, que es específica de la arquitectura IBM Z. Para obtener información sobre DASD, consulte:
- Configuración de una instancia de Linux en IBM Z
- El artículo Lo que debe saber sobre DASD en el Centro de Conocimiento de IBM
El número máximo de particiones
El número de particiones en un dispositivo está limitado por el tipo de tabla de particiones:
En un dispositivo formateado con la tabla de particiones Master Boot Record (MBR), puede tener cualquiera de los dos:
- Hasta cuatro particiones primarias, o
- Hasta tres particiones primarias, una partición extendida y múltiples particiones lógicas dentro de la extendida.
-
En un dispositivo formateado con el GUID Partition Table (GPT), el número máximo de particiones es 128. Aunque la especificación GPT permite más particiones aumentando el área reservada para la tabla de particiones, la práctica común utilizada por la utilidad
partedes limitarla a un área suficiente para 128 particiones.
Red Hat recomienda que, a menos que tenga una razón para hacer lo contrario, debería at least crear las siguientes particiones: swap, /boot/, y / (raíz).
El tamaño máximo de una partición
El tamaño de una partición en un dispositivo está limitado por el tipo de tabla de particiones:
- En un dispositivo formateado con la tabla de particiones Master Boot Record (MBR), el tamaño máximo es de 2TiB.
- En un dispositivo formateado con el GUID Partition Table (GPT), el tamaño máximo es de 8ZiB.
Si quieres crear una partición mayor de 2TiB, el disco debe estar formateado con GPT.
Alineación de tamaños
La utilidad parted le permite especificar el tamaño de la partición utilizando varios sufijos diferentes:
- MiB, GiB o TiB
Tamaño expresado en potencias de 2.
- El punto inicial de la partición se alinea con el sector exacto especificado por el tamaño.
- El punto final se alinea con el tamaño especificado menos 1 sector.
- MB, GB o TB
Tamaño expresado en potencias de 10.
El punto inicial y final se alinea dentro de la mitad de la unidad especificada: por ejemplo, ±500KB cuando se utiliza el sufijo MB.
3.5.2. Redimensionar una partición con parted
Este procedimiento redimensiona una partición de disco utilizando la utilidad parted.
Requisitos previos
Si quieres reducir una partición, haz una copia de seguridad de los datos que están almacenados en ella.
AvisoReducir una partición puede provocar la pérdida de datos en la partición.
- Si quiere redimensionar una partición para que sea mayor de 2TiB, el disco debe estar formateado con la tabla de particiones GUID (GPT). Para más detalles sobre cómo formatear el disco, consulte Sección 3.2, “Creación de una tabla de particiones en un disco”.
Procedimiento
- Si quiere reducir la partición, reduzca primero el sistema de archivos en ella para que no sea mayor que la partición redimensionada. Tenga en cuenta que XFS no admite la contracción.
Inicie el shell interactivo
parted:# parted block-device-
Sustituya block-device por la ruta del dispositivo en el que desea redimensionar una partición: por ejemplo,
/dev/sda.
-
Sustituya block-device por la ruta del dispositivo en el que desea redimensionar una partición: por ejemplo,
Ver la tabla de particiones actual:
Impresión (parcial)
A partir de la tabla de particiones, determinar:
- El número menor de la partición
- La ubicación de la partición existente y su nuevo punto final tras el redimensionamiento
Redimensiona la partición:
(parted) resizepart minor-number new-end
-
Sustituya minor-number por el número menor de la partición que está redimensionando: por ejemplo,
3. -
Sustituya new-end con el tamaño que determina el nuevo punto final de la partición redimensionada, contando desde el principio del disco. Puede utilizar sufijos de tamaño, como
512MiB,20GiB, o1.5TiB. El tamaño por defecto es de megabytes.
Ejemplo 3.4. Ampliar una partición
Por ejemplo, para ampliar una partición situada al principio del disco para que tenga un tamaño de 2GiB, utilice:
(parted) resizepart 1 2GiB
Los cambios empiezan a producirse en cuanto se introduce este comando, así que revísalo antes de ejecutarlo.
-
Sustituya minor-number por el número menor de la partición que está redimensionando: por ejemplo,
Vea la tabla de particiones para confirmar que la partición redimensionada está en la tabla de particiones con el tamaño correcto:
Impresión (parcial)
Salga del shell
parted:(separada) dejar de fumar
Verifique que el kernel reconoce la nueva partición:
# cat /proc/partitions
- Si ha ampliado la partición, amplíe también el sistema de archivos en ella. Consulte (referencia) para más detalles.
Recursos adicionales
-
La página de manual
parted(8).
3.6. Estrategias para reparticionar un disco
Hay varias maneras de reparticionar un disco. En esta sección se analizan los siguientes enfoques posibles:
- Hay espacio libre sin particionar
- Se dispone de una partición no utilizada
- Hay espacio libre en una partición utilizada activamente
Tenga en cuenta que esta sección discute los conceptos mencionados anteriormente sólo teóricamente y no incluye ningún paso de procedimiento sobre cómo realizar la repartición del disco paso a paso.
Las ilustraciones siguientes están simplificadas en aras de la claridad y no reflejan la disposición exacta de las particiones que encontrará cuando instale realmente Red Hat Enterprise Linux.
3.6.1. Uso del espacio libre no particionado
En esta situación, las particiones ya definidas no abarcan todo el disco duro, dejando espacio sin asignar que no forma parte de ninguna partición definida. El siguiente diagrama muestra cómo podría ser esto:
Figura 3.5. Disco con espacio libre no particionado
En el ejemplo anterior, el primer diagrama representa un disco con una partición primaria y una partición indefinida con espacio no asignado, y el segundo diagrama representa un disco con dos particiones definidas con espacio asignado.
Un disco duro no utilizado también entra en esta categoría. La única diferencia es que all el espacio no forma parte de ninguna partición definida.
En cualquier caso, puede crear las particiones necesarias a partir del espacio no utilizado. Este escenario es más probable para un disco nuevo. La mayoría de los sistemas operativos preinstalados están configurados para ocupar todo el espacio disponible en una unidad de disco.
3.6.2. Utilizar el espacio de una partición no utilizada
En este caso, puede tener una o más particiones que ya no utilice. El siguiente diagrama ilustra esta situación.
Figura 3.6. Disco con una partición no utilizada
En el ejemplo anterior, el primer diagrama representa un disco con una partición no utilizada, y el segundo diagrama representa la reasignación de una partición no utilizada para Linux.
En esta situación, puede utilizar el espacio asignado a la partición no utilizada. Debe eliminar la partición y luego crear la(s) partición(es) Linux apropiada(s) en su lugar. Puede eliminar la partición no utilizada y crear manualmente nuevas particiones durante el proceso de instalación.
3.6.3. Utilizar el espacio libre de una partición activa
Esta es la situación más común. También es la más difícil de manejar, porque incluso si tiene suficiente espacio libre, actualmente está asignado a una partición que ya está en uso. Si has comprado un ordenador con software preinstalado, lo más probable es que el disco duro tenga una gran partición con el sistema operativo y los datos.
Además de añadir un nuevo disco duro a su sistema, puede elegir entre repartición destructiva y no destructiva.
3.6.3.1. Repartición destructiva
Esto elimina la partición y crea varias más pequeñas en su lugar. Debes hacer una copia de seguridad completa porque cualquier dato en la partición original se destruye. Cree dos copias de seguridad, utilice la verificación (si está disponible en su software de copia de seguridad) e intente leer los datos de la copia de seguridad before borrando la partición.
Si se instaló un sistema operativo en esa partición, deberá reinstalarlo si quiere utilizar también ese sistema. Tenga en cuenta que algunos ordenadores que se venden con sistemas operativos preinstalados pueden no incluir los medios de instalación para reinstalar el sistema operativo original. Debes comprobar si esto se aplica a tu sistema before y destruir la partición original y su instalación del sistema operativo.
Después de crear una partición más pequeña para su sistema operativo existente, puede reinstalar el software, restaurar sus datos e iniciar su instalación de Red Hat Enterprise Linux.
Figura 3.7. Acción destructiva de repartición en disco
Cualquier dato presente previamente en la partición original se pierde.
3.6.3.2. Repartición no destructiva
Con la repartición no destructiva se ejecuta un programa que hace más pequeña una partición grande sin perder ninguno de los archivos almacenados en esa partición. Este método suele ser fiable, pero puede llevar mucho tiempo en unidades grandes.
El proceso de repartición no destructiva es sencillo y consta de tres pasos:
- Compresión y copia de seguridad de los datos existentes
- Redimensionar la partición existente
- Crear nueva(s) partición(es)
Cada paso se describe con más detalle.
3.6.3.2.1. Compresión de datos existentes
El primer paso es comprimir los datos de la partición existente. La razón para hacer esto es reorganizar los datos para maximizar el espacio libre disponible en el "final" de la partición.
Figura 3.8. Compresión en disco
En el ejemplo anterior, el primer diagrama representa el disco antes de la compresión, y el segundo diagrama después de la compresión.
Este paso es crucial. Sin él, la ubicación de los datos podría impedir que la partición se redimensionara en la medida deseada. Tenga en cuenta que algunos datos no se pueden mover. En este caso, se restringe severamente el tamaño de sus nuevas particiones, y podría verse obligado a reparticionar destructivamente su disco.
3.6.3.2.2. Redimensionar la partición existente
La siguiente figura muestra el proceso real de redimensionamiento. Aunque el resultado real de la operación de redimensionamiento varía, dependiendo del software utilizado, en la mayoría de los casos el espacio recién liberado se utiliza para crear una partición sin formato del mismo tipo que la partición original.
Figura 3.9. Redimensionamiento de la partición en el disco
En el ejemplo anterior, el primer diagrama representa la partición antes del redimensionamiento, y el segundo diagrama después del redimensionamiento.
Es importante entender lo que el software de redimensionamiento que usas hace con el espacio recién liberado, para que puedas tomar los pasos apropiados. En el caso ilustrado aquí, lo mejor sería borrar la nueva partición DOS y crear la o las particiones Linux apropiadas.
3.6.3.2.3. Creación de nuevas particiones
Como se mencionó en el ejemplo Redimensionamiento de la partición existente, podría ser necesario o no crear nuevas particiones. Sin embargo, a menos que su software de redimensionamiento soporte sistemas con Linux instalado, es probable que deba eliminar la partición que se creó durante el proceso de redimensionamiento.
Figura 3.10. Disco con la configuración final de la partición
En el ejemplo anterior, el primer diagrama representa el disco antes de la configuración, y el segundo diagrama después de la configuración.
Capítulo 4. Visión general de los atributos de nomenclatura persistente
Como administrador del sistema, usted necesita referirse a los volúmenes de almacenamiento utilizando atributos de nomenclatura persistentes para construir configuraciones de almacenamiento que sean confiables a través de múltiples arranques del sistema.
4.1. Desventajas de los atributos de denominación no persistentes
Red Hat Enterprise Linux proporciona varias formas de identificar los dispositivos de almacenamiento. Es importante utilizar la opción correcta para identificar cada dispositivo cuando se utiliza para evitar acceder inadvertidamente al dispositivo equivocado, particularmente cuando se instalan o reformatean unidades.
Tradicionalmente, los nombres no persistentes en forma de /dev/sd(major number)(minor number) se utilizan en Linux para referirse a los dispositivos de almacenamiento. El rango de números mayores y menores y los nombres sd asociados se asignan a cada dispositivo cuando se detecta. Esto significa que la asociación entre el rango de números mayores y menores y los nombres sd asociados puede cambiar si el orden de detección del dispositivo cambia.
Este cambio en el ordenamiento podría ocurrir en las siguientes situaciones:
- La paralelización del proceso de arranque del sistema detecta los dispositivos de almacenamiento en un orden diferente con cada arranque del sistema.
-
Un disco no se enciende o no responde a la controladora SCSI. Esto hace que no sea detectado por la sonda normal de dispositivos. El disco no es accesible para el sistema y los dispositivos subsiguientes tendrán su rango de números mayores y menores, incluyendo los nombres asociados
sddesplazados hacia abajo. Por ejemplo, si un disco normalmente referido comosdbno es detectado, un disco normalmente referido comosdcaparecerá comosdb. -
Un controlador SCSI (adaptador de bus de host, o HBA) no se inicializa, lo que provoca que no se detecten todos los discos conectados a ese HBA. A todos los discos conectados a los HBA comprobados posteriormente se les asignan diferentes rangos de números mayores y menores, y diferentes nombres asociados
sd. - El orden de inicialización del controlador cambia si hay diferentes tipos de HBA en el sistema. Esto hace que los discos conectados a esos HBAs sean detectados en un orden diferente. Esto también puede ocurrir si los HBA se mueven a diferentes ranuras PCI en el sistema.
-
Los discos conectados al sistema con adaptadores de canal de fibra, iSCSI o FCoE pueden ser inaccesibles en el momento en que se comprueban los dispositivos de almacenamiento, debido a que una matriz de almacenamiento o un interruptor intermedio están apagados, por ejemplo. Esto puede ocurrir cuando un sistema se reinicia después de un fallo de alimentación, si la matriz de almacenamiento tarda más en ponerse en línea que el sistema en arrancar. Aunque algunos controladores de Canal de Fibra soportan un mecanismo para especificar un mapeo persistente de SCSI target ID a WWPN, esto no hace que se reserven los rangos de números mayores y menores, y los nombres asociados
sd; sólo proporciona números SCSI target ID consistentes.
Estas razones hacen que no sea deseable utilizar el rango de números mayores y menores o los nombres asociados de sd al referirse a los dispositivos, como en el archivo /etc/fstab. Existe la posibilidad de que se monte el dispositivo incorrecto y se produzca una corrupción de datos.
Ocasionalmente, sin embargo, sigue siendo necesario referirse a los nombres de sd incluso cuando se utiliza otro mecanismo, como cuando se informan errores de un dispositivo. Esto se debe a que el núcleo de Linux utiliza los nombres de sd (y también las tuplas SCSI host/channel/target/LUN) en los mensajes del núcleo relativos al dispositivo.
4.2. Sistema de archivos e identificadores de dispositivos
Esta sección explica la diferencia entre los atributos persistentes que identifican los sistemas de archivos y los dispositivos de bloque.
Identificadores del sistema de archivos
Los identificadores del sistema de archivos están vinculados a un sistema de archivos concreto creado en un dispositivo de bloques. El identificador también se almacena como parte del sistema de archivos. Si copias el sistema de archivos a un dispositivo diferente, sigue llevando el mismo identificador del sistema de archivos. Por otro lado, si reescribes el dispositivo, por ejemplo, formateándolo con la utilidad mkfs, el dispositivo pierde el atributo.
Los identificadores del sistema de archivos son:
- Identificador único (UUID)
- Etiqueta
Identificadores de dispositivos
Los identificadores de dispositivo están vinculados a un dispositivo de bloque: por ejemplo, un disco o una partición. Si se reescribe el dispositivo, por ejemplo, formateándolo con la utilidad mkfs, el dispositivo mantiene el atributo, porque no se almacena en el sistema de archivos.
Los identificadores de los dispositivos son:
- Identificador mundial (WWID)
- UUID de la partición
- Número de serie
Recomendaciones
- Algunos sistemas de archivos, como los volúmenes lógicos, abarcan varios dispositivos. Red Hat recomienda acceder a estos sistemas de archivos utilizando identificadores de sistemas de archivos en lugar de identificadores de dispositivos.
4.3. Nombres de dispositivos gestionados por el mecanismo udev en /dev/disk/
Esta sección enumera los diferentes tipos de atributos de nomenclatura persistente que el servicio udev proporciona en el directorio /dev/disk/.
El mecanismo udev se utiliza para todo tipo de dispositivos en Linux, no sólo para los dispositivos de almacenamiento. En el caso de los dispositivos de almacenamiento, Red Hat Enterprise Linux contiene reglas udev que crean enlaces simbólicos en el directorio /dev/disk/. Esto le permite referirse a los dispositivos de almacenamiento por:
- Su contenido
- Un identificador único
- Su número de serie.
Aunque los atributos de nomenclatura de udev son persistentes, en el sentido de que no cambian por sí solos en los reinicios del sistema, algunos también son configurables.
4.3.1. Identificadores del sistema de archivos
El atributo UUID en /dev/disk/by-uuid/
Las entradas de este directorio proporcionan un nombre simbólico que hace referencia al dispositivo de almacenamiento mediante un unique identifier (UUID) en el contenido (es decir, los datos) almacenado en el dispositivo. Por ejemplo:
/dev/disco/por-uuid/3e6be9de-8139-11d1-9106-a43f08d823a6
Puede utilizar el UUID para referirse al dispositivo en el archivo /etc/fstab utilizando la siguiente sintaxis:
UUID=3e6be9de-8139-11d1-9106-a43f08d823a6Puedes configurar el atributo UUID al crear un sistema de archivos, y también puedes cambiarlo posteriormente.
El atributo Label en /dev/disk/by-label/
Las entradas de este directorio proporcionan un nombre simbólico que hace referencia al dispositivo de almacenamiento mediante un label en el contenido (es decir, los datos) almacenado en el dispositivo.
Por ejemplo:
/dev/disco/por-etiqueta/Boot
Puede utilizar la etiqueta para referirse al dispositivo en el archivo /etc/fstab utilizando la siguiente sintaxis:
ETIQUETA=BootPuede configurar el atributo Etiqueta al crear un sistema de archivos, y también puede modificarlo posteriormente.
4.3.2. Identificadores de dispositivos
El atributo WWID en /dev/disk/by-id/
El World Wide Identifier (WWID) es un identificador persistente, system-independent identifier, que el estándar SCSI exige a todos los dispositivos SCSI. Se garantiza que el identificador WWID es único para cada dispositivo de almacenamiento, e independiente de la ruta que se utilice para acceder al dispositivo. El identificador es una propiedad del dispositivo, pero no se almacena en el contenido (es decir, los datos) de los dispositivos.
Este identificador puede obtenerse emitiendo una consulta SCSI para recuperar los datos vitales del producto de identificación del dispositivo (página 0x83) o el número de serie de la unidad (página 0x80).
Red Hat Enterprise Linux mantiene automáticamente el mapeo apropiado del nombre del dispositivo basado en WWID a un nombre actual de /dev/sd en ese sistema. Las aplicaciones pueden usar el nombre /dev/disk/by-id/ para referenciar los datos en el disco, incluso si la ruta al dispositivo cambia, e incluso cuando se accede al dispositivo desde diferentes sistemas.
Ejemplo 4.1. Asignaciones WWID
| Enlace simbólico WWID | Dispositivo no persistente | Nota |
|---|---|---|
|
|
|
Un dispositivo con un identificador de página |
|
|
|
Un dispositivo con un identificador de página |
|
|
| Una partición de disco |
Además de estos nombres persistentes proporcionados por el sistema, también puede utilizar las reglas de udev para implementar nombres persistentes propios, asignados al WWID del almacenamiento.
El atributo UUID de la partición en /dev/disk/by-partuuid
El atributo UUID de la partición (PARTUUID) identifica las particiones tal y como se definen en la tabla de particiones GPT.
Ejemplo 4.2. Asignaciones de UUID de partición
| PARTUUID symlink | Dispositivo no persistente |
|---|---|
|
|
|
|
|
|
|
|
|
El atributo Path en /dev/disk/by-path/
Este atributo proporciona un nombre simbólico que hace referencia al dispositivo de almacenamiento mediante la dirección hardware path utilizada para acceder al dispositivo.
El atributo Path falla si cualquier parte de la ruta de hardware (por ejemplo, el ID PCI, el puerto de destino o el número LUN) cambia. Por lo tanto, el atributo Path no es fiable. Sin embargo, el atributo Path puede ser útil en uno de los siguientes escenarios:
- Es necesario identificar un disco que se piensa sustituir más adelante.
- Usted planea instalar un servicio de almacenamiento en un disco en una ubicación específica.
4.4. El identificador mundial con DM Multipath
Esta sección describe el mapeo entre el World Wide Identifier (WWID) y los nombres de dispositivos no persistentes en una configuración de Device Mapper Multipath.
Si hay varias rutas desde un sistema a un dispositivo, DM Multipath utiliza el WWID para detectarlo. DM Multipath presenta entonces un único "pseudo-dispositivo" en el directorio /dev/mapper/wwid, como /dev/mapper/3600508b400105df70000e00000ac0000.
El comando multipath -l muestra la asignación a los identificadores no persistentes:
-
Host:Channel:Target:LUN -
/dev/sdnombre -
major:minornúmero
Ejemplo 4.3. Asignaciones WWID en una configuración multirruta
Un ejemplo de salida del comando multipath -l:
3600508b400105df70000e00000ac0000 dm-2 vendor,product [size=20G][features=1 queue_if_no_path][hwhandler=0][rw] \_ round-robin 0 [prio=0][active] \_ 5:0:1:1 sdc 8:32 [active][undef] \_ 6:0:1:1 sdg 8:96 [active][undef] \_ round-robin 0 [prio=0][enabled] \_ 5:0:0:1 sdb 8:16 [active][undef] \_ 6:0:0:1 sdf 8:80 [active][undef]
DM Multipath mantiene automáticamente la asignación adecuada de cada nombre de dispositivo basado en WWID a su correspondiente nombre /dev/sd en el sistema. Estos nombres son persistentes a través de los cambios de ruta, y son consistentes cuando se accede al dispositivo desde diferentes sistemas.
Cuando se utiliza la función user_friendly_names de DM Multipath, el WWID se asigna a un nombre de la forma /dev/mapper/mpathN. Por defecto, esta asignación se mantiene en el archivo /etc/multipath/bindings. Estos nombres de mpathN nombres son persistentes mientras se mantenga ese archivo.
Si se utiliza user_friendly_names, se requieren pasos adicionales para obtener nombres consistentes en un clúster.
4.5. Limitaciones de la convención de nombres de dispositivos udev
Las siguientes son algunas limitaciones de la convención de nombres udev:
-
Es posible que el dispositivo no esté accesible en el momento en que se realiza la consulta porque el mecanismo de
udevpuede depender de la capacidad de consultar el dispositivo de almacenamiento cuando se procesan las reglas deudevpara un evento deudev. Esto es más probable que ocurra con los dispositivos de almacenamiento Fibre Channel, iSCSI o FCoE cuando el dispositivo no se encuentra en el chasis del servidor. -
El kernel puede enviar eventos
udeven cualquier momento, haciendo que las reglas sean procesadas y posiblemente haciendo que los enlaces/dev/disk/by-*/sean eliminados si el dispositivo no es accesible. -
Puede haber un retraso entre el momento en que se genera el evento
udevy el momento en que se procesa, como cuando se detecta un gran número de dispositivos y el servicioudevddel espacio de usuario tarda cierto tiempo en procesar las reglas de cada uno. Esto puede causar un retraso entre el momento en que el kernel detecta el dispositivo y cuando los nombres de/dev/disk/by-*/están disponibles. -
Los programas externos como
blkidinvocados por las reglas podrían abrir el dispositivo durante un breve período de tiempo, haciendo que el dispositivo sea inaccesible para otros usos. -
Los nombres de los dispositivos gestionados por el mecanismo
udeven /dev/disk/ pueden cambiar entre las principales versiones, lo que obliga a actualizar los enlaces.
4.6. Listado de atributos de nomenclatura persistente
Este procedimiento describe cómo averiguar los atributos de nomenclatura persistente de los dispositivos de almacenamiento no persistentes.
Procedimiento
Para listar los atributos UUID y Label, utilice la utilidad
lsblk:$ lsblk --fs storage-devicePor ejemplo:
Ejemplo 4.4. Ver el UUID y la etiqueta de un sistema de archivos
$ lsblk --fs /dev/sda1 NAME FSTYPE LABEL UUID MOUNTPOINT sda1 xfs Boot afa5d5e3-9050-48c3-acc1-bb30095f3dc4 /boot
Para listar el atributo PARTUUID, utilice la utilidad
lsblkcon la opción--output PARTUUID:$ lsblk --output PARTUUID
Por ejemplo:
Ejemplo 4.5. Ver el atributo PARTUUID de una partición
$ lsblk --output +PARTUUID /dev/sda1 NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT PARTUUID sda1 8:1 0 512M 0 part /boot 4cd1448a-01
Para listar el atributo WWID, examine los objetivos de los enlaces simbólicos en el directorio
/dev/disk/by-id/. Por ejemplo:Ejemplo 4.6. Ver el WWID de todos los dispositivos de almacenamiento del sistema
$ file /dev/disk/by-id/* /dev/disk/by-id/ata-QEMU_HARDDISK_QM00001 symbolic link to ../../sda /dev/disk/by-id/ata-QEMU_HARDDISK_QM00001-part1 symbolic link to ../../sda1 /dev/disk/by-id/ata-QEMU_HARDDISK_QM00001-part2 symbolic link to ../../sda2 /dev/disk/by-id/dm-name-rhel_rhel8-root symbolic link to ../../dm-0 /dev/disk/by-id/dm-name-rhel_rhel8-swap symbolic link to ../../dm-1 /dev/disk/by-id/dm-uuid-LVM-QIWtEHtXGobe5bewlIUDivKOz5ofkgFhP0RMFsNyySVihqEl2cWWbR7MjXJolD6g symbolic link to ../../dm-1 /dev/disk/by-id/dm-uuid-LVM-QIWtEHtXGobe5bewlIUDivKOz5ofkgFhXqH2M45hD2H9nAf2qfWSrlRLhzfMyOKd symbolic link to ../../dm-0 /dev/disk/by-id/lvm-pv-uuid-atlr2Y-vuMo-ueoH-CpMG-4JuH-AhEF-wu4QQm symbolic link to ../../sda2
4.7. Modificación de los atributos de nomenclatura persistente
Este procedimiento describe cómo cambiar el atributo de nomenclatura persistente UUID o Label de un sistema de archivos.
El cambio de los atributos de udev se produce en segundo plano y puede llevar mucho tiempo. El comando udevadm settle espera hasta que el cambio esté completamente registrado, lo que garantiza que su siguiente comando podrá utilizar el nuevo atributo correctamente.
En los siguientes comandos:
-
Sustituya new-uuid por el UUID que quieras establecer; por ejemplo,
1cdfbc07-1c90-4984-b5ec-f61943f5ea50. Puedes generar un UUID utilizando el comandouuidgen. -
Sustituya new-label por una etiqueta; por ejemplo,
backup_data.
Requisitos previos
- Si va a modificar los atributos de un sistema de archivos XFS, desmóntelo primero.
Procedimiento
Para cambiar los atributos UUID o Label de un sistema de archivos XFS, utilice la utilidad
xfs_admin:# xfs_admin -U new-uuid -L new-label storage-device # udevadm settle
Para cambiar los atributos UUID o Label de un sistema de archivos ext4, ext3, o ext2, utilice la utilidad
tune2fs:# tune2fs -U new-uuid -L new-label storage-device # udevadm settle
Para cambiar el UUID o los atributos de la etiqueta de un volumen de intercambio, utilice la utilidad
swaplabel:# swaplabel --uuid new-uuid --label new-label swap-device # udevadm settle
Capítulo 5. Uso del almacenamiento de memoria persistente NVDIMM
Como administrador del sistema, puede habilitar y gestionar varios tipos de almacenamiento en los dispositivos de memoria no volátil de doble línea (NVDIMM) conectados a su sistema.
Para instalar Red Hat Enterprise Linux 8 en un almacenamiento NVDIMM, consulte Instalación en un dispositivo NVDIMM.
5.1. La tecnología de memoria persistente NVDIMM
La memoria persistente NVDIMM, también llamada memoria de clase de almacenamiento o pmem, es una combinación de memoria y almacenamiento.
Los NVDIMM combinan la durabilidad del almacenamiento con la baja latencia de acceso y el gran ancho de banda de la RAM dinámica (DRAM):
-
El almacenamiento NVDIMM es direccionable por bytes, por lo que se puede acceder a él utilizando las instrucciones de carga y almacenamiento de la CPU. Además de las llamadas al sistema
read()ywrite(), necesarias para acceder al almacenamiento tradicional basado en bloques, NVDIMM también admite el modelo de programación de carga y almacenamiento directo. - Las características de rendimiento de los NVDIMM son similares a las de la DRAM, con una latencia de acceso muy baja, normalmente de entre decenas y cientos de nanosegundos.
- Los datos almacenados en los NVDIMM se conservan cuando se desconecta la alimentación, al igual que el almacenamiento.
- La tecnología de acceso directo (DAX) permite a las aplicaciones mapear la memoria directamente, sin pasar por la caché de páginas del sistema. Esto libera la DRAM para otros fines.
Los NVDIMM son beneficiosos en casos de uso como:
- Bases de datos
- La reducción de la latencia de acceso al almacenamiento en NVDIMM puede mejorar drásticamente el rendimiento de las bases de datos.
- Reinicio rápido
El reinicio rápido también se denomina efecto de caché caliente. Por ejemplo, un servidor de archivos no tiene ninguno de los contenidos de los archivos en la memoria después de arrancar. A medida que los clientes se conectan y leen o escriben datos, éstos se almacenan en la caché de páginas. Finalmente, la caché contiene en su mayoría datos calientes. Después de un reinicio, el sistema debe iniciar el proceso de nuevo en el almacenamiento tradicional.
NVDIMM permite que una aplicación mantenga la caché caliente a través de los reinicios si la aplicación está diseñada correctamente. En este ejemplo, no habría ninguna caché de página involucrada: la aplicación almacenaría los datos directamente en la memoria persistente.
- Caché de escritura rápida
- Los servidores de archivos no suelen acusar recibo de la solicitud de escritura de un cliente hasta que los datos están en un soporte duradero. El uso de NVDIMM como caché de escritura rápida permite a un servidor de archivos reconocer la solicitud de escritura rápidamente gracias a la baja latencia.
5.2. Intercalación de NVDIMM y regiones
Los dispositivos NVDIMM admiten la agrupación en regiones intercaladas.
Los dispositivos NVDIMM pueden agruparse en conjuntos intercalados de la misma manera que la DRAM normal. Un conjunto intercalado es similar a una configuración de nivel RAID 0 (stripe) en múltiples DIMMs. Un conjunto intercalado también se denomina region.
El intercalado tiene las siguientes ventajas:
- Los dispositivos NVDIMM se benefician de un mayor rendimiento cuando se configuran en conjuntos intercalados.
- El intercalado puede combinar varios dispositivos NVDIMM más pequeños en un dispositivo lógico más grande.
Los conjuntos de intercalación de NVDIMM se configuran en la BIOS del sistema o en el firmware UEFI.
Red Hat Enterprise Linux crea un dispositivo de región para cada conjunto de intercalación.
5.3. Espacios de nombres NVDIMM
Las regiones NVDIMM se dividen en uno o más espacios de nombres. Los espacios de nombres permiten acceder al dispositivo utilizando diferentes métodos, basados en el tipo del espacio de nombres.
Algunos dispositivos NVDIMM no admiten varios espacios de nombres en una región:
- Si su dispositivo NVDIMM admite etiquetas, puede subdividir la región en espacios de nombres.
- Si su dispositivo NVDIMM no soporta etiquetas, la región sólo puede contener un único espacio de nombres. En ese caso, Red Hat Enterprise Linux crea un espacio de nombres por defecto que cubre toda la región.
5.4. Modos de acceso NVDIMM
Puede configurar los espacios de nombres NVDIMM para utilizar cualquiera de los siguientes modos:
sectorPresenta el almacenamiento como un dispositivo de bloque rápido. Este modo es útil para las aplicaciones heredadas que no han sido modificadas para utilizar el almacenamiento NVDIMM, o para las aplicaciones que hacen uso de toda la pila de E/S, incluyendo Device Mapper.
Un dispositivo
sectorpuede utilizarse de la misma manera que cualquier otro dispositivo de bloque del sistema. Puedes crear particiones o sistemas de archivos en él, configurarlo como parte de un conjunto RAID por software o utilizarlo como dispositivo de caché paradm-cache.Los dispositivos en este modo están disponibles en
/dev/pmemNs. Consulte el valor deblockdevque aparece después de crear el espacio de nombres.devdax, o acceso directo al dispositivo (DAX)Permite que los dispositivos NVDIMM soporten la programación de acceso directo, tal y como se describe en la especificación del modelo de programación de la memoria no volátil (NVM) de la Storage Networking Industry Association (SNIA). En este modo, la E/S pasa por alto la pila de almacenamiento del kernel. Por lo tanto, no se pueden utilizar controladores Device Mapper.
El dispositivo DAX proporciona acceso bruto al almacenamiento NVDIMM utilizando un nodo de dispositivo de carácter DAX. Los datos de un dispositivo
devdaxpueden hacerse duraderos utilizando instrucciones de vaciado de caché de la CPU y de cercado. Algunas bases de datos e hipervisores de máquinas virtuales pueden beneficiarse de este modo. Los sistemas de archivos no pueden crearse en los dispositivosdevdax.Los dispositivos en este modo están disponibles en
/dev/daxN.M. Consulte el valor dechardevque aparece después de crear el espacio de nombres.fsdax, o acceso directo al sistema de archivos (DAX)Permite que los dispositivos NVDIMM soporten la programación de acceso directo, tal y como se describe en la especificación del modelo de programación de la memoria no volátil (NVM) de la Storage Networking Industry Association (SNIA). En este modo, la E/S pasa por alto la pila de almacenamiento del kernel, por lo que no se pueden utilizar muchos controladores de Device Mapper.
Puede crear sistemas de archivos en dispositivos DAX del sistema de archivos.
Los dispositivos en este modo están disponibles en
/dev/pmemN. Consulte el valor deblockdevque aparece después de crear el espacio de nombres.ImportanteLa tecnología DAX del sistema de archivos se proporciona sólo como una Muestra de Tecnología, y no es soportada por Red Hat.
rawPresenta un disco de memoria que no soporta DAX. En este modo, los espacios de nombres tienen varias limitaciones y no deben utilizarse.
Los dispositivos en este modo están disponibles en
/dev/pmemN. Consulte el valor deblockdevque aparece después de crear el espacio de nombres.
5.5. Creación de un espacio de nombres de sector en un NVDIMM para que actúe como dispositivo de bloque
Puede configurar un dispositivo NVDIMM en modo sectorial, que también se denomina legacy mode, para soportar el almacenamiento tradicional basado en bloques.
Puedes hacerlo:
- reconfigurar un espacio de nombres existente al modo sectorial, o
- crear un nuevo espacio de nombres del sector si hay espacio disponible.
Requisitos previos
- Un dispositivo NVDIMM está conectado a su sistema.
5.5.1. Instalación de ndctl
Este procedimiento instala la utilidad ndctl, que se utiliza para configurar y supervisar los dispositivos NVDIMM.
Procedimiento
Para instalar la utilidad
ndctl, utilice el siguiente comando:# yum install ndctl
5.5.2. Reconfiguración de un espacio de nombres NVDIMM existente al modo sectorial
Este procedimiento reconfigura un espacio de nombres NVDIMM al modo sectorial para su uso como dispositivo de bloque rápido.
Al reconfigurar un espacio de nombre se borran todos los datos almacenados anteriormente en el espacio de nombre.
Requisitos previos
-
La utilidad
ndctlestá instalada. Véase Sección 5.5.1, “Instalación de ndctl”.
Procedimiento
Reconfigura el espacio de nombres seleccionado al modo sectorial:
# ndctl create-namespace \ --force \ --reconfig=namespace-ID \ --mode=sectorEjemplo 5.1. Reconfiguración del espacio de nombres1.0 en modo sectorial
Para reconfigurar el espacio de nombres
namespace1.0para utilizar el modosector:# ndctl create-namespace \ --force \ --reconfig=namespace1.0 \ --mode=sector { "dev":"namespace1.0", "mode":"sector", "size":"11.99 GiB (12.87 GB)", "uuid":"5805480e-90e6-407e-96a4-23e1cde2ed78", "raw_uuid":"879d9e9f-fd43-4ed5-b64f-3bcd0781391a", "sector_size":4096, "blockdev":"pmem1s", "numa_node":1 }-
El espacio de nombres reconfigurado está ahora disponible en el directorio
/devcomo/dev/pmemNs.
Recursos adicionales
-
La página de manual
ndctl-create-namespace(1)
5.5.3. Creación de un nuevo espacio de nombres NVDIMM en modo sectorial
Este procedimiento crea un nuevo espacio de nombres de sector en un dispositivo NVDIMM, permitiéndole utilizarlo como un dispositivo de bloque tradicional.
Requisitos previos
-
La utilidad
ndctlestá instalada. Véase Sección 5.5.1, “Instalación de ndctl”. - El dispositivo NVDIMM admite etiquetas.
Procedimiento
Enumere las regiones de
pmemen su sistema que tienen espacio disponible. En el siguiente ejemplo, hay espacio disponible en las regionesregion5yregion4:# ndctl list --regions [ { "dev":"region5", "size":270582939648, "available_size":270582939648, "type":"pmem", "iset_id":-7337419320239190016 }, { "dev":"region4", "size":270582939648, "available_size":270582939648, "type":"pmem", "iset_id":-137289417188962304 } ]En cualquiera de las regiones disponibles, asigne uno o más espacios de nombres:
# ndctl create-namespace \ --mode=sector \ --region=regionN \ --size=namespace-sizeEjemplo 5.2. Creación de un espacio de nombres en una región
El siguiente comando crea un espacio de nombres de sector de 36 GiB en
region4:# ndctl create-namespace \ --mode=sector \ --region=region4 \ --size=36G-
El nuevo espacio de nombres está ahora disponible en el directorio
/devcomo/dev/pmemNs.
Recursos adicionales
-
La página de manual
ndctl-create-namespace(1)
5.6. Creación de un espacio de nombres DAX de dispositivo en un NVDIMM
Puede configurar un dispositivo NVDIMM en el modo DAX del dispositivo para soportar el almacenamiento de caracteres con capacidades de acceso directo.
Puedes hacerlo:
- reconfigurar un espacio de nombres existente al modo DAX del dispositivo, o
- crear un nuevo espacio de nombres DAX del dispositivo si hay espacio disponible.
Requisitos previos
- Un dispositivo NVDIMM está conectado a su sistema.
5.6.1. NVDIMM en modo de acceso directo al dispositivo
El acceso directo al dispositivo (device DAX, devdax) proporciona un medio para que las aplicaciones accedan directamente al almacenamiento, sin la participación de un sistema de archivos. La ventaja de device DAX es que proporciona una granularidad de fallos garantizada, que puede configurarse mediante la opción --align de la utilidad ndctl
Para la arquitectura Intel 64 y AMD64, se admiten las siguientes granularidades de fallo:
- 4 KiB
- 2 MiB
- 1 GiB
Los nodos DAX del dispositivo sólo admiten las siguientes llamadas al sistema:
-
open() -
close() -
mmap()
Las variantes read() y write() no son compatibles porque el caso de uso del dispositivo DAX está vinculado a la programación de la memoria persistente.
5.6.2. Instalación de ndctl
Este procedimiento instala la utilidad ndctl, que se utiliza para configurar y supervisar los dispositivos NVDIMM.
Procedimiento
Para instalar la utilidad
ndctl, utilice el siguiente comando:# yum install ndctl
5.6.3. Reconfiguración de un espacio de nombres NVDIMM existente al modo DAX del dispositivo
Este procedimiento reconfigura un espacio de nombres en un dispositivo NVDIMM al modo DAX del dispositivo, y le permite almacenar datos en el espacio de nombres.
Al reconfigurar un espacio de nombre se borran todos los datos almacenados anteriormente en el espacio de nombre.
Requisitos previos
-
La utilidad
ndctlestá instalada. Véase Sección 5.6.2, “Instalación de ndctl”.
Procedimiento
Enumera todos los espacios de nombres de tu sistema:
# ndctl list --namespaces --idle [ { "dev":"namespace1.0", "mode":"raw", "size":34359738368, "state":"disabled", "numa_node":1 }, { "dev":"namespace0.0", "mode":"raw", "size":34359738368, "state":"disabled", "numa_node":0 } ]Reconfigurar cualquier espacio de nombres:
# ndctl create-namespace \ --force \ --mode=devdax \ --reconfig=namespace-IDEjemplo 5.3. Reconfiguración de un espacio de nombres como dispositivo DAX
El siguiente comando reconfigura
namespace0.0para el almacenamiento de datos que soporta DAX. Está alineado con una granularidad de fallos de 2-MiB para asegurar que el sistema operativo falle en páginas de 2-MiB a la vez:# ndctl create-namespace \ --force \ --mode=devdax \ --align=2M \ --reconfig=namespace0.0-
El espacio de nombres está ahora disponible en la
/dev/daxN.Mruta de acceso.
Recursos adicionales
-
La página de manual
ndctl-create-namespace(1)
5.6.4. Creación de un nuevo espacio de nombres NVDIMM en modo DAX del dispositivo
Este procedimiento crea un nuevo espacio de nombres DAX de dispositivo en un dispositivo NVDIMM, permitiéndole almacenar datos en el espacio de nombres.
Requisitos previos
-
La utilidad
ndctlestá instalada. Véase Sección 5.6.2, “Instalación de ndctl”. - El dispositivo NVDIMM admite etiquetas.
Procedimiento
Enumere las regiones de
pmemen su sistema que tienen espacio disponible. En el siguiente ejemplo, hay espacio disponible en las regionesregion5yregion4:# ndctl list --regions [ { "dev":"region5", "size":270582939648, "available_size":270582939648, "type":"pmem", "iset_id":-7337419320239190016 }, { "dev":"region4", "size":270582939648, "available_size":270582939648, "type":"pmem", "iset_id":-137289417188962304 } ]En cualquiera de las regiones disponibles, asigne uno o más espacios de nombres:
# ndctl create-namespace \ --mode=devdax \ --region=regionN \ --size=namespace-sizeEjemplo 5.4. Creación de un espacio de nombres en una región
El siguiente comando crea un espacio de nombres DAX de dispositivo de 36-GiB en
region4. Está alineado con una granularidad de fallos de 2-MiB para asegurar que el sistema operativo falle en páginas de 2-MiB a la vez:# ndctl create-namespace \ --mode=devdax \ --region=region4 \ --align=2M \ --size=36G { "dev":"namespace1.2", "mode":"devdax", "map":"dev", "size":"35.44 GiB (38.05 GB)", "uuid":"5ae01b9c-1ebf-4fb6-bc0c-6085f73d31ee", "raw_uuid":"4c8be2b0-0842-4bcb-8a26-4bbd3b44add2", "daxregion":{ "id":1, "size":"35.44 GiB (38.05 GB)", "align":2097152, "devices":[ { "chardev":"dax1.2", "size":"35.44 GiB (38.05 GB)" } ] }, "numa_node":1 }-
El espacio de nombres está ahora disponible en la
/dev/daxN.Mruta de acceso.
Recursos adicionales
-
La página de manual
ndctl-create-namespace(1)
5.7. Creación de un espacio de nombres DAX del sistema de archivos en un NVDIMM
Puede configurar un dispositivo NVDIMM en modo DAX de sistema de archivos para que admita un sistema de archivos con capacidades de acceso directo.
Puedes hacerlo:
- reconfigurar un espacio de nombres existente al modo DAX del sistema de archivos, o
- crear un nuevo espacio de nombres DAX del sistema de archivos si hay espacio disponible.
La tecnología DAX del sistema de archivos se proporciona sólo como una Muestra de Tecnología, y no es soportada por Red Hat.
Requisitos previos
- Un dispositivo NVDIMM está conectado a su sistema.
5.7.1. NVDIMM en modo de acceso directo al sistema de archivos
Cuando un dispositivo NVDIMM está configurado en modo de acceso directo al sistema de archivos (file system DAX, fsdax), se puede crear un sistema de archivos sobre él.
Cualquier aplicación que realice una operación mmap() en un archivo de este sistema de archivos obtiene acceso directo a su almacenamiento. Esto permite el modelo de programación de acceso directo en NVDIMM. El sistema de archivos debe montarse con la opción -o dax para que se produzca la asignación directa.
Asignación de metadatos por página
Este modo requiere la asignación de metadatos por página en la DRAM del sistema o en el propio dispositivo NVDIMM. La sobrecarga de esta estructura de datos es de 64 bytes por cada página de 4 KB:
- En los dispositivos pequeños, la cantidad de sobrecarga es lo suficientemente pequeña como para caber en la DRAM sin problemas. Por ejemplo, un espacio de nombres de 16 GiB sólo requiere 256 MiB para las estructuras de página. Dado que los dispositivos NVDIMM suelen ser pequeños y caros, es preferible almacenar las estructuras de datos de seguimiento de páginas en la DRAM.
- En los dispositivos NVDIMM que tienen un tamaño de terabytes o más, la cantidad de memoria necesaria para almacenar las estructuras de datos de seguimiento de páginas puede superar la cantidad de DRAM del sistema. Un TiB de NVDIMM requiere 16 GiB sólo para las estructuras de página. Por ello, en estos casos es preferible almacenar las estructuras de datos en el propio NVDIMM.
Puede configurar dónde se almacenan los metadatos por página utilizando la opción --map al configurar un espacio de nombres:
-
Para asignar en la RAM del sistema, utilice
--map=mem. -
Para asignar en el NVDIMM, utilice
--map=dev.
Particiones y sistemas de archivos en fsdax
Cuando se crean particiones en un dispositivo fsdax, las particiones deben estar alineadas en los límites de página. En la arquitectura Intel 64 y AMD64, se requiere una alineación de al menos 4 KiB para el inicio y el final de la partición. La alineación preferida es de 2 MiB.
En Red Hat Enterprise Linux 8, tanto el sistema de archivos XFS como el ext4 pueden ser creados en NVDIMM como Technology Preview.
5.7.2. Instalación de ndctl
Este procedimiento instala la utilidad ndctl, que se utiliza para configurar y supervisar los dispositivos NVDIMM.
Procedimiento
Para instalar la utilidad
ndctl, utilice el siguiente comando:# yum install ndctl
5.7.3. Reconfiguración de un espacio de nombres NVDIMM existente al modo DAX del sistema de archivos
Este procedimiento reconfigura un espacio de nombres en un dispositivo NVDIMM al modo DAX del sistema de archivos, y le permite almacenar archivos en el espacio de nombres.
Al reconfigurar un espacio de nombre se borran todos los datos almacenados anteriormente en el espacio de nombre.
Requisitos previos
-
La utilidad
ndctlestá instalada. Véase Sección 5.7.2, “Instalación de ndctl”.
Procedimiento
Enumera todos los espacios de nombres de tu sistema:
# ndctl list --namespaces --idle [ { "dev":"namespace1.0", "mode":"raw", "size":34359738368, "state":"disabled", "numa_node":1 }, { "dev":"namespace0.0", "mode":"raw", "size":34359738368, "state":"disabled", "numa_node":0 } ]Reconfigurar cualquier espacio de nombres:
# ndctl create-namespace \ --force \ --mode=fsdax \ --reconfig=namespace-IDEjemplo 5.5. Reconfiguración de un espacio de nombres como sistema de archivos DAX
Para utilizar
namespace0.0para un sistema de archivos que soporta DAX, utilice el siguiente comando:# ndctl create-namespace \ --force \ --mode=fsdax \ --reconfig=namespace0.0 { "dev":"namespace0.0", "mode":"fsdax", "size":"32.00 GiB (34.36 GB)", "uuid":"ab91cc8f-4c3e-482e-a86f-78d177ac655d", "blockdev":"pmem0", "numa_node":0 }-
El espacio de nombres está ahora disponible en la
/dev/pmemNruta de acceso.
Recursos adicionales
-
La página de manual
ndctl-create-namespace(1)
5.7.4. Creación de un nuevo espacio de nombres NVDIMM en el modo DAX del sistema de archivos
Este procedimiento crea un nuevo espacio de nombres DAX del sistema de archivos en un dispositivo NVDIMM, permitiéndole almacenar archivos en el espacio de nombres.
Requisitos previos
-
La utilidad
ndctlestá instalada. Véase Sección 5.7.2, “Instalación de ndctl”. - El dispositivo NVDIMM admite etiquetas.
Procedimiento
Enumere las regiones de
pmemen su sistema que tienen espacio disponible. En el siguiente ejemplo, hay espacio disponible en las regionesregion5yregion4:# ndctl list --regions [ { "dev":"region5", "size":270582939648, "available_size":270582939648, "type":"pmem", "iset_id":-7337419320239190016 }, { "dev":"region4", "size":270582939648, "available_size":270582939648, "type":"pmem", "iset_id":-137289417188962304 } ]En cualquiera de las regiones disponibles, asigne uno o más espacios de nombres:
# ndctl create-namespace \ --mode=fsdax \ --region=regionN \ --size=namespace-sizeEjemplo 5.6. Creación de un espacio de nombres en una región
El siguiente comando crea un espacio de nombres DAX de 36 GiB en
region4:# ndctl create-namespace \ --mode=fsdax \ --region=region4 \ --size=36G { "dev":"namespace4.0", "mode":"fsdax", "size":"35.44 GiB (38.05 GB)", "uuid":"9c5330b5-dc90-4f7a-bccd-5b558fa881fe", "blockdev":"pmem4", "numa_node":0 }-
El espacio de nombres está ahora disponible en la
/dev/pmemNruta de acceso.
Recursos adicionales
-
La página de manual
ndctl-create-namespace(1)
5.7.5. Creación de un sistema de archivos en un dispositivo DAX del sistema de archivos
Este procedimiento crea un sistema de archivos en un dispositivo DAX del sistema de archivos y monta el sistema de archivos.
Procedimiento
Opcionalmente, cree una partición en el dispositivo DAX del sistema de archivos. Véase Sección 3.3, “Crear una partición”.
Por defecto, la herramienta
partedalinea las particiones en límites de 1 MiB. Para la primera partición, especifique 2 MiB como inicio de la partición. Si el tamaño de la partición es un múltiplo de 2 MiB, todas las demás particiones también se alinean.Cree un sistema de archivos XFS o ext4 en la partición o en el dispositivo NVDIMM.
En el caso de XFS, desactive los extensiones de datos compartidos de copia en escritura, ya que son incompatibles con la opción de montaje dax. Además, para aumentar la probabilidad de mapeos de páginas grandes, establezca la unidad de franja y el ancho de franja.
# mkfs.xfs -m reflink=0 -d su=2m,sw=1 fsdax-partition-or-deviceMonte el sistema de archivos con la opción de montaje
-o dax:# mount -o dax fsdax-partition-or-device mount-point
-
Las aplicaciones pueden ahora utilizar la memoria persistente y crear archivos en el mount-point directorio, abrir los archivos y utilizar la operación
mmappara asignar los archivos para el acceso directo.
Recursos adicionales
-
La página de manual
mkfs.xfs(8)
5.8. Solución de problemas de la memoria persistente NVDIMM
Puede detectar y corregir diferentes tipos de errores en los dispositivos NVDIMM.
Requisitos previos
- Un dispositivo NVDIMM está conectado a su sistema y configurado.
5.8.1. Instalación de ndctl
Este procedimiento instala la utilidad ndctl, que se utiliza para configurar y supervisar los dispositivos NVDIMM.
Procedimiento
Para instalar la utilidad
ndctl, utilice el siguiente comando:# yum install ndctl
5.8.2. Supervisión del estado de los NVDIMM mediante S.M.A.R.T.
Algunos dispositivos NVDIMM admiten interfaces de tecnología de autocontrol, análisis e informes (S.M.A.R.T.) para la recuperación de información sanitaria.
Supervise regularmente el estado de los NVDIMM para evitar la pérdida de datos. Si el S.M.A.R.T. informa de problemas con el estado de salud de un dispositivo NVDIMM, sustitúyalo como se describe en Sección 5.8.3, “Detección y sustitución de un dispositivo NVDIMM roto”.
Requisitos previos
En algunos sistemas, el controlador
acpi_ipmidebe ser cargado para recuperar la información de salud utilizando el siguiente comando:# modprobe acpi_ipmi
Procedimiento
Para acceder a la información sanitaria, utilice el siguiente comando:
# ndctl list --dimms --health ... { "dev":"nmem0", "id":"802c-01-1513-b3009166", "handle":1, "phys_id":22, "health": { "health_state":"ok", "temperature_celsius":25.000000, "spares_percentage":99, "alarm_temperature":false, "alarm_spares":false, "temperature_threshold":50.000000, "spares_threshold":20, "life_used_percentage":1, "shutdown_state":"clean" } } ...
Recursos adicionales
-
La página de manual
ndctl-list(1)
5.8.3. Detección y sustitución de un dispositivo NVDIMM roto
Si encuentra mensajes de error relacionados con NVDIMM reportados en el registro del sistema o por S.M.A.R.T., podría significar que un dispositivo NVDIMM está fallando. En ese caso, es necesario:
- Detectar qué dispositivo NVDIMM está fallando
- Haz una copia de seguridad de los datos almacenados en él
- Sustituir físicamente el dispositivo
Procedimiento
Para detectar el dispositivo roto, utilice el siguiente comando:
# ndctl list --dimms --regions --health --media-errors --human
El campo
badblocksmuestra qué NVDIMM está roto. Anote su nombre en el campodev.Ejemplo 5.7. Estado de salud de los dispositivos NVDIMM
En el siguiente ejemplo, el NVDIMM llamado
nmem0está roto:# ndctl list --dimms --regions --health --media-errors --human ... "regions":[ { "dev":"region0", "size":"250.00 GiB (268.44 GB)", "available_size":0, "type":"pmem", "numa_node":0, "iset_id":"0xXXXXXXXXXXXXXXXX", "mappings":[ { "dimm":"nmem1", "offset":"0x10000000", "length":"0x1f40000000", "position":1 }, { "dimm":"nmem0", "offset":"0x10000000", "length":"0x1f40000000", "position":0 } ], "badblock_count":1, "badblocks":[ { "offset":65536, "length":1, "dimms":[ "nmem0" ] } ], "persistence_domain":"memory_controller" } ] }Utilice el siguiente comando para encontrar el atributo
phys_iddel NVDIMM roto:# ndctl list --dimms --human
Por el ejemplo anterior, sabes que
nmem0es el NVDIMM roto. Por lo tanto, encuentra el atributophys_iddenmem0.Ejemplo 5.8. Los atributos phys_id de los módulos NVDIMM
En el siguiente ejemplo, el
phys_ides0x10:# ndctl list --dimms --human [ { "dev":"nmem1", "id":"XXXX-XX-XXXX-XXXXXXXX", "handle":"0x120", "phys_id":"0x1c" }, { "dev":"nmem0", "id":"XXXX-XX-XXXX-XXXXXXXX", "handle":"0x20", "phys_id":"0x10", "flag_failed_flush":true, "flag_smart_event":true } ]Utilice el siguiente comando para encontrar la ranura de memoria del NVDIMM roto:
# dmidecode
En la salida, busque la entrada en la que el identificador
Handlecoincida con el atributophys_iddel NVDIMM roto. El campoLocatorenumera la ranura de memoria utilizada por el NVDIMM roto.Ejemplo 5.9. Listado de ranuras de memoria NVDIMM
En el siguiente ejemplo, el dispositivo
nmem0coincide con el identificador0x0010y utiliza la ranura de memoriaDIMM-XXX-YYYY:# dmidecode ... Handle 0x0010, DMI type 17, 40 bytes Memory Device Array Handle: 0x0004 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: 125 GB Form Factor: DIMM Set: 1 Locator: DIMM-XXX-YYYY Bank Locator: Bank0 Type: Other Type Detail: Non-Volatile Registered (Buffered) ...Haga una copia de seguridad de todos los datos de los espacios de nombre del NVDIMM. Si no hace una copia de seguridad de los datos antes de sustituir el NVDIMM, los datos se perderán cuando retire el NVDIMM del sistema.
AvisoEn algunos casos, como cuando el NVDIMM está completamente roto, la copia de seguridad podría fallar.
Para evitarlo, supervise regularmente sus dispositivos NVDIMM utilizando el S.M.A.R.T. como se describe en Sección 5.8.2, “Supervisión del estado de los NVDIMM mediante S.M.A.R.T.” y sustituya los NVDIMM que fallen antes de que se rompan.
Utilice el siguiente comando para listar los espacios de nombres en el NVDIMM:
# ndctl list --namespaces --dimm=DIMM-ID-numberEjemplo 5.10. Listado de espacios de nombres NVDIMM
En el siguiente ejemplo, el dispositivo
nmem0contiene los espacios de nombrenamespace0.0ynamespace0.2, de los que hay que hacer una copia de seguridad:# ndctl list --namespaces --dimm=0 [ { "dev":"namespace0.2", "mode":"sector", "size":67042312192, "uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "raw_uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "sector_size":4096, "blockdev":"pmem0.2s", "numa_node":0 }, { "dev":"namespace0.0", "mode":"sector", "size":67042312192, "uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "raw_uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "sector_size":4096, "blockdev":"pmem0s", "numa_node":0 } ]- Reemplace el NVDIMM roto físicamente.
Recursos adicionales
-
La página de manual
ndctl-list(1) -
La página de manual
dmidecode(8)
Capítulo 6. Descartar los bloques no utilizados
Puede realizar o programar operaciones de descarte en los dispositivos de bloque que las admitan.
6.1. Operaciones de descarte de bloques
Las operaciones de descarte de bloques descartan los bloques que ya no están en uso por un sistema de archivos montado. Son útiles en:
- Unidades de estado sólido (SSD)
- Almacenamiento con aprovisionamiento ligero
Requisitos
El dispositivo de bloque subyacente al sistema de archivos debe soportar operaciones de descarte físico.
Las operaciones de descarte físico se admiten si el valor del /sys/block/device/queue/discard_max_bytes es distinto de cero.
6.2. Tipos de operaciones de descarte de bloques
Se pueden ejecutar operaciones de descarte utilizando diferentes métodos:
- Descarte de lotes
- Son ejecutadas explícitamente por el usuario. Descartan todos los bloques no utilizados en los sistemas de archivos seleccionados.
- Descarte en línea
- Se especifican en el momento del montaje. Se ejecutan en tiempo real sin intervención del usuario. Las operaciones de descarte en línea sólo descartan los bloques que están pasando de usados a libres.
- Descarte periódico
-
Son operaciones por lotes que se ejecutan regularmente por un servicio de
systemd.
Todos los tipos son compatibles con los sistemas de archivos XFS y ext4 y con VDO.
Recomendaciones
Red Hat recomienda utilizar el descarte por lotes o periódico.
Utilice el descarte en línea sólo si:
- la carga de trabajo del sistema es tal que el descarte por lotes no es factible, o
- las operaciones de descarte en línea son necesarias para mantener el rendimiento.
6.3. Realizar el descarte de bloques por lotes
Este procedimiento realiza una operación de descarte de bloques por lotes para descartar los bloques no utilizados en un sistema de archivos montado.
Requisitos previos
- El sistema de archivos está montado.
- El dispositivo de bloques subyacente al sistema de archivos admite operaciones de descarte físico.
Procedimiento
Utilice la utilidad
fstrim:Para realizar el descarte sólo en un sistema de archivos seleccionado, utilice:
# fstrim mount-pointPara realizar el descarte en todos los sistemas de archivos montados, utilice:
# fstrim --all
Si ejecuta el comando fstrim en:
- un dispositivo que no admite operaciones de descarte, o
- un dispositivo lógico (LVM o MD) compuesto por múltiples dispositivos, donde cualquiera de ellos no soporta operaciones de descarte,
aparece el siguiente mensaje:
# fstrim /mnt/non_discard fstrim: /mnt/non_discard: the discard operation is not supported
Recursos adicionales
-
La página de manual
fstrim(8)
6.4. Activación del descarte de bloques en línea
Este procedimiento permite realizar operaciones de descarte de bloques en línea que descartan automáticamente los bloques no utilizados en todos los sistemas de archivos compatibles.
Procedimiento
Activar el descarte en línea en el momento del montaje:
Al montar un sistema de archivos manualmente, añada la opción de montaje
-o discard:# mount -o discard device mount-point
-
Al montar un sistema de archivos de forma persistente, añada la opción
discarda la entrada de montaje en el archivo/etc/fstab.
Recursos adicionales
-
La página de manual
mount(8) -
La página de manual
fstab(5)
6.5. Habilitación del descarte de bloques en línea mediante RHEL System Roles
Esta sección describe cómo habilitar el descarte de bloques en línea utilizando el rol storage.
Requisitos previos
-
Existe un playbook de Ansible que incluye el rol
storage.
Para obtener información sobre cómo aplicar un libro de jugadas de este tipo, consulte Aplicar un rol.
6.5.1. Ejemplo de libro de jugadas de Ansible para activar el descarte de bloques en línea
Esta sección proporciona un ejemplo de libro de jugadas de Ansible. Este libro de jugadas aplica el rol storage para montar un sistema de archivos XFS con el descarte de bloques en línea activado.
Ejemplo 6.1. Un libro de jugadas que permite descartar bloques en línea en /mnt/data/
---
- hosts: all
vars:
storage_volumes:
- name: barefs
type: disk
disks:
- sdb
fs_type: xfs
mount_point: /mnt/data
mount_options: discard
roles:
- rhel-system-roles.storageRecursos adicionales
- Este libro de jugadas también realiza todas las operaciones del ejemplo de montaje persistente descrito en Sección 2.4, “Ejemplo de playbook de Ansible para montar persistentemente un sistema de archivos”.
-
Para más detalles sobre los parámetros utilizados en el rol de sistema
storage, consulte el archivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
6.6. Activación del descarte periódico de bloques
Este procedimiento habilita un temporizador systemd que descarta regularmente los bloques no utilizados en todos los sistemas de archivos compatibles.
Procedimiento
Activar e iniciar el temporizador
systemd:# systemctl enable --now fstrim.timer
Capítulo 7. Introducción a iSCSI
Red Hat Enterprise Linux 8 utiliza el shell targetcli como interfaz de línea de comandos para realizar las siguientes operaciones:
- Añada, elimine, vea y supervise las interconexiones de almacenamiento iSCSI para utilizar el hardware iSCSI.
- Exporta recursos de almacenamiento local respaldados por archivos, volúmenes, dispositivos SCSI locales o por discos RAM a sistemas remotos.
La herramienta targetcli tiene un diseño basado en un árbol que incluye el completamiento de pestañas integrado, soporte de autocompletado y documentación en línea.
7.1. Añadir un objetivo iSCSI
Como administrador del sistema, puede añadir un objetivo iSCSI utilizando la herramienta targetcli.
7.1.1. Instalación de targetcli
Instale la herramienta targetcli para añadir, supervisar y eliminar interconexiones de almacenamiento iSCSI .
Procedimiento
Instalar
targetcli:# yum install targetcli
Inicie el servicio de destino:
# systemctl start target
Configurar el objetivo para que se inicie en el momento del arranque:
# systemctl enable target
Abra el puerto
3260en el firewall y recargue la configuración del firewall:# firewall-cmd --permanent --add-port=3260/tcp Success # firewall-cmd --reload Success
Vea el diseño de
targetcli:# targetcli /> ls o- /........................................[...] o- backstores.............................[...] | o- block.................[Storage Objects: 0] | o- fileio................[Storage Objects: 0] | o- pscsi.................[Storage Objects: 0] | o- ramdisk...............[Storage Objects: 0] o- iscsi...........................[Targets: 0] o- loopback........................[Targets: 0]
Recursos adicionales
-
La página de manual
targetcli.
7.1.2. Creación de un objetivo iSCSI
La creación de un objetivo iSCSI permite al iniciador iSCSI del cliente acceder a los dispositivos de almacenamiento del servidor. Tanto los objetivos como los iniciadores tienen nombres de identificación únicos.
Requisitos previos
-
Instalado y funcionando
targetcli. Para más información, consulte Sección 7.1.1, “Instalación de targetcli”.
Procedimiento
Navegue hasta el directorio iSCSI:
/> iscsi/
NotaEl comando
cdse utiliza para cambiar de directorio, así como para listar la ruta a la que se va a mover.Utilice una de las siguientes opciones para crear un objetivo iSCSI:
Creación de un objetivo iSCSI con un nombre de objetivo por defecto:
/iscsi> create Created target iqn.2003-01.org.linux-iscsi.hostname.x8664:sn.78b473f296ff Created TPG1
Creación de un objetivo iSCSI con un nombre específico:
/iscsi> create iqn.2006-04.com.example:444 Created target iqn.2006-04.com.example:444 Created TPG1 Here
iqn.2006-04.com.example:444is target_iqn_nameSustituya iqn.2006-04.com.example:444 por el nombre del objetivo específico.
Verifique el objetivo recién creado:
/iscsi> ls o- iscsi.......................................[1 Target] o- iqn.2006-04.com.example:444................[1 TPG] o- tpg1...........................[enabled, auth] o- acls...............................[0 ACL] o- luns...............................[0 LUN] o- portals.........................[0 Portal]
Recursos adicionales
-
La página de manual
targetcli.
7.1.3. backstore iSCSI
Un backstore iSCSI permite soportar diferentes métodos de almacenamiento de los datos de un LUN exportado en la máquina local. La creación de un objeto de almacenamiento define los recursos que utiliza el backstore. Un administrador puede elegir cualquiera de los siguientes dispositivos de backstore que soporta Linux-IO (LIO):
-
fileiobackstore: Cree un objeto de almacenamientofileiosi está utilizando archivos regulares en el sistema de archivos local como imágenes de disco. Para crear un backstorefileio, consulte Sección 7.1.4, “Creación de un objeto de almacenamiento fileio”. -
blockbackstore: Cree un objeto de almacenamientoblocksi está utilizando cualquier dispositivo de bloque local y dispositivo lógico. Para crear un backstoreblock, consulte Sección 7.1.5, “Creación de un objeto de almacenamiento en bloque”. -
pscsibackstore: Cree un objeto de almacenamientopscsisi su objeto de almacenamiento admite el paso directo de comandos SCSI. Para crear un backstorepscsi, consulte Sección 7.1.6, “Creación de un objeto de almacenamiento pscsi” -
ramdiskbackstore: Cree un objeto de almacenamientoramdisksi desea crear un dispositivo temporal respaldado por RAM. Para crear un backstoreramdisk, consulte Sección 7.1.7, “Creación de un objeto de almacenamiento en disco RAM de copia de memoria”.
Recursos adicionales
-
La página de manual
targetcli.
7.1.4. Creación de un objeto de almacenamiento fileio
los objetos de almacenamientofileio pueden soportar las operaciones write_back o write_thru. La operación write_back habilita la caché del sistema de archivos local. Esto mejora el rendimiento pero aumenta el riesgo de pérdida de datos. Se recomienda utilizar write_back=false para desactivar la operación write_back en favor de la operación write_thru.
Requisitos previos
-
Instalado y funcionando
targetcli. Para más información, consulte Sección 7.1.1, “Instalación de targetcli”.
Procedimiento
Navegue hasta el directorio de backstores:
/>almacenes de fondo/
Crear un objeto de almacenamiento
fileio:/> backstores/fileio create file1 /tmp/disk1.img 200M write_back=false Created fileio file1 with size 209715200
Verifique el objeto de almacenamiento
fileiocreado:/almacenes> ls
Recursos adicionales
-
La página de manual
targetcli.
7.1.5. Creación de un objeto de almacenamiento en bloque
El controlador de bloque permite el uso de cualquier dispositivo de bloque que aparezca en el directorio /sys/block/ para ser utilizado con Linux-IO (LIO). Esto incluye dispositivos físicos (por ejemplo, HDDs, SSDs, CDs, DVDs) y dispositivos lógicos (por ejemplo, volúmenes RAID por software o hardware, o volúmenes LVM).
Requisitos previos
-
Instalado y funcionando
targetcli. Para más información, consulte Sección 7.1.1, “Instalación de targetcli”.
Procedimiento
Navegue hasta el directorio de backstores:
/>almacenes de fondo/
Crear un backstore
block:/> backstores/block create name=block_backend dev=/dev/sdb Generating a wwn serial. Created block storage object block_backend using /dev/vdb.
Verifique el objeto de almacenamiento
blockcreado:/almacenes> ls
NotaTambién puedes crear un backstore de bloques en un volumen lógico.
Recursos adicionales
-
La página de manual
targetcli.
7.1.6. Creación de un objeto de almacenamiento pscsi
Puede configurar, como backstore, cualquier objeto de almacenamiento que soporte el pass-through directo de comandos SCSI sin emulación SCSI, y con un dispositivo SCSI subyacente que aparezca con lsscsi en el /proc/scsi/scsi (como un disco duro SAS) . Este subsistema soporta SCSI-3 y superiores.
pscsi sólo debería ser utilizado por usuarios avanzados. Los comandos SCSI avanzados, como los de asignación de unidades lógicas asimétricas (ALUA) o reservas persistentes (por ejemplo, los utilizados por VMware ESX y vSphere), no suelen estar implementados en el firmware del dispositivo y pueden provocar fallos de funcionamiento o caídas. En caso de duda, utilice block backstore para las configuraciones de producción.
Requisitos previos
-
Instalado y funcionando
targetcli. Para más información, consulte Sección 7.1.1, “Instalación de targetcli”.
Procedimiento
Navegue hasta el directorio de backstores:
/>almacenes de fondo/
Cree un backstore
pscsipara un dispositivo SCSI físico, un dispositivo TYPE_ROM utilizando/dev/sr0en este ejemplo:/> backstores/pscsi/ create name=pscsi_backend dev=/dev/sr0 Generating a wwn serial. Created pscsi storage object pscsi_backend using /dev/sr0Verifique el objeto de almacenamiento
pscsicreado:/almacenes> ls
Recursos adicionales
-
La página de manual
targetcli.
7.1.7. Creación de un objeto de almacenamiento en disco RAM de copia de memoria
Los discos RAM con copia de memoria (ramdisk) proporcionan discos RAM con emulación SCSI completa y asignaciones de memoria separadas utilizando la copia de memoria para los iniciadores. Esto proporciona capacidad para multisesiones y es particularmente útil para el almacenamiento masivo rápido y volátil para fines de producción.
Requisitos previos
-
Instalado y funcionando
targetcli. Para más información, consulte Sección 7.1.1, “Instalación de targetcli”.
Procedimiento
Navegue hasta el directorio de backstores:
/>almacenes de fondo/
Crear un backstore de disco de 1GB de RAM:
/> backstores/ramdisk/ create name=rd_backend size=1GB Generating a wwn serial. Created rd_mcp ramdisk rd_backend with size 1GB.
Verifique el objeto de almacenamiento
ramdiskcreado:/almacenes> ls
Recursos adicionales
-
La página de manual
targetcli.
7.1.8. Creación de un portal iSCSI
La creación de un portal iSCSI añade una dirección IP y un puerto al objetivo que mantiene el objetivo habilitado.
Requisitos previos
-
Instalado y funcionando
targetcli. Para más información, consulte Sección 7.1.1, “Instalación de targetcli”. - Un objetivo iSCSI asociado a un Grupo de Portales de Destino (TPG). Para más información, consulte Sección 7.1.2, “Creación de un objetivo iSCSI”.
Procedimiento
Navegue hasta el directorio TPG:
/iscsi> iqn.2006-04.example:444/tpg1/
Utilice una de las siguientes opciones para crear un portal iSCSI:
La creación de un portal por defecto utiliza el puerto iSCSI por defecto
3260y permite que el objetivo escuche todas las direcciones IP en ese puerto:/iscsi/iqn.20...mple:444/tpg1> portals/ create Using default IP port 3260 Binding to INADDR_Any (0.0.0.0) Created network portal 0.0.0.0:3260
NotaCuando se crea un objetivo iSCSI, también se crea un portal por defecto. Este portal está configurado para escuchar todas las direcciones IP con el número de puerto por defecto que es:
0.0.0.0:3260.Para eliminar el portal por defecto:
/iscsi/iqn-name/tpg1/portals delete ip_address=0.0.0.0 ip_port=3260Creación de un portal con una dirección IP específica:
/iscsi/iqn.20...mple:444/tpg1> portals/ create 192.168.122.137 Using default IP port 3260 Created network portal 192.168.122.137:3260
Verifique el portal recién creado:
/iscsi/iqn.20...mple:444/tpg1> ls o- tpg.................................. [enambled, auth] o- acls ......................................[0 ACL] o- luns ......................................[0 LUN] o- portals ................................[1 Portal] o- 192.168.122.137:3260......................[OK]
Recursos adicionales
-
La página de manual
targetcli.
7.1.9. Creación de un LUN iSCSI
El número de unidad lógica (LUN) es un dispositivo físico que está respaldado por el backstore iSCSI. Cada LUN tiene un número único.
Requisitos previos
-
Instalado y funcionando
targetcli. Para más información, consulte Sección 7.1.1, “Instalación de targetcli”. - Un objetivo iSCSI asociado a un Grupo de Portales de Destino (TPG). Para más información, consulte Sección 7.1.2, “Creación de un objetivo iSCSI”.
- Objetos de almacenamiento creados. Para más información, consulte Sección 7.1.3, “backstore iSCSI”.
Procedimiento
Crear LUNs de objetos de almacenamiento ya creados:
/iscsi/iqn.20...mple:444/tpg1> luns/ create /backstores/ramdisk/rd_backend Created LUN 0. /iscsi/iqn.20...mple:444/tpg1> luns/ create /backstores/block/block_backend Created LUN 1. /iscsi/iqn.20...mple:444/tpg1> luns/ create /backstores/fileio/file1 Created LUN 2.
Verifique los LUNs creados:
/iscsi/iqn.20...mple:444/tpg1> ls o- tpg.................................. [enambled, auth] o- acls ......................................[0 ACL] o- luns .....................................[3 LUNs] | o- lun0.........................[ramdisk/ramdisk1] | o- lun1.................[block/block1 (/dev/vdb1)] | o- lun2...................[fileio/file1 (/foo.img)] o- portals ................................[1 Portal] o- 192.168.122.137:3260......................[OK]El nombre del LUN por defecto comienza en
0.ImportantePor defecto, los LUNs se crean con permisos de lectura-escritura. Si se añade un nuevo LUN después de crear las ACL, el LUN se asigna automáticamente a todas las ACL disponibles y puede causar un riesgo de seguridad. Para crear un LUN con permisos de sólo lectura, consulte Sección 7.1.10, “Creación de un LUN iSCSI de sólo lectura”.
- Configurar ACLs. Para más información, consulte Sección 7.1.11, “Creación de una ACL iSCSI”.
Recursos adicionales
-
La página de manual
targetcli.
7.1.10. Creación de un LUN iSCSI de sólo lectura
Por defecto, los LUNs se crean con permisos de lectura-escritura. Este procedimiento describe cómo crear un LUN de sólo lectura.
Requisitos previos
-
Instalado y funcionando
targetcli. Para más información, consulte Sección 7.1.1, “Instalación de targetcli”. - Un objetivo iSCSI asociado a un Grupo de Portales de Destino (TPG). Para más información, consulte Sección 7.1.2, “Creación de un objetivo iSCSI”.
- Objetos de almacenamiento creados. Para más información, consulte Sección 7.1.3, “backstore iSCSI”.
Procedimiento
Establecer permisos de sólo lectura:
/> set global auto_add_mapped_luns=false Parameter auto_add_mapped_luns is now 'false'.
Esto evita el mapeo automático de LUNs a ACLs existentes permitiendo el mapeo manual de LUNs.
Cree el LUN:
/> iscsi/target_iqn_name/tpg1/acls/initiator_iqn_name/ create mapped_lun=next_sequential_LUN_number tpg_lun_or_backstore=backstore write_protect=1
Ejemplo:
/> iscsi/iqn.2006-04.example:444/tpg1/acls/2006-04.com.example.foo:888/ create mapped_lun=1 tpg_lun_or_backstore=/backstores/block/block2 write_protect=1 Created LUN 1. Created Mapped LUN 1.
Verifique el LUN creado:
/> ls o- / ...................................................... [...] o- backstores ........................................... [...] <snip> o- iscsi ......................................... [Targets: 1] | o- iqn.2006-04.example:444 .................. [TPGs: 1] | o- tpg1 ............................ [no-gen-acls, no-auth] | o- acls ....................................... [ACLs: 2] | | o- 2006-04.com.example.foo:888 .. [Mapped LUNs: 2] | | | o- mapped_lun0 .............. [lun0 block/disk1 (rw)] | | | o- mapped_lun1 .............. [lun1 block/disk2 (ro)] | o- luns ....................................... [LUNs: 2] | | o- lun0 ...................... [block/disk1 (/dev/vdb)] | | o- lun1 ...................... [block/disk2 (/dev/vdc)] <snip>
La línea mapped_lun1 tiene ahora (
ro) al final (a diferencia de la línea mapped_lun0 (rw)) indicando que es de sólo lectura.- Configurar ACLs. Para más información, consulte Sección 7.1.11, “Creación de una ACL iSCSI”.
Recursos adicionales
-
La página de manual
targetcli.
7.1.11. Creación de una ACL iSCSI
En targetcli, se utilizan listas de control de acceso (ACL) para definir las reglas de acceso y cada iniciador tiene acceso exclusivo a un LUN. Tanto los objetivos como los iniciadores tienen nombres de identificación únicos. Debe conocer el nombre único del iniciador para configurar las ACL. Los iniciadores iSCSI se pueden encontrar en el archivo /etc/iscsi/initiatorname.iscsi.
Requisitos previos
-
Instalado y funcionando
targetcli. Para más información, consulte Sección 7.1.1, “Instalación de targetcli”. - Un objetivo iSCSI asociado a un Grupo de Portales de Destino (TPG). Para más información, consulte Sección 7.1.2, “Creación de un objetivo iSCSI”.
Procedimiento
Navegue hasta el directorio acls
/iscsi/iqn.20...mple:444/tpg1> acls/
Utilice una de las siguientes opciones para crear una ACL :
-
Utilizando el nombre del iniciador del archivo
/etc/iscsi/initiatorname.iscsien el iniciador. Utilizando un nombre que sea más fácil de recordar, consulte la sección Sección 7.1.12, “Creación de un iniciador iSCSI” para asegurarse de que la ACL coincide con el iniciador.
/iscsi/iqn.20...444/tpg1/acls> create iqn.2006-04.com.example.foo:888 Created Node ACL for iqn.2006-04.com.example.foo:888 Created mapped LUN 2. Created mapped LUN 1. Created mapped LUN 0.
NotaLa configuración global
auto_add_mapped_lunsutilizada en el ejemplo anterior, asigna automáticamente los LUNs a cualquier ACL creada.Puede establecer ACLs creadas por el usuario dentro del nodo TPG en el servidor de destino:
/iscsi/iqn.20...scsi:444/tpg1> set attribute generate_node_acls=1
-
Utilizando el nombre del iniciador del archivo
Verifique la ACL creada:
/iscsi/iqn.20...444/tpg1/acls> ls o- acls .................................................[1 ACL] o- iqn.2006-04.com.example.foo:888 ....[3 Mapped LUNs, auth] o- mapped_lun0 .............[lun0 ramdisk/ramdisk1 (rw)] o- mapped_lun1 .................[lun1 block/block1 (rw)] o- mapped_lun2 .................[lun2 fileio/file1 (rw)]
Recursos adicionales
-
La página de manual
targetcli.
7.1.12. Creación de un iniciador iSCSI
Un iniciador iSCSI forma una sesión para conectarse al objetivo iSCSI. Para más información sobre el objetivo iSCSI, consulte Sección 7.1.2, “Creación de un objetivo iSCSI”. Por defecto, se inicia un servicio iSCSI lazily y el servicio se inicia después de ejecutar el comando iscsiadm. Si la raíz no está en un dispositivo iSCSI o no hay nodos marcados con node.startup = automatic, el servicio iSCSI no se iniciará hasta que se ejecute un comando iscsiadm que requiera el inicio de iscsid o de los módulos del kernel iscsi.
Para forzar la ejecución del demonio iscsid y la carga de los módulos del kernel iSCSI:
# systemctl start iscsid.service
Requisitos previos
-
Instalar y ejecutar
targetclien un equipo servidor. Para más información, consulte Sección 7.1.1, “Instalación de targetcli”. - Un objetivo iSCSI asociado a un Grupo de Portales de Destino (TPG) en un equipo servidor. Para obtener más información, consulte Sección 7.1.2, “Creación de un objetivo iSCSI”.
- Creación de ACL iSCSI. Para más información, consulte Sección 7.1.11, “Creación de una ACL iSCSI”.
Procedimiento
Instalar
iscsi-initiator-utilsen la máquina del cliente:# yum install iscsi-initiator-utils
Comprueba el nombre del iniciador:
# cat /etc/iscsi/initiatorname.iscsi InitiatorName=2006-04.com.example.foo:888
Si la ACL recibió un nombre personalizado en Sección 7.1.11, “Creación de una ACL iSCSI”, modifique el archivo
/etc/iscsi/initiatorname.iscsien consecuencia.# vi /etc/iscsi/initiatorname.iscsi
Descubra el objetivo y acceda a él con el IQN del objetivo mostrado:
# iscsiadm -m discovery -t st -p 10.64.24.179 10.64.24.179:3260,1 iqn.2006-04.example:444 # iscsiadm -m node -T iqn.2006-04.example:444 -l Logging in to [iface: default, target: iqn.2006-04.example:444, portal: 10.64.24.179,3260] (multiple) Login to [iface: default, target: iqn.2006-04.example:444, portal: 10.64.24.179,3260] successful.
Sustituya 10.64.24.179 por la dirección IP de destino.
Puede utilizar este procedimiento para cualquier número de iniciadores conectados al mismo objetivo si sus respectivos nombres de iniciadores se añaden a la ACL como se describe en la página Sección 7.1.11, “Creación de una ACL iSCSI”.
Busque el nombre del disco iSCSI y cree un sistema de archivos en este disco iSCSI:
# grep "Attached SCSI" /var/log/messages # mkfs.ext4 /dev/disk_nameSustituya disk_name por el nombre del disco iSCSI que aparece en el archivo
/var/log/messages.Montar el sistema de archivos:
# mkdir /mount/point # mount /dev/disk_name /mount/point
Sustituya /mount/point por el punto de montaje de la partición.
Edite el archivo
/etc/fstabpara montar el sistema de archivos automáticamente cuando el sistema arranque:# vi /etc/fstab /dev/disk_name /mount/point ext4 _netdev 0 0Sustituya disk_name por el nombre del disco iSCSI y /mount/point por el punto de montaje de la partición.
Recursos adicionales
-
La página de manual
targetcli. -
La página de manual
iscsiadm.
7.1.13. Configuración del protocolo de autenticación Challenge-Handshake para el objetivo
El Challenge-Handshake Authentication Protocol (CHAP) permite al usuario proteger el objetivo con una contraseña. El iniciador debe conocer esta contraseña para poder conectarse al objetivo.
Requisitos previos
- Creación de ACL iSCSI. Para más información, consulte Sección 7.1.11, “Creación de una ACL iSCSI”.
Procedimiento
Establecer la autenticación de atributos:
/iscsi/iqn.20...mple:444/tpg1> set attribute authentication=1 Parameter authentication is now '1'.
Establecer
useridypassword:/tpg1> set auth userid=redhat Parameter userid is now 'redhat'. /iscsi/iqn.20...689dcbb3/tpg1> set auth password=redhat_passwd Parameter password is now 'redhat_passwd'.
Recursos adicionales
-
La página de manual
targetcli.
7.1.14. Configuración del protocolo de autenticación Challenge-Handshake para el iniciador
El Challenge-Handshake Authentication Protocol (CHAP) permite al usuario proteger el objetivo con una contraseña. El iniciador debe conocer esta contraseña para poder conectarse al objetivo.
Requisitos previos
- Se ha creado un iniciador iSCSI. Para más información, consulte Sección 7.1.12, “Creación de un iniciador iSCSI”.
-
Establezca el
CHAPpara el objetivo. Para más información, consulte Sección 7.1.13, “Configuración del protocolo de autenticación Challenge-Handshake para el objetivo”.
Procedimiento
Active la autenticación CHAP en el archivo
iscsid.conf:# vi /etc/iscsi/iscsid.conf node.session.auth.authmethod = CHAP
Por defecto, la dirección
node.session.auth.authmethodestá configurada comoNoneAñada el objetivo
usernameypassworden el archivoiscsid.conf:node.session.auth.username = redhat node.session.auth.password = redhat_passwd
Inicie el demonio
iscsid:# systemctl start iscsid.service
Recursos adicionales
-
La página de manual
iscsiadm
7.2. Supervisión de una sesión iSCSI
Como administrador del sistema, puede supervisar la sesión iSCSI utilizando la utilidad iscsiadm.
7.2.1. Monitorización de una sesión iSCSI mediante la utilidad iscsiadm
Este procedimiento describe cómo supervisar la sesión iscsi utilizando la utilidad iscsiadm.
Por defecto, un servicio iSCSI se inicia lazily y el servicio se inicia después de ejecutar el comando iscsiadm. Si la raíz no está en un dispositivo iSCSI o no hay nodos marcados con node.startup = automatic entonces el servicio iSCSI no se iniciará hasta que se ejecute un comando iscsiadm que requiera el inicio de iscsid o de los módulos del kernel iscsi.
Para forzar la ejecución del demonio iscsid y la carga de los módulos del kernel iSCSI:
# systemctl start iscsid.service
Requisitos previos
Instalado iscsi-initiator-utils en la máquina cliente:
yum install iscsi-initiator-utils
Procedimiento
Encuentre información sobre las sesiones de carrera:
# iscsiadm -m session -P 3
Este comando muestra el estado de la sesión o del dispositivo, el ID de la sesión (sid), algunos parámetros negociados y los dispositivos SCSI accesibles a través de la sesión.
Para una salida más corta, por ejemplo, para mostrar sólo la cartografía
sid-to-node, ejecute:# iscsiadm -m session -P 0 or # iscsiadm -m session tcp [2] 10.15.84.19:3260,2 iqn.1992-08.com.netapp:sn.33615311 tcp [3] 10.15.85.19:3260,3 iqn.1992-08.com.netapp:sn.33615311Estos comandos imprimen la lista de sesiones en ejecución en el siguiente formato:
driver [sid] target_ip:port,target_portal_group_tag proper_target_name.
Recursos adicionales
-
/usr/share/doc/iscsi-initiator-utils-version/READMEarchivo. -
La página de manual
iscsiadm.
7.3. Eliminación de un objetivo iSCSI
Como administrador del sistema, puede eliminar el objetivo iSCSI.
7.3.1. Eliminación de un objeto iSCSI mediante la herramienta targetcli
Este procedimiento describe cómo eliminar los objetos iSCSI utilizando la herramienta targetcli.
Procedimiento
Desconéctate del objetivo:
# iscsiadm -m node -T iqn.2006-04.example:444 -uPara obtener más información sobre cómo iniciar sesión en el objetivo, consulte Sección 7.1.12, “Creación de un iniciador iSCSI”.
Elimina todo el objetivo, incluyendo todas las ACLs, LUNs y portales:
/> iscsi/ borrar iqn.2006-04.com.example:444Sustituya iqn.2006-04.com.example:444 por el nombre de target_iqn_.
Para eliminar un backstore iSCSI:
/> backstores/backstore-type/ borrar block_backend
-
Sustituya backstore-type por
fileio,block,pscsi, oramdisk. - Sustituya block_backend por el backstore-name que desea eliminar.
-
Sustituya backstore-type por
Para eliminar partes de un objetivo iSCSI, como una ACL:
/> /iscsi/nombre-iqn/tpg/acls/ borrar iqn.2006-04.com.example:444
Vea los cambios:
/> iscsi/ ls
Recursos adicionales
-
La página de manual
targetcli.
7.4. DM Multipath anula el tiempo de espera del dispositivo
La opción recovery_tmo sysfs controla el tiempo de espera para un dispositivo iSCSI concreto. Las siguientes opciones anulan globalmente los valores de recovery_tmo:
-
La opción de configuración
replacement_timeoutanula globalmente el valor derecovery_tmopara todos los dispositivos iSCSI. Para todos los dispositivos iSCSI gestionados por DM Multipath, la opción
fast_io_fail_tmoen DM Multipath anula globalmente el valor derecovery_tmo.La opción
fast_io_fail_tmoen DM Multipath también anula la opciónfast_io_fail_tmoen los dispositivos Fibre Channel.
La opción de DM Multipath fast_io_fail_tmo tiene prioridad sobre replacement_timeout. Red Hat no recomienda utilizar replacement_timeout para anular recovery_tmo en los dispositivos gestionados por DM Multipath porque DM Multipath siempre restablece recovery_tmo cuando el servicio multipathd se recarga.
Capítulo 8. Uso de dispositivos Fibre Channel
RHEL 8 proporciona los siguientes controladores nativos de canal de fibra:
-
lpfc -
qla2xxx -
zfcp
8.1. Cambio de tamaño de las unidades lógicas de Fibre Channel
Como administrador del sistema, puede cambiar el tamaño de las unidades lógicas de Fibre Channel.
Procedimiento
Para determinar qué dispositivos son rutas para una unidad lógica
multipath:multipath -ll
Para volver a escanear unidades lógicas de canal de fibra en un sistema que utiliza multipathing:
$ echo 1 > /sys/block/sdX/device/rescan
Recursos adicionales
-
La página de manual
multipath.
8.2. Determinación del comportamiento de la pérdida de enlace del dispositivo que utiliza el canal de fibra
Si un controlador implementa la llamada de retorno de Transporte dev_loss_tmo, los intentos de acceso a un dispositivo a través de un enlace se bloquearán cuando se detecte un problema de transporte.
Procedimiento
Determina el estado de un puerto remoto:
$ cat /sys/class/fc_remote_port/rport-host:bus:remote-port/port_state
Este comando devuelve una de las siguientes salidas:
-
Blockedcuando el puerto remoto junto con los dispositivos a los que se accede a través de él están bloqueados. -
Onlinesi el puerto remoto funciona normalmente
Si el problema no se resuelve en
dev_loss_tmosegundos, elrporty los dispositivos se desbloquearán. Todas las E/S que se ejecuten en ese dispositivo junto con cualquier nueva E/S enviada a ese dispositivo fallarán.-
Cuando una pérdida de enlace supera dev_loss_tmo, los scsi_device y sdN se eliminan los dispositivos. Normalmente, la clase de Canal de Fibra dejará el dispositivo como está; es decir /dev/sdx permanecerá /dev/sdx. Esto se debe a que el controlador de Canal de Fibra guarda el enlace de destino y cuando el puerto de destino regresa, las direcciones SCSI se recrean fielmente. Sin embargo, esto no se puede garantizar; el dispositivo sdx dispositivo se restaurará sólo si no se realiza ningún cambio adicional en la configuración de los LUNs en la caja de almacenamiento.
Recursos adicionales
-
La página de manual
multipath.conf A través de
multipath, puede modificar el comportamiento de pérdida de enlaces del dispositivo. Para obtener más información, consulte los siguientes artículos de la base de conocimientos:
8.3. Archivos de configuración del canal de fibra
A continuación se muestra la lista de archivos de configuración en el directorio /sys/class/ que proporcionan la API de espacio de usuario para el canal de fibra.
Los artículos utilizan las siguientes variables:
H- Número de anfitrión
B- Número de autobús
T- Objetivo
L- Unidad lógica (LUNs)
R- Número de puerto remoto
Si su sistema utiliza software multipath, Red Hat recomienda que consulte a su proveedor de hardware antes de cambiar cualquiera de los valores descritos en esta sección.
Configuración del transporte en /sys/class/fc_transport/targetH:B:T/
port_id- ID/dirección de puerto de 24 bits
node_name- Nombre del nodo de 64 bits
port_name- Nombre del puerto de 64 bits
Configuración de puertos remotos en /sys/class/fc_remote_ports/rport-H:B-R/
-
port_id -
node_name -
port_name dev_loss_tmoControla cuándo se elimina el dispositivo scsi del sistema. Después de que
dev_loss_tmose dispare, el dispositivo scsi se elimina. En el archivomultipath.conf, se puede establecerdev_loss_tmoainfinity.En Red Hat Enterprise Linux 8, si no establece la opción
fast_io_fail_tmo,dev_loss_tmose limita a600segundos. Por defecto,fast_io_fail_tmose establece en5segundos en Red Hat Enterprise Linux 8 si el serviciomultipathdse está ejecutando; de lo contrario, se establece enoff.fast_io_fail_tmoEspecifica el número de segundos que se debe esperar antes de marcar un enlace como "malo". Una vez que un enlace es marcado como malo, la E/S existente o cualquier nueva E/S en su ruta correspondiente falla.
Si la E/S está en una cola bloqueada, no fallará hasta que
dev_loss_tmoexpire y la cola se desbloquee.Si
fast_io_fail_tmose establece en cualquier valor, excepto en off,dev_loss_tmono tiene límite. Sifast_io_fail_tmose establece en off, ninguna E/S falla hasta que el dispositivo se retira del sistema. Sifast_io_fail_tmose establece en un número, la E/S falla inmediatamente cuando se dispara el tiempo de espera defast_io_fail_tmo.
Configuración del host en /sys/class/fc_host/hostH/
-
port_id -
node_name -
port_name issue_lipOrdena al controlador que redescubra los puertos remotos.
8.4. DM Multipath anula el tiempo de espera del dispositivo
La opción recovery_tmo sysfs controla el tiempo de espera para un dispositivo iSCSI concreto. Las siguientes opciones anulan globalmente los valores de recovery_tmo:
-
La opción de configuración
replacement_timeoutanula globalmente el valor derecovery_tmopara todos los dispositivos iSCSI. Para todos los dispositivos iSCSI gestionados por DM Multipath, la opción
fast_io_fail_tmoen DM Multipath anula globalmente el valor derecovery_tmo.La opción
fast_io_fail_tmoen DM Multipath también anula la opciónfast_io_fail_tmoen los dispositivos Fibre Channel.
La opción de DM Multipath fast_io_fail_tmo tiene prioridad sobre replacement_timeout. Red Hat no recomienda utilizar replacement_timeout para anular recovery_tmo en los dispositivos gestionados por DM Multipath porque DM Multipath siempre restablece recovery_tmo cuando el servicio multipathd se recarga.
Capítulo 9. Configuración del canal de fibra sobre Ethernet
Basado en el estándar IEEE T11 FC-BB-5, Fibre Channel over Ethernet (FCoE) es un protocolo para transmitir tramas de Fibre Channel a través de redes Ethernet. Normalmente, los centros de datos tienen una LAN y una red de área de almacenamiento (SAN) dedicadas y separadas entre sí con su propia configuración específica. FCoE combina estas redes en una estructura de red única y convergente. Las ventajas de FCoE son, por ejemplo, menores costes de hardware y energía.
9.1. Uso de HBAs FCoE por hardware en RHEL
En Red Hat Enterprise Linux se puede utilizar el adaptador de bus de host (HBA) FCoE por hardware con el apoyo de los siguientes controladores:
-
qedf -
bnx2fc -
fnic
Si utiliza un HBA de este tipo, configure los ajustes de FCoE en la configuración del HBA. Para más detalles, consulte la documentación del adaptador.
Después de configurar el HBA en su configuración, los números de unidad lógica (LUN) exportados desde la red de área de almacenamiento (SAN) están automáticamente disponibles para RHEL como dispositivos /dev/sd*. Puede utilizar estos dispositivos de forma similar a los dispositivos de almacenamiento local.
9.2. Configuración de un dispositivo FCoE por software
Un dispositivo FCoE por software permite acceder a Números de Unidad Lógica (LUN) a través de FCoE utilizando un adaptador Ethernet que soporta parcialmente la descarga de FCoE.
RHEL no admite dispositivos FCoE por software que requieran el módulo del kernel fcoe.ko. Para más detalles, consulte la eliminación del software FCoE en la documentación de Considerations in adopting RHEL 8.
Después de completar este procedimiento, los LUNs exportados de la Red de Área de Almacenamiento (SAN) están automáticamente disponibles para RHEL como dispositivos /dev/sd*. Puede utilizar estos dispositivos de forma similar a los dispositivos de almacenamiento local.
Requisitos previos
-
El adaptador de bus de host (HBA) utiliza el controlador
qedf,bnx2fc, ofnicy no requiere el módulo del kernelfcoe.ko. - La SAN utiliza una VLAN para separar el tráfico de almacenamiento del tráfico Ethernet normal.
- El conmutador de red ha sido configurado para soportar la VLAN.
- El HBA del servidor se configura en su BIOS. Para más detalles, consulte la documentación de su HBA.
- El HBA está conectado a la red y el enlace está activo.
Procedimiento
Instale el paquete
fcoe-utils:#
yum install fcoe-utilsCopie el archivo de plantilla
/etc/fcoe/cfg-ethxen/etc/fcoe/cfg-interface_name. Por ejemplo, si desea configurar la interfazenp1s0para utilizar FCoE, introduzca#
cp /etc/fcoe/cfg-ethx /etc/fcoe/cfg-enp1s0Habilite e inicie el servicio
fcoe:#
systemctl enable --now fcoeDescubra el ID de la VLAN FCoE, inicie el iniciador y cree un dispositivo de red para la VLAN descubierta:
#
fipvlan -s -c enp1s0Created VLAN device enp1s0.200 Starting FCoE on interface enp1s0.200 Fibre Channel Forwarders Discovered interface | VLAN | FCF MAC ------------------------------------------ enp1s0 | 200 | 00:53:00:a7:e7:1bOpcional: Para mostrar detalles sobre los objetivos descubiertos, los LUNs y los dispositivos asociados a los LUNs, introduzca:
#
fcoeadm -tInterface: enp1s0.200 Roles: FCP Target Node Name: 0x500a0980824acd15 Port Name: 0x500a0982824acd15 Target ID: 0 MaxFrameSize: 2048 bytes OS Device Name: rport-11:0-1 FC-ID (Port ID): 0xba00a0 State: Online LUN ID Device Name Capacity Block Size Description ------ ----------- ---------- ---------- --------------------- 0 sdb 28.38 GiB 512 NETAPP LUN (rev 820a) ...Este ejemplo muestra que el LUN 0 de la SAN se ha conectado al host como dispositivo
/dev/sdb.
Pasos de verificación
Utilice el comando
fcoeadm -ipara mostrar información sobre todas las interfaces FCoE activas:#
fcoeadm -iDescription: BCM57840 NetXtreme II 10 Gigabit Ethernet Revision: 11 Manufacturer: Broadcom Inc. and subsidiaries Serial Number: 000AG703A9B7 Driver: bnx2x Unknown Number of Ports: 1 Symbolic Name: bnx2fc (QLogic BCM57840) v2.12.13 over enp1s0.200 OS Device Name: host11 Node Name: 0x2000000af70ae935 Port Name: 0x2001000af70ae935 Fabric Name: 0x20c8002a6aa7e701 Speed: 10 Gbit Supported Speed: 1 Gbit, 10 Gbit MaxFrameSize: 2048 bytes FC-ID (Port ID): 0xba02c0 State: Online
Recursos adicionales
-
Para más detalles sobre la utilidad
fcoeadm, consulte la página de manualfcoeadm(8). -
Para obtener detalles sobre cómo montar el almacenamiento conectado a través de un software FCoE cuando el sistema se inicia, consulte el archivo
/usr/share/doc/fcoe-utils/README.
9.3. Recursos adicionales
- Para obtener más información sobre el uso de dispositivos de canal de fibra, consulte Sección 8.1, “Cambio de tamaño de las unidades lógicas de Fibre Channel”
Capítulo 10. Configuración del tiempo máximo de recuperación de errores de almacenamiento con eh_deadline
Puede configurar el tiempo máximo permitido para recuperar los dispositivos SCSI que han fallado. Esta configuración garantiza un tiempo de respuesta de E/S incluso cuando el hardware de almacenamiento deja de responder debido a un fallo.
10.1. El parámetro eh_deadline
El mecanismo de manejo de errores SCSI (EH) intenta realizar la recuperación de errores en los dispositivos SCSI fallidos. El parámetro SCSI host object eh_deadline le permite configurar la cantidad máxima de tiempo para la recuperación. Después de que el tiempo configurado expira, SCSI EH se detiene y reinicia todo el adaptador de bus de host (HBA).
El uso de eh_deadline puede reducir el tiempo:
- para cerrar una ruta fallida,
- para cambiar de ruta, o
- para desactivar una porción de RAID.
Cuando eh_deadline expira, SCSI EH reinicia el HBA, lo que afecta a todas las rutas de destino de ese HBA, no sólo a la que falla. Si algunas de las rutas redundantes no están disponibles por otras razones, pueden producirse errores de E/S. Habilite eh_deadline sólo si tiene una configuración multirruta totalmente redundante en todos los objetivos.
Escenarios en los que eh_deadline es útil
En la mayoría de los escenarios, no es necesario habilitar eh_deadline. El uso de eh_deadline puede ser útil en ciertos escenarios específicos, por ejemplo, si se produce una pérdida de enlace entre un conmutador de canal de fibra (FC) y un puerto de destino, y el HBA no recibe notificaciones de cambio de estado registrado (RSCN). En tal caso, las solicitudes de E/S y los comandos de recuperación de errores se agotan en lugar de encontrar un error. La configuración de eh_deadline en este entorno pone un límite superior al tiempo de recuperación. Esto permite que la E/S fallida sea reintentada en otra ruta disponible por DM Multipath.
En las siguientes condiciones, la funcionalidad eh_deadline no proporciona ningún beneficio adicional, porque los comandos de E/S y de recuperación de errores fallan inmediatamente, lo que permite a DM Multipath reintentar:
- Si los RSCN están activados
- Si el HBA no registra que el enlace no está disponible
Valores posibles
El valor de eh_deadline se especifica en segundos.
La configuración por defecto es off, que desactiva el límite de tiempo y permite que se produzca toda la recuperación de errores.
10.2. Fijación del parámetro eh_deadline
Este procedimiento configura el valor del parámetro eh_deadline para limitar el tiempo máximo de recuperación SCSI.
Procedimiento
Puede configurar
eh_deadlineutilizando cualquiera de los siguientes métodos:sysfs-
Escriba el número de segundos en los archivos
/sys/class/scsi_host/host*/eh_deadline. - Parámetro del núcleo
-
Establezca un valor por defecto para todos los HBAs SCSI utilizando el parámetro del kernel
scsi_mod.eh_deadline.
Capítulo 11. Empezar a usar el swap
Esta sección describe el espacio de intercambio y cómo utilizarlo.
11.1. Espacio de intercambio
Swap space en Linux se utiliza cuando la cantidad de memoria física (RAM) está llena. Si el sistema necesita más recursos de memoria y la RAM está llena, las páginas inactivas en la memoria se mueven al espacio de intercambio. Mientras que el espacio de intercambio puede ayudar a las máquinas con una pequeña cantidad de RAM, no debe ser considerado como un reemplazo de más RAM. El espacio de intercambio se encuentra en los discos duros, que tienen un tiempo de acceso más lento que la memoria física. El espacio de intercambio puede ser una partición de intercambio dedicada (recomendada), un archivo de intercambio, o una combinación de particiones de intercambio y archivos de intercambio.
En el pasado, la cantidad recomendada de espacio de intercambio aumentaba linealmente con la cantidad de RAM en el sistema. Sin embargo, los sistemas modernos suelen incluir cientos de gigabytes de RAM. Como consecuencia, el espacio de intercambio recomendado se considera una función de la carga de trabajo de la memoria del sistema, no de la memoria del sistema.
Sección 11.2, “Espacio de intercambio del sistema recomendado” ilustra el tamaño recomendado de una partición de intercambio en función de la cantidad de memoria RAM de su sistema y de si desea disponer de suficiente memoria para hibernar el sistema. El tamaño recomendado de la partición de intercambio se establece automáticamente durante la instalación. Sin embargo, para permitir la hibernación, es necesario editar el espacio de intercambio en la etapa de particionamiento personalizado.
Las recomendaciones de Sección 11.2, “Espacio de intercambio del sistema recomendado” son especialmente importantes en sistemas con poca memoria (1 GB o menos). No asignar suficiente espacio de intercambio en estos sistemas puede causar problemas como la inestabilidad o incluso hacer que el sistema instalado no pueda arrancar.
11.2. Espacio de intercambio del sistema recomendado
Esta sección ofrece recomendaciones sobre el espacio de intercambio.
| Cantidad de RAM en el sistema | Espacio de intercambio recomendado | Espacio de intercambio recomendado si se permite la hibernación |
|---|---|---|
| ࣘ 2 GB | 2 veces la cantidad de RAM | 3 veces la cantidad de RAM |
| > 2 GB | Igual a la cantidad de RAM | 2 veces la cantidad de RAM |
| > 8 GB | Al menos 4 GB | 1.5 veces la cantidad de RAM |
| > 64 GB | Al menos 4 GB | No se recomienda la hibernación |
En el límite entre cada rango enumerado en la tabla anterior, por ejemplo un sistema con 2 GB, 8 GB o 64 GB de RAM del sistema, se puede ejercer la discreción con respecto al espacio de intercambio elegido y el soporte de hibernación. Si los recursos de su sistema lo permiten, aumentar el espacio de intercambio puede conducir a un mejor rendimiento. Se recomienda un espacio de intercambio de al menos 100 GB para sistemas con más de 140 procesadores lógicos o más de 3 TB de RAM.
Tenga en cuenta que la distribución del espacio de intercambio en varios dispositivos de almacenamiento también mejora el rendimiento del espacio de intercambio, especialmente en sistemas con unidades, controladores e interfaces rápidos.
Los sistemas de archivos y los volúmenes LVM2 asignados como espacio de intercambio should not están en uso cuando se modifican. Cualquier intento de modificar el swap falla si un proceso del sistema o el kernel está utilizando el espacio de swap. Utilice los comandos free y cat /proc/swaps para verificar la cantidad y el lugar de uso de la swap.
Debe modificar el espacio de intercambio mientras el sistema se inicia en el modo rescue, consulte las opciones de arranque de depuración en el Performing an advanced RHEL installation. Cuando se le pida que monte el sistema de archivos, seleccione .
11.3. Añadir espacio de intercambio
Esta sección describe cómo añadir más espacio de intercambio después de la instalación. Por ejemplo, puede aumentar la cantidad de RAM en su sistema de 1 GB a 2 GB, pero sólo hay 2 GB de espacio de intercambio. Podría ser ventajoso aumentar la cantidad de espacio de intercambio a 4 GB si realiza operaciones que requieren mucha memoria o ejecuta aplicaciones que requieren una gran cantidad de memoria.
Hay tres opciones: crear una nueva partición de intercambio, crear un nuevo archivo de intercambio o ampliar el intercambio en un volumen lógico LVM2 existente. Se recomienda ampliar un volumen lógico existente.
11.3.1. Ampliación del intercambio en un volumen lógico LVM2
Este procedimiento describe cómo ampliar el espacio de intercambio en un volumen lógico LVM2 existente. Suponiendo que /dev/VolGroup00/LogVol01 es el volumen que desea ampliar en 2 GB.
Requisitos previos
- Suficiente espacio en el disco.
Procedimiento
Desactivar el intercambio para el volumen lógico asociado:
# swapoff -v /dev/VolGroup00/LogVol01
Redimensiona el volumen lógico LVM2 en 2 GB:
# lvresize /dev/VolGroup00/LogVol01 -L 2G
Formatea el nuevo espacio de intercambio:
# mkswap /dev/VolGroup00/LogVol01
Habilitar el volumen lógico extendido:
# swapon -v /dev/VolGroup00/LogVol01
Para comprobar si el volumen lógico de intercambio se ha ampliado y activado correctamente, inspeccione el espacio de intercambio activo:
$ cat /proc/swaps $ free -h
11.3.2. Creación de un volumen lógico LVM2 para swap
Este procedimiento describe cómo crear un volumen lógico LVM2 para swap. Asumiendo que /dev/VolGroup00/LogVol02 es el volumen de swap que quieres añadir.
Requisitos previos
- Suficiente espacio en el disco.
Procedimiento
Cree el volumen lógico LVM2 de tamaño 2 GB:
# lvcreate VolGroup00 -n LogVol02 -L 2G
Formatea el nuevo espacio de intercambio:
# mkswap /dev/VolGroup00/LogVol02
Añada la siguiente entrada al archivo
/etc/fstab:/dev/VolGroup00/LogVol02 swap swap defaults 0 0
Regenere las unidades de montaje para que su sistema registre la nueva configuración:
# systemctl daemon-reload
Activar el intercambio en el volumen lógico:
# swapon -v /dev/VolGroup00/LogVol02
Para comprobar si el volumen lógico de intercambio se ha creado y activado correctamente, inspeccione el espacio de intercambio activo:
$ cat /proc/swaps $ free -h
11.3.3. Creación de un archivo de intercambio
Este procedimiento describe cómo crear un archivo de intercambio.
Requisitos previos
- Suficiente espacio en el disco.
Procedimiento
- Determine el tamaño del nuevo archivo de intercambio en megabytes y multiplique por 1024 para determinar el número de bloques. Por ejemplo, el tamaño de los bloques de un archivo de intercambio de 64 MB es de 65536.
Crear un archivo vacío:
# dd if=/dev/zero of=/swapfile bs=1024 count=65536
Sustituya count por el valor equivalente al tamaño de bloque deseado.
Configure el archivo de intercambio con el comando
# mkswap /swapfile
Cambiar la seguridad del archivo de intercambio para que no sea legible por el mundo.
# chmod 0600 /swapfile
Para habilitar el archivo de intercambio en el momento del arranque, edite
/etc/fstabcomo root para incluir la siguiente entrada:/swapfile swap swap defaults 0 0
La próxima vez que el sistema arranque, activará el nuevo archivo de intercambio.
Regenere las unidades de montaje para que su sistema registre la nueva configuración de
/etc/fstab:# systemctl daemon-reload
Para activar el archivo de intercambio inmediatamente:
# swapon /swapfile
Para comprobar si el nuevo archivo de intercambio se ha creado y activado correctamente, inspeccione el espacio de intercambio activo:
$ cat /proc/swaps $ free -h
11.4. Eliminación del espacio de intercambio
Esta sección describe cómo reducir el espacio de intercambio después de la instalación. Por ejemplo, usted ha reducido la cantidad de RAM en su sistema de 1 GB a 512 MB, pero todavía hay 2 GB de espacio de intercambio asignados. Podría ser ventajoso reducir la cantidad de espacio de intercambio a 1 GB, ya que los 2 GB más grandes podrían estar desperdiciando espacio en el disco.
Dependiendo de lo que necesite, puede elegir una de estas tres opciones: reducir el espacio de intercambio en un volumen lógico LVM2 existente, eliminar un volumen lógico LVM2 completo utilizado para el intercambio, o eliminar un archivo de intercambio.
11.4.1. Reducir el intercambio en un volumen lógico LVM2
Este procedimiento describe cómo reducir el swap en un volumen lógico LVM2. Asumiendo que /dev/VolGroup00/LogVol01 es el volumen que se quiere reducir.
Procedimiento
Desactivar el intercambio para el volumen lógico asociado:
# swapoff -v /dev/VolGroup00/LogVol01
Reduzca el volumen lógico LVM2 en 512 MB:
# lvreduce /dev/VolGroup00/LogVol01 -L -512M
Formatea el nuevo espacio de intercambio:
# mkswap /dev/VolGroup00/LogVol01
Activar el intercambio en el volumen lógico:
# swapon -v /dev/VolGroup00/LogVol01
Para comprobar si el volumen lógico de intercambio se redujo con éxito, inspeccione el espacio de intercambio activo:
$ cat /proc/swaps $ free -h
11.4.2. Eliminación de un volumen lógico LVM2 para swap
Este procedimiento describe cómo eliminar un volumen lógico LVM2 para swap. Asumiendo que /dev/VolGroup00/LogVol02 es el volumen de swap que desea eliminar.
Procedimiento
Desactivar el intercambio para el volumen lógico asociado:
# swapoff -v /dev/VolGroup00/LogVol02
Eliminar el volumen lógico LVM2:
# lvremove /dev/VolGroup00/LogVol02
Elimine la siguiente entrada asociada del archivo
/etc/fstab:/dev/VolGroup00/LogVol02 swap swap defaults 0 0
Regenere las unidades de montaje para que su sistema registre la nueva configuración:
# systemctl daemon-reload
Para comprobar si el volumen lógico se ha eliminado correctamente, inspeccione el espacio de intercambio activo:
$ cat /proc/swaps $ free -h
11.4.3. Eliminación de un archivo de intercambio
Este procedimiento describe cómo eliminar un archivo de intercambio.
Procedimiento
En un prompt del shell, ejecute el siguiente comando para desactivar el archivo de intercambio (donde
/swapfilees el archivo de intercambio):# swapoff -v /swapfile
-
Elimine su entrada del archivo
/etc/fstaben consecuencia. Regenere las unidades de montaje para que su sistema registre la nueva configuración:
# systemctl daemon-reload
Eliminar el archivo actual:
# rm /swapfile
Capítulo 12. Gestión de las actualizaciones del sistema con instantáneas
Como administrador del sistema, puede realizar actualizaciones con capacidad de retroceso de los sistemas Red Hat Enterprise Linux utilizando el gestor de arranque Boom, la utilidad Leapp y el marco de modernización del sistema operativo.
Los procedimientos mencionados en este capítulo no funcionan en sistemas de archivos múltiples en su árbol de sistemas, por ejemplo, una partición separada /var o /usr.
12.1. Visión general del proceso Boom
Usando Boom, puede crear entradas de arranque, a las que se puede acceder y seleccionar desde el menú del cargador de arranque de GRUB 2. Al crear entradas de arranque, el proceso de preparación para una actualización con capacidad de reversión se simplifica ahora.
A continuación se muestran las diferentes entradas de arranque, que forman parte del proceso de actualización y reversión:
Upgrade boot entry-
Arranca el entorno de actualización de
Leapp. Utilice la utilidadleapppara crear y gestionar esta entrada de arranque. Esta entrada de arranque se elimina automáticamente en el curso de la actualización deleapp. Red Hat Enterprise Linux 8 boot entry-
Arranca el entorno del sistema actualizado. Utilice la utilidad
leapppara crear esta entrada de arranque después de un proceso de actualización exitoso. Snapshot boot entry-
Arranca la instantánea del sistema original y puede utilizarse para revisar y probar el estado anterior del sistema tras un intento de actualización exitoso o fallido. Antes de actualizar el sistema, utilice el comando
boompara crear esta entrada de arranque. Rollback boot entry-
Arranca el entorno original del sistema y revierte cualquier actualización al estado anterior del sistema. Utilice el comando
boompara crear esta entrada de arranque al iniciar una reversión del procedimiento de actualización.
Las actualizaciones con capacidad de retroceso se realizan mediante el siguiente proceso sin editar ningún archivo de configuración:
- Crear una instantánea o copia del sistema de archivos raíz.
-
Utilice el comando
boompara crear una entrada de arranque para el entorno actual (más antiguo). - Actualice su sistema Red Hat Enterprise Linux.
- Reinicie el sistema y seleccione la versión que desea utilizar.
Las entradas de Red Hat Enterprise Linux 8, snapshot y rollback deben ser limpiadas al final del procedimiento dependiendo del resultado del proceso de actualización:
-
Si desea mantener el sistema actualizado de Red Hat Enterprise Linux 8, elimine las entradas de instantáneas creadas y de retroceso utilizando el comando
boomy elimine los volúmenes lógicos de instantáneas con el comandolvremove. Para más información, consulte Sección 12.4, “Borrar la instantánea”. - Si desea volver al estado original del sistema, fusione la instantánea y la entrada de arranque de reversión y, después de reiniciar el sistema, elimine las entradas de instantánea y de arranque de reversión no utilizadas. Para más información, consulte Sección 12.5, “Creación de una entrada de arranque de reversión”.
Recursos adicionales
-
La página de manual
boom.
12.2. Actualizar a otra versión con Boom
Además de Boom, en este proceso de actualización se utilizan los siguientes componentes de Red Hat Enterprise Linux:
- Gestor de volúmenes lógicos (LVM)
- Cargador de arranque GRUB 2
-
Leappherramienta de actualización
Este procedimiento describe cómo actualizar de Red Hat Enterprise Linux 7 a Red Hat Enterprise Linux 8 utilizando el comando boom.
Requisitos previos
Instale el paquete
boom:# yum install lvm2-python-boom
Asegúrese de que la versión del paquete
lvm2-python-boomes al menosboom-0.9(idealmenteboom-1.2).NotaSi desea instalar el paquete
boomen Red Hat Enterprise Linux 8, ejecute el siguiente comando:# yum install boom-boot
Debe haber suficiente espacio disponible para la instantánea. Utilice los siguientes comandos para encontrar el espacio libre en los grupos de volúmenes y volúmenes lógicos:
# vgs VG #PV #LV #SN Attr VSize VFree rhel 4 2 0 wz--n- 103.89g 29.99g # lvs LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert root rhel -wi-ao--- 68.88g swap rhel -wi-ao--- 5.98g
Aquí, rhel es el grupo de volúmenes del sistema, y root y swap son los volúmenes lógicos del sistema.
Encuentra todos los volúmenes lógicos montados:
# mount | grep rhel /dev/mapper/rhel-root on / type xfs (rw,relatime,seclabel,attr2,inode64,noquota)
NotaSi hay más de una entrada y los puntos de montaje de las entradas adicionales incluyen '/usr' o '/var', los pasos mencionados no pueden seguirse sin ejecutar pasos adicionales que están fuera del alcance de esta historia de usuario.
-
El paquete
Leappestá instalado y los repositorios de software están habilitados. Para obtener más información, consulte la sección Preparación de un sistema RHEL 7 para la actualización, para descargar los paquetes necesarios para la actualización.
Procedimiento
Cree una instantánea de su volumen lógico root:
Si su sistema de archivos raíz utiliza el aprovisionamiento fino, cree una instantánea fina:
Al crear una instantánea delgada, no defina el tamaño de la instantánea. La instantánea se asigna desde el grupo ligero.
# lvcreate -s rhel/root -n root_snapshot_before_changesAquí:
-
-sse utiliza para crear la instantánea -
rhel/rootes el sistema de archivos que se está copiando en el volumen lógico -
-nroot_snapshot_before_changes es el nombre de la instantánea
-
Si su sistema de archivos raíz utiliza el aprovisionamiento grueso, cree una instantánea gruesa:
Al crear una instantánea gruesa, defina el tamaño de la instantánea que es capaz de mantener todos los cambios durante la actualización.
# lvcreate -s rhel/root -n root_snapshot_before_changes -L 25g
Aquí:
-
-sse utiliza para crear la instantánea -
rhel/rootes el sistema de archivos que se está copiando -
-nroot_snapshot_before_changes es el nombre de la instantánea -L25g es el tamaño de la instantánea. Esta instantánea debe ser capaz de mantener todos los cambios durante la actualizaciónImportanteDespués de crear la instantánea, cualquier cambio adicional del sistema no se incluye.
-
Crear el perfil:
# boom profile create --from-host --uname-pattern el7
NotaSi desea crear el perfil
boomen Red Hat Enterprise Linux 8, utilice elel8como patrón de uname.Cree una entrada de arranque instantánea del sistema original, utilizando copias de seguridad de las imágenes de arranque originales:
Para la versión
boom-1.2o posterior:# boom create --backup --title "Root LV snapshot before changes" --rootlv rhel/root_snapshot_before_changes
Aquí:
-
--titleRoot LV snapshot before changes es el nombre de la entrada de arranque, que se muestra en la lista durante el arranque del sistema -
--rootlves el volumen lógico raíz que corresponde a la nueva entrada de arranque
-
Para la versión
boom-1.1o anterior:# cp /boot/vmlinuz-$(uname r) /boot/vmlinuz$(uname -r).bak # cp /boot/initramfs-$(uname r).img /boot/initramfs$(uname -r).img.bak # boom create -title "Root LV snapshot before changes" --rootlv rhel/root_snapshot_before_changes --linux /boot/vmlinuz$(uname r).bak --initrd /boot/initramfs$(uname -r).img.bak
Si ejecuta el comando
boom createpor primera vez, aparece el siguiente mensaje:WARNING - Boom configuration not found in grub.cfg WARNING - Run 'grub2-mkconfig > /boot/grub2/grub.cfg' to enable
Para activar Boom en GRUB 2:
# grub2-mkconfig > /boot/grub2/grub.cfg
Actualice a Red Hat Enterprise Linux 8 utilizando la utilidad
Leapp:# leapp upgrade
Revise y solucione los bloqueos indicados en el informe del comando
leapp upgrade.Tras resolver los bloqueos identificados en los informes previos a la actualización, vuelva a ejecutar el comando de actualización con la opción
--reboot:# leapp upgrade --reboot
Este comando reinicia en la entrada de arranque actualizada creada por la utilidad
leappy procede a ejecutar la actualización in situ a Red Hat Enterprise Linux 8. El argumento reboot inicia un reinicio automático del sistema después del proceso de actualización.Durante el reinicio, se muestra la pantalla de GRUB 2:
 Nota
NotaSi está en un sistema Red Hat Enterprise Linux 8, el submenú Snapshots de la pantalla de arranque de GRUB2 no está disponible.
Pasos de verificación
Seleccione la entrada RHEL Upgrade Initramfs y pulse ENTER. La actualización continúa y se instalan los nuevos paquetes RPM de Red Hat Enterprise Linux 8. Una vez completada la actualización, el sistema se reinicia automáticamente y la pantalla de GRUB 2 muestra la versión actualizada y la versión anterior del sistema disponible. La versión actualizada del sistema es la selección por defecto.
Además, la entrada de arranque creada Root LV snapshot before changes está presente, lo que proporciona un acceso instantáneo al estado del sistema antes de la actualización.
Recursos adicionales
-
La página de manual
boom. - ¿Qué es BOOM y cómo instalarlo? Artículo de la base de conocimientos.
- Cómo crear una entrada de arranque BOOM Artículo de la base de conocimientos.
- Datos requeridos por la utilidad Leapp para una actualización in situ de RHEL 7 a RHEL 8 Artículo de la base de conocimientos.
12.3. Cambio entre versiones nuevas y antiguas de Red Hat Enterprise Linux
The Boom boot manager reduces the risks associated with upgrading a system and also helps to reduce hardware downtime. For example, you can upgrade a Red Hat Enterprise Linux 7 system to Red Hat Enterprise Linux 8, while retaining the original Red Hat Enterprise Linux 7 environment. This ability to switch between environments allows you to:
- Compare rápidamente ambos entornos de forma paralela y cambie de uno a otro con una sobrecarga mínima.
- Recuperar el contenido del sistema de archivos más antiguo.
- Siga accediendo al sistema antiguo mientras se ejecuta el host actualizado.
- Detener y revertir el proceso de actualización en cualquier momento, incluso mientras la propia actualización se está ejecutando.
Este procedimiento describe cómo cambiar entre la nueva y la antigua versión de Red Hat Enterprise Linux una vez completada la actualización.
Requisitos previos
- Actualización de la versión de Red Hat Enterprise Linux. Para más información, consulte Sección 12.2, “Actualizar a otra versión con Boom”.
Procedimiento
Reinicia el sistema:
# rebote
Seleccione la entrada de arranque deseada en la pantalla del gestor de arranque GRUB 2.
Pasos de verificación
Compruebe que se muestra el volumen de arranque seleccionado:
# cat /proc/cmdline root=/dev/rhel/root_snapshot_before_changes ro rd.lvm.lv=rhel/root_snapshot_before_changes rd.lvm.lv=vg_root/swap rhgb quiet
Recursos adicionales
-
La página de manual
boom.
12.4. Borrar la instantánea
La entrada de arranque de la instantánea arranca la instantánea del sistema original y puede utilizarse para revisar y probar el estado anterior del sistema tras un intento de actualización exitoso o fallido. Este procedimiento describe los pasos para eliminar la instantánea.
Requisitos previos
- Actualización a una nueva versión de RHEL. Para más información, consulte Sección 12.2, “Actualizar a otra versión con Boom”.
Procedimiento
Arranque en Red Hat Enterprise Linux 8 desde la entrada GRUB 2. La siguiente salida confirma que la nueva instantánea está seleccionada:
# boom list BootID Version Name RootDevice 6d2ec72 3.10.0-957.21.3.el7.x86_64 Red Hat Enterprise Linux Server /dev/rhel/root_snapshot_before_changes
Elimina la entrada de la instantánea utilizando el valor
BootID:# boom delete --boot-id 6d2ec72Esto elimina la entrada del menú de GRUB 2.
Eliminar la instantánea de LV:
# lvremove rhel/root_snapshot_before_changes Do you really want to remove active logical volume rhel/root_snapshot_before_changes? [y/n]: y Logical volume "root_snapshot_before_changes" successfully removed
Recursos adicionales
-
La página de manual
boom.
-
La página de manual
12.5. Creación de una entrada de arranque de reversión
La entrada de arranque Rollback arranca el entorno original del sistema y revierte cualquier actualización al estado anterior del sistema. La reversión de la entrada de arranque actualizada y de reversión al entorno original después de revisarla, está ahora disponible a través de la entrada de arranque de instantáneas.
Se puede preparar una entrada de arranque de reversión desde el sistema actualizado o desde el entorno de instantáneas.
Requisitos previos
- Actualización a una nueva versión de RHEL. Para más información, consulte Sección 12.2, “Actualizar a otra versión con Boom”.
Procedimiento
Fusiona la instantánea:
# lvconvert --merge rhel/root_snapshot_before_changesCree una entrada de arranque de reversión para la instantánea fusionada:
Para la versión
boom-1.2o posterior:boom create --backup --title "RHEL Rollback" --rootlv rhel/rootPara la versión
boom-1.1o anterior:boom create --title "RHEL Rollback" --rootlv rhel/root --linux /boot/vmlinuz$(uname r).bak --initrd /boot/initramfs$(uname -r).img.bak
Opcional: Arrancar el entorno de reversión y restaurar el estado del sistema:
# rebote
Una vez que el sistema se reinicie, seleccione la entrada de RHEL Rollback entrada de arranque utilizando las teclas de flecha y pulse Enter para arrancar esta entrada.
El sistema inicia automáticamente la operación de fusión de instantáneas una vez que se activa el volumen lógico
root.NotaUna vez iniciada la operación de fusión, el volumen de instantánea ya no está disponible. Después de arrancar con éxito la entrada de arranque RHEL Rollback, la entrada de arranque Root LV snapshot before changes ya no funciona porque ahora está fusionada en el volumen lógico original. Al fusionar un volumen lógico de instantánea, se destruye la instantánea y se restaura el estado anterior del volumen de origen.
Opcional: Una vez finalizada la operación de fusión, elimine las entradas no utilizadas y restaure la entrada de arranque original:
Elimine las entradas de arranque de Red Hat Enterprise Linux 8 no utilizadas del sistema de archivos
/booty actualice la configuración deGrub2:# rm -f /boot/el8 # grub2-mkconfig -o /boot/grub2/grub.cfg
Restaurar la entrada de arranque original de Red Hat Enterprise Linux 7:
# new-kernel-pkg --update $(uname -r)
Después de la reversión exitosa del sistema, borre la entrada de arranque
boom:# boom list # boom delete boot-id
Recursos adicionales
-
La página de manual
boom.
Capítulo 13. Visión general de los dispositivos NVMe sobre tejido
Non-volatile Memory Express (NVMe) es una interfaz que permite a las utilidades de software del host comunicarse con las unidades de estado sólido.
Utilice los siguientes tipos de transporte de tejido para configurar NVMe sobre dispositivos de tejido:
-
NVMesobre tejidos utilizandoRemote Direct Memory Access (RDMA). Para obtener información sobre cómo configurar NVMe/RDMA, consulte Sección 13.1, “NVMe sobre tejidos utilizando RDMA”. -
NVMesobre tejidos utilizandoFibre Channel (FC). Para obtener información sobre cómo configurarFC-NVMe, consulte Sección 13.2, “NVMe sobre tejidos utilizando FC”.
Cuando se utiliza FC y RDMA, la unidad de estado sólido no tiene que estar localizada en el sistema; puede configurarse de forma remota a través de un controlador FC o RDMA.
13.1. NVMe sobre tejidos utilizando RDMA
En la configuración de NVMe/RDMA, se configura el objetivo NVMe y el iniciador NVMe.
Como administrador del sistema, complete las tareas de las siguientes secciones para desplegar el NVMe sobre tejidos utilizando RDMA (NVMe/RDMA):
13.1.1. Configuración de un objetivo NVMe/RDMA mediante configfs
Utilice este procedimiento para configurar un objetivo NVMe/RDMA utilizando configfs.
Requisitos previos
-
Verifique que tiene un dispositivo de bloque para asignar al subsistema
nvmet.
Procedimiento
Cree el subsistema
nvmet-rdma:# modprobe nvmet-rdma # mkdir /sys/kernel/config/nvmet/subsystems/testnqn # cd /sys/kernel/config/nvmet/subsystems/testnqn
Sustituya testnqn por el nombre del subsistema.
Permitir que cualquier host se conecte a este objetivo:
# echo 1 > attr_allow_any_host
Configure un
namespace:# mkdir namespaces/10 # cd namespaces/10
Sustituya 10 por el número de espacio de nombres
Establezca una ruta de acceso al dispositivo
NVMe:#echo -n /dev/nvme0n1 > device_pathHabilitar el espacio de nombres:
# echo 1 > enable
Cree un directorio con un puerto
NVMe:# mkdir /sys/kernel/config/nvmet/ports/1 # cd /sys/kernel/config/nvmet/ports/1
Muestra la dirección IP de mlx5_ib0:
# ip addr show mlx5_ib0 8: mlx5_ib0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 4092 qdisc mq state UP group default qlen 256 link/infiniband 00:00:06:2f:fe:80:00:00:00:00:00:00:e4:1d:2d:03:00:e7:0f:f6 brd 00:ff:ff:ff:ff:12:40:1b:ff:ff:00:00:00:00:00:00:ff:ff:ff:ff inet 172.31.0.202/24 brd 172.31.0.255 scope global noprefixroute mlx5_ib0 valid_lft forever preferred_lft forever inet6 fe80::e61d:2d03:e7:ff6/64 scope link noprefixroute valid_lft forever preferred_lft foreverEstablezca la dirección de transporte para el objetivo:
# echo -n 172.31.0.202 > addr_traddr
Establezca
RDMAcomo tipo de transporte:# echo rdma > addr_trtype # echo 4420 > addr_trsvcid
Establezca la familia de direcciones para el puerto:
# echo ipv4 > addr_adrfam
Crear un enlace suave:
# ln -s /sys/kernel/config/nvmet/subsystems/testnqn /sys/kernel/config/nvmet/ports/1/subsystems/testnqn
Pasos de verificación
Comprueba que el destino
NVMeestá escuchando en el puerto indicado y está preparado para recibir peticiones de conexión:# dmesg | grep "enabling port" [ 1091.413648] nvmet_rdma: enabling port 1 (172.31.0.202:4420)
Recursos adicionales
-
La página de manual
nvme.
13.1.2. Configuración del objetivo NVMe/RDMA mediante nvmetcli
Utilice el nvmetcli para editar, ver e iniciar el objetivo NVMe. El nvmetcli proporciona una línea de comandos y una opción de shell interactiva. Utilice este procedimiento para configurar el objetivo NVMe/RDMA mediante nvmetcli.
Requisitos previos
-
Verifique que tiene un dispositivo de bloque para asignar al subsistema
nvmet. -
Ejecute las operaciones de
nvmetclicomo usuario root.
Procedimiento
Instale el paquete
nvmetcli:# yum install nvmetcli
Descargue el archivo
rdma.json# wget http://git.infradead.org/users/hch/nvmetcli.git/blob_plain/0a6b088db2dc2e5de11e6f23f1e890e4b54fee64:/rdma.json
-
Edite el archivo
rdma.jsony cambie el valor detraddrpor 172.31.0.202. Configure el objetivo cargando el archivo de configuración del objetivo NVMe:
# nvmetcli restore rdma.json
Si no se especifica el nombre del archivo de configuración del destino NVMe, nvmetcli utiliza el archivo /etc/nvmet/config.json.
Pasos de verificación
Comprueba que el destino
NVMeestá escuchando en el puerto indicado y está preparado para recibir peticiones de conexión:#dmesg | tail -1 [ 4797.132647] nvmet_rdma: enabling port 2 (172.31.0.202:4420)
(Opcional) Borra el objetivo NVMe actual:
# nvmetcli clear
Recursos adicionales
-
La página de manual
nvmetcli. -
La página de manual
nvme.
13.1.3. Configuración de un cliente NVMe/RDMA
Utilice este procedimiento para configurar un cliente NVMe/RDMA utilizando la herramienta de línea de comandos de gestión de NVMe (nvme-cli).
Procedimiento
Instale la herramienta
nvme-cli:# yum install nvme-cli
Cargue el módulo
nvme-rdmasi no está cargado:# modprobe nvme-rdma
Descubre los subsistemas disponibles en el objetivo
NVMe:# nvme discover -t rdma -a 172.31.0.202 -s 4420 Discovery Log Number of Records 1, Generation counter 2 =====Discovery Log Entry 0====== trtype: rdma adrfam: ipv4 subtype: nvme subsystem treq: not specified, sq flow control disable supported portid: 1 trsvcid: 4420 subnqn: testnqn traddr: 172.31.0.202 rdma_prtype: not specified rdma_qptype: connected rdma_cms: rdma-cm rdma_pkey: 0x0000
Conecta con los subsistemas descubiertos:
# nvme connect -t rdma -n testnqn -a 172.31.0.202 -s 4420 # lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 465.8G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 464.8G 0 part ├─rhel_rdma--virt--03-root 253:0 0 50G 0 lvm / ├─rhel_rdma--virt--03-swap 253:1 0 4G 0 lvm [SWAP] └─rhel_rdma--virt--03-home 253:2 0 410.8G 0 lvm /home nvme0n1 #cat /sys/class/nvme/nvme0/transport rdma
Sustituya testnqn por el nombre del subsistema
NVMe.Sustituya 172.31.0.202 por la dirección IP de destino.
Sustituya 4420 por el número de puerto.
Pasos de verificación
Enumera los dispositivos NVMe que están conectados actualmente:
# lista nvme
(Opcional) Desconéctese del objetivo:
# nvme disconnect -n testnqn NQN:testnqn disconnected 1 controller(s) # lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 465.8G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 464.8G 0 part ├─rhel_rdma--virt--03-root 253:0 0 50G 0 lvm / ├─rhel_rdma--virt--03-swap 253:1 0 4G 0 lvm [SWAP] └─rhel_rdma--virt--03-home 253:2 0 410.8G 0 lvm /home
Recursos adicionales
-
La página de manual
nvme. - Nvme-cli Repositorio Github
13.2. NVMe sobre tejidos utilizando FC
El NVMe sobre Canal de Fibra (FC-NVMe) es totalmente compatible en modo iniciador cuando se utiliza con ciertos adaptadores de Canal de Fibra Broadcom Emulex y Marvell Qlogic. Como administrador del sistema, complete las tareas de las siguientes secciones para desplegar el FC-NVMe:
13.2.1. Configuración del iniciador NVMe para adaptadores Broadcom
Utilice este procedimiento para configurar el iniciador NVMe para el cliente de adaptadores Broadcom utilizando la herramienta de línea de comandos de gestión de NVMe (nvme-cli).
Procedimiento
Instale la herramienta
nvme-cli:# yum install nvme-cli
Esto crea el archivo
hostnqnen el directorio/etc/nvme/. El archivohostnqnidentifica el hostNVMe.Para generar un nuevo
hostnqn:#nvme gen-hostnqn
Encuentra los
WWNNyWWPNde los puertos locales y remotos y utiliza la salida para encontrar el subsistemaNQN:# cat /sys/class/scsi_host/host*/nvme_info NVME Initiator Enabled XRI Dist lpfc0 Total 6144 IO 5894 ELS 250 NVME LPORT lpfc0 WWPN x10000090fae0b5f5 WWNN x20000090fae0b5f5 DID x010f00 ONLINE NVME RPORT WWPN x204700a098cbcac6 WWNN x204600a098cbcac6 DID x01050e TARGET DISCSRVC ONLINE NVME Statistics LS: Xmt 000000000e Cmpl 000000000e Abort 00000000 LS XMIT: Err 00000000 CMPL: xb 00000000 Err 00000000 Total FCP Cmpl 00000000000008ea Issue 00000000000008ec OutIO 0000000000000002 abort 00000000 noxri 00000000 nondlp 00000000 qdepth 00000000 wqerr 00000000 err 00000000 FCP CMPL: xb 00000000 Err 00000000# nvme discover --transport fc --traddr nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 --host-traddr nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 Discovery Log Number of Records 2, Generation counter 49530 =====Discovery Log Entry 0====== trtype: fc adrfam: fibre-channel subtype: nvme subsystem treq: not specified portid: 0 trsvcid: none subnqn: nqn.1992-08.com.netapp:sn.e18bfca87d5e11e98c0800a098cbcac6:subsystem.st14_nvme_ss_1_1 traddr: nn-0x204600a098cbcac6:pn-0x204700a098cbcac6
Sustituya nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 por el
traddr.Sustituya nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 por el
host-traddr.Conéctese al objetivo NVMe utilizando la página web
nvme-cli:# nvme connect --transport fc --traddr nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 --host-traddr nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 -n nqn.1992-08.com.netapp:sn.e18bfca87d5e11e98c0800a098cbcac6:subsystem.st14_nvme_ss_1_1
Sustituya nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 por el
traddr.Sustituya nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 por el
host-traddr.Sustituya nqn.1992-08.com.netapp:sn.e18bfca87d5e11e98c0800a098cbcac6:subsystem.st14_nvme_ss_1_1 por el
subnqn.
Pasos de verificación
Enumera los dispositivos NVMe que están conectados actualmente:
# nvme list Node SN Model Namespace Usage Format FW Rev ---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- -------- /dev/nvme0n1 80BgLFM7xMJbAAAAAAAC NetApp ONTAP Controller 1 107.37 GB / 107.37 GB 4 KiB + 0 B FFFFFFFF
# lsblk |grep nvme nvme0n1 259:0 0 100G 0 disk
Recursos adicionales
-
La página de manual
nvme. - Nvme-cli Repositorio Github
13.2.2. Configuración del iniciador NVMe para adaptadores QLogic
Utilice este procedimiento para configurar el iniciador NVMe para el cliente de adaptadores Qlogic utilizando la herramienta de línea de comandos de gestión de NVMe (nvme-cli).
Procedimiento
Instale la herramienta
nvme-cli:# yum install nvme-cli
Esto crea el archivo
hostnqnen el directorio/etc/nvme/. El archivohostnqnidentifica el hostNVMe.Para generar un nuevo
hostnqn:#nvme gen-hostnqn
Retire y vuelva a cargar el módulo
qla2xxx:# rmmod qla2xxx # modprobe qla2xxx
Encuentre el
WWNNyWWPNde los puertos locales y remotos:# dmesg |grep traddr [ 6.139862] qla2xxx [0000:04:00.0]-ffff:0: register_localport: host-traddr=nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 on portID:10700 [ 6.241762] qla2xxx [0000:04:00.0]-2102:0: qla_nvme_register_remote: traddr=nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 PortID:01050d
Utilizando estos valores de
host-traddrytraddr, encuentre el subsistemaNQN:nvme discover --transport fc --traddr nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 --host-traddr nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 Discovery Log Number of Records 2, Generation counter 49530 =====Discovery Log Entry 0====== trtype: fc adrfam: fibre-channel subtype: nvme subsystem treq: not specified portid: 0 trsvcid: none subnqn: nqn.1992-08.com.netapp:sn.c9ecc9187b1111e98c0800a098cbcac6:subsystem.vs_nvme_multipath_1_subsystem_468 traddr: nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6
Sustituya nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 por el
traddr.Sustituya nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 por el
host-traddr.Conéctese al objetivo NVMe utilizando la herramienta
nvme-cli:# nvme connect --transport fc --traddr nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 --host-traddr nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 -n nqn.1992-08.com.netapp:sn.c9ecc9187b1111e98c0800a098cbcac6:subsystem.vs_nvme_multipath_1_subsystem_468
Sustituya nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 por el
traddr.Sustituya nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 por el
host-traddr.Sustituya nqn.1992-08.com.netapp:sn.c9ecc9187b1111e98c0800a098cbcac6:subsystem.vs_nvme_multipath_1_subsystem_468 por el
subnqn.
Pasos de verificación
Enumera los dispositivos NVMe que están conectados actualmente:
# nvme list Node SN Model Namespace Usage Format FW Rev ---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- -------- /dev/nvme0n1 80BgLFM7xMJbAAAAAAAC NetApp ONTAP Controller 1 107.37 GB / 107.37 GB 4 KiB + 0 B FFFFFFFF # lsblk |grep nvme nvme0n1 259:0 0 100G 0 disk
Recursos adicionales
-
La página de manual
nvme. - Nvme-cli Repositorio Github
Capítulo 14. Configuración del programador de discos
El programador de disco es responsable de ordenar las peticiones de E/S enviadas a un dispositivo de almacenamiento.
Puede configurar el programador de varias maneras:
- Configure el programador mediante Tuned, como se describe en Sección 14.6, “Configuración del programador de discos mediante Tuned”
-
Configure el programador mediante
udev, como se describe en Sección 14.7, “Configuración del programador de discos mediante reglas udev” - Cambiar temporalmente el planificador en un sistema en funcionamiento, como se describe en Sección 14.8, “Establecer temporalmente un programador para un disco específico”
14.1. Cambios en el programador de discos en RHEL 8
En RHEL 8, los dispositivos de bloque sólo admiten la programación de colas múltiples. Esto permite que el rendimiento de la capa de bloques escale bien con unidades de estado sólido (SSD) rápidas y sistemas multinúcleo.
Se han eliminado los programadores tradicionales de cola única, que estaban disponibles en RHEL 7 y versiones anteriores.
14.2. Programadores de disco disponibles
Los siguientes programadores de disco de cola múltiple son compatibles con RHEL 8:
none- Implementa un algoritmo de programación FIFO (first-in first-out). Combina las solicitudes en la capa de bloques genéricos a través de una simple caché de último golpe.
mq-deadlineIntenta proporcionar una latencia garantizada para las solicitudes desde el punto en que éstas llegan al planificador.
El planificador de
mq-deadlineclasifica las solicitudes de E/S en cola en un lote de lectura o de escritura y, a continuación, las programa para su ejecución en orden creciente de direccionamiento lógico de bloques (LBA). Por defecto, los lotes de lectura tienen prioridad sobre los de escritura, ya que es más probable que las aplicaciones se bloqueen en las operaciones de E/S de lectura. Después de quemq-deadlineprocese un lote, comprueba cuánto tiempo han estado las operaciones de escritura sin tiempo de procesador y programa el siguiente lote de lectura o de escritura según corresponda.Este planificador es adecuado para la mayoría de los casos de uso, pero sobre todo para aquellos en los que las operaciones de escritura son mayoritariamente asíncronas.
bfqDirigido a sistemas de escritorio y tareas interactivas.
El programador
bfqgarantiza que una sola aplicación nunca utilice todo el ancho de banda. En efecto, el dispositivo de almacenamiento siempre responde como si estuviera inactivo. En su configuración por defecto,bfqse centra en ofrecer la menor latencia en lugar de lograr el máximo rendimiento.bfqse basa en el códigocfq. No concede el disco a cada proceso durante una franja de tiempo fija, sino que asigna al proceso un budget medido en número de sectores.Este programador es adecuado cuando se copian archivos grandes y el sistema no deja de responder en este caso.
kyberEl planificador se ajusta a un objetivo de latencia. Puede configurar las latencias objetivo para las solicitudes de lectura y escritura síncrona.
Este programador es adecuado para dispositivos rápidos, por ejemplo NVMe, SSD u otros dispositivos de baja latencia.
14.3. Diferentes programadores de disco para diferentes casos de uso
Dependiendo de la tarea que realice su sistema, se recomiendan los siguientes programadores de disco como línea de base antes de cualquier tarea de análisis y ajuste:
Tabla 14.1. Programadores de disco para diferentes casos de uso
| Caso de uso | Programador de discos |
|---|---|
| Disco duro tradicional con interfaz SCSI |
Utilice |
| SSD de alto rendimiento o un sistema con CPU con almacenamiento rápido |
Utilice |
| Tareas de escritorio o interactivas |
Utilice |
| Invitado virtual |
Utilice |
14.4. El programador de discos por defecto
Los dispositivos de bloque utilizan el programador de discos por defecto a menos que se especifique otro programador.
Para los dispositivos de bloque non-volatile Memory Express (NVMe) específicamente, el programador por defecto es none y Red Hat recomienda no cambiarlo.
El kernel selecciona un programador de disco por defecto basado en el tipo de dispositivo. El programador seleccionado automáticamente es normalmente la configuración óptima. Si necesita un planificador diferente, Red Hat recomienda utilizar las reglas de udev o la aplicación Tuned para configurarlo. Compare los dispositivos seleccionados y cambie el planificador sólo para esos dispositivos.
14.5. Determinación del programador de disco activo
Este procedimiento determina qué programador de disco está actualmente activo en un dispositivo de bloque dado.
Procedimiento
Leer el contenido del
/sys/block/device/queue/schedulerarchivo:# cat /sys/block/device/queue/scheduler [mq-deadline] kyber bfq noneEn el nombre del archivo, sustituya device por el nombre del dispositivo de bloque, por ejemplo
sdc.El programador activo aparece entre corchetes (
[ ]).
14.6. Configuración del programador de discos mediante Tuned
Este procedimiento crea y habilita un perfil Tuned que establece un programador de disco determinado para los dispositivos de bloque seleccionados. La configuración persiste a través de los reinicios del sistema.
En los siguientes comandos y la configuración, reemplazar:
-
device con el nombre del dispositivo de bloque, por ejemplo
sdf -
selected-scheduler con el programador de disco que se desea establecer para el dispositivo, por ejemplo
bfq
Requisitos previos
El servicio
tunedestá instalado y habilitado.
Procedimiento
Opcional: Seleccione un perfil existente de Tuned en el que se basará su perfil. Para ver una lista de perfiles disponibles, consulte https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/monitoring_and_managing_system_status_and_performance/getting-started-with-tuned_monitoring-and-managing-system-status-and-performance#tuned-profiles-distributed-with-rhel_getting-started-with-tuned.
Para ver qué perfil está actualmente activo, utilice:
$ tuned-adm active
Cree un nuevo directorio para albergar su perfil de Tuned:
# mkdir /etc/tuned/my-profileBusca el identificador único del sistema del dispositivo de bloque seleccionado:
$ udevadm info --query=property --name=/dev/device | grep -E '(WWN|SERIAL)' ID_WWN=0x5002538d00000000 ID_SERIAL=Generic-_SD_MMC_20120501030900000-0:0 ID_SERIAL_SHORT=20120501030900000
NotaEl comando de este ejemplo devolverá todos los valores identificados como World Wide Name (WWN) o número de serie asociados al dispositivo de bloque especificado. Aunque es preferible utilizar un WWN, el WWN no siempre está disponible para un dispositivo determinado y cualquier valor devuelto por el comando del ejemplo es aceptable para utilizarlo como el device system unique ID.
Cree el
/etc/tuned/my-profile/tuned.confarchivo de configuración. En el archivo, establezca las siguientes opciones:Opcional: Incluir un perfil existente:
[main] include=existing-profileEstablece el programador de discos seleccionado para el dispositivo que coincide con el identificador WWN:
[disk] devices_udev_regex=IDNAME=device system unique id elevator=selected-scheduler
-
Sustituya IDNAME por el nombre del identificador utilizado (por ejemplo,
ID_WWN). -
Sustituya device system unique id por el valor del identificador elegido (por ejemplo,
0x5002538d00000000).
Para hacer coincidir varios dispositivos en la opción
devices_udev_regex, encierre los identificadores entre paréntesis y sepárelos con barras verticales:-
Sustituya IDNAME por el nombre del identificador utilizado (por ejemplo,
devices_udev_regex=(ID_WWN=0x5002538d00000000)|(ID_WWN=0x1234567800000000)
Habilita tu perfil:
# perfil tuned-adm my-profileCompruebe que el perfil Tuned está activo y aplicado:
$ tuned-adm active Current active profile: my-profile$ tuned-adm verify Verification succeeded, current system settings match the preset profile. See tuned log file ('/var/log/tuned/tuned.log') for details.
Recursos adicionales
- Para obtener más información sobre la creación de un perfil Tuned, consulte https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/monitoring_and_managing_system_status_and_performance/customizing-tuned-profiles_monitoring-and-managing-system-status-and-performance.
14.7. Configuración del programador de discos mediante reglas udev
Este procedimiento establece un programador de disco determinado para dispositivos de bloque específicos utilizando las reglas de udev. La configuración persiste a través de los reinicios del sistema.
En los siguientes comandos y la configuración, reemplazar:
-
device con el nombre del dispositivo de bloque, por ejemplo
sdf -
selected-scheduler con el programador de disco que se desea establecer para el dispositivo, por ejemplo
bfq
Procedimiento
Encuentra el identificador único del sistema del dispositivo de bloque:
$ udevadm info --name=/dev/device | grep -E '(WWN|SERIAL)' E: ID_WWN=0x5002538d00000000 E: ID_SERIAL=Generic-_SD_MMC_20120501030900000-0:0 E: ID_SERIAL_SHORT=20120501030900000
NotaEl comando de este ejemplo devolverá todos los valores identificados como World Wide Name (WWN) o número de serie asociados al dispositivo de bloque especificado. Aunque es preferible utilizar un WWN, el WWN no siempre está disponible para un dispositivo determinado y cualquier valor devuelto por el comando del ejemplo es aceptable para utilizarlo como el device system unique ID.
Configure la regla
udev. Cree el archivo/etc/udev/rules.d/99-scheduler.rulescon el siguiente contenido:ACTION=="add|change", SUBSYSTEM=="block", ENV{{{}IDNAME}=="device system unique id", ATTR{queue/scheduler}="selected-scheduler"-
Sustituya IDNAME por el nombre del identificador utilizado (por ejemplo,
ID_WWN). -
Sustituya device system unique id por el valor del identificador elegido (por ejemplo,
0x5002538d00000000).
-
Sustituya IDNAME por el nombre del identificador utilizado (por ejemplo,
Recargue las reglas de
udev:# udevadm control --reload-rules
Aplicar la configuración del programador:
# udevadm trigger --type=devices --action=change
Verifique el programador activo:
# cat /sys/block/device/queue/scheduler
14.8. Establecer temporalmente un programador para un disco específico
Este procedimiento establece un programador de disco determinado para dispositivos de bloque específicos. La configuración no persiste a través de los reinicios del sistema.
Procedimiento
Escriba el nombre del programador seleccionado en el
/sys/block/device/queue/schedulerarchivo:# echo selected-scheduler > /sys/block/device/cola/programador
En el nombre del archivo, sustituya device por el nombre del dispositivo de bloque, por ejemplo
sdc.
Pasos de verificación
Compruebe que el programador está activo en el dispositivo:
# cat /sys/block/device/queue/scheduler
Capítulo 15. Configuración de un sistema remoto sin disco
Las siguientes secciones describen los procedimientos necesarios para desplegar sistemas remotos sin disco en un entorno de red. Es útil implementar esta solución cuando se requieren múltiples clientes con idéntica configuración. Además, así se ahorrará el coste de los discos duros por el número de los clientes. Asumiendo que el servidor tiene instalado el sistema operativo Red Hat Enterprise Linux 8.
Figura 15.1. Diagrama de configuración del sistema remoto sin disco
Tenga en cuenta que la puerta de enlace puede estar configurada en un servidor distinto.
15.1. Preparación de un entorno para el sistema remoto sin disco
Este procedimiento describe la preparación del entorno para el sistema remoto sin disco.
El arranque remoto del sistema sin disco requiere un servicio tftp (proporcionado por tftp-server) y un servicio DHCP (proporcionado por dhcp). El servicio tftp se utiliza para recuperar la imagen del kernel y initrd a través de la red mediante el cargador PXE.
Requisitos previos
Instale los siguientes paquetes:
-
tftp-server -
xinetd -
dhcp-server -
syslinux
-
- Configure la conexión de red.
Procedimiento
Instale el paquete
dracut-network:# yum install dracut-network
Después de instalar el paquete
dracut-network, añada la siguiente línea a/etc/dracut.conf:add_dracutmodules =\ "nfs"
Algunos paquetes RPM han comenzado a utilizar capacidades de archivo (como setcap y getcap). Sin embargo, NFS no los soporta actualmente, por lo que el intento de instalar o actualizar cualquier paquete que utilice capacidades de archivo fallará.
En este punto tienes el servidor listo para continuar con la implementación del sistema remoto sin disco.
15.2. Configurar un servicio tftp para clientes sin disco
Este procedimiento describe cómo configurar un servicio tftp para un cliente sin disco.
Requisitos previos
- Instale los paquetes necesarios. Consulte los requisitos previos en Sección 15.1, “Preparación de un entorno para el sistema remoto sin disco”.
Para configurar tftp
Habilitar el arranque PXE a través de la red:
#systemctl enable --now tftpEl directorio raíz de
tftp(chroot) se encuentra en/var/lib/tftpboot. Copie/usr/share/syslinux/pxelinux.0en/var/lib/tftpboot/:#cp /usr/share/syslinux/pxelinux.0 /var/lib/tftpboot/Cree un directorio
pxelinux.cfgdentro del directorio raíz detftp:#mkdir -p /var/lib/tftpboot/pxelinux.cfg/-
Después de configurar
tftppara los clientes sin disco, configure el DHCP, el NFS y el sistema de archivos exportado como corresponde.
15.3. Configuración del servidor DHCP para clientes sin disco
Este procedimiento describe cómo configurar DHCP para un sistema sin disco.
Requisitos previos
- Instale los paquetes necesarios. Consulte los requisitos previos en Sección 15.1, “Preparación de un entorno para el sistema remoto sin disco”.
-
Configurar
tftp. Ver Sección 15.2, “Configurar un servicio tftp para clientes sin disco”.
Procedimiento
Configure un servidor DHCP y habilite el arranque PXE añadiendo la siguiente configuración a
/etc/dhcp/dhcpd.conf:allow booting; allow bootp; subnet 192.168.205.0 netmask 255.255.255.0 { pool { range 192.168.205.10 192.168.205.25; } option subnet-mask 255.255.255.0; option routers 192.168.205.1; } class "pxeclients" { match if substring(option vendor-class-identifier, 0, 9) = "PXEClient"; next-server server-ip; filename "pxelinux.0"; }Esta configuración no arrancará sobre UEFI. Para realizar la instalación para UEFI, siga el procedimiento de esta documentación: Configuración de un servidor TFTP para clientes basados en UEFI. Además, tenga en cuenta que el
/etc/dhcp/dhcpd.confes un archivo de ejemplo.NotaCuando las máquinas virtuales
libvirtse utilizan como cliente sin disco,libvirtproporciona el servicio DHCP y no se utiliza el servidor DHCP independiente. En esta situación, el arranque en red debe ser habilitado con la opciónbootp file='filename'opción en la configuración de redlibvirt,virsh net-edit.Habilite
dhcpd.serviceintroduciendo el siguiente comando:# systemctl enable --now dhcpd.service
15.4. Configuración de un sistema de archivos exportado para clientes sin disco
Este procedimiento describe cómo configurar un sistema de archivos exportado para un cliente sin disco.
Requisitos previos
- Instale los paquetes necesarios. Consulte los requisitos previos en Sección 15.1, “Preparación de un entorno para el sistema remoto sin disco”.
-
Configurar
tftp. Ver Sección 15.2, “Configurar un servicio tftp para clientes sin disco”. - Configurar DHCP. Véase Sección 15.3, “Configuración del servidor DHCP para clientes sin disco”.
Procedimiento
-
Configure el servidor NFS para exportar el directorio raíz añadiéndolo a
/etc/exports. Para las instrucciones, véase la configuración del servidor NFS. Para acomodar clientes completamente sin disco, el directorio raíz debe contener una instalación completa de Red Hat Enterprise Linux. Puede instalar un nuevo sistema base o clonar una instalación existente:
Para instalar Red Hat Enterprise Linux en la ubicación exportada, utilice la utilidad
yumcon la opción--installroot:#yum install @Base kernel dracut-network nfs-utils \ --installroot=exported-root-directory --releasever=/Para sincronizar con un sistema en funcionamiento, utilice la utilidad
rsync:#rsync -a -e ssh --exclude='/proc/' --exclude='/sys/' \ example.com:/exported-root-directory-
Sustituya hostname.com por el nombre del sistema en ejecución con el que se va a sincronizar a través de la utilidad
rsync. Sustituya exported-root-directory por la ruta del sistema de archivos exportado.
Tenga en cuenta que para esta opción debe tener un sistema independiente en ejecución, que clonará en el servidor mediante el comando anterior.
-
Sustituya hostname.com por el nombre del sistema en ejecución con el que se va a sincronizar a través de la utilidad
El sistema de archivos que se va a exportar aún debe configurarse más antes de que pueda ser utilizado por los clientes sin disco. Para ello, realice el siguiente procedimiento:
Configurar el sistema de archivos
Seleccione el kernel que los clientes sin disco deben utilizar (
vmlinuz-kernel-version) y cópielo en el directorio de arranque detftp:#cp /exported-root-directory/boot/vmlinuz-kernel-version /var/lib/tftpboot/Crear el
initrd(es decir,initramfs-kernel-version.img) con soporte NFS:#dracut --add nfs initramfs-kernel-version.img kernel-versionCambie los permisos de los archivos de
initrda 644 utilizando el siguiente comando:#chmod 644 /exported-root-directory/boot/initramfs-<kernel-version>.imgAvisoSi no cambias los permisos del archivo initrd, el gestor de arranque
pxelinux.0fallará con un error de "archivo no encontrado".Copie el archivo resultante
initramfs-kernel-version.imgen el directorio de arranque detftp:#cp /exported-root-directory/boot/initramfs-kernel-version.img /var/lib/tftpboot/Edite la configuración de arranque por defecto para utilizar el
initrdy el kernel en el directorio/var/lib/tftpboot/. Esta configuración debe indicar al root del cliente sin disco que monte el sistema de archivos exportado (/exported-root-directory) como lectura-escritura. Agregue la siguiente configuración en el archivo/var/lib/tftpboot/pxelinux.cfg/default:default rhel8 label rhel8 kernel vmlinuz-kernel-version append initrd=initramfs-kernel-version.img root=nfs:server-ip:/exported-root-directory rw
Sustituya
server-ipcon la dirección IP del equipo anfitrión en el que residen los serviciostftpy DHCP.Opcionalmente, puede montar el sistema en formato read-only utilizando la siguiente configuración en el archivo
/var/lib/tftpboot/pxelinux.cfg/default:default rhel8 label rhel8 kernel vmlinuz-kernel-version append initrd=initramfs-kernel-version.img root=nfs:server-ip:/exported-root-directory ro
- Reinicie el servidor NFS.
El recurso compartido NFS está ahora listo para ser exportado a clientes sin disco. Estos clientes pueden arrancar a través de la red mediante PXE.
15.5. Reconfiguración de un sistema remoto sin disco
En algunos casos es necesario reconfigurar el sistema. Los pasos siguientes muestran cómo cambiar la contraseña de un usuario, cómo instalar software en un sistema y describen cómo dividir el sistema en un /usr que está en modo de sólo lectura y un /var que está en modo de lectura y escritura.
Requisitos previos
-
no_root_squashopción está activada en el sistema de archivos exportado.
Procedimiento
Para cambiar la contraseña del usuario, siga los siguientes pasos:
Cambie la línea de comandos a /exported/root/directory:
# chroot /exported/root/directory /bin/bashCambia la contraseña del usuario que quieras:
# passwd <username>Sustituya el <username> por un usuario real al que quiera cambiar la contraseña.
Salir de la línea de comandos:
# exit
Para instalar software en un sistema remoto sin disco, utilice el siguiente comando:
# yum install <package> --installroot=/exportado/root/directorio --releasever=/ --config /etc/dnf/dnf.conf --setopt=reposdir=/etc/yum.repos.d/Sustituya <package> por el paquete real que desea instalar.
- Para dividir un sistema remoto sin disco en un /usr y un /var debe configurar dos exportaciones separadas. Lea la documentación de configuración del servidor NFS para más detalles.
15.6. Los problemas más comunes al cargar un sistema remoto sin disco
La siguiente sección describe los problemas durante la carga del sistema remoto sin disco en un cliente sin disco y muestra la posible solución para ellos.
15.6.1. El cliente no obtiene una dirección IP
Para solucionar ese problema:
Compruebe si el servicio DHCP está activado en el servidor.
Compruebe si el
dhcp.serviceestá funcionando:# systemctl status dhcpd.service
Si el
dhcp.serviceestá inactivo, debe activarlo e iniciarlo:# systemctl enable dhcpd.service # systemctl start dhcpd.service
Reinicie el cliente sin disco.
- Si el problema persiste, compruebe el archivo de configuración DHCP /etc/dhcp/dhcpd.conf en un servidor. Para más información, consulte Sección 15.3, “Configuración del servidor DHCP para clientes sin disco”.
Compruebe si los puertos del Firewall están abiertos.
Compruebe si la dirección
tftp.serviceaparece en los servicios activos:# firewall-cmd --get-active-zones # firewall-cmd --info-zone=public
Si el
tftp.serviceno aparece en los servicios activos, añádalo a la lista:# firewall-cmd --add-service=tftp
Compruebe si la dirección
nfs.serviceaparece en los servicios activos:# firewall-cmd --get-active-zones # firewall-cmd --info-zone=public
Si el
nfs.serviceno aparece en los servicios activos, añádalo a la lista:# firewall-cmd --add-service=nfs
15.6.2. Los archivos no están disponibles durante el arranque de un sistema remoto sin disco
Para solucionar este problema:
- Compruebe si el archivo está en su sitio. La ubicación en un servidor /var/lib/tftpboot/.
Si el archivo está en su sitio, compruebe sus permisos:
# chmod 644 pxelinux.0
- Compruebe si los puertos del Firewall están abiertos.
15.6.3. El arranque del sistema falló después de cargar el kernel/initrd
Para solucionar este problema:
Comprueba si el servicio NFS está activado en un servidor.
Compruebe si
nfs.serviceestá funcionando:# systemctl status nfs.service
Si el
nfs.serviceestá inactivo, debe activarlo e iniciarlo:# systemctl enable nfs.service # systemctl start nfs.service
- Compruebe si los parámetros son correctos en pxelinux.cfg. Para más detalles, consulte Sección 15.4, “Configuración de un sistema de archivos exportado para clientes sin disco”.
- Compruebe si los puertos del Firewall están abiertos.
Capítulo 16. Gestión de RAID
Este capítulo describe la matriz redundante de discos independientes (RAID). El usuario puede utilizar RAID para almacenar datos en varias unidades. También ayuda a evitar la pérdida de datos si una unidad ha fallado.
16.1. Matriz redundante de discos independientes (RAID)
La idea básica de RAID es combinar varios dispositivos, como HDD, SSD o NVMe, en una matriz para lograr objetivos de rendimiento o redundancia que no se pueden alcanzar con una sola unidad grande y cara. Este conjunto de dispositivos aparece ante el ordenador como una única unidad de almacenamiento lógico o disco.
El RAID permite repartir la información entre varios dispositivos. RAID utiliza técnicas como disk striping (RAID Nivel 0), disk mirroring (RAID Nivel 1) y disk striping with parity (RAID Niveles 4, 5 y 6) para conseguir redundancia, menor latencia, mayor ancho de banda y maximizar la capacidad de recuperación ante fallos de los discos duros.
RAID distribuye los datos en cada dispositivo de la matriz dividiéndolos en trozos de tamaño uniforme (normalmente 256K o 512k, aunque se aceptan otros valores). Cada trozo se escribe en un disco duro de la matriz RAID según el nivel RAID empleado. Cuando se leen los datos, el proceso se invierte, dando la ilusión de que los múltiples dispositivos de la matriz son en realidad una gran unidad.
Los administradores de sistemas y otras personas que gestionan grandes cantidades de datos se beneficiarían del uso de la tecnología RAID. Las principales razones para desplegar RAID incluyen:
- Mejora la velocidad
- Aumenta la capacidad de almacenamiento utilizando un único disco virtual
- Minimiza la pérdida de datos por fallo de disco
- Disposición de RAID y conversión de niveles en línea
16.2. Tipos de RAID
Hay tres enfoques posibles de RAID: RAID por firmware, RAID por hardware y RAID por software.
Firmware RAID
Firmware RAID, también conocido como ATARAID, es un tipo de RAID por software en el que los conjuntos RAID pueden configurarse mediante un menú basado en el firmware. El firmware utilizado por este tipo de RAID también se engancha a la BIOS, permitiéndole arrancar desde sus conjuntos RAID. Los distintos proveedores utilizan diferentes formatos de metadatos en el disco para marcar los miembros del conjunto RAID. El Intel Matrix RAID es un buen ejemplo de sistema RAID por firmware.
RAID por hardware
La matriz basada en hardware gestiona el subsistema RAID independientemente del host. Puede presentar varios dispositivos por matriz RAID al host.
Los dispositivos RAID por hardware pueden ser internos o externos al sistema. Los dispositivos internos suelen consistir en una tarjeta controladora especializada que gestiona las tareas RAID de forma transparente para el sistema operativo. Los dispositivos externos suelen conectarse al sistema a través de SCSI, Fibre Channel, iSCSI, InfiniBand u otra interconexión de red de alta velocidad y presentan volúmenes como unidades lógicas al sistema.
Las tarjetas controladoras RAID funcionan como una controladora SCSI para el sistema operativo y se encargan de todas las comunicaciones de las unidades. El usuario conecta las unidades a la controladora RAID (igual que una controladora SCSI normal) y luego las añade a la configuración de la controladora RAID. El sistema operativo no podrá notar la diferencia.
RAID por software
El RAID por software implementa los distintos niveles de RAID en el código de dispositivo de bloque del kernel. Ofrece la solución más barata posible, ya que no se requieren costosas tarjetas controladoras de disco o chasis de intercambio en caliente [1] no son necesarios. El RAID por software también funciona con cualquier almacenamiento en bloque soportado por el kernel de Linux, como SATA, SCSI, y NVMe. Con las CPUs más rápidas de hoy en día, el RAID por software también suele superar al RAID por hardware, a menos que se utilicen dispositivos de almacenamiento de alta gama.
El núcleo de Linux contiene un controlador multiple device (MD) que permite que la solución RAID sea completamente independiente del hardware. El rendimiento de un array basado en software depende del rendimiento y la carga de la CPU del servidor.
Características principales de la pila RAID por software de Linux:
- Diseño multihilo
- Portabilidad de matrices entre máquinas Linux sin reconstrucción
- Reconstrucción de matrices en segundo plano utilizando recursos del sistema ociosos
- Soporte de unidades intercambiables en caliente
- Detección automática de la CPU para aprovechar ciertas características de la misma, como la compatibilidad con la transmisión de instrucciones múltiples (SIMD)
- Corrección automática de sectores defectuosos en los discos de una matriz
- Comprobación periódica de la consistencia de los datos del RAID para garantizar la salud de la matriz
- Supervisión proactiva de las matrices con el envío de alertas por correo electrónico a una dirección de correo electrónico designada sobre eventos importantes
Mapas de bits con intención de escritura que aumentan drásticamente la velocidad de los eventos de resincronización al permitir que el núcleo sepa con precisión qué partes de un disco deben resincronizarse en lugar de tener que resincronizar toda la matriz tras un fallo del sistema
Tenga en cuenta que resync es un proceso para sincronizar los datos en los dispositivos del RAID existente para lograr la redundancia
- Resincronización de puntos de control para que, si se reinicia el ordenador durante una resincronización, al iniciarse la resincronización continúe donde se quedó y no vuelva a empezar
- La capacidad de cambiar los parámetros del array después de la instalación, que se llama reshaping. Por ejemplo, puedes ampliar una matriz RAID5 de 4 discos a una matriz RAID5 de 5 discos cuando tengas un nuevo dispositivo que añadir. Esta operación de crecimiento se realiza en vivo y no requiere que se reinstale en la nueva matriz
- La remodelación permite cambiar el número de dispositivos, el algoritmo RAID o el tamaño del tipo de matriz RAID, como RAID4, RAID5, RAID6 o RAID10
- La toma de posesión admite la conversión de niveles RAID, como RAID0 a RAID6
16.3. Niveles RAID y soporte lineal
RAID soporta varias configuraciones, incluyendo los niveles 0, 1, 4, 5, 6, 10 y lineal. Estos tipos de RAID se definen como sigue:
- Nivel 0
El nivel 0 de RAID, a menudo llamado striping, es una técnica de asignación de datos en franjas orientada al rendimiento. Esto significa que los datos que se escriben en la matriz se dividen en franjas y se escriben en los discos miembros de la matriz, lo que permite un alto rendimiento de E/S con un bajo coste inherente, pero no proporciona redundancia.
Muchas implementaciones de RAID de nivel 0 sólo dividen los datos entre los dispositivos miembros hasta el tamaño del dispositivo más pequeño de la matriz. Esto significa que si tiene varios dispositivos con tamaños ligeramente diferentes, cada dispositivo se trata como si tuviera el mismo tamaño que la unidad más pequeña. Por lo tanto, la capacidad de almacenamiento común de un array de nivel 0 es igual a la capacidad del disco miembro más pequeño en un RAID de hardware o la capacidad de la partición miembro más pequeña en un RAID de software multiplicada por el número de discos o particiones del array.
- Nivel 1
El nivel 1 de RAID, o mirroring, proporciona redundancia escribiendo datos idénticos en cada disco miembro de la matriz, dejando una copia "en espejo" en cada disco. El mirroring sigue siendo popular debido a su simplicidad y a su alto nivel de disponibilidad de datos. El nivel 1 funciona con dos o más discos y proporciona una muy buena fiabilidad de los datos y mejora el rendimiento de las aplicaciones de lectura intensiva, pero a un coste relativamente alto.
El nivel RAID 1 tiene un coste elevado porque escribe la misma información en todos los discos de la matriz, lo que proporciona fiabilidad a los datos, pero de una forma mucho menos eficiente en cuanto a espacio que los niveles RAID basados en paridad, como el nivel 5. Sin embargo, esta ineficiencia de espacio viene acompañada de un beneficio de rendimiento: los niveles RAID basados en la paridad consumen considerablemente más potencia de la CPU para generar la paridad, mientras que el nivel RAID 1 simplemente escribe los mismos datos más de una vez en los múltiples miembros del RAID con muy poca sobrecarga de la CPU. Por ello, el nivel RAID 1 puede superar a los niveles RAID basados en la paridad en máquinas en las que se emplea el software RAID y los recursos de la CPU de la máquina se ven sometidos a una carga constante de operaciones distintas de las actividades RAID.
La capacidad de almacenamiento de la matriz de nivel 1 es igual a la capacidad del disco duro duplicado más pequeño en un RAID de hardware o de la partición duplicada más pequeña en un RAID de software. La redundancia de nivel 1 es la más alta posible entre todos los tipos de RAID, ya que la matriz puede funcionar con un solo disco presente.
- Nivel 4
El nivel 4 utiliza la paridad concentrada en una sola unidad de disco para proteger los datos. La información de paridad se calcula basándose en el contenido del resto de los discos miembros de la matriz. Esta información puede utilizarse para reconstruir los datos cuando falla un disco de la matriz. Los datos reconstruidos pueden utilizarse entonces para satisfacer las solicitudes de E/S al disco que ha fallado antes de que sea sustituido y para repoblar el disco que ha fallado después de que haya sido sustituido.
Debido a que el disco de paridad dedicado representa un cuello de botella inherente en todas las transacciones de escritura en la matriz RAID, el nivel 4 rara vez se utiliza sin tecnologías de acompañamiento como el almacenamiento en caché de escritura, o en circunstancias específicas en las que el administrador del sistema está diseñando intencionadamente el dispositivo RAID por software teniendo en cuenta este cuello de botella (como una matriz que tendrá pocas o ninguna transacción de escritura una vez que la matriz esté llena de datos). El nivel 4 de RAID se utiliza tan raramente que no está disponible como opción en Anaconda. Sin embargo, puede ser creado manualmente por el usuario si es realmente necesario.
La capacidad de almacenamiento del hardware RAID de nivel 4 es igual a la capacidad de la partición miembro más pequeña multiplicada por el número de particiones minus one. El rendimiento de una matriz RAID de nivel 4 es siempre asimétrico, lo que significa que las lecturas superan a las escrituras. Esto se debe a que las escrituras consumen un ancho de banda extra de la CPU y de la memoria principal cuando se genera la paridad, y también consumen un ancho de banda extra del bus cuando se escriben los datos reales en los discos, porque se están escribiendo no sólo los datos, sino también la paridad. Las lecturas sólo necesitan leer los datos y no la paridad, a menos que la matriz esté en un estado degradado. Como resultado, las lecturas generan menos tráfico en los discos y en los buses del ordenador para la misma cantidad de transferencia de datos en condiciones normales de funcionamiento.
- Nivel 5
Este es el tipo más común de RAID. Al distribuir la paridad entre todas las unidades de disco miembros de una matriz, el nivel RAID 5 elimina el cuello de botella de escritura inherente al nivel 4. El único cuello de botella en el rendimiento es el propio proceso de cálculo de la paridad. Con las CPUs modernas y el RAID por software, esto no suele ser un cuello de botella en absoluto, ya que las CPUs modernas pueden generar la paridad muy rápidamente. Sin embargo, si tiene un número suficientemente grande de dispositivos miembros en una matriz RAID 5 por software, de forma que la velocidad de transferencia de datos combinada entre todos los dispositivos sea lo suficientemente alta, entonces este cuello de botella puede empezar a entrar en juego.
Al igual que el nivel 4, el nivel 5 tiene un rendimiento asimétrico, y las lecturas superan sustancialmente a las escrituras. La capacidad de almacenamiento del nivel RAID 5 se calcula de la misma manera que la del nivel 4.
- Nivel 6
Este es un nivel común de RAID cuando la redundancia y la preservación de los datos, y no el rendimiento, son las principales preocupaciones, pero cuando la ineficiencia de espacio del nivel 1 no es aceptable. El nivel 6 utiliza un complejo esquema de paridad para poder recuperarse de la pérdida de dos unidades cualesquiera de la matriz. Este complejo esquema de paridad crea una carga de CPU significativamente mayor en los dispositivos RAID por software y también impone una mayor carga durante las transacciones de escritura. Como tal, el nivel 6 es considerablemente más asimétrico en rendimiento que los niveles 4 y 5.
La capacidad total de una matriz RAID de nivel 6 se calcula de forma similar a la de las matrices RAID de nivel 5 y 4, con la salvedad de que hay que restar 2 dispositivos (en lugar de 1) del recuento de dispositivos para el espacio de almacenamiento de paridad adicional.
- Nivel 10
Este nivel RAID intenta combinar las ventajas de rendimiento del nivel 0 con la redundancia del nivel 1. También ayuda a aliviar parte del espacio desperdiciado en las matrices de nivel 1 con más de 2 dispositivos. Con el nivel 10, es posible, por ejemplo, crear una matriz de 3 unidades configurada para almacenar sólo 2 copias de cada dato, lo que permite que el tamaño total de la matriz sea 1,5 veces el tamaño de los dispositivos más pequeños, en lugar de ser sólo igual al dispositivo más pequeño (como ocurriría con una matriz de 3 dispositivos de nivel 1). Esto evita el uso del proceso de la CPU para calcular la paridad como en el nivel 6 de RAID, pero es menos eficiente en cuanto al espacio.
La creación de un RAID de nivel 10 no es posible durante la instalación. Es posible crear uno manualmente después de la instalación.
- RAID lineal
El RAID lineal es una agrupación de unidades para crear una unidad virtual más grande.
En el RAID lineal, los trozos se asignan secuencialmente desde una unidad miembro, pasando a la siguiente unidad sólo cuando la primera está completamente llena. Esta agrupación no proporciona ninguna ventaja de rendimiento, ya que es poco probable que las operaciones de E/S se dividan entre las unidades miembro. El RAID lineal tampoco ofrece redundancia y disminuye la fiabilidad. Si una de las unidades miembro falla, no se puede utilizar toda la matriz. La capacidad es el total de todos los discos miembros.
16.4. Subsistemas RAID de Linux
Los siguientes subsistemas componen RAID en Linux:
16.4.1. Controladores de controladores RAID de hardware de Linux
Las controladoras RAID por hardware no tienen un subsistema RAID específico en Linux. Debido a que utilizan conjuntos de chips RAID especiales, las controladoras RAID por hardware vienen con sus propios controladores; estos controladores permiten que el sistema detecte los conjuntos RAID como discos normales.
16.4.2. mdraid
El subsistema mdraid fue diseñado como una solución RAID por software para Linux; también es la solución preferida para RAID por software en Linux. Este subsistema utiliza su propio formato de metadatos, generalmente conocido como metadatos MD nativos.
mdraid también soporta otros formatos de metadatos, conocidos como metadatos externos. Red Hat Enterprise Linux 8 utiliza mdraid con metadatos externos para acceder a los conjuntos ISW / IMSM (Intel firmware RAID) y SNIA DDF. Los conjuntos mdraid se configuran y controlan a través de la utilidad mdadm.
16.5. Creación de RAID por software
Siga los pasos de este procedimiento para crear un dispositivo RAID (Redundant Arrays of Independent Disks). Los dispositivos RAID se construyen a partir de varios dispositivos de almacenamiento que se organizan para proporcionar un mayor rendimiento y, en algunas configuraciones, una mayor tolerancia a los fallos.
Un dispositivo RAID se crea en un solo paso y los discos se añaden o eliminan según sea necesario. Puede configurar una partición RAID para cada disco físico de su sistema, por lo que el número de discos disponibles para el programa de instalación determina los niveles de dispositivo RAID disponibles. Por ejemplo, si su sistema tiene dos discos duros, no puede crear un dispositivo RAID 10, ya que requiere un mínimo de tres discos separados.
En IBM Z, el subsistema de almacenamiento utiliza RAID de forma transparente. No es necesario configurar manualmente el RAID por software.
Requisitos previos
- Si ha seleccionado dos o más discos para la instalación, las opciones de configuración de RAID serán visibles. Se necesitan al menos dos discos para crear un dispositivo RAID.
- Ha creado un punto de montaje. Al configurar un punto de montaje, se configura el dispositivo RAID.
-
Ha seleccionado el botón de radio
Customen la ventanaInstallation Destination.
Procedimiento
- En el panel izquierdo de la ventana Manual Partitioning, seleccione la partición deseada.
- En la sección Device(s), haga clic en . Se abre el cuadro de diálogo Configure Mount Point.
- Seleccione los discos que desea incluir en el dispositivo RAID y haga clic en .
- Haga clic en el menú desplegable Device Type y seleccione RAID.
- Haga clic en el menú desplegable File System y seleccione su tipo de sistema de archivos preferido.
- Haga clic en el menú desplegable RAID Level y seleccione su nivel preferido de RAID.
- Haga clic en para guardar los cambios.
- Haga clic en para aplicar los ajustes y volver a la ventana Installation Summary.
Se muestra un mensaje en la parte inferior de la ventana si el nivel RAID especificado requiere más discos.
Para crear y configurar un volumen RAID mediante el rol de sistema de almacenamiento, consulte Sección 2.9, “Configuración de un volumen RAID mediante el rol de sistema de almacenamiento”
16.6. Creación de un RAID por software después de la instalación
Este procedimiento describe cómo crear una matriz redundante de discos independientes (RAID) por software en un sistema existente utilizando la utilidad mdadm.
Requisitos previos
-
El paquete
mdadminstalado. - Existen dos o más particiones en su sistema. Para obtener instrucciones detalladas, consulte Sección 3.3, “Crear una partición”.
Procedimiento
Para crear un RAID de dos dispositivos de bloque, por ejemplo /dev/sda1 y /dev/sdc1, utilice el siguiente comando:
# mdadm --create /dev/md0 --level=<level_value> --raid-devices=2 /dev/sda1 /dev/sdc1Sustituye <level_value> por una opción de nivel RAID. Para más información, consulte la página man
mdadm(8).Opcionalmente, para comprobar el estado del RAID, utilice el siguiente comando:
# mdadm --detail /dev/md0
Opcionalmente, para observar la información detallada de cada dispositivo RAID, utilice el siguiente comando:
# mdadm --examine /dev/sda1 /dev/sdc1
Para crear un sistema de archivos en una unidad RAID, utilice el siguiente comando:
# mkfs -t <file-system-name> /dev/md0donde <file-system-name> es un sistema de archivos específico con el que ha elegido formatear la unidad. Para más información, consulte la página de manual
mkfs.Para crear un punto de montaje para la unidad RAID y montarla, utilice los siguientes comandos:
# mkdir /mnt/raid1 # mount /dev/md0 /mnt/raid1
Una vez terminados los pasos anteriores, el RAID está listo para ser utilizado.
16.7. Configuración de un volumen RAID mediante el rol de sistema de almacenamiento
Con el rol de sistema storage, puede configurar un volumen RAID en RHEL utilizando Red Hat Ansible Automation Platform. En esta sección aprenderá a configurar un playbook de Ansible con los parámetros disponibles para configurar un volumen RAID que se adapte a sus necesidades.
Requisitos previos
Tiene instalado Red Hat Ansible Engine en el sistema desde el que desea ejecutar el libro de jugadas.
NotaNo es necesario tener Red Hat Ansible Automation Platform instalado en los sistemas en los que se desea implementar la solución
storage.-
Tienes el paquete
rhel-system-rolesinstalado en el sistema desde el que quieres ejecutar el playbook. -
Tienes un archivo de inventario que detalla los sistemas en los que quieres desplegar un volumen RAID usando el rol de sistema
storage.
Procedimiento
Cree un nuevo
playbook.ymlarchivo con el siguiente contenido:- hosts: all vars: storage_safe_mode: false storage_volumes: - name: data type: raid disks: [sdd, sde, sdf, sdg] raid_level: raid0 raid_chunk_size: 32 KiB mount_point: /mnt/data state: present roles: - name: rhel-system-roles.storageAvisoLos nombres de los dispositivos pueden cambiar en determinadas circunstancias; por ejemplo, cuando se añade un nuevo disco a un sistema. Por lo tanto, para evitar la pérdida de datos, no se recomienda utilizar nombres de discos específicos en el libro de jugadas.
Opcional. Verificar la sintaxis del libro de jugadas.
# ansible-playbook --syntax-check playbook.ymlEjecute el libro de jugadas en su archivo de inventario:
# ansible-playbook -i inventory.file /path/to/file/playbook.yml
Recursos adicionales
-
Para obtener detalles sobre los parámetros utilizados en el rol del sistema de almacenamiento, consulte el archivo
/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
16.8. Reconfiguración de RAID
La sección siguiente describe cómo modificar un RAID existente. Para ello, elija uno de los métodos:
- Cambio de atributos RAID (también conocido como RAID reshape).
- Conversión del nivel RAID (también conocido como RAID takeover).
16.8.1. Reestructuración de RAID
En este capítulo se describe cómo redimensionar el RAID. Puede elegir uno de los métodos para redimensionar el RAID:
- Ampliar (extender) el RAID.
- Reducción de RAID.
16.8.1.1. Redimensionamiento del RAID (ampliación)
Este procedimiento describe cómo ampliar el RAID. Asumiendo que /dev/md0 es el RAID que quiere ampliar.
Requisitos previos
- Suficiente espacio en el disco.
-
El paquete
partedestá instalado.
Procedimiento
- Amplíe las particiones RAID. Para ello, siga las instrucciones de la documentación sobre el redimensionamiento de una parti ción.
Para ampliar el RAID hasta el máximo de la capacidad de la partición, utilice este comando:
# mdadm --grow --size=max /dev/md0
Tenga en cuenta que para determinar un tamaño específico, debe escribir el parámetro --size en kB (por ejemplo --size=524228).
- Aumente el tamaño del sistema de archivos. Para más información, consulte la documentación sobre la gestión de los sistemas de archivos.
16.8.1.2. Redimensionar el RAID (reducir)
Este procedimiento describe cómo reducir el RAID. Suponiendo que /dev/md0 es el RAID que desea reducir a 512 MB.
Requisitos previos
-
El paquete
partedestá instalado.
Procedimiento
Reduzca el sistema de archivos. Para ello, consulte la documentación sobre la gestión de los sistemas de archivos.
ImportanteEl sistema de archivos XFS no admite la reducción de tamaño.
Para reducir el RAID al tamaño de 512 MB, utilice este comando:
# mdadm --grow --size=524228 /dev/md0
Tenga en cuenta que debe escribir el parámetro --size en kB.
- Reduzca la partición al tamaño que necesita. Para ello, siga las instrucciones de la documentación sobre el cambio de tamaño de una parti ción.
16.8.2. Toma de posesión de RAID
Este capítulo describe las conversiones soportadas en RAID y contiene los procedimientos para realizar dichas conversiones.
16.8.2.1. Conversiones RAID soportadas
Es posible convertir de un nivel RAID a otro. Esta sección proporciona una tabla que enumera las conversiones RAID soportadas.
| RAID0 | RAID1 | RAID4 | RAID5 | RAID6 | RAID10 | |
|---|---|---|---|---|---|---|
| RAID0 | ઝ | ઝ | ઙ | ઙ | ઝ | ઙ |
| RAID1 | ઝ | ઝ | ઝ | ઙ | ઝ | ઝ |
| RAID4 | ઝ | ઝ | ઝ | ઙ | ઝ | ઝ |
| RAID5 | ઙ | ઙ | ઙ | ઝ | ઙ | ઙ |
| RAID6 | ઝ | ઝ | ઝ | ઙ | ઝ | ઝ |
| RAID10 | ઙ | ઝ | ઝ | ઝ | ઝ | ઝ |
Por ejemplo, puede convertir el nivel RAID 0 en el nivel RAID 4, el nivel RAID 5 y el nivel RAID 10
Recursos adicionales
-
Para más información sobre la conversión de niveles RAID, lea la página man
mdadm.
16.8.2.2. Conversión del nivel RAID
Este procedimiento describe cómo convertir un RAID a un nivel RAID diferente. Suponiendo que quiera convertir el nivel 0 de RAID /dev/md0 al nivel 5 de RAID y añadir un disco más /dev/sdd a la matriz.
Requisitos previos
- Suficientes discos para la conversión.
-
El paquete
mdadmestá instalado. - Asegúrese de que la conversión prevista es compatible. Para comprobar si es el caso, consulte la tabla en Sección 16.8.2.1, “Conversiones RAID soportadas”.
Procedimiento
Para convertir el RAID
/dev/md0a nivel RAID 5, utilice el siguiente comando:# mdadm --grow --level=5 -n 3 /dev/md0 --force
Para añadir un nuevo disco a la matriz, utilice el siguiente comando:
# mdadm --manage /dev/md0 --add /dev/sdd
Para comprobar nuevos detalles de la matriz convertida, utilice el siguiente comando:
# mdadm --detail /dev/md0
Recursos adicionales
-
Para más información sobre la conversión de niveles RAID, lea la página man
mdadm.
16.9. Convertir un disco raíz en RAID1 después de la instalación
Esta sección describe cómo convertir un disco raíz no RAID en un espejo RAID1 después de instalar Red Hat Enterprise Linux 8.
En la arquitectura PowerPC (PPC), siga los siguientes pasos adicionales:
Requisitos previos
- Las instrucciones en el siguiente artículo de Red Hat Knowledgebase se han completado: ¿Cómo puedo convertir mi disco raíz en RAID1 después de la instalación de Red Hat Enterprise Linux 7?
Procedimiento
Copie el contenido de la partición de arranque de la Plataforma de Referencia PowerPC (PReP) de
/dev/sda1a/dev/sdb1:#dd if=/dev/sda1 of=/dev/sdb1Actualice la Prep y la bandera de arranque en la primera partición de ambos discos:
$parted /dev/sda set 1 prep on$parted /dev/sda set 1 boot on$parted /dev/sdb set 1 prep on$parted /dev/sdb set 1 boot on
La ejecución del comando grub2-install /dev/sda no funciona en una máquina PowerPC y devuelve un error, pero el sistema arranca como se espera.
16.10. Creación de dispositivos RAID avanzados
En algunos casos, es posible que desee instalar el sistema operativo en un array que no pueda crearse una vez finalizada la instalación. Por lo general, esto significa configurar las matrices de /boot o del sistema de archivos raíz en un dispositivo RAID complejo; en estos casos, es posible que tenga que utilizar opciones de matrices que no son compatibles con el Anaconda instalador. Para evitar esto, realice el siguiente procedimiento:
Procedimiento
- Inserte el disco de instalación.
-
Durante el arranque inicial, seleccione
Rescue Modeen lugar deInstalloUpgrade. Cuando el sistema arranque completamente en Rescue mode, el usuario se encontrará con un terminal de línea de comandos. -
Desde este terminal, utiliza
partedpara crear particiones RAID en los discos duros de destino. A continuación, utilicemdadmpara crear manualmente matrices RAID a partir de esas particiones utilizando todas y cada una de las configuraciones y opciones disponibles. Para más información sobre cómo hacer esto, veaman partedyman mdadm. - Una vez creadas las matrices, puede crear opcionalmente sistemas de archivos en las matrices también.
-
Reinicie el ordenador y seleccione
InstalloUpgradepara instalarlo normalmente. Cuando el instalador de Anaconda instalador busca en los discos del sistema, encontrará los dispositivos RAID preexistentes. -
Cuando se le pregunte cómo utilizar los discos en el sistema, seleccione
Custom Layouty haga clic en . En el listado de dispositivos, aparecerán los dispositivos MD RAID preexistentes. - Seleccione un dispositivo RAID, haga clic en y configure su punto de montaje y (opcionalmente) el tipo de sistema de archivos que debe utilizar (si no creó uno anteriormente) y luego haga clic en Anaconda realizará la instalación en este dispositivo RAID preexistente, conservando las opciones personalizadas que seleccionó cuando lo creó en Rescue Mode.
La versión limitada Rescue Mode del instalador no incluye las páginas man. Tanto man mdadm como man md contienen información útil para crear matrices RAID personalizadas, y pueden ser necesarias a lo largo de la solución. Por lo tanto, puede ser útil tener acceso a una máquina con estas páginas man, o imprimirlas antes de arrancar en Rescue Mode y crear sus matrices personalizadas.
16.11. Monitorización de RAID
Este módulo describe cómo configurar la opción de monitorización de RAID con la herramienta mdadm.
Requisitos previos
-
El paquete
mdadmestá instalado - El servicio de correo está configurado.
Procedimiento
Para crear un archivo de configuración para la monitorización de la matriz hay que escanear los detalles y enviar el resultado al archivo
/etc/mdadm.conf. Para ello, utilice el siguiente comando:# mdadm --detail --scan >> /etc/mdadm.conf
Tenga en cuenta que ARRAY y MAILADDR son variables obligatorias.
-
Abra el archivo de configuración
/etc/mdadm.confcon un editor de texto de su elección. Añada la variable MAILADDR con la dirección de correo para la notificación. Por ejemplo, añada una nueva línea:
MAILADDR <example@example.com>
donde example@example.com es una dirección de correo electrónico a la que desea recibir las alertas de la monitorización del array.
-
Guarde los cambios en el archivo
/etc/mdadm.confy ciérrelo.
Una vez completados los pasos anteriores, el sistema de vigilancia enviará las alertas a la dirección de correo electrónico.
Recursos adicionales
-
Para más información, lea la página man
mdadm.conf 5.
16.12. Mantenimiento de RAID
Esta sección proporciona varios procedimientos para el mantenimiento del RAID.
16.12.1. Sustitución de un disco defectuoso en un RAID
Este procedimiento describe cómo sustituir el disco defectuoso en una matriz redundante de discos independientes (RAID). Suponiendo que tenga /dev/md0 RAID de nivel 10. En este escenario, el disco /dev/sdg está defectuoso y necesita reemplazarlo por un nuevo disco /dev/sdh.
Requisitos previos
- Disco adicional de repuesto.
-
El paquete
mdadmestá instalado. - Una notificación sobre un disco defectuoso en un array. Para configurar la monitorización de arrays, consulte Sección 16.11, “Monitorización de RAID”.
Procedimiento
Asegúrese de qué disco está fallando. Para ello, introduzca el siguiente comando:
# journalctl -k -f
Encontrará un mensaje que le indica qué disco ha fallado:
md/raid:md0: Disk failure on sdg, disabling device. md/raid:md0: Operation continuing on 5 devices.
-
Pulse
Ctrl Cen su teclado para salir del programajournalctl. Añade un nuevo disco al array. Para ello, introduzca el siguiente comando:
# mdadm --manage /dev/md0 --add /dev/sdh
Marque el disco que ha fallado como defectuoso. Para ello, introduzca el siguiente comando:
# mdadm --manage /dev/md0 --fail /dev/sdg
Compruebe si el disco defectuoso fue enmascarado correctamente utilizando el siguiente comando:
# mdadm --detail /dev/md0
Al final de la última salida del comando verá información sobre los discos RAID similar a esta donde el disco /dev/sdg tiene un estado faulty:
Number Major Minor RaidDevice State 0 8 16 0 active sync /dev/sdb 1 8 32 1 active sync /dev/sdc 2 8 48 2 active sync /dev/sdd 3 8 64 3 active sync /dev/sde 4 8 80 4 active sync /dev/sdf 6 8 112 5 active sync /dev/sdh 5 8 96 - faulty /dev/sdgPor último, elimine el disco defectuoso de la matriz. Para ello, introduzca el siguiente comando:
# mdadm --manage /dev/md0 --remove /dev/sdg
Compruebe los detalles del RAID utilizando el siguiente comando:
# mdadm --detail /dev/md0
Al final de la salida del último comando verá información sobre los discos RAID similar a esta:
Number Major Minor RaidDevice State 0 8 16 0 active sync /dev/sdb 1 8 32 1 active sync /dev/sdc 2 8 48 2 active sync /dev/sdd 3 8 64 3 active sync /dev/sde 4 8 80 4 active sync /dev/sdf 6 8 112 5 active sync /dev/sdh
Después de completar los pasos anteriores tendrá el RAID /dev/md0 con un nuevo disco /dev/sdh.
16.12.2. Sustitución de un disco roto en la matriz
Este procedimiento describe cómo sustituir el disco roto en una matriz redundante de discos independientes (RAID). Asumiendo que tiene /dev/md0 RAID nivel 6. En este escenario, el disco /dev/sdb tiene un problema de hardware y no puede seguir utilizándose. Usted necesita reemplazarlo con el nuevo disco /dev/sdi.
Requisitos previos
- Nuevo disco de sustitución.
-
El paquete
mdadmestá instalado.
Procedimiento
Compruebe el mensaje de registro utilizando el siguiente comando:
# journalctl -k -f
Encontrará un mensaje que le indica qué disco ha fallado:
md/raid:md0: Disk failure on sdb, disabling device. md/raid:md0: Operation continuing on 5 devices.
-
Pulse
Ctrl Cen su teclado para salir del programajournalctl. Añada el nuevo disco al array como disco de reserva. Para ello, introduzca el siguiente comando:
# mdadm --manage /dev/md0 --add /dev/sdi
Marque el disco roto como faulty. Para ello, introduzca el siguiente comando:
# mdadm --manage /dev/md0 --fail /dev/sdb
Retire el disco defectuoso de la matriz. Para ello, introduzca el siguiente comando:
# mdadm --manage /dev/md0 --remove /dev/sdb
Compruebe el estado de la matriz mediante el siguiente comando:
# mdadm --detail /dev/md0
Al final de la salida del último comando verá información sobre los discos RAID similar a esta:
Number Major Minor RaidDevice State 7 8 128 0 active sync /dev/sdi 1 8 32 1 active sync /dev/sdc 2 8 48 2 active sync /dev/sdd 3 8 64 3 active sync /dev/sde 4 8 80 4 active sync /dev/sdf 6 8 112 5 active sync /dev/sdh
Después de completar los pasos anteriores tendrá el RAID /dev/md0 con un nuevo disco /dev/sdi.
16.12.3. Resincronización de discos RAID
Este procedimiento describe cómo resincronizar los discos de una matriz RAID. Suponiendo que tenga /dev/md0 RAID.
Requisitos previos
-
El paquete
mdadmestá instalado.
Procedimiento
Para comprobar el comportamiento de los discos que han fallado en el array, introduzca el siguiente comando:
# echo check > /sys/block/md0/md/sync_action
Esa acción comprobará la matriz y escribirá el resultado en el archivo
/sys/block/md0/md/sync_action.-
Abra el archivo
/sys/block/md0/md/sync_actioncon el editor de texto de su elección y vea si hay algún mensaje sobre los fallos de sincronización del disco. Para resincronizar los discos de la matriz, introduzca el siguiente comando:
# echo repair > /sys/block/md0/md/sync_action
Esta acción resincronizará los discos de la matriz y escribirá el resultado en el archivo
/sys/block/md0/md/sync_action.Para ver el progreso de la sincronización, introduzca el siguiente comando:
# cat /proc/mdstat
Capítulo 17. Cifrado de dispositivos de bloque mediante LUKS
El cifrado de discos protege los datos de un dispositivo de bloque cifrándolos. Para acceder al contenido descifrado del dispositivo, el usuario debe proporcionar una frase de paso o una clave como autenticación. Esto es especialmente importante cuando se trata de ordenadores móviles y medios extraíbles: ayuda a proteger el contenido del dispositivo aunque se haya retirado físicamente del sistema. El formato LUKS es una implementación por defecto del cifrado de dispositivos en bloque en RHEL.
17.1. Cifrado de disco LUKS
El sistema Linux Unified Key Setup-on-disk-format (LUKS) permite cifrar dispositivos de bloque y proporciona un conjunto de herramientas que simplifica la gestión de los dispositivos cifrados. LUKS permite que varias claves de usuario descifren una clave maestra, que se utiliza para el cifrado masivo de la partición.
RHEL utiliza LUKS para realizar el cifrado del dispositivo de bloque. Por defecto, la opción de cifrar el dispositivo de bloque está desmarcada durante la instalación. Si selecciona la opción de cifrar el disco, el sistema le pedirá una frase de contraseña cada vez que arranque el ordenador. Esta frase de contraseña “desbloquea” la clave de cifrado masivo que descifra su partición. Si eliges modificar la tabla de particiones por defecto, puedes elegir qué particiones quieres cifrar. Esto se establece en la configuración de la tabla de particiones.
Qué hace LUKS
- LUKS encripta dispositivos de bloques enteros y, por tanto, es muy adecuado para proteger el contenido de dispositivos móviles, como medios de almacenamiento extraíbles o unidades de disco de ordenadores portátiles.
- El contenido subyacente del dispositivo de bloque cifrado es arbitrario, lo que lo hace útil para cifrar dispositivos de intercambio. También puede ser útil con ciertas bases de datos que utilizan dispositivos de bloque con un formato especial para el almacenamiento de datos.
- LUKS utiliza el subsistema del kernel de mapeo de dispositivos existente.
- LUKS proporciona un refuerzo de la frase de contraseña que protege contra los ataques de diccionario.
- Los dispositivos LUKS contienen varias ranuras para claves, lo que permite a los usuarios añadir claves de seguridad o frases de contraseña.
Qué hace LUKS not
- Las soluciones de cifrado de discos como LUKS protegen los datos sólo cuando el sistema está apagado. Una vez que el sistema está encendido y LUKS ha descifrado el disco, los archivos de ese disco están disponibles para cualquiera que normalmente tendría acceso a ellos.
- LUKS no es adecuado para escenarios que requieran que muchos usuarios tengan claves de acceso distintas para el mismo dispositivo. El formato LUKS1 proporciona ocho ranuras para llaves, LUKS2 hasta 32 ranuras para llaves.
- LUKS no es adecuado para aplicaciones que requieran encriptación a nivel de archivo.
Cifras
El cifrado por defecto utilizado para LUKS es aes-xts-plain64. El tamaño de la clave por defecto para LUKS es de 512 bits. El tamaño de la clave por defecto para LUKS con Anaconda (modo XTS) es de 512 bits. Los cifrados disponibles son:
- AES - Estándar de cifrado avanzado - FIPS PUB 197
- Twofish (un cifrado en bloque de 128 bits)
- Serpent
Recursos adicionales
17.2. Versiones de LUKS en RHEL 8
En RHEL 8, el formato por defecto para el cifrado LUKS es LUKS2. El formato heredado LUKS1 sigue siendo totalmente compatible y se proporciona como un formato compatible con las versiones anteriores de RHEL.
El formato LUKS2 está diseñado para permitir futuras actualizaciones de varias partes sin necesidad de modificar las estructuras binarias. LUKS2 utiliza internamente el formato de texto JSON para los metadatos, proporciona redundancia de metadatos, detecta la corrupción de metadatos y permite la reparación automática a partir de una copia de metadatos.
No utilice LUKS2 en sistemas que necesiten ser compatibles con sistemas heredados que sólo soporten LUKS1. Tenga en cuenta que RHEL 7 admite el formato LUKS2 desde la versión 7.6.
LUKS2 y LUKS1 utilizan diferentes comandos para cifrar el disco. Utilizar el comando incorrecto para una versión de LUKS podría causar la pérdida de datos.
| Versión LUKS | Comando de encriptación |
|---|---|
| LUKS2 |
|
| LUKS1 |
|
Reencriptación en línea
El formato LUKS2 permite volver a encriptar los dispositivos encriptados mientras éstos están en uso. Por ejemplo, no es necesario desmontar el sistema de archivos del dispositivo para realizar las siguientes tareas:
- Cambiar la tecla de volumen
- Cambiar el algoritmo de encriptación
Cuando se encripta un dispositivo no encriptado, hay que desmontar el sistema de archivos. Puedes volver a montar el sistema de archivos tras una breve inicialización del cifrado.
El formato LUKS1 no admite la recodificación en línea.
Conversión
El formato LUKS2 se inspira en LUKS1. En determinadas situaciones, se puede convertir LUKS1 en LUKS2. La conversión no es posible específicamente en los siguientes escenarios:
-
Un dispositivo LUKS1 está marcado como utilizado por una solución de descifrado basada en políticas (PBD - Clevis). La herramienta
cryptsetupse niega a convertir el dispositivo cuando se detectan algunos metadatos deluksmeta. - Un dispositivo está activo. El dispositivo debe estar en estado inactivo antes de que sea posible cualquier conversión.
17.3. Opciones de protección de datos durante la recodificación de LUKS2
LUKS2 ofrece varias opciones que priorizan el rendimiento o la protección de los datos durante el proceso de recodificación:
checksumEste es el modo por defecto. Equilibra la protección de los datos y el rendimiento.
Este modo almacena sumas de comprobación individuales de los sectores en el área de recodificación, por lo que el proceso de recuperación puede detectar los sectores que LUKS2 ya ha recodificado. El modo requiere que la escritura del sector del dispositivo de bloque sea atómica.
journal- Es el modo más seguro pero también el más lento. Este modo registra el área de recodificación en el área binaria, por lo que LUKS2 escribe los datos dos veces.
none-
Este modo da prioridad al rendimiento y no proporciona ninguna protección de datos. Protege los datos sólo contra la terminación segura del proceso, como la señal
SIGTERMo que el usuario presione Ctrl+C. Cualquier fallo inesperado del sistema o de la aplicación puede provocar la corrupción de los datos.
Puede seleccionar el modo mediante la opción --resilience de cryptsetup.
Si un proceso de recodificación de LUKS2 termina inesperadamente por la fuerza, LUKS2 puede realizar la recuperación de una de las siguientes maneras:
-
Automáticamente, durante la siguiente acción de apertura del dispositivo LUKS2. Esta acción se desencadena mediante el comando
cryptsetup openo al adjuntar el dispositivo consystemd-cryptsetup. -
Manualmente, utilizando el comando
cryptsetup repairen el dispositivo LUKS2.
17.4. Cifrado de datos existentes en un dispositivo de bloques mediante LUKS2
Este procedimiento encripta los datos existentes en un dispositivo aún no encriptado utilizando el formato LUKS2. Se almacena una nueva cabecera LUKS en el cabezal del dispositivo.
Requisitos previos
- El dispositivo de bloque contiene un sistema de archivos.
Has hecho una copia de seguridad de tus datos.
AvisoPodrías perder tus datos durante el proceso de encriptación: debido a un fallo de hardware, del núcleo o humano. Asegúrate de tener una copia de seguridad fiable antes de empezar a encriptar los datos.
Procedimiento
Desmonte todos los sistemas de archivos del dispositivo que vaya a cifrar. Por ejemplo:
# umount /dev/sdb1Deje espacio libre para almacenar una cabecera LUKS. Elija una de las siguientes opciones que se adapte a su escenario:
En el caso de la encriptación de un volumen lógico, se puede ampliar el volumen lógico sin cambiar el tamaño del sistema de archivos. Por ejemplo:
# lvextend -L 32M vg00/lv00
-
Amplíe la partición utilizando herramientas de gestión de particiones, como
parted. -
Reduzca el sistema de archivos del dispositivo. Puede utilizar la utilidad
resize2fspara los sistemas de archivos ext2, ext3 o ext4. Tenga en cuenta que no puede reducir el sistema de archivos XFS.
Inicializar la encriptación. Por ejemplo:
# cryptsetup reencrypt \ --encrypt \ --init-only \ --reduce-device-size 32M \ /dev/sdb1 sdb1_encryptedEl comando le pide una frase de contraseña y comienza el proceso de encriptación.
Monta el dispositivo:
# mount /dev/mapper/sdb1_encrypted /mnt/sdb1_encrypted
Inicie la codificación en línea:
# cryptsetup reencrypt --resume-only /dev/sdb1
Recursos adicionales
-
Para más detalles, consulte las páginas de manual
cryptsetup(8),lvextend(8),resize2fs(8), yparted(8).
17.5. Cifrado de datos existentes en un dispositivo de bloque mediante LUKS2 con una cabecera separada
Este procedimiento encripta los datos existentes en un dispositivo de bloque sin crear espacio libre para almacenar una cabecera LUKS. La cabecera se almacena en una ubicación independiente, lo que también sirve como capa adicional de seguridad. El procedimiento utiliza el formato de cifrado LUKS2.
Requisitos previos
- El dispositivo de bloque contiene un sistema de archivos.
Has hecho una copia de seguridad de tus datos.
AvisoPodrías perder tus datos durante el proceso de encriptación: debido a un fallo de hardware, del núcleo o humano. Asegúrate de tener una copia de seguridad fiable antes de empezar a encriptar los datos.
Procedimiento
Desmontar todos los sistemas de archivos del dispositivo. Por ejemplo:
# umount /dev/sdb1Inicializar la encriptación:
# cryptsetup reencrypt \ --encrypt \ --init-only \ --header /path/to/header \ /dev/sdb1 sdb1_encryptedSustituya /path/to/header por una ruta al archivo con una cabecera LUKS separada. La cabecera LUKS separada tiene que ser accesible para que el dispositivo encriptado pueda ser desbloqueado posteriormente.
El comando le pide una frase de contraseña y comienza el proceso de encriptación.
Monta el dispositivo:
# mount /dev/mapper/sdb1_encrypted /mnt/sdb1_encrypted
Inicie la codificación en línea:
# cryptsetup reencrypt --resume-only --header /path/to/header /dev/sdb1
Recursos adicionales
-
Para más detalles, consulte la página de manual
cryptsetup(8).
17.6. Cifrado de un dispositivo de bloque en blanco mediante LUKS2
Este procedimiento proporciona información sobre el cifrado de un dispositivo de bloque en blanco utilizando el formato LUKS2.
Requisitos previos
- Un dispositivo de bloque en blanco.
Procedimiento
Configurar una partición como una partición LUKS cifrada:
# cryptsetup luksFormat /dev/sdb1Abra una partición LUKS encriptada:
# cryptsetup open /dev/sdb1 sdb1_encryptedEsto desbloquea la partición y la asigna a un nuevo dispositivo utilizando el mapeador de dispositivos. Esto alerta al kernel de que
devicees un dispositivo encriptado y debe ser direccionado a través de LUKS usando el/dev/mapper/device_mapped_namepara no sobrescribir los datos encriptados.Para escribir datos encriptados en la partición, se debe acceder a ella a través del nombre mapeado del dispositivo. Para ello, debes crear un sistema de archivos. Por ejemplo:
# mkfs -t ext4 /dev/mapper/sdb1_encryptedMonta el dispositivo:
# montaje /dev/mapper/sdb1_encrypted
Recursos adicionales
-
Para más detalles, consulte la página de manual
cryptsetup(8).
17.7. Creación de un volumen encriptado LUKS utilizando el rol de almacenamiento
Puede utilizar el rol storage para crear y configurar un volumen encriptado con LUKS ejecutando un playbook de Ansible.
Requisitos previos
Tiene instalado Red Hat Ansible Engine en el sistema desde el que desea ejecutar el libro de jugadas.
NotaNo es necesario tener Red Hat Ansible Automation Platform instalado en los sistemas en los que se desea crear el volumen.
-
Tiene el paquete
rhel-system-rolesinstalado en el controlador Ansible. - Dispone de un archivo de inventario en el que se detallan los sistemas en los que desea desplegar un volumen encriptado LUKS mediante el rol de sistema de almacenamiento.
Procedimiento
Cree un nuevo
playbook.ymlarchivo con el siguiente contenido:- hosts: all vars: storage_volumes: - name: barefs type: disk disks: - sdb fs_type: xfs fs_label: label-name mount_point: /mnt/data encryption: true encryption_password: your-password roles: - rhel-system-roles.storageOpcional. Verificar la sintaxis del libro de jugadas:
# ansible-playbook --syntax-check playbook.ymlEjecute el libro de jugadas en su archivo de inventario:
# ansible-playbook -i inventory.file /path/to/file/playbook.yml
Recursos adicionales
- Para más información sobre LUKS, véase 17. Cifrado de dispositivos de bloque mediante LUKS..
-
Para más detalles sobre los parámetros utilizados en el rol de sistema
storage, consulte el archivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
Capítulo 18. Gestión de dispositivos de cinta
Un dispositivo de cinta es una cinta magnética donde se almacenan los datos y se accede a ellos de forma secuencial. Los datos se escriben en este dispositivo de cinta con la ayuda de una unidad de cinta. No es necesario crear un sistema de archivos para almacenar datos en un dispositivo de cinta. Las unidades de cinta pueden conectarse a un ordenador anfitrión con varias interfaces, como SCSI, FC, USB, SATA y otras.
A continuación se detallan los diferentes tipos de dispositivos de cinta:
-
/dev/stes un dispositivo de rebobinado de cintas. -
/dev/nstes un dispositivo de cinta sin rebobinado. Utilice dispositivos sin rebobinado para las copias de seguridad diarias.
Ventajas de los dispositivos de cinta:
- Costos eficientes
- Resistente a la corrupción de datos
- Conservación de datos
- Estable
18.1. Instalación de la herramienta de gestión de unidades de cinta
Utilice el comando mt para enrollar los datos de un lado a otro. La utilidad mt controla las operaciones de la unidad de cinta magnética y la utilidad st se utiliza para el controlador de cinta SCSI. Este procedimiento describe cómo instalar el paquete mt-st para las operaciones de la unidad de cinta.
Procedimiento
Instale el paquete
mt-st:# yum install mt-st
Recursos adicionales
-
La página de manual
mt. -
La página de manual
st.
18.2. Escritura en dispositivos de cinta
Este procedimiento describe cómo hacer una copia de seguridad de los datos utilizando el comando tar. Por defecto, block size es de 10KB (bs=10k) en dispositivos de cinta. La opción de dispositivo -f especifica el archivo del dispositivo de cinta, pero esta opción no es necesaria si ha establecido la variable de entorno TAPE utilizando el atributo export TAPE=/dev/st0 atributo.
Requisitos previos
-
El paquete
mt-stestá instalado. Para más información, consulte Sección 18.1, “Instalación de la herramienta de gestión de unidades de cinta”. Cargue la unidad de cinta:
# mt -f /dev/st0 load
Procedimiento
Compruebe el cabezal de la cinta:
# mt -f /dev/st0 status SCSI 2 tape drive: File number=-1, block number=-1, partition=0. Tape block size 0 bytes. Density code 0x0 (default). Soft error count since last status=0 General status bits on (50000): DR_OPEN IM_REP_ENAquí:
-
el actual
file numberes -1. -
el
block numberdefine la cabeza de la cinta. Por defecto, se establece en -1. -
el
block size0 indica que el dispositivo de cinta no tiene un tamaño de bloque fijo. -
el
Soft error countindica el número de errores encontrados después de ejecutar el comando mt status. -
el
General status bitsexplica las estadísticas del dispositivo de cinta. -
DR_OPENindica que la puerta está abierta y el dispositivo de cinta está vacío.IM_REP_ENes el modo de informe inmediato.
-
el actual
Si el dispositivo de cinta no está vacío, especifique el cabezal de la cinta:
# mt -f /dev/st0 rewind # tar -czf /dev/st0 /etc
Este comando sobrescribe los datos de un dispositivo de cinta con el contenido del directorio /etc
Opcional: Para añadir los datos en el dispositivo de cinta:
# mt -f /dev/st0 eodHaga una copia de seguridad del directorio /etc en el dispositivo de cinta:
# tar -czf /dev/st0 /etc tar: Removing leading `/' from member names /etc/ /etc/man_db.conf /etc/DIR_COLORS /etc/rsyslog.conf [...]Ver el estado del dispositivo de cinta:
# mt -f /dev/st0 status
Pasos de verificación
Ver la lista de todos los archivos en el dispositivo de cinta:
# tar -tzf /dev/st0 /etc/ /etc/man_db.conf /etc/DIR_COLORS /etc/rsyslog.conf [...]
Recursos adicionales
-
La página de manual
mt. -
La página de manual
tar. -
La página de manual
st. - Elsoporte de la unidad de cinta se detecta como protegido contra escritura Artículo de Red Hat Knowlegebase.
- Cómo comprobar si se detectan las unidades de cinta en el sistema Artículo de Red Hat Knowlegebase.
18.3. Cambio del cabezal de la cinta en los dispositivos de cinta
Utilice el siguiente procedimiento para cambiar el cabezal de la cinta en el dispositivo de cinta. Mientras se añaden los datos a los dispositivos de cinta, utilice la opción eod para cambiar el cabezal de la cinta.
Requisitos previos
-
El paquete
mt-stestá instalado. Para más información, consulte Sección 18.1, “Instalación de la herramienta de gestión de unidades de cinta”. - Los datos se escriben en el dispositivo de cinta. Para más información, consulte Sección 18.2, “Escritura en dispositivos de cinta”.
Procedimiento
Para ir al final de los datos:
# mt -f /dev/st0 eodPara ir al registro anterior:
# mt -f /dev/st0 bsfm 1Para ir al registro de avance:
# mt -f /dev/st0 fsf 1
Recursos adicionales
-
La página de manual
mt.
18.4. Restauración de datos desde dispositivos de cinta
Para restaurar los datos de un dispositivo de cinta, utilice el comando tar.
Requisitos previos
-
El paquete
mt-stestá instalado. Para más información, consulte Sección 18.1, “Instalación de la herramienta de gestión de unidades de cinta”. - Los datos se escriben en el dispositivo de cinta. Para más información, consulte Sección 18.2, “Escritura en dispositivos de cinta”.
Procedimiento
Rebobina el dispositivo de cinta:
# mt -f /dev/st0 rewindRestaurar el directorio /etc:
# tar -xzf /dev/st0 /etc
Recursos adicionales
-
La página de manual
mt. -
La página de manual
tar.
18.5. Borrado de datos de dispositivos de cinta
Para borrar los datos de un dispositivo de cinta, utilice la opción erase.
Requisitos previos
-
El paquete
mt-stestá instalado. Para más información, consulte Sección 18.1, “Instalación de la herramienta de gestión de unidades de cinta”. - Los datos se escriben en el dispositivo de cinta. Para más información, consulte Sección 18.2, “Escritura en dispositivos de cinta”.
Procedimiento
Borrar los datos del dispositivo de cinta:
# mt -f /dev/st0 eraseDescargue el dispositivo de cinta:
mt -f /dev/st0 sin conexión
Recursos adicionales
-
La página de manual
mt.
18.6. Comandos de cinta
Los siguientes son los comandos comunes de mt:
Tabla 18.1. comandos mt
| Comando | Descripción |
|---|---|
|
| Muestra el estado del dispositivo de cinta. |
|
| Rebobina el dispositivo de cinta. |
|
| Borra toda la cinta. |
|
| Cambia la cabeza de la cinta al registro de avance. Aquí, n es un recuento de archivos opcional. Si se especifica un recuento de archivos, la cabeza de la cinta se salta n registros. |
|
| Cambia el cabezal de la cinta a la grabación anterior. |
|
| Cambia la cabeza de la cinta al final de los datos. |
Directiva no resuelta en master.adoc - include::assemblies/assembly_removing-storage-devices.adoc[leveloffset= 1]
Capítulo 19. Gestión del almacenamiento local en capas con Stratis
Podrá configurar y gestionar fácilmente complejas configuraciones de almacenamiento integradas por el sistema de alto nivel Stratis.
Stratis está disponible como Technology Preview. Para obtener información sobre el alcance del soporte de Red Hat para las características de la Technology Preview, consulte el documento sobre el alcance del soporte de las características de la Technology Preview.
Se anima a los clientes que implanten Stratis a que envíen sus comentarios a Red Hat.
19.1. Configuración de los sistemas de archivos Stratis
Como administrador del sistema, puede habilitar y configurar el sistema de archivos de gestión de volumen Stratis en su sistema para gestionar fácilmente el almacenamiento en capas.
19.1.1. Objetivo y características de Stratis
Stratis es una solución de gestión de almacenamiento local para Linux. Se centra en la simplicidad y la facilidad de uso, y le da acceso a funciones de almacenamiento avanzadas.
Stratis facilita las siguientes actividades:
- Configuración inicial del almacenamiento
- Realización de cambios a posteriori
- Uso de las funciones de almacenamiento avanzadas
Stratis es un sistema híbrido de gestión de almacenamiento local de usuario y de núcleo que admite funciones avanzadas de almacenamiento. El concepto central de Stratis es un pool de almacenamiento pool. Este pool se crea a partir de uno o más discos o particiones locales, y los volúmenes se crean a partir del pool.
La piscina permite muchas funciones útiles, como:
- Instantáneas del sistema de archivos
- Aprovisionamiento ligero
- Nivelación
19.1.2. Componentes de un volumen Stratis
Externamente, Stratis presenta los siguientes componentes de volumen en la interfaz de línea de comandos y en la API:
blockdev- Dispositivos de bloque, como un disco o una partición de disco.
poolCompuesto por uno o varios dispositivos en bloque.
Un pool tiene un tamaño total fijo, igual al tamaño de los dispositivos de bloque.
El pool contiene la mayoría de las capas de Stratis, como la caché de datos no volátil que utiliza el objetivo
dm-cache.Stratis crea un
/stratis/my-pool/directorio para cada pool. Este directorio contiene enlaces a dispositivos que representan sistemas de archivos Stratis en el pool.
filesystemCada pool puede contener uno o más sistemas de archivos, que almacenan archivos.
Los sistemas de archivos se aprovisionan de forma ligera y no tienen un tamaño total fijo. El tamaño real de un sistema de archivos crece con los datos almacenados en él. Si el tamaño de los datos se acerca al tamaño virtual del sistema de archivos, Stratis hace crecer el volumen delgado y el sistema de archivos automáticamente.
Los sistemas de archivos están formateados con XFS.
ImportanteStratis rastrea información sobre los sistemas de archivos creados con Stratis que XFS no conoce, y los cambios realizados con XFS no crean automáticamente actualizaciones en Stratis. Los usuarios no deben reformatear o reconfigurar los sistemas de archivos XFS que son administrados por Stratis.
Stratis crea enlaces a sistemas de archivos en la
/stratis/my-pool/my-fsruta de acceso.
Stratis utiliza muchos dispositivos Device Mapper, que aparecen en los listados de dmsetup y en el archivo /proc/partitions. Del mismo modo, la salida del comando lsblk refleja el funcionamiento interno y las capas de Stratis.
19.1.3. Dispositivos en bloque utilizables con Stratis
Esta sección enumera los dispositivos de almacenamiento que puede utilizar para Stratis.
Dispositivos compatibles
Las piscinas Stratis han sido probadas para funcionar en este tipo de dispositivos de bloque:
- LUKS
- Volúmenes lógicos LVM
- MD RAID
- DM Multipath
- iSCSI
- Discos duros y unidades de estado sólido (SSD)
- Dispositivos NVMe
En la versión actual, Stratis no maneja fallos en los discos duros u otro hardware. Si se crea un pool de Stratis sobre múltiples dispositivos de hardware, se incrementa el riesgo de pérdida de datos porque varios dispositivos deben estar operativos para acceder a los datos.
Dispositivos no compatibles
Debido a que Stratis contiene una capa de aprovisionamiento fino, Red Hat no recomienda colocar un pool de Stratis en dispositivos de bloque que ya están aprovisionados de forma fina.
Recursos adicionales
-
Para iSCSI y otros dispositivos de bloque que requieren red, consulte la página man
systemd.mount(5)para obtener información sobre la opción de montaje_netdev.
19.1.4. Instalación de Stratis
Este procedimiento instala todos los paquetes necesarios para utilizar Stratis.
Procedimiento
Instale los paquetes que proporcionan el servicio Stratis y las utilidades de línea de comandos:
# yum install stratisd stratis-cli
Asegúrese de que el servicio
stratisdestá activado:# systemctl enable --now stratisd
19.1.5. Creación de un pool de Stratis
Este procedimiento describe cómo crear un pool Stratis encriptado o no encriptado a partir de uno o varios dispositivos de bloque.
Las siguientes notas se aplican a los pools Stratis encriptados:
-
Cada dispositivo de bloque se encripta utilizando la biblioteca
cryptsetupe implementa el formatoLUKS2. - Cada pool de Stratis puede tener una clave única o puede compartir la misma clave con otros pools. Estas claves se almacenan en el llavero del kernel.
- Todos los dispositivos de bloque que componen un pool Stratis están encriptados o sin encriptar. No es posible tener dispositivos de bloque encriptados y no encriptados en el mismo pool de Stratis.
- Los dispositivos de bloque añadidos al nivel de datos de un pool Stratis encriptado se encriptan automáticamente.
Requisitos previos
- Stratis v2.2.1 está instalado en su sistema. Consulte Sección 19.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando. - Los dispositivos de bloque en los que está creando un pool de Stratis no están en uso y no están montados.
- Los dispositivos de bloque en los que está creando un pool de Stratis tienen un tamaño mínimo de 1 GiB cada uno.
En la arquitectura IBM Z, los dispositivos de bloque
/dev/dasd*deben ser particionados. Utilice la partición en el pool de Stratis.Para obtener información sobre la partición de dispositivos DASD, consulte Configuración de una instancia de Linux en IBM Z.
Procedimiento
Si el dispositivo de bloque seleccionado contiene firmas del sistema de archivos, de la tabla de particiones o del RAID, bórrelas con el siguiente comando:
# wipefs --all block-devicedonde
block-devicees la ruta de acceso al dispositivo de bloque; por ejemplo,/dev/sdb.Cree el nuevo pool de Stratis en el o los dispositivos de bloque seleccionados:
NotaEspecifique varios dispositivos de bloque en una sola línea, separados por un espacio:
# stratis pool create my-pool block-device-1 block-device-2
Para crear un pool Stratis no encriptado, utilice el siguiente comando y vaya al paso 3:
# stratis pool create my-pool block-device
donde
block-devicees la ruta a un dispositivo de bloque vacío o borrado.NotaNo se puede encriptar un pool Stratis no encriptado después de crearlo.
Para crear un pool Stratis encriptado, complete los siguientes pasos:
Si aún no ha creado un conjunto de claves, ejecute el siguiente comando y siga las indicaciones para crear un conjunto de claves que se utilizará para el cifrado:
# stratis key set --capture-key key-descriptiondonde
key-descriptiones la descripción o el nombre del conjunto de claves.Cree el pool Stratis encriptado y especifique la descripción de la clave a utilizar para la encriptación. También puede especificar la ruta de la clave utilizando el parámetro
--keyfile-pathen su lugar.# stratis pool create --key-desc key-description my-pool block-device
donde
key-description- Especifica la descripción o el nombre del archivo de claves que se utilizará para el cifrado.
my-pool- Especifica el nombre del nuevo pool de Stratis.
block-device- Especifica la ruta de acceso a un dispositivo de bloque vacío o borrado.
Compruebe que se ha creado el nuevo pool de Stratis:
# lista de piscinas de stratis
Solución de problemas
Después de un reinicio del sistema, a veces puede que no vea su pool Stratis encriptado o los dispositivos de bloque que lo componen. Si se encuentra con este problema, debe desbloquear el pool Stratis para hacerlo visible.
Para desbloquear el pool de Stratis, complete los siguientes pasos:
Vuelva a crear el conjunto de claves utilizando la misma descripción de claves que se utilizó anteriormente:
# stratis key set --capture-key key-descriptionDesbloquea el pool de Stratis y el/los dispositivo/s de bloque:
# stratis pool unlock
Compruebe que el pool de Stratis es visible:
# lista de piscinas de stratis
Recursos adicionales
-
La página de manual
stratis(8).
Próximos pasos
- Cree un sistema de archivos Stratis en el pool. Para más información, consulte Sección 19.1.6, “Creación de un sistema de archivos Stratis”.
19.1.6. Creación de un sistema de archivos Stratis
Este procedimiento crea un sistema de archivos Stratis en un pool Stratis existente.
Requisitos previos
- Stratis está instalado. Véase Sección 19.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando. - Ha creado un pool de Stratis. Véase Sección 19.1.5, “Creación de un pool de Stratis”.
Procedimiento
Para crear un sistema de archivos Stratis en un pool, utilice:
# stratis fs create my-pool my-fs
- Sustituya my-pool con el nombre de su pool Stratis existente.
- Sustituya my-fs con un nombre arbitrario para el sistema de archivos.
Para verificarlo, liste los sistemas de archivos dentro del pool:
# stratis fs list my-pool
Recursos adicionales
-
La página de manual
stratis(8)
Próximos pasos
- Monte el sistema de archivos Stratis. Véase Sección 19.1.7, “Montaje de un sistema de archivos Stratis”.
19.1.7. Montaje de un sistema de archivos Stratis
Este procedimiento monta un sistema de archivos Stratis existente para acceder al contenido.
Requisitos previos
- Stratis está instalado. Véase Sección 19.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando. - Ha creado un sistema de archivos Stratis. Ver Sección 19.1.6, “Creación de un sistema de archivos Stratis”.
Procedimiento
Para montar el sistema de archivos, utilice las entradas que Stratis mantiene en el directorio
/stratis/:# mount /stratis/my-pool/my-fs mount-point
El sistema de archivos está ahora montado en el directorio mount-point y está listo para ser utilizado.
Recursos adicionales
-
La página de manual
mount(8)
19.1.8. Montaje persistente de un sistema de archivos Stratis
Este procedimiento monta persistentemente un sistema de archivos Stratis para que esté disponible automáticamente después de arrancar el sistema.
Requisitos previos
- Stratis está instalado. Véase Sección 19.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando. - Ha creado un sistema de archivos Stratis. Ver Sección 19.1.6, “Creación de un sistema de archivos Stratis”.
Procedimiento
Determina el atributo UUID del sistema de archivos:
$ lsblk --output=UUID /stratis/my-pool/my-fs
Por ejemplo:
Ejemplo 19.1. Ver el UUID del sistema de archivos Stratis
$ lsblk --output=UUID /stratis/my-pool/fs1 UUID a1f0b64a-4ebb-4d4e-9543-b1d79f600283
Si el directorio del punto de montaje no existe, créelo:
# mkdir --parents mount-pointComo root, edita el archivo
/etc/fstaby añade una línea para el sistema de archivos, identificado por el UUID. Utilizaxfscomo tipo de sistema de archivos y añade la opciónx-systemd.requires=stratisd.service.Por ejemplo:
Ejemplo 19.2. El punto de montaje /fs1 en /etc/fstab
UUID=a1f0b64a-4ebb-4d4e-9543-b1d79f600283 /fs1 xfs defaults,x-systemd.requires=stratisd.service 0 0
Regenere las unidades de montaje para que su sistema registre la nueva configuración:
# systemctl daemon-reload
Intente montar el sistema de archivos para verificar que la configuración funciona:
# montaje mount-point
Recursos adicionales
19.2. Ampliación de un volumen Stratis con dispositivos de bloque adicionales
Puede adjuntar dispositivos de bloque adicionales a un pool Stratis para proporcionar más capacidad de almacenamiento para los sistemas de archivos Stratis.
19.2.1. Componentes de un volumen Stratis
Externamente, Stratis presenta los siguientes componentes de volumen en la interfaz de línea de comandos y en la API:
blockdev- Dispositivos de bloque, como un disco o una partición de disco.
poolCompuesto por uno o varios dispositivos en bloque.
Un pool tiene un tamaño total fijo, igual al tamaño de los dispositivos de bloque.
El pool contiene la mayoría de las capas de Stratis, como la caché de datos no volátil que utiliza el objetivo
dm-cache.Stratis crea un
/stratis/my-pool/directorio para cada pool. Este directorio contiene enlaces a dispositivos que representan sistemas de archivos Stratis en el pool.
filesystemCada pool puede contener uno o más sistemas de archivos, que almacenan archivos.
Los sistemas de archivos se aprovisionan de forma ligera y no tienen un tamaño total fijo. El tamaño real de un sistema de archivos crece con los datos almacenados en él. Si el tamaño de los datos se acerca al tamaño virtual del sistema de archivos, Stratis hace crecer el volumen delgado y el sistema de archivos automáticamente.
Los sistemas de archivos están formateados con XFS.
ImportanteStratis rastrea información sobre los sistemas de archivos creados con Stratis que XFS no conoce, y los cambios realizados con XFS no crean automáticamente actualizaciones en Stratis. Los usuarios no deben reformatear o reconfigurar los sistemas de archivos XFS que son administrados por Stratis.
Stratis crea enlaces a sistemas de archivos en la
/stratis/my-pool/my-fsruta de acceso.
Stratis utiliza muchos dispositivos Device Mapper, que aparecen en los listados de dmsetup y en el archivo /proc/partitions. Del mismo modo, la salida del comando lsblk refleja el funcionamiento interno y las capas de Stratis.
19.2.2. Añadir dispositivos de bloque a un pool de Stratis
Este procedimiento añade uno o más dispositivos de bloque a un pool de Stratis para que puedan ser utilizados por los sistemas de archivos Stratis.
Requisitos previos
- Stratis está instalado. Véase Sección 19.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando. - Los dispositivos de bloque que está añadiendo al pool de Stratis no están en uso y no están montados.
- Los dispositivos de bloque que está añadiendo al pool de Stratis tienen un tamaño mínimo de 1 GiB cada uno.
Procedimiento
Para añadir uno o más dispositivos de bloque al pool, utilice:
# stratis pool add-data my-pool device-1 device-2 device-n
Recursos adicionales
-
La página de manual
stratis(8)
19.3. Supervisión de los sistemas de archivos Stratis
Como usuario de Stratis, puede ver información sobre los volúmenes de Stratis en su sistema para controlar su estado y el espacio libre.
19.3.1. Tamaños de estratis reportados por diferentes empresas de servicios públicos
Esta sección explica la diferencia entre los tamaños de Stratis reportados por utilidades estándar como df y la utilidad stratis.
Las utilidades estándar de Linux como df reportan el tamaño de la capa del sistema de archivos XFS en Stratis, que es de 1 TiB. Esta información no es útil, porque el uso real de almacenamiento de Stratis es menor debido al thin provisioning, y también porque Stratis hace crecer automáticamente el sistema de archivos cuando la capa XFS está cerca de llenarse.
Supervise regularmente la cantidad de datos escritos en sus sistemas de archivos Stratis, que se reporta como el valor Total Physical Used. Asegúrese de que no supera el valor de Total Physical Size.
Recursos adicionales
-
La página de manual
stratis(8)
19.3.2. Visualización de información sobre los volúmenes de Stratis
Este procedimiento muestra las estadísticas de sus volúmenes Stratis, como el tamaño total, usado y libre, o los sistemas de archivos y dispositivos de bloques pertenecientes a un pool.
Requisitos previos
- Stratis está instalado. Véase Sección 19.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando.
Procedimiento
Para mostrar información sobre todos los block devices utilizados para Stratis en su sistema:
# stratis blockdev Pool Name Device Node Physical Size State Tier my-pool /dev/sdb 9.10 TiB In-use Data
Para mostrar información sobre todos los Stratis pools en su sistema:
# stratis pool Name Total Physical Size Total Physical Used my-pool 9.10 TiB 598 MiB
Para mostrar información sobre todos los Stratis file systems en su sistema:
# stratis filesystem Pool Name Name Used Created Device my-pool my-fs 546 MiB Nov 08 2018 08:03 /stratis/my-pool/my-fs
Recursos adicionales
-
La página de manual
stratis(8)
19.4. Uso de instantáneas en los sistemas de archivos Stratis
Puede utilizar instantáneas en los sistemas de archivos Stratis para capturar el estado del sistema de archivos en momentos arbitrarios y restaurarlo en el futuro.
19.4.1. Características de las instantáneas de Stratis
Esta sección describe las propiedades y limitaciones de las instantáneas del sistema de archivos en Stratis.
En Stratis, una instantánea es un sistema de archivos Stratis regular creado como una copia de otro sistema de archivos Stratis. La instantánea contiene inicialmente el mismo contenido de archivos que el sistema de archivos original, pero puede cambiar a medida que se modifica la instantánea. Cualquier cambio que se haga en la instantánea no se reflejará en el sistema de archivos original.
La implementación actual de la instantánea en Stratis se caracteriza por lo siguiente:
- Una instantánea de un sistema de archivos es otro sistema de archivos.
- Una instantánea y su origen no están vinculados en cuanto a su vida. Un sistema de archivos instantáneo puede vivir más tiempo que el sistema de archivos del que se creó.
- No es necesario montar un sistema de archivos para crear una instantánea a partir de él.
- Cada instantánea utiliza alrededor de medio gigabyte de almacenamiento de respaldo real, que es necesario para el registro XFS.
19.4.2. Creación de una instantánea de Stratis
Este procedimiento crea un sistema de archivos Stratis como una instantánea de un sistema de archivos Stratis existente.
Requisitos previos
- Stratis está instalado. Véase Sección 19.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando. - Ha creado un sistema de archivos Stratis. Ver Sección 19.1.6, “Creación de un sistema de archivos Stratis”.
Procedimiento
Para crear una instantánea de Stratis, utilice:
# stratis fs snapshot my-pool my-fs my-fs-snapshot
Recursos adicionales
-
La página de manual
stratis(8)
19.4.3. Acceso al contenido de una instantánea de Stratis
Este procedimiento monta una instantánea de un sistema de archivos Stratis para que sea accesible para operaciones de lectura y escritura.
Requisitos previos
- Stratis está instalado. Véase Sección 19.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando. - Ha creado una instantánea de Stratis. Véase Sección 19.4.2, “Creación de una instantánea de Stratis”.
Procedimiento
Para acceder a la instantánea, móntela como un sistema de archivos normal desde el directorio
/stratis/my-pool/directorio:# mount /stratis/my-pool/my-fs-snapshot mount-point
Recursos adicionales
- Sección 19.1.7, “Montaje de un sistema de archivos Stratis”
-
La página de manual
mount(8)
19.4.4. Revertir un sistema de archivos Stratis a una instantánea anterior
Este procedimiento revierte el contenido de un sistema de archivos Stratis al estado capturado en una instantánea Stratis.
Requisitos previos
- Stratis está instalado. Véase Sección 19.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando. - Ha creado una instantánea de Stratis. Véase Sección 19.4.2, “Creación de una instantánea de Stratis”.
Procedimiento
Opcionalmente, haga una copia de seguridad del estado actual del sistema de archivos para poder acceder a él más tarde:
# stratis filesystem snapshot my-pool my-fs my-fs-backup
Desmontar y eliminar el sistema de archivos original:
# umount /stratis/my-pool/my-fs # stratis filesystem destroy my-pool my-fs
Cree una copia de la instantánea con el nombre del sistema de archivos original:
# stratis filesystem snapshot my-pool my-fs-snapshot my-fs
Monte la instantánea, que ahora es accesible con el mismo nombre que el sistema de archivos original:
# mount /stratis/my-pool/my-fs mount-point
El contenido del sistema de archivos llamado my-fs es ahora idéntico al de la instantánea my-fs-snapshot.
Recursos adicionales
-
La página de manual
stratis(8)
19.4.5. Eliminación de una instantánea de Stratis
Este procedimiento elimina una instantánea de Stratis de un pool. Los datos de la instantánea se pierden.
Requisitos previos
- Stratis está instalado. Véase Sección 19.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando. - Ha creado una instantánea de Stratis. Véase Sección 19.4.2, “Creación de una instantánea de Stratis”.
Procedimiento
Desmontar la instantánea:
# umount /stratis/my-pool/my-fs-snapshot
Destruye la instantánea:
# stratis filesystem destroy my-pool my-fs-snapshot
Recursos adicionales
-
La página de manual
stratis(8)
19.5. Eliminación de los sistemas de archivos Stratis
Puede eliminar un sistema de archivos Stratis existente o un pool Stratis, destruyendo los datos en ellos.
19.5.1. Componentes de un volumen Stratis
Externamente, Stratis presenta los siguientes componentes de volumen en la interfaz de línea de comandos y en la API:
blockdev- Dispositivos de bloque, como un disco o una partición de disco.
poolCompuesto por uno o varios dispositivos en bloque.
Un pool tiene un tamaño total fijo, igual al tamaño de los dispositivos de bloque.
El pool contiene la mayoría de las capas de Stratis, como la caché de datos no volátil que utiliza el objetivo
dm-cache.Stratis crea un
/stratis/my-pool/directorio para cada pool. Este directorio contiene enlaces a dispositivos que representan sistemas de archivos Stratis en el pool.
filesystemCada pool puede contener uno o más sistemas de archivos, que almacenan archivos.
Los sistemas de archivos se aprovisionan de forma ligera y no tienen un tamaño total fijo. El tamaño real de un sistema de archivos crece con los datos almacenados en él. Si el tamaño de los datos se acerca al tamaño virtual del sistema de archivos, Stratis hace crecer el volumen delgado y el sistema de archivos automáticamente.
Los sistemas de archivos están formateados con XFS.
ImportanteStratis rastrea información sobre los sistemas de archivos creados con Stratis que XFS no conoce, y los cambios realizados con XFS no crean automáticamente actualizaciones en Stratis. Los usuarios no deben reformatear o reconfigurar los sistemas de archivos XFS que son administrados por Stratis.
Stratis crea enlaces a sistemas de archivos en la
/stratis/my-pool/my-fsruta de acceso.
Stratis utiliza muchos dispositivos Device Mapper, que aparecen en los listados de dmsetup y en el archivo /proc/partitions. Del mismo modo, la salida del comando lsblk refleja el funcionamiento interno y las capas de Stratis.
19.5.2. Eliminación de un sistema de archivos Stratis
Este procedimiento elimina un sistema de archivos Stratis existente. Los datos almacenados en él se pierden.
Requisitos previos
- Stratis está instalado. Véase Sección 19.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando. - Ha creado un sistema de archivos Stratis. Ver Sección 19.1.6, “Creación de un sistema de archivos Stratis”.
Procedimiento
Desmontar el sistema de archivos:
# umount /stratis/my-pool/my-fs
Destruye el sistema de archivos:
# stratis filesystem destroy my-pool my-fs
Compruebe que el sistema de archivos ya no existe:
# stratis filesystem list my-pool
Recursos adicionales
-
La página de manual
stratis(8)
19.5.3. Eliminación de una piscina Stratis
Este procedimiento elimina un pool de Stratis existente. Los datos almacenados en él se pierden.
Requisitos previos
- Stratis está instalado. Véase Sección 19.1.4, “Instalación de Stratis”.
-
El servicio
stratisdestá funcionando. - Ha creado un pool de Stratis. Véase Sección 19.1.5, “Creación de un pool de Stratis”.
Procedimiento
Lista de sistemas de archivos en el pool:
# stratis filesystem list my-poolDesmontar todos los sistemas de archivos del pool:
# umount /stratis/my-pool/my-fs-1 \ /stratis/my-pool/my-fs-2 \ /stratis/my-pool/my-fs-n
Destruye los sistemas de archivos:
# stratis filesystem destroy my-pool my-fs-1 my-fs-2
Destruye la piscina:
# stratis pool destroy my-poolCompruebe que la piscina ya no existe:
# lista de piscinas de stratis
Recursos adicionales
-
La página de manual
stratis(8)