
Red Hat Training
A Red Hat training course is available for RHEL 8
Managing, monitoring, and updating the kernel
Guía para la gestión del kernel de Linux en Red Hat Enterprise Linux 8
Resumen
Hacer que el código abierto sea más inclusivo
Red Hat se compromete a sustituir el lenguaje problemático en nuestro código, documentación y propiedades web. Estamos empezando con estos cuatro términos: maestro, esclavo, lista negra y lista blanca. Debido a la enormidad de este esfuerzo, estos cambios se implementarán gradualmente a lo largo de varias versiones próximas. Para más detalles, consulte el mensaje de nuestro CTO Chris Wright.
Proporcionar comentarios sobre la documentación de Red Hat
Agradecemos su opinión sobre nuestra documentación. Por favor, díganos cómo podemos mejorarla. Para ello:
Para comentarios sencillos sobre pasajes concretos:
- Asegúrese de que está viendo la documentación en el formato Multi-page HTML. Además, asegúrese de ver el botón Feedback en la esquina superior derecha del documento.
- Utilice el cursor del ratón para resaltar la parte del texto que desea comentar.
- Haga clic en la ventana emergente Add Feedback que aparece debajo del texto resaltado.
- Siga las instrucciones mostradas.
Para enviar comentarios más complejos, cree un ticket de Bugzilla:
- Vaya al sitio web de Bugzilla.
- Como componente, utilice Documentation.
- Rellene el campo Description con su sugerencia de mejora. Incluya un enlace a la(s) parte(s) pertinente(s) de la documentación.
- Haga clic en Submit Bug.
Capítulo 1. El RPM del núcleo de Linux
Las siguientes secciones describen el paquete RPM del kernel de Linux proporcionado y mantenido por Red Hat.
1.1. Qué es un RPM
Un paquete RPM es un archivo que contiene otros archivos y sus metadatos (información sobre los archivos que necesita el sistema).
En concreto, un paquete RPM consiste en el archivo cpio.
El archivo cpio contiene:
- Archivos
Cabecera del RPM (metadatos del paquete)
El gestor de paquetes
rpmutiliza estos metadatos para determinar las dependencias, dónde instalar los archivos y otra información.
Tipos de paquetes RPM
Hay dos tipos de paquetes RPM. Ambos tipos comparten el formato de archivo y las herramientas, pero tienen contenidos diferentes y sirven para fines distintos:
Fuente RPM (SRPM)
Un SRPM contiene el código fuente y un archivo SPEC, que describe cómo construir el código fuente en un RPM binario. Opcionalmente, también se incluyen los parches del código fuente.
RPM binario
Un RPM binario contiene los binarios construidos a partir de las fuentes y los parches.
1.2. Visión general del paquete RPM del núcleo de Linux
El RPM kernel es un metapaquete que no contiene ningún archivo, sino que asegura que los siguientes subpaquetes se instalen correctamente:
-
kernel-core- contiene un número mínimo de módulos del kernel necesarios para la funcionalidad principal. Este subpaquete por sí solo podría utilizarse en entornos virtualizados y de nube para proporcionar un kernel de Red Hat Enterprise Linux 8 con un tiempo de arranque rápido y un tamaño de disco reducido. -
kernel-modules- contiene más módulos del kernel. -
kernel-modules-extra- contiene módulos del kernel para hardware raro.
El pequeño conjunto de subpaquetes de kernel tiene como objetivo proporcionar una superficie de mantenimiento reducida a los administradores de sistemas, especialmente en entornos virtualizados y en la nube.
Los otros paquetes comunes del kernel son, por ejemplo:
-
kernel-debug- Contiene un núcleo con numerosas opciones de depuración habilitadas para el diagnóstico del núcleo, a expensas de un rendimiento reducido. -
kernel-tools- Contiene herramientas para manipular el núcleo de Linux y documentación de apoyo. -
kernel-devel- Contiene las cabeceras del kernel y los archivos makefiles suficientes para construir módulos contra el paquetekernel. -
kernel-abi-whitelists- Contiene información relativa a la ABI del kernel de Red Hat Enterprise Linux, incluyendo una lista de símbolos del kernel que necesitan los módulos externos del kernel de Linux y un complemento deyumpara ayudar a su aplicación. -
kernel-headers- Incluye los archivos de cabecera C que especifican la interfaz entre el núcleo de Linux y las bibliotecas y programas del espacio de usuario. Los archivos de cabecera definen estructuras y constantes que son necesarias para construir la mayoría de los programas estándar.
1.3. Visualización del contenido del paquete del núcleo
El siguiente procedimiento describe cómo ver el contenido del paquete del kernel y sus subpaquetes sin instalarlos utilizando el comando rpm.
Requisitos previos
-
Obtenido
kernel,kernel-core,kernel-modules,kernel-modules-extrapaquetes RPM para su arquitectura de CPU
Procedimiento
Lista de módulos para
kernel:$ rpm -qlp <kernel_rpm>(contains no files) …Lista de módulos para
kernel-core:$ rpm -qlp <kernel-core_rpm>… /lib/modules/4.18.0-80.el8.x86_64/kernel/fs/udf/udf.ko.xz /lib/modules/4.18.0-80.el8.x86_64/kernel/fs/xfs /lib/modules/4.18.0-80.el8.x86_64/kernel/fs/xfs/xfs.ko.xz /lib/modules/4.18.0-80.el8.x86_64/kernel/kernel /lib/modules/4.18.0-80.el8.x86_64/kernel/kernel/trace /lib/modules/4.18.0-80.el8.x86_64/kernel/kernel/trace/ring_buffer_benchmark.ko.xz /lib/modules/4.18.0-80.el8.x86_64/kernel/lib /lib/modules/4.18.0-80.el8.x86_64/kernel/lib/cordic.ko.xz …Lista de módulos para
kernel-modules:$ rpm -qlp <kernel-modules_rpm>… /lib/modules/4.18.0-80.el8.x86_64/kernel/drivers/infiniband/hw/mlx4/mlx4_ib.ko.xz /lib/modules/4.18.0-80.el8.x86_64/kernel/drivers/infiniband/hw/mlx5/mlx5_ib.ko.xz /lib/modules/4.18.0-80.el8.x86_64/kernel/drivers/infiniband/hw/qedr/qedr.ko.xz /lib/modules/4.18.0-80.el8.x86_64/kernel/drivers/infiniband/hw/usnic/usnic_verbs.ko.xz /lib/modules/4.18.0-80.el8.x86_64/kernel/drivers/infiniband/hw/vmw_pvrdma/vmw_pvrdma.ko.xz …Lista de módulos para
kernel-modules-extra:$ rpm -qlp <kernel-modules-extra_rpm>… /lib/modules/4.18.0-80.el8.x86_64/extra/net/sched/sch_cbq.ko.xz /lib/modules/4.18.0-80.el8.x86_64/extra/net/sched/sch_choke.ko.xz /lib/modules/4.18.0-80.el8.x86_64/extra/net/sched/sch_drr.ko.xz /lib/modules/4.18.0-80.el8.x86_64/extra/net/sched/sch_dsmark.ko.xz /lib/modules/4.18.0-80.el8.x86_64/extra/net/sched/sch_gred.ko.xz …
Recursos adicionales
-
Para obtener información sobre cómo utilizar el comando
rpmen el RPMkernelya instalado, incluidos sus subpaquetes, consulte la página del manualrpm(8). - Introducción a RPM packages
Capítulo 2. Actualización del kernel con yum
Las siguientes secciones aportan información sobre el kernel de Linux proporcionado y mantenido por Red Hat (kernel de Red Hat), y sobre cómo mantener el kernel de Red Hat actualizado. Como consecuencia, el sistema operativo tendrá todas las últimas correcciones de errores, mejoras de rendimiento y parches que garantizan la compatibilidad con el nuevo hardware.
2.1. Qué es el núcleo
El kernel es la parte central de un sistema operativo Linux, que gestiona los recursos del sistema y proporciona la interfaz entre el hardware y las aplicaciones de software. El kernel de Red Hat es un kernel personalizado basado en el kernel principal de Linux que los ingenieros de Red Hat desarrollan y endurecen con un enfoque en la estabilidad y la compatibilidad con las últimas tecnologías y hardware.
Antes de que Red Hat publique una nueva versión del kernel, éste debe pasar una serie de rigurosas pruebas de control de calidad.
Los kernels de Red Hat están empaquetados en el formato RPM para que sean fáciles de actualizar y verificar por el yum gestor de paquetes.
Los kernels que no han sido compilados por Red Hat son not soportados por Red Hat.
2.2. Qué es yum
Esta sección se refiere a la descripción del yum package manager.
Recursos adicionales
-
Para más información sobre
yum, consulte las secciones correspondientes de Configuring basic system settings.
2.3. Actualización del kernel
El siguiente procedimiento describe cómo actualizar el kernel utilizando el yum gestor de paquetes.
Procedimiento
Para actualizar el kernel, utilice lo siguiente:
# yum update kernelEste comando actualiza el kernel junto con todas las dependencias a la última versión disponible.
- Reinicie su sistema para que los cambios surtan efecto.
Cuando actualice de Red Hat Enterprise Linux 7 a Red Hat Enterprise Linux 8, siga las secciones relevantes del Upgrading from RHEL 7 to RHEL 8 documento.
2.4. Instalación del kernel
El siguiente procedimiento describe cómo instalar nuevos kernels utilizando el yum gestor de paquetes.
Procedimiento
Para instalar una versión específica del kernel, utilice lo siguiente:
# yum install kernel-{version}
Recursos adicionales
- Para obtener una lista de los núcleos disponibles, consulte Red Hat Code Browser.
- Para obtener una lista de las fechas de lanzamiento de versiones específicas del núcleo, consulte this article.
Capítulo 3. Gestión de los módulos del núcleo
Las siguientes secciones explican qué son los módulos del núcleo, cómo mostrar su información y cómo realizar tareas administrativas básicas con los módulos del núcleo.
3.1. Introducción a los módulos del núcleo
El kernel de Red Hat Enterprise Linux puede ser extendido con piezas opcionales de funcionalidad adicional, llamadas módulos del kernel, sin tener que reiniciar el sistema. En Red Hat Enterprise Linux 8, los módulos del kernel son código extra del kernel que se construye en archivos de objetos comprimidos en <KERNEL_MODULE_NAME>.ko.xz.
Las funcionalidades más comunes habilitadas por los módulos del kernel son:
- Controlador de dispositivo que añade compatibilidad con el nuevo hardware
-
Soporte para un sistema de archivos como
GFS2oNFS - Llamadas al sistema
En los sistemas modernos, los módulos del núcleo se cargan automáticamente cuando se necesitan. Sin embargo, en algunos casos es necesario cargar o descargar los módulos manualmente.
Al igual que el propio núcleo, los módulos pueden tomar parámetros que personalicen su comportamiento si es necesario.
Se proporcionan herramientas para inspeccionar qué módulos se están ejecutando actualmente, qué módulos están disponibles para cargar en el núcleo y qué parámetros acepta un módulo. Las herramientas también proporcionan un mecanismo para cargar y descargar módulos del kernel en el kernel en ejecución.
3.2. Introducción a la especificación del cargador de arranque
La especificación BootLoader (BLS) define un esquema y el formato de archivo para gestionar la configuración del cargador de arranque para cada opción de arranque en el directorio drop-in sin necesidad de manipular los archivos de configuración del cargador de arranque. A diferencia de los enfoques anteriores, cada entrada de arranque está ahora representada por un archivo de configuración separado en el directorio drop-in. El directorio drop-in amplía su configuración sin necesidad de editar o regenerar los archivos de configuración. El BLS extiende este concepto para las entradas del menú de arranque.
Utilizando BLS, puedes gestionar las opciones del menú del cargador de arranque añadiendo, eliminando o editando archivos individuales de entrada de arranque en un directorio. Esto hace que el proceso de instalación del kernel sea significativamente más sencillo y consistente en las diferentes arquitecturas.
La herramienta grubby es una fina envoltura de script alrededor del BLS y soporta los mismos argumentos y opciones de grubby. Ejecuta el dracut para crear una imagen inicial de ramdisk. Con esta configuración, los archivos de configuración del núcleo del gestor de arranque son estáticos y no se modifican después de la instalación del kernel.
Esta premisa es particularmente relevante en Red Hat Enterprise Linux 8 porque no se utiliza el mismo gestor de arranque en todas las arquitecturas. GRUB2 se utiliza en la mayoría de ellas como el ARM de 64 bits, pero las variantes little-endian de IBM Power Systems con Open Power Abstraction Layer (OPAL) utiliza Petitboot y la arquitectura IBM Z utiliza zipl.
Recursos adicionales
-
Para más información sobre la utilidad de
grubby, consulte Qué es el grubby. - Para más detalles sobre las entradas de arranque, consulte Qué son las entradas de arranque
-
Para más detalles, consulte la página del manual
grubby(8).
3.3. Dependencias de los módulos del núcleo
Algunos módulos del kernel a veces dependen de uno o más módulos del kernel. El archivo /lib/modules/<KERNEL_VERSION>/modules.dep contiene una lista completa de las dependencias de los módulos del núcleo para la versión respectiva del mismo.
El archivo de dependencias es generado por el programa depmod, que forma parte del paquete kmod. Muchas de las utilidades proporcionadas por kmod tienen en cuenta las dependencias de los módulos a la hora de realizar operaciones, por lo que el seguimiento de las dependencias de manual rara vez es necesario.
El código de los módulos del kernel se ejecuta en el espacio del kernel en modo no restringido. Por ello, debes tener en cuenta qué módulos estás cargando.
Recursos adicionales
-
Para más información sobre
/lib/modules/<KERNEL_VERSION>/modules.dep, consulte la página del manualmodules.dep(5). -
Para más detalles, incluyendo la sinopsis y las opciones de
depmod, consulte la página del manualdepmod(8).
3.4. Listado de los módulos del kernel actualmente cargados
El siguiente procedimiento describe cómo ver los módulos del kernel actualmente cargados.
Requisitos previos
-
El paquete
kmodestá instalado.
Procedimiento
Para listar todos los módulos del kernel actualmente cargados, ejecute
$ lsmod Module Size Used by fuse 126976 3 uinput 20480 1 xt_CHECKSUM 16384 1 ipt_MASQUERADE 16384 1 xt_conntrack 16384 1 ipt_REJECT 16384 1 nft_counter 16384 16 nf_nat_tftp 16384 0 nf_conntrack_tftp 16384 1 nf_nat_tftp tun 49152 1 bridge 192512 0 stp 16384 1 bridge llc 16384 2 bridge,stp nf_tables_set 32768 5 nft_fib_inet 16384 1 …En el ejemplo anterior:
- La primera columna proporciona la names de los módulos cargados actualmente.
- La segunda columna muestra la cantidad de memory por módulo en kilobytes.
- La última columna muestra el número y, opcionalmente, los nombres de los módulos que son dependent en un módulo particular.
Recursos adicionales
-
Para más información sobre
kmod, consulte el archivo/usr/share/doc/kmod/READMEo la página del manuallsmod(8).
3.5. Listado de todos los kernels instalados
El siguiente procedimiento describe cómo utilizar la herramienta de línea de comandos grubby para listar las entradas de arranque de GRUB2.
Procedimiento
Para listar las entradas de arranque del kernel:
Para listar las entradas de arranque del kernel, ejecute
# grubby --info=ALL | grep titleEl comando muestra las entradas de arranque del kernel. El campo
kernelmuestra la ruta del kernel.El siguiente procedimiento describe cómo utilizar la utilidad
grubbypara listar todos los kernels instalados en sus sistemas utilizando la línea de comandos del kernel.
Como ejemplo, considere la lista grubby-8.40-17, en el menú Grub2 tanto en las instalaciones BLS como en las que no lo son.
Procedimiento
Para listar todos los módulos del kernel instalados:
Ejecute el siguiente comando:
# grubby --info=ALL | grep titleLa lista de todos los kernels instalados se muestra de la siguiente manera:
title=Red Hat Enterprise Linux (4.18.0-20.el8.x86_64) 8.0 (Ootpa) title=Red Hat Enterprise Linux (4.18.0-19.el8.x86_64) 8.0 (Ootpa) title=Red Hat Enterprise Linux (4.18.0-12.el8.x86_64) 8.0 (Ootpa) title=Red Hat Enterprise Linux (4.18.0) 8.0 (Ootpa) title=Red Hat Enterprise Linux (0-rescue-2fb13ddde2e24fde9e6a246a942caed1) 8.0 (Ootpa)
La salida anterior muestra la lista de todos los kernels instalados para grubby-8.40-17, utilizando el menú Grub2.
3.6. Establecer un núcleo por defecto
El siguiente procedimiento describe cómo establecer un núcleo específico como predeterminado utilizando la herramienta de línea de comandos grubby y GRUB2.
Procedimiento
- Configurar el kernel como predeterminado, utilizando la herramienta
grubby -
Ejecute el siguiente comando para establecer el kernel como predeterminado utilizando la herramienta
grubby:
# grubby --set-default $kernel_pathEl comando utiliza como argumento un ID de máquina sin el sufijo
.conf.NotaEl ID de la máquina se encuentra en el directorio
/boot/loader/entries/.-
Ejecute el siguiente comando para establecer el kernel como predeterminado utilizando la herramienta
- Establecer el núcleo por defecto, utilizando el argumento
id -
Enumera las entradas de arranque utilizando el argumento
idy luego establece un núcleo previsto como predeterminado:
# grubby --info ALL | grep id # grubby --set-default /boot/vmlinuz-<version>.<architecture>
NotaPara listar las entradas de arranque utilizando el argumento
title, ejecute el comando# grubby --info=ALL | grep titlecomando.-
Enumera las entradas de arranque utilizando el argumento
- Establecer el kernel por defecto sólo para el siguiente arranque
-
Ejecute el siguiente comando para establecer el kernel por defecto sólo para el próximo reinicio utilizando el comando
grub2-reboot:
# grub2-reboot <index|title|id>AvisoEstablezca el kernel por defecto sólo para el siguiente arranque con cuidado. La instalación de nuevos RPM del kernel, kernels autoconstruidos y la adición manual de las entradas al directorio
/boot/loader/entries/pueden cambiar los valores del índice.-
Ejecute el siguiente comando para establecer el kernel por defecto sólo para el próximo reinicio utilizando el comando
3.7. Visualización de información sobre los módulos del kernel
Cuando se trabaja con un módulo del núcleo, es posible que se quiera ver más información sobre ese módulo. Este procedimiento describe cómo mostrar información adicional sobre los módulos del núcleo.
Requisitos previos
-
El paquete
kmodestá instalado.
Procedimiento
Para mostrar información sobre cualquier módulo del kernel, ejecute
$ modinfo <KERNEL_MODULE_NAME> For example: $ modinfo virtio_net filename: /lib/modules/4.18.0-94.el8.x86_64/kernel/drivers/net/virtio_net.ko.xz license: GPL description: Virtio network driver rhelversion: 8.1 srcversion: 2E9345B281A898A91319773 alias: virtio:d00000001v* depends: net_failover intree: Y name: virtio_net vermagic: 4.18.0-94.el8.x86_64 SMP mod_unload modversions … parm: napi_weight:int parm: csum:bool parm: gso:bool parm: napi_tx:bool
El comando
modinfomuestra información detallada sobre el módulo del núcleo especificado. Puede consultar información sobre todos los módulos disponibles, independientemente de si están cargados o no. Las entradas deparmmuestran los parámetros que el usuario puede establecer para el módulo, y qué tipo de valor esperan.NotaCuando introduzca el nombre de un módulo del núcleo, no añada la extensión
.ko.xzal final del nombre. Los nombres de los módulos del núcleo no tienen extensiones; sus archivos correspondientes sí.
Recursos adicionales
-
Para más información sobre el
modinfo, consulte la página del manualmodinfo(8).
3.8. Carga de módulos del kernel en tiempo de ejecución del sistema
La forma óptima de ampliar la funcionalidad del núcleo de Linux es cargando módulos del núcleo. El siguiente procedimiento describe cómo utilizar el comando modprobe para encontrar y cargar un módulo del kernel en el kernel que se está ejecutando actualmente.
Requisitos previos
- Permisos de la raíz
-
El paquete
kmodestá instalado. - El módulo del núcleo correspondiente no está cargado. Para asegurarse de ello, liste los módulos del kernel cargados.
Procedimiento
Seleccione un módulo del kernel que desee cargar.
Los módulos se encuentran en el directorio
/lib/modules/$(uname -r)/kernel/<SUBSYSTEM>/.Cargue el módulo del kernel correspondiente:
# modprobe <MODULE_NAME>NotaCuando introduzca el nombre de un módulo del núcleo, no añada la extensión
.ko.xzal final del nombre. Los nombres de los módulos del núcleo no tienen extensiones; sus archivos correspondientes sí.Opcionalmente, verifique que se cargó el módulo correspondiente:
$ lsmod | grep <MODULE_NAME>Si el módulo se ha cargado correctamente, este comando muestra el módulo del kernel correspondiente. Por ejemplo:
$ lsmod | grep serio_raw serio_raw 16384 0
Los cambios descritos en este procedimiento will not persist después de reiniciar el sistema.
Recursos adicionales
-
Para más detalles sobre
modprobe, consulte la página del manualmodprobe(8).
3.9. Descarga de módulos del kernel en tiempo de ejecución del sistema
A veces, se encuentra que necesita descargar ciertos módulos del kernel del kernel en ejecución. El siguiente procedimiento describe cómo utilizar el comando modprobe para encontrar y descargar un módulo del kernel en tiempo de ejecución del sistema del kernel actualmente cargado.
Requisitos previos
- Permisos de la raíz
-
El paquete
kmodestá instalado.
Procedimiento
Ejecute el comando
lsmody seleccione un módulo del kernel que desee descargar.Si un módulo del núcleo tiene dependencias, descárguelas antes de descargar el módulo del núcleo. Para más detalles sobre la identificación de módulos con dependencias, consulte Sección 3.4, “Listado de los módulos del kernel actualmente cargados”.
Descargue el módulo del kernel correspondiente:
# modprobe -r <MODULE_NAME>Cuando introduzca el nombre de un módulo del núcleo, no añada la extensión
.ko.xzal final del nombre. Los nombres de los módulos del núcleo no tienen extensiones; sus archivos correspondientes sí.AvisoNo descargue los módulos del kernel cuando sean utilizados por el sistema en funcionamiento. Hacerlo puede llevar a un sistema inestable o no operativo.
Opcionalmente, verifique que el módulo correspondiente fue descargado:
$ lsmod | grep <MODULE_NAME>Si el módulo se ha descargado con éxito, este comando no muestra ninguna salida.
Después de terminar este procedimiento, los módulos del kernel que están definidos para cargarse automáticamente en el arranque, will not stay unloaded después de reiniciar el sistema. Para obtener información sobre cómo contrarrestar este resultado, consulte Evitar que los módulos del kernel se carguen automáticamente al arrancar el sistema.
Recursos adicionales
-
Para más detalles sobre
modprobe, consulte la página del manualmodprobe(8).
3.10. Carga automática de los módulos del kernel en el arranque del sistema
El siguiente procedimiento describe cómo configurar un módulo del kernel para que se cargue automáticamente durante el proceso de arranque.
Requisitos previos
- Permisos de la raíz
-
El paquete
kmodestá instalado.
Procedimiento
Seleccione un módulo del kernel que desee cargar durante el proceso de arranque.
Los módulos se encuentran en el directorio
/lib/modules/$(uname -r)/kernel/<SUBSYSTEM>/.Crear un archivo de configuración para el módulo:
# echo <MODULE_NAME> > /etc/modules-load.d/<MODULE_NAME>.confNotaCuando introduzca el nombre de un módulo del núcleo, no añada la extensión
.ko.xzal final del nombre. Los nombres de los módulos del núcleo no tienen extensiones; sus archivos correspondientes sí.Opcionalmente, después de reiniciar, verifique que se cargó el módulo correspondiente:
$ lsmod | grep <MODULE_NAME>El comando de ejemplo anterior debería tener éxito y mostrar el módulo del kernel correspondiente.
Los cambios descritos en este procedimiento will persist después de reiniciar el sistema.
Recursos adicionales
-
Para más detalles sobre la carga de módulos del kernel durante el proceso de arranque, consulte la página del manual
modules-load.d(5).
3.11. Evitar que los módulos del kernel se carguen automáticamente al arrancar el sistema
El siguiente procedimiento describe cómo añadir un módulo del kernel a una denylist para que no se cargue automáticamente durante el proceso de arranque.
Requisitos previos
- Permisos de la raíz
-
El paquete
kmodestá instalado. - Asegúrese de que un módulo del núcleo en una lista de denegación no es vital para la configuración actual de su sistema.
Procedimiento
Seleccione un módulo del kernel que quiera poner en una denylist:
$ lsmod Module Size Used by fuse 126976 3 xt_CHECKSUM 16384 1 ipt_MASQUERADE 16384 1 uinput 20480 1 xt_conntrack 16384 1 …El comando
lsmodmuestra una lista de módulos cargados en el kernel que se está ejecutando actualmente.Alternativamente, identifique un módulo del kernel no cargado que quiera evitar que se cargue potencialmente.
Todos los módulos del núcleo se encuentran en el directorio
/lib/modules/<KERNEL_VERSION>/kernel/<SUBSYSTEM>/.
Crear un archivo de configuración para una lista de denegación:
# vim /etc/modprobe.d/blacklist.conf # Blacklists <KERNEL_MODULE_1> blacklist <MODULE_NAME_1> install <MODULE_NAME_1> /bin/false # Blacklists <KERNEL_MODULE_2> blacklist <MODULE_NAME_2> install <MODULE_NAME_2> /bin/false # Blacklists <KERNEL_MODULE_n> blacklist <MODULE_NAME_n> install <MODULE_NAME_n> /bin/false …
El ejemplo muestra el contenido del archivo
blacklist.conf, editado por el editorvim. La líneablacklistasegura que el módulo del kernel relevante no se cargará automáticamente durante el proceso de arranque. El comandoblacklist, sin embargo, no evita que el módulo se cargue como dependencia de otro módulo del kernel que no esté en una denylist. Por lo tanto, la líneainstallhace que se ejecute el/bin/falseen lugar de instalar un módulo.Las líneas que comienzan con un signo de almohadilla son comentarios para hacer el archivo más legible.
NotaCuando introduzca el nombre de un módulo del núcleo, no añada la extensión
.ko.xzal final del nombre. Los nombres de los módulos del núcleo no tienen extensiones; sus archivos correspondientes sí.Cree una copia de seguridad de la imagen inicial del ramdisk actual antes de reconstruirlo:
# cp /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).bak.$(date %m-\r%H%M%S).imgEl comando anterior crea una imagen de copia de seguridad
initramfsen caso de que la nueva versión tenga un problema inesperado.Alternativamente, cree una copia de seguridad de otra imagen inicial de ramdisk que corresponda a la versión del kernel para la que quiere poner los módulos del kernel en una denylist:
# cp /boot/initramfs-<SOME_VERSION>.img /boot/initramfs-<SOME_VERSION>.img.bak.$(date %m-\r%H%M%S)
Genera una nueva imagen inicial de ramdisk para reflejar los cambios:
# dracut -f -vSi está construyendo una imagen inicial de ramdisk para una versión de kernel diferente a la que está arrancando actualmente, especifique tanto el destino
initramfscomo la versión del kernel:# dracut -f -v /boot/initramfs-<TARGET_VERSION>.img <CORRESPONDING_TARGET_KERNEL_VERSION>
Reinicia el sistema:
$ reboot
Los cambios descritos en este procedimiento will take effect and persist después de reiniciar el sistema. Si coloca incorrectamente un módulo clave del kernel en una lista de denegación, puede enfrentarse a un sistema inestable o no operativo.
Recursos adicionales
-
Para más detalles sobre la utilidad
dracut, consulte la página del manualdracut(8).
3.12. Firma de módulos del kernel para el arranque seguro
Puede mejorar la seguridad de su sistema utilizando módulos del kernel firmados. Las siguientes secciones describen cómo autofirmar los módulos del kernel construidos de forma privada para su uso con RHEL 8 en sistemas de construcción basados en UEFI en los que está habilitado el arranque seguro. Estas secciones también proporcionan una visión general de las opciones disponibles para importar su clave pública en un sistema de destino en el que desee desplegar sus módulos del kernel.
Para firmar y cargar los módulos del kernel, es necesario:
Si el Arranque Seguro está habilitado, los cargadores de arranque del sistema operativo UEFI, el kernel de Red Hat Enterprise Linux y todos los módulos del kernel tienen que ser firmados con una clave privada y autenticados con la clave pública correspondiente. Si no están firmados y autenticados, el sistema no podrá terminar el proceso de arranque.
La distribución RHEL 8 incluye:
- Cargadores de arranque firmados
- Granos firmados
- Módulos del kernel firmados
Además, el cargador de arranque de primera etapa firmado y el kernel firmado incluyen claves públicas de Red Hat incrustadas. Estos binarios ejecutables firmados y las claves incrustadas permiten que RHEL 8 se instale, arranque y ejecute con las claves de la Autoridad de Certificación de Arranque Seguro de Microsoft UEFI que son proporcionadas por el firmware UEFI en los sistemas que soportan el Arranque Seguro UEFI. Tenga en cuenta que no todos los sistemas basados en UEFI incluyen soporte para Secure Boot.
Requisitos previos
Para poder firmar módulos del kernel construidos externamente, instale en el sistema de compilación las utilidades que se indican en la siguiente tabla.
Tabla 3.1. Servicios públicos necesarios
| Utilidad | Proporcionado por el paquete | Utilizado en | Propósito |
|---|---|---|---|
|
|
| Sistema de construcción | Genera un par de claves X.509 públicas y privadas |
|
|
| Sistema de construcción | Archivo ejecutable utilizado para firmar un módulo del kernel con la clave privada |
|
|
| Sistema objetivo | Utilidad opcional utilizada para inscribir manualmente la clave pública |
|
|
| Sistema objetivo | Utilidad opcional utilizada para mostrar las claves públicas en el llavero del sistema |
El sistema de compilación, donde se construye y firma el módulo del kernel, no necesita tener habilitado el arranque seguro de UEFI y ni siquiera necesita ser un sistema basado en UEFI.
3.12.1. Autenticación de módulos del núcleo con claves X.509
En RHEL 8, cuando se carga un módulo del núcleo, éste comprueba la firma del módulo con las claves públicas X.509 del llavero del sistema del núcleo (.builtin_trusted_keys) y del llavero de la plataforma del núcleo (.platform). El llavero .platform contiene claves de proveedores de plataforma de terceros y claves públicas personalizadas. Las claves del llavero del sistema del kernel .blacklist están excluidas de la verificación. Las siguientes secciones ofrecen una visión general de las fuentes de claves, los llaveros y ejemplos de claves cargadas de diferentes fuentes en el sistema. Además, puedes ver cómo autenticar un módulo del kernel.
3.12.1.1. Requisitos de autentificación
Es necesario cumplir ciertas condiciones para cargar módulos del kernel en sistemas con la funcionalidad UEFI Secure Boot activada.
Si el arranque seguro de UEFI está activado o si se ha especificado el parámetro de kernel module.sig_enforce:
-
Sólo puede cargar aquellos módulos del kernel firmados cuyas firmas fueron autenticadas contra claves del llavero del sistema (
.builtin_trusted_keys) y del llavero de la plataforma (.platform). -
La clave pública no debe estar en el llavero de claves revocadas del sistema (
.blacklist).
Si el arranque seguro de UEFI está desactivado y no se ha especificado el parámetro de kernel module.sig_enforce:
- Puedes cargar módulos del núcleo sin firmar y módulos del núcleo firmados sin clave pública.
Si el sistema no está basado en UEFI o si el arranque seguro de UEFI está desactivado:
-
En
.builtin_trusted_keysy.platformsólo se cargan las claves incrustadas en el núcleo. - No se puede aumentar ese conjunto de claves sin reconstruir el núcleo.
Tabla 3.2. Requisitos de autentificación del módulo del kernel para la carga
| Módulo firmado | Clave pública encontrada y firma válida | Estado de arranque seguro UEFI | sig_enforce | Carga del módulo | Núcleo contaminado |
|---|---|---|---|---|---|
| Sin firma | - | No habilitado | No habilitado | Tiene éxito | Sí |
| No habilitado | Activado | Falla | - | ||
| Activado | - | Falla | - | ||
| Firmado | No | No habilitado | No habilitado | Tiene éxito | Sí |
| No habilitado | Activado | Falla | - | ||
| Activado | - | Falla | - | ||
| Firmado | Sí | No habilitado | No habilitado | Tiene éxito | No |
| No habilitado | Activado | Tiene éxito | No | ||
| Activado | - | Tiene éxito | No |
3.12.1.2. Fuentes de claves públicas
Durante el arranque, el kernel carga claves X.509 de un conjunto de almacenes de claves persistentes en los siguientes llaveros:
-
El llavero del sistema (
.builtin_trusted_keys) -
El llavero
.platform -
El sistema
.blacklistllavero
Tabla 3.3. Fuentes de los llaveros del sistema
| Fuente de claves X.509 | El usuario puede añadir llaves | Estado de arranque seguro UEFI | Teclas cargadas durante el arranque |
|---|---|---|---|
| Integrado en el núcleo | No | - |
|
| UEFI Secure Boot "db" | Limitado | No habilitado | No |
| Activado |
| ||
|
Integrado en el cargador de arranque | No | No habilitado | No |
| Activado |
| ||
| Lista de claves del propietario de la máquina (MOK) | Sí | No habilitado | No |
| Activado |
|
.builtin_trusted_keys:
- un llavero que se construye en el arranque
- contiene claves públicas de confianza
-
los privilegios de
rootson necesarios para ver las claves
.platform:
- un llavero que se construye en el arranque
- contiene claves de proveedores de plataformas de terceros y claves públicas personalizadas
-
los privilegios de
rootson necesarios para ver las claves
.blacklist
- un llavero con claves X.509 que han sido revocadas
-
un módulo firmado por una clave de
.blacklistfallará la autenticación incluso si su clave pública está en.builtin_trusted_keys
UEFI Secure Boot db:
- una base de datos de firmas
- almacena las claves (hashes) de las aplicaciones UEFI, los controladores UEFI y los cargadores de arranque
- las llaves se pueden cargar en la máquina
UEFI Secure Boot dbx:
- una base de datos de firmas revocadas
- impide que se carguen las llaves
-
las claves revocadas de esta base de datos se añaden al llavero
.blacklist
3.12.1.3. Generar un par de claves públicas y privadas
Necesita generar un par de claves X.509 públicas y privadas para tener éxito en sus esfuerzos de utilizar módulos del kernel en un sistema habilitado para el Arranque Seguro. Más tarde utilizará la clave privada para firmar el módulo del kernel. También tendrá que añadir la clave pública correspondiente a la Clave del Propietario de la Máquina (MOK) para el Arranque Seguro para validar el módulo firmado.
Algunos de los parámetros para esta generación de pares de claves se especifican mejor con un archivo de configuración.
Procedimiento
Crear un archivo de configuración con parámetros para la generación de pares de claves:
# cat << EOF > configuration_file.config [ req ] default_bits = 4096 distinguished_name = req_distinguished_name prompt = no string_mask = utf8only x509_extensions = myexts [ req_distinguished_name ] O = Organization CN = Organization signing key emailAddress = E-mail address [ myexts ] basicConstraints=critical,CA:FALSE keyUsage=digitalSignature subjectKeyIdentifier=hash authorityKeyIdentifier=keyid EOF
Cree un par de claves públicas y privadas X.509 como se muestra en el siguiente ejemplo:
# openssl req -x509 -new -nodes -utf8 -sha256 -days 36500 \ -batch -config configuration_file.config -outform DER \ -out my_signing_key_pub.der \ -keyout my_signing_key.privLa clave pública se escribirá en el archivo
my_signing_key_pub.dery la clave privada se escribirá en el archivomy_signing_key.privarchivo.ImportanteEn RHEL 8, las fechas de validez del par de claves son importantes. La clave no caduca, pero el módulo del núcleo debe ser firmado dentro del período de validez de su clave de firma. Por ejemplo, una clave que sólo es válida en 2019 puede utilizarse para autenticar un módulo del núcleo firmado en 2019 con esa clave. Sin embargo, los usuarios no pueden utilizar esa clave para firmar un módulo del núcleo en 2020.
Opcionalmente, puede revisar las fechas de validez de sus claves públicas como en el ejemplo siguiente:
# openssl x509 -inform der -text -noout -in <my_signing_key_pub.der> Validity Not Before: Feb 14 16:34:37 2019 GMT Not After : Feb 11 16:34:37 2029 GMT- Registre su clave pública en todos los sistemas en los que desee autenticarse y cargue su módulo del kernel.
Aplique fuertes medidas de seguridad y políticas de acceso para proteger el contenido de su clave privada. En las manos equivocadas, la clave podría utilizarse para comprometer cualquier sistema que esté autenticado por la clave pública correspondiente.
Recursos adicionales
-
Para más información sobre la utilidad
openssl, consulte la página del manualopenssl(1). -
Para más información sobre el uso de
openssl, consulte el RHEL Security Guide - Para más detalles sobre la inscripción de claves públicas en los sistemas de destino, consulte Sección 3.12.3.2, “Añadir manualmente la clave pública a la lista MOK”.
3.12.2. Ejemplo de salida de los llaveros del sistema
Puedes mostrar información sobre las llaves de los llaveros del sistema utilizando la utilidad keyctl.
El siguiente es un ejemplo abreviado de la salida de los llaveros .builtin_trusted_keys, .platform, y .blacklist de un sistema RHEL 8 donde el arranque seguro UEFI está habilitado.
# keyctl list %:.builtin_trusted_keys 6 keys in keyring: ...asymmetric: Red Hat Enterprise Linux Driver Update Program (key 3): bf57f3e87... ...asymmetric: Red Hat Secure Boot (CA key 1): 4016841644ce3a810408050766e8f8a29... ...asymmetric: Microsoft Corporation UEFI CA 2011: 13adbf4309bd82709c8cd54f316ed... ...asymmetric: Microsoft Windows Production PCA 2011: a92902398e16c49778cd90f99e... ...asymmetric: Red Hat Enterprise Linux kernel signing key: 4249689eefc77e95880b... ...asymmetric: Red Hat Enterprise Linux kpatch signing key: 4d38fd864ebe18c5f0b7... # keyctl list %:.platform 4 keys in keyring: ...asymmetric: VMware, Inc.: 4ad8da0472073... ...asymmetric: Red Hat Secure Boot CA 5: cc6fafe72... ...asymmetric: Microsoft Windows Production PCA 2011: a929f298e1... ...asymmetric: Microsoft Corporation UEFI CA 2011: 13adbf4e0bd82... # keyctl list %:.blacklist 4 keys in keyring: ...blacklist: bin:f5ff83a... ...blacklist: bin:0dfdbec... ...blacklist: bin:38f1d22... ...blacklist: bin:51f831f...
El llavero .builtin_trusted_keys de arriba muestra la adición de dos claves de la UEFI Secure Boot \ "db", así como la Red Hat Secure Boot (CA key 1), que está incrustado en el cargador de arranque shim.efi.
El siguiente ejemplo muestra la salida de la consola del kernel. Los mensajes identifican las claves con una fuente relacionada con UEFI Secure Boot. Estos incluyen UEFI Secure Boot db, shim incrustado, y la lista MOK.
# dmesg | grep 'EFI: Loaded cert'
[5.160660] EFI: Loaded cert 'Microsoft Windows Production PCA 2011: a9290239...
[5.160674] EFI: Loaded cert 'Microsoft Corporation UEFI CA 2011: 13adbf4309b...
[5.165794] EFI: Loaded cert 'Red Hat Secure Boot (CA key 1): 4016841644ce3a8...Recursos adicionales
-
Para más información sobre
keyctl, consulte la página del manualkeyctl(1). -
Para más información sobre
dmesg, consulte la página del manualdmesg(1).
3.12.3. Inscripción de la clave pública en el sistema de destino
Cuando RHEL 8 arranca en un sistema basado en UEFI con Secure Boot activado, el kernel carga en el llavero del sistema (.builtin_trusted_keys) todas las claves públicas que están en la base de datos de claves db de Secure Boot. Al mismo tiempo, el kernel excluye las claves de la base de datos dbx de claves revocadas. Las secciones siguientes describen diferentes maneras de importar una clave pública en un sistema de destino para que el llavero del sistema (.builtin_trusted_keys) sea capaz de utilizar la clave pública para autenticar un módulo del kernel.
3.12.3.1. Imagen de firmware de fábrica que incluye la clave pública
Para facilitar la autenticación de su módulo de kernel en sus sistemas, considere solicitar a su proveedor de sistemas que incorpore su clave pública en la base de datos de claves de arranque seguro de UEFI en su imagen de firmware de fábrica.
3.12.3.2. Añadir manualmente la clave pública a la lista MOK
La función de la llave del propietario de la máquina (MOK) se puede utilizar para ampliar la base de datos de claves de arranque seguro de UEFI. Cuando RHEL 8 arranca en un sistema habilitado para UEFI con Secure Boot activado, las claves de la lista MOK también se añaden al llavero del sistema (.builtin_trusted_keys) además de las claves de la base de datos de claves. Las claves de la lista MOK también se almacenan de forma persistente y segura de la misma manera que las claves de la base de datos de Secure Boot, pero se trata de dos instalaciones distintas. La facilidad MOK es soportada por shim.efi, MokManager.efi, grubx64.efi, y la utilidad mokutil.
La inscripción de una clave MOK requiere la interacción manual de un usuario en la consola del sistema UEFI en cada sistema de destino. Sin embargo, la instalación MOK proporciona un método conveniente para probar los pares de claves recién generados y probar los módulos del kernel firmados con ellos.
Procedimiento
Solicite la adición de su clave pública a la lista MOK:
# mokutil --import my_signing_key_pub.derSe le pedirá que introduzca y confirme una contraseña para esta solicitud de inscripción en el MOK.
Reinicie la máquina.
La solicitud de inscripción de clave MOK pendiente será notada por
shim.efiy lanzaráMokManager.efipara permitirle completar la inscripción desde la consola UEFI.Introduzca la contraseña que ha asociado previamente a esta solicitud y confirme la inscripción.
Su clave pública se añade a la lista MOK, que es persistente.
Una vez que una clave está en la lista MOK, se propagará automáticamente al llavero del sistema en este y en los siguientes arranques cuando el arranque seguro UEFI esté habilitado.
3.12.4. Firma de los módulos del kernel con la clave privada
Los usuarios pueden obtener mayores beneficios de seguridad en sus sistemas cargando módulos del kernel firmados si el mecanismo de arranque seguro de UEFI está habilitado. Las siguientes secciones describen cómo firmar los módulos del kernel con la clave privada.
Requisitos previos
- Ha generado un par de claves públicas y privadas y conoce las fechas de validez de sus claves públicas. Para más detalles, consulte Sección 3.12.1.3, “Generar un par de claves públicas y privadas”.
- Ha registrado su clave pública en el sistema de destino. Para más detalles, consulte Sección 3.12.3, “Inscripción de la clave pública en el sistema de destino”.
- Tienes un módulo del kernel en formato de imagen ELF disponible para firmar.
Procedimiento
Ejecute la utilidad
sign-filecon los parámetros que se muestran en el siguiente ejemplo:# /usr/src/kernels/$(uname -r)/scripts/sign-file \ sha256 \ my_signing_key.priv \ my_signing_key_pub.der \ my_module.kosign-filecalcula y añade la firma directamente a la imagen ELF en su archivo de módulo del kernel. La utilidadmodinfopuede utilizarse para mostrar información sobre la firma del módulo del núcleo, si está presente.NotaLa firma anexa no está contenida en una sección de la imagen ELF y no es una parte formal de la imagen ELF. Por lo tanto, utilidades como
readelfno podrán mostrar la firma en su módulo del kernel.Su módulo del kernel está ahora listo para ser cargado. Tenga en cuenta que su módulo del kernel firmado también se puede cargar en sistemas en los que el arranque seguro de UEFI está deshabilitado o en un sistema no UEFI. Esto significa que no necesita proporcionar una versión firmada y otra sin firmar de su módulo del kernel.
ImportanteEn RHEL 8, las fechas de validez del par de claves son importantes. La clave no caduca, pero el módulo del kernel debe ser firmado dentro del periodo de validez de su clave de firma. La utilidad
sign-fileno le advertirá de esto. Por ejemplo, una clave que sólo es válida en 2019 puede utilizarse para autenticar un módulo del núcleo firmado en 2019 con esa clave. Sin embargo, los usuarios no pueden utilizar esa clave para firmar un módulo del núcleo en 2020.
Recursos adicionales
-
Para más detalles sobre el uso de
modinfopara obtener información sobre los módulos del núcleo, consulte Sección 3.7, “Visualización de información sobre los módulos del kernel”.
3.12.5. Carga de módulos del kernel firmados
Una vez que su clave pública está inscrita en el llavero del sistema (.builtin_trusted_keys) y en la lista MOK, y después de haber firmado el módulo del núcleo respectivo con su clave privada, puede finalmente cargar su módulo del núcleo firmado con el comando modprobe como se describe en la siguiente sección.
Requisitos previos
- Ha generado el par de claves públicas y privadas. Para más detalles, consulte Sección 3.12.1.3, “Generar un par de claves públicas y privadas”.
- Ha registrado la clave pública en el llavero del sistema. Para más detalles, consulte Sección 3.12.3.2, “Añadir manualmente la clave pública a la lista MOK”.
- Ha firmado un módulo del kernel con la clave privada. Para más detalles, consulte Sección 3.12.4, “Firma de los módulos del kernel con la clave privada”.
Procedimiento
Compruebe que sus claves públicas están en el llavero del sistema:
# keyctl list %:.builtin_trusted_keysCopie el módulo del núcleo en el directorio
/extra/del núcleo que desee:# cp my_module.ko /lib/modules/$(uname -r)/extra/Actualizar la lista de dependencias modulares:
# depmod -aCargue el módulo del kernel y compruebe que se ha cargado correctamente:
# modprobe -v my_module # lsmod | grep my_module
Opcionalmente, para cargar el módulo en el arranque, añádalo al archivo
/etc/modules-loaded.d/my_module.conf:# echo "my_module" > /etc/modules-load.d/my_module.conf
Recursos adicionales
- Para más información sobre la carga de módulos del núcleo, consulte las secciones correspondientes de Capítulo 3, Gestión de los módulos del núcleo.
Capítulo 4. Configuración de los parámetros de la línea de comandos del kernel
Los parámetros de la línea de comandos del kernel son una forma de cambiar el comportamiento de ciertos aspectos del kernel de Red Hat Enterprise Linux en el momento del arranque. Como administrador del sistema, usted tiene el control total sobre las opciones que se establecen en el arranque. Ciertos comportamientos del kernel sólo pueden establecerse en el momento del arranque, por lo que entender cómo hacer estos cambios es una habilidad clave para la administración.
Optar por cambiar el comportamiento del sistema modificando los parámetros de la línea de comandos del kernel puede tener efectos negativos en su sistema. Por lo tanto, debería probar los cambios antes de desplegarlos en producción. Para obtener más orientación, póngase en contacto con el Soporte de Red Hat.
4.1. Comprender los parámetros de la línea de comandos del kernel
Los parámetros de la línea de comandos del kernel se utilizan para la configuración del tiempo de arranque de:
- El núcleo de Red Hat Enterprise Linux
- El disco RAM inicial
- Las características del espacio del usuario
Los parámetros del tiempo de arranque del kernel se utilizan a menudo para sobrescribir los valores por defecto y para establecer configuraciones específicas del hardware.
Por defecto, los parámetros de la línea de comandos del kernel para los sistemas que utilizan el gestor de arranque GRUB2 se definen en la variable kernelopts del archivo /boot/grub2/grubenv para todas las entradas de arranque del kernel.
Para IBM Z, los parámetros de la línea de comandos del kernel se almacenan en el archivo de configuración de la entrada de arranque porque el cargador de arranque zipl no admite variables de entorno. Por lo tanto, no se puede utilizar la variable de entorno kernelopts.
Recursos adicionales
-
Para más información sobre los parámetros de la línea de comandos del kernel que puede modificar, consulte las páginas de manual
kernel-command-line(7),bootparam(7)ydracut.cmdline(7). -
Para más información sobre la variable
kernelopts, consulte el artículo de la base de conocimientos, Cómo instalar y arrancar kernels personalizados en Red Hat Enterprise Linux 8.
4.2. Lo que es mugriento
grubby es una utilidad para manipular archivos de configuración específicos del cargador de arranque.
Puede utilizar grubby también para cambiar la entrada de arranque por defecto, y para añadir/eliminar argumentos de una entrada de menú de GRUB2.
Para más detalles, consulte la página del manual grubby(8).
4.3. Qué son las entradas de arranque
Una entrada de arranque es una colección de opciones que se almacenan en un archivo de configuración y están vinculadas a una versión particular del kernel. En la práctica, tiene al menos tantas entradas de arranque como núcleos instalados tenga su sistema. El archivo de configuración de la entrada de arranque se encuentra en el directorio /boot/loader/entries/ y puede tener el siguiente aspecto:
6f9cc9cb7d7845d49698c9537337cedc-4.18.0-5.el8.x86_64.conf
El nombre del archivo anterior consiste en un ID de máquina almacenado en el archivo /etc/machine-id, y una versión del kernel.
El archivo de configuración de la entrada de arranque contiene información sobre la versión del kernel, la imagen inicial del ramdisk y la variable de entorno kernelopts, que contiene los parámetros de la línea de comandos del kernel. El contenido de una configuración de entrada de arranque se puede ver a continuación:
title Red Hat Enterprise Linux (4.18.0-74.el8.x86_64) 8.0 (Ootpa) version 4.18.0-74.el8.x86_64 linux /vmlinuz-4.18.0-74.el8.x86_64 initrd /initramfs-4.18.0-74.el8.x86_64.img $tuned_initrd options $kernelopts $tuned_params id rhel-20190227183418-4.18.0-74.el8.x86_64 grub_users $grub_users grub_arg --unrestricted grub_class kernel
La variable de entorno kernelopts se define en el archivo /boot/grub2/grubenv.
Recursos adicionales
Para más información sobre la variable kernelopts, consulte el artículo de la base de conocimientos Cómo instalar y arrancar kernels personalizados en Red Hat Enterprise Linux 8.
4.4. Configuración de los parámetros de la línea de comandos del kernel
Para ajustar el comportamiento de su sistema desde las primeras etapas del proceso de arranque, necesita establecer ciertos parámetros de la línea de comandos del kernel.
Esta sección explica cómo cambiar los parámetros de la línea de comandos del kernel en varias arquitecturas de CPU.
4.4.1. Cambio de los parámetros de la línea de comandos del kernel para todas las entradas de arranque
Este procedimiento describe cómo cambiar los parámetros de la línea de comandos del kernel para todas las entradas de arranque de su sistema.
Requisitos previos
-
Compruebe que las utilidades
grubbyyziplestán instaladas en su sistema.
Procedimiento
Para añadir un parámetro:
# grubby --update-kernel=ALL --args="<NEW_PARAMETER>"Para los sistemas que utilizan el gestor de arranque GRUB2, el comando actualiza el archivo
/boot/grub2/grubenvañadiendo un nuevo parámetro del kernel a la variablekerneloptsde ese archivo.En los IBM Z que utilizan el cargador de arranque zIPL, el comando añade un nuevo parámetro del kernel a cada
/boot/loader/entries/<ENTRY>.confarchivo.-
En IBM Z, ejecute el comando
ziplsin opciones para actualizar el menú de arranque.
-
En IBM Z, ejecute el comando
Para eliminar un parámetro:
# grubby --update-kernel=ALL --remove-args="<PARAMETER_TO_REMOVE>"-
En IBM Z, ejecute el comando
ziplsin opciones para actualizar el menú de arranque.
-
En IBM Z, ejecute el comando
Recursos adicionales
- Para más información sobre los parámetros de la línea de comandos del kernel, consulte Sección 4.1, “Comprender los parámetros de la línea de comandos del kernel”.
-
Para obtener información sobre la utilidad
grubby, consulte la página del manualgrubby(8). -
Para ver más ejemplos de cómo utilizar
grubby, consulte la página grubby tool. -
Para obtener información sobre la utilidad
zipl, consulte la página del manualzipl(8).
4.4.2. Cambio de los parámetros de la línea de comandos del kernel para una sola entrada de arranque
Este procedimiento describe cómo cambiar los parámetros de la línea de comandos del kernel para una sola entrada de arranque en su sistema.
Requisitos previos
-
Compruebe que las utilidades
grubbyyziplestán instaladas en su sistema.
Procedimiento
Para añadir un parámetro:
# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="<NEW_PARAMETER>"-
En IBM Z, ejecute el comando
ziplsin opciones para actualizar el menú de arranque.
-
En IBM Z, ejecute el comando
Para eliminar un parámetro utilice lo siguiente:
# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --remove-args="<PARAMETER_TO_REMOVE>"-
En IBM Z, ejecute el comando
ziplsin opciones para actualizar el menú de arranque.
-
En IBM Z, ejecute el comando
En los sistemas que utilizan el archivo grub.cfg, existe, por defecto, el parámetro options para cada entrada de arranque del kernel, que se establece en la variable kernelopts. Esta variable se define en el archivo de configuración /boot/grub2/grubenv.
En sistemas GRUB2:
-
Si los parámetros de la línea de comandos del kernel se modifican para todas las entradas de arranque, la utilidad
grubbyactualiza la variablekerneloptsen el archivo/boot/grub2/grubenv. -
Si los parámetros de la línea de comandos del kernel se modifican para una sola entrada de arranque, la variable
kerneloptsse expande, los parámetros del kernel se modifican y el valor resultante se almacena en el archivo/boot/loader/entries/<RELEVANT_KERNEL_BOOT_ENTRY.conf>de la entrada de arranque respectiva.
En los sistemas zIPL:
-
grubbymodifica y almacena los parámetros de la línea de comandos del kernel de una entrada individual de arranque del kernel en el archivo/boot/loader/entries/<ENTRY>.confarchivo.
Recursos adicionales
- Para más información sobre los parámetros de la línea de comandos del kernel, consulte Sección 4.1, “Comprender los parámetros de la línea de comandos del kernel”.
-
Para obtener información sobre la utilidad
grubby, consulte la página del manualgrubby(8). -
Para ver más ejemplos de cómo utilizar
grubby, consulte la página grubby tool. -
Para obtener información sobre la utilidad
zipl, consulte la página del manualzipl(8).
Capítulo 5. Configuración de los parámetros del núcleo en tiempo de ejecución
Como administrador del sistema, puede modificar muchas facetas del comportamiento del kernel de Red Hat Enterprise Linux en tiempo de ejecución. Esta sección describe cómo configurar los parámetros del kernel en tiempo de ejecución utilizando el comando sysctl y modificando los archivos de configuración en los directorios /etc/sysctl.d/ y /proc/sys/.
5.1. Qué son los parámetros del núcleo
Los parámetros del kernel son valores que se pueden ajustar mientras el sistema está en funcionamiento. No es necesario reiniciar o recompilar el kernel para que los cambios surtan efecto.
Es posible dirigirse a los parámetros del núcleo a través de:
-
El comando
sysctl -
El sistema de archivos virtual montado en el directorio
/proc/sys/ -
Los archivos de configuración en el directorio
/etc/sysctl.d/
Los sintonizables se dividen en clases según el subsistema del kernel. Red Hat Enterprise Linux tiene las siguientes clases de sintonizables:
Tabla 5.1. Tabla de clases sysctl
| Clase ajustable | Subsistema |
|---|---|
| abi | Dominios de ejecución y personalidades |
| cripto | Interfaces criptográficas |
| depurar | Interfaces de depuración del núcleo |
| dev | Información específica del dispositivo |
| fs | Ajustes globales y específicos del sistema de archivos |
| núcleo | Ajustes globales del kernel |
| red | Redes sintonizables |
| sunrpc | Sun Remote Procedure Call (NFS) |
| usuario | Límites del espacio de nombres del usuario |
| vm | Ajuste y gestión de la memoria, los búferes y la caché |
Recursos adicionales
-
Para más información sobre
sysctl, consulte las páginas del manualsysctl(8). -
Para más información sobre
/etc/sysctl.d/, consulte las páginas del manualsysctl.d(5).
5.2. Configuración de los parámetros del kernel en tiempo de ejecución
La configuración de los parámetros del kernel en un sistema de producción requiere una planificación cuidadosa. Los cambios no planificados pueden hacer que el kernel sea inestable, requiriendo un reinicio del sistema. Verifique que está utilizando opciones válidas antes de cambiar cualquier valor del kernel.
5.2.1. Configurar temporalmente los parámetros del kernel con sysctl
El siguiente procedimiento describe cómo utilizar el comando sysctl para establecer temporalmente los parámetros del kernel en tiempo de ejecución. El comando también es útil para listar y filtrar sintonizables.
Requisitos previos
- Introducción a los parámetros del núcleo
- Permisos de la raíz
Procedimiento
Para listar todos los parámetros y sus valores, utilice lo siguiente:
# sysctl -aNotaEl comando
# sysctl -amuestra los parámetros del kernel, que pueden ajustarse en tiempo de ejecución y en tiempo de arranque.Para configurar un parámetro temporalmente, utilice el comando como en el siguiente ejemplo:
# sysctl <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE>El comando de ejemplo anterior cambia el valor del parámetro mientras el sistema está en funcionamiento. Los cambios surten efecto inmediatamente, sin necesidad de reiniciar el sistema.
NotaLos cambios vuelven a ser por defecto después de reiniciar el sistema.
Recursos adicionales
-
Para más información sobre
sysctl, consulte la página del manualsysctl(8). -
Para modificar permanentemente los parámetros del kernel, utilice el comando
sysctlpara escribir los valores en el archivo/etc/sysctl.confo realice cambios manuales en los archivos de configuración en el directorio/etc/sysctl.d/.
5.2.2. Configurar los parámetros del kernel de forma permanente con sysctl
El siguiente procedimiento describe cómo utilizar el comando sysctl para establecer permanentemente los parámetros del kernel.
Requisitos previos
- Introducción a los parámetros del núcleo
- Permisos de la raíz
Procedimiento
Para listar todos los parámetros, utilice lo siguiente:
# sysctl -aEl comando muestra todos los parámetros del kernel que se pueden configurar en tiempo de ejecución.
Para configurar un parámetro de forma permanente:
# sysctl -w <TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE> >> /etc/sysctl.confEl comando de ejemplo cambia el valor sintonizable y lo escribe en el archivo
/etc/sysctl.conf, que anula los valores por defecto de los parámetros del kernel. Los cambios tienen efecto inmediato y persistente, sin necesidad de reiniciar.
Para modificar permanentemente los parámetros del kernel, también puede realizar cambios manuales en los archivos de configuración del directorio /etc/sysctl.d/.
Recursos adicionales
-
Para más información sobre
sysctl, consulte las páginas del manualsysctl(8)ysysctl.conf(5). -
Para más información sobre el uso de los archivos de configuración en el directorio
/etc/sysctl.d/para realizar cambios permanentes en los parámetros del kernel, consulte la sección Uso de los archivos de configuración en /etc/sysctl.d/ para ajustar los parámetros del kernel.
5.2.3. Uso de los archivos de configuración en /etc/sysctl.d/ para ajustar los parámetros del kernel
El siguiente procedimiento describe cómo modificar manualmente los archivos de configuración en el directorio /etc/sysctl.d/ para establecer permanentemente los parámetros del kernel.
Requisitos previos
- Introducción a los parámetros del núcleo
- Permisos de la raíz
Procedimiento
Cree un nuevo archivo de configuración en
/etc/sysctl.d/:# vim /etc/sysctl.d/<some_file.conf>Incluya los parámetros del núcleo, uno por línea, como sigue:
<TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE><TUNABLE_CLASS>.<PARAMETER>=<TARGET_VALUE>- Guarde el archivo de configuración.
Reinicie la máquina para que los cambios surtan efecto.
Alternativamente, para aplicar los cambios sin reiniciar, ejecute:
# sysctl -p /etc/sysctl.d/<some_file.conf>Este comando le permite leer los valores del archivo de configuración, que creó anteriormente.
Recursos adicionales
-
Para más información sobre
sysctl, consulte la página del manualsysctl(8). -
Para más información sobre
/etc/sysctl.d/, consulte la página del manualsysctl.d(5).
5.2.4. Configurar los parámetros del kernel temporalmente a través de /proc/sys/
El siguiente procedimiento describe cómo configurar los parámetros del kernel temporalmente a través de los archivos del directorio del sistema de archivos virtual /proc/sys/.
Requisitos previos
- Introducción a los parámetros del núcleo
- Permisos de la raíz
Procedimiento
Identifique un parámetro del núcleo que desee configurar:
# ls -l /proc/sys/<TUNABLE_CLASS>/Los archivos con permisos de escritura devueltos por el comando pueden utilizarse para configurar el kernel. Los archivos con permisos de sólo lectura proporcionan información sobre la configuración actual.
Asigna un valor objetivo al parámetro del núcleo:
# echo <TARGET_VALUE> > /proc/sys/<TUNABLE_CLASS>/<PARAMETER>El comando realiza cambios de configuración que desaparecerán una vez que se reinicie el sistema.
Opcionalmente, verifique el valor del parámetro del núcleo recién establecido:
# cat /proc/sys/<TUNABLE_CLASS>/<PARAMETER>
Recursos adicionales
-
Para modificar permanentemente los parámetros del kernel, utilice el comando
sysctlo realice cambios manuales en los archivos de configuración en el directorio/etc/sysctl.d/.
5.3. Mantener desactivados los parámetros de pánico del kernel en entornos virtualizados
Cuando configure un entorno virtualizado en Red Hat Enterprise Linux 8 (RHEL 8), no debe habilitar los parámetros del kernel softlockup_panic y nmi_watchdog, ya que el entorno virtualizado puede desencadenar un soft lockup espurio que no debería requerir un pánico del sistema.
En las siguientes secciones se explican las razones de este consejo resumiendo:
- Qué causa un bloqueo suave.
- Describe los parámetros del kernel que controlan el comportamiento de un sistema en un bloqueo suave.
- Explicación de cómo pueden activarse los bloqueos blandos en un entorno virtualizado.
5.3.1. ¿Qué es un bloqueo suave?
Un bloqueo suave es una situación causada generalmente por un error, cuando una tarea se ejecuta en el espacio del núcleo en una CPU sin reprogramar. La tarea tampoco permite que ninguna otra tarea se ejecute en esa CPU en particular. Como resultado, se muestra una advertencia al usuario a través de la consola del sistema. Este problema también se conoce como disparo de bloqueo suave.
Recursos adicionales
- Para conocer el motivo técnico de un bloqueo suave, ejemplos de mensajes de registro y otros detalles, consulte lo siguiente Knowledge Article.
5.3.2. Parámetros que controlan el pánico del núcleo
Los siguientes parámetros del kernel pueden establecerse para controlar el comportamiento del sistema cuando se detecta un bloqueo suave.
- softlockup_panic
Controla si el kernel entrará en pánico o no cuando se detecte un bloqueo suave.
Tipo Valor Efecto Entero
0
el kernel no entra en pánico al bloquearse suavemente
Entero
1
el kernel entra en pánico al bloquearse suavemente
Por defecto, en RHEL8 este valor es 0.
Para entrar en pánico, el sistema necesita detectar primero un bloqueo duro. La detección se controla con el parámetro
nmi_watchdog.- nmi_watchdog
Controla si los mecanismos de detección de bloqueos (
watchdogs) están activos o no. Este parámetro es de tipo entero.Valor Efecto 0
desactiva el detector de bloqueo
1
permite la detección de bloqueo
El detector de bloqueos duros supervisa cada CPU en cuanto a su capacidad de respuesta a las interrupciones.
- watchdog_thresh
Controla la frecuencia del watchdog
hrtimer, los eventos NMI y los umbrales de bloqueo suave/duro.Umbral por defecto Umbral de bloqueo suave 10 segundos
2 *
watchdog_threshSi este parámetro se pone a cero, se desactiva la detección de bloqueos por completo.
Recursos adicionales
-
Para más información sobre
nmi_watchdogysoftlockup_panic, consulte el Softlockup detector and hardlockup detector documento. -
Para más detalles sobre
watchdog_thresh, consulte el Kernel sysctl documento.
5.3.3. Bloqueos suaves espurios en entornos virtualizados
El bloqueo suave que se produce en los hosts físicos, tal y como se describe en Sección 5.3.1, “¿Qué es un bloqueo suave?”, suele representar un fallo del kernel o del hardware. El mismo fenómeno que ocurre en los sistemas operativos invitados en entornos virtualizados puede representar una falsa advertencia.
Una gran carga de trabajo en un host o una alta contención sobre algún recurso específico, como la memoria, suele provocar un disparo de bloqueo suave espurio. Esto se debe a que el host puede programar la salida de la CPU del huésped durante un periodo superior a 20 segundos. Entonces, cuando la CPU del huésped se programa de nuevo para ejecutarse en el host, experimenta un time jump que dispara los temporizadores debidos. Los temporizadores incluyen también el watchdog hrtimer, que puede, en consecuencia, informar de un bloqueo suave en la CPU huésped.
Debido a que un soft lockup en un entorno virtualizado puede ser espurio, no debe habilitar los parámetros del kernel que causarían un pánico en el sistema cuando se reporta un soft lockup en una CPU huésped.
Para entender los bloqueos suaves en los invitados, es esencial saber que el anfitrión programa el invitado como una tarea, y el invitado entonces programa sus propias tareas.
Recursos adicionales
- Para conocer la definición de bloqueo suave y los tecnicismos de su funcionamiento, véase Sección 5.3.1, “¿Qué es un bloqueo suave?”.
- Para conocer los componentes de los entornos virtualizados de RHEL 8 y su interacción, consulte RHEL 8 virtual machine components and their interaction.
5.4. Ajuste de los parámetros del núcleo para los servidores de bases de datos
Existen diferentes conjuntos de parámetros del kernel que pueden afectar al rendimiento de determinadas aplicaciones de bases de datos. Las siguientes secciones explican qué parámetros del kernel hay que configurar para asegurar un funcionamiento eficiente de los servidores de bases de datos y de las bases de datos.
5.4.1. Introducción a los servidores de bases de datos
Un servidor de base de datos es un dispositivo de hardware que tiene una cierta cantidad de memoria principal, y una aplicación de base de datos (DB) instalada. Esta aplicación de base de datos proporciona servicios como medio para escribir los datos almacenados en la memoria principal, que suele ser pequeña y costosa, en archivos de base de datos (DB). Estos servicios se prestan a múltiples clientes en una red. Puede haber tantos servidores de BD como lo permita la memoria principal y el almacenamiento de una máquina.
Red Hat Enterprise Linux 8 proporciona las siguientes aplicaciones de bases de datos:
- MariaDB 10.3
- MySQL 8.0
- PostgreSQL 10
- PostgreSQL 9.6
- PostgreSQL 12 - disponible desde RHEL 8.1.1
5.4.2. Parámetros que afectan al rendimiento de las aplicaciones de bases de datos
Los siguientes parámetros del kernel afectan al rendimiento de las aplicaciones de bases de datos.
- fs.aio-max-nr
Define el número máximo de operaciones de E/S asíncronas que el sistema puede manejar en el servidor.
NotaAumentar el parámetro
fs.aio-max-nrno produce ningún cambio adicional más allá de aumentar el límite de aio.- fs.file-max
Define el número máximo de manejadores de archivos (nombres de archivos temporales o IDs asignados a archivos abiertos) que el sistema soporta en cualquier instancia.
El kernel asigna dinámicamente los manejadores de archivo cada vez que un manejador de archivo es solicitado por una aplicación. Sin embargo, el núcleo no libera estos manejadores de archivo cuando son liberados por la aplicación. El kernel recicla estos manejadores de archivo en su lugar. Esto significa que, con el tiempo, el número total de manejadores de archivo asignados aumentará aunque el número de manejadores de archivo utilizados actualmente sea bajo.
- kernel.shmall
-
Define el número total de páginas de memoria compartida que se pueden utilizar en todo el sistema. Para utilizar toda la memoria principal, el valor del parámetro
kernel.shmalldebe ser ≤ tamaño total de la memoria principal. - kernel.shmmax
- Define el tamaño máximo en bytes de un único segmento de memoria compartida que un proceso Linux puede asignar en su espacio de direcciones virtual.
- kernel.shmmni
- Define el número máximo de segmentos de memoria compartida que puede manejar el servidor de la base de datos.
- net.ipv4.ip_local_port_range
- Define el rango de puertos que el sistema puede utilizar para los programas que quieren conectarse a un servidor de base de datos sin un número de puerto específico.
- net.core.rmem_default
- Define la memoria del socket de recepción por defecto a través del Protocolo de Control de Transmisión (TCP).
- net.core.rmem_max
- Define la memoria máxima del socket de recepción a través del Protocolo de Control de Transmisión (TCP).
- net.core.wmem_default
- Define la memoria del socket de envío por defecto a través del Protocolo de Control de Transmisión (TCP).
- net.core.wmem_max
- Define la memoria máxima del socket de envío a través del Protocolo de Control de Transmisión (TCP).
- vm.dirty_bytes / vm.dirty_ratio
-
Define un umbral en bytes / en porcentaje de memoria sucia a partir del cual se inicia un proceso que genera datos sucios en la función
write().
Either vm.dirty_bytes or vm.dirty_ratio se puede especificar a la vez.
- vm.dirty_background_bytes / vm.dirty_background_ratio
- Define un umbral en bytes / en porcentaje de memoria sucia a partir del cual el núcleo intenta escribir activamente datos sucios en el disco duro.
Either vm.dirty_background_bytes or vm.dirty_background_ratio se puede especificar a la vez.
- vm.dirty_writeback_centisecs
Define un intervalo de tiempo entre los despertares periódicos de los hilos del kernel responsables de escribir los datos sucios en el disco duro.
Estos parámetros del núcleo se miden en centésimas de segundo.
- vm.dirty_expire_centisecs
Define el tiempo después del cual los datos sucios son lo suficientemente viejos para ser escritos en el disco duro.
Estos parámetros del núcleo se miden en centésimas de segundo.
Recursos adicionales
- Para la explicación de las devoluciones de datos sucios, cómo funcionan y qué parámetros del kernel se relacionan con ellos, vea el Dirty pagecache writeback and vm.dirty parameters documento.
Capítulo 6. Introducción al registro del núcleo
Los archivos de registro son archivos que contienen mensajes sobre el sistema, incluyendo el kernel, los servicios y las aplicaciones que se ejecutan en él. El sistema de registro en Red Hat Enterprise Linux está basado en el protocolo incorporado syslog. Varias utilidades utilizan este sistema para registrar eventos y organizarlos en archivos de registro. Estos archivos son útiles cuando se audita el sistema operativo o se solucionan problemas.
6.1. ¿Qué es el buffer del núcleo?
Durante el proceso de arranque, la consola proporciona mucha información importante sobre la fase inicial del arranque del sistema. Para evitar la pérdida de los primeros mensajes, el kernel utiliza lo que se llama un buffer de anillo. Este búfer almacena todos los mensajes, incluidos los de arranque, generados por la función printk() dentro del código del kernel. Los mensajes del ring buffer del kernel son leídos y almacenados en archivos de registro en el almacenamiento permanente, por ejemplo, por el servicio syslog.
El buffer mencionado anteriormente es una estructura de datos cíclica que tiene un tamaño fijo, y está codificado en el núcleo. Los usuarios pueden mostrar los datos almacenados en la memoria intermedia del núcleo a través del comando dmesg o del archivo /var/log/boot.log. Cuando el ring buffer está lleno, los nuevos datos sobrescriben los antiguos.
Recursos adicionales
-
Para más información sobre
syslog, consulte la página del manualsyslog(2). -
Para más detalles sobre cómo examinar o controlar los mensajes del registro de arranque con
dmesg, consulte la página del manualdmesg(1).
6.2. Papel de printk en los niveles de registro y en el registro del núcleo
Cada mensaje que el kernel reporta tiene un nivel de registro asociado que define la importancia del mensaje. El buffer del kernel, como se describe en Sección 6.1, “¿Qué es el buffer del núcleo?”, recoge los mensajes del kernel de todos los niveles de registro. Es el parámetro kernel.printk el que define qué mensajes del buffer se imprimen en la consola.
Los valores del nivel de registro se desglosan en este orden:
- 0 - Emergencia del núcleo. El sistema es inutilizable.
- 1 - Alerta del núcleo. Hay que actuar inmediatamente.
- 2 - El estado del núcleo se considera crítico.
- 3 - Condición de error general del kernel.
- 4 - Condición de advertencia general del núcleo.
- 5 - Aviso del núcleo de una condición normal pero significativa.
- 6 - Mensaje informativo del kernel.
- 7 - Mensajes de nivel de depuración del kernel.
Por defecto, kernel.printk en RHEL 8 contiene los siguientes cuatro valores:
# sysctl kernel.printk
kernel.printk = 7 4 1 7Los cuatro valores definen lo siguiente:
- valor. Nivel de registro de la consola, define la prioridad más baja de los mensajes impresos en la consola.
- valor. Nivel de registro por defecto para los mensajes sin un nivel de registro explícito asociado a ellos.
- valor. Establece la configuración del nivel de registro más bajo posible para el nivel de registro de la consola.
valor. Establece el valor por defecto para el nivel de registro de la consola en el momento del arranque.
Cada uno de estos valores define una regla diferente para manejar los mensajes de error.
El valor por defecto 7 4 1 7 printk permite una mejor depuración de la actividad del kernel. Sin embargo, cuando se combina con una consola en serie, esta configuración printk es capaz de causar intensas ráfagas de E/S que podrían llevar a que un sistema RHEL deje de responder temporalmente. Para evitar estas situaciones, establecer un valor printk de 4 4 1 7 suele funcionar, pero a costa de perder la información de depuración adicional.
Tenga en cuenta también que ciertos parámetros de la línea de comandos del kernel, como quiet o debug, cambian los valores por defecto de kernel.printk.
Recursos adicionales
-
Para más información sobre
kernel.printky los niveles de registro, consulte la página del manualsyslog(2).
Capítulo 7. Instalación y configuración de kdump
7.1. Qué es kdump
kdump es un servicio que proporciona un mecanismo de volcado de fallos. El servicio permite guardar el contenido de la memoria del sistema para su posterior análisis. kdump utiliza la llamada al sistema kexec para arrancar en el segundo núcleo (un capture kernel) sin reiniciar; y luego captura el contenido de la memoria del núcleo accidentado (un crash dump o un vmcore) y lo guarda. El segundo núcleo reside en una parte reservada de la memoria del sistema.
Un volcado del kernel puede ser la única información disponible en caso de fallo del sistema (un error crítico). Por lo tanto, asegurarse de que kdump está operativo es importante en entornos de misión crítica. Red Hat aconseja que los administradores de sistemas actualicen y prueben regularmente kexec-tools en su ciclo normal de actualización del kernel. Esto es especialmente importante cuando se implementan nuevas características del kernel.
7.2. Instalación de kdump
En muchos casos, el servicio kdump está instalado y activado por defecto en las nuevas instalaciones de Red Hat Enterprise Linux. El instalador de Anaconda instalador proporciona una pantalla para la configuración de kdump cuando se realiza una instalación interactiva utilizando la interfaz gráfica o de texto. La pantalla del instalador se titula Kdump y está disponible desde la pantalla principal Installation Summary, y sólo permite una configuración limitada - sólo puede seleccionar si kdump está activado y cuánta memoria está reservada.
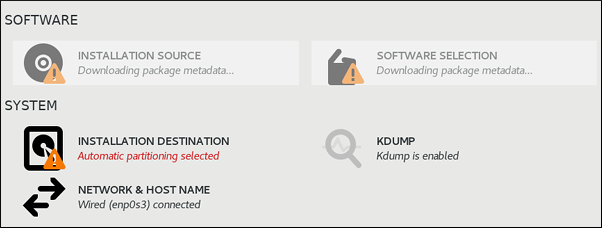
Algunas opciones de instalación, como las instalaciones Kickstart personalizadas, en algunos casos no instalan o habilitan kdump por defecto. Si este es el caso en su sistema, siga el procedimiento siguiente para instalar kdump.
Requisitos previos
- Una suscripción activa a Red Hat Enterprise Linux
- Un repositorio que contiene el kexec-tools para la arquitectura de la CPU de su sistema
-
Cumplió con los requisitos de
kdump
Procedimiento
Ejecute el siguiente comando para comprobar si
kdumpestá instalado en su sistema:$ rpm -q kexec-toolsSalida si el paquete está instalado:
kexec-tools-2.0.17-11.el8.x86_64Salida si el paquete no está instalado:
package kexec-tools is not installedInstalar
kdumpy otros paquetes necesarios por:# yum install kexec-tools
A partir de Red Hat Enterprise Linux 7.4 (kernel-3.10.0-693.el7) el controlador Intel IOMMU es soportado con kdump. Para versiones anteriores, Red Hat Enterprise Linux 7.3 (kernel-3.10.0-514[.XYZ].el7) y anteriores, se aconseja desactivar el soporte de Intel IOMMU, de lo contrario es probable que el kernel kdump no responda.
Recursos adicionales
-
La información sobre los requisitos de memoria de
kdumpestá disponible en Sección 7.5.1, “Requisitos de memoria para kdump”.
7.3. Configuración de kdump en la línea de comandos
7.3.1. Configuración del uso de memoria de kdump
La memoria para kdump se reserva durante el arranque del sistema. El tamaño de la memoria se configura en el archivo de configuración del Grand Unified Bootloader (GRUB) 2 del sistema. El tamaño de la memoria depende del valor de crashkernel= especificado en el archivo de configuración y del tamaño de la memoria física del sistema.
La opción crashkernel= puede definirse de múltiples maneras. Puede especificar el valor crashkernel= o configurar la opción auto. La opción de arranque crashkernel=auto, reserva la memoria automáticamente, dependiendo de la cantidad total de la memoria física del sistema. Cuando se configura, el kernel reservará automáticamente una cantidad apropiada de memoria requerida para el kernel kdump. Esto ayuda a evitar que se produzcan errores de falta de memoria (OOM).
La asignación automática de memoria para kdump varía en función de la arquitectura del hardware del sistema y del tamaño de la memoria disponible.
Por ejemplo, en AMD64 e Intel 64, el parámetro crashkernel=auto sólo funciona cuando la memoria disponible es superior a 1GB y la arquitectura ARM de 64 bits e IBM Power Systems tienen una memoria disponible superior a 2GB.
Si el sistema tiene menos del umbral mínimo de memoria para la asignación automática, puede configurar la cantidad de memoria reservada manualmente.
Requisitos previos
-
Cumplió con los requisitos de
kdump
Procedimiento
-
Edite el archivo
/etc/default/grubutilizando los permisos de root. Ajuste la opción
crashkernel=al valor deseado.Por ejemplo, para reservar 128 MB de memoria, utilice lo siguiente:
crashkernel=128M
Alternativamente, puede establecer la cantidad de memoria reservada en una variable en función de la cantidad total de memoria instalada. La sintaxis para la reserva de memoria en una variable es
crashkernel=<range1>:<size1>,<range2>:<size2>. Por ejemplo:crashkernel=512M-2G:64M,2G-:128M
El ejemplo anterior reserva 64 MB de memoria si la cantidad total de memoria del sistema es de 512 MB o superior e inferior a 2 GB. Si la cantidad total de memoria es superior a 2 GB, se reservan 128 MB para
kdump.Desplazar la memoria reservada.
Algunos sistemas requieren reservar la memoria con un cierto offset fijo ya que la reserva del crashkernel es muy temprana, y quiere reservar algún área para uso especial. Si se establece el offset, la memoria reservada comienza allí. Para compensar la memoria reservada, utilice la siguiente sintaxis:
crashkernel=128M@16M
El ejemplo anterior significa que
kdumpreserva 128 MB de memoria comenzando en 16 MB (dirección física 0x01000000). Si el parámetro offset se establece en 0 o se omite por completo,kdumpdesplaza la memoria reservada automáticamente. Esta sintaxis también se puede utilizar cuando se establece una reserva de memoria variable como se ha descrito anteriormente; en este caso, el offset siempre se especifica en último lugar (por ejemplo,crashkernel=512M-2G:64M,2G-:128M@16M).
Utilice el siguiente comando para actualizar el archivo de configuración de GRUB2:
# grub2-mkconfig -o /boot/grub2/grub.cfg
La forma alternativa de configurar la memoria para kdump es añadir el parámetro crashkernel=<SOME_VALUE> parámetro a la variable kernelopts con el grub2-editenv que actualizará todas sus entradas de arranque. O puede utilizar la utilidad grubby para actualizar los parámetros de la línea de comandos del kernel de una sola entrada.
Recursos adicionales
-
Para más información sobre las entradas de arranque,
kernelopts, y cómo trabajar congrub2-editenvygrubbyvea Configuración de los parámetros de la línea de comandos del kernel.
7.3.2. Configuración del objetivo kdump
Cuando se captura un fallo del kernel, el volcado del núcleo puede almacenarse como un archivo en un sistema de archivos local, escribirse directamente en un dispositivo o enviarse a través de una red utilizando el protocolo NFS (Network File System) o SSH (Secure Shell). Sólo se puede establecer una de estas opciones a la vez, y el comportamiento por defecto es almacenar el archivo vmcore en el directorio /var/crash/ del sistema de archivos local.
Requisitos previos
-
Cumplió con los requisitos de
kdump
Procedimiento
Para almacenar el archivo vmcore en el directorio /var/crash/ del sistema de archivos local:
Edite el archivo
/etc/kdump.confy especifique la ruta:ruta /var/crash
La opción
path /var/crashrepresenta la ruta del sistema de archivos en la quekdumpguarda el archivovmcore. Cuando se especifica un objetivo de volcado en el archivo/etc/kdump.conf, entonces elpathes relativo al objetivo de volcado especificado.Si no se especifica un objetivo de volcado en el archivo
/etc/kdump.conf, entonces elpathrepresenta la ruta absoluta desde el directorio raíz. Dependiendo de lo que esté montado en el sistema actual, el objetivo de volcado y la ruta de volcado ajustada se toman automáticamente.
kdump guarda el archivo vmcore en el directorio /var/crash/var/crash, cuando el objetivo de volcado está montado en /var/crash y la opción path también se establece como /var/crash en el archivo /etc/kdump.conf. Por ejemplo, en el siguiente caso, el sistema de archivos ext4 ya está montado en /var/crash y la opción path está configurada como /var/crash:
grep -v ^# etc/kdump.conf | grep -v ^$ ext4 /dev/mapper/vg00-varcrashvol path /var/crash core_collector makedumpfile -c --message-level 1 -d 31
El resultado es la ruta /var/crash/var/crash. Para solucionar este problema, utilice la opción path / en lugar de path /var/crash
Para cambiar el directorio local en el que se debe guardar el volcado del núcleo, como root, edite el archivo de configuración /etc/kdump.conf como se describe a continuación.
-
Elimine el signo de almohadilla (\ "#") del principio de la línea
#path /var/crash. Sustituya el valor por la ruta del directorio deseado. Por ejemplo:
ruta /usr/local/cores
ImportanteEn Red Hat Enterprise Linux 8, el directorio definido como el objetivo de kdump utilizando la directiva
pathdebe existir cuando se inicia el serviciokdumpsystemd - de lo contrario el servicio falla. Este comportamiento es diferente de las versiones anteriores de Red Hat Enterprise Linux, donde el directorio se creaba automáticamente si no existía al iniciar el servicio.
Para escribir el archivo en una partición diferente, como root, edite el archivo de configuración /etc/kdump.conf como se describe a continuación.
Elimine el signo de almohadilla (\ "#") del principio de la línea
#ext4, según su elección.-
nombre del dispositivo (la línea
#ext4 /dev/vg/lv_kdump) -
etiqueta del sistema de archivos (la línea
#ext4 LABEL=/boot) -
UUID (la línea
#ext4 UUID=03138356-5e61-4ab3-b58e-27507ac41937)
-
nombre del dispositivo (la línea
Cambie el tipo de sistema de archivos así como el nombre del dispositivo, la etiqueta o el UUID a los valores deseados. Por ejemplo:
ext4 UUID=03138356-5e61-4ab3-b58e-27507ac41937
ImportanteSe recomienda especificar los dispositivos de almacenamiento utilizando un
LABEL=oUUID=. No se garantiza que los nombres de los dispositivos de disco, como/dev/sda3, sean consistentes entre los reinicios.ImportanteCuando se realiza un volcado a un dispositivo de almacenamiento de acceso directo (DASD) en el hardware IBM Z, es esencial que los dispositivos de volcado estén correctamente especificados en
/etc/dasd.confantes de proceder.
Para escribir el volcado directamente en un dispositivo:
-
Elimine el signo de almohadilla (\ "#") del principio de la línea
#raw /dev/vg/lv_kdump. Sustituya el valor por el nombre del dispositivo previsto. Por ejemplo:
raw /dev/sdb1
Para almacenar el volcado en una máquina remota utilizando el protocolo NFS:
-
Elimine el signo de almohadilla (\ "#") del principio de la línea
#nfs my.server.com:/export/tmp. Sustituya el valor por un nombre de host y una ruta de directorio válidos. Por ejemplo:
nfs pingüino.ejemplo.com:/exportar/núcleos
Para almacenar el volcado en una máquina remota utilizando el protocolo SSH:
-
Elimine el signo de almohadilla (\ "#") del principio de la
#ssh user@my.server.comlínea. - Sustituya el valor por un nombre de usuario y un nombre de host válidos.
Incluya su clave
SSHen la configuración.-
Elimine el signo de almohadilla del principio de la línea
#sshkey /root/.ssh/kdump_id_rsa. Cambie el valor por la ubicación de una clave válida en el servidor al que está intentando hacer el volcado. Por ejemplo:
ssh john@penguin.example.com sshkey /root/.ssh/mykey
-
Elimine el signo de almohadilla del principio de la línea
Recursos adicionales
- Para obtener una lista completa de los objetivos admitidos y no admitidos actualmente, ordenados por tipo, consulte Sección 7.5.3, “Objetivos de kdump compatibles”.
- Para obtener información sobre cómo configurar un servidor SSH y establecer una autenticación basada en claves, consulte Configuring basic system settings en Red Hat Enterprise Linux.
7.3.3. Configuración del colector central
El servicio kdump utiliza un programa core_collector para capturar la imagen vmcore. En RHEL, la utilidad makedumpfile es el recolector de núcleos por defecto.
makedumpfile es un programa de volcado que ayuda a comprimir el tamaño de un archivo de volcado y a copiar sólo las páginas necesarias utilizando varios niveles de volcado.
makedumpfile hace un archivo de volcado pequeño, ya sea comprimiendo los datos de volcado o excluyendo las páginas innecesarias, o ambas cosas. Necesita la primera información de depuración del kernel para entender cómo el primer kernel utiliza la memoria. Esto ayuda a detectar las páginas necesarias.
Sintaxis
core_collector makedumpfile -l --message-level 1 -d 31
Opciones
-
-c,-lo-p: especifica el formato del archivo de volcado por cada página utilizando la opciónzlibpara-c,lzopara-losnappypara-p. -
-d(dump_level): excluye las páginas para que no se copien en el archivo de volcado. -
--message-level: especifica los tipos de mensajes. Puede restringir las salidas impresas especificandomessage_levelcon esta opción. Por ejemplo, especificando 7 comomessage_levelse imprimen los mensajes comunes y los mensajes de error. El valor máximo demessage_leveles 31
Requisitos previos
-
Cumplió con los requisitos de
kdump
Procedimiento
-
Como
root, edite el archivo de configuración/etc/kdump.confy elimine el signo de almohadilla ("#") del comienzo de#core_collector makedumpfile -l --message-level 1 -d 31. - Para activar la compresión del archivo de volcado, ejecute:
core_collector makedumpfile -l --message-level 1 -d 31
donde,
-
-lespecifica el formato de archivo comprimidodump. -
-despecifica el nivel de volcado como 31. -
--message-levelespecifica el nivel del mensaje como 1.
Además, considere los siguientes ejemplos utilizando las opciones -c y -p:
-
Para comprimir el archivo de volcado utilizando
-c:
core_collector makedumpfile -c -d 31 --message-level 1
-
Para comprimir el archivo de volcado utilizando
-p:
core_collector makedumpfile -p -d 31 --message-level 1
Recursos adicionales
-
Consulte la página de manual
makedumpfile(8)para obtener una lista completa de las opciones disponibles.
7.3.4. Configuración de las respuestas a fallos por defecto de kdump
Por defecto, cuando kdump no consigue crear un archivo vmcore en la ubicación de destino especificada en Sección 7.3.2, “Configuración del objetivo kdump”, el sistema se reinicia y el volcado se pierde en el proceso. Para cambiar este comportamiento, siga el procedimiento siguiente.
Requisitos previos
-
Cumplió con los requisitos de
kdump
Procedimiento
-
Como
root, elimine el signo de almohadilla (\ "#") del comienzo de la línea#failure_actionen el archivo de configuración/etc/kdump.conf. Sustituya el valor por la acción deseada, como se describe en Sección 7.5.5, “Respuestas a fallos por defecto soportadas”. Por ejemplo:
failure_action poweroff
7.3.5. Activación y desactivación del servicio kdump
Para iniciar el servicio kdump en el momento del arranque, siga el siguiente procedimiento.
Requisitos previos
-
Cumplió los requisitos de
kdump. - Toda la configuración se establece de acuerdo con sus necesidades.
Procedimiento
Para activar el servicio
kdump, utilice el siguiente comando:# systemctl enable kdump.serviceEsto permite el servicio para
multi-user.target.Para iniciar el servicio en la sesión actual, utilice el siguiente comando:
# systemctl start kdump.servicePara detener el servicio
kdump, escriba el siguiente comando:# systemctl stop kdump.servicePara desactivar el servicio
kdump, ejecute el siguiente comando:# systemctl disable kdump.service
Se recomienda establecer kptr_restrict=1 como valor predeterminado. Cuando kptr_restrict se establece como (1) por defecto, el servicio kdumpctl carga el kernel de colisión incluso si Kernel Address Space Layout (KASLR) está habilitado o no.
Paso para la resolución de problemas
Cuando kptr_restrict no está configurado como (1), y si KASLR está activado, el contenido del archivo /proc/kore se genera como todos los ceros. En consecuencia, el servicio kdumpctl no puede acceder a /proc/kcore y cargar el kernel de colisión.
Para solucionar este problema, el archivo kexec-kdump-howto.txt muestra un mensaje de advertencia, en el que se especifica que se mantenga la configuración recomendada como kptr_restrict=1.
Para asegurarse de que el servicio kdumpctl carga el kernel de colisión, verifique que:
-
Kernel
kptr_restrict=1en el archivosysctl.conf.
Recursos adicionales
-
Para más información sobre
systemdy la configuración de servicios en general, consulte Configuring basic system settings en Red Hat Enterprise Linux.
7.4. Configuración de kdump en la consola web
Establezca y pruebe la configuración de kdump en la consola web de RHEL 8.
La consola web forma parte de la instalación por defecto de Red Hat Enterprise Linux 8 y activa o desactiva el servicio kdump en el momento del arranque. Además, la consola web le permite configurar convenientemente la memoria reservada para kdump; o seleccionar la ubicación de guardado de vmcore en un formato descomprimido o comprimido.
Requisitos previos
- Consulte Red Hat Enterprise Linux web console para más detalles.
7.4.1. Configurar el uso de memoria de kdump y la ubicación del objetivo en la consola web
El procedimiento siguiente le muestra cómo utilizar la pestaña Kernel Dump en la interfaz de la consola web de Red Hat Enterprise Linux para configurar la cantidad de memoria que se reserva para el kernel kdump. El procedimiento también describe cómo especificar la ubicación de destino del archivo de volcado de vmcore y cómo probar su configuración.
Requisitos previos
- Introducción al funcionamiento del web console
Procedimiento
-
Abra la pestaña
Kernel Dumpe inicie el serviciokdump. -
Configure el uso de la memoria de
kdumpa través del command line. Haga clic en el enlace junto a la opción
Crash dump location.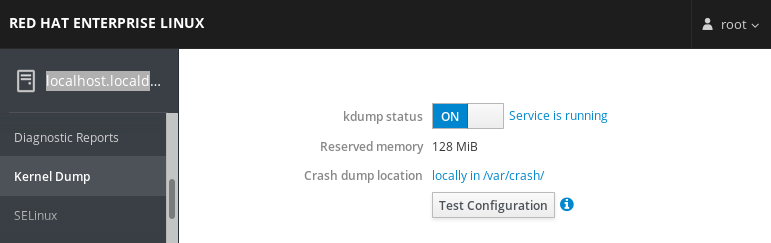
Seleccione la opción
Local Filesystemen el menú desplegable y especifique el directorio en el que desea guardar el volcado.
Alternativamente, seleccione la opción
Remote over SSHdel menú desplegable para enviar el vmcore a una máquina remota utilizando el protocolo SSH.Rellene los campos
Server,ssh key, yDirectorycon la dirección de la máquina remota, la ubicación de la clave ssh y un directorio de destino.Otra opción es seleccionar la opción
Remote over NFSen el desplegable y rellenar el campoMountpara enviar el vmcore a una máquina remota utilizando el protocolo NFS.NotaMarque la casilla
Compressionpara reducir el tamaño del archivo vmcore.
Pruebe su configuración haciendo fallar el kernel.
 Aviso
AvisoEste paso interrumpe la ejecución del kernel y provoca la caída del sistema y la pérdida de datos.
Recursos adicionales
-
Para obtener una lista completa de los objetivos actualmente admitidos en
kdump, consulte Supported kdump targets. - Para obtener información sobre cómo configurar un servidor SSH y establecer una autenticación basada en claves, consulte Using secure communications between two systems with OpenSSH.
7.5. Configuraciones y objetivos de kdump compatibles
7.5.1. Requisitos de memoria para kdump
Para que kdump pueda capturar un volcado del núcleo y guardarlo para su posterior análisis, una parte de la memoria del sistema tiene que estar permanentemente reservada para el núcleo de captura. Cuando se reserva, esta parte de la memoria del sistema no está disponible para el núcleo principal.
Los requisitos de memoria varían en función de ciertos parámetros del sistema. Uno de los principales factores es la arquitectura de hardware del sistema. Para averiguar la arquitectura exacta de la máquina (como Intel 64 y AMD64, también conocida como x86_64) e imprimirla en la salida estándar, utilice el siguiente comando:
$ uname -m
La siguiente tabla contiene una lista de requisitos mínimos de memoria para reservar automáticamente un tamaño de memoria para kdump. El tamaño cambia según la arquitectura del sistema y la memoria física total disponible.
Tabla 7.1. Cantidad mínima de memoria reservada necesaria para kdump
| Arquitectura | Memoria disponible | Memoria mínima reservada |
|---|---|---|
|
AMD64 e Intel 64 ( | De 1 GB a 4 GB | 160 MB de RAM. |
| De 4 GB a 64 GB | 192 MB de RAM. | |
| De 64 GB a 1 TB | 256 MB de RAM. | |
| 1 TB y más | 512 MB de RAM. | |
|
Arquitectura ARM de 64 bits ( | 2 GB y más | 448 MB de RAM. |
|
IBM Power Systems ( | De 2 GB a 4 GB | 384 MB de RAM. |
| De 4 GB a 16 GB | 512 MB de RAM. | |
| De 16 GB a 64 GB | 1 GB de RAM. | |
| De 64 GB a 128 GB | 2 GB de RAM. | |
| 128 GB y más | 4 GB de RAM. | |
|
IBM Z ( | De 1 GB a 4 GB | 160 MB de RAM. |
| De 4 GB a 64 GB | 192 MB de RAM. | |
| De 64 GB a 1 TB | 256 MB de RAM. | |
| 1 TB y más | 512 MB de RAM. |
En muchos sistemas, kdump es capaz de estimar la cantidad de memoria necesaria y reservarla automáticamente. Este comportamiento está activado por defecto, pero sólo funciona en sistemas que tienen más de una determinada cantidad de memoria total disponible, que varía en función de la arquitectura del sistema.
La configuración automática de la memoria reservada basada en la cantidad total de memoria del sistema es una estimación del mejor esfuerzo. La memoria real requerida puede variar debido a otros factores como los dispositivos de E/S. Utilizar una cantidad insuficiente de memoria puede provocar que un kernel de depuración no sea capaz de arrancar como un kernel de captura en caso de pánico del kernel. Para evitar este problema, aumente suficientemente la memoria del kernel de captura.
Recursos adicionales
- Para obtener información sobre cómo cambiar la configuración de la memoria en la línea de comandos, consulte Sección 7.3.1, “Configuración del uso de memoria de kdump”.
- Para obtener instrucciones sobre cómo configurar la cantidad de memoria reservada a través de la consola web, consulte Sección 7.4.1, “Configurar el uso de memoria de kdump y la ubicación del objetivo en la consola web”.
- Para más información sobre las diversas capacidades y límites de la tecnología de Red Hat Enterprise Linux, consulte el technology capabilities and limits tables.
7.5.2. Umbral mínimo para la reserva automática de memoria
En algunos sistemas, es posible asignar memoria para kdump automáticamente, ya sea utilizando el parámetro crashkernel=auto en el archivo de configuración del cargador de arranque, o habilitando esta opción en la utilidad de configuración gráfica. Sin embargo, para que esta reserva automática funcione, es necesario que haya una cierta cantidad de memoria total disponible en el sistema. Esta cantidad varía en función de la arquitectura del sistema.
La tabla siguiente enumera los umbrales para la asignación automática de memoria. Si el sistema tiene menos memoria que la especificada en la tabla, es necesario reservar la memoria manualmente.
Tabla 7.2. Cantidad mínima de memoria necesaria para la reserva automática de memoria
| Arquitectura | Memoria necesaria |
|---|---|
|
AMD64 e Intel 64 ( | 2 GB |
|
IBM Power Systems ( | 2 GB |
|
IBM Z ( | 4 GB |
Recursos adicionales
- Para obtener información sobre cómo cambiar manualmente estos ajustes en la línea de comandos, consulte Sección 7.3.1, “Configuración del uso de memoria de kdump”.
- Para obtener instrucciones sobre cómo cambiar manualmente la cantidad de memoria reservada a través de la consola web, consulte Sección 7.4.1, “Configurar el uso de memoria de kdump y la ubicación del objetivo en la consola web”.
7.5.3. Objetivos de kdump compatibles
Cuando se captura un fallo del kernel, el archivo de volcado de vmcore puede escribirse directamente en un dispositivo, almacenarse como un archivo en un sistema de archivos local o enviarse a través de una red. La siguiente tabla contiene una lista completa de los objetivos de volcado que actualmente son compatibles o que no son explícitamente compatibles con kdump.
Tabla 7.3. Objetivos kdump compatibles
| Tipo | Objetivos compatibles | Objetivos no compatibles |
|---|---|---|
| Dispositivo en bruto | Todos los discos y particiones raw conectados localmente. | |
| Sistema de archivos local |
|
Cualquier sistema de archivos local que no aparezca explícitamente en esta tabla, incluido el tipo |
| Directorio remoto |
Directorios remotos a los que se accede mediante el protocolo |
Directorios remotos en el sistema de archivos |
|
Directorios remotos a los que se accede mediante el protocolo |
Directorios remotos a los que se accede mediante el protocolo | Almacenes basados en la trayectoria múltiple. |
|
Directorios remotos a los que se accede a través de | ||
|
Directorios remotos a los que se accede mediante el protocolo | ||
|
Directorios remotos a los que se accede mediante el protocolo | ||
| Directorios remotos a los que se accede mediante interfaces de red inalámbricas. | ||
Utilizar el volcado asistido por el firmware (fadump) para capturar un vmcore y almacenarlo en una máquina remota utilizando el protocolo SSH o NFS provoca el cambio de nombre de la interfaz de red a kdump-<interface-name>. El cambio de nombre ocurre si el <interface-name> es genérico, por ejemplo *eth#, net#, y así sucesivamente. Este problema se produce porque los scripts de captura de vmcore en el disco RAM inicial (initrd) añaden el prefijo kdump- al nombre de la interfaz de red para asegurar la persistencia del nombre. Como el mismo initrd se utiliza también para un arranque normal, el nombre de la interfaz se cambia también para el kernel de producción.
Recursos adicionales
- Para obtener información sobre cómo configurar el tipo de destino en la línea de comandos, consulte Sección 7.3.2, “Configuración del objetivo kdump”.
- Para obtener información sobre cómo configurar el objetivo a través de la consola web, consulte Sección 7.4.1, “Configurar el uso de memoria de kdump y la ubicación del objetivo en la consola web”.
7.5.4. Niveles de filtrado de kdump soportados
Para reducir el tamaño del archivo de volcado, kdump utiliza el recopilador central makedumpfile para comprimir los datos y, opcionalmente, para omitir la información no deseada. La siguiente tabla contiene una lista completa de los niveles de filtrado que actualmente admite la utilidad makedumpfile.
Tabla 7.4. Niveles de filtrado admitidos
| Opción | Descripción |
|---|---|
|
| Cero páginas |
|
| Páginas de caché |
|
| Caché privado |
|
| Páginas de usuarios |
|
| Páginas libres |
El comando makedumpfile soporta la eliminación de páginas enormes transparentes y páginas hugetlbfs. Considere estos dos tipos de páginas de usuario hugepages y elimínelos utilizando el nivel -8.
Recursos adicionales
- Para obtener instrucciones sobre cómo configurar el recopilador de núcleos en la línea de comandos, consulte Sección 7.3.3, “Configuración del colector central”.
7.5.5. Respuestas a fallos por defecto soportadas
Por defecto, cuando kdump no consigue crear un volcado de núcleo, el sistema operativo se reinicia. Sin embargo, puede configurar kdump para que realice una operación diferente en caso de que falle al guardar el volcado del núcleo en el objetivo primario. La siguiente tabla enumera todas las acciones por defecto que se admiten actualmente.
Tabla 7.5. Acciones por defecto soportadas
| Opción | Descripción |
|---|---|
|
| Intenta guardar el volcado del núcleo en el sistema de archivos raíz. Esta opción es especialmente útil en combinación con un objetivo de red: si el objetivo de red es inalcanzable, esta opción configura kdump para guardar el volcado del núcleo localmente. El sistema se reinicia después. |
|
| Reinicie el sistema, perdiendo el volcado del núcleo en el proceso. |
|
| Detener el sistema, perdiendo el volcado del núcleo en el proceso. |
|
| Apagar el sistema, perdiendo el volcado del núcleo en el proceso. |
|
| Ejecuta una sesión de shell desde el initramfs, permitiendo al usuario grabar el volcado del núcleo manualmente. |
Recursos adicionales
- Para obtener información detallada sobre cómo configurar las respuestas a fallos por defecto en la línea de comandos, consulte Sección 7.3.4, “Configuración de las respuestas a fallos por defecto de kdump”.
7.5.6. Estimación del tamaño del kdump
Cuando se planifica y se construye el entorno de kdump, es necesario saber cuánto espacio se necesita para el archivo de volcado antes de producir uno.
El comando makedumpfile --mem-usage proporciona un informe útil sobre las páginas excluibles, y puede utilizarse para determinar el nivel de volcado que desea asignar. Ejecute este comando cuando el sistema esté bajo una carga representativa, de lo contrario makedumpfile --mem-usage devuelve un valor menor del que se espera en su entorno de producción.
[root@hostname ~]# makedumpfile --mem-usage /proc/kcore
TYPE PAGES EXCLUDABLE DESCRIPTION
----------------------------------------------------------------------
ZERO 501635 yes Pages filled with zero
CACHE 51657 yes Cache pages
CACHE_PRIVATE 5442 yes Cache pages + private
USER 16301 yes User process pages
FREE 77738211 yes Free pages
KERN_DATA 1333192 no Dumpable kernel data
El comando makedumpfile --mem-usage informa en pages. Esto significa que tiene que calcular el tamaño de la memoria en uso contra el tamaño de página del kernel. Por defecto, el kernel de Red Hat Enterprise Linux utiliza páginas de 4 KB para las arquitecturas AMD64 e Intel 64, y páginas de 64 KB para las arquitecturas IBM POWER.
7.6. Probando la configuración de kdump
El siguiente procedimiento describe cómo probar que el proceso de volcado del núcleo funciona y es válido antes de que la máquina entre en producción.
Los siguientes comandos hacen que el kernel se bloquee. Tenga cuidado al seguir estos pasos, y nunca los use sin cuidado en un sistema de producción activo.
Procedimiento
-
Reinicie el sistema con
kdumpactivado. Asegúrese de que
kdumpestá funcionando:~]# systemctl is-active kdump activeForzar la caída del kernel de Linux:
echo 1 > /proc/sys/kernel/sysrqecho c > /proc/sysrq-triggerAvisoEl comando anterior bloquea el kernel y se requiere un reinicio.
Una vez arrancado de nuevo, el archivo
address-YYYY-MM-DD-HH:MM:SS/vmcorese crea en la ubicación que hayas especificado en/etc/kdump.conf(por defecto en/var/crash/).NotaAdemás de confirmar la validez de la configuración, es posible usar esta acción para registrar el tiempo que tarda en completarse un volcado de fallos, mientras se ejecuta una carga representativa.
7.7. Uso de kexec para reiniciar el kernel
La llamada al sistema kexec permite cargar y arrancar en otro kernel desde el kernel que se está ejecutando actualmente, realizando así una función de cargador de arranque desde el kernel.
La utilidad kexec carga el kernel y la imagen initramfs para que la llamada al sistema kexec arranque en otro kernel.
El siguiente procedimiento describe cómo invocar manualmente la llamada al sistema kexec cuando se utiliza la utilidad kexec para reiniciar en otro núcleo.
Procedimiento
Ejecute la utilidad
kexec:# kexec -l /boot/vmlinuz-3.10.0-1040.el7.x86_64 --initrd=/boot/initramfs-3.10.0-1040.el7.x86_64.img --reuse-cmdlineEl comando carga manualmente el kernel y la imagen initramfs para la llamada al sistema
kexec.Reinicia el sistema:
# rebootEl comando detecta el kernel, apaga todos los servicios y luego llama a la llamada del sistema
kexecpara reiniciar en el kernel que proporcionaste en el paso anterior.
Cuando se utiliza el comando kexec -e para reiniciar el kernel, el sistema no pasa por la secuencia de apagado estándar antes de iniciar el siguiente kernel, lo que puede provocar la pérdida de datos o que el sistema no responda.
7.8. Lista negra de controladores del kernel para kdump
Poner en la lista negra los controladores del kernel para kdump es un mecanismo para evitar que se carguen los controladores del kernel previstos. La inclusión en la lista negra de los controladores del kernel evita los fallos de oom killer u otros fallos del kernel.
Para poner en la lista negra los controladores del kernel, puede actualizar la variable KDUMP_COMMANDLINE_APPEND= en el archivo /etc/sysconfig/kdump y especificar una de las siguientes opciones de lista negra:
-
rd.driver.blacklist=<modules> -
modprobe.blacklist=<modules>
Cuando se incluye una lista negra de controladores en el archivo /etc/sysconfig/kdump, se impide que kdump initramfs cargue los módulos incluidos en la lista negra.
El siguiente procedimiento describe cómo poner en la lista negra un controlador del kernel para evitar fallos en el kernel.
Procedimiento
Seleccione el módulo del kernel que desea incluir en la lista negra:
$ lsmod Module Size Used by fuse 126976 3 xt_CHECKSUM 16384 1 ipt_MASQUERADE 16384 1 uinput 20480 1 xt_conntrack 16384 1El comando
lsmodmuestra una lista de los módulos que se cargan en el kernel que se está ejecutando actualmente.Actualice la línea
KDUMP_COMMANDLINE_APPEND=en el archivo/etc/sysconfig/kdumpcomo sigue:KDUMP_COMMANDLINE_APPEND="rd.driver.blacklist=hv_vmbus,hv_storvsc,hv_utils,hv_netvsc,hid-hyperv"
También puede actualizar la línea
KDUMP_COMMANDLINE_APPEND=en el archivo/etc/sysconfig/kdumpde la siguiente manera:KDUMP_COMMANDLINE_APPEND="modprobe.blacklist=emcp modprobe.blacklist=bnx2fc modprobe.blacklist=libfcoe modprobe.blacklist=fcoe"
Reinicie el servicio
kdump:$ systemctl restart kdump
Recursos adicionales
-
Para más información sobre la página web
oom killer, consulte el siguiente artículo de conocimiento. -
La página de manual
dracut.cmdlinepara las opciones de la lista negra de módulos.
7.9. Ejecución de kdump en sistemas con disco encriptado
Cuando se ejecuta una partición cifrada creada por la herramienta Logical Volume Manager (LVM), los sistemas requieren una cierta cantidad de memoria disponible. Si el sistema tiene menos de la cantidad requerida de memoria disponible, la utilidad cryptsetup falla al montar la partición. Como resultado, la captura del archivo vmcore a una ubicación de destino local kdump (con LVM y cifrado activado), falla en el segundo núcleo (núcleo de captura).
Este procedimiento describe el mecanismo de ejecución de kdump aumentando el valor de crashkernel=, utilizando un objetivo remoto kdump, o utilizando una función de derivación de claves (KDF).
Procedimiento
Ejecute el mecanismo kdump utilizando uno de los siguientes procedimientos:
Para ejecutar el
kdumpdefina una de las siguientes opciones:-
Configurar un objetivo remoto
kdump. - Definir el volcado a una partición no cifrada.
-
Especifique un valor incrementado de
crashkernel=hasta el nivel requerido.
-
Configurar un objetivo remoto
Añade una ranura de clave adicional utilizando una función de derivación de clave (KDF):
-
cryptsetup luksAddKey --pbkdf pbkdf2 /dev/vda2 -
cryptsetup config --key-slot 1 --priority prefer /dev/vda2 -
cryptsetup luksDump /dev/vda2
-
El uso del KDF por defecto de la partición cifrada puede consumir mucha memoria. Debe proporcionar manualmente la contraseña en el segundo kernel (captura), incluso si se encuentra con un mensaje de error de memoria insuficiente (OOM).
Añadir una ranura de llave adicional puede tener un efecto negativo en la seguridad, ya que varias llaves pueden descifrar un volumen cifrado. Esto puede causar un riesgo potencial para el volumen.
7.10. Mecanismos de volcado asistidos por el firmware
El volcado asistido por el firmware (fadump) es un mecanismo de captura de volcados, proporcionado como alternativa al mecanismo kdump en los sistemas IBM POWER. Los mecanismos kexec y kdump son útiles para capturar volcados de núcleo en sistemas AMD64 e Intel 64. Sin embargo, algunos hardware, como los minisistemas y los ordenadores centrales, aprovechan el firmware de la placa para aislar regiones de la memoria y evitar cualquier sobrescritura accidental de datos que sean importantes para el análisis del fallo. Esta sección cubre los mecanismos de fadump y cómo se integran con RHEL. La utilidad fadump está optimizada para estas funciones de volcado ampliadas en los sistemas IBM POWER.
7.10.1. Volcado asistido de firmware en hardware IBM PowerPC
La utilidad fadump captura el archivo vmcore de un sistema totalmente reiniciado con dispositivos PCI y de E/S. Este mecanismo utiliza el firmware para preservar las regiones de memoria durante un fallo y luego reutiliza los scripts de espacio de usuario kdump para guardar el archivo vmcore. Las regiones de memoria consisten en todo el contenido de la memoria del sistema, excepto la memoria de arranque, los registros del sistema y las entradas de la tabla de páginas del hardware (PTE).
El mecanismo fadump ofrece una mayor fiabilidad que el tipo de volcado tradicional, al reiniciar la partición y utilizar un nuevo núcleo para volcar los datos del fallo del núcleo anterior. El fadump requiere una plataforma de hardware basada en el procesador IBM POWER6 o una versión posterior.
Para más detalles sobre el mecanismo fadump, incluyendo los métodos específicos de PowerPC para restablecer el hardware, consulte el archivo /usr/share/doc/kexec-tools/fadump-howto.txt.
El área de memoria que no se conserva, conocida como memoria de arranque, es la cantidad de RAM necesaria para arrancar con éxito el kernel después de un evento de caída. Por defecto, el tamaño de la memoria de arranque es de 256MB o el 5% del total de la RAM del sistema, lo que sea mayor.
A diferencia del evento kexec-initiated, el mecanismo fadump utiliza el kernel de producción para recuperar un volcado de colisión. Al arrancar después de un fallo, el hardware PowerPC pone el nodo de dispositivo /proc/device-tree/rtas/ibm.kernel-dump a disposición del sistema de archivos proc (procfs). Los scripts fadump-aware kdump, comprueban el vmcore almacenado, y luego completan el reinicio del sistema limpiamente.
7.10.2. Habilitación del mecanismo de volcado asistido por el firmware
Las capacidades de volcado de fallos de los sistemas IBM POWER pueden mejorarse activando el mecanismo de volcado asistido por el firmware (fadump).
Procedimiento
-
Instale y configure
kdumpcomo se describe en el capítulo 7, "Instalación y configuración de kdump". Añada
fadump=ona la líneaGRUB_CMDLINE_LINUXen el archivo/etc/default/grub:GRUB_CMDLINE_LINUX="rd.lvm.lv=rhel/swap crashkernel=auto rd.lvm.lv=rhel/root rhgb quiet fadump=on"
(Opcional) Si desea especificar la memoria de arranque reservada en lugar de utilizar los valores predeterminados, configure
crashkernel=xxMaGRUB_CMDLINE_LINUXen/etc/default/grub, dondexxes la cantidad de memoria necesaria en megabytes:GRUB_CMDLINE_LINUX="rd.lvm.lv=rhel/swap crashkernel=xxM rd.lvm.lv=rhel/root rhgb quiet fadump=on"
ImportanteRed Hat recomienda probar todas las opciones de configuración de arranque antes de ejecutarlas. Si observa errores de falta de memoria (OOM) al arrancar desde el kernel de bloqueo, incremente el valor especificado en el argumento
crashkernel=hasta que el kernel de bloqueo pueda arrancar limpiamente. En este caso puede ser necesario un poco de prueba y error.
7.10.3. Mecanismos de volcado asistidos por el firmware en el hardware IBM Z
Los sistemas IBM Z soportan los siguientes mecanismos de volcado asistidos por firmware:
-
Stand-alone dump (sadump) -
VMDUMP
La infraestructura kdump es soportada y utilizada en sistemas IBM Z. Para configurar kdump desde RHEL, véase el capítulo 7, "Instalación y configuración de kdump".
Sin embargo, el uso de uno de los métodos de volcado asistido por firmware (fadump) para IBM Z puede proporcionar varios beneficios:
-
El mecanismo
sadumpse inicia y controla desde la consola del sistema, y se almacena en un dispositivo de arranqueIPL. -
El mecanismo de
VMDUMPes similar al desadump. Esta herramienta también se inicia desde la consola del sistema, pero recupera el volcado resultante del hardware y lo copia en el sistema para su análisis. -
Estos métodos (al igual que otros mecanismos de volcado basados en hardware) tienen la capacidad de capturar el estado de una máquina en la fase inicial de arranque, antes de que se inicie el servicio
kdump. -
Aunque
VMDUMPcontiene un mecanismo para recibir el archivo de volcado en un sistema Red Hat Enterprise Linux, la configuración y el control deVMDUMPse gestiona desde la consola de IBM Z Hardware.
IBM discute sadump en detalle en el artículo del programa de volcado autónomo y VMDUMP en el artículo Creación de volcados en z/VM con VMDUMP.
IBM también tiene un conjunto de documentación para usar las herramientas de volcado en Red Hat Enterprise Linux 7 en el artículo Uso de las herramientas de volcado en Red Hat Enterprise Linux 7.4.
7.10.4. Uso de sadump en los sistemas Fujitsu PRIMEQUEST
El mecanismo de Fujitsu sadump está diseñado para proporcionar una captura de volcado de fallback en caso de que kdump no pueda completarse con éxito. El mecanismo sadump se invoca manualmente desde la interfaz de la placa de gestión del sistema (MMB). Utilizando la MMB, configure kdump como para un servidor Intel 64 o AMD 64 y luego realice los siguientes pasos adicionales para habilitar sadump.
Procedimiento
Añada o edite las siguientes líneas en el archivo
/etc/sysctl.confpara asegurarse de quekdumpse inicie como se espera parasadump:kernel.panic=0 kernel.unknown_nmi_panic=1
AvisoEn particular, asegúrese de que después de
kdump, el sistema no se reinicie. Si el sistema se reinicia después de quekdumpno haya guardado el archivovmcore, entonces no será posible invocar el programasadump.Establezca el parámetro
failure_actionen/etc/kdump.confadecuadamente comohaltoshell.shell failure_action
Recursos adicionales
Para obtener detalles sobre la configuración de su hardware para sadump, consulte el Manual de instalación del servidor FUJITSU PRIMEQUEST Serie 2000.
7.11. Analizar un volcado de núcleo
Para determinar la causa del fallo del sistema, puede utilizar la utilidad crash que proporciona un indicador interactivo muy similar al depurador de GNU (GDB). Esta utilidad le permite analizar interactivamente un volcado de núcleo creado por kdump, netdump, diskdump o xendump así como un sistema Linux en funcionamiento. Como alternativa, tiene la opción de utilizar el botón Kdump Helper o Kernel Oops Analyzer.
7.11.1. Instalación de la utilidad de choque
El siguiente procedimiento describe cómo instalar la crash herramienta de análisis.
Procedimiento
Habilite los repositorios correspondientes:
# subscription-manager repos --enable baseos repository# subscription-manager repos --enable appstream repository# subscription-manager repos --enable rhel-8-for-x86_64-baseos-debug-rpmsInstale el paquete
crash:# yum install crashInstale el paquete
kernel-debuginfo:# yum install kernel-debuginfoEl paquete corresponde a su núcleo en funcionamiento y proporciona los datos necesarios para el análisis del volcado.
Recursos adicionales
-
Para obtener más información sobre cómo trabajar con los repositorios utilizando la utilidad
subscription-manager, consulte Configuring basic system settings.
7.11.2. Ejecutar y salir de la utilidad de choque
El siguiente procedimiento describe cómo iniciar la utilidad de bloqueo para analizar la causa del bloqueo del sistema.
Requisitos previos
-
Identifica el núcleo que se está ejecutando actualmente (por ejemplo
4.18.0-5.el8.x86_64).
Procedimiento
Para iniciar la utilidad
crash, hay que pasar dos parámetros necesarios al comando:-
El debug-info (una imagen vmlinuz descomprimida), por ejemplo
/usr/lib/debug/lib/modules/4.18.0-5.el8.x86_64/vmlinuxproporcionada a través de un paquete específicokernel-debuginfo. El archivo vmcore real, por ejemplo
/var/crash/127.0.0.1-2018-10-06-14:05:33/vmcoreEl comando
crashresultante tiene el siguiente aspecto:# crash /usr/lib/debug/lib/modules/4.18.0-5.el8.x86_64/vmlinux /var/crash/127.0.0.1-2018-10-06-14:05:33/vmcoreUtilice la misma versión de <kernel> que fue capturada por
kdump.Ejemplo 7.1. Ejecución de la utilidad de choque
El siguiente ejemplo muestra el análisis de un volcado de núcleo creado el 6 de octubre de 2018 a las 14:05 PM, utilizando el kernel 4.18.0-5.el8.x86_64.
... WARNING: kernel relocated [202MB]: patching 90160 gdb minimal_symbol values KERNEL: /usr/lib/debug/lib/modules/4.18.0-5.el8.x86_64/vmlinux DUMPFILE: /var/crash/127.0.0.1-2018-10-06-14:05:33/vmcore [PARTIAL DUMP] CPUS: 2 DATE: Sat Oct 6 14:05:16 2018 UPTIME: 01:03:57 LOAD AVERAGE: 0.00, 0.00, 0.00 TASKS: 586 NODENAME: localhost.localdomain RELEASE: 4.18.0-5.el8.x86_64 VERSION: #1 SMP Wed Aug 29 11:51:55 UTC 2018 MACHINE: x86_64 (2904 Mhz) MEMORY: 2.9 GB PANIC: "sysrq: SysRq : Trigger a crash" PID: 10635 COMMAND: "bash" TASK: ffff8d6c84271800 [THREAD_INFO: ffff8d6c84271800] CPU: 1 STATE: TASK_RUNNING (SYSRQ) crash>
-
El debug-info (una imagen vmlinuz descomprimida), por ejemplo
Para salir del indicador interactivo y terminar
crash, escribaexitoq.Ejemplo 7.2. Salir de la utilidad de choque
crash> exit ~]#
El comando crash también puede utilizarse como una poderosa herramienta para depurar un sistema en vivo. Sin embargo, utilízalo con precaución para no romper tu sistema.
7.11.3. Visualización de varios indicadores en la utilidad de choque
Los siguientes procedimientos describen cómo utilizar la utilidad de bloqueo y mostrar varios indicadores, como un búfer de mensajes del kernel, un backtrace, un estado del proceso, información de la memoria virtual y archivos abiertos.
- Visualización del buffer de mensajes
-
Para mostrar el búfer de mensajes del kernel, escriba el comando
logen el indicador interactivo como se muestra en el ejemplo siguiente:
crash> log ... several lines omitted ... EIP: 0060:[<c068124f>] EFLAGS: 00010096 CPU: 2 EIP is at sysrq_handle_crash+0xf/0x20 EAX: 00000063 EBX: 00000063 ECX: c09e1c8c EDX: 00000000 ESI: c0a09ca0 EDI: 00000286 EBP: 00000000 ESP: ef4dbf24 DS: 007b ES: 007b FS: 00d8 GS: 00e0 SS: 0068 Process bash (pid: 5591, ti=ef4da000 task=f196d560 task.ti=ef4da000) Stack: c068146b c0960891 c0968653 00000003 00000000 00000002 efade5c0 c06814d0 <0> fffffffb c068150f b7776000 f2600c40 c0569ec4 ef4dbf9c 00000002 b7776000 <0> efade5c0 00000002 b7776000 c0569e60 c051de50 ef4dbf9c f196d560 ef4dbfb4 Call Trace: [<c068146b>] ? __handle_sysrq+0xfb/0x160 [<c06814d0>] ? write_sysrq_trigger+0x0/0x50 [<c068150f>] ? write_sysrq_trigger+0x3f/0x50 [<c0569ec4>] ? proc_reg_write+0x64/0xa0 [<c0569e60>] ? proc_reg_write+0x0/0xa0 [<c051de50>] ? vfs_write+0xa0/0x190 [<c051e8d1>] ? sys_write+0x41/0x70 [<c0409adc>] ? syscall_call+0x7/0xb Code: a0 c0 01 0f b6 41 03 19 d2 f7 d2 83 e2 03 83 e0 cf c1 e2 04 09 d0 88 41 03 f3 c3 90 c7 05 c8 1b 9e c0 01 00 00 00 0f ae f8 89 f6 <c6> 05 00 00 00 00 01 c3 89 f6 8d bc 27 00 00 00 00 8d 50 d0 83 EIP: [<c068124f>] sysrq_handle_crash+0xf/0x20 SS:ESP 0068:ef4dbf24 CR2: 0000000000000000
Escriba
help logpara obtener más información sobre el uso del comando.NotaEl búfer de mensajes del kernel incluye la información más esencial sobre el fallo del sistema y, como tal, siempre se vuelca primero en el archivo
vmcore-dmesg.txt. Esto es útil cuando un intento de obtener el archivovmcorecompleto falla, por ejemplo, por falta de espacio en la ubicación de destino. Por defecto,vmcore-dmesg.txtse encuentra en el directorio/var/crash/.-
Para mostrar el búfer de mensajes del kernel, escriba el comando
- Visualización de un backtrace
-
Para mostrar el seguimiento de la pila del kernel, utilice el comando
bt.
crash> bt PID: 5591 TASK: f196d560 CPU: 2 COMMAND: "bash" #0 [ef4dbdcc] crash_kexec at c0494922 #1 [ef4dbe20] oops_end at c080e402 #2 [ef4dbe34] no_context at c043089d #3 [ef4dbe58] bad_area at c0430b26 #4 [ef4dbe6c] do_page_fault at c080fb9b #5 [ef4dbee4] error_code (via page_fault) at c080d809 EAX: 00000063 EBX: 00000063 ECX: c09e1c8c EDX: 00000000 EBP: 00000000 DS: 007b ESI: c0a09ca0 ES: 007b EDI: 00000286 GS: 00e0 CS: 0060 EIP: c068124f ERR: ffffffff EFLAGS: 00010096 #6 [ef4dbf18] sysrq_handle_crash at c068124f #7 [ef4dbf24] __handle_sysrq at c0681469 #8 [ef4dbf48] write_sysrq_trigger at c068150a #9 [ef4dbf54] proc_reg_write at c0569ec2 #10 [ef4dbf74] vfs_write at c051de4e #11 [ef4dbf94] sys_write at c051e8cc #12 [ef4dbfb0] system_call at c0409ad5 EAX: ffffffda EBX: 00000001 ECX: b7776000 EDX: 00000002 DS: 007b ESI: 00000002 ES: 007b EDI: b7776000 SS: 007b ESP: bfcb2088 EBP: bfcb20b4 GS: 0033 CS: 0073 EIP: 00edc416 ERR: 00000004 EFLAGS: 00000246Escriba
bt <pid>para mostrar el backtrace de un proceso específico o escribahelp btpara obtener más información sobre el uso debt.-
Para mostrar el seguimiento de la pila del kernel, utilice el comando
- Visualización del estado de un proceso
-
Para mostrar el estado de los procesos en el sistema, utilice el comando
ps.
crash>
psPID PPID CPU TASK ST %MEM VSZ RSS COMM > 0 0 0 c09dc560 RU 0.0 0 0 [swapper] > 0 0 1 f7072030 RU 0.0 0 0 [swapper] 0 0 2 f70a3a90 RU 0.0 0 0 [swapper] > 0 0 3 f70ac560 RU 0.0 0 0 [swapper] 1 0 1 f705ba90 IN 0.0 2828 1424 init ... several lines omitted ... 5566 1 1 f2592560 IN 0.0 12876 784 auditd 5567 1 2 ef427560 IN 0.0 12876 784 auditd 5587 5132 0 f196d030 IN 0.0 11064 3184 sshd > 5591 5587 2 f196d560 RU 0.0 5084 1648 bashUtilice
ps <pid>para mostrar el estado de un solo proceso específico. Utilice help ps para obtener más información sobre el uso deps.-
Para mostrar el estado de los procesos en el sistema, utilice el comando
- Visualización de la información de la memoria virtual
-
Para mostrar la información básica de la memoria virtual, escriba el comando
vmen el indicador interactivo.
crash> vm PID: 5591 TASK: f196d560 CPU: 2 COMMAND: "bash" MM PGD RSS TOTAL_VM f19b5900 ef9c6000 1648k 5084k VMA START END FLAGS FILE f1bb0310 242000 260000 8000875 /lib/ld-2.12.so f26af0b8 260000 261000 8100871 /lib/ld-2.12.so efbc275c 261000 262000 8100873 /lib/ld-2.12.so efbc2a18 268000 3ed000 8000075 /lib/libc-2.12.so efbc23d8 3ed000 3ee000 8000070 /lib/libc-2.12.so efbc2888 3ee000 3f0000 8100071 /lib/libc-2.12.so efbc2cd4 3f0000 3f1000 8100073 /lib/libc-2.12.so efbc243c 3f1000 3f4000 100073 efbc28ec 3f6000 3f9000 8000075 /lib/libdl-2.12.so efbc2568 3f9000 3fa000 8100071 /lib/libdl-2.12.so efbc2f2c 3fa000 3fb000 8100073 /lib/libdl-2.12.so f26af888 7e6000 7fc000 8000075 /lib/libtinfo.so.5.7 f26aff2c 7fc000 7ff000 8100073 /lib/libtinfo.so.5.7 efbc211c d83000 d8f000 8000075 /lib/libnss_files-2.12.so efbc2504 d8f000 d90000 8100071 /lib/libnss_files-2.12.so efbc2950 d90000 d91000 8100073 /lib/libnss_files-2.12.so f26afe00 edc000 edd000 4040075 f1bb0a18 8047000 8118000 8001875 /bin/bash f1bb01e4 8118000 811d000 8101873 /bin/bash f1bb0c70 811d000 8122000 100073 f26afae0 9fd9000 9ffa000 100073 ... several lines omitted ...
Utilice
vm <pid>para mostrar información sobre un solo proceso específico, o utilicehelp vmpara obtener más información sobre el uso devm.-
Para mostrar la información básica de la memoria virtual, escriba el comando
- Visualización de expedientes abiertos
-
Para mostrar información sobre los archivos abiertos, utilice el comando
files.
crash>
filesPID: 5591 TASK: f196d560 CPU: 2 COMMAND: "bash" ROOT: / CWD: /root FD FILE DENTRY INODE TYPE PATH 0 f734f640 eedc2c6c eecd6048 CHR /pts/0 1 efade5c0 eee14090 f00431d4 REG /proc/sysrq-trigger 2 f734f640 eedc2c6c eecd6048 CHR /pts/0 10 f734f640 eedc2c6c eecd6048 CHR /pts/0 255 f734f640 eedc2c6c eecd6048 CHR /pts/0Utilice
files <pid>para mostrar los archivos abiertos por un solo proceso seleccionado, o utilicehelp filespara obtener más información sobre el uso defiles.-
Para mostrar información sobre los archivos abiertos, utilice el comando
7.11.4. Uso de Kernel Oops Analyzer
El Kernel Oops Analyzer es una herramienta que analiza el volcado de fallos comparando los mensajes oops con los problemas conocidos en la base de conocimientos.
Requisitos previos
- Asegure un mensaje oops para alimentar el Kernel Oops Analyzer siguiendo las instrucciones en Red Hat Labs.
Procedimiento
- Siga el Kernel Oops Analyzer enlace para acceder a la herramienta.
Busque el mensaje oops pulsando el botón .
-
Haga clic en el botón para comparar el mensaje oops basado en la información de
makedumpfilecon las soluciones conocidas.
7.12. Uso de kdump temprano para capturar los fallos en el tiempo de arranque
Como administrador del sistema, puede utilizar el soporte de early kdump del servicio kdump para capturar un archivo vmcore del kernel que falla durante las primeras etapas del proceso de arranque. Esta sección describe qué es early kdump, cómo configurarlo y cómo comprobar el estado de este mecanismo.
7.12.1. Qué es el kdump temprano
Los fallos del kernel durante la fase de arranque se producen cuando el servicio kdump aún no se ha iniciado, y no puede facilitar la captura y el almacenamiento del contenido de la memoria del kernel accidentado. Por lo tanto, se pierde la información vital para la resolución de problemas.
Para solucionar este problema, RHEL 8 introdujo la función early kdump como parte del servicio kdump.
Recursos adicionales
-
Para más información sobre
early kdumpy su uso, consulte el archivo/usr/share/doc/kexec-tools/early-kdump-howto.txty la solución ¿Qué es el soporte de kdump temprano y cómo lo configuro? -
Para más información sobre el servicio
kdump, consulte la página web Sección 7.1, “Qué es kdump”.
7.12.2. Habilitación de kdump temprano
Esta sección describe cómo habilitar la función early kdump para eliminar el riesgo de perder información sobre los primeros fallos del kernel de arranque.
Requisitos previos
- Una suscripción activa a Red Hat Enterprise Linux
-
Un repositorio que contiene el paquete
kexec-toolspara la arquitectura de la CPU de su sistema -
Cumplió con los requisitos de
kdump
Procedimiento
Compruebe que el servicio
kdumpestá habilitado y activo:# systemctl is-enabled kdump.service && systemctl is-active kdump.service enabled activeSi
kdumpno está habilitado y en funcionamiento vea, Sección 7.3.5, “Activación y desactivación del servicio kdump”.Reconstruir la imagen
initramfsdel kernel de arranque con la funcionalidadearly kdump:dracut -f --add earlykdumpAñade el parámetro de línea de comandos del kernel
rd.earlykdump:grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="rd.earlykdump"Reinicie el sistema para reflejar los cambios
rebootOpcionalmente, verifique que
rd.earlykdumpfue agregado exitosamente y que la funciónearly kdumpfue habilitada:# cat /proc/cmdline BOOT_IMAGE=(hd0,msdos1)/vmlinuz-4.18.0-187.el8.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet rd.earlykdump # journalctl -x | grep early-kdump Mar 20 15:44:41 redhat dracut-cmdline[304]: early-kdump is enabled. Mar 20 15:44:42 redhat dracut-cmdline[304]: kexec: loaded early-kdump kernel
Recursos adicionales
-
Para más información sobre la activación de
early kdump, consulte el archivo/usr/share/doc/kexec-tools/early-kdump-howto.txty la solución ¿Qué es el soporte de kdump temprano y cómo lo configuro?
Capítulo 8. Aplicación de parches con kernel live patching
Puede utilizar la solución de parcheo en vivo del kernel de Red Hat Enterprise Linux para parchear un kernel en ejecución sin reiniciar o reiniciar ningún proceso.
Con esta solución, los administradores de sistemas:
- Puede aplicar inmediatamente los parches de seguridad críticos al kernel.
- No tenga que esperar a que se completen las tareas de larga duración, a que los usuarios se desconecten o al tiempo de inactividad programado.
- Controle más el tiempo de actividad del sistema y no sacrifique la seguridad ni la estabilidad.
Tenga en cuenta que no todas las CVE críticas o importantes se resolverán utilizando la solución de parches en vivo del kernel. Nuestro objetivo es reducir los reinicios necesarios para los parches relacionados con la seguridad, no eliminarlos por completo. Para obtener más detalles sobre el alcance de los parches en vivo, consulte la página Customer Portal Solutions article.
Existen algunas incompatibilidades entre el kernel live patching y otros subcomponentes del kernel. Lea atentamente la página Sección 8.1, “Limitaciones de kpatch” antes de utilizar el kernel live patching.
8.1. Limitaciones de kpatch
-
La función
kpatchno es un mecanismo de actualización del núcleo de uso general. Se utiliza para aplicar actualizaciones sencillas de seguridad y corrección de errores cuando no es posible reiniciar el sistema inmediatamente. -
No utilice las herramientas
SystemTapokprobedurante o después de cargar un parche. El parche podría no surtir efecto hasta después de haber eliminado dichas sondas.
8.2. Soporte para el live patching de terceros
La utilidad kpatch es la única utilidad de parcheo en vivo del kernel soportada por Red Hat con los módulos RPM proporcionados por los repositorios de Red Hat. Red Hat no soportará ningún parche en vivo que no haya sido proporcionado por la propia Red Hat.
Si necesita soporte para un problema que surja con un parche activo de terceros, Red Hat recomienda que abra un caso con el proveedor de parches activos al principio de cualquier investigación en la que sea necesario determinar la causa raíz. Esto permite que se suministre el código fuente si el proveedor lo permite, y que su organización de soporte proporcione asistencia en la determinación de la causa raíz antes de escalar la investigación al Soporte de Red Hat.
En el caso de cualquier sistema que funcione con parches activos de terceros, Red Hat se reserva el derecho de solicitar su reproducción con el software suministrado y soportado por Red Hat. En el caso de que esto no sea posible, requerimos que se implemente un sistema y una carga de trabajo similares en su entorno de prueba sin parches activos aplicados, para confirmar si se observa el mismo comportamiento.
Para obtener más información sobre las políticas de soporte de software de terceros, consulte ¿Cómo manejan los Servicios de Soporte Global de Red Hat el software de terceros, los controladores y/o el hardware/hipervisores no certificados o los sistemas operativos invitados?
8.3. Acceso a los parches vivos del núcleo
La capacidad de parcheo en vivo del kernel se implementa como un módulo del kernel (kmod) que se entrega como un paquete RPM.
Todos los clientes tienen acceso a los parches del kernel en vivo, que se entregan a través de los canales habituales. Sin embargo, los clientes que no se suscriban a una oferta de soporte extendido perderán el acceso a los nuevos parches para la versión menor actual una vez que la siguiente versión menor esté disponible. Por ejemplo, los clientes con suscripciones estándar sólo podrán acceder a los parches en vivo del núcleo RHEL 8.2 hasta que se publique el núcleo RHEL 8.3.
8.4. Componentes de la aplicación de parches en el núcleo
Los componentes del kernel live patching son los siguientes:
- Módulo de parche del núcleo
- El mecanismo de entrega de los parches vivos del núcleo.
- Un módulo del kernel que se construye específicamente para el kernel que se parchea.
- El módulo de parches contiene el código de las correcciones deseadas para el kernel.
-
Los módulos de parche se registran en el subsistema del kernel
livepatchy proporcionan información sobre las funciones originales que se van a sustituir, con los correspondientes punteros a las funciones de reemplazo. Los módulos de parche del núcleo se entregan como RPM. -
La convención de nomenclatura es
kpatch_<kernel version>_<kpatch version>_<kpatch release>. La parte "versión del núcleo" del nombre tiene dots y dashes sustituida por underscores.
- La utilidad
kpatch - Una utilidad de línea de comandos para gestionar los módulos de parche.
- El servicio
kpatch -
Un servicio de
systemdrequerido pormultiuser.target. Este objetivo carga el módulo de parches del kernel en el momento del arranque.
8.5. Cómo funciona el kernel live patching
La solución de parcheo del kernel kpatch utiliza el subsistema del kernel livepatch para redirigir las funciones antiguas a las nuevas. Cuando se aplica un parche del kernel en vivo a un sistema, suceden las siguientes cosas:
-
El módulo de parche del kernel se copia en el directorio
/var/lib/kpatch/y se registra para su reaplicación en el kernel mediantesystemden el siguiente arranque. -
El módulo kpatch se carga en el núcleo en ejecución y las nuevas funciones se registran en el mecanismo
ftracecon un puntero a la ubicación en memoria del nuevo código. -
Cuando el núcleo accede a la función parcheada, es redirigido por el mecanismo
ftraceque pasa por alto las funciones originales y redirige el núcleo a la versión parcheada de la función.
Figura 8.1. Cómo funciona el kernel live patching
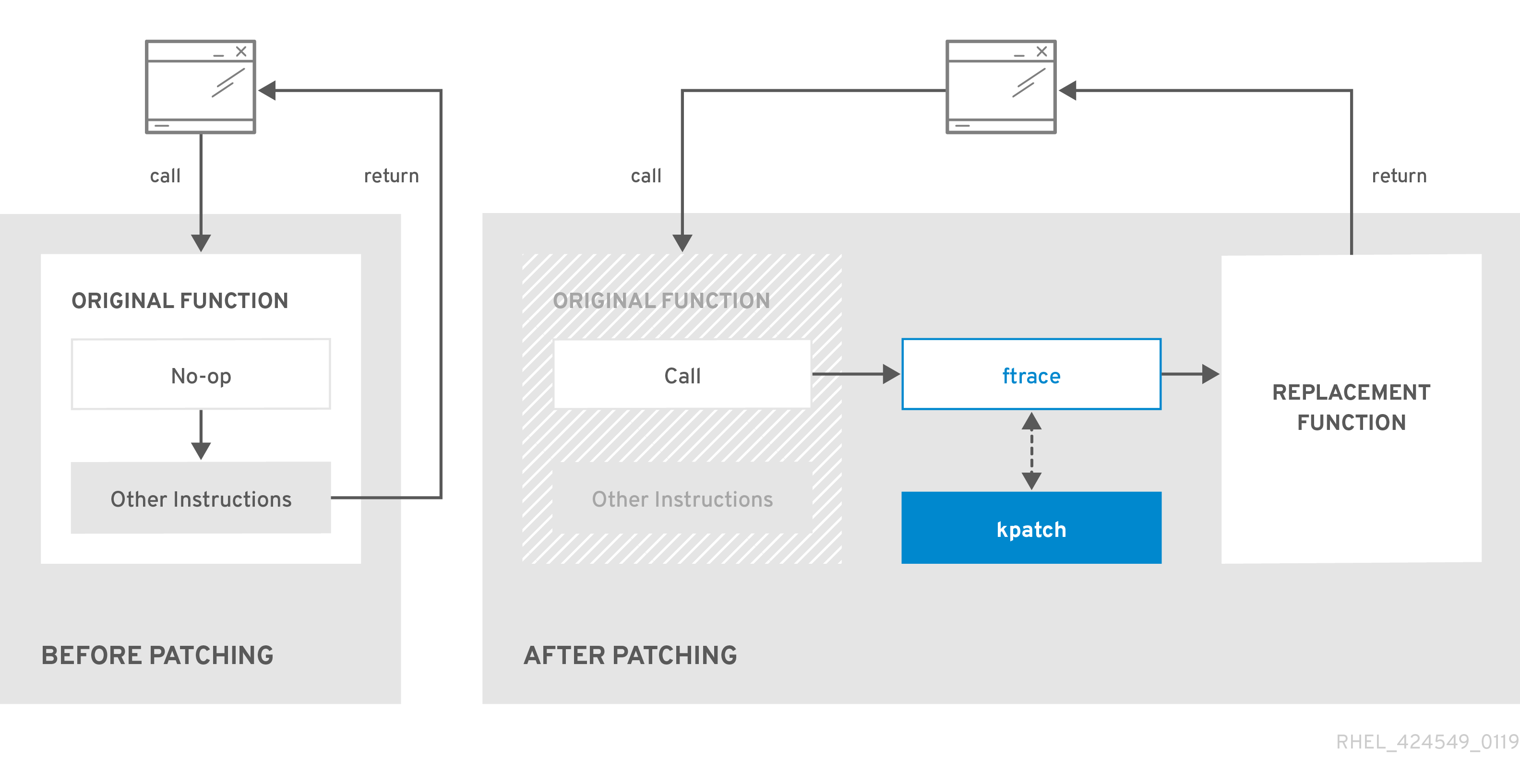
8.6. Activación de los parches en vivo del kernel
Un módulo de parche del kernel se entrega en un paquete RPM, específico para la versión del kernel que se parchea. Cada paquete RPM se actualizará de forma acumulativa a lo largo del tiempo.
Las siguientes secciones describen cómo asegurarse de recibir todas las futuras actualizaciones de parches acumulativos en vivo para un determinado kernel.
Red Hat no admite ningún parche activo de terceros aplicado a un sistema soportado por Red Hat.
8.6.1. Suscripción al flujo de parches en directo
Este procedimiento describe la instalación de un paquete de parches en vivo en particular. Al hacerlo, usted se suscribe al flujo de parches en vivo para un núcleo determinado y se asegura de recibir todas las futuras actualizaciones acumulativas de parches en vivo para ese núcleo.
Dado que los parches en vivo son acumulativos, no se puede seleccionar qué parches individuales se despliegan para un núcleo determinado.
Requisitos previos
- Permisos de la raíz
Procedimiento
Opcionalmente, compruebe la versión de su kernel:
# uname -r 4.18.0-94.el8.x86_64Busque un paquete de parches en vivo que corresponda a la versión de su kernel:
# yum search $(uname -r)Instale el paquete de parches en vivo:
# yum install "kpatch-patch = $(uname -r)"El comando anterior instala y aplica los últimos parches acumulativos en vivo sólo para ese núcleo específico.
El paquete de live patching contiene un módulo de parches, si la versión del paquete es 1-1 o superior. En ese caso, el kernel será parcheado automáticamente durante la instalación del paquete de parcheo en vivo.
El módulo de parche del kernel también se instala en el directorio
/var/lib/kpatch/para ser cargado por el sistemasystemdy el gestor de servicios durante los futuros reinicios.NotaSi todavía no hay parches vivos disponibles para el núcleo dado, se instalará un paquete de parches vivos vacío. Un paquete de parches en vivo vacío tendrá un kpatch_version-kpatch_release de 0-0, por ejemplo
kpatch-patch-4_18_0-94-0-0.el8.x86_64.rpm. La instalación del RPM vacío suscribe el sistema a todos los futuros parches en vivo para el núcleo dado.Opcionalmente, verifique que el kernel está parcheado:
# kpatch list Loaded patch modules: kpatch_4_18_0_94_1_1 [enabled] Installed patch modules: kpatch_4_18_0_94_1_1 (4.18.0-94.el8.x86_64) …La salida muestra que el módulo de parche del kernel se ha cargado en el kernel, que ahora está parcheado con las últimas correcciones del paquete
kpatch-patch-4_18_0-94-1-1.el8.x86_64.rpm.
Recursos adicionales
-
Para más información sobre la utilidad de línea de comandos
kpatch, consulte la página del manualkpatch(1). - Refiérase a las secciones relevantes del Configuring basic system settings para más información sobre la instalación de paquetes de software en Red Hat Enterprise Linux 8.
8.7. Actualización de los módulos de parche del kernel
Dado que los módulos de parche del núcleo se entregan y aplican a través de paquetes RPM, la actualización de un módulo de parche del núcleo acumulativo es como la actualización de cualquier otro paquete RPM.
Requisitos previos
- El sistema está suscrito al flujo de parches en vivo, como se describe en Sección 8.6.1, “Suscripción al flujo de parches en directo”.
Procedimiento
Actualizar a una nueva versión acumulativa para el kernel actual:
# yum update "kpatch-patch = $(uname -r)"El comando anterior instala y aplica automáticamente cualquier actualización que esté disponible para el kernel que se está ejecutando actualmente. Incluyendo cualquier parche acumulativo en vivo que se publique en el futuro.
Alternativamente, actualice todos los módulos de parche del kernel instalados:
# yum update "kpatch-patch\ ~ -"
Cuando el sistema se reinicia en el mismo kernel, el kernel es automáticamente parcheado en vivo de nuevo por el servicio kpatch.service systemd.
Recursos adicionales
- Para más información sobre la actualización de paquetes de software, vea las secciones relevantes de Configuring basic system settings en Red Hat Enterprise Linux 8.
8.8. Desactivación de los parches en vivo del kernel
En caso de que los administradores de sistemas encuentren algunos efectos negativos no anticipados relacionados con la solución de parcheo en vivo del kernel de Red Hat Enterprise Linux, tienen la opción de desactivar el mecanismo. Las siguientes secciones describen las formas de desactivar la solución de live patching.
Actualmente, Red Hat no permite revertir los parches en vivo sin reiniciar el sistema. En caso de cualquier problema, contacte con nuestro equipo de soporte.
8.8.1. Eliminación del paquete de parches en vivo
El siguiente procedimiento describe cómo desactivar la solución de parcheo en vivo del kernel de Red Hat Enterprise Linux eliminando el paquete de parcheo en vivo.
Requisitos previos
- Permisos de la raíz
- El paquete de parches en vivo está instalado.
Procedimiento
Seleccione el paquete de parches en vivo:
# yum list installed | grep kpatch-patch kpatch-patch-4_18_0-94.x86_64 1-1.el8 @@commandline …La salida del ejemplo anterior muestra los paquetes de parches vivos que ha instalado.
Retire el paquete de parches en vivo:
# yum remove kpatch-patch-4_18_0-94.x86_64Cuando se elimina un paquete de parcheo en vivo, el núcleo sigue parcheado hasta el siguiente reinicio, pero el módulo de parcheo del núcleo se elimina del disco. Tras el siguiente reinicio, el núcleo correspondiente dejará de estar parcheado.
- Reinicie su sistema.
Verifique que el paquete de parcheo en vivo haya sido eliminado:
# yum list installed | grep kpatch-patchEl comando no muestra ninguna salida si el paquete ha sido eliminado con éxito.
Opcionalmente, verifique que la solución de parcheo en vivo del kernel esté desactivada:
# kpatch list Loaded patch modules:La salida del ejemplo muestra que el kernel no está parcheado y que la solución de parcheo en vivo no está activa porque no hay módulos de parcheo cargados actualmente.
Recursos adicionales
-
Para más información sobre la utilidad de línea de comandos
kpatch, consulte la página del manualkpatch(1). - Para más información sobre la eliminación de paquetes de software en RHEL 8, consulte las secciones pertinentes de Configuring basic system settings.
8.8.2. Desinstalación del módulo de parches del kernel
El siguiente procedimiento describe cómo evitar que la solución de parcheo en vivo del kernel de Red Hat Enterprise Linux aplique un módulo de parcheo del kernel en los siguientes arranques.
Requisitos previos
- Permisos de la raíz
- Se instala un paquete de parches en vivo.
- Se instala y carga un módulo de parche del kernel.
Procedimiento
Seleccione un módulo de parche del kernel:
# kpatch list Loaded patch modules: kpatch_4_18_0_94_1_1 [enabled] Installed patch modules: kpatch_4_18_0_94_1_1 (4.18.0-94.el8.x86_64) …Desinstalar el módulo de parche del kernel seleccionado:
# kpatch uninstall kpatch_4_18_0_94_1_1 uninstalling kpatch_4_18_0_94_1_1 (4.18.0-94.el8.x86_64)Tenga en cuenta que el módulo de parche del kernel desinstalado sigue cargado:
# kpatch list Loaded patch modules: kpatch_4_18_0_94_1_1 [enabled] Installed patch modules: <NO_RESULT>
Cuando se desinstala el módulo seleccionado, el núcleo permanece parcheado hasta el siguiente reinicio, pero el módulo de parche del núcleo se elimina del disco.
- Reinicie su sistema.
Opcionalmente, verifique que el módulo de parche del kernel ha sido desinstalado:
# kpatch list Loaded patch modules: …La salida del ejemplo anterior muestra que no hay módulos de parche del kernel cargados o instalados, por lo que el kernel no está parcheado y la solución de parcheo en vivo del kernel no está activa.
Recursos adicionales
-
Para más información sobre la utilidad de línea de comandos
kpatch, consulte la página del manualkpatch(1).
8.8.3. Desactivación de kpatch.service
El siguiente procedimiento describe cómo evitar que la solución de parcheo en vivo del kernel de Red Hat Enterprise Linux aplique todos los módulos de parcheo del kernel de forma global en los siguientes arranques.
Requisitos previos
- Permisos de la raíz
- Se instala un paquete de parches en vivo.
- Se instala y carga un módulo de parche del kernel.
Procedimiento
Compruebe que
kpatch.serviceestá activado:# systemctl is-enabled kpatch.service enabledDesactivar
kpatch.service:# systemctl disable kpatch.service Removed /etc/systemd/system/multi-user.target.wants/kpatch.service.Tenga en cuenta que el módulo de parche del kernel aplicado sigue cargado:
# kpatch list Loaded patch modules: kpatch_4_18_0_94_1_1 [enabled] Installed patch modules: kpatch_4_18_0_94_1_1 (4.18.0-94.el8.x86_64)
- Reinicie su sistema.
Opcionalmente, verifique el estado de
kpatch.service:# systemctl status kpatch.service ● kpatch.service - "Apply kpatch kernel patches" Loaded: loaded (/usr/lib/systemd/system/kpatch.service; disabled; vendor preset: disabled) Active: inactive (dead)La salida del ejemplo atestigua que
kpatch.servicese ha desactivado y no se está ejecutando. Por lo tanto, la solución de parcheo en vivo del kernel no está activa.Verifique que el módulo de parche del kernel ha sido descargado:
# kpatch list Loaded patch modules: <NO_RESULT> Installed patch modules: kpatch_4_18_0_94_1_1 (4.18.0-94.el8.x86_64)
La salida del ejemplo anterior muestra que un módulo de parche del kernel sigue instalado pero el kernel no está parcheado.
Recursos adicionales
-
Para más información sobre la utilidad de línea de comandos
kpatch, consulte la página del manualkpatch(1). -
Para obtener más información sobre el sistema
systemdy el gestor de servicios, los archivos de configuración de las unidades, sus ubicaciones, así como una lista completa de los tipos de unidades desystemd, consulte las secciones correspondientes en Configuring basic system settings.
Capítulo 9. Fijar los límites de las aplicaciones
Como administrador del sistema, utilice la funcionalidad del kernel de grupos de control para establecer límites, priorizar o aislar los recursos de hardware de los procesos para que las aplicaciones de su sistema sean estables y no se queden sin memoria.
9.1. Entender los grupos de control
Control groups es una característica del kernel de Linux que permite organizar los procesos en grupos ordenados jerárquicamente - cgroups. La jerarquía (árbol de grupos de control) se define dotando de estructura a cgroups sistema de archivos virtual, montado por defecto en el directorio /sys/fs/cgroup/. Se hace manualmente creando y eliminando subdirectorios en /sys/fs/cgroup/. Alternativamente, utilizando el sistema systemd y el gestor de servicios.
Los controladores de recursos (un componente del kernel) modifican entonces el comportamiento de los procesos en cgroups limitando, priorizando o asignando los recursos del sistema, (como el tiempo de CPU, la memoria, el ancho de banda de la red o varias combinaciones) de esos procesos.
El valor añadido de cgroups es la agregación de procesos que permite dividir los recursos de hardware entre las aplicaciones y los usuarios. De este modo, se puede lograr un aumento de la eficiencia general, la estabilidad y la seguridad del entorno de los usuarios.
- Grupos de control versión 1
Control groups version 1 (
cgroups-v1) proporcionan una jerarquía de control por recurso. Esto significa que cada recurso, como la CPU, la memoria, la E/S, etc., tiene su propia jerarquía de grupos de control. Es posible combinar diferentes jerarquías de grupos de control de forma que un controlador pueda coordinarse con otro en la gestión de sus respectivos recursos. Sin embargo, los dos controladores pueden pertenecer a diferentes jerarquías de procesos, lo que no permite su correcta coordinación.Los controladores de
cgroups-v1se desarrollaron a lo largo de un amplio periodo de tiempo y, por tanto, el comportamiento y la denominación de sus archivos de control no son uniformes.- Grupos de control versión 2
Los problemas de coordinación de los controladores, derivados de la flexibilidad de las jerarquías, condujeron al desarrollo de control groups version 2.
Control groups version 2 (
cgroups-v2) proporciona una única jerarquía de grupo de control contra la que se montan todos los controladores de recursos.El comportamiento y la denominación de los archivos de control son coherentes entre los distintos controladores.
AvisoRHEL 8 proporciona
cgroups-v2como vista previa de la tecnología con un número limitado de controladores de recursos. Para obtener más información sobre los controladores de recursos pertinentes, consulte la página cgroups-v2 release note.
Esta subsección se basó en una presentación de Devconf.cz 2019.[1]
Recursos adicionales
-
Para más información sobre los controladores de recursos, consulte la sección Sección 9.2, “Qué son los controladores de recursos del núcleo” y las páginas del manual
cgroups(7). -
Para más información sobre las jerarquías de
cgroupsy las versiones decgroups, consulte las páginas del manualcgroups(7). -
Para más información sobre la cooperación en
systemdycgroups, véase la sección Papel de systemd en los grupos de control.
9.2. Qué son los controladores de recursos del núcleo
La funcionalidad de los grupos de control está habilitada por los controladores de recursos del kernel. RHEL 8 soporta varios controladores para control groups version 1 (cgroups-v1) y control groups version 2 (cgroups-v2).
Un controlador de recursos, también llamado subsistema de grupo de control, es un subsistema del núcleo que representa un único recurso, como el tiempo de la CPU, la memoria, el ancho de banda de la red o la E/S del disco. El núcleo de Linux proporciona una serie de controladores de recursos que son montados automáticamente por el sistema systemd y el administrador de servicios. La lista de los controladores de recursos montados actualmente se encuentra en el archivo /proc/cgroups.
Los siguientes controladores están disponibles para cgroups-v1:
-
blkio- puede establecer límites en el acceso de entrada/salida a y desde los dispositivos de bloque. -
cpu- puede ajustar los parámetros del programador Completely Fair Scheduler (CFS) para las tareas del grupo de control. Se monta junto con el controladorcpuaccten el mismo montaje. -
cpuacct- crea informes automáticos sobre los recursos de la CPU utilizados por las tareas de un grupo de control. Se monta junto con el controladorcpuen el mismo montaje. -
cpuset- se puede utilizar para restringir las tareas del grupo de control para que se ejecuten sólo en un subconjunto especificado de CPUs y para dirigir las tareas para utilizar la memoria sólo en nodos de memoria especificados. -
devices- puede controlar el acceso a los dispositivos para las tareas de un grupo de control. -
freezer- se puede utilizar para suspender o reanudar las tareas en un grupo de control. -
memory- puede utilizarse para establecer límites en el uso de la memoria por parte de las tareas de un grupo de control y genera informes automáticos sobre los recursos de memoria utilizados por dichas tareas. -
net_cls- etiqueta los paquetes de red con un identificador de clase (classid) que permite al controlador de tráfico de Linux (el comandotc) identificar los paquetes que se originan en una tarea de grupo de control particular. Un subsistema denet_cls, elnet_filter(iptables), también puede utilizar esta etiqueta para realizar acciones sobre dichos paquetes. Elnet_filteretiqueta los sockets de red con un identificador de cortafuegos (fwid) que permite al cortafuegos de Linux (a través del comandoiptables) identificar los paquetes que se originan en una tarea de grupo de control particular. -
net_prio- establece la prioridad del tráfico de red. -
pids- puede establecer límites para un número de procesos y sus hijos en un grupo de control. -
perf_event- puede agrupar las tareas para su supervisión por la utilidad de supervisión e informes de rendimientoperf. -
rdma- puede establecer límites en los recursos específicos de Remote Direct Memory Access/InfiniBand en un grupo de control. -
hugetlb- puede utilizarse para limitar el uso de páginas de memoria virtual de gran tamaño por parte de las tareas de un grupo de control.
Los siguientes controladores están disponibles para cgroups-v2:
-
io- Un seguimiento deblkiodecgroups-v1. -
memory- Un seguimiento dememorydecgroups-v1. -
pids- Igual quepidsencgroups-v1. -
rdma- Igual querdmaencgroups-v1. -
cpu- Una continuación decpuycpuacctdecgroups-v1. -
cpuset- Sólo admite la funcionalidad principal (cpus{,.effective},mems{,.effective}) con una nueva función de partición. -
perf_event- El soporte es inherente, no hay un archivo de control explícito. Puede especificar unv2 cgroupcomo parámetro del comandoperfque perfilará todas las tareas dentro de esecgroup.
Un controlador de recursos puede utilizarse en una jerarquía cgroups-v1 o en una jerarquía cgroups-v2, pero no simultáneamente en ambas.
Recursos adicionales
-
Para más información sobre los controladores de recursos en general, consulte la página del manual
cgroups(7). -
Para obtener descripciones detalladas de los controladores de recursos específicos, consulte la documentación en el directorio
/usr/share/doc/kernel-doc-<kernel_version>/Documentation/cgroups-v1/. -
Para más información sobre
cgroups-v2, consulte la página del manualcgroups(7).
9.3. Uso de grupos de control a través de un sistema de archivos virtual
Puede utilizar control groups (cgroups) para establecer límites, priorizar o controlar el acceso a los recursos de hardware para grupos de procesos. Esto le permite controlar granularmente el uso de recursos de las aplicaciones para utilizarlos de forma más eficiente. Las siguientes secciones proporcionan una visión general de las tareas relacionadas con la gestión de cgroups tanto para la versión 1 como para la versión 2 utilizando un sistema de archivos virtual.
9.3.1. Establecimiento de límites de CPU a las aplicaciones mediante cgroups-v1
A veces una aplicación consume mucho tiempo de CPU, lo que puede afectar negativamente a la salud general de su entorno. Utilice el sistema de archivos virtuales /sys/fs/ para configurar los límites de CPU a una aplicación utilizando control groups version 1 (cgroups-v1).
Requisitos previos
- Una aplicación cuyo consumo de CPU se quiere restringir.
Verifique que los controladores de
cgroups-v1fueron montados:# mount -l | grep cgroup tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,seclabel,mode=755) cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd) cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpu,cpuacct) cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,perf_event) cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,pids) ...
Procedimiento
Identifique el ID del proceso (PID) de la aplicación que desea restringir en el consumo de la CPU:
# top top - 11:34:09 up 11 min, 1 user, load average: 0.51, 0.27, 0.22 Tasks: 267 total, 3 running, 264 sleeping, 0 stopped, 0 zombie %Cpu(s): 49.0 us, 3.3 sy, 0.0 ni, 47.5 id, 0.0 wa, 0.2 hi, 0.0 si, 0.0 st MiB Mem : 1826.8 total, 303.4 free, 1046.8 used, 476.5 buff/cache MiB Swap: 1536.0 total, 1396.0 free, 140.0 used. 616.4 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6955 root 20 0 228440 1752 1472 R 99.3 0.1 0:32.71 sha1sum 5760 jdoe 20 0 3603868 205188 64196 S 3.7 11.0 0:17.19 gnome-shell 6448 jdoe 20 0 743648 30640 19488 S 0.7 1.6 0:02.73 gnome-terminal- 1 root 20 0 245300 6568 4116 S 0.3 0.4 0:01.87 systemd 505 root 20 0 0 0 0 I 0.3 0.0 0:00.75 kworker/u4:4-events_unbound ...La salida de ejemplo del programa
toprevela quePID 6955(aplicación ilustrativasha1sum) consume muchos recursos de la CPU.Cree un subdirectorio en el directorio del controlador de recursos
cpu:# mkdir /sys/fs/cgroup/cpu/Example/El directorio anterior representa un grupo de control, donde se pueden colocar procesos específicos y aplicar ciertos límites de CPU a los procesos. Al mismo tiempo, se crearán en el directorio algunos archivos de la interfaz
cgroups-v1y archivos específicos del controladorcpu.Opcionalmente, inspeccione el grupo de control recién creado:
# ll /sys/fs/cgroup/cpu/Example/ -rw-r—r--. 1 root root 0 Mar 11 11:42 cgroup.clone_children -rw-r—r--. 1 root root 0 Mar 11 11:42 cgroup.procs -r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.stat -rw-r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage -r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_all -r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_percpu -r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_percpu_sys -r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_percpu_user -r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_sys -r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_user -rw-r—r--. 1 root root 0 Mar 11 11:42 cpu.cfs_period_us -rw-r—r--. 1 root root 0 Mar 11 11:42 cpu.cfs_quota_us -rw-r—r--. 1 root root 0 Mar 11 11:42 cpu.rt_period_us -rw-r—r--. 1 root root 0 Mar 11 11:42 cpu.rt_runtime_us -rw-r—r--. 1 root root 0 Mar 11 11:42 cpu.shares -r—r—r--. 1 root root 0 Mar 11 11:42 cpu.stat -rw-r—r--. 1 root root 0 Mar 11 11:42 notify_on_release -rw-r—r--. 1 root root 0 Mar 11 11:42 tasksLa salida de ejemplo muestra archivos, como
cpuacct.usage,cpu.cfs._period_us, que representan configuraciones y/o límites específicos, que pueden establecerse para los procesos en el grupo de controlExample. Observe que los nombres de los archivos respectivos llevan como prefijo el nombre del controlador del grupo de control al que pertenecen.Por defecto, el grupo de control recién creado hereda el acceso a todos los recursos de la CPU del sistema sin límite.
Configurar los límites de la CPU para el grupo de control:
# echo "1000000" > /sys/fs/cgroup/cpu/Example/cpu.cfs_period_us # echo "200000" > /sys/fs/cgroup/cpu/Example/cpu.cfs_quota_us
El archivo
cpu.cfs_period_usrepresenta un periodo de tiempo en microsegundos (µs, representado aquí como \ "us") para la frecuencia con la que se debe reasignar el acceso de un grupo de control a los recursos de la CPU. El límite superior es de 1 segundo y el inferior de 1000 microsegundos.El archivo
cpu.cfs_quota_usrepresenta la cantidad total de tiempo en microsegundos que todos los procesos de un grupo de control pueden ejecutar durante un periodo (definido porcpu.cfs_period_us). Tan pronto como los procesos de un grupo de control, durante un solo período, utilizan todo el tiempo especificado por la cuota, son estrangulados para el resto del período y no se les permite ejecutar hasta el siguiente período. El límite inferior es de 1000 microsegundos.Los comandos de ejemplo anteriores establecen los límites de tiempo de la CPU para que todos los procesos colectivamente en el grupo de control
Examplepuedan ejecutarse sólo durante 0,2 segundos (definido porcpu.cfs_quota_us) de cada 1 segundo (definido porcpu.cfs_period_us).Opcionalmente, verifique los límites:
# cat /sys/fs/cgroup/cpu/Example/cpu.cfs_period_us /sys/fs/cgroup/cpu/Example/cpu.cfs_quota_us 1000000 200000Añada el PID de la aplicación al grupo de control
Example:# echo "6955" > /sys/fs/cgroup/cpu/Example/cgroup.procs or # echo "6955" > /sys/fs/cgroup/cpu/Example/tasks
El comando anterior asegura que una aplicación deseada se convierta en miembro del grupo de control
Exampley por lo tanto no exceda los límites de CPU configurados para el grupo de controlExample. El PID debe representar un proceso existente en el sistema. ElPID 6955aquí fue asignado al procesosha1sum /dev/zero &, utilizado para ilustrar el caso de uso del controladorcpu.Compruebe que la aplicación se ejecuta en el grupo de control especificado:
# cat /proc/6955/cgroup 12:cpuset:/ 11:hugetlb:/ 10:net_cls,net_prio:/ 9:memory:/user.slice/user-1000.slice/user@1000.service 8:devices:/user.slice 7:blkio:/ 6:freezer:/ 5:rdma:/ 4:pids:/user.slice/user-1000.slice/user@1000.service 3:perf_event:/ 2:cpu,cpuacct:/Example 1:name=systemd:/user.slice/user-1000.slice/user@1000.service/gnome-terminal-server.serviceEl ejemplo anterior muestra que el proceso de la aplicación deseada se ejecuta en el grupo de control
Example, que aplica límites de CPU al proceso de la aplicación.Identifique el consumo actual de CPU de su aplicación estrangulada:
# top top - 12:28:42 up 1:06, 1 user, load average: 1.02, 1.02, 1.00 Tasks: 266 total, 6 running, 260 sleeping, 0 stopped, 0 zombie %Cpu(s): 11.0 us, 1.2 sy, 0.0 ni, 87.5 id, 0.0 wa, 0.2 hi, 0.0 si, 0.2 st MiB Mem : 1826.8 total, 287.1 free, 1054.4 used, 485.3 buff/cache MiB Swap: 1536.0 total, 1396.7 free, 139.2 used. 608.3 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6955 root 20 0 228440 1752 1472 R 20.6 0.1 47:11.43 sha1sum 5760 jdoe 20 0 3604956 208832 65316 R 2.3 11.2 0:43.50 gnome-shell 6448 jdoe 20 0 743836 31736 19488 S 0.7 1.7 0:08.25 gnome-terminal- 505 root 20 0 0 0 0 I 0.3 0.0 0:03.39 kworker/u4:4-events_unbound 4217 root 20 0 74192 1612 1320 S 0.3 0.1 0:01.19 spice-vdagentd ...Observe que el consumo de la CPU de
PID 6955ha disminuido del 99% al 20%.
Recursos adicionales
- Para obtener información sobre el concepto de grupos de control, consulte Sección 9.1, “Entender los grupos de control”.
-
Para más información sobre los controladores de recursos, consulte la sección Sección 9.2, “Qué son los controladores de recursos del núcleo” y la página del manual
cgroups(7). -
Para más información sobre el sistema de archivos virtual
/sys/fs/, consulte la página del manualsysfs(5).
9.3.2. Establecimiento de límites de CPU a las aplicaciones mediante cgroups-v2
A veces una aplicación utiliza mucho tiempo de CPU, lo que puede afectar negativamente a la salud general de su entorno. Utilice control groups version 2 (cgroups-v2) para configurar los límites de la CPU a la aplicación, y restringir su consumo.
Requisitos previos
- Una aplicación cuyo consumo de CPU se quiere restringir.
- Sección 9.1, “Entender los grupos de control”
Procedimiento
Evitar que
cgroups-v1se monte automáticamente durante el arranque del sistema:# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="cgroup_no_v1=all"El comando añade un parámetro de línea de comandos del kernel a la entrada de arranque actual. El parámetro
cgroup_no_v1=allevita quecgroups-v1se monte automáticamente.Como alternativa, utilice el parámetro de línea de comandos del kernel
systemd.unified_cgroup_hierarchy=1para montarcgroups-v2durante el arranque del sistema por defecto.NotaRHEL 8 soporta tanto
cgroups-v1comocgroups-v2. Sin embargo,cgroups-v1está activado y montado por defecto durante el proceso de arranque.- Reinicie el sistema para que los cambios surtan efecto.
Opcionalmente, verifique que la funcionalidad de
cgroups-v1ha sido desactivada:# mount -l | grep cgroup tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,seclabel,mode=755) cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)Si
cgroups-v1se ha desactivado con éxito, la salida no muestra ninguna referencia "tipo cgroup", excepto las que pertenecen asystemd.Monte
cgroups-v2en cualquier lugar del sistema de archivos:# mount -t cgroup2 none <MOUNT_POINT>Opcionalmente, verifique que la funcionalidad de
cgroups-v2ha sido montada:# mount -l | grep cgroup2 none on /cgroups-v2 type cgroup2 (rw,relatime,seclabel)La salida del ejemplo muestra que
cgroups-v2se ha montado en el directorio/cgroups-v2/.Opcionalmente, inspeccione el contenido del directorio
/cgroups-v2/:# ll /cgroups-v2/ -r—r—r--. 1 root root 0 Mar 13 11:57 cgroup.controllers -rw-r—r--. 1 root root 0 Mar 13 11:57 cgroup.max.depth -rw-r—r--. 1 root root 0 Mar 13 11:57 cgroup.max.descendants -rw-r—r--. 1 root root 0 Mar 13 11:57 cgroup.procs -r—r—r--. 1 root root 0 Mar 13 11:57 cgroup.stat -rw-r—r--. 1 root root 0 Mar 13 11:58 cgroup.subtree_control -rw-r—r--. 1 root root 0 Mar 13 11:57 cgroup.threads -rw-r—r--. 1 root root 0 Mar 13 11:57 cpu.pressure -r—r—r--. 1 root root 0 Mar 13 11:57 cpuset.cpus.effective -r—r—r--. 1 root root 0 Mar 13 11:57 cpuset.mems.effective -rw-r—r--. 1 root root 0 Mar 13 11:57 io.pressure -rw-r—r--. 1 root root 0 Mar 13 11:57 memory.pressureEl directorio
/cgroups-v2/, también llamado grupo de control raíz, contiene algunos archivos de interfaz (empezando porcgroup) y algunos archivos específicos del controlador comocpuset.cpus.effective.Identifique los ID de proceso (PID) de las aplicaciones que desea restringir en el consumo de la CPU:
# top top - 15:39:52 up 3:45, 1 user, load average: 0.79, 0.20, 0.07 Tasks: 265 total, 3 running, 262 sleeping, 0 stopped, 0 zombie %Cpu(s): 74.3 us, 6.1 sy, 0.0 ni, 19.4 id, 0.0 wa, 0.2 hi, 0.0 si, 0.0 st MiB Mem : 1826.8 total, 243.8 free, 1102.1 used, 480.9 buff/cache MiB Swap: 1536.0 total, 1526.2 free, 9.8 used. 565.6 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 5473 root 20 0 228440 1740 1456 R 99.7 0.1 0:12.11 sha1sum 5439 root 20 0 222616 3420 3052 R 60.5 0.2 0:27.08 cpu_load_generator 2170 jdoe 20 0 3600716 209960 67548 S 0.3 11.2 1:18.50 gnome-shell 3051 root 20 0 274424 3976 3092 R 0.3 0.2 1:01.25 top 1 root 20 0 245448 10256 5448 S 0.0 0.5 0:02.52 systemd ...La salida de ejemplo del programa
toprevela quePID 5473y5439(aplicación ilustrativasha1sumycpu_load_generator) consumen muchos recursos, concretamente la CPU. Ambas son aplicaciones de ejemplo utilizadas para demostrar la gestión de la funcionalidad decgroups-v2.Habilitar los controladores relacionados con la CPU:
# echo "+cpu" > /cgroups-v2/cgroup.subtree_control # echo "+cpuset" > /cgroups-v2/cgroup.subtree_control
Los comandos anteriores habilitan los controladores
cpuycpusetpara los grupos de subcontrol inmediatos del grupo de control raíz/cgroups-v2/.Cree un subdirectorio en el directorio
/cgroups-v2/creado anteriormente:# mkdir /cgroups-v2/Example/El directorio
/cgroups-v2/Example/representa un subgrupo de control, donde se pueden colocar procesos específicos y aplicar varios límites de CPU a los procesos. Además, el paso anterior habilitó los controladorescpuycpusetpara este grupo de subcontrol.En el momento de la creación de
/cgroups-v2/Example/, se crearán en el directorio algunos archivos de la interfazcgroups-v2y archivos específicos del controladorcpuycpuset.Opcionalmente, inspeccione el grupo de control recién creado:
# ll /cgroups-v2/Example/ -r—r—r--. 1 root root 0 Mar 13 14:48 cgroup.controllers -r—r—r--. 1 root root 0 Mar 13 14:48 cgroup.events -rw-r—r--. 1 root root 0 Mar 13 14:48 cgroup.freeze -rw-r—r--. 1 root root 0 Mar 13 14:48 cgroup.max.depth -rw-r—r--. 1 root root 0 Mar 13 14:48 cgroup.max.descendants -rw-r—r--. 1 root root 0 Mar 13 14:48 cgroup.procs -r—r—r--. 1 root root 0 Mar 13 14:48 cgroup.stat -rw-r—r--. 1 root root 0 Mar 13 14:48 cgroup.subtree_control -rw-r—r--. 1 root root 0 Mar 13 14:48 cgroup.threads -rw-r—r--. 1 root root 0 Mar 13 14:48 cgroup.type -rw-r—r--. 1 root root 0 Mar 13 14:48 cpu.max -rw-r—r--. 1 root root 0 Mar 13 14:48 cpu.pressure -rw-r—r--. 1 root root 0 Mar 13 14:48 cpuset.cpus -r—r—r--. 1 root root 0 Mar 13 14:48 cpuset.cpus.effective -rw-r—r--. 1 root root 0 Mar 13 14:48 cpuset.cpus.partition -rw-r—r--. 1 root root 0 Mar 13 14:48 cpuset.mems -r—r—r--. 1 root root 0 Mar 13 14:48 cpuset.mems.effective -r—r—r--. 1 root root 0 Mar 13 14:48 cpu.stat -rw-r—r--. 1 root root 0 Mar 13 14:48 cpu.weight -rw-r—r--. 1 root root 0 Mar 13 14:48 cpu.weight.nice -rw-r—r--. 1 root root 0 Mar 13 14:48 io.pressure -rw-r—r--. 1 root root 0 Mar 13 14:48 memory.pressureLa salida del ejemplo muestra archivos como
cpuset.cpusycpu.max. Los archivos son específicos de los controladorescpusetycpuque usted habilitó para los grupos de control hijos directos de la raíz (/cgroups-v2/) utilizando el archivo/cgroups-v2/cgroup.subtree_control. Además, hay archivos generales de interfaz de controlcgroupcomocgroup.procsocgroup.controllers, que son comunes a todos los grupos de control, independientemente de los controladores habilitados.Por defecto, el grupo de subcontrol recién creado hereda el acceso a todos los recursos de la CPU del sistema sin límite.
Asegúrese de que los procesos que desea limitar compiten por el tiempo de CPU en la misma CPU:
# echo "1" > /cgroups-v2/Example/cpuset.cpusEl comando anterior asegura los procesos que usted colocó en el grupo de subcontrol
Example, compiten en la misma CPU. Esta configuración es importante para que el controladorcpuse active.ImportanteEl controlador
cpusólo se activa si el grupo de subcontrol correspondiente tiene al menos 2 procesos, que compiten por el tiempo en una sola CPU.Configurar los límites de la CPU del grupo de control:
# echo "200000 1000000" > /cgroups-v2/Example/cpu.maxEl primer valor es la cuota de tiempo permitida en microsegundos para que todos los procesos colectivamente en un subgrupo de control puedan ejecutarse durante un período (especificado por el segundo valor). Durante un solo periodo, cuando los procesos de un grupo de control agotan colectivamente todo el tiempo especificado por esta cuota, se estrangulan durante el resto del periodo y no se les permite ejecutarse hasta el siguiente periodo.
El comando de ejemplo establece los límites de tiempo de la CPU para que todos los procesos colectivamente en el grupo de subcontrol
Examplepuedan funcionar en la CPU sólo durante 0,2 segundos de cada 1 segundo.Opcionalmente, verifique los límites:
# cat /cgroups-v2/Example/cpu.max 200000 1000000Añada los PID de las aplicaciones al grupo de subcontrol
Example:# echo "5473" > /cgroups-v2/Example/cgroup.procs # echo "5439" > /cgroups-v2/Example/cgroup.procs
Los comandos de ejemplo garantizan que las aplicaciones deseadas se conviertan en miembros del grupo de subcontrol
Exampley, por tanto, no superen los límites de CPU configurados para el grupo de subcontrolExample.Compruebe que las aplicaciones se ejecutan en el grupo de control especificado:
# cat /proc/5473/cgroup /proc/5439/cgroup 1:name=systemd:/user.slice/user-1000.slice/user@1000.service/gnome-terminal-server.service 0::/Example 1:name=systemd:/user.slice/user-1000.slice/user@1000.service/gnome-terminal-server.service 0::/ExampleEl ejemplo anterior muestra que los procesos de las aplicaciones deseadas se ejecutan en el grupo de subcontrol
Example.Inspeccione el consumo actual de la CPU de sus aplicaciones estranguladas:
# top top - 15:56:27 up 4:02, 1 user, load average: 0.03, 0.41, 0.55 Tasks: 265 total, 4 running, 261 sleeping, 0 stopped, 0 zombie %Cpu(s): 9.6 us, 0.8 sy, 0.0 ni, 89.4 id, 0.0 wa, 0.2 hi, 0.0 si, 0.0 st MiB Mem : 1826.8 total, 243.4 free, 1102.1 used, 481.3 buff/cache MiB Swap: 1536.0 total, 1526.2 free, 9.8 used. 565.5 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 5439 root 20 0 222616 3420 3052 R 10.0 0.2 6:15.83 cpu_load_generator 5473 root 20 0 228440 1740 1456 R 10.0 0.1 9:20.65 sha1sum 2753 jdoe 20 0 743928 35328 20608 S 0.7 1.9 0:20.36 gnome-terminal- 2170 jdoe 20 0 3599688 208820 67552 S 0.3 11.2 1:33.06 gnome-shell 5934 root 20 0 274428 5064 4176 R 0.3 0.3 0:00.04 top ...Obsérvese que el consumo de CPU de
PID 5439yPID 5473ha disminuido al 10%. El subgrupo de controlExamplelimita sus procesos al 20% del tiempo de CPU de forma colectiva. Como hay 2 procesos en el grupo de control, cada uno puede utilizar el 10% del tiempo de CPU.
Recursos adicionales
- Para obtener información sobre el concepto de grupos de control, consulte Sección 9.1, “Entender los grupos de control”.
-
Para más información sobre los controladores de recursos, consulte la sección Sección 9.2, “Qué son los controladores de recursos del núcleo” y la página del manual
cgroups(7). -
Para más información sobre el sistema de archivos virtual
/sys/fs/, consulte la página del manualsysfs(5).
9.4. Función de systemd en los grupos de control versión 1
Red Hat Enterprise Linux 8 traslada la configuración de la gestión de recursos desde el nivel de proceso al nivel de aplicación vinculando el sistema de jerarquías cgroup con el árbol de unidades systemd. Por lo tanto, puede gestionar los recursos del sistema con el comando systemctl, o modificando los archivos de unidad systemd.
Por defecto, el gestor de sistemas y servicios systemd utiliza las unidades slice, scope y service para organizar y estructurar los procesos en los grupos de control. El comando systemctl permite modificar aún más esta estructura mediante la creación de slices personalizada. Además, systemd monta automáticamente jerarquías para los controladores de recursos importantes del kernel en el directorio /sys/fs/cgroup/.
Para el control de los recursos se utilizan tres tipos de unidades systemd:
Service - Un proceso o un grupo de procesos, que
systemdinició de acuerdo con un archivo de configuración de la unidad. Los servicios encapsulan los procesos especificados para que puedan iniciarse y detenerse como un conjunto. Los servicios se nombran de la siguiente manera:<name>.serviceScope - Un grupo de procesos creados externamente. Los ámbitos encapsulan procesos que son iniciados y detenidos por los procesos arbitrarios a través de la función
fork()y luego registrados porsystemden tiempo de ejecución. Por ejemplo, las sesiones de usuario, los contenedores y las máquinas virtuales se tratan como ámbitos. Los ámbitos se denominan como sigue:<name>.scopeSlice - Un grupo de unidades organizadas jerárquicamente. Las rebanadas organizan una jerarquía en la que se colocan ámbitos y servicios. Los procesos reales están contenidos en ámbitos o en servicios. Cada nombre de una unidad de slice corresponde a la ruta de acceso a una ubicación en la jerarquía. El carácter guión ("-") actúa como separador de los componentes de la ruta a una slice desde la slice raíz
-.slice. En el siguiente ejemplo:<parent-name>.sliceparent-name.slicees una subcorrida deparent.slice, que es una subcorrida de la rodaja raíz-.slice.parent-name.slicepuede tener su propia subcorrida llamadaparent-name-name2.slice, y así sucesivamente.
Las unidades service, scope y slice se asignan directamente a los objetos de la jerarquía del grupo de control. Cuando estas unidades se activan, se asignan directamente a las rutas de los grupos de control construidas a partir de los nombres de las unidades.
A continuación se presenta un ejemplo abreviado de la jerarquía de un grupo de control:
Control group /: -.slice ├─user.slice │ ├─user-42.slice │ │ ├─session-c1.scope │ │ │ ├─ 967 gdm-session-worker [pam/gdm-launch-environment] │ │ │ ├─1035 /usr/libexec/gdm-x-session gnome-session --autostart /usr/share/gdm/greeter/autostart │ │ │ ├─1054 /usr/libexec/Xorg vt1 -displayfd 3 -auth /run/user/42/gdm/Xauthority -background none -noreset -keeptty -verbose 3 │ │ │ ├─1212 /usr/libexec/gnome-session-binary --autostart /usr/share/gdm/greeter/autostart │ │ │ ├─1369 /usr/bin/gnome-shell │ │ │ ├─1732 ibus-daemon --xim --panel disable │ │ │ ├─1752 /usr/libexec/ibus-dconf │ │ │ ├─1762 /usr/libexec/ibus-x11 --kill-daemon │ │ │ ├─1912 /usr/libexec/gsd-xsettings │ │ │ ├─1917 /usr/libexec/gsd-a11y-settings │ │ │ ├─1920 /usr/libexec/gsd-clipboard … ├─init.scope │ └─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 18 └─system.slice ├─rngd.service │ └─800 /sbin/rngd -f ├─systemd-udevd.service │ └─659 /usr/lib/systemd/systemd-udevd ├─chronyd.service │ └─823 /usr/sbin/chronyd ├─auditd.service │ ├─761 /sbin/auditd │ └─763 /usr/sbin/sedispatch ├─accounts-daemon.service │ └─876 /usr/libexec/accounts-daemon ├─example.service │ ├─ 929 /bin/bash /home/jdoe/example.sh │ └─4902 sleep 1 …
El ejemplo anterior muestra que los servicios y los ámbitos contienen procesos y se colocan en rebanadas que no contienen procesos propios.
Recursos adicionales
-
Para obtener más información sobre
systemd, archivos de unidades y una lista completa de los tipos de unidades desystemd, consulte las secciones correspondientes en Configuring basic system settings. -
Para más información sobre los controladores de recursos, consulte la sección Qué son los controladores de recursos del kernel y las páginas del manual
systemd.resource-control(5),cgroups(7). -
Para más información sobre
fork(), consulte las páginas del manualfork(2).
9.5. Uso de grupos de control versión 1 con systemd
Las siguientes secciones proporcionan una visión general de las tareas relacionadas con la creación, modificación y eliminación de los grupos de control (cgroups). Las utilidades proporcionadas por el sistema systemd y el gestor de servicios son la forma preferida de la gestión de cgroups y serán apoyadas en el futuro.
9.5.1. Creación de grupos de control versión 1 con systemd
Puede utilizar el sistema systemd y el administrador de servicios para crear grupos de control transitorios y persistentes (cgroups) para establecer límites, priorizar o controlar el acceso a los recursos de hardware para grupos de procesos.
9.5.1.1. Creación de grupos de control transitorios
Los transitorios cgroups establecen límites a los recursos consumidos por una unidad (servicio o ámbito) durante su tiempo de ejecución.
Procedimiento
Para crear un grupo de control transitorio, utilice el comando
systemd-runcon el siguiente formato:# systemd-run --unit=<name> --slice=<name>.slice <command>Este comando crea e inicia un servicio transitorio o una unidad de alcance y ejecuta un comando personalizado en dicha unidad.
-
La opción
--unit=<name>da un nombre a la unidad. Si no se especifica--unit, el nombre se genera automáticamente. -
La opción
--slice=<name>.slicehace que su servicio o unidad de alcance sea miembro de una porción especificada. Sustituya<name>.slicecon el nombre de una porción existente (como se muestra en la salida desystemctl -t slice), o cree una nueva porción pasando un nombre único. Por defecto, los servicios y ámbitos se crean como miembros desystem.slice. Sustituya
<command>por el comando que desea ejecutar en el servicio o en la unidad de alcance.Se muestra el siguiente mensaje para confirmar que ha creado e iniciado el servicio o el ámbito de aplicación con éxito:
# Ejecutando como unidad <name>.service
-
La opción
Opcionalmente, mantenga la unidad en funcionamiento después de que sus procesos hayan finalizado para recopilar información en tiempo de ejecución:
# systemd-run --unit=<name> --slice=<name>.slice --remain-after-exit <command>El comando crea e inicia una unidad de servicio transitoria y ejecuta un comando personalizado en dicha unidad. La opción
--remain-after-exitasegura que el servicio siga funcionando después de que sus procesos hayan terminado.
Recursos adicionales
- Para más información sobre el concepto de grupos de control, véase Sección 9.1, “Entender los grupos de control”.
-
Para más información sobre el papel de
systemden los grupos de control, véase Sección 9.4, “Función de systemd en los grupos de control versión 1”. -
Para obtener más información sobre
systemd, los archivos de configuración de las unidades y sus ubicaciones, y una lista completa de los tipos de unidades desystemd, consulte las secciones correspondientes en Configuring basic system settings. -
Para una descripción detallada de
systemd-run, incluyendo otras opciones y ejemplos, consulte las páginas del manualsystemd-run(1).
9.5.1.2. Creación de grupos de control persistentes
Para asignar un grupo de control persistente a un servicio, es necesario editar su archivo de configuración de unidad. La configuración se conserva tras el reinicio del sistema, por lo que puede utilizarse para gestionar los servicios que se inician automáticamente.
Procedimiento
Para crear un grupo de control persistente, ejecute:
# systemctl enable <name>.serviceEl comando anterior crea automáticamente un archivo de configuración de la unidad en el directorio
/usr/lib/systemd/system/y, por defecto, asigna<name>.servicea la unidadsystem.slice.
Recursos adicionales
- Para más información sobre el concepto de grupos de control, véase Sección 9.1, “Entender los grupos de control”.
-
Para más información sobre el papel de
systemden los grupos de control, véase Sección 9.4, “Función de systemd en los grupos de control versión 1”. -
Para obtener más información sobre
systemd, los archivos de configuración de las unidades y sus ubicaciones, y una lista completa de los tipos de unidades desystemd, consulte las secciones correspondientes en Configuring basic system settings. -
Para una descripción detallada de
systemd-run, incluyendo otras opciones y ejemplos, consulte las páginas del manualsystemd-run(1).
9.5.2. Modificación de los grupos de control versión 1 con systemd
Cada unidad persistente está supervisada por el sistema systemd y el gestor de servicios, y tiene un archivo de configuración de la unidad en el directorio /usr/lib/systemd/system/. Para cambiar los ajustes de control de recursos de las unidades persistentes, modifique su archivo de configuración de unidades, ya sea manualmente en un editor de texto o desde la interfaz de línea de comandos.
9.5.2.1. Configuración de los ajustes de control de los recursos de memoria en la línea de comandos
La ejecución de comandos en la interfaz de línea de comandos es una de las formas de establecer límites, priorizar o controlar el acceso a los recursos de hardware para grupos de procesos.
Procedimiento
Para limitar el uso de memoria de un servicio, ejecute lo siguiente:
# systemctl set-property example.service MemoryLimit=1500KEl comando asigna instantáneamente el límite de memoria de 1.500 kilobytes a los procesos ejecutados en un grupo de control al que pertenece el servicio
example.service. El parámetroMemoryLimit, en esta variante de configuración, se define en el archivo/etc/systemd/system.control/example.service.d/50-MemoryLimit.confy controla el valor del archivo/sys/fs/cgroup/memory/system.slice/example.service/memory.limit_in_bytes.Opcionalmente, para limitar temporalmente el uso de memoria de un servicio, ejecute
# systemctl set-property --runtime example.service MemoryLimit=1500KEl comando asigna instantáneamente el límite de memoria al servicio
example.service. El parámetroMemoryLimitse define hasta el siguiente reinicio en el archivo/run/systemd/system.control/example.service.d/50-MemoryLimit.conf. Con un reinicio, se elimina todo el directorio/run/systemd/system.control/yMemoryLimit.
El archivo 50-MemoryLimit.conf almacena el límite de memoria como un múltiplo de 4096 bytes - un tamaño de página del kernel específico para AMD64 e Intel 64. El número real de bytes depende de la arquitectura de la CPU.
Recursos adicionales
- Para más información sobre el concepto de grupos de control, véase Sección 9.1, “Entender los grupos de control”.
-
Para más información sobre los controladores de recursos, consulte las páginas del manual Sección 9.2, “Qué son los controladores de recursos del núcleo” y
systemd.resource-control(5),cgroups(7). -
Para más información sobre el papel de
systemden los grupos de control, véase Sección 9.4, “Función de systemd en los grupos de control versión 1”.
9.5.2.2. Configuración de los ajustes de control de recursos de memoria con archivos de unidad
Modificar manualmente los archivos de unidad es una de las formas de establecer límites, priorizar o controlar el acceso a los recursos de hardware para grupos de procesos.
Procedimiento
Para limitar el uso de la memoria de un servicio, modifique el archivo
/usr/lib/systemd/system/example.servicecomo sigue:… [Service] MemoryLimit=1500K …
La configuración anterior pone un límite al consumo máximo de memoria de los procesos ejecutados en un grupo de control, del que forma parte
example.service.NotaUtilice los sufijos K, M, G o T para identificar el Kilobyte, Megabyte, Gigabyte o Terabyte como unidad de medida.
Recarga todos los archivos de configuración de la unidad:
# systemctl daemon-reloadReinicie el servicio:
# systemctl restart example.service- Reinicia el sistema.
Opcionalmente, compruebe que los cambios surtieron efecto:
# cat /sys/fs/cgroup/memory/system.slice/example.service/memory.limit_in_bytes 1536000La salida del ejemplo muestra que el consumo de memoria se limitó a unos 1.500 Kilobytes.
NotaEl archivo
memory.limit_in_bytesalmacena el límite de memoria como un múltiplo de 4096 bytes - un tamaño de página del kernel específico para AMD64 e Intel 64. El número real de bytes depende de la arquitectura de la CPU.
Recursos adicionales
- Para más información sobre el concepto de grupos de control, véase Sección 9.1, “Entender los grupos de control”.
-
Para más información sobre los controladores de recursos, consulte las páginas del manual Sección 9.2, “Qué son los controladores de recursos del núcleo” y
systemd.resource-control(5),cgroups(7). -
Para obtener más información sobre
systemd, los archivos de configuración de las unidades y sus ubicaciones, así como una lista completa de los tipos de unidades desystemd, consulte las secciones correspondientes en Configuring basic system settings. -
Para más información sobre el papel de
systemden los grupos de control, véase Sección 9.4, “Función de systemd en los grupos de control versión 1”.
9.5.3. Eliminación de grupos de control versión 1 con systemd
Puede utilizar el sistema systemd y el gestor de servicios para eliminar los grupos de control transitorios y persistentes (cgroups) si ya no necesita limitar, priorizar o controlar el acceso a los recursos de hardware para grupos de procesos.
9.5.3.1. Eliminación de grupos de control transitorios
Los transitorios cgroups se liberan automáticamente una vez que terminan todos los procesos que contiene un servicio o una unidad de alcance.
Procedimiento
Para detener la unidad de servicio con todos sus procesos, ejecute:
# systemctl stop <name>.servicePara terminar uno o más procesos de la unidad, ejecute:
# systemctl kill <name>.service --kill-who=PID,… --signal=signalEl comando anterior utiliza la opción
--kill-whopara seleccionar los procesos del grupo de control que desea terminar. Para matar varios procesos al mismo tiempo, pase una lista de PIDs separada por comas. La opción--signaldetermina el tipo de señal POSIX que se enviará a los procesos especificados. La señal por defecto es SIGTERM.
Recursos adicionales
- Para más información sobre el concepto de grupos de control, véase Sección 9.1, “Entender los grupos de control”.
-
Para más información sobre los controladores de recursos, consulte las páginas del manual Sección 9.2, “Qué son los controladores de recursos del núcleo” y
systemd.resource-control(5),cgroups(7). -
Para más información sobre el papel de
systemden los grupos de control, véase Sección 9.4, “Función de systemd en los grupos de control versión 1”. -
Para obtener más información sobre
systemd, los archivos de configuración de las unidades y sus ubicaciones, así como una lista completa de los tipos de unidades desystemd, consulte las secciones correspondientes en Configuring basic system settings.
9.5.3.2. Eliminación de grupos de control persistentes
Los cgroups persistentes se liberan cuando un servicio o una unidad de ámbito se detiene o se desactiva y se borra su archivo de configuración.
Procedimiento
Detenga la unidad de servicio:
# systemctl stop <name>.serviceDesactivar la unidad de servicio:
# systemctl disable <name>.serviceEliminar el archivo de configuración de la unidad correspondiente:
# rm /usr/lib/systemd/system/<name>.serviceRecarga todos los archivos de configuración de las unidades para que los cambios surtan efecto:
# systemctl daemon-reload
Recursos adicionales
- Para más información sobre el concepto de grupos de control, véase Sección 9.1, “Entender los grupos de control”.
-
Para más información sobre los controladores de recursos, consulte las páginas del manual Sección 9.2, “Qué son los controladores de recursos del núcleo” y
systemd.resource-control(5),cgroups(7). -
Para más información sobre el papel de
systemden los grupos de control, véase Sección 9.4, “Función de systemd en los grupos de control versión 1”. -
Para obtener más información sobre
systemd, los archivos de configuración de las unidades y sus ubicaciones, así como una lista completa de los tipos de unidades desystemd, consulte las secciones correspondientes en Configuring basic system settings. -
Para más información sobre cómo matar procesos con
systemd, consulte la página del manualsystemd.kill(5).
9.6. Obtención de información sobre los grupos de control versión 1
Las siguientes secciones describen cómo visualizar diversas informaciones sobre los grupos de control (cgroups):
-
Listado de unidades de
systemdy visualización de su estado -
Visualización de la jerarquía
cgroups - Control del consumo de recursos en tiempo real
9.6.1. Listado de unidades systemd
El siguiente procedimiento describe cómo utilizar el sistema systemd y el gestor de servicios para listar sus unidades.
Requisitos previos
Procedimiento
Para listar todas las unidades activas en el sistema, ejecute el comando
# systemctly el terminal devolverá una salida similar al siguiente ejemplo:# systemctl UNIT LOAD ACTIVE SUB DESCRIPTION … init.scope loaded active running System and Service Manager session-2.scope loaded active running Session 2 of user jdoe abrt-ccpp.service loaded active exited Install ABRT coredump hook abrt-oops.service loaded active running ABRT kernel log watcher abrt-vmcore.service loaded active exited Harvest vmcores for ABRT abrt-xorg.service loaded active running ABRT Xorg log watcher … -.slice loaded active active Root Slice machine.slice loaded active active Virtual Machine and Container Slice system-getty.slice loaded active active system-getty.slice system-lvm2\x2dpvscan.slice loaded active active system-lvm2\x2dpvscan.slice system-sshd\x2dkeygen.slice loaded active active system-sshd\x2dkeygen.slice system-systemd\x2dhibernate\x2dresume.slice loaded active active system-systemd\x2dhibernate\x2dresume> system-user\x2druntime\x2ddir.slice loaded active active system-user\x2druntime\x2ddir.slice system.slice loaded active active System Slice user-1000.slice loaded active active User Slice of UID 1000 user-42.slice loaded active active User Slice of UID 42 user.slice loaded active active User and Session Slice …-
UNIT: nombre de una unidad que también refleja la posición de la unidad en una jerarquía de grupos de control. Las unidades relevantes para el control de recursos son un slice, un scope, y un service. -
LOAD- indica si el archivo de configuración de la unidad se cargó correctamente. Si el archivo de la unidad no se cargó, el campo contiene el estado error en lugar de loaded. Otros estados de carga de unidades son: stub , merged, y masked. -
ACTIVE- el estado de activación de la unidad de alto nivel, que es una generalización deSUB. -
SUB- el estado de activación de la unidad de bajo nivel. El rango de valores posibles depende del tipo de unidad. -
DESCRIPTION- la descripción del contenido y la funcionalidad de la unidad.
-
Para listar las unidades inactivas, ejecute:
# systemctl --allPara limitar la cantidad de información en la salida, ejecute:
# systemctl --type service,maskedLa opción
--typerequiere una lista separada por comas de tipos de unidades como service y slice, o estados de carga de unidades como loaded y masked.
Recursos adicionales
-
Para obtener más información sobre
systemd, archivos de unidades y una lista completa de los tipos de unidades desystemd, consulte las secciones correspondientes en Configuring basic system settings.
9.6.2. Visualización de una jerarquía de grupo de control versión 1
El siguiente procedimiento describe cómo mostrar la jerarquía de los grupos de control (cgroups) y los procesos que se ejecutan en un cgroups específico.
Requisitos previos
Procedimiento
Para mostrar toda la jerarquía de
cgroupsen su sistema, ejecute# systemd-cgls:# systemd-cgls Control group /: -.slice ├─user.slice │ ├─user-42.slice │ │ ├─session-c1.scope │ │ │ ├─ 965 gdm-session-worker [pam/gdm-launch-environment] │ │ │ ├─1040 /usr/libexec/gdm-x-session gnome-session --autostart /usr/share/gdm/greeter/autostart … ├─init.scope │ └─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 18 └─system.slice … ├─example.service │ ├─6882 /bin/bash /home/jdoe/example.sh │ └─6902 sleep 1 ├─systemd-journald.service └─629 /usr/lib/systemd/systemd-journald …La salida del ejemplo devuelve toda la jerarquía de
cgroups, donde el nivel más alto está formado por slices.Para mostrar la jerarquía
cgroupsfiltrada por un controlador de recursos, ejecute# systemd-cgls <resource_controller>:# systemd-cgls memory Controller memory; Control group /: ├─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 18 ├─user.slice │ ├─user-42.slice │ │ ├─session-c1.scope │ │ │ ├─ 965 gdm-session-worker [pam/gdm-launch-environment] … └─system.slice | … ├─chronyd.service │ └─844 /usr/sbin/chronyd ├─example.service │ ├─8914 /bin/bash /home/jdoe/example.sh │ └─8916 sleep 1 …El ejemplo de salida del comando anterior enumera los servicios que interactúan con el controlador seleccionado.
Para mostrar información detallada sobre una determinada unidad y su parte de la jerarquía
cgroups, ejecute# systemctl status <system_unit>:# systemctl status example.service ● example.service - My example service Loaded: loaded (/usr/lib/systemd/system/example.service; enabled; vendor preset: disabled) Active: active (running) since Tue 2019-04-16 12:12:39 CEST; 3s ago Main PID: 17737 (bash) Tasks: 2 (limit: 11522) Memory: 496.0K (limit: 1.5M) CGroup: /system.slice/example.service ├─17737 /bin/bash /home/jdoe/example.sh └─17743 sleep 1 Apr 16 12:12:39 redhat systemd[1]: Started My example service. Apr 16 12:12:39 redhat bash[17737]: The current time is Tue Apr 16 12:12:39 CEST 2019 Apr 16 12:12:40 redhat bash[17737]: The current time is Tue Apr 16 12:12:40 CEST 2019
Recursos adicionales
-
Para más información sobre los controladores de recursos, consulte la sección Sección 9.2, “Qué son los controladores de recursos del núcleo” y las páginas del manual
systemd.resource-control(5),cgroups(7).
9.6.3. Visualización de los controladores de recursos
El siguiente procedimiento describe cómo aprender qué procesos utilizan qué controladores de recursos.
Requisitos previos
Procedimiento
Para ver con qué controladores de recursos interactúa un proceso, ejecute el
# cat proc/<PID>/cgroupcomando:# cat /proc/11269/cgroup 12:freezer:/ 11:cpuset:/ 10:devices:/system.slice 9:memory:/system.slice/example.service 8:pids:/system.slice/example.service 7:hugetlb:/ 6:rdma:/ 5:perf_event:/ 4:cpu,cpuacct:/ 3:net_cls,net_prio:/ 2:blkio:/ 1:name=systemd:/system.slice/example.serviceEl ejemplo de salida se refiere a un proceso de interés. En este caso, se trata de un proceso identificado por
PID 11269, que pertenece a la unidadexample.service. Se puede determinar si el proceso fue colocado en un grupo de control correcto, tal como se define en las especificaciones del archivo de la unidadsystemd.NotaPor defecto, los elementos y su ordenación en la lista de controladores de recursos es la misma para todas las unidades iniciadas por
systemd, ya que monta automáticamente todos los controladores de recursos por defecto.
Recursos adicionales
-
Para más información sobre los controladores de recursos en general, consulte las páginas del manual
cgroups(7). -
Para una descripción detallada de los controladores de recursos específicos, consulte la documentación en el directorio
/usr/share/doc/kernel-doc-<kernel_version>/Documentation/cgroups-v1/.
9.6.4. Control del consumo de recursos
El siguiente procedimiento describe cómo ver una lista de los grupos de control que se están ejecutando (cgroups) y su consumo de recursos en tiempo real.
Requisitos previos
Procedimiento
Para ver una cuenta dinámica de la ejecución actual de
cgroups, ejecute el comando# systemd-cgtop:# systemd-cgtop Control Group Tasks %CPU Memory Input/s Output/s / 607 29.8 1.5G - - /system.slice 125 - 428.7M - - /system.slice/ModemManager.service 3 - 8.6M - - /system.slice/NetworkManager.service 3 - 12.8M - - /system.slice/accounts-daemon.service 3 - 1.8M - - /system.slice/boot.mount - - 48.0K - - /system.slice/chronyd.service 1 - 2.0M - - /system.slice/cockpit.socket - - 1.3M - - /system.slice/colord.service 3 - 3.5M - - /system.slice/crond.service 1 - 1.8M - - /system.slice/cups.service 1 - 3.1M - - /system.slice/dev-hugepages.mount - - 244.0K - - /system.slice/dev-mapper-rhel\x2dswap.swap - - 912.0K - - /system.slice/dev-mqueue.mount - - 48.0K - - /system.slice/example.service 2 - 2.0M - - /system.slice/firewalld.service 2 - 28.8M - - ...La salida del ejemplo muestra los
cgroupsque se están ejecutando actualmente ordenados por su uso de recursos (CPU, memoria, carga de E/S del disco). La lista se actualiza por defecto cada 1 segundo. Por lo tanto, ofrece una visión dinámica del uso real de recursos de cada grupo de control.
Recursos adicionales
-
Para más información sobre la supervisión dinámica del uso de los recursos, consulte las páginas del manual
systemd-cgtop(1).
9.7. Qué son los espacios de nombres
Los espacios de nombres son uno de los métodos más importantes para organizar e identificar los objetos de software.
Un espacio de nombres envuelve un recurso global del sistema (por ejemplo, un punto de montaje, un dispositivo de red o un nombre de host) en una abstracción que hace parecer a los procesos dentro del espacio de nombres que tienen su propia instancia aislada del recurso global. Una de las tecnologías más comunes que utilizan espacios de nombres son los contenedores.
Los cambios en un determinado recurso global sólo son visibles para los procesos de ese espacio de nombres y no afectan al resto del sistema ni a otros espacios de nombres.
Para inspeccionar de qué espacios de nombres es miembro un proceso, puedes comprobar los enlaces simbólicos en el directorio /proc/<PID>/ns/ del directorio.
La siguiente tabla muestra los espacios de nombres compatibles y los recursos que aíslan:
| Espacio de nombres | Aislados |
|---|---|
| Mount | Puntos de montaje |
| UTS | Nombre de host y nombre de dominio NIS |
| IPC | IPC de System V, colas de mensajes POSIX |
| PID | Identificación de procesos |
| Network | Dispositivos de red, pilas, puertos, etc |
| User | Identificación de usuarios y grupos |
| Control groups | Directorio raíz del grupo de control |
Recursos adicionales
-
Para más información sobre los espacios de nombres, consulte las páginas del manual
namespaces(7)ycgroup_namespaces(7). -
Para más información sobre
cgroups, véase Sección 9.1, “Entender los grupos de control”.
Capítulo 10. Análisis del rendimiento del sistema con BPF Compiler Collection
Como administrador del sistema, utilice la biblioteca BPF Compiler Collection (BCC) para crear herramientas que le permitan analizar el rendimiento de su sistema operativo Linux y recopilar información, que podría ser difícil de obtener a través de otras interfaces.
10.1. Una introducción a BCC
BPF Compiler Collection (BCC) es una biblioteca que facilita la creación de los programas Berkeley Packet Filter (eBPF) ampliados. La principal utilidad de los programas eBPF es analizar el rendimiento del sistema operativo y el rendimiento de la red sin experimentar problemas de sobrecarga o seguridad.
BCC elimina la necesidad de que los usuarios conozcan detalles técnicos profundos de eBPF, y proporciona muchos puntos de partida listos para usar, como el paquete bcc-tools con programas de eBPF precreados.
Los programas eBPF se activan en eventos, como la E/S de disco, las conexiones TCP y la creación de procesos. Es poco probable que los programas provoquen el bloqueo del kernel, bucles o que dejen de responder, ya que se ejecutan en una máquina virtual segura en el kernel.
10.2. Instalación del paquete bcc-tools
Esta sección describe cómo instalar el paquete bcc-tools, que también instala la biblioteca BPF Compiler Collection (BCC) como dependencia.
Requisitos previos
- Un activo Red Hat Enterprise Linux subscription
-
Un enabled repository que contiene el paquete
bcc-tools - Núcleo actualizado
- Permisos de raíz.
Procedimiento
Instalar
bcc-tools:#yum install bcc-toolsLas herramientas BCC se instalan en el directorio
/usr/share/bcc/tools/.Opcionalmente, inspeccione las herramientas:
#ll /usr/share/bcc/tools/... -rwxr-xr-x. 1 root root 4198 Dec 14 17:53 dcsnoop -rwxr-xr-x. 1 root root 3931 Dec 14 17:53 dcstat -rwxr-xr-x. 1 root root 20040 Dec 14 17:53 deadlock_detector -rw-r--r--. 1 root root 7105 Dec 14 17:53 deadlock_detector.c drwxr-xr-x. 3 root root 8192 Mar 11 10:28 doc -rwxr-xr-x. 1 root root 7588 Dec 14 17:53 execsnoop -rwxr-xr-x. 1 root root 6373 Dec 14 17:53 ext4dist -rwxr-xr-x. 1 root root 10401 Dec 14 17:53 ext4slower ...El directorio
docde la lista anterior contiene la documentación de cada herramienta.
10.3. Utilización de determinadas herramientas bcc para el análisis del rendimiento
Esta sección describe cómo utilizar ciertos programas precreados de la biblioteca BPF Compiler Collection (BCC) para analizar de forma eficiente y segura el rendimiento del sistema en base a cada evento. El conjunto de programas precreados en la biblioteca BCC puede servir de ejemplo para la creación de programas adicionales.
Requisitos previos
- Biblioteca BCC instalada
- Permisos de la raíz
Uso de execsnoop para examinar los procesos del sistema
Ejecute el programa
execsnoopen un terminal:# /usr/share/bcc/tools/execsnoopEn otro terminal ejecutar por ejemplo:
$ ls /usr/share/bcc/tools/doc/Lo anterior crea un proceso de corta duración del comando
ls.El terminal que ejecuta
execsnoopmuestra una salida similar a la siguiente:PCOMM PID PPID RET ARGS ls 8382 8287 0 /usr/bin/ls --color=auto /usr/share/bcc/tools/doc/ sed 8385 8383 0 /usr/bin/sed s/^ *[0-9]\+ *// ...
El programa
execsnoopimprime una línea de salida por cada nuevo proceso, que consume recursos del sistema. Incluso detecta procesos de programas que se ejecutan muy poco tiempo, comols, y la mayoría de las herramientas de monitorización no los registrarían.La salida de
execsnoopmuestra los siguientes campos:-
PCOMM - El nombre del proceso padre. (
ls) -
PID - El ID del proceso. (
8382) -
PPID - El ID del proceso padre. (
8287) -
RET - El valor de retorno de la llamada al sistema
exec()(0), que carga el código del programa en nuevos procesos. - ARGS - La ubicación del programa iniciado con argumentos.
-
PCOMM - El nombre del proceso padre. (
Para ver más detalles, ejemplos y opciones de execsnoop, consulte el archivo /usr/share/bcc/tools/doc/execsnoop_example.txt.
Para más información sobre exec(), consulte las páginas del manual exec(3).
Uso de opensnoop para rastrear qué archivos abre un comando
Ejecute el programa
opensnoopen un terminal:# /usr/share/bcc/tools/opensnoop -n unameLo anterior imprime la salida para los archivos, que son abiertos sólo por el proceso del comando
uname.En otra terminal ejecutar:
$ unameEl comando anterior abre ciertos archivos, que se capturan en el siguiente paso.
El terminal que ejecuta
opensnoopmuestra una salida similar a la siguiente:PID COMM FD ERR PATH 8596 uname 3 0 /etc/ld.so.cache 8596 uname 3 0 /lib64/libc.so.6 8596 uname 3 0 /usr/lib/locale/locale-archive ...
El programa
opensnoopvigila la llamada al sistemaopen()en todo el sistema, e imprime una línea de salida para cada archivo queunameintentó abrir en el camino.La salida de
opensnoopmuestra los siguientes campos:-
PID - El ID del proceso. (
8596) -
COMM - El nombre del proceso. (
uname) -
FD - El descriptor del archivo - un valor que
open()devuelve para referirse al archivo abierto. (3) - ERR - Cualquier error.
PATH - La ubicación de los archivos que
open()intentó abrir.Si un comando intenta leer un archivo inexistente, la columna
FDdevuelve-1y la columnaERRimprime un valor correspondiente al error en cuestión. Como resultado,opensnooppuede ayudarle a identificar una aplicación que no se comporta correctamente.
-
PID - El ID del proceso. (
Para ver más detalles, ejemplos y opciones de opensnoop, consulte el archivo /usr/share/bcc/tools/doc/opensnoop_example.txt.
Para más información sobre open(), consulte las páginas del manual open(2).
Uso de biotop para examinar las operaciones de E/S en el disco
Ejecute el programa
biotopen un terminal:# /usr/share/bcc/tools/biotop 30El comando permite supervisar los procesos principales, que realizan operaciones de E/S en el disco. El argumento asegura que el comando producirá un resumen de 30 segundos.
NotaSi no se proporciona ningún argumento, la pantalla de salida se actualiza por defecto cada 1 segundo.
En otro terminal ejecute por ejemplo :
# dd if=/dev/vda of=/dev/zeroEl comando anterior lee el contenido del dispositivo de disco duro local y escribe la salida en el archivo
/dev/zero. Este paso genera cierto tráfico de E/S para ilustrarbiotop.El terminal que ejecuta
biotopmuestra una salida similar a la siguiente:PID COMM D MAJ MIN DISK I/O Kbytes AVGms 9568 dd R 252 0 vda 16294 14440636.0 3.69 48 kswapd0 W 252 0 vda 1763 120696.0 1.65 7571 gnome-shell R 252 0 vda 834 83612.0 0.33 1891 gnome-shell R 252 0 vda 1379 19792.0 0.15 7515 Xorg R 252 0 vda 280 9940.0 0.28 7579 llvmpipe-1 R 252 0 vda 228 6928.0 0.19 9515 gnome-control-c R 252 0 vda 62 6444.0 0.43 8112 gnome-terminal- R 252 0 vda 67 2572.0 1.54 7807 gnome-software R 252 0 vda 31 2336.0 0.73 9578 awk R 252 0 vda 17 2228.0 0.66 7578 llvmpipe-0 R 252 0 vda 156 2204.0 0.07 9581 pgrep R 252 0 vda 58 1748.0 0.42 7531 InputThread R 252 0 vda 30 1200.0 0.48 7504 gdbus R 252 0 vda 3 1164.0 0.30 1983 llvmpipe-1 R 252 0 vda 39 724.0 0.08 1982 llvmpipe-0 R 252 0 vda 36 652.0 0.06 ...
La salida de
biotopmuestra los siguientes campos:-
PID - El ID del proceso. (
9568) -
COMM - El nombre del proceso. (
dd) -
DISK - El disco que realiza las operaciones de lectura. (
vda) - I/O - El número de operaciones de lectura realizadas. (16294)
- Kbytes - La cantidad de Kbytes alcanzados por las operaciones de lectura. (14,440,636)
- AVGms - El tiempo medio de E/S de las operaciones de lectura. (3.69)
-
PID - El ID del proceso. (
Para ver más detalles, ejemplos y opciones de biotop, consulte el archivo /usr/share/bcc/tools/doc/biotop_example.txt.
Para más información sobre dd, consulte las páginas del manual dd(1).
Uso de xfsslower para exponer operaciones del sistema de archivos inesperadamente lentas
Ejecute el programa
xfssloweren un terminal:# /usr/share/bcc/tools/xfsslower 1El comando anterior mide el tiempo que el sistema de archivos XFS emplea en realizar operaciones de lectura, escritura, apertura o sincronización (
fsync). El argumento1asegura que el programa muestra sólo las operaciones que son más lentas que 1 ms.NotaCuando no se proporcionan argumentos,
xfsslowermuestra por defecto las operaciones más lentas de 10 ms.En otro terminal ejecute, por ejemplo, lo siguiente:
$ vim textEl comando anterior crea un archivo de texto en el editor
vimpara iniciar cierta interacción con el sistema de archivos XFS.El terminal que ejecuta
xfsslowermuestra algo similar al guardar el archivo del paso anterior:TIME COMM PID T BYTES OFF_KB LAT(ms) FILENAME 13:07:14 b'bash' 4754 R 256 0 7.11 b'vim' 13:07:14 b'vim' 4754 R 832 0 4.03 b'libgpm.so.2.1.0' 13:07:14 b'vim' 4754 R 32 20 1.04 b'libgpm.so.2.1.0' 13:07:14 b'vim' 4754 R 1982 0 2.30 b'vimrc' 13:07:14 b'vim' 4754 R 1393 0 2.52 b'getscriptPlugin.vim' 13:07:45 b'vim' 4754 S 0 0 6.71 b'text' 13:07:45 b'pool' 2588 R 16 0 5.58 b'text' ...
Cada línea de arriba representa una operación en el sistema de archivos, que tomó más tiempo que un determinado umbral.
xfssloweres bueno para exponer posibles problemas del sistema de archivos, que pueden tomar la forma de operaciones inesperadamente lentas.La salida de
xfsslowermuestra los siguientes campos:-
COMM - El nombre del proceso. (
b’bash') T - El tipo de operación. (
R)- Read
- Write
- Sync
- OFF_KB - El desplazamiento del archivo en KB. (0)
- FILENAME - El archivo que se está leyendo, escribiendo o sincronizando.
-
COMM - El nombre del proceso. (
Para ver más detalles, ejemplos y opciones de xfsslower, consulte el archivo /usr/share/bcc/tools/doc/xfsslower_example.txt.
Para más información sobre fsync, consulte las páginas del manual fsync(2).
Capítulo 11. Mejora de la seguridad con el subsistema de integridad del núcleo
Puedes aumentar la protección de tu sistema utilizando componentes del subsistema de integridad del kernel. En las siguientes secciones se presentan los componentes relevantes y se ofrece orientación sobre su configuración.
11.1. El subsistema de integridad del núcleo
El subsistema de integridad es una parte del núcleo que se encarga de mantener la integridad de los datos del sistema en general. Este subsistema ayuda a mantener el estado de un determinado sistema igual desde el momento en que se construyó, por lo que evita la modificación no deseada de archivos específicos del sistema por parte de los usuarios.
El subsistema de integridad del núcleo consta de dos componentes principales:
- Arquitectura de medición de la integridad (IMA)
- Mide el contenido de los archivos cada vez que se ejecutan o abren. Los usuarios pueden cambiar este comportamiento aplicando políticas personalizadas.
- Coloca los valores medidos dentro del espacio de memoria del kernel, impidiendo así cualquier modificación por parte de los usuarios del sistema.
- Permite a las partes local y remota verificar los valores medidos.
- Módulo de verificación ampliado (EVM)
- Protege los atributos extendidos de los archivos (también conocidos como xattr) que están relacionados con la seguridad del sistema, como las medidas de IMA y los atributos de SELinux, mediante el hashing criptográfico de sus valores correspondientes.
Tanto IMA como EVM contienen también numerosas extensiones de características que aportan funcionalidades adicionales. Por ejemplo:
- IMA-Appraisal
- Proporciona una validación local del contenido del archivo actual con respecto a los valores almacenados previamente en el archivo de medidas dentro de la memoria del núcleo. Esta extensión prohíbe que se realice cualquier operación sobre un archivo específico en caso de que la medida actual y la anterior no coincidan.
- Firmas digitales de EVM
- Permite el uso de firmas digitales a través de claves criptográficas almacenadas en el llavero del kernel.
Las extensiones de funciones se complementan entre sí, pero puedes configurarlas y utilizarlas de forma independiente.
El subsistema de integridad del núcleo puede aprovechar el módulo de plataforma de confianza (TPM) para reforzar aún más la seguridad del sistema. El TPM es una especificación del Trusted Computing Group (TCG) para importantes funciones criptográficas. Los TPM suelen construirse como hardware dedicado que se acopla a la placa base de la plataforma y evita los ataques basados en software al proporcionar funciones criptográficas desde una zona protegida y a prueba de manipulaciones del chip de hardware. Algunas de las características del TPM son
- Generador de números aleatorios
- Generador y almacenamiento seguro de claves criptográficas
- Generador de hashing
- Certificación a distancia
Recursos adicionales
- Para más detalles sobre el subsistema de integridad del kernel, véase el archivo official upstream wiki page.
- Para más información sobre el TPM, véase el Trusted Computing Group resources.
11.2. Arquitectura de medición de la integridad
La Arquitectura de Medición de Integridad (IMA) es un componente del subsistema de integridad del núcleo. El objetivo de IMA es mantener el contenido de los archivos locales. En concreto, IMA mide, almacena y evalúa los hashes de los archivos antes de que se acceda a ellos, lo que impide la lectura y ejecución de datos no fiables. De este modo, IMA mejora la seguridad del sistema.
11.3. Módulo de verificación ampliado
El Módulo de Verificación Extendida (EVM) es un componente del subsistema de integridad del kernel, que supervisa los cambios en los atributos extendidos de los archivos (xattr). Muchas tecnologías orientadas a la seguridad, incluida la Arquitectura de Medición de la Integridad (IMA), almacenan información sensible de los archivos, como los hash de contenido, en los atributos extendidos. EVM crea otro hash a partir de estos atributos extendidos y de una clave especial, que se carga en el momento del arranque. El hash resultante se valida cada vez que se utiliza el atributo extendido. Por ejemplo, cuando IMA evalúa el archivo.
RHEL 8 acepta la clave cifrada especial bajo el llavero evm-key. La clave fue creada por un master key mantenido en los llaveros del kernel.
11.4. Claves de confianza y encriptadas
La siguiente sección presenta las claves de confianza y encriptadas como una parte importante para mejorar la seguridad del sistema.
Trusted y encrypted keys son claves simétricas de longitud variable generadas por el núcleo que utilizan el servicio de llavero del núcleo. El hecho de que este tipo de claves nunca aparezcan en el espacio de usuario en forma no cifrada significa que su integridad puede ser verificada, lo que a su vez significa que pueden ser utilizadas, por ejemplo, por el módulo de verificación extendido (EVM) para verificar y confirmar la integridad de un sistema en ejecución. Los programas a nivel de usuario sólo pueden acceder a las claves en forma de cifrado blobs.
Las claves de confianza necesitan un componente de hardware: el chip Trusted Platform Module (TPM), que se utiliza tanto para crear como para cifrar (sellar) las claves. El TPM sella las claves utilizando una clave RSA de 2048 bits denominada storage root key (SRK).
Para utilizar una especificación TPM 1.2, hay que habilitarla y activarla mediante un ajuste en el firmware de la máquina o utilizando el comando tpm_setactive del paquete de utilidades tpm-tools. Además, es necesario instalar la pila de software TrouSers y ejecutar el demonio tcsd para comunicarse con el TPM (hardware dedicado). El demonio tcsd forma parte de la suite TrouSers, que está disponible a través del paquete trousers. El TPM 2.0, más reciente e incompatible con las versiones anteriores, utiliza una pila de software diferente, en la que las utilidades tpm2-tools o ibm-tss proporcionan acceso al hardware dedicado.
Además, el usuario puede sellar las claves de confianza con un conjunto específico de valores del TPM platform configuration register (PCR). El PCR contiene un conjunto de valores de gestión de la integridad que reflejan el firmware, el cargador de arranque y el sistema operativo. Esto significa que las claves selladas por PCR sólo pueden ser descifradas por el TPM en el mismo sistema en el que fueron cifradas. Sin embargo, una vez que se carga una clave de confianza sellada por PCR (añadida a un llavero), y por lo tanto se verifican sus valores de PCR asociados, puede actualizarse con valores de PCR nuevos (o futuros), de modo que pueda arrancarse un nuevo kernel, por ejemplo. Una sola clave también puede guardarse como múltiples blobs, cada uno con diferentes valores de PCR.
Las claves cifradas no requieren un TPM, ya que utilizan el Estándar de Cifrado Avanzado (AES) del núcleo, lo que las hace más rápidas que las claves de confianza. Las claves encriptadas se crean utilizando números aleatorios generados por el núcleo y se encriptan mediante un master key cuando se exportan a blobs del espacio de usuario. La clave maestra es una clave de confianza o una clave de usuario. Si la clave maestra no es de confianza, la clave encriptada sólo es tan segura como la clave de usuario utilizada para encriptarla.
11.4.1. Trabajar con claves de confianza
La siguiente sección describe cómo crear, exportar, cargar o actualizar claves de confianza con la utilidad keyctl para mejorar la seguridad del sistema.
Requisitos previos
-
Para la arquitectura ARM de 64 bits e IBM Z, es necesario cargar el módulo del kernel
trusted. Para obtener más información sobre cómo cargar los módulos del kernel, consulte Capítulo 3, Gestión de los módulos del núcleo. - El módulo de plataforma de confianza (TPM) debe estar habilitado y activo. Para más información sobre el TPM, consulte el subsistema de integridad del kernel y las claves de confianza y cifradas.
Procedimiento
Para crear una clave de confianza utilizando un TPM, ejecute:
# keyctl add trusted <name> "new <key_length> [options]" <key_ring>Basándose en la sintaxis, construya un comando de ejemplo como el siguiente:
# keyctl add trusted kmk "new 32" @u 642500861El comando crea una clave de confianza llamada
kmkcon una longitud de 32 bytes (256 bits) y la coloca en el llavero del usuario (@u). Las claves pueden tener una longitud de 32 a 128 bytes (256 a 1024 bits).
Para listar la estructura actual de los llaveros del núcleo:
# keyctl show Session Keyring -3 --alswrv 500 500 keyring: ses 97833714 --alswrv 500 -1 \ keyring: uid.1000 642500861 --alswrv 500 500 \ trusted: kmk
Para exportar la clave a un blob del espacio de usuario, ejecute
# keyctl pipe 642500861 > kmk.blobEl comando utiliza el subcomando
pipey el número de serie dekmk.Para cargar la clave de confianza desde el blob del espacio de usuario, utilice el subcomando
addcon el blob como argumento:# keyctl add trusted kmk "load `cat kmk.blob`" @u 268728824Crear claves cifradas seguras basadas en la clave de confianza sellada por el TPM:
# keyctl add encrypted <name> "new [format] <key_type>:<primary_key_name> <keylength>" <key_ring>Basándose en la sintaxis, genere una clave cifrada utilizando la clave de confianza ya creada:
# keyctl add encrypted encr-key "new trusted:kmk 32" @u 159771175El comando utiliza la clave de confianza sellada por el TPM (
kmk), producida en el paso anterior, como primary key para generar claves cifradas.
Recursos adicionales
-
Para obtener información detallada sobre el uso de
keyctl, consulte la página del manualkeyctl(1). - Para más información sobre las claves de confianza y encriptadas, consulte Sección 11.4, “Claves de confianza y encriptadas”.
- Para obtener más información sobre el servicio de llavero del núcleo, consulte la documentación del núcleo ascendente.
- Para más información sobre el TPM, consulte Sección 11.1, “El subsistema de integridad del núcleo”.
11.4.2. Trabajar con claves encriptadas
En la siguiente sección se describe la gestión de las claves cifradas para mejorar la seguridad del sistema en los sistemas en los que no se dispone de un módulo de plataforma de confianza (TPM).
Requisitos previos
-
Para la arquitectura ARM de 64 bits e IBM Z, es necesario cargar el módulo del kernel
encrypted-keys. Para obtener más información sobre cómo cargar los módulos del kernel, consulte Capítulo 3, Gestión de los módulos del núcleo.
Procedimiento
Utiliza una secuencia aleatoria de números para generar una clave de usuario:
# keyctl add user kmk-user “dd if=/dev/urandom bs=1 count=32 2>/dev/null” @u 427069434El comando genera una clave de usuario llamada
kmk-userque actúa como primary key y se utiliza para sellar las claves cifradas reales.Generar una clave cifrada utilizando la clave primaria del paso anterior:
# keyctl add encrypted encr-key "new user:kmk-user 32" @u 1012412758Opcionalmente, lista todas las llaves del llavero del usuario especificado:
# keyctl list @u 2 keys in keyring: 427069434: --alswrv 1000 1000 user: kmk-user 1012412758: --alswrv 1000 1000 encrypted: encr-key
Ten en cuenta que las claves encriptadas que no están selladas por una clave primaria de confianza sólo son tan seguras como la clave primaria de usuario (clave de número aleatorio) que se utilizó para encriptarlas. Por lo tanto, la clave primaria de usuario debe cargarse de la forma más segura posible y preferiblemente al principio del proceso de arranque.
Recursos adicionales
-
Para obtener información detallada sobre el uso de
keyctl, consulte la página del manualkeyctl(1). - Para obtener más información sobre el servicio de llavero del núcleo, consulte la documentación del núcleo ascendente.
11.5. Arquitectura de medición de la integridad y módulo de verificación ampliado
La arquitectura de medición de integridad (IMA) y el módulo de verificación extendido (EVM) pertenecen al subsistema de integridad del kernel y mejoran la seguridad del sistema de varias maneras. La siguiente sección describe cómo activar y configurar IMA y EVM para mejorar la seguridad del sistema operativo.
Requisitos previos
Compruebe que el sistema de archivos
securityfsestá montado en el directorio/sys/kernel/security/y que el directorio/sys/kernel/security/integrity/ima/existe.# mount … securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime) …Compruebe que el gestor de servicios
systemdya está parcheado para soportar IMA y EVM en el momento del arranque:# dmesg | grep -i -e EVM -e IMA [ 0.000000] Command line: BOOT_IMAGE=(hd0,msdos1)/vmlinuz-4.18.0-167.el8.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet [ 0.000000] kvm-clock: cpu 0, msr 23601001, primary cpu clock [ 0.000000] Using crashkernel=auto, the size chosen is a best effort estimation. [ 0.000000] Kernel command line: BOOT_IMAGE=(hd0,msdos1)/vmlinuz-4.18.0-167.el8.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet [ 0.911527] ima: No TPM chip found, activating TPM-bypass! [ 0.911538] ima: Allocated hash algorithm: sha1 [ 0.911580] evm: Initialising EVM extended attributes: [ 0.911581] evm: security.selinux [ 0.911581] evm: security.ima [ 0.911582] evm: security.capability [ 0.911582] evm: HMAC attrs: 0x1 [ 1.715151] systemd[1]: systemd 239 running in system mode. (+PAM +AUDIT +SELINUX +IMA -APPARMOR +SMACK +SYSVINIT +UTMP +LIBCRYPTSETUP +GCRYPT +GNUTLS +ACL +XZ +LZ4 +SECCOMP +BLKID +ELFUTILS +KMOD +IDN2 -IDN +PCRE2 default-hierarchy=legacy) [ 3.824198] fbcon: qxldrmfb (fb0) is primary device [ 4.673457] PM: Image not found (code -22) [ 6.549966] systemd[1]: systemd 239 running in system mode. (+PAM +AUDIT +SELINUX +IMA -APPARMOR +SMACK +SYSVINIT +UTMP +LIBCRYPTSETUP +GCRYPT +GNUTLS +ACL +XZ +LZ4 +SECCOMP +BLKID +ELFUTILS +KMOD +IDN2 -IDN +PCRE2 default-hierarchy=legacy)
Procedimiento
Añade los siguientes parámetros de la línea de comandos del kernel:
# grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="ima_policy=appraise_tcb ima_appraise=fix evm=fix"El comando habilita IMA y EVM en el modo fix para la entrada de arranque actual y permite a los usuarios recopilar y actualizar las mediciones de IMA.
El parámetro de la línea de comandos del kernel
ima_policy=appraise_tcbgarantiza que el kernel utilice la política de medición predeterminada de Trusted Computing Base (TCB) y el paso de evaluación. La parte de evaluación prohíbe el acceso a los archivos cuyas medidas anteriores y actuales no coinciden.- Reinicie para que los cambios surtan efecto.
Opcionalmente, verifique que los parámetros han sido añadidos a la línea de comandos del kernel:
# cat /proc/cmdline BOOT_IMAGE=(hd0,msdos1)/vmlinuz-4.18.0-167.el8.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet ima_policy=appraise_tcb ima_appraise=fix evm=fixCrear una clave maestra del núcleo para proteger la clave EVM:
# keyctl add user kmk dd if=/dev/urandom bs=1 count=32 2> /dev/null @u 748544121La clave maestra del kernel (
kmk) se mantiene enteramente en la memoria del espacio del kernel. El valor de 32 bytes de longitud de la clave maestra del núcleokmkse genera a partir de bytes aleatorios del archivo/dev/urandomy se coloca en el llavero del usuario (@u). El número de serie de la llave está en la segunda línea de la salida anterior.Crear una clave EVM encriptada basada en la clave
kmk:# keyctl add encrypted evm-key "new user:kmk 64" @u 641780271El comando utiliza
kmkpara generar y cifrar una clave de usuario de 64 bytes de longitud (llamadaevm-key) y la coloca en el llavero del usuario (@u). El número de serie de la clave está en la segunda línea de la salida anterior.ImportanteEs necesario nombrar la clave de usuario como evm-key porque ese es el nombre que espera el subsistema EVM y con el que trabaja.
Crear un directorio para las claves exportadas:
# mkdir -p /etc/keys/Busque la clave
kmky exporte su valor a un archivo:# keyctl pipe
keyctl search @u user kmk> /etc/keys/kmk *El comando coloca el valor no encriptado de la llave maestra del kernel (
kmk) en un archivo de ubicación previamente definida (/etc/keys/).Busque la clave de usuario
evm-keyy exporte su valor a un archivo:# keyctl pipe
keyctl search @u encrypted evm-key> /etc/keys/evm-keyEl comando coloca el valor encriptado de la clave del usuario
evm-keyen un archivo de ubicación arbitraria. Elevm-keyha sido encriptado por la llave maestra del kernel anteriormente.Opcionalmente, puede ver las llaves recién creadas:
# keyctl show Session Keyring 974575405 --alswrv 0 0 keyring: ses 299489774 --alswrv 0 65534 \ keyring: uid.0 748544121 --alswrv 0 0 \ user: kmk 641780271 --alswrv 0 0 \_ encrypted: evm-key
Debería poder ver una salida similar.
Activar el EVM:
# echo 1 > /sys/kernel/security/evmOpcionalmente, verifique que el EVM ha sido inicializado:
# dmesg | tail -1 […] evm: key initialized
Recursos adicionales
- Para más información sobre el subsistema de integridad del kernel, consulte Sección 11.1, “El subsistema de integridad del núcleo”.
- Para más información sobre la arquitectura de medición de la integridad, consulte Sección 11.2, “Arquitectura de medición de la integridad”.
- Para más información sobre el módulo de verificación ampliado, consulte Sección 11.3, “Módulo de verificación ampliado”.
- Para más información sobre la creación de claves encriptadas, consulte Sección 11.4, “Claves de confianza y encriptadas”.
11.6. Recogida de hashes de archivos con arquitectura de medición de la integridad
El primer nivel de funcionamiento de la arquitectura de medición de la integridad (IMA) es la fase measurement, que permite crear hashes de archivos y almacenarlos como atributos extendidos (xattrs) de dichos archivos. La siguiente sección describe cómo crear e inspeccionar los hashes de los archivos.
Requisitos previos
- Habilitar la arquitectura de medición de la integridad (IMA) y el módulo de verificación ampliado (EVM) como se describe en Sección 11.5, “Arquitectura de medición de la integridad y módulo de verificación ampliado”.
Compruebe que los paquetes
ima-evm-utils,attr, ykeyutilsya están instalados:# yum install ima-evm-utils attr keyutils Updating Subscription Management repositories. This system is registered to Red Hat Subscription Management, but is not receiving updates. You can use subscription-manager to assign subscriptions. Last metadata expiration check: 0:58:22 ago on Fri 14 Feb 2020 09:58:23 AM CET. Package ima-evm-utils-1.1-5.el8.x86_64 is already installed. Package attr-2.4.48-3.el8.x86_64 is already installed. Package keyutils-1.5.10-7.el8.x86_64 is already installed. Dependencies resolved. Nothing to do. Complete!
Procedimiento
Cree un archivo de prueba:
# echo <Test_text> > test_fileIMA y EVM garantizan que al archivo de ejemplo
test_filese le asignen valores hash, que se almacenan como sus atributos extendidos.Inspeccionar los atributos extendidos del archivo:
# getfattr -m . -d test_file # file: test_file security.evm=0sAnDIy4VPA0HArpPO/EqiutnNyBql security.ima=0sAQOEDeuUnWzwwKYk+n66h/vby3eD security.selinux="unconfined_u:object_r:admin_home_t:s0"
La salida del ejemplo anterior muestra los atributos extendidos relacionados con SELinux y los valores hash de IMA y EVM. EVM añade activamente un atributo extendido
security.evmy detecta cualquier manipulación fuera de línea de las xattrs de otros archivos comosecurity.imaque están directamente relacionadas con la integridad del contenido de los archivos. El valor del camposecurity.evmestá en código de autenticación de mensajes basado en Hash (HMAC-SHA1), que fue generado con la clave de usuarioevm-key.
Recursos adicionales
- Para más información sobre los conceptos generales de seguridad en Red Hat Enterprise Linux 8, consulte las secciones relevantes de Security hardening.
- Para obtener información sobre la arquitectura de medición de la integridad, consulte Sección 11.2, “Arquitectura de medición de la integridad”.
- Para obtener información sobre el módulo de verificación ampliado, consulte Sección 11.3, “Módulo de verificación ampliado”.
Capítulo 12. Uso de los roles de Ansible para configurar permanentemente los parámetros del kernel
Como usuario experimentado con buenos conocimientos de Red Hat Ansible Engine, puede utilizar el rol kernel_settings para configurar los parámetros del kernel en varios clientes a la vez. Esta solución:
- Ofrece una interfaz amigable con una configuración de entrada eficiente.
- Mantiene todos los parámetros del kernel previstos en un solo lugar.
Después de ejecutar el rol kernel_settings desde la máquina de control, los parámetros del kernel se aplican a los sistemas gestionados inmediatamente y persisten a través de los reinicios.
12.1. Introducción a la función de configuración del núcleo
RHEL System Roles es una colección de roles y módulos de Ansible Automation Platform que proporcionan una interfaz de configuración consistente para gestionar remotamente múltiples sistemas.
Los roles de sistema de RHEL se introdujeron para las configuraciones automatizadas del kernel utilizando el rol de sistema kernel_settings. El paquete rhel-system-roles contiene este rol de sistema, así como la documentación de referencia.
Para aplicar los parámetros del kernel en uno o más sistemas de forma automatizada, utilice el rol kernel_settings con una o más de sus variables de rol de su elección en un playbook. Un libro de jugadas es una lista de una o más jugadas que son legibles para los humanos, y están escritas en el formato YAML.
Puede utilizar un archivo de inventario para definir un conjunto de sistemas que desea que el motor Ansible configure de acuerdo con el libro de jugadas.
Con el rol kernel_settings se puede configurar:
-
Los parámetros del núcleo utilizando la variable de rol
kernel_settings_sysctl -
Varios subsistemas del kernel, dispositivos de hardware y controladores de dispositivos que utilizan la variable de rol
kernel_settings_sysfs -
La afinidad de la CPU para el gestor de servicios
systemdy los procesos que bifurca utilizando la variable de rolkernel_settings_systemd_cpu_affinity -
El subsistema de memoria del kernel transparente hugepages utilizando las variables de rol
kernel_settings_transparent_hugepagesykernel_settings_transparent_hugepages_defrag
Recursos adicionales
-
Para una referencia detallada sobre las variables de rol de
kernel_settingsy para los playbooks de ejemplo, instale el paqueterhel-system-roles, y vea los archivosREADME.mdyREADME.htmlen el directorio/usr/share/doc/rhel-system-roles/kernel_settings/. - Para más información sobre los playbooks, consulte Trabajar con playbooks en la documentación de Ansible.
- Para obtener más información sobre la creación y el uso de inventarios, consulte Cómo crear su inventario en la documentación de Ansible.
12.2. Aplicación de los parámetros del núcleo seleccionados mediante la función de configuración del núcleo
Siga estos pasos para preparar y aplicar un playbook de Ansible para configurar remotamente los parámetros del kernel con efecto persistente en varios sistemas operativos gestionados.
Requisitos previos
-
Su suscripción a Red Hat Ansible Engine está adjunta al sistema, también llamado control machine, desde el cual desea ejecutar el rol
kernel_settings. Consulte el artículo Cómo descargar e instalar Red Hat Ansible Engine para obtener más información. - El repositorio del motor Ansible está habilitado en la máquina de control.
El motor Ansible está instalado en la máquina de control.
NotaNo es necesario tener instalado el motor de Ansible en los sistemas, también llamados managed hosts, en los que se desea configurar los parámetros del kernel.
-
El paquete
rhel-system-rolesestá instalado en la máquina de control. - En la máquina de control hay un inventario de hosts gestionados y el motor Ansible puede conectarse a ellos.
Procedimiento
Opcionalmente, revise el archivo
inventorya modo de ilustración:# cat /home/jdoe/<ansible_project_name>/inventory [testingservers] pdoe@192.168.122.98 fdoe@192.168.122.226 [db-servers] db1.example.com db2.example.com [webservers] web1.example.com web2.example.com 192.0.2.42El archivo define el grupo
[testingservers]y otros grupos. Permite ejecutar el motor Ansible de forma más eficaz contra un conjunto específico de sistemas.Crear un archivo de configuración para establecer los valores predeterminados y la escalada de privilegios para las operaciones del motor Ansible.
Cree un nuevo archivo YAML y ábralo en un editor de texto, por ejemplo:
# vi /home/jdoe/<ansible_project_name>/ansible.cfgInserte el siguiente contenido en el archivo:
[defaults] inventory = ./inventory [privilege_escalation] become = true become_method = sudo become_user = root become_ask_pass = true
La sección
[defaults]especifica una ruta al archivo de inventario de los hosts gestionados. La sección[privilege_escalation]define que los privilegios de usuario sean cambiados arooten los hosts administrados especificados. Esto es necesario para la configuración exitosa de los parámetros del kernel. Cuando se ejecute el playbook de Ansible, se le pedirá la contraseña del usuario. El usuario cambia automáticamente arootmediantesudodespués de conectarse a un host gestionado.
Cree un libro de jugadas de Ansible que utilice el rol
kernel_settings.Cree un nuevo archivo YAML y ábralo en un editor de texto, por ejemplo:
# vi /home/jdoe/<ansible_project_name>/kernel_roles.ymlEste archivo representa un libro de jugadas y normalmente contiene una lista ordenada de tareas, también llamadas plays, que se ejecutan contra hosts gestionados específicos seleccionados de su archivo
inventory.Inserte el siguiente contenido en el archivo:
--- - name: Configure kernel settings hosts: testingservers vars: kernel_settings_sysctl: - name: fs.file-max value: 400000 - name: kernel.threads-max value: 65536 kernel_settings_sysfs: - name: /sys/class/net/lo/mtu value: 65000 kernel_settings_transparent_hugepages: madvise roles: - linux-system-roles.kernel_settingsLa clave
namees opcional. Asocia una cadena arbitraria a la obra como etiqueta e identifica para qué sirve la obra. La clavehostsen la obra especifica los hosts contra los que se ejecuta la obra. El valor o los valores de esta clave pueden proporcionarse como nombres individuales de hosts gestionados o como grupos de hosts definidos en el archivoinventory.La sección
varsrepresenta una lista de variables que contienen los nombres de los parámetros del núcleo seleccionados y los valores a los que deben ajustarse.La clave
rolesespecifica qué rol del sistema va a configurar los parámetros y valores mencionados en la secciónvars.NotaPuede modificar los parámetros del núcleo y sus valores en el libro de jugadas para adaptarlos a sus necesidades.
Opcionalmente, verifique que la sintaxis de su obra es correcta.
# ansible-playbook --syntax-check kernel-roles.yml playbook: kernel-roles.ymlEste ejemplo muestra la verificación exitosa de un libro de jugadas.
Ejecuta tu libro de jugadas.
# ansible-playbook kernel-roles.yml BECOME password: PLAY [Configure kernel settings] ... PLAY RECAP ** fdoe@192.168.122.226 : ok=10 changed=4 unreachable=0 failed=0 skipped=6 rescued=0 ignored=0 pdoe@192.168.122.98 : ok=10 changed=4 unreachable=0 failed=0 skipped=6 rescued=0 ignored=0
Antes de que el motor de Ansible ejecute su libro de jugadas, se le pedirá su contraseña y para que un usuario en los hosts administrados pueda ser cambiado a
root, lo cual es necesario para configurar los parámetros del kernel.La sección de recapitulación muestra que la reproducción ha finalizado con éxito (
failed=0) para todos los hosts gestionados, y que se han aplicado 4 parámetros del kernel (changed=4).- Reinicie sus hosts gestionados y compruebe los parámetros del kernel afectados para verificar que los cambios se han aplicado y persisten a través de los reinicios.
Recursos adicionales
- Para obtener más información sobre las funciones del sistema RHEL, consulte Introducción a las funciones del sistema RHEL.
-
Para más información sobre todas las variables actualmente soportadas en
kernel_settings, consulte los archivosREADME.htmlyREADME.mden el directorio/usr/share/doc/rhel-system-roles/kernel_settings/. - Para más detalles sobre los inventarios de Ansible, consulte la documentación sobre el trabajo con el inventario en Ansible.
- Para más detalles sobre los archivos de configuración de Ansible, consulte Configuración de Ansible en la documentación de Ansible.
- Para más detalles sobre los playbooks de Ansible, consulte Trabajar con playbooks en la documentación de Ansible.
- Para más detalles sobre las variables de Ansible, consulte la documentación sobre el uso de variables en Ansible.
- Para más detalles sobre los roles de Ansible, consulte la documentación de Roles en Ansible.