
Red Hat Training
A Red Hat training course is available for Red Hat Enterprise Linux
Guía de ajuste de rendimiento
Optimización de resultados en Red Hat Enterprise Linux 6
Edición 4.0
Resumen
Capítulo 1. Visión general
- Funcionalidades
- Cada capítulo de subsistema describe funcionalidades de rendimiento únicas (o implementadas de una forma diferente) en Red Hat Enterprise Linux 6. Estos capítulos también describen actualizaciones para Red Hat Enterprise Linux 6 que mejoraron el rendimiento de una forma significativa de subsistemas específicos en Red Hat Enterprise Linux 5.
- Análisis
- Este libro enumera los indicadores de rendimiento para cada subsistema. Los valores típicos para dichos indicadores se describen en el contexto de servicios específicos, ayudándole así a entender su importancia en el mundo real de los sistemas de producción.Además, la Guía de ajuste de rendimiento también presenta diversas formas de recuperar datos de rendimiento para un sistema. Observe que algunas de las herramientas presentadas aquí se documentan en más detalle en otros documentos.
- Configuración
- Las instrucciones sobre cómo ajustar el rendimiento de un subsistema en Red Hat Enterprise Linux 6, son quizás la información más importante en este libro. La Guía de ajuste de rendimiento explica cómo ajustar un subsistema de Red Hat Enterprise Linux 6 para servicios específicos.
1.1. Audiencia
- Analista de negocios/sistemas
- Este libro enumera y explica las funcionalidades de rendimiento de Red Hat Enterprise Linux 6 en un alto nivel, proporcionando información suficiente sobre cómo rinden los subsistemas para cargas de trabajo específicas (tanto predeterminadas como optimizadas). El nivel de detalle utilizado para describir las funcionalidades de rendimiento de Red Hat Enterprise Linux 6 ayuda a los clientes potenciales y a los ingenieros de ventas a entender la conveniencia de esta plataforma al proveer servicios intensivos de recursos en un nivel aceptable.La Guía de ajuste de rendimiento también proporciona, en lo posible, enlaces de documentación más detallada sobre cada funcionalidad. En ese nivel de detalle, los lectores pueden entender el rendimiento de estas funcionalidades para formar una estrategia de alto nivel al implementar y optimizar Red Hat Enterprise Linux 6. Esto permite a los lectores desarrollar y evaluar propuestas de infraestructura.Esta característica enfocada en el nivel de documentación es apropiada para lectores con un alto nivel de entendimiento sobre los subsistemas de Linux y de redes a nivel empresarial.
- Administrador de sistemas
- Los procedimientos enumerados en este libro son apropiados para administradores de sistemas certificados con RHCE [1] nivel de destrezas (o su equivalente, es decir, 3 o 5 años de experiencia en implementar y administrar Linux). La Guía de ajuste de rendimiento tiene como objetivo proporcionar información detallada en lo posible sobre los efectos de cada configuración; esto significa la descripción de cualquier pérdida o ganancia en rendimiento que pueda ocurrir.La destreza subyacente en el ajuste de rendimiento radica en no saber cómo analizar y ajustar un subsistema. En su lugar, un administrador de sistemas conocedor de ajustes de rendimiento sabe cómo balancear y optimizar un sistema de Red Hat Enterprise Linux 6 para propósitos específicos. Esto significa que también conoce qué pérdidas y ganancias y precio son aceptables al intentar implementar una configuración diseñada para impulsar un rendimiento de subsistema específico.
1.2. Escalabilidad horizontal
1.2.1. Computación paralela
1.3. Sistemas distribuidos
- Comunicación
- La escalabilidad horizontal requiere que muchas tareas se realicen de forma simultánea (en paralelo). Como tal, estas tareas deben tener comunicación de interprocesos para coordinar su trabajo. Además, una plataforma con escalabilidad horizontal debe poder compartir tareas a través de varios sistemas.
- Almacenamiento
- El almacenamiento a través de discos locales no es suficiente para los requerimientos de escalabilidad horizontal. Alguna forma de almacenaje compartido o distribuido es necesaria, una con una capa de abstracción que permita una capacidad de volumen para almacenaje individual crecer sin problemas con la adición de un nuevo hardware de almacenamiento.
- Administración
- La labor más importante en computación distribuida es la capa de administración. Esta capa de administración coordina todos los componentes de software y hardware, administrando de forma eficiente la comunicación, almacenaje y el uso de recursos compartidos.
1.3.1. Comunicación
- Hardware
- Software
La forma más común de comunicación entre computadores es por Ethernet. Hoy en día, Gigabit Ethernet (GbE) se proporciona de forma predeterminada en sistemas y la mayoría de servidores incluyen 2a 4 puertos de Gigabit Ethernet. GbE proporciona un buen ancho de banda y latencia. Esta es la base de la mayoría de sistemas distribuidos en uso hoy en día. Incluso cuando los sistemas incluyen hardware de redes más rápidas, es común usar GbE para una interfaz de administración dedicada.
Ethernet de 10 Gigabits (10GbE) está creciendo rápidamente en aceptación para servidores de alta gama e incluso para servidores de rangos medios. 10GbE proporciona diez veces el ancho de banda de GbE. Una de sus ventajas principales es con modernos procesadores multinúcleos, donde restaura el equilibrio entre comunicación y computación. Puede comparar un sistema de núcleo único mediante GbE con un sistema de ocho núcleos mediante 10GbE. Utilizado de esta forma, 10GbE es valioso para mantener el rendimiento de todo el sistema general y evitar cuellos de botella en comunicación.
Infiniband ofrece incluso un mayor rendimiento que 10GbE. Además de las conexiones de redes TCP/IP y UDP utilizadas con Ethernet, Infiniband soporta comunicación de memoria compartida. Esto permite a Infiniband operar entre sistemas vía acceso remoto de memoria (RDMA).
RDMA en Ethernet (RoCCE) implementa comunicaciones de estilo Infiniband (incluidas RDMA) en una infraestructura de 10GbE. Dado el costo de mejoras asociadas con el volumen creciente de productos de 10GbE, se puede esperar un uso más amplio de RDMA y RoCCE en un amplio rango de sistemas y aplicaciones.
1.3.2. Almacenamiento
- Los sistemas múltiples almacenan datos en un solo sitio
- La unidad de almacenamiento (e.j. un volumen) compuesto de varios aparatos de almacenaje
El Sistema de archivos de red (NFS) permite múltiples servidores o usuarios montar y usar la misma instancia de almacenaje remoto a través de TCP o UDP. NFS es comúnmente utilizada por múltiples aplicaciones para guardar datos. También es conveniente para almacenaje en de grandes cantidades de datos.
Redes de área de almacenaje (SAN) usan tanto Canal de fibra o protocolo iSCSI para proveer acceso al almacenaje. La infraestructura de fibra de canal (tal como adaptadores de bus de host de canal de fibra, cambia y almacena arrays) combina rendimiento de alto rendimiento y alta banda ancha y almacenamiento masivo. Los SAN separan almacenaje del procesamiento, proporcionando flexibilidad considerable en el diseño del sistema.
- Control de acceso de almacenaje
- Administración de grandes cantidades de datos
- Aprovisionamiento de sistemas
- Copia de seguridad y replicación de datos
- Toma de instantáneas
- Soporte de conmutación de sistema
- Garantía de integridad de datos
- Migración de datos
El Sistema de archivos global 2 (GFS2) de Red Hat proporciona varias habilidades especializadas. La función básica de GFS2 es proporcionar un sistema de archivos único, incluido el acceso concurrente de lectura y escritura, compartido a través de múltiples miembros de un clúster. Esto significa que cada miembro del clúster ve exactamente los mismos datos "en disco" en el sistema de archivos denominado GFS2.
1.3.3. Redes convergentes
Con los comandos de FCoE, los comandos de canal de fibra estándar y los paquetes de datos se transportan en una infraestructura física 10GbE a través de una sola tarjeta de red convergente (CNA). El tráfico de Ethernet estándar TCP/IP y las operaciones de almacenamiento de canal de fibra se pueden transportar a través del mismo enlace. FCoE usa una tarjeta de interfaz de red física (y un cable) para múltiples conexiones lógicas de almacenamiento y red.
- Número reducido de conexiones
- FCoE reduce a la mitad el número de conexiones de red a un servidor. Usted puede tener múltiples conexiones para rendimiento o disponibilidad; sin embargo, una sola conexión proporciona conexión de almacenamiento y redes. Esto es muy útil para servidor de caja de pizza y servidor de cuchilla, ya que ambos tienen espacio muy limitado para componentes.
- Menor costo
- El número reducido de conexiones significa una reducción de cables, interruptores y otro equipo de redes. La historia de Ethernet también presenta grandes economías de escala; el costo de redes cae de forma dramática cuando la cantidad de dispositivos en el mercado pasa de millones a mil millones, como se vio declinar el precio de dispositivos de Ethernet de 100Mb y Ethernet de gigabits.Igualmente, 10GbE serán más baratos cuando más negocios adapten su uso. Puesto que el hardware de CNA se integra en un solo chip, el uso extendido también aumentará su volumen en el mercado, lo cual se traducirá en una caída de precio significativa con el tiempo.
Internet SCSI (iSCSI) es otro tipo de protocolo de red convergente; es una alternativa para FCoE. Al igual que canal de fibra, iSCSI proporciona almacenamiento de nivel de bloques en una red. Sin embargo, iSCSI no proporciona una administración total del entorno. La ventaja principal sobre iSCSI en FCoE es que iSCSI proporciona mucha de la habilidad y flexibilidad de canal de fibra, pero a un bajo costo.
Capítulo 2. Funcionalidades de rendimiento de Red Hat Enterprise Linux 6
2.1. Soporte para 64 bits
- Páginas gigantes y páginas gigantes transparentes
- Mejoras Memoria de Acceso No-Uniforme
La implementación de páginas gigantes en Red Hat Enterprise Linux 6, permite al sistema administrar eficientemente el uso de memoria mediante cargas de trabajo de memoria. Las páginas gigantes usan 2 MB de páginas comparados con el tamaño estándar de página de 4 KB, lo cual permite a las aplicaciones escalar bien del procesamiento de GB a incluso TB de memoria.
Muchos de los sistemas ahora soportan Memoria de Acceso No-Uniforme (NUMA). NUMA simplifica el diseño y la creación de hardware para grandes sistemas; sin embargo, también añade una capa de complejidad para el desarrollo de aplicaciones. Por ejemplo, NUMA implementa memoria local y remota, donde acceder a la memoria remota puede tardar varias veces más que el acceso a la memoria local. Esta característica (entre otras) tiene muchas implicaciones en el rendimiento que impactan a los sistemas operativos, aplicaciones y configuraciones de sistema sobre los que deberían ser desplegados.
2.2. Cerrojos en bucle de tiquetes
2.3. Estructura de lista dinámica
2.4. Kernel sin intervalo
2.5. Grupos de control
- Una lista de tareas asignadas al Cgroup
- Recursos asignados a aquellas tareas
- CPUsets
- Memoria
- E/S
- Redes (ancho de banda)
2.6. Mejoras de almacenaje y sistemas de archivos
Ext4 es el sistema de archivos predeterminado de Red Hat Enterprise Linux 6. Es la versión de la cuarta generación de la familia del sistema de archivos EXT, que soporta en teoría un tamaño de sistema de archivos máximo de 1 exabyte, y un archivo único máximo de 16TB. Red Hat Enterprise Linux 6 soporta un tamaño de sistema máximo de 16TB, y un archivo único de 16TB. Además de ofrecer una mayor capacidad, ext4 también incluye nuevas funcionalidades, tales como:
- Metadatos basados en extensión
- Asignación demorada
- Suma de verificación en el diario
XFS es un sistema de archivos de diario robusto y maduro de 64 bits que soporta grandes archivos y sistemas de archivos en un solo host. Este sistema de archivos fue desarrollado inicialmente por SGI, y tiene una larga historia de ejecución en servidores extremadamente grandes y matrices de almacenamiento. Las funcionalidades XFS incluyen:
- Asignación demorada
- Inodos asignados de forma dinámica
- Indexación de Árbol-B para escalabilidad de administración de espacio libre.
- Desfragmentación en línea y crecimiento de sistema de archivos
- Metadatos sofisticados de algoritmos de lectura anticipada
El BIOS tradicional soporta un disco máximo de 2.2TB. Los sistemas de Red Hat Enterprise Linux 6 que utilizan BIOS pueden soportar discos de más de 2.2TB mediante una nueva estructura de disco llamada Tabla de particiones global (GPT). GPT puede utilizarse únicamente para discos de datos; no se puede utilizar para unidades de arranque con BIOS; por lo tanto, las unidades de arranque solo pueden tener un tamaño máximo de 2.2TB. El BIOS fue creado en un principio para los PC de IBM; aunque el BIOS evolucionó considerablemente para adaptarse al hardware moderno, la Interfaz de Firmware Extensible Unificada (UEFI) fue diseñada para soportar el nuevo hardware emergente.
Importante
Importante
Capítulo 3. Monitorización y análisis de rendimiento de sistemas
3.1. El sistema de archivos 'proc'
proc es un directorio que contiene una jerarquía de archivos que representan el estado actual del kernel de Linux.
proc también contiene información sobre hardware del sistema y cualquier proceso que esté actualmente en ejecución. La mayoría de estos archivos son solo de lectura, pero algunos archivos (principalmente los que están en /proc/sys) pueden ser manipulados por usuarios y las aplicaciones para comunicar los cambios al kernel.
proc, consulte la Guía de implementación, disponible en http://access.redhat.com/site/documentation/Red_Hat_Enterprise_Linux/.
3.2. Monitores de sistema KDE y GNOME
El Monitor del sistema GNOME muestra información básica y le permite monitorizar sus procesos del sistema, recursos y uso del sistema de archivos. Ábralo con el comando gnome-system-monitor en la Terminal, o haga clic en el menú de y seleccione > .
- Muestra la información básica sobre el hardware y software del computador
- Muestra los procesos activos y las relaciones entre los procesos, y la información detallada sobre cada uno de ellos. También le permite filtrar los procesos y realizar algunas acciones en dichos procesos (iniciar, detener, matar, cambiar prioridad, etc)
- Muestra el uso del tiempo de la CPU actual, la memoria y el espacio de intercambio y el uso de la red.
- Lista todos los sistemas de archivos montados junto con información básica de cada uno, tal como el tipo de sistema de archivos, punto de montaje y uso de memoria.
El Guardián del sistema de KDE le permite monitorizar la carga del sistema actual y los procesos que están en ejecución. También le permite realizar acciones en procesos. Ábralo mediante el comando ksysguard en la Terminal, o haga clic en el y seleccione > > .
- Muestra una lista de los procesos que se ejecutan, de forma predeterminad, en orden alfabético. También puede clasificar los procesos por un número de propiedades, incluidas el uso de CPU, el uso de memoria física y compartida, el propietario y prioridad. Además, puede filtrar los resultados visibles, buscar procesos específicos o realizar algunas acciones en un proceso.
- Muestra gráficas del historial de uso de CPU, espacio de memoria e intercambio y uso de red. Vaya sobre las gráficas para obtener un análisis detallado y claves de gráfico.
3.3. Herramientas de monitorización de línea de comandos
topLa herramienta top proporciona una vista dinámica en tiempo real de los procesos en un sistema en ejecución. Puede mostrar una variedad de información que incluye un resumen del sistema y las tareas que son administradas en el momento por el kernel de Linux. También tiene una habilidad limitada para manipular procesos. Tanto la operación como la información que presenta se pueden configurar muy bien y cualquier detalle de configuración puede hacerse persistente a través los reinicios.
man top.
psLa herramienta ps toma una instantánea de un grupo selecto de procesos activos. Este grupo se limita, de forma predeterminada, a los procesos pertenecientes al usuario actual y que están asociados a la misma terminal.
man ps.
vmstatvmstat (Estadísticas de memoria virtual) produce reportes instantáneos sobre los procesos de sistema, memoria, paginación, E/S de bloques, interrupciones y actividad de CPU.
man vmstat.
sarEl SAR (Reportero de actividad del sistema) recolecta y reporta información sobre la actividad del sistema hasta el momento de hoy. La salida predeterminada cubre el uso de CPU de hoy en intervalos de 10 minutos desde el comienzo del día.
12:00:01 AM CPU %user %nice %system %iowait %steal %idle 12:10:01 AM all 0.10 0.00 0.15 2.96 0.00 96.79 12:20:01 AM all 0.09 0.00 0.13 3.16 0.00 96.61 12:30:01 AM all 0.09 0.00 0.14 2.11 0.00 97.66 ...
man sar.
3.4. Tuned y ktune
default- El perfil predeterminado de ahorro de energía. Es el perfil de ahorro de energía más básico. Habilita únicamente los complementos de disco y CPU. Observe que no es lo mismo que apagar tuned-adm, donde tanto tunedy ktune están inactivos.
latency-performance- Un perfil de servidores para ajuste de rendimiento de latencia típico. Desactiva los mecanismos de ahorro de energía de tuned y ktune. El modo de
cpuspeedcambia arendimiento. El elevador de E/S cambia afecha límitepara cada dispositivo. Para calidad de administración de energía de servicio, el valor de requerimiento decpu_dma_latencyse registra con un valor de0. throughput-performance- Un perfil de servidor para ajuste de rendimiento típico. Este perfil se recomienda si el sistema no tiene almacenamiento de clase empresarial. Es igual a
latency-performance, excepto:kernel.sched_min_granularity_ns(granularidad de preferencia mínima del programador) se establece a10milisegundos,kernel.sched_wakeup_granularity_ns(granularidad de despertador del programador) se establece a15milisegundos,vm.dirty_ratio(relación sucia de máquina virtual) se establece a 40%, y- las páginas gigantes transparentes se activan.
enterprise-storage- Este perfil se recomienda para configuraciones de servidor de tamaño empresarial con almacenamiento de clase empresarial, que incluye protección de cache y administración de controlador de batería de respaldo de cache en disco. Es similar al perfil de
throughput-performancecon una sola adición: los sistemas de archivos se remontan conbarrier=0. virtual-guest- Este perfil se recomienda para configuraciones de servidor de tamaño empresarial con almacenamiento de clase empresarial, que incluye protección de cache y administración de controlador de batería de respaldo de cache en disco. Es igual que el perfil de
throughput-performance, excepto que:- el valor
readaheadse establece a4x, y - los sistemas de archivos no root/boot se remontan con
barrier=0.
virtual-host- Basándose en el perfil de almacenaje de
enterprise-storage,virtual-hosttambién decrece en swappiness de memoria virtual y habilita más retro-escritura agresiva de páginas sucias. Este perfil está disponible en Red Hat Enterprise Linux 6.3 y posterior, y es el perfil recomendado para hosts de virtualización, incluidos los hosts de KVM y de Red Hat Enterprise Virtualization.
3.5. Perfiladores de aplicaciones
3.5.1. SystemTap
3.5.2. OProfile
- Las muestras de monitorización de rendimiento no pueden ser precisas, puesto que el procesador puede ejecutar instrucciones que no funcionan o registrar una muestra de una instrucción cercana, en lugar de la instrucción que produjo la interrupción.
- Puesto que OProfile es un sistema amplio y espera que los procesos inicien y se detengan varias veces, se permite que las muestras acumulen múltiples ejecuciones. Es decir, que puede es posible que tenga que limpiar datos de muestras de ejecuciones anteriores.
- Se enfoca en la identificación de problemas con procesos de CPU limitada y por lo tanto, no identifica los procesos que están durmiendo mientras esperan cerrojos para otros eventos.
/usr/share/doc/oprofile-<versión>.
3.5.3. Valgrind
man valgrind cuando sea instalado el paquete de valgrind. También encontrará documentación en:
/usr/share/doc/valgrind-<versión>/valgrind_manual.pdf/usr/share/doc/valgrind-<version>/html/index.html
3.5.4. Perf
perf stat- Este comando proporciona las estadísticas generales para eventos de rendimiento, que incluyen instrucciones ejecutadas y ciclos de reloj consumidos. Utilice los indicadores para reunir estadísticas sobre eventos diferentes a los eventos de medidas predeterminados. A partir de Red Hat Enterprise Linux 6.4, es posible usar
perf statpara filtrar monitorización basada en uno o más grupos de control (cgroups). Para obtener mayor información, consulte la página de manual:man perf-stat. perf record- Este comando registra datos de rendimiento en un archivo que puede ser analizado más adelante mediante
perf report. Para obtener mayor información, consulte la página de manual:man perf-record. perf report- Este comando lee los datos de rendimiento de un archivo y analiza los datos registrados. Para obtener mayor información, consulte la página de manual:
man perf-report. perf list- Este comando lista los eventos disponibles en una determinada máquina. Dichos eventos varían según el hardware de monitorización de rendimiento y el software de configuración del sistema. Para obtener mayor informacón, consulte la página de manual:
man perf-list. perf top- Este comando realiza una función similar a la herramienta top. Genera y despliega un perfil de contador de rendimiento en tiempo real. Para obtener mayor información, consulte la página de manual:
man perf-top.
3.6. Red Hat Enterprise MRG
- Los parámetros de BIOS relacionados con la administración de energía, detección de errores e interrupciones de administración del sistema;
- los parámetros de redes, tales como interrupción de coalescencia, y el uso de TCP;
- Actividad de diario en sistemas de archivos de diario
- ingreso a sistema;
- Si las interrupciones o procesos de usuario son manejadas por una CPU o un rango de CPU específicas;
- Si el espacio swap es utilizado; y
- cómo tratar excepciones de falta de memoria.
Capítulo 4. CPU
Topología
Hilos
Interrupciones
4.1. Topología de CPU
4.1.1. Topología de CPU y Numa
- Buses seriales
- Topologías de NUMA
- ¿Qué significa topología del sistema?
- ¿En dónde se está ejecutando la aplicación?
- ¿En dónde se encuentra el banco de memoria más cercano?
4.1.2. Ajuste de rendimiento de la CPU
- Una CPU (0-3) presenta la dirección de memoria para el controlador local.
- El controlador de memoria configura el acceso a la dirección de memoria.
- La CPU realiza operaciones de lectura y escritura en esa dirección de memoria.
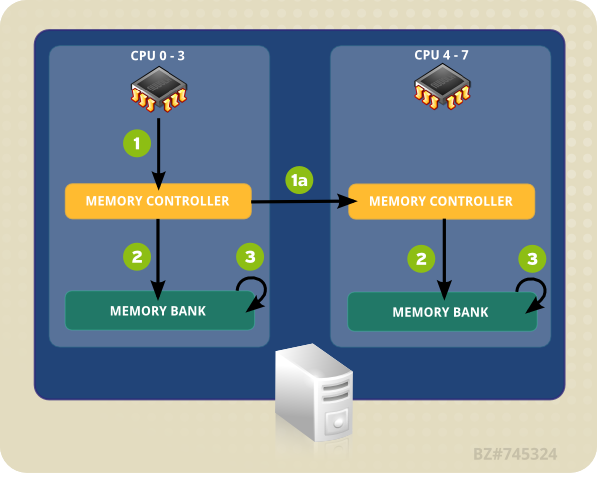
Figura 4.1. El acceso de memoria remota y local en topología de NUMA
- Una CPU (0-3) presenta la dirección de memoria remota para el controlador de memoria local.
- La solicitud de CPU para la dirección de memoria remota se pasa a un controlador de memoria remota, local al nodo que contiene la dirección de memoria.
- El controlador de memoria remota configura el acceso a la dirección de memoria remota.
- La CPU realiza operaciones de lectura y escritura en esa dirección de memoria remota.
- la topología de los componentes del sistema (cómo se conectan sus componentes),
- el núcleo en el cual se ejecuta la aplicación, y
- la ubicación del banco de memoria más cercano.
4.1.2.1. Configuración de afinidad de CPU con taskset
0x00000001 representa procesador 0, y 0x00000003 representa procesador 0 y 1.
# taskset -p máscara pid
# taskset mask -- program
-c para proporcionar una lista delimitada por comas o un rango de procesadores, como:
# taskset -c 0,5,7-9 -- myprogram
man taskset.
4.1.2.2. Control de la política NUMA con numactl
numactl ejecuta procesos con programación especificada o política de ubicación de memoria. La política seleccionada se establece para este proceso y todos sus hijos. numactl también puede establecer política persistente para segmentos o archivos de memoria compartida y establece afinidad de CPU y afinidad de memoria de un proceso. Utiliza el sistema de archivos /sys para determinar la topología del sistema.
/sys contiene información sobre cómo se conectan las CPU, la memoria y los dispositivos periféricos mediante interconexiones NUMA. En particular, el directorio /sys/devices/system/cpu contiene información sobre cómo se conectan las CPU de un sistema a otro. El directorio /sys/devices/system/node contiene información sobre los nodos NUMA en el sistema, y las distancias relativas entre dichos nodos.
--show- Despliega lo parámetros de política NUMA del proceso actual. Este parámetro no requiere parámetros adicionales y puede ser utilizado como tal:
numactl --show. --hardware- Despliega un inventario de los nodos disponibles en el sistema
--membind- Solamente asigna memoria desde los nodos especificados. Cuando está en uso, la asignación de memoria fallará en estos nodos si es insuficiente. El uso para este parámetro es
numactl --membind=nodos programa, where nodos es la lista de nodos de la cual desea asignar memoria y programa es el programa cuyos requerimientos de memoria deberían asignarse desde ese nodo. Los números de nodos puede otorgarse como una lista delimitada por comas, un rango o una combinación de los dos. Para obtener mayor información sobre numactl, consulte la página de manual:man numactl. --cpunodebind- Solamente ejecute un comando (y sus procesos hijos) en las CPU pertenecientes al nodo especificado. El uso para este parámetro es
numactl --cpunodebind=nodos programa, donde nodos es la lista de nodos a cuyas CPU será vinculado el programa especificado (programa). Los números de nodos pueden presentarse como una lista delimitada por comas, un rango o combinación de dos. Para mayor información sobre numactl, consulte la página de manual:man numactl. --physcpubind- Solamente ejecute un comando (y sus procesos hijos) en las CPU especificadas. El uso para este parámetro es
numactl --physcpubind=cpu program, donde cpu es una lista delimitada por comas de los números de CPU como aparecen en los campos de/proc/cpuinfo, y programa es el programa que debe ejecutarse solo en esas CPU. Las CPU también pueden especificarse con relación a lacpusetactual. Para obtener mayor información sobre numactl, consulte la página de manual:man numactl. --localalloc- Especifica que la memoria siempre debe asignarse en el nodo actual
--preferred- Donde sea posible, la memoria es asignada en el nodo especificado. Si la memoria no puede asignarse en el nodo especificado, se conmutará a otros nodos. Esta opción toma únicamente un nodo individual, así:
numactl --preferred=nodo. Para obtener mayor información sobre numactl, por favor consulte la página de manual:man numactl.
man numa(3).
4.1.3. numastat
Importante
numastat, sin opciones ni parámetros) mantiene una compatibilidad estricta con la versión anterior a la herramienta, observe que las provisiones de iones o parámetros para este comando cambia de forma significativa tanto el contenido de salida como el formato.
numastat se despliega de forma predeterminada el número de páginas de memoria ocupadas por las siguientes categorías de eventos para cada nodo.
numa_miss y numa_foreign.
Categorías de trazado predeterminado
- numa_hit
- El número de asignaciones intentadas en este nodo que no fueron exitosas.
- numa_miss
- El número de asignaciones designadas a otro nodo que fueron asignadas en este nodo debido a baja memoria en el nodo designado. Cada evento
numa_misstiene un evento correspondientenuma_foreignen otro nodo. - numa_foreign
- El número de asignaciones que destinadas inicialmente para este nodo que fueron asignadas a otro nodo. Cada evento
numa_foreigntiene un eventonuma_misscorrespondiente en otro nodo. - interleave_hit
- El número de asignaciones de políticas de intercalación intentadas en este nodo que fueron exitosas.
- local_node
- El número de veces que un proceso en este nodo asignó memoria correctamente en este nodo.
- other_node
- El número de veces que un proceso en este nodo asigna memoria correctamente en este nodo.
-c- De forma horizontal condensa la tabla de información desplegada. Es útil en sistemas con un gran número de nodos NUMA, pero la anchura de columnas y el espacio entre columnas son, de alguna manera, predecibles. Cuando se utiliza esta opción, la cantidad de memoria se redondea al megabyte más cercano.
-m- Muestra la información de uso de memoria en todo el sistema en una base por nodo, similar a la información que se encuentra en
/proc/meminfo. -n- Muestra la misma información que la original de
numastat(numa_hit, numa_miss, numa_foreign, interleave_hit, local_node, and other_node), con un formato actualizado, mediante MB como la unidad de medida -p patrón- Muestra información de memoria por nodo para un patrón específico. Si el valor para el patrón consta de dígitos, numastat supone que es un identificador de procesos numérico. De lo contrario, numastat busca líneas de comando de procesos para el patrón especificado.Se asume que los argumentos de línea de comandos ingresados después del valor de la opción
-psean patrones adicionales para ser filtrados. Los patrones adicionales expanden el filtro, en lugar de estrecharlo. -s- Clasifica los datos desplegados en orden descendente para que los que consumen más memoria (según la columna
total) estén en la lista de primeros.También puede especificar un nodo, y la tabla será organizada según la columna de nodo. Al usar esta opción, el valor de nodo debe ir acompañado de la opción-sinmediatamente, como se muestra aquí:numastat -s2
No incluya el espacio en blanco entre la opción y su valor. -v- Muestra información más detallada. Es decir, información del proceso para múltiples procesos desplegará información detallada para cada proceso.
-V- Despliega información sobre la versión de numastat.
-z- Omite las filas y columnas de tabla con valores de cero únicamente. Observe que los valores cercanos a cero se redondean a cero para propósitos de despliegue y no serán omitidos de la salida desplegada.
4.1.4. Daemon de administración de afinidad NUMA (numad)
/proc para monitorizar los recursos del sistema disponibles por nodo. En daemon intenta entonces colocar los procesos importantes en nodos de NUMA que tienen alineada suficiente memoria y recursos de CPU para óptimo rendimiento de NUMA. El umbral actual para administración de procesos es de por lo menos 50% de una CPU y al menos 300 MB de memoria. numad intenta mantener un nivel de utilización de recursos y re-equilibrar las asignaciones cuando sea necesario al trasladar los procesos entre nodos de NUMA.
-w para consejo de pre-colocación, consulte la página de manual: man numad.
4.1.4.1. Se beneficia de numad
4.1.4.2. Modos de operación
Nota
- como un servicio
- como un ejecutable
4.1.4.2.1. Uso de numad como un servicio
# service numad start
# chkconfig numad on
4.1.4.2.2. Uso de numad como un ejecutable
# numad
/var/log/numad.log.
# numad -S 0 -p pid
-p pid- Añade el pid especificado a una lista de inclusión explícita. El proceso especificado no será administrado, sino hasta cuando alcance el umbral de importancia del proceso de numad.
-S modo- El parámetro
-Sespecifica el tipo de proceso que escanea. Al establecerlo a0limita la administración de numad a proceso incluidos de forma explícita.
# numad -i 0
man numad.
4.2. Programación de CPU
- Políticas de Realtime
- SCHED_FIFO
- SCHED_RR
- Políticas normales
- SCHED_OTHER
- SCHED_BATCH
- SCHED_IDLE
4.2.1. Políticas de programación Realtime
SCHED_FIFO- Esta política también se conoce como programación de prioridad estática, porque define una prioridad fijada (entre 1 y 99) para cada hilo. El programador escanea una lista de hilos SCHED_FIFO en orden de prioridad y programa el hilo con prioridad más alta listo para ejecutarse. Este hilo se ejecuta hasta que se bloquea, sale o es prevaciado por una prioridad mayor que está lista para ejecutarse.La prioridad inferior del hilo de tiempo real será programada por antes de cualquier hilo con una política de no-realtime; si únicamente existe un hilo de tiempo real, el valor de prioridad
SCHED_FIFOno es problema. SCHED_RR- Una variante round-robin de la política
SCHED_FIFO. Los hilos deSCHED_RRtambién reciben una prioridad fijada entre 1 y 99. Sin embargo, los hilos con la misma prioridad se reprograman al estilo round-robin dentro de un cierto quantum, o porción de tiempo. La llamada de sistemasched_rr_get_interval(2)retorna el valor de la porción de tiempo, pero la duración de la porción del tiempo no puede ser establecida por usuario. Esta política es útil si se necesita múltiples hilos con la misma prioridad.
SCHED_FIFO se ejecutan hasta que se bloqueen, salgan, o sean prevaciadas por un hilo con una prioridad superior. Por lo tanto, establecer una prioridad de 99 no se recomienda, ya que esto sitúa su proceso al mismo nivel de prioridad como hilos de migración y vigilancia. Si estos hilos se bloquean debido a que su hilo va a un bucle de computación, no podrán ejecutarse. Los sistemas de un procesador, terminarán bloqueándose en esta situación.
SCHED_FIFO incluye un mecanismo de capa de banda ancha. Esto protege a los programadores de aplicaciones de tiempo real de las tareas de tiempo real que podrían monopolizar la CPU. Este mecanismo puede ajustarse mediante los siguientes parámetros del sistema de archivos /proc:
/proc/sys/kernel/sched_rt_period_us- Define el periodo de tiempo para considerarse cien por ciento de ancho de banda de CPU, en microsegundos ('us' siendo el equivalente más cercano a 'µs' en texto plano). El valor predeterminado es 1000000µs, o 1 segundo.
/proc/sys/kernel/sched_rt_runtime_us- Define el periodo de tiempo dedicado a la ejecución de hilos en tiempo real, en microsegundos (siendo 'us' la forma más cercana en texto plano a 'µs'). El valor predeterminado es 950000µs, o 0.95 segundos.
4.2.2. Políticas de programación normales
SCHED_OTHER, SCHED_BATCH y SCHED_IDLE. Sin embargo, las políticas SCHED_BATCH y SCHED_IDLE son para trabajos de una prioridad muy baja, y como tal son de interés limitado en una guía de ajuste de rendimiento.
SCHED_OTHER, oSCHED_NORMAL- La política de programación predeterminada. Esta política usa el Programador de reparto justo (CFS) para proporcionar periodos de acceso justo a todos los hilos por medio de esta política. CFS establece una lista dinámica de prioridades en parte basada en el valor de
nicenessde cada hilo de proceso. (Consulte la Guía de implementación para obtener mayor información sobre este parámetro y el sistema de archivos/proc.) Esto le otorga a los usuarios un nivel de control indirecto sobre la prioridad de procesos, pero la lista de prioridad dinámica solamente puede ser cambiada por el CFS.
4.2.3. Selección de políticas
SCHED_OTHER y permita que el sistema administre el uso de CPU por usted.
SCHED_FIFO. Si tiene una pequeña cantidad de hilos, considere aislar un socket y trasladarlo a núcleos de socket para que no haya hilos compitiendo entre sí por tiempo en los núcleos.
4.3. Interrupciones y ajuste de IRQ
/proc/interrupts lista el número de interrupciones por CPU por dispositivo de E/S. Muestra el número de IRQ, el número de dicha interrupción manejada por cada núcleo de CPU, el tipo de interrupción y la lista delimitada por comas de controladores registrados para recibir esa interrupción. (Para obtener mayor información, consulte la página de manual: man 5 proc)
smp_affinity, que define los núcleos de CPU permitidos para ejecutar la ISR de dicha IRQ. Esta propiedad puede servir para mejorar el rendimiento de aplicaciones al asignar tanto afinidad de interrupciones como afinidad de hilos de aplicaciones a uno o más núcleos de CPU específicos. Así permite compartir la línea de cache entre aplicaciones de interrupciones e hilos.
/proc/irq/NÚMERO_IRQ/smp_affinity asociado, el cual se puede ver y modificar mediante el usuario de root. El valor almacenado en estee archivo es una máscara de bits hexadecimal que representa todos los núcleos de CPU en el sistema.
# grep eth0 /proc/interrupts 32: 0 140 45 850264 PCI-MSI-edge eth0
smp_affinity:
# cat /proc/irq/32/smp_affinity f
f, lo que significa que la IRQ puede servirse de las CPU en el sistema. Si configura este valor a 1, como se muestra a continuación, significa que solamente la CPU 0 puede servir esta interrupción:
# echo 1 >/proc/irq/32/smp_affinity # cat /proc/irq/32/smp_affinity 1
smp_affinity para grupos de 32 bits. Esto se requiere en sistemas con más de 32 núcleos. Por ejemplo, el siguiente ejemplo muestra que la IRQ 40 se sirve en todos los núcleos de un sistema de núcleos de 64:
# cat /proc/irq/40/smp_affinity ffffffff,ffffffff
# echo 0xffffffff,00000000 > /proc/irq/40/smp_affinity # cat /proc/irq/40/smp_affinity ffffffff,00000000
Nota
smp_affinity de una IRQ se configura el hardware para que la decisión de servir una interrupción con una CPU determinada se haga en el nivel del hardware, sin ninguna intervención del kernel.
4.4. Mejoras a NUMA en Red Hat Enterprise Linux 6
4.4.1. Optimización de escalabilidad y en vacío
4.4.1.1. Mejoras en reconocimiento de topología
- Detección de topología mejorada
- Permite al sistema operativo detectar información de hardware de bajo nivel (tal como CPU, hiper procesos, núcleos, conectores, nodos de NUMA y tiempos de acceso en su sistema.
- Programador de reparto justo
- Este nuevo modo de programación garantiza que el tiempo de ejecución sea compartido por igual entre los procesos elegibles. Al combinarlo con esta detección de topología permite la programación de los procesos en las CPU dentro del mismo conector para evitar el costoso acceso de memoria remota, y garantizar que el contenido de cache sea preservado siempre que sea posible.
mallocmallocahora se ha optimizado para garantizar que las regiones de memoria asignadas al proceso sean tan físicas como sea posible. Incluido el aumento de velocidad de acceso de memoria.- asignación de búfer de E/S skbuff
- Al igual que
malloc, ha sido optimizado para usar memoria que está cerca físicamente a las operaciones de manejo de E/S tales como la interrupciones. - Afinidad de interrupciones de dispositivo
- La información registrada por los controladores de dispositivos acerca de cuál CPU maneja cada una de las interrupciones, puede utilizarse para restringir el manejo de interrupciones a las CPU dentro del mismo conector físico, preservando así, la afinidad de cache y limitando la comunicación entre conectores de alto volumen.
4.4.1.2. Mejoras en sincronización de multiprocesador
- Cerrojos de Leer-Copiar-Actualizar (RCU)
- El 90% de cerrojos suele adquirirse para propósitos de lectura. El cerramiento de RCU retira la necesidad para obtener un cerrojo de acceso exclusivo cuando los datos que se acceden no sean modificados. Este modo de cerramiento ahora se utiliza para asignar o desasignar operaciones.
- algoritmos por CPU y por socket
- Muchos algoritmos han sido actualizados para realizar coordinación de cerrojos entre las CPU que cooperan en el mismo socket para permitir un cerramiento más específico. Numerosos Spinlocks han sido sustituidos por métodos de cerramiento por socket, y zonas de asignador de memoria actualizadas y listas de páginas de memoria relacionadas con la lógica de asignación de memoria para atravesar un subconjunto de estructuras de datos de operaciones de asignación o desasignación de memoria.
4.4.2. Optimización de virtualización
- Enclavar la CPU
- Los huéspedes virtuales pueden ser vinculados para que se ejecuten en un conector específico, con el fin de optimizar el uso de la cache local y retirar la necesidad de costosas comunicaciones interconectadas y acceso de memoria remota.
- Páginas gigantes transparentes (THP)
- Con las THP habilitadas, el sistema realiza automáticamente las solicitudes de asignación de memoria de reconocimiento de NUMA para grandes cantidades de memoria contigua, reduciendo así, la contención del cerrojo y el número de operaciones requeridas de Translation Lookaside Buffer (TLB) y generando un aumento de rendimiento de más de 20% en huéspedes virtuales.
- Implementación de E/S basada en Kernel
- El subsistema de E/S del huésped virtual ahora se implementa en el kernel, reduciendo así, el costo de la comunicación internodal y el acceso de memoria al evitar una cantidad significativa de cambios de contexto, y sincronización y gasto de comunicaciones.
Capítulo 5. Memoria
5.1. Huge Translation Lookaside Buffer (HugeTLB)
/usr/share/doc/kernel-doc-version/Documentation/vm/hugetlbpage.txt
5.2. Páginas gigantes y páginas gigantes transparentes
- Aumentar el número de entradas de tabla de páginas en la unidad de administración de memoria
- Aumentar el tamaño de página
5.3. Cómo utilizar Valgrind para perfilar el uso de memoria
valgrind --tool=nombre de herramienta programa
memcheck, massif, o cachegrind), y programa por el programa que desea perfilar con Valgrind. Tenga en cuenta que la instrumentación de Valgrind hará que su programa se ejecute más lentamente que lo normal.
man valgrind cuando el paquete valgrind esté instalado o se encuentre en los siguientes sitios:
/usr/share/doc/valgrind-versión/valgrind_manual.pdf, y/usr/share/doc/valgrind-version/html/index.html.
5.3.1. Perfilar uso de memoria con Memcheck
valgrind programa, sin especificar --tool=memcheck. Detecta y reporta una serie de errores que pueden dificultar la detección y el diagnóstico, tal como el acceso a la memoria, lo cual no debería ocurrir, el uso de valores indefinidos o no inicializados, memoria de montículo liberada incorrectamente, punteros superpuestos y escapes de memoria. Los programas se ejecutan diez o treinta veces más lentamente con Memcheck que cuando se ejecutan normalmente.
/usr/share/doc/valgrind-versión/valgrind_manual.pdf.
--leak-check- Si Memcheck está habilitada, buscará escapes de memoria cuando el programa de cliente termine. El valor predeterminado es
summary, el cual emite el número de escapes que encuentra. Otros valores posibles sonyesyfull, ambos informan sobre cada escape, y el valorno, desactiva la verificación de escape de memoria. --undef-value-errors- Si Memcheck está habilitada (
yes), reportará errores cuando se utilicen valores indefinidos. Si Memcheck está inhabilitada (no), los valores de errores indefinidos no se reportarán. Este valor es el predeterminado. Al inhabilitarlo se agiliza un poco Memcheck. --ignore-ranges- Permite al usuario especificar uno más rangos que Memcheck debe ignorar al verificar el direccionamiento. Los múltiples rangos están delimitados por comas, por ejemplo,
--ignore-ranges=0xPP-0xQQ,0xRR-0xSS.
/usr/share/doc/valgrind-version/valgrind_manual.pdf.
5.3.2. Perfilar uso de cache con Cachegrind
# valgrind --tool=cachegrind programa
- lecturas de cache de instrucciones de primer nivel (o instrucciones ejecutadas) y pérdidas de lecturas, y pérdidas de lectura de instrucción cache de último nivel;
- lecturas de cache de datos (o lecturas de memoria), pérdidas de lectura y pérdidas de lectura de datos cache de último nivel;
- escrituras de cache de datos (o escrituras de memoria), pérdidas de escritura y pérdidas de escritura de cache de último nivel.
- saltos condicionales ejecutados y predichos erróneamente; y
- saltos indirectos ejecutados y predichos erróneamente
cachegrind.out.pid predeterminado, donde pid es el número de proceso en el que se ejecutó Cachegrind). Este archivo puede ser procesado por la herramienta de acompañamiento cg_annotate , de esta manera:
# cg_annotate cachegrind.out.pid
Nota
# cg_diff primero segundo
--I1- Especifica el tamaño, la capacidad de asociación y el tamaño de línea de la cache de instrucción de primer nivel, separados por comas:
--I1=tamaño,asociatividad,tamaño de línea. --D1- Especifica el tamaño, capacidad de asociación y tamaño de línea de cache de datos de primer nivel, separados por comas:
--D1=tamaño,asociatividad,tamaño de línea. --LL- Especifica el tamaño, la capacidad de asociación y el tamaño de línea de la cache de instrucción de último nivel, separados por comas:
--LL=tamaño,asociatividad,tamaño de línea. --cache-sim- Habilita o inhabilita la recolección de acceso de datos y conteos de pérdidas. El valor predeterminado es
yes(habilitado).Observe que al inhabilitar ambos saltos y--branch-simno le dejará a Cachegrind ninguna información para recolectar. --branch-sim- Habilita o inhabilita la instrucción de saltos y conteos predichos erróneamente. Se establece a
no(inhabilitado) de forma predeterminada, ya que ralentiza a Cachegrind en un 25 por ciento.Observe que al inhabilitar ambos saltos y--cache-simdejará a Cachegrind sin ninguna información para recolectar.
/usr/share/doc/valgrind-version/valgrind_manual.pdf.
5.3.3. Cómo perfilar montículo y espacio de montículo con Massif
massif como la herramienta de Valgrind que desea utilizar:
# valgrind --tool=massif program
massif.out.pid, donde pid es el ID del proceso del programa especificado.
ms_print, así:
# ms_print massif.out.pid
--heap- Especifica si realiza o no el perfilado de montículo. El valor predeterminado es
yes. El perfilado de montículo puede ser desactivado al establecer esta opción ano. --heap-admin- Especifica el número de bytes por bloque a usar para administrar el perfilado de montículo. El valor predeterminado es de
8bytes por bloque. --stacks- Especifica si realiza o no el perfilado de pila. El valor predeterminado es
no(desactivado). Para habilitar el perfilado de pila, establezca esta opción ayes, pero tenga en cuenta que al hacerlo ralentizará ampliamente a Massif. Observe también que Massif supone que la pila principal tiene un tamaño de cero al inicio para indicar el tamaño de porción de pila sobre el cual el ente perfilado tiene control. --time-unit- Especifica la unidad de tiempo utilizada para el perfilado. Hay tres valores válidos para esta opción: instrucciones ejecutadas (
i), el valor predeterminado, el cual es útil en la mayoría de los casos; tiempo real (ms, en milisegundos), el cual puede ser útil en algunos casos; y bytes asignados o desasignados en el montículo y/o en la pila (B), el cual sirve para la mayoría de programas de ejecución corta y para pruebas, porque es el más reproducible a través de diferentes máquinas. Esta opción sirve para graficar salida de Massif conms_print.
/usr/share/doc/valgrind-version/valgrind_manual.pdf.
5.4. Capacidad de ajuste
overcommit_memory a 1, ejecute:
# echo 1 > /proc/sys/vm/overcommit_memory
sysctl. Para obtener mayor información, consulte la Guía de implementación, disponible en http://access.redhat.com/site/documentation/Red_Hat_Enterprise_Linux/.
Ajustables de memoria relacionados con la capacidad
/proc/sys/vm/ .
overcommit_memory- Define las condiciones que determinan si se acepta o niega una solicitud de memoria grande. Hay tres valores posibles para este parámetro:
0— el parámetro predeterminado. El kernel realiza sobre-envío de memoria heurística al estimar la cantidad de memoria disponible y fallar solicitudes que son evidentemente inválidas. Infortunadamente, como la memoria se asigna mediante una heurística en lugar de un algoritmo preciso, este parámetro, algunas veces autoriza la sobrecarga de memoria disponible en el sistema.1— el kernel realiza el manejo de sobre-envío de no memoria. Bajo este parámetro, la memoria potencial para sobrecarga aumenta, pero también el rendimiento para tareas intensivas de rendimiento.2— el kernel niega solicitudes para memoria igual o mayor que swap y el porcentaje de RAM físico especificado enovercommit_ratio. Este parámetro es mejor si desea un menor riesgo de sobreasignación de memoria.Nota
Este parámetro únicamente se recomienda para sistemas con áreas de swap más grandes que su memoria física.
overcommit_ratio- Especifica el porcentaje de memoria RAM física que se tiene en cuenta cuando
overcommit_memoryse establece a2. El valor predeterminado es50. max_map_count- Define el número máximo de áreas de mapas que un proceso puede usar . En la mayoría de los casos, el valor predeterminado de
65530es el apropiado. Aumente este valor si su aplicación necesita asignar más de este número de archivos. nr_hugepages- Define el número de páginas gigantes configuradas en el kernel. El valor predeterminado es 0. Solamente se pueden asignar (o desasignar) páginas gigantes si hay las suficientes páginas libres físicas contiguas. Las páginas reservadas por este parámetro no se pueden usar para otros propósitos. Puede obtener mayor información de la documentación instalada en:
/usr/share/doc/kernel-doc-kernel_version/Documentation/vm/hugetlbpage.txt
Ajustables de kernel relacionados con la capacidad
/proc/sys/kernel/.
msgmax- Define el tamaño máximo permitido en bytes de un mensaje individual en bytes de cualquier mensaje en la cola de mensajes. Este valor no debe exceder el tamaño de la cola (
msgmnb). El valor predeterminado es65536. msgmnb- Define el tamaño máximo en bytes de una cola de mensajes. El valor predeterminado es
65536. msgmni- Define el número máximo de identificadores de cola de mensajes (y por lo tanto, el número máximo de colas). El valor predeterminado en máquinas de arquitectura de 64 bits es
1985; para arquitectura de 32 bits, el valor predeterminado es1736. shmall- Define la cantidad total de memoria compartida en bytes que puede utilizarse en el sistema al mismo tiempo. El valor predeterminado en máquinas de arquitectura de 64 bits es
4294967296; para arquitectura de 32 bits, el valor predeterminado es268435456. shmmax- Define el máximo segmento de memoria compartida por el kernel, en bytes. El valor predeterminado en máquinas de arquitectura de 64 bits es
68719476736; para arquitectura de 32 bits, el valor predeterminado es4294967295. Sin embargo, el kernel soporta valores mucho más grandes. shmmni- Define el número máximo de todo el sistema de segmentos de memoria compartida. El valor predeterminado es
4096tanto en arquitectura de 64 bits como en la de 32 bits. threads-max- Define el número máximo de hilos (tareas) en todo el sistema que van a ser utilizados por el kernel al mismo tiempo. El valor predeterminado es igual al valor de kernel
max_threads. La fórmula en uso es:max_threads = mempages / (8 * THREAD_SIZE / PAGE_SIZE )
El valor mínimo dethreads-maxes20.
Ajustables de sistema de archivos relacionados con la capacidad
/proc/sys/fs/
aio-max-nr- Define el máximo número de eventos permitidos en todos los contextos asíncronos de E/S. El valor predeterminado es
65536. Observe que al cambiar este valor no se preasigna o redimensiona ninguna estructura de datos de kernel. file-max- Lista el número máximo de identificadores de archivos asignados por el kernel. El valor predeterminado coincide con el valor de
files_stat.max_filesen el kernel, el cual se establece al valor más grande, ya sea de(mempages * (PAGE_SIZE / 1024)) / 10, oNR_FILE(8192 en Red Hat Enterprise Linux). El aumento de este valor puede corregir errores ocasionados por la falta de identificadores de archivos disponibles.
Ajustables para matar un proceso en falta de memoria
/proc/sys/vm/panic_on_oom a 0 instruye al kernel para que llame a la función oom_killer cuando se presente una OOM. oom_killer puede matar procesos no autorizados y el sistema sobrevive.
oom_killer puede matar. Dicha función se localiza en el sistema de archivos proc, /proc/pid/, donde pid es el número de ID de proceso.
oom_adj- Define un valor de
-16a15que ayuda a determinar eloom_scorede un proceso. Entre más alto sea el valor deoom_score, más probabilidad habrá de queoom_killermate el proceso. Si estableceoom_adja un valor de-17se desactivará eloom_killerpara ese proceso.Importante
Cualquier proceso generado por el proceso ajustado heredará eseoom_scorede proceso. Por ejemplo, si un procesosshdestá protegido de la funciónoom_killer, todos los procesos iniciados por dicha sesión SSH también se protegerán. Esto puede afectar la capacidad de la funciónoom_killerpara rescatar el sistema si se presenta una OOM.
5.5. Ajuste de memoria virtual
swappiness- Un valor de 0 a 100 que controla el punto en el que cambia el sistema. Un valor alto da prioridad al rendimiento del sistema, al intercambiar de forma agresiva los procesos de memoria física cuando no están activos. Un valor bajo da prioridad a la interacción y evita el intercambio de procesos de memoria física por el tiempo que sea posible, lo cual decrece la latencia de respuesta. El valor predeterminado es
60. min_free_kbytes- El número mínimo de kilobytes a mantener libres a través del sistema. Este valor sirve para computar un valor de marca de agua para cada zona de memoria baja, a la cual se le asigna un número de páginas libres reservadas, proporcional a su tamaño.
Aviso
Sea cauteloso al establecer este parámetro, puesto que si los valores son demasiado altos o demasiado bajos pueden ocasionar daños.Si establece amin_free_kbytesdemasiado lento, evitará que el sistema reclame memoria. Esto hará que el sistema se cuelgue y ocasione procesos múltiples de OOM-killing.Sin embargo, si establece este parámetro a un valor demasiado alto (5-10 % de la memoria total del sistema) hará que la memoria de su sistema se agote inmediatamente. Linux está diseñado para usar todos los datos del sistema de archivos cache de RAM disponible. Si establece un valor demin_free_kbyteshará que el sistema consuma mucho tiempo reclamando memoria. dirty_ratio- Define un valor de porcentaje. La escritura de datos sucios comienza (a través de pdflush) cuando los datos sucios comprenden este porcentaje del total de memoria del sistema. El valor predeterminado es
20. dirty_background_ratio- Define un valor de porcentaje. La escritura de datos sucios comienza en el segundo plano (mediante pdflush) cuando los datos sucios comprimen este porcentaje de memoria total. El valor predeterminado es
10. drop_caches- Si establece este valor a
1,2, o3hará que el kernel envíe varias combinaciones de cache de página y de cache de plancha.- 1
- El sistema invalida y libera toda la memoria de cache de página.
- 2
- El sistema libera toda la cache de plancha de memoria no utilizada
- 3
- El sistema libera toda la cache de página y la memoria cache de plancha.
Esta es una operación no destructiva. Puesto que los objetos sucios no pueden ser liberados, se recomienda la ejecución desyncantes de establecer el valor de parámetro.Importante
El uso dedrop_cachespara liberar memoria no se recomienda en un entorno de producción.
swappiness a 50, ejecute:
# echo 50 > /proc/sys/vm/swappiness
sysctl. Para obtener mayor información, consulte la Guía de implementación, disponible en http://access.redhat.com/site/documentation/Red_Hat_Enterprise_Linux/.
Capítulo 6. Entrada/Salida
6.1. Funcionalidades
- Los discos de estado sólido (SSD) ahora se reconocen de forma automática, y el rendimiento del programador de E/S se ajusta para aprovechar el alto porcentaje de E/S por segundo (IOPS) que estos dispositivos pueden realizar.
- Se ha adicionado el soporte de descarte al kernel para reportar los rangos de bloques al almacenaje subyacente. Esto ayuda a los SSD con sus algoritmos de nivelación de uso. También ayuda a soportar el aprovisionamiento de bloques lógico (una clase de espacio de dirección virtual para almacenamiento) al mantener etiquetas más cerca en la cantidad de almacenamiento en uso.
- La implementación de la barrera del sistema de archivos ha sido revisada en Red Hat Enterprise Linux 6.1 para hacerla más funcional.
pdflushha sido remplazado por hilos de vaciador de dispositivos por respaldo, el cual mejora la escalabilidad del sistema en configuraciones con grandes cuentas de LUN.
6.2. Análisis

Figura 6.1. salida aio-stress para hilo 1, archivo 1
- aio-stress
- iozone
- fio
6.3. Herramientas
si (swap in), so (swap out), bi (block in), bo (block out), y wa (I/O wait time). si y so sirven cuando su espacio swap está en el mismo dispositivo de su partición de datos y como un indicador de presión de memoria general. si y bi son operaciones de lectura, mientras que so y bo son operaciones de escritura. Cada una de estas categorías se reporta en kilobytes. wa es el tiempo inactivo; indica qué porción de la cola de ejecución se bloquea al esperar a que la E/S termine.
free, buff, y cache son importantes. El valor de la memoria cache que aumenta junto al valor bo, seguido de una caída de la cache y un aumento en free indica que el sistema está realizando escritura diferida e invalidación de memoria cache de página.
avgqu-sz), podrá estimar cómo realizar el almacenaje mediante gráficas que genera y al caracterizar el rendimiento de su almacenaje. Algunas generalizaciones aplican: por ejemplo, si el tamaño de solicitud promedio es de 4KB y el tamaño de cola es 1, será poco probable que el rendimiento sea muy efectivo.
8,64 3 1 0.000000000 4162 Q RM 73992 + 8 [fs_mark] 8,64 3 0 0.000012707 0 m N cfq4162S / alloced 8,64 3 2 0.000013433 4162 G RM 73992 + 8 [fs_mark] 8,64 3 3 0.000015813 4162 P N [fs_mark] 8,64 3 4 0.000017347 4162 I R 73992 + 8 [fs_mark] 8,64 3 0 0.000018632 0 m N cfq4162S / insert_request 8,64 3 0 0.000019655 0 m N cfq4162S / add_to_rr 8,64 3 0 0.000021945 0 m N cfq4162S / idle=0 8,64 3 5 0.000023460 4162 U N [fs_mark] 1 8,64 3 0 0.000025761 0 m N cfq workload slice:300 8,64 3 0 0.000027137 0 m N cfq4162S / set_active wl_prio:0 wl_type:2 8,64 3 0 0.000028588 0 m N cfq4162S / fifo=(null) 8,64 3 0 0.000029468 0 m N cfq4162S / dispatch_insert 8,64 3 0 0.000031359 0 m N cfq4162S / dispatched a request 8,64 3 0 0.000032306 0 m N cfq4162S / activate rq, drv=1 8,64 3 6 0.000032735 4162 D R 73992 + 8 [fs_mark] 8,64 1 1 0.004276637 0 C R 73992 + 8 [0]
Total (sde): Reads Queued: 19, 76KiB Writes Queued: 142,183, 568,732KiB Read Dispatches: 19, 76KiB Write Dispatches: 25,440, 568,732KiB Reads Requeued: 0 Writes Requeued: 125 Reads Completed: 19, 76KiB Writes Completed: 25,315, 568,732KiB Read Merges: 0, 0KiB Write Merges: 116,868, 467,472KiB IO unplugs: 20,087 Timer unplugs: 0
- Q — Una E/S de bloque está en cola
- G — Obtener solicitudUna nueva E/S de bloque en cola no era candidata para fusionar con ninguna solicitud existente, por lo tanto se asigna una nueva petición de capa de bloque.
- M — Una E/S de bloque se fusiona con una solicitud existente.
- I — Una solicitud se inserta dentro de la cola de dispositivo.
- D — Una solicitud se expide al Dispositivo.
- C — Una solicitud es completada por el controlador.
- P — La cola de dispositivo se tapona para permitir que las solicitudes se acumulen.
- U — La cola de dispositivo se destapona para permitir que las solicitudes acumuladas se envíen al dispositivo.
- Q2Q — tiempo entre solicitudes enviadas a la capa de bloques
- Q2G — tiempo que se tarda desde el momento que una E/S de bloque es puesta en cola hasta el tiempo que obtiene una solicitud asignada.
- G2I — tiempo que se tarda desde que se asigna una solicitud al tiempo que se inserta en la cola del dispositivo.
- Q2M — tiempo que se tarda desde que E/S de un bloque es puesta en cola al tiempo que se fusiona con la solicitud existente.
- I2D — tiempo que se tarda desde que se inserta una solicitud en un dispositivo al tiempo que se emite al dispositivo.
- M2D — tiempo que se tarda desde la fusión de una E/S de bloque con la solicitud de salida hasta la emisión de la solicitud al dispositivo
- D2C — tiempo de servicio de la solicitud por dispositivo
- Q2C — tiempo total utilizado en la capa de bloques para una solicitud
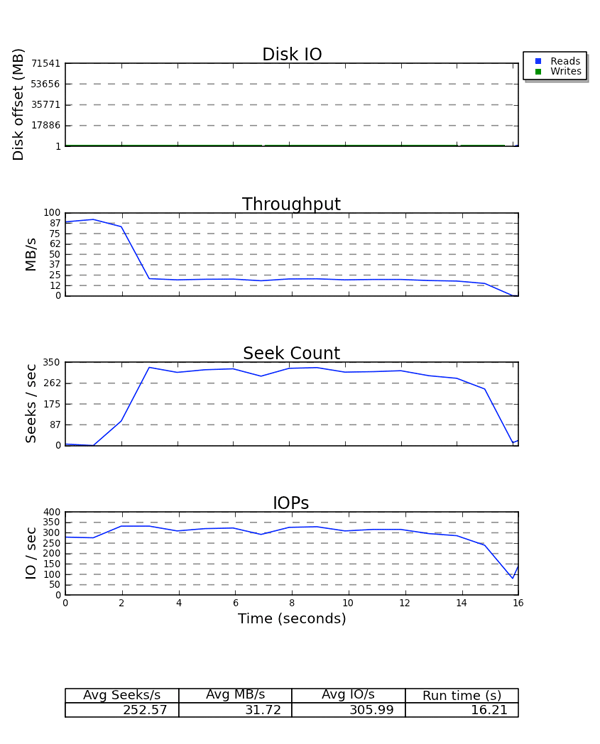
Figura 6.2. Ejemplo de salida de Seekwatcher
6.4. Configuración
6.4.1. Cola de reparto justo (CFQ)
ionice o asignada de forma programática con la llamada del sistema ioprio_set. Los procesos se sitúan de forma predeterminada en la clase de programación de mejor-esfuerzo. Las clases de programación de tiempo-real y el mejor-esfuerzo se subdividen en ocho prioridades de E/S dentro de cada clase, la prioridad superior es 0 y la prioridad inferior es 7. Los procesos en la clase de programación del tiempo se programan de una forma más agresiva que los procesos de mejor-esfuerzo e inactivos, por lo tanto cualquier E/S en tiempo-real programada siempre se realizará antes de E/S de mejor-esfuerzo o inactiva. Esto significa que la prioridad de E/S de tiempo-real no otorgará recursos a las clases de mejor-esfuerzo e inactivas. El mejor-esfuerzo de programación es la clase de programación predeterminada y 4 es la prioridad predeterminada dentro de esta clase. Los estados en clase de programación inactiva solo se sirven cuando no hay otra E/S pendiente en el sistema. Por lo tanto, es muy importante establecer a inactiva únicamente la clase de programación de E/S de un proceso, si E/S del proceso no se requiere de ninguna manera para continuar.
/sys/block/dispositivo/queue/iosched/:
slice_idle = 0 quantum = 64 group_idle = 1
group_idle a 1, aún existe el potencial para paradas de E/S (donde el almacenamiento de back-end no esté ocupado debido a inactividad). Sin embargo, estas paradas serán menos frecuentes que inactivas en cada cola en el sistema.
Ajustables
back_seek_max- Las búsquedas en retroceso no suelen tener un buen rendimiento, ya que incurren en mayor demora que las búsquedas anticipadas al reubicar las cabezas. Sin embargo, CFQ las realizará, si son lo suficientemente pequeñas. Este ajustable controla la distancia máxima en KB que el programador de E/S permitirá en búsquedas en retroceso. La predeterminada es
16KB. back_seek_penalty- Debido a la ineficacia de búsquedas en retroceso, la multa se asocia con cada una de ellas. La multa es un multiplicador; por ejemplo, considere una cabeza de disco en una posición de 1024KB. Asuma que hay dos solicitudes en la cola, una a 1008KB y otra a 1040KB. Las dos solicitudes son equidistantes a la posición de la cabeza actual. Sin embargo, después de aplicar la multa de búsqueda en retroceso (predeterminada: 2), la solicitud a una posición posterior en disco estará dos veces más cerca de la solicitud anterior. Por lo tanto, la cabeza avanzará.
fifo_expire_async- Este ajustable controla el tiempo que lleva una solicitud async sin servicio. Después del tiempo de expiración, (en milisegundos), una solicitud async sin servicio será trasladada a la lista de envío. El predeterminado es
250ms. fifo_expire_sync- Es el mismo ajustable fifo_expire_async, para solicitudes en sincronía (lectura y escritura O_DIRECT). El predeterminado es
125ms. group_idle- Si está configurado, CFQ se inactiva en el último proceso entregando E/S en un cgroup. Se debe configurar a
1cuando se usan cgroups de E/S de peso proporcional y se estableceslice_idlea0(típicamente se realiza en almacenamiento rápido). group_isolation- Si el aislamiento de grupo se activa (establece a
1), proporciona un aislamiento mayor entre grupos en gasto de rendimiento. Por lo general, si el aislamiento del grupo se desactiva, se hace justicia para las cargas de trabajo secuenciales únicamente. Al habilitar el aislamiento de grupos se hace justicia tanto a las cargas de trabajo secuenciales como a las aleatorias. El valor predeterminado es0(inhabilitado). ConsulteDocumentation/cgroups/blkio-controller.txtpara obtener mayor información. low_latency- Cuando la latencia baja está habilitada (
1), CFQ intenta proporcionar un tiempo máximo de espera de 300 ms para cada proceso que emite E/S en un dispositivo. Esto favorece la justicia en el rendimiento. Al inhabilitar la latencia baja (0) se ignora la latencia de destino, lo cual permite que cada proceso en el sistema obtenga una porción de tiempo completo. La latencia baja es la predeterminada. quantum- El quantum controla la cantidad de E/S que CFQ enviará al almacenaje al mismo tiempo, esencialmente la profundidad de cola de dispositivo que se predetermina a
8. El almacenamiento puede soportar mucha más profundidad de cola, pero el aumento dequantumtambién tendrá un impacto negativo en la latencia, sobre todo en la presencia de grandes cargas de trabajo de escritura secuenciales. slice_async- Este ajustable controla el tiempo asignado a cada proceso que se realiza E/S asíncrona (escritura en búfer). Por defecto, se predetermina a
40ms. slice_idle- Especifica el tiempo que CFQ debe estar inactivo mientras espera las siguientes solicitudes. El valor predeterminado en Red Hat Enterprise Linux 6.1 y anterior es
8ms. En Red Hat Enterprise Linux 6.2 y posterior, el valor predeterminado es0. El valor de cero mejora el rendimiento de almacenaje de RAID externo al retirar todo lo inactivo a nivel de cola y árbol de servicios. Sin embargo, un valor de cero puede degradar el rendimiento en almacenamiento interno non-RAID, puesto que aumenta el número total de búsquedas. Para almacenaje non-RAID, recomendamos que el valor deslice_idlesea mayor que 0. slice_sync- Este ajustable dicta la porción del tiempo asignado al proceso que se emite E/S en sincronía (lectura o escritura directa). La predeterminada es
100ms.
6.4.2. Programador de tiempo límite de E/S
Ajustables
fifo_batch- Determina el número de lectura y escritura a emitir en un lote sencillo. El predeterminado es
16. Un valor más alto, puede producir un mejor rendimiento, pero también un aumento en la latencia. front_merges- Puede establecer este ajustable a
0si sabe que su carga de trabajo nunca generará fusiones frontales. A menos que haya medido la sobrecarga de esta revisión, es aconsejable dejar el parámetro predeterminado:1. read_expire- Este ajustable le permite establecer el número en milisegundos, en el cual una solicitud de lectura debe ser servida. El predeterminado es
500ms (medio segundo). write_expire- Este ajustable le permite establecer el número en milisegundos, en el cual una solicitud de lectura debe ser servida. El predeterminado es
5000ms (cinco segundos). writes_starved- Este ajustable controla cuántos lotes de lectura pueden ser procesados antes de procesar un lote de escritura individual. Entre más alto se establezca, más preferencia se dará a las lecturas.
6.4.3. Noop
Ajustables /sys/block/sdX/queue
- add_random
- En algunos casos, los eventos de sobrecarga de E/S que contribuyen al grupo entrópico para
/dev/randomes medible. Algunas veces puede establecerse a un valor de 0. max_sectors_kb- El tamaño de solicitud máximo predeterminado enviado a disco es
512KB. Este ajustable sirve para aumentar o disminuir dicho valor. El valor mínimo está limitado por el tamaño de bloque lógico y el valor máximo está limitado pormax_hw_sectors_kb. Hay algunos SSD que funcionan peor cuando los tamaños de E/S exceden el tamaño de bloque de borrado interno. En estos casos, se recomienda ajustarmax_hw_sectors_kbal tamaño de bloque de borrado. Puede probarlo con un generador de E/S tal como iozone o aio-stress, variando el tamaño de registro de512bytes a1MB, por ejemplo. nomerges- Este ajustable es principalmente una ayuda de depuración. La mayoría de cargas de trabajo se benefician de la fusión de solicitudes (incluso en un almacenamiento más rápido tal como SSD). En algunos casos, sin embargo, es deseable desactivar la fusión, como cuando se desee ver cuántos IOPS puede procesar un back-end de almacenamiento sin desactivar la lectura anticipada o realizar E/S aleatoria.
nr_requests- Cada cola de solicitud tiene un límite en el total de solicitudes de descriptores que pueden asignarse para cada E/S de lectura y escritura . El número predeterminado es
128, es decir 128 lecturas y 128 escrituras pueden ser puestas en cola a la vez antes de poner a dormir el proceso. El proceso que fue puesto a dormir es el siguiente que intenta asignar una solicitud, no necesariamente el haya asignado todas las solicitudes disponibles.Si tiene una aplicación sensible de latencia, debe considerar disminuir el valor denr_requestsen su cola de solicitudes y limitar la profundidad de cola de comandos en el almacenaje a un número bajo (incluso tan bajo como1), así, la retro-escritura de E/S no puede asignar todos los descriptores de solicitudes disponibles y llenar la cola de dispositivo con E/S de escritura. Una vez se haya asignadonr_requests, todos los procesos que intentan realizar E/S serán puestos a dormir para esperar que las solicitudes estén disponibles. Esto hace que las cosas sean justas, ya que las solicitudes se distribuyen en round-robin (en lugar de permitir a un solo proceso consumirlos todos en una rápida sucesión). Observe que solamente es un problema cuando se usan los programadores de tiempo límite o Noop, ya que el CFQ predeterminado protege contra esta situación. optimal_io_size- En algunas circunstancias, el almacenamiento subyacente reportará un tamaño de E/S óptimo. Esto es más común en RAID de hardware y software, donde el tamaño de E/S óptimo es el tamaño de banda. Si este valor se reporta, las aplicaciones deberán emitir E/S alineada y en múltiples del tamaño óptimo de E/S siempre y cuando sea posible.
read_ahead_kb- El sistema operativo puede detectar cuándo una aplicación está leyendo datos en forma secuencial desde un archivo o un disco. En dichos casos, realiza un algoritmo de lectura anticipada inteligente, donde se leen más datos en el disco que los solicitados por el usuario. Así, cuando el usuario intenta leer un bloque de datos, ya habrá puesto en memoria cache de página del sistema operativo. La desventaja en potencia es que el sistema operativo puede leer más datos que los necesarios, lo cual ocupa espacio en la cache de página hasta que es desalojada debido a una presión de alta memoria. Al tener múltiples procesos haciendo una lectura anticipada, aumentaría la presión de memoria en estas circunstancias.Para dispositivos de mapeador de dispositivos, suele ser una buena idea aumentar el valor de
read_ahead_kba un número más grande, tal como8192. La razón es que ese dispositivo de mapeador de dispositivos suele componerse de varias dispositivos subyacentes. Establecer este parámetro al predeterminado (128KB) multiplicado por el número de dispositivos que usted está asignando es un buen comienzo para el ajuste. rotational- Los discos duros tradicionales han sido rotatorios (compuestos por bandejas rotatorias). No obstante, los SSD, no lo son. La mayoría de SSD lo publicará adecuadamente. Sin embargo, si se encuentra un dispositivo que no publique este indicador adecuadamente, deberá establecer, de forma manual, el rotatorio a
0; cuando el rotatorio esté desactivado, el elevador de E/S no emplea la lógica que se espera para reducir búsquedas, puesto que hay una pequeña multa para las operaciones de búsqueda en medios que no son rotatorios. rq_affinity- La afinación de E/S puede ser procesada en una CPU diferente a la que expidió la E/S. La configuración de
rq_affinitya1hace que el kernel entregue ajustes a la CPU en la cual se emitió E/S. Esto puede mejorar la efectividad de puesta en cache de datos de CPU.
Capítulo 7. Sistemas de archivos
7.1. Consideraciones de ajuste para sistemas de archivos
7.1.1. Opciones de formateo
El tamaño de bloque puede seleccionarse en tiempo de mkfs. El rango de dimensiones válidas depende del sistema: el límite superior es la dimensión de página máxima del sistema de host, mientras que el límite inferior depende del sistema de archivos utilizado. El tamaño de bloque predeterminado en el apropiado en la mayoría de los casos.
Si su sistema usa un almacenaje en banda tal como RAID5, puede mejorar el rendimiento al alinear los datos y metadatos con la geometría de almacenamiento subyacente en tiempo mkfs. Para RAID por software (LVM o MD) y algún almacenaje de hardware empresarial, esta información se solicita y establece automáticamente, pero en muchos casos el administrador debe especificar de forma manual dicha geometría con mkfs en la línea de comandos.
Las cargas de trabajo de metadatos intensivos significan que la sección de registro de un sistema de archivos de diario (tal como un ext4 y XFS) se actualiza con mucha frecuencia. Para minimizar el tiempo de búsqueda de un sistema de archivos a un diario, coloque el diario en un almacenaje dedicado. No obstante, observe que al colocar el diario en almacenaje externo que sea más lento que en el sistema de archivos primario, anulará cualquier ventaja potencial asociada al uso de almacenaje externo.
Aviso
mkfs con dispositivos de diario que se especifican en tiempo de montaje. Consulte las páginas de manual mke2fs(8), mkfs.xfs(8), y mount(8) para obtener mayor información.
7.1.2. Opciones de montaje
Una barrera de escritura es un mecanismo de kernel usado para verificar si los metadatos del sistema de archivos están escritos correctamente y ordenados en almacenaje persistente, incluso cuando los dispositivos de almacenaje con memorias caches volátiles pierden energía. Los sistemas de archivos con barreras habilitadas también se aseguran de que los datos transmitidos a través de fsync() persistan a través de pérdidas de energía. Red Hat Enterprise Linux habilita barreras predeterminadas en todo el hardware que las soportan.
fsync() o crean y borran muchos archivos pequeños. Para almacenaje sin cache de escritura no volátil o en un caso raro en el que las inconsistencias de sistemas de archivos y pérdida de datos después de una pérdida de energía sea aceptable, se pueden desactivar las barreras con la opción de montaje nobarrier. Para obtener mayor información, consulte la Guía de administración de almacenamiento.
Anteriormente, cuando el archivo era leído, el tiempo de acceso (atime) para ese archivo debía ser actualizado en los metadatos del inodo, lo cual implica E/S de escritura adicional. Si no se requieren los metadatos exactos de atime, monte el sistema de archivos con la opción noatime para eliminar estas actualizaciones de metadatos. En la mayoría de los casos, sin embargo,atime no es una gasto debido al atime predeterminado relativo (o la conducta relatime) en el kernel de Red Hat Enterprise Linux 6. La conducta de relatime solamente actualiza atime si el atime anterior es mayor que el tiempo de modificación (mtime) o el tiempo de cambio de estatus (ctime).
Nota
noatime también se habilita la conducta nodiratime; no hay necesidad de establecer noatime y nodiratime.
El acceso al archivo de lectura anticipada se agiliza al pre-obtener datos y cargarlos en la memoria cache de la página para que puedan estar disponibles más temprano en memoria en lugar de en disco. Algunas cargas de trabajo, tales como las que implican flujos pesados de E/S, se benefician de los valores de lectura anticipada.
blockdev para ver y modificar el valor de lectura anticipada. Para ver el valor de lectura anticipada actual para un dispositivo de bloques particular, ejecute:
# blockdev -getra dispositivo
# blockdev -setra N dispositivo
blockdev no persistirá entre inicios. Le recomendamos crear un nivel de ejecución de script init.d para establecer este valor durante el inicio.
7.1.3. Mantenimiento de sistema de archivos
El descarte de lotes y las operaciones de descarte son funcionalidades de sistemas de archivos montados que descartan los bloques que el sistema de archivos no está utilizando. Estas operaciones sirven tanto para unidades de estado sólido como de almacenamiento finamente-aprovisionado.
fstrim. Este comando descarta todos los bloques no utilizados en un sistema de archivos coincidente con los criterios del usuario. Ambos tipos de operaciones están soportados para usar con los sistemas de archivos XFS y ext4 en Red Hat Enterprise Linux 6.2 y posteriores junto con el dispositivo de bloque subyacente soporta las operaciones de descarte físico. Las operaciones de descarte físico están soportadas si el valor de /sys/block/device/queue/discard_max_bytes no es cero.
-o discard (ya sea en /etc/fstab o como parte del comando mount), y se ejecutan en tiempo real sin intervención del usuario. Las operaciones de descarte en línea solamente descartan bloques que están en transición de usados a libres. Las operaciones de descarte están soportadas en sistemas de archivos ext4 en Red Hat Enterprise Linux 6.2 y posteriores, y en sistemas de archivos XFS en Red Hat Enterprise Linux 6.4 y posteriores.
7.1.4. Consideraciones de aplicaciones
Los sistemas de archivos ext4, XFS, y GFS2 soportan la pre-asignación de espacio eficiente mediante llamada glib de fallocate(2). En los casos en que los archivos sean fragmentados erróneamente debido a patrones de escritura, que conducen a un pobre rendimiento de lectura, la pre-asignación de espacio puede ser una técnica útil. La pre-asignación de espacio marca el espacio de disco como si hubiese sido asignado a un archivo, sin escribir ningún dato dentro de dicho espacio. Mientras que no se haya escrito nada en un bloque pre-asignado, las operaciones de lectura retornarán ceros.
7.2. Perfiles para rendimiento de sistema de archivos
latency-performance- Un perfil de servidores para ajuste de rendimiento de latencia típico. Desactiva los mecanismos de ahorro de energía de tuned y ktune. El modo de
cpuspeedcambia arendimiento. El elevador de E/S cambia afecha límitepara cada dispositivo. El parámetrocpu_dma_latencyse registra con un valor de0(la latencia más baja posible) para que el servicio de calidad de administración de energía limite la latencia cuando sea posible. throughput-performance- Un perfil de servidor para ajuste de rendimiento típico. Este perfil se recomienda si el sistema no tiene almacenamiento de clase empresarial. Es igual a
latency-performance, excepto:kernel.sched_min_granularity_ns(programador granularidad de preferencia mínima) se establece a10milisegundos,kernel.sched_wakeup_granularity_ns(programador de granularidad de despertador) se establece a15milisegundos,vm.dirty_ratio(relación sucia de máquina virtual) se establece a 40%, y- las páginas gigantes transparentes se activan.
enterprise-storage- Este perfil se recomienda para configuraciones de servidor de tamaño empresarial con almacenamiento de clase empresarial, que incluye protección de cache y administración de controlador de batería de respaldo de cache en disco. Es igual que el perfil de
throughput-performance, excepto:- el valor
readaheadse establece a4x, y - los sistemas de archivos no root/boot se remontan con
barrier=0.
man tuned-adm), o la Guía de administración de energía disponible en http://access.redhat.com/site/documentation/Red_Hat_Enterprise_Linux/.
7.3. Sistemas de archivos
7.3.1. El sistema de archivos Ext4
Nota
Para sistemas de archivos muy grandes, el proceso de mkfs.ext4 puede tardarse en inicializar todas las tablas de inodo en el sistema de archivos. Este proceso puede diferirse con la opción -E lazy_itable_init=1. Al utilizar esta opción, los procesos de kernel continuarán inicializando el sistema de archivos después de que es montado. La tasa en la cual se presenta esta inicialización, puede controlarse con la opción -o init_itable=n para el comando mount, donde la cantidad de tiempo utilizado realizando esta inicialización de fondo es aproximadamente 1/n. El valor predeterminado para n es 10.
Debido a que algunas aplicaciones no siempre se sincronizan correctamente con fsync() después de renombrar un archivo existente o truncar y rescribir, ext4 se predetermina para sincronizar automáticamente los archivos después de las operaciones 'replace-via-rename' y 'replace-via-truncate'. Esta conducta es bastante consistente con la conducta anterior del sistema de archivos ext3. Sin embargo, las operaciones fsync() pueden consumir bastante tiempo, por lo tanto si esta conducta automática no se requiere, use la opción -o noauto_da_alloc con el comando mount para desactivarla. Esto significará que la aplicación debe usar explícitamente fsync() para garantizar la persistencia de datos.
El envío de datos de E/S de diario predeterminados recibe una leve prioridad que journal_ioprio=n del comando mount. El valor predeterminado es 3. El rango de valores válidos va de 0 a 7, siendo 0 la E/S de prioridad más alta.
mkfs y ajuste, por favor consulte las páginas de manual mkfs.ext4(8) y mount(8), como también el archivo Documentation/filesystems/ext4.txt en el paquete kernel-doc.
7.3.2. Sistema de archivos XFS
mkfs varían la anchura de los árboles-b, lo cual cambia las características de escalabilidad de diferentes subsistemas.
7.3.2.1. Ajuste básico para XFS
mkfs.xfs se configurará automáticamente con la unidad de banda correcta para alinearse con el hardware. Este proceso debe ser configurado de forma manual si el RAID de hardware está en uso.
inode64 se recomienda altamente para sistemas de archivos, excepto cuando el sistema de archivos es exportado mediante NFS y los clientes NFS de legado de 32 bits requieren acceder al sistema de archivos.
logbsize es la recomendad para los sistemas de archivos que son modificados con frecuencia o en ráfagas. El valor predeterminado es MAX (32 KB, unidad de bandas de registro), y el tamaño máximo es 256 KB. Para sistemas de archivos que sufren modificaciones profundas, se recomienda un valor de 256 KB .
7.3.2.2. Ajuste avanzado para XFS
XFS impone un límite arbitrario del número de archivos que puede guardar un sistema de archivos. En general, este límite es lo suficientemente alto que nunca será alcanzado. Si usted sabe con anterioridad que el límite predeterminado es insuficiente, puede aumentar el porcentaje del espacio del sistema de archivos permitidos por inodos con el comando mkfs.xfs. Si se da cuenta del límite de archivos después de crear el sistema de archivos (que suele indicarse mediante errores ENOSPC cuando se intente crear un archivo o directorio aunque el espacio libre esté disponible), puede ajustar el límite con el comando xfs_growfs.
El tamaño de bloque de directorio se fija para el archivo del sistema de archivos, y no puede cambiarse excepto durante el formato inicial con mkfs. El bloque de directorio mínimo es el tamaño de bloque del sistema de archivos, el cual se predetermina aMAX (4 KB, tamaño de bloque de archivos). En general, no hay razón para reducir el tamaño de bloque de directorio.
A diferencia de otros sistemas de archivos, XFS puede realizar al mismo tiempo varios tipos de operaciones de asignación o desasignación, siempre y cuando las operaciones se presenten en objetos no compartidos. La operaciones de asignación o desasignación de extensiones pueden presentarse de manera concurrente, siempre y cuando las operaciones concurrentes se presenten en diferentes grupos de asignación. Igualmente, los inodos de asignación o desasignación pueden ocurrir al mismo tiempo, siempre y cuando las operaciones simultáneas afecten diferentes grupos de asignación.
XFS puede almacenar directamente atributos en el inodo si hay espacio disponible en el inodo. Si el atributo se ajusta dentro del inodo, entonces puede ser recuperado y modificado sin requerir E/S adicional para recuperar bloques de atributos independientes. La diferencia de rendimiento entre los atributos en-línea y fuera de línea puede fácilmente ser una orden de magnitud más lenta para atributos fuera de línea.
El tamaño de registro es el factor principal para determinar el nivel alcanzable de modificación de metadatos sostenidos. El dispositivo de registro es circular, por lo tanto antes de la cola pueden sobrescribirse todas las modificaciones en el registro en disco. Esto puede implicar una cantidad significativa de búsqueda para restaurar todos los datos sucios de metadatos. La configuración predeterminada escala el tamaño de registro en relación con el tamaño de sistema en general, por lo tanto en la mayoría de los casos el tamaño de registro no requerirá ajuste.
mkfs lo hace de forma predeterminada para dispositivos MD y DM, pero debe especificarse para RAID de hardware. Al configurarlo correctamente se evita toda posibilidad de que registro de E/S cause E/S no alineada y posteriores operaciones de 'lectura-modificar-escritura' al escribir los cambios al disco.
logbsize) aumenta la velocidad de los cambios que pueden escribirse al registro. El tamaño de registro predeterminado es MAX (32 KB, unidad de banda de registro), y el tamaño máximo es 256 KB. En general, un valor superior produce un rendimiento más rápido. Sin embargo, en cargas de trabajo pesadas de fsync, los búferes de registro pequeño pueden ser notablemente más rápidos que los búferes grandes con una alineación de unidad de banda grande.
delaylog también mejora el rendimiento de modificaciones de metadatos sostenidos mediante la reducción del número de cambios al registro. Esto se produce al agregar cambios individuales en memoria antes de escribirlos al registro: en lugar de escribir los metadatos frecuentes cada vez se modifican, se escriben al registro de forma periódica . Esta opción aumenta el uso de memoria de rastreo de metadatos sucios y aumenta las operaciones de pérdida potenciales cuando se presenta una falla, pero puede mejorar la velocidad de modificación de metadatos y la escalabilidad mediante un orden de magnitud o más. El uso de esta opción no reduce la integridad de los datos o metadatos cuando fsync, fdatasync o sync sean utilizados para garantizar que los datos y metadatos sean escritos a disco.
7.4. Agrupamiento
7.4.1. Sistema de archivos global 2
- Pre-asignar archivos y directorios con
fallocatecuando sea posible para optimizar el proceso de asignación y evitar así tener que bloquear las páginas de origen. - Minimizar las áreas del sistema de archivos que se comparten entre múltiples nodos para minimizar la invalidación de cache a través de nodos y mejorar el rendimiento. Por ejemplo, si varios nodos montan el mismo sistema de archivos, es muy probable que obtenga un mejor rendimiento si traslada un subdirectorio a un sistema de archivos independiente.
- Seleccionar un tamaño y número de grupo de recursos óptimo. Esto depende del tamaño de archivos y del espacio libre disponible en el sistema, y afecta la probabilidad de que múltiples nodos intenten usar un grupo de recursos de forma simultánea. Demasiados grupos de recursos pueden demorar la asignación de bloques cuando se localiza el espacio de asignación. Suele ser mejor probar las configuraciones para determinar cuál es mejor para su carga de trabajo.
- Seleccione su hardware de almacenamiento según los patrones de E/S esperados de los nodos de clúster y los requerimientos de rendimiento del sistema de archivos.
- Use el almacenamiento de estado sólido en donde sea posible disminuir el tiempo de búsqueda.
- Cree un sistema de archivos con el tamaño apropiado para su carga de trabajo y asegúrese de que el sistema de archivos no esté nunca a una capacidad mayor que 80%. Los sistemas de archivos más pequeños tendrán en forma proporcional, tiempos más cortos de copia de seguridad, pero estarán sujetos a una alta fragmentación si son demasiado pequeños para la carga de trabajo.
- Establezca tamaños de diarios para cargas de trabajo intensivas de metadatos o cuando los datos puestos en diario estén en uso. Aunque se usa más memoria, mejora el rendimiento, ya que el espacio de diario está disponible para almacenar datos antes de que una escritura sea necesaria.
- Asegúrese de que los relojes en nodos GFS2 estén sincronizados para evitar problemas con aplicaciones en red. Le recomendamos el uso de NTP ( Protocolo de tiempo de red).
- A menos que los tiempos de acceso de directorio o archivos sean críticos para la operación de su aplicación, monte el sistema de archivos con las opciones de montaje de
noatimeynodiratime.Nota
Red Hat recomienda el uso de la opciónnoatimecon GFS2. - Si necesita utilizar cuotas, trate de reducir la frecuencia de transacciones de sincronización de cuotas o utilice la sincronización de cuota difusa para evitar problemas de rendimiento que surgen de constantes actualizaciones de archivos
Nota
Las cuotas de conteo difuso permiten a los usuarios y grupos excederse un poco del límite de cuota. Para minimizar este problema, GFS2 reduce de forma dinámica el periodo de sincronización cuando el usuario o grupo se acerca a la cuota límite.
Capítulo 8. Redes
8.1. Mejoras de rendimiento de redes
Direccionamiento de paquetes recibidos (RPS)
rx que tiene su carga de recepción softirq distribuida entre varias CPU. Esto ayuda a evitar el embotellamiento de tráfico de redes de en una sola cola de hardware de NIC.
/sys/class/net/ethX/queues/rx-N/rps_cpus, remplace ethX por el nombre de dispositivo correspondiente de NIC (por ejemplo, eth1, eth2) y rx-N con la cola de recepción del NIC especificado. Así, permitirá a las CPU especificadas en el archivo procesar datos de la cola rx-N en ethX. Al especificar las CPU, considere la afinidad de cache [4].
Direccionamiento de flujo recibido
/proc/sys/net/core/rps_sock_flow_entries- Este ajustable controla el número máximo de sockets/flujos que el kernel puede dirigir hacia cualquier CPU especificada. Se trata de un sistema amplio y de límite compartido.
/sys/class/net/ethX/colas/rx-N/rps_flow_cnt- Este ajustable controla el máximo número de sockets/flujos que el kernel puede dirigir para una cola de recibo especificada (
rx-N) en un NIC (ethX). Observe que la suma de todos los valores por cola para este ajustable en todos los NIC deben ser igual o menor que los/proc/sys/net/core/rps_sock_flow_entries.
Soporte getsockopt para corrientes finas TCP
getsockopt ha sido mejorada para soportar dos opciones adicionales:
- TCP_THIN_DUPACK
- Este booleano habilita la activación dinámica de retransmisiones después de un dupACK para flujos finos.
- TCP_THIN_LINEAR_TIMEOUTS
- Este booleano habilita la activación dinámica de tiempos de espera para flujos finos.
file:///usr/share/doc/kernel-doc-version/Documentation/networking/ip-sysctl.txt. Para obtener mayor información sobre flujos finos, consulte file:///usr/share/doc/kernel-doc-version/Documentation/networking/tcp-thin.txt.
Soporte de proxy transparente (TProxy)
file:///usr/share/doc/kernel-doc-versión/Documentation/networking/tproxy.txt.
8.2. Parámetros de redes optimizadas
- netstat
- Una herramienta de línea de comandos que imprime conexiones de redes, tablas de rutas, estadísticas de interfaz, conexiones de máscara y membresías multidifusión. Recupera la información sobre el subsistema de redes del sistema de archivos
/proc/net/. Dichos archivos incluyen:/proc/net/dev(información de dispositivos)/proc/net/tcp(Información de socket TCP)/proc/net/unix(Informaciónn de sockete de dominio Unix)
Para obtener mayor información sobrenetstaty sus archivos mencionados en/proc/net/, consulte la página de manualnetstat:man netstat. - dropwatch
- Una herramienta que monitoriza los paquetes eliminados por el kernel. Para mayor información, consulte la página de manual
dropwatch:man dropwatch. - ip
- Una herramienta para administrar y monitorizar rutas, dispositivos, y políticas túneles y rutas de políticas . Para obtener mayor información, consulte la página de manual de
ip:man ip. - ethtool
- Una herramienta para desplegar y cambiar los parámetros NIC. Para obtener mayor información, consulte la página de manual
ethtool:man ethtool. - /proc/net/snmp
- Un archivo que muestra datos ASCII necesarios para las bases de información de administración de IP, ICMP, TCP, y UDP para un agente
snmp. También despliega estadísticas de UDP-lite en tiempo real
/proc/net/snmp indica que uno o más conectores de colas de recepción se llena cuando la pila de redes intenta poner en cola nuevos marcos dentro de un socket de aplicación.
Tamaño de búfer de recepción de socket
sk_stream_wait_memory.stp sugiere que la tasa de drenaje de cola de socket sea demasiado baja, para que luego usted pueda aumentar la profundidad de cola del socket de la aplicación. Para hacerlo, aumente el tamaño de los búferes utilizados por conectores, mediante la configuración de alguno de los siguientes valores:
- rmem_default
- Un parámetro de kernel que controla el tamaño predeterminado de búferes de recepción utilizado por conectores. Para configurarlo, ejecute el siguiente comando:
sysctl -w net.core.rmem_default=N
RemplaceNpor el tamaño en bytes del búfer deseado. Para determinar el valor para este parámetro de kernel, vea/proc/sys/net/core/rmem_default. Tenga en cuenta que el valor dermem_defaultno debería ser mayor quermem_max(/proc/sys/net/core/rmem_max); en caso de serlo, aumente el valor dermem_max. - SO_RCVBUF
- Una opción de conexión que controla el tamaño máximo de un búfer de recepción de socket, en bytes. Para obtener mayor información sobre
SO_RCVBUF, consulte la página de manual:man 7 socket.Para configurarSO_RCVBUF, use la herramientasetsockopt. Puede recuperar el valor actual deSO_RCVBUFcongetsockopt. Para obtener mayor información sobre el uso de estas dos herramientas, consulte la página de manual desetsockopt:man setsockopt.
8.3. Visión general de recepción de paquetes

Figura 8.1. Diagrama de rutas de recepción de redes
- Recepción de hardware: la tarjeta de interfaz de red (NIC) recibe el marco en el alambre. Según su configuración de controlador, el NIC transfiere el marco ya sea a una memoria de hardware interna o a un búfer de anillo determinado.
- IRQ dura: el NIC impone la presencia de un marco de red al interrumpir la CPU. Así, el controlador reconoce la interrupción y programa la operación de IRQ blanda.
- La IRQ blanda: esta etapa implementa el proceso de recepción de marcos y se ejecuta en contexto
softirq. Es decir que la etapa prevacía todas las aplicaciones que se ejecutan en la CPU especificada, pero aún permite que los IRQ duros sean impuestos.En este contexto (ejecutándose en la misma CPU como IRQ dura, minimizando así la sobrecarga de cerramiento), el kernel retira el marco de los búferes de hardware de NIC y lo procesa mediante la pila de red. Desde ese punto, el marco puede ser reenviado, descartado o trasladado a un destino de socket de escucha.Cuando pasa a un socket, el marco se añade a la aplicación que posee el socket. Este proceso se realiza de forma repetitiva hasta que se agoten los marcos del búfer de hardware de NIC o hasta que el peso de dispositivo (dev_weight). Para obtener mayor información sobre peso de dispositivos, consulte la Sección 8.4.1, “Búfer de hardware de NIC” - Recibos de aplicación : la aplicación recibe el marco y saca de la cola los sockets que posea vía las llamadas POSIX (
read,recv,recvfrom). En este punto, los datos recibidos en la red ya no existen en la pila de red.
Afinidad CPU/cache
8.4. Solución de problemas comunes de colas y pérdida de marcos
8.4.1. Búfer de hardware de NIC
softirq, el cual NIC afirma a través de una interrupción. Para interrogar el estatus de esta cola, use el siguiente comando:
ethtool -S ethX
ethX por el nombre de dispositivo del NIC correspondiente. Así desplegará el número de marcos que han sido eliminados dentro de ethX. Una pérdida suele ocurrir debido a que a la cola se le acaba el espacio de búfer para almacenar marcos.
- Tráfico de entrada
- Puede evitar excesos de cola si disminuye el paso del tráfico de entrada. Esto se logra por filtraje, reduciendo el número de grupos de multidifusión y disminuyendo el tráfico de difusión, entre otros.
- Longitud de cola
- También, puede aumentar la longitud de cola. Esto implica el aumento del número de búferes en una cola especificada para cualquier máximo que permita el controlador. Para hacerlo, modifique los parámetros de anillo
rx/txdeethXmediante:ethtool --set-ring ethX
Añada los valoresrxortxapropiados al comando antes mencionado. Para obtener mayor información, consulteman ethtool. - Peso de dispositivo
- También puede aumentar la tasa a la que se drena una cola. Para hacerlo, ajuste el peso del dispositivo como corresponde. Este atributo se refiere al número máximo de marcos que el NIC puede recibir antes que el contexto
softirqtenga que entregar la CPU y reprogramarse. Se controla mediante la variable/proc/sys/net/core/dev_weight.
8.4.2. Cola de socket
softirq. Luego, las aplicaciones drenan las colas de los sockets correspondientes mediante llamadas a read, recvfrom, y similares.
netstat; la columna Recv-Q muestra el tamaño de la cola. En general, la exceso de ejecución en la cola del socket se administra en la misma forma que los excesos de ejecución de búfer de hardware de NIC (e.j. Sección 8.4.1, “Búfer de hardware de NIC”):
- Tráfico de entrada
- La primera opción es disminuir el tráfico de entrada al configurar la tasa en la cual se llena la cola. Para hacerlo, puede filtrar marcos o prevaciarlos. También puede retardar el tráfico de entrada al disminuir el peso de dispositivos[6].
- Profundidad de cola
- También puede evitar que la cola se exceda al aumentar la profundidad de cola. Para hacerlo, aumente el valor del parámetro de kernel
rmem_defaulto la opción de socketSO_RCVBUF. Para mayor información, consulte la Sección 8.2, “Parámetros de redes optimizadas”. - Frecuencia de llamada de aplicación
- Cuando sea posible, optimice la aplicación para realizar llamadas de una forma más frecuente. Esto implica modificar o reconfigurar la aplicación de redes para realizar más llamadas POSIX (tales como
recv,read). A su vez, esto permite a una aplicación drenar la cola de una forma más rápida.
8.5. Consideraciones de multidifusión
softirq.
softirq. La adición de un oyente a un grupo de multidifusión, implica que el kernel debe crear una copia adicional de cada marco recibido para dicho grupo.
softirq puede conducir a pérdidas de marcos tanto en tarjetas de red como en colas de sockets. El aumento de tiempos de ejecución de softirq se traduce en una oportunidad reducida para que las aplicaciones se ejecuten en sistemas de carga pesada, entonces la tasa en la que los marcos de multidifusión se pierden aumenta a medida que aumenta el número de aplicaciones que escuchan al grupo de multidifusión de alto volumen.
/proc/sys/net/core/dev_weight. Para obtener mayor información sobre el peso de dispositivos y las implicaciones de su ajuste, consulte la Sección 8.4.1, “Búfer de hardware de NIC”.
Apéndice A. Historial de revisiones
| Historial de revisiones | |||||
|---|---|---|---|---|---|
| Revisión 4.0-22.2.400 | 2013-10-31 | ||||
| |||||
| Revisión 4.0-22.2 | Thu Jun 27 2013 | ||||
| |||||
| Revisión 4.0-22.1 | Thu Apr 18 2013 | ||||
| |||||
| Revisión 4.0-22 | Fri Feb 15 2013 | ||||
| |||||
| Revisión 4.0-19 | Wed Jan 16 2013 | ||||
| |||||
| Revisión 4.0-18 | Tue Nov 27 2012 | ||||
| |||||
| Revisión 4.0-17 | Mon Nov 19 2012 | ||||
| |||||
| Revisión 4.0-16 | Thu Nov 08 2012 | ||||
| |||||
| Revisión 4.0-15 | Wed Oct 17 2012 | ||||
| |||||
| Revisión 4.0-13 | Wed Oct 17 2012 | ||||
| |||||
| Revisión 4.0-12 | Tue Oct 16 2012 | ||||
| |||||
| Revisión 4.0-9 | Tue Oct 9 2012 | ||||
| |||||
| Revisión 4.0-6 | Thu Oct 4 2012 | ||||
| |||||
| Revisión 4.0-3 | Tue Sep 18 2012 | ||||
| |||||
| Revisión 4.0-2 | Mon Sep 10 2012 | ||||
| |||||
| Revisión 3.0-15 | Thursday March 22 2012 | ||||
| |||||
| Revisión 3.0-10 | Friday March 02 2012 | ||||
| |||||
| Revisión 3.0-8 | Thursday February 02 2012 | ||||
| |||||
| Revisión 3.0-5 | Tuesday January 17 2012 | ||||
| |||||
| Revisión 3.0-3 | Wednesday January 11 2012 | ||||
| |||||
| Revisión 1.0-0 | Friday December 02 2011 | ||||
| |||||