
Red Hat Training
A Red Hat training course is available for Red Hat Enterprise Linux
1.8. Servidor virtual de Linux
El servidor virtual de Linux (LVS) es un grupo de componentes de software integrado para balancear la carga de IP a lo largo de un conjunto de servidores reales. LVS se ejecuta en un par de computadores configurados de la misma forma: uno que funciona como un enrutador LVS activo y otro que funciona como un enrutador LVS de respaldo. El enrutador LVS activo tiene dos roles:
- Balancear la carga entre los servidores reales.
- Revisar la integridad de los servicios en cada servidor real.
El enrutador LVS de respaldo sondea el estado del enrutador LVS activo y toma el control de sus tareas en caso de que éste falle.
Figura 1.19, “Components of a Running LVS Cluster” provides an overview of the LVS components and their interrelationship.
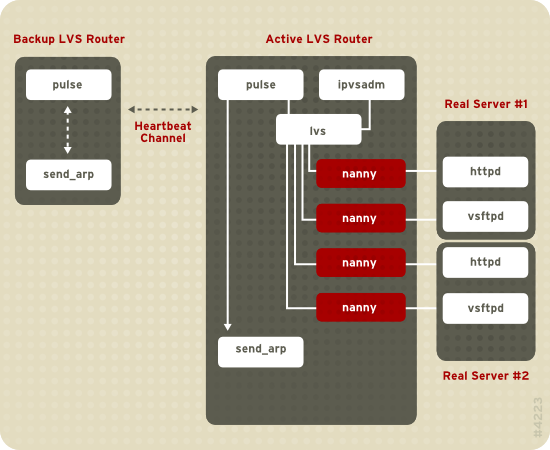
Figura 1.19. Components of a Running LVS Cluster
El daemon
pulse se ejecuta tanto en el servidor LVS activo como en el pasivo. En el enrutador LVS de respaldo, pulse envía un latido a la interfaz pública del enrutador LVS activo para asegurarse de que éste esté funcionando apropiadamente. En el enrutador LVS activo, pulse inicia el daemon lvs y responde a los latidos que provienen del enrutador LVS de respaldo.
Una vez iniciado, el daemon
lvs llama a la utilidad ipvsadmin para configurar y mantener la tabla de rutas IPVS (IP Virtual Server) en el kernel e inicia un proceso nanny para cada servidor virtual configurado en cada servidor real. Cada proceso nanny revisa el estado de cada servidor configurado en un servidor real e informa al daemon lvs si el servicio en el servidor real no está funcionando. Si el servicio no está funcionando, el daemon lvs ordena a ipvsadm que remueva el servidor real de la tabla de rutas IPVS.
Si el enrutador LVS de respaldo no recibe una respuesta desde el enrutador LVS activo, el primero inicia un proceso de recuperación contra fallos llamando a
send_arp para que asigne nuevamente todas las direcciones IP virtuales a las direcciones de hardware NIC (direcciones MAC) del enrutador LVS de respaldo, envía un comando para activar el enrutador LVS activo a través de las interfaces de red pública y privada para apagar el daemon lvs en el enrutador LVS activo e inicia el daemon lvs en el enrutador LVS de respaldo para que acepte solicitudes para los servidores virtuales configurados.
Para un usuario externo que accede al servicio hospedado (tal como un sitio web o una base de datos), LVS aparece como un servidor. Sin embargo, el usuario está accediendo al servidor real tras los enrutadores LVS.
Ya que no existen componentes internos en LVS para compartir los datos entre servidores reales, hay dos opciones básicas:
- Sincronizar los datos entre los servidores reales.
- Añadir una tercera capa a la topología para el acceso de datos compartidos.
La primera opción es la preferida en aquellos servidores que no permiten a un gran número de usuarios cargar o cambiar datos en el servidor real. Si los servidores reales permiten que los datos sean modificados por un gran número de usuarios, por ejemplo los sitios web de comercio electrónico, es preferible añadir una nueva capa.
Hay varios métodos para sincronizar los datos entre los servidores reales. Por ejemplo, puede utilizar un script de shell para publicar las páginas web actualizadas a los servidores reales de forma simultánea. Asimismo, puede utilizar programas como
rsync para replicar los cambios de datos a lo largo de todos los nodos cada cierto intervalo de tiempo. Sin embargo, en los entornos donde los usuarios cargan archivos o ejecutan transacciones a la base de datos, el uso de scripts o del comando rsync para la sincronización de datos no funciona de forma óptima. Por lo cual, para servidores reales con una gran cantidad de cargas, transacciones a bases de datos o tráfico similar, una topología de tres capas es la opción más apropiada para la sincronización de datos.
1.8.1. Two-Tier LVS Topology
Figura 1.20, “Two-Tier LVS Topology” shows a simple LVS configuration consisting of two tiers: LVS routers and real servers. The LVS-router tier consists of one active LVS router and one backup LVS router. The real-server tier consists of real servers connected to the private network. Each LVS router has two network interfaces: one connected to a public network (Internet) and one connected to a private network. A network interface connected to each network allows the LVS routers to regulate traffic between clients on the public network and the real servers on the private network. In Figura 1.20, “Two-Tier LVS Topology”, the active LVS router uses Network Address Translation (NAT) to direct traffic from the public network to real servers on the private network, which in turn provide services as requested. The real servers pass all public traffic through the active LVS router. From the perspective of clients on the public network, the LVS router appears as one entity.

Figura 1.20. Two-Tier LVS Topology
Los servicios solicitados a un enrutador LVS son dirigidos a una dirección IP virtual o VIP. Esta es una dirección enrutada públicamente que el administrador del sitio asocia con el nombre de dominio totalmente calificado, tal como www.example.com, y que se asigna a uno o más servidores virtuales[1]. Observe que una dirección VIP migra de un enrutador LVS a otro durante el proceso de recuperación contra fallos. Esto hace que siempre haya una presencia en la dirección IP (conocida también como dirección IP flotante).
Las direcciones VIP pueden tener sobrenombres que se dirijan al mismo dispositivo que conecta al enrutador LVS con la red pública. Por ejemplo, si eth0 está conectado a Internet, puede haber varios servidores virtuales con sobrenombres a
eth0:1. Alternativamente, cada servidor virtual puede estar asociado con un dispositivo separado por servicio. Por ejemplo, el tráfico HTTP puede ser manejado en eth0:1 y el tráfico FTP puede ser manejado en eth0:2.
Solo un enrutador LVS está activo a la vez. El rol del enrutador LVS activo es redireccionar la solicitud del servicio desde la dirección IP virtual al servidor real. La redirección está basada en uno de ocho algoritmos de balance de carga:
- Programador Round-Robin — Distribuye cada solicitud secuencialmente alrededor de los servidores reales. Al usar este algoritmo, todos los servidores reales son tratados del mismo modo, sin importar su capacidad o carga.
- Programador Weighted Round-Robin — Distribuye cada solicitud secuencialmente alrededor de los servidores reales dando más tareas a los servidores con mayor capacidad. La capacidad es indicada por el usuario y se ajusta gracias a la información de carga dinámica. Esta es la opción preferida si los servidores reales tienen distintas capacidades. Sin embargo, si la carga de solicitudes cambia dramáticamente, un servidor con gran capacidad podría responder a más solicitudes que las que debe.
- Least-Connection — Distribuye más solicitudes a los servidores reales que tienen menos conexiones activas. Este es un tipo de algoritmo de programación dinámico. Es una buena opción si hay altos grados de variación en las solicitudes. Es ideal en las infraestructuras donde cada servidor tiene aproximadamente la misma capacidad. Si los servidores reales tienen capacidades variadas, la programación weighted least-connection es una mejor opción.
- Weighted Least-Connections (predeterminado) — Distribuye más solicitudes a los servidores con menos conexiones activas en relación con sus capacidades. La capacidad es indicada por el usuario y es ajustada por la información de carga dinámica. La adición del parámetro de capacidad hace que este algoritmo sea ideal cuando la infraestructura tiene servidores reales con capacidades de hardware variado.
- Locality-Based Least-Connection Scheduling — Distribuye más solicitudes a los servidores con menos conexiones activas en relación con sus IP de destino. Este algoritmo se utiliza en cluster de servidores de caché proxy. Enruta el paquete para una dirección IP para el servidor con esa dirección a menos que el servidor esté sobrecargado, en dicho caso se asigna la dirección IP al servidor real con menos carga.
- Locality-Based Least-Connection Scheduling with Replication Scheduling — Distribuye más solicitudes a los servidores con menos conexiones activas de acuerdo con la IP de destino. Este algoritmo es usado en servidores de caché de proxy. Se diferencia de "Locality-Based Least-Connection Scheduling" al relacionar la dirección IP objetivo con un grupo de servidores reales. Las solicitudes son luego enviadas al servidor en el grupo con menos número de conexiones. Si la capacidad de todos los nodos para el IP de destino está sobre el límite, añade un nuevo servidor real del grupo general al grupo de servidores para el IP de destino. El nodo con mayor carga es desplazado fuera del grupo para evitar un exceso de replicación.
- Source Hash Scheduling — Distribuye todas las solicitudes de acuerdo con un diccionario estático de direcciones IP. Este algoritmo se utiliza en enrutadores LVS con varios cortafuegos.
Asimismo, el enrutador LVS activo sondea dinámicamente la salud de los servicios especificados en los servidores reales a través de un script de envío y espera. Para ayudar en la detección de servicios que requieren datos dinámicos, tal como HTTPS o SSL, se puede incluso llamar a programas ejecutables externos. Si un servicio en un servidor real no funciona adecuadamente, el enrutador LVS activo no envía solicitudes a ese servidor hasta que retorne a la operación normal.
El enrutador LVS de respaldo cumple el rol de asistente del sistema. Periódicamente, el enrutador LVS intercambia mensajes llamados pulsos a través de la interfaz pública externa primaria y, en caso de procesos de recuperación contra fallos, a través de la interfaz privada. Si el enrutador LVS de respaldo no recibe un pulso dentro de un intervalo de tiempo determinado, éste inicia el proceso de recuperación contra fallos y asume el rol del enrutador LVS activo. Durante el proceso de recuperación, el enrutador LVS de respaldo toma la dirección VIP servida por el enrutador fallido utilizando una técnica llamada suplantación de identidad ARP — en donde el enrutador LVS de respaldo se anuncia como el servidor de destino para los paquetes IP dirigidos al nodo fallido. Cuando el nodo fallido retorna al servicio activo, el enrutador LVS de respaldo asume su rol de asistente de nuevo.
The simple, two-tier configuration in Figura 1.20, “Two-Tier LVS Topology” is suited best for clusters serving data that does not change very frequently — such as static web pages — because the individual real servers do not automatically synchronize data among themselves.