
Chapter 2. Active-Active Disaster Recovery
2.1. Active-Active Overview
The active-active disaster recovery failover configuration can span two sites. Both sites are active, and if the primary site becomes unavailable, the Red Hat Virtualization environment continues to operate in the secondary site to ensure business continuity.
The active-active failover configuration includes a stretch cluster in which hosts capable of running the virtual machines are located in both the primary and secondary sites. All the hosts belong to the same Red Hat Virtualization cluster.
This configuration requires replicated storage that is writeable on both sites so virtual machines can migrate between the two sites and continue running on both sites' storage.
Figure 2.1. Stretch Cluster Configuration
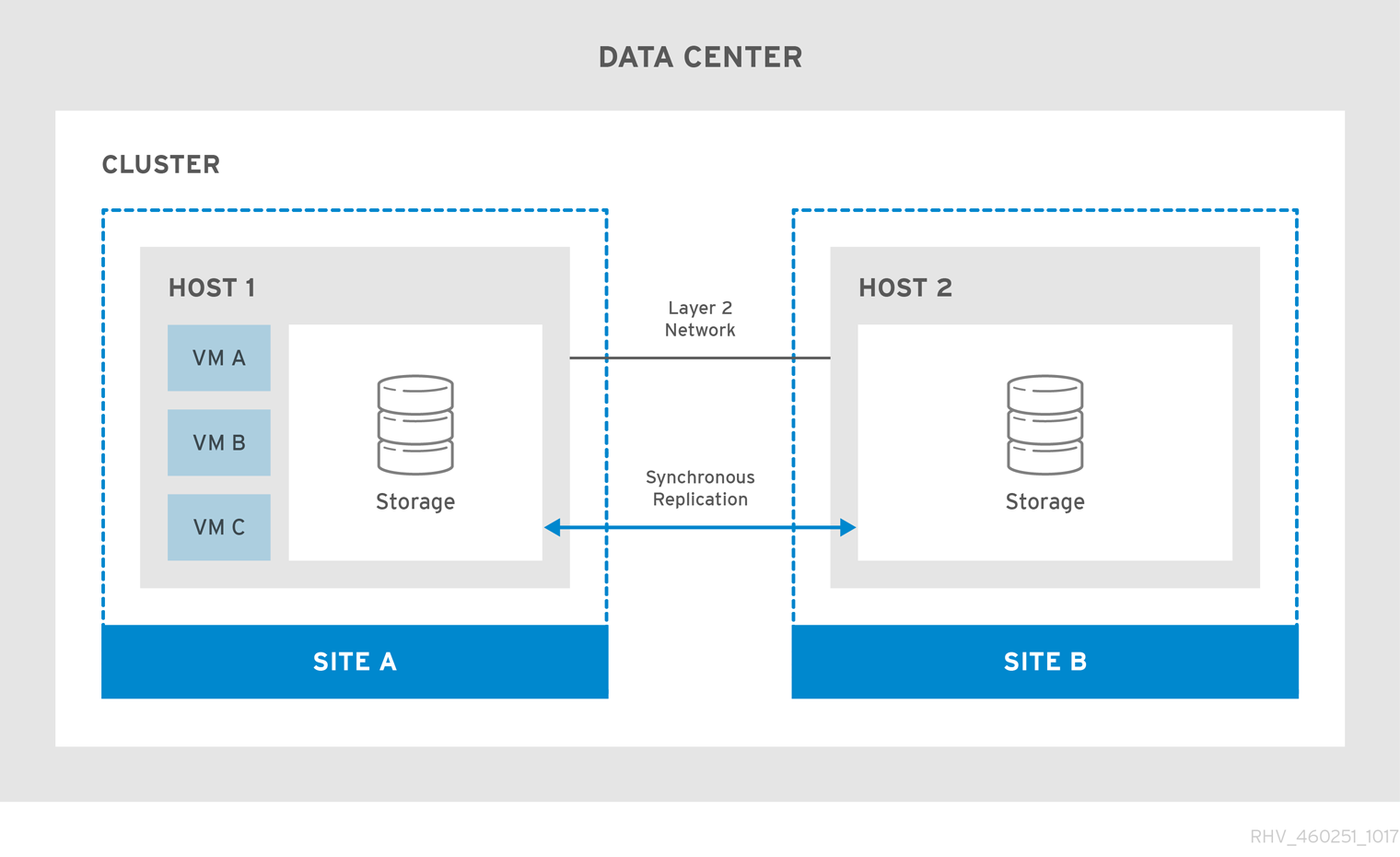
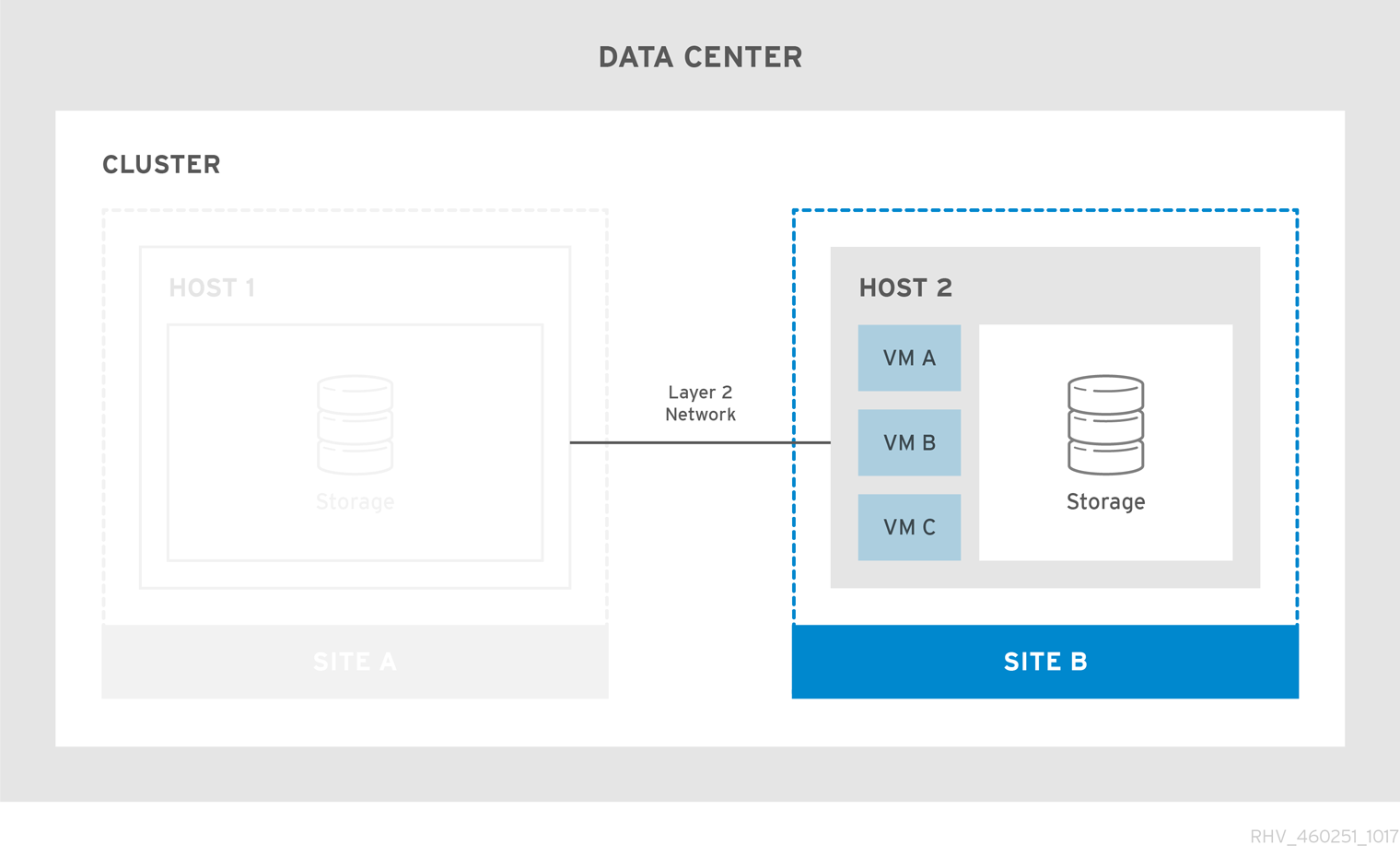
Virtual machines migrate to the secondary site if the primary site becomes unavailable. The virtual machines automatically failback to the primary site when the site becomes available and the storage is replicated in both sites.
Figure 2.2. Failed Over Stretch Cluster
To ensure virtual machine failover and failback works:
- Virtual machines must be configured to be highly available, and each virtual machine must have a lease on a target storage domain to ensure the virtual machine can start even without power management.
- Soft enforced virtual machine to host affinity must be configured to ensure the virtual machines only start on the selected hosts.
For more information see Improving Uptime with Virtual Machine High Availability and Affinity Groups in the Virtual Machine Management Guide.
The stretched cluster configuration can be implemented using a self-hosted engine environment, or a standalone Manager environment. For more information about the different types of deployments see Red Hat Virtualization Architecture in the Product Guide.
2.2. Network Considerations
All hosts in the cluster must be on the same broadcast domain over an L2 network. So connectivity between the two sites must be L2.
The maximum latency requirements between the sites across the L2 network differ for the two setups. The standalone Manager environment requires a maximum latency of 100ms, while the self-hosted engine environment requires a maximum latency of 7ms.
2.3. Storage Considerations
The storage domain for Red Hat Virtualization can comprise either block devices (SAN - iSCSI or FCP) or a file system (NAS - NFS, GlusterFS, or other POSIX compliant file systems). For more information about Red Hat Virtualization storage, see Storage in the Administration Guide.
GlusterFS Storage is deprecated, and will no longer be supported in future releases.
The sites require synchronously replicated storage that is writeable on both sites with shared layer 2 (L2) network connectivity. The replicated storage is required to allow virtual machines to migrate between sites and continue running on the site’s storage. All storage replication options supported by Red Hat Enterprise Linux 7 and later can be used in the stretch cluster.
If you have a custom multipath configuration that is recommended by the storage vendor, see the instructions and important limitations in Customizing Multipath Configurations for SAN Vendors.
Set the SPM role on a host at the primary site to have precedence. To do so, configure SPM priority as high in the primary site hosts and SPM priority as low on secondary site hosts. If you have a primary site failure that impacts network devices inside the primary site, preventing the fencing device for the SPM host from being reachable, such as power loss, the hosts in the seconday site are not able to take over the SPM role.
In such a scenario virtual machines do a failover, but operations that require the SPM role in place cannot be executed, including adding new disks, extending existing disks, and exporting virtual machines.
To restore full functionality, detect the actual nature of the disaster and after fixing the root cause and rebooting the SPM host, select Confirm 'Host has been Rebooted' for the SPM host.
Additional resources
Manually Fencing or Isolating a Non-Responsive Host in the Administration Guide.
2.4. Configuring a Self-hosted Engine Stretch Cluster Environment
This procedure provides instructions to configure a stretch cluster using a self-hosted engine deployment.
Prerequisites
- A writable storage server in both sites with L2 network connectivity.
- Real-time storage replication service to duplicate the storage.
Limitations
- Maximum 7ms latency between sites.
Configuring the Self-hosted Engine Stretch Cluster
- Deploy the self-hosted engine. See Installing Red Hat Virtualization as a self-hosted engine using the command line.
- Install additional self-hosted engine nodes in each site and add them to your cluster. See Adding Self-hosted Engine Nodes to the Red Hat Virtualization Manager in Installing Red Hat Virtualization as a self-hosted engine using the command line.
- Optionally, install additional standard hosts. See Adding Standard Hosts to the Red Hat Virtualization Manager in Installing Red Hat Virtualization as a self-hosted engine using the command line.
- Configure the SPM priority to be higher on all hosts in the primary site to ensure SPM failover to the secondary site occurs only when all hosts in the primary site are unavailable. See SPM Priority in the Administration Guide.
- Configure all virtual machines that must failover as highly available, and ensure that the virtual machine has a lease on the target storage domain. See Configuring a Highly Available Virtual Machine in the Virtual Machine Management Guide.
- Configure virtual machine to host soft affinity and define the behavior you expect from the affinity group. See Affinity Groups in the Virtual Machine Management Guide and Scheduling Policies in the Administration Guide.
The active-active failover can be manually performed by placing the main site’s hosts into maintenance mode.
2.5. Configuring a Standalone Manager Stretch Cluster Environment
This procedure provides instructions to configure a stretch cluster using a standalone Manager deployment.
Prerequisites
- A writable storage server in both sites with L2 network connectivity.
- Real-time storage replication service to duplicate the storage.
Limitations
- Maximum 100ms latency between sites.
The Manager must be highly available for virtual machines to failover and failback between sites. If the Manager goes down with the site, the virtual machines will not failover.
The standalone Manager is only highly available when managed externally. For example:
- Using Red Hat’s High Availability Add-On.
- As a highly available virtual machine in a separate virtualization environment.
- Using Red Hat Enterprise Linux Cluster Suite.
- In a public cloud.
Procedure
- Install and configure the Red Hat Virtualization Manager. See Installing Red Hat Virtualization as a standalone Manager with local databases.
- Install the hosts in each site and add them to the cluster. See Installing Hosts for Red Hat Virtualization in Installing Red Hat Virtualization as a standalone Manager with local databases.
- Configure the SPM priority to be higher on all hosts in the primary site to ensure SPM failover to the secondary site occurs only when all hosts in the primary site are unavailable. See SPM Priority in the Administration Guide.
- Configure all virtual machines that must failover as highly available, and ensure that the virtual machine has a lease on the target storage domain. See Configuring a Highly Available Virtual Machine in the Virtual Machine Management Guide.
- Configure virtual machine to host soft affinity and define the behavior you expect from the affinity group. See Affinity Groups in the Virtual Machine Management Guide and Scheduling Policies in the Administration Guide.
The active-active failover can be manually performed by placing the main site’s hosts into maintenance mode.