
Red Hat Training
A Red Hat training course is available for Red Hat Process Automation Manager
Managing and monitoring Process Server
Abstract
Preface
As a systems administrator, you can install, configure, and upgrade Red Hat Process Automation Manager for production environments, quickly and easily troubleshoot system failures, and ensure that systems are running optimally.
Prerequisites
- Red Hat JBoss Enterprise Application Platform 7.2 is installed. For more information, see Red Hat JBoss EAP 7.2 Installation Guide.
- Red Hat Process Automation Manager is installed. For more information, see Planning a Red Hat Process Automation Manager installation.
-
Red Hat Process Automation Manager is running and you can log in to Business Central with the
adminrole. For more information, see Planning a Red Hat Process Automation Manager installation.
Chapter 1. Red Hat Process Automation Manager components
Red Hat Process Automation Manager is made up of Business Central and Process Server.
Business Central is the graphical user interface where you create and manage business rules. You can install Business Central in a Red Hat JBoss EAP instance or on the Red Hat OpenShift Container Platform (OpenShift).
Business Central is also available as a standalone JAR file. You can use the Business Central standalone JAR file to run Business Central without needing to deploy it to an application server.
Process Server is the server where processes, rules, and other artifacts are executed. It is used to instantiate and execute processes and rules and solve planning problems. You can install Process Server in a Red Hat JBoss EAP instance, on OpenShift, in an Oracle WebLogic server instance, in an IBM WebSphere Application Server instance, or as a part of Spring Boot application.
You can configure Process Server to run in managed or unmanaged mode. If Process Server is unmanaged, you must manually create and maintain KIE containers (deployment units). A KIE container is a specific version of a project. If Process Server is managed, the Process Automation Manager controller manages the Process Server configuration and you interact with the Process Automation Manager controller to create and maintain KIE containers.
Chapter 2. System integration with Maven
Red Hat Process Automation Manager is designed to be used with Red Hat JBoss Middleware Maven Repository and Maven Central repository as dependency sources. Ensure that both the dependencies are available for projects builds.
Ensure that your project depends on specific versions of an artifact. LATEST or RELEASE are commonly used to specify and manage dependency versions in your application.
-
LATESTrefers to the latest deployed (snapshot) version of an artifact. -
RELEASErefers to the last non-snapshot version release in the repository.
By using LATEST or RELEASE, you do not have to update version numbers when a new release of a third-party library is released, however, you lose control over your build being affected by a software release.
2.1. Preemptive authentication for local projects
If your environment does not have access to the internet, set up an in-house Nexus and use it instead of Maven Central or other public repositories. To import JARs from the remote Maven repository of Red Hat Process Automation Manager server to a local Maven project, turn on pre-emptive authentication for the repository server. You can do this by configuring authentication for guvnor-m2-repo in the pom.xml file as shown below:
<server>
<id>guvnor-m2-repo</id>
<username>admin</username>
<password>admin</password>
<configuration>
<wagonProvider>httpclient</wagonProvider>
<httpConfiguration>
<all>
<usePreemptive>true</usePreemptive>
</all>
</httpConfiguration>
</configuration>
</server>Alternatively, you can set Authorization HTTP header with Base64 encoded credentials:
<server>
<id>guvnor-m2-repo</id>
<configuration>
<httpHeaders>
<property>
<name>Authorization</name>
<!-- Base64-encoded "admin:admin" -->
<value>Basic YWRtaW46YWRtaW4=</value>
</property>
</httpHeaders>
</configuration>
</server>2.2. Duplicate GAV detection in Business Central
In Business Central, all Maven repositories are checked for any duplicated GroupId, ArtifactId, and Version (GAV) values in a project. If a GAV duplicate exists, the performed operation is canceled.
Duplicate GAV detection is executed every time you perform the following operations:
- Save a project definition for the project.
-
Save the
pom.xmlfile. - Install, build, or deploy a project.
The following Maven repositories are checked for duplicate GAVs:
-
Repositories specified in the
<repositories>and<distributionManagement>elements of thepom.xmlfile. -
Repositories specified in the Maven
settings.xmlconfiguration file.
2.3. Managing duplicate GAV detection settings in Business Central
Business Central users with the admin role can modify the list of repositories that are checked for duplicate GroupId, ArtifactId, and Version (GAV) values for a project.
Procedure
- In Business Central, go to Menu → Design → Projects and click the project name.
- Click the project Settings tab and then click Validation to open the list of repositories.
Select or clear any of the listed repository options to enable or disable duplicate GAV detection.
In the future, duplicate GAVs will be reported for only the repositories you have enabled for validation.
NoteTo disable this feature, set the
org.guvnor.project.gav.check.disabledsystem property totruefor Business Central at system startup:$ ~/EAP_HOME/bin/standalone.sh -c standalone-full.xml -Dorg.guvnor.project.gav.check.disabled=true
Chapter 3. Applying patch updates and minor release upgrades to Red Hat Process Automation Manager
Automated update tools are often provided with both patch updates and new minor versions of Red Hat Process Automation Manager to facilitate updating certain components of Red Hat Process Automation Manager, such as Business Central, Process Server, and the headless Process Automation Manager controller. Other Red Hat Process Automation Manager artifacts, such as the process engine and standalone Business Central, are released as new artifacts with each minor release and you must re-install them to apply the update.
You can use the same automated update tool to apply both patch updates and minor release upgrades to Red Hat Process Automation Manager 7.2. Patch updates of Red Hat Process Automation Manager, such as an update from version 7.2 to 7.2.1, include the latest security updates and bug fixes. Minor release upgrades of Red Hat Process Automation Manager, such as an upgrade from version 7.2.x to 7.3, include enhancements, security updates, and bug fixes.
Before you upgrade to a new minor release, apply the latest patch update to your current version of Red Hat Process Automation Manager to ensure that the minor release upgrade is successful.
To upgrade from Red Hat Process Automation Manager 7.1 to 7.2, first update to Red Hat Process Automation Manager 7.1.1 (latest patch update) and then follow this procedure again to upgrade to Red Hat Process Automation Manager 7.2. Adjust the example upgrade versions provided in this section as needed.
Only updates for Red Hat Process Automation Manager are included in Red Hat Process Automation Manager update tools. Updates to Red Hat JBoss EAP must be applied using Red Hat JBoss EAP patch distributions. For more information about Red Hat JBoss EAP patching, see the Red Hat JBoss EAP Patching and upgrading guide.
Prerequisites
- Your Red Hat Process Automation Manager and Process Server instances are not running. Do not apply updates while you are running an instance of Red Hat Process Automation Manager or Process Server.
Procedure
Navigate to the Software Downloads page in the Red Hat Customer Portal (login required), and select the product and version from the drop-down options.
Example:
- Product: Process Automation Manager
- Version: 7.2.1
If you are upgrading to a new minor release of Red Hat Process Automation Manager, such as an upgrade from version 7.2.x to 7.3, first apply the latest patch update to your current version of Red Hat Process Automation Manager and then follow this procedure again to upgrade to the new minor release.
Click Patches, download the Red Hat Process Automation Manager [VERSION] Update Tool, and extract the downloaded
rhpam-$VERSION-update.zipfile to a temporary directory.This update tool automates the update of certain components of Red Hat Process Automation Manager, such as Business Central, Process Server, and the headless Process Automation Manager controller. Use this update tool first to apply updates and then install any other updates or new release artifacts that are relevant to your Red Hat Process Automation Manager distribution.
If you want to preserve any files from being updated by the update tool, navigate to the extracted
rhpam-$VERSION-updatefolder, open theblacklist.txtfile, and add the relative paths to the files that you do not want to be updated.When a file is listed in the
blacklist.txtfile, the update script does not replace the file with the new version but instead leaves the file in place and in the same location adds the new version with a.newsuffix. If you blacklist files that are no longer being distributed, the update tool creates an empty marker file with a.removedsuffix. You can then choose to retain, merge, or delete these new files manually.Example files to be excluded in
blacklist.txtfile:WEB-INF/web.xml // Custom file styles/base.css // Obsolete custom file kept for record
The contents of the blacklisted file directories after the update:
$ ls WEB-INF web.xml web.xml.new
$ ls styles base.css base.css.removed
In your command terminal, navigate to the temporary directory where you extracted the
rhpam-$VERSION-update.zipfile and run theapply-updatesscript in the following format:ImportantMake sure that your Red Hat Process Automation Manager and Process Server instances are not running before you apply updates. Do not apply updates while you are running an instance of Red Hat Process Automation Manager or Process Server.
On Linux or Unix-based systems:
$ ./apply-updates.sh $DISTRO_PATH $DISTRO_TYPE
On Windows:
$ .\apply-updates.bat $DISTRO_PATH $DISTRO_TYPE
The
$DISTRO_PATHportion is the path to the relevant distribution directory and the$DISTRO_TYPEportion is the type of distribution that you are updating with this update.The following distribution types are supported in Red Hat Process Automation Manager update tool:
-
rhpam-business-central-eap7-deployable: Updates Business Central (business-central.war) rhpam-kie-server-ee8: Updates Process Server (kie-server.war)NoteThe update tool will update Red Hat JBoss EAP EE7 to Red Hat JBoss EAP EE8.
-
rhpam-controller-ee7: Updates the headless Process Automation Manager controller (controller.war)
Example update to Business Central and Process Server for a full Red Hat Process Automation Manager distribution on Red Hat JBoss EAP:
./apply-updates.sh ~EAP_HOME/standalone/deployments/business-central.war rhpam-business-central-eap7-deployable ./apply-updates.sh ~EAP_HOME/standalone/deployments/kie-server.war rhpam-kie-server-ee7
Example update to headless Process Automation Manager controller, if used:
./apply-updates.sh ~EAP_HOME/standalone/deployments/controller.war rhpam-controller-ee7
The update script creates a
backupfolder in the extractedrhpam-$VERSION-updatefolder with a copy of the specified distribution, and then proceeds with the update.-
After the update tool completes, return to the Software Downloads page of the Red Hat Customer Portal where you downloaded the update tool and install any other updates or new release artifacts that are relevant to your Red Hat Process Automation Manager distribution.
For files that already exist in your Red Hat Process Automation Manager distribution, such as
.jarfiles for the process engine or other add-ons, replace the existing version of the file with the new version from the Red Hat Customer Portal.If you use the standalone Red Hat Process Automation Manager 7.2.0 Maven Repository artifact (
rhpam-7.2.0-maven-repository.zip), such as in air-gap environments, download Red Hat Process Automation Manager [VERSION] Incremental Maven Repository and extract the downloadedrhpam-$VERSION-incremental-maven-repository.zipfile to your existing~/maven-repositorydirectory to update the relevant contents.Example Maven repository update:
$ unzip -o rhpam-7.2.1-incremental-maven-repository.zip -d $REPO_PATH/rhpam-7.2.0-maven-repository/maven-repository/
- After you finish applying all relevant updates, start Red Hat Process Automation Manager and Process Server and log in to Business Central.
Verify that all project data is present and accurate in Business Central, and in the top-right corner of the Business Central window, click your profile name and click About to verify the updated product version number.
If you encounter errors or notice any missing data in Business Central, you can restore the contents in the
backupfolder within therhpam-$VERSION-updatefolder to revert the update tool changes. You can also re-install the relevant release artifacts from your previous version of Red Hat Process Automation Manager in the Red Hat Customer Portal. After restoring your previous distribution, you can try again to run the update.
Chapter 4. Configuring and starting Process Server
You can configure your Process Server location, user name, password, and other related properties by defining the necessary configurations when you start Process Server.
Procedure
Navigate to the Red Hat Process Automation Manager 7.2 bin directory and start the new Process Server with the following properties. Adjust the specific properties according to your environment.
$ ~/EAP_HOME/bin/standalone.sh --server-config=standalone-full.xml 1 -Dorg.kie.server.id=myserver 2 -Dorg.kie.server.user=process_server_username 3 -Dorg.kie.server.pwd=process_server_password 4 -Dorg.kie.server.controller=http://localhost:8080/business-central/rest/controller 5 -Dorg.kie.server.controller.user=controller_username 6 -Dorg.kie.server.controller.pwd=controller_password 7 -Dorg.kie.server.location=http://localhost:8080/kie-server/services/rest/server 8 -Dorg.kie.server.persistence.dialect=org.hibernate.dialect.PostgreSQLDialect 9 -Dorg.kie.server.persistence.ds=java:jboss/datasources/psjbpmDS 10
- 1
- Start command with
standalone-full.xmlserver profile - 2
- Server ID that must match the server configuration name defined in Business Central
- 3
- User name to connect with Process Server from the Process Automation Manager controller
- 4
- Password to connect with Process Server from the Process Automation Manager controller
- 5
- Process Automation Manager controller location, Business Central URL with
/rest/controllersuffix - 6
- User name to connect to the Process Automation Manager controller REST API
- 7
- Password to connect to the Process Automation Manager controller REST API
- 8
- Process Server location (on the same instance as Business Central in this example)
- 9
- Hibernate dialect to be used
- 10
- JNDI name of the data source used for your previous Red Hat JBoss BPM Suite database
If Business Central and Process Server are installed on separate application server instances (Red Hat JBoss EAP or other), use a separate port for the Process Server location to avoid port conflicts with Business Central. If a separate Process Server port has not already been configured, you can add a port offset and adjust the Process Server port value accordingly in the Process Server properties.
Example:
-Djboss.socket.binding.port-offset=150 -Dorg.kie.server.location=http://localhost:8230/kie-server/services/rest/server
If the Business Central port is 8080, as in this example, then the Process Server port, with a defined offset of 150, is 8230.
Process Server connects to the new Business Central and collects the list of deployment units (KIE containers) to be deployed.
When you use a class inside a dependency JAR file to access Process Server from Process Server client, you get the ConversionException and ForbiddenClassException in Business Central. To avoid generating these exceptions in Business Central, do one of the following:
- If the exceptions are generated on the client-side, add following system property to the kie-server client:
System.setProperty("org.kie.server.xstream.enabled.packages", "org.example.**");-
If the exceptions are generated on the server-side, open
standalone-full.xmlfrom the Red Hat Process Automation Manager installation directory, set the following property under the <system-properties> tag:
<property name="org.kie.server.xstream.enabled.packages" value="org.example.**"/>
- Set the following JVM property:
-Dorg.kie.server.xstream.enabled.packages=org.example.**
It is expected that you do not configure the classes that exists in KJAR using these system property. Ensure that only known classes are used in the system property to avoid any vulnerabilities.
The org.example is an example package, you can define any package that you want to use. You can specify multiple packages separated by comma , for example, org.example1.* * , org.example2.* * , org.example3.* *.
You can also add specific classes , for example, org.example1.Mydata1, org.example2.Mydata2.
Chapter 5. Configuring JDBC data sources for Process Server
A data source is an object that enables a Java Database Connectivity (JDBC) client, such as an application server, to establish a connection with a database. Applications look up the data source on the Java Naming and Directory Interface (JNDI) tree or in the local application context and request a database connection to retrieve data. You must configure data sources for Process Server to ensure proper data exchange between the servers and the designated database.
Prerequisites
- The JDBC providers that you want to use to create database connections are configured on all servers on which you want to deploy Process Server, as described in the "Creating Datasources" and "JDBC Drivers" sections of the Red Hat JBoss Enterprise Application Server Configuration Guide.
- The Red Hat Process Automation Manager 7.2.0 Add Ons (rhpam-7.2.0-add-ons.zip) file is downloaded from the Software Downloads page in the Red Hat Customer Portal.
Procedure
-
Open
EAP_HOME/standalone/configuration/standalone-full.xmlin a text editor and locate the<system-properties>tag. Add the following properties to the
<system-properties>tag where<DATASOURCE>is the name of your data source and<HIBERNATE_DIALECT>is the hibernate dialect for your database.NoteThe default value of the
org.kie.server.persistence.dsproperty isjava:jboss/datasources/ExampleDS. The default value of theorg.kie.server.persistence.dialectproperty isorg.hibernate.dialect.H2Dialect.<property name="org.kie.server.persistence.ds" value="<DATASOURCE>"/> <property name="org.kie.server.persistence.dialect" value="<HIBERNATE_DIALECT>"/>
For example:
<system-properties> <property name="org.kie.server.repo" value="${jboss.server.data.dir}"/> <property name="org.kie.example" value="true"/> <property name="org.jbpm.designer.perspective" value="full"/> <property name="designerdataobjects" value="false"/> <property name="org.kie.server.user" value="rhpamUser"/> <property name="org.kie.server.pwd" value="rhpam123!"/> <property name="org.kie.server.location" value="http://localhost:8080/kie-server/services/rest/server"/> <property name="org.kie.server.controller" value="http://localhost:8080/business-central/rest/controller"/> <property name="org.kie.server.controller.user" value="kieserver"/> <property name="org.kie.server.controller.pwd" value="kieserver1!"/> <property name="org.kie.server.id" value="local-server-123"/> <!-- Data source properties. --> <property name="org.kie.server.persistence.ds" value="java:jboss/datasources/KieServerDS"/> <property name="org.kie.server.persistence.dialect" value="org.hibernate.dialect.PostgreSQLDialect"/> </system-properties>
The following dialects are supported:
-
DB2:
org.hibernate.dialect.DB2Dialect -
MSSQL:
org.hibernate.dialect.SQLServer2012Dialect -
MySQL:
org.hibernate.dialect.MySQL5InnoDBDialect -
MariaDB:
org.hibernate.dialect.MySQL5InnoDBDialect -
Oracle:
org.hibernate.dialect.Oracle10gDialect -
PostgreSQL:
org.hibernate.dialect.PostgreSQL82Dialect -
PostgreSQL plus:
org.hibernate.dialect.PostgresPlusDialect -
Sybase:
org.hibernate.dialect.SybaseASE157Dialect
Chapter 6. Configuring Process Server with the integrated Process Automation Manager controller
Only make the changes described in this section if Process Server will be managed by Business Central and you installed Red Hat Process Automation Manager from the ZIP files. If you did not install Business Central, you can use the headless Process Automation Manager controller to manage Process Server, as described in Chapter 7, Installing and running the headless Process Automation Manager controller.
Process Server can be managed or it can be unmanaged. If Process Server is unmanaged, you must manually create and maintain KIE containers (deployment units). If Process Server is managed, the Process Automation Manager controller manages the Process Server configuration and you interact with the Process Automation Manager controller to create and maintain KIE containers.
The Process Automation Manager controller is integrated with Business Central. If you install Business Central, you can use the Execution Server page in Business Central to interact with the Process Automation Manager controller.
If you installed Red Hat Process Automation Manager from the ZIP files, you must edit the standalone-full.xml file in both the Process Server and Business Central installations to configure Process Server with the integrated Process Automation Manager controller.
Prerequisites
Business Central and Process Server are installed in the base directory of the Red Hat JBoss EAP installation (
EAP_HOME).NoteYou should install Business Central and Process Server on different servers in production environments. However, if you install Process Server and Business Central on the same server, for example in a development environment, make the changes described in this section in the shared
standalone-full.xmlfile.On Business Central server nodes, a user with the
rest-allrole exists.Procedure
In the Business Central
EAP_HOME/standalone/configuration/standalone-full.xmlfile, uncomment the following properties in the<system-properties>section and replace<USERNAME>and<USER_PWD>with the credentials of a user with thekie-serverrole:<property name="org.kie.server.user" value="<USERNAME>"/> <property name="org.kie.server.pwd" value="<USER_PWD>"/>
In the Process Server
EAP_HOME/standalone/configuration/standalone-full.xmlfile, uncomment the following properties in the<system-properties>section.<property name="org.kie.server.controller.user" value="<CONTROLLER_USER>"/> <property name="org.kie.server.controller.pwd" value="<CONTROLLER_PWD>"/> <property name="org.kie.server.id" value="<KIE_SERVER_ID>"/> <property name="org.kie.server.location" value="http://<HOST>:<PORT>/kie-server/services/rest/server"/> <property name="org.kie.server.controller" value="<CONTROLLER_URL>"/>
- Replace the following values:
-
Replace
<CONTROLLER_USER>and<CONTROLLER_PWD>with the credentials of a user with therest-allrole. -
Replace
<KIE_SERVER_ID>with the ID or name of the Process Server installation, for example,rhpam-7.2.0-process_server-1. -
Replace
<HOST>with the ID or name of the Process Server host, for example,localhostor192.7.8.9. Replace
<PORT>with the port of the Process Server host, for example,8080.NoteThe
org.kie.server.locationproperty specifies the location of Process Server.Replace
<CONTROLLER_URL>with the URL of Business Central. Process Server connects to this URL during startup.If you installed Business Central using the installer or Red Hat JBoss EAP zip installations,
<CONTROLLER_URL>has this format:http://<HOST>:<PORT>/business-central/rest/controllerIf you are running Business Central using the
standalone.jarfile,<CONTROLLER_URL>has this format:http://<HOST>:<PORT>/rest/controller
Chapter 7. Installing and running the headless Process Automation Manager controller
You can configure Process Server to run in managed or unmanaged mode. If Process Server is unmanaged, you must manually create and maintain KIE containers (deployment units). If Process Server is managed, the Process Automation Manager controller manages the Process Server configuration and you interact with the Process Automation Manager controller to create and maintain KIE containers.
Business Central has an embedded Process Automation Manager controller. If you install Business Central, use the Execution Server page to create and maintain KIE containers. If you want to automate Process Server management without Business Central, you can use the headless Process Automation Manager controller.
7.1. Using the installer to configure Process Server with the Process Automation Manager controller
Process Server can be managed by the Process Automation Manager controller or it can be unmanaged. If Process Server is unmanaged, you must manually create and maintain KIE containers (deployment units). If Process Server is managed, the Process Automation Manager controller manages the Process Server configuration and you interact with the Process Automation Manager controller to create and maintain KIE containers.
The Process Automation Manager controller is integrated with Business Central. If you install Business Central, you can use the Execution Server page in Business Central to interact with the Process Automation Manager controller.
You can use the installer in interactive or CLI mode to install Business Central and Process Server, and then configure Process Server with the Process Automation Manager controller.
If you do not install Business Central, see Chapter 7, Installing and running the headless Process Automation Manager controller for information about using the headless Process Automation Manager controller.
Prerequisites
- Two computers with backed-up Red Hat JBoss EAP 7.2 or higher server installations are available.
- Sufficient user permissions to complete the installation are granted.
Procedure
- On the first computer, run the installer in interactive mode or CLI mode. See Installing and configuring Red Hat Process Automation Manager on Red Hat JBoss EAP for more information.
- On the Component Selection page, clear the Process Server box.
- Complete the Business Central installation.
- On the second computer, run the installer in interactive mode or CLI mode.
- On the Component Selection page, clear the Business Central box.
- On the Configure Runtime Environment page, select Perform Advanced Configuration.
- Select Customize Process Server properties and click Next.
- On the Process Server Properties Configuration page, click New Server Configuration to add a Process Server and specify a unique name for that Process Server. This name will appear in Business Central and enable you to distinguish between different Process Servers.
7.2. Installing the headless Process Automation Manager controller
You can install the headless Process Automation Manager controller and use the REST API or the Process Server Java Client API to interact with it.
Prerequisites
-
A backed-up Red Hat JBoss EAP installation version 7.2 or higher is available. The base directory of the Red Hat JBoss EAP installation is referred to as
EAP_HOME. - Sufficient user permissions to complete the installation are granted.
Procedure
Navigate to the Software Downloads page in the Red Hat Customer Portal (login required), and select the product and version from the drop-down options:
- Product: Process Automation Manager
- Version: 7.2
-
Download Red Hat Process Automation Manager 7.2.0 Add Ons (the
rhpam-7.2.0-add-ons.zipfile). -
Unzip the
rhpam-7.2.0-add-ons.zipfile. Therhpam-7.2-controller-ee7.zipfile is in the unzipped directory. -
Extract the
rhpam-7.2-controller-ee7archive to a temporary directory. In the following examples this directory is calledTEMP_DIR. Copy the
TEMP_DIR/rhpam-7.2-controller-ee7/controller.wardirectory toEAP_HOME/standalone/deployments/.WarningEnsure that the names of the headless Process Automation Manager controller deployments you are copying do not conflict with your existing deployments in the Red Hat JBoss EAP instance.
-
Copy the contents of the
TEMP_DIR/rhpam-7.2-controller-ee7/SecurityPolicy/directory toEAP_HOME/bin. When asked to overwrite files, select Yes. -
In the
EAP_HOME/standalone/deployments/directory, create an empty file namedcontroller.war.dodeploy. This file ensures that the headless Process Automation Manager controller is automatically deployed when the server starts.
7.2.1. Creating a headless Process Automation Manager controller user
Before you can use the headless Process Automation Manager controller, you must create a user that has the kie-server role.
Prerequisites
-
The headless Process Automation Manager controller is installed in the base directory of the Red Hat JBoss EAP installation (
EAP_HOME).
Procedure
-
In a terminal application, navigate to the
EAP_HOME/bindirectory. Enter the following command and replace
<USER_NAME>and<PASSWORD>with the user name and password of your choice.$ ./add-user.sh -a --user <USER_NAME> --password <PASSWORD> --role kie-server
NoteMake sure that the specified user name is not the same as an existing user, role, or group. For example, do not create a user with the user name
admin.The password must have at least eight characters and must contain at least one number and one non-alphanumeric character, but not & (ampersand).
- Make a note of your user name and password.
7.2.2. Configuring Process Server and the headless Process Automation Manager controller
If Process Server will be managed by the headless Process Automation Manager controller, you must edit the standalone-full.xml file in Process Server installation and the standalone.xml file in the headless Process Automation Manager controller installation, as described in this section.
Prerequisites
-
Process Server is installed in the base directory of the Red Hat JBoss EAP installation (
EAP_HOME). The headless Process Automation Manager controller is installed in an
EAP_HOME.NoteYou should install Process Server and the headless Process Automation Manager controller on different servers in production environments. However, if you install Process Server and the headless Process Automation Manager controller on the same server, for example in a development environment, make these changes in the shared
standalone-full.xmlfile.-
On Process Server nodes, a user with the
kie-serverrole exists. On the server nodes, a user with the
kie-serverrole exists.Procedure
In the
EAP_HOME/standalone/configuration/standalone-full.xmlfile, add the following properties to the<system-properties>section and replace<USERNAME>and<USER_PWD>with the credentials of a user with thekie-serverrole:<property name="org.kie.server.user" value="<USERNAME>"/> <property name="org.kie.server.pwd" value="<USER_PWD>"/>
In the Process Server
EAP_HOME/standalone/configuration/standalone-full.xmlfile, add the following properties to the<system-properties>section:<property name="org.kie.server.controller.user" value="<CONTROLLER_USER>"/> <property name="org.kie.server.controller.pwd" value="<CONTROLLER_PWD>"/> <property name="org.kie.server.id" value="<KIE_SERVER_ID>"/> <property name="org.kie.server.location" value="http://<HOST>:<PORT>/kie-server/services/rest/server"/> <property name="org.kie.server.controller" value="<CONTROLLER_URL>"/>
- In this file, replace the following values:
-
Replace
<CONTROLLER_USER>and<CONTROLLER_PWD>with the credentials of a user with thekie-serverrole. -
Replace
<KIE_SERVER_ID>with the ID or name of the Process Server installation, for example,rhpam-7.2.0-process_server-1. -
Replace
<HOST>with the ID or name of the Process Server host, for example,localhostor192.7.8.9. Replace
<PORT>with the port of the Process Server host, for example,8080.NoteThe
org.kie.server.locationproperty specifies the location of Process Server.Replace
<CONTROLLER_URL>with the URL of the headless Process Automation Manager controller.- Process Server connects to this URL during startup.
7.3. Running the headless Process Automation Manager controller
After you have installed the headless Process Automation Manager controller on Red Hat JBoss EAP, use this procedure to run the headless Process Automation Manager controller.
Prerequisites
-
The headless Process Automation Manager controller is installed and configured in the base directory of the Red Hat JBoss EAP installation (
EAP_HOME).
Procedure
-
In a terminal application, navigate to
EAP_HOME/bin. If you installed the headless Process Automation Manager controller on the same Red Hat JBoss EAP instance as the Red Hat JBoss EAP instance where you installed the Process Server, enter one of the following commands:
On Linux or UNIX-based systems:
$ ./standalone.sh -c standalone-full.xml
On Windows:
standalone.bat -c standalone-full.xml
If you installed the headless Process Automation Manager controller on a separate Red Hat JBoss EAP instance from the Red Hat JBoss EAP instance where you installed the Process Server, you can start the headless Process Automation Manager controller with the
standalone.shscript:NoteIn this case, ensure that you made all required configuration changes to the
standalone.xmlfile.On Linux or UNIX-based systems:
$ ./standalone.sh
On Windows:
standalone.bat
To verify that the headless Process Automation Manager controller is working on Red Hat JBoss EAP, enter the following command where
<CONTROLLER>and<CONTROLLER_PWD>is the user name and password. The output of this command provides information about the Process Server instance.curl -X GET "http://<HOST>:<PORT>/controller/rest/controller/management/servers" -H "accept: application/xml" -u '<CONTROLLER>:<CONTROLLER_PWD>'
Alternatively, you can use the Process Server Java API Client to access the headless Process Automation Manager controller.
7.4. Clustering with the headless Process Automation Manager controller
The Process Automation Manager controller is integrated with Business Central. However, if you do not install Business Central, you can install the headless Process Automation Manager controller and use the REST API or the Process Server Java Client API to interact with it.
Prerequisites
-
A backed-up Red Hat JBoss EAP installation version 7.2 or later is available. The base directory of the Red Hat JBoss EAP installation is referred to as
EAP_HOME. - Sufficient user permissions to complete the installation are granted.
- An NFS server with a mounted partition is available.
Procedure
Navigate to the Software Downloads page in the Red Hat Customer Portal (login required), and select the product and version from the drop-down options:
- Product: Process Automation Manager
- Version: 7.2
-
Download Red Hat Process Automation Manager 7.2.0 Add Ons (the
rhpam-7.2.0-add-ons.zipfile). -
Unzip the
rhpam-7.2.0-add-ons.zipfile. Therhpam-7.2-controller-ee7.zipfile is in the unzipped directory. -
Extract the
rhpam-7.2-controller-ee7archive to a temporary directory. In the following examples this directory is calledTEMP_DIR. Copy the
TEMP_DIR/rhpam-7.2-controller-ee7/controller.wardirectory toEAP_HOME/standalone/deployments/.WarningEnsure that the names of the headless Process Automation Manager controller deployments you are copying do not conflict with your existing deployments in the Red Hat JBoss EAP instance.
-
Copy the contents of the
TEMP_DIR/rhpam-7.2-controller-ee7/SecurityPolicy/directory toEAP_HOME/bin. When asked to overwrite files, select Yes. -
In the
EAP_HOME/standalone/deployments/directory, create an empty file namedcontroller.war.dodeploy. This file ensures that the headless Process Automation Manager controller is automatically deployed when the server starts. -
Open the
EAP_HOME/standalone/configuration/standalone.xmlfile in a text editor. Add the following properties to the
<system-properties>element and replace<NFS_STORAGE>with the absolute path to the NFS storage where the template configuration is stored:<system-properties> <property name="org.kie.server.controller.templatefile.watcher.enabled" value="true"/> <property name="org.kie.server.controller.templatefile" value="<NFS_STORAGE>"/> </system-properties>
If the value of the
org.kie.server.controller.templatefile.watcher.enabledproperty is set to true, a separate thread is started to watch for modifications of the template file. The default interval for these checks is 30000 milliseconds and can be further controlled by theorg.kie.server.controller.templatefile.watcher.intervalsystem property. If the value of this property is set to false, changes to the template file are detected only when the server restarts.To start the headless Process Automation Manager controller, navigate to
EAP_HOME/binand enter the following command:On Linux or UNIX-based systems:
$ ./standalone.sh
On Windows:
standalone.bat
For more information about running Red Hat Process Automation Manager in a Red Hat JBoss Enterprise Application Platform clustered environment, see Installing and configuring Red Hat Process Automation Manager in a Red Hat JBoss EAP clustered environment.
Chapter 8. Configuring a Process Server to connect to Business Central
If a Process Server is not already configured in your Red Hat Process Automation Manager environment, or if you require additional Process Servers in your Red Hat Process Automation Manager environment, you must configure a Process Server to connect to Business Central.
If you are deploying Process Server on Red Hat OpenShift Container Platform, see Deploying a Red Hat Process Automation Manager managed server environment on Red Hat OpenShift Container Platform for instructions about configuring it to connect to Business Central.
Prerequisite
Process Server is installed. For installation options, see Planning a Red Hat Process Automation Manager installation.
Procedure
-
In your Red Hat Process Automation Manager installation directory, navigate to the
standalone-full.xmlfile. For example, if you use a Red Hat JBoss EAP installation for Red Hat Process Automation Manager, go to$EAP_HOME/standalone/configuration/standalone-full.xml. Open
standalone-full.xmland under the<system-properties>tag, set the following properties:- org.kie.server.controller.user: The user name of a user who can log in to the Business Central.
- org.kie.server.controller.pwd: The password of the user who can log in to the Business Central.
-
org.kie.server.controller: The URL for connecting to the API of Business Central. Normally, the URL is
http://<centralhost>:<centralport>/business-central/rest/controller, where<centralhost>and<centralport>are the host name and port for Business Central. If Business Central is deployed on OpenShift, removebusiness-central/from the URL. -
org.kie.server.location: The URL for connecting to the API of Process Server. Normally, the URL is
http://<serverhost>:<serverport>/kie-server/services/rest/server, where<serverhost>and<serverport>are the host name and port for Process Server. - org.kie.server.id: The name of a server configuration. If this server configuration does not exist in Business Central, it is created automatically when Process Server connects to Business Central.
Example:
<property name="org.kie.server.controller.user" value="central_user"/> <property name="org.kie.server.controller.pwd" value="central_password"/> <property name="org.kie.server.controller" value="http://central.example.com:8080/business-central/rest/controller"/> <property name="org.kie.server.location" value="http://kieserver.example.com:8080/kie-server/services/rest/server"/> <property name="org.kie.server.id" value="production-servers"/>
- Start or restart the Process Server.
Chapter 9. Configuring Process Server Managed by Business Central
This section provides a sample setup that you can use for testing purposes. Some of the values are unsuitable for a production environment, and are marked as such.
Use this procedure to configure Business Central to manage a Process Server instance.
Prerequisite
Users with the following roles exist:
-
In Business Central, a user with the role
rest-all. -
On the Process Server, a user with the role
kie-server.
In production environments, use two distinct users, each with one role. In this sample situation, we use only one user named controllerUser that has both the rest-all and the kie-server roles.
Procedure
Set the following JVM properties.
The location of Business Central and the Process Server may be different. In such case, ensure you set the properties on the correct server instances.
On Red Hat JBoss EAP, modify the
<system-properties>section in:-
EAP_HOME/standalone/configuration/standalone*.xmlfor standalone mode. -
EAP_HOME/domain/configuration/domain.xmlfor domain mode.
-
Table 9.1. JVM Properties for Process Server Instance
Property Value Note org.kie.server.iddefault-kie-serverThe Process Server ID.
org.kie.server.controllerhttp://localhost:8080/decision-central/rest/controllerThe location of Business Central.
org.kie.server.controller.usercontrollerUserThe user name with the role
rest-allas mentioned in the previous step.org.kie.server.controller.pwdcontrollerUser1234;The password of the user mentioned in the previous step.
org.kie.server.locationhttp://localhost:8080/kie-server/services/rest/serverThe location of the Process Server.
Table 9.2. JVM Properties for Business Central Instance
Property Value Note org.kie.server.usercontrollerUserThe user name with the role
kie-serveras mentioned in the previous step.org.kie.server.pwdcontrollerUser1234;The password of the user mentioned in the previous step.
Verify the successful start of the Process Server by sending a GET request to
http://SERVER:PORT/kie-server/services/rest/server/. Once authenticated, you get an XML response similar to this:<response type="SUCCESS" msg="Kie Server info"> <kie-server-info> <capabilities>KieServer</capabilities> <capabilities>BRM</capabilities> <capabilities>BPM</capabilities> <capabilities>CaseMgmt</capabilities> <capabilities>BPM-UI</capabilities> <capabilities>BRP</capabilities> <capabilities>DMN</capabilities> <capabilities>Swagger</capabilities> <location>http://localhost:8230/kie-server/services/rest/server</location> <messages> <content>Server KieServerInfo{serverId='first-kie-server', version='7.5.1.Final-redhat-1', location='http://localhost:8230/kie-server/services/rest/server', capabilities=[KieServer, BRM, BPM, CaseMgmt, BPM-UI, BRP, DMN, Swagger]}started successfully at Mon Feb 05 15:44:35 AEST 2018</content> <severity>INFO</severity> <timestamp>2018-02-05T15:44:35.355+10:00</timestamp> </messages> <name>first-kie-server</name> <id>first-kie-server</id> <version>7.5.1.Final-redhat-1</version> </kie-server-info> </response>Verify successful registration:
- Log in to Business Central.
Click Menu → Deploy → Execution Servers.
If registration is successful, you can see the registered server ID.
9.1. Configuring Smart Router for TLS support
You can now configure Smart Router (previously, KIE Server Router) for TLS support to allow HTTPS traffic.
Procedure
Open a terminal and enter the following command to start the smart router with TLS support:
java -Dorg.kie.server.router.tls.keystore=PATH_TO_YOUR_KEYSTORE -Dorg.kie.server.router.tls.keystore.password=YOUR_KEYSTORE_PASSWD -Dorg.kie.server.router.tls.keystore.keyalias=YOUR_KEYSTORE_ALIAS -jar kie-server-router-proxy-YOUR_VERSION.jarReplace
PATH_TO_YOUR_KEYSTORE,YOUR_KEYSTORE_PASSWD,YOUR_KEYSTORE_ALIAS, andYOUR_VERSIONwith the relevant data.
Chapter 10. Managed Process Server
A managed instance requires an available Process Automation Manager controller to start the Process Server.
A Process Automation Manager controller manages the Process Server configuration in a centralized way. Each Process Automation Manager controller can manage multiple configurations at once, and there can be multiple Process Automation Manager controllers in the environment. Managed Process Server can be configured with a list of Process Automation Manager controllers, but will only connect to one at a time.
All Process Automation Manager controllers should be synchronized to ensure that the same set of configuration is provided to the server, regardless of the Process Automation Manager controller to which it connects.
When the Process Server is configured with a list of Process Automation Manager controllers, it will attempt to connect to each of them at startup until a connection is successfully established with one of them. If a connection cannot be established, the server will not start, even if there is a local storage available with configuration. This ensures consistence and prevents the server from running with redundant configuration.
To run the Process Server in standalone mode without connecting to Process Automation Manager controllers, see Chapter 11, Unmanaged Process Server.
Chapter 11. Unmanaged Process Server
An unmanaged Process Server is a standalone instance, and therefore must be configured individually using REST/JMS API from the Process Server itself. The configuration is automatically persisted by the server into a file and that is used as the internal server state, in case of restarts.
The configuration is updated during the following operations:
- Deploy KIE container
- Undeploy KIE container
- Start KIE container
- Stop KIE container
If the Process Server is restarted, it will attempt to re-establish the same state that was persisted before shutdown. Therefore, KIE containers (deployment units) that were running will be started, but the ones that were stopped will not.
Chapter 12. Activating or deactivating a KIE container on Process Server
You can now stop the creation of new process instances from a given container by deactivating it but at the same time continue working on its existing process instances and tasks. In case the deactivation is temporary, you can activate the container again later. The activation or deactivation of KIE containers do not require restarting of KIE server.
Prerequisite
A container has been created and configured in Business Central.
Procedure
- Log in to Business Central.
- In the main menu, click Menu → Deploy → Execution Servers.
- From the Server Configurations pane, which is on the left of the page, select your server.
- From the Deployment Units pane, select the deployment unit you want to activate or deactivate.
Click Activate or Deactivate in the upper-right corner of the deployment unit pane.
Once you deactivate a given KIE container, you cannot create new process instances from it.
Chapter 13. Deployment descriptors
Processes and rules are stored in Apache Maven based packaging and are known as knowledge archives, or KJAR. The rules, processes, assets, and other project artifacts are part of a JAR file built and managed by Maven. A file kept inside the META-INF directory of the KJAR called kmodule.xml can be used to define the KIE bases and sessions. This kmodule.xml file, by default, is empty.
Whenever a runtime component such as Business Central is about to process the KJAR, it looks up kmodule.xml to build the runtime representation.
Deployment descriptors supplement the kmodule.xml file and provide granular control over your deployment. The presence of these descriptors is optional and your deployment will proceed successfully without them. You can set purely technical properties using these descriptors, including meta values such as persistence, auditing, and runtime strategy.
These descriptors allow you to configure the Process Server on multiple levels (server level default, different deployment descriptor per KJAR, and other server configurations). This allows you to make simple customizations to the default Process Server configuration (possibly per KJAR).
You can define these descriptors in a file called kie-deployment-descriptor.xml and place this file next to your kmodule.xml file in the META-INF folder. You can change this default location and the file name by specifying it as a system parameter:
-Dorg.kie.deployment.desc.location=file:/path/to/file/company-deployment-descriptor.xml
13.1. Deployment descriptor configuration
Deployment descriptors allow the user to configure the execution server on multiple levels:
- Server level: The main level and the one that applies to all KJARs deployed on the server.
- KJAR level: This allows you to configure descriptors on a per KJAR basis.
- Deploy time level: Descriptors that apply while a KJAR is being deployed.
The granular configuration items specified by the deployment descriptors take precedence over the server level ones, except in case of configuration items that are collection based, which are merged. The hierarchy works like this: deploy time configuration > KJAR configuration > server configuration.
The deploy time configuration applies to deployments done via the REST API.
For example, if the persistence mode (one of the items you can configure) defined at the server level is NONE but the same mode is specified as JPA at the KJAR level, the actual mode will be JPA for that KJAR. If nothing is specified for the persistence mode in the deployment descriptor for that KJAR (or if there is no deployment descriptor), it will fall back to the server level configuration, which in this case is NONE (or to JPA if there is no server level deployment descriptor).
What Can You Configure?
High level technical configuration details can be configured via deployment descriptors. The following table lists these along with the permissible and default values for each.
Table 13.1. Deployment Descriptors
| Configuration | XML Entry | Permissible Values | Default Value |
|---|---|---|---|
| Persistence unit name for runtime data | persistence-unit | Any valid persistence package name | org.jbpm.domain |
| Persistence unit name for audit data | audit-persistence-unit | Any valid persistence package name | org.jbpm.domain |
| Persistence mode | persistence-mode | JPA, NONE | JPA |
| Audit mode | audit-mode | JPA, JMS or NONE | JPA |
| Runtime Strategy | runtime-strategy | SINGLETON, PER_REQUEST or PER_PROCESS_INSTANCE | SINGLETON |
| List of Event Listeners to be registered | event-listeners |
Valid listener class names as | No default value |
| List of Task Event Listeners to be registered | task-event-listeners |
Valid listener class names as | No default value |
| List of Work Item Handlers to be registered | work-item-handlers |
Valid Work Item Handler classes given as | No default value |
| List of Globals to be registered | globals |
Valid Global variables given as | No default value |
| Marshalling strategies to be registered (for pluggable variable persistence) | marshalling-strategies |
Valid | No default value |
| Required Roles to be granted access to the resources of the KJAR | required-roles | String role names | No default value |
| Additional Environment Entries for KIE session | environment-entries |
Valid | No default value |
| Additional configuration options of KIE session | configurations |
Valid | No default value |
| Classes used for serialization in the remote services | remoteable-class |
Valid | No default value |
13.2. Managing deployment descriptors
Deployment descriptors can be configured in Business Central in Menu → Design → $PROJECT_NAME → Settings → Deployments.
Every time a project is created, a stock kie-deployment-descriptor.xml file is generated with default values.
It is not necessary to provide a full deployment descriptor for all KJARs. Providing partial deployment descriptors is possible and recommended. For example, if you need to use a different audit mode, you can specify that for the KJAR only, all other properties will have the default value defined at the server level.
When using OVERRIDE_ALL merge mode, all configuration items must be specified, because the relevant KJAR will always use specified configuration and will not merge with any other deployment descriptor in the hierarchy.
13.3. Restricting access to the runtime engine
The required-roles configuration item can be edited in the deployment descriptors. This property restricts access to the runtime engine on a per-KJAR or per-server level by ensuring that access to certain processes is only granted to users that belong to groups defined by this property.
The security role can be used to restrict access to process definitions or restrict access at run time.
The default behavior is to add required roles to this property based on repository restrictions. You can edit these properties manually if required by providing roles that match actual roles defined in the security realm.
Procedure
- To open the project deployment descriptors configuration in Business Central, open Menu → Design → $PROJECT_NAME → Settings → Deployments.
- From the list of configuration settings, click Required Roles, then click Add Required Role.
- In the Add Required Role window, type the name of the role that you want to have permission to access this deployment, then click Add.
- To add more roles with permission to access the deployment, repeat the previous steps.
- When you have finished adding all required roles, click Save.
Chapter 14. Accessing runtime data from Business Central
The following pages in Business Central allow you to view the runtime data of the Process Server:
- Process Reports
- Task Reports
- Process Definitions
- Process Instances
- Execution Errors
- Jobs
- Tasks
These pages use the credentials of the currently logged in user to load data from the Process Server. Therefore, to be able to view the runtime data in Business Central, ensure that the following conditions are met:
-
The user exists in the KIE container (deployment unit) running the Business Central application. This user must have
admin,analyst, ordeveloperroles assigned, in addition to thekie-serverrole, with full access to the runtime data. Themanagerandprocess_adminroles also allow access to runtime data pages in Business Central. -
The user exists in the KIE container (deployment unit) running the Process Server and has
kie-serverrole assigned. - Communication between Business Central and the Process Server is established. That is, the Process Server is registered in the Process Automation Manager controller, which is part of Business Central.
The
deployment.business-central.warlogin module is present in thestandalone.xmlconfiguration of the server running Business Central:<login-module code="org.kie.security.jaas.KieLoginModule" flag="optional" module="deployment.business-central.war"/>
Chapter 15. Execution error management
When an execution error occurs the process stops and rolls back to the most recent stable state (the closest safe point) and continues its execution. If an error of any kind is not handled by the process the entire transaction rolls back, leaving the process instance in the previous wait state. Any trace of this is only visible in the logs, and usually displayed to the caller who sent the request to the process engine.
Users with process administrator (process-admin) or administrator (admin) roles are able to access error messages in Business Central, which has the following features:
- Better traceability
- Visibility in case of critical processes
- Reporting and analytics based on error situations
- External system error handling and compensation
Configurable error handling is responsible for receiving any technical errors thrown throughout the process engine execution (including task service). The following technical exceptions apply:
-
Anything that extends
java.lang.Throwable. - Process level error handling and any other exceptions not previously handled.
There are several components that make up the error handling mechanism and allow a pluggable approach to extend its capabilities.
The process engine entry point for error handling is the ExecutionErrorManager. This is integrated with RuntimeManager, which is then responsible for providing it to underlying components - KieSession and TaskService. From the API point of view, ExecutionErrorManager gives access to:
-
ExecutionErrorHandler- the primary mechanism for error handling. -
ExecutionErrorStorage- pluggable storage for execution error information.
15.1. Manage execution errors
By definition, every error that is caught and stored is unacknowledged, meaning that it is to be handled by someone or something (in case of automatic error recovery). Errors are filtered on the basis of whether or not they have been acknowledged. Acknowledging an error saves the user information and time stamp for traceability.
You can access the Error Management view at any time.
- In Business Central, click Menu → Manage → Execution Errors.
- Select an error from the list to open the Details tab. This displays information about the error or errors.
- Click the Acknowledge button to acknowledge and clear the error. The error can still be viewed later by selecting Yes on the Acknowledged filter in the Manage Execution Errors page.
If the error was related to a task, a Go to Task button is displayed.
Click the Go to Task button to view the associated job information in the Manage Tasks page.
The Manage Tasks page allows you to restart, reschedule, or retry the corresponding task.
15.2. The ExecutionErrorHandler
The ExecutionErrorHandler is the primary mechanism for all process error handling. It is bound to the life cycle of RuntimeEngine; meaning it is created when a new runtime engine is created, and is destroyed when RuntimeEngine is disposed. A single instance of the ExecutionErrorHandler is used within a given execution context or transaction. Both KieSession and TaskService use that instance to inform the error handling about processed nodes/tasks. ExecutionErrorHandler is informed about:
- Starting of processing of a given node instance.
- Completion of processing of a given node instance.
- Starting of processing of a given task instance.
- Completion of processing of a given task instance.
This information is mainly used for errors that are of unknown type; that is, errors that do not provide information about the process context. For example, upon commit time, database exceptions do not carry any process information.
15.3. Execution error storage
ExecutionErrorStorage is a pluggable strategy that permits various ways of persisting information about execution errors. Storage is used directly by the handler that gets an instance of the store when it is created (when RuntimeEngine is created). Default storage implementation is based on the database table, which stores every error and includes all of the available information. Some errors may not contain details, as this depends on the type of error and whether or not it is possible to extract specific information.
15.4. Error types and filters
Error handling attempts to catch and handle any kind of error, therefore it needs a way to categorize errors. By doing this, it is able to properly extract information from the error and make it pluggable, as some users may require specific types of errors to be thrown and handled in different ways than what is provided by default.
Error categorization and filtering is based on ExecutionErrorFilters. This interface is solely responsible for building instances of ExecutionError, which are later stored by way of the ExecutionErrorStorage strategy. It has following methods:
-
accept: indicates if given error can be handled by the filter. -
filter: where the actual filtering, handling, and so on happens. -
getPriority: indicates the priority that is used when calling filters.
As only one filter can process given error, filters use a priority system to avoid having multiple filters returning alternative “views” of the same error. Priority allows more specialized filters to see if the error can be accepted, or otherwise allow another filter to handle it.
ExecutionErrorFilter can be provided using the ServiceLoader mechanism, which allows the capability of error handling to be easily extended.
Red Hat Process Automation Manager ships with the following ExecutionErrorFilters :
Table 15.1. ExecutionErrorFilters
| Class name | Type | Priority |
|---|---|---|
| org.jbpm.runtime.manager.impl.error.filters.ProcessExecutionErrorFilter | Process | 100 |
| org.jbpm.runtime.manager.impl.error.filters.TaskExecutionErrorFilter | Task | 80 |
| org.jbpm.runtime.manager.impl.error.filters.DBExecutionErrorFilter | DB | 200 |
| org.jbpm.executor.impl.error.JobExecutionErrorFilter | Job | 100 |
Filters are given a higher execution order based on the lowest value of the priority. In above table, filters are invoked in following order:
- Task
- Process
- Job
- DB
15.5. Auto acknowledging execution errors
When executions errors occur they are unacknowledged by default, and require a manual acknowledgment to be performed otherwise they are always seen as information that requires attention. In case of larger volumes, manual actions can be time consuming and not suitable in some situations.
Auto acknowledgment resolves this issue. It is based on scheduled jobs by way of the jbpm-executor, with the following three types of jobs available:
org.jbpm.executor.commands.error.JobAutoAckErrorCommand-
Responsible for finding jobs that previously failed but now are either canceled, completed, or rescheduled for another execution. This job only acknowledges execution errors of type
Job. org.jbpm.executor.commands.error.TaskAutoAckErrorCommand-
Responsible for auto acknowledgment of user task execution errors for tasks that previously failed but now are in one of the exit states (completed, failed, exited, obsolete). This job only acknowledges execution errors of type
Task. org.jbpm.executor.commands.error.ProcessAutoAckErrorCommand-
Responsible for auto acknowledgment of process instances that have errors attached. It acknowledges errors where the process instance is already finished (completed or aborted), or the task that the error originated from is already finished. This is based on
init_activity_idvalue. This job acknowledges any type of execution error that matches the above criteria.
Jobs can be registered on the Process Server. In Business Central you can configure auto acknowledge jobs for errors:
Prerequisite
- Execution errors of one or more type have accumulated during processes execution but require no further attention.
Procedure
- In Business Central, click Menu → Manage → Jobs.
- In the top right of the screen, click New Job.
- Type the process correlation key into the Business Key field.
- In the Type field, add type of the auto acknowledge job type from the list above.
Select a Due On time for the job to be completed:
-
To run the job immediately, select the
Run nowoption. To run the job at a specific time, select
Run later. A date and time field appears next to theRun lateroption. Click the field to open the calendar and schedule a specific time and date for the job.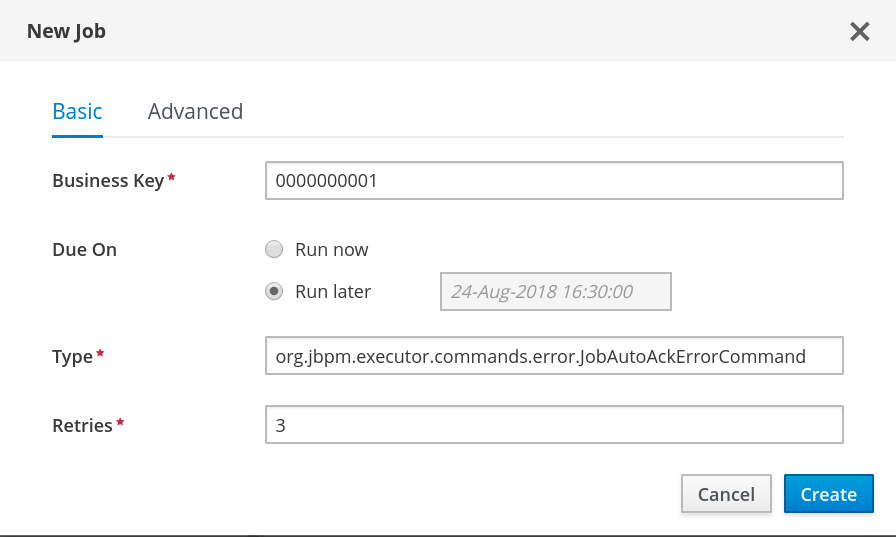
-
To run the job immediately, select the
- Click Create to create the job and return to the Manage Jobs page.
The following steps are optional, and allow you to configure auto acknowledge jobs to run either once (SingleRun), on specific time intervals (NextRun), or using the custom name of an entity manager factory to search for jobs to acknowledge (EmfName).
- Click on the Advanced tab.
- Click the Add Parameter button.
Enter the configuration parameter you want to apply to the job:
-
SingleRun:trueorfalse -
NextRun: time expression, such as 2h, 5d, 1m, and so on. EmfName: custom entity manager factory name.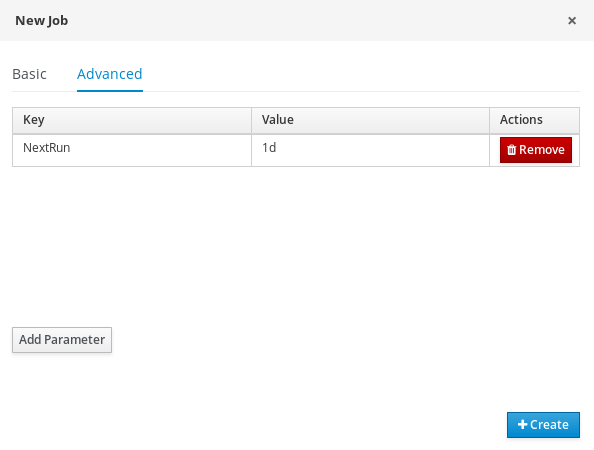
-
15.6. Cleaning up the error list
The ExecutionErrorInfo error list table can be cleaned up to remove redundant information. Depending on the life cycle of the process, errors may remain in the list for some time, and there is no direct API with which to clean up the list. Instead, the ExecutionErrorCleanupCommand command can be scheduled to periodically clean up errors.
The following parameters can be set for the clean up command. The command is restricted to deleting execution errors of already completed or aborted process instances:
DateFormat-
Date format for further date related parameters - if not given
yyyy-MM-ddis used (pattern ofSimpleDateFormatclass).
-
Date format for further date related parameters - if not given
EmfName- Name of the entity manager factory to be used for queries (valid persistence unit name).
SingleRun-
Indicates if execution should be single run only (
true|false).
-
Indicates if execution should be single run only (
NextRun- Provides next execution time (valid time expression, for example: 1d, 5h, and so on)
OlderThan- Indicates what errors should be deleted - older than given date.
OlderThanPeriod- Indicated what errors should be deleted older than given time expression (valid time expression e.g. 1d, 5h, and so on)
ForProcess- Indicates errors to be deleted only for given process definition.
ForProcessInstance- Indicates errors to be deleted only for given process instance.
ForDeployment- Indicates errors to be deleted that are from given deployment ID.
Chapter 16. Configuring OpenShift connection timeout
By default, the OpenShift route is configured to time out HTTP requests that are longer than 30 seconds. This may cause session timeout issues in Business Central resulting in the following behaviors:
- "Unable to complete your request. The following exception occurred: (TypeError) : Cannot read property 'indexOf' of null."
- "Unable to complete your request. The following exception occurred: (TypeError) : b is null."
- A blank page is displayed when clicking the Project or Server links in Business Central.
All Business Central templates already include extended timeout configuration.
To configure longer timeout on Business Central OpenShift routes, add the haproxy.router.openshift.io/timeout: 60s annotation on the target route:
- kind: Route
apiVersion: v1
id: "$APPLICATION_NAME-rhdmcentr-http"
metadata:
name: "$APPLICATION_NAME-rhdmcentr"
labels:
application: "$APPLICATION_NAME"
annotations:
description: Route for Decision Central's http service.
haproxy.router.openshift.io/timeout: 60s
spec:
host: "$DECISION_CENTRAL_HOSTNAME_HTTP"
to:
name: "$APPLICATION_NAME-rhdmcentr"For a full list of global route-specific timeout annotations, see the OpenShift Documentation.
Chapter 17. Persistence
Binary persistence, or marshaling, converts the state of the process instance into a binary data set. Binary persistence is a mechanism used to store and retrieve information persistently. The same mechanism is also applied to the session state and work item states.
When you enable persistence of a process instance:
- Red Hat Process Automation Manager transforms the process instance information into binary data. Custom serialization is used instead of Java serialization for performance reasons.
- The binary data is stored together with other process instance metadata, such as process instance ID, process ID, and the process start date.
The session can also store other forms of state, such as the state of timer jobs, or data required for business rules evaluation. Session state is stored separately as a binary data set along with the ID of the session and metadata. You can restore the session state by reloading a session with given ID. Use ksession.getId() to get the session ID.
Red Hat Process Automation Manager will persist the following when persistence is configured:
- Session state: This includes the session ID, date of last modification, the session data that business rules would need for evaluation, state of timer jobs.
- Process instance state: This includes the process instance ID, process ID, date of last modification, date of last read access, process instance start date, runtime data (the execution status including the node being executed, variable values, and other process instance data) and the event types.
- Work item runtime state: This includes the work item ID, creation date, name, process instance ID, and the work item state itself.
Based on the persisted data, you can restore the state of execution of all running process instances in case of failure or to temporarily remove running instances from memory and restore them later.
17.1. Configuring Process Server persistence
You can configure the Process Server persistence by passing Hibernate or JPA parameters as system properties.
The Process Server can acknowledge the system properties with the following prefixes and you can use every Hibernate or JPA parameters with these prefixes:
-
javax.persistence -
hibernate
Procedure
To configure Process Server persistence, complete any of the following tasks:
If you want to configure Process Server persistence using Red Hat JBoss EAP configuration file, complete the following tasks:
-
In your Red Hat Process Automation Manager installation directory, navigate to the
standalone-full.xmlfile. For example, if you use Red Hat JBoss EAP installation for Red Hat Process Automation Manager, go to$EAP_HOME/standalone/configuration/standalone-full.xmlfile. Open the
standalone-full.xmlfile and under the<system-properties>tag, set your Hibernate or JPA parameters as system properties.Example of configuring Process Server persistence using Hibernate parameters
<system-properties> ... <property name="hibernate.hbm2ddl.auto" value="create-drop"/> ... <system-properties>Example of configuring Process Server persistence using JPA parameters
<system-properties> ... <property name="javax.persistence.jdbc.url" value="jdbc:mysql://mysql.db.server:3306/my_database?useSSL=false&serverTimezone=UTC"/> ... <system-properties>
If you want to configure Process Server persistence using command line, complete the following tasks:
Pass the parameters directly from the command line using
-Dkey=valueas follows:Example of configuring Process Server persistence using Hibernate parameters:
$EAP_HOME/bin/standalone.sh -Dhibernate.hbm2ddl.auto=create-drop
Example of configuring Process Server persistence using JPA parameters:
$EAP_HOME/bin/standalone.sh -Djavax.persistence.jdbc.url=jdbc:mysql://mysql.db.server:3306/my_database?useSSL=false&serverTimezone=UTC
-
In your Red Hat Process Automation Manager installation directory, navigate to the
17.2. Configuring safe points
To allow persistence, add the jbpm-persistence JAR files to the classpath of your application and configure the process engine to use persistence. The process engine automatically stores the runtime state in the storage when the process engine reaches a safe point.
Safe points are points where the process instance has paused. When a process instance invocation reaches a safe point in the process engine, the process engine stores any changes to the process instance as a snapshot of the process runtime data. However, when a process instance is completed, the persisted snapshot of process instance runtime data is automatically deleted.
If a failure occurs and you need to restore the process engine runtime from the storage, the process instances are automatically restored and their execution resumes so there is no need to reload and trigger the process instances manually.
The runtime persistence data is to be considered internal to the process engine. You should not access persisted runtime data or modify them directly as this might have unexpected side effects.
For more information about the current execution state, refer to the history log. Query the database for runtime data only if absolutely necessary.
17.3. Session persistence entities
Sessions are persisted as SessionInfo entities. These persist the state of the runtime KIE session, and store the following data:
Table 17.1. SessionInfo
| Field | Description | Nullable |
|---|---|---|
|
| The primary key. | NOT NULL |
|
| The last time that entity was saved to a database. | |
|
| The state of a session. | NOT NULL |
|
| The session start time. | |
|
| A version field containing a lock value. |
17.4. Process instance persistence entities
Process instances are persisted as ProcessInstanceInfo entities, which persist the state of a process instance on runtime and store the following data:
Table 17.2. ProcessInstanceInfo
| Field | Description | Nullable |
|---|---|---|
|
| The primary key. | NOT NULL |
|
| The last time that the entity was saved to a database. | |
|
| The last time that the entity was retrieved from the database. | |
|
| The ID of the process. | |
|
| The state of a process instance in form of a binary data set. | NOT NULL |
|
| The start time of the process. | |
|
| An integer representing the state of a process instance. | NOT NULL |
|
| A version field containing a lock value. |
ProcessInstanceInfo has a 1:N relationship to the EventTypes entity.
The EventTypes entity contains the following data:
Table 17.3. EventTypes
| Field | Description | Nullable |
|---|---|---|
|
|
A reference to the | NOT NULL |
|
| A finished event in the process. |
17.5. Work item persistence entities
Work items are persisted as workiteminfo entities, which persist the state of the particular work item instance on runtime and store the following data:
Table 17.4. WorkItemInfo
| Field | Description | Nullable |
|---|---|---|
|
| The primary key. | NOT NULL |
|
| The name of the work item. | |
|
| The (primary key) ID of the process. There is no foreign key constraint on this field. | NOT NULL |
|
| The state of a work item. | NOT NULL |
|
| A version field containing a lock value. | |
|
| The work item state in as a binary data set. | NOT NULL |
17.6. Correlation key entities
The CorrelationKeyInfo entity contains information about the correlation key assigned to the given process instance. This table is optional. Use it only when you require correlation capabilities.
Table 17.5. CorrelationKeyInfo
| Field | Description | Nullable |
|---|---|---|
|
| The primary key. | NOT NULL |
|
| The assigned name of the correlation key. | |
|
| The ID of the process instance which is assigned to the correlation key. | NOT NULL |
|
| A version field containing a lock value. |
The CorrelationPropertyInfo entity contains information about correlation properties for a correlation key assigned the process instance.
Table 17.6. CorrelationPropertyInfo
| Field | Description | Nullable |
|---|---|---|
|
| The primary key. | NOT NULL |
|
| The name of the property. | |
|
| The value of the property. | NOT NULL |
|
| A version field containing a lock value. | |
|
| A foreign key mapped to the correlation key. | NOT NULL |
17.7. Context mapping entity
The ContextMappingInfo entity contains information about the contextual information mapped to a KieSession. This is an internal part of RuntimeManager and can be considered optional when RuntimeManager is not used.
Table 17.7. ContextMappingInfo
| Field | Description | Nullable |
|---|---|---|
|
| The primary key. | NOT NULL |
|
| The context identifier. | NOT NULL |
|
|
The | NOT NULL |
|
| A version field containing a lock value. | |
|
| Holds the identifier of the deployment unit that the given mapping is associated with |
17.8. Pessimistic Locking Support
The default locking mechanism for persistence of processes is optimistic. With multi-thread high concurrency to the same process instance, this locking strategy can result in bad performance.
This can be changed at runtime to allow the user to set locking on a per process basis and to allow it to be pessimistic (the change can be made at a per KIE Session level or Runtime Manager level as well and not just at the process level).
To set a process to use pessimistic locking, use the following configuration in the runtime environment:
import org.kie.api.runtime.Environment; import org.kie.api.runtime.EnvironmentName; import org.kie.api.runtime.manager.RuntimeManager; import org.kie.api.runtime.manager.RuntimeManagerFactory; ... env.set(EnvironmentName.USE_PESSIMISTIC_LOCKING, true); 1 RuntimeManager manager = RuntimeManagerFactory.Factory.get().newPerRequestRuntimeManager(environment); 2
Chapter 18. Define the LDAP login domain
When you are setting up Red Hat Process Automation Manager to use LDAP for authentication and authorization, define the LDAP login domain. This is because the Git SSH authentication may be using another security domain, in which case you may face authentication failure.
To define the LDAP login domain, use the org.uberfire.domain system property. For example, on Red Hat JBoss Enterprise Application Platform, add this property in the standalone.xml file as shown below:
<system-properties> <!-- other system properties --> <property name="org.uberfire.domain" value="LDAPAuth"/> </system-properties>
Ensure that the authenticated user has appropriate roles (admin,analyst,reviewer) associated with it in LDAP.
Chapter 19. Authenticating third-party clients through RH-SSO
To use the different remote services provided by Business Central or by Process Server, your client, such as curl, wget, web browser, or a custom REST client, must authenticate through the RH-SSO server and have a valid token to perform the requests. To use the remote services, the authenticated user must have the following roles:
-
rest-allfor using Business Central remote services. -
kie-serverfor using the Process Server remote services.
Use the RH-SSO Admin Console to create these roles and assign them to the users that will consume the remote services.
Your client can authenticate through RH-SSO using one of these options:
- Basic authentication, if it is supported by the client
- Token-based authentication
19.1. Basic authentication
If you enabled basic authentication in the RH-SSO client adapter configuration for both Business Central and Process Server, you can avoid the token grant and refresh calls and call the services as shown in the following examples:
For web based remote repositories endpoint:
curl http://admin:password@localhost:8080/business-central/rest/repositories
For Process Server:
curl http://admin:password@localhost:8080/kie-execution-server/services/rest/server/
Chapter 20. Process Server system properties
The Process Server accepts the following system properties (bootstrap switches) to configure the behavior of the server:
Table 20.1. System properties for disabling Process Server extensions
| Property | Values | Default | Description |
|---|---|---|---|
|
|
|
|
If set to |
|
|
|
|
If set to |
|
|
|
|
If set to |
|
|
|
|
If set to |
|
|
|
|
If set to |
|
|
|
|
If set to |
|
|
|
|
If set to |
Some Process Automation Manager controller properties listed in the following table are marked as required. Set these properties when you create or remove Process Server containers in Business Central. If you use the Process Server separately without any interaction with Business Central, you do not need to set the required properties.
Table 20.2. System properties required for Process Automation Manager controller
| Property | Values | Default | Description |
|---|---|---|---|
|
| String | N/A | An arbitrary ID to be assigned to the server. If a headless Process Automation Manager controller is configured outside of Business Central, this is the ID under which the server connects to the headless Process Automation Manager controller to fetch the KIE container configurations. If not provided, the ID is automatically generated. |
|
| String |
| The user name used to connect with the Process Server from the Process Automation Manager controller, required when running in managed mode. Set this property in Business Central system properties. Set this property when using a Process Automation Manager controller. |
|
| String |
| The password used to connect with the Process Server from the Process Automation Manager controller, required when running in managed mode. Set this property in Business Central system properties. Set this property when using a Process Automation Manager controller. |
|
| String | N/A | A property that enables you to use token-based authentication between the Process Automation Manager controller and the Process Server instead of the basic user name and password authentication. The Process Automation Manager controller sends the token as a parameter in the request header. The server requires long-lived access tokens because the tokens are not refreshed. |
|
| URL | N/A |
The URL of the Process Server instance used by the Process Automation Manager controller to call back on this server, for example, |
|
| Comma-separated list | N/A |
A comma-separated list of URLs to the Process Automation Manager controller REST endpoints, for example, |
|
| String |
| The user name to connect to the Process Automation Manager controller REST API. Setting this property is required when using a Process Automation Manager controller. |
|
| String |
| The password to connect to the Process Automation Manager controller REST API. Setting this property is required when using a Process Automation Manager controller. |
|
| String | N/A | A property that enables you to use token-based authentication between the Process Server and the Process Automation Manager controller instead of the basic user name and password authentication. The server sends the token as a parameter in the request header. The server requires long-lived access tokens because the tokens are not refreshed. |
|
| Long |
| The waiting time in milliseconds between repeated attempts to connect the Process Server to the Process Automation Manager controller when the server starts. |
Table 20.3. Persistence system properties
| Property | Values | Default | Description |
|---|---|---|---|
|
| String | N/A | A data source JNDI name. Set this property when enabling the BPM support. |
|
| String | N/A | A transaction manager platform for Hibernate properties. Set this property when enabling the BPM support. |
|
| String | N/A | The Hibernate dialect to be used. Set this property when enabling the BPM support. |
|
| String | N/A | The database schema to be used. |
Table 20.4. Executor system properties
| Property | Values | Default | Description |
|---|---|---|---|
|
| Integer |
|
The time between the moment the Red Hat Process Automation Manager executor finishes a job and the moment it starts a new one, in a time unit specified in the |
|
|
|
|
The time unit in which the |
|
| Integer |
| The number of threads used by the Red Hat Process Automation Manager executor. |
|
| Integer |
| The number of retries the Red Hat Process Automation Manager executor attempts on a failed job. |
|
| String |
| Job executor JMS queue for Process Server. |
|
|
|
|
If set to |
Table 20.5. Human task system properties
| Property | Values | Default | Description |
|---|---|---|---|
|
|
|
| A property that specifies the implementation of user group callback to be used:
|
|
| Fully qualified name | N/A |
A custom implementation of the |
|
|
|
| Enables task cleanup job listener to remove tasks once the process instance is completed. |
|
|
|
| Enables task BAM module to store task related information. |
|
| String |
| User who can access all the tasks from Process Server. |
|
| String |
| The group that users must belong to in order to view all the tasks from Process Server. |
Table 20.6. System properties for loading keystore
| Property | Values | Default | Description |
|---|---|---|---|
|
| URL | N/A |
The URL is used to load a Java Cryptography Extension KeyStore (JCEKS). For example, |
|
| String | N/A | The password is used for the JCEKS. |
|
| String | N/A | The alias name of the key for REST services where the password is stored. |
|
| String | N/A | The password of an alias for REST services. |
|
| String | N/A | The alias of the key for default REST Process Automation Manager controller. |
|
| String | N/A | The password of an alias for default REST Process Automation Manager controller. |
Table 20.7. Other system properties
| Property | Values | Default | Description |
|---|---|---|---|
|
| Path | N/A |
The location of a custom |
|
| String |
| The response queue JNDI name for JMS. |
|
|
|
|
When set to |
|
|
|
| A property that enables you to bypass the authenticated user for task-related operations, for example queries. |
|
| Integer |
| This property specifies the maximum number of executed rules to avoid situations where rules run into an infinite loop and make the server completely unresponsive. |
|
| String | N/A |
The JAAS |
|
| Path |
| The location where Process Server state files are stored. |
|
|
|
| A property that instructs the Process Server to hold the deployment until the Process Automation Manager controller provides the container deployment configuration. This property only affects servers running in managed mode. The following options are available:
* |
|
|
|
| The Startup strategy of Process Server used to control the KIE containers that are deployed and the order in which they are deployed. |
|
|
|
|
When set to |
|
|
Java packages like | N/A | A property that specifies additional packages to whitelist for marshalling using XStream. |
|
| String |
|
Fully qualified name of the class that implements |
Chapter 21. Process Server capabilities and extensions
The capabilities in Process Server are determined by plug-in extensions that you can enable, disable, or further extend to meet your business needs. Process Server supports the following default capabilities and extensions:
Table 21.1. Process Server capabilities and extensions
| Capability name | Extension name | Description |
|---|---|---|
|
|
| Provides the core capabilities of Process Server, such as creating and disposing KIE containers on your server instance |
|
|
| Provides the Business Rule Management (BRM) capabilities, such as inserting facts and executing business rules |
|
|
| Provides the Business Process Management (BPM) capabilities, such as managing user tasks and executing business processes |
|
|
| Provides additional user-interface capabilities related to business processes, such as rendering XML forms and SVG images in process diagrams |
|
|
| Provides the case management capabilities for business processes, such as managing case definitions and milestones |
|
|
| Provides the Business Resource Planning (BRP) capabilities, such as implementing solvers |
|
|
| Provides the Decision Model and Notation (DMN) capabilities, such as managing DMN data types and executing DMN models |
|
|
| Provides the Swagger web-interface capabilities for interacting with the Process Server REST API |
To view the supported extensions of a running Process Server instance, send a GET request to the following REST API endpoint and review the XML or JSON server response:
Base URL for GET request for Process Server information
http://SERVER:PORT/kie-server/services/rest/server
Example JSON response with Process Server information
{
"type": "SUCCESS",
"msg": "Kie Server info",
"result": {
"kie-server-info": {
"id": "test-kie-server",
"version": "7.26.0.20190818-050814",
"name": "test-kie-server",
"location": "http://localhost:8080/kie-server/services/rest/server",
"capabilities": [
"KieServer",
"BRM",
"BPM",
"CaseMgmt",
"BPM-UI",
"BRP",
"DMN",
"Swagger"
],
"messages": [
{
"severity": "INFO",
"timestamp": {
"java.util.Date": 1566169865791
},
"content": [
"Server KieServerInfo{serverId='test-kie-server', version='7.26.0.20190818-050814', name='test-kie-server', location='http:/localhost:8080/kie-server/services/rest/server', capabilities=[KieServer, BRM, BPM, CaseMgmt, BPM-UI, BRP, DMN, Swagger]', messages=null', mode=DEVELOPMENT}started successfully at Sun Aug 18 23:11:05 UTC 2019"
]
}
],
"mode": "DEVELOPMENT"
}
}
}
To enable or disable Process Server extensions, configure the related *.server.ext.disabled Process Server system property. For example, to disable the BRM capability, set the system property org.drools.server.ext.disabled=true. For all Process Server system properties, see Chapter 20, Process Server system properties.
By default, Process Server extensions are exposed through REST or JMS data transports and use predefined client APIs. You can extend existing Process Server capabilities with additional REST endpoints, extend supported transport methods beyond REST or JMS, or extend functionality in the Process Server client.
This flexibility in Process Server functionality enables you to adapt your Process Server instances to your business needs, instead of adapting your business needs to the default Process Server capabilities.
If you extend Process Server functionality, Red Hat does not support the custom code that you use as part of your custom implementations and extensions.
21.1. Extending an existing Process Server capability with a custom REST API endpoint
The Process Server REST API enables you to interact with your KIE containers and business assets (such as business rules, processes, and solvers) in Red Hat Process Automation Manager without using the Business Central user interface. The available REST endpoints are determined by the capabilities enabled in your Process Server system properties (for example, org.drools.server.ext.disabled=false for the BRM capability). You can extend an existing Process Server capability with a custom REST API endpoint to further adapt the Process Server REST API to your business needs.
As an example, this procedure extends the Drools Process Server extension (for the BRM capability) with the following custom REST API endpoint:
Example custom REST API endpoint
/server/containers/instances/{containerId}/ksession/{ksessionId}
This example custom endpoint accepts a list of facts to be inserted into the working memory of the {DECISION_ENGINE}, automatically executes all rules, and retrieves all objects from the KIE session in the specified KIE container.
Procedure
Create an empty Maven project and define the following packaging type and dependencies in the
pom.xmlfile for the project:Example pom.xml file in the sample project
<packaging>jar</packaging> <properties> <version.org.kie>7.14.0.Final-redhat-00002</version.org.kie> </properties> <dependencies> <dependency> <groupId>org.kie</groupId> <artifactId>kie-api</artifactId> <version>${version.org.kie}</version> </dependency> <dependency> <groupId>org.kie</groupId> <artifactId>kie-internal</artifactId> <version>${version.org.kie}</version> </dependency> <dependency> <groupId>org.kie.server</groupId> <artifactId>kie-server-api</artifactId> <version>${version.org.kie}</version> </dependency> <dependency> <groupId>org.kie.server</groupId> <artifactId>kie-server-services-common</artifactId> <version>${version.org.kie}</version> </dependency> <dependency> <groupId>org.kie.server</groupId> <artifactId>kie-server-services-drools</artifactId> <version>${version.org.kie}</version> </dependency> <dependency> <groupId>org.kie.server</groupId> <artifactId>kie-server-rest-common</artifactId> <version>${version.org.kie}</version> </dependency> <dependency> <groupId>org.drools</groupId> <artifactId>drools-core</artifactId> <version>${version.org.kie}</version> </dependency> <dependency> <groupId>org.drools</groupId> <artifactId>drools-compiler</artifactId> <version>${version.org.kie}</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>1.7.25</version> </dependency> </dependencies>Implement the
org.kie.server.services.api.KieServerApplicationComponentsServiceinterface in a Java class in your project, as shown in the following example:Sample implementation of the
KieServerApplicationComponentsServiceinterfacepublic class CusomtDroolsKieServerApplicationComponentsService implements KieServerApplicationComponentsService { 1 private static final String OWNER_EXTENSION = "Drools"; 2 public Collection<Object> getAppComponents(String extension, SupportedTransports type, Object... services) { 3 // Do not accept calls from extensions other than the owner extension: if ( !OWNER_EXTENSION.equals(extension) ) { return Collections.emptyList(); } RulesExecutionService rulesExecutionService = null; 4 KieServerRegistry context = null; for( Object object : services ) { if( RulesExecutionService.class.isAssignableFrom(object.getClass()) ) { rulesExecutionService = (RulesExecutionService) object; continue; } else if( KieServerRegistry.class.isAssignableFrom(object.getClass()) ) { context = (KieServerRegistry) object; continue; } } List<Object> components = new ArrayList<Object>(1); if( SupportedTransports.REST.equals(type) ) { components.add(new CustomResource(rulesExecutionService, context)); 5 } return components; } }- 1
- Delivers REST endpoints to the Process Server infrastructure that is deployed when the application starts.
- 2
- Specifies the extension that you are extending, such as the
Droolsextension in this example. - 3
- Returns all resources that the REST container must deploy. Each extension that is enabled in your Process Server instance calls the
getAppComponentsmethod, so theif ( !OWNER_EXTENSION.equals(extension) )call returns an empty collection for any extensions other than the specifiedOWNER_EXTENSIONextension. - 4
- Lists the services from the specified extension that you want to use, such as the
RulesExecutionServiceandKieServerRegistryservices from theDroolsextension in this example. - 5
- Specifies the transport type for the extension, either
RESTorJMS(RESTin this example), and theCustomResourceclass that returns the resource as part of thecomponentslist.
Implement the
CustomResourceclass that the Process Server can use to provide the additional functionality for the new REST resource, as shown in the following example:Sample implementation of the
CustomResourceclass// Custom base endpoint: @Path("server/containers/instances/{containerId}/ksession") public class CustomResource { private static final Logger logger = LoggerFactory.getLogger(CustomResource.class); private KieCommands commandsFactory = KieServices.Factory.get().getCommands(); private RulesExecutionService rulesExecutionService; private KieServerRegistry registry; public CustomResource() { } public CustomResource(RulesExecutionService rulesExecutionService, KieServerRegistry registry) { this.rulesExecutionService = rulesExecutionService; this.registry = registry; } // Supported HTTP method, path parameters, and data formats: @POST @Path("/{ksessionId}") @Consumes({MediaType.APPLICATION_XML, MediaType.APPLICATION_JSON}) @Produces({MediaType.APPLICATION_XML, MediaType.APPLICATION_JSON}) public Response insertFireReturn(@Context HttpHeaders headers, @PathParam("containerId") String id, @PathParam("ksessionId") String ksessionId, String cmdPayload) { Variant v = getVariant(headers); String contentType = getContentType(headers); // Marshalling behavior and supported actions: MarshallingFormat format = MarshallingFormat.fromType(contentType); if (format == null) { format = MarshallingFormat.valueOf(contentType); } try { KieContainerInstance kci = registry.getContainer(id); Marshaller marshaller = kci.getMarshaller(format); List<?> listOfFacts = marshaller.unmarshall(cmdPayload, List.class); List<Command<?>> commands = new ArrayList<Command<?>>(); BatchExecutionCommand executionCommand = commandsFactory.newBatchExecution(commands, ksessionId); for (Object fact : listOfFacts) { commands.add(commandsFactory.newInsert(fact, fact.toString())); } commands.add(commandsFactory.newFireAllRules()); commands.add(commandsFactory.newGetObjects()); ExecutionResults results = rulesExecutionService.call(kci, executionCommand); String result = marshaller.marshall(results); logger.debug("Returning OK response with content '{}'", result); return createResponse(result, v, Response.Status.OK); } catch (Exception e) { // If marshalling fails, return the `call-container` response to maintain backward compatibility: String response = "Execution failed with error : " + e.getMessage(); logger.debug("Returning Failure response with content '{}'", response); return createResponse(response, v, Response.Status.INTERNAL_SERVER_ERROR); } } }In this example, the
CustomResourceclass for the custom endpoint specifies the following data and behavior:-
Uses the base endpoint
server/containers/instances/{containerId}/ksession -
Uses
POSTHTTP method Expects the following data to be given in REST requests:
-
The
containerIdas a path argument -
The
ksessionIdas a path argument - List of facts as a message payload
-
The
Supports all Process Server data formats:
- XML (JAXB, XStream)
- JSON
-
Unmarshals the payload into a
List<?>collection and, for each item in the list, creates anInsertCommandinstance followed byFireAllRulesandGetObjectcommands. -
Adds all commands to the
BatchExecutionCommandinstance that calls to the {DECISION_ENGINE}.
-
Uses the base endpoint
-
To make the new endpoint discoverable for Process Server, create a
META-INF/services/org.kie.server.services.api.KieServerApplicationComponentsServicefile in your Maven project and add the fully qualified class name of theKieServerApplicationComponentsServiceimplementation class within the file. For this example, the file contains the single lineorg.kie.server.ext.drools.rest.CusomtDroolsKieServerApplicationComponentsService. -
Build your project and copy the resulting JAR file into the
~/kie-server.war/WEB-INF/libdirectory of your project. For example, on Red Hat JBoss EAP, the path to this directory isEAP_HOME/standalone/deployments/kie-server.war/WEB-INF/lib. Start the Process Server and deploy the built project to the running Process Server. You can deploy the project using either the Business Central interface or the Process Server REST API (a
PUTrequest tohttp://SERVER:PORT/kie-server/services/rest/server/containers/{containerId}).After your project is deployed on a running Process Server, you can start interacting with your new REST endpoint.
For this example, you can use the following information to invoke the new endpoint:
-
Example request URL:
http://localhost:8080/kie-server/services/rest/server/containers/instances/demo/ksession/defaultKieSession -
HTTP method:
POST HTTP headers:
-
Content-Type: application/json -
Accept: application/json
-
Example message payload:
[ { "org.jbpm.test.Person": { "name": "john", "age": 25 } }, { "org.jbpm.test.Person": { "name": "mary", "age": 22 } } ]-
Example server response:
200(success) Example server log output:
13:37:20,347 INFO [stdout] (default task-24) Hello mary 13:37:20,348 INFO [stdout] (default task-24) Hello john
-
Example request URL:
21.2. Extending Process Server to use a custom data transport
By default, Process Server extensions are exposed through REST or JMS data transports. You can extend Process Server to support a custom data transport to adapt Process Server transport protocols to your business needs.
As an example, this procedure adds a custom data transport to Process Server that uses the Drools extension and that is based on Apache MINA, an open-source Java network-application framework. The example custom MINA transport exchanges string-based data that relies on existing marshalling operations and supports only JSON format.
Procedure
Create an empty Maven project and define the following packaging type and dependencies in the
pom.xmlfile for the project:Example pom.xml file in the sample project
<packaging>jar</packaging> <properties> <version.org.kie>7.14.0.Final-redhat-00002</version.org.kie> </properties> <dependencies> <dependency> <groupId>org.kie</groupId> <artifactId>kie-api</artifactId> <version>${version.org.kie}</version> </dependency> <dependency> <groupId>org.kie</groupId> <artifactId>kie-internal</artifactId> <version>${version.org.kie}</version> </dependency> <dependency> <groupId>org.kie.server</groupId> <artifactId>kie-server-api</artifactId> <version>${version.org.kie}</version> </dependency> <dependency> <groupId>org.kie.server</groupId> <artifactId>kie-server-services-common</artifactId> <version>${version.org.kie}</version> </dependency> <dependency> <groupId>org.kie.server</groupId> <artifactId>kie-server-services-drools</artifactId> <version>${version.org.kie}</version> </dependency> <dependency> <groupId>org.drools</groupId> <artifactId>drools-core</artifactId> <version>${version.org.kie}</version> </dependency> <dependency> <groupId>org.drools</groupId> <artifactId>drools-compiler</artifactId> <version>${version.org.kie}</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>1.7.25</version> </dependency> <dependency> <groupId>org.apache.mina</groupId> <artifactId>mina-core</artifactId> <version>2.1.3</version> </dependency> </dependencies>Implement the
org.kie.server.services.api.KieServerExtensioninterface in a Java class in your project, as shown in the following example:Sample implementation of the
KieServerExtensioninterfacepublic class MinaDroolsKieServerExtension implements KieServerExtension { private static final Logger logger = LoggerFactory.getLogger(MinaDroolsKieServerExtension.class); public static final String EXTENSION_NAME = "Drools-Mina"; private static final Boolean disabled = Boolean.parseBoolean(System.getProperty("org.kie.server.drools-mina.ext.disabled", "false")); private static final String MINA_HOST = System.getProperty("org.kie.server.drools-mina.ext.port", "localhost"); private static final int MINA_PORT = Integer.parseInt(System.getProperty("org.kie.server.drools-mina.ext.port", "9123")); // Taken from dependency on the `Drools` extension: private KieContainerCommandService batchCommandService; // Specific to MINA: private IoAcceptor acceptor; public boolean isActive() { return disabled == false; } public void init(KieServerImpl kieServer, KieServerRegistry registry) { KieServerExtension droolsExtension = registry.getServerExtension("Drools"); if (droolsExtension == null) { logger.warn("No Drools extension available, quiting..."); return; } List<Object> droolsServices = droolsExtension.getServices(); for( Object object : droolsServices ) { // If the given service is null (not configured), continue to the next service: if (object == null) { continue; } if( KieContainerCommandService.class.isAssignableFrom(object.getClass()) ) { batchCommandService = (KieContainerCommandService) object; continue; } } if (batchCommandService != null) { acceptor = new NioSocketAcceptor(); acceptor.getFilterChain().addLast( "codec", new ProtocolCodecFilter( new TextLineCodecFactory( Charset.forName( "UTF-8" )))); acceptor.setHandler( new TextBasedIoHandlerAdapter(batchCommandService) ); acceptor.getSessionConfig().setReadBufferSize( 2048 ); acceptor.getSessionConfig().setIdleTime( IdleStatus.BOTH_IDLE, 10 ); try { acceptor.bind( new InetSocketAddress(MINA_HOST, MINA_PORT) ); logger.info("{} -- Mina server started at {} and port {}", toString(), MINA_HOST, MINA_PORT); } catch (IOException e) { logger.error("Unable to start Mina acceptor due to {}", e.getMessage(), e); } } } public void destroy(KieServerImpl kieServer, KieServerRegistry registry) { if (acceptor != null) { acceptor.dispose(); acceptor = null; } logger.info("{} -- Mina server stopped", toString()); } public void createContainer(String id, KieContainerInstance kieContainerInstance, Map<String, Object> parameters) { // Empty, already handled by the `Drools` extension } public void disposeContainer(String id, KieContainerInstance kieContainerInstance, Map<String, Object> parameters) { // Empty, already handled by the `Drools` extension } public List<Object> getAppComponents(SupportedTransports type) { // Nothing for supported transports (REST or JMS) return Collections.emptyList(); } public <T> T getAppComponents(Class<T> serviceType) { return null; } public String getImplementedCapability() { return "BRM-Mina"; } public List<Object> getServices() { return Collections.emptyList(); } public String getExtensionName() { return EXTENSION_NAME; } public Integer getStartOrder() { return 20; } @Override public String toString() { return EXTENSION_NAME + " KIE Server extension"; } }The
KieServerExtensioninterface is the main extension interface that Process Server can use to provide the additional functionality for the new MINA transport. The interface consists of the following components:Overview of the
KieServerExtensioninterfacepublic interface KieServerExtension { boolean isActive(); void init(KieServerImpl kieServer, KieServerRegistry registry); void destroy(KieServerImpl kieServer, KieServerRegistry registry); void createContainer(String id, KieContainerInstance kieContainerInstance, Map<String, Object> parameters); void disposeContainer(String id, KieContainerInstance kieContainerInstance, Map<String, Object> parameters); List<Object> getAppComponents(SupportedTransports type); <T> T getAppComponents(Class<T> serviceType); String getImplementedCapability(); 1 List<Object> getServices(); String getExtensionName(); 2 Integer getStartOrder(); 3 }- 1
- Specifies the capability that is covered by this extension. The capability must be unique within Process Server.
- 2
- Defines a human-readable name for the extension.
- 3
- Determines when the specified extension should be started. For extensions that have dependencies on other extensions, this setting must not conflict with the parent setting. For example, in this case, this custom extension depends on the
Droolsextension, which hasStartOrderset to0, so this custom add-on extension must be greater than0(set to20in the sample implementation).
In the previous
MinaDroolsKieServerExtensionsample implementation of this interface, theinitmethod is the main element for collecting services from theDroolsextension and for bootstrapping the MINA server. All other methods in theKieServerExtensioninterface can remain with the standard implementation to fulfill interface requirements.The
TextBasedIoHandlerAdapterclass is the handler on the MINA server that reacts to incoming requests.Implement the
TextBasedIoHandlerAdapterhandler for the MINA server, as shown in the following example:Sample implementation of the
TextBasedIoHandlerAdapterhandlerpublic class TextBasedIoHandlerAdapter extends IoHandlerAdapter { private static final Logger logger = LoggerFactory.getLogger(TextBasedIoHandlerAdapter.class); private KieContainerCommandService batchCommandService; public TextBasedIoHandlerAdapter(KieContainerCommandService batchCommandService) { this.batchCommandService = batchCommandService; } @Override public void messageReceived( IoSession session, Object message ) throws Exception { String completeMessage = message.toString(); logger.debug("Received message '{}'", completeMessage); if( completeMessage.trim().equalsIgnoreCase("quit") || completeMessage.trim().equalsIgnoreCase("exit") ) { session.close(false); return; } String[] elements = completeMessage.split("\\|"); logger.debug("Container id {}", elements[0]); try { ServiceResponse<String> result = batchCommandService.callContainer(elements[0], elements[1], MarshallingFormat.JSON, null); if (result.getType().equals(ServiceResponse.ResponseType.SUCCESS)) { session.write(result.getResult()); logger.debug("Successful message written with content '{}'", result.getResult()); } else { session.write(result.getMsg()); logger.debug("Failure message written with content '{}'", result.getMsg()); } } catch (Exception e) { } } }In this example, the handler class receives text messages and executes them in the
Droolsservice.Consider the following handler requirements and behavior when you use the
TextBasedIoHandlerAdapterhandler implementation:- Anything that you submit to the handler must be a single line because each incoming transport request is a single line.
-
You must pass a KIE container ID in this single line so that the handler expects the format
containerID|payload. - You can set a response in the way that it is produced by the marshaller. The response can be multiple lines.
-
The handler supports a stream mode that enables you to send commands without disconnecting from a Process Server session. To end a Process Server session in stream mode, send either an
exitorquitcommand to the server.
-
To make the new data transport discoverable for Process Server, create a
META-INF/services/org.kie.server.services.api.KieServerExtensionfile in your Maven project and add the fully qualified class name of theKieServerExtensionimplementation class within the file. For this example, the file contains the single lineorg.kie.server.ext.mina.MinaDroolsKieServerExtension. -
Build your project and copy the resulting JAR file and the
mina-core-2.0.9.jarfile (which the extension depends on in this example) into the~/kie-server.war/WEB-INF/libdirectory of your project. For example, on Red Hat JBoss EAP, the path to this directory isEAP_HOME/standalone/deployments/kie-server.war/WEB-INF/lib. Start the Process Server and deploy the built project to the running Process Server. You can deploy the project using either the Business Central interface or the Process Server REST API (a
PUTrequest tohttp://SERVER:PORT/kie-server/services/rest/server/containers/{containerId}).After your project is deployed on a running Process Server, you can view the status of the new data transport in your Process Server log and start using your new data transport:
New data transport in the server log
Drools-Mina KIE Server extension -- Mina server started at localhost and port 9123 Drools-Mina KIE Server extension has been successfully registered as server extension
For this example, you can use Telnet to interact with the new MINA-based data transport in Process Server:
Starting Telnet and connecting to Process Server on port 9123 in a command terminal
telnet 127.0.0.1 9123
Example interactions with Process Server in a command terminal
Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. # Request body: demo|{"lookup":"defaultKieSession","commands":[{"insert":{"object":{"org.jbpm.test.Person":{"name":"john","age":25}}}},{"fire-all-rules":""}]} # Server response: { "results" : [ { "key" : "", "value" : 1 } ], "facts" : [ ] } demo|{"lookup":"defaultKieSession","commands":[{"insert":{"object":{"org.jbpm.test.Person":{"name":"mary","age":22}}}},{"fire-all-rules":""}]} { "results" : [ { "key" : "", "value" : 1 } ], "facts" : [ ] } demo|{"lookup":"defaultKieSession","commands":[{"insert":{"object":{"org.jbpm.test.Person":{"name":"james","age":25}}}},{"fire-all-rules":""}]} { "results" : [ { "key" : "", "value" : 1 } ], "facts" : [ ] } exit Connection closed by foreign host.Example server log output
16:33:40,206 INFO [stdout] (NioProcessor-2) Hello john 16:34:03,877 INFO [stdout] (NioProcessor-2) Hello mary 16:34:19,800 INFO [stdout] (NioProcessor-2) Hello james
21.3. Extending the Process Server client with a custom client API
Process Server uses predefined client APIs that you can interact with to use Process Server services. You can extend the Process Server client with a custom client API to adapt Process Server services to your business needs.
As an example, this procedure adds a custom client API to Process Server to accommodate a custom data transport (configured previously for this scenario) that is based on Apache MINA, an open-source Java network-application framework.
Procedure
Create an empty Maven project and define the following packaging type and dependencies in the
pom.xmlfile for the project:Example pom.xml file in the sample project
<packaging>jar</packaging> <properties> <version.org.kie>7.14.0.Final-redhat-00002</version.org.kie> </properties> <dependencies> <dependency> <groupId>org.kie.server</groupId> <artifactId>kie-server-api</artifactId> <version>${version.org.kie}</version> </dependency> <dependency> <groupId>org.kie.server</groupId> <artifactId>kie-server-client</artifactId> <version>${version.org.kie}</version> </dependency> <dependency> <groupId>org.drools</groupId> <artifactId>drools-compiler</artifactId> <version>${version.org.kie}</version> </dependency> </dependencies>Implement the relevant
ServicesClientinterface in a Java class in your project, as shown in the following example:Sample
RulesMinaServicesClientinterfacepublic interface RulesMinaServicesClient extends RuleServicesClient { }A specific interface is required because you must register client implementations based on the interface, and you can have only one implementation for a given interface.
For this example, the custom MINA-based data transport uses the
Droolsextension, so this exampleRulesMinaServicesClientinterface extends the existingRuleServicesClientclient API from theDroolsextension.Implement the
RulesMinaServicesClientinterface that the Process Server can use to provide the additional client functionality for the new MINA transport, as shown in the following example:Sample implementation of the
RulesMinaServicesClientinterfacepublic class RulesMinaServicesClientImpl implements RulesMinaServicesClient { private String host; private Integer port; private Marshaller marshaller; public RulesMinaServicesClientImpl(KieServicesConfiguration configuration, ClassLoader classloader) { String[] serverDetails = configuration.getServerUrl().split(":"); this.host = serverDetails[0]; this.port = Integer.parseInt(serverDetails[1]); this.marshaller = MarshallerFactory.getMarshaller(configuration.getExtraJaxbClasses(), MarshallingFormat.JSON, classloader); } public ServiceResponse<String> executeCommands(String id, String payload) { try { String response = sendReceive(id, payload); if (response.startsWith("{")) { return new ServiceResponse<String>(ResponseType.SUCCESS, null, response); } else { return new ServiceResponse<String>(ResponseType.FAILURE, response); } } catch (Exception e) { throw new KieServicesException("Unable to send request to KIE Server", e); } } public ServiceResponse<String> executeCommands(String id, Command<?> cmd) { try { String response = sendReceive(id, marshaller.marshall(cmd)); if (response.startsWith("{")) { return new ServiceResponse<String>(ResponseType.SUCCESS, null, response); } else { return new ServiceResponse<String>(ResponseType.FAILURE, response); } } catch (Exception e) { throw new KieServicesException("Unable to send request to KIE Server", e); } } protected String sendReceive(String containerId, String content) throws Exception { // Flatten the content to be single line: content = content.replaceAll("\\n", ""); Socket minaSocket = null; PrintWriter out = null; BufferedReader in = null; StringBuffer data = new StringBuffer(); try { minaSocket = new Socket(host, port); out = new PrintWriter(minaSocket.getOutputStream(), true); in = new BufferedReader(new InputStreamReader(minaSocket.getInputStream())); // Prepare and send data: out.println(containerId + "|" + content); // Wait for the first line: data.append(in.readLine()); // Continue as long as data is available: while (in.ready()) { data.append(in.readLine()); } return data.toString(); } finally { out.close(); in.close(); minaSocket.close(); } } }This example implementation specifies the following data and behavior:
- Uses socket-based communication for simplicity
-
Relies on default configurations from the Process Server client and uses
ServerUrlfor providing the host and port of the MINA server - Specifies JSON as the marshalling format
-
Requires received messages to be JSON objects that start with an open bracket
{ - Uses direct socket communication with a blocking API while waiting for the first line of the response and then reads all lines that are available
- Does not use stream mode and therefore disconnects the Process Server session after invoking a command
Implement the
org.kie.server.client.helper.KieServicesClientBuilderinterface in a Java class in your project, as shown in the following example:Sample implementation of the
KieServicesClientBuilderinterfacepublic class MinaClientBuilderImpl implements KieServicesClientBuilder { 1 public String getImplementedCapability() { 2 return "BRM-Mina"; } public Map<Class<?>, Object> build(KieServicesConfiguration configuration, ClassLoader classLoader) { 3 Map<Class<?>, Object> services = new HashMap<Class<?>, Object>(); services.put(RulesMinaServicesClient.class, new RulesMinaServicesClientImpl(configuration, classLoader)); return services; } }- 1
- Enables you to provide additional client APIs to the generic Process Server client infrastructure
- 2
- Defines the Process Server capability (extension) that the client uses
- 3
- Provides a map of the client implementations, where the key is the interface and the value is the fully initialized implementation
-
To make the new client API discoverable for the Process Server client, create a
META-INF/services/org.kie.server.client.helper.KieServicesClientBuilderfile in your Maven project and add the fully qualified class name of theKieServicesClientBuilderimplementation class within the file. For this example, the file contains the single lineorg.kie.server.ext.mina.client.MinaClientBuilderImpl. -
Build your project and copy the resulting JAR file into the
~/kie-server.war/WEB-INF/libdirectory of your project. For example, on Red Hat JBoss EAP, the path to this directory isEAP_HOME/standalone/deployments/kie-server.war/WEB-INF/lib. Start the Process Server and deploy the built project to the running Process Server. You can deploy the project using either the Business Central interface or the Process Server REST API (a
PUTrequest tohttp://SERVER:PORT/kie-server/services/rest/server/containers/{containerId}).After your project is deployed on a running Process Server, you can start interacting with your new Process Server client. You use your new client in the same way as the standard Process Server client, by creating the client configuration and client instance, retrieving the service client by type, and invoking client methods.
For this example, you can create a
RulesMinaServiceClientclient instance and invoke operations on Process Server through the MINA transport:Sample implementation to create the
RulesMinaServiceClientclientprotected RulesMinaServicesClient buildClient() { KieServicesConfiguration configuration = KieServicesFactory.newRestConfiguration("localhost:9123", null, null); List<String> capabilities = new ArrayList<String>(); // Explicitly add capabilities (the MINA client does not respond to `get-server-info` requests): capabilities.add("BRM-Mina"); configuration.setCapabilities(capabilities); configuration.setMarshallingFormat(MarshallingFormat.JSON); configuration.addJaxbClasses(extraClasses); KieServicesClient kieServicesClient = KieServicesFactory.newKieServicesClient(configuration); RulesMinaServicesClient rulesClient = kieServicesClient.getServicesClient(RulesMinaServicesClient.class); return rulesClient; }Sample configuration to invoke operations on Process Server through the MINA transport
RulesMinaServicesClient rulesClient = buildClient(); List<Command<?>> commands = new ArrayList<Command<?>>(); BatchExecutionCommand executionCommand = commandsFactory.newBatchExecution(commands, "defaultKieSession"); Person person = new Person(); person.setName("mary"); commands.add(commandsFactory.newInsert(person, "person")); commands.add(commandsFactory.newFireAllRules("fired")); ServiceResponse<String> response = rulesClient.executeCommands(containerId, executionCommand); Assert.assertNotNull(response); Assert.assertEquals(ResponseType.SUCCESS, response.getType()); String data = response.getResult(); Marshaller marshaller = MarshallerFactory.getMarshaller(extraClasses, MarshallingFormat.JSON, this.getClass().getClassLoader()); ExecutionResultImpl results = marshaller.unmarshall(data, ExecutionResultImpl.class); Assert.assertNotNull(results); Object personResult = results.getValue("person"); Assert.assertTrue(personResult instanceof Person); Assert.assertEquals("mary", ((Person) personResult).getName()); Assert.assertEquals("JBoss Community", ((Person) personResult).getAddress()); Assert.assertEquals(true, ((Person) personResult).isRegistered());
Chapter 22. Additional resources
- Installing and configuring Red Hat Process Automation Manager on Red Hat JBoss EAP
- Planning a Red Hat Process Automation Manager installation
- Installing and configuring Red Hat Process Automation Manager on Red Hat JBoss EAP
- Deploying a Red Hat Process Automation Manager immutable server environment on Red Hat OpenShift Container Platform
- Deploying a Red Hat Process Automation Manager authoring environment on Red Hat OpenShift Container Platform
- Deploying a Red Hat Process Automation Manager managed server environment on Red Hat OpenShift Container Platform
Appendix A. Versioning information
Documentation last updated on Monday, June 07, 2021.