Chapter 67. Persistence and transactions in the process engine
The process engine implements persistence for process states. The implementation uses the JPA framework with an SQL database backend. It can also store audit log information in the database.
The process engine also enables transactional execution of processes using the JTA framework, relying on the persistence backend to support the transactions.
67.1. Persistence of process runtime states
The process engine supports persistent storage of the runtime state of running process instances. Because it stores the runtime states, it can continue execution of a process instance if the process engine stopped or encountered a problem at any point.
The process engine also persistently stores the process definitions and the history logs of current and previous process states.
You can use the persistence.xml file, specified by the JPA framework, to configure persistence in an SQL database. You can plug in different persistence strategies. For more information about the persistence.xml file, see Section 67.4.1, “Configuration in the persistence.xml file”.
By default, if you do not configure persistence in the process engine, process information, including process instance states, is not made persistent.
When the process engine starts a process, it creates a process instance, which represents the execution of the process in that specific context. For example, when executing a process that processes a sales order, one process instance is created for each sales request.
The process instance contains the current runtime state and context of a process, including current values of any process variables. However, it does not include information about the history of past states of the process, as this information is not required for ongoing execution of a process.
When the runtime state of process instances is made persistent, you can restore the state of execution of all running processes in case the process engine fails or is stopped. You can also remove a particular process instance from memory and then restore it at a later time.
If you configure the process engine to use persistence, it automatically stores the runtime state into the database. You do not need to trigger persistence in the code.
When you restore the state of the process engine from a database, all instances are automatically restored to their last recorded state. Process instances automatically resume execution if they are triggered, for example, by an expired timer, the completion of a task that was requested by the process instance, or a signal being sent to the process instance. You do not need to load separate instances and trigger their execution manually.
The process engine also automatically reloads process instances on demand.
67.1.1. Safe points for persistence
The process engine saves the state of a process instance to persistent storage at safe points during the execution of the process.
When a process instance is started or resumes execution from a previous wait state, the process engine continues the execution until no more actions can be performed. If no more actions can be performed, it means that the process has completed or else has reached a wait state. If the process contains several parallel paths, all the paths must reach a wait state.
This point in the execution of the process is considered a safe point. At this point, the process engine stores the state of the process instance, and of any other process instances that were affected by the execution, to persistent storage.
67.2. The persistent audit log
The process engine can store information about the execution of process instances, including the successive historical states of the instances.
This information can be useful in many cases. For example, you might want to verify which actions have been executed for a particular process instance or to monitor and analyze the efficiency of a particular process.
However, storing history information in the runtime database would result in the database rapidly increasing in size and would also affect the performance of the persistence layer. Therefore, history log information is stored separately.
The process engine creates a log based on events that it generates during execution of processes. It uses the event listener mechanism to receive events and extract the necessary information, then persists this information to a database. The jbpm-audit module contains an event listener that stores process-related information in a database using JPA.
You can use filters to limit the scope of the logged information.
67.2.1. The process engine audit log data model
You can query process engine audit log information to use it in different scenarios, for example, creating a history log for one specific process instance or analyzing the performance of all instances of a specific process.
The audit log data model is a default implementation. Depending on your use cases, you might also define your own data model for storing the information you require. You can use process event listeners to extract the information.
The data model contains three entities: one for process instance information, one for node instance information, and one for process variable instance information.
The ProcessInstanceLog table contains the basic log information about a process instance.
Table 67.1. ProcessInstanceLog table fields
| Field | Description | Nullable |
|---|---|---|
|
| The primary key and ID of the log entity | NOT NULL |
|
| The correlation of this process instance | |
|
| Actual duration of this process instance since its start date | |
|
| When applicable, the end date of the process instance | |
|
| Optional external identifier used to correlate to some elements, for example, a deployment ID | |
|
| Optional identifier of the user who started the process instance | |
|
| The outcome of the process instance. This field contains the error code if the process instance was finished with an error event. | |
|
| The process instance ID of the parent process instance, if applicable | |
|
| The ID of the process | |
|
| The process instance ID | NOT NULL |
|
| The name of the process | |
|
| The type of the instance (process or case) | |
|
| The version of the process | |
|
| The due date of the process according to the service level agreement (SLA) | |
|
| The level of compliance with the SLA | |
|
| The start date of the process instance | |
|
| The status of the process instance that maps to the process instance state |
The NodeInstanceLog table contains more information about which nodes were executed inside each process instance. Whenever a node instance is entered from one of its incoming connections or is exited through one of its outgoing connections, information about the event is stored in this table.
Table 67.2. NodeInstanceLog table fields
| Field | Description | Nullable |
|---|---|---|
|
| The primary key and ID of the log entity | NOT NULL |
|
| Actual identifier of the sequence flow that led to this node instance | |
|
| The date of the event | |
|
| Optional external identifier used to correlate to some elements, for example, a deployment ID | |
|
| The node ID of the corresponding node in the process definition | |
|
| The node instance ID | |
|
| The name of the node | |
|
| The type of the node | |
|
| The ID of the process that the process instance is executing | |
|
| The process instance ID | NOT NULL |
|
| The due date of the node according to the service level agreement (SLA) | |
|
| The level of compliance with the SLA | |
|
| The type of the event (0 = enter, 1 = exit) | NOT NULL |
|
| (Optional, only for certain node types) The identifier of the work item | |
|
| The identifier of the container, if the node is inside an embedded sub-process node | |
|
| The reference identifier |
The VariableInstanceLog table contains information about changes in variable instances. By default, the process engine generates log entries after a variable changes its value. The process engine can also log entries before the changes.
Table 67.3. VariableInstanceLog table fields
| Field | Description | Nullable |
|---|---|---|
|
| The primary key and ID of the log entity | NOT NULL |
|
| Optional external identifier used to correlate to some elements, for example, a deployment ID | |
|
| The date of the event | |
|
| The ID of the process that the process instance is executing | |
|
| The process instance ID | NOT NULL |
|
| The previous value of the variable at the time that the log is made | |
|
| The value of the variable at the time that the log is made | |
|
| The variable ID in the process definition | |
|
| The ID of the variable instance |
The AuditTaskImpl table contains information about user tasks.
Table 67.4. AuditTaskImpl table fields
| Field | Description | Nullable |
|---|---|---|
|
| The primary key and ID of the task log entity | |
|
| Time when this task was activated | |
|
| Actual owner assigned to this task. This value is set set only when the owner claims the task. | |
|
| User who created this task | |
|
| Date when the task was created | |
|
| The ID of the deployment of which this task is a part | |
|
| Description of the task | |
|
| Due date set on this task | |
|
| Name of the task | |
|
| Parent task ID | |
|
| Priority of the task | |
|
| Process definition ID to which this task belongs | |
|
| Process instance ID with which this task is associated | |
|
| KIE session ID used to create this task | |
|
| Current status of the task | |
|
| Identifier of the task | |
|
| Identifier of the work item assigned on the process side to this task ID | |
|
| The date and time when the process instance state was last recorded in the persistence database |
The BAMTaskSummary table collects information about tasks that is used by the BAM engine to build charts and dashboards.
Table 67.5. BAMTaskSummary table fields
| Field | Description | Nullable |
|---|---|---|
|
| The primary key and ID of the log entity | NOT NULL |
|
| Date when the task was created | |
|
| Duration since the task was created | |
|
| Date when the task reached an end state (complete, exit, fail, skip) | |
|
| The process instance ID | |
|
| Date when the task was started | |
|
| Current status of the task | |
|
| Identifier of the task | |
|
| Name of the task | |
|
| User ID assigned to the task | |
|
| The version field that serves as its optimistic lock value |
The TaskVariableImpl table contains information about task variable instances.
Table 67.6. TaskVariableImpl table fields
| Field | Description | Nullable |
|---|---|---|
|
| The primary key and ID of the log entity | NOT NULL |
|
| Date when the variable was modified most recently | |
|
| Name of the task | |
|
| The ID of the process that the process instance is executing | |
|
| The process instance ID | |
|
| Identifier of the task | |
|
| Type of the variable: either input or output of the task | |
|
| Variable value |
The TaskEvent table contains information about changes in task instances. Operations such as claim, start, and stop are stored in this table to provide a timeline view of events that happened to the given task.
Table 67.7. TaskEvent table fields
| Field | Description | Nullable |
|---|---|---|
|
| The primary key and ID of the log entity | NOT NULL |
|
| Date when this event was saved | |
|
| Log event message | |
|
| The process instance ID | |
|
| Identifier of the task | |
|
| Type of the event. Types correspond to life cycle phases of the task | |
|
| User ID assigned to the task | |
|
| Identifier of the work item to which the task is assigned | |
|
| The version field that serves as its optimistic lock value | |
|
| Correlation key of the process instance | |
|
| Type of the process instance (process or case) |
67.2.2. Configuration for storing the process events log in a database
To log process history information in a database with a default data model, you must register the logger on your session.
Registering the logger on your KIE session
KieSession ksession = ...; ksession.addProcessEventListener(AuditLoggerFactory.newInstance(Type.JPA, ksession, null)); // invoke methods for your session here
To specify the database for storing the information, you must modify the persistence.xml file to include the audit log classes: ProcessInstanceLog, NodeInstanceLog, and VariableInstanceLog.
Modified persistence.xml file that includes the audit log classes
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<persistence
version="2.0"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd
http://java.sun.com/xml/ns/persistence/orm http://java.sun.com/xml/ns/persistence/orm_2_0.xsd"
xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:orm="http://java.sun.com/xml/ns/persistence/orm"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<persistence-unit name="org.jbpm.persistence.jpa" transaction-type="JTA">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>jdbc/jbpm-ds</jta-data-source>
<mapping-file>META-INF/JBPMorm.xml</mapping-file>
<class>org.drools.persistence.info.SessionInfo</class>
<class>org.jbpm.persistence.processinstance.ProcessInstanceInfo</class>
<class>org.drools.persistence.info.WorkItemInfo</class>
<class>org.jbpm.persistence.correlation.CorrelationKeyInfo</class>
<class>org.jbpm.persistence.correlation.CorrelationPropertyInfo</class>
<class>org.jbpm.runtime.manager.impl.jpa.ContextMappingInfo</class>
<class>org.jbpm.process.audit.ProcessInstanceLog</class>
<class>org.jbpm.process.audit.NodeInstanceLog</class>
<class>org.jbpm.process.audit.VariableInstanceLog</class>
<properties>
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>
<property name="hibernate.max_fetch_depth" value="3"/>
<property name="hibernate.hbm2ddl.auto" value="update"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.connection.release_mode" value="after_transaction"/>
<property name="hibernate.transaction.jta.platform" value="org.hibernate.service.jta.platform.internal.JBossStandAloneJtaPlatform"/>
</properties>
</persistence-unit>
</persistence>
67.2.3. Configuration for sending the process events log to a JMS queue
When the process engine stores events in the database with the default audit log implementation, the database operation is completed synchronously, within the same transaction as the actual execution of the process instance. This operation takes time, and on highly loaded systems it might have some impact on database performance, especially when both the history log and the runtime data are stored in the same database.
As an alternative, you can use the JMS-based logger that the process engine provides. You can configure this logger to submit process log entries as messages to a JMS queue, instead of directly persisting them in the database.
You can configure the JMS logger to be transactional, in order to avoid data inconsistencies if a process engine transaction is rolled back.
Using the JMS audit logger
ConnectionFactory factory = ...;
Queue queue = ...;
StatefulKnowledgeSession ksession = ...;
Map<String, Object> jmsProps = new HashMap<String, Object>();
jmsProps.put("jbpm.audit.jms.transacted", true);
jmsProps.put("jbpm.audit.jms.connection.factory", factory);
jmsProps.put("jbpm.audit.jms.queue", queue);
ksession.addProcessEventListener(AuditLoggerFactory.newInstance(Type.JMS, ksession, jmsProps));
// invoke methods one your session here
This is just one of the possible ways to configure JMS audit logger. You can use the AuditLoggerFactory class to set additional configuration parameters.
67.2.4. Auditing of variables
By default, values of process and task variables are stored in audit tables as string representations. To create string representations of non-string variable types, the process engine calls the variable.toString() method. If you use a custom class for a variable, you can implement this method for the class. In many cases this representation is sufficient.
However, sometimes a string representation in the logs might not be sufficient, especially when there is a need for efficient queries by process or task variables. For example, a Person object, used as a value for a variable, might have the following structure:
Example Person object, used as a process or task variable value
public class Person implements Serializable {
private static final long serialVersionUID = -5172443495317321032L;
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
}
The toString() method provides a human-readable format. However, it might not be sufficient for a search. A sample string value is Person [name="john", age="34"]. Searching through a large number of such strings to find people of age 34 would make a database query inefficient.
To enable more efficient searching, you can audit variables using VariableIndexer objects, which extract relevant parts of the variable for storage in the audit log.
Definition of the VariableIndexer interface
/**
* Variable indexer that transforms a variable instance into another representation (usually string)
* for use in log queries.
*
* @param <V> type of the object that will represent the indexed variable
*/
public interface VariableIndexer<V> {
/**
* Tests if this indexer can index a given variable
*
* NOTE: only one indexer can be used for a given variable
*
* @param variable variable to be indexed
* @return true if the variable should be indexed with this indexer
*/
boolean accept(Object variable);
/**
* Performs an index/transform operation on the variable. The result of this operation can be
* either a single value or a list of values, to support complex type separation.
* For example, when the variable is of the type Person that has name, address, and phone fields,
* the indexer could build three entries out of it to represent individual fields:
* person = person.name
* address = person.address.street
* phone = person.phone
* this configuration allows advanced queries for finding relevant entries.
* @param name name of the variable
* @param variable actual variable value
* @return
*/
List<V> index(String name, Object variable);
}
The default indexer uses the toString() method to produce a single audit entry for a single variable. Other indexers can return a list of objects from indexing a single variable.
To enable efficient queries for the Person type, you can build a custom indexer that indexes a Person instance into separate audit entries, one representing the name and another representing the age.
Sample indexer for the Person type
public class PersonTaskVariablesIndexer implements TaskVariableIndexer {
@Override
public boolean accept(Object variable) {
if (variable instanceof Person) {
return true;
}
return false;
}
@Override
public List<TaskVariable> index(String name, Object variable) {
Person person = (Person) variable;
List<TaskVariable> indexed = new ArrayList<TaskVariable>();
TaskVariableImpl personNameVar = new TaskVariableImpl();
personNameVar.setName("person.name");
personNameVar.setValue(person.getName());
indexed.add(personNameVar);
TaskVariableImpl personAgeVar = new TaskVariableImpl();
personAgeVar.setName("person.age");
personAgeVar.setValue(person.getAge()+"");
indexed.add(personAgeVar);
return indexed;
}
}
The process engine can use this indexer to index values when they are of the Person type, while all other variables are indexed with the default toString() method. Now, to query for process instances or tasks that refer to a person with age 34, you can use the following query:
-
variable name:
person.age -
variable value:
34
As a LIKE type query is not used, the database server can optimize the query and make it efficient on a large set of data.
Custom indexers
The process engine supports indexers for both process and task variables. However, it uses different interfaces for the indexers, because they must produce different types of objects that represent an audit view of the variable.
You must implement the following interfaces to build custom indexers:
-
For process variables:
org.kie.internal.process.ProcessVariableIndexer -
For task variables:
org.kie.internal.task.api.TaskVariableIndexer
You must implement two methods for either of the interfaces:
-
accept: Indicates whether a type is handled by this indexer. The process engine expects that only one indexer can index a given variable value, so it uses the first indexer that accepts the type. -
index: Indexes a value, producing a object or list of objects (usually strings) for inclusion in the audit log.
After implementing the interface, you must package this implementation as a JAR file and list the implementation in one of the following files:
-
For process variables, the
META-INF/services/org.kie.internal.process.ProcessVariableIndexerfile, which lists fully qualified class names of process variable indexers (single class name per line) -
For task variables, the
META-INF/services/org.kie.internal.task.api.TaskVariableIndexerfile, which lists fully qualified class names of task variable indexers (single class name per line)
The ServiceLoader mechanism discovers the indexers using these files. When indexing a process or task variable, the process engine examines the registered indexers to find any indexer that accepts the value of the variable. If no other indexer accepts the value, the process engine applies the default indexer that uses the toString() method.
67.3. Transactions in the process engine
The process engine supports Java Transaction API (JTA) transactions.
The current version of the process engine does not support pure local transactions.
If you do not provide transaction boundaries inside your application, the process engine automatically executes each method invocation on the process engine in a separate transaction.
Optionally, you can specify the transaction boundaries in the application code, for example, to combine multiple commands into one transaction.
67.3.1. Registration of a transaction manager
You must register a transaction manager in the environment to use user-defined transactions.
The following sample code registers the transaction manager and uses JTA calls to specify transaction boundaries.
Registering a transaction manager and using transactions
// Create the entity manager factory
EntityManagerFactory emf = EntityManagerFactoryManager.get().getOrCreate("org.jbpm.persistence.jpa");
TransactionManager tm = TransactionManagerServices.getTransactionManager();
// Set up the runtime environment
RuntimeEnvironment environment = RuntimeEnvironmentBuilder.Factory.get()
.newDefaultBuilder()
.addAsset(ResourceFactory.newClassPathResource("MyProcessDefinition.bpmn2"), ResourceType.BPMN2)
.addEnvironmentEntry(EnvironmentName.TRANSACTION_MANAGER, tm)
.get();
// Get the KIE session
RuntimeManager manager = RuntimeManagerFactory.Factory.get().newPerRequestRuntimeManager(environment);
RuntimeEngine runtime = manager.getRuntimeEngine(ProcessInstanceIdContext.get());
KieSession ksession = runtime.getKieSession();
// Start the transaction
UserTransaction ut = InitialContext.doLookup("java:comp/UserTransaction");
ut.begin();
// Perform multiple commands inside one transaction
ksession.insert( new Person( "John Doe" ) );
ksession.startProcess("MyProcess");
// Commit the transaction
ut.commit();
You must provide a jndi.properties file in you root class path to create a JNDI InitialContextFactory object, because transaction-related objects like UserTransaction, TransactionManager, and TransactionSynchronizationRegistry are registered in JNDI.
If your project includes the jbpm-test module, this file is already included by default.
Otherwise, you must create the jndi.properties file with the following content:
Content of the jndi.properties file
java.naming.factory.initial=org.jbpm.test.util.CloseSafeMemoryContextFactory org.osjava.sj.root=target/test-classes/config org.osjava.jndi.delimiter=/ org.osjava.sj.jndi.shared=true
This configuration assumes that the simple-jndi:simple-jndi artifact is present in the class path of your project. You can also use a different JNDI implementation.
By default, the Narayana JTA transaction manager is used. If you want to use a different JTA transaction manager, you can change the persistence.xml file to use the required transaction manager. For example, if your application runs on Red Hat JBoss EAP version 7 or later, you can use the JBoss transaction manager. In this case, change the transaction manager property in the persistence.xml file:
Transaction manager property in the persistence.xml file for the JBoss transaction manager
<property name="hibernate.transaction.jta.platform" value="org.hibernate.service.jta.platform.internal.JBossAppServerJtaPlatform" />
Using the Singleton strategy of the RuntimeManager class with JTA transactions (UserTransaction or CMT) creates a race condition. This race condition can result in an IllegalStateException exception with a message similar to Process instance XXX is disconnected.
To avoid this race condition, explicitly synchronize around the KieSession instance when invoking the transaction in the user application code.
synchronized (ksession) {
try {
tx.begin();
// use ksession
// application logic
tx.commit();
} catch (Exception e) {
//...
}
}67.3.2. Configuring container-managed transactions
If you embed the process engine in an application that executes in container-managed transaction (CMT) mode, for example, EJB beans, you must complete additional configuration. This configuration is especially important if the application runs on an application server that does not allow a CMT application to access a UserTransaction instance from JNDI, for example, WebSphere Application Server.
The default transaction manager implementation in the process engine relies on UserTransaction to query transaction status and then uses the status to determine whether to start a transaction. In environments that prevent access to a UserTransaction instance, this implementation fails.
To enable proper execution in CMT environments, the process engine provides a dedicated transaction manager implementation: org.jbpm.persistence.jta.ContainerManagedTransactionManager. This transaction manager expects that the transaction is active and always returns ACTIVE when the getStatus() method is invoked. Operations such as begin, commit, and rollback are no-op methods, because the transaction manager cannot affect these operations in container-managed transaction mode.
During process execution your code must propagate any exceptions thrown by the engine to the container to ensure that the container rolls transactions back when necessary.
To configure this transaction manager, complete the steps in this procedure.
Procedure
In your code, insert the transaction manager and persistence context manager into the environment before creating or loading a session:
Inserting the transaction manager and persistence context manager into the environment
Environment env = EnvironmentFactory.newEnvironment(); env.set(EnvironmentName.ENTITY_MANAGER_FACTORY, emf); env.set(EnvironmentName.TRANSACTION_MANAGER, new ContainerManagedTransactionManager()); env.set(EnvironmentName.PERSISTENCE_CONTEXT_MANAGER, new JpaProcessPersistenceContextManager(env)); env.set(EnvironmentName.TASK_PERSISTENCE_CONTEXT_MANAGER, new JPATaskPersistenceContextManager(env));
In the
persistence.xmlfile, configure the JPA provider. The following example useshibernateand WebSphere Application Server.Configuring the JPA provider in the
persistence.xmlfile<property name="hibernate.transaction.factory_class" value="org.hibernate.transaction.CMTTransactionFactory"/> <property name="hibernate.transaction.jta.platform" value="org.hibernate.service.jta.platform.internal.WebSphereJtaPlatform"/>
To dispose a KIE session, do not dispose it directly. Instead, execute the
org.jbpm.persistence.jta.ContainerManagedTransactionDisposeCommandcommand. This commands ensures that the session is disposed at the completion of the current transaction. In the following example,ksessionis theKieSessionobject that you want to dispose.Disposing a KIE session using the
ContainerManagedTransactionDisposeCommandcommandksession.execute(new ContainerManagedTransactionDisposeCommand());
Directly disposing the session causes an exception at the completion of the transaction, because the process engine registers transaction synchronization to clean up the session state.
67.4. Configuration of persistence in the process engine
If you use the process engine without configuring any persistence, it does not save runtime data to any database; no in-memory database is available by default. You can use this mode if it is required for performance reasons or when you want to manage persistence yourself.
To use JPA persistence in the process engine, you must configure it.
Configuration usually requires adding the necessary dependencies, configuring a data source, and creating the process engine classes with persistence configured.
67.4.1. Configuration in the persistence.xml file
To use JPA persistence, you must add a persistence.xml persistence configuration to your class path to configure JPA to use Hibernate and the H2 database (or any other database that you prefer). Place this file in the META-INF directory of your project.
Sample persistence.xml file
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<persistence
version="2.0"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd
http://java.sun.com/xml/ns/persistence/orm http://java.sun.com/xml/ns/persistence/orm_2_0.xsd"
xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:orm="http://java.sun.com/xml/ns/persistence/orm"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<persistence-unit name="org.jbpm.persistence.jpa" transaction-type="JTA">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<jta-data-source>jdbc/jbpm-ds</jta-data-source>
<mapping-file>META-INF/JBPMorm.xml</mapping-file>
<class>org.drools.persistence.info.SessionInfo</class>
<class>org.jbpm.persistence.processinstance.ProcessInstanceInfo</class>
<class>org.drools.persistence.info.WorkItemInfo</class>
<class>org.jbpm.persistence.correlation.CorrelationKeyInfo</class>
<class>org.jbpm.persistence.correlation.CorrelationPropertyInfo</class>
<class>org.jbpm.runtime.manager.impl.jpa.ContextMappingInfo</class>
<properties>
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>
<property name="hibernate.max_fetch_depth" value="3"/>
<property name="hibernate.hbm2ddl.auto" value="update"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.connection.release_mode" value="after_transaction"/>
<property name="hibernate.transaction.jta.platform" value="org.hibernate.service.jta.platform.internal.JBossStandAloneJtaPlatform"/>
</properties>
</persistence-unit>
</persistence>
The example refers to a jdbc/jbpm-ds data source. For instructions about configuring a data source, see Section 67.4.2, “Configuration of data sources for process engine persistence”.
67.4.2. Configuration of data sources for process engine persistence
To configure JPA persistence in the process engine, you must provide a data source, which represents a database backend.
If you run your application in an application server, such as Red Hat JBoss EAP, you can use the application server to set up data sources, for example, by adding a data source configuration file in the deploy directory. For instructions about creating data sources, see the documentaion for the application server.
If you deploy your application to Red Hat JBoss EAP, you can create a data source by creating a configuration file in the deploy directory:
Example data source configuration file for Red Hat JBoss EAP
<?xml version="1.0" encoding="UTF-8"?>
<datasources>
<local-tx-datasource>
<jndi-name>jdbc/jbpm-ds</jndi-name>
<connection-url>jdbc:h2:tcp://localhost/~/test</connection-url>
<driver-class>org.h2.jdbcx.JdbcDataSource</driver-class>
<user-name>sa</user-name>
<password></password>
</local-tx-datasource>
</datasources>
If your application runs in a plain Java environment, you can use Narayana and Tomcat DBCP by using the DataSourceFactory class from the kie-test-util module supplied by Red Hat Process Automation Manager. See the following code fragment. This example uses the H2 in-memory database in combination with Narayana and Tomcat DBCP.
Example code configuring an H2 in-memory database data source
Properties driverProperties = new Properties();
driverProperties.put("user", "sa");
driverProperties.put("password", "sa");
driverProperties.put("url", "jdbc:h2:mem:jbpm-db;MVCC=true");
driverProperties.put("driverClassName", "org.h2.Driver");
driverProperties.put("className", "org.h2.jdbcx.JdbcDataSource");
PoolingDataSourceWrapper pdsw = DataSourceFactory.setupPoolingDataSource("jdbc/jbpm-ds", driverProperties);
67.4.3. Dependencies for persistence
Persistence requires certain JAR artifact dependencies.
The jbpm-persistence-jpa.jar file is always required. This file contains the code for saving the runtime state whenever necessary.
Depending on the persistence solution and database you are using, you might need additional dependencies. The default configuration combination includes the following components:
- Hibernate as the JPA persistence provider
- H2 in-memory database
- Narayana for JTA-based transaction management
- Tomcat DBCP for connection pooling capabilities
This configuration requires the following additional dependencies:
-
jbpm-persistence-jpa(org.jbpm) -
drools-persistence-jpa(org.drools) -
persistence-api(javax.persistence) -
hibernate-entitymanager(org.hibernate) -
hibernate-annotations(org.hibernate) -
hibernate-commons-annotations(org.hibernate) -
hibernate-core(org.hibernate) -
commons-collections(commons-collections) -
dom4j(org.dom4j) -
jta(javax.transaction) -
narayana-jta(org.jboss.narayana.jta) -
tomcat-dbcp(org.apache.tomcat) -
jboss-transaction-api_1.2_spec(org.jboss.spec.javax.transaction) -
javassist(javassist) -
slf4j-api(org.slf4j) -
slf4j-jdk14(org.slf4j) -
simple-jndi(simple-jndi) -
h2(com.h2database) -
jbpm-test(org.jbpm) only for testing, do not include this artifact in the production application
67.4.4. Creating a KIE session with persistence
If your code creates KIE sessions directly, you can use the JPAKnowledgeService class to create your KIE session. This approach provides full access to the underlying configuration.
Procedure
Create a KIE session using the
JPAKnowledgeServiceclass, based on a KIE base, a KIE session configuration (if necessary), and an environment. The environment must contain a reference to the Entity Manager Factory that you use for persistence.Creating a KIE session with persistence
// create the entity manager factory and register it in the environment EntityManagerFactory emf = Persistence.createEntityManagerFactory( "org.jbpm.persistence.jpa" ); Environment env = KnowledgeBaseFactory.newEnvironment(); env.set( EnvironmentName.ENTITY_MANAGER_FACTORY, emf ); // create a new KIE session that uses JPA to store the runtime state StatefulKnowledgeSession ksession = JPAKnowledgeService.newStatefulKnowledgeSession( kbase, null, env ); int sessionId = ksession.getId(); // invoke methods on your method here ksession.startProcess( "MyProcess" ); ksession.dispose();To re-create a session from the database based on a specific session ID, use the
JPAKnowledgeService.loadStatefulKnowledgeSession()method:Re-creating a KIE session from the persistence database
// re-create the session from database using the sessionId ksession = JPAKnowledgeService.loadStatefulKnowledgeSession(sessionId, kbase, null, env );
67.4.5. Persistence in the runtime manager
If your code uses the RuntimeManager class, use the RuntimeEnvironmentBuilder class to configure the environment for persistence. By default, the runtime manager searches for the org.jbpm.persistence.jpa persistence unit.
The following example creates a KieSession with an empty context.
Creating a KIE session with an empty context using the runtime manager
RuntimeEnvironmentBuilder builder = RuntimeEnvironmentBuilder.Factory.get()
.newDefaultBuilder()
.knowledgeBase(kbase);
RuntimeManager manager = RuntimeManagerFactory.Factory.get()
.newSingletonRuntimeManager(builder.get(), "com.sample:example:1.0");
RuntimeEngine engine = manager.getRuntimeEngine(EmptyContext.get());
KieSession ksession = engine.getKieSession();
The prevous example requires a KIE base as the kbase parameter. You can use a kmodule.xml KJAR descriptor on the class path to buld the KIE base.
Building a KIE base from a kmodule.xml KJAR descriptor
KieServices ks = KieServices.Factory.get();
KieContainer kContainer = ks.getKieClasspathContainer();
KieBase kbase = kContainer.getKieBase("kbase");
A kmodule.xml descriptor file can include an attribute for resource packages to scan to find and deploy process engine workflows.
Sample kmodule.xml descriptor file
<kmodule xmlns="http://jboss.org/kie/6.0.0/kmodule"> <kbase name="kbase" packages="com.sample"/> </kmodule>
To control the persistence, you can use the RuntimeEnvironmentBuilder::entityManagerFactory methods.
Controlling configuration of persistence in the runtime manager
EntityManagerFactory emf = Persistence.createEntityManagerFactory("org.jbpm.persistence.jpa");
RuntimeEnvironment runtimeEnv = RuntimeEnvironmentBuilder.Factory
.get()
.newDefaultBuilder()
.entityManagerFactory(emf)
.knowledgeBase(kbase)
.get();
StatefulKnowledgeSession ksession = (StatefulKnowledgeSession) RuntimeManagerFactory.Factory.get()
.newSingletonRuntimeManager(runtimeEnv)
.getRuntimeEngine(EmptyContext.get())
.getKieSession();
After creating the ksession KIE session in this example, you can call methods in ksession, for example, StartProcess(). The process engine persists the runtime state in the configured data source.
You can restore a process instance from persistent storage by using the process instance ID. The runtime manager automatically re-creates the required session.
Re-creating a KIE session from the persistence database using a process instance ID
RuntimeEngine runtime = manager.getRuntimeEngine(ProcessInstanceIdContext.get(processInstanceId)); KieSession session = runtime.getKieSession();
67.5. Persisting process variables in a separate database schema in Red Hat Process Automation Manager
When you create process variables to use within the processes that you define, Red Hat Process Automation Manager stores those process variables as binary data in a default database schema. You can persist process variables in a separate database schema for greater flexibility in maintaining and implementing your process data.
For example, persisting your process variables in a separate database schema can help you perform the following tasks:
- Maintain process variables in human-readable format
- Make the variables available to services outside of Red Hat Process Automation Manager
- Clear the log of the default database tables in Red Hat Process Automation Manager without losing process variable data
This procedure applies to process variables only. This procedure does not apply to case variables.
Prerequisites
- You have defined processes in Red Hat Process Automation Manager for which you want to implement variables.
- If you want to persist variables in a database schema outside of Red Hat Process Automation Manager, you have created a data source and the separate database schema that you want to use. For information about creating data sources, see Configuring Business Central settings and properties.
Procedure
In the data object file that you use as a process variable, add the following elements to configure variable persistence:
Example Person.java object configured for variable persistence
@javax.persistence.Entity 1 @javax.persistence.Table(name = "Person") 2 public class Person extends org.drools.persistence.jpa.marshaller.VariableEntity 3 implements java.io.Serializable { 4 static final long serialVersionUID = 1L; @javax.persistence.GeneratedValue(strategy = javax.persistence.GenerationType.AUTO, generator = "PERSON_ID_GENERATOR") @javax.persistence.Id 5 @javax.persistence.SequenceGenerator(name = "PERSON_ID_GENERATOR", sequenceName = "PERSON_ID_SEQ") private java.lang.Long id; private java.lang.String name; private java.lang.Integer age; public Person() { } public java.lang.Long getId() { return this.id; } public void setId(java.lang.Long id) { this.id = id; } public java.lang.String getName() { return this.name; } public void setName(java.lang.String name) { this.name = name; } public java.lang.Integer getAge() { return this.age; } public void setAge(java.lang.Integer age) { this.age = age; } public Person(java.lang.Long id, java.lang.String name, java.lang.Integer age) { this.id = id; this.name = name; this.age = age; } }
- 1
- Configures the data object as a persistence entity.
- 2
- Defines the database table name used for the data object.
- 3
- Creates a separate
MappedVariablemapping table that maintains the relationship between this data object and the associated process instance. If you do not need this relationship maintained, you do not need to extend theVariableEntityclass. Without this extension, the data object is still persisted, but contains no additional data. - 4
- Configures the data object as a serializable object.
- 5
- Sets a persistence ID for the object.
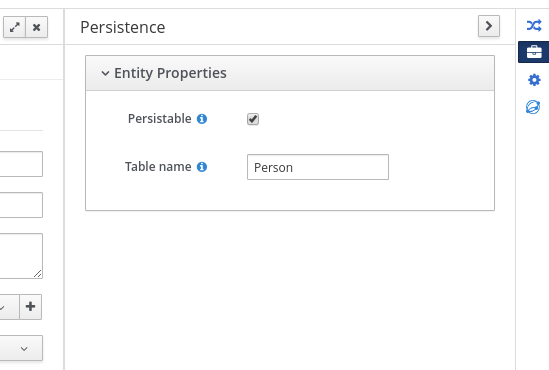
To make the data object persistable using Business Central, navigate to the data object file in your project, click the Persistence icon in the upper-right corner of the window, and configure the persistence behavior:
Figure 67.1. Persistence configuration in Business Central
In the
pom.xmlfile of your project, add the following dependency for persistence support. This dependency contains theVariableEntityclass that you configured in your data object.Project dependency for persistence
<dependency> <groupId>org.drools</groupId> <artifactId>drools-persistence-jpa</artifactId> <version>${rhpam.version}</version> <scope>provided</scope> </dependency>In the
~/META-INF/kie-deployment-descriptor.xmlfile of your project, configure the JPA marshalling strategy and a persistence unit to be used with the marshaller. The JPA marshalling strategy and persistence unit are required for objects defined as entities.JPA marshaller and persistence unit configured in the kie-deployment-descriptor.xml file
<marshalling-strategy> <resolver>mvel</resolver> <identifier>new org.drools.persistence.jpa.marshaller.JPAPlaceholderResolverStrategy("myPersistenceUnit", classLoader)</identifier> <parameters/> </marshalling-strategy>In the
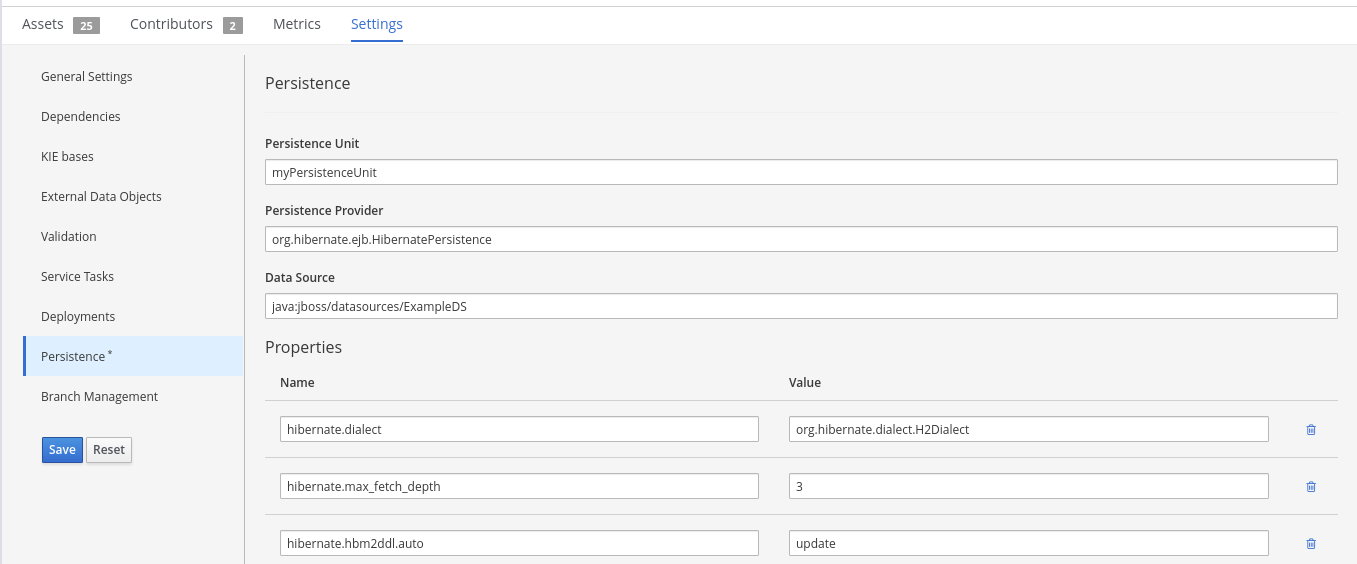
~/META-INFdirectory of your project, create apersistence.xmlfile that specifies in which data source you want to persist the process variable:Example persistence.xml file with data source configuration
<persistence xmlns="http://java.sun.com/xml/ns/persistence" xmlns:orm="http://java.sun.com/xml/ns/persistence/orm" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" version="2.0" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd http://java.sun.com/xml/ns/persistence/orm http://java.sun.com/xml/ns/persistence/orm_2_0.xsd"> <persistence-unit name="myPersistenceUnit" transaction-type="JTA"> <provider>org.hibernate.jpa.HibernatePersistenceProvider</provider> <jta-data-source>java:jboss/datasources/ExampleDS</jta-data-source> 1 <class>org.space.example.Person</class> <exclude-unlisted-classes>true</exclude-unlisted-classes> <properties> <property name="hibernate.dialect" value="org.hibernate.dialect.PostgreSQLDialect"/> <property name="hibernate.max_fetch_depth" value="3"/> <property name="hibernate.hbm2ddl.auto" value="update"/> <property name="hibernate.show_sql" value="true"/> <property name="hibernate.id.new_generator_mappings" value="false"/> <property name="hibernate.transaction.jta.platform" value="org.hibernate.service.jta.platform.internal.JBossAppServerJtaPlatform"/> </properties> </persistence-unit> </persistence>- 1
- Sets the data source in which the process variable is persisted
To configure the marshalling strategy, persistence unit, and data source using Business Central, navigate to project Settings → Deployments → Marshalling Strategies and to project Settings → Persistence:
Figure 67.2. JPA marshaller configuration in Business Central
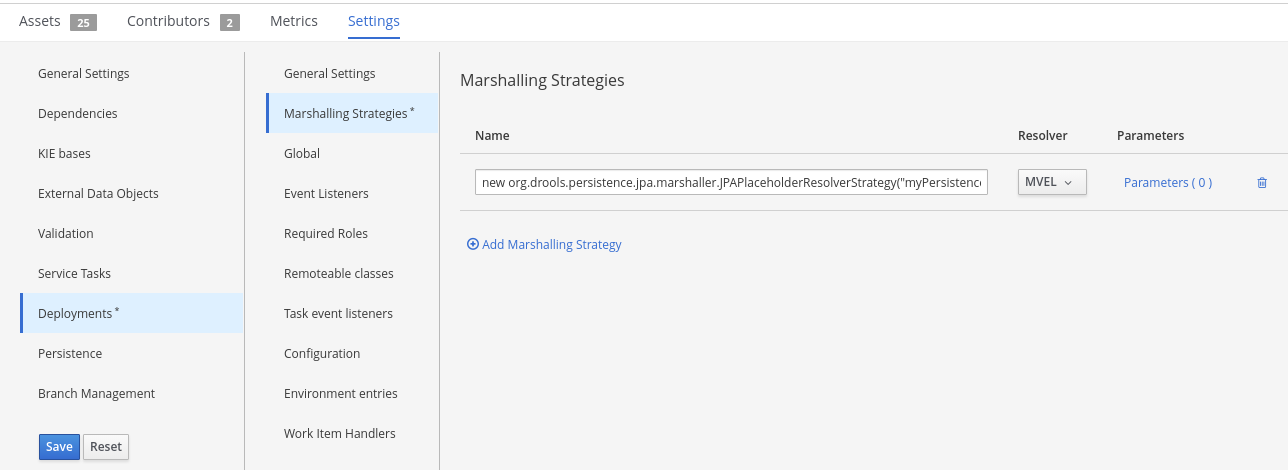
Figure 67.3. Persistence unit and data source configuration in Business Central