
Red Hat Training
A Red Hat training course is available for Red Hat Process Automation Manager
Chapter 5. Creating sub cases in case management projects
Subcases give you the flexibility to compose advanced cases that consists of other cases. This means that you can split large and complex cases into multiple layers of abstraction and even multiple case projects. This is similar to splitting a process into multiple subprocesses.
A subcase is another case definition that is invoked from within another case instance or a regular process instance. It has all of the capabilities of a regular case instance:
- It has a dedicated case file.
- It is isolated from any other case instance.
- It has its own set of case roles.
- It has its own case prefix.
5.1. Configuring subcases
You can add subcases to your case definition using the process designer. A subcase is another case within your case project, similar to having a subprocess within your process. Subcases can also be added to a regular business process, which enables you to start a case from within a process instance.
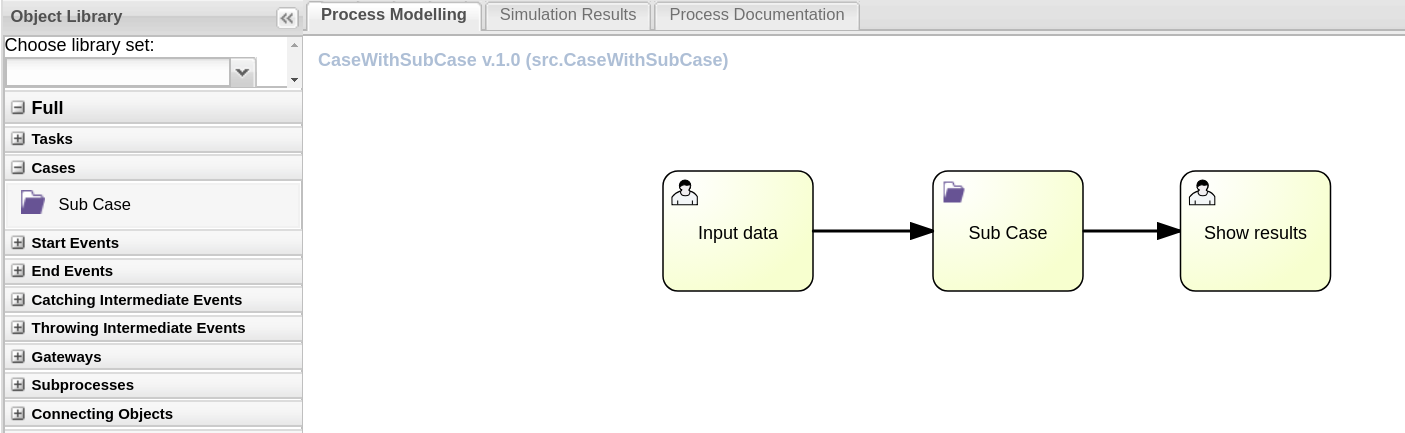
The Sub Case asset can be found in the case definition process designer Object Library under Cases:
Prerequisite
- A case management process has been created and configured in Business Central.
Procedure
-
With your case process open in the process designer, click
 to open the Object Library on the left side of the design palette.
to open the Object Library on the left side of the design palette.
-
Click Cases to open the object menu and drag the
Sub Casedata object on to the design palette and add it to the case definition. Click
 to open the Properties panel and click Assignments to open the data assignment editor. Alternatively, click
to open the Properties panel and click Assignments to open the data assignment editor. Alternatively, click
 on the
on the Sub Casenode in the design palette. The Sub Case Data I/O window supports the following set of input parameters to properly configure and start the subcase: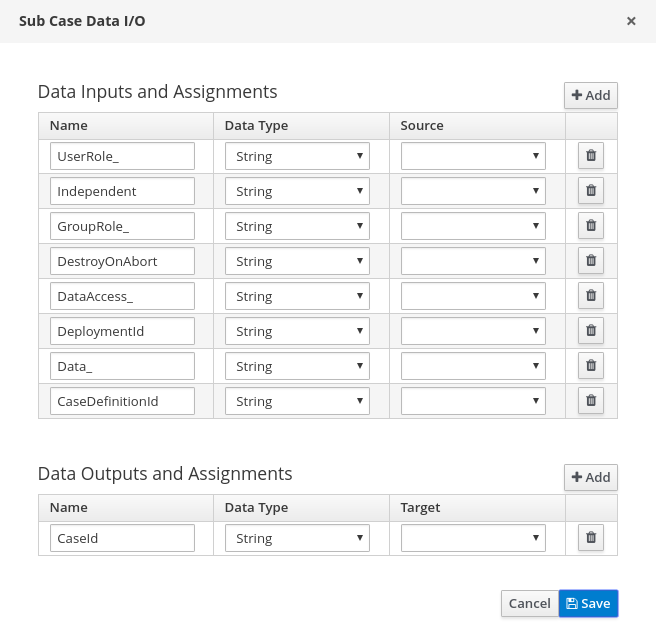
- Independent
-
Optional indicator that tells the process engine if the case instance is independent. If it is independent, the main case instance will not wait for its completion. This property is
falseby default. - GroupRole_XXX
-
Optional group to case role mapping. The role names belonging to this case instance can be referenced here, meaning that participants of the main case can be mapped to participants of the subcase. This means that whatever group was assigned to the main case will be automatically assigned to subcase, where
XXXis the role name and thevalueis the group role assignment. - DataAccess_XXX
-
Optional data access restrictions where
XXXis the name of data item and thevalueis the access restrictions. - DestroyOnAbort
-
Optional indicator that tells the process engine what to do when the subcase activity is aborted: cancel or destroy the subcase. This defaults to
true, which destroys the subcase and removes the case file. - UserRole_XXX
-
Optional user to case role mapping. You can reference the case instance role names here, meaning that an owner of the main case can be mapped to an owner of the subcase. Whoever was assigned to main case will be automatically assigned to the subcase, where
XXXis the role name andvalueis the user role assignment. - Data_XXX
-
Optional data mapping from this case instance or business process to a subcase, where
XXXis the name of the data in subcase being targeted. This can be given as many times as needed. - DeploymentId
- Optional deployment ID (or container ID in context of Process Server) that indicates where the targeted case definition is located.
- CaseDefinitionId
- The mandatory case definition ID to be started.
Regardless of the settings of the
Independentflag, there will always be output variable available named:- CaseId
- This is the case instance ID of the subcases after it is started.