
Chapter 1. Multi-cell overcloud deployments
You can use cells to divide Compute nodes in large deployments into groups, each with a message queue and dedicated database that contains instance information.
By default, director installs the overcloud with a single cell for all Compute nodes. This cell contains all the Compute services and databases, and all the instances and instance metadata. For larger deployments, you can deploy the overcloud with multiple cells to accommodate a larger number of Compute nodes. You can add cells to your environment when you install a new overcloud or at any time afterwards.
In multi-cell deployments, each cell runs standalone copies of the cell-specific Compute services and databases, and stores instance metadata only for instances in that cell. Global information and cell mappings are stored in the global Controller cell, which provides security and recovery in case one of the cells fails.
If you add cells to an existing overcloud, the conductor in the default cell also performs the role of the super conductor. This has a negative effect on conductor communication with the cells in the deployment, and on the performance of the overcloud. Also, if you take the default cell offline, you take the super conductor offline as well, which stops the entire overcloud deployment. Therefore, to scale an existing overcloud, do not add any Compute nodes to the default cell. Instead, add Compute nodes to the new cells you create, allowing the default cell to act as the super conductor.
To create a multi-cell overcloud, you must perform the following tasks:
- Configure and deploy your overcloud to handle multiple cells.
- Create and provision the new cells that you require within your deployment.
- Add Compute nodes to each cell.
- Add each Compute cell to an availability zone.
1.1. Prerequisites
- You have deployed a basic overcloud with the required number of Controller nodes.
1.2. Global components and services
The following components are deployed in a Controller cell once for each overcloud, regardless of the number of Compute cells.
- Compute API
- Provides the external REST API to users.
- Compute scheduler
- Determines on which Compute node to assign the instances.
- Placement service
- Monitors and allocates Compute resources to the instances.
- API database
Used by the Compute API and the Compute scheduler services to track location information about instances, and provides a temporary location for instances that are built but not scheduled.
In multi-cell deployments, this database also contains cell mappings that specify the database connection for each cell.
cell0database- Dedicated database for information about instances that failed to be scheduled.
- Super conductor
-
This service exists only in multi-cell deployments to coordinate between the global services and each Compute cell. This service also sends failed instance information to the
cell0database.
1.3. Cell-specific components and services
The following components are deployed in each Compute cell.
- Cell database
- Contains most of the information about instances. Used by the global API, the conductor, and the Compute services.
- Conductor
- Coordinates database queries and long-running tasks from the global services, and insulates Compute nodes from direct database access.
- Message queue
- Messaging service used by all services to communicate with each other within the cell and with the global services.
1.4. Cell deployments architecture
The default overcloud that director installs has a single cell for all Compute nodes. You can scale your overcloud by adding more cells, as illustrated by the following architecture diagrams.
Single-cell deployment architecture
The following diagram shows an example of the basic structure and interaction in a default single-cell overcloud.

In this deployment, all services are configured to use a single conductor to communicate between the Compute API and the Compute nodes, and a single database stores all live instance data.
In smaller deployments this configuration might be sufficient, but if any global API service or database fails, the entire Compute deployment cannot send or receive information, regardless of high availability configurations.
Multi-cell deployment architecture
The following diagram shows an example of the basic structure and interaction in a custom multi-cell overcloud.
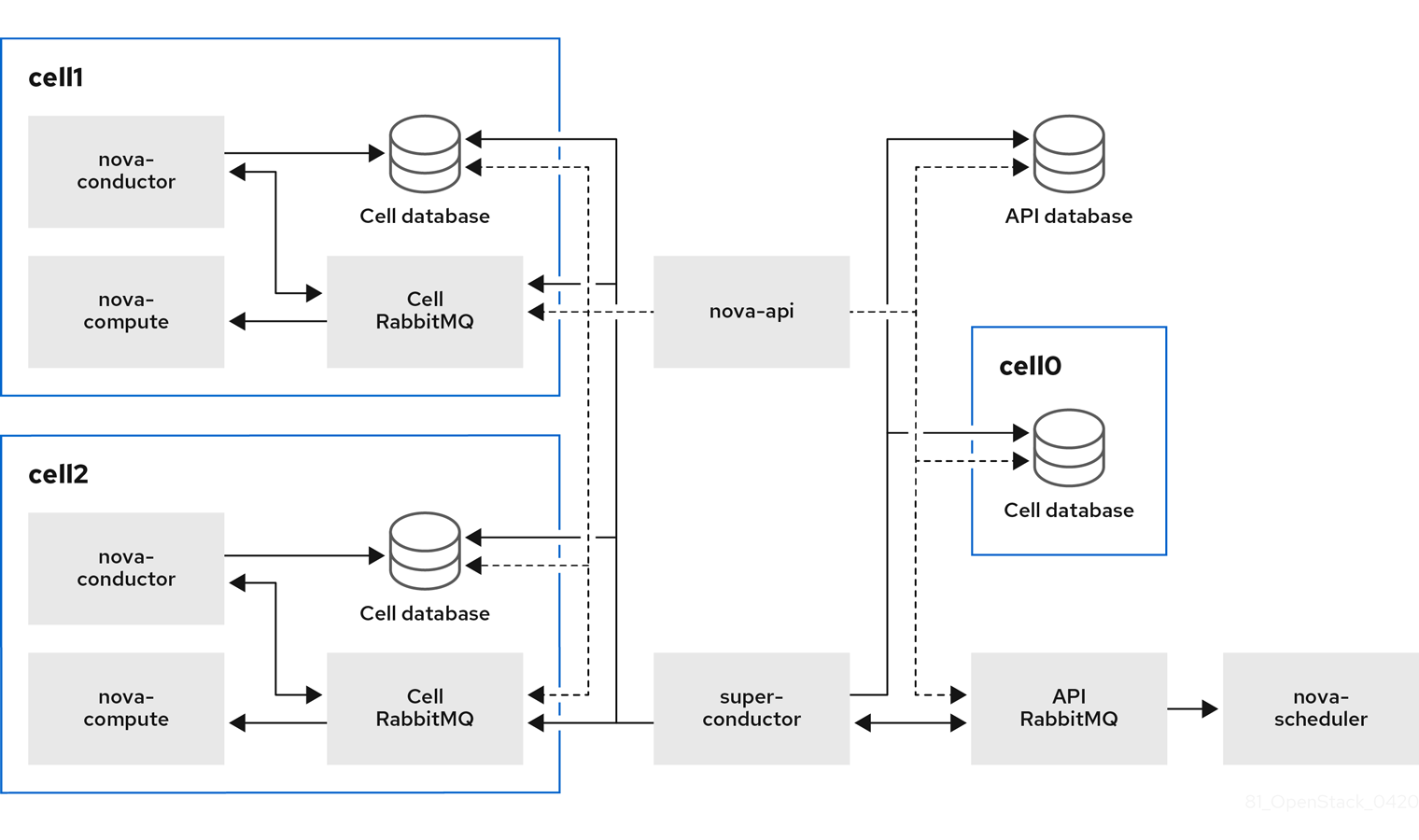
In this deployment, the Compute nodes are divided to multiple cells, each with their own conductor, database, and message queue. The global services use the super conductor to communicate with each cell, and the global database contains only information required for the whole overcloud.
The cell-level services cannot access global services directly. This isolation provides additional security and fail-safe capabilities in case of cell failure.
Do not run any Compute services on the first cell, which is named "default". Instead, deploy each new cell containing the Compute nodes separately.
1.5. Considerations for multi-cell deployments
- Maximum number of Compute nodes in a multi-cell deployment
- The maximum number of Compute nodes is 500 across all cells.
- Cross-cell instance migrations
Migrating an instance from a host in one cell to a host in another cell is not supported. This limitation affects the following operations:
- cold migration
- live migration
- unshelve
- resize
- evacuation
- Service quotas
Compute service quotas are calculated dynamically at each resource consumption point, instead of statically in the database. In multi-cell deployments, unreachable cells cannot provide usage information in real-time, which might cause the quotas to be exceeded when the cell is reachable again.
You can use the Placement service and API database to configure the quota calculation to withstand failed or unreachable cells.
- API database
- The Compute API database is always global for all cells and cannot be duplicated for each cell.
- Console proxies
-
You must configure console proxies for each cell, because console token authorizations are stored in cell databases. Each console proxy server needs to access the
database.connectioninformation of the corresponding cell database. - Compute metadata API
If you use the same network for all the cells in your multiple cell environment, you must run the Compute metadata API globally so that it can bridge between the cells. When the Compute metadata API is run globally it needs access to the
api_database.connectioninformation.If you deploy a multiple cell environment with routed networks, you must run the Compute metadata API separately in each cell to improve performance and data isolation. When the Compute metadata API runs in each cell, the
neutron-metadata-agentservice must point to the correspondingnova-api-metadataservice.You use the parameter
NovaLocalMetadataPerCellto control where the Compute metadata API runs.