
Storage Guide
Understanding, using, and managing persistent storage in OpenStack
Abstract
Making open source more inclusive
Red Hat is committed to replacing problematic language in our code, documentation, and web properties. We are beginning with these four terms: master, slave, blacklist, and whitelist. Because of the enormity of this endeavor, these changes will be implemented gradually over several upcoming releases. For more details, see our CTO Chris Wright’s message.
Providing feedback on Red Hat documentation
We appreciate your input on our documentation. Tell us how we can make it better.
Using the Direct Documentation Feedback (DDF) function
Use the Add Feedback DDF function for direct comments on specific sentences, paragraphs, or code blocks.
- View the documentation in the Multi-page HTML format.
- Ensure that you see the Feedback button in the upper right corner of the document.
- Highlight the part of text that you want to comment on.
- Click Add Feedback.
- Complete the Add Feedback field with your comments.
- Optional: Add your email address so that the documentation team can contact you for clarification on your issue.
- Click Submit.
Chapter 1. Introduction to Persistent Storage in Red Hat OpenStack Platform
This guide discusses procedures for creating and managing persistent storage. Within Red Hat OpenStack Platform (RHOSP), this storage is provided by three main services:
- Block Storage (openstack-cinder)
- Object Storage (openstack-swift)
- Shared File System Storage (openstack-manila)
These services provide different types of persistent storage, each with its own set of advantages in different use cases. This guide discusses the suitability of each for general enterprise storage requirements.
You can manage cloud storage by using either the RHOSP dashboard or the command-line clients. You can perform most procedures by using either method. However, you can complete some of the more advanced procedures only on the command line. This guide provides procedures for the dashboard where possible.
For the complete suite of documentation for Red Hat OpenStack Platform, see Red Hat OpenStack Platform Documentation.
This guide documents the use of crudini to apply some custom service settings. As such, you need to install the crudini package first:
# dnf install crudini -y
RHOSP recognizes two types of storage: ephemeral and persistent. Ephemeral storage is storage that is associated only to a specific Compute instance. Once that instance is terminated, so is its ephemeral storage. This type of storage is useful for basic runtime requirements, such as storing the instance’s operating system.
Persistent storage, is designed to survive (persist) independent of any running instance. This storage is used for any data that needs to be reused, either by different instances or beyond the life of a specific instance. RHOSP uses the following types of persistent storage:
- Volumes
The OpenStack Block Storage service (openstack-cinder) allows users to access block storage devices through volumes. Users can attach volumes to instances in order to augment their ephemeral storage with general-purpose persistent storage. Volumes can be detached and re-attached to instances at will, and can only be accessed through the instance they are attached to.
You can also configure instances to not use ephemeral storage. Instead of using ephemeral storage, you can configure the Block Storage service to write images to a volume. You can then use the volume as a bootable root volume for an instance.
Volumes also provide inherent redundancy and disaster recovery through backups and snapshots. In addition, you can also encrypt volumes for added security.
- Containers
The OpenStack Object Storage service (openstack-swift) provides a fully-distributed storage solution used to store any kind of static data or binary object, such as media files, large datasets, and disk images. The Object Storage service organizes these objects by using containers.
Although the content of a volume can be accessed only through instances, the objects inside a container can be accessed through the Object Storage REST API. As such, the Object Storage service can be used as a repository by nearly every service within the cloud.
- Shares
- The Shared File Systems service (openstack-manila) provides the means to easily provision remote, shareable file systems, or shares. Shares allow tenants within the cloud to openly share storage, and can be consumed by multiple instances simultaneously.
Each storage type is designed to address specific storage requirements. Containers are designed for wide access, and as such feature the highest throughput, access, and fault tolerance among all storage types. Container usage is geared more towards services.
On the other hand, volumes are used primarily for instance consumption. They do not enjoy the same level of access and performance as containers, but they do have a larger feature set and have more native security features than containers. Shares are similar to volumes in this regard, except that they can be consumed by multiple instances.
The following sections discuss each storage type’s architecture and feature set in detail, within the context of specific storage criteria.
1.1. Scalability and Back End
In general, a clustered storage solution provides greater back-end scalability. For example, when you use Red Hat Ceph as a Block Storage (cinder) back end, you can scale storage capacity and redundancy by adding more Ceph Object Storage Daemon (OSD) nodes. Block Storage, Object Storage (swift) and Shared File Systems Storage (manila) services support Red Hat Ceph Storage as a back end.
The Block Storage service can use multiple storage solutions as discrete back ends. At the back-end level, you can scale capacity by adding more back ends and restarting the service. The Block Storage service also features a large list of supported back-end solutions, some of which feature additional scalability features.
By default, the Object Storage service uses the file system on configured storage nodes, and it can use as much space as is available. The Object Storage service supports the XFS and ext4 file systems, and both can be scaled up to consume as much underlying block storage as is available. You can also scale capacity by adding more storage devices to the storage node.
The Shared File Systems service provisions file shares from designated storage pools that are managed by one or more third-party back-end storage systems. You can scale this shared storage by increasing the size or number of storage pools available to the service or by adding more third-party back-end storage systems to the deployment.
1.2. Accessibility and Administration
Volumes are consumed only through instances, and can only be attached to and mounted within one instance at a time. Users can create snapshots of volumes, which can be used for cloning or restoring a volume to a previous state (see Section 1.4, “Redundancy and Disaster Recovery”). The Block Storage service also allows you to create volume types, which aggregate volume settings (for example, size and back end) that can be easily invoked by users when creating new volumes. These types can be further associated with Quality-of-Service specifications, which allow you to create different storage tiers for users.
Like volumes, shares are consumed through instances. However, shares can be directly mounted within an instance, and do not need to be attached through the dashboard or CLI. Shares can also be mounted by multiple instances simultaneously. The Shared File Systems service also supports share snapshots and cloning; you can also create share types to aggregate settings (similar to volume types).
Objects in a container are accessible via API, and can be made accessible to instances and services within the cloud. This makes them ideal as object repositories for services; for example, the Image service (openstack-glance) can store its images in containers managed by the Object Storage service.
1.3. Security
The Block Storage service (cinder) provides basic data security through volume encryption. With this, you can configure a volume type to be encrypted through a static key; the key is then used to encrypt all volumes that are created from the configured volume type. For more information, see Section 2.2.6, “Configure volume encryption”.
Object and container security is configured at the service and node level. The Object Storage service (swift) provides no native encryption for containers and objects. Rather, the Object Storage service prioritizes accessibility within the cloud, and, as such, relies solely on the cloud network security to protect object data.
The Shared File Systems service (manila) can secure shares through access restriction, whether by instance IP, user or group, or TLS certificate. In addition, some Shared File Systems service deployments can feature separate share servers to manage the relationship between share networks and shares; some share servers support, or even require, additional network security. For example, a CIFS share server requires the deployment of an LDAP, Active Directory, or Kerberos authentication service.
For more information about how to secure the Image service (glance), such as image signing and verification and metadata definition (metadef) API restrictions, see Image service in the Creating and Managing Images guide.
1.4. Redundancy and Disaster Recovery
The Block Storage service features volume backup and restoration, providing basic disaster recovery for user storage. Backups allow you to protect volume contents. On top of this, the service also supports snapshots; aside from cloning, snapshots are also useful in restoring a volume to a previous state.
In a multi-backend environment, you can also migrate volumes between back ends. This is useful if you need to take a back end offline for maintenance. Backups are typically stored in a storage back end separate from their source volumes to help protect the data. This is not possible, however, with snapshots, as snapshots are dependent on their source volumes.
The Block Storage service also supports the creation of consistency groups, which allow you to group volumes together for simultaneous snapshot creation. This, in turn, allows for a greater level of data consistency across multiple volumes. See Section 2.2.9, “Configure and use consistency groups” for more details.
The Object Storage service provides no built-in backup features. As such, all backups must be performed at the file system or node level. The service, however, features more robust redundancy and fault tolerance; even the most basic deployment of the Object Storage service replicates objects multiple times. You can use failover features like dm-multipath to enhance redundancy.
The Shared File Systems service provides no built-in backup features for shares, but it does allow you to create snapshots for cloning and restoration.
Chapter 2. Block Storage and Volumes
The Block Storage service (openstack-cinder) manages the administration, security, scheduling, and overall management of all volumes. Volumes are used as the primary form of persistent storage for Compute instances.
For more information about volume backups, refer to the Block Storage Backup Guide.
2.1. Back Ends
Red Hat OpenStack Platform is deployed using the OpenStack Platform director. Doing so helps ensure the proper configuration of each service, including the Block Storage service (and, by extension, its back end). The director also has several integrated back end configurations.
Red Hat OpenStack Platform supports Red Hat Ceph and NFS as Block Storage back ends. By default, the Block Storage service uses an LVM back end as a repository for volumes. While this back end is suitable for test environments, LVM is not supported in production environments.
For instructions on how to deploy Ceph with OpenStack, see Deploying an Overcloud with Containerized Red Hat Ceph.
For instructions on how to set up NFS storage in the overcloud, see Configuring NFS Storage in the Advanced Overcloud Customization Guide.
2.1.1. Third-Party Storage Providers
You can also configure the Block Storage service to use supported third-party storage appliances. The director includes the necessary components for easily deploying different back end solutions.
For a complete list of supported back end appliances and drivers, see Component, Plug-In, and Driver Support in RHEL OpenStack Platform. All third-party back end appliances and drivers have additional deployment guides. Review the appropriate deployment guide to determine if a back end appliance or driver requires a plugin. For more information about deploying a third-party storage appliance plugin, see Deploying a vendor plugin in the Advanced Overcloud Customization guide.
2.2. Block Storage Service Administration
The following procedures explain how to configure the Block Storage service to suit your needs. All of these procedures require administrator privileges.
You must install host bus adapters (HBAs) on all Controller nodes and Compute nodes in any deployment that uses the Block Storage service (cinder) and a Fibre Channel (FC) back end.
2.2.1. Active-active deployment for high availability
- Important
- Active-active mode is supported only in distributed compute node (DCN) architecture at edge sites.
In active-passive mode, if the Block Storage service fails in a hyperconverged deployment, node fencing is undesirable. This is because node fencing can trigger storage to be rebalanced unnecessarily. Edge sites do not deploy Pacemaker, although Pacemaker is still present at the control site. Instead, edge sites deploy the Block Storage service in an active-active configuration to support highly available hyperconverged deployments.
Active-active deployments improve scaling, performance, and reduce response time by balancing workloads across all available nodes. Deploying the Block Storage service in an active-active configuration creates a highly available environment that maintains the management layer during partial network outages and single- or multi-node hardware failures. Active-active deployments allow a cluster to continue providing Block Storage services during a node outage.
Active-active deployments do not, however, enable workflows to resume automatically. If a service stops, individual operations running on the failed node will also fail during the outage. In this situation, confirm that the service is down and initiate a cleanup of resources that had in-flight operations.
2.2.1.1. Enabling active-active configuration for high availability
The cinder-volume-active-active.yaml file enables you to deploy the Block Storage service in an active-active configuration. This file ensures director uses the non-Pacemaker cinder-volume heat template and adds the etcd service to the deployment as a distributed lock manager (DLM).
The cinder-volume-active-active.yaml file also defines the active-active cluster name by assigning a value to the CinderVolumeCluster parameter. CinderVolumeCluster is a global Block Storage parameter. Therefore, you cannot include clustered (active-active) and non-clustered back ends in the same deployment.
Currently, active-active configuration for Block Storage works only with Ceph RADOS Block Device (RBD) back ends. If you plan to use multiple back ends, all back ends must support the active-active configuration. If a back end that does not support the active-active configuration is included in the deployment, that back end will not be available for storage. In an active-active deployment, you risk data loss if you save data on a back end that does not support the active-active configuration.
Procedure
To enable active-active Block Storage service volumes, include the following environment file in your overcloud deployment:
-e /usr/share/openstack-tripleo-heat-templates/environments/cinder-volume-active-active.yaml
2.2.1.2. Maintenance commands for active-active configurations
After deploying an active-active configuration, there are several commands you can use to interact with the environment when using API version 3.17 and later.
| User goal | Command |
| See the service listing, including details such as cluster name, host, zone, status, state, disabled reason, and back end state.
NOTE: When deployed by director for the Ceph back end, the default cluster name is |
|
| See detailed and summary information about clusters as a whole as opposed to individual services. |
NOTE: This command requires a cinder API microversion of 3.7 or later. |
| See detailed information about a specific cluster. |
NOTE: This command requires a cinder API microversion of 3.7 or later. |
| Enable a disabled service. |
NOTE: This command requires a cinder API microversion of 3.7 or later. |
| Disable a clustered service. |
NOTE: This command requires a cinder API microversion of 3.7 or later. |
2.2.1.3. Volume manage and unmanage
The unmanage and manage mechanisms facilitate moving volumes from one service using version X to another service using version X+1. Both services remain running during this process.
In API version 3.17 or later, you can see lists of volumes and snapshots that are available for management in Block Storage clusters. To see these lists, use the --cluster argument with cinder manageable-list or cinder snapshot-manageable-list.
In API version 3.16 and later, the cinder manage command also accepts the optional --cluster argument so that you can add previously unmanaged volumes to a Block Storage cluster.
2.2.1.4. Volume migration on a clustered service
With API version 3.16 and later, the cinder migrate and cinder-manage commands accept the --cluster argument to define the destination for active-active deployments.
When you migrate a volume on a Block Storage clustered service, pass the optional --cluster argument and omit the host positional argument, because the arguments are mutually exclusive.
2.2.1.5. Initiating server maintenance
All Block Storage volume services perform their own maintenance when they start. In an environment with multiple volume services grouped in a cluster, you can clean up services that are not currently running.
The command work-cleanup triggers server cleanups. The command returns:
- A list of the services that the command can clean.
- A list of the services that the command cannot clean because they are not currently running in the cluster.
The work-cleanup command works only on servers running API version 3.24 or later.
Procedure
Run the following command to verify whether all of the services for a cluster are running:
$ cinder cluster-list --detailed
Alternatively, run the
cluster showcommand.If any services are not running, run the following command to identify those specific services:
$ cinder service-list
Run the following command to trigger the server cleanup:
$ cinder work-cleanup [--cluster <cluster-name>] [--host <hostname>] [--binary <binary>] [--is-up <True|true|False|false>] [--disabled <True|true|False|false>] [--resource-id <resource-id>] [--resource-type <Volume|Snapshot>]
NoteFilters, such as
--cluster,--host, and--binary, define what the command cleans. You can filter on cluster name, host name, type of service, and resource type, including a specific resource. If you do not apply filtering, the command attempts to clean everything that can be cleaned.The following example filters by cluster name:
$ cinder work-cleanup --cluster tripleo@tripleo_ceph
2.2.2. Group Volume Settings with Volume Types
With Red Hat OpenStack Platform you can create volume types so that you can apply associated settings to the volume type. You can apply settings during volume creation, see Create a Volume. You can also apply settings after you create a volume, see Changing the Type of a Volume (Volume Re-typing). The following list shows some of the associated setting that you can apply to a volume type:
- The encryption of a volume. For more information, see Configure Volume Type Encryption.
- The back end that a volume uses. For more information, see Specify Back End for Volume Creation and Migrate a Volume.
- Quality-of-Service (QoS) Specs
Settings are associated with volume types using key-value pairs called Extra Specs. When you specify a volume type during volume creation, the Block Storage scheduler applies these key-value pairs as settings. You can associate multiple key-value pairs to the same volume type.
Volume types provide the capability to provide different users with storage tiers. By associating specific performance, resilience, and other settings as key-value pairs to a volume type, you can map tier-specific settings to different volume types. You can then apply tier settings when creating a volume by specifying the corresponding volume type.
2.2.2.1. List the Capabilities of a Host Driver
Available and supported Extra Specs vary per back end driver. Consult the driver documentation for a list of valid Extra Specs.
Alternatively, you can query the Block Storage host directly to determine which well-defined standard Extra Specs are supported by its driver. Start by logging in (through the command line) to the node hosting the Block Storage service. Then:
# cinder service-list
This command will return a list containing the host of each Block Storage service (cinder-backup, cinder-scheduler, and cinder-volume). For example:
+------------------+---------------------------+------+--------- | Binary | Host | Zone | Status ... +------------------+---------------------------+------+--------- | cinder-backup | localhost.localdomain | nova | enabled ... | cinder-scheduler | localhost.localdomain | nova | enabled ... | cinder-volume | *localhost.localdomain@lvm* | nova | enabled ... +------------------+---------------------------+------+---------
To display the driver capabilities (and, in turn, determine the supported Extra Specs) of a Block Storage service, run:
# cinder get-capabilities _VOLSVCHOST_
Where VOLSVCHOST is the complete name of the cinder-volume's host. For example:
# cinder get-capabilities localhost.localdomain@lvm
+---------------------+-----------------------------------------+
| Volume stats | Value |
+---------------------+-----------------------------------------+
| description | None |
| display_name | None |
| driver_version | 3.0.0 |
| namespace | OS::Storage::Capabilities::localhost.loc...
| pool_name | None |
| storage_protocol | iSCSI |
| vendor_name | Open Source |
| visibility | None |
| volume_backend_name | lvm |
+---------------------+-----------------------------------------+
+--------------------+------------------------------------------+
| Backend properties | Value |
+--------------------+------------------------------------------+
| compression | {u'type': u'boolean', u'description'...
| qos | {u'type': u'boolean', u'des ...
| replication | {u'type': u'boolean', u'description'...
| thin_provisioning | {u'type': u'boolean', u'description': u'S...
+--------------------+------------------------------------------+The Backend properties column shows a list of Extra Spec Keys that you can set, while the Value column provides information on valid corresponding values.
2.2.2.2. Create and Configure a Volume Type
- As an admin user in the dashboard, select Admin > Volumes > Volume Types.
- Click Create Volume Type.
- Enter the volume type name in the Name field.
- Click Create Volume Type. The new type appears in the Volume Types table.
- Select the volume type’s View Extra Specs action.
- Click Create and specify the Key and Value. The key-value pair must be valid; otherwise, specifying the volume type during volume creation will result in an error.
- Click Create. The associated setting (key-value pair) now appears in the Extra Specs table.
By default, all volume types are accessible to all OpenStack tenants. If you need to create volume types with restricted access, you will need to do so through the CLI. For instructions, see Section 2.2.2.5, “Create and Configure Private Volume Types”.
You can also associate a QoS Spec to the volume type. For more information, see Section 2.2.5.4, “Associate a QOS Spec with a Volume Type”.
2.2.2.3. Edit a Volume Type
- As an admin user in the dashboard, select Admin > Volumes > Volume Types.
- In the Volume Types table, select the volume type’s View Extra Specs action.
On the Extra Specs table of this page, you can:
- Add a new setting to the volume type. To do this, click Create and specify the key/value pair of the new setting you want to associate to the volume type.
- Edit an existing setting associated with the volume type by selecting the setting’s Edit action.
- Delete existing settings associated with the volume type by selecting the extra specs' check box and clicking Delete Extra Specs in this and the next dialog screen.
2.2.2.4. Delete a Volume Type
To delete a volume type, select its corresponding check boxes from the Volume Types table and click Delete Volume Types.
2.2.2.5. Create and Configure Private Volume Types
By default, all volume types are available to all tenants. You can create a restricted volume type by marking it private. To do so, set the type’s is-public flag to false.
Private volume types are useful for restricting access to volumes with certain attributes. Typically, these are settings that should only be usable by specific tenants; examples include new back ends or ultra-high performance configurations that are being tested.
To create a private volume type, run:
$ cinder type-create --is-public false <TYPE-NAME>
By default, private volume types are only accessible to their creators. However, admin users can find and view private volume types using the following command:
$ cinder type-list --all
This command lists both public and private volume types, and it also includes the name and ID of each one. You need the volume type’s ID to provide access to it.
Access to a private volume type is granted at the tenant level. To grant a tenant access to a private volume type, run:
$ cinder type-access-add --volume-type <TYPE-ID> --project-id <TENANT-ID>
To view which tenants have access to a private volume type, run:
$ cinder type-access-list --volume-type <TYPE-ID>
To remove a tenant from the access list of a private volume type, run:
$ cinder type-access-remove --volume-type <TYPE-ID> --project-id <TENANT-ID>
By default, only users with administrative privileges can create, view, or configure access for private volume types.
2.2.3. Create and Configure an Internal Tenant for the Block Storage service
Some Block Storage features (for example, the Image-Volume cache) require the configuration of an internal tenant. The Block Storage service uses this tenant (or project) to manage block storage items that do not necessarily need to be exposed to normal users. Examples of such items are images cached for frequent volume cloning or temporary copies of volumes being migrated.
To configure an internal project, first create a generic project and user, both named cinder-internal. To do so, log in to the Controller node and run:
# openstack project create --enable --description "Block Storage Internal Tenant" cinder-internal
+-------------+----------------------------------+
| Property | Value |
+-------------+----------------------------------+
| description | Block Storage Internal Tenant |
| enabled | True |
| id | cb91e1fe446a45628bb2b139d7dccaef |
| name | cinder-internal |
+-------------+----------------------------------+
# openstack user create --project cinder-internal cinder-internal
+----------+----------------------------------+
| Property | Value |
+----------+----------------------------------+
| email | None |
| enabled | True |
| id | 84e9672c64f041d6bfa7a930f558d946 |
| name | cinder-internal |
|project_id| cb91e1fe446a45628bb2b139d7dccaef |
| username | cinder-internal |
+----------+----------------------------------+The procedure for adding Extra Config options creates an internal tenant. For more information, see Section 2.2.4, “Configure and Enable the Image-Volume Cache”.
2.2.4. Configure and Enable the Image-Volume Cache
The Block Storage service features an optional Image-Volume cache which can be used when creating volumes from images. This cache is designed to improve the speed of volume creation from frequently-used images. For information on how to create volumes from images, see Section 2.3.1, “Create a volume”.
When enabled, the Image-Volume cache stores a copy of an image the first time a volume is created from it. This stored image is cached locally to the Block Storage back end to help improve performance the next time the image is used to create a volume. The Image-Volume cache’s limit can be set to a size (in GB), number of images, or both.
The Image-Volume cache is supported by several back ends. If you are using a third-party back end, refer to its documentation for information on Image-Volume cache support.
The Image-Volume cache requires that an internal tenant be configured for the Block Storage service. For instructions, see Section 2.2.3, “Create and Configure an Internal Tenant for the Block Storage service”.
To enable and configure the Image-Volume cache on a back end (BACKEND), add the values to an ExtraConfig section of an environment file on the undercloud. For example:
parameter_defaults:
ExtraConfig:
cinder::config::cinder_config:
DEFAULT/cinder_internal_tenant_project_id:
value: TENANTID
DEFAULT/cinder_internal_tenant_user_id:
value: USERID
BACKEND/image_volume_cache_enabled: 1
value: True
BACKEND/image_volume_cache_max_size_gb:
value: MAXSIZE 2
BACKEND/image_volume_cache_max_count:
value: MAXNUMBER 3The Block Storage service database uses a time stamp to track when each cached image was last used to create an image. If either or both MAXSIZE and MAXNUMBER are set, the Block Storage service will delete cached images as needed to make way for new ones. Cached images with the oldest time stamp are deleted first whenever the Image-Volume cache limits are met.
After you create the environment file in /home/stack/templates/, log in as the stack user and deploy the configuration by running:
$ openstack overcloud deploy --templates \ -e /home/stack/templates/<ENV_FILE>.yaml
Where ENV_FILE.yaml is the name of the file with the ExtraConfig settings added earlier.
If you passed any extra environment files when you created the overcloud, pass them again here using the -e option to avoid making undesired changes to the overcloud.
For additional information on the openstack overcloud deploy command, see Deployment command in the Director Installation and Usage Guide.
2.2.5. Use Quality-of-Service Specifications
You can map multiple performance settings to a single Quality-of-Service specification (QOS Specs). Doing so allows you to provide performance tiers for different user types.
Performance settings are mapped as key-value pairs to QOS Specs, similar to the way volume settings are associated to a volume type. However, QOS Specs are different from volume types in the following respects:
QOS Specs are used to apply performance settings, which include limiting read/write operations to disks. Available and supported performance settings vary per storage driver.
To determine which QOS Specs are supported by your back end, consult the documentation of your back end device’s volume driver.
- Volume types are directly applied to volumes, whereas QOS Specs are not. Rather, QOS Specs are associated to volume types. During volume creation, specifying a volume type also applies the performance settings mapped to the volume type’s associated QOS Specs.
2.2.5.1. Basic volume Quality of Service
You can define performance limits for volumes on a per-volume basis using basic volume QOS values. The Block Storage service supports the following options:
-
read_iops_sec -
write_iops_sec -
total_iops_sec -
read_bytes_sec -
write_bytes_sec -
total_bytes_sec -
read_iops_sec_max -
write_iops_sec_max -
total_iops_sec_max -
read_bytes_sec_max -
write_bytes_sec_max -
total_bytes_sec_max -
size_iops_sec
2.2.5.2. Create and Configure a QOS Spec
As an administrator, you can create and configure a QOS Spec through the QOS Specs table. You can associate more than one key/value pair to the same QOS Spec.
- As an admin user in the dashboard, select Admin > Volumes > Volume Types.
- On the QOS Specs table, click Create QOS Spec.
- Enter a name for the QOS Spec.
In the Consumer field, specify where the QOS policy should be enforced:
Table 2.1. Consumer Types
Type Description back-endQOS policy will be applied to the Block Storage back end.
front-endQOS policy will be applied to Compute.
bothQOS policy will be applied to both Block Storage and Compute.
- Click Create. The new QOS Spec should now appear in the QOS Specs table.
- In the QOS Specs table, select the new spec’s Manage Specs action.
Click Create, and specify the Key and Value. The key-value pair must be valid; otherwise, specifying a volume type associated with this QOS Spec during volume creation will fail.
For example, to set read limit IOPS to
500, use the following Key/Value pair:read_iops_sec=500
- Click Create. The associated setting (key-value pair) now appears in the Key-Value Pairs table.
2.2.5.3. Set Capacity-Derived QoS Limits
You can use volume types to implement capacity-derived Quality-of-Service (QoS) limits on volumes. This will allow you to set a deterministic IOPS throughput based on the size of provisioned volumes. Doing this simplifies how storage resources are provided to users — namely, providing a user with pre-determined (and, ultimately, highly predictable) throughput rates based on the volume size they provision.
In particular, the Block Storage service allows you to set how much IOPS to allocate to a volume based on the actual provisioned size. This throughput is set on an IOPS per GB basis through the following QoS keys:
read_iops_sec_per_gb write_iops_sec_per_gb total_iops_sec_per_gb
These keys allow you to set read, write, or total IOPS to scale with the size of provisioned volumes. For example, if the volume type uses read_iops_sec_per_gb=500, then a provisioned 3GB volume would automatically have a read IOPS of 1500.
Capacity-derived QoS limits are set per volume type, and configured like any normal QoS spec. In addition, these limits are supported by the underlying Block Storage service directly, and is not dependent on any particular driver.
For more information about volume types, see Section 2.2.2, “Group Volume Settings with Volume Types” and Section 2.2.2.2, “Create and Configure a Volume Type”. For instructions on how to set QoS specs, Section 2.2.5, “Use Quality-of-Service Specifications”.
When you apply a volume type (or perform a volume re-type) with capacity-derived QoS limits to an attached volume, the limits will not be applied. The limits will only be applied once you detach the volume from its instance.
See Section 2.3.16, “Volume retyping” for information about volume re-typing.
2.2.5.4. Associate a QOS Spec with a Volume Type
As an administrator, you can associate a QOS Spec to an existing volume type using the Volume Types table.
- As an administrator in the dashboard, select Admin > Volumes > Volume Types.
- In the Volume Types table, select the type’s Manage QOS Spec Association action.
- Select a QOS Spec from the QOS Spec to be associated list.
- Click Associate. The selected QOS Spec now appears in the Associated QOS Spec column of the edited volume type.
2.2.5.5. Disassociate a QOS Spec from a Volume Type
- As an administrator in the dashboard, select Admin > Volumes > Volume Types.
- In the Volume Types table, select the type’s Manage QOS Spec Association action.
- Select None from the QOS Spec to be associated list.
- Click Associate. The selected QOS Spec is no longer in the Associated QOS Spec column of the edited volume type.
2.2.6. Configure volume encryption
Volume encryption provides basic data protection in case the volume back end is either compromised or stolen. Both Compute and Block Storage services are integrated to allow instances to read access and use encrypted volumes. You must deploy the Key Manager service (barbican) to use volume encryption.
- Volume encryption is not supported on file-based volumes (such as NFS).
- Retyping an unencrypted volume to an encrypted volume of the same size is not supported, because encrypted volumes require additional space to store encryption data. For more information about encrypting unencrypted volumes, see Encrypting unencrypted volumes.
Volume encryption is applied by using volume type. See Section 2.2.6.1, “Configure Volume Type Encryption Through the Dashboard” for information about encrypted volume types.
2.2.6.1. Configure Volume Type Encryption Through the Dashboard
To create encrypted volumes, you first need an encrypted volume type. Encrypting a volume type involves setting what provider class, cipher, and key size it should use:
- As an admin user in the dashboard, select Admin > Volumes > Volume Types.
- In the Actions column of the volume to be encrypted, select Create Encryption to launch the Create Volume Type Encryption wizard.
From there, configure the Provider, Control Location, Cipher, and Key Size settings of the volume type’s encryption. The Description column describes each setting.
ImportantThe values listed below are the only supported options for Provider, Cipher, and Key Size.
-
Enter
luksfor Provider. -
Enter
aes-xts-plain64for Cipher. -
Enter
256for Key Size.
-
Enter
- Click Create Volume Type Encryption.
Once you have an encrypted volume type, you can invoke it to automatically create encrypted volumes. For more information on creating a volume type, see Section 2.2.2.2, “Create and Configure a Volume Type”. Specifically, select the encrypted volume type from the Type drop-down list in the Create Volume window (see Section 2.3, “Basic volume usage and configuration”).
To configure an encrypted volume type through the CLI, see Section 2.2.6.2, “Configure Volume Type Encryption Through the CLI”.
You can also re-configure the encryption settings of an encrypted volume type.
- Select Update Encryption from the Actions column of the volume type to launch the Update Volume Type Encryption wizard.
- In Project > Compute > Volumes, check the Encrypted column in the Volumes table to determine whether the volume is encrypted.
- If the volume is encrypted, click Yes in that column to view the encryption settings.
2.2.6.2. Configure Volume Type Encryption Through the CLI
To configure Block Storage volume encryption, do the following:
Create a volume type:
$ cinder type-create encrypt-type
Configure the cipher, key size, control location, and provider settings:
$ cinder encryption-type-create --cipher aes-xts-plain64 --key-size 256 --control-location front-end encrypt-type luks
Create an encrypted volume:
$ cinder --debug create 1 --volume-type encrypt-type --name DemoEncVol
2.2.6.3. Automatic deletion of volume image encryption key
The Block Storage service (cinder) creates an encryption key in the Key Management service (barbican) when it uploads an encrypted volume to the Image service (glance). This creates a 1:1 relationship between an encryption key and a stored image.
Encryption key deletion prevents unlimited resource consumption of the Key Management service. The Block Storage, Key Management, and Image services automatically manage the key for an encrypted volume, including the deletion of the key.
The Block Storage service automatically adds two properties to a volume image:
-
cinder_encryption_key_id- The identifier of the encryption key that the Key Management service stores for a specific image. -
cinder_encryption_key_deletion_policy- The policy that tells the Image service to tell the Key Management service whether to delete the key associated with this image.
The values of these properties are automatically assigned. To avoid unintentional data loss, do not adjust these values.
When you create a volume image, the Block Storage service sets the cinder_encryption_key_deletion_policy property to on_image_deletion. When you delete a volume image, the Image service deletes the corresponding encryption key if the cinder_encryption_key_deletion_policy equals on_image_deletion.
Red Hat does not recommend manual manipulation of the cinder_encryption_key_id or cinder_encryption_key_deletion_policy properties. If you use the encryption key that is identified by the value of cinder_encryption_key_id for any other purpose, you risk data loss.
For additional information, refer to the Manage secrets with the OpenStack Key Manager guide.
2.2.7. Configure How Volumes are Allocated to Multiple Back Ends
If the Block Storage service is configured to use multiple back ends, you can use configured volume types to specify where a volume should be created. For details, see Section 2.3.2, “Specify back end for volume creation”.
The Block Storage service will automatically choose a back end if you do not specify one during volume creation. Block Storage sets the first defined back end as a default; this back end will be used until it runs out of space. At that point, Block Storage will set the second defined back end as a default, and so on.
If this is not suitable for your needs, you can use the filter scheduler to control how Block Storage should select back ends. This scheduler can use different filters to triage suitable back ends, such as:
- AvailabilityZoneFilter
- Filters out all back ends that do not meet the availability zone requirements of the requested volume.
- CapacityFilter
- Selects only back ends with enough space to accommodate the volume.
- CapabilitiesFilter
- Selects only back ends that can support any specified settings in the volume.
- InstanceLocality
- Configures clusters to use volumes local to the same node.
To configure the filter scheduler, add an environment file to your deployment containing:
parameter_defaults: ControllerExtraConfig: # 1 cinder::config::cinder_config: DEFAULT/scheduler_default_filters: value: 'AvailabilityZoneFilter,CapacityFilter,CapabilitiesFilter,InstanceLocality'
- 1
- You can also add the
ControllerExtraConfig:hook and its nested sections to theparameter_defaults:section of an existing environment file.
2.2.8. Deploying availability zones
An availability zone is a provider-specific method of grouping cloud instances and services. Director uses CinderXXXAvailabilityZone parameters (where XXX is associated with a specific back end) to configure different availability zones for Block Storage volume back ends.
Procedure
To deploy different availability zones for Block Storage volume back ends:
Add the following parameters to the environment file to create two availability zones:
parameter_defaults: CinderXXXAvailabilityZone: zone1 CinderYYYAvailabilityZone: zone2
Replace XXX and YYY with supported back-end values, such as:
CinderISCSIAvailabilityZone CinderNfsAvailabilityZone CinderRbdAvailabilityZone
NoteSearch the
/usr/share/openstack-tripleo-heat-templates/deployment/cinder/directory for the heat template associated with your back end for the correct back-end value.The following example deploys two back ends where
rbdis zone 1 andiSCSIis zone 2:parameter_defaults: CinderRbdAvailabilityZone: zone1 CinderISCSIAvailabilityZone: zone2
- Deploy the overcloud and include the updated environment file.
2.2.9. Configure and use consistency groups
You can use the Block Storage (cinder) service to set consistency groups to group multiple volumes together as a single entity. This means that you can perform operations on multiple volumes at the same time instead of individually. You can use consistency groups to create snapshots for multiple volumes simultaneously. This also means that you can restore or clone those volumes simultaneously.
A volume can be a member of multiple consistency groups. However, you cannot delete, retype, or migrate volumes after you add them to a consistency group.
2.2.9.1. Configure consistency groups
By default, Block Storage security policy disables consistency groups APIs. You must enable it here before you use the feature. The related consistency group entries in the /etc/cinder/policy.json file of the node that hosts the Block Storage API service, openstack-cinder-api list the default settings:
"consistencygroup:create" : "group:nobody", "consistencygroup:delete": "group:nobody", "consistencygroup:update": "group:nobody", "consistencygroup:get": "group:nobody", "consistencygroup:get_all": "group:nobody", "consistencygroup:create_cgsnapshot" : "group:nobody", "consistencygroup:delete_cgsnapshot": "group:nobody", "consistencygroup:get_cgsnapshot": "group:nobody", "consistencygroup:get_all_cgsnapshots": "group:nobody",
You must change these settings in an environment file and then deploy them to the overcloud by using the openstack overcloud deploy command. Do not edit the JSON file directly because the changes are overwritten next time the overcloud is deployed.
Procedure
-
Edit an environment file and add a new entry to the
parameter_defaultssection. This ensures that the entries are updated in the containers and are retained whenever the environment is re-deployed by director with theopenstack overcloud deploycommand. Add a new section to an environment file using
CinderApiPoliciesto set the consistency group settings. The equivalentparameter_defaultssection with the default settings from the JSON file appear in the following way:parameter_defaults: CinderApiPolicies: { \ cinder-consistencygroup_create: { key: 'consistencygroup:create', value: 'group:nobody' }, \ cinder-consistencygroup_delete: { key: 'consistencygroup:delete', value: 'group:nobody' }, \ cinder-consistencygroup_update: { key: 'consistencygroup:update', value: 'group:nobody' }, \ cinder-consistencygroup_get: { key: 'consistencygroup:get', value: 'group:nobody' }, \ cinder-consistencygroup_get_all: { key: 'consistencygroup:get_all', value: 'group:nobody' }, \ cinder-consistencygroup_create_cgsnapshot: { key: 'consistencygroup:create_cgsnapshot', value: 'group:nobody' }, \ cinder-consistencygroup_delete_cgsnapshot: { key: 'consistencygroup:delete_cgsnapshot', value: 'group:nobody' }, \ cinder-consistencygroup_get_cgsnapshot: { key: 'consistencygroup:get_cgsnapshot', value: 'group:nobody' }, \ cinder-consistencygroup_get_all_cgsnapshots: { key: 'consistencygroup:get_all_cgsnapshots', value: 'group:nobody' }, \ }-
The value
‘group:nobody’determines that no group can use this feature so it is effectively disabled. To enable it, change the group to another value. For increased security, set the permissions for both consistency group API and volume type management API to be identical. The volume type management API is set to
"rule:admin_or_owner"by default in the same/etc/cinder/policy.json_ file:"volume_extension:types_manage": "rule:admin_or_owner",
To make the consistency groups feature available to all users, set the API policy entries to allow users to create, use, and manage their own consistency groups. To do so, use
rule:admin_or_owner:CinderApiPolicies: { \ cinder-consistencygroup_create: { key: 'consistencygroup:create', value: 'rule:admin_or_owner' }, \ cinder-consistencygroup_delete: { key: 'consistencygroup:delete', value: 'rule:admin_or_owner' }, \ cinder-consistencygroup_update: { key: 'consistencygroup:update', value: 'rule:admin_or_owner' }, \ cinder-consistencygroup_get: { key: 'consistencygroup:get', value: 'rule:admin_or_owner' }, \ cinder-consistencygroup_get_all: { key: 'consistencygroup:get_all', value: 'rule:admin_or_owner' }, \ cinder-consistencygroup_create_cgsnapshot: { key: 'consistencygroup:create_cgsnapshot', value: 'rule:admin_or_owner' }, \ cinder-consistencygroup_delete_cgsnapshot: { key: 'consistencygroup:delete_cgsnapshot', value: 'rule:admin_or_owner' }, \ cinder-consistencygroup_get_cgsnapshot: { key: 'consistencygroup:get_cgsnapshot', value: 'rule:admin_or_owner' }, \ cinder-consistencygroup_get_all_cgsnapshots: { key: 'consistencygroup:get_all_cgsnapshots', value: 'rule:admin_or_owner’ }, \ }When you have created the environment file in
/home/stack/templates/, log in as the stack user and deploy the configuration:$ openstack overcloud deploy --templates \ -e /home/stack/templates/<ENV_FILE>.yaml
Replace
<ENV_FILE.yaml>with the name of the file with theExtraConfigsettings you added.ImportantIf you passed any extra environment files when you created the overcloud, pass them again here by using the
-eoption to avoid making undesired changes to the overcloud.
For more information about the openstack overcloud deploy command, see Creating the Overcloud with the CLI Tools in the Director Installation and Usage guide.
2.2.9.2. Creating consistency groups
After you enable the consistency groups API, you can start creating consistency groups.
Procedure
- As an admin user in the dashboard, select Project > Compute > Volumes > Volume Consistency Groups.
- Click Create Consistency Group.
- In the Consistency Group Information tab of the wizard, enter a name and description for your consistency group. Then, specify its Availability Zone.
- You can also add volume types to your consistency group. When you create volumes within the consistency group, the Block Storage service will apply compatible settings from those volume types. To add a volume type, click its + button from the All available volume types list.
- Click Create Consistency Group. It appears next in the Volume Consistency Groups table.
2.2.9.3. Managing consistency groups
Procedure
- Optional: You can change the name or description of a consistency group by selecting Edit Consistency Group from its Action column.
- To add or remove volumes from a consistency group directly, as an admin user in the dashboard, select Project > Compute > Volumes > Volume Consistency Groups.
Find the consistency group you want to configure. In the Actions column of that consistency group, select Manage Volumes. This launches the Add/Remove Consistency Group Volumes wizard.
- To add a volume to the consistency group, click its + button from the All available volumes list.
- To remove a volume from the consistency group, click its - button from the Selected volumes list.
- Click Edit Consistency Group.
2.2.9.4. Create and manage consistency group snapshots
After you add volumes to a consistency group, you can now create snapshots from it.
Procedure
Log in as
adminuser from the command line on the node that hosts theopenstack-cinder-apiand enter:# export OS_VOLUME_API_VERSION=2
This configures the client to use version
2of theopenstack-cinder-api.List all available consistency groups and their respective IDs:
# cinder consisgroup-list
Create snapshots using the consistency group:
# cinder cgsnapshot-create --name <CGSNAPNAME> --description "<DESCRIPTION>" <CGNAMEID>
Replace:
-
<CGSNAPNAME>with the name of the snapshot (optional). -
<DESCRIPTION>with a description of the snapshot (optional). -
<CGNAMEID>with the name or ID of the consistency group.
-
Display a list of all available consistency group snapshots:
# cinder cgsnapshot-list
2.2.9.5. Clone consistency groups
You can also use consistency groups to create a whole batch of pre-configured volumes simultaneously. You can do this by cloning an existing consistency group or restoring a consistency group snapshot. Both processes use the same command.
Procedure
To clone an existing consistency group:
# cinder consisgroup-create-from-src --source-cg <CGNAMEID> --name <CGNAME> --description "<DESCRIPTION>"
Replace:
-
<CGNAMEID>is the name or ID of the consistency group you want to clone. -
<CGNAME>is the name of your consistency group (optional). -
<DESCRIPTION>is a description of your consistency group (optional).
-
To create a consistency group from a consistency group snapshot:
# cinder consisgroup-create-from-src --cgsnapshot <CGSNAPNAME> --name <CGNAME> --description "<DESCRIPTION>
Replace
<CGSNAPNAME>with the name or ID of the snapshot you are using to create the consistency group.
2.3. Basic volume usage and configuration
The following procedures describe how to perform basic end-user volume management. These procedures do not require administrative privileges.
You must install host bus adapters (HBAs) on all Controller nodes and Compute nodes in any deployment that uses the Block Storage service (cinder) and a Fibre Channel (FC) back end.
2.3.1. Create a volume
The default maximum number of volumes you can create for a project is 10.
Procedure
- In the dashboard, select Project > Compute > Volumes.
Click Create Volume, and edit the following fields:
Field Description Volume name
Name of the volume.
Description
Optional, short description of the volume.
Type
Optional volume type (see Section 2.2.2, “Group Volume Settings with Volume Types”).
If you have multiple Block Storage back ends, you can use this to select a specific back end. See Section 2.3.2, “Specify back end for volume creation”.
Size (GB)
Volume size (in gigabytes). If you want to create an encrypted volume from an unencrypted image, you must ensure that the volume size is at least 1GB larger than the image size so that the encryption data does not truncate the volume data.
Availability Zone
Availability zones (logical server groups), along with host aggregates, are a common method for segregating resources within OpenStack. Availability zones are defined during installation. For more information about availability zones and host aggregates, see Creating and managing host aggregates.
Specify a Volume Source:
Source Description No source, empty volume
The volume is empty and does not contain a file system or partition table.
Snapshot
Use an existing snapshot as a volume source. If you select this option, a new Use snapshot as a source list opens; you can then choose a snapshot from the list. If you want to create a new volume from a snapshot of an encrypted volume, you must ensure that the new volume is at least 1GB larger than the old volume. For more information about volume snapshots, see Section 2.3.10, “Create, use, or delete volume snapshots”.
Image
Use an existing image as a volume source. If you select this option, a new Use snapshot as a source list opens; you can then choose an image from the list.
Volume
Use an existing volume as a volume source. If you select this option, a new Use snapshot as a source list opens; you can then choose a volume from the list.
- Click Create Volume. After the volume is created, its name appears in the Volumes table.
You can also change the volume type later on. For more information, see Section 2.3.16, “Volume retyping”.
2.3.2. Specify back end for volume creation
Whenever multiple Block Storage (cinder) back ends are configured, you must also create a volume type for each back end. You can then use the type to specify which back end to use for a created volume. For more information about volume types, see Section 2.2.2, “Group Volume Settings with Volume Types”.
To specify a back end when creating a volume, select its corresponding volume type from the Type list (see Section 2.3.1, “Create a volume”).
If you do not specify a back end during volume creation, the Block Storage service automatically chooses one for you. By default, the service chooses the back end with the most available free space. You can also configure the Block Storage service to choose randomly among all available back ends instead. For more information, see Section 2.2.7, “Configure How Volumes are Allocated to Multiple Back Ends”.
2.3.3. Edit a volume name or description
- In the dashboard, select Project > Compute > Volumes.
- Select the volume’s Edit Volume button.
- Edit the volume name or description as required.
- Click Edit Volume to save your changes.
To create an encrypted volume, you must first have a volume type configured specifically for volume encryption. In addition, you must configure both Compute and Block Storage services to use the same static key. For information about how to set up the requirements for volume encryption, see Section 2.2.6, “Configure volume encryption”.
2.3.4. Resize (extend) a volume
The ability to resize a volume in use is supported but is driver dependant. RBD is supported. You cannot extend in-use multi-attach volumes. For more information about support for this feature, contact Red Hat Support.
List the volumes to retrieve the ID of the volume you want to extend:
$ cinder list
To resize the volume, run the following commands to specify the correct API microversion, then pass the volume ID and the new size (a value greater than the old size) as parameters:
$ OS_VOLUME_API_VERSION=<API microversion> $ cinder extend <volume ID> <size>
Replace <API_microversion>, <volume_ID>, and <size> with appropriate values, for example:
$ OS_VOLUME_API_VERSION=3.42 $ cinder extend 573e024d-5235-49ce-8332-be1576d323f8 10
2.3.5. Delete a volume
- In the dashboard, select Project > Compute > Volumes.
- In the Volumes table, select the volume to delete.
- Click Delete Volumes.
A volume cannot be deleted if it has existing snapshots. For instructions on how to delete snapshots, see Section 2.3.10, “Create, use, or delete volume snapshots”.
2.3.6. Attach and detach a volume to an instance
Instances can use a volume for persistent storage. A volume can only be attached to one instance at a time. For more information, see Attaching a volume to an instance in the Creating and Managing Instances guide.
2.3.6.1. Attaching a volume to an instance
- In the dashboard, select Project > Compute > Volumes.
- Select the Edit Attachments action. If the volume is not attached to an instance, the Attach To Instance drop-down list is visible.
- From the Attach To Instance list, select the instance to which you want to attach the volume.
- Click Attach Volume.
2.3.6.2. Detaching a volume from an instance
- In the dashboard, select Project > Compute > Volumes.
- Select the volume’s Manage Attachments action. If the volume is attached to an instance, the instance’s name is displayed in the Attachments table.
- Click Detach Volume in this and the next dialog screen.
2.3.7. Attach a volume to multiple instances
Volume multi-attach gives multiple instances simultaneous read/write access to a Block Storage volume. The Ceph RBD driver is supported.
You must use a multi-attach or cluster-aware file system to manage write operations from multiple instances. Failure to do so causes data corruption.
Limitations of multi-attach volumes
- The Block Storage (cinder) back end must support multi-attach volumes. For information about supported back ends, contact Red Hat Support.
Your Block Storage (cinder) driver must support multi-attach volumes. Contact Red Hat support to verify that multi-attach is supported for your vendor plugin. For more information about the certification for your vendor plugin, see the following locations:
- Read-only multi-attach volumes are not supported.
- Live migration of multi-attach volumes is not available.
- Encryption of multi-attach volumes is not supported.
- Multi-attach volumes are not supported by the Bare Metal Provisioning service (ironic) virt driver. Multi-attach volumes are supported only by the libvirt virt driver.
- You cannot retype an attached volume from a multi-attach type to a non-multi-attach type, and you cannot retype a non-multi-attach type to a multi-attach type.
- You cannot use multi-attach volumes that have multiple read write attachments as the source or destination volume during an attached volume migration.
- You cannot attach multi-attach volumes to shelved offloaded instances.
2.3.7.1. Creating a multi-attach volume type
To attach a volume to multiple instances, set the multiattach flag to <is> True in the volume extra specs. When you create a multi-attach volume type, the volume inherits the flag and becomes a multi-attach volume.
By default, creating a new volume type is an admin-only operation.
Procedure
Run the following commands to create a multi-attach volume type:
$ cinder type-create multiattach $ cinder type-key multiattach set multiattach="<is> True"
NoteThis procedure creates a volume on any back end that supports multiattach. Therefore, if there are two back ends that support multiattach, the scheduler decides which back end to use based on the available space at the time of creation.
Run the following command to specify the back end:
$ cinder type-key multiattach set volume_backend_name=<backend_name>
2.3.7.2. Volume retyping
You can retype a volume to be multi-attach capable or retype a multi-attach capable volume to make it incapable of attaching to multiple instances. However, you can retype a volume only when it is not in use and its status is available.
When you attach a multi-attach volume, some hypervisors require special considerations, such as when you disable caching. Currently, there is no way to safely update an attached volume while keeping it attached the entire time. Retyping fails if you attempt to retype a volume that is attached to multiple instances.
2.3.7.3. Creating a multi-attach volume
After you create a multi-attach volume type, create a multi-attach volume.
Procedure
Run the following command to create a multi-attach volume:
$ cinder create <volume_size> --name <volume_name> --volume-type multiattach
Run the following command to verify that a volume is multi-attach capable. If the volume is multi-attach capable, the
multiattachfield equalsTrue.$ cinder show <vol_id> | grep multiattach | multiattach | True |
You can now attach the volume to multiple instances. For information about how to attach a volume to an instance, see Attach a volume to an instance.
2.3.7.4. Supported back ends
The Block Storage back end must support multi-attach. For information about supported back ends, contact Red Hat Support.
2.3.8. Read-only volumes
A volume can be marked read-only to protect its data from being accidentally overwritten or deleted. To do so, set the volume to read-only by using the following command:
# cinder readonly-mode-update <VOLUME-ID> true
To set a read-only volume back to read-write, run:
# cinder readonly-mode-update <VOLUME-ID> false
2.3.9. Change a volume owner
To change the owner of a volume, you must perform a volume transfer. A volume transfer is initiated by the volume owner, and the change in ownership is complete after the transfer is accepted by the new owner.
2.3.9.1. Transfer a volume from the command line
- Log in as the volume’s current owner.
List the available volumes:
# cinder list
Initiate the volume transfer:
# cinder transfer-create VOLUME
Where
VOLUMEis the name orIDof the volume you wish to transfer. For example,+------------+--------------------------------------+ | Property | Value | +------------+--------------------------------------+ | auth_key | f03bf51ce7ead189 | | created_at | 2014-12-08T03:46:31.884066 | | id | 3f5dc551-c675-4205-a13a-d30f88527490 | | name | None | | volume_id | bcf7d015-4843-464c-880d-7376851ca728 | +------------+--------------------------------------+
The
cinder transfer-createcommand clears the ownership of the volume and creates anidandauth_keyfor the transfer. These values can be given to, and used by, another user to accept the transfer and become the new owner of the volume.The new user can now claim ownership of the volume. To do so, the user should first log in from the command line and run:
# cinder transfer-accept TRANSFERID TRANSFERKEY
Where
TRANSFERIDandTRANSFERKEYare theidandauth_keyvalues returned by thecinder transfer-createcommand, respectively. For example,# cinder transfer-accept 3f5dc551-c675-4205-a13a-d30f88527490 f03bf51ce7ead189
You can view all available volume transfers using:
# cinder transfer-list
2.3.9.2. Transfer a volume by using the dashboard
Create a volume transfer from the dashboard
- As the volume owner in the dashboard, select Projects > Volumes.
- In the Actions column of the volume to transfer, select Create Transfer.
In the Create Transfer dialog box, enter a name for the transfer and click Create Volume Transfer.
The volume transfer is created, and in the Volume Transfer screen you can capture the
transfer IDand theauthorization keyto send to the recipient project.Click the Download transfer credentials button to download a
.txtfile containing thetransfer name,transfer ID, andauthorization key.NoteThe authorization key is available only in the Volume Transfer screen. If you lose the authorization key, you must cancel the transfer and create another transfer to generate a new authorization key.
Close the Volume Transfer screen to return to the volume list.
The volume status changes to
awaiting-transferuntil the recipient project accepts the transfer
Accept a volume transfer from the dashboard
- As the recipient project owner in the dashboard, select Projects > Volumes.
- Click Accept Transfer.
In the Accept Volume Transfer dialog box, enter the
transfer IDand theauthorization keythat you received from the volume owner and click Accept Volume Transfer.The volume now appears in the volume list for the active project.
2.3.10. Create, use, or delete volume snapshots
You can preserve the state of a volume at a specific point in time by creating a volume snapshot. You can then use the snapshot to clone new volumes.
Volume backups are different from snapshots. Backups preserve the data contained in the volume, whereas snapshots preserve the state of a volume at a specific point in time. You cannot delete a volume if it has existing snapshots. Volume backups prevent data loss, whereas snapshots facilitate cloning.
For this reason, snapshot back ends are typically colocated with volume back ends to minimize latency during cloning. By contrast, a backup repository is usually located in a different location, for example, on a different node, physical storage, or even geographical location in a typical enterprise deployment. This is to protect the backup repository from any damage that might occur to the volume back end.
For more information about volume backups, see the Block Storage Backup Guide.
To create a volume snapshot:
- In the dashboard, select Project > Compute > Volumes.
- Select the Create Snapshot action of the target volume.
- Provide a Snapshot Name for the snapshot and click Create a Volume Snapshot. The Volume Snapshots tab displays all snapshots.
You can clone new volumes from a snapshot when it appears in the Volume Snapshots table. Select the Create Volume action of the snapshot. For more information about volume creation, see Section 2.3.1, “Create a volume”.
If you want to create a new volume from a snapshot of an encrypted volume, ensure that the new volume is at least 1GB larger than the old volume.
To delete a snapshot, select its Delete Volume Snapshot action.
If your OpenStack deployment uses a Red Hat Ceph back end, see Section 2.3.10.1, “Protected and unprotected snapshots in a Red Hat Ceph Storage back end” for more information about snapshot security and troubleshooting.
For RADOS block device (RBD) volumes for the Block Storage service (cinder) that are created from snapshots, you can use the CinderRbdFlattenVolumeFromSnapshot heat parameter to flatten and remove the dependency on the snapshot. When you set CinderRbdFlattenVolumeFromSnapshot to true, the Block Storage service flattens RBD volumes and removes the dependency on the snapshot and also flattens all future snapshots. The default value is false, which is also the default value for the cinder RBD driver.
Be aware that flattening a snapshot removes any potential block sharing with the parent and results in larger snapshot sizes on the back end and increases the time for snapshot creation.
2.3.10.1. Protected and unprotected snapshots in a Red Hat Ceph Storage back end
When using Red Hat Ceph Storage as a back end for your OpenStack deployment, you can set a snapshot to protected in the back end. Attempting to delete protected snapshots through OpenStack (as in, through the dashboard or the cinder snapshot-delete command) will fail.
When this occurs, set the snapshot to unprotected in the Red Hat Ceph back end first. Afterwards, you should be able to delete the snapshot through OpenStack as normal.
For more information, see the following links in the Red Hat Ceph Storage Block Device Guide:
2.3.11. Use a snapshot to restore to the last state of a volume
You can recover the most recent snapshot of a volume. This means that you can perform an in-place revert of the volume data to its most recent snapshot.
- Warning
- The ability to recover the most recent snapshot of a volume is supported but is driver dependent. The correct implementation of this feature is driver assisted. For more information about support for this feature, contact your driver vendor.
Limitations
- There might be limitations to using the revert-to-snapshot feature with multi-attach volumes. Check whether such limitations apply before you use this feature.
- You cannot revert a volume that you resize (extend) after you take a snapshot.
- You cannot use the revert-to-snapshot feature on an attached or in-use volume.
Prerequisites
- Block Storage (cinder) API microversion 3.40 or later.
- You must have created at least one snapshot for the volume.
Procedure
-
Log in to the undercloud as the
stackuser. Source the
overcloudrcfile:[stack@undercloud ~] $ source overcloudrc
Detach your volume:
$ nova volume-detach <instance_id> <vol_id>
Replace <instance_id> and <vol_id> with the IDs of the instance and volume that you want to revert.
Locate the ID or name of the snapshot that you want to revert. You can only revert the latest snapshot.
$ cinder snapshot-list
Revert the snapshot:
$ cinder --os-volume-api-version=3.40 revert-to-snapshot <snapshot_id or snapshot_name>
Replace <snapshot_id or snapshot_name> with the ID or the name of the snapshot.
Optional: You can use the
cinder snapshot-listcommand to check that the volume you are reverting is in a reverting state.$ cinder snapshot-list
Reattach the volume:
$ nova volume-attach <instance_id> <vol_id>
Replace <instance_id> and <vol_id> with the IDs of the instance and volume that you reverted.
2.3.11.1. Verifying that your revert is successful
Procedure
To check that the procedure is successful, you can use the
cinder listcommand to verify that the volume you reverted is now in the available state.$ cinder list
- Note
-
If you used Block Storage (cinder) as a bootable root volume, you cannot use the revert-to-snapshot feature on that volume because it is not in the available state. To use this feature, the instance must have been booted with the
delete_on_termination=false(default) property to preserve the boot volume if the instance is terminated. When you want to revert to a snapshot, you must first delete the initial instance so that the volume is available. You can then revert it and create a new instance from the volume.
2.3.12. Upload a volume to the Image Service
You can upload an existing volume as an image to the Image service directly. To do so:
- In the dashboard, select Project > Compute > Volumes.
- Select the target volume’s Upload to Image action.
- Provide an Image Name for the volume and select a Disk Format from the list.
- Click Upload.
To view the uploaded image, select Project > Compute > Images. The new image appears in the Images table. For information on how to use and configure images, see Manage images in the Creating and Managing Images guide.
2.3.13. Moving volumes between back ends
There are many reasons to move volumes from one storage back end to another, such as:
- To retire storage systems that are no longer supported.
- To change the storage class or tier of a volume.
- To change the availability zone of a volume.
With the Block Storage service (cinder), you can move volumes between back ends in the following ways:
- Retype: The default policy allows volume owners and administrators to retype a volume. The retype operation is the most common way to move volumes between back ends.
- Migrate: The default policy allows only administrators to migrate a volume. Volume migration is reserved for specific use cases, because it is restrictive and requires a clear understanding about how deployments work. For more information, see Migrate a volume.
Restrictions
Red Hat supports moving volumes between back ends within and across availability zones (AZs), but with the following restrictions:
- Volumes must have either available or in-use status to move.
- Support for in-use volumes is driver dependent.
- Volumes cannot have snapshots.
- Volumes cannot belong to a group or consistency group.
2.3.14. Moving available volumes
You can move available volumes between all back ends, but performance depends on the back ends that you use. Many back ends support assisted migration. For more information about back-end support for assisted migration, contact the vendor.
Assisted migration works with both volume retype and volume migration. With assisted migration, the back end optimizes the movement of the data from the source back end to the destination back end, but both back ends must be from the same vendor.
Red Hat supports back end-assisted migrations only with multi-pool back ends or when you use the cinder migrate operation for single-pool back ends, such as RBD.
2.3.14.1. Generic volume migration
When assisted migrations between back ends are not possible, the Block Storage service performs a generic volume migration.
Generic volume migration requires volumes on both back ends to be connected before the Block Storage (cinder) service moves data from the source volume to the Controller node and from the Controller node to the destination volume. The Block Storage service seamlessly performs the process regardless of the type of storage from the source and destination back ends.
Ensure that you have adequate bandwidth before you perform a generic volume migration. The duration of a generic volume migration is directly proportional to the size of the volume, which makes the operation slower than assisted migration.
2.3.15. Moving in-use volumes
There is no optimized or assisted option for moving in-use volumes. When you move in-use volumes, the Compute service (nova) must use the hypervisor to transfer data from a volume in the source back end to a volume in the destination back end. This requires coordination with the hypervisor that runs the instance where the volume is in use.
The Block Storage service (cinder) and the Compute service work together to perform this operation. The Compute service manages most of the work, because the data is copied from one volume to another through the Compute node.
Ensure that you have adequate bandwidth before you move in-use volumes. The duration of this operation is directly proportional to the size of the volume, which makes the operation slower than assisted migration.
Restrictions
- In-use multi-attach volumes cannot be moved while they are attached to more than one nova instance.
- Non block devices are not supported, which limits storage protocols on the target back end to be iSCSI, Fibre Channel (FC), or RBD.
2.3.16. Volume retyping
Volume retyping is the standard way to move volumes from one back end to another. The operation requires the administrator to define the appropriate volume types for the different back ends. The default policy allows volume owners and administrators to retype volumes.
When you retype a volume, you apply a volume type and its settings to an already existing volume. For more information about volume types, see Section 2.2.2, “Group Volume Settings with Volume Types”.
You can retype a volume provided that the extra specs of the new volume type can be applied to the existing volume. You can retype a volume to apply pre-defined settings or storage attributes to an existing volume, such as:
- To move the volume to a different back end.
- To change the storage class or tier of a volume.
- To enable or disable features such as replication.
Retyping a volume does not necessarily mean that you must move the volume from one back end to another. However, there are circumstances in which you must move a volume to complete a retype:
-
The new volume type has a different
volume_backend_namedefined. -
The
volume_backend_nameof the current volume type is undefined, and the volume is stored in a different back end than the one specified by thevolume_backend_nameof the new volume type.
Moving a volume from one back end to another can require extensive time and resources. Therefore, when a retype requires moving data, the Block Storage service does not move data by default. The operation fails unless it is explicitly allowed by specifying a migration policy as part of the retype request. For more information, see Section 2.3.16.2, “Retyping a volume from the command line”.
Restrictions
- You cannot retype all volumes. For more information about moving volumes between back ends, see Section 2.3.13, “Moving volumes between back ends”.
- You cannot retype unencrypted volumes to be encrypted volume types, but you can retype encrypted volumes to be unencrypted.
- Users with no administrative privileges can only retype volumes that they own.
2.3.16.1. Retyping a volume from the dashboard UI
Use the dashboard UI to retype a volume.
Retyping an unencrypted volume to an encrypted volume of the same size is not supported, because encrypted volumes require additional space to store encryption data. For more information about encrypting unencrypted volumes, see Encrypting unencrypted volumes.
Prerequisites
- A successful undercloud installation. For more information, see Installing director on the undercloud.
- A successful overcloud deployment. For more information, see Creating a basic overcloud with CLI tools.
- Access to the Red Hat OpenStack Platform (RHOSP) Dashboard (horizon). For more information, see Overcloud deployment output.
Procedure
- In the dashboard, select Project > Compute > Volumes.
- In the Actions column of the volume you want to migrate, select Change Volume Type.
- In the Change Volume Type dialog, select the target volume type and define the new back end from the Type list.
- If you are migrating the volume to another back end, select On Demand from the Migration Policy list. For more information, see Section 2.3.13, “Moving volumes between back ends”.
- Click Change Volume Type to start the migration.
2.3.16.2. Retyping a volume from the command line
Similar to the dashboard UI procedure, you can retype a volume from the command line.
Retyping an unencrypted volume to an encrypted volume of the same size is not supported, because encrypted volumes require additional space to store encryption data. For more information about encrypting unencrypted volumes, see Encrypting unencrypted volumes.
Prerequisites
- A successful undercloud installation. For more information, see Installing director on the undercloud.
- A successful overcloud deployment. For more information, see Creating a basic overcloud with CLI tools.
Procedure
Enter the following command to retype a volume:
$ cinder retype <volume id> <new volume type name>
If the retype operation requires moving the volume from one back end to another, the Block Storage service requires a specific flag:
$ cinder retype --migration-policy on-demand <volume id> <new volume type name>
NoteAs the retype operation progresses, the volume status changes to
retyping.Enter the following command and review the
volume_typefield to confirm that the retype operation succeeded. Thevolume_typefield shows the new volume type.$ cinder show <volume id>
NoteWhen you initiate a retype operation, the volume name is duplicated. If you enter the
cinder showcommand with the volume name, the cinder client will return an error similar toERROR: Multiple volume matches found for '<volume name>'. To avoid this error, use the volume ID instead.
2.3.17. Enabling LVM2 filtering on overcloud nodes
If you use LVM2 (Logical Volume Management) volumes with certain Block Storage service (cinder) back ends, the volumes that you create inside Red Hat OpenStack Platform (RHOSP) guests might become visible on the overcloud nodes that host cinder-volume or nova-compute containers. In this case, the LVM2 tools on the host scan the LVM2 volumes that the OpenStack guest creates, which can result in one or more of the following problems on Compute or Controller nodes:
- LVM appears to see volume groups from guests
- LVM reports duplicate volume group names
- Volume detachments fail because LVM is accessing the storage
- Guests fail to boot due to problems with LVM
- The LVM on the guest machine is in a partial state due to a missing disk that actually exists
- Block Storage service (cinder) actions fail on devices that have LVM
- Block Storage service (cinder) snapshots fail to remove correctly
-
Errors during live migration:
/etc/multipath.confdoes not exist
To prevent this erroneous scanning, and to segregate guest LVM2 volumes from the host node, you can enable and configure a filter with the LVMFilterEnabled heat parameter when you deploy or update the overcloud. This filter is computed from the list of physical devices that host active LVM2 volumes. You can also allow and deny block devices explicitly with the LVMFilterAllowlist and LVMFilterDenylist parameters. You can apply this filtering globally, to specific node roles, or to specific devices.
This feature is available in this release as a Technology Preview, and therefore is not fully supported by Red Hat. It should only be used for testing, and should not be deployed in a production environment. For more information about Technology Preview features, see Scope of Coverage Details.
Prerequisites
- A successful undercloud installation. For more information, see Installing the undercloud.
Procedure
-
Log in to the undercloud host as the
stackuser. Source the undercloud credentials file:
$ source ~/stackrc
Create a new environment file, or modify an existing environment file. In this example, create a new file
lvm2-filtering.yaml:$ touch ~/lvm2-filtering.yaml
Include the following parameter in the environment file:
parameter_defaults: LVMFilterEnabled: true
You can further customize the implementation of the LVM2 filter. For example, to enable filtering only on Compute nodes, use the following configuration:
parameter_defaults: ComputeParameters: LVMFilterEnabled: trueThese parameters also support regular expression. To enable filtering only on Compute nodes, and ignore all devices that start with
/dev/sd, use the following configuration:parameter_defaults: ComputeParameters: LVMFilterEnabled: true LVMFilterDenylist: - /dev/sd.*Run the
openstack overcloud deploycommand and include the environment file that contains the LVM2 filtering configuration, as well as any other environment files that are relevant to your overcloud deployment:$ openstack overcloud deploy --templates \ <environment-files> \ -e lvm2-filtering.yaml
2.4. Advanced Volume Configuration
The following procedures describe how to perform advanced volume management procedures.
You must install host bus adapters (HBAs) on all Controller nodes and Compute nodes in any deployment that uses the Block Storage service (cinder) and a Fibre Channel (FC) back end.
2.4.1. Migrate a Volume
With the Block Storage service (cinder) you can migrate volumes between back ends within and across availability zones (AZs). This is the least common way to move volumes from one back end to another. The default policy allows only administrators to migrate volumes. Do not change the default policy.
In highly customized deployments or in situations in which you must retire a storage system, an administrator can migrate volumes. In both use cases, multiple storage systems share the same volume_backend_name, or it is undefined.
Restrictions
- The volume cannot be replicated.
- The destination back end must be different from the current back end of the volume.
The existing volume type must be valid for the new back end, which means the following must be true:
-
Volume type must not have the
backend_volume_namedefined in its extra specs, or both Block Storage back ends must be configured with the samebackend_volume_name. - Both back ends must support the same features configured in the volume type, such as support for thin provisioning, support for thick provisioning, or other feature configurations.
-
Volume type must not have the
Moving volumes from one back end to another might require extensive time and resources. For more information, see Section 2.3.13, “Moving volumes between back ends”.
2.4.1.1. Migrate between back ends
Use the dashboard UI to migrate a volume between back ends.
Procedure
- In the dashboard, select Admin > Volumes.
- In the Actions column of the volume you want to migrate, select Migrate Volume.
In the Migrate Volume dialog, select the target host from the Destination Host drop-down list.
NoteTo bypass any driver optimizations for the host migration, select the Force Host Copy check box.
- Click Migrate to start the migration.
2.4.1.2. Migrating between back ends from the command line
- A successful undercloud installation. For more information, see Installing director on the undercloud.
Procedure
Enter the following command to retrieve the name of the destination back end:
$ cinder get-pools --detail Property | Value ... | name | localdomain@lvmdriver-1#lvmdriver-1 | pool_name | lvmdriver-1 ... | volume_backend_name | lvmdriver-1 ... Property | Value ... | | name | localdomain@lvmdriver-2#lvmdriver-1 | pool_name | lvmdriver-1 ... | volume_backend_name | lvmdriver-1 ...The back end names take the form
host@volume_backend_name#pool.In the example output, there are two LVM back ends exposed in the Block Storage service:
localdomain@lvmdriver-1#lvmdriver-1andlocaldomain@lvmdriver-2#lvmdriver-1. Notice that both back ends share the samevolume_backend_name,lvmdriver-1.NoteUse of LVM is for example only. LVM is not supported in production environments.
Enter the following command to migrate a volume from one back end to another:
$ cinder migrate <volume id or name> <new host>
2.4.1.3. Verifying volume migration
When you create a volume, the migration_status value equals None. When you initiate the migration, the status changes to migrating. When the migration completes, the status changes to either success or error.
After the Block Storage service accepts the migration request, the cinder client responds with a message similar to Request to migrate volume <volume id> has been accepted. However, it takes time for the migration to complete. As an administrator, you can verify the status of the migration.
Procedure
Enter the following command and review the
migration_statusfield:$ cinder show <volume id>
NoteWhen you initiate a generic volume migration, the volume name is duplicated. If you enter the
cinder showcommand with the volume name, the cinder client returns an error similar toERROR: Multiple volume matches found for '<volume name>'. To avoid this error, use the volume ID instead.
After a successful migration, the host field matches the <new host> value set in the cinder migrate command.
2.4.2. Encrypting unencrypted volumes
To encrypt an unencrypted volume, you must either back up the unencrypted volume and then restore it to a new encrypted volume, or create an Image service (glance) image from the unencrypted volume and then create a new encrypted volume from the image.
Prerequisites
- An unencrypted volume that you want to encrypt.
Procedure
If the
cinder-backupservice is available, back up the current unencrypted volume:$ cinder backup-create <unencrypted_volume>
-
Replace
<unencrypted_volume>with the name or ID of the unencrypted volume.
-
Replace
Create a new encrypted volume:
$ cinder create <encrypted_volume_size> --volume-type <encrypted_volume_type>
-
Replace
<encrypted_volume_size>with the size of the new volume in GB. This value must be larger than the size of the unencrypted volume by 1GB to accommodate the encryption metadata. -
Replace
<encrypted_volume_type>with the encryption type that you require.
-
Replace
Restore the backup of the unencrypted volume to the new encrypted volume:
$ cinder backup-restore <backup> --volume <encrypted_volume>
-
Replace
<backup>with the name or ID of the unencrypted volume backup. -
Replace
<encrypted_volume>with the ID of the new encrypted volume.
-
Replace
If the cinder-backup service is unavailable, use the upload-to-image command to create an image of the unencrypted volume, and then create a new encrypted volume from the image.
Create an Image service image of the unencrypted volume:
$ cinder upload-to-image <unencrypted_volume> <new_image>
-
Replace
<unencrypted_volume>with the name or ID of the unencrypted volume. -
Replace
<new_image>with a name for the new image.
-
Replace
Create a new volume from the image that is 1GB larger than the image:
$ cinder volume create --size <size> --volume-type luks --image <new_image> <encrypted_volume_name>
-
Replace
<size>with the size of the new volume. This value must be 1GB larger than the size of the old unencrypted volume. -
Replace
<new_image>with the name of the image that you created from the unencrypted volume. -
Replace
<encrypted_volume_name>with a name for the new encrypted volume.
-
Replace
2.5. Multipath configuration
Use multipath to configure multiple I/O paths between server nodes and storage arrays into a single device to create redundancy and improve performance. You can configure multipath on new and existing overcloud deployments.
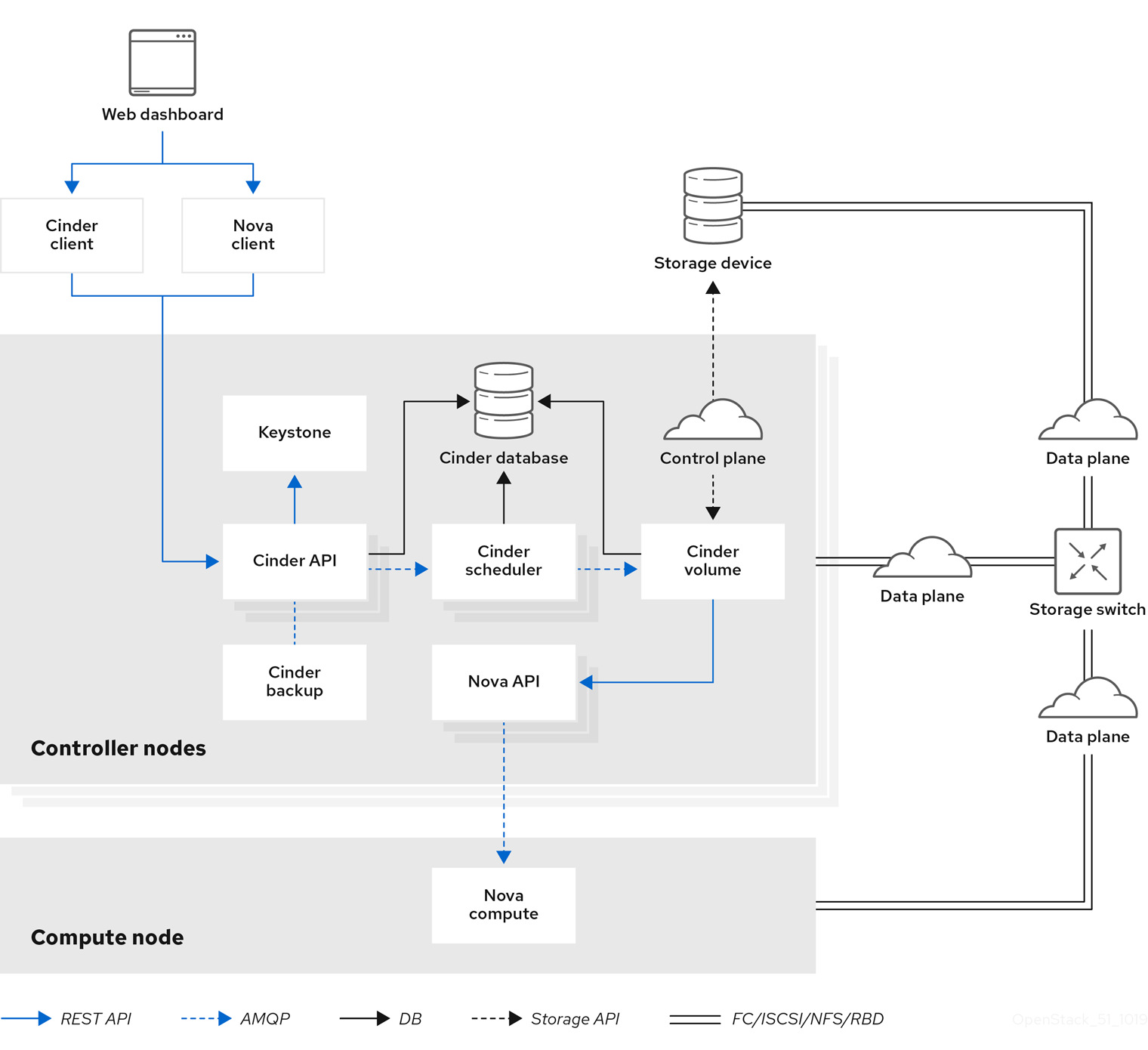
2.5.1. Configuring multipath on new deployments
Complete this procedure to configure multipath on a new overcloud deployment.
For information about how to configure multipath on existing overcloud deployments, see Section 2.5.2, “Configuring multipath on existing deployments”.
Prerequisites
The overcloud Controller and Compute nodes must have access to the Red Hat Enterprise Linux server repository. For more information, see Downloading the base cloud image in the Director Installation and Usage guide.
Procedure
Configure the overcloud.
NoteFor more information, see Configuring a basic overcloud with CLI tools in the Director Installation and Usage guide.
Update the heat template to enable multipath:
parameter_defaults: NovaLibvirtVolumeUseMultipath: true NovaComputeOptVolumes: - /etc/multipath.conf:/etc/multipath.conf:ro - /etc/multipath/:/etc/multipath/:rw CinderVolumeOptVolumes: - /etc/multipath.conf:/etc/multipath.conf:ro - /etc/multipath/:/etc/multipath/:rwOptional: If you are using Block Storage (cinder) as an Image service (glance) back end, you must also complete the following steps:
Add the following
GlanceApiOptVolumesconfiguration to the heat template:parameter_defaults: GlanceApiOptVolumes: - /etc/multipath.conf:/etc/multipath.conf:ro - /etc/multipath/:/etc/multipath/:rwSet the
ControllerExtraConfigparameter in the following way:parameter_defaults: ControllerExtraConfig: glance::config::api_config: default_backend/cinder_use_multipath: value: true- Note
-
Ensure that both
default_backendand theGlanceBackendIDheat template default value match.
For every configured back end, set
use_multipath_for_image_xfertotrue:parameter_defaults: ExtraConfig: cinder::config::cinder_config: <backend>/use_multipath_for_image_xfer: value: trueDeploy the overcloud:
$ openstack overcloud deploy
NoteFor information about creating the overcloud using overcloud parameters, see Creating the Overcloud with the CLI Tools in the Director Installation and Usage guide.
Before containers are running, install multipath on all Controller and Compute nodes:
$ sudo dnf install -y device-mapper-multipath
NoteDirector provides a set of hooks to support custom configuration for specific node roles after the first boot completes and before the core configuration begins. For more information about custom overcloud configuration, see Pre-Configuration: Customizing Specific Overcloud Roles in the Advanced Overcloud Customization guide.
Configure the multipath daemon on all Controller and Compute nodes:
$ mpathconf --enable --with_multipathd y --user_friendly_names n --find_multipaths y
NoteThe example code creates a basic multipath configuration that works for most environments. However, check with your storage vendor for recommendations, because some vendors have optimized configurations that are specific to their hardware. For more information about multipath, see the Configuring device mapper multipath guide.
Run the following command on all Controller and Compute nodes to prevent partition creation:
$ sed -i "s/^defaults {/defaults {\n\tskip_kpartx yes\n\trecheck_wwid yes/" /etc/multipath.confNoteSetting
skip_kpartxtoyesprevents kpartx on the Compute node from automatically creating partitions on the device, which prevents unnecessary device mapper entries. For more information about configuration attributes, see Modifying the DM-Multipath configuration file in the Configuring device mapper multipath guide.Start the multipath daemon on all Controller and Compute nodes:
$ systemctl enable --now multipathd
2.5.2. Configuring multipath on existing deployments
Configure multipath on existing deployments so that your workloads can use multipath functionality.
Any new workloads that you create after you configure multipath on existing deployments are multipath-aware by default. If you have any pre-existing workloads, you must shelve and unshelve the instances to enable multipath on these instances.
For more information about how to configure multipath on new overcloud deployments, see Section 2.5.1, “Configuring multipath on new deployments”.
Prerequisites
The overcloud Controller and Compute nodes must have access to the Red Hat Enterprise Linux server repository. For more information, see Downloading the base cloud image in the Director Installation and Usage guide.
Procedure
Verify that multipath is installed on all Controller and Compute nodes:
$ rpm -qa | grep device-mapper-multipath device-mapper-multipath-0.4.9-127.el8.x86_64 device-mapper-multipath-libs-0.4.9-127.el8.x86_64
If multipath is not installed, install it on all Controller and Compute nodes:
$ sudo dnf install -y device-mapper-multipath
Configure the multipath daemon on all Controller and Compute nodes:
$ mpathconf --enable --with_multipathd y --user_friendly_names n --find_multipaths y
NoteThe example code creates a basic multipath configuration that works for most environments. However, check with your storage vendor for recommendations, because some vendors have optimized configurations specific to their hardware. For more information about multipath, see the Configuring device mapper multipath guide.
Run the following command on all Controller and Compute nodes to prevent partition creation:
$ sed -i "s/^defaults {/defaults {\n\tskip_kpartx yes\n\trecheck_wwid yes/" /etc/multipath.confNoteSetting
skip_kpartxtoyesprevents kpartx on the Compute node from automatically creating partitions on the device, which prevents unnecessary device mapper entries. For more information about configuration attributes, see Modifying the DM-Multipath configuration file in the Configuring device mapper multipath guide.Start the multipath daemon on all Controller and Compute nodes:
$ systemctl enable --now multipathd
Update the heat template to enable multipath:
parameter_defaults: NovaLibvirtVolumeUseMultipath: true NovaComputeOptVolumes: - /etc/multipath.conf:/etc/multipath.conf:ro - /etc/multipath/:/etc/multipath/:rw CinderVolumeOptVolumes: - /etc/multipath.conf:/etc/multipath.conf:ro - /etc/multipath/:/etc/multipath/:rwOptional: If you are using Block Storage (cinder) as an Image service (glance) back end, you must also complete the following steps:
Add the following
GlanceApiOptVolumesconfiguration to the heat template:parameter_defaults: GlanceApiOptVolumes: - /etc/multipath.conf:/etc/multipath.conf:ro - /etc/multipath/:/etc/multipath/:rwSet the
ControllerExtraConfigparameter in the following way:parameter_defaults: ControllerExtraConfig: glance::config::api_config: default_backend/cinder_use_multipath: value: true- Note
-
Ensure that both
default_backendand theGlanceBackendIDheat template default value match.
For every configured back end, set
use_multipath_for_image_xfertotrue:parameter_defaults: ExtraConfig: cinder::config::cinder_config: <backend>/use_multipath_for_image_xfer: value: trueRun the following command to update the overcloud:
$ openstack overcloud deploy
NoteWhen you run the
openstack overcloud deploycommand to install and configure multipath, you must pass all previous roles and environment files that you used to deploy the overcloud, such as--templates,--roles-file,-efor all environment files, and--timeout. Failure to pass all previous roles and environment files can cause problems with your overcloud deployment. For more information about using overcloud parameters, see Creating the Overcloud with the CLI Tools in the Director Installation and Usage guide.
2.5.3. Verifying multipath configuration
This procedure describes how to verify multipath configuration on new or existing overcloud deployments.
Procedure
- Create a VM.
- Attach a non-encrypted volume to the VM.
Get the name of the Compute node that contains the instance:
$ nova show INSTANCE | grep OS-EXT-SRV-ATTR:hostReplace INSTANCE with the name of the VM that you booted.
Retrieve the virsh name of the instance:
$ nova show INSTANCE | grep instance_nameReplace INSTANCE with the name of the VM that you booted.
Get the IP address of the Compute node:
$ . stackrc $ nova list | grep compute_nameReplace compute_name with the name from the output of the
nova show INSTANCEcommand.SSH into the Compute node that runs the VM:
$ ssh heat-admin@COMPUTE_NODE_IPReplace COMPUTE_NODE_IP with the IP address of the Compute node.
Log in to the container that runs virsh:
$ podman exec -it nova_libvirt /bin/bash
Enter the following command on a Compute node instance to verify that it is using multipath in the cinder volume host location:
virsh domblklist VIRSH_INSTANCE_NAME | grep /dev/dmReplace VIRSH_INSTANCE_NAME with the output of the
nova show INSTANCE | grep instance_namecommand.If the instance shows a value other than
/dev/dm-, the connection is non-multipath and you must refresh the connection info with thenova shelveandnova unshelvecommands:$ nova shelve <instance> $ nova unshelve <instance>
NoteIf you have more than one type of back end, you must verify the instances and volumes on all back ends, because connection info that each back end returns might vary.
Chapter 3. Object Storage service
OpenStack Object Storage (swift) stores its objects (data) in containers, which are similar to directories in a file system although they cannot be nested. Containers provide an easy way for users to store any kind of unstructured data. For example, objects might include photos, text files, or images. Stored objects are not compressed.
3.1. Object Storage rings
Object Storage uses a data structure called the Ring to distribute partition space across the cluster. This partition space is core to the data durability engine in the Object Storage service. It allows the Object Storage service to quickly and easily synchronize each partition across the cluster.
Rings contain information about Object Storage partitions and how partitions are distributed among the different nodes and disks. When any Object Storage component interacts with data, a quick lookup is performed locally in the ring to determine the possible partitions for each object.
The Object Storage service has three rings to store different types of data: one for account information, another for containers (to facilitate organizing objects under an account), and another for object replicas.
3.1.1. Rebalancing rings
When you change the Object Storage environment by adding or removing storage capacity, nodes, or disks, you must rebalance the rings. You can run openstack overcloud deploy to rebalance the rings, but this method redeploys the entire overcloud. This can be cumbersome, especially if you have a large overcloud. Alternatively, run the following command on the undercloud to rebalance the rings:
source ~/stackrc ansible-playbook -i /usr/bin/tripleo-ansible-inventory /usr/share/openstack-tripleo-common/playbooks/swift_ring_rebalance.yaml
3.1.2. Checking cluster health
The Object Storage service runs many processes in the background to ensure long-term data availability, durability, and persistence. For example:
- Auditors constantly re-read database and object files and compare them using checksums to make sure there is no silent bit-rot. Any database or object file that no longer matches its checksum is quarantined and becomes unreadable on that node. The replicators then copy one of the other replicas to make the local copy available again.
- Objects and files can disappear when you replace disks or nodes or when objects are quarantined. When this happens, replicators copy missing objects or database files to one of the other nodes.
The Object Storage service includes a tool called swift-recon that collects data from all nodes and checks the overall cluster health.
To use swift-recon, log in to one of the controller nodes and run the following command:
[root@overcloud-controller-2 ~]# sudo podman exec -it -u swift swift_object_server /usr/bin/swift-recon -arqlT --md5 ======================================================================--> Starting reconnaissance on 3 hosts (object) ======================================================================[2018-12-14 14:55:47] Checking async pendings [async_pending] - No hosts returned valid data. ======================================================================[2018-12-14 14:55:47] Checking on replication [replication_failure] low: 0, high: 0, avg: 0.0, total: 0, Failed: 0.0%, no_result: 0, reported: 3 [replication_success] low: 0, high: 0, avg: 0.0, total: 0, Failed: 0.0%, no_result: 0, reported: 3 [replication_time] low: 0, high: 0, avg: 0.0, total: 0, Failed: 0.0%, no_result: 0, reported: 3 [replication_attempted] low: 0, high: 0, avg: 0.0, total: 0, Failed: 0.0%, no_result: 0, reported: 3 Oldest completion was 2018-12-14 14:55:39 (7 seconds ago) by 172.16.3.186:6000. Most recent completion was 2018-12-14 14:55:42 (4 seconds ago) by 172.16.3.174:6000. ======================================================================[2018-12-14 14:55:47] Checking load averages [5m_load_avg] low: 1, high: 2, avg: 2.1, total: 6, Failed: 0.0%, no_result: 0, reported: 3 [15m_load_avg] low: 2, high: 2, avg: 2.6, total: 7, Failed: 0.0%, no_result: 0, reported: 3 [1m_load_avg] low: 0, high: 0, avg: 0.8, total: 2, Failed: 0.0%, no_result: 0, reported: 3 ======================================================================[2018-12-14 14:55:47] Checking ring md5sums 3/3 hosts matched, 0 error[s] while checking hosts. ======================================================================[2018-12-14 14:55:47] Checking swift.conf md5sum 3/3 hosts matched, 0 error[s] while checking hosts. ======================================================================[2018-12-14 14:55:47] Checking quarantine [quarantined_objects] low: 0, high: 0, avg: 0.0, total: 0, Failed: 0.0%, no_result: 0, reported: 3 [quarantined_accounts] low: 0, high: 0, avg: 0.0, total: 0, Failed: 0.0%, no_result: 0, reported: 3 [quarantined_containers] low: 0, high: 0, avg: 0.0, total: 0, Failed: 0.0%, no_result: 0, reported: 3 ======================================================================[2018-12-14 14:55:47] Checking time-sync 3/3 hosts matched, 0 error[s] while checking hosts. ======================================================================
As an alternative, use the --all option to return additional output.
This command queries all servers on the ring for the following data:
- Async pendings: If the cluster load is too high and processes can’t update database files fast enough, some updates will occur asynchronously. These numbers should decrease over time.
- Replication metrics: Notice the replication timestamps; full replication passes should happen frequently and there should be few errors. An old entry, (for example, an entry with a timestamp from six months ago) indicates that replication on the node has not completed in the last six months.
- Ring md5sums: This ensures that all ring files are consistent on all nodes.
-
swift.confmd5sums: This ensures that all ring files are consistent on all nodes. - Quarantined files: There should be no (or very few) quarantined files for all nodes.
- Time-sync: All nodes must be synchronized.
3.1.3. Increasing ring partition power
The ring power determines the partition to which a resource (account, container, or object) is mapped. The partition is included in the path under which the resource is stored in a back end file system. Therefore, changing the partition power requires relocating resources to new paths in the back end file systems.
In a heavily populated cluster, a relocation process is time-consuming. To avoid downtime, relocate resources while the cluster is still operating. You must do this without temporarily losing access to data or compromising the performance of processes, such as replication and auditing. For assistance with increasing ring partition power, contact Red Hat support.
3.1.4. Creating custom rings
As technology advances and demands for storage capacity increase, creating custom rings is a way to update existing Object Storage clusters.
When you add new nodes to a cluster, their characteristics may differ from those of the original nodes. Without custom adjustments, the larger capacity of the new nodes may be underutilized. Or, if weights change in the rings, data dispersion can become uneven, which reduces safety.
Automation may not keep pace with future technology trends. For example, some older Object Storage clusters in use today originated before SSDs were available.
The ring builder helps manage Object Storage as clusters grow and technologies evolve. For assistance with creating custom rings, contact Red Hat support.
3.2. Object Storage service administration
The following procedures explain how to customize the Object Storage service.
3.2.1. Configuring fast-post
By default, the Object Storage service copies an object whole whenever any part of its metadata changes. You can prevent this by using the fast-post feature. The fast-post feature saves time when you change the content types of multiple large objects.
To enable the fast-post feature, disable the object_post_as_copy option on the Object Storage proxy service by doing the following:
Edit
swift_params.yaml:cat > swift_params.yaml << EOF parameter_defaults: ExtraConfig: swift::proxy::copy::object_post_as_copy: False EOFInclude the parameter file when you deploy or update the overcloud:
openstack overcloud deploy [... previous args ...] -e swift_params.yaml
3.2.2. Enabling at-rest encryption
By default, objects uploaded to Object Storage are kept unencrypted. Because of this, it is possible to access objects directly from the file system. This can present a security risk if disks are not properly erased before they are discarded.
You can use OpenStack Key Manager (barbican) to encrypt at-rest swift objects. For more information, see Encrypt at-rest swift objects.
3.2.3. Deploying a standalone Object Storage cluster
You can use the composable role concept to deploy a standalone Object Storage (openstack-swift) cluster with the bare minimum of additional services (for example Keystone, HAProxy). The Creating a roles_data File section has information on roles.
3.2.3.1. Creating the roles_data.yaml File
-
Copy the
roles_data.yamlfrom/usr/share/openstack-tripleo-heat-templates. - Edit the new file.
- Remove unneeded controller roles, for example Aodh*, Ceilometer*, Ceph*, Cinder*, Glance*, Heat*, Ironic*, Manila*, Mistral*, Nova*, Octavia*, Swift*.
-
Locate the ObjectStorage role within
roles_data.yaml. -
Copy this role to a new role within that same file and name it
ObjectProxy. -
Replace
SwiftStoragewithSwiftProxyin this role.
The example roles_data.yaml file below shows sample roles.
- name: Controller description: | Controller role that has all the controller services loaded and handles Database, Messaging and Network functions. CountDefault: 1 tags: - primary - controller networks: - External - InternalApi - Storage - StorageMgmt - Tenant HostnameFormatDefault: '%stackname%-controller-%index%' ServicesDefault: - OS::TripleO::Services::AuditD - OS::TripleO::Services::CACerts - OS::TripleO::Services::CertmongerUser - OS::TripleO::Services::Clustercheck - OS::TripleO::Services::Docker - OS::TripleO::Services::Ec2Api - OS::TripleO::Services::Etcd - OS::TripleO::Services::HAproxy - OS::TripleO::Services::Keepalived - OS::TripleO::Services::Kernel - OS::TripleO::Services::Keystone - OS::TripleO::Services::Memcached - OS::TripleO::Services::MySQL - OS::TripleO::Services::MySQLClient - OS::TripleO::Services::Ntp - OS::TripleO::Services::Pacemaker - OS::TripleO::Services::RabbitMQ - OS::TripleO::Services::Securetty - OS::TripleO::Services::Snmp - OS::TripleO::Services::Sshd - OS::TripleO::Services::Timezone - OS::TripleO::Services::TripleoFirewall - OS::TripleO::Services::TripleoPackages - OS::TripleO::Services::Vpp - name: ObjectStorage CountDefault: 1 description: | Swift Object Storage node role networks: - InternalApi - Storage - StorageMgmt disable_upgrade_deployment: True ServicesDefault: - OS::TripleO::Services::AuditD - OS::TripleO::Services::CACerts - OS::TripleO::Services::CertmongerUser - OS::TripleO::Services::Collectd - OS::TripleO::Services::Docker - OS::TripleO::Services::FluentdClient - OS::TripleO::Services::Kernel - OS::TripleO::Services::MySQLClient - OS::TripleO::Services::Ntp - OS::TripleO::Services::Securetty - OS::TripleO::Services::SensuClient - OS::TripleO::Services::Snmp - OS::TripleO::Services::Sshd - OS::TripleO::Services::SwiftRingBuilder - OS::TripleO::Services::SwiftStorage - OS::TripleO::Services::Timezone - OS::TripleO::Services::TripleoFirewall - OS::TripleO::Services::TripleoPackages - name: ObjectProxy CountDefault: 1 description: | Swift Object proxy node role networks: - InternalApi - Storage - StorageMgmt disable_upgrade_deployment: True ServicesDefault: - OS::TripleO::Services::AuditD - OS::TripleO::Services::CACerts - OS::TripleO::Services::CertmongerUser - OS::TripleO::Services::Collectd - OS::TripleO::Services::Docker - OS::TripleO::Services::FluentdClient - OS::TripleO::Services::Kernel - OS::TripleO::Services::MySQLClient - OS::TripleO::Services::Ntp - OS::TripleO::Services::Securetty - OS::TripleO::Services::SensuClient - OS::TripleO::Services::Snmp - OS::TripleO::Services::Sshd - OS::TripleO::Services::SwiftRingBuilder - OS::TripleO::Services::SwiftProxy - OS::TripleO::Services::Timezone - OS::TripleO::Services::TripleoFirewall - OS::TripleO::Services::TripleoPackages
3.2.3.2. Deploying the New Roles
Deploy the overcloud with your regular openstack deploy command, including the new roles.
openstack overcloud deploy --templates -r roles_data.yaml -e [...]
3.2.4. Using external SAN disks
By default, when the Red Hat OpenStack Platform director deploys the Object Storage service (swift), Object Storage is configured and optimized to use independent local disks. This configuration ensures that the workload is distributed across all disks, which helps minimize performance impacts during node failure or other system issues.
In similar performance-impacting events, an environment that uses a single SAN can experience decreased performance across all LUNs. The Object Storage service cannot mitigate performance issues in an environment that uses SAN disks.
Therefore, Red Hat strongly recommends that you use additional local disks for Object Storage instead to meet performance and disk space requirements. For more information, see Object Storage in the Deployment Recommendations for Specific Red Hat OpenStack Platform Services guide.
Using an external SAN for Object Storage requires evaluation on a per-case basis. For more information, contact Red Hat Support.
If you choose to use an external SAN for Object Storage, be aware of the following conditions:
- The Object Storage service stores telemetry data and Image service (glance) images by default. Glance images require more disk space, but from a performance perspective, the impact of storing glance images impacts performance less than storing telemetry data. Storing and processing telemetry data requires increased performance. Red Hat does not provide support for issues related to performance that result from using an external SAN for Object Storage.
- Red Hat does not provide support for issues that arise outside of the core Object Storage service offering. For support with high availability and performance, contact your storage vendor.
- Red Hat does not test SAN solutions with the Object Storage service. For more information about compatibility, guidance, and support for third-party products, contact your storage vendor.
- Red Hat recommends that you evaluate and test performance demands with your deployment. To confirm that your SAN deployment is tested, supported, and meets your performance requirements, contact your storage vendor.
3.2.4.1. SAN disk deployment configuration
This template is an example of how to use two devices (/dev/mapper/vdb and /dev/mapper/vdc) for Object Storage storage:
parameter_defaults:
SwiftMountCheck: true
SwiftUseLocalDir: false
SwiftRawDisks: {"vdb": {"base_dir":"/dev/mapper/"}, "vdc": {"base_dir":"/dev/mapper/"}}3.3. Install and configure storage nodes for Red Hat Enterprise Linux
To use Red Hat OpenStack Platform Object Storage service (swift) on external storage nodes, you must install and configure the storage nodes that operate the account, container, and object services processes. This configuration references two storage nodes, each of which contain two empty local block storage devices.
The internal network for the Object Storage service is not authenticated. For security purposes, Red Hat recommends that you keep the storage nodes on a dedicated network or VLAN.
The instructions use /dev/sdb and /dev/sdc as device names, but you can substitute the values for specific nodes in your environment.
3.3.1. Preparing storage devices
Before you install and configure the Object Storage service on the storage nodes, you must prepare the storage devices.
Perform all of these steps on each storage node.
Procedure
Install the supporting utility packages:
# yum install xfsprogs rsync
Format the
/dev/sdband/dev/sdcdevices as XFS:# mkfs.xfs /dev/sdb # mkfs.xfs /dev/sdc
Create the mount point directory structure:
# mkdir -p /srv/node/sdb # mkdir -p /srv/node/sdc
Edit the
/etc/fstabfile and add the following data to it:/dev/sdb /srv/node/sdb xfs defaults 0 2 /dev/sdc /srv/node/sdc xfs defaults 0 2
Mount the devices:
# mount /srv/node/sdb # mount /srv/node/sdc
Create or edit the
/etc/rsyncd.conffile to contain the following data:uid = swift gid = swift log file = /var/log/rsyncd.log pid file = /var/run/rsyncd.pid address = MANAGEMENT_INTERFACE_IP_ADDRESS [account] max connections = 2 path = /srv/node/ read only = False lock file = /var/lock/account.lock [container] max connections = 2 path = /srv/node/ read only = False lock file = /var/lock/container.lock [object] max connections = 2 path = /srv/node/ read only = False lock file = /var/lock/object.lockReplace MANAGEMENT_INTERFACE_IP_ADDRESS with the IP address of the management network on the storage node.
Start the
rsyncdservice and configure it to start when the system boots:# systemctl enable rsyncd.service # systemctl start rsyncd.service
3.3.2. Configuring components
Configure the account, container, and object storage servers.
Procedure
Install the packages:
# yum install openstack-swift-account openstack-swift-container \ openstack-swift-object
Edit the
/etc/swift/account-server.conffile and complete the following actions:In the
[DEFAULT]section, configure the bind IP address, bind port, user, configuration directory, and mount point directory:[DEFAULT] ... bind_ip = MANAGEMENT_INTERFACE_IP_ADDRESS bind_port = 6202 user = swift swift_dir = /etc/swift devices = /srv/node mount_check = TrueReplace MANAGEMENT_INTERFACE_IP_ADDRESS with the IP address of the management network on the storage node.
In the
[pipeline:main]section, enable thehealthcheckandreconmodules:[pipeline:main] pipeline = healthcheck recon account-server
In the
[filter:recon]section, configure the recon cache directory:[filter:recon] use = egg:swift#recon ... recon_cache_path = /var/cache/swift
Open the default firewall port for the account service:
# firewall-cmd --permanent --add-port=6202/tcp
Edit the
/etc/swift/container-server.conffile and complete the following actions:In the
[DEFAULT]section, configure the bind IP address, bind port, user, configuration directory, and mount point directory:[DEFAULT] ... bind_ip = MANAGEMENT_INTERFACE_IP_ADDRESS bind_port = 6201 user = swift swift_dir = /etc/swift devices = /srv/node mount_check = TrueReplace MANAGEMENT_INTERFACE_IP_ADDRESS with the IP address of the management network on the storage node.
In the
[pipeline:main]section, enable thehealthcheckandreconmodules:[pipeline:main] pipeline = healthcheck recon container-server
In the
[filter:recon]section, configure the recon cache directory:[filter:recon] use = egg:swift#recon ... recon_cache_path = /var/cache/swift
Open the default firewall port for the container service:
# firewall-cmd --permanent --add-port=6201/tcp
Edit the
/etc/swift/object-server.conffile and complete the following actions:In the
[DEFAULT]section, configure the bind IP address, bind port, user, configuration directory, and mount point directory:[DEFAULT] ... bind_ip = MANAGEMENT_INTERFACE_IP_ADDRESS bind_port = 6200 user = swift swift_dir = /etc/swift devices = /srv/node mount_check = TrueReplace MANAGEMENT_INTERFACE_IP_ADDRESS with the IP address of the management network on the storage node.
In the
[pipeline:main]section, enable thehealthcheckandreconmodules:[pipeline:main] pipeline = healthcheck recon object-server
In the
[filter:recon]section, configure therecon_cache_pathand therecon_lock_pathdirectories:[filter:recon] use = egg:swift#recon ... recon_cache_path = /var/cache/swift recon_lock_path = /var/lock
Open the default firewall port for the object service:
# firewall-cmd --permanent --add-port=6200/tcp
Ensure that the ownership of the mount point directory structure is correct:
# chown -R swift:swift /srv/node
Create the
recondirectory and ensure proper ownership of it:# mkdir -p /var/cache/swift # chown -R root:swift /var/cache/swift # chmod -R 775 /var/cache/swift
3.4. Basic container management
To help with organization, pseudo-folders are logical devices that can contain objects (and can be nested). For example, you might create an Images folder in which to store pictures and a Media folder in which to store videos.
You can create one or more containers in each project, and one or more objects or pseudo-folders in each container.
3.4.1. Creating a container
- In the dashboard, select Project > Object Store > Containers.
- Click Create Container.
Specify the Container Name, and select one of the following in the Container Access field.
Type Description PrivateLimits access to a user in the current project.
PublicPermits API access to anyone with the public URL. However, in the dashboard, project users cannot see public containers and data from other projects.
- Click Create Container.
New containers use the default storage policy. If you have multiple storage policies defined (for example, a default and another that enables erasure coding), you can configure a container to use a non-default storage policy through the command line. To do so, run:
# swift post -H "X-Storage-Policy:POLICY" CONTAINERNAME
Where:
- POLICY is the name or alias of the policy you want the container to use.
- CONTAINERNAME is the name of the container.
3.4.2. Creating a pseudo folder for a container
- In the dashboard, select Project > Object Store > Containers.
- Click the name of the container to which you want to add the pseudo-folder.
- Click Create Pseudo-folder.
- Specify the name in the Pseudo-folder Name field, and click Create.
3.4.3. Deleting a container
- In the dashboard, select Project > Object Store > Containers.
- Browse for the container in the Containers section, and ensure all objects have been deleted (see Section 3.4.6, “Deleting an object”).
- Select Delete Container in the container’s arrow menu.
- Click Delete Container to confirm the container’s removal.
3.4.4. Uploading an object
If you do not upload an actual file, the object is still created (as placeholder) and can later be used to upload the file.
- In the dashboard, select Project > Object Store > Containers.
- Click the name of the container in which the uploaded object will be placed; if a pseudo-folder already exists in the container, you can click its name.
- Browse for your file, and click Upload Object.
Specify a name in the Object Name field:
- Pseudo-folders can be specified in the name using a / character (for example, Images/myImage.jpg). If the specified folder does not already exist, it is created when the object is uploaded.
- A name that is not unique to the location (that is, the object already exists) overwrites the object’s contents.
- Click Upload Object.
3.4.5. Copying an object
- In the dashboard, select Project > Object Store > Containers.
- Click the name of the object’s container or folder (to display the object).
- Click Upload Object.
- Browse for the file to be copied, and select Copy in its arrow menu.
Specify the following:
Field Description Destination container
Target container for the new object.
Path
Pseudo-folder in the destination container; if the folder does not already exist, it is created.
Destination object name
New object’s name. If you use a name that is not unique to the location (that is, the object already exists), it overwrites the object’s previous contents.
- Click Copy Object.
3.4.6. Deleting an object
- In the dashboard, select Project > Object Store > Containers.
- Browse for the object, and select Delete Object in its arrow menu.
- Click Delete Object to confirm the object’s removal.