
Chapter 7. Configuring Compute nodes for performance
You can configure the scheduling and placement of instances for optimal performance by creating customized flavors to target specialized workloads, including NFV and High Performance Computing (HPC).
Use the following features to tune your instances for optimal performance:
- CPU pinning: Pin virtual CPUs to physical CPUs.
- Emulator threads: Pin emulator threads associated with the instance to physical CPUs.
- Huge pages: Tune instance memory allocation policies both for normal memory (4k pages) and huge pages (2 MB or 1 GB pages).
Configuring any of these features creates an implicit NUMA topology on the instance if there is no NUMA topology already present.
7.1. Configuring CPU pinning with NUMA
This chapter describes how to use NUMA topology awareness to configure an OpenStack environment on systems with a NUMA architecture. The procedures detailed in this chapter show you how to pin virtual machines (VMs) to dedicated CPU cores, which improves scheduling and VM performance.
Background information about NUMA is available in the following article: What is NUMA and how does it work on Linux?
The following diagram provides an example of a two-node NUMA system and the way the CPU cores and memory pages are made available:
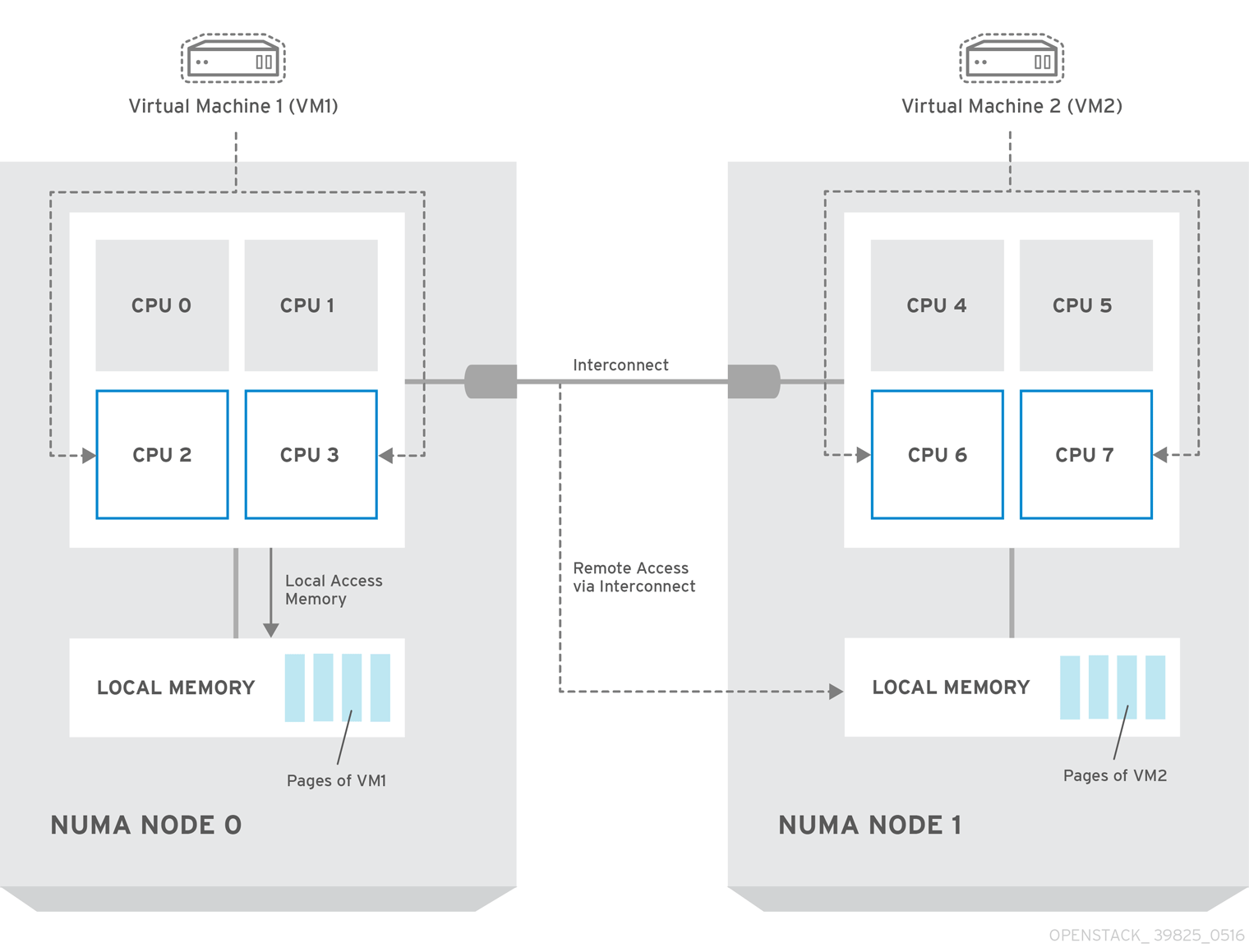
Remote memory available via Interconnect is accessed only if VM1 from NUMA node 0 has a CPU core in NUMA node 1. In this case, the memory of NUMA node 1 will act as local for the third CPU core of VM1 (for example, if VM1 is allocated with CPU 4 in the diagram above), but at the same time, it will act as remote memory for the other CPU cores of the same VM.
For more details on NUMA tuning with libvirt, see the Configuring and managing virtualization.
7.1.1. Compute node configuration
The exact configuration depends on the NUMA topology of your host system. However, you must reserve some CPU cores across all the NUMA nodes for host processes and let the rest of the CPU cores handle your virtual machines (VMs). The following example illustrates the layout of eight CPU cores evenly spread across two NUMA nodes.
Table 7.1. Example of NUMA Topology
| Node 0 | Node 1 | |||
| Host processes | Core 0 | Core 1 | Core 4 | Core 5 |
| VMs | Core 2 | Core 3 | Core 6 | Core 7 |
Determine the number of cores to reserve for host processes by observing the performance of the host under typical workloads.
Procedure
Reserve CPU cores for the VMs by setting the
NovaVcpuPinSetconfiguration in the Compute environment file:NovaVcpuPinSet: 2,3,6,7
Set the
NovaReservedHostMemoryoption in the same file to the amount of RAM to reserve for host processes. For example, if you want to reserve 512 MB, use:NovaReservedHostMemory: 512
To ensure that host processes do not run on the CPU cores reserved for VMs, set the parameter
IsolCpusListin the Compute environment file to the CPU cores you have reserved for VMs. Specify the value of theIsolCpusListparameter using a list of CPU indices, or ranges separated by a whitespace. For example:IsolCpusList: 2 3 6 7
NoteThe
IsolCpusListparameter ensures that the underlying compute node is not able to use the corresponding pCPUs for itself. The pCPUs are dedicated to the VMs.To apply this configuration, deploy the overcloud:
(undercloud) $ openstack overcloud deploy --templates \ -e /home/stack/templates/<compute_environment_file>.yaml
7.1.2. Scheduler configuration
Procedure
- Open your Compute environment file.
Add the following values to the
NovaSchedulerDefaultFiltersparameter, if they are not already present:-
NUMATopologyFilter -
AggregateInstanceExtraSpecsFilter
-
- Save the configuration file.
- Deploy the overcloud.
7.1.3. Aggregate and flavor configuration
Configure host aggregates to deploy instances that use CPU pinning on different hosts from instances that do not, to avoid unpinned instances using the resourcing requirements of pinned instances.
Do not deploy instances with NUMA topology on the same hosts as instances that do not have NUMA topology.
Prepare your OpenStack environment for running virtual machine instances pinned to specific resources by completing the following steps on a system with the Compute CLI.
Procedure
Load the
admincredentials:source ~/keystonerc_admin
Create an aggregate for the hosts that will receive pinning requests:
nova aggregate-create <aggregate-name-pinned>
Enable the pinning by editing the metadata for the aggregate:
nova aggregate-set-metadata <aggregate-pinned-UUID> pinned=true
Create an aggregate for other hosts:
nova aggregate-create <aggregate-name-unpinned>
Edit the metadata for this aggregate accordingly:
nova aggregate-set-metadata <aggregate-unpinned-UUID> pinned=false
Change your existing flavors' specifications to this one:
for i in $(nova flavor-list | cut -f 2 -d ' ' | grep -o '[0-9]*'); do nova flavor-key $i set "aggregate_instance_extra_specs:pinned"="false"; done
Create a flavor for the hosts that will receive pinning requests:
nova flavor-create <flavor-name-pinned> <flavor-ID> <RAM> <disk-size> <vCPUs>
Where:
-
<flavor-ID>- Set toautoif you wantnovato generate a UUID. -
<RAM>- Specify the required RAM in MB. -
<disk-size>- Specify the required disk size in GB. -
<vCPUs>- The number of virtual CPUs that you want to reserve.
-
Set the
hw:cpu_policyspecification of this flavor todedicatedso as to require dedicated resources, which enables CPU pinning, and also thehw:cpu_thread_policyspecification torequire, which places each vCPU on thread siblings:nova flavor-key <flavor-name-pinned> set hw:cpu_policy=dedicated nova flavor-key <flavor-name-pinned> set hw:cpu_thread_policy=require
NoteIf the host does not have an SMT architecture or enough CPU cores with free thread siblings, scheduling will fail. If such behavior is undesired, or if your hosts simply do not have an SMT architecture, do not use the
hw:cpu_thread_policyspecification, or set it topreferinstead ofrequire. The (default)preferpolicy ensures that thread siblings are used when available.Set the
aggregate_instance_extra_specs:pinnedspecification to "true" to ensure that instances based on this flavor have this specification in their aggregate metadata:nova flavor-key <flavor-name-pinned> set aggregate_instance_extra_specs:pinned=true
Add some hosts to the new aggregates:
nova aggregate-add-host <aggregate-pinned-UUID> <host_name> nova aggregate-add-host <aggregate-unpinned-UUID> <host_name>
Boot an instance using the new flavor:
nova boot --image <image-name> --flavor <flavor-name-pinned> <server-name>
To verify that the new server has been placed correctly, run the following command and check for
OS-EXT-SRV-ATTR:hypervisor_hostnamein the output:nova show <server-name>
7.2. Configuring huge pages on the Compute node
Configure the Compute node to enable instances to request huge pages.
Procedure
Configure the amount of huge page memory to reserve on each NUMA node for processes that are not instances:
parameter_defaults: NovaReservedHugePages: ["node:0,size:2048,count:64","node:1,size:1GB,count:1"]
Where:
Attribute
Description
size
The size of the allocated huge page. Valid values: * 2048 (for 2MB) * 1GB
count
The number of huge pages used by OVS per NUMA node. For example, for 4096 of socket memory used by Open vSwitch, set this to 2.
(Optional) To allow instances to allocate 1GB huge pages, configure the CPU feature flags,
cpu_model_extra_flags, to include "pdpe1gb":parameter_defaults: ComputeExtraConfig: nova::compute::libvirt::libvirt_cpu_mode: 'custom' nova::compute::libvirt::libvirt_cpu_model: 'Haswell-noTSX' nova::compute::libvirt::libvirt_cpu_model_extra_flags: 'vmx, pdpe1gb'Note- CPU feature flags do not need to be configured to allow instances to only request 2 MB huge pages.
- You can only allocate 1G huge pages to an instance if the host supports 1G huge page allocation.
-
You only need to set
cpu_model_extra_flagstopdpe1gbwhencpu_modeis set tohost-modelorcustom. -
If the host supports
pdpe1gb, andhost-passthroughis used as thecpu_mode, then you do not need to setpdpe1gbas acpu_model_extra_flags. Thepdpe1gbflag is only included in Opteron_G4 and Opteron_G5 CPU models, it is not included in any of the Intel CPU models supported by QEMU. - To mitigate for CPU hardware issues, such as Microarchitectural Data Sampling (MDS), you might need to configure other CPU flags. For more information, see RHOS Mitigation for MDS ("Microarchitectural Data Sampling") Security Flaws.
To avoid loss of performance after applying Meltdown protection, configure the CPU feature flags,
cpu_model_extra_flags, to include "+pcid":parameter_defaults: ComputeExtraConfig: nova::compute::libvirt::libvirt_cpu_mode: 'custom' nova::compute::libvirt::libvirt_cpu_model: 'Haswell-noTSX' nova::compute::libvirt::libvirt_cpu_model_extra_flags: 'vmx, pdpe1gb, +pcid'TipFor more information, see Reducing the performance impact of Meltdown CVE fixes for OpenStack guests with "PCID" CPU feature flag.
-
Add
NUMATopologyFilterto theNovaSchedulerDefaultFiltersparameter in each Compute environment file, if not already present. Apply this huge page configuration by adding the environment file(s) to your deployment command and deploying the overcloud:
(undercloud) $ openstack overcloud deploy --templates \ -e [your environment files] -e /home/stack/templates/<compute_environment_file>.yaml
7.2.1. Allocating huge pages to instances
Create a flavor with the hw:mem_page_size extra specification key to specify that the instance should use huge pages.
Prerequisites
- The Compute node is configured for huge pages. For more information, see Configuring huge pages on the Compute node.
Procedure
Create a flavor for instances that require huge pages:
$ openstack flavor create --ram <size-mb> --disk <size-gb> --vcpus <no_reserved_vcpus> huge_pages
Set the flavor for huge pages:
$ openstack flavor set huge_pages --property hw:mem_page_size=1GB
Valid values for
hw:mem_page_size:-
large- Selects the largest page size supported on the host, which may be 2 MB or 1 GB on x86_64 systems. -
small- (Default) Selects the smallest page size supported on the host. On x86_64 systems this is 4 kB (normal pages). -
any- Selects the largest available huge page size, as determined by the libvirt driver. - <pagesize>: (string) Set an explicit page size if the workload has specific requirements. Use an integer value for the page size in KB, or any standard suffix. For example: 4KB, 2MB, 2048, 1GB.
-
Create an instance using the new flavor:
$ openstack server create --flavor huge_pages --image <image> huge_pages_instance
Validation
The scheduler identifies a host with enough free huge pages of the required size to back the memory of the instance. If the scheduler is unable to find a host and NUMA node with enough pages, then the request will fail with a NoValidHost error.