
Chapter 1. OpenStack Shared File System service with CephFS via NFS
The OpenStack Shared File System service (manila) with Ceph File System (CephFS) via NFS provides a fault-tolerant NFS share service for the Red Hat OpenStack Platform. See the Shared File System service chapter in the Storage Guide for additional information.
1.1. Introduction to CephFS via NFS
CephFS is the highly scalable, open-source distributed file system component of Ceph, a unified distributed storage platform. Ceph implements object, block, and file storage using Reliable Autonomic Distributed Object Store (RADOS). CephFS, which is POSIX compatible, provides file access to a Ceph storage cluster.
The Shared File System service enables users to create shares in CephFS and access them using NFS 4.1 via NFS-Ganesha. NFS-Ganesha controls access to the shares and exports them to clients via the NFS 4.1 protocol. The Shared File System service manages the life cycle of these shares from within OpenStack. When cloud administrators set up the service to use CephFS via NFS, these file shares come from the CephFS cluster, but are created and accessed as familiar NFS shares.
1.2. Benefits of using Shared File System service with CephFS via NFS
The Shared File System service (manila) with CephFS via NFS enables cloud administrators to use the same Ceph cluster they use for block and object storage to provide file shares through the familiar NFS protocol, which is available by default on most operating systems. CephFS maximizes Ceph clusters that are already used as storage back ends for other services in the OpenStack cloud, such as Block Storage (cinder), object storage, and so forth.
Adding CephFS to an externally deployed Ceph cluster that was not configured by Red Hat OpenStack director is not supported at this time. Currently, only one CephFS back end can be defined in director.
This version of Red Hat OpenStack Platform fully supports the CephFS NFS driver (NFS-Ganesha), unlike the CephFS native driver, which is a Technology Preview feature.
Red Hat CephFS native driver is available only as a Technology Preview, and therefore is not fully supported by Red Hat.
For more information about Technology Preview features, see Scope of Coverage Details.
In CephFS via NFS deployments, the Ceph storage back end is separated from the user’s network, which makes the underlying Ceph storage less vulnerable to malicious attacks and inadvertent mistakes.
Separate networks used for data-plane traffic and the API networks used to communicate with control plane services, such as Shared File System services, make file storage more secure.
The Ceph client is under administrative control. The end user controls an NFS client (an isolated user VM, for example) that has no direct access to the Ceph cluster storage back end.
1.3. Ceph File System architecture
Ceph File System (CephFS) is a distributed file system that can be used with either NFS-Ganesha using the NFS v4 protocol (supported) or CephFS native driver (technology preview).
1.3.1. CephFS with native driver
The CephFS native driver combines the OpenStack Shared File System service (manila) and Red Hat Ceph Storage. When deployed via director, the controller nodes host the Ceph daemons, such as the manager, metadata servers (MDS), and monitors (MON) as well as the Shared File System services.
Compute nodes may host one or more tenants. Tenants, represented by the white boxes, which contain user-managed VMs (gray boxes with two NICs), access the ceph and manila daemons by connecting to them over the public Ceph storage network. This network also allows access to the data on the storage nodes provided by the Ceph Object Storage Daemons (OSDs). Instances (VMs) hosted on the tenant boot with two NICs: one dedicated to the storage provider network and the second to tenant-owned routers to the external provider network.
The storage provider network connects the VMs running on the tenants to the public Ceph storage network. The Ceph public network provides back end access to the Ceph object storage nodes, metadata servers (MDS), and controller nodes. Using the native driver, CephFS relies on cooperation with the clients and servers to enforce quotas, guarantee tenant isolation, and for security. CephFS with the native driver works well in an environment with trusted end users on a private cloud. This configuration requires software that is running under user control to cooperate and work properly.
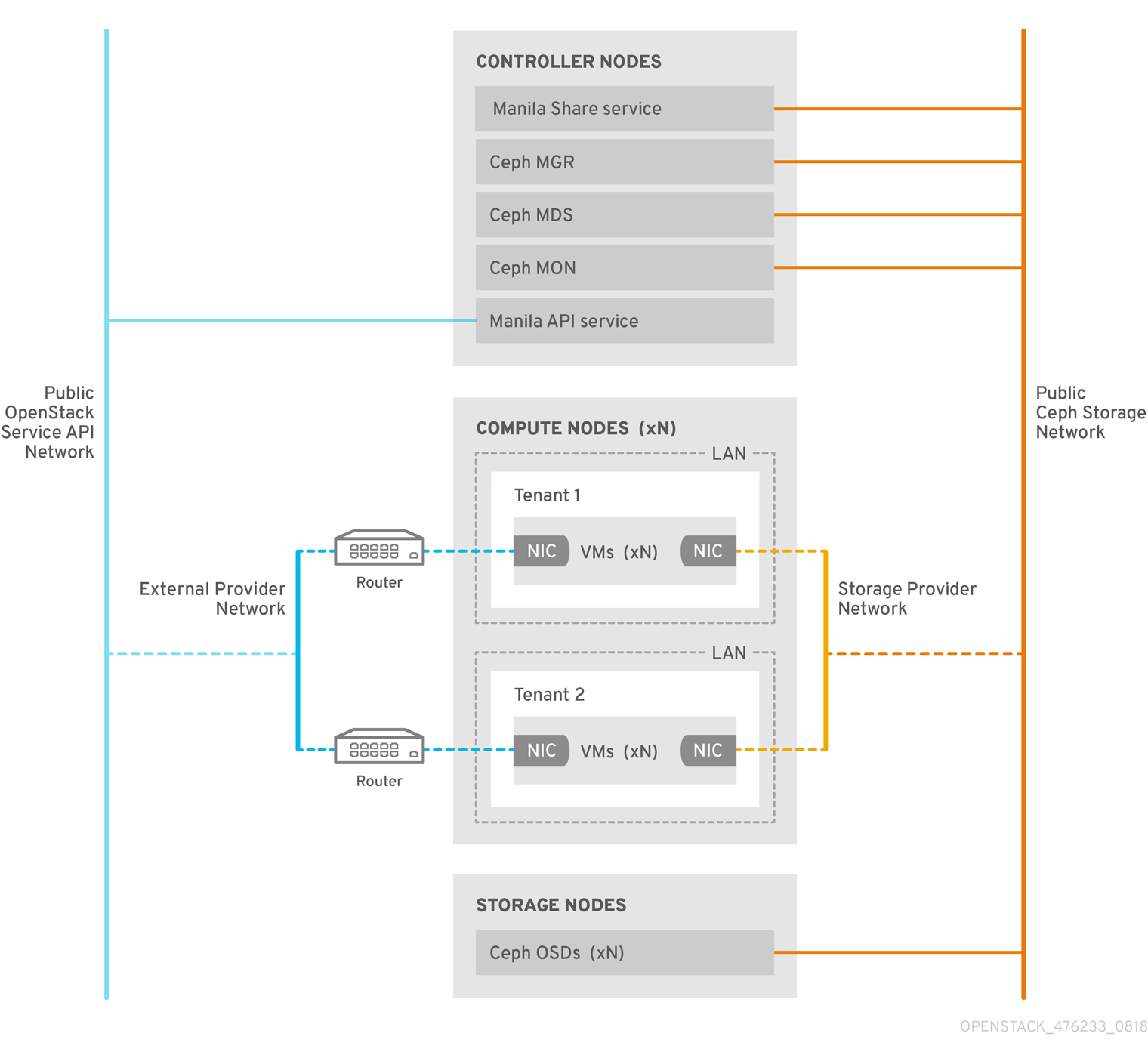
1.3.2. CephFS via NFS
The CephFS via NFS back end in the OpenStack Shared File Systems service (manila) is composed of Ceph metadata servers (MDS), the CephFS via NFS gateway (NFS-Ganesha), and the Ceph cluster service components. The Shared File System service’s CephFS NFS driver uses NFS-Ganesha gateway to provide NFSv4 protocol access to CephFS shares. The Ceph MDS service maps the directories and file names of the file system to objects stored in RADOS clusters. NFS gateways can serve NFS file shares with different storage back ends, such as Ceph. The NFS-Ganesha service runs on the controller nodes along with the Ceph services.
Instances are booted with at least two NICs: one connects to the tenant router, and the second NIC connects to the StorageNFS network, which connects directly to the NFS-Ganesha gateway. The instance mounts shares using the NFS protocol. CephFS shares hosted on Ceph OSD nodes are provided through the NFS gateway.
NFS-Ganesha improves security by preventing user instances from directly accessing the MDS and other Ceph services. Instances do not have direct access to the Ceph daemons.

1.3.2.1. Ceph services and client access
In addition to the monitor, OSD, Rados Gateway (RGW), and manager services deployed when Ceph provides object and/or block storage, a Ceph metadata service (MDS) is required for CephFS and an NFS-Ganesha service is required as a gateway to native CephFS using the NFS protocol. (For user-facing object storage, an RGW service is also deployed). The gateway runs the CephFS client to access the Ceph public network and is under administrative rather than end-user control.
NFS-Ganesha runs in its own container that interfaces both to the Ceph public network and to a new isolated network, StorageNFS. OpenStack director’s composable network feature is used to deploy this network and connect it to the controller nodes. The cloud administrator then configures the network as a neutron provider network.
NFS-Ganesha accesses CephFS over the Ceph public network and binds its NFS service using an address on the StorageNFS network.
To access NFS shares, user VMs (nova instances) are provisioned with an additional NIC that connects to the Storage NFS network. Export locations for CephFS shares appear as standard NFS IP:<path> tuples using the NFS-Ganesha server’s VIP on the StorageNFS network. Access control for user VMs is done using the user VM’s IP on that network.
Neutron security groups prevent the user VM belonging to tenant 1 from accessing a user VM belonging to tenant 2 over the StorageNFS network. Tenants share the same CephFS filesystem but tenant data path separation is enforced because user VMs can only access files under export trees: /path/to/share1/…., /path/to/share2/….
1.3.2.2. Shared File System service with CephFS via NFS fault tolerance
When OpenStack director starts the Ceph service daemons, they manage their own high availability (HA) state and, in general, there are multiple instances of these daemons running. By contrast, in this release, only one instance of NFS-Ganesha can serve file shares at a time.
To avoid a single point of failure in the data path for CephFS via NFS shares, NFS-Ganesha runs on an OpenStack controller node in an active-passive configuration managed by a Pacemaker-Corosync cluster. NFS-Ganesha acts across the controller nodes as a virtual service with a virtual service IP address.
If a controller fails (or the service on a particular controller node fails and cannot be recovered on that node) Pacemaker-Corosync starts a new NFS-Ganesha instance on a different controller using the same virtual IP. Existing client mounts are preserved because they use the virtual IP for the export location of shares.
Using default NFS mount-option settings and NFS 4.1 or greater, after a failure, TCP connections are reset and clients reconnect. I/O operations temporarily stop responding during failover, but they will not fail. Application I/O also stops responding, but resumes after failover completes.
New connections, new lock-state, and so forth are refused until after a grace period of up to 90 seconds during which the server waits for clients to reclaim their locks. NFS-Ganesha keeps a list of the clients and will exit the grace period earlier, if it sees that all clients reclaimed their locks.
The default value of the grace period is 90 seconds. This value is tunable through the NFSv4 Grace_Period configuration option.