
Chapter 1. Overview of the Block Storage backup service
The Block Storage service (cinder) includes a horizontally scalable backup service that you can use to back up cinder volumes to diverse storage back ends. You can use the Block Storage backup service to create and restore full or incremental backups. The service is volume-array independent.
The Red Hat OpenStack Platform (RHOSP) director is a toolset to install and manage a complete RHOSP environment called the overcloud. For more information about the director, see the Director Installation and Usage guide. The overcloud contains the components that provide services to end users, including Block Storage. The Block Storage backup service is an optional service that you deploy on Controller nodes.
1.1. Backups and snapshots
A volume backup is a persistent copy of the contents of a volume. Volume backups are typically created as object stores, and are managed through the OpenStack Object Storage service (swift) by default. You can use Red Hat Ceph and NFS as alternative back ends for backups.
When you create a volume backup, all of the backup metadata is stored in the Block Storage service database. The cinder-backup service uses this metadata when it restores a volume from the backup. This means that when you perform a recovery from a catastrophic database loss, you must restore the Block Storage service database first before you restore any volumes from backups, provided that the original volume backup metadata of the Block Storage service database is intact. If you want to configure only a subset of volume backups to survive a catastrophic database loss, you can also export the backup metadata. You can then re-import the metadata to the Block Storage database by using the REST API or the cinder client, and restore the volume backup as normal.
Volume backups are different from snapshots. Backups preserve the data contained in the volume, and snapshots preserve the state of a volume at a specific point in time. You cannot delete a volume if it has existing snapshots. Volume backups prevent data loss, whereas snapshots facilitate cloning. For this reason, snapshot back ends are typically colocated with volume back ends in order to minimize latency during cloning. By contrast, the backup repository is typically located separately from the back ends, either on a different node or different physical storage. This protects the backup repository from any damage that might occur to the volume back end.
For more information about volume snapshots, see "Create, Use, or Delete Volume Snapshots" in the Storage Guide.
1.2. How backups and restores work
The following subsections, 1.2.1 and 1.2.2, illustrate the workflows for backups and restores.
1.2.1. Volume backup workflow
When the Block Storage backup service performs a back up, it receives a request from the cinder API to back up a targeted volume. The backup service completes the request and stores the content on the back end.
The following diagram illustrates how the request interacts with the Block Storage (cinder) services to perform the backup.
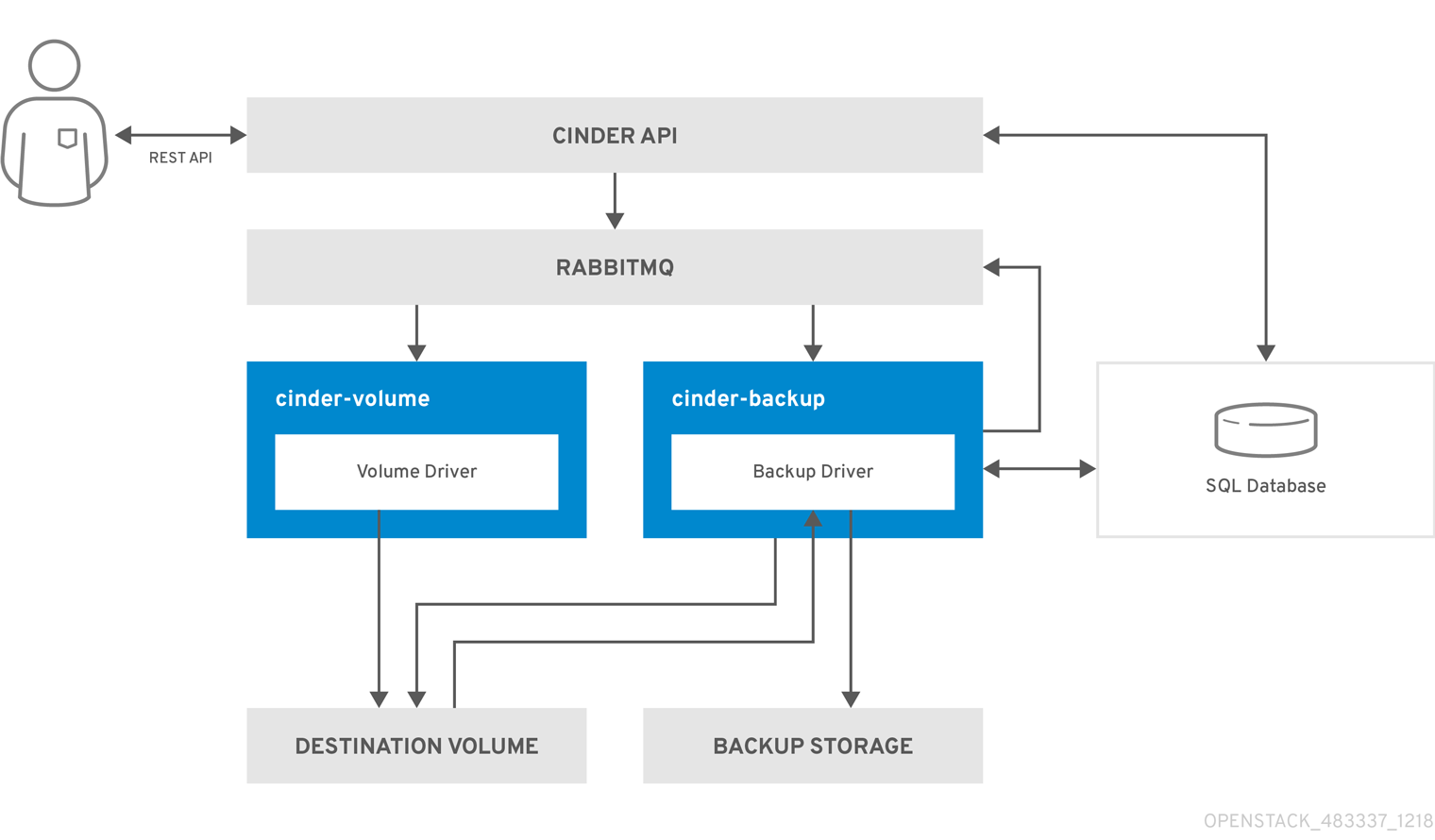
- The client issues a request to back up a Block Storage volume by invoking the cinder API.
- The cinder API service receives the request from HAProxy and validates the request, the user credentials, and other information.
- Creates the backup record in the SQL database.
- Makes an asynchronous RPC call to the cinder-backup service via AMQP to back up the volume.
- Returns current backup record, with an ID, to the API caller.
- An RPC create message arrives on one of the backup services.
-
The
cinder-backupservice performs a synchronous RPC call toget_backup_device. -
The
cinder-volumeservice ensures that the correct device is returned to the caller. Normally, it is the same volume, but if the volume is in use, the service returns a temporary cloned volume or a temporary snapshot, depending on the configuration. -
The
cinder-backupservice issues another synchronous RPC call tocinder-volumeto expose the source device. -
The
cinder-volumeservice exports and maps the source device, either a volume or snapshot, and returns the appropriate connection information. -
The
cinder-backupservice attaches source volume by using connection information. -
The
cinder-backupservice calls the backup driver, with the device already attached, which begins the data transfer to the backup destination. - The volume is detached from the backup host.
-
The
cinder-backupservice issues a synchronous RPC call tocinder-volumeto disconnect the source device. -
The
cinder-volumeservice unmaps and removes the export for the device. -
If a temporary volume or temporary snapshot was created,
cinder-backupcallscinder-volumeto remove it. -
The
cinder-volumeservice removes the temporary volume. - When the backup is completed, the backup record is updated in the database.
1.2.2. Volume restore workflow
The following diagram illustrates the steps that occur when a user requests to restore a Block Storage service (cinder) backup.
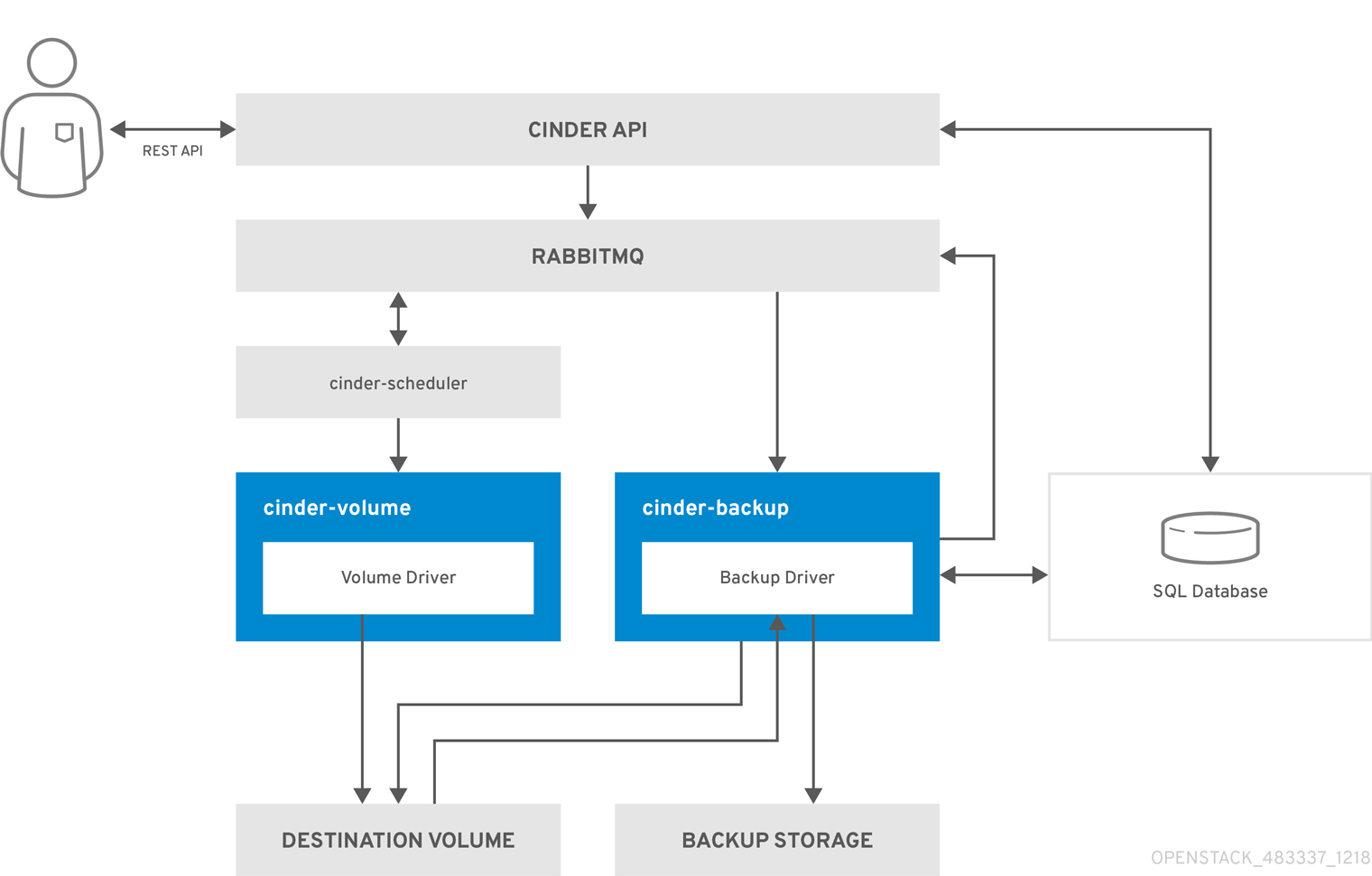
- The client issues a request to restore a Block Storage backup by invoking the CinderREST API.
- The cinder API receives the request from HAProxy and validates the request, the user credentials, and other information.
- If the request does not contain an existing volume as the destination, the API makes an asynchronous RPC call to create a new volume and polls the status of the volume until it becomes available.
-
The
cinder-schedulerselects a volume service and makes the RPC call to create the volume. -
Selected
cinder-volumeservice creates the volume. -
When
cinder-apidetects that the volume is available, the backup record is created in the database. - Makes an asynchronous RPC call to the backup service via AMQP to restore the backup.
- Returns the current volume ID, backup ID, and volume name to the API caller.
- An RPC create message arrives on one of the backup services.
-
The
cinder-backupservice performs a synchronous RPC call tocinder-volumeto expose the destination volume. -
The
cinder-volumeservice exports and maps the destination volume and returns the appropriate connection information. -
The
cinder-backupservice attaches source volume by using connection information. -
The
cinder-backupservice calls the driver, with the device already attached, which begins the data restoration to the volume destination. - The volume is detached from the backup host.
-
The
cinder-backupservice issues a synchronous RPC call tocinder-volumeto disconnect the source device. -
The
cinder-volumeservice unmaps and removes the export for the device. - When the backup is completed, the backup record is updated in the database.
1.3. Cloud storage versus local storage
The Google Cloud Storage driver is the only cloud driver that is supported by the Block Storage backup service. By default, the Google Cloud Storage driver uses the least expensive storage solution, Nearline, for this type of backup.
Configure the backup service to optimize performance. For example, if you create backups from Europe, change the backup region to Europe. If you do not change the backup region from the default, US, the performance might be slower due to the geographical distance between the two regions.
Google Cloud Storage requires special configuration. For more information, see Appendix A, Google Cloud Storage configuration.
The following table lists the benefits and limitations of cloud storage and local storage based on the situation.
| Situation | Cloud storage | Local storage |
|---|---|---|
| Offsite backup | Cloud storage is in the data center of another company and is therefore automatically offsite. You can access data from many locations. Remote copy is available for disaster recovery. | Requires additional planning and expense. |
| Hardware control | Relies on the availability and expertise of another service. | You have complete control over storage hardware. Requires management and expertise. |
| Cost considerations | Different pricing policies or tiers depending on the services you use from the vendor. | Adding additional hardware as needed is a known cost. |
| Network speed and data access | Overall data access is slower and requires internet access. Speed and latency depend on multiple factors. | Access to data is fast and immediate. No internet access is required. |