
Chapter 1. Introduction to metro disaster recovery using stretch cluster
Red Hat OpenShift Container Storage deployment can be stretched between two different geographical locations to provide the storage infrastructure with disaster recovery capabilities. When faced with a disaster such as one of the two locations is partially or totally not available, OpenShift Container Storage deployed on the OpenShift Container Platform deployment must be able to survive. This solution is available only for metropolitan spanned data centers with specific latency requirements between the servers of the infrastructure.
Currently, the Metro-DR solution using stretch cluster can be deployed where latencies do not exceed 4 milliseconds round-trip time (RTT) between OpenShift Container Platform nodes in different locations. Contact Red Hat Customer Support if you are planning to deploy with higher latencies.
The following diagram shows the simplest deployment for a Metro-DR stretched cluster.
OpenShift nodes and OpenShift Container Storage daemons
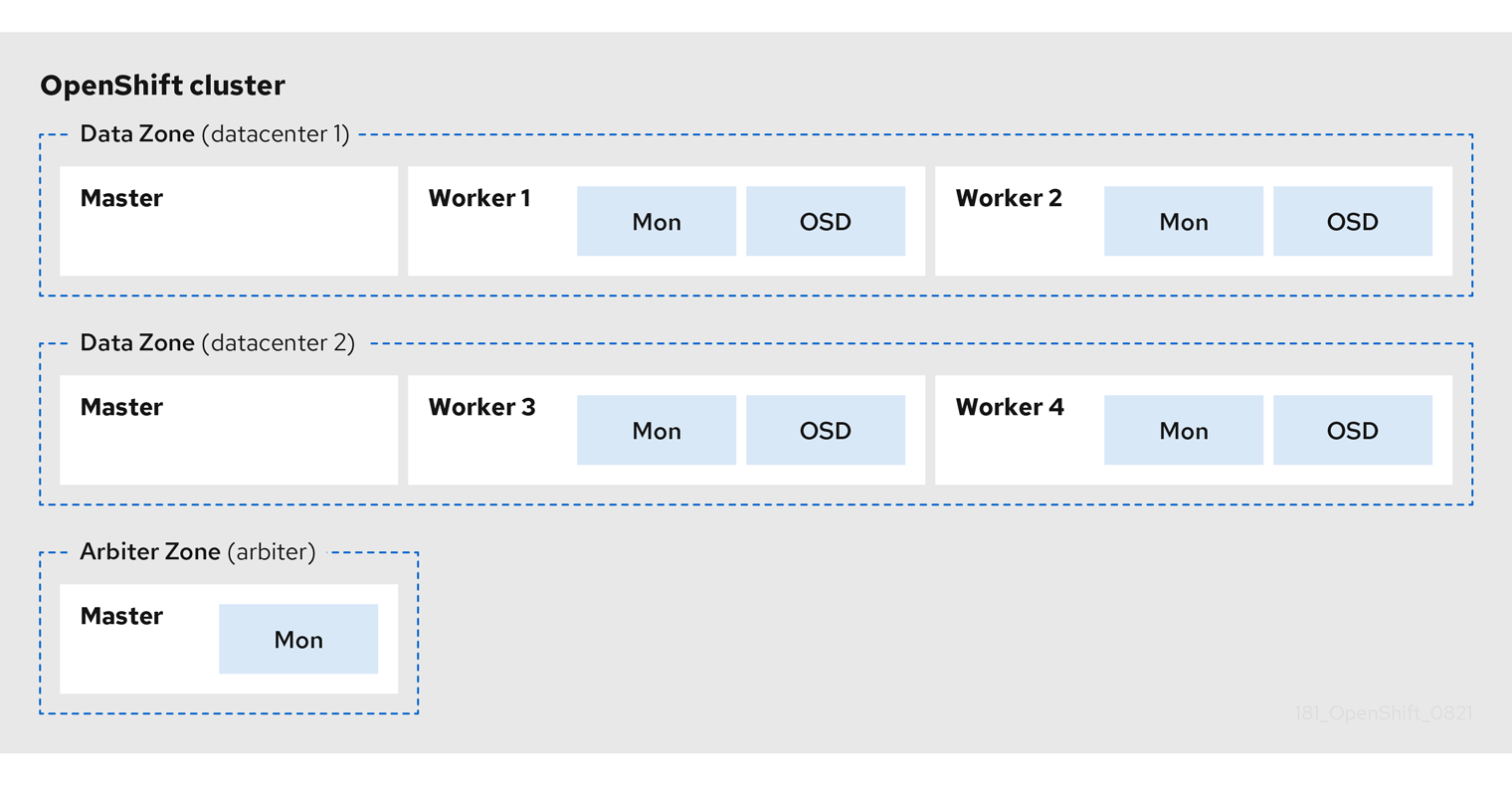
In the diagram the OpenShift Container Storage monitor pod deployed in the Arbiter zone has a built-in tolerance for master nodes. The master nodes are required for a highly available OpenShift Container Platform control plane. Also, it is critical that the OpenShift Container Platform nodes in one zone have network connectivity with the OpenShift Container Platform nodes in the other two zones.