
Chapter 1. Planning your deployment
1.1. Introduction to Red Hat OpenShift Container Storage
Red Hat OpenShift Container Storage is a highly integrated collection of cloud storage and data services for Red Hat OpenShift Container Platform. It is available as part of the Red Hat OpenShift Container Platform Service Catalog, packaged as an operator to facilitate simple deployment and management.
Red Hat OpenShift Container Storage services are primarily made available to applications by way of storage classes that represent the following components:
- Block storage devices, catering primarily to database workloads. Prime examples include Red Hat OpenShift Container Platform logging and monitoring, and PostgreSQL.
- Shared and distributed file system, catering primarily to software development, messaging, and data aggregation workloads. Examples include Jenkins build sources and artifacts, Wordpress uploaded content, Red Hat OpenShift Container Platform registry, and messaging using JBoss AMQ.
- Multicloud object storage, featuring a lightweight S3 API endpoint that can abstract the storage and retrieval of data from multiple cloud object stores.
- On premises object storage, featuring a robust S3 API endpoint that scales to tens of petabytes and billions of objects, primarily targeting data intensive applications. Examples include the storage and access of row, columnar, and semi-structured data with applications like Spark, Presto, Red Hat AMQ Streams (Kafka), and even machine learning frameworks like TensorFlow and Pytorch.
OpenShift Container Storage 4.6 on IBM Power Systems supports only block and file storage and not the object storage.
Red Hat OpenShift Container Storage version 4.x integrates a collection of software projects, including:
- Ceph, providing block storage, a shared and distributed file system, and on-premises object storage
- Ceph CSI, to manage provisioning and lifecycle of persistent volumes and claims
- NooBaa, providing a Multicloud Object Gateway
- OpenShift Container Storage, Rook-Ceph, and NooBaa operators to initialize and manage OpenShift Container Storage services.
1.2. Architecture of OpenShift Container Storage
Red Hat OpenShift Container Storage provides services for, and can run internally from Red Hat OpenShift Container Platform.
Red Hat OpenShift Container Storage architecture
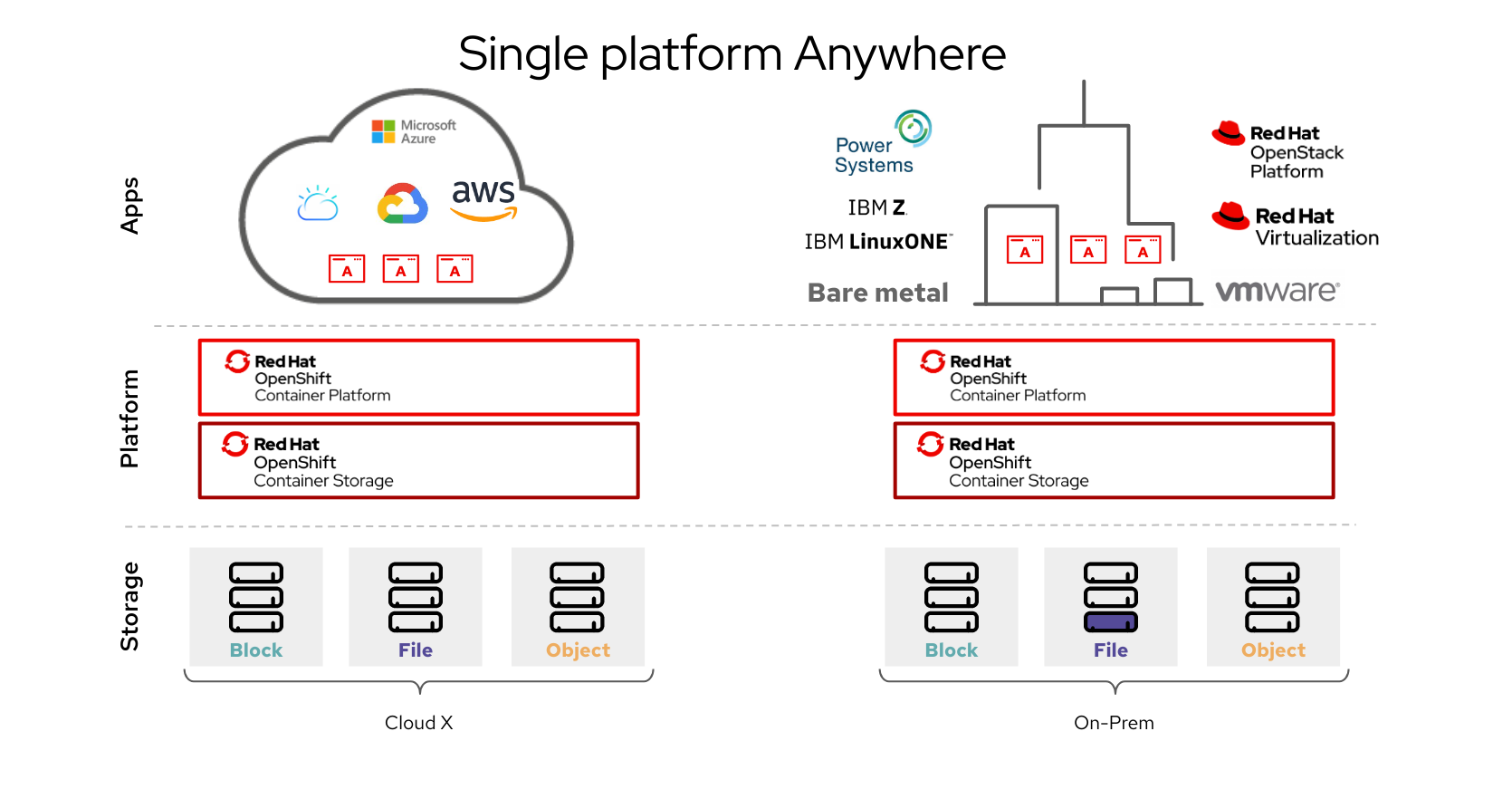
Red Hat OpenShift Container Storage supports deployment into Red Hat OpenShift Container Platform clusters deployed on Installer Provisioned Infrastructure or User Provisioned Infrastructure. For details about these two approaches, see OpenShift Container Platform - Installation process.
For information about the architecture and lifecycle of OpenShift Container Platform, see OpenShift Container Platform architecture.
1.2.1. About operators
Red Hat OpenShift Container Storage comprises three main operators, which codify administrative tasks and custom resources so that task and resource characteristics can be easily automated. Administrators define the desired end state of the cluster, and the OpenShift Container Storage operators ensure the cluster is either in that state, or approaching that state, with minimal administrator intervention.
OpenShift Container Storage operator
A meta-operator that codifies and enforces the recommendations and requirements of a supported Red Hat OpenShift Container Storage deployment by drawing on other operators in specific, tested ways. This operator provides the storage cluster resource that wraps resources provided by the Rook-Ceph and NooBaa operators.
Rook-Ceph operator
This operator automates the packaging, deployment, management, upgrading, and scaling of persistent storage and file, block, and object services. It creates block and file storage classes for all environments, and creates an object storage class and services object bucket claims made against it in on-premises environments.
Additionally, for internal mode clusters, it provides the Ceph cluster resource, which manages the deployments and services representing the following:
- Object storage daemons (OSDs)
- Monitors (MONs)
- Manager (MGR)
- Metadata servers (MDS)
- Object gateways (RGW) on-premises only
NooBaa operator
This operator automates the packaging, deployment, management, upgrading, and scaling of the Multicloud Object Gateway object service. It creates an object storage class and services object bucket claims made against it.
Additionally, it provides the NooBaa cluster resource, which manages the deployments and services for NooBaa core, database, and endpoint.
1.2.2. Storage cluster deployment approach
Flexibility is a core tenet of Red Hat OpenShift Container Storage, as evidenced by its growing list of operating modalities. This section provides you with information that will help you understand deployment of OpenShift Container Storage within OpenShift Container Platform.
Deployment of Red Hat OpenShift Container Storage entirely within Red Hat OpenShift Container Platform has all the benefits of operator based deployment and management. There are two different deployment modalities available when Red Hat OpenShift Container Storage is running entirely within Red Hat OpenShift Container Platform:
- Simple
- Optimized
Simple deployment
Red Hat OpenShift Container Storage services run co-resident with applications, managed by operators in Red Hat OpenShift Container Platform.
A simple deployment is best for situations where
- Storage requirements are not clear
- OpenShift Container Storage services will run co-resident with applications
- Creating a node instance of a specific size is difficult (bare metal)
In order for Red Hat OpenShift Container Storage to run co-resident with applications, they must have local storage devices, or portable storage devices attached to them dynamically. For example, SAN volumes dynamically provisioned by PowerVC.
Optimized deployment
OpenShift Container Storage services run on dedicated infrastructure nodes managed by Red Hat OpenShift Container Platform.
An optimized approach is best for situations when:
- Storage requirements are clear
- OpenShift Container Storage services run on dedicated infrastructure nodes
- Creating a node instance of a specific size is easy (Cloud, Virtualized environment, etc.)
1.2.3. Node types
Nodes run the container runtime, as well as services, to ensure that containers are running, and maintain network communication and separation between pods. In OpenShift Container Storage, there are three types of nodes.
Table 1.1. Types of nodes
| Node Type | Description |
|---|---|
| Master | These nodes run processes that expose the Kubernetes API, watch and schedule newly created pods, maintain node health and quantity, and control interaction with underlying cloud providers. |
| Infrastructure (Infra) | Infra nodes run cluster level infrastructure services such as logging, metrics, registry, and routing. These are optional in OpenShift Container Platform clusters. It is recommended to use infra nodes for OpenShift Container Storage in virtualized and cloud environments.
To create Infra nodes, you can provision new nodes labeled as |
| Worker | Worker nodes are also known as application nodes since they run applications. When OpenShift Container Storage is deployed in internal mode, a minimal cluster of 3 worker nodes is required, where the nodes are recommended to be spread across three different racks, or availability zones, to ensure availability. In order for OpenShift Container Storage to run on worker nodes, they must either have local storage devices, or portable storage devices attached to them dynamically. When it is deployed in external mode, it runs on multiple nodes to allow rescheduling by K8S on available nodes in case of a failure. Examples of portable storage devices are EBS volumes on EC2, or vSphere Virtual Volumes on VMware. |
Nodes that run only storage workloads require a subscription for Red Hat OpenShift Container Storage. Nodes that run other workloads in addition to storage workloads require both Red Hat OpenShift Container Storage and Red Hat OpenShift Container Platform subscriptions. See Section 1.4, “Subscriptions” for more information.
1.3. Security considerations
1.3.1. Data encryption options
Encryption lets you encode and obscure your data to make it impossible to understand if it is stolen. Red Hat OpenShift Container Storage 4.6 provides support for at-rest encryption of all disks in the storage cluster, meaning that your data is encrypted when it is written to disk, and decrypted when it is read from the disk.
OpenShift Container Storage 4.6 uses Linux Unified Key System (LUKS) version 2 based encryption with a key size of 512 bits and the aes-xts-plain64 cipher. Each device has a different encryption key, which is stored as a Kubernetes secret.
You can enable or disable encryption for your whole cluster during cluster deployment. It is disabled by default. Working with encrypted data incurs only a very small penalty to performance.
Data encryption is only supported for new clusters deployed using OpenShift Container Storage 4.6. It is not supported on existing clusters that are upgraded to version 4.6.
1.4. Subscriptions
1.4.1. Subscription offerings
Red Hat OpenShift Container Storage subscription is based on “core-pairs,” similar to Red Hat OpenShift Container Platform. The Red Hat OpenShift Container Storage 2-core subscription is based on the number of logical cores on the CPUs in the system where OpenShift Container Platform runs.
As with OpenShift Container Platform:
- OpenShift Container Storage subscriptions are stackable to cover larger hosts.
- Cores can be distributed across as many virtual machines (VMs) as needed. For example, a 2-core subscription at SMT level of 8 will provide 2 cores or 16 vCPUs that can be used across any number of VMs.
- OpenShift Container Storage subscriptions are available with Premium or Standard support.
1.4.2. Disaster recovery subscriptions
Red Hat OpenShift Container Storage does not offer disaster recovery (DR), cold backup, or other subscription types. Any system with OpenShift Container Storage installed, powered-on or powered-off, running workload or not, requires an active subscription.
1.4.3. Cores versus vCPUs and simultaneous multithreading (SMT)
Making a determination about whether or not a particular system consumes one or more cores is currently dependent on the level of simultaneous multithreading configured (SMT). IBM Power systems provide simultaneous multithreading levels of 1, 2, 4 or 8.
For systems where SMT is configured the calculation of cores depends on the SMT level. Therefore, a 2-core subscription 2 vCPU on SMT level of 1, 4 vCPUs on SMT level of 2, 8 vCPUs on SMT level of 4 and 16 vCPUs on SMT level of 8. A large virtual machine (VM) might have 16 vCPUs, which at a SMT level 8 will be equivalent of 2 subscription cores. As subscriptions come in 2-core units, you will need 1 2-core subscription to cover these 2 cores or 16 vCPUs.
1.4.4. Shared Processor Pools
IBM Power Systems have a notion of shared processor pools. The processors in a shared processor pool can be shared across the nodes in the cluster. The aggregate compute capacity required for a OpenShift Container Storage should be a multiple of core-pairs.
1.4.5. Subscription requirements
OpenShift Container Storage components can run on either OpenShift Container Platform worker or infrastructure nodes, for which either Red Hat CoreOS (RHCOS) or Red Hat Enterprise Linux (RHEL) 7 can be used as the host operating system. When worker nodes are used for OpenShift Container Storage components, those nodes are required to have subscriptions for both OpenShift Container Platform and OpenShift Container Storage. When infrastructure nodes are used, those nodes are only required to have OpenShift Container Storage subscriptions. Labels are used to indicate whether a node should be considered a worker or infrastructure node, see How to use dedicated worker nodes for Red Hat OpenShift Container Storage in the Managing and Allocating Storage Resources guide.
1.5. Infrastructure requirements
1.5.1. Platform requirements
Red Hat OpenShift Container Storage can be combined with an OpenShift Container Platform release that is one minor release behind or ahead of the OpenShift Container Storage version.
OpenShift Container Storage 4.6 can run on:
- OpenShift Container Platform 4.5 (one version behind) for internal mode only
- OpenShift Container Platform 4.6 (same version)
For a complete list of supported platform versions, see the Red Hat OpenShift Container Storage and Red Hat OpenShift Container Platform interoperability matrix.
When upgrading Red Hat OpenShift Container Platform, you must upgrade Local Storage Operator version to match with the Red Hat OpenShift Container Platform version in order to have the Local Storage Operator fully supported with Red Hat OpenShift Container Storage.
1.5.1.1. IBM Power Systems [Technology Preview]
Supports internal Red Hat Openshift Container Storage clusters only.
An Internal cluster must both meet storage device requirements and have a storage class providing local SSD via the Local Storage Operator.
1.5.2. Resource requirements
OpenShift Container Storage services consist of an initial set of base services, followed by additional device sets. All of these OpenShift Container Storage services pods are scheduled by kubernetes on OpenShift Container Platform nodes according to Pod Placement Rules.
Table 1.2. Aggregate minimum resource requirements
| Deployment Mode | Base services |
|---|---|
| Internal |
|
| External |
|
Example: For a 3 node cluster in an internal-attached devices mode deployment, a minimum of 3 x 16 = 48 units of CPU and 3 x 64 = 192 GB of memory is required.
1.5.3. Pod placement rules
Kubernetes is responsible for pod placement based on declarative placement rules. The OpenShift Container Storage base service placement rules for Internal cluster can be summarized as follows:
-
Nodes are labeled with the
cluster.ocs.openshift.io/openshift-storagekey - Nodes are sorted into pseudo failure domains if none exist
- Components requiring high availability are spread across failure domains
- A storage device must be accessible in each failure domain
This leads to the requirement that there be at least three nodes, and that nodes be in three distinct rack or zone failure domains in the case of pre-existing topology labels.
For additional device sets, there must be a storage device, and sufficient resources for the pod consuming it, in each of the three failure domains. Manual placement rules can be used to override default placement rules, but generally this approach is only suitable for bare metal deployments.
1.5.4. Storage device requirements
Use this section to understand the different storage capacity requirements that you can consider when planning deployments and upgrades on IBM Power Systems.
Local storage devices
For local storage deployment, any disk size of 4 TiB or less can be used, and all disks should be of the same size and type. The number of local storage devices that can run per node is a function of the node size and resource requirements. Expanding the cluster in multiples of three, one node in each failure domain, is an easy way to satisfy pod placement rules.
Disk partitioning is not supported.
Capacity planning
Always ensure that available storage capacity stays ahead of consumption. Recovery is difficult if available storage capacity is completely exhausted, and requires more intervention than simply adding capacity or deleting or migrating content.
Capacity alerts are issued when cluster storage capacity reaches 75% (near-full) and 85% (full) of total capacity. Always address capacity warnings promptly, and review your storage regularly to ensure that you do not run out of storage space. If you do run out of storage space completely, contact Red Hat Customer Support.
The following tables show example node configurations for Red Hat OpenShift Container Storage with dynamic storage devices.
Table 1.3. Example initial configurations with 3 nodes
| Storage Device size | Storage Devices per node | Total capacity | Usable storage capacity |
|---|---|---|---|
| 0.5 TiB | 1 | 1.5 TiB | 0.5 TiB |
| 2 TiB | 1 | 6 TiB | 2 TiB |
| 4 TiB | 1 | 12 TiB | 4 TiB |
Table 1.4. Example of expanded configurations with 30 nodes (N)
| Storage Device size (D) | Storage Devices per node (M) | Total capacity (D * M * N) | Usable storage capacity (D*M*N/3) |
|---|---|---|---|
| 0.5 TiB | 3 | 45 TiB | 15 TiB |
| 2 TiB | 6 | 360 TiB | 120 TiB |
| 4 TiB | 9 | 1080 TiB | 360 TiB |
To start deploying your OpenShift Container Storage on IBM Power Systems, you can use the deployment guide.