
Monitoring OpenShift Container Storage
Monitoring OpenShift Container Storage using storage dashboards
Abstract
Chapter 1. Cluster health
1.1. Verifying OpenShift Container Storage is healthy
Storage health is visible on the Persistent Storage and Object Service dashboards.
Procedure
- Log in to OpenShift Web Console.
Check the Status card in the following locations.
- Home → Overview → Persistent Storage
Home → Overview → Object Service
If Green Tick appears on the Status card, the cluster is healthy.
If the state is not Healthy, see Section 1.2, “Storage health levels and cluster state” for more information about the current state and any alerts that appear.
1.2. Storage health levels and cluster state
Status information and alerts related to OpenShift Container Storage are displayed in the storage dashboards.
1.2.1. Persistent storage dashboard indicators
The Persistent Storage dashboard shows the state of OpenShift Container Storage as a whole, as well as the state of persistent volumes.
The states that are possible for each resource type are listed in the following table.
Table 1.1. OpenShift Container Storage health levels
| State | Icon | Description |
|---|---|---|
| UNKNOWN |
| OpenShift Container Storage is not deployed or unavailable. |
| Green Tick |
| Cluster health is good. |
| Warning |
| When OCS cluster is in a warning state. In internal mode, an alert will be displayed along with the issue details. Alerts are not displayed for external mode. |
| Error |
| When the OCS cluster has encountered an error and some component is nonfunctional. In internal mode, an alert will be displayed along with the issue details. Alerts are not displayed for external mode. |
1.2.2. Object Service dashboard indicators
The Object Service dashboard shows the state of the Multicloud Object Gateway and any object claims in the cluster.
The states that are possible for each resource type are listed in the following table.
Table 1.2. Object Service health levels
| State | Description |
|---|---|
| Green Tick | Object Storage is healthy. |
| Multicloud Object Gateway is not running | Shown when NooBaa system is not found. |
| All resources are unhealthy | Shown when all NooBaa pools are unhealthy. |
| Many buckets have issues | Shown when >= 50% of buckets encounter error(s). |
| Some buckets have issues | Shown when >= 30% of buckets encounter error(s). |
| Unavailable | Shown when network issues and/or errors exist. |
1.2.3. Alert panel
The Alert panel appears below the Status card in both the Persistent Storage dashboard and the Object Service dashboard when the cluster state is not healthy.
Information about specific alerts and how to respond to them is available in Troubleshooting OpenShift Container Storage.
Chapter 2. Metrics
2.1. Viewing metrics in persistent storage dashboard
To view the persistent storage dashboard, click Home → Overview → Persistent Storage in OpenShift Web Console.
Figure 2.1. Example of Persistent Storage Overview Dashboard for internal mode

The following cards on Persistent Storage dashboard provides the metrics based on deployment mode (internal or external):
- Details card
The Details card shows the following:
- Service Name
- Cluster name
- The name of the Provider on which the system runs (example: AWS, VSphere, ‘None’ for Bare metal)
- Mode (deployment mode as either Internal or External)
- OpenShift Container Storage operator version.
- Inventory card
- The Inventory card shows the number of active nodes, PVCs and PVs backed by OpenShift Container Storage provisioner. On the left hand side of the card, total number of storage nodes, PVCs and PVs are displayed. While on the corresponding right hand side of the card, number of storage nodes in Not Ready state, count of PVCs in Pending state and PVs in Released state are shown.
For external mode, the number of nodes will be 0 by default, since there are no dedicated nodes for OpenShift Container Storage.
- Status card
This card shows whether the cluster is up and running without any errors or is experiencing some issues.
For internal mode, Data Resiliency indicates the status of data re-balancing in Ceph across the replicas. When the internal mode cluster is in a warning or error state, the Alerts section is shown along with the relevant alerts.
For external mode, Data Resiliency and alerts will not be displayed
- Capacity breakdown card
In this card, you can view graphic breakdown of capacity per project, storage classes and pods. You can choose between Projects, Storage Classes and Pods from the drop down menu on the top of the card. These options are for filtering the data shown in the graph.
Option Display Projects
The aggregated capacity of each project which is using the OpenShift Container storage and how much is being used.
Storage Classes
Will show aggregate capacity based on OpenShift Container Storage based storage classes.
Pods
All the pods trying to use the PVC backed by OpenShift Container Storage provisioner.
For external mode, this graph shows only the used capacity details.
- Utilization card
The card shows Used Capacity, input/output operations per second, latency, throughput, and recovery information for the internal mode cluster.
For external mode, this card shows only the used and requested capacity details for that cluster.
2.2. Viewing metrics in object service dashboard
To view the object service dashboard, click Home → Overview → Object Service in OpenShift Web Console.
Figure 2.2. Example of Object Service Overview Dashboard
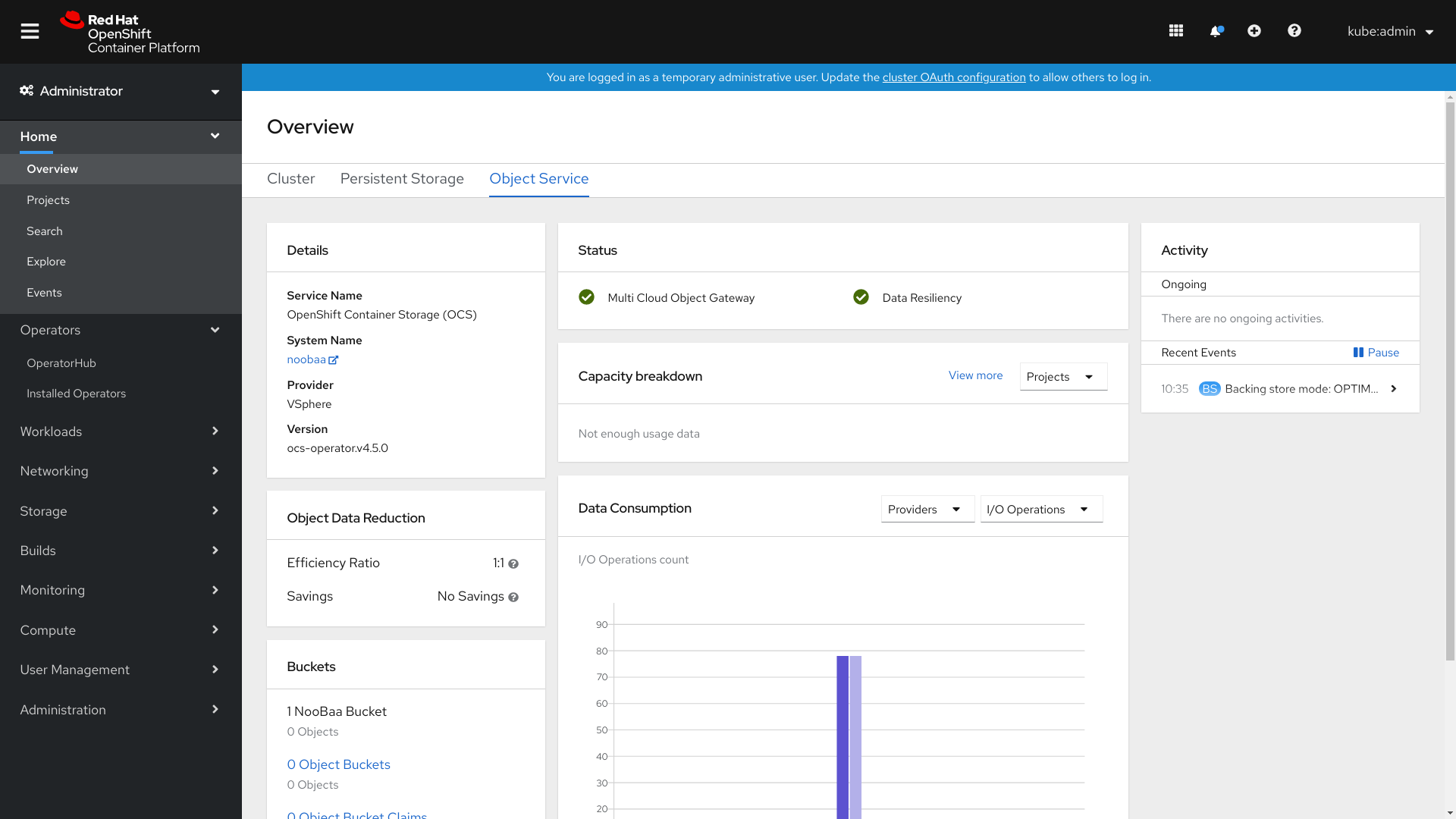
The following metrics are available in Object Service dashboard:
- Details card
This card shows the following information:
- The Multicloud Object Gateway (MCG) service name.
- The system name, which is also a hyperlink to the MCG management user interface.
- The name of the provider on which the system runs (example: AWS, VSphere, ‘None’ for Baremetal)
- OpenShift Container Storage operator version.
- Object Data Reduction card
- In this card you can view how the MCG optimizes the consumption of the storage backend resources through deduplication and compression and provides you with a calculated efficiency ratio (application data vs logical data) and an estimated savings figure (how many bytes the MCG did not send to the storage provider).
- Buckets card
Buckets are containers maintained by the MCG to store data on behalf of the applications. These buckets are created and accessed through object bucket claims (OBCs). A specific policy can be applied to bucket to customize data placement, data spill-over, data resiliency, capacity quotas, and so on.
In this card, information about object buckets (OB) and object bucket claims (OBCs) is shown separately. OB includes all the buckets that are created using S3 or the user interface(UI) and OBC includes all the buckets created using YAMLs or the command line interface (CLI). The number displayed on the left of the bucket type is the total count of OBs or OBCs. The number displayed on the right shows the error count and is visible only when the error count is greater that zero. You can click on the number to see the list of buckets that has the warning or error status.
- Resource Providers card
- This card displays a list of all Multicloud gateway(MCG) resources that are currently in use. Those resources are used to store data according to the buckets policies and can be a cloud-based resource or a bare metal resource.
- Status card
This card shows if the system is up and running without any issues. When the system is in a warning or error state, the alerts section is shown and the relevant alerts are displayed there. You can click on the links on the right of the alerts to get more information about the issue. For information about health checks, see Cluster health.
Data resiliency in the status card, indicates if there is any resiliency issue regarding the data stored through MCG.
- Capacity breakdown card
- In this card you can visualize how applications consume the object storage through the MCG. The card, through its drop-down box, offers graphic breakdowns per project and bucket class. You can choose between Projects and Bucket Class options from the drop down menu on the top of the card. These options are the filtering options that change the data shown in the graph.
Savings are two fold: Capacity savings (applies to bare metal and cloud based storage providers) and egress traffic savings (applies to storage cloud based providers).
- Data Consumption card
In this card, you can view physical usage (raw storage), logical usage (usable storage), I/O, and egress traffic per provider and MCG account.
For MCG accounts, you can view the I/O operations and logical used capacity. For providers, you can view I/O operation, physical and logical usage, and egress.
The following table provides the different key performance indicators (KPIs) that you can view based on your selection from the drop down menus on the top of the card:
Consumer types KPIs Chart Display Accounts
I/O operations
Displays read and write I/O operations for the top five consumers. The total reads and writes of all the consumers is displayed at the bottom. This information helps you monitor the throughput demand (IOPS) per application or account.
Accounts
Logical Used Capacity
Displays total logical usage of each account for the top five consumers. This helps you monitor the throughput demand per application or account.
Providers
I/O operations
Displays the count of I/O operations generated by the MCG when accessing the storage backend hosted by the provider. This helps you understand the traffic in the cloud so that you can improve resource allocation according to the I/O pattern, thereby optimizing the cost.
Providers
Physical vs Logical usage
Displays the data consumption in the system by comparing the physical usage with the logical usage per provider. This helps you control the storage resources and devise a placement strategy in line with your usage characteristics and your performance requirements while potentially optimizing your costs.
Providers
Egress
The amount of data the MCG retrieves from each provider (read bandwidth originated with the applications). This helps you understand the traffic in the cloud to improve resource allocation according to the egress pattern, thereby optimizing the cost.
Chapter 3. Alerts
3.1. Setting up alerts
For internal Mode clusters, various alerts related to the storage metrics services, storage cluster, disk devices, cluster health, cluster capacity, and so on are displayed in the persistent storage and the object service dashboards. These alerts are not available for external Mode.
It might take a few minutes for alerts to be shown in the alert panel, because only firing alerts are visible in this panel.
You can also view alerts with additional details and customize the display of Alerts in the OpenShift Container Platform. For more information, see Managing cluster alerts.
Chapter 4. Remote health monitoring
OpenShift Container Storage collects anonymized aggregated information about the health, usage, and size of clusters and reports it to Red Hat via an integrated component called Telemetry. This information allows Red Hat to improve OpenShift Container Storage and to react to issues that impact customers more quickly.
A cluster that reports data to Red Hat via Telemetry is considered a connected cluster.
4.1. About Telemetry
Telemetry sends a carefully chosen subset of the cluster monitoring metrics to Red Hat. These metrics are sent continuously and describe:
- The size of an OpenShift Container Storage cluster
- The health and status of OpenShift Container Storage components
- The health and status of any upgrade being performed
- Limited usage information about OpenShift Container Storage components and features
- Summary info about alerts reported by the cluster monitoring component
This continuous stream of data is used by Red Hat to monitor the health of clusters in real time and to react as necessary to problems that impact our customers. It also allows Red Hat to roll out OpenShift Container Storage upgrades to customers so as to minimize service impact and continuously improve the upgrade experience.
This debugging information is available to Red Hat Support and engineering teams with the same restrictions as accessing data reported via support cases. All connected cluster information is used by Red Hat to help make OpenShift Container Storage better and more intuitive to use. None of the information is shared with third parties.
4.2. Information collected by Telemetry
Primary information collected by Telemetry includes:
-
The size of ceph cluster in bytes :
{_name_="ceph_cluster_total_bytes"}, -
The amount of ceph cluster storage used in bytes :
{_name_="ceph_cluster_total_used_raw_bytes"}, -
Ceph cluster health status :
{_name_="ceph_health_status"}, -
The total count of osds :
{_name_="job:ceph_osd_metadata:count"}, -
The total number of Persistent Volumes present in OCP cluster :
{_name_="job:kube_pv:count"}, -
The total iops (reads+writes) value for all the pools in ceph cluster :
{_name_="job:ceph_pools_iops:total"}, -
The total iops (reads+writes) value in bytes for all the pools in ceph cluster :
{_name_="job:ceph_pools_iops_bytes:total"}, -
The total count of ceph cluster versions running :
{_name_="job:ceph_versions_running:count"} -
The total number of unhealthy noobaa buckets :
{_name_="job:noobaa_total_unhealthy_buckets:sum"}, -
The total number of noobaa buckets :
{_name_="job:noobaa_bucket_count:sum"}, -
The total number of noobaa objects :
{_name_="job:noobaa_total_object_count:sum"}, -
The count of noobaa’s accounts :
{_name_="noobaa_accounts_num"}, -
The total usage of noobaa’s storage in bytes. :
{_name_="noobaa_total_usage"}
Telemetry does not collect identifying information such as user names, passwords, or the names or addresses of user resources. In addition to the telemetry information stated above, NooBaa sends statistical information about accounts, buckets, objects, capacity, nodes, and connectivity health to phonehome.noobaa.com.