
Red Hat Training
A Red Hat training course is available for Red Hat JBoss Operations Network
Managing Resource Configuration
for editing resource settings and configuration through the JBoss ON UI
Abstract
1. Summary: Using JBoss ON to Make Changes in Resource Configuration
- Directly edit resource configuration. JBoss ON can edit the configuration files of a variety of different managed resources through the JBoss ON UI.
- Audit and revert resource configuration changes. For the specific configuration files that JBoss ON manages for supported resources, you can view individual changes to the configuration properties and revert them to any previous version.
- Define and monitor configuration drift. System configuration is a much more holistic entity than specific configuration properties in specific configuration files. Multiple files for an application or even an entire platform work together to create an optimum configuration. Drift is the (natural and inevitable) deviation from that optimal configuration. Drift management allows you to define what the baseline, desired configuration is and then tracks all changes from that baseline.
1.1. Easy, Structured Configuration
key1 = value1 key2 value2
<default-configuration>
<ci:list-property name="my-list">
<c:simple-property name="element" type="string"/>
<ci:values>
<ci:simple-value value="a"/>
<ci:simple-value value="b"/>
<ci:simple-value value="c"/>
</ci:values>
</ci:list-property>
</default-configuration>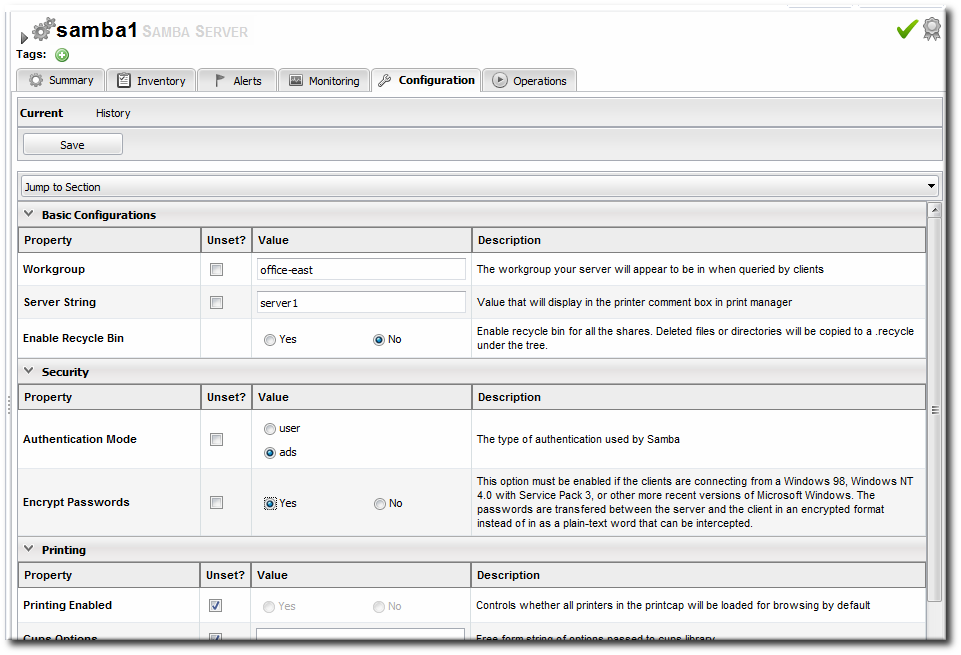
Figure 1. Configuration Form for a Samba Server
Note
- There is instant validation on the format of properties that are set through the UI.
- Audit trails for all configuration changes can be viewed in the resource history for both external and JBoss ON-initiated configuration changes.
- Configuration changes can be reverted to a previous stable state if an error occurs.
- Configuration changes can be made to groups of resource of the same type, so multiple resources (even on different machines) can be changed simultaneously.
- Alerts can be used in conjunction with configuration changes, either simply to send automatic announcements of any configuration changes or to initiate operations or scripts on related resources as configuration changes are made.
- Access control rules are in effect for configuration changes, so JBoss ON users can be prevented from viewing or initiating changes on certain resources.
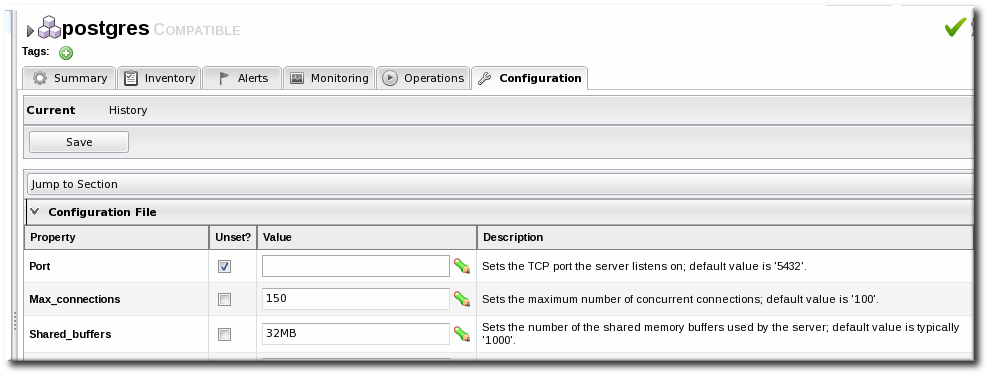
1.2. Identifying What Configuration Properties Can Be Changed

Figure 2. Configuration Tab
1.3. Auditing and Reverting Resource Configuration Changes
1.4. Tracking Configuration Drift
Note
- Drift looks at whole files within a directory, including added and deleted files and binary files.
- Drift supports user-defined templates which can be applied to any resource which supports drift monitoring.
- Drift can keep a running history of changes where each changeset (snapshot) is compared against the previous set of changes. Alternatively, JBoss ON can compare each change against a defined baseline snapshot.
- System password changes
- System ACL changes
- Database and server URL changes
- JBoss settings changes
- Changed JAR, WAR, and other binary files used by applications
- Script changes
Note
2. Changing the Configuration for a Resource
2.1. Changing the Configuration on a Single Resource
- Click the Inventory tab in the top menu.
- Select the resource type in the Resources menu table on the left, and then browse or search for the resource.
- Open the Configuration tab for the resource.
- Click the Current subtab.
- To edit a field, make sure the Unset checkbox is not selected. The Unset checkbox means that JBoss ON won't submit any values for that resource and any values are taken from the resource itself.Then, make any changes to the configuration.The list of available configuration properties, and their descriptions, are listed for each resource type in the Resource Reference: Monitoring, Operation, and Configuration Options.
- Click the button at the top of the properties list.
2.2. Changing the Configuration for a Compatible Group
Note
- The group members must all be the same resource type.
- All group member resources must be available (
UP). - No other configuration update requests can be in progress for the group or any of its member resources.
- The current member configurations must be successfully retrieved from the agents.
- Click the Inventory tab in the top menu.
- In the Groups box in the left menu, select the Compatible Group link.
- Select the group to edit.
- Open the Configuration tab.
- Click the Current subtab.
- To edit a field, make sure the Unset checkbox is not selected. The Unset checkbox means that JBoss ON won't submit any values for that resource and any values are taken from the resource itself.Then, make any changes to the configuration.The list of available configuration properties, and their descriptions, are listed for each resource type in the Resource Reference: Monitoring, Operation, and Configuration Options.
Note
It is possible to change the configuration for all members by editing the form directly, but it is also possible to change the configuration for a subset of the group members. Click the green pencil icon, and then change the configuration settings for the members individually. - Click the button at the top of the form.
2.3. Editing Script Environment Variables
Important
- Click the Inventory tab in the top menu.
- Search for the script resource.
- Open the Configuration tab for the script resource.
- Click the green plus sign (+) to add an environment variable.

- Enter the environment variable. Each new environment variable has the format name=value; and is added on a new line.
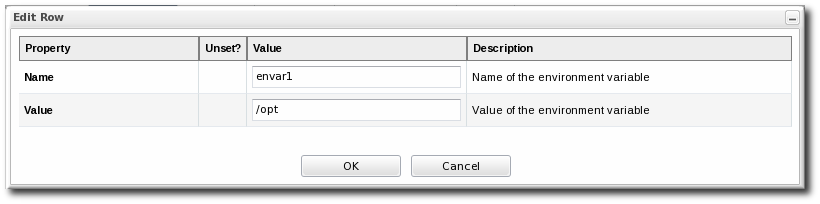 If the variable's value contains properties with the syntax
If the variable's value contains properties with the syntax%propertyName%, then JBoss ON interprets the value as the current values of the corresponding properties from the script's parent resource's connection properties. - After resetting an environment variable, restart the JBoss ON agent to propagate the changes. If the agent isn't restarted, new variables will not be propagated to the resource and will not resolve when the script is next executed, even if the configuration is correct.
Note
@echo off in Windows scripts to prevent echoing the executed commands along with the execution results.
2.4. Configuring Apache for Configuration Management
Note
- Click the Inventory tab in the top menu.
- Select the resource type in the Resources menu table on the left, and then search for the Apache resource.
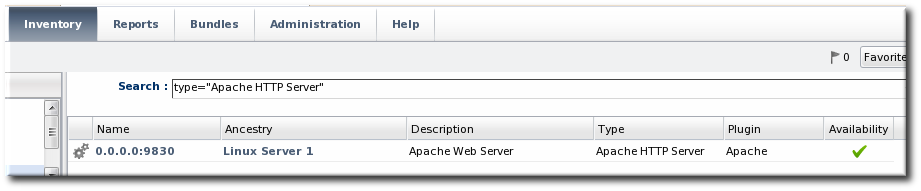
- Click the IP address of the Apache instance.
- Open the Inventory tab, then click the Connections subtab.
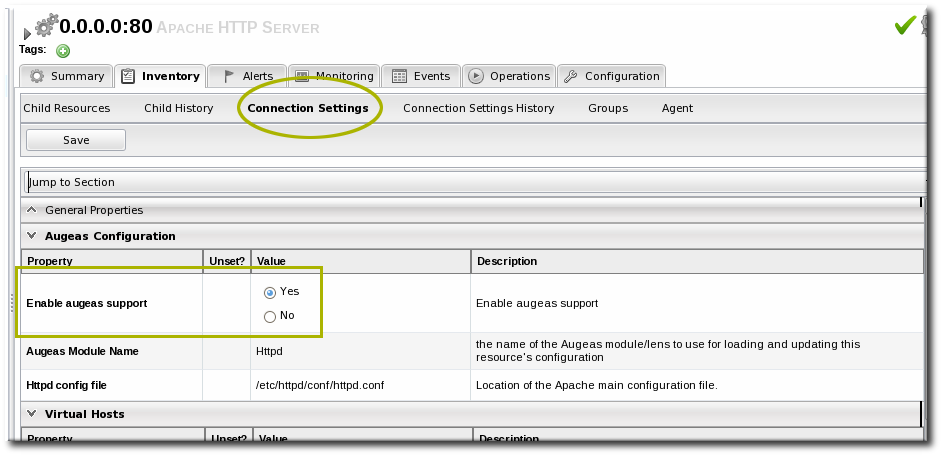
- Jump to the Augeas Configuration section.
- Select the Yes radio button to enable the Augeas lens.
3. Tracking Resource Configuration Changes
Note
3.1. Tracking and Comparing Configuration Changes
- Click the Inventory tab in the top menu.
- Select the resource type in the Resources menu table on the left, and then browse or search for the resource.
- Open the Configuration tab for the resource.
- Click the History subtab.
- Select the line of the configuration version to view or compare. Use the Ctrl key to select multiple versions. The current (most recent successful) configuration state is marked by a green check mark.

- Click the button.
- The pop-up window shows all of the changes in a directory-style layout, with each of the configuration areas as a high-level directory. Any changes are marked in red, and the values are shown for each selected version.
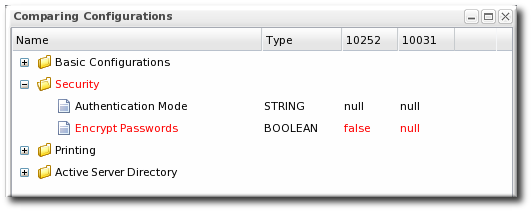
3.2. Reverting Configuration Changes
- Click the Inventory tab in the top menu.
- Select the resource type in the Resources menu table on the left, and then browse or search for the resource.
- Open the Configuration tab for the resource.
- Click the History subtab.
- Select the line of the configuration version to roll back to. The current (most recent successful) configuration state is marked by a green check mark.
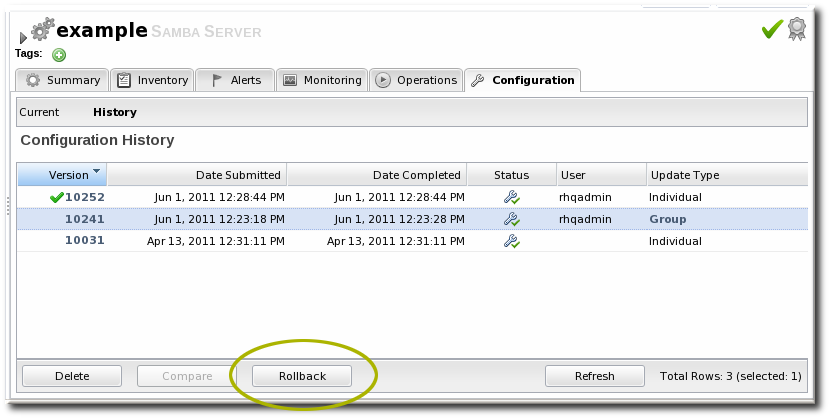
- Click the button.
4. Managing Configuration Drift
4.1. Understanding Drift
- What directories (and files within those directories) matter for drift monitoring? Even though a drift definition is defined for a resource, the actual drift detection is performed at the directory level. Drift monitoring, then, can hit anywhere on a platform — even outside resources managed by JBoss ON.
- How do you identify a change? Do you compare it to the version immediately before it or to an established baseline?
4.1.1. Drift Definitions and Detection
/etc/ that only includes changes to *.conf files, the elements in the drift definition are:
Value context: fileSystem Value name: /etc Includes: **/*.conf
Note
Table 1. Combinations to Include Specific Files
| Files to Monitor for Drift | 'Includes' Path | 'Includes' Pattern |
|---|---|---|
| /etc and all its subdirectories | Blank | Blank |
| For *.conf files in /etc and all subdirectories | . | **/*.conf[a] |
| For *.conf files only in the /etc directory, with no subdirectories (/etc/*.conf) | . | *.conf |
| For *.conf files only in a subdirectory one level below /etc (/etc/*/*.conf) | Not possible | Not possible |
| For any file in a specific subdirectory (yum.repos.d/) below /etc | yum.repos.d (subdirectory name) | Blank |
[a]
This must have a double asterisk for the directory part. It will not work with a single asterisk.
| ||
Note
4.1.2. Snapshots, Deltas, and Baseline Images
Note
- It can compare against the next-most recent version of the files.
- It can compare against a defined, stable baseline.

Figure 3. Rolling Snapshots
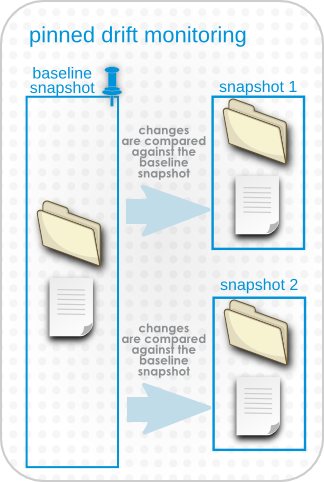
Figure 4. Pinned Snapshots
4.1.3. Destination Directories with Special File Types
ln -ls /home/dev/libs /usr/share/jbossas/server/libs
libs/ directory in the JBoss AS home directory, it will follow the symlink back to /home/dev/libs, and include all of those files in the drift snapshot.
Important
excludes parameter in the drift definition to exclude the symlink.
Note
excludes parameter in the drift definition to exclude any named pipes in the target directory.
Table 2. Drift Definitions and Unix File Types
| File Type | Supported by Drift? |
|---|---|
| File | Yes |
| Directory | Yes |
| Symbolic link | Yes |
| Pipe | No |
| Socket | No |
| Device | No |
4.1.4. Drift and Resource Types
rhq-plugin.xml descriptor, then that resource type supports drift. The template is a starting point (not an enforced configuration, like alert or metric collection templates).
- All platforms
- JBoss AS/EAP 4
- JBoss AS/EAP 5, and all resources which use the JBoss AS 5 plug-in
Note
4.1.5. Back to Drift Monitoring
Drift monitoring is the ability to track changes to target locations. The JBoss ON GUI allows you to view snapshots all together, compare changes for individual files between snapshots, view the current configuration, and view change details. It also provides inventory and drift reports and indicates, at a glance, whether a resource is compliant with an associated pinned snapshot.
A specific alert condition exists that will trigger an alert whenever there is drift. For rolling snapshots, this will send an alert once (and only once) for each drift snapshot. For pinned snapshots, the drift alert is fired for every detection run for as long as the resource is out of compliance, even if there are no subsequent changes.
Note
4.2. Adding a Drift Definition for a Resource
Important
- Click the Inventory tab in the top menu.
- Select the resource type in the Resources menu table on the left, and then browse or search for the resource.
- Open the Drift tab for the resource.
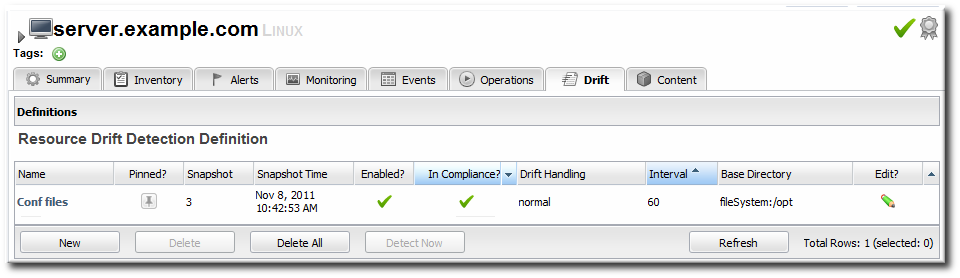
- Click the at the bottom to add a new definition.
- Select the template to use to as the basis for the new definition.Plug-in defined templates are defined in the platform and JBoss server resources, as well as any other resource which supports drift monitoring. Additional, user-defined templates can be also be created and applied.
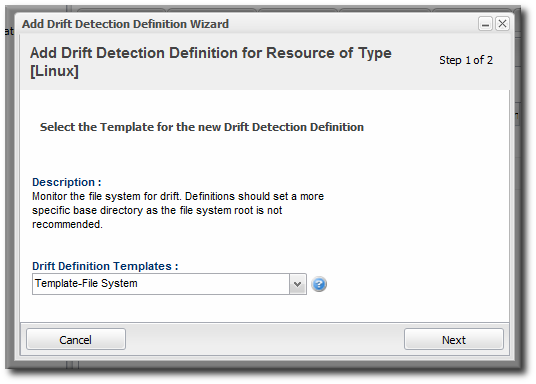
- Give a unique name to the definition. The name and the base directory are combined to identify the definition within JBoss ON.
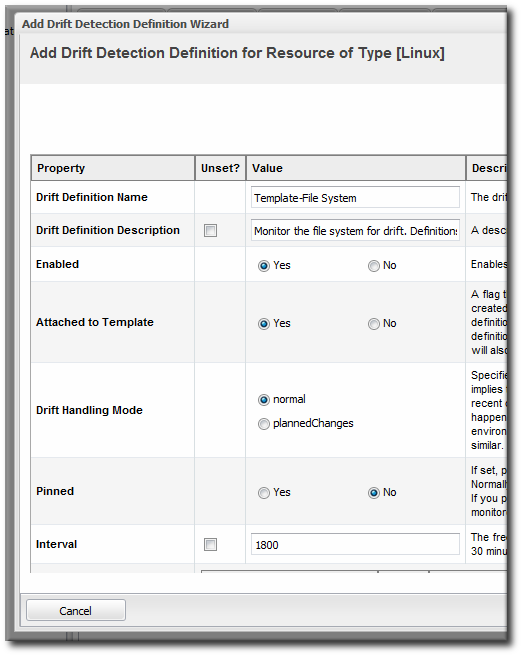
- Define the settings for the definition, like the interval and whether it is associated with the template. The properties are listed in Table 3, “Drift Definition Properties”.
- Set the base directory. This is the top-most directory where drift detection is run for the definition, and the scan recurses down.The template itself defines an initial directory, but it may be useful to set a more specific directory to use.
- Click the button with the green plus (+) sign to add a subdirectory to include or exclude. The directory can be the base directory by specifying a period (.) as the directory. The pattern identifies which files within the directory to recognize by the service, either to explicitly include or explicitly exclude.The filters support Ant-like FilePatterns, using a path and pattern. The patterns support asterisks (*) as wildcards for any number of characters and question marks (?) for single character wild cards. For example,
**/*.confcan be used to include only.conffiles in any subdirectory. There can be multiple include/exclude filters. Each directory and pattern can be added separately.
There can be multiple include/exclude filters. Each directory and pattern can be added separately.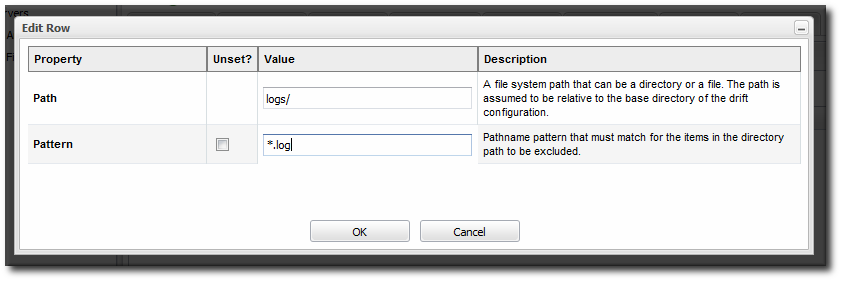
Note
If a pattern is used, then a path must be specified, even if the path is the base directory. For example, to include only.conffiles in the base directory, the pattern is*.confand the path is a period (.) to indicate the local directory.
Table 3. Drift Definition Properties
| Property | Description |
|---|---|
| Name | A name for the drift detection definition. The name and the base directory, together, uniquely identify the definition. |
| Base Directory: Value Context | The type of configuration property which is used to identify the base directory. This identifies what type of element in the resource supplies the value. There are four options:
|
| Base Directory: Value Name | The actual value for the drift detection definition to use for the base directory context. For example, if this is a file system context, then the value name is the directory path. |
| Includes | Explicitly includes directories, files, or files and directories matching a pattern, relative to the base directory, in the drift detection.
The filters support Ant-like FilePatterns, using a path and pattern. The patterns support asterisks (*) as wildcards for any number of characters and question marks (?) for single character wild cards.
If a pattern is used, then a path must be specified, even if the path is the base directory. For example, to include only
.conf files in the base directory, the pattern is *.conf and the path is a period (.) to indicate the local directory.
|
| Excludes | Explicitly excludes directories, files, or files and directories matching a pattern, relative to the base directory, from the drift detection.
The filters support Ant-like FilePatterns, using a path and pattern. The patterns support asterisks (*) as wildcards for any number of characters and question marks (?) for single character wild cards.
If a pattern is used, then a path must be specified, even if the path is the base directory. For example, to include only
.conf files in the base directory, the pattern is *.conf and the path is a period (.) to indicate the local directory.
|
| Enabled | Enables or disables the definition. Disabling a definition means that no detection scans are run. |
| Interval | Sets the frequency, in seconds, where the definition is eligible for a detection run. This is not a hard setting. Because load or other scheduled operations for the agent, the detection run is not guaranteed to run at the specified interval. |
| Pinned | Sets whether drift is determined in a rolling way or if it is associated (pinned) with a baseline snapshot. If this is set when the definition is created, then the initial snapshot is used as the baseline.
Definitions attached to a pinned template cannot be unpinned. Definitions which are attached to an unpinned template or which are not attached to a template can be pinned or unpinned freely.
|
| Drift Handling Mode | Sets whether drift changes are treated as events which trigger an alert (the default) or as expected, so that no alerts are triggered. |
| Attached to Template | Sets whether the resource-level definition is subordinate to a template. If it is attached to a template, then any changes to the template are reflected in the resource definition, including if the template is deleted.
By default, definitions are attached to the template from which they are created.
|
| Description | A simple text description of the definition. |
4.3. Creating a Drift Definition Template
4.3.1. About Resources and Drift Definition Templates
Example 1. A JBoss Server Drift Definition Template
<drift-definition name="Template-Base Files"
description="Monitor base application server files for drift. It defines monitoring for some standard sub-directories of the HOME directory. Note, it is not recommeded to monitor all files for an application server. There are many files, and many temp files.">
<basedir>
<value-context>pluginConfiguration</value-context>
<value-name>homeDir</value-name>
</basedir>
<includes>
<include path="bin" />
<include path="lib" />
<include path="client" />
</includes>
</drift-definition>- Drift templates are not automatically applied to a resource, unlike other template types in JBoss ON. Drift templates are used as the basis for creating resource-level definitions.
- Default drift templates are defined for resources as part of their plug-in descriptor. Custom, user-defined templates can be added along with those defaults.
- Every drift definition is based on a template initially, even if that definition is not attached to that template post-creation.
- Snapshots (the file sets associated with drift definitions) always originate on a resource with a drift definition first. For any content to be associate with a template, the resource-level snapshot has to be promoted up to the template. Drift templates do not generate snapshots or files and then push that down to the resource.
4.3.2. Creating a Drift Definition Template
- Click the Administration tab in the top menu.
- Select the Drift Definition Templates menu table on the left.
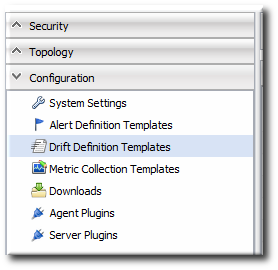
- Click the pencil icon for the resource type to add the template to. Not all resources support drift, so they cannot be selected.
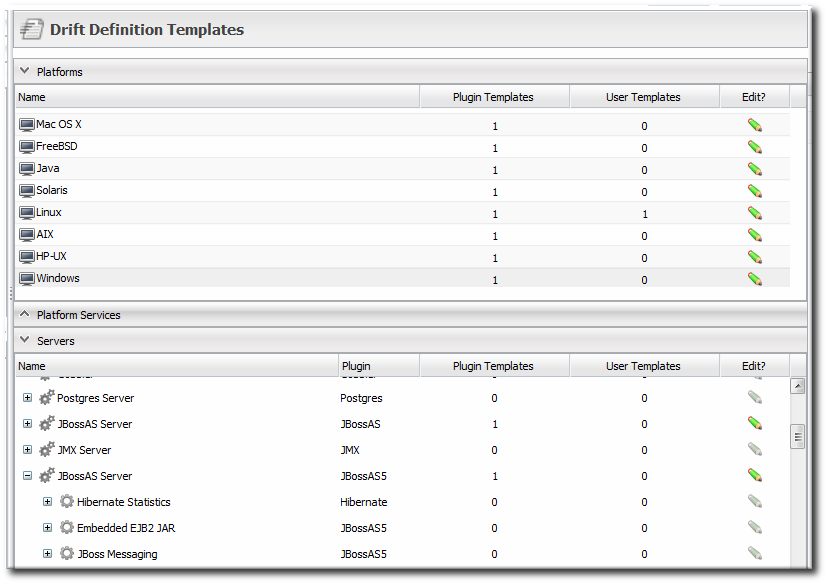
- Click the at the bottom to add a new template.
- Select the template to use to as the basis for the new template.Plug-in defined templates are defined in the platform and JBoss server resources, as well as any other resource which supports drift monitoring. Additional, user-defined templates can be also be created and applied.
- Give a unique name to the template. The name and the base directory are combined to identify the definition within JBoss ON.

- Define the settings for the definition, like the interval and whether it is enabled by default. The properties are listed in Table 3, “Drift Definition Properties”.
- Set the base directory. This is the top-most directory where drift detection is run for the definition, and the scan recurses down.
- Click the button with the green plus (+) sign to add a subdirectory to include or exclude. The directory can be the base directory by specifying a period (.) as the directory. The pattern identifies which files within the directory to recognize by the service, either to explicitly include or explicitly exclude.The filters support Ant-like FilePatterns, using a path and pattern. The patterns support asterisks (*) as wildcards for any number of characters and question marks (?) for single character wild cards. For example,
**/*.confcan be used to include only.conffiles in any subdirectory.Note
If a pattern is used, then a path must be specified, even if the path is the base directory. For example, to include only.conffiles in the base directory, the pattern is*.confand the path is a period (.) to indicate the local directory.
4.4. Editing Drift Definitions
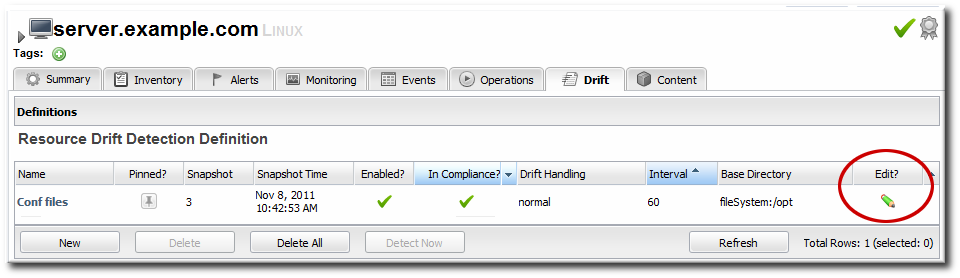
4.5. Viewing Snapshots and Changes
Note
4.5.1. Viewing the Snapshot Carousel
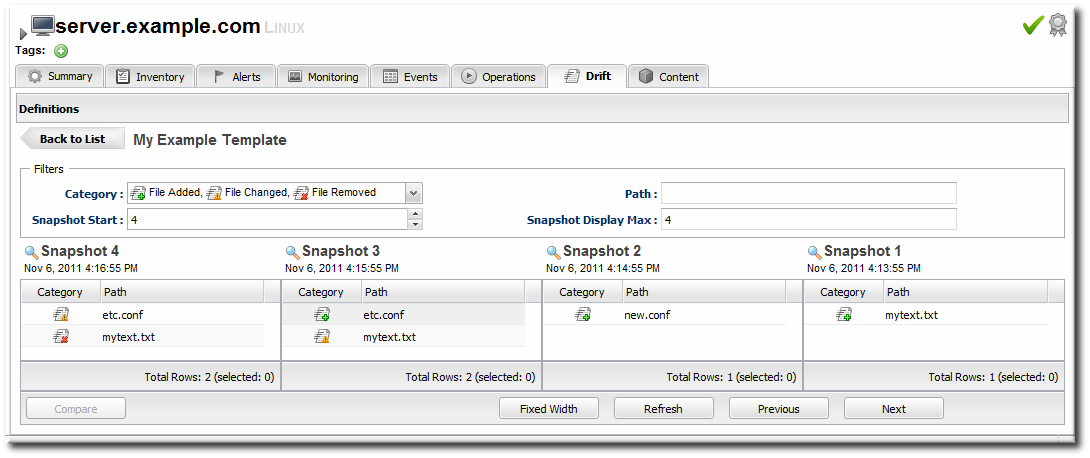
Figure 5. Viewing Snapshots
- Click the Inventory tab in the top menu.
- Search for the resource.
- Click the Drift tab for the resource.
- Click the name of the drift definition.
- The snapshot carousel shows, by default, the four most recent snapshots.
- Optionally, filter the snapshots to view. There are two elements that can be used to search for snapshots:
- The change type within the snapshot, whether a file was added, deleted, or modified.
- The path of a change within the snapshot. This path filter is a substring filter based on the paths and files in the drift entries.

4.5.2. Comparing Drift Changes
Note
- Click the Inventory tab in the top menu.
- Search for the resource.
- Click the Drift tab for the resource.
- Click the name of the drift definition.
- Click the names of the files to compare.

- Click .
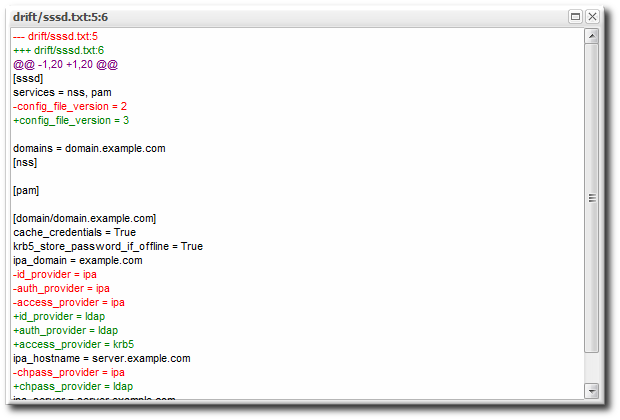
Figure 6. Change Set Diffs
4.5.3. Viewing Snapshot Details
- Click the Inventory tab in the top menu.
- Search for the resource.
- Click the Drift tab for the resource.
- Click the name of the drift definition.
- In the snapshot carousel, click the magnifying glass by the name of the snapshot to view.

- Expand the directory to show the list of changes for that snapshot.

- To see the details of a specific change, click the (view) link.
- The details for that file shows links to display the immediate previous version of the file, the changed version of the file, and a diff between the two.
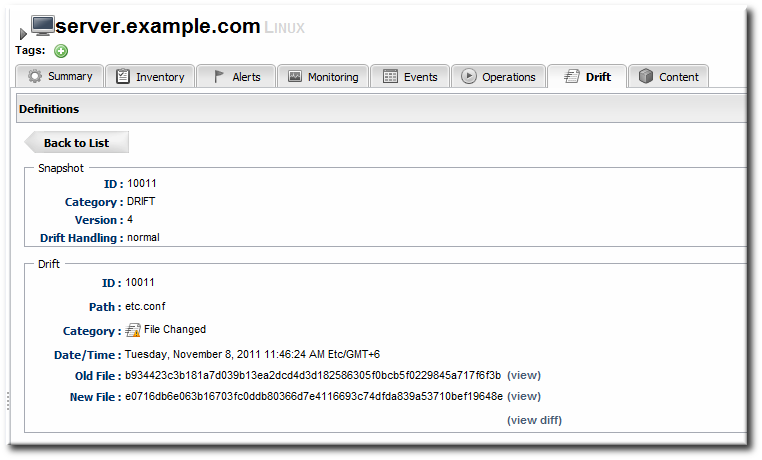 When clicking the view link, the page title has the version number along with the file name. For example, when viewing version 6 of
When clicking the view link, the page title has the version number along with the file name. For example, when viewing version 6 ofmyfile.txt, the title is myfile.txt:6.
4.5.4. Seeing Drift Events in the Timeline
- Click the Inventory tab in the top menu.
- Search for the resource.
- In the Summary tab, click the Timeline subtab.
- The detection runs where drift was detected show up in the timeline as Drift Detected. To see only drift events in the timeline, clear all but the Drift checkbox.The time interval can be reset to adjust the span of the timeline.
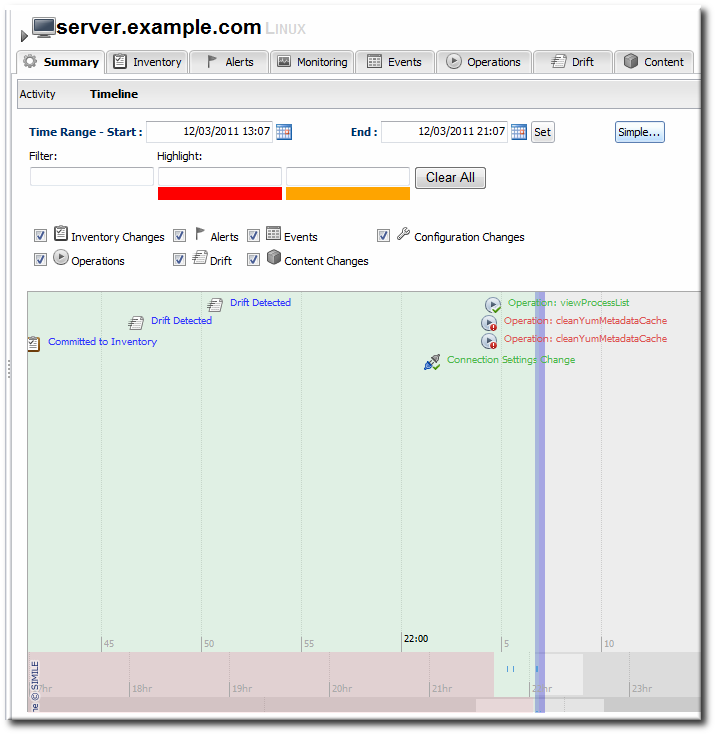
4.5.5. Checking Drift Snapshot Reports
- Click the Reports tab in the top navigation menu.
- Select the Recent Drift report from the Subsystems report list.
- Every drift instance is listed, sorted by the snapshot creation time.

- Optionally, filter the list of drift changes. There are four filter options:
- The definition name
- The snapshot number (which crosses drift definitions)
- The change type within the snapshot, whether a file was added, deleted, or modified.
- The path of a change within the snapshot. This path can be a directory, a specific file name, or a search expression.
4.6. Pinning Snapshots and Managing Compliance
4.6.1. More About Pinning Snapshots
- It removes any snapshots that were created before that snapshot. For example, if an administrator decides to pin Snapshot 7, Snapshot 0 (the initial image) through Snapshot 6 are all deleted, and Snapshot 7 becomes the new Snapshot 0.
- It creates a baseline image that every change is compared against rather than keeping a moving tally of changes.
- It changes the behavior of drift alerts (Section 4.8, “Defining Drift Alerts”) so that alerts are sent continually until the system configuration is back in compliance with the pinned snapshot.
- The definition it is pinned to cannot be deleted until the snapshot is unpinned.
- If a snapshot is pinned to a template, then all of the resource-level definitions attached to that template automatically use the pinned snapshot as their baseline.
- Any new file added after a snapshot is pinned (or any file deleted) is going to be reported as a new file in every subsequent snapshot. This is because the new snapshot is always compared against the baseline snapshot, so the file is always new to the baseline.There is some logic to prevent drift from reporting the same change incessantly. If
file1.txtis added, the agent creates snapshot 1. When the agent does its next detection run, it recognizes thatfile1.txtis not in the baseline, but as long as the SHA forfile1.txthas not changed, the agent does not report it as new drift and does not take a new snapshot. Iffile1.txtis modified, however, the agent notices the new SHA and sends a new snapshot — with the modifiedfile1.txtstill listed as a new file, because it is compared against the baseline, not the previous version.
4.6.2. When to Pin to a Resource and When to Pin to a Template
- Pinning a snapshot to a resource-level definition establishes a baseline for that resource alone. This makes sense while you are still developing an ideal baseline image or for unique environments that may not transition over to other resources.Pinning to a resource definition allows a lot of flexibility. It is easy to pin and unpin and select a new snapshot as the baseline, to let administrators develop an ideal configuration with a minimal impact on drift events, alerting, and monitoring because the changes are contained.
- Pinning a snapshot to a template means that baseline can be applied to every resource that uses that template; it allows that one single snapshot to be used across multiple resources. This is makes sense for any kind of repeatable configuration areas and for production or critical systems which must have consistent configuration.Pinning to a template is very powerful for maintaining consistency across an entire infrastructure once an ideal configuration has been developed.
Note
4.6.3. Pinning to a Resource-Level Definition
- Click the Inventory tab in the top menu.
- Search for the resource.
- Click the Drift tab.
- Click the name of the drift definition.
- In the snapshot carousel, click the magnifying glass by the name of the snapshot to pin.
Note
The initial snapshot is not displayed in the carousel. To pin the initial snapshot, click the thumbtack icon in the Pinned column of the drift definition list. That opens the initial snapshot.If a snapshot has already been pinned, then clicking the thumbtack icon opens the pinned snapshot. - At the bottom of the change list, click the button.
4.6.4. Pinning to a Template
- Click the Inventory tab in the top menu.
- Search for the resource.
- Click the Drift tab.
- Click the name of the drift definition.
- In the snapshot carousel, click the magnifying glass by the name of the snapshot to pin.
Note
The initial snapshot is not displayed in the carousel. To pin the initial snapshot, click the thumbtack icon in the Pinned column of the drift definition list. That opens the initial snapshot.If a snapshot has already been pinned, then clicking the thumbtack icon opens the pinned snapshot. - At the bottom of the change list, click the button.
- If the resource-level template is based on or attached to an existing template, then you can associate the snapshot with that existing template. If the base directory for the resource-level snapshot does not match any existing drift template, then you must create a new template.
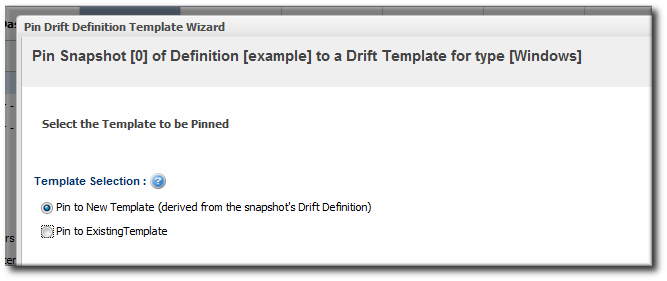
- Create the drift template, as in Section 4.3, “Creating a Drift Definition Template”.
4.6.5. Checking Drift Compliance Reports
- Click the Reports tab in the top navigation menu.
- Select the Drift Compliance report from the Inventory report list.
- Every resource with a drift definition is listed by type and with an icon to indicate whether it is compliant (
 ) or non-compliant (
) or non-compliant (
 ).
).
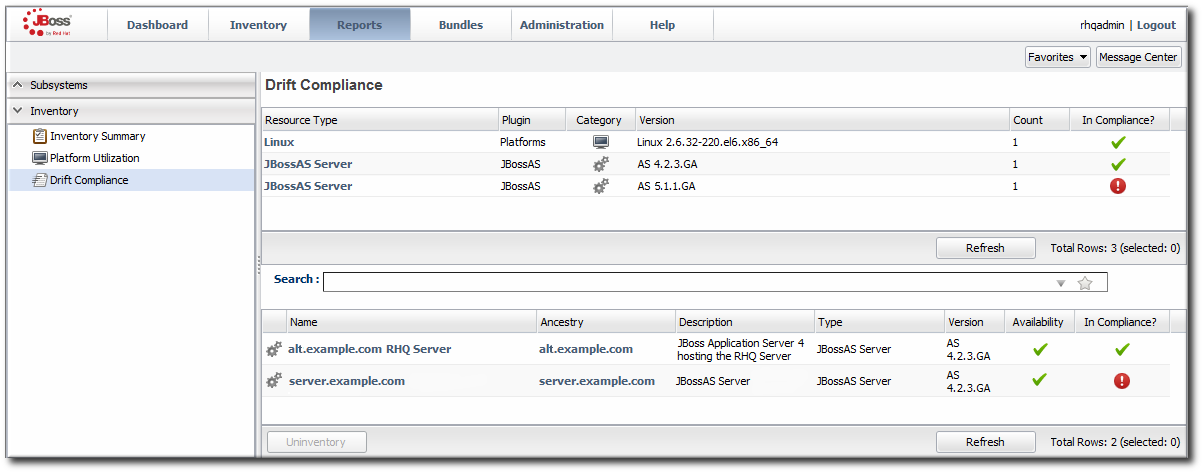
- To get information about the specific resources, click the resource type name; this opens a second inventory report under the main report. All of the resources of that type are listed with their compliance state.
4.6.6. Unpinning a Snapshot
- Click the Inventory tab in the top menu.
- Search for the resource.
- Click the Drift tab.
- Click the pin icon for the drift definition.
4.7. Extended Example: Defining Required EAP Configuration
Tim the IT Guy at Example Corp. has one EAP server running in his production environment. Because of the production load, the EAP server was routinely running out of memory, which was degrading its performance and causing downtime for Example Corp.'s website.
There are three things that Tim wants to accomplish to maintain his EAP performance:
- Find a way to consistently apply configuration to EAP instances.He defines a template for JBoss EAP instances (Section 4.3, “Creating a Drift Definition Template”). To maintain consistency, the template sets the Attach to template value to true, and each resource-level drift definition will preserve that settings. This ensures that any changes to the template are automatically applied to the JBoss resource drift definitions.
- Use his current production settings as a basis for future EAP instances.He pins his latest snapshot, with the higher heap settings, to the template definition (Section 4.6.4, “Pinning to a Template”). Every EAP instance is going to be compared against that baseline, so any with the wrong heap setting will immediately be marked out of compliance.
- Be made aware of specific differences between his current EAP settings and his preferred settings.He creates an alert definition (Section 4.8, “Defining Drift Alerts”) which specifically targets the
bin/run.conffile. This way, he knows precisely whether the heap settings and other JVM settings are wrong for his new instance. He can even use alerts to gather more information about how his EAP instance configuration is different, like using a CLI script to compare the current EAP configuration against the pinned snapshot and then send him the diff.
Tim brings a new server online, with a new EAP instance for the production environment. He applies the drift template to the new resource and, within a few minutes, receives a notification that his run.conf file is not compliant with his preferred configuration. He changes the heap settings on the new EAP instance without having to wait for performance degradation to remember the change.
4.8. Defining Drift Alerts
Note
- Click the Inventory tab in the top menu.
- Select the resource type in the Resources menu table on the left, and then browse or search for the resource.
- Click the resource name in the list.
- Click the Alerts tab for the resource.
- In the Definitions subtab, click the New button to create the new alert.
- In the General Properties tab, give the basic information about the alert.
 It may be useful to set a Priority if the drift definition contains critical configuration files.
It may be useful to set a Priority if the drift definition contains critical configuration files. - In the Conditions tab, select the Drift Detection option from the conditions list. To use the alert for all drift changes, leave the fields blank. Otherwise, enter the specific drift definition name and (optionally) the directories or files that must be modified for the alert to be triggered.
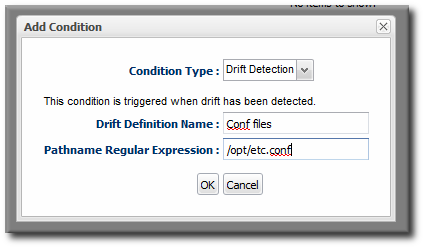
Note
There can be more than one condition set to trigger an alert, meaning that you can use the same alert for multiple drift definitions or files. - In the Notifications tab, click Add to set a notification for the alert.Select the method to use to send the alert notification in the Sender option, and fill in the required information.
 The Sender option first sets the specific type of alert method (such as email or SNMP) and then opens the appropriate form to fill in the details for that specific method.
The Sender option first sets the specific type of alert method (such as email or SNMP) and then opens the appropriate form to fill in the details for that specific method. - Optionally, in the Dampening tab, give the dampening (or frequency) rule on how often to send notifications for drift.
Note
For pinned snapshots, it can be useful to use dampening rules to keep from getting a flood of alerts before a drift problem is remediated.Dampening only makes sense for a definition with a pinned snapshot. A pinned definition will fire alerts with every alert scan (every 10 minutes) for as long as it is out of compliance, even if there are no further changes. A rolling definition only fires an alert once, when drift is detected. Any of the dampening rules can be used. The ultimate goal is to limit the number of times that the same alert is set for a resource that is out of compliance with a pinned definition. For example, Time period sets a limit on the number of times in a given time period that an alert is issued if the alert condition occurs. Setting the occurrence to 1 and the time period to 4 hours means that when drift is detected once, the server sends an alert and then waits another 4 hours before sending the next alert.
Any of the dampening rules can be used. The ultimate goal is to limit the number of times that the same alert is set for a resource that is out of compliance with a pinned definition. For example, Time period sets a limit on the number of times in a given time period that an alert is issued if the alert condition occurs. Setting the occurrence to 1 and the time period to 4 hours means that when drift is detected once, the server sends an alert and then waits another 4 hours before sending the next alert. - Click OK to save the alert definition.
4.9. Extended Example: Reverting a JBoss Server to Its Original Configuration Using Bundles and Server Scripts
In Section 4.7, “Extended Example: Defining Required EAP Configuration”, Tim the IT Guy at Example Corp. set up drift templates and alerts to help manage the configuration on his production EAP servers. However, his resolution was done manually. When the drift alert notified him that his EAP server was out of compliance, he edited the run.conf directly to adjust the heap size.
The goal is to have JBoss ON respond intelligently to drift without requiring any action from Tim the IT Guy. There are two features that allow automated responses:
- Using bundles to provision updated files or applications. A bundle is a ZIP file that contains an Ant recipe and any required content (such as configuration files or JARs) for an application. JBoss ON can provision this content on a platform or a JBoss server in a specified directory.More information about provisioning bundles is covered in Deploying Applications and Content.
- Launching JBoss ON CLI scripts in response to an alert. One of the possible alert notifications is a server-side alert sender. A JBoss ON CLI script is loaded as content and stored in the JBoss ON server; when the alert fires, it initiates the specified, stored CLI script.More information about writing CLI scripts is covered in Running JBoss ON Command-Line Scripts, and general alert information is covered in Setting up Monitoring, Alerts, and Operations.
- Create a bundle file based on the pinned snapshot configuration. The content of the bundle depends on the needs of the deployment. It can be specific configuration files, like
bin/run.conf, or it can be a full EAP server.Note
If the bundle contains the full EAP server, then it can be used to create the initial EAP server. - Set up the bundle, the destination, and the compatible group to use with the bundle. (The full procedure is described in Deploying Applications and Content.
- Deploy the bundle with the full EAP server to create the new EAP instance. (Or, if the bundle only has configuration files, create the EAP instances.)
- Set up the drift definitions, based on the previously configured template (Section 4.7, “Extended Example: Defining Required EAP Configuration”), for the new EAP instance.
- Create a JBoss ON CLI script (in JavaScript) that will automatically deploy the specified bundle to the appropriate destination. An example is in Example 2, “fix-eap.js Script”; in that script, replace the
destinationIdandbundleVersionIdwith the real ID numbers for the destination entry and bundle version entry in JBoss ON. - Create an alert definition that triggers on the drift detection condition and uses the CLI script notification type, pointing to the JavaScript file that you created.
Any time drift is detected on the EAP server, it triggers an alert, same as in Section 4.7, “Extended Example: Defining Required EAP Configuration”. This time, the alert launches the CLI script in response and automatically deploys the bundle — which already has the approved EAP configuration — to the resource. This means that the EAP server is never more than a few minutes out of compliance, roughly the length of one alert scan. All without requiring intervention from Tim the IT Guy.
Example 2. fix-eap.js Script
/**
* If obj is a JS array or a java.util.Collection, each element is passed to
* the callback function. If obj is a java.util.Map, each map entry is passed
* to the callback function as a key/value pair. If obj is none of the
* aforementioned types, it is treated as a generic object and each of its
* properties is passed to the callback function as a name/value pair.
*/
function foreach(obj, fn) {
if (obj instanceof Array) {
for (i in obj) {
fn(obj[i]);
}
}
else if (obj instanceof java.util.Collection) {
var iterator = obj.iterator();
while (iterator.hasNext()) {
fn(iterator.next());
}
}
else if (obj instanceof java.util.Map) {
var iterator = obj.entrySet().iterator()
while (iterator.hasNext()) {
var entry = iterator.next();
fn(entry.key, entry.value);
}
}
else { // assume we have a generic object
for (i in obj) {
fn(i, obj[i]);
}
}
}
/**
* Iterates over obj similar to foreach. fn should be a predicate that evaluates
* to true or false. The first match that is found is returned.
*/
function find(obj, fn) {
if (obj instanceof Array) {
for (i in obj) {
if (fn(obj[i])) {
return obj[i]
}
}
}
else if (obj instanceof java.util.Collection) {
var iterator = obj.iterator();
while (iterator.hasNext()) {
var next = iterator.next();
if (fn(next)) {
return next;
}
}
}
else if (obj instanceof java.util.Map) {
var iterator = obj.entrySet().iterator();
while (iterator.hasNext()) {
var entry = iterator.next();
if (fn(entry.key, entry.value)) {
return {key: entry.key, value: entry.value};
}
}
}
else {
for (i in obj) {
if (fn(i, obj[i])) {
return {key: i, value: obj[i]};
}
}
}
return null;
}
/**
* Iterates over obj similar to foreach. fn should be a predicate that evaluates
* to true or false. All of the matches are returned in a java.util.List.
*/
function findAll(obj, fn) {
var matches = java.util.ArrayList();
if ((obj instanceof Array) || (obj instanceof java.util.Collection)) {
foreach(obj, function(element) {
if (fn(element)) {
matches.add(element);
}
});
}
else {
foreach(obj, function(key, value) {
if (fn(theKey, theValue)) {
matches.add({key: theKey, value: theValue});
}
});
}
return matches;
}
/**
* A convenience function to convert javascript hashes into RHQ's configuration
* objects.
* <p>
* The conversion of individual keys in the hash follows these rules:
* <ol>
* <li> if a value of a key is a javascript array, it is interpreted as PropertyList
* <li> if a value is a hash, it is interpreted as a PropertyMap
* <li> otherwise it is interpreted as a PropertySimple
* <li> a null or undefined value is ignored
* </ol>
* <p>
* Note that the conversion isn't perfect, because the hash does not contain enough
* information to restore the names of the list members.
* <p>
* Example: <br/>
* <pre><code>
* {
* simple : "value",
* list : [ "value1", "value2"],
* listOfMaps : [ { k1 : "value", k2 : "value" }, { k1 : "value2", k2 : "value2" } ]
* }
* </code></pre>
* gets converted to a configuration object:
* Configuration:
* <ul>
* <li> PropertySimple(name = "simple", value = "value")
* <li> PropertyList(name = "list")
* <ol>
* <li>PropertySimple(name = "list", value = "value1")
* <li>PropertySimple(name = "list", value = "value2")
* </ol>
* <li> PropertyList(name = "listOfMaps")
* <ol>
* <li> PropertyMap(name = "listOfMaps")
* <ul>
* <li>PropertySimple(name = "k1", value = "value")
* <li>PropertySimple(name = "k2", value = "value")
* </ul>
* <li> PropertyMap(name = "listOfMaps")
* <ul>
* <li>PropertySimple(name = "k1", value = "value2")
* <li>PropertySimple(name = "k2", value = "value2")
* </ul>
* </ol>
* </ul>
* Notice that the members of the list have the same name as the list itself
* which generally is not the case.
*/
function asConfiguration(hash) {
config = new Configuration;
for(key in hash) {
value = hash[key];
if (value == null) {
continue;
}
(function(parent, key, value) {
function isArray(obj) {
return typeof(obj) == 'object' && (obj instanceof Array);
}
function isHash(obj) {
return typeof(obj) == 'object' && !(obj instanceof Array);
}
function isPrimitive(obj) {
return typeof(obj) != 'object';
}
//this is an anonymous function, so the only way it can call itself
//is by getting its reference via argument.callee. Let's just assign
//a shorter name for it.
var me = arguments.callee;
var prop = null;
if (isPrimitive(value)) {
prop = new PropertySimple(key, new java.lang.String(value));
} else if (isArray(value)) {
prop = new PropertyList(key);
for(var i = 0; i < value.length; ++i) {
var v = value[i];
if (v != null) {
me(prop, key, v);
}
}
} else if (isHash(value)) {
prop = new PropertyMap(key);
for(var i in value) {
var v = value[i];
if (value != null) {
me(prop, i, v);
}
}
}
if (parent instanceof PropertyList) {
parent.add(prop);
} else {
parent.put(prop);
}
})(config, key, value);
}
return config;
}
/**
* Opposite of <code>asConfiguration</code>. Converts an RHQ's configuration object
* into a javascript hash.
*
* @param configuration
*/
function asHash(configuration) {
ret = {}
iterator = configuration.getMap().values().iterator();
while(iterator.hasNext()) {
prop = iterator.next();
(function(parent, prop) {
function isArray(obj) {
return typeof(obj) == 'object' && (obj instanceof Array);
}
function isHash(obj) {
return typeof(obj) == 'object' && !(obj instanceof Array);
}
var me = arguments.callee;
var representation = null;
if (prop instanceof PropertySimple) {
representation = prop.stringValue;
} else if (prop instanceof PropertyList) {
representation = [];
for(var i = 0; i < prop.list.size(); ++i) {
var child = prop.list.get(i);
me(representation, child);
}
} else if (prop instanceof PropertyMap) {
representation = {};
var childIterator = prop.getMap().values().iterator();
while(childIterator.hasNext()) {
var child = childIterator.next();
me(representation, child);
}
}
if (isArray(parent)) {
parent.push(representation);
} else if (isHash(parent)) {
parent[prop.name] = representation;
}
})(ret, prop);
}
(function(parent) {
})(configuration);
return ret;
}
/**
* A simple function to create a new bundle version from a zip file containing
* the bundle.
*
* @param pathToBundleZipFile the path to the bundle on the local file system
*
* @return an instance of BundleVersion class describing what's been created on
* the RHQ server.
*/
function createBundleVersion(pathToBundleZipFile) {
var bytes = getFileBytes(pathToBundleZipFile)
return BundleManager.createBundleVersionViaByteArray(bytes)
}
/**
* This is a helper function that one can use to find out what base directories
* given resource type defines.
* <p>
* These base directories then can be used when specifying bundle destinations.
*
* @param resourceTypeId
* @returns a java.util.Set of ResourceTypeBundleConfiguration objects
*/
function getAllBaseDirectories(resourceTypeId) {
var crit = new ResourceTypeCriteria;
crit.addFilterId(resourceTypeId);
crit.fetchBundleConfiguration(true);
var types = ResourceTypeManager.findResourceTypesByCriteria(crit);
if (types.size() == 0) {
throw "Could not find a resource type with id " + resourceTypeId;
} else if (types.size() > 1) {
throw "More than one resource type found with id " + resourceTypeId + "! How did that happen!";
}
var type = types.get(0);
return type.getResourceTypeBundleConfiguration().getBundleDestinationBaseDirectories();
}
/**
* Creates a new destination for given bundle. Once a destination exists,
* actual bundle versions can be deployed to it.
* <p>
* Note that this only differs from the <code>BundleManager.createBundleDestination</code>
* method in the fact that one can provide bundle and resource group names instead of their
* ids.
*
* @param destinationName the name of the destination to be created
* @param description the description for the destination
* @param bundleName the name of the bundle to create the destination for
* @param groupName name of a group of resources that the destination will handle
* @param baseDirName the name of the basedir definition that represents where inside the
* deployment of the individual resources the bundle will get deployed
* @param deployDir the specific sub directory of the base dir where the bundles will get deployed
*
* @return BundleDestination object
*/
function createBundleDestination(destinationName, description, bundleName, groupName, baseDirName, deployDir) {
var groupCrit = new ResourceGroupCriteria;
groupCrit.addFilterName(groupName);
var groups = ResourceGroupManager.findResourceGroupsByCriteria(groupCrit);
if (groups.empty) {
throw "No group called '" + groupName + "' found.";
}
var group = groups.get(0);
var bundleCrit = new BundleCriteria;
bundleCrit.addFilterName(bundleName);
var bundles = BundleManager.findBundlesByCriteria(bundleCrit);
if (bundles.empty) {
throw "No bundle called '" + bundleName + "' found.";
}
var bundle = bundles.get(0);
return BundleManager.createBundleDestination(bundle.id, destinationName, description, baseDirName, deployDir, group.id);
}
/**
* Tries to deploy given bundle version to provided destination using given configuration.
* <p>
* This method blocks while waiting for the deployment to complete or fail.
*
* @param destination the bundle destination (or id thereof)
* @param bundleVersion the bundle version to deploy (or id thereof)
* @param deploymentConfiguration the deployment configuration. This can be an ordinary
* javascript object (hash) or an instance of RHQ's Configuration. If it is the former,
* it is converted to a Configuration instance using the <code>asConfiguration</code>
* function from <code>util.js</code>. Please consult the documentation of that method
* to understand the limitations of that approach.
* @param description the deployment description
* @param isCleanDeployment if true, perform a wipe of the deploy directory prior to the deployment; if false,
* perform as an upgrade to the existing deployment, if any
*
* @return the BundleDeployment instance describing the deployment
*/
function deployBundle(destination, bundleVersion, deploymentConfiguration, description, isCleanDeployment) {
var destinationId = destination;
if (typeof(destination) == 'object') {
destinationId = destination.id;
}
var bundleVersionId = bundleVersion;
if (typeof(bundleVersion) == 'object') {
bundleVersionId = bundleVersion.id;
}
var deploymentConfig = deploymentConfiguration;
if (!(deploymentConfiguration instanceof Configuration)) {
deploymentConfig = asConfiguration(deploymentConfiguration);
}
var deployment = BundleManager.createBundleDeployment(bundleVersionId, destinationId, description, deploymentConfig);
deployment = BundleManager.scheduleBundleDeployment(deployment.id, isCleanDeployment);
var crit = new BundleDeploymentCriteria;
crit.addFilterId(deployment.id);
while (deployment.status == BundleDeploymentStatus.PENDING || deployment.status == BundleDeploymentStatus.IN_PROGRESS) {
java.lang.Thread.currentThread().sleep(1000);
var dps = BundleManager.findBundleDeploymentsByCriteria(crit);
if (dps.empty) {
throw "The deployment disappeared while we were waiting for it to complete.";
}
deployment = dps.get(0);
}
return deployment;
}
var destinationId = 10002;
var bundleVersionId = 10002;
var deploymentConfig = null;
var description = "redeploy due to drift";
// NOTE: It's essential that isCleanDeployment=true, otherwise files that have drifted will not be replaced with their
// original versions from the bundle.
var isCleanDeployment = true;
deployBundle(10002, 10002, deploymentConfig, description, true);4.10. Running Drift Detection Manually
- Click the Inventory tab in the top menu.
- Search for the resource.
- Click the Drift tab.
- Select the drift definition to run the scan for.
- Click the button.
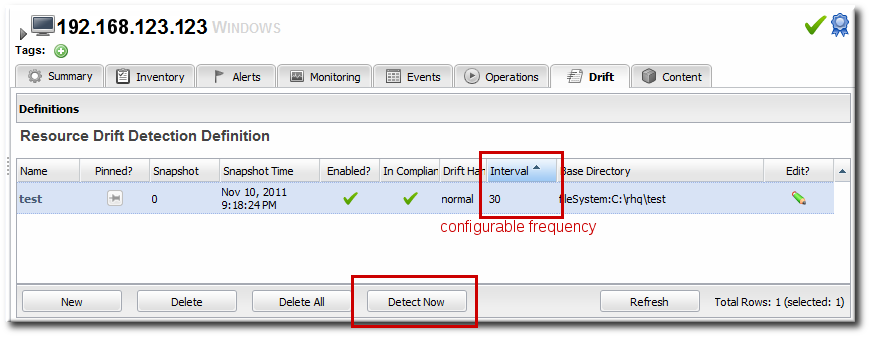
4.11. Setting Planned Changes or Disabling Drift Definitions
- Set the drift handling mode to planned changes. This keeps running drift detection scans and records changes. Since the changes are expected, though, it doesn't trigger a drift detection event, so it does not issue a drift alert.
- Actually disable the drift definition. This suspends the drift detection runs for the definition, not just drift events.
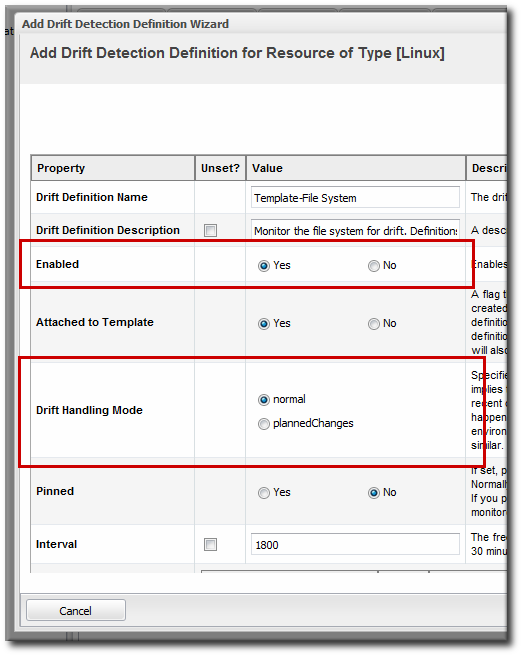
Figure 7. Drift Handling Mode and Enable Options
4.12. Understanding Drift and JBoss ON Agents and Servers
4.12.1. Drift Inventory
agentRoot/rhq-agent/data/ directory. The information in this directory is deleted if the agent is started with new configuration (--cleanconfig) or it can be intentionally purged (--purgedata). If the drift information is lost, then the agent requests the last snapshot from the JBoss ON server.
4.12.2. The Drift Server Plug-in
Warning
4.13. Managing Drift Definitions through the JBoss ON CLI
/rhq-remoting-cli-version#/samples/ directory.
5. Document Information
5.1. Document History
| Revision History | |||
|---|---|---|---|
| Revision 3.0.1-5 | 2013-10-31 | ||
| |||
| Revision 3.0.1-0 | March 18, 2012 | ||
| |||
| Revision 3.0-0 | December 7, 2011 | ||
| |||
Index
A
- Apache
- configuring for configuration management, Configuring Apache for Configuration Management
- auditing
- viewing configuration changes, Tracking and Comparing Configuration Changes
C
- CLI, Managing Drift Definitions through the JBoss ON CLI
- configuration
- Apache for configuration management, Configuring Apache for Configuration Management
- changing a single resource, Changing the Configuration on a Single Resource
- drift management, Managing Configuration Drift
- for groups, Changing the Configuration for a Compatible Group
- overview, Summary: Using JBoss ON to Make Changes in Resource Configuration
- reverting changes, Reverting Configuration Changes
- viewing and comparing changes, Tracking and Comparing Configuration Changes
- configuration drift, Managing Configuration Drift
D
- drift
G
- groups
- changing resource configuration, Changing the Configuration for a Compatible Group
R
- resources
- changing configuration for single resources, Changing the Configuration on a Single Resource
- changing group configuration, Changing the Configuration for a Compatible Group
- reverting configuration changes, Reverting Configuration Changes
- scripts as resources, Editing Script Environment Variables
- viewing configuration changes, Tracking and Comparing Configuration Changes
S
- scripts
- as resources, Editing Script Environment Variables
- symlinks, Destination Directories with Special File Types