
Red Hat Training
A Red Hat training course is available for Red Hat JBoss Enterprise Application Platform
23.2. Configuration
23.2.1. Minimum Configuration
Directory Provider must be configured, along with its properties. The default Directory Provider is filesystem, which uses the local filesystem for index storage. For details of available Directory Providers and their configuration, see Section 23.2.3, “DirectoryProvider Configuration”.
hibernate.properties or hibernate.cfg.xml. If you are using Hibernate via JPA the configuration file is persistence.xml.
23.2.2. Configuring the IndexManager
directory-based: the default implementation which uses the LuceneDirectoryabstraction to manage index files.near-real-time: avoids flushing writes to disk at each commit. This index manager is alsoDirectorybased, but uses Lucene's near real-time (NRT) functionality.
hibernate.search.[default|<indexname>].indexmanager = near-real-time
23.2.2.1. Directory-based
Directory-based implementation is the default IndexManager implementation. It is highly configurable and allows separate configurations for the reader strategy, back ends, and directory providers.
23.2.2.2. Near Real Time
NRTIndexManager is an extension of the default IndexManager and leverages the Lucene NRT (Near Real Time) feature for low latency index writes. However, it ignores configuration settings for alternative back ends other than lucene and acquires exclusive write locks on the Directory.
IndexWriter does not flush every change to the disk to provide low latency. Queries can read the updated states from the unflushed index writer buffers. However, this means that if the IndexWriter is killed or the application crashes, updates can be lost so the indexes must be rebuilt.
23.2.2.3. Custom
IndexManager. Set up a no-argument constructor for the implementation as follows:
[default|<indexname>].indexmanager = my.corp.myapp.CustomIndexManager
Directory interface.
23.2.3. DirectoryProvider Configuration
DirectoryProvider is the Hibernate Search abstraction around a Lucene Directory and handles the configuration and the initialization of the underlying Lucene resources. Directory Providers and their Properties shows the list of the directory providers available in Hibernate Search together with their corresponding options.
index property of the @Indexed annotation. If the index property is not specified the fully qualified name of the indexed class will be used as name (recommended).
hibernate.search.<indexname>. The name default (hibernate.search.default) is reserved and can be used to define properties which apply to all indexes. Example 23.2, “Configuring Directory Providers” shows how hibernate.search.default.directory_provider is used to set the default directory provider to be the filesystem one. hibernate.search.default.indexBase sets then the default base directory for the indexes. As a result the index for the entity Status is created in /usr/lucene/indexes/org.hibernate.example.Status.
Rule entity, however, is using an in-memory directory, because the default directory provider for this entity is overridden by the property hibernate.search.Rules.directory_provider.
Action entity uses a custom directory provider CustomDirectoryProvider specified via hibernate.search.Actions.directory_provider.
Example 23.1. Specifying the Index Name
package org.hibernate.example;
@Indexed
public class Status { ... }
@Indexed(index="Rules")
public class Rule { ... }
@Indexed(index="Actions")
public class Action { ... }Example 23.2. Configuring Directory Providers
hibernate.search.default.directory_provider = filesystem hibernate.search.default.indexBase=/usr/lucene/indexes hibernate.search.Rules.directory_provider = ram hibernate.search.Actions.directory_provider = com.acme.hibernate.CustomDirectoryProvider
Note
Directory Providers and their Properties
- ram
- None
- filesystem
- File system based directory. The directory used will be <indexBase>/< indexName >
indexBase: base directoryindexName: override @Indexed.index (useful for sharded indexes)locking_strategy: optional, see Section 23.2.7, “LockFactory Configuration”filesystem_access_type: allows to determine the exact type ofFSDirectoryimplementation used by thisDirectoryProvider. Allowed values areauto(the default value, selectsNIOFSDirectoryon non Windows systems,SimpleFSDirectoryon Windows),simple(SimpleFSDirectory),nio(NIOFSDirectory),mmap(MMapDirectory). Refer to Javadocs of theseDirectoryimplementations before changing this setting. Even thoughNIOFSDirectoryorMMapDirectorycan bring substantial performance boosts they also have their issues.
- filesystem-master
- File system based directory. Like
filesystem. It also copies the index to a source directory (aka copy directory) on a regular basis.The recommended value for the refresh period is (at least) 50% higher that the time to copy the information (default 3600 seconds - 60 minutes).Note that the copy is based on an incremental copy mechanism reducing the average copy time.DirectoryProvider typically used on the master node in a JMS back end cluster.Thebuffer_size_on_copyoptimum depends on your operating system and available RAM; most people reported good results using values between 16 and 64MB.indexBase: base directoryindexName: override @Indexed.index (useful for sharded indexes)sourceBase: source (copy) base directory.source: source directory suffix (default to@Indexed.index). The actual source directory name being<sourceBase>/<source>refresh: refresh period in seconds (the copy will take place everyrefreshseconds). If a copy is still in progress when the followingrefreshperiod elapses, the second copy operation will be skipped.buffer_size_on_copy: The amount of MegaBytes to move in a single low level copy instruction; defaults to 16MB.locking_strategy: optional, see Section 23.2.7, “LockFactory Configuration”filesystem_access_type: allows to determine the exact type ofFSDirectoryimplementation used by thisDirectoryProvider. Allowed values areauto(the default value, selectsNIOFSDirectoryon non Windows systems,SimpleFSDirectoryon Windows),simple(SimpleFSDirectory),nio(NIOFSDirectory),mmap(MMapDirectory). Refer to Javadocs of theseDirectoryimplementations before changing this setting. Even thoughNIOFSDirectoryorMMapDirectorycan bring substantial performance boosts, there are also issues of which you need to be aware.
- filesystem-slave
- File system based directory. Like
filesystem, but retrieves a master version (source) on a regular basis. To avoid locking and inconsistent search results, 2 local copies are kept.The recommended value for the refresh period is (at least) 50% higher that the time to copy the information (default 3600 seconds - 60 minutes).Note that the copy is based on an incremental copy mechanism reducing the average copy time. If a copy is still in progress whenrefreshperiod elapses, the second copy operation will be skipped.DirectoryProvider typically used on slave nodes using a JMS back end.Thebuffer_size_on_copyoptimum depends on your operating system and available RAM; most people reported good results using values between 16 and 64MB.indexBase: Base directoryindexName: override @Indexed.index (useful for sharded indexes)sourceBase: Source (copy) base directory.source: Source directory suffix (default to@Indexed.index). The actual source directory name being<sourceBase>/<source>refresh: refresh period in second (the copy will take place every refresh seconds).buffer_size_on_copy: The amount of MegaBytes to move in a single low level copy instruction; defaults to 16MB.locking_strategy: optional, see Section 23.2.7, “LockFactory Configuration”retry_marker_lookup: optional, default to 0. Defines how many times Hibernate Search checks for the marker files in the source directory before failing. Waiting 5 seconds between each try.retry_initialize_period: optional, set an integer value in seconds to enable the retry initialize feature: if the slave can't find the master index it will try again until it's found in background, without preventing the application to start: fullText queries performed before the index is initialized are not blocked but will return empty results. When not enabling the option or explicitly setting it to zero it will fail with an exception instead of scheduling a retry timer. To prevent the application from starting without an invalid index but still control an initialization timeout, seeretry_marker_lookupinstead.filesystem_access_type: allows to determine the exact type ofFSDirectoryimplementation used by thisDirectoryProvider. Allowed values areauto(the default value, selectsNIOFSDirectoryon non Windows systems,SimpleFSDirectoryon Windows),simple(SimpleFSDirectory),nio(NIOFSDirectory),mmap(MMapDirectory). Refer to Javadocs of theseDirectoryimplementations before changing this setting. Even thoughNIOFSDirectoryorMMapDirectorycan bring substantial performance boosts you need also to be aware of the issues.
Note
org.hibernate.store.DirectoryProvider interface. In this case, pass the fully qualified class name of your provider into the directory_provider property. You can pass any additional properties using the prefix hibernate.search.<indexname>.
23.2.4. Sharding Indexes
Warning
- A single index is so large that index update times are slowing the application down.
- A typical search will only hit a subset of the index, such as when data is naturally segmented by customer, region or application.
hibernate.search.<indexName>.sharding_strategy.nbr_of_shards property.
Example 23.3. Enabling Index Sharding
hibernate.search.<indexName>.sharding_strategy.nbr_of_shards = 5
IndexShardingStrategy. The default sharding strategy splits the data according to the hash value of the ID string representation (generated by the FieldBridge). This ensures a fairly balanced sharding. You can replace the default strategy by implementing a custom IndexShardingStrategy. To use your custom strategy you have to set the hibernate.search.<indexName>.sharding_strategy property.
Example 23.4. Specifying a Custom Sharding Strategy
hibernate.search.<indexName>.sharding_strategy = my.shardingstrategy.Implementation
IndexShardingStrategy property also allows for optimizing searches by selecting which shard to run the query against. By activating a filter a sharding strategy can select a subset of the shards used to answer a query (IndexShardingStrategy.getIndexManagersForQuery) and thus speed up the query execution.
IndexManager and so can be configured to use a different directory provider and back end configuration. The IndexManager index names for the Animal entity in Example 23.5, “Sharding Configuration for Entity Animal” are Animal.0 to Animal.4. In other words, each shard has the name of its owning index followed by . (dot) and its index number.
Example 23.5. Sharding Configuration for Entity Animal
hibernate.search.default.indexBase = /usr/lucene/indexes hibernate.search.Animal.sharding_strategy.nbr_of_shards = 5 hibernate.search.Animal.directory_provider = filesystem hibernate.search.Animal.0.indexName = Animal00 hibernate.search.Animal.3.indexBase = /usr/lucene/sharded hibernate.search.Animal.3.indexName = Animal03
Animal index into 5 sub-indexes. All sub-indexes are filesystem instances and the directory where each sub-index is stored is as followed:
- for sub-index 0:
/usr/lucene/indexes/Animal00(shared indexBase but overridden indexName) - for sub-index 1:
/usr/lucene/indexes/Animal.1(shared indexBase, default indexName) - for sub-index 2:
/usr/lucene/indexes/Animal.2(shared indexBase, default indexName) - for sub-index 3:
/usr/lucene/shared/Animal03(overridden indexBase, overridden indexName) - for sub-index 4:
/usr/lucene/indexes/Animal.4(shared indexBase, default indexName)
IndexShardingStrategy any field can be used to determine the sharding selection. Consider that to handle deletions, purge and purgeAll operations, the implementation might need to return one or more indexes without being able to read all the field values or the primary identifier. In that case the information is not enough to pick a single index, all indexes should be returned, so that the delete operation will be propagated to all indexes potentially containing the documents to be deleted.
23.2.5. Worker Configuration
Worker. An implementation of the Worker interface is responsible for receiving all entity changes, queuing them by context and applying them once a context ends. The most intuitive context, especially in connection with ORM, is the transaction. For this reason Hibernate Search will per default use the TransactionalWorker to scope all changes per transaction. One can, however, imagine a scenario where the context depends for example on the number of entity changes or some other application (lifecycle) events. For this reason the Worker implementation is configurable as shown in Table 23.1, “Scope configuration”.
Table 23.1. Scope configuration
| Property | Description |
| hibernate.search.worker.scope | The fully qualified class name of the Worker implementation to use. If this property is not set, empty or transaction the default TransactionalWorker is used. |
| hibernate.search.worker.* | All configuration properties prefixed with hibernate.search.worker are passed to the Worker during initialization. This allows adding custom, worker specific parameters. |
| hibernate.search.worker.batch_size | Defines the maximum number of indexing operation batched per context. Once the limit is reached indexing will be triggered even though the context has not ended yet. This property only works if the Worker implementation delegates the queued work to BatchedQueueingProcessor (which is what the TransactionalWorker does) |
Note
default to set the default value for all indexes.
Table 23.2. Execution configuration
| Property | Description |
| hibernate.search.<indexName>.worker.execution | sync: synchronous execution (default)
async: asynchronous execution
|
| hibernate.search.<indexName>.worker.thread_pool.size | The backend can apply updates from the same transaction context (or batch) in parallel, using a threadpool. The default value is 1. You can experiment with larger values if you have many operations per transaction. |
| hibernate.search.<indexName>.worker.buffer_queue.max | Defines the maximal number of work queue if the thread poll is starved. Useful only for asynchronous execution. Default to infinite. If the limit is reached, the work is done by the main thread. |
Table 23.3. Backend configuration
| Property | Description |
| hibernate.search.<indexName>.worker.backend | lucene: The default backend which runs index updates in the same VM. Also used when the property is undefined or empty.
jms: JMS backend. Index updates are send to a JMS queue to be processed by an indexing master. See Table 23.4, “JMS backend configuration” for additional configuration options and Section 23.2.5.1, “JMS Master/Slave Back End” for a more detailed description of this setup.
blackhole: Mainly a test/developer setting which ignores all indexing work
You can also specify the fully qualified name of a class implementing
BackendQueueProcessor. This way you can implement your own communication layer. The implementation is responsible for returning a Runnable instance which on execution will process the index work.
|
Table 23.4. JMS backend configuration
| Property | Description |
|---|---|
| hibernate.search.<indexName>.worker.jndi.* | Defines the JNDI properties to initiate the InitialContext (if needed). JNDI is only used by the JMS back end. |
| hibernate.search.<indexName>.worker.jms.connection_factory | Mandatory for the JMS back end. Defines the JNDI name to lookup the JMS connection factory from (/ConnectionFactory by default in Red Hat JBoss Enterprise Application Platform) |
| hibernate.search.<indexName>.worker.jms.queue | Mandatory for the JMS back end. Defines the JNDI name to lookup the JMS queue from. The queue will be used to post work messages. |
Warning
Worker or BackendQueueProcessor implementation.
23.2.5.1. JMS Master/Slave Back End
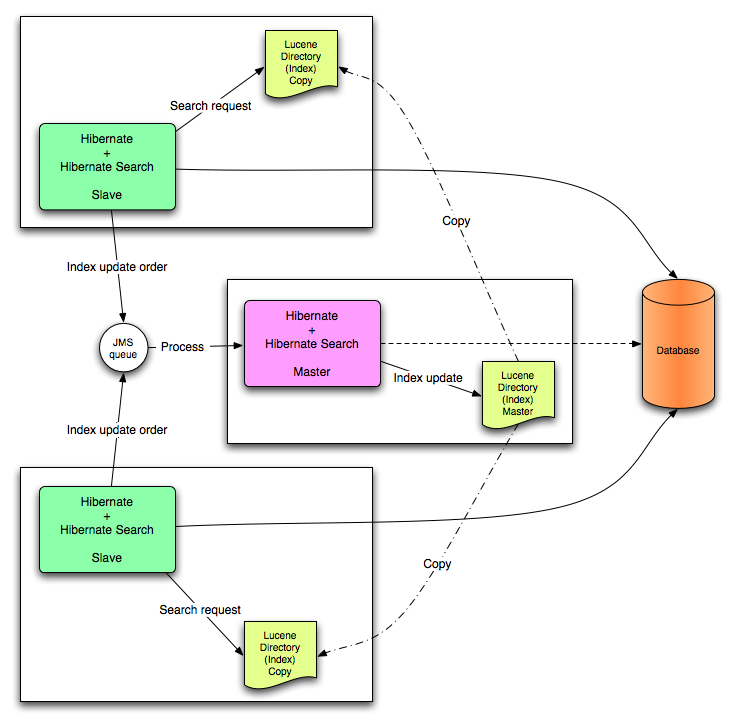
Figure 23.3. JMS Backend Configuration
23.2.5.2. Slave Nodes
Example 23.6. JMS Slave configuration
### slave configuration ## DirectoryProvider # (remote) master location hibernate.search.default.sourceBase = /mnt/mastervolume/lucenedirs/mastercopy # local copy location hibernate.search.default.indexBase = /Users/prod/lucenedirs # refresh every half hour hibernate.search.default.refresh = 1800 # appropriate directory provider hibernate.search.default.directory_provider = filesystem-slave ## Backend configuration hibernate.search.default.worker.backend = jms hibernate.search.default.worker.jms.connection_factory = /ConnectionFactory hibernate.search.default.worker.jms.queue = queue/hibernatesearch #optional jndi configuration (check your JMS provider for more information) ## Optional asynchronous execution strategy # hibernate.search.default.worker.execution = async # hibernate.search.default.worker.thread_pool.size = 2 # hibernate.search.default.worker.buffer_queue.max = 50
Note
23.2.5.3. Master Node
Example 23.7. JMS Master configuration
### master configuration ## DirectoryProvider # (remote) master location where information is copied to hibernate.search.default.sourceBase = /mnt/mastervolume/lucenedirs/mastercopy # local master location hibernate.search.default.indexBase = /Users/prod/lucenedirs # refresh every half hour hibernate.search.default.refresh = 1800 # appropriate directory provider hibernate.search.default.directory_provider = filesystem-master ## Backend configuration #Backend is the default lucene one
Example 23.8. Message Driven Bean processing the indexing queue
@MessageDriven(activationConfig = {
@ActivationConfigProperty(propertyName="destinationType",
propertyValue="javax.jms.Queue"),
@ActivationConfigProperty(propertyName="destination",
propertyValue="queue/hibernatesearch"),
@ActivationConfigProperty(propertyName="DLQMaxResent", propertyValue="1")
} )
public class MDBSearchController extends AbstractJMSHibernateSearchController
implements MessageListener {
@PersistenceContext EntityManager em;
//method retrieving the appropriate session
protected Session getSession() {
return (Session) em.getDelegate();
}
//potentially close the session opened in #getSession(), not needed here
protected void cleanSessionIfNeeded(Session session)
}
}getSession() and cleanSessionIfNeeded(), see AbstractJMSHibernateSearchController's javadoc.
23.2.6. Tuning Lucene Indexing
23.2.6.1. Tuning Lucene Indexing Performance
IndexWriter such as mergeFactor, maxMergeDocs, and maxBufferedDocs. Specify these parameters either as default values applying for all indexes, on a per index basis, or even per shard.
IndexWriter settings which can be tuned for different use cases. These parameters are grouped by the indexwriter keyword:
hibernate.search.[default|<indexname>].indexwriter.<parameter_name>
indexwriter value in a specific shard configuration, Hibernate Search checks the index section, then at the default section.
Animal index:
max_merge_docs= 10merge_factor= 20ram_buffer_size= 64MBterm_index_interval= Lucene default
2.4. For more information about Lucene indexing performance, see the Lucene documentation.
Note
batch and transaction properties. This is no longer the case as the backend will always perform work using the same settings.
Table 23.5. List of indexing performance and behavior properties
| Property | Description | Default Value |
|---|---|---|
|
hibernate.search.[default|<indexname>].exclusive_index_use
|
Set to
true when no other process will need to write to the same index. This enables Hibernate Search to work in exclusive mode on the index and improve performance when writing changes to the index.
| true (improved performance, releases locks only at shutdown) |
|
hibernate.search.[default|<indexname>].max_queue_length
|
Each index has a separate "pipeline" which contains the updates to be applied to the index. When this queue is full adding more operations to the queue becomes a blocking operation. Configuring this setting doesn't make much sense unless the
worker.execution is configured as async.
| 1000 |
|
hibernate.search.[default|<indexname>].indexwriter.max_buffered_delete_terms
|
Determines the minimal number of delete terms required before the buffered in-memory delete terms are applied and flushed. If there are documents buffered in memory at the time, they are merged and a new segment is created.
| Disabled (flushes by RAM usage) |
|
hibernate.search.[default|<indexname>].indexwriter.max_buffered_docs
|
Controls the amount of documents buffered in memory during indexing. The bigger the more RAM is consumed.
| Disabled (flushes by RAM usage) |
|
hibernate.search.[default|<indexname>].indexwriter.max_merge_docs
|
Defines the largest number of documents allowed in a segment. Smaller values perform better on frequently changing indexes, larger values provide better search performance if the index does not change often.
| Unlimited (Integer.MAX_VALUE) |
|
hibernate.search.[default|<indexname>].indexwriter.merge_factor
|
Controls segment merge frequency and size.
Determines how often segment indexes are merged when insertion occurs. With smaller values, less RAM is used while indexing, and searches on unoptimized indexes are faster, but indexing speed is slower. With larger values, more RAM is used during indexing, and while searches on unoptimized indexes are slower, indexing is faster. Thus larger values (> 10) are best for batch index creation, and smaller values (< 10) for indexes that are interactively maintained. The value must not be lower than 2.
| 10 |
|
hibernate.search.[default|<indexname>].indexwriter.merge_min_size
|
Controls segment merge frequency and size.
Segments smaller than this size (in MB) are always considered for the next segment merge operation.
Setting this too large might result in expensive merge operations, even tough they are less frequent.
See also
org.apache.lucene.index.LogDocMergePolicy. minMergeSize.
| 0 MB (actually ~1K) |
|
hibernate.search.[default|<indexname>].indexwriter.merge_max_size
|
Controls segment merge frequency and size.
Segments larger than this size (in MB) are never merged in bigger segments.
This helps reduce memory requirements and avoids some merging operations at the cost of optimal search speed. When optimizing an index this value is ignored.
See also
org.apache.lucene.index.LogDocMergePolicy. maxMergeSize.
| Unlimited |
|
hibernate.search.[default|<indexname>].indexwriter.merge_max_optimize_size
|
Controls segment merge frequency and size.
Segments larger than this size (in MB) are not merged in bigger segments even when optimizing the index (see
merge_max_size setting as well).
Applied to
org.apache.lucene.index.LogDocMergePolicy. maxMergeSizeForOptimize.
| Unlimited |
|
hibernate.search.[default|<indexname>].indexwriter.merge_calibrate_by_deletes
|
Controls segment merge frequency and size.
Set to
false to not consider deleted documents when estimating the merge policy.
Applied to
org.apache.lucene.index.LogMergePolicy. calibrateSizeByDeletes.
| true |
|
hibernate.search.[default|<indexname>].indexwriter.ram_buffer_size
|
Controls the amount of RAM in MB dedicated to document buffers. When used together max_buffered_docs a flush occurs for whichever event happens first.
Generally for faster indexing performance it's best to flush by RAM usage instead of document count and use as large a RAM buffer as you can.
| 16 MB |
|
hibernate.search.[default|<indexname>].indexwriter.term_index_interval
|
Expert: Set the interval between indexed terms.
Large values cause less memory to be used by IndexReader, but slow random-access to terms. Small values cause more memory to be used by an IndexReader, and speed random-access to terms. See Lucene documentation for more details.
| 128 |
|
hibernate.search.[default|<indexname>].indexwriter.use_compound_file
| The advantage of using the compound file format is that less file descriptors are used. The disadvantage is that indexing takes more time and temporary disk space. You can set this parameter to false in an attempt to improve the indexing time, but you could run out of file descriptors if mergeFactor is also large.
Boolean parameter, use "
true" or "false". The default value for this option is true.
| true |
|
hibernate.search.enable_dirty_check
|
Not all entity changes require a Lucene index update. If all of the updated entity properties (dirty properties) are not indexed, Hibernate Search skips the re-indexing process.
Disable this option if you use custom
FieldBridges which need to be invoked at each update event (even though the property for which the field bridge is configured has not changed).
This optimization will not be applied on classes using a
@ClassBridge or a @DynamicBoost.
Boolean parameter, use "
true" or "false". The default value for this option is true.
| true |
Warning
blackhole backend is not meant to be used in production, only as a tool to identify indexing bottlenecks.
23.2.6.2. The Lucene IndexWriter
IndexWriter settings which can be tuned for different use cases. These parameters are grouped by the indexwriter keyword:
default.<indexname>.indexwriter.<parameter_name>
indexwriter in a shard configuration, Hibernate Search looks at the index section and then at the default section.
23.2.6.3. Performance Option Configuration
Animal index:
Example 23.9. Example performance option configuration
default.Animals.2.indexwriter.max_merge_docs = 10 default.Animals.2.indexwriter.merge_factor = 20 default.Animals.2.indexwriter.term_index_interval = default default.indexwriter.max_merge_docs = 100 default.indexwriter.ram_buffer_size = 64
max_merge_docs= 10merge_factor= 20ram_buffer_size= 64MBterm_index_interval= Lucene default
2.4. For more information about Lucene indexing performance, see the Lucene documentation.
Note
Table 23.6. List of indexing performance and behavior properties
| Property | Description | Default Value |
|---|---|---|
|
default.<indexname>.exclusive_index_use
|
Set to
true when no other process will need to write to the same index. This enables Hibernate Search to work in exclusive mode on the index and improve performance when writing changes to the index.
| true (improved performance, releases locks only at shutdown) |
|
default.<indexname>.max_queue_length
|
Each index has a separate "pipeline" which contains the updates to be applied to the index. When this queue is full adding more operations to the queue becomes a blocking operation. Configuring this setting doesn't make much sense unless the
worker.execution is configured as async.
| 1000 |
|
default.<indexname>.indexwriter.max_buffered_delete_terms
|
Determines the minimal number of delete terms required before the buffered in-memory delete terms are applied and flushed. If there are documents buffered in memory at the time, they are merged and a new segment is created.
| Disabled (flushes by RAM usage) |
|
default.<indexname>.indexwriter.max_buffered_docs
|
Controls the amount of documents buffered in memory during indexing. The bigger the more RAM is consumed.
| Disabled (flushes by RAM usage) |
|
default.<indexname>.indexwriter.max_merge_docs
|
Defines the largest number of documents allowed in a segment. Smaller values perform better on frequently changing indexes, larger values provide better search performance if the index does not change often.
| Unlimited (Integer.MAX_VALUE) |
|
default.<indexname>.indexwriter.merge_factor
|
Controls segment merge frequency and size.
Determines how often segment indexes are merged when insertion occurs. With smaller values, less RAM is used while indexing, and searches on unoptimized indexes are faster, but indexing speed is slower. With larger values, more RAM is used during indexing, and while searches on unoptimized indexes are slower, indexing is faster. Thus larger values (> 10) are best for batch index creation, and smaller values (< 10) for indexes that are interactively maintained. The value must not be lower than 2.
| 10 |
|
default.<indexname>.indexwriter.merge_min_size
|
Controls segment merge frequency and size.
Segments smaller than this size (in MB) are always considered for the next segment merge operation.
Setting this too large might result in expensive merge operations, even tough they are less frequent.
See also
org.apache.lucene.index.LogDocMergePolicy. minMergeSize.
| 0 MB (actually ~1K) |
|
default.<indexname>.indexwriter.merge_max_size
|
Controls segment merge frequency and size.
Segments larger than this size (in MB) are never merged in bigger segments.
This helps reduce memory requirements and avoids some merging operations at the cost of optimal search speed. When optimizing an index this value is ignored.
See also
org.apache.lucene.index.LogDocMergePolicy. maxMergeSize.
| Unlimited |
|
default.<indexname>.indexwriter.merge_max_optimize_size
|
Controls segment merge frequency and size.
Segments larger than this size (in MB) are not merged in bigger segments even when optimizing the index (see
merge_max_size setting as well).
Applied to
org.apache.lucene.index.LogDocMergePolicy. maxMergeSizeForOptimize.
| Unlimited |
|
default.<indexname>.indexwriter.merge_calibrate_by_deletes
|
Controls segment merge frequency and size.
Set to
false to not consider deleted documents when estimating the merge policy.
Applied to
org.apache.lucene.index.LogMergePolicy. calibrateSizeByDeletes.
| true |
|
default.<indexname>.indexwriter.ram_buffer_size
|
Controls the amount of RAM in MB dedicated to document buffers. When used together max_buffered_docs a flush occurs for whichever event happens first.
Generally for faster indexing performance it's best to flush by RAM usage instead of document count and use as large a RAM buffer as you can.
| 16 MB |
|
default.<indexname>.indexwriter.term_index_interval
|
Expert: Set the interval between indexed terms.
Large values cause less memory to be used by IndexReader, but slow random-access to terms. Small values cause more memory to be used by an IndexReader, and speed random-access to terms. See Lucene documentation for more details.
| 128 |
|
default.<indexname>.indexwriter.use_compound_file
| The advantage of using the compound file format is that less file descriptors are used. The disadvantage is that indexing takes more time and temporary disk space. You can set this parameter to false in an attempt to improve the indexing time, but you could run out of file descriptors if mergeFactor is also large.
Boolean parameter, use "
true" or "false". The default value for this option is true.
| true |
|
default.enable_dirty_check
|
Not all entity changes require a Lucene index update. If all of the updated entity properties (dirty properties) are not indexed, Hibernate Search skips the re-indexing process.
Disable this option if you use custom
FieldBridges which need to be invoked at each update event (even though the property for which the field bridge is configured has not changed).
This optimization will not be applied on classes using a
@ClassBridge or a @DynamicBoost.
Boolean parameter, use "
true" or "false". The default value for this option is true.
| true |
23.2.6.4. Tuning the Indexing Speed
default.exclusive_index_use=true for improved index writing efficiency.
blackhole as worker back end and start your indexing routines. This back end does not disable Hibernate Search: it generates the required change sets to the index, but discards them instead of flushing them to the index. In contrast to setting the hibernate.search.indexing_strategy to manual, using blackhole will possibly load more data from the database because associated entities are re-indexed as well.
hibernate.search.[default|<indexname>].worker.backend blackhole
Warning
blackhole back end is not to be used in production, only as a diagnostic tool to identify indexing bottlenecks.
23.2.6.5. Control Segment Size
merge_max_sizemerge_max_optimize_sizemerge_calibrate_by_deletes
Example 23.10. Control Segment Size
//to be fairly confident no files grow above 15MB, use: hibernate.search.default.indexwriter.ram_buffer_size = 10 hibernate.search.default.indexwriter.merge_max_optimize_size = 7 hibernate.search.default.indexwriter.merge_max_size = 7
max_size for merge operations to less than half of the hard limit segment size, as merging segments combines two segments into one larger segment.
ram_buffer_size. This threshold is checked as an estimate.
23.2.7. LockFactory Configuration
LockingFactory for each index managed by Hibernate Search.
IndexBase configuration option must be specified to point to a filesystem location in which to store the lock marker files.
hibernate.search.<index>.locking_strategy option to one the following options:
simplenativesinglenone
Table 23.7. List of available LockFactory implementations
| name | Class | Description |
|---|---|---|
| simple | org.apache.lucene.store.SimpleFSLockFactory |
Safe implementation based on Java's File API, it marks the usage of the index by creating a marker file.
If for some reason you had to kill your application, you will need to remove this file before restarting it.
|
| native | org.apache.lucene.store.NativeFSLockFactory |
As does
simple this also marks the usage of the index by creating a marker file, but this one is using native OS file locks so that even if the JVM is terminated the locks will be cleaned up.
This implementation has known problems on NFS, avoid it on network shares.
native is the default implementation for the filesystem, filesystem-master and filesystem-slave directory providers.
|
| single | org.apache.lucene.store.SingleInstanceLockFactory |
This LockFactory doesn't use a file marker but is a Java object lock held in memory; therefore it's possible to use it only when you are sure the index is not going to be shared by any other process.
This is the default implementation for the
ram directory provider.
|
| none | org.apache.lucene.store.NoLockFactory |
Changes to this index are not coordinated by a lock.
|
hibernate.search.default.locking_strategy = simple hibernate.search.Animals.locking_strategy = native hibernate.search.Books.locking_strategy = org.custom.components.MyLockingFactory
23.2.8. Exception Handling Configuration
hibernate.search.error_handler = log
ErrorHandler interface, which provides the handle(ErrorContext context) method. ErrorContext provides a reference to the primary LuceneWork instance, the underlying exception and any subsequent LuceneWork instances that could not be processed due to the primary exception.
public interface ErrorContext {
List<LuceneWork> getFailingOperations();
LuceneWork getOperationAtFault();
Throwable getThrowable();
boolean hasErrors();
}
ErrorHandler implementation in the configuration properties:
hibernate.search.error_handler = CustomerErrorHandler
23.2.9. Index Format Compatibility
Warning
hibernate.search.lucene_version configuration property. This property instructs Analyzers and other Lucene classes to conform to their behaviour as defined in an older version of Lucene. See also org.apache.lucene.util.Version contained in the lucene-core.jar. If the option is not specified, Hibernate Search instructs Lucene to use the version default. It is recommended that the version used is explicitly defined in the configuration to prevent automatic changes when an upgrade occurs. After an upgrade, the configuration values can be updated explicitly if required.
Example 23.11. Force Analyzers to be compatible with a Lucene 3.0 created index
hibernate.search.lucene_version = LUCENE_30
SearchFactory is global and affects all Lucene APIs that contain the relevant parameter. If Lucene is used and Hibernate Search is bypassed, apply the same value to it for consistent results.
23.2.10. Disable Hibernate Search
To disable Hibernate Search indexing, change the indexing_strategy configuration option to manual, then restart JBoss EAP.
hibernate.search.indexing_strategy = manual
To disable Hibernate Search completely, disable all listeners by changing the autoregister_listeners configuration option to false, then restart JBoss EAP.
hibernate.search.autoregister_listeners = false