
Red Hat Training
A Red Hat training course is available for Red Hat JBoss Data Virtualization
3.4. Clustering
You can create a hierarchical database repository that stands alone and is self-contained, or you can create a cluster of repositories that all work together to ensure all content is accessible to each of the repositories.
When you create a cluster, a client talking to any of the processes in the cluster will see exactly the same content and the same events. In fact, from a client perspective, there is no difference between talking to a repository that is clustered versus one that is not.
The hierarchical database can be clustered in a variety of ways, but the biggest decision will be to determine where to store the content. Much of this flexibility comes from the power and flexibility of Infinispan, which can use a variety of topologies.
3.4.1. Local Caching
In a local mode, the hierarchical database is not clustered at all. This is the default, so if you do not tell both the database and Infinispan to cluster, each process will happily operate without communicating or sharing any content. Updates on one process will not be visible to any of the other processes.
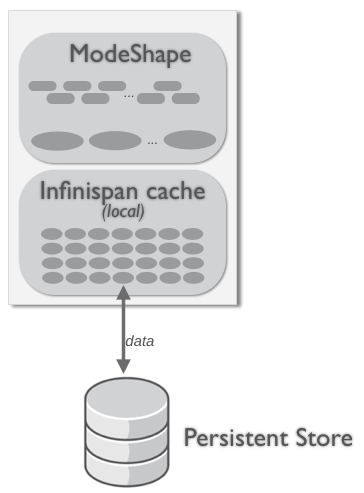
Figure 3.3. Local topology
Note that in the local, non-clustered topology data must be persisted to disk or some other system. Otherwise, if the hierarchical database process terminates, all data will be lost.
3.4.2. Replicated Clustering
The simplest clustering topology is to have each replicate all content across each member of the cluster. This means that each cluster member has its own storage for content, binaries, and indexes - nothing is shared. However, hierarchical database (and Infinispan) processes in the cluster communicate to ensure that locks are acquired as necessary and that committed changes in each member are replicated to all other members of the cluster.
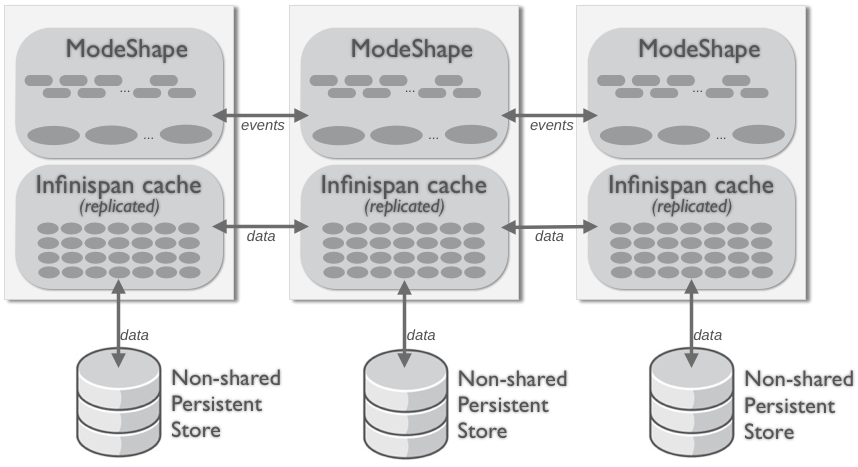
Figure 3.4. Replicated cluster topology with non-shared storage
The advantage of this topology is that each member of the cluster has a complete set of content, so all reads can be satisfied with locally-held data. This works great for small to medium-sized repositories. Additionally, because repositories share nothing, it is simple to add or remove cluster instances.
Replication works well for repositories with fairly large amounts of content, and with relatively few members of the cluster. Typically replication is used when you want clustering for fault-tolerance purpose, to handle larger workloads of clients, or when the hardware is not terribly powerful.
Note that the diagram above shows that each process has its own non-shared persistent store. Persistently storing the content is recommended, typically because all of the cluster members will likely be in a single data center and thus share some risk of common failure.
However, it is also possible to avoid persistent storage altogether, since the data is copied to multiple locations. But it is also possible for all of the members to share a persistent store, as long as that persistent store is transactional and capable of coordinating multiple concurrent operations. (An example of this is a relational database.)

Figure 3.5. Replicated cluster topology with shared storage
3.4.3. Distributed Clustering
With larger cluster sizes, however, it is not as efficient for every member in the cluster to have a complete copy of all of the data. Additionally, the overhead of coordination of locks and inter-process communication starts to grow. This is when the distributed cluster topology becomes very advantageous.
In a distributed cluster, each piece of data is owned/managed by more than two members but fewer than the total size of the cluster. In other words, each bit of data is distributed across enough members so that no data will be lost if members catastrophically fail. And because of this, you can choose to not use persistent storage but to instead rely upon the multiple copies of the in-memory data, especially if the cluster is hosted in multiple data centers (or sites). In fact, a distributed cluster can have a very large number of members.
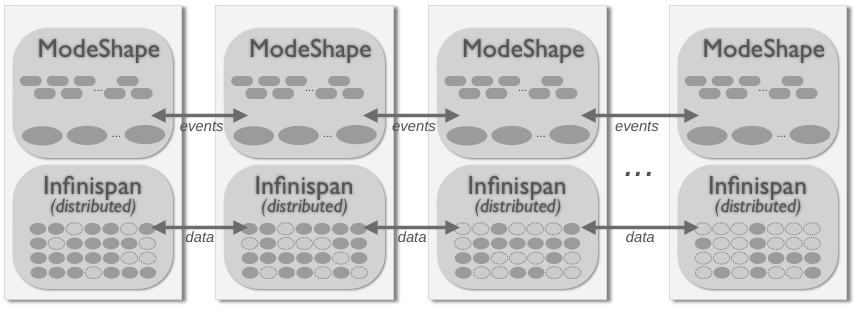
Figure 3.6. Distributed cluster topology
In this scenario, when a client requests some node or binary value, the hierarchical database (via Infinispan) looks to see which member owns the node and forwards the request to that node. (Each repository instance maintains a cache of nodes, so subsequent reads of the same node will be very quick.)
3.4.4. Remote Clustering
The final topology is to cluster the hierarchical database as normal but to configure Infinispan to use a remote data grid. The benefit here is that the data grid is a self contained and separately managed system, and all of the specifics of the Infinispan configuration can be hidden by the data grid. Additionally, the data grid could itself be replicated or distributed across one or multiple physical sites.
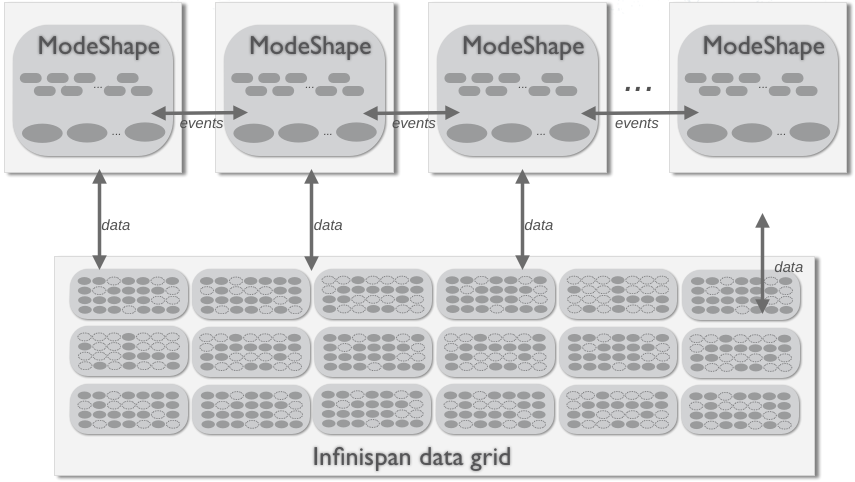
Figure 3.7. Cluster topology with remote (data grid) storage
Because of differences in the remote and local Infinispan interfaces, the only way to get this to work is to use a local cache with a remote cache store.