
Chapter 11. Data Virtualization Architecture
- Transport
- Transport services manage client connections: security authentication, encryption, and so forth.
- Query Engine
- The query engine has several layers and components. At a high level, request processing is structured as follows:
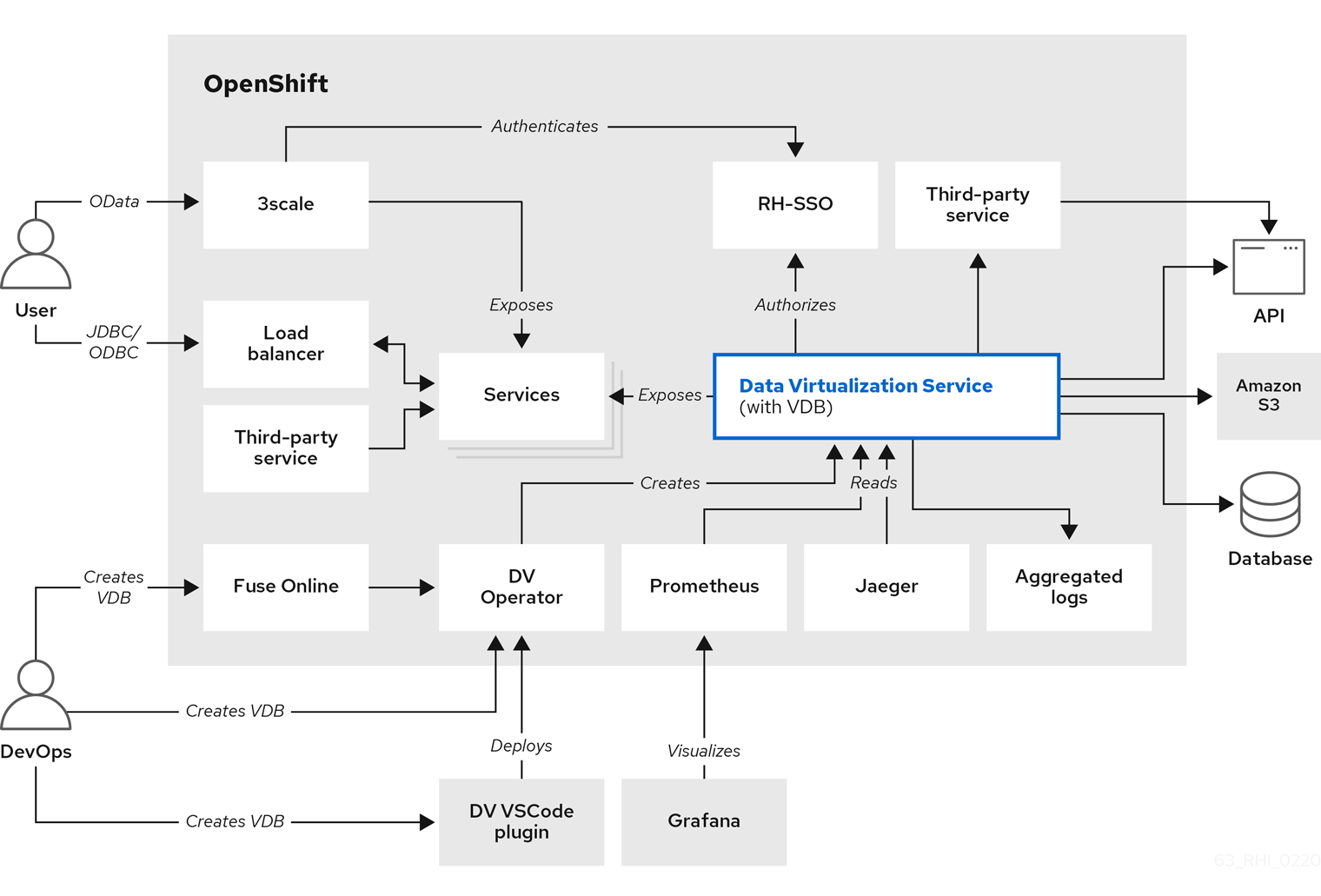
The following diagram shows the components that make up the data virtualization service in greater detail:
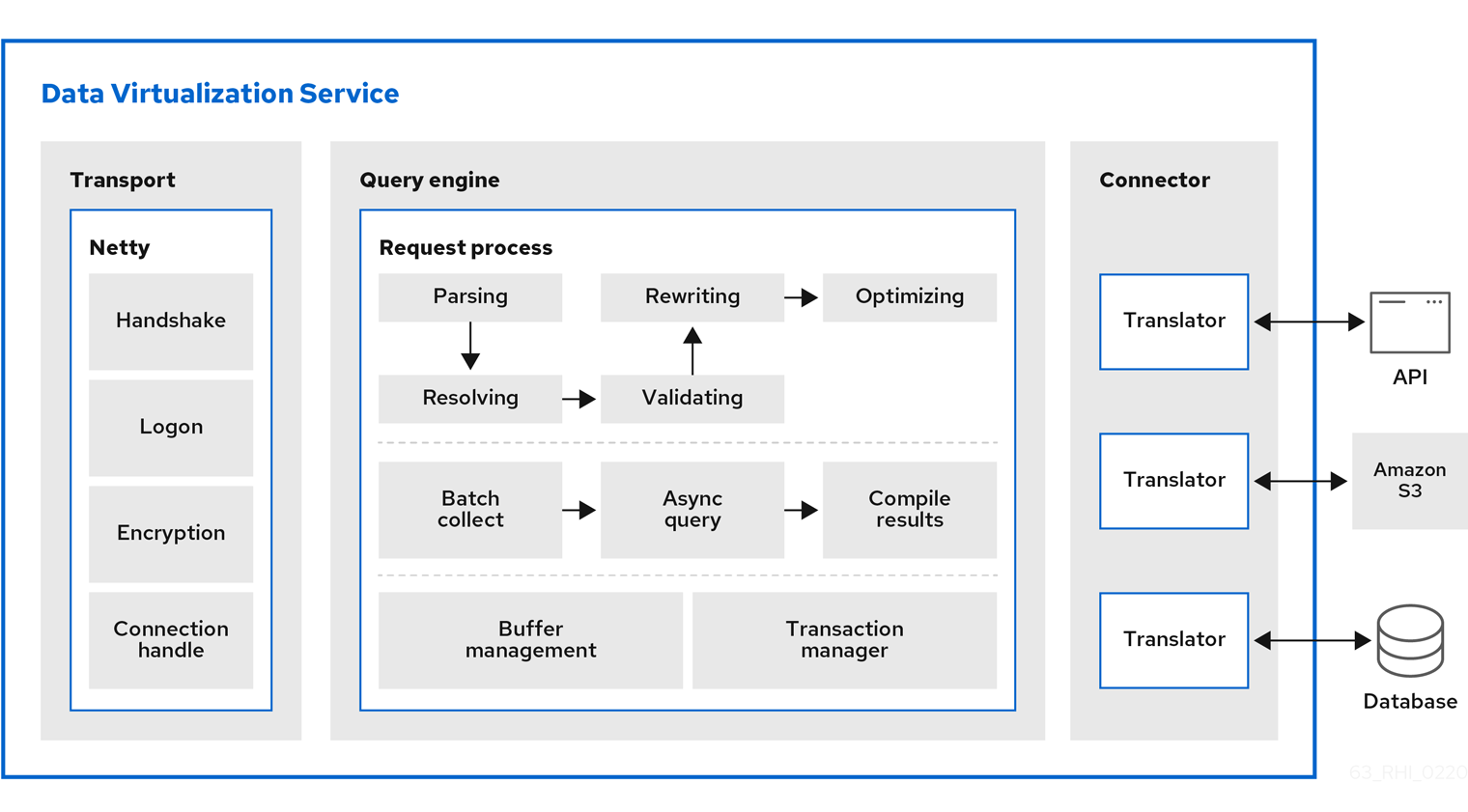
- SQL is converted to a processor plan. The engine receives an incoming SQL query. It is parsed to a internal command. Then the command is converted a logical plan via resolving, validating, and rewriting. Finally, rule and cost-based optimization convert the logical plan to a final processor plan. For more information, see Federated planning.
- Batch processing. The source and other aspects of query processing may return results asynchronously to the processing thread. As soon as possible, batches of results are made available to the client.
- Buffer management controls the bulk of the on and off heap memory that Data Virtualization is using. It prevents consuming too much memory that otherwise might exceed the VM size.
Transaction management determines when transactions are needed and interacts with the TransactionManager subsystem to coordinate XA transactions.
Source queries are handled by the data tier layer which interfaces with the query engine and the connector layer which utilizes a translator to interact directly with a source. Connectivity is provided for heterogeneous data stores, such as databases or data warehouses, NoSQL, Hadoop, data grid/cache, files, SaaS, and so on.
- Translator
- Data Virtualization has developed a series of translators. For more information, see Translators.
11.1. Terminology
- VM or process
- A Spring Boot instance of Data Virtualization.
- Host
- A machine that runs one or more VMs.
- Service
A subsystem that runs in a VM (often in many VMs) and provides a related set of functionality. In addition to these main components, the service platform makes the following core set of services available to the applications that are built on top of it:
- Session
- The Session service manages active session information.
- Buffer manager
- The Buffer Manager service provides access to data management for intermediate results. For more information, see Buffer management in Data management.
- Transaction
- The Transaction service manages global, local, and request scoped transactions. For more information, see Transactions.
11.2. Data management
Cursoring and batching
Data Virtualization cursors all results, regardless of whether they are from one source or many sources, and regardless of what type of processing (joins, unions, and so forth.) have been performed on the results.
Data Virtualization processes results in batches. A batch is simply a set of records. The number of rows in a batch is determined by the buffer system property processor-batch-size and is scaled upon the estimated memory footprint of the batch.
Client applications have no direct knowledge of batches or batch sizes, but rather specify fetch size. However the first batch, regardless of fetch size is always proactively returned to synchronous clients. Subsequent batches are returned based on client demand for the data. Pre-fetching is utilized at both the client and connector levels.
Buffer management
The buffer manager manages memory for all result sets used in the query engine. That includes result sets read from a connection factory, result sets used temporarily during processing, and result sets prepared for a user. Each result set is referred to in the buffer manager as a tuple source.
When retrieving batches from the buffer manager, the size of a batch in bytes is estimated and then allocated against the max limit.
Memory management
The buffer manager has two storage managers - a memory manager and a disk manager. The buffer manager maintains the state of all the batches, and determines when batches must be moved from memory to disk.
Disk management
Each tuple source has a dedicated file (named by the ID) on disk. This file will be created only if at least one batch for the tuple source had to be swapped to disk. The file is random access. The processor batch size property defines how many rows should nominally exist in a batch assuming 2048 bits worth of data in a row. If the row is larger or smaller than that target, the engine will adjust the batch size for those tuples accordingly. Batches are always read and written from the storage manager whole.
The disk storage manager caps the maximum number of open files to prevent running out of file handles. In cases with heavy buffering, this can cause wait times while waiting for a file handle to become available (the default maximum open files is 64).
Cleanup
When a tuple source is no longer needed, it is removed from the buffer manager. The buffer manager will remove it from both the memory storage manager and the disk storage manager. The disk storage manager will delete the file. In addition, every tuple source is tagged with a "group name" which is typically the session ID of the client. When the client’s session is terminated (by closing the connection, server detecting client shutdown, or administrative termination), a call is sent to the buffer manager to remove all tuple sources for the session.
In addition, when the query engine is shutdown, the buffer manager is shut down, which will remove all state from the disk storage manager and cause all files to be closed. When the query engine is stopped, it is safe to delete any files in the buffer directory as they are not used across query engine restarts and must be due to a system crash where buffer files were not cleaned up.
11.3. Query termination
Canceling queries
When a query is canceled, processing will be stopped in the query engine and in all connectors involved in the query. The semantics of what a connector does in response to a cancellation command depends on the connector implementation. For example, JDBC connectors will asynchronously call cancel on the underlying JDBC driver, which might or might not be compatible with this method.
User query timeouts
User query timeouts in Data Virtualization can be managed on the client-side or the server-side. Timeouts are only relevant for the first record returned. If the first record has not been received by the client within the specified timeout period, a cancel command is issued to the server for the request and no results are returned to the client. The cancel command is issued asynchronously without the client’s intervention.
The JDBC API uses the query timeout set by the java.sql.Statement.setQueryTimeout method. You can also set a default statement timeout via the connection property "QUERYTIMEOUT". ODBC clients can also use QUERYTIMEOUT as an execution property via a set statement to control the default timeout setting. See the Client Developer’s Guide for more on connection/execution properties and set statements.
Server-side timeouts start when the query is received by the engine. Network latency or server load can delays the processing of I/O work after a client issues the query. The timeout will be cancelled if the first result is sent back before the timeout has ended. For more information about setting the query-timeout property for a virtual database, see Virtual database properties. For more information about modifying system properties to set a default query timeout for all queries, see System properties in the Administrator’s Guide.
11.4. Processing
Join algorithms
Nested loop does the most obvious processing. For every row in the outer source, it compares with every row in the inner source. Nested loop is only used when the join criteria has no equi-join predicates.
A merge join first sorts the input sources on the joined columns. You can then walk through each side in parallel (effectively one pass through each sorted source), and when you have a match, emit a row. In general, merge join is on the order of n+m rather than n*m in nested loop. Merge join is the default algorithm.
Using costing information the engine may also delay the decision to perform a full sort merge join. Based upon the actual row counts involved, the engine can choose to build an index of the smaller side (which will perform similarly to a hash join) or to only partially sort the larger side of the relation.
Joins involving equi-join predicates can be converted into dependent joins. For more information, see Dependent joins in Federated optimizations.
Sort-based algorithms
Sorting is used as the basis of the Sort (ORDER BY), Grouping (GROUP BY), and DupRemoval (SELECT DISTINCT) operations. The sort algorithm is a multi-pass merge-sort that does not require all of the result set to ever be in memory, yet uses the maximal amount of memory allowed by the buffer manager.
Sorting consists of two phases. In the first phase ("sort"), the algorithm processes an unsorted input stream to produce one or more sorted input streams. Each pass reads as much of the unsorted stream as possible, sorts it, and writes it back out as a new stream. When an unsorted stream is processed, the resulting sorted stream might be too large to reside in memory. If the size of a sorted stream exceeds the available memory, it is written out to multiple sorted streams.
The second phase of the sort algorithm ("merge") consists of a set of phases that grab the next batch from as many sorted input streams as will fit in memory. It then repeatedly grabs the next tuple in sorted order from each stream and outputs merged sorted batches to a new sorted stream. At completion of the phase, all input streams are dropped. In this way, each phase reduces the number of sorted streams. When only one stream remains, it is the final output.