
Chapter 12. Deployment errors
12.1. Order of cleanup operations
Depending on where deployment fails, you may need to perform a number of cleanup operations.
Always perform cleanup for tasks in reverse order to the order of the tasks themselves. For example, during deployment, we perform the following tasks in order:
- Configure Network-Bound Disk Encryption using Ansible.
- Configure Red Hat Gluster Storage using the Web Console.
- Configure the Hosted Engine using the Web Console.
If deployment fails at step 2, perform cleanup for step 2. Then, if necessary, perform cleanup for step 1.
12.2. Failed to deploy storage
If an error occurs during storage deployment, the deployment process halts and Deployment failed is displayed.
Deploying storage failed
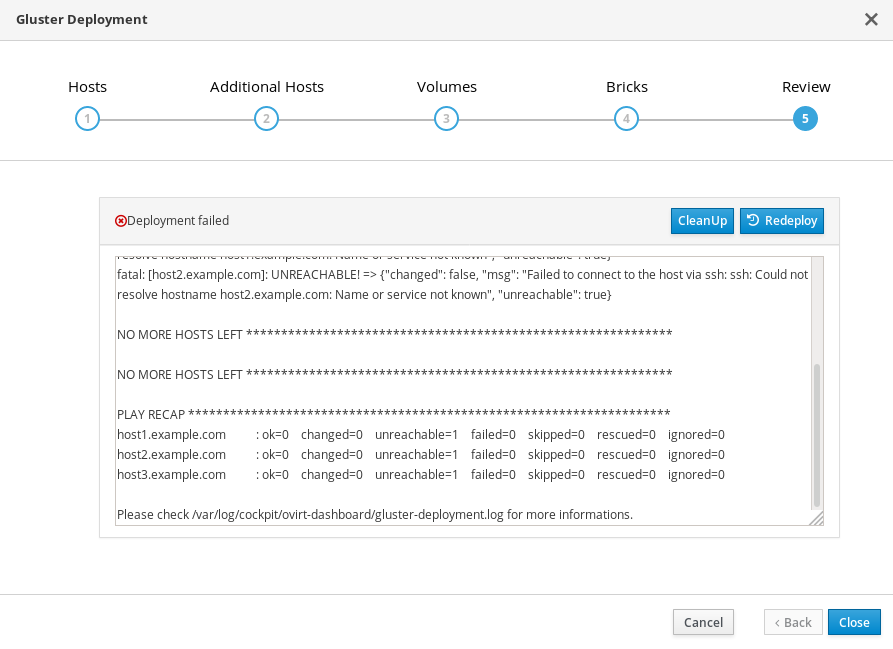
- Review the Web Console output for error information.
- Click Clean up to remove any potentially incorrect changes to the system. If your deployment uses Network-Bound Disk Encryption, you must then follow the process in Cleaning up Network-Bound Disk Encryption after a failed deployment.
- Click Redeploy and correct any entered values that may have caused errors. If you need help resolving errors, contact Red Hat Support with details.
- Return to storage deployment to try again.
12.2.1. Cleaning up Network-Bound Disk Encryption after a failed deployment
If you are using Network-Bound Disk Encryption and deployment fails, you cannot just click the Cleanup button in order to try again. You must also run the luks_device_cleanup.yml playbook to complete the cleaning process before you start again.
Run this playbook as shown, providing the same luks_tang_inventory.yml file that you provided during setup.
# ansible-playbook -i luks_tang_inventory.yml /etc/ansible/roles/gluster.ansible/playbooks/hc-ansible-deployment/tasks/luks_device_cleanup.yml --ask-vault-pass
12.2.2. Error: VDO signature detected on device
During storage deployment, the Create VDO with specified size task may fail with the VDO signature detected on device error.
TASK [gluster.infra/roles/backend_setup : Create VDO with specified size] task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/vdo_create.yml:9 failed: [host1.example.com] (item={u'writepolicy': u'auto', u'name': u'vdo_sdb', u'readcachesize': u'20M', u'readcache': u'enabled', u'emulate512': u'off', u'logicalsize': u'11000G', u'device': u'/dev/sdb', u'slabsize': u'32G', u'blockmapcachesize': u'128M'}) => {"ansible_loop_var": "item", "changed": false, "err": "vdo: ERROR - vdo signature detected on /dev/sdb at offset 0; use --force to override\n", "item": {"blockmapcachesize": "128M", "device": "/dev/sdb", "emulate512": "off", "logicalsize": "11000G", "name": "vdo_sdb", "readcache": "enabled", "readcachesize": "20M", "slabsize": "32G", "writepolicy": "auto"}, "msg": "Creating VDO vdo_sdb failed.", "rc": 5}
This error occurs when the specified device is already a VDO device, or when the device was previously configured as a VDO device and was not cleaned up correctly.
- If you specified a VDO device accidentally, return to storage configuration and specify a different non-VDO device.
If you specified a device that has been used as a VDO device previously:
Check the device type.
# blkid -p /dev/sdb /dev/sdb: UUID="fee52367-c2ca-4fab-a6e9-58267895fe3f" TYPE="vdo" USAGE="other"
If you see
TYPE="vdo"in the output, this device was not cleaned correctly.- Follow the steps in Manually cleaning up a VDO device to use this device. Then return to storage deployment to try again.
Avoid this error by specifying clean devices, and by using the Clean up button in the storage deployment window to clean up any failed deployments.
12.2.3. Manually cleaning up a VDO device
Follow this process to manually clean up a VDO device that has caused a deployment failure.
This is a destructive process. You will lose all data on the device that you clean up.
Procedure
Clean the device using wipefs.
# wipefs -a /dev/sdX
Verify
Confirm that the device does not have
TYPE="vdo"set any more.# blkid -p /dev/sdb /dev/sdb: UUID="fee52367-c2ca-4fab-a6e9-58267895fe3f" TYPE="vdo" USAGE="other"
Next steps
- Return to storage deployment to try again.
12.3. Failed to prepare virtual machine
If an error occurs while preparing the virtual machine in deployment, deployment pauses, and you see a screen similar to the following:
Preparing virtual machine failed
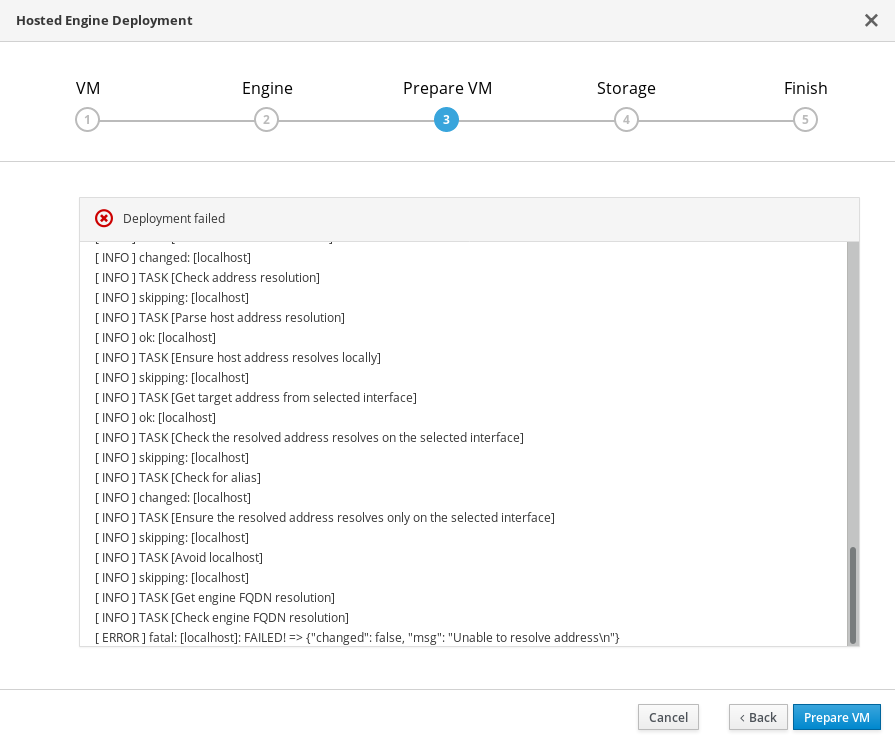
- Review the Web Console output for error information.
- Click Back and correct any entered values that may have caused errors. Ensure proper values for network configurations are provided in VM tab. If you need help resolving errors, contact Red Hat Support with details.
Ensure that the
rhvm-appliancepackage is available on the first hyperconverged host.# yum install rhvm-appliance
Return to Hosted Engine deployment to try again.
If you closed the deployment wizard while you resolved errors, you can select Use existing configuration when you retry the deployment process.
12.4. Failed to deploy hosted engine
If an error occurs during hosted engine deployment, deployment pauses and Deployment failed is displayed.
Hosted engine deployment failed
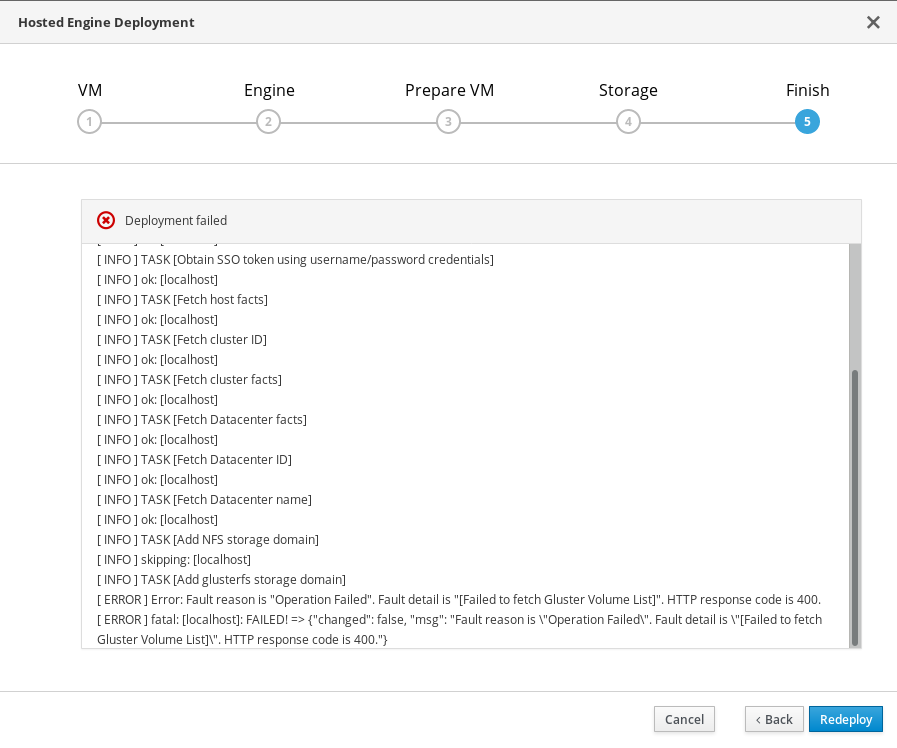
- Review the Web Console output for error information.
Remove the contents of the
enginevolume.Mount the
enginevolume.# mount -t glusterfs <server1>:/engine /mnt/test
Remove the contents of the volume.
# rm -rf /mnt/test/*
Unmount the
enginevolume.# umount /mnt/test
- Click Redeploy and correct any entered values that may have caused errors.
If the deployment fails after performing the above steps a, b and c. Perform these steps again and this time clean the Hosted Engine:
# ovirt-hosted-engine-cleanup
Return to deployment to try again.
If you closed the deployment wizard while you resolved errors, you can select Use existing configuration when you retry the deployment process.
If you need help resolving errors, contact Red Hat Support with details.