
3.8. Appendix - Performance Categorization
There are a number of infrastructure and architectural factors that determine the potential performance that Red Hat Gluster Storage within Microsoft Azure can deliver.
3.8.1. Storage Type
Microsoft Azure offers two classes of physical storage: standard and premium. Standard storage is backed by hard disk drives, whereas premium storage is delivered by solid state drives. These classes of storage provide an IOPS target of 500 IOPS and 5,000 IOPS per disk, respectively.
A more general consideration is how the data are protected. By default, Microsoft Azure protects the data by synchronously storing three copies of data in separate failure domains, and then asynchronously places another three copies of the data in a secondary datacenter (a default GRS replication scheme).
3.8.2. Bandwidth
A simple test was performed using
iperf to determine the upper limit between the client and Red Hat Gluster Storage node. This testing showed that a single network interface can be expected to deliver between 600 - 700 Mbit.
3.8.3. Disk Latencies
Four disks were attached to a Standard Tier/A2 instance and aggregated to form a RAID0 set using the
mdadm tool. The LUN was then configured using recommended best practices, based on LVM, dm-thinp, and the XFS file system. The fio tool was then used to reveal the random read profile of the underlying disks at increasing levels of concurrency.
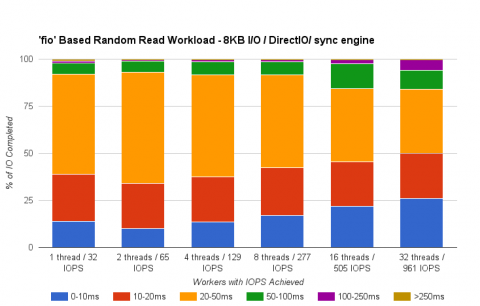
Figure 3.3. Disk Latencies
This benchmark does not produce a definitive result, but it indicates the potential I/O profile of the underlying storage.
Observations
- Typical latencies are in the 20 - 50 ms range.
- Attaining higher IOPS requires a multi-threaded workload; that is, one thread=32 IOPS, 32 threads = 961 IOPS.
- Combining the virtual drives with
mdadmallows the LUN to deliver IOPS beyond that of a single virtual disk.
3.8.4. GlusterFS
The performance tests for Gluster Storage are only indicative and illustrate the expected performance from a similar environment. For the purposes of benchmarking, the smallfile tool has been used to simulate multiple concurrent file creations that are typical of user environments.
The create workload creates a series of 10 MB files within a nested directory hierarchy, exercising metadata operations as well as file creation and throughput.

Figure 3.4. Gluster Performance: Small File "Create" Workload

Observations:
- Although the native file system starts well, a performance cross-over occurs between 8 - 12 threads, with the native file system fading and the GlusterFS volume continuing to scale.
- The throughput of the GlusterFS volume scales linearly with the increase in client workload.
- At higher concurrency, the GlusterFS volume outperforms the local file system by up to 47%.
- During high concurrency, the native file system slows down under load. Examining the disk subsystems statistics during the test run revealed the issue was increased I/O wait times (70 - 90%).