
1.5. Red Hat GFS
Red Hat GFS is a cluster file system that allows a cluster of nodes to simultaneously access a block device that is shared among the nodes. GFS is a native file system that interfaces directly with the VFS layer of the Linux kernel file-system interface. GFS employs distributed metadata and multiple journals for optimal operation in a cluster. To maintain file system integrity, GFS uses a lock manager to coordinate I/O. When one node changes data on a GFS file system, that change is immediately visible to the other cluster nodes using that file system.
Using Red Hat GFS, you can achieve maximum application uptime through the following benefits:
- Simplifying your data infrastructure
- Install and patch applications once for the entire cluster.
- Eliminates the need for redundant copies of application data (duplication).
- Enables concurrent read/write access to data by many clients.
- Simplifies backup and disaster recovery (only one file system to back up or recover).
- Maximize the use of storage resources; minimize storage administration costs.
- Manage storage as a whole instead of by partition.
- Decrease overall storage needs by eliminating the need for data replications.
- Scale the cluster seamlessly by adding servers or storage on the fly.
- No more partitioning storage through complicated techniques.
- Add servers to the cluster on the fly by mounting them to the common file system.
Nodes that run Red Hat GFS are configured and managed with Red Hat Cluster Suite configuration and management tools. Volume management is managed through CLVM (Cluster Logical Volume Manager). Red Hat GFS provides data sharing among GFS nodes in a Red Hat cluster. GFS provides a single, consistent view of the file-system name space across the GFS nodes in a Red Hat cluster. GFS allows applications to install and run without much knowledge of the underlying storage infrastructure. Also, GFS provides features that are typically required in enterprise environments, such as quotas, multiple journals, and multipath support.
GFS provides a versatile method of networking storage according to the performance, scalability, and economic needs of your storage environment. This chapter provides some very basic, abbreviated information as background to help you understand GFS.
You can deploy GFS in a variety of configurations to suit your needs for performance, scalability, and economy. For superior performance and scalability, you can deploy GFS in a cluster that is connected directly to a SAN. For more economical needs, you can deploy GFS in a cluster that is connected to a LAN with servers that use GNBD (Global Network Block Device) or to iSCSI (Internet Small Computer System Interface) devices. (For more information about GNBD, refer to Section 1.7, “Global Network Block Device”.)
The following sections provide examples of how GFS can be deployed to suit your needs for performance, scalability, and economy:
Note
The GFS deployment examples reflect basic configurations; your needs might require a combination of configurations shown in the examples.
1.5.1. Superior Performance and Scalability
You can obtain the highest shared-file performance when applications access storage directly. The GFS SAN configuration in Figure 1.12, “GFS with a SAN” provides superior file performance for shared files and file systems. Linux applications run directly on cluster nodes using GFS. Without file protocols or storage servers to slow data access, performance is similar to individual Linux servers with directly connected storage; yet, each GFS application node has equal access to all data files. GFS supports over 300 GFS nodes.
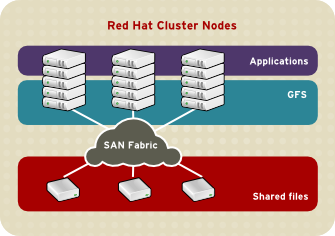
Figure 1.12. GFS with a SAN