
7.2. Common Replication Scenarios
Decide how the updates flow from server to server and how the servers interact when propagating updates. There are the four basic scenarios and a few strategies for deciding the method appropriate for the environment. These basic scenarios can be combined to build the replication topology that best suits the network environment.
7.2.1. Single-Supplier Replication
In the most basic replication configuration, a supplier server copies a replica directly to one or more consumer servers. In this configuration, all directory modifications occur on the read-write replica on the supplier server, and the consumer servers contain read-only replicas of the data.
The supplier server must perform all modifications to the read-write replicas stored on the consumer servers. This is illustrated below.

Figure 7.1. Single-Supplier Replication
The supplier server can replicate a read-write replica to several consumer servers. The total number of consumer servers that a single supplier server can manage depends on the speed of the networks and the total number of entries that are modified on a daily basis. However, a supplier server is capable of maintaining several consumer servers.
7.2.2. Multi-Supplier Replication
In a multi-supplier replication environment, main copies of the same information can exist on multiple servers. This means that data can be updated simultaneously in different locations. The changes that occur on each server are replicated to the other servers. This means that each server functions as both a supplier and a consumer.
Note
Red Hat Directory Server supports a maximum of 20 supplier servers in any replication environment, as well as an unlimited number of hub suppliers. The number of consumer servers that hold the read-only replicas is unlimited.
When the same data is modified on multiple servers, there is a conflict resolution procedure to determine which change is kept. The Directory Server considers the valid change to be the most recent one.
Multiple servers can have main copies of the same data, but, within the scope of a single replication agreement, there is only one supplier server and one consumer. Consequently, to create a multi-supplier environment between two supplier servers that share responsibility for the same data, create more than one replication agreement.
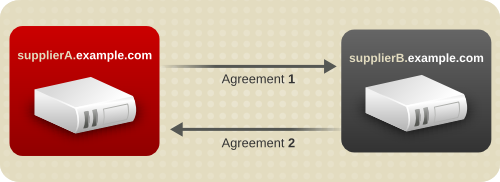
Figure 7.2. Simplified Multi-Supplier Replication Configuration
In Figure 7.2, “Simplified Multi-Supplier Replication Configuration”, supplier A and supplier B each hold a read-write replica of the same data.
Figure 7.3, “Replication Traffic in a Simple Multi-Supplier Environment” illustrates the replication traffic with two suppliers (read-write replicas in the illustration), and two consumers (read-only replicas in the illustration). The consumers can be updated by both suppliers. The supplier servers ensure that the changes do not collide.
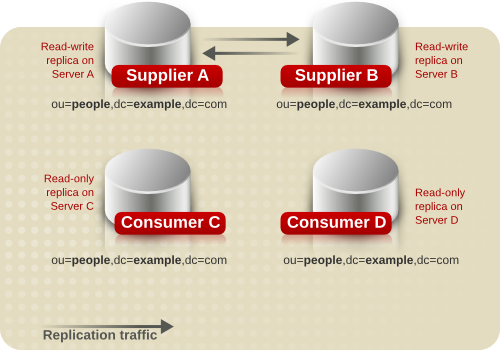
Figure 7.3. Replication Traffic in a Simple Multi-Supplier Environment
Replication in Directory Server can support as many as 20 suppliers, which all share responsibility for the same data. Using that many suppliers requires creating a range of replication agreements. (Also remember that in multi-supplier replication, each of the suppliers can be configured in different topologies — meaning there can be 20 different directory trees and even schema differences. There are many variables that have a direct impact on the topology selection.)
In multi-supplier replication, the suppliers can send updates to all other suppliers or to some subset of other suppliers. Sending updates to all other suppliers means that changes are propogated faster and the overall scenario has much better failure-tolerance. However, it also increases the complexity of configuring suppliers and introduces high network demand and high server demand. Sending updates to a subset of suppliers is much simpler to configure and reduces the network and server loads, but there is a risk that data could be lost if there were multiple server failures.
Figure 7.4, “Multi-Supplier Replication Configuration A” illustrates a fully connected mesh topology where four supplier servers feed data to the other three supplier servers (which also function as consumers). A total of twelve replication agreements exist between the four supplier servers.
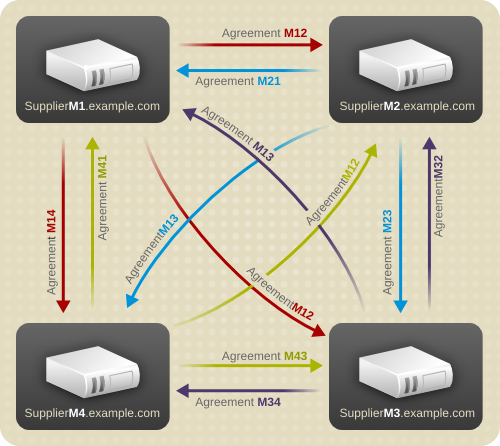
Figure 7.4. Multi-Supplier Replication Configuration A
Figure 7.5, “Multi-Supplier Replication Configuration B” illustrates a topology where each supplier server feeds data to two other supplier servers (which also function as consumers). Only eight replication agreements exist between the four supplier servers, compared to the twelve agreements shown for the topology in Figure 7.4, “Multi-Supplier Replication Configuration A”. This topology is beneficial where the possibility of two or more servers failing at the same time is negligible.

Figure 7.5. Multi-Supplier Replication Configuration B
Those two examples are simplified multi-supplier scenarios. Since Red Hat Directory Server can have as many as 20 suppliers and an unlimited number of hub suppliers in a single multi-supplier environment, the replication topology can become much more complex. For example, Figure 7.4, “Multi-Supplier Replication Configuration A” has 12 replication agreements (four suppliers with three agreements each). If there are 20 suppliers, then there are 380 replication agreements (20 servers with 19 agreements each).
WHen planning multi-supplier replication, consider:
- How many suppliers there will be
- What their geographic locations are
- The path the suppliers will use to update servers in other locations
- The topologies, directory trees, and schemas of the different suppliers
- The network quality
- The server load and performance
- The update interval required for directory data
7.2.3. Cascading Replication
In a cascading replication scenario, a hub supplier receives updates from a supplier server and replays those updates on consumer servers. The hub supplier is a hybrid; it holds a read-only replica, like a typical consumer server, and it also maintains a changelog like a typical supplier server.
Hub suppliers forward supplier data as they receive it from the original suppliers. Similarly, when a hub supplier receives an update request from a directory client, it refers the client to the supplier server.
Cascading replication is useful if some of the network connections between various locations in the organization are better than others. For example, Example Corp. keeps the main copy of its directory data in Minneapolis, and the consumer servers in New York and Chicago. The network connection between Minneapolis and New York is very good, but the connection between Minneapolis and Chicago is poor. Since the network between New York and Chicago is fair, Example administrators use cascading replication to move directory data from Minneapolis to New York to Chicago.
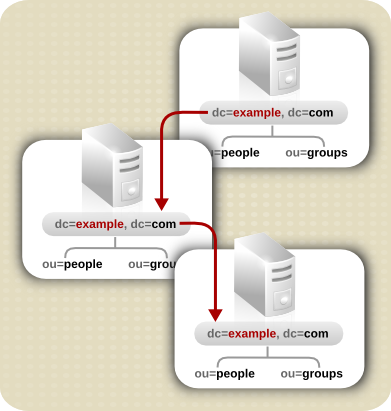
Figure 7.6. Cascading Replication Scenario
Figure 7.7, “Replication Traffic and Changelogs in Cascading Replication” illustrates the same scenario from a different perspective, which shows how the replicas are configured on each server (read-write or read-only), and which servers maintain a changelog.
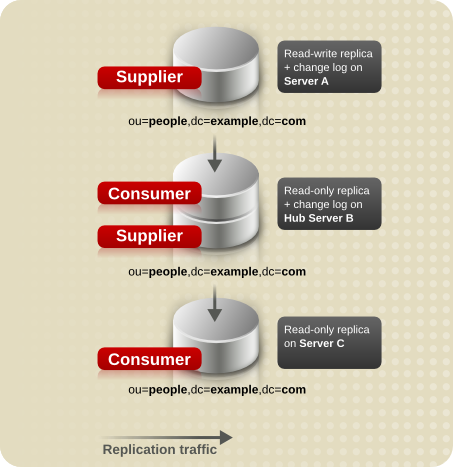
Figure 7.7. Replication Traffic and Changelogs in Cascading Replication
7.2.4. Mixed Environments
Any of the replication scenarios can be combined to suit the needs of the network and directory environment. One common combination is to use a multi-supplier configuration with a cascading configuration.
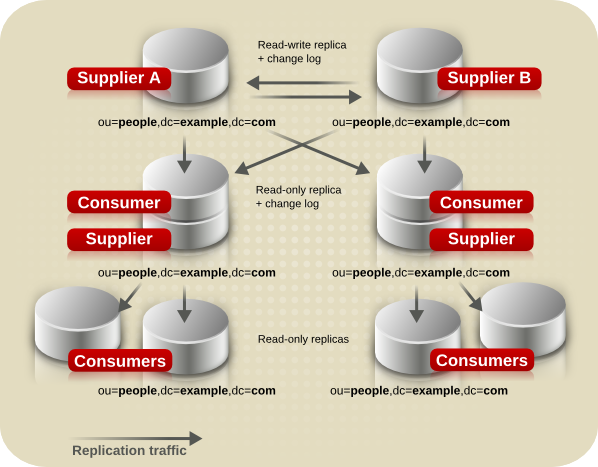
Figure 7.8. Combined Multi-Supplier and Cascading Replication