
6.3. About Knowledge References
- Referrals — The server returns a piece of information to the client application indicating that the client application needs to contact another server to fulfill the request.
- Chaining — The server contacts other servers on behalf of the client application and returns the combined results to the client application when the operation is finished.
6.3.1. Using Referrals
- Default referrals — The directory returns a default referral when a client application presents a DN for which the server does not have a matching suffix. Default referrals are stored in the configuration file of the server. One default referral can be set for the Directory Server and a separate default referral for each database.The default referral for each database is done through the suffix configuration information. When the suffix of the database is disabled, configure the directory service to return a default referral to client requests made to that suffix.For more information about suffixes, see Section 6.2.2, “About Suffixes”. For information on configuring suffixes, see the Red Hat Directory Server Administration Guide .
- Smart referrals — Smart referrals are stored on entries within the directory service itself. Smart referrals point to Directory Servers that have knowledge of the subtree whose DN matches the DN of the entry containing the smart referral.
6.3.1.1. The Structure of an LDAP Referral
- The host name of the server to contact.
- The port number on the server that is configured to listen for LDAP requests.
- The base DN (for search operations) or target DN (for add, delete, and modify operations).
dc=example,dc=com for entries with a surname value of Jensen. A referral returns the following LDAP URL to the client application:
ldap://europe.example.com:389/ou=people, l=europe,dc=example,dc=com
europe.example.com on port 389 and submit a search using the root suffix ou=people, l=europe,dc=example,dc=com.
6.3.1.2. About Default Referrals
uid=bjensen,ou=people,dc=example,dc=com
dc=europe,dc=example,dc=com suffix. The directory returns a referral to the client that indicates which server to contact for entries stored under the dc=example,dc=com suffix. The client then contacts the appropriate server and resubmits the original request.
nsslapd-referral attribute. Default referrals for each database in the directory installation are set by the nsslapd-referral attribute in the database entry in the configuration. These attribute values are stored in the dse.ldif file.
6.3.1.3. Smart Referrals
- The same namespace contained on a different server.
- Different namespaces on a local server.
- Different namespaces on the same server.
ou=people,dc=example,dc=com directory branch point.
ou=people branch of the European office of Example Corp. by specifying a smart referral on the ou=people entry itself. The smart referral is ldap://europe.example.com:389/ou=people,dc=example,dc=com.
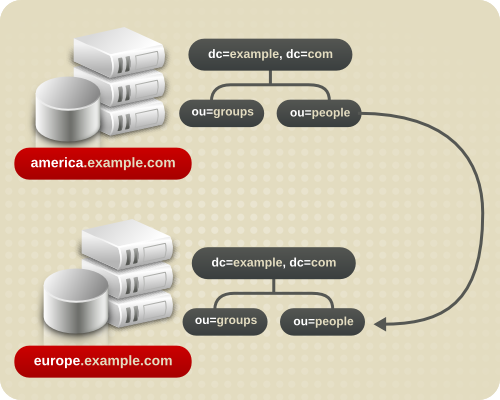
Figure 6.7. Using Smart Referrals to Redirect Requests
ldap://europe.example.com:389/ou=US employees,dc=example,dc=com.
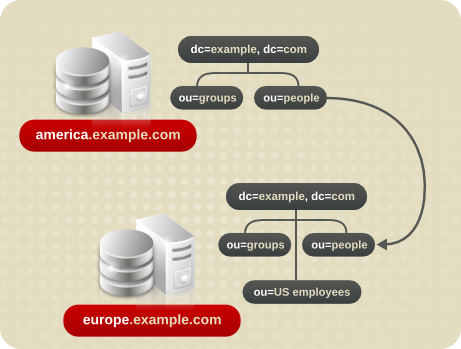
Figure 6.8. Redirecting a Query to a Different Server and Namespace
o=example,c=us to dc=example,dc=com, then put the smart referral ldap:///dc=example,dc=com on the o=example,c=us entry.
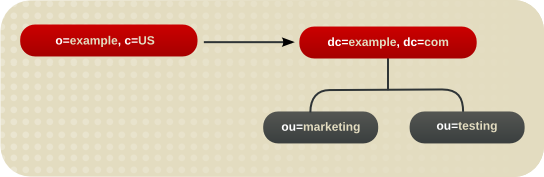
Figure 6.9. Redirecting a Query from One Namespace to Another Namespace on the Same Server
Note
ou=people,o=example,c=US, are not performed correctly.
6.3.1.4. Tips for Designing Smart Referrals
- Keep the design simple.Deploying the directory service using a complex web of referrals makes administration difficult. Overusing smart referrals can also lead to circular referral patterns. For example, a referral points to an LDAP URL, which in turn points to another LDAP URL, and so on until a referral somewhere in the chain points back to the original server. This is illustrated below:
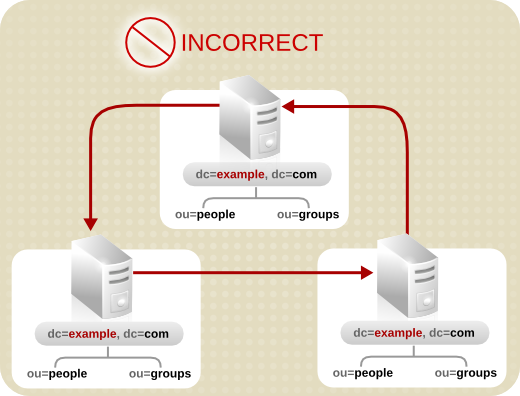
Figure 6.10. A Circular Referral Pattern
- Redirect at major branchpoints.Limit referral usage to handle redirection at the suffix level of the directory tree. Smart referrals redirect lookup requests for leaf (non-branch) entries to different servers and DNs. As a result, it is tempting to use smart referrals as an aliasing mechanism, leading to a complex and difficult method to secure directory structure. Limiting referrals to the suffix or major branch points of the directory tree limits the number of referrals that have to be managed, subsequently reducing the directory's administrative overhead.
- Consider the security implications.Access control does not cross referral boundaries. Even if the server where the request originated allows access to an entry, when a smart referral sends a client request to another server, the client application may not be allowed access.In addition, the client's credentials need to be available on the server to which the client is referred for client authentication to occur.
6.3.2. Using Chaining

- Invisible access to remote data.Because the database link resolves client requests, data distribution is completely hidden from the client.
- Dynamic management.A part of the directory service can be added or removed from the system while the entire system remains available to client applications. The database link can temporarily return referrals to the application until entries have been redistributed across the directory service.This can also be implemented through the suffix itself, which can return a referral rather than forwarding a client application to the database.
- Access control.The database link impersonates the client application, providing the appropriate authorization identity to the remote server. User impersonation can be disabled on the remote servers when access control evaluation is not required. For more information on configuring database links, see the Red Hat Directory Server Administration Guide.
6.3.3. Deciding Between Referrals and Chaining
6.3.3.1. Usage Differences
6.3.3.2. Evaluating Access Controls
The following diagram illustrates a client request to a server using referrals:

Figure 6.11. Sending a Client Request to a Server Using Referrals
- The client application first binds with Server A.
- Server A contains an entry for the client that provides a user name and password, so it returns a bind acceptance message. In order for the referral to work, the client entry must be present on server A.
- The client application sends the operation request to Server A.
- However, Server A does not contain the requested information. Instead, Server A returns a referral to the client application instructing it to contact Server B.
- The client application then sends a bind request to Server B. To bind successfully, Server B must also contain an entry for the client application.
- The bind is successful, and the client application can now resubmit its search operation to Server B.
The problem of replicating client entries across servers is resolved using chaining. On a chained system, the search request is forwarded multiple times until there is a response.
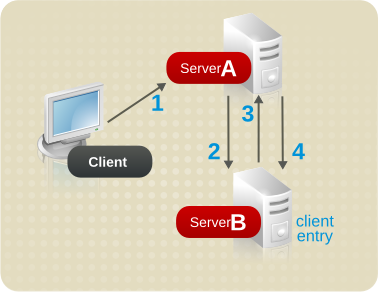
Figure 6.12. Sending a Client Request to a Server Using Chaining
- The client application binds with Server A, and Server A tries to confirm that the user name and password are correct.
- Server A does not contain an entry corresponding to the client application. Instead, it contains a database link to Server B, which contains the actual entry of the client. Server A sends a bind request to Server B.
- Server B sends an acceptance response to Server A.
- Server A then processes the client application's request using the database link. The database link contacts a remote data store located on Server B to process the search operation.
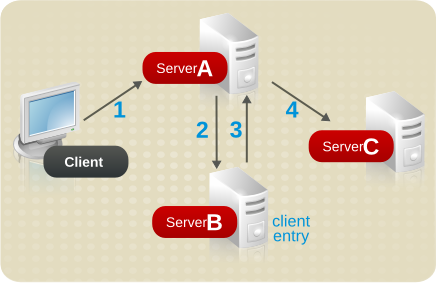
Figure 6.13. Authenticating a Client and Retrieving Data Using Different Servers
- The client application binds with Server A, and Server A tries to confirm that the user name and password are correct.
- Server A does not contain an entry corresponding to the client application. Instead, it contains a database link to Server B, which contains the actual entry of the client. Server A sends a bind request to Server B.
- Server B sends an acceptance response to Server A.
- Server A then processes the client application's request using another database link. The database link contacts a remote data store located on Server C to process the search operation.
Database links do not support the following access controls:
- Controls that must access the content of the user entry are not supported when the user entry is located on a different server. This includes access controls based on groups, filters, and roles.
- Controls based on client IP addresses or DNS domains may be denied. This is because the database link impersonates the client when it contacts remote servers. If the remote database contains IP-based access controls, it evaluates them using the database link's domain rather than the original client domain.