
4.2. Designing the Directory Tree
- Choosing a suffix to contain the data.
- Determining the hierarchical relationship among data entries.
- Naming the entries in the directory tree hierarchy.
4.2.1. Choosing a Suffix
4.2.1.1. Suffix Naming Conventions
- Globally unique.
- Static, so it rarely, if ever, changes.
- Short, so that entries beneath it are easier to read on screen.
- Easy for a person to type and remember.
example.com, then the directory suffix is logically dc=example,dc=com.
dc attribute represents the suffix by breaking the domain name into its component parts.
dcdefines an component of the domain name.ccontains the two-digit code representing the country name, as defined by ISO.lidentifies the county, city, or other geographical area where the entry is located or that is associated with the entry.stidentifies the state or province where the entry resides.oidentifies the name of the organization to which the entry belongs.
example_a, such as o=example_a, st=Washington,c=US.
4.2.1.2. Naming Multiple Suffixes
example_a and example_b and store them in separate databases.

Figure 4.1. Including Multiple Directory Trees in a Database
4.2.2. Creating the Directory Tree Structure
4.2.2.1. Branching the Directory
- Branch the tree to represent only the largest organizational subdivisions in the enterprise.Any such branch points should be limited to divisions (such as Corporate Information Services, Customer Support, Sales, and Engineering). Make sure that the divisions used to branch the directory tree are stable; do not perform this kind of branching if the enterprise reorganizes frequently.
- Use functional or generic names rather than actual organizational names for the branch points.Names change. While subtrees can be renamed, it can be a long and resource-intensive process for large suffixes with many children entries. Using generic names that represent the function of the organization (for example, use
Engineeringinstead ofWidget Research and Development) makes it much less likely that you will need to rename a subtree after organizational or project changes. - If there are multiple organizations that perform similar functions, try creating a single branch point for that function instead of branching based along divisional lines.For example, even if there are multiple marketing organizations, each of which is responsible for a specific product line, create a single
ou=Marketingsubtree. All marketing entries then belong to that tree.
Name changes can be avoided if the directory tree structure is based on information that is not likely to change. For example, base the structure on types of objects in the tree rather than organizations. This helps avoid shuffling an entry between organizational units, which requires modifying the distinguished name (DN), which is an expensive operation.
ou=peopleou=groupsou=services

Figure 4.2. Example Environment Directory Tree
For a hosting environment, create a tree that contains two entries of the object class organization (o) and one entry of the object class organizationalUnit (ou) beneath the root suffix. For example, Example ISP branches their directory as shown below.
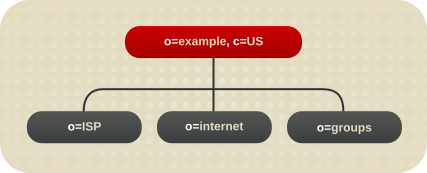
Figure 4.3. Example Hosting Directory Tree
4.2.2.2. Identifying Branch Points
uid=bjensen,ou=people,dc=example,dc=com.

Figure 4.4. The Directory Tree for Example Corp.

Figure 4.5. Directory Tree for Example ISP
c=US,o=example, the tree is split into three branches. The ISP branch contains customer data and internal information for Example ISP. The internet branch is the domain tree. The groups branch contains information about the administrative groups.
- Be consistent.Some LDAP client applications may be confused if the distinguished name (DN) format is inconsistent across the directory tree. That is, if
lis subordinate toouin one part of the directory tree, then make surelis subordinate toouin all other parts of the directory service. - Try to use only the traditional attributes (shown in Section 4.2.2.2, “Identifying Branch Points”).Using traditional attributes increases the likelihood of retaining compatibility with third-party LDAP client applications. Using the traditional attributes also means that they are known to the default directory schema, which makes it easier to build entries for the branch DN.
Table 4.1. Traditional DN Branch Point Attributes
| Attribute | Definition |
|---|---|
dc | An element of the domain name, such as dc=example; this is frequently specified in pairs, or even longer, depending on the domain, such as dc=example,dc=com or dc=mtv,dc=example,dc=com. |
c | A country name. |
o | An organization name. This attribute is typically used to represent a large divisional branching such as a corporate division, academic discipline (the humanities, the sciences), subsidiary, or other major branching within the enterprise, as in Section 4.2.1.1, “Suffix Naming Conventions”. |
ou | An organizational unit. This attribute is typically used to represent a smaller divisional branching of the enterprise than an organization. Organizational units are generally subordinate to the preceding organization. |
st | A state or province name. |
l or locality | A locality, such as a city, country, office, or facility name. |
Note
uid=bjensen,ou=People,dc=example,dc=com, then a search for dc=example does not match that entry unless dc:example has explicitly been added as an attribute in that entry.
4.2.2.3. Replication Considerations
flightdeck.example.com, tickets.example.com, and hangar.example.com. They initially branch their directory tree into three main groups for their major organizational divisions.

Figure 4.6. Initial Branching of the Directory Tree for Example Corp.
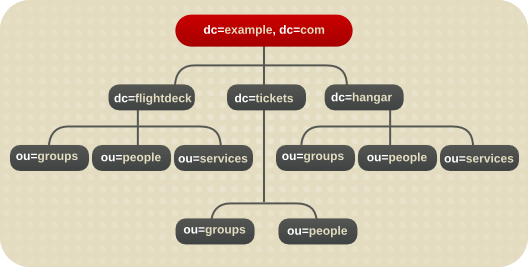
Figure 4.7. Extended Branching for Example Corp.

Figure 4.8. Directory Branching for Example ISP

Figure 4.9. Extended Branching for Example ISP
4.2.2.4. Access Control Considerations
ou=Sales.
4.2.3. Naming Entries
- The attribute selected for naming should be unlikely to change.
- The name must be unique across the directory.A unique name ensures that a DN can see at most one entry in the directory.
l to represent an organization, or c to represent an organizational unit.
4.2.3.1. Naming Person Entries
commonName, or cn, attribute to name their person entries. That is, an entry for a person named Babs Jensen might have the distinguished name of cn=Babs Jensen,dc=example,dc=com.
cn=Babs Jensen+employeeNumber=23,dc=example,dc=com.
cn. Consider using one of the following attributes:
uidUse theuidattribute to specify some unique value of the person. Possibilities include a user login ID or an employee number. A subscriber in a hosting environment should be identified by theuidattribute.mailThemailattribute contains a person's email address, which is always unique. This option can lead to awkward DNs that include duplicate attribute values (such asmail=bjensen@example.com,dc=example,dc=com), so use this option only if there is not some other unique value to use with theuidattribute. For example, use themailattribute instead of theuidattribute if the enterprise does not assign employee numbers or user IDs for temporary or contract employees.employeeNumberFor employees of theinetOrgPersonobject class, consider using an employer assigned attribute value such asemployeeNumber.
uid=bjensen,dc=example,dc=com is preferable to uid=b12r56A,dc=example,dc=com because recognizable DNs simplify some directory tasks, such as changing directory entries based on their distinguished names. Also, some directory client applications assume that the uid and cn attributes use human-readable names.
If a person is a subscriber to a service, the entry should be of object class inetUser, and the entry should contain the uid attribute. The attribute must be unique within a customer subtree.
inetOrgPerson with the nsManagedPerson object class.
The following are some guidelines for placing person entries in the directory tree:
- People in an enterprise should be located in the directory tree below the organization's entry.
- Subscribers to a hosting organization need to be below the
ou=peoplebranch for the hosted organization.
4.2.3.2. Naming Group Entries
- A static group explicitly defines is members. The
groupOfNamesorgroupOfUniqueNamesobject classes contain values naming the members of the group. Static groups are suitable for groups with few members, such as the group of directory administrators. Static groups are not suitable for groups with thousands of members.Static group entries must contain auniqueMemberattribute value becauseuniqueMemberis a mandatory attribute of thegroupOfUniqueNamesobject. This object class requires thecnattribute, which can be used to form the DN of the group entry. - A dynamic group uses an entry representing the group with a search filter and subtree. Entries matching the filter are members of the group.
- Roles unify the static and dynamic group concept. See Section 4.3, “Grouping Directory Entries” for more information.
groupOfUniqueNames object class to contain the values naming the members of groups used in directory administration. In a hosted organization, we also recommend that group entries used for directory administration be located under the ou=Groups branch.
4.2.3.3. Naming Organization Entries
o=example_a+st=Washington,o=ISP,c=US.
organization (o) attribute as the naming attribute.
4.2.3.4. Naming Other Kinds of Entries
cn attribute in the RDN if possible. Then, for naming a group entry, name it something like cn=administrators,dc=example,dc=com.
commonName attribute. Instead, use an attribute that is supported by the entry's object class.
4.2.4. Renaming Entries and Subtrees
Example 4.1. Building Entry DNs
dc=example,dc=com => root suffix
ou=People,dc=example,dc=com => org unit
st=California,ou=People,dc=example,dc=com => state/province
l=Mountain View,st=California,ou=People,dc=example,dc=com => city
ou=Engineering,l=Mountain View,st=California,ou=People,dc=example,dc=com => org unit
uid=jsmith,ou=Engineering,l=Mountain View,st=California,ou=People,dc=example,dc=com => leaf entry
Figure 4.10. modrdn Operations for a Leaf Entry

Figure 4.11. modrdn Operations for a Subtree Entry
Important
newsuperior attribute which moves the entry from one parent to another.

Figure 4.12. modrdn Operations to a New Parent Entry
entryrdn.db index. Each entry is identified by its own key (a self-link) and then a subkey which identifies its parent (the parent link) and any children. This has a format that lays out the directory tree hierarchy by treating parents and children as attribute to an entry, and every entry is described by a unique ID and its RDN, rather than the full DN.
numeric_id:RDN => self link
ID: #; RDN: "rdn"; NRDN: normalized_rdn
P#:RDN => parent link
ID: #; RDN: "rdn"; NRDN: normalized_rdn
C#:RDN => child link
ID: #; RDN: "rdn"; NRDN: normalized_rdnou=people subtree has a parent of dc=example,dc=com and a child of uid=jsmith.
4:ou=people ID: 4; RDN: "ou=People"; NRDN: "ou=people" P4:ou=people ID: 1; RDN: "dc=example,dc=com"; NRDN: "dc=example,dc=com" C4:ou=people ID: 10; RDN: "uid=jsmith"; NRDN: "uid=jsmith"
- You cannot rename the root suffix.
- Subtree rename operations have minimal effect on replication. Replication agreements are applied to an entire database, not a subtree within the database, so a subtree rename operation does not require re-configuring a replication agreement. All of the name changes after a subtree rename operation are replicated as normal.
- Renaming a subtree may require any synchronization agreements to be re-configured. Sync agreements are set at the suffix or subtree level, so renaming a subtree may break synchronization.
- Renaming a subtree requires that any subtree-level ACIs set for the subtree be re-configured manually, as well as any entry-level ACIs set for child entries of the subtree.
- You can rename a subtree with children, but you cannot delete a subtree with children.
- Trying to change the component of a subtree, like moving from
outodc, may fail with a schema violation. For example, theorganizationalUnitobject class requires theouattribute. If that attribute is removed as part of renaming the subtree, then the operation will fail.