
Chapter 20. Client/Server
Red Hat Data Grid offers two alternative access methods: embedded mode and client-server mode.
- In Embedded mode the Red Hat Data Grid libraries co-exist with the user application in the same JVM as shown in the following diagram
Figure 20.1. Peer-to-peer access

- Client-server mode is when applications access the data stored in a remote Red Hat Data Grid server using some kind of network protocol
20.1. Why Client/Server?
There are situations when accessing Red Hat Data Grid in a client-server mode might make more sense than embedding it within your application, for example, when trying to access Red Hat Data Grid from a non-JVM environment. Since Red Hat Data Grid is written in Java, if someone had a C\\ application that wanted to access it, it couldn’t just do it in a p2p way. On the other hand, client-server would be perfectly suited here assuming that a language neutral protocol was used and the corresponding client and server implementations were available.
Figure 20.2. Non-JVM access

In other situations, Red Hat Data Grid users want to have an elastic application tier where you start/stop business processing servers very regularly. Now, if users deployed Red Hat Data Grid configured with distribution or state transfer, startup time could be greatly influenced by the shuffling around of data that happens in these situations. So in the following diagram, assuming Red Hat Data Grid was deployed in p2p mode, the app in the second server could not access Red Hat Data Grid until state transfer had completed.
Figure 20.3. Elasticity issue with P2P
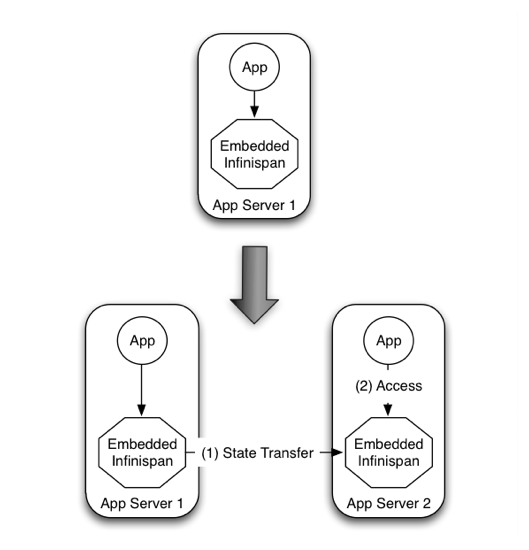
This effectively means that bringing up new application-tier servers is impacted by things like state transfer because applications cannot access Red Hat Data Grid until these processes have finished and if the state being shifted around is large, this could take some time. This is undesirable in an elastic environment where you want quick application-tier server turnaround and predictable startup times. Problems like this can be solved by accessing Red Hat Data Grid in a client-server mode because starting a new application-tier server is just a matter of starting a lightweight client that can connect to the backing data grid server. No need for rehashing or state transfer to occur and as a result server startup times can be more predictable which is very important for modern cloud-based deployments where elasticity in your application tier is important.
Figure 20.4. Achieving elasticity
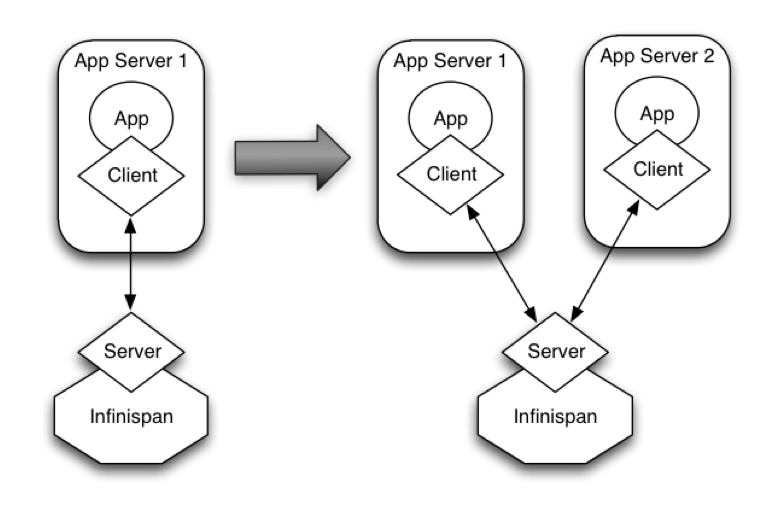
Other times, it’s common to find multiple applications needing access to data storage. In this cases, you could in theory deploy an Red Hat Data Grid instance per each of those applications but this could be wasteful and difficult to maintain. Think about databases here, you don’t deploy a database alongside each of your applications, do you? So, alternatively you could deploy Red Hat Data Grid in client-server mode keeping a pool of Red Hat Data Grid data grid nodes acting as a shared storage tier for your applications.
Figure 20.5. Shared data storage
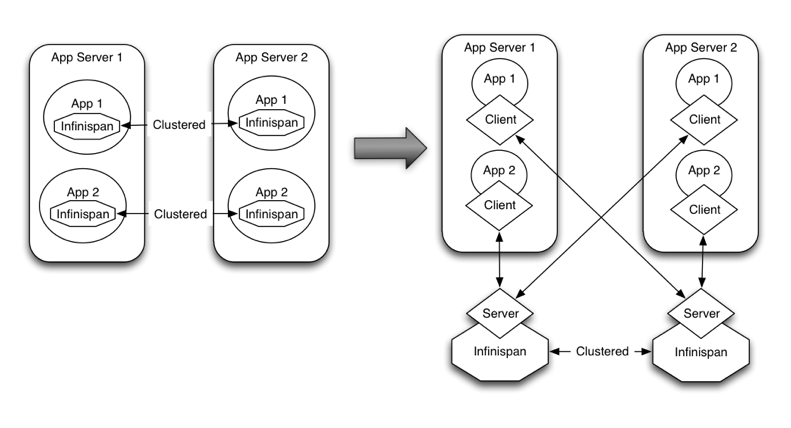
Deploying Red Hat Data Grid in this way also allows you to manage each tier independently, for example, you can upgrade you application or app server without bringing down your Red Hat Data Grid data grid nodes.
20.2. Why use embedded mode?
Before talking about individual Red Hat Data Grid server modules, it’s worth mentioning that in spite of all the benefits, client-server Red Hat Data Grid still has disadvantages over p2p. Firstly, p2p deployments are simpler than client-server ones because in p2p, all peers are equals to each other and hence this simplifies deployment. So, if this is the first time you’re using Red Hat Data Grid, p2p is likely to be easier for you to get going compared to client-server.
Client-server Red Hat Data Grid requests are likely to take longer compared to p2p requests, due to the serialization and network cost in remote calls. So, this is an important factor to take in account when designing your application. For example, with replicated Red Hat Data Grid caches, it might be more performant to have lightweight HTTP clients connecting to a server side application that accesses Red Hat Data Grid in p2p mode, rather than having more heavyweight client side apps talking to Red Hat Data Grid in client-server mode, particularly if data size handled is rather large. With distributed caches, the difference might not be so big because even in p2p deployments, you’re not guaranteed to have all data available locally.
Environments where application tier elasticity is not so important, or where server side applications access state-transfer-disabled, replicated Red Hat Data Grid cache instances are amongst scenarios where Red Hat Data Grid p2p deployments can be more suited than client-server ones.
20.3. Server Modules
So, now that it’s clear when it makes sense to deploy Red Hat Data Grid in client-server mode, what are available solutions? All Red Hat Data Grid server modules are based on the same pattern where the server backend creates an embedded Red Hat Data Grid instance and if you start multiple backends, they can form a cluster and share/distribute state if configured to do so. The server types below primarily differ in the type of listener endpoint used to handle incoming connections.
Here’s a brief summary of the available server endpoints.
Hot Rod Server Module - This module is an implementation of the Hot Rod binary protocol backed by Red Hat Data Grid which allows clients to do dynamic load balancing and failover and smart routing.
- A variety of clients exist for this protocol.
- If you’re clients are running Java, this should be your defacto server module choice because it allows for dynamic load balancing and failover. This means that Hot Rod clients can dynamically detect changes in the topology of Hot Rod servers as long as these are clustered, so when new nodes join or leave, clients update their Hot Rod server topology view. On top of that, when Hot Rod servers are configured with distribution, clients can detect where a particular key resides and so they can route requests smartly.
- Load balancing and failover is dynamically provided by Hot Rod client implementations using information provided by the server.
REST Server Module - The REST server, which is distributed as a WAR file, can be deployed in any servlet container to allow Red Hat Data Grid to be accessed via a RESTful HTTP interface.
- To connect to it, you can use any HTTP client out there and there’re tons of different client implementations available out there for pretty much any language or system.
- This module is particularly recommended for those environments where HTTP port is the only access method allowed between clients and servers.
- Clients wanting to load balance or failover between different Red Hat Data Grid REST servers can do so using any standard HTTP load balancer such as mod_cluster . It’s worth noting though these load balancers maintain a static view of the servers in the backend and if a new one was to be added, it would require manual update of the load balancer.
Memcached Server Module - This module is an implementation of the Memcached text protocol backed by Red Hat Data Grid.
- To connect to it, you can use any of the existing Memcached clients which are pretty diverse.
- As opposed to Memcached servers, Red Hat Data Grid based Memcached servers can actually be clustered and hence they can replicate or distribute data using consistent hash algorithms around the cluster. So, this module is particularly of interest to those users that want to provide failover capabilities to the data stored in Memcached servers.
- In terms of load balancing and failover, there’re a few clients that can load balance or failover given a static list of server addresses (perl’s Cache::Memcached for example) but any server addition or removal would require manual intervention.
20.4. Which protocol should I use?
Choosing the right protocol depends on a number of factors.
| Hot Rod | HTTP / REST | Memcached | |
|---|---|---|---|
| Topology-aware | Y | N | N |
| Hash-aware | Y | N | N |
| Encryption | Y | Y | N |
| Authentication | Y | Y | N |
| Conditional ops | Y | Y | Y |
| Bulk ops | Y | N | N |
| Transactions | N | N | N |
| Listeners | Y | N | N |
| Query | Y | Y | N |
| Execution | Y | N | N |
| Cross-site failover | Y | N | N |
20.5. Using Hot Rod Server
The Red Hat Data Grid Server distribution contains a server module that implements Red Hat Data Grid’s custom binary protocol called Hot Rod. The protocol was designed to enable faster client/server interactions compared to other existing text based protocols and to allow clients to make more intelligent decisions with regards to load balancing, failover and even data location operations. Please refer to Red Hat Data Grid Server’s documentation for instructions on how to configure and run a HotRod server.
To connect to Red Hat Data Grid over this highly efficient Hot Rod protocol you can either use one of the clients described in this chapter, or use higher level tools such as Hibernate OGM.
20.6. Hot Rod Protocol
The following articles provides detailed information about each version of the custom TCP client/server Hot Rod protocol.
20.6.1. Hot Rod Protocol 1.0
This version of the protocol is implemented since Infinispan 4.1.0.Final
All key and values are sent and stored as byte arrays. Hot Rod makes no assumptions about their types.
Some clarifications about the other types:
vInt : Variable-length integers are defined defined as compressed, positive integers where the high-order bit of each byte indicates whether more bytes need to be read. The low-order seven bits are appended as increasingly more significant bits in the resulting integer value making it efficient to decode. Hence, values from zero to 127 are stored in a single byte, values from 128 to 16,383 are stored in two bytes, and so on:
ValueFirst byteSecond byteThird byte000000000100000001200000010…12701111111128100000000000000112910000001000000011301000001000000001…16,383111111110111111116,38410000000100000000000000116,385100000011000000000000001…- signed vInt: The vInt above is also able to encode negative values, but will always use the maximum size (5 bytes) no matter how small the endoded value is. In order to have a small payload for negative values too, signed vInts uses ZigZag encoding on top of the vInt encoding. More details here
- vLong : Refers to unsigned variable length long values similar to vInt but applied to longer values. They’re between 1 and 9 bytes long.
- String : Strings are always represented using UTF-8 encoding.
20.6.1.1. Request Header
The header for a request is composed of:
Table 20.1. Request header
| Field Name | Size | Value |
|---|---|---|
| Magic | 1 byte | 0xA0 = request |
| Message ID | vLong | ID of the message that will be copied back in the response. This allows for Hot Rod clients to implement the protocol in an asynchronous way. |
| Version | 1 byte | Hot Rod server version. In this particular case, this is 10 |
| Opcode | 1 byte |
Request operation code: |
| Cache Name Length | vInt | Length of cache name. If the passed length is 0 (followed by no cache name), the operation will interact with the default cache. |
| Cache Name | string | Name of cache on which to operate. This name must match the name of predefined cache in the Red Hat Data Grid configuration file. |
| Flags | vInt |
A variable length number representing flags passed to the system. Each flags is represented by a bit. Note that since this field is sent as variable length, the most significant bit in a byte is used to determine whether more bytes need to be read, hence this bit does not represent any flag. Using this model allows for flags to be combined in a short space. Here are the current values for each flag: |
| Client Intelligence | 1 byte |
This byte hints the server on the client capabilities: |
| Topology Id | vInt | This field represents the last known view in the client. Basic clients will only send 0 in this field. When topology-aware or hash-distribution-aware clients will send 0 until they have received a reply from the server with the current view id. Afterwards, they should send that view id until they receive a new view id in a response. |
| Transaction Type | 1 byte |
This is a 1 byte field, containing one of the following well-known supported transaction types (For this version of the protocol, the only supported transaction type is 0): |
| Transaction Id | byte array | The byte array uniquely identifying the transaction associated to this call. Its length is determined by the transaction type. If transaction type is 0, no transaction id will be present. |
20.6.1.2. Response Header
The header for a response is composed of:
Table 20.2. Response header
| Field Name | Size | Value |
|---|---|---|
| Magic | 1 byte | 0xA1 = response |
| Message ID | vLong | ID of the message, matching the request for which the response is sent. |
| Opcode | 1 byte |
Response operation code: |
| Status | 1 byte |
Status of the response, possible values: |
| Topology Change Marker | string | This is a marker byte that indicates whether the response is prepended with topology change information. When no topology change follows, the content of this byte is 0. If a topology change follows, its contents are 1. |
Exceptional error status responses, those that start with 0x8 …, are followed by the length of the error message (as a vInt ) and error message itself as String.
20.6.1.3. Topology Change Headers
The following section discusses how the response headers look for topology-aware or hash-distribution-aware clients when there’s been a cluster or view formation change. Note that it’s the server that makes the decision on whether it sends back the new topology based on the current topology id and the one the client sent. If they’re different, it will send back the new topology.
20.6.1.4. Topology-Aware Client Topology Change Header
This is what topology-aware clients receive as response header when a topology change is sent back:
| Field Name | Size | Value |
|---|---|---|
| Response header with topology change marker | variable | See previous section. |
| Topology Id | vInt | Topology ID |
| Num servers in topology | vInt | Number of Hot Rod servers running within the cluster. This could be a subset of the entire cluster if only a fraction of those nodes are running Hot Rod servers. |
| m1: Host/IP length | vInt | Length of hostname or IP address of individual cluster member that Hot Rod client can use to access it. Using variable length here allows for covering for hostnames, IPv4 and IPv6 addresses. |
| m1: Host/IP address | string | String containing hostname or IP address of individual cluster member that Hot Rod client can use to access it. |
| m1: Port | 2 bytes (Unsigned Short) | Port that Hot Rod clients can use to communicate with this cluster member. |
| m2: Host/IP length | vInt | |
| m2: Host/IP address | string | |
| m2: Port | 2 bytes (Unsigned Short) | |
| …etc |
20.6.1.5. Distribution-Aware Client Topology Change Header
This is what hash-distribution-aware clients receive as response header when a topology change is sent back:
| Field Name | Size | Value |
|---|---|---|
| Response header with topology change marker | variable | See previous section. |
| Topology Id | vInt | Topology ID |
| Num Key Owners | 2 bytes (Unsigned Short) | Globally configured number of copies for each Red Hat Data Grid distributed key |
| Hash Function Version | 1 byte | Hash function version, pointing to a specific hash function in use. See Hot Rod hash functions for details. |
| Hash space size | vInt | Modulus used by Red Hat Data Grid for for all module arithmetic related to hash code generation. Clients will likely require this information in order to apply the correct hash calculation to the keys. |
| Num servers in topology | vInt | Number of Red Hat Data Grid Hot Rod servers running within the cluster. This could be a subset of the entire cluster if only a fraction of those nodes are running Hot Rod servers. |
| m1: Host/IP length | vInt | Length of hostname or IP address of individual cluster member that Hot Rod client can use to access it. Using variable length here allows for covering for hostnames, IPv4 and IPv6 addresses. |
| m1: Host/IP address | string | String containing hostname or IP address of individual cluster member that Hot Rod client can use to access it. |
| m1: Port | 2 bytes (Unsigned Short) | Port that Hot Rod clients can use to communicat with this cluster member. |
| m1: Hashcode | 4 bytes | 32 bit integer representing the hashcode of a cluster member that a Hot Rod client can use indentify in which cluster member a key is located having applied the CSA to it. |
| m2: Host/IP length | vInt | |
| m2: Host/IP address | string | |
| m2: Port | 2 bytes (Unsigned Short) | |
| m2: Hashcode | 4 bytes | |
| …etc |
It’s important to note that since hash headers rely on the consistent hash algorithm used by the server and this is a factor of the cache interacted with, hash-distribution-aware headers can only be returned to operations that target a particular cache. Currently ping command does not target any cache (this is to change as per ISPN-424) , hence calls to ping command with hash-topology-aware client settings will return a hash-distribution-aware header with "Num Key Owners", "Hash Function Version", "Hash space size" and each individual host’s hash code all set to 0. This type of header will also be returned as response to operations with hash-topology-aware client settings that are targeting caches that are not configured with distribution.
20.6.1.6. Operations
Get (0x03)/Remove (0x0B)/ContainsKey (0x0F)/GetWithVersion (0x11)
Common request format:
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Key Length | vInt | Length of key. Note that the size of a vint can be up to 5 bytes which in theory can produce bigger numbers than Integer.MAX_VALUE. However, Java cannot create a single array that’s bigger than Integer.MAX_VALUE, hence the protocol is limiting vint array lengths to Integer.MAX_VALUE. |
| Key | byte array | Byte array containing the key whose value is being requested. |
Get response (0x04):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Response status | 1 byte |
0x00 = success, if key retrieved |
| Value Length | vInt | If success, length of value |
| Value | byte array | If success, the requested value |
Remove response (0x0C):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Response status | 1 byte |
0x00 = success, if key removed |
| Previous value Length | vInt | If force return previous value flag was sent in the request and the key was removed, the length of the previous value will be returned. If the key does not exist, value length would be 0. If no flag was sent, no value length would be present. |
| Previous value | byte array | If force return previous value flag was sent in the request and the key was removed, previous value. |
ContainsKey response (0x10):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Response status | 1 byte |
0x00 = success, if key exists |
GetWithVersion response (0x12):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Response status | 1 byte |
0x00 = success, if key retrieved |
| Entry Version | 8 bytes | Unique value of an existing entry’s modification. The protocol does not mandate that entry_version values are sequential. They just need to be unique per update at the key level. |
| Value Length | vInt | If success, length of value |
| Value | byte array | If success, the requested value |
BulkGet
Request (0x19):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Entry count | vInt | Maximum number of Red Hat Data Grid entries to be returned by the server (entry == key + associated value). Needed to support CacheLoader.load(int). If 0 then all entries are returned (needed for CacheLoader.loadAll()). |
Response (0x20):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Response status | 1 byte |
0x00 = success, data follows |
| More | 1 byte | One byte representing whether more entries need to be read from the stream. So, when it’s set to 1, it means that an entry follows, whereas when it’s set to 0, it’s the end of stream and no more entries are left to read. For more information on BulkGet look here |
| Key 1 Length | vInt | Length of key |
| Key 1 | byte array | Retrieved key |
| Value 1 Length | vInt | Length of value |
| Value 1 | byte array | Retrieved value |
| More | 1 byte | |
| Key 2 Length | vInt | |
| Key 2 | byte array | |
| Value 2 Length | vInt | |
| Value 2 | byte array | |
| … etc |
Put (0x01)/PutIfAbsent (0x05)/Replace (0x07)
Common request format:
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Key Length | vInt | Length of key. Note that the size of a vint can be up to 5 bytes which in theory can produce bigger numbers than Integer.MAX_VALUE. However, Java cannot create a single array that’s bigger than Integer.MAX_VALUE, hence the protocol is limiting vint array lengths to Integer.MAX_VALUE. |
| Key | byte array | Byte array containing the key whose value is being requested. |
| Lifespan | vInt | Number of seconds that a entry during which the entry is allowed to life. If number of seconds is bigger than 30 days, this number of seconds is treated as UNIX time and so, represents the number of seconds since 1/1/1970. If set to 0, lifespan is unlimited. |
| Max Idle | vInt | Number of seconds that a entry can be idle before it’s evicted from the cache. If 0, no max idle time. |
| Value Length | vInt | Length of value |
| Value | byte-array | Value to be stored |
Put response (0x02):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Response status | 1 byte |
0x00 = success, if stored |
| Previous value Length | vInt | If force return previous value flag was sent in the request and the key was put, the length of the previous value will be returned. If the key does not exist, value length would be 0. If no flag was sent, no value length would be present. |
| Previous value | byte array | If force return previous value flag was sent in the request and the key was put, previous value. |
Replace response (0x08):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Response status | 1 byte |
0x00 = success, if stored |
| Previous value Length | vInt | If force return previous value flag was sent in the request, the length of the previous value will be returned. If the key does not exist, value length would be 0. If no flag was sent, no value length would be present. |
| Previous value | byte array | If force return previous value flag was sent in the request and the key was replaced, previous value. |
PutIfAbsent response (0x06):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Response status | 1 byte |
0x00 = success, if stored |
| Previous value Length | vInt | If force return previous value flag was sent in the request, the length of the previous value will be returned. If the key does not exist, value length would be 0. If no flag was sent, no value length would be present. |
| Previous value | byte array | If force return previous value flag was sent in the request and the key was replaced, previous value. |
ReplaceIfUnmodified
Request (0x09):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Key Length | vInt | Length of key. Note that the size of a vint can be up to 5 bytes which in theory can produce bigger numbers than Integer.MAX_VALUE. However, Java cannot create a single array that’s bigger than Integer.MAX_VALUE, hence the protocol is limiting vint array lengths to Integer.MAX_VALUE. |
| Key | byte array | Byte array containing the key whose value is being requested. |
| Lifespan | vInt | Number of seconds that a entry during which the entry is allowed to life. If number of seconds is bigger than 30 days, this number of seconds is treated as UNIX time and so, represents the number of seconds since 1/1/1970. If set to 0, lifespan is unlimited. |
| Max Idle | vInt | Number of seconds that a entry can be idle before it’s evicted from the cache. If 0, no max idle time. |
| Entry Version | 8 bytes | Use the value returned by GetWithVersion operation. |
| Value Length | vInt | Length of value |
| Value | byte-array | Value to be stored |
Response (0x0A):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Response status | 1 byte |
0x00 = success, if replaced |
| Previous value Length | vInt | If force return previous value flag was sent in the request, the length of the previous value will be returned. If the key does not exist, value length would be 0. If no flag was sent, no value length would be present. |
| Previous value | byte array | If force return previous value flag was sent in the request and the key was replaced, previous value. |
RemoveIfUnmodified
Request (0x0D):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Key Length | vInt | Length of key. Note that the size of a vint can be up to 5 bytes which in theory can produce bigger numbers than Integer.MAX_VALUE. However, Java cannot create a single array that’s bigger than Integer.MAX_VALUE, hence the protocol is limiting vint array lengths to Integer.MAX_VALUE. |
| Key | byte array | Byte array containing the key whose value is being requested. |
| Entry Version | 8 bytes | Use the value returned by GetWithMetadata operation. |
Response (0x0E):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Response status | 1 byte |
0x00 = success, if removed |
| Previous value Length | vInt | If force return previous value flag was sent in the request, the length of the previous value will be returned. If the key does not exist, value length would be 0. If no flag was sent, no value length would be present. |
| Previous value | byte array | If force return previous value flag was sent in the request and the key was removed, previous value. |
Clear
Request (0x13):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
Response (0x14):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Response status | 1 byte |
0x00 = success, if cleared |
PutAll
Bulk operation to put all key value entries into the cache at the same time.
Request (0x2D):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Lifespan | vInt | Number of seconds that provided entries are allowed to live. If number of seconds is bigger than 30 days, this number of seconds is treated as UNIX time and so, represents the number of seconds since 1/1/1970. If set to 0, lifespan is unlimited. |
| Max Idle | vInt | Number of seconds that each entry can be idle before it’s evicted from the cache. If 0, no max idle time. |
| Entry count | vInt | How many entries are being inserted |
| Key 1 Length | vInt | Length of key |
| Key 1 | byte array | Retrieved key |
| Value 1 Length | vInt | Length of value |
| Value 1 | byte array | Retrieved value |
| Key 2 Length | vInt | |
| Key 2 | byte array | |
| Value 2 Length | vInt | |
| Value 2 | byte array | |
| … continues until entry count is reached |
Response (0x2E):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Response status | 1 byte |
0x00 = success, if all put |
GetAll
Bulk operation to get all entries that map to a given set of keys.
Request (0x2F):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Key count | vInt | How many keys to find entries for |
| Key 1 Length | vInt | Length of key |
| Key 1 | byte array | Retrieved key |
| Key 2 Length | vInt | |
| Key 2 | byte array | |
| … continues until key count is reached |
Response (0x30):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Response status | 1 byte | |
| Entry count | vInt | How many entries are being returned |
| Key 1 Length | vInt | Length of key |
| Key 1 | byte array | Retrieved key |
| Value 1 Length | vInt | Length of value |
| Value 1 | byte array | Retrieved value |
| Key 2 Length | vInt | |
| Key 2 | byte array | |
| Value 2 Length | vInt | |
| Value 2 | byte array | |
| … continues until entry count is reached |
0x00 = success, if the get returned sucessfully |
Stats
Returns a summary of all available statistics. For each statistic returned, a name and a value is returned both in String UTF-8 format. The supported stats are the following:
| Name | Explanation |
|---|---|
| timeSinceStart | Number of seconds since Hot Rod started. |
| currentNumberOfEntries | Number of entries currently in the Hot Rod server. |
| totalNumberOfEntries | Number of entries stored in Hot Rod server. |
| stores | Number of put operations. |
| retrievals | Number of get operations. |
| hits | Number of get hits. |
| misses | Number of get misses. |
| removeHits | Number of removal hits. |
| removeMisses | Number of removal misses. |
Request (0x15):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
Response (0x16):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Response status | 1 byte |
0x00 = success, if stats retrieved |
| Number of stats | vInt | Number of individual stats returned. |
| Name 1 length | vInt | Length of named statistic. |
| Name 1 | string | String containing statistic name. |
| Value 1 length | vInt | Length of value field. |
| Value 1 | string | String containing statistic value. |
| Name 2 length | vInt | |
| Name 2 | string | |
| Value 2 length | vInt | |
| Value 2 | String | |
| …etc |
Ping
Application level request to see if the server is available.
Request (0x17):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
Response (0x18):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Response status | 1 byte |
0x00 = success, if no errors |
Error Handling
Error response (0x50)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Response status | 1 byte |
0x8x = error response code |
| Error Message Length | vInt | Length of error message |
| Error Message | string | Error message. In the case of 0x84 , this error field contains the latest version supported by the Hot Rod server. Length is defined by total body length. |
Multi-Get Operations
A multi-get operation is a form of get operation that instead of requesting a single key, requests a set of keys. The Hot Rod protocol does not include such operation but remote Hot Rod clients could easily implement this type of operations by either parallelizing/pipelining individual get requests. Another possibility would be for remote clients to use async or non-blocking get requests. For example, if a client wants N keys, it could send send N async get requests and then wait for all the replies. Finally, multi-get is not to be confused with bulk-get operations. In bulk-gets, either all or a number of keys are retrieved, but the client does not know which keys to retrieve, whereas in multi-get, the client defines which keys to retrieve.
20.6.1.7. Example - Put request
- Coded request
| Byte | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 8 | 0xA0 | 0x09 | 0x41 | 0x01 | 0x07 | 0x4D ('M') | 0x79 ('y') | 0x43 ('C') |
| 16 | 0x61 ('a') | 0x63 ('c') | 0x68 ('h') | 0x65 ('e') | 0x00 | 0x03 | 0x00 | 0x00 |
| 24 | 0x00 | 0x05 | 0x48 ('H') | 0x65 ('e') | 0x6C ('l') | 0x6C ('l') | 0x6F ('o') | 0x00 |
| 32 | 0x00 | 0x05 | 0x57 ('W') | 0x6F ('o') | 0x72 ('r') | 0x6C ('l') | 0x64 ('d') |
|
- Field explanation
| Field Name | Value | Field Name | Value |
|---|---|---|---|
| Magic (0) | 0xA0 | Message Id (1) | 0x09 |
| Version (2) | 0x41 | Opcode (3) | 0x01 |
| Cache name length (4) | 0x07 | Cache name(5-11) | 'MyCache' |
| Flag (12) | 0x00 | Client Intelligence (13) | 0x03 |
| Topology Id (14) | 0x00 | Transaction Type (15) | 0x00 |
| Transaction Id (16) | 0x00 | Key field length (17) | 0x05 |
| Key (18 - 22) | 'Hello' | Lifespan (23) | 0x00 |
| Max idle (24) | 0x00 | Value field length (25) | 0x05 |
| Value (26-30) | 'World' |
- Coded response
| Byte | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 8 | 0xA1 | 0x09 | 0x01 | 0x00 | 0x00 |
|
|
|
- Field Explanation
| Field Name | Value | Field Name | Value |
|---|---|---|---|
| Magic (0) | 0xA1 | Message Id (1) | 0x09 |
| Opcode (2) | 0x01 | Status (3) | 0x00 |
| Topology change marker (4) | 0x00 |
|
20.6.2. Hot Rod Protocol 1.1
This version of the protocol is implemented since Infinispan 5.1.0.FINAL
20.6.2.1. Request Header
The version field in the header is updated to 11.
20.6.2.2. Distribution-Aware Client Topology Change Header
This section has been modified to be more efficient when talking to distributed caches with virtual nodes enabled.
This is what hash-distribution-aware clients receive as response header when a topology change is sent back:
| Field Name | Size | Value |
|---|---|---|
| Response header with topology change marker | variable | See previous section. |
| Topology Id | vInt | Topology ID |
| Num Key Owners | 2 bytes (Unsigned Short) | Globally configured number of copies for each Red Hat Data Grid distributed key |
| Hash Function Version | 1 byte | Hash function version, pointing to a specific hash function in use. See Hot Rod hash functions for details. |
| Hash space size | vInt | Modulus used by Red Hat Data Grid for for all module arithmetic related to hash code generation. Clients will likely require this information in order to apply the correct hash calculation to the keys. |
| Num servers in topology | vInt | Number of Hot Rod servers running within the cluster. This could be a subset of the entire cluster if only a fraction of those nodes are running Hot Rod servers. |
| Num Virtual Nodes Owners | vInt | Field added in version 1.1 of the protocol that represents the number of configured virtual nodes. If no virtual nodes are configured or the cache is not configured with distribution, this field will contain 0. |
| m1: Host/IP length | vInt | Length of hostname or IP address of individual cluster member that Hot Rod client can use to access it. Using variable length here allows for covering for hostnames, IPv4 and IPv6 addresses. |
| m1: Host/IP address | string | String containing hostname or IP address of individual cluster member that Hot Rod client can use to access it. |
| m1: Port | 2 bytes (Unsigned Short) | Port that Hot Rod clients can use to communicat with this cluster member. |
| m1: Hashcode | 4 bytes | 32 bit integer representing the hashcode of a cluster member that a Hot Rod client can use indentify in which cluster member a key is located having applied the CSA to it. |
| m2: Host/IP length | vInt | |
| m2: Host/IP address | string | |
| m2: Port | 2 bytes (Unsigned Short) | |
| m2: Hashcode | 4 bytes | |
| …etc |
20.6.2.3. Server node hash code calculation
Adding support for virtual nodes has made version 1.0 of the Hot Rod protocol impractical due to bandwidth it would have taken to return hash codes for all virtual nodes in the clusters (this number could easily be in the millions). So, as of version 1.1 of the Hot Rod protocol, clients are given the base hash id or hash code of each server, and then they have to calculate the real hash position of each server both with and without virtual nodes configured. Here are the rules clients should follow when trying to calculate a node’s hash code:
1\. With virtual nodes disabled : Once clients have received the base hash code of the server, they need to normalize it in order to find the exact position of the hash wheel. The process of normalization involves passing the base hash code to the hash function, and then do a small calculation to avoid negative values. The resulting number is the node’s position in the hash wheel:
public static int getNormalizedHash(int nodeBaseHashCode, Hash hashFct) {
return hashFct.hash(nodeBaseHashCode) & Integer.MAX_VALUE; // make sure no negative numbers are involved.
}2\. With virtual nodes enabled : In this case, each node represents N different virtual nodes, and to calculate each virtual node’s hash code, we need to take the the range of numbers between 0 and N-1 and apply the following logic:
- For virtual node with 0 as id, use the technique used to retrieve a node’s hash code, as shown in the previous section.
- For virtual nodes from 1 to N-1 ids, execute the following logic:
public static int virtualNodeHashCode(int nodeBaseHashCode, int id, Hash hashFct) {
int virtualNodeBaseHashCode = id;
virtualNodeBaseHashCode = 31 * virtualNodeBaseHashCode + nodeBaseHashCode;
return getNormalizedHash(virtualNodeBaseHashCode, hashFct);
}20.6.3. Hot Rod Protocol 1.2
This version of the protocol is implemented since Red Hat Data Grid 5.2.0.Final. Since Red Hat Data Grid 5.3.0, HotRod supports encryption via SSL. However, since this only affects the transport, the version number of the protocol has not been incremented.
20.6.3.1. Request Header
The version field in the header is updated to 12.
Two new request operation codes have been added:
- 0x1B = getWithMetadata request
- 0x1D = bulkKeysGet request
Two new flags have been added too:
- 0x0002 = use cache-level configured default lifespan
- 0x0004 = use cache-level configured default max idle
20.6.3.2. Response Header
Two new response operation codes have been added:
- 0x1C = getWithMetadata response
- 0x1E = bulkKeysGet response
20.6.3.3. Operations
GetWithMetadata
Request (0x1B):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Key Length | vInt | Length of key. Note that the size of a vint can be up to 5 bytes which in theory can produce bigger numbers than Integer.MAX_VALUE. However, Java cannot create a single array that’s bigger than Integer.MAX_VALUE, hence the protocol is limiting vint array lengths to Integer.MAX_VALUE. |
| Key | byte array | Byte array containing the key whose value is being requested. |
Response (0x1C):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Response status | 1 byte |
0x00 = success, if key retrieved |
| Flag | 1 byte |
A flag indicating whether the response contains expiration information. The value of the flag is obtained as a bitwise OR operation between INFINITE_LIFESPAN (0x01) and |
| Created | Long | (optional) a Long representing the timestamp when the entry was created on the server. This value is returned only if the flag’s INFINITE_LIFESPAN bit is not set. |
| Lifespan | vInt | (optional) a vInt representing the lifespan of the entry in seconds. This value is returned only if the flag’s INFINITE_LIFESPAN bit is not set. |
| LastUsed | Long |
(optional) a Long representing the timestamp when the entry was last accessed on the server. This value is returned only if the flag’s |
| MaxIdle | vInt |
(optional) a vInt representing the maxIdle of the entry in seconds. This value is returned only if the flag’s |
| Entry Version | 8 bytes | Unique value of an existing entry’s modification. The protocol does not mandate that entry_version values are sequential. They just need to be unique per update at the key level. |
| Value Length | vInt | If success, length of value |
| Value | byte array | If success, the requested value |
BulkKeysGet
Request (0x1D):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Scope | vInt |
0 = Default Scope - This scope is used by RemoteCache.keySet() method. If the remote cache is a distributed cache, the server launch a stream operation to retrieve all keys from all of the nodes. (Remember, a topology-aware Hot Rod Client could be load balancing the request to any one node in the cluster). Otherwise, it’ll get keys from the cache instance local to the server receiving the request (that is because the keys should be the same across all nodes in a replicated cache). |
Response (0x1E):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Response status | 1 byte |
0x00 = success, data follows |
| More | 1 byte | One byte representing whether more keys need to be read from the stream. So, when it’s set to 1, it means that an entry follows, whereas when it’s set to 0, it’s the end of stream and no more entries are left to read. For more information on BulkGet look here |
| Key 1 Length | vInt | Length of key |
| Key 1 | byte array | Retrieved key |
| More | 1 byte | |
| Key 2 Length | vInt | |
| Key 2 | byte array | |
| … etc |
20.6.4. Hot Rod Protocol 1.3
This version of the protocol is implemented since Infinispan 6.0.0.Final.
20.6.4.1. Request Header
The version field in the header is updated to 13.
A new request operation code has been added:
- 0x1F = query request
20.6.4.2. Response Header
A new response operation code has been added:
- 0x20 = query response
20.6.4.3. Operations
Query
Request (0x1F):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Query Length | vInt | The length of the protobuf encoded query object |
| Query | byte array | Byte array containing the protobuf encoded query object, having a length specified by previous field. |
Response (0x20):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Response payload Length | vInt | The length of the protobuf encoded response object |
| Response payload | byte array | Byte array containing the protobuf encoded response object, having a length specified by previous field. |
As of Infinispan 6.0, the query and response objects are specified by the protobuf message types 'org.infinispan.client.hotrod.impl.query.QueryRequest' and 'org.infinispan.client.hotrod.impl.query.QueryResponse' defined in remote-query/remote-query-client/src/main/resources/org/infinispan/query/remote/client/query.proto. These definitions could change in future Infinispan versions, but as long as these evolutions will be kept backward compatible (according to the rules defined here) no new Hot Rod protocol version will be introduced to accommodate this.
20.6.5. Hot Rod Protocol 2.0
This version of the protocol is implemented since Infinispan 7.0.0.Final.
20.6.5.1. Request Header
The request header no longer contains Transaction Type and Transaction ID elements since they’re not in use, and even if they were in use, there are several operations for which they would not make sense, such as ping or stats commands. Once transactions are implemented, the protocol version will be upped, with the necessary changes in the request header.
The version field in the header is updated to 20.
Two new flags have been added:
- 0x0008 = operation skips loading from configured cache loader.
- 0x0010 = operation skips indexing. Only relevant when the query module is enabled for the cache
The following new request operation codes have been added:
- 0x21 = auth mech list request
- 0x23 = auth request
- 0x25 = add client remote event listener request
- 0x27 = remove client remote event listener request
- 0x29 = size request
20.6.5.2. Response Header
The following new response operation codes have been added:
- 0x22 = auth mech list response
- 0x24 = auth mech response
- 0x26 = add client remote event listener response
- 0x28 = remove client remote event listener response
- 0x2A = size response
Two new error codes have also been added to enable clients more intelligent decisions, particularly when it comes to fail-over logic:
- 0x87 = Node suspected. When a client receives this error as response, it means that the node that responded had an issue sending an operation to a third node, which was suspected. Generally, requests that return this error should be failed-over to other nodes.
- 0x88 = Illegal lifecycle state. When a client receives this error as response, it means that the server-side cache or cache manager are not available for requests because either stopped, they’re stopping or similar situation. Generally, requests that return this error should be failed-over to other nodes.
Some adjustments have been made to the responses for the following commands in order to better handle response decoding without the need to keep track of the information sent. More precisely, the way previous values are parsed has changed so that the status of the command response provides clues on whether the previous value follows or not. More precisely:
-
Put response returns
0x03status code when put was successful and previous value follows. -
PutIfAbsent response returns
0x04status code only when the putIfAbsent operation failed because the key was present and its value follows in the response. If the putIfAbsent worked, there would have not been a previous value, and hence it does not make sense returning anything extra. -
Replace response returns
0x03status code only when replace happened and the previous or replaced value follows in the response. If the replace did not happen, it means that the cache entry was not present, and hence there’s no previous value that can be returned. -
ReplaceIfUnmodified returns
0x03status code only when replace happened and the previous or replaced value follows in the response. -
ReplaceIfUnmodified returns
0x04status code only when replace did not happen as a result of the key being modified, and the modified value follows in the response. -
Remove returns
0x03status code when the remove happened and the previous or removed value follows in the response. If the remove did not occur as a result of the key not being present, it does not make sense sending any previous value information. -
RemoveIfUnmodified returns
0x03status code only when remove happened and the previous or replaced value follows in the response. -
RemoveIfUnmodified returns
0x04status code only when remove did not happen as a result of the key being modified, and the modified value follows in the response.
20.6.5.3. Distribution-Aware Client Topology Change Header
In Infinispan 5.2, virtual nodes based consistent hashing was abandoned and instead segment based consistent hash was implemented. In order to satisfy the ability for Hot Rod clients to find data as reliably as possible, Red Hat Data Grid has been transforming the segment based consistent hash to fit Hot Rod 1.x protocol. Starting with version 2.0, a brand new distribution-aware topology change header has been implemented which suppors segment based consistent hashing suitably and provides 100% data location guarantees.
| Field Name | Size | Value |
|---|---|---|
| Response header with topology change marker | variable | |
| Topology Id | vInt | Topology ID |
| Num servers in topology | vInt | Number of Red Hat Data Grid Hot Rod servers running within the cluster. This could be a subset of the entire cluster if only a fraction of those nodes are running Hot Rod servers. |
| m1: Host/IP length | vInt | Length of hostname or IP address of individual cluster member that Hot Rod client can use to access it. Using variable length here allows for covering for hostnames, IPv4 and IPv6 addresses. |
| m1: Host/IP address | string | String containing hostname or IP address of individual cluster member that Hot Rod client can use to access it. |
| m1: Port | 2 bytes (Unsigned Short) | Port that Hot Rod clients can use to communicat with this cluster member. |
| m2: Host/IP length | vInt | |
| m2: Host/IP address | string | |
| m2: Port | 2 bytes (Unsigned Short) | |
| … | … | |
| Hash Function Version | 1 byte | Hash function version, pointing to a specific hash function in use. See Hot Rod hash functions for details. |
| Num segments in topology | vInt | Total number of segments in the topology |
| Number of owners in segment | 1 byte | This can be either 0, 1 or 2 owners. |
| First owner’s index | vInt | Given the list of all nodes, the position of this owner in this list. This is only present if number of owners for this segment is 1 or 2. |
| Second owner’s index | vInt | Given the list of all nodes, the position of this owner in this list. This is only present if number of owners for this segment is 2. |
Given this information, Hot Rod clients should be able to recalculate all the hash segments and be able to find out which nodes are owners for each segment. Even though there could be more than 2 owners per segment, Hot Rod protocol limits the number of owners to send for efficiency reasons.
20.6.5.4. Operations
Auth Mech List
Request (0x21):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
Response (0x22):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Mech count | vInt | The number of mechs |
| Mech 1 | string | String containing the name of the SASL mech in its IANA-registered form (e.g. GSSAPI, CRAM-MD5, etc) |
| Mech 2 | string | |
| …etc |
The purpose of this operation is to obtain the list of valid SASL authentication mechs supported by the server. The client will then need to issue an Authenticate request with the preferred mech.
Authenticate
Request (0x23):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Mech | string | String containing the name of the mech chosen by the client for authentication. Empty on the successive invocations |
| Response length | vInt | Length of the SASL client response |
| Response data | byte array | The SASL client response |
Response (0x24):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Completed | byte | 0 if further processing is needed, 1 if authentication is complete |
| Challenge length | vInt | Length of the SASL server challenge |
| Challenge data | byte array | The SASL server challenge |
The purpose of this operation is to authenticate a client against a server using SASL. The authentication process, depending on the chosen mech, might be a multi-step operation. Once complete the connection becomes authenticated
Add client listener for remote events
Request (0x25):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Listener ID | byte array | Listener identifier |
| Include state | byte |
When this byte is set to |
| Key/value filter factory name | string |
Optional name of the key/value filter factory to be used with this listener. The factory is used to create key/value filter instances which allow events to be filtered directly in the Hot Rod server, avoiding sending events that the client is not interested in. If no factory is to be used, the length of the string is |
| Key/value filter factory parameter count | byte | The key/value filter factory, when creating a filter instance, can take an arbitrary number of parameters, enabling the factory to be used to create different filter instances dynamically. This count field indicates how many parameters will be passed to the factory. If no factory name was provided, this field is not present in the request. |
| Key/value filter factory parameter 1 | byte array | First key/value filter factory parameter |
| Key/value filter factory parameter 2 | byte array | Second key/value filter factory parameter |
| … | ||
| Converter factory name | string |
Optional name of the converter factory to be used with this listener. The factory is used to transform the contents of the events sent to clients. By default, when no converter is in use, events are well defined, according to the type of event generated. However, there might be situations where users want to add extra information to the event, or they want to reduce the size of the events. In these cases, a converter can be used to transform the event contents. The given converter factory name produces converter instances to do this job. If no factory is to be used, the length of the string is |
| Converter factory parameter count | byte | The converter factory, when creating a converter instance, can take an arbitrary number of parameters, enabling the factory to be used to create different converter instances dynamically. This count field indicates how many parameters will be passed to the factory. If no factory name was provided, this field is not present in the request. |
| Converter factory parameter 1 | byte array | First converter factory parameter |
| Converter factory parameter 2 | byte array | Second converter factory parameter |
| … |
Response (0x26):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
Remove client listener for remote events
Request (0x27):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Listener ID | byte array | Listener identifier |
Response (0x28):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
Size
Request (0x29):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
Response (0x2A):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Size | vInt | Size of the remote cache, which is calculated globally in the clustered set ups, and if present, takes cache store contents into account as well. |
Exec
Request (0x2B):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Script | string | Name of the task to execute |
| Parameter Count | vInt | The number of parameters |
| Parameter 1 Name | string | The name of the first parameter |
| Parameter 1 Length | vInt | The length of the first parameter |
| Parameter 1 Value | byte array | The value of the first parameter |
Response (0x2C):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Response status | 1 byte |
0x00 = success, if execution completed successfully |
| Value Length | vInt | If success, length of return value |
| Value | byte array | If success, the result of the execution |
20.6.5.5. Remote Events
Starting with Hot Rod 2.0, clients can register listeners for remote events happening in the server. Sending these events commences the moment a client adds a client listener for remote events.
Event Header:
| Field Name | Size | Value |
|---|---|---|
| Magic | 1 byte | 0xA1 = response |
| Message ID | vLong | ID of event |
| Opcode | 1 byte |
Event type: |
| Status | 1 byte |
Status of the response, possible values: |
| Topology Change Marker | 1 byte |
Since events are not associated with a particular incoming topology ID to be able to decide whether a new topology is required to be sent or not, new topologies will never be sent with events. Hence, this marker will always have |
Table 20.3. Cache entry created event
| Field Name | Size | Value |
|---|---|---|
| Header | variable |
Event header with |
| Listener ID | byte array | Listener for which this event is directed |
| Custom marker | byte |
Custom event marker. For created events, this is |
| Command retried | byte |
Marker for events that are result of retried commands. If command is retried, it returns |
| Key | byte array | Created key |
| Version | long | Version of the created entry. This version information can be used to make conditional operations on this cache entry. |
Table 20.4. Cache entry modified event
| Field Name | Size | Value |
|---|---|---|
| Header | variable |
Event header with |
| Listener ID | byte array | Listener for which this event is directed |
| Custom marker | byte |
Custom event marker. For created events, this is |
| Command retried | byte |
Marker for events that are result of retried commands. If command is retried, it returns |
| Key | byte array | Modified key |
| Version | long | Version of the modified entry. This version information can be used to make conditional operations on this cache entry. |
Table 20.5. Cache entry removed event
| Field Name | Size | Value |
|---|---|---|
| Header | variable |
Event header with |
| Listener ID | byte array | Listener for which this event is directed |
| Custom marker | byte |
Custom event marker. For created events, this is |
| Command retried | byte |
Marker for events that are result of retried commands. If command is retried, it returns |
| Key | byte array | Removed key |
Table 20.6. Custom event
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Event header with event specific operation code |
| Listener ID | byte array | Listener for which this event is directed |
| Custom marker | byte |
Custom event marker. For custom events, this is |
| Event data | byte array | Custom event data, formatted according to the converter implementation logic. |
20.6.6. Hot Rod Protocol 2.1
This version of the protocol is implemented since Infinispan 7.1.0.Final.
20.6.6.1. Request Header
The version field in the header is updated to 21.
20.6.6.2. Operations
Add client listener for remote events
An extra byte parameter is added at the end which indicates whether the client prefers client listener to work with raw binary data for filter/converter callbacks. If using raw data, its value is 1 otherwise 0.
Request format:
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Listener ID | byte array | … |
| Include state | byte | … |
| Key/value filter factory parameter count | byte | … |
| … | ||
| Converter factory name | string | … |
| Converter factory parameter count | byte | … |
| … | ||
| Use raw data | byte |
If filter/converter parameters should be raw binary, then |
Custom event
Starting with Hot Rod 2.1, custom events can return raw data that the Hot Rod client should not try to unmarshall before passing it on to the user. The way this is transmitted to the Hot Rod client is by sending 2 as the custom event marker. So, the format of the custom event remains like this:
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Event header with event specific operation code |
| Listener ID | byte array | Listener for which this event is directed |
| Custom marker | byte |
Custom event marker. For custom events whose event data needs to be unmarshalled before returning to user the value is |
| Event data | byte array |
Custom event data. If the custom marker is |
20.6.7. Hot Rod Protocol 2.2
This version of the protocol is implemented since Infinispan 8.0
Added support for different time units.
20.6.7.1. Operations
Put/PutAll/PutIfAbsent/Replace/ReplaceIfUnmodified
Common request format:
| Field Name | Size | Value |
|---|---|---|
| TimeUnits | Byte |
Time units of lifespan (first 4 bits) and maxIdle (last 4 bits). Special units DEFAULT and INFINITE can be used for default server expiration and no expiration respectively. Possible values: |
| Lifespan | vLong | Duration which the entry is allowed to life. Only sent when time unit is not DEFAULT or INFINITE |
| Max Idle | vLong | Duration that each entry can be idle before it’s evicted from the cache. Only sent when time unit is not DEFAULT or INFINITE |
20.6.8. Hot Rod Protocol 2.3
This version of the protocol is implemented since Infinispan 8.0
20.6.8.1. Operations
Iteration Start
Request (0x31):
| Field Name | Size | Value |
|---|---|---|
| Segments size | signed vInt |
Size of the bitset encoding of the segments ids to iterate on. The size is the maximum segment id rounded to nearest multiple of 8. |
| Segments | byte array |
(Optional) Contains the segments ids bitset encoded, where each bit with value 1 represents a segment in the set. Byte order is little-endian. |
| FilterConverter size | signed vInt | The size of the String representing a KeyValueFilterConverter factory name deployed on the server, or -1 if no filter will be used |
| FilterConverter | UTF-8 byte array | (Optional) KeyValueFilterConverter factory name deployed on the server. Present if previous field is not negative |
| BatchSize | vInt | number of entries to transfers from the server at one go |
Response (0x32):
| Field Name | Size | Value |
|---|---|---|
| IterationId | String | The unique id of the iteration |
Iteration Next
Request (0x33):
| Field Name | Size | Value |
|---|---|---|
| IterationId | String | The unique id of the iteration |
Response (0x34):
| Field Name | Size | Value |
|---|---|---|
| Finished segments size | vInt | size of the bitset representing segments that were finished iterating |
| Finished segments | byte array | bitset encoding of the segments that were finished iterating |
| Entry count | vInt | How many entries are being returned |
| Key 1 Length | vInt | Length of key |
| Key 1 | byte array | Retrieved key |
| Value 1 Length | vInt | Length of value |
| Value 1 | byte array | Retrieved value |
| Key 2 Length | vInt | |
| Key 2 | byte array | |
| Value 2 Length | vInt | |
| Value 2 | byte array | |
| … continues until entry count is reached |
Iteration End
Request (0x35):
| Field Name | Size | Value |
|---|---|---|
| IterationId | String | The unique id of the iteration |
Response (0x36):
| Header | variable | Response header |
|---|---|---|
| Response status | 1 byte |
0x00 = success, if execution completed successfully |
20.6.9. Hot Rod Protocol 2.4
This version of the protocol is implemented since Infinispan 8.1
This Hot Rod protocol version adds three new status code that gives the client hints on whether the server has compatibility mode enabled or not:
-
0x06: Success status and compatibility mode is enabled. -
0x07: Success status and return previous value, with compatibility mode is enabled. -
0x08: Not executed and return previous value, with compatibility mode is enabled.
The Iteration Start operation can optionally send parameters if a custom filter is provided and it’s parametrised:
20.6.9.1. Operations
Iteration Start
Request (0x31):
| Field Name | Size | Value |
|---|---|---|
| Segments size | signed vInt | same as protocol version 2.3. |
| Segments | byte array | same as protocol version 2.3. |
| FilterConverter size | signed vInt | same as protocol version 2.3. |
| FilterConverter | UTF-8 byte array | same as protocol version 2.3. |
| Parameters size | byte | the number of params of the filter. Only present when FilterConverter is provided. |
| Parameters | byte[][] | an array of parameters, each parameter is a byte array. Only present if Parameters size is greater than 0. |
| BatchSize | vInt | same as protocol version 2.3. |
The Iteration Next operation can optionally return projections in the value, meaning more than one value is contained in the same entry.
Iteration Next
Response (0x34):
| Field Name | Size | Value |
|---|---|---|
| Finished segments size | vInt | same as protocol version 2.3. |
| Finished segments | byte array | same as protocol version 2.3. |
| Entry count | vInt | same as protocol version 2.3. |
| Number of value projections | vInt | Number of projections for the values. If 1, behaves like version protocol version 2.3. |
| Key1 Length | vInt | same as protocol version 2.3. |
| Key1 | byte array | same as protocol version 2.3. |
| Value1 projection1 length | vInt | length of value1 first projection |
| Value1 projection1 | byte array | retrieved value1 first projection |
| Value1 projection2 length | vInt | length of value2 second projection |
| Value1 projection2 | byte array | retrieved value2 second projection |
| … continues until all projections for the value retrieved | Key2 Length | vInt |
| same as protocol version 2.3. | Key2 | byte array |
| same as protocol version 2.3. | Value2 projection1 length | vInt |
| length of value 2 first projection | Value2 projection1 | byte array |
| retrieved value 2 first projection | Value2 projection2 length | vInt |
| length of value 2 second projection | Value2 projection2 | byte array |
| retrieved value 2 second projection | … continues until entry count is reached |
- Stats:
Statistics returned by previous Hot Rod protocol versions were local to the node where the Hot Rod operation had been called. Starting with 2.4, new statistics have been added which provide global counts for the statistics returned previously. If the Hot Rod is running in local mode, these statistics are not returned:
| Name | Explanation |
|---|---|
| globalCurrentNumberOfEntries | Number of entries currently across the Hot Rod cluster. |
| globalStores | Total number of put operations across the Hot Rod cluster. |
| globalRetrievals | Total number of get operations across the Hot Rod cluster. |
| globalHits | Total number of get hits across the Hot Rod cluster. |
| globalMisses | Total number of get misses across the Hot Rod cluster. |
| globalRemoveHits | Total number of removal hits across the Hot Rod cluster. |
| globalRemoveMisses | Total number of removal misses across the Hot Rod cluster. |
20.6.10. Hot Rod Protocol 2.5
This version of the protocol is implemented since Infinispan 8.2
This Hot Rod protocol version adds support for metadata retrieval along with entries in the iterator. It includes two changes:
- Iteration Start request includes an optional flag
- IterationNext operation may include metadata info for each entry if the flag above is set
Iteration Start
Request (0x31):
| Field Name | Size | Value |
|---|---|---|
| Segments size | signed vInt | same as protocol version 2.4. |
| Segments | byte array | same as protocol version 2.4. |
| FilterConverter size | signed vInt | same as protocol version 2.4. |
| FilterConverter | UTF-8 byte array | same as protocol version 2.4. |
| Parameters size | byte | same as protocol version 2.4. |
| Parameters | byte[][] | same as protocol version 2.4. |
| BatchSize | vInt | same as protocol version 2.4. |
| Metadata | 1 byte | 1 if metadata is to be returned for each entry, 0 otherwise |
Iteration Next
Response (0x34):
| Field Name | Size | Value |
|---|---|---|
| Finished segments size | vInt | same as protocol version 2.4. |
| Finished segments | byte array | same as protocol version 2.4. |
| Entry count | vInt | same as protocol version 2.4. |
| Number of value projections | vInt | same as protocol version 2.4. |
| Metadata (entry 1) | 1 byte | If set, entry has metadata associated |
| Expiration (entry 1) | 1 byte |
A flag indicating whether the response contains expiration information. The value of the flag is obtained as a bitwise OR operation between INFINITE_LIFESPAN (0x01) and |
| Created (entry 1) | Long | (optional) a Long representing the timestamp when the entry was created on the server. This value is returned only if the flag’s INFINITE_LIFESPAN bit is not set. |
| Lifespan (entry 1) | vInt | (optional) a vInt representing the lifespan of the entry in seconds. This value is returned only if the flag’s INFINITE_LIFESPAN bit is not set. |
| LastUsed (entry 1) | Long |
(optional) a Long representing the timestamp when the entry was last accessed on the server. This value is returned only if the flag’s |
| MaxIdle (entry 1) | vInt |
(optional) a vInt representing the maxIdle of the entry in seconds. This value is returned only if the flag’s |
| Entry Version (entry 1) | 8 bytes | Unique value of an existing entry’s modification. Only present if Metadata flag is set |
| Key 1 Length | vInt | same as protocol version 2.4. |
| Key 1 | byte array | same as protocol version 2.4. |
| Value 1 Length | vInt | same as protocol version 2.4. |
| Value 1 | byte array | same as protocol version 2.4. |
| Metadata (entry 2) | 1 byte | Same as for entry 1 |
| Expiration (entry 2) | 1 byte | Same as for entry 1 |
| Created (entry 2) | Long | Same as for entry 1 |
| Lifespan (entry 2) | vInt | Same as for entry 1 |
| LastUsed (entry 2) | Long | Same as for entry 1 |
| MaxIdle (entry 2) | vInt | Same as for entry 1 |
| Entry Version (entry 2) | 8 bytes | Same as for entry 1 |
| Key 2 Length | vInt | |
| Key 2 | byte array | |
| Value 2 Length | vInt | |
| Value 2 | byte array | |
| … continues until entry count is reached |
20.6.11. Hot Rod Protocol 2.6
This version of the protocol is implemented since Infinispan 9.0
This Hot Rod protocol version adds support for streaming get and put operations. It includes two new operations:
- GetStream for retrieving data as a stream, with an optional initial offset
- PutStream for writing data as a stream, optionally by specifying a version
GetStream
Request (0x37):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Offset | vInt | The offset in bytes from which to start retrieving. Set to 0 to retrieve from the beginning |
| Key Length | vInt | Length of key. Note that the size of a vint can be up to 5 bytes which in theory can produce bigger numbers than Integer.MAX_VALUE. However, Java cannot create a single array that’s bigger than Integer.MAX_VALUE, hence the protocol is limiting vint array lengths to Integer.MAX_VALUE. |
| Key | byte array | Byte array containing the key whose value is being requested. |
GetStream
Response (0x38):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Response status | 1 byte |
0x00 = success, if key retrieved |
| Flag | 1 byte |
A flag indicating whether the response contains expiration information. The value of the flag is obtained as a bitwise OR operation between INFINITE_LIFESPAN (0x01) and |
| Created | Long | (optional) a Long representing the timestamp when the entry was created on the server. This value is returned only if the flag’s INFINITE_LIFESPAN bit is not set. |
| Lifespan | vInt | (optional) a vInt representing the lifespan of the entry in seconds. This value is returned only if the flag’s INFINITE_LIFESPAN bit is not set. |
| LastUsed | Long |
(optional) a Long representing the timestamp when the entry was last accessed on the server. This value is returned only if the flag’s |
| MaxIdle | vInt |
(optional) a vInt representing the maxIdle of the entry in seconds. This value is returned only if the flag’s |
| Entry Version | 8 bytes | Unique value of an existing entry’s modification. The protocol does not mandate that entry_version values are sequential. They just need to be unique per update at the key level. |
| Value Length | vInt | If success, length of value |
| Value | byte array | If success, the requested value |
PutStream
Request (0x39)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Entry Version | 8 bytes |
Possible values |
| Key Length | vInt | Length of key. Note that the size of a vint can be up to 5 bytes which in theory can produce bigger numbers than Integer.MAX_VALUE. However, Java cannot create a single array that’s bigger than Integer.MAX_VALUE, hence the protocol is limiting vint array lengths to Integer.MAX_VALUE. |
| Key | byte array | Byte array containing the key whose value is being requested. |
| Value Chunk 1 Length | vInt | The size of the first chunk of data. If this value is 0 it means the client has completed transferring the value and the operation should be performed. |
| Value Chunk 1 | byte array | Array of bytes forming the fist chunk of data. |
| …continues until the value is complete |
Response (0x3A):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
On top of these additions, this Hot Rod protocol version improves remote listener registration by adding a byte that indicates at a global level, which type of events the client is interested in. For example, a client can indicate that only created events, or only expiration and removal events…etc. More fine grained event interests, e.g. per key, can be defined using the key/value filter parameter.
So, the new add listener request looks like this:
Add client listener for remote events
Request (0x25):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Listener ID | byte array | Listener identifier |
| Include state | byte |
When this byte is set to |
| Key/value filter factory name | string |
Optional name of the key/value filter factory to be used with this listener. The factory is used to create key/value filter instances which allow events to be filtered directly in the Hot Rod server, avoiding sending events that the client is not interested in. If no factory is to be used, the length of the string is |
| Key/value filter factory parameter count | byte | The key/value filter factory, when creating a filter instance, can take an arbitrary number of parameters, enabling the factory to be used to create different filter instances dynamically. This count field indicates how many parameters will be passed to the factory. If no factory name was provided, this field is not present in the request. |
| Key/value filter factory parameter 1 | byte array | First key/value filter factory parameter |
| Key/value filter factory parameter 2 | byte array | Second key/value filter factory parameter |
| … | ||
| Converter factory name | string |
Optional name of the converter factory to be used with this listener. The factory is used to transform the contents of the events sent to clients. By default, when no converter is in use, events are well defined, according to the type of event generated. However, there might be situations where users want to add extra information to the event, or they want to reduce the size of the events. In these cases, a converter can be used to transform the event contents. The given converter factory name produces converter instances to do this job. If no factory is to be used, the length of the string is |
| Converter factory parameter count | byte | The converter factory, when creating a converter instance, can take an arbitrary number of parameters, enabling the factory to be used to create different converter instances dynamically. This count field indicates how many parameters will be passed to the factory. If no factory name was provided, this field is not present in the request. |
| Converter factory parameter 1 | byte array | First converter factory parameter |
| Converter factory parameter 2 | byte array | Second converter factory parameter |
| … | ||
| Listener even type interests | vInt |
A variable length number representing listener event type interests. Each event type is represented by a bit. Each flags is represented by a bit. Note that since this field is sent as variable length, the most significant bit in a byte is used to determine whether more bytes need to be read, hence this bit does not represent any flag. Using this model allows for flags to be combined in a short space. Here are the current values for each flag: |
20.6.12. Hot Rod Protocol 2.7
This version of the protocol is implemented since Infinispan 9.2
This Hot Rod protocol version adds support for transaction operations. It includes 3 new operations:
- Prepare, with the transaction write set (i.e. modified keys), it tries to prepare and validate the transaction in the server.
- Commit, commits a prepared transaction.
- Rollback, rollbacks a prepared transaction.
Prepare Request
Request (0x3B):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Xid | XID | The transaction ID (XID) |
| OnePhaseCommit | byte |
When it is set to |
| Number of keys | vInt | The number of keys |
| For each key (keys must be distinct) | ||
| Key Length | vInt |
Length of key. Note that the size of a vInt can be up to 5 bytes which in theory can produce bigger numbers than |
| Key | byte array | Byte array containing the key |
| Control Byte | Byte |
A bit set with the following meaning: |
| Version Read | long |
The version read. Only sent when |
| TimeUnits | Byte |
Time units of lifespan (first 4 bits) and maxIdle (last 4 bits). Special units |
| Lifespan | vLong |
Duration which the entry is allowed to life. Only sent when time unit is not |
| Max Idle | vLong |
Duration that each entry can be idle before it’s evicted from the cache. Only sent when time unit is not |
| Value Length | vInt |
Length of value. Only sent if |
| Value | byte-array |
Value to be stored. Only sent if |
Commit and Rollback Request
Request. Commit (0x3D) and Rollback (0x3F):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Xid | XID | The transaction ID (XID) |
Response from prepare, commit and rollback request.
Response. Prepare (0x3C), Commit (0x3E) and Rollback (0x40)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| XA return code | vInt |
The XA code representing the prepare response. |
XID Format
The XID in the requests has the following format:
| Field Name | Size | Value |
|---|---|---|
| Format ID | signed vInt | The XID format. |
| Length of Global Transaction id | byte |
The length of global transaction id byte array. It max value is |
| Global Transaction Id | byte array | The global transaction id. |
| Length of Branch Qualifier | byte |
The length of branch qualifier byte array. It max value is |
| Branch Qualifier | byte array | The branch qualifier. |
Counter Configuration encoding format
The CounterConfiguration class encoding format is the following:
In counter related operation, the Cache Name field in Request Header can be empty.
Summary of Status value in the Response Header:
* 0x00: Operation successful.
* 0x01: Operation failed.
* 0x02: The counter isn’t defined.
* 0x04: The counter reached a boundary. Only possible for STRONG counters.
| Field Name | Size | Value |
|---|---|---|
| Flags | byte |
The |
| Concurrency Level | vInt |
(Optional) the counter’s concurrency-level. Only present if the counter is |
| Lower bound | long |
(Optional) the lower bound of a bounded counter. Only present if the counter is |
| Upper bound | long |
(Optional) the upper bound of a bounded counter. Only present if the counter is |
| Initial value | long | The counter’s initial value. |
Counter create operation
Creates a counter if it doesn’t exist.
Table 20.7. Request (0x4B)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Name | string | The counter’s name |
| Counter Configuration | variable | The counter’s configuration. See CounterConfiguration encode. |
Table 20.8. Response (0x4C)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
Response Header Status possible values:
-
0x00: Operation successful. -
0x01: Operation failed. Counter is already defined. - See the Reponse Header for error codes.
Counter get configuration operation
Returns the counter’s configuration.
Table 20.9. Request (0x4D)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Name | string | The counter’s name. |
Table 20.10. Response (0x4E)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Counter Configuration | variable |
(Optional) The counter’s configuration. Only present if |
Response Header Status possible values:
-
0x00: Operation successful. -
0x02: Counter doesn’t exist. - See the Reponse Header for error codes.
Counter is defined operation
Checks if the counter is defined.
Table 20.11. Request (0x4F)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Name | string | The counter’s name |
Table 20.12. Response (0x51)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
Response Header Status possible values:
-
0x00: Counter is defined. -
0x01: Counter isn’t defined. - See the Reponse Header for error codes.
Counter add-and-get operation
Adds a value to the counter and returns the new value.
Table 20.13. Request (0x52)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Name | string | The counter’s name |
| Value | long | The value to add |
Table 20.14. Response (0x53)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Value | long |
(Optional) the counter’s new value. Only present if |
Since the WeakCounter doesn’t have access to the new value, the value is zero.
Response Header Status possible values:
-
0x00: Operation successful. -
0x02: The counter isn’t defined. -
0x04: The counter reached its boundary. Only possible forSTRONGcounters. - See the Reponse Header for error codes.
Counter reset operation
Resets the counter’s value.
Table 20.15. Request (0x54)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Name | string | The counter’s name |
Table 20.16. Response (0x55)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
Response Header Status possible values:
-
0x00: Operation successful. -
0x02: Counter isn’t defined. - See the Reponse Header for error codes.
Counter get operation
Returns the counter’s value.
Table 20.17. Request (0x56)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Name | string | The counter’s name |
Table 20.18. Response (0x57)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Value | long |
(Optional) the counter’s value. Only present if |
Response Header Status possible values:
-
0x00: Operation successful. -
0x02: Counter isn’t defined. - See the Reponse Header for error codes.
Counter compare-and-swap operation
Compares and only updates the counter value if the current value is the expected.
Table 20.19. Request (0x58)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Name | string | The counter’s name |
| Expect | long | The counter’s expected value. |
| Update | long | The counter’s value to set. |
Table 20.20. Response (0x59)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Value | long |
(Optional) the counter’s value. Only present if |
Response Header Status possible values:
-
0x00: Operation successful. -
0x02: The counter isn’t defined. -
0x04: The counter reached its boundary. Only possible forSTRONGcounters. - See the Reponse Header for error codes.
Counter add and remove listener
Adds/Removes a listener for a counter
Table 20.21. Request ADD (0x5A) / REMOVE (0x5C)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Name | string | The counter’s name |
| Listener-id | byte array | The listener’s id |
Table 20.22. Response: ADD (0x5B) / REMOVE (0x5D)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
Response Header Status possible values:
-
0x00: Operation successful and the connection used in the request will be used to send event (add) or the connection can be removed (remove). -
0x01: Operation successful and the current connection is still in use. -
0x02: The counter isn’t defined. - See the Reponse Header for error codes.
Table 20.23. Counter Event (0x66)
| Field Name | Size | Value |
|---|---|---|
| Header | variable |
Event header with operation code |
| Name | string | The counter’s name |
| Listener-id | byte array | The listener’s id |
| Encoded Counter State | byte |
Encoded old and new counter state. Bit set: |
| Old value | long | Counter’s old value |
| New value | long | Counter’s new value |
All counters under a CounterManager implementation can use the same listener-id.
A connection is dedicated to a single listener-id and can receive events from different counters.
Counter remove operation
Removes the counter from the cluster.
The counter is re-created if it is accessed again.
Table 20.24. Request (0x5E)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Name | string | The counter’s name |
Table 20.25. Response (0x5F)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
Response Header Status possible values:
-
0x00: Operation successful. -
0x02: The counter isn’t defined. - See the Reponse Header for error codes.
20.6.13. Hot Rod Protocol 2.8
This version of the protocol is implemented since Infinispan 9.3
Events
The protocol allows clients to send requests on the same connection that was previously used for Add Client Listener operation, and in protocol < 2.8 is reserved for sending events to the client. This includes registering additional listeners, therefore receiving events for multiple listeners.
The binary format of requests/responses/events does not change but the previously meaningless messageId in events must be set to:
-
messageIdof the Add Client Listener operation for the include-current-state events -
0for the events sent after the Add Client Listener operation has been finished (response sent).
The same holds for counter events: client can send further requests after Counter Add Listener. Previously meaningless messageId in counter event is always set to 0.
These modifications of the protocol do not require any changes on the client side (as the client simply won’t send additional operations if it does not support that; the changes are more permissive to the clients) but the server has to handle load on the connection correctly.
MediaType
This Hot Rod protocol version also adds support for specifying the MediaType of Keys and Values, allowing data to be read (and written) in different formats. This information is part of the Header.
The data formats are described using a MediaType object, that is represented as follows:
| Field Name | Size | Value |
|---|---|---|
| type | 1 byte |
0x00 = No MediaType supplied |
| id | vInt | (Optional) For a pre-defined MediaType (type=0x01), the Id of the MediaType. The currently supported Ids can be found at MediaTypeIds |
| customString | string | (Optional) If a custom MediaType is supplied (type=0x02), the custom MediaType of the key, including type and subtype. E.g.: text/plain, application/json, etc. |
| paramSize | vInt | The size of the parameters for the MediaType |
| paramKey1 | string | (Optional) The first parameter’s key |
| paramValue1 | string | (Optional) The first parameter’s value |
| … | … | … |
| paramKeyN | string | (Optional) The nth parameter’s key |
| paramValueN | string | (Optional) The nth parameter’s value |
20.6.13.1. Request Header
The request header has the following extra fields:
| Field Name | Type | Value |
|---|---|---|
| Key Format | MediaType | The MediaType to be used for keys during the operation. It applies to both the keys sent and received. |
| Value Format | MediaType | Analogous to Key Format, but applied for the values. |
20.6.14. Hot Rod Protocol 2.9
This version of the protocol is implemented since Infinispan 9.4
Compatibility Mode removal
The compatibility mode hint from the Response status fields from the operations is not sent anymore. Consequently, the following statuses are removed:
-
0x06: Success status with compatibility mode. -
0x07: Success status with return previous value and compatibility mode. -
0x08: Not executed with return previous value and compatibility mode.
To figure out what is the server’s storage, the configured MediaType of keys and values are returned on the ping operation:
Ping Response (0x18):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | same as before |
| Response status | 1 byte | same as before |
| Key Type | MediaType | Media Type of the key stored in the server |
| Value Type | MediaType | Media Type of the value stored in the server |
New query format
This version supports query requests and responses in JSON format. The format of the operations 0x1F (Query Request) and 0x20 (Query Response) are not changed.
To send JSON payloads, the "Value Format" field in the header should be application/json.
Query Request (0x1F):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Query Length | vInt | The length of the UTF-8 encoded query object. |
| Query | byte array | Byte array containing the JSON (UTF-8) encoded query object, having a length specified by the previous field. Example of payload: {
"query":"From Entity where field1:'value1'",
"offset": 12,
"max-results": 1000,
"query-mode": "FETCH"
}
Where: query: the Ickle query String. offset: the index of the first result to return. max_results: the maximum number of results to return. query_mode: the indexed query mode. Either FETCH or BROADCAST. FECTH is the default. |
Query Response (0x20):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Response payload Length | vInt | The length of the UTF-8 encoded response object |
| Response payload | byte array | Byte array containing the JSON encoded response object, having a length specified by previous field. Example payload: {
"total_results":801,
"hits":[
{
"hit":{
"field1":565,
"field2":"value2"
}
},
{
"hit":{
"field1":34,
"field2":"value22"
}
}
]
}
Where: total_results: the total number of results of the query. hits: an ARRAY of OBJECT representing the results. hit: each OBJECT above contain another OBJECT in the "hit" field, containing the result of the query, in JSON format. |
Also, this version introduces 3 new operations for Hot Rod transactions:
- Prepare Request V2: It adds new parameters to the request. The response stays the same.
- Forget Transaction Request: Removes transaction information in the server.
- Fetch In-Doubt Transactions Request: Fetches all in-doubt transactions’s Xid.
Prepare Request V2
Request (0x7D):
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Xid | XID | The transaction ID (XID) |
| OnePhaseCommit | byte |
When it is set to |
| Recoverable | byte |
Set to |
| Timeout | long |
The idle timeout in milliseconds. If the transaction isn’t recoverable ( |
| Number of keys | vInt | The number of keys |
| For each key (keys must be distinct) | ||
| Key Length | vInt |
Length of key. Note that the size of a vInt can be up to 5 bytes which in theory can produce bigger numbers than |
| Key | byte array | Byte array containing the key |
| Control Byte | Byte |
A bit set with the following meaning: |
| Version Read | long |
The version read. Only sent when |
| TimeUnits | Byte |
Time units of lifespan (first 4 bits) and maxIdle (last 4 bits). Special units |
| Lifespan | vLong |
Duration which the entry is allowed to life. Only sent when time unit is not |
| Max Idle | vLong |
Duration that each entry can be idle before it’s evicted from the cache. Only sent when time unit is not |
| Value Length | vInt |
Length of value. Only sent if |
| Value | byte-array |
Value to be stored. Only sent if |
Response (0x7E)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| XA return code | vInt |
The XA code representing the prepare response. |
Forget Transaction
Request (0x79)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
| Xid | XID | The transaction ID (XID) |
Response (0x7A)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
Fetch in-doubt transactions
Request (0x7B)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Request header |
Response (0x7C)
| Field Name | Size | Value |
|---|---|---|
| Header | variable | Response header |
| Number of Xid | vInt | The number of Xid in response |
| For each entry: | ||
| Xid | XID | The transaction ID (XID) |
20.6.15. Hot Rod Hash Functions
Red Hat Data Grid makes use of a consistent hash function to place nodes on a hash wheel, and to place keys of entries on the same wheel to determine where entries live.
In Infinispan 4.2 and earlier, the hash space was hardcoded to 10240, but since 5.0, the hash space is Integer.MAX_INT . Please note that since Hot Rod clients should not assume a particular hash space by default, every time a hash-topology change is detected, this value is sent back to the client via the Hot Rod protocol.
When interacting with Red Hat Data Grid via the Hot Rod protocol, it is mandated that keys (and values) are byte arrays, to ensure platform neutral behavior. As such, smart-clients which are aware of hash distribution on the backend would need to be able to calculate the hash codes of such byte array keys, again in a platform-neutral manner. To this end, the hash functions used by Red Hat Data Grid are versioned and documented, so that it can be re-implemented by non-Java clients if needed.
The version of the hash function in use is provided in the Hot Rod protocol, as the hash function version parameter.
- Version 1 (single byte, 0x01) The initial version of the hash function in use is based on Austin Appleby’s MurmurHash 2.0 algorithm , a fast, non-cryptographic hash that exhibits excellent distribution, collision resistance and avalanche behavior. The specific version of the algorithm used is the slightly slower, endian-neutral version that allows consistent behavior across both big- and little-endian CPU architectures. Red Hat Data Grid’s version also hard-codes the hash seed as -1. For details of the algorithm, please visit Austin Appleby’s MurmurHash 2.0 page. Other implementations are detailed on Wikipedia . This hash function was the default one used by the Hot Rod server until Infinispan 4.2.1. Since Infinispan 5.0, the server never uses hash version 1. Since Infinispan 9.0, the client ignores hash version 1.
- Version 2 (single byte, 0x02) Since Infinispan 5.0, a new hash function is used by default which is based on Austin Appleby’s MurmurHash 3.0 algorithm. Detailed information about the hash function can be found in this wiki. Compared to 2.0, it provides better performance and spread. Since Infinispan 7.0, the server only uses version 2 for HotRod 1.x clients.
- Version 3 (single byte, 0x03) Since Infinispan 7.0, a new hash function is used by default. The function is still based on wiki, but is also aware of the hash segments used in the server’s ConsistentHash.
20.6.16. Hot Rod Admin Tasks
Admin operations are handled by the Exec operation with a set of well known tasks. Admin tasks are named according to the following rules:
@@context@name
All parameters are UTF-8 encoded strings. Parameters are specific to each task, with the exception of the flags parameter which is common to all commands. The flags parameter contains zero or more space-separated values which may affect the behaviour of the command. The following table lists all currently available flags.
Admin tasks return the result of the operation represented as a JSON string.
Table 20.26. FLAGS
| Flag | Description |
|---|---|
| permanent | Requests that the command’s effect be made permanent into the server’s configuration. If the server cannot comply with the request, the entire operation will fail with an error |
20.6.16.1. Admin tasks
Table 20.27. @@cache@create
| Parameter | Description | Required |
|---|---|---|
| name | The name of the cache to create. | Yes |
| template | The name of the cache configuration template to use for the new cache. | No |
| configuration | the XML declaration of a cache configuration to use. | No |
| flags | See the flags table above. | No |
Table 20.28. @@cache@remove
| Parameter | Description | Required |
|---|---|---|
| name | The name of the cache to remove. | Yes |
| flags | See the flags table above. | No |
@@cache@names
Returns the cache names as a JSON array of strings, e.g. ["cache1", "cache2"]
Table 20.29. @@cache@reindex
| Parameter | Description | Required |
|---|---|---|
| name | The name of the cache to reindex. | Yes |
| flags | See the flags table above. | No, all flags will be ignored |
20.7. Java Hot Rod client
Hot Rod is a binary, language neutral protocol. This article explains how a Java client can interact with a server via the Hot Rod protocol. A reference implementation of the protocol written in Java can be found in all Red Hat Data Grid distributions, and this article focuses on the capabilities of this java client.
Looking for more clients? Visit this website for clients written in a variety of different languages.
20.7.1. Configuration
The Java Hot Rod client can be configured both programmatically and externally, through a configuration file.
The code snippet below illustrates the creation of a client instance using the available Java fluent API:
org.infinispan.client.hotrod.configuration.ConfigurationBuilder cb
= new org.infinispan.client.hotrod.configuration.ConfigurationBuilder();
cb.tcpNoDelay(true)
.statistics()
.enable()
.jmxDomain("org.infinispan")
.addServer()
.host("127.0.0.1")
.port(11222);
RemoteCacheManager rmc = new RemoteCacheManager(cb.build());For a complete reference to the available configuration option please refer to the ConfigurationBuilder's javadoc.
It is also possible to configure the Java Hot Rod client using a properties file, e.g.:
# Hot Rod client configuration infinispan.client.hotrod.server_list = 127.0.0.1:11222 infinispan.client.hotrod.marshaller = org.infinispan.commons.marshall.jboss.GenericJBossMarshaller infinispan.client.hotrod.async_executor_factory = org.infinispan.client.hotrod.impl.async.DefaultAsyncExecutorFactory infinispan.client.hotrod.default_executor_factory.pool_size = 1 infinispan.client.hotrod.hash_function_impl.2 = org.infinispan.client.hotrod.impl.consistenthash.ConsistentHashV2 infinispan.client.hotrod.tcp_no_delay = true infinispan.client.hotrod.tcp_keep_alive = false infinispan.client.hotrod.request_balancing_strategy = org.infinispan.client.hotrod.impl.transport.tcp.RoundRobinBalancingStrategy infinispan.client.hotrod.key_size_estimate = 64 infinispan.client.hotrod.value_size_estimate = 512 infinispan.client.hotrod.force_return_values = false ## Connection pooling configuration maxActive=-1 maxIdle = -1 whenExhaustedAction = 1 minEvictableIdleTimeMillis=300000 minIdle = 1
The properties file is then passed to one of constructors of RemoteCacheManager. You can use property substitution to replace values at runtime with Java system properties:
infinispan.client.hotrod.server_list = ${server_list}
In the above example the value of the infinispan.client.hotrod.server_list property will be expanded to the value of the server_list Java system property, which means that the value should be taken from a system property named jboss.bind.address.management and if it is not defined use 127.0.0.1.
To use hotrod-client.properties somewhere other than your classpath, do:
ConfigurationBuilder b = new ConfigurationBuilder();
Properties p = new Properties();
try(Reader r = new FileReader("/path/to/hotrod-client.properties")) {
p.load(r);
b.withProperties(p);
}
RemoteCacheManager rcm = new RemoteCacheManager(b.build());For a complete reference of the available configuration options for the properties file please refer to remote client configuration javadoc.
20.7.2. Authentication
If the server has set up authentication, you need to configure your client accordingly. Depending on the mechs enabled on the server, the client must provide the required information.
20.7.2.1. DIGEST-MD5
DIGEST-MD5 is the recommended approach for simple username/password authentication scenarios. If you are using the default realm on the server ("ApplicationRealm"), all you need to do is provide your credentials as follows:
Hot Rod client configuration with DIGEST-MD5 authentication
ConfigurationBuilder clientBuilder = new ConfigurationBuilder();
clientBuilder
.addServer()
.host("127.0.0.1")
.port(11222)
.security()
.ssl()
.username("myuser")
.password("qwer1234!");
remoteCacheManager = new RemoteCacheManager(clientBuilder.build());
RemoteCache<String, String> cache = remoteCacheManager.getCache("secured");
20.7.2.2. PLAIN
The PLAIN mechanism is not really recommended unless the connection is also encrypted, as anyone can sniff the clear-text password being sent along the wire.
Hot Rod client configuration with DIGEST-MD5 authentication
ConfigurationBuilder clientBuilder = new ConfigurationBuilder();
clientBuilder
.addServer()
.host("127.0.0.1")
.port(11222)
.security()
.authentication()
.saslMechanism("PLAIN")
.username("myuser")
.password("qwer1234!");
remoteCacheManager = new RemoteCacheManager(clientBuilder.build());
RemoteCache<String, String> cache = remoteCacheManager.getCache("secured");
20.7.2.3. EXTERNAL
The EXTERNAL mechanism is special in that it doesn’t explicitly provide credentials but uses the client certificate as identity. In order for this to work, in addition to the TrustStore (to validate the server certificate) you need to provide a KeyStore (to supply the client certificate).
Hot Rod client configuration with EXTERNAL authentication (client cert)
ConfigurationBuilder clientBuilder = new ConfigurationBuilder();
clientBuilder
.addServer()
.host("127.0.0.1")
.port(11222)
.security()
.ssl()
// TrustStore is a KeyStore which contains part of the server certificate chain (e.g. the CA Root public cert)
.trustStoreFileName("/path/to/truststore")
.trustStorePassword("truststorepassword".toCharArray())
// KeyStore containing this client's own certificate
.keyStoreFileName("/path/to/keystore")
.keyStorePassword("keystorepassword".toCharArray())
.authentication()
.saslMechanism("EXTERNAL");
remoteCacheManager = new RemoteCacheManager(clientBuilder.build());
RemoteCache<String, String> cache = remoteCacheManager.getCache("secured");
For more details, read the Encryption section below.
20.7.2.4. GSSAPI (Kerberos)
GSSAPI/Kerberos requires a much more complex setup, but it is used heavily in enterprises with centralized authentication servers. To successfully authenticate with Kerberos, you need to create a LoginContext. This will obtain a Ticket Granting Ticket (TGT) which will be used as a token to authenticate with the service.
You will need to define a login module in a login configuration file:
gss.conf
GssExample {
com.sun.security.auth.module.Krb5LoginModule required client=TRUE;
};
If you are using the IBM JDK, the above becomes:
gss-ibm.conf
GssExample {
com.ibm.security.auth.module.Krb5LoginModule required client=TRUE;
};
You will also need to set the following system properties:
java.security.auth.login.config=gss.conf
java.security.krb5.conf=/etc/krb5.conf
The krb5.conf file is dependent on your environment and needs to point to your KDC. Ensure that you can authenticate via Kerberos using kinit.
Next up, configure your client as follows:
Hot Rod client GSSAPI configuration
LoginContext lc = new LoginContext("GssExample", new BasicCallbackHandler("krb_user", "krb_password".toCharArray()));
lc.login();
Subject clientSubject = lc.getSubject();
ConfigurationBuilder clientBuilder = new ConfigurationBuilder();
clientBuilder
.addServer()
.host("127.0.0.1")
.port(11222)
.security()
.authentication()
.enable()
.serverName("infinispan-server")
.saslMechanism("GSSAPI")
.clientSubject(clientSubject)
.callbackHandler(new BasicCallbackHandler());
remoteCacheManager = new RemoteCacheManager(clientBuilder.build());
RemoteCache<String, String> cache = remoteCacheManager.getCache("secured");
For brevity we used the same callback handler both for obtaining the client subject and for handling authentication in the SASL GSSAPI mech, however different callbacks will actually be invoked: NameCallback and PasswordCallback are needed to construct the client subject, while the AuthorizeCallback will be called during the SASL authentication.
20.7.2.5. Custom CallbackHandlers
In all of the above examples, the Hot Rod client is setting up a default CallbackHandler for you that supplies the provided credentials to the SASL mechanism. For advanced scenarios it may be necessary to provide your own custom CallbackHandler:
Hot Rod client configuration with authentication via callback
public class MyCallbackHandler implements CallbackHandler {
final private String username;
final private char[] password;
final private String realm;
public MyCallbackHandler(String username, String realm, char[] password) {
this.username = username;
this.password = password;
this.realm = realm;
}
@Override
public void handle(Callback[] callbacks) throws IOException, UnsupportedCallbackException {
for (Callback callback : callbacks) {
if (callback instanceof NameCallback) {
NameCallback nameCallback = (NameCallback) callback;
nameCallback.setName(username);
} else if (callback instanceof PasswordCallback) {
PasswordCallback passwordCallback = (PasswordCallback) callback;
passwordCallback.setPassword(password);
} else if (callback instanceof AuthorizeCallback) {
AuthorizeCallback authorizeCallback = (AuthorizeCallback) callback;
authorizeCallback.setAuthorized(authorizeCallback.getAuthenticationID().equals(
authorizeCallback.getAuthorizationID()));
} else if (callback instanceof RealmCallback) {
RealmCallback realmCallback = (RealmCallback) callback;
realmCallback.setText(realm);
} else {
throw new UnsupportedCallbackException(callback);
}
}
}
}
ConfigurationBuilder clientBuilder = new ConfigurationBuilder();
clientBuilder
.addServer()
.host("127.0.0.1")
.port(11222)
.security()
.authentication()
.enable()
.serverName("myhotrodserver")
.saslMechanism("DIGEST-MD5")
.callbackHandler(new MyCallbackHandler("myuser", "ApplicationRealm", "qwer1234!".toCharArray()));
remoteCacheManager = new RemoteCacheManager(clientBuilder.build());
RemoteCache<String, String> cache = remoteCacheManager.getCache("secured");
The actual type of callbacks that your CallbackHandler will need to be able to handle are mech-specific, so the above is just a simple example.
20.7.3. Encryption
Encryption uses TLS/SSL, so it requires setting up an appropriate server certificate chain. Generally, a certificate chain looks like the following:
Figure 20.6. Certificate chain
In the above example there is one certificate authority "CA" which has issued a certificate for "HotRodServer". In order for a client to trust the server, it needs at least a portion of the above chain (usually, just the public certificate for "CA"). This certificate needs to placed in a keystore and used as a TrustStore on the client and used as shown below:
Hot Rod client configuration with TLS (server cert)
ConfigurationBuilder clientBuilder = new ConfigurationBuilder();
clientBuilder
.addServer()
.host("127.0.0.1")
.port(11222)
.security()
.ssl()
// TrustStore is a KeyStore which contains part of the server certificate chain (e.g. the CA Root public cert)
.trustStoreFileName("/path/to/truststore")
.trustStorePassword("truststorepassword".toCharArray());
RemoteCache<String, String> cache = remoteCacheManager.getCache("secured");
20.7.3.1. SNI
The server may have been configured with TLS/SNI support (Server Name Indication). This means that the server is presenting multiple identities (probably bound to separate cache containers). The client can specify which identity to connect to by specifying its name:
Hot Rod client configuration with SNI (server cert)
ConfigurationBuilder clientBuilder = new ConfigurationBuilder();
clientBuilder
.addServer()
.host("127.0.0.1")
.port(11222)
.security()
.ssl()
.sniHostName("myservername")
// TrustStore is a KeyStore which contains part of the server certificate chain (e.g. the CA Root public cert)
.trustStoreFileName("/path/to/truststore")
.trustStorePassword("truststorepassword".toCharArray());
RemoteCache<String, String> cache = remoteCacheManager.getCache("secured");
20.7.3.2. Client certificates
With the above configurations the client trusts the server. For increased security, a server administrator may have set up the server to require the client to offer a valid certificate for mutual trust. This kind of configuration requires the client to present its own certificate, usually issued by the same certificate authority as the server. This certificate must be stored in a keystore and used as follows:
Hot Rod client configuration with TLS (server and client cert)
ConfigurationBuilder clientBuilder = new ConfigurationBuilder();
clientBuilder
.addServer()
.host("127.0.0.1")
.port(11222)
.security()
.ssl()
// TrustStore is a KeyStore which contains part of the server certificate chain (e.g. the CA Root public cert)
.trustStoreFileName("/path/to/truststore")
.trustStorePassword("truststorepassword".toCharArray())
// KeyStore containing this client's own certificate
.keyStoreFileName("/path/to/keystore")
.keyStorePassword("keystorepassword".toCharArray())
RemoteCache<String, String> cache = remoteCacheManager.getCache("secured");
Please read the KeyTool documentation for more details on KeyStores. Additionally, the KeyStore Explorer is a great GUI tool for easily managing KeyStores.
20.7.4. Basic API
Below is a sample code snippet on how the client API can be used to store or retrieve information from a Hot Rod server using the Java Hot Rod client. It assumes that a Hot Rod server has been started bound to the default location (localhost:11222)
//API entry point, by default it connects to localhost:11222
CacheContainer cacheContainer = new RemoteCacheManager();
//obtain a handle to the remote default cache
Cache<String, String> cache = cacheContainer.getCache();
//now add something to the cache and make sure it is there
cache.put("car", "ferrari");
assert cache.get("car").equals("ferrari");
//remove the data
cache.remove("car");
assert !cache.containsKey("car") : "Value must have been removed!";The client API maps the local API: RemoteCacheManager corresponds to DefaultCacheManager (both implement CacheContainer ). This common API facilitates an easy migration from local calls to remote calls through Hot Rod: all one needs to do is switch between DefaultCacheManager and RemoteCacheManager - which is further simplified by the common CacheContainer interface that both inherit.
20.7.5. RemoteCache(.keySet|.entrySet|.values)
The collection methods keySet, entrySet and values are backed by the remote cache. That is that every method is called back into the RemoteCache. This is useful as it allows for the various keys, entries or values to be retrieved lazily, and not requiring them all be stored in the client memory at once if the user does not want. These collections adhere to the Map specification being that add and addAll are not supported but all other methods are supported.
One thing to note is the Iterator.remove and Set.remove or Collection.remove methods require more than 1 round trip to the server to operate. You can check out the RemoteCache Javadoc to see more details about these and the other methods.
Iterator Usage
The iterator method of these collections uses retrieveEntries internally, which is described below. If you notice retrieveEntries takes an argument for the batch size. There is no way to provide this to the iterator. As such the batch size can be configured via system property infinispan.client.hotrod.batch_size or through the ConfigurationBuilder when configuring the RemoteCacheManager.
Also the retrieveEntries iterator returned is Closeable as such the iterators from keySet, entrySet and values return an AutoCloseable variant. Therefore you should always close these `Iterator`s when you are done with them.
try (CloseableIterator<Entry<K, V>> iterator = remoteCache.entrySet().iterator) {
...
}What if I want a deep copy and not a backing collection?
Previous version of RemoteCache allowed for the retrieval of a deep copy of the keySet. This is still possible with the new backing map, you just have to copy the contents yourself. Also you can do this with entrySet and values, which we didn’t support before.
Set<K> keysCopy = remoteCache.keySet().stream().collect(Collectors.toSet());
Please use extreme cautiong with this as a large number of keys can and will cause OutOfMemoryError in the client.
Set keys = remoteCache.keySet();
20.7.6. Remote Iterator
Alternatively, if memory is a concern (different batch size) or you wish to do server side filtering or conversion), use the remote iterator api to retrieve entries from the server. With this method you can limit the entries that are retrieved or even returned a converted value if you dont' need all properties of your entry.
// Retrieve all entries in batches of 1000
int batchSize = 1000;
try (CloseableIterator<Entry<Object, Object>> iterator = remoteCache.retrieveEntries(null, batchSize)) {
while(iterator.hasNext()) {
// Do something
}
}
// Filter by segment
Set<Integer> segments = ...
try (CloseableIterator<Entry<Object, Object>> iterator = remoteCache.retrieveEntries(null, segments, batchSize)) {
while(iterator.hasNext()) {
// Do something
}
}
// Filter by custom filter
try (CloseableIterator<Entry<Object, Object>> iterator = remoteCache.retrieveEntries("myFilterConverterFactory", segments, batchSize)) {
while(iterator.hasNext()) {
// Do something
}
}In order to use custom filters, it’s necessary to deploy them first in the server. Follow the steps:
- Create a factory for the filter extending KeyValueFilterConverterFactory, annotated with @NamedFactory containing the name of the factory, example:
import java.io.Serializable;
import org.infinispan.filter.AbstractKeyValueFilterConverter;
import org.infinispan.filter.KeyValueFilterConverter;
import org.infinispan.filter.KeyValueFilterConverterFactory;
import org.infinispan.filter.NamedFactory;
import org.infinispan.metadata.Metadata;
@NamedFactory(name = "myFilterConverterFactory")
public class MyKeyValueFilterConverterFactory implements KeyValueFilterConverterFactory {
@Override
public KeyValueFilterConverter<String, SampleEntity1, SampleEntity2> getFilterConverter() {
return new MyKeyValueFilterConverter();
}
// Filter implementation. Should be serializable or externalizable for DIST caches
static class MyKeyValueFilterConverter extends AbstractKeyValueFilterConverter<String, SampleEntity1, SampleEntity2> implements Serializable {
@Override
public SampleEntity2 filterAndConvert(String key, SampleEntity1 entity, Metadata metadata) {
// returning null will case the entry to be filtered out
// return SampleEntity2 will convert from the cache type SampleEntity1
}
@Override
public MediaType format() {
// returns the MediaType that data should be presented to this converter.
// When ommitted, the server will use "application/x-java-object".
// Returning null will cause the filter/converter to be done in the storage format.
}
}
}-
Create a jar with a
META-INF/services/org.infinispan.filter.KeyValueFilterConverterFactoryfile and within it, write the fully qualified class name of the filter factory class implementation. - Optional: If the filter uses custom key/value classes, these must be included in the JAR so that the filter can correctly unmarshall key and/or value instances.
- Deploy the JAR file in the Red Hat Data Grid Server.
20.7.7. Versioned API
A RemoteCacheManager provides instances of RemoteCache interface that represents a handle to the named or default cache on the remote cluster. API wise, it extends the Cache interface to which it also adds some new methods, including the so called versioned API. Please find below some examples of this API link:#server_hotrod_failover[but to understand the motivation behind it, make sure you read this section.
The code snippet bellow depicts the usage of these versioned methods:
// To use the versioned API, remote classes are specifically needed
RemoteCacheManager remoteCacheManager = new RemoteCacheManager();
RemoteCache<String, String> cache = remoteCacheManager.getCache();
remoteCache.put("car", "ferrari");
RemoteCache.VersionedValue valueBinary = remoteCache.getVersioned("car");
// removal only takes place only if the version has not been changed
// in between. (a new version is associated with 'car' key on each change)
assert remoteCache.remove("car", valueBinary.getVersion());
assert !cache.containsKey("car");In a similar way, for replace:
remoteCache.put("car", "ferrari");
RemoteCache.VersionedValue valueBinary = remoteCache.getVersioned("car");
assert remoteCache.replace("car", "lamborghini", valueBinary.getVersion());For more details on versioned operations refer to RemoteCache 's javadoc.
20.7.8. Async API
This is "borrowed" from the Red Hat Data Grid core and it is largely discussed here.
20.7.9. Streaming API
When sending / receiving large objects, it might make sense to stream them between the client and the server. The Streaming API implements methods similar to the Hot Rod Basic API and Hot Rod Versioned API described above but, instead of taking the value as a parameter, they return instances of InputStream and OutputStream. The following example shows how one would write a potentially large object:
RemoteStreamingCache<String> streamingCache = remoteCache.streaming();
OutputStream os = streamingCache.put("a_large_object");
os.write(...);
os.close();Reading such an object through streaming:
RemoteStreamingCache<String> streamingCache = remoteCache.streaming();
InputStream is = streamingCache.get("a_large_object");
for(int b = is.read(); b >= 0; b = is.read()) {
...
}
is.close();The streaming API does not apply marshalling/unmarshalling to the values. For this reason you cannot access the same entries using both the streaming and non-streaming API at the same time, unless you provide your own marshaller to detect this situation.
The InputStream returned by the RemoteStreamingCache.get(K key) method implements the VersionedMetadata interface, so you can retrieve version and expiration information:
RemoteStreamingCache<String> streamingCache = remoteCache.streaming();
InputStream is = streamingCache.get("a_large_object");
int version = ((VersionedMetadata) is).getVersion();
for(int b = is.read(); b >= 0; b = is.read()) {
...
}
is.close();
Conditional write methods (putIfAbsent, replace) only perform the actual condition check once the value has been completely sent to the server (i.e. when the close() method has been invoked on the OutputStream.
20.7.10. Creating Event Listeners
Java Hot Rod clients can register listeners to receive cache-entry level events. Cache entry created, modified and removed events are supported.
Creating a client listener is very similar to embedded listeners, except that different annotations and event classes are used. Here’s an example of a client listener that prints out each event received:
import org.infinispan.client.hotrod.annotation.*;
import org.infinispan.client.hotrod.event.*;
@ClientListener
public class EventPrintListener {
@ClientCacheEntryCreated
public void handleCreatedEvent(ClientCacheEntryCreatedEvent e) {
System.out.println(e);
}
@ClientCacheEntryModified
public void handleModifiedEvent(ClientCacheEntryModifiedEvent e) {
System.out.println(e);
}
@ClientCacheEntryRemoved
public void handleRemovedEvent(ClientCacheEntryRemovedEvent e) {
System.out.println(e);
}
}
ClientCacheEntryCreatedEvent and ClientCacheEntryModifiedEvent instances provide information on the affected key, and the version of the entry. This version can be used to invoke conditional operations on the server, such as replaceWithVersion or removeWithVersion.
ClientCacheEntryRemovedEvent events are only sent when the remove operation succeeds. In other words, if a remove operation is invoked but no entry is found or no entry should be removed, no event is generated. Users interested in removed events, even when no entry was removed, can develop event customization logic to generate such events. More information can be found in the customizing client events section.
All ClientCacheEntryCreatedEvent, ClientCacheEntryModifiedEvent and ClientCacheEntryRemovedEvent event instances also provide a boolean isCommandRetried() method that will return true if the write command that caused this had to be retried again due to a topology change. This could be a sign that this event has been duplicated or another event was dropped and replaced (eg: ClientCacheEntryModifiedEvent replaced ClientCacheEntryCreatedEvent).
Once the client listener implementation has been created, it needs to be registered with the server. To do so, execute:
RemoteCache<?, ?> cache = ... cache.addClientListener(new EventPrintListener());
20.7.11. Removing Event Listeners
When an client event listener is not needed any more, it can be removed:
EventPrintListener listener = ... cache.removeClientListener(listener);
20.7.12. Filtering Events
In order to avoid inundating clients with events, users can provide filtering functionality to limit the number of events fired by the server for a particular client listener. To enable filtering, a cache event filter factory needs to be created that produces filter instances:
import org.infinispan.notifications.cachelistener.filter.CacheEventFilterFactory;
import org.infinispan.filter.NamedFactory;
@NamedFactory(name = "static-filter")
class StaticCacheEventFilterFactory implements CacheEventFilterFactory {
@Override
public CacheEventFilterFactory<Integer, String> getFilter(Object[] params) {
return new StaticCacheEventFilter();
}
}
// Serializable, Externalizable or marshallable with Infinispan Externalizers
// needed when running in a cluster
class StaticCacheEventFilter implements CacheEventFilter<Integer, String>, Serializable {
@Override
public boolean accept(Integer key, String oldValue, Metadata oldMetadata,
String newValue, Metadata newMetadata, EventType eventType) {
if (key.equals(1)) // static key
return true;
return false;
}
}
The cache event filter factory instance defined above creates filter instances which statically filter out all entries except the one whose key is 1.
To be able to register a listener with this cache event filter factory, the factory has to be given a unique name, and the Hot Rod server needs to be plugged with the name and the cache event filter factory instance. Plugging the Red Hat Data Grid Server with a custom filter involves the following steps:
- Create a JAR file with the filter implementation within it.
-
Optional: If the cache uses custom key/value classes, these must be included in the JAR so that the callbacks can be executed with the correctly unmarshalled key and/or value instances. If the client listener has
useRawDataenabled, this is not necessary since the callback key/value instances will be provided in binary format. -
Create a
META-INF/services/org.infinispan.notifications.cachelistener.filter.CacheEventFilterFactoryfile within the JAR file and within it, write the fully qualified class name of the filter class implementation. - Deploy the JAR file in the Red Hat Data Grid Server.
On top of that, the client listener needs to be linked with this cache event filter factory by adding the factory’s name to the @ClientListener annotation:
@ClientListener(filterFactoryName = "static-filter")
public class EventPrintListener { ... }And, register the listener with the server:
RemoteCache<?, ?> cache = ... cache.addClientListener(new EventPrintListener());
Dynamic filter instances that filter based on parameters provided when the listener is registered are also possible. Filters use the parameters received by the filter factories to enable this option. For example:
import org.infinispan.notifications.cachelistener.filter.CacheEventFilterFactory;
import org.infinispan.notifications.cachelistener.filter.CacheEventFilter;
class DynamicCacheEventFilterFactory implements CacheEventFilterFactory {
@Override
public CacheEventFilter<Integer, String> getFilter(Object[] params) {
return new DynamicCacheEventFilter(params);
}
}
// Serializable, Externalizable or marshallable with Infinispan Externalizers
// needed when running in a cluster
class DynamicCacheEventFilter implements CacheEventFilter<Integer, String>, Serializable {
final Object[] params;
DynamicCacheEventFilter(Object[] params) {
this.params = params;
}
@Override
public boolean accept(Integer key, String oldValue, Metadata oldMetadata,
String newValue, Metadata newMetadata, EventType eventType) {
if (key.equals(params[0])) // dynamic key
return true;
return false;
}
}The dynamic parameters required to do the filtering are provided when the listener is registered:
RemoteCache<?, ?> cache = ...
cache.addClientListener(new EventPrintListener(), new Object[]{1}, null);
Filter instances have to marshallable when they are deployed in a cluster so that the filtering can happen right where the event is generated, even if the even is generated in a different node to where the listener is registered. To make them marshallable, either make them extend Serializable, Externalizable, or provide a custom Externalizer for them.
20.7.13. Skipping Notifications
Include the SKIP_LISTENER_NOTIFICATION flag when calling remote API methods to perform operations without getting event notifications from the server. For example, to prevent listener notifications when creating or modifying values, set the flag as follows:
remoteCache.withFlags(Flag.SKIP_LISTENER_NOTIFICATION).put(1, "one");
The SKIP_LISTENER_NOTIFICATION flag is available from Red Hat Data Grid version 7.3.2. You must upgrade both the Red Hat Data Grid and Hot Rod client to this version or later before you can set the flag.
20.7.14. Customizing Events
The events generated by default contain just enough information to make the event relevant but they avoid cramming too much information in order to reduce the cost of sending them. Optionally, the information shipped in the events can be customised in order to contain more information, such as values, or to contain even less information. This customization is done with CacheEventConverter instances generated by a CacheEventConverterFactory:
import org.infinispan.notifications.cachelistener.filter.CacheEventConverterFactory;
import org.infinispan.notifications.cachelistener.filter.CacheEventConverter;
import org.infinispan.filter.NamedFactory;
@NamedFactory(name = "static-converter")
class StaticConverterFactory implements CacheEventConverterFactory {
final CacheEventConverter<Integer, String, CustomEvent> staticConverter = new StaticCacheEventConverter();
public CacheEventConverter<Integer, String, CustomEvent> getConverter(final Object[] params) {
return staticConverter;
}
}
// Serializable, Externalizable or marshallable with Infinispan Externalizers
// needed when running in a cluster
class StaticCacheEventConverter implements CacheEventConverter<Integer, String, CustomEvent>, Serializable {
public CustomEvent convert(Integer key, String oldValue, Metadata oldMetadata, String newValue, Metadata newMetadata, EventType eventType) {
return new CustomEvent(key, newValue);
}
}
// Needs to be Serializable, Externalizable or marshallable with Infinispan Externalizers
// regardless of cluster or local caches
static class CustomEvent implements Serializable {
final Integer key;
final String value;
CustomEvent(Integer key, String value) {
this.key = key;
this.value = value;
}
}In the example above, the converter generates a new custom event which includes the value as well as the key in the event. This will result in bigger event payloads compared with default events, but if combined with filtering, it can reduce its network bandwidth cost.
The target type of the converter must be either Serializable or Externalizable. In this particular case of converters, providing an Externalizer will not work by default since the default Hot Rod client marshaller does not support them.
Handling custom events requires a slightly different client listener implementation to the one demonstrated previously. To be more precise, it needs to handle ClientCacheEntryCustomEvent instances:
import org.infinispan.client.hotrod.annotation.*;
import org.infinispan.client.hotrod.event.*;
@ClientListener
public class CustomEventPrintListener {
@ClientCacheEntryCreated
@ClientCacheEntryModified
@ClientCacheEntryRemoved
public void handleCustomEvent(ClientCacheEntryCustomEvent<CustomEvent> e) {
System.out.println(e);
}
}
The ClientCacheEntryCustomEvent received in the callback exposes the custom event via getEventData method, and the getType method provides information on whether the event generated was as a result of cache entry creation, modification or removal.
Similar to filtering, to be able to register a listener with this converter factory, the factory has to be given a unique name, and the Hot Rod server needs to be plugged with the name and the cache event converter factory instance. Plugging the Red Hat Data Grid Server with an event converter involves the following steps:
- Create a JAR file with the converter implementation within it.
-
Optional: If the cache uses custom key/value classes, these must be included in the JAR so that the callbacks can be executed with the correctly unmarshalled key and/or value instances. If the client listener has
useRawDataenabled, this is not necessary since the callback key/value instances will be provided in binary format. -
Create a
META-INF/services/org.infinispan.notifications.cachelistener.filter.CacheEventConverterFactoryfile within the JAR file and within it, write the fully qualified class name of the converter class implementation. - Deploy the JAR file in the Red Hat Data Grid Server.
On top of that, the client listener needs to be linked with this converter factory by adding the factory’s name to the @ClientListener annotation:
@ClientListener(converterFactoryName = "static-converter")
public class CustomEventPrintListener { ... }And, register the listener with the server:
RemoteCache<?, ?> cache = ... cache.addClientListener(new CustomEventPrintListener());
Dynamic converter instances that convert based on parameters provided when the listener is registered are also possible. Converters use the parameters received by the converter factories to enable this option. For example:
import org.infinispan.notifications.cachelistener.filter.CacheEventConverterFactory;
import org.infinispan.notifications.cachelistener.filter.CacheEventConverter;
@NamedFactory(name = "dynamic-converter")
class DynamicCacheEventConverterFactory implements CacheEventConverterFactory {
public CacheEventConverter<Integer, String, CustomEvent> getConverter(final Object[] params) {
return new DynamicCacheEventConverter(params);
}
}
// Serializable, Externalizable or marshallable with Infinispan Externalizers needed when running in a cluster
class DynamicCacheEventConverter implements CacheEventConverter<Integer, String, CustomEvent>, Serializable {
final Object[] params;
DynamicCacheEventConverter(Object[] params) {
this.params = params;
}
public CustomEvent convert(Integer key, String oldValue, Metadata oldMetadata,
String newValue, Metadata newMetadata, EventType eventType) {
// If the key matches a key given via parameter, only send the key information
if (params[0].equals(key))
return new CustomEvent(key, null);
return new CustomEvent(key, newValue);
}
}The dynamic parameters required to do the conversion are provided when the listener is registered:
RemoteCache<?, ?> cache = ...
cache.addClientListener(new EventPrintListener(), null, new Object[]{1});
Converter instances have to marshallable when they are deployed in a cluster, so that the conversion can happen right where the event is generated, even if the even is generated in a different node to where the listener is registered. To make them marshallable, either make them extend Serializable, Externalizable, or provide a custom Externalizer for them.
20.7.15. Filter and Custom Events
If you want to do both event filtering and customization, it’s easier to implement org.infinispan.notifications.cachelistener.filter.CacheEventFilterConverter which allows both filter and customization to happen in a single step. For convenience, it’s recommended to extend org.infinispan.notifications.cachelistener.filter.AbstractCacheEventFilterConverter instead of implementing org.infinispan.notifications.cachelistener.filter.CacheEventFilterConverter directly. For example:
import org.infinispan.notifications.cachelistener.filter.CacheEventConverterFactory;
import org.infinispan.notifications.cachelistener.filter.CacheEventConverter;
@NamedFactory(name = "dynamic-filter-converter")
class DynamicCacheEventFilterConverterFactory implements CacheEventFilterConverterFactory {
public CacheEventFilterConverter<Integer, String, CustomEvent> getFilterConverter(final Object[] params) {
return new DynamicCacheEventFilterConverter(params);
}
}
// Serializable, Externalizable or marshallable with Infinispan Externalizers needed when running in a cluster
//
class DynamicCacheEventFilterConverter extends AbstractCacheEventFilterConverter<Integer, String, CustomEvent>, Serializable {
final Object[] params;
DynamicCacheEventFilterConverter(Object[] params) {
this.params = params;
}
public CustomEvent filterAndConvert(Integer key, String oldValue, Metadata oldMetadata,
String newValue, Metadata newMetadata, EventType eventType) {
// If the key matches a key given via parameter, only send the key information
if (params[0].equals(key))
return new CustomEvent(key, null);
return new CustomEvent(key, newValue);
}
}
Similar to filters and converters, to be able to register a listener with this combined filter/converter factory, the factory has to be given a unique name via the @NamedFactory annotation, and the Hot Rod server needs to be plugged with the name and the cache event converter factory instance. Plugging the Red Hat Data Grid Server with an event converter involves the following steps:
- Create a JAR file with the converter implementation within it.
-
Optional: If the cache uses custom key/value classes, these must be included in the JAR so that the callbacks can be executed with the correctly unmarshalled key and/or value instances. If the client listener has
useRawDataenabled, this is not necessary since the callback key/value instances will be provided in binary format. -
Create a
META-INF/services/org.infinispan.notifications.cachelistener.filter.CacheEventFilterConverterFactoryfile within the JAR file and within it, write the fully qualified class name of the converter class implementation. - Deploy the JAR file in the Red Hat Data Grid Server.
From a client perspective, to be able to use the combined filter and converter class, the client listener must define the same filter factory and converter factory names, e.g.:
@ClientListener(filterFactoryName = "dynamic-filter-converter", converterFactoryName = "dynamic-filter-converter")
public class CustomEventPrintListener { ... }The dynamic parameters required in the example above are provided when the listener is registered via either filter or converter parameters. If filter parameters are non-empty, those are used, otherwise, the converter parameters:
RemoteCache<?, ?> cache = ...
cache.addClientListener(new CustomEventPrintListener(), new Object[]{1}, null);20.7.16. Event Marshalling
Hot Rod servers can store data in different formats, but in spite of that, Java Hot Rod client users can still develop CacheEventConverter or CacheEventFilter instances that work on typed objects. By default, filters and converter will use data as POJO (application/x-java-object) but it is possible to override the desired format by overriding the method format() from the filter/converter. If the format returns null, the filter/converter will receive data as it’s stored.
As indicated in the Marshalling Data section, Hot Rod Java clients can be configured to use a different org.infinispan.commons.marshall.Marshaller instance. If doing this and deploying CacheEventConverter or CacheEventFilter instances, to be able to present filters/converter with Java Objects rather than marshalled content, the server needs to be able to convert between objects and the binary format produced by the marshaller.
To deploy a Marshaller instance server-side, follow a similar method to the one used to deploy CacheEventConverter or CacheEventFilter instances:
- Create a JAR file with the converter implementation within it.
-
Create a
META-INF/services/org.infinispan.commons.marshall.Marshallerfile within the JAR file and within it, write the fully qualified class name of the marshaller class implementation. - Deploy the JAR file in the Red Hat Data Grid Server.
Note that the Marshaller could be deployed in either a separate jar, or in the same jar as the CacheEventConverter and/or CacheEventFilter instances.
20.7.16.1. Deploying Protostream Marshallers
If a cache stores protobuf content, as it happens when using protostream marshaller in the Hot Rod client, it’s not necessary to deploy a custom marshaller since the format is already support by the server: there are transcoders from protobuf format to most common formats like JSON and POJO.
When using filters/converters with those caches, and it’s desirable to use filter/converters with Java Objects rather binary prototobuf data, it’s necessary to deploy the extra protostream marshallers so that the server can unmarshall the data before filtering/converting. To do so, follow these steps:
Create a JAR file that includes an implementation of the following interface:
org.infinispan.query.remote.client.ProtostreamSerializationContextInitializer
Your implementation should add extra marshallers and optional Protobuf (
.proto) files to theSerializationcontext for the Cache Manager.Create the following file inside your JAR file:
META-INF/services/org.infinispan.query.remote.client.ProtostreamSerializationContextInitializer
This file should contain the fully qualified class name of your
ProtostreamSerializationContextInitializerimplementation.Create a
META-INF/MANIFEST.MFfile inside your JAR file that contains the following:Dependencies: org.infinispan.protostream, org.infinispan.remote-query.client
Update your JBoss deployment structure file,
jboss-deployment-structure.xml, to include the following content so that Red Hat Data Grid Server can access your custom classes:<jboss-deployment-structure xmlns="urn:jboss:deployment-structure:1.2"> <deployment> <dependencies> <module name="org.infinispan.protostream" /> <module name="org.infinispan.remote-query.client" services="import"/> </dependencies> </deployment> </jboss-deployment-structure>-
Deploy the JAR file to Red Hat Data Grid Server by adding it to the
standalone/deploymentsfolder. Configure the deployment in the appropriate Cache Manager as follows:
<cache-container name="local" default-cache="default"> <modules> <module name="deployment.my-file.jar"/> </modules> ... </cache-container>
JAR files that deploy custom classes to Red Hat Data Grid Server must be available at startup. You cannot deploy JARs to running server instances.
20.7.17. Listener State Handling
Client listener annotation has an optional includeCurrentState attribute that specifies whether state will be sent to the client when the listener is added or when there’s a failover of the listener.
By default, includeCurrentState is false, but if set to true and a client listener is added in a cache already containing data, the server iterates over the cache contents and sends an event for each entry to the client as a ClientCacheEntryCreated (or custom event if configured). This allows clients to build some local data structures based on the existing content. Once the content has been iterated over, events are received as normal, as cache updates are received. If the cache is clustered, the entire cluster wide contents are iterated over.
includeCurrentState also controls whether state is received when the node where the client event listener is registered fails and it’s moved to a different node. The next section discusses this topic in depth.
20.7.18. Listener Failure Handling
When a Hot Rod client registers a client listener, it does so in a single node in a cluster. If that node fails, the Java Hot Rod client detects that transparently and fails over all listeners registered in the node that failed to another node.
During this fail over the client might miss some events. To avoid missing these events, the client listener annotation contains an optional parameter called includeCurrentState which if set to true, when the failover happens, the cache contents can iterated over and ClientCacheEntryCreated events (or custom events if configured) are generated. By default, includeCurrentState is set to false.
Java Hot Rod clients can be made aware of such fail over event by adding a callback to handle it:
@ClientCacheFailover
public void handleFailover(ClientCacheFailoverEvent e) {
...
}This is very useful in use cases where the client has cached some data, and as a result of the fail over, taking in account that some events could be missed, it could decide to clear any locally cached data when the fail over event is received, with the knowledge that after the fail over event, it will receive events for the contents of the entire cache.
20.7.19. Near Caching
The Java Hot Rod client can be optionally configured with a near cache, which means that the Hot Rod client can keep a local cache that stores recently used data. Enabling near caching can significantly improve the performance of read operations get and getVersioned since data can potentially be located locally within the Hot Rod client instead of having to go remote.
To enable near caching, the user must set the near cache mode to INVALIDATED. By doing that near cache is populated upon retrievals from the server via calls to get or getVersioned operations. When near cached entries are updated or removed server-side, the cached near cache entries are invalidated. If a key is requested after it’s been invalidated, it’ll have to be re-fetched from the server.
You should not use maxIdle expiration with near caches, as near-cache reads will not propagate the last access change to the server and to the other clients.
When near cache is enabled, its size must be configured by defining the maximum number of entries to keep in the near cache. When the maximum is reached, near cached entries are evicted. If providing 0 or a negative value, it is assumed that the near cache is unbounded.
Users should be careful when configuring near cache to be unbounded since it shifts the responsibility to keep the near cache’s size within the boundaries of the client JVM to the user.
The Hot Rod client’s near cache mode is configured using the NearCacheMode enumeration and calling:
import org.infinispan.client.hotrod.configuration.ConfigurationBuilder; import org.infinispan.client.hotrod.configuration.NearCacheMode; ... // Unbounded invalidated near cache ConfigurationBuilder unbounded = new ConfigurationBuilder(); unbounded.nearCache().mode(NearCacheMode.INVALIDATED).maxEntries(-1); // Bounded invalidated near cache ConfigurationBuilder bounded = new ConfigurationBuilder(); bounded.nearCache().mode(NearCacheMode.INVALIDATED).maxEntries(100);
Since the configuration is shared by all caches obtained from a single RemoteCacheManager, you may not want to enable near-caching for all of them. You can use the cacheNamePattern configuration attribute to define a regular expression which matches the names of the caches for which you want near-caching. Caches whose name don’t match the regular expression, will not have near-caching enabled.
// Bounded invalidated near cache with pattern matching
ConfigurationBuilder bounded = new ConfigurationBuilder();
bounded.nearCache()
.mode(NearCacheMode.INVALIDATED)
.maxEntries(100)
.cacheNamePattern("near.*"); // enable near-cache only for caches whose name starts with 'near'Near caches work the same way for local caches as they do for clustered caches, but in a clustered cache scenario, if the server node sending the near cache notifications to the Hot Rod client goes down, the Hot Rod client transparently fails over to another node in the cluster, clearing the near cache along the way.
20.7.20. Unsupported methods
Some of the Cache methods are not being supported by the RemoteCache . Calling one of these methods results in an UnsupportedOperationException being thrown. Most of these methods do not make sense on the remote cache (e.g. listener management operations), or correspond to methods that are not supported by local cache as well (e.g. containsValue). Another set of unsupported operations are some of the atomic operations inherited from ConcurrentMap :
boolean remove(Object key, Object value); boolean replace(Object key, Object value); boolean replace(Object key, Object oldValue, Object value);
RemoteCache offers alternative versioned methods for these atomic operations, that are also network friendly, by not sending the whole value object over the network, but a version identifier. See the section on versioned API.
Each one of these unsupported operation is documented in the RemoteCache javadoc.
20.7.21. Return values
There is a set of methods that alter a cached entry and return the previous existing value, e.g.:
V remove(Object key); V put(K key, V value);
By default on RemoteCache, these operations return null even if such a previous value exists. This approach reduces the amount of data sent over the network. However, if these return values are needed they can be enforced on a per invocation basis using flags:
cache.put("aKey", "initialValue");
assert null == cache.put("aKey", "aValue");
assert "aValue".equals(cache.withFlags(Flag.FORCE_RETURN_VALUE).put("aKey",
"newValue"));This default behavior can can be changed through force-return-value=true configuration parameter (see configuration section bellow).
20.7.22. Hot Rod Transactions
You can configure and use Hot Rod clients in JTA Transactions.
To participate in a transaction, the Hot Rod client requires the TransactionManager with which it interacts and whether it participates in the transaction through the Synchronization or XAResource interface.
Transactions are optimistic in that clients acquire write locks on entries during the prepare phase. To avoid data inconsistency, be sure to read about Detecting Conflicts with Transactions.
20.7.22.1. Configuring the Server
Caches in the server must also be transactional for clients to participate in JTA Transactions.
The following server configuration is required, otherwise transactions rollback only:
-
Isolation level must be
REPEATABLE_READ. -
Locking mode must be
PESSIMISTIC. In a future release,OPTIMISTIClocking mode will be supported. -
Transaction mode should be
NON_XAorNON_DURABLE_XA. Hot Rod transactions cannot useFULL_XAbecause it degrades performance.
Hot Rod transactions have their own recovery mechanism.
20.7.22.2. Configuring Hot Rod Clients
When you create the RemoteCacheManager, you can set the default TransactionManager and TransactionMode that the RemoteCache uses.
The RemoteCacheManager lets you create only one configuration for transactional caches, as in the following example:
org.infinispan.client.hotrod.configuration.ConfigurationBuilder cb = new org.infinispan.client.hotrod.configuration.ConfigurationBuilder(); //other client configuration parameters cb.transaction().transactionManagerLookup(GenericTransactionManagerLookup.getInstance()); cb.transaction().transactionMode(TransactionMode.NON_XA); cb.transaction().timeout(1, TimeUnit.MINUTES) RemoteCacheManager rmc = new RemoteCacheManager(cb.build());
The preceding configuration applies to all instances of a remote cache. If you need to apply different configurations to remote cache instances, you can override the RemoteCache configuration. See Overriding RemoteCacheManager Configuration.
See ConfigurationBuilder Javadoc for documentation on configuration parameters.
You can also configure the Java Hot Rod client with a properties file, as in the following example:
infinispan.client.hotrod.transaction.transaction_manager_lookup = org.infinispan.client.hotrod.transaction.lookup.GenericTransactionManagerLookup infinispan.client.hotrod.transaction.transaction_mode = NON_XA infinispan.client.hotrod.transaction.timeout = 60000
20.7.22.2.1. TransactionManagerLookup Interface
TransactionManagerLookup provides an entry point to fetch a TransactionManager.
Available implementations of TransactionManagerLookup:
- GenericTransactionManagerLookup
- A lookup class that locates TransactionManagers running in Java EE application servers. Defaults to the RemoteTransactionManager if it cannot find a TransactionManager.
In most cases, GenericTransactionManagerLookup is suitable. However, you can implement the TransactionManagerLookup interface if you need to integrate a custom TransactionManager.
- RemoteTransactionManagerLookup
- A basic, and volatile, TransactionManager if no other implementation is available. Note that this implementation has significant limitations when handling concurrent transactions and recovery.
20.7.22.2.2. Transaction Modes
TransactionMode controls how a RemoteCache interacts with the TransactionManager.
Configure transaction modes on both the Red Hat Data Grid server and your client application. If clients attempt to perform transactional operations on non-transactional caches, runtime exceptions can occur.
Transaction modes are the same in both the Red Hat Data Grid configuration and client settings. Use the following modes with your client, see the Red Hat Data Grid configuration schema for the server:
NONE- The RemoteCache does not interact with the TransactionManager. This is the default mode and is non-transactional.
NON_XA- The RemoteCache interacts with the TransactionManager via Synchronization.
NON_DURABLE_XA- The RemoteCache interacts with the TransactionManager via XAResource. Recovery capabilities are disabled.
FULL_XA-
The RemoteCache interacts with the TransactionManager via XAResource. Recovery capabilities are enabled. Invoke the
XaResource.recover()method to retrieve transactions to recover.
20.7.22.3. Overriding Configuration for Cache Instances
Because RemoteCacheManager does not support different configurations for each cache instance. However, RemoteCacheManager includes the getCache(String) method that returns the RemoteCache instances and lets you override some configuration parameters, as follows:
getCache(String cacheName, TransactionMode transactionMode)- Returns a RemoteCache and overrides the configured TransactionMode.
getCache(String cacheName, boolean forceReturnValue, TransactionMode transactionMode)- Same as previous, but can also force return values for write operations.
getCache(String cacheName, TransactionManager transactionManager)- Returns a RemoteCache and overrides the configured TransactionManager.
getCache(String cacheName, boolean forceReturnValue, TransactionManager transactionManager)- Same as previous, but can also force return values for write operations.
getCache(String cacheName, TransactionMode transactionMode, TransactionManager transactionManager)-
Returns a RemoteCache and overrides the configured TransactionManager and TransactionMode. Uses the configured values, if
transactionManagerortransactionModeis null. getCache(String cacheName, boolean forceReturnValue, TransactionMode transactionMode, TransactionManager transactionManager)- Same as previous, but can also force return values for write operations.
The getCache(String) method returns RemoteCache instances regardless of whether they are transaction or not. RemoteCache includes a getTransactionManager() method that returns the TransactionManager that the cache uses. If the RemoteCache is not transactional, the method returns null.
20.7.22.4. Detecting Conflicts with Transactions
Transactions use the initial values of keys to detect conflicts. For example, "k" has a value of "v" when a transaction begins. During the prepare phase, the transaction fetches "k" from the server to read the value. If the value has changed, the transaction rolls back to avoid a conflict.
Transactions use versions to detect changes instead of checking value equality.
The forceReturnValue parameter controls write operations to the RemoteCache and helps avoid conflicts. It has the following values:
-
If
true, the TransactionManager fetches the most recent value from the server before performing write operations. However, theforceReturnValueparameter applies only to write operations that access the key for the first time. -
If
false, the TransactionManager does not fetch the most recent value from the server before performing write operations. Because this setting
This parameter does not affect conditional write operations such as replace or putIfAbsent because they require the most recent value.
The following transactions provide an example where the forceReturnValue parameter can prevent conflicting write operations:
Transaction 1 (TX1)
RemoteCache<String, String> cache = ...
TransactionManager tm = ...
tm.begin();
cache.put("k", "v1");
tm.commit();
Transaction 2 (TX2)
RemoteCache<String, String> cache = ...
TransactionManager tm = ...
tm.begin();
cache.put("k", "v2");
tm.commit();
In this example, TX1 and TX2 are executed in parallel. The initial value of "k" is "v".
-
If
forceReturnValue = true, thecache.put()operation fetches the value for "k" from the server in both TX1 and TX2. The transaction that acquires the lock for "k" first then commits. The other transaction rolls back during the commit phase because the transaction can detect that "k" has a value other than "v". -
If
forceReturnValue = false, thecache.put()operation does not fetch the value for "k" from the server and returns null. Both TX1 and TX2 can successfully commit, which results in a conflict. This occurs because neither transaction can detect that the initial value of "k" changed.
The following transactions include cache.get() operations to read the value for "k" before doing the cache.put() operations:
Transaction 1 (TX1)
RemoteCache<String, String> cache = ...
TransactionManager tm = ...
tm.begin();
cache.get("k");
cache.put("k", "v1");
tm.commit();
Transaction 2 (TX2)
RemoteCache<String, String> cache = ...
TransactionManager tm = ...
tm.begin();
cache.get("k");
cache.put("k", "v2");
tm.commit();
In the preceding examples, TX1 and TX2 both read the key so the forceReturnValue parameter does not take effect. One transaction commits, the other rolls back. However, the cache.get() operation requires an additional server request. If you do not need the return value for the cache.put() operation that server request is inefficient.
20.7.22.5. Using the Configured Transaction Manager and Transaction Mode
The following example shows how to use the TransactionManager and TransactionMode that you configure in the RemoteCacheManager:
//Configure the transaction manager and transaction mode.
org.infinispan.client.hotrod.configuration.ConfigurationBuilder cb = new org.infinispan.client.hotrod.configuration.ConfigurationBuilder();
cb.transaction().transactionManagerLookup(RemoteTransactionManagerLookup.getInstance());
cb.transaction().transactionMode(TransactionMode.NON_XA);
RemoteCacheManager rcm = new RemoteCacheManager(cb.build());
//The my-cache instance uses the RemoteCacheManager configuration.
RemoteCache<String, String> cache = rcm.getCache("my-cache");
//Return the transaction manager that the cache uses.
TransactionManager tm = cache.getTransactionManager();
//Perform a simple transaction.
tm.begin();
cache.put("k1", "v1");
System.out.println("K1 value is " + cache.get("k1"));
tm.commit();20.7.22.6. Overriding the Transaction Manager
The following example shows how to override TransactionManager with the getCache method:
//Configure the transaction manager and transaction mode.
org.infinispan.client.hotrod.configuration.ConfigurationBuilder cb = new org.infinispan.client.hotrod.configuration.ConfigurationBuilder();
cb.transaction().transactionManagerLookup(RemoteTransactionManagerLookup.getInstance());
cb.transaction().transactionMode(TransactionMode.NON_XA);
RemoteCacheManager rcm = new RemoteCacheManager(cb.build());
//Define a custom TransactionManager.
TransactionManager myCustomTM = ...
//Override the TransactionManager for the my-cache instance. Use the default configuration if null is returned.
RemoteCache<String, String> cache = rcm.getCache("my-cache", null, myCustomTM);
//Perform a simple transaction.
myCustomTM.begin();
cache.put("k1", "v1");
System.out.println("K1 value is " + cache.get("k1"));
myCustomTM.commit();20.7.22.7. Overriding the Transaction Mode
The following example shows how to override TransactionMode with the getCache method:
//Configure the transaction manager and transaction mode.
org.infinispan.client.hotrod.configuration.ConfigurationBuilder cb = new org.infinispan.client.hotrod.configuration.ConfigurationBuilder();
cb.transaction().transactionManagerLookup(RemoteTransactionManagerLookup.getInstance());
cb.transaction().transactionMode(TransactionMode.NON_XA);
RemoteCacheManager rcm = new RemoteCacheManager(cb.build());
//Override the transaction mode for the my-cache instance.
RemoteCache<String, String> cache = rcm.getCache("my-cache", TransactionMode.NON_DURABLE_XA, null);
//Return the transaction manager that the cache uses.
TransactionManager tm = cache.getTransactionManager();
//Perform a simple transaction.
tm.begin();
cache.put("k1", "v1");
System.out.println("K1 value is " + cache.get("k1"));
tm.commit();20.7.23. Client Intelligence
Client intelligence refers to mechanisms the HotRod protocol provides for clients to locate and send requests to Red Hat Data Grid servers.
Basic intelligence
Clients do not store any information about Red Hat Data Grid clusters or key hash values.
Topology-aware
Clients receive and store information about Red Hat Data Grid clusters. Clients maintain an internal mapping of the cluster topology that changes whenever servers join or leave clusters.
To receive a cluster topology, clients need the address (IP:HOST) of at least one Hot Rod server at startup. After the client connects to the server, Red Hat Data Grid transmits the topology to the client. When servers join or leave the cluster, Red Hat Data Grid transmits an updated topology to the client.
Distribution-aware
Clients are topology-aware and store consistent hash values for keys.
For example, take a put(k,v) operation. The client calculates the hash value for the key so it can locate the exact server on which the data resides. Clients can then connect directly to the owner to dispatch the operation.
The benefit of distribution-aware intelligence is that Red Hat Data Grid servers do not need to look up values based on key hashes, which uses less resources on the server side. Another benefit is that servers respond to client requests more quickly because it skips additional network roundtrips.
20.7.23.1. Request Balancing
Clients that use topology-aware intelligence use request balancing for all requests. The default balancing strategy is round-robin, so topology-aware clients always send requests to servers in round-robin order.
For example, s1, s2, s3 are servers in a Red Hat Data Grid cluster. Clients perform request balancing as follows:
CacheContainer cacheContainer = new RemoteCacheManager();
Cache<String, String> cache = cacheContainer.getCache();
//client sends put request to s1
cache.put("key1", "aValue");
//client sends put request to s2
cache.put("key2", "aValue");
//client sends get request to s3
String value = cache.get("key1");
//client dispatches to s1 again
cache.remove("key2");
//and so on...Clients that use distribution-aware intelligence use request balancing only for failed requests. When requests fail, distribution-aware clients retry the request on the next available server.
Custom balancing policies
You can implement FailoverRequestBalancingStrategy and specify your class in your hotrod-client.properties configuration.
20.7.24. Persistent connections
In order to avoid creating a TCP connection on each request (which is a costly operation), the client keeps a pool of persistent connections to all the available servers and it reuses these connections whenever it is possible. The validity of the connections is checked using an async thread that iterates over the connections in the pool and sends a HotRod ping command to the server. By using this connection validation process the client is being proactive: there’s a hight chance for broken connections to be found while being idle in the pool and no on actual request from the application.
The number of connections per server, total number of connections, how long should a connection be kept idle in the pool before being closed - all these (and more) can be configured. Please refer to the javadoc of RemoteCacheManager for a list of all possible configuration elements.
20.7.25. Marshalling data
The Hot Rod client allows one to plug in a custom marshaller for transforming user objects into byte arrays and the other way around. This transformation is needed because of Hot Rod’s binary nature - it doesn’t know about objects.
The marshaller can be plugged through the "marshaller" configuration element (see Configuration section): the value should be the fully qualified name of a class implementing the Marshaller interface. This is a optional parameter, if not specified it defaults to the GenericJBossMarshaller - a highly optimized implementation based on the JBoss Marshalling library.
Since version 6.0, there’s a new marshaller available to Java Hot Rod clients based on Protostream which generates portable payloads. You can find more information about it here.
WARNING: If developing your own custom marshaller, take care of potential injection attacks.
To avoid such attacks, make the marshaller verify that any class names read, before instantiating it, is amongst the expected/allowed class names.
The client configuration can be enhanced with a list of regular expressions for classes that are allowed to be read.
WARNING: These checks are opt-in, so if not configured, any class can be read.
In the example below, only classes with fully qualified names containing Person or Employee would be allowed:
import org.infinispan.client.hotrod.configuration.ConfigurationBuilder;
...
ConfigurationBuilder configBuilder = ...
configBuilder.addJavaSerialWhiteList(".*Person.*", ".*Employee.*");20.7.26. Reading data in different data formats
By default, every Hot Rod client operation will use the configured marshaller when reading and writing from the server for both keys and values. See Marshalling Data. Using the DataFormat API, it’s possible to decorate remote caches so that all operations can happen with a custom data format.
20.7.26.1. Using different marshallers for Key and Values
Marshallers for Keys and Values can be overridden at run time. For example, to bypass all serialization in the Hot Rod client and read the byte[] as they are stored in the server:
// Existing Remote cache instance RemoteCache<String, Pojo> remoteCache = ... // IdentityMarshaller is a no-op marshaller DataFormat rawKeyAndValues = DataFormat.builder().keyMarshaller(IdentityMarshaller.INSTANCE).valueMarshaller(IdentityMarshaller.INSTANCE).build(); // Will create a new instance of RemoteCache with the supplied DataFormat RemoteCache<byte[], byte[]> rawResultsCache = remoteCache.withDataFormat(rawKeyAndValues);
20.7.26.2. Reading data in different formats
Apart from defining custom key and value marshallers, it’s also possible to request/send data in different formats specified by a org.infinispan.commons.dataconversion.MediaType:
// Existing remote cache using ProtostreamMarshaller RemoteCache<String, Pojo> protobufCache = ... // Request values returned as JSON, using the UTF8StringMarshaller that converts between UTF-8 to String: DataFormat jsonString = DataFormat.builder().valueType(MediaType.APPLICATION_JSON).valueMarshaller(new UTF8StringMarshaller().build(); RemoteCache<String, String> jsonStrCache = remoteCache.withDataFormat(jsonString); // Alternativelly, it's possible to request JSON values but marshalled/unmarshalled with a custom value marshaller that returns `org.codehaus.jackson.JsonNode` objects: DataFormat jsonNode = DataFormat.builder().valueType(MediaType.APPLICATION_JSON).valueMarshaller(new CustomJacksonMarshaller().build(); RemoteCache<String, JsonNode> jsonNodeCache = remoteCache.withDataFormat(jsonNode);
The data conversions happen in the server, and if it doesn’t support converting from the storage format to the request format and vice versa, an error will be returned. For more details on server data format configuration and supported conversions, see here.
Using different marshallers and formats for the key, with .keyMarshaller() and .keyType() may interfere with the client intelligence routing mechanism, causing it contact the server that is not the owner of the key during Hot Rod operations. This will not result in errors but can result in extra hops inside the cluster to execute the operation. If performance is critical, make sure to use the keys in the format stored by the server.
20.7.27. Statistics
Various server usage statistics can be obtained through the RemoteCache .stats() method. This returns a ServerStatistics object - please refer to javadoc for details on the available statistics.
20.7.28. Multi-Get Operations
The Java Hot Rod client does not provide multi-get functionality out of the box but clients can build it themselves with the given APIs.
20.7.29. Failover capabilities
Hot Rod clients' capabilities to keep up with topology changes helps with request balancing and more importantly, with the ability to failover operations if one or several of the servers fail.
Some of the conditional operations mentioned above, including putIfAbsent, replace with and without version, and conditional remove have strict method return guarantees, as well as those operations where returning the previous value is forced.
In spite of failures, these methods return values need to be guaranteed, and in order to do so, it’s necessary that these methods are not applied partially in the cluster in the event of failure. For example, imagine a replace() operation called in a server for key=k1 with Flag.FORCE_RETURN_VALUE, whose current value is A and the replace wants to set it to B. If the replace fails, it could happen that some servers contain B and others contain A, and during the failover, the original replace() could end up returning B, if the replace failovers to a node where B is set, or could end up returning A.
To avoid this kind of situations, whenever Java Hot Rod client users want to use conditional operations, or operations whose previous value is required, it’s important that the cache is configured to be transactional in order to avoid incorrect conditional operations or return values.
20.7.30. Site Cluster Failover
On top of the in-cluster failover, Hot Rod clients are also able to failover to different clusters, which could be represented as an independent site.
The way site cluster failover works is that if all the main cluster nodes are not available, the client checks to see if any other clusters have been defined in which cases it tries to failover to the alternative cluster. If the failover succeeds, the client will remain connected to the alternative cluster until this becomes unavailable, in which case it’ll try any other clusters defined, and ultimately, it’ll try the original server settings.
To configure a cluster in the Hot Rod client, one host/port pair details must be provided for each of the clusters configured. For example:
org.infinispan.client.hotrod.configuration.ConfigurationBuilder cb
= new org.infinispan.client.hotrod.configuration.ConfigurationBuilder();
cb.addCluster().addClusterNode("remote-cluster-host", 11222);
RemoteCacheManager rmc = new RemoteCacheManager(cb.build());Remember that regardless of the cluster definitions, the initial server(s) configuration must be provided unless the initial servers can be resolved using the default server host and port details.
20.7.31. Manual Site Cluster Switch
As well as supporting automatic site cluster failover, Java Hot Rod clients can also switch between site clusters manually by calling RemoteCacheManager’s switchToCluster(clusterName) and switchToDefaultCluster().
Using switchToCluster(clusterName), users can force a client to switch to one of the clusters pre-defined in the Hot Rod client configuration. To switch to the initial servers defined in the client configuration, call switchToDefaultCluster().
20.7.32. Monitoring the Hot Rod client
The Hot Rod client can be monitored and managed via JMX similarly to what is described in the Management chapter. By enabling statistics, an MBean will be registered for the RemoteCacheManager as well as for each RemoteCache obtained through it. Through these MBeans it is possible to obtain statistics about remote and near-cache hits/misses and connection pool usage.
20.7.33. Concurrent Updates
Data structures, such as Red Hat Data Grid Cache , that are accessed and modified concurrently can suffer from data consistency issues unless there’re mechanisms to guarantee data correctness. Red Hat Data Grid Cache, since it implements ConcurrentMap , provides operations such as conditional replace , putIfAbsent , and conditional remove to its clients in order to guarantee data correctness. It even allows clients to operate against cache instances within JTA transactions, hence providing the necessary data consistency guarantees.
However, when it comes to Hot Rod protocol backed servers, clients do not yet have the ability to start remote transactions but they can call instead versioned operations to mimic the conditional methods provided by the embedded Red Hat Data Grid cache instance API. Let’s look at a real example to understand how it works.
20.7.33.1. Data Consistency Problem
Imagine you have two ATMs that connect using Hot Rod to a bank where an account’s balance is stored. Two closely followed operations to retrieve the latest balance could return 500 CHF (swiss francs) as shown below:
Figure 20.7. Concurrent readers
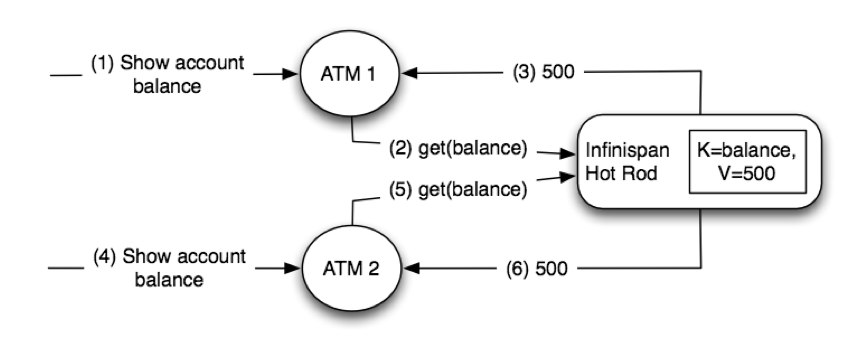
Next a customer connects to the first ATM and requests 400 CHF to be retrieved. Based on the last value read, the ATM could calculate what the new balance is, which is 100 CHF, and request a put with this new value. Let’s imagine now that around the same time another customer connects to the ATM and requests 200 CHF to be retrieved. Let’s assume that the ATM thinks it has the latest balance and based on its calculations it sets the new balance to 300 CHF:
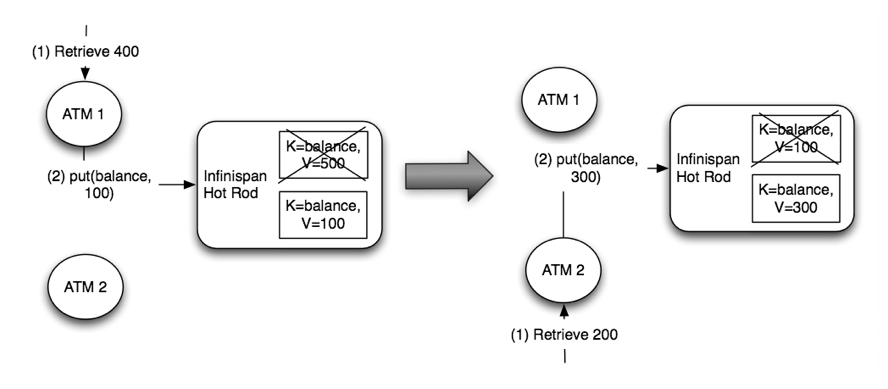
Obviously, this would be wrong. Two concurrent updates have resulted in an incorrect account balance. The second update should not have been allowed since the balance the second ATM had was incorrect. Even if the ATM would have retrieved the balance before calculating the new balance, someone could have updated between the new balance being retrieved and the update. Before finding out how to solve this issue in a client-server scenario with Hot Rod, let’s look at how this is solved when Red Hat Data Grid clients run in peer-to-peer mode where clients and Red Hat Data Grid live within the same JVM.
20.7.33.2. Embedded-mode Solution
If the ATM and the Red Hat Data Grid instance storing the bank account lived in the same JVM, the ATM could use the conditional replace API referred at the beginning of this article. So, it could send the previous known value to verify whether it has changed since it was last read. By doing so, the first operation could double check that the balance is still 500 CHF when it was to update to 100 CHF. Now, when the second operation comes, the current balance would not be 500 CHF any more and hence the conditional replace call would fail, hence avoiding data consistency issues:
Figure 20.8. P2P solution
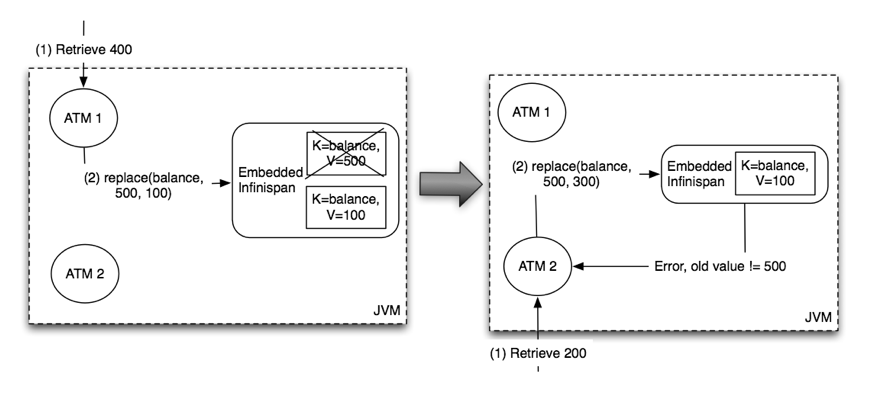
20.7.33.3. Client-Server Solution
In theory, Hot Rod could use the same p2p solution but sending the previous value would be not practical. In this example, the previous value is just an integer but the value could be a lot bigger and hence forcing clients to send it to the server would be rather wasteful. Instead, Hot Rod offers versioned operations to deal with this situation.
Basically, together with each key/value pair, Hot Rod stores a version number which uniquely identifies each modification. So, using an operation called getVersioned or getWithVersion , clients can retrieve not only the value associated with a key, but also the current version. So, if we look at the previous example once again, the ATMs could call getVersioned and get the balance’s version:
Figure 20.9. Get versioned
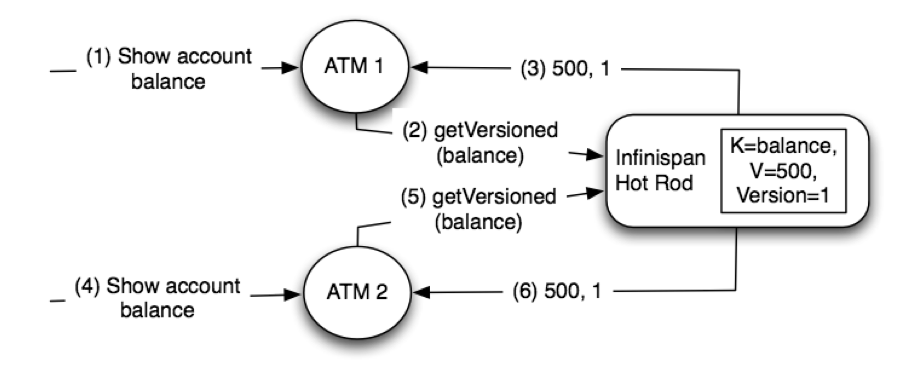
When the ATMs wanted to modify the balance, instead of just calling put, they could call replaceIfUnmodified operation passing the latest version number of which the clients are aware of. The operation will only succeed if the version passed matches the version in the server. So, the first modification by the ATM would be allowed since the client passes 1 as version and the server side version for the balance is also 1. On the other hand, the second ATM would not be able to make the modification because after the first ATMs modification the version would have been incremented to 2, and now the passed version (1) and the server side version (2) would not match:
Figure 20.10. Replace if versions match

20.7.34. Javadocs
It is highly recommended to read the following Javadocs (this is pretty much all the public API of the client):
20.8. REST Server
The Red Hat Data Grid Server distribution contains a module that implements RESTful HTTP access to the Red Hat Data Grid data grid, built on Netty.
20.8.1. Running the REST server
The REST server endpoint is part of the Red Hat Data Grid Server and by default listens on port 8080. To run the server locally, download the zip distribution and execute in the extracted directory:
bin/standalone.sh -b 0.0.0.0
or alternatively, run via docker:
docker run -it -p 8080:8080 -e "APP_USER=user" -e "APP_PASS=changeme" jboss/infinispan-server
20.8.1.1. Security
The REST server is protected by authentication, so before usage it is necessary to create an application login. When running via docker, this is achieved by the APP_USER and APP_PASS command line arguments, but when running locally, this can be done with:
bin/add-user.sh -u user -p changeme -a
20.8.2. Supported protocols
The REST Server supports HTTP/1.1 as well as HTTP/2 protocols. It is possible to switch to HTTP/2 by either performing a HTTP/1.1 Upgrade procedure or by negotiating communication protocol using TLS/ALPN extension.
Note: TLS/ALPN with JDK8 requires additional steps from the client perspective. Please refer to your client documentation but it is very likely that you will need Jetty ALPN Agent or OpenSSL bindings.
20.8.3. REST API
HTTP PUT and POST methods are used to place data in the cache, with URLs to address the cache name and key(s) - the data being the body of the request (the data can be anything you like). Other headers are used to control the cache settings and behaviour.
20.8.3.1. Data formats
20.8.3.1.1. Configuration
Each cache exposed via REST stores data in a configurable data format defined by a MediaType. More details in the configuration here.
An example of storage configuration is as follows:
<cache>
<encoding>
<key media-type="application/x-java-object; type=java.lang.Integer"/>
<value media-type="application/xml; charset=UTF-8"/>
</encoding>
</cache>When no MediaType is configured, Red Hat Data Grid assumes "application/octet-stream" for both keys and values, with the following exceptions:
- If the cache is indexed, it assumes "application/x-protostream"
- If the cache is configured with compatibility mode, it assumes "application/x-java-object"
20.8.3.1.2. Supported formats
Data can be written and read in different formats than the storage format; Red Hat Data Grid can convert between those formats when required.
The following "standard" formats can be converted interchangeably:
- application/x-java-object
- application/octet-stream
- application/x-www-form-urlencoded
- text/plain
The following formats can be converted to/from the formats above:
- application/xml
- application/json
- application/x-jboss-marshalling
- application/x-protostream
- application/x-java-serialized
Finally, the following conversion is also supported:
- Between application/x-protostream and application/json
All the REST API calls can provide headers describing the content written or the required format of the content when reading. Red Hat Data Grid supports the standard HTTP/1.1 headers "Content-Type" and "Accept" that are applied for values, plus the "Key-Content-Type" with similar effect for keys.
20.8.3.1.3. Accept header
The REST server is compliant with the RFC-2616 Accept header, and will negotiate the correct MediaType based on the conversions supported. Example, sending the following header when reading data:
Accept: text/plain;q=0.7, application/json;q=0.8, */*;q=0.6
will cause Red Hat Data Grid to try first to return content in JSON format (higher priority 0.8). If it’s not possible to convert the storage format to JSON, next format tried will be text/plain (second highest priority 0.7), and finally it falls back to */*, that will pick a format suitable for displaying automatically based on the cache configuration.
20.8.3.1.4. Key-Content-Type header
Most REST API calls have the Key included in the URL. Red Hat Data Grid will assume the Key is a java.lang.String when handling those calls, but it’s possible to use a specific header Key-Content-Type for keys in different formats.
Examples:
- Specifying a byte[] Key as a Base64 string:
API call:
`PUT /my-cache/AQIDBDM=`
Headers:
Key-Content-Type: application/octet-stream
- Specifying a byte[] Key as a hexadecimal string:
API call:
GET /my-cache/0x01CA03042F
Headers:
Key-Content-Type: application/octet-stream; encoding=hex
- Specifying a double Key:
API call:
POST /my-cache/3.141456
Headers:
Key-Content-Type: application/x-java-object;type=java.lang.Double
The type parameter for application/x-java-object is restricted to:
- Primitive wrapper types
- java.lang.String
- Bytes, making application/x-java-object;type=Bytes equivalent to application/octet-stream;encoding=hex
20.8.3.2. Putting data in
20.8.3.2.1. PUT /{cacheName}/{cacheKey}
A PUT request of the above URL form will place the payload (body) in the given cache, with the given key (the named cache must exist on the server). For example http://someserver/hr/payRoll-3 (in which case hr is the cache name, and payRoll-3 is the key). Any existing data will be replaced, and Time-To-Live and Last-Modified values etc will updated (if applicable).
20.8.3.2.2. POST /{cacheName}/{cacheKey}
Exactly the same as PUT, only if a value in a cache/key already exists, it will return a Http CONFLICT status (and the content will not be updated).
Headers
- Key-Content-Type: OPTIONAL The content type for the Key present in the URL.
- Content-Type : OPTIONAL The MediaType of the Value being sent.
- performAsync : OPTIONAL true/false (if true, this will return immediately, and then replicate data to the cluster on its own. Can help with bulk data inserts/large clusters.)
- timeToLiveSeconds : OPTIONAL number (the number of seconds before this entry will automatically be deleted). If no parameter is sent, Red Hat Data Grid assumes configuration default value. Passing any negative value will create an entry which will live forever.
- maxIdleTimeSeconds : OPTIONAL number (the number of seconds after last usage of this entry when it will automatically be deleted). If no parameter is sent, Red Hat Data Grid configuration default value. Passing any negative value will create an entry which will live forever.
Passing 0 as parameter for timeToLiveSeconds and/or maxIdleTimeSeconds
-
If both
timeToLiveSecondsandmaxIdleTimeSecondsare 0, the cache will use the defaultlifespanandmaxIdlevalues configured in XML/programmatically -
If only
maxIdleTimeSecondsis 0, it uses thetimeToLiveSecondsvalue passed as parameter (or -1 if not present), and defaultmaxIdleconfigured in XML/programmatically -
If only
timeToLiveSecondsis 0, it uses defaultlifespanconfigured in XML/programmatically, andmaxIdleis set to whatever came as parameter (or -1 if not present)
JSON/Protostream conversion
When caches are indexed, or specifically configured to store application/x-protostream, it’s possible to send and receive JSON documents that are automatically converted to/from protostream. In order for the conversion to work, a protobuf schema must be registered.
The registration can be done via REST, by doing a POST/PUT in the ___protobuf_metadata cache. Example using cURL:
curl -u user:password -X POST --data-binary @./schema.proto http://127.0.0.1:8080/rest/___protobuf_metadata/schema.proto
When writing a JSON document, a special field _type must be present in the document to identity the protobuf Message corresponding to the document.
For example, consider the following schema:
message Person {
required string name = 1;
required int32 age = 2;
}A conformant JSON document would be:
{
"_type": "Person",
"name": "user1",
"age": 32
}20.8.3.3. Getting data back out
HTTP GET and HEAD are used to retrieve data from entries.
20.8.3.3.1. GET /{cacheName}/{cacheKey}
This will return the data found in the given cacheName, under the given key - as the body of the response. A Content-Type header will be present in the response according to the Media Type negotiation. Browsers can use the cache directly of course (eg as a CDN). An ETag will be returned unique for each entry, as will the Last-Modified and Expires headers field indicating the state of the data at the given URL. ETags allow browsers (and other clients) to ask for data only in the case where it has changed (to save on bandwidth) - this is standard HTTP and is honoured by Red Hat Data Grid.
Headers
- Key-Content-Type: OPTIONAL The content type for the Key present in the URL. When omitted, application/x-java-object; type=java.lang.String is assumed
- Accept: OPTIONAL The required format to return the content
It is possible to obtain additional information by appending the "extended" parameter on the query string, as follows:
GET /cacheName/cacheKey?extended
This will return the following custom headers:
- Cluster-Primary-Owner: the node name of the primary owner for this key
- Cluster-Node-Name: the JGroups node name of the server that has handled the request
- Cluster-Physical-Address: the physical JGroups address of the server that has handled the request.
20.8.3.3.2. HEAD /{cacheName}/{cacheKey}
The same as GET, only no content is returned (only the header fields). You will receive the same content that you stored. E.g., if you stored a String, this is what you get back. If you stored some XML or JSON, this is what you will receive. If you stored a binary (base 64 encoded) blob, perhaps a serialized; Java; object - you will need to; deserialize this yourself.
Similarly to the GET method, the HEAD method also supports returning extended information via headers. See above.
Headers
- Key-Content-Type: OPTIONAL The content type for the Key present in the URL. When omitted, application/x-java-object; type=java.lang.String is assumed
20.8.3.4. Listing keys
20.8.3.4.1. GET /{cacheName}
This will return a list of keys present in the given cacheName as the body of the response. The format of the response can be controlled via the Accept header as follows:
- application/xml - the list of keys will be returned in XML format.
- application/json - the list of keys will be return in JSON format.
- text/plain - the list of keys will be returned in plain text format, one key per line
If the cache identified by cacheName is distributed, only the keys owned by the node handling the request will be returned. To return all keys, append the "global" parameter to the query, as follows:
GET /cacheName?global
20.8.3.5. Removing data
Data can be removed at the cache key/element level, or via a whole cache name using the HTTP delete method.
20.8.3.5.1. DELETE /{cacheName}/{cacheKey}
Removes the given key name from the cache.
Headers
- Key-Content-Type: OPTIONAL The content type for the Key present in the URL. When omitted, application/x-java-object; type=java.lang.String is assumed
20.8.3.5.2. DELETE /{cacheName}
Removes ALL the entries in the given cache name (i.e., everything from that path down). If the operation is successful, it returns 200 code.
Set the header performAsync to true to return immediately and let the removal happen in the background.
20.8.3.6. Querying
The REST server supports Ickle Queries in JSON format. It’s important that the cache is configured with application/x-protostream for both Keys and Values. If the cache is indexed, no configuration is needed.
20.8.3.6.1. GET /{cacheName}?action=search&query={ickle query}
Will execute an Ickle query in the given cache name.
Request parameters
- query: REQUIRED the query string
- max_results: OPTIONAL the number of results to return, default is 10
- offset: OPTIONAL the index of the first result to return, default is 0
- query_mode: OPTIONAL the execution mode of the query once it’s received by server. Valid values are FETCH and BROADCAST. Default is FETCH.
Query Result
Results are JSON documents containing one or more hits. Example:
{
"total_results" : 150,
"hits" : [ {
"hit" : {
"name" : "user1",
"age" : 35
}
}, {
"hit" : {
"name" : "user2",
"age" : 42
}
}, {
"hit" : {
"name" : "user3",
"age" : 12
}
} ]
}- total_results: NUMBER, the total number of results from the query.
- hits: ARRAY, list of matches from the query
- hit: OBJECT, each result from the query. Can contain all fields or just a subset of fields in case a Select clause is used.
20.8.3.6.2. POST /{cacheName}?action=search
Similar to que query using GET, but the body of the request is used instead to specify the query parameters.
Example:
{
"query":"from Entity where name:\"user1\"",
"max_results":20,
"offset":10
}20.8.4. CORS
The REST server supports CORS including preflight and rules based on the request origin.
Example:
<rest-connector name="rest1" socket-binding="rest" cache-container="default">
<cors-rules>
<cors-rule name="restrict host1" allow-credentials="false">
<allowed-origins>http://host1,https://host1</allowed-origins>
<allowed-methods>GET</allowed-methods>
</cors-rule>
<cors-rule name="allow ALL" allow-credentials="true" max-age-seconds="2000">
<allowed-origins>*</allowed-origins>
<allowed-methods>GET,OPTIONS,POST,PUT,DELETE</allowed-methods>
<allowed-headers>Key-Content-Type</allowed-headers>
</cors-rule>
</cors-rules>
</rest-connector>The rules are evaluated sequentially based on the "Origin" header set by the browser; in the example above if the origin is either "http://host1" or "https://host1" the rule "restrict host1" will apply, otherwise the next rule will be tested. Since the rule "allow ALL" permits all origins, any script coming from a different origin will be able to perform the methods specified and use the headers supplied.
The <cors-rule> element can be configured as follows:
| Config | Description | Mandatory |
|---|---|---|
| name | The name of the rule | yes |
| allow-credentials | Enable CORS requests to use credentials | no |
| allowed-origins | A comma separated list used to set the CORS 'Access-Control-Allow-Origin' header to indicate the response can be shared with the origins | yes |
| allowed-methods | A comma separated list used to set the CORS 'Access-Control-Allow-Methods' header in the preflight response to specify the methods allowed for the configured origin(s) | yes |
| max-age-seconds | The amount of time CORS preflight request headers can be cached | no |
| expose-headers | A comma separated list used to set the CORS 'Access-Control-Expose-Headers' in the preflight response to specify which headers can be exposed to the configured origin(s) | no |
20.8.5. Client side code
Part of the point of a RESTful service is that you don’t need to have tightly coupled client libraries/bindings. All you need is a HTTP client library. For Java, Apache HTTP Commons Client works just fine (and is used in the integration tests), or you can use java.net API.
20.8.5.1. Ruby example
# Shows how to interact with the REST api from ruby.
# No special libraries, just standard net/http
#
# Author: Michael Neale
#
require 'net/http'
uri = URI.parse('http://localhost:8080/rest/default/MyKey')
http = Net::HTTP.new(uri.host, uri.port)
#Create new entry
post = Net::HTTP::Post.new(uri.path, {"Content-Type" => "text/plain"})
post.basic_auth('user','pass')
post.body = "DATA HERE"
resp = http.request(post)
puts "POST response code : " + resp.code
#get it back
get = Net::HTTP::Get.new(uri.path)
get.basic_auth('user','pass')
resp = http.request(get)
puts "GET response code: " + resp.code
puts "GET Body: " + resp.body
#use PUT to overwrite
put = Net::HTTP::Put.new(uri.path, {"Content-Type" => "text/plain"})
put.basic_auth('user','pass')
put.body = "ANOTHER DATA HERE"
resp = http.request(put)
puts "PUT response code : " + resp.code
#and remove...
delete = Net::HTTP::Delete.new(uri.path)
delete.basic_auth('user','pass')
resp = http.request(delete)
puts "DELETE response code : " + resp.code
#Create binary data like this... just the same...
uri = URI.parse('http://localhost:8080/rest/default/MyLogo')
put = Net::HTTP::Put.new(uri.path, {"Content-Type" => "application/octet-stream"})
put.basic_auth('user','pass')
put.body = File.read('./logo.png')
resp = http.request(put)
puts "PUT response code : " + resp.code
#and if you want to do json...
require 'rubygems'
require 'json'
#now for fun, lets do some JSON !
uri = URI.parse('http://localhost:8080/rest/jsonCache/user')
put = Net::HTTP::Put.new(uri.path, {"Content-Type" => "application/json"})
put.basic_auth('user','pass')
data = {:name => "michael", :age => 42 }
put.body = data.to_json
resp = http.request(put)
puts "PUT response code : " + resp.code
get = Net::HTTP::Get.new(uri.path)
get.basic_auth('user','pass')
resp = http.request(get)
puts "GET Body: " + resp.body20.8.5.2. Python 3 example
import urllib.request
# Setup basic auth
base_uri = 'http://localhost:8080/rest/default'
auth_handler = urllib.request.HTTPBasicAuthHandler()
auth_handler.add_password(user='user', passwd='pass', realm='ApplicationRealm', uri=base_uri)
opener = urllib.request.build_opener(auth_handler)
urllib.request.install_opener(opener)
# putting data in
data = "SOME DATA HERE \!"
req = urllib.request.Request(url=base_uri + '/Key', data=data.encode("UTF-8"), method='PUT',
headers={"Content-Type": "text/plain"})
with urllib.request.urlopen(req) as f:
pass
print(f.status)
print(f.reason)
# getting data out
resp = urllib.request.urlopen(base_uri + '/Key')
print(resp.read().decode('utf-8'))20.8.5.3. Java example
package org.infinispan;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.Base64;
/**
* Rest example accessing a cache.
*
* @author Samuel Tauil (samuel@redhat.com)
*/
public class RestExample {
/**
* Method that puts a String value in cache.
*
* @param urlServerAddress URL containing the cache and the key to insert
* @param value Text to insert
* @param user Used for basic auth
* @param password Used for basic auth
*/
public void putMethod(String urlServerAddress, String value, String user, String password) throws IOException {
System.out.println("----------------------------------------");
System.out.println("Executing PUT");
System.out.println("----------------------------------------");
URL address = new URL(urlServerAddress);
System.out.println("executing request " + urlServerAddress);
HttpURLConnection connection = (HttpURLConnection) address.openConnection();
System.out.println("Executing put method of value: " + value);
connection.setRequestMethod("PUT");
connection.setRequestProperty("Content-Type", "text/plain");
addAuthorization(connection, user, password);
connection.setDoOutput(true);
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(connection.getOutputStream());
outputStreamWriter.write(value);
connection.connect();
outputStreamWriter.flush();
System.out.println("----------------------------------------");
System.out.println(connection.getResponseCode() + " " + connection.getResponseMessage());
System.out.println("----------------------------------------");
connection.disconnect();
}
/**
* Method that gets a value by a key in url as param value.
*
* @param urlServerAddress URL containing the cache and the key to read
* @param user Used for basic auth
* @param password Used for basic auth
* @return String value
*/
public String getMethod(String urlServerAddress, String user, String password) throws IOException {
String line;
StringBuilder stringBuilder = new StringBuilder();
System.out.println("----------------------------------------");
System.out.println("Executing GET");
System.out.println("----------------------------------------");
URL address = new URL(urlServerAddress);
System.out.println("executing request " + urlServerAddress);
HttpURLConnection connection = (HttpURLConnection) address.openConnection();
connection.setRequestMethod("GET");
connection.setRequestProperty("Content-Type", "text/plain");
addAuthorization(connection, user, password);
connection.setDoOutput(true);
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(connection.getInputStream()));
connection.connect();
while ((line = bufferedReader.readLine()) != null) {
stringBuilder.append(line).append('\n');
}
System.out.println("Executing get method of value: " + stringBuilder.toString());
System.out.println("----------------------------------------");
System.out.println(connection.getResponseCode() + " " + connection.getResponseMessage());
System.out.println("----------------------------------------");
connection.disconnect();
return stringBuilder.toString();
}
private void addAuthorization(HttpURLConnection connection, String user, String pass) {
String credentials = user + ":" + pass;
String basic = Base64.getEncoder().encodeToString(credentials.getBytes());
connection.setRequestProperty("Authorization", "Basic " + basic);
}
/**
* Main method example.
*/
public static void main(String[] args) throws IOException {
RestExample restExample = new RestExample();
String user = "user";
String pass = "pass";
restExample.putMethod("http://localhost:8080/rest/default/1", "Infinispan REST Test", user, pass);
restExample.getMethod("http://localhost:8080/rest/default/1", user, pass);
}
}20.9. Memcached Server
The Red Hat Data Grid Server distribution contains a server module that implements the Memcached text protocol. This allows Memcached clients to talk to one or several Red Hat Data Grid backed Memcached servers. These servers could either be working standalone just like Memcached does where each server acts independently and does not communicate with the rest, or they could be clustered where servers replicate or distribute their contents to other Red Hat Data Grid backed Memcached servers, thus providing clients with failover capabilities. Please refer to Red Hat Data Grid Server’s memcached server guide for instructions on how to configure and run a Memcached server.
20.9.1. Client Encoding
The memcached text protocol assumes data values read and written by clients are raw bytes. The support for type negotiation will come with the memcached binary protocol implementation, as part of ISPN-8726.
Although it’s not possible for a memcached client to negotiate the data type to obtain data from the server or send data in different formats, the server can optionally be configured to handle values encoded with a certain Media Type. By setting the client-encoding attribute in the memcached-connector element, the server will return content in this configured format, and clients also send data in this format.
The client-encoding is useful when a single cache is accessed from multiple remote endpoints (Rest, HotRod, Memcached) and it allows to tailor the responses/requests to memcached text clients. For more infomarmation on interoperability between endpoints, consult Endpoint Interop guide.
20.9.2. Command Clarifications
20.9.2.1. Flush All
Even in a clustered environment, flush_all command leads to the clearing of the Red Hat Data Grid Memcached server where the call lands. There’s no attempt to propagate this flush to other nodes in the cluster. This is done so that flush_all with delay use case can be reproduced with the Red Hat Data Grid Memcached server. The aim of passing a delay to flush_all is so that different Memcached servers in a full can be flushed at different times, and hence avoid overloading the database with requests as a result of all Memcached servers being empty. For more info, check the Memcached text protocol section on flush_all .
20.9.3. Unsupported Features
This section explains those parts of the memcached text protocol that for one reason or the other, are not currently supported by the Red Hat Data Grid based memcached implementation.
20.9.3.1. Individual Stats
Due to difference in nature between the original memcached implementation which is C/C\\ based and the Red Hat Data Grid implementation which is Java based, there’re some general purpose stats that are not supported. For these unsupported stats, Red Hat Data Grid memcached server always returns 0.
Unsupported statistics
- pid
- pointer_size
- rusage_user
- rusage_system
- bytes
- curr_connections
- total_connections
- connection_structures
- auth_cmds
- auth_errors
- limit_maxbytes
- threads
- conn_yields
- reclaimed
20.9.3.2. Statistic Settings
The settings statistics section of the text protocol has not been implemented due to its volatility.
20.9.3.3. Settings with Arguments Parameter
Since the arguments that can be send to the Memcached server are not documented, Red Hat Data Grid Memcached server does not support passing any arguments to stats command. If any parameters are passed, the Red Hat Data Grid Memcached server will respond with a CLIENT_ERROR .
20.9.3.4. Delete Hold Time Parameter
Memcached does no longer honor the optional hold time parameter to delete command and so the Red Hat Data Grid based memcached server does not implement such feature either.
20.9.3.5. Verbosity Command
Verbosity command is not supported since Red Hat Data Grid logging cannot be simplified to defining the logging level alone.
20.9.4. Talking To Red Hat Data Grid Memcached Servers From Non-Java Clients
This section shows how to talk to Red Hat Data Grid memcached server via non-java client, such as a python script.
20.9.4.1. Multi Clustered Server Tutorial
The example showcases the distribution capabilities of Red Hat Data Grid memcached severs that are not available in the original memcached implementation.
Start two clustered nodes: This configuration is the same one used for the GUI demo:
$ ./bin/standalone.sh -c clustered.xml -Djboss.node.name=nodeA $ ./bin/standalone.sh -c clustered.xml -Djboss.node.name=nodeB -Djboss.socket.binding.port-offset=100
Alternatively use
$ ./bin/domain.sh
Which automatically starts two nodes.
Execute test_memcached_write.py script which basically executes several write operations against the Red Hat Data Grid memcached server bound to port 11211. If the script is executed successfully, you should see an output similar to this:
Connecting to 127.0.0.1:11211 Testing set ['Simple_Key': Simple value] ... OK Testing set ['Expiring_Key' : 999 : 3] ... OK Testing increment 3 times ['Incr_Key' : starting at 1 ] Initialise at 1 ... OK Increment by one ... OK Increment again ... OK Increment yet again ... OK Testing decrement 1 time ['Decr_Key' : starting at 4 ] Initialise at 4 ... OK Decrement by one ... OK Testing decrement 2 times in one call ['Multi_Decr_Key' : 3 ] Initialise at 3 ... OK Decrement by 2 ... OK
- Execute test_memcached_read.py script which connects to server bound to 127.0.0.1:11311 and verifies that it can read the data that was written by the writer script to the first server. If the script is executed successfully, you should see an output similar to this:
Connecting to 127.0.0.1:11311 Testing get ['Simple_Key'] should return Simple value ... OK Testing get ['Expiring_Key'] should return nothing... OK Testing get ['Incr_Key'] should return 4 ... OK Testing get ['Decr_Key'] should return 3 ... OK Testing get ['Multi_Decr_Key'] should return 1 ... OK
20.10. Executing code in the Remote Grid
In an earlier section we described executing code in the grid. Unfortunately these methods are designed to be used in an embedded scenario with direct access to the grid. This section will detail how you can perform similar functions but while using a remote client connected to the grid.
20.11. Scripting
Scripting is a feature of Red Hat Data Grid Server which allows invoking server-side scripts from remote clients. Scripting leverages the JDK’s javax.script ScriptEngines, therefore allowing the use of any JVM languages which offer one. By default, the JDK comes with Nashorn, a ScriptEngine capable of running JavaScript.
20.11.1. Installing scripts
Scripts are stored in a special script cache, named '___script_cache'. Adding a script is therefore as simple as put+ting it into the cache itself. If the name of the script contains a filename extension, e.g. +myscript.js, then that extension determines the engine that will be used to execute it. Alternatively the script engine can be selected using script metadata (see below). Be aware that, when security is enabled, access to the script cache via the remote protocols requires that the user belongs to the '___script_manager' role.
20.11.2. Script metadata
Script metadata is additional information about the script that the user can provide to the server to affect how a script is executed. It is contained in a specially-formatted comment on the first lines of the script.
Properties are specified as key=value pairs, separated by commas. You can use several different comment styles: The //, ;;, # depending on the scripting language you use. You can split metadata over multiple lines if necessary, and you can use single (') or double (") quotes to delimit your values.
The following are examples of valid metadata comments:
// name=test, language=javascript // mode=local, parameters=[a,b,c]
20.11.2.1. Metadata properties
The following metadata property keys are available
mode: defines the mode of execution of a script. Can be one of the following values:
- local: the script will be executed only by the node handling the request. The script itself however can invoke clustered operations
- distributed: runs the script using the Distributed Executor Service
- language: defines the script engine that will be used to execute the script, e.g. Javascript
- extension: an alternative method of specifying the script engine that will be used to execute the script, e.g. js
- role: a specific role which is required to execute the script
- parameters: an array of valid parameter names for this script. Invocations which specify parameter names not included in this list will cause an exception.
-
datatype: optional property providing information, in the form of Media Types (also known as MIME) about the type of the data stored in the caches, as well as parameter and return values. Currently it only accepts a single value which is
text/plain; charset=utf-8, indicating that data is String UTF-8 format. This metadata parameter is designed for remote clients that only support a particular type of data, making it easy for them to retrieve, store and work with parameters.
Since the execution mode is a characteristic of the script, nothing special needs to be done on the client to invoke scripts in different modes.
20.11.3. Script bindings
The script engine within Red Hat Data Grid exposes several internal objects as bindings in the scope of the script execution. These are:
- cache: the cache against which the script is being executed
- marshaller: the marshaller to use for marshalling/unmarshalling data to the cache
- cacheManager: the cacheManager for the cache
- scriptingManager: the instance of the script manager which is being used to run the script. This can be used to run other scripts from a script.
20.11.4. Script parameters
Aside from the standard bindings described above, when a script is executed it can be passed a set of named parameters which also appear as bindings. Parameters are passed as name,value pairs where name is a string and value can be any value that is understood by the marshaller in use.
The following is an example of a JavaScript script which takes two parameters, multiplicand and multiplier and multiplies them. Because the last operation is an expression evaluation, its result is returned to the invoker.
// mode=local,language=javascript multiplicand * multiplier
To store the script in the script cache, use the following Hot Rod code:
RemoteCache<String, String> scriptCache = cacheManager.getCache("___script_cache");
scriptCache.put("multiplication.js",
"// mode=local,language=javascript\n" +
"multiplicand * multiplier\n");20.11.5. Running Scripts using the Hot Rod Java client
The following example shows how to invoke the above script by passing two named parameters.
RemoteCache<String, Integer> cache = cacheManager.getCache();
// Create the parameters for script execution
Map<String, Object> params = new HashMap<>();
params.put("multiplicand", 10);
params.put("multiplier", 20);
// Run the script on the server, passing in the parameters
Object result = cache.execute("multiplication.js", params);20.11.6. Distributed execution
The following is a script which runs on all nodes. Each node will return its address, and the results from all nodes will be collected in a List and returned to the client.
// mode:distributed,language=javascript cacheManager.getAddress().toString();
20.12. Server Tasks
Server tasks are server-side scripts defined in Java language. To develop a server task, you should define a class that extends org.infinispan.tasks.ServerTask interface, defined in infinispan-tasks-api module.
A typical server task implementation would implement these methods:
-
setTaskContextallows server tasks implementors to access execution context information. This includes task parameters, cache reference on which the task is executed…etc. Normally, implementors would store this information locally and use it when the task is actually executed. -
getNameshould return a unique name for the task. The client will use this name to to invoke the task. -
getExecutionModeis used to decide whether to invoke the task in 1 node in a cluster of N nodes or invoke it in N nodes. For example, server tasks that invoke stream processing are only required to be executed in 1 node in the cluster. This is because stream processing itself makes sure processing is distributed to all nodes in cluster. -
callis the method that’s invoked when the user invokes the server task.
Here’s an example of a hello greet task that takes as parameter the name of the person to greet.
package example;
import org.infinispan.tasks.ServerTask;
import org.infinispan.tasks.TaskContext;
public class HelloTask implements ServerTask<String> {
private TaskContext ctx;
@Override
public void setTaskContext(TaskContext ctx) {
this.ctx = ctx;
}
@Override
public String call() throws Exception {
String name = (String) ctx.getParameters().get().get("name");
return "Hello " + name;
}
@Override
public String getName() {
return "hello-task";
}
}Once the task has been implemented, it needs to be wrapped inside a jar. The jar is then deployed to the Red Hat Data Grid Server and from them on it can be invoked. The Red Hat Data Grid Server uses service loader pattern to load the task, so implementations need to adhere to these requirements. For example, server task implementations must have a zero-argument constructor.
Moreover, the jar must contain a META-INF/services/org.infinispan.tasks.ServerTask file containing the fully qualified name(s) of the server tasks included in the jar. For example:
example.HelloTask
With jar packaged, the next step is to push the jar to the Red Hat Data Grid Server. The server is powered by WildFly Application Server, so if using Maven Wildfly’s Maven plugin can be used for this:
<plugin> <groupId>org.wildfly.plugins</groupId> <artifactId>wildfly-maven-plugin</artifactId> <version>1.2.0.Final</version> </plugin>
Then call the following from command line:
$ mvn package wildfly:deploy
Alternative ways of deployment jar files to Wildfly Application Server are explained here.
Executing the task can be done using the following code:
// Create a configuration for a locally-running server
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.addServer().host("127.0.0.1").port(11222);
// Connect to the server
RemoteCacheManager cacheManager = new RemoteCacheManager(builder.build());
// Obtain the remote cache
RemoteCache<String, String> cache = cacheManager.getCache();
// Create task parameters
Map<String, String> parameters = new HashMap<>();
parameters.put("name", "developer");
// Execute task
String greet = cache.execute("hello-task", parameters);
System.out.println(greet);