
Chapter 2. Considerations and recommendations
As a storage administrator, a basic understanding about what to consider before running a Ceph Object Gateway and implementing a multi-site Ceph Object Gateway solution is important. You can learn the hardware and network requirements, knowing what type of workloads work well with a Ceph Object Gateway, and Red Hat’s recommendations.
2.1. Prerequisites
- Time to understand, consider, and plan a storage solution.
2.2. Network considerations for Red Hat Ceph Storage
An important aspect of a cloud storage solution is that storage clusters can run out of IOPS due to network latency, and other factors. Also, the storage cluster can run out of throughput due to bandwidth constraints long before the storage clusters run out of storage capacity. This means that the network hardware configuration must support the chosen workloads to meet price versus performance requirements.
Storage administrators prefer that a storage cluster recovers as quickly as possible. Carefully consider bandwidth requirements for the storage cluster network, be mindful of network link oversubscription, and segregate the intra-cluster traffic from the client-to-cluster traffic. Also consider that network performance is increasingly important when considering the use of Solid State Disks (SSD), flash, NVMe, and other high performing storage devices.
Ceph supports a public network and a storage cluster network. The public network handles client traffic and communication with Ceph Monitors. The storage cluster network handles Ceph OSD heartbeats, replication, backfilling, and recovery traffic. At a minimum, a single 10 Gb/s Ethernet link should be used for storage hardware, and you can add additional 10 Gb/s Ethernet links for connectivity and throughput.
Red Hat recommends allocating bandwidth to the storage cluster network, such that it is a multiple of the public network using the osd_pool_default_size as the basis for the multiple on replicated pools. Red Hat also recommends running the public and storage cluster networks on separate network cards.
Red Hat recommends using 10 Gb/s Ethernet for Red Hat Ceph Storage deployments in production. A 1 Gb/s Ethernet network is not suitable for production storage clusters.
In the case of a drive failure, replicating 1 TB of data across a 1 Gb/s network takes 3 hours and replicating 10 TB across a 1 Gb/s network takes 30 hours. Using 10 TB is the typical drive configuration. By contrast, with a 10 Gb/s Ethernet network, the replication times would be 20 minutes for 1 TB and 1 hour for 10 TB. Remember that when a Ceph OSD fails, the storage cluster recovers by replicating the data it contained to other OSDs within the same failure domain and device class as the failed OSD.
The failure of a larger domain such as a rack means that the storage cluster utilizes considerably more bandwidth. When building a storage cluster consisting of multiple racks, which is common for large storage implementations, consider utilizing as much network bandwidth between switches in a "fat tree" design for optimal performance. A typical 10 Gb/s Ethernet switch has 48 10 Gb/s ports and four 40 Gb/s ports. Use the 40 Gb/s ports on the spine for maximum throughput. Alternatively, consider aggregating unused 10 Gb/s ports with QSFP+ and SFP+ cables into more 40 Gb/s ports to connect to other rack and spine routers. Also, consider using LACP mode 4 to bond network interfaces. Additionally, use jumbo frames, with a maximum transmission unit (MTU) of 9000, especially on the backend or cluster network.
Before installing and testing a Red Hat Ceph Storage cluster, verify the network throughput. Most performance-related problems in Ceph usually begin with a networking issue. Simple network issues like a kinked or bent Cat-6 cable could result in degraded bandwidth. Use a minimum of 10 Gb/s ethernet for the front side network. For large clusters, consider using 40 Gb/s ethernet for the backend or cluster network.
For network optimization, Red Hat recommends using jumbo frames for a better CPU per bandwidth ratio, and a non-blocking network switch back-plane. Red Hat Ceph Storage requires the same MTU value throughout all networking devices in the communication path, end-to-end for both public and cluster networks. Verify that the MTU value is the same on all hosts and networking equipment in the environment before using a Red Hat Ceph Storage cluster in production.
Additional Resources
- See the Configuring a private network section in the Red Hat Ceph Storage Configuration Guide for more details.
- See the Configuring a public network section in the Red Hat Ceph Storage Configuration Guide for more details.
- See the Configuring multiple public networks to the cluster section in the Red Hat Ceph Storage Configuration Guide for more details.
2.3. Basic Red Hat Ceph Storage considerations
The first consideration for using Red Hat Ceph Storage is developing a storage strategy for the data. A storage strategy is a method of storing data that serves a particular use case. If you need to store volumes and images for a cloud platform like OpenStack, you can choose to store data on faster Serial Attached SCSI (SAS) drives with Solid State Drives (SSD) for journals. By contrast, if you need to store object data for an S3- or Swift-compliant gateway, you can choose to use something more economical, like traditional Serial Advanced Technology Attachment (SATA) drives. Red Hat Ceph Storage can accommodate both scenarios in the same storage cluster, but you need a means of providing the fast storage strategy to the cloud platform, and a means of providing more traditional storage for your object store.
One of the most important steps in a successful Ceph deployment is identifying a price-to-performance profile suitable for the storage cluster’s use case and workload. It is important to choose the right hardware for the use case. For example, choosing IOPS-optimized hardware for a cold storage application increases hardware costs unnecessarily. Whereas, choosing capacity-optimized hardware for its more attractive price point in an IOPS-intensive workload will likely lead to unhappy users complaining about slow performance.
Red Hat Ceph Storage can support multiple storage strategies. Use cases, cost versus benefit performance tradeoffs, and data durability are the primary considerations that help develop a sound storage strategy.
Use Cases
Ceph provides massive storage capacity, and it supports numerous use cases, such as:
- The Ceph Block Device client is a leading storage backend for cloud platforms that provides limitless storage for volumes and images with high performance features like copy-on-write cloning.
- The Ceph Object Gateway client is a leading storage backend for cloud platforms that provides a RESTful S3-compliant and Swift-compliant object storage for objects like audio, bitmap, video, and other data.
- The Ceph File System for traditional file storage.
Cost vs. Benefit of Performance
Faster is better. Bigger is better. High durability is better. However, there is a price for each superlative quality, and a corresponding cost versus benefit tradeoff. Consider the following use cases from a performance perspective: SSDs can provide very fast storage for relatively small amounts of data and journaling. Storing a database or object index can benefit from a pool of very fast SSDs, but proves too expensive for other data. SAS drives with SSD journaling provide fast performance at an economical price for volumes and images. SATA drives without SSD journaling provide cheap storage with lower overall performance. When you create a CRUSH hierarchy of OSDs, you need to consider the use case and an acceptable cost versus performance tradeoff.
Data Durability
In large scale storage clusters, hardware failure is an expectation, not an exception. However, data loss and service interruption remain unacceptable. For this reason, data durability is very important. Ceph addresses data durability with multiple replica copies of an object or with erasure coding and multiple coding chunks. Multiple copies or multiple coding chunks present an additional cost versus benefit tradeoff: it is cheaper to store fewer copies or coding chunks, but it can lead to the inability to service write requests in a degraded state. Generally, one object with two additional copies, or two coding chunks can allow a storage cluster to service writes in a degraded state while the storage cluster recovers.
Replication stores one or more redundant copies of the data across failure domains in case of a hardware failure. However, redundant copies of data can become expensive at scale. For example, to store 1 petabyte of data with triple replication would require a cluster with at least 3 petabytes of storage capacity.
Erasure coding stores data as data chunks and coding chunks. In the event of a lost data chunk, erasure coding can recover the lost data chunk with the remaining data chunks and coding chunks. Erasure coding is substantially more economical than replication. For example, using erasure coding with 8 data chunks and 3 coding chunks provides the same redundancy as 3 copies of the data. However, such an encoding scheme uses approximately 1.5x the initial data stored compared to 3x with replication.
The CRUSH algorithm aids this process by ensuring that Ceph stores additional copies or coding chunks in different locations within the storage cluster. This ensures that the failure of a single storage device or host does not lead to a loss of all of the copies or coding chunks necessary to preclude data loss. You can plan a storage strategy with cost versus benefit tradeoffs, and data durability in mind, then present it to a Ceph client as a storage pool.
ONLY the data storage pool can use erasure coding. Pools storing service data and bucket indexes use replication.
Ceph’s object copies or coding chunks make RAID solutions obsolete. Do not use RAID, because Ceph already handles data durability, a degraded RAID has a negative impact on performance, and recovering data using RAID is substantially slower than using deep copies or erasure coding chunks.
Additional Resources
- See the Minimum hardware considerations for Red Hat Ceph Storage section of the Red Hat Ceph Storage Installation Guide for more details.
2.3.1. Colocating Ceph daemons and its advantages
You can colocate containerized Ceph daemons on the same host. Here are the advantages of colocating some of Ceph’s daemons:
- Significantly improves the total cost of ownership (TCO) at small scale.
- Can increase overall performance.
- Reduces the amount of physical hosts for a minimum configuration.
- Better resource utilization.
- Upgrading Red Hat Ceph Storage is easier.
By using containers you can colocate one daemon from the following list with a Ceph OSD daemon (ceph-osd). Additionally, for the Ceph Object Gateway (radosgw), Ceph Metadata Server (ceph-mds), and Grafana, you can colocate it either with a Ceph OSD daemon, plus a daemon from the list below.
-
Ceph Metadata Server (
ceph-mds) -
Ceph Monitor (
ceph-mon) -
Ceph Manager (
ceph-mgr) -
NFS Ganesha (
nfs-ganesha) -
Ceph Manager (
ceph-grafana)
Table 2.1. Daemon Placement Example
| Host Name | Daemon | Daemon | Daemon |
|---|---|---|---|
| host1 | OSD | Monitor & Manager | Prometheus |
| host2 | OSD | Monitor & Manager | RGW |
| host3 | OSD | Monitor & Manager | RGW |
| host4 | OSD | Metadata Server | |
| host5 | OSD | Metadata Server |
Because ceph-mon and ceph-mgr work closely together, they are not considered two separate daemons for the purposes of colocation.
Colocating Ceph daemons can be done from the command line interface, by using the --placement option to the ceph orch command, or you can use a service specification YAML file.
Command line Example
[ceph: root@host01 /]# ceph orch apply mon --placement="host1 host2 host3"
Service Specification YAML File Example
service_type: mon placement: hosts: - host01 - host02 - host03
[ceph: root@host01 /]# ceph orch apply -i mon.yml
Red Hat recommends colocating the Ceph Object Gateway with Ceph OSD containers to increase performance. To achieve the highest performance without incurring additional hardware cost, use two Ceph Object Gateway daemons per host.
Ceph Object Gateway Command line Example
[ceph: root@host01 /]# ceph orch apply rgw example --placement="6 host1 host2 host3"
Ceph Object Gateway Service Specification YAML File Example
service_type: rgw service_id: example placement: count: 6 hosts: - host01 - host02 - host03
[ceph: root@host01 /]# ceph orch apply -i rgw.yml
The diagrams below shows the difference between storage clusters with colocated and non-colocated daemons.
Figure 2.1. Colocated Daemons
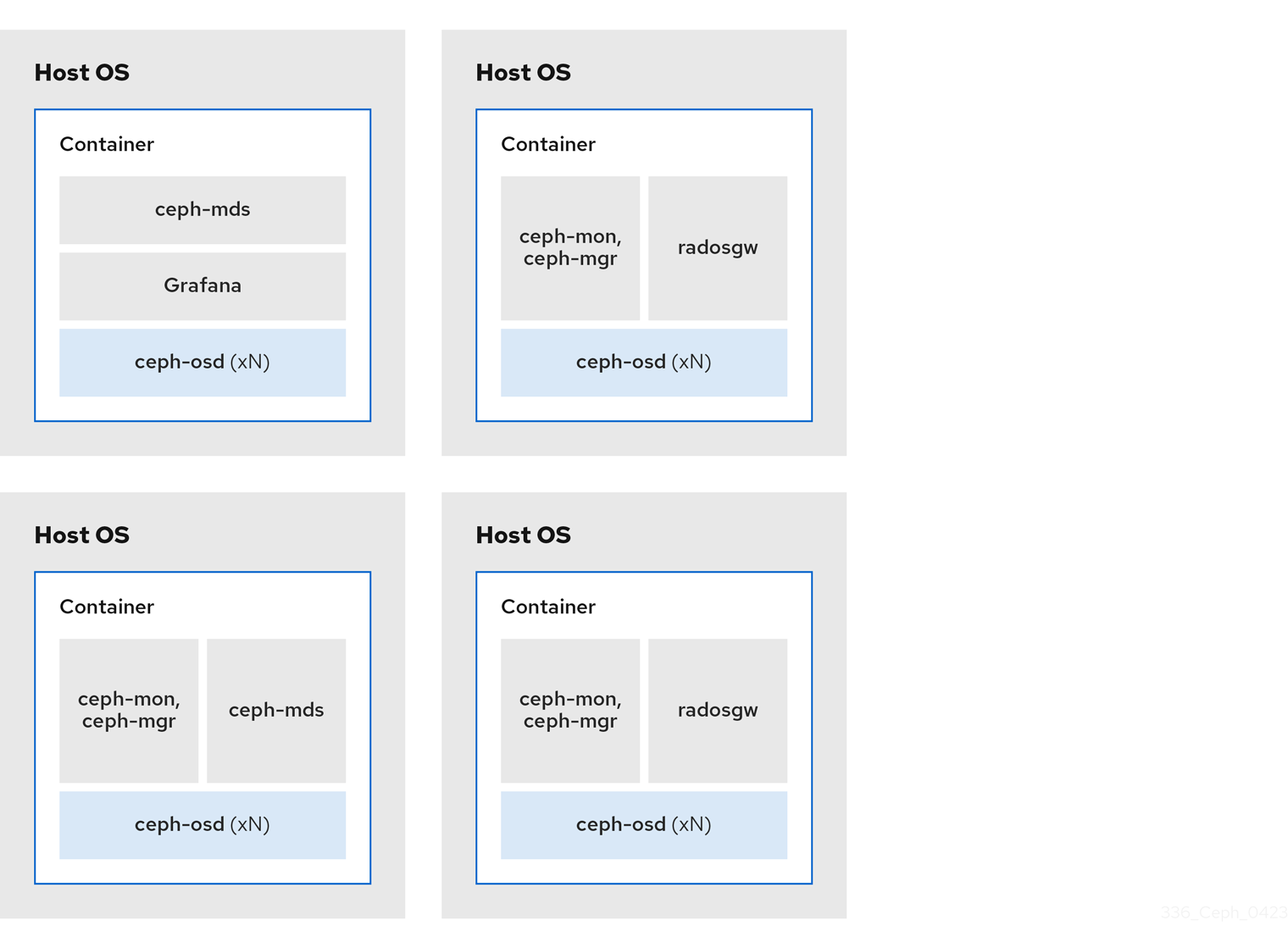
Figure 2.2. Non-colocated Daemons

Additional resources
-
See the Management of services using the Ceph Orchestrator chapter in the Red Hat Ceph Storage Operations Guide for more details on using the
--placementoption. - See the Red Hat Ceph Storage RGW deployment strategies and sizing guidance article for more information.
2.4. Red Hat Ceph Storage workload considerations
One of the key benefits of a Ceph storage cluster is the ability to support different types of workloads within the same storage cluster using performance domains. Different hardware configurations can be associated with each performance domain. Storage administrators can deploy storage pools on the appropriate performance domain, providing applications with storage tailored to specific performance and cost profiles. Selecting appropriately sized and optimized servers for these performance domains is an essential aspect of designing a Red Hat Ceph Storage cluster.
To the Ceph client interface that reads and writes data, a Ceph storage cluster appears as a simple pool where the client stores data. However, the storage cluster performs many complex operations in a manner that is completely transparent to the client interface. Ceph clients and Ceph object storage daemons, referred to as Ceph OSDs, or simply OSDs, both use the Controlled Replication Under Scalable Hashing (CRUSH) algorithm for the storage and retrieval of objects. Ceph OSDs can run in containers within the storage cluster.
A CRUSH map describes a topography of cluster resources, and the map exists both on client hosts as well as Ceph Monitor hosts within the cluster. Ceph clients and Ceph OSDs both use the CRUSH map and the CRUSH algorithm. Ceph clients communicate directly with OSDs, eliminating a centralized object lookup and a potential performance bottleneck. With awareness of the CRUSH map and communication with their peers, OSDs can handle replication, backfilling, and recovery—allowing for dynamic failure recovery.
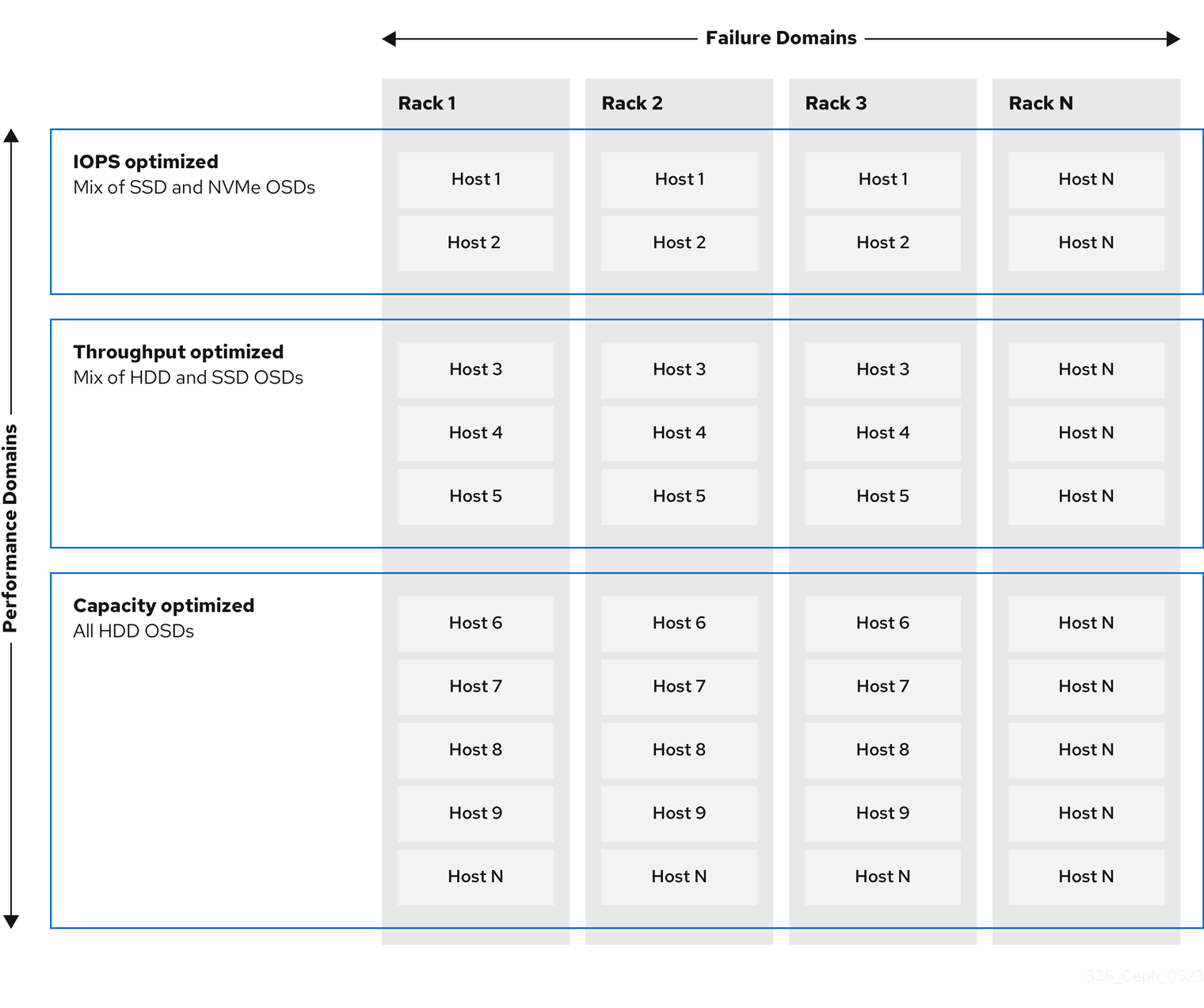
Ceph uses the CRUSH map to implement failure domains. Ceph also uses the CRUSH map to implement performance domains, which simply take the performance profile of the underlying hardware into consideration. The CRUSH map describes how Ceph stores data, and it is implemented as a simple hierarchy, specifically an acyclic graph, and a ruleset. The CRUSH map can support multiple hierarchies to separate one type of hardware performance profile from another. Ceph implements performance domains with device "classes".
For example, you can have these performance domains coexisting in the same Red Hat Ceph Storage cluster:
- Hard disk drives (HDDs) are typically appropriate for cost and capacity-focused workloads.
- Throughput-sensitive workloads typically use HDDs with Ceph write journals on solid state drives (SSDs).
- IOPS-intensive workloads, such as MySQL and MariaDB, often use SSDs.
Figure 2.3. Performance and Failure Domains
Workloads
Red Hat Ceph Storage is optimized for three primary workloads.
Carefully consider the workload being run by Red Hat Ceph Storage clusters BEFORE considering what hardware to purchase, because it can significantly impact the price and performance of the storage cluster. For example, if the workload is capacity-optimized and the hardware is better suited to a throughput-optimized workload, then hardware will be more expensive than necessary. Conversely, if the workload is throughput-optimized and the hardware is better suited to a capacity-optimized workload, then the storage cluster can suffer from poor performance.
IOPS optimized: Input, output per second (IOPS) optimization deployments are suitable for cloud computing operations, such as running MYSQL or MariaDB instances as virtual machines on OpenStack. IOPS optimized deployments require higher performance storage such as 15k RPM SAS drives and separate SSD journals to handle frequent write operations. Some high IOPS scenarios use all flash storage to improve IOPS and total throughput.
An IOPS-optimized storage cluster has the following properties:
- Lowest cost per IOPS.
- Highest IOPS per GB.
- 99th percentile latency consistency.
Uses for an IOPS-optimized storage cluster are:
- Typically block storage.
- 3x replication for hard disk drives (HDDs) or 2x replication for solid state drives (SSDs).
- MySQL on OpenStack clouds.
Throughput optimized: Throughput-optimized deployments are suitable for serving up significant amounts of data, such as graphic, audio, and video content. Throughput-optimized deployments require high bandwidth networking hardware, controllers, and hard disk drives with fast sequential read and write characteristics. If fast data access is a requirement, then use a throughput-optimized storage strategy. Also, if fast write performance is a requirement, using Solid State Disks (SSD) for journals will substantially improve write performance.
A throughput-optimized storage cluster has the following properties:
- Lowest cost per MBps (throughput).
- Highest MBps per TB.
- Highest MBps per BTU.
- Highest MBps per Watt.
- 97th percentile latency consistency.
Uses for a throughput-optimized storage cluster are:
- Block or object storage.
- 3x replication.
- Active performance storage for video, audio, and images.
- Streaming media, such as 4k video.
Capacity optimized: Capacity-optimized deployments are suitable for storing significant amounts of data as inexpensively as possible. Capacity-optimized deployments typically trade performance for a more attractive price point. For example, capacity-optimized deployments often use slower and less expensive SATA drives and co-locate journals rather than using SSDs for journaling.
A cost and capacity-optimized storage cluster has the following properties:
- Lowest cost per TB.
- Lowest BTU per TB.
- Lowest Watts required per TB.
Uses for a cost and capacity-optimized storage cluster are:
- Typically object storage.
- Erasure coding for maximizing usable capacity
- Object archive.
- Video, audio, and image object repositories.
2.5. Ceph Object Gateway considerations
Another important aspect of designing a storage cluster is to determine if the storage cluster will be in one data center site or span multiple data center sites. Multi-site storage clusters benefit from geographically distributed failover and disaster recovery, such as long-term power outages, earthquakes, hurricanes, floods or other disasters. Additionally, multi-site storage clusters can have an active-active configuration, which can direct client applications to the closest available storage cluster. This is a good storage strategy for content delivery networks. Consider placing data as close to the client as possible. This is important for throughput-intensive workloads, such as streaming 4k video.
Red Hat recommends identifying realm, zone group and zone names BEFORE creating Ceph’s storage pools. Prepend some pool names with the zone name as a standard naming convention.
Additional Resources
- See the Multi-site configuration and administration section in the Red Hat Ceph Storage Object Gateway Guide for more information.
2.5.1. Administrative data storage
A Ceph Object Gateway stores administrative data in a series of pools defined in an instance’s zone configuration. For example, the buckets, users, user quotas, and usage statistics discussed in the subsequent sections are stored in pools in the Ceph storage cluster. By default, Ceph Object Gateway creates the following pools and maps them to the default zone.
-
.rgw.root -
.default.rgw.control -
.default.rgw.meta -
.default.rgw.log -
.default.rgw.buckets.index -
.default.rgw.buckets.data -
.default.rgw.buckets.non-ec
The .default.rgw.buckets.index pool is created only after the bucket is created in Ceph Object Gateway, while the .default.rgw.buckets.data pool is created after the data is uploaded to the bucket.
Consider creating these pools manually so you can set the CRUSH ruleset and the number of placement groups. In a typical configuration, the pools that store the Ceph Object Gateway’s administrative data will often use the same CRUSH ruleset, and use fewer placement groups, because there are 10 pools for the administrative data.
Red Hat recommends that the .rgw.root pool and the service pools use the same CRUSH hierarchy, and use at least node as the failure domain in the CRUSH rule. Red Hat recommends using replicated for data durability, and NOT erasure for the .rgw.root pool, and the service pools.
The mon_pg_warn_max_per_osd setting warns you if you assign too many placement groups to a pool, 300 by default. You may adjust the value to suit your needs and the capabilities of your hardware where n is the maximum number of PGs per OSD.
mon_pg_warn_max_per_osd = n
For service pools, including .rgw.root, the suggested PG count from the Ceph placement groups (PGs) per pool calculator is substantially less than the target PGs per Ceph OSD. Also, ensure the number of Ceph OSDs is set in step 4 of the calculator.
Garbage collection uses the .log pool with regular RADOS objects instead of OMAP. In future releases, more features will store metadata on the .log pool. Therefore, Red Hat recommends using NVMe/SSD Ceph OSDs for the .log pool.
.rgw.root Pool
The pool where the Ceph Object Gateway configuration is stored. This includes realms, zone groups, and zones. By convention, its name is not prepended with the zone name.
Service Pools
The service pools store objects related to service control, garbage collection, logging, user information, and usage. By convention, these pool names have the zone name prepended to the pool name.
-
.ZONE_NAME.rgw.control: The control pool. -
.ZONE_NAME.log: The log pool contains logs of all bucket, container, and object actions, such as create, read, update, and delete. -
.ZONE_NAME.rgw.buckets.index: This pool stores index of the buckets. -
.ZONE_NAME.rgw.buckets.data: This pool stores data of the buckets. -
.ZONE_NAME.rgw.meta: The metadata pool stores user_keys and other critical metadata. -
.ZONE_NAME.meta:users.uid: The user ID pool contains a map of unique user IDs. -
.ZONE_NAME.meta:users.keys: The keys pool contains access keys and secret keys for each user ID. -
.ZONE_NAME.meta:users.email: The email pool contains email addresses associated to a user ID. -
.ZONE_NAME.meta:users.swift: The Swift pool contains the Swift subuser information for a user ID.
Additional Resources
- See the About pools section in the Red Hat Ceph Storage Object Gateway Guide for more details.
- See the Red Hat Ceph Storage Storage Strategies Guide for additional details.
2.5.2. Index pool
When selecting OSD hardware for use with a Ceph Object Gateway--irrespective of the use case--an OSD node that has at least one high performance drive, either an SSD or NVMe drive, is required for storing the index pool. This is particularly important when buckets contain a large number of objects.
For Red Hat Ceph Storage running Bluestore, Red Hat recommends deploying an NVMe drive as a block.db device, rather than as a separate pool.
Ceph Object Gateway index data is written only into an object map (OMAP). OMAP data for BlueStore resides on the block.db device on an OSD. When an NVMe drive functions as a block.db device for an HDD OSD and when the index pool is backed by HDD OSDs, the index data will ONLY be written to the block.db device. As long as the block.db partition/lvm is sized properly at 4% of block, this configuration is all that is needed for BlueStore.
Red Hat does not support HDD devices for index pools. For more information on supported configurations, see the Red Hat Ceph Storage: Supported configurations article.
An index entry is approximately 200 bytes of data, stored as an OMAP in rocksdb. While this is a trivial amount of data, some uses of Ceph Object Gateway can result in tens or hundreds of millions of objects in a single bucket. By mapping the index pool to a CRUSH hierarchy of high performance storage media, the reduced latency provides a dramatic performance improvement when buckets contain very large numbers of objects.
In a production cluster, a typical OSD node will have at least one SSD or NVMe drive for storing the OSD journal and the index pool or block.db device, which use separate partitions or logical volumes for the same physical drive.
2.5.3. Data pool
The data pool is where the Ceph Object Gateway stores the object data for a particular storage policy. The data pool has a full complement of placement groups (PGs), not the reduced number of PGs for service pools. Consider using erasure coding for the data pool, as it is substantially more efficient than replication, and can significantly reduce the capacity requirements while maintaining data durability.
To use erasure coding, create an erasure code profile. See the Erasure Code Profiles section in the Red Hat Ceph Storage Storage Strategies Guide for more details.
Choosing the correct profile is important because you cannot change the profile after you create the pool. To modify a profile, you must create a new pool with a different profile and migrate the objects from the old pool to the new pool.
The default configuration is two data chunks (k) and two encoding chunks (m), which means only one OSD can be lost. For higher resiliency, consider a larger number of data and encoding chunks. For example, some large scale systems use 8 data chunks and 3 encoding chunks, which allows 3 OSDs to fail without losing data.
Each data and encoding chunk SHOULD get stored on a different node or host at a minimum. For smaller storage clusters, this makes using rack impractical as the minimum CRUSH failure domain for a larger number of data and encoding chunks. Consequently, it is common for the data pool to use a separate CRUSH hierarchy with host as the minimum CRUSH failure domain. Red Hat recommends host as the minimum failure domain. If erasure code chunks get stored on Ceph OSDs within the same host, a host failure, such as a failed journal or network card, could lead to data loss.
To create a data pool, run the ceph osd pool create command with the pool name, the number of PGs and PGPs, the erasure data durability method, the erasure code profile, and the name of the rule.
2.5.4. Data extra pool
The data_extra_pool is for data that cannot use erasure coding. For example, multi-part uploads allow uploading a large object, such as a movie in multiple parts. These parts must first be stored without erasure coding. Erasure coding applies to the whole object, not the partial uploads.
The placement group (PG) per Pool Calculator recommends a smaller number of PGs per pool for the data_extra_pool; however, the PG count is approximately twice the number of PGs as the service pools and the same as the bucket index pool.
To create a data extra pool, run the ceph osd pool create command with the pool name, the number of PGs and PGPs, the replicated data durability method, and the name of the rule. For example:
# ceph osd pool create .us-west.rgw.buckets.non-ec 64 64 replicated rgw-service
2.6. Developing CRUSH hierarchies
As a storage administrator, when deploying a Ceph storage cluster and an Object Gateway, typically the Ceph Object Gateway has a default zone group and zone. The Ceph storage cluster will have default pools, which in turn will use a CRUSH map with a default CRUSH hierarchy and a default CRUSH rule.
The default rbd pool can use the default CRUSH rule. DO NOT delete the default rule or hierarchy if Ceph clients have used them to store client data.
Production gateways typically use a custom realm, zone group and zone named according to the use and geographic location of the gateways. Additionally, the Ceph storage cluster will have a CRUSH map that has multiple CRUSH hierarchies.
-
Service Pools: At least one CRUSH hierarchy will be for service pools and potentially for data. The service pools include
.rgw.rootand the service pools associated with the zone. Service pools typically fall under a single CRUSH hierarchy, and use replication for data durability. A data pool may also use the CRUSH hierarchy, but the pool will usually be configured with erasure coding for data durability. - Index: At least one CRUSH hierarchy SHOULD be for the index pool, where the CRUSH hierarchy maps to high performance media, such as SSD or NVMe drives. Bucket indices can be a performance bottleneck. Red Hat recommends to use SSD or NVMe drives in this CRUSH hierarchy. Create partitions for indices on SSDs or NVMe drives used for Ceph OSD journals. Additionally, an index should be configured with bucket sharding.
- Placement Pools: The placement pools for each placement target include the bucket index, the data bucket, and the bucket extras. These pools can fall under separate CRUSH hierarchies. Since the Ceph Object Gateway can support multiple storage policies, the bucket pools of the storage policies may be associated with different CRUSH hierarchies, reflecting different use cases, such as IOPS-optimized, throughput-optimized, and capacity-optimized. The bucket index pool SHOULD use its own CRUSH hierarchy to map the bucket index pool to higher performance storage media, such as SSD or NVMe drives.
2.6.1. Creating CRUSH roots
From the command line on the administration node, create CRUSH roots in the CRUSH map for each CRUSH hierarchy. There MUST be at least one CRUSH hierarchy for service pools that may also potentially serve data storage pools. There SHOULD be at least one CRUSH hierarchy for the bucket index pool, mapped to high performance storage media, such as SSDs or NVMe drives.
For details on CRUSH hierarchies, see the CRUSH Hierarchies section in the Red Hat Ceph Storage Storage Strategies Guide 5.
To manually edit a CRUSH map, see the Editing a CRUSH Map section in the Red Hat Ceph Storage Storage Strategies Guide 5.
In the following examples, the hosts named data0, data1, and data2 use extended logical names, such as data0-sas-ssd, data0-index, and so forth in the CRUSH map, because there are multiple CRUSH hierarchies pointing to the same physical hosts.
A typical CRUSH root might represent nodes with SAS drives and SSDs for journals. For example:
##
# SAS-SSD ROOT DECLARATION
##
root sas-ssd {
id -1 # do not change unnecessarily
# weight 0.000
alg straw
hash 0 # rjenkins1
item data2-sas-ssd weight 4.000
item data1-sas-ssd weight 4.000
item data0-sas-ssd weight 4.000
}A CRUSH root for bucket indexes SHOULD represent high performance media, such as SSD or NVMe drives. Consider creating partitions on SSD or NVMe media that store OSD journals. For example:
##
# INDEX ROOT DECLARATION
##
root index {
id -2 # do not change unnecessarily
# weight 0.000
alg straw
hash 0 # rjenkins1
item data2-index weight 1.000
item data1-index weight 1.000
item data0-index weight 1.000
}2.6.2. Creating CRUSH rules
Like the default CRUSH hierarchy, the CRUSH map also contains a default CRUSH rule.
The default rbd pool may use this rule. DO NOT delete the default rule if other pools have used it to store customer data.
For general details on CRUSH rules, see the CRUSH rules section in the Red Hat Ceph Storage Storage Strategies Guide for Red Hat Ceph Storage 5. To manually edit a CRUSH map, see the Editing a CRUSH map section in the Red Hat Ceph Storage Storage Strategies Guide for Red Hat Ceph Storage 5.
For each CRUSH hierarchy, create a CRUSH rule. The following example illustrates a rule for the CRUSH hierarchy that will store the service pools, including .rgw.root. In this example, the root sas-ssd serves as the main CRUSH hierarchy. It uses the name rgw-service to distinguish itself from the default rule. The step take sas-ssd line tells the pool to use the sas-ssd root created in Creating CRUSH roots, whose child buckets contain OSDs with SAS drives and high performance storage media, such as SSD or NVMe drives, for journals in a high throughput hardware configuration. The type rack portion of step chooseleaf is the failure domain. In the following example, it is a rack.
##
# SERVICE RULE DECLARATION
##
rule rgw-service {
type replicated
min_size 1
max_size 10
step take sas-ssd
step chooseleaf firstn 0 type rack
step emit
}In the foregoing example, if data gets replicated three times, there should be at least three racks in the cluster containing a similar number of OSD nodes.
The type replicated setting has NOTHING to do with data durability, the number of replicas, or the erasure coding. Only replicated is supported.
The following example illustrates a rule for the CRUSH hierarchy that will store the data pool. In this example, the root sas-ssd serves as the main CRUSH hierarchy—the same CRUSH hierarchy as the service rule. It uses rgw-throughput to distinguish itself from the default rule and rgw-service. The step take sas-ssd line tells the pool to use the sas-ssd root created in Creating CRUSH roots, whose child buckets contain OSDs with SAS drives and high performance storage media, such as SSD or NVMe drives, in a high throughput hardware configuration. The type host portion of step chooseleaf is the failure domain. In the following example, it is a host. Notice that the rule uses the same CRUSH hierarchy, but a different failure domain.
##
# THROUGHPUT RULE DECLARATION
##
rule rgw-throughput {
type replicated
min_size 1
max_size 10
step take sas-ssd
step chooseleaf firstn 0 type host
step emit
}
In the foregoing example, if the pool uses erasure coding with a larger number of data and encoding chunks than the default, there should be at least as many racks in the cluster containing a similar number of OSD nodes to facilitate the erasure coding chunks. For smaller clusters, this may not be practical, so the foregoing example uses host as the CRUSH failure domain.
The following example illustrates a rule for the CRUSH hierarchy that will store the index pool. In this example, the root index serves as the main CRUSH hierarchy. It uses rgw-index to distinguish itself from rgw-service and rgw-throughput. The step take index line tells the pool to use the index root created in Creating CRUSH roots, whose child buckets contain high performance storage media, such as SSD or NVMe drives, or partitions on SSD or NVMe drives that also store OSD journals. The type rack portion of step chooseleaf is the failure domain. In the following example, it is a rack.
##
# INDEX RULE DECLARATION
##
rule rgw-index {
type replicated
min_size 1
max_size 10
step take index
step chooseleaf firstn 0 type rack
step emit
}2.6.3. Additional Resources
- For general details on CRUSH hierarchies, see the CRUSH Administration section of the Red Hat Ceph Storage Storage Strategies Guide.
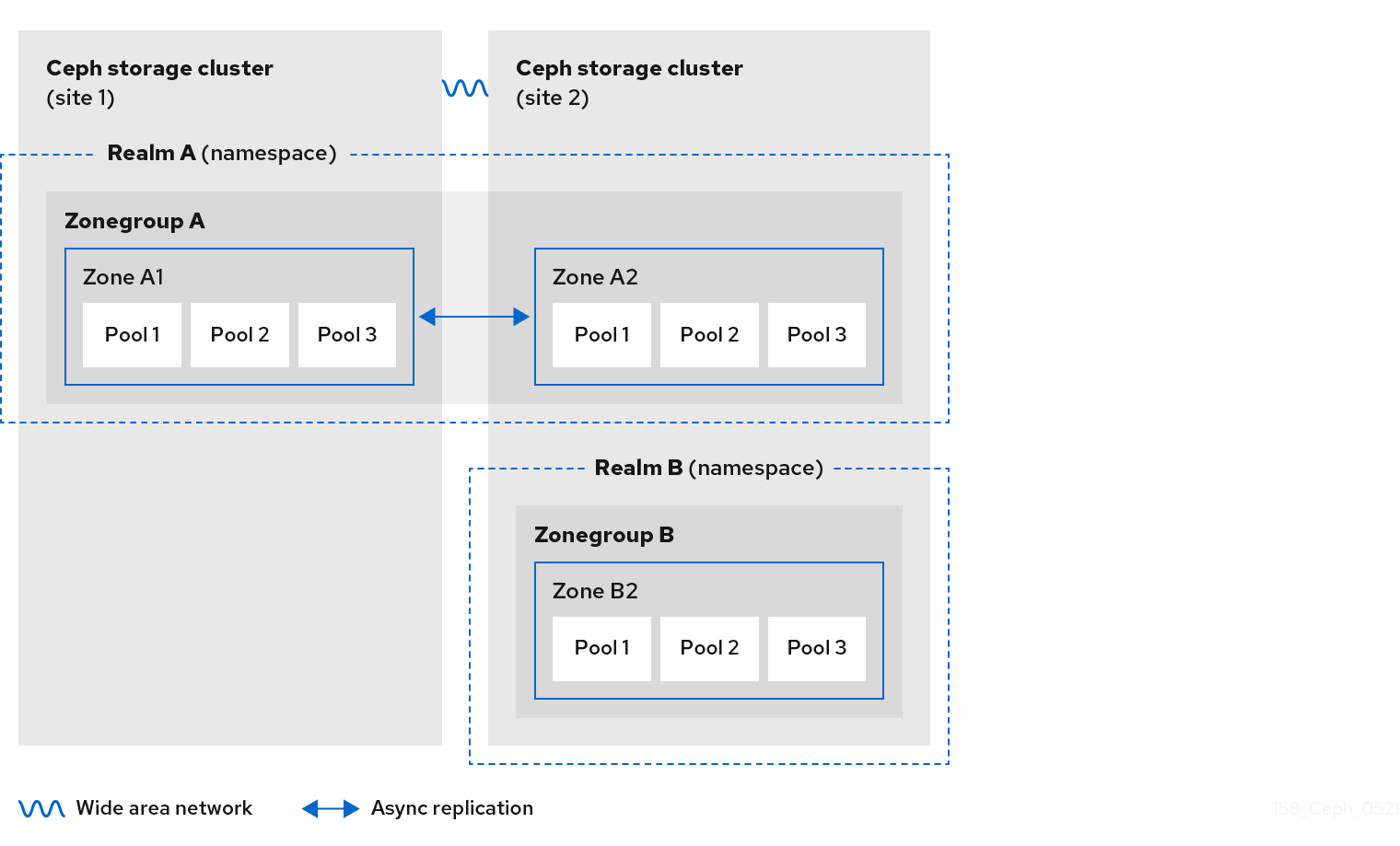
2.7. Ceph Object Gateway multi-site considerations
A Ceph Object Gateway multi-site configuration requires at least two Red Hat Ceph Storage clusters, and at least two Ceph Object Gateway instances, one for each Red Hat Ceph Storage cluster. Typically, the two Red Hat Ceph Storage clusters will be in geographically separate locations; however, this same multi-site configuration can work on two Red Hat Ceph Storage clusters located at the same physical site.
Multi-site configurations require a primary zone group and a primary zone. Additionally, each zone group requires a primary zone. Zone groups might have one or more secondary zones.
The primary zone within the primary zone group of a realm is responsible for storing the primary copy of the realm’s metadata, including users, quotas, and buckets. This metadata gets synchronized to secondary zones and secondary zone groups automatically. Metadata operations issued with the radosgw-admin command line interface (CLI) MUST be issued on a node within the primary zone of the primary zone group to ensure that they synchronize to the secondary zone groups and zones. Currently, it is possible to issue metadata operations on secondary zones and zone groups, but it is NOT recommended because they WILL NOT be synchronized, which can lead to fragmentation of the metadata.
The diagrams below illustrate the possible one, and two realm configurations in multi-site Ceph Object Gateway environments.
Figure 2.4. One Realm
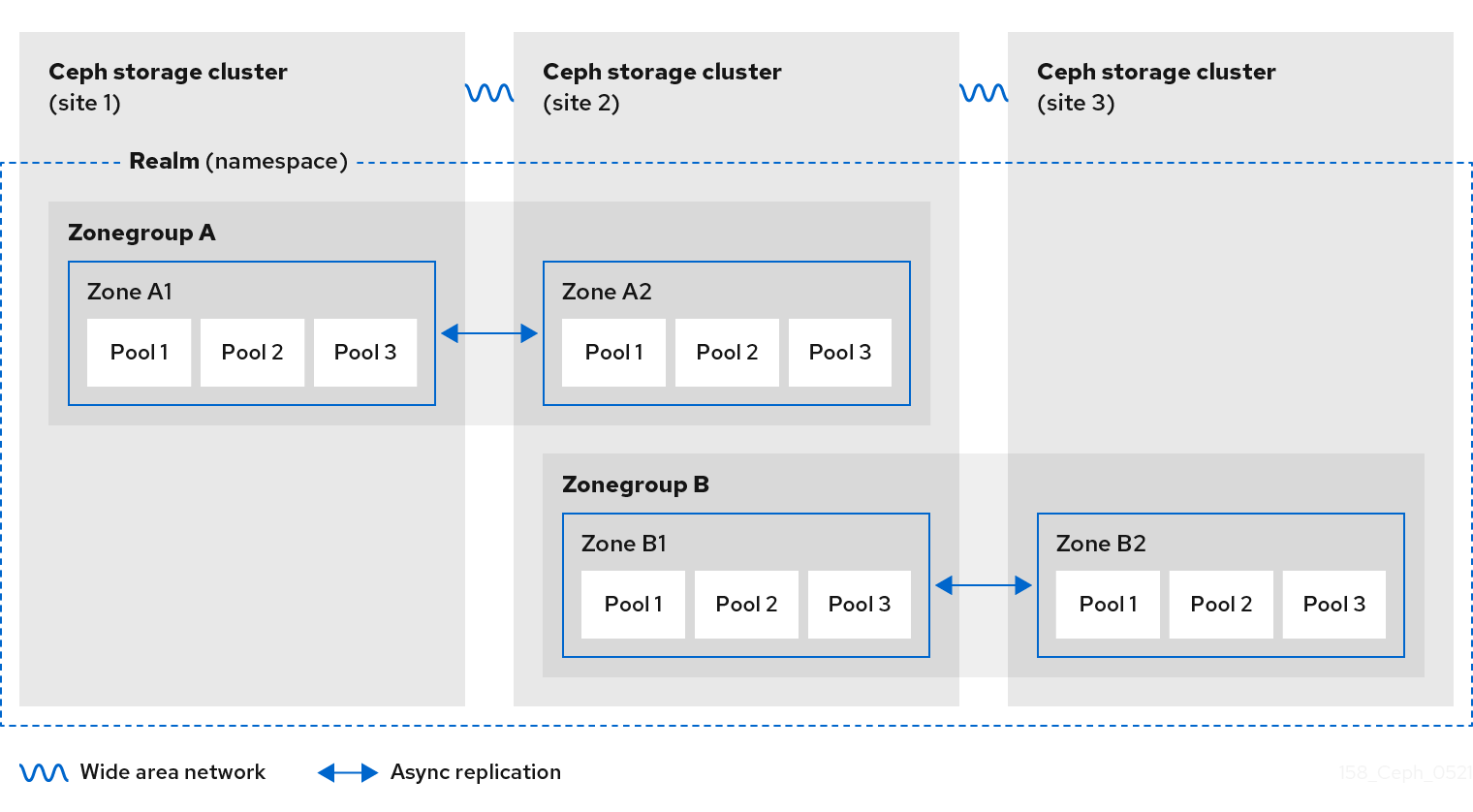
Figure 2.5. Two Realms
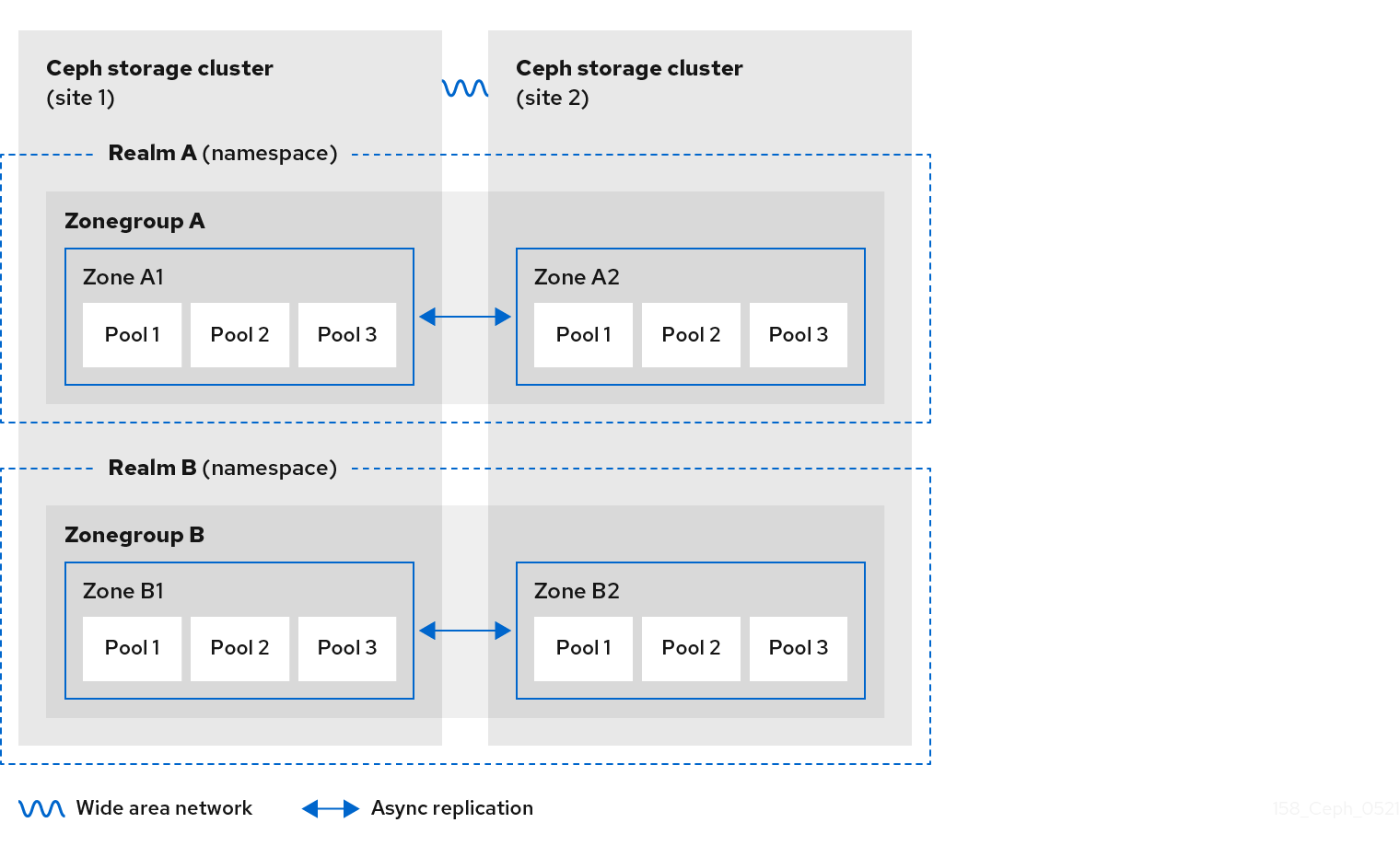
Figure 2.6. Two Realms Variant
2.8. Considering storage sizing
One of the most important factors in designing a cluster is to determine the storage requirements (sizing). Ceph Storage is designed to scale into petabytes and beyond. The following examples are common sizes for Ceph storage clusters.
- Small: 250 terabytes
- Medium: 1 petabyte
- Large: 2 petabytes or more
Sizing includes current needs and near future needs. Consider the rate at which the gateway client will add new data to the cluster. That can differ from use-case to use-case. For example, recording 4k videos or storing medical images can add significant amounts of data faster than less storage-intensive information, such as financial market data. Additionally, consider that the data durability methods, such as replication versus erasure coding, can have a significant impact on the storage media required.
For additional information on sizing, see the Red Hat Ceph Storage Hardware Guide and its associated links for selecting OSD hardware.
2.9. Considering storage density
Another important aspect of Ceph’s design, includes storage density. Generally, a storage cluster stores data across at least 10 nodes to ensure reasonable performance when replicating, backfilling, and recovery. If a node fails, with at least 10 nodes in the storage cluster, only 10% of the data has to move to the surviving nodes. If the number of nodes is substantially less, a higher percentage of the data must move to the surviving nodes. Additionally, the full_ratio and near_full_ratio options need to be set to accommodate a node failure to ensure that the storage cluster can write data. For this reason, it is important to consider storage density. Higher storage density is not necessarily a good idea.
Another factor that favors more nodes over higher storage density is erasure coding. When writing an object using erasure coding and using node as the minimum CRUSH failure domain, the Ceph storage cluster will need as many nodes as data and coding chunks. For example, a cluster using k=8, m=3 should have at least 11 nodes so that each data or coding chunk is stored on a separate node.
Hot-swapping is also an important consideration. Most modern servers support drive hot-swapping. However, some hardware configurations require removing more than one drive to replace a drive. Red Hat recommends avoiding such configurations, because they can bring down more Ceph OSDs than required when swapping out failed disks.
2.10. Considering disks for the Ceph Monitor nodes
Ceph Monitors use rocksdb, which is sensitive to synchronous write latency. Red Hat strongly recommends using SSD disks to store the Ceph Monitor data. Choose SSD disks that have sufficient sequential write and throughput characteristics.
2.11. Adjusting backfill and recovery settings
I/O is negatively impacted by both backfilling and recovery operations, leading to poor performance and unhappy end users. To help accommodate I/O demand during a cluster expansion or recovery, set the following options and values in the Ceph Configuration file:
[osd] osd_max_backfills = 1 osd_recovery_max_active = 1 osd_recovery_op_priority = 1
2.12. Adjusting the cluster map size
By default, the ceph-osd daemon caches 500 previous osdmaps. Even with deduplication, the map might consume a lot of memory per daemon. Tuning the cache size in the Ceph configuration might help reduce memory consumption significantly. For example:
[ceph: root@host01 /]# ceph config set global osd_map_message_max 10 [ceph: root@host01 /]# ceph config set osd osd_map_cache_size 20 [ceph: root@host01 /]# ceph config set osd osd_map_share_max_epochs 10 [ceph: root@host01 /]# ceph config set osd osd_pg_epoch_persisted_max_stale 10
For Red Hat Ceph Storage version 3 and later, the ceph-manager daemon handles PG queries, so the cluster map should not impact performance.
2.13. Adjusting scrubbing
By default, Ceph performs light scrubbing daily and deep scrubbing weekly. Light scrubbing checks object sizes and checksums to ensure that PGs are storing the same object data. Over time, disk sectors can go bad irrespective of object sizes and checksums. Deep scrubbing checks an object’s content with that of its replicas to ensure that the actual contents are the same. In this respect, deep scrubbing ensures data integrity in the manner of fsck, but the procedure imposes an I/O penalty on the cluster. Even light scrubbing can impact I/O.
The default settings may allow Ceph OSDs to initiate scrubbing at inopportune times, such as peak operating times or periods with heavy loads. End users may experience latency and poor performance when scrubbing operations conflict with end user operations.
To prevent end users from experiencing poor performance, Ceph provides a number of scrubbing settings that can limit scrubbing to periods with lower loads or during off-peak hours. For details, see the Scrubbing the OSD section in the Red Hat Ceph Storage Configuration Guide.
If the cluster experiences high loads during the day and low loads late at night, consider restricting scrubbing to night time hours. For example:
[osd] osd_scrub_begin_hour = 23 #23:01H, or 10:01PM. osd_scrub_end_hour = 6 #06:01H or 6:01AM.
If time constraints aren’t an effective method of determining a scrubbing schedule, consider using the osd_scrub_load_threshold. The default value is 0.5, but it could be modified for low load conditions. For example:
[osd] osd_scrub_load_threshold = 0.25
2.14. Increase objecter_inflight_ops
To improve scalability, you can edit the value of the objecter_inflight_ops parameter, which specifies the maximum number of unsent I/O requests allowed. This parameter is used for client traffic control.
objecter_inflight_ops = 24576
2.15. Increase rgw_thread_pool_size
To improve scalability, you can edit the value of the rgw_thread_pool_size parameter, which is the size of the thread pool. The new beast frontend is not restricted by the thread pool size to accept new connections.
rgw_thread_pool_size = 512
2.16. Tuning considerations for the Linux kernel when running Ceph
Production Red Hat Ceph Storage clusters generally benefit from tuning the operating system, specifically around limits and memory allocation. Ensure that adjustments are set for all hosts within the storage cluster. You can also open a case with Red Hat support asking for additional guidance.
Increase the File Descriptors
The Ceph Object Gateway can hang if it runs out of file descriptors. You can modify the /etc/security/limits.conf file on Ceph Object Gateway hosts to increase the file descriptors for the Ceph Object Gateway.
ceph soft nofile unlimited
Adjusting the ulimit value for Large Storage Clusters
When running Ceph administrative commands on large storage clusters, for example, with 1024 Ceph OSDs or more, create an /etc/security/limits.d/50-ceph.conf file on each host that runs administrative commands with the following contents:
USER_NAME soft nproc unlimitedReplace USER_NAME with the name of the non-root user account that runs the Ceph administrative commands.
The root user’s ulimit value is already set to unlimited by default on Red Hat Enterprise Linux.
2.17. Additional Resources
- For more details about Ceph’s various internal components and the strategies around those components, see the Red Hat Ceph Storage Storage Strategies Guide.