
Chapter 2. Red Hat Ceph Storage considerations and recommendations
As a storage administrator, you can have a basic understanding about what things to consider before running a Red Hat Ceph Storage cluster. Understanding such things as, the hardware and network requirements, understanding what type of workloads work well with a Red Hat Ceph Storage cluster, along with Red Hat’s recommendations. Red Hat Ceph Storage can be used for different workloads based on a particular business need or set of requirements. Doing the necessary planning before installing a Red Hat Ceph Storage is critical to the success of running a Ceph storage cluster efficiently and achieving the business requirements.
Want help with planning a Red Hat Ceph Storage cluster for a specific use case? Contact your Red Hat representative for assistance.
2.1. Prerequisites
- Time to understand, consider, and plan a storage solution.
2.2. Basic Red Hat Ceph Storage considerations
The first consideration for using Red Hat Ceph Storage is developing a storage strategy for the data. A storage strategy is a method of storing data that serves a particular use case. If you need to store volumes and images for a cloud platform like OpenStack, you can choose to store data on faster Serial Attached SCSI (SAS) drives with Solid State Drives (SSD) for journals. By contrast, if you need to store object data for an S3- or Swift-compliant gateway, you can choose to use something more economical, like traditional Serial Advanced Technology Attachment (SATA) drives. Red Hat Ceph Storage can accommodate both scenarios in the same storage cluster, but you need a means of providing the fast storage strategy to the cloud platform, and a means of providing more traditional storage for your object store.
One of the most important steps in a successful Ceph deployment is identifying a price-to-performance profile suitable for the storage cluster’s use case and workload. It is important to choose the right hardware for the use case. For example, choosing IOPS-optimized hardware for a cold storage application increases hardware costs unnecessarily. Whereas, choosing capacity-optimized hardware for its more attractive price point in an IOPS-intensive workload will likely lead to unhappy users complaining about slow performance.
Red Hat Ceph Storage can support multiple storage strategies. Use cases, cost versus benefit performance tradeoffs, and data durability are the primary considerations that help develop a sound storage strategy.
Use Cases
Ceph provides massive storage capacity, and it supports numerous use cases, such as:
- The Ceph Block Device client is a leading storage backend for cloud platforms that provides limitless storage for volumes and images with high performance features like copy-on-write cloning.
- The Ceph Object Gateway client is a leading storage backend for cloud platforms that provides a RESTful S3-compliant and Swift-compliant object storage for objects like audio, bitmap, video, and other data.
- The Ceph File System for traditional file storage.
Cost vs. Benefit of Performance
Faster is better. Bigger is better. High durability is better. However, there is a price for each superlative quality, and a corresponding cost versus benefit tradeoff. Consider the following use cases from a performance perspective: SSDs can provide very fast storage for relatively small amounts of data and journaling. Storing a database or object index can benefit from a pool of very fast SSDs, but proves too expensive for other data. SAS drives with SSD journaling provide fast performance at an economical price for volumes and images. SATA drives without SSD journaling provide cheap storage with lower overall performance. When you create a CRUSH hierarchy of OSDs, you need to consider the use case and an acceptable cost versus performance tradeoff.
Data Durability
In large scale storage clusters, hardware failure is an expectation, not an exception. However, data loss and service interruption remain unacceptable. For this reason, data durability is very important. Ceph addresses data durability with multiple replica copies of an object or with erasure coding and multiple coding chunks. Multiple copies or multiple coding chunks present an additional cost versus benefit tradeoff: it is cheaper to store fewer copies or coding chunks, but it can lead to the inability to service write requests in a degraded state. Generally, one object with two additional copies, or two coding chunks can allow a storage cluster to service writes in a degraded state while the storage cluster recovers.
Replication stores one or more redundant copies of the data across failure domains in case of a hardware failure. However, redundant copies of data can become expensive at scale. For example, to store 1 petabyte of data with triple replication would require a cluster with at least 3 petabytes of storage capacity.
Erasure coding stores data as data chunks and coding chunks. In the event of a lost data chunk, erasure coding can recover the lost data chunk with the remaining data chunks and coding chunks. Erasure coding is substantially more economical than replication. For example, using erasure coding with 8 data chunks and 3 coding chunks provides the same redundancy as 3 copies of the data. However, such an encoding scheme uses approximately 1.5x the initial data stored compared to 3x with replication.
The CRUSH algorithm aids this process by ensuring that Ceph stores additional copies or coding chunks in different locations within the storage cluster. This ensures that the failure of a single storage device or host does not lead to a loss of all of the copies or coding chunks necessary to preclude data loss. You can plan a storage strategy with cost versus benefit tradeoffs, and data durability in mind, then present it to a Ceph client as a storage pool.
ONLY the data storage pool can use erasure coding. Pools storing service data and bucket indexes use replication.
Ceph’s object copies or coding chunks make RAID solutions obsolete. Do not use RAID, because Ceph already handles data durability, a degraded RAID has a negative impact on performance, and recovering data using RAID is substantially slower than using deep copies or erasure coding chunks.
Additional Resources
- See the Minimum hardware considerations for Red Hat Ceph Storage section of the Red Hat Ceph Storage Installation Guide for more details.
2.3. Red Hat Ceph Storage workload considerations
One of the key benefits of a Ceph storage cluster is the ability to support different types of workloads within the same storage cluster using performance domains. Different hardware configurations can be associated with each performance domain. Storage administrators can deploy storage pools on the appropriate performance domain, providing applications with storage tailored to specific performance and cost profiles. Selecting appropriately sized and optimized servers for these performance domains is an essential aspect of designing a Red Hat Ceph Storage cluster.
To the Ceph client interface that reads and writes data, a Ceph storage cluster appears as a simple pool where the client stores data. However, the storage cluster performs many complex operations in a manner that is completely transparent to the client interface. Ceph clients and Ceph object storage daemons, referred to as Ceph OSDs, or simply OSDs, both use the Controlled Replication Under Scalable Hashing (CRUSH) algorithm for the storage and retrieval of objects. Ceph OSDs can run in containers within the storage cluster.
A CRUSH map describes a topography of cluster resources, and the map exists both on client hosts as well as Ceph Monitor hosts within the cluster. Ceph clients and Ceph OSDs both use the CRUSH map and the CRUSH algorithm. Ceph clients communicate directly with OSDs, eliminating a centralized object lookup and a potential performance bottleneck. With awareness of the CRUSH map and communication with their peers, OSDs can handle replication, backfilling, and recovery—allowing for dynamic failure recovery.
Ceph uses the CRUSH map to implement failure domains. Ceph also uses the CRUSH map to implement performance domains, which simply take the performance profile of the underlying hardware into consideration. The CRUSH map describes how Ceph stores data, and it is implemented as a simple hierarchy, specifically an acyclic graph, and a ruleset. The CRUSH map can support multiple hierarchies to separate one type of hardware performance profile from another. Ceph implements performance domains with device "classes".
For example, you can have these performance domains coexisting in the same Red Hat Ceph Storage cluster:
- Hard disk drives (HDDs) are typically appropriate for cost and capacity-focused workloads.
- Throughput-sensitive workloads typically use HDDs with Ceph write journals on solid state drives (SSDs).
- IOPS-intensive workloads, such as MySQL and MariaDB, often use SSDs.
Figure 2.1. Performance and Failure Domains

Workloads
Red Hat Ceph Storage is optimized for three primary workloads.
Carefully consider the workload being run by Red Hat Ceph Storage clusters BEFORE considering what hardware to purchase, because it can significantly impact the price and performance of the storage cluster. For example, if the workload is capacity-optimized and the hardware is better suited to a throughput-optimized workload, then hardware will be more expensive than necessary. Conversely, if the workload is throughput-optimized and the hardware is better suited to a capacity-optimized workload, then the storage cluster can suffer from poor performance.
IOPS optimized: Input, output per second (IOPS) optimization deployments are suitable for cloud computing operations, such as running MYSQL or MariaDB instances as virtual machines on OpenStack. IOPS optimized deployments require higher performance storage such as 15k RPM SAS drives and separate SSD journals to handle frequent write operations. Some high IOPS scenarios use all flash storage to improve IOPS and total throughput.
An IOPS-optimized storage cluster has the following properties:
- Lowest cost per IOPS.
- Highest IOPS per GB.
- 99th percentile latency consistency.
Uses for an IOPS-optimized storage cluster are:
- Typically block storage.
- 3x replication for hard disk drives (HDDs) or 2x replication for solid state drives (SSDs).
- MySQL on OpenStack clouds.
Throughput optimized: Throughput-optimized deployments are suitable for serving up significant amounts of data, such as graphic, audio, and video content. Throughput-optimized deployments require high bandwidth networking hardware, controllers, and hard disk drives with fast sequential read and write characteristics. If fast data access is a requirement, then use a throughput-optimized storage strategy. Also, if fast write performance is a requirement, using Solid State Disks (SSD) for journals will substantially improve write performance.
A throughput-optimized storage cluster has the following properties:
- Lowest cost per MBps (throughput).
- Highest MBps per TB.
- Highest MBps per BTU.
- Highest MBps per Watt.
- 97th percentile latency consistency.
Uses for a throughput-optimized storage cluster are:
- Block or object storage.
- 3x replication.
- Active performance storage for video, audio, and images.
- Streaming media, such as 4k video.
Capacity optimized: Capacity-optimized deployments are suitable for storing significant amounts of data as inexpensively as possible. Capacity-optimized deployments typically trade performance for a more attractive price point. For example, capacity-optimized deployments often use slower and less expensive SATA drives and co-locate journals rather than using SSDs for journaling.
A cost and capacity-optimized storage cluster has the following properties:
- Lowest cost per TB.
- Lowest BTU per TB.
- Lowest Watts required per TB.
Uses for a cost and capacity-optimized storage cluster are:
- Typically object storage.
- Erasure coding for maximizing usable capacity
- Object archive.
- Video, audio, and image object repositories.
2.4. Network considerations for Red Hat Ceph Storage
An important aspect of a cloud storage solution is that storage clusters can run out of IOPS due to network latency, and other factors. Also, the storage cluster can run out of throughput due to bandwidth constraints long before the storage clusters run out of storage capacity. This means that the network hardware configuration must support the chosen workloads to meet price versus performance requirements.
Storage administrators prefer that a storage cluster recovers as quickly as possible. Carefully consider bandwidth requirements for the storage cluster network, be mindful of network link oversubscription, and segregate the intra-cluster traffic from the client-to-cluster traffic. Also consider that network performance is increasingly important when considering the use of Solid State Disks (SSD), flash, NVMe, and other high performing storage devices.
Ceph supports a public network and a storage cluster network. The public network handles client traffic and communication with Ceph Monitors. The storage cluster network handles Ceph OSD heartbeats, replication, backfilling, and recovery traffic. At a minimum, a single 10 Gb/s Ethernet link should be used for storage hardware, and you can add additional 10 Gb/s Ethernet links for connectivity and throughput.
Red Hat recommends allocating bandwidth to the storage cluster network, such that it is a multiple of the public network using the osd_pool_default_size as the basis for the multiple on replicated pools. Red Hat also recommends running the public and storage cluster networks on separate network cards.
Red Hat recommends using 10 Gb/s Ethernet for Red Hat Ceph Storage deployments in production. A 1 Gb/s Ethernet network is not suitable for production storage clusters.
In the case of a drive failure, replicating 1 TB of data across a 1 Gb/s network takes 3 hours and replicating 10 TB across a 1 Gb/s network takes 30 hours. Using 10 TB is the typical drive configuration. By contrast, with a 10 Gb/s Ethernet network, the replication times would be 20 minutes for 1 TB and 1 hour for 10 TB. Remember that when a Ceph OSD fails, the storage cluster recovers by replicating the data it contained to other OSDs within the same failure domain and device class as the failed OSD.
The failure of a larger domain such as a rack means that the storage cluster utilizes considerably more bandwidth. When building a storage cluster consisting of multiple racks, which is common for large storage implementations, consider utilizing as much network bandwidth between switches in a "fat tree" design for optimal performance. A typical 10 Gb/s Ethernet switch has 48 10 Gb/s ports and four 40 Gb/s ports. Use the 40 Gb/s ports on the spine for maximum throughput. Alternatively, consider aggregating unused 10 Gb/s ports with QSFP+ and SFP+ cables into more 40 Gb/s ports to connect to other rack and spine routers. Also, consider using LACP mode 4 to bond network interfaces. Additionally, use jumbo frames, with a maximum transmission unit (MTU) of 9000, especially on the backend or cluster network.
Before installing and testing a Red Hat Ceph Storage cluster, verify the network throughput. Most performance-related problems in Ceph usually begin with a networking issue. Simple network issues like a kinked or bent Cat-6 cable could result in degraded bandwidth. Use a minimum of 10 Gb/s ethernet for the front side network. For large clusters, consider using 40 Gb/s ethernet for the backend or cluster network.
For network optimization, Red Hat recommends using jumbo frames for a better CPU per bandwidth ratio, and a non-blocking network switch back-plane. Red Hat Ceph Storage requires the same MTU value throughout all networking devices in the communication path, end-to-end for both public and cluster networks. Verify that the MTU value is the same on all hosts and networking equipment in the environment before using a Red Hat Ceph Storage cluster in production.
Additional Resources
- See the Configuring a private network section in the Red Hat Ceph Storage Configuration Guide for more details.
- See the Configuring a public network section in the Red Hat Ceph Storage Configuration Guide for more details.
- See the Configuring multiple public networks to the cluster section in the Red Hat Ceph Storage Configuration Guide for more details.
2.5. Considerations for using a RAID controller with OSD hosts
Optionally, you can consider using a RAID controller on the OSD hosts. Here are some things to consider:
- If an OSD host has a RAID controller with 1-2 Gb of cache installed, enabling the write-back cache might result in increased small I/O write throughput. However, the cache must be non-volatile.
- Most modern RAID controllers have super capacitors that provide enough power to drain volatile memory to non-volatile NAND memory during a power-loss event. It is important to understand how a particular controller and its firmware behave after power is restored.
- Some RAID controllers require manual intervention. Hard drives typically advertise to the operating system whether their disk caches should be enabled or disabled by default. However, certain RAID controllers and some firmware do not provide such information. Verify that disk level caches are disabled to avoid file system corruption.
- Create a single RAID 0 volume with write-back for each Ceph OSD data drive with write-back cache enabled.
- If Serial Attached SCSI (SAS) or SATA connected Solid-state Drive (SSD) disks are also present on the RAID controller, then investigate whether the controller and firmware support pass-through mode. Enabling pass-through mode helps avoid caching logic, and generally results in much lower latency for fast media.
2.6. Tuning considerations for the Linux kernel when running Ceph
Production Red Hat Ceph Storage clusters generally benefit from tuning the operating system, specifically around limits and memory allocation. Ensure that adjustments are set for all hosts within the storage cluster. You can also open a case with Red Hat support asking for additional guidance.
Increase the File Descriptors
The Ceph Object Gateway can hang if it runs out of file descriptors. You can modify the /etc/security/limits.conf file on Ceph Object Gateway hosts to increase the file descriptors for the Ceph Object Gateway.
ceph soft nofile unlimited
Adjusting the ulimit value for Large Storage Clusters
When running Ceph administrative commands on large storage clusters, for example, with 1024 Ceph OSDs or more, create an /etc/security/limits.d/50-ceph.conf file on each host that runs administrative commands with the following contents:
USER_NAME soft nproc unlimitedReplace USER_NAME with the name of the non-root user account that runs the Ceph administrative commands.
The root user’s ulimit value is already set to unlimited by default on Red Hat Enterprise Linux.
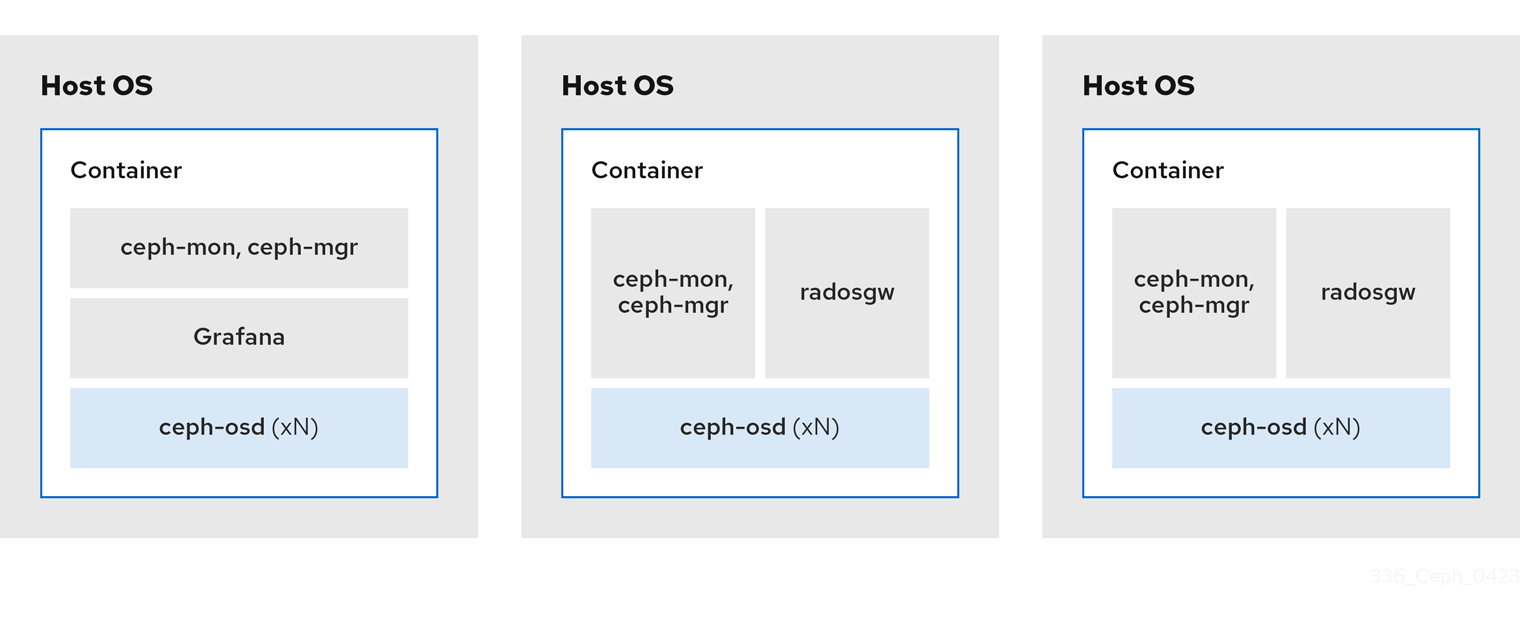
2.7. How colocation works and its advantages
You can colocate containerized Ceph daemons on the same host. Here are the advantages of colocating some of Ceph’s services:
- Significant improvement in total cost of ownership (TCO) at small scale
- Reduction from six hosts to three for the minimum configuration
- Easier upgrade
- Better resource isolation
How Colocation Works
With the help of the Cephadm orchestrator, you can colocate one daemon from the following list with one or more OSD daemons (ceph-osd):
-
Ceph Monitor (
ceph-mon) and Ceph Manager (ceph-mgr) daemons -
NFS Ganesha (
nfs-ganesha) for Ceph Object Gateway (nfs-ganesha) -
RBD Mirror (
rbd-mirror) - Observability Stack (Grafana)
Additionally, for Ceph Object Gateway (radosgw) (RGW) and Ceph File System (ceph-mds), you can colocate either with an OSD daemon plus a daemon from the above list, excluding RBD mirror.
Collocating two of the same kind of daemons on a given node is not supported.
Because ceph-mon and ceph-mgr work together closely they do not count as two separate daemons for the purposes of colocation.
Red Hat recommends colocating the Ceph Object Gateway with Ceph OSD containers to increase performance.
With the colocation rules shared above, we have the following minimum clusters sizes that comply with these rules:
Example 1
- Media: Full flash systems (SSDs)
- Use case: Block (RBD) and File (CephFS), or Object (Ceph Object Gateway)
- Number of nodes: 3
- Replication scheme: 2
| Host | Daemon | Daemon | Daemon |
|---|---|---|---|
| host1 | OSD | Monitor/Manager | Grafana |
| host2 | OSD | Monitor/Manager | RGW or CephFS |
| host3 | OSD | Monitor/Manager | RGW or CephFS |
The minimum size for a storage cluster with three replicas is four nodes. Similarly, the size of a storage cluster with two replicas is a three node cluster. It is a requirement to have a certain number of nodes for the replication factor with an extra node in the cluster to avoid extended periods with the cluster in a degraded state.
Figure 2.2. Colocated Daemons Example 1
Example 2
- Media: Full flash systems (SSDs) or spinning devices (HDDs)
- Use case: Block (RBD), File (CephFS), and Object (Ceph Object Gateway)
- Number of nodes: 4
- Replication scheme: 3
| Host | Daemon | Daemon | Daemon |
|---|---|---|---|
| host1 | OSD | Grafana | CephFS |
| host2 | OSD | Monitor/Manager | RGW |
| host3 | OSD | Monitor/Manager | RGW |
| host4 | OSD | Monitor/Manager | CephFS |
Figure 2.3. Colocated Daemons Example 2

Example 3
- Media: Full flash systems (SSDs) or spinning devices (HDDs)
- Use case: Block (RBD), Object (Ceph Object Gateway), and NFS for Ceph Object Gateway
- Number of nodes: 4
- Replication scheme: 3
| Host | Daemon | Daemon | Daemon |
|---|---|---|---|
| host1 | OSD | Grafana | |
| host2 | OSD | Monitor/Manager | RGW |
| host3 | OSD | Monitor/Manager | RGW |
| host4 | OSD | Monitor/Manager | NFS (RGW) |
Figure 2.4. Colocated Daemons Example 3
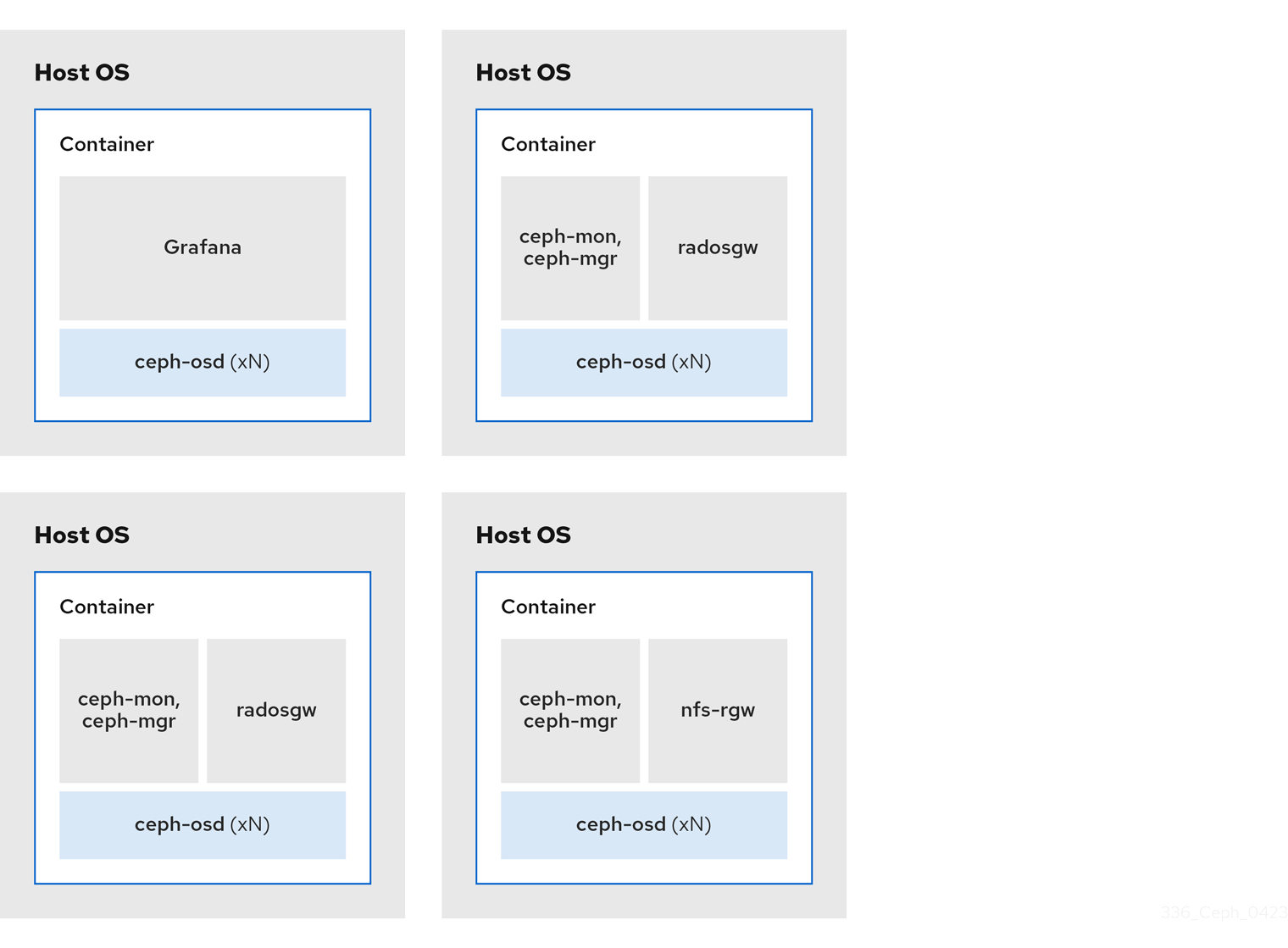
The diagrams below shows the differences between storage clusters with colocated and non-colocated daemons.
Figure 2.5. Colocated Daemons
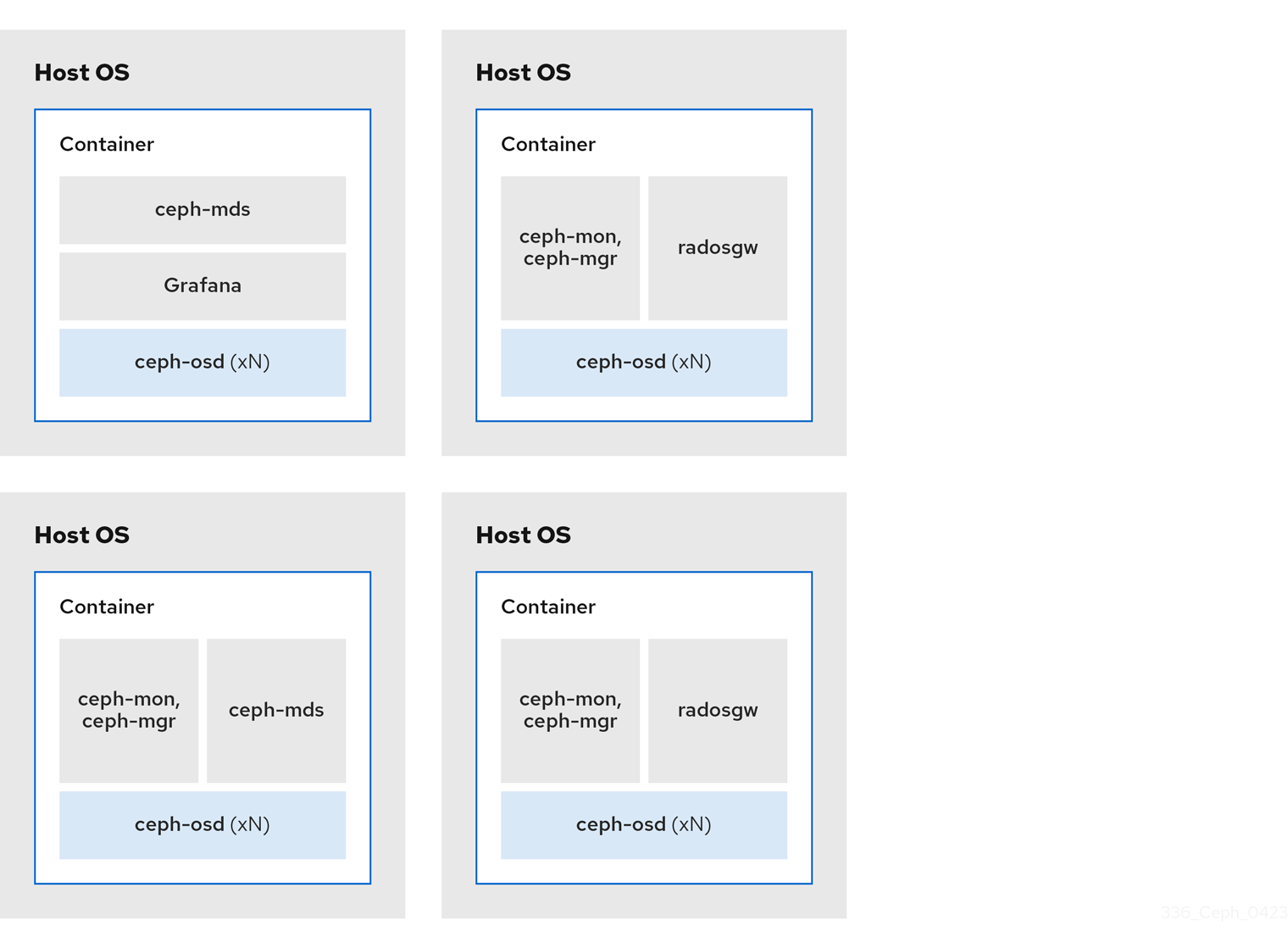
Figure 2.6. Non-colocated Daemons

2.8. Operating system requirements for Red Hat Ceph Storage
Red Hat Enterprise Linux entitlements are included in the Red Hat Ceph Storage subscription.
The release of Red Hat Ceph Storage 5 is supported on Red Hat Enterprise Linux 8.4 EUS or later.
Red Hat Ceph Storage 5 is supported on container-based deployments only.
Use the same operating system version, architecture, and deployment type across all nodes. For example, do not use a mixture of nodes with both AMD64 and Intel 64 architectures, a mixture of nodes with Red Hat Enterprise Linux 8 operating systems, or a mixture of nodes with container-based deployments.
Red Hat does not support clusters with heterogeneous architectures, operating system versions, or deployment types.
SELinux
By default, SELinux is set to Enforcing mode and the ceph-selinux packages are installed. For additional information on SELinux, see the Data Security and Hardening Guide, and Red Hat Enterprise Linux 8 Using SELinux Guide.
Additional Resources
- The documentation set for Red Hat Enterprise Linux 8.
2.9. Minimum hardware considerations for Red Hat Ceph Storage
Red Hat Ceph Storage can run on non-proprietary commodity hardware. Small production clusters and development clusters can run without performance optimization with modest hardware.
Disk space requirements are based on the Ceph daemons' default path under /var/lib/ceph/ directory.
Table 2.1. Containers
| Process | Criteria | Minimum Recommended |
|---|---|---|
|
| Processor | 1x AMD64 or Intel 64 CPU CORE per OSD container. |
| RAM | Minimum of 5 GB of RAM per OSD container. | |
| Number of nodes | Minimum of 3 nodes required. | |
| OS Disk | 1x OS disk per host. | |
| OSD Storage | 1x storage drive per OSD container. Cannot be shared with OS Disk. | |
|
|
Optional, but Red Hat recommended, 1x SSD or NVMe or Optane partition or lvm per daemon. Sizing is 4% of | |
|
|
Optionally, 1x SSD or NVMe or Optane partition or logical volume per daemon. Use a small size, for example 10 GB, and only if it’s faster than the | |
| Network | 2x 10 GB Ethernet NICs |
|
| Processor | 1x AMD64 or Intel 64 CPU CORE per mon-container | |
| RAM |
3 GB per | |
| Disk Space |
10 GB per | |
| Monitor Disk |
Optionally, 1x SSD disk for | |
| Network | 2x 1 GB Ethernet NICs, 10 GB Recommended | |
| Prometheus |
20 GB to 50 GB under |
|
| Processor |
1x AMD64 or Intel 64 CPU CORE per | |
| RAM |
3 GB per | |
| Network | 2x 1 GB Ethernet NICs, 10 GB Recommended |
|
| Processor | 1x AMD64 or Intel 64 CPU CORE per radosgw-container | |
| RAM | 1 GB per daemon | |
| Disk Space | 5 GB per daemon | |
| Network | 1x 1 GB Ethernet NICs |
|
| Processor | 1x AMD64 or Intel 64 CPU CORE per mds-container | |
| RAM |
3 GB per
This number is highly dependent on the configurable MDS cache size. The RAM requirement is typically twice as much as the amount set in the | |
| Disk Space |
2 GB per |
2.10. Additional Resources
- If you want to take a deeper look into Ceph’s various internal components, and the strategies around those components, see the Red Hat Ceph Storage Storage Strategies Guide for more details.