
Chapter 7. Ceph Monitor and OSD interaction configuration
As a storage administrator, you must properly configure the interactions between the Ceph Monitors and OSDs to ensure a stable working environment.
7.1. Prerequisites
- Installation of the Red Hat Ceph Storage software.
7.2. Ceph Monitor and OSD interaction
After you have completed your initial Ceph configuration, you can deploy and run Ceph. When you execute a command such as ceph health or ceph -s, the Ceph Monitor reports on the current state of the Ceph storage cluster. The Ceph Monitor knows about the Ceph storage cluster by requiring reports from each Ceph OSD daemon, and by receiving reports from Ceph OSD daemons about the status of their neighboring Ceph OSD daemons. If the Ceph Monitor does not receive reports, or if it receives reports of changes in the Ceph storage cluster, the Ceph Monitor updates the status of the Ceph cluster map.
Ceph provides reasonable default settings for Ceph Monitor and OSD interaction. However, you can override the defaults. The following sections describe how Ceph Monitors and Ceph OSD daemons interact for the purposes of monitoring the Ceph storage cluster.
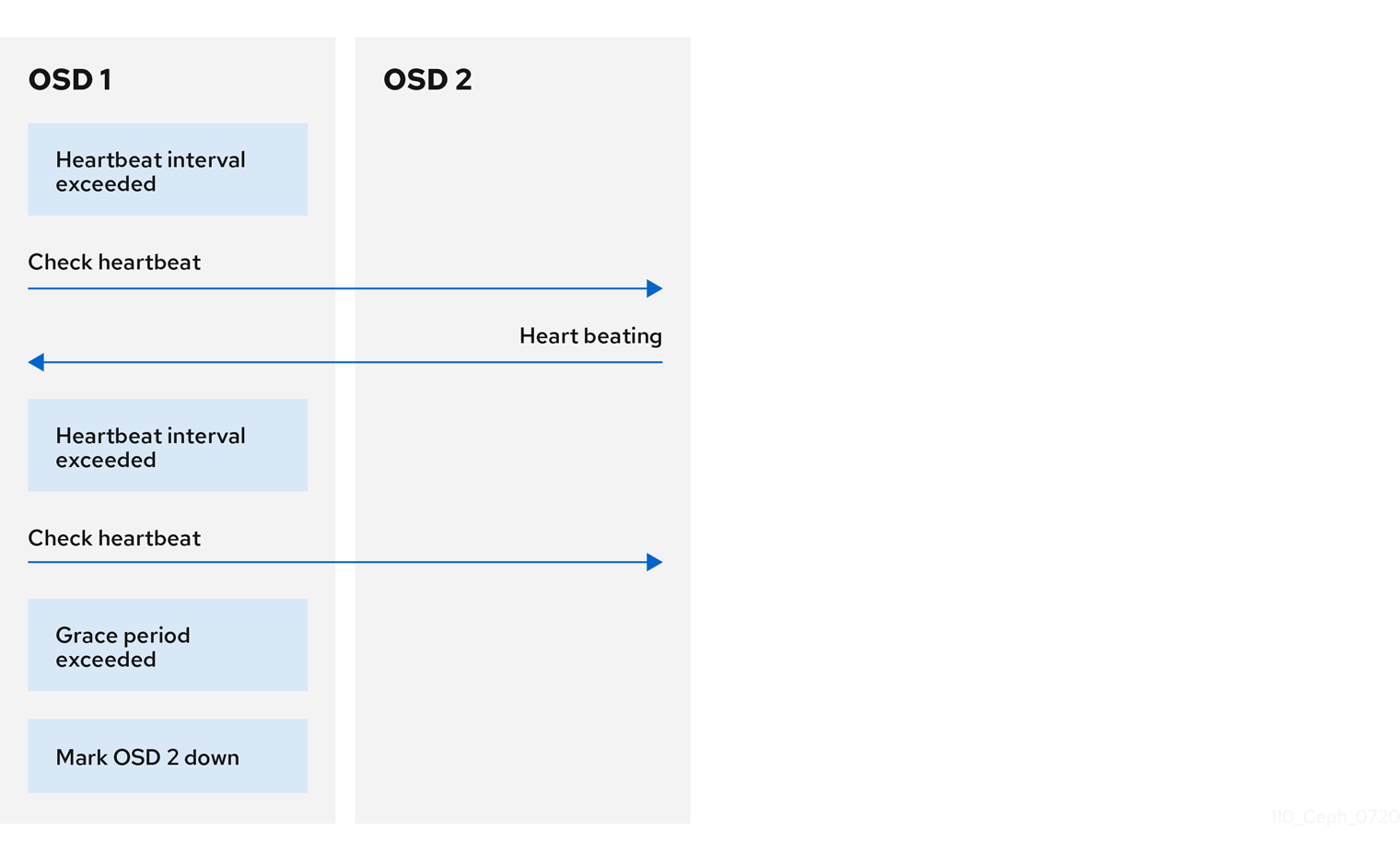
7.3. OSD heartbeat
Each Ceph OSD daemon checks the heartbeat of other Ceph OSD daemons every 6 seconds. To change the heartbeat interval, change the value at runtime:
Syntax
ceph config set osd osd_heartbeat_interval TIME_IN_SECONDS
Example
[ceph: root@host01 /]# ceph config set osd osd_heartbeat_interval 60
If a neighboring Ceph OSD daemon does not send heartbeat packets within a 20 second grace period, the Ceph OSD daemon might consider the neighboring Ceph OSD daemon down. It can report it back to a Ceph Monitor, which updates the Ceph cluster map. To change the grace period, set the value at runtime:
Syntax
ceph config set osd osd_heartbeat_grace TIME_IN_SECONDS
Example
[ceph: root@host01 /]# ceph config set osd osd_heartbeat_grace 30
7.4. Reporting an OSD as down
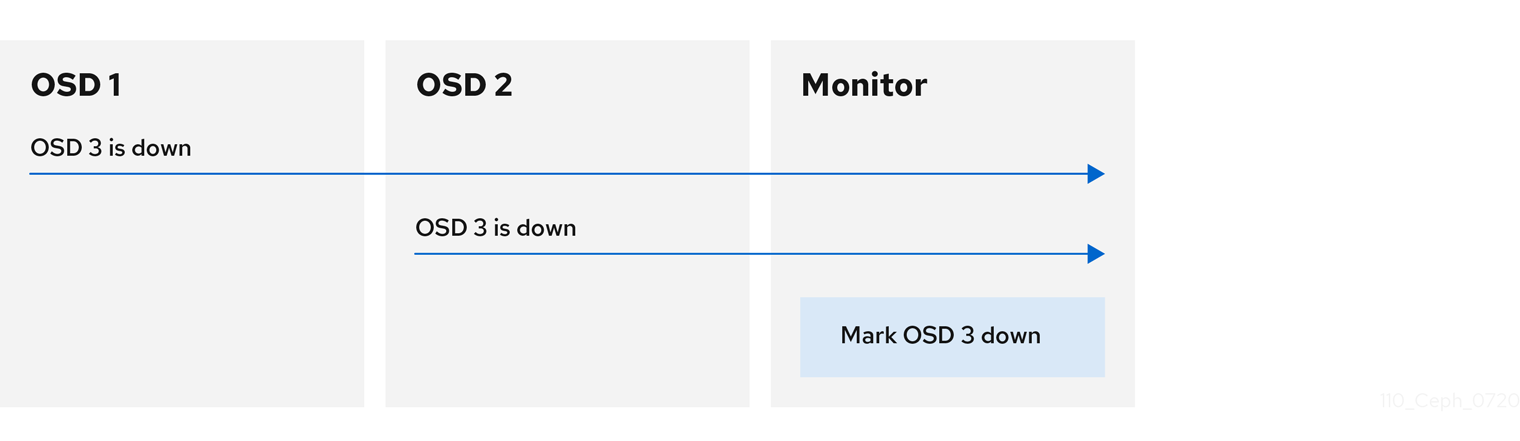
By default, two Ceph OSD Daemons from different hosts must report to the Ceph Monitors that another Ceph OSD Daemon is down before the Ceph Monitors acknowledge that the reported Ceph OSD Daemon is down.
However, there is the chance that all the OSDs reporting the failure are in different hosts in a rack with a bad switch that causes connection problems between OSDs.
To avoid a "false alarm," Ceph considers the peers reporting the failure as a proxy for a "subcluster" that is similarly laggy. While this is not always the case, it may help administrators localize the grace correction to a subset of the system that is performing poorly.
Ceph uses the mon_osd_reporter_subtree_level setting to group the peers into the "subcluster" by their common ancestor type in the CRUSH map.
By default, only two reports from a different subtree are required to report another Ceph OSD Daemon down. Administrators can change the number of reporters from unique subtrees and the common ancestor type required to report a Ceph OSD Daemon down to a Ceph Monitor by setting the mon_osd_min_down_reporters and mon_osd_reporter_subtree_level values at runtime:
Syntax
ceph config set mon mon_osd_min_down_reporters NUMBER
Example
[ceph: root@host01 /]# ceph config set mon mon_osd_min_down_reporters 4
Syntax
ceph config set mon mon_osd_reporter_subtree_level CRUSH_ITEM
Example
[ceph: root@host01 /]# ceph config set mon mon_osd_reporter_subtree_level host [ceph: root@host01 /]# ceph config set mon mon_osd_reporter_subtree_level rack [ceph: root@host01 /]# ceph config set mon mon_osd_reporter_subtree_level osd
7.5. Reporting a peering failure
If a Ceph OSD daemon cannot peer with any of the Ceph OSD daemons defined in its Ceph configuration file or the cluster map, it pings a Ceph Monitor for the most recent copy of the cluster map every 30 seconds. You can change the Ceph Monitor heartbeat interval by setting the value at runtime:
Syntax
ceph config set osd osd_mon_heartbeat_interval TIME_IN_SECONDS
Example
[ceph: root@host01 /]# ceph config set osd osd_mon_heartbeat_interval 60

7.6. OSD reporting status
If a Ceph OSD Daemon does not report to a Ceph Monitor, the Ceph Monitor marks the Ceph OSD Daemon down after the mon_osd_report_timeout, which is 900 seconds, elapses. A Ceph OSD Daemon sends a report to a Ceph Monitor when a reportable event such as a failure, a change in placement group stats, a change in up_thru or when it boots within 5 seconds.
You can change the Ceph OSD Daemon minimum report interval by setting the osd_mon_report_interval value at runtime:
Syntax
ceph config set osd osd_mon_report_interval TIME_IN_SECONDS
To get, set, and verify the config you can use the following example:
Example
[ceph: root@host01 /]# ceph config get osd osd_mon_report_interval 5 [ceph: root@host01 /]# ceph config set osd osd_mon_report_interval 20 [ceph: root@host01 /]# ceph config dump | grep osd global advanced osd_pool_default_crush_rule -1 osd basic osd_memory_target 4294967296 osd advanced osd_mon_report_interval 20

7.7. Additional Resources
- See all the Red Hat Ceph Storage Ceph Monitor and OSD configuration options in Appendix G for specific option descriptions and usage.