
Red Hat Training
A Red Hat training course is available for Red Hat Ceph Storage
Chapter 3. Placement Groups (PGs)
Placement Groups (PGs) are invisible to Ceph clients, but they play an important role in Ceph Storage Clusters.
A Ceph Storage Cluster may require many thousands of OSDs to reach an exabyte level of storage capacity. Ceph clients store objects in pools, which are a logical subset of the overall cluster. The number of objects stored in a pool may easily run into the millions and beyond. A system with millions of objects or more cannot realistically track placement on a per-object basis and still perform well. Ceph assigns objects to placement groups, and placement groups to OSDs to make re-balancing dynamic and efficient.
All problems in computer science can be solved by another level of indirection, except of course for the problem of too many indirections. | ||
| -- David Wheeler | ||
3.1. About Placement Groups
Tracking object placement on a per-object basis within a pool is computationally expensive at scale. To facilitate high performance at scale, Ceph subdivides a pool into placement groups, assigns each individual object to a placement group, and assigns the placement group to a primary OSD. If an OSD fails or the cluster re-balances, Ceph can move or replicate an entire placement group—i.e., all of the objects in the placement groups—without having to address each object individually. This allows a Ceph cluster to re-balance or recover efficiently.
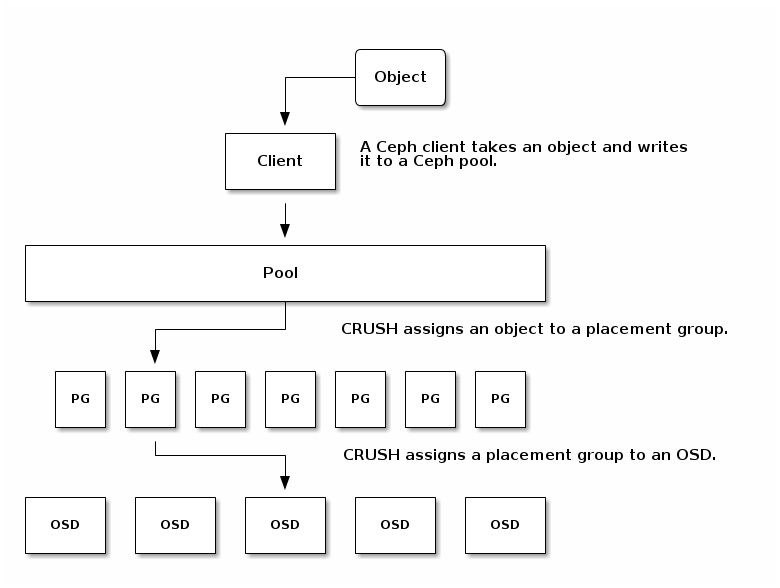
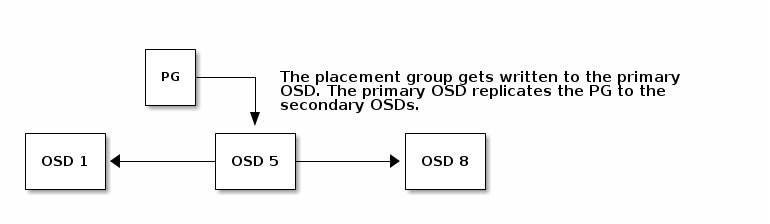
When CRUSH assigns a placement group to an OSD, it calculates a series of OSDs—the first being the primary. The osd_pool_default_size setting minus 1 for replicated pools, and the number of coding chunks M for erasure-coded pools determine the number of OSDs storing a placement group that can fail without losing data permanently. Primary OSDs use CRUSH to identify the secondary OSDs and copy the placement group’s contents to the secondary OSDs. For example, if CRUSH assigns an object to a placement group, and the placement group is assigned to OSD 5 as the primary OSD, if CRUSH calculates that OSD 1 and OSD 8 are secondary OSDs for the placement group, the primary OSD 5 will copy the data to OSDs 1 and 8. By copying data on behalf of clients, Ceph simplifies the client interface and reduces the client workload. The same process allows the Ceph cluster to recover and rebalance dynamically.
When the primary OSD fails and gets marked out of the cluster, CRUSH assigns the placement group to another OSD, which receives copies of objects in the placement group. Another OSD in the Up Set will assume the role of the primary OSD.
When you increase the number of object replicas or coding chunks, CRUSH will assign each placement group to additional OSDs as required.
PGs do not own OSDs. CRUSH assigns many placement groups to each OSD pseudo-randomly to ensure that data gets distributed evenly across the cluster.
3.2. Placement Group Tradeoffs
Data durability and data distribution among all OSDs call for more placement groups but their number should be reduced to the minimum required for maximum performance to conserve CPU and memory resources.
3.2.1. Data Durability
Ceph strives to prevent the permanent loss of data. However, after an OSD fails, the risk of permanent data loss increases until the data it contained is fully recovered. Permanent data loss, though rare, is still possible. The following scenario describes how Ceph could permanently lose data in a single placement group with three copies of the data:
- An OSD fails and all copies of the object it contains are lost. For all objects within a placement group stored on the OSD, the number of replicas suddenly drops from three to two.
- Ceph starts recovery for each placement group stored on the failed OSD by choosing a new OSD to re-create the third copy of all objects for each placement group.
- The second OSD containing a copy of the same placement group fails before the new OSD is fully populated with the third copy. Some objects will then only have one surviving copy.
- Ceph picks yet another OSD and keeps copying objects to restore the desired number of copies.
- The third OSD containing a copy of the same placement group fails before recovery is complete. If this OSD contained the only remaining copy of an object, the object is lost permanently.
Hardware failure isn’t an exception, but an expectation. To prevent the foregoing scenario, ideally the recovery process should be as fast as reasonably possible. The size of your cluster, your hardware configuration and the number of placement groups play an important role in total recovery time.
Small clusters don’t recover as quickly.
In a cluster containing 10 OSDs with 512 placement groups in a three replica pool, CRUSH will give each placement group three OSDs. Each OSD will end up hosting (512 * 3) / 10 = ~150 placement groups. When the first OSD fails, the cluster will start recovery for all 150 placement groups simultaneously.
It is likely that Ceph stored the remaining 150 placement groups randomly across the 9 remaining OSDs. Therefore, each remaining OSD is likely to send copies of objects to all other OSDs and also receive some new objects, because the remaining OSDs become responsible for some of the 150 placement groups now assigned to them.
The total recovery time depends upon the hardware supporting the pool. For example, in a 10 OSD cluster, if a host contains one OSD with a 1TB SSD, and a 10GB/s switch connects each of the 10 hosts, the recovery time will take M minutes. By contrast, if a host contains two SATA OSDs and a 1GB/s switch connects the five hosts, recovery will take substantially longer. Interestingly, in a cluster of this size, the number of placement groups has almost no influence on data durability. The placement group count could be 128 or 8192 and the recovery would not be slower or faster.
However, growing the same Ceph cluster to 20 OSDs instead of 10 OSDs is likely to speed up recovery and therefore improve data durability significantly. Why? Each OSD now participates in only 75 placement groups instead of 150. The 20 OSD cluster will still require all 19 remaining OSDs to perform the same amount of copy operations in order to recover. In the 10 OSD cluster, each OSDs had to copy approximately 100GB. In the 20 OSD cluster each OSD only has to copy 50GB each. If the network was the bottleneck, recovery will happen twice as fast. In other words, recovery time decreases as the number of OSDs increases.
In large clusters, PG count is important!
If the exemplary cluster grows to 40 OSDs, each OSD will only host 35 placement groups. If an OSD dies, recovery time will decrease unless another bottleneck precludes improvement. However, if this cluster grows to 200 OSDs, each OSD will only host approximately 7 placement groups. If an OSD dies, recovery will happen between at most of 21 (7 * 3) OSDs in these placement groups: recovery will take longer than when there were 40 OSDs, meaning the number of placement groups should be increased!
No matter how short the recovery time, there is a chance for another OSD storing the placement group to fail while recovery is in progress.
In the 10 OSD cluster described above, if any OSD fails, then approximately 8 placement groups (i.e. 75 pgs / 9 osds being recovered) will only have one surviving copy. And if any of the 8 remaining OSDs fail, the last objects of one placement group are likely to be lost (i.e. 8 pgs / 8 osds with only one remaining copy being recovered). This is why starting with a somewhat larger cluster is preferred (e.g., 50 OSDs).
When the size of the cluster grows to 20 OSDs, the number of placement groups damaged by the loss of three OSDs drops. The second OSD lost will degrade approximately 2 (i.e. 35 pgs / 19 osds being recovered) instead of 8 and the third OSD lost will only lose data if it is one of the two OSDs containing the surviving copy. In other words, if the probability of losing one OSD is 0.0001% during the recovery time frame, it goes from 8 * 0.0001% in the cluster with 10 OSDs to 2 * 0.0001% in the cluster with 20 OSDs. Having 512 or 4096 placement groups is roughly equivalent in a cluster with less than 50 OSDs as far as data durability is concerned.
In a nutshell, more OSDs means faster recovery and a lower risk of cascading failures leading to the permanent loss of a placement group and its objects.
When you add an OSD to the cluster, it may take a long time top populate the new OSD with placement groups and objects. However there is no degradation of any object and adding the OSD has no impact on data durability.
3.2.2. Data Distribution
Ceph seeks to avoid hot spots—i.e., some OSDs receive substantially more traffic than other OSDs. Ideally, CRUSH assigns objects to placement groups evenly so that when the placement groups get assigned to OSDs (also pseudo randomly), the primary OSDs store objects such that they are evenly distributed across the cluster and hot spots and network over-subscription problems cannot develop because of data distribution.
Since CRUSH computes the placement group for each object, but does not actually know how much data is stored in each OSD within this placement group, the ratio between the number of placement groups and the number of OSDs may influence the distribution of the data significantly.
For instance, if there was only one a placement group with ten OSDs in a three replica pool, Ceph would only use three OSDs to store data because CRUSH would have no other choice. When more placement groups are available, CRUSH is more likely to be evenly spread objects across OSDs. CRUSH also evenly assigns placement groups to OSDs.
As long as there are one or two orders of magnitude more placement groups than OSDs, the distribution should be even. For instance, 300 placement groups for 3 OSDs, 1000 placement groups for 10 OSDs etc.
The ratio between OSDs and placement groups usually solves the problem of uneven data distribution for Ceph clients that implement advanced features like object striping. For example, a 4TB block device might get sharded up into 4MB objects.
The ratio between OSDs and placement groups does not address uneven data distribution in other cases, because CRUSH does not take object size into account. Using the librados interface to store some relatively small objects and some very large objects can lead to uneven data distribution. For example, one million 4K objects totaling 4GB are evenly spread among 1000 placement groups on 10 OSDs. They will use 4GB / 10 = 400MB on each OSD. If one 400MB object is added to the pool, the three OSDs supporting the placement group in which the object has been placed will be filled with 400MB + 400MB = 800MB while the seven others will remain occupied with only 400MB.
3.2.3. Resource Usage
For each placement group, OSDs and Ceph monitors need memory, network and CPU at all times, and even more during recovery. Sharing this overhead by clustering objects within a placement group is one of the main reasons placement groups exist.
Minimizing the number of placement groups saves significant amounts of resources.
3.3. PG Count
The number of placement groups in a pool plays a significant role in how a cluster peers, distributes data and rebalances. Small clusters don’t see as many performance improvements compared to large clusters by increasing the number of placement groups. However, clusters that have many pools accessing the same OSDs may need to carefully consider PG count so that Ceph OSDs use resources efficiently.
Red Hat recommends 100 to 200 PGs per OSD.
3.3.1. PG Calculator
The PG calculator calculates the number of placement groups for you and addresses specific use cases. The PG calculator is especially helpful when using Ceph clients like the Ceph Object Gateway where there are many pools typically using same ruleset (CRUSH hierarchy). You may still calculate PGs manually using the guidelines in PG Count for Small Clusters and Calculating PG Count. However, the PG calculator is the preferred method of calculating PGs.
See Ceph Placement Groups (PGs) per Pool Calculator on the Red Hat Customer Portal for details.
3.3.2. Configuring Default PG Counts
When you create a pool, you also create a number of placement groups for the pool. If you don’t specify the number of placement groups, Ceph will use the default value of 8, which is unacceptably low. You can increase the number of placement groups for a pool, but we recommend setting reasonable default values in your Ceph configuration file too.
osd pool default pg num = 100 osd pool default pgp num = 100
You need to set both the number of placement groups (total), and the number of placement groups used for objects (used in PG splitting). They should be equal.
3.3.3. PG Count for Small Clusters
Small clusters don’t benefit from large numbers of placement groups. So you should consider the following values:
-
Less than 5 OSDs set
pg_numandpgp_numto 128. -
Between 5 and 10 OSDs set
pg_numandpgp_numto 512 -
Between 10 and 50 OSDs set
pg_numandpgp_numto 1024 -
If you have more than 50 OSDs, you need to understand the tradeoffs and how to calculate the
pg_numandpgp_numvalues. See Calculating PG Count.
As the number of OSDs increase, choosing the right value for pg_num and pgp_num becomes more important because it has a significant influence on the behavior of the cluster as well as the durability of the data when something goes wrong (i.e. the probability that a catastrophic event leads to data loss).
3.3.4. Calculating PG Count
If you have more than 50 OSDs, we recommend approximately 50-100 placement groups per OSD to balance out resource usage, data durability and distribution. If you have less than 50 OSDs, choosing among the PG Count for Small Clusters is ideal. For a single pool of objects, you can use the following formula to get a baseline:
(OSDs * 100)
Total PGs = ------------
pool size
Where pool size is either the number of replicas for replicated pools or the K+M sum for erasure coded pools (as returned by ceph osd erasure-code-profile get).
You should then check if the result makes sense with the way you designed your Ceph cluster to maximize data durability, data distribution and minimize resource usage.
The result should be rounded up to the nearest power of two. Rounding up is optional, but recommended for CRUSH to evenly balance the number of objects among placement groups.
For a cluster with 200 OSDs and a pool size of 3 replicas, you would estimate your number of PGs as follows:
(200 * 100)
----------- = 6667. Nearest power of 2: 8192
3With 8192 placement groups distributed across 200 OSDs, that evaluates to approximately 41 placement groups per OSD. You also need to consider the number of pools you are likely to use in your cluster, since each pool will create placement groups too. Ensure that you have a reasonable maximum PG count.
3.3.5. Maximum PG Count
When using multiple data pools for storing objects, you need to ensure that you balance the number of placement groups per pool with the number of placement groups per OSD so that you arrive at a reasonable total number of placement groups. The aim is to achieve reasonably low variance per OSD without taxing system resources or making the peering process too slow.
In an exemplary Ceph Storage Cluster consisting of 10 pools, each pool with 512 placement groups on ten OSDs, there is a total of 5,120 placement groups spread over ten OSDs, or 512 placement groups per OSD. That may not use too many resources depending on your hardware configuration. By contrast, if you create 1,000 pools with 512 placement groups each, the OSDs will handle ~50,000 placement groups each and it would require significantly more resources. Operating with too many placement groups per OSD can significantly reduce performance, especially during rebalancing or recovery.
The Ceph Storage Cluster has a default maximum value of 300 placement groups per OSD. You can set a different maximum value in your Ceph configuration file.
mon pg warn max per osd
Ceph Object Gateways deploy with 10-15 pools, so you may consider using less than 100 PGs per OSD to arrive at a reasonable maximum number.
3.4. Enabling FileStore random splits on existing placement groups
Adding new OSDs running on Ceph 10.2.10-16.el7cp and above, have random splits are enabled by default when placement groups (PGs) get mapped to the new OSD. For older OSDs with existing PGs, you can enable random splits manually.
Prerequisites
- Red Hat Ceph Storage 2.5 and above.
-
A
HEALTH_OKstorage cluster. - Root-level access to the OSD nodes.
Procedure
Enable the
nooutOSD option:[root@osd ~]# ceph osd set noout
Stop the OSD:
systemctl stop ceph-osd@OSD_IDExample
[root@osd ~]# systemctl stop ceph-osd@1
Customized the
$CEPH_ARGSenvironment variable:CEPH_ARGS="--filestore-split-rand-factor INTEGER --log-file LOG_FILE_NAME --debug-filestore 20"
Example
[root@osd ~]# CEPH_ARGS="--filestore-split-rand-factor 200 --log-file foo.log --debug-filestore 20"
NoteThe INTEGER value is a random factor added to the split threshold.
For each pool on the OSD, apply the following layout settings:
ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-OSD_ID --journal-path /var/lib/ceph/osd/ceph-OSD_ID/journal --op apply-layout-settings --pool POOL_NAME
Example
[root@osd ~]# ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-1 --journal-path /var/lib/ceph/osd/ceph-1/journal --op apply-layout-settings --pool default.rgw.buckets.data
Start the OSD:
systemctl start ceph-osd@OSD_IDExample
[root@osd ~]# systemctl start ceph-osd@1
For other OSDs, repeat steps 2-5, as needed.
ImportantEnable the random splits on one OSD at a time. Wait on the PGs to go into an
active+cleanstate before starting the next OSD.Once finished, disable the
nooutOSD option:[root@osd ~]# ceph osd unset noout
3.5. PG Command-Line Reference
The ceph CLI allows you to set and get the number of placement groups for a pool, view the PG map and retrieve PG statistics.
3.5.1. Set the Number of PGs
To set the number of placement groups in a pool, you must specify the number of placement groups at the time you create the pool. See Create a Pool for details. Once you set placement groups for a pool, you can increase the number of placement groups (but you cannot decrease the number of placement groups). To increase the number of placement groups, execute the following:
ceph osd pool set {pool-name} pg_num {pg_num}
Once you increase the number of placement groups, you must also increase the number of placement groups for placement (pgp_num) before your cluster will rebalance. The pgp_num should be equal to the pg_num. To increase the number of placement groups for placement, execute the following:
ceph osd pool set {pool-name} pgp_num {pgp_num}3.5.2. Get the Number of PGs
To get the number of placement groups in a pool, execute the following:
ceph osd pool get {pool-name} pg_num3.5.3. Get a Cluster PG Statistics
To get the statistics for the placement groups in your cluster, execute the following:
ceph pg dump [--format {format}]
Valid formats are plain (default) and json.
3.5.4. Get Statistics for Stuck PGs
To get the statistics for all placement groups stuck in a specified state, execute the following:
ceph pg dump_stuck inactive|unclean|stale [--format <format>] [-t|--threshold <seconds>]
Inactive Placement groups cannot process reads or writes because they are waiting for an OSD with the most up-to-date data to come up and in.
Unclean Placement groups contain objects that are not replicated the desired number of times. They should be recovering.
Stale Placement groups are in an unknown state - the OSDs that host them have not reported to the monitor cluster in a while (configured by mon_osd_report_timeout).
Valid formats are plain (default) and json. The threshold defines the minimum number of seconds the placement group is stuck before including it in the returned statistics (default 300 seconds).
3.5.5. Get a PG Map
To get the placement group map for a particular placement group, execute the following:
ceph pg map {pg-id}For example:
ceph pg map 1.6c
Ceph will return the placement group map, the placement group, and the OSD status:
osdmap e13 pg 1.6c (1.6c) -> up [1,0] acting [1,0]
3.5.6. Get a PGs Statistics
To retrieve statistics for a particular placement group, execute the following:
ceph pg {pg-id} query3.5.7. Scrub a Placement Group
To scrub a placement group, execute the following:
ceph pg scrub {pg-id}Ceph checks the primary and any replica nodes, generates a catalog of all objects in the placement group and compares them to ensure that no objects are missing or mismatched, and their contents are consistent. Assuming the replicas all match, a final semantic sweep ensures that all of the snapshot-related object metadata is consistent. Errors are reported via logs.
3.5.8. Revert Lost
If the cluster has lost one or more objects, and you have decided to abandon the search for the lost data, you must mark the unfound objects as lost.
If all possible locations have been queried and objects are still lost, you may have to give up on the lost objects. This is possible given unusual combinations of failures that allow the cluster to learn about writes that were performed before the writes themselves are recovered.
Currently the only supported option is "revert", which will either roll back to a previous version of the object or (if it was a new object) forget about it entirely. To mark the "unfound" objects as "lost", execute the following:
ceph pg {pg-id} mark_unfound_lost revert|deleteUse this feature with caution, because it may confuse applications that expect the object(s) to exist.