
Chapter 21. Clustering Building Blocks
The clustering features in JBoss Enterprise Application Platform are built on top of lower level libraries that provide much of the core functionality. Figure 21.1, “The JBoss Enterprise Application Platform clustering architecture” shows the main pieces:
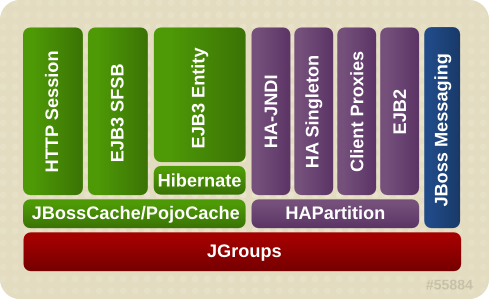
Figure 21.1. The JBoss Enterprise Application Platform clustering architecture
JGroups is a toolkit for reliable point-to-point and point-to-multipoint communication. JGroups is used for all clustering-related communications between nodes in a JBoss Enterprise Application Platform cluster.
JBoss Cache is a highly flexible clustered transactional caching library. Many Enterprise Application Platform clustering services need to cache some state in memory while (1) ensuring for high availability purposes that a backup copy of that state is available on another node if it can not otherwise be recreated (e.g. the contents of a web session) and (2) ensuring that the data cached on each node in the cluster is consistent. JBoss Cache handles these concerns for most JBoss Enterprise Application Platform clustered services. JBoss Cache uses JGroups to handle its group communication requirements. POJO Cache is an extension of the core JBoss Cache that JBoss Enterprise Application Platform uses to support fine-grained replication of clustered web session state. See Section 21.2, “Distributed Caching with JBoss Cache” for more on how JBoss Enterprise Application Platform uses JBoss Cache and POJO Cache.
HAPartition is an adapter on top of a JGroups channel that allows multiple services to use the channel. HAPartition also supports a distributed registry of which HAPartition-based services are running on which cluster members. It provides notifications to interested listeners when the cluster membership changes or the clustered service registry changes. See Section 21.3, “The HAPartition Service” for more details on HAPartition.
The other higher level clustering services make use of JBoss Cache or HAPartition, or, in the case of HA-JNDI, both. The exception to this is JBoss Messaging's clustering features, which interact with JGroups directly.
21.1. Group Communication with JGroups
JGroups provides the underlying group communication support for JBoss Enterprise Application Platform clusters. Services deployed on JBoss Enterprise Application Platform which need group communication with their peers will obtain a JGroups
Channel and use it to communicate. The Channel handles such tasks as managing which nodes are members of the group, detecting node failures, ensuring lossless, first-in-first-out delivery of messages to all group members, and providing flow control to ensure fast message senders cannot overwhelm slow message receivers.
The characteristics of a JGroups
Channel are determined by the set of protocols that compose it. Each protocol handles a single aspect of the overall group communication task; for example the UDP protocol handles the details of sending and receiving UDP datagrams. A Channel that uses the UDP protocol is capable of communicating with UDP unicast and multicast; alternatively one that uses the TCP protocol uses TCP unicast for all messages. JGroups supports a wide variety of different protocols (see Section 28.1, “Configuring a JGroups Channel's Protocol Stack” for details), but the Enterprise Application Platform ships with a default set of channel configurations that should meet most needs.
By default, all JGroups channels of the Enterprise Application Platform use the UDP multicast (an exception to this is a JBoss Messaging channel, which is TCP-based). To change the default multicast type for a server, in
<JBOSS_HOME>/bin/ create run.conf. Open the file and add the following: JAVA_OPTS="$JAVA_OPTS -Djboss.default.jgroups.stack=<METHOD>".
21.1.1. The Channel Factory Service
A significant difference in JBoss Enterprise Application Platform 5 versus previous releases is that JGroups Channels needed by clustering services (for example, a channel used by a distributed HttpSession cache) are no longer configured in detail as part of the consuming service's configuration, and are no longer directly instantiated by the consuming service. Instead, a new
ChannelFactory service is used as a registry for named channel configurations and as a factory for Channel instances. A service that needs a channel requests the channel from the ChannelFactory, passing in the name of the desired configuration.
The ChannelFactory service is deployed in the
server/production/deploy/cluster/jgroups-channelfactory.sar. On start up the ChannelFactory service parses the server/production/deploy/cluster/jgroups-channelfactory.sar/META-INF/jgroups-channelfactory-stacks.xml file, which includes various standard JGroups configurations identified by name (for example, UDP or TCP). Services needing a channel access the channel factory and ask for a channel with a particular named configuration.
Note
If several services request a channel with the same configuration name from the ChannelFactory, they are not handed a reference to the same underlying Channel. Each receives its own Channel, but the channels will have an identical configuration. A logical question is how those channels avoid forming a group with each other if each, for example, is using the same multicast address and port. The answer is that when a consuming service connects its Channel, it passes a unique-to-that-service
cluster_name argument to the Channel.connect(String cluster_name) method. The Channel uses that cluster_name as one of the factors that determine whether a particular message received over the network is intended for it.
21.1.1.1. Standard Protocol Stack Configurations
The standard protocol stack configurations that ship with Enterprise Application Platform 5 are described below. Note that not all of these are actually used; many are included as a convenience to users who may wish to alter the default server profile. The configurations actually used in a stock Enterprise Application Platform 5 production server profile are
udp, jbm-control and jbm-data, with all clustering services other than JBoss Messaging using udp.
You can add a new stack configuration by adding a new
stack element to the server/production/deploy/cluster/jgroups-channelfactory.sar/META-INF/jgroups-channelfactory-stacks.xml file. You can alter the behavior of an existing configuration by editing this file. Before doing this though, have a look at the other standard configurations the Enterprise Application Platform ships; perhaps one of those meets your needs. Also, please note that before editing a configuration you should understand what services are using that configuration; make sure the change you are making is appropriate for all affected services. If the change is not appropriate for a particular service, create a new configuration and change some services to use that new configuration.
- udpUDP multicast based stack meant to be shared between different channels. Message bundling is disabled, as it can add latency to synchronous group RPCs. Services that only make asynchronous RPCs (for example, JBoss Cache configured for REPL_ASYNC) and do so in high volume may be able to improve performance by configuring their cache to use the
udp-asyncstack below. Services that only make synchronous RPCs (for example JBoss Cache configured for REPL_SYNC or INVALIDATION_SYNC) may be able to improve performance by using theudp-syncstack below, which does not include flow control. - udp-asyncSame as the default
udpstack above, except message bundling is enabled in the transport protocol (enable_bundling=true). Useful for services that make high-volume asynchronous RPCs (e.g. high volume JBoss Cache instances configured for REPL_ASYNC) where message bundling may improve performance. - udp-syncUDP multicast based stack, without flow control and without message bundling. This can be used instead of
udpif (1) synchronous calls are used and (2) the message volume (rate and size) is not that large. Do not use this configuration if you send messages at a high sustained rate, or you might run out of memory. - tcpTCP based stack, with flow control and message bundling. TCP stacks are usually used when IP multicasting cannot be used in a network (e.g. routers discard multicast).
- tcp-syncTCP based stack, without flow control and without message bundling. TCP stacks are usually used when IP multicasting cannot be used in a network (e.g.routers discard multicast). This configuration should be used instead of
tcpabove when (1) synchronous calls are used and (2) the message volume (rate and size) is not that large. Do not use this configuration if you send messages at a high sustained rate, or you might run out of memory. - jbm-controlStack optimized for the JBoss Messaging Control Channel. By default uses the same UDP transport protocol configuration as is used for the default
udpstack defined above. This allows the JBoss Messaging Control Channel to use the same sockets, network buffers and thread pools as are used by the other standard JBoss Enterprise Application Platform clustered services (see Section 21.1.2, “The JGroups Shared Transport”) - jbm-dataTCP-based stack optimized for the JBoss Messaging Data Channel.
21.1.1.2. Changing the Protocol Stack Configuration
By default, all clustering services other than JBoss Messaging use the
udp protocol stack configuration. If you want to use a TCP-based configuration, set the system property jboss.default.jgroups.stack to the tcp value (-Djboss.default.jgroups.stack=tcp). This change configures most of the services that use a JGroups channel to use the TCP-based configuration. To make tcp the default protocol stack, add the system property to the JAVA_OPTS environment variable in the <JBOSS_HOME>/bin/run.conf file on Linux platforms or <JBOSS_HOME>/bin/run.conf.bat on Windows platforms.
The
tcp stack uses UDP multicast (via the MPING layer) for peer discovery. This allows the stack to avoid environment-specific configuration of hosts and work out of the box. If you cannot use UDP multicast, you need to change to a non-UDP-based peer-discovery layer (the TCPPING layer) and configure the addresses/ports of the possible cluster nodes. You can change the protocol stack configuration in jgroups-channelfactory-stacks.xml. The file contains definitions for both peer-discovery layers: by default, the definition of MPING layer is uncommented and the TCPPING layer is commented. To switch to non-UDP based peer-discovery, comment out the MPING layer, and uncomment and configure the TCPPING layer. For more information on MPING and TCPPING, refer to Section 28.1.3, “Discovery Protocols”.
21.1.1.3. Changing the Protocol Stack Configuration of JBoss Messaging
JBoss Messaging uses the
jbm-control and jbm-data protocol stack configurations by default. The jbm-control protocol stack is fully UDP-based and jbm-data uses the MPING discovery protocol, which uses UDP multicast. Therefore, if you want JBoss Messaging to use only TCP-based configurations, you need to configure the JBoss Messaging control channel to use the tcp protocol stack instead of the jbm-control stack and modify the jbm-data protocol stack to use TCPPING layer instead of the MPING layer.
To configure the JBoss Messaging control channel to use the
tcp protocol stack, open the deploy/messaging/RDMS-persistence-service.xml file (the RDMS value depends on the relational database management system you are using for message persistence) and change the ControlChannelName attribute value of the org.jboss.messaging.core.jmx.MessagingPostOfficeService mbean to tcp:
<!--<attribute name="ControlChannelName">jbm-control</attribute>--> <attribute name="ControlChannelName">tcp</attribute>
To modify the jbm-data protocol stack definition so that it uses the TCPPING layer instead of the MPING layer, open
Make sure the defined ports do not conflict with ports used by other TCPPING layers. You can also use the system property -Djbm.data.tcpping.initial_hosts to configure the set of initial hosts for this layer from JAVA_OPTS.
/server/PROFILE/deploy/cluster/jgroups-channelfactory.sar/META-INF/jgroups-channelfactory-stacks.xml and replace the MPING layer with an equivalent TCPPING layer as shown in Example 21.1, “Definition of the jbm-data protocol stack with TCPPING definition”.
Example 21.1. Definition of the jbm-data protocol stack with TCPPING definition
<!--
<MPING timeout="3000"
num_initial_members="3"
mcast_addr="${jboss.jgroups.tcp.mping_mcast_addr:230.11.11.11}"
mcast_port="${jgroups.tcp.mping_mcast_port:45700}"
ip_ttl="${jgroups.udp.ip_ttl:2}"/>
-->
<TCPPING timeout="5000"
initial_hosts="${jbm.data.tcpping.initial_hosts:localhost[7900],localhost[7901]}"
port_range="1"
num_initial_members="3"/>
21.1.2. The JGroups Shared Transport
As the number of JGroups-based clustering services running in the Enterprise Application Platform has risen over the years, the need to share the resources (particularly sockets and threads) used by these channels became a glaring problem. A stock Enterprise Application Platform 5 production configuration will connect 4 JGroups channels during start up, and a total of 7 or 8 will be connected if distributable web apps, clustered EJB3 SFSBs and a clustered JPA/Hibernate second level cache are all used. So many channels can consume a lot of resources, and can be a real configuration nightmare if the network environment requires configuration to ensure cluster isolation.
Beginning with Enterprise Application Platform 5, JGroups supports sharing of transport protocol instances between channels. A JGroups channel is composed of a stack of individual protocols, each of which is responsible for one aspect of the channel's behavior. A transport protocol is a protocol that is responsible for actually sending messages on the network and receiving them from the network. The resources that are most desirable for sharing (sockets and thread pools) are managed by the transport protocol, so sharing a transport protocol between channels efficiently accomplishes JGroups resource sharing.
To configure a transport protocol for sharing, simply add a
singleton_name="someName" attribute to the protocol's configuration. All channels whose transport protocol configuration uses the same singleton_name value will share their transport. All other protocols in the stack will not be shared. Figure 21.2, “Services using a Shared Transport” illustrates 4 services running in a VM, each with its own channel. Three of the services are sharing a transport; the fourth is using its own transport.
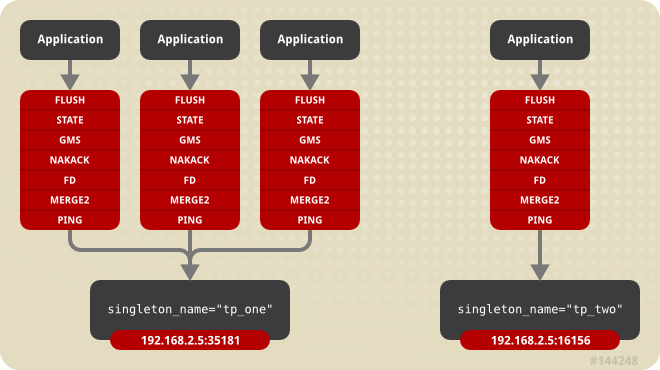
Figure 21.2. Services using a Shared Transport
The protocol stack configurations used by the Enterprise Application Platform 5 ChannelFactory all have a
singleton_name configured. In fact, if you add a stack to the ChannelFactory that does not include a singleton_name, before creating any channels for that stack, the ChannelFactory will synthetically create a singleton_name by concatenating the stack name to the string "unnamed_", e.g. unnamed_customStack.